正規化の手順
非正規形
ある売上伝票は,次のように1枚の伝票に3つの商品を連記することができるとします。
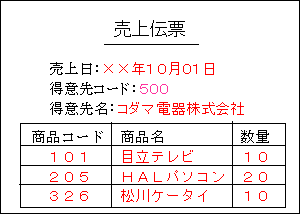
これをそのままファイルにすると,図の「非正規形」のようになります(ここでは,図を単純にするかめに,商品区分や単価を省略しています)。伝票に記載された商品数が少ないときは,レコードの右側に空白がならび無駄になってしまいます。
第1正規化
第1正規化とは,繰り返しの部分を複数のレコードにして,繰り返しを排除する操作です。第1正規化をした結果を第1正規形といいます。

第1正規形のファイルが次のようであるとします。
売上ファイル1=年月日
+得意先コード+得意先名
+商品コード+商品名
+商品区分コード+商品区分名
+数量+単価

関数従属性
このとき,年月日,得意先コード,商品コードのすべてが定まると,そのレコードが決まります。そのとき,これらを主キーといいます。得意先コードが定まると得意先名が定まるというように,ある属性(項目)が定まると他の属性が定まるという関係を関数従属といいます。そして,数量は年月日,得意先コード,商品コードのすべての主キーが定まりますが,このように主キー全体に従属することを完全関数従属といい,得意先コードと得意先名の関係のように,主キーの一部に従属することを部分関数従属といいます。また,商品コードから商品区分コードがわかり,それにより商品区分名がわかるというように,間接的に従属することを推移関数従属といいます。
第2正規化
第2正規化とは,部分関数従属する項目を分離することです。その結果のファイルを第2正規形といいます。主キーは年月日,得意先コード,商品コードですが,他の項目とは次の関係があります。
- 年月日が決まっても,決まる項目はない。
- 得意先コードが決まれば得意先名が決まる。
- 商品コードが決まれば商品名,商品区分コード,商品区分名,単価が決まる。
(単価はどの得意先でも同一とする) - 数量は,すべての主キーが決まらなければ決まらない(完全関数従属)。
それで,
得意先マスタ=得意先コード+得意先名
商品マスタ=商品コード+商品名+商品区分コード+商品区分名+単価
が分離されます。残った項目と分離したファイルのユニークキーからなるファイルは,
売上ファイル=年月日+得意先コード+商品コード+数量
となります(ファイル名は任意)。

第3正規化
第3正規化は,主キー以外のキーに関数従属する項目を分離します。その結果を第3正規形といいます。
得意先マスタは,得意先名は主キーである得意先コードに従属しているから完全関数従属であり,売上ファイルでは,数量がすべての主キーに完全関数従属しているので,これ以上は分割できません。
ここでは,商品マスタが対象になります。
商品マスタ=商品コード+商品名+商品区分コード+商品区分名+単価
において,主キー以外のキーとは商品区分コードであり,商品区分コードが決まれば商品区分名が決まるので,
商品区分マスタ=商品区分コード+商品区分名
が分離できます。それで残った項目(分離ファイルの主キーを含む)で,
商品マスタ=商品コード+商品名+商品区分コード+単価
の2ファイルになります。

すなわち,第3正規形のファイル群は,次の4ファイルになります。
売上ファイル=年月日+得意先コード+商品コード+数量
得意先マスタ=得意先コード+得意先名
商品マスタ=商品コード+商品名+商品区分コード+単価
商品区分マスタ=商品区分コード+商品区分名
これは,「ファイルの概念」での結果と同じになります。

なお,データの内容は次のようになります。

(参考)高度な正規形
通常では第3正規形までで十分ですが、さらに高度な正規形があります。ここでは単に名称と定義だけを掲げるだけにします。
- ボイス・コッド正規形(BCNF)
- 第3正規形は候補キーを構成する属性の間に候補キーを決定項としない関数従属性が存在することを許すが、ボイス・コッド正規形では、その関係を分解します。
- 第4正規形
- 候補キーではない属性への多値従属性をもった属性があるとき、それを分解します。
- 第5正規形
- 第4正規形の結合従属性の決定項が候補キーのみになるように分解します。
主キーと外部キー
得意先表では得意先コードにより、商品表では商品コードにより、商品区分表では商品区分コードにより行が特定します。このように表の行を特定する項目を主キーといいます。通常は、主キーの値はすべて異なります。同じ値をもたない主キーをユニークキーということもあります。
売上表では、主キーに相当する項目がありません。同一日に同一得意先に同一商品の売上はないと仮定すれば「年月日+得意先コード+商品コード」をまとめた項目(複合キーという)が主キーになります。また、複合キーを構成する、年月日、得意先コード、商品コードのそれぞれを候補キーといいます・
商品表の商品コードは商品表の主キーです。売上表の得意先コードと商品コードは、それぞれ得意先表、商品表の主キーです。このように、他表の主キーである項目を外部キーといいます。外部キーは二つの表を結合するときの項目になります。
整合性制約(一貫性制約)
整合性制約とは、データベースを常に正しい状態に保つための規則のことです。整合性制約に適合したデータベースにすることも正規化を行う目的の一つです。また、整合性制約を理解することにより、適切な正規化ができます。
- 定義域制約
- 属性項目は、これ以上細分化できないのが望ましい。例えば、「年月日」を単に日付として用いるのではなく、「年」「月」「日」により操作することが多いならば、それぞれを独立した項目にするべきだということです。
- 検査制約
- 各フィールドの値について、データの型や上下限値などの制約条件をSQLLのCREATE TABLEでCHECK句により指定します。そして、データ挿入や更新時に、制約条件をチェックし,条件を満たさないデータの場合は操作を抑止することで表データの整合性を保つ機能です。
- 主キーの制約
- 主キー(複合キーも含む)には次の制約があります。
NOT NULL制約:主キーの値はNULLであってはなりません。
UNIQUE制約(一意性制約):主キーはユニークでなけらばならないという制約です。例えば、得意先名を主キーにすると同名が存在することがあります。それでユニークとなる得意先コードを設定して主キーとし、得意先名は属性にするのです。 - 参照制約
- 外部キーの必要性に関する制約です。売上ファイルには、得意先マスタや商品マスタとの結合が必要になります。そのためには、売上ファイルには、得意先コードと商品コードを外部キーとして持たなければなりません。
そして、その外部キーを主キーとする得意先マスタにない得意先コード、商品マスタにない商品コードが売上ファイルにあってはなりません。
すなわち、新規の得意先や商品を取り扱うとき、得意先マスタと商品マスタへの登録をした後でないと、売上ファイルに追加できないのです。
候補キー
候補キーとは、主キーになるかもしれないキーのことです。候補キーは一意性制約だけですが、そのうち主キーになるにはNOT NULL制約が必要になります。
例えば、社員テーブルに、社員コード+マイナンバー+氏名+・・・がある場合、社員コードもマイナンバーも同じキーがなく、それが決まれば他の属性が一意に決まる(一意性制約)ので、候補キーになります。しかし、社員コードは社員になれば必ずありますが、マイナンバーのファイルへの登録は個人の自由だとすれば、登録していない(NULL)社員もいるので、主キーにはなりません。全員が登録すれば、マイナンバーを主キーとすることができます。
正規化の練習
正規化の手順を習得するために,いくつかの練習問題をやってみましょう。次の第1正規形のファイルをベースにします(簡単にするために,商品区分を省略しました)。単価は商品により決まり,全得意先で同一とします。
売上ファイル=年月日
+得意先コード+得意先名
+商品コード+商品名
+数量+単価
主キーは,年月日,得意先コード,商品コードです。
このファイルの第3正規形は次のようになります。
得意先マスタ=得意先コード+得意先名
商品マスタ=商品コード+商品名+単価
売上ファイル=年月日+得意先コード+商品コード+数量
図示をすると,次のようになります。

● 練習問題1
上の例題では,単価はどの得意先についても同一商品同一価格であると仮定していました。それを得意先ごとに単価が違う(同一得意先ではいつも同じ)としたら,第3正規化された結果はどうなりますか。
解答
第2正規化では,主キーのどれかが決まると決まる項目を調べます。
- 得意先コードが決まれば,得意先名が決まる。
- 商品コードが決まれば,商品名が決まる。(単価は決まらない)
- 得意先コードと商品コードが決まれば,単価が決まる。
それで,次のものが分離されます。
- 得意先マスタ=得意先コード+得意先名
- 商品マスタ=商品コード+商品名
- 単価マスタ=得意先コード+商品コード+単価
残ったものは,
売上ファイル=年月日+得意先コード+商品コード+数量
となります。
これらのファイルには,主キー以外のキー項目がないので,すでに3次正規化されています。

● 練習問題2
単価は全得意先で共通とすします。各得意先が複数の店舗を持っており,請求書とは別に店舗別に納入明細書を必要とするとき,次の第1正規形のファイルになります。これを第3正規化しなさい。
売上ファイル=年月日
+得意先コード+得意先名
+店舗コード+店舗名
+商品コード+商品名
+数量+単価
解答
得意先と店舗の関係は,「得意先はいくつかの店舗を持つ」「各店舗はそれぞれ唯一の得意先に属する」関係があります。このとき,得意先と店舗には1:Nの関連があるといい,得意先を親(上位),店舗を子(下位)といいます。得意先よりも店舗のほうが細かいのですから,このファイルの主キーは,年月日,店舗コード,商品コードになります。
第2正規化:部分関数従属の分離
- 店舗コードが決まれば店舗名,得意先コード,得意先名が決まる。
- 商品コードが決まれば商品名と単価が決まる。
それに従い次の3つのファイルに分解できます。
- 店舗マスタ=店舗コード+店舗名+得意先コード+得意先名
- 商品マスタ=商品コード+商品名+単価
- 売上ファイル=年月日+店舗コード+商品コード+数量
商品マスタと売上ファイルがこれ以上分解できませんが,店舗マスタはさらに第3正規化により分解できます。
店舗マスタでは,主キーの店舗コード以外にキーとなる項目である得意先コードがあり,それに得意先名が従属していますので,次のように分解できます。
- 得意先マスタ=得意先マスタ+得意先名
- 店舗マスタ=店舗コード+店舗名+得意先コード

正規化の目的等
非正規形あるいは第1正規形のファイルを第3正規形のテーブル群にすることにより、どのような利点や欠点が生じるかを列挙します。
利点:データの重複・冗長性の排除
得意先マスタを例にします。得意先は、販売システム以外にも、流通システム、会計システムなど多くのシステムで使われます。正規化されていないと、売上ファイル、請求書ファイル、出荷ファイル、売掛金ファイル、債権ファイルなど夥しい数のファイルが得意先情報をもつことになります。
しかも、得意先情報には、得意先コード、得意先名、住所、電話番号、担当者名など多様な項目が重複して記録されています。
正規化することにより、得意先に関する項目は得意先マスタに一本化され、個々のファイルには得意先コードだけがあればよいことになります。
正規化することにより、ファイル全体の記憶容量が非常に少なくできます。
住所などの変更、新得意先の登録など、得意先に関することは、得意先マスタだけを変更するだけでよく、それが販売システムや流通システムなどに自動的に反映されます。
利点:矛盾の排除
例えば得意先の住所が変更になったとき、正規化されていないと、その住所がある多数のファイルを調べて修整することになります。その作業量が大きいだけでなく、該当するファイルを見落す危険性があります。そのため、変更したのに前の住所になっていたというような矛盾が生じます。
正規化してあれば、得意先マスタだけを修正すればよいので、更新時におけるデータの不整合の発生を防止することができます。
新得意先の店舗を追加するとき、得意先マスタに新得意先を追加せずに、店舗マスタで新店舗を登録することができると、どの得意先にも所属しない店舗があるという矛盾が生じます。正規化をすることにより新店舗の属性に得意先コードが必要なので、その得意先コードが得意先マスタに存在しない限り新店舗の登録ができません。
このようにデータ、正規化をすることにより、、データ更新での矛盾をなくし、一貫性・整合性(インテグリティ)を高めることができます。
利点:データ管理の容易化
このように正規化をすることにより、得意先や商品などの固定的な情報は、販売システムや流通システムなど個々のシステムを離れて、マスタファイルを一元管理すれびょいことになります。データ管理が容易になります。これが正規化をする最大の目的です。
欠点:結合による処理効率の低下
得意先別商品別の売上一覧表作成を例にします。売上ファイルに得意先名や商品名があれば一つのファイルから作成できます。ところが正規化されているときは、それらを得意先マスタや商品マスタから取り出すために、売上ファイルとそれらのマスタを照合する操作が必要になります。
処理速度を上げるためには、高性能のコンピュータや記憶装置が必要になり、コスト高になります。昔は、正規化の利点は認識されていたのに、ハードウェアの性能の壁で採用されないこともありました。現在は、ハードウェアの性能向上、照合処理のアルゴリズムの進歩により、この欠点は重視されなくなってきました。
欠点:処理記述が複雑
売上一覧表を作成するのに、「どのテーブルをどのように結合するのか」の知識が必要になります。
欠点:過去データの扱い
得意先住所が変更になる以前のデータを使う場合、非正規形であれば変更前の住所が入っていますが、正規化したとき、すべて現在の住所になってしまいます。得意先マスタに旧住所と変更日付の項目をもつ方法がありますが、複雑になってしまいます。