|
32 | 32 |
|
33 | 33 |
|
34 | 34 | 见其名知其意,有倒排索引,对应肯定,有正向索引。 |
35 | | - 正向索引(forward index),反向索引(inverted index)更熟悉的名字是倒排索引。 |
| 35 | + 正向索引(forward index),反向索引(inverted index)更熟悉的名字是倒排索引。 |
36 | 36 |
|
37 | 37 | 在搜索引擎中每个文件都对应一个文件ID,文件内容被表示为一系列关键词的集合(实际上在搜索引擎索引库中,关键词也已经转换为关键词ID)。例如“文档1”经过分词,提取了20个关键词,每个关键词都会记录它在文档中的出现次数和出现位置。 |
38 | 38 |
|
39 | 39 | 得到正向索引的结构如下: |
40 | 40 |
|
41 | | -“文档1”的ID > 单词1:出现次数,出现位置列表;单词2:出现次数,出现位置列表;…………。 |
| 41 | +“文档1”的ID >单词1:出现次数,出现位置列表;单词2:出现次数,出现位置列表;…………。 |
42 | 42 |
|
43 | | -“文档2”的ID > 此文档出现的关键词列表。 |
| 43 | +“文档2”的ID >此文档出现的关键词列表。 |
44 | 44 |
|
45 | 45 | 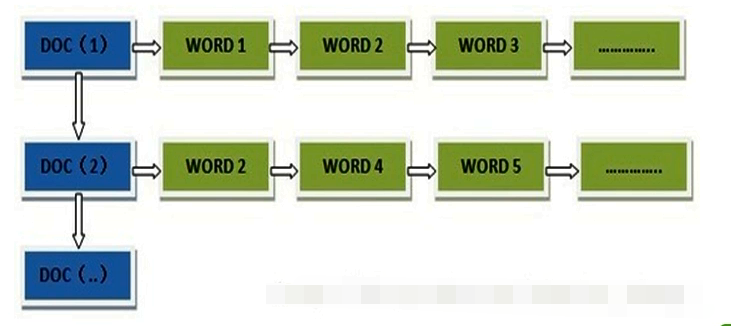 |
46 | 46 |
|
|
101 | 101 |
|
102 | 102 | 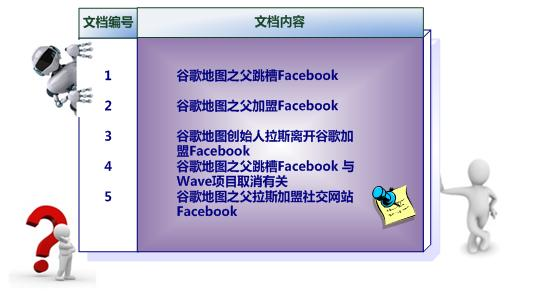 |
103 | 103 |
|
104 | | -图3 文档集合 |
| 104 | +图3 文档集合 |
105 | 105 |
|
106 | 106 | 中文和英文等语言不同,单词之间没有明确分隔符号,所以首先要用分词系统将文档自动切分成单词序列。这样每个文档就转换为由单词序列构成的数据流,为了系统后续处理方便,需要对每个不同的单词赋予唯一的单词编号,同时记录下哪些文档包含这个单词,在如此处理结束后,我们可以得到最简单的倒排索引(参考图3-4)。在图4中,“单词ID”一栏记录了每个单词的单词编号,第二栏是对应的单词,第三栏即每个单词对应的倒排列表。比如单词“谷歌”,其单词编号为1,倒排列表为{1,2,3,4,5},说明文档集合中每个文档都包含了这个单词。 |
107 | 107 |
|
108 | 108 | 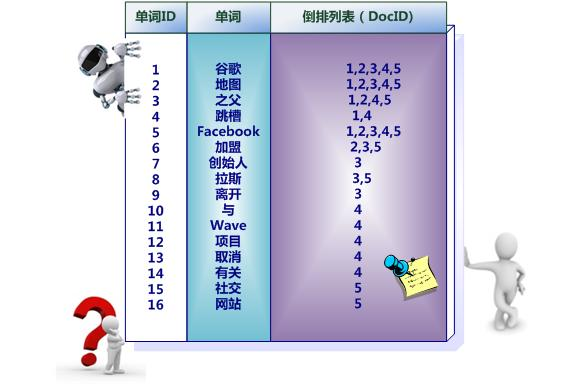 |
109 | 109 |
|
110 | | -图4 简单的倒排索引 |
| 110 | +图4 简单的倒排索引 |
111 | 111 |
|
112 | 112 | 之所以说图4所示倒排索引是最简单的,是因为这个索引系统只记载了哪些文档包含某个单词,而事实上,索引系统还可以记录除此之外的更多信息。图5是一个相对复杂些的倒排索引,与图4的基本索引系统比,在单词对应的倒排列表中不仅记录了文档编号,还记载了单词频率信息(TF),即这个单词在某个文档中的出现次数,之所以要记录这个信息,是因为词频信息在搜索结果排序时,计算查询和文档相似度是很重要的一个计算因子,所以将其记录在倒排列表中,以方便后续排序时进行分值计算。在图5的例子里,单词“创始人”的单词编号为7,对应的倒排列表内容为:(3:1),其中的3代表文档编号为3的文档包含这个单词,数字1代表词频信息,即这个单词在3号文档中只出现过1次,其它单词对应的倒排列表所代表含义与此相同。 |
113 | 113 |
|
|
119 | 119 |
|
120 | 120 | 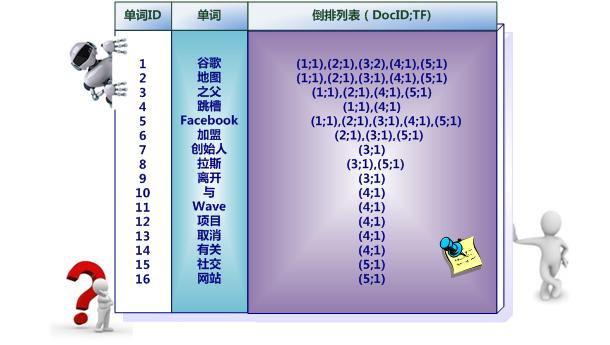 |
121 | 121 |
|
122 | | -图6 带有单词频率、文档频率和出现位置信息的倒排索引 |
| 122 | +图6 带有单词频率、文档频率和出现位置信息的倒排索引 |
123 | 123 |
|
124 | 124 | “文档频率信息”代表了在文档集合中有多少个文档包含某个单词,之所以要记录这个信息,其原因与单词频率信息一样,这个信息在搜索结果排序计算中是非常重要的一个因子。而单词在某个文档中出现的位置信息并非索引系统一定要记录的,在实际的索引系统里可以包含,也可以选择不包含这个信息,之所以如此,因为这个信息对于搜索系统来说并非必需的,位置信息只有在支持“短语查询”的时候才能够派上用场。 |
125 | 125 |
|
|
131 | 131 |
|
132 | 132 | ## 4\. 单词词典 |
133 | 133 |
|
134 | | -单词词典是倒排索引中非常重要的组成部分,它用来维护文档集合中出现过的所有单词的相关信息,同时用来记载某个单词对应的倒排列表在倒排文件中的位置信息。在支持搜索时,根据用户的查询词,去单词词典里查询,就能够获得相应的倒排列表,并以此作为后续排序的基础。 对于一个规模很大的文档集合来说,可能包含几十万甚至上百万的不同单词,能否快速定位某个单词,这直接影响搜索时的响应速度,所以需要高效的数据结构来对单词词典进行构建和查找,常用的数据结构包括哈希加链表结构和树形词典结构。 |
135 | | -4.1 哈希加链表 |
136 | | - 图7是这种词典结构的示意图。这种词典结构主要由两个部分构成: |
| 134 | +单词词典是倒排索引中非常重要的组成部分,它用来维护文档集合中出现过的所有单词的相关信息,同时用来记载某个单词对应的倒排列表在倒排文件中的位置信息。在支持搜索时,根据用户的查询词,去单词词典里查询,就能够获得相应的倒排列表,并以此作为后续排序的基础。 对于一个规模很大的文档集合来说,可能包含几十万甚至上百万的不同单词,能否快速定位某个单词,这直接影响搜索时的响应速度,所以需要高效的数据结构来对单词词典进行构建和查找,常用的数据结构包括哈希加链表结构和树形词典结构。 |
| 135 | +4.1 哈希加链表 |
| 136 | + 图7是这种词典结构的示意图。这种词典结构主要由两个部分构成: |
137 | 137 |
|
138 | 138 | 主体部分是哈希表,每个哈希表项保存一个指针,指针指向冲突链表,在冲突链表里,相同哈希值的单词形成链表结构。之所以会有冲突链表,是因为两个不同单词获得相同的哈希值,如果是这样,在哈希方法里被称做是一次冲突,可以将相同哈希值的单词存储在链表里,以供后续查找。 |
139 | 139 |
|
|
143 | 143 |
|
144 | 144 | 在响应用户查询请求时,其过程与建立词典类似,不同点在于即使词典里没出现过某个单词,也不会添加到词典内。以图7为例,假设用户输入的查询请求为单词3,对这个单词进行哈希,定位到哈希表内的2号槽,从其保留的指针可以获得冲突链表,依次将单词3和冲突链表内的单词比较,发现单词3在冲突链表内,于是找到这个单词,之后可以读出这个单词对应的倒排列表来进行后续的工作,如果没有找到这个单词,说明文档集合内没有任何文档包含单词,则搜索结果为空。 |
145 | 145 |
|
146 | | -4.2 树形结构 |
147 | | - B树(或者B+树)是另外一种高效查找结构,图8是一个 B树结构示意图。B树与哈希方式查找不同,需要字典项能够按照大小排序(数字或者字符序),而哈希方式则无须数据满足此项要求。 |
148 | | - B树形成了层级查找结构,中间节点用于指出一定顺序范围的词典项目存储在哪个子树中,起到根据词典项比较大小进行导航的作用,最底层的叶子节点存储单词的地址信息,根据这个地址就可以提取出单词字符串。 |
| 146 | +4.2 树形结构 |
| 147 | + B树(或者B+树)是另外一种高效查找结构,图8是一个 B树结构示意图。B树与哈希方式查找不同,需要字典项能够按照大小排序(数字或者字符序),而哈希方式则无须数据满足此项要求。 |
| 148 | + B树形成了层级查找结构,中间节点用于指出一定顺序范围的词典项目存储在哪个子树中,起到根据词典项比较大小进行导航的作用,最底层的叶子节点存储单词的地址信息,根据这个地址就可以提取出单词字符串。 |
149 | 149 |
|
150 | 150 | 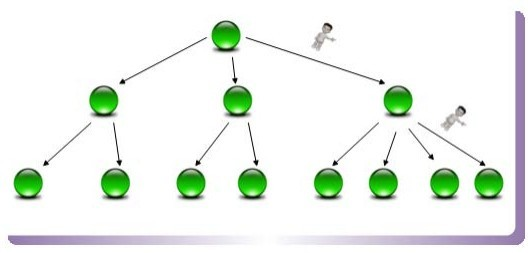 |
151 | 151 |
|
152 | | -图8 B树查找结构 |
| 152 | +图8 B树查找结构 |
153 | 153 |
|
154 | 154 | 总结 |
155 | 155 |
|
|
164 | 164 | DocId:单词出现的文档id |
165 | 165 | TF:单词在某个文档中出现的次数 |
166 | 166 | POS:单词在文档中出现的位置 |
167 | | - 以单词“加盟”为例,其单词编号为6,文档频率为3,代表整个文档集合中有三个文档包含这个单词,对应的倒排列表为{(2;1;<4>),(3;1;<7>),(5;1;<5>)},含义是在文档2,3,5出现过这个单词,在每个文档的出现过1次,单词“加盟”在第一个文档的POS是4,即文档的第四个单词是“加盟”,其他的类似。 |
| 167 | + 以单词“加盟”为例,其单词编号为6,文档频率为3,代表整个文档集合中有三个文档包含这个单词,对应的倒排列表为{(2;1;<4>),(3;1;<7>),(5;1;<5>)},含义是在文档2,3,5出现过这个单词,在每个文档的出现过1次,单词“加盟”在第一个文档的POS是4,即文档的第四个单词是“加盟”,其他的类似。 |
168 | 168 | 这个倒排索引已经是一个非常完备的索引系统,实际搜索系统的索引结构基本如此。 |
0 commit comments