diff --git a/.gitignore b/.gitignore
index daaf937..6e46418 100644
--- a/.gitignore
+++ b/.gitignore
@@ -4,3 +4,5 @@
tags
tags.*
+idea.*
+.idea
diff --git a/Array/02.ThreeSum/README.md b/Array/02.ThreeSum/README.md
deleted file mode 100644
index 2c7404c..0000000
--- a/Array/02.ThreeSum/README.md
+++ /dev/null
@@ -1,26 +0,0 @@
-# Three Sum (三数之和)
-**LeetCode 15**
-
-- [英文版](https://leetcode.com/problems/3sum/)
-
-- [中文版](https://leetcode-cn.com/problems/3sum/)
-
-## 题目
-给定一个包含 n 个整数的数组 nums,判断 nums 中是否存在三个元素 a,b,c ,使得 a + b + c = 0 ?找出所有满足条件且不重复的三元组。
-
-注意:答案中不可以包含重复的三元组。
-
-例如, 给定数组 nums = [-1, 0, 1, 2, -1, -4],
-
-满足要求的三元组集合为:
-[
- [-1, 0, 1],
- [-1, -1, 2]
-]
-
-## 思路
-
-## 代码实现
-| C | C++ | Java | Python | JavaScript | PHP |
-| :--: | :--: | :--: | :--: | :---: | :---: |
-| 🤔 | 🤔 | 🤔 | [😀](ThreeSum.py) | 🤔 | 🤔 |
diff --git a/Array/06.FirstMissingPositive/README.md b/Array/06.FirstMissingPositive/README.md
deleted file mode 100644
index a312995..0000000
--- a/Array/06.FirstMissingPositive/README.md
+++ /dev/null
@@ -1,34 +0,0 @@
-# First Missing Positive(缺失的第一个正数)
-
-**LeetCode 41**
-
-- [英文版](https://leetcode.com/problems/first-missing-positive/)
-
-- [中文版](https://leetcode-cn.com/problems/first-missing-positive/)
-
-## 题目
-给定一个未排序的整数数组,找出其中没有出现的最小的正整数。
-
-示例 1:
-```
-输入: [3,4,-1,1]
-输出: 2
-```
-
-示例 3:
-```
-输入: [7,8,9,11,12]
-输出: 1
-```
-
-说明:
-
-你的算法的时间复杂度应为O(n),并且只能使用常数级别的空间。
-
-## 思路
-
-
-## 代码实现
-| C | C++ | Java | Python | JavaScript | Go | PHP |
-| :--: | :--: | :--: | :--: | :--: | :--: | :--: |
-| 🤔 | 🤔 | 🤔 | [😀](FirstMissingPositive.py) | 🤔 | 🤔 | 🤔 |
diff --git a/Array/07.KthLargestElement/README.md b/Array/07.KthLargestElement/README.md
deleted file mode 100644
index 6535a63..0000000
--- a/Array/07.KthLargestElement/README.md
+++ /dev/null
@@ -1,37 +0,0 @@
-# Kth Largest Element in an Array(数组中的第K个最大元素)
-
-**LeetCode 215**
-
-- [英文版](https://leetcode.com/problems/kth-largest-element-in-an-array/)
-
-- [中文版](https://leetcode-cn.com/problems/kth-largest-element-in-an-array/)
-
-## 题目
-在未排序的数组中找到第 k 个最大的元素。请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素。
-
-示例 1:
-```
-输入: [3,2,1,5,6,4] 和 k = 2
-输出: 5
-```
-示例 2:
-```
-输入: [3,2,3,1,2,4,5,5,6] 和 k = 4
-输出: 4
-```
-
-说明:
-
-你可以假设 k 总是有效的,且 1 ≤ k ≤ 数组的长度。
-
-## 思路
-
-点击展开
-使用快速排序的思想
-
-
-## 代码实现
-
-| C | C++ | Java | Python | JavaScript | Go | PHP |
-| :--: | :--: | :--: | :--: | :--: | :--: | :--: |
-| 🤔 | 🤔 | 🤔 | [😀](KthLargestElement.py) | 🤔 | 🤔 | 🤔 |
diff --git a/Array/FindAllDuplicates/FindAllDuplicates.cpp b/Array/FindAllDuplicates/FindAllDuplicates.cpp
new file mode 100644
index 0000000..feca9e7
--- /dev/null
+++ b/Array/FindAllDuplicates/FindAllDuplicates.cpp
@@ -0,0 +1,13 @@
+
+class Solution {
+public:
+ vector findDuplicates(vector& nums) {
+ vector res;
+ for(int i=0; i& nums) {
+ int len = nums.size();
+ for (int i = 0; i < len; ++i) {
+ int tmp = nums[i];
+ while (tmp > 0 && tmp <= len && nums[tmp-1] != tmp) {
+ nums[i] = nums[tmp-1];
+ nums[tmp-1] = tmp;
+ tmp = nums[i];
+ }
+ }
+ for (int i = 0; i < len; ++i) {
+ if (nums[i]-1 != i) { return i + 1; }
+ }
+
+ return len + 1;
+ }
+};
\ No newline at end of file
diff --git a/Array/06.FirstMissingPositive/FirstMissingPositive.py b/Array/FirstMissingPositive/FirstMissingPositive.py
similarity index 100%
rename from Array/06.FirstMissingPositive/FirstMissingPositive.py
rename to Array/FirstMissingPositive/FirstMissingPositive.py
diff --git a/Array/FirstMissingPositive/README.md b/Array/FirstMissingPositive/README.md
new file mode 100644
index 0000000..35f5883
--- /dev/null
+++ b/Array/FirstMissingPositive/README.md
@@ -0,0 +1,52 @@
+# First Missing Positive(缺失的第一个正数)
+
+## LeetCode 41
+
+- [英文版](https://leetcode.com/problems/first-missing-positive/)
+
+- [中文版](https://leetcode-cn.com/problems/first-missing-positive/)
+
+## 题目
+
+给定一个未排序的整数数组,找出其中没有出现的最小的正整数。
+
+示例 1:
+
+```js
+输入: [3,4,-1,1]
+输出: 2
+```
+
+示例 3:
+
+```js
+输入: [7,8,9,11,12]
+输出: 1
+```
+
+说明:
+
+你的算法的时间复杂度应为O(n),并且只能使用常数级别的空间。
+
+## 思路
+
+
+点击展开
+这道题如果对空间复杂度没有限制,遍历一次数组,将元素作为 key 存入字典;再遍历一次字典,查找从 [1, n) 中缺失的最小 key 即可。
+
+然而,题目说只能使用常数空间,说明只能在原地倒腾数组,数组的特性是下标有序,而题目中查找缺失的最小正整数,肯定要按照 [1, n) 的顺序排除查找,它们之间恰好存在差为 1 的关系。
+
+因此,我们可以遍历一次数组,如果当前元素的值没有超过数组大小,就交换到 [元素值 - 1] 的下标,交换完成后,再次遍历新数组,[下标 + 1] 应该等于当前的元素值,否者就是缺失的最小正整数。
+
+交换后的数组:a[0] = 1, a[1] = 2, a[2] = 3…
+
+大致思路已经有了,看上去也并不难,但这是一道 Hard 的题目,还是有坑的。以 [3, 4, -1, 1] 为例,交换到下标 1 后,变为 [-1, 1, 3, 4],此次交换虽然元素 3 交换到了目标位置,然而 1 并没有,元素 1 应该在下标 0 处的,否者第二次遍历检测不到元素 1。
+
+因此在交换成功后,不能立即交换下一个元素,而是要再次交换当前元素,直到当前元素不满足交换条件为止。
+
+
+## 代码实现
+
+| C++ | Java | Python | JavaScript | Go | PHP |
+| :--: | :--: | :--: | :--: | :--: | :--: |
+| [😀](FirstMissingPositive.cpp) | 🤔 | [😀](FirstMissingPositive.py) | [😀](./index) | 🤔 | 🤔 |
diff --git a/Array/FirstMissingPositive/index.js b/Array/FirstMissingPositive/index.js
new file mode 100644
index 0000000..fc78bde
--- /dev/null
+++ b/Array/FirstMissingPositive/index.js
@@ -0,0 +1,24 @@
+/**
+ * @param {number[]} nums
+ * @return {number}
+ */
+var firstMissingPositive = function(nums) {
+ const n = nums.length;
+ let i = 0;
+ while (i < n) {
+ if (nums[i] > 0 && nums[i] <= n && nums[nums[i] - 1] != nums[i]) {
+ // swap nums[nums[i] - 1] and nums[i]
+ [nums[nums[i] - 1], nums[i]] = [nums[i], nums[nums[i] - 1]]
+ } else {
+ ++i;
+ }
+ }
+
+ for (let i = 0; i < n; ++i) {
+ if (nums[i] != i + 1) {
+ return i + 1
+ }
+ }
+
+ return nums.length + 1;
+};
\ No newline at end of file
diff --git a/Array/FizzBuzz/FizzBuzz.cpp b/Array/FizzBuzz/FizzBuzz.cpp
new file mode 100644
index 0000000..b38b2ee
--- /dev/null
+++ b/Array/FizzBuzz/FizzBuzz.cpp
@@ -0,0 +1,17 @@
+
+class Solution {
+public:
+ vector fizzBuzz(int n) {
+ vector res(n, "");
+ for(int i = 1; i<=n; ++i) {
+ bool multiplesOfThree = (i % 3 == 0);
+ bool multiplesOfFive = (i % 5 == 0);
+
+ if(multiplesOfThree && multiplesOfFive) { res[i-1] = "FizzBuzz"; }
+ else if(multiplesOfThree) { res[i-1] = "Fizz"; }
+ else if(multiplesOfFive) {res[i-1] = "Buzz"; }
+ else { res[i-1] = to_string(i); }
+ }
+ return res;
+ }
+};
\ No newline at end of file
diff --git a/Array/04.FizzBuzz/FizzBuzz.py b/Array/FizzBuzz/FizzBuzz.py
similarity index 100%
rename from Array/04.FizzBuzz/FizzBuzz.py
rename to Array/FizzBuzz/FizzBuzz.py
diff --git a/Array/04.FizzBuzz/README.md b/Array/FizzBuzz/README.md
similarity index 89%
rename from Array/04.FizzBuzz/README.md
rename to Array/FizzBuzz/README.md
index 310393b..1c2680e 100644
--- a/Array/04.FizzBuzz/README.md
+++ b/Array/FizzBuzz/README.md
@@ -41,4 +41,4 @@ n = 15,
## 代码实现
| C | C++ | Java | Python | JavaScript | Go | PHP |
| :--: | :--: | :--: | :--: | :--: | :--: | :--: |
-| 🤔 | 🤔 | 🤔 | [😀](./FizzBuzz.py) | 🤔 | 🤔 | 🤔 |
+| 🤔 | [😀](./FizzBuzz.cpp) | 🤔 | [😀](./FizzBuzz.py) | 🤔 | 🤔 | 🤔 |
diff --git a/Array/KthLargestElement/KthLargestElement.cpp b/Array/KthLargestElement/KthLargestElement.cpp
new file mode 100644
index 0000000..cbdda60
--- /dev/null
+++ b/Array/KthLargestElement/KthLargestElement.cpp
@@ -0,0 +1,32 @@
+
+class Solution {
+public:
+ int findKthLargest(vector& nums, int k) {
+ return _quickSelect(nums, 0, nums.size()-1, k-1);
+ }
+
+ int _quickSelect(vector nums, int left, int right, int k) {
+ int origin_left = left, origin_right = right;
+ int pivot = nums[origin_right];
+ while (left < right) {
+ while (left < right && nums[left] > pivot) { left++; }
+ while (left < right && nums[right] <= pivot) { right--; }
+ int tmp = nums[left];
+ nums[left] = nums[right];
+ nums[right] = tmp;
+ }
+ nums[origin_right] = nums[left];
+ nums[left] = pivot;
+
+
+ if (k == left) {
+ return nums[left];
+ }
+ else if (k > left) {
+ return _quickSelect(nums, left+1, origin_right, k);
+ }
+ else {
+ return _quickSelect(nums, origin_left, left-1, k);
+ }
+ }
+};
\ No newline at end of file
diff --git a/Array/07.KthLargestElement/KthLargestElement.py b/Array/KthLargestElement/KthLargestElement.py
similarity index 100%
rename from Array/07.KthLargestElement/KthLargestElement.py
rename to Array/KthLargestElement/KthLargestElement.py
diff --git a/Array/KthLargestElement/README.md b/Array/KthLargestElement/README.md
new file mode 100644
index 0000000..c78bc1b
--- /dev/null
+++ b/Array/KthLargestElement/README.md
@@ -0,0 +1,48 @@
+# Kth Largest Element in an Array(数组中的第K个最大元素)
+
+**LeetCode 215**
+
+- [英文版](https://leetcode.com/problems/kth-largest-element-in-an-array/)
+
+- [中文版](https://leetcode-cn.com/problems/kth-largest-element-in-an-array/)
+
+## 题目
+在未排序的数组中找到第 k 个最大的元素。请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素。
+
+示例 1:
+```
+输入: [3,2,1,5,6,4] 和 k = 2
+输出: 5
+```
+示例 2:
+```
+输入: [3,2,3,1,2,4,5,5,6] 和 k = 4
+输出: 4
+```
+
+说明:
+
+你可以假设 k 总是有效的,且 1 ≤ k ≤ 数组的长度。
+
+## 思路
+
+点击展开
+
+题中有个要点容易误解,目标值位于数组从大到小排序的第 k 下标,而不是去重后按元素值从大到小的序位;
+
+对于无序数组查找的场景,首先要想到的是二分查找,它的时间复杂度仅次于有序数组查找 O(n)。
+
+对于二分比较关键的优化点是,pvoit 的确定,会影响实际的效率,工业算法一般会随机一个下标。
+
+不过随机算法也有一定的开销,这题就直接用最右边的下标作为 pvoit 了。
+
+这像是快排的简化版本。
+
+二分查找是一种解法,另一个解法可以采用大顶堆,请自行尝试~
+
+
+## 代码实现
+
+| C++ | Java | Python | JavaScript | Go | PHP |
+| :--: | :--: | :--: | :--: | :--: | :--: | :--: |
+| [😀](KthLargestElement.cpp) | 🤔 | [😀](KthLargestElement.py) | [😀](./index.js) | 🤔 | 🤔 |
diff --git a/Array/KthLargestElement/index.js b/Array/KthLargestElement/index.js
new file mode 100644
index 0000000..f33c897
--- /dev/null
+++ b/Array/KthLargestElement/index.js
@@ -0,0 +1,35 @@
+/**
+ * @param {number[]} nums
+ * @param {number} k
+ * @return {number}
+ */
+// 时间复杂度 O(NlogN)
+var findKthLargest = function(nums, k) {
+ // 二分查找
+ const quickSelect = (nums, left, right, tIndex) => {
+ const pvoit = nums[right];
+ let l = left, r = right;
+ while (l < r) {
+ // 左边跳过比 pvoit 大的数
+ while (nums[l] > pvoit && l < r) l++;
+ // 右边跳过不大于 pvoit 的数
+ while (nums[r] <= pvoit && l < r) r--;
+ // 此时 num[l] 一定大于或等于 nums[r],交换它们
+ [nums[l], nums[r]] = [nums[r], nums[l]];
+ }
+ // 一次二分结束,将 pvoit 交换的中间位置
+ [nums[right], nums[l]] = [nums[l], nums[right]];
+
+ if (tIndex > l) {
+ // 目标值在右边
+ return quickSelect(nums, l + 1, right, tIndex);
+ } else if (tIndex < l) {
+ // 目标值在左边
+ return quickSelect(nums, left, l - 1, tIndex);
+ } else {
+ return nums[l];
+ }
+ }
+
+ return quickSelect(nums, 0, nums.length - 1, k - 1);
+};
\ No newline at end of file
diff --git a/Array/MajorityElement/MajorityElement.cpp b/Array/MajorityElement/MajorityElement.cpp
new file mode 100644
index 0000000..9b93e82
--- /dev/null
+++ b/Array/MajorityElement/MajorityElement.cpp
@@ -0,0 +1,13 @@
+
+class Solution {
+public:
+ int majorityElement(vector& nums) {
+ int major;
+ int count = 0;
+ for(auto num : nums) {
+ if(count == 0) { major = num; }
+ count += (num == major) ? 1 : -1;
+ }
+ return major;
+ }
+};
\ No newline at end of file
diff --git a/Array/03.MajorityElement/MajorityElement.java b/Array/MajorityElement/MajorityElement.java
similarity index 100%
rename from Array/03.MajorityElement/MajorityElement.java
rename to Array/MajorityElement/MajorityElement.java
diff --git a/Array/03.MajorityElement/MajorityElement.js b/Array/MajorityElement/MajorityElement.js
similarity index 100%
rename from Array/03.MajorityElement/MajorityElement.js
rename to Array/MajorityElement/MajorityElement.js
diff --git a/Array/03.MajorityElement/README.md b/Array/MajorityElement/README.md
similarity index 73%
rename from Array/03.MajorityElement/README.md
rename to Array/MajorityElement/README.md
index 2212f0a..c82d3dd 100644
--- a/Array/03.MajorityElement/README.md
+++ b/Array/MajorityElement/README.md
@@ -29,6 +29,6 @@
使用 major 变量记录众数,count 记录遇到 major +1,非 major -1,最终 count 会大于0,major 即代表众数。
## 代码实现
-| C | C++ | Java | Python | JavaScript | PHP |
-| :--: | :--: | :--: | :--: | :---: | :---: |
-| 🤔 | 🤔 | 🤔 | 🤔 | [😀](./MajorityElement.js) | 🤔 |
+| C | C++ | Java | Python | JavaScript | PHP | Go |
+| :--: | :--: | :--: | :--: | :---: | :---: | :---: |
+| 🤔 | [😀](./MajorityElement.cpp) | [😀](./MajorityElement.java) | 🤔 | [😀](./MajorityElement.js) | 🤔 | [😀](./majority_elements.go) |
diff --git a/Array/03.MajorityElement/majority_elements.go b/Array/MajorityElement/majority_elements.go
similarity index 100%
rename from Array/03.MajorityElement/majority_elements.go
rename to Array/MajorityElement/majority_elements.go
diff --git a/Array/MergeSortedArray/MergeSortedArray.cpp b/Array/MergeSortedArray/MergeSortedArray.cpp
new file mode 100644
index 0000000..368f74d
--- /dev/null
+++ b/Array/MergeSortedArray/MergeSortedArray.cpp
@@ -0,0 +1,20 @@
+
+class Solution {
+public:
+ void merge(vector& nums1, int m, vector& nums2, int n) {
+ while(m && n) {
+ if(nums1[m-1] > nums2[n-1]) {
+ nums1[m+n-1] = nums1[m-1];
+ m--;
+ }
+ else {
+ nums1[m+n-1] = nums2[n-1];
+ n--;
+ }
+ }
+ while(n) {
+ nums1[n-1] = nums2[n-1];
+ n--;
+ }
+ }
+};
\ No newline at end of file
diff --git a/Array/05.MergeSortedArray/MergeSortedArray.py b/Array/MergeSortedArray/MergeSortedArray.py
similarity index 100%
rename from Array/05.MergeSortedArray/MergeSortedArray.py
rename to Array/MergeSortedArray/MergeSortedArray.py
diff --git a/Array/05.MergeSortedArray/README.md b/Array/MergeSortedArray/README.md
similarity index 56%
rename from Array/05.MergeSortedArray/README.md
rename to Array/MergeSortedArray/README.md
index 396722e..7fc9f22 100644
--- a/Array/05.MergeSortedArray/README.md
+++ b/Array/MergeSortedArray/README.md
@@ -2,20 +2,22 @@
**LeetCode 88**
-- [英文版](https://leetcode.com/problems/merge-sorted-array/)
+* [英文版](https://leetcode.com/problems/merge-sorted-array/)
-- [中文版](https://leetcode-cn.com/problems/merge-sorted-array/)
+* [中文版](https://leetcode-cn.com/problems/merge-sorted-array/)
## 题目
+
给定两个有序整数数组 nums1 和 nums2,将 nums2 合并到 nums1 中,使得 num1 成为一个有序数组。
说明:
-- 初始化 nums1 和 nums2 的元素数量分别为 m 和 n。
-- 你可以假设 nums1 有足够的空间(空间大小大于或等于 m + n)来保存 nums2 中的元素。
+* 初始化 nums1 和 nums2 的元素数量分别为 m 和 n。
+* 你可以假设 nums1 有足够的空间(空间大小大于或等于 m + n)来保存 nums2 中的元素。
示例:
-```
+
+```
输入:
nums1 = [1,2,3,0,0,0], m = 3
nums2 = [2,5,6], n = 3
@@ -25,7 +27,11 @@ nums2 = [2,5,6], n = 3
## 思路
+从右往左,存元素。
+
## 代码实现
+
| C | C++ | Java | Python | JavaScript | Go | PHP |
| :--: | :--: | :--: | :--: | :--: | :--: | :--: |
-| 🤔 | 🤔 | 🤔 | [😀](MergeSortedArray.py) | 🤔 | 🤔 | 🤔 |
+| 🤔 | [😀](MergeSortedArray.cpp) | 🤔 | [😀](MergeSortedArray.py) | 🤔 | 🤔 | 🤔 |
+
diff --git a/Array/NextPremutation/NextPremutation.cpp b/Array/NextPremutation/NextPremutation.cpp
new file mode 100644
index 0000000..8784311
--- /dev/null
+++ b/Array/NextPremutation/NextPremutation.cpp
@@ -0,0 +1,23 @@
+
+class Solution {
+public:
+ void nextPermutation(vector& nums) {
+ if(nums.size() < 2) { return; }
+ int len = nums.size();
+ int i = len - 1;
+ for(; i>0; --i) {
+ if(nums[i] > nums[i-1]) { break; }
+ }
+ if(i==0) {
+ reverse(nums.begin(), nums.end());
+ return;
+ }
+ int j = len - 1;
+ for(; j>=i; --j){
+ if(nums[j] > nums[i-1]) { break; }
+ }
+ swap(nums[i-1], nums[j]);
+ reverse(nums.begin()+i, nums.end());
+ // sort(nums.begin()+i, nums.end());
+ }
+};
\ No newline at end of file
diff --git a/Array/NextPremutation/NextPremutation.js b/Array/NextPremutation/NextPremutation.js
new file mode 100644
index 0000000..2aa1761
--- /dev/null
+++ b/Array/NextPremutation/NextPremutation.js
@@ -0,0 +1,36 @@
+var nextPermutation = function(nums) {
+ const len = nums.length;
+ if (len < 2) return nums;
+
+ let prev = nums[len - 1];
+ let k = len - 2;
+ for (k; k >= 0; --k) {
+ if (prev > nums[k]) {
+ break;
+ }
+ prev = nums[k];
+ }
+ if (k < 0) {
+ return nums.reverse();
+ }
+ // find rightest index for which value larger than nums[k]
+ let l = len - 1;
+ for(l; l > k; --l) {
+ if (nums[l] > nums[k]) {
+ break;
+ }
+ }
+ // swap in-place
+ [nums[k], nums[l]] = [nums[l], nums[k]];
+ // reverse start with i, equal to sort
+ const reverse = (arr, i) => {
+ const end = arr.length - 1;
+ const mid = (i + end) / 2;
+ for (let j = i; j <= mid; ++j) {
+ [arr[j], arr[end-(j-i)]] = [arr[end-(j-i)], arr[j]];
+ }
+ return arr;
+ };
+ return reverse(nums, k + 1);
+};
+
diff --git a/Array/NextPremutation/README.md b/Array/NextPremutation/README.md
new file mode 100644
index 0000000..99b32bf
--- /dev/null
+++ b/Array/NextPremutation/README.md
@@ -0,0 +1,13 @@
+
+https://leetcode.com/problems/next-permutation/
+
+ 思路:
+1. 从右往左查找,找到第一个破坏递增序列的数,所在的下标 k,如果没找到返回原序列的逆序列;
+2. 在 k 下标的右侧查找比 nums[k] 大的,下标最大的数 nums[l];
+3. 交换 nums[l] 和 nums[k];
+4. 将 k 下标之后的元素,从小到大排序。
+
+## 代码实现
+| C | C++ | Java | Objective-C | Swift | Python | JavaScript | Go | PHP |
+| :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: |
+| 🤔 | [😀](./NextPremutation.cpp) | 🤔 | 🤔 | 🤔 | 🤔 | [😀](./NextPremutation.js) | 🤔 | 🤔 |
\ No newline at end of file
diff --git a/Array/README.md b/Array/README.md
index 5641021..57e1cb6 100644
--- a/Array/README.md
+++ b/Array/README.md
@@ -1,20 +1,21 @@
-## Array(数组)
+# Array
-[01. Two Sum(两数之和)](./01.TwoSum)
+- [Two Sum](./TwoSum)
-[02. Three Sum(三数之和)](./02.ThreeSum)
+- [Three Sum](./ThreeSum)
-[03. Majority Element(在数组中出现次数超过一半的数)](./03.MajorityElement)
+- [Majority Element](./MajorityElement)
-[04. FizzBuzz(3 和 5 的倍数)](./04.FizzBuzz)
+- [FizzBuzz](./FizzBuzz)
-[05. Merge Sorted Array(合并两个有序数组)](./05.MergeSortedArray)
+- [Merge Sorted Array](./MergeSortedArray)
-[06. First Missing Positive(寻找缺失的最小正数)](./06.FirstMissingPositive)
+- [First Missing Positive](./FirstMissingPositive)
-[07. Kth Largest Element in an Array(查找第K大的数)](./07.KthLargestElement)
+- [Kth Largest Element in an Array](./KthLargestElement)
-[08. Single Number(数组中只出现一次的数)](./08.SingleNnumber)
+- [Single Number](./SingleNumber)
-[09. Find All Duplicates in an Array(数组中重复的数字)](./09.FindAllDuplicates)
+- [Find All Duplicates in an Array](./FindAllDuplicates)
+- [Next Premutation](./NextPremutation)
diff --git a/Array/08.SingleNnumber/README.md b/Array/SingleNumber/README.md
similarity index 88%
rename from Array/08.SingleNnumber/README.md
rename to Array/SingleNumber/README.md
index 21781c0..2f464fc 100644
--- a/Array/08.SingleNnumber/README.md
+++ b/Array/SingleNumber/README.md
@@ -34,5 +34,5 @@
## 代码实现
| C | C++ | Java | Objective-C | Swift | Python | JavaScript | Go | PHP |
| :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: |
-| 🤔 | 🤔 | 🤔 | 🤔 | 🤔 | 🤔 | [😀](./SingleNumber.js) | 🤔 | 🤔 |
+| 🤔 | [😀](./SingleNumber.cpp) | 🤔 | 🤔 | 🤔 | 🤔 | [😀](./SingleNumber.js) | 🤔 | 🤔 |
diff --git a/Array/SingleNumber/SingleNumber.cpp b/Array/SingleNumber/SingleNumber.cpp
new file mode 100644
index 0000000..f727a17
--- /dev/null
+++ b/Array/SingleNumber/SingleNumber.cpp
@@ -0,0 +1,9 @@
+
+class Solution {
+public:
+ int singleNumber(vector& nums) {
+ int res = 0;
+ for(auto num : nums) { res^=num; }
+ return res;
+ }
+};
\ No newline at end of file
diff --git a/Array/08.SingleNnumber/SingleNumber.js b/Array/SingleNumber/SingleNumber.js
similarity index 60%
rename from Array/08.SingleNnumber/SingleNumber.js
rename to Array/SingleNumber/SingleNumber.js
index e5c3b51..e54206f 100644
--- a/Array/08.SingleNnumber/SingleNumber.js
+++ b/Array/SingleNumber/SingleNumber.js
@@ -7,3 +7,8 @@ var singleNumber = function(nums) {
nums.forEach((num) => { result ^= num; });
return result;
};
+
+// 方法二,使用 reduce
+var singleNumber = function(nums) {
+ return nums.reduce((res, ele) => res^ele , 0);
+}
\ No newline at end of file
diff --git a/Array/ThreeSum/README.md b/Array/ThreeSum/README.md
new file mode 100644
index 0000000..7385731
--- /dev/null
+++ b/Array/ThreeSum/README.md
@@ -0,0 +1,35 @@
+# Three Sum (三数之和)
+
+**LeetCode 15**
+
+* [英文版](https://leetcode.com/problems/3sum/)
+
+* [中文版](https://leetcode-cn.com/problems/3sum/)
+
+## 题目
+
+给定一个包含 n 个整数的数组 nums,判断 nums 中是否存在三个元素 a,b,c ,使得 a + b + c = 0 ?找出所有满足条件且不重复的三元组。
+
+注意:答案中不可以包含重复的三元组。
+
+例如, 给定数组 nums = [-1, 0, 1, 2, -1, -4],
+
+满足要求的三元组集合为:
+[
+ [-1, 0, 1],
+ [-1, -1, 2]
+]
+
+## 思路
+
+1. 先对原数组排序
+2. 从小到大遍历排序的数组
+3. 在当前遍历下标的后面剩余数组中使用两边夹逼的方式查找两个数
+4. 如果这两个数与当前下标的数之和等于 0,则存入结果数组
+5. 否则继续夹逼查找
+
+## 代码实现
+
+| C++ | Java | Python | JavaScript | Go |
+| :--: | :--: | :--: | :--: | :---: | :---: | :---: |
+| [😀](ThreeSum.cpp) | [😀](ThreeSum.java) | [😀](ThreeSum.py) | [😀](./ThreeSum.js) | [😀](three_sum.go) |
diff --git a/Array/ThreeSum/ThreeSum.cpp b/Array/ThreeSum/ThreeSum.cpp
new file mode 100644
index 0000000..ea77cda
--- /dev/null
+++ b/Array/ThreeSum/ThreeSum.cpp
@@ -0,0 +1,33 @@
+
+class Solution {
+public:
+ vector> threeSum(vector& nums) {
+ vector> res;
+ if(nums.size() < 3) { return res; }
+ sort(nums.begin(), nums.end());
+ for(int i=0; i 0) { break; }
+ if(i>0 && nums[i] == nums[i-1]) { continue; }
+ int l = i + 1, r = nums.size() - 1;
+ while(l < r) {
+ int sum = nums[i] + nums[l] + nums[r];
+ if(sum == 0) {
+ res.push_back({nums[i], nums[l], nums[r]});
+ while(l < r && nums[l] == nums[l+1]) { l++; }
+ while(l < r && nums[r] == nums[r-1]) { r--; }
+ l++;
+ r--;
+ }
+ else if(sum < 0) {
+ while(l < r && nums[l] == nums[l+1]) { l++; }
+ l++;
+ }
+ else {
+ while(l < r && nums[r] == nums[r-1]) { r--; }
+ r--;
+ }
+ }
+ }
+ return res;
+ }
+};
\ No newline at end of file
diff --git a/Array/02.ThreeSum/ThreeSum.java b/Array/ThreeSum/ThreeSum.java
similarity index 100%
rename from Array/02.ThreeSum/ThreeSum.java
rename to Array/ThreeSum/ThreeSum.java
diff --git a/Array/ThreeSum/ThreeSum.js b/Array/ThreeSum/ThreeSum.js
new file mode 100644
index 0000000..ffaf72f
--- /dev/null
+++ b/Array/ThreeSum/ThreeSum.js
@@ -0,0 +1,34 @@
+/**
+ * @param {number[]} nums
+ * @return {number[][]}
+ */
+var threeSum = function(nums) {
+ const res = [];
+ nums.sort((a, b) => a - b);
+ for (let i = 0, n = nums.length - 2; i < n; ++i) {
+ if (i > 0 && nums[i] === nums[i - 1]) continue;
+
+ let l = i + 1;
+ let r = nums.length - 1;
+
+ while (l < r) {
+ s = nums[i] + nums[l] + nums[r];
+ if (s < 0) {
+ l++;
+ } else if ( s > 0) {
+ r--;
+ } else {
+ res.push([nums[i], nums[l], nums[r]]);
+ while (l < r && nums[l] === nums[l + 1]) {
+ l++;
+ }
+ while (l < r && nums[r] === nums[r - 1]) {
+ r--;
+ }
+ l++;
+ r--;
+ }
+ }
+ }
+ return res;
+};
\ No newline at end of file
diff --git a/Array/02.ThreeSum/ThreeSum.py b/Array/ThreeSum/ThreeSum.py
similarity index 100%
rename from Array/02.ThreeSum/ThreeSum.py
rename to Array/ThreeSum/ThreeSum.py
diff --git a/Array/02.ThreeSum/three_sum.go b/Array/ThreeSum/three_sum.go
similarity index 100%
rename from Array/02.ThreeSum/three_sum.go
rename to Array/ThreeSum/three_sum.go
diff --git a/Array/01.TwoSum/README.md b/Array/TwoSum/README.md
similarity index 66%
rename from Array/01.TwoSum/README.md
rename to Array/TwoSum/README.md
index 2eb086f..b290845 100644
--- a/Array/01.TwoSum/README.md
+++ b/Array/TwoSum/README.md
@@ -1,4 +1,5 @@
# Two Sum(两数之和)
+
**LeetCode 1**
- [英文版](https://leetcode.com/problems/two-sum/)
@@ -6,12 +7,14 @@
- [中文版](https://leetcode-cn.com/problems/two-sum/)
## 题目
+
给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那*两个*整数,并返回他们的数组下标。
你可以假设每种输入只会对应一个答案。但是,你不能重复利用这个数组中同样的元素。
示例:
-```
+
+```js
给定 nums = [2, 7, 11, 15], target = 9
因为 nums[0] + nums[1] = 2 + 7 = 9
@@ -19,12 +22,15 @@
```
## 思路
+
点击展开
-借助散列表存储访问过元素的值和下标,时间复杂度 O(n)。
+使用散列表,缓存访问过的元素和下标,遍历数组,查找缓存中是否存在元素和当前元素的和等于目标值。
+时间复杂度 O(n)。
## 代码实现
-| C | C++ | Java | Python | JavaScript | PHP |
-| :--: | :--: | :--: | :--: | :---: | :---: |
-| 🤔 | 🤔 | 🤔 | [😀](TwoSum.py) | [😀](TwoSum.js) | 🤔 |
+
+| C++ | Java | Python | JS |
+| :--: | :--: | :--: | :---: |
+|[😀](TwoSum.cpp) | [😀](TwoSum.java) | [😀](TwoSum.py) | [😀](TwoSum.js) |
diff --git a/Array/TwoSum/TwoSum.cpp b/Array/TwoSum/TwoSum.cpp
new file mode 100644
index 0000000..d8f7bc6
--- /dev/null
+++ b/Array/TwoSum/TwoSum.cpp
@@ -0,0 +1,18 @@
+
+class Solution {
+public:
+ vector twoSum(vector& nums, int target) {
+ vector res;
+ map hashMap;
+ for(int i=0; i
-点击展开
-// TODO
-
-
-## 代码实现
-| C | C++ | Java | Objective-C | Swift | Python | JavaScript | Go | PHP |
-| :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: |
-| 🤔 | 🤔 | 🤔 | 🤔 | 🤔 | 🤔 | 🤔 | 🤔 | 🤔 |
-
diff --git a/DynamicProgramming/README.md b/DynamicProgramming/README.md
deleted file mode 100644
index 1c52c62..0000000
--- a/DynamicProgramming/README.md
+++ /dev/null
@@ -1,17 +0,0 @@
-# 动态规划(Dynamic Programming)
-
-[01. Minimum Path Sum(最小路径和)](./01.MinimumPathSum)
-
-[02. Coin Change (零钱兑换)](./02.CoinChange)
-
-[03. Best Time to Buy and Sell Stock(买卖股票的最佳时机)](./03.BuyAndSellStock)
-
-[04. Maximum Product Subarray](./04.MaximumProductSubarray)
-
-[05. Climbing Stairs(爬楼梯)](./05.ClimbingStairs)
-
-[06. Triangle(三角形最小路径和)](./06.Triangle)
-
-[07. EditDistance(最短编辑距离](./07.EditDistance)
-
-[08. Longest Increating Subseque(最长子序列)](./LongestIncreasingSubsequence)
diff --git a/LinkedList/05.ReverseNodesKGroup/ReverseNodesKGroup.py b/LinkedList/05.ReverseNodesKGroup/ReverseNodesKGroup.py
deleted file mode 100644
index b6f7935..0000000
--- a/LinkedList/05.ReverseNodesKGroup/ReverseNodesKGroup.py
+++ /dev/null
@@ -1,4 +0,0 @@
-class ListNode(object):
- def __init__(self, x):
- this.val = x;
- thit.next = Node;
diff --git a/LinkedList/LinkedListCycle/LinkedListCycle.cpp b/LinkedList/LinkedListCycle/LinkedListCycle.cpp
new file mode 100644
index 0000000..a425c74
--- /dev/null
+++ b/LinkedList/LinkedListCycle/LinkedListCycle.cpp
@@ -0,0 +1,12 @@
+class Solution {
+public:
+ bool hasCycle(ListNode *head) {
+ ListNode *fast = head, *slow = head;
+ while(fast && fast->next) {
+ fast = fast->next->next;
+ slow = slow->next;
+ if(fast == slow) { return true; }
+ }
+ return false;
+ }
+};
\ No newline at end of file
diff --git a/LinkedList/02.LinkedListCycle/LinkedListCycle.java b/LinkedList/LinkedListCycle/LinkedListCycle.java
similarity index 100%
rename from LinkedList/02.LinkedListCycle/LinkedListCycle.java
rename to LinkedList/LinkedListCycle/LinkedListCycle.java
diff --git a/LinkedList/02.LinkedListCycle/LinkedListCycle.py b/LinkedList/LinkedListCycle/LinkedListCycle.py
similarity index 100%
rename from LinkedList/02.LinkedListCycle/LinkedListCycle.py
rename to LinkedList/LinkedListCycle/LinkedListCycle.py
diff --git a/LinkedList/02.LinkedListCycle/README.md b/LinkedList/LinkedListCycle/README.md
similarity index 75%
rename from LinkedList/02.LinkedListCycle/README.md
rename to LinkedList/LinkedListCycle/README.md
index 4a19333..8282470 100644
--- a/LinkedList/02.LinkedListCycle/README.md
+++ b/LinkedList/LinkedListCycle/README.md
@@ -39,11 +39,11 @@
## 思路
点击展开
-// TODO
+快慢指针,快指针每次前进两步,慢指针每次前进一步。如果链表中不存在环,则快指针先到达链表尾;若存在环,则快慢指针总会相遇。
## 代码实现
| C | C++ | Java | Objective-C | Swift | Python | JavaScript | Go | PHP |
| :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: |
-| 🤔 | 🤔 | 🤔 | 🤔 | 🤔 | [😀](./LinkedListCycle.py) | 🤔 | 🤔 | 🤔 |
+| 🤔 | [😀](./LinkedListCycle.cpp) | [😀](./LinkedListCycle.java) | 🤔 | 🤔 | [😀](./LinkedListCycle.py) | 🤔 | [😀](./linked_list_cycle.go) | 🤔 |
diff --git a/LinkedList/02.LinkedListCycle/linked_list_cycle.go b/LinkedList/LinkedListCycle/linked_list_cycle.go
similarity index 89%
rename from LinkedList/02.LinkedListCycle/linked_list_cycle.go
rename to LinkedList/LinkedListCycle/linked_list_cycle.go
index 5b6d536..25fc2c9 100644
--- a/LinkedList/02.LinkedListCycle/linked_list_cycle.go
+++ b/LinkedList/LinkedListCycle/linked_list_cycle.go
@@ -14,7 +14,7 @@ func hasCycle(head *ListNode) bool {
fast := head
//fast move 2 step, slow move 1 step
- for fast != nil && st.Next != nil {
+ for fast != nil && fast.Next != nil {
fast = fast.Next.Next
slow = slow.Next
diff --git a/LinkedList/LinkedListCycle2/LinkedListCycle2.cpp b/LinkedList/LinkedListCycle2/LinkedListCycle2.cpp
new file mode 100644
index 0000000..940a3b5
--- /dev/null
+++ b/LinkedList/LinkedListCycle2/LinkedListCycle2.cpp
@@ -0,0 +1,19 @@
+class Solution {
+public:
+ ListNode *detectCycle(ListNode *head) {
+ ListNode *fast = head, *slow = head;
+ while (fast && fast->next) {
+ fast = fast->next->next;
+ slow = slow->next;
+ if (fast == slow) {
+ fast = head;
+ while (fast != slow) {
+ fast = fast->next;
+ slow = slow->next;
+ }
+ return fast;
+ }
+ }
+ return nullptr;
+ }
+};
\ No newline at end of file
diff --git a/LinkedList/03.LinkedListCycle2/LinkedListCycle2.py b/LinkedList/LinkedListCycle2/LinkedListCycle2.py
similarity index 100%
rename from LinkedList/03.LinkedListCycle2/LinkedListCycle2.py
rename to LinkedList/LinkedListCycle2/LinkedListCycle2.py
diff --git a/LinkedList/03.LinkedListCycle2/README.md b/LinkedList/LinkedListCycle2/README.md
similarity index 70%
rename from LinkedList/03.LinkedListCycle2/README.md
rename to LinkedList/LinkedListCycle2/README.md
index 4d12eae..0006655 100644
--- a/LinkedList/03.LinkedListCycle2/README.md
+++ b/LinkedList/LinkedListCycle2/README.md
@@ -39,12 +39,14 @@
## 思路
点击展开
-// TODO
+快慢指针找到相遇点;快指针指回链表头部,慢指针指向相遇点,每次将它们向前移动一步,直到再次相遇,相遇点就是环的入口。
+
+说明:
+
+设链表头部到环的入口长度为`a`,环的长度为`b`,环的入口到相遇点的长度为`c`:则`f=2s=s+nb`,`s=nb=a+c+(n-1)b`,`b=a+c`,即慢指针从相遇点继续前进`a`步就是环的入口。
## 代码实现
| C | C++ | Java | Objective-C | Swift | Python | JavaScript | Go | PHP |
| :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: |
-| 🤔 | 🤔 | 🤔 | 🤔 | 🤔 | [😀](./LinkedListCycle2.py) | 🤔 | 🤔 | 🤔 |
-
-完成 😀,待完成 🤔
+| 🤔 | [😀](./LinkedListCycle2.cpp) | 🤔 | 🤔 | 🤔 | [😀](./LinkedListCycle2.py) | 🤔 | 🤔 | 🤔 |
diff --git a/LinkedList/06.MergeKSortedLists/ListNode.java b/LinkedList/MergeKSortedLists/ListNode.java
similarity index 100%
rename from LinkedList/06.MergeKSortedLists/ListNode.java
rename to LinkedList/MergeKSortedLists/ListNode.java
diff --git a/LinkedList/MergeKSortedLists/MergeKSortedLists.cpp b/LinkedList/MergeKSortedLists/MergeKSortedLists.cpp
new file mode 100644
index 0000000..8bf5552
--- /dev/null
+++ b/LinkedList/MergeKSortedLists/MergeKSortedLists.cpp
@@ -0,0 +1,95 @@
+/*
+* 递归
+* Runtime: 324 ms
+* Memory Usage: 43.1 MB
+*/
+class Solution {
+public:
+ ListNode* mergeKLists(vector& lists) {
+ lists.erase(remove(lists.begin(), lists.end(), nullptr), lists.end());
+ if(lists.empty()) { return nullptr; }
+ auto min_iter = min_element(lists.begin(), lists.end(), [](ListNode *p1, ListNode *p2){ return p1->val < p2->val; });
+ ListNode *minNode = *min_iter;
+ *min_iter = (*min_iter)->next;
+ if(*min_iter == nullptr) { lists.erase(min_iter); }
+ minNode->next = mergeKLists(lists);
+ return minNode;
+ }
+};
+
+/*
+* 分治1(迭代实现归并)
+* Runtime: 24 ms
+* Memory Usage: 11.1 MB
+*/
+class Solution {
+public:
+ ListNode* _mergeTwolists(ListNode* l1, ListNode* l2) {
+ ListNode *dummy = new ListNode(0);
+ ListNode *newHead = dummy;
+ while (l1 && l2) {
+ if(l1->val < l2->val) {
+ dummy->next = l1;
+ l1 = l1->next;
+ }
+ else {
+ dummy->next = l2;
+ l2 = l2->next;
+ }
+ dummy = dummy->next;
+ }
+ dummy->next = l1 ? l1 : l2;
+ return newHead->next;
+ }
+
+ ListNode* mergeKLists(vector& lists) {
+ if(lists.empty()) { return nullptr; }
+ int interval = 1;
+ while(interval < lists.size()) {
+ for(int i=0; ival < l2->val) {
+ dummy->next = l1;
+ l1 = l1->next;
+ }
+ else {
+ dummy->next = l2;
+ l2 = l2->next;
+ }
+ dummy = dummy->next;
+ }
+ dummy->next = l1 ? l1 : l2;
+ return newHead->next;
+ }
+
+ ListNode* _mergeKLists(vector& lists, int l, int r) {
+ if (l == r) { return lists[l]; }
+ int mid = (l+r) / 2;
+ ListNode *l1 = _mergeKLists(lists, l, mid);
+ ListNode *l2 = _mergeKLists(lists, mid+1, r);
+ return _mergeTwolists(l1, l2);
+ }
+
+ ListNode* mergeKLists(vector& lists) {
+ if(lists.empty()) { return nullptr; }
+ return _mergeKLists(lists, 0, lists.size()-1);
+ }
+};
\ No newline at end of file
diff --git a/LinkedList/06.MergeKSortedLists/MergeKSortedLists.java b/LinkedList/MergeKSortedLists/MergeKSortedLists.java
similarity index 100%
rename from LinkedList/06.MergeKSortedLists/MergeKSortedLists.java
rename to LinkedList/MergeKSortedLists/MergeKSortedLists.java
diff --git a/LinkedList/MergeKSortedLists/MergeKSortedLists.php b/LinkedList/MergeKSortedLists/MergeKSortedLists.php
new file mode 100644
index 0000000..84f3a02
--- /dev/null
+++ b/LinkedList/MergeKSortedLists/MergeKSortedLists.php
@@ -0,0 +1,89 @@
+val = $val; }
+ * }
+ */
+class Solution
+{
+
+ /**
+ * @param ListNode[] $lists
+ * @return ListNode
+ *暴力破解法
+ * 取出所有的数 排序 重新生成一个新的链表e
+ */
+ function mergeKLists($lists)
+ {
+ $res = [];
+ for ($i = 0; $i < count($lists); $i++) {
+ $node = $lists[$i];
+ while ($node) {
+ $res[] = $node->val;
+ $node = $node->next;
+ }
+ }
+ // sort($res); 不使用php内置函数排序
+ $res = $this->merge_sort($res);
+ $result = $newList = new listNode(-1);
+
+ foreach ($res as $item) {
+ $newList->next = new listNode($item);
+ $newList = $newList->next;
+
+ }
+ return $result->next;
+ }
+
+ function merge_sort($nums)
+ {
+ if (count($nums) <= 1) {
+ return $nums;
+ }
+ $this->merge_sort_c($nums, 0, count($nums) - 1);
+ return $nums;
+ }
+
+ function merge_sort_c(&$nums, $p, $r)
+ {
+ if ($p >= $r) {
+ return;
+ }
+ $middle = $p + (($r - $p) >> 1);
+ $this->merge_sort_c($nums, $p, $middle);
+ $this->merge_sort_c($nums, $middle + 1, $r);
+ $this->merge($nums, ['start' => $p, 'end' => $middle], ['start' => $middle + 1, 'end' => $r]);
+ }
+
+ function merge(&$nums, $array_p, $array_r)
+ {
+ $temp = [];
+ $p = $array_p['start'];
+ $r = $array_r['start'];
+ $k = 0;
+ while ($p <= $array_p['end'] && $r <= $array_r['end']) {
+ if ($nums[$p] < $nums[$r]) {
+ $temp[$k++] = $nums[$p++];
+ } else {
+ $temp[$k++] = $nums[$r++];
+ }
+ }
+ while ($p <= $array_p['end']) {
+ $temp[$k++] = $nums[$p++];
+ }
+ while ($r <= $array_r['end']) {
+ $temp[$k++] = $nums[$r++];
+ }
+
+ for ($i = 0; $i < $k; $i++) {
+ $nums[$i + $array_p['start']] = $temp[$i];
+ }
+
+ }
+
+
+}
\ No newline at end of file
diff --git a/LinkedList/06.MergeKSortedLists/README.md b/LinkedList/MergeKSortedLists/README.md
similarity index 63%
rename from LinkedList/06.MergeKSortedLists/README.md
rename to LinkedList/MergeKSortedLists/README.md
index 4f46d58..ad9d5dc 100644
--- a/LinkedList/06.MergeKSortedLists/README.md
+++ b/LinkedList/MergeKSortedLists/README.md
@@ -22,11 +22,15 @@
## 思路
点击展开
-// TODO
+
+思路一:纯递归实现,每次从`lists`中找出`val`最小的节点,将其指针前进一步;
+
+思路二:分治思想,将问题划分为更小规模的子问题([合并2个有序链表](../04.MergeSortedLists))。
+
## 代码实现
| C | C++ | Java | Objective-C | Swift | Python | JavaScript | Go | PHP |
| :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: |
-| 🤔 | 🤔 | 🤔 | 🤔 | 🤔 | 🤔 | 🤔 | 🤔 | 🤔 |
+| 🤔 | [😀](./MergeKSortedLists.cpp) | [😀](./MergeKSortedLists.java) | 🤔 | 🤔 | 🤔 | 🤔 | 🤔 | 🤔 |
diff --git a/LinkedList/MergeSortedLists/MergeSortedLists.cpp b/LinkedList/MergeSortedLists/MergeSortedLists.cpp
new file mode 100644
index 0000000..8762b87
--- /dev/null
+++ b/LinkedList/MergeSortedLists/MergeSortedLists.cpp
@@ -0,0 +1,39 @@
+/// 迭代
+class Solution {
+public:
+ ListNode* mergeTwoLists(ListNode* l1, ListNode* l2) {
+ ListNode *mergeNode = new ListNode(0);
+ ListNode *newHead = mergeNode;
+ while(l1 && l2) {
+ if(l1->val < l2->val) {
+ mergeNode->next = l1;
+ l1 = l1->next;
+ }
+ else {
+ mergeNode->next = l2;
+ l2 = l2->next;
+ }
+ mergeNode = mergeNode->next;
+ }
+ mergeNode->next = l1 ? l1 : l2;
+ return newHead->next;
+ }
+};
+
+/// 递归
+class Solution {
+public:
+ ListNode* mergeTwoLists(ListNode* l1, ListNode* l2) {
+ if (l1 && l2) {
+ if(l1->val < l2->val){
+ l1->next = mergeTwoLists(l1->next, l2);
+ return l1;
+ }
+ else {
+ l2->next = mergeTwoLists(l1, l2->next);
+ return l2;
+ }
+ }
+ return l1 ? l1 : l2;
+ }
+};
\ No newline at end of file
diff --git a/LinkedList/MergeSortedLists/MergeSortedLists.php b/LinkedList/MergeSortedLists/MergeSortedLists.php
new file mode 100644
index 0000000..b23c05b
--- /dev/null
+++ b/LinkedList/MergeSortedLists/MergeSortedLists.php
@@ -0,0 +1,52 @@
+val = $val; }
+ * }
+ */
+class Solution
+{
+
+ /**
+ * @param ListNode $l1
+ * @param ListNode $l2
+ * @return ListNode
+ */
+ function mergeTwoLists($l1, $l2)
+ {
+ $pc = $newList = new ListNode(null);
+ while ($l1 && $l2) {
+ if ($l1->val <= $l2->val) {
+ $newList->next = $l1;
+ $newList = $newList->next;
+ $l1 = $l1->next;
+ } else {
+ $newList->next = $l2;
+ $newList = $newList->next;
+ $l2 = $l2->next;
+ }
+
+ }
+ $newList->next = $l1 ?? $l2;
+ return $pc->next;
+ }
+
+ //递归
+ function mergeTwoListsForRecursion($l1, $l2)
+ {
+ if (!$l1) return $l2;
+ if (!$l2) return $l1;
+
+ if ($l1->val <= $l2->val) {
+ $l1->next = $this->mergeTwoLists($l1->next, $l2);
+ return $l1;
+ } else {
+ $l2->next = $this->mergeTwoLists($l2->next, $l1);
+ return $l2;
+ }
+ }
+}
\ No newline at end of file
diff --git a/LinkedList/04.MergeSortedLists/MergeSortedLists.py b/LinkedList/MergeSortedLists/MergeSortedLists.py
similarity index 87%
rename from LinkedList/04.MergeSortedLists/MergeSortedLists.py
rename to LinkedList/MergeSortedLists/MergeSortedLists.py
index 824b627..8c8877e 100644
--- a/LinkedList/04.MergeSortedLists/MergeSortedLists.py
+++ b/LinkedList/MergeSortedLists/MergeSortedLists.py
@@ -16,6 +16,6 @@ def mergeTwoLists(self, l1, l2):
l2 = l2.next
dummy = dummy.next
- dummy.next = l1 ? l1 : l2
+ dummy.next = l1 if l1 else l2
- return head.next
+ return head.next
diff --git a/LinkedList/04.MergeSortedLists/README.md b/LinkedList/MergeSortedLists/README.md
similarity index 84%
rename from LinkedList/04.MergeSortedLists/README.md
rename to LinkedList/MergeSortedLists/README.md
index 8f62073..20ceafa 100644
--- a/LinkedList/04.MergeSortedLists/README.md
+++ b/LinkedList/MergeSortedLists/README.md
@@ -24,6 +24,4 @@
## 代码实现
| C | C++ | Java | Objective-C | Swift | Python | JavaScript | Go | PHP |
| :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: |
-| 🤔 | 🤔 | 🤔 | 🤔 | 🤔 | [😀](./MergeSortedLists.py) | 🤔 | 🤔 | 🤔 |
-
-完成 😀,待完成 🤔
+| 🤔 | [😀](./MergeSortedLists.cpp) | 🤔 | 🤔 | 🤔 | [😀](./MergeSortedLists.py) | 🤔 | 🤔 | 🤔 |
diff --git a/LinkedList/README.md b/LinkedList/README.md
index bde7728..478bee9 100644
--- a/LinkedList/README.md
+++ b/LinkedList/README.md
@@ -1,13 +1,13 @@
-# LinkedList(链表)
+# LinkedList
-[01. Reverse Linked List(反转链表)](./01.ReverseLinkedList)
+- [Reverse Linked List](./ReverseLinkedList)
-[02. Linked List Cycle(检测链表是否有环)](./02.LinkedListCycle)
+- [Linked List Cycle](./LinkedListCycle)
-[03. Linked List Cycle II(检测链表是否有环II)](./03.LinkedListCycle2)
+- [Lnked List Cycle II](./LinkedListCycle2)
-[04. Merge Two Sorted Lists(合并两个有序链表)](./04.MergeSortedLists)
+- [Merge Two Sorted Lists](./MergeSortedLists)
-[05. Reverse Nodes in k-Group(以 k 为一组反转链表)](./05.ReverseNodesKGroup)
+- [Merge k Sorted Lists](./MergeKSortedLists)
-[06. Merge k Sorted Lists(合并 k 个排序链表)](./06.MergeKSortedLists)
+- [Reverse Nodes in k-Group](./ReverseNodesKGroup)
diff --git a/LinkedList/01.ReverseLinkedList/README.md b/LinkedList/ReverseLinkedList/README.md
similarity index 64%
rename from LinkedList/01.ReverseLinkedList/README.md
rename to LinkedList/ReverseLinkedList/README.md
index 3a0340d..d6d4b06 100644
--- a/LinkedList/01.ReverseLinkedList/README.md
+++ b/LinkedList/ReverseLinkedList/README.md
@@ -20,11 +20,15 @@
## 思路
点击展开
-// TODO
+
+1. 迭代:引入两个指针,prev记录上一个节点,back记录下一个节点,时间复杂度O(n),空间复杂度O(1);
+
+2. 递归:head.next.next = head;时间复杂度O(n),空间复杂度O(n)。
+
## 代码实现
| C | C++ | Java | Objective-C | Swift | Python | JavaScript | Go | PHP |
| :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: |
-| 🤔 | 🤔 | 🤔 | 🤔 | 🤔 | [😀](./ReverseLinkedList.py) | 🤔 | 🤔 | 🤔 |
+| 🤔 | [😀](./ReverseLinkedList.cpp) | 🤔 | 🤔 | 🤔 | [😀](./ReverseLinkedList.py) | 🤔 | 🤔 | 🤔 |
diff --git a/LinkedList/ReverseLinkedList/ReverseLinkedList.cpp b/LinkedList/ReverseLinkedList/ReverseLinkedList.cpp
new file mode 100644
index 0000000..42bd130
--- /dev/null
+++ b/LinkedList/ReverseLinkedList/ReverseLinkedList.cpp
@@ -0,0 +1,44 @@
+/// 迭代
+class Solution {
+public:
+ ListNode* reverseList(ListNode *head) {
+ ListNode *prev = nullptr;
+ ListNode *back;
+ while(head) {
+ back = head->next;
+ head->next = prev;
+ prev = head;
+ head = back;
+ }
+ return prev;
+ }
+};
+
+
+/// 递归一:
+class Solution {
+public:
+ ListNode* _reverseList(ListNode *head, ListNode *prev = nullptr){
+ if (head == nullptr) { return prev; }
+ ListNode *back = head->next;
+ head->next = prev;
+ return _reverseList(back, head);
+ }
+
+ ListNode* reverseList(ListNode* head) {
+ return _reverseList(head);
+ }
+};
+
+
+/// 递归二:
+class Solution {
+public:
+ ListNode* reverseList(ListNode *head) {
+ if(head == nullptr || head->next == nullptr) { return head; }
+ ListNode *new_head = reverseList(head->next);
+ head->next->next = head;
+ head->next = nullptr;
+ return new_head;
+ }
+};
diff --git a/DynamicProgramming/03.BuyAndSellStock/buyAndSellStock.js b/LinkedList/ReverseLinkedList/ReverseLinkedList.js
old mode 100755
new mode 100644
similarity index 100%
rename from DynamicProgramming/03.BuyAndSellStock/buyAndSellStock.js
rename to LinkedList/ReverseLinkedList/ReverseLinkedList.js
diff --git a/LinkedList/ReverseLinkedList/ReverseLinkedList.php b/LinkedList/ReverseLinkedList/ReverseLinkedList.php
new file mode 100644
index 0000000..298dcb3
--- /dev/null
+++ b/LinkedList/ReverseLinkedList/ReverseLinkedList.php
@@ -0,0 +1,46 @@
+val = $val; }
+ * }
+ */
+class Solution
+{
+
+
+ /**
+ * @param ListNode $head
+ * @return ListNode
+ */
+ function reverseList($head)
+ {
+ $current = $head;
+ $newList = null;
+ while ($current) {
+ $nextNode = $current->next;
+ $current->next = $newList;
+ $newList = $current;
+ $current = $nextNode;
+ }
+
+ return $newList;
+ }
+
+
+ //recursion
+ function reverseListForRecursion($head){
+
+ if(!$head || !$head->next){
+ return $head;
+ }
+ $newList=$this->reverseList($head->next);
+ //we want n(k+1)'s next node to point k(n),so
+ $head->next->next=$head;
+ $head->next=null;
+ return $newList;
+ }
+}
\ No newline at end of file
diff --git a/LinkedList/01.ReverseLinkedList/ReverseLinkedList.py b/LinkedList/ReverseLinkedList/ReverseLinkedList.py
similarity index 100%
rename from LinkedList/01.ReverseLinkedList/ReverseLinkedList.py
rename to LinkedList/ReverseLinkedList/ReverseLinkedList.py
diff --git a/LinkedList/05.ReverseNodesKGroup/README.md b/LinkedList/ReverseNodesKGroup/README.md
similarity index 54%
rename from LinkedList/05.ReverseNodesKGroup/README.md
rename to LinkedList/ReverseNodesKGroup/README.md
index d043fb1..f820c65 100644
--- a/LinkedList/05.ReverseNodesKGroup/README.md
+++ b/LinkedList/ReverseNodesKGroup/README.md
@@ -28,10 +28,18 @@ k 是一个正整数,它的值小于或等于链表的长度。如果节点总
## 思路
点击展开
-// TODO
+
+该题有两种解法,递归和迭代。
+
+递归:取前 k 个节点,进行翻转,如果不足 k 个,则不翻转。剩下的链表其实是题目的子问题,递归调用即可。将递归调用后的链表与前 k 个翻转的链表进行连接。连接后的结果返回,就是目标解。
+
+迭代:迭代的解法比递归的难。需要借助辅助节点。开始时辅助节点指向头节点。
+用两个指针(prev、back)分别记录前驱后继,另外两个指针(begin、end)记录子链表首尾;子链表翻转后将其与前面已翻转链表和后面未翻转链表进行连接。
+
## 代码实现
-| C | C++ | Java | Objective-C | Swift | Python | JavaScript | Go | PHP |
+| C++ | Java | Swift | Python | JavaScript | Go |
| :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: |
-| 🤔 | 🤔 | 🤔 | 🤔 | 🤔 | 🤔 | 🤔 | 🤔 | 🤔 |
+| [😀](./ReverseNodesKGroup.cpp) | 🤔 | 🤔 | 🤔 | [😀](./ReverseNodesKGroup.js)| 🤔 |
+
diff --git a/LinkedList/ReverseNodesKGroup/ReverseNodesKGroup.cpp b/LinkedList/ReverseNodesKGroup/ReverseNodesKGroup.cpp
new file mode 100644
index 0000000..aa93cf4
--- /dev/null
+++ b/LinkedList/ReverseNodesKGroup/ReverseNodesKGroup.cpp
@@ -0,0 +1,40 @@
+/**
+ * Definition for singly-linked list.
+ * struct ListNode {
+ * int val;
+ * ListNode *next;
+ * ListNode(int x) : val(x), next(NULL) {}
+ * };
+ */
+class Solution {
+public:
+ ListNode* _reverseKGroup(ListNode* head) {
+ ListNode *prev = nullptr, *curr = head, *back;
+ while (curr) {
+ back = curr->next;
+ curr->next = prev;
+ prev = curr;
+ curr = back;
+ }
+ return prev;
+ }
+
+ ListNode* reverseKGroup(ListNode* head, int k) {
+ ListNode *dummy = new ListNode(0); dummy->next = head;
+ ListNode *end, *begin = head; // 链表首尾
+ ListNode *back, *prev = dummy; // 前驱后继
+ while(1){
+ end = begin;
+ for(int i=1; inext; }
+ if(end == nullptr) { break; }
+ back = end->next; // 记录后继
+ // 链表反转
+ end->next = nullptr;
+ prev->next = _reverseKGroup(begin); // 连接前面已翻转链表
+ begin->next = back; // 连接后面未翻转链表
+ prev = begin; // 更新前驱
+ begin = back; // 更新链表首
+ }
+ return dummy->next;
+ }
+};
\ No newline at end of file
diff --git a/LinkedList/ReverseNodesKGroup/ReverseNodesKGroup.js b/LinkedList/ReverseNodesKGroup/ReverseNodesKGroup.js
new file mode 100644
index 0000000..983acb7
--- /dev/null
+++ b/LinkedList/ReverseNodesKGroup/ReverseNodesKGroup.js
@@ -0,0 +1,77 @@
+// 以 k 为一组翻转链表
+// https://leetcode.com/problems/reverse-nodes-in-k-group/
+//
+/**
+ * 题解,递归解法
+ * 1. 尝试将头结点后移动 k 位,如果不足 k 位,直接返回头结点
+ * 2. 如果存在 k 个结点,用新的头结点,递归
+ * 3. 得到的结果连接到头 k 的节点的逆序链表后面
+ * 4. 重新设置头结点,返回
+ */
+var reverseKGroup = function(head, k) {
+ let curr = head;
+ let count = 0;
+ while (curr && count != k) {
+ curr = curr.next;
+ ++count;
+ }
+ if (count === k) {
+ curr = reverseKGroup(curr, k);
+
+ while (count-- > 0) {
+ let tmp = head.next;
+ head.next = curr;
+ curr = head;
+ head = tmp;
+ }
+ head = curr;
+ }
+ return head;
+};
+
+/**
+ * 迭代解法
+ * 遍历链表,如果有 k 个,就翻转,然后将翻转后的 group 与已翻转和未翻转的链表合并
+ */
+
+ // Runtime: 68 ms, faster than 92.95% of JavaScript online submissions for Reverse Nodes in k-Group.
+var reverseKGroup2 = function(head, k) {
+ // 初始化一个节点用于指向头结点
+ var dump = jump = new ListNode(0);
+ dump.next = head;
+
+ // l 前一个 group 的 head
+ // r 后一个 group 的 head
+ var l = r = head;
+
+ while (true) {
+ var count = 0;
+ // r 移到下一组 group 的头部
+ while (r && count < k) {
+ r = r.next;
+ count++;
+ }
+ // 翻转 [l, r) 之间的链表
+ if (count === k) {
+ let cur = l, pre = r;
+ while(count--) {
+ let tmp = cur.next;
+ cur.next = pre;
+ pre = cur;
+ cur = tmp;
+ }
+ // 翻转后 pre 为当前 group 头节点
+ // jump 为前一个 group 的尾结点或辅助节点
+ // 将前一个 group 的尾结点指向当前 group 的节点
+ jump.next = pre;
+ // jump 指向当前 group 的最后一个节点
+ jump = l;
+ // l 指向下一组 group 的头节点
+ l = r;
+ } else {
+ // 因为 dump 等于 jump 的初始
+ // 而 jump 的初值的 next 指向链表的头部
+ return dump.next;
+ }
+ }
+};
diff --git a/LinkedList/ReverseNodesKGroup/ReverseNodesKGroup.php b/LinkedList/ReverseNodesKGroup/ReverseNodesKGroup.php
new file mode 100644
index 0000000..de1bcb5
--- /dev/null
+++ b/LinkedList/ReverseNodesKGroup/ReverseNodesKGroup.php
@@ -0,0 +1,39 @@
+val = $val; }
+ * }
+ */
+class Solution
+{
+
+ /**
+ * @param ListNode $head
+ * @param Integer $k
+ * @return ListNode
+ */
+ function reverseKGroup($head, $k)
+ {
+ $dummy = new ListNode(-1);
+ $pre = $cur = $dummy;
+ $dummy->next = $head;
+ $num = 0;
+ while ($cur = $cur->next) ++$num;
+ while ($num >= $k) {
+ $cur = $pre->next;
+ for ($i = 1; $i < $k; ++$i) {
+ $t = $cur->next;
+ $cur->next = $t->next;
+ $t->next = $pre->next;
+ $pre->next = $t;
+ }
+ $pre = $cur;
+ $num -= $k;
+ }
+ return $dummy->next;
+ }
+}
\ No newline at end of file
diff --git a/Queue/03.QueueUsingStacks/QueueUsingStacks.php b/Queue/03.QueueUsingStacks/QueueUsingStacks.php
new file mode 100644
index 0000000..771bcdd
--- /dev/null
+++ b/Queue/03.QueueUsingStacks/QueueUsingStacks.php
@@ -0,0 +1,70 @@
+stock)) {
+ array_unshift($this->temp, array_shift($this->stock));
+ }
+ array_unshift($this->stock, $x);
+
+ while (!empty($this->temp)) {
+ array_unshift($this->stock, array_shift($this->temp));
+ }
+
+ }
+
+ /**
+ * Removes the element from in front of queue and returns that element.
+ * @return Integer
+ */
+ function pop()
+ {
+ return array_shift($this->stock);
+ }
+
+ /**
+ * Get the front element.
+ * @return Integer
+ */
+ function peek()
+ {
+ return current($this->stock);
+ }
+
+ /**
+ * Returns whether the queue is empty.
+ * @return Boolean
+ */
+ function empty()
+ {
+ return empty($this->stock);
+ }
+}
+
+/**
+ * Your MyQueue object will be instantiated and called as such:
+ * $obj = MyQueue();
+ * $obj->push($x);
+ * $ret_2 = $obj->pop();
+ * $ret_3 = $obj->peek();
+ * $ret_4 = $obj->empty();
+ */
\ No newline at end of file
diff --git a/Queue/03.QueueUsingStacks/README.md b/Queue/03.QueueUsingStacks/README.md
index 8a1d1ff..104fb27 100644
--- a/Queue/03.QueueUsingStacks/README.md
+++ b/Queue/03.QueueUsingStacks/README.md
@@ -35,5 +35,5 @@ queue.empty(); // 返回 false
## 代码实现
| C | C++ | Java | Objective-C | Swift | Python | JavaScript | Go | PHP |
| :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: |
-| 🤔 | 🤔 | 🤔 | 🤔 | 🤔 | 🤔 | 🤔 | 🤔 | 🤔 |
+| 🤔 | [😀](./implementQueueUsingStacks.hpp) | 🤔 | 🤔 | 🤔 | 🤔 | 🤔 | 🤔 | 🤔 |
diff --git a/Queue/03.QueueUsingStacks/implementQueueUsingStacks.hpp b/Queue/03.QueueUsingStacks/implementQueueUsingStacks.hpp
new file mode 100644
index 0000000..238b944
--- /dev/null
+++ b/Queue/03.QueueUsingStacks/implementQueueUsingStacks.hpp
@@ -0,0 +1,66 @@
+#ifndef IMPLEMENTQUEUEUSINGSTACKS_HPP
+#define IMPLEMENTQUEUEUSINGSTACKS_HPP
+
+/*
+ * 232. Implement Queue using Stacks
+ * https://leetcode.com/problems/implement-queue-using-stacks/
+ */
+
+#include
+
+using namespace std;
+
+class MyQueue {
+public:
+ stack s1;
+ stack s2;
+
+ /** Initialize your data structure here. */
+ MyQueue() { }
+
+ /** Push element x to the back of queue. */
+ void push(int x) {
+ s1.push(x);
+ }
+
+ /** Removes the element from in front of queue and returns that element. */
+ int pop() {
+ if (s2.empty()) {
+ while (!s1.empty()) {
+ s2.push(s1.top());
+ s1.pop();
+ }
+ }
+ int front = s2.top();
+ s2.pop();
+ return front;
+ }
+
+ /** Get the front element. */
+ int peek() {
+ if (s2.empty()) {
+ while (!s1.empty()) {
+ s2.push(s1.top());
+ s1.pop();
+ }
+ }
+ return s2.top();
+ }
+
+ /** Returns whether the queue is empty. */
+ bool empty() {
+ return s1.empty() && s2.empty();
+ }
+};
+
+/**
+ * Your MyQueue object will be instantiated and called as such:
+ * MyQueue* obj = new MyQueue();
+ * obj->push(x);
+ * int param_2 = obj->pop();
+ * int param_3 = obj->peek();
+ * bool param_4 = obj->empty();
+ */
+
+
+#endif //IMPLEMENTQUEUEUSINGSTACKS_HPP
diff --git a/Queue/04.CircularDeque/CircularDeque.hpp b/Queue/04.CircularDeque/CircularDeque.hpp
new file mode 100644
index 0000000..6463ffb
--- /dev/null
+++ b/Queue/04.CircularDeque/CircularDeque.hpp
@@ -0,0 +1,67 @@
+class MyCircularDeque {
+public:
+ vector _vec;
+ int _head;
+ int _tail;
+ int _size;
+
+public:
+ /** Initialize your data structure here. Set the size of the deque to be k. */
+ MyCircularDeque(int k) {
+ _size = k + 1; // tail不存数据,循环队列会浪费一个数组的存储空间
+ _vec.resize(_size, 0);
+ _head = _tail = 0;
+ }
+
+ /** Adds an item at the front of Deque. Return true if the operation is successful. */
+ bool insertFront(int value) {
+ if (isFull()) { return false; }
+ _head = (_head - 1 + _size) % _size;
+ _vec[_head] = value;
+ return true;
+ }
+
+ /** Adds an item at the rear of Deque. Return true if the operation is successful. */
+ bool insertLast(int value) {
+ if (isFull()) { return false; }
+ _vec[_tail] = value;
+ _tail = (_tail + 1) % _size;
+ return true;
+ }
+
+ /** Deletes an item from the front of Deque. Return true if the operation is successful. */
+ bool deleteFront() {
+ if (isEmpty()) { return false; }
+ _head = (_head + 1) % _size;
+ return true;
+ }
+
+ /** Deletes an item from the rear of Deque. Return true if the operation is successful. */
+ bool deleteLast() {
+ if (isEmpty()) { return false; }
+ _tail = (_tail - 1 + _size) % _size;
+ return true;
+ }
+
+ /** Get the front item from the deque. */
+ int getFront() {
+ if (isEmpty()) { return -1; }
+ return _vec[_head];
+ }
+
+ /** Get the last item from the deque. */
+ int getRear() {
+ if (isEmpty()) { return -1; }
+ return _vec[(_tail - 1 + _size) % _size];
+ }
+
+ /** Checks whether the circular deque is empty or not. */
+ bool isEmpty() {
+ return _head == _tail;
+ }
+
+ /** Checks whether the circular deque is full or not. */
+ bool isFull() {
+ return (_tail + 1) % _size == _head;
+ }
+};
\ No newline at end of file
diff --git a/Queue/04.CircularDeque/CircularDeque.py b/Queue/04.CircularDeque/CircularDeque.py
index 0353d4e..488210d 100644
--- a/Queue/04.CircularDeque/CircularDeque.py
+++ b/Queue/04.CircularDeque/CircularDeque.py
@@ -49,12 +49,12 @@ def deleteFront(self):
"""
if self.isEmpty():
return False
- self._data[self._front] = -1;
+ self._data[self._front] = -1
self._front = (self._front - 1) % self._capacity
self._size -= 1
if self.isEmpty():
self._rear = self._front
- return True;
+ return True
def deleteLast(self):
"""
@@ -65,7 +65,7 @@ def deleteLast(self):
return False
self._data[self._rear] = -1
self._rear = (self._rear + 1) % self._capacity
- self._size -= 1;
+ self._size -= 1
if self.isEmpty():
self._front = self._rear
return True
@@ -97,5 +97,5 @@ def isFull(self):
Checks whether the circular deque is full or not.
:rtype: bool
"""
- return self._size == self._capacity;
+ return self._size == self._capacity
diff --git a/Queue/04.CircularDeque/README.md b/Queue/04.CircularDeque/README.md
index 75a617e..d21e421 100644
--- a/Queue/04.CircularDeque/README.md
+++ b/Queue/04.CircularDeque/README.md
@@ -17,6 +17,6 @@
## 代码实现
| C | C++ | Java | Objective-C | Swift | Python | JavaScript | Go | PHP |
| :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: |
-| 🤔 | 🤔 | 🤔 | 🤔 | 🤔 | [😀](./CircularDeque.py) | 🤔 | 🤔 | 🤔 |
+| 🤔 | [😀](./CircularDeque.hpp) | 🤔 | 🤔 | 🤔 | [😀](./CircularDeque.py) | 🤔 | 🤔 | 🤔 |
完成 😀,待完成 🤔
diff --git a/Queue/05.SlidingWindowMaximum/README.md b/Queue/05.SlidingWindowMaximum/README.md
index cdcbdaa..714c2f0 100644
--- a/Queue/05.SlidingWindowMaximum/README.md
+++ b/Queue/05.SlidingWindowMaximum/README.md
@@ -42,5 +42,5 @@
## 代码实现
| C | C++ | Java | Objective-C | Swift | Python | JavaScript | Go | PHP |
| :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: |
-| 🤔 | 🤔 | 🤔 | 🤔 | 🤔 | 🤔 | [😀](./SlidingWindowMaximum.js) | 🤔 | 🤔 |
+| 🤔 | [😀](./SlidingWindowMaximum.cpp) | 🤔 | 🤔 | 🤔 | 🤔 | [😀](./SlidingWindowMaximum.js) | 🤔 | 🤔 |
diff --git a/Queue/05.SlidingWindowMaximum/SlidingWindowMaximum.cpp b/Queue/05.SlidingWindowMaximum/SlidingWindowMaximum.cpp
new file mode 100644
index 0000000..e3b6e1f
--- /dev/null
+++ b/Queue/05.SlidingWindowMaximum/SlidingWindowMaximum.cpp
@@ -0,0 +1,17 @@
+class Solution {
+public:
+ vector maxSlidingWindow(vector& nums, int k) {
+ vector res;
+ deque que;
+ for (int i =0; i < nums.size(); ++i) {
+ if (!que.empty() && que.front() == i - k) // 队列头超出滑动窗口
+ que.pop_front();
+ while (!que.empty() && nums[i] >= nums[que.back()]) // 删除队列尾元素,直到大于当前元素的元素
+ que.pop_back();
+ que.push_back(i); // 当前元素入队
+ if (i >= k - 1)
+ res.push_back(nums[que.front()]);
+ }
+ return res;
+ }
+};
\ No newline at end of file
diff --git a/Sort/08.SortColors/README.md b/Sort/08.SortColors/README.md
index e162168..3bb3d6e 100644
--- a/Sort/08.SortColors/README.md
+++ b/Sort/08.SortColors/README.md
@@ -24,11 +24,11 @@ LeetCode 75
## 思路
点击展开
-// TODO
+使用三个指针,分别指向当前元素、最右侧的0和最左侧的2;当前元素为0则与左侧的2交换,当前元素为2则与右侧的0交换。
## 代码实现
| C | C++ | Java | Objective-C | Swift | Python | JavaScript | Go | PHP |
| :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: |
-| 🤔 | 🤔 | 🤔 | 🤔 | 🤔 | 🤔 | 🤔 | 🤔 | 🤔 |
+| 🤔 | [😀](./sortColors.cpp) | 🤔 | 🤔 | 🤔 | 🤔 | 🤔 | 🤔 | 🤔 |
diff --git a/Sort/08.SortColors/sortColors.cpp b/Sort/08.SortColors/sortColors.cpp
new file mode 100644
index 0000000..db950d7
--- /dev/null
+++ b/Sort/08.SortColors/sortColors.cpp
@@ -0,0 +1,24 @@
+/* 荷兰国旗问题
+ * 使用三个指针,分别指向当前元素、最右侧的0和最左侧的2
+ */
+
+class Solution {
+public:
+ void sortColors(vector& nums) {
+ int left = 0, right = nums.size() - 1;
+ int curr = 0;
+ while(curr <= right){
+ if(nums[curr] == 0 && curr > left){
+ swap(nums[curr], nums[left]);
+ left++;
+ }
+ else if(nums[curr] == 2){
+ swap(nums[curr], nums[right]);
+ right--;
+ }
+ else{
+ curr++;
+ }
+ }
+ }
+};
\ No newline at end of file
diff --git a/Stack/03.ValidParentheses/README.md b/Stack/03.ValidParentheses/README.md
index c613b1f..8b6ad1b 100644
--- a/Stack/03.ValidParentheses/README.md
+++ b/Stack/03.ValidParentheses/README.md
@@ -51,6 +51,6 @@
## 代码实现
| C | C++ | Java | Objective-C | Swift | Python | JavaScript | Go | PHP |
| :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: |
-| 🤔 | 🤔 | 🤔 | 🤔 | 🤔 | 🤔 | [🤔](./validParentheses.js) | [🤔](./valid_parentheses.go) | 🤔 |
+| 🤔 | [😀](./validParentheses.cpp) | 🤔 | 🤔 | 🤔 | 🤔 | [😀](./validParentheses.js) | [😀](./valid_parentheses.go) | 🤔 |
完成 😀,待完成 🤔
diff --git a/Stack/03.ValidParentheses/validParentheses.cpp b/Stack/03.ValidParentheses/validParentheses.cpp
new file mode 100644
index 0000000..f5240fd
--- /dev/null
+++ b/Stack/03.ValidParentheses/validParentheses.cpp
@@ -0,0 +1,20 @@
+class Solution {
+public:
+ bool isValid(string s) {
+ stack myStack;
+ for(auto ch : s) {
+ if(ch == '(' || ch == '[' || ch == '{') {
+ myStack.push(ch);
+ }
+ else {
+ if(myStack.empty()) { return false; }
+ auto top_ch = myStack.top();
+ if((top_ch == '(' && ch == ')') || (top_ch == '[' && ch == ']') || (top_ch == '{' && ch == '}')) {
+ myStack.pop();
+ }
+ else { return false; }
+ }
+ }
+ return myStack.empty();
+ }
+};
\ No newline at end of file
diff --git a/Stack/04.LongestValidParentheses/README.md b/Stack/04.LongestValidParentheses/README.md
index 4a9c37c..bfcfacf 100644
--- a/Stack/04.LongestValidParentheses/README.md
+++ b/Stack/04.LongestValidParentheses/README.md
@@ -31,4 +31,4 @@
## 代码实现
| C | C++ | Java | Objective-C | Swift | Python | JavaScript | Go | PHP |
| :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: |
-| 🤔 | 🤔 | 🤔 | 🤔 | 🤔 | 🤔 | 🤔 | 🤔 | 🤔 |
+| 🤔 | [😀](./longestvalidparentheses.cpp) | 🤔 | 🤔 | 🤔 | 🤔 | [😀](./longestvalidparentheses.js) | 🤔 | 🤔 |
diff --git a/Stack/04.LongestValidParentheses/longestvalidparentheses.cpp b/Stack/04.LongestValidParentheses/longestvalidparentheses.cpp
new file mode 100644
index 0000000..cda9adc
--- /dev/null
+++ b/Stack/04.LongestValidParentheses/longestvalidparentheses.cpp
@@ -0,0 +1,26 @@
+class Solution {
+public:
+ int longestValidParentheses(string s) {
+ int longest = 0;
+ // 使用 vector 模拟栈,存储接下来遇到的匹配括号的长度
+ vector stk;
+ stk.push_back(0);
+ for (auto ch : s) {
+ if (ch == '(') {
+ stk.push_back(0);
+ }
+ else {
+ if (stk.size() > 1) {
+ int v = stk.back(); stk.pop_back();
+ int lastCount = stk[stk.size() - 1];
+ stk[stk.size() - 1] = lastCount + v + 2;
+ longest = max(longest, stk[stk.size() - 1]);
+ }
+ else {
+ stk.clear(); stk.push_back(0);
+ }
+ }
+ }
+ return longest;
+ }
+};
\ No newline at end of file
diff --git a/Stack/05.EvaluateReversePolishNotation/README.md b/Stack/05.EvaluateReversePolishNotation/README.md
index 03a2c00..2042541 100644
--- a/Stack/05.EvaluateReversePolishNotation/README.md
+++ b/Stack/05.EvaluateReversePolishNotation/README.md
@@ -48,5 +48,5 @@
## 代码实现
| C | C++ | Java | Objective-C | Swift | Python | JavaScript | Go | PHP |
| :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: |
-| 🤔 | 🤔 | 🤔 | 🤔 | 🤔 | 🤔 | 🤔 | 🤔 | 🤔 |
+| 🤔 | [😀](./evaluateReversePolishNotation.cpp) | 🤔 | 🤔 | 🤔 | 🤔 | 🤔 | [😀](./evaluate_reverse_polish_notation.go) | 🤔 |
diff --git a/Stack/05.EvaluateReversePolishNotation/evaluateReversePolishNotation.cpp b/Stack/05.EvaluateReversePolishNotation/evaluateReversePolishNotation.cpp
new file mode 100644
index 0000000..648696b
--- /dev/null
+++ b/Stack/05.EvaluateReversePolishNotation/evaluateReversePolishNotation.cpp
@@ -0,0 +1,40 @@
+class Solution {
+public:
+ int evalRPN(vector& tokens) {
+ stack myStack;
+ for(auto str : tokens) {
+ if(str != "+" && str != "-" && str != "*" && str != "/") {
+ myStack.push(stoi(str));
+ }
+ else {
+ int second = myStack.top(); myStack.pop();
+ int first = myStack.top(); myStack.pop();
+ int result;
+ switch (str[0]) {
+ case '+':{
+ result = first + second;
+ break;
+ }
+ case '-':{
+ result = first - second;
+ break;
+ }
+ case '*':{
+ result = first * second;
+ break;
+ }
+ case '/':{
+ result = first / second;
+ break;
+ }
+ default:{
+ result = 0;
+ break;
+ }
+ }
+ myStack.push(result);
+ }
+ }
+ return myStack.size() == 1 ? myStack.top() : 0;
+ }
+};
\ No newline at end of file
diff --git a/String/04.BM/README.md b/String/ACAuto/README.md
similarity index 100%
rename from String/04.BM/README.md
rename to String/ACAuto/README.md
diff --git a/String/LengthOfLongestSubstring/README.md b/String/LengthOfLongestSubstring/README.md
new file mode 100644
index 0000000..e983c32
--- /dev/null
+++ b/String/LengthOfLongestSubstring/README.md
@@ -0,0 +1,28 @@
+# Longest Substring Without Repeating Characters
+
+[LeetCode 3](https://leetcode.com/problems/longest-substring-without-repeating-characters/)
+
+## 题目
+给定一个字符串,请你找出其中不含有重复字符的 最长子串 的长度。
+
+示例 1:
+
+输入: "abcabcbb"
+输出: 3
+解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。
+示例 2:
+
+输入: "bbbbb"
+输出: 1
+解释: 因为无重复字符的最长子串是 "b",所以其长度为 1。
+示例 3:
+
+输入: "pwwkew"
+输出: 3
+解释: 因为无重复字符的最长子串是 "wke",所以其长度为 3。
+ 请注意,你的答案必须是 子串 的长度,"pwke" 是一个子序列,不是子串。
+
+## 代码实现
+| C++ | Java | Python | JS |
+| :--: | :--: | :--: | :---: |
+|[🤔]() | [🤔]() | [🤔]() | [😀](index.js) |
diff --git a/String/LengthOfLongestSubstring/index.js b/String/LengthOfLongestSubstring/index.js
new file mode 100644
index 0000000..4962c45
--- /dev/null
+++ b/String/LengthOfLongestSubstring/index.js
@@ -0,0 +1,31 @@
+// 解法一:O(n)
+const lengthOfLongestSubstring = (str) => {
+ let maxLength = 0;
+ const queue = []; // 使用队列存储无重复子串
+ for (const element of str) {
+ // 从头部开始检测是否有重复 O(n)
+ const eleIdx = queue.indexOf(element);
+ if (eleIdx != -1) {
+ // 移除重复元素前的元素
+ queue.splice(0, eleIdx + 1);
+ }
+ queue.push(element);
+
+ maxLength = Math.max(queue.length, maxLength);
+ }
+ return maxLength;
+}
+
+// 解法二:O(n^2)
+const lengthOfLongestSubstring2 = (str) => {
+ const cache = {};
+ let start = max = 0;
+ for (let i = 0, n = str.length; i < n; ++i) {
+ const char = str[i];
+ const newStart = typeof cache[char] === 'undefined' ? 0 : cache[char] + 1;
+ start = Math.max(start, newStart);
+ cache[char] = i;
+ max = Math.max(i - start + 1, max);
+ }
+ return max;
+}
\ No newline at end of file
diff --git a/String/README.md b/String/README.md
index 798ce73..b7f570d 100644
--- a/String/README.md
+++ b/String/README.md
@@ -1,3 +1,5 @@
# String(字符串)
-[01. 反转字符串](./01.ReverseString)
+- [ReverseString](./ReverseString)
+
+- [LengthOfLongestSubstring](./LengthOfLongestSubstring)
diff --git a/String/01.ReverseString/README.md b/String/ReverseString/README.md
similarity index 100%
rename from String/01.ReverseString/README.md
rename to String/ReverseString/README.md
diff --git a/String/02.ReverseWords/README.md b/String/ReverseWords/README.md
similarity index 100%
rename from String/02.ReverseWords/README.md
rename to String/ReverseWords/README.md
diff --git a/String/03.StringToInteger/README.md b/String/StringToInteger/README.md
similarity index 100%
rename from String/03.StringToInteger/README.md
rename to String/StringToInteger/README.md
diff --git a/String/longest-palindromic-substring/index.js b/String/longest-palindromic-substring/index.js
new file mode 100644
index 0000000..ba00420
--- /dev/null
+++ b/String/longest-palindromic-substring/index.js
@@ -0,0 +1,60 @@
+/*
+ * @lc app=leetcode id=5 lang=javascript
+ *
+ * [5] Longest Palindromic Substring
+ */
+/**
+ * @param {string} s
+ * @return {string}
+ */
+
+ // Time: O(n^2)
+ var longestPalindrome = function(s) {
+ // 检测字符串 s 是否是回文
+ const isPalindrome = (s) => {
+ for (let i = 0, len = s.length; i < parseInt(len/2); ++i) {
+ if (s.charAt(i) === s.charAt(len - i - 1)) {
+ continue;
+ }
+ return false;
+ }
+ return true;
+ }
+
+ let longestPal = '';
+ for (let i = 0, len = s.length; i < len; ++i) {
+ for (let j = i + 1; j <= len; ++j) {
+ const ts = s.slice(i, j);
+ if (ts.length > longestPal.length && isPalindrome(ts)) {
+ longestPal = ts;
+ }
+ }
+ }
+
+ return longestPal;
+};
+
+// Time: O(n*m)
+var longestPalindrome2 = function(s) {
+ const len = s.length;
+ let start = maxLen = 0;
+
+ // 最长回文探测
+ const palindromeDetect = (s, left, right) => {
+ while (left >= 0 && right < len && s.charAt(left) === s.charAt(right)) {
+ left--;
+ right++;
+ }
+ if (maxLen < right - left - 1) {
+ start = left + 1;
+ maxLen = right - left - 1;
+ }
+ }
+
+ for (let i = 0; i <= len - 1; ++i) {
+ palindromeDetect(s, i, i); // 奇数长度
+ palindromeDetect(s, i, i+1); // 偶数长度
+ }
+
+ return s.slice(start, start + maxLen);
+}
\ No newline at end of file
diff --git a/String/05.RK/README.md b/String/string-match/BF/README.md
similarity index 100%
rename from String/05.RK/README.md
rename to String/string-match/BF/README.md
diff --git a/String/06.KMP/README.md b/String/string-match/BM/README.md
similarity index 100%
rename from String/06.KMP/README.md
rename to String/string-match/BM/README.md
diff --git a/String/07.ACAuto/README.md b/String/string-match/KMP/README.md
similarity index 100%
rename from String/07.ACAuto/README.md
rename to String/string-match/KMP/README.md
diff --git a/String/string-match/RK/README.md b/String/string-match/RK/README.md
new file mode 100644
index 0000000..e69de29
diff --git a/DynamicProgramming/03.BuyAndSellStock/README.md b/dp/BuyAndSellStock/README.md
similarity index 100%
rename from DynamicProgramming/03.BuyAndSellStock/README.md
rename to dp/BuyAndSellStock/README.md
diff --git a/dp/BuyAndSellStock/buyAndSellStock.js b/dp/BuyAndSellStock/buyAndSellStock.js
new file mode 100755
index 0000000..e69de29
diff --git a/DynamicProgramming/05.ClimbingStairs/README.md b/dp/ClimbingStairs/README.md
similarity index 100%
rename from DynamicProgramming/05.ClimbingStairs/README.md
rename to dp/ClimbingStairs/README.md
diff --git a/DynamicProgramming/05.ClimbingStairs/climb-stairs.go b/dp/ClimbingStairs/climb-stairs.go
similarity index 100%
rename from DynamicProgramming/05.ClimbingStairs/climb-stairs.go
rename to dp/ClimbingStairs/climb-stairs.go
diff --git a/DynamicProgramming/02.CoinChange/README.md b/dp/CoinChange/README.md
similarity index 100%
rename from DynamicProgramming/02.CoinChange/README.md
rename to dp/CoinChange/README.md
diff --git a/DynamicProgramming/07.EditDistance/README.md b/dp/EditDistance/README.md
similarity index 100%
rename from DynamicProgramming/07.EditDistance/README.md
rename to dp/EditDistance/README.md
diff --git a/DynamicProgramming/07.EditDistance/editDistance.js b/dp/EditDistance/editDistance.js
similarity index 100%
rename from DynamicProgramming/07.EditDistance/editDistance.js
rename to dp/EditDistance/editDistance.js
diff --git a/DynamicProgramming/08.LongestIncreasingSubsequence/README.md b/dp/LongestIncreasingSubsequence/README.md
similarity index 100%
rename from DynamicProgramming/08.LongestIncreasingSubsequence/README.md
rename to dp/LongestIncreasingSubsequence/README.md
diff --git a/DynamicProgramming/08.LongestIncreasingSubsequence/lis.js b/dp/LongestIncreasingSubsequence/lis.js
similarity index 100%
rename from DynamicProgramming/08.LongestIncreasingSubsequence/lis.js
rename to dp/LongestIncreasingSubsequence/lis.js
diff --git a/DynamicProgramming/01.MinimumPathSum/README.md b/dp/MinimumPathSum/README.md
similarity index 100%
rename from DynamicProgramming/01.MinimumPathSum/README.md
rename to dp/MinimumPathSum/README.md
diff --git a/DynamicProgramming/01.MinimumPathSum/minimumPathSum.js b/dp/MinimumPathSum/minimumPathSum.js
similarity index 100%
rename from DynamicProgramming/01.MinimumPathSum/minimumPathSum.js
rename to dp/MinimumPathSum/minimumPathSum.js
diff --git a/dp/README.md b/dp/README.md
new file mode 100644
index 0000000..b7f459f
--- /dev/null
+++ b/dp/README.md
@@ -0,0 +1,17 @@
+# 动态规划(Dynamic Programming)
+
+[Minimum Path Sum(最小路径和)](./MinimumPathSum)
+
+[Coin Change (零钱兑换)](./CoinChange)
+
+[Best Time to Buy and Sell Stock(买卖股票的最佳时机)](./BuyAndSellStock)
+
+[Climbing Stairs(爬楼梯)](./ClimbingStairs)
+
+[Triangle(三角形最小路径和)](./Triangle)
+
+[EditDistance(最短编辑距离](./EditDistance)
+
+[Longest Increating Subseque(最长子序列)](./LongestIncreasingSubsequence)
+
+[Regular Expression Matching(正则表达式匹配)](./regular-expression-matching)
\ No newline at end of file
diff --git a/DynamicProgramming/06.Triangle/README.md b/dp/Triangle/README.md
similarity index 100%
rename from DynamicProgramming/06.Triangle/README.md
rename to dp/Triangle/README.md
diff --git a/dp/regular-expression-matching/README.md b/dp/regular-expression-matching/README.md
new file mode 100644
index 0000000..6336015
--- /dev/null
+++ b/dp/regular-expression-matching/README.md
@@ -0,0 +1,161 @@
+# 正则表达式匹配
+
+## 题目
+
+给你一个字符串 s 和一个字符规律 p,请你来实现一个支持 '.' 和 '*' 的正则表达式匹配。
+
+'.' 匹配任意单个字符
+'*' 匹配零个或多个前面的那一个元素
+所谓匹配,是要涵盖 整个 字符串 s的,而不是部分字符串。
+
+说明:
+
+s 可能为空,且只包含从 a-z 的小写字母。
+p 可能为空,且只包含从 a-z 的小写字母,以及字符 . 和 *。
+
+示例 1:
+
+```
+输入:
+s = "aa"
+p = "a"
+输出: false
+```
+
+解释: "a" 无法匹配 "aa" 整个字符串。
+
+示例 2:
+
+```
+输入:
+s = "aa"
+p = "a*"
+输出: true
+```
+
+解释: 因为 '*' 代表可以匹配零个或多个前面的那一个元素, 在这里前面的元素就是 'a'。因此,字符串 "aa" 可被视为 'a' 重复了一次。
+
+示例 3:
+
+```
+输入:
+s = "ab"
+p = ".*"
+输出: true
+```
+
+解释: ".*" 表示可匹配零个或多个('*')任意字符('.')。
+
+示例 4:
+
+```
+输入:
+s = "aab"
+p = "c*a*b"
+输出: true
+```
+
+解释: 因为 '*' 表示零个或多个,这里 'c' 为 0 个, 'a' 被重复一次。因此可以匹配字符串 "aab"。
+示例 5:
+
+```
+输入:
+s = "mississippi"
+p = "mis*is*p*."
+输出: false
+```
+
+## 思路
+
+两个字符串进行比较,容易想到的是采用两层循环对比。但是这两个字符串并不是一对一进行比较的, `*` 字符存在匹配 0 个或者多个字符的情况,因此需要额外的变量保存前面已经遍历过的状态。
+
+维护零散的变量并不是简单的事情,我们可以考虑将这些变量使用集合来维护。
+
+在遍历过程中,当前的匹配状态依赖于子串的匹配状态的。因此我们可以考虑使用动态规划来做。
+
+动态规划的三要素:
+
+1. base case
+2. 最优子结构
+3. 状态转移方程
+
+我们采用二维数组 dp,来存储子串的匹配状态,横向表示 p 字符,纵向表示 s 字符。
+
+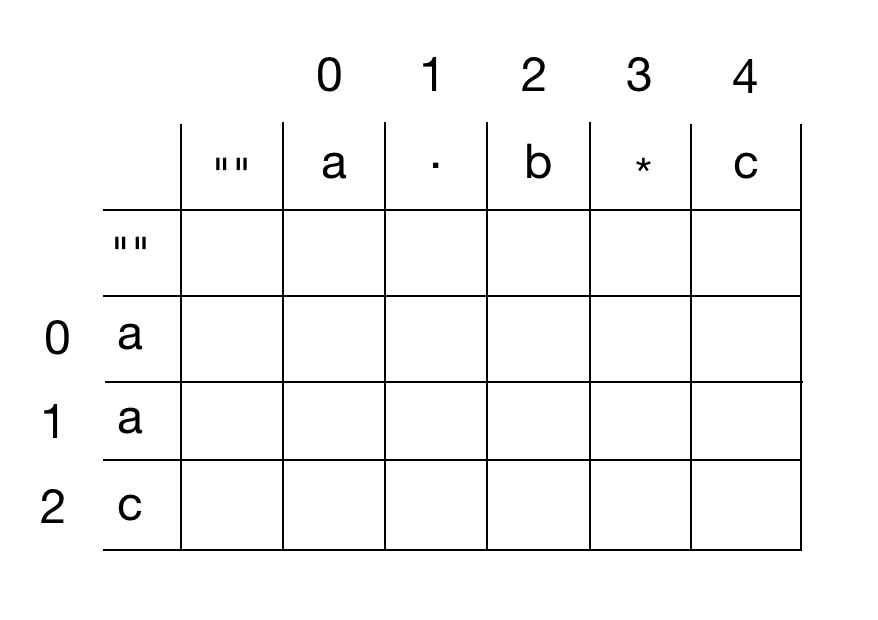
+
+## 1.base case
+
+base case 是状态转移的初始值,横向初始值是以 s 作为空字符串("")与 p 模式字符进行匹配的结果,纵向初始值是以 s 字符串与空模式串 p 进行匹配的结果。
+
+模式串 p 为空字符串时,当且仅当 s 为空字符时才会匹配。
+
+当 s 为空字符时,就不仅仅只与空字符串 p 匹配了。它还与 `a*` 、 `a*b*` 、 `a*b*c*` 、... 匹配。
+
+因此在遇到 `*` 时,空字符串 s 与 p 的匹配情况需要根据 `*` 向前退两个字符的子串匹配情况决定。
+
+> 根据题意 `*` 能够与重复它前面一个字符 0 次或者多次的字符匹配,因此 `*` 前面的字符必然不能为空字符。
+
+以 `s = ""` 和 `p = "a.b*"` 为例子, 当遇到 `*` 时, `"a.b*"` 回退两位的子串是 `"a."` , `s = ""` 和 `"a."` 不匹配,所以 `s = ""` 与 `a*b*` 也不匹配。
+
+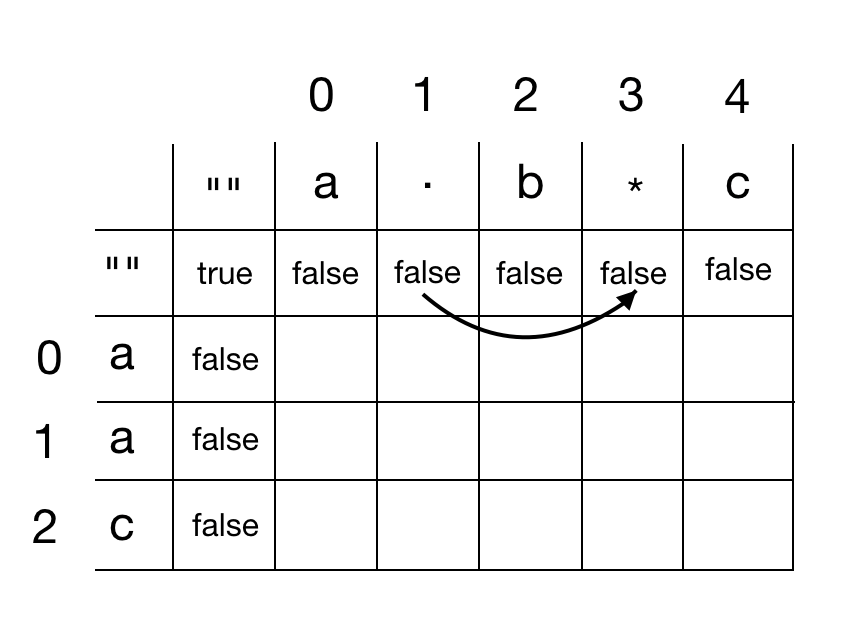
+
+用伪代码表示:
+
+``` js
+if (p[j] == '*') {
+ dp[i][j] = dp[i][j - 2];
+}
+```
+
+## 2. 最优子结构
+
+s 的子串 s[0:i] 和 p 的子串 p[0:j] 的匹配关系,可以根据 p 在下标 j 处的字符内容分为三种子结构:
+
+1. p[j] == a-z
+2. p[j] == '.'
+3. p[j] == '*'
+
+如果 p[j] 字符为 a-z ,并且 p[j] != s[i] 那么 dp[i][j] 必然是 false。如果 p[j] == s[i] 或者 p[j] = '.' 字符,s[0:i] 和 p[0:j] 的匹配关系由 dp[i][j] 由 dp[i-1][j-1] 决定。
+
+如果 p[j] 为 `*` ,要考虑当前 s[i] 字符与 `*` 前一个字符 p[j-1] 发生匹配的次数。分为 0 次、1 次和多次情况来讨论。
+
+上述情况都可以由 s[0:i] 和 p[0:j] 子串的三种子结构记录在 dp[i][j] 数组内的状态推导而来。
+
+## 3. 状态转移方程
+
+1. p[j] == s[i],p[i] 和 s[j] 字符相同,则 s[0:i] 和 p[0:j] 子串的匹配情况由 s[0:i-1] 和 p[0:i-1] 的情况决定;
+2. p[j] == '.', `.` 点符号能够匹配任意的字符,因此 p[0:i] 和 p[0:j] 子串匹配情况由 s[0:i-1] 和 p[0:i-1] 的情况决定;
+3. p[j] == '*', `*` 的处理需分为匹配次数来讨论,我们接下来会讨论;
+4. 其它情况均不匹配。
+
+### 星号匹配 0 次
+
+如果星号匹配 0 次,则需要忽略星号以及它前面的一个字符,dp[i][j] 的前一个状态由 s[i] 与 p[j-2] 字符串的匹配情况 dp[i][j-2] 推导。
+
+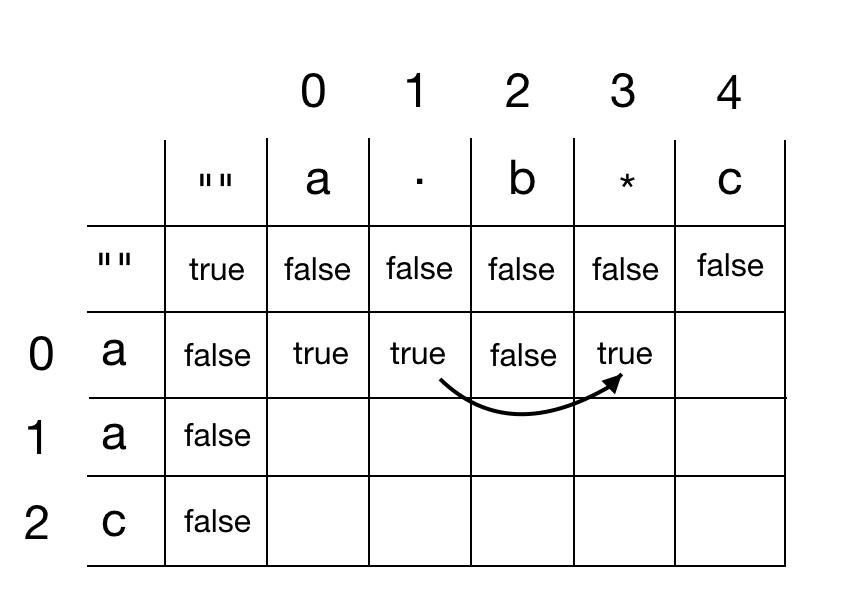
+
+### 星号匹配 1 次
+
+模式串 `a.b*` 与 `aab` 中的 `b` 发生一次匹配。它们的匹配关系由 `a.b` 和 `aab` 的匹配关系 dp[i][j-1] 推导而来。
+
+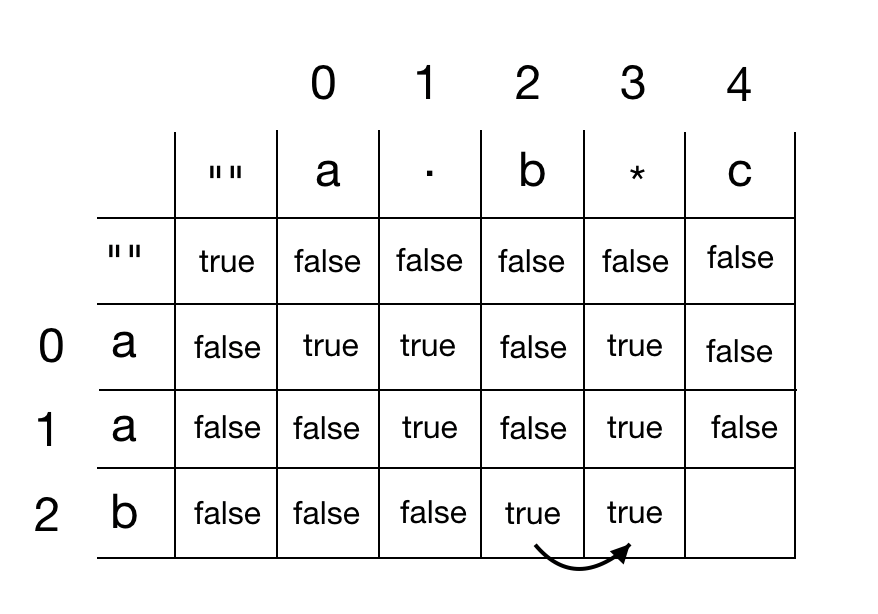
+
+### 星号匹配多次
+
+模式串 `a.b*` 与 `aabb` 中的 `b` 发生多次匹配。它们的匹配关系由 `a.b*` 和 `aab` 的匹配关系 dp[i-1][j] 推导而来。
+
+
+
+为什么?
+
+多次匹配的推导关系有点难以理解,它为什么不是由 dp[i-1][j-1] 推导而来呢?如果由 dp[i-1][j-1] 推导而来,前一个字符可能和当前字符不相同,就不属于重复匹配了。
+
+多次匹配的前提是已经发生了一次匹配,即在 `a.b*` 和 `aab` 的基础上的匹配情况,也就是 dp[i-1][j] 的值。
+
+> 注:图中 dp 数组的维度会比 s 和 p 字符的长度大 1,新增的维度用于存储推导初始值。文中为了方便当前待匹配情况用 dp[i][j] 表示,代码中实际使用的是 dp[i+1][j+1]。
+
+## 链接
+
+[LeetCode](https://leetcode.com/problems/regular-expression-matching/)
+
+[力扣](https://leetcode-cn.com/problems/regular-expression-matching/)
\ No newline at end of file
diff --git a/dp/regular-expression-matching/index.js b/dp/regular-expression-matching/index.js
new file mode 100644
index 0000000..5b34feb
--- /dev/null
+++ b/dp/regular-expression-matching/index.js
@@ -0,0 +1,40 @@
+/**
+ * @param {string} s
+ * @param {string} p
+ * @return {boolean}
+ */
+var isMatch = function(s, p) {
+ const dp = new Array(s.length + 1);
+ for (let i = 0; i <= s.length; ++i) {
+ dp[i] = (new Array(p.length + 1)).fill(false)
+ }
+
+ // base case
+ dp[0][0] = true;
+ for (let i = 0; i < p.length; ++i) {
+ if (p[i] === '*') {
+ dp[0][i+1] = dp[0][i-1];
+ }
+ }
+
+ for (let i = 0; i < s.length; ++i) {
+ for (let j = 0; j < p.length; ++j) {
+ if (p[j] === s[i] || p[j] === '.') {
+ dp[i+1][j+1] = dp[i][j];
+ }
+
+ if (p[j] === '*') {
+ if (p[j-1] !== s[i] && p[j-1] !== '.') {
+ // 0 occurrence
+ dp[i+1][j+1] = dp[i+1][j-1];
+ } else {
+ // 1 occurrence dp[i+1][j]
+ // n occurrence dp[i][j-1]
+ dp[i+1][j+1] = (dp[i][j+1] || dp[i+1][j-1] || dp[i+1][j]);
+ }
+ }
+ }
+ }
+
+ return !!dp[s.length][p.length];
+ };
\ No newline at end of file