diff --git a/.gitattributes b/.gitattributes
deleted file mode 100644
index e85bf95..0000000
--- a/.gitattributes
+++ /dev/null
@@ -1,6 +0,0 @@
-* text=auto
-*.js linguist-language=java
-*.css linguist-language=java
-*.html linguist-language=java
-
-
diff --git a/.gitignore b/.gitignore
index 517ec8a..e233607 100644
--- a/.gitignore
+++ b/.gitignore
@@ -9,3 +9,5 @@ out
gen
/target/
+
+
diff --git a/ReadMe.md b/ReadMe.md
index b382ce2..84572da 100644
--- a/ReadMe.md
+++ b/ReadMe.md
@@ -1,4 +1,21 @@
-本仓库为【Java工程师技术指南】力求打造最完整最实用的Java工程师学习指南!
+
+
+
+
+
+
+力求打造最完整最实用的Java工程师学习指南!
这些文章和总结都是我近几年学习Java总结和整理出来的,非常实用,对于学习Java后端的朋友来说应该是最全面最完整的技术仓库。
我靠着这些内容进行复习,拿到了BAT等大厂的offer,这个仓库也已经帮助了很多的Java学习者,如果对你有用,希望能给个star支持我,谢谢!
@@ -9,366 +26,467 @@
-  +
+ 
-
-推荐使用 https://how2playlife.com/ 在线阅读,在线阅读内容本仓库同步一致。这种方式阅读的优势在于:左侧边栏有目录,阅读体验更好。
-
-
-## 目录
-
-- [Java基础](#Java基础)
- - [基础知识](#基础知识)
- - [容器](#容器)
- - [设计模式](#设计模式)
-- [JavaWeb](#JavaWeb)
- - [Srping](#Spring)
- - [SpringMVC](#SpringMVC)
- - [SpringBoot](#SpringBoot)
-- [Java进阶](#Java进阶)
- - [并发](#并发)
- - [JVM](#JVM)
- - [Java网络编程](#Java网络编程)
-- [计算机基础](#计算机基础)
- - [计算机网络](#计算机网络)
- - [操作系统](#操作系统)
- - [Linux相关](#linux相关)
- - [数据结构与算法](#数据结构与算法)
- - [数据结构](#数据结构)
- - [算法](#算法)
-- [数据库](#数据库)
- - [MySQL](#MySQL)
-- [缓存](#缓存)
- - [Redis](#Redis)
-- [消息队列](#消息队列)
- - [Kafka](#Kafka)
-- [大后端](#大后端)
-- [分布式](#分布式)
- - [理论](#理论)
- - [实战](#实战)
-- [面试指南](#面试指南)
- - [校招指南](#校招指南)
- - [面经](#面经)
-- [工具](#工具)
- - [Git](#git)
-- [资料](#资料)
- - [书单](#书单)
-- [待办](#待办)
-- [说明](#说明)
-- [微信公众号](#微信公众号)
-
-## Java基础
-
-### 基础知识
-
-* [面向对象基础](docs/java/basic/1、面向对象基础.md)
-* [Java基本数据类型](docs/java/basic/2、Java基本数据类型.md)
-* [string和包装类](docs/java/basic/3、string和包装类.md)
-* [final关键字特性](docs/java/basic/4、final关键字特性.md)
-* [Java类和包](docs/java/basic/5、Java类和包.md)
-* [抽象类和接口](docs/java/basic/6、抽象类和接口.md)
-* [代码块和代码执行顺序](docs/java/basic/7、代码块和代码执行顺序.md)
-* [Java自动拆箱装箱里隐藏的秘密](docs/java/basic/8、Java自动拆箱装箱里隐藏的秘密.md)
-* [Java中的Class类和Object类](docs/java/basic/9、Java中的Class类和Object类.md)
-* [Java异常](docs/java/basic/10、Java异常.md)
-* [解读Java中的回调](docs/java/basic/11、解读Java中的回调.md)
-* [反射](docs/java/basic/12、反射.md)
-* [泛型](docs/java/basic/13、泛型.md)
-* [枚举类](docs/java/basic/14、枚举类.md)
-* [Java注解和最佳实践](docs/java/basic/15、Java注解和最佳实践.md)
-* [JavaIO流](docs/java/basic/16、JavaIO流.md)
-* [多线程](docs/java/basic/17、多线程.md)
-* [深入理解内部类](docs/java/basic/18、深入理解内部类.md)
-* [javac和javap](docs/java/basic/20、javac和javap.md)
-* [Java8新特性终极指南](docs/java/basic/21、Java8新特性终极指南.md)
-* [序列化和反序列化](docs/java/basic/22、序列化和反序列化.md)
-* [继承、封装、多态的实现原理](docs/java/basic/23、继承、封装、多态的实现原理.md)
-
-### 容器
-
-* [Java集合类总结](docs/java/collection/Java集合类总结.md)
-* [Java集合详解1:一文读懂ArrayList,Vector与Stack使用方法和实现原理](docs/java/collection/Java集合详解1:一文读懂ArrayList,Vector与Stack使用方法和实现原理.md)
-* [Java集合详解2:Queue和LinkedList](docs/java/collection/Java集合详解2:Queue和LinkedList.md)
-* [Java集合详解3:Iterator,fail-fast机制与比较器](docs/java/collection/Java集合详解3:Iterator,fail-fast机制与比较器.md)
-* [Java集合详解4:HashMap和HashTable](docs/java/collection/Java集合详解4:HashMap和HashTable.md)
-* [Java集合详解5:深入理解LinkedHashMap和LRU缓存](docs/java/collection/Java集合详解5:深入理解LinkedHashMap和LRU缓存.md)
-* [Java集合详解6:TreeMap和红黑树](docs/java/collection/Java集合详解6:TreeMap和红黑树.md)
-* [Java集合详解7:HashSet,TreeSet与LinkedHashSet](docs/java/collection/Java集合详解7:HashSet,TreeSet与LinkedHashSet.md)
-* [Java集合详解8:Java集合类细节精讲](docs/java/collection/Java集合详解8:Java集合类细节精讲.md)
-
-### 设计模式
-
-* [设计模式学习总结](docs/java/design-parttern/设计模式学习总结.md)
-* [初探Java设计模式1:创建型模式(工厂,单例等).md](docs/java/design-parttern/初探Java设计模式1:创建型模式(工厂,单例等).md)
-* [初探Java设计模式2:结构型模式(代理模式,适配器模式等).md](docs/java/design-parttern/初探Java设计模式2:结构型模式(代理模式,适配器模式等).md)
-* [初探Java设计模式3:行为型模式(策略,观察者等).md](docs/java/design-parttern/初探Java设计模式3:行为型模式(策略,观察者等).md)
-* [初探Java设计模式4:JDK中的设计模式.md](docs/java/design-parttern/初探Java设计模式4:JDK中的设计模式.md)
-* [初探Java设计模式5:Spring涉及到的9种设计模式.md](docs/java/design-parttern/初探Java设计模式5:Spring涉及到的9种设计模式.md)
-
-## JavaWeb
-
-* [走进JavaWeb技术世界1:JavaWeb的由来和基础知识](docs/java-web/走进JavaWeb技术世界1:JavaWeb的由来和基础知识.md)
-* [走进JavaWeb技术世界2:JSP与Servlet的曾经与现在](docs/java-web/走进JavaWeb技术世界2:JSP与Servlet的曾经与现在.md)
-* [走进JavaWeb技术世界3:JDBC的进化与连接池技术](docs/java-web/走进JavaWeb技术世界3:JDBC的进化与连接池技术.md)
-* [走进JavaWeb技术世界4:Servlet 工作原理详解](docs/java-web/走进JavaWeb技术世界4:Servlet%20工作原理详解.md)
-* [走进JavaWeb技术世界5:初探Tomcat的HTTP请求过程](docs/java-web/走进JavaWeb技术世界5:初探Tomcat的HTTP请求过程.md)
-* [走进JavaWeb技术世界6:Tomcat5总体架构剖析](docs/java-web/走进JavaWeb技术世界6:Tomcat5总体架构剖析.md)
-* [走进JavaWeb技术世界7:Tomcat和其他WEB容器的区别](docs/java-web/走进JavaWeb技术世界7:Tomcat和其他WEB容器的区别.md)
-* [走进JavaWeb技术世界8:浅析Tomcat9请求处理流程与启动部署过程](docs/java-web/走进JavaWeb技术世界8:浅析Tomcat9请求处理流程与启动部署过程.md)
-* [走进JavaWeb技术世界9:Java日志系统的诞生与发展](docs/java-web/走进JavaWeb技术世界9:Java日志系统的诞生与发展.md)
-* [走进JavaWeb技术世界10:从JavaBean讲到Spring](docs/java-web/走进JavaWeb技术世界10:从JavaBean讲到Spring.md)
-* [走进JavaWeb技术世界11:单元测试框架Junit](docs/java-web/走进JavaWeb技术世界11:单元测试框架Junit.md)
-* [走进JavaWeb技术世界12:从手动编译打包到项目构建工具Maven](docs/java-web/走进JavaWeb技术世界12:从手动编译打包到项目构建工具Maven.md)
-* [走进JavaWeb技术世界13:Hibernate入门经典与注解式开发](docs/java-web/走进JavaWeb技术世界13:Hibernate入门经典与注解式开发.md)
-* [走进JavaWeb技术世界14:Mybatis入门](docs/java-web/走进JavaWeb技术世界14:Mybatis入门.md)
-* [深入JavaWeb技术世界15:深入浅出Mybatis基本原理](docs/java-web/深入JavaWeb技术世界15:深入浅出Mybatis基本原理.md)
-* [走进JavaWeb技术世界16:极简配置的SpringBoot](docs/java-web/走进JavaWeb技术世界16:极简配置的SpringBoot.md)
-
-### Spring
-
-* [Spring源码剖析1:Spring概述](docs/java-web/Spring/Spring源码剖析1:Spring概述.md)
-* [Spring源码剖析2:初探Spring IOC核心流程](docs/java-web/Spring/Spring源码剖析2:初探Spring%20IOC核心流程.md)
-* [Spring源码剖析3:Spring IOC容器的加载过程 ](docs/java-web/Spring/Spring源码剖析3:Spring%20IOC容器的加载过程.md)
-* [Spring源码剖析4:懒加载的单例Bean获取过程分析](docs/java-web/Spring/Spring源码剖析4:懒加载的单例Bean获取过程分析.md)
-* [Spring源码剖析5:JDK和cglib动态代理原理详解 ](docs/java-web/Spring/Spring源码剖析5:JDK和cglib动态代理原理详解.md)
-* [Spring源码剖析6:Spring AOP概述](docs/java-web/Spring/Spring源码剖析6:Spring%20AOP概述.md)
-* [Spring源码剖析7:AOP实现原理详解 ](docs/java-web/Spring/Spring源码剖析7:AOP实现原理详解.md)
-* [Spring源码剖析8:Spring事务概述](docs/java-web/Spring/Spring源码剖析8:Spring事务概述.md)
-* [Spring源码剖析9:Spring事务源码剖析](docs/java-web/Spring/Spring源码剖析9:Spring事务源码剖析.md)
-
-### SpringMVC
-
-* [SpringMVC源码分析1:SpringMVC概述](docs/java-web/Spring/SSM/SpringMVC源码分析1:SpringMVC概述.md)
-* [SpringMVC源码分析2:SpringMVC设计理念与DispatcherServlet](docs/java-web/Spring/SSM/SpringMVC源码分析2:SpringMVC设计理念与DispatcherServlet.md)
-* [SpringMVC源码分析3:DispatcherServlet的初始化与请求转发 ](docs/java-web/Spring/SSM/SpringMVC源码分析3:DispatcherServlet的初始化与请求转发.md)
-* [SpringMVC源码分析4:DispatcherServlet如何找到正确的Controller ](docs/java-web/Spring/SSM/SpringMVC源码分析4:DispatcherServlet如何找到正确的Controller.md)
-* [SpringMVC源码剖析5:消息转换器HttpMessageConverter与@ResponseBody注解](docs/java-web/Spring/SSM/SpringMVC源码剖析5:消息转换器HttpMessageConverter与@ResponseBody注解.md)
-* [SpringMVC源码分析6:SpringMVC的视图解析原理 ](docs/java-web/Spring/SSM/SpringMVC源码分析6:SpringMVC的视图解析原理.md)
-
-### SpringBoot
-
-todo
-
-### SpringCloud
-
-todo
-
-## Java进阶
-
-### 并发
-
-* [Java并发指南1:并发基础与Java多线程](docs/java/currency/Java并发指南1:并发基础与Java多线程.md)
-* [Java并发指南2:深入理解Java内存模型JMM](docs/java/currency/Java并发指南2:深入理解Java内存模型JMM.md)
-* [Java并发指南3:并发三大问题与volatile关键字,CAS操作](docs/java/currency/Java并发指南3:并发三大问题与volatile关键字,CAS操作.md)
-* [Java并发指南4:Java中的锁 Lock和synchronized](docs/java/currency/Java并发指南4:Java中的锁%20Lock和synchronized.md)
-* [Java并发指南5:JMM中的final关键字解析](docs/java/currency/Java并发指南5:JMM中的final关键字解析.md)
-* [Java并发指南6:Java内存模型JMM总结](docs/java/currency/Java并发指南6:Java内存模型JMM总结.md)
-* [Java并发指南7:JUC的核心类AQS详解](docs/java/currency/Java并发指南7:JUC的核心类AQS详解.md)
-* [Java并发指南8:AQS中的公平锁与非公平锁,Condtion](docs/java/currency/Java并发指南8:AQS中的公平锁与非公平锁,Condtion.md)
-* [Java并发指南9:AQS共享模式与并发工具类的实现](docs/java/currency/Java并发指南9:AQS共享模式与并发工具类的实现.md)
-* [Java并发指南10:Java 读写锁 ReentrantReadWriteLock 源码分析](docs/java/currency/Java并发指南10:Java%20读写锁%20ReentrantReadWriteLock%20源码分析.md)
-* [Java并发指南11:解读 Java 阻塞队列 BlockingQueue](docs/java/currency/Java并发指南11:解读%20Java%20阻塞队列%20BlockingQueue.md)
-* [Java并发指南12:深度解读 java 线程池设计思想及源码实现](docs/java/currency/Java并发指南12:深度解读%20java%20线程池设计思想及源码实现.md)
-* [Java并发指南13:Java 中的 HashMap 和 ConcurrentHashMap 全解析](https://github.com/h2pl/Java-Tutorial/blob/master/docs/java/currency/Java%E5%B9%B6%E5%8F%91%E6%8C%87%E5%8D%9713%EF%BC%9AJava%20%E4%B8%AD%E7%9A%84%20HashMap%20%E5%92%8C%20ConcurrentHashMap%20%E5%85%A8%E8%A7%A3%E6%9E%90.md)
-* [Java并发指南14:JUC中常用的Unsafe和Locksupport](docs/java/currency/Java并发指南14:JUC中常用的Unsafe和Locksupport.md)
-* [Java并发指南15:Fork join并发框架与工作窃取算法剖析](docs/java/currency/Java并发编程指南15:Fork%20join并发框架与工作窃取算法剖析.md)
-* [Java并发编程学习总结](https://github.com/h2pl/Java-Tutorial/blob/master/docs/java/currency/Java%E5%B9%B6%E5%8F%91%E6%80%BB%E7%BB%93.md)
-
-### JVM
-
-* [JVM总结](docs/java/jvm/JVM总结.md)
-* [深入理解JVM虚拟机1:JVM内存的结构与消失的永久代](docs/java/jvm/深入理解JVM虚拟机1:JVM内存的结构与消失的永久代.md)
-* [深入理解JVM虚拟机2:JVM垃圾回收基本原理和算法](docs/java/jvm/深入理解JVM虚拟机2:JVM垃圾回收基本原理和算法.md)
-* [深入理解JVM虚拟机3:垃圾回收器详解](docs/java/jvm/深入理解JVM虚拟机3:垃圾回收器详解.md)
-* [深入理解JVM虚拟机4:Javaclass介绍与解析实践](docs/java/jvm/深入理解JVM虚拟机4:Javaclass介绍与解析实践.md)
-* [深入理解JVM虚拟机5:虚拟机字节码执行引擎](docs/java/jvm/深入理解JVM虚拟机5:虚拟机字节码执行引擎.md)
-* [深入理解JVM虚拟机6:深入理解JVM类加载机制](docs/java/jvm/深入理解JVM虚拟机6:深入理解JVM类加载机制.md)
-* [深入理解JVM虚拟机7:JNDI,OSGI,Tomcat类加载器实现](docs/java/jvm/深入理解JVM虚拟机7:JNDI,OSGI,Tomcat类加载器实现.md)
-* [深入了解JVM虚拟机8:Java的编译期优化与运行期优化](docs/java/jvm/深入了解JVM虚拟机8:Java的编译期优化与运行期优化.md)
-* [深入理解JVM虚拟机9:JVM监控工具与诊断实践](docs/java/jvm/深入理解JVM虚拟机9:JVM监控工具与诊断实践.md)
-* [深入理解JVM虚拟机10:JVM常用参数以及调优实践](docs/java/jvm/深入理解JVM虚拟机10:JVM常用参数以及调优实践.md)
-* [深入理解JVM虚拟机11:Java内存异常原理与实践](docs/java/jvm/深入理解JVM虚拟机11:Java内存异常原理与实践.md)
-* [深入理解JVM虚拟机12:JVM性能管理神器VisualVM介绍与实战](docs/java/jvm/深入理解JVM虚拟机12:JVM性能管理神器VisualVM介绍与实战.md)
-* [深入理解JVM虚拟机13:再谈四种引用及GC实践](docs/java/jvm/深入理解JVM虚拟机13:再谈四种引用及GC实践.md)
-* [深入理解JVM虚拟机14:GC调优思路与常用工具](docs/java/jvm/深入理解JVM虚拟机:GC调优思路与常用工具.md)
-
-### Java网络编程
-
-* [Java网络编程和NIO详解1:JAVA 中原生的 socket 通信机制](docs/java/jvm/Java网络编程和NIO详解1:JAVA%20中原生的%20socket%20通信机制.md)
-* [Java网络编程与NIO详解2:JAVA NIO 一步步构建IO多路复用的请求模型](docs/java/jvm/Java网络编程与NIO详解2:JAVA%20NIO%20一步步构建IO多路复用的请求模型.md)
-* [Java网络编程和NIO详解3:IO模型与Java网络编程模型](docs/java/jvm/Java网络编程和NIO详解3:IO模型与Java网络编程模型.md)
-* [Java网络编程与NIO详解4:浅析NIO包中的Buffer、Channel 和 Selector](https://github.com/h2pl/Java-Tutorial/blob/master/docs/java/network-programming/Java%E7%BD%91%E7%BB%9C%E7%BC%96%E7%A8%8B%E4%B8%8ENIO%E8%AF%A6%E8%A7%A34%EF%BC%9A%E6%B5%85%E6%9E%90NIO%E5%8C%85%E4%B8%AD%E7%9A%84Buffer%E3%80%81Channel%20%E5%92%8C%20Selector.md)
-* [Java网络编程和NIO详解5:Java 非阻塞 IO 和异步 IO](https://github.com/h2pl/Java-Tutorial/blob/master/docs/java/network-programming/Java%E7%BD%91%E7%BB%9C%E7%BC%96%E7%A8%8B%E5%92%8CNIO%E8%AF%A6%E8%A7%A35%EF%BC%9AJava%20%E9%9D%9E%E9%98%BB%E5%A1%9E%20IO%20%E5%92%8C%E5%BC%82%E6%AD%A5%20IO.md)
-* [Java网络编程和NIO详解6:Linux epoll实现原理详解](docs/java/jvm/Java网络编程和NIO详解6:Linux%20epoll实现原理详解.md)
-* [Java网络编程和NIO详解7:浅谈 Linux 中NIO Selector 的实现原理](Java网络编程和NIO详解7:浅谈%20Linux%20中NIO%20Selector%20的实现原理.md)
-* [Java网络编程与NIO详解8:浅析mmap和Direct Buffer](https://github.com/h2pl/Java-Tutorial/blob/master/docs/java/network-programming/Java%E7%BD%91%E7%BB%9C%E7%BC%96%E7%A8%8B%E4%B8%8ENIO%E8%AF%A6%E8%A7%A38%EF%BC%9A%E6%B5%85%E6%9E%90mmap%E5%92%8CDirect%20Buffer.md)
-* [Java网络编程和NIO详解9:基于NIO的网络编程框架Netty](docs/java/jvm/Java网络编程和NIO详解9:基于NIO的网络编程框架Netty.md)
-* [Java网络编程与NIO详解10:深度解读Tomcat中的NIO模型](https://github.com/h2pl/Java-Tutorial/blob/master/docs/java/network-programming/Java%E7%BD%91%E7%BB%9C%E7%BC%96%E7%A8%8B%E4%B8%8ENIO%E8%AF%A6%E8%A7%A310%EF%BC%9A%E6%B7%B1%E5%BA%A6%E8%A7%A3%E8%AF%BBTomcat%E4%B8%AD%E7%9A%84NIO%E6%A8%A1%E5%9E%8B.md)
-* [Java网络编程与NIO详解11:Tomcat中的Connector源码分析(NIO)](docs/java/jvm/Java网络编程与NIO详解11:Tomcat中的Connector源码分析(NIO).md)
-
-## 计算机基础
-
-### 计算机网络
+
+
+# Java基础
+
+## 基础知识
+* [面向对象基础](docs/Java/basic/面向对象基础.md)
+* [Java基本数据类型](docs/Java/basic/Java基本数据类型.md)
+* [string和包装类](docs/Java/basic/string和包装类.md)
+* [final关键字特性](docs/Java/basic/final关键字特性.md)
+* [Java类和包](docs/Java/basic/Java类和包.md)
+* [抽象类和接口](docs/Java/basic/抽象类和接口.md)
+* [代码块和代码执行顺序](docs/Java/basic/代码块和代码执行顺序.md)
+* [Java自动拆箱装箱里隐藏的秘密](docs/Java/basic/Java自动拆箱装箱里隐藏的秘密.md)
+* [Java中的Class类和Object类](docs/Java/basic/Java中的Class类和Object类.md)
+* [Java异常](docs/Java/basic/Java异常.md)
+* [解读Java中的回调](docs/Java/basic/解读Java中的回调.md)
+* [反射](docs/Java/basic/反射.md)
+* [泛型](docs/Java/basic/泛型.md)
+* [枚举类](docs/Java/basic/枚举类.md)
+* [Java注解和最佳实践](docs/Java/basic/Java注解和最佳实践.md)
+* [JavaIO流](docs/Java/basic/JavaIO流.md)
+* [多线程](docs/Java/basic/多线程.md)
+* [深入理解内部类](docs/Java/basic/深入理解内部类.md)
+* [javac和javap](docs/Java/basic/javac和javap.md)
+* [Java8新特性终极指南](docs/Java/basic/Java8新特性终极指南.md)
+* [序列化和反序列化](docs/Java/basic/序列化和反序列化.md)
+* [继承封装多态的实现原理](docs/Java/basic/继承封装多态的实现原理.md)
+
+## 集合类
+
+* [Java集合类总结](docs/Java/collection/Java集合类总结.md)
+* [Java集合详解:一文读懂ArrayList,Vector与Stack使用方法和实现原理](docs/Java/collection/Java集合详解:一文读懂ArrayList,Vector与Stack使用方法和实现原理.md)
+* [Java集合详解:Queue和LinkedList](docs/Java/collection/Java集合详解:Queue和LinkedList.md)
+* [Java集合详解:Iterator,fail-fast机制与比较器](docs/Java/collection/Java集合详解:Iterator,fail-fast机制与比较器.md)
+* [Java集合详解:HashMap和HashTable](docs/Java/collection/Java集合详解:HashMap和HashTable.md)
+* [Java集合详解:深入理解LinkedHashMap和LRU缓存](docs/Java/collection/Java集合详解:深入理解LinkedHashMap和LRU缓存.md)
+* [Java集合详解:TreeMap和红黑树](docs/Java/collection/Java集合详解:TreeMap和红黑树.md)
+* [Java集合详解:HashSet,TreeSet与LinkedHashSet](docs/Java/collection/Java集合详解:HashSet,TreeSet与LinkedHashSet.md)
+* [Java集合详解:Java集合类细节精讲](docs/Java/collection/Java集合详解:Java集合类细节精讲.md)
+
+# JavaWeb
+
+* [走进JavaWeb技术世界:JavaWeb的由来和基础知识](docs/JavaWeb/走进JavaWeb技术世界:JavaWeb的由来和基础知识.md)
+* [走进JavaWeb技术世界:JSP与Servlet的曾经与现在](docs/JavaWeb/走进JavaWeb技术世界:JSP与Servlet的曾经与现在.md)
+* [走进JavaWeb技术世界:JDBC的进化与连接池技术](docs/JavaWeb/走进JavaWeb技术世界:JDBC的进化与连接池技术.md)
+* [走进JavaWeb技术世界:Servlet工作原理详解](docs/JavaWeb/走进JavaWeb技术世界:Servlet工作原理详解.md)
+* [走进JavaWeb技术世界:初探Tomcat的HTTP请求过程](docs/JavaWeb/走进JavaWeb技术世界:初探Tomcat的HTTP请求过程.md)
+* [走进JavaWeb技术世界:Tomcat5总体架构剖析](docs/JavaWeb/走进JavaWeb技术世界:Tomcat5总体架构剖析.md)
+* [走进JavaWeb技术世界:Tomcat和其他WEB容器的区别](docs/JavaWeb/走进JavaWeb技术世界:Tomcat和其他WEB容器的区别.md)
+* [走进JavaWeb技术世界:浅析Tomcat9请求处理流程与启动部署过程](docs/JavaWeb/走进JavaWeb技术世界:浅析Tomcat9请求处理流程与启动部署过程.md)
+* [走进JavaWeb技术世界:Java日志系统的诞生与发展](docs/JavaWeb/走进JavaWeb技术世界:Java日志系统的诞生与发展.md)
+* [走进JavaWeb技术世界:从JavaBean讲到Spring](docs/JavaWeb/走进JavaWeb技术世界:从JavaBean讲到Spring.md)
+* [走进JavaWeb技术世界:单元测试框架Junit](docs/JavaWeb/走进JavaWeb技术世界:单元测试框架Junit.md)
+* [走进JavaWeb技术世界:从手动编译打包到项目构建工具Maven](docs/JavaWeb/走进JavaWeb技术世界:从手动编译打包到项目构建工具Maven.md)
+* [走进JavaWeb技术世界:Hibernate入门经典与注解式开发](docs/JavaWeb/走进JavaWeb技术世界:Hibernate入门经典与注解式开发.md)
+* [走进JavaWeb技术世界:Mybatis入门](docs/JavaWeb/走进JavaWeb技术世界:Mybatis入门.md)
+* [走进JavaWeb技术世界:深入浅出Mybatis基本原理](docs/JavaWeb/走进JavaWeb技术世界:深入浅出Mybatis基本原理.md)
+* [走进JavaWeb技术世界:极简配置的SpringBoot](docs/JavaWeb/走进JavaWeb技术世界:极简配置的SpringBoot.md)
+
+# Java进阶
+
+## 并发编程
+
+* [Java并发指南:并发基础与Java多线程](docs/Java/concurrency/Java并发指南:并发基础与Java多线程.md)
+* [Java并发指南:深入理解Java内存模型JMM](docs/Java/concurrency/Java并发指南:深入理解Java内存模型JMM.md)
+* [Java并发指南:并发三大问题与volatile关键字,CAS操作](docs/Java/concurrency/Java并发指南:并发三大问题与volatile关键字,CAS操作.md)
+* [Java并发指南:Java中的锁Lock和synchronized](docs/Java/concurrency/Java并发指南:Java中的锁Lock和synchronized.md)
+* [Java并发指南:JMM中的final关键字解析](docs/Java/concurrency/Java并发指南:JMM中的final关键字解析.md)
+* [Java并发指南:Java内存模型JMM总结](docs/Java/concurrency/Java并发指南:Java内存模型JMM总结.md)
+* [Java并发指南:JUC的核心类AQS详解](docs/Java/concurrency/Java并发指南:JUC的核心类AQS详解.md)
+* [Java并发指南:AQS中的公平锁与非公平锁,Condtion](docs/Java/concurrency/Java并发指南:AQS中的公平锁与非公平锁,Condtion.md)
+* [Java并发指南:AQS共享模式与并发工具类的实现](docs/Java/concurrency/Java并发指南:AQS共享模式与并发工具类的实现.md)
+* [Java并发指南:Java读写锁ReentrantReadWriteLock源码分析](docs/Java/concurrency/Java并发指南:Java读写锁ReentrantReadWriteLock源码分析.md)
+* [Java并发指南:解读Java阻塞队列BlockingQueue](docs/Java/concurrency/Java并发指南:解读Java阻塞队列BlockingQueue.md)
+* [Java并发指南:深度解读java线程池设计思想及源码实现](docs/Java/concurrency/Java并发指南:深度解读Java线程池设计思想及源码实现.md)
+* [Java并发指南:Java中的HashMap和ConcurrentHashMap全解析](docs/Java/concurrency/Java并发指南:Java中的HashMap和ConcurrentHashMap全解析.md)
+* [Java并发指南:JUC中常用的Unsafe和Locksupport](docs/Java/concurrency/Java并发指南:JUC中常用的Unsafe和Locksupport.md)
+* [Java并发指南:ForkJoin并发框架与工作窃取算法剖析](docs/Java/concurrency/Java并发指南:ForkJoin并发框架与工作窃取算法剖析.md)
+* [Java并发编程学习总结](docs/Java/concurrency/Java并发编程学习总结.md)
+
+## JVM
+
+* [JVM总结](docs/Java/JVM/JVM总结.md)
+* [深入理解JVM虚拟机:JVM内存的结构与消失的永久代](docs/Java/JVM/深入理解JVM虚拟机:JVM内存的结构与消失的永久代.md)
+* [深入理解JVM虚拟机:JVM垃圾回收基本原理和算法](docs/Java/JVM/深入理解JVM虚拟机:JVM垃圾回收基本原理和算法.md)
+* [深入理解JVM虚拟机:垃圾回收器详解](docs/Java/JVM/深入理解JVM虚拟机:垃圾回收器详解.md)
+* [深入理解JVM虚拟机:Javaclass介绍与解析实践](docs/Java/JVM/深入理解JVM虚拟机:Java字节码介绍与解析实践.md)
+* [深入理解JVM虚拟机:虚拟机字节码执行引擎](docs/Java/JVM/深入理解JVM虚拟机:虚拟机字节码执行引擎.md)
+* [深入理解JVM虚拟机:深入理解JVM类加载机制](docs/Java/JVM/深入理解JVM虚拟机:深入理解JVM类加载机制.md)
+* [深入理解JVM虚拟机:JNDI,OSGI,Tomcat类加载器实现](docs/Java/JVM/深入理解JVM虚拟机:JNDI,OSGI,Tomcat类加载器实现.md)
+* [深入了解JVM虚拟机:Java的编译期优化与运行期优化](docs/Java/JVM/深入理解JVM虚拟机:Java的编译期优化与运行期优化.md)
+* [深入理解JVM虚拟机:JVM监控工具与诊断实践](docs/Java/JVM/深入理解JVM虚拟机:JVM监控工具与诊断实践.md)
+* [深入理解JVM虚拟机:JVM常用参数以及调优实践](docs/Java/JVM/深入理解JVM虚拟机:JVM常用参数以及调优实践.md)
+* [深入理解JVM虚拟机:Java内存异常原理与实践](docs/Java/JVM/深入理解JVM虚拟机:Java内存异常原理与实践.md)
+* [深入理解JVM虚拟机:JVM性能管理神器VisualVM介绍与实战](docs/Java/JVM/深入理解JVM虚拟机:JVM性能管理神器VisualVM介绍与实战.md)
+* [深入理解JVM虚拟机:再谈四种引用及GC实践](docs/Java/JVM/深入理解JVM虚拟机:再谈四种引用及GC实践.md)
+* [深入理解JVM虚拟机:GC调优思路与常用工具](docs/Java/JVM/深入理解JVM虚拟机:GC调优思路与常用工具.md)
+
+## Java网络编程
+
+* [Java网络编程和NIO详解:JAVA 中原生的 socket 通信机制](docs/Java/network/Java网络编程与NIO详解:JAVA中原生的socket通信机制.md)
+* [Java网络编程与NIO详解:JAVA NIO 一步步构建IO多路复用的请求模型](docs/Java/network/Java网络编程与NIO详解:JavaNIO一步步构建IO多路复用的请求模型.md)
+* [Java网络编程和NIO详解:IO模型与Java网络编程模型](docs/Java/network/Java网络编程与NIO详解:IO模型与Java网络编程模型.md)
+* [Java网络编程与NIO详解:浅析NIO包中的BufferChannel和Selector](docs/Java/network/Java网络编程与NIO详解:浅析NIO包中的BufferChannel和Selector.md)
+* [Java网络编程和NIO详解:Java非阻塞IO和异步IO](docs/Java/network/Java网络编程与NIO详解:Java非阻塞IO和异步IO.md)
+* [Java网络编程与NIO详解:LinuxEpoll实现原理详解](docs/Java/network/Java网络编程与NIO详解:LinuxEpoll实现原理详解.md.md)
+* [Java网络编程与NIO详解:浅谈Linux中Selector的实现原理](docs/Java/network/Java网络编程与NIO详解:浅谈Linux中Selector的实现原理.md)
+* [Java网络编程与NIO详解:浅析mmap和DirectBuffer](docs/Java/network/Java网络编程与NIO详解:浅析mmap和DirectBuffer.md)
+* [Java网络编程与NIO详解:基于NIO的网络编程框架Netty](docs/Java/network/Java网络编程与NIO详解:基于NIO的网络编程框架Netty.md)
+* [Java网络编程与NIO详解:Java网络编程与NIO详解](docs/Java/network/Java网络编程与NIO详解:深度解读Tomcat中的NIO模型.md)
+* [Java网络编程与NIO详解:Tomcat中的Connector源码分析(NIO)](docs/Java/network/Java网络编程与NIO详解:Tomcat中的Connector源码分析(NIO).md)
+
+# Spring全家桶
+
+## Spring
+
+* [SpringAOP的概念与作用](docs/Spring全家桶/Spring/Spring常见注解.md)
+* [SpringBean的定义与管理(核心)](docs/Spring全家桶/Spring/Spring常见注解.md)
+* [Spring中对于数据库的访问](docs/Spring全家桶/Spring/Spring常见注解.md)
+* [Spring中对于校验功能的支持](docs/Spring全家桶/Spring/Spring常见注解.md)
+* [Spring中的Environment环境变量](docs/Spring全家桶/Spring/Spring常见注解.md)
+* [Spring中的事件处理机制](docs/Spring全家桶/Spring/Spring常见注解.md)
+* [Spring中的资源管理](docs/Spring全家桶/Spring/Spring常见注解.md)
+* [Spring中的配置元数据(管理配置的基本数据)](docs/Spring全家桶/Spring/Spring常见注解.md)
+* [Spring事务基本用法](docs/Spring全家桶/Spring/Spring常见注解.md)
+* [Spring合集](docs/Spring全家桶/Spring/Spring常见注解.md)
+* [Spring容器与IOC](docs/Spring全家桶/Spring/Spring常见注解.md)
+* [Spring常见注解](docs/Spring全家桶/Spring/Spring常见注解.md)
+* [Spring概述](docs/Spring全家桶/Spring/Spring常见注解.md)
+* [第一个Spring应用](docs/Spring全家桶/Spring/Spring常见注解.md)
+
+## Spring源码分析
+
+### 综合
+* [Spring源码剖析:初探SpringIOC核心流程](docs/Spring全家桶/Spring源码分析/Spring源码剖析:初探SpringIOC核心流程.md)
+* [Spring源码剖析:SpringIOC容器的加载过程 ](docs/Spring全家桶/Spring源码分析/Spring源码剖析:SpringIOC容器的加载过程.md)
+* [Spring源码剖析:懒加载的单例Bean获取过程分析](docs/Spring全家桶/Spring源码分析/Spring源码剖析:懒加载的单例Bean获取过程分析.md)
+* [Spring源码剖析:JDK和cglib动态代理原理详解 ](docs/Spring全家桶/Spring源码分析/Spring源码剖析:JDK和cglib动态代理原理详解.md)
+* [Spring源码剖析:SpringAOP概述](docs/Spring全家桶/Spring源码分析/Spring源码剖析:SpringAOP概述.md)
+* [Spring源码剖析:AOP实现原理详解 ](docs/Spring全家桶/Spring源码分析/Spring源码剖析:AOP实现原理详解.md)
+* [Spring源码剖析:Spring事务概述](docs/Spring全家桶/Spring源码分析/Spring源码剖析:Spring事务概述.md)
+* [Spring源码剖析:Spring事务源码剖析](docs/Spring全家桶/Spring源码分析/Spring源码剖析:Spring事务源码剖析.md)
+
+### AOP
+* [AnnotationAwareAspectJAutoProxyCreator 分析(上)](docs/Spring全家桶/Spring源码分析/SpringAOP/AnnotationAwareAspectJAutoProxyCreator分析(上).md)
+* [AnnotationAwareAspectJAutoProxyCreator 分析(下)](docs/Spring全家桶/Spring源码分析/SpringAOP/AnnotationAwareAspectJAutoProxyCreator分析(下).md)
+* [AOP示例demo及@EnableAspectJAutoProxy](docs/Spring全家桶/Spring源码分析/SpringAOP/AOP示例demo及@EnableAspectJAutoProxy.md)
+* [SpringAop(四):jdk 动态代理](docs/Spring全家桶/Spring源码分析/SpringAOP/SpringAop(四):jdk动态代理.md)
+* [SpringAop(五):cglib 代理](docs/Spring全家桶/Spring源码分析/SpringAOP/SpringAop(五):cglib代理.md)
+* [SpringAop(六):aop 总结](docs/Spring全家桶/Spring源码分析/SpringAOP/SpringAop(六):aop总结.md)
+
+### 事务
+* [spring 事务(一):认识事务组件](docs/Spring全家桶/Spring源码分析/Spring事务/Spring事务(一):认识事务组件.md)
+* [spring 事务(二):事务的执行流程](docs/Spring全家桶/Spring源码分析/Spring事务/Spring事务(二):事务的执行流程.md)
+* [spring 事务(三):事务的隔离级别与传播方式的处理](docs/Spring全家桶/Spring源码分析/Spring事务/Spring事务(三):事务的隔离级别与传播方式的处理01.md)
+* [spring 事务(四):事务的隔离级别与传播方式的处理](docs/Spring全家桶/Spring源码分析/Spring事务/Spring事务(四):事务的隔离级别与传播方式的处理02.md)
+* [spring 事务(五):事务的隔离级别与传播方式的处理](docs/Spring全家桶/Spring源码分析/Spring事务/Spring事务(五):事务的隔离级别与传播方式的处理03.md)
+* [spring 事务(六):事务的隔离级别与传播方式的处理](docs/Spring全家桶/Spring源码分析/Spring事务/Spring事务(六):事务的隔离级别与传播方式的处理04.md)
+
+### 启动流程
+* [spring启动流程(一):启动流程概览](docs/Spring全家桶/Spring源码分析/Spring启动流程/Spring启动流程(一):启动流程概览.md)
+* [spring启动流程(二):ApplicationContext 的创建](docs/Spring全家桶/Spring源码分析/Spring启动流程/Spring启动流程(二):ApplicationContext的创建.md)
+* [spring启动流程(三):包的扫描流程](docs/Spring全家桶/Spring源码分析/Spring启动流程/Spring启动流程(三):包的扫描流程.md)
+* [spring启动流程(四):启动前的准备工作](docs/Spring全家桶/Spring源码分析/Spring启动流程/Spring启动流程(四):启动前的准备工作.md)
+* [spring启动流程(五):执行 BeanFactoryPostProcessor](docs/Spring全家桶/Spring源码分析/Spring启动流程/Spring启动流程(五):执行BeanFactoryPostProcessor.md)
+* [spring启动流程(六):注册 BeanPostProcessor](docs/Spring全家桶/Spring源码分析/Spring启动流程/Spring启动流程(六):注册BeanPostProcessor.md)
+* [spring启动流程(七):国际化与事件处理](docs/Spring全家桶/Spring源码分析/Spring启动流程/Spring启动流程(七):国际化与事件处理.md)
+* [spring启动流程(八):完成 BeanFactory 的初始化](docs/Spring全家桶/Spring源码分析/Spring启动流程/Spring启动流程(八):完成BeanFactory的初始化.md)
+* [spring启动流程(九):单例 bean 的创建](docs/Spring全家桶/Spring源码分析/Spring启动流程/Spring启动流程(九):单例bean的创建.md)
+* [spring启动流程(十):启动完成的处理](docs/Spring全家桶/Spring源码分析/Spring启动流程/Spring启动流程(十):启动完成的处理.md)
+* [spring启动流程(十一):启动流程总结](docs/Spring全家桶/Spring源码分析/Spring启动流程/Spring启动流程(十一):启动流程总结.md)
+
+### 组件分析
+* [spring 组件之 ApplicationContext](docs/Spring全家桶/Spring源码分析/Spring组件分析/Spring组件之ApplicationContext.md)
+* [spring 组件之 BeanDefinition](docs/Spring全家桶/Spring源码分析/Spring组件分析/Spring组件之BeanDefinition.md)
+* [Spring 组件之 BeanFactory](docs/Spring全家桶/Spring源码分析/Spring组件分析/Spring组件之BeanFactory.md)
+* [spring 组件之 BeanFactoryPostProcessor](docs/Spring全家桶/Spring源码分析/Spring组件分析/Spring组件之BeanFactoryPostProcessor.md)
+* [spring 组件之 BeanPostProcessor](docs/Spring全家桶/Spring源码分析/Spring组件分析/Spring组件之BeanPostProcessor.md)
+
+### 重要机制探秘
+
+* [ConfigurationClassPostProcessor(一):处理 @ComponentScan 注解](docs/Spring全家桶/Spring源码分析/Spring重要机制探秘/ConfigurationClassPostProcessor(一):处理@ComponentScan注解.md)
+* [ConfigurationClassPostProcessor(三):处理 @Import 注解](docs/Spring全家桶/Spring源码分析/Spring重要机制探秘/ConfigurationClassPostProcessor(三):处理@Import注解.md)
+* [ConfigurationClassPostProcessor(二):处理 @Bean 注解](docs/Spring全家桶/Spring源码分析/Spring重要机制探秘/ConfigurationClassPostProcessor(二):处理@Bean注解.md)
+* [ConfigurationClassPostProcessor(四):处理 @Conditional 注解](docs/Spring全家桶/Spring源码分析/Spring重要机制探秘/ConfigurationClassPostProcessor(四):处理@Conditional注解.md)
+* [Spring 探秘之 AOP 的执行顺序](docs/Spring全家桶/Spring源码分析/Spring重要机制探秘/Spring探秘之AOP的执行顺序.md)
+* [Spring 探秘之 Spring 事件机制](docs/Spring全家桶/Spring源码分析/Spring重要机制探秘/Spring探秘之Spring事件机制.md)
+* [spring 探秘之循环依赖的解决(一):理论基石](docs/Spring全家桶/Spring源码分析/Spring重要机制探秘/Spring探秘之循环依赖的解决(一):理论基石.md)
+* [spring 探秘之循环依赖的解决(二):源码分析](docs/Spring全家桶/Spring源码分析/Spring重要机制探秘/Spring探秘之循环依赖的解决(二):源码分析.md)
+* [spring 探秘之监听器注解 @EventListener](docs/Spring全家桶/Spring源码分析/Spring重要机制探秘/spring探秘之监听器注解@EventListener.md)
+* [spring 探秘之组合注解的处理](docs/Spring全家桶/Spring源码分析/Spring重要机制探秘/Spring探秘之组合注解的处理.md)
+
+## SpringMVC
+
+* [SpringMVC中的国际化功能](docs/Spring全家桶/SpringMVC/SpringMVC中的国际化功能.md)
+* [SpringMVC中的异常处理器](docs/Spring全家桶/SpringMVC/SpringMVC中的异常处理器.md)
+* [SpringMVC中的拦截器](docs/Spring全家桶/SpringMVC/SpringMVC中的拦截器.md)
+* [SpringMVC中的视图解析器](docs/Spring全家桶/SpringMVC/SpringMVC中的视图解析器.md)
+* [SpringMVC中的过滤器Filter](docs/Spring全家桶/SpringMVC/SpringMVC中的过滤器Filter.md)
+* [SpringMVC基本介绍与快速入门](docs/Spring全家桶/SpringMVC/SpringMVC基本介绍与快速入门.md)
+* [SpringMVC如何实现文件上传](docs/Spring全家桶/SpringMVC/SpringMVC如何实现文件上传.md)
+* [SpringMVC中的常用功能](docs/Spring全家桶/SpringMVC/SpringMVC中的常用功能.md)
+
+## SpringMVC源码分析
+
+* [SpringMVC源码分析:SpringMVC概述](docs/Spring全家桶/SpringMVC源码分析/SpringMVC源码分析:SpringMVC概述.md)
+* [SpringMVC源码分析:SpringMVC设计理念与DispatcherServlet](docs/Spring全家桶/SpringMVC源码分析/SpringMVC源码分析:SpringMVC设计理念与DispatcherServlet.md)
+* [SpringMVC源码分析:DispatcherServlet的初始化与请求转发 ](docs/Spring全家桶/SpringMVC源码分析/SpringMVC源码分析:DispatcherServlet的初始化与请求转发.md)
+* [SpringMVC源码分析:DispatcherServlet如何找到正确的Controller ](docs/Spring全家桶/SpringMVC源码分析/SpringMVC源码分析:DispatcherServlet如何找到正确的Controller.md)
+* [SpringMVC源码剖析:消息转换器HttpMessageConverter与@ResponseBody注解](docs/Spring全家桶/SpringMVC/SpringMVC源码剖析:消息转换器HttpMessageConverter与@ResponseBody注解.md)
+* [DispatcherServlet 初始化流程 ](docs/Spring全家桶/SpringMVC源码分析/DispatcherServlet初始化流程.md)
+* [RequestMapping 初始化流程 ](docs/Spring全家桶/SpringMVC源码分析/RequestMapping初始化流程.md)
+* [Spring 容器启动 Tomcat ](docs/Spring全家桶/SpringMVC源码分析/Spring容器启动Tomcat.md)
+* [SpringMVC demo 与@EnableWebMvc 注解 ](docs/Spring全家桶/SpringMVC源码分析/SpringMVC的Demo与@EnableWebMvc注解.md)
+* [SpringMVC 整体源码结构总结 ](docs/Spring全家桶/SpringMVC源码分析/SpringMVC整体源码结构总结.md)
+* [请求执行流程(一)之获取 Handler ](docs/Spring全家桶/SpringMVC源码分析/请求执行流程(一)之获取Handler.md)
+* [请求执行流程(二)之执行 Handler 方法 ](docs/Spring全家桶/SpringMVC源码分析/请求执行流程(二)之执行Handler方法.md)
+
+## SpringBoot
+
+* [SpringBoot系列:SpringBoot的前世今生](docs/Spring全家桶/SpringBoot/SpringBoot的前世今生.md)
+* [给你一份SpringBoot知识清单.md](docs/Spring全家桶/SpringBoot/给你一份SpringBoot知识清单.md)
+* [Spring常见注解使用指南(包含Spring+SpringMVC+SpringBoot)](docs/Spring全家桶/SpringBoot/Spring常见注解使用指南(包含Spring+SpringMVC+SpringBoot).md)
+* [SpringBoot中的日志管理](docs/Spring全家桶/SpringBoot/SpringBoot中的日志管理.md)
+* [SpringBoot常见注解](docs/Spring全家桶/SpringBoot/SpringBoot常见注解.md)
+* [SpringBoot应用也可以部署到外部Tomcat](docs/Spring全家桶/SpringBoot/SpringBoot应用也可以部署到外部Tomcat.md)
+* [SpringBoot生产环境工具Actuator](docs/Spring全家桶/SpringBoot/SpringBoot生产环境工具Actuator.md)
+* [SpringBoot的Starter机制](docs/Spring全家桶/SpringBoot/SpringBoot的Starter机制.md)
+* [SpringBoot的前世今生](docs/Spring全家桶/SpringBoot/SpringBoot的前世今生.md)
+* [SpringBoot的基本使用](docs/Spring全家桶/SpringBoot/SpringBoot的基本使用.md)
+* [SpringBoot的配置文件管理](docs/Spring全家桶/SpringBoot/SpringBoot的配置文件管理.md)
+* [SpringBoot自带的热部署工具](docs/Spring全家桶/SpringBoot/SpringBoot自带的热部署工具.md)
+* [SpringBoot中的任务调度与@Async](docs/Spring全家桶/SpringBoot/SpringBoot中的任务调度与@Async.md)
+* [基于SpringBoot中的开源监控工具SpringBootAdmin](docs/Spring全家桶/SpringBoot/基于SpringBoot中的开源监控工具SpringBootAdmin.md)
+
+## SpringBoot源码分析
+* [@SpringBootApplication 注解](docs/Spring全家桶/SpringBoot源码解析/@SpringBootApplication注解.md)
+* [springboot web应用(一):servlet 组件的注册流程](docs/Spring全家桶/SpringBoot源码解析/SpringBootWeb应用(一):servlet组件的注册流程.md)
+* [springboot web应用(二):WebMvc 装配过程](docs/Spring全家桶/SpringBoot源码解析/SpringBootWeb应用(二):WebMvc装配过程.md)
+
+* [SpringBoot 启动流程(一):准备 SpringApplication](docs/Spring全家桶/SpringBoot源码解析/SpringBoot启动流程(一):准备SpringApplication.md)
+* [SpringBoot 启动流程(二):准备运行环境](docs/Spring全家桶/SpringBoot源码解析/SpringBoot启动流程(二):准备运行环境.md)
+* [SpringBoot 启动流程(三):准备IOC容器](docs/Spring全家桶/SpringBoot源码解析/SpringBoot启动流程(三):准备IOC容器.md)
+* [springboot 启动流程(四):启动IOC容器](docs/Spring全家桶/SpringBoot源码解析/SpringBoot启动流程(四):启动IOC容器.md)
+* [springboot 启动流程(五):完成启动](docs/Spring全家桶/SpringBoot源码解析/SpringBoot启动流程(五):完成启动.md)
+* [springboot 启动流程(六):启动流程总结](docs/Spring全家桶/SpringBoot源码解析/SpringBoot启动流程(六):启动流程总结.md)
+
+* [springboot 自动装配(一):加载自动装配类](docs/Spring全家桶/SpringBoot源码解析/SpringBoot自动装配(一):加载自动装配类.md)
+* [springboot 自动装配(二):条件注解](docs/Spring全家桶/SpringBoot源码解析/SpringBoot自动装配(二):条件注解.md)
+* [springboot 自动装配(三):自动装配顺序](docs/Spring全家桶/SpringBoot源码解析/SpringBoot自动装配(三):自动装配顺序.md)
+
+## SpringCloud
+* [SpringCloud概述](docs/Spring全家桶/SpringCloud/SpringCloud概述.md)
+* [Spring Cloud Config](docs/Spring全家桶/SpringCloud/SpringCloudConfig.md)
+* [Spring Cloud Consul](docs/Spring全家桶/SpringCloud/SpringCloudConsul.md)
+* [Spring Cloud Eureka](docs/Spring全家桶/SpringCloud/SpringCloudEureka.md)
+* [Spring Cloud Gateway](docs/Spring全家桶/SpringCloud/SpringCloudGateway.md)
+* [Spring Cloud Hystrix](docs/Spring全家桶/SpringCloud/SpringCloudHystrix.md)
+* [Spring Cloud LoadBalancer](docs/Spring全家桶/SpringCloud/SpringCloudLoadBalancer.md)
+* [Spring Cloud OpenFeign](docs/Spring全家桶/SpringCloud/SpringCloudOpenFeign.md)
+* [Spring Cloud Ribbon](docs/Spring全家桶/SpringCloud/SpringCloudRibbon.md)
+* [Spring Cloud Sleuth](docs/Spring全家桶/SpringCloud/SpringCloudSleuth.md)
+* [Spring Cloud Zuul](docs/Spring全家桶/SpringCloud/SpringCloudZuul.md)
+
+## SpringCloud 源码分析
+* [Spring Cloud Config源码分析](docs/Spring全家桶/SpringCloud源码分析/SpringCloudConfig源码分析.md)
+* [Spring Cloud Eureka源码分析](docs/Spring全家桶/SpringCloud源码分析/SpringCloudEureka源码分析.md)
+* [Spring Cloud Gateway源码分析](docs/Spring全家桶/SpringCloud源码分析/SpringCloudGateway源码分析.md)
+* [Spring Cloud Hystrix源码分析](docs/Spring全家桶/SpringCloud源码分析/SpringCloudHystrix源码分析.md)
+* [Spring Cloud LoadBalancer源码分析](docs/Spring全家桶/SpringCloud源码分析/SpringCloudLoadBalancer源码分析.md)
+* [Spring Cloud OpenFeign源码分析](docs/Spring全家桶/SpringCloud源码分析/SpringCloudOpenFeign源码分析.md)
+* [Spring Cloud Ribbon源码分析](docs/Spring全家桶/SpringCloud源码分析/SpringCloudRibbon源码分析.md)
+
+## SpringCloud Alibaba
+* [SpringCloud Alibaba概览](docs/Spring全家桶/SpringCloudAlibaba/SpringCloudAlibaba概览.md)
+* [SpringCloud Alibaba nacos](docs/Spring全家桶/SpringCloudAlibaba/SpringCloudAlibabaNacos.md)
+* [SpringCloud Alibaba RocketMQ](docs/Spring全家桶/SpringCloudAlibaba/SpringCloudAlibabaRocketMQ.md)
+* [SpringCloud Alibaba sentinel](docs/Spring全家桶/SpringCloudAlibaba/SpringCloudAlibabaSentinel.md)
+* [SpringCloud Alibaba skywalking](docs/Spring全家桶/SpringCloudAlibaba/SpringCloudAlibabaSkywalking.md)
+* [SpringCloud Alibaba seata](docs/Spring全家桶/SpringCloudAlibaba/SpringCloudAlibabaSeata.md)
+
+## SpringCloud Alibaba源码分析
+* [Spring Cloud Seata源码分析](docs/Spring全家桶/SpringCloudAlibaba源码分析/SpringCloudSeata源码分析.md)
+* [Spring Cloud Sentinel源码分析](docs/Spring全家桶/SpringCloudAlibaba源码分析/SpringCloudSentinel源码分析.md)
+* [SpringCloudAlibaba nacos源码分析:概览](docs/Spring全家桶/SpringCloudAlibaba源码分析/SpringCloudAlibabaNacos源码分析:概览.md)
+* [SpringCloudAlibaba nacos源码分析:服务发现](docs/Spring全家桶/SpringCloudAlibaba源码分析/SpringCloudAlibabaNacos源码分析:服务发现.md)
+* [SpringCloudAlibaba nacos源码分析:服务注册](docs/Spring全家桶/SpringCloudAlibaba源码分析/SpringCloudAlibabaNacos源码分析:服务注册.md)
+* [SpringCloudAlibaba nacos源码分析:配置中心](docs/Spring全家桶/SpringCloudAlibaba源码分析/SpringCloudAlibabaNacos源码分析:配置中心.md)
+* [Spring Cloud RocketMQ源码分析](docs/Spring全家桶/SpringCloudAlibaba源码分析/SpringCloudRocketMQ源码分析.md)
+
+# 设计模式
+
+* [设计模式学习总结](docs/Java/design-parttern/设计模式学习总结.md)
+* [初探Java设计模式:创建型模式(工厂,单例等).md](docs/Java/design-parttern/初探Java设计模式:创建型模式(工厂,单例等).md)
+* [初探Java设计模式:结构型模式(代理模式,适配器模式等).md](docs/Java/design-parttern/初探Java设计模式:结构型模式(代理模式,适配器模式等).md)
+* [初探Java设计模式:行为型模式(策略,观察者等).md](docs/Java/design-parttern/初探Java设计模式:行为型模式(策略,观察者等).md)
+* [初探Java设计模式:JDK中的设计模式.md](docs/Java/design-parttern/初探Java设计模式:JDK中的设计模式.md)
+* [初探Java设计模式:Spring涉及到的种设计模式.md](docs/Java/design-parttern/初探Java设计模式:Spring涉及到的种设计模式.md)
+
+
+# 计算机基础
+
+## 计算机网络
todo
-### 操作系统
+## 操作系统
todo
-#### Linux相关
+## Linux相关
todo
-### 数据结构与算法
+## 数据结构与算法
todo
-#### 数据结构
+## 数据结构
todo
-#### 算法
+## 算法
todo
-## 数据库
+# 数据库
todo
-### MySQL
+## MySQL
* [Mysql原理与实践总结](docs/database/Mysql原理与实践总结.md)
-* [重新学习Mysql数据库1:无废话MySQL入门](docs/database/重新学习Mysql数据库1:无废话MySQL入门.md)
-* [重新学习Mysql数据库2:『浅入浅出』MySQL 和 InnoDB](docs/database/重新学习Mysql数据库2:%20『浅入浅出』MySQL%20和%20InnoDB.md)
-* [重新学习Mysql数据库3:Mysql存储引擎与数据存储原理](docs/database/重新学习Mysql数据库3:Mysql存储引擎与数据存储原理.md)
-* [重新学习Mysql数据库4:Mysql索引实现原理和相关数据结构算法](docs/database/重新学习Mysql数据库4:Mysql索引实现原理和相关数据结构算法.md)
-* [重新学习Mysql数据库5:根据MySQL索引原理进行分析与优化](docs/database/重新学习Mysql数据库5:根据MySQL索引原理进行分析与优化.md)
-* [重新学习MySQL数据库6:浅谈MySQL的中事务与锁](docs/database/重新学习MySQL数据库6:浅谈MySQL的中事务与锁.md)
-* [重新学习Mysql数据库7:详解MyIsam与InnoDB引擎的锁实现](docs/database/重新学习Mysql数据库7:详解MyIsam与InnoDB引擎的锁实现.md)
-* [重新学习Mysql数据库8:MySQL的事务隔离级别实战](docs/database/重新学习Mysql数据库8:MySQL的事务隔离级别实战.md)
-* [重新学习MySQL数据库9:Innodb中的事务隔离级别和锁的关系](docs/database/重新学习MySQL数据库9:Innodb中的事务隔离级别和锁的关系.md)
-* [重新学习MySQL数据库10:MySQL里的那些日志们](docs/database/重新学习MySQL数据库10:MySQL里的那些日志们.md)
-* [重新学习MySQL数据库11:以Java的视角来聊聊SQL注入](docs/database/重新学习MySQL数据库11:以Java的视角来聊聊SQL注入.md)
-* [重新学习MySQL数据库12:从实践sql语句优化开始](docs/database/重新学习MySQL数据库12:从实践sql语句优化开始.md)
-* [重新学习Mysql数据库13:Mysql主从复制,读写分离,分表分库策略与实践](docs/database/重新学习Mysql数据13:Mysql主从复制,读写分离,分表分库策略与实践.md)
-
-
-## 缓存
-
-### Redis
+* [重新学习Mysql数据库:无废话MySQL入门](docs/database/重新学习MySQL数据库:无废话MySQL入门.md)
+* [重新学习Mysql数据库:『浅入浅出』MySQL和InnoDB](docs/database/重新学习MySQL数据库:『浅入浅出』MySQL和InnoDB.md)
+* [重新学习Mysql数据库:Mysql存储引擎与数据存储原理](docs/database/重新学习MySQL数据库:Mysql存储引擎与数据存储原理.md)
+* [重新学习Mysql数据库:Mysql索引实现原理和相关数据结构算法](docs/database/重新学习MySQL数据库:Mysql索引实现原理和相关数据结构算法.md)
+* [重新学习Mysql数据库:根据MySQL索引原理进行分析与优化](docs/database/重新学习MySQL数据库:根据MySQL索引原理进行分析与优化.md)
+* [重新学习MySQL数据库:浅谈MySQL的中事务与锁](docs/database/重新学习MySQL数据库:浅谈MySQL的中事务与锁.md)
+* [重新学习Mysql数据库:详解MyIsam与InnoDB引擎的锁实现](docs/database/重新学习MySQL数据库:详解MyIsam与InnoDB引擎的锁实现.md)
+* [重新学习Mysql数据库:MySQL的事务隔离级别实战](docs/database/重新学习MySQL数据库:MySQL的事务隔离级别实战.md)
+* [重新学习MySQL数据库:Innodb中的事务隔离级别和锁的关系](docs/database/重新学习MySQL数据库:Innodb中的事务隔离级别和锁的关系.md)
+* [重新学习MySQL数据库:MySQL里的那些日志们](docs/database/重新学习MySQL数据库:MySQL里的那些日志们.md)
+* [重新学习MySQL数据库:以Java的视角来聊聊SQL注入](docs/database/重新学习MySQL数据库:以Java的视角来聊聊SQL注入.md)
+* [重新学习MySQL数据库:从实践sql语句优化开始](docs/database/重新学习MySQL数据库:从实践sql语句优化开始.md)
+* [重新学习Mysql数据库:Mysql主从复制,读写分离,分表分库策略与实践](docs/database/重新学习MySQL数据库:Mysql主从复制,读写分离,分表分库策略与实践.md)
+
+
+# 缓存
+
+## Redis
* [Redis原理与实践总结](docs/cache/Redis原理与实践总结.md)
* [探索Redis设计与实现开篇:什么是Redis](docs/cache/探索Redis设计与实现开篇:什么是Redis.md)
-* [探索Redis设计与实现1:Redis 的基础数据结构概览](docs/cache/探索Redis设计与实现1:Redis%20的基础数据结构概览.md)
-* [探索Redis设计与实现2:Redis内部数据结构详解——dict](docs/cache/探索Redis设计与实现2:Redis内部数据结构详解——dict.md)
-* [探索Redis设计与实现3:Redis内部数据结构详解——sds](docs/cache/探索Redis设计与实现3:Redis内部数据结构详解——sds.md)
-* [探索Redis设计与实现4:Redis内部数据结构详解——ziplist](docs/cache/探索Redis设计与实现4:Redis内部数据结构详解——ziplist.md)
-* [探索Redis设计与实现5:Redis内部数据结构详解——quicklist](docs/cache/探索Redis设计与实现5:Redis内部数据结构详解——quicklist.md)
-* [探索Redis设计与实现6:Redis内部数据结构详解——skiplist](docs/cache/探索Redis设计与实现6:Redis内部数据结构详解——skiplist.md)
-* [探索Redis设计与实现7:Redis内部数据结构详解——intset](docs/cache/探索Redis设计与实现7:Redis内部数据结构详解——intset.md)
-* [探索Redis设计与实现8:连接底层与表面的数据结构robj](docs/cache/探索Redis设计与实现8:连接底层与表面的数据结构robj.md)
-* [探索Redis设计与实现9:数据库redisDb与键过期删除策略](docs/cache/探索Redis设计与实现9:数据库redisDb与键过期删除策略.md)
-* [探索Redis设计与实现10:Redis的事件驱动模型与命令执行过程](docs/cache/探索Redis设计与实现10:Redis的事件驱动模型与命令执行过程.md)
-* [探索Redis设计与实现11:使用快照和AOF将Redis数据持久化到硬盘中](docs/cache/探索Redis设计与实现11:使用快照和AOF将Redis数据持久化到硬盘中.md)
-* [探索Redis设计与实现12:浅析Redis主从复制](docs/cache/探索Redis设计与实现12:浅析Redis主从复制.md)
-* [探索Redis设计与实现13:Redis集群机制及一个Redis架构演进实例](docs/cache/探索Redis设计与实现13:Redis集群机制及一个Redis架构演进实例.md)
-* [探索Redis设计与实现14:Redis事务浅析与ACID特性介绍](docs/cache/探索Redis设计与实现14:Redis事务浅析与ACID特性介绍.md)
-* [探索Redis设计与实现15:Redis分布式锁进化史 ](docs/cache/探索Redis设计与实现15:Redis分布式锁进化史.md )
-
-## 消息队列
-
-### Kafka
-
-## 大后端
-* [后端技术杂谈开篇:云计算,大数据与AI的故事](docs/big-backEnd/后端技术杂谈开篇:云计算,大数据与AI的故事.md)
-* [后端技术杂谈1:搜索引擎基础倒排索引](docs/big-backEnd/后端技术杂谈1:搜索引擎基础倒排索引.md)
-* [后端技术杂谈2:搜索引擎工作原理](docs/big-backEnd/后端技术杂谈2:搜索引擎工作原理.md)
-* [后端技术杂谈3:Lucene基础原理与实践](docs/big-backEnd/后端技术杂谈3:Lucene基础原理与实践.md)
-* [后端技术杂谈4:Elasticsearch与solr入门实践](docs/big-backEnd/后端技术杂谈4:Elasticsearch与solr入门实践.md)
-* [后端技术杂谈5:云计算的前世今生](docs/big-backEnd/后端技术杂谈5:云计算的前世今生.md)
-* [后端技术杂谈6:白话虚拟化技术](docs/big-backEnd/后端技术杂谈6:白话虚拟化技术.md )
-* [后端技术杂谈7:OpenStack的基石KVM](docs/big-backEnd/后端技术杂谈7:OpenStack的基石KVM.md)
-* [后端技术杂谈8:OpenStack架构设计](docs/big-backEnd/后端技术杂谈8:OpenStack架构设计.md)
-* [后端技术杂谈9:先搞懂Docker核心概念吧](docs/big-backEnd/后端技术杂谈9:先搞懂Docker核心概念吧.md)
-* [后端技术杂谈10:Docker 核心技术与实现原理](docs/big-backEnd/后端技术杂谈10:Docker%20核心技术与实现原理.md)
-* [后端技术杂谈11:十分钟理解Kubernetes核心概念](docs/big-backEnd/后端技术杂谈11:十分钟理解Kubernetes核心概念.md)
-* [后端技术杂谈12:捋一捋大数据研发的基本概念](docs/big-backEnd/后端技术杂谈12:捋一捋大数据研发的基本概念.md)
-
-## 分布式
-### 理论
-* [分布式系统理论基础开篇:从放弃到入门](docs/distrubuted/理论/分布式系统理论基础开篇:从放弃到入门.md)
-* [分布式系统理论基础1: 一致性、2PC和3PC ](docs/distrubuted/理论/分布式系统理论基础1:%20一致性、2PC和3PC.md)
-* [分布式系统理论基础2:CAP ](docs/distrubuted/理论/分布式系统理论基础2%20:CAP.md)
-* [分布式系统理论基础3: 时间、时钟和事件顺序](docs/distrubuted/理论/分布式系统理论基础3:%20时间、时钟和事件顺序.md)
-* [分布式系统理论基础4:Paxos](docs/distrubuted/理论/分布式系统理论基础4:Paxos.md)
-* [分布式系统理论基础5:选举、多数派和租约](docs/distrubuted/理论/分布式系统理论基础5:选举、多数派和租约.md)
-* [分布式系统理论基础6:Raft、Zab ](docs/distrubuted/理论/分布式系统理论基础6:Raft、Zab.md)
-* [分布式系统理论进阶7:Paxos变种和优化 ](docs/distrubuted/理论/分布式系统理论进阶7:Paxos变种和优化.md)
-* [分布式系统理论基础8:zookeeper分布式协调服务 ](docs/distrubuted/理论/分布式系统理论基础8:zookeeper分布式协调服务.md)
-
-### 技术
-* [搞懂分布式技术1:分布式系统的一些基本概念 ](docs/distrubuted/实战/搞懂分布式技术1:分布式系统的一些基本概念.md )
-* [搞懂分布式技术2:分布式一致性协议与Paxos,Raft算法](docs/distrubuted/实战/搞懂分布式技术2:分布式一致性协议与Paxos,Raft算法.md)
-* [搞懂分布式技术3:初探分布式协调服务zookeeper ](docs/distrubuted/实战/搞懂分布式技术3:初探分布式协调服务zookeeper.md )
-* [搞懂分布式技术4:ZAB协议概述与选主流程详解 ](docs/distrubuted/实战/搞懂分布式技术4:ZAB协议概述与选主流程详解.md )
-* [搞懂分布式技术5:Zookeeper的配置与集群管理实战](docs/distrubuted/实战/搞懂分布式技术5:Zookeeper的配置与集群管理实战.md)
-* [搞懂分布式技术6:Zookeeper典型应用场景及实践 ](docs/distrubuted/实战/搞懂分布式技术6:Zookeeper典型应用场景及实践.md )
-* [搞懂分布式技术7:负载均衡概念与主流方案](docs/distrubuted/实战/搞懂分布式技术7:负载均衡概念与主流方案.md)
-* [搞懂分布式技术8:负载均衡原理剖析 ](docs/distrubuted/实战/搞懂分布式技术8:负载均衡原理剖析.md )
-* [搞懂分布式技术9:Nginx负载均衡原理与实践 ](docs/distrubuted/实战/搞懂分布式技术9:Nginx负载均衡原理与实践.md)
-* [搞懂分布式技术10:LVS实现负载均衡的原理与实践 ](docs/distrubuted/实战/搞懂分布式技术10:LVS实现负载均衡的原理与实践.md )
-* [搞懂分布式技术11:分布式session解决方案与一致性hash](docs/distrubuted/实战/搞懂分布式技术11:分布式session解决方案与一致性hash.md)
-* [搞懂分布式技术12:分布式ID生成方案 ](docs/distrubuted/实战/搞懂分布式技术12:分布式ID生成方案.md )
-* [搞懂分布式技术13:缓存的那些事](docs/distrubuted/实战/搞懂分布式技术13:缓存的那些事.md)
-* [搞懂分布式技术14:Spring Boot使用注解集成Redis缓存](docs/distrubuted/实战/搞懂分布式技术14:Spring%20Boot使用注解集成Redis缓存.md)
-* [搞懂分布式技术15:缓存更新的套路 ](docs/distrubuted/实战/搞懂分布式技术15:缓存更新的套路.md )
-* [搞懂分布式技术16:浅谈分布式锁的几种方案 ](docs/distrubuted/实战/搞懂分布式技术16:浅谈分布式锁的几种方案.md )
-* [搞懂分布式技术17:浅析分布式事务 ](docs/distrubuted/实战/搞懂分布式技术17:浅析分布式事务.md )
-* [搞懂分布式技术18:分布式事务常用解决方案 ](docs/distrubuted/实战/搞懂分布式技术18:分布式事务常用解决方案.md )
-* [搞懂分布式技术19:使用RocketMQ事务消息解决分布式事务 ](docs/distrubuted/实战/搞懂分布式技术19:使用RocketMQ事务消息解决分布式事务.md )
-* [搞懂分布式技术20:消息队列因何而生](docs/distrubuted/实战/搞懂分布式技术20:消息队列因何而生.md)
-* [搞懂分布式技术21:浅谈分布式消息技术 Kafka ](docs/distrubuted/实战/搞懂分布式技术21:浅谈分布式消息技术%20Kafka.md )
-
-
-## 面试指南
+* [探索Redis设计与实现:Redis的基础数据结构概览](docs/cache/探索Redis设计与实现:Redis的基础数据结构概览.md)
+* [探索Redis设计与实现:Redis内部数据结构详解——dict](docs/cache/探索Redis设计与实现:Redis内部数据结构详解——dict.md)
+* [探索Redis设计与实现:Redis内部数据结构详解——sds](docs/cache/探索Redis设计与实现:Redis内部数据结构详解——sds.md)
+* [探索Redis设计与实现:Redis内部数据结构详解——ziplist](docs/cache/探索Redis设计与实现:Redis内部数据结构详解——ziplist.md)
+* [探索Redis设计与实现:Redis内部数据结构详解——quicklist](docs/cache/探索Redis设计与实现:Redis内部数据结构详解——quicklist.md)
+* [探索Redis设计与实现:Redis内部数据结构详解——skiplist](docs/cache/探索Redis设计与实现:Redis内部数据结构详解——skiplist.md)
+* [探索Redis设计与实现:Redis内部数据结构详解——intset](docs/cache/探索Redis设计与实现:Redis内部数据结构详解——intset.md)
+* [探索Redis设计与实现:连接底层与表面的数据结构robj](docs/cache/探索Redis设计与实现:连接底层与表面的数据结构robj.md)
+* [探索Redis设计与实现:数据库redisDb与键过期删除策略](docs/cache/探索Redis设计与实现:数据库redisDb与键过期删除策略.md)
+* [探索Redis设计与实现:Redis的事件驱动模型与命令执行过程](docs/cache/探索Redis设计与实现:Redis的事件驱动模型与命令执行过程.md)
+* [探索Redis设计与实现:使用快照和AOF将Redis数据持久化到硬盘中](docs/cache/探索Redis设计与实现:使用快照和AOF将Redis数据持久化到硬盘中.md)
+* [探索Redis设计与实现:浅析Redis主从复制](docs/cache/探索Redis设计与实现:浅析Redis主从复制.md)
+* [探索Redis设计与实现:Redis集群机制及一个Redis架构演进实例](docs/cache/探索Redis设计与实现:Redis集群机制及一个Redis架构演进实例.md)
+* [探索Redis设计与实现:Redis事务浅析与ACID特性介绍](docs/cache/探索Redis设计与实现:Redis事务浅析与ACID特性介绍.md)
+* [探索Redis设计与实现:Redis分布式锁进化史 ](docs/cache/探索Redis设计与实现:Redis分布式锁进化史.md )
+
+# 消息队列
+
+## Kafka
+* [消息队列kafka详解:Kafka快速上手(Java版)](docs/mq/kafka/消息队列kafka详解:Kafka快速上手(Java版).md)
+* [消息队列kafka详解:Kafka一条消息存到broker的过程](docs/mq/kafka/消息队列kafka详解:Kafka一条消息存到broker的过程.md)
+* [消息队列kafka详解:消息队列kafka详解:Kafka介绍](docs/mq/kafka/消息队列kafka详解:Kafka介绍.md)
+* [消息队列kafka详解:Kafka原理分析总结篇](docs/mq/kafka/消息队列kafka详解:Kafka原理分析总结篇.md)
+* [消息队列kafka详解:Kafka常见命令及配置总结](docs/mq/kafka/消息队列kafka详解:Kafka常见命令及配置总结.md)
+* [消息队列kafka详解:Kafka架构介绍](docs/mq/kafka/消息队列kafka详解:Kafka架构介绍.md)
+* [消息队列kafka详解:Kafka的集群工作原理](docs/mq/kafka/消息队列kafka详解:Kafka的集群工作原理.md)
+* [消息队列kafka详解:Kafka重要知识点+面试题大全](docs/mq/kafka/消息队列kafka详解:Kafka重要知识点+面试题大全.md)
+* [消息队列kafka详解:如何实现延迟队列](docs/mq/kafka/消息队列kafka详解:如何实现延迟队列.md)
+* [消息队列kafka详解:如何实现死信队列](docs/mq/kafka/消息队列kafka详解:如何实现死信队列.md)
+
+## RocketMQ
+* [RocketMQ系列:事务消息(最终一致性)](docs/mq/RocketMQ/RocketMQ系列:事务消息(最终一致性).md)
+* [RocketMQ系列:基本概念](docs/mq/RocketMQ/RocketMQ系列:基本概念.md)
+* [RocketMQ系列:广播与延迟消息](docs/mq/RocketMQ/RocketMQ系列:广播与延迟消息.md)
+* [RocketMQ系列:批量发送与过滤](docs/mq/RocketMQ/RocketMQ系列:批量发送与过滤.md)
+* [RocketMQ系列:消息的生产与消费](docs/mq/RocketMQ/RocketMQ系列:消息的生产与消费.md)
+* [RocketMQ系列:环境搭建](docs/mq/RocketMQ/RocketMQ系列:环境搭建.md)
+* [RocketMQ系列:顺序消费](docs/mq/RocketMQ/RocketMQ系列:顺序消费.md)
+
+# 大后端
+* [后端技术杂谈开篇:云计算,大数据与AI的故事](docs/backend/后端技术杂谈开篇:云计算,大数据与AI的故事.md)
+* [后端技术杂谈:搜索引擎基础倒排索引](docs/backend/后端技术杂谈:搜索引擎基础倒排索引.md)
+* [后端技术杂谈:搜索引擎工作原理](docs/backend/后端技术杂谈:搜索引擎工作原理.md)
+* [后端技术杂谈:Lucene基础原理与实践](docs/backend/后端技术杂谈:Lucene基础原理与实践.md)
+* [后端技术杂谈:Elasticsearch与solr入门实践](docs/backend/后端技术杂谈:Elasticsearch与solr入门实践.md)
+* [后端技术杂谈:云计算的前世今生](docs/backend/后端技术杂谈:云计算的前世今生.md)
+* [后端技术杂谈:白话虚拟化技术](docs/backend/后端技术杂谈:白话虚拟化技术.md )
+* [后端技术杂谈:OpenStack的基石KVM](docs/backend/后端技术杂谈:OpenStack的基石KVM.md)
+* [后端技术杂谈:OpenStack架构设计](docs/backend/后端技术杂谈:OpenStack架构设计.md)
+* [后端技术杂谈:先搞懂Docker核心概念吧](docs/backend/后端技术杂谈:先搞懂Docker核心概念吧.md)
+* [后端技术杂谈:Docker 核心技术与实现原理](docs/backend/后端技术杂谈:Docker%核心技术与实现原理.md)
+* [后端技术杂谈:十分钟理解Kubernetes核心概念](docs/backend/后端技术杂谈:十分钟理解Kubernetes核心概念.md)
+* [后端技术杂谈:捋一捋大数据研发的基本概念](docs/backend/后端技术杂谈:捋一捋大数据研发的基本概念.md)
+
+# 分布式
+## 分布式理论
+* [分布式系统理论基础:一致性PC和PC ](docs/distributed/basic/分布式系统理论基础:一致性PC和PC.md)
+* [分布式系统理论基础:CAP ](docs/distributed/basic/分布式系统理论基础:CAP.md)
+* [分布式系统理论基础:时间时钟和事件顺序](docs/distributed/basic/分布式系统理论基础:时间时钟和事件顺序.md)
+* [分布式系统理论基础:Paxos](docs/distributed/basic/分布式系统理论基础:Paxos.md)
+* [分布式系统理论基础:选举多数派和租约](docs/distributed/basic/分布式系统理论基础:选举多数派和租约.md)
+* [分布式系统理论基础:RaftZab ](docs/distributed/basic/分布式系统理论基础:RaftZab.md)
+* [分布式系统理论进阶:Paxos变种和优化 ](docs/distributed/basic/分布式系统理论进阶:Paxos变种和优化.md)
+* [分布式系统理论基础:zookeeper分布式协调服务 ](docs/distributed/basic/分布式系统理论基础:zookeeper分布式协调服务.md)
+* [分布式理论总结](docs/distributed/分布式技术实践总结.md)
+
+## 分布式技术
+* [搞懂分布式技术:分布式系统的一些基本概念](docs/distributed/practice/搞懂分布式技术:分布式系统的一些基本概念.md )
+* [搞懂分布式技术:分布式一致性协议与Paxos,Raft算法](docs/distributed/practice/搞懂分布式技术:分布式一致性协议与Paxos,Raft算法.md)
+* [搞懂分布式技术:初探分布式协调服务zookeeper](docs/distributed/practice/搞懂分布式技术:初探分布式协调服务zookeeper.md )
+* [搞懂分布式技术:ZAB协议概述与选主流程详解](docs/distributed/practice/搞懂分布式技术:ZAB协议概述与选主流程详解.md )
+* [搞懂分布式技术:Zookeeper的配置与集群管理实战](docs/distributed/practice/搞懂分布式技术:Zookeeper的配置与集群管理实战.md)
+* [搞懂分布式技术:Zookeeper典型应用场景及实践](docs/distributed/practice/搞懂分布式技术:Zookeeper典型应用场景及实践.md )
+* [搞懂分布式技术:LVS实现负载均衡的原理与实践 ](docs/distributed/practice/搞懂分布式技术:LVS实现负载均衡的原理与实践.md )
+* [搞懂分布式技术:分布式session解决方案与一致性hash](docs/distributed/practice/搞懂分布式技术:分布式session解决方案与一致性hash.md)
+* [搞懂分布式技术:分布式ID生成方案 ](docs/distributed/practice/搞懂分布式技术:分布式ID生成方案.md )
+* [搞懂分布式技术:缓存的那些事](docs/distributed/practice/搞懂分布式技术:缓存的那些事.md)
+* [搞懂分布式技术:SpringBoot使用注解集成Redis缓存](docs/distributed/practice/搞懂分布式技术:SpringBoot使用注解集成Redis缓存.md)
+* [搞懂分布式技术:缓存更新的套路 ](docs/distributed/practice/搞懂分布式技术:缓存更新的套路.md )
+* [搞懂分布式技术:浅谈分布式锁的几种方案 ](docs/distributed/practice/搞懂分布式技术:浅谈分布式锁的几种方案.md )
+* [搞懂分布式技术:浅析分布式事务](docs/distributed/practice/搞懂分布式技术:浅析分布式事务.md )
+* [搞懂分布式技术:分布式事务常用解决方案 ](docs/distributed/practice/搞懂分布式技术:分布式事务常用解决方案.md )
+* [搞懂分布式技术:使用RocketMQ事务消息解决分布式事务 ](docs/distributed/practice/搞懂分布式技术:使用RocketMQ事务消息解决分布式事务.md )
+* [搞懂分布式技术:消息队列因何而生](docs/distributed/practice/搞懂分布式技术:消息队列因何而生.md)
+* [搞懂分布式技术:浅谈分布式消息技术Kafka](docs/distributed/practice/搞懂分布式技术:浅谈分布式消息技术Kafka.md )
+* [分布式技术实践总结](docs/distributed/分布式理论总结.md)
+
+# 面试指南
todo
-### 校招指南
+## 校招指南
todo
-### 面经
+## 面经
todo
-## 工具
+# 工具
todo
-## 资料
+# 资料
todo
-### 书单
+## 书单
todo
-## 待办
+# 待办
springboot和springcloud
-## 微信公众号
-
-### Java技术江湖
-
-如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号【Java技术江湖】一位阿里 Java 工程师的技术小站,作者黄小斜,专注 Java 相关技术:SSM、SpringBoot、MySQL、分布式、中间件、集群、Linux、网络、多线程,偶尔讲点Docker、ELK,同时也分享技术干货和学习经验,致力于Java全栈开发!
-
-**Java工程师技术学习资料:** 一些Java工程师常用学习资源,关注公众号后,后台回复关键字 **“Java”** 即可免费无套路获取。
-
-**Java进阶架构师资料:** 关注公众号后回复 **”架构师“** 即可领取 Java基础、进阶、项目和架构师等免费学习资料,更有数据库、分布式、微服务等热门技术学习视频,内容丰富,兼顾原理和实践,另外也将赠送作者原创的Java学习指南、Java程序员面试指南等干货资源
-
-
-
-### 个人公众号:程序员黄小斜
-
-黄小斜是 985 硕士,阿里巴巴Java工程师,在自学编程、技术求职、Java学习等方面有丰富经验和独到见解,希望帮助到更多想要从事互联网行业的程序员们。
-
-作者专注于 JAVA 后端技术栈,热衷于分享程序员干货、学习经验、求职心得,以及自学编程和Java技术栈的相关干货。
-
-黄小斜是一个斜杠青年,坚持学习和写作,相信终身学习的力量,希望和更多的程序员交朋友,一起进步和成长!
-
-**原创电子书:** 关注微信公众号【程序员黄小斜】后回复 **"原创电子书"** 即可领取我原创的电子书《菜鸟程序员修炼手册:从技术小白到阿里巴巴Java工程师》这份电子书总结了我2年的Java学习之路,包括学习方法、技术总结、求职经验和面试技巧等内容,已经帮助很多的程序员拿到了心仪的offer!
-
-**程序员3T技术学习资源:** 一些程序员学习技术的资源大礼包,关注公众号【程序员黄小斜】后,后台回复关键字 **“资料”** 即可免费无套路获取,包括Java、python、C++、大数据、机器学习、前端、移动端等方向的技术资料。
+# 微信公众号
-
+## Java技术江湖
+如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号【Java技术江湖】
+
diff --git a/_config.yml b/_config.yml
deleted file mode 100644
index 34ac42a..0000000
--- a/_config.yml
+++ /dev/null
@@ -1,2 +0,0 @@
-theme: jekyll-theme-cayman
-
diff --git a/backup.md b/backup.md
deleted file mode 100644
index f2fb131..0000000
--- a/backup.md
+++ /dev/null
@@ -1,81 +0,0 @@
-## 声明
-
-**关于仓库**
-
-本仓库是笔者在准备 2018 年秋招复习过程中的学习总结,内容以Java后端的知识总结为主,其中大部分都是笔者根据自己的理解加上个人博客总结而来的。
-
-其中有少数内容可能会包含瞎XX说,语句不通顺,内容不全面等各方面问题,还请见谅。
-
-每篇文章都会有笔者更加详细的一系列博客可供参考,这些文章也被我发表在CSDN技术博客上,整理成博客专栏,欢迎查看━(*`∀´*)ノ亻!
-
-详细内容请见我的CSDN技术博客:https://blog.csdn.net/a724888
-
-**更多校招干货和技术文章请关注我的公众号:黄小斜**
-
-| Ⅰ | Ⅱ | Ⅲ | Ⅳ | Ⅴ | Ⅵ | Ⅶ | Ⅷ | Ⅸ |
-| :----------------------------: | :--------------------------------------: | :------------------------: | :----------------------------------------: | :--------------------------: | :---------------------------------: | :-----------------------------------------: | :----------------------------------: | :--------------------------------------------: |
-| 算法[:pencil2:](#算法-pencil2) | 操作系统[:computer:](#操作系统-computer) | 网络[:cloud:](#网络-cloud) | 数据库[:floppy_disk:](#数据库-floppy_disk) | Java[:couple:](#Java-couple) | JavaWeb [:coffee:](#JavaWeb-coffee) | 分布式 [:sweat_drops:](#分布式-sweat_drops) | 设计模式[:hammer:](#设计模式-hammer) | Hadoop[:speak_no_evil:](#Hadoop-speak_no_evil) |
-
-## 算法 :pencil2:
-
-> [剑指offer算法总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/%E5%89%91%E6%8C%87offer.md)
-
-> [LeetCode刷题指南](https://github.com/h2pl/Java-Tutorial/blob/master/md/LeetCode%E5%88%B7%E9%A2%98%E6%8C%87%E5%8D%97.md)
-
-## 操作系统 :computer:
-
-> [操作系统学习总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/%E6%93%8D%E4%BD%9C%E7%B3%BB%E7%BB%9F%E5%AD%A6%E4%B9%A0%E6%80%BB%E7%BB%93.md)
-
-> [Linux内核与基础命令学习总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/Linux%E5%86%85%E6%A0%B8%E4%B8%8E%E5%9F%BA%E7%A1%80%E5%91%BD%E4%BB%A4%E5%AD%A6%E4%B9%A0%E6%80%BB%E7%BB%93.md)
-
-## 网络 :cloud:
-
-> [计算机网络学习总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BD%91%E7%BB%9C%E5%AD%A6%E4%B9%A0%E6%80%BB%E7%BB%93.md)
-
-## 数据库 :floppy_disk:
-
-> [Mysql原理与实践总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/Mysql%E5%8E%9F%E7%90%86%E4%B8%8E%E5%AE%9E%E8%B7%B5%E6%80%BB%E7%BB%93.md)
-
-> [Redis原理与实践总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/Redis%E5%8E%9F%E7%90%86%E4%B8%8E%E5%AE%9E%E8%B7%B5%E6%80%BB%E7%BB%93.md)
-
-## Java :couple:
-
-> [Java核心技术总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/Java%E6%A0%B8%E5%BF%83%E6%8A%80%E6%9C%AF%E6%80%BB%E7%BB%93.md)
-
-> [Java集合类总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/Java%E9%9B%86%E5%90%88%E7%B1%BB%E6%80%BB%E7%BB%93.md)
-
-> [Java并发技术总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/Java%E5%B9%B6%E5%8F%91%E6%80%BB%E7%BB%93.md)
-
-> [JVM原理学习总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/JVM%E6%80%BB%E7%BB%93.md)
-
-> [Java网络与NIO总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/Java%E7%BD%91%E7%BB%9C%E4%B8%8ENIO%E6%80%BB%E7%BB%93.md)
-
-## JavaWeb :coffee:
-
-> [JavaWeb技术学习总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/JavaWeb%E6%8A%80%E6%9C%AF%E6%80%BB%E7%BB%93.md)
-
-> [Spring与SpringMVC源码解析](https://github.com/h2pl/Java-Tutorial/blob/master/md/Spring%E4%B8%8ESpringMVC%E6%BA%90%E7%A0%81%E8%A7%A3%E6%9E%90%E6%80%BB%E7%BB%93.md)
-
-## 分布式 :sweat_drops:
-
-> [分布式理论学习总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/%E5%88%86%E5%B8%83%E5%BC%8F%E7%90%86%E8%AE%BA%E6%80%BB%E7%BB%93.md)
-
-> [分布式技术学习总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/%E5%88%86%E5%B8%83%E5%BC%8F%E6%8A%80%E6%9C%AF%E5%AE%9E%E8%B7%B5%E6%80%BB%E7%BB%93.md)
-
-## 设计模式 :hammer:
-> [设计模式学习总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/%E8%AE%BE%E8%AE%A1%E6%A8%A1%E5%BC%8F%E5%AD%A6%E4%B9%A0%E6%80%BB%E7%BB%93.md)
-
-## Hadoop :speak_no_evil:
-
-> [Hadoop生态学习总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/Hadoop%E7%94%9F%E6%80%81%E6%80%BB%E7%BB%93.md)
-
-
-
-**关于转载**
-
-转载的时候请注明一下出处就行啦。
-
-另外我这个仓库的格式模仿的是@CyC2018 大佬的仓库
-
-并且其中一篇LeetCode刷题指南也是fork这位大佬而来的。我只是自己刷了一遍然后稍微加了一些解析,站在大佬肩膀上。
-
diff --git "a/docs/java/jvm/JVM\346\200\273\347\273\223.md" "b/docs/Java/JVM/JVM\346\200\273\347\273\223.md"
similarity index 86%
rename from "docs/java/jvm/JVM\346\200\273\347\273\223.md"
rename to "docs/Java/JVM/JVM\346\200\273\347\273\223.md"
index 2762768..60b89e6 100644
--- "a/docs/java/jvm/JVM\346\200\273\347\273\223.md"
+++ "b/docs/Java/JVM/JVM\346\200\273\347\273\223.md"
@@ -1,4 +1,4 @@
-# Table of Contents
+# 目录
* [JVM介绍和源码](#jvm介绍和源码)
* [JVM内存模型](#jvm内存模型)
@@ -11,9 +11,7 @@
* [编译期优化和运行期优化](#编译期优化和运行期优化)
* [JVM的垃圾回收](#jvm的垃圾回收)
* [JVM的锁优化](#jvm的锁优化)
- * [微信公众号](#微信公众号)
- * [Java技术江湖](#java技术江湖)
- * [个人公众号:黄小斜](#个人公众号:黄小斜)
+
---
@@ -153,20 +151,4 @@ g1收集器和cms的收集方式类似,但是g1将堆内存划分成了大小
在Java并发中讲述了synchronized重量级锁以及锁优化的方法,包括轻量级锁,偏向锁,自旋锁等。详细内容可以参考我的专栏:Java并发技术指南
-## 微信公众号
-
-### Java技术江湖
-
-如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号【Java技术江湖】一位阿里 Java 工程师的技术小站,作者黄小斜,专注 Java 相关技术:SSM、SpringBoot、MySQL、分布式、中间件、集群、Linux、网络、多线程,偶尔讲点Docker、ELK,同时也分享技术干货和学习经验,致力于Java全栈开发!
-
-**Java工程师必备学习资源:** 一些Java工程师常用学习资源,关注公众号后,后台回复关键字 **“Java”** 即可免费无套路获取。
-
-
-
-### 个人公众号:黄小斜
-
-作者是 985 硕士,蚂蚁金服 JAVA 工程师,专注于 JAVA 后端技术栈:SpringBoot、MySQL、分布式、中间件、微服务,同时也懂点投资理财,偶尔讲点算法和计算机理论基础,坚持学习和写作,相信终身学习的力量!
-
-**程序员3T技术学习资源:** 一些程序员学习技术的资源大礼包,关注公众号后,后台回复关键字 **“资料”** 即可免费无套路获取。
-
diff --git "a/docs/Java/JVM/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232GC\350\260\203\344\274\230\346\200\235\350\267\257\344\270\216\345\270\270\347\224\250\345\267\245\345\205\267.md" "b/docs/Java/JVM/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232GC\350\260\203\344\274\230\346\200\235\350\267\257\344\270\216\345\270\270\347\224\250\345\267\245\345\205\267.md"
new file mode 100644
index 0000000..ceda305
--- /dev/null
+++ "b/docs/Java/JVM/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232GC\350\260\203\344\274\230\346\200\235\350\267\257\344\270\216\345\270\270\347\224\250\345\267\245\345\205\267.md"
@@ -0,0 +1,838 @@
+# 目录
+
+* [核心概念(Core Concepts)](#核心概念core-concepts)
+ * [Latency(延迟)](#latency延迟)
+ * [Throughput(吞吐量)](#throughput吞吐量)
+ * [Capacity(系统容量)](#capacity系统容量)
+* [相关示例](#相关示例)
+ * [Tuning for Latency(调优延迟指标)](#tuning-for-latency调优延迟指标)
+ * [Tuning for Throughput(吞吐量调优)](#tuning-for-throughput吞吐量调优)
+ * [Tuning for Capacity(调优系统容量)](#tuning-for-capacity调优系统容量)
+ * [6\. GC 调优(工具篇) - GC参考手册](#6-gc-调优工具篇---gc参考手册)
+ * [JMX API](#jmx-api)
+ * [JVisualVM](#jvisualvm)
+ * [jstat](#jstat)
+ * [GC日志(GC logs)](#gc日志gc-logs)
+ * [GCViewer](#gcviewer)
+ * [分析器(Profilers)](#分析器profilers)
+ * [hprof](#hprof)
+ * [Java VisualVM](#java-visualvm)
+ * [AProf](#aprof)
+ * [参考文章](#参考文章)
+
+
+
+本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
+> https://github.com/h2pl/Java-Tutorial
+
+喜欢的话麻烦点下Star哈
+
+文章首发于我的个人博客:
+> www.how2playlife.com
+
+本文是微信公众号【Java技术江湖】的《深入理解JVM虚拟机》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。
+该系列博文会告诉你如何从入门到进阶,一步步地学习JVM基础知识,并上手进行JVM调优实战,JVM是每一个Java工程师必须要学习和理解的知识点,你必须要掌握其实现原理,才能更完整地了解整个Java技术体系,形成自己的知识框架。为了更好地总结和检验你的学习成果,本系列文章也会提供每个知识点对应的面试题以及参考答案。
+
+如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。
+
+
+
+> **说明**:
+>
+> **Capacity**: 性能,能力,系统容量; 文中翻译为”**系统容量**“; 意为硬件配置。
+
+您应该已经阅读了前面的章节:
+
+1. 垃圾收集简介 - GC参考手册
+2. Java中的垃圾收集 - GC参考手册
+3. GC 算法(基础篇) - GC参考手册
+4. GC 算法(实现篇) - GC参考手册
+
+GC调优(Tuning Garbage Collection)和其他性能调优是同样的原理。初学者可能会被 200 多个 GC参数弄得一头雾水, 然后随便调整几个来试试结果,又或者修改几行代码来测试。其实只要参照下面的步骤,就能保证你的调优方向正确:
+
+1. 列出性能调优指标(State your performance goals)
+2. 执行测试(Run tests)
+3. 检查结果(Measure the results)
+4. 与目标进行对比(Compare the results with the goals)
+5. 如果达不到指标, 修改配置参数, 然后继续测试(go back to running tests)
+
+第一步, 我们需要做的事情就是: 制定明确的GC性能指标。对所有性能监控和管理来说, 有三个维度是通用的:
+
+* Latency(延迟)
+* Throughput(吞吐量)
+* Capacity(系统容量)
+
+我们先讲解基本概念,然后再演示如何使用这些指标。如果您对 延迟、吞吐量和系统容量等概念很熟悉, 可以跳过这一小节。
+
+### 核心概念(Core Concepts)
+
+我们先来看一家工厂的装配流水线。工人在流水线将现成的组件按顺序拼接,组装成自行车。通过实地观测, 我们发现从组件进入生产线,到另一端组装成自行车需要4小时。
+
+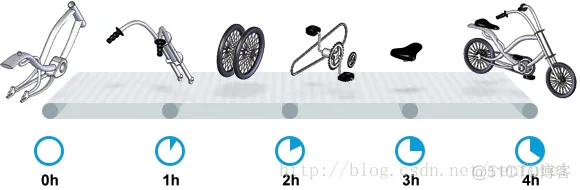
+继续观察,我们还发现,此后每分钟就有1辆自行车完成组装, 每天24小时,一直如此。将这个模型简化, 并忽略维护窗口期后得出结论:**这条流水线每小时可以组装60辆自行车**。
+
+> **说明**: 时间窗口/窗口期,请类比车站卖票的窗口,是一段规定/限定做某件事的时间段。
+
+通过这两种测量方法, 就知道了生产线的相关性能信息:**延迟**与**吞吐量**:
+
+* 生产线的延迟:**4小时**
+* 生产线的吞吐量:**60辆/小时**
+
+请注意, 衡量延迟的时间单位根据具体需要而确定 —— 从纳秒(nanosecond)到几千年(millennia)都有可能。系统的吞吐量是每个单位时间内完成的操作。操作(Operations)一般是特定系统相关的东西。在本例中,选择的时间单位是小时, 操作就是对自行车的组装。
+
+掌握了延迟和吞吐量两个概念之后, 让我们对这个工厂来进行实际的调优。自行车的需求在一段时间内都很稳定, 生产线组装自行车有四个小时延迟, 而吞吐量在几个月以来都很稳定: 60辆/小时。假设某个销售团队突然业绩暴涨, 对自行车的需求增加了1倍。客户每天需要的自行车不再是 60 * 24 = 1440辆, 而是 2*1440 = 2880辆/天。老板对工厂的产能不满意,想要做些调整以提升产能。
+
+看起来总经理很容易得出正确的判断, 系统的延迟没法子进行处理 —— 他关注的是每天的自行车生产总量。得出这个结论以后, 假若工厂资金充足, 那么应该立即采取措施, 改善吞吐量以增加产能。
+
+我们很快会看到, 这家工厂有两条相同的生产线。每条生产线一分钟可以组装一辆成品自行车。 可以想象,每天生产的自行车数量会增加一倍。达到 2880辆/天。要注意的是, 不需要减少自行车的装配时间 —— 从开始到结束依然需要 4 小时。
+
+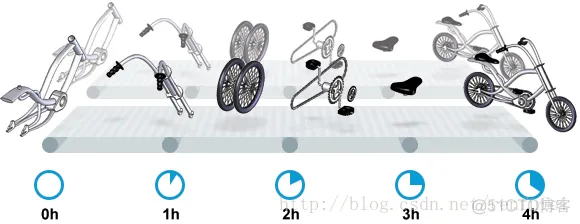
+
+巧合的是,这样进行的性能优化,同时增加了吞吐量和产能。一般来说,我们会先测量当前的系统性能, 再设定新目标, 只优化系统的某个方面来满足性能指标。
+
+在这里做了一个很重要的决定 —— 要增加吞吐量,而不是减小延迟。在增加吞吐量的同时, 也需要增加系统容量。比起原来的情况, 现在需要两条流水线来生产出所需的自行车。在这种情况下, 增加系统的吞吐量并不是免费的, 需要水平扩展, 以满足增加的吞吐量需求。
+
+在处理性能问题时, 应该考虑到还有另一种看似不相关的解决办法。假如生产线的延迟从1分钟降低为30秒,那么吞吐量同样可以增长 1 倍。
+
+或者是降低延迟, 或者是客户非常有钱。软件工程里有一种相似的说法 —— 每个性能问题背后,总有两种不同的解决办法。 可以用更多的机器, 或者是花精力来改善性能低下的代码。
+
+#### Latency(延迟)
+
+GC的延迟指标由一般的延迟需求决定。延迟指标通常如下所述:
+
+* 所有交易必须在10秒内得到响应
+* 90%的订单付款操作必须在3秒以内处理完成
+* 推荐商品必须在 100 ms 内展示到用户面前
+
+面对这类性能指标时, 需要确保在交易过程中, GC暂停不能占用太多时间,否则就满足不了指标。“不能占用太多” 的意思需要视具体情况而定, 还要考虑到其他因素, 比如外部数据源的交互时间(round-trips), 锁竞争(lock contention), 以及其他的安全点等等。
+
+假设性能需求为:`90%`的交易要在`1000ms`以内完成, 每次交易最长不能超过`10秒`。 根据经验, 假设GC暂停时间比例不能超过10%。 也就是说, 90%的GC暂停必须在`100ms`内结束, 也不能有超过`1000ms`的GC暂停。为简单起见, 我们忽略在同一次交易过程中发生多次GC停顿的可能性。
+
+有了正式的需求,下一步就是检查暂停时间。有许多工具可以使用, 在接下来的6\. GC 调优(工具篇)
+
+
+
+```
+2015-06-04T13:34:16.974-0200: 2.578: [Full GC (Ergonomics)
+ [PSYoungGen: 93677K->70109K(254976K)]
+ [ParOldGen: 499597K->511230K(761856K)]
+ 593275K->581339K(1016832K),
+ [Metaspace: 2936K->2936K(1056768K)]
+ , 0.0713174 secs]
+ [Times: user=0.21 sys=0.02, real=0.07 secs
+```
+
+
+
+这表示一次GC暂停, 在`2015-06-04T13:34:16`这个时刻触发. 对应于JVM启动之后的`2,578 ms`。
+
+此事件将应用线程暂停了`0.0713174`秒。虽然花费的总时间为 210 ms, 但因为是多核CPU机器, 所以最重要的数字是应用线程被暂停的总时间, 这里使用的是并行GC, 所以暂停时间大约为`70ms`。 这次GC的暂停时间小于`100ms`的阈值,满足需求。
+
+继续分析, 从所有GC日志中提取出暂停相关的数据, 汇总之后就可以得知是否满足需求。
+
+#### Throughput(吞吐量)
+
+吞吐量和延迟指标有很大区别。当然两者都是根据一般吞吐量需求而得出的。一般吞吐量需求(Generic requirements for throughput) 类似这样:
+
+* 解决方案每天必须处理 100万个订单
+* 解决方案必须支持1000个登录用户,同时在5-10秒内执行某个操作: A、B或C
+* 每周对所有客户进行统计, 时间不能超过6小时,时间窗口为每周日晚12点到次日6点之间。
+
+可以看出,吞吐量需求不是针对单个操作的, 而是在给定的时间内, 系统必须完成多少个操作。和延迟需求类似, GC调优也需要确定GC行为所消耗的总时间。每个系统能接受的时间不同, 一般来说, GC占用的总时间比不能超过`10%`。
+
+现在假设需求为: 每分钟处理 1000 笔交易。同时, 每分钟GC暂停的总时间不能超过6秒(即10%)。
+
+有了正式的需求, 下一步就是获取相关的信息。依然是从GC日志中提取数据, 可以看到类似这样的信息:
+
+
+
+```
+2015-06-04T13:34:16.974-0200: 2.578: [Full GC (Ergonomics)
+ [PSYoungGen: 93677K->70109K(254976K)]
+ [ParOldGen: 499597K->511230K(761856K)]
+ 593275K->581339K(1016832K),
+ [Metaspace: 2936K->2936K(1056768K)],
+ 0.0713174 secs]
+ [Times: user=0.21 sys=0.02, real=0.07 secs
+```
+
+
+
+此时我们对 用户耗时(user)和系统耗时(sys)感兴趣, 而不关心实际耗时(real)。在这里, 我们关心的时间为`0.23s`(user + sys = 0.21 + 0.02 s), 这段时间内, GC暂停占用了 cpu 资源。 重要的是, 系统运行在多核机器上, 转换为实际的停顿时间(stop-the-world)为`0.0713174秒`, 下面的计算会用到这个数字。
+
+提取出有用的信息后, 剩下要做的就是统计每分钟内GC暂停的总时间。看看是否满足需求: 每分钟内总的暂停时间不得超过6000毫秒(6秒)。
+
+#### Capacity(系统容量)
+
+系统容量(Capacity)需求,是在达成吞吐量和延迟指标的情况下,对硬件环境的额外约束。这类需求大多是来源于计算资源或者预算方面的原因。例如:
+
+* 系统必须能部署到小于512 MB内存的Android设备上
+* 系统必须部署在Amazon**EC2**实例上, 配置不得超过**c3.xlarge(4核8GB)**。
+* 每月的 Amazon EC2 账单不得超过`$12,000`
+
+因此, 在满足延迟和吞吐量需求的基础上必须考虑系统容量。可以说, 假若有无限的计算资源可供挥霍, 那么任何 延迟和吞吐量指标 都不成问题, 但现实情况是, 预算(budget)和其他约束限制了可用的资源。
+
+### 相关示例
+
+介绍完性能调优的三个维度后, 我们来进行实际的操作以达成GC性能指标。
+
+请看下面的代码:
+
+
+
+```
+//imports skipped for brevity
+public class Producer implements Runnable {
+
+ private static ScheduledExecutorService executorService
+ = Executors.newScheduledThreadPool(2);
+
+ private Deque deque;
+ private int objectSize;
+ private int queueSize;
+
+ public Producer(int objectSize, int ttl) {
+ this.deque = new ArrayDeque();
+ this.objectSize = objectSize;
+ this.queueSize = ttl * 1000;
+ }
+
+ @Override
+ public void run() {
+ for (int i = 0; i < 100; i++) {
+ deque.add(new byte[objectSize]);
+ if (deque.size() > queueSize) {
+ deque.poll();
+ }
+ }
+ }
+
+ public static void main(String[] args)
+ throws InterruptedException {
+ executorService.scheduleAtFixedRate(
+ new Producer(200 * 1024 * 1024 / 1000, 5),
+ 0, 100, TimeUnit.MILLISECONDS
+ );
+ executorService.scheduleAtFixedRate(
+ new Producer(50 * 1024 * 1024 / 1000, 120),
+ 0, 100, TimeUnit.MILLISECONDS);
+ TimeUnit.MINUTES.sleep(10);
+ executorService.shutdownNow();
+ }
+}
+```
+
+
+
+这段程序代码, 每 100毫秒 提交两个作业(job)来。每个作业都模拟特定的生命周期: 创建对象, 然后在预定的时间释放, 接着就不管了, 由GC来自动回收占用的内存。
+
+在运行这个示例程序时,通过以下JVM参数打开GC日志记录:
+
+
+
+```
+-XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps
+```
+
+
+
+还应该加上JVM参数`-Xloggc`以指定GC日志的存储位置,类似这样:
+
+
+
+```
+-Xloggc:C:\\Producer_gc.log
+```
+
+
+
+* 1
+* 2
+
+在日志文件中可以看到GC的行为, 类似下面这样:
+
+
+
+```
+2015-06-04T13:34:16.119-0200: 1.723: [GC (Allocation Failure)
+ [PSYoungGen: 114016K->73191K(234496K)]
+ 421540K->421269K(745984K),
+ 0.0858176 secs]
+ [Times: user=0.04 sys=0.06, real=0.09 secs]
+
+2015-06-04T13:34:16.738-0200: 2.342: [GC (Allocation Failure)
+ [PSYoungGen: 234462K->93677K(254976K)]
+ 582540K->593275K(766464K),
+ 0.2357086 secs]
+ [Times: user=0.11 sys=0.14, real=0.24 secs]
+
+2015-06-04T13:34:16.974-0200: 2.578: [Full GC (Ergonomics)
+ [PSYoungGen: 93677K->70109K(254976K)]
+ [ParOldGen: 499597K->511230K(761856K)]
+ 593275K->581339K(1016832K),
+ [Metaspace: 2936K->2936K(1056768K)],
+ 0.0713174 secs]
+ [Times: user=0.21 sys=0.02, real=0.07 secs]
+```
+
+
+
+基于日志中的信息, 可以通过三个优化目标来提升性能:
+
+1. 确保最坏情况下,GC暂停时间不超过预定阀值
+2. 确保线程暂停的总时间不超过预定阀值
+3. 在确保达到延迟和吞吐量指标的情况下, 降低硬件配置以及成本。
+
+为此, 用三种不同的配置, 将代码运行10分钟, 得到了三种不同的结果, 汇总如下:
+
+
+| **堆内存大小(Heap)** | **GC算法(GC Algorithm)** | **有效时间比(Useful work)** | **最长停顿时间(Longest pause)** |
+| -Xmx12g | -XX:+UseConcMarkSweepGC | 89.8% | **560 ms** |
+| -Xmx12g | -XX:+UseParallelGC | 91.5% | 1,104 ms |
+| -Xmx8g | -XX:+UseConcMarkSweepGC | 66.3% | 1,610 ms |
+
+使用不同的GC算法,和不同的内存配置,运行相同的代码, 以测量GC暂停时间与 延迟、吞吐量的关系。实验的细节和结果在后面章节详细介绍。
+
+注意, 为了尽量简单, 示例中只改变了很少的输入参数, 此实验也没有在不同CPU数量或者不同的堆布局下进行测试。
+
+#### Tuning for Latency(调优延迟指标)
+
+假设有一个需求,**每次作业必须在 1000ms 内处理完成**。我们知道, 实际的作业处理只需要100 ms,简化后, 两者相减就可以算出对 GC暂停的延迟要求。现在需求变成:**GC暂停不能超过900ms**。这个问题很容易找到答案, 只需要解析GC日志文件, 并找出GC暂停中最大的那个暂停时间即可。
+
+再来看测试所用的三个配置:
+
+
+| **堆内存大小(Heap)** | **GC算法(GC Algorithm)** | **有效时间比(Useful work)** | **最长停顿时间(Longest pause)** |
+| -Xmx12g | -XX:+UseConcMarkSweepGC | 89.8% | **560 ms** |
+| -Xmx12g | -XX:+UseParallelGC | 91.5% | 1,104 ms |
+| -Xmx8g | -XX:+UseConcMarkSweepGC | 66.3% | 1,610 ms |
+
+可以看到,其中有一个配置达到了要求。运行的参数为:
+
+
+
+```
+java -Xmx12g -XX:+UseConcMarkSweepGC Producer
+```
+
+
+
+对应的GC日志中,暂停时间最大为`560 ms`, 这达到了延迟指标`900 ms`的要求。如果还满足吞吐量和系统容量需求的话,就可以说成功达成了GC调优目标, 调优结束。
+
+#### Tuning for Throughput(吞吐量调优)
+
+假定吞吐量指标为:**每小时完成 1300万次操作处理**。同样是上面的配置, 其中有一种配置满足了需求:
+
+
+| **堆内存大小(Heap)** | **GC算法(GC Algorithm)** | **有效时间比(Useful work)** | **最长停顿时间(Longest pause)** |
+| -Xmx12g | -XX:+UseConcMarkSweepGC | 89.8% | 560 ms |
+| -Xmx12g | -XX:+UseParallelGC | **91.5%** | 1,104 ms |
+| -Xmx8g | -XX:+UseConcMarkSweepGC | 66.3% | 1,610 ms |
+
+此配置对应的命令行参数为:
+
+
+
+```
+java -Xmx12g -XX:+UseParallelGC Producer
+```
+
+
+
+* 可以看到,GC占用了 8.5%的CPU时间,剩下的`91.5%`是有效的计算时间。为简单起见, 忽略示例中的其他安全点。现在需要考虑:
+
+1. 每个CPU核心处理一次作业需要耗时`100ms`
+2. 因此, 一分钟内每个核心可以执行 60,000 次操作(**每个job完成100次操作**)
+3. 一小时内, 一个核心可以执行 360万次操作
+4. 有四个CPU内核, 则每小时可以执行: 4 x 3.6M = 1440万次操作
+
+理论上,通过简单的计算就可以得出结论, 每小时可以执行的操作数为:`14.4 M * 91.5% = 13,176,000`次, 满足需求。
+
+值得一提的是, 假若还要满足延迟指标, 那就有问题了, 最坏情况下, GC暂停时间为`1,104 ms`, 最大延迟时间是前一种配置的两倍。
+
+#### Tuning for Capacity(调优系统容量)
+
+假设需要将软件部署到服务器上(commodity-class hardware), 配置为`4核10G`。这样的话, 系统容量的要求就变成: 最大的堆内存空间不能超过`8GB`。有了这个需求, 我们需要调整为第三套配置进行测试:
+
+
+| **堆内存大小(Heap)** | **GC算法(GC Algorithm)** | **有效时间比(Useful work)** | **最长停顿时间(Longest pause)** |
+| -Xmx12g | -XX:+UseConcMarkSweepGC | 89.8% | 560 ms |
+| -Xmx12g | -XX:+UseParallelGC | 91.5% | 1,104 ms |
+| **-Xmx8g** | -XX:+UseConcMarkSweepGC | 66.3% | 1,610 ms |
+
+程序可以通过如下参数执行:
+
+
+
+```
+java -Xmx8g -XX:+UseConcMarkSweepGC Producer
+```
+
+
+
+* 测试结果是延迟大幅增长, 吞吐量同样大幅降低:
+* 现在,GC占用了更多的CPU资源, 这个配置只有`66.3%`的有效CPU时间。因此,这个配置让吞吐量从最好的情况**13,176,000 操作/小时**下降到**不足 9,547,200次操作/小时**.
+* 最坏情况下的延迟变成了**1,610 ms**, 而不再是**560ms**。
+
+通过对这三个维度的介绍, 你应该了解, 不是简单的进行“性能(performance)”优化, 而是需要从三种不同的维度来进行考虑, 测量, 并调优延迟和吞吐量, 此外还需要考虑系统容量的约束。
+
+请继续阅读下一章:6\. GC 调优(工具篇) - GC参考手册
+
+原文链接:[GC Tuning: Basics](https://plumbr.eu/handbook/gc-tuning)
+
+翻译时间: 2016年02月06日
+
+## 6\. GC 调优(工具篇) - GC参考手册
+
+2017年02月23日 18:56:02
+
+阅读数:6469
+
+进行GC性能调优时, 需要明确了解, 当前的GC行为对系统和用户有多大的影响。有多种监控GC的工具和方法, 本章将逐一介绍常用的工具。
+
+您应该已经阅读了前面的章节:
+
+1. 垃圾收集简介 - GC参考手册
+2. Java中的垃圾收集 - GC参考手册
+3. GC 算法(基础篇) - GC参考手册
+4. GC 算法(实现篇) - GC参考手册
+5. GC 调优(基础篇) - GC参考手册
+
+JVM 在程序执行的过程中, 提供了GC行为的原生数据。那么, 我们就可以利用这些原生数据来生成各种报告。原生数据(_raw data_) 包括:
+
+* 各个内存池的当前使用情况,
+* 各个内存池的总容量,
+* 每次GC暂停的持续时间,
+* GC暂停在各个阶段的持续时间。
+
+可以通过这些数据算出各种指标, 例如: 程序的内存分配率, 提升率等等。本章主要介绍如何获取原生数据。 后续的章节将对重要的派生指标(derived metrics)展开讨论, 并引入GC性能相关的话题。
+
+## JMX API
+
+从 JVM 运行时获取GC行为数据, 最简单的办法是使用标准[JMX API 接口](https://docs.oracle.com/javase/tutorial/jmx/index.html). JMX是获取 JVM内部运行时状态信息 的标准API. 可以编写程序代码, 通过 JMX API 来访问本程序所在的JVM,也可以通过JMX客户端执行(远程)访问。
+
+最常见的 JMX客户端是[JConsole](http://docs.oracle.com/javase/7/docs/technotes/guides/management/jconsole.html)和[JVisualVM](http://docs.oracle.com/javase/7/docs/technotes/tools/share/jvisualvm.html)(可以安装各种插件,十分强大)。两个工具都是标准JDK的一部分, 而且很容易使用. 如果使用的是 JDK 7u40 及更高版本, 还可以使用另一个工具:[Java Mission Control](http://www.oracle.com/technetwork/java/javaseproducts/mission-control/java-mission-control-1998576.html)( 大致翻译为 Java控制中心,`jmc.exe`)。
+
+> JVisualVM安装MBeans插件的步骤: 通过 工具(T) – 插件(G) – 可用插件 – 勾选VisualVM-MBeans – 安装 – 下一步 – 等待安装完成…… 其他插件的安装过程基本一致。
+
+所有 JMX客户端都是独立的程序,可以连接到目标JVM上。目标JVM可以在本机, 也可能是远端JVM. 如果要连接远端JVM, 则目标JVM启动时必须指定特定的环境变量,以开启远程JMX连接/以及端口号。 示例如下:
+
+
+
+```
+java -Dcom.sun.management.jmxremote.port=5432 com.yourcompany.YourApp
+```
+
+
+
+在此处, JVM 打开端口`5432`以支持JMX连接。
+
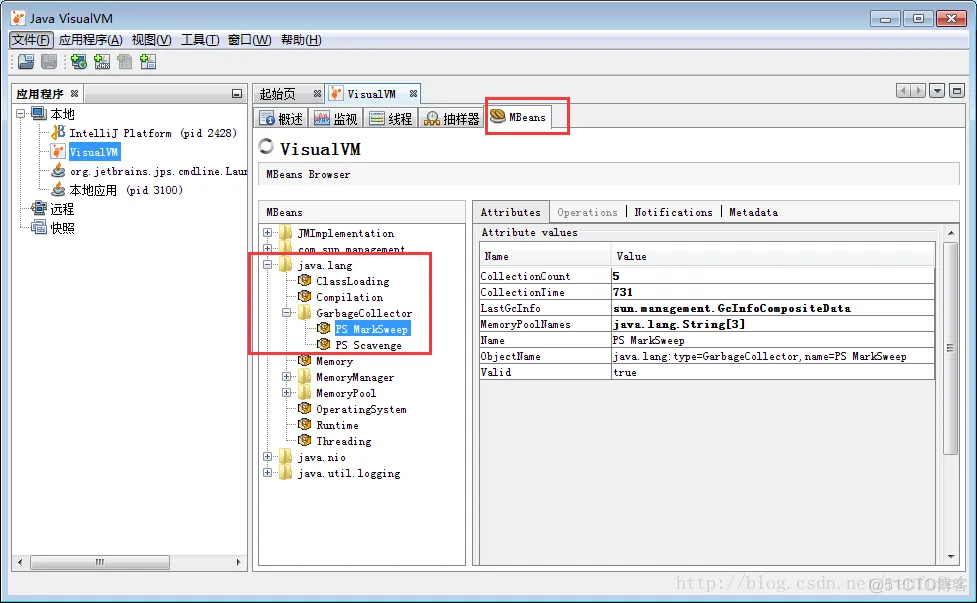
+通过 JVisualVM 连接到某个JVM以后, 切换到 MBeans 标签, 展开 “java.lang/GarbageCollector” . 就可以看到GC行为信息, 下图是 JVisualVM 中的截图:
+
+
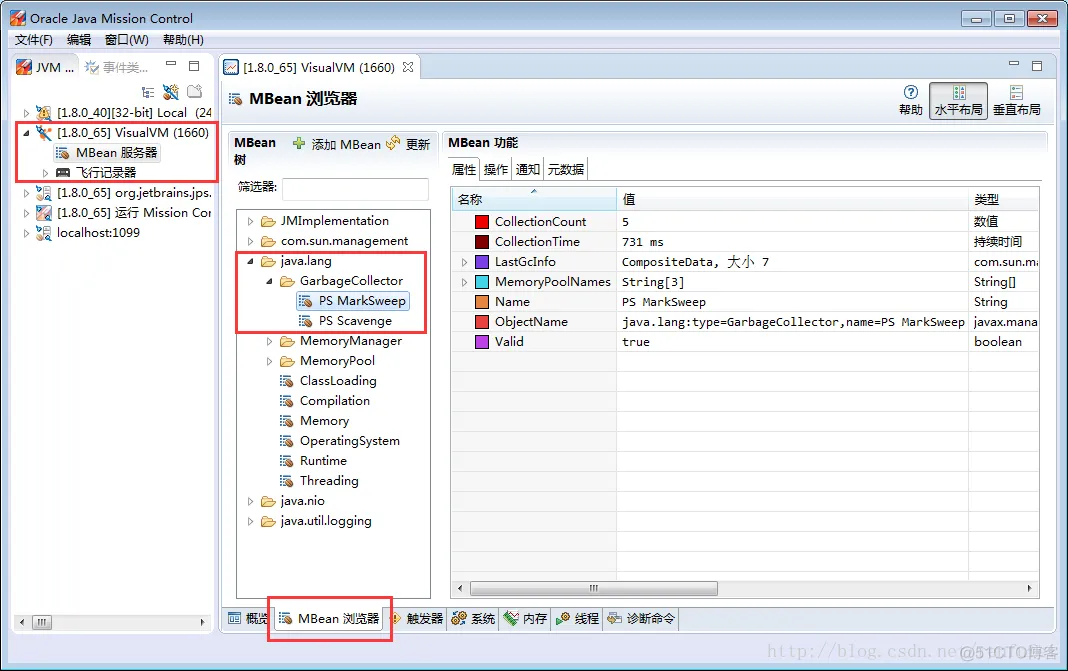
+
+下图是Java Mission Control 中的截图:
+
+
+
+从以上截图中可以看到两款垃圾收集器。其中一款负责清理年轻代(**PS Scavenge**),另一款负责清理老年代(**PS MarkSweep**); 列表中显示的就是垃圾收集器的名称。可以看到 , jmc 的功能和展示数据的方式更强大。
+
+对所有的垃圾收集器, 通过 JMX API 获取的信息包括:
+
+* **CollectionCount**: 垃圾收集器执行的GC总次数,
+* **CollectionTime**: 收集器运行时间的累计。这个值等于所有GC事件持续时间的总和,
+* **LastGcInfo**: 最近一次GC事件的详细信息。包括 GC事件的持续时间(duration), 开始时间(startTime) 和 结束时间(endTime), 以及各个内存池在最近一次GC之前和之后的使用情况,
+* **MemoryPoolNames**: 各个内存池的名称,
+* **Name**: 垃圾收集器的名称
+* **ObjectName**: 由JMX规范定义的 MBean的名字,,
+* **Valid**: 此收集器是否有效。本人只见过 “`true`“的情况 (^_^)
+
+根据经验, 这些信息对GC的性能来说,不能得出什么结论. 只有编写程序, 获取GC相关的 JMX 信息来进行统计和分析。 在下文可以看到, 一般也不怎么关注 MBean , 但 MBean 对于理解GC的原理倒是挺有用的。
+
+## JVisualVM
+
+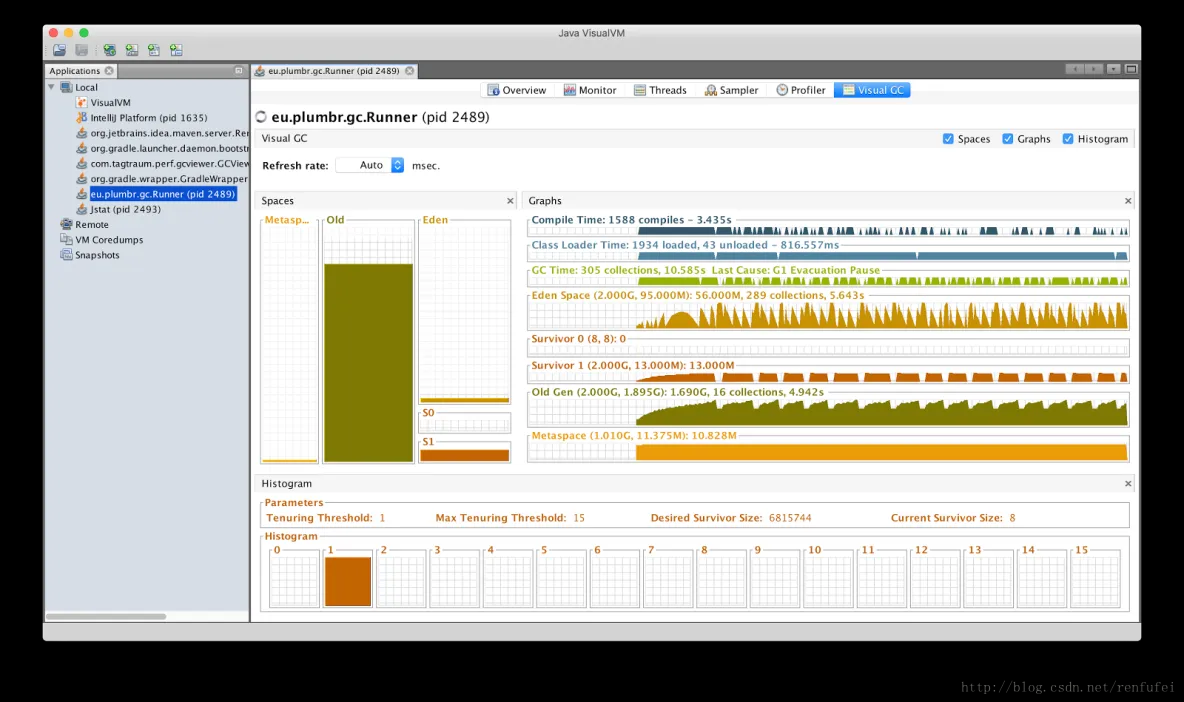
+
+Visual GC 插件常用来监控本机运行的Java程序, 比如开发者和性能调优专家经常会使用此插件, 以快速获取程序运行时的GC信息。
+
+
+
+左侧的图表展示了各个内存池的使用情况: Metaspace/永久代, 老年代, Eden区以及两个存活区。
+
+在右边, 顶部的两个图表与 GC无关, 显示的是 JIT编译时间 和 类加载时间。下面的6个图显示的是内存池的历史记录, 每个内存池的GC次数,GC总时间, 以及最大值,峰值, 当前使用情况。
+
+再下面是 HistoGram, 显示了年轻代对象的年龄分布。至于对象的年龄监控(objects tenuring monitoring), 本章不进行讲解。
+
+与纯粹的JMX工具相比, VisualGC 插件提供了更友好的界面, 如果没有其他趁手的工具, 请选择VisualGC. 本章接下来会介绍其他工具, 这些工具可以提供更多的信息, 以及更好的视角. 当然, 在“Profilers(分析器)”一节中,也会介绍 JVisualVM 的适用场景 —— 如: 分配分析(allocation profiling), 所以我们绝不会贬低哪一款工具, 关键还得看实际情况。
+
+## jstat
+
+[jstat](https://docs.oracle.com/javase/8/docs/technotes/tools/unix/jstat.html)也是标准JDK提供的一款监控工具(Java Virtual Machine statistics monitoring tool),可以统计各种指标。既可以连接到本地JVM,也可以连到远程JVM. 查看支持的指标和对应选项可以执行 “`jstat -options`” 。例如:
+
+
+
+```
++-----------------+---------------------------------------------------------------+
+| Option | Displays... |
++-----------------+---------------------------------------------------------------+
+|class | Statistics on the behavior of the class loader |
+|compiler | Statistics on the behavior of the HotSpot Just-In-Time com- |
+| | piler |
+|gc | Statistics on the behavior of the garbage collected heap |
+|gccapacity | Statistics of the capacities of the generations and their |
+| | corresponding spaces. |
+|gccause | Summary of garbage collection statistics (same as -gcutil), |
+| | with the cause of the last and current (if applicable) |
+| | garbage collection events. |
+|gcnew | Statistics of the behavior of the new generation. |
+|gcnewcapacity | Statistics of the sizes of the new generations and its corre- |
+| | sponding spaces. |
+|gcold | Statistics of the behavior of the old and permanent genera- |
+| | tions. |
+|gcoldcapacity | Statistics of the sizes of the old generation. |
+|gcpermcapacity | Statistics of the sizes of the permanent generation. |
+|gcutil | Summary of garbage collection statistics. |
+|printcompilation | Summary of garbage collection statistics. |
++-----------------+---------------------------------------------------------------+
+```
+
+
+
+* jstat 对于快速确定GC行为是否健康非常有用。启动方式为: “`jstat -gc -t PID 1s`” , 其中,PID 就是要监视的Java进程ID。可以通过`jps`命令查看正在运行的Java进程列表。
+
+
+
+```
+jps
+
+jstat -gc -t 2428 1s
+```
+
+
+
+以上命令的结果, 是 jstat 每秒向标准输出输出一行新内容, 比如:
+
+
+
+```
+Timestamp S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
+200.0 8448.0 8448.0 8448.0 0.0 67712.0 67712.0 169344.0 169344.0 21248.0 20534.3 3072.0 2807.7 34 0.720 658 133.684 134.404
+201.0 8448.0 8448.0 8448.0 0.0 67712.0 67712.0 169344.0 169343.2 21248.0 20534.3 3072.0 2807.7 34 0.720 662 134.712 135.432
+202.0 8448.0 8448.0 8102.5 0.0 67712.0 67598.5 169344.0 169343.6 21248.0 20534.3 3072.0 2807.7 34 0.720 667 135.840 136.559
+203.0 8448.0 8448.0 8126.3 0.0 67712.0 67702.2 169344.0 169343.6 21248.0 20547.2 3072.0 2807.7 34 0.720 669 136.178 136.898
+204.0 8448.0 8448.0 8126.3 0.0 67712.0 67702.2 169344.0 169343.6 21248.0 20547.2 3072.0 2807.7 34 0.720 669 136.178 136.898
+205.0 8448.0 8448.0 8134.6 0.0 67712.0 67712.0 169344.0 169343.5 21248.0 20547.2 3072.0 2807.7 34 0.720 671 136.234 136.954
+206.0 8448.0 8448.0 8134.6 0.0 67712.0 67712.0 169344.0 169343.5 21248.0 20547.2 3072.0 2807.7 34 0.720 671 136.234 136.954
+207.0 8448.0 8448.0 8154.8 0.0 67712.0 67712.0 169344.0 169343.5 21248.0 20547.2 3072.0 2807.7 34 0.720 673 136.289 137.009
+208.0 8448.0 8448.0 8154.8 0.0 67712.0 67712.0 169344.0 169343.5 21248.0 20547.2 3072.0 2807.7 34 0.720 673 136.289 137.009
+```
+
+
+
+稍微解释一下上面的内容。参考[jstat manpage](http://www.manpagez.com/man/1/jstat/), 我们可以知道:
+
+* jstat 连接到 JVM 的时间, 是JVM启动后的 200秒。此信息从第一行的 “**Timestamp**” 列得知。继续看下一行, jstat 每秒钟从JVM 接收一次信息, 也就是命令行参数中 “`1s`” 的含义。
+* 从第一行的 “**YGC**” 列得知年轻代共执行了34次GC, 由 “**FGC**” 列得知整个堆内存已经执行了 658次 full GC。
+* 年轻代的GC耗时总共为`0.720 秒`, 显示在“**YGCT**” 这一列。
+* Full GC 的总计耗时为`133.684 秒`, 由“**FGCT**”列得知。 这立马就吸引了我们的目光, 总的JVM 运行时间只有 200 秒,**但其中有 66% 的部分被 Full GC 消耗了**。
+
+再看下一行, 问题就更明显了。
+
+* 在接下来的一秒内共执行了 4 次 Full GC。参见 “**FGC**” 列.
+* 这4次 Full GC 暂停占用了差不多 1秒的时间(根据**FGCT**列的差得知)。与第一行相比, Full GC 耗费了`928 毫秒`, 即`92.8%`的时间。
+* 根据 “**OC**和 “**OU**” 列得知,**整个老年代的空间**为`169,344.0 KB`(“OC“), 在 4 次 Full GC 后依然占用了`169,344.2 KB`(“OU“)。用了`928ms`的时间却只释放了 800 字节的内存, 怎么看都觉得很不正常。
+
+只看这两行的内容, 就知道程序出了很严重的问题。继续分析下一行, 可以确定问题依然存在,而且变得更糟。
+
+JVM几乎完全卡住了(stalled), 因为GC占用了90%以上的计算资源。GC之后, 所有的老代空间仍然还在占用。事实上, 程序在一分钟以后就挂了, 抛出了 “[java.lang.OutOfMemoryError: GC overhead limit exceeded](https://plumbr.eu/outofmemoryerror/gc-overhead-limit-exceeded)” 错误。
+
+可以看到, 通过 jstat 能很快发现对JVM健康极为不利的GC行为。一般来说, 只看 jstat 的输出就能快速发现以下问题:
+
+* 最后一列 “**GCT**”, 与JVM的总运行时间 “**Timestamp**” 的比值, 就是GC 的开销。如果每一秒内, “**GCT**” 的值都会明显增大, 与总运行时间相比, 就暴露出GC开销过大的问题. 不同系统对GC开销有不同的容忍度, 由性能需求决定, 一般来讲, 超过`10%`的GC开销都是有问题的。
+* “**YGC**” 和 “**FGC**” 列的快速变化往往也是有问题的征兆。频繁的GC暂停会累积,并导致更多的线程停顿(stop-the-world pauses), 进而影响吞吐量。
+* 如果看到 “**OU**” 列中,老年代的使用量约等于老年代的最大容量(**OC**), 并且不降低的话, 就表示虽然执行了老年代GC, 但基本上属于无效GC。
+
+## GC日志(GC logs)
+
+通过日志内容也可以得到GC相关的信息。因为GC日志模块内置于JVM中, 所以日志中包含了对GC活动最全面的描述。 这就是事实上的标准, 可作为GC性能评估和优化的最真实数据来源。
+
+GC日志一般输出到文件之中, 是纯 text 格式的, 当然也可以打印到控制台。有多个可以控制GC日志的JVM参数。例如,可以打印每次GC的持续时间, 以及程序暂停时间(`-XX:+PrintGCApplicationStoppedTime`), 还有GC清理了多少引用类型(`-XX:+PrintReferenceGC`)。
+
+要打印GC日志, 需要在启动脚本中指定以下参数:
+
+
+
+```
+-XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintGCDetails -Xloggc:
+```
+
+
+
+以上参数指示JVM: 将所有GC事件打印到日志文件中, 输出每次GC的日期和时间戳。不同GC算法输出的内容略有不同. ParallelGC 输出的日志类似这样:
+
+
+
+```
+199.879: [Full GC (Ergonomics) [PSYoungGen: 64000K->63998K(74240K)] [ParOldGen: 169318K->169318K(169472K)] 233318K->233317K(243712K), [Metaspace: 20427K->20427K(1067008K)], 0.1473386 secs] [Times: user=0.43 sys=0.01, real=0.15 secs]
+200.027: [Full GC (Ergonomics) [PSYoungGen: 64000K->63998K(74240K)] [ParOldGen: 169318K->169318K(169472K)] 233318K->233317K(243712K), [Metaspace: 20427K->20427K(1067008K)], 0.1567794 secs] [Times: user=0.41 sys=0.00, real=0.16 secs]
+200.184: [Full GC (Ergonomics) [PSYoungGen: 64000K->63998K(74240K)] [ParOldGen: 169318K->169318K(169472K)] 233318K->233317K(243712K), [Metaspace: 20427K->20427K(1067008K)], 0.1621946 secs] [Times: user=0.43 sys=0.00, real=0.16 secs]
+200.346: [Full GC (Ergonomics) [PSYoungGen: 64000K->63998K(74240K)] [ParOldGen: 169318K->169318K(169472K)] 233318K->233317K(243712K), [Metaspace: 20427K->20427K(1067008K)], 0.1547695 secs] [Times: user=0.41 sys=0.00, real=0.15 secs]
+200.502: [Full GC (Ergonomics) [PSYoungGen: 64000K->63999K(74240K)] [ParOldGen: 169318K->169318K(169472K)] 233318K->233317K(243712K), [Metaspace: 20427K->20427K(1067008K)], 0.1563071 secs] [Times: user=0.42 sys=0.01, real=0.16 secs]
+200.659: [Full GC (Ergonomics) [PSYoungGen: 64000K->63999K(74240K)] [ParOldGen: 169318K->169318K(169472K)] 233318K->233317K(243712K), [Metaspace: 20427K->20427K(1067008K)], 0.1538778 secs] [Times: user=0.42 sys=0.00, real=0.16 secs]
+```
+
+
+
+在 “04\. GC算法:实现篇” 中详细介绍了这些格式, 如果对此不了解, 可以先阅读该章节。
+
+分析以上日志内容, 可以得知:
+
+* 这部分日志截取自JVM启动后200秒左右。
+* 日志片段中显示, 在`780毫秒`以内, 因为垃圾回收 导致了5次 Full GC 暂停(去掉第六次暂停,这样更精确一些)。
+* 这些暂停事件的总持续时间是`777毫秒`, 占总运行时间的**99.6%**。
+* 在GC完成之后, 几乎所有的老年代空间(`169,472 KB`)依然被占用(`169,318 KB`)。
+
+通过日志信息可以确定, 该应用的GC情况非常糟糕。JVM几乎完全停滞, 因为GC占用了超过`99%`的CPU时间。 而GC的结果是, 老年代空间仍然被占满, 这进一步肯定了我们的结论。 示例程序和jstat 小节中的是同一个, 几分钟之后系统就挂了, 抛出 “[java.lang.OutOfMemoryError: GC overhead limit exceeded](https://plumbr.eu/outofmemoryerror/gc-overhead-limit-exceeded)” 错误, 不用说, 问题是很严重的.
+
+从此示例可以看出, GC日志对监控GC行为和JVM是否处于健康状态非常有用。一般情况下, 查看 GC 日志就可以快速确定以下症状:
+
+* GC开销太大。如果GC暂停的总时间很长, 就会损害系统的吞吐量。不同的系统允许不同比例的GC开销, 但一般认为, 正常范围在`10%`以内。
+* 极个别的GC事件暂停时间过长。当某次GC暂停时间太长, 就会影响系统的延迟指标. 如果延迟指标规定交易必须在`1,000 ms`内完成, 那就不能容忍任何超过`1000毫秒`的GC暂停。
+* 老年代的使用量超过限制。如果老年代空间在 Full GC 之后仍然接近全满, 那么GC就成为了性能瓶颈, 可能是内存太小, 也可能是存在内存泄漏。这种症状会让GC的开销暴增。
+
+可以看到,GC日志中的信息非常详细。但除了这些简单的小程序, 生产系统一般都会生成大量的GC日志, 纯靠人工是很难阅读和进行解析的。
+
+## GCViewer
+
+我们可以自己编写解析器, 来将庞大的GC日志解析为直观易读的图形信息。 但很多时候自己写程序也不是个好办法, 因为各种GC算法的复杂性, 导致日志信息格式互相之间不太兼容。那么神器来了:[GCViewer](https://github.com/chewiebug/GCViewer)。
+
+[GCViewer](https://github.com/chewiebug/GCViewer)是一款开源的GC日志分析工具。项目的 GitHub 主页对各项指标进行了完整的描述. 下面我们介绍最常用的一些指标。
+
+第一步是获取GC日志文件。这些日志文件要能够反映系统在性能调优时的具体场景. 假若运营部门(operational department)反馈: 每周五下午,系统就运行缓慢, 不管GC是不是主要原因, 分析周一早晨的日志是没有多少意义的。
+
+获取到日志文件之后, 就可以用 GCViewer 进行分析, 大致会看到类似下面的图形界面:
+
+
+
+使用的命令行大致如下:
+
+
+
+```
+java -jar gcviewer_1.3.4.jar gc.log
+```
+
+
+
+当然, 如果不想打开程序界面,也可以在后面加上其他参数,直接将分析结果输出到文件。
+
+命令大致如下:
+
+
+
+```
+java -jar gcviewer_1.3.4.jar gc.log summary.csv chart.png
+```
+
+
+
+以上命令将信息汇总到当前目录下的 Excel 文件`summary.csv`之中, 将图形信息保存为`chart.png`文件。
+
+点击下载:gcviewer的jar包及使用示例
+
+上图中, Chart 区域是对GC事件的图形化展示。包括各个内存池的大小和GC事件。上图中, 只有两个可视化指标: 蓝色线条表示堆内存的使用情况, 黑色的Bar则表示每次GC暂停时间的长短。
+
+从图中可以看到, 内存使用量增长很快。一分钟左右就达到了堆内存的最大值. 堆内存几乎全部被消耗, 不能顺利分配新对象, 并引发频繁的 Full GC 事件. 这说明程序可能存在内存泄露, 或者启动时指定的内存空间不足。
+
+从图中还可以看到 GC暂停的频率和持续时间。`30秒`之后, GC几乎不间断地运行,最长的暂停时间超过`1.4秒`。
+
+在右边有三个选项卡。“`**Summary**`(摘要)” 中比较有用的是 “`Throughput`”(吞吐量百分比) 和 “`Number of GC pauses`”(GC暂停的次数), 以及“`Number of full GC pauses`”(Full GC 暂停的次数). 吞吐量显示了有效工作的时间比例, 剩下的部分就是GC的消耗。
+
+以上示例中的吞吐量为`**6.28%**`。这意味着有`**93.72%**`
+
+下一个有意思的地方是“**Pause**”(暂停)选项卡:
+
+
+
+“`Pause`” 展示了GC暂停的总时间,平均值,最小值和最大值, 并且将 total 与minor/major 暂停分开统计。如果要优化程序的延迟指标, 这些统计可以很快判断出暂停时间是否过长。另外, 我们可以得出明确的信息: 累计暂停时间为`634.59 秒`, GC暂停的总次数为`3,938 次`, 这在`11分钟/660秒`的总运行时间里那不是一般的高。
+
+更详细的GC暂停汇总信息, 请查看主界面中的 “**Event details**” 标签:
+
+
+
+从“**Event details**” 标签中, 可以看到日志中所有重要的GC事件汇总:`普通GC停顿`和`Full GC 停顿次数`, 以及`并发执行数`,`非 stop-the-world 事件`等。此示例中, 可以看到一个明显的地方, Full GC 暂停严重影响了吞吐量和延迟, 依据是:`3,928 次 Full GC`, 暂停了`634秒`。
+
+可以看到, GCViewer 能用图形界面快速展现异常的GC行为。一般来说, 图像化信息能迅速揭示以下症状:
+
+* 低吞吐量。当应用的吞吐量下降到不能容忍的地步时, 有用工作的总时间就大量减少. 具体有多大的 “容忍度”(tolerable) 取决于具体场景。按照经验, 低于 90% 的有效时间就值得警惕了, 可能需要好好优化下GC。
+* 单次GC的暂停时间过长。只要有一次GC停顿时间过长,就会影响程序的延迟指标. 例如, 延迟需求规定必须在 1000 ms以内完成交易, 那就不能容忍任何一次GC暂停超过1000毫秒。
+* 堆内存使用率过高。如果老年代空间在 Full GC 之后仍然接近全满, 程序性能就会大幅降低, 可能是资源不足或者内存泄漏。这种症状会对吞吐量产生严重影响。
+
+业界良心 —— 图形化展示的GC日志信息绝对是我们重磅推荐的。不用去阅读冗长而又复杂的GC日志,通过容易理解的图形, 也可以得到同样的信息。
+
+## 分析器(Profilers)
+
+下面介绍分析器([profilers](http://zeroturnaround.com/rebellabs/developer-productivity-report-2015-java-performance-survey-results/3/), Oracle官方翻译是:`抽样器`)。相对于前面的工具, 分析器只关心GC中的一部分领域. 本节我们也只关注分析器相关的GC功能。
+
+首先警告 —— 不要认为分析器适用于所有的场景。分析器有时确实作用很大, 比如检测代码中的CPU热点时。但某些情况使用分析器不一定是个好方案。
+
+对GC调优来说也是一样的。要检测是否因为GC而引起延迟或吞吐量问题时, 不需要使用分析器. 前面提到的工具(`jstat`或 原生/可视化GC日志)就能更好更快地检测出是否存在GC问题. 特别是从生产环境中收集性能数据时, 最好不要使用分析器, 因为性能开销非常大。
+
+如果确实需要对GC进行优化, 那么分析器就可以派上用场了, 可以对 Object 的创建信息一目了然. 换个角度看, 如果GC暂停的原因不在某个内存池中, 那就只会是因为创建对象太多了。 所有分析器都能够跟踪对象分配(via allocation profiling), 根据内存分配的轨迹, 让你知道**实际驻留在内存中的是哪些对象**。
+
+分配分析能定位到在哪个地方创建了大量的对象. 使用分析器辅助进行GC调优的好处是, 能确定哪种类型的对象最占用内存, 以及哪些线程创建了最多的对象。
+
+下面我们通过实例介绍3种分配分析器:`**hprof**`,`**JVisualV**`**M**和`**AProf**`。实际上还有很多分析器可供选择, 有商业产品,也有免费工具, 但其功能和应用基本上都是类似的。
+
+### hprof
+
+[hprof 分析器](http://docs.oracle.com/javase/8/docs/technotes/samples/hprof.html)内置于JDK之中。 在各种环境下都可以使用, 一般优先使用这款工具。
+
+要让`hprof`和程序一起运行, 需要修改启动脚本, 类似这样:
+
+
+
+```
+java -agentlib:hprof=heap=sites com.yourcompany.YourApplication
+```
+
+
+
+在程序退出时,会将分配信息dump(转储)到工作目录下的`java.hprof.txt`文件中。使用文本编辑器打开, 并搜索 “**SITES BEGIN**” 关键字, 可以看到:
+
+
+
+```
+SITES BEGIN (ordered by live bytes) Tue Dec 8 11:16:15 2015
+ percent live alloc'ed stack class
+ rank self accum bytes objs bytes objs trace name
+ 1 64.43% 4.43% 8370336 20121 27513408 66138 302116 int[]
+ 2 3.26% 88.49% 482976 20124 1587696 66154 302104 java.util.ArrayList
+ 3 1.76% 88.74% 241704 20121 1587312 66138 302115 eu.plumbr.demo.largeheap.ClonableClass0006
+ ... 部分省略 ...
+
+SITES END
+```
+
+
+
+从以上片段可以看到, allocations 是根据每次创建的对象数量来排序的。第一行显示所有对象中有`**64.43%**`的对象是整型数组(`int[]`), 在标识为`302116`的位置创建。搜索 “**TRACE 302116**” 可以看到:
+
+
+
+```
+TRACE 302116:
+ eu.plumbr.demo.largeheap.ClonableClass0006.(GeneratorClass.java:11)
+ sun.reflect.GeneratedConstructorAccessor7.newInstance(:Unknown line)
+ sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
+ java.lang.reflect.Constructor.newInstance(Constructor.java:422)
+```
+
+
+
+现在, 知道有`64.43%`的对象是整数数组, 在`ClonableClass0006`类的构造函数中, 第11行的位置, 接下来就可以优化代码, 以减少GC的压力。
+
+### Java VisualVM
+
+本章前面的第一部分, 在监控 JVM 的GC行为工具时介绍了 JVisualVM , 本节介绍其在分配分析上的应用。
+
+JVisualVM 通过GUI的方式连接到正在运行的JVM。 连接上目标JVM之后 :
+
+1. 打开 “工具” –> “选项” 菜单, 点击**性能分析(Profiler)**标签, 新增配置, 选择 Profiler 内存, 确保勾选了 “Record allocations stack traces”(记录分配栈跟踪)。
+2. 勾选 “Settings”(设置) 复选框, 在内存设置标签下,修改预设配置。
+3. 点击 “Memory”(内存) 按钮开始进行内存分析。
+4. 让程序运行一段时间,以收集关于对象分配的足够信息。
+5. 单击下方的 “Snapshot”(快照) 按钮。可以获取收集到的快照信息。
+
+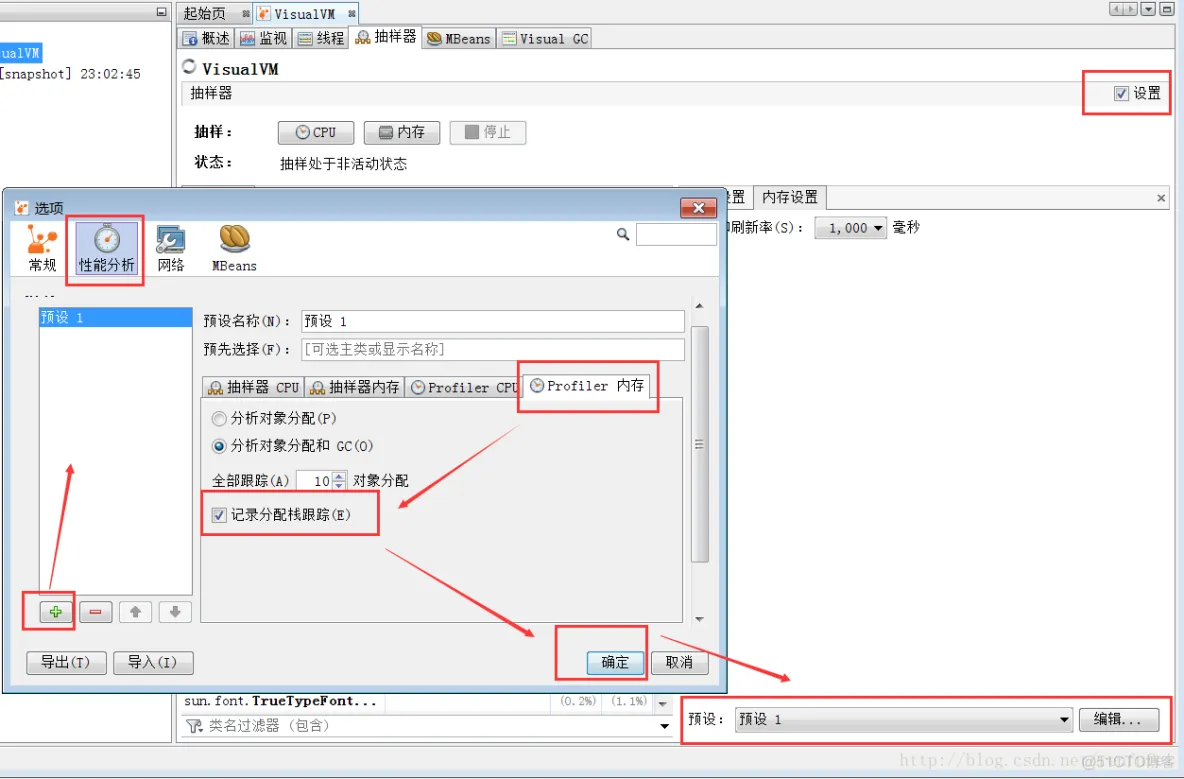
+
+完成上面的步骤后, 可以得到类似这样的信息:
+
+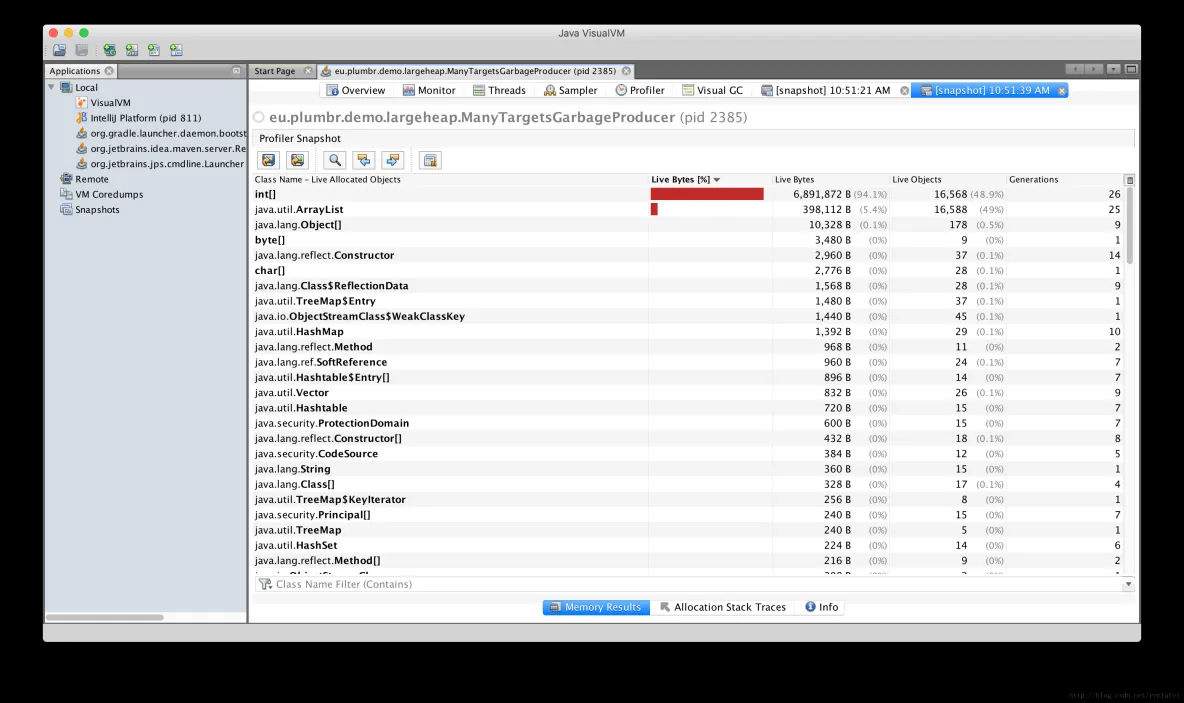
+
+上图按照每个类被创建的对象数量多少来排序。看第一行可以知道, 创建的最多的对象是`int[]`数组. 鼠标右键单击这行, 就可以看到这些对象都在哪些地方创建的:
+
+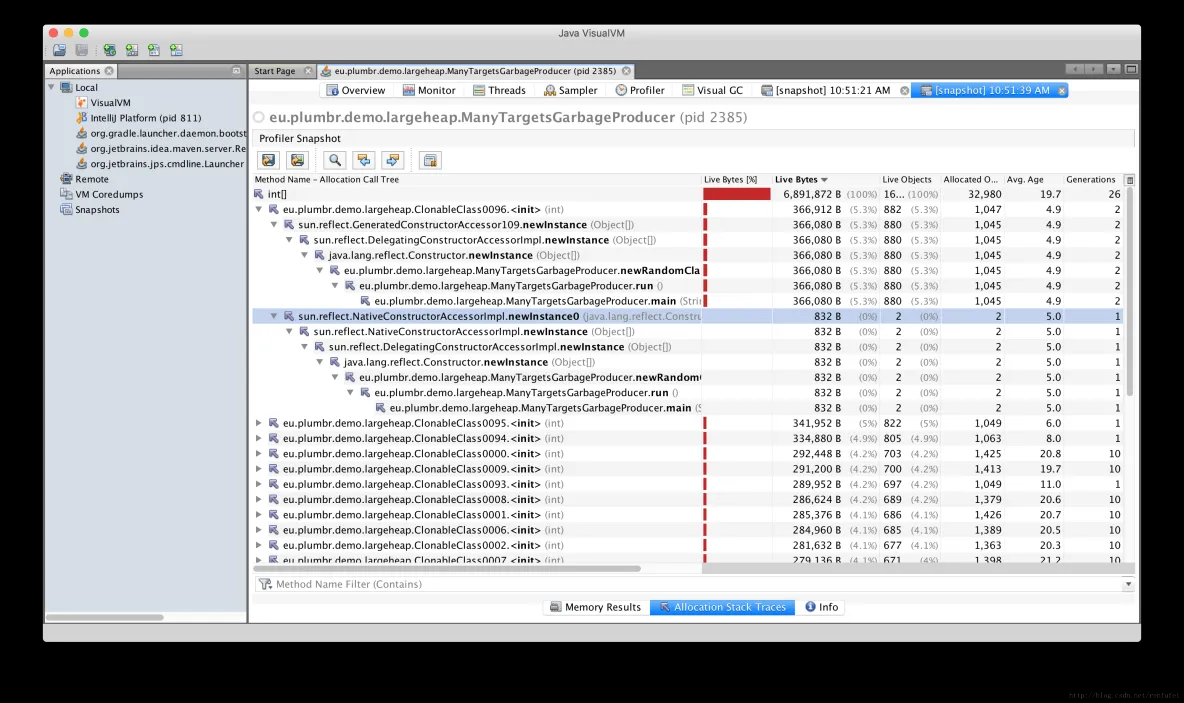
+
+与`hprof`相比, JVisualVM 更加容易使用 —— 比如上面的截图中, 在一个地方就可以看到所有`int[]`的分配信息, 所以多次在同一处代码进行分配的情况就很容易发现。
+
+### AProf
+
+最重要的一款分析器,是由 Devexperts 开发的[**AProf**](https://code.devexperts.com/display/AProf/About+Aprof)。 内存分配分析器 AProf 也被打包为 Java agent 的形式。
+
+用 AProf 分析应用程序, 需要修改 JVM 启动脚本,类似这样:
+
+
+
+```
+java -javaagent:/path-to/aprof.jar com.yourcompany.YourApplication
+```
+
+
+
+重启应用之后, 工作目录下会生成一个`aprof.txt`文件。此文件每分钟更新一次, 包含这样的信息:
+
+
+
+```
+========================================================================================================================
+TOTAL allocation dump for 91,289 ms (0h01m31s)
+Allocated 1,769,670,584 bytes in 24,868,088 objects of 425 classes in 2,127 locations
+========================================================================================================================
+
+Top allocation-inducing locations with the data types allocated from them
+------------------------------------------------------------------------------------------------------------------------
+eu.plumbr.demo.largeheap.ManyTargetsGarbageProducer.newRandomClassObject: 1,423,675,776 (80.44%) bytes in 17,113,721 (68.81%) objects (avg size 83 bytes)
+ int[]: 711,322,976 (40.19%) bytes in 1,709,911 (6.87%) objects (avg size 416 bytes)
+ char[]: 369,550,816 (20.88%) bytes in 5,132,759 (20.63%) objects (avg size 72 bytes)
+ java.lang.reflect.Constructor: 136,800,000 (7.73%) bytes in 1,710,000 (6.87%) objects (avg size 80 bytes)
+ java.lang.Object[]: 41,079,872 (2.32%) bytes in 1,710,712 (6.87%) objects (avg size 24 bytes)
+ java.lang.String: 41,063,496 (2.32%) bytes in 1,710,979 (6.88%) objects (avg size 24 bytes)
+ java.util.ArrayList: 41,050,680 (2.31%) bytes in 1,710,445 (6.87%) objects (avg size 24 bytes)
+ ... cut for brevity ...
+```
+
+
+
+上面的输出是按照`size`进行排序的。可以看出,`80.44%`的 bytes 和`68.81%`的 objects 是在`ManyTargetsGarbageProducer.newRandomClassObject()`方法中分配的。 其中,**int[]**数组占用了`40.19%`的内存, 是最大的一个。
+
+继续往下看, 会发现`allocation traces`(分配痕迹)相关的内容, 也是以 allocation size 排序的:
+
+
+
+```
+Top allocated data types with reverse location traces
+------------------------------------------------------------------------------------------------------------------------
+int[]: 725,306,304 (40.98%) bytes in 1,954,234 (7.85%) objects (avg size 371 bytes)
+ eu.plumbr.demo.largeheap.ClonableClass0006.: 38,357,696 (2.16%) bytes in 92,206 (0.37%) objects (avg size 416 bytes)
+ java.lang.reflect.Constructor.newInstance: 38,357,696 (2.16%) bytes in 92,206 (0.37%) objects (avg size 416 bytes)
+ eu.plumbr.demo.largeheap.ManyTargetsGarbageProducer.newRandomClassObject: 38,357,280 (2.16%) bytes in 92,205 (0.37%) objects (avg size 416 bytes)
+ java.lang.reflect.Constructor.newInstance: 416 (0.00%) bytes in 1 (0.00%) objects (avg size 416 bytes)
+... cut for brevity ...
+```
+
+
+
+可以看到,`int[]`数组的分配, 在`ClonableClass0006`构造函数中继续增大。
+
+和其他工具一样,`AProf`揭露了 分配的大小以及位置信息(`allocation size and locations`), 从而能够快速找到最耗内存的部分。在我们看来,**AProf**是最有用的分配分析器, 因为它只专注于内存分配, 所以做得最好。 当然, 这款工具是开源免费的, 资源开销也最小。
+
+请继续阅读下一章:7\. GC 调优(实战篇) - GC参考手册
+
+原文链接:[GC Tuning: Tooling](https://plumbr.eu/handbook/gc-tuning-measuring)
+
+翻译时间: 2016年02月06日
+
+## 参考文章
+
+
+
+
+
+
+
+
+
+https://blog.csdn.net/android_hl/article/details/53228348
+
+
diff --git "a/docs/Java/JVM/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232JNDI\357\274\214OSGI\357\274\214Tomcat\347\261\273\345\212\240\350\275\275\345\231\250\345\256\236\347\216\260.md" "b/docs/Java/JVM/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232JNDI\357\274\214OSGI\357\274\214Tomcat\347\261\273\345\212\240\350\275\275\345\231\250\345\256\236\347\216\260.md"
new file mode 100644
index 0000000..6c1b066
--- /dev/null
+++ "b/docs/Java/JVM/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232JNDI\357\274\214OSGI\357\274\214Tomcat\347\261\273\345\212\240\350\275\275\345\231\250\345\256\236\347\216\260.md"
@@ -0,0 +1,372 @@
+# 目录
+ * [打破双亲委派模型](#打破双亲委派模型)
+ * [JNDI](#jndi)
+ * [JNDI 的理解](#[jndi-的理解])
+ * [OSGI](#osgi)
+ * [1.如何正确的理解和认识OSGI技术?](#1如何正确的理解和认识osgi技术?)
+ * [Tomcat类加载器以及应用间class隔离与共享](#tomcat类加载器以及应用间class隔离与共享)
+ * [类加载器](#类加载器)
+ * [参考文章](#参考文章)
+
+
+
+本文转自互联网,侵删
+
+本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
+> https://github.com/h2pl/Java-Tutorial
+
+喜欢的话麻烦点下Star哈
+
+文章将同步到我的个人博客:
+> www.how2playlife.com
+
+本文是微信公众号【Java技术江湖】的《深入理解JVM虚拟机》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。
+
+该系列博文会告诉你如何从入门到进阶,一步步地学习JVM基础知识,并上手进行JVM调优实战,JVM是每一个Java工程师必须要学习和理解的知识点,你必须要掌握其实现原理,才能更完整地了解整个Java技术体系,形成自己的知识框架。
+
+为了更好地总结和检验你的学习成果,本系列文章也会提供每个知识点对应的面试题以及参考答案。
+
+如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。
+
+
+
+## 打破双亲委派模型
+
+### JNDI
+
+### JNDI 的理解
+
+
+JNDI是 Java 命名与文件夹接口(Java Naming and Directory Interface),在J2EE规范中是重要的规范之中的一个,不少专家觉得,没有透彻理解JNDI的意义和作用,就没有真正掌握J2EE特别是EJB的知识。
+
+那么,JNDI究竟起什么作用?//带着问题看文章是最有效的
+
+要了解JNDI的作用,我们能够从“假设不用JNDI我们如何做?用了JNDI后我们又将如何做?”这个问题来探讨。
+
+没有JNDI的做法:
+
+程序猿开发时,知道要开发訪问MySQL数据库的应用,于是将一个对 MySQL JDBC 驱动程序类的引用进行了编码,并通过使用适当的 JDBC URL 连接到数据库。
+就像以下代码这样:
+
+````
+ 1. Connectionconn=null;
+ 2. try{
+ 3. Class.forName("com.mysql.jdbc.Driver",
+ 4. true,Thread.currentThread().getContextClassLoader());
+ 5. conn=DriverManager.
+ 6. getConnection("jdbc:mysql://MyDBServer?user=qingfeng&password=mingyue");
+ 7. ......
+ 8. conn.close();
+ 9. }catch(Exceptione){
+ 10. e.printStackTrace();
+ 11. }finally{
+ 12. if(conn!=null){
+ 13. try{
+ 14. conn.close();
+ 15. }catch(SQLExceptione){}
+ 16. }
+ 17. }
+````
+
+
+这是传统的做法,也是曾经非Java程序猿(如Delphi、VB等)常见的做法。
+
+这种做法一般在小规模的开发过程中不会产生问题,仅仅要程序猿熟悉Java语言、了解JDBC技术和MySQL,能够非常快开发出对应的应用程序。
+
+没有JNDI的做法存在的问题:
+
+ 1、数据库server名称MyDBServer 、username和口令都可能须要改变,由此引发JDBC URL须要改动;
+ 2、数据库可能改用别的产品,如改用DB2或者Oracle,引发JDBC驱动程序包和类名须要改动;
+ 3、随着实际使用终端的添加,原配置的连接池參数可能须要调整;
+ 4、......
+
+解决的方法:
+
+程序猿应该不须要关心“详细的数据库后台是什么?JDBC驱动程序是什么?JDBC URL格式是什么?訪问数据库的username和口令是什么?”等等这些问题。
+
+程序猿编写的程序应该没有对 JDBC驱动程序的引用,没有server名称,没实username称或口令 —— 甚至没有数据库池或连接管理。
+
+而是把这些问题交给J2EE容器(比方weblogic)来配置和管理,程序猿仅仅须要对这些配置和管理进行引用就可以。
+
+由此,就有了JNDI。
+
+//看的出来。是为了一个最最核心的问题:是为了解耦,是为了开发出更加可维护、可扩展//的系统
+
+用了JNDI之后的做法:
+首先。在在J2EE容器中配置JNDI參数,定义一个数据源。也就是JDBC引用參数,给这个数据源设置一个名称;然后,在程序中,通过数据源名称引用数据源从而訪问后台数据库。
+
+//红色的字能够看出。JNDI是由j2ee容器提供的功能
+
+详细操作例如以下(以JBoss为例):
+1、配置数据源
+在JBoss 的 D:\jboss420GA\docs\examples\jca 文件夹以下。有非常多不同数据库引用的数据源定义模板。
+
+将当中的 mysql-ds.xml 文件Copy到你使用的server下,如 D:\jboss420GA\server\default\deploy。
+改动 mysql-ds.xml 文件的内容,使之能通过JDBC正确訪问你的MySQL数据库。例如以下:
+
+
+
+````
+
+
+
+MySqlDS
+jdbc:mysql://localhost:3306/lw
+com.mysql.jdbc.Driver
+root
+rootpassword
+
+org.jboss.resource.adapter.jdbc.vendor.MySQLExceptionSorter
+
+
+mySQL
+
+
+
+````
+
+
+这里,定义了一个名为MySqlDS的数据源。其參数包含JDBC的URL。驱动类名,username及密码等。
+
+2、在程序中引用数据源:
+
+````
+1. Connectionconn=null;
+2. try{
+3. Contextctx=newInitialContext();
+4. ObjectdatasourceRef=ctx.lookup("java:MySqlDS");//引用数据源
+5. DataSourceds=(Datasource)datasourceRef;
+6. conn=ds.getConnection();
+7. ......
+8. c.close();
+9. }catch(Exceptione){
+10. e.printStackTrace();
+11. }finally{
+12. if(conn!=null){
+13. try{
+14. conn.close();
+15. }catch(SQLExceptione){}
+16. }
+17. }
+````
+
+
+直接使用JDBC或者通过JNDI引用数据源的编程代码量相差无几,可是如今的程序能够不用关心详细JDBC參数了。
+
+//解藕了。可扩展了
+在系统部署后。假设数据库的相关參数变更。仅仅须要又一次配置 mysql-ds.xml 改动当中的JDBC參数,仅仅要保证数据源的名称不变,那么程序源码就无需改动。
+
+由此可见。JNDI避免了程序与数据库之间的紧耦合,使应用更加易于配置、易于部署。
+
+JNDI的扩展:
+JNDI在满足了数据源配置的要求的基础上。还进一步扩充了作用:全部与系统外部的资源的引用,都能够通过JNDI定义和引用。
+
+//注意什么叫资源
+
+所以,在J2EE规范中,J2EE 中的资源并不局限于 JDBC 数据源。
+
+引用的类型有非常多,当中包含资源引用(已经讨论过)、环境实体和 EJB 引用。
+
+特别是 EJB 引用,它暴露了 JNDI 在 J2EE 中的另外一项关键角色:查找其它应用程序组件。
+
+EJB 的 JNDI 引用非常相似于 JDBC 资源的引用。在服务趋于转换的环境中,这是一种非常有效的方法。能够对应用程序架构中所得到的全部组件进行这类配置管理,从 EJB 组件到 JMS 队列和主题。再到简单配置字符串或其它对象。这能够降低随时间的推移服务变更所产生的维护成本,同一时候还能够简化部署,降低集成工作。外部资源”。
+
+总结:
+
+J2EE 规范要求全部 J2EE 容器都要提供 JNDI 规范的实现。//sun 果然喜欢制定规范JNDI 在 J2EE 中的角色就是“交换机” —— J2EE 组件在执行时间接地查找其它组件、资源或服务的通用机制。在多数情况下,提供 JNDI 供应者的容器能够充当有限的数据存储。这样管理员就能够设置应用程序的执行属性,并让其它应用程序引用这些属性(Java 管理扩展(Java Management Extensions,JMX)也能够用作这个目的)。JNDI 在 J2EE 应用程序中的主要角色就是提供间接层,这样组件就能够发现所须要的资源,而不用了解这些间接性。
+
+在 J2EE 中,JNDI 是把 J2EE 应用程序合在一起的粘合剂。JNDI 提供的间接寻址同意跨企业交付可伸缩的、功能强大且非常灵活的应用程序。
+
+这是 J2EE 的承诺,并且经过一些计划和预先考虑。这个承诺是全然能够实现的。
+
+ 从上面的文章中能够看出:
+1、JNDI 提出的目的是为了解藕,是为了开发更加easy维护,easy扩展。easy部署的应用。
+2、JNDI 是一个sun提出的一个规范(相似于jdbc),详细的实现是各个j2ee容器提供商。sun 仅仅是要求,j2ee容器必须有JNDI这种功能。
+
+3、JNDI 在j2ee系统中的角色是“交换机”,是J2EE组件在执行时间接地查找其它组件、资源或服务的通用机制。
+4、JNDI 是通过资源的名字来查找的,资源的名字在整个j2ee应用中(j2ee容器中)是唯一的。
+
+
+ 上文提到过双亲委派模型并不是一个强制性的约束模型,而是Java设计者推荐给开发者的类加载器实现方式。在Java的世界中大部分的类加载器都遵循这个模型,但也有例外。
+
+ 双亲委派模型的一次“被破坏”是由这个模型自身的缺陷所导致的,双亲委派很好地解决了各个类加载器的基础类的统一问题(越基础的类由越上层的加载器进行加载),基础类之所以称为“基础”,是因为它们总是作为被用户代码调用的API,但世事往往没有绝对的完美,如果基础类又要调用回用户的代码,那该怎么办?
+
+这并非是不可能的事情,一个典型的例子便是JNDI服务,JNDI现在已经是Java的标准服务,它的代码由启动类加载器去加载(在JDK 1.3时放进去的rt.jar),但JNDI的目的就是对资源进行集中管理和查找,它需要调用由独立厂商实现并部署在应用程序的ClassPath下的JNDI接口提供者(SPI,Service Provider Interface)的代码,但启动类加载器不可能“认识”这些代码,因为启动类加载器的搜索范围中找不到用户应用程序类,那该怎么办?
+
+
+为了解决这个问题,Java设计团队只好引入了一个不太优雅的设计:线程上下文类加载器(Thread Context ClassLoader)。这个类加载器可以通过java.lang.Thread类的setContextClassLoader()方法进行设置,如果创建线程时还未设置,它将会从父线程中继承一个,如果在应用程序的全局范围内都没有设置过的话,那这个类加载器默认就是应用程序类加载器(Application ClassLoader)。
+
+ 有了线程上下文类加载器,就可以做一些“舞弊”的事情了,JNDI服务使用这个线程上下文类加载器去加载所需要的SPI代码,也就是父类加载器请求子类加载器去完成类加载的动作,这种行为实际上就是打通了双亲委派模型的层次结构来逆向使用类加载器,实际上已经违背了双亲委派模型的一般性原则,但这也是无可奈何的事情。Java中所有涉及SPI的加载动作基本上都采用这种方式,例如JNDI、JDBC、JCE、JAXB和JBI等。
+
+
+
+## OSGI
+
+
+
+目前,业内关于OSGI技术的学习资源或者技术文档还是很少的。我在某宝网搜索了一下“OSGI”的书籍,结果倒是有,但是种类少的可怜,而且几乎没有人购买。
+因为工作的原因我需要学习OSGI,所以我不得不想尽办法来主动学习OSGI。我将用文字记录学习OSGI的整个过程,通过整理书籍和视频教程,来让我更加了解这门技术,同时也让需要学习这门技术的同志们有一个清晰的学习路线。
+
+我们需要解决一下几问题:
+
+### 1.如何正确的理解和认识OSGI技术?
+
+我们从外文资料上或者从翻译过来的资料上看到OSGi解释和定义,都是直译过来的,但是OSGI的真实意义未必是中文直译过来的意思。OSGI的解释就是Open Service Gateway Initiative,直译过来就是“开放的服务入口(网关)的初始化”,听起来非常费解,什么是服务入口初始化?
+
+所以我们不去直译这个OSGI,我们换一种说法来描述OSGI技术。
+
+我们来回到我们以前的某些开发场景中去,假设我们使用SSH(struts+spring+hibernate)框架来开发我们的Web项目,我们做产品设计和开发的时候都是分模块的,我们分模块的目的就是实现模块之间的“解耦”,更进一步的目的是方便对一个项目的控制和管理。
+我们对一个项目进行模块化分解之后,我们就可以把不同模块交给不同的开发人员来完成开发,然后项目经理把大家完成的模块集中在一起,然后拼装成一个最终的产品。一般我们开发都是这样的基本情况。
+
+那么我们开发的时候预计的是系统的功能,根据系统的功能来进行模块的划分,也就是说,这个产品的功能或客户的需求是划分的重要依据。
+
+但是我们在开发过程中,我们模块之间还要彼此保持联系,比如A模块要从B模块拿到一些数据,而B模块可能要调用C模块中的一些方法(除了公共底层的工具类之外)。所以这些模块只是一种逻辑意义上的划分。
+
+最重要的一点是,我们把最终的项目要去部署到tomcat或者jBoss的服务器中去部署。那么我们启动服务器的时候,能不能关闭项目的某个模块或功能呢?很明显是做不到的,一旦服务器启动,所有模块就要一起启动,都要占用服务器资源,所以关闭不了模块,假设能强制拿掉,就会影响其它的功能。
+
+以上就是我们传统模块式开发的一些局限性。
+
+我们做软件开发一直在追求一个境界,就是模块之间的真正“解耦”、“分离”,这样我们在软件的管理和开发上面就会更加的灵活,甚至包括给客户部署项目的时候都可以做到更加的灵活可控。但是我们以前使用SSH框架等架构模式进行产品开发的时候我们是达不到这种要求的。
+
+所以我们“架构师”或顶尖的技术高手都在为模块化开发努力的摸索和尝试,然后我们的OSGI的技术规范就应运而生。
+
+现在我们的OSGI技术就可以满足我们之前所说的境界:在不同的模块中做到彻底的分离,而不是逻辑意义上的分离,是物理上的分离,也就是说在运行部署之后都可以在不停止服务器的时候直接把某些模块拿下来,其他模块的功能也不受影响。
+
+由此,OSGI技术将来会变得非常的重要,因为它在实现模块化解耦的路上,走得比现在大家经常所用的SSH框架走的更远。这个技术在未来大规模、高访问、高并发的Java模块化开发领域,或者是项目规范化管理中,会大大超过SSH等框架的地位。
+
+现在主流的一些应用服务器,Oracle的weblogic服务器,IBM的WebSphere,JBoss,还有Sun公司的glassfish服务器,都对OSGI提供了强大的支持,都是在OSGI的技术基础上实现的。有那么多的大型厂商支持OSGI这门技术,我们既可以看到OSGI技术的重要性。所以将来OSGI是将来非常重要的技术。
+
+但是OSGI仍然脱离不了框架的支持,因为OSGI本身也使用了很多spring等框架的基本控件(因为要实现AOP依赖注入等功能),但是哪个项目又不去依赖第三方jar呢?
+
+
+ 双亲委派模型的另一次“被破坏”是由于用户对程序动态性的追求而导致的,这里所说的“动态性”指的是当前一些非常“热门”的名词:代码热替换(HotSwap)、模块热部署(HotDeployment)等,说白了就是希望应用程序能像我们的计算机外设那样,接上鼠标、U盘,不用重启机器就能立即使用,鼠标有问题或要升级就换个鼠标,不用停机也不用重启。
+
+ 对于个人计算机来说,重启一次其实没有什么大不了的,但对于一些生产系统来说,关机重启一次可能就要被列为生产事故,这种情况下热部署就对软件开发者,尤其是企业级软件开发者具有很大的吸引力。Sun公司所提出的JSR-294、JSR-277规范在与JCP组织的模块化规范之争中落败给JSR-291(即OSGi R4.2),虽然Sun不甘失去Java模块化的主导权,独立在发展Jigsaw项目,但目前OSGi已经成为了业界“事实上”的Java模块化标准,而OSGi实现模块化热部署的关键则是它自定义的类加载器机制的实现。
+
+ 每一个程序模块(OSGi中称为Bundle)都有一个自己的类加载器,当需要更换一个Bundle时,就把Bundle连同类加载器一起换掉以实现代码的热替换。
+
+ 在OSGi环境下,类加载器不再是双亲委派模型中的树状结构,而是进一步发展为更加复杂的网状结构,当收到类加载请求时,OSGi将按照下面的顺序进行类搜索:
+
+ 1)将以java.*开头的类委派给父类加载器加载。
+
+ 2)否则,将委派列表名单内的类委派给父类加载器加载。
+
+ 3)否则,将Import列表中的类委派给Export这个类的Bundle的类加载器加载。
+
+ 4)否则,查找当前Bundle的ClassPath,使用自己的类加载器加载。
+
+ 5)否则,查找类是否在自己的Fragment Bundle中,如果在,则委派给Fragment Bundle的类加载器加载。
+
+ 6)否则,查找Dynamic Import列表的Bundle,委派给对应Bundle的类加载器加载。
+
+ 7)否则,类查找失败。
+
+ 上面的查找顺序中只有开头两点仍然符合双亲委派规则,其余的类查找都是在平级的类加载器中进行的。
+
+ 只要有足够意义和理由,突破已有的原则就可认为是一种创新。正如OSGi中的类加载器并不符合传统的双亲委派的类加载器,并且业界对其为了实现热部署而带来的额外的高复杂度还存在不少争议,但在Java程序员中基本有一个共识:OSGi中对类加载器的使用是很值得学习的,弄懂了OSGi的实现,就可以算是掌握了类加载器的精髓。
+
+
+## Tomcat类加载器以及应用间class隔离与共享
+
+
+
+Tomcat的用户一定都使用过其应用部署功能,无论是直接拷贝文件到webapps目录,还是修改server.xml以目录的形式部署,或者是增加虚拟主机,指定新的appBase等等。
+
+但部署应用时,不知道你是否曾注意过这几点:
+
+1. 如果在一个Tomcat内部署多个应用,甚至多个应用内使用了某个类似的几个不同版本,但它们之间却互不影响。这是如何做到的。
+
+2. 如果多个应用都用到了某类似的相同版本,是否可以统一提供,不在各个应用内分别提供,占用内存呢。
+
+3. 还有时候,在开发Web应用时,在pom.xml中添加了servlet-api的依赖,那实际应用的class加载时,会加载你的servlet-api 这个jar吗
+
+以上提到的这几点,在Tomcat以及各类的应用服务器中,都是通过类加载器(ClasssLoader)来实现的。通过本文,你可以了解到Tomcat内部提供的各种类加载器,Web应用的class和资源等加载的方式,以及其内部的实现原理。在遇到类似问题时,更胸有成竹。
+
+### 类加载器
+
+Java语言本身,以及现在其它的一些基于JVM之上的语言(Groovy,Jython, Scala...),都是在将代码编译生成class文件,以实现跨多平台,write once, run anywhere。最终的这些class文件,在应用中,又被加载到JVM虚拟机中,开始工作。而把class文件加载到JVM的组件,就是我们所说的类加载器。而对于类加载器的抽象,能面对更多的class数据提供形式,例如网络、文件系统等。
+
+Java中常见的那个ClassNotFoundException和NoClassDefFoundError就是类加载器告诉我们的。
+
+Servlet规范指出,容器用于加载Web应用内Servlet的class loader, 允许加载位于Web应用内的资源。但不允许重写java.*, javax.*以及容器实现的类。同时
+
+每个应用内使用Thread.currentThread.getContextClassLoader()获得的类加载器,都是该应用区别于其它应用的类加载器等等。
+
+根据Servlet规范,各个应用服务器厂商自行实现。所以像其他的一些应用服务器一样, Tomcat也提供了多种的类加载器,以便应用服务器内的class以及部署的Web应用类文件运行在容器中时,可以使用不同的class repositories。
+
+在Java中,类加载器是以一种父子关系树来组织的。除Bootstrap外,都会包含一个parent 类加载器。(这里写parent 类加载器,而不是父类加载器,不是为了装X,是为了避免和Java里的父类混淆)一般以类加载器需要加载一个class或者资源文件的时候,他会先委托给他的parent类加载器,让parent类加载器先来加载,如果没有,才再在自己的路径上加载。这就是人们常说的双亲委托,即把类加载的请求委托给parent。
+
+但是...,这里需要注意一下
+
+> 对于Web应用的类加载,和上面的双亲委托是有区别的。
+
+ 主流的Java Web服务器(也就是Web容器),如Tomcat、Jetty、WebLogic、WebSphere或其他笔者没有列举的服务器,都实现了自己定义的类加载器(一般都不止一个)。因为一个功能健全的Web容器,要解决如下几个问题:
+
+ 1)部署在同一个Web容器上的两个Web应用程序所使用的Java类库可以实现相互隔离。这是最基本的需求,两个不同的应用程序可能会依赖同一个第三方类库的不同版本,不能要求一个类库在一个服务器中只有一份,服务器应当保证两个应用程序的类库可以互相独立使用。
+
+ 2)部署在同一个Web容器上的两个Web应用程序所使用的Java类库可以互相共享。这个需求也很常见,例如,用户可能有10个使用[spring](https://yq.aliyun.com/go/articleRenderRedirect?url=https%3A%2F%2Flink.juejin.im%2F%3Ftarget%3Dhttp%253A%252F%252Flib.csdn.net%252Fbase%252Fjavaee "Java EE知识库")组织的应用程序部署在同一台服务器上,如果把10份Spring分别存放在各个应用程序的隔离目录中,将会是很大的资源浪费——这主要倒不是浪费磁盘空间的问题,而是指类库在使用时都要被加载到Web容器的内存,如果类库不能共享,虚拟机的方法区就会很容易出现过度膨胀的风险。
+
+ 3)Web容器需要尽可能地保证自身的安全不受部署的Web应用程序影响。目前,有许多主流的Java Web容器自身也是使用Java语言来实现的。因此,Web容器本身也有类库依赖的问题,一般来说,基于安全考虑,容器所使用的类库应该与应用程序的类库互相独立。
+
+ 4)支持JSP应用的Web容器,大多数都需要支持HotSwap功能。我们知道,JSP文件最终要编译成Java Class才能由虚拟机执行,但JSP文件由于其纯文本存储的特性,运行时修改的概率远远大于第三方类库或程序自身的Class文件。而且ASP、[PHP](https://yq.aliyun.com/go/articleRenderRedirect?url=https%3A%2F%2Flink.juejin.im%2F%3Ftarget%3Dhttp%253A%252F%252Flib.csdn.net%252Fbase%252Fphp "PHP知识库")和JSP这些网页应用也把修改后无须重启作为一个很大的“优势”来看待,因此“主流”的Web容器都会支持JSP生成类的热替换,当然也有“非主流”的,如运行在生产模式(Production Mode)下的WebLogic服务器默认就不会处理JSP文件的变化。
+
+ 由于存在上述问题,在部署Web应用时,单独的一个Class Path就无法满足需求了,所以各种Web容都“不约而同”地提供了好几个Class Path路径供用户存放第三方类库,这些路径一般都以“lib”或“classes”命名。被放置到不同路径中的类库,具备不同的访问范围和服务对象,通常,每一个目录都会有一个相应的自定义类加载器去加载放置在里面的Java类库。现在,就以Tomcat容器为例,看一看Tomcat具体是如何规划用户类库结构和类加载器的。
+
+ 在Tomcat目录结构中,有3组目录(“/common/*”、“/server/*”和“/shared/*”)可以存放Java类库,另外还可以加上Web应用程序自身的目录“/WEB-INF/*”,一共4组,把Java类库放置在这些目录中的含义分别如下:
+
+ ①放置在/common目录中:类库可被Tomcat和所有的Web应用程序共同使用。
+
+ ②放置在/server目录中:类库可被Tomcat使用,对所有的Web应用程序都不可见。
+
+ ③放置在/shared目录中:类库可被所有的Web应用程序共同使用,但对Tomcat自己不可见。
+
+ ④放置在/WebApp/WEB-INF目录中:类库仅仅可以被此Web应用程序使用,对Tomcat和其他Web应用程序都不可见。
+
+ 为了支持这套目录结构,并对目录里面的类库进行加载和隔离,Tomcat自定义了多个类加载器,这些类加载器按照经典的双亲委派模型来实现,其关系如下图所示。
+
+
+
+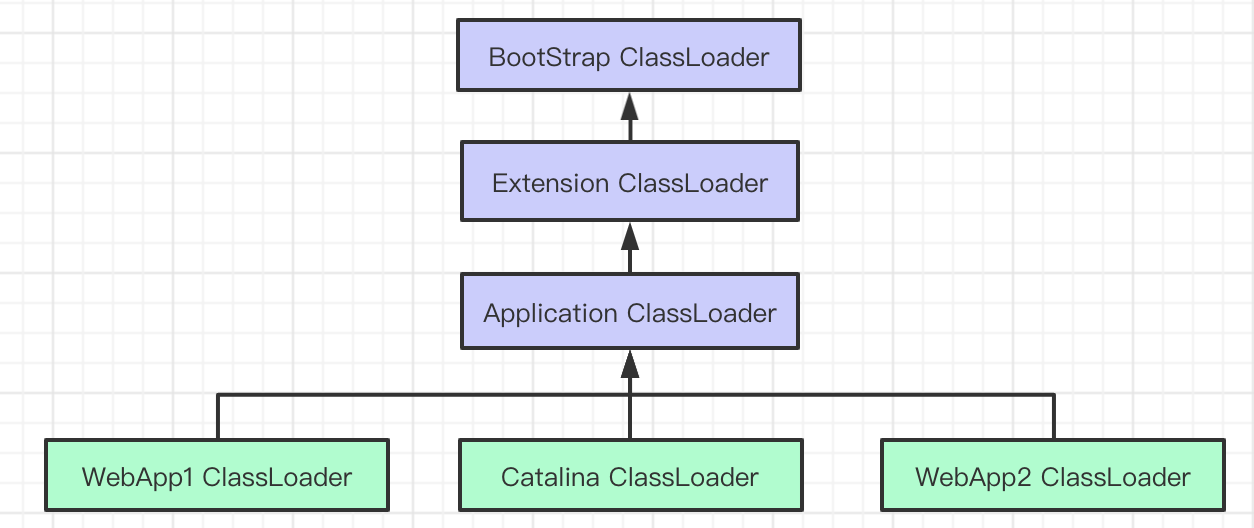
+
+
+
+
+
+
+ 上图中灰色背景的3个类加载器是JDK默认提供的类加载器,这3个加载器的作用已经介绍过了。而CommonClassLoader、CatalinaClassLoader、SharedClassLoader和WebappClassLoader则是Tomcat自己定义的类加载器,它们分别加载/common/*、/server/*、/shared/*和/WebApp/WEB-INF/*中的Java类库。其中WebApp类加载器和Jsp类加载器通常会存在多个实例,每一个Web应用程序对应一个WebApp类加载器,每一个JSP文件对应一个Jsp类加载器。
+
+ 从图中的委派关系中可以看出,CommonClassLoader能加载的类都可以被CatalinaClassLoader和SharedClassLoader使用,而CatalinaClassLoader和SharedClassLoader自己能加载的类则与对方相互隔离。WebAppClassLoader可以使用SharedClassLoader加载到的类,但各个WebAppClassLoader实例之间相互隔离。
+
+ 而JasperLoader的加载范围仅仅是这个JSP文件所编译出来的那一个.Class文件,它出现的目的就是为了被丢弃:当Web容器检测到JSP文件被修改时,会替换掉目前的JasperLoader的实例,并通过再建立一个新的Jsp类加载器来实现JSP文件的HotSwap功能。
+
+对于Tomcat的6.x版本,只有指定了tomcat/conf/catalina.properties配置文件的server.loader和share.loader项后才会真正建立CatalinaClassLoader和Shared ClassLoader的实例,否则在用到这两个类加载器的地方都会用Common ClassLoader的实例代替,而默认的配置文件中没有设置这两个loader项,所以Tomcat 6.x顺理成章地把/common、/server和/shared三个目录默认合并到一起变成一个/lib目录,这个目录里的类库相当于以前/common目录中类库的作用。
+
+这是Tomcat设计团队为了简化大多数的部署场景所做的一项改进,如果默认设置不能满足需要,用户可以通过修改配置文件指定server.loader和share.loader的方式重新启用Tomcat 5.x的加载器[架构](https://yq.aliyun.com/go/articleRenderRedirect?url=https%3A%2F%2Flink.juejin.im%2F%3Ftarget%3Dhttp%253A%252F%252Flib.csdn.net%252Fbase%252Farchitecture "大型网站架构知识库")。
+
+ Tomcat加载器的实现清晰易懂,并且采用了官方推荐的“正统”的使用类加载器的方式。如果读者阅读完上面的案例后,能完全理解Tomcat设计团队这样布置加载器架构的用意,那说明已经大致掌握了类加载器“主流”的使用方式,那么笔者不妨再提一个问题让读者思考一下:前面曾经提到过一个场景,如果有10个Web应用程序都是用Spring来进行组织和管理的话,可以把Spring放到Common或Shared目录下让这些程序共享。
+
+ Spring要对用户程序的类进行管理,自然要能访问到用户程序的类,而用户的程序显然是放在/WebApp/WEB-INF目录中的,那么被CommonClassLoader或SharedClassLoader加载的Spring如何访问并不在其加载范围内的用户程序呢?如果研究过虚拟机类加载器机制中的双亲委派模型,相信读者可以很容易地回答这个问题。
+
+分析:如果按主流的双亲委派机制,显然无法做到让父类加载器加载的类去访问子类加载器加载的类,上面在类加载器一节中提到过通过线程上下文方式传播类加载器。
+
+ 答案是使用线程上下文类加载器来实现的,使用线程上下文加载器,可以让父类加载器请求子类加载器去完成类加载的动作。
+
+ 看spring源码发现,spring加载类所用的Classloader是通过Thread.currentThread().getContextClassLoader()来获取的,而当线程创建时会默认setContextClassLoader(AppClassLoader),即线程上下文类加载器被设置为AppClassLoader,spring中始终可以获取到这个AppClassLoader(在Tomcat里就是WebAppClassLoader)子类加载器来加载bean,以后任何一个线程都可以通过getContextClassLoader()获取到WebAppClassLoader来getbean了。
+
+
+
+本篇博文内容取材自《深入理解Java虚拟机:JVM高级特性与最佳实践》
+
+## 参考文章
+
+
+
+
+
+
+
+
+
+https://blog.csdn.net/android_hl/article/details/53228348
+
+
diff --git "a/docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\2721\357\274\232JVM\345\206\205\345\255\230\347\232\204\347\273\223\346\236\204\344\270\216\346\266\210\345\244\261\347\232\204\346\260\270\344\271\205\344\273\243.md" "b/docs/Java/JVM/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232JVM\345\206\205\345\255\230\347\232\204\347\273\223\346\236\204\344\270\216\346\266\210\345\244\261\347\232\204\346\260\270\344\271\205\344\273\243.md"
similarity index 75%
rename from "docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\2721\357\274\232JVM\345\206\205\345\255\230\347\232\204\347\273\223\346\236\204\344\270\216\346\266\210\345\244\261\347\232\204\346\260\270\344\271\205\344\273\243.md"
rename to "docs/Java/JVM/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232JVM\345\206\205\345\255\230\347\232\204\347\273\223\346\236\204\344\270\216\346\266\210\345\244\261\347\232\204\346\260\270\344\271\205\344\273\243.md"
index d040fa5..17431e9 100644
--- "a/docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\2721\357\274\232JVM\345\206\205\345\255\230\347\232\204\347\273\223\346\236\204\344\270\216\346\266\210\345\244\261\347\232\204\346\260\270\344\271\205\344\273\243.md"
+++ "b/docs/Java/JVM/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232JVM\345\206\205\345\255\230\347\232\204\347\273\223\346\236\204\344\270\216\346\266\210\345\244\261\347\232\204\346\260\270\344\271\205\344\273\243.md"
@@ -1,5 +1,4 @@
-# Table of Contents
-
+# 目录
* [前言](#前言)
* [Java堆(Heap)](#java堆(heap))
* [方法区(Method Area)](#方法区(method-area))
@@ -7,25 +6,22 @@
* [JVM栈(JVM Stacks)](#jvm栈(jvm-stacks))
* [本地方法栈(Native Method Stacks)](#本地方法栈(native-method-stacks))
* [哪儿的OutOfMemoryError](#哪儿的outofmemoryerror)
-* [[JDK8-废弃永久代(PermGen)迎来元空间(Metaspace)](https://www.cnblogs.com/yulei126/p/6777323.html)](#[jdk8-废弃永久代(permgen)迎来元空间(metaspace)]httpswwwcnblogscomyulei126p6777323html)
* [一、背景](#一、背景)
* [1.1 永久代(PermGen)在哪里?](#11-永久代(permgen)在哪里?)
* [1.2 JDK8永久代的废弃](#12-jdk8永久代的废弃)
- * [ 二、为什么废弃永久代(PermGen)](# 二、为什么废弃永久代(permgen))
- * [ 2.1 官方说明](# 21-官方说明)
+ * [二、为什么废弃永久代(PermGen)](#二、为什么废弃永久代(permgen))
+ * [2.1 官方说明](#21-官方说明)
* [Motivation](#motivation)
- * [ 2.2 现实使用中易出问题](# 22-现实使用中易出问题)
+ * [2.2 现实使用中易出问题](#22-现实使用中易出问题)
* [三、深入理解元空间(Metaspace)](#三、深入理解元空间(metaspace))
* [3.1元空间的内存大小](#31元空间的内存大小)
* [3.2常用配置参数](#32常用配置参数)
* [3.3测试并追踪元空间大小](#33测试并追踪元空间大小)
- * [ 3.3.1.测试字符串常量](# 331测试字符串常量)
+ * [3.3.1.测试字符串常量](#331测试字符串常量)
* [3.3.2.测试元空间溢出](#332测试元空间溢出)
- * [ 四、总结](# 四、总结)
+ * [四、总结](#四、总结)
* [参考文章](#参考文章)
- * [微信公众号](#微信公众号)
- * [Java技术江湖](#java技术江湖)
- * [个人公众号:黄小斜](#个人公众号:黄小斜)
+
本文转自互联网,侵删
@@ -54,11 +50,9 @@
其实如果你经常解决服务器性能问题,那么这些问题就会变的非常常见,了解JVM内存也是为了服务器出现性能问题的时候可以快速的了解那块的内存区域出现问题,以便于快速的解决生产故障。
-
-
先看一张图,这张图能很清晰的说明JVM内存结构布局。
-
+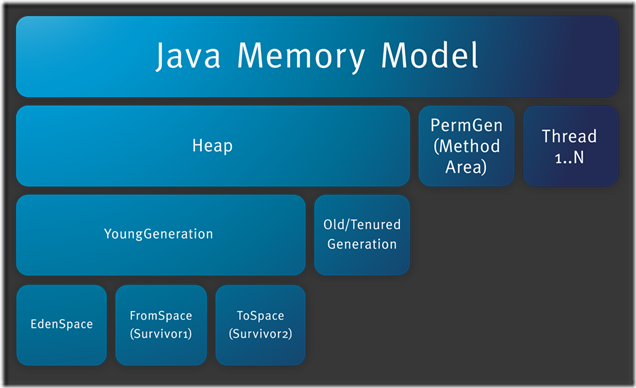
JVM内存结构主要有三大块:堆内存、方法区和栈。堆内存是JVM中最大的一块由年轻代和老年代组成,而年轻代内存又被分成三部分,Eden空间、From Survivor空间、To Survivor空间,默认情况下年轻代按照8:1:1的比例来分配;
@@ -66,8 +60,7 @@ JVM内存结构主要有三大块:堆内存、方法区和栈。堆内存是JV
在通过一张图来了解如何通过参数来控制各区域的内存大小
-
-
+
控制参数
* -Xms设置堆的最小空间大小。
@@ -84,7 +77,7 @@ JVM内存结构主要有三大块:堆内存、方法区和栈。堆内存是JV
从更高的一个维度再次来看JVM和系统调用之间的关系
-
+
方法区和对是所有线程共享的内存区域;而java栈、本地方法栈和程序员计数器是运行是线程私有的内存区域。
@@ -112,7 +105,7 @@ Java虚拟机规范对这个区域的限制非常宽松,除了和Java堆一样
方法区有时被称为持久代(PermGen)。
-
+
所有的对象在实例化后的整个运行周期内,都被存放在堆内存中。堆内存又被划分成不同的部分:伊甸区(Eden),幸存者区域(Survivor Sapce),老年代(Old Generation Space)。
@@ -121,27 +114,26 @@ Java虚拟机规范对这个区域的限制非常宽松,除了和Java堆一样
-
-import java.text.SimpleDateFormat;import java.util.Date;import org.apache.log4j.Logger;
+````
+import java.text.SimpleDateFormat;import java.util.Date;import org.apache.log4j.Logger;
public class HelloWorld {
- private static Logger LOGGER = Logger.getLogger(HelloWorld.class.getName());
- public void sayHello(String message) {
- SimpleDateFormat formatter = new SimpleDateFormat("dd.MM.YYYY");
- String today = formatter.format(new Date());
- LOGGER.info(today + ": " + message);
- }}
-
+ private static Logger LOGGER = Logger.getLogger(HelloWorld.class.getName());
+ public void sayHello(String message) {
+ SimpleDateFormat formatter = new SimpleDateFormat("dd.MM.YYYY");
+ String today = formatter.format(new Date());
+ LOGGER.info(today + ": " + message);
+ }}
+````
这段程序的数据在内存中的存放如下:
-
-
+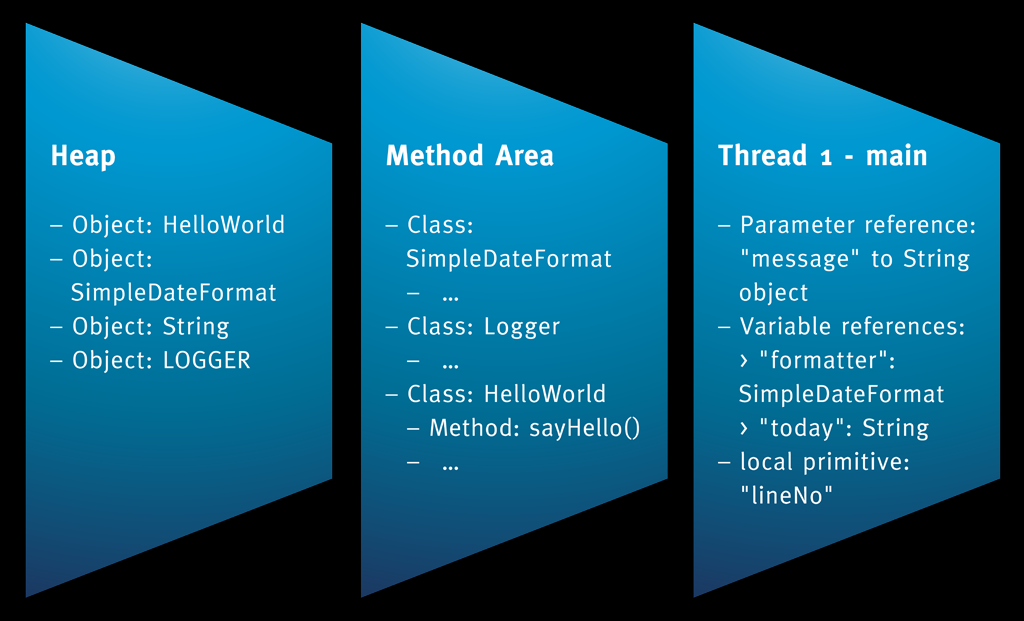
通过JConsole工具可以查看运行中的Java程序(比如Eclipse)的一些信息:堆内存的分配,线程的数量以及加载的类的个数;
-
+
## 程序计数器(Program Counter Register)
@@ -172,69 +164,38 @@ Java虚拟机规范对这个区域的限制非常宽松,除了和Java堆一样
对内存结构清晰的认识同样可以帮助理解不同OutOfMemoryErrors:
-
-
-
-Exception in thread “main”: java.lang.OutOfMemoryError: Java heap space
-
-
-
+Exception in thread “main”: java.lang.OutOfMemoryError: Java heap space
原因:对象不能被分配到堆内存中
-
-
-
-Exception in thread “main”: java.lang.OutOfMemoryError: PermGen space
-
-
-
+Exception in thread “main”: java.lang.OutOfMemoryError: PermGen space
原因:类或者方法不能被加载到持久代。它可能出现在一个程序加载很多类的时候,比如引用了很多第三方的库;
-
-
-
-
-Exception in thread “main”: java.lang.OutOfMemoryError: Requested array size exceeds VM limit
-
-
-
+Exception in thread “main”: java.lang.OutOfMemoryError: Requested array size exceeds VM limit
原因:创建的数组大于堆内存的空间
-
-
-
-Exception in thread “main”: java.lang.OutOfMemoryError: request bytes for . Out of swap space?
-
-
-
+Exception in thread “main”: java.lang.OutOfMemoryError: request bytes for . Out of swap space?
原因:分配本地分配失败。JNI、本地库或者Java虚拟机都会从本地堆中分配内存空间。
-
-
-
-Exception in thread “main”: java.lang.OutOfMemoryError: (Native method)
-
-
-
+Exception in thread “main”: java.lang.OutOfMemoryError: (Native method)
原因:同样是本地方法内存分配失败,只不过是JNI或者本地方法或者Java虚拟机发现
-# [JDK8-废弃永久代(PermGen)迎来元空间(Metaspace)](https://www.cnblogs.com/yulei126/p/6777323.html)
-
-
+关于永久代的废弃可以参考这篇文章
+JDK8-废弃永久代(PermGen)迎来元空间(Metaspace)
+(https://www.cnblogs.com/yulei126/p/6777323.html)
1.背景
@@ -253,8 +214,7 @@ Java虚拟机规范对这个区域的限制非常宽松,除了和Java堆一样
根据,hotspot jvm结构如下(虚拟机栈和本地方法栈合一起了):
-
-
+
上图引自网络,但有个问题:方法区和heap堆都是线程共享的内存区域。
关于方法区和永久代:
@@ -265,17 +225,16 @@ Java虚拟机规范对这个区域的限制非常宽松,除了和Java堆一样
JDK8 永久代变化如下图:
-
-
+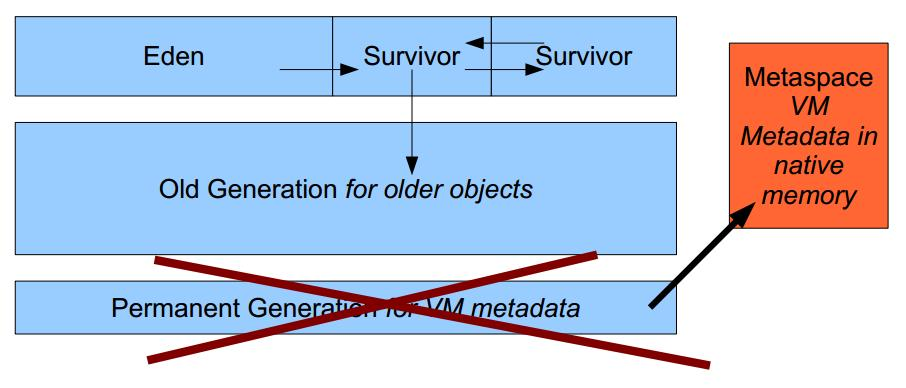
1.新生代:Eden+From Survivor+To Survivor
2.老年代:OldGen
3.永久代(方法区的实现) : PermGen----->替换为Metaspace(本地内存中)
-## 二、为什么废弃永久代(PermGen)
+## 二、为什么废弃永久代(PermGen)
-### 2.1 官方说明
+### 2.1 官方说明
参照JEP122:http://openjdk.java.net/jeps/122,原文截取:
@@ -283,9 +242,9 @@ JDK8 永久代变化如下图:
This is part of the JRockit and Hotspot convergence effort. JRockit customers do not need to configure the permanent generation (since JRockit does not have a permanent generation) and are accustomed to not configuring the permanent generation.
- 即:移除永久代是为融合HotSpot JVM与 JRockit VM而做出的努力,因为JRockit没有永久代,不需要配置永久代。
+即:移除永久代是为融合HotSpot JVM与 JRockit VM而做出的努力,因为JRockit没有永久代,不需要配置永久代。
-### 2.2 现实使用中易出问题
+### 2.2 现实使用中易出问题
由于永久代内存经常不够用或发生内存泄露,爆出异常java.lang.OutOfMemoryError: PermGen
@@ -303,7 +262,7 @@ This is part of the JRockit and Hotspot convergence effort. JRockit customers do
1.MetaspaceSize
-初始化的Metaspace大小,控制元空间发生GC的阈值。GC后,动态增加或降低MetaspaceSize。在默认情况下,这个值大小根据不同的平台在12M到20M浮动。使用[Java](http://lib.csdn.net/base/javase "Java SE知识库") -XX:+PrintFlagsInitial命令查看本机的初始化参数
+初始化的Metaspace大小,控制元空间发生GC的阈值。GC后,动态增加或降低MetaspaceSize。在默认情况下,这个值大小根据不同的平台在12M到20M浮动。使用[Java](http://lib.csdn.net/base/javase "Java SE知识库")-XX:+PrintFlagsInitial命令查看本机的初始化参数
2.MaxMetaspaceSize
@@ -327,40 +286,32 @@ Metaspace增长时的最小幅度。在本机上该参数的默认值为340784B
### 3.3测试并追踪元空间大小
-#### 3.3.1.测试字符串常量
-
-
-
-
-
-
- 1 public class StringOomMock {
- 2 static String base = "string";
- 3
- 4 public static void main(String[] args) {
- 5 List list = new ArrayList();
- 6 for (int i=0;i< Integer.MAX_VALUE;i++){
- 7 String str = base + base;
- 8 base = str;
- 9 list.add(str.intern());
-10 }
-11 }
-12 }
-
-
-
-
-
+#### 3.3.1.测试字符串常量
+
+````
+public class StringOomMock {
+ static String base = "string";
+
+ public static void main(String[] args) {
+ List list = new ArrayList();
+ for (int i=0;i< Integer.MAX_VALUE;i++){
+ String str = base + base;
+ base = str;
+ list.add(str.intern());
+ }
+ }
+}
+````
在eclipse中选中类--》run configuration-->java application--》new 参数如下:
-
+
- 由于设定了最大内存20M,很快就溢出,如下图:
+由于设定了最大内存20M,很快就溢出,如下图:
-
+
- 可见在jdk8中:
+可见在jdk8中:
1.字符串常量由永久代转移到堆中。
@@ -369,86 +320,71 @@ Metaspace增长时的最小幅度。在本机上该参数的默认值为340784B
#### 3.3.2.测试元空间溢出
根据定义,我们以加载类来测试元空间溢出,代码如下:
-
-
-
-
-
-
- 1 package jdk8;
- 2
- 3 import java.io.File;
- 4 import java.lang.management.ClassLoadingMXBean;
- 5 import java.lang.management.ManagementFactory;
- 6 import java.net.URL;
- 7 import java.net.URLClassLoader;
- 8 import java.util.ArrayList;
- 9 import java.util.List;
-10
-11 /**
-12 *
-13 * @ClassName:OOMTest
-14 * @Description:模拟类加载溢出(元空间oom)
-15 * @author diandian.zhang
-16 * @date 2017年4月27日上午9:45:40
-17 */
-18 public class OOMTest {
-19 public static void main(String[] args) {
-20 try {
-21 //准备url
-22 URL url = new File("D:/58workplace/11study/src/main/java/jdk8").toURI().toURL();
-23 URL[] urls = {url};
-24 //获取有关类型加载的JMX接口
-25 ClassLoadingMXBean loadingBean = ManagementFactory.getClassLoadingMXBean();
-26 //用于缓存类加载器
-27 List classLoaders = new ArrayList();
-28 while (true) {
-29 //加载类型并缓存类加载器实例
-30 ClassLoader classLoader = new URLClassLoader(urls);
-31 classLoaders.add(classLoader);
-32 classLoader.loadClass("ClassA");
-33 //显示数量信息(共加载过的类型数目,当前还有效的类型数目,已经被卸载的类型数目)
-34 System.out.println("total: " + loadingBean.getTotalLoadedClassCount());
-35 System.out.println("active: " + loadingBean.getLoadedClassCount());
-36 System.out.println("unloaded: " + loadingBean.getUnloadedClassCount());
-37 }
-38 } catch (Exception e) {
-39 e.printStackTrace();
-40 }
-41 }
-42 }
-
-
-
-
-
+````
+package jdk8;
+
+import java.io.File;
+import java.lang.management.ClassLoadingMXBean;
+import java.lang.management.ManagementFactory;
+import java.net.URL;
+import java.net.URLClassLoader;
+import java.util.ArrayList;
+import java.util.List;
+
+/**
+ *
+ * @ClassName:OOMTest
+ * @Description:模拟类加载溢出(元空间oom)
+ * @author diandian.zhang
+ * @date 2017年4月27日上午9:45:40
+ */
+public class OOMTest {
+ public static void main(String[] args) {
+ try {
+ //准备url
+ URL url = new File("D:/58workplace/11study/src/main/java/jdk8").toURI().toURL();
+ URL[] urls = {url};
+ //获取有关类型加载的JMX接口
+ ClassLoadingMXBean loadingBean = ManagementFactory.getClassLoadingMXBean();
+ //用于缓存类加载器
+ List classLoaders = new ArrayList();
+ while (true) {
+ //加载类型并缓存类加载器实例
+ ClassLoader classLoader = new URLClassLoader(urls);
+ classLoaders.add(classLoader);
+ classLoader.loadClass("ClassA");
+ //显示数量信息(共加载过的类型数目,当前还有效的类型数目,已经被卸载的类型数目)
+ System.out.println("total: " + loadingBean.getTotalLoadedClassCount());
+ System.out.println("active: " + loadingBean.getLoadedClassCount());
+ System.out.println("unloaded: " + loadingBean.getUnloadedClassCount());
+ }
+ } catch (Exception e) {
+ e.printStackTrace();
+ }
+ }
+}
+````
为了快速溢出,设置参数:-XX:MetaspaceSize=8m -XX:MaxMetaspaceSize=80m,运行结果如下:
-
+
- 上图证实了,我们的JDK8中类加载(方法区的功能)已经不在永久代PerGem中了,而是Metaspace中。可以配合JVisualVM来看,更直观一些。
+上图证实了,我们的JDK8中类加载(方法区的功能)已经不在永久代PerGem中了,而是Metaspace中。可以配合JVisualVM来看,更直观一些。
-## 四、总结
+## 四、总结
本文讲解了元空间(Metaspace)的由来和本质,常用配置,以及监控测试。元空间的大小是动态变更的,但不是无限大的,最好也时常关注一下大小,以免影响服务器内存。
-
-
-
-
-
-
## 参考文章
-
+https://segmentfault.com/a/1190000009707894
-
+https://www.cnblogs.com/hysum/p/7100874.html
-
+http://c.biancheng.net/view/939.html
-
+https://www.runoob.com
https://blog.csdn.net/android_hl/article/details/53228348
diff --git "a/docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\2722\357\274\232JVM\345\236\203\345\234\276\345\233\236\346\224\266\345\237\272\346\234\254\345\216\237\347\220\206\345\222\214\347\256\227\346\263\225.md" "b/docs/Java/JVM/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232JVM\345\236\203\345\234\276\345\233\236\346\224\266\345\237\272\346\234\254\345\216\237\347\220\206\345\222\214\347\256\227\346\263\225.md"
similarity index 80%
rename from "docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\2722\357\274\232JVM\345\236\203\345\234\276\345\233\236\346\224\266\345\237\272\346\234\254\345\216\237\347\220\206\345\222\214\347\256\227\346\263\225.md"
rename to "docs/Java/JVM/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232JVM\345\236\203\345\234\276\345\233\236\346\224\266\345\237\272\346\234\254\345\216\237\347\220\206\345\222\214\347\256\227\346\263\225.md"
index e8a7e29..8048fb5 100644
--- "a/docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\2722\357\274\232JVM\345\236\203\345\234\276\345\233\236\346\224\266\345\237\272\346\234\254\345\216\237\347\220\206\345\222\214\347\256\227\346\263\225.md"
+++ "b/docs/Java/JVM/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232JVM\345\236\203\345\234\276\345\233\236\346\224\266\345\237\272\346\234\254\345\216\237\347\220\206\345\222\214\347\256\227\346\263\225.md"
@@ -1,5 +1,4 @@
-# Table of Contents
-
+# 目录
* [JVM GC基本原理与GC算法](#jvm-gc基本原理与gc算法)
* [Java关键术语](#java关键术语)
* [Java HotSpot 虚拟机](#java-hotspot-虚拟机)
@@ -15,7 +14,7 @@
* [垃圾回收中实例的终结](#垃圾回收中实例的终结)
* [对象什么时候符合垃圾回收的条件?](#对象什么时候符合垃圾回收的条件?)
* [GC Scope 示例程序](#gc-scope-示例程序)
- * [[JVM GC算法](https://www.cnblogs.com/wupeixuan/p/8670341.html)](#[jvm-gc算法]httpswwwcnblogscomwupeixuanp8670341html)
+ * [JVM GC算法](#JVM GC算法)
* [JVM垃圾判定算法](#jvm垃圾判定算法)
* [引用计数算法(Reference Counting)](#引用计数算法reference-counting)
* [可达性分析算法(根搜索算法)](#可达性分析算法(根搜索算法))
@@ -26,9 +25,7 @@
* [标记—整理算法(Mark-Compact)](#标记整理算法(mark-compact))
* [分代收集算法(Generational Collection)](#分代收集算法generational-collection)
* [参考文章](#参考文章)
- * [微信公众号](#微信公众号)
- * [Java技术江湖](#java技术江湖)
- * [个人公众号:黄小斜](#个人公众号:黄小斜)
+
本文转自互联网,侵删
@@ -53,8 +50,6 @@
## JVM GC基本原理与GC算法
-
-
Java的内存分配与回收全部由JVM垃圾回收进程自动完成。与C语言不同,Java开发者不需要自己编写代码实现垃圾回收。这是Java深受大家欢迎的众多特性之一,能够帮助程序员更好地编写Java程序。
下面四篇教程是了解Java 垃圾回收(GC)的基础:
@@ -100,7 +95,7 @@ Java 垃圾回收是一项自动化的过程,用来管理程序所使用的运
虽然这个请求机制提供给程序员一个启动 GC 过程的机会,但是启动由 JVM负责。JVM可以拒绝这个请求,所以并不保证这些调用都将执行垃圾回收。启动时机的选择由JVM决定,并且取决于堆内存中Eden区是否可用。JVM将这个选择留给了Java规范的实现,不同实现具体使用的算法不尽相同。
-毋庸置疑,我们知道垃圾回收过程是不能被强制执行的。我刚刚发现了一个调用`System.gc()`有意义的场景。通过这篇文章了解一下[适合调用System.gc() ](http://javapapers.com/core-java/system-gc-invocation-a-suitable-scenario/)这种极端情况。
+毋庸置疑,我们知道垃圾回收过程是不能被强制执行的。我刚刚发现了一个调用`System.gc()`有意义的场景。通过这篇文章了解一下[适合调用System.gc()](http://javapapers.com/core-java/system-gc-invocation-a-suitable-scenario/)这种极端情况。
## 各种GC的触发时机(When)
@@ -125,11 +120,11 @@ Java 垃圾回收是一项自动化的过程,用来管理程序所使用的运
除直接调用System.gc外,触发Full GC执行的情况有如下四种。
-1. 旧生代空间不足
+1.旧生代空间不足
旧生代空间只有在新生代对象转入及创建为大对象、大数组时才会出现不足的现象,当执行Full GC后空间仍然不足,则抛出如下错误:
-java.lang.OutOfMemoryError: Java heap space
+java.lang.OutOfMemoryError:Javaheapspace
为避免以上两种状况引起的Full GC,调优时应尽量做到让对象在Minor GC阶段被回收、让对象在新生代多存活一段时间及不要创建过大的对象及数组。
@@ -137,7 +132,7 @@ java.lang.OutOfMemoryError: Java heap space
Permanet Generation中存放的为一些class的信息等,当系统中要加载的类、反射的类和调用的方法较多时,Permanet Generation可能会被占满,在未配置为采用CMS GC的情况下会执行Full GC。如果经过Full GC仍然回收不了,那么JVM会抛出如下错误信息:
-java.lang.OutOfMemoryError: PermGen space
+java.lang.OutOfMemoryError:PermGenspace
为避免Perm Gen占满造成Full GC现象,可采用的方法为增大Perm Gen空间或转为使用CMS GC。
@@ -149,7 +144,7 @@ promotion failed是在进行Minor GC时,survivor space放不下、对象只能
应对措施为:增大survivor space、旧生代空间或调低触发并发GC的比率,但在JDK 5.0+、6.0+的版本中有可能会由于JDK的bug29导致CMS在remark完毕后很久才触发sweeping动作。对于这种状况,可通过设置-XX: CMSMaxAbortablePrecleanTime=5(单位为ms)来避免。
-4. 统计得到的Minor GC晋升到旧生代的平均大小大于旧生代的剩余空间
+4.统计得到的Minor GC晋升到旧生代的平均大小大于旧生代的剩余空间
这是一个较为复杂的触发情况,Hotspot为了避免由于新生代对象晋升到旧生代导致旧生代空间不足的现象,在进行Minor GC时,做了一个判断,如果之前统计所得到的Minor GC晋升到旧生代的平均大小大于旧生代的剩余空间,那么就直接触发Full GC。
@@ -161,7 +156,7 @@ promotion failed是在进行Minor GC时,survivor space放不下、对象只能
### 总结
-** Minor GC ,Full GC 触发条件**
+**Minor GC ,Full GC 触发条件**
Minor GC触发条件:当Eden区满时,触发Minor GC。
@@ -201,7 +196,7 @@ JVM里有一条特殊的线程--VM Threads,专门用来执行一些特殊
Eden 区:当一个实例被创建了,首先会被存储在堆内存年轻代的 Eden 区中。
-注意:如果你不能理解这些词汇,我建议你阅读这篇 [垃圾回收介绍](http://javapapers.com/java/java-garbage-collection-introduction/) ,这篇教程详细地介绍了内存模型、JVM 架构以及这些术语。
+注意:如果你不能理解这些词汇,我建议你阅读这篇[垃圾回收介绍](http://javapapers.com/java/java-garbage-collection-introduction/),这篇教程详细地介绍了内存模型、JVM 架构以及这些术语。
Survivor 区(S0 和 S1):作为年轻代 GC(Minor GC)周期的一部分,存活的对象(仍然被引用的)从 Eden 区被移动到 Survivor 区的 S0 中。类似的,垃圾回收器会扫描 S0 然后将存活的实例移动到 S1 中。
@@ -209,7 +204,7 @@ Survivor 区(S0 和 S1):作为年轻代 GC(Minor GC)周期的一部分
死亡的实例(不再被引用)被标记为垃圾回收。根据垃圾回收器(有四种常用的垃圾回收器,将在下一教程中介绍它们)选择的不同,要么被标记的实例都会不停地从内存中移除,要么回收过程会在一个单独的进程中完成。
-老年代: 老年代(Old or tenured generation)是堆内存中的第二块逻辑区。当垃圾回收器执行 Minor GC 周期时,在 S1 Survivor 区中的存活实例将会被晋升到老年代,而未被引用的对象被标记为回收。
+老年代:老年代(Old or tenured generation)是堆内存中的第二块逻辑区。当垃圾回收器执行 Minor GC 周期时,在 S1 Survivor 区中的存活实例将会被晋升到老年代,而未被引用的对象被标记为回收。
老年代 GC(Major GC):相对于 Java 垃圾回收过程,老年代是实例生命周期的最后阶段。Major GC 扫描老年代的垃圾回收过程。如果实例不再被引用,那么它们会被标记为回收,否则它们会继续留在老年代中。
@@ -217,7 +212,7 @@ Survivor 区(S0 和 S1):作为年轻代 GC(Minor GC)周期的一部分
## 垃圾回收中实例的终结
-在释放一个实例和回收内存空间之前,Java 垃圾回收器会调用实例各自的 `finalize()` 方法,从而该实例有机会释放所持有的资源。虽然可以保证 `finalize()` 会在回收内存空间之前被调用,但是没有指定的顺序和时间。多个实例间的顺序是无法被预知,甚至可能会并行发生。程序不应该预先调整实例之间的顺序并使用 `finalize()` 方法回收资源。
+在释放一个实例和回收内存空间之前,Java 垃圾回收器会调用实例各自的`finalize()`方法,从而该实例有机会释放所持有的资源。虽然可以保证`finalize()`会在回收内存空间之前被调用,但是没有指定的顺序和时间。多个实例间的顺序是无法被预知,甚至可能会并行发生。程序不应该预先调整实例之间的顺序并使用`finalize()`方法回收资源。
* 任何在 finalize过程中未被捕获的异常会自动被忽略,然后该实例的 finalize 过程被取消。
* JVM 规范中并没有讨论关于弱引用的垃圾回收机制,也没有很明确的要求。具体的实现都由实现方决定。
@@ -237,8 +232,8 @@ Survivor 区(S0 和 S1):作为年轻代 GC(Minor GC)周期的一部分
| 弱引用(Weak Reference) | 符合垃圾收集 |
| 虚引用(Phantom Reference) | 符合垃圾收集 |
-在编译过程中作为一种优化技术,Java 编译器能选择给实例赋 `null` 值,从而标记实例为可回收。
-
+在编译过程中作为一种优化技术,Java 编译器能选择给实例赋`null`值,从而标记实例为可回收。
+````
class Animal {
public static void main(String[] args) {
@@ -258,140 +253,143 @@ Survivor 区(S0 和 S1):作为年轻代 GC(Minor GC)周期的一部分
}
}
-
-在上面的类中,`lion` 对象在实例化行后从未被使用过。因此 Java 编译器作为一种优化措施可以直接在实例化行后赋值`lion = null`。因此,即使在 SOP 输出之前, finalize 函数也能够打印出 `'Rest in Peace!'`。我们不能证明这确定会发生,因为它依赖JVM的实现方式和运行时使用的内存。然而,我们还能学习到一点:如果编译器看到该实例在未来再也不会被引用,能够选择并提早释放实例空间。
+````
+在上面的类中,`lion`对象在实例化行后从未被使用过。因此 Java 编译器作为一种优化措施可以直接在实例化行后赋值`lion = null`。因此,即使在 SOP 输出之前, finalize 函数也能够打印出`'Rest in Peace!'`。我们不能证明这确定会发生,因为它依赖JVM的实现方式和运行时使用的内存。然而,我们还能学习到一点:如果编译器看到该实例在未来再也不会被引用,能够选择并提早释放实例空间。
* 关于对象什么时候符合垃圾回收有一个更好的例子。实例的所有属性能被存储在寄存器中,随后寄存器将被访问并读取内容。无一例外,这些值将被写回到实例中。虽然这些值在将来能被使用,这个实例仍然能被标记为符合垃圾回收。这是一个很经典的例子,不是吗?
* 当被赋值为null时,这是很简单的一个符合垃圾回收的示例。当然,复杂的情况可以像上面的几点。这是由 JVM 实现者所做的选择。目的是留下尽可能小的内存占用,加快响应速度,提高吞吐量。为了实现这一目标, JVM 的实现者可以选择一个更好的方案或算法在垃圾回收过程中回收内存空间。
-* 当 `finalize()` 方法被调用时,JVM 会释放该线程上的所有同步锁。
+* 当`finalize()`方法被调用时,JVM 会释放该线程上的所有同步锁。
### GC Scope 示例程序
- Class GCScope {
-
- GCScope t;
-
- static int i = 1;
-
-
-
- public static void main(String args[]) {
-
- GCScope t1 = new GCScope();
-
- GCScope t2 = new GCScope();
-
- GCScope t3 = new GCScope();
-
-
-
- // No Object Is Eligible for GC
-
-
-
- t1.t = t2; // No Object Is Eligible for GC
-
- t2.t = t3; // No Object Is Eligible for GC
-
- t3.t = t1; // No Object Is Eligible for GC
-
-
-
- t1 = null;
-
- // No Object Is Eligible for GC (t3.t still has a reference to t1)
-
-
-
- t2 = null;
-
- // No Object Is Eligible for GC (t3.t.t still has a reference to t2)
-
-
-
- t3 = null;
-
- // All the 3 Object Is Eligible for GC (None of them have a reference.
-
- // only the variable t of the objects are referring each other in a
-
- // rounded fashion forming the Island of objects with out any external
-
- // reference)
-
- }
-
-
-
- protected void finalize() {
-
- System.out.println("Garbage collected from object" + i);
-
- i++;
-
- }
-
-
-
- class GCScope {
-
- GCScope t;
-
- static int i = 1;
-
-
-
- public static void main(String args[]) {
-
- GCScope t1 = new GCScope();
-
- GCScope t2 = new GCScope();
-
- GCScope t3 = new GCScope();
-
-
-
- // 没有对象符合GC
-
- t1.t = t2; // 没有对象符合GC
-
- t2.t = t3; // 没有对象符合GC
-
- t3.t = t1; // 没有对象符合GC
-
-
-
- t1 = null;
-
- // 没有对象符合GC (t3.t 仍然有一个到 t1 的引用)
-
-
-
- t2 = null;
-
- // 没有对象符合GC (t3.t.t 仍然有一个到 t2 的引用)
-
-
-
- t3 = null;
-
- // 所有三个对象都符合GC (它们中没有一个拥有引用。
-
- // 只有各对象的变量 t 还指向了彼此,
-
- // 形成了一个由对象组成的环形的岛,而没有任何外部的引用。)
-
- }
-
-
-
- protected void finalize() {
-
- System.out.println("Garbage collected from object" + i);
-
- i++;
-
- }
-## [JVM GC算法](https://www.cnblogs.com/wupeixuan/p/8670341.html)
+````
+Class GCScope {
+
+ GCScope t;
+
+ static int i = 1;
+
+
+
+ public static void main(String args[]) {
+
+ GCScope t1 = new GCScope();
+
+ GCScope t2 = new GCScope();
+
+ GCScope t3 = new GCScope();
+
+
+
+ // No Object Is Eligible for GC
+
+
+
+ t1.t = t2; // No Object Is Eligible for GC
+
+ t2.t = t3; // No Object Is Eligible for GC
+
+ t3.t = t1; // No Object Is Eligible for GC
+
+
+
+ t1 = null;
+
+ // No Object Is Eligible for GC (t3.t still has a reference to t1)
+
+
+
+ t2 = null;
+
+ // No Object Is Eligible for GC (t3.t.t still has a reference to t2)
+
+
+
+ t3 = null;
+
+ // All the 3 Object Is Eligible for GC (None of them have a reference.
+
+ // only the variable t of the objects are referring each other in a
+
+ // rounded fashion forming the Island of objects with out any external
+
+ // reference)
+
+ }
+
+
+
+ protected void finalize() {
+
+ System.out.println("Garbage collected from object" + i);
+
+ i++;
+
+ }
+
+
+
+class GCScope {
+
+ GCScope t;
+
+ static int i = 1;
+
+
+
+ public static void main(String args[]) {
+
+ GCScope t1 = new GCScope();
+
+ GCScope t2 = new GCScope();
+
+ GCScope t3 = new GCScope();
+
+
+
+ // 没有对象符合GC
+
+ t1.t = t2; // 没有对象符合GC
+
+ t2.t = t3; // 没有对象符合GC
+
+ t3.t = t1; // 没有对象符合GC
+
+
+
+ t1 = null;
+
+ // 没有对象符合GC (t3.t 仍然有一个到 t1 的引用)
+
+
+
+ t2 = null;
+
+ // 没有对象符合GC (t3.t.t 仍然有一个到 t2 的引用)
+
+
+
+ t3 = null;
+
+ // 所有三个对象都符合GC (它们中没有一个拥有引用。
+
+ // 只有各对象的变量 t 还指向了彼此,
+
+ // 形成了一个由对象组成的环形的岛,而没有任何外部的引用。)
+
+ }
+
+
+
+ protected void finalize() {
+
+ System.out.println("Garbage collected from object" + i);
+
+ i++;
+
+ }
+}
+````
+## JVM GC算法
在判断哪些内存需要回收和什么时候回收用到GC 算法,本文主要对GC 算法进行讲解。
@@ -433,7 +431,6 @@ public class ReferenceCountingGC {
运行结果
```
-
[GC (System.gc()) [PSYoungGen: 3329K->744K(38400K)] 3329K->752K(125952K), 0.0341414 secs] [Times: user=0.00 sys=0.00, real=0.06 secs]
[Full GC (System.gc()) [PSYoungGen: 744K->0K(38400K)] [ParOldGen: 8K->628K(87552K)] 752K->628K(125952K), [Metaspace: 3450K->3450K(1056768K)], 0.0060728 secs] [Times: user=0.05 sys=0.00, real=0.01 secs]
Heap
@@ -457,7 +454,7 @@ Process finished with exit code 0
从GC Roots(每种具体实现对GC Roots有不同的定义)作为起点,向下搜索它们引用的对象,可以生成一棵引用树,树的节点视为可达对象,反之视为不可达。
-
+
在Java语言中,可以作为GC Roots的对象包括下面几种:
@@ -524,8 +521,7 @@ Stop-the-world意味着 JVM由于要执行GC而停止了应用程序的执行,
* 标记和清除过程效率都不高
* 会产生大量碎片,内存碎片过多可能导致无法给大对象分配内存。
-
-
+
## 复制算法(Copying)
将内存划分为大小相等的两块,每次只使用其中一块,当这一块内存用完了就将还存活的对象复制到另一块上面,然后再把使用过的内存空间进行一次清理。
@@ -537,7 +533,7 @@ Stop-the-world意味着 JVM由于要执行GC而停止了应用程序的执行,
* 将内存缩小为原来的一半,浪费了一半的内存空间,代价太高;如果不想浪费一半的空间,就需要有额外的空间进行分配担保,以应对被使用的内存中所有对象都100%存活的极端情况,所以在老年代一般不能直接选用这种算法。
* 复制收集算法在对象存活率较高时就要进行较多的复制操作,效率将会变低。
-
+
## 标记—整理算法(Mark-Compact)
@@ -547,7 +543,7 @@ Stop-the-world意味着 JVM由于要执行GC而停止了应用程序的执行,
效率不高,不仅要标记存活对象,还要整理所有存活对象的引用地址,在效率上不如复制算法。
-
+
## 分代收集算法(Generational Collection)
@@ -569,20 +565,4 @@ Stop-the-world意味着 JVM由于要执行GC而停止了应用程序的执行,
https://blog.csdn.net/android_hl/article/details/53228348
-## 微信公众号
-
-### Java技术江湖
-
-如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号【Java技术江湖】一位阿里 Java 工程师的技术小站,作者黄小斜,专注 Java 相关技术:SSM、SpringBoot、MySQL、分布式、中间件、集群、Linux、网络、多线程,偶尔讲点Docker、ELK,同时也分享技术干货和学习经验,致力于Java全栈开发!
-
-**Java工程师必备学习资源:** 一些Java工程师常用学习资源,关注公众号后,后台回复关键字 **“Java”** 即可免费无套路获取。
-
-
-
-### 个人公众号:黄小斜
-
-作者是 985 硕士,蚂蚁金服 JAVA 工程师,专注于 JAVA 后端技术栈:SpringBoot、MySQL、分布式、中间件、微服务,同时也懂点投资理财,偶尔讲点算法和计算机理论基础,坚持学习和写作,相信终身学习的力量!
-
-**程序员3T技术学习资源:** 一些程序员学习技术的资源大礼包,关注公众号后,后台回复关键字 **“资料”** 即可免费无套路获取。
-
diff --git "a/docs/Java/JVM/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232JVM\345\270\270\347\224\250\345\217\202\346\225\260\344\273\245\345\217\212\350\260\203\344\274\230\345\256\236\350\267\265.md" "b/docs/Java/JVM/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232JVM\345\270\270\347\224\250\345\217\202\346\225\260\344\273\245\345\217\212\350\260\203\344\274\230\345\256\236\350\267\265.md"
new file mode 100644
index 0000000..caac027
--- /dev/null
+++ "b/docs/Java/JVM/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232JVM\345\270\270\347\224\250\345\217\202\346\225\260\344\273\245\345\217\212\350\260\203\344\274\230\345\256\236\350\267\265.md"
@@ -0,0 +1,659 @@
+# 目录
+
+ * [JVM优化的必要性](#jvm优化的必要性)
+ * [JVM调优原则](#jvm调优原则)
+ * [JVM运行参数设置](#jvm运行参数设置)
+ * [JVM性能调优工具](#jvm性能调优工具)
+ * [常用调优策略](#常用调优策略)
+ * [六、JVM调优实例](#六、jvm调优实例)
+ * [七、一个具体的实战案例分析](#七、一个具体的实战案例分析)
+ * [参考资料](#参考资料)
+ * [参考文章](#参考文章)
+
+
+
+
+
+
+## JVM优化的必要性
+
+**1.1: 项目上线后,什么原因使得我们需要进行jvm调优**
+
+1)、垃圾太多(java线程,对象占满内存),内存占满了,程序跑不动了!!
+2)、垃圾回收线程太多,频繁地回收垃圾(垃圾回收线程本身也会占用资源: 占用内存,cpu资源),导致程序性能下降
+3)、回收垃圾频繁导致STW
+
+因此基于以上的原因,程序上线后,必须进行调优,否则程序性能就无法提升;也就是程序上线后,必须设置合理的垃圾回收策略;
+
+**1.2: jvm调优的本质是什么??**
+
+答案: 回收垃圾,及时回收没有用垃圾对象,及时释放掉内存空间
+
+**1.3: 基于服务器环境,jvm堆内存到底应用设置多少内存?**
+
+1、32位的操作系统 --- 寻址能力 2^32 = 4GB ,最大的能支持4gb; jvm可以分配 2g+
+
+2、64位的操作系统 --- 寻址能力 2^64 = 16384PB , 高性能计算机(IBM Z unix 128G 200+)
+
+
+
+Jvm堆内存不能设置太大,否则会导致寻址垃圾的时间过长,也就是导致整个程序STW, 也不能设置太小,否则会导致回收垃圾过于频繁;
+
+**1.4:总结**
+
+如果你遇到以下情况,就需要考虑进行JVM调优了:
+
+* Heap内存(老年代)持续上涨达到设置的最大内存值;
+
+* Full GC 次数频繁;
+
+* GC 停顿时间过长(超过1秒);
+
+* 应用出现OutOfMemory 等内存异常;
+
+* 应用中有使用本地缓存且占用大量内存空间;
+
+* 系统吞吐量与响应性能不高或下降。
+
+## JVM调优原则
+
+
+
+JVM调优是一个手段,但并不一定所有问题都可以通过JVM进行调优解决,因此,在进行JVM调优时,我们要遵循一些原则:
+
+* 大多数的Java应用不需要进行JVM优化;
+
+* 大多数导致GC问题的原因是代码层面的问题导致的(代码层面);
+
+* 上线之前,应先考虑将机器的JVM参数设置到最优;
+
+* 减少创建对象的数量(代码层面);
+
+* 减少使用全局变量和大对象(代码层面);
+
+* 优先架构调优和代码调优,JVM优化是不得已的手段(代码、架构层面);
+
+* 分析GC情况优化代码比优化JVM参数更好(代码层面);
+
+通过以上原则,我们发现,其实最有效的优化手段是架构和代码层面的优化,而JVM优化则是最后不得已的手段,也可以说是对服务器配置的最后一次“压榨”。
+
+**2.1 JVM调优目标**
+
+调优的最终目的都是为了令应用程序使用最小的硬件消耗来承载更大的吞吐。jvm调优主要是针对垃圾收集器的收集性能优化,令运行在虚拟机上的应用能够使用更少的内存以及延迟获取更大的吞吐量。
+
+* 延迟:GC低停顿和GC低频率;
+
+* 低内存占用;
+
+* 高吞吐量;
+
+其中,任何一个属性性能的提高,几乎都是以牺牲其他属性性能的损为代价的,不可兼得。具体根据在业务中的重要性确定。
+
+**2.2 JVM调优量化目标**
+
+下面展示了一些JVM调优的量化目标参考实例:
+
+* Heap 内存使用率 <= 70%;
+
+* Old generation内存使用率<= 70%;
+
+* avgpause <= 1秒;
+
+* Full gc 次数0 或 avg pause interval >= 24小时 ;
+
+注意:不同应用的JVM调优量化目标是不一样的。
+
+**2.3 JVM调优的步骤**
+
+一般情况下,JVM调优可通过以下步骤进行:
+
+* 分析GC日志及dump文件,判断是否需要优化,确定瓶颈问题点;
+
+* 确定JVM调优量化目标;
+
+* 确定JVM调优参数(根据历史JVM参数来调整);
+
+* 依次调优内存、延迟、吞吐量等指标;
+
+* 对比观察调优前后的差异;
+
+* 不断的分析和调整,直到找到合适的JVM参数配置;
+
+* 找到最合适的参数,将这些参数应用到所有服务器,并进行后续跟踪。
+
+以上操作步骤中,某些步骤是需要多次不断迭代完成的。一般是从满足程序的内存使用需求开始的,之后是时间延迟的要求,最后才是吞吐量的要求,要基于这个步骤来不断优化,每一个步骤都是进行下一步的基础,不可逆行之。
+
+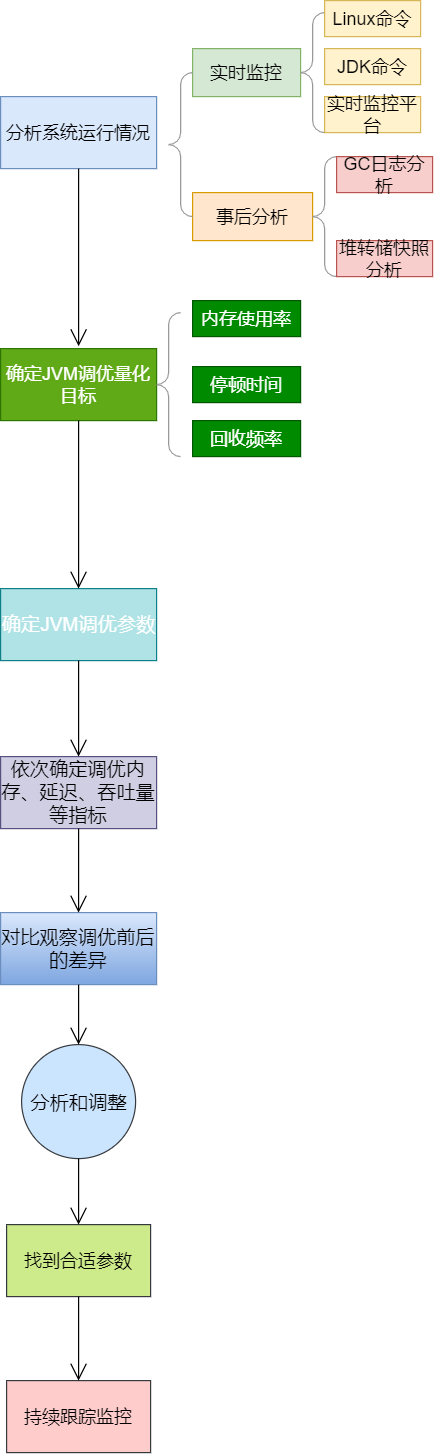
+
+**调优原则总结**
+
+JVM的自动内存管理本来就是为了将开发人员从内存管理的泥潭里拉出来。JVM调优不是常规手段,性能问题一般第一选择是优化程序,最后的选择才是进行JVM调优。
+
+即使不得不进行JVM调优,也绝对不能拍脑门就去调整参数,一定要全面监控,详细分析性能数据。
+
+**附录:系统性能优化指导**
+
+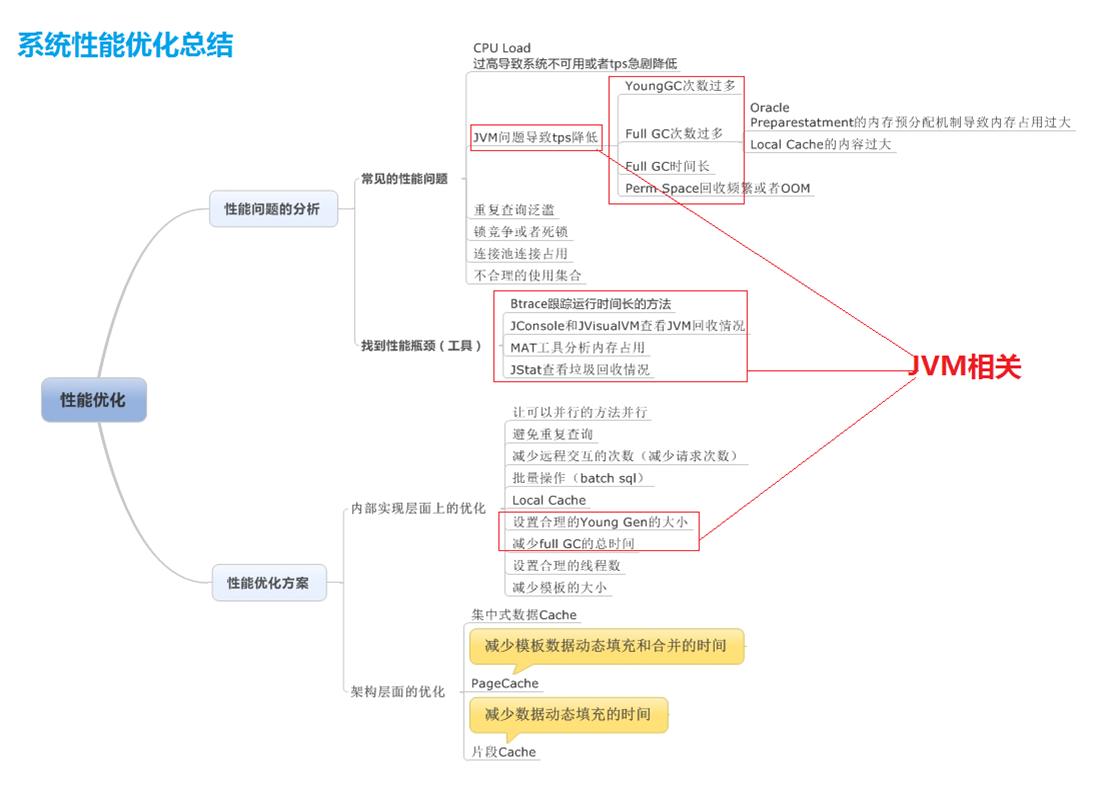
+
+### JVM运行参数设置
+
+**3.1、堆参数设置**
+
+**-XX:+PrintGC**使用这个参数,虚拟机启动后,只要遇到GC就会打印日志
+
+**-XX:+UseSerialGC**配置串行回收器
+
+**-XX:+PrintGCDetails**可以查看详细信息,包括各个区的情况
+
+**-Xms**设置Java程序启动时初始化堆大小
+
+**-Xmx**设置Java程序能获得最大的堆大小
+
+**-Xmx20m -Xms5m -XX:+PrintCommandLineFlags**可以将隐式或者显示传给虚拟机的参数输出
+
+**3.2、新生代参数配置**
+
+**-Xmn**可以设置新生代的大小,设置一个比较大的新生代会减少老年代的大小,这个参数对系统性能以及GC行为有很大的影响,新生代大小一般会设置整个堆空间的1/3到1/4左右
+
+**-XX:SurvivorRatio**用来设置新生代中eden空间和from/to空间的比例。含义:-XX:SurvivorRatio=eden/from**/**eden/to
+
+不同的堆分布情况,对系统执行会产生一定的影响,在实际工作中,应该根据系统的特点做出合理的配置,基本策略:尽可能将对象预留在新生代,减少老年代的GC次数
+
+除了可以设置新生代的绝对大小(-Xmn),还可以使用(-XX:NewRatio)设置新生代和老年代的比例:-XX:NewRatio=老年代/新生代
+
+**配置运行时参数:**
+
+-Xms20m -Xmx20m -Xmn1m -XX:SurvivorRatio=2 -XX:+PrintGCDetails -XX:+UseSerialGC
+
+**3.3、堆溢出参数配置**
+
+在Java程序在运行过程中,如果对空间不足,则会抛出内存溢出的错误(Out Of Memory)OOM,一旦这类问题发生在生产环境,则可能引起严重的业务中断,Java虚拟机提供了**-XX:+
+HeapDumpOnOutOfMemoryError**,使用该参数可以在内存溢出时导出整个堆信息,与之配合使用的还有参数**-XX:HeapDumpPath**,可以设置导出堆的存放路径
+
+内存分析工具:Memory Analyzer
+
+**配置运行时参数**-Xms1m -Xmx1m -XX:+
+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=d:/Demo3.dump
+
+**3.4、栈参数配置**
+
+Java虚拟机提供了参数**-Xss**来指定线程的最大栈空间,整个参数也直接决定了函数可调用的最大深度。
+
+**配置运行时参数:**-Xss1m
+
+3.5、方法区参数配置
+
+和Java堆一样,方法区是一块所有线程共享的内存区域,它用于保存系统的类信息,方法区(永久区)可以保存多少信息可以对其进行配置,在默认情况下,**-XX:MaxPermSize**为64M,如果系统运行时生产大量的类,就需要设置一个相对合适的方法区,以免出现永久区内存溢出的问题
+
+-XX:PermSize=64M -XX:MaxPermSize=64M
+
+**3.6、直接内存参数配置**
+
+直接内存也是Java程序中非常重要的组成部分,特别是广泛用在NIO中,直接内存跳过了Java堆,使用Java程序可以直接访问原生堆空间,因此在一定程度上加快了内存空间的访问速度
+
+但是说直接内存一定就可以提高内存访问速度也不见得,具体情况具体分析
+
+**相关配置参数:-XX:MaxDirectMemorySize**,如果不设置,默认值为最大堆空间,即-Xmx。直接内存使用达到上限时,就会触发垃圾回收,如果不能有效的释放空间,就会引起系统的OOM
+
+**3.7、对象进入老年代的参数配置**
+
+一般而言,对象首次创建会被放置在新生代的eden区,如果没有GC介入,则对象不会离开eden区,那么eden区的对象如何进入老年代呢?
+
+通常情况下,只要对象的年龄达到一定的大小,就会自动离开年轻代进入老年代,对象年龄是由对象经历数次GC决定的,在新生代每次GC之后如果对象没有被回收,则年龄加1
+
+虚拟机提供了一个参数来控制新生代对象的最大年龄,当超过这个年龄范围就会晋升老年代
+
+**-XX:MaxTenuringThreshold**,默认情况下为15
+
+**配置运行时参数:**-Xmx64M -Xms64M -XX:+PrintGCDetails
+
+**结论**:对象首次创建会被放置在新生代的eden区,因此输出结果中from和to区都为0%
+
+根据设置MaxTenuringThreshold参数,可以指定新生代对象经过多少次回收后进入老年代。另外,大对象新生代eden区无法装入时,也会直接进入老年代。
+
+JVM里有个参数可以设置对象的大小超过在指定的大小之后,直接晋升老年代 **-XX:PretenureSizeThreshold=15**
+
+参数:-Xmx1024M -Xms1024M -XX:+UseSerialGC -XX:MaxTenuringThreshold=15 -XX:+PrintGCDetails
+
+使用PretenureSizeThreshold可以进行指定进入老年代的对象大小,但是要注意TLAB区域优先分配空间。虚拟机对于体积不大的对象 会优先把数据分配到TLAB区域中,因此就失去了在老年代分配的机会
+
+参数:-Xmx30M -Xms30M -XX:+UseSerialGC -XX:+PrintGCDetails
+-XX:PretenureSizeThreshold=1000 -XX:-UseTLAB
+
+**3.8、TLAB参数配置**
+
+TLAB全称是Thread Local Allocation Buffer,即线程本地分配缓存,从名字上看是一个线程专用的内存分配区域,是为了加速对象分配对象而生的。每一个线程都会产生一个TLAB,该线程独享的工作区域,Java虚拟机使用这种TLAB区来避免多线程冲突问题,提高了对象分配的效率
+
+TLAB空间一般不会太大,当大对象无法在TLAB分配时,则会直接分配到堆上
+
+**-XX:+UseTLAB**使用TLAB
+
+**-XX:+TLABSize**设置TLAB大小
+
+**-XX:TLABRefillWasteFraction**设置维护进入TLAB空间的单个对象大小,它是一个比例值,默认为64,即如果对象大于整个空间的1/64,则在堆创建对象
+
+**-XX:+PrintTLAB**查看TLAB信息
+
+**-XX:ResizeTLAB**自调整TLABRefillWasteFraction阈值
+
+参数:-XX:+UseTLAB -XX:+PrintTLAB -XX:+PrintGC -XX:TLABSize=102400 -XX:-ResizeTLAB
+-XX:TLABRefillWasteFraction=100 -XX:-DoEscapeAnalysis -server
+
+内存参数
+
+
+
+
+
+
+
+
+
+
+
+## JVM性能调优工具
+
+这个篇幅在这里就不过多介绍了,可以参照:
+
+深入理解JVM虚拟机——Java虚拟机的监控及诊断工具大全
+
+## 常用调优策略
+
+这里还是要提一下,及时确定要进行JVM调优,也不要陷入“知见障”,进行分析之后,发现可以通过优化程序提升性能,仍然首选优化程序。
+
+**5.1、选择合适的垃圾回收器**
+
+CPU单核,那么毫无疑问Serial 垃圾收集器是你唯一的选择。
+
+CPU多核,关注吞吐量 ,那么选择PS+PO组合。
+
+CPU多核,关注用户停顿时间,JDK版本1.6或者1.7,那么选择CMS。
+
+CPU多核,关注用户停顿时间,JDK1.8及以上,JVM可用内存6G以上,那么选择G1。
+
+参数配置:
+
+> //设置Serial垃圾收集器(新生代)
+>
+> 开启:-XX:+UseSerialGC
+>
+> //设置PS+PO,新生代使用功能Parallel Scavenge 老年代将会使用Parallel Old收集器
+>
+> 开启 -XX:+UseParallelOldGC
+>
+> //CMS垃圾收集器(老年代)
+>
+> 开启 -XX:+UseConcMarkSweepGC
+>
+> //设置G1垃圾收集器
+>
+> 开启 -XX:+UseG1GC
+
+**5.2、调整内存大小**
+
+现象:垃圾收集频率非常频繁。
+
+原因:如果内存太小,就会导致频繁的需要进行垃圾收集才能释放出足够的空间来创建新的对象,所以增加堆内存大小的效果是非常显而易见的。
+
+注意:如果垃圾收集次数非常频繁,但是每次能回收的对象非常少,那么这个时候并非内存太小,而可能是内存泄露导致对象无法回收,从而造成频繁GC。
+
+参数配置:
+
+> //设置堆初始值
+>
+> 指令1:-Xms2g
+>
+> 指令2:-XX:InitialHeapSize=2048m
+>
+> //设置堆区最大值
+>
+> 指令1:`-Xmx2g`
+>
+> 指令2: -XX:MaxHeapSize=2048m
+>
+> //新生代内存配置
+>
+> 指令1:-Xmn512m
+>
+> 指令2:-XX:MaxNewSize=512m
+
+**5.3、设置符合预期的停顿时间**
+
+**现象**:程序间接性的卡顿
+
+**原因**:如果没有确切的停顿时间设定,垃圾收集器以吞吐量为主,那么垃圾收集时间就会不稳定。
+
+**注意**:不要设置不切实际的停顿时间,单次时间越短也意味着需要更多的GC次数才能回收完原有数量的垃圾.
+
+**参数配置**:
+
+> //GC停顿时间,垃圾收集器会尝试用各种手段达到这个时间
+>
+> -XX:MaxGCPauseMillis
+
+**5.4、调整内存区域大小比率**
+
+现象:某一个区域的GC频繁,其他都正常。
+
+原因:如果对应区域空间不足,导致需要频繁GC来释放空间,在JVM堆内存无法增加的情况下,可以调整对应区域的大小比率。
+
+注意:也许并非空间不足,而是因为内存泄造成内存无法回收。从而导致GC频繁。
+
+参数配置:
+
+> //survivor区和Eden区大小比率
+>
+> 指令:-XX:SurvivorRatio=6 //S区和Eden区占新生代比率为1:6,两个S区2:6
+>
+> //新生代和老年代的占比
+>
+> -XX:NewRatio=4 //表示新生代:老年代 = 1:4 即老年代占整个堆的4/5;默认值=2
+
+**5.5、调整对象升老年代的年龄**
+
+**现象**:老年代频繁GC,每次回收的对象很多。
+
+**原因**:如果升代年龄小,新生代的对象很快就进入老年代了,导致老年代对象变多,而这些对象其实在随后的很短时间内就可以回收,这时候可以调整对象的升级代年龄,让对象不那么容易进入老年代解决老年代空间不足频繁GC问题。
+
+**注意**:增加了年龄之后,这些对象在新生代的时间会变长可能导致新生代的GC频率增加,并且频繁复制这些对象新生的GC时间也可能变长。
+
+配置参数:
+
+> //进入老年代最小的GC年龄,年轻代对象转换为老年代对象最小年龄值,默认值7
+>
+> -XX:InitialTenuringThreshol=7
+
+**5.6、调整大对象的标准**
+
+**现象**:老年代频繁GC,每次回收的对象很多,而且单个对象的体积都比较大。
+
+**原因**:如果大量的大对象直接分配到老年代,导致老年代容易被填满而造成频繁GC,可设置对象直接进入老年代的标准。
+
+**注意**:这些大对象进入新生代后可能会使新生代的GC频率和时间增加。
+
+配置参数:
+
+> //新生代可容纳的最大对象,大于则直接会分配到老年代,0代表没有限制。
+>
+> -XX:PretenureSizeThreshold=1000000
+
+**5.7、调整GC的触发时机**
+
+**现象**:CMS,G1 经常 Full GC,程序卡顿严重。
+
+**原因**:G1和CMS 部分GC阶段是并发进行的,业务线程和垃圾收集线程一起工作,也就说明垃圾收集的过程中业务线程会生成新的对象,所以在GC的时候需要预留一部分内存空间来容纳新产生的对象,如果这个时候内存空间不足以容纳新产生的对象,那么JVM就会停止并发收集暂停所有业务线程(STW)来保证垃圾收集的正常运行。这个时候可以调整GC触发的时机(比如在老年代占用60%就触发GC),这样就可以预留足够的空间来让业务线程创建的对象有足够的空间分配。
+
+**注意**:提早触发GC会增加老年代GC的频率。
+
+配置参数:
+
+> //使用多少比例的老年代后开始CMS收集,默认是68%,如果频繁发生SerialOld卡顿,应该调小
+>
+> -XX:CMSInitiatingOccupancyFraction
+>
+> //G1混合垃圾回收周期中要包括的旧区域设置占用率阈值。默认占用率为 65%
+>
+> -XX:G1MixedGCLiveThresholdPercent=65
+
+5.8、调整 JVM本地内存大小
+
+**现象**:GC的次数、时间和回收的对象都正常,堆内存空间充足,但是报OOM
+
+**原因**: JVM除了堆内存之外还有一块堆外内存,这片内存也叫本地内存,可是这块内存区域不足了并不会主动触发GC,只有在堆内存区域触发的时候顺带会把本地内存回收了,而一旦本地内存分配不足就会直接报OOM异常。
+
+**注意**: 本地内存异常的时候除了上面的现象之外,异常信息可能是OutOfMemoryError:Direct buffer memory。 解决方式除了调整本地内存大小之外,也可以在出现此异常时进行捕获,手动触发GC(System.gc())。
+
+配置参数:
+
+> XX:MaxDirectMemorySize
+
+## 六、JVM调优实例
+
+整理的一些JVM调优实例:
+
+**6.1、网站流量浏览量暴增后,网站反应页面响很慢**
+
+> 1、问题推测:在测试环境测速度比较快,但是一到生产就变慢,所以推测可能是因为垃圾收集导致的业务线程停顿。
+>
+> 2、定位:为了确认推测的正确性,在线上通过jstat -gc 指令 看到JVM进行GC 次数频率非常高,GC所占用的时间非常长,所以基本推断就是因为GC频率非常高,所以导致业务线程经常停顿,从而造成网页反应很慢。
+>
+> 3、解决方案:因为网页访问量很高,所以对象创建速度非常快,导致堆内存容易填满从而频繁GC,所以这里问题在于新生代内存太小,所以这里可以增加JVM内存就行了,所以初步从原来的2G内存增加到16G内存。
+>
+> 4、第二个问题:增加内存后的确平常的请求比较快了,但是又出现了另外一个问题,就是不定期的会间断性的卡顿,而且单次卡顿的时间要比之前要长很多。
+>
+> 5、问题推测:练习到是之前的优化加大了内存,所以推测可能是因为内存加大了,从而导致单次GC的时间变长从而导致间接性的卡顿。
+>
+> 6、定位:还是通过jstat -gc 指令 查看到 的确FGC次数并不是很高,但是花费在FGC上的时间是非常高的,根据GC日志 查看到单次FGC的时间有达到几十秒的。
+>
+> 7、解决方案: 因为JVM默认使用的是PS+PO的组合,PS+PO垃圾标记和收集阶段都是STW,所以内存加大了之后,需要进行垃圾回收的时间就变长了,所以这里要想避免单次GC时间过长,所以需要更换并发类的收集器,因为当前的JDK版本为1.7,所以最后选择CMS垃圾收集器,根据之前垃圾收集情况设置了一个预期的停顿的时间,上线后网站再也没有了卡顿问题。
+
+**6.2、后台导出数据引发的OOM**
+
+**问题描述:**公司的后台系统,偶发性的引发OOM异常,堆内存溢出。
+
+> 1、因为是偶发性的,所以第一次简单的认为就是堆内存不足导致,所以单方面的加大了堆内存从4G调整到8G。
+>
+> 2、但是问题依然没有解决,只能从堆内存信息下手,通过开启了-XX:+
+> HeapDumpOnOutOfMemoryError参数 获得堆内存的dump文件。
+>
+> 3、VisualVM 对 堆dump文件进行分析,通过VisualVM查看到占用内存最大的对象是String对象,本来想跟踪着String对象找到其引用的地方,但dump文件太大,跟踪进去的时候总是卡死,而String对象占用比较多也比较正常,最开始也没有认定就是这里的问题,于是就从线程信息里面找突破点。
+>
+> 4、通过线程进行分析,先找到了几个正在运行的业务线程,然后逐一跟进业务线程看了下代码,发现有个引起我注意的方法,导出订单信息。
+>
+> 5、因为订单信息导出这个方法可能会有几万的数据量,首先要从数据库里面查询出来订单信息,然后把订单信息生成excel,这个过程会产生大量的String对象。
+>
+> 6、为了验证自己的猜想,于是准备登录后台去测试下,结果在测试的过程中发现到处订单的按钮前端居然没有做点击后按钮置灰交互事件,结果按钮可以一直点,因为导出订单数据本来就非常慢,使用的人员可能发现点击后很久后页面都没反应,结果就一直点,结果就大量的请求进入到后台,堆内存产生了大量的订单对象和EXCEL对象,而且方法执行非常慢,导致这一段时间内这些对象都无法被回收,所以最终导致内存溢出。
+>
+> 7、知道了问题就容易解决了,最终没有调整任何JVM参数,只是在前端的导出订单按钮上加上了置灰状态,等后端响应之后按钮才可以进行点击,然后减少了查询订单信息的非必要字段来减少生成对象的体积,然后问题就解决了。
+
+**6.3、单个缓存数据过大导致的系统CPU飚高**
+
+> 1、系统发布后发现CPU一直飚高到600%,发现这个问题后首先要做的是定位到是哪个应用占用CPU高,通过top 找到了对应的一个java应用占用CPU资源600%。
+>
+> 2、如果是应用的CPU飚高,那么基本上可以定位可能是锁资源竞争,或者是频繁GC造成的。
+>
+> 3、所以准备首先从GC的情况排查,如果GC正常的话再从线程的角度排查,首先使用jstat -gc PID 指令打印出GC的信息,结果得到得到的GC 统计信息有明显的异常,应用在运行了才几分钟的情况下GC的时间就占用了482秒,那么问这很明显就是频繁GC导致的CPU飚高。
+>
+> 4、定位到了是GC的问题,那么下一步就是找到频繁GC的原因了,所以可以从两方面定位了,可能是哪个地方频繁创建对象,或者就是有内存泄露导致内存回收不掉。
+>
+> 5、根据这个思路决定把堆内存信息dump下来看一下,使用jmap -dump 指令把堆内存信息dump下来(堆内存空间大的慎用这个指令否则容易导致会影响应用,因为我们的堆内存空间才2G所以也就没考虑这个问题了)。
+>
+> 6、把堆内存信息dump下来后,就使用visualVM进行离线分析了,首先从占用内存最多的对象中查找,结果排名第三看到一个业务VO占用堆内存约10%的空间,很明显这个对象是有问题的。
+>
+> 7、通过业务对象找到了对应的业务代码,通过代码的分析找到了一个可疑之处,这个业务对象是查看新闻资讯信息生成的对象,由于想提升查询的效率,所以把新闻资讯保存到了redis缓存里面,每次调用资讯接口都是从缓存里面获取。
+>
+> 8、把新闻保存到redis缓存里面这个方式是没有问题的,有问题的是新闻的50000多条数据都是保存在一个key里面,这样就导致每次调用查询新闻接口都会从redis里面把50000多条数据都拿出来,再做筛选分页拿出10条返回给前端。50000多条数据也就意味着会产生50000多个对象,每个对象280个字节左右,50000个对象就有13.3M,这就意味着只要查看一次新闻信息就会产生至少13.3M的对象,那么并发请求量只要到10,那么每秒钟都会产生133M的对象,而这种大对象会被直接分配到老年代,这样的话一个2G大小的老年代内存,只需要几秒就会塞满,从而触发GC。
+>
+> 9、知道了问题所在后那么就容易解决了,问题是因为单个缓存过大造成的,那么只需要把缓存减小就行了,这里只需要把缓存以页的粒度进行缓存就行了,每个key缓存10条作为返回给前端1页的数据,这样的话每次查询新闻信息只会从缓存拿出10条数据,就避免了此问题的 产生。
+
+**6.4、CPU经常100% 问题定位**
+
+问题分析:CPU高一定是某个程序长期占用了CPU资源。
+
+1、所以先需要找出那个进行占用CPU高。
+
+> top 列出系统各个进程的资源占用情况。
+
+2、然后根据找到对应进行里哪个线程占用CPU高。
+
+> top -Hp 进程ID 列出对应进程里面的线程占用资源情况
+
+3、找到对应线程ID后,再打印出对应线程的堆栈信息
+
+> printf "%x\n" PID 把线程ID转换为16进制。
+>
+> jstack PID 打印出进程的所有线程信息,从打印出来的线程信息中找到上一步转换为16进制的线程ID对应的线程信息。
+
+4、最后根据线程的堆栈信息定位到具体业务方法,从代码逻辑中找到问题所在。
+
+> 查看是否有线程长时间的watting 或blocked
+>
+> 如果线程长期处于watting状态下, 关注watting on xxxxxx,说明线程在等待这把锁,然后根据锁的地址找到持有锁的线程。
+
+**6.5、内存飚高问题定位**
+
+分析: 内存飚高如果是发生在java进程上,一般是因为创建了大量对象所导致,持续飚高说明垃圾回收跟不上对象创建的速度,或者内存泄露导致对象无法回收。
+
+1、先观察垃圾回收的情况
+
+> jstat -gcPID 1000查看GC次数,时间等信息,每隔一秒打印一次。
+>
+> jmap -histo PID | head -20 查看堆内存占用空间最大的前20个对象类型,可初步查看是哪个对象占用了内存。
+
+如果每次GC次数频繁,而且每次回收的内存空间也正常,那说明是因为对象创建速度快导致内存一直占用很高;如果每次回收的内存非常少,那么很可能是因为内存泄露导致内存一直无法被回收。
+
+2、导出堆内存文件快照
+
+> jmap -dump:live,format=b,file=/home/myheapdump.hprof PID dump堆内存信息到文件。
+
+3、使用visualVM对dump文件进行离线分析,找到占用内存高的对象,再找到创建该对象的业务代码位置,从代码和业务场景中定位具体问题。
+
+**6.6、数据分析平台系统频繁 Full GC**
+
+平台主要对用户在 App 中行为进行定时分析统计,并支持报表导出,使用 CMS GC 算法。
+
+数据分析师在使用中发现系统页面打开经常卡顿,通过 jstat 命令发现系统每次 Young GC 后大约有 10% 的存活对象进入老年代。
+
+原来是因为 Survivor 区空间设置过小,每次 Young GC 后存活对象在 Survivor 区域放不下,提前进入老年代。
+
+通过调大 Survivor 区,使得 Survivor 区可以容纳 Young GC 后存活对象,对象在 Survivor 区经历多次 Young GC 达到年龄阈值才进入老年代。
+
+调整之后每次 Young GC 后进入老年代的存活对象稳定运行时仅几百 Kb,Full GC 频率大大降低。
+
+**6.7、业务对接网关 OOM**
+
+网关主要消费 Kafka 数据,进行数据处理计算然后转发到另外的 Kafka 队列,系统运行几个小时候出现 OOM,重启系统几个小时之后又 OOM。
+
+通过 jmap 导出堆内存,在 eclipse MAT 工具分析才找出原因:代码中将某个业务 Kafka 的 topic 数据进行日志异步打印,该业务数据量较大,大量对象堆积在内存中等待被打印,导致 OOM。
+
+**6.8、鉴权系统频繁长时间 Full GC**
+
+系统对外提供各种账号鉴权服务,使用时发现系统经常服务不可用,通过 Zabbix 的监控平台监控发现系统频繁发生长时间 Full GC,且触发时老年代的堆内存通常并没有占满,发现原来是业务代码中调用了
+
+## 七、一个具体的实战案例分析
+
+**7.1 典型调优参数设置**
+
+> 服务器配置: 4cpu,8GB内存 ---- jvm调优实际上是设置一个合理大小的jvm堆内存(既不能太大,也不能太小)
+
+> -Xmx3550m 设置jvm堆内存最大值 (经验值设置: 根据压力测试,根据线上程序运行效果情况)
+>
+> -Xms3550m 设置jvm堆内存初始化大小,一般情况下必须设置此值和最大的最大的堆内存空间保持一致,防止内存抖动,消耗性能
+>
+> -Xmn2g 设置年轻代占用的空间大小
+>
+> -Xss256k 设置线程堆栈的大小;jdk5.0以后默认线程堆栈大小为1MB; 在相同的内存情况下,减小堆栈大小,可以使得操作系统创建更多的业务线程;
+
+jvm堆内存设置:
+
+> nohup java -Xmx3550m -Xms3550m -Xmn2g -Xss256k -jar jshop-web-1.0-SNAPSHOT.jar --spring.addition-location=application.yaml > jshop.log 2>&1 ><
+
+TPS性能曲线:
+
+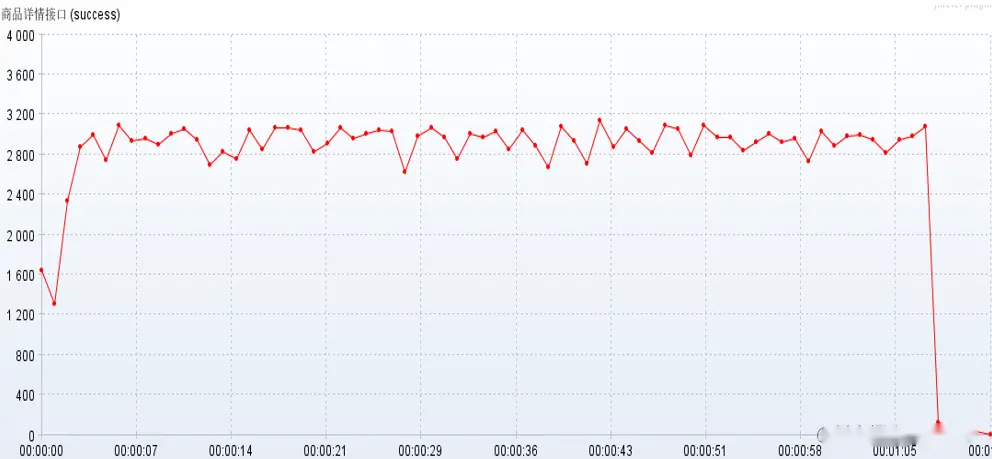
+
+**7.2 分析gc日志**
+
+如果需要分析gc日志,就必须使得服务gc输入gc详情到log日志文件中,然后使用相应gc日志分析工具来对日志进行分析即可;
+
+把gc详情输出到一个gc.log日志文件中,便于gc分析
+
+> -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:gc.log
+
+Throughput: 业务线程执行时间 / (gc时间+业务线程时间)
+
+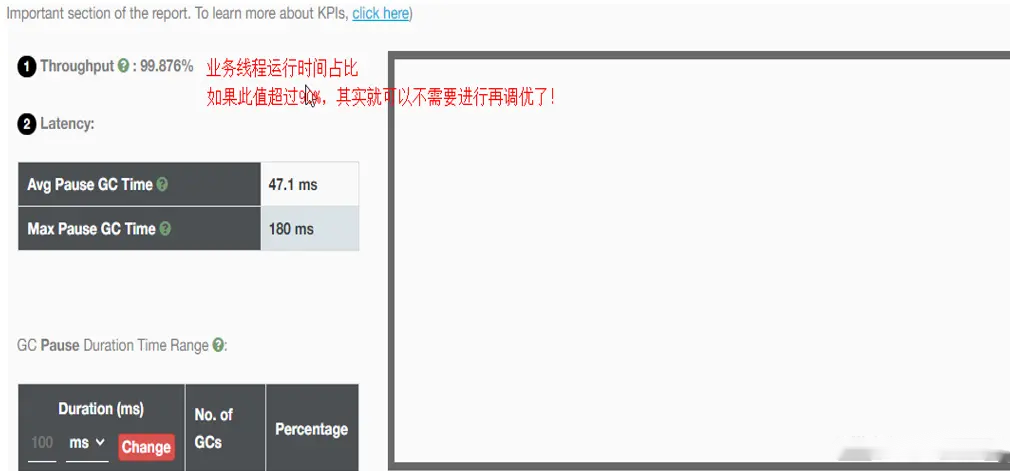
+
+分析gc日志,发现,一开始就发生了3次fullgc,很明显jvm优化参数的设置是有问题的;
+
+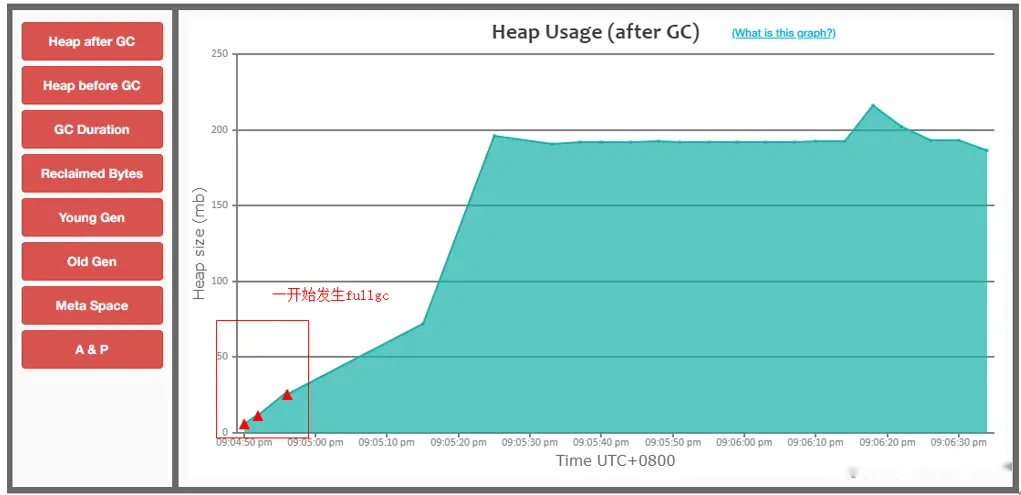
+
+查看fullgc发生问题原因: jstat -gcutil pid
+
+
+
+Metaspace持久代: 初始化分配大小20m , 当metaspace被占满后,必须对持久代进行扩容,如果metaspace每进行一次扩容,fullgc就需要执行一次;(fullgc回收整个堆空间,非常占用时间)
+
+调整gc配置: 修改永久代空间初始化大小:
+
+> nohup java -Xmx3550m -Xms3550m -Xmn2g -Xss256k -XX:MetaspaceSize=256m -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:gc.log -jar jshop-web-1.0-SNAPSHOT.jar --spring.addition-location=application.yaml > jshop.log 2>&1 ><
+
+经过调优后,fullgc现象已经消失了:
+
+
+
+**7.3 Young&Old比例**
+
+年轻代和老年代比例:1:2 参数:-XX:NewRetio = 4 , 表示年轻代(eden,s0,s1)和老年代所占比值为1:4
+
+1) -XX:NewRetio = 4
+
+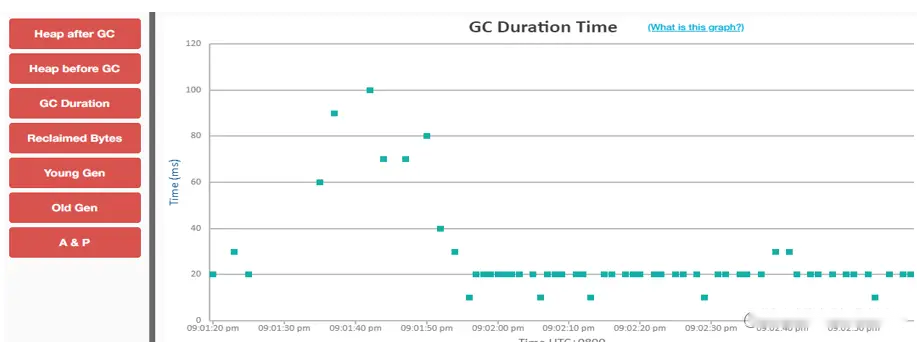
+
+年轻代分配的内存大小变小了,这样YGC次数变多了,虽然fullgc不发生了,但是YGC花费的时间更多了!
+
+2) -XX:NewRetio = 2 YGC发生的次数必然会减少;因为eden区域的大小变大了,因此YGC就会变少;
+
+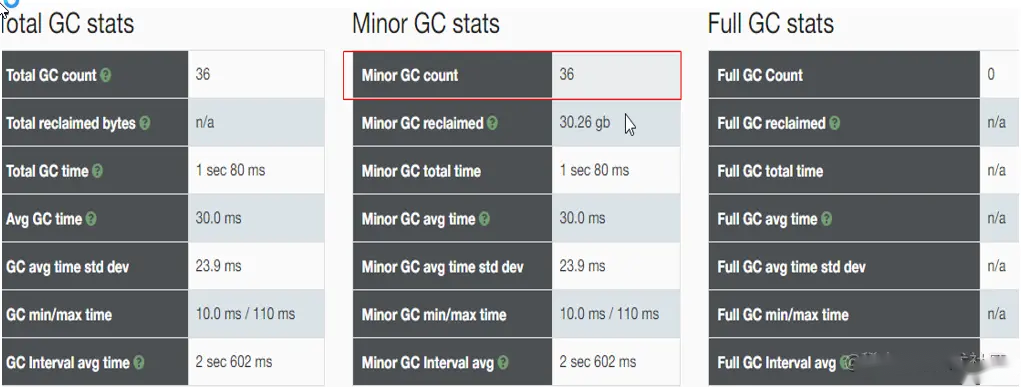
+
+7.4 Eden&S0S1
+
+为了进一步减少YGC, 可以设置 enden ,s 区域的比值大小; 设置方式: -XX:SurvivorRatio=8
+
+1) 设置比值:8:1:1
+
+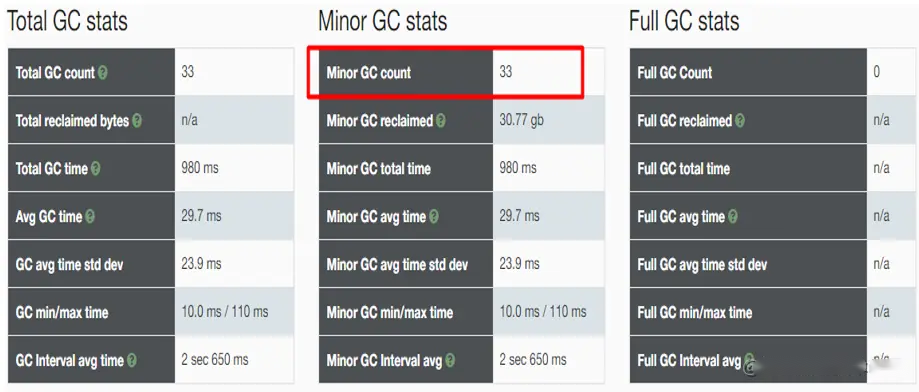
+
+2) Xmn2g 8:1:1
+
+nohup java -Xmx3550m -Xms3550m -Xmn2g -XX:SurvivorRatio=8 -Xss256k -XX:MetaspaceSize=256m -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:gc.log -jar jshop-web-1.0-SNAPSHOT.jar --spring.addition-location=application.yaml > jshop.log 2>&1 ><
+
+根据gc调优,垃圾回收次数,时间,吞吐量都是一个比较优的一个配置;
+
+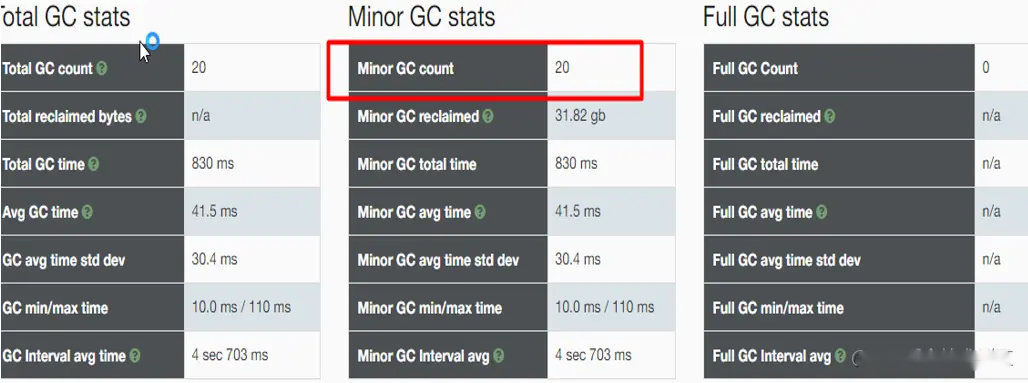
+
+**7.5 吞吐量优先**
+
+使用并行的垃圾回收器,可以充分利用多核心cpu来帮助进行垃圾回收;这样的gc方式,就叫做吞吐量优先的调优方式
+
+垃圾回收器组合: ps(parallel scavenge) + po (parallel old) 此垃圾回收器是Jdk1.8 默认的垃圾回收器组合;
+
+> nohup java -Xmx3550m -Xms3550m -Xmn2g -XX:SurvivorRatio=8 -Xss256k -XX:+UseParallelGC -XX:UseParallelOldGC -XX:MetaspaceSize=256m -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:gc.log -jar jshop-web-1.0-SNAPSHOT.jar --spring.addition-location=application.yaml > jshop.log 2>&1 ><
+
+**7.6 响应时间优先**
+
+使用cms垃圾回收器,就是一个响应时间优先的组合; cms垃圾回收器(垃圾回收和业务线程交叉执行,不会让业务线程进行停顿stw)尽可能的减少stw的时间,因此使用cms垃圾回收器组合,是响应时间优先组合
+
+> nohup java -Xmx3550m -Xms3550m -Xmn2g -XX:SurvivorRatio=8 -Xss256k -XX:+UseParNewGC -XX:UseConcMarkSweepGC -XX:MetaspaceSize=256m -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:gc.log -jar jshop-web-1.0-SNAPSHOT.jar --spring.addition-location=application.yaml > jshop.log 2>&1 ><
+
+可以发现,cms垃圾回收器时间变长;
+
+**7.7 g1**
+
+配置方式如下所示:
+
+> nohup java -Xmx3550m -Xms3550m -Xmn2g -XX:SurvivorRatio=8 -Xss256k -XX:+UseG1GC -XX:MetaspaceSize=256m -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:gc.log -jar jshop-web-1.0-SNAPSHOT.jar --spring.addition-location=application.yaml > jshop.log 2>&1 ><
+
+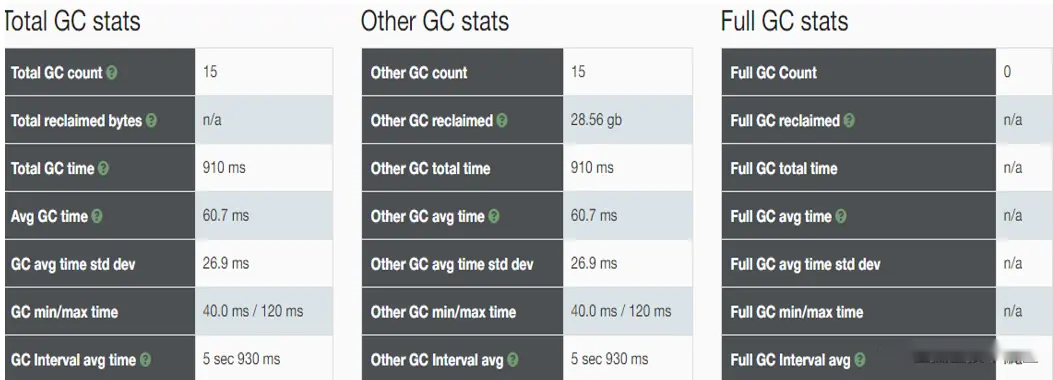
+
+
+## 参考资料
+
+* [Java HotSpot™ Virtual Machine Performance Enhancements](http://docs.oracle.com/javase/8/docs/technotes/guides/vm/performance-enhancements-7.html)
+* [Java HotSpot Virtual Machine Garbage Collection Tuning Guide](http://docs.oracle.com/javase/8/docs/technotes/guides/vm/gctuning/index.html)
+* [[HotSpot VM] JVM调优的”标准参数”的各种陷阱](http://hllvm.group.iteye.com/group/topic/27945)
+
+
+## 参考文章
+
+
+
+
+
+
+
+
+
+https://blog.csdn.net/android_hl/article/details/53228348
+
+
diff --git "a/docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\27212\357\274\232JVM\346\200\247\350\203\275\347\256\241\347\220\206\347\245\236\345\231\250VisualVM\344\273\213\347\273\215\344\270\216\345\256\236\346\210\230.md" "b/docs/Java/JVM/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232JVM\346\200\247\350\203\275\347\256\241\347\220\206\347\245\236\345\231\250VisualVM\344\273\213\347\273\215\344\270\216\345\256\236\346\210\230.md"
similarity index 90%
rename from "docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\27212\357\274\232JVM\346\200\247\350\203\275\347\256\241\347\220\206\347\245\236\345\231\250VisualVM\344\273\213\347\273\215\344\270\216\345\256\236\346\210\230.md"
rename to "docs/Java/JVM/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232JVM\346\200\247\350\203\275\347\256\241\347\220\206\347\245\236\345\231\250VisualVM\344\273\213\347\273\215\344\270\216\345\256\236\346\210\230.md"
index 9df9174..e2547b3 100644
--- "a/docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\27212\357\274\232JVM\346\200\247\350\203\275\347\256\241\347\220\206\347\245\236\345\231\250VisualVM\344\273\213\347\273\215\344\270\216\345\256\236\346\210\230.md"
+++ "b/docs/Java/JVM/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232JVM\346\200\247\350\203\275\347\256\241\347\220\206\347\245\236\345\231\250VisualVM\344\273\213\347\273\215\344\270\216\345\256\236\346\210\230.md"
@@ -1,5 +1,4 @@
-# Table of Contents
-
+# 目录
* [一、VisualVM是什么?](#一、visualvm是什么?)
* [二、如何获取VisualVM?](#二、如何获取visualvm?)
* [三、获取那个版本?](#三、获取那个版本?)
@@ -9,9 +8,6 @@
* [查找JAVA应用程序耗时的方法函数](#查找java应用程序耗时的方法函数)
* [排查JAVA应用程序线程锁](#排查java应用程序线程锁)
* [参考文章](#参考文章)
- * [微信公众号](#微信公众号)
- * [Java技术江湖](#java技术江湖)
- * [个人公众号:黄小斜](#个人公众号:黄小斜)
本文转自互联网,侵删
@@ -36,9 +32,6 @@
## 一、VisualVM是什么?
VisualVM是一款免费的JAVA虚拟机图形化监控分析工具。
-
-
-
1. 拥有图形化的监控界面。
2. 提供本地、远程的JVM监控分析功能。
3. 是一款免费的JAVA工具。
@@ -49,13 +42,7 @@
VisualVM各版本下载页面: http://visualvm.java.net/releases.html
下载VisualVM时也应该注意,不同的JDK版本对应不同版本的VisualVM,具体根据安装的JDK版本来下载第一的VisualVM。
-
-
-
-
-
## 三、获取那个版本?
-
下载版本参考:Java虚拟机性能管理神器 - VisualVM(4) - JDK版本与VisualVM版本对应关系
@@ -257,20 +244,4 @@
https://blog.csdn.net/android_hl/article/details/53228348
-## 微信公众号
-
-### Java技术江湖
-
-如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号【Java技术江湖】一位阿里 Java 工程师的技术小站,作者黄小斜,专注 Java 相关技术:SSM、SpringBoot、MySQL、分布式、中间件、集群、Linux、网络、多线程,偶尔讲点Docker、ELK,同时也分享技术干货和学习经验,致力于Java全栈开发!
-
-**Java工程师必备学习资源:** 一些Java工程师常用学习资源,关注公众号后,后台回复关键字 **“Java”** 即可免费无套路获取。
-
-
-
-### 个人公众号:黄小斜
-
-作者是 985 硕士,蚂蚁金服 JAVA 工程师,专注于 JAVA 后端技术栈:SpringBoot、MySQL、分布式、中间件、微服务,同时也懂点投资理财,偶尔讲点算法和计算机理论基础,坚持学习和写作,相信终身学习的力量!
-
-**程序员3T技术学习资源:** 一些程序员学习技术的资源大礼包,关注公众号后,后台回复关键字 **“资料”** 即可免费无套路获取。
-
diff --git "a/docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\2729\357\274\232JVM\347\233\221\346\216\247\345\267\245\345\205\267\344\270\216\350\257\212\346\226\255\345\256\236\350\267\265.md" "b/docs/Java/JVM/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232JVM\347\233\221\346\216\247\345\267\245\345\205\267\344\270\216\350\257\212\346\226\255\345\256\236\350\267\265.md"
similarity index 89%
rename from "docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\2729\357\274\232JVM\347\233\221\346\216\247\345\267\245\345\205\267\344\270\216\350\257\212\346\226\255\345\256\236\350\267\265.md"
rename to "docs/Java/JVM/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232JVM\347\233\221\346\216\247\345\267\245\345\205\267\344\270\216\350\257\212\346\226\255\345\256\236\350\267\265.md"
index ab03095..1d57b95 100644
--- "a/docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\2729\357\274\232JVM\347\233\221\346\216\247\345\267\245\345\205\267\344\270\216\350\257\212\346\226\255\345\256\236\350\267\265.md"
+++ "b/docs/Java/JVM/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232JVM\347\233\221\346\216\247\345\267\245\345\205\267\344\270\216\350\257\212\346\226\255\345\256\236\350\267\265.md"
@@ -1,5 +1,4 @@
-# Table of Contents
-
+# 目录
* [一、jvm常见监控工具&指令](#一、jvm常见监控工具指令)
* [1、 jps:jvm进程状况工具](#1、-jpsjvm进程状况工具)
* [2、jstat: jvm统计信息监控工具](#2、jstat-jvm统计信息监控工具)
@@ -14,9 +13,7 @@
* [2.查看java进程的线程快照信息](#2查看java进程的线程快照信息)
* [3、OOM内存泄露](#3、oom内存泄露)
* [参考文章](#参考文章)
- * [微信公众号](#微信公众号)
- * [Java技术江湖](#java技术江湖)
- * [个人公众号:黄小斜](#个人公众号:黄小斜)
+
本文转自:https://juejin.im/post/59e6c1f26fb9a0451c397a8c
@@ -57,10 +54,10 @@
```
-jps [options] [hostid]复制代码
+jps [options] [hostid]
```
-
+
如果不指定hostid就默认为当前主机或服务器。
@@ -95,6 +92,7 @@ generalOption - 单个的常用的命令行选项,如-help, -options, 或 -ver
outputOptions -一个或多个输出选项,由单个的statOption选项组成,可以和-t, -h, and -J等选项配合使用。复制代码
```
+
参数选项:
@@ -117,7 +115,6 @@ outputOptions -一个或多个输出选项,由单个的statOption选项组成
查看gc 情况执行:jstat-gcutil 27777
-
### 3、jinfo: java配置信息
@@ -129,11 +126,10 @@ outputOptions -一个或多个输出选项,由单个的statOption选项组成
jinfo[option] pid复制代码
```
-
+
比如:获取一些当前进程的jvm运行和启动信息。
-
### 4、jmap: java 内存映射工具
@@ -150,7 +146,7 @@ jmap [ option ] executable core
jmap [ option ] [server-id@]remote-hostname-or-IP复制代码
```
-
+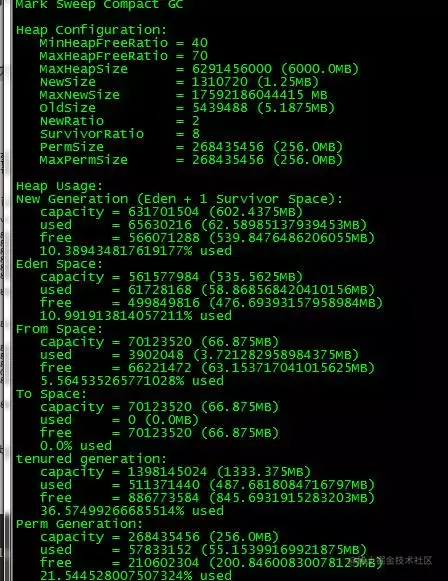
参数选项:
@@ -175,10 +171,12 @@ jmap [ option ] [server-id@]remote-hostname-or-IP复制代码
-J 传递参数给jmap启动的jvm. 复制代码
```
+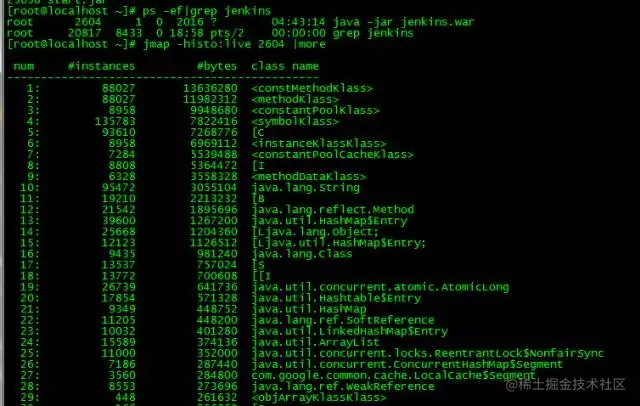
### 5、jhat:jvm堆快照分析工具
jhat 命令与jamp搭配使用,用来分析map生产的堆快存储快照。jhat内置了一个微型http/Html服务器,可以在浏览器找那个查看。不过建议尽量不用,既然有dumpt文件,可以从生产环境拉取下来,然后通过本地可视化工具来分析,这样既减轻了线上服务器压力,有可以分析的足够详尽(比如 MAT/jprofile/visualVm)等。
+
### 6、jstack:java堆栈跟踪工具
jstack用于生成java虚拟机当前时刻的线程快照。线程快照是当前java虚拟机内每一条线程正在执行的方法堆栈的集合,生成线程快照的主要目的是定位线程出现长时间停顿的原因,如线程间死锁、死循环、请求外部资源导致的长时间等待等。
@@ -391,20 +389,4 @@ jmap -dump:format=b,file=/tmp/dump.dat 11869
https://blog.csdn.net/android_hl/article/details/53228348
-## 微信公众号
-
-### Java技术江湖
-
-如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号【Java技术江湖】一位阿里 Java 工程师的技术小站,作者黄小斜,专注 Java 相关技术:SSM、SpringBoot、MySQL、分布式、中间件、集群、Linux、网络、多线程,偶尔讲点Docker、ELK,同时也分享技术干货和学习经验,致力于Java全栈开发!
-
-**Java工程师必备学习资源:** 一些Java工程师常用学习资源,关注公众号后,后台回复关键字 **“Java”** 即可免费无套路获取。
-
-
-
-### 个人公众号:黄小斜
-
-作者是 985 硕士,蚂蚁金服 JAVA 工程师,专注于 JAVA 后端技术栈:SpringBoot、MySQL、分布式、中间件、微服务,同时也懂点投资理财,偶尔讲点算法和计算机理论基础,坚持学习和写作,相信终身学习的力量!
-
-**程序员3T技术学习资源:** 一些程序员学习技术的资源大礼包,关注公众号后,后台回复关键字 **“资料”** 即可免费无套路获取。
-
diff --git "a/docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\27211\357\274\232Java\345\206\205\345\255\230\345\274\202\345\270\270\345\216\237\347\220\206\344\270\216\345\256\236\350\267\265.md" "b/docs/Java/JVM/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232Java\345\206\205\345\255\230\345\274\202\345\270\270\345\216\237\347\220\206\344\270\216\345\256\236\350\267\265.md"
similarity index 87%
rename from "docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\27211\357\274\232Java\345\206\205\345\255\230\345\274\202\345\270\270\345\216\237\347\220\206\344\270\216\345\256\236\350\267\265.md"
rename to "docs/Java/JVM/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232Java\345\206\205\345\255\230\345\274\202\345\270\270\345\216\237\347\220\206\344\270\216\345\256\236\350\267\265.md"
index 0805113..a999de2 100644
--- "a/docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\27211\357\274\232Java\345\206\205\345\255\230\345\274\202\345\270\270\345\216\237\347\220\206\344\270\216\345\256\236\350\267\265.md"
+++ "b/docs/Java/JVM/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232Java\345\206\205\345\255\230\345\274\202\345\270\270\345\216\237\347\220\206\344\270\216\345\256\236\350\267\265.md"
@@ -1,5 +1,4 @@
-# Table of Contents
-
+# 目录
* [实战内存溢出异常](#实战内存溢出异常)
* [1 . 对象的创建过程](#1--对象的创建过程)
* [2 . 对象的内存布局](#2--对象的内存布局)
@@ -22,9 +21,7 @@
* [6、单例模式](#6、单例模式)
* [如何检测内存泄漏](#如何检测内存泄漏)
* [参考文章](#参考文章)
- * [微信公众号](#微信公众号)
- * [Java技术江湖](#java技术江湖)
- * [个人公众号:黄小斜](#个人公众号:黄小斜)
+
本文转自互联网,侵删
@@ -77,16 +74,16 @@ Student stu =new Student("张三","18");
* 实例数据
* 对齐填充
-**对象头:** 对象头中包含了对象运行时一些必要的信息,如GC分代信息,锁信息,哈希码,指向Class类元信息的指针等,其中对Javaer比较有用的是**锁信息与指向Class对象的指针**,关于锁信息,后期有机会讲解并发编程JUC时再扩展,关于指向Class对象的指针其实很好理解。比如上面那个Student的例子,当我们拿到stu对象时,调用Class stuClass=stu.getClass();的时候,其实就是根据这个指针去拿到了stu对象所属的Student类在方法区存放的Class类对象。虽然说的有点拗口,但这句话我反复琢磨了好几遍,应该是说清楚了。
+**对象头:**对象头中包含了对象运行时一些必要的信息,如GC分代信息,锁信息,哈希码,指向Class类元信息的指针等,其中对Javaer比较有用的是**锁信息与指向Class对象的指针**,关于锁信息,后期有机会讲解并发编程JUC时再扩展,关于指向Class对象的指针其实很好理解。比如上面那个Student的例子,当我们拿到stu对象时,调用Class stuClass=stu.getClass();的时候,其实就是根据这个指针去拿到了stu对象所属的Student类在方法区存放的Class类对象。虽然说的有点拗口,但这句话我反复琢磨了好几遍,应该是说清楚了。
-**实例数据:** 实例数据部分是对象真正存储的有效信息,就是程序代码中所定义的各种类型的字段内容。
+**实例数据:**实例数据部分是对象真正存储的有效信息,就是程序代码中所定义的各种类型的字段内容。
-**对齐填充:** 虚拟机规范要求对象大小必须是8字节的整数倍。对齐填充其实就是来补全对象大小的。
+**对齐填充:**虚拟机规范要求对象大小必须是8字节的整数倍。对齐填充其实就是来补全对象大小的。
## 3 . 对象的访问定位
谈到对象的访问,还拿上面学生的例子来说,当我们拿到stu对象时,直接调用stu.getName();时,其实就完成了对对象的访问。但这里要累赘说一下的是,stu虽然通常被认为是一个对象,其实准确来说是不准确的,stu只是一个变量,变量里存储的是指向对象的指针,(如果干过C或者C++的小伙伴应该比较清楚指针这个概念),当我们调用stu.getName()时,虚拟机会根据指针找到堆里面的对象然后拿到实例数据name.需要注意的是,当我们调用stu.getClass()时,虚拟机会首先根据stu指针定位到堆里面的对象,然后根据对象头里面存储的指向Class类元信息的指针再次到方法区拿到Class对象,进行了两次指针寻找。具体讲解图如下:
-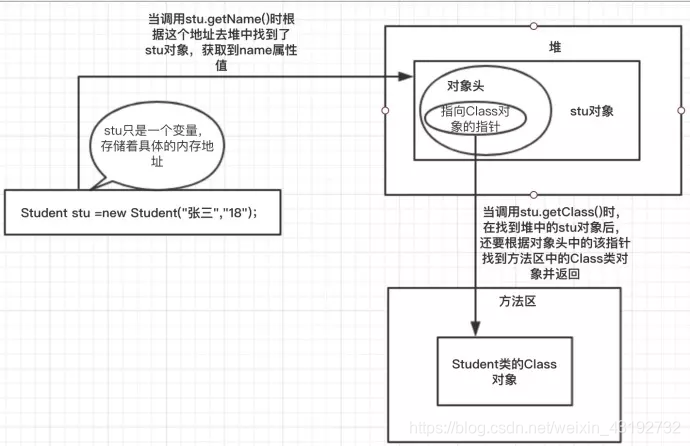
+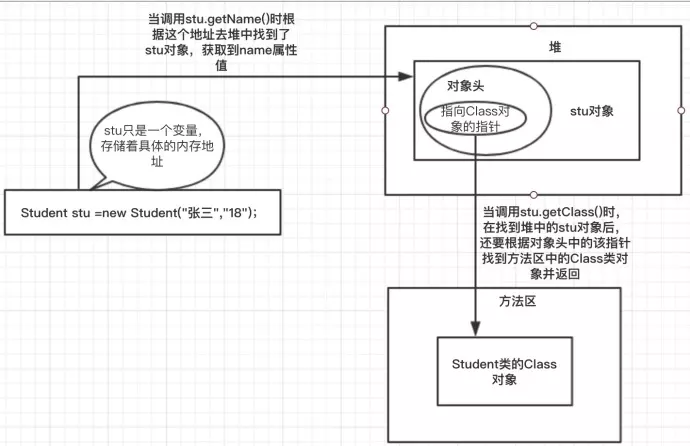
## 4 .实战内存异常
@@ -140,8 +137,10 @@ Dumping heap to /Users/zdy/Desktop/dump/java_pid1099.hprof …
可以看到生成了dump文件到指定目录。并且爆出了OutOfMemoryError,还告诉了你是哪一片区域出的问题:heap space
打开VisualVM工具导入对应的heapDump文件(如何使用请读者自行查阅相关资料),相应的说明见图:
-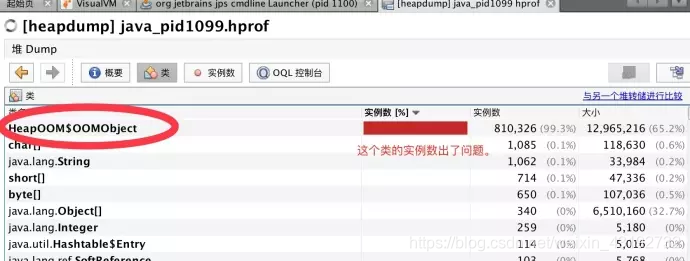
-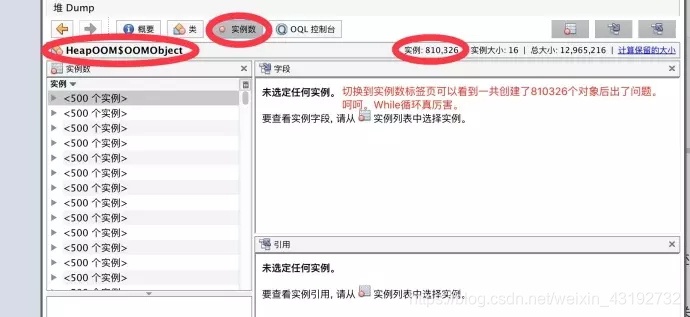
+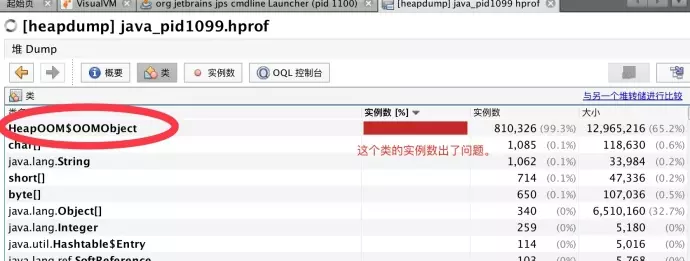
+
+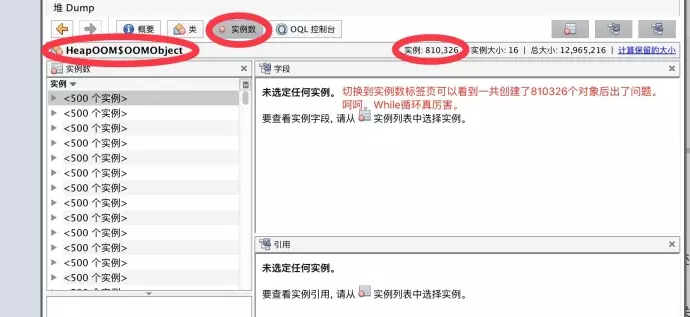
+
分析dump文件后,我们可以知道,OOMObject这个类创建了810326个实例。所以它能不溢出吗?接下来就在代码里找这个类在哪new的。排查问题。(我们的样例代码就不用排查了,While循环太凶猛了)分析dump文件后,我们可以知道,OOMObject这个类创建了810326个实例。所以它能不溢出吗?接下来就在代码里找这个类在哪new的。排查问题。(我们的样例代码就不用排查了,While循环太凶猛了)
### Java栈内存异常
@@ -182,7 +181,7 @@ public class JavaVMStackSOF {
可以看到,递归调用了751次,栈容量不够用了。
默认的栈容量在正常的方法调用时,栈深度可以达到1000-2000深度,所以,一般的递归是可以承受的住的。如果你的代码出现了StackOverflowError,首先检查代码,而不是改参数。
-这里顺带提一下,很多人在做多线程开发时,当创建很多线程时,**容易出现OOM(OutOfMemoryError),** 这时可以通过具体情况,减少最大堆容量,或者栈容量来解决问题,这是为什么呢。请看下面的公式:
+这里顺带提一下,很多人在做多线程开发时,当创建很多线程时,**容易出现OOM(OutOfMemoryError),**这时可以通过具体情况,减少最大堆容量,或者栈容量来解决问题,这是为什么呢。请看下面的公式:
线程数*(最大栈容量)+最大堆值+其他内存(忽略不计或者一般不改动)=机器最大内存
@@ -190,10 +189,10 @@ public class JavaVMStackSOF {
### 方法区内存异常
-写到这里时,作者本来想写一个无限创建动态代理对象的例子来演示方法区溢出,避开谈论JDK7与JDK8的内存区域变更的过渡,但细想一想,还是把这一块从始致终的说清楚。在上一篇文章中JVM系列之Java内存结构详解讲到方法区时提到,JDK7环境下方法区包括了(运行时常量池),其实这么说是不准确的。因为从JDK7开始,HotSpot团队就想到开始去"永久代",大家首先明确一个概念,**方法区和"永久代"(PermGen space)是两个概念,方法区是JVM虚拟机规范,任何虚拟机实现(J9等)都不能少这个区间,而"永久代"只是HotSpot对方法区的一个实现。** 为了把知识点列清楚,我还是才用列表的形式:
+写到这里时,作者本来想写一个无限创建动态代理对象的例子来演示方法区溢出,避开谈论JDK7与JDK8的内存区域变更的过渡,但细想一想,还是把这一块从始致终的说清楚。在上一篇文章中JVM系列之Java内存结构详解讲到方法区时提到,JDK7环境下方法区包括了(运行时常量池),其实这么说是不准确的。因为从JDK7开始,HotSpot团队就想到开始去"永久代",大家首先明确一个概念,**方法区和"永久代"(PermGen space)是两个概念,方法区是JVM虚拟机规范,任何虚拟机实现(J9等)都不能少这个区间,而"永久代"只是HotSpot对方法区的一个实现。**为了把知识点列清楚,我还是才用列表的形式:
-* [ ] JDK7之前(包括JDK7)拥有"永久代"(PermGen space),用来实现方法区。但在JDK7中已经逐渐在实现中把永久代中把很多东西移了出来,比如:符号引用(Symbols)转移到了native heap,运行时常量池(interned strings)转移到了java heap;类的静态变量(class statics)转移到了java heap.
-* [ ] 所以这就是为什么我说上一篇文章中说方法区中包含运行时常量池是不正确的,因为已经移动到了java heap;
+* [ ] JDK7之前(包括JDK7)拥有"永久代"(PermGen space),用来实现方法区。但在JDK7中已经逐渐在实现中把永久代中把很多东西移了出来,比如:符号引用(Symbols)转移到了native heap,运行时常量池(interned strings)转移到了java heap;类的静态变量(class statics)转移到了java heap.
+* [ ] 所以这就是为什么我说上一篇文章中说方法区中包含运行时常量池是不正确的,因为已经移动到了java heap;
**在JDK7之前(包括7)可以通过-XX:PermSize -XX:MaxPermSize来控制永久代的大小.
JDK8正式去除"永久代",换成Metaspace(元空间)作为JVM虚拟机规范中方法区的实现。**
元空间与永久代之间最大的区别在于:元空间并不在虚拟机中,而是使用本地内存。因此,默认情况下,元空间的大小仅受本地内存限制,但仍可以通过参数控制:-XX:MetaspaceSize与-XX:MaxMetaspaceSize来控制大小。
@@ -316,7 +315,8 @@ Java的一个重要优点就是通过垃圾收集器(Garbage Collection,GC)自
为了更好理解GC的工作原理,我们可以将对象考虑为有向图的顶点,将引用关系考虑为图的有向边,有向边从引用者指向被引对象。另外,每个线程对象可以作为一个图的起始顶点,例如大多程序从main进程开始执行,那么该图就是以main进程顶点开始的一棵根树。在这个有向图中,根顶点可达的对象都是有效对象,GC将不回收这些对象。如果某个对象 (连通子图)与这个根顶点不可达(注意,该图为有向图),那么我们认为这个(这些)对象不再被引用,可以被GC回收。
以下,我们举一个例子说明如何用有向图表示内存管理。对于程序的每一个时刻,我们都有一个有向图表示JVM的内存分配情况。以下右图,就是左边程序运行到第6行的示意图。
-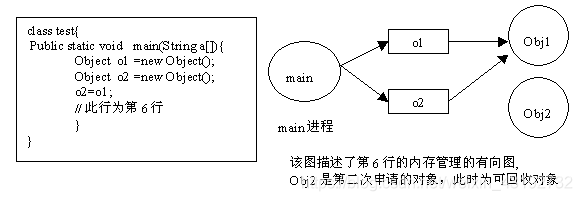
+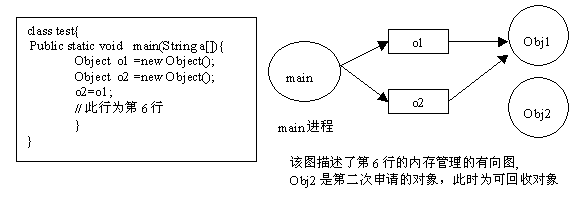
+
Java使用有向图的方式进行内存管理,可以消除引用循环的问题,例如有三个对象,相互引用,只要它们和根进程不可达的,那么GC也是可以回收它们的。这种方式的优点是管理内存的精度很高,但是效率较低。另外一种常用的内存管理技术是使用计数器,例如COM模型采用计数器方式管理构件,它与有向图相比,精度行低(很难处理循环引用的问题),但执行效率很高。
## 什么是Java中的内存泄露?
@@ -326,7 +326,8 @@ Java使用有向图的方式进行内存管理,可以消除引用循环的问
在C++中,内存泄漏的范围更大一些。有些对象被分配了内存空间,然后却不可达,由于C++中没有GC,这些内存将永远收不回来。在Java中,这些不可达的对象都由GC负责回收,因此程序员不需要考虑这部分的内存泄露。
通过分析,我们得知,对于C++,程序员需要自己管理边和顶点,而对于Java程序员只需要管理边就可以了(不需要管理顶点的释放)。通过这种方式,Java提高了编程的效率。
-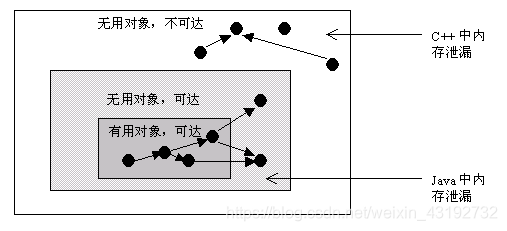
+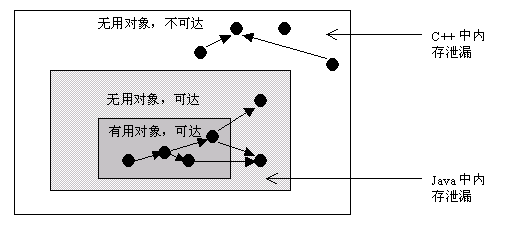
+
因此,通过以上分析,我们知道在Java中也有内存泄漏,但范围比C++要小一些。因为Java从语言上保证,任何对象都是可达的,所有的不可达对象都由GC管理。
对于程序员来说,GC基本是透明的,不可见的。虽然,我们只有几个函数可以访问GC,例如运行GC的函数System.gc(),但是根据Java语言规范定义, 该函数不保证JVM的垃圾收集器一定会执行。因为,不同的JVM实现者可能使用不同的算法管理GC。通常,GC的线程的优先级别较低。JVM调用GC的策略也有很多种,有的是内存使用到达一定程度时,GC才开始工作,也有定时执行的,有的是平缓执行GC,有的是中断式执行GC。但通常来说,我们不需要关心这些。除非在一些特定的场合,GC的执行影响应用程序的性能,例如对于基于Web的实时系统,如网络游戏等,用户不希望GC突然中断应用程序执行而进行垃圾回收,那么我们需要调整GC的参数,让GC能够通过平缓的方式释放内存,例如将垃圾回收分解为一系列的小步骤执行,Sun提供的HotSpot JVM就支持这一特性。
@@ -443,12 +444,6 @@ Optimizeit Profiler版本4.11支持Application,Applet,Servlet和Romote Appli
当设置好所有的参数了,我们就可以在OptimizeIt环境下运行被测程序,在程序运行过程中,Optimizeit可以监视内存的使用曲线(如下图),包括JVM申请的堆(heap)的大小,和实际使用的内存大小。另外,在运行过程中,我们可以随时暂停程序的运行,甚至强行调用GC,让GC进行内存回收。通过内存使用曲线,我们可以整体了解程序使用内存的情况。这种监测对于长期运行的应用程序非常有必要,也很容易发现内存泄露。
-
-
-
-
-
-
## 参考文章
@@ -461,20 +456,4 @@ Optimizeit Profiler版本4.11支持Application,Applet,Servlet和Romote Appli
https://blog.csdn.net/android_hl/article/details/53228348
-## 微信公众号
-
-### Java技术江湖
-
-如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号【Java技术江湖】一位阿里 Java 工程师的技术小站,作者黄小斜,专注 Java 相关技术:SSM、SpringBoot、MySQL、分布式、中间件、集群、Linux、网络、多线程,偶尔讲点Docker、ELK,同时也分享技术干货和学习经验,致力于Java全栈开发!
-
-**Java工程师必备学习资源:** 一些Java工程师常用学习资源,关注公众号后,后台回复关键字 **“Java”** 即可免费无套路获取。
-
-
-
-### 个人公众号:黄小斜
-
-作者是 985 硕士,蚂蚁金服 JAVA 工程师,专注于 JAVA 后端技术栈:SpringBoot、MySQL、分布式、中间件、微服务,同时也懂点投资理财,偶尔讲点算法和计算机理论基础,坚持学习和写作,相信终身学习的力量!
-
-**程序员3T技术学习资源:** 一些程序员学习技术的资源大礼包,关注公众号后,后台回复关键字 **“资料”** 即可免费无套路获取。
-
diff --git "a/docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\2724\357\274\232Java class\344\273\213\347\273\215\344\270\216\350\247\243\346\236\220\345\256\236\350\267\265.md" "b/docs/Java/JVM/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232Java\345\255\227\350\212\202\347\240\201\344\273\213\347\273\215\344\270\216\350\247\243\346\236\220\345\256\236\350\267\265.md"
similarity index 97%
rename from "docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\2724\357\274\232Java class\344\273\213\347\273\215\344\270\216\350\247\243\346\236\220\345\256\236\350\267\265.md"
rename to "docs/Java/JVM/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232Java\345\255\227\350\212\202\347\240\201\344\273\213\347\273\215\344\270\216\350\247\243\346\236\220\345\256\236\350\267\265.md"
index 2371f8f..cf18680 100644
--- "a/docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\2724\357\274\232Java class\344\273\213\347\273\215\344\270\216\350\247\243\346\236\220\345\256\236\350\267\265.md"
+++ "b/docs/Java/JVM/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232Java\345\255\227\350\212\202\347\240\201\344\273\213\347\273\215\344\270\216\350\247\243\346\236\220\345\256\236\350\267\265.md"
@@ -1,5 +1,4 @@
-# Table of Contents
-
+# 目录
* [前言](#前言)
* [Class文件](#class文件)
* [什么是Class文件?](#什么是class文件?)
@@ -50,8 +49,7 @@ java之所以能够实现跨平台,便在于其编译阶段不是将代码直
随便找到一个class文件,用Sublime Text打开是这样的:
-
-
+
是不是一脸懵逼,不过java虚拟机规范中给出了class文件的基本格式,只要按照这个格式去解析就可以了:
@@ -337,11 +335,7 @@ for (int j = 0; j < methodInfo.attributesCount; j++) {
整个项目终于写完了,接下来就来看看效果如何,随便找一个class文件解析运行:
-
-
-
-
-
+
哈哈,是不是很赞!
diff --git "a/docs/java/jvm/\346\267\261\345\205\245\344\272\206\350\247\243JVM\350\231\232\346\213\237\346\234\2728\357\274\232Java\347\232\204\347\274\226\350\257\221\346\234\237\344\274\230\345\214\226\344\270\216\350\277\220\350\241\214\346\234\237\344\274\230\345\214\226.md" "b/docs/Java/JVM/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232Java\347\232\204\347\274\226\350\257\221\346\234\237\344\274\230\345\214\226\344\270\216\350\277\220\350\241\214\346\234\237\344\274\230\345\214\226.md"
similarity index 85%
rename from "docs/java/jvm/\346\267\261\345\205\245\344\272\206\350\247\243JVM\350\231\232\346\213\237\346\234\2728\357\274\232Java\347\232\204\347\274\226\350\257\221\346\234\237\344\274\230\345\214\226\344\270\216\350\277\220\350\241\214\346\234\237\344\274\230\345\214\226.md"
rename to "docs/Java/JVM/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232Java\347\232\204\347\274\226\350\257\221\346\234\237\344\274\230\345\214\226\344\270\216\350\277\220\350\241\214\346\234\237\344\274\230\345\214\226.md"
index 2db99f7..58b8166 100644
--- "a/docs/java/jvm/\346\267\261\345\205\245\344\272\206\350\247\243JVM\350\231\232\346\213\237\346\234\2728\357\274\232Java\347\232\204\347\274\226\350\257\221\346\234\237\344\274\230\345\214\226\344\270\216\350\277\220\350\241\214\346\234\237\344\274\230\345\214\226.md"
+++ "b/docs/Java/JVM/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232Java\347\232\204\347\274\226\350\257\221\346\234\237\344\274\230\345\214\226\344\270\216\350\277\220\350\241\214\346\234\237\344\274\230\345\214\226.md"
@@ -1,6 +1,5 @@
-# Table of Contents
-
- * [[java编译期优化](https://www.cnblogs.com/LeonNew/p/6187411.html)](#[java编译期优化]httpswwwcnblogscomleonnewp6187411html)
+# 目录
+ * [java编译期优化](#[java编译期优化])
* [早期(编译期)优化](#早期(编译期)优化)
* [泛型与类型擦除](#泛型与类型擦除)
* [自动装箱、拆箱与遍历循环](#自动装箱、拆箱与遍历循环)
@@ -12,9 +11,7 @@
* [编译优化技术](#编译优化技术)
* [java与C/C++编译器对比](#java与cc编译器对比)
* [参考文章](#参考文章)
- * [微信公众号](#微信公众号)
- * [Java技术江湖](#java技术江湖)
- * [个人公众号:黄小斜](#个人公众号:黄小斜)
+
本文转自互联网,侵删
@@ -37,24 +34,14 @@
-
-
-
-
-
-
-## [java编译期优化](https://www.cnblogs.com/LeonNew/p/6187411.html)
-
-
-
-
+## java编译期优化
java语言的编译期其实是一段不确定的操作过程,因为它可以分为三类编译过程:
1.前端编译:把_.java文件转变为_.class文件
2.后端编译:把字节码转变为机器码
3.静态提前编译:直接把*.java文件编译成本地机器代码
从JDK1.3开始,虚拟机设计团队就把对性能的优化集中到了后端的即时编译中,这样可以让那些不是由Javac产生的Class文件(如JRuby、Groovy等语言的Class文件)也能享受到编译期优化所带来的好处
-**Java中即时编译在运行期的优化过程对于程序运行来说更重要,而前端编译期在编译期的优化过程对于程序编码来说关系更加密切 **
+**Java中即时编译在运行期的优化过程对于程序运行来说更重要,而前端编译期在编译期的优化过程对于程序编码来说关系更加密切**
### 早期(编译期)优化
@@ -115,11 +102,10 @@ public static void main(String[] args) {
##### 解释器与编译器
-Java程序最初是通过解释器进行解释执行的,当程序需要迅速启动和执行时,解释器可以首先发挥作用,省去编译时间,立即执行;当程序运行后,随着时间的推移,编译期逐渐发挥作用,把越来越多的代码编译成本地代码,获得更高的执行效率。**解释执行节约内存,编译执行提升效率。** 同时,解释器可以作为编译器激进优化时的一个“逃生门”,让编译器根据概率选择一些大多数时候都能提升运行速度的优化手段,当激进优化的假设不成立,则通过逆优化退回到解释状态继续执行。
+Java程序最初是通过解释器进行解释执行的,当程序需要迅速启动和执行时,解释器可以首先发挥作用,省去编译时间,立即执行;当程序运行后,随着时间的推移,编译期逐渐发挥作用,把越来越多的代码编译成本地代码,获得更高的执行效率。**解释执行节约内存,编译执行提升效率。**同时,解释器可以作为编译器激进优化时的一个“逃生门”,让编译器根据概率选择一些大多数时候都能提升运行速度的优化手段,当激进优化的假设不成立,则通过逆优化退回到解释状态继续执行。
HotSpot虚拟机中内置了两个即时编译器,分别称为Client Compiler(C1编译器)和Server Compiler(C2编译器),默认采用解释器与其中一个编译器直接配合的方式工作,使用哪个编译器取决于虚拟机运行的模式,也可以自己去指定。若强制虚拟机运行与“解释模式”,编译器完全不介入工作,若强制虚拟机运行于“编译模式”,则优先采用编译方式执行程序,解释器仍然要在编译无法进行的情况下介入执行过程。
-
-
+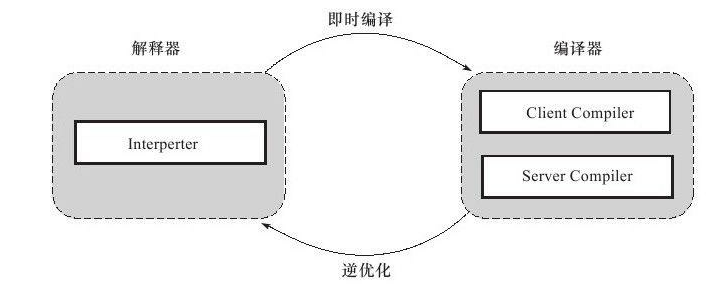
##### 分层编译策略
```
@@ -143,13 +129,11 @@ HotSpot虚拟机中内置了两个即时编译器,分别称为Client Compiler(
```
HotSpot虚拟机使用的是第二种,它为每个方法准备了两类计数器:方法调用计数器和回边计数器,下图表示方法调用计数器触发即时编译:
-
-
+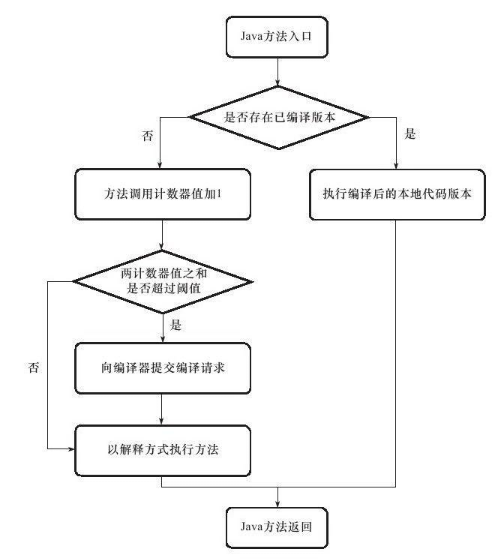
如果不做任何设置,执行引擎会继续进入解释器按照解释方式执行字节码,直到提交的请求被编译器编译完成,下次调用才会使用已编译的版本。另外,方法调用计数器的值也不是一个绝对次数,而是一段时间之内被调用的次数,超过这个时间,次数就减半,这称为计数器热度的衰减。
下图表示回边计数器触发即时编译:
-
-
+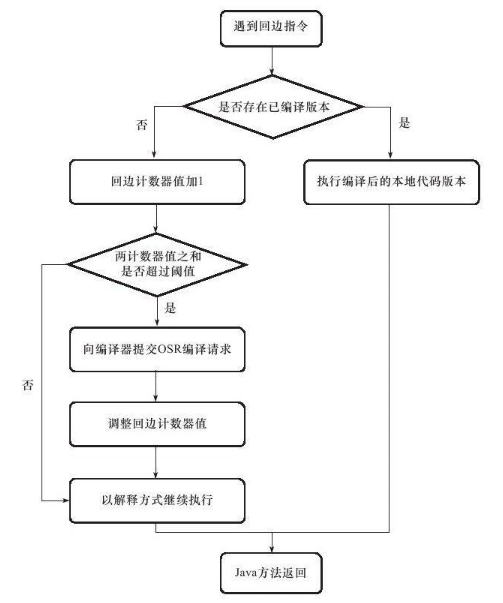
回边计数器没有计数器热度衰减的过程,因此统计的就是绝对次数,并且当计数器溢出时,它还会把方法计数器的值也调整到溢出状态,这样下次进入该方法的时候就会执行标准编译过程。
##### 编译优化技术
@@ -235,20 +219,4 @@ Java虚拟机的即时编译器与C/C++的静态编译器相比,可能会由
https://blog.csdn.net/android_hl/article/details/53228348
-## 微信公众号
-
-### Java技术江湖
-
-如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号【Java技术江湖】一位阿里 Java 工程师的技术小站,作者黄小斜,专注 Java 相关技术:SSM、SpringBoot、MySQL、分布式、中间件、集群、Linux、网络、多线程,偶尔讲点Docker、ELK,同时也分享技术干货和学习经验,致力于Java全栈开发!
-
-**Java工程师必备学习资源:** 一些Java工程师常用学习资源,关注公众号后,后台回复关键字 **“Java”** 即可免费无套路获取。
-
-
-
-### 个人公众号:黄小斜
-
-作者是 985 硕士,蚂蚁金服 JAVA 工程师,专注于 JAVA 后端技术栈:SpringBoot、MySQL、分布式、中间件、微服务,同时也懂点投资理财,偶尔讲点算法和计算机理论基础,坚持学习和写作,相信终身学习的力量!
-
-**程序员3T技术学习资源:** 一些程序员学习技术的资源大礼包,关注公众号后,后台回复关键字 **“资料”** 即可免费无套路获取。
-
diff --git "a/docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\27213\357\274\232\345\206\215\350\260\210\345\233\233\347\247\215\345\274\225\347\224\250\345\217\212GC\345\256\236\350\267\265.md" "b/docs/Java/JVM/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232\345\206\215\350\260\210\345\233\233\347\247\215\345\274\225\347\224\250\345\217\212GC\345\256\236\350\267\265.md"
similarity index 81%
rename from "docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\27213\357\274\232\345\206\215\350\260\210\345\233\233\347\247\215\345\274\225\347\224\250\345\217\212GC\345\256\236\350\267\265.md"
rename to "docs/Java/JVM/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232\345\206\215\350\260\210\345\233\233\347\247\215\345\274\225\347\224\250\345\217\212GC\345\256\236\350\267\265.md"
index 3167cfa..cca62d4 100644
--- "a/docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\27213\357\274\232\345\206\215\350\260\210\345\233\233\347\247\215\345\274\225\347\224\250\345\217\212GC\345\256\236\350\267\265.md"
+++ "b/docs/Java/JVM/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232\345\206\215\350\260\210\345\233\233\347\247\215\345\274\225\347\224\250\345\217\212GC\345\256\236\350\267\265.md"
@@ -1,5 +1,4 @@
-# Table of Contents
-
+# 目录
* [一、背景](#一、背景)
* [二、简介](#二、简介)
* [1.强引用 StrongReference](#1强引用-strongreference)
@@ -8,9 +7,7 @@
* [4.虚引用 PhantomReference](#4虚引用-phantomreference)
* [三、小结](#三、小结)
* [参考文章](#参考文章)
- * [微信公众号](#微信公众号)
- * [Java技术江湖](#java技术江湖)
- * [个人公众号:黄小斜](#个人公众号:黄小斜)
+
本文转自互联网,侵删
@@ -35,15 +32,15 @@
## 一、背景
-Java的内存回收不需要程序员负责,JVM会在必要时启动Java GC完成垃圾回收。Java以便我们控制对象的生存周期,提供给了我们四种引用方式,引用强度从强到弱分别为:强引用、软引用、弱引用、虚引用。
+Java的内存回收不需要程序员负责,JVM会在必要时启动Java GC完成垃圾回收。Java以便我们控制对象的生存周期,提供给了我们四种引用方式,引用强度从强到弱分别为:强引用、软引用、弱引用、虚引用。
## 二、简介
### 1.强引用 StrongReference
StrongReference是Java的默认引用形式,使用时不需要显示定义。任何通过强引用所使用的对象不管系统资源有多紧张,Java GC都不会主动回收具有强引用的对象。
-
-public class StrongReferenceTest {
+````
+public class StrongReferenceTest {
public static int M = 1024*1024;
@@ -76,17 +73,16 @@ StrongReference是Java的默认引用形式,使用时不需要显示定义。
System.out.println("strongReference : "+strongReference);
}
}
-
+````
运行结果:
-
-
+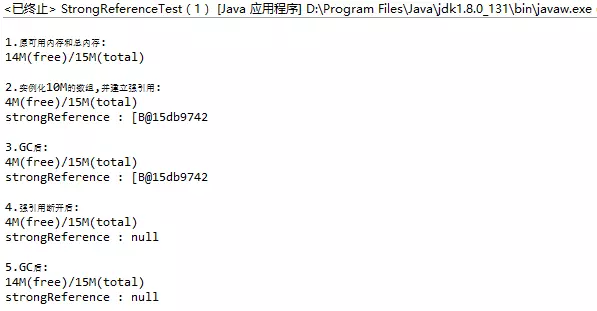
### 2.弱引用 WeakReference
如果一个对象只具有弱引用,无论内存充足与否,Java GC后对象如果只有弱引用将会被自动回收。
-
-public class WeakReferenceTest {
+````
+public class WeakReferenceTest {
public static int M = 1024*1024;
@@ -110,17 +106,16 @@ StrongReference是Java的默认引用形式,使用时不需要显示定义。
System.out.println("weakRerference.get() : "+weakRerference.get());
}
}
-
+````
运行结果:
-
-
+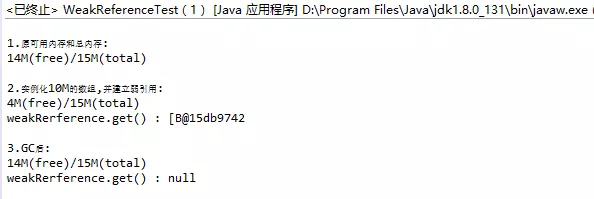
### 3.软引用 SoftReference
软引用和弱引用的特性基本一致, 主要的区别在于软引用在内存不足时才会被回收。如果一个对象只具有软引用,Java GC在内存充足的时候不会回收它,内存不足时才会被回收。
-
-public class SoftReferenceTest {
+````
+public class SoftReferenceTest {
public static int M = 1024*1024;
@@ -151,17 +146,16 @@ StrongReference是Java的默认引用形式,使用时不需要显示定义。
System.out.println("softRerference2.get() : "+softRerference2.get());
}
}
-
+````
运行结果:
-
-
+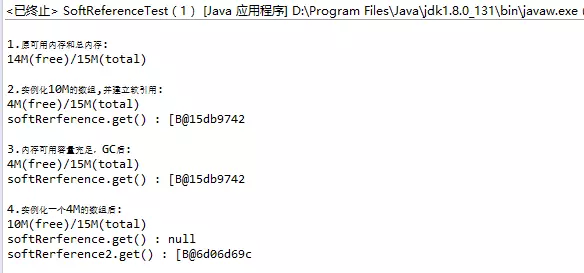
### 4.虚引用 PhantomReference
从PhantomReference类的源代码可以知道,它的get()方法无论何时返回的都只会是null。所以单独使用虚引用时,没有什么意义,需要和引用队列ReferenceQueue类联合使用。当执行Java GC时如果一个对象只有虚引用,就会把这个对象加入到与之关联的ReferenceQueue中。
-
-public class PhantomReferenceTest {
+````
+public class PhantomReferenceTest {
public static int M = 1024*1024;
@@ -205,12 +199,11 @@ StrongReference是Java的默认引用形式,使用时不需要显示定义。
System.out.println("referenceQueue.poll() : "+referenceQueue.poll());
}
}
-
+````
运行结果:
-
-
+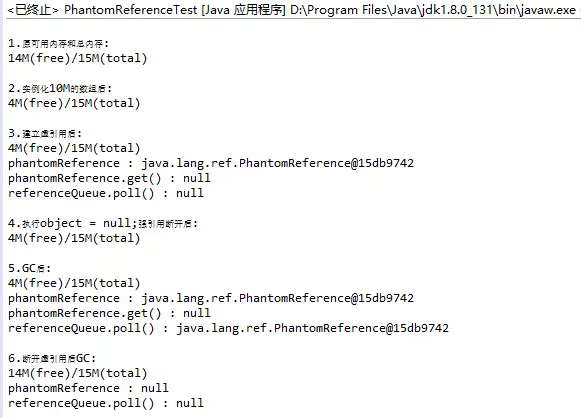
## 三、小结
强引用是 Java 的默认引用形式,使用时不需要显示定义,是我们平时最常使用到的引用方式。不管系统资源有多紧张,Java GC都不会主动回收具有强引用的对象。 弱引用和软引用一般在引用对象为非必需对象的时候使用。它们的区别是被弱引用关联的对象在垃圾回收时总是会被回收,被软引用关联的对象只有在内存不足时才会被回收。 虚引用的get()方法获取的永远是null,无法获取对象实例。Java GC会把虚引用的对象放到引用队列里面。可用来在对象被回收时做额外的一些资源清理或事物回滚等处理。 由于无法从虚引获取到引用对象的实例。它的使用情况比较特别,所以这里不把虚引用放入表格进行对比。这里对强引用、弱引用、软引用进行对比:
@@ -229,20 +222,4 @@ StrongReference是Java的默认引用形式,使用时不需要显示定义。
https://blog.csdn.net/android_hl/article/details/53228348
-## 微信公众号
-
-### Java技术江湖
-
-如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号【Java技术江湖】一位阿里 Java 工程师的技术小站,作者黄小斜,专注 Java 相关技术:SSM、SpringBoot、MySQL、分布式、中间件、集群、Linux、网络、多线程,偶尔讲点Docker、ELK,同时也分享技术干货和学习经验,致力于Java全栈开发!
-
-**Java工程师必备学习资源:** 一些Java工程师常用学习资源,关注公众号后,后台回复关键字 **“Java”** 即可免费无套路获取。
-
-
-
-### 个人公众号:黄小斜
-
-作者是 985 硕士,蚂蚁金服 JAVA 工程师,专注于 JAVA 后端技术栈:SpringBoot、MySQL、分布式、中间件、微服务,同时也懂点投资理财,偶尔讲点算法和计算机理论基础,坚持学习和写作,相信终身学习的力量!
-
-**程序员3T技术学习资源:** 一些程序员学习技术的资源大礼包,关注公众号后,后台回复关键字 **“资料”** 即可免费无套路获取。
-
diff --git "a/docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\2723\357\274\232\345\236\203\345\234\276\345\233\236\346\224\266\345\231\250\350\257\246\350\247\243.md" "b/docs/Java/JVM/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232\345\236\203\345\234\276\345\233\236\346\224\266\345\231\250\350\257\246\350\247\243.md"
similarity index 77%
rename from "docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\2723\357\274\232\345\236\203\345\234\276\345\233\236\346\224\266\345\231\250\350\257\246\350\247\243.md"
rename to "docs/Java/JVM/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232\345\236\203\345\234\276\345\233\236\346\224\266\345\231\250\350\257\246\350\247\243.md"
index 741c437..7e89241 100644
--- "a/docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\2723\357\274\232\345\236\203\345\234\276\345\233\236\346\224\266\345\231\250\350\257\246\350\247\243.md"
+++ "b/docs/Java/JVM/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232\345\236\203\345\234\276\345\233\236\346\224\266\345\231\250\350\257\246\350\247\243.md"
@@ -1,5 +1,4 @@
-# Table of Contents
-
+# 目录
* [1 概述](#1-概述)
* [2 对象已经死亡?](#2-对象已经死亡?)
* [2.1引用计数法](#21引用计数法)
@@ -85,8 +84,7 @@ Minor Gc和Full GC 有什么不同呢?
### 2.2可达性分析算法
-这个算法的基本思想就是通过一系列的称为 **“GC Roots”** 的对象作为起点,从这些节点开始向下搜索,节点所走过的路径称为引用链,当一个对象到GC Roots没有任何引用链相连的话,则证明此对象是不可用的。
-
+这个算法的基本思想就是通过一系列的称为**“GC Roots”**的对象作为起点,从这些节点开始向下搜索,节点所走过的路径称为引用链,当一个对象到GC Roots没有任何引用链相连的话,则证明此对象是不可用的。
### 2.3 再谈引用
@@ -114,7 +112,7 @@ JDK1.2以后,Java对引用的感念进行了扩充,将引用分为强引用
**虚引用主要用来跟踪对象被垃圾回收的活动**。
-**虚引用与软引用和弱引用的一个区别在于:** 虚引用必须和引用队列(ReferenceQueue)联合使用。当垃 圾回收器准备回收一个对象时,如果发现它还有虚引用,就会在回收对象的内存之前,把这个虚引用加入到与之关联的引用队列中。程序可以通过判断引用队列中是 否已经加入了虚引用,来了解被引用的对象是否将要被垃圾回收。程序如果发现某个虚引用已经被加入到引用队列,那么就可以在所引用的对象的内存被回收之前采取必要的行动。
+**虚引用与软引用和弱引用的一个区别在于:**虚引用必须和引用队列(ReferenceQueue)联合使用。当垃 圾回收器准备回收一个对象时,如果发现它还有虚引用,就会在回收对象的内存之前,把这个虚引用加入到与之关联的引用队列中。程序可以通过判断引用队列中是 否已经加入了虚引用,来了解被引用的对象是否将要被垃圾回收。程序如果发现某个虚引用已经被加入到引用队列,那么就可以在所引用的对象的内存被回收之前采取必要的行动。
特别注意,在程序设计中一般很少使用弱引用与虚引用,使用软引用的情况较多,这是因为**软引用可以加速JVM对垃圾内存的回收速度,可以维护系统的运行安全,防止内存溢出(OutOfMemory)等问题的产生**。
@@ -126,7 +124,7 @@ JDK1.2以后,Java对引用的感念进行了扩充,将引用分为强引用
方法区(或Hotspot虚拟中的永久代)的垃圾收集主要回收两部分内容:**废弃常量和无用的类。**
-判定一个常量是否是“废弃常量”比较简单,而要判定一个类是否是“无用的类”的条件则相对苛刻许多。类需要同时满足下面3个条件才能算是 **“无用的类”** :
+判定一个常量是否是“废弃常量”比较简单,而要判定一个类是否是“无用的类”的条件则相对苛刻许多。类需要同时满足下面3个条件才能算是**“无用的类”**:
- 该类所有的实例都已经被回收,也就是Java堆中不存在该类的任何实例。
- 加载该类的ClassLoader已经被回收。
- 该类对应的java.lang.Class对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法。
@@ -136,19 +134,16 @@ JDK1.2以后,Java对引用的感念进行了扩充,将引用分为强引用
### 3.1 标记-清除算法
算法分为“标记”和“清除”阶段:首先标记出所有需要回收的对象,在标记完成后统一回收所有被标记的对象。它是最基础的收集算法,会带来两个明显的问题;1:效率问题和2:空间问题(标记清除后会产生大量不连续的碎片)
-
### 3.2 复制算法
为了解决效率问题,“复制”收集算法出现了。它可以将内存分为大小相同的两块,每次使用其中的一块。当这一块的内存使用完后,就将还存活的对象复制到另一块去,然后再把使用的空间一次清理掉。这样就使每次的内存回收都是对内存区间的一半进行回收。
-
### 3.3 标记-整理算法
根据老年代的特点特出的一种标记算法,标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象回收,而是让所有存活的对象向一段移动,然后直接清理掉端边界以外的内存。
-
### 3.4分代收集算法
@@ -156,7 +151,7 @@ JDK1.2以后,Java对引用的感念进行了扩充,将引用分为强引用
比如在新生代中,每次收集都会有大量对象死去,所以可以选择复制算法,只需要付出少量对象的复制成本就可以完成每次垃圾收集。而老年代的对象存活几率是比较高的所以我们可以选择“标记-清理”或“标记-整理”算法进行垃圾收集。
-**延伸面试问题:** HotSpot为什么要分为新生代和老年代?
+**延伸面试问题:**HotSpot为什么要分为新生代和老年代?
根据上面的对分代收集算法的介绍回答。
@@ -167,8 +162,7 @@ JDK1.2以后,Java对引用的感念进行了扩充,将引用分为强引用
### 4.1 Serial收集器
-Serial(串行)收集器收集器是最基本、历史最悠久的垃圾收集器了。大家看名字就知道这个收集器是一个单线程收集器了。它的 **“单线程”** 的意义不仅仅意味着它只会使用一条垃圾收集线程去完成垃圾收集工作,更重要的是它在进行垃圾收集工作的时候必须暂停其他所有的工作线程( **“Stop The World”** 了解一下),直到它收集结束。
-
+Serial(串行)收集器收集器是最基本、历史最悠久的垃圾收集器了。大家看名字就知道这个收集器是一个单线程收集器了。它的**“单线程”**的意义不仅仅意味着它只会使用一条垃圾收集线程去完成垃圾收集工作,更重要的是它在进行垃圾收集工作的时候必须暂停其他所有的工作线程(**“Stop The World”**了解一下),直到它收集结束。
虚拟机的设计者们当然知道Stop The World带来的不良用户体验,所以在后续的垃圾收集器设计中停顿时间在不断缩短(仍然还有停顿,寻找最优秀的垃圾收集器的过程仍然在继续)。
@@ -178,12 +172,11 @@ Serial(串行)收集器收集器是最基本、历史最悠久的垃圾收
**ParNew收集器其实就是Serial收集器的多线程版本,除了使用多线程进行垃圾收集外,其余行为(控制参数、收集算法、回收策略等等)和Serial收集器完全一样。**
-
它是许多运行在Server模式下的虚拟机的首要选择,除了Serial收集器外,只有它能与CMS收集器(真正意义上的并发收集器,后面会介绍到)配合工作。
**并行和并发概念补充:**
-* **并行(Parallel)** :指多条垃圾收集线程并行工作,但此时用户线程仍然处于等待状态。
+* **并行(Parallel)**:指多条垃圾收集线程并行工作,但此时用户线程仍然处于等待状态。
* **并发(Concurrent)**:指用户线程与垃圾收集线程同时执行(但不一定是并行,可能会交替执行),用户程序在继续运行,而垃圾收集器运行在另一个CPU上。
@@ -191,7 +184,7 @@ Serial(串行)收集器收集器是最基本、历史最悠久的垃圾收
Parallel Scavenge收集器是一个新生代收集器,它也是使用复制算法的收集器,又是并行的的多线程收集器。。。那么它有什么特别之处呢?
-**Parallel Scavenge收集器关注点是吞吐量(高效率的利用CPU)。CMS等垃圾收集器的关注点更多的是用户线程的停顿时间(提高用户体验)。所谓吞吐量就是CPU中用于运行用户代码的时间与CPU总消耗时间的比值。** Parallel Scavenge收集器提供了很多参数供用户找到最合适的停顿时间或最大吞吐量,如果对于收集器运作不太了解的话,手工优化存在的话可以选择把内存管理优化交给虚拟机去完成也是一个不错的选择。
+**Parallel Scavenge收集器关注点是吞吐量(高效率的利用CPU)。CMS等垃圾收集器的关注点更多的是用户线程的停顿时间(提高用户体验)。所谓吞吐量就是CPU中用于运行用户代码的时间与CPU总消耗时间的比值。**Parallel Scavenge收集器提供了很多参数供用户找到最合适的停顿时间或最大吞吐量,如果对于收集器运作不太了解的话,手工优化存在的话可以选择把内存管理优化交给虚拟机去完成也是一个不错的选择。
### 4.4.Serial Old收集器
@@ -205,45 +198,41 @@ Parallel Scavenge收集器是一个新生代收集器,它也是使用复制算
**CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器。它而非常符合在注重用户体验的应用上使用。**
-从名字中的**Mark Sweep**这两个词可以看出,CMS收集器是一种 **“标记-清除”算法**实现的,它的运作过程相比于前面几种垃圾收集器来说更加复杂一些。整个过程分为四个步骤:
-
-* **初始标记:** 暂停所有的其他线程,并记录下直接与root相连的对象,速度很快 ;
-* **并发标记:** 同时开启GC和用户线程,用一个闭包结构去记录可达对象。但在这个阶段结束,这个闭包结构并不能保证包含当前所有的可达对象。因为用户线程可能会不断的更新引用域,所以GC线程无法保证可达性分析的实时性。所以这个算法里会跟踪记录这些发生引用更新的地方。
-* **重新标记:** 重新标记阶段就是为了修正并发标记期间因为用户程序继续运行而导致标记产生变动的那一部分对象的标记记录,这个阶段的停顿时间一般会比初始标记阶段的时间稍长,远远比并发标记阶段时间短
-* **并发清除:** 开启用户线程,同时GC线程开始对为标记的区域做清扫。
+从名字中的**Mark Sweep**这两个词可以看出,CMS收集器是一种**“标记-清除”算法**实现的,它的运作过程相比于前面几种垃圾收集器来说更加复杂一些。整个过程分为四个步骤:
-
+* **初始标记:**暂停所有的其他线程,并记录下直接与root相连的对象,速度很快 ;
+* **并发标记:**同时开启GC和用户线程,用一个闭包结构去记录可达对象。但在这个阶段结束,这个闭包结构并不能保证包含当前所有的可达对象。因为用户线程可能会不断的更新引用域,所以GC线程无法保证可达性分析的实时性。所以这个算法里会跟踪记录这些发生引用更新的地方。
+* **重新标记:**重新标记阶段就是为了修正并发标记期间因为用户程序继续运行而导致标记产生变动的那一部分对象的标记记录,这个阶段的停顿时间一般会比初始标记阶段的时间稍长,远远比并发标记阶段时间短
+* **并发清除:**开启用户线程,同时GC线程开始对为标记的区域做清扫。
从它的名字就可以看出它是一款优秀的垃圾收集器,主要优点:**并发收集、低停顿**。但是它有下面三个明显的缺点:
-- **对CPU资源敏感;**
-- **无法处理浮动垃圾;**
-- **它使用的回收算法-“标记-清除”算法会导致收集结束时会有大量空间碎片产生。**
+-**对CPU资源敏感;**
+-**无法处理浮动垃圾;**
+-**它使用的回收算法-“标记-清除”算法会导致收集结束时会有大量空间碎片产生。**
### 4.7 G1收集器
上一代的垃圾收集器(串行serial, 并行parallel, 以及CMS)都把堆内存划分为固定大小的三个部分: 年轻代(young generation), 年老代(old generation), 以及持久代(permanent generation).
-
**G1 (Garbage-First)是一款面向服务器的垃圾收集器,主要针对配备多颗处理器及大容量内存的机器. 以极高概率满足GC停顿时间要求的同时,还具备高吞吐量性能特征.**
被视为JDK1.7中HotSpot虚拟机的一个重要进化特征。它具备一下特点:
-- **并行与并发**:G1能充分利用CPU、多核环境下的硬件优势,使用多个CPU(CPU或者CPU核心)来缩短stop-The-World停顿时间。部分其他收集器原本需要停顿Java线程执行的GC动作,G1收集器仍然可以通过并发的方式让java程序继续执行。
-- **分代收集**:虽然G1可以不需要其他收集器配合就能独立管理整个GC堆,但是还是保留了分代的概念。
-- **空间整合**:与CMS的“标记–清理”算法不同,G1从整体来看是基于“标记整理”算法实现的收集器;从局部上来看是基于“复制”算法实现的。
-- **可预测的停顿**:这是G1相对于CMS的另一个大优势,降低停顿时间是G1和CMS共同的关注点,但G1除了追求低停顿外,还能建立可预测的停顿时间模型,能让使用者明确指定在一个长度为M毫秒的时间片段内。
+-**并行与并发**:G1能充分利用CPU、多核环境下的硬件优势,使用多个CPU(CPU或者CPU核心)来缩短stop-The-World停顿时间。部分其他收集器原本需要停顿Java线程执行的GC动作,G1收集器仍然可以通过并发的方式让java程序继续执行。
+-**分代收集**:虽然G1可以不需要其他收集器配合就能独立管理整个GC堆,但是还是保留了分代的概念。
+-**空间整合**:与CMS的“标记–清理”算法不同,G1从整体来看是基于“标记整理”算法实现的收集器;从局部上来看是基于“复制”算法实现的。
+-**可预测的停顿**:这是G1相对于CMS的另一个大优势,降低停顿时间是G1和CMS共同的关注点,但G1除了追求低停顿外,还能建立可预测的停顿时间模型,能让使用者明确指定在一个长度为M毫秒的时间片段内。
**G1收集器在后台维护了一个优先列表,每次根据允许的收集时间,优先选择回收价值最大的Region(这也就是它的名字Garbage-First的由来)**。这种使用Region划分内存空间以及有优先级的区域回收方式,保证了GF收集器在有限时间内可以尽可能高的收集效率(把内存化整为零)。
G1收集器的运作大致分为以下几个步骤:
-- **初始标记**
-- **并发标记**
-- **最终标记**
-- **筛选回收**
+-**初始标记**
+-**并发标记**
+-**最终标记**
+-**筛选回收**
上面几个步骤的运作过程和CMS有很多相似之处。初始标记阶段仅仅只是标记一下GC Roots能直接关联到的对象,并且修改TAMS的值,让下一个阶段用户程序并发运行时,能在正确可用的Region中创建新对象,这一阶段需要停顿线程,但是耗时很短,并发标记阶段是从GC Root开始对堆中对象进行可达性分析,找出存活的对象,这阶段时耗时较长,但可与用户程序并发执行。而最终标记阶段则是为了修正在并发标记期间因用户程序继续运作而导致标记产生变动的那一部分标记记录,虚拟机将这段时间对象变化记录在线程Remenbered Set Logs里面,最终标记阶段需要把Remembered Set Logs的数据合并到Remembered Set Logs里面,最终标记阶段需要把Remembered Set Logs的数据合并到Remembered Set中,这一阶段需要停顿线程,但是可并行执行。最后在筛选回收阶段首先对各个Region的回收价值和成本进行排序,根据用户所期望的GC停顿时间来制定回收计划。
-
## 5 内存分配与回收策略
diff --git "a/docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\2726\357\274\232\346\267\261\345\205\245\347\220\206\350\247\243JVM\347\261\273\345\212\240\350\275\275\346\234\272\345\210\266.md" "b/docs/Java/JVM/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232\346\267\261\345\205\245\347\220\206\350\247\243JVM\347\261\273\345\212\240\350\275\275\346\234\272\345\210\266.md"
similarity index 82%
rename from "docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\2726\357\274\232\346\267\261\345\205\245\347\220\206\350\247\243JVM\347\261\273\345\212\240\350\275\275\346\234\272\345\210\266.md"
rename to "docs/Java/JVM/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232\346\267\261\345\205\245\347\220\206\350\247\243JVM\347\261\273\345\212\240\350\275\275\346\234\272\345\210\266.md"
index 60ad7b7..198ce72 100644
--- "a/docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\2726\357\274\232\346\267\261\345\205\245\347\220\206\350\247\243JVM\347\261\273\345\212\240\350\275\275\346\234\272\345\210\266.md"
+++ "b/docs/Java/JVM/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232\346\267\261\345\205\245\347\220\206\350\247\243JVM\347\261\273\345\212\240\350\275\275\346\234\272\345\210\266.md"
@@ -1,5 +1,4 @@
-# Table of Contents
-
+# 目录
* [一.目标:](#一目标:)
* [二.原理 (类的加载过程及其最终产品):](#二原理-(类的加载过程及其最终产品))
* [三.过程(类的生命周期):](#三过程(类的生命周期):)
@@ -11,9 +10,6 @@
* [四.类加载器:](#四类加载器:)
* [五.双亲委派机制:](#五双亲委派机制:)
* [参考文章](#参考文章)
- * [微信公众号](#微信公众号)
- * [Java技术江湖](#java技术江湖)
- * [个人公众号:黄小斜](#个人公众号:黄小斜)
本文转自互联网,侵删
@@ -36,7 +32,6 @@
-
## 一.目标:
1.什么是类的加载?
@@ -56,14 +51,7 @@ JVM将class文件字节码文件加载到内存中, 并将这些静态数据
JVM类加载机制分为五个部分:加载,验证,准备,解析,初始化,下面我们就分别来看一下这五个过程。其中加载、检验、准备、初始化和卸载这个五个阶段的顺序是固定的,而解析则未必。为了支持动态绑定,解析这个过程可以发生在初始化阶段之后。
-
-
-
-
-
-
-
-
+
### 加载:
@@ -139,13 +127,7 @@ java中,对于初始化阶段,有且只有以下五种情况才会对要求
## 五.双亲委派机制:
-
-
-
-
-
-
-
+
双亲委派机制工作过程:
@@ -169,20 +151,4 @@ java中,对于初始化阶段,有且只有以下五种情况才会对要求
https://blog.csdn.net/android_hl/article/details/53228348
-## 微信公众号
-
-### Java技术江湖
-
-如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号【Java技术江湖】一位阿里 Java 工程师的技术小站,作者黄小斜,专注 Java 相关技术:SSM、SpringBoot、MySQL、分布式、中间件、集群、Linux、网络、多线程,偶尔讲点Docker、ELK,同时也分享技术干货和学习经验,致力于Java全栈开发!
-
-**Java工程师必备学习资源:** 一些Java工程师常用学习资源,关注公众号后,后台回复关键字 **“Java”** 即可免费无套路获取。
-
-
-
-### 个人公众号:黄小斜
-
-作者是 985 硕士,蚂蚁金服 JAVA 工程师,专注于 JAVA 后端技术栈:SpringBoot、MySQL、分布式、中间件、微服务,同时也懂点投资理财,偶尔讲点算法和计算机理论基础,坚持学习和写作,相信终身学习的力量!
-
-**程序员3T技术学习资源:** 一些程序员学习技术的资源大礼包,关注公众号后,后台回复关键字 **“资料”** 即可免费无套路获取。
-
diff --git "a/docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\2725\357\274\232\350\231\232\346\213\237\346\234\272\345\255\227\350\212\202\347\240\201\346\211\247\350\241\214\345\274\225\346\223\216.md" "b/docs/Java/JVM/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232\350\231\232\346\213\237\346\234\272\345\255\227\350\212\202\347\240\201\346\211\247\350\241\214\345\274\225\346\223\216.md"
similarity index 85%
rename from "docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\2725\357\274\232\350\231\232\346\213\237\346\234\272\345\255\227\350\212\202\347\240\201\346\211\247\350\241\214\345\274\225\346\223\216.md"
rename to "docs/Java/JVM/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232\350\231\232\346\213\237\346\234\272\345\255\227\350\212\202\347\240\201\346\211\247\350\241\214\345\274\225\346\223\216.md"
index faebc2d..aabb34c 100644
--- "a/docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\2725\357\274\232\350\231\232\346\213\237\346\234\272\345\255\227\350\212\202\347\240\201\346\211\247\350\241\214\345\274\225\346\223\216.md"
+++ "b/docs/Java/JVM/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232\350\231\232\346\213\237\346\234\272\345\255\227\350\212\202\347\240\201\346\211\247\350\241\214\345\274\225\346\223\216.md"
@@ -1,5 +1,4 @@
-# Table of Contents
-
+# 目录
* [1 概述](#1-概述)
* [2 运行时栈帧结构](#2-运行时栈帧结构)
* [2.1 局部变量表](#21-局部变量表)
@@ -45,14 +44,13 @@
## 2 运行时栈帧结构
-**栈帧(Stack Frame)** 是用于支持虚拟机方法调用和方法执行的数据结构,它是虚拟机运行时数据区中**虚拟机栈(Virtual Machine Stack)的栈元素**。
+**栈帧(Stack Frame)**是用于支持虚拟机方法调用和方法执行的数据结构,它是虚拟机运行时数据区中**虚拟机栈(Virtual Machine Stack)的栈元素**。
栈帧存储了方法的局部变量表、操作数栈、动态连接和方法返回地址等信息。每一个方法从调用开始至执行完成的过程,都对应着一个栈帧在虚拟机栈里面从入栈到出栈的过程。
**栈帧概念结构如下图所示:**
-
-
+
### 2.1 局部变量表
**局部变量表是一组变量值存储空间,用于存放方法参数和方法内定义的局部变量。
@@ -66,17 +64,16 @@
### 2.2 操作数栈
-**操作数栈(Operand Stack)** 也常称为操作栈,它是一个**后入先出栈**。当一个方法执行开始时,这个方法的操作数栈是空的,在方法执行过程中,会有各种字节码指令往操作数栈中写入和提取内容,也就是 **出栈/入栈**操作。
-
-
+**操作数栈(Operand Stack)**也常称为操作栈,它是一个**后入先出栈**。当一个方法执行开始时,这个方法的操作数栈是空的,在方法执行过程中,会有各种字节码指令往操作数栈中写入和提取内容,也就是**出栈/入栈**操作。
+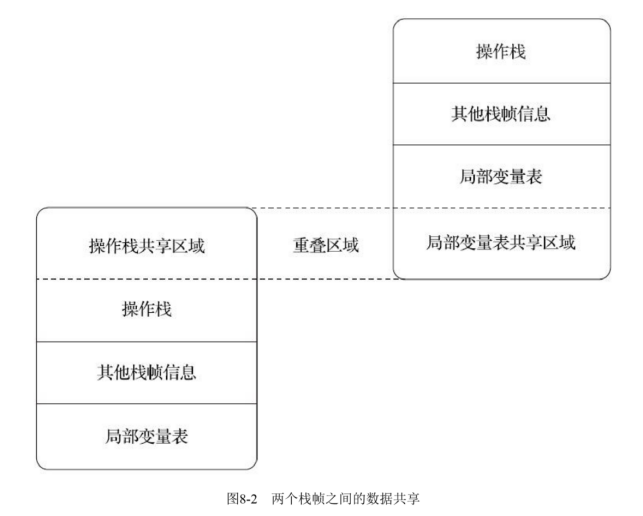
在概念模型中,一个活动线程中两个栈帧是相互独立的。但大多数虚拟机实现都会做一些优化处理:让下一个栈帧的部分操作数栈与上一个栈帧的部分局部变量表重叠在一起,这样的好处是方法调用时可以共享一部分数据,而无须进行额外的参数复制传递。
### 2.3 动态连接
每个栈帧都包含一个指向运行时常量池中该栈帧所属方法的引用,持有这个引用是为了支持方法调用过程中的**动态连接**;
-字节码中方法调用指令是以常量池中的指向方法的符号引用为参数的,有一部分符号引用会在类加载阶段或第一次使用的时候转化为直接引用,这种转化称为 **静态解析**,另外一部分在每次的运行期间转化为直接引用,这部分称为**动态连接**。
+字节码中方法调用指令是以常量池中的指向方法的符号引用为参数的,有一部分符号引用会在类加载阶段或第一次使用的时候转化为直接引用,这种转化称为**静态解析**,另外一部分在每次的运行期间转化为直接引用,这部分称为**动态连接**。
### 2.4 方法返回地址
@@ -106,11 +103,11 @@
“编译期可知,运行期不可变”的方法(静态方法和私有方法),在类加载的解析阶段,会将其符号引用转化为直接引用(入口地址)。这类方法的调用称为“**解析(Resolution)**”。
在Java虚拟机中提供了5条方法调用字节码指令:
-- **invokestatic** : 调用静态方法
-- **invokespecial**:调用实例构造器方法、私有方法、父类方法
-- **invokevirtual**:调用所有的虚方法
-- **invokeinterface**:调用接口方法,会在运行时在确定一个实现此接口的对象
-- **invokedynamic**:先在运行时动态解析出点限定符所引用的方法,然后再执行该方法,在此之前的4条调用命令的分派逻辑是固化在Java虚拟机内部的,而invokedynamic指令的分派逻辑是由用户所设定的引导方法决定的。
+-**invokestatic**: 调用静态方法
+-**invokespecial**:调用实例构造器方法、私有方法、父类方法
+-**invokevirtual**:调用所有的虚方法
+-**invokeinterface**:调用接口方法,会在运行时在确定一个实现此接口的对象
+-**invokedynamic**:先在运行时动态解析出点限定符所引用的方法,然后再执行该方法,在此之前的4条调用命令的分派逻辑是固化在Java虚拟机内部的,而invokedynamic指令的分派逻辑是由用户所设定的引导方法决定的。
### 3.2 分派
@@ -252,14 +249,14 @@ JDK新增加了invokedynamic指令来是实现“动态类型语言”。
**静态语言和动态语言的区别:**
* **静态语言(强类型语言)**:
- 静态语言是在编译时变量的数据类型即可确定的语言,多数静态类型语言要求在使用变量之前必须声明数据类型。
+ 静态语言是在编译时变量的数据类型即可确定的语言,多数静态类型语言要求在使用变量之前必须声明数据类型。
例如:C++、Java、Delphi、C#等。
-* **动态语言(弱类型语言)** :
- 动态语言是在运行时确定数据类型的语言。变量使用之前不需要类型声明,通常变量的类型是被赋值的那个值的类型。
+* **动态语言(弱类型语言)**:
+ 动态语言是在运行时确定数据类型的语言。变量使用之前不需要类型声明,通常变量的类型是被赋值的那个值的类型。
例如PHP/ASP/Ruby/Python/Perl/ABAP/SQL/JavaScript/Unix Shell等等。
-* **强类型定义语言** :
+* **强类型定义语言**:
强制数据类型定义的语言。也就是说,一旦一个变量被指定了某个数据类型,如果不经过强制转换,那么它就永远是这个数据类型了。举个例子:如果你定义了一个整型变量a,那么程序根本不可能将a当作字符串类型处理。强类型定义语言是类型安全的语言。
-* **弱类型定义语言** :
+* **弱类型定义语言**:
数据类型可以被忽略的语言。它与强类型定义语言相反, 一个变量可以赋不同数据类型的值。强类型定义语言在速度上可能略逊色于弱类型定义语言,但是强类型定义语言带来的严谨性能够有效的避免许多错误。
## 4 基于栈的字节码解释执行引擎
@@ -268,15 +265,13 @@ JDK新增加了invokedynamic指令来是实现“动态类型语言”。
### 4.1 解释执行
-Java语言经常被人们定位为 **“解释执行”语言**,在Java初生的JDK1.0时代,这种定义还比较准确的,但当主流的虚拟机中都包含了即时编译后,Class文件中的代码到底会被解释执行还是编译执行,就成了只有虚拟机自己才能准确判断的事情。再后来,Java也发展出来了直接生成本地代码的编译器[如何GCJ(GNU Compiler for the Java)],而C/C++也出现了通过解释器执行的版本(如CINT),这时候再笼统的说“解释执行”,对于整个Java语言来说就成了几乎没有任何意义的概念,**只有确定了谈论对象是某种具体的Java实现版本和执行引擎运行模式时,谈解释执行还是编译执行才会比较确切**。
-
-
+Java语言经常被人们定位为**“解释执行”语言**,在Java初生的JDK1.0时代,这种定义还比较准确的,但当主流的虚拟机中都包含了即时编译后,Class文件中的代码到底会被解释执行还是编译执行,就成了只有虚拟机自己才能准确判断的事情。再后来,Java也发展出来了直接生成本地代码的编译器[如何GCJ(GNU Compiler for the Java)],而C/C++也出现了通过解释器执行的版本(如CINT),这时候再笼统的说“解释执行”,对于整个Java语言来说就成了几乎没有任何意义的概念,**只有确定了谈论对象是某种具体的Java实现版本和执行引擎运行模式时,谈解释执行还是编译执行才会比较确切**。
Java语言中,javac编译器完成了程序代码经过词法分析、语法分析到抽象语法树,再遍历语法树生成线性的字节码指令流的过程,因为这一部分动作是在Java虚拟机之外进行的,而解释器在虚拟机内部,所以Java程序的编译就是半独立实现的,
### 4.2 基于栈的指令集和基于寄存器的指令集
-Java编译器输出的指令流,基本上是一种**基于栈的指令集架构(Instruction Set Architecture,ISA)**,**依赖操作数栈进行工作**。与之相对应的另一套常用的指令集架构是**基于寄存器的指令集**, **依赖寄存器进行工作**。
+Java编译器输出的指令流,基本上是一种**基于栈的指令集架构(Instruction Set Architecture,ISA)**,**依赖操作数栈进行工作**。与之相对应的另一套常用的指令集架构是**基于寄存器的指令集**,**依赖寄存器进行工作**。
那么,**基于栈的指令集和基于寄存器的指令集这两者有什么不同呢?**
diff --git "a/docs/java/basic/21\343\200\201Java8\346\226\260\347\211\271\346\200\247\347\273\210\346\236\201\346\214\207\345\215\227.md" "b/docs/Java/basic/Java8\346\226\260\347\211\271\346\200\247\347\273\210\346\236\201\346\214\207\345\215\227.md"
similarity index 81%
rename from "docs/java/basic/21\343\200\201Java8\346\226\260\347\211\271\346\200\247\347\273\210\346\236\201\346\214\207\345\215\227.md"
rename to "docs/Java/basic/Java8\346\226\260\347\211\271\346\200\247\347\273\210\346\236\201\346\214\207\345\215\227.md"
index 14b4137..fa70648 100644
--- "a/docs/java/basic/21\343\200\201Java8\346\226\260\347\211\271\346\200\247\347\273\210\346\236\201\346\214\207\345\215\227.md"
+++ "b/docs/Java/basic/Java8\346\226\260\347\211\271\346\200\247\347\273\210\346\236\201\346\214\207\345\215\227.md"
@@ -16,18 +16,7 @@
* [Java虚拟机(JVM)的新特性](#java虚拟机(jvm)的新特性)
* [总结](#总结)
* [参考文章](#参考文章)
- * [微信公众号](#微信公众号)
- * [Java技术江湖](#java技术江湖)
- * [个人公众号:黄小斜](#个人公众号:黄小斜)
----
-title: 夯实Java基础系列21:Java8新特性终极指南
-date: 2019-9-21 15:56:26 # 文章生成时间,一般不改
-categories:
- - Java技术江湖
- - Java基础
-tags:
- - Java8
----
+
本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
> https://github.com/h2pl/Java-Tutorial
@@ -48,8 +37,7 @@ tags:
这是一个Java8新增特性的总结图。接下来让我们一次实践一下这些新特性吧
-
-
+
## Java语言新特性
### Lambda表达式
@@ -100,13 +88,14 @@ java.lang.Runnable与java.util.concurrent.Callable是函数式接口最典型的
在实际使用过程中,函数式接口是容易出错的:如有某个人在接口定义中增加了另一个方法,这时,这个接口就不再是函数式的了,并且编译过程也会失败。
为了克服函数式接口的这种脆弱性并且能够明确声明接口作为函数式接口的意图,Java8增加了一种特殊的注解@FunctionalInterface(Java8中所有类库的已有接口都添加了@FunctionalInterface注解)。让我们看一下这种函数式接口的定义:
-
+````
@FunctionalInterface
public interface Functional {
void method();
}
+````
需要记住的一件事是:默认方法与静态方法并不影响函数式接口的契约,可以任意使用:
-
+````
@FunctionalInterface
public interface FunctionalDefaultMethods {
void method();
@@ -114,82 +103,83 @@ public interface FunctionalDefaultMethods {
default void defaultMethod() {
}
}
+````
Lambda是Java 8最大的卖点。它具有吸引越来越多程序员到Java平台上的潜力,并且能够在纯Java语言环境中提供一种优雅的方式来支持函数式编程。更多详情可以参考官方文档。
下面看一个例子:
+````
+public class lambda和函数式编程 {
+ @Test
+ public void test1() {
+ List names = Arrays.asList("peter", "anna", "mike", "xenia");
- public class lambda和函数式编程 {
- @Test
- public void test1() {
- List names = Arrays.asList("peter", "anna", "mike", "xenia");
-
- Collections.sort(names, new Comparator() {
- @Override
- public int compare(String a, String b) {
- return b.compareTo(a);
- }
- });
- System.out.println(Arrays.toString(names.toArray()));
- }
-
- @Test
- public void test2() {
- List names = Arrays.asList("peter", "anna", "mike", "xenia");
-
- Collections.sort(names, (String a, String b) -> {
+ Collections.sort(names, new Comparator() {
+ @Override
+ public int compare(String a, String b) {
return b.compareTo(a);
- });
-
- Collections.sort(names, (String a, String b) -> b.compareTo(a));
-
- Collections.sort(names, (a, b) -> b.compareTo(a));
- System.out.println(Arrays.toString(names.toArray()));
- }
-
+ }
+ });
+ System.out.println(Arrays.toString(names.toArray()));
}
-
- static void add(double a,String b) {
- System.out.println(a + b);
- }
- @Test
- public void test5() {
- D d = (a,b) -> add(a,b);
- // interface D {
- // void get(int i,String j);
- // }
- //这里要求,add的两个参数和get的两个参数吻合并且返回类型也要相等,否则报错
- // static void add(double a,String b) {
- // System.out.println(a + b);
- // }
- }
-
- @FunctionalInterface
- interface D {
- void get(int i,String j);
- }
-接下来看看Lambda和匿名内部类的区别
+ @Test
+ public void test2() {
+ List names = Arrays.asList("peter", "anna", "mike", "xenia");
-匿名内部类仍然是一个类,只是不需要我们显式指定类名,编译器会自动为该类取名。比如有如下形式的代码:
+ Collections.sort(names, (String a, String b) -> {
+ return b.compareTo(a);
+ });
- public class LambdaTest {
- public static void main(String[] args) {
- new Thread(new Runnable() {
- @Override
- public void run() {
- System.out.println("Hello World");
- }
- }).start();
- }
+ Collections.sort(names, (String a, String b) -> b.compareTo(a));
+
+ Collections.sort(names, (a, b) -> b.compareTo(a));
+ System.out.println(Arrays.toString(names.toArray()));
+ }
+
+}
+
+ static void add(double a,String b) {
+ System.out.println(a + b);
+ }
+ @Test
+ public void test5() {
+ D d = (a,b) -> add(a,b);
+// interface D {
+// void get(int i,String j);
+// }
+ //这里要求,add的两个参数和get的两个参数吻合并且返回类型也要相等,否则报错
+// static void add(double a,String b) {
+// System.out.println(a + b);
+// }
}
+ @FunctionalInterface
+ interface D {
+ void get(int i,String j);
+ }
+````
+接下来看看Lambda和匿名内部类的区别
+
+匿名内部类仍然是一个类,只是不需要我们显式指定类名,编译器会自动为该类取名。比如有如下形式的代码:
+````
+public class LambdaTest {
+ public static void main(String[] args) {
+ new Thread(new Runnable() {
+ @Override
+ public void run() {
+ System.out.println("Hello World");
+ }
+ }).start();
+ }
+}
+````
编译之后将会产生两个 class 文件:
LambdaTest.class
LambdaTest$1.class
使用 javap -c LambdaTest.class 进一步分析 LambdaTest.class 的字节码,部分结果如下:
-
+````
public static void main(java.lang.String[]);
Code:
0: new #2 // class java/lang/Thread
@@ -200,28 +190,28 @@ Lambda是Java 8最大的卖点。它具有吸引越来越多程序员到Java平
11: invokespecial #5 // Method java/lang/Thread."":(Ljava/lang/Runnable;)V
14: invokevirtual #6 // Method java/lang/Thread.start:()V
17: return
-
+````
可以发现在 4: new #3 这一行创建了匿名内部类的对象。
而对于 Lambda表达式的实现, 接下来我们将上面的示例代码使用 Lambda 表达式实现,代码如下:
-
- public class LambdaTest {
- public static void main(String[] args) {
- new Thread(() -> System.out.println("Hello World")).start();
- }
+````
+public class LambdaTest {
+ public static void main(String[] args) {
+ new Thread(() -> System.out.println("Hello World")).start();
}
-
+}
+````
此时编译后只会产生一个文件 LambdaTest.class,再来看看通过 javap 对该文件反编译后的结果:
-
- public static void main(java.lang.String[]);
- Code:
- 0: new #2 // class java/lang/Thread
- 3: dup
- 4: invokedynamic #3, 0 // InvokeDynamic #0:run:()Ljava/lang/Runnable;
- 9: invokespecial #4 // Method java/lang/Thread."":(Ljava/lang/Runnable;)V
- 12: invokevirtual #5 // Method java/lang/Thread.start:()V
- 15: return
-
+````
+public static void main(java.lang.String[]);
+Code:
+ 0: new #2 // class java/lang/Thread
+ 3: dup
+ 4: invokedynamic #3, 0 // InvokeDynamic #0:run:()Ljava/lang/Runnable;
+ 9: invokespecial #4 // Method java/lang/Thread."":(Ljava/lang/Runnable;)V
+ 12: invokevirtual #5 // Method java/lang/Thread.start:()V
+ 15: return
+````
从上面的结果我们发现 Lambda 表达式被封装成了主类的一个私有方法,并通过 invokedynamic 指令进行调用。
因此,我们可以得出结论:Lambda 表达式是通过 invokedynamic 指令实现的,并且书写 Lambda 表达式不会产生新的类。
@@ -238,50 +228,50 @@ lambda表达式是如何符合 Java 类型系统的?每个lambda对应于一
我们可以使用任意的接口作为lambda表达式,只要这个接口只包含一个抽象方法。为了保证你的接口满足需求,你需要增加@FunctionalInterface注解。编译器知道这个注解,一旦你试图给这个接口增加第二个抽象方法声明时,它将抛出一个编译器错误。
下面举几个例子
-
- public class 函数式接口使用 {
- @FunctionalInterface
- interface A {
- void say();
- default void talk() {
-
- }
- }
- @Test
- public void test1() {
- A a = () -> System.out.println("hello");
- a.say();
- }
-
- @FunctionalInterface
- interface B {
- void say(String i);
- }
- public void test2() {
- //下面两个是等价的,都是通过B接口来引用一个方法,而方法可以直接使用::来作为方法引用
- B b = System.out::println;
- B b1 = a -> Integer.parseInt("s");//这里的a其实换成别的也行,只是将方法传给接口作为其方法实现
- B b2 = Integer::valueOf;//i与方法传入参数的变量类型一直时,可以直接替换
- B b3 = String::valueOf;
- //B b4 = Integer::parseInt;类型不符,无法使用
-
- }
- @FunctionalInterface
- interface C {
- int say(String i);
- }
- public void test3() {
- C c = Integer::parseInt;//方法参数和接口方法的参数一样,可以替换。
- int i = c.say("1");
- //当我把C接口的int替换为void时就会报错,因为返回类型不一致。
- System.out.println(i);
- //综上所述,lambda表达式提供了一种简便的表达方式,可以将一个方法传到接口中。
- //函数式接口是只提供一个抽象方法的接口,其方法由lambda表达式注入,不需要写实现类,
- //也不需要写匿名内部类,可以省去很多代码,比如实现runnable接口。
- //函数式编程就是指把方法当做一个参数或引用来进行操作。除了普通方法以外,静态方法,构造方法也是可以这样操作的。
+````
+public class 函数式接口使用 {
+ @FunctionalInterface
+ interface A {
+ void say();
+ default void talk() {
+
}
}
+ @Test
+ public void test1() {
+ A a = () -> System.out.println("hello");
+ a.say();
+ }
+ @FunctionalInterface
+ interface B {
+ void say(String i);
+ }
+ public void test2() {
+ //下面两个是等价的,都是通过B接口来引用一个方法,而方法可以直接使用::来作为方法引用
+ B b = System.out::println;
+ B b1 = a -> Integer.parseInt("s");//这里的a其实换成别的也行,只是将方法传给接口作为其方法实现
+ B b2 = Integer::valueOf;//i与方法传入参数的变量类型一直时,可以直接替换
+ B b3 = String::valueOf;
+ //B b4 = Integer::parseInt;类型不符,无法使用
+
+ }
+ @FunctionalInterface
+ interface C {
+ int say(String i);
+ }
+ public void test3() {
+ C c = Integer::parseInt;//方法参数和接口方法的参数一样,可以替换。
+ int i = c.say("1");
+ //当我把C接口的int替换为void时就会报错,因为返回类型不一致。
+ System.out.println(i);
+ //综上所述,lambda表达式提供了一种简便的表达方式,可以将一个方法传到接口中。
+ //函数式接口是只提供一个抽象方法的接口,其方法由lambda表达式注入,不需要写实现类,
+ //也不需要写匿名内部类,可以省去很多代码,比如实现runnable接口。
+ //函数式编程就是指把方法当做一个参数或引用来进行操作。除了普通方法以外,静态方法,构造方法也是可以这样操作的。
+ }
+}
+````
请记住如果@FunctionalInterface 这个注解被遗漏,此代码依然有效。
### 方法引用
@@ -290,7 +280,7 @@ Lambda表达式和方法引用
有了函数式接口之后,就可以使用Lambda表达式和方法引用了。其实函数式接口的表中的函数描述符就是Lambda表达式,在函数式接口中Lambda表达式相当于匿名内部类的效果。 举个简单的例子:
-
+````
public class TestLambda {
public static void execute(Runnable runnable) {
@@ -310,7 +300,7 @@ public class TestLambda {
execute(() -> System.out.println("run"));
}
}
-
+````
可以看到,相比于使用匿名内部类的方式,Lambda表达式可以使用更少的代码但是有更清晰的表述。注意,Lambda表达式也不是完全等价于匿名内部类的, 两者的不同点在于this的指向和本地变量的屏蔽上。
方法引用可以看作Lambda表达式的更简洁的一种表达形式,使用::操作符,方法引用主要有三类:
@@ -351,31 +341,31 @@ public class TestLambda {
### 接口的默认方法
Java 8 使我们能够使用default 关键字给接口增加非抽象的方法实现。这个特性也被叫做 扩展方法(Extension Methods)。如下例所示:
-
- public class 接口的默认方法 {
- class B implements A {
- // void a(){}实现类方法不能重名
- }
- interface A {
- //可以有多个默认方法
- public default void a(){
- System.out.println("a");
- }
- public default void b(){
- System.out.println("b");
- }
- //报错static和default不能同时使用
- // public static default void c(){
- // System.out.println("c");
- // }
+````
+public class 接口的默认方法 {
+ class B implements A {
+// void a(){}实现类方法不能重名
+ }
+ interface A {
+ //可以有多个默认方法
+ public default void a(){
+ System.out.println("a");
}
- public void test() {
- B b = new B();
- b.a();
-
+ public default void b(){
+ System.out.println("b");
}
+ //报错static和default不能同时使用
+// public static default void c(){
+// System.out.println("c");
+// }
}
+ public void test() {
+ B b = new B();
+ b.a();
+ }
+}
+````
默认方法出现的原因是为了对原有接口的扩展,有了默认方法之后就不怕因改动原有的接口而对已经使用这些接口的程序造成的代码不兼容的影响。 在Java8中也对一些接口增加了一些默认方法,比如Map接口等等。一般来说,使用默认方法的场景有两个:可选方法和行为的多继承。
默认方法的使用相对来说比较简单,唯一要注意的点是如何处理默认方法的冲突。关于如何处理默认方法的冲突可以参考以下三条规则:
@@ -385,7 +375,7 @@ Java 8 使我们能够使用default 关键字给接口增加非抽象的方法
如果无法依据第一条规则进行判断,那么子接口的优先级更高:函数签名相同时,优先选择拥有最具体实现的默认方法的接口。即如果B继承了A,那么B就比A更具体。
最后,如果还是无法判断,继承了多个接口的类必须通过显式覆盖和调用期望的方法,显式地选择使用哪一个默认方法的实现。那么如何显式地指定呢:
-
+````
public class C implements B, A {
public void hello() {
@@ -393,43 +383,46 @@ Java 8 使我们能够使用default 关键字给接口增加非抽象的方法
}
}
+````
使用X.super.m(..)显式地调用希望调用的方法。
Java 8用默认方法与静态方法这两个新概念来扩展接口的声明。默认方法使接口有点像Traits(Scala中特征(trait)类似于Java中的Interface,但它可以包含实现代码,也就是目前Java8新增的功能),但与传统的接口又有些不一样,它允许在已有的接口中添加新方法,而同时又保持了与旧版本代码的兼容性。
默认方法与抽象方法不同之处在于抽象方法必须要求实现,但是默认方法则没有这个要求。相反,每个接口都必须提供一个所谓的默认实现,这样所有的接口实现者将会默认继承它(如果有必要的话,可以覆盖这个默认实现)。让我们看看下面的例子:
-
- private interface Defaulable {
- // Interfaces now allow default methods, the implementer may or
- // may not implement (override) them.
- default String notRequired() {
- return "Default implementation";
- }
- }
-
- private static class DefaultableImpl implements Defaulable {
- }
+````
+private interface Defaulable {
+ // Interfaces now allow default methods, the implementer may or
+ // may not implement (override) them.
+ default String notRequired() {
+ return "Default implementation";
+ }
+}
- private static class OverridableImpl implements Defaulable {
- @Override
- public String notRequired() {
- return "Overridden implementation";
- }
+private static class DefaultableImpl implements Defaulable {
+}
+
+private static class OverridableImpl implements Defaulable {
+ @Override
+ public String notRequired() {
+ return "Overridden implementation";
}
+}
+````
Defaulable接口用关键字default声明了一个默认方法notRequired(),Defaulable接口的实现者之一DefaultableImpl实现了这个接口,并且让默认方法保持原样。Defaulable接口的另一个实现者OverridableImpl用自己的方法覆盖了默认方法。
Java 8带来的另一个有趣的特性是接口可以声明(并且可以提供实现)静态方法。例如:
-
+````
private interface DefaulableFactory {
// Interfaces now allow static methods
static Defaulable create( Supplier< Defaulable > supplier ) {
return supplier.get();
}
}
+````
下面的一小段代码片段把上面的默认方法与静态方法黏合到一起。
-
+````
public static void main( String[] args ) {
Defaulable defaulable = DefaulableFactory.create( DefaultableImpl::new );
System.out.println( defaulable.notRequired() );
@@ -437,6 +430,7 @@ Java 8带来的另一个有趣的特性是接口可以声明(并且可以提
defaulable = DefaulableFactory.create( OverridableImpl::new );
System.out.println( defaulable.notRequired() );
}
+````
这个程序的控制台输出如下:
Default implementation
@@ -450,58 +444,57 @@ Overridden implementation
自从Java 5引入了注解机制,这一特性就变得非常流行并且广为使用。然而,使用注解的一个限制是相同的注解在同一位置只能声明一次,不能声明多次。Java 8打破了这条规则,引入了重复注解机制,这样相同的注解可以在同一地方声明多次。
重复注解机制本身必须用@Repeatable注解。事实上,这并不是语言层面上的改变,更多的是编译器的技巧,底层的原理保持不变。让我们看一个快速入门的例子:
-
- package com.javacodegeeks.java8.repeatable.annotations;
+````
+package com.javacodegeeks.java8.repeatable.annotations;
+
+import java.lang.annotation.ElementType;
+import java.lang.annotation.Repeatable;
+import java.lang.annotation.Retention;
+import java.lang.annotation.RetentionPolicy;
+import java.lang.annotation.Target;
+
+public class RepeatingAnnotations {
+ @Target( ElementType.TYPE )
+ @Retention( RetentionPolicy.RUNTIME )
+ public @interface Filters {
+ Filter[] value();
+ }
- import java.lang.annotation.ElementType;
- import java.lang.annotation.Repeatable;
- import java.lang.annotation.Retention;
- import java.lang.annotation.RetentionPolicy;
- import java.lang.annotation.Target;
+ @Target( ElementType.TYPE )
+ @Retention( RetentionPolicy.RUNTIME )
+ @Repeatable( Filters.class )
+ public @interface Filter {
+ String value();
+ };
- public class RepeatingAnnotations {
- @Target( ElementType.TYPE )
- @Retention( RetentionPolicy.RUNTIME )
- public @interface Filters {
- Filter[] value();
- }
-
- @Target( ElementType.TYPE )
- @Retention( RetentionPolicy.RUNTIME )
- @Repeatable( Filters.class )
- public @interface Filter {
- String value();
- };
-
- @Filter( "filter1" )
- @Filter( "filter2" )
- public interface Filterable {
- }
-
- public static void main(String[] args) {
- for( Filter filter: Filterable.class.getAnnotationsByType( Filter.class ) ) {
- System.out.println( filter.value() );
- }
+ @Filter( "filter1" )
+ @Filter( "filter2" )
+ public interface Filterable {
+ }
+
+ public static void main(String[] args) {
+ for( Filter filter: Filterable.class.getAnnotationsByType( Filter.class ) ) {
+ System.out.println( filter.value() );
}
}
+}
+````
正如我们看到的,这里有个使用@Repeatable( Filters.class )注解的注解类Filter,Filters仅仅是Filter注解的数组,但Java编译器并不想让程序员意识到Filters的存在。这样,接口Filterable就拥有了两次Filter(并没有提到Filter)注解。
同时,反射相关的API提供了新的函数getAnnotationsByType()来返回重复注解的类型(请注意Filterable.class.getAnnotation( Filters.class )经编译器处理后将会返回Filters的实例)。
程序输出结果如下:
-filter1
-filter2
+ filter1
+ filter2
更多详情请参考官方文档
-
-
## Java编译器的新特性
### 方法参数名字可以反射获取
很长一段时间里,Java程序员一直在发明不同的方式使得方法参数的名字能保留在Java字节码中,并且能够在运行时获取它们(比如,Paranamer类库)。最终,在Java 8中把这个强烈要求的功能添加到语言层面(通过反射API与Parameter.getName()方法)与字节码文件(通过新版的javac的–parameters选项)中。
-
+````
package com.javacodegeeks.java8.parameter.names;
import java.lang.reflect.Method;
@@ -515,6 +508,7 @@ public class ParameterNames {
}
}
}
+````
如果不使用–parameters参数来编译这个类,然后运行这个类,会得到下面的输出:
Parameter: arg0
@@ -531,7 +525,7 @@ Java 8 通过增加大量新类,扩展已有类的功能的方式来改善对
Optional实际上是个容器:它可以保存类型T的值,或者仅仅保存null。Optional提供很多有用的方法,这样我们就不用显式进行空值检测。更多详情请参考官方文档。
我们下面用两个小例子来演示如何使用Optional类:一个允许为空值,一个不允许为空值。
-
+````
public class 空指针Optional {
public static void main(String[] args) {
@@ -554,7 +548,7 @@ Optional实际上是个容器:它可以保存类型T的值,或者仅仅保
//输出Optional.empty。
}
}
-
+````
如果Optional类的实例为非空值的话,isPresent()返回true,否从返回false。为了防止Optional为空值,orElseGet()方法通过回调函数来产生一个默认值。map()函数对当前Optional的值进行转化,然后返回一个新的Optional实例。orElse()方法和orElseGet()方法类似,但是orElse接受一个默认值而不是一个回调函数。下面是这个程序的输出:
Full Name is set? false
@@ -581,14 +575,15 @@ Hey Tom!
Stream API极大简化了集合框架的处理(但它的处理的范围不仅仅限于集合框架的处理,这点后面我们会看到)。让我们以一个简单的Task类为例进行介绍:
Task类有一个分数的概念(或者说是伪复杂度),其次是还有一个值可以为OPEN或CLOSED的状态.让我们引入一个Task的小集合作为演示例子:
-
+````
final Collection< Task > tasks = Arrays.asList(
new Task( Status.OPEN, 5 ),
new Task( Status.OPEN, 13 ),
new Task( Status.CLOSED, 8 )
);
+````
我们下面要讨论的第一个问题是所有状态为OPEN的任务一共有多少分数?在Java 8以前,一般的解决方式用foreach循环,但是在Java 8里面我们可以使用stream:一串支持连续、并行聚集操作的元素。
-
+````
// Calculate total points of all active tasks using sum()
final long totalPointsOfOpenTasks = tasks
.stream()
@@ -597,9 +592,10 @@ Task类有一个分数的概念(或者说是伪复杂度),其次是还有
.sum();
System.out.println( "Total points: " + totalPointsOfOpenTasks );
+````
程序在控制台上的输出如下:
-Total points: 18
+ Total points: 18
这里有几个注意事项。
@@ -617,7 +613,7 @@ Total points: 18
stream另一个有价值的地方是能够原生支持并行处理。让我们来看看这个算task分数和的例子。
stream另一个有价值的地方是能够原生支持并行处理。让我们来看看这个算task分数和的例子。
-
+````
// Calculate total points of all tasks
final double totalPoints = tasks
.stream()
@@ -626,23 +622,28 @@ stream另一个有价值的地方是能够原生支持并行处理。让我们
.reduce( 0, Integer::sum );
System.out.println( "Total points (all tasks): " + totalPoints );
+````
这个例子和第一个例子很相似,但这个例子的不同之处在于这个程序是并行运行的,其次使用reduce方法来算最终的结果。
下面是这个例子在控制台的输出:
Total points (all tasks): 26.0
经常会有这个一个需求:我们需要按照某种准则来对集合中的元素进行分组。Stream也可以处理这样的需求,下面是一个例子:
-
+````
// Group tasks by their status
final Map< Status, List< Task > > map = tasks
.stream()
.collect( Collectors.groupingBy( Task::getStatus ) );
System.out.println( map );
+````
+
这个例子的控制台输出如下:
-{CLOSED=[[CLOSED, 8]], OPEN=[[OPEN, 5], [OPEN, 13]]}
+ {CLOSED=[[CLOSED, 8]], OPEN=[[OPEN, 5], [OPEN, 13]]}
+
让我们来计算整个集合中每个task分数(或权重)的平均值来结束task的例子。
+````
// Calculate the weight of each tasks (as percent of total points)
final Collection< String > result = tasks
.stream() // Stream< String >
@@ -655,15 +656,19 @@ Total points (all tasks): 26.0
.collect( Collectors.toList() ); // List< String >
System.out.println( result );
+````
+
下面是这个例子的控制台输出:
[19%, 50%, 30%]
最后,就像前面提到的,Stream API不仅仅处理Java集合框架。像从文本文件中逐行读取数据这样典型的I/O操作也很适合用Stream API来处理。下面用一个例子来应证这一点。
-
+````
final Path path = new File( filename ).toPath();
try( Stream< String > lines = Files.lines( path, StandardCharsets.UTF_8 ) ) {
lines.onClose( () -> System.out.println("Done!") ).forEach( System.out::println );
}
+````
+
对一个stream对象调用onClose方法会返回一个在原有功能基础上新增了关闭功能的stream对象,当对stream对象调用close()方法时,与关闭相关的处理器就会执行。
Stream API、Lambda表达式与方法引用在接口默认方法与静态方法的配合下是Java 8对现代软件开发范式的回应。更多详情请参考官方文档。
@@ -674,19 +679,19 @@ Java 8通过发布新的Date-Time API (JSR 310)来进一步加强对日期与时
这种情况直接导致了Joda-Time——一个可替换标准日期/时间处理且功能非常强大的Java API的诞生。Java 8新的Date-Time API (JSR 310)在很大程度上受到Joda-Time的影响,并且吸取了其精髓。新的java.time包涵盖了所有处理日期,时间,日期/时间,时区,时刻(instants),过程(during)与时钟(clock)的操作。在设计新版API时,十分注重与旧版API的兼容性:不允许有任何的改变(从java.util.Calendar中得到的深刻教训)。如果需要修改,会返回这个类的一个新实例。
让我们用例子来看一下新版API主要类的使用方法。第一个是Clock类,它通过指定一个时区,然后就可以获取到当前的时刻,日期与时间。Clock可以替换System.currentTimeMillis()与TimeZone.getDefault()。
-
+````
// Get the system clock as UTC offset
final Clock clock = Clock.systemUTC();
System.out.println( clock.instant() );
System.out.println( clock.millis() );
-
+````
下面是程序在控制台上的输出:
2014-04-12T15:19:29.282Z
1397315969360
我们需要关注的其他类是LocaleDate与LocalTime。LocaleDate只持有ISO-8601格式且无时区信息的日期部分。相应的,LocaleTime只持有ISO-8601格式且无时区信息的时间部分。LocaleDate与LocalTime都可以从Clock中得到。
-
+````
// Get the local date and local time
final LocalDate date = LocalDate.now();
final LocalDate dateFromClock = LocalDate.now( clock );
@@ -700,7 +705,7 @@ Java 8通过发布新的Date-Time API (JSR 310)来进一步加强对日期与时
System.out.println( time );
System.out.println( timeFromClock );
-
+````
下面是程序在控制台上的输出:
2014-04-12
@@ -715,7 +720,7 @@ Java 8通过发布新的Date-Time API (JSR 310)来进一步加强对日期与时
2014-04-12T08:47:01.017-07:00[America/Los_Angeles]
最后,让我们看一下Duration类:在秒与纳秒级别上的一段时间。Duration使计算两个日期间的不同变的十分简单。下面让我们看一个这方面的例子。
-
+````
// Get duration between two dates
final LocalDateTime from = LocalDateTime.of( 2014, Month.APRIL, 16, 0, 0, 0 );
final LocalDateTime to = LocalDateTime.of( 2015, Month.APRIL, 16, 23, 59, 59 );
@@ -723,7 +728,7 @@ Java 8通过发布新的Date-Time API (JSR 310)来进一步加强对日期与时
final Duration duration = Duration.between( from, to );
System.out.println( "Duration in days: " + duration.toDays() );
System.out.println( "Duration in hours: " + duration.toHours() );
-
+````
上面的例子计算了两个日期2014年4月16号与2014年4月16号之间的过程。下面是程序在控制台上的输出:
Duration in days: 365
@@ -733,7 +738,7 @@ Duration in hours: 8783
### 并行(parallel)数组
Java 8增加了大量的新方法来对数组进行并行处理。可以说,最重要的是parallelSort()方法,因为它可以在多核机器上极大提高数组排序的速度。下面的例子展示了新方法(parallelXxx)的使用。
-
+````
package com.javacodegeeks.java8.parallel.arrays;
import java.util.Arrays;
@@ -755,7 +760,7 @@ Java 8增加了大量的新方法来对数组进行并行处理。可以说,
System.out.println();
}
}
-
+````
上面的代码片段使用了parallelSetAll()方法来对一个有20000个元素的数组进行随机赋值。然后,调用parallelSort方法。这个程序首先打印出前10个元素的值,之后对整个数组排序。这个程序在控制台上的输出如下(请注意数组元素是随机生产的):
Unsorted: 591217 891976 443951 424479 766825 351964 242997 642839 119108 552378
@@ -766,7 +771,7 @@ Sorted: 39 220 263 268 325 607 655 678 723 793
在Java8之前,我们会使用JDK提供的Future接口来进行一些异步的操作,其实CompletableFuture也是实现了Future接口, 并且基于ForkJoinPool来执行任务,因此本质上来讲,CompletableFuture只是对原有API的封装, 而使用CompletableFuture与原来的Future的不同之处在于可以将两个Future组合起来,或者如果两个Future是有依赖关系的,可以等第一个执行完毕后再实行第二个等特性。
**先来看看基本的使用方式:**
-
+````
public Future getPriceAsync(final String product) {
final CompletableFuture futurePrice = new CompletableFuture<>();
new Thread(() -> {
@@ -775,13 +780,14 @@ Sorted: 39 220 263 268 325 607 655 678 723 793
}).start();
return futurePrice;
}
+````
得到Future之后就可以使用get方法来获取结果,CompletableFuture提供了一些工厂方法来简化这些API,并且使用函数式编程的方式来使用这些API,例如:
Fufure price = CompletableFuture.supplyAsync(() -> calculatePrice(product));
代码是不是一下子简洁了许多呢。之前说了,CompletableFuture可以组合多个Future,不管是Future之间有依赖的,还是没有依赖的。
**如果第二个请求依赖于第一个请求的结果,那么可以使用thenCompose方法来组合两个Future**
-
+````
public List findPriceAsync(String product) {
List> priceFutures = tasks.stream()
.map(task -> CompletableFuture.supplyAsync(() -> task.getPrice(product),executor))
@@ -791,24 +797,26 @@ Fufure price = CompletableFuture.supplyAsync(() -> calculatePrice(produc
return priceFutures.stream().map(CompletableFuture::join).collect(Collectors.toList());
}
+````
上面这段代码使用了thenCompose来组合两个CompletableFuture。supplyAsync方法第二个参数接受一个自定义的Executor。 首先使用CompletableFuture执行一个任务,调用getPrice方法,得到一个Future,之后使用thenApply方法,将Future的结果应用parse方法, 之后再使用执行完parse之后的结果作为参数再执行一个applyCount方法,然后收集成一个CompletableFuture的List, 最后再使用一个流,调用CompletableFuture的join方法,这是为了等待所有的异步任务执行完毕,获得最后的结果。
注意,这里必须使用两个流,如果在一个流里调用join方法,那么由于Stream的延迟特性,所有的操作还是会串行的执行,并不是异步的。
**再来看一个两个Future之间没有依赖关系的例子:**
-
+````
Future futurePriceInUsd = CompletableFuture.supplyAsync(() -> shop.getPrice(“price1”))
.thenCombine(CompletableFuture.supplyAsync(() -> shop.getPrice(“price2”)), (s1, s2) -> s1 + s2);
+````
这里有两个异步的任务,使用thenCombine方法来组合两个Future,thenCombine方法的第二个参数就是用来合并两个Future方法返回值的操作函数。
有时候,我们并不需要等待所有的异步任务结束,只需要其中的一个完成就可以了,CompletableFuture也提供了这样的方法:
-
+````
//假设getStream方法返回一个Stream>
CompletableFuture[] futures = getStream(“listen”).map(f -> f.thenAccept(System.out::println)).toArray(CompletableFuture[]::new);
//等待其中的一个执行完毕
CompletableFuture.anyOf(futures).join();
使用anyOf方法来响应CompletableFuture的completion事件。
-
+````
## Java虚拟机(JVM)的新特性
PermGen空间被移除了,取而代之的是Metaspace(JEP 122)。JVM选项-XX:PermSize与-XX:MaxPermSize分别被-XX:MetaSpaceSize与-XX:MaxMetaspaceSize所代替。
@@ -824,20 +832,3 @@ https://www.jianshu.com/p/4df02599aeb2
https://www.cnblogs.com/yangzhilong/p/10973006.html
https://www.cnblogs.com/JackpotHan/p/9701147.html
-## 微信公众号
-
-### Java技术江湖
-
-如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号【Java技术江湖】一位阿里 Java 工程师的技术小站,作者黄小斜,专注 Java 相关技术:SSM、SpringBoot、MySQL、分布式、中间件、集群、Linux、网络、多线程,偶尔讲点Docker、ELK,同时也分享技术干货和学习经验,致力于Java全栈开发!
-
-**Java工程师必备学习资源:** 一些Java工程师常用学习资源,关注公众号后,后台回复关键字 **“Java”** 即可免费无套路获取。
-
-
-
-### 个人公众号:黄小斜
-
-作者是 985 硕士,蚂蚁金服 JAVA 工程师,专注于 JAVA 后端技术栈:SpringBoot、MySQL、分布式、中间件、微服务,同时也懂点投资理财,偶尔讲点算法和计算机理论基础,坚持学习和写作,相信终身学习的力量!
-
-**程序员3T技术学习资源:** 一些程序员学习技术的资源大礼包,关注公众号后,后台回复关键字 **“资料”** 即可免费无套路获取。
-
-
diff --git "a/docs/java/basic/16\343\200\201JavaIO\346\265\201.md" "b/docs/Java/basic/JavaIO\346\265\201.md"
similarity index 88%
rename from "docs/java/basic/16\343\200\201JavaIO\346\265\201.md"
rename to "docs/Java/basic/JavaIO\346\265\201.md"
index a405b7f..9d1ecd1 100644
--- "a/docs/java/basic/16\343\200\201JavaIO\346\265\201.md"
+++ "b/docs/Java/basic/JavaIO\346\265\201.md"
@@ -21,18 +21,7 @@
* [说说File类](#说说file类)
* [说说RandomAccessFile?](#说说randomaccessfile)
* [参考文章](#参考文章)
- * [微信公众号](#微信公众号)
- * [Java技术江湖](#java技术江湖)
- * [个人公众号:黄小斜](#个人公众号:黄小斜)
----
-title: 夯实Java基础系列16:一文读懂Java IO流和常见面试题
-date: 2019-9-16 15:56:26 # 文章生成时间,一般不改
-categories:
- - Java技术江湖
- - Java基础
-tags:
- - Java IO流
----
+
本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
> https://github.com/h2pl/Java-Tutorial
@@ -60,7 +49,6 @@ tags:
> 在这一小节,我会试着给出Java IO(java.io)包下所有类的概述。更具体地说,我会根据类的用途对类进行分组。这个分组将会使你在未来的工作中,进行类的用途判定时,或者是为某个特定用途选择类时变得更加容易。
-
**输入和输出**
术语“输入”和“输出”有时候会有一点让人疑惑。一个应用程序的输入往往是另外一个应用程序的输出
@@ -174,7 +162,7 @@ java.io.InputStream类是所有Java IO输入流的基类。如果你正在开发
这使得RandomAccessFile可以覆盖一个文件的某些部分、或者追加内容到它的末尾、或者删除它的某些内容,当然它也可以从文件的任何位置开始读取文件。
下面是具体例子:
-
+````
@Test
//文件流范例,打开一个文件的输入流,读取到字节数组,再写入另一个文件的输出流
public void test1() {
@@ -193,6 +181,7 @@ java.io.InputStream类是所有Java IO输入流的基类。如果你正在开发
e.printStackTrace();
}
}
+````
### 字符流和字节流
Java IO的Reader和Writer除了基于字符之外,其他方面都与InputStream和OutputStream非常类似。他们被用于读写文本。InputStream和OutputStream是基于字节的,还记得吗?
@@ -204,46 +193,47 @@ Writer
Writer类是Java IO中所有Writer的基类。子类包括BufferedWriter和PrintWriter等等。
这是一个简单的Java IO Reader的例子:
+````
+Reader reader = new FileReader("c:\\data\\myfile.txt");
- Reader reader = new FileReader("c:\\data\\myfile.txt");
-
- int data = reader.read();
-
- while(data != -1){
-
- char dataChar = (char) data;
-
- data = reader.read();
-
- }
+int data = reader.read();
+
+while(data != -1){
+
+ char dataChar = (char) data;
+ data = reader.read();
+
+}
+````
你通常会使用Reader的子类,而不会直接使用Reader。Reader的子类包括InputStreamReader,CharArrayReader,FileReader等等。可以查看Java IO概述浏览完整的Reader表格。
**整合Reader与InputStream**
一个Reader可以和一个InputStream相结合。如果你有一个InputStream输入流,并且想从其中读取字符,可以把这个InputStream包装到InputStreamReader中。把InputStream传递到InputStreamReader的构造函数中:
-
- Reader reader = new InputStreamReader(inputStream);
+````
+Reader reader = new InputStreamReader(inputStream);
+````
在构造函数中可以指定解码方式。
**Writer**
Writer类是Java IO中所有Writer的基类。子类包括BufferedWriter和PrintWriter等等。这是一个Java IO Writer的例子:
+````
+Writer writer = new FileWriter("c:\\data\\file-output.txt");
- Writer writer = new FileWriter("c:\\data\\file-output.txt");
-
- writer.write("Hello World Writer");
-
- writer.close();
+writer.write("Hello World Writer");
+writer.close();
+````
同样,你最好使用Writer的子类,不需要直接使用Writer,因为子类的实现更加明确,更能表现你的意图。常用子类包括OutputStreamWriter,CharArrayWriter,FileWriter等。Writer的write(int c)方法,会将传入参数的低16位写入到Writer中,忽略高16位的数据。
**整合Writer和OutputStream**
与Reader和InputStream类似,一个Writer可以和一个OutputStream相结合。把OutputStream包装到OutputStreamWriter中,所有写入到OutputStreamWriter的字符都将会传递给OutputStream。这是一个OutputStreamWriter的例子:
-
- Writer writer = new OutputStreamWriter(outputStream);
-
+````
+Writer writer = new OutputStreamWriter(outputStream);
+````
### IO管道
Java IO中的管道为运行在同一个JVM中的两个线程提供了通信的能力。所以管道也可以作为数据源以及目标媒介。
@@ -258,37 +248,38 @@ Java IO中的管道为运行在同一个JVM中的两个线程提供了通信的
Java IO管道示例
这是一个如何将PipedInputStream和PipedOutputStream关联起来的简单例子:
-
- //使用管道来完成两个线程间的数据点对点传递
- @Test
- public void test2() throws IOException {
- PipedInputStream pipedInputStream = new PipedInputStream();
- PipedOutputStream pipedOutputStream = new PipedOutputStream(pipedInputStream);
- new Thread(new Runnable() {
- @Override
- public void run() {
- try {
- pipedOutputStream.write("hello input".getBytes());
- pipedOutputStream.close();
- } catch (IOException e) {
- e.printStackTrace();
- }
+````
+//使用管道来完成两个线程间的数据点对点传递
+ @Test
+ public void test2() throws IOException {
+ PipedInputStream pipedInputStream = new PipedInputStream();
+ PipedOutputStream pipedOutputStream = new PipedOutputStream(pipedInputStream);
+ new Thread(new Runnable() {
+ @Override
+ public void run() {
+ try {
+ pipedOutputStream.write("hello input".getBytes());
+ pipedOutputStream.close();
+ } catch (IOException e) {
+ e.printStackTrace();
}
- }).start();
- new Thread(new Runnable() {
- @Override
- public void run() {
- try {
- byte []arr = new byte[128];
- while (pipedInputStream.read(arr) != -1) {
- System.out.println(Arrays.toString(arr));
- }
- pipedInputStream.close();
- } catch (IOException e) {
- e.printStackTrace();
+ }
+ }).start();
+ new Thread(new Runnable() {
+ @Override
+ public void run() {
+ try {
+ byte []arr = new byte[128];
+ while (pipedInputStream.read(arr) != -1) {
+ System.out.println(Arrays.toString(arr));
}
+ pipedInputStream.close();
+ } catch (IOException e) {
+ e.printStackTrace();
}
- }).start();
+ }
+ }).start();
+````
管道和线程
请记得,当使用两个相关联的管道流时,务必将它们分配给不同的线程。read()方法和write()方法调用时会导致流阻塞,这意味着如果你尝试在一个线程中同时进行读和写,可能会导致线程死锁。
@@ -304,7 +295,7 @@ Java中网络的内容或多或少的超出了Java IO的范畴。关于Java网
当两个进程之间建立了网络连接之后,他们通信的方式如同操作文件一样:利用InputStream读取数据,利用OutputStream写入数据。换句话来说,Java网络API用来在不同进程之间建立网络连接,而Java IO则用来在建立了连接之后的进程之间交换数据。
基本上意味着如果你有一份能够对文件进行写入某些数据的代码,那么这些数据也可以很容易地写入到网络连接中去。你所需要做的仅仅只是在代码中利用OutputStream替代FileOutputStream进行数据的写入。因为FileOutputStream是OuputStream的子类,所以这么做并没有什么问题。
-
+````
//从网络中读取字节流也可以直接使用OutputStream
public void test3() {
//读取网络进程的输出流
@@ -318,7 +309,7 @@ Java中网络的内容或多或少的超出了Java IO的范畴。关于Java网
//处理网络信息
//do something with the OutputStream
}
-
+````
### 字节和字符数组
@@ -330,7 +321,7 @@ Java中网络的内容或多或少的超出了Java IO的范畴。关于Java网
前面的例子中,字符数组或字节数组是用来缓存数据的临时存储空间,不过它们同时也可以作为数据来源或者写入目的地。
举个例子:
-
+````
//字符数组和字节数组在io过程中的作用
public void test4() {
//arr和brr分别作为数据源
@@ -339,7 +330,7 @@ Java中网络的内容或多或少的超出了Java IO的范畴。关于Java网
byte []brr = {1,2,3,4,5};
ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(brr);
}
-
+````
### System.in, System.out, System.err
System.in, System.out, System.err这3个流同样是常见的数据来源和数据流目的地。使用最多的可能是在控制台程序里利用System.out将输出打印到控制台上。
@@ -358,7 +349,7 @@ JVM启动的时候通过Java运行时初始化这3个流,所以你不需要初
System.out和System.err的简单例子:
这是一个System.out和System.err结合使用的简单示例:
-
+````
//测试System.in, System.out, System.err
public static void main(String[] args) {
int in = new Scanner(System.in).nextInt();
@@ -370,7 +361,7 @@ System.out和System.err的简单例子:
// 10
// out
}
-
+````
### 字符流的Buffered和Filter
@@ -437,8 +428,6 @@ Filter Stream是一种IO流主要作用是用来对存在的流增加一些额
在java.io包中主要由4个可用的filter Stream。两个字节filter stream,两个字符filter stream. 分别是FilterInputStream, FilterOutputStream, FilterReader and FilterWriter.这些类是抽象类,不能被实例化的。
-
-
### 在文件拷贝的时候,那一种流可用提升更多的性能?
在字节流的时候,使用BufferedInputStream和BufferedOutputStream。
在字符流的时候,使用BufferedReader 和 BufferedWriter
@@ -459,20 +448,3 @@ https://www.cnblogs.com/UncleWang001/articles/10454685.html
https://www.cnblogs.com/Jixiangwei/p/Java.html
https://blog.csdn.net/baidu_37107022/article/details/76890019
-## 微信公众号
-
-### Java技术江湖
-
-如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号【Java技术江湖】一位阿里 Java 工程师的技术小站,作者黄小斜,专注 Java 相关技术:SSM、SpringBoot、MySQL、分布式、中间件、集群、Linux、网络、多线程,偶尔讲点Docker、ELK,同时也分享技术干货和学习经验,致力于Java全栈开发!
-
-**Java工程师必备学习资源:** 一些Java工程师常用学习资源,关注公众号后,后台回复关键字 **“Java”** 即可免费无套路获取。
-
-
-
-### 个人公众号:黄小斜
-
-作者是 985 硕士,蚂蚁金服 JAVA 工程师,专注于 JAVA 后端技术栈:SpringBoot、MySQL、分布式、中间件、微服务,同时也懂点投资理财,偶尔讲点算法和计算机理论基础,坚持学习和写作,相信终身学习的力量!
-
-**程序员3T技术学习资源:** 一些程序员学习技术的资源大礼包,关注公众号后,后台回复关键字 **“资料”** 即可免费无套路获取。
-
-
diff --git "a/docs/java/basic/9\343\200\201Java\344\270\255\347\232\204Class\347\261\273\345\222\214Object\347\261\273.md" "b/docs/Java/basic/Java\344\270\255\347\232\204Class\347\261\273\345\222\214Object\347\261\273.md"
similarity index 91%
rename from "docs/java/basic/9\343\200\201Java\344\270\255\347\232\204Class\347\261\273\345\222\214Object\347\261\273.md"
rename to "docs/Java/basic/Java\344\270\255\347\232\204Class\347\261\273\345\222\214Object\347\261\273.md"
index 4caf35a..7ff3baa 100644
--- "a/docs/java/basic/9\343\200\201Java\344\270\255\347\232\204Class\347\261\273\345\222\214Object\347\261\273.md"
+++ "b/docs/Java/basic/Java\344\270\255\347\232\204Class\347\261\273\345\222\214Object\347\261\273.md"
@@ -1,4 +1,4 @@
-# Table of Contents
+# 目录
* [Java中Class类及用法](#java中class类及用法)
* [Class类原理](#class类原理)
@@ -16,9 +16,7 @@
* [finalize()方法](#finalize方法)
* [CLass类和Object类的关系](#class类和object类的关系)
* [参考文章](#参考文章)
- * [微信公众号](#微信公众号)
- * [Java技术江湖](#java技术江湖)
- * [个人公众号:黄小斜](#个人公众号:黄小斜)
+
本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
> https://github.com/h2pl/Java-Tutorial
@@ -48,25 +46,25 @@ Java程序在运行时,Java运行时系统一直对所有的对象进行所谓
> Class类的对象内容是你创建的类的类型信息,比如你创建一个shapes类,那么,Java会生成一个内容是shapes的Class类的对象
> Class类的对象不能像普通类一样,以 new shapes() 的方式创建,它的对象只能由JVM创建,因为这个类没有public构造函数
-
- /*
- * Private constructor. Only the Java Virtual Machine creates Class objects.
- * This constructor is not used and prevents the default constructor being
- * generated.
- */
- //私有构造方法,只能由jvm进行实例化
- private Class(ClassLoader loader) {
- // Initialize final field for classLoader. The initialization value of non-null
- // prevents future JIT optimizations from assuming this final field is null.
- classLoader = loader;
- }
-
+````
+/*
+ * Private constructor. Only the Java Virtual Machine creates Class objects.
+ * This constructor is not used and prevents the default constructor being
+ * generated.
+ */
+ //私有构造方法,只能由jvm进行实例化
+private Class(ClassLoader loader) {
+ // Initialize final field for classLoader. The initialization value of non-null
+ // prevents future JIT optimizations from assuming this final field is null.
+ classLoader = loader;
+}
+````
> Class类的作用是运行时提供或获得某个对象的类型信息,和C++中的typeid()函数类似。这些信息也可用于反射。
### Class类原理
看一下Class类的部分源码
-
+````
//Class类中封装了类型的各种信息。在jvm中就是通过Class类的实例来获取每个Java类的所有信息的。
public class Class类 {
@@ -161,6 +159,7 @@ Java程序在运行时,Java运行时系统一直对所有的对象进行所谓
// }
// }
}
+````
> 我们都知道所有的java类都是继承了object这个类,在object这个类中有一个方法:getclass().这个方法是用来取得该类已经被实例化了的对象的该类的引用,这个引用指向的是Class类的对象。
>
@@ -172,11 +171,7 @@ Java程序在运行时,Java运行时系统一直对所有的对象进行所谓
{
return defineClass(name, b, off, len, null);
}
->
-> 我们生成的对象都会有个字段记录该对象所属类在CLass类的对象的所在位置。如下图所示:
-
-[外链图片转存失败(img-ZfMJTzO4-1569074134147)(http://dl.iteye.com/upload/picture/pic/101542/0047a6e9-6608-3c3c-a67c-d8ee95e7fcb8.jpg)]
-
+>
### 如何获得一个Class类对象
@@ -204,7 +199,7 @@ Java程序在运行时,Java运行时系统一直对所有的对象进行所谓
> 生成不精确的object实例
>
-==获取一个Class类的对象后,可以用 newInstance() 函数来生成目标类的一个实例。然而,该函数并不能直接生成目标类的实例,只能生成object类的实例==
+获取一个Class类的对象后,可以用 newInstance() 函数来生成目标类的一个实例。然而,该函数并不能直接生成目标类的实例,只能生成object类的实例
> Class obj=Class.forName("shapes");
> Object ShapesInstance=obj.newInstance();
@@ -214,7 +209,7 @@ Java程序在运行时,Java运行时系统一直对所有的对象进行所谓
> Class obj=shapes.class;
> shapes newShape=obj.newInstance();
> 因为有了类型限制,所以使用泛化Class语法的对象引用不能指向别的类。
-
+
Class obj1=int.class;
Class obj2=int.class;
obj1=double.class;
@@ -236,11 +231,12 @@ Java程序在运行时,Java运行时系统一直对所有的对象进行所谓
Class rclass=round.class;
Class sclass= rclass.getSuperClass();
//Class sclass=rclass.getSuperClass();
+
我们明知道,round的基类就是shapes,但是却不能直接声明 Class < shapes >,必须使用特殊语法
Class < ? super round >
-
-这个记住就可以啦。
+
+ 这个记住就可以啦。
## Object类
@@ -288,7 +284,9 @@ Object类位于java.lang包中,java.lang包包含着Java最基础和核心的
### registerNatives()方法;
+````
private static native void registerNatives();
+````
> registerNatives函数前面有native关键字修饰,Java中,用native关键字修饰的函数表明该方法的实现并不是在Java中去完成,而是由C/C++去完成,并被编译成了.dll,由Java去调用。
>
@@ -298,19 +296,16 @@ private static native void registerNatives();
>
> 既然如此,可能有人会问,registerNatives()修饰符为private,且并没有执行,作用何以达到?其实,在Java源码中,此方法的声明后有紧接着一段静态代码块:
-
- private static native void registerNatives();
- static {
- registerNatives();
- }
-
+````
+private static native void registerNatives();
+static {
+ registerNatives();
+}
+````
### Clone()方法实现浅拷贝
-
- protected native Object clone() throwsCloneNotSupportedException;
-
-
-
-
+````
+protected native Object clone() throwsCloneNotSupportedException;
+````
> 看,clode()方法又是一个被声明为native的方法,因此,我们知道了clone()方法并不是Java的原生方法,具体的实现是有C/C++完成的。clone英文翻译为"克隆",其目的是创建并返回此对象的一个副本。
> 形象点理解,这有一辆科鲁兹,你看着不错,想要个一模一样的。你调用此方法即可像变魔术一样变出一辆一模一样的科鲁兹出来。配置一样,长相一样。但从此刻起,原来的那辆科鲁兹如果进行了新的装饰,与你克隆出来的这辆科鲁兹没有任何关系了。
@@ -321,7 +316,7 @@ private static native void registerNatives();
首先看一下下面的这个例子:
-
+````
package com.corn.objectsummary;
import com.corn.Person;
@@ -336,9 +331,7 @@ private static native void registerNatives();
}
}
-
-
-
+````
> 例子很简单,在main()方法中,new一个Oject对象后,想直接调用此对象的clone方法克隆一个对象,但是出现错误提示:"The method clone() from the type Object is not visible"
>
@@ -350,25 +343,23 @@ private static native void registerNatives();
于是,上例改成如下形式,我们发现,可以正常编译:
-
- public class clone方法 {
- public static void main(String[] args) {
+````
+public class clone方法 {
+ public static void main(String[] args) {
- }
- public void test1() {
+ }
+ public void test1() {
- User user = new User();
- // User copy = user.clone();
- }
- public void test2() {
- User user = new User();
- // User copy = (User)user.clone();
- }
+ User user = new User();
+ //User copy = user.clone();
}
+ public void test2() {
+ User user = new User();
+ //User copy = (User)user.clone();
+ }
+}
-
-
-
+````
是的,因为此时的主调已经是子类的引用了。
> 上述代码在运行过程中会抛出"java.lang.CloneNotSupportedException",表明clone()方法并未正确执行完毕,问题的原因在与Java中的语法规定:
@@ -378,9 +369,8 @@ private static native void registerNatives();
> Cloneable接口仅是一个表示接口,接口本身不包含任何方法,用来指示Object.clone()可以合法的被子类引用所调用。
>
> 于是,上述代码改成如下形式,即可正确指定clone()方法以实现克隆。
-
-
- public class User implements Cloneable{
+````
+public class User implements Cloneable{
public int id;
public String name;
public UserInfo userInfo;
@@ -407,11 +397,12 @@ private static native void registerNatives();
// com.javase.Class和Object.Object方法.用到的类.User@6ff3c5b5
// com.javase.Class和Object.Object方法.用到的类.UserInfo@d716361
}
+````
总结:
clone方法实现的是浅拷贝,只拷贝当前对象,并且在堆中分配新的空间,放这个复制的对象。但是对象如果里面有其他类的子对象,那么就不会拷贝到新的对象中。
-==深拷贝和浅拷贝的区别==
+深拷贝和浅拷贝的区别
> 浅拷贝
> 浅拷贝是按位拷贝对象,它会创建一个新对象,这个对象有着原始对象属性值的一份精确拷贝。如果属性是基本类型,拷贝的就是基本类型的值;如果属性是内存地址(引用类型),拷贝的就是内存地址 ,因此如果其中一个对象改变了这个地址,就会影响到另一个对象。
@@ -430,12 +421,13 @@ clone方法实现的是浅拷贝,只拷贝当前对象,并且在堆中分配
>
> 填充完成之后,clone方法返回,一个新的相同的对象被创建,同样可以把这个新对象的引用发布到外部。
-==也就是说,一个对象在浅拷贝以后,只是把对象复制了一份放在堆空间的另一个地方,但是成员变量如果有引用指向其他对象,这个引用指向的对象和被拷贝的对象中引用指向的对象是一样的。当然,基本数据类型还是会重新拷贝一份的。==
-
+也就是说,一个对象在浅拷贝以后,只是把对象复制了一份放在堆空间的另一个地方,但是成员变量如果有引用指向其他对象,这个引用指向的对象和被拷贝的对象中引用指向的对象是一样的。当然,基本数据类型还是会重新拷贝一份的。
### getClass()方法
+````
+public final native Class getClass();
-4.public final native Class getClass();
+````
> getClass()也是一个native方法,返回的是此Object对象的类对象/运行时类对象Class。效果与Object.class相同。
>
@@ -443,8 +435,8 @@ clone方法实现的是浅拷贝,只拷贝当前对象,并且在堆中分配
>
> 作为概念层次的类,其本身也具有某些共同的特性,如都具有类名称、由类加载器去加载,都具有包,具有父类,属性和方法等。
>
-> 于是,Java中有专门定义了一个类,Class,去描述其他类所具有的这些特性,因此,从此角度去看,类本身也都是属于Class类的对象。为与经常意义上的对象相区分,在此称之为"类对象"。
-
+> 于是,Java中定义了一个类,Class,去描述其他类所具有的这些特性,因此,从此角度去看,类本身也都是属于Class类的对象。为与经常意义上的对象相区分,在此称之为"类对象"。
+````
public class getClass方法 {
public static void main(String[] args) {
User user = new User();
@@ -470,6 +462,7 @@ clone方法实现的是浅拷贝,只拷贝当前对象,并且在堆中分配
}
}
}
+````
此处主要大量涉及到Java中的反射知识
@@ -490,9 +483,6 @@ clone方法实现的是浅拷贝,只拷贝当前对象,并且在堆中分配
return (this == obj);
}
-
-
-
> 由此可见,Object原生的equals()方法内部调用的正是==,与==具有相同的含义。既然如此,为什么还要定义此equals()方法?
>
> equals()方法的正确理解应该是:判断两个对象是否相等。那么判断对象相等的标尺又是什么?
@@ -506,10 +496,10 @@ ObjectTest中打印出true,因为User类定义中重写了equals()方法,这
> 如上重写equals方法表面上看上去是可以了,实则不然。因为它破坏了Java中的约定:重写equals()方法必须重写hasCode()方法。
-
### hashCode()方法;
-
-6. public native int hashCode()
+````
+public native int hashCode()
+````
hashCode()方法返回一个整形数值,表示该对象的哈希码值。
@@ -549,16 +539,16 @@ hashCode()具有如下约定:
### toString()方法
-7.public String toString();
+````
+public String toString();
toString()方法返回该对象的字符串表示。先看一下Object中的具体方法体:
public String toString() {
return getClass().getName() + "@" + Integer.toHexString(hashCode());
}
-
-
-
+
+````
> toString()方法相信大家都经常用到,即使没有显式调用,但当我们使用System.out.println(obj)时,其内部也是通过toString()来实现的。
>
@@ -570,7 +560,7 @@ hashCode()具有如下约定:
### wait() notify() notifAll()
-8/9/10/11/12. wait(...) / notify() / notifyAll()
+
>
> 一说到wait(...) / notify() | notifyAll()几个方法,首先想到的是线程。确实,这几个方法主要用于java多线程之间的协作。先具体看下这几个方法的主要含义:
>
@@ -583,8 +573,7 @@ hashCode()具有如下约定:
> wait(...) / notify() | notifyAll()一般情况下都是配套使用。下面来看一个简单的例子:
这是一个生产者消费者的模型,只不过这里只用flag来标识哪个线程需要工作
-
-
+````
public class wait和notify {
//volatile保证线程可见性
volatile static int flag = 1;
@@ -652,6 +641,7 @@ hashCode()具有如下约定:
// notify t2
//不断循环
}
+````
> 从上述例子的输出结果中可以得出如下结论:
>
@@ -661,13 +651,11 @@ hashCode()具有如下约定:
在Java源码中,可以看到wait()具体定义如下:
-
- public final void wait() throws InterruptedException {
- wait(0);
- }
-
-
-
+````
+public final void wait() throws InterruptedException {
+ wait(0);
+}
+````
> 且wait(long timeout, int nanos)方法定义内部实质上也是通过调用wait(long timeout)完成。而wait(long timeout)是一个native方法。因此,wait(...)方法本质上都是native方式实现。
@@ -676,15 +664,11 @@ notify()/notifyAll()方法也都是native方法。
Java中线程具有较多的知识点,是一块比较大且重要的知识点。后期会有博文专门针对Java多线程作出详细总结。此处不再细述。
### finalize()方法
-13. protected void finalize();
-
finalize方法主要与Java垃圾回收机制有关。首先我们看一下finalized方法在Object中的具体定义:
-
- protected void finalize() throws Throwable { }
-
-
-
+````
+protected void finalize() throws Throwable { }
+````
> 我们发现Object类中finalize方法被定义成一个空方法,为什么要如此定义呢?finalize方法的调用时机是怎么样的呢?
>
@@ -727,21 +711,11 @@ https://blog.csdn.net/dufufd/article/details/80537638
https://blog.csdn.net/farsight1/article/details/80664104
https://blog.csdn.net/xiaomingdetianxia/article/details/77429180
-## 微信公众号
-
### Java技术江湖
如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号【Java技术江湖】一位阿里 Java 工程师的技术小站,作者黄小斜,专注 Java 相关技术:SSM、SpringBoot、MySQL、分布式、中间件、集群、Linux、网络、多线程,偶尔讲点Docker、ELK,同时也分享技术干货和学习经验,致力于Java全栈开发!
**Java工程师必备学习资源:** 一些Java工程师常用学习资源,关注公众号后,后台回复关键字 **“Java”** 即可免费无套路获取。
-
-
-### 个人公众号:黄小斜
-
-作者是 985 硕士,蚂蚁金服 JAVA 工程师,专注于 JAVA 后端技术栈:SpringBoot、MySQL、分布式、中间件、微服务,同时也懂点投资理财,偶尔讲点算法和计算机理论基础,坚持学习和写作,相信终身学习的力量!
-
-**程序员3T技术学习资源:** 一些程序员学习技术的资源大礼包,关注公众号后,后台回复关键字 **“资料”** 即可免费无套路获取。
-
-
+
diff --git "a/docs/java/basic/2\343\200\201Java\345\237\272\346\234\254\346\225\260\346\215\256\347\261\273\345\236\213.md" "b/docs/Java/basic/Java\345\237\272\346\234\254\346\225\260\346\215\256\347\261\273\345\236\213.md"
similarity index 84%
rename from "docs/java/basic/2\343\200\201Java\345\237\272\346\234\254\346\225\260\346\215\256\347\261\273\345\236\213.md"
rename to "docs/Java/basic/Java\345\237\272\346\234\254\346\225\260\346\215\256\347\261\273\345\236\213.md"
index 655b4c2..b871b14 100644
--- "a/docs/java/basic/2\343\200\201Java\345\237\272\346\234\254\346\225\260\346\215\256\347\261\273\345\236\213.md"
+++ "b/docs/Java/basic/Java\345\237\272\346\234\254\346\225\260\346\215\256\347\261\273\345\236\213.md"
@@ -15,9 +15,7 @@
* [存在栈中](#存在栈中)
* [存在堆里](#存在堆里)
* [参考文章](#参考文章)
- * [微信公众号](#微信公众号)
- * [Java技术江湖](#java技术江湖)
- * [个人公众号:黄小斜](#个人公众号:黄小斜)
+
@@ -34,9 +32,6 @@
如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。
-
-
-
# Java 基本数据类型
@@ -53,7 +48,6 @@
- 内置数据类型
- 引用数据类型
-- - *
### 内置数据类型
@@ -128,50 +122,6 @@ Java语言提供了八种基本类型。六种数字类型(四个整数型,
- char 数据类型可以储存任何字符;
- 例子:char letter = 'A';。
-```
-//8位
-byte bx = Byte.MAX_VALUE;
-byte bn = Byte.MIN_VALUE;
-//16位
-short sx = Short.MAX_VALUE;
-short sn = Short.MIN_VALUE;
-//32位
-int ix = Integer.MAX_VALUE;
-int in = Integer.MIN_VALUE;
-//64位
-long lx = Long.MAX_VALUE;
-long ln = Long.MIN_VALUE;
-//32位
-float fx = Float.MAX_VALUE;
-float fn = Float.MIN_VALUE;
-//64位
-double dx = Double.MAX_VALUE;
-double dn = Double.MIN_VALUE;
-//16位
-char cx = Character.MAX_VALUE;
-char cn = Character.MIN_VALUE;
-//1位
-boolean bt = Boolean.TRUE;
-boolean bf = Boolean.FALSE;
-```
-
- `127`
- `-128`
- `32767`
- `-32768`
- `2147483647`
- `-2147483648`
- `9223372036854775807`
- `-9223372036854775808`
- `3.4028235E38`
- `1.4E-45`
- `1.7976931348623157E308`
- `4.9E-324`
- ``
-
- `true`
- `false`
-
### 引用类型
- 在Java中,引用类型的变量非常类似于C/C++的指针。引用类型指向一个对象,指向对象的变量是引用变量。这些变量在声明时被指定为一个特定的类型,比如 Employee、Puppy 等。变量一旦声明后,类型就不能被改变了。
@@ -202,22 +152,24 @@ char a = 'A'
## 自动拆箱和装箱(详解)
Java 5增加了自动装箱与自动拆箱机制,方便基本类型与包装类型的相互转换操作。在Java 5之前,如果要将一个int型的值转换成对应的包装器类型Integer,必须显式的使用new创建一个新的Integer对象,或者调用静态方法Integer.valueOf()。
-
- //在Java 5之前,只能这样做
- Integer value = new Integer(10);
- //或者这样做
- Integer value = Integer.valueOf(10);
- //直接赋值是错误的
- //Integer value = 10;`
-
+````
+//在Java 5之前,只能这样做
+Integer value = new Integer(10);
+//或者这样做
+Integer value = Integer.valueOf(10);
+//直接赋值是错误的
+//Integer value = 10;
+````
在Java 5中,可以直接将整型赋给Integer对象,由编译器来完成从int型到Integer类型的转换,这就叫自动装箱。
- `//在Java 5中,直接赋值是合法的,由编译器来完成转换`
- `Integer value = 10;`
- `与此对应的,自动拆箱就是可以将包装类型转换为基本类型,具体的转换工作由编译器来完成。`
- `//在Java 5 中可以直接这么做`
- `Integer value = new Integer(10);`
- `int i = value;`
+````
+//在Java 5中,直接赋值是合法的,由编译器来完成转换
+Integer value = 10;
+与此对应的,自动拆箱就是可以将包装类型转换为基本类型,具体的转换工作由编译器来完成。
+//在Java 5 中可以直接这么做
+Integer value = new Integer(10);
+int i = value;
+````
自动装箱与自动拆箱为程序员提供了很大的方便,而在实际的应用中,自动装箱与拆箱也是使用最广泛的特性之一。自动装箱和自动拆箱其实是Java编译器提供的一颗语法糖(语法糖是指在计算机语言中添加的某种语法,这种语法对语言的功能并没有影响,但是更方便程序员使用。通过可提高开发效率,增加代码可读性,增加代码的安全性)。
@@ -229,43 +181,41 @@ Java 5增加了自动装箱与自动拆箱机制,方便基本类型与包装
实例方法xxxValue():将具体的包装类型对象转换成基本类型;
下面我们以int和Integer为例,说明Java中自动装箱与自动拆箱的实现机制。看如下代码:
-
- class Auto //code1
- {
- public static void main(String[] args)
- {
- //自动装箱
- Integer inte = 10;
- //自动拆箱
- int i = inte;
-
- //再double和Double来验证一下
- Double doub = 12.40;
- double d = doub;
-
- }
-
- }
+````
+ class Auto //code1
+ {
+ public static void main(String[] args)
+ {
+ //自动装箱
+ Integer inte = 10;
+ //自动拆箱
+ int i = inte;
+
+ //再double和Double来验证一下
+ Double doub = 12.40;
+ double d = doub;
+
+ }
+
+ }
+````
上面的代码先将int型转为Integer对象,再讲Integer对象转换为int型,毫无疑问,这是可以正确运行的。可是,这种转换是怎么进行的呢?使用反编译工具,将生成的Class文件在反编译为Java文件,让我们看看发生了什么:
+````
class Auto//code2
{
public static void main(String[] paramArrayOfString)
{
Integer localInteger = Integer.valueOf(10);
-
-
-
- int i = localInteger.intValue();
-
-
-
-
- Double localDouble = Double.valueOf(12.4D);
- double d = localDouble.doubleValue();
-
- }
- }
+
+ int i = localInteger.intValue();
+
+ Double localDouble = Double.valueOf(12.4D);
+ double d = localDouble.doubleValue();
+
+ }
+ }
+````
我们可以看到经过javac编译之后,code1的代码被转换成了code2,实际运行时,虚拟机运行的就是code2的代码。也就是说,虚拟机根本不知道有自动拆箱和自动装箱这回事;在将Java源文件编译为class文件的过程中,javac编译器在自动装箱的时候,调用了Integer.valueOf()方法,在自动拆箱时,又调用了intValue()方法。我们可以看到,double和Double也是如此。
实现总结:其实自动装箱和自动封箱是编译器为我们提供的一颗语法糖。在自动装箱时,编译器调用包装类型的valueOf()方法;在自动拆箱时,编译器调用了相应的xxxValue()方法。
@@ -276,7 +226,7 @@ Java 5增加了自动装箱与自动拆箱机制,方便基本类型与包装
Integer源码
-```
+````
public final class Integer extends Number implements Comparable {
private final int value;
@@ -343,7 +293,7 @@ public final class Integer extends Number implements Comparable {
private IntegerCache() {}
}
-```
+````
以上是Oracle(Sun)公司JDK 1.7中Integer源码的一部分,通过分析上面的代码,得到:
@@ -363,21 +313,22 @@ public final class Integer extends Number implements Comparable {
5)调用intValue(),直接返回value的值。
通过3)和4)可以发现,默认情况下,在使用自动装箱时,VM会复用[-128,127]之间的Integer对象。
-
- Integer a1 = 1;
- Integer a2 = 1;
- Integer a3 = new Integer(1);
- //会打印true,因为a1和a2是同一个对象,都是Integer.cache[129]
- System.out.println(a1 == a2);
- //false,a3构造了一个新的对象,不同于a1,a2
- System.out.println(a1 == a3);
-
+````
+Integer a1 = 1;
+Integer a2 = 1;
+Integer a3 = new Integer(1);
+//会打印true,因为a1和a2是同一个对象,都是Integer.cache[129]
+System.out.println(a1 == a2);
+//false,a3构造了一个新的对象,不同于a1,a2
+System.out.println(a1 == a3);
+````
### 了解基本类型缓存(常量池)的最佳实践
```
//基本数据类型的常量池是-128到127之间。
// 在这个范围中的基本数据类的包装类可以自动拆箱,比较时直接比较数值大小。
public static void main(String[] args) {
+
//int的自动拆箱和装箱只在-128到127范围中进行,超过该范围的两个integer的 == 判断是会返回false的。
Integer a1 = 128;
Integer a2 = -128;
@@ -394,7 +345,6 @@ public static void main(String[] args) {
System.out.println(b1 == b2);
System.out.println(b3 == b4);
- //
Long c1 = 128L;
Long c2 = 128L;
Long c3 = -128L;
@@ -411,7 +361,6 @@ public static void main(String[] args) {
System.out.println(d1 == d2);
System.out.println(d3 == d4);
-
`结果`
`false`
@@ -423,8 +372,6 @@ public static void main(String[] args) {
`false`
`true`
-
-
Integer i = 10;
Byte b = 10;
//比较Byte和Integer.两个对象无法直接比较,报错
@@ -460,8 +407,6 @@ public static void main(String[] args) {
需要注意的是:“==”在没遇到算术运算时,不会自动拆箱;基本类型只会自动装箱为对应的包装类型,代码中最后一条说明的内容。
-
-
在JDK 1.5中提供了自动装箱与自动拆箱,这其实是Java 编译器的语法糖,编译器通过调用包装类型的valueOf()方法实现自动装箱,调用xxxValue()方法自动拆箱。自动装箱和拆箱会有一些陷阱,那就是包装类型复用了某些对象。
(1)Integer默认复用了[-128,127]这些对象,其中高位置可以修改;
@@ -574,10 +519,6 @@ System.out.println(s3 == s4);
JDK1.6以及以下:false false
JDK1.7以及以上:false true
```
-
-
-
-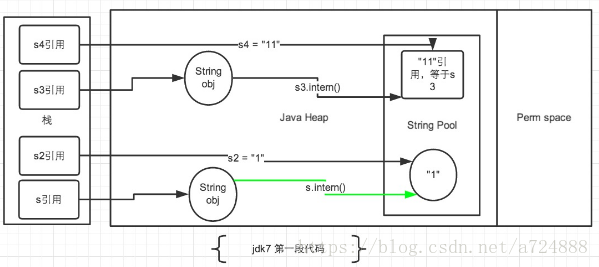
JDK1.6查找到常量池存在相同值的对象时会直接返回该对象的地址。
JDK 1.7后,intern方法还是会先去查询常量池中是否有已经存在,如果存在,则返回常量池中的引用,这一点与之前没有区别,区别在于,如果在常量池找不到对应的字符串,则不会再将字符串拷贝到常量池,而只是在常量池中生成一个对原字符串的引用。
@@ -602,20 +543,4 @@ https://blog.csdn.net/a724888/article/details/80033043
-## 微信公众号
-
-### Java技术江湖
-
-如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号【Java技术江湖】一位阿里 Java 工程师的技术小站,作者黄小斜,专注 Java 相关技术:SSM、SpringBoot、MySQL、分布式、中间件、集群、Linux、网络、多线程,偶尔讲点Docker、ELK,同时也分享技术干货和学习经验,致力于Java全栈开发!
-
-**Java工程师必备学习资源:** 一些Java工程师常用学习资源,关注公众号后,后台回复关键字 **“Java”** 即可免费无套路获取。
-
-
-
-### 个人公众号:黄小斜
-
-作者是 985 硕士,蚂蚁金服 JAVA 工程师,专注于 JAVA 后端技术栈:SpringBoot、MySQL、分布式、中间件、微服务,同时也懂点投资理财,偶尔讲点算法和计算机理论基础,坚持学习和写作,相信终身学习的力量!
-
-**程序员3T技术学习资源:** 一些程序员学习技术的资源大礼包,关注公众号后,后台回复关键字 **“资料”** 即可免费无套路获取。
-
diff --git "a/docs/java/basic/10\343\200\201Java\345\274\202\345\270\270.md" "b/docs/Java/basic/Java\345\274\202\345\270\270.md"
similarity index 64%
rename from "docs/java/basic/10\343\200\201Java\345\274\202\345\270\270.md"
rename to "docs/Java/basic/Java\345\274\202\345\270\270.md"
index c937417..4f77437 100644
--- "a/docs/java/basic/10\343\200\201Java\345\274\202\345\270\270.md"
+++ "b/docs/Java/basic/Java\345\274\202\345\270\270.md"
@@ -15,14 +15,7 @@
* [当finally遇上return](#当finally遇上return)
* [JAVA异常常见面试题](#java异常常见面试题)
* [参考文章](#参考文章)
- * [微信公众号](#微信公众号)
- * [Java技术江湖](#java技术江湖)
- * [个人公众号:黄小斜](#个人公众号:黄小斜)
----
-
- - Java异常
----
本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
> https://github.com/h2pl/Java-Tutorial
@@ -51,7 +44,7 @@
> 3、 由调用函数来分析异常,这要求程序员对库函数有很深的了解。
>
- 在OO中提供的异常处理机制是提供代码健壮的强有力的方式。使用异常机制它能够降低错误处理代码的复杂度,如果不使用异常,那么就必须检查特定的错误,并在程序中的许多地方去处理它。
+在OO中提供的异常处理机制是提供代码健壮的强有力的方式。使用异常机制它能够降低错误处理代码的复杂度,如果不使用异常,那么就必须检查特定的错误,并在程序中的许多地方去处理它。
而如果使用异常,那就不必在方法调用处进行检查,因为异常机制将保证能够捕获这个错误,并且,只需在一个地方处理错误,即所谓的异常处理程序中。
@@ -61,21 +54,20 @@
## 异常基本定义
-> 在《Think in java》中是这样定义异常的:异常情形是指阻止当前方法或者作用域继续执行的问题。在这里一定要明确一点:异常代码某种程度的错误,尽管Java有异常处理机制,但是我们不能以“正常”的眼光来看待异常,异常处理机制的原因就是告诉你:这里可能会或者已经产生了错误,您的程序出现了不正常的情况,可能会导致程序失败!
+> 在《Think in java》中是这样定义异常的:异常情形是指阻止当前方法或者作用域继续执行的问题。在这里一定要明确一点:异常代码某种程度的错误,尽管Java有异常处理机制,但是我们不能以“正常”的眼光来看待异常,异常处理机制的原因就是告诉你:这里可能会或者已经产生了错误,您的程序出现了不正常的情况,可能会导致程序失败!
-> 那么什么时候才会出现异常呢?只有在你当前的环境下程序无法正常运行下去,也就是说程序已经无法来正确解决问题了,这时它所就会从当前环境中跳出,并抛出异常。抛出异常后,它首先会做几件事。
+> 那么什么时候才会出现异常呢?只有在你当前的环境下程序无法正常运行下去,也就是说程序已经无法来正确解决问题了,这时它所就会从当前环境中跳出,并抛出异常。抛出异常后,它首先会做几件事。
> 首先,它会使用new创建一个异常对象,然后在产生异常的位置终止程序,并且从当前环境中弹出对异常对象的引用,这时。异常处理机制就会接管程序,并开始寻找一个恰当的地方来继续执行程序,这个恰当的地方就是异常处理程序。
-> 总的来说异常处理机制就是当程序发生异常时,它强制终止程序运行,记录异常信息并将这些信息反馈给我们,由我们来确定是否处理异常。
+> 总的来说异常处理机制就是当程序发生异常时,它强制终止程序运行,记录异常信息并将这些信息反馈给我们,由我们来确定是否处理异常。
## 异常体系
-[外链图片转存失败(img-KNxcBTK0-1569073569353)(https://images0.cnblogs.com/blog/381060/201311/22185952-834d92bc2bfe498f9a33414cc7a2c8a4.png)]
+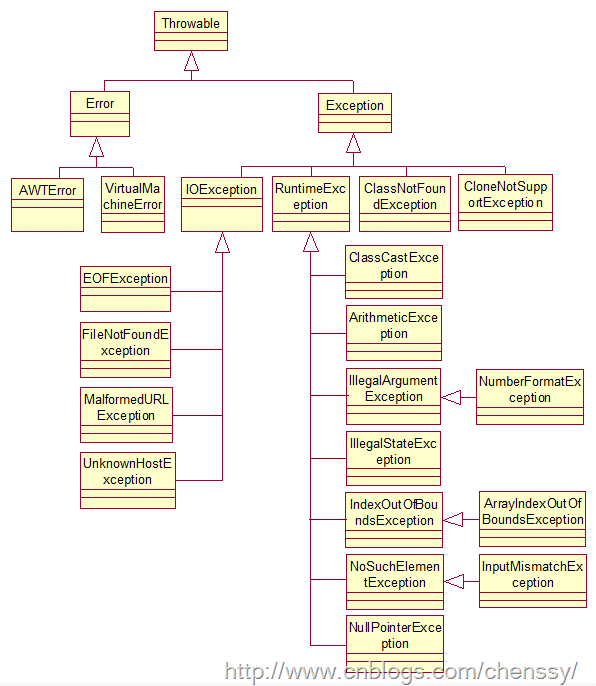
从上面这幅图可以看出,Throwable是java语言中所有错误和异常的超类(万物即可抛)。它有两个子类:Error、Exception。
-
Java标准库内建了一些通用的异常,这些类以Throwable为顶层父类。
Throwable又派生出Error类和Exception类。
@@ -103,7 +95,7 @@ Throwable又派生出Error类和Exception类。
异常是在执行某个函数时引发的,而函数又是层级调用,形成调用栈的,因为,只要一个函数发生了异常,那么他的所有的caller都会被异常影响。当这些被影响的函数以异常信息输出时,就形成的了异常追踪栈。
异常最先发生的地方,叫做异常抛出点。
-
+````
public class 异常 {
public static void main (String [] args )
{
@@ -130,9 +122,7 @@ Throwable又派生出Error类和Exception类。
// at com.javase.异常.异常.devide(异常.java:24)
// at com.javase.异常.异常.CMDCalculate(异常.java:19)
// at com.javase.异常.异常.main(异常.java:12)
-
-
-
+
// ----欢迎使用命令行除法计算器----
// r
// Exception in thread "main" java.util.InputMismatchException
@@ -143,8 +133,7 @@ Throwable又派生出Error类和Exception类。
// at com.javase.异常.异常.CMDCalculate(异常.java:17)
// at com.javase.异常.异常.main(异常.java:12)
-
-[外链图片转存失败(img-9rqUQJQj-1569073569354)(http://incdn1.b0.upaiyun.com/2017/09/0b3e4ca2f4cf8d7116c7ad354940601f.png)]
+````
从上面的例子可以看出,当devide函数发生除0异常时,devide函数将抛出ArithmeticException异常,因此调用他的CMDCalculate函数也无法正常完成,因此也发送异常,而CMDCalculate的caller——main 因为CMDCalculate抛出异常,也发生了异常,这样一直向调用栈的栈底回溯。
@@ -157,7 +146,7 @@ Throwable又派生出Error类和Exception类。
## 异常和错误
下面看一个例子
-
+````
//错误即error一般指jvm无法处理的错误
//异常是Java定义的用于简化错误处理流程和定位错误的一种工具。
public class 错误和错误 {
@@ -198,7 +187,7 @@ Throwable又派生出Error类和Exception类。
// at com.javase.异常.错误.main(错误.java:11)
}
-
+````
## 异常的处理方式
在编写代码处理异常时,对于检查异常,有2种不同的处理方式:
@@ -213,7 +202,7 @@ Throwable又派生出Error类和Exception类。
上面的例子是运行时异常,不需要显示捕获。
下面这个例子是可检查异常需,要显示捕获或者抛出。
-
+````
@Test
public void testException() throws IOException
{
@@ -309,6 +298,7 @@ Throwable又派生出Error类和Exception类。
// at com.javase.异常.异常处理方式.test(异常处理方式.java:62)
throw new StringIndexOutOfBoundsException();
}
+````
其实有的语言在遇到异常后仍然可以继续运行
@@ -321,11 +311,12 @@ Throwable又派生出Error类和Exception类。
throws是另一种处理异常的方式,它不同于try…catch…finally,throws仅仅是将函数中可能出现的异常向调用者声明,而自己则不具体处理。
采取这种异常处理的原因可能是:方法本身不知道如何处理这样的异常,或者说让调用者处理更好,调用者需要为可能发生的异常负责。
-
- public void foo() throws ExceptionType1 , ExceptionType2 ,ExceptionTypeN
- {
- //foo内部可以抛出 ExceptionType1 , ExceptionType2 ,ExceptionTypeN 类的异常,或者他们的子类的异常对象。
- }
+````
+public void foo() throws ExceptionType1 , ExceptionType2 ,ExceptionTypeN
+{
+ //foo内部可以抛出 ExceptionType1 , ExceptionType2 ,ExceptionTypeN 类的异常,或者他们的子类的异常对象。
+}
+````
## 纠结的finally
@@ -341,6 +332,7 @@ finally块不管异常是否发生,只要对应的try执行了,则它一定
3、在同一try…catch…finally块中 ,try发生异常,且匹配的catch块中处理异常时也抛出异常,那么后面的finally也会执行:首先执行finally块,然后去外围调用者中寻找合适的catch块。
+````
public class finally使用 {
public static void main(String[] args) {
try {
@@ -357,6 +349,7 @@ finally块不管异常是否发生,只要对应的try执行了,则它一定
}
}
}
+````
## throw : JRE也使用的关键字
@@ -365,15 +358,14 @@ throw exceptionObject
程序员也可以通过throw语句手动显式的抛出一个异常。throw语句的后面必须是一个异常对象。
throw 语句必须写在函数中,执行throw 语句的地方就是一个异常抛出点,==它和由JRE自动形成的异常抛出点没有任何差别。==
-
- public void save(User user)
- {
- if(user == null)
- throw new IllegalArgumentException("User对象为空");
- //......
-
- }
-
+````
+public void save(User user)
+{
+ if(user == null)
+ throw new IllegalArgumentException("User对象为空");
+ //......
+}
+````
后面开始的大部分内容都摘自http://www.cnblogs.com/lulipro/p/7504267.html
该文章写的十分细致到位,令人钦佩,是我目前为之看到关于异常最详尽的文章,可以说是站在巨人的肩膀上了。
@@ -389,88 +381,86 @@ throw 语句必须写在函数中,执行throw 语句的地方就是一个异
> 异常链化:以一个异常对象为参数构造新的异常对象。新的异对象将包含先前异常的信息。这项技术主要是异常类的一个带Throwable参数的函数来实现的。这个当做参数的异常,我们叫他根源异常(cause)。
查看Throwable类源码,可以发现里面有一个Throwable字段cause,就是它保存了构造时传递的根源异常参数。这种设计和链表的结点类设计如出一辙,因此形成链也是自然的了。
-
- public class Throwable implements Serializable {
- private Throwable cause = this;
-
- public Throwable(String message, Throwable cause) {
- fillInStackTrace();
- detailMessage = message;
- this.cause = cause;
- }
- public Throwable(Throwable cause) {
- fillInStackTrace();
- detailMessage = (cause==null ? null : cause.toString());
- this.cause = cause;
- }
-
- //........
+````
+public class Throwable implements Serializable {
+ private Throwable cause = this;
+ public Throwable(String message, Throwable cause) {
+ fillInStackTrace();
+ detailMessage = message;
+ this.cause = cause;
}
-
+ public Throwable(Throwable cause) {
+ fillInStackTrace();
+ detailMessage = (cause==null ? null : cause.toString());
+ this.cause = cause;
+ }
+ //........
+}
+````
下面看一个比较实在的异常链例子哈
-
- public class 异常链 {
- @Test
- public void test() {
- C();
- }
- public void A () throws Exception {
- try {
- int i = 1;
- i = i / 0;
- //当我注释掉这行代码并使用B方法抛出一个error时,运行结果如下
- // 四月 27, 2018 10:12:30 下午 org.junit.platform.launcher.core.ServiceLoaderTestEngineRegistry loadTestEngines
- // 信息: Discovered TestEngines with IDs: [junit-jupiter]
- // java.lang.Error: B也犯了个错误
- // at com.javase.异常.异常链.B(异常链.java:33)
- // at com.javase.异常.异常链.C(异常链.java:38)
- // at com.javase.异常.异常链.test(异常链.java:13)
- // at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
- // Caused by: java.lang.Error
- // at com.javase.异常.异常链.B(异常链.java:29)
-
- }catch (ArithmeticException e) {
- //这里通过throwable类的构造方法将最底层的异常重新包装并抛出,此时注入了A方法的信息。最后打印栈信息时可以看到caused by
- A方法的异常。
- //如果直接抛出,栈信息打印结果只能看到上层方法的错误信息,不能看到其实是A发生了错误。
- //所以需要包装并抛出
- throw new Exception("A方法计算错误", e);
- }
-
+````
+public class 异常链 {
+ @Test
+ public void test() {
+ C();
+ }
+ public void A () throws Exception {
+ try {
+ int i = 1;
+ i = i / 0;
+ //当我注释掉这行代码并使用B方法抛出一个error时,运行结果如下
+// 四月 27, 2018 10:12:30 下午 org.junit.platform.launcher.core.ServiceLoaderTestEngineRegistry loadTestEngines
+// 信息: Discovered TestEngines with IDs: [junit-jupiter]
+// java.lang.Error: B也犯了个错误
+// at com.javase.异常.异常链.B(异常链.java:33)
+// at com.javase.异常.异常链.C(异常链.java:38)
+// at com.javase.异常.异常链.test(异常链.java:13)
+// at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
+// Caused by: java.lang.Error
+// at com.javase.异常.异常链.B(异常链.java:29)
+
+ }catch (ArithmeticException e) {
+ //这里通过throwable类的构造方法将最底层的异常重新包装并抛出,此时注入了A方法的信息。最后打印栈信息时可以看到caused by
+ A方法的异常。
+ //如果直接抛出,栈信息打印结果只能看到上层方法的错误信息,不能看到其实是A发生了错误。
+ //所以需要包装并抛出
+ throw new Exception("A方法计算错误", e);
}
- public void B () throws Exception,Error {
- try {
- //接收到A的异常,
- A();
- throw new Error();
- }catch (Exception e) {
- throw e;
- }catch (Error error) {
- throw new Error("B也犯了个错误", error);
- }
+
+ }
+ public void B () throws Exception,Error {
+ try {
+ //接收到A的异常,
+ A();
+ throw new Error();
+ }catch (Exception e) {
+ throw e;
+ }catch (Error error) {
+ throw new Error("B也犯了个错误", error);
}
- public void C () {
- try {
- B();
- }catch (Exception | Error e) {
- e.printStackTrace();
- }
-
+ }
+ public void C () {
+ try {
+ B();
+ }catch (Exception | Error e) {
+ e.printStackTrace();
}
-
- //最后结果
- // java.lang.Exception: A方法计算错误
- // at com.javase.异常.异常链.A(异常链.java:18)
- // at com.javase.异常.异常链.B(异常链.java:24)
- // at com.javase.异常.异常链.C(异常链.java:31)
- // at com.javase.异常.异常链.test(异常链.java:11)
- // 省略
- // Caused by: java.lang.ArithmeticException: / by zero
- // at com.javase.异常.异常链.A(异常链.java:16)
- // ... 31 more
+
}
+ //最后结果
+// java.lang.Exception: A方法计算错误
+// at com.javase.异常.异常链.A(异常链.java:18)
+// at com.javase.异常.异常链.B(异常链.java:24)
+// at com.javase.异常.异常链.C(异常链.java:31)
+// at com.javase.异常.异常链.test(异常链.java:11)
+// 省略
+// Caused by: java.lang.ArithmeticException: / by zero
+// at com.javase.异常.异常链.A(异常链.java:16)
+// ... 31 more
+}
+````
## 自定义异常
如果要自定义异常类,则扩展Exception类即可,因此这样的自定义异常都属于检查异常(checked exception)。如果要自定义非检查异常,则扩展自RuntimeException。
@@ -482,7 +472,7 @@ throw 语句必须写在函数中,执行throw 语句的地方就是一个异
一个带有String参数和Throwable参数,并都传递给父类构造函数
一个带有Throwable 参数的构造函数,并传递给父类的构造函数。
下面是IOException类的完整源代码,可以借鉴。
-
+````
public class IOException extends Exception
{
static final long serialVersionUID = 7818375828146090155L;
@@ -507,7 +497,7 @@ throw 语句必须写在函数中,执行throw 语句的地方就是一个异
super(cause);
}
}
-
+````
## 异常的注意事项
异常的注意事项
@@ -517,47 +507,47 @@ throw 语句必须写在函数中,执行throw 语句的地方就是一个异
> 例如,父类方法throws 的是2个异常,子类就不能throws 3个及以上的异常。父类throws IOException,子类就必须throws IOException或者IOException的子类。
至于为什么?我想,也许下面的例子可以说明。
-
- class Father
+````
+class Father
+{
+ public void start() throws IOException
{
- public void start() throws IOException
- {
- throw new IOException();
- }
+ throw new IOException();
}
-
- class Son extends Father
+}
+
+class Son extends Father
+{
+ public void start() throws Exception
{
- public void start() throws Exception
- {
- throw new SQLException();
- }
+ throw new SQLException();
}
+}
/**********************假设上面的代码是允许的(实质是错误的)***********************/
- class Test
+class Test
+{
+ public static void main(String[] args)
{
- public static void main(String[] args)
+ Father[] objs = new Father[2];
+ objs[0] = new Father();
+ objs[1] = new Son();
+
+ for(Father obj:objs)
{
- Father[] objs = new Father[2];
- objs[0] = new Father();
- objs[1] = new Son();
-
- for(Father obj:objs)
+ //因为Son类抛出的实质是SQLException,而IOException无法处理它。
+ //那么这里的try。。catch就不能处理Son中的异常。
+ //多态就不能实现了。
+ try {
+ obj.start();
+ }catch(IOException)
{
- //因为Son类抛出的实质是SQLException,而IOException无法处理它。
- //那么这里的try。。catch就不能处理Son中的异常。
- //多态就不能实现了。
- try {
- obj.start();
- }catch(IOException)
- {
- //处理IOException
- }
- }
- }
- }
-
+ //处理IOException
+ }
+ }
+ }
+}
+````
==Java的异常执行流程是线程独立的,线程之间没有影响==
> Java程序可以是多线程的。每一个线程都是一个独立的执行流,独立的函数调用栈。如果程序只有一个线程,那么没有被任何代码处理的异常 会导致程序终止。如果是多线程的,那么没有被任何代码处理的异常仅仅会导致异常所在的线程结束。
@@ -565,44 +555,44 @@ throw 语句必须写在函数中,执行throw 语句的地方就是一个异
> 也就是说,Java中的异常是线程独立的,线程的问题应该由线程自己来解决,而不要委托到外部,也不会直接影响到其它线程的执行。
下面看一个例子
-
- public class 多线程的异常 {
- @Test
- public void test() {
- go();
- }
- public void go () {
- ExecutorService executorService = Executors.newFixedThreadPool(3);
- for (int i = 0;i <= 2;i ++) {
- int finalI = i;
- try {
- Thread.sleep(2000);
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- executorService.execute(new Runnable() {
- @Override
- //每个线程抛出异常时并不会影响其他线程的继续执行
- public void run() {
- try {
- System.out.println("start thread" + finalI);
- throw new Exception();
- }catch (Exception e) {
- System.out.println("thread" + finalI + " go wrong");
- }
- }
- });
+````
+public class 多线程的异常 {
+ @Test
+ public void test() {
+ go();
+ }
+ public void go () {
+ ExecutorService executorService = Executors.newFixedThreadPool(3);
+ for (int i = 0;i <= 2;i ++) {
+ int finalI = i;
+ try {
+ Thread.sleep(2000);
+ } catch (InterruptedException e) {
+ e.printStackTrace();
}
- // 结果:
- // start thread0
- // thread0 go wrong
- // start thread1
- // thread1 go wrong
- // start thread2
- // thread2 go wrong
- }
+ executorService.execute(new Runnable() {
+ @Override
+ //每个线程抛出异常时并不会影响其他线程的继续执行
+ public void run() {
+ try {
+ System.out.println("start thread" + finalI);
+ throw new Exception();
+ }catch (Exception e) {
+ System.out.println("thread" + finalI + " go wrong");
+ }
+ }
+ });
+ }
+// 结果:
+// start thread0
+// thread0 go wrong
+// start thread1
+// thread1 go wrong
+// start thread2
+// thread2 go wrong
}
-
+}
+````
## 当finally遇上return
@@ -610,163 +600,160 @@ throw 语句必须写在函数中,执行throw 语句的地方就是一个异
首先一个不容易理解的事实:
在 try块中即便有return,break,continue等改变执行流的语句,finally也会执行。
+````
+public static void main(String[] args)
+{
+ int re = bar();
+ System.out.println(re);
+}
+private static int bar()
+{
+ try{
+ return 5;
+ } finally{
+ System.out.println("finally");
+ }
+}
+/*输出:
+finally
+*/
+````
- public static void main(String[] args)
+也就是说:try…catch…finally中的return 只要能执行,就都执行了,他们共同向同一个内存地址(假设地址是0×80)写入返回值,后执行的将覆盖先执行的数据,而真正被调用者取的返回值就是最后一次写入的。那么,按照这个思想,下面的这个例子也就不难理解了。
+
+finally中的return 会覆盖 try 或者catch中的返回值。
+````
+public static void main(String[] args)
{
- int re = bar();
- System.out.println(re);
+ int result;
+
+ result = foo();
+ System.out.println(result); /////////2
+
+ result = bar();
+ System.out.println(result); /////////2
}
- private static int bar()
+
+ @SuppressWarnings("finally")
+ public static int foo()
{
- try{
- return 5;
+ trz{
+ int a = 5 / 0;
+ } catch (Exception e){
+ return 1;
} finally{
- System.out.println("finally");
+ return 2;
}
+
}
- /*输出:
- finally
- */
-很多人面对这个问题时,总是在归纳执行的顺序和规律,不过我觉得还是很难理解。我自己总结了一个方法。用如下GIF图说明。
-
-
-[外链图片转存失败(img-SceF4t85-1569073569354)(http://incdn1.b0.upaiyun.com/2017/09/0471c2805ebd5a463211ced478eaf7f8.gif)]
-
-也就是说:try…catch…finally中的return 只要能执行,就都执行了,他们共同向同一个内存地址(假设地址是0×80)写入返回值,后执行的将覆盖先执行的数据,而真正被调用者取的返回值就是最后一次写入的。那么,按照这个思想,下面的这个例子也就不难理解了。
-
-
-finally中的return 会覆盖 try 或者catch中的返回值。
-
- public static void main(String[] args)
- {
- int result;
-
- result = foo();
- System.out.println(result); /////////2
-
- result = bar();
- System.out.println(result); /////////2
- }
-
- @SuppressWarnings("finally")
- public static int foo()
- {
- trz{
- int a = 5 / 0;
- } catch (Exception e){
- return 1;
- } finally{
- return 2;
- }
-
- }
-
- @SuppressWarnings("finally")
- public static int bar()
- {
- try {
- return 1;
- }finally {
- return 2;
- }
+
+ @SuppressWarnings("finally")
+ public static int bar()
+ {
+ try {
+ return 1;
+ }finally {
+ return 2;
}
-
+ }
+````
finally中的return会抑制(消灭)前面try或者catch块中的异常
-
- class TestException
+````
+class TestException
+{
+ public static void main(String[] args)
{
- public static void main(String[] args)
- {
- int result;
- try{
- result = foo();
- System.out.println(result); //输出100
- } catch (Exception e){
- System.out.println(e.getMessage()); //没有捕获到异常
- }
-
- try{
- result = bar();
- System.out.println(result); //输出100
- } catch (Exception e){
- System.out.println(e.getMessage()); //没有捕获到异常
- }
+ int result;
+ try{
+ result = foo();
+ System.out.println(result); //输出100
+ } catch (Exception e){
+ System.out.println(e.getMessage()); //没有捕获到异常
}
-
- //catch中的异常被抑制
- @SuppressWarnings("finally")
- public static int foo() throws Exception
- {
- try {
- int a = 5/0;
- return 1;
- }catch(ArithmeticException amExp) {
- throw new Exception("我将被忽略,因为下面的finally中使用了return");
- }finally {
- return 100;
- }
+
+ try{
+ result = bar();
+ System.out.println(result); //输出100
+ } catch (Exception e){
+ System.out.println(e.getMessage()); //没有捕获到异常
}
-
- //try中的异常被抑制
- @SuppressWarnings("finally")
- public static int bar() throws Exception
- {
- try {
- int a = 5/0;
- return 1;
- }finally {
- return 100;
- }
+ }
+
+ //catch中的异常被抑制
+ @SuppressWarnings("finally")
+ public static int foo() throws Exception
+ {
+ try {
+ int a = 5/0;
+ return 1;
+ }catch(ArithmeticException amExp) {
+ throw new Exception("我将被忽略,因为下面的finally中使用了return");
+ }finally {
+ return 100;
}
}
+
+ //try中的异常被抑制
+ @SuppressWarnings("finally")
+ public static int bar() throws Exception
+ {
+ try {
+ int a = 5/0;
+ return 1;
+ }finally {
+ return 100;
+ }
+ }
+}
+````
finally中的异常会覆盖(消灭)前面try或者catch中的异常
-
- class TestException
+````
+class TestException
+{
+ public static void main(String[] args)
{
- public static void main(String[] args)
- {
- int result;
- try{
- result = foo();
- } catch (Exception e){
- System.out.println(e.getMessage()); //输出:我是finaly中的Exception
- }
-
- try{
- result = bar();
- } catch (Exception e){
- System.out.println(e.getMessage()); //输出:我是finaly中的Exception
- }
+ int result;
+ try{
+ result = foo();
+ } catch (Exception e){
+ System.out.println(e.getMessage()); //输出:我是finaly中的Exception
}
-
- //catch中的异常被抑制
- @SuppressWarnings("finally")
- public static int foo() throws Exception
- {
- try {
- int a = 5/0;
- return 1;
- }catch(ArithmeticException amExp) {
- throw new Exception("我将被忽略,因为下面的finally中抛出了新的异常");
- }finally {
- throw new Exception("我是finaly中的Exception");
- }
+
+ try{
+ result = bar();
+ } catch (Exception e){
+ System.out.println(e.getMessage()); //输出:我是finaly中的Exception
}
-
- //try中的异常被抑制
- @SuppressWarnings("finally")
- public static int bar() throws Exception
- {
- try {
- int a = 5/0;
- return 1;
- }finally {
- throw new Exception("我是finaly中的Exception");
- }
-
+ }
+
+ //catch中的异常被抑制
+ @SuppressWarnings("finally")
+ public static int foo() throws Exception
+ {
+ try {
+ int a = 5/0;
+ return 1;
+ }catch(ArithmeticException amExp) {
+ throw new Exception("我将被忽略,因为下面的finally中抛出了新的异常");
+ }finally {
+ throw new Exception("我是finaly中的Exception");
}
}
-
+
+ //try中的异常被抑制
+ @SuppressWarnings("finally")
+ public static int bar() throws Exception
+ {
+ try {
+ int a = 5/0;
+ return 1;
+ }finally {
+ throw new Exception("我是finaly中的Exception");
+ }
+
+ }
+}
+````
上面的3个例子都异于常人的编码思维,因此我建议:
> 不要在fianlly中使用return。
@@ -782,22 +769,24 @@ finally中的异常会覆盖(消灭)前面try或者catch中的异常
下面是我个人总结的在Java和J2EE开发者在面试中经常被问到的有关Exception和Error的知识。在分享我的回答的时候,我也给这些问题作了快速修订,并且提供源码以便深入理解。我总结了各种难度的问题,适合新手码农和高级Java码农。如果你遇到了我列表中没有的问题,并且这个问题非常好,请在下面评论中分享出来。你也可以在评论中分享你面试时答错的情况。
**1) Java中什么是Exception?**
- 这个问题经常在第一次问有关异常的时候或者是面试菜鸟的时候问。我从来没见过面高级或者资深工程师的时候有人问这玩意,但是对于菜鸟,是很愿意问这个的。简单来说,异常是Java传达给你的系统和程序错误的方式。在java中,异常功能是通过实现比如Throwable,Exception,RuntimeException之类的类,然后还有一些处理异常时候的关键字,比如throw,throws,try,catch,finally之类的。 所有的异常都是通过Throwable衍生出来的。Throwable把错误进一步划分为 java.lang.Exception
-和 java.lang.Error. java.lang.Error 用来处理系统错误,例如java.lang.StackOverFlowError 之类的。然后 Exception用来处理程序错误,请求的资源不可用等等。
+这个问题经常在第一次问有关异常的时候或者是面试菜鸟的时候问。我从来没见过面高级或者资深工程师的时候有人问这玩意,但是对于菜鸟,是很愿意问这个的。简单来说,异常是Java传达给你的系统和程序错误的方式。在java中,异常功能是通过实现比如Throwable,Exception,RuntimeException之类的类,然后还有一些处理异常时候的关键字,比如throw,throws,try,catch,finally之类的。所有的异常都是通过Throwable衍生出来的。Throwable把错误进一步划分为java.lang.Exception
+和 java.lang.Error.
+
+java.lang.Error 用来处理系统错误,例如java.lang.StackOverFlowError 之类的。然后Exception用来处理程序错误,请求的资源不可用等等。
**2) Java中的检查型异常和非检查型异常有什么区别?**
- 这又是一个非常流行的Java异常面试题,会出现在各种层次的Java面试中。检查型异常和非检查型异常的主要区别在于其处理方式。检查型异常需要使用try, catch和finally关键字在编译期进行处理,否则会出现编译器会报错。对于非检查型异常则不需要这样做。Java中所有继承自java.lang.Exception类的异常都是检查型异常,所有继承自RuntimeException的异常都被称为非检查型异常。
+这又是一个非常流行的Java异常面试题,会出现在各种层次的Java面试中。检查型异常和非检查型异常的主要区别在于其处理方式。检查型异常需要使用try, catch和finally关键字在编译期进行处理,否则会出现编译器会报错。对于非检查型异常则不需要这样做。Java中所有继承自java.lang.Exception类的异常都是检查型异常,所有继承自RuntimeException的异常都被称为非检查型异常。
**3) Java中的NullPointerException和ArrayIndexOutOfBoundException之间有什么相同之处?**
- 在Java异常面试中这并不是一个很流行的问题,但会出现在不同层次的初学者面试中,用来测试应聘者对检查型异常和非检查型异常的概念是否熟悉。顺便说一下,该题的答案是,这两个异常都是非检查型异常,都继承自RuntimeException。该问题可能会引出另一个问题,即Java和C的数组有什么不同之处,因为C里面的数组是没有大小限制的,绝对不会抛出ArrayIndexOutOfBoundException。
+在Java异常面试中这并不是一个很流行的问题,但会出现在不同层次的初学者面试中,用来测试应聘者对检查型异常和非检查型异常的概念是否熟悉。顺便说一下,该题的答案是,这两个异常都是非检查型异常,都继承自RuntimeException。该问题可能会引出另一个问题,即Java和C的数组有什么不同之处,因为C里面的数组是没有大小限制的,绝对不会抛出ArrayIndexOutOfBoundException。
**4)在Java异常处理的过程中,你遵循的那些最好的实践是什么?**
- 这个问题在面试技术经理是非常常见的一个问题。因为异常处理在项目设计中是非常关键的,所以精通异常处理是十分必要的。异常处理有很多最佳实践,下面列举集中,它们提高你代码的健壮性和灵活性:
+这个问题在面试技术经理是非常常见的一个问题。因为异常处理在项目设计中是非常关键的,所以精通异常处理是十分必要的。异常处理有很多最佳实践,下面列举集中,它们提高你代码的健壮性和灵活性:
- 1) 调用方法的时候返回布尔值来代替返回null,这样可以 NullPointerException。由于空指针是java异常里最恶心的异常
+ 1) 调用方法的时候返回布尔值来代替返回null,这样可以NullPointerException。由于空指针是java异常里最恶心的异常
2) catch块里别不写代码。空catch块是异常处理里的错误事件,因为它只是捕获了异常,却没有任何处理或者提示。通常你起码要打印出异常信息,当然你最好根据需求对异常信息进行处理。
@@ -809,32 +798,20 @@ finally中的异常会覆盖(消灭)前面try或者catch中的异常
**5) 既然我们可以用RuntimeException来处理错误,那么你认为为什么Java中还存在检查型异常?**
- 这是一个有争议的问题,在回答该问题时你应当小心。虽然他们肯定愿意听到你的观点,但其实他们最感兴趣的还是有说服力的理由。我认为其中一个理由是,存在检查型异常是一个设计上的决定,受到了诸如C++等比Java更早编程语言设计经验的影响。绝大多数检查型异常位于java.io包内,这是合乎情理的,因为在你请求了不存在的系统资源的时候,一段强壮的程序必须能够优雅的处理这种情况。通过把IOException声明为检查型异常,Java 确保了你能够优雅的对异常进行处理。另一个可能的理由是,可以使用catch或finally来确保数量受限的系统资源(比如文件描述符)在你使用后尽早得到释放。 Joshua
-Bloch编写的 [Effective Java 一书](http://www.amazon.com/dp/0321356683/?tag=javamysqlanta-20) 中多处涉及到了该话题,值得一读。
-
-**6) throw 和 throws这两个关键字在java中有什么不同?**
-
- 一个java初学者应该掌握的面试问题。 throw 和 throws乍看起来是很相似的尤其是在你还是一个java初学者的时候。尽管他们看起来相似,都是在处理异常时候使用到的。但在代码里的使用方法和用到的地方是不同的。throws总是出现在一个函数头中,用来标明该成员函数可能抛出的各种异常, 你也可以申明未检查的异常,但这不是编译器强制的。如果方法抛出了异常那么调用这个方法的时候就需要将这个异常处理。另一个关键字 throw 是用来抛出任意异常的,按照语法你可以抛出任意 Throwable (i.e. Throwable
-或任何Throwable的衍生类) , throw可以中断程序运行,因此可以用来代替return . 最常见的例子是用 throw 在一个空方法中需要return的地方抛出 UnSupportedOperationException 代码如下 :
-
-
-
-
-
-| 123 | `private``static` `void` `show() {``throw``new` `UnsupportedOperationException(``"Notyet implemented"``);``}` |
-| --- | --- |
+这是一个有争议的问题,在回答该问题时你应当小心。虽然他们肯定愿意听到你的观点,但其实他们最感兴趣的还是有说服力的理由。我认为其中一个理由是,存在检查型异常是一个设计上的决定,受到了诸如C++等比Java更早编程语言设计经验的影响。绝大多数检查型异常位于java.io包内,这是合乎情理的,因为在你请求了不存在的系统资源的时候,一段强壮的程序必须能够优雅的处理这种情况。通过把IOException声明为检查型异常,Java 确保了你能够优雅的对异常进行处理。另一个可能的理由是,可以使用catch或finally来确保数量受限的系统资源(比如文件描述符)在你使用后尽早得到释放。Joshua
+Bloch编写的[Effective Java 一书](http://www.amazon.com/dp/0321356683/?tag=javamysqlanta-20)中多处涉及到了该话题,值得一读。
+**6) throw 和 throws这两个关键字在java中有什么不同?**
-
-
-
- 可以看下这篇 [文章](http://javarevisited.blogspot.com/2012/02/difference-between-throw-and-throws-in.html)查看这两个关键字在java中更多的差异 。
+ 一个java初学者应该掌握的面试问题。throw 和 throws乍看起来是很相似的尤其是在你还是一个java初学者的时候。尽管他们看起来相似,都是在处理异常时候使用到的。但在代码里的使用方法和用到的地方是不同的。throws总是出现在一个函数头中,用来标明该成员函数可能抛出的各种异常, 你也可以申明未检查的异常,但这不是编译器强制的。如果方法抛出了异常那么调用这个方法的时候就需要将这个异常处理。另一个关键字 throw 是用来抛出任意异常的,按照语法你可以抛出任意 Throwable(i.e. Throwable
+或任何Throwable的衍生类) , throw可以中断程序运行,因此可以用来代替return . 最常见的例子是用 throw 在一个空方法中需要return的地方抛出 UnSupportedOperationException.
+可以看下这篇[文章](http://javarevisited.blogspot.com/2012/02/difference-between-throw-and-throws-in.html)查看这两个关键字在java中更多的差异 。
**7) 什么是“异常链”?**
“异常链”是Java中非常流行的异常处理概念,是指在进行一个异常处理时抛出了另外一个异常,由此产生了一个异常链条。该技术大多用于将“ 受检查异常” ( checked exception)封装成为“非受检查异常”(unchecked exception)或者RuntimeException。顺便说一下,如果因为因为异常你决定抛出一个新的异常,你一定要包含原有的异常,这样,处理程序才可以通过getCause()和initCause()方法来访问异常最终的根源。
-**) 你曾经自定义实现过异常吗?怎么写的?**
+**8) 你曾经自定义实现过异常吗?怎么写的?**
很显然,我们绝大多数都写过自定义或者业务异常,像AccountNotFoundException。在面试过程中询问这个Java异常问题的主要原因是去发现你如何使用这个特性的。这可以更准确和精致的去处理异常,当然这也跟你选择checked 还是unchecked exception息息相关。通过为每一个特定的情况创建一个特定的异常,你就为调用者更好的处理异常提供了更好的选择。相比通用异常(general exception),我更倾向更为精确的异常。大量的创建自定义异常会增加项目class的个数,因此,在自定义异常和通用异常之间维持一个平衡是成功的关键。
@@ -862,21 +839,4 @@ http://c.biancheng.net/view/1038.html
https://blog.csdn.net/Lisiluan/article/details/88745820
https://blog.csdn.net/michaelgo/article/details/82790253
-## 微信公众号
-
-### Java技术江湖
-
-如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号【Java技术江湖】一位阿里 Java 工程师的技术小站,作者黄小斜,专注 Java 相关技术:SSM、SpringBoot、MySQL、分布式、中间件、集群、Linux、网络、多线程,偶尔讲点Docker、ELK,同时也分享技术干货和学习经验,致力于Java全栈开发!
-
-**Java工程师必备学习资源:** 一些Java工程师常用学习资源,关注公众号后,后台回复关键字 **“Java”** 即可免费无套路获取。
-
-
-
-### 个人公众号:黄小斜
-
-作者是 985 硕士,蚂蚁金服 JAVA 工程师,专注于 JAVA 后端技术栈:SpringBoot、MySQL、分布式、中间件、微服务,同时也懂点投资理财,偶尔讲点算法和计算机理论基础,坚持学习和写作,相信终身学习的力量!
-
-**程序员3T技术学习资源:** 一些程序员学习技术的资源大礼包,关注公众号后,后台回复关键字 **“资料”** 即可免费无套路获取。
-
-
diff --git "a/docs/java/basic/15\343\200\201Java\346\263\250\350\247\243\345\222\214\346\234\200\344\275\263\345\256\236\350\267\265.md" "b/docs/Java/basic/Java\346\263\250\350\247\243\345\222\214\346\234\200\344\275\263\345\256\236\350\267\265.md"
similarity index 85%
rename from "docs/java/basic/15\343\200\201Java\346\263\250\350\247\243\345\222\214\346\234\200\344\275\263\345\256\236\350\267\265.md"
rename to "docs/Java/basic/Java\346\263\250\350\247\243\345\222\214\346\234\200\344\275\263\345\256\236\350\267\265.md"
index ab4a401..435e587 100644
--- "a/docs/java/basic/15\343\200\201Java\346\263\250\350\247\243\345\222\214\346\234\200\344\275\263\345\256\236\350\267\265.md"
+++ "b/docs/Java/basic/Java\346\263\250\350\247\243\345\222\214\346\234\200\344\275\263\345\256\236\350\267\265.md"
@@ -22,21 +22,7 @@
* [什么是元注解?](#什么是元注解?)
* [下面的代码会编译吗?](#下面的代码会编译吗?)
* [参考文章](#参考文章)
- * [微信公众号](#微信公众号)
- * [Java技术江湖](#java技术江湖)
- * [个人公众号:黄小斜](#个人公众号:黄小斜)
-
-
----
-title: 夯实Java基础系列15:Java注解简介和最佳实践
-date: 2019-9-15 15:56:26 # 文章生成时间,一般不改
-categories:
- - Java技术江湖
- - Java基础
-tags:
- - annotation
- - Java注解
----
+
本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
> https://github.com/h2pl/Java-Tutorial
@@ -73,9 +59,7 @@ Annotation 中文译过来就是注解、标释的意思,在 Java 中注解是
并且,往抽象地说,标签并不一定是一张纸,它可以是对人和事物的属性评价。也就是说,标签具备对于抽象事物的解释。
-
-
-
+
所以,基于如此,我完成了自我的知识认知升级,我决定用标签来解释注解。
@@ -166,8 +150,8 @@ java.lang.annotation提供了四种元注解,专门注解其他的注解(在
JDK 内置注解
先来看几个 Java 内置的注解,让大家热热身。
- @Override 演示
-
+@Override 演示
+````
class Parent {
public void run() {
}
@@ -182,7 +166,9 @@ JDK 内置注解
public void run() {
}
}
+````
@Deprecated 演示
+````
class Parent {
/**
@@ -201,7 +187,9 @@ class Parent {
parent.run(); // 在编译器中此方法会显示过时标志
}
}
+````
@SuppressWarnings 演示
+````
class Parent {
// 因为定义的 name 没有使用,那么编译器就会有警告,这时候使用此注解可以屏蔽掉警告
@@ -209,8 +197,10 @@ class Parent {
@SuppressWarnings("all")
private String name;
}
-
+````
@FunctionalInterface 演示
+
+````
/**
* 此注解是 Java8 提出的函数式接口,接口中只允许有一个抽象方法
* 加上这个注解之后,类中多一个抽象方法或者少一个抽象方法都会报错
@@ -219,7 +209,7 @@ class Parent {
interface Func {
void run();
}
-
+````
## 注解处理器实战
@@ -230,27 +220,30 @@ interface Func {
我们先来了解下如何通过在运行时使用反射获取在程序中的使用的注解信息。如下类注解和方法注解。
类注解
- Class aClass = ApiController.class;
- Annotation[] annotations = aClass.getAnnotations();
-
- for(Annotation annotation : annotations) {
- if(annotation instanceof ApiAuthAnnotation) {
- ApiAuthAnnotation apiAuthAnnotation = (ApiAuthAnnotation) annotation;
- System.out.println("name: " + apiAuthAnnotation.name());
- System.out.println("age: " + apiAuthAnnotation.age());
- }
+
+````
+Class aClass = ApiController.class;
+Annotation[] annotations = aClass.getAnnotations();
+
+for(Annotation annotation : annotations) {
+ if(annotation instanceof ApiAuthAnnotation) {
+ ApiAuthAnnotation apiAuthAnnotation = (ApiAuthAnnotation) annotation;
+ System.out.println("name: " + apiAuthAnnotation.name());
+ System.out.println("age: " + apiAuthAnnotation.age());
}
- 方法注解
- Method method = ... //通过反射获取方法对象
- Annotation[] annotations = method.getDeclaredAnnotations();
-
- for(Annotation annotation : annotations) {
- if(annotation instanceof ApiAuthAnnotation) {
- ApiAuthAnnotation apiAuthAnnotation = (ApiAuthAnnotation) annotation;
- System.out.println("name: " + apiAuthAnnotation.name());
- System.out.println("age: " + apiAuthAnnotation.age());
- }
- }
+}
+方法注解
+Method method = ... //通过反射获取方法对象
+Annotation[] annotations = method.getDeclaredAnnotations();
+
+for(Annotation annotation : annotations) {
+ if(annotation instanceof ApiAuthAnnotation) {
+ ApiAuthAnnotation apiAuthAnnotation = (ApiAuthAnnotation) annotation;
+ System.out.println("name: " + apiAuthAnnotation.name());
+ System.out.println("age: " + apiAuthAnnotation.age());
+ }
+}
+````
此部分内容可参考: 通过反射获取注解信息
注解处理器实战
@@ -260,33 +253,33 @@ interface Func {
接下来要做的事情: 写一个切面,拦截浏览器访问带注解的接口,取出注解信息,判断年龄来确定是否可以继续访问。
在 dispatcher-servlet.xml 文件中定义 aop 切面
-
-
-
-
-
-
-
-
-
+````
+
+
+
+
+
+
+
+
+````
切面类处理逻辑即注解处理器代码如
-
- @Component("apiAuthAspect")
- public class ApiAuthAspect {
-
- public Object auth(ProceedingJoinPoint pjp) throws Throwable {
- Method method = ((MethodSignature) pjp.getSignature()).getMethod();
- ApiAuthAnnotation apiAuthAnnotation = method.getAnnotation(ApiAuthAnnotation.class);
- Integer age = apiAuthAnnotation.age();
- if (age > 18) {
- return pjp.proceed();
- } else {
- throw new RuntimeException("你未满18岁,禁止访问");
- }
+````
+@Component("apiAuthAspect")
+public class ApiAuthAspect {
+
+ public Object auth(ProceedingJoinPoint pjp) throws Throwable {
+ Method method = ((MethodSignature) pjp.getSignature()).getMethod();
+ ApiAuthAnnotation apiAuthAnnotation = method.getAnnotation(ApiAuthAnnotation.class);
+ Integer age = apiAuthAnnotation.age();
+ if (age > 18) {
+ return pjp.proceed();
+ } else {
+ throw new RuntimeException("你未满18岁,禁止访问");
}
}
-
-
+}
+````
## 不同类型的注解
@@ -295,7 +288,7 @@ interface Func {
你可以在运行期访问类,方法或者变量的注解信息,下是一个访问类注解的例子:
```
- Class aClass = TheClass.class;
+Class aClass = TheClass.class;
Annotation[] annotations = aClass.getAnnotations();
for(Annotation annotation : annotations){
@@ -410,8 +403,8 @@ public class TheClass {
你可以像这样来访问变量的注解:
```
-Field field = ... //获取方法对象
-Annotation[] annotations = field.getDeclaredAnnotations();
+Field field = ... //获取方法对象目录
+Annotation[] annotations = field.getDeclaredAnnotations();
for(Annotation annotation : annotations){
if(annotation instanceof MyAnnotation){
@@ -425,8 +418,8 @@ for(Annotation annotation : annotations){
你可以像这样访问指定的变量注解:
```
-Field field = ...//获取方法对象
-
+Field field = ...//获取方法对象目录
+
Annotation annotation = field.getAnnotation(MyAnnotation.class);
if(annotation instanceof MyAnnotation){
@@ -668,20 +661,5 @@ https://blog.51cto.com/4247649/2109129
https://www.jianshu.com/p/2f2460e6f8e7
https://blog.csdn.net/yuzongtao/article/details/83306182
-## 微信公众号
-
-### Java技术江湖
-
-如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号【Java技术江湖】一位阿里 Java 工程师的技术小站,作者黄小斜,专注 Java 相关技术:SSM、SpringBoot、MySQL、分布式、中间件、集群、Linux、网络、多线程,偶尔讲点Docker、ELK,同时也分享技术干货和学习经验,致力于Java全栈开发!
-
-**Java工程师必备学习资源:** 一些Java工程师常用学习资源,关注公众号后,后台回复关键字 **“Java”** 即可免费无套路获取。
-
-
-
-### 个人公众号:黄小斜
-
-作者是 985 硕士,蚂蚁金服 JAVA 工程师,专注于 JAVA 后端技术栈:SpringBoot、MySQL、分布式、中间件、微服务,同时也懂点投资理财,偶尔讲点算法和计算机理论基础,坚持学习和写作,相信终身学习的力量!
-**程序员3T技术学习资源:** 一些程序员学习技术的资源大礼包,关注公众号后,后台回复关键字 **“资料”** 即可免费无套路获取。
-
diff --git "a/docs/java/basic/5\343\200\201Java\347\261\273\345\222\214\345\214\205.md" "b/docs/Java/basic/Java\347\261\273\345\222\214\345\214\205.md"
similarity index 67%
rename from "docs/java/basic/5\343\200\201Java\347\261\273\345\222\214\345\214\205.md"
rename to "docs/Java/basic/Java\347\261\273\345\222\214\345\214\205.md"
index 4084792..43d7244 100644
--- "a/docs/java/basic/5\343\200\201Java\347\261\273\345\222\214\345\214\205.md"
+++ "b/docs/Java/basic/Java\347\261\273\345\222\214\345\214\205.md"
@@ -1,27 +1,21 @@
# 目录
- * [Java中的包概念](#java中的包概念)
+* [Java中的包概念](#java中的包概念)
* [包的作用](#包的作用)
* [package 的目录结构](#package-的目录结构)
* [设置 CLASSPATH 系统变量](#设置-classpath-系统变量)
- * [常用jar包](#常用jar包)
+* [常用jar包](#常用jar包)
* [java软件包的类型](#java软件包的类型)
* [dt.jar](#dtjar)
* [rt.jar](#rtjar)
- * [*.java文件的奥秘](#java文件的奥秘)
+* [*.java文件的奥秘](#java文件的奥秘)
* [*.Java文件简介](#java文件简介)
* [为什么一个java源文件中只能有一个public类?](#为什么一个java源文件中只能有一个public类?)
* [Main方法](#main方法)
* [外部类的访问权限](#外部类的访问权限)
* [Java包的命名规则](#java包的命名规则)
- * [参考文章](#参考文章)
- * [微信公众号](#微信公众号)
- * [Java技术江湖](#java技术江湖)
- * [个人公众号:黄小斜](#个人公众号:黄小斜)
+* [参考文章](#参考文章)
----
- - Java类
----
本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
@@ -74,11 +68,7 @@ Java 使用包(package)这种机制是为了防止命名冲突,访问控
package net.java.util; public class Something{ ... }
-
-
-
-
-那么它的路径应该是 **net/java/util/Something.java** 这样保存的。 package(包) 的作用是把不同的 java 程序分类保存,更方便的被其他 java 程序调用。
+那么它的路径应该是**net/java/util/Something.java**这样保存的。 package(包) 的作用是把不同的 java 程序分类保存,更方便的被其他 java 程序调用。
一个包(package)可以定义为一组相互联系的类型(类、接口、枚举和注释),为这些类型提供访问保护和命名空间管理的功能。
@@ -91,8 +81,6 @@ Java 使用包(package)这种机制是为了防止命名冲突,访问控
由于包创建了新的命名空间(namespace),所以不会跟其他包中的任何名字产生命名冲突。使用包这种机制,更容易实现访问控制,并且让定位相关类更加简单。
-
-
### package 的目录结构
类放在包中会有两种主要的结果:
@@ -104,28 +92,18 @@ Java 使用包(package)这种机制是为了防止命名冲突,访问控
将类、接口等类型的源码放在一个文本中,这个文件的名字就是这个类型的名字,并以.java作为扩展名。例如:
-
-
-
-
-// 文件名 : Car.java package vehicle; public class Car { // 类实现 }
-
-
-
-
+````
+// 文件名 : Car.java
+package vehicle;
+public class Car {
+// 类实现
+}
+````
接下来,把源文件放在一个目录中,这个目录要对应类所在包的名字。
-
-
-
-
....\vehicle\Car.java
-
-
-
-
现在,正确的类名和路径将会是如下样子:
* 类名 -> vehicle.Car
@@ -134,51 +112,49 @@ Java 使用包(package)这种机制是为了防止命名冲突,访问控
通常,一个公司使用它互联网域名的颠倒形式来作为它的包名.例如:互联网域名是 runoob.com,所有的包名都以 com.runoob 开头。包名中的每一个部分对应一个子目录。
-例如:有一个 **com.runoob.test** 的包,这个包包含一个叫做 Runoob.java 的源文件,那么相应的,应该有如下面的一连串子目录:
-
-
-
-
+例如:有一个**com.runoob.test**的包,这个包包含一个叫做 Runoob.java 的源文件,那么相应的,应该有如下面的一连串子目录:
....\com\runoob\test\Runoob.java
-
-
-
-
编译的时候,编译器为包中定义的每个类、接口等类型各创建一个不同的输出文件,输出文件的名字就是这个类型的名字,并加上 .class 作为扩展后缀。 例如:
-
-
-
-
-
-// 文件名: Runoob.java package com.runoob.test; public class Runoob { } class Google { }
-
-
-
+````
+// 文件名: Runoob.java
+package com.runoob.test;
+public class Runoob { }
+class Google { }
+````
现在,我们用-d选项来编译这个文件,如下:
-
-$javac -d . Runoob.java
-
+````
+ $javac -d . Runoob.java
+````
这样会像下面这样放置编译了的文件:
-.\com\runoob\test\Runoob.class .\com\runoob\test\Google.class
+````
+ .\com\runoob\test\Runoob.class
+ .\com\runoob\test\Google.class
+````
-你可以像下面这样来导入所有** \com\runoob\test\ **中定义的类、接口等:
-
-import com.runoob.test.*;
+你可以像下面这样来导入所有**\com\runoob\test\**中定义的类、接口等:
+````
+ import com.runoob.test.*;
+````
编译之后的 .class 文件应该和 .java 源文件一样,它们放置的目录应该跟包的名字对应起来。但是,并不要求 .class 文件的路径跟相应的 .java 的路径一样。你可以分开来安排源码和类的目录。
-\sources\com\runoob\test\Runoob.java \classes\com\runoob\test\Google.class
+````
+ \sources\com\runoob\test\Runoob.java
+ \classes\com\runoob\test\Google.class
+````
这样,你可以将你的类目录分享给其他的编程人员,而不用透露自己的源码。用这种方法管理源码和类文件可以让编译器和java 虚拟机(JVM)可以找到你程序中使用的所有类型。
-类目录的绝对路径叫做 **class path**。设置在系统变量 **CLASSPATH** 中。编译器和 java 虚拟机通过将 package 名字加到 class path 后来构造 .class 文件的路径。
+类目录的绝对路径叫做**class path**。设置在系统变量**CLASSPATH**中。编译器和 java 虚拟机通过将 package 名字加到 class path 后来构造 .class 文件的路径。
-\classes 是 class path,package 名字是 com.runoob.test,而编译器和 JVM 会在 \classes\com\runoob\test 中找 .class 文件。
+````
+ \classes 是 class path,package 名字是 com.runoob.test,而编译器和 JVM 会在 \classes\com\runoob\test 中找 .class 文件。
+````
一个 class path 可能会包含好几个路径,多路径应该用分隔符分开。默认情况下,编译器和 JVM 查找当前目录。JAR 文件按包含 Java 平台相关的类,所以他们的目录默认放在了 class path 中。
@@ -222,55 +198,54 @@ java包的作用是为了区别类名的命名空间
在 animals 包中加入一个接口(interface):
- package animals;
-
- interface Animal {
- public void eat();
- public void travel();
- }
- 接下来,在同一个包中加入该接口的实现:
-
- package animals;
-
- /* 文件名 : MammalInt.java */
- public class MammalInt implements Animal{
-
- public void eat(){
- System.out.println("Mammal eats");
- }
-
- public void travel(){
- System.out.println("Mammal travels");
- }
-
- public int noOfLegs(){
- return 0;
- }
-
- public static void main(String args[]){
- MammalInt m = new MammalInt();
- m.eat();
- m.travel();
- }
- }
-
+````
+package animals;
+interface Animal {
+ public void eat();
+ public void travel();
+}
+````
+
+接下来,在同一个包中加入该接口的实现:
+
+````
+package animals;
+/* 文件名 : MammalInt.java */
+public class MammalInt implements Animal{
+ public void eat(){
+ System.out.println("Mammal eats");
+ }
+ public void travel(){
+ System.out.println("Mammal travels");
+ }
+ public int noOfLegs(){
+ return 0;
+ }
+ public static void main(String args[]){
+ MammalInt m = new MammalInt();
+ m.eat();
+ m.travel();
+ }
+}
+````
import 关键字
为了能够使用某一个包的成员,我们需要在 Java 程序中明确导入该包。使用 "import" 语句可完成此功能。
在 java 源文件中 import 语句应位于 package 语句之后,所有类的定义之前,可以没有,也可以有多条,其语法格式为:
-1
-import package1[.package2…].(classname|*);
- 如果在一个包中,一个类想要使用本包中的另一个类,那么该包名可以省略。
+````
+ import package1[.package2…].(classname|*);
+````
+
+如果在一个包中,一个类想要使用本包中的另一个类,那么该包名可以省略。
通常,一个公司使用它互联网域名的颠倒形式来作为它的包名.例如:互联网域名是 runoob.com,所有的包名都以 com.runoob 开头。包名中的每一个部分对应一个子目录。
例如:有一个 com.runoob.test 的包,这个包包含一个叫做 Runoob.java 的源文件,那么相应的,应该有如下面的一连串子目录:
-
-1
-....\com\runoob\test\Runoob.java
-
+```
+ ....\com\runoob\test\Runoob.java
+```
## 常用jar包
### java软件包的类型
@@ -291,36 +266,30 @@ import package1[.package2…].(classname|*);
6) java.net:包含支持网络操作的类。
### dt.jar
-> SUN对于dt.jar的定义:Also includes dt.jar, the DesignTime archive of BeanInfo files that tell interactive development environments (IDE's) how to display the Java components and how to let the developer customize them for the application。
-
-中文翻译过来就是:dt.jar是BeanInfo文件的DesignTime归档,BeanInfo文件用来告诉集成开发环境(IDE)如何显示Java组件还有如何让开发人员根据应用程序自定义它们。这段文字中提到了几个关键字:DesignTime,BeanInfo,IDE,Java components。其实dt.jar就是DesignTime Archive的缩写。那么何为DesignTime。
- 何为DesignTime?翻译过来就是设计时。其实了解JavaBean的人都知道design time和runtime(运行时)这两个术语的含义。设计时(DesignTIme)是指在开发环境中通过添加控件,设置控件或窗体属性等方法,建立应用程序的时间。
-
- 与此相对应的运行时(RunTIme)是指可以象用户那样与应用程序交互作用的时间。那么现在再理解一下上面的翻译,其实dt.jar包含了swing控件中的BeanInfo,而IDE的GUI Designer需要这些信息。那让我们看一下dt.jar中到底有什么?下面是一张dt.jar下面的内容截图:
+> SUN对于dt.jar的定义:Also includesdt.jar, the DesignTime archive of BeanInfo files that tell interactive development environments (IDE's) how to display the Java components and how to let the developer customize them for the application。
-
+中文翻译过来就是:dt.jar是BeanInfo文件的DesignTime归档,BeanInfo文件用来告诉集成开发环境(IDE)如何显示Java组件还有如何让开发人员根据应用程序自定义它们。这段文字中提到了几个关键字:DesignTime,BeanInfo,IDE,Java components。其实dt.jar就是DesignTime Archive的缩写。那么何为DesignTime。
- 从上面的截图可以看出,dt.jar中全部是Swing组件的BeanInfo。那么到底什么是BeanInfo呢?
+何为DesignTime?翻译过来就是设计时。其实了解JavaBean的人都知道design time和runtime(运行时)这两个术语的含义。设计时(DesignTIme)是指在开发环境中通过添加控件,设置控件或窗体属性等方法,建立应用程序的时间。
- 何为BeanInfo?JavaBean和BeanInfo有很大的关系。Sun所制定的JavaBean规范,很大程度上是为IDE准备的——它让IDE能够以可视化的方式设置JavaBean的属性。如果在IDE中开发一个可视化应用程序,我们需要通过属性设置的方式对组成应用的各种组件进行定制,IDE通过属性编辑器让开发人员使用可视化的方式设置组件的属性。
+与此相对应的运行时(RunTIme)是指可以象用户那样与应用程序交互作用的时间。那么现在再理解一下上面的翻译,其实dt.jar包含了swing控件中的BeanInfo,而IDE的GUI Designer需要这些信息。那让我们看一下dt.jar中到底有什么?
- 一般的IDE都支持JavaBean规范所定义的属性编辑器,当组件开发商发布一个组件时,它往往将组件对应的属性编辑器捆绑发行,这样开发者就可以在IDE环境下方便地利用属性编辑器对组件进行定制工作。JavaBean规范通过java.beans.PropertyEditor定义了设置JavaBean属性的方法,通过BeanInfo描述了JavaBean哪些属性是可定制的,此外还描述了可定制属性与PropertyEditor的对应关系。
+dt.jar中全部是Swing组件的BeanInfo。那么到底什么是BeanInfo呢?
- BeanInfo与JavaBean之间的对应关系,通过两者之间规范的命名确立:对应JavaBean的BeanInfo采用如下的命名规范:BeanInfo。当JavaBean连同其属性编辑器相同的组件注册到IDE中后,当在开发界面中对JavaBean进行定制时,IDE就会根据JavaBean规范找到对应的BeanInfo,再根据BeanInfo中的描述信息找到JavaBean属性描述(是否开放、使用哪个属性编辑器),进而为JavaBean生成特定开发编辑界面。
+何为BeanInfo?JavaBean和BeanInfo有很大的关系。Sun所制定的JavaBean规范,很大程度上是为IDE准备的——它让IDE能够以可视化的方式设置JavaBean的属性。如果在IDE中开发一个可视化应用程序,我们需要通过属性设置的方式对组成应用的各种组件进行定制,IDE通过属性编辑器让开发人员使用可视化的方式设置组件的属性。
- dt.jar里面主要是swing组件的BeanInfo。IDE根据这些BeanInfo显示这些组件以及开发人员如何定制他们。
+dt.jar里面主要是swing组件的BeanInfo。IDE根据这些BeanInfo显示这些组件以及开发人员如何定制他们。
### rt.jar
rt.jar是runtime的归档。Java基础类库,也就是Java doc里面看到的所有的类的class文件。
-
-
- rt.jar 默认就在Root Classloader的加载路径里面的,而在Claspath配置该变量是不需要的;同时jre/lib目录下的其他jar:jce.jar、jsse.jar、charsets.jar、resources.jar都在Root Classloader中。
+
-## *.java文件的奥秘
+rt.jar 默认就在Root Classloader的加载路径里面的,而在Claspath配置该变量是不需要的;同时jre/lib目录下的其他jar:jce.jar、jsse.jar、charsets.jar、resources.jar都在Root Classloader中。
-### *.Java文件简介
+## java文件的奥秘
+### Java文件简介
.java文件你可以认为只是一个文本文件, 这个文件即是用java语言写成的程序,或者说任务的代码块。
@@ -335,43 +304,41 @@ rt.jar是runtime的归档。Java基础类库,也就是Java doc里面看到的
这里的.class文件在计算的体系结构中本质上对应的是一种机器语言(而这里的机器叫作JVM),所以JVM本身是可以直接运行这里的.class文件。所以 你可以进一步地认为,.java与.class与其它的编程语法一样,它们都是程序员用来描述自己的任务的一种语言,只是它们面向的对象不一样,而计算机本身只能识别它自已定义的那些指令什么的(再次强调,这里的计算机本身没有那么严格的定义)
> In short:
->
+>
> .java是Java的源文件后缀,里面存放程序员编写的功能代码。
->
+>
> .class文件是字节码文件,由.java源文件通过javac命令编译后生成的文件。是可以运行在任何支持Java虚拟机的硬件平台和操作系统上的二进制文件。
->
+>
> .class文件并不本地的可执行程序。Java虚拟机就是去运行.class文件从而实现程序的运行。
-
-
### 为什么一个java源文件中只能有一个public类?
- 在java编程思想(第四版)一书中有这样3段话(6.4 类的访问权限):
+在java编程思想(第四版)一书中有这样3段话(6.4 类的访问权限):
> 1.每个编译单元(文件)都只能有一个public类,这表示,每个编译单元都有单一的公共接口,用public类来表现。该接口可以按要求包含众多的支持包访问权限的类。如果在某个编译单元内有一个以上的public类,编译器就会给出错误信息。
->
+>
> 2.public类的名称必须完全与含有该编译单元的文件名相同,包含大小写。如果不匹配,同样将得到编译错误。
->
+>
> 3.虽然不是很常用,但编译单元内完全不带public类也是可能的。在这种情况下,可以随意对文件命名。
总结相关的几个问题:
1、一个”.java”源文件中是否可以包括多个类(不是内部类)?有什么限制?
-> 答:可以有多个类,但只能有一个public的类,并且public的类名必须与文件名相一致。
+> 答:可以有多个类,但只能有一个public的类,并且public的类名必须与文件名相一致。
2、为什么一个文件中只能有一个public的类
-> 答:编译器在编译时,针对一个java源代码文件(也称为“编译单元”)只会接受一个public类。否则报错。
+> 答:编译器在编译时,针对一个java源代码文件(也称为“编译单元”)只会接受一个public类。否则报错。
3、在java文件中是否可以没有public类
-> 答:public类不是必须的,java文件中可以没有public类。
+> 答:public类不是必须的,java文件中可以没有public类。
4、为什么这个public的类的类名必须和文件名相同
-> 答: 是为了方便虚拟机在相应的路径中找到相应的类所对应的字节码文件。
+> 答: 是为了方便虚拟机在相应的路径中找到相应的类所对应的字节码文件。
### Main方法
@@ -400,27 +367,25 @@ rt.jar是runtime的归档。Java基础类库,也就是Java doc里面看到的
为什么要对外部类或类做修饰呢?
-> 1.存在包概念:public 和 default 能区分这个外部类能对不同包作一个划分 (default修饰的类,其他包中引入不了这个类,public修饰的类才能被import)
->
+> 1.存在包概念:public 和 default 能区分这个外部类能对不同包作一个划分 (default修饰的类,其他包中引入不了这个类,public修饰的类才能被import)
+>
> 2.protected是包内可见并且子类可见,但是当一个外部类想要继承一个protected修饰的非同包类时,压根找不到这个类,更别提几层了
->
+>
> 3.private修饰的外部类,其他任何外部类都无法导入它。
-
- //Java中的文件名要和public修饰的类名相同,否则会报错
- //如果没有public修饰的类,则文件可以随意命名
- public class Java中的类文件 {
-
- }
-
- //非公共开类的访问权限默认是包访问权限,不能用private和protected
- //一个外部类的访问权限只有两种,一种是包内可见,一种是包外可见。
- //如果用private修饰,其他类根本无法看到这个类,也就没有意义了。
- //如果用protected,虽然也是包内可见,但是如果有子类想要继承该类但是不同包时,
- //压根找不到这个类,也不可能继承它了,所以干脆用default代替。
- class A{
-
- }
+````
+//Java中的文件名要和public修饰的类名相同,否则会报错
+//如果没有public修饰的类,则文件可以随意命名
+public class Java中的类文件 {
+}
+//非公共开类的访问权限默认是包访问权限,不能用private和protected
+//一个外部类的访问权限只有两种,一种是包内可见,一种是包外可见。
+//如果用private修饰,其他类根本无法看到这个类,也就没有意义了。
+//如果用protected,虽然也是包内可见,但是如果有子类想要继承该类但是不同包时,
+//压根找不到这个类,也不可能继承它了,所以干脆用default代替。
+class A{
+}
+````
### Java包的命名规则
@@ -444,20 +409,3 @@ https://www.runoob.com/java/java-package.html
https://www.breakyizhan.com/java/4260.html
https://blog.csdn.net/qq_36626914/article/details/80627454
-## 微信公众号
-
-### Java技术江湖
-
-如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号【Java技术江湖】一位阿里 Java 工程师的技术小站,作者黄小斜,专注 Java 相关技术:SSM、SpringBoot、MySQL、分布式、中间件、集群、Linux、网络、多线程,偶尔讲点Docker、ELK,同时也分享技术干货和学习经验,致力于Java全栈开发!
-
-**Java工程师必备学习资源:** 一些Java工程师常用学习资源,关注公众号后,后台回复关键字 **“Java”** 即可免费无套路获取。
-
-
-
-### 个人公众号:黄小斜
-
-作者是 985 硕士,蚂蚁金服 JAVA 工程师,专注于 JAVA 后端技术栈:SpringBoot、MySQL、分布式、中间件、微服务,同时也懂点投资理财,偶尔讲点算法和计算机理论基础,坚持学习和写作,相信终身学习的力量!
-
-**程序员3T技术学习资源:** 一些程序员学习技术的资源大礼包,关注公众号后,后台回复关键字 **“资料”** 即可免费无套路获取。
-
-
diff --git "a/docs/java/basic/8\343\200\201Java\350\207\252\345\212\250\346\213\206\347\256\261\350\243\205\347\256\261\351\207\214\351\232\220\350\227\217\347\232\204\347\247\230\345\257\206.md" "b/docs/Java/basic/Java\350\207\252\345\212\250\346\213\206\347\256\261\350\243\205\347\256\261\351\207\214\351\232\220\350\227\217\347\232\204\347\247\230\345\257\206.md"
similarity index 63%
rename from "docs/java/basic/8\343\200\201Java\350\207\252\345\212\250\346\213\206\347\256\261\350\243\205\347\256\261\351\207\214\351\232\220\350\227\217\347\232\204\347\247\230\345\257\206.md"
rename to "docs/Java/basic/Java\350\207\252\345\212\250\346\213\206\347\256\261\350\243\205\347\256\261\351\207\214\351\232\220\350\227\217\347\232\204\347\247\230\345\257\206.md"
index c6ed3af..4d2dfac 100644
--- "a/docs/java/basic/8\343\200\201Java\350\207\252\345\212\250\346\213\206\347\256\261\350\243\205\347\256\261\351\207\214\351\232\220\350\227\217\347\232\204\347\247\230\345\257\206.md"
+++ "b/docs/Java/basic/Java\350\207\252\345\212\250\346\213\206\347\256\261\350\243\205\347\256\261\351\207\214\351\232\220\350\227\217\347\232\204\347\247\230\345\257\206.md"
@@ -14,14 +14,8 @@
* [存在栈中:](#存在栈中:)
* [存在堆里](#存在堆里)
* [参考文章](#参考文章)
- * [微信公众号](#微信公众号)
- * [Java技术江湖](#java技术江湖)
- * [个人公众号:黄小斜](#个人公众号:黄小斜)
- - Java基本数据类型
----
-
本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
> https://github.com/h2pl/Java-Tutorial
@@ -148,14 +142,14 @@ float fn = Float.MIN_VALUE;
//64位
double dx = Double.MAX_VALUE;
double dn = Double.MIN_VALUE;
-//16位
-char cx = Character.MAX_VALUE;
-char cn = Character.MIN_VALUE;
//1位
boolean bt = Boolean.TRUE;
boolean bf = Boolean.FALSE;
```
+```
+打印它们的结果可以得到
+
`127`
`-128`
`32767`
@@ -168,10 +162,9 @@ boolean bf = Boolean.FALSE;
`1.4E-45`
`1.7976931348623157E308`
`4.9E-324`
-``
-
`true`
`false`
+```
### 引用类型
@@ -203,23 +196,23 @@ char a = 'A'
## 自动拆箱和装箱(详解)
Java 5增加了自动装箱与自动拆箱机制,方便基本类型与包装类型的相互转换操作。在Java 5之前,如果要将一个int型的值转换成对应的包装器类型Integer,必须显式的使用new创建一个新的Integer对象,或者调用静态方法Integer.valueOf()。
-
+````
//在Java 5之前,只能这样做
Integer value = new Integer(10);
//或者这样做
Integer value = Integer.valueOf(10);
//直接赋值是错误的
//Integer value = 10;`
-
+````
在Java 5中,可以直接将整型赋给Integer对象,由编译器来完成从int型到Integer类型的转换,这就叫自动装箱。
-
-`//在Java 5中,直接赋值是合法的,由编译器来完成转换`
-`Integer value = 10;`
-`与此对应的,自动拆箱就是可以将包装类型转换为基本类型,具体的转换工作由编译器来完成。`
-`//在Java 5 中可以直接这么做`
-`Integer value = new Integer(10);`
-`int i = value;`
-
+````
+//在Java 5中,直接赋值是合法的,由编译器来完成转换
+Integer value = 10;
+与此对应的,自动拆箱就是可以将包装类型转换为基本类型,具体的转换工作由编译器来完成。
+//在Java 5 中可以直接这么做
+Integer value = new Integer(10);
+int i = value;
+````
自动装箱与自动拆箱为程序员提供了很大的方便,而在实际的应用中,自动装箱与拆箱也是使用最广泛的特性之一。自动装箱和自动拆箱其实是Java编译器提供的一颗语法糖(语法糖是指在计算机语言中添加的某种语法,这种语法对语言的功能并没有影响,但是更方便程序员使用。通过可提高开发效率,增加代码可读性,增加代码的安全性)。
### 简易实现
@@ -231,6 +224,7 @@ Integer value = Integer.valueOf(10);
实例方法xxxValue():将具体的包装类型对象转换成基本类型;
下面我们以int和Integer为例,说明Java中自动装箱与自动拆箱的实现机制。看如下代码:
+````
class Auto //code1
{
public static void main(String[] args)
@@ -246,7 +240,10 @@ class Auto //code1
}
}
+````
+
上面的代码先将int型转为Integer对象,再讲Integer对象转换为int型,毫无疑问,这是可以正确运行的。可是,这种转换是怎么进行的呢?使用反编译工具,将生成的Class文件在反编译为Java文件,让我们看看发生了什么:
+````
class Auto//code2
{
public static void main(String[] paramArrayOfString)
@@ -254,17 +251,11 @@ class Auto//code2
Integer localInteger = Integer.valueOf(10);
int i = localInteger.intValue();
-
-
-
-
-
-
-
Double localDouble = Double.valueOf(12.4D);
double d = localDouble.doubleValue();
}
}
+````
我们可以看到经过javac编译之后,code1的代码被转换成了code2,实际运行时,虚拟机运行的就是code2的代码。也就是说,虚拟机根本不知道有自动拆箱和自动装箱这回事;在将Java源文件编译为class文件的过程中,javac编译器在自动装箱的时候,调用了Integer.valueOf()方法,在自动拆箱时,又调用了intValue()方法。我们可以看到,double和Double也是如此。
实现总结:其实自动装箱和自动封箱是编译器为我们提供的一颗语法糖。在自动装箱时,编译器调用包装类型的valueOf()方法;在自动拆箱时,编译器调用了相应的xxxValue()方法。
@@ -274,128 +265,132 @@ class Auto//code2
Integer源码
+````
public final class Integer extends Number implements Comparable {
- private final int value;
-
- /*Integer的构造方法,接受一个整型参数,Integer对象表示的int值,保存在value中*/
- public Integer(int value) {
- this.value = value;
- }
-
- /*equals()方法判断的是:所代表的int型的值是否相等*/
- public boolean equals(Object obj) {
- if (obj instanceof Integer) {
- return value == ((Integer)obj).intValue();
- }
- return false;
- }
-
- /*返回这个Integer对象代表的int值,也就是保存在value中的值*/
- public int intValue() {
- return value;
- }
-
- /**
- * 首先会判断i是否在[IntegerCache.low,Integer.high]之间
- * 如果是,直接返回Integer.cache中相应的元素
- * 否则,调用构造方法,创建一个新的Integer对象
- */
- public static Integer valueOf(int i) {
- assert IntegerCache.high >= 127;
- if (i >= IntegerCache.low && i <= IntegerCache.high)
- return IntegerCache.cache[i + (-IntegerCache.low)];
- return new Integer(i);
- }
-
- /**
- * 静态内部类,缓存了从[low,high]对应的Integer对象
- * low -128这个值不会被改变
- * high 默认是127,可以改变,最大不超过:Integer.MAX_VALUE - (-low) -1
- * cache 保存从[low,high]对象的Integer对象
- */
- private static class IntegerCache {
- static final int low = -128;
- static final int high;
- static final Integer cache[];
-
- static {
- // high value may be configured by property
- int h = 127;
- String integerCacheHighPropValue =
- sun.misc.VM.getSavedProperty("java.lang.Integer.IntegerCache.high");
- if (integerCacheHighPropValue != null) {
- int i = parseInt(integerCacheHighPropValue);
- i = Math.max(i, 127);
- // Maximum array size is Integer.MAX_VALUE
- h = Math.min(i, Integer.MAX_VALUE - (-low) -1);
- }
- high = h;
-
- cache = new Integer[(high - low) + 1];
- int j = low;
- for(int k = 0; k < cache.length; k++)
- cache[k] = new Integer(j++);
- }
-
- private IntegerCache() {}
- }
+ private final int value;
+
+ /*Integer的构造方法,接受一个整型参数,Integer对象表示的int值,保存在value中*/
+ public Integer(int value) {
+ this.value = value;
+ }
+
+ /*equals()方法判断的是:所代表的int型的值是否相等*/
+ public boolean equals(Object obj) {
+ if (obj instanceof Integer) {
+ return value == ((Integer)obj).intValue();
+ }
+ return false;
+ }
+
+ /*返回这个Integer对象代表的int值,也就是保存在value中的值*/
+ public int intValue() {
+ return value;
+ }
+
+ /**
+ * 首先会判断i是否在[IntegerCache.low,Integer.high]之间
+ * 如果是,直接返回Integer.cache中相应的元素
+ * 否则,调用构造方法,创建一个新的Integer对象
+ */
+ public static Integer valueOf(int i) {
+ assert IntegerCache.high >= 127;
+ if (i >= IntegerCache.low && i <= IntegerCache.high)
+ return IntegerCache.cache[i + (-IntegerCache.low)];
+ return new Integer(i);
+ }
+
+ /**
+ * 静态内部类,缓存了从[low,high]对应的Integer对象
+ * low -128这个值不会被改变
+ * high 默认是127,可以改变,最大不超过:Integer.MAX_VALUE - (-low) -1
+ * cache 保存从[low,high]对象的Integer对象
+ */
+ private static class IntegerCache {
+ static final int low = -128;
+ static final int high;
+ static final Integer cache[];
+
+ static {
+ // high value may be configured by property
+ int h = 127;
+ String integerCacheHighPropValue =
+ sun.misc.VM.getSavedProperty("java.lang.Integer.IntegerCache.high");
+ if (integerCacheHighPropValue != null) {
+ int i = parseInt(integerCacheHighPropValue);
+ i = Math.max(i, 127);
+ // Maximum array size is Integer.MAX_VALUE
+ h = Math.min(i, Integer.MAX_VALUE - (-low) -1);
+ }
+ high = h;
+
+ cache = new Integer[(high - low) + 1];
+ int j = low;
+ for(int k = 0; k < cache.length; k++)
+ cache[k] = new Integer(j++);
+ }
+
+ private IntegerCache() {}
+ }
}
-以上是Oracle(Sun)公司JDK 1.7中Integer源码的一部分,通过分析上面的代码,得到:
-1)Integer有一个实例域value,它保存了这个Integer所代表的int型的值,且它是final的,也就是说这个Integer对象一经构造完成,它所代表的值就不能再被改变。
-2)Integer重写了equals()方法,它通过比较两个Integer对象的value,来判断是否相等。
-3)重点是静态内部类IntegerCache,通过类名就可以发现:它是用来缓存数据的。它有一个数组,里面保存的是连续的Integer对象。
- (a) low:代表缓存数据中最小的值,固定是-128。
- (b) high:代表缓存数据中最大的值,它可以被该改变,默认是127。high最小是127,最大是Integer.MAX_VALUE-(-low)-1,如果high超过了这个值,那么cache[ ]的长度就超过Integer.MAX_VALUE了,也就溢出了。
- (c) cache[]:里面保存着从[low,high]所对应的Integer对象,长度是high-low+1(因为有元素0,所以要加1)。
-4)调用valueOf(int i)方法时,首先判断i是否在[low,high]之间,如果是,则复用Integer.cache[i-low]。比如,如果Integer.valueOf(3),直接返回Integer.cache[131];如果i不在这个范围,则调用构造方法,构造出一个新的Integer对象。
-5)调用intValue(),直接返回value的值。
-通过3)和4)可以发现,默认情况下,在使用自动装箱时,VM会复用[-128,127]之间的Integer对象。
-
-Integer a1 = 1;
-Integer a2 = 1;
-Integer a3 = new Integer(1);
-//会打印true,因为a1和a2是同一个对象,都是Integer.cache[129]
-System.out.println(a1 == a2);
-//false,a3构造了一个新的对象,不同于a1,a2
-System.out.println(a1 == a3);
+````
+
+ 以上是Oracle(Sun)公司JDK 1.7中Integer源码的一部分,通过分析上面的代码,得到:
+ 1)Integer有一个实例域value,它保存了这个Integer所代表的int型的值,且它是final的,也就是说这个Integer对象一经构造完成,它所代表的值就不能再被改变。
+ 2)Integer重写了equals()方法,它通过比较两个Integer对象的value,来判断是否相等。
+ 3)重点是静态内部类IntegerCache,通过类名就可以发现:它是用来缓存数据的。它有一个数组,里面保存的是连续的Integer对象。
+ (a) low:代表缓存数据中最小的值,固定是-128。
+ (b) high:代表缓存数据中最大的值,它可以被该改变,默认是127。high最小是127,最大是Integer.MAX_VALUE-(-low)-1,如果high超过了这个值,那么cache[ ]的长度就超过Integer.MAX_VALUE了,也就溢出了。
+ (c) cache[]:里面保存着从[low,high]所对应的Integer对象,长度是high-low+1(因为有元素0,所以要加1)。
+ 4)调用valueOf(int i)方法时,首先判断i是否在[low,high]之间,如果是,则复用Integer.cache[i-low]。比如,如果Integer.valueOf(3),直接返回Integer.cache[131];如果i不在这个范围,则调用构造方法,构造出一个新的Integer对象。
+ 5)调用intValue(),直接返回value的值。
+ 通过3)和4)可以发现,默认情况下,在使用自动装箱时,VM会复用[-128,127]之间的Integer对象。
+
+ Integer a1 = 1;
+ Integer a2 = 1;
+ Integer a3 = new Integer(1);
+ //会打印true,因为a1和a2是同一个对象,都是Integer.cache[129]
+ System.out.println(a1 == a2);
+ //false,a3构造了一个新的对象,不同于a1,a2
+ System.out.println(a1 == a3);
### 了解基本类型缓存(常量池)的最佳实践
- //基本数据类型的常量池是-128到127之间。
- // 在这个范围中的基本数据类的包装类可以自动拆箱,比较时直接比较数值大小。
- public static void main(String[] args) {
- //int的自动拆箱和装箱只在-128到127范围中进行,超过该范围的两个integer的 == 判断是会返回false的。
- Integer a1 = 128;
- Integer a2 = -128;
- Integer a3 = -128;
- Integer a4 = 128;
- System.out.println(a1 == a4);
- System.out.println(a2 == a3);
-
- Byte b1 = 127;
- Byte b2 = 127;
- Byte b3 = -128;
- Byte b4 = -128;
- //byte都是相等的,因为范围就在-128到127之间
- System.out.println(b1 == b2);
- System.out.println(b3 == b4);
-
- //
- Long c1 = 128L;
- Long c2 = 128L;
- Long c3 = -128L;
- Long c4 = -128L;
- System.out.println(c1 == c2);
- System.out.println(c3 == c4);
-
- //char没有负值
- //发现char也是在0到127之间自动拆箱
- Character d1 = 128;
- Character d2 = 128;
- Character d3 = 127;
- Character d4 = 127;
- System.out.println(d1 == d2);
- System.out.println(d3 == d4);
+````
+//基本数据类型的常量池是-128到127之间。
+// 在这个范围中的基本数据类的包装类可以自动拆箱,比较时直接比较数值大小。
+public static void main(String[] args) {
+
+//int的自动拆箱和装箱只在-128到127范围中进行,超过该范围的两个integer的 == 判断是会返回false的。
+Integer a1 = 128;
+Integer a2 = -128;
+Integer a3 = -128;
+Integer a4 = 128;
+System.out.println(a1 == a4);
+System.out.println(a2 == a3);
+
+Byte b1 = 127;
+Byte b2 = 127;
+Byte b3 = -128;
+Byte b4 = -128;
+//byte都是相等的,因为范围就在-128到127之间
+System.out.println(b1 == b2);
+System.out.println(b3 == b4);
+
+Long c1 = 128L;
+Long c2 = 128L;
+Long c3 = -128L;
+Long c4 = -128L;
+System.out.println(c1 == c2);
+System.out.println(c3 == c4);
+
+//char没有负值
+//发现char也是在0到127之间自动拆箱
+Character d1 = 128;
+Character d2 = 128;
+Character d3 = 127;
+Character d4 = 127;
+System.out.println(d1 == d2);
+System.out.println(d3 == d4);
`结果`
@@ -409,27 +404,29 @@ System.out.println(a1 == a3);
`true`
- Integer i = 10;
- Byte b = 10;
- //比较Byte和Integer.两个对象无法直接比较,报错
- //System.out.println(i == b);
- System.out.println("i == b " + i.equals(b));
- //答案是false,因为包装类的比较时先比较是否是同一个类,不是的话直接返回false.
- int ii = 128;
- short ss = 128;
- long ll = 128;
- char cc = 128;
- System.out.println("ii == bb " + (ii == ss));
- System.out.println("ii == ll " + (ii == ll));
- System.out.println("ii == cc " + (ii == cc));
-
- 结果
- i == b false
- ii == bb true
- ii == ll true
- ii == cc true
-
- //这时候都是true,因为基本数据类型直接比较值,值一样就可以。
+Integer i = 10;
+Byte b = 10;
+//比较Byte和Integer.两个对象无法直接比较,报错
+//System.out.println(i == b);
+System.out.println("i == b " + i.equals(b));
+//答案是false,因为包装类的比较时先比较是否是同一个类,不是的话直接返回false.
+
+int ii = 128;
+short ss = 128;
+long ll = 128;
+char cc = 128;
+System.out.println("ii == bb " + (ii == ss));
+System.out.println("ii == ll " + (ii == ll));
+System.out.println("ii == cc " + (ii == cc));
+
+结果
+i == b false
+ii == bb true
+ii == ll true
+ii == cc true
+
+//这时候都是true,因为基本数据类型直接比较值,值一样就可以。
+````
### 总结:
@@ -439,12 +436,10 @@ System.out.println(a1 == a3);
(2)当需要一个基本类型时会自动拆箱,比如int a = new Integer(10);算术运算是在基本类型间进行的,所以当遇到算术运算时会自动拆箱,比如代码中的 c == (a + b);
-(3) 包装类型 == 基本类型时,包装类型自动拆箱;
+(3)包装类型 == 基本类型时,包装类型自动拆箱;
需要注意的是:“==”在没遇到算术运算时,不会自动拆箱;基本类型只会自动装箱为对应的包装类型,代码中最后一条说明的内容。
-
-
在JDK 1.5中提供了自动装箱与自动拆箱,这其实是Java 编译器的语法糖,编译器通过调用包装类型的valueOf()方法实现自动装箱,调用xxxValue()方法自动拆箱。自动装箱和拆箱会有一些陷阱,那就是包装类型复用了某些对象。
(1)Integer默认复用了[-128,127]这些对象,其中高位置可以修改;
@@ -468,11 +463,13 @@ Boolean没有自动装箱与拆箱,它也复用了Boolean.TRUE和Boolean.FALSE
上面自动拆箱和装箱的原理其实与常量池有关。
### 存在栈中:
-public void(int a)
-{
-int i = 1;
-int j = 1;
-}
+
+ public void(int a)
+ {
+ int i = 1;
+ int j = 1;
+ }
+
方法中的i 存在虚拟机栈的局部变量表里,i是一个引用,j也是一个引用,它们都指向局部变量表里的整型值 1.
int a是传值引用,所以a也会存在局部变量表。
@@ -485,50 +482,53 @@ i是类的成员变量。类实例化的对象存在堆中,所以成员变量
3 包装类对象怎么存
其实我们说的常量池也可以叫对象池。
+
比如String a= new String("a").intern()时会先在常量池找是否有“a"对象如果有的话直接返回“a"对象在常量池的地址,即让引用a指向常量”a"对象的内存地址。
-public native String intern();
Integer也是同理。
下图是Integer类型在常量池中查找同值对象的方法。
- public static Integer valueOf(int i) {
- if (i >= IntegerCache.low && i <= IntegerCache.high)
- return IntegerCache.cache[i + (-IntegerCache.low)];
- return new Integer(i);
- }
- private static class IntegerCache {
- static final int low = -128;
- static final int high;
- static final Integer cache[];
-
- static {
- // high value may be configured by property
- int h = 127;
- String integerCacheHighPropValue =
- sun.misc.VM.getSavedProperty("java.lang.Integer.IntegerCache.high");
- if (integerCacheHighPropValue != null) {
- try {
- int i = parseInt(integerCacheHighPropValue);
- i = Math.max(i, 127);
- // Maximum array size is Integer.MAX_VALUE
- h = Math.min(i, Integer.MAX_VALUE - (-low) -1);
- } catch( NumberFormatException nfe) {
- // If the property cannot be parsed into an int, ignore it.
- }
+````
+public static Integer valueOf(int i) {
+ if (i >= IntegerCache.low && i <= IntegerCache.high)
+ return IntegerCache.cache[i + (-IntegerCache.low)];
+ return new Integer(i);
+}
+private static class IntegerCache {
+ static final int low = -128;
+ static final int high;
+ static final Integer cache[];
+
+ static {
+ // high value may be configured by property
+ int h = 127;
+ String integerCacheHighPropValue =
+ sun.misc.VM.getSavedProperty("java.lang.Integer.IntegerCache.high");
+ if (integerCacheHighPropValue != null) {
+ try {
+ int i = parseInt(integerCacheHighPropValue);
+ i = Math.max(i, 127);
+ // Maximum array size is Integer.MAX_VALUE
+ h = Math.min(i, Integer.MAX_VALUE - (-low) -1);
+ } catch( NumberFormatException nfe) {
+ // If the property cannot be parsed into an int, ignore it.
}
- high = h;
-
- cache = new Integer[(high - low) + 1];
- int j = low;
- for(int k = 0; k < cache.length; k++)
- cache[k] = new Integer(j++);
-
- // range [-128, 127] must be interned (JLS7 5.1.7)
- assert IntegerCache.high >= 127;
}
-
- private IntegerCache() {}
+ high = h;
+
+ cache = new Integer[(high - low) + 1];
+ int j = low;
+ for(int k = 0; k < cache.length; k++)
+ cache[k] = new Integer(j++);
+
+ // range [-128, 127] must be interned (JLS7 5.1.7)
+ assert IntegerCache.high >= 127;
}
+
+ private IntegerCache() {}
+}
+````
+
所以基本数据类型的包装类型可以在常量池查找对应值的对象,找不到就会自动在常量池创建该值的对象。
而String类型可以通过intern来完成这个操作。
@@ -537,7 +537,6 @@ JDK1.7后,常量池被放入到堆空间中,这导致intern()函数的功能
```
-[java] view plain copy
String s = new String("1");
s.intern();
String s2 = "1";
@@ -554,9 +553,6 @@ JDK1.6以及以下:false false
JDK1.7以及以上:false true
```
-
-
-
JDK1.6查找到常量池存在相同值的对象时会直接返回该对象的地址。
JDK 1.7后,intern方法还是会先去查询常量池中是否有已经存在,如果存在,则返回常量池中的引用,这一点与之前没有区别,区别在于,如果在常量池找不到对应的字符串,则不会再将字符串拷贝到常量池,而只是在常量池中生成一个对原字符串的引用。
@@ -581,23 +577,6 @@ https://blog.csdn.net/a724888/article/details/80033043
-## 微信公众号
-
-### Java技术江湖
-
-如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号【Java技术江湖】一位阿里 Java 工程师的技术小站,作者黄小斜,专注 Java 相关技术:SSM、SpringBoot、MySQL、分布式、中间件、集群、Linux、网络、多线程,偶尔讲点Docker、ELK,同时也分享技术干货和学习经验,致力于Java全栈开发!
-
-**Java工程师必备学习资源:** 一些Java工程师常用学习资源,关注公众号后,后台回复关键字 **“Java”** 即可免费无套路获取。
-
-
-
-### 个人公众号:黄小斜
-
-作者是 985 硕士,蚂蚁金服 JAVA 工程师,专注于 JAVA 后端技术栈:SpringBoot、MySQL、分布式、中间件、微服务,同时也懂点投资理财,偶尔讲点算法和计算机理论基础,坚持学习和写作,相信终身学习的力量!
-
-**程序员3T技术学习资源:** 一些程序员学习技术的资源大礼包,关注公众号后,后台回复关键字 **“资料”** 即可免费无套路获取。
-
-
diff --git "a/docs/java/basic/19\343\200\201Java\351\233\206\345\220\210\346\241\206\346\236\266\346\242\263\347\220\206.md" "b/docs/Java/basic/Java\351\233\206\345\220\210\346\241\206\346\236\266\346\242\263\347\220\206.md"
similarity index 67%
rename from "docs/java/basic/19\343\200\201Java\351\233\206\345\220\210\346\241\206\346\236\266\346\242\263\347\220\206.md"
rename to "docs/Java/basic/Java\351\233\206\345\220\210\346\241\206\346\236\266\346\242\263\347\220\206.md"
index 8ad5827..16fe721 100644
--- "a/docs/java/basic/19\343\200\201Java\351\233\206\345\220\210\346\241\206\346\236\266\346\242\263\347\220\206.md"
+++ "b/docs/Java/basic/Java\351\233\206\345\220\210\346\241\206\346\236\266\346\242\263\347\220\206.md"
@@ -26,9 +26,7 @@
* [线程安全的阻塞队列](#线程安全的阻塞队列)
* [同步队列](#同步队列)
* [参考文章](#参考文章)
- * [微信公众号](#微信公众号)
- * [Java技术江湖](#java技术江湖)
- * [个人公众号:黄小斜](#个人公众号:黄小斜)
+
---
title: 夯实Java基础系列19:一文搞懂Java集合类框架,以及常见面试题
date: 2019-9-19 15:56:26 # 文章生成时间,一般不改
@@ -61,8 +59,7 @@ tags:
在编写java程序中,我们最常用的除了八种基本数据类型,String对象外还有一个集合类,在我们的的程序中到处充斥着集合类的身影!
-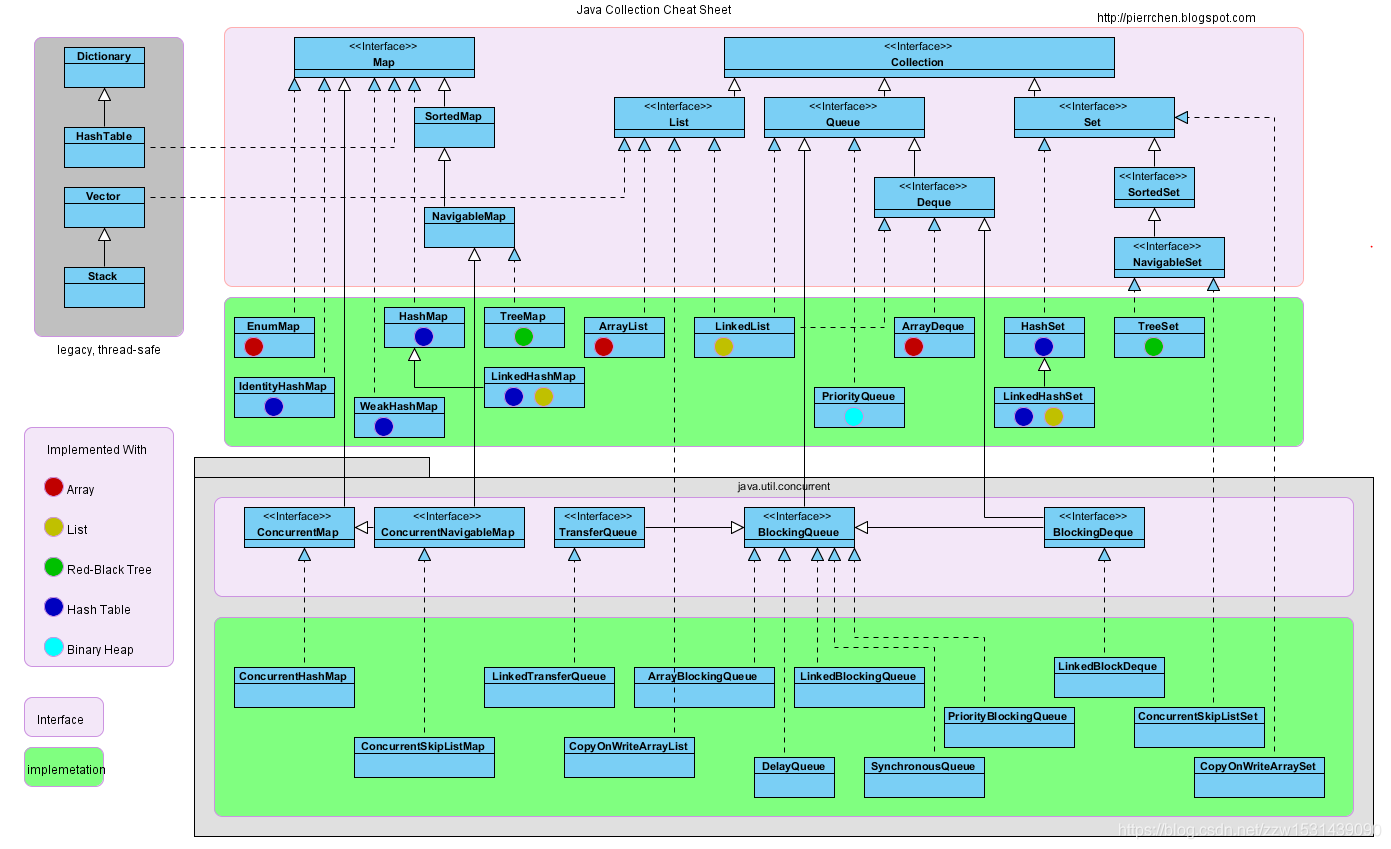
-
+
java中集合大家族的成员实在是太丰富了,有常用的ArrayList、HashMap、HashSet,也有不常用的Stack、Queue,有线程安全的Vector、HashTable,也有线程不安全的LinkedList、TreeMap等等!
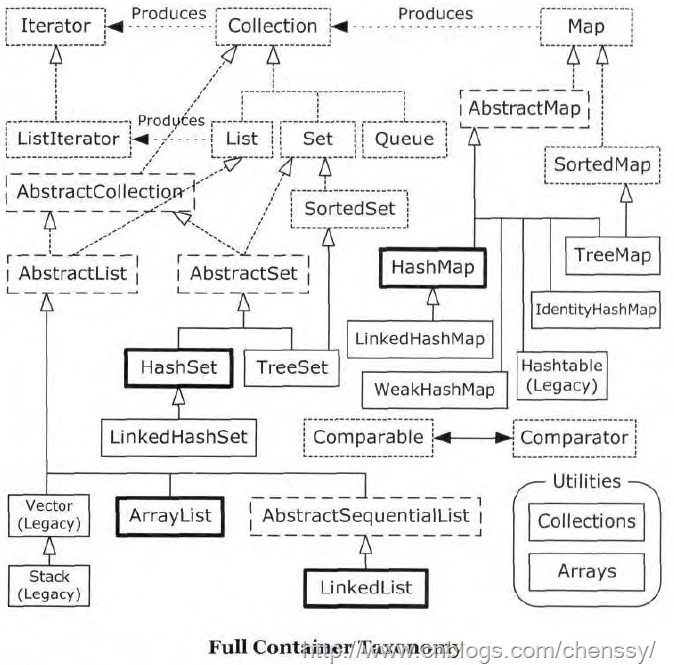
@@ -90,63 +87,63 @@ java中集合大家族的成员实在是太丰富了,有常用的ArrayList、H
在Java中所有实现了Collection接口的类都必须提供两套标准的构造函数,一个是无参,用于创建一个空的Collection,一个是带有Collection参数的有参构造函数,用于创建一个新的Collection,这个新的Collection与传入进来的Collection具备相同的元素。
//要求实现基本的增删改查方法,并且需要能够转换为数组类型
+````
+public class Collection接口 {
+ class collect implements Collection {
- public class Collection接口 {
- class collect implements Collection {
-
- @Override
- public int size() {
- return 0;
- }
-
- @Override
- public boolean isEmpty() {
- return false;
- }
-
- @Override
- public boolean contains(Object o) {
- return false;
- }
-
- @Override
- public Iterator iterator() {
- return null;
- }
-
- @Override
- public Object[] toArray() {
- return new Object[0];
- }
-
- @Override
- public boolean add(Object o) {
- return false;
- }
-
- @Override
- public boolean remove(Object o) {
- return false;
- }
-
- @Override
- public boolean addAll(Collection c) {
- return false;
- }
-
- @Override
- public void clear() {
-
- }
- //省略部分代码
-
- @Override
- public Object[] toArray(Object[] a) {
- return new Object[0];
- }
+ @Override
+ public int size() {
+ return 0;
+ }
+
+ @Override
+ public boolean isEmpty() {
+ return false;
+ }
+
+ @Override
+ public boolean contains(Object o) {
+ return false;
+ }
+
+ @Override
+ public Iterator iterator() {
+ return null;
+ }
+
+ @Override
+ public Object[] toArray() {
+ return new Object[0];
+ }
+
+ @Override
+ public boolean add(Object o) {
+ return false;
+ }
+
+ @Override
+ public boolean remove(Object o) {
+ return false;
+ }
+
+ @Override
+ public boolean addAll(Collection c) {
+ return false;
}
- }
+ @Override
+ public void clear() {
+
+ }
+//省略部分代码
+
+ @Override
+ public Object[] toArray(Object[] a) {
+ return new Object[0];
+ }
+ }
+}
+````
## List接口
> List接口为Collection直接接口。List所代表的是有序的Collection,即它用某种特定的插入顺序来维护元素顺序。用户可以对列表中每个元素的插入位置进行精确地控制,同时可以根据元素的整数索引(在列表中的位置)访问元素,并搜索列表中的元素。实现List接口的集合主要有:ArrayList、LinkedList、Vector、Stack。
@@ -173,84 +170,84 @@ java中集合大家族的成员实在是太丰富了,有常用的ArrayList、H
>
> 2.4、Stack
> Stack继承自Vector,实现一个后进先出的堆栈。Stack提供5个额外的方法使得Vector得以被当作堆栈使用。基本的push和pop 方法,还有peek方法得到栈顶的元素,empty方法测试堆栈是否为空,search方法检测一个元素在堆栈中的位置。Stack刚创建后是空栈。。
+````
+public class List接口 {
+ //下面是List的继承关系,由于List接口规定了包括诸如索引查询,迭代器的实现,所以实现List接口的类都会有这些方法。
+ //所以不管是ArrayList和LinkedList底层都可以使用数组操作,但一般不提供这样外部调用方法。
+ // public interface Iterable
+// public interface Collection extends Iterable
+// public interface List extends Collection
+ class MyList implements List {
+
+ @Override
+ public int size() {
+ return 0;
+ }
- public class List接口 {
- //下面是List的继承关系,由于List接口规定了包括诸如索引查询,迭代器的实现,所以实现List接口的类都会有这些方法。
- //所以不管是ArrayList和LinkedList底层都可以使用数组操作,但一般不提供这样外部调用方法。
- // public interface Iterable
- // public interface Collection extends Iterable
- // public interface List extends Collection
- class MyList implements List {
-
- @Override
- public int size() {
- return 0;
- }
-
- @Override
- public boolean isEmpty() {
- return false;
- }
-
- @Override
- public boolean contains(Object o) {
- return false;
- }
-
- @Override
- public Iterator iterator() {
- return null;
- }
-
- @Override
- public Object[] toArray() {
- return new Object[0];
- }
-
- @Override
- public boolean add(Object o) {
- return false;
- }
-
- @Override
- public boolean remove(Object o) {
- return false;
- }
-
- @Override
- public void clear() {
-
- }
-
- //省略部分代码
-
- @Override
- public Object get(int index) {
- return null;
- }
-
- @Override
- public ListIterator listIterator() {
- return null;
- }
-
- @Override
- public ListIterator listIterator(int index) {
- return null;
- }
-
- @Override
- public List subList(int fromIndex, int toIndex) {
- return null;
- }
-
- @Override
- public Object[] toArray(Object[] a) {
- return new Object[0];
- }
+ @Override
+ public boolean isEmpty() {
+ return false;
+ }
+
+ @Override
+ public boolean contains(Object o) {
+ return false;
+ }
+
+ @Override
+ public Iterator iterator() {
+ return null;
+ }
+
+ @Override
+ public Object[] toArray() {
+ return new Object[0];
+ }
+
+ @Override
+ public boolean add(Object o) {
+ return false;
}
- }
+ @Override
+ public boolean remove(Object o) {
+ return false;
+ }
+
+ @Override
+ public void clear() {
+
+ }
+
+ //省略部分代码
+
+ @Override
+ public Object get(int index) {
+ return null;
+ }
+
+ @Override
+ public ListIterator listIterator() {
+ return null;
+ }
+
+ @Override
+ public ListIterator listIterator(int index) {
+ return null;
+ }
+
+ @Override
+ public List subList(int fromIndex, int toIndex) {
+ return null;
+ }
+
+ @Override
+ public Object[] toArray(Object[] a) {
+ return new Object[0];
+ }
+ }
+}
+````
## Set接口
> Set是一种不包括重复元素的Collection。它维持它自己的内部排序,所以随机访问没有任何意义。与List一样,它同样运行null的存在但是仅有一个。由于Set接口的特殊性,所有传入Set集合中的元素都必须不同,同时要注意任何可变对象,如果在对集合中元素进行操作时,导致e1.equals(e2)==true,则必定会产生某些问题。实现了Set接口的集合有:EnumSet、HashSet、TreeSet。
@@ -261,83 +258,84 @@ java中集合大家族的成员实在是太丰富了,有常用的ArrayList、H
> 3.2、HashSet
> HashSet堪称查询速度最快的集合,因为其内部是以HashCode来实现的。它内部元素的顺序是由哈希码来决定的,所以它不保证set 的迭代顺序;特别是它不保证该顺序恒久不变。
- public class Set接口 {
- // Set接口规定将set看成一个集合,并且使用和数组类似的增删改查方式,同时提供iterator迭代器
- // public interface Set extends Collection
- // public interface Collection extends Iterable
- // public interface Iterable
- class MySet implements Set {
-
- @Override
- public int size() {
- return 0;
- }
-
- @Override
- public boolean isEmpty() {
- return false;
- }
-
- @Override
- public boolean contains(Object o) {
- return false;
- }
-
- @Override
- public Iterator iterator() {
- return null;
- }
-
- @Override
- public Object[] toArray() {
- return new Object[0];
- }
-
- @Override
- public boolean add(Object o) {
- return false;
- }
-
- @Override
- public boolean remove(Object o) {
- return false;
- }
-
- @Override
- public boolean addAll(Collection c) {
- return false;
- }
-
- @Override
- public void clear() {
-
- }
-
- @Override
- public boolean removeAll(Collection c) {
- return false;
- }
-
- @Override
- public boolean retainAll(Collection c) {
- return false;
- }
-
- @Override
- public boolean containsAll(Collection c) {
- return false;
- }
-
- @Override
- public Object[] toArray(Object[] a) {
- return new Object[0];
- }
+````
+public class Set接口 {
+ // Set接口规定将set看成一个集合,并且使用和数组类似的增删改查方式,同时提供iterator迭代器
+ // public interface Set extends Collection
+ // public interface Collection extends Iterable
+ // public interface Iterable
+ class MySet implements Set {
+
+ @Override
+ public int size() {
+ return 0;
}
- }
+ @Override
+ public boolean isEmpty() {
+ return false;
+ }
+
+ @Override
+ public boolean contains(Object o) {
+ return false;
+ }
+
+ @Override
+ public Iterator iterator() {
+ return null;
+ }
+
+ @Override
+ public Object[] toArray() {
+ return new Object[0];
+ }
+
+ @Override
+ public boolean add(Object o) {
+ return false;
+ }
+
+ @Override
+ public boolean remove(Object o) {
+ return false;
+ }
+
+ @Override
+ public boolean addAll(Collection c) {
+ return false;
+ }
+
+ @Override
+ public void clear() {
+
+ }
+
+ @Override
+ public boolean removeAll(Collection c) {
+ return false;
+ }
+
+ @Override
+ public boolean retainAll(Collection c) {
+ return false;
+ }
+
+ @Override
+ public boolean containsAll(Collection c) {
+ return false;
+ }
+
+ @Override
+ public Object[] toArray(Object[] a) {
+ return new Object[0];
+ }
+ }
+}
+````
## Map接口
-> Map与List、Set接口不同,它是由一系列键值对组成的集合,提供了key到Value的映射。同时它也没有继承Collection。在Map中它保证了key与value之间的一一对应关系。也就是说一个key对应一个value,所以它不能存在相同的key值,当然value值可以相同。实现map的有:HashMap、TreeMap、HashTable、Properties、EnumMap。
+> Map与List、Set接口不同,它是由一系列键值对组成的集合,提供了key到Value的映射。同时它也没有继承Collection。在Map中它保证了key与value之间的一一对应关系。也就是说一个key对应一个value,所以它不能存在相同的key值,当然value值可以相同。实现map的有:HashMap、TreeMap、HashTable、Properties、EnumMap。
> 4.1、HashMap
> 以哈希表数据结构实现,查找对象时通过哈希函数计算其位置,它是为快速查询而设计的,其内部定义了一个hash表数组(Entry[] table),元素会通过哈希转换函数将元素的哈希地址转换成数组中存放的索引,如果有冲突,则使用散列链表的形式将所有相同哈希地址的元素串起来,可能通过查看HashMap.Entry的源码它是一个单链表结构。
@@ -347,152 +345,152 @@ java中集合大家族的成员实在是太丰富了,有常用的ArrayList、H
>
> 4.3、HashTable
> 也是以哈希表数据结构实现的,解决冲突时与HashMap也一样也是采用了散列链表的形式,不过性能比HashMap要低
+````
+public class Map接口 {
+ //Map接口是最上层接口,Map接口实现类必须实现put和get等哈希操作。
+ //并且要提供keyset和values,以及entryset等查询结构。
+ //public interface Map
+ class MyMap implements Map {
+
+ @Override
+ public int size() {
+ return 0;
+ }
- public class Map接口 {
- //Map接口是最上层接口,Map接口实现类必须实现put和get等哈希操作。
- //并且要提供keyset和values,以及entryset等查询结构。
- //public interface Map
- class MyMap implements Map {
-
- @Override
- public int size() {
- return 0;
- }
-
- @Override
- public boolean isEmpty() {
- return false;
- }
-
- @Override
- public boolean containsKey(Object key) {
- return false;
- }
-
- @Override
- public boolean containsValue(Object value) {
- return false;
- }
-
- @Override
- public Object get(Object key) {
- return null;
- }
-
- @Override
- public Object put(Object key, Object value) {
- return null;
- }
-
- @Override
- public Object remove(Object key) {
- return null;
- }
-
- @Override
- public void putAll(Map m) {
-
- }
-
- @Override
- public void clear() {
-
- }
-
- @Override
- public Set keySet() {
- return null;
- }
-
- @Override
- public Collection values() {
- return null;
- }
-
- @Override
- public Set entrySet() {
- return null;
- }
+ @Override
+ public boolean isEmpty() {
+ return false;
+ }
+
+ @Override
+ public boolean containsKey(Object key) {
+ return false;
+ }
+
+ @Override
+ public boolean containsValue(Object value) {
+ return false;
}
- }
+ @Override
+ public Object get(Object key) {
+ return null;
+ }
+
+ @Override
+ public Object put(Object key, Object value) {
+ return null;
+ }
+
+ @Override
+ public Object remove(Object key) {
+ return null;
+ }
+
+ @Override
+ public void putAll(Map m) {
+
+ }
+
+ @Override
+ public void clear() {
+
+ }
+
+ @Override
+ public Set keySet() {
+ return null;
+ }
+
+ @Override
+ public Collection values() {
+ return null;
+ }
+
+ @Override
+ public Set entrySet() {
+ return null;
+ }
+ }
+}
+````
## Queue
> 队列,它主要分为两大类,一类是阻塞式队列,队列满了以后再插入元素则会抛出异常,主要包括ArrayBlockQueue、PriorityBlockingQueue、LinkedBlockingQueue。另一种队列则是双端队列,支持在头、尾两端插入和移除元素,主要包括:ArrayDeque、LinkedBlockingDeque、LinkedList。
+````
+public class Queue接口 {
+ //queue接口是对队列的一个实现,需要提供队列的进队出队等方法。一般使用linkedlist作为实现类
+ class MyQueue implements Queue {
+
+ @Override
+ public int size() {
+ return 0;
+ }
- public class Queue接口 {
- //queue接口是对队列的一个实现,需要提供队列的进队出队等方法。一般使用linkedlist作为实现类
- class MyQueue implements Queue {
-
- @Override
- public int size() {
- return 0;
- }
-
- @Override
- public boolean isEmpty() {
- return false;
- }
-
- @Override
- public boolean contains(Object o) {
- return false;
- }
-
- @Override
- public Iterator iterator() {
- return null;
- }
-
- @Override
- public Object[] toArray() {
- return new Object[0];
- }
-
- @Override
- public Object[] toArray(Object[] a) {
- return new Object[0];
- }
-
- @Override
- public boolean add(Object o) {
- return false;
- }
-
- @Override
- public boolean remove(Object o) {
- return false;
- }
-
- //省略部分代码
- @Override
- public boolean offer(Object o) {
- return false;
- }
-
- @Override
- public Object remove() {
- return null;
- }
-
- @Override
- public Object poll() {
- return null;
- }
-
- @Override
- public Object element() {
- return null;
- }
-
- @Override
- public Object peek() {
- return null;
- }
+ @Override
+ public boolean isEmpty() {
+ return false;
}
- }
+ @Override
+ public boolean contains(Object o) {
+ return false;
+ }
+ @Override
+ public Iterator iterator() {
+ return null;
+ }
+
+ @Override
+ public Object[] toArray() {
+ return new Object[0];
+ }
+
+ @Override
+ public Object[] toArray(Object[] a) {
+ return new Object[0];
+ }
+
+ @Override
+ public boolean add(Object o) {
+ return false;
+ }
+
+ @Override
+ public boolean remove(Object o) {
+ return false;
+ }
+
+ //省略部分代码
+ @Override
+ public boolean offer(Object o) {
+ return false;
+ }
+
+ @Override
+ public Object remove() {
+ return null;
+ }
+
+ @Override
+ public Object poll() {
+ return null;
+ }
+
+ @Override
+ public Object element() {
+ return null;
+ }
+
+ @Override
+ public Object peek() {
+ return null;
+ }
+ }
+}
+
+````
## 关于Java集合的小抄
这部分内容转自我偶像 江南白衣 的博客:http://calvin1978.blogcn.com/articles/collection.html
@@ -712,20 +710,3 @@ https://www.cnblogs.com/uodut/p/7067162.html
https://www.jb51.net/article/135672.htm
https://www.cnblogs.com/suiyue-/p/6052456.html
-## 微信公众号
-
-### Java技术江湖
-
-如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号【Java技术江湖】一位阿里 Java 工程师的技术小站,作者黄小斜,专注 Java 相关技术:SSM、SpringBoot、MySQL、分布式、中间件、集群、Linux、网络、多线程,偶尔讲点Docker、ELK,同时也分享技术干货和学习经验,致力于Java全栈开发!
-
-**Java工程师必备学习资源:** 一些Java工程师常用学习资源,关注公众号后,后台回复关键字 **“Java”** 即可免费无套路获取。
-
-
-
-### 个人公众号:黄小斜
-
-作者是 985 硕士,蚂蚁金服 JAVA 工程师,专注于 JAVA 后端技术栈:SpringBoot、MySQL、分布式、中间件、微服务,同时也懂点投资理财,偶尔讲点算法和计算机理论基础,坚持学习和写作,相信终身学习的力量!
-
-**程序员3T技术学习资源:** 一些程序员学习技术的资源大礼包,关注公众号后,后台回复关键字 **“资料”** 即可免费无套路获取。
-
-
diff --git "a/docs/java/basic/4\343\200\201final\345\205\263\351\224\256\345\255\227\347\211\271\346\200\247.md" "b/docs/Java/basic/final\345\205\263\351\224\256\345\255\227\347\211\271\346\200\247.md"
similarity index 91%
rename from "docs/java/basic/4\343\200\201final\345\205\263\351\224\256\345\255\227\347\211\271\346\200\247.md"
rename to "docs/Java/basic/final\345\205\263\351\224\256\345\255\227\347\211\271\346\200\247.md"
index ff1118c..6b28474 100644
--- "a/docs/java/basic/4\343\200\201final\345\205\263\351\224\256\345\255\227\347\211\271\346\200\247.md"
+++ "b/docs/Java/basic/final\345\205\263\351\224\256\345\255\227\347\211\271\346\200\247.md"
@@ -18,9 +18,7 @@
* [读 final 域的重排序规则](#读-final-域的重排序规则)
* [如果 final 域是引用类型](#如果-final-域是引用类型)
* [参考文章](#参考文章)
- * [微信公众号](#微信公众号)
- * [Java技术江湖](#java技术江湖)
- * [个人公众号:黄小斜](#个人公众号:黄小斜)
+
本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
> https://github.com/h2pl/Java-Tutorial
@@ -184,7 +182,7 @@ final方法的好处:
2. final变量在多线程中并发安全,无需额外的同步开销
3. final方法是静态编译的,提高了调用速度
4. **final类创建的对象是只可读的,在多线程可以安全共享**
-5.
+
## final关键字的最佳实践
### final的用法
@@ -198,7 +196,7 @@ final修饰的变量有三种:静态变量、实例变量和局部变量,分
另外,final变量定义的时候,可以先声明,而不给初值,这中变量也称为final空白,无论什么情况,编译器都确保空白final在使用之前必须被初始化。
但是,final空白在final关键字final的使用上提供了更大的灵活性,为此,一个类中的final数据成员就可以实现依对象而有所不同,却有保持其恒定不变的特征。
-
+````
public class FinalTest {
final int p;
final int q=3;
@@ -210,19 +208,20 @@ final修饰的变量有三种:静态变量、实例变量和局部变量,分
q=i;//不能为一个final变量赋值
}
}
-
+````
### final内存分配
刚提到了内嵌机制,现在详细展开。
要知道调用一个函数除了函数本身的执行时间之外,还需要额外的时间去寻找这个函数(类内部有一个函数签名和函数地址的映射表)。所以减少函数调用次数就等于降低了性能消耗。
final修饰的函数会被编译器优化,优化的结果是减少了函数调用的次数。如何实现的,举个例子给你看:
-
+````
public class Test{
final void func(){System.out.println("g");};
public void main(String[] args){
for(int j=0;j<1000;j++)
func();
}}
+
经过编译器优化之后,这个类变成了相当于这样写:
public class Test{
final void func(){System.out.println("g");};
@@ -230,7 +229,7 @@ final修饰的函数会被编译器优化,优化的结果是减少了函数调
for(int j=0;j<1000;j++)
{System.out.println("g");}
}}
-
+````
看出来区别了吧?编译器直接将func的函数体内嵌到了调用函数的地方,这样的结果是节省了1000次函数调用,当然编译器处理成字节码,只是我们可以想象成这样,看个明白。
不过,当函数体太长的话,用final可能适得其反,因为经过编译器内嵌之后代码长度大大增加,于是就增加了jvm解释字节码的时间。
@@ -243,7 +242,7 @@ final修饰的函数会被编译器优化,优化的结果是减少了函数调
见下面的测试代码,我会执行五次:
-
+````
public class Test
{
public static void getJava()
@@ -283,6 +282,7 @@ final修饰的函数会被编译器优化,优化的结果是减少了函数调
}
}
+````
结果为:
第一次:
@@ -308,13 +308,13 @@ final修饰的函数会被编译器优化,优化的结果是减少了函数调
由以上运行结果不难看出,执行最快的是“正常的执行”即代码直接编写,而使用final修饰的方法,不像有些书上或者文章上所说的那样,速度与效率与“正常的执行”无异,而是位于第二位,最差的是调用不加final修饰的方法。
-观点:加了比不加好一点。
+ 观点:加了比不加好一点。
### 使用final修饰变量会让变量的值不能被改变吗;
见代码:
-
+````
public class Final
{
public static void main(String[] args)
@@ -335,18 +335,18 @@ final修饰的函数会被编译器优化,优化的结果是减少了函数调
red blue yellow white
看!,黑色变成了白色。
-
-
- 在使用findbugs插件时,就会提示public static String[] color = { "red", "blue", "yellow", "black" };这行代码不安全,但加上final修饰,这行代码仍然是不安全的,因为final没有做到保证变量的值不会被修改!
-
- 原因是:final关键字只能保证变量本身不能被赋与新值,而不能保证变量的内部结构不被修改。例如在main方法有如下代码Color.color = new String[]{""};就会报错了。
+````
+
+ 在使用findbugs插件时,就会提示public static String[] color = { "red", "blue", "yellow", "black" };这行代码不安全,但加上final修饰,这行代码仍然是不安全的,因为final没有做到保证变量的值不会被修改!
+
+ 原因是:final关键字只能保证变量本身不能被赋与新值,而不能保证变量的内部结构不被修改。例如在main方法有如下代码Color.color = new String[]{""};就会报错了。
### 如何保证数组内部不被修改
那可能有的同学就会问了,加上final关键字不能保证数组不会被外部修改,那有什么方法能够保证呢?答案就是降低访问级别,把数组设为private。这样的话,就解决了数组在外部被修改的不安全性,但也产生了另一个问题,那就是这个数组要被外部使用的。
解决这个问题见代码:
-
+````
import java.util.AbstractList;
import java.util.List;
@@ -384,7 +384,7 @@ final修饰的函数会被编译器优化,优化的结果是减少了函数调
}
-
+````
这样就OK了,既保证了代码安全,又能让数组中的元素被访问了。
@@ -397,7 +397,7 @@ final修饰的函数会被编译器优化,优化的结果是减少了函数调
规则3:父类中private final方法,子类可以重新定义,这种情况不是重写。
代码示例
-
+````
规则1代码
public class FinalMethodTest
@@ -429,7 +429,7 @@ final修饰的函数会被编译器优化,优化的结果是减少了函数调
// 下面方法定义将不会出现问题
public void test(){}
}
-
+````
## final 和 jvm的关系
@@ -439,8 +439,8 @@ final修饰的函数会被编译器优化,优化的结果是减少了函数调
2. 初次读一个包含 final 域的对象的引用,与随后初次读这个 final 域,这两个操作之间不能重排序。
下面,我们通过一些示例性的代码来分别说明这两个规则:
-
-public class FinalExample {
+````
+public class FinalExample {
int i; // 普通变量
final int j; //final 变量
static FinalExample obj;
@@ -460,7 +460,7 @@ final修饰的函数会被编译器优化,优化的结果是减少了函数调
int b = object.j; // 读 final 域
}
}
-
+````
这里假设一个线程 A 执行 writer () 方法,随后另一个线程 B 执行 reader () 方法。下面我们通过这两个线程的交互来说明这两个规则。
@@ -478,7 +478,7 @@ final修饰的函数会被编译器优化,优化的结果是减少了函数调
假设线程 B 读对象引用与读对象的成员域之间没有重排序(马上会说明为什么需要这个假设),下图是一种可能的执行时序:
-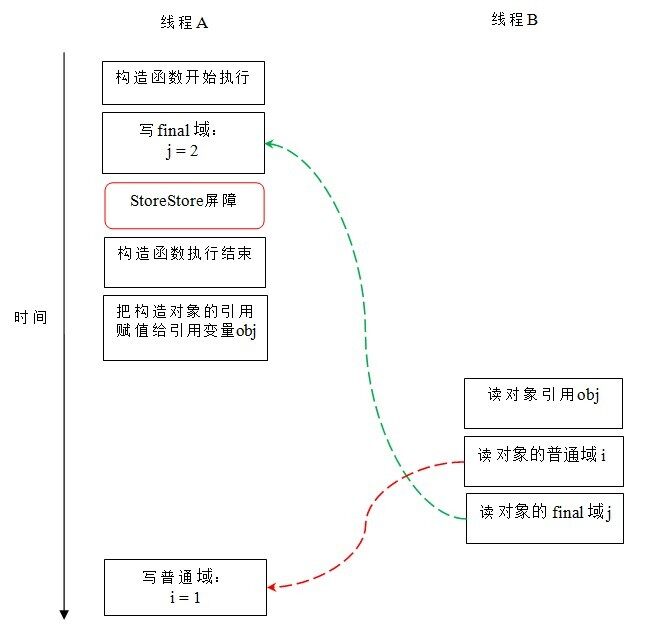
+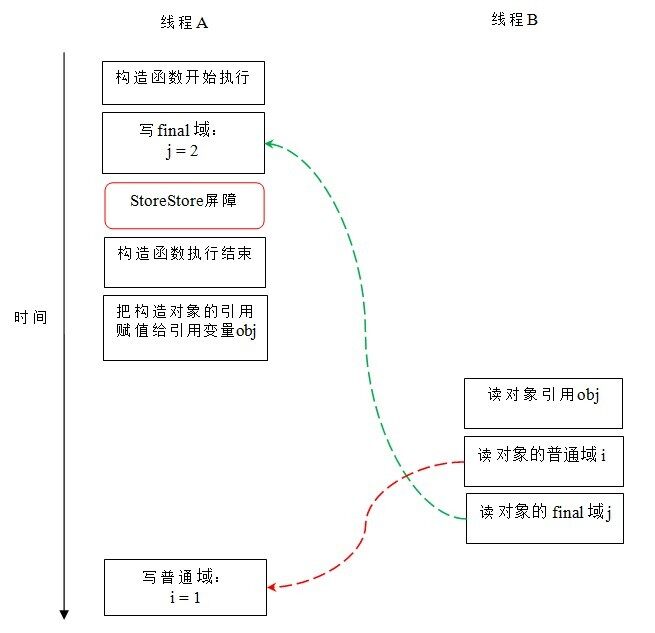
在上图中,写普通域的操作被编译器重排序到了构造函数之外,读线程 B 错误的读取了普通变量 i 初始化之前的值。而写 final 域的操作,被写 final 域的重排序规则“限定”在了构造函数之内,读线程 B 正确的读取了 final 变量初始化之后的值。
@@ -511,8 +511,8 @@ reader() 方法包含三个操作:
上面我们看到的 final 域是基础数据类型,下面让我们看看如果 final 域是引用类型,将会有什么效果?
请看下列示例代码:
-
-public class FinalReferenceExample {
+````
+public class FinalReferenceExample {
final int[] intArray; //final 是引用类型
static FinalReferenceExample obj;
@@ -535,7 +535,7 @@ public static void reader () { // 读线程 C 执行
}
}
}
-
+````
这里 final 域为一个引用类型,它引用一个 int 型的数组对象。对于引用类型,写 final 域的重排序规则对编译器和处理器增加了如下约束:
@@ -543,14 +543,14 @@ public static void reader () { // 读线程 C 执行
对上面的示例程序,我们假设首先线程 A 执行 writerOne() 方法,执行完后线程 B 执行 writerTwo() 方法,执行完后线程 C 执行 reader () 方法。下面是一种可能的线程执行时序:
-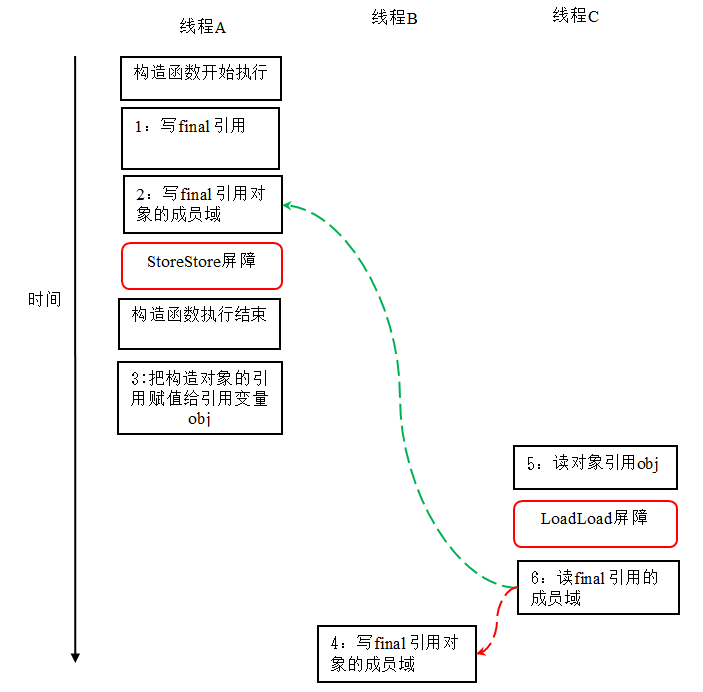
-
+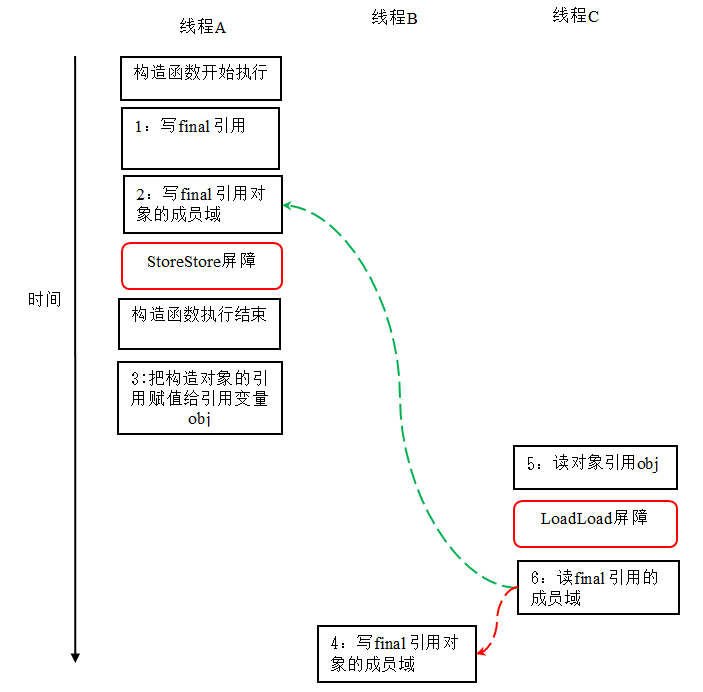
在上图中,1 是对 final 域的写入,2 是对这个 final 域引用的对象的成员域的写入,3 是把被构造的对象的引用赋值给某个引用变量。这里除了前面提到的 1 不能和 3 重排序外,2 和 3 也不能重排序。
JMM 可以确保读线程 C 至少能看到写线程 A 在构造函数中对 final 引用对象的成员域的写入。即 C 至少能看到数组下标 0 的值为 1。而写线程 B 对数组元素的写入,读线程 C 可能看的到,也可能看不到。JMM 不保证线程 B 的写入对读线程 C 可见,因为写线程 B 和读线程 C 之间存在数据竞争,此时的执行结果不可预知。
如果想要确保读线程 C 看到写线程 B 对数组元素的写入,写线程 B 和读线程 C 之间需要使用同步原语(lock 或 volatile)来确保内存可见性。
+
## 参考文章
https://www.infoq.cn/article/java-memory-model-6
@@ -561,20 +561,4 @@ https://www.iteye.com/blog/cakin24-2334965
https://blog.csdn.net/chengqiuming/article/details/70139503
https://blog.csdn.net/hupuxiang/article/details/7362267
-## 微信公众号
-
-### Java技术江湖
-
-如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号【Java技术江湖】一位阿里 Java 工程师的技术小站,作者黄小斜,专注 Java 相关技术:SSM、SpringBoot、MySQL、分布式、中间件、集群、Linux、网络、多线程,偶尔讲点Docker、ELK,同时也分享技术干货和学习经验,致力于Java全栈开发!
-
-**Java工程师必备学习资源:** 一些Java工程师常用学习资源,关注公众号后,后台回复关键字 **“Java”** 即可免费无套路获取。
-
-
-
-### 个人公众号:黄小斜
-
-作者是 985 硕士,蚂蚁金服 JAVA 工程师,专注于 JAVA 后端技术栈:SpringBoot、MySQL、分布式、中间件、微服务,同时也懂点投资理财,偶尔讲点算法和计算机理论基础,坚持学习和写作,相信终身学习的力量!
-
-**程序员3T技术学习资源:** 一些程序员学习技术的资源大礼包,关注公众号后,后台回复关键字 **“资料”** 即可免费无套路获取。
-
diff --git "a/docs/java/basic/20\343\200\201javac\345\222\214javap.md" "b/docs/Java/basic/javac\345\222\214javap.md"
similarity index 74%
rename from "docs/java/basic/20\343\200\201javac\345\222\214javap.md"
rename to "docs/Java/basic/javac\345\222\214javap.md"
index dde513d..f797af7 100644
--- "a/docs/java/basic/20\343\200\201javac\345\222\214javap.md"
+++ "b/docs/Java/basic/javac\345\222\214javap.md"
@@ -18,28 +18,10 @@
* [-encoding](#-encoding)
* [-verbose](#-verbose)
* [其他命令](#其他命令)
- * [使用javac构建项目](#使用javac构建项目)
- * [](#)
-* [java文件列表目录](#java文件列表目录)
- * [放入列表文件中](#放入列表文件中)
- * [生成bin目录](#生成bin目录)
- * [列表](#列表)
- * [通过-cp指定所有的引用jar包,将src下的所有java文件进行编译](#通过-cp指定所有的引用jar包,将src下的所有java文件进行编译)
- * [通过-cp指定所有的引用jar包,指定入口函数运行](#通过-cp指定所有的引用jar包,指定入口函数运行)
+ * [使用javac构建项目](#使用javac构建项目)
* [javap 的使用](#javap-的使用)
* [参考文章](#参考文章)
- * [微信公众号](#微信公众号)
- * [Java技术江湖](#java技术江湖)
- * [个人公众号:黄小斜](#个人公众号:黄小斜)
----
-title: 夯实Java基础系列20:从IDE的实现原理聊起,谈谈那些年我们用过的Java命令
-date: 2019-9-20 15:56:26 # 文章生成时间,一般不改
-categories:
- - Java技术江湖
- - Java基础
-tags:
- - Java命令行
----
+
本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
> https://github.com/h2pl/Java-Tutorial
@@ -81,119 +63,119 @@ java提供了JavaCompiler,我们可以通过它来编译java源文件为class
通过上面一个查找class,得到Class对象后,可以通过newInstance()或构造器的newInstance()得到对象。然后得到Method,最后调用方法,传入相关参数即可。
示例代码:
-
- public class MyIDE {
-
- public static void main(String[] args) throws IOException, ClassNotFoundException, NoSuchMethodException, IllegalAccessException, InvocationTargetException, InstantiationException {
- // 定义java代码,并保存到文件(Test.java)
- StringBuilder sb = new StringBuilder();
- sb.append("package com.tommy.core.test.reflect;\n");
- sb.append("public class Test {\n");
- sb.append(" private String name;\n");
- sb.append(" public Test(String name){\n");
- sb.append(" this.name = name;\n");
- sb.append(" System.out.println(\"hello,my name is \" + name);\n");
- sb.append(" }\n");
- sb.append(" public String sayHello(String name) {\n");
- sb.append(" return \"hello,\" + name;\n");
- sb.append(" }\n");
- sb.append("}\n");
-
- System.out.println(sb.toString());
-
- String baseOutputDir = "F:\\output\\classes\\";
- String baseDir = baseOutputDir + "com\\tommy\\core\\test\\reflect\\";
- String targetJavaOutputPath = baseDir + "Test.java";
- // 保存为java文件
- FileWriter fileWriter = new FileWriter(targetJavaOutputPath);
- fileWriter.write(sb.toString());
- fileWriter.flush();
- fileWriter.close();
-
- // 编译为class文件
- JavaCompiler compiler = ToolProvider.getSystemJavaCompiler();
- StandardJavaFileManager manager = compiler.getStandardFileManager(null,null,null);
- List files = new ArrayList<>();
- files.add(new File(targetJavaOutputPath));
- Iterable compilationUnits = manager.getJavaFileObjectsFromFiles(files);
-
- // 编译
- // 设置编译选项,配置class文件输出路径
- Iterable options = Arrays.asList("-d",baseOutputDir);
- JavaCompiler.CompilationTask task = compiler.getTask(null, manager, null, options, null, compilationUnits);
- // 执行编译任务
- task.call();
-
-
-
- // 通过反射得到对象
- // Class clazz = Class.forName("com.tommy.core.test.reflect.Test");
- // 使用自定义的类加载器加载class
- Class clazz = new MyClassLoader(baseOutputDir).loadClass("com.tommy.core.test.reflect.Test");
- // 得到构造器
- Constructor constructor = clazz.getConstructor(String.class);
- // 通过构造器new一个对象
- Object test = constructor.newInstance("jack.tsing");
- // 得到sayHello方法
- Method method = clazz.getMethod("sayHello", String.class);
- // 调用sayHello方法
- String result = (String) method.invoke(test, "jack.ma");
- System.out.println(result);
- }
- }
-
+````
+public class MyIDE {
+
+ public static void main(String[] args) throws IOException, ClassNotFoundException, NoSuchMethodException, IllegalAccessException, InvocationTargetException, InstantiationException {
+ // 定义java代码,并保存到文件(Test.java)
+ StringBuilder sb = new StringBuilder();
+ sb.append("package com.tommy.core.test.reflect;\n");
+ sb.append("public class Test {\n");
+ sb.append(" private String name;\n");
+ sb.append(" public Test(String name){\n");
+ sb.append(" this.name = name;\n");
+ sb.append(" System.out.println(\"hello,my name is \" + name);\n");
+ sb.append(" }\n");
+ sb.append(" public String sayHello(String name) {\n");
+ sb.append(" return \"hello,\" + name;\n");
+ sb.append(" }\n");
+ sb.append("}\n");
+
+ System.out.println(sb.toString());
+
+ String baseOutputDir = "F:\\output\\classes\\";
+ String baseDir = baseOutputDir + "com\\tommy\\core\\test\\reflect\\";
+ String targetJavaOutputPath = baseDir + "Test.java";
+ // 保存为java文件
+ FileWriter fileWriter = new FileWriter(targetJavaOutputPath);
+ fileWriter.write(sb.toString());
+ fileWriter.flush();
+ fileWriter.close();
+
+ // 编译为class文件
+ JavaCompiler compiler = ToolProvider.getSystemJavaCompiler();
+ StandardJavaFileManager manager = compiler.getStandardFileManager(null,null,null);
+ List files = new ArrayList<>();
+ files.add(new File(targetJavaOutputPath));
+ Iterable compilationUnits = manager.getJavaFileObjectsFromFiles(files);
+
+ // 编译
+ // 设置编译选项,配置class文件输出路径
+ Iterable options = Arrays.asList("-d",baseOutputDir);
+ JavaCompiler.CompilationTask task = compiler.getTask(null, manager, null, options, null, compilationUnits);
+ // 执行编译任务
+ task.call();
+
+
+
+ // 通过反射得到对象
+// Class clazz = Class.forName("com.tommy.core.test.reflect.Test");
+ // 使用自定义的类加载器加载class
+ Class clazz = new MyClassLoader(baseOutputDir).loadClass("com.tommy.core.test.reflect.Test");
+ // 得到构造器
+ Constructor constructor = clazz.getConstructor(String.class);
+ // 通过构造器new一个对象
+ Object test = constructor.newInstance("jack.tsing");
+ // 得到sayHello方法
+ Method method = clazz.getMethod("sayHello", String.class);
+ // 调用sayHello方法
+ String result = (String) method.invoke(test, "jack.ma");
+ System.out.println(result);
+ }
+}
+````
自定义类加载器代码:
+````
+
+public class MyClassLoader extends ClassLoader {
+ private String baseDir;
+ public MyClassLoader(String baseDir) {
+ this.baseDir = baseDir;
+ }
+ @Override
+ protected Class findClass(String name) throws ClassNotFoundException {
+ String fullClassFilePath = this.baseDir + name.replace("\\.","/") + ".class";
+ File classFilePath = new File(fullClassFilePath);
+ if (classFilePath.exists()) {
+ FileInputStream fileInputStream = null;
+ ByteArrayOutputStream byteArrayOutputStream = null;
+ try {
+ fileInputStream = new FileInputStream(classFilePath);
+ byte[] data = new byte[1024];
+ int len = -1;
+ byteArrayOutputStream = new ByteArrayOutputStream();
+ while ((len = fileInputStream.read(data)) != -1) {
+ byteArrayOutputStream.write(data,0,len);
+ }
-
- public class MyClassLoader extends ClassLoader {
- private String baseDir;
- public MyClassLoader(String baseDir) {
- this.baseDir = baseDir;
- }
- @Override
- protected Class findClass(String name) throws ClassNotFoundException {
- String fullClassFilePath = this.baseDir + name.replace("\\.","/") + ".class";
- File classFilePath = new File(fullClassFilePath);
- if (classFilePath.exists()) {
- FileInputStream fileInputStream = null;
- ByteArrayOutputStream byteArrayOutputStream = null;
- try {
- fileInputStream = new FileInputStream(classFilePath);
- byte[] data = new byte[1024];
- int len = -1;
- byteArrayOutputStream = new ByteArrayOutputStream();
- while ((len = fileInputStream.read(data)) != -1) {
- byteArrayOutputStream.write(data,0,len);
- }
-
- return defineClass(name,byteArrayOutputStream.toByteArray(),0,byteArrayOutputStream.size());
- } catch (FileNotFoundException e) {
- e.printStackTrace();
- } catch (IOException e) {
- e.printStackTrace();
- } finally {
- if (null != fileInputStream) {
- try {
- fileInputStream.close();
- } catch (IOException e) {
- e.printStackTrace();
- }
+ return defineClass(name,byteArrayOutputStream.toByteArray(),0,byteArrayOutputStream.size());
+ } catch (FileNotFoundException e) {
+ e.printStackTrace();
+ } catch (IOException e) {
+ e.printStackTrace();
+ } finally {
+ if (null != fileInputStream) {
+ try {
+ fileInputStream.close();
+ } catch (IOException e) {
+ e.printStackTrace();
}
-
- if (null != byteArrayOutputStream) {
- try {
- byteArrayOutputStream.close();
- } catch (IOException e) {
- e.printStackTrace();
- }
+ }
+
+ if (null != byteArrayOutputStream) {
+ try {
+ byteArrayOutputStream.close();
+ } catch (IOException e) {
+ e.printStackTrace();
}
}
}
- return super.findClass(name);
}
- }
-
+ return super.findClass(name);
+ }
+}
+````
## javac命令初窥
注:以下红色标记的参数在下文中有所讲解。
@@ -316,7 +298,7 @@ javac:如果当前你要编译的java文件中引用了其它的类(比如说
> 这里展示一个web项目的.classpath
Xml代码
-
+````
@@ -328,7 +310,7 @@ Xml代码
……
-
+````
> XML文档包含一个根元素,就是classpath,类路径,那么这里面包含了什么信息呢?子元素是classpathentry,kind属性区别了种 类信息,src源码,con你看看后面的path就知道是JRE容器的信息。lib是项目依赖的第三方类库,output是src编译后的位置。
> 既然是web项目,那么就是WEB-INF/classes目录,可能用MyEclipse的同学会说他们那里是WebRoot或者是WebContext而不是webapp,有区别么?回答:完全没有!
@@ -393,27 +375,27 @@ Xml代码
举个例子,
-
- public class A
- {
- public static void main(String[] args) {
- B b = new B();
- b.print();
- }
+````
+public class A
+{
+ public static void main(String[] args) {
+ B b = new B();
+ b.print();
}
+}
-
-
- public class B
- {
- public void print()
- {
- System.out.println("old");
- }
- }
+public class B
+{
+ public void print()
+ {
+ System.out.println("old");
+ }
+}
+````
+
目录结构如下:
@@ -451,19 +433,19 @@ sourcepath //此处为当前目录
这里我用来实现一下这个功能,假设项目名称为project,此目录为当前目录,且在src/com目录中有一个Main.java文件。‘
-
- package com;
- public class Main
- {
- public static void main(String[] args) {
- System.out.println("Hello");
- }
- }
+````
+ package com;
+ public class Main
+ {
+ public static void main(String[] args) {
+ System.out.println("Hello");
+ }
+ }
-
-
- javac -d bin src/com/Main.java
+````
+
+javac -d bin src/com/Main.java
上面的语句将Main.class生成在bin/com目录下。
@@ -472,23 +454,23 @@ sourcepath //此处为当前目录
•如果有文件为A.java(其中有类A),且在类A中使用了类B,类B在B.java中,则编译A.java时,默认会自动编译B.java,且生成B.class。
•implicit:none:不自动生成隐式引用的类文件。
•implicit:class(默认):自动生成隐式引用的类文件。
-
- public class A
- {
- public static void main(String[] args) {
- B b = new B();
- }
+````
+public class A
+{
+ public static void main(String[] args) {
+ B b = new B();
}
-
- public class B
- {
- }
-
- 如果使用:
+}
+
+public class B
+{
+}
+````
+如果使用:
-
- javac -implicit:none A.java
+
+javac -implicit:none A.java
则不会生成 B.class。
@@ -578,18 +560,18 @@ src/com/yp/test/HelloWorld.java
build/
-```
+````
├─build
└─src
└─com
└─yp
└─test
HelloWorld.java
-```
+````
java文件非常简单
-
+````
package com.yp.test;
public class HelloWorld {
@@ -597,12 +579,14 @@ java文件非常简单
System.out.println("helloWorld");
}
}
+````
+
编译:
javac src/com/yp/test/HelloWorld.java -d build
-d 表示编译到 build文件夹下
-```
+````
查看build文件夹
├─build
│ └─com
@@ -615,10 +599,11 @@ javac src/com/yp/test/HelloWorld.java -d build
└─yp
└─test
HelloWorld.java
-```
+````
运行文件
+
> E:\codeplace\n_learn\java\javacmd> java com/yp/test/HelloWorld.class
> 错误: 找不到或无法加载主类 build.com.yp.test.HelloWorld.class
>
@@ -677,27 +662,28 @@ javac src/com/yp/test/HelloWorld.java -d build
先下一个jar包 这里直接下 log4j
- * main函数改成
-
- import com.yp.test.entity.Cat;
- import org.apache.log4j.Logger;
-
- public class HelloWorld {
-
- static Logger log = Logger.getLogger(HelloWorld.class);
-
- public static void main(String[] args) {
- Cat c = new Cat("keyboard");
- log.info("这是log4j");
- System.out.println("hello," + c.getName());
- }
-
+* main函数改成
+
+````
+import com.yp.test.entity.Cat;
+import org.apache.log4j.Logger;
+
+public class HelloWorld {
+
+ static Logger log = Logger.getLogger(HelloWorld.class);
+
+ public static void main(String[] args) {
+ Cat c = new Cat("keyboard");
+ log.info("这是log4j");
+ System.out.println("hello," + c.getName());
}
+}
+````
现的文件是这样的
-```
+````
├─build
├─lib
│ log4j-1.2.17.jar
@@ -710,8 +696,7 @@ javac src/com/yp/test/HelloWorld.java -d build
│
└─entity
Cat.java
-```
-
+````
这个时候 javac命令要接上 -cp ./lib/*.jar
E:\codeplace\n_learn\java\javacmd>javac -encoding "utf8" src/com/yp/test/HelloWorld.java -sourcepath src -d build -g -cp ./lib/*.jar
@@ -729,21 +714,22 @@ javac src/com/yp/test/HelloWorld.java -d build
由于没有 log4j的配置文件,所以提示上面的问题,往 build 里面加上 log4j.xml
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
+````
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+````
再运行
E:\codeplace\n_learn\java\javacmd>java -cp lib/log4j-1.2.17.jar;build com.yp.tes t.HelloWorld
@@ -757,7 +743,7 @@ ok 一个简单的java 工程就运行完了
但是 貌似有些繁琐, 需要手动键入 java文件 以及相应的jar包 很是麻烦,
so 可以用 shell 来脚本来简化相关操作
shell 文件整理如下:
-
+````
#!/bin/bash
echo "build start"
@@ -788,6 +774,7 @@ shell 文件整理如下:
#运行 通过-cp指定所有的引用jar包,指定入口函数运行
java -cp $BIN_PATH$jarfile com.zuiapps.danmaku.server.Main
+````
> 有一点需要注意的是, javac -d $BIN_PATH/ -cp $jarfile @$SRC_FILE_LIST_PATH
> 在要编译的文件很多时候,一个个敲命令会显得很长,也不方便修改,
@@ -805,7 +792,7 @@ shell 文件整理如下:
1.需要吧 编译时设置的bin目录和 所有jar包加入到 classpath 中去
-
+
## javap 的使用
> javap是jdk自带的一个工具,可以对代码反编译,也可以查看java编译器生成的字节码。
@@ -815,37 +802,37 @@ shell 文件整理如下:
>
>
> javap命令分解一个class文件,它根据options来决定到底输出什么。如果没有使用options,那么javap将会输出包,类里的protected和public域以及类里的所有方法。javap将会把它们输出在标准输出上。来看这个例子,先编译(javac)下面这个类。
-
- import java.awt.*;
- import java.applet.*;
-
- public class DocFooter extends Applet {
- String date;
- String email;
-
- public void init() {
- resize(500,100);
- date = getParameter("LAST_UPDATED");
- email = getParameter("EMAIL");
- }
- }
-
+````
+import java.awt.*;
+import java.applet.*;
+
+public class DocFooter extends Applet {
+ String date;
+ String email;
+
+ public void init() {
+ resize(500,100);
+ date = getParameter("LAST_UPDATED");
+ email = getParameter("EMAIL");
+ }
+}
+````
在命令行上键入javap DocFooter后,输出结果如下
Compiled from "DocFooter.java"
-
- public class DocFooter extends java.applet.Applet {
- java.lang.String date;
- java.lang.String email;
- public DocFooter();
- public void init();
- }
-
+````
+public class DocFooter extends java.applet.Applet {
+ java.lang.String date;
+ java.lang.String email;
+ public DocFooter();
+ public void init();
+}
+````
如果加入了-c,即javap -c DocFooter,那么输出结果如下
Compiled from "DocFooter.java"
-
+````
public class DocFooter extends java.applet.Applet {
java.lang.String date;
@@ -876,6 +863,7 @@ Compiled from "DocFooter.java"
29: return
}
+````
上面输出的内容就是字节码。
用法摘要
@@ -903,20 +891,3 @@ https://www.jianshu.com/p/6a8997560b05
https://blog.csdn.net/w372426096/article/details/81664431
https://blog.csdn.net/qincidong/article/details/82492140
-## 微信公众号
-
-### Java技术江湖
-
-如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号【Java技术江湖】一位阿里 Java 工程师的技术小站,作者黄小斜,专注 Java 相关技术:SSM、SpringBoot、MySQL、分布式、中间件、集群、Linux、网络、多线程,偶尔讲点Docker、ELK,同时也分享技术干货和学习经验,致力于Java全栈开发!
-
-**Java工程师必备学习资源:** 一些Java工程师常用学习资源,关注公众号后,后台回复关键字 **“Java”** 即可免费无套路获取。
-
-
-
-### 个人公众号:黄小斜
-
-作者是 985 硕士,蚂蚁金服 JAVA 工程师,专注于 JAVA 后端技术栈:SpringBoot、MySQL、分布式、中间件、微服务,同时也懂点投资理财,偶尔讲点算法和计算机理论基础,坚持学习和写作,相信终身学习的力量!
-
-**程序员3T技术学习资源:** 一些程序员学习技术的资源大礼包,关注公众号后,后台回复关键字 **“资料”** 即可免费无套路获取。
-
-
diff --git "a/docs/java/basic/3\343\200\201string\345\222\214\345\214\205\350\243\205\347\261\273.md" "b/docs/Java/basic/string\345\222\214\345\214\205\350\243\205\347\261\273.md"
similarity index 50%
rename from "docs/java/basic/3\343\200\201string\345\222\214\345\214\205\350\243\205\347\261\273.md"
rename to "docs/Java/basic/string\345\222\214\345\214\205\350\243\205\347\261\273.md"
index 13dfe0a..9adf53e 100644
--- "a/docs/java/basic/3\343\200\201string\345\222\214\345\214\205\350\243\205\347\261\273.md"
+++ "b/docs/Java/basic/string\345\222\214\345\214\205\350\243\205\347\261\273.md"
@@ -27,9 +27,7 @@
* [不可变有什么好处?](#不可变有什么好处?)
* [String常用工具类](#string常用工具类)
* [参考文章](#参考文章)
- * [微信公众号](#微信公众号)
- * [Java技术江湖](#java技术江湖)
- * [个人公众号:黄小斜](#个人公众号:黄小斜)
+
@@ -46,11 +44,8 @@
如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。
-
-
-
## string基础
### Java String 类
@@ -70,9 +65,14 @@ String greeting = "菜鸟教程";
String 类有 11 种构造方法,这些方法提供不同的参数来初始化字符串,比如提供一个字符数组参数:
### StringDemo.java 文件代码:
-
- public class StringDemo{ public static void main(String args[]){ char[] helloArray = { 'r', 'u', 'n', 'o', 'o', 'b'}; String helloString = new String(helloArray); System.out.println( helloString ); } }
-
+````
+public class StringDemo{
+public static void main(String args[]){
+char[] helloArray = { 'r', 'u', 'n', 'o', 'o', 'b'};
+String helloString = new String(helloArray);
+System.out.println( helloString );
+} }
+````
以上实例编译运行结果如下:
```
@@ -87,35 +87,37 @@ runoob
### 创建String对象的常用方法
-(1) String s1 = "mpptest"
+(1) String s1 = "mpptest"
- (2) String s2 = new String();
+(2) String s2 = new String();
- (3) String s3 = new String("mpptest")
+(3) String s3 = new String("mpptest")
### String中常用的方法,用法如图所示,具体问度娘

### 三个方法的使用: lenth() substring() charAt()
-
-
-
-package com.mpp.string; public class StringDemo1 { public static void main(String[] args) { //定义一个字符串"晚来天欲雪 能饮一杯无"
+````
+package com.mpp.string;
+public class StringDemo1 {
+ public static void main(String[] args) { //定义一个字符串"晚来天欲雪 能饮一杯无"
String str = "晚来天欲雪 能饮一杯无";
System.out.println("字符串的长度是:"+str.length()); //字符串的雪字打印输出 charAt(int index)
System.out.println(str.charAt(4)); //取出子串 天欲
System.out.println(str.substring(2)); //取出从index2开始直到最后的子串,包含2
System.out.println(str.substring(2,4)); //取出index从2到4的子串,包含2不包含4 顾头不顾尾
- }
-}
-
-
+ }
+}
+````
- 两个方法的使用,求字符或子串第一次/最后一次在字符串中出现的位置: indexOf() lastIndexOf()
+两个方法的使用,求字符或子串第一次/最后一次在字符串中出现的位置:
+indexOf() lastIndexOf()
-package com.mpp.string; public class StringDemo2 { public static void main(String[] args) {
+````
+package com.mpp.string; public class StringDemo2 {
+ public static void main(String[] args) {
String str = new String("赵客缦胡缨 吴钩胡缨霜雪明"); //查找胡在字符串中第一次出现的位置
System.out.println("\"胡\"在字符串中第一次出现的位置:"+str.indexOf("胡")); //查找子串"胡缨"在字符串中第一次出现的位置
System.out.println("\"胡缨\"在字符串中第一次出现的位置"+str.indexOf("胡缨")); //查找胡在字符串中最后一次次出现的位置
@@ -123,35 +125,40 @@ runoob
System.out.println(str.lastIndexOf("胡缨")); //从indexof为5的位置,找第一次出现的"吴"
System.out.println(str.indexOf("吴",5));
}
-}
-
+}
+````
### 字符串与byte数组间的相互转换
-
-package com.mpp.string; import java.io.UnsupportedEncodingException; public class StringDemo3 { public static void main(String[] args) throws UnsupportedEncodingException { //字符串和byte数组之间的相互转换
- String str = new String("hhhabc银鞍照白马 飒沓如流星"); //将字符串转换为byte数组,并打印输出
- byte[] arrs = str.getBytes("GBK"); for(int i=0;i){
+````
+package com.mpp.string; import java.io.UnsupportedEncodingException;
+public class StringDemo3 {
+ public static void main(String[] args) throws UnsupportedEncodingException {
+
+ //字符串和byte数组之间的相互转换
+ String str = new String("hhhabc银鞍照白马 飒沓如流星"); //将字符串转换为byte数组,并打印输出
+ byte[] arrs = str.getBytes("GBK");
+ for(int i=0;i){
System.out.print(arrs[i]);
- } //将byte数组转换成字符串
- System.out.println();
+ }
+
+ //将byte数组转换成字符串
+ System.out.println();
String str1 = new String(arrs,"GBK"); //保持字符集的一致,否则会出现乱码
- System.out.println(str1);
+ System.out.println(str1);
}
-}
-
+}
+````
### ==运算符和equals之间的区别:
-引用指向的内容和引用指向的地址
+引用指向的内容和引用指向的地址
-
-
-
-
-package com.mpp.string; public class StringDemo5 { public static void main(String[] args) {
+````
+package com.mpp.string; public class StringDemo5 {
+ public static void main(String[] args) {
String str1 = "mpp";
String str2 = "mpp";
String str3 = new String("mpp");
@@ -160,9 +167,9 @@ runoob
System.out.println(str1.equals(str3)); //true 内容相同
System.out.println(str1==str2); //true 地址相同
System.out.println(str1==str3); //false 地址不同
- }
-}
-
+ }
+}
+````
### 字符串的不可变性
@@ -170,7 +177,7 @@ String的对象一旦被创建,则不能修改,是不可变的
所谓的修改其实是创建了新的对象,所指向的内存空间不变
-
+
上图中,s1不再指向imooc所在的内存空间,而是指向了hello,imooc
### String的连接
@@ -218,85 +225,86 @@ String str = "aa"+"bb"+"cc";
## String类的源码分析
### String类型的intern
-
- public void intern () {
- //2:string的intern使用
- //s1是基本类型,比较值。s2是string实例,比较实例地址
- //字符串类型用equals方法比较时只会比较值
- String s1 = "a";
- String s2 = new String("a");
- //调用intern时,如果s2中的字符不在常量池,则加入常量池并返回常量的引用
- String s3 = s2.intern();
- System.out.println(s1 == s2);
- System.out.println(s1 == s3);
- }
-
+````
+public void intern () {
+ //2:string的intern使用
+ //s1是基本类型,比较值。s2是string实例,比较实例地址
+ //字符串类型用equals方法比较时只会比较值
+ String s1 = "a";
+ String s2 = new String("a");
+ //调用intern时,如果s2中的字符不在常量池,则加入常量池并返回常量的引用
+ String s3 = s2.intern();
+ System.out.println(s1 == s2);
+ System.out.println(s1 == s3);
+}
+````
### String类型的equals
-
- //字符串的equals方法
- // public boolean equals(Object anObject) {
- // if (this == anObject) {
- // return true;
- // }
- // if (anObject instanceof String) {
- // String anotherString = (String)anObject;
- // int n = value.length;
- // if (n == anotherString.value.length) {
- // char v1[] = value;
- // char v2[] = anotherString.value;
- // int i = 0;
- // while (n-- != 0) {
- // if (v1[i] != v2[i])
- // return false;
- // i++;
- // }
- // return true;
- // }
- // }
- // return false;
- // }
-
+````
+//字符串的equals方法
+// public boolean equals(Object anObject) {
+// if (this == anObject) {
+// return true;
+// }
+// if (anObject instanceof String) {
+// String anotherString = (String)anObject;
+// int n = value.length;
+// if (n == anotherString.value.length) {
+// char v1[] = value;
+// char v2[] = anotherString.value;
+// int i = 0;
+// while (n-- != 0) {
+// if (v1[i] != v2[i])
+// return false;
+// i++;
+// }
+// return true;
+// }
+// }
+// return false;
+// }
+````
### StringBuffer和Stringbuilder
底层是继承父类的可变字符数组value
+````
+/**
+
+- The value is used for character storage.
+ */
+ char[] value;
+ 初始化容量为16
+
+/**
+
+- Constructs a string builder with no characters in it and an
+- initial capacity of 16 characters.
+ */
+ public StringBuilder() {
+ super(16);
+ }
+ 这两个类的append方法都是来自父类AbstractStringBuilder的方法
+
+public AbstractStringBuilder append(String str) {
+ if (str == null)
+ return appendNull();
+ int len = str.length();
+ ensureCapacityInternal(count + len);
+ str.getChars(0, len, value, count);
+ count += len;
+ return this;
+}
+@Override
+public StringBuilder append(String str) {
+ super.append(str);
+ return this;
+}
- /**
-
- - The value is used for character storage.
- */
- char[] value;
- 初始化容量为16
-
- /**
-
- - Constructs a string builder with no characters in it and an
- - initial capacity of 16 characters.
- */
- public StringBuilder() {
- super(16);
- }
- 这两个类的append方法都是来自父类AbstractStringBuilder的方法
-
- public AbstractStringBuilder append(String str) {
- if (str == null)
- return appendNull();
- int len = str.length();
- ensureCapacityInternal(count + len);
- str.getChars(0, len, value, count);
- count += len;
- return this;
- }
- @Override
- public StringBuilder append(String str) {
- super.append(str);
- return this;
- }
-
- @Override
- public synchronized StringBuffer append(String str) {
- toStringCache = null;
- super.append(str);
- return this;
- }
+@Override
+public synchronized StringBuffer append(String str) {
+ toStringCache = null;
+ super.append(str);
+ return this;
+}
+````
### append方法
Stringbuffer在大部分涉及字符串修改的操作上加了synchronized关键字来保证线程安全,效率较低。
@@ -312,19 +320,19 @@ a = a + a;时,实际上先把a封装成stringbuilder,调用append方法后
ensureCapacityInternal(count + len);
该方法是计算append之后的空间是否足够,不足的话需要进行扩容
-
- public void ensureCapacity(int minimumCapacity) {
- if (minimumCapacity > 0)
- ensureCapacityInternal(minimumCapacity);
- }
- private void ensureCapacityInternal(int minimumCapacity) {
- // overflow-conscious code
- if (minimumCapacity - value.length > 0) {
- value = Arrays.copyOf(value,
- newCapacity(minimumCapacity));
- }
+````
+public void ensureCapacity(int minimumCapacity) {
+ if (minimumCapacity > 0)
+ ensureCapacityInternal(minimumCapacity);
+}
+private void ensureCapacityInternal(int minimumCapacity) {
+ // overflow-conscious code
+ if (minimumCapacity - value.length > 0) {
+ value = Arrays.copyOf(value,
+ newCapacity(minimumCapacity));
}
-
+}
+````
如果新字符串长度大于value数组长度则进行扩容
扩容后的长度一般为原来的两倍 + 2;
@@ -334,42 +342,39 @@ ensureCapacityInternal(count + len);
考虑两种情况
如果新的字符串长度超过int最大值,则抛出异常,否则直接使用数组最大长度作为新数组的长度。
-
- private int hugeCapacity(int minCapacity) {
- if (Integer.MAX_VALUE - minCapacity < 0) { // overflow
- throw new OutOfMemoryError();
- }
- return (minCapacity > MAX_ARRAY_SIZE)
- ? minCapacity : MAX_ARRAY_SIZE;
+````
+private int hugeCapacity(int minCapacity) {
+ if (Integer.MAX_VALUE - minCapacity < 0) { // overflow
+ throw new OutOfMemoryError();
}
-
+ return (minCapacity > MAX_ARRAY_SIZE)
+ ? minCapacity : MAX_ARRAY_SIZE;
+}
+````
### 删除
这两个类型的删除操作:
都是调用父类的delete方法进行删除
-
- public AbstractStringBuilder delete(int start, int end) {
- if (start < 0)
- throw new StringIndexOutOfBoundsException(start);
- if (end > count)
- end = count;
- if (start > end)
- throw new StringIndexOutOfBoundsException();
- int len = end - start;
- if (len > 0) {
- System.arraycopy(value, start+len, value, start, count-end);
- count -= len;
- }
- return this;
- }
-
+````
+public AbstractStringBuilder delete(int start, int end) {
+ if (start < 0)
+ throw new StringIndexOutOfBoundsException(start);
+ if (end > count)
+ end = count;
+ if (start > end)
+ throw new StringIndexOutOfBoundsException();
+ int len = end - start;
+ if (len > 0) {
+ System.arraycopy(value, start+len, value, start, count-end);
+ count -= len;
+ }
+ return this;
+}
+````
事实上是将剩余的字符重新拷贝到字符数组value。
这里用到了system.arraycopy来拷贝数组,速度是比较快的
-
-
-
### system.arraycopy方法
转自知乎:
@@ -386,37 +391,26 @@ ensureCapacityInternal(count + len);
## String和JVM的关系
-
-
-
下面我们了解下Java栈、Java堆、方法区和常量池:
-
-
Java栈(线程私有数据区):
```
每个Java虚拟机线程都有自己的Java虚拟机栈,Java虚拟机栈用来存放栈帧,每个方法被执行的时候都会同时创建一个栈帧(Stack Frame)用于存储局部变量表、操作栈、动态链接、方法出口等信息。每一个方法被调用直至执行完成的过程,就对应着一个栈帧在虚拟机栈中从入栈到出栈的过程。
```
-
-
Java堆(线程共享数据区):
```
在虚拟机启动时创建,此内存区域的唯一目的就是存放对象实例,几乎所有的对象实例都在这里分配。
```
-
-
方法区(线程共享数据区):
```
方法区在虚拟机启动的时候被创建,它存储了每一个类的结构信息,例如运行时常量池、字段和方法数据、构造函数和普通方法的字节码内容、还包括在类、实例、接口初始化时用到的特殊方法。在JDK8之前永久代是方法区的一种实现,而JDK8元空间替代了永久代,永久代被移除,也可以理解为元空间是方法区的一种实现。
```
-
-
常量池(线程共享数据区):
```
@@ -437,23 +431,18 @@ Java堆(线程共享数据区):
使用字符串常量池,每当我们使用字面量(String s=”1”;)创建字符串常量时,JVM会首先检查字符串常量池,如果该字符串已经存在常量池中,那么就将此字符串对象的地址赋值给引用s(引用s在Java栈中)。如果字符串不存在常量池中,就会实例化该字符串并且将其放到常量池中,并将此字符串对象的地址赋值给引用s(引用s在Java栈中)。
```
-
-
```
使用字符串常量池,每当我们使用关键字new(String s=new String(”1”);)创建字符串常量时,JVM会首先检查字符串常量池,如果该字符串已经存在常量池中,那么不再在字符串常量池创建该字符串对象,而直接堆中复制该对象的副本,然后将堆中对象的地址赋值给引用s,如果字符串不存在常量池中,就会实例化该字符串并且将其放到常量池中,然后在堆中复制该对象的副本,然后将堆中对象的地址赋值给引用s。
```
-
-
-
## String为什么不可变?
翻开JDK源码,java.lang.String类起手前三行,是这样写的:
-
- public final class String implements java.io.Serializable, Comparable, CharSequence {
- /** String本质是个char数组. 而且用final关键字修饰.*/
- private final char value[]; ... ...
- }
-
+````
+public final class String implements java.io.Serializable, Comparable, CharSequence {
+ /** String本质是个char数组. 而且用final关键字修饰.*/
+private final char value[]; ... ...
+ }
+````
首先String类是用final关键字修饰,这说明String不可继承。再看下面,String类的主力成员字段value是个char[]数组,而且是用final修饰的。
final修饰的字段创建以后就不可改变。 有的人以为故事就这样完了,其实没有。因为虽然value是不可变,也只是value这个引用地址不可变。挡不住Array数组是可变的事实。
@@ -463,16 +452,16 @@ Array的数据结构看下图。
也就是说Array变量只是stack上的一个引用,数组的本体结构在heap堆。
String类里的value用final修饰,只是说stack里的这个叫value的引用地址不可变。没有说堆里array本身数据不可变。看下面这个例子,
-
- final int[] value={1,2,3} ;
- int[] another={4,5,6};
- value=another; //编译器报错,final不可变 value用final修饰,编译器不允许我把value指向堆区另一个地址。
- 但如果我直接对数组元素动手,分分钟搞定。
-
- final int[] value={1,2,3};
- value[2]=100; //这时候数组里已经是{1,2,100} 所以String是不可变,关键是因为SUN公司的工程师。
- 在后面所有String的方法里很小心的没有去动Array里的元素,没有暴露内部成员字段。private final char value[]这一句里,private的私有访问权限的作用都比final大。而且设计师还很小心地把整个String设成final禁止继承,避免被其他人继承后破坏。所以String是不可变的关键都在底层的实现,而不是一个final。考验的是工程师构造数据类型,封装数据的功力。
-
+````
+final int[] value={1,2,3} ;
+int[] another={4,5,6};
+ value=another; //编译器报错,final不可变 value用final修饰,编译器不允许我把value指向堆区另一个地址。
+但如果我直接对数组元素动手,分分钟搞定。
+
+ final int[] value={1,2,3};
+ value[2]=100; //这时候数组里已经是{1,2,100} 所以String是不可变,关键是因为SUN公司的工程师。
+ 在后面所有String的方法里很小心的没有去动Array里的元素,没有暴露内部成员字段。private final char value[]这一句里,private的私有访问权限的作用都比final大。而且设计师还很小心地把整个String设成final禁止继承,避免被其他人继承后破坏。所以String是不可变的关键都在底层的实现,而不是一个final。考验的是工程师构造数据类型,封装数据的功力。
+````
### 不可变有什么好处?
这个最简单地原因,就是为了安全。看下面这个场景(有评论反应例子不够清楚,现在完整地写出来),一个函数appendStr( )在不可变的String参数后面加上一段“bbb”后返回。appendSb( )负责在可变的StringBuilder后面加“bbb”。
@@ -485,28 +474,28 @@ String类里的value用final修饰,只是说stack里的这个叫value的引用
> 3 final修饰的char数组保证了char数组的引用不可变。但是可以通过char[0] = 'a’来修改值。不过String内部并不提供方法来完成这一操作,所以String的不可变也是基于代码封装和访问控制的。
举个例子
+````
+final class Fi {
+ int a;
+ final int b = 0;
+ Integer s;
- final class Fi {
- int a;
- final int b = 0;
- Integer s;
-
- }
- final char[]a = {'a'};
- final int[]b = {1};
- @Test
- public void final修饰类() {
- //引用没有被final修饰,所以是可变的。
- //final只修饰了Fi类型,即Fi实例化的对象在堆中内存地址是不可变的。
- //虽然内存地址不可变,但是可以对内部的数据做改变。
- Fi f = new Fi();
- f.a = 1;
- System.out.println(f);
- f.a = 2;
- System.out.println(f);
- //改变实例中的值并不改变内存地址。
-
-```
+}
+final char[]a = {'a'};
+final int[]b = {1};
+@Test
+public void final修饰类() {
+ //引用没有被final修饰,所以是可变的。
+ //final只修饰了Fi类型,即Fi实例化的对象在堆中内存地址是不可变的。
+ //虽然内存地址不可变,但是可以对内部的数据做改变。
+ Fi f = new Fi();
+ f.a = 1;
+ System.out.println(f);
+ f.a = 2;
+ System.out.println(f);
+ //改变实例中的值并不改变内存地址。
+````
+````
Fi ff = f;
//让引用指向新的Fi对象,原来的f对象由新的引用ff持有。
//引用的指向改变也不会改变原来对象的地址
@@ -515,7 +504,7 @@ System.out.println(f);
System.out.println(ff);
}
-```
+````
这里的对f.a的修改可以理解为char[0] = 'a'这样的操作。只改变数据值,不改变内存值。
@@ -523,301 +512,288 @@ System.out.println(ff);
问题描述
很多时候我们需要对字符串进行很多固定的操作,而这些操作在JDK/JRE中又没有预置,于是我们想到了apache-commons组件,但是它也不能完全覆盖我们的业务需求,所以很多时候还是要自己写点代码的,下面就是基于apache-commons组件写的部分常用方法:
- MAVEN依赖
+
+````
org.apache.commons
commons-lang3
${commons-lang3.version}
+````
代码成果
- public class StringUtils extends org.apache.commons.lang3.StringUtils {
-
- /** 值为"NULL"的字符串 */
- private static final String NULL_STRING = "NULL";
-
- private static final char SEPARATOR = '_';
-
-
- /**
- * 满足一下情况返回true
- * ①.入参为空
- * ②.入参为空字符串
- * ③.入参为"null"字符串
- *
- * @param string 需要判断的字符型
- * @return boolean
- */
- public static boolean isNullOrEmptyOrNULLString(String string) {
- return isBlank(string) || NULL_STRING.equalsIgnoreCase(string);
- }
-
- /**
- * 把字符串转为二进制码
- * 本方法不会返回null
- *
- * @param str 需要转换的字符串
- * @return 二进制字节码数组
- */
- public static byte[] toBytes(String str) {
- return isBlank(str) ? new byte[]{} : str.getBytes();
- }
-
- /**
- * 把字符串转为二进制码
- * 本方法不会返回null
- *
- * @param str 需要转换的字符串
- * @param charset 编码类型
- * @return 二进制字节码数组
- * @throws UnsupportedEncodingException 字符串转换的时候编码不支持时出现
- */
- public static byte[] toBytes(String str, Charset charset) throws UnsupportedEncodingException {
- return isBlank(str) ? new byte[]{} : str.getBytes(charset.displayName());
- }
-
- /**
- * 把字符串转为二进制码
- * 本方法不会返回null
- *
- * @param str 需要转换的字符串
- * @param charset 编码类型
- * @param locale 编码类型对应的地区
- * @return 二进制字节码数组
- * @throws UnsupportedEncodingException 字符串转换的时候编码不支持时出现
- */
- public static byte[] toBytes(String str, Charset charset, Locale locale) throws UnsupportedEncodingException {
- return isBlank(str) ? new byte[]{} : str.getBytes(charset.displayName(locale));
- }
-
- /**
- * 二进制码转字符串
- * 本方法不会返回null
- *
- * @param bytes 二进制码
- * @return 字符串
- */
- public static String bytesToString(byte[] bytes) {
- return bytes == null || bytes.length == 0 ? EMPTY : new String(bytes);
- }
-
- /**
- * 二进制码转字符串
- * 本方法不会返回null
- *
- * @param bytes 二进制码
- * @param charset 编码集
- * @return 字符串
- * @throws UnsupportedEncodingException 当前二进制码可能不支持传入的编码
- */
- public static String byteToString(byte[] bytes, Charset charset) throws UnsupportedEncodingException {
- return bytes == null || bytes.length == 0 ? EMPTY : new String(bytes, charset.displayName());
- }
-
- /**
- * 二进制码转字符串
- * 本方法不会返回null
- *
- * @param bytes 二进制码
- * @param charset 编码集
- * @param locale 本地化
- * @return 字符串
- * @throws UnsupportedEncodingException 当前二进制码可能不支持传入的编码
- */
- public static String byteToString(byte[] bytes, Charset charset, Locale locale) throws UnsupportedEncodingException {
- return bytes == null || bytes.length == 0 ? EMPTY : new String(bytes, charset.displayName(locale));
- }
-
- /**
- * 把对象转为字符串
- *
- * @param object 需要转化的字符串
- * @return 字符串, 可能为空
- */
- public static String parseString(Object object) {
- if (object == null) {
- return null;
- }
- if (object instanceof byte[]) {
- return bytesToString((byte[]) object);
- }
- return object.toString();
- }
-
- /**
- * 把字符串转为int类型
- *
- * @param str 需要转化的字符串
- * @return int
- * @throws NumberFormatException 字符串格式不正确时抛出
- */
- public static int parseInt(String str) throws NumberFormatException {
- return isBlank(str) ? 0 : Integer.parseInt(str);
- }
-
- /**
- * 把字符串转为double类型
- *
- * @param str 需要转化的字符串
- * @return double
- * @throws NumberFormatException 字符串格式不正确时抛出
- */
- public static double parseDouble(String str) throws NumberFormatException {
- return isBlank(str) ? 0D : Double.parseDouble(str);
- }
-
- /**
- * 把字符串转为long类型
- *
- * @param str 需要转化的字符串
- * @return long
- * @throws NumberFormatException 字符串格式不正确时抛出
- */
- public static long parseLong(String str) throws NumberFormatException {
- return isBlank(str) ? 0L : Long.parseLong(str);
+````
+public class StringUtils extends org.apache.commons.lang3.StringUtils {
+
+/** 值为"NULL"的字符串 */
+private static final String NULL_STRING = "NULL";
+
+private static final char SEPARATOR = '_';
+
+
+/**
+ * 满足一下情况返回true
+ * ①.入参为空
+ * ②.入参为空字符串
+ * ③.入参为"null"字符串
+ *
+ * @param string 需要判断的字符型
+ * @return boolean
+ */
+public static boolean isNullOrEmptyOrNULLString(String string) {
+ return isBlank(string) || NULL_STRING.equalsIgnoreCase(string);
+}
+
+/**
+ * 把字符串转为二进制码
+ * 本方法不会返回null
+ *
+ * @param str 需要转换的字符串
+ * @return 二进制字节码数组
+ */
+public static byte[] toBytes(String str) {
+ return isBlank(str) ? new byte[]{} : str.getBytes();
+}
+
+/**
+ * 把字符串转为二进制码
+ * 本方法不会返回null
+ *
+ * @param str 需要转换的字符串
+ * @param charset 编码类型
+ * @return 二进制字节码数组
+ * @throws UnsupportedEncodingException 字符串转换的时候编码不支持时出现
+ */
+public static byte[] toBytes(String str, Charset charset) throws UnsupportedEncodingException {
+ return isBlank(str) ? new byte[]{} : str.getBytes(charset.displayName());
+}
+
+/**
+ * 把字符串转为二进制码
+ * 本方法不会返回null
+ *
+ * @param str 需要转换的字符串
+ * @param charset 编码类型
+ * @param locale 编码类型对应的地区
+ * @return 二进制字节码数组
+ * @throws UnsupportedEncodingException 字符串转换的时候编码不支持时出现
+ */
+public static byte[] toBytes(String str, Charset charset, Locale locale) throws UnsupportedEncodingException {
+ return isBlank(str) ? new byte[]{} : str.getBytes(charset.displayName(locale));
+}
+
+/**
+ * 二进制码转字符串
+ * 本方法不会返回null
+ *
+ * @param bytes 二进制码
+ * @return 字符串
+ */
+public static String bytesToString(byte[] bytes) {
+ return bytes == null || bytes.length == 0 ? EMPTY : new String(bytes);
+}
+
+/**
+ * 二进制码转字符串
+ * 本方法不会返回null
+ *
+ * @param bytes 二进制码
+ * @param charset 编码集
+ * @return 字符串
+ * @throws UnsupportedEncodingException 当前二进制码可能不支持传入的编码
+ */
+public static String byteToString(byte[] bytes, Charset charset) throws UnsupportedEncodingException {
+ return bytes == null || bytes.length == 0 ? EMPTY : new String(bytes, charset.displayName());
+}
+
+/**
+ * 二进制码转字符串
+ * 本方法不会返回null
+ *
+ * @param bytes 二进制码
+ * @param charset 编码集
+ * @param locale 本地化
+ * @return 字符串
+ * @throws UnsupportedEncodingException 当前二进制码可能不支持传入的编码
+ */
+public static String byteToString(byte[] bytes, Charset charset, Locale locale) throws UnsupportedEncodingException {
+ return bytes == null || bytes.length == 0 ? EMPTY : new String(bytes, charset.displayName(locale));
+}
+
+/**
+ * 把对象转为字符串
+ *
+ * @param object 需要转化的字符串
+ * @return 字符串, 可能为空
+ */
+public static String parseString(Object object) {
+ if (object == null) {
+ return null;
}
-
- /**
- * 把字符串转为float类型
- *
- * @param str 需要转化的字符串
- * @return float
- * @throws NumberFormatException 字符串格式不正确时抛出
- */
- public static float parseFloat(String str) throws NumberFormatException {
- return isBlank(str) ? 0L : Float.parseFloat(str);
+ if (object instanceof byte[]) {
+ return bytesToString((byte[]) object);
}
-
- /**
- * 获取i18n字符串
- *
- * @param code
- * @param args
- * @return
- */
- public static String getI18NMessage(String code, Object[] args) {
- //LocaleResolver localLocaleResolver = (LocaleResolver) SpringContextHolder.getBean(LocaleResolver.class);
- //HttpServletRequest request = ((ServletRequestAttributes)RequestContextHolder.getRequestAttributes()).getRequest();
- //Locale locale = localLocaleResolver.resolveLocale(request);
- //return SpringContextHolder.getApplicationContext().getMessage(code, args, locale);
+ return object.toString();
+}
+
+/**
+ * 把字符串转为int类型
+ *
+ * @param str 需要转化的字符串
+ * @return int
+ * @throws NumberFormatException 字符串格式不正确时抛出
+ */
+public static int parseInt(String str) throws NumberFormatException {
+ return isBlank(str) ? 0 : Integer.parseInt(str);
+}
+
+/**
+ * 把字符串转为double类型
+ *
+ * @param str 需要转化的字符串
+ * @return double
+ * @throws NumberFormatException 字符串格式不正确时抛出
+ */
+public static double parseDouble(String str) throws NumberFormatException {
+ return isBlank(str) ? 0D : Double.parseDouble(str);
+}
+
+/**
+ * 把字符串转为long类型
+ *
+ * @param str 需要转化的字符串
+ * @return long
+ * @throws NumberFormatException 字符串格式不正确时抛出
+ */
+public static long parseLong(String str) throws NumberFormatException {
+ return isBlank(str) ? 0L : Long.parseLong(str);
+}
+
+/**
+ * 把字符串转为float类型
+ *
+ * @param str 需要转化的字符串
+ * @return float
+ * @throws NumberFormatException 字符串格式不正确时抛出
+ */
+public static float parseFloat(String str) throws NumberFormatException {
+ return isBlank(str) ? 0L : Float.parseFloat(str);
+}
+
+/**
+ * 获取i18n字符串
+ *
+ * @param code
+ * @param args
+ * @return
+ */
+public static String getI18NMessage(String code, Object[] args) {
+ //LocaleResolver localLocaleResolver = (LocaleResolver) SpringContextHolder.getBean(LocaleResolver.class);
+ //HttpServletRequest request = ((ServletRequestAttributes)RequestContextHolder.getRequestAttributes()).getRequest();
+ //Locale locale = localLocaleResolver.resolveLocale(request);
+ //return SpringContextHolder.getApplicationContext().getMessage(code, args, locale);
+ return "";
+}
+
+/**
+ * 获得用户远程地址
+ *
+ * @param request 请求头
+ * @return 用户ip
+ */
+public static String getRemoteAddr(HttpServletRequest request) {
+ String remoteAddr = request.getHeader("X-Real-IP");
+ if (isNotBlank(remoteAddr)) {
+ remoteAddr = request.getHeader("X-Forwarded-For");
+ } else if (isNotBlank(remoteAddr)) {
+ remoteAddr = request.getHeader("Proxy-Client-IP");
+ } else if (isNotBlank(remoteAddr)) {
+ remoteAddr = request.getHeader("WL-Proxy-Client-IP");
+ }
+ return remoteAddr != null ? remoteAddr : request.getRemoteAddr();
+}
+
+/**
+ * 驼峰命名法工具
+ *
+ * @return toCamelCase(" hello_world ") == "helloWorld"
+ * toCapitalizeCamelCase("hello_world") == "HelloWorld"
+ * toUnderScoreCase("helloWorld") = "hello_world"
+ */
+public static String toCamelCase(String s, Locale locale, char split) {
+ if (isBlank(s)) {
return "";
}
-
- /**
- * 获得用户远程地址
- *
- * @param request 请求头
- * @return 用户ip
- */
- public static String getRemoteAddr(HttpServletRequest request) {
- String remoteAddr = request.getHeader("X-Real-IP");
- if (isNotBlank(remoteAddr)) {
- remoteAddr = request.getHeader("X-Forwarded-For");
- } else if (isNotBlank(remoteAddr)) {
- remoteAddr = request.getHeader("Proxy-Client-IP");
- } else if (isNotBlank(remoteAddr)) {
- remoteAddr = request.getHeader("WL-Proxy-Client-IP");
- }
- return remoteAddr != null ? remoteAddr : request.getRemoteAddr();
- }
-
- /**
- * 驼峰命名法工具
- *
- * @return toCamelCase(" hello_world ") == "helloWorld"
- * toCapitalizeCamelCase("hello_world") == "HelloWorld"
- * toUnderScoreCase("helloWorld") = "hello_world"
- */
- public static String toCamelCase(String s, Locale locale, char split) {
- if (isBlank(s)) {
- return "";
- }
-
- s = s.toLowerCase(locale);
-
- StringBuilder sb = new StringBuilder();
- for (char c : s.toCharArray()) {
- sb.append(c == split ? Character.toUpperCase(c) : c);
- }
-
- return sb.toString();
- }
-
- public static String toCamelCase(String s) {
- return toCamelCase(s, Locale.getDefault(), SEPARATOR);
- }
-
- public static String toCamelCase(String s, Locale locale) {
- return toCamelCase(s, locale, SEPARATOR);
- }
-
- public static String toCamelCase(String s, char split) {
- return toCamelCase(s, Locale.getDefault(), split);
- }
-
- public static String toUnderScoreCase(String s, char split) {
- if (isBlank(s)) {
- return "";
- }
-
- StringBuilder sb = new StringBuilder();
- for (int i = 0; i < s.length(); i++) {
- char c = s.charAt(i);
- boolean nextUpperCase = (i < (s.length() - 1)) && Character.isUpperCase(s.charAt(i + 1));
- boolean upperCase = (i > 0) && Character.isUpperCase(c);
- sb.append((!upperCase || !nextUpperCase) ? split : "").append(Character.toLowerCase(c));
- }
-
- return sb.toString();
- }
-
- public static String toUnderScoreCase(String s) {
- return toUnderScoreCase(s, SEPARATOR);
- }
-
- /**
- * 把字符串转换为JS获取对象值的三目运算表达式
- *
- * @param objectString 对象串
- * 例如:入参:row.user.id/返回:!row?'':!row.user?'':!row.user.id?'':row.user.id
- */
- public static String toJsGetValueExpression(String objectString) {
- StringBuilder result = new StringBuilder();
- StringBuilder val = new StringBuilder();
- String[] fileds = split(objectString, ".");
- for (int i = 0; i < fileds.length; i++) {
- val.append("." + fileds[i]);
- result.append("!" + (val.substring(1)) + "?'':");
- }
- result.append(val.substring(1));
- return result.toString();
- }
+ s = s.toLowerCase(locale);
+ StringBuilder sb = new StringBuilder();
+ for (char c : s.toCharArray()) {
+ sb.append(c == split ? Character.toUpperCase(c) : c);
}
-## 参考文章
-https://blog.csdn.net/qq_34490018/article/details/82110578
-https://www.runoob.com/java/java-string.html
-https://www.cnblogs.com/zhangyinhua/p/7689974.html
-https://blog.csdn.net/sinat_21925975/article/details/86493248
-https://www.cnblogs.com/niew/p/9597379.html
+ return sb.toString();
+}
-## 微信公众号
+public static String toCamelCase(String s) {
+ return toCamelCase(s, Locale.getDefault(), SEPARATOR);
+}
-### Java技术江湖
+public static String toCamelCase(String s, Locale locale) {
+ return toCamelCase(s, locale, SEPARATOR);
+}
-如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号【Java技术江湖】一位阿里 Java 工程师的技术小站,作者黄小斜,专注 Java 相关技术:SSM、SpringBoot、MySQL、分布式、中间件、集群、Linux、网络、多线程,偶尔讲点Docker、ELK,同时也分享技术干货和学习经验,致力于Java全栈开发!
+public static String toCamelCase(String s, char split) {
+ return toCamelCase(s, Locale.getDefault(), split);
+}
-**Java工程师必备学习资源:** 一些Java工程师常用学习资源,关注公众号后,后台回复关键字 **“Java”** 即可免费无套路获取。
+public static String toUnderScoreCase(String s, char split) {
+ if (isBlank(s)) {
+ return "";
+ }
-
+ StringBuilder sb = new StringBuilder();
+ for (int i = 0; i < s.length(); i++) {
+ char c = s.charAt(i);
+ boolean nextUpperCase = (i < (s.length() - 1)) && Character.isUpperCase(s.charAt(i + 1));
+ boolean upperCase = (i > 0) && Character.isUpperCase(c);
+ sb.append((!upperCase || !nextUpperCase) ? split : "").append(Character.toLowerCase(c));
+ }
-### 个人公众号:黄小斜
+ return sb.toString();
+}
-作者是 985 硕士,蚂蚁金服 JAVA 工程师,专注于 JAVA 后端技术栈:SpringBoot、MySQL、分布式、中间件、微服务,同时也懂点投资理财,偶尔讲点算法和计算机理论基础,坚持学习和写作,相信终身学习的力量!
+public static String toUnderScoreCase(String s) {
+ return toUnderScoreCase(s, SEPARATOR);
+}
-**程序员3T技术学习资源:** 一些程序员学习技术的资源大礼包,关注公众号后,后台回复关键字 **“资料”** 即可免费无套路获取。
+/**
+ * 把字符串转换为JS获取对象值的三目运算表达式
+ *
+ * @param objectString 对象串
+ * 例如:入参:row.user.id/返回:!row?'':!row.user?'':!row.user.id?'':row.user.id
+ */
+public static String toJsGetValueExpression(String objectString) {
+ StringBuilder result = new StringBuilder();
+ StringBuilder val = new StringBuilder();
+ String[] fileds = split(objectString, ".");
+ for (int i = 0; i < fileds.length; i++) {
+ val.append("." + fileds[i]);
+ result.append("!" + (val.substring(1)) + "?'':");
+ }
+ result.append(val.substring(1));
+ return result.toString();
+}
+
+
+}
+````
+
+## 参考文章
+https://blog.csdn.net/qq_34490018/article/details/82110578
+https://www.runoob.com/java/java-string.html
+https://www.cnblogs.com/zhangyinhua/p/7689974.html
+https://blog.csdn.net/sinat_21925975/article/details/86493248
+https://www.cnblogs.com/niew/p/9597379.html
-
diff --git "a/docs/java/basic/7\343\200\201\344\273\243\347\240\201\345\235\227\345\222\214\344\273\243\347\240\201\346\211\247\350\241\214\351\241\272\345\272\217.md" "b/docs/Java/basic/\344\273\243\347\240\201\345\235\227\345\222\214\344\273\243\347\240\201\346\211\247\350\241\214\351\241\272\345\272\217.md"
similarity index 89%
rename from "docs/java/basic/7\343\200\201\344\273\243\347\240\201\345\235\227\345\222\214\344\273\243\347\240\201\346\211\247\350\241\214\351\241\272\345\272\217.md"
rename to "docs/Java/basic/\344\273\243\347\240\201\345\235\227\345\222\214\344\273\243\347\240\201\346\211\247\350\241\214\351\241\272\345\272\217.md"
index 09dc5b5..7ebb784 100644
--- "a/docs/java/basic/7\343\200\201\344\273\243\347\240\201\345\235\227\345\222\214\344\273\243\347\240\201\346\211\247\350\241\214\351\241\272\345\272\217.md"
+++ "b/docs/Java/basic/\344\273\243\347\240\201\345\235\227\345\222\214\344\273\243\347\240\201\346\211\247\350\241\214\351\241\272\345\272\217.md"
@@ -17,9 +17,7 @@
* [静态代码块](#静态代码块)
* [Java代码块、构造方法(包含继承关系)的执行顺序](#java代码块、构造方法(包含继承关系)的执行顺序)
* [参考文章](#参考文章)
- * [微信公众号](#微信公众号)
- * [Java技术江湖](#java技术江湖)
- * [个人公众号:黄小斜](#个人公众号:黄小斜)
+
本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
> https://github.com/h2pl/Java-Tutorial
@@ -40,20 +38,20 @@
## Java中的构造方法
### 构造方法简介
-构造方法是类的一种特殊方法,用来初始化类的一个新的对象。[Java](http://c.biancheng.net/java/) 中的每个类都有一个默认的构造方法,它必须具有和类名相同的名称,而且没有返回类型。构造方法的默认返回类型就是对象类型本身,并且构造方法不能被 static、final、synchronized、abstract 和 native 修饰。
+构造方法是类的一种特殊方法,用来初始化类的一个新的对象。[Java](http://c.biancheng.net/java/)中的每个类都有一个默认的构造方法,它必须具有和类名相同的名称,而且没有返回类型。构造方法的默认返回类型就是对象类型本身,并且构造方法不能被 static、final、synchronized、abstract 和 native 修饰。
提示:构造方法用于初始化一个新对象,所以用 static 修饰没有意义;构造方法不能被子类继承,所以用 final 和 abstract 修饰没有意义;多个线程不会同时创建内存地址相同的同一个对象,所以用 synchronized 修饰没有必要。
构造方法的语法格式如下:
-
-class class_name
+````
+class class_name
{
public class_name(){} //默认无参构造方法
public ciass_name([paramList]){} //定义构造方法
…
//类主体
-}
-
+}
+````
在一个类中,与类名相同的方法就是构造方法。每个类可以具有多个构造方法,但要求它们各自包含不同的方法参数。
### 构造方法实例
@@ -61,8 +59,8 @@
#### 例 1
构造方法主要有无参构造方法和有参构造方法两种,示例如下:
-
-public class MyClass
+````
+public class MyClass
{
private int m; //定义私有变量
MyClass()
@@ -75,8 +73,8 @@
//定义有参的构造方法
this.m=m;
}
-}
-
+}
+````
该示例定义了两个构造方法,分别是无参构造方法和有参构造方法。在一个类中定义多个具有不同参数的同名方法,这就是方法的重载。这两个构造方法的名称都与类名相同,均为 MyClass。在实例化该类时可以调用不同的构造方法进行初始化。
注意:类的构造方法不是要求必须定义的。如果在类中没有定义任何一个构造方法,则 Java 会自动为该类生成一个默认的构造方法。默认的构造方法不包含任何参数,并且方法体为空。如果类中显式地定义了一个或多个构造方法,则 Java 不再提供默认构造方法。
@@ -86,8 +84,8 @@
要在不同的条件下使用不同的初始化行为创建类的对象,这时候就需要在一个类中创建多个构造方法。下面通过一个示例来演示构造方法的使用。
(1) 首先在员工类 Worker 中定义两个构造方法,代码如下:
-
-public class Worker
+````
+public class Worker
{
public String name; //姓名
private int age; //年龄
@@ -106,15 +104,15 @@
{
return"大家好!我是新来的员工,我叫"+name+",今年"+age+"岁。";
}
-}
-
+}
+````
在 Worker 类中定义了两个属性,其中 name 属性不可改变。分别定义了带有一个参数和带有两个参数的构造方法,并对其属性进行初始化。最后定义了该类的 toString() 方法,返回一条新进员工的介绍语句。
提示:Object 类具有一个 toString() 方法,该方法是个特殊的方法,创建的每个类都会继承该方法,它返回一个 String 类型的字符串。如果一个类中定义了该方法,则在调用该类对象时,将会自动调用该类对象的 toString() 方法返回一个字符串,然后使用“System.out.println(对象名)”就可以将返回的字符串内容打印出来。
(2) 在 TestWorker 类中创建 main() 方法作为程序的入口处,在 main() 方法中调用不同的构造方法实例化 Worker 对象,并对该对象中的属性进行初始化,代码如下:
-
-public class TestWorker
+````
+public class TestWorker
{
public static void main(String[] args)
{
@@ -127,16 +125,16 @@
Worker worker2=new Worker("李丽",25);
System.out.println(worker2);
}
-}
-
+}
+````
在上述代码中,创建了两个不同的 Worker 对象:一个是姓名为张强的员工对象,一个是姓名为李丽、年龄为 25 的员工对象。对于第一个 Worker 对象 Worker1,并未指定 age 属性值,因此程序会将其值采用默认值 0。对于第二个 Worker 对象 Worker2,分别对其指定了 name 属性值和 age 属性值,因此程序会将传递的参数值重新赋值给 Worker 类中的属性值。
运行 TestWorker 类,输出的结果如下:
------------带有一个参数的构造方法-----------
-大家好!我是新来的员工,我叫张强,今年0岁。
------------带有两个参数的构造方法------------
-大家好!我是新来的员工,我叫李丽,今年25岁。
+ -----------带有一个参数的构造方法-----------
+ 大家好!我是新来的员工,我叫张强,今年0岁。
+ -----------带有两个参数的构造方法------------
+ 大家好!我是新来的员工,我叫李丽,今年25岁。
通过调用带参数的构造方法,在创建对象时,一并完成了对象成员的初始化工作,简化了对象初始化的代码。
@@ -152,7 +150,7 @@
不能被static、final、abstract修饰(有final和static修饰的是不能被子类继承的,abstract修饰的是抽象类,抽象类是不能实例化的,也就是不能new)
可以被private修饰,可以在本类里面实例化,但是外部不能实例化对象(注意!!!)
-
+````
public class A{
int i=0;
public A(){
@@ -162,25 +160,26 @@
this.i=i;
}
}
-
+````
### 默认构造方法
如果没有任何的构造方法,编译时系统会自动添加一个默认无参构造方法
隐含的默认构造方法
-
+````
public A(){}
-
+````
显示的默认构造方法
-
+````
public A(){
System.out.print("显示的默认构造方法")
}
+````
### 重载构造方法
比如原本的类里的构造方法是一个参数的,现在新建的对象是有三个参数,此时就要重载构造方法
当一个类中有多个构造方法,有可能会出现重复性操作,这时可以用this语句调用其他的构造方法。
-
+````
public class A{
private int age;
private String name;
@@ -209,6 +208,7 @@
System.out.println(name);
System.out.println(name1);
System.out.println(age);
+````
### java子类构造方法调用父类构造方法
@@ -265,9 +265,9 @@
> 调用:调用其所在的方法时执行
-
-
- public class 局部代码块 {
+
+````
+public class 局部代码块 {
@Test
public void test (){
B b = new B();
@@ -294,7 +294,7 @@
System.out.println("hello");
}
}
-
+````
### 构造代码块
>位置:类成员的位置,就是类中方法之外的位置
@@ -302,7 +302,7 @@
>作用:把多个构造方法共同的部分提取出来,共用构造代码块
>调用:每次调用构造方法时,都会优先于构造方法执行,也就是每次new一个对象时自动调用,对 对象的初始化
-
+````
class A{
int i = 1;
int initValue;//成员变量的初始化交给代码块来完成
@@ -340,7 +340,7 @@
A a = new A();
}
}
-
+````
### 静态代码块
位置:类成员位置,用static修饰的代码块
@@ -348,7 +348,8 @@
作用:对类进行一些初始化 只加载一次,当new多个对象时,只有第一次会调用静态代码块,因为,静态代码块 是属于类的,所有对象共享一份
调用: new 一个对象时自动调用
-
+
+ ````
public class 静态代码块 {
@Test
@@ -376,7 +377,7 @@
System.out.println("静态代码块调用");
}
}
-
+````
## Java代码块、构造方法(包含继承关系)的执行顺序
这是一道常见的面试题,要回答这个问题,先看看这个实例吧。
@@ -385,7 +386,7 @@
其中A是B的父类,C无继承仅作为输出
A类:
-
+````
public class A {
static {
@@ -408,8 +409,9 @@ A类:
}
}
+````
B类:
-
+````
public class B extends A {
private static C c1 = new C("B静态成员");
@@ -434,14 +436,16 @@ B类:
}
}
+````
C类:
-
+````
public class C {
public C(String str) {
Log.i("HIDETAG", str + "构造方法");
}
}
+````
执行语句:new B();
输出结果如下:
@@ -473,7 +477,7 @@ C类:
**看完上面这个demo,再来看看下面这道题,看看你搞得定吗?**
看下面一段代码,求执行顺序:
-
+````
class A {
public A() {
System.out.println("1A类的构造方法");
@@ -485,7 +489,7 @@ C类:
System.out.println("3A类的静态块");
}
}
-
+
public class B extends A {
public B() {
System.out.println("4B类的构造方法");
@@ -503,6 +507,7 @@ C类:
System.out.println("8");
}
}
+````
执行顺序结果为:367215421548
@@ -535,20 +540,3 @@ http://c.biancheng.net/view/976.html
https://blog.csdn.net/evilcry2012/article/details/79499786
https://www.jb51.net/article/129990.htm
-## 微信公众号
-
-### Java技术江湖
-
-如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号【Java技术江湖】一位阿里 Java 工程师的技术小站,作者黄小斜,专注 Java 相关技术:SSM、SpringBoot、MySQL、分布式、中间件、集群、Linux、网络、多线程,偶尔讲点Docker、ELK,同时也分享技术干货和学习经验,致力于Java全栈开发!
-
-**Java工程师必备学习资源:** 一些Java工程师常用学习资源,关注公众号后,后台回复关键字 **“Java”** 即可免费无套路获取。
-
-
-
-### 个人公众号:黄小斜
-
-作者是 985 硕士,蚂蚁金服 JAVA 工程师,专注于 JAVA 后端技术栈:SpringBoot、MySQL、分布式、中间件、微服务,同时也懂点投资理财,偶尔讲点算法和计算机理论基础,坚持学习和写作,相信终身学习的力量!
-
-**程序员3T技术学习资源:** 一些程序员学习技术的资源大礼包,关注公众号后,后台回复关键字 **“资料”** 即可免费无套路获取。
-
-
diff --git "a/docs/java/basic/12\343\200\201\345\217\215\345\260\204.md" "b/docs/Java/basic/\345\217\215\345\260\204.md"
similarity index 51%
rename from "docs/java/basic/12\343\200\201\345\217\215\345\260\204.md"
rename to "docs/Java/basic/\345\217\215\345\260\204.md"
index 0513f67..14629eb 100644
--- "a/docs/java/basic/12\343\200\201\345\217\215\345\260\204.md"
+++ "b/docs/Java/basic/\345\217\215\345\260\204.md"
@@ -22,18 +22,6 @@
* [Java反射机制的作用](#java反射机制的作用)
* [如何使用Java的反射?](#如何使用java的反射)
* [参考文章](#参考文章)
- * [微信公众号](#微信公众号)
- * [Java技术江湖](#java技术江湖)
- * [个人公众号:黄小斜](#个人公众号:黄小斜)
----
-title: 夯实Java基础系列12:深入理解Java中的反射机制
-date: 2019-9-12 15:56:26 # 文章生成时间,一般不改
-categories:
- - Java技术江湖
- - Java基础
-tags:
- - Java反射
----
本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
@@ -61,11 +49,11 @@ Oracle官方对反射的解释是
> The API accommodates applications that need access to either the public members of a target object (based on its runtime class) or the members declared by a given class. It also allows programs to suppress default reflective access control.
>
-> 简而言之,通过反射,我们可以在运行时获得程序或程序集中每一个类型的成员和成员的信息。
+> 简而言之,通过反射,我们可以在运行时获得程序或程序集中每一个类型的成员和成员的信息。
>
> 程序中一般的对象的类型都是在编译期就确定下来的,而Java反射机制可以动态地创建对象并调用其属性,这样的对象的类型在编译期是未知的。所以我们可以通过反射机制直接创建对象,即使这个对象的类型在编译期是未知的。
>
-> 反射的核心是JVM在运行时才动态加载类或调用方法/访问属性,它不需要事先(写代码的时候或编译期)知道运行对象是谁。
+> 反射的核心是JVM在运行时才动态加载类或调用方法/访问属性,它不需要事先(写代码的时候或编译期)知道运行对象是谁。
Java反射框架主要提供以下功能:
@@ -82,27 +70,15 @@ Java反射框架主要提供以下功能:
## 反射的主要用途
-> 很多人都认为反射在实际的Java开发应用中并不广泛,其实不然。
+> 很多人都认为反射在实际的Java开发应用中并不广泛,其实不然。
-> 当我们在使用IDE(如Eclipse,IDEA)时,当我们输入一个对象或类并想调用它的属性或方法时,一按点号,编译器就会自动列出它的属性或方法,这里就会用到反射。
+> 当我们在使用IDE(如Eclipse,IDEA)时,当我们输入一个对象或类并想调用它的属性或方法时,一按点号,编译器就会自动列出它的属性或方法,这里就会用到反射。
-> 反射最重要的用途就是开发各种通用框架。
+> 反射最重要的用途就是开发各种通用框架。
-> 很多框架(比如Spring)都是配置化的(比如通过XML文件配置JavaBean,Action之类的),为了保证框架的通用性,它们可能需要根据配置文件加载不同的对象或类,调用不同的方法,这个时候就必须用到反射——运行时动态加载需要加载的对象。
+> 很多框架(比如Spring)都是配置化的(比如通过XML文件配置JavaBean,Action之类的),为了保证框架的通用性,它们可能需要根据配置文件加载不同的对象或类,调用不同的方法,这个时候就必须用到反射——运行时动态加载需要加载的对象。
-> 举一个例子,在运用Struts 2框架的开发中我们一般会在struts.xml里去配置Action,比如:
-
-
- /shop/shop-index.jsp
- login.jsp
-
-配置文件与Action建立了一种映射关系,当View层发出请求时,请求会被StrutsPrepareAndExecuteFilter拦截,然后StrutsPrepareAndExecuteFilter会去动态地创建Action实例。
-
-——比如我们请求login.action,那么StrutsPrepareAndExecuteFilter就会去解析struts.xml文件,检索action中name为login的Action,并根据class属性创建SimpleLoginAction实例,并用invoke方法来调用execute方法,这个过程离不开反射。
-
-> 对与框架开发人员来说,反射虽小但作用非常大,它是各种容器实现的核心。而对于一般的开发者来说,不深入框架开发则用反射用的就会少一点,不过了解一下框架的底层机制有助于丰富自己的编程思想,也是很有益的。
+> 对于框架开发人员来说,反射虽小但作用非常大,它是各种容器实现的核心。而对于一般的开发者来说,不深入框架开发则用反射用的就会少一点,不过了解一下框架的底层机制有助于丰富自己的编程思想,也是很有益的。
## 反射的基础:关于Class类
@@ -117,25 +93,26 @@ Java反射框架主要提供以下功能:
> 4、Class 对象只能由系统建立对象
>
> 5、一个类在 JVM 中只会有一个Class实例
-
- //总结一下就是,JDK有一个类叫做Class,这个类用来封装所有Java类型,包括这些类的所有信息,JVM中类信息是放在方法区的。
-
- //所有类在加载后,JVM会为其在堆中创建一个Class<类名称>的对象,并且每个类只会有一个Class对象,这个类的所有对象都要通过Class<类名称>来进行实例化。
-
- //上面说的是JVM进行实例化的原理,当然实际上在Java写代码时只需要用 类名称就可以进行实例化了。
-
- public final class Class implements java.io.Serializable,
- GenericDeclaration,
- Type,
- AnnotatedElement {
- 虚拟机会保持唯一一
- //通过类名.class获得唯一的Class对象。
- Class cls = UserBean.class;
- //通过integer.TYPEl来获取Class对象
- Class inti = Integer.TYPE;
- //接口本质也是一个类,一样可以通过.class获取
- Class userClass = User.class;
-
+>
+````
+//总结一下就是,JDK有一个类叫做Class,这个类用来封装所有Java类型,包括这些类的所有信息,JVM中类信息是放在方法区的。
+
+//所有类在加载后,JVM会为其在堆中创建一个Class<类名称>的对象,并且每个类只会有一个Class对象,这个类的所有对象都要通过Class<类名称>来进行实例化。
+
+//上面说的是JVM进行实例化的原理,当然实际上在Java写代码时只需要用 类名称就可以进行实例化了。
+
+public final class Class implements java.io.Serializable,
+ GenericDeclaration,
+ Type,
+ AnnotatedElement {
+ //通过类名.class获得唯一的Class对象。
+ Class cls = UserBean.class;
+ //通过integer.TYPEl来获取Class对象
+ Class inti = Integer.TYPE;
+ //接口本质也是一个类,一样可以通过.class获取
+ Class userClass = User.class;
+}
+````
JAVA反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为java语言的反射机制。
要想解剖一个类,必须先要获取到该类的字节码文件对象。而解剖使用的就是Class类中的方法.所以先要获取到每一个字节码文件对应的Class类型的对象.
@@ -146,8 +123,7 @@ JAVA反射机制是在运行状态中,对于任意一个类,都能够知道
如图是类的正常加载过程:反射的原理在与class对象。
熟悉一下加载的时候:Class对象的由来是将class文件读入内存,并为之创建一个Class对象。
-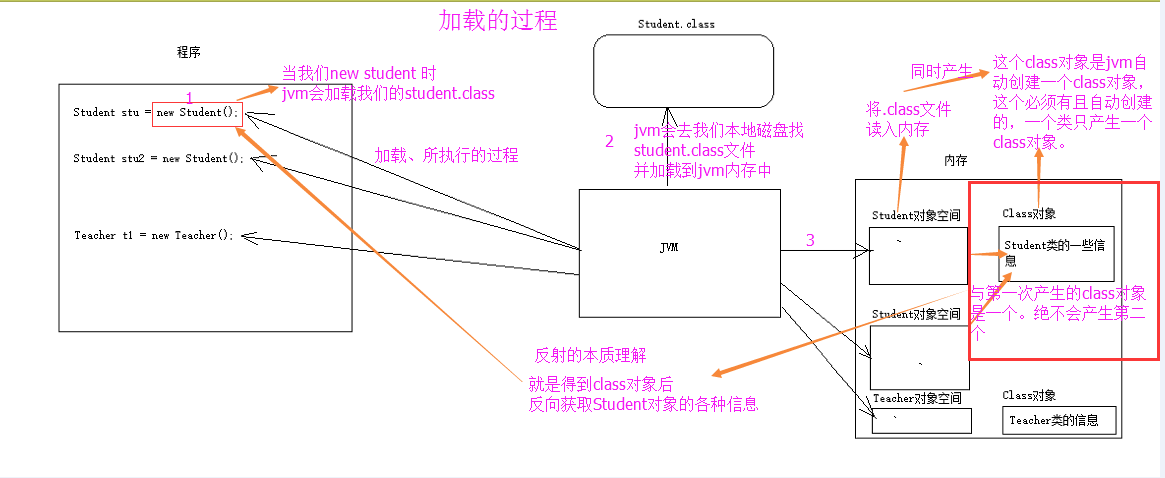
-
+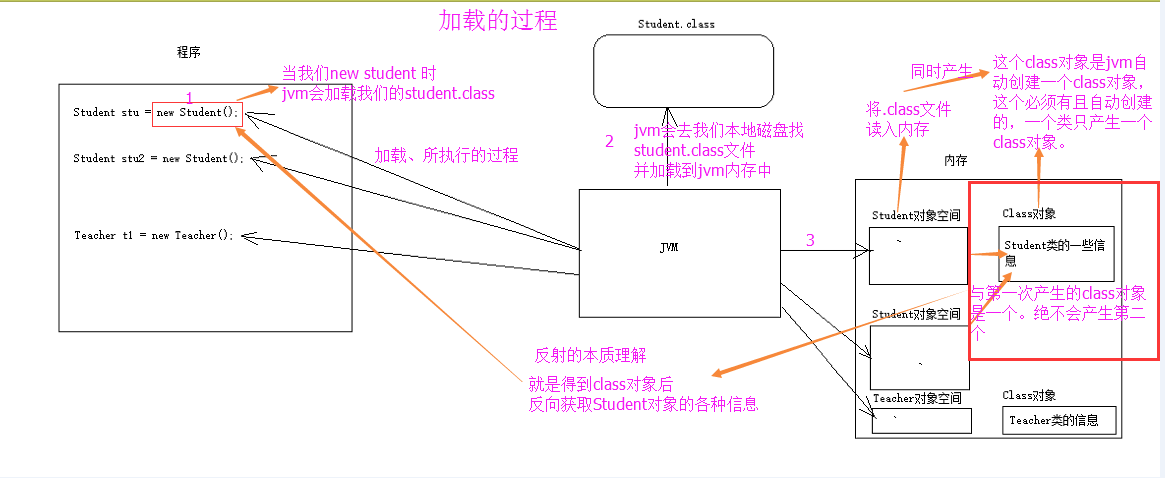
## Java为什么需要反射?反射要解决什么问题?
Java中编译类型有两种:
@@ -176,29 +152,31 @@ Array类:提供了动态创建数组,以及访问数组的元素的静态方
1、获得Class对象方法有三种
(1)使用Class类的forName静态方法:
-
- public static Class forName(String className)
- ```
- 在JDBC开发中常用此方法加载数据库驱动:
- 要使用全类名来加载这个类,一般数据库驱动的配置信息会写在配置文件中。加载这个驱动前要先导入jar包
- ```java
- Class.forName(driver);
+````
+public static Class forName(String className)
+````
+在JDBC开发中常用此方法加载数据库驱动:
+要使用全类名来加载这个类,一般数据库驱动的配置信息会写在配置文件中。加载这个驱动前要先导入jar包
+````
+Class.forName(driver);
+````
(2)直接获取某一个对象的class,比如:
-
- //Class是一个泛型表示,用于获取一个类的类型。
- Class klass = int.class;
- Class classInt = Integer.TYPE;
+````
+//Class是一个泛型表示,用于获取一个类的类型。
+Class klass = int.class;
+Class classInt = Integer.TYPE;
+````
(3)调用某个对象的getClass()方法,比如:
-
- StringBuilder str = new StringBuilder("123");
- Class klass = str.getClass();
-
+````
+StringBuilder str = new StringBuilder("123");
+Class klass = str.getClass();
+````
## 判断是否为某个类的实例
一般地,我们用instanceof关键字来判断是否为某个类的实例。同时我们也可以借助反射中Class对象的isInstance()方法来判断是否为某个类的实例,它是一个Native方法:
-
-==public native boolean isInstance(Object obj);==
-
+````
+public native boolean isInstance(Object obj);
+````
## 创建实例
通过反射来生成对象主要有两种方式。
@@ -206,20 +184,20 @@ Array类:提供了动态创建数组,以及访问数组的元素的静态方
(1)使用Class对象的newInstance()方法来创建Class对象对应类的实例。
注意:利用newInstance创建对象:调用的类必须有无参的构造器
-
- //Class代表任何类的一个类对象。
- //使用这个类对象可以为其他类进行实例化
- //因为jvm加载类以后自动在堆区生成一个对应的*.Class对象
- //该对象用于让JVM对进行所有*对象实例化。
- Class c = String.class;
-
- //Class 中的 ? 是通配符,其实就是表示任意符合泛类定义条件的类,和直接使用 Class
- //效果基本一致,但是这样写更加规范,在某些类型转换时可以避免不必要的 unchecked 错误。
-
- Object str = c.newInstance();
-
+````
+//Class代表任何类的一个类对象。
+//使用这个类对象可以为其他类进行实例化
+//因为jvm加载类以后自动在堆区生成一个对应的*.Class对象
+//该对象用于让JVM对进行所有*对象实例化。
+Class c = String.class;
+
+//Class 中的 ? 是通配符,其实就是表示任意符合泛类定义条件的类,和直接使用 Class
+//效果基本一致,但是这样写更加规范,在某些类型转换时可以避免不必要的 unchecked 错误。
+
+Object str = c.newInstance();
+````
(2)先通过Class对象获取指定的Constructor对象,再调用Constructor对象的newInstance()方法来创建实例。这种方法可以用指定的构造器构造类的实例。
-
+````
//获取String所对应的Class对象
Class c = String.class;
//获取String类带一个String参数的构造器
@@ -227,33 +205,35 @@ Array类:提供了动态创建数组,以及访问数组的元素的静态方
//根据构造器创建实例
Object obj = constructor.newInstance("23333");
System.out.println(obj);
-
+````
## 获取方法
获取某个Class对象的方法集合,主要有以下几个方法:
getDeclaredMethods()方法返回类或接口声明的所有方法,==包括公共、保护、默认(包)访问和私有方法,但不包括继承的方法==。
-
- public Method[] getDeclaredMethods() throws SecurityException
-
+````
+public Method[] getDeclaredMethods() throws SecurityException
+````
getMethods()方法返回某个类的所有公用(public)方法,==包括其继承类的公用方法。==
-
- public Method[] getMethods() throws SecurityException
+````
+public Method[] getMethods() throws SecurityException
+````
getMethod方法返回一个特定的方法,其中第一个参数为方法名称,后面的参数为方法的参数对应Class的对象
-
-
- public Method getMethod(String name, Class... parameterTypes)
+````
+public Method getMethod(String name, Class... parameterTypes)
+````
只是这样描述的话可能难以理解,我们用例子来理解这三个方法:
本文中的例子用到了以下这些类,用于反射的测试。
+````
//注解类,可可用于表示方法,可以通过反射获取注解的内容。
//Java注解的实现是很多注框架实现注解配置的基础
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface Invoke {
}
-
+````
userbean的父类personbean
-
+````
public class PersonBean {
private String name;
@@ -266,20 +246,17 @@ userbean的父类personbean
public void setName(String name) {
this.name = name;
}
-
-
-
}
-
+````
接口user
-
+````
public interface User {
public void login ();
}
-
+````
userBean实现user接口,继承personbean
-
+````
public class UserBean extends PersonBean implements User{
@Override
public void login() {
@@ -318,100 +295,100 @@ userBean实现user接口,继承personbean
System.out.println("I'm a private method");
}
}
-
+````
1 getMethods和getDeclaredMethods的区别
-
- public class 动态加载类的反射 {
- public static void main(String[] args) {
- try {
- Class clazz = Class.forName("com.javase.反射.UserBean");
- for (Field field : clazz.getDeclaredFields()) {
- // field.setAccessible(true);
- System.out.println(field);
- }
- //getDeclaredMethod*()获取的是类自身声明的所有方法,包含public、protected和private方法。
- System.out.println("------共有方法------");
- // getDeclaredMethod*()获取的是类自身声明的所有方法,包含public、protected和private方法。
- // getMethod*()获取的是类的所有共有方法,这就包括自身的所有public方法,和从基类继承的、从接口实现的所有public方法。
- for (Method method : clazz.getMethods()) {
- String name = method.getName();
- System.out.println(name);
- //打印出了UserBean.java的所有方法以及父类的方法
- }
- System.out.println("------独占方法------");
-
- for (Method method : clazz.getDeclaredMethods()) {
- String name = method.getName();
- System.out.println(name);
- }
- } catch (ClassNotFoundException e) {
- e.printStackTrace();
+````
+public class 动态加载类的反射 {
+ public static void main(String[] args) {
+ try {
+ Class clazz = Class.forName("com.javase.反射.UserBean");
+ for (Field field : clazz.getDeclaredFields()) {
+// field.setAccessible(true);
+ System.out.println(field);
}
+ //getDeclaredMethod*()获取的是类自身声明的所有方法,包含public、protected和private方法。
+ System.out.println("------共有方法------");
+// getDeclaredMethod*()获取的是类自身声明的所有方法,包含public、protected和private方法。
+// getMethod*()获取的是类的所有共有方法,这就包括自身的所有public方法,和从基类继承的、从接口实现的所有public方法。
+ for (Method method : clazz.getMethods()) {
+ String name = method.getName();
+ System.out.println(name);
+ //打印出了UserBean.java的所有方法以及父类的方法
+ }
+ System.out.println("------独占方法------");
+
+ for (Method method : clazz.getDeclaredMethods()) {
+ String name = method.getName();
+ System.out.println(name);
+ }
+ } catch (ClassNotFoundException e) {
+ e.printStackTrace();
}
}
+}
-
+````
2 打印一个类的所有方法及详细信息:
-
- public class 打印所有方法 {
-
- public static void main(String[] args) {
- Class userBeanClass = UserBean.class;
- Field[] fields = userBeanClass.getDeclaredFields();
- //注意,打印方法时无法得到局部变量的名称,因为jvm只知道它的类型
- Method[] methods = userBeanClass.getDeclaredMethods();
- for (Method method : methods) {
- //依次获得方法的修饰符,返回类型和名称,外加方法中的参数
- String methodString = Modifier.toString(method.getModifiers()) + " " ; // private static
- methodString += method.getReturnType().getSimpleName() + " "; // void
- methodString += method.getName() + "("; // staticMethod
- Class[] parameters = method.getParameterTypes();
- Parameter[] p = method.getParameters();
-
- for (Class parameter : parameters) {
- methodString += parameter.getSimpleName() + " " ; // String
- }
- methodString += ")";
- System.out.println(methodString);
+````
+public class 打印所有方法 {
+
+ public static void main(String[] args) {
+ Class userBeanClass = UserBean.class;
+ Field[] fields = userBeanClass.getDeclaredFields();
+ //注意,打印方法时无法得到局部变量的名称,因为jvm只知道它的类型
+ Method[] methods = userBeanClass.getDeclaredMethods();
+ for (Method method : methods) {
+ //依次获得方法的修饰符,返回类型和名称,外加方法中的参数
+ String methodString = Modifier.toString(method.getModifiers()) + " " ; // private static
+ methodString += method.getReturnType().getSimpleName() + " "; // void
+ methodString += method.getName() + "("; // staticMethod
+ Class[] parameters = method.getParameterTypes();
+ Parameter[] p = method.getParameters();
+
+ for (Class parameter : parameters) {
+ methodString += parameter.getSimpleName() + " " ; // String
}
- //注意方法只能获取到其类型,拿不到变量名
- /* public String getName()
- public long getId()
- public static void staticMethod(String int )
- public void publicMethod()
- private void privateMethod()*/
+ methodString += ")";
+ System.out.println(methodString);
}
+ //注意方法只能获取到其类型,拿不到变量名
+/* public String getName()
+ public long getId()
+ public static void staticMethod(String int )
+ public void publicMethod()
+ private void privateMethod()*/
}
-
+}
+````
## 获取构造器信息
获取类构造器的用法与上述获取方法的用法类似。主要是通过Class类的getConstructor方法得到Constructor类的一个实例,而Constructor类有一个newInstance方法可以创建一个对象实例:
-
- public class 打印构造方法 {
- public static void main(String[] args) {
- // constructors
- Class clazz = UserBean.class;
-
- Class userBeanClass = UserBean.class;
- //获得所有的构造方法
- Constructor[] constructors = userBeanClass.getDeclaredConstructors();
- for (Constructor constructor : constructors) {
- String s = Modifier.toString(constructor.getModifiers()) + " ";
- s += constructor.getName() + "(";
- //构造方法的参数类型
- Class[] parameters = constructor.getParameterTypes();
- for (Class parameter : parameters) {
- s += parameter.getSimpleName() + ", ";
- }
- s += ")";
- System.out.println(s);
- //打印结果//public com.javase.反射.UserBean(String, long, )
-
+````
+public class 打印构造方法 {
+ public static void main(String[] args) {
+ // constructors
+ Class clazz = UserBean.class;
+
+ Class userBeanClass = UserBean.class;
+ //获得所有的构造方法
+ Constructor[] constructors = userBeanClass.getDeclaredConstructors();
+ for (Constructor constructor : constructors) {
+ String s = Modifier.toString(constructor.getModifiers()) + " ";
+ s += constructor.getName() + "(";
+ //构造方法的参数类型
+ Class[] parameters = constructor.getParameterTypes();
+ for (Class parameter : parameters) {
+ s += parameter.getSimpleName() + ", ";
}
+ s += ")";
+ System.out.println(s);
+ //打印结果//public com.javase.反射.UserBean(String, long, )
+
}
}
-
+}
+````
## 获取类的成员变量(字段)信息
主要是这几个方法,在此不再赘述:
@@ -419,140 +396,138 @@ getFiled: 访问公有的成员变量
getDeclaredField:所有已声明的成员变量。但不能得到其父类的成员变量
getFileds和getDeclaredFields用法同上(参照Method)
- public class 打印成员变量 {
- public static void main(String[] args) {
- Class userBeanClass = UserBean.class;
- //获得该类的所有成员变量,包括static private
- Field[] fields = userBeanClass.getDeclaredFields();
-
- for(Field field : fields) {
- //private属性即使不用下面这个语句也可以访问
- // field.setAccessible(true);
-
- //因为类的私有域在反射中默认可访问,所以flag默认为true。
- String fieldString = "";
- fieldString += Modifier.toString(field.getModifiers()) + " "; // `private`
- fieldString += field.getType().getSimpleName() + " "; // `String`
- fieldString += field.getName(); // `userName`
- fieldString += ";";
- System.out.println(fieldString);
-
- //打印结果
- // public String userName;
- // protected int i;
- // static int j;
- // private int l;
- // private long userId;
- }
-
+````
+public class 打印成员变量 {
+ public static void main(String[] args) {
+ Class userBeanClass = UserBean.class;
+ //获得该类的所有成员变量,包括static private
+ Field[] fields = userBeanClass.getDeclaredFields();
+
+ for(Field field : fields) {
+ //private属性即使不用下面这个语句也可以访问
+// field.setAccessible(true);
+
+ //因为类的私有域在反射中默认可访问,所以flag默认为true。
+ String fieldString = "";
+ fieldString += Modifier.toString(field.getModifiers()) + " "; // `private`
+ fieldString += field.getType().getSimpleName() + " "; // `String`
+ fieldString += field.getName(); // `userName`
+ fieldString += ";";
+ System.out.println(fieldString);
+
+ //打印结果
+// public String userName;
+// protected int i;
+// static int j;
+// private int l;
+// private long userId;
}
- }
+ }
+}
+````
## 调用方法
当我们从类中获取了一个方法后,我们就可以用invoke()方法来调用这个方法。invoke方法的原型为:
-
- public Object invoke(Object obj, Object... args)
- throws IllegalAccessException, IllegalArgumentException,
- InvocationTargetException
-
- public class 使用反射调用方法 {
- public static void main(String[] args) throws InvocationTargetException, IllegalAccessException, InstantiationException, NoSuchMethodException {
- Class userBeanClass = UserBean.class;
- //获取该类所有的方法,包括静态方法,实例方法。
- //此处也包括了私有方法,只不过私有方法在用invoke访问之前要设置访问权限
- //也就是使用setAccessible使方法可访问,否则会抛出异常
- // // IllegalAccessException的解释是
- // * An IllegalAccessException is thrown when an application tries
- // * to reflectively create an instance (other than an array),
- // * set or get a field, or invoke a method, but the currently
- // * executing method does not have access to the definition of
- // * the specified class, field, method or constructor.
-
- // getDeclaredMethod*()获取的是类自身声明的所有方法,包含public、protected和private方法。
- // getMethod*()获取的是类的所有共有方法,这就包括自身的所有public方法,和从基类继承的、从接口实现的所有public方法。
-
- //就是说,当这个类,域或者方法被设为私有访问,使用反射调用但是却没有权限时会抛出异常。
- Method[] methods = userBeanClass.getDeclaredMethods(); // 获取所有成员方法
- for (Method method : methods) {
- //反射可以获取方法上的注解,通过注解来进行判断
- if (method.isAnnotationPresent(Invoke.class)) { // 判断是否被 @Invoke 修饰
- //判断方法的修饰符是是static
- if (Modifier.isStatic(method.getModifiers())) { // 如果是 static 方法
- //反射调用该方法
- //类方法可以直接调用,不必先实例化
- method.invoke(null, "wingjay",2); // 直接调用,并传入需要的参数 devName
- } else {
- //如果不是类方法,需要先获得一个实例再调用方法
- //传入构造方法需要的变量类型
- Class[] params = {String.class, long.class};
- //获取该类指定类型的构造方法
- //如果没有这种类型的方法会报错
- Constructor constructor = userBeanClass.getDeclaredConstructor(params); // 获取参数格式为 String,long 的构造函数
- //通过构造方法的实例来进行实例化
- Object userBean = constructor.newInstance("wingjay", 11); // 利用构造函数进行实例化,得到 Object
- if (Modifier.isPrivate(method.getModifiers())) {
- method.setAccessible(true); // 如果是 private 的方法,需要获取其调用权限
- // Set the {@code accessible} flag for this object to
- // * the indicated boolean value. A value of {@code true} indicates that
- // * the reflected object should suppress Java language access
- // * checking when it is used. A value of {@code false} indicates
- // * that the reflected object should enforce Java language access checks.
- //通过该方法可以设置其可见或者不可见,不仅可以用于方法
- //后面例子会介绍将其用于成员变量
- //打印结果
- // I'm a public method
- // Hi wingjay, I'm a static methodI'm a private method
- }
- method.invoke(userBean); // 调用 method,无须参数
-
-
-
-
+````
+public Object invoke(Object obj, Object... args)
+ throws IllegalAccessException, IllegalArgumentException,
+ InvocationTargetException
+
+public class 使用反射调用方法 {
+ public static void main(String[] args) throws InvocationTargetException, IllegalAccessException, InstantiationException, NoSuchMethodException {
+ Class userBeanClass = UserBean.class;
+ //获取该类所有的方法,包括静态方法,实例方法。
+ //此处也包括了私有方法,只不过私有方法在用invoke访问之前要设置访问权限
+ //也就是使用setAccessible使方法可访问,否则会抛出异常
+// // IllegalAccessException的解释是
+// * An IllegalAccessException is thrown when an application tries
+// * to reflectively create an instance (other than an array),
+// * set or get a field, or invoke a method, but the currently
+// * executing method does not have access to the definition of
+// * the specified class, field, method or constructor.
+
+// getDeclaredMethod*()获取的是类自身声明的所有方法,包含public、protected和private方法。
+// getMethod*()获取的是类的所有共有方法,这就包括自身的所有public方法,和从基类继承的、从接口实现的所有public方法。
+
+ //就是说,当这个类,域或者方法被设为私有访问,使用反射调用但是却没有权限时会抛出异常。
+ Method[] methods = userBeanClass.getDeclaredMethods(); // 获取所有成员方法
+ for (Method method : methods) {
+ //反射可以获取方法上的注解,通过注解来进行判断
+ if (method.isAnnotationPresent(Invoke.class)) { // 判断是否被 @Invoke 修饰
+ //判断方法的修饰符是是static
+ if (Modifier.isStatic(method.getModifiers())) { // 如果是 static 方法
+ //反射调用该方法
+ //类方法可以直接调用,不必先实例化
+ method.invoke(null, "wingjay",2); // 直接调用,并传入需要的参数 devName
+ } else {
+ //如果不是类方法,需要先获得一个实例再调用方法
+ //传入构造方法需要的变量类型
+ Class[] params = {String.class, long.class};
+ //获取该类指定类型的构造方法
+ //如果没有这种类型的方法会报错
+ Constructor constructor = userBeanClass.getDeclaredConstructor(params); // 获取参数格式为 String,long 的构造函数
+ //通过构造方法的实例来进行实例化
+ Object userBean = constructor.newInstance("wingjay", 11); // 利用构造函数进行实例化,得到 Object
+ if (Modifier.isPrivate(method.getModifiers())) {
+ method.setAccessible(true); // 如果是 private 的方法,需要获取其调用权限
+// Set the {@code accessible} flag for this object to
+// * the indicated boolean value. A value of {@code true} indicates that
+// * the reflected object should suppress Java language access
+// * checking when it is used. A value of {@code false} indicates
+// * that the reflected object should enforce Java language access checks.
+ //通过该方法可以设置其可见或者不可见,不仅可以用于方法
+ //后面例子会介绍将其用于成员变量
+ //打印结果
+// I'm a public method
+// Hi wingjay, I'm a static methodI'm a private method
}
+ method.invoke(userBean); // 调用 method,无须参数
}
}
}
}
-
+}
+````
## 利用反射创建数组
数组在Java里是比较特殊的一种类型,它可以赋值给一个Object Reference。下面我们看一看利用反射创建数组的例子:
-
- public class 用反射创建数组 {
- public static void main(String[] args) {
- Class cls = null;
- try {
- cls = Class.forName("java.lang.String");
- } catch (ClassNotFoundException e) {
- e.printStackTrace();
- }
- Object array = Array.newInstance(cls,25);
- //往数组里添加内容
- Array.set(array,0,"hello");
- Array.set(array,1,"Java");
- Array.set(array,2,"fuck");
- Array.set(array,3,"Scala");
- Array.set(array,4,"Clojure");
- //获取某一项的内容
- System.out.println(Array.get(array,3));
- //Scala
+````
+public class 用反射创建数组 {
+ public static void main(String[] args) {
+ Class cls = null;
+ try {
+ cls = Class.forName("java.lang.String");
+ } catch (ClassNotFoundException e) {
+ e.printStackTrace();
}
-
+ Object array = Array.newInstance(cls,25);
+ //往数组里添加内容
+ Array.set(array,0,"hello");
+ Array.set(array,1,"Java");
+ Array.set(array,2,"fuck");
+ Array.set(array,3,"Scala");
+ Array.set(array,4,"Clojure");
+ //获取某一项的内容
+ System.out.println(Array.get(array,3));
+ //Scala
}
+}
+````
其中的Array类为java.lang.reflect.Array类。我们通过Array.newInstance()创建数组对象,它的原型是:
-
- public static Object newInstance(Class componentType, int length)
- throws NegativeArraySizeException {
- return newArray(componentType, length);
+````
+public static Object newInstance(Class componentType, int length)
+ throws NegativeArraySizeException {
+ return newArray(componentType, length);
}
+````
而newArray()方法是一个Native方法,它在Hotspot JVM里的具体实现我们后边再研究,这里先把源码贴出来
+````
+private static native Object newArray(Class componentType, int length)
+ throws NegativeArraySizeException;
- private static native Object newArray(Class componentType, int length)
- throws NegativeArraySizeException;
-
-
-
+````
+
## Java反射常见面试题
@@ -637,20 +612,3 @@ https://blog.csdn.net/grandgrandpa/article/details/84832343
http://blog.csdn.net/lylwo317/article/details/52163304
https://blog.csdn.net/qq_37875585/article/details/89340495
-## 微信公众号
-
-### Java技术江湖
-
-如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号【Java技术江湖】一位阿里 Java 工程师的技术小站,作者黄小斜,专注 Java 相关技术:SSM、SpringBoot、MySQL、分布式、中间件、集群、Linux、网络、多线程,偶尔讲点Docker、ELK,同时也分享技术干货和学习经验,致力于Java全栈开发!
-
-**Java工程师必备学习资源:** 一些Java工程师常用学习资源,关注公众号后,后台回复关键字 **“Java”** 即可免费无套路获取。
-
-
-
-### 个人公众号:黄小斜
-
-作者是 985 硕士,蚂蚁金服 JAVA 工程师,专注于 JAVA 后端技术栈:SpringBoot、MySQL、分布式、中间件、微服务,同时也懂点投资理财,偶尔讲点算法和计算机理论基础,坚持学习和写作,相信终身学习的力量!
-
-**程序员3T技术学习资源:** 一些程序员学习技术的资源大礼包,关注公众号后,后台回复关键字 **“资料”** 即可免费无套路获取。
-
-
diff --git "a/docs/java/basic/17\343\200\201\345\244\232\347\272\277\347\250\213.md" "b/docs/Java/basic/\345\244\232\347\272\277\347\250\213.md"
similarity index 94%
rename from "docs/java/basic/17\343\200\201\345\244\232\347\272\277\347\250\213.md"
rename to "docs/Java/basic/\345\244\232\347\272\277\347\250\213.md"
index e2cc758..35e3ada 100644
--- "a/docs/java/basic/17\343\200\201\345\244\232\347\272\277\347\250\213.md"
+++ "b/docs/Java/basic/\345\244\232\347\272\277\347\250\213.md"
@@ -16,18 +16,7 @@
* [Java多线程优先级](#java多线程优先级)
* [Java多线程面试题](#java多线程面试题)
* [参考文章](#参考文章)
- * [微信公众号](#微信公众号)
- * [Java技术江湖](#java技术江湖)
- * [个人公众号:黄小斜](#个人公众号:黄小斜)
----
-title: 夯实Java基础系列17:一文搞懂Java多线程使用方式、实现原理以及常见面试题
-date: 2019-9-17 15:56:26 # 文章生成时间,一般不改
-categories:
- - Java技术江湖
- - Java基础
-tags:
- - 多线程
----
+
本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
> https://github.com/h2pl/Java-Tutorial
@@ -91,7 +80,7 @@ Java 给多线程编程提供了内置的支持。 一条线程指的是进程
* **新建状态:**
- 使用 **new** 关键字和 **Thread** 类或其子类建立一个线程对象后,该线程对象就处于新建状态。它保持这个状态直到程序 **start()** 这个线程。
+ 使用**new**关键字和**Thread**类或其子类建立一个线程对象后,该线程对象就处于新建状态。它保持这个状态直到程序**start()**这个线程。
* **就绪状态:**
@@ -99,7 +88,7 @@ Java 给多线程编程提供了内置的支持。 一条线程指的是进程
* **运行状态:**
- 如果就绪状态的线程获取 CPU 资源,就可以执行 **run()**,此时线程便处于运行状态。处于运行状态的线程最为复杂,它可以变为阻塞状态、就绪状态和死亡状态。
+ 如果就绪状态的线程获取 CPU 资源,就可以执行**run()**,此时线程便处于运行状态。处于运行状态的线程最为复杂,它可以变为阻塞状态、就绪状态和死亡状态。
* **阻塞状态:**
@@ -642,21 +631,4 @@ https://blog.csdn.net/qq_38038480/article/details/80584715
https://blog.csdn.net/tongxuexie/article/details/80145663
https://www.cnblogs.com/snow-flower/p/6114765.html
-## 微信公众号
-
-### Java技术江湖
-
-如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号【Java技术江湖】一位阿里 Java 工程师的技术小站,作者黄小斜,专注 Java 相关技术:SSM、SpringBoot、MySQL、分布式、中间件、集群、Linux、网络、多线程,偶尔讲点Docker、ELK,同时也分享技术干货和学习经验,致力于Java全栈开发!
-
-**Java工程师必备学习资源:** 一些Java工程师常用学习资源,关注公众号后,后台回复关键字 **“Java”** 即可免费无套路获取。
-
-
-
-### 个人公众号:黄小斜
-
-作者是 985 硕士,蚂蚁金服 JAVA 工程师,专注于 JAVA 后端技术栈:SpringBoot、MySQL、分布式、中间件、微服务,同时也懂点投资理财,偶尔讲点算法和计算机理论基础,坚持学习和写作,相信终身学习的力量!
-
-**程序员3T技术学习资源:** 一些程序员学习技术的资源大礼包,关注公众号后,后台回复关键字 **“资料”** 即可免费无套路获取。
-
-
diff --git "a/docs/java/basic/22\343\200\201\345\272\217\345\210\227\345\214\226\345\222\214\345\217\215\345\272\217\345\210\227\345\214\226.md" "b/docs/Java/basic/\345\272\217\345\210\227\345\214\226\345\222\214\345\217\215\345\272\217\345\210\227\345\214\226.md"
similarity index 57%
rename from "docs/java/basic/22\343\200\201\345\272\217\345\210\227\345\214\226\345\222\214\345\217\215\345\272\217\345\210\227\345\214\226.md"
rename to "docs/Java/basic/\345\272\217\345\210\227\345\214\226\345\222\214\345\217\215\345\272\217\345\210\227\345\214\226.md"
index 6de5ffb..c6d33a7 100644
--- "a/docs/java/basic/22\343\200\201\345\272\217\345\210\227\345\214\226\345\222\214\345\217\215\345\272\217\345\210\227\345\214\226.md"
+++ "b/docs/Java/basic/\345\272\217\345\210\227\345\214\226\345\222\214\345\217\215\345\272\217\345\210\227\345\214\226.md"
@@ -9,18 +9,7 @@
* [为什么要实现Serializable](#为什么要实现serializable)
* [序列化知识点总结](#序列化知识点总结)
* [参考文章](#参考文章)
- * [微信公众号](#微信公众号)
- * [Java技术江湖](#java技术江湖)
- * [个人公众号:黄小斜](#个人公众号:黄小斜)
----
-title: 夯实Java基础系列22:一文读懂Java序列化和反序列化
-date: 2019-9-22 15:56:26 # 文章生成时间,一般不改
-categories:
- - Java技术江湖
- - Java基础
-tags:
- - Java序列化
----
+
本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
> https://github.com/h2pl/Java-Tutorial
@@ -37,7 +26,6 @@ tags:
-
本文参考 http://www.importnew.com/17964.html和
https://www.ibm.com/developerworks/cn/java/j-lo-serial/
@@ -86,96 +74,93 @@ Java为了方便开发人员将Java对象进行序列化及反序列化提供了
如果要序列化的类有父类,要想同时将在父类中定义过的变量持久化下来,那么父类也应该集成java.io.Serializable接口。
下面是一个实现了java.io.Serializable接口的类
+````
+public class 序列化和反序列化 {
+ public static void main(String[] args) {
- public class 序列化和反序列化 {
-
-
-
- public static void main(String[] args) {
-
- }
- //注意,内部类不能进行序列化,因为它依赖于外部类
- @Test
- public void test() throws IOException {
- A a = new A();
- a.i = 1;
- a.s = "a";
- FileOutputStream fileOutputStream = null;
- FileInputStream fileInputStream = null;
- try {
- //将obj写入文件
- fileOutputStream = new FileOutputStream("temp");
- ObjectOutputStream objectOutputStream = new ObjectOutputStream(fileOutputStream);
- objectOutputStream.writeObject(a);
- fileOutputStream.close();
- //通过文件读取obj
- fileInputStream = new FileInputStream("temp");
- ObjectInputStream objectInputStream = new ObjectInputStream(fileInputStream);
- A a2 = (A) objectInputStream.readObject();
- fileInputStream.close();
- System.out.println(a2.i);
- System.out.println(a2.s);
- //打印结果和序列化之前相同
- } catch (IOException e) {
- e.printStackTrace();
- } catch (ClassNotFoundException e) {
- e.printStackTrace();
- }
- }
}
-
- class A implements Serializable {
-
- int i;
- String s;
+ //注意,内部类不能进行序列化,因为它依赖于外部类
+ @Test
+ public void test() throws IOException {
+ A a = new A();
+ a.i = 1;
+ a.s = "a";
+ FileOutputStream fileOutputStream = null;
+ FileInputStream fileInputStream = null;
+ try {
+ //将obj写入文件
+ fileOutputStream = new FileOutputStream("temp");
+ ObjectOutputStream objectOutputStream = new ObjectOutputStream(fileOutputStream);
+ objectOutputStream.writeObject(a);
+ fileOutputStream.close();
+ //通过文件读取obj
+ fileInputStream = new FileInputStream("temp");
+ ObjectInputStream objectInputStream = new ObjectInputStream(fileInputStream);
+ A a2 = (A) objectInputStream.readObject();
+ fileInputStream.close();
+ System.out.println(a2.i);
+ System.out.println(a2.s);
+ //打印结果和序列化之前相同
+ } catch (IOException e) {
+ e.printStackTrace();
+ } catch (ClassNotFoundException e) {
+ e.printStackTrace();
+ }
}
+}
+
+class A implements Serializable {
+ int i;
+ String s;
+}
+````
**Externalizable接口**
除了Serializable 之外,java中还提供了另一个序列化接口Externalizable
为了了解Externalizable接口和Serializable接口的区别,先来看代码,我们把上面的代码改成使用Externalizable的形式。
+````
+class B implements Externalizable {
+ //必须要有公开无参构造函数。否则报错
+ public B() {
- class B implements Externalizable {
- //必须要有公开无参构造函数。否则报错
- public B() {
-
- }
- int i;
- String s;
- @Override
- public void writeExternal(ObjectOutput out) throws IOException {
-
- }
-
- @Override
- public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException {
-
- }
}
-
- @Test
- public void test2() throws IOException, ClassNotFoundException {
- B b = new B();
- b.i = 1;
- b.s = "a";
- //将obj写入文件
- FileOutputStream fileOutputStream = new FileOutputStream("temp");
- ObjectOutputStream objectOutputStream = new ObjectOutputStream(fileOutputStream);
- objectOutputStream.writeObject(b);
- fileOutputStream.close();
- //通过文件读取obj
- FileInputStream fileInputStream = new FileInputStream("temp");
- ObjectInputStream objectInputStream = new ObjectInputStream(fileInputStream);
- B b2 = (B) objectInputStream.readObject();
- fileInputStream.close();
- System.out.println(b2.i);
- System.out.println(b2.s);
- //打印结果为0和null,即初始值,没有被赋值
- //0
- //null
- }
+ int i;
+ String s;
+ @Override
+ public void writeExternal(ObjectOutput out) throws IOException {
+
+ }
+
+ @Override
+ public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException {
+ }
+}
+
+@Test
+ public void test2() throws IOException, ClassNotFoundException {
+ B b = new B();
+ b.i = 1;
+ b.s = "a";
+ //将obj写入文件
+ FileOutputStream fileOutputStream = new FileOutputStream("temp");
+ ObjectOutputStream objectOutputStream = new ObjectOutputStream(fileOutputStream);
+ objectOutputStream.writeObject(b);
+ fileOutputStream.close();
+ //通过文件读取obj
+ FileInputStream fileInputStream = new FileInputStream("temp");
+ ObjectInputStream objectInputStream = new ObjectInputStream(fileInputStream);
+ B b2 = (B) objectInputStream.readObject();
+ fileInputStream.close();
+ System.out.println(b2.i);
+ System.out.println(b2.s);
+ //打印结果为0和null,即初始值,没有被赋值
+ //0
+ //null
+ }
+````
通过上面的实例可以发现,对B类进行序列化及反序列化之后得到的对象的所有属性的值都变成了默认值。也就是说,之前的那个对象的状态并没有被持久化下来。这就是Externalizable接口和Serializable接口的区别:
Externalizable继承了Serializable,该接口中定义了两个抽象方法:writeExternal()与readExternal()。
@@ -184,54 +169,56 @@ Externalizable继承了Serializable,该接口中定义了两个抽象方法:
> 还有一点值得注意:在使用Externalizable进行序列化的时候,在读取对象时,会调用被序列化类的无参构造器去创建一个新的对象,然后再将被保存对象的字段的值分别填充到新对象中。所以,实现Externalizable接口的类必须要提供一个public的无参的构造器。
- class C implements Externalizable {
- int i;
- int j;
- String s;
- public C() {
-
- }
- //实现下面两个方法可以选择序列化中需要被复制的成员。
- //并且,写入顺序和读取顺序要一致,否则报错。
- //可以写入多个同类型变量,顺序保持一致即可。
- @Override
- public void writeExternal(ObjectOutput out) throws IOException {
- out.writeInt(i);
- out.writeInt(j);
- out.writeObject(s);
- }
-
- @Override
- public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException {
- i = in.readInt();
- j = in.readInt();
- s = (String) in.readObject();
- }
+````
+class C implements Externalizable {
+ int i;
+ int j;
+ String s;
+ public C() {
+
+ }
+ //实现下面两个方法可以选择序列化中需要被复制的成员。
+ //并且,写入顺序和读取顺序要一致,否则报错。
+ //可以写入多个同类型变量,顺序保持一致即可。
+ @Override
+ public void writeExternal(ObjectOutput out) throws IOException {
+ out.writeInt(i);
+ out.writeInt(j);
+ out.writeObject(s);
}
-
- @Test
- public void test3() throws IOException, ClassNotFoundException {
- C c = new C();
- c.i = 1;
- c.j = 2;
- c.s = "a";
- //将obj写入文件
- FileOutputStream fileOutputStream = new FileOutputStream("temp");
- ObjectOutputStream objectOutputStream = new ObjectOutputStream(fileOutputStream);
- objectOutputStream.writeObject(c);
- fileOutputStream.close();
- //通过文件读取obj
- FileInputStream fileInputStream = new FileInputStream("temp");
- ObjectInputStream objectInputStream = new ObjectInputStream(fileInputStream);
- C c2 = (C) objectInputStream.readObject();
- fileInputStream.close();
- System.out.println(c2.i);
- System.out.println(c2.j);
- System.out.println(c2.s);
- //打印结果为0和null,即初始值,没有被赋值
- //0
- //null
- }
+
+ @Override
+ public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException {
+ i = in.readInt();
+ j = in.readInt();
+ s = (String) in.readObject();
+ }
+}
+
+@Test
+public void test3() throws IOException, ClassNotFoundException {
+ C c = new C();
+ c.i = 1;
+ c.j = 2;
+ c.s = "a";
+ //将obj写入文件
+ FileOutputStream fileOutputStream = new FileOutputStream("temp");
+ ObjectOutputStream objectOutputStream = new ObjectOutputStream(fileOutputStream);
+ objectOutputStream.writeObject(c);
+ fileOutputStream.close();
+ //通过文件读取obj
+ FileInputStream fileInputStream = new FileInputStream("temp");
+ ObjectInputStream objectInputStream = new ObjectInputStream(fileInputStream);
+ C c2 = (C) objectInputStream.readObject();
+ fileInputStream.close();
+ System.out.println(c2.i);
+ System.out.println(c2.j);
+ System.out.println(c2.s);
+ //打印结果为0和null,即初始值,没有被赋值
+ //0
+ //null
+}
+````
## 序列化ID
@@ -241,87 +228,89 @@ Externalizable继承了Serializable,该接口中定义了两个抽象方法:
问题:C 对象的全类路径假设为 com.inout.Test,在 A 和 B 端都有这么一个类文件,功能代码完全一致。也都实现了 Serializable 接口,但是反序列化时总是提示不成功。
解决:虚拟机是否允许反序列化,不仅取决于类路径和功能代码是否一致,一个非常重要的一点是两个类的序列化 ID 是否一致(就是 private static final long serialVersionUID = 1L)。清单 1 中,虽然两个类的功能代码完全一致,但是序列化 ID 不同,他们无法相互序列化和反序列化。
-
- package com.inout;
-
- import java.io.Serializable;
-
- public class A implements Serializable {
-
- private static final long serialVersionUID = 1L;
-
- private String name;
-
- public String getName()
- {
- return name;
- }
-
- public void setName(String name)
- {
- this.name = name;
- }
+````
+package com.inout;
+
+import java.io.Serializable;
+
+public class A implements Serializable {
+
+ private static final long serialVersionUID = 1L;
+
+ private String name;
+
+ public String getName()
+ {
+ return name;
}
-
- package com.inout;
-
- import java.io.Serializable;
-
- public class A implements Serializable {
-
- private static final long serialVersionUID = 2L;
-
- private String name;
-
- public String getName()
- {
- return name;
- }
-
- public void setName(String name)
- {
- this.name = name;
- }
- }
+
+ public void setName(String name)
+ {
+ this.name = name;
+ }
+}
+
+package com.inout;
+
+import java.io.Serializable;
+
+public class A implements Serializable {
+
+ private static final long serialVersionUID = 2L;
+
+ private String name;
+
+ public String getName()
+ {
+ return name;
+ }
+
+ public void setName(String name)
+ {
+ this.name = name;
+ }
+}
+````
### 静态变量不参与序列化
清单 2 中的 main 方法,将对象序列化后,修改静态变量的数值,再将序列化对象读取出来,然后通过读取出来的对象获得静态变量的数值并打印出来。依照清单 2,这个 System.out.println(t.staticVar) 语句输出的是 10 还是 5 呢?
-
- public class Test implements Serializable {
-
- private static final long serialVersionUID = 1L;
-
- public static int staticVar = 5;
-
- public static void main(String[] args) {
- try {
- //初始时staticVar为5
- ObjectOutputStream out = new ObjectOutputStream(
- new FileOutputStream("result.obj"));
- out.writeObject(new Test());
- out.close();
-
- //序列化后修改为10
- Test.staticVar = 10;
-
- ObjectInputStream oin = new ObjectInputStream(new FileInputStream(
- "result.obj"));
- Test t = (Test) oin.readObject();
- oin.close();
-
- //再读取,通过t.staticVar打印新的值
- System.out.println(t.staticVar);
-
- } catch (FileNotFoundException e) {
- e.printStackTrace();
- } catch (IOException e) {
- e.printStackTrace();
- } catch (ClassNotFoundException e) {
- e.printStackTrace();
- }
+````
+public class Test implements Serializable {
+
+ private static final long serialVersionUID = 1L;
+
+ public static int staticVar = 5;
+
+ public static void main(String[] args) {
+ try {
+ //初始时staticVar为5
+ ObjectOutputStream out = new ObjectOutputStream(
+ new FileOutputStream("result.obj"));
+ out.writeObject(new Test());
+ out.close();
+
+ //序列化后修改为10
+ Test.staticVar = 10;
+
+ ObjectInputStream oin = new ObjectInputStream(new FileInputStream(
+ "result.obj"));
+ Test t = (Test) oin.readObject();
+ oin.close();
+
+ //再读取,通过t.staticVar打印新的值
+ System.out.println(t.staticVar);
+
+ } catch (FileNotFoundException e) {
+ e.printStackTrace();
+ } catch (IOException e) {
+ e.printStackTrace();
+ } catch (ClassNotFoundException e) {
+ e.printStackTrace();
}
}
+}
+````
最后的输出是 10,对于无法理解的读者认为,打印的 staticVar 是从读取的对象里获得的,应该是保存时的状态才对。之所以打印 10 的原因在于序列化时,并不保存静态变量,这其实比较容易理解,序列化保存的是对象的状态,静态变量属于类的状态,因此 序列化并不保存静态变量。
@@ -334,6 +323,7 @@ ArrayList的序列化
带着这个问题,我们来看java.util.ArrayList的源码
+````
public class ArrayList extends AbstractList
implements List, RandomAccess, Cloneable, java.io.Serializable
{
@@ -341,26 +331,27 @@ ArrayList的序列化
transient Object[] elementData; // non-private to simplify nested class access
private int size;
}
+````
笔者省略了其他成员变量,从上面的代码中可以知道ArrayList实现了java.io.Serializable接口,那么我们就可以对它进行序列化及反序列化。
因为elementData是transient的(1.8好像改掉了这一点),所以我们认为这个成员变量不会被序列化而保留下来。我们写一个Demo,验证一下我们的想法:
-
- public class ArrayList的序列化 {
- public static void main(String[] args) throws IOException, ClassNotFoundException {
- ArrayList list = new ArrayList();
- list.add("a");
- list.add("b");
- ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream("arr"));
- objectOutputStream.writeObject(list);
- objectOutputStream.close();
- ObjectInputStream objectInputStream = new ObjectInputStream(new FileInputStream("arr"));
- ArrayList list1 = (ArrayList) objectInputStream.readObject();
- objectInputStream.close();
- System.out.println(Arrays.toString(list.toArray()));
- //序列化成功,里面的元素保持不变。
- }
-
+````
+public class ArrayList的序列化 {
+ public static void main(String[] args) throws IOException, ClassNotFoundException {
+ ArrayList list = new ArrayList();
+ list.add("a");
+ list.add("b");
+ ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream("arr"));
+ objectOutputStream.writeObject(list);
+ objectOutputStream.close();
+ ObjectInputStream objectInputStream = new ObjectInputStream(new FileInputStream("arr"));
+ ArrayList list1 = (ArrayList) objectInputStream.readObject();
+ objectInputStream.close();
+ System.out.println(Arrays.toString(list.toArray()));
+ //序列化成功,里面的元素保持不变。
+ }
+````
了解ArrayList的人都知道,ArrayList底层是通过数组实现的。那么数组elementData其实就是用来保存列表中的元素的。通过该属性的声明方式我们知道,他是无法通过序列化持久化下来的。那么为什么code 4的结果却通过序列化和反序列化把List中的元素保留下来了呢?
**writeObject和readObject方法**
@@ -376,50 +367,48 @@ ArrayList的序列化
> 用户自定义的 writeObject 和 readObject 方法可以允许用户控制序列化的过程,比如可以在序列化的过程中动态改变序列化的数值。
来看一下这两个方法的具体实现:
+````
+private void readObject(java.io.ObjectInputStream s)
+ throws java.io.IOException, ClassNotFoundException {
+ elementData = EMPTY_ELEMENTDATA;
- private void readObject(java.io.ObjectInputStream s)
- throws java.io.IOException, ClassNotFoundException {
- elementData = EMPTY_ELEMENTDATA;
-
- // Read in size, and any hidden stuff
- s.defaultReadObject();
-
- // Read in capacity
- s.readInt(); // ignored
-
- if (size > 0) {
- // be like clone(), allocate array based upon size not capacity
- ensureCapacityInternal(size);
-
- Object[] a = elementData;
- // Read in all elements in the proper order.
- for (int i=0; i 0) {
+ // be like clone(), allocate array based upon size not capacity
+ ensureCapacityInternal(size);
+
+ Object[] a = elementData;
+ // Read in all elements in the proper order.
+ for (int i=0; i writeObject0 --->writeOrdinaryObject--->writeSerialData--->invokeWriteObject
这里看一下invokeWriteObject:
-
- void invokeWriteObject(Object obj, ObjectOutputStream out)
- throws IOException, UnsupportedOperationException
- {
- if (writeObjectMethod != null) {
- try {
- writeObjectMethod.invoke(obj, new Object[]{ out });
- } catch (InvocationTargetException ex) {
- Throwable th = ex.getTargetException();
- if (th instanceof IOException) {
- throw (IOException) th;
- } else {
- throwMiscException(th);
- }
- } catch (IllegalAccessException ex) {
- // should not occur, as access checks have been suppressed
- throw new InternalError(ex);
+````
+void invokeWriteObject(Object obj, ObjectOutputStream out)
+ throws IOException, UnsupportedOperationException
+ {
+ if (writeObjectMethod != null) {
+ try {
+ writeObjectMethod.invoke(obj, new Object[]{ out });
+ } catch (InvocationTargetException ex) {
+ Throwable th = ex.getTargetException();
+ if (th instanceof IOException) {
+ throw (IOException) th;
+ } else {
+ throwMiscException(th);
}
- } else {
- throw new UnsupportedOperationException();
+ } catch (IllegalAccessException ex) {
+ // should not occur, as access checks have been suppressed
+ throw new InternalError(ex);
}
+ } else {
+ throw new UnsupportedOperationException();
}
+ }
+````
其中writeObjectMethod.invoke(obj, new Object[]{ out });是关键,通过反射的方式调用writeObjectMethod方法。官方是这么解释这个writeObjectMethod的:
class-defined writeObject method, or null if none
@@ -489,45 +479,45 @@ class-defined writeObject method, or null if none
如果一个类中包含writeObject 和 readObject 方法,那么这两个方法是怎么被调用的?
答:在使用ObjectOutputStream的writeObject方法和ObjectInputStream的readObject方法时,会通过反射的方式调用。
-
-
-
+
## 为什么要实现Serializable
至此,我们已经介绍完了ArrayList的序列化方式。那么,不知道有没有人提出这样的疑问:
Serializable明明就是一个空的接口,它是怎么保证只有实现了该接口的方法才能进行序列化与反序列化的呢?
+````
+Serializable接口的定义:
- Serializable接口的定义:
-
- public interface Serializable {
- }
- 读者可以尝试把code 1中的继承Serializable的代码去掉,再执行code 2,会抛出java.io.NotSerializableException。
+public interface Serializable {
+}
+````
+
+读者可以尝试把code 1中的继承Serializable的代码去掉,再执行code 2,会抛出java.io.NotSerializableException。
其实这个问题也很好回答,我们再回到刚刚ObjectOutputStream的writeObject的调用栈:
writeObject ---> writeObject0 --->writeOrdinaryObject--->writeSerialData--->invokeWriteObject
writeObject0方法中有这么一段代码:
-
- if (obj instanceof String) {
- writeString((String) obj, unshared);
- } else if (cl.isArray()) {
- writeArray(obj, desc, unshared);
- } else if (obj instanceof Enum) {
- writeEnum((Enum) obj, desc, unshared);
- } else if (obj instanceof Serializable) {
- writeOrdinaryObject(obj, desc, unshared);
- } else {
- if (extendedDebugInfo) {
- throw new NotSerializableException(
- cl.getName() + "\n" + debugInfoStack.toString());
- } else {
- throw new NotSerializableException(cl.getName());
- }
- }
+````
+if (obj instanceof String) {
+ writeString((String) obj, unshared);
+} else if (cl.isArray()) {
+ writeArray(obj, desc, unshared);
+} else if (obj instanceof Enum) {
+ writeEnum((Enum) obj, desc, unshared);
+} else if (obj instanceof Serializable) {
+ writeOrdinaryObject(obj, desc, unshared);
+} else {
+ if (extendedDebugInfo) {
+ throw new NotSerializableException(
+ cl.getName() + "\n" + debugInfoStack.toString());
+ } else {
+ throw new NotSerializableException(cl.getName());
+ }
+}
+````
在进行序列化操作时,会判断要被序列化的类是否是Enum、Array和Serializable类型,如果不是则直接抛出NotSerializableException。
-
## 序列化知识点总结
> 1、如果一个类想被序列化,需要实现Serializable接口。否则将抛出NotSerializableException异常,这是因为,在序列化操作过程中会对类型进行检查,要求被序列化的类必须属于Enum、Array和Serializable类型其中的任何一种。
@@ -558,20 +548,3 @@ https://segmentfault.com/a/1190000012220863
https://my.oschina.net/wuxinshui/blog/1511484
https://blog.csdn.net/hukailee/article/details/81107412
-## 微信公众号
-
-### Java技术江湖
-
-如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号【Java技术江湖】一位阿里 Java 工程师的技术小站,作者黄小斜,专注 Java 相关技术:SSM、SpringBoot、MySQL、分布式、中间件、集群、Linux、网络、多线程,偶尔讲点Docker、ELK,同时也分享技术干货和学习经验,致力于Java全栈开发!
-
-**Java工程师必备学习资源:** 一些Java工程师常用学习资源,关注公众号后,后台回复关键字 **“Java”** 即可免费无套路获取。
-
-
-
-### 个人公众号:黄小斜
-
-作者是 985 硕士,蚂蚁金服 JAVA 工程师,专注于 JAVA 后端技术栈:SpringBoot、MySQL、分布式、中间件、微服务,同时也懂点投资理财,偶尔讲点算法和计算机理论基础,坚持学习和写作,相信终身学习的力量!
-
-**程序员3T技术学习资源:** 一些程序员学习技术的资源大礼包,关注公众号后,后台回复关键字 **“资料”** 即可免费无套路获取。
-
-
diff --git "a/docs/java/basic/6\343\200\201\346\212\275\350\261\241\347\261\273\345\222\214\346\216\245\345\217\243.md" "b/docs/Java/basic/\346\212\275\350\261\241\347\261\273\345\222\214\346\216\245\345\217\243.md"
similarity index 91%
rename from "docs/java/basic/6\343\200\201\346\212\275\350\261\241\347\261\273\345\222\214\346\216\245\345\217\243.md"
rename to "docs/Java/basic/\346\212\275\350\261\241\347\261\273\345\222\214\346\216\245\345\217\243.md"
index e3bd41a..40cd496 100644
--- "a/docs/java/basic/6\343\200\201\346\212\275\350\261\241\347\261\273\345\222\214\346\216\245\345\217\243.md"
+++ "b/docs/Java/basic/\346\212\275\350\261\241\347\261\273\345\222\214\346\216\245\345\217\243.md"
@@ -15,9 +15,7 @@
* [设计思想区别](#设计思想区别)
* [如何回答面试题:接口和抽象类的区别?](#如何回答面试题:接口和抽象类的区别)
* [参考文章](#参考文章)
- * [微信公众号](#微信公众号)
- * [Java技术江湖](#java技术江湖)
- * [个人公众号:黄小斜](#个人公众号:黄小斜)
+
本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
> https://github.com/h2pl/Java-Tutorial
@@ -32,8 +30,6 @@
如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。
-
-
@@ -50,7 +46,7 @@
包含一个或多个抽象方法的类也必须被声明为抽象类。
使用abstract修饰符来表示抽象方法以及抽象类。
-
+````
//有抽象方法的类也必须被声明为abstract
public abstract class Test1 {
@@ -58,10 +54,11 @@
public abstract void f();
}
+````
抽象类除了包含抽象方法外,还可以包含具体的变量和具体的方法。类即使不包含抽象方法,也可以被声明为抽象类,防止被实例化。
抽象类不能被实例化,也就是不能使用new关键字来得到一个抽象类的实例,抽象方法必须在子类中被实现。
-
+````
//有抽象方法的类也必须被声明为abstract
public class Test1 {
@@ -72,7 +69,6 @@
Driver driver=new Driver("驾驶员");
driver.work();
}
-
}
//一个抽象类
abstract class People{
@@ -87,8 +83,7 @@
@Override
public void work() {
System.out.println("我的职业是"+this.work);
- }
-
+ }
}
class Driver extends People{
private String work;
@@ -99,29 +94,30 @@
public void work() {
System.out.println("我的职业是"+this.work);
}
-
}
+````
+
> 运行结果:
> 我的职业是教师
> 我的职业是驾驶员
> 几点说明:
抽象类不能直接使用,需要子类去实现抽象类,然后使用其子类的实例。然而可以创建一个变量,其类型也是一个抽象类,并让他指向具体子类的一个实例,也就是可以使用抽象类来充当形参,实际实现类为实参,也就是多态的应用。
-
+````
People people=new Teacher("教师");
people.work();
-
+````
不能有抽象构造方法或抽象静态方法。
如果非要使用new关键在来创建一个抽象类的实例的话,可以这样:
-
+````
People people=new People() {
@Override
public void work() {
//实现这个方法的具体功能
}
};
-
+````
个人不推荐这种方法,代码读起来有点累。
在下列情况下,一个类将成为抽象类:
@@ -147,14 +143,14 @@
### 一个抽象类小故事
下面看一个关于抽象类的小故事
-
-问你个问题,你知道什么是“东西”吗?什么是“物体”吗?
-“麻烦你,小王。帮我把那个东西拿过来好吗”
-在生活中,你肯定用过这个词--东西。
-小王:“你要让我帮你拿那个水杯吗?”
-你要的是水杯类的对象。而东西是水杯的父类。通常东西类没有实例对象,但我们有时需要东西的引用指向它的子类实例。
-
-你看你的房间乱成什么样子了,以后不要把东西乱放了,知道么?
+
+ 问你个问题,你知道什么是“东西”吗?什么是“物体”吗?
+ “麻烦你,小王。帮我把那个东西拿过来好吗”
+ 在生活中,你肯定用过这个词--东西。
+ 小王:“你要让我帮你拿那个水杯吗?”
+ 你要的是水杯类的对象。而东西是水杯的父类。通常东西类没有实例对象,但我们有时需要东西的引用指向它的子类实例。
+
+ 你看你的房间乱成什么样子了,以后不要把东西乱放了,知道么?
上面讲的只是子类和父类。而没有说明抽象类的作用。抽象类是据有一个或多个抽象方法的类,必须声明为抽象类。抽象类的特点是,不能创建实例。
@@ -165,6 +161,7 @@
### 一个抽象类小游戏
接下来,我们来写一个小游戏。俄罗斯方块!我们来分析一下它需要什么类?
+
我知道它要在一个矩形的房子里完成。这个房子的上面出现一个方块,慢慢的下落,当它接触到地面或是其它方块的尸体时,它就停止下落了。然后房子的上面又会出现一个新的方块,与前一个方块一样,也会慢慢的下落。在它还没有死亡之前,我可以尽量的移动和翻转它。这样可以使它起到落地时起到一定的作用,如果好的话,还可以减下少几行呢。这看起来好象人生一样,它在为后来人努力着。
当然,我们不是真的要写一个游戏。所以我们简化它。我抽象出两个必须的类,一个是那个房间,或者就它地图也行。另一个是方块。我发现方块有很多种,数一下,共6种。它们都是四个小矩形构成的。但是它们还有很多不同,例如:它们的翻转方法不同。先把这个问题放到一边去,我们回到房子这个类中。
@@ -182,7 +179,7 @@
把那些和“东西”差不多的类写成抽象的。而水杯一样的类就可以不是抽象的了。当然水杯也有几千块钱一个的和几块钱一个的。水杯也有子类,例如,我用的水杯都很高档,大多都是一次性的纸水杯。
-记住一点,面向对象不是来自于Java,面向对象就在你的生活中。而Java的面向对象是方便你解决复杂的问题。这不是说面向对象很简单,虽然面向对象很复杂,但Java知道,你很了解面向对象,因为它就在你身边。
+记住一点,面向对象不是来自于Java,面向对象就在你的生活中。而Java的面向对象是方便你解决复杂的问题。这不是说面向对象很简单,虽然面向对象很复杂,但Java知道,你很了解面向对象,因为它就在你身边。
## 接口介绍
@@ -230,7 +227,7 @@
我们来举个例子,定义一个抽象类People,一个普通子类Student,两个接口。子类Student继承父类People,并实现接口Study,Write
代码演示:
-
+````
package demo;
//构建一个抽象类People
abstract class People{
@@ -307,7 +304,7 @@
student.stu();
}
}
-
+````
代码讲解:上述例子结合了抽象类和接口的知识,内容较多,同学们可以多看多敲一下,学习学习。
接口的实现:类名 implements 接口名,有多个接口名,用“,”隔开即可。
@@ -320,7 +317,7 @@
如电脑可以和各个设备连接,提供统一的USB接口,其他设备只能通过USB接口和电脑相连
代码实现:
-
+````
package demo;
interface USB
@@ -378,12 +375,12 @@
computer.plugin(usb) ; //实例化接口类, 在电脑上使用U盘
}
}
+````
代码讲解:我们修改了主函数后,发现,使用了两次的向上转型给了USB,虽然使用的都是usb对象,但赋值的子类对象不一样,实现的方法体也不同,这就很像现实生活,无论我使用的是打印机,还是U盘,我都是通过USB接口和电脑连接的,这就是接口的作用之一——制定标准
我们来个图继续帮助大家理解一下:
-
-
+
上面的图:我们学习前面的章节多态可以知道对象的多态可以通过动态绑定来实现,即使用向上转型,我们知道类,数组,接口都是引用类型变量,什么是引用类型变量?
引用类型变量都会有一个地址的概念,即指向性的概念,当USB usb = new Print(),此时usb对象是指向new Print()的,当usb = new Flash()后,这时候usb变量就会指向new Flash(),我们会说这是子类对象赋值给了父类对象usb,而在内存中,我们应该说,usb指向了new Flash();
@@ -397,7 +394,7 @@
由于创建过程都由工厂统一管理,所以发生业务逻辑变化,不需要找到所有需要创建B的地方去逐个修正,只需要在工厂里修改即可,降低维护成本。同理,想把所有调用B的地方改成B的子类C,只需要在对应生产B的工厂中或者工厂的方法中修改其生产的对象为C即可,而不需要找到所有的new B()改为newC()。
代码演示:
-
+````
package demo;
import java.util.Scanner;
@@ -452,9 +449,12 @@
sc.close();
}
}
+````
代码讲解:上述代码部分我们讲一下factory这个类,类中有一个getInstance方法,我们用了static关键字修饰,在使用的时候我们就在main中使用类名.方法名调用。
-
+````
Fruit f = factory.getInstance(ans); //初始化参数
+
+````
在Factory的getInstance()方法中,我们就可以通过逻辑的实现,将对象的创建和使用的过程分开了。
@@ -466,50 +466,57 @@ Fruit f = factory.getInstance(ans); //初始化参数
### 基本语法区别
在 Java 中,接口和抽象类的定义语法是不一样的。这里以动物类为例来说明,其中定义接口的示意代码如下:
-
-public interface Animal
+````
+public interface Animal
{
//所有动物都会吃
public void eat();
//所有动物都会飞
public void fly();
-}
+}
+````
定义抽象类的示意代码如下:
-public abstract class Animal
+````
+public abstract class Animal
{
//所有动物都会吃
public abstract void eat();
//所有动物都会飞
public void fly(){};
-}
+}
+````
可以看到,在接口内只能是功能的定义,而抽象类中则可以包括功能的定义和功能的实现。在接口中,所有的属性肯定是 public、static 和 final,所有的方法都是 abstract,所以可以默认不写上述标识符;在抽象类中,既可以包含抽象的定义,也可以包含具体的实现方法。
在具体的实现类上,接口和抽象类的实 现类定义方式也是不一样的,其中接口实现类的示意代码如下:
-public class concreteAnimal implements Animal
+````
+public class concreteAnimal implements Animal
{
//所有动物都会吃
public void eat(){}
//所有动物都会飞
public void fly(){}
-}
+}
+````
抽象类的实现类示意代码如下:
-public class concreteAnimal extends Animal
+````
+public class concreteAnimal extends Animal
{
//所有动物都会吃
public void eat(){}
//所有动物都会飞
public void fly(){}
-}
+}
+````
可以看到,在接口的实现类中使用 implements 关键字;而在抽象类的实现类中,则使用 extends 关键字。一个接口的实现类可以实现多个接口,而一个抽象类的实现类则只能实现一个抽象类。
@@ -521,48 +528,53 @@ Fruit f = factory.getInstance(ans); //初始化参数
仍然以前面动物类的设计为例来说明接口和抽象类关于设计思想的区别,该动物类默认所有的动物都具有吃的功能,其中定义接口的示意代码如下:
-public interface Animal
+````
+public interface Animal
{
//所有动物都会吃
public void eat();
-}
+}
+````
定义抽象类的示意代码如下:
-public abstract class Animal
+````
+public abstract class Animal
{
//所有动物都会吃
public abstract void eat();
-}
+}
+````
不管是实现接口,还是继承抽象类的具体动物,都具有吃的功能,具体的动物类的示意代码如下。
接口实现类的示意代码如下:
-public class concreteAnimal implements Animal
+````
+public class concreteAnimal implements Animal
{
//所有动物都会吃
public void eat(){}
-}
+}
抽象类的实现类示意代码如下:
-public class concreteAnimal extends Animal
+public class concreteAnimal extends Animal
{
//所有动物都会吃
public void eat(){}
-}
+}
当然,具体的动物类不光具有吃的功能,比如有些动物还会飞,而有些动物却会游泳,那么该如何设计这个抽象的动物类呢?可以别在接口和抽象类中增加飞的功能,其中定义接口的示意代码如下:
-public interface Animal
+public interface Animal
{
//所有动物都会吃
public void eat();
//所有动物都会飞
public void fly();
-}
+}
定义抽象类的示意代码如下:
@@ -577,38 +589,38 @@ Fruit f = factory.getInstance(ans); //初始化参数
这样一来,不管是接口还是抽象类的实现类,都具有飞的功能,这显然不能满足要求,因为只有一部分动物会飞,而会飞的却不一定是动物,比如飞机也会飞。那该如何设计呢?有很多种方案,比如再设计一个动物的接口类,该接口具有飞的功能,示意代码如下:
-public interface AnimaiFly
+public interface AnimaiFly
{
//所有动物都会飞
public void fly();
-}
+}
那些具体的动物类,如果有飞的功能的话,除了实现吃的接口外,再实现飞的接口,示意代码如下:
-public class concreteAnimal implements Animal,AnimaiFly
+public class concreteAnimal implements Animal,AnimaiFly
{
//所有动物都会吃
public void eat(){}
//动物会飞
public void fly();
-}
+}
那些不需要飞的功能的具体动物类只实现具体吃的功能的接口即可。另外一种解决方案是再设计一个动物的抽象类,该抽象类具有飞的功能,示意代码如下:
-public abstract class AnimaiFly
+public abstract class AnimaiFly
{
//动物会飞
public void fly();
-}
+}
但此时没有办法实现那些既有吃的功能,又有飞的功能的具体动物类。因为在 Java 中具体的实现类只能实现一个抽象类。一个折中的解决办法是,让这个具有飞的功能的抽象类,继承具有吃的功能的抽象类,示意代码如下:
-public abstract class AnimaiFly extends Animal
+public abstract class AnimaiFly extends Animal
{
//动物会飞
public void fly();
-}
+}
此时,对那些只需要吃的功能的具体动物类来说,继承 Animal 抽象类即可。对那些既有吃的功能又有飞的功能的具体动物类来说,则需要继承 AnimalFly 抽象类。
@@ -618,57 +630,58 @@ Fruit f = factory.getInstance(ans); //初始化参数
具有吃的功能的抽象动物类用抽象类来实现,示意代码如下:
-public abstract class Animal
+public abstract class Animal
{
//所有动物都会吃
public abstract void eat();
-}
+}
具有飞的功能的类用接口实现,示意代码如下:
-public interface AnimaiFly
+public interface AnimaiFly
{
//动物会飞
public void fly();
-}
+}
既具有吃的功能又具有飞的功能的具体的动物类,则继承 Animal 动物抽象类,实现 AnimalFly 接口,示意代码如下:
-public class concreteAnimal extends Animal implements AnimaiFly
+public class concreteAnimal extends Animal implements AnimaiFly
{
//所有动物都会吃
public void eat(){}
//动物会飞
public void fly();
-}
+}
或者具有吃的功能的抽象动物类用接口来实现,示意代码如下:
-public interface Animal
+public interface Animal
{
//所有动物都会吃
public abstract void eat();
-}
+}
具有飞的功能的类用抽象类实现,示意代码如下:
-public abstract class AnimaiFly
+public abstract class AnimaiFly
{
//动物会飞
public void fly(){};
-}
+}
既具有吃的功能又具有飞的功能的具体的动物类,则实现 Animal 动物类接口,继承 AnimaiFly 抽象类,示意代码如下:
-public class concreteAnimal extends AnimaiFly implements Animal
+public class concreteAnimal extends AnimaiFly implements Animal
{
//所有动物都会吃
public void eat(){}
//动物会飞
public void fly();
-}
+}
+````
这些解决方案有什么不同呢?再回过头来看接口和抽象类的区别:抽象类是对一组具有相同属性和方法的逻辑上有关系的事物的一种抽象,而接口则是对一组具有相同属性和方法的逻辑上不相关的事物的一种抽象,因此抽象类表示的是“is a”关系,接口表示的是“like a”关系。
@@ -717,21 +730,4 @@ https://www.runoob.com/java/java-interfaces.html
https://blog.csdn.net/fengyunjh/article/details/6605085
https://blog.csdn.net/xkfanhua/article/details/80567557
-## 微信公众号
-
-### Java技术江湖
-
-如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号【Java技术江湖】一位阿里 Java 工程师的技术小站,作者黄小斜,专注 Java 相关技术:SSM、SpringBoot、MySQL、分布式、中间件、集群、Linux、网络、多线程,偶尔讲点Docker、ELK,同时也分享技术干货和学习经验,致力于Java全栈开发!
-
-**Java工程师必备学习资源:** 一些Java工程师常用学习资源,关注公众号后,后台回复关键字 **“Java”** 即可免费无套路获取。
-
-
-
-### 个人公众号:黄小斜
-
-作者是 985 硕士,蚂蚁金服 JAVA 工程师,专注于 JAVA 后端技术栈:SpringBoot、MySQL、分布式、中间件、微服务,同时也懂点投资理财,偶尔讲点算法和计算机理论基础,坚持学习和写作,相信终身学习的力量!
-
-**程序员3T技术学习资源:** 一些程序员学习技术的资源大礼包,关注公众号后,后台回复关键字 **“资料”** 即可免费无套路获取。
-
-
diff --git "a/docs/java/basic/14\343\200\201\346\236\232\344\270\276\347\261\273.md" "b/docs/Java/basic/\346\236\232\344\270\276\347\261\273.md"
similarity index 69%
rename from "docs/java/basic/14\343\200\201\346\236\232\344\270\276\347\261\273.md"
rename to "docs/Java/basic/\346\236\232\344\270\276\347\261\273.md"
index 2891f98..5fc7cb6 100644
--- "a/docs/java/basic/14\343\200\201\346\236\232\344\270\276\347\261\273.md"
+++ "b/docs/Java/basic/\346\236\232\344\270\276\347\261\273.md"
@@ -1,5 +1,4 @@
# 目录
-
* [初探枚举类](#初探枚举类)
* [枚举类-语法](#枚举类-语法)
* [枚举类的具体使用](#枚举类的具体使用)
@@ -20,9 +19,7 @@
* [枚举 API](#枚举-api)
* [总结](#总结)
* [参考文章](#参考文章)
- * [微信公众号](#微信公众号)
- * [Java技术江湖](#java技术江湖)
- * [个人公众号:黄小斜](#个人公众号:黄小斜)
+
---
本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
@@ -94,136 +91,136 @@
### 枚举类的具体使用
这部分内容参考https://blog.csdn.net/qq_27093465/article/details/52180865
#### 常量
-
- public class 常量 {
- }
- enum Color {
- Red, Green, Blue, Yellow
- }
-
+````
+public class 常量 {
+}
+enum Color {
+ Red, Green, Blue, Yellow
+}
+````
#### switch
JDK1.6之前的switch语句只支持int,char,enum类型,使用枚举,能让我们的代码可读性更强。
-
- public static void showColor(Color color) {
- switch (color) {
- case Red:
- System.out.println(color);
- break;
- case Blue:
- System.out.println(color);
- break;
- case Yellow:
- System.out.println(color);
- break;
- case Green:
- System.out.println(color);
- break;
- }
- }
-
+````
+public static void showColor(Color color) {
+ switch (color) {
+ case Red:
+ System.out.println(color);
+ break;
+ case Blue:
+ System.out.println(color);
+ break;
+ case Yellow:
+ System.out.println(color);
+ break;
+ case Green:
+ System.out.println(color);
+ break;
+ }
+}
+````
#### 向枚举中添加新方法
如果打算自定义自己的方法,那么必须在enum实例序列的最后添加一个分号。而且 Java 要求必须先定义 enum 实例。
-
- enum Color {
- //每个颜色都是枚举类的一个实例,并且构造方法要和枚举类的格式相符合。
- //如果实例后面有其他内容,实例序列结束时要加分号。
- Red("红色", 1), Green("绿色", 2), Blue("蓝色", 3), Yellow("黄色", 4);
- String name;
- int index;
- Color(String name, int index) {
- this.name = name;
- this.index = index;
- }
- public void showAllColors() {
- //values是Color实例的数组,在通过index和name可以获取对应的值。
- for (Color color : Color.values()) {
- System.out.println(color.index + ":" + color.name);
- }
+````
+enum Color {
+ //每个颜色都是枚举类的一个实例,并且构造方法要和枚举类的格式相符合。
+ //如果实例后面有其他内容,实例序列结束时要加分号。
+ Red("红色", 1), Green("绿色", 2), Blue("蓝色", 3), Yellow("黄色", 4);
+ String name;
+ int index;
+ Color(String name, int index) {
+ this.name = name;
+ this.index = index;
+ }
+ public void showAllColors() {
+ //values是Color实例的数组,在通过index和name可以获取对应的值。
+ for (Color color : Color.values()) {
+ System.out.println(color.index + ":" + color.name);
}
}
-
+}
+````
#### 覆盖枚举的方法
所有枚举类都继承自Enum类,所以可以重写该类的方法
下面给出一个toString()方法覆盖的例子。
-
- @Override
- public String toString() {
- return this.index + ":" + this.name;
- }
-
+````
+@Override
+public String toString() {
+ return this.index + ":" + this.name;
+}
+````
#### 实现接口
所有的枚举都继承自java.lang.Enum类。由于Java 不支持多继承,所以枚举对象不能再继承其他类。
-
- enum Color implements Print{
- @Override
- public void print() {
- System.out.println(this.name);
- }
+````
+enum Color implements Print{
+ @Override
+ public void print() {
+ System.out.println(this.name);
}
-
+}
+````
#### 使用接口组织枚举
搞个实现接口,来组织枚举,简单讲,就是分类吧。如果大量使用枚举的话,这么干,在写代码的时候,就很方便调用啦。
-
- public class 用接口组织枚举 {
- public static void main(String[] args) {
- Food cf = chineseFood.dumpling;
- Food jf = Food.JapaneseFood.fishpiece;
- for (Food food : chineseFood.values()) {
- System.out.println(food);
- }
- for (Food food : Food.JapaneseFood.values()) {
- System.out.println(food);
- }
+````
+public class 用接口组织枚举 {
+ public static void main(String[] args) {
+ Food cf = chineseFood.dumpling;
+ Food jf = Food.JapaneseFood.fishpiece;
+ for (Food food : chineseFood.values()) {
+ System.out.println(food);
}
- }
- interface Food {
- enum JapaneseFood implements Food {
- suse, fishpiece
+ for (Food food : Food.JapaneseFood.values()) {
+ System.out.println(food);
}
}
- enum chineseFood implements Food {
- dumpling, tofu
+}
+interface Food {
+ enum JapaneseFood implements Food {
+ suse, fishpiece
}
-
+}
+enum chineseFood implements Food {
+ dumpling, tofu
+}
+````
#### 枚举类集合
java.util.EnumSet和java.util.EnumMap是两个枚举集合。EnumSet保证集合中的元素不重复;EnumMap中的 key是enum类型,而value则可以是任意类型。
EnumSet在JDK中没有找到实现类,这里写一个EnumMap的例子
-
- public class 枚举类集合 {
- public static void main(String[] args) {
- EnumMap map = new EnumMap(Color.class);
- map.put(Color.Blue, "Blue");
- map.put(Color.Yellow, "Yellow");
- map.put(Color.Red, "Red");
- System.out.println(map.get(Color.Red));
- }
+````
+public class 枚举类集合 {
+ public static void main(String[] args) {
+ EnumMap map = new EnumMap(Color.class);
+ map.put(Color.Blue, "Blue");
+ map.put(Color.Yellow, "Yellow");
+ map.put(Color.Red, "Red");
+ System.out.println(map.get(Color.Red));
}
-
+}
+````
## 使用枚举类的注意事项
-
+
枚举类型对象之间的值比较,是可以使用==,直接来比较值,是否相等的,不是必须使用equals方法的哟。
因为枚举类Enum已经重写了equals方法
-
- /**
- * Returns true if the specified object is equal to this
- * enum constant.
- *
- * @param other the object to be compared for equality with this object.
- * @return true if the specified object is equal to this
- * enum constant.
- */
- public final boolean equals(Object other) {
- return this==other;
- }
-
+````
+/**
+ * Returns true if the specified object is equal to this
+ * enum constant.
+ *
+ * @param other the object to be compared for equality with this object.
+ * @return true if the specified object is equal to this
+ * enum constant.
+ */
+public final boolean equals(Object other) {
+ return this==other;
+}
+````
## 枚举类的实现原理
这部分参考https://blog.csdn.net/mhmyqn/article/details/48087247
@@ -235,46 +232,46 @@ EnumSet在JDK中没有找到实现类,这里写一个EnumMap的例子
> Java在1.5中添加了java.lang.Enum抽象类,它是所有枚举类型基类。提供了一些基础属性和基础方法。同时,对把枚举用作Set和Map也提供了支持,即java.util.EnumSet和java.util.EnumMap。
接下来定义一个简单的枚举类
-
- public enum Day {
- MONDAY {
- @Override
- void say() {
- System.out.println("MONDAY");
- }
+````
+public enum Day {
+ MONDAY {
+ @Override
+ void say() {
+ System.out.println("MONDAY");
}
- , TUESDAY {
- @Override
- void say() {
- System.out.println("TUESDAY");
- }
- }, FRIDAY("work"){
- @Override
- void say() {
- System.out.println("FRIDAY");
- }
- }, SUNDAY("free"){
- @Override
- void say() {
- System.out.println("SUNDAY");
- }
- };
- String work;
- //没有构造参数时,每个实例可以看做常量。
- //使用构造参数时,每个实例都会变得不一样,可以看做不同的类型,所以编译后会生成实例个数对应的class。
- private Day(String work) {
- this.work = work;
+ }
+ , TUESDAY {
+ @Override
+ void say() {
+ System.out.println("TUESDAY");
}
- private Day() {
-
+ }, FRIDAY("work"){
+ @Override
+ void say() {
+ System.out.println("FRIDAY");
}
- //枚举实例必须实现枚举类中的抽象方法
- abstract void say ();
-
+ }, SUNDAY("free"){
+ @Override
+ void say() {
+ System.out.println("SUNDAY");
+ }
+ };
+ String work;
+ //没有构造参数时,每个实例可以看做常量。
+ //使用构造参数时,每个实例都会变得不一样,可以看做不同的类型,所以编译后会生成实例个数对应的class。
+ private Day(String work) {
+ this.work = work;
}
+ private Day() {
-反编译结果
+ }
+ //枚举实例必须实现枚举类中的抽象方法
+ abstract void say ();
+}
+````
+反编译结果
+````
D:\MyTech\out\production\MyTech\com\javase\枚举类>javap Day.class
Compiled from "Day.java"
@@ -291,43 +288,43 @@ EnumSet在JDK中没有找到实现类,这里写一个EnumMap的例子
com.javase.枚举类.Day(java.lang.String, int, java.lang.String, com.javase.枚举类.Day$1);
static {};
}
-
+````
> 可以看到,一个枚举在经过编译器编译过后,变成了一个抽象类,它继承了java.lang.Enum;而枚举中定义的枚举常量,变成了相应的public static final属性,而且其类型就抽象类的类型,名字就是枚举常量的名字.
>
> 同时我们可以在Operator.class的相同路径下看到四个内部类的.class文件com/mikan/Day$1.class、com/mikan/Day$2.class、com/mikan/Day$3.class、com/mikan/Day$4.class,也就是说这四个命名字段分别使用了内部类来实现的;同时添加了两个方法values()和valueOf(String);我们定义的构造方法本来只有一个参数,但却变成了三个参数;同时还生成了一个静态代码块。这些具体的内容接下来仔细看看。
下面分析一下字节码中的各部分,其中:
-
- InnerClasses:
- static #23; //class com/javase/枚举类/Day$4
- static #18; //class com/javase/枚举类/Day$3
- static #14; //class com/javase/枚举类/Day$2
- static #10; //class com/javase/枚举类/Day$1
-
+````
+InnerClasses:
+ static #23; //class com/javase/枚举类/Day$4
+ static #18; //class com/javase/枚举类/Day$3
+ static #14; //class com/javase/枚举类/Day$2
+ static #10; //class com/javase/枚举类/Day$1
+````
从中可以看到它有4个内部类,这四个内部类的详细信息后面会分析。
-
- static {};
- descriptor: ()V
- flags: ACC_STATIC
- Code:
- stack=5, locals=0, args_size=0
- 0: new #10 // class com/javase/枚举类/Day$1
- 3: dup
- 4: ldc #11 // String MONDAY
- 6: iconst_0
- 7: invokespecial #12 // Method com/javase/枚举类/Day$1."":(Ljava/lang/String;I)V
- 10: putstatic #13 // Field MONDAY:Lcom/javase/枚举类/Day;
- 13: new #14 // class com/javase/枚举类/Day$2
- 16: dup
- 17: ldc #15 // String TUESDAY
- 19: iconst_1
- 20: invokespecial #16 // Method com/javase/枚举类/Day$2."":(Ljava/lang/String;I)V
- //后面类似,这里省略
- }
-
+````
+static {};
+ descriptor: ()V
+ flags: ACC_STATIC
+ Code:
+ stack=5, locals=0, args_size=0
+ 0: new #10 // class com/javase/枚举类/Day$1
+ 3: dup
+ 4: ldc #11 // String MONDAY
+ 6: iconst_0
+ 7: invokespecial #12 // Method com/javase/枚举类/Day$1."":(Ljava/lang/String;I)V
+ 10: putstatic #13 // Field MONDAY:Lcom/javase/枚举类/Day;
+ 13: new #14 // class com/javase/枚举类/Day$2
+ 16: dup
+ 17: ldc #15 // String TUESDAY
+ 19: iconst_1
+ 20: invokespecial #16 // Method com/javase/枚举类/Day$2."":(Ljava/lang/String;I)V
+ //后面类似,这里省略
+}
+````
其实编译器生成的这个静态代码块做了如下工作:分别设置生成的四个公共静态常量字段的值,同时编译器还生成了一个静态字段$VALUES,保存的是枚举类型定义的所有枚举常量
编译器添加的values方法:
-
+````
public static com.javase.Day[] values();
flags: ACC_PUBLIC, ACC_STATIC
Code:
@@ -336,16 +333,17 @@ EnumSet在JDK中没有找到实现类,这里写一个EnumMap的例子
3: invokevirtual #3 // Method "[Lcom/mikan/Day;".clone:()Ljava/lang/Object;
6: checkcast #4 // class "[Lcom/javase/Day;"
9: areturn
- 这个方法是一个公共的静态方法,所以我们可以直接调用该方法(Day.values()),返回这个枚举值的数组,另外,这个方法的实现是,克隆在静态代码块中初始化的$VALUES字段的值,并把类型强转成Day[]类型返回。
+````
+这个方法是一个公共的静态方法,所以我们可以直接调用该方法(Day.values()),返回这个枚举值的数组,另外,这个方法的实现是,克隆在静态代码块中初始化的$VALUES字段的值,并把类型强转成Day[]类型返回。
造方法为什么增加了两个参数?
有一个问题,构造方法我们明明只定义了一个参数,为什么生成的构造方法是三个参数呢?
- 从Enum类中我们可以看到,为每个枚举都定义了两个属性,name和ordinal,name表示我们定义的枚举常量的名称,如FRIDAY、TUESDAY,而ordinal是一个顺序号,根据定义的顺序分别赋予一个整形值,从0开始。在枚举常量初始化时,会自动为初始化这两个字段,设置相应的值,所以才在构造方法中添加了两个参数。即:
-
- 另外三个枚举常量生成的内部类基本上差不多,这里就不重复说明了。
+从Enum类中我们可以看到,为每个枚举都定义了两个属性,name和ordinal,name表示我们定义的枚举常量的名称,如FRIDAY、TUESDAY,而ordinal是一个顺序号,根据定义的顺序分别赋予一个整形值,从0开始。在枚举常量初始化时,会自动为初始化这两个字段,设置相应的值,所以才在构造方法中添加了两个参数。即:
+
+另外三个枚举常量生成的内部类基本上差不多,这里就不重复说明了。
> 我们可以从Enum类的代码中看到,定义的name和ordinal属性都是final的,而且大部分方法也都是final的,特别是clone、readObject、writeObject这三个方法,这三个方法和枚举通过静态代码块来进行初始化一起。
@@ -507,20 +505,3 @@ https://segmentfault.com/a/1190000012220863
https://my.oschina.net/wuxinshui/blog/1511484
https://blog.csdn.net/hukailee/article/details/81107412
-## 微信公众号
-
-### Java技术江湖
-
-如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号【Java技术江湖】一位阿里 Java 工程师的技术小站,作者黄小斜,专注 Java 相关技术:SSM、SpringBoot、MySQL、分布式、中间件、集群、Linux、网络、多线程,偶尔讲点Docker、ELK,同时也分享技术干货和学习经验,致力于Java全栈开发!
-
-**Java工程师必备学习资源:** 一些Java工程师常用学习资源,关注公众号后,后台回复关键字 **“Java”** 即可免费无套路获取。
-
-
-
-### 个人公众号:黄小斜
-
-作者是 985 硕士,蚂蚁金服 JAVA 工程师,专注于 JAVA 后端技术栈:SpringBoot、MySQL、分布式、中间件、微服务,同时也懂点投资理财,偶尔讲点算法和计算机理论基础,坚持学习和写作,相信终身学习的力量!
-
-**程序员3T技术学习资源:** 一些程序员学习技术的资源大礼包,关注公众号后,后台回复关键字 **“资料”** 即可免费无套路获取。
-
-
diff --git "a/docs/java/basic/13\343\200\201\346\263\233\345\236\213.md" "b/docs/Java/basic/\346\263\233\345\236\213.md"
similarity index 58%
rename from "docs/java/basic/13\343\200\201\346\263\233\345\236\213.md"
rename to "docs/Java/basic/\346\263\233\345\236\213.md"
index 2251e75..f9a9ba6 100644
--- "a/docs/java/basic/13\343\200\201\346\263\233\345\236\213.md"
+++ "b/docs/Java/basic/\346\263\233\345\236\213.md"
@@ -15,9 +15,7 @@
* [泛型上下边界](#泛型上下边界)
* [泛型常见面试题](#泛型常见面试题)
* [参考文章](#参考文章)
- * [微信公众号](#微信公众号)
- * [Java技术江湖](#java技术江湖)
- * [个人公众号:黄小斜](#个人公众号:黄小斜)
+
本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
> https://github.com/h2pl/Java-Tutorial
@@ -44,48 +42,45 @@
>
> 泛型的本质是为了参数化类型(在不创建新的类型的情况下,通过泛型指定的不同类型来控制形参具体限制的类型)。也就是说在泛型使用过程中,操作的数据类型被指定为一个参数,这种参数类型可以用在类、接口和方法中,分别被称为泛型类、泛型接口、泛型方法。
-
-
### 一个栗子
一个被举了无数次的例子:
-
- List arrayList = new ArrayList();
- arrayList.add("aaaa");
- arrayList.add(100);
-
- for(int i = 0; i< arrayList.size();i++){
- String item = (String)arrayList.get(i);
- Log.d("泛型测试","item = " + item);
- }
-
+````
+List arrayList = new ArrayList();
+arrayList.add("aaaa");
+arrayList.add(100);
+
+for(int i = 0; i< arrayList.size();i++){
+ String item = (String)arrayList.get(i);
+ Log.d("泛型测试","item = " + item);
+}
+````
毫无疑问,程序的运行结果会以崩溃结束:
-java.lang.ClassCastException: java.lang.Integer cannot be cast to java.lang.String
+ java.lang.ClassCastException: java.lang.Integer cannot be cast to java.lang.String
ArrayList可以存放任意类型,例子中添加了一个String类型,添加了一个Integer类型,再使用时都以String的方式使用,因此程序崩溃了。为了解决类似这样的问题(在编译阶段就可以解决),泛型应运而生。
我们将第一行声明初始化list的代码更改一下,编译器会在编译阶段就能够帮我们发现类似这样的问题。
-
+````
List arrayList = new ArrayList();
...
//arrayList.add(100); 在编译阶段,编译器就会报错
-
+````
### 特性
泛型只在编译阶段有效。看下面的代码:
+````
+List stringArrayList = new ArrayList();
+List integerArrayList = new ArrayList();
- List stringArrayList = new ArrayList();
- List integerArrayList = new ArrayList();
-
- Class classStringArrayList = stringArrayList.getClass();
- Class classIntegerArrayList = integerArrayList.getClass();
-
- if(classStringArrayList.equals(classIntegerArrayList)){
- Log.d("泛型测试","类型相同");
- }
-
+Class classStringArrayList = stringArrayList.getClass();
+Class classIntegerArrayList = integerArrayList.getClass();
+if(classStringArrayList.equals(classIntegerArrayList)){
+ Log.d("泛型测试","类型相同");
+}
+````
> 通过上面的例子可以证明,在编译之后程序会采取去泛型化的措施。也就是说Java中的泛型,只在编译阶段有效。在编译过程中,正确检验泛型结果后,会将泛型的相关信息擦出,并且在对象进入和离开方法的边界处添加类型检查和类型转换的方法。也就是说,泛型信息不会进入到运行时阶段。
>
对此总结成一句话:泛型类型在逻辑上看以看成是多个不同的类型,实际上都是相同的基本类型。
@@ -101,49 +96,49 @@ List arrayList = new ArrayList();
> 泛型类型用于类的定义中,被称为泛型类。通过泛型可以完成对一组类的操作对外开放相同的接口。最典型的就是各种容器类,如:List、Set、Map。
>
> 泛型类的最基本写法(这么看可能会有点晕,会在下面的例子中详解):
-
+````
class 类名称 <泛型标识:可以随便写任意标识号,标识指定的泛型的类型>{
private 泛型标识 /*(成员变量类型)*/ var;
.....
}
-
+````
一个最普通的泛型类:
//此处T可以随便写为任意标识,常见的如T、E、K、V等形式的参数常用于表示泛型
+````
+//在实例化泛型类时,必须指定T的具体类型
+public class Generic{
+ //在类中声明的泛型整个类里面都可以用,除了静态部分,因为泛型是实例化时声明的。
+ //静态区域的代码在编译时就已经确定,只与类相关
+ class A {
+ T t;
+ }
+ //类里面的方法或类中再次声明同名泛型是允许的,并且该泛型会覆盖掉父类的同名泛型T
+ class B {
+ T t;
+ }
+ //静态内部类也可以使用泛型,实例化时赋予泛型实际类型
+ static class C {
+ T t;
+ }
+ public static void main(String[] args) {
+ //报错,不能使用T泛型,因为泛型T属于实例不属于类
+// T t = null;
+ }
- //在实例化泛型类时,必须指定T的具体类型
- public class Generic{
- //在类中声明的泛型整个类里面都可以用,除了静态部分,因为泛型是实例化时声明的。
- //静态区域的代码在编译时就已经确定,只与类相关
- class A {
- T t;
- }
- //类里面的方法或类中再次声明同名泛型是允许的,并且该泛型会覆盖掉父类的同名泛型T
- class B {
- T t;
- }
- //静态内部类也可以使用泛型,实例化时赋予泛型实际类型
- static class C {
- T t;
- }
- public static void main(String[] args) {
- //报错,不能使用T泛型,因为泛型T属于实例不属于类
- // T t = null;
- }
-
- //key这个成员变量的类型为T,T的类型由外部指定
- private T key;
-
- public Generic(T key) { //泛型构造方法形参key的类型也为T,T的类型由外部指定
- this.key = key;
- }
-
- public T getKey(){ //泛型方法getKey的返回值类型为T,T的类型由外部指定
- return key;
- }
+ //key这个成员变量的类型为T,T的类型由外部指定
+ private T key;
+
+ public Generic(T key) { //泛型构造方法形参key的类型也为T,T的类型由外部指定
+ this.key = key;
}
+ public T getKey(){ //泛型方法getKey的返回值类型为T,T的类型由外部指定
+ return key;
+ }
+}
+````
> 12-27 09:20:04.432 13063-13063/? D/泛型测试: key is 123456
> 12-27 09:20:04.432 13063-13063/? D/泛型测试: key is key_vlaue
@@ -151,22 +146,22 @@ List arrayList = new ArrayList();
> 定义的泛型类,就一定要传入泛型类型实参么?并不是这样,在使用泛型的时候如果传入泛型实参,则会根据传入的泛型实参做相应的限制,此时泛型才会起到本应起到的限制作用。如果不传入泛型类型实参的话,在泛型类中使用泛型的方法或成员变量定义的类型可以为任何的类型。
看一个例子:
-
- Generic generic = new Generic("111111");
- Generic generic1 = new Generic(4444);
- Generic generic2 = new Generic(55.55);
- Generic generic3 = new Generic(false);
-
- Log.d("泛型测试","key is " + generic.getKey());
- Log.d("泛型测试","key is " + generic1.getKey());
- Log.d("泛型测试","key is " + generic2.getKey());
- Log.d("泛型测试","key is " + generic3.getKey());
-
- D/泛型测试: key is 111111
- D/泛型测试: key is 4444
- D/泛型测试: key is 55.55
- D/泛型测试: key is false
-
+````
+Generic generic = new Generic("111111");
+Generic generic1 = new Generic(4444);
+Generic generic2 = new Generic(55.55);
+Generic generic3 = new Generic(false);
+
+Log.d("泛型测试","key is " + generic.getKey());
+Log.d("泛型测试","key is " + generic1.getKey());
+Log.d("泛型测试","key is " + generic2.getKey());
+Log.d("泛型测试","key is " + generic3.getKey());
+
+D/泛型测试: key is 111111
+D/泛型测试: key is 4444
+D/泛型测试: key is 55.55
+D/泛型测试: key is false
+````
注意:
泛型的类型参数只能是类类型,不能是简单类型。
不能对确切的泛型类型使用instanceof操作。如下面的操作是非法的,编译时会出错。
@@ -176,78 +171,78 @@ List arrayList = new ArrayList();
### 泛型接口
泛型接口与泛型类的定义及使用基本相同。泛型接口常被用在各种类的生产器中,可以看一个例子:
-
- //定义一个泛型接口
- public interface Generator {
- public T next();
- }
-
+````
+//定义一个泛型接口
+public interface Generator {
+ public T next();
+}
+````
当实现泛型接口的类,未传入泛型实参时:
-
- /**
- * 未传入泛型实参时,与泛型类的定义相同,在声明类的时候,需将泛型的声明也一起加到类中
- * 即:class FruitGenerator implements Generator{
- * 如果不声明泛型,如:class FruitGenerator implements Generator,编译器会报错:"Unknown class"
- */
- class FruitGenerator implements Generator{
- @Override
- public T next() {
- return null;
- }
+````
+/**
+ * 未传入泛型实参时,与泛型类的定义相同,在声明类的时候,需将泛型的声明也一起加到类中
+ * 即:class FruitGenerator implements Generator{
+ * 如果不声明泛型,如:class FruitGenerator implements Generator,编译器会报错:"Unknown class"
+ */
+class FruitGenerator implements Generator{
+ @Override
+ public T next() {
+ return null;
}
-
+}
+````
当实现泛型接口的类,传入泛型实参时:
-
- /**
- * 传入泛型实参时:
- * 定义一个生产器实现这个接口,虽然我们只创建了一个泛型接口Generator
- * 但是我们可以为T传入无数个实参,形成无数种类型的Generator接口。
- * 在实现类实现泛型接口时,如已将泛型类型传入实参类型,则所有使用泛型的地方都要替换成传入的实参类型
- * 即:Generator,public T next();中的的T都要替换成传入的String类型。
- */
- public class FruitGenerator implements Generator {
-
- private String[] fruits = new String[]{"Apple", "Banana", "Pear"};
-
- @Override
- public String next() {
- Random rand = new Random();
- return fruits[rand.nextInt(3)];
- }
+````
+/**
+ * 传入泛型实参时:
+ * 定义一个生产器实现这个接口,虽然我们只创建了一个泛型接口Generator
+ * 但是我们可以为T传入无数个实参,形成无数种类型的Generator接口。
+ * 在实现类实现泛型接口时,如已将泛型类型传入实参类型,则所有使用泛型的地方都要替换成传入的实参类型
+ * 即:Generator,public T next();中的的T都要替换成传入的String类型。
+ */
+public class FruitGenerator implements Generator {
+
+ private String[] fruits = new String[]{"Apple", "Banana", "Pear"};
+
+ @Override
+ public String next() {
+ Random rand = new Random();
+ return fruits[rand.nextInt(3)];
}
-
+}
+````
### 泛型通配符
我们知道Ingeter是Number的一个子类,同时在特性章节中我们也验证过Generic与Generic实际上是相同的一种基本类型。那么问题来了,在使用Generic作为形参的方法中,能否使用Generic的实例传入呢?在逻辑上类似于Generic和Generic是否可以看成具有父子关系的泛型类型呢?
为了弄清楚这个问题,我们使用Generic这个泛型类继续看下面的例子:
+````
+public void showKeyValue1(Generic obj){
+ Log.d("泛型测试","key value is " + obj.getKey());
+}
- public void showKeyValue1(Generic obj){
- Log.d("泛型测试","key value is " + obj.getKey());
- }
-
- Generic gInteger = new Generic(123);
- Generic gNumber = new Generic(456);
-
- showKeyValue(gNumber);
-
- // showKeyValue这个方法编译器会为我们报错:Generic
- // cannot be applied to Generic
- // showKeyValue(gInteger);
+Generic gInteger = new Generic(123);
+Generic gNumber = new Generic(456);
+
+showKeyValue(gNumber);
+// showKeyValue这个方法编译器会为我们报错:Generic
+// cannot be applied to Generic
+// showKeyValue(gInteger);
+````
通过提示信息我们可以看到Generic不能被看作为`Generic的子类。由此可以看出:同一种泛型可以对应多个版本(因为参数类型是不确定的),不同版本的泛型类实例是不兼容的。
回到上面的例子,如何解决上面的问题?总不能为了定义一个新的方法来处理Generic类型的类,这显然与java中的多台理念相违背。因此我们需要一个在逻辑上可以表示同时是Generic和Generic父类的引用类型。由此类型通配符应运而生。
我们可以将上面的方法改一下:
-
- public void showKeyValue1(Generic obj){
- Log.d("泛型测试","key value is " + obj.getKey());
-
+````
+public void showKeyValue1(Generic obj){
+ Log.d("泛型测试","key value is " + obj.getKey());
+````
类型通配符一般是使用?代替具体的类型实参,注意, 此处的?和Number、String、Integer一样都是一种实际的类型,可以把?看成所有类型的父类。是一种真实的类型。
可以解决当具体类型不确定的时候,这个通配符就是 ? ;当操作类型时,不需要使用类型的具体功能时,只使用Object类中的功能。那么可以用 ? 通配符来表未知类型
-
+````
public void showKeyValue(Generic obj){
System.out.println(obj);
}
@@ -266,7 +261,7 @@ public void showKeyValue(Generic obj){
// showKeyValue这个方法编译器会为我们报错:Generic
// cannot be applied to Generic
// showKeyValue(gInteger);
-。
+````
### 泛型方法
@@ -274,167 +269,165 @@ public void showKeyValue(Generic obj){
尤其是我们见到的大多数泛型类中的成员方法也都使用了泛型,有的甚至泛型类中也包含着泛型方法,这样在初学者中非常容易将泛型方法理解错了。
泛型类,是在实例化类的时候指明泛型的具体类型;泛型方法,是在调用方法的时候指明泛型的具体类型 。
+````
+/**
+ * 泛型方法的基本介绍
+ * @param tClass 传入的泛型实参
+ * @return T 返回值为T类型
+ * 说明:
+ * 1)public 与 返回值中间非常重要,可以理解为声明此方法为泛型方法。
+ * 2)只有声明了的方法才是泛型方法,泛型类中的使用了泛型的成员方法并不是泛型方法。
+ * 3)表明该方法将使用泛型类型T,此时才可以在方法中使用泛型类型T。
+ * 4)与泛型类的定义一样,此处T可以随便写为任意标识,常见的如T、E、K、V等形式的参数常用于表示泛型。
+ */
+ public T genericMethod(Class tClass)throws InstantiationException ,
+ IllegalAccessException{
+ T instance = tClass.newInstance();
+ return instance;
+ }
- /**
- * 泛型方法的基本介绍
- * @param tClass 传入的泛型实参
- * @return T 返回值为T类型
- * 说明:
- * 1)public 与 返回值中间非常重要,可以理解为声明此方法为泛型方法。
- * 2)只有声明了的方法才是泛型方法,泛型类中的使用了泛型的成员方法并不是泛型方法。
- * 3)表明该方法将使用泛型类型T,此时才可以在方法中使用泛型类型T。
- * 4)与泛型类的定义一样,此处T可以随便写为任意标识,常见的如T、E、K、V等形式的参数常用于表示泛型。
- */
- public T genericMethod(Class tClass)throws InstantiationException ,
- IllegalAccessException{
- T instance = tClass.newInstance();
- return instance;
- }
-
- Object obj = genericMethod(Class.forName("com.test.test"));
-
+Object obj = genericMethod(Class.forName("com.test.test"));
+````
### 泛型方法的基本用法
光看上面的例子有的同学可能依然会非常迷糊,我们再通过一个例子,把我泛型方法再总结一下。
-
- /**
- * 这才是一个真正的泛型方法。
- * 首先在public与返回值之间的必不可少,这表明这是一个泛型方法,并且声明了一个泛型T
- * 这个T可以出现在这个泛型方法的任意位置.
- * 泛型的数量也可以为任意多个
- * 如:public K showKeyName(Generic container){
- * ...
- * }
- */
-
- public class 泛型方法 {
- @Test
- public void test() {
- test1();
- test2(new Integer(2));
- test3(new int[3],new Object());
-
- //打印结果
- // null
- // 2
- // [I@3d8c7aca
- // java.lang.Object@5ebec15
- }
- //该方法使用泛型T
- public void test1() {
- T t = null;
- System.out.println(t);
- }
- //该方法使用泛型T
- //并且参数和返回值都是T类型
- public T test2(T t) {
- System.out.println(t);
- return t;
- }
-
- //该方法使用泛型T,E
- //参数包括T,E
- public void test3(T t, E e) {
- System.out.println(t);
- System.out.println(e);
- }
+````
+/**
+ * 这才是一个真正的泛型方法。
+ * 首先在public与返回值之间的必不可少,这表明这是一个泛型方法,并且声明了一个泛型T
+ * 这个T可以出现在这个泛型方法的任意位置.
+ * 泛型的数量也可以为任意多个
+ * 如:public K showKeyName(Generic container){
+ * ...
+ * }
+ */
+
+ public class 泛型方法 {
+ @Test
+ public void test() {
+ test1();
+ test2(new Integer(2));
+ test3(new int[3],new Object());
+
+ //打印结果
+ //null
+ //2
+ //[I@3d8c7aca
+ //java.lang.Object@5ebec15
+ }
+ //该方法使用泛型T
+ public void test1() {
+ T t = null;
+ System.out.println(t);
+ }
+ //该方法使用泛型T
+ //并且参数和返回值都是T类型
+ public T test2(T t) {
+ System.out.println(t);
+ return t;
}
-
-
+ //该方法使用泛型T,E
+ //参数包括T,E
+ public void test3(T t, E e) {
+ System.out.println(t);
+ System.out.println(e);
+ }
+}
+````
### 类中的泛型方法
当然这并不是泛型方法的全部,泛型方法可以出现杂任何地方和任何场景中使用。但是有一种情况是非常特殊的,当泛型方法出现在泛型类中时,我们再通过一个例子看一下
-
- //注意泛型类先写类名再写泛型,泛型方法先写泛型再写方法名
- //类中声明的泛型在成员和方法中可用
- class A {
- {
- T t1 ;
- }
- A (T t){
- this.t = t;
- }
- T t;
-
- public void test1() {
- System.out.println(this.t);
- }
-
- public void test2(T t,E e) {
- System.out.println(t);
- System.out.println(e);
- }
+````
+//注意泛型类先写类名再写泛型,泛型方法先写泛型再写方法名
+//类中声明的泛型在成员和方法中可用
+class A {
+ {
+ T t1 ;
}
- @Test
- public void run () {
- A a = new A<>(1);
- a.test1();
- a.test2(2,"ds");
- // 1
- // 2
- // ds
+ A (T t){
+ this.t = t;
}
-
- static class B {
- T t;
- public void go () {
- System.out.println(t);
- }
+ T t;
+
+ public void test1() {
+ System.out.println(this.t);
}
+ public void test2(T t,E e) {
+ System.out.println(t);
+ System.out.println(e);
+ }
+}
+@Test
+public void run () {
+ A a = new A<>(1);
+ a.test1();
+ a.test2(2,"ds");
+// 1
+// 2
+// ds
+}
+
+static class B {
+ T t;
+ public void go () {
+ System.out.println(t);
+ }
+}
+````
### 泛型方法与可变参数
再看一个泛型方法和可变参数的例子:
-
- public class 泛型和可变参数 {
- @Test
- public void test () {
- printMsg("dasd",1,"dasd",2.0,false);
- print("dasdas","dasdas", "aa");
- }
- //普通可变参数只能适配一种类型
- public void print(String ... args) {
- for(String t : args){
- System.out.println(t);
- }
+````
+public class 泛型和可变参数 {
+ @Test
+ public void test () {
+ printMsg("dasd",1,"dasd",2.0,false);
+ print("dasdas","dasdas", "aa");
+ }
+ //普通可变参数只能适配一种类型
+ public void print(String ... args) {
+ for(String t : args){
+ System.out.println(t);
}
- //泛型的可变参数可以匹配所有类型的参数。。有点无敌
- public void printMsg( T... args){
- for(T t : args){
- System.out.println(t);
- }
+ }
+ //泛型的可变参数可以匹配所有类型的参数。。有点无敌
+ public void printMsg( T... args){
+ for(T t : args){
+ System.out.println(t);
}
- //打印结果:
- //dasd
- //1
- //dasd
- //2.0
- //false
-
}
+ //打印结果:
+ //dasd
+ //1
+ //dasd
+ //2.0
+ //false
+}
+````
### 静态方法与泛型
静态方法有一种情况需要注意一下,那就是在类中的静态方法使用泛型:静态方法无法访问类上定义的泛型;如果静态方法操作的引用数据类型不确定的时候,必须要将泛型定义在方法上。
即:如果静态方法要使用泛型的话,必须将静态方法也定义成泛型方法 。
+````
+public class StaticGenerator {
+ ....
+ ....
+ /**
+ * 如果在类中定义使用泛型的静态方法,需要添加额外的泛型声明(将这个方法定义成泛型方法)
+ * 即使静态方法要使用泛型类中已经声明过的泛型也不可以。
+ * 如:public static void show(T t){..},此时编译器会提示错误信息:
+ "StaticGenerator cannot be refrenced from static context"
+ */
+ public static void show(T t){
- public class StaticGenerator {
- ....
- ....
- /**
- * 如果在类中定义使用泛型的静态方法,需要添加额外的泛型声明(将这个方法定义成泛型方法)
- * 即使静态方法要使用泛型类中已经声明过的泛型也不可以。
- * 如:public static void show(T t){..},此时编译器会提示错误信息:
- "StaticGenerator cannot be refrenced from static context"
- */
- public static void show(T t){
-
- }
}
-
+}
+````
## 泛型方法总结
泛型方法能使方法独立于类而产生变化,以下是一个基本的指导原则:
@@ -445,90 +438,93 @@ public void showKeyValue(Generic obj){
在使用泛型的时候,我们还可以为传入的泛型类型实参进行上下边界的限制,如:类型实参只准传入某种类型的父类或某种类型的子类。
为泛型添加上边界,即传入的类型实参必须是指定类型的子类型
+````
+public class 泛型通配符与边界 {
+ public void showKeyValue(Generic obj){
+ System.out.println("key value is " + obj.getKey());
+ }
+ @Test
+ public void main() {
+ Generic gInteger = new Generic(123);
+ Generic gNumber = new Generic(456);
+ showKeyValue(gNumber);
+ //泛型中的子类也无法作为父类引用传入
+// showKeyValue(gInteger);
+ }
+ //直接使用?通配符可以接受任何类型作为泛型传入
+ public void showKeyValueYeah(Generic obj) {
+ System.out.println(obj);
+ }
+ //只能传入number的子类或者number
+ public void showKeyValue1(Generic obj){
+ System.out.println(obj);
+ }
- public class 泛型通配符与边界 {
- public void showKeyValue(Generic obj){
- System.out.println("key value is " + obj.getKey());
- }
- @Test
- public void main() {
- Generic gInteger = new Generic(123);
- Generic gNumber = new Generic(456);
- showKeyValue(gNumber);
- //泛型中的子类也无法作为父类引用传入
- // showKeyValue(gInteger);
- }
- //直接使用?通配符可以接受任何类型作为泛型传入
- public void showKeyValueYeah(Generic obj) {
- System.out.println(obj);
- }
- //只能传入number的子类或者number
- public void showKeyValue1(Generic obj){
- System.out.println(obj);
- }
-
- //只能传入Integer的父类或者Integer
- public void showKeyValue2(Generic obj){
- System.out.println(obj);
- }
-
- @Test
- public void testup () {
- //这一行代码编译器会提示错误,因为String类型并不是Number类型的子类
- //showKeyValue1(generic1);
- Generic generic1 = new Generic("11111");
- Generic generic2 = new Generic(2222);
- Generic generic3 = new Generic(2.4f);
- Generic generic4 = new Generic(2.56);
-
- showKeyValue1(generic2);
- showKeyValue1(generic3);
- showKeyValue1(generic4);
- }
-
- @Test
- public void testdown () {
-
- Generic generic1 = new Generic("11111");
- Generic generic2 = new Generic(2222);
- Generic generic3 = new Generic(2);
- // showKeyValue2(generic1);本行报错,因为String并不是Integer的父类
- showKeyValue2(generic2);
- showKeyValue2(generic3);
- }
+ //只能传入Integer的父类或者Integer
+ public void showKeyValue2(Generic obj){
+ System.out.println(obj);
+ }
+
+ @Test
+ public void testup () {
+ //这一行代码编译器会提示错误,因为String类型并不是Number类型的子类
+ //showKeyValue1(generic1);
+ Generic generic1 = new Generic("11111");
+ Generic generic2 = new Generic(2222);
+ Generic generic3 = new Generic(2.4f);
+ Generic generic4 = new Generic(2.56);
+
+ showKeyValue1(generic2);
+ showKeyValue1(generic3);
+ showKeyValue1(generic4);
}
+ @Test
+ public void testdown () {
+
+ Generic
 +
+
+
+ +
+  +
+  +
+  +
+  +
+  +
+