diff --git a/.gitattributes b/.gitattributes
new file mode 100644
index 0000000000..7ecfd88a34
--- /dev/null
+++ b/.gitattributes
@@ -0,0 +1,2 @@
+*.md linguist-detectable=true
+*.md linguist-documentation=false
\ No newline at end of file
diff --git a/.github/ISSUE_TEMPLATE/.wait.md b/.github/ISSUE_TEMPLATE/.wait.md
deleted file mode 100644
index 23436ee86c..0000000000
--- a/.github/ISSUE_TEMPLATE/.wait.md
+++ /dev/null
@@ -1,30 +0,0 @@
----
-name: 等待翻译
-about: 我想翻译的文章暂时被别人占着,我有意作为下一个占有者
-title: 'wait '
-labels: waiting
-assignees: ''
-
----
-
-
-
-
-
-
-
-
-
-我已阅读过[翻译组工作流程](https://github.com/labuladong/fucking-algorithm/issues/9),我是按照规定的流程图选择的任务,我开启的 issue 是【等待翻译】。
-
-我已阅读过[翻译要求](https://github.com/labuladong/fucking-algorithm/blob/english/README.md),我的翻译会按照要求,认真负责。
-
-我正在等待如下文章的翻译工作结束(点击可查看目标文章):
-
-
-[动态规划系列/抢房子.md](https://github.com/labuladong/fucking-algorithm/blob/master/动态规划系列/抢房子.md)
-
-
-该文章的提交权限暂时被 #XX 占有,我已经开始了我的翻译工作,且开启了对该 issue 的 Subscribe,待上述 issue 结束后,我可能会很快占有该文章的翻译权,结合我的翻译成果和他人的成果将这篇文章翻译得更好。
-
-
\ No newline at end of file
diff --git a/.github/ISSUE_TEMPLATE/01-algo-website-bug.md b/.github/ISSUE_TEMPLATE/01-algo-website-bug.md
new file mode 100644
index 0000000000..78a19e2e7a
--- /dev/null
+++ b/.github/ISSUE_TEMPLATE/01-algo-website-bug.md
@@ -0,0 +1,21 @@
+---
+name: Website bug
+about: Report bug on website `labuladong.online`
+title: ''
+labels: algo-websie-bug
+assignees: labuladong
+
+---
+
+**Network condition:**
+China network or Global network?
+
+**Describe the bug**
+A clear and concise description of what the bug is.
+
+**Screenshots**
+If applicable, add screenshots to help explain your problem.
+
+**Platform**
+Mobile phone or PC?
+What kind of web browser? (chrome/edge/...)
diff --git a/.github/ISSUE_TEMPLATE/02-algo-visualize-bug.md b/.github/ISSUE_TEMPLATE/02-algo-visualize-bug.md
new file mode 100644
index 0000000000..12244361fa
--- /dev/null
+++ b/.github/ISSUE_TEMPLATE/02-algo-visualize-bug.md
@@ -0,0 +1,10 @@
+---
+name: Algo-visualize bug
+about: Report bug for algo-visualize tool in website/plugins
+title: ''
+labels: algo-visualize-bug
+assignees: labuladong
+
+---
+
+
diff --git a/.github/ISSUE_TEMPLATE/03-chrome-extension-bug.md b/.github/ISSUE_TEMPLATE/03-chrome-extension-bug.md
new file mode 100644
index 0000000000..f86bb86a35
--- /dev/null
+++ b/.github/ISSUE_TEMPLATE/03-chrome-extension-bug.md
@@ -0,0 +1,17 @@
+---
+name: Chrome extension bug
+about: Report bug on Chrome extension
+title: ''
+labels: algo-website, chrome-extension-bug
+assignees: labuladong
+
+---
+
+**Describe the bug**
+A clear and concise description of what the bug is.
+
+**Screenshots**
+If applicable, add screenshots to help explain your problem.
+
+**Platform**
+What kind of web browser are you using? (chrome/edge/...)
diff --git a/.github/ISSUE_TEMPLATE/04-vscode-extension-bug.md b/.github/ISSUE_TEMPLATE/04-vscode-extension-bug.md
new file mode 100644
index 0000000000..14ade83a08
--- /dev/null
+++ b/.github/ISSUE_TEMPLATE/04-vscode-extension-bug.md
@@ -0,0 +1,17 @@
+---
+name: VSCode extension bug
+about: Report bug on vscode extension
+title: ''
+labels: vscode-extension-bug
+assignees: labuladong
+
+---
+
+**Version:**
+What's the extension version are you using?
+
+**Describe the bug**
+A clear and concise description of what the bug is.
+
+**Screenshots**
+If applicable, add screenshots to help explain your problem.
diff --git a/.github/ISSUE_TEMPLATE/05-jetbrain-plugin-bug.md b/.github/ISSUE_TEMPLATE/05-jetbrain-plugin-bug.md
new file mode 100644
index 0000000000..edc29bf017
--- /dev/null
+++ b/.github/ISSUE_TEMPLATE/05-jetbrain-plugin-bug.md
@@ -0,0 +1,17 @@
+---
+name: JetBrain plugin bug
+about: Report bug on JetBrain plugin
+title: ''
+labels: jb-plugin-bug
+assignees: labuladong
+
+---
+
+**Version:**
+What's the plugin version are you using?
+
+**Describe the bug**
+A clear and concise description of what the bug is.
+
+**Screenshots**
+If applicable, add screenshots to help explain your problem.
diff --git a/.github/ISSUE_TEMPLATE/06-suggestion.md b/.github/ISSUE_TEMPLATE/06-suggestion.md
new file mode 100644
index 0000000000..628282c5d4
--- /dev/null
+++ b/.github/ISSUE_TEMPLATE/06-suggestion.md
@@ -0,0 +1,12 @@
+---
+name: Suggestion
+about: Suggest an idea/improvement for this project
+title: ''
+labels: feature-request
+assignees: labuladong
+
+---
+
+Do you have any suggestions?
+
+Is there anything that you feel inconvenient to use?
diff --git a/.github/ISSUE_TEMPLATE/bug_report.md b/.github/ISSUE_TEMPLATE/bug_report.md
deleted file mode 100644
index df5b188691..0000000000
--- a/.github/ISSUE_TEMPLATE/bug_report.md
+++ /dev/null
@@ -1,21 +0,0 @@
----
-name: 发现问题
-about: 我发现了某处链接或者知识点的错误
-title: 'bug '
-labels: bug
-assignees: ''
-
----
-
-
-
-你好,我发现如下文章有 bug(点击文字可跳转到相关文章):
-
-[动态规划系列/抢房子.md](https://github.com/labuladong/fucking-algorithm/blob/master/动态规划系列/抢房子.md)
-
-问题描述:
-
-某章图片链接失效/其中的 XXX 内容有误/等等。
diff --git a/.github/ISSUE_TEMPLATE/others.md b/.github/ISSUE_TEMPLATE/others.md
deleted file mode 100644
index f03e25ec2c..0000000000
--- a/.github/ISSUE_TEMPLATE/others.md
+++ /dev/null
@@ -1,10 +0,0 @@
----
-name: 其他issue
-about: 我还有一些其他的建议/问题
-title: ''
-labels: ''
-assignees: ''
-
----
-
-
diff --git a/.github/ISSUE_TEMPLATE/translate.md b/.github/ISSUE_TEMPLATE/translate.md
deleted file mode 100644
index 2f38032020..0000000000
--- a/.github/ISSUE_TEMPLATE/translate.md
+++ /dev/null
@@ -1,28 +0,0 @@
----
-name: 参与翻译
-about: 我想参与仓库中文章的翻译工作
-title: 'translate '
-labels: translate
-assignees: ''
-
----
-
-
-
-
-
-
-
-
-
-我已阅读过[翻译组工作流程](https://github.com/labuladong/fucking-algorithm/issues/9),我已阅读过[翻译要求](https://github.com/labuladong/fucking-algorithm/blob/english/README.md),我拥有了向主仓库提交 pull request 的权限,会对负责此次翻译的质量。
-
-我将开始翻译如下文章(点击可查看目标文章):
-
-
-[动态规划系列/抢房子.md](https://github.com/labuladong/fucking-algorithm/blob/master/动态规划系列/抢房子.md)
-
-我对如何翻译此文章已经心中有数,我准备将它翻译成:**英文**
-
-
-**预计 3 天内翻译完成**,我会尽可能快地完成翻译,主仓库允许第一个完成的 pull request 添加翻译者昵称/姓名及 Github profile 链接(或任意你希望的链接)。
\ No newline at end of file
diff --git a/.github/PULL_REQUEST_TEMPLATE.md b/.github/PULL_REQUEST_TEMPLATE.md
new file mode 100644
index 0000000000..e69de29bb2
diff --git a/.gitignore b/.gitignore
new file mode 100644
index 0000000000..63123fbe81
--- /dev/null
+++ b/.gitignore
@@ -0,0 +1 @@
+.DS_store
diff --git a/README.md b/README.md
index 9094d6fd69..cbd530297a 100644
--- a/README.md
+++ b/README.md
@@ -1,119 +1,433 @@
-English translation is processing…… Star this repo and go back sonn:)
+[](https://star-history.com/#labuladong/fucking-algorithm&Date)
-没想到两天就火了,招募翻译组啦,有兴趣可查看这个置顶 [issue](https://github.com/labuladong/fucking-algorithm/issues/9),成为本仓库的贡献者就是这么容易!
-# 前言
+English version is on [labuladong.online](https://labuladong.online/algo/en/) too. Just enjoy:)
-本仓库总共 60 多篇原创文章,基本上都是基于 LeetCode 的题目,涵盖了所有题型和技巧,而且一定要做到**举一反三,通俗易懂**,绝不是简单的代码堆砌,后面有目录。
+# labuladong 的算法笔记
+
+本仓库总共 60 多篇原创文章,都是基于 LeetCode 的题目,涵盖了所有题型和技巧,而且一定要做到**举一反三,通俗易懂**,绝不是简单的代码堆砌,后面有目录。
我先吐槽几句。**刷题刷题,刷的是题,培养的是思维,本仓库的目的就是传递这种算法思维**。我要是只写一个包含 LeetCode 题目代码的仓库,有个锤子用?没有思路解释,没有思维框架,顶多写个时间复杂度,那玩意一眼就能看出来。
只想要答案的话很容易,题目评论区五花八门的答案,动不动就秀 python 一行代码解决,有那么多人点赞。问题是,你去做算法题,是去学习编程语言的奇技淫巧的,还是学习算法思维的呢?你的快乐,到底源自复制别人的一行代码通过测试,已完成题目 +1,还是源自自己通过逻辑推理和算法框架不看答案写出解法?
-网上总有大佬喷我,说我写这玩意太基础了,根本没必要啰嗦。我只能说大家刷算法就是找工作吃饭的,不是打竞赛的,我也是一路摸爬滚打过来的,我们要的是清楚明白有所得,不是故弄玄虚无所指。不想办法做到通俗易懂,难道要上来先把《算法导论》吹上天,然后把人家都心怀敬仰地劝退?别的不说,公众号几万读者,PDF 版本上万次下载,联系我的出版社都好几家,说明质量还过得去吧?
+网上总有大佬喷我,说我写的东西太基础,要么说不能借助框架思维来学习算法。我只能说大家刷算法就是找工作吃饭的,不是打竞赛的,我也是一路摸爬滚打过来的,我们要的是清楚明白有所得,不是故弄玄虚无所指。
+
+不想办法做到通俗易懂,难道要上来先把《算法导论》吹上天,然后把人家都心怀敬仰地劝退?
**做啥事情做多了,都能发现套路的,我把各种算法套路框架总结出来,相信可以帮助其他人少走弯路**。我这个纯靠自学的小童鞋,花了一年时间刷题和总结,自己写了一份算法小抄,后面有目录,这里就不废话了。
-### 使用方法
-
-1、**先给本仓库点个 star,满足一下我的虚荣心**,文章质量绝对值你一个 star。我还在继续创作,给我一点继续写文的动力,感谢。
-
-2、可以在我的 gitbook 上直接查看所有文章,会和公众号同步持续更新文章,建议收藏。地址:https://labuladong.gitbook.io/algo
-
-3、可以关注我的公众号 **labuladong** 及时获取更新。我不喜欢转载乱七八糟的低质文章,**坚持高质量原创,说是最良心最硬核的技术公众号都不为过**。
-
-这些文章就是从公众号里整理出来的,目前主要发文平台是微信公众号,公众号后台回复关键词【电子书】可以获得这份小抄的电子书版本,方便你做笔记:
-
- -
-其他的先不多说了,直接上干货吧,我们一起日穿 LeetCode,感受一下支配算法的乐趣。
-
-# 目录
-
-* 第零章、必读系列
- * [学习算法和刷题的框架思维](算法思维系列/学习数据结构和算法的高效方法.md)
- * [学习数据结构和算法读什么书](算法思维系列/为什么推荐算法4.md)
- * [动态规划解题框架](动态规划系列/动态规划详解进阶.md)
- * [动态规划答疑篇](动态规划系列/最优子结构.md)
- * [回溯算法解题框架](算法思维系列/回溯算法详解修订版.md)
- * [二分查找解题框架](算法思维系列/二分查找详解.md)
- * [滑动窗口解题框架](算法思维系列/滑动窗口技巧.md)
- * [双指针技巧解题框架](算法思维系列/双指针技巧.md)
- * [Linux的进程、线程、文件描述符是什么](技术/linux进程.md)
- * [Git/SQL/正则表达式的在线练习平台](技术/在线练习平台.md)
-* 第一章、动态规划系列
- * [动态规划详解](动态规划系列/动态规划详解进阶.md)
- * [动态规划答疑篇](动态规划系列/最优子结构.md)
- * [动态规划设计:最长递增子序列](动态规划系列/动态规划设计:最长递增子序列.md)
- * [编辑距离](动态规划系列/编辑距离.md)
- * [经典动态规划问题:高楼扔鸡蛋](动态规划系列/高楼扔鸡蛋问题.md)
- * [经典动态规划问题:高楼扔鸡蛋(进阶)](动态规划系列/高楼扔鸡蛋进阶.md)
- * [动态规划之子序列问题解题模板](动态规划系列/子序列问题模板.md)
- * [动态规划之博弈问题](动态规划系列/动态规划之博弈问题.md)
- * [贪心算法之区间调度问题](动态规划系列/贪心算法之区间调度问题.md)
- * [动态规划之KMP字符匹配算法](动态规划系列/动态规划之KMP字符匹配算法.md)
- * [团灭 LeetCode 股票买卖问题](动态规划系列/团灭股票问题.md)
- * [团灭 LeetCode 打家劫舍问题](动态规划系列/抢房子.md)
- * [动态规划之四键键盘](动态规划系列/动态规划之四键键盘.md)
- * [动态规划之正则表达](动态规划系列/动态规划之正则表达.md)
- * [最长公共子序列](动态规划系列/最长公共子序列.md)
-* 第二章、数据结构系列
- * [学习算法和刷题的思路指南](算法思维系列/学习数据结构和算法的高效方法.md)
- * [学习数据结构和算法读什么书](算法思维系列/为什么推荐算法4.md)
- * [二叉堆详解实现优先级队列](数据结构系列/二叉堆详解实现优先级队列.md)
- * [LRU算法详解](高频面试系列/LRU算法.md)
- * [二叉搜索树操作集锦](数据结构系列/二叉搜索树操作集锦.md)
- * [特殊数据结构:单调栈](数据结构系列/单调栈.md)
- * [特殊数据结构:单调队列](数据结构系列/单调队列.md)
- * [设计Twitter](数据结构系列/设计Twitter.md)
- * [递归反转链表的一部分](数据结构系列/递归反转链表的一部分.md)
- * [队列实现栈\|栈实现队列](数据结构系列/队列实现栈栈实现队列.md)
-* 第三章、算法思维系列
- * [算法学习之路](算法思维系列/算法学习之路.md)
- * [回溯算法详解](算法思维系列/回溯算法详解修订版.md)
- * [回溯算法团灭排列、组合、子集问题](高频面试系列/子集排列组合.md)
- * [二分查找详解](算法思维系列/二分查找详解.md)
- * [双指针技巧总结](算法思维系列/双指针技巧.md)
- * [滑动窗口技巧](算法思维系列/滑动窗口技巧.md)
- * [twoSum问题的核心思想](算法思维系列/twoSum问题的核心思想.md)
- * [常用的位操作](算法思维系列/常用的位操作.md)
- * [拆解复杂问题:实现计算器](数据结构系列/实现计算器.md)
- * [烧饼排序](算法思维系列/烧饼排序.md)
- * [前缀和技巧](算法思维系列/前缀和技巧.md)
- * [字符串乘法](算法思维系列/字符串乘法.md)
- * [FloodFill算法详解及应用](算法思维系列/FloodFill算法详解及应用.md)
- * [区间调度之区间合并问题](算法思维系列/区间调度问题之区间合并.md)
- * [区间调度之区间交集问题](算法思维系列/区间交集问题.md)
- * [信封嵌套问题](算法思维系列/信封嵌套问题.md)
- * [几个反直觉的概率问题](算法思维系列/几个反直觉的概率问题.md)
- * [洗牌算法](算法思维系列/洗牌算法.md)
- * [递归详解](算法思维系列/递归详解.md)
-* 第四章、高频面试系列
- * [如何实现LRU算法](高频面试系列/LRU算法.md)
- * [如何高效寻找素数](高频面试系列/打印素数.md)
- * [如何计算编辑距离](动态规划系列/编辑距离.md)
- * [如何运用二分查找算法](高频面试系列/koko偷香蕉.md)
- * [如何高效解决接雨水问题](高频面试系列/接雨水.md)
- * [如何去除有序数组的重复元素](高频面试系列/如何去除有序数组的重复元素.md)
- * [如何寻找最长回文子串](高频面试系列/最长回文子串.md)
- * [如何k个一组反转链表](高频面试系列/k个一组反转链表.md)
- * [如何判定括号合法性](高频面试系列/合法括号判定.md)
- * [如何寻找消失的元素](高频面试系列/消失的元素.md)
- * [如何寻找缺失和重复的元素](高频面试系列/缺失和重复的元素.md)
- * [如何判断回文链表](高频面试系列/判断回文链表.md)
- * [如何在无限序列中随机抽取元素](高频面试系列/水塘抽样.md)
- * [如何调度考生的座位](高频面试系列/座位调度.md)
- * [Union-Find算法详解](算法思维系列/UnionFind算法详解.md)
- * [Union-Find算法应用](算法思维系列/UnionFind算法应用.md)
- * [一行代码就能解决的算法题](高频面试系列/一行代码解决的智力题.md)
- * [二分查找高效判定子序列](高频面试系列/二分查找判定子序列.md)
-* 第五章、计算机技术
- * [Linux的进程、线程、文件描述符是什么](技术/linux进程.md)
- * [一文看懂 session 和 cookie](技术/session和cookie.md)
- * [关于 Linux shell 你必须知道的](技术/linuxshell.md)
- * [加密算法的前身今世](技术/密码技术.md)
- * [Git/SQL/正则表达式的在线练习平台](技术/在线练习平台.md)
+## 在开始学习之前
+
+**1、先给本仓库点个 star,满足一下我的虚荣心**,文章质量绝对值你一个 star。我还在继续创作,给我一点继续写文的动力,感谢。
+
+**2、建议收藏我的在线网站,每篇文章开头都有对应的力扣题目链接,可以边看文章边刷题,一共可以手把手带你刷 500 道题目**:
+
+2024 最新地址:https://labuladong.online/algo/
+
+~~GitHub Pages 地址:https://labuladong.online/algo/~~
+
+~~Gitee Pages 地址:https://labuladong.gitee.io/algo/~~
+
+## labuladong 刷题全家桶简介
+
+### 一、算法可视化面板
+
+我的算法网站、所有配套插件都集成了一个算法可视化工具,可以对数据结构和递归过程进行可视化,大幅降低理解算法的难度。几乎每道题目的解法代码都有对应的可视化面板,具体参见下方介绍。
+
+
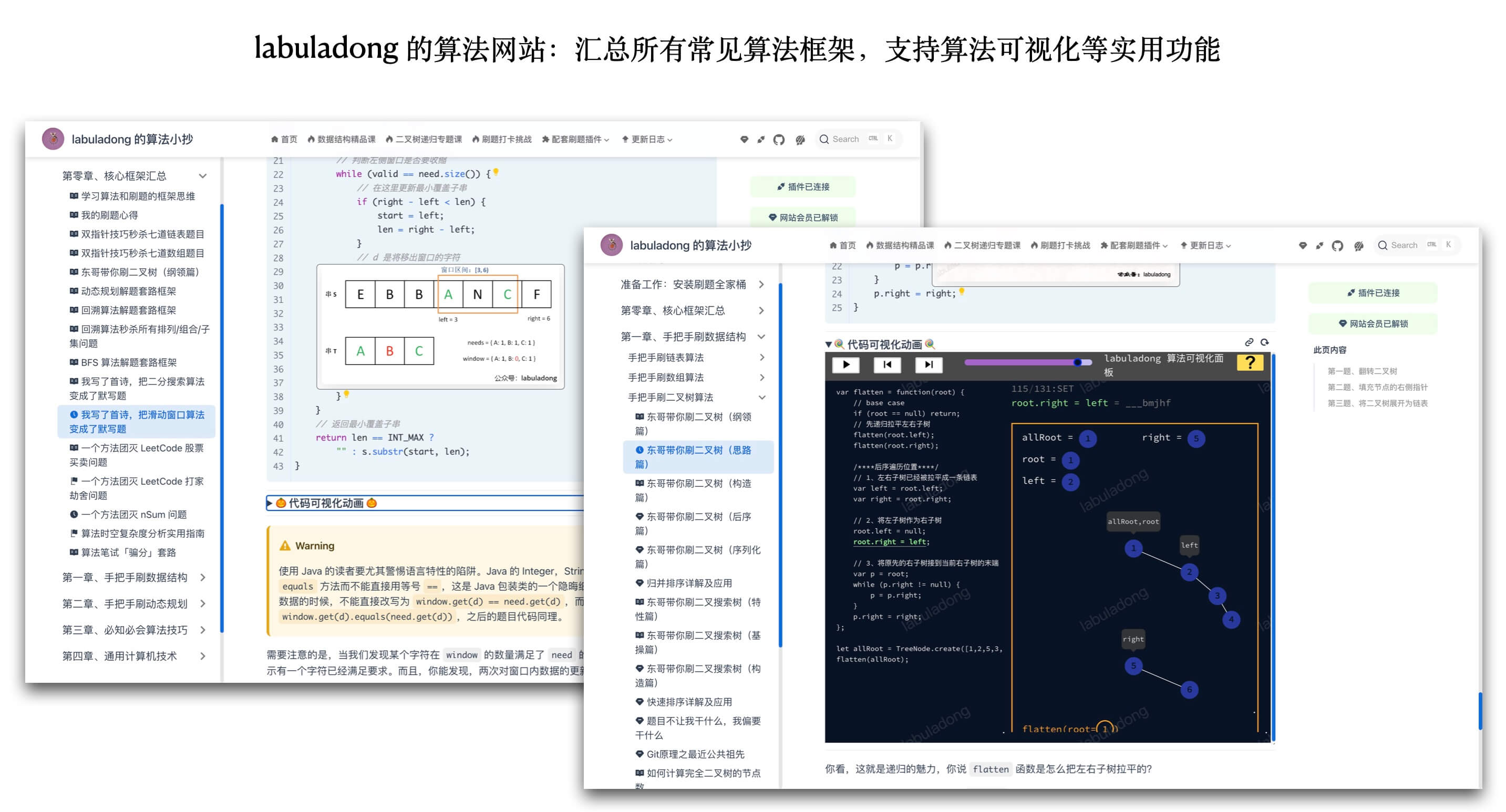
+### 二、学习网站
+
+内容当然是我的系列算法教程中最核心的部分,我的算法教程都发布在网站 [labuladong.online](https://labuladong.online/algo/) 上,相信你会未来会在这里花费大量的学习时间,而不是仅仅加入收藏夹~
+
+
+
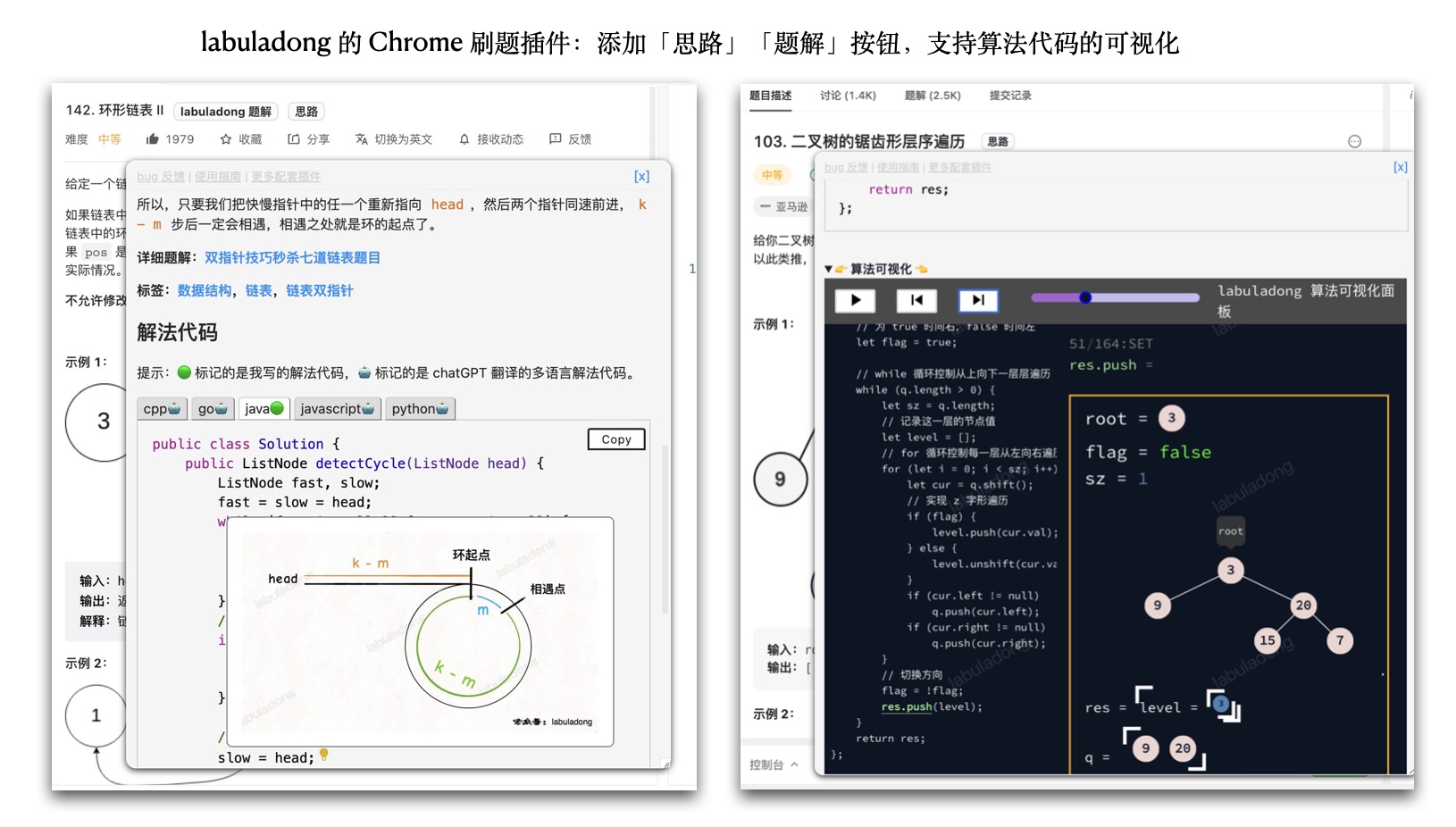
+### 三、Chrome 插件
+
+**主要功能**:Chrome 插件可以在中文版力扣或英文版 LeetCode 上快捷查看我的「题解」或「思路」,并添加了题目和算法技巧之间的引用关系,可以和我的网站/公众号/课程联动,给我的读者提供最丝滑的刷题体验。安装使用手册见下方目录。
+
+
+
+
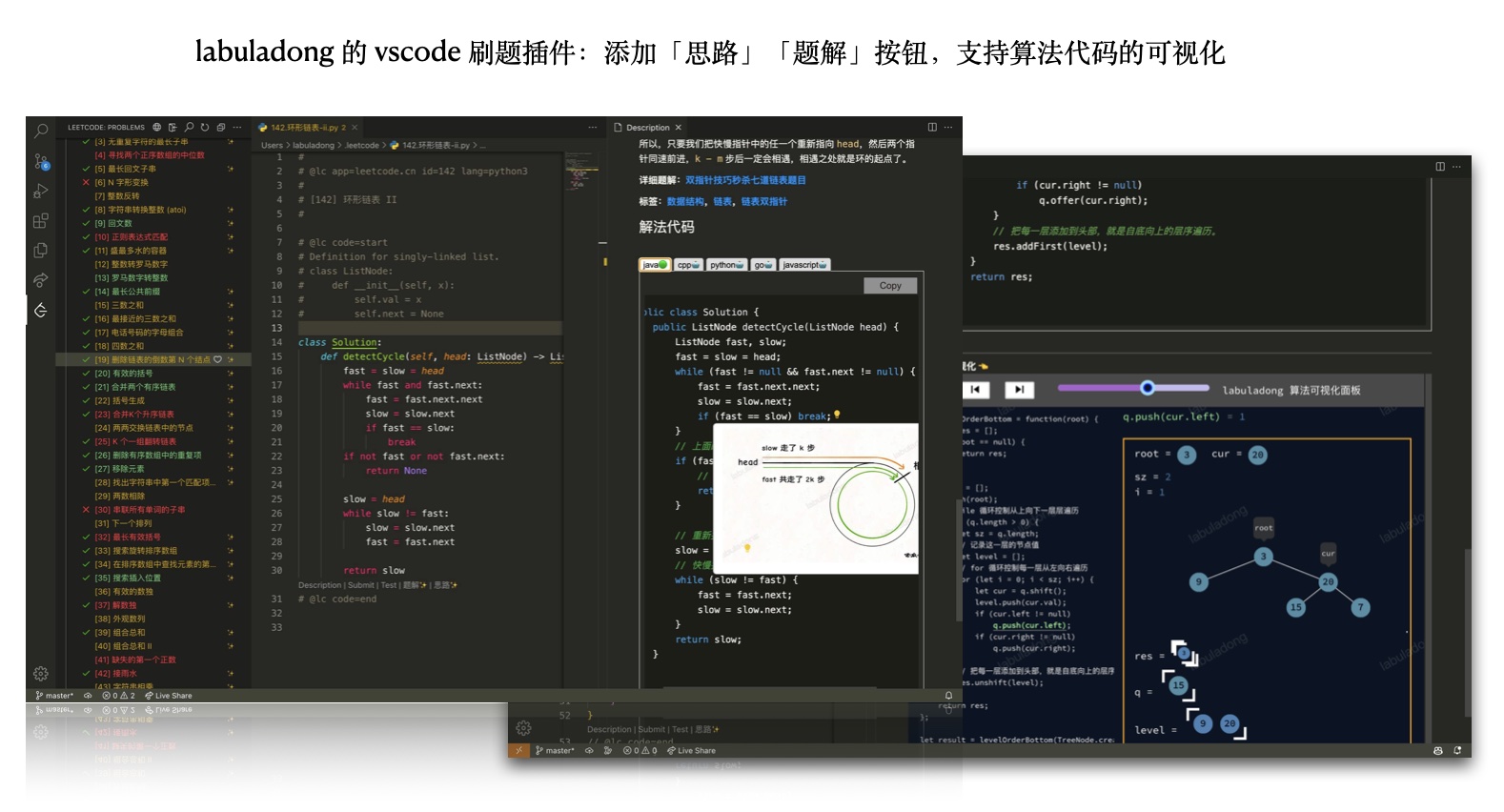
+### 四、vscode 插件
+
+**主要功能**:和 Chrome 插件功能基本相同,习惯在 vscode 上刷题的读者可以使用该插件。安装使用手册见下方目录。
+
+
+
+
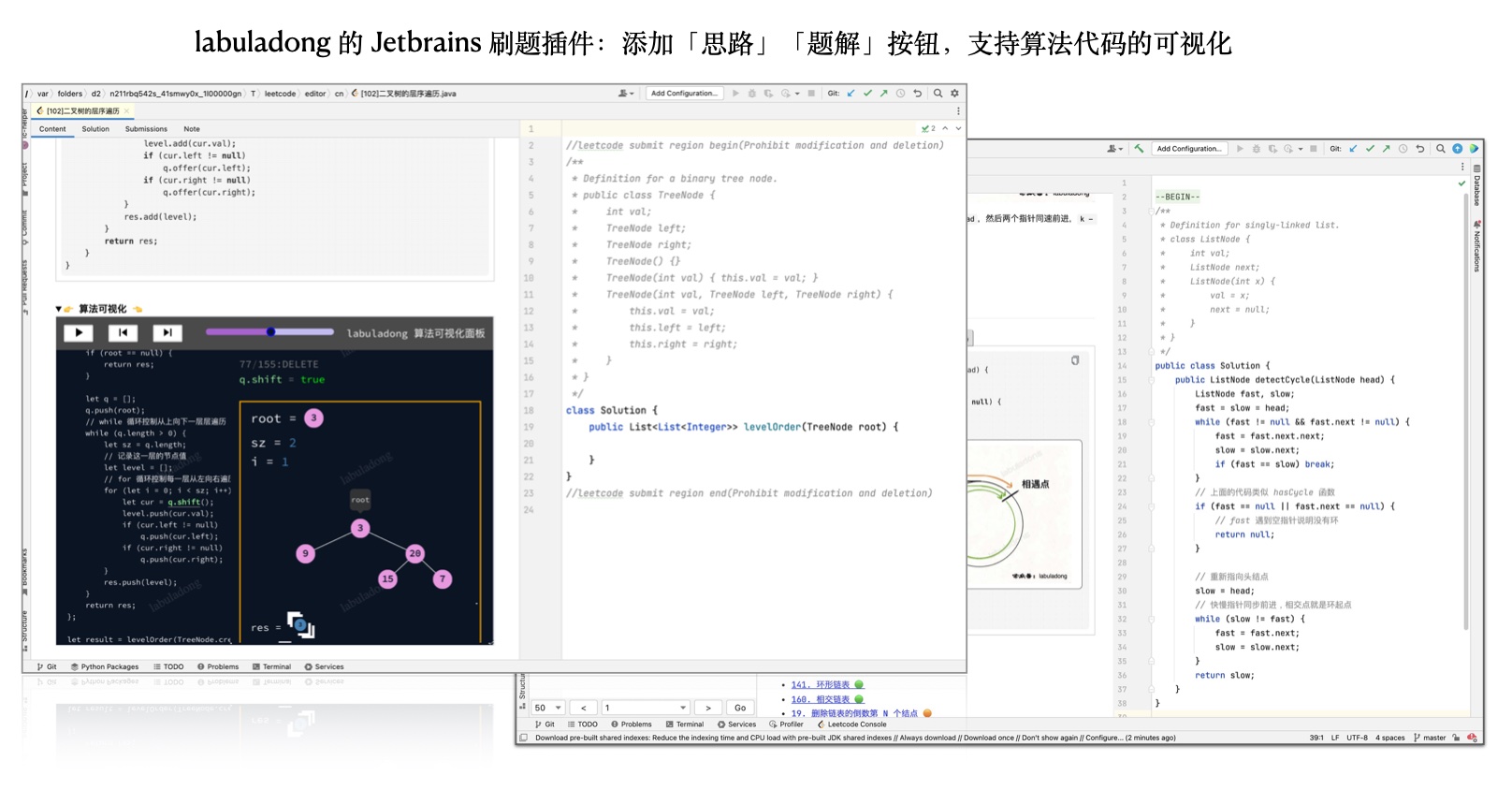
+### 五、Jetbrains 插件
+
+**主要功能**:和 Chrome 插件功能基本相同,习惯在 Jetbrains 家的 IDE(PyCharm/Intellij/Goland 等)上刷题的读者可以使用该插件。安装使用手册见下方目录。
+
+
+
+
+最后祝大家学习愉快,在题海中自在遨游!
+
+
+# 文章目录
+
+
+
+### [本站简介](https://labuladong.online/algo/home/)
+
+### [配套插件及算法可视化](https://labuladong.online/algo/menu/tools/)
+ * [配套 Chrome 刷题插件](https://labuladong.online/algo/intro/chrome/)
+ * [配套 vscode 刷题插件](https://labuladong.online/algo/intro/vscode/)
+ * [配套 JetBrains 刷题插件](https://labuladong.online/algo/intro/jetbrains/)
+ * [算法可视化面板使用说明](https://labuladong.online/algo/intro/visualize/)
+ * [本站付费会员](https://labuladong.online/algo/intro/site-vip/)
+
+### [针对初学和速成的学习规划](https://labuladong.online/algo/menu/plan/)
+ * [算法刷题的重点和坑](https://labuladong.online/algo/intro/how-to-learn-algorithms/)
+ * [初学者学习规划](https://labuladong.online/algo/intro/beginner-learning-plan/)
+ * [速成学习规划](https://labuladong.online/algo/intro/quick-learning-plan/)
+ * [习题章节的练习/复习方法](https://labuladong.online/algo/intro/how-to-practice/)
+ * [算法可视化速查页](https://labuladong.online/algo/intro/visualize-catalog/)
+
+### [入门:编程语言基础及练习](https://labuladong.online/algo/menu/)
+ * [本章导读](https://labuladong.online/algo/intro/programming-language-basic/)
+ * [C++ 语言基础](https://labuladong.online/algo/programming-language-basic/cpp/)
+ * [Java 语言基础](https://labuladong.online/algo/programming-language-basic/java/)
+ * [Golang 语言基础](https://labuladong.online/algo/programming-language-basic/golang/)
+ * [Python 语言基础](https://labuladong.online/algo/programming-language-basic/python/)
+ * [JavaScript 语言基础](https://labuladong.online/algo/intro/js/)
+ * [力扣/LeetCode 解题须知](https://labuladong.online/algo/intro/leetcode/)
+ * [编程语言刷题实践](https://labuladong.online/algo/programming-language-basic/lc-practice/)
+
+### [基础:数据结构及排序精讲](https://labuladong.online/algo/menu/quick-start/)
+ * [本章导读](https://labuladong.online/algo/intro/data-structure-basic/)
+ * [时间空间复杂度入门](https://labuladong.online/algo/intro/complexity-basic/)
+
+ * [手把手带你实现动态数组](https://labuladong.online/algo/menu/dynamic-array/)
+ * [数组(顺序存储)基本原理](https://labuladong.online/algo/data-structure-basic/array-basic/)
+ * [动态数组代码实现](https://labuladong.online/algo/data-structure-basic/array-implement/)
+
+ * [手把手带你实现单/双链表](https://labuladong.online/algo/menu/linked-list/)
+ * [链表(链式存储)基本原理](https://labuladong.online/algo/data-structure-basic/linkedlist-basic/)
+ * [链表代码实现](https://labuladong.online/algo/data-structure-basic/linkedlist-implement/)
+
+ * [手把手带你实现队列/栈](https://labuladong.online/algo/menu/queue-stack/)
+ * [队列/栈基本原理](https://labuladong.online/algo/data-structure-basic/queue-stack-basic/)
+ * [用链表实现队列/栈](https://labuladong.online/algo/data-structure-basic/linked-queue-stack/)
+ * [环形数组技巧](https://labuladong.online/algo/data-structure-basic/cycle-array/)
+ * [用数组实现队列/栈](https://labuladong.online/algo/data-structure-basic/array-queue-stack/)
+ * [双端队列(Deque)原理及实现](https://labuladong.online/algo/data-structure-basic/deque-implement/)
+
+ * [哈希表的原理及实现](https://labuladong.online/algo/menu/)
+ * [哈希表核心原理](https://labuladong.online/algo/data-structure-basic/hashmap-basic/)
+ * [用拉链法实现哈希表](https://labuladong.online/algo/data-structure-basic/hashtable-chaining/)
+ * [线性探查法的两个难点](https://labuladong.online/algo/data-structure-basic/linear-probing-key-point/)
+ * [线性探查法的两种代码实现](https://labuladong.online/algo/data-structure-basic/linear-probing-code/)
+ * [哈希集合的原理及代码实现](https://labuladong.online/algo/data-structure-basic/hash-set/)
+
+ * [哈希表结构的种种变换](https://labuladong.online/algo/menu/)
+ * [用链表加强哈希表(LinkedHashMap)](https://labuladong.online/algo/data-structure-basic/hashtable-with-linked-list/)
+ * [用数组加强哈希表(ArrayHashMap)](https://labuladong.online/algo/data-structure-basic/hashtable-with-array/)
+
+ * [二叉树结构及遍历](https://labuladong.online/algo/menu/binary-tree/)
+ * [二叉树基础及常见类型](https://labuladong.online/algo/data-structure-basic/binary-tree-basic/)
+ * [二叉树的递归/层序遍历](https://labuladong.online/algo/data-structure-basic/binary-tree-traverse-basic/)
+ * [多叉树的递归/层序遍历](https://labuladong.online/algo/data-structure-basic/n-ary-tree-traverse-basic/)
+
+ * [二叉树结构的种种变换](https://labuladong.online/algo/menu/binary-tree/)
+ * [二叉搜索树的应用及可视化](https://labuladong.online/algo/data-structure-basic/tree-map-basic/)
+ * [红黑树的完美平衡及可视化](https://labuladong.online/algo/data-structure-basic/rbtree-basic/)
+ * [Trie/字典树/前缀树原理及可视化](https://labuladong.online/algo/data-structure-basic/trie-map-basic/)
+ * [二叉堆核心原理及可视化](https://labuladong.online/algo/data-structure-basic/binary-heap-basic/)
+ * [二叉堆/优先级队列代码实现](https://labuladong.online/algo/data-structure-basic/binary-heap-implement/)
+ * [线段树核心原理及可视化](https://labuladong.online/algo/data-structure-basic/segment-tree-basic/)
+ * [正在更新 ing](https://labuladong.online/algo/intro/updating/)
+
+ * [图论数据结构及遍历](https://labuladong.online/algo/menu/graph-theory/)
+ * [图结构基础及通用代码实现](https://labuladong.online/algo/data-structure-basic/graph-basic/)
+ * [图结构的 DFS/BFS 遍历](https://labuladong.online/algo/data-structure-basic/graph-traverse-basic/)
+ * [Union Find 并查集原理](https://labuladong.online/algo/data-structure-basic/union-find-basic/)
+ * [正在更新 ing](https://labuladong.online/algo/intro/updating/)
+
+ * [十大排序算法原理及可视化](https://labuladong.online/algo/menu/sorting/)
+ * [本章导读](https://labuladong.online/algo/intro/sorting/)
+ * [排序算法的关键指标](https://labuladong.online/algo/data-structure-basic/sort-basic/)
+ * [选择排序所面临的问题](https://labuladong.online/algo/data-structure-basic/select-sort/)
+ * [拥有稳定性:冒泡排序](https://labuladong.online/algo/data-structure-basic/bubble-sort/)
+ * [运用逆向思维:插入排序](https://labuladong.online/algo/data-structure-basic/insertion-sort/)
+ * [突破 O(N^2):希尔排序](https://labuladong.online/algo/data-structure-basic/shell-sort/)
+ * [妙用二叉树前序位置:快速排序](https://labuladong.online/algo/data-structure-basic/quick-sort/)
+ * [妙用二叉树后序位置:归并排序](https://labuladong.online/algo/data-structure-basic/merge-sort/)
+ * [二叉堆结构的运用:堆排序](https://labuladong.online/algo/data-structure-basic/heap-sort/)
+ * [全新的排序原理:计数排序](https://labuladong.online/algo/data-structure-basic/counting-sort/)
+ * [博采众长:桶排序](https://labuladong.online/algo/data-structure-basic/bucket-sort/)
+ * [基数排序(Radix Sort)](https://labuladong.online/algo/data-structure-basic/radix-sort/)
+
+ * [正在更新 ing](https://labuladong.online/algo/intro/updating/)
+
+
+### [第零章、核心刷题框架汇总](https://labuladong.online/algo/menu/core/)
+ * [本章导读](https://labuladong.online/algo/intro/core-intro/)
+ * [学习数据结构和算法的框架思维](https://labuladong.online/algo/essential-technique/algorithm-summary/)
+ * [双指针技巧秒杀七道链表题目](https://labuladong.online/algo/essential-technique/linked-list-skills-summary/)
+ * [双指针技巧秒杀七道数组题目](https://labuladong.online/algo/essential-technique/array-two-pointers-summary/)
+ * [滑动窗口算法核心代码模板](https://labuladong.online/algo/essential-technique/sliding-window-framework/)
+ * [二分搜索算法核心代码模板](https://labuladong.online/algo/essential-technique/binary-search-framework/)
+ * [动态规划解题套路框架](https://labuladong.online/algo/essential-technique/dynamic-programming-framework/)
+ * [回溯算法解题套路框架](https://labuladong.online/algo/essential-technique/backtrack-framework/)
+ * [BFS 算法解题套路框架](https://labuladong.online/algo/essential-technique/bfs-framework/)
+ * [二叉树系列算法核心纲领](https://labuladong.online/algo/essential-technique/binary-tree-summary/)
+ * [回溯算法秒杀所有排列/组合/子集问题](https://labuladong.online/algo/essential-technique/permutation-combination-subset-all-in-one/)
+ * [贪心算法解题套路框架](https://labuladong.online/algo/essential-technique/greedy/)
+ * [分治算法解题套路框架](https://labuladong.online/algo/essential-technique/divide-and-conquer/)
+ * [算法时空复杂度分析实用指南](https://labuladong.online/algo/essential-technique/complexity-analysis/)
+
+
+### [第一章、经典数据结构算法](https://labuladong.online/algo/menu/ds/)
+ * [手把手刷链表算法](https://labuladong.online/algo/menu/linked-list/)
+ * [双指针技巧秒杀七道链表题目](https://labuladong.online/algo/essential-technique/linked-list-skills-summary/)
+ * [【强化练习】链表双指针经典习题](https://labuladong.online/algo/problem-set/linkedlist-two-pointers/)
+ * [单链表的花式反转方法汇总](https://labuladong.online/algo/data-structure/reverse-linked-list-recursion/)
+ * [如何判断回文链表](https://labuladong.online/algo/data-structure/palindrome-linked-list/)
+
+ * [手把手刷数组算法](https://labuladong.online/algo/menu/array/)
+ * [双指针技巧秒杀七道数组题目](https://labuladong.online/algo/essential-technique/array-two-pointers-summary/)
+ * [二维数组的花式遍历技巧](https://labuladong.online/algo/practice-in-action/2d-array-traversal-summary/)
+ * [一个方法团灭 nSum 问题](https://labuladong.online/algo/practice-in-action/nsum/)
+ * [【强化练习】数组双指针经典习题](https://labuladong.online/algo/problem-set/array-two-pointers/)
+ * [小而美的算法技巧:前缀和数组](https://labuladong.online/algo/data-structure/prefix-sum/)
+ * [【强化练习】前缀和技巧经典习题](https://labuladong.online/algo/problem-set/perfix-sum/)
+ * [小而美的算法技巧:差分数组](https://labuladong.online/algo/data-structure/diff-array/)
+ * [滑动窗口算法核心代码模板](https://labuladong.online/algo/essential-technique/sliding-window-framework/)
+ * [【强化练习】滑动窗口算法经典习题](https://labuladong.online/algo/problem-set/sliding-window/)
+ * [滑动窗口延伸:Rabin Karp 字符匹配算法](https://labuladong.online/algo/practice-in-action/rabinkarp/)
+ * [二分搜索算法核心代码模板](https://labuladong.online/algo/essential-technique/binary-search-framework/)
+ * [实际运用二分搜索时的思维框架](https://labuladong.online/algo/frequency-interview/binary-search-in-action/)
+ * [【强化练习】二分搜索算法经典习题](https://labuladong.online/algo/problem-set/binary-search/)
+ * [带权重的随机选择算法](https://labuladong.online/algo/frequency-interview/random-pick-with-weight/)
+ * [田忌赛马背后的算法决策](https://labuladong.online/algo/practice-in-action/advantage-shuffle/)
+
+
+ * [手把手刷二叉树算法](https://labuladong.online/algo/menu/binary-tree/)
+ * [二叉树系列算法核心纲领](https://labuladong.online/algo/essential-technique/binary-tree-summary/)
+ * [二叉树心法(思路篇)](https://labuladong.online/algo/data-structure/binary-tree-part1/)
+ * [二叉树心法(构造篇)](https://labuladong.online/algo/data-structure/binary-tree-part2/)
+ * [二叉树心法(后序篇)](https://labuladong.online/algo/data-structure/binary-tree-part3/)
+ * [二叉树心法(序列化篇)](https://labuladong.online/algo/data-structure/serialize-and-deserialize-binary-tree/)
+ * [二叉搜索树心法(特性篇)](https://labuladong.online/algo/data-structure/bst-part1/)
+ * [二叉搜索树心法(基操篇)](https://labuladong.online/algo/data-structure/bst-part2/)
+ * [二叉搜索树心法(构造篇)](https://labuladong.online/algo/data-structure/bst-part3/)
+ * [二叉搜索树心法(后序篇)](https://labuladong.online/algo/data-structure/bst-part4/)
+
+ * [套模板解决 100 道二叉树习题](https://labuladong.online/algo/menu/100-bt/)
+ * [本章导读](https://labuladong.online/algo/intro/binary-tree-practice/)
+ * [【强化练习】用「遍历」思维解题 I](https://labuladong.online/algo/problem-set/binary-tree-traverse-i/)
+ * [【强化练习】用「遍历」思维解题 II](https://labuladong.online/algo/problem-set/binary-tree-traverse-ii/)
+ * [【强化练习】用「遍历」思维解题 III](https://labuladong.online/algo/problem-set/binary-tree-traverse-iii/)
+ * [【强化练习】用「分解问题」思维解题 I](https://labuladong.online/algo/problem-set/binary-tree-divide-i/)
+ * [【强化练习】用「分解问题」思维解题 II](https://labuladong.online/algo/problem-set/binary-tree-divide-ii/)
+ * [【强化练习】同时运用两种思维解题](https://labuladong.online/algo/problem-set/binary-tree-combine-two-view/)
+ * [【强化练习】利用后序位置解题 I](https://labuladong.online/algo/problem-set/binary-tree-post-order-i/)
+ * [【强化练习】利用后序位置解题 II](https://labuladong.online/algo/problem-set/binary-tree-post-order-ii/)
+ * [【强化练习】利用后序位置解题 III](https://labuladong.online/algo/problem-set/binary-tree-post-order-iii/)
+ * [【强化练习】运用层序遍历解题 I](https://labuladong.online/algo/problem-set/binary-tree-level-i/)
+ * [【强化练习】运用层序遍历解题 II](https://labuladong.online/algo/problem-set/binary-tree-level-ii/)
+ * [【强化练习】二叉搜索树经典例题 I](https://labuladong.online/algo/problem-set/bst1/)
+ * [【强化练习】二叉搜索树经典例题 II](https://labuladong.online/algo/problem-set/bst2/)
+
+ * [二叉树的拓展延伸](https://labuladong.online/algo/menu/more-bt/)
+ * [拓展:最近公共祖先系列解题框架](https://labuladong.online/algo/practice-in-action/lowest-common-ancestor-summary/)
+ * [拓展:如何计算完全二叉树的节点数](https://labuladong.online/algo/data-structure/count-complete-tree-nodes/)
+ * [拓展:惰性展开多叉树](https://labuladong.online/algo/data-structure/flatten-nested-list-iterator/)
+ * [拓展:归并排序详解及应用](https://labuladong.online/algo/practice-in-action/merge-sort/)
+ * [拓展:快速排序详解及应用](https://labuladong.online/algo/practice-in-action/quick-sort/)
+ * [拓展:用栈模拟递归迭代遍历二叉树](https://labuladong.online/algo/data-structure/iterative-traversal-binary-tree/)
+
+ * [手把手设计数据结构](https://labuladong.online/algo/menu/design/)
+ * [队列实现栈以及栈实现队列](https://labuladong.online/algo/data-structure/stack-queue/)
+ * [【强化练习】栈的经典习题](https://labuladong.online/algo/problem-set/stack/)
+ * [【强化练习】括号类问题汇总](https://labuladong.online/algo/problem-set/parentheses/)
+ * [【强化练习】队列的经典习题](https://labuladong.online/algo/problem-set/queue/)
+ * [单调栈算法模板解决三道例题](https://labuladong.online/algo/data-structure/monotonic-stack/)
+ * [【强化练习】单调栈的几种变体及经典习题](https://labuladong.online/algo/problem-set/monotonic-stack/)
+ * [单调队列结构解决滑动窗口问题](https://labuladong.online/algo/data-structure/monotonic-queue/)
+ * [【强化练习】单调队列的通用实现及经典习题](https://labuladong.online/algo/problem-set/monotonic-queue/)
+ * [算法就像搭乐高:手撸 LRU 算法](https://labuladong.online/algo/data-structure/lru-cache/)
+ * [算法就像搭乐高:手撸 LFU 算法](https://labuladong.online/algo/frequency-interview/lfu/)
+ * [常数时间删除/查找数组中的任意元素](https://labuladong.online/algo/data-structure/random-set/)
+ * [【强化练习】哈希表更多习题](https://labuladong.online/algo/problem-set/hash-table/)
+ * [【强化练习】优先级队列经典习题](https://labuladong.online/algo/problem-set/binary-heap/)
+ * [TreeMap/TreeSet 代码实现](https://labuladong.online/algo/data-structure-basic/tree-map-implement/)
+ * [SegmentTree 线段树代码实现](https://labuladong.online/algo/data-structure/segment-tree-implement/)
+ * [Trie/字典树/前缀树代码实现](https://labuladong.online/algo/data-structure/trie-implement/)
+ * [【强化练习】Trie 树算法习题](https://labuladong.online/algo/problem-set/trie/)
+ * [设计朋友圈时间线功能](https://labuladong.online/algo/data-structure/design-twitter/)
+ * [设计考场座位分配算法](https://labuladong.online/algo/frequency-interview/exam-room/)
+ * [【强化练习】更多经典设计习题](https://labuladong.online/algo/problem-set/ds-design/)
+ * [拓展:如何实现一个计算器](https://labuladong.online/algo/data-structure/implement-calculator/)
+ * [拓展:两个二叉堆实现中位数算法](https://labuladong.online/algo/practice-in-action/find-median-from-data-stream/)
+ * [拓展:数组去重问题(困难版)](https://labuladong.online/algo/frequency-interview/remove-duplicate-letters/)
+
+
+ * [手把手刷图算法](https://labuladong.online/algo/menu/graph/)
+ * [环检测及拓扑排序算法](https://labuladong.online/algo/data-structure/topological-sort/)
+ * [众里寻他千百度:名流问题](https://labuladong.online/algo/frequency-interview/find-celebrity/)
+ * [二分图判定算法](https://labuladong.online/algo/data-structure/bipartite-graph/)
+ * [Union-Find 并查集算法](https://labuladong.online/algo/data-structure/union-find/)
+ * [【强化练习】并查集经典习题](https://labuladong.online/algo/problem-set/union-find/)
+ * [Kruskal 最小生成树算法](https://labuladong.online/algo/data-structure/kruskal/)
+ * [Prim 最小生成树算法](https://labuladong.online/algo/data-structure/prim/)
+ * [Dijkstra 算法模板及应用](https://labuladong.online/algo/data-structure/dijkstra/)
+ * [【强化练习】Dijkstra 算法经典习题](https://labuladong.online/algo/problem-set/dijkstra/)
+
+### [第二章、经典暴力搜索算法](https://labuladong.online/algo/menu/braute-force-search/)
+ * [DFS/回溯算法](https://labuladong.online/algo/menu/dfs/)
+ * [回溯算法解题套路框架](https://labuladong.online/algo/essential-technique/backtrack-framework/)
+ * [回溯算法实践:数独和 N 皇后问题](https://labuladong.online/algo/practice-in-action/sudoku-nqueue/)
+ * [回溯算法秒杀所有排列/组合/子集问题](https://labuladong.online/algo/essential-technique/permutation-combination-subset-all-in-one/)
+ * [球盒模型:回溯算法穷举的两种视角](https://labuladong.online/algo/practice-in-action/two-views-of-backtrack/)
+ * [解答回溯算法/DFS算法的若干疑问](https://labuladong.online/algo/essential-technique/backtrack-vs-dfs/)
+ * [一文秒杀所有岛屿题目](https://labuladong.online/algo/frequency-interview/island-dfs-summary/)
+ * [回溯算法实践:括号生成](https://labuladong.online/algo/practice-in-action/generate-parentheses/)
+ * [回溯算法实践:集合划分](https://labuladong.online/algo/practice-in-action/partition-to-k-equal-sum-subsets/)
+ * [【强化练习】回溯算法经典习题 I](https://labuladong.online/algo/problem-set/backtrack-i/)
+ * [【强化练习】回溯算法经典习题 II](https://labuladong.online/algo/problem-set/backtrack-ii/)
+ * [【强化练习】回溯算法经典习题 III](https://labuladong.online/algo/problem-set/backtrack-iii/)
+
+ * [BFS 算法](https://labuladong.online/algo/menu/bfs/)
+ * [BFS 算法解题套路框架](https://labuladong.online/algo/essential-technique/bfs-framework/)
+ * [【强化练习】BFS 经典习题 I](https://labuladong.online/algo/problem-set/bfs/)
+ * [【强化练习】BFS 经典习题 II](https://labuladong.online/algo/problem-set/bfs-ii/)
+ * [正在更新 ing](https://labuladong.online/algo/intro/updating/)
+
+
+### [第三章、经典动态规划算法](https://labuladong.online/algo/menu/dp/)
+ * [动态规划基本技巧](https://labuladong.online/algo/menu/dp-basic/)
+ * [动态规划解题套路框架](https://labuladong.online/algo/essential-technique/dynamic-programming-framework/)
+ * [动态规划设计:最长递增子序列](https://labuladong.online/algo/dynamic-programming/longest-increasing-subsequence/)
+ * [base case 和备忘录的初始值怎么定?](https://labuladong.online/algo/dynamic-programming/memo-fundamental/)
+ * [动态规划穷举的两种视角](https://labuladong.online/algo/dynamic-programming/two-views-of-dp/)
+ * [动态规划和回溯算法的思维转换](https://labuladong.online/algo/dynamic-programming/word-break/)
+ * [对动态规划进行降维打击](https://labuladong.online/algo/dynamic-programming/space-optimization/)
+ * [最优子结构原理和 dp 数组遍历方向](https://labuladong.online/algo/dynamic-programming/faq-summary/)
+
+ * [子序列类型问题](https://labuladong.online/algo/menu/subsequence/)
+ * [经典动态规划:编辑距离](https://labuladong.online/algo/dynamic-programming/edit-distance/)
+ * [动态规划设计:最大子数组](https://labuladong.online/algo/dynamic-programming/maximum-subarray/)
+ * [经典动态规划:最长公共子序列](https://labuladong.online/algo/dynamic-programming/longest-common-subsequence/)
+ * [动态规划之子序列问题解题模板](https://labuladong.online/algo/dynamic-programming/subsequence-problem/)
+
+ * [背包类型问题](https://labuladong.online/algo/menu/knapsack/)
+ * [经典动态规划:0-1 背包问题](https://labuladong.online/algo/dynamic-programming/knapsack1/)
+ * [经典动态规划:子集背包问题](https://labuladong.online/algo/dynamic-programming/knapsack2/)
+ * [经典动态规划:完全背包问题](https://labuladong.online/algo/dynamic-programming/knapsack3/)
+ * [背包问题的变体:目标和](https://labuladong.online/algo/dynamic-programming/target-sum/)
+
+ * [用动态规划玩游戏](https://labuladong.online/algo/menu/dp-game/)
+ * [动态规划之最小路径和](https://labuladong.online/algo/dynamic-programming/minimum-path-sum/)
+ * [动态规划帮我通关了《魔塔》](https://labuladong.online/algo/dynamic-programming/magic-tower/)
+ * [动态规划帮我通关了《辐射4》](https://labuladong.online/algo/dynamic-programming/freedom-trail/)
+ * [旅游省钱大法:加权最短路径](https://labuladong.online/algo/dynamic-programming/cheap-travel/)
+ * [经典动态规划:正则表达式](https://labuladong.online/algo/dynamic-programming/regular-expression-matching/)
+ * [经典动态规划:高楼扔鸡蛋](https://labuladong.online/algo/dynamic-programming/egg-drop/)
+ * [经典动态规划:戳气球](https://labuladong.online/algo/dynamic-programming/burst-balloons/)
+ * [经典动态规划:博弈问题](https://labuladong.online/algo/dynamic-programming/game-theory/)
+ * [一个方法团灭 LeetCode 打家劫舍问题](https://labuladong.online/algo/dynamic-programming/house-robber/)
+ * [一个方法团灭 LeetCode 股票买卖问题](https://labuladong.online/algo/dynamic-programming/stock-problem-summary/)
+
+ * [贪心类型问题](https://labuladong.online/algo/menu/greedy/)
+ * [贪心算法解题套路框架](https://labuladong.online/algo/essential-technique/greedy/)
+ * [老司机加油算法](https://labuladong.online/algo/frequency-interview/gas-station-greedy/)
+ * [贪心算法之区间调度问题](https://labuladong.online/algo/frequency-interview/interval-scheduling/)
+ * [扫描线技巧:安排会议室](https://labuladong.online/algo/frequency-interview/scan-line-technique/)
+ * [剪视频剪出一个贪心算法](https://labuladong.online/algo/frequency-interview/cut-video/)
+
+
+### [第四章、其他常见算法技巧](https://labuladong.online/algo/menu/other/)
+ * [数学运算技巧](https://labuladong.online/algo/menu/math/)
+ * [一行代码就能解决的算法题](https://labuladong.online/algo/frequency-interview/one-line-solutions/)
+ * [常用的位操作](https://labuladong.online/algo/frequency-interview/bitwise-operation/)
+ * [谈谈游戏中的随机算法](https://labuladong.online/algo/frequency-interview/random-algorithm/)
+ * [讲两道常考的阶乘算法题](https://labuladong.online/algo/frequency-interview/factorial-problems/)
+ * [如何高效寻找素数](https://labuladong.online/algo/frequency-interview/print-prime-number/)
+ * [如何高效进行模幂运算](https://labuladong.online/algo/frequency-interview/quick-power/)
+ * [如何同时寻找缺失和重复的元素](https://labuladong.online/algo/frequency-interview/mismatch-set/)
+ * [几个反直觉的概率问题](https://labuladong.online/algo/frequency-interview/probability-problem/)
+ * [【强化练习】数学技巧相关习题](https://labuladong.online/algo/problem-set/math-tricks/)
+
+ * [经典面试题](https://labuladong.online/algo/menu/interview/)
+ * [算法笔试「骗分」套路](https://labuladong.online/algo/other-skills/tips-in-exam/)
+ * [如何高效解决接雨水问题](https://labuladong.online/algo/frequency-interview/trapping-rain-water/)
+ * [一文秒杀所有丑数系列问题](https://labuladong.online/algo/frequency-interview/ugly-number-summary/)
+ * [一个方法解决三道区间问题](https://labuladong.online/algo/practice-in-action/interval-problem-summary/)
+ * [谁能想到,斗地主也能玩出算法](https://labuladong.online/algo/practice-in-action/split-array-into-consecutive-subsequences/)
+ * [烧饼排序算法](https://labuladong.online/algo/frequency-interview/pancake-sorting/)
+ * [字符串乘法计算](https://labuladong.online/algo/practice-in-action/multiply-strings/)
+ * [如何判定完美矩形](https://labuladong.online/algo/frequency-interview/perfect-rectangle/)
+
+### [附录](https://labuladong.online/algo/menu/appendix/)
+ * [labuladong.online 更新日志](https://labuladong.online/algo/changelog/website/)
+ * [可视化面板更新日志](https://labuladong.online/algo/changelog/visualize/)
+ * [Chrome 刷题插件更新日志](https://labuladong.online/algo/changelog/chrome/)
+ * [vscode 刷题插件更新日志](https://labuladong.online/algo/changelog/vscode/)
+ * [Jetbrain 刷题插件更新日志](https://labuladong.online/algo/changelog/jetbrain/)
+ * [网站/插件问题反馈](https://labuladong.online/algo/intro/bug-report/)
+
+
+
+# 感谢如下大佬参与翻译
+
+按照昵称字典序排名:
+
+[ABCpril](https://github.com/ABCpril),
+[andavid](https://github.com/andavid),
+[bryceustc](https://github.com/bryceustc),
+[build2645](https://github.com/build2645),
+[CarrieOn](https://github.com/CarrieOn),
+[cooker](https://github.com/xiaochuhub),
+[Dong Wang](https://github.com/Coder2Programmer),
+[ExcaliburEX](https://github.com/ExcaliburEX),
+[floatLig](https://github.com/floatLig),
+[ForeverSolar](https://github.com/foreversolar),
+[Fulin Li](https://fulinli.github.io/),
+[Funnyyanne](https://github.com/Funnyyanne),
+[GYHHAHA](https://github.com/GYHHAHA),
+[Hi_archer](https://hiarcher.top/),
+[Iruze](https://github.com/Iruze),
+[Jieyixia](https://github.com/Jieyixia),
+[Justin](https://github.com/Justin-YGG),
+[Kevin](https://github.com/Kevin-free),
+[Lrc123](https://github.com/Lrc123),
+[lriy](https://github.com/lriy),
+[Lyjeeq](https://github.com/Lyjeeq),
+[MasonShu](https://greenwichmt.github.io/),
+[Master-cai](https://github.com/Master-cai),
+[miaoxiaozui2017](https://github.com/miaoxiaozui2017),
+[natsunoyoru97](https://github.com/natsunoyoru97),
+[nettee](https://github.com/nettee),
+[PaperJets](https://github.com/PaperJets),
+[qy-yang](https://github.com/qy-yang),
+[realism0331](https://github.com/realism0331),
+[SCUhzs](https://github.com/brucecat),
+[Seaworth](https://github.com/Seaworth),
+[shazi4399](https://github.com/shazi4399),
+[ShuozheLi](https://github.com/ShuoZheLi/),
+[sinjoywong](https://blog.csdn.net/SinjoyWong),
+[sunqiuming526](https://github.com/sunqiuming526),
+[Tianhao Zhou](https://github.com/tianhaoz95),
+[timmmGZ](https://github.com/timmmGZ),
+[tommytim0515](https://github.com/tommytim0515),
+[ucsk](https://github.com/ucsk),
+[wadegrc](https://github.com/wadegrc),
+[walsvid](https://github.com/walsvid),
+[warmingkkk](https://github.com/warmingkkk),
+[Wonderxie](https://github.com/Wonderxie),
+[wsyzxxxx](https://github.com/wsyzxxxx),
+[xiaodp](https://github.com/xiaodp),
+[youyun](https://github.com/youyun),
+[yx-tan](https://github.com/yx-tan),
+[Zero](https://github.com/Mr2er0),
+[Ziming](https://github.com/ML-ZimingMeng/LeetCode-Python3)
# Donate
-
-
-其他的先不多说了,直接上干货吧,我们一起日穿 LeetCode,感受一下支配算法的乐趣。
-
-# 目录
-
-* 第零章、必读系列
- * [学习算法和刷题的框架思维](算法思维系列/学习数据结构和算法的高效方法.md)
- * [学习数据结构和算法读什么书](算法思维系列/为什么推荐算法4.md)
- * [动态规划解题框架](动态规划系列/动态规划详解进阶.md)
- * [动态规划答疑篇](动态规划系列/最优子结构.md)
- * [回溯算法解题框架](算法思维系列/回溯算法详解修订版.md)
- * [二分查找解题框架](算法思维系列/二分查找详解.md)
- * [滑动窗口解题框架](算法思维系列/滑动窗口技巧.md)
- * [双指针技巧解题框架](算法思维系列/双指针技巧.md)
- * [Linux的进程、线程、文件描述符是什么](技术/linux进程.md)
- * [Git/SQL/正则表达式的在线练习平台](技术/在线练习平台.md)
-* 第一章、动态规划系列
- * [动态规划详解](动态规划系列/动态规划详解进阶.md)
- * [动态规划答疑篇](动态规划系列/最优子结构.md)
- * [动态规划设计:最长递增子序列](动态规划系列/动态规划设计:最长递增子序列.md)
- * [编辑距离](动态规划系列/编辑距离.md)
- * [经典动态规划问题:高楼扔鸡蛋](动态规划系列/高楼扔鸡蛋问题.md)
- * [经典动态规划问题:高楼扔鸡蛋(进阶)](动态规划系列/高楼扔鸡蛋进阶.md)
- * [动态规划之子序列问题解题模板](动态规划系列/子序列问题模板.md)
- * [动态规划之博弈问题](动态规划系列/动态规划之博弈问题.md)
- * [贪心算法之区间调度问题](动态规划系列/贪心算法之区间调度问题.md)
- * [动态规划之KMP字符匹配算法](动态规划系列/动态规划之KMP字符匹配算法.md)
- * [团灭 LeetCode 股票买卖问题](动态规划系列/团灭股票问题.md)
- * [团灭 LeetCode 打家劫舍问题](动态规划系列/抢房子.md)
- * [动态规划之四键键盘](动态规划系列/动态规划之四键键盘.md)
- * [动态规划之正则表达](动态规划系列/动态规划之正则表达.md)
- * [最长公共子序列](动态规划系列/最长公共子序列.md)
-* 第二章、数据结构系列
- * [学习算法和刷题的思路指南](算法思维系列/学习数据结构和算法的高效方法.md)
- * [学习数据结构和算法读什么书](算法思维系列/为什么推荐算法4.md)
- * [二叉堆详解实现优先级队列](数据结构系列/二叉堆详解实现优先级队列.md)
- * [LRU算法详解](高频面试系列/LRU算法.md)
- * [二叉搜索树操作集锦](数据结构系列/二叉搜索树操作集锦.md)
- * [特殊数据结构:单调栈](数据结构系列/单调栈.md)
- * [特殊数据结构:单调队列](数据结构系列/单调队列.md)
- * [设计Twitter](数据结构系列/设计Twitter.md)
- * [递归反转链表的一部分](数据结构系列/递归反转链表的一部分.md)
- * [队列实现栈\|栈实现队列](数据结构系列/队列实现栈栈实现队列.md)
-* 第三章、算法思维系列
- * [算法学习之路](算法思维系列/算法学习之路.md)
- * [回溯算法详解](算法思维系列/回溯算法详解修订版.md)
- * [回溯算法团灭排列、组合、子集问题](高频面试系列/子集排列组合.md)
- * [二分查找详解](算法思维系列/二分查找详解.md)
- * [双指针技巧总结](算法思维系列/双指针技巧.md)
- * [滑动窗口技巧](算法思维系列/滑动窗口技巧.md)
- * [twoSum问题的核心思想](算法思维系列/twoSum问题的核心思想.md)
- * [常用的位操作](算法思维系列/常用的位操作.md)
- * [拆解复杂问题:实现计算器](数据结构系列/实现计算器.md)
- * [烧饼排序](算法思维系列/烧饼排序.md)
- * [前缀和技巧](算法思维系列/前缀和技巧.md)
- * [字符串乘法](算法思维系列/字符串乘法.md)
- * [FloodFill算法详解及应用](算法思维系列/FloodFill算法详解及应用.md)
- * [区间调度之区间合并问题](算法思维系列/区间调度问题之区间合并.md)
- * [区间调度之区间交集问题](算法思维系列/区间交集问题.md)
- * [信封嵌套问题](算法思维系列/信封嵌套问题.md)
- * [几个反直觉的概率问题](算法思维系列/几个反直觉的概率问题.md)
- * [洗牌算法](算法思维系列/洗牌算法.md)
- * [递归详解](算法思维系列/递归详解.md)
-* 第四章、高频面试系列
- * [如何实现LRU算法](高频面试系列/LRU算法.md)
- * [如何高效寻找素数](高频面试系列/打印素数.md)
- * [如何计算编辑距离](动态规划系列/编辑距离.md)
- * [如何运用二分查找算法](高频面试系列/koko偷香蕉.md)
- * [如何高效解决接雨水问题](高频面试系列/接雨水.md)
- * [如何去除有序数组的重复元素](高频面试系列/如何去除有序数组的重复元素.md)
- * [如何寻找最长回文子串](高频面试系列/最长回文子串.md)
- * [如何k个一组反转链表](高频面试系列/k个一组反转链表.md)
- * [如何判定括号合法性](高频面试系列/合法括号判定.md)
- * [如何寻找消失的元素](高频面试系列/消失的元素.md)
- * [如何寻找缺失和重复的元素](高频面试系列/缺失和重复的元素.md)
- * [如何判断回文链表](高频面试系列/判断回文链表.md)
- * [如何在无限序列中随机抽取元素](高频面试系列/水塘抽样.md)
- * [如何调度考生的座位](高频面试系列/座位调度.md)
- * [Union-Find算法详解](算法思维系列/UnionFind算法详解.md)
- * [Union-Find算法应用](算法思维系列/UnionFind算法应用.md)
- * [一行代码就能解决的算法题](高频面试系列/一行代码解决的智力题.md)
- * [二分查找高效判定子序列](高频面试系列/二分查找判定子序列.md)
-* 第五章、计算机技术
- * [Linux的进程、线程、文件描述符是什么](技术/linux进程.md)
- * [一文看懂 session 和 cookie](技术/session和cookie.md)
- * [关于 Linux shell 你必须知道的](技术/linuxshell.md)
- * [加密算法的前身今世](技术/密码技术.md)
- * [Git/SQL/正则表达式的在线练习平台](技术/在线练习平台.md)
+## 在开始学习之前
+
+**1、先给本仓库点个 star,满足一下我的虚荣心**,文章质量绝对值你一个 star。我还在继续创作,给我一点继续写文的动力,感谢。
+
+**2、建议收藏我的在线网站,每篇文章开头都有对应的力扣题目链接,可以边看文章边刷题,一共可以手把手带你刷 500 道题目**:
+
+2024 最新地址:https://labuladong.online/algo/
+
+~~GitHub Pages 地址:https://labuladong.online/algo/~~
+
+~~Gitee Pages 地址:https://labuladong.gitee.io/algo/~~
+
+## labuladong 刷题全家桶简介
+
+### 一、算法可视化面板
+
+我的算法网站、所有配套插件都集成了一个算法可视化工具,可以对数据结构和递归过程进行可视化,大幅降低理解算法的难度。几乎每道题目的解法代码都有对应的可视化面板,具体参见下方介绍。
+
+
+### 二、学习网站
+
+内容当然是我的系列算法教程中最核心的部分,我的算法教程都发布在网站 [labuladong.online](https://labuladong.online/algo/) 上,相信你会未来会在这里花费大量的学习时间,而不是仅仅加入收藏夹~
+
+
+
+### 三、Chrome 插件
+
+**主要功能**:Chrome 插件可以在中文版力扣或英文版 LeetCode 上快捷查看我的「题解」或「思路」,并添加了题目和算法技巧之间的引用关系,可以和我的网站/公众号/课程联动,给我的读者提供最丝滑的刷题体验。安装使用手册见下方目录。
+
+
+
+
+### 四、vscode 插件
+
+**主要功能**:和 Chrome 插件功能基本相同,习惯在 vscode 上刷题的读者可以使用该插件。安装使用手册见下方目录。
+
+
+
+
+### 五、Jetbrains 插件
+
+**主要功能**:和 Chrome 插件功能基本相同,习惯在 Jetbrains 家的 IDE(PyCharm/Intellij/Goland 等)上刷题的读者可以使用该插件。安装使用手册见下方目录。
+
+
+
+
+最后祝大家学习愉快,在题海中自在遨游!
+
+
+# 文章目录
+
+
+
+### [本站简介](https://labuladong.online/algo/home/)
+
+### [配套插件及算法可视化](https://labuladong.online/algo/menu/tools/)
+ * [配套 Chrome 刷题插件](https://labuladong.online/algo/intro/chrome/)
+ * [配套 vscode 刷题插件](https://labuladong.online/algo/intro/vscode/)
+ * [配套 JetBrains 刷题插件](https://labuladong.online/algo/intro/jetbrains/)
+ * [算法可视化面板使用说明](https://labuladong.online/algo/intro/visualize/)
+ * [本站付费会员](https://labuladong.online/algo/intro/site-vip/)
+
+### [针对初学和速成的学习规划](https://labuladong.online/algo/menu/plan/)
+ * [算法刷题的重点和坑](https://labuladong.online/algo/intro/how-to-learn-algorithms/)
+ * [初学者学习规划](https://labuladong.online/algo/intro/beginner-learning-plan/)
+ * [速成学习规划](https://labuladong.online/algo/intro/quick-learning-plan/)
+ * [习题章节的练习/复习方法](https://labuladong.online/algo/intro/how-to-practice/)
+ * [算法可视化速查页](https://labuladong.online/algo/intro/visualize-catalog/)
+
+### [入门:编程语言基础及练习](https://labuladong.online/algo/menu/)
+ * [本章导读](https://labuladong.online/algo/intro/programming-language-basic/)
+ * [C++ 语言基础](https://labuladong.online/algo/programming-language-basic/cpp/)
+ * [Java 语言基础](https://labuladong.online/algo/programming-language-basic/java/)
+ * [Golang 语言基础](https://labuladong.online/algo/programming-language-basic/golang/)
+ * [Python 语言基础](https://labuladong.online/algo/programming-language-basic/python/)
+ * [JavaScript 语言基础](https://labuladong.online/algo/intro/js/)
+ * [力扣/LeetCode 解题须知](https://labuladong.online/algo/intro/leetcode/)
+ * [编程语言刷题实践](https://labuladong.online/algo/programming-language-basic/lc-practice/)
+
+### [基础:数据结构及排序精讲](https://labuladong.online/algo/menu/quick-start/)
+ * [本章导读](https://labuladong.online/algo/intro/data-structure-basic/)
+ * [时间空间复杂度入门](https://labuladong.online/algo/intro/complexity-basic/)
+
+ * [手把手带你实现动态数组](https://labuladong.online/algo/menu/dynamic-array/)
+ * [数组(顺序存储)基本原理](https://labuladong.online/algo/data-structure-basic/array-basic/)
+ * [动态数组代码实现](https://labuladong.online/algo/data-structure-basic/array-implement/)
+
+ * [手把手带你实现单/双链表](https://labuladong.online/algo/menu/linked-list/)
+ * [链表(链式存储)基本原理](https://labuladong.online/algo/data-structure-basic/linkedlist-basic/)
+ * [链表代码实现](https://labuladong.online/algo/data-structure-basic/linkedlist-implement/)
+
+ * [手把手带你实现队列/栈](https://labuladong.online/algo/menu/queue-stack/)
+ * [队列/栈基本原理](https://labuladong.online/algo/data-structure-basic/queue-stack-basic/)
+ * [用链表实现队列/栈](https://labuladong.online/algo/data-structure-basic/linked-queue-stack/)
+ * [环形数组技巧](https://labuladong.online/algo/data-structure-basic/cycle-array/)
+ * [用数组实现队列/栈](https://labuladong.online/algo/data-structure-basic/array-queue-stack/)
+ * [双端队列(Deque)原理及实现](https://labuladong.online/algo/data-structure-basic/deque-implement/)
+
+ * [哈希表的原理及实现](https://labuladong.online/algo/menu/)
+ * [哈希表核心原理](https://labuladong.online/algo/data-structure-basic/hashmap-basic/)
+ * [用拉链法实现哈希表](https://labuladong.online/algo/data-structure-basic/hashtable-chaining/)
+ * [线性探查法的两个难点](https://labuladong.online/algo/data-structure-basic/linear-probing-key-point/)
+ * [线性探查法的两种代码实现](https://labuladong.online/algo/data-structure-basic/linear-probing-code/)
+ * [哈希集合的原理及代码实现](https://labuladong.online/algo/data-structure-basic/hash-set/)
+
+ * [哈希表结构的种种变换](https://labuladong.online/algo/menu/)
+ * [用链表加强哈希表(LinkedHashMap)](https://labuladong.online/algo/data-structure-basic/hashtable-with-linked-list/)
+ * [用数组加强哈希表(ArrayHashMap)](https://labuladong.online/algo/data-structure-basic/hashtable-with-array/)
+
+ * [二叉树结构及遍历](https://labuladong.online/algo/menu/binary-tree/)
+ * [二叉树基础及常见类型](https://labuladong.online/algo/data-structure-basic/binary-tree-basic/)
+ * [二叉树的递归/层序遍历](https://labuladong.online/algo/data-structure-basic/binary-tree-traverse-basic/)
+ * [多叉树的递归/层序遍历](https://labuladong.online/algo/data-structure-basic/n-ary-tree-traverse-basic/)
+
+ * [二叉树结构的种种变换](https://labuladong.online/algo/menu/binary-tree/)
+ * [二叉搜索树的应用及可视化](https://labuladong.online/algo/data-structure-basic/tree-map-basic/)
+ * [红黑树的完美平衡及可视化](https://labuladong.online/algo/data-structure-basic/rbtree-basic/)
+ * [Trie/字典树/前缀树原理及可视化](https://labuladong.online/algo/data-structure-basic/trie-map-basic/)
+ * [二叉堆核心原理及可视化](https://labuladong.online/algo/data-structure-basic/binary-heap-basic/)
+ * [二叉堆/优先级队列代码实现](https://labuladong.online/algo/data-structure-basic/binary-heap-implement/)
+ * [线段树核心原理及可视化](https://labuladong.online/algo/data-structure-basic/segment-tree-basic/)
+ * [正在更新 ing](https://labuladong.online/algo/intro/updating/)
+
+ * [图论数据结构及遍历](https://labuladong.online/algo/menu/graph-theory/)
+ * [图结构基础及通用代码实现](https://labuladong.online/algo/data-structure-basic/graph-basic/)
+ * [图结构的 DFS/BFS 遍历](https://labuladong.online/algo/data-structure-basic/graph-traverse-basic/)
+ * [Union Find 并查集原理](https://labuladong.online/algo/data-structure-basic/union-find-basic/)
+ * [正在更新 ing](https://labuladong.online/algo/intro/updating/)
+
+ * [十大排序算法原理及可视化](https://labuladong.online/algo/menu/sorting/)
+ * [本章导读](https://labuladong.online/algo/intro/sorting/)
+ * [排序算法的关键指标](https://labuladong.online/algo/data-structure-basic/sort-basic/)
+ * [选择排序所面临的问题](https://labuladong.online/algo/data-structure-basic/select-sort/)
+ * [拥有稳定性:冒泡排序](https://labuladong.online/algo/data-structure-basic/bubble-sort/)
+ * [运用逆向思维:插入排序](https://labuladong.online/algo/data-structure-basic/insertion-sort/)
+ * [突破 O(N^2):希尔排序](https://labuladong.online/algo/data-structure-basic/shell-sort/)
+ * [妙用二叉树前序位置:快速排序](https://labuladong.online/algo/data-structure-basic/quick-sort/)
+ * [妙用二叉树后序位置:归并排序](https://labuladong.online/algo/data-structure-basic/merge-sort/)
+ * [二叉堆结构的运用:堆排序](https://labuladong.online/algo/data-structure-basic/heap-sort/)
+ * [全新的排序原理:计数排序](https://labuladong.online/algo/data-structure-basic/counting-sort/)
+ * [博采众长:桶排序](https://labuladong.online/algo/data-structure-basic/bucket-sort/)
+ * [基数排序(Radix Sort)](https://labuladong.online/algo/data-structure-basic/radix-sort/)
+
+ * [正在更新 ing](https://labuladong.online/algo/intro/updating/)
+
+
+### [第零章、核心刷题框架汇总](https://labuladong.online/algo/menu/core/)
+ * [本章导读](https://labuladong.online/algo/intro/core-intro/)
+ * [学习数据结构和算法的框架思维](https://labuladong.online/algo/essential-technique/algorithm-summary/)
+ * [双指针技巧秒杀七道链表题目](https://labuladong.online/algo/essential-technique/linked-list-skills-summary/)
+ * [双指针技巧秒杀七道数组题目](https://labuladong.online/algo/essential-technique/array-two-pointers-summary/)
+ * [滑动窗口算法核心代码模板](https://labuladong.online/algo/essential-technique/sliding-window-framework/)
+ * [二分搜索算法核心代码模板](https://labuladong.online/algo/essential-technique/binary-search-framework/)
+ * [动态规划解题套路框架](https://labuladong.online/algo/essential-technique/dynamic-programming-framework/)
+ * [回溯算法解题套路框架](https://labuladong.online/algo/essential-technique/backtrack-framework/)
+ * [BFS 算法解题套路框架](https://labuladong.online/algo/essential-technique/bfs-framework/)
+ * [二叉树系列算法核心纲领](https://labuladong.online/algo/essential-technique/binary-tree-summary/)
+ * [回溯算法秒杀所有排列/组合/子集问题](https://labuladong.online/algo/essential-technique/permutation-combination-subset-all-in-one/)
+ * [贪心算法解题套路框架](https://labuladong.online/algo/essential-technique/greedy/)
+ * [分治算法解题套路框架](https://labuladong.online/algo/essential-technique/divide-and-conquer/)
+ * [算法时空复杂度分析实用指南](https://labuladong.online/algo/essential-technique/complexity-analysis/)
+
+
+### [第一章、经典数据结构算法](https://labuladong.online/algo/menu/ds/)
+ * [手把手刷链表算法](https://labuladong.online/algo/menu/linked-list/)
+ * [双指针技巧秒杀七道链表题目](https://labuladong.online/algo/essential-technique/linked-list-skills-summary/)
+ * [【强化练习】链表双指针经典习题](https://labuladong.online/algo/problem-set/linkedlist-two-pointers/)
+ * [单链表的花式反转方法汇总](https://labuladong.online/algo/data-structure/reverse-linked-list-recursion/)
+ * [如何判断回文链表](https://labuladong.online/algo/data-structure/palindrome-linked-list/)
+
+ * [手把手刷数组算法](https://labuladong.online/algo/menu/array/)
+ * [双指针技巧秒杀七道数组题目](https://labuladong.online/algo/essential-technique/array-two-pointers-summary/)
+ * [二维数组的花式遍历技巧](https://labuladong.online/algo/practice-in-action/2d-array-traversal-summary/)
+ * [一个方法团灭 nSum 问题](https://labuladong.online/algo/practice-in-action/nsum/)
+ * [【强化练习】数组双指针经典习题](https://labuladong.online/algo/problem-set/array-two-pointers/)
+ * [小而美的算法技巧:前缀和数组](https://labuladong.online/algo/data-structure/prefix-sum/)
+ * [【强化练习】前缀和技巧经典习题](https://labuladong.online/algo/problem-set/perfix-sum/)
+ * [小而美的算法技巧:差分数组](https://labuladong.online/algo/data-structure/diff-array/)
+ * [滑动窗口算法核心代码模板](https://labuladong.online/algo/essential-technique/sliding-window-framework/)
+ * [【强化练习】滑动窗口算法经典习题](https://labuladong.online/algo/problem-set/sliding-window/)
+ * [滑动窗口延伸:Rabin Karp 字符匹配算法](https://labuladong.online/algo/practice-in-action/rabinkarp/)
+ * [二分搜索算法核心代码模板](https://labuladong.online/algo/essential-technique/binary-search-framework/)
+ * [实际运用二分搜索时的思维框架](https://labuladong.online/algo/frequency-interview/binary-search-in-action/)
+ * [【强化练习】二分搜索算法经典习题](https://labuladong.online/algo/problem-set/binary-search/)
+ * [带权重的随机选择算法](https://labuladong.online/algo/frequency-interview/random-pick-with-weight/)
+ * [田忌赛马背后的算法决策](https://labuladong.online/algo/practice-in-action/advantage-shuffle/)
+
+
+ * [手把手刷二叉树算法](https://labuladong.online/algo/menu/binary-tree/)
+ * [二叉树系列算法核心纲领](https://labuladong.online/algo/essential-technique/binary-tree-summary/)
+ * [二叉树心法(思路篇)](https://labuladong.online/algo/data-structure/binary-tree-part1/)
+ * [二叉树心法(构造篇)](https://labuladong.online/algo/data-structure/binary-tree-part2/)
+ * [二叉树心法(后序篇)](https://labuladong.online/algo/data-structure/binary-tree-part3/)
+ * [二叉树心法(序列化篇)](https://labuladong.online/algo/data-structure/serialize-and-deserialize-binary-tree/)
+ * [二叉搜索树心法(特性篇)](https://labuladong.online/algo/data-structure/bst-part1/)
+ * [二叉搜索树心法(基操篇)](https://labuladong.online/algo/data-structure/bst-part2/)
+ * [二叉搜索树心法(构造篇)](https://labuladong.online/algo/data-structure/bst-part3/)
+ * [二叉搜索树心法(后序篇)](https://labuladong.online/algo/data-structure/bst-part4/)
+
+ * [套模板解决 100 道二叉树习题](https://labuladong.online/algo/menu/100-bt/)
+ * [本章导读](https://labuladong.online/algo/intro/binary-tree-practice/)
+ * [【强化练习】用「遍历」思维解题 I](https://labuladong.online/algo/problem-set/binary-tree-traverse-i/)
+ * [【强化练习】用「遍历」思维解题 II](https://labuladong.online/algo/problem-set/binary-tree-traverse-ii/)
+ * [【强化练习】用「遍历」思维解题 III](https://labuladong.online/algo/problem-set/binary-tree-traverse-iii/)
+ * [【强化练习】用「分解问题」思维解题 I](https://labuladong.online/algo/problem-set/binary-tree-divide-i/)
+ * [【强化练习】用「分解问题」思维解题 II](https://labuladong.online/algo/problem-set/binary-tree-divide-ii/)
+ * [【强化练习】同时运用两种思维解题](https://labuladong.online/algo/problem-set/binary-tree-combine-two-view/)
+ * [【强化练习】利用后序位置解题 I](https://labuladong.online/algo/problem-set/binary-tree-post-order-i/)
+ * [【强化练习】利用后序位置解题 II](https://labuladong.online/algo/problem-set/binary-tree-post-order-ii/)
+ * [【强化练习】利用后序位置解题 III](https://labuladong.online/algo/problem-set/binary-tree-post-order-iii/)
+ * [【强化练习】运用层序遍历解题 I](https://labuladong.online/algo/problem-set/binary-tree-level-i/)
+ * [【强化练习】运用层序遍历解题 II](https://labuladong.online/algo/problem-set/binary-tree-level-ii/)
+ * [【强化练习】二叉搜索树经典例题 I](https://labuladong.online/algo/problem-set/bst1/)
+ * [【强化练习】二叉搜索树经典例题 II](https://labuladong.online/algo/problem-set/bst2/)
+
+ * [二叉树的拓展延伸](https://labuladong.online/algo/menu/more-bt/)
+ * [拓展:最近公共祖先系列解题框架](https://labuladong.online/algo/practice-in-action/lowest-common-ancestor-summary/)
+ * [拓展:如何计算完全二叉树的节点数](https://labuladong.online/algo/data-structure/count-complete-tree-nodes/)
+ * [拓展:惰性展开多叉树](https://labuladong.online/algo/data-structure/flatten-nested-list-iterator/)
+ * [拓展:归并排序详解及应用](https://labuladong.online/algo/practice-in-action/merge-sort/)
+ * [拓展:快速排序详解及应用](https://labuladong.online/algo/practice-in-action/quick-sort/)
+ * [拓展:用栈模拟递归迭代遍历二叉树](https://labuladong.online/algo/data-structure/iterative-traversal-binary-tree/)
+
+ * [手把手设计数据结构](https://labuladong.online/algo/menu/design/)
+ * [队列实现栈以及栈实现队列](https://labuladong.online/algo/data-structure/stack-queue/)
+ * [【强化练习】栈的经典习题](https://labuladong.online/algo/problem-set/stack/)
+ * [【强化练习】括号类问题汇总](https://labuladong.online/algo/problem-set/parentheses/)
+ * [【强化练习】队列的经典习题](https://labuladong.online/algo/problem-set/queue/)
+ * [单调栈算法模板解决三道例题](https://labuladong.online/algo/data-structure/monotonic-stack/)
+ * [【强化练习】单调栈的几种变体及经典习题](https://labuladong.online/algo/problem-set/monotonic-stack/)
+ * [单调队列结构解决滑动窗口问题](https://labuladong.online/algo/data-structure/monotonic-queue/)
+ * [【强化练习】单调队列的通用实现及经典习题](https://labuladong.online/algo/problem-set/monotonic-queue/)
+ * [算法就像搭乐高:手撸 LRU 算法](https://labuladong.online/algo/data-structure/lru-cache/)
+ * [算法就像搭乐高:手撸 LFU 算法](https://labuladong.online/algo/frequency-interview/lfu/)
+ * [常数时间删除/查找数组中的任意元素](https://labuladong.online/algo/data-structure/random-set/)
+ * [【强化练习】哈希表更多习题](https://labuladong.online/algo/problem-set/hash-table/)
+ * [【强化练习】优先级队列经典习题](https://labuladong.online/algo/problem-set/binary-heap/)
+ * [TreeMap/TreeSet 代码实现](https://labuladong.online/algo/data-structure-basic/tree-map-implement/)
+ * [SegmentTree 线段树代码实现](https://labuladong.online/algo/data-structure/segment-tree-implement/)
+ * [Trie/字典树/前缀树代码实现](https://labuladong.online/algo/data-structure/trie-implement/)
+ * [【强化练习】Trie 树算法习题](https://labuladong.online/algo/problem-set/trie/)
+ * [设计朋友圈时间线功能](https://labuladong.online/algo/data-structure/design-twitter/)
+ * [设计考场座位分配算法](https://labuladong.online/algo/frequency-interview/exam-room/)
+ * [【强化练习】更多经典设计习题](https://labuladong.online/algo/problem-set/ds-design/)
+ * [拓展:如何实现一个计算器](https://labuladong.online/algo/data-structure/implement-calculator/)
+ * [拓展:两个二叉堆实现中位数算法](https://labuladong.online/algo/practice-in-action/find-median-from-data-stream/)
+ * [拓展:数组去重问题(困难版)](https://labuladong.online/algo/frequency-interview/remove-duplicate-letters/)
+
+
+ * [手把手刷图算法](https://labuladong.online/algo/menu/graph/)
+ * [环检测及拓扑排序算法](https://labuladong.online/algo/data-structure/topological-sort/)
+ * [众里寻他千百度:名流问题](https://labuladong.online/algo/frequency-interview/find-celebrity/)
+ * [二分图判定算法](https://labuladong.online/algo/data-structure/bipartite-graph/)
+ * [Union-Find 并查集算法](https://labuladong.online/algo/data-structure/union-find/)
+ * [【强化练习】并查集经典习题](https://labuladong.online/algo/problem-set/union-find/)
+ * [Kruskal 最小生成树算法](https://labuladong.online/algo/data-structure/kruskal/)
+ * [Prim 最小生成树算法](https://labuladong.online/algo/data-structure/prim/)
+ * [Dijkstra 算法模板及应用](https://labuladong.online/algo/data-structure/dijkstra/)
+ * [【强化练习】Dijkstra 算法经典习题](https://labuladong.online/algo/problem-set/dijkstra/)
+
+### [第二章、经典暴力搜索算法](https://labuladong.online/algo/menu/braute-force-search/)
+ * [DFS/回溯算法](https://labuladong.online/algo/menu/dfs/)
+ * [回溯算法解题套路框架](https://labuladong.online/algo/essential-technique/backtrack-framework/)
+ * [回溯算法实践:数独和 N 皇后问题](https://labuladong.online/algo/practice-in-action/sudoku-nqueue/)
+ * [回溯算法秒杀所有排列/组合/子集问题](https://labuladong.online/algo/essential-technique/permutation-combination-subset-all-in-one/)
+ * [球盒模型:回溯算法穷举的两种视角](https://labuladong.online/algo/practice-in-action/two-views-of-backtrack/)
+ * [解答回溯算法/DFS算法的若干疑问](https://labuladong.online/algo/essential-technique/backtrack-vs-dfs/)
+ * [一文秒杀所有岛屿题目](https://labuladong.online/algo/frequency-interview/island-dfs-summary/)
+ * [回溯算法实践:括号生成](https://labuladong.online/algo/practice-in-action/generate-parentheses/)
+ * [回溯算法实践:集合划分](https://labuladong.online/algo/practice-in-action/partition-to-k-equal-sum-subsets/)
+ * [【强化练习】回溯算法经典习题 I](https://labuladong.online/algo/problem-set/backtrack-i/)
+ * [【强化练习】回溯算法经典习题 II](https://labuladong.online/algo/problem-set/backtrack-ii/)
+ * [【强化练习】回溯算法经典习题 III](https://labuladong.online/algo/problem-set/backtrack-iii/)
+
+ * [BFS 算法](https://labuladong.online/algo/menu/bfs/)
+ * [BFS 算法解题套路框架](https://labuladong.online/algo/essential-technique/bfs-framework/)
+ * [【强化练习】BFS 经典习题 I](https://labuladong.online/algo/problem-set/bfs/)
+ * [【强化练习】BFS 经典习题 II](https://labuladong.online/algo/problem-set/bfs-ii/)
+ * [正在更新 ing](https://labuladong.online/algo/intro/updating/)
+
+
+### [第三章、经典动态规划算法](https://labuladong.online/algo/menu/dp/)
+ * [动态规划基本技巧](https://labuladong.online/algo/menu/dp-basic/)
+ * [动态规划解题套路框架](https://labuladong.online/algo/essential-technique/dynamic-programming-framework/)
+ * [动态规划设计:最长递增子序列](https://labuladong.online/algo/dynamic-programming/longest-increasing-subsequence/)
+ * [base case 和备忘录的初始值怎么定?](https://labuladong.online/algo/dynamic-programming/memo-fundamental/)
+ * [动态规划穷举的两种视角](https://labuladong.online/algo/dynamic-programming/two-views-of-dp/)
+ * [动态规划和回溯算法的思维转换](https://labuladong.online/algo/dynamic-programming/word-break/)
+ * [对动态规划进行降维打击](https://labuladong.online/algo/dynamic-programming/space-optimization/)
+ * [最优子结构原理和 dp 数组遍历方向](https://labuladong.online/algo/dynamic-programming/faq-summary/)
+
+ * [子序列类型问题](https://labuladong.online/algo/menu/subsequence/)
+ * [经典动态规划:编辑距离](https://labuladong.online/algo/dynamic-programming/edit-distance/)
+ * [动态规划设计:最大子数组](https://labuladong.online/algo/dynamic-programming/maximum-subarray/)
+ * [经典动态规划:最长公共子序列](https://labuladong.online/algo/dynamic-programming/longest-common-subsequence/)
+ * [动态规划之子序列问题解题模板](https://labuladong.online/algo/dynamic-programming/subsequence-problem/)
+
+ * [背包类型问题](https://labuladong.online/algo/menu/knapsack/)
+ * [经典动态规划:0-1 背包问题](https://labuladong.online/algo/dynamic-programming/knapsack1/)
+ * [经典动态规划:子集背包问题](https://labuladong.online/algo/dynamic-programming/knapsack2/)
+ * [经典动态规划:完全背包问题](https://labuladong.online/algo/dynamic-programming/knapsack3/)
+ * [背包问题的变体:目标和](https://labuladong.online/algo/dynamic-programming/target-sum/)
+
+ * [用动态规划玩游戏](https://labuladong.online/algo/menu/dp-game/)
+ * [动态规划之最小路径和](https://labuladong.online/algo/dynamic-programming/minimum-path-sum/)
+ * [动态规划帮我通关了《魔塔》](https://labuladong.online/algo/dynamic-programming/magic-tower/)
+ * [动态规划帮我通关了《辐射4》](https://labuladong.online/algo/dynamic-programming/freedom-trail/)
+ * [旅游省钱大法:加权最短路径](https://labuladong.online/algo/dynamic-programming/cheap-travel/)
+ * [经典动态规划:正则表达式](https://labuladong.online/algo/dynamic-programming/regular-expression-matching/)
+ * [经典动态规划:高楼扔鸡蛋](https://labuladong.online/algo/dynamic-programming/egg-drop/)
+ * [经典动态规划:戳气球](https://labuladong.online/algo/dynamic-programming/burst-balloons/)
+ * [经典动态规划:博弈问题](https://labuladong.online/algo/dynamic-programming/game-theory/)
+ * [一个方法团灭 LeetCode 打家劫舍问题](https://labuladong.online/algo/dynamic-programming/house-robber/)
+ * [一个方法团灭 LeetCode 股票买卖问题](https://labuladong.online/algo/dynamic-programming/stock-problem-summary/)
+
+ * [贪心类型问题](https://labuladong.online/algo/menu/greedy/)
+ * [贪心算法解题套路框架](https://labuladong.online/algo/essential-technique/greedy/)
+ * [老司机加油算法](https://labuladong.online/algo/frequency-interview/gas-station-greedy/)
+ * [贪心算法之区间调度问题](https://labuladong.online/algo/frequency-interview/interval-scheduling/)
+ * [扫描线技巧:安排会议室](https://labuladong.online/algo/frequency-interview/scan-line-technique/)
+ * [剪视频剪出一个贪心算法](https://labuladong.online/algo/frequency-interview/cut-video/)
+
+
+### [第四章、其他常见算法技巧](https://labuladong.online/algo/menu/other/)
+ * [数学运算技巧](https://labuladong.online/algo/menu/math/)
+ * [一行代码就能解决的算法题](https://labuladong.online/algo/frequency-interview/one-line-solutions/)
+ * [常用的位操作](https://labuladong.online/algo/frequency-interview/bitwise-operation/)
+ * [谈谈游戏中的随机算法](https://labuladong.online/algo/frequency-interview/random-algorithm/)
+ * [讲两道常考的阶乘算法题](https://labuladong.online/algo/frequency-interview/factorial-problems/)
+ * [如何高效寻找素数](https://labuladong.online/algo/frequency-interview/print-prime-number/)
+ * [如何高效进行模幂运算](https://labuladong.online/algo/frequency-interview/quick-power/)
+ * [如何同时寻找缺失和重复的元素](https://labuladong.online/algo/frequency-interview/mismatch-set/)
+ * [几个反直觉的概率问题](https://labuladong.online/algo/frequency-interview/probability-problem/)
+ * [【强化练习】数学技巧相关习题](https://labuladong.online/algo/problem-set/math-tricks/)
+
+ * [经典面试题](https://labuladong.online/algo/menu/interview/)
+ * [算法笔试「骗分」套路](https://labuladong.online/algo/other-skills/tips-in-exam/)
+ * [如何高效解决接雨水问题](https://labuladong.online/algo/frequency-interview/trapping-rain-water/)
+ * [一文秒杀所有丑数系列问题](https://labuladong.online/algo/frequency-interview/ugly-number-summary/)
+ * [一个方法解决三道区间问题](https://labuladong.online/algo/practice-in-action/interval-problem-summary/)
+ * [谁能想到,斗地主也能玩出算法](https://labuladong.online/algo/practice-in-action/split-array-into-consecutive-subsequences/)
+ * [烧饼排序算法](https://labuladong.online/algo/frequency-interview/pancake-sorting/)
+ * [字符串乘法计算](https://labuladong.online/algo/practice-in-action/multiply-strings/)
+ * [如何判定完美矩形](https://labuladong.online/algo/frequency-interview/perfect-rectangle/)
+
+### [附录](https://labuladong.online/algo/menu/appendix/)
+ * [labuladong.online 更新日志](https://labuladong.online/algo/changelog/website/)
+ * [可视化面板更新日志](https://labuladong.online/algo/changelog/visualize/)
+ * [Chrome 刷题插件更新日志](https://labuladong.online/algo/changelog/chrome/)
+ * [vscode 刷题插件更新日志](https://labuladong.online/algo/changelog/vscode/)
+ * [Jetbrain 刷题插件更新日志](https://labuladong.online/algo/changelog/jetbrain/)
+ * [网站/插件问题反馈](https://labuladong.online/algo/intro/bug-report/)
+
+
+
+# 感谢如下大佬参与翻译
+
+按照昵称字典序排名:
+
+[ABCpril](https://github.com/ABCpril),
+[andavid](https://github.com/andavid),
+[bryceustc](https://github.com/bryceustc),
+[build2645](https://github.com/build2645),
+[CarrieOn](https://github.com/CarrieOn),
+[cooker](https://github.com/xiaochuhub),
+[Dong Wang](https://github.com/Coder2Programmer),
+[ExcaliburEX](https://github.com/ExcaliburEX),
+[floatLig](https://github.com/floatLig),
+[ForeverSolar](https://github.com/foreversolar),
+[Fulin Li](https://fulinli.github.io/),
+[Funnyyanne](https://github.com/Funnyyanne),
+[GYHHAHA](https://github.com/GYHHAHA),
+[Hi_archer](https://hiarcher.top/),
+[Iruze](https://github.com/Iruze),
+[Jieyixia](https://github.com/Jieyixia),
+[Justin](https://github.com/Justin-YGG),
+[Kevin](https://github.com/Kevin-free),
+[Lrc123](https://github.com/Lrc123),
+[lriy](https://github.com/lriy),
+[Lyjeeq](https://github.com/Lyjeeq),
+[MasonShu](https://greenwichmt.github.io/),
+[Master-cai](https://github.com/Master-cai),
+[miaoxiaozui2017](https://github.com/miaoxiaozui2017),
+[natsunoyoru97](https://github.com/natsunoyoru97),
+[nettee](https://github.com/nettee),
+[PaperJets](https://github.com/PaperJets),
+[qy-yang](https://github.com/qy-yang),
+[realism0331](https://github.com/realism0331),
+[SCUhzs](https://github.com/brucecat),
+[Seaworth](https://github.com/Seaworth),
+[shazi4399](https://github.com/shazi4399),
+[ShuozheLi](https://github.com/ShuoZheLi/),
+[sinjoywong](https://blog.csdn.net/SinjoyWong),
+[sunqiuming526](https://github.com/sunqiuming526),
+[Tianhao Zhou](https://github.com/tianhaoz95),
+[timmmGZ](https://github.com/timmmGZ),
+[tommytim0515](https://github.com/tommytim0515),
+[ucsk](https://github.com/ucsk),
+[wadegrc](https://github.com/wadegrc),
+[walsvid](https://github.com/walsvid),
+[warmingkkk](https://github.com/warmingkkk),
+[Wonderxie](https://github.com/Wonderxie),
+[wsyzxxxx](https://github.com/wsyzxxxx),
+[xiaodp](https://github.com/xiaodp),
+[youyun](https://github.com/youyun),
+[yx-tan](https://github.com/yx-tan),
+[Zero](https://github.com/Mr2er0),
+[Ziming](https://github.com/ML-ZimingMeng/LeetCode-Python3)
# Donate
- +如果本仓库对你有帮助,可以请作者喝杯速溶咖啡
+
+
diff --git a/contributor.jpg b/contributor.jpg
new file mode 100644
index 0000000000..716a4a79a0
Binary files /dev/null and b/contributor.jpg differ
diff --git a/pictures/4keyboard/1.jpg b/pictures/4keyboard/1.jpg
index e7e543e234..43c7985b4e 100644
Binary files a/pictures/4keyboard/1.jpg and b/pictures/4keyboard/1.jpg differ
diff --git a/pictures/4keyboard/title.png b/pictures/4keyboard/title.png
index b5b71adb9e..6413dee2c8 100644
Binary files a/pictures/4keyboard/title.png and b/pictures/4keyboard/title.png differ
diff --git a/pictures/BST/BST_example.png b/pictures/BST/BST_example.png
index 5306f18673..3e150d1d99 100644
Binary files a/pictures/BST/BST_example.png and b/pictures/BST/BST_example.png differ
diff --git a/pictures/BST/bst_deletion_case_1.png b/pictures/BST/bst_deletion_case_1.png
index 46dcfabda2..923f5e85d2 100644
Binary files a/pictures/BST/bst_deletion_case_1.png and b/pictures/BST/bst_deletion_case_1.png differ
diff --git a/pictures/BST/bst_deletion_case_2.png b/pictures/BST/bst_deletion_case_2.png
index 6edd38d83c..c8c8217797 100644
Binary files a/pictures/BST/bst_deletion_case_2.png and b/pictures/BST/bst_deletion_case_2.png differ
diff --git a/pictures/BST/bst_deletion_case_3.png b/pictures/BST/bst_deletion_case_3.png
index 78473707ca..1a13586540 100644
Binary files a/pictures/BST/bst_deletion_case_3.png and b/pictures/BST/bst_deletion_case_3.png differ
diff --git "a/pictures/BST/\345\201\207BST.png" "b/pictures/BST/\345\201\207BST.png"
index 3028c69c28..47ac2b32fa 100644
Binary files "a/pictures/BST/\345\201\207BST.png" and "b/pictures/BST/\345\201\207BST.png" differ
diff --git "a/pictures/Chrome\346\217\222\344\273\266/baidumonkey.png" "b/pictures/Chrome\346\217\222\344\273\266/baidumonkey.png"
index 3dfb9c5287..b02f566d23 100644
Binary files "a/pictures/Chrome\346\217\222\344\273\266/baidumonkey.png" and "b/pictures/Chrome\346\217\222\344\273\266/baidumonkey.png" differ
diff --git "a/pictures/Chrome\346\217\222\344\273\266/baidu\345\271\277\345\221\212.png" "b/pictures/Chrome\346\217\222\344\273\266/baidu\345\271\277\345\221\212.png"
index ee8dfe2706..1af676e9e7 100644
Binary files "a/pictures/Chrome\346\217\222\344\273\266/baidu\345\271\277\345\221\212.png" and "b/pictures/Chrome\346\217\222\344\273\266/baidu\345\271\277\345\221\212.png" differ
diff --git "a/pictures/Chrome\346\217\222\344\273\266/csdnBlock.png" "b/pictures/Chrome\346\217\222\344\273\266/csdnBlock.png"
index ae129f8b5b..8b57fedc8a 100644
Binary files "a/pictures/Chrome\346\217\222\344\273\266/csdnBlock.png" and "b/pictures/Chrome\346\217\222\344\273\266/csdnBlock.png" differ
diff --git "a/pictures/Chrome\346\217\222\344\273\266/githubzip.png" "b/pictures/Chrome\346\217\222\344\273\266/githubzip.png"
index 3dfb74cd56..41fbf53a1e 100644
Binary files "a/pictures/Chrome\346\217\222\344\273\266/githubzip.png" and "b/pictures/Chrome\346\217\222\344\273\266/githubzip.png" differ
diff --git "a/pictures/Chrome\346\217\222\344\273\266/listen1.png" "b/pictures/Chrome\346\217\222\344\273\266/listen1.png"
index 034f236e75..0af8e0bb34 100644
Binary files "a/pictures/Chrome\346\217\222\344\273\266/listen1.png" and "b/pictures/Chrome\346\217\222\344\273\266/listen1.png" differ
diff --git "a/pictures/Chrome\346\217\222\344\273\266/monkey.png" "b/pictures/Chrome\346\217\222\344\273\266/monkey.png"
index 194d64deae..6b3545cbee 100644
Binary files "a/pictures/Chrome\346\217\222\344\273\266/monkey.png" and "b/pictures/Chrome\346\217\222\344\273\266/monkey.png" differ
diff --git "a/pictures/Chrome\346\217\222\344\273\266/oneTab.png" "b/pictures/Chrome\346\217\222\344\273\266/oneTab.png"
index 7c033bdb9c..ad84073735 100644
Binary files "a/pictures/Chrome\346\217\222\344\273\266/oneTab.png" and "b/pictures/Chrome\346\217\222\344\273\266/oneTab.png" differ
diff --git "a/pictures/Chrome\346\217\222\344\273\266/pin.png" "b/pictures/Chrome\346\217\222\344\273\266/pin.png"
index eeeb0061c3..045d79b045 100644
Binary files "a/pictures/Chrome\346\217\222\344\273\266/pin.png" and "b/pictures/Chrome\346\217\222\344\273\266/pin.png" differ
diff --git "a/pictures/Chrome\346\217\222\344\273\266/tree.png" "b/pictures/Chrome\346\217\222\344\273\266/tree.png"
index 6df887f0c5..eeaa173338 100644
Binary files "a/pictures/Chrome\346\217\222\344\273\266/tree.png" and "b/pictures/Chrome\346\217\222\344\273\266/tree.png" differ
diff --git "a/pictures/Chrome\346\217\222\344\273\266/youhou\344\274\230\345\214\226.png" "b/pictures/Chrome\346\217\222\344\273\266/youhou\344\274\230\345\214\226.png"
index 73de685316..ae944dd791 100644
Binary files "a/pictures/Chrome\346\217\222\344\273\266/youhou\344\274\230\345\214\226.png" and "b/pictures/Chrome\346\217\222\344\273\266/youhou\344\274\230\345\214\226.png" differ
diff --git a/pictures/LCS/1.png b/pictures/LCS/1.png
index db53c702e8..c3fa9fcf09 100644
Binary files a/pictures/LCS/1.png and b/pictures/LCS/1.png differ
diff --git a/pictures/LCS/2.png b/pictures/LCS/2.png
index f8a4ecb0cf..8d1db3538d 100644
Binary files a/pictures/LCS/2.png and b/pictures/LCS/2.png differ
diff --git a/pictures/LCS/3.png b/pictures/LCS/3.png
index eeb5489913..ed7a3f91fd 100644
Binary files a/pictures/LCS/3.png and b/pictures/LCS/3.png differ
diff --git a/pictures/LCS/dp.png b/pictures/LCS/dp.png
index 7df4b5524e..163f88307f 100644
Binary files a/pictures/LCS/dp.png and b/pictures/LCS/dp.png differ
diff --git a/pictures/LCS/lcs.png b/pictures/LCS/lcs.png
index b7ff2d01b6..b0a76e29a2 100644
Binary files a/pictures/LCS/lcs.png and b/pictures/LCS/lcs.png differ
diff --git "a/pictures/LRU\347\256\227\346\263\225/1.jpg" "b/pictures/LRU\347\256\227\346\263\225/1.jpg"
index df7c9560d0..2cd627bacf 100644
Binary files "a/pictures/LRU\347\256\227\346\263\225/1.jpg" and "b/pictures/LRU\347\256\227\346\263\225/1.jpg" differ
diff --git "a/pictures/LRU\347\256\227\346\263\225/2.jpg" "b/pictures/LRU\347\256\227\346\263\225/2.jpg"
index c9a407eef4..a774ec5f1f 100644
Binary files "a/pictures/LRU\347\256\227\346\263\225/2.jpg" and "b/pictures/LRU\347\256\227\346\263\225/2.jpg" differ
diff --git "a/pictures/LRU\347\256\227\346\263\225/3.jpg" "b/pictures/LRU\347\256\227\346\263\225/3.jpg"
index 9bdea69c14..d61f20690a 100644
Binary files "a/pictures/LRU\347\256\227\346\263\225/3.jpg" and "b/pictures/LRU\347\256\227\346\263\225/3.jpg" differ
diff --git "a/pictures/LRU\347\256\227\346\263\225/4.jpg" "b/pictures/LRU\347\256\227\346\263\225/4.jpg"
index ce1a22a3f4..30af4fb8bf 100644
Binary files "a/pictures/LRU\347\256\227\346\263\225/4.jpg" and "b/pictures/LRU\347\256\227\346\263\225/4.jpg" differ
diff --git "a/pictures/LRU\347\256\227\346\263\225/put.jpg" "b/pictures/LRU\347\256\227\346\263\225/put.jpg"
new file mode 100644
index 0000000000..ca580eb634
Binary files /dev/null and "b/pictures/LRU\347\256\227\346\263\225/put.jpg" differ
diff --git a/pictures/algo4/1.jpg b/pictures/algo4/1.jpg
index bc5c41c00e..fbb9b05013 100644
Binary files a/pictures/algo4/1.jpg and b/pictures/algo4/1.jpg differ
diff --git a/pictures/algo4/2.jpg b/pictures/algo4/2.jpg
index 533f783eb6..853c5c7147 100644
Binary files a/pictures/algo4/2.jpg and b/pictures/algo4/2.jpg differ
diff --git a/pictures/algo4/3.jpg b/pictures/algo4/3.jpg
index e317098a2c..0dec5070f9 100644
Binary files a/pictures/algo4/3.jpg and b/pictures/algo4/3.jpg differ
diff --git a/pictures/algo4/title.png b/pictures/algo4/title.png
index aabe966dfb..988f8b5737 100644
Binary files a/pictures/algo4/title.png and b/pictures/algo4/title.png differ
diff --git a/pictures/backtrack/ink-image (1).png b/pictures/backtrack/ink-image (1).png
index 1cf2957d12..b0df286974 100644
Binary files a/pictures/backtrack/ink-image (1).png and b/pictures/backtrack/ink-image (1).png differ
diff --git a/pictures/backtrack/ink-image (2).png b/pictures/backtrack/ink-image (2).png
index bf791a9117..5aa69b5c21 100644
Binary files a/pictures/backtrack/ink-image (2).png and b/pictures/backtrack/ink-image (2).png differ
diff --git a/pictures/backtrack/ink-image (3).png b/pictures/backtrack/ink-image (3).png
index 0ffa62c1d6..dd12af2bc3 100644
Binary files a/pictures/backtrack/ink-image (3).png and b/pictures/backtrack/ink-image (3).png differ
diff --git a/pictures/backtrack/ink-image (4).png b/pictures/backtrack/ink-image (4).png
index 6dcafa1beb..6c0c54d307 100644
Binary files a/pictures/backtrack/ink-image (4).png and b/pictures/backtrack/ink-image (4).png differ
diff --git a/pictures/backtrack/ink-image (5).png b/pictures/backtrack/ink-image (5).png
index e4d2130ee1..eb73a4dd5a 100644
Binary files a/pictures/backtrack/ink-image (5).png and b/pictures/backtrack/ink-image (5).png differ
diff --git a/pictures/backtrack/ink-image (6).png b/pictures/backtrack/ink-image (6).png
index f6fc968bea..75c0f4a0f6 100644
Binary files a/pictures/backtrack/ink-image (6).png and b/pictures/backtrack/ink-image (6).png differ
diff --git a/pictures/backtrack/ink-image.png b/pictures/backtrack/ink-image.png
index ec1ea64d50..5440b0667c 100644
Binary files a/pictures/backtrack/ink-image.png and b/pictures/backtrack/ink-image.png differ
diff --git a/pictures/backtrack/nqueens.png b/pictures/backtrack/nqueens.png
index 4c9e01f560..464ff529ab 100644
Binary files a/pictures/backtrack/nqueens.png and b/pictures/backtrack/nqueens.png differ
diff --git a/pictures/backtrack/permutation.png b/pictures/backtrack/permutation.png
index 421a36e67e..d9f4c6d325 100644
Binary files a/pictures/backtrack/permutation.png and b/pictures/backtrack/permutation.png differ
diff --git "a/pictures/backtrack/\344\273\243\347\240\201.png" "b/pictures/backtrack/\344\273\243\347\240\201.png"
index 85be66b34e..25d7c88cdd 100644
Binary files "a/pictures/backtrack/\344\273\243\347\240\201.png" and "b/pictures/backtrack/\344\273\243\347\240\201.png" differ
diff --git "a/pictures/backtrack/\344\273\243\347\240\2011.png" "b/pictures/backtrack/\344\273\243\347\240\2011.png"
index b029f5f776..f156208f94 100644
Binary files "a/pictures/backtrack/\344\273\243\347\240\2011.png" and "b/pictures/backtrack/\344\273\243\347\240\2011.png" differ
diff --git "a/pictures/backtrack/\344\273\243\347\240\2012.png" "b/pictures/backtrack/\344\273\243\347\240\2012.png"
index ae4a5734ee..c1671f1bfd 100644
Binary files "a/pictures/backtrack/\344\273\243\347\240\2012.png" and "b/pictures/backtrack/\344\273\243\347\240\2012.png" differ
diff --git "a/pictures/backtrack/\344\273\243\347\240\2013.png" "b/pictures/backtrack/\344\273\243\347\240\2013.png"
index c6d842db5e..0dc5eaf30b 100644
Binary files "a/pictures/backtrack/\344\273\243\347\240\2013.png" and "b/pictures/backtrack/\344\273\243\347\240\2013.png" differ
diff --git "a/pictures/backtrack/\345\205\250\346\216\222\345\210\227.png" "b/pictures/backtrack/\345\205\250\346\216\222\345\210\227.png"
index 6fb4f92f97..e7cc064f0a 100644
Binary files "a/pictures/backtrack/\345\205\250\346\216\222\345\210\227.png" and "b/pictures/backtrack/\345\205\250\346\216\222\345\210\227.png" differ
diff --git a/pictures/backtracking/1.jpg b/pictures/backtracking/1.jpg
index e54c8a3c20..b847370747 100644
Binary files a/pictures/backtracking/1.jpg and b/pictures/backtracking/1.jpg differ
diff --git a/pictures/backtracking/2.jpg b/pictures/backtracking/2.jpg
index ff57c7fdd3..2bca873678 100644
Binary files a/pictures/backtracking/2.jpg and b/pictures/backtracking/2.jpg differ
diff --git a/pictures/backtracking/3.jpg b/pictures/backtracking/3.jpg
index ca97cdaa03..b016864ae8 100644
Binary files a/pictures/backtracking/3.jpg and b/pictures/backtracking/3.jpg differ
diff --git a/pictures/backtracking/4.jpg b/pictures/backtracking/4.jpg
index b93cafd72e..3690d9637c 100644
Binary files a/pictures/backtracking/4.jpg and b/pictures/backtracking/4.jpg differ
diff --git a/pictures/backtracking/5.jpg b/pictures/backtracking/5.jpg
index 893c87e682..727ed1ecd0 100644
Binary files a/pictures/backtracking/5.jpg and b/pictures/backtracking/5.jpg differ
diff --git a/pictures/backtracking/6.jpg b/pictures/backtracking/6.jpg
index 0b4d68eea5..368dee24ba 100644
Binary files a/pictures/backtracking/6.jpg and b/pictures/backtracking/6.jpg differ
diff --git a/pictures/backtracking/7.jpg b/pictures/backtracking/7.jpg
index 1eee2f8c36..a146fd6b92 100644
Binary files a/pictures/backtracking/7.jpg and b/pictures/backtracking/7.jpg differ
diff --git a/pictures/calculator/1.1.jpg b/pictures/calculator/1.1.jpg
index 100ca61a10..2ead09ba04 100644
Binary files a/pictures/calculator/1.1.jpg and b/pictures/calculator/1.1.jpg differ
diff --git a/pictures/calculator/1.jpg b/pictures/calculator/1.jpg
index 862bbdd41c..c66e7ab379 100644
Binary files a/pictures/calculator/1.jpg and b/pictures/calculator/1.jpg differ
diff --git a/pictures/calculator/2.jpg b/pictures/calculator/2.jpg
index 62e40b92e8..f3123387da 100644
Binary files a/pictures/calculator/2.jpg and b/pictures/calculator/2.jpg differ
diff --git a/pictures/calculator/3.jpg b/pictures/calculator/3.jpg
index 073f6e39c4..2f3b9a4247 100644
Binary files a/pictures/calculator/3.jpg and b/pictures/calculator/3.jpg differ
diff --git a/pictures/calculator/4.jpg b/pictures/calculator/4.jpg
index 0b0c9ce4b6..4f878ed3b7 100644
Binary files a/pictures/calculator/4.jpg and b/pictures/calculator/4.jpg differ
diff --git a/pictures/calculator/5.jpg b/pictures/calculator/5.jpg
index c1610cc021..528309bb67 100644
Binary files a/pictures/calculator/5.jpg and b/pictures/calculator/5.jpg differ
diff --git a/pictures/calculator/6.jpg b/pictures/calculator/6.jpg
index 92800a3ece..f0563fd2e5 100644
Binary files a/pictures/calculator/6.jpg and b/pictures/calculator/6.jpg differ
diff --git a/pictures/cover.jpg b/pictures/cover.jpg
new file mode 100644
index 0000000000..646769e6cc
Binary files /dev/null and b/pictures/cover.jpg differ
diff --git a/pictures/dupmissing/2.jpg b/pictures/dupmissing/2.jpg
index 781e142ade..91fa41a3c2 100644
Binary files a/pictures/dupmissing/2.jpg and b/pictures/dupmissing/2.jpg differ
diff --git a/pictures/dupmissing/3.jpg b/pictures/dupmissing/3.jpg
index 00d90d6794..babdd3f3c3 100644
Binary files a/pictures/dupmissing/3.jpg and b/pictures/dupmissing/3.jpg differ
diff --git a/pictures/editDistance/1.jpg b/pictures/editDistance/1.jpg
index 7a2e3d58f4..3f2f0b50ad 100644
Binary files a/pictures/editDistance/1.jpg and b/pictures/editDistance/1.jpg differ
diff --git a/pictures/editDistance/2.jpg b/pictures/editDistance/2.jpg
index 0e32faa854..1339bd16b8 100644
Binary files a/pictures/editDistance/2.jpg and b/pictures/editDistance/2.jpg differ
diff --git a/pictures/editDistance/3.jpg b/pictures/editDistance/3.jpg
index c201c6daa2..387c16886a 100644
Binary files a/pictures/editDistance/3.jpg and b/pictures/editDistance/3.jpg differ
diff --git a/pictures/editDistance/4.jpg b/pictures/editDistance/4.jpg
index 13631d1edf..a80c026ae2 100644
Binary files a/pictures/editDistance/4.jpg and b/pictures/editDistance/4.jpg differ
diff --git a/pictures/editDistance/5.jpg b/pictures/editDistance/5.jpg
index 8f5c006323..9106380751 100644
Binary files a/pictures/editDistance/5.jpg and b/pictures/editDistance/5.jpg differ
diff --git a/pictures/editDistance/6.jpg b/pictures/editDistance/6.jpg
index 589f8aef6b..5880bae6b4 100644
Binary files a/pictures/editDistance/6.jpg and b/pictures/editDistance/6.jpg differ
diff --git a/pictures/editDistance/dp.jpg b/pictures/editDistance/dp.jpg
index 41e72a4903..4519d891e6 100644
Binary files a/pictures/editDistance/dp.jpg and b/pictures/editDistance/dp.jpg differ
diff --git a/pictures/editDistance/title.png b/pictures/editDistance/title.png
index 85a392fbde..15dc923107 100644
Binary files a/pictures/editDistance/title.png and b/pictures/editDistance/title.png differ
diff --git a/pictures/floodfill/floodfill.png b/pictures/floodfill/floodfill.png
index 14eebee95b..3c79709bce 100644
Binary files a/pictures/floodfill/floodfill.png and b/pictures/floodfill/floodfill.png differ
diff --git a/pictures/floodfill/leetcode.png b/pictures/floodfill/leetcode.png
index 52f723e266..1ffdc937a7 100644
Binary files a/pictures/floodfill/leetcode.png and b/pictures/floodfill/leetcode.png differ
diff --git a/pictures/floodfill/ppt1.PNG b/pictures/floodfill/ppt1.PNG
index 22046455d0..1667b0f18f 100644
Binary files a/pictures/floodfill/ppt1.PNG and b/pictures/floodfill/ppt1.PNG differ
diff --git a/pictures/floodfill/ppt2.PNG b/pictures/floodfill/ppt2.PNG
index 28a220d614..58dd272514 100644
Binary files a/pictures/floodfill/ppt2.PNG and b/pictures/floodfill/ppt2.PNG differ
diff --git a/pictures/floodfill/ppt3.PNG b/pictures/floodfill/ppt3.PNG
index 6957ffe4ae..0f2a1a80f2 100644
Binary files a/pictures/floodfill/ppt3.PNG and b/pictures/floodfill/ppt3.PNG differ
diff --git a/pictures/floodfill/ppt4.PNG b/pictures/floodfill/ppt4.PNG
index 9ceb6ed044..f90e4b9e6d 100644
Binary files a/pictures/floodfill/ppt4.PNG and b/pictures/floodfill/ppt4.PNG differ
diff --git a/pictures/floodfill/ppt5.PNG b/pictures/floodfill/ppt5.PNG
index b2583eef11..f6e5cc0b25 100644
Binary files a/pictures/floodfill/ppt5.PNG and b/pictures/floodfill/ppt5.PNG differ
diff --git a/pictures/floodfill/xiaoxiaole.jpg b/pictures/floodfill/xiaoxiaole.jpg
index fa443f0cda..fcf657ac8d 100644
Binary files a/pictures/floodfill/xiaoxiaole.jpg and b/pictures/floodfill/xiaoxiaole.jpg differ
diff --git "a/pictures/floodfill/\346\211\253\351\233\267.png" "b/pictures/floodfill/\346\211\253\351\233\267.png"
index 9b04e0392c..d25e1deac1 100644
Binary files "a/pictures/floodfill/\346\211\253\351\233\267.png" and "b/pictures/floodfill/\346\211\253\351\233\267.png" differ
diff --git "a/pictures/floodfill/\346\212\240\345\233\276.jpeg" "b/pictures/floodfill/\346\212\240\345\233\276.jpeg"
index fa112468c5..66097dd104 100644
Binary files "a/pictures/floodfill/\346\212\240\345\233\276.jpeg" and "b/pictures/floodfill/\346\212\240\345\233\276.jpeg" differ
diff --git a/pictures/group.jpg b/pictures/group.jpg
new file mode 100644
index 0000000000..6d942cfcc4
Binary files /dev/null and b/pictures/group.jpg differ
diff --git a/pictures/header.jpg b/pictures/header.jpg
new file mode 100644
index 0000000000..06a2048f45
Binary files /dev/null and b/pictures/header.jpg differ
diff --git a/pictures/heap/1.png b/pictures/heap/1.png
index 93f4387839..8d99c0d9b1 100644
Binary files a/pictures/heap/1.png and b/pictures/heap/1.png differ
diff --git a/pictures/intersection/1.jpg b/pictures/intersection/1.jpg
index 03b9cbf67c..97f313fe08 100644
Binary files a/pictures/intersection/1.jpg and b/pictures/intersection/1.jpg differ
diff --git a/pictures/intersection/2.jpg b/pictures/intersection/2.jpg
index 3434de4d1e..555688e4e7 100644
Binary files a/pictures/intersection/2.jpg and b/pictures/intersection/2.jpg differ
diff --git a/pictures/intersection/3.jpg b/pictures/intersection/3.jpg
index b5e805df66..9ba0b61d8a 100644
Binary files a/pictures/intersection/3.jpg and b/pictures/intersection/3.jpg differ
diff --git a/pictures/intersection/title.png b/pictures/intersection/title.png
index 4b0529a808..d06d89249b 100644
Binary files a/pictures/intersection/title.png and b/pictures/intersection/title.png differ
diff --git a/pictures/interval/2.jpg b/pictures/interval/2.jpg
index aa0440f0e1..06e34bd6a2 100644
Binary files a/pictures/interval/2.jpg and b/pictures/interval/2.jpg differ
diff --git a/pictures/interval/3.jpg b/pictures/interval/3.jpg
index 89b4e6eff1..68741642ea 100644
Binary files a/pictures/interval/3.jpg and b/pictures/interval/3.jpg differ
diff --git a/pictures/interval/4.jpg b/pictures/interval/4.jpg
index c6735d83ad..d9fb1f4a19 100644
Binary files a/pictures/interval/4.jpg and b/pictures/interval/4.jpg differ
diff --git a/pictures/interval/title1.png b/pictures/interval/title1.png
index 551c259902..e90959bad5 100644
Binary files a/pictures/interval/title1.png and b/pictures/interval/title1.png differ
diff --git a/pictures/interval/title2.png b/pictures/interval/title2.png
index 41261129bc..626d0c5c9b 100644
Binary files a/pictures/interval/title2.png and b/pictures/interval/title2.png differ
diff --git a/pictures/kgroup/1.jpg b/pictures/kgroup/1.jpg
index ca0c8ff8b4..ab874fcab4 100644
Binary files a/pictures/kgroup/1.jpg and b/pictures/kgroup/1.jpg differ
diff --git a/pictures/kgroup/2.jpg b/pictures/kgroup/2.jpg
index 653d31f4dc..ca29ffd706 100644
Binary files a/pictures/kgroup/2.jpg and b/pictures/kgroup/2.jpg differ
diff --git a/pictures/kgroup/3.jpg b/pictures/kgroup/3.jpg
index 8718e51c31..e2255241ec 100644
Binary files a/pictures/kgroup/3.jpg and b/pictures/kgroup/3.jpg differ
diff --git a/pictures/kgroup/4.jpg b/pictures/kgroup/4.jpg
index f2fed3e33a..6126add251 100644
Binary files a/pictures/kgroup/4.jpg and b/pictures/kgroup/4.jpg differ
diff --git a/pictures/kgroup/5.jpg b/pictures/kgroup/5.jpg
index 4cd3b33242..2b626b30e4 100644
Binary files a/pictures/kgroup/5.jpg and b/pictures/kgroup/5.jpg differ
diff --git a/pictures/kgroup/6.jpg b/pictures/kgroup/6.jpg
index 4e1772b0bc..f11088f7cb 100644
Binary files a/pictures/kgroup/6.jpg and b/pictures/kgroup/6.jpg differ
diff --git a/pictures/kgroup/7.jpg b/pictures/kgroup/7.jpg
index 073ba61f3e..8b4bf79934 100644
Binary files a/pictures/kgroup/7.jpg and b/pictures/kgroup/7.jpg differ
diff --git a/pictures/kgroup/title.png b/pictures/kgroup/title.png
index 794f5a5cc5..1a2028185e 100644
Binary files a/pictures/kgroup/title.png and b/pictures/kgroup/title.png differ
diff --git a/pictures/kmp/1.gif b/pictures/kmp/1.gif
index a049ff3456..95732bf8ee 100644
Binary files a/pictures/kmp/1.gif and b/pictures/kmp/1.gif differ
diff --git a/pictures/kmp/2.gif b/pictures/kmp/2.gif
index 418d02b7bc..ed1059d958 100644
Binary files a/pictures/kmp/2.gif and b/pictures/kmp/2.gif differ
diff --git a/pictures/kmp/3.gif b/pictures/kmp/3.gif
index 309e95efa0..e91497f4ca 100644
Binary files a/pictures/kmp/3.gif and b/pictures/kmp/3.gif differ
diff --git a/pictures/kmp/A.gif b/pictures/kmp/A.gif
index 10c48fb569..dd0800e17b 100644
Binary files a/pictures/kmp/A.gif and b/pictures/kmp/A.gif differ
diff --git a/pictures/kmp/allstate.jpg b/pictures/kmp/allstate.jpg
index bfbd26bcc4..f8e40777d1 100644
Binary files a/pictures/kmp/allstate.jpg and b/pictures/kmp/allstate.jpg differ
diff --git a/pictures/kmp/back.jpg b/pictures/kmp/back.jpg
index e33cc25cd7..368d091098 100644
Binary files a/pictures/kmp/back.jpg and b/pictures/kmp/back.jpg differ
diff --git a/pictures/kmp/dfa.gif b/pictures/kmp/dfa.gif
index 0e9bdaa4f8..0f5dc54224 100644
Binary files a/pictures/kmp/dfa.gif and b/pictures/kmp/dfa.gif differ
diff --git a/pictures/kmp/exp1.jpg b/pictures/kmp/exp1.jpg
index 5bb393523e..9e413d0438 100644
Binary files a/pictures/kmp/exp1.jpg and b/pictures/kmp/exp1.jpg differ
diff --git a/pictures/kmp/exp2.jpg b/pictures/kmp/exp2.jpg
index f277b7e81b..244fc4ee4b 100644
Binary files a/pictures/kmp/exp2.jpg and b/pictures/kmp/exp2.jpg differ
diff --git a/pictures/kmp/exp3.jpg b/pictures/kmp/exp3.jpg
index a7e48efb38..11eae5a6d2 100644
Binary files a/pictures/kmp/exp3.jpg and b/pictures/kmp/exp3.jpg differ
diff --git a/pictures/kmp/exp4.jpg b/pictures/kmp/exp4.jpg
index f7f98ee58c..e969c48d8a 100644
Binary files a/pictures/kmp/exp4.jpg and b/pictures/kmp/exp4.jpg differ
diff --git a/pictures/kmp/exp5.jpg b/pictures/kmp/exp5.jpg
index 979d91e31d..2a16a868ab 100644
Binary files a/pictures/kmp/exp5.jpg and b/pictures/kmp/exp5.jpg differ
diff --git a/pictures/kmp/exp6.jpg b/pictures/kmp/exp6.jpg
index 423b244d43..87c723f3b8 100644
Binary files a/pictures/kmp/exp6.jpg and b/pictures/kmp/exp6.jpg differ
diff --git a/pictures/kmp/exp7.jpg b/pictures/kmp/exp7.jpg
index 10da813832..95634204bd 100644
Binary files a/pictures/kmp/exp7.jpg and b/pictures/kmp/exp7.jpg differ
diff --git a/pictures/kmp/forward.jpg b/pictures/kmp/forward.jpg
index 66beca0ebe..2f887c8933 100644
Binary files a/pictures/kmp/forward.jpg and b/pictures/kmp/forward.jpg differ
diff --git a/pictures/kmp/kmp.gif b/pictures/kmp/kmp.gif
index e33dad97b3..18cd52dbd8 100644
Binary files a/pictures/kmp/kmp.gif and b/pictures/kmp/kmp.gif differ
diff --git a/pictures/kmp/shadow.jpg b/pictures/kmp/shadow.jpg
index 0733b546e2..9b2f536aab 100644
Binary files a/pictures/kmp/shadow.jpg and b/pictures/kmp/shadow.jpg differ
diff --git a/pictures/kmp/shadow1.jpg b/pictures/kmp/shadow1.jpg
index 13d0377725..07389fc897 100644
Binary files a/pictures/kmp/shadow1.jpg and b/pictures/kmp/shadow1.jpg differ
diff --git a/pictures/kmp/shadow2.jpg b/pictures/kmp/shadow2.jpg
index a9abb79d7d..f68660afe0 100644
Binary files a/pictures/kmp/shadow2.jpg and b/pictures/kmp/shadow2.jpg differ
diff --git a/pictures/kmp/state.jpg b/pictures/kmp/state.jpg
index 073060b2bf..3fd084cca8 100644
Binary files a/pictures/kmp/state.jpg and b/pictures/kmp/state.jpg differ
diff --git a/pictures/kmp/state2.jpg b/pictures/kmp/state2.jpg
index 3be64c091f..f20fde5d12 100644
Binary files a/pictures/kmp/state2.jpg and b/pictures/kmp/state2.jpg differ
diff --git a/pictures/kmp/state4.jpg b/pictures/kmp/state4.jpg
index d5ba19eaf2..8873fd38be 100644
Binary files a/pictures/kmp/state4.jpg and b/pictures/kmp/state4.jpg differ
diff --git a/pictures/kmp/txt1.jpg b/pictures/kmp/txt1.jpg
index a123d9e360..3b10191619 100644
Binary files a/pictures/kmp/txt1.jpg and b/pictures/kmp/txt1.jpg differ
diff --git a/pictures/kmp/txt2.jpg b/pictures/kmp/txt2.jpg
index bbb7cd3781..c6c5041e66 100644
Binary files a/pictures/kmp/txt2.jpg and b/pictures/kmp/txt2.jpg differ
diff --git a/pictures/kmp/txt3.jpg b/pictures/kmp/txt3.jpg
index e4edfd70ae..29830ba73e 100644
Binary files a/pictures/kmp/txt3.jpg and b/pictures/kmp/txt3.jpg differ
diff --git a/pictures/kmp/txt4.jpg b/pictures/kmp/txt4.jpg
index 50e36d1fb1..55e53e7719 100644
Binary files a/pictures/kmp/txt4.jpg and b/pictures/kmp/txt4.jpg differ
diff --git a/pictures/kmp/z.jpg b/pictures/kmp/z.jpg
index aebf0b8609..56b945efcf 100644
Binary files a/pictures/kmp/z.jpg and b/pictures/kmp/z.jpg differ
diff --git a/pictures/labuladong.jpg b/pictures/labuladong.jpg
deleted file mode 100644
index cb385ab0ad..0000000000
Binary files a/pictures/labuladong.jpg and /dev/null differ
diff --git a/pictures/labuladong.png b/pictures/labuladong.png
index fe2100acdd..a63a5bd890 100644
Binary files a/pictures/labuladong.png and b/pictures/labuladong.png differ
diff --git a/pictures/linux-fs/application.png b/pictures/linux-fs/application.png
index 17185b81d5..9b39088f36 100644
Binary files a/pictures/linux-fs/application.png and b/pictures/linux-fs/application.png differ
diff --git a/pictures/linux-fs/apt.png b/pictures/linux-fs/apt.png
index bed240ba9d..5038c8c267 100644
Binary files a/pictures/linux-fs/apt.png and b/pictures/linux-fs/apt.png differ
diff --git a/pictures/linux-fs/bin.png b/pictures/linux-fs/bin.png
index 755491a457..353baa7bf8 100644
Binary files a/pictures/linux-fs/bin.png and b/pictures/linux-fs/bin.png differ
diff --git a/pictures/linux-fs/boot.png b/pictures/linux-fs/boot.png
index 1f1b225007..d5848e8cd5 100644
Binary files a/pictures/linux-fs/boot.png and b/pictures/linux-fs/boot.png differ
diff --git a/pictures/linux-fs/cpu.png b/pictures/linux-fs/cpu.png
index 721b66cd92..12d949e9d9 100644
Binary files a/pictures/linux-fs/cpu.png and b/pictures/linux-fs/cpu.png differ
diff --git a/pictures/linux-fs/desktop.png b/pictures/linux-fs/desktop.png
index 4cb1239f70..7a46ecef21 100644
Binary files a/pictures/linux-fs/desktop.png and b/pictures/linux-fs/desktop.png differ
diff --git a/pictures/linux-fs/dev.png b/pictures/linux-fs/dev.png
index dd892e6538..c9275dc85e 100644
Binary files a/pictures/linux-fs/dev.png and b/pictures/linux-fs/dev.png differ
diff --git a/pictures/linux-fs/etc.png b/pictures/linux-fs/etc.png
index 3a3d1063ef..5de3a4cf78 100644
Binary files a/pictures/linux-fs/etc.png and b/pictures/linux-fs/etc.png differ
diff --git a/pictures/linux-fs/home.png b/pictures/linux-fs/home.png
index d35c71bba6..dad402e25a 100644
Binary files a/pictures/linux-fs/home.png and b/pictures/linux-fs/home.png differ
diff --git a/pictures/linux-fs/linux-filesystem.png b/pictures/linux-fs/linux-filesystem.png
index c43b2922d2..225efb8ab3 100644
Binary files a/pictures/linux-fs/linux-filesystem.png and b/pictures/linux-fs/linux-filesystem.png differ
diff --git a/pictures/linux-fs/log.png b/pictures/linux-fs/log.png
index a4416e1059..ee40ca0a6e 100644
Binary files a/pictures/linux-fs/log.png and b/pictures/linux-fs/log.png differ
diff --git a/pictures/linux-fs/opt.png b/pictures/linux-fs/opt.png
index 7b2092f234..b46535ec66 100644
Binary files a/pictures/linux-fs/opt.png and b/pictures/linux-fs/opt.png differ
diff --git a/pictures/linux-fs/proc.png b/pictures/linux-fs/proc.png
index 06006000f1..0e2820a1b5 100644
Binary files a/pictures/linux-fs/proc.png and b/pictures/linux-fs/proc.png differ
diff --git a/pictures/linux-fs/root.png b/pictures/linux-fs/root.png
index 00df4f75ec..3ba9697367 100644
Binary files a/pictures/linux-fs/root.png and b/pictures/linux-fs/root.png differ
diff --git a/pictures/linux-fs/sbin.png b/pictures/linux-fs/sbin.png
index 2fc99208df..907c3a0f3e 100644
Binary files a/pictures/linux-fs/sbin.png and b/pictures/linux-fs/sbin.png differ
diff --git a/pictures/linux-fs/tmp.png b/pictures/linux-fs/tmp.png
index 361146697d..54ea9dd615 100644
Binary files a/pictures/linux-fs/tmp.png and b/pictures/linux-fs/tmp.png differ
diff --git a/pictures/linux-fs/usr.png b/pictures/linux-fs/usr.png
index 29e389ce35..0619c44937 100644
Binary files a/pictures/linux-fs/usr.png and b/pictures/linux-fs/usr.png differ
diff --git a/pictures/linux-fs/usrbin.png b/pictures/linux-fs/usrbin.png
index 7dfd72a84f..e1c5e82f6c 100644
Binary files a/pictures/linux-fs/usrbin.png and b/pictures/linux-fs/usrbin.png differ
diff --git a/pictures/linuxProcess/1.jpg b/pictures/linuxProcess/1.jpg
index a3b4383b8a..a42365fe73 100644
Binary files a/pictures/linuxProcess/1.jpg and b/pictures/linuxProcess/1.jpg differ
diff --git a/pictures/linuxProcess/2.jpg b/pictures/linuxProcess/2.jpg
index 821ff340fa..9aa08f1401 100644
Binary files a/pictures/linuxProcess/2.jpg and b/pictures/linuxProcess/2.jpg differ
diff --git a/pictures/linuxProcess/3.jpg b/pictures/linuxProcess/3.jpg
index d7d3ae97ff..a3800a8f21 100644
Binary files a/pictures/linuxProcess/3.jpg and b/pictures/linuxProcess/3.jpg differ
diff --git a/pictures/linuxProcess/4.jpg b/pictures/linuxProcess/4.jpg
index 6ada0ef14e..c74fdd3722 100644
Binary files a/pictures/linuxProcess/4.jpg and b/pictures/linuxProcess/4.jpg differ
diff --git a/pictures/linuxProcess/5.jpg b/pictures/linuxProcess/5.jpg
index c4c51ca759..e7b1f74c1d 100644
Binary files a/pictures/linuxProcess/5.jpg and b/pictures/linuxProcess/5.jpg differ
diff --git a/pictures/linuxProcess/6.jpg b/pictures/linuxProcess/6.jpg
index c2637d131b..9e36322eba 100644
Binary files a/pictures/linuxProcess/6.jpg and b/pictures/linuxProcess/6.jpg differ
diff --git a/pictures/linuxProcess/7.jpg b/pictures/linuxProcess/7.jpg
index 6abd83436f..80e86879cb 100644
Binary files a/pictures/linuxProcess/7.jpg and b/pictures/linuxProcess/7.jpg differ
diff --git a/pictures/linuxProcess/8.jpg b/pictures/linuxProcess/8.jpg
index eafae087d3..2b4cb97101 100644
Binary files a/pictures/linuxProcess/8.jpg and b/pictures/linuxProcess/8.jpg differ
diff --git a/pictures/linuxshell/1.png b/pictures/linuxshell/1.png
index 0657e4d62f..292baa29d0 100644
Binary files a/pictures/linuxshell/1.png and b/pictures/linuxshell/1.png differ
diff --git a/pictures/mergeInterval/1.jpg b/pictures/mergeInterval/1.jpg
index 915f33607a..5d8a8dbc2e 100644
Binary files a/pictures/mergeInterval/1.jpg and b/pictures/mergeInterval/1.jpg differ
diff --git a/pictures/mergeInterval/2.jpg b/pictures/mergeInterval/2.jpg
index 79a8ef7f22..28aabd731a 100644
Binary files a/pictures/mergeInterval/2.jpg and b/pictures/mergeInterval/2.jpg differ
diff --git a/pictures/mergeInterval/title.png b/pictures/mergeInterval/title.png
index ac1a373946..26e42c14e8 100644
Binary files a/pictures/mergeInterval/title.png and b/pictures/mergeInterval/title.png differ
diff --git a/pictures/online/1.png b/pictures/online/1.png
index 11da044f4d..68db13bada 100644
Binary files a/pictures/online/1.png and b/pictures/online/1.png differ
diff --git a/pictures/online/10.png b/pictures/online/10.png
index 63041fc421..ec2095fd15 100644
Binary files a/pictures/online/10.png and b/pictures/online/10.png differ
diff --git a/pictures/online/11.png b/pictures/online/11.png
index 2aac442a00..87d3368cb5 100644
Binary files a/pictures/online/11.png and b/pictures/online/11.png differ
diff --git a/pictures/online/2.png b/pictures/online/2.png
index b8e460ac25..de635fa8dd 100644
Binary files a/pictures/online/2.png and b/pictures/online/2.png differ
diff --git a/pictures/online/3.png b/pictures/online/3.png
index 1f465a69f6..c8868697a9 100644
Binary files a/pictures/online/3.png and b/pictures/online/3.png differ
diff --git a/pictures/online/4.png b/pictures/online/4.png
index 5d99ec999a..7534e3e76f 100644
Binary files a/pictures/online/4.png and b/pictures/online/4.png differ
diff --git a/pictures/online/5.png b/pictures/online/5.png
index c118acd3a6..9d9ae0a2d8 100644
Binary files a/pictures/online/5.png and b/pictures/online/5.png differ
diff --git a/pictures/online/6.png b/pictures/online/6.png
index f77e12a989..06c079fdca 100644
Binary files a/pictures/online/6.png and b/pictures/online/6.png differ
diff --git a/pictures/online/7.png b/pictures/online/7.png
index a031c195a6..9098f63ad4 100644
Binary files a/pictures/online/7.png and b/pictures/online/7.png differ
diff --git a/pictures/online/8.png b/pictures/online/8.png
index 0822ef48d9..b462ad6d7c 100644
Binary files a/pictures/online/8.png and b/pictures/online/8.png differ
diff --git a/pictures/online/9.png b/pictures/online/9.png
index a94900f779..f879e25516 100644
Binary files a/pictures/online/9.png and b/pictures/online/9.png differ
diff --git a/pictures/others/leetcode.jpeg b/pictures/others/leetcode.jpeg
index 8b2c7c776b..2fd2c684db 100644
Binary files a/pictures/others/leetcode.jpeg and b/pictures/others/leetcode.jpeg differ
diff --git a/pictures/pancakeSort/1.jpg b/pictures/pancakeSort/1.jpg
index 10f9dd6568..903dec371b 100644
Binary files a/pictures/pancakeSort/1.jpg and b/pictures/pancakeSort/1.jpg differ
diff --git a/pictures/pancakeSort/2.png b/pictures/pancakeSort/2.png
index e57fd31a48..57e16de2dd 100644
Binary files a/pictures/pancakeSort/2.png and b/pictures/pancakeSort/2.png differ
diff --git a/pictures/pancakeSort/3.jpg b/pictures/pancakeSort/3.jpg
index c492e8bf8b..b36f6fcc80 100644
Binary files a/pictures/pancakeSort/3.jpg and b/pictures/pancakeSort/3.jpg differ
diff --git a/pictures/pancakeSort/4.jpg b/pictures/pancakeSort/4.jpg
index 53341a3554..f9245e5937 100644
Binary files a/pictures/pancakeSort/4.jpg and b/pictures/pancakeSort/4.jpg differ
diff --git a/pictures/pancakeSort/title.png b/pictures/pancakeSort/title.png
index f91a8132ce..76a52a0f38 100644
Binary files a/pictures/pancakeSort/title.png and b/pictures/pancakeSort/title.png differ
diff --git a/pictures/pay.jpg b/pictures/pay.jpg
index 5322a657db..39e9d402a4 100644
Binary files a/pictures/pay.jpg and b/pictures/pay.jpg differ
diff --git a/pictures/plugin/chrome.gif b/pictures/plugin/chrome.gif
new file mode 100644
index 0000000000..d3ad03cff9
Binary files /dev/null and b/pictures/plugin/chrome.gif differ
diff --git a/pictures/plugin/chrome.jpg b/pictures/plugin/chrome.jpg
new file mode 100644
index 0000000000..4f5fc680a4
Binary files /dev/null and b/pictures/plugin/chrome.jpg differ
diff --git a/pictures/plugin/jetbrain.gif b/pictures/plugin/jetbrain.gif
new file mode 100644
index 0000000000..e2deb6d05c
Binary files /dev/null and b/pictures/plugin/jetbrain.gif differ
diff --git a/pictures/plugin/jetbrain.jpg b/pictures/plugin/jetbrain.jpg
new file mode 100644
index 0000000000..061aee41e4
Binary files /dev/null and b/pictures/plugin/jetbrain.jpg differ
diff --git a/pictures/plugin/vscode.gif b/pictures/plugin/vscode.gif
new file mode 100644
index 0000000000..a0962b45df
Binary files /dev/null and b/pictures/plugin/vscode.gif differ
diff --git a/pictures/plugin/vscode.jpg b/pictures/plugin/vscode.jpg
new file mode 100644
index 0000000000..3c68f20389
Binary files /dev/null and b/pictures/plugin/vscode.jpg differ
diff --git "a/pictures/plugin/\345\205\250\345\256\266\346\241\266.jpg" "b/pictures/plugin/\345\205\250\345\256\266\346\241\266.jpg"
new file mode 100644
index 0000000000..b97e4cbb4b
Binary files /dev/null and "b/pictures/plugin/\345\205\250\345\256\266\346\241\266.jpg" differ
diff --git a/pictures/qrcode.jpg b/pictures/qrcode.jpg
index d6beb95c7b..83e46cb25f 100644
Binary files a/pictures/qrcode.jpg and b/pictures/qrcode.jpg differ
diff --git "a/pictures/redis\345\205\245\344\276\265/1.png" "b/pictures/redis\345\205\245\344\276\265/1.png"
index fb2e59dc41..e021d3eb44 100644
Binary files "a/pictures/redis\345\205\245\344\276\265/1.png" and "b/pictures/redis\345\205\245\344\276\265/1.png" differ
diff --git "a/pictures/redis\345\205\245\344\276\265/2.png" "b/pictures/redis\345\205\245\344\276\265/2.png"
index 94fcae0456..a9f03e65e9 100644
Binary files "a/pictures/redis\345\205\245\344\276\265/2.png" and "b/pictures/redis\345\205\245\344\276\265/2.png" differ
diff --git "a/pictures/redis\345\205\245\344\276\265/3.png" "b/pictures/redis\345\205\245\344\276\265/3.png"
index d559c635db..b4c9980e83 100644
Binary files "a/pictures/redis\345\205\245\344\276\265/3.png" and "b/pictures/redis\345\205\245\344\276\265/3.png" differ
diff --git "a/pictures/redis\345\205\245\344\276\265/4.png" "b/pictures/redis\345\205\245\344\276\265/4.png"
index 2abc2eedcf..44b390d666 100644
Binary files "a/pictures/redis\345\205\245\344\276\265/4.png" and "b/pictures/redis\345\205\245\344\276\265/4.png" differ
diff --git "a/pictures/redis\345\205\245\344\276\265/5.png" "b/pictures/redis\345\205\245\344\276\265/5.png"
index 2d6c01e14b..60dc5ab738 100644
Binary files "a/pictures/redis\345\205\245\344\276\265/5.png" and "b/pictures/redis\345\205\245\344\276\265/5.png" differ
diff --git "a/pictures/redis\345\205\245\344\276\265/6.png" "b/pictures/redis\345\205\245\344\276\265/6.png"
index 48cd894f7d..618c28c203 100644
Binary files "a/pictures/redis\345\205\245\344\276\265/6.png" and "b/pictures/redis\345\205\245\344\276\265/6.png" differ
diff --git a/pictures/robber/1.jpg b/pictures/robber/1.jpg
index 62cec652a6..23b590f6a9 100644
Binary files a/pictures/robber/1.jpg and b/pictures/robber/1.jpg differ
diff --git a/pictures/robber/2.jpg b/pictures/robber/2.jpg
index 89ffabb077..95761fddbc 100644
Binary files a/pictures/robber/2.jpg and b/pictures/robber/2.jpg differ
diff --git a/pictures/robber/3.jpg b/pictures/robber/3.jpg
index 35e169e770..6c54da1aa9 100644
Binary files a/pictures/robber/3.jpg and b/pictures/robber/3.jpg differ
diff --git a/pictures/robber/title.png b/pictures/robber/title.png
index c4bd7822bf..8f60633f9d 100644
Binary files a/pictures/robber/title.png and b/pictures/robber/title.png differ
diff --git a/pictures/robber/title1.png b/pictures/robber/title1.png
index 736ece0c9f..b6096939dd 100644
Binary files a/pictures/robber/title1.png and b/pictures/robber/title1.png differ
diff --git a/pictures/session/1.png b/pictures/session/1.png
index 2b7c7b1b9f..906f7090f7 100644
Binary files a/pictures/session/1.png and b/pictures/session/1.png differ
diff --git a/pictures/session/2.png b/pictures/session/2.png
index 4662883971..d2660b2219 100644
Binary files a/pictures/session/2.png and b/pictures/session/2.png differ
diff --git a/pictures/session/3.png b/pictures/session/3.png
index 59c12d4988..622a8f707e 100644
Binary files a/pictures/session/3.png and b/pictures/session/3.png differ
diff --git a/pictures/session/4.jpg b/pictures/session/4.jpg
index a838e406a3..81e92eedd1 100644
Binary files a/pictures/session/4.jpg and b/pictures/session/4.jpg differ
diff --git a/pictures/souyisou.png b/pictures/souyisou.png
new file mode 100644
index 0000000000..94d9f67c1e
Binary files /dev/null and b/pictures/souyisou.png differ
diff --git a/pictures/souyisou2.png b/pictures/souyisou2.png
new file mode 100644
index 0000000000..744d478f16
Binary files /dev/null and b/pictures/souyisou2.png differ
diff --git a/pictures/unionfind/1.jpg b/pictures/unionfind/1.jpg
index 7e5f6fb607..77aaf0ee22 100644
Binary files a/pictures/unionfind/1.jpg and b/pictures/unionfind/1.jpg differ
diff --git a/pictures/unionfind/2.jpg b/pictures/unionfind/2.jpg
index af87343e6f..a5396986e9 100644
Binary files a/pictures/unionfind/2.jpg and b/pictures/unionfind/2.jpg differ
diff --git a/pictures/unionfind/3.jpg b/pictures/unionfind/3.jpg
index 84a97b403c..d3c6051348 100644
Binary files a/pictures/unionfind/3.jpg and b/pictures/unionfind/3.jpg differ
diff --git a/pictures/unionfind/4.jpg b/pictures/unionfind/4.jpg
index d967c663c6..4004791778 100644
Binary files a/pictures/unionfind/4.jpg and b/pictures/unionfind/4.jpg differ
diff --git a/pictures/unionfind/5.jpg b/pictures/unionfind/5.jpg
index aed3cd1574..273302945c 100644
Binary files a/pictures/unionfind/5.jpg and b/pictures/unionfind/5.jpg differ
diff --git a/pictures/unionfind/6.jpg b/pictures/unionfind/6.jpg
index ca30431e28..ae37f8d0ba 100644
Binary files a/pictures/unionfind/6.jpg and b/pictures/unionfind/6.jpg differ
diff --git a/pictures/unionfind/7.jpg b/pictures/unionfind/7.jpg
index b9cc6e1347..251dd20f05 100644
Binary files a/pictures/unionfind/7.jpg and b/pictures/unionfind/7.jpg differ
diff --git a/pictures/unionfind/8.jpg b/pictures/unionfind/8.jpg
index 7a544068b7..fd74212075 100644
Binary files a/pictures/unionfind/8.jpg and b/pictures/unionfind/8.jpg differ
diff --git "a/pictures/unionfind\345\272\224\347\224\250/1.jpg" "b/pictures/unionfind\345\272\224\347\224\250/1.jpg"
index f3a311a27e..583e66121b 100644
Binary files "a/pictures/unionfind\345\272\224\347\224\250/1.jpg" and "b/pictures/unionfind\345\272\224\347\224\250/1.jpg" differ
diff --git "a/pictures/unionfind\345\272\224\347\224\250/2.jpg" "b/pictures/unionfind\345\272\224\347\224\250/2.jpg"
index 7c1e6acd50..5e4c40b9b4 100644
Binary files "a/pictures/unionfind\345\272\224\347\224\250/2.jpg" and "b/pictures/unionfind\345\272\224\347\224\250/2.jpg" differ
diff --git "a/pictures/unionfind\345\272\224\347\224\250/3.jpg" "b/pictures/unionfind\345\272\224\347\224\250/3.jpg"
index dca81a8366..a21dd12d70 100644
Binary files "a/pictures/unionfind\345\272\224\347\224\250/3.jpg" and "b/pictures/unionfind\345\272\224\347\224\250/3.jpg" differ
diff --git a/pictures/youtube/1.png b/pictures/youtube/1.png
index 3c8c59589a..f7f96878a2 100644
Binary files a/pictures/youtube/1.png and b/pictures/youtube/1.png differ
diff --git a/pictures/youtube/1573133096614.jpeg b/pictures/youtube/1573133096614.jpeg
index c34c38eeb6..27f85dc3ab 100644
Binary files a/pictures/youtube/1573133096614.jpeg and b/pictures/youtube/1573133096614.jpeg differ
diff --git a/pictures/youtube/1573133131308.jpeg b/pictures/youtube/1573133131308.jpeg
index 0c75129dc0..c464ef3bec 100644
Binary files a/pictures/youtube/1573133131308.jpeg and b/pictures/youtube/1573133131308.jpeg differ
diff --git a/pictures/youtube/2.jpg b/pictures/youtube/2.jpg
index 2eeae31b5d..490c1c40be 100644
Binary files a/pictures/youtube/2.jpg and b/pictures/youtube/2.jpg differ
diff --git a/pictures/youtube/3.jpg b/pictures/youtube/3.jpg
index d1112a6447..7d24d92b33 100644
Binary files a/pictures/youtube/3.jpg and b/pictures/youtube/3.jpg differ
diff --git a/pictures/youtube/4.jpg b/pictures/youtube/4.jpg
index 0f4cd6b3df..3ea617d104 100644
Binary files a/pictures/youtube/4.jpg and b/pictures/youtube/4.jpg differ
diff --git "a/pictures/\344\272\214\345\210\206\345\272\224\347\224\250/title1.png" "b/pictures/\344\272\214\345\210\206\345\272\224\347\224\250/title1.png"
index 410b4e66d5..cb85d759a8 100644
Binary files "a/pictures/\344\272\214\345\210\206\345\272\224\347\224\250/title1.png" and "b/pictures/\344\272\214\345\210\206\345\272\224\347\224\250/title1.png" differ
diff --git "a/pictures/\344\272\214\345\210\206\345\272\224\347\224\250/title2.png" "b/pictures/\344\272\214\345\210\206\345\272\224\347\224\250/title2.png"
index adc29e78c4..6dc47c6c99 100644
Binary files "a/pictures/\344\272\214\345\210\206\345\272\224\347\224\250/title2.png" and "b/pictures/\344\272\214\345\210\206\345\272\224\347\224\250/title2.png" differ
diff --git "a/pictures/\344\272\214\345\210\206\346\237\245\346\211\276/1.jpg" "b/pictures/\344\272\214\345\210\206\346\237\245\346\211\276/1.jpg"
new file mode 100644
index 0000000000..da0a55ba88
Binary files /dev/null and "b/pictures/\344\272\214\345\210\206\346\237\245\346\211\276/1.jpg" differ
diff --git "a/pictures/\344\272\214\345\210\206\346\237\245\346\211\276/2.jpg" "b/pictures/\344\272\214\345\210\206\346\237\245\346\211\276/2.jpg"
new file mode 100644
index 0000000000..6865c24b13
Binary files /dev/null and "b/pictures/\344\272\214\345\210\206\346\237\245\346\211\276/2.jpg" differ
diff --git "a/pictures/\344\272\214\345\210\206\346\237\245\346\211\276/3.jpg" "b/pictures/\344\272\214\345\210\206\346\237\245\346\211\276/3.jpg"
new file mode 100644
index 0000000000..a360ba8767
Binary files /dev/null and "b/pictures/\344\272\214\345\210\206\346\237\245\346\211\276/3.jpg" differ
diff --git "a/pictures/\344\272\214\345\210\206\346\237\245\346\211\276/4.jpg" "b/pictures/\344\272\214\345\210\206\346\237\245\346\211\276/4.jpg"
new file mode 100644
index 0000000000..35e46116bf
Binary files /dev/null and "b/pictures/\344\272\214\345\210\206\346\237\245\346\211\276/4.jpg" differ
diff --git "a/pictures/\344\272\214\345\210\206\346\237\245\346\211\276/binarySearch1.png" "b/pictures/\344\272\214\345\210\206\346\237\245\346\211\276/binarySearch1.png"
index 911bde51e7..d5a410abcd 100644
Binary files "a/pictures/\344\272\214\345\210\206\346\237\245\346\211\276/binarySearch1.png" and "b/pictures/\344\272\214\345\210\206\346\237\245\346\211\276/binarySearch1.png" differ
diff --git "a/pictures/\344\272\214\345\210\206\346\237\245\346\211\276/binarySearch2.png" "b/pictures/\344\272\214\345\210\206\346\237\245\346\211\276/binarySearch2.png"
index d6ca59b939..abff601aba 100644
Binary files "a/pictures/\344\272\214\345\210\206\346\237\245\346\211\276/binarySearch2.png" and "b/pictures/\344\272\214\345\210\206\346\237\245\346\211\276/binarySearch2.png" differ
diff --git "a/pictures/\344\272\214\345\210\206\346\237\245\346\211\276/poem.png" "b/pictures/\344\272\214\345\210\206\346\237\245\346\211\276/poem.png"
new file mode 100644
index 0000000000..6262c33549
Binary files /dev/null and "b/pictures/\344\272\214\345\210\206\346\237\245\346\211\276/poem.png" differ
diff --git "a/pictures/\344\275\215\346\223\215\344\275\234/1.png" "b/pictures/\344\275\215\346\223\215\344\275\234/1.png"
index 89bfd0cef5..c4463610a4 100644
Binary files "a/pictures/\344\275\215\346\223\215\344\275\234/1.png" and "b/pictures/\344\275\215\346\223\215\344\275\234/1.png" differ
diff --git "a/pictures/\344\275\215\346\223\215\344\275\234/title.png" "b/pictures/\344\275\215\346\223\215\344\275\234/title.png"
index 9b961475cc..953f1c3a86 100644
Binary files "a/pictures/\344\275\215\346\223\215\344\275\234/title.png" and "b/pictures/\344\275\215\346\223\215\344\275\234/title.png" differ
diff --git "a/pictures/\344\277\241\345\260\201\345\265\214\345\245\227/0.jpg" "b/pictures/\344\277\241\345\260\201\345\265\214\345\245\227/0.jpg"
index 3a19e9d3ef..48728e408c 100644
Binary files "a/pictures/\344\277\241\345\260\201\345\265\214\345\245\227/0.jpg" and "b/pictures/\344\277\241\345\260\201\345\265\214\345\245\227/0.jpg" differ
diff --git "a/pictures/\344\277\241\345\260\201\345\265\214\345\245\227/1.jpg" "b/pictures/\344\277\241\345\260\201\345\265\214\345\245\227/1.jpg"
index 337378019b..df0cc5fb3a 100644
Binary files "a/pictures/\344\277\241\345\260\201\345\265\214\345\245\227/1.jpg" and "b/pictures/\344\277\241\345\260\201\345\265\214\345\245\227/1.jpg" differ
diff --git "a/pictures/\344\277\241\345\260\201\345\265\214\345\245\227/2.jpg" "b/pictures/\344\277\241\345\260\201\345\265\214\345\245\227/2.jpg"
index 5c9d52b608..4e256327c4 100644
Binary files "a/pictures/\344\277\241\345\260\201\345\265\214\345\245\227/2.jpg" and "b/pictures/\344\277\241\345\260\201\345\265\214\345\245\227/2.jpg" differ
diff --git "a/pictures/\344\277\241\345\260\201\345\265\214\345\245\227/title.png" "b/pictures/\344\277\241\345\260\201\345\265\214\345\245\227/title.png"
index 771fa0c075..fbd9329141 100644
Binary files "a/pictures/\344\277\241\345\260\201\345\265\214\345\245\227/title.png" and "b/pictures/\344\277\241\345\260\201\345\265\214\345\245\227/title.png" differ
diff --git "a/pictures/\345\205\250\345\256\266\346\241\266.jpg" "b/pictures/\345\205\250\345\256\266\346\241\266.jpg"
new file mode 100644
index 0000000000..b97e4cbb4b
Binary files /dev/null and "b/pictures/\345\205\250\345\256\266\346\241\266.jpg" differ
diff --git "a/pictures/\345\211\215\347\274\200\345\222\214/1.jpg" "b/pictures/\345\211\215\347\274\200\345\222\214/1.jpg"
index 5c748457ee..3b1c46fbb7 100644
Binary files "a/pictures/\345\211\215\347\274\200\345\222\214/1.jpg" and "b/pictures/\345\211\215\347\274\200\345\222\214/1.jpg" differ
diff --git "a/pictures/\345\211\215\347\274\200\345\222\214/2.jpg" "b/pictures/\345\211\215\347\274\200\345\222\214/2.jpg"
index b0e9993d39..1306f903f3 100644
Binary files "a/pictures/\345\211\215\347\274\200\345\222\214/2.jpg" and "b/pictures/\345\211\215\347\274\200\345\222\214/2.jpg" differ
diff --git "a/pictures/\345\211\215\347\274\200\345\222\214/title.png" "b/pictures/\345\211\215\347\274\200\345\222\214/title.png"
index 9e52a72f6a..cb19e8180f 100644
Binary files "a/pictures/\345\211\215\347\274\200\345\222\214/title.png" and "b/pictures/\345\211\215\347\274\200\345\222\214/title.png" differ
diff --git "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/coindp.png" "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/coindp.png"
index 0b06a4f426..0d1b8a0a12 100644
Binary files "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/coindp.png" and "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/coindp.png" differ
diff --git "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/coinfunc.png" "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/coinfunc.png"
index a07c92ec8c..26e6460f53 100644
Binary files "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/coinfunc.png" and "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/coinfunc.png" differ
diff --git "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/cointree.png" "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/cointree.png"
index 6a57937cb7..26c978a9c6 100644
Binary files "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/cointree.png" and "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/cointree.png" differ
diff --git "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/fibdp.png" "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/fibdp.png"
index 986b4d21b2..f121f029fd 100644
Binary files "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/fibdp.png" and "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/fibdp.png" differ
diff --git "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/fibfunc.png" "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/fibfunc.png"
index a1044f232c..8657eae81b 100644
Binary files "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/fibfunc.png" and "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/fibfunc.png" differ
diff --git "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/fibmemo.png" "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/fibmemo.png"
index 536a793923..359d1b0cc5 100644
Binary files "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/fibmemo.png" and "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/fibmemo.png" differ
diff --git "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/fibtree.png" "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/fibtree.png"
index dc5bf5732d..b5e6f028ca 100644
Binary files "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/fibtree.png" and "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/fibtree.png" differ
diff --git "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/img_20190514_013033.441.png" "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/img_20190514_013033.441.png"
index a1044f232c..8657eae81b 100644
Binary files "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/img_20190514_013033.441.png" and "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/img_20190514_013033.441.png" differ
diff --git "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/img_20190514_013830.397.png" "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/img_20190514_013830.397.png"
index a07c92ec8c..26e6460f53 100644
Binary files "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/img_20190514_013830.397.png" and "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/img_20190514_013830.397.png" differ
diff --git "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/ink-image (1).png" "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/ink-image (1).png"
index 536a793923..359d1b0cc5 100644
Binary files "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/ink-image (1).png" and "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/ink-image (1).png" differ
diff --git "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/ink-image (2).png" "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/ink-image (2).png"
index 986b4d21b2..f121f029fd 100644
Binary files "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/ink-image (2).png" and "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/ink-image (2).png" differ
diff --git "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/ink-image (3).png" "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/ink-image (3).png"
index 6a57937cb7..26c978a9c6 100644
Binary files "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/ink-image (3).png" and "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/ink-image (3).png" differ
diff --git "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/ink-image (4).png" "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/ink-image (4).png"
index 0b06a4f426..0d1b8a0a12 100644
Binary files "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/ink-image (4).png" and "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/ink-image (4).png" differ
diff --git "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/ink-image.png" "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/ink-image.png"
index dc5bf5732d..b5e6f028ca 100644
Binary files "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/ink-image.png" and "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/ink-image.png" differ
diff --git "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/1.jpg" "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/1.jpg"
index 6178c1abf4..b4732ffc9d 100644
Binary files "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/1.jpg" and "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/1.jpg" differ
diff --git "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/2.jpg" "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/2.jpg"
index 229d05bd79..386669df9b 100644
Binary files "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/2.jpg" and "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/2.jpg" differ
diff --git "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/3.jpg" "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/3.jpg"
index 9ce9c1bdd5..3d543edccc 100644
Binary files "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/3.jpg" and "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/3.jpg" differ
diff --git "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/4.jpg" "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/4.jpg"
index 6946a5546b..58e2a3a53a 100644
Binary files "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/4.jpg" and "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/4.jpg" differ
diff --git "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/5.jpg" "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/5.jpg"
index 1d8af7a881..64100c8440 100644
Binary files "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/5.jpg" and "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/5.jpg" differ
diff --git "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/6.jpg" "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/6.jpg"
index b57a81ecc9..fbd22932b8 100644
Binary files "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/6.jpg" and "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/6.jpg" differ
diff --git "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/coin.png" "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/coin.png"
index 2b2bdf99cb..2b99fb680c 100644
Binary files "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/coin.png" and "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/coin.png" differ
diff --git "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/fib.png" "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/fib.png"
index f122fd8df5..c90a9c6473 100644
Binary files "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/fib.png" and "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/fib.png" differ
diff --git "a/pictures/\345\215\225\350\260\203\346\240\210/1.png" "b/pictures/\345\215\225\350\260\203\346\240\210/1.png"
index a3729004bb..1a2575d094 100644
Binary files "a/pictures/\345\215\225\350\260\203\346\240\210/1.png" and "b/pictures/\345\215\225\350\260\203\346\240\210/1.png" differ
diff --git "a/pictures/\345\215\225\350\260\203\346\240\210/2.png" "b/pictures/\345\215\225\350\260\203\346\240\210/2.png"
index bdc7ea6b48..aa6635831b 100644
Binary files "a/pictures/\345\215\225\350\260\203\346\240\210/2.png" and "b/pictures/\345\215\225\350\260\203\346\240\210/2.png" differ
diff --git "a/pictures/\345\215\225\350\260\203\346\240\210/3.png" "b/pictures/\345\215\225\350\260\203\346\240\210/3.png"
index 71d78b84ea..4d067ce487 100644
Binary files "a/pictures/\345\215\225\350\260\203\346\240\210/3.png" and "b/pictures/\345\215\225\350\260\203\346\240\210/3.png" differ
diff --git "a/pictures/\345\215\225\350\260\203\351\230\237\345\210\227/1.png" "b/pictures/\345\215\225\350\260\203\351\230\237\345\210\227/1.png"
index ce6d3f1daa..131253f93e 100644
Binary files "a/pictures/\345\215\225\350\260\203\351\230\237\345\210\227/1.png" and "b/pictures/\345\215\225\350\260\203\351\230\237\345\210\227/1.png" differ
diff --git "a/pictures/\345\215\225\350\260\203\351\230\237\345\210\227/2.png" "b/pictures/\345\215\225\350\260\203\351\230\237\345\210\227/2.png"
index ab02276bdc..49e658cd4c 100644
Binary files "a/pictures/\345\215\225\350\260\203\351\230\237\345\210\227/2.png" and "b/pictures/\345\215\225\350\260\203\351\230\237\345\210\227/2.png" differ
diff --git "a/pictures/\345\215\225\350\260\203\351\230\237\345\210\227/3.png" "b/pictures/\345\215\225\350\260\203\351\230\237\345\210\227/3.png"
index 4a8bf8743f..500cf80a8e 100644
Binary files "a/pictures/\345\215\225\350\260\203\351\230\237\345\210\227/3.png" and "b/pictures/\345\215\225\350\260\203\351\230\237\345\210\227/3.png" differ
diff --git "a/pictures/\345\215\225\350\260\203\351\230\237\345\210\227/title.png" "b/pictures/\345\215\225\350\260\203\351\230\237\345\210\227/title.png"
index 62b1f9d26a..13e2a28f5e 100644
Binary files "a/pictures/\345\215\225\350\260\203\351\230\237\345\210\227/title.png" and "b/pictures/\345\215\225\350\260\203\351\230\237\345\210\227/title.png" differ
diff --git "a/pictures/\345\215\232\345\274\210\351\227\256\351\242\230/1.png" "b/pictures/\345\215\232\345\274\210\351\227\256\351\242\230/1.png"
index 10426deb7d..965db46ef9 100644
Binary files "a/pictures/\345\215\232\345\274\210\351\227\256\351\242\230/1.png" and "b/pictures/\345\215\232\345\274\210\351\227\256\351\242\230/1.png" differ
diff --git "a/pictures/\345\215\232\345\274\210\351\227\256\351\242\230/2.png" "b/pictures/\345\215\232\345\274\210\351\227\256\351\242\230/2.png"
index 1f0efb0b7d..5205c28ad1 100644
Binary files "a/pictures/\345\215\232\345\274\210\351\227\256\351\242\230/2.png" and "b/pictures/\345\215\232\345\274\210\351\227\256\351\242\230/2.png" differ
diff --git "a/pictures/\345\215\232\345\274\210\351\227\256\351\242\230/3.png" "b/pictures/\345\215\232\345\274\210\351\227\256\351\242\230/3.png"
index 1c7a3be316..469f3835f5 100644
Binary files "a/pictures/\345\215\232\345\274\210\351\227\256\351\242\230/3.png" and "b/pictures/\345\215\232\345\274\210\351\227\256\351\242\230/3.png" differ
diff --git "a/pictures/\345\215\232\345\274\210\351\227\256\351\242\230/4.png" "b/pictures/\345\215\232\345\274\210\351\227\256\351\242\230/4.png"
index 137f39b556..0929ea854d 100644
Binary files "a/pictures/\345\215\232\345\274\210\351\227\256\351\242\230/4.png" and "b/pictures/\345\215\232\345\274\210\351\227\256\351\242\230/4.png" differ
diff --git "a/pictures/\345\217\214\346\214\207\351\222\210/1.png" "b/pictures/\345\217\214\346\214\207\351\222\210/1.png"
index a5aa914f25..c1fe49a237 100644
Binary files "a/pictures/\345\217\214\346\214\207\351\222\210/1.png" and "b/pictures/\345\217\214\346\214\207\351\222\210/1.png" differ
diff --git "a/pictures/\345\217\214\346\214\207\351\222\210/2.png" "b/pictures/\345\217\214\346\214\207\351\222\210/2.png"
index 6c829a2055..7d7bd77193 100644
Binary files "a/pictures/\345\217\214\346\214\207\351\222\210/2.png" and "b/pictures/\345\217\214\346\214\207\351\222\210/2.png" differ
diff --git "a/pictures/\345\217\214\346\214\207\351\222\210/3.png" "b/pictures/\345\217\214\346\214\207\351\222\210/3.png"
index 5d1f57e8ec..de27d35383 100644
Binary files "a/pictures/\345\217\214\346\214\207\351\222\210/3.png" and "b/pictures/\345\217\214\346\214\207\351\222\210/3.png" differ
diff --git "a/pictures/\345\217\214\346\214\207\351\222\210/center.png" "b/pictures/\345\217\214\346\214\207\351\222\210/center.png"
index 487902356b..586e6e38fc 100644
Binary files "a/pictures/\345\217\214\346\214\207\351\222\210/center.png" and "b/pictures/\345\217\214\346\214\207\351\222\210/center.png" differ
diff --git "a/pictures/\345\217\214\346\214\207\351\222\210/title.png" "b/pictures/\345\217\214\346\214\207\351\222\210/title.png"
index 280d516953..ff32a9c7e5 100644
Binary files "a/pictures/\345\217\214\346\214\207\351\222\210/title.png" and "b/pictures/\345\217\214\346\214\207\351\222\210/title.png" differ
diff --git "a/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/1.jpg" "b/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/1.jpg"
index 151357e5b9..b9fff89cb1 100644
Binary files "a/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/1.jpg" and "b/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/1.jpg" differ
diff --git "a/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/2.jpg" "b/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/2.jpg"
index d50918c554..c244744301 100644
Binary files "a/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/2.jpg" and "b/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/2.jpg" differ
diff --git "a/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/3.jpg" "b/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/3.jpg"
index ff2be512a6..be3eed15a2 100644
Binary files "a/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/3.jpg" and "b/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/3.jpg" differ
diff --git "a/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/4.jpg" "b/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/4.jpg"
index acfb32e827..bc1a5fa325 100644
Binary files "a/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/4.jpg" and "b/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/4.jpg" differ
diff --git "a/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/5.jpg" "b/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/5.jpg"
index c3a5537c85..69362da683 100644
Binary files "a/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/5.jpg" and "b/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/5.jpg" differ
diff --git "a/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/6.jpg" "b/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/6.jpg"
index a29283ca33..df31967e27 100644
Binary files "a/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/6.jpg" and "b/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/6.jpg" differ
diff --git "a/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/7.jpg" "b/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/7.jpg"
index 1faecf7542..f962eeb29e 100644
Binary files "a/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/7.jpg" and "b/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/7.jpg" differ
diff --git "a/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/title.png" "b/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/title.png"
index 5a411d6c50..915c1a33d1 100644
Binary files "a/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/title.png" and "b/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/title.png" differ
diff --git "a/pictures/\345\233\236\346\226\207/title.png" "b/pictures/\345\233\236\346\226\207/title.png"
index 5c6e77d9e6..3ec4774981 100644
Binary files "a/pictures/\345\233\236\346\226\207/title.png" and "b/pictures/\345\233\236\346\226\207/title.png" differ
diff --git "a/pictures/\345\233\236\346\226\207\351\223\276\350\241\250/1.jpg" "b/pictures/\345\233\236\346\226\207\351\223\276\350\241\250/1.jpg"
index be6f1d165f..e3f9643f57 100644
Binary files "a/pictures/\345\233\236\346\226\207\351\223\276\350\241\250/1.jpg" and "b/pictures/\345\233\236\346\226\207\351\223\276\350\241\250/1.jpg" differ
diff --git "a/pictures/\345\233\236\346\226\207\351\223\276\350\241\250/2.jpg" "b/pictures/\345\233\236\346\226\207\351\223\276\350\241\250/2.jpg"
index 217a7c9f4c..828ec0ae41 100644
Binary files "a/pictures/\345\233\236\346\226\207\351\223\276\350\241\250/2.jpg" and "b/pictures/\345\233\236\346\226\207\351\223\276\350\241\250/2.jpg" differ
diff --git "a/pictures/\345\233\236\346\226\207\351\223\276\350\241\250/3.jpg" "b/pictures/\345\233\236\346\226\207\351\223\276\350\241\250/3.jpg"
index fbe86512b8..b5162e61ba 100644
Binary files "a/pictures/\345\233\236\346\226\207\351\223\276\350\241\250/3.jpg" and "b/pictures/\345\233\236\346\226\207\351\223\276\350\241\250/3.jpg" differ
diff --git "a/pictures/\345\233\236\346\226\207\351\223\276\350\241\250/4.jpg" "b/pictures/\345\233\236\346\226\207\351\223\276\350\241\250/4.jpg"
index 47589f384f..679314382f 100644
Binary files "a/pictures/\345\233\236\346\226\207\351\223\276\350\241\250/4.jpg" and "b/pictures/\345\233\236\346\226\207\351\223\276\350\241\250/4.jpg" differ
diff --git "a/pictures/\345\255\220\345\272\217\345\210\227/1.jpg" "b/pictures/\345\255\220\345\272\217\345\210\227/1.jpg"
index a936d379e3..580a9bcc9b 100644
Binary files "a/pictures/\345\255\220\345\272\217\345\210\227/1.jpg" and "b/pictures/\345\255\220\345\272\217\345\210\227/1.jpg" differ
diff --git "a/pictures/\345\255\220\345\272\217\345\210\227/2.jpg" "b/pictures/\345\255\220\345\272\217\345\210\227/2.jpg"
index 21a0244d0b..92993c52d1 100644
Binary files "a/pictures/\345\255\220\345\272\217\345\210\227/2.jpg" and "b/pictures/\345\255\220\345\272\217\345\210\227/2.jpg" differ
diff --git "a/pictures/\345\255\220\345\272\217\345\210\227/3.jpg" "b/pictures/\345\255\220\345\272\217\345\210\227/3.jpg"
index b46eb2f158..b54b6cdd81 100644
Binary files "a/pictures/\345\255\220\345\272\217\345\210\227/3.jpg" and "b/pictures/\345\255\220\345\272\217\345\210\227/3.jpg" differ
diff --git "a/pictures/\345\255\220\351\233\206/1.jpg" "b/pictures/\345\255\220\351\233\206/1.jpg"
index af13075733..85e712e3a3 100644
Binary files "a/pictures/\345\255\220\351\233\206/1.jpg" and "b/pictures/\345\255\220\351\233\206/1.jpg" differ
diff --git "a/pictures/\345\255\220\351\233\206/2.jpg" "b/pictures/\345\255\220\351\233\206/2.jpg"
index 8a0341aa1e..b02026d8f2 100644
Binary files "a/pictures/\345\255\220\351\233\206/2.jpg" and "b/pictures/\345\255\220\351\233\206/2.jpg" differ
diff --git "a/pictures/\345\255\220\351\233\206/3.jpg" "b/pictures/\345\255\220\351\233\206/3.jpg"
index e9ad4c34f5..0b34ef306f 100644
Binary files "a/pictures/\345\255\220\351\233\206/3.jpg" and "b/pictures/\345\255\220\351\233\206/3.jpg" differ
diff --git "a/pictures/\345\255\227\347\254\246\344\270\262\344\271\230\346\263\225/1.jpg" "b/pictures/\345\255\227\347\254\246\344\270\262\344\271\230\346\263\225/1.jpg"
index 01f78f5fac..d771001d86 100644
Binary files "a/pictures/\345\255\227\347\254\246\344\270\262\344\271\230\346\263\225/1.jpg" and "b/pictures/\345\255\227\347\254\246\344\270\262\344\271\230\346\263\225/1.jpg" differ
diff --git "a/pictures/\345\255\227\347\254\246\344\270\262\344\271\230\346\263\225/2.jpg" "b/pictures/\345\255\227\347\254\246\344\270\262\344\271\230\346\263\225/2.jpg"
index c71e96dbf5..0e3f07f896 100644
Binary files "a/pictures/\345\255\227\347\254\246\344\270\262\344\271\230\346\263\225/2.jpg" and "b/pictures/\345\255\227\347\254\246\344\270\262\344\271\230\346\263\225/2.jpg" differ
diff --git "a/pictures/\345\255\227\347\254\246\344\270\262\344\271\230\346\263\225/3.jpg" "b/pictures/\345\255\227\347\254\246\344\270\262\344\271\230\346\263\225/3.jpg"
index 6e3fa2e6b2..9fd5077199 100644
Binary files "a/pictures/\345\255\227\347\254\246\344\270\262\344\271\230\346\263\225/3.jpg" and "b/pictures/\345\255\227\347\254\246\344\270\262\344\271\230\346\263\225/3.jpg" differ
diff --git "a/pictures/\345\255\227\347\254\246\344\270\262\344\271\230\346\263\225/6.jpg" "b/pictures/\345\255\227\347\254\246\344\270\262\344\271\230\346\263\225/6.jpg"
index 221176e91e..b873dd7a50 100644
Binary files "a/pictures/\345\255\227\347\254\246\344\270\262\344\271\230\346\263\225/6.jpg" and "b/pictures/\345\255\227\347\254\246\344\270\262\344\271\230\346\263\225/6.jpg" differ
diff --git "a/pictures/\345\255\227\347\254\246\344\270\262\344\271\230\346\263\225/title.png" "b/pictures/\345\255\227\347\254\246\344\270\262\344\271\230\346\263\225/title.png"
index 7866cff6f1..e9cf410f06 100644
Binary files "a/pictures/\345\255\227\347\254\246\344\270\262\344\271\230\346\263\225/title.png" and "b/pictures/\345\255\227\347\254\246\344\270\262\344\271\230\346\263\225/title.png" differ
diff --git "a/pictures/\345\257\206\347\240\201\346\212\200\346\234\257/1.jpg" "b/pictures/\345\257\206\347\240\201\346\212\200\346\234\257/1.jpg"
index 1770e44e90..dacbb65bd2 100644
Binary files "a/pictures/\345\257\206\347\240\201\346\212\200\346\234\257/1.jpg" and "b/pictures/\345\257\206\347\240\201\346\212\200\346\234\257/1.jpg" differ
diff --git "a/pictures/\345\257\206\347\240\201\346\212\200\346\234\257/2.jpg" "b/pictures/\345\257\206\347\240\201\346\212\200\346\234\257/2.jpg"
index 16086b9803..e6d28f0ef1 100644
Binary files "a/pictures/\345\257\206\347\240\201\346\212\200\346\234\257/2.jpg" and "b/pictures/\345\257\206\347\240\201\346\212\200\346\234\257/2.jpg" differ
diff --git "a/pictures/\345\257\206\347\240\201\346\212\200\346\234\257/3.jpg" "b/pictures/\345\257\206\347\240\201\346\212\200\346\234\257/3.jpg"
index 8ab2b8f11c..b5fc5e217c 100644
Binary files "a/pictures/\345\257\206\347\240\201\346\212\200\346\234\257/3.jpg" and "b/pictures/\345\257\206\347\240\201\346\212\200\346\234\257/3.jpg" differ
diff --git "a/pictures/\345\257\206\347\240\201\346\212\200\346\234\257/4.jpg" "b/pictures/\345\257\206\347\240\201\346\212\200\346\234\257/4.jpg"
index 0c86ab9765..09989d4013 100644
Binary files "a/pictures/\345\257\206\347\240\201\346\212\200\346\234\257/4.jpg" and "b/pictures/\345\257\206\347\240\201\346\212\200\346\234\257/4.jpg" differ
diff --git "a/pictures/\345\257\206\347\240\201\346\212\200\346\234\257/5.jpg" "b/pictures/\345\257\206\347\240\201\346\212\200\346\234\257/5.jpg"
index e5cd2b74d9..27b67d7c43 100644
Binary files "a/pictures/\345\257\206\347\240\201\346\212\200\346\234\257/5.jpg" and "b/pictures/\345\257\206\347\240\201\346\212\200\346\234\257/5.jpg" differ
diff --git "a/pictures/\345\257\206\347\240\201\346\212\200\346\234\257/6.jpg" "b/pictures/\345\257\206\347\240\201\346\212\200\346\234\257/6.jpg"
index e78fa6f9eb..e99f74dfb8 100644
Binary files "a/pictures/\345\257\206\347\240\201\346\212\200\346\234\257/6.jpg" and "b/pictures/\345\257\206\347\240\201\346\212\200\346\234\257/6.jpg" differ
diff --git "a/pictures/\345\257\206\347\240\201\346\212\200\346\234\257/7.jpg" "b/pictures/\345\257\206\347\240\201\346\212\200\346\234\257/7.jpg"
index 76dced4d54..a368d636db 100644
Binary files "a/pictures/\345\257\206\347\240\201\346\212\200\346\234\257/7.jpg" and "b/pictures/\345\257\206\347\240\201\346\212\200\346\234\257/7.jpg" differ
diff --git "a/pictures/\345\272\247\344\275\215\350\260\203\345\272\246/1.jpg" "b/pictures/\345\272\247\344\275\215\350\260\203\345\272\246/1.jpg"
index 6971d39a64..a0c943df93 100644
Binary files "a/pictures/\345\272\247\344\275\215\350\260\203\345\272\246/1.jpg" and "b/pictures/\345\272\247\344\275\215\350\260\203\345\272\246/1.jpg" differ
diff --git "a/pictures/\345\272\247\344\275\215\350\260\203\345\272\246/2.jpg" "b/pictures/\345\272\247\344\275\215\350\260\203\345\272\246/2.jpg"
index 3025b3d386..b0d46a2c8d 100644
Binary files "a/pictures/\345\272\247\344\275\215\350\260\203\345\272\246/2.jpg" and "b/pictures/\345\272\247\344\275\215\350\260\203\345\272\246/2.jpg" differ
diff --git "a/pictures/\345\272\247\344\275\215\350\260\203\345\272\246/3.jpg" "b/pictures/\345\272\247\344\275\215\350\260\203\345\272\246/3.jpg"
index 4eaa1c7c3b..159b32bfdd 100644
Binary files "a/pictures/\345\272\247\344\275\215\350\260\203\345\272\246/3.jpg" and "b/pictures/\345\272\247\344\275\215\350\260\203\345\272\246/3.jpg" differ
diff --git "a/pictures/\345\272\247\344\275\215\350\260\203\345\272\246/4.jpg" "b/pictures/\345\272\247\344\275\215\350\260\203\345\272\246/4.jpg"
index 96fb8b964c..1eb30ff5c9 100644
Binary files "a/pictures/\345\272\247\344\275\215\350\260\203\345\272\246/4.jpg" and "b/pictures/\345\272\247\344\275\215\350\260\203\345\272\246/4.jpg" differ
diff --git "a/pictures/\345\272\247\344\275\215\350\260\203\345\272\246/5.jpg" "b/pictures/\345\272\247\344\275\215\350\260\203\345\272\246/5.jpg"
index 0ead3214e1..f88315e344 100644
Binary files "a/pictures/\345\272\247\344\275\215\350\260\203\345\272\246/5.jpg" and "b/pictures/\345\272\247\344\275\215\350\260\203\345\272\246/5.jpg" differ
diff --git "a/pictures/\345\272\247\344\275\215\350\260\203\345\272\246/6.jpg" "b/pictures/\345\272\247\344\275\215\350\260\203\345\272\246/6.jpg"
index c9ce5a42a9..1095324265 100644
Binary files "a/pictures/\345\272\247\344\275\215\350\260\203\345\272\246/6.jpg" and "b/pictures/\345\272\247\344\275\215\350\260\203\345\272\246/6.jpg" differ
diff --git "a/pictures/\345\272\247\344\275\215\350\260\203\345\272\246/7.jpg" "b/pictures/\345\272\247\344\275\215\350\260\203\345\272\246/7.jpg"
index e4c2fbc0e4..0c22c5375c 100644
Binary files "a/pictures/\345\272\247\344\275\215\350\260\203\345\272\246/7.jpg" and "b/pictures/\345\272\247\344\275\215\350\260\203\345\272\246/7.jpg" differ
diff --git "a/pictures/\346\211\224\351\270\241\350\233\213/1.jpg" "b/pictures/\346\211\224\351\270\241\350\233\213/1.jpg"
index d711bb29af..0bc912961b 100644
Binary files "a/pictures/\346\211\224\351\270\241\350\233\213/1.jpg" and "b/pictures/\346\211\224\351\270\241\350\233\213/1.jpg" differ
diff --git "a/pictures/\346\211\224\351\270\241\350\233\213/2.jpg" "b/pictures/\346\211\224\351\270\241\350\233\213/2.jpg"
index 72748efb91..5f7f9edf58 100644
Binary files "a/pictures/\346\211\224\351\270\241\350\233\213/2.jpg" and "b/pictures/\346\211\224\351\270\241\350\233\213/2.jpg" differ
diff --git "a/pictures/\346\211\224\351\270\241\350\233\213/3.jpg" "b/pictures/\346\211\224\351\270\241\350\233\213/3.jpg"
index 5ba41f1e4f..069d53cfb2 100644
Binary files "a/pictures/\346\211\224\351\270\241\350\233\213/3.jpg" and "b/pictures/\346\211\224\351\270\241\350\233\213/3.jpg" differ
diff --git "a/pictures/\346\211\224\351\270\241\350\233\213/dp.png" "b/pictures/\346\211\224\351\270\241\350\233\213/dp.png"
index aa8ff334c8..70169d3d52 100644
Binary files "a/pictures/\346\211\224\351\270\241\350\233\213/dp.png" and "b/pictures/\346\211\224\351\270\241\350\233\213/dp.png" differ
diff --git "a/pictures/\346\216\245\351\233\250\346\260\264/0.jpg" "b/pictures/\346\216\245\351\233\250\346\260\264/0.jpg"
index 2d2e1cb645..ec17d57f58 100644
Binary files "a/pictures/\346\216\245\351\233\250\346\260\264/0.jpg" and "b/pictures/\346\216\245\351\233\250\346\260\264/0.jpg" differ
diff --git "a/pictures/\346\216\245\351\233\250\346\260\264/1.jpg" "b/pictures/\346\216\245\351\233\250\346\260\264/1.jpg"
index 6e5196cadf..03e5217171 100644
Binary files "a/pictures/\346\216\245\351\233\250\346\260\264/1.jpg" and "b/pictures/\346\216\245\351\233\250\346\260\264/1.jpg" differ
diff --git "a/pictures/\346\216\245\351\233\250\346\260\264/2.jpg" "b/pictures/\346\216\245\351\233\250\346\260\264/2.jpg"
index 5aa7684553..839a8bf812 100644
Binary files "a/pictures/\346\216\245\351\233\250\346\260\264/2.jpg" and "b/pictures/\346\216\245\351\233\250\346\260\264/2.jpg" differ
diff --git "a/pictures/\346\216\245\351\233\250\346\260\264/3.jpg" "b/pictures/\346\216\245\351\233\250\346\260\264/3.jpg"
index 5f74da29ac..a48dc5afcc 100644
Binary files "a/pictures/\346\216\245\351\233\250\346\260\264/3.jpg" and "b/pictures/\346\216\245\351\233\250\346\260\264/3.jpg" differ
diff --git "a/pictures/\346\216\245\351\233\250\346\260\264/4.jpg" "b/pictures/\346\216\245\351\233\250\346\260\264/4.jpg"
index 953add1171..f97488589e 100644
Binary files "a/pictures/\346\216\245\351\233\250\346\260\264/4.jpg" and "b/pictures/\346\216\245\351\233\250\346\260\264/4.jpg" differ
diff --git "a/pictures/\346\216\245\351\233\250\346\260\264/5.jpg" "b/pictures/\346\216\245\351\233\250\346\260\264/5.jpg"
index 9d53111988..718509a03f 100644
Binary files "a/pictures/\346\216\245\351\233\250\346\260\264/5.jpg" and "b/pictures/\346\216\245\351\233\250\346\260\264/5.jpg" differ
diff --git "a/pictures/\346\216\245\351\233\250\346\260\264/title.png" "b/pictures/\346\216\245\351\233\250\346\260\264/title.png"
index f4c908625f..177355ac2b 100644
Binary files "a/pictures/\346\216\245\351\233\250\346\260\264/title.png" and "b/pictures/\346\216\245\351\233\250\346\260\264/title.png" differ
diff --git "a/pictures/\346\225\260\347\273\204\344\272\244\346\215\242/ink-image (1).png" "b/pictures/\346\225\260\347\273\204\344\272\244\346\215\242/ink-image (1).png"
index 650f77d1fe..db21abcfb6 100644
Binary files "a/pictures/\346\225\260\347\273\204\344\272\244\346\215\242/ink-image (1).png" and "b/pictures/\346\225\260\347\273\204\344\272\244\346\215\242/ink-image (1).png" differ
diff --git "a/pictures/\346\225\260\347\273\204\344\272\244\346\215\242/ink-image (2).png" "b/pictures/\346\225\260\347\273\204\344\272\244\346\215\242/ink-image (2).png"
index 4ceccb84f1..213ad2a38a 100644
Binary files "a/pictures/\346\225\260\347\273\204\344\272\244\346\215\242/ink-image (2).png" and "b/pictures/\346\225\260\347\273\204\344\272\244\346\215\242/ink-image (2).png" differ
diff --git "a/pictures/\346\225\260\347\273\204\344\272\244\346\215\242/ink-image (3).png" "b/pictures/\346\225\260\347\273\204\344\272\244\346\215\242/ink-image (3).png"
index 931f98e23b..1c9989acf3 100644
Binary files "a/pictures/\346\225\260\347\273\204\344\272\244\346\215\242/ink-image (3).png" and "b/pictures/\346\225\260\347\273\204\344\272\244\346\215\242/ink-image (3).png" differ
diff --git "a/pictures/\346\225\260\347\273\204\344\272\244\346\215\242/ink-image.png" "b/pictures/\346\225\260\347\273\204\344\272\244\346\215\242/ink-image.png"
index 0fda0bf947..e1a1afa3fc 100644
Binary files "a/pictures/\346\225\260\347\273\204\344\272\244\346\215\242/ink-image.png" and "b/pictures/\346\225\260\347\273\204\344\272\244\346\215\242/ink-image.png" differ
diff --git "a/pictures/\346\234\200\344\274\230\345\255\220\347\273\223\346\236\204/1.jpg" "b/pictures/\346\234\200\344\274\230\345\255\220\347\273\223\346\236\204/1.jpg"
index e20dafac67..a8cc3f4cbe 100644
Binary files "a/pictures/\346\234\200\344\274\230\345\255\220\347\273\223\346\236\204/1.jpg" and "b/pictures/\346\234\200\344\274\230\345\255\220\347\273\223\346\236\204/1.jpg" differ
diff --git "a/pictures/\346\234\200\351\225\277\345\233\236\346\226\207\345\255\220\345\272\217\345\210\227/1.jpg" "b/pictures/\346\234\200\351\225\277\345\233\236\346\226\207\345\255\220\345\272\217\345\210\227/1.jpg"
index c15af92ce7..7e3281a560 100644
Binary files "a/pictures/\346\234\200\351\225\277\345\233\236\346\226\207\345\255\220\345\272\217\345\210\227/1.jpg" and "b/pictures/\346\234\200\351\225\277\345\233\236\346\226\207\345\255\220\345\272\217\345\210\227/1.jpg" differ
diff --git "a/pictures/\346\234\200\351\225\277\345\233\236\346\226\207\345\255\220\345\272\217\345\210\227/2.jpg" "b/pictures/\346\234\200\351\225\277\345\233\236\346\226\207\345\255\220\345\272\217\345\210\227/2.jpg"
index 541665ce23..9f0baa5a8d 100644
Binary files "a/pictures/\346\234\200\351\225\277\345\233\236\346\226\207\345\255\220\345\272\217\345\210\227/2.jpg" and "b/pictures/\346\234\200\351\225\277\345\233\236\346\226\207\345\255\220\345\272\217\345\210\227/2.jpg" differ
diff --git "a/pictures/\346\234\200\351\225\277\345\233\236\346\226\207\345\255\220\345\272\217\345\210\227/3.jpg" "b/pictures/\346\234\200\351\225\277\345\233\236\346\226\207\345\255\220\345\272\217\345\210\227/3.jpg"
index ac73079c07..aafb4d028e 100644
Binary files "a/pictures/\346\234\200\351\225\277\345\233\236\346\226\207\345\255\220\345\272\217\345\210\227/3.jpg" and "b/pictures/\346\234\200\351\225\277\345\233\236\346\226\207\345\255\220\345\272\217\345\210\227/3.jpg" differ
diff --git "a/pictures/\346\234\200\351\225\277\345\233\236\346\226\207\345\255\220\345\272\217\345\210\227/4.jpg" "b/pictures/\346\234\200\351\225\277\345\233\236\346\226\207\345\255\220\345\272\217\345\210\227/4.jpg"
index e78e87866e..843ffacd36 100644
Binary files "a/pictures/\346\234\200\351\225\277\345\233\236\346\226\207\345\255\220\345\272\217\345\210\227/4.jpg" and "b/pictures/\346\234\200\351\225\277\345\233\236\346\226\207\345\255\220\345\272\217\345\210\227/4.jpg" differ
diff --git "a/pictures/\346\234\200\351\225\277\345\233\236\346\226\207\345\255\220\345\272\217\345\210\227/5.jpg" "b/pictures/\346\234\200\351\225\277\345\233\236\346\226\207\345\255\220\345\272\217\345\210\227/5.jpg"
index d9211a9b39..1dc29efc2b 100644
Binary files "a/pictures/\346\234\200\351\225\277\345\233\236\346\226\207\345\255\220\345\272\217\345\210\227/5.jpg" and "b/pictures/\346\234\200\351\225\277\345\233\236\346\226\207\345\255\220\345\272\217\345\210\227/5.jpg" differ
diff --git "a/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/1.jpeg" "b/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/1.jpeg"
index 6af4e101f6..3640ab127d 100644
Binary files "a/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/1.jpeg" and "b/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/1.jpeg" differ
diff --git "a/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/2.jpeg" "b/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/2.jpeg"
index 8dbbbe94c7..c96ed6399b 100644
Binary files "a/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/2.jpeg" and "b/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/2.jpeg" differ
diff --git "a/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/3.jpeg" "b/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/3.jpeg"
index 5cb141327d..4490d13fdd 100644
Binary files "a/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/3.jpeg" and "b/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/3.jpeg" differ
diff --git "a/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/poker1.jpeg" "b/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/poker1.jpeg"
index 1560d39ebd..093306bee4 100644
Binary files "a/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/poker1.jpeg" and "b/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/poker1.jpeg" differ
diff --git "a/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/poker2.jpeg" "b/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/poker2.jpeg"
index e4e5bd433e..2ad0c604ab 100644
Binary files "a/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/poker2.jpeg" and "b/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/poker2.jpeg" differ
diff --git "a/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/poker3.jpeg" "b/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/poker3.jpeg"
index c1b979816d..efa99bd717 100644
Binary files "a/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/poker3.jpeg" and "b/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/poker3.jpeg" differ
diff --git "a/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/poker4.jpeg" "b/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/poker4.jpeg"
index 429a23120c..ba781198ca 100644
Binary files "a/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/poker4.jpeg" and "b/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/poker4.jpeg" differ
diff --git "a/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/title.png" "b/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/title.png"
index 820075da24..65c3aa9222 100644
Binary files "a/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/title.png" and "b/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/title.png" differ
diff --git "a/pictures/\346\234\211\345\272\217\346\225\260\347\273\204\345\216\273\351\207\215/title.png" "b/pictures/\346\234\211\345\272\217\346\225\260\347\273\204\345\216\273\351\207\215/title.png"
index 47c0ab0faf..5b986b9d0d 100644
Binary files "a/pictures/\346\234\211\345\272\217\346\225\260\347\273\204\345\216\273\351\207\215/title.png" and "b/pictures/\346\234\211\345\272\217\346\225\260\347\273\204\345\216\273\351\207\215/title.png" differ
diff --git "a/pictures/\346\240\210\351\230\237\345\210\227/1.jpg" "b/pictures/\346\240\210\351\230\237\345\210\227/1.jpg"
index c2788a7ffe..cb72cc5f72 100644
Binary files "a/pictures/\346\240\210\351\230\237\345\210\227/1.jpg" and "b/pictures/\346\240\210\351\230\237\345\210\227/1.jpg" differ
diff --git "a/pictures/\346\240\210\351\230\237\345\210\227/2.jpg" "b/pictures/\346\240\210\351\230\237\345\210\227/2.jpg"
index 6eafa08bdd..982c344fd3 100644
Binary files "a/pictures/\346\240\210\351\230\237\345\210\227/2.jpg" and "b/pictures/\346\240\210\351\230\237\345\210\227/2.jpg" differ
diff --git "a/pictures/\346\240\210\351\230\237\345\210\227/3.jpg" "b/pictures/\346\240\210\351\230\237\345\210\227/3.jpg"
index 1b59b8d2c4..ae9a8ef8d7 100644
Binary files "a/pictures/\346\240\210\351\230\237\345\210\227/3.jpg" and "b/pictures/\346\240\210\351\230\237\345\210\227/3.jpg" differ
diff --git "a/pictures/\346\240\210\351\230\237\345\210\227/4.jpg" "b/pictures/\346\240\210\351\230\237\345\210\227/4.jpg"
index 7d2c558b5b..e29c85ea55 100644
Binary files "a/pictures/\346\240\210\351\230\237\345\210\227/4.jpg" and "b/pictures/\346\240\210\351\230\237\345\210\227/4.jpg" differ
diff --git "a/pictures/\346\240\210\351\230\237\345\210\227/5.jpg" "b/pictures/\346\240\210\351\230\237\345\210\227/5.jpg"
index 5b47d0eb82..d19d22355b 100644
Binary files "a/pictures/\346\240\210\351\230\237\345\210\227/5.jpg" and "b/pictures/\346\240\210\351\230\237\345\210\227/5.jpg" differ
diff --git "a/pictures/\346\240\210\351\230\237\345\210\227/6.jpg" "b/pictures/\346\240\210\351\230\237\345\210\227/6.jpg"
index 60a6f2d042..891301d6ef 100644
Binary files "a/pictures/\346\240\210\351\230\237\345\210\227/6.jpg" and "b/pictures/\346\240\210\351\230\237\345\210\227/6.jpg" differ
diff --git "a/pictures/\346\246\202\347\216\207\351\227\256\351\242\230/p.png" "b/pictures/\346\246\202\347\216\207\351\227\256\351\242\230/p.png"
index 794f5a5cc5..959c02bb27 100644
Binary files "a/pictures/\346\246\202\347\216\207\351\227\256\351\242\230/p.png" and "b/pictures/\346\246\202\347\216\207\351\227\256\351\242\230/p.png" differ
diff --git "a/pictures/\346\246\202\347\216\207\351\227\256\351\242\230/sanmen.png" "b/pictures/\346\246\202\347\216\207\351\227\256\351\242\230/sanmen.png"
index daf212d629..121a3cfd14 100644
Binary files "a/pictures/\346\246\202\347\216\207\351\227\256\351\242\230/sanmen.png" and "b/pictures/\346\246\202\347\216\207\351\227\256\351\242\230/sanmen.png" differ
diff --git "a/pictures/\346\246\202\347\216\207\351\227\256\351\242\230/tree.png" "b/pictures/\346\246\202\347\216\207\351\227\256\351\242\230/tree.png"
index 0b59308f5b..98c51178da 100644
Binary files "a/pictures/\346\246\202\347\216\207\351\227\256\351\242\230/tree.png" and "b/pictures/\346\246\202\347\216\207\351\227\256\351\242\230/tree.png" differ
diff --git "a/pictures/\346\255\243\345\210\231/1.jpeg" "b/pictures/\346\255\243\345\210\231/1.jpeg"
new file mode 100644
index 0000000000..e5977fcae6
Binary files /dev/null and "b/pictures/\346\255\243\345\210\231/1.jpeg" differ
diff --git "a/pictures/\346\255\243\345\210\231/2.jpeg" "b/pictures/\346\255\243\345\210\231/2.jpeg"
new file mode 100644
index 0000000000..f3fa3711a5
Binary files /dev/null and "b/pictures/\346\255\243\345\210\231/2.jpeg" differ
diff --git "a/pictures/\346\255\243\345\210\231/3.jpeg" "b/pictures/\346\255\243\345\210\231/3.jpeg"
new file mode 100644
index 0000000000..11d9838ddc
Binary files /dev/null and "b/pictures/\346\255\243\345\210\231/3.jpeg" differ
diff --git "a/pictures/\346\255\243\345\210\231/4.jpeg" "b/pictures/\346\255\243\345\210\231/4.jpeg"
new file mode 100644
index 0000000000..24de168927
Binary files /dev/null and "b/pictures/\346\255\243\345\210\231/4.jpeg" differ
diff --git "a/pictures/\346\255\243\345\210\231/example.png" "b/pictures/\346\255\243\345\210\231/example.png"
index 3646b16793..9eaace9963 100644
Binary files "a/pictures/\346\255\243\345\210\231/example.png" and "b/pictures/\346\255\243\345\210\231/example.png" differ
diff --git "a/pictures/\346\255\243\345\210\231/title.png" "b/pictures/\346\255\243\345\210\231/title.png"
index 2423900773..6debfa67d6 100644
Binary files "a/pictures/\346\255\243\345\210\231/title.png" and "b/pictures/\346\255\243\345\210\231/title.png" differ
diff --git "a/pictures/\346\264\227\347\211\214\347\256\227\346\263\225/1.png" "b/pictures/\346\264\227\347\211\214\347\256\227\346\263\225/1.png"
index d85e0093d3..1414c8c4dc 100644
Binary files "a/pictures/\346\264\227\347\211\214\347\256\227\346\263\225/1.png" and "b/pictures/\346\264\227\347\211\214\347\256\227\346\263\225/1.png" differ
diff --git "a/pictures/\346\264\227\347\211\214\347\256\227\346\263\225/2.png" "b/pictures/\346\264\227\347\211\214\347\256\227\346\263\225/2.png"
index 0536a15701..9f769de386 100644
Binary files "a/pictures/\346\264\227\347\211\214\347\256\227\346\263\225/2.png" and "b/pictures/\346\264\227\347\211\214\347\256\227\346\263\225/2.png" differ
diff --git "a/pictures/\346\264\227\347\211\214\347\256\227\346\263\225/3.png" "b/pictures/\346\264\227\347\211\214\347\256\227\346\263\225/3.png"
index d9fbe24d5d..157d082613 100644
Binary files "a/pictures/\346\264\227\347\211\214\347\256\227\346\263\225/3.png" and "b/pictures/\346\264\227\347\211\214\347\256\227\346\263\225/3.png" differ
diff --git "a/pictures/\346\264\227\347\211\214\347\256\227\346\263\225/4.png" "b/pictures/\346\264\227\347\211\214\347\256\227\346\263\225/4.png"
index 0547caaeeb..06f0c04092 100644
Binary files "a/pictures/\346\264\227\347\211\214\347\256\227\346\263\225/4.png" and "b/pictures/\346\264\227\347\211\214\347\256\227\346\263\225/4.png" differ
diff --git "a/pictures/\346\264\227\347\211\214\347\256\227\346\263\225/5.jpg" "b/pictures/\346\264\227\347\211\214\347\256\227\346\263\225/5.jpg"
index af797bacc6..0a1f94a022 100644
Binary files "a/pictures/\346\264\227\347\211\214\347\256\227\346\263\225/5.jpg" and "b/pictures/\346\264\227\347\211\214\347\256\227\346\263\225/5.jpg" differ
diff --git "a/pictures/\346\264\227\347\211\214\347\256\227\346\263\225/6.png" "b/pictures/\346\264\227\347\211\214\347\256\227\346\263\225/6.png"
index e6be333570..44c2c35a80 100644
Binary files "a/pictures/\346\264\227\347\211\214\347\256\227\346\263\225/6.png" and "b/pictures/\346\264\227\347\211\214\347\256\227\346\263\225/6.png" differ
diff --git "a/pictures/\346\273\221\345\212\250\347\252\227\345\217\243/0.png" "b/pictures/\346\273\221\345\212\250\347\252\227\345\217\243/0.png"
index ad4ff28c15..974e71fc83 100644
Binary files "a/pictures/\346\273\221\345\212\250\347\252\227\345\217\243/0.png" and "b/pictures/\346\273\221\345\212\250\347\252\227\345\217\243/0.png" differ
diff --git "a/pictures/\346\273\221\345\212\250\347\252\227\345\217\243/1.png" "b/pictures/\346\273\221\345\212\250\347\252\227\345\217\243/1.png"
index 0825d34608..2967070a4a 100644
Binary files "a/pictures/\346\273\221\345\212\250\347\252\227\345\217\243/1.png" and "b/pictures/\346\273\221\345\212\250\347\252\227\345\217\243/1.png" differ
diff --git "a/pictures/\346\273\221\345\212\250\347\252\227\345\217\243/2.png" "b/pictures/\346\273\221\345\212\250\347\252\227\345\217\243/2.png"
index 04d583c605..95bfa5c2fe 100644
Binary files "a/pictures/\346\273\221\345\212\250\347\252\227\345\217\243/2.png" and "b/pictures/\346\273\221\345\212\250\347\252\227\345\217\243/2.png" differ
diff --git "a/pictures/\346\273\221\345\212\250\347\252\227\345\217\243/3.png" "b/pictures/\346\273\221\345\212\250\347\252\227\345\217\243/3.png"
index e07f12455e..65b5510a3e 100644
Binary files "a/pictures/\346\273\221\345\212\250\347\252\227\345\217\243/3.png" and "b/pictures/\346\273\221\345\212\250\347\252\227\345\217\243/3.png" differ
diff --git "a/pictures/\346\273\221\345\212\250\347\252\227\345\217\243/title1.png" "b/pictures/\346\273\221\345\212\250\347\252\227\345\217\243/title1.png"
index c84081f9c5..3d5d2bc76c 100644
Binary files "a/pictures/\346\273\221\345\212\250\347\252\227\345\217\243/title1.png" and "b/pictures/\346\273\221\345\212\250\347\252\227\345\217\243/title1.png" differ
diff --git "a/pictures/\346\273\221\345\212\250\347\252\227\345\217\243/title2.png" "b/pictures/\346\273\221\345\212\250\347\252\227\345\217\243/title2.png"
index cb33c71545..ce357d5db2 100644
Binary files "a/pictures/\346\273\221\345\212\250\347\252\227\345\217\243/title2.png" and "b/pictures/\346\273\221\345\212\250\347\252\227\345\217\243/title2.png" differ
diff --git "a/pictures/\346\273\221\345\212\250\347\252\227\345\217\243/title3.png" "b/pictures/\346\273\221\345\212\250\347\252\227\345\217\243/title3.png"
index 9a1ad10542..0de1770c3f 100644
Binary files "a/pictures/\346\273\221\345\212\250\347\252\227\345\217\243/title3.png" and "b/pictures/\346\273\221\345\212\250\347\252\227\345\217\243/title3.png" differ
diff --git "a/pictures/\347\274\272\345\244\261\345\205\203\347\264\240/1.jpg" "b/pictures/\347\274\272\345\244\261\345\205\203\347\264\240/1.jpg"
index 7bbc566938..180b57081a 100644
Binary files "a/pictures/\347\274\272\345\244\261\345\205\203\347\264\240/1.jpg" and "b/pictures/\347\274\272\345\244\261\345\205\203\347\264\240/1.jpg" differ
diff --git "a/pictures/\347\274\272\345\244\261\345\205\203\347\264\240/2.jpg" "b/pictures/\347\274\272\345\244\261\345\205\203\347\264\240/2.jpg"
index 7458897d9f..44e1b8076e 100644
Binary files "a/pictures/\347\274\272\345\244\261\345\205\203\347\264\240/2.jpg" and "b/pictures/\347\274\272\345\244\261\345\205\203\347\264\240/2.jpg" differ
diff --git "a/pictures/\347\274\272\345\244\261\345\205\203\347\264\240/3.jpg" "b/pictures/\347\274\272\345\244\261\345\205\203\347\264\240/3.jpg"
index 6114a5fc3a..bec62f3fff 100644
Binary files "a/pictures/\347\274\272\345\244\261\345\205\203\347\264\240/3.jpg" and "b/pictures/\347\274\272\345\244\261\345\205\203\347\264\240/3.jpg" differ
diff --git "a/pictures/\347\274\272\345\244\261\345\205\203\347\264\240/title.png" "b/pictures/\347\274\272\345\244\261\345\205\203\347\264\240/title.png"
index 18065d570d..4b2eff0e45 100644
Binary files "a/pictures/\347\274\272\345\244\261\345\205\203\347\264\240/title.png" and "b/pictures/\347\274\272\345\244\261\345\205\203\347\264\240/title.png" differ
diff --git "a/pictures/\347\274\272\345\244\261\345\205\203\347\264\240/xor.png" "b/pictures/\347\274\272\345\244\261\345\205\203\347\264\240/xor.png"
index 20d360007c..1cd5e85a6f 100644
Binary files "a/pictures/\347\274\272\345\244\261\345\205\203\347\264\240/xor.png" and "b/pictures/\347\274\272\345\244\261\345\205\203\347\264\240/xor.png" differ
diff --git "a/pictures/\350\202\241\347\245\250\351\227\256\351\242\230/1.png" "b/pictures/\350\202\241\347\245\250\351\227\256\351\242\230/1.png"
index db1b56a9ef..298b497197 100644
Binary files "a/pictures/\350\202\241\347\245\250\351\227\256\351\242\230/1.png" and "b/pictures/\350\202\241\347\245\250\351\227\256\351\242\230/1.png" differ
diff --git "a/pictures/\350\202\241\347\245\250\351\227\256\351\242\230/title.png" "b/pictures/\350\202\241\347\245\250\351\227\256\351\242\230/title.png"
index 44406abe31..f2f9779541 100644
Binary files "a/pictures/\350\202\241\347\245\250\351\227\256\351\242\230/title.png" and "b/pictures/\350\202\241\347\245\250\351\227\256\351\242\230/title.png" differ
diff --git "a/pictures/\350\256\276\350\256\241Twitter/design.png" "b/pictures/\350\256\276\350\256\241Twitter/design.png"
index 623b58242b..2427a47e3f 100644
Binary files "a/pictures/\350\256\276\350\256\241Twitter/design.png" and "b/pictures/\350\256\276\350\256\241Twitter/design.png" differ
diff --git "a/pictures/\350\256\276\350\256\241Twitter/tweet.jpg" "b/pictures/\350\256\276\350\256\241Twitter/tweet.jpg"
index 89b5bfe2c1..cee1199abd 100644
Binary files "a/pictures/\350\256\276\350\256\241Twitter/tweet.jpg" and "b/pictures/\350\256\276\350\256\241Twitter/tweet.jpg" differ
diff --git "a/pictures/\350\256\276\350\256\241Twitter/user.jpg" "b/pictures/\350\256\276\350\256\241Twitter/user.jpg"
index 0471ec44b6..dce6b67e0a 100644
Binary files "a/pictures/\350\256\276\350\256\241Twitter/user.jpg" and "b/pictures/\350\256\276\350\256\241Twitter/user.jpg" differ
diff --git a/starHistory.jpg b/starHistory.jpg
new file mode 100644
index 0000000000..2847906b4b
Binary files /dev/null and b/starHistory.jpg differ
diff --git a/starHistory.png b/starHistory.png
new file mode 100644
index 0000000000..340e80263c
Binary files /dev/null and b/starHistory.png differ
diff --git "a/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/LCS.md" "b/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/LCS.md"
new file mode 100644
index 0000000000..253d6f1239
--- /dev/null
+++ "b/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/LCS.md"
@@ -0,0 +1,408 @@
+# 经典动态规划:最长公共子序列
+
+
+
+
+
+**通知:为满足广大读者的需求,网站上架 [速成目录](https://labuladong.online/algo/intro/quick-learning-plan/),如有需要可以看下,谢谢大家的支持~另外,建议你在我的 [网站](https://labuladong.online/algo/) 学习文章,体验更好。**
+
+
+
+读完本文,你不仅学会了算法套路,还可以顺便解决如下题目:
+
+| LeetCode | 力扣 | 难度 |
+| :----: | :----: | :----: |
+| [1143. Longest Common Subsequence](https://leetcode.com/problems/longest-common-subsequence/) | [1143. 最长公共子序列](https://leetcode.cn/problems/longest-common-subsequence/) | 🟠 |
+| [583. Delete Operation for Two Strings](https://leetcode.com/problems/delete-operation-for-two-strings/) | [583. 两个字符串的删除操作](https://leetcode.cn/problems/delete-operation-for-two-strings/) | 🟠 |
+| [712. Minimum ASCII Delete Sum for Two Strings](https://leetcode.com/problems/minimum-ascii-delete-sum-for-two-strings/) | [712. 两个字符串的最小ASCII删除和](https://leetcode.cn/problems/minimum-ascii-delete-sum-for-two-strings/) | 🟠 |
+
+**-----------**
+
+
+
+> [!NOTE]
+> 阅读本文前,你需要先学习:
+>
+> - [动态规划核心框架](https://labuladong.online/algo/essential-technique/dynamic-programming-framework/)
+
+不知道大家做算法题有什么感觉,我总结出来做算法题的技巧就是,把大的问题细化到一个点,先研究在这个小的点上如何解决问题,然后再通过递归/迭代的方式扩展到整个问题。
+
+比如说我们前文 [手把手带你刷二叉树第三期](https://labuladong.online/algo/data-structure/binary-tree-part3/),解决二叉树的题目,我们就会把整个问题细化到某一个节点上,想象自己站在某个节点上,需要做什么,然后套二叉树递归框架就行了。
+
+动态规划系列问题也是一样,尤其是子序列相关的问题。**本文从「最长公共子序列问题」展开,总结三道子序列问题**,解这道题仔细讲讲这种子序列问题的套路,你就能感受到这种思维方式了。
+
+## 最长公共子序列
+
+计算最长公共子序列(Longest Common Subsequence,简称 LCS)是一道经典的动态规划题目,力扣第 1143 题「最长公共子序列」就是这个问题:
+
+给你输入两个字符串 `s1` 和 `s2`,请你找出他们俩的最长公共子序列,返回这个子序列的长度。函数签名如下:
+
+```java
+int longestCommonSubsequence(String s1, String s2);
+```
+
+比如说输入 `s1 = "zabcde", s2 = "acez"`,它俩的最长公共子序列是 `lcs = "ace"`,长度为 3,所以算法返回 3。
+
+如果没有做过这道题,一个最简单的暴力算法就是,把 `s1` 和 `s2` 的所有子序列都穷举出来,然后看看有没有公共的,然后在所有公共子序列里面再寻找一个长度最大的。
+
+显然,这种思路的复杂度非常高,你要穷举出所有子序列,这个复杂度就是指数级的,肯定不实际。
+
+正确的思路是不要考虑整个字符串,而是细化到 `s1` 和 `s2` 的每个字符。前文 [子序列解题模板](https://labuladong.online/algo/dynamic-programming/subsequence-problem/) 中总结的一个规律:
+
+
+
+
+
+
+
+**对于两个字符串求子序列的问题,都是用两个指针 `i` 和 `j` 分别在两个字符串上移动,大概率是动态规划思路**。
+
+最长公共子序列的问题也可以遵循这个规律,我们可以先写一个 `dp` 函数:
+
+```java
+// 定义:计算 s1[i..] 和 s2[j..] 的最长公共子序列长度
+int dp(String s1, int i, String s2, int j)
+```
+
+根据这个 `dp` 函数的定义,那么我们想要的答案就是 `dp(s1, 0, s2, 0)`,且 base case 就是 `i == len(s1)` 或 `j == len(s2)` 时,因为这时候 `s1[i..]` 或 `s2[j..]` 就相当于空串了,最长公共子序列的长度显然是 0:
+
+```java
+int longestCommonSubsequence(String s1, String s2) {
+ return dp(s1, 0, s2, 0);
+}
+
+// 定义:计算 s1[i..] 和 s2[j..] 的最长公共子序列长度
+int dp(String s1, int i, String s2, int j) {
+ // base case
+ if (i == s1.length() || j == s2.length()) {
+ return 0;
+ }
+ // ...
+}
+```
+
+**接下来,咱不要看 `s1` 和 `s2` 两个字符串,而是要具体到每一个字符,思考每个字符该做什么**。
+
+
+
+我们只看 `s1[i]` 和 `s2[j]`,**如果 `s1[i] == s2[j]`,说明这个字符一定在 `lcs` 中**:
+
+
+
+这样,就找到了一个 `lcs` 中的字符,根据 `dp` 函数的定义,我们可以完善一下代码:
+
+```java
+// 定义:计算 s1[i..] 和 s2[j..] 的最长公共子序列长度
+int dp(String s1, int i, String s2, int j) {
+ if (s1.charAt(i) == s2.charAt(j)) {
+ // s1[i] 和 s2[j] 必然在 lcs 中,
+ // 加上 s1[i+1..] 和 s2[j+1..] 中的 lcs 长度,就是答案
+ return 1 + dp(s1, i + 1, s2, j + 1);
+ } else {
+ // ...
+ }
+}
+```
+
+刚才说的 `s1[i] == s2[j]` 的情况,但如果 `s1[i] != s2[j]`,应该怎么办呢?
+
+**`s1[i] != s2[j]` 意味着,`s1[i]` 和 `s2[j]` 中至少有一个字符不在 `lcs` 中**:
+
+
+
+如上图,总共可能有三种情况,我怎么知道具体是那种情况呢?
+
+其实我们也不知道,那就把这三种情况的答案都算出来,取其中结果最大的那个呗,因为题目让我们算「最长」公共子序列的长度嘛。
+
+这三种情况的答案怎么算?回想一下我们的 `dp` 函数定义,不就是专门为了计算它们而设计的嘛!
+
+代码可以再进一步:
+
+```java
+// 定义:计算 s1[i..] 和 s2[j..] 的最长公共子序列长度
+int dp(String s1, int i, String s2, int j) {
+ if (s1.charAt(i) == s2.charAt(j)) {
+ return 1 + dp(s1, i + 1, s2, j + 1);
+ } else {
+ // s1[i] 和 s2[j] 中至少有一个字符不在 lcs 中,
+ // 穷举三种情况的结果,取其中的最大结果
+ return max(
+ // 情况一、s1[i] 不在 lcs 中
+ dp(s1, i + 1, s2, j),
+ // 情况二、s2[j] 不在 lcs 中
+ dp(s1, i, s2, j + 1),
+ // 情况三、都不在 lcs 中
+ dp(s1, i + 1, s2, j + 1)
+ );
+ }
+}
+```
+
+这里就已经非常接近我们的最终答案了,**还有一个小的优化,情况三「`s1[i]` 和 `s2[j]` 都不在 lcs 中」其实可以直接忽略**。
+
+因为我们在求最大值嘛,情况三在计算 `s1[i+1..]` 和 `s2[j+1..]` 的 `lcs` 长度,这个长度肯定是小于等于情况二 `s1[i..]` 和 `s2[j+1..]` 中的 `lcs` 长度的,因为 `s1[i+1..]` 比 `s1[i..]` 短嘛,那从这里面算出的 `lcs` 当然也不可能更长嘛。
+
+同理,情况三的结果肯定也小于等于情况一。**说白了,情况三被情况一和情况二包含了**,所以我们可以直接忽略掉情况三,完整代码如下:
+
+```java
+class Solution {
+ // 备忘录,消除重叠子问题
+ int[][] memo;
+
+ // 主函数
+ public int longestCommonSubsequence(String s1, String s2) {
+ int m = s1.length(), n = s2.length();
+ // 备忘录值为 -1 代表未曾计算
+ memo = new int[m][n];
+ for (int[] row : memo)
+ Arrays.fill(row, -1);
+ // 计算 s1[0..] 和 s2[0..] 的 lcs 长度
+ return dp(s1, 0, s2, 0);
+ }
+
+ // 定义:计算 s1[i..] 和 s2[j..] 的最长公共子序列长度
+ int dp(String s1, int i, String s2, int j) {
+ // base case
+ if (i == s1.length() || j == s2.length()) {
+ return 0;
+ }
+ // 如果之前计算过,则直接返回备忘录中的答案
+ if (memo[i][j] != -1) {
+ return memo[i][j];
+ }
+ // 根据 s1[i] 和 s2[j] 的情况做选择
+ if (s1.charAt(i) == s2.charAt(j)) {
+ // s1[i] 和 s2[j] 必然在 lcs 中
+ memo[i][j] = 1 + dp(s1, i + 1, s2, j + 1);
+ } else {
+ // s1[i] 和 s2[j] 至少有一个不在 lcs 中
+ memo[i][j] = Math.max(
+ dp(s1, i + 1, s2, j),
+ dp(s1, i, s2, j + 1)
+ );
+ }
+ return memo[i][j];
+ }
+}
+```
+
+以上思路完全就是按照我们之前的爆文 [动态规划套路框架](https://labuladong.online/algo/essential-technique/dynamic-programming-framework/) 来的,应该是很容易理解的。至于为什么要加 `memo` 备忘录,我们之前写过很多次,为了照顾新来的读者,这里再简单重复一下,首先抽象出我们核心 `dp` 函数的递归框架:
+
+```java
+int dp(int i, int j) {
+ dp(i + 1, j + 1); // #1
+ dp(i, j + 1); // #2
+ dp(i + 1, j); // #3
+}
+```
+
+你看,假设我想从 `dp(i, j)` 转移到 `dp(i+1, j+1)`,有不止一种方式,可以直接走 `#1`,也可以走 `#2 -> #3`,也可以走 `#3 -> #2`。
+
+这就是重叠子问题,如果我们不用 `memo` 备忘录消除子问题,那么 `dp(i+1, j+1)` 就会被多次计算,这是没有必要的。
+
+至此,最长公共子序列问题就完全解决了,用的是自顶向下带备忘录的动态规划思路,我们当然也可以使用自底向上的迭代的动态规划思路,和我们的递归思路一样,关键是如何定义 `dp` 数组,我这里也写一下自底向上的解法吧:
+
+```java
+class Solution {
+ public int longestCommonSubsequence(String s1, String s2) {
+ int m = s1.length(), n = s2.length();
+ int[][] dp = new int[m + 1][n + 1];
+ // 定义:s1[0..i-1] 和 s2[0..j-1] 的 lcs 长度为 dp[i][j]
+ // 目标:s1[0..m-1] 和 s2[0..n-1] 的 lcs 长度,即 dp[m][n]
+ // base case: dp[0][..] = dp[..][0] = 0
+
+ for (int i = 1; i <= m; i++) {
+ for (int j = 1; j <= n; j++) {
+ // 现在 i 和 j 从 1 开始,所以要减一
+ if (s1.charAt(i - 1) == s2.charAt(j - 1)) {
+ // s1[i-1] 和 s2[j-1] 必然在 lcs 中
+ dp[i][j] = 1 + dp[i - 1][j - 1];
+ } else {
+ // s1[i-1] 和 s2[j-1] 至少有一个不在 lcs 中
+ dp[i][j] = Math.max(dp[i][j - 1], dp[i - 1][j]);
+ }
+ }
+ }
+
+ return dp[m][n];
+ }
+}
+```
+
+
+
+如果本仓库对你有帮助,可以请作者喝杯速溶咖啡
+
+
diff --git a/contributor.jpg b/contributor.jpg
new file mode 100644
index 0000000000..716a4a79a0
Binary files /dev/null and b/contributor.jpg differ
diff --git a/pictures/4keyboard/1.jpg b/pictures/4keyboard/1.jpg
index e7e543e234..43c7985b4e 100644
Binary files a/pictures/4keyboard/1.jpg and b/pictures/4keyboard/1.jpg differ
diff --git a/pictures/4keyboard/title.png b/pictures/4keyboard/title.png
index b5b71adb9e..6413dee2c8 100644
Binary files a/pictures/4keyboard/title.png and b/pictures/4keyboard/title.png differ
diff --git a/pictures/BST/BST_example.png b/pictures/BST/BST_example.png
index 5306f18673..3e150d1d99 100644
Binary files a/pictures/BST/BST_example.png and b/pictures/BST/BST_example.png differ
diff --git a/pictures/BST/bst_deletion_case_1.png b/pictures/BST/bst_deletion_case_1.png
index 46dcfabda2..923f5e85d2 100644
Binary files a/pictures/BST/bst_deletion_case_1.png and b/pictures/BST/bst_deletion_case_1.png differ
diff --git a/pictures/BST/bst_deletion_case_2.png b/pictures/BST/bst_deletion_case_2.png
index 6edd38d83c..c8c8217797 100644
Binary files a/pictures/BST/bst_deletion_case_2.png and b/pictures/BST/bst_deletion_case_2.png differ
diff --git a/pictures/BST/bst_deletion_case_3.png b/pictures/BST/bst_deletion_case_3.png
index 78473707ca..1a13586540 100644
Binary files a/pictures/BST/bst_deletion_case_3.png and b/pictures/BST/bst_deletion_case_3.png differ
diff --git "a/pictures/BST/\345\201\207BST.png" "b/pictures/BST/\345\201\207BST.png"
index 3028c69c28..47ac2b32fa 100644
Binary files "a/pictures/BST/\345\201\207BST.png" and "b/pictures/BST/\345\201\207BST.png" differ
diff --git "a/pictures/Chrome\346\217\222\344\273\266/baidumonkey.png" "b/pictures/Chrome\346\217\222\344\273\266/baidumonkey.png"
index 3dfb9c5287..b02f566d23 100644
Binary files "a/pictures/Chrome\346\217\222\344\273\266/baidumonkey.png" and "b/pictures/Chrome\346\217\222\344\273\266/baidumonkey.png" differ
diff --git "a/pictures/Chrome\346\217\222\344\273\266/baidu\345\271\277\345\221\212.png" "b/pictures/Chrome\346\217\222\344\273\266/baidu\345\271\277\345\221\212.png"
index ee8dfe2706..1af676e9e7 100644
Binary files "a/pictures/Chrome\346\217\222\344\273\266/baidu\345\271\277\345\221\212.png" and "b/pictures/Chrome\346\217\222\344\273\266/baidu\345\271\277\345\221\212.png" differ
diff --git "a/pictures/Chrome\346\217\222\344\273\266/csdnBlock.png" "b/pictures/Chrome\346\217\222\344\273\266/csdnBlock.png"
index ae129f8b5b..8b57fedc8a 100644
Binary files "a/pictures/Chrome\346\217\222\344\273\266/csdnBlock.png" and "b/pictures/Chrome\346\217\222\344\273\266/csdnBlock.png" differ
diff --git "a/pictures/Chrome\346\217\222\344\273\266/githubzip.png" "b/pictures/Chrome\346\217\222\344\273\266/githubzip.png"
index 3dfb74cd56..41fbf53a1e 100644
Binary files "a/pictures/Chrome\346\217\222\344\273\266/githubzip.png" and "b/pictures/Chrome\346\217\222\344\273\266/githubzip.png" differ
diff --git "a/pictures/Chrome\346\217\222\344\273\266/listen1.png" "b/pictures/Chrome\346\217\222\344\273\266/listen1.png"
index 034f236e75..0af8e0bb34 100644
Binary files "a/pictures/Chrome\346\217\222\344\273\266/listen1.png" and "b/pictures/Chrome\346\217\222\344\273\266/listen1.png" differ
diff --git "a/pictures/Chrome\346\217\222\344\273\266/monkey.png" "b/pictures/Chrome\346\217\222\344\273\266/monkey.png"
index 194d64deae..6b3545cbee 100644
Binary files "a/pictures/Chrome\346\217\222\344\273\266/monkey.png" and "b/pictures/Chrome\346\217\222\344\273\266/monkey.png" differ
diff --git "a/pictures/Chrome\346\217\222\344\273\266/oneTab.png" "b/pictures/Chrome\346\217\222\344\273\266/oneTab.png"
index 7c033bdb9c..ad84073735 100644
Binary files "a/pictures/Chrome\346\217\222\344\273\266/oneTab.png" and "b/pictures/Chrome\346\217\222\344\273\266/oneTab.png" differ
diff --git "a/pictures/Chrome\346\217\222\344\273\266/pin.png" "b/pictures/Chrome\346\217\222\344\273\266/pin.png"
index eeeb0061c3..045d79b045 100644
Binary files "a/pictures/Chrome\346\217\222\344\273\266/pin.png" and "b/pictures/Chrome\346\217\222\344\273\266/pin.png" differ
diff --git "a/pictures/Chrome\346\217\222\344\273\266/tree.png" "b/pictures/Chrome\346\217\222\344\273\266/tree.png"
index 6df887f0c5..eeaa173338 100644
Binary files "a/pictures/Chrome\346\217\222\344\273\266/tree.png" and "b/pictures/Chrome\346\217\222\344\273\266/tree.png" differ
diff --git "a/pictures/Chrome\346\217\222\344\273\266/youhou\344\274\230\345\214\226.png" "b/pictures/Chrome\346\217\222\344\273\266/youhou\344\274\230\345\214\226.png"
index 73de685316..ae944dd791 100644
Binary files "a/pictures/Chrome\346\217\222\344\273\266/youhou\344\274\230\345\214\226.png" and "b/pictures/Chrome\346\217\222\344\273\266/youhou\344\274\230\345\214\226.png" differ
diff --git a/pictures/LCS/1.png b/pictures/LCS/1.png
index db53c702e8..c3fa9fcf09 100644
Binary files a/pictures/LCS/1.png and b/pictures/LCS/1.png differ
diff --git a/pictures/LCS/2.png b/pictures/LCS/2.png
index f8a4ecb0cf..8d1db3538d 100644
Binary files a/pictures/LCS/2.png and b/pictures/LCS/2.png differ
diff --git a/pictures/LCS/3.png b/pictures/LCS/3.png
index eeb5489913..ed7a3f91fd 100644
Binary files a/pictures/LCS/3.png and b/pictures/LCS/3.png differ
diff --git a/pictures/LCS/dp.png b/pictures/LCS/dp.png
index 7df4b5524e..163f88307f 100644
Binary files a/pictures/LCS/dp.png and b/pictures/LCS/dp.png differ
diff --git a/pictures/LCS/lcs.png b/pictures/LCS/lcs.png
index b7ff2d01b6..b0a76e29a2 100644
Binary files a/pictures/LCS/lcs.png and b/pictures/LCS/lcs.png differ
diff --git "a/pictures/LRU\347\256\227\346\263\225/1.jpg" "b/pictures/LRU\347\256\227\346\263\225/1.jpg"
index df7c9560d0..2cd627bacf 100644
Binary files "a/pictures/LRU\347\256\227\346\263\225/1.jpg" and "b/pictures/LRU\347\256\227\346\263\225/1.jpg" differ
diff --git "a/pictures/LRU\347\256\227\346\263\225/2.jpg" "b/pictures/LRU\347\256\227\346\263\225/2.jpg"
index c9a407eef4..a774ec5f1f 100644
Binary files "a/pictures/LRU\347\256\227\346\263\225/2.jpg" and "b/pictures/LRU\347\256\227\346\263\225/2.jpg" differ
diff --git "a/pictures/LRU\347\256\227\346\263\225/3.jpg" "b/pictures/LRU\347\256\227\346\263\225/3.jpg"
index 9bdea69c14..d61f20690a 100644
Binary files "a/pictures/LRU\347\256\227\346\263\225/3.jpg" and "b/pictures/LRU\347\256\227\346\263\225/3.jpg" differ
diff --git "a/pictures/LRU\347\256\227\346\263\225/4.jpg" "b/pictures/LRU\347\256\227\346\263\225/4.jpg"
index ce1a22a3f4..30af4fb8bf 100644
Binary files "a/pictures/LRU\347\256\227\346\263\225/4.jpg" and "b/pictures/LRU\347\256\227\346\263\225/4.jpg" differ
diff --git "a/pictures/LRU\347\256\227\346\263\225/put.jpg" "b/pictures/LRU\347\256\227\346\263\225/put.jpg"
new file mode 100644
index 0000000000..ca580eb634
Binary files /dev/null and "b/pictures/LRU\347\256\227\346\263\225/put.jpg" differ
diff --git a/pictures/algo4/1.jpg b/pictures/algo4/1.jpg
index bc5c41c00e..fbb9b05013 100644
Binary files a/pictures/algo4/1.jpg and b/pictures/algo4/1.jpg differ
diff --git a/pictures/algo4/2.jpg b/pictures/algo4/2.jpg
index 533f783eb6..853c5c7147 100644
Binary files a/pictures/algo4/2.jpg and b/pictures/algo4/2.jpg differ
diff --git a/pictures/algo4/3.jpg b/pictures/algo4/3.jpg
index e317098a2c..0dec5070f9 100644
Binary files a/pictures/algo4/3.jpg and b/pictures/algo4/3.jpg differ
diff --git a/pictures/algo4/title.png b/pictures/algo4/title.png
index aabe966dfb..988f8b5737 100644
Binary files a/pictures/algo4/title.png and b/pictures/algo4/title.png differ
diff --git a/pictures/backtrack/ink-image (1).png b/pictures/backtrack/ink-image (1).png
index 1cf2957d12..b0df286974 100644
Binary files a/pictures/backtrack/ink-image (1).png and b/pictures/backtrack/ink-image (1).png differ
diff --git a/pictures/backtrack/ink-image (2).png b/pictures/backtrack/ink-image (2).png
index bf791a9117..5aa69b5c21 100644
Binary files a/pictures/backtrack/ink-image (2).png and b/pictures/backtrack/ink-image (2).png differ
diff --git a/pictures/backtrack/ink-image (3).png b/pictures/backtrack/ink-image (3).png
index 0ffa62c1d6..dd12af2bc3 100644
Binary files a/pictures/backtrack/ink-image (3).png and b/pictures/backtrack/ink-image (3).png differ
diff --git a/pictures/backtrack/ink-image (4).png b/pictures/backtrack/ink-image (4).png
index 6dcafa1beb..6c0c54d307 100644
Binary files a/pictures/backtrack/ink-image (4).png and b/pictures/backtrack/ink-image (4).png differ
diff --git a/pictures/backtrack/ink-image (5).png b/pictures/backtrack/ink-image (5).png
index e4d2130ee1..eb73a4dd5a 100644
Binary files a/pictures/backtrack/ink-image (5).png and b/pictures/backtrack/ink-image (5).png differ
diff --git a/pictures/backtrack/ink-image (6).png b/pictures/backtrack/ink-image (6).png
index f6fc968bea..75c0f4a0f6 100644
Binary files a/pictures/backtrack/ink-image (6).png and b/pictures/backtrack/ink-image (6).png differ
diff --git a/pictures/backtrack/ink-image.png b/pictures/backtrack/ink-image.png
index ec1ea64d50..5440b0667c 100644
Binary files a/pictures/backtrack/ink-image.png and b/pictures/backtrack/ink-image.png differ
diff --git a/pictures/backtrack/nqueens.png b/pictures/backtrack/nqueens.png
index 4c9e01f560..464ff529ab 100644
Binary files a/pictures/backtrack/nqueens.png and b/pictures/backtrack/nqueens.png differ
diff --git a/pictures/backtrack/permutation.png b/pictures/backtrack/permutation.png
index 421a36e67e..d9f4c6d325 100644
Binary files a/pictures/backtrack/permutation.png and b/pictures/backtrack/permutation.png differ
diff --git "a/pictures/backtrack/\344\273\243\347\240\201.png" "b/pictures/backtrack/\344\273\243\347\240\201.png"
index 85be66b34e..25d7c88cdd 100644
Binary files "a/pictures/backtrack/\344\273\243\347\240\201.png" and "b/pictures/backtrack/\344\273\243\347\240\201.png" differ
diff --git "a/pictures/backtrack/\344\273\243\347\240\2011.png" "b/pictures/backtrack/\344\273\243\347\240\2011.png"
index b029f5f776..f156208f94 100644
Binary files "a/pictures/backtrack/\344\273\243\347\240\2011.png" and "b/pictures/backtrack/\344\273\243\347\240\2011.png" differ
diff --git "a/pictures/backtrack/\344\273\243\347\240\2012.png" "b/pictures/backtrack/\344\273\243\347\240\2012.png"
index ae4a5734ee..c1671f1bfd 100644
Binary files "a/pictures/backtrack/\344\273\243\347\240\2012.png" and "b/pictures/backtrack/\344\273\243\347\240\2012.png" differ
diff --git "a/pictures/backtrack/\344\273\243\347\240\2013.png" "b/pictures/backtrack/\344\273\243\347\240\2013.png"
index c6d842db5e..0dc5eaf30b 100644
Binary files "a/pictures/backtrack/\344\273\243\347\240\2013.png" and "b/pictures/backtrack/\344\273\243\347\240\2013.png" differ
diff --git "a/pictures/backtrack/\345\205\250\346\216\222\345\210\227.png" "b/pictures/backtrack/\345\205\250\346\216\222\345\210\227.png"
index 6fb4f92f97..e7cc064f0a 100644
Binary files "a/pictures/backtrack/\345\205\250\346\216\222\345\210\227.png" and "b/pictures/backtrack/\345\205\250\346\216\222\345\210\227.png" differ
diff --git a/pictures/backtracking/1.jpg b/pictures/backtracking/1.jpg
index e54c8a3c20..b847370747 100644
Binary files a/pictures/backtracking/1.jpg and b/pictures/backtracking/1.jpg differ
diff --git a/pictures/backtracking/2.jpg b/pictures/backtracking/2.jpg
index ff57c7fdd3..2bca873678 100644
Binary files a/pictures/backtracking/2.jpg and b/pictures/backtracking/2.jpg differ
diff --git a/pictures/backtracking/3.jpg b/pictures/backtracking/3.jpg
index ca97cdaa03..b016864ae8 100644
Binary files a/pictures/backtracking/3.jpg and b/pictures/backtracking/3.jpg differ
diff --git a/pictures/backtracking/4.jpg b/pictures/backtracking/4.jpg
index b93cafd72e..3690d9637c 100644
Binary files a/pictures/backtracking/4.jpg and b/pictures/backtracking/4.jpg differ
diff --git a/pictures/backtracking/5.jpg b/pictures/backtracking/5.jpg
index 893c87e682..727ed1ecd0 100644
Binary files a/pictures/backtracking/5.jpg and b/pictures/backtracking/5.jpg differ
diff --git a/pictures/backtracking/6.jpg b/pictures/backtracking/6.jpg
index 0b4d68eea5..368dee24ba 100644
Binary files a/pictures/backtracking/6.jpg and b/pictures/backtracking/6.jpg differ
diff --git a/pictures/backtracking/7.jpg b/pictures/backtracking/7.jpg
index 1eee2f8c36..a146fd6b92 100644
Binary files a/pictures/backtracking/7.jpg and b/pictures/backtracking/7.jpg differ
diff --git a/pictures/calculator/1.1.jpg b/pictures/calculator/1.1.jpg
index 100ca61a10..2ead09ba04 100644
Binary files a/pictures/calculator/1.1.jpg and b/pictures/calculator/1.1.jpg differ
diff --git a/pictures/calculator/1.jpg b/pictures/calculator/1.jpg
index 862bbdd41c..c66e7ab379 100644
Binary files a/pictures/calculator/1.jpg and b/pictures/calculator/1.jpg differ
diff --git a/pictures/calculator/2.jpg b/pictures/calculator/2.jpg
index 62e40b92e8..f3123387da 100644
Binary files a/pictures/calculator/2.jpg and b/pictures/calculator/2.jpg differ
diff --git a/pictures/calculator/3.jpg b/pictures/calculator/3.jpg
index 073f6e39c4..2f3b9a4247 100644
Binary files a/pictures/calculator/3.jpg and b/pictures/calculator/3.jpg differ
diff --git a/pictures/calculator/4.jpg b/pictures/calculator/4.jpg
index 0b0c9ce4b6..4f878ed3b7 100644
Binary files a/pictures/calculator/4.jpg and b/pictures/calculator/4.jpg differ
diff --git a/pictures/calculator/5.jpg b/pictures/calculator/5.jpg
index c1610cc021..528309bb67 100644
Binary files a/pictures/calculator/5.jpg and b/pictures/calculator/5.jpg differ
diff --git a/pictures/calculator/6.jpg b/pictures/calculator/6.jpg
index 92800a3ece..f0563fd2e5 100644
Binary files a/pictures/calculator/6.jpg and b/pictures/calculator/6.jpg differ
diff --git a/pictures/cover.jpg b/pictures/cover.jpg
new file mode 100644
index 0000000000..646769e6cc
Binary files /dev/null and b/pictures/cover.jpg differ
diff --git a/pictures/dupmissing/2.jpg b/pictures/dupmissing/2.jpg
index 781e142ade..91fa41a3c2 100644
Binary files a/pictures/dupmissing/2.jpg and b/pictures/dupmissing/2.jpg differ
diff --git a/pictures/dupmissing/3.jpg b/pictures/dupmissing/3.jpg
index 00d90d6794..babdd3f3c3 100644
Binary files a/pictures/dupmissing/3.jpg and b/pictures/dupmissing/3.jpg differ
diff --git a/pictures/editDistance/1.jpg b/pictures/editDistance/1.jpg
index 7a2e3d58f4..3f2f0b50ad 100644
Binary files a/pictures/editDistance/1.jpg and b/pictures/editDistance/1.jpg differ
diff --git a/pictures/editDistance/2.jpg b/pictures/editDistance/2.jpg
index 0e32faa854..1339bd16b8 100644
Binary files a/pictures/editDistance/2.jpg and b/pictures/editDistance/2.jpg differ
diff --git a/pictures/editDistance/3.jpg b/pictures/editDistance/3.jpg
index c201c6daa2..387c16886a 100644
Binary files a/pictures/editDistance/3.jpg and b/pictures/editDistance/3.jpg differ
diff --git a/pictures/editDistance/4.jpg b/pictures/editDistance/4.jpg
index 13631d1edf..a80c026ae2 100644
Binary files a/pictures/editDistance/4.jpg and b/pictures/editDistance/4.jpg differ
diff --git a/pictures/editDistance/5.jpg b/pictures/editDistance/5.jpg
index 8f5c006323..9106380751 100644
Binary files a/pictures/editDistance/5.jpg and b/pictures/editDistance/5.jpg differ
diff --git a/pictures/editDistance/6.jpg b/pictures/editDistance/6.jpg
index 589f8aef6b..5880bae6b4 100644
Binary files a/pictures/editDistance/6.jpg and b/pictures/editDistance/6.jpg differ
diff --git a/pictures/editDistance/dp.jpg b/pictures/editDistance/dp.jpg
index 41e72a4903..4519d891e6 100644
Binary files a/pictures/editDistance/dp.jpg and b/pictures/editDistance/dp.jpg differ
diff --git a/pictures/editDistance/title.png b/pictures/editDistance/title.png
index 85a392fbde..15dc923107 100644
Binary files a/pictures/editDistance/title.png and b/pictures/editDistance/title.png differ
diff --git a/pictures/floodfill/floodfill.png b/pictures/floodfill/floodfill.png
index 14eebee95b..3c79709bce 100644
Binary files a/pictures/floodfill/floodfill.png and b/pictures/floodfill/floodfill.png differ
diff --git a/pictures/floodfill/leetcode.png b/pictures/floodfill/leetcode.png
index 52f723e266..1ffdc937a7 100644
Binary files a/pictures/floodfill/leetcode.png and b/pictures/floodfill/leetcode.png differ
diff --git a/pictures/floodfill/ppt1.PNG b/pictures/floodfill/ppt1.PNG
index 22046455d0..1667b0f18f 100644
Binary files a/pictures/floodfill/ppt1.PNG and b/pictures/floodfill/ppt1.PNG differ
diff --git a/pictures/floodfill/ppt2.PNG b/pictures/floodfill/ppt2.PNG
index 28a220d614..58dd272514 100644
Binary files a/pictures/floodfill/ppt2.PNG and b/pictures/floodfill/ppt2.PNG differ
diff --git a/pictures/floodfill/ppt3.PNG b/pictures/floodfill/ppt3.PNG
index 6957ffe4ae..0f2a1a80f2 100644
Binary files a/pictures/floodfill/ppt3.PNG and b/pictures/floodfill/ppt3.PNG differ
diff --git a/pictures/floodfill/ppt4.PNG b/pictures/floodfill/ppt4.PNG
index 9ceb6ed044..f90e4b9e6d 100644
Binary files a/pictures/floodfill/ppt4.PNG and b/pictures/floodfill/ppt4.PNG differ
diff --git a/pictures/floodfill/ppt5.PNG b/pictures/floodfill/ppt5.PNG
index b2583eef11..f6e5cc0b25 100644
Binary files a/pictures/floodfill/ppt5.PNG and b/pictures/floodfill/ppt5.PNG differ
diff --git a/pictures/floodfill/xiaoxiaole.jpg b/pictures/floodfill/xiaoxiaole.jpg
index fa443f0cda..fcf657ac8d 100644
Binary files a/pictures/floodfill/xiaoxiaole.jpg and b/pictures/floodfill/xiaoxiaole.jpg differ
diff --git "a/pictures/floodfill/\346\211\253\351\233\267.png" "b/pictures/floodfill/\346\211\253\351\233\267.png"
index 9b04e0392c..d25e1deac1 100644
Binary files "a/pictures/floodfill/\346\211\253\351\233\267.png" and "b/pictures/floodfill/\346\211\253\351\233\267.png" differ
diff --git "a/pictures/floodfill/\346\212\240\345\233\276.jpeg" "b/pictures/floodfill/\346\212\240\345\233\276.jpeg"
index fa112468c5..66097dd104 100644
Binary files "a/pictures/floodfill/\346\212\240\345\233\276.jpeg" and "b/pictures/floodfill/\346\212\240\345\233\276.jpeg" differ
diff --git a/pictures/group.jpg b/pictures/group.jpg
new file mode 100644
index 0000000000..6d942cfcc4
Binary files /dev/null and b/pictures/group.jpg differ
diff --git a/pictures/header.jpg b/pictures/header.jpg
new file mode 100644
index 0000000000..06a2048f45
Binary files /dev/null and b/pictures/header.jpg differ
diff --git a/pictures/heap/1.png b/pictures/heap/1.png
index 93f4387839..8d99c0d9b1 100644
Binary files a/pictures/heap/1.png and b/pictures/heap/1.png differ
diff --git a/pictures/intersection/1.jpg b/pictures/intersection/1.jpg
index 03b9cbf67c..97f313fe08 100644
Binary files a/pictures/intersection/1.jpg and b/pictures/intersection/1.jpg differ
diff --git a/pictures/intersection/2.jpg b/pictures/intersection/2.jpg
index 3434de4d1e..555688e4e7 100644
Binary files a/pictures/intersection/2.jpg and b/pictures/intersection/2.jpg differ
diff --git a/pictures/intersection/3.jpg b/pictures/intersection/3.jpg
index b5e805df66..9ba0b61d8a 100644
Binary files a/pictures/intersection/3.jpg and b/pictures/intersection/3.jpg differ
diff --git a/pictures/intersection/title.png b/pictures/intersection/title.png
index 4b0529a808..d06d89249b 100644
Binary files a/pictures/intersection/title.png and b/pictures/intersection/title.png differ
diff --git a/pictures/interval/2.jpg b/pictures/interval/2.jpg
index aa0440f0e1..06e34bd6a2 100644
Binary files a/pictures/interval/2.jpg and b/pictures/interval/2.jpg differ
diff --git a/pictures/interval/3.jpg b/pictures/interval/3.jpg
index 89b4e6eff1..68741642ea 100644
Binary files a/pictures/interval/3.jpg and b/pictures/interval/3.jpg differ
diff --git a/pictures/interval/4.jpg b/pictures/interval/4.jpg
index c6735d83ad..d9fb1f4a19 100644
Binary files a/pictures/interval/4.jpg and b/pictures/interval/4.jpg differ
diff --git a/pictures/interval/title1.png b/pictures/interval/title1.png
index 551c259902..e90959bad5 100644
Binary files a/pictures/interval/title1.png and b/pictures/interval/title1.png differ
diff --git a/pictures/interval/title2.png b/pictures/interval/title2.png
index 41261129bc..626d0c5c9b 100644
Binary files a/pictures/interval/title2.png and b/pictures/interval/title2.png differ
diff --git a/pictures/kgroup/1.jpg b/pictures/kgroup/1.jpg
index ca0c8ff8b4..ab874fcab4 100644
Binary files a/pictures/kgroup/1.jpg and b/pictures/kgroup/1.jpg differ
diff --git a/pictures/kgroup/2.jpg b/pictures/kgroup/2.jpg
index 653d31f4dc..ca29ffd706 100644
Binary files a/pictures/kgroup/2.jpg and b/pictures/kgroup/2.jpg differ
diff --git a/pictures/kgroup/3.jpg b/pictures/kgroup/3.jpg
index 8718e51c31..e2255241ec 100644
Binary files a/pictures/kgroup/3.jpg and b/pictures/kgroup/3.jpg differ
diff --git a/pictures/kgroup/4.jpg b/pictures/kgroup/4.jpg
index f2fed3e33a..6126add251 100644
Binary files a/pictures/kgroup/4.jpg and b/pictures/kgroup/4.jpg differ
diff --git a/pictures/kgroup/5.jpg b/pictures/kgroup/5.jpg
index 4cd3b33242..2b626b30e4 100644
Binary files a/pictures/kgroup/5.jpg and b/pictures/kgroup/5.jpg differ
diff --git a/pictures/kgroup/6.jpg b/pictures/kgroup/6.jpg
index 4e1772b0bc..f11088f7cb 100644
Binary files a/pictures/kgroup/6.jpg and b/pictures/kgroup/6.jpg differ
diff --git a/pictures/kgroup/7.jpg b/pictures/kgroup/7.jpg
index 073ba61f3e..8b4bf79934 100644
Binary files a/pictures/kgroup/7.jpg and b/pictures/kgroup/7.jpg differ
diff --git a/pictures/kgroup/title.png b/pictures/kgroup/title.png
index 794f5a5cc5..1a2028185e 100644
Binary files a/pictures/kgroup/title.png and b/pictures/kgroup/title.png differ
diff --git a/pictures/kmp/1.gif b/pictures/kmp/1.gif
index a049ff3456..95732bf8ee 100644
Binary files a/pictures/kmp/1.gif and b/pictures/kmp/1.gif differ
diff --git a/pictures/kmp/2.gif b/pictures/kmp/2.gif
index 418d02b7bc..ed1059d958 100644
Binary files a/pictures/kmp/2.gif and b/pictures/kmp/2.gif differ
diff --git a/pictures/kmp/3.gif b/pictures/kmp/3.gif
index 309e95efa0..e91497f4ca 100644
Binary files a/pictures/kmp/3.gif and b/pictures/kmp/3.gif differ
diff --git a/pictures/kmp/A.gif b/pictures/kmp/A.gif
index 10c48fb569..dd0800e17b 100644
Binary files a/pictures/kmp/A.gif and b/pictures/kmp/A.gif differ
diff --git a/pictures/kmp/allstate.jpg b/pictures/kmp/allstate.jpg
index bfbd26bcc4..f8e40777d1 100644
Binary files a/pictures/kmp/allstate.jpg and b/pictures/kmp/allstate.jpg differ
diff --git a/pictures/kmp/back.jpg b/pictures/kmp/back.jpg
index e33cc25cd7..368d091098 100644
Binary files a/pictures/kmp/back.jpg and b/pictures/kmp/back.jpg differ
diff --git a/pictures/kmp/dfa.gif b/pictures/kmp/dfa.gif
index 0e9bdaa4f8..0f5dc54224 100644
Binary files a/pictures/kmp/dfa.gif and b/pictures/kmp/dfa.gif differ
diff --git a/pictures/kmp/exp1.jpg b/pictures/kmp/exp1.jpg
index 5bb393523e..9e413d0438 100644
Binary files a/pictures/kmp/exp1.jpg and b/pictures/kmp/exp1.jpg differ
diff --git a/pictures/kmp/exp2.jpg b/pictures/kmp/exp2.jpg
index f277b7e81b..244fc4ee4b 100644
Binary files a/pictures/kmp/exp2.jpg and b/pictures/kmp/exp2.jpg differ
diff --git a/pictures/kmp/exp3.jpg b/pictures/kmp/exp3.jpg
index a7e48efb38..11eae5a6d2 100644
Binary files a/pictures/kmp/exp3.jpg and b/pictures/kmp/exp3.jpg differ
diff --git a/pictures/kmp/exp4.jpg b/pictures/kmp/exp4.jpg
index f7f98ee58c..e969c48d8a 100644
Binary files a/pictures/kmp/exp4.jpg and b/pictures/kmp/exp4.jpg differ
diff --git a/pictures/kmp/exp5.jpg b/pictures/kmp/exp5.jpg
index 979d91e31d..2a16a868ab 100644
Binary files a/pictures/kmp/exp5.jpg and b/pictures/kmp/exp5.jpg differ
diff --git a/pictures/kmp/exp6.jpg b/pictures/kmp/exp6.jpg
index 423b244d43..87c723f3b8 100644
Binary files a/pictures/kmp/exp6.jpg and b/pictures/kmp/exp6.jpg differ
diff --git a/pictures/kmp/exp7.jpg b/pictures/kmp/exp7.jpg
index 10da813832..95634204bd 100644
Binary files a/pictures/kmp/exp7.jpg and b/pictures/kmp/exp7.jpg differ
diff --git a/pictures/kmp/forward.jpg b/pictures/kmp/forward.jpg
index 66beca0ebe..2f887c8933 100644
Binary files a/pictures/kmp/forward.jpg and b/pictures/kmp/forward.jpg differ
diff --git a/pictures/kmp/kmp.gif b/pictures/kmp/kmp.gif
index e33dad97b3..18cd52dbd8 100644
Binary files a/pictures/kmp/kmp.gif and b/pictures/kmp/kmp.gif differ
diff --git a/pictures/kmp/shadow.jpg b/pictures/kmp/shadow.jpg
index 0733b546e2..9b2f536aab 100644
Binary files a/pictures/kmp/shadow.jpg and b/pictures/kmp/shadow.jpg differ
diff --git a/pictures/kmp/shadow1.jpg b/pictures/kmp/shadow1.jpg
index 13d0377725..07389fc897 100644
Binary files a/pictures/kmp/shadow1.jpg and b/pictures/kmp/shadow1.jpg differ
diff --git a/pictures/kmp/shadow2.jpg b/pictures/kmp/shadow2.jpg
index a9abb79d7d..f68660afe0 100644
Binary files a/pictures/kmp/shadow2.jpg and b/pictures/kmp/shadow2.jpg differ
diff --git a/pictures/kmp/state.jpg b/pictures/kmp/state.jpg
index 073060b2bf..3fd084cca8 100644
Binary files a/pictures/kmp/state.jpg and b/pictures/kmp/state.jpg differ
diff --git a/pictures/kmp/state2.jpg b/pictures/kmp/state2.jpg
index 3be64c091f..f20fde5d12 100644
Binary files a/pictures/kmp/state2.jpg and b/pictures/kmp/state2.jpg differ
diff --git a/pictures/kmp/state4.jpg b/pictures/kmp/state4.jpg
index d5ba19eaf2..8873fd38be 100644
Binary files a/pictures/kmp/state4.jpg and b/pictures/kmp/state4.jpg differ
diff --git a/pictures/kmp/txt1.jpg b/pictures/kmp/txt1.jpg
index a123d9e360..3b10191619 100644
Binary files a/pictures/kmp/txt1.jpg and b/pictures/kmp/txt1.jpg differ
diff --git a/pictures/kmp/txt2.jpg b/pictures/kmp/txt2.jpg
index bbb7cd3781..c6c5041e66 100644
Binary files a/pictures/kmp/txt2.jpg and b/pictures/kmp/txt2.jpg differ
diff --git a/pictures/kmp/txt3.jpg b/pictures/kmp/txt3.jpg
index e4edfd70ae..29830ba73e 100644
Binary files a/pictures/kmp/txt3.jpg and b/pictures/kmp/txt3.jpg differ
diff --git a/pictures/kmp/txt4.jpg b/pictures/kmp/txt4.jpg
index 50e36d1fb1..55e53e7719 100644
Binary files a/pictures/kmp/txt4.jpg and b/pictures/kmp/txt4.jpg differ
diff --git a/pictures/kmp/z.jpg b/pictures/kmp/z.jpg
index aebf0b8609..56b945efcf 100644
Binary files a/pictures/kmp/z.jpg and b/pictures/kmp/z.jpg differ
diff --git a/pictures/labuladong.jpg b/pictures/labuladong.jpg
deleted file mode 100644
index cb385ab0ad..0000000000
Binary files a/pictures/labuladong.jpg and /dev/null differ
diff --git a/pictures/labuladong.png b/pictures/labuladong.png
index fe2100acdd..a63a5bd890 100644
Binary files a/pictures/labuladong.png and b/pictures/labuladong.png differ
diff --git a/pictures/linux-fs/application.png b/pictures/linux-fs/application.png
index 17185b81d5..9b39088f36 100644
Binary files a/pictures/linux-fs/application.png and b/pictures/linux-fs/application.png differ
diff --git a/pictures/linux-fs/apt.png b/pictures/linux-fs/apt.png
index bed240ba9d..5038c8c267 100644
Binary files a/pictures/linux-fs/apt.png and b/pictures/linux-fs/apt.png differ
diff --git a/pictures/linux-fs/bin.png b/pictures/linux-fs/bin.png
index 755491a457..353baa7bf8 100644
Binary files a/pictures/linux-fs/bin.png and b/pictures/linux-fs/bin.png differ
diff --git a/pictures/linux-fs/boot.png b/pictures/linux-fs/boot.png
index 1f1b225007..d5848e8cd5 100644
Binary files a/pictures/linux-fs/boot.png and b/pictures/linux-fs/boot.png differ
diff --git a/pictures/linux-fs/cpu.png b/pictures/linux-fs/cpu.png
index 721b66cd92..12d949e9d9 100644
Binary files a/pictures/linux-fs/cpu.png and b/pictures/linux-fs/cpu.png differ
diff --git a/pictures/linux-fs/desktop.png b/pictures/linux-fs/desktop.png
index 4cb1239f70..7a46ecef21 100644
Binary files a/pictures/linux-fs/desktop.png and b/pictures/linux-fs/desktop.png differ
diff --git a/pictures/linux-fs/dev.png b/pictures/linux-fs/dev.png
index dd892e6538..c9275dc85e 100644
Binary files a/pictures/linux-fs/dev.png and b/pictures/linux-fs/dev.png differ
diff --git a/pictures/linux-fs/etc.png b/pictures/linux-fs/etc.png
index 3a3d1063ef..5de3a4cf78 100644
Binary files a/pictures/linux-fs/etc.png and b/pictures/linux-fs/etc.png differ
diff --git a/pictures/linux-fs/home.png b/pictures/linux-fs/home.png
index d35c71bba6..dad402e25a 100644
Binary files a/pictures/linux-fs/home.png and b/pictures/linux-fs/home.png differ
diff --git a/pictures/linux-fs/linux-filesystem.png b/pictures/linux-fs/linux-filesystem.png
index c43b2922d2..225efb8ab3 100644
Binary files a/pictures/linux-fs/linux-filesystem.png and b/pictures/linux-fs/linux-filesystem.png differ
diff --git a/pictures/linux-fs/log.png b/pictures/linux-fs/log.png
index a4416e1059..ee40ca0a6e 100644
Binary files a/pictures/linux-fs/log.png and b/pictures/linux-fs/log.png differ
diff --git a/pictures/linux-fs/opt.png b/pictures/linux-fs/opt.png
index 7b2092f234..b46535ec66 100644
Binary files a/pictures/linux-fs/opt.png and b/pictures/linux-fs/opt.png differ
diff --git a/pictures/linux-fs/proc.png b/pictures/linux-fs/proc.png
index 06006000f1..0e2820a1b5 100644
Binary files a/pictures/linux-fs/proc.png and b/pictures/linux-fs/proc.png differ
diff --git a/pictures/linux-fs/root.png b/pictures/linux-fs/root.png
index 00df4f75ec..3ba9697367 100644
Binary files a/pictures/linux-fs/root.png and b/pictures/linux-fs/root.png differ
diff --git a/pictures/linux-fs/sbin.png b/pictures/linux-fs/sbin.png
index 2fc99208df..907c3a0f3e 100644
Binary files a/pictures/linux-fs/sbin.png and b/pictures/linux-fs/sbin.png differ
diff --git a/pictures/linux-fs/tmp.png b/pictures/linux-fs/tmp.png
index 361146697d..54ea9dd615 100644
Binary files a/pictures/linux-fs/tmp.png and b/pictures/linux-fs/tmp.png differ
diff --git a/pictures/linux-fs/usr.png b/pictures/linux-fs/usr.png
index 29e389ce35..0619c44937 100644
Binary files a/pictures/linux-fs/usr.png and b/pictures/linux-fs/usr.png differ
diff --git a/pictures/linux-fs/usrbin.png b/pictures/linux-fs/usrbin.png
index 7dfd72a84f..e1c5e82f6c 100644
Binary files a/pictures/linux-fs/usrbin.png and b/pictures/linux-fs/usrbin.png differ
diff --git a/pictures/linuxProcess/1.jpg b/pictures/linuxProcess/1.jpg
index a3b4383b8a..a42365fe73 100644
Binary files a/pictures/linuxProcess/1.jpg and b/pictures/linuxProcess/1.jpg differ
diff --git a/pictures/linuxProcess/2.jpg b/pictures/linuxProcess/2.jpg
index 821ff340fa..9aa08f1401 100644
Binary files a/pictures/linuxProcess/2.jpg and b/pictures/linuxProcess/2.jpg differ
diff --git a/pictures/linuxProcess/3.jpg b/pictures/linuxProcess/3.jpg
index d7d3ae97ff..a3800a8f21 100644
Binary files a/pictures/linuxProcess/3.jpg and b/pictures/linuxProcess/3.jpg differ
diff --git a/pictures/linuxProcess/4.jpg b/pictures/linuxProcess/4.jpg
index 6ada0ef14e..c74fdd3722 100644
Binary files a/pictures/linuxProcess/4.jpg and b/pictures/linuxProcess/4.jpg differ
diff --git a/pictures/linuxProcess/5.jpg b/pictures/linuxProcess/5.jpg
index c4c51ca759..e7b1f74c1d 100644
Binary files a/pictures/linuxProcess/5.jpg and b/pictures/linuxProcess/5.jpg differ
diff --git a/pictures/linuxProcess/6.jpg b/pictures/linuxProcess/6.jpg
index c2637d131b..9e36322eba 100644
Binary files a/pictures/linuxProcess/6.jpg and b/pictures/linuxProcess/6.jpg differ
diff --git a/pictures/linuxProcess/7.jpg b/pictures/linuxProcess/7.jpg
index 6abd83436f..80e86879cb 100644
Binary files a/pictures/linuxProcess/7.jpg and b/pictures/linuxProcess/7.jpg differ
diff --git a/pictures/linuxProcess/8.jpg b/pictures/linuxProcess/8.jpg
index eafae087d3..2b4cb97101 100644
Binary files a/pictures/linuxProcess/8.jpg and b/pictures/linuxProcess/8.jpg differ
diff --git a/pictures/linuxshell/1.png b/pictures/linuxshell/1.png
index 0657e4d62f..292baa29d0 100644
Binary files a/pictures/linuxshell/1.png and b/pictures/linuxshell/1.png differ
diff --git a/pictures/mergeInterval/1.jpg b/pictures/mergeInterval/1.jpg
index 915f33607a..5d8a8dbc2e 100644
Binary files a/pictures/mergeInterval/1.jpg and b/pictures/mergeInterval/1.jpg differ
diff --git a/pictures/mergeInterval/2.jpg b/pictures/mergeInterval/2.jpg
index 79a8ef7f22..28aabd731a 100644
Binary files a/pictures/mergeInterval/2.jpg and b/pictures/mergeInterval/2.jpg differ
diff --git a/pictures/mergeInterval/title.png b/pictures/mergeInterval/title.png
index ac1a373946..26e42c14e8 100644
Binary files a/pictures/mergeInterval/title.png and b/pictures/mergeInterval/title.png differ
diff --git a/pictures/online/1.png b/pictures/online/1.png
index 11da044f4d..68db13bada 100644
Binary files a/pictures/online/1.png and b/pictures/online/1.png differ
diff --git a/pictures/online/10.png b/pictures/online/10.png
index 63041fc421..ec2095fd15 100644
Binary files a/pictures/online/10.png and b/pictures/online/10.png differ
diff --git a/pictures/online/11.png b/pictures/online/11.png
index 2aac442a00..87d3368cb5 100644
Binary files a/pictures/online/11.png and b/pictures/online/11.png differ
diff --git a/pictures/online/2.png b/pictures/online/2.png
index b8e460ac25..de635fa8dd 100644
Binary files a/pictures/online/2.png and b/pictures/online/2.png differ
diff --git a/pictures/online/3.png b/pictures/online/3.png
index 1f465a69f6..c8868697a9 100644
Binary files a/pictures/online/3.png and b/pictures/online/3.png differ
diff --git a/pictures/online/4.png b/pictures/online/4.png
index 5d99ec999a..7534e3e76f 100644
Binary files a/pictures/online/4.png and b/pictures/online/4.png differ
diff --git a/pictures/online/5.png b/pictures/online/5.png
index c118acd3a6..9d9ae0a2d8 100644
Binary files a/pictures/online/5.png and b/pictures/online/5.png differ
diff --git a/pictures/online/6.png b/pictures/online/6.png
index f77e12a989..06c079fdca 100644
Binary files a/pictures/online/6.png and b/pictures/online/6.png differ
diff --git a/pictures/online/7.png b/pictures/online/7.png
index a031c195a6..9098f63ad4 100644
Binary files a/pictures/online/7.png and b/pictures/online/7.png differ
diff --git a/pictures/online/8.png b/pictures/online/8.png
index 0822ef48d9..b462ad6d7c 100644
Binary files a/pictures/online/8.png and b/pictures/online/8.png differ
diff --git a/pictures/online/9.png b/pictures/online/9.png
index a94900f779..f879e25516 100644
Binary files a/pictures/online/9.png and b/pictures/online/9.png differ
diff --git a/pictures/others/leetcode.jpeg b/pictures/others/leetcode.jpeg
index 8b2c7c776b..2fd2c684db 100644
Binary files a/pictures/others/leetcode.jpeg and b/pictures/others/leetcode.jpeg differ
diff --git a/pictures/pancakeSort/1.jpg b/pictures/pancakeSort/1.jpg
index 10f9dd6568..903dec371b 100644
Binary files a/pictures/pancakeSort/1.jpg and b/pictures/pancakeSort/1.jpg differ
diff --git a/pictures/pancakeSort/2.png b/pictures/pancakeSort/2.png
index e57fd31a48..57e16de2dd 100644
Binary files a/pictures/pancakeSort/2.png and b/pictures/pancakeSort/2.png differ
diff --git a/pictures/pancakeSort/3.jpg b/pictures/pancakeSort/3.jpg
index c492e8bf8b..b36f6fcc80 100644
Binary files a/pictures/pancakeSort/3.jpg and b/pictures/pancakeSort/3.jpg differ
diff --git a/pictures/pancakeSort/4.jpg b/pictures/pancakeSort/4.jpg
index 53341a3554..f9245e5937 100644
Binary files a/pictures/pancakeSort/4.jpg and b/pictures/pancakeSort/4.jpg differ
diff --git a/pictures/pancakeSort/title.png b/pictures/pancakeSort/title.png
index f91a8132ce..76a52a0f38 100644
Binary files a/pictures/pancakeSort/title.png and b/pictures/pancakeSort/title.png differ
diff --git a/pictures/pay.jpg b/pictures/pay.jpg
index 5322a657db..39e9d402a4 100644
Binary files a/pictures/pay.jpg and b/pictures/pay.jpg differ
diff --git a/pictures/plugin/chrome.gif b/pictures/plugin/chrome.gif
new file mode 100644
index 0000000000..d3ad03cff9
Binary files /dev/null and b/pictures/plugin/chrome.gif differ
diff --git a/pictures/plugin/chrome.jpg b/pictures/plugin/chrome.jpg
new file mode 100644
index 0000000000..4f5fc680a4
Binary files /dev/null and b/pictures/plugin/chrome.jpg differ
diff --git a/pictures/plugin/jetbrain.gif b/pictures/plugin/jetbrain.gif
new file mode 100644
index 0000000000..e2deb6d05c
Binary files /dev/null and b/pictures/plugin/jetbrain.gif differ
diff --git a/pictures/plugin/jetbrain.jpg b/pictures/plugin/jetbrain.jpg
new file mode 100644
index 0000000000..061aee41e4
Binary files /dev/null and b/pictures/plugin/jetbrain.jpg differ
diff --git a/pictures/plugin/vscode.gif b/pictures/plugin/vscode.gif
new file mode 100644
index 0000000000..a0962b45df
Binary files /dev/null and b/pictures/plugin/vscode.gif differ
diff --git a/pictures/plugin/vscode.jpg b/pictures/plugin/vscode.jpg
new file mode 100644
index 0000000000..3c68f20389
Binary files /dev/null and b/pictures/plugin/vscode.jpg differ
diff --git "a/pictures/plugin/\345\205\250\345\256\266\346\241\266.jpg" "b/pictures/plugin/\345\205\250\345\256\266\346\241\266.jpg"
new file mode 100644
index 0000000000..b97e4cbb4b
Binary files /dev/null and "b/pictures/plugin/\345\205\250\345\256\266\346\241\266.jpg" differ
diff --git a/pictures/qrcode.jpg b/pictures/qrcode.jpg
index d6beb95c7b..83e46cb25f 100644
Binary files a/pictures/qrcode.jpg and b/pictures/qrcode.jpg differ
diff --git "a/pictures/redis\345\205\245\344\276\265/1.png" "b/pictures/redis\345\205\245\344\276\265/1.png"
index fb2e59dc41..e021d3eb44 100644
Binary files "a/pictures/redis\345\205\245\344\276\265/1.png" and "b/pictures/redis\345\205\245\344\276\265/1.png" differ
diff --git "a/pictures/redis\345\205\245\344\276\265/2.png" "b/pictures/redis\345\205\245\344\276\265/2.png"
index 94fcae0456..a9f03e65e9 100644
Binary files "a/pictures/redis\345\205\245\344\276\265/2.png" and "b/pictures/redis\345\205\245\344\276\265/2.png" differ
diff --git "a/pictures/redis\345\205\245\344\276\265/3.png" "b/pictures/redis\345\205\245\344\276\265/3.png"
index d559c635db..b4c9980e83 100644
Binary files "a/pictures/redis\345\205\245\344\276\265/3.png" and "b/pictures/redis\345\205\245\344\276\265/3.png" differ
diff --git "a/pictures/redis\345\205\245\344\276\265/4.png" "b/pictures/redis\345\205\245\344\276\265/4.png"
index 2abc2eedcf..44b390d666 100644
Binary files "a/pictures/redis\345\205\245\344\276\265/4.png" and "b/pictures/redis\345\205\245\344\276\265/4.png" differ
diff --git "a/pictures/redis\345\205\245\344\276\265/5.png" "b/pictures/redis\345\205\245\344\276\265/5.png"
index 2d6c01e14b..60dc5ab738 100644
Binary files "a/pictures/redis\345\205\245\344\276\265/5.png" and "b/pictures/redis\345\205\245\344\276\265/5.png" differ
diff --git "a/pictures/redis\345\205\245\344\276\265/6.png" "b/pictures/redis\345\205\245\344\276\265/6.png"
index 48cd894f7d..618c28c203 100644
Binary files "a/pictures/redis\345\205\245\344\276\265/6.png" and "b/pictures/redis\345\205\245\344\276\265/6.png" differ
diff --git a/pictures/robber/1.jpg b/pictures/robber/1.jpg
index 62cec652a6..23b590f6a9 100644
Binary files a/pictures/robber/1.jpg and b/pictures/robber/1.jpg differ
diff --git a/pictures/robber/2.jpg b/pictures/robber/2.jpg
index 89ffabb077..95761fddbc 100644
Binary files a/pictures/robber/2.jpg and b/pictures/robber/2.jpg differ
diff --git a/pictures/robber/3.jpg b/pictures/robber/3.jpg
index 35e169e770..6c54da1aa9 100644
Binary files a/pictures/robber/3.jpg and b/pictures/robber/3.jpg differ
diff --git a/pictures/robber/title.png b/pictures/robber/title.png
index c4bd7822bf..8f60633f9d 100644
Binary files a/pictures/robber/title.png and b/pictures/robber/title.png differ
diff --git a/pictures/robber/title1.png b/pictures/robber/title1.png
index 736ece0c9f..b6096939dd 100644
Binary files a/pictures/robber/title1.png and b/pictures/robber/title1.png differ
diff --git a/pictures/session/1.png b/pictures/session/1.png
index 2b7c7b1b9f..906f7090f7 100644
Binary files a/pictures/session/1.png and b/pictures/session/1.png differ
diff --git a/pictures/session/2.png b/pictures/session/2.png
index 4662883971..d2660b2219 100644
Binary files a/pictures/session/2.png and b/pictures/session/2.png differ
diff --git a/pictures/session/3.png b/pictures/session/3.png
index 59c12d4988..622a8f707e 100644
Binary files a/pictures/session/3.png and b/pictures/session/3.png differ
diff --git a/pictures/session/4.jpg b/pictures/session/4.jpg
index a838e406a3..81e92eedd1 100644
Binary files a/pictures/session/4.jpg and b/pictures/session/4.jpg differ
diff --git a/pictures/souyisou.png b/pictures/souyisou.png
new file mode 100644
index 0000000000..94d9f67c1e
Binary files /dev/null and b/pictures/souyisou.png differ
diff --git a/pictures/souyisou2.png b/pictures/souyisou2.png
new file mode 100644
index 0000000000..744d478f16
Binary files /dev/null and b/pictures/souyisou2.png differ
diff --git a/pictures/unionfind/1.jpg b/pictures/unionfind/1.jpg
index 7e5f6fb607..77aaf0ee22 100644
Binary files a/pictures/unionfind/1.jpg and b/pictures/unionfind/1.jpg differ
diff --git a/pictures/unionfind/2.jpg b/pictures/unionfind/2.jpg
index af87343e6f..a5396986e9 100644
Binary files a/pictures/unionfind/2.jpg and b/pictures/unionfind/2.jpg differ
diff --git a/pictures/unionfind/3.jpg b/pictures/unionfind/3.jpg
index 84a97b403c..d3c6051348 100644
Binary files a/pictures/unionfind/3.jpg and b/pictures/unionfind/3.jpg differ
diff --git a/pictures/unionfind/4.jpg b/pictures/unionfind/4.jpg
index d967c663c6..4004791778 100644
Binary files a/pictures/unionfind/4.jpg and b/pictures/unionfind/4.jpg differ
diff --git a/pictures/unionfind/5.jpg b/pictures/unionfind/5.jpg
index aed3cd1574..273302945c 100644
Binary files a/pictures/unionfind/5.jpg and b/pictures/unionfind/5.jpg differ
diff --git a/pictures/unionfind/6.jpg b/pictures/unionfind/6.jpg
index ca30431e28..ae37f8d0ba 100644
Binary files a/pictures/unionfind/6.jpg and b/pictures/unionfind/6.jpg differ
diff --git a/pictures/unionfind/7.jpg b/pictures/unionfind/7.jpg
index b9cc6e1347..251dd20f05 100644
Binary files a/pictures/unionfind/7.jpg and b/pictures/unionfind/7.jpg differ
diff --git a/pictures/unionfind/8.jpg b/pictures/unionfind/8.jpg
index 7a544068b7..fd74212075 100644
Binary files a/pictures/unionfind/8.jpg and b/pictures/unionfind/8.jpg differ
diff --git "a/pictures/unionfind\345\272\224\347\224\250/1.jpg" "b/pictures/unionfind\345\272\224\347\224\250/1.jpg"
index f3a311a27e..583e66121b 100644
Binary files "a/pictures/unionfind\345\272\224\347\224\250/1.jpg" and "b/pictures/unionfind\345\272\224\347\224\250/1.jpg" differ
diff --git "a/pictures/unionfind\345\272\224\347\224\250/2.jpg" "b/pictures/unionfind\345\272\224\347\224\250/2.jpg"
index 7c1e6acd50..5e4c40b9b4 100644
Binary files "a/pictures/unionfind\345\272\224\347\224\250/2.jpg" and "b/pictures/unionfind\345\272\224\347\224\250/2.jpg" differ
diff --git "a/pictures/unionfind\345\272\224\347\224\250/3.jpg" "b/pictures/unionfind\345\272\224\347\224\250/3.jpg"
index dca81a8366..a21dd12d70 100644
Binary files "a/pictures/unionfind\345\272\224\347\224\250/3.jpg" and "b/pictures/unionfind\345\272\224\347\224\250/3.jpg" differ
diff --git a/pictures/youtube/1.png b/pictures/youtube/1.png
index 3c8c59589a..f7f96878a2 100644
Binary files a/pictures/youtube/1.png and b/pictures/youtube/1.png differ
diff --git a/pictures/youtube/1573133096614.jpeg b/pictures/youtube/1573133096614.jpeg
index c34c38eeb6..27f85dc3ab 100644
Binary files a/pictures/youtube/1573133096614.jpeg and b/pictures/youtube/1573133096614.jpeg differ
diff --git a/pictures/youtube/1573133131308.jpeg b/pictures/youtube/1573133131308.jpeg
index 0c75129dc0..c464ef3bec 100644
Binary files a/pictures/youtube/1573133131308.jpeg and b/pictures/youtube/1573133131308.jpeg differ
diff --git a/pictures/youtube/2.jpg b/pictures/youtube/2.jpg
index 2eeae31b5d..490c1c40be 100644
Binary files a/pictures/youtube/2.jpg and b/pictures/youtube/2.jpg differ
diff --git a/pictures/youtube/3.jpg b/pictures/youtube/3.jpg
index d1112a6447..7d24d92b33 100644
Binary files a/pictures/youtube/3.jpg and b/pictures/youtube/3.jpg differ
diff --git a/pictures/youtube/4.jpg b/pictures/youtube/4.jpg
index 0f4cd6b3df..3ea617d104 100644
Binary files a/pictures/youtube/4.jpg and b/pictures/youtube/4.jpg differ
diff --git "a/pictures/\344\272\214\345\210\206\345\272\224\347\224\250/title1.png" "b/pictures/\344\272\214\345\210\206\345\272\224\347\224\250/title1.png"
index 410b4e66d5..cb85d759a8 100644
Binary files "a/pictures/\344\272\214\345\210\206\345\272\224\347\224\250/title1.png" and "b/pictures/\344\272\214\345\210\206\345\272\224\347\224\250/title1.png" differ
diff --git "a/pictures/\344\272\214\345\210\206\345\272\224\347\224\250/title2.png" "b/pictures/\344\272\214\345\210\206\345\272\224\347\224\250/title2.png"
index adc29e78c4..6dc47c6c99 100644
Binary files "a/pictures/\344\272\214\345\210\206\345\272\224\347\224\250/title2.png" and "b/pictures/\344\272\214\345\210\206\345\272\224\347\224\250/title2.png" differ
diff --git "a/pictures/\344\272\214\345\210\206\346\237\245\346\211\276/1.jpg" "b/pictures/\344\272\214\345\210\206\346\237\245\346\211\276/1.jpg"
new file mode 100644
index 0000000000..da0a55ba88
Binary files /dev/null and "b/pictures/\344\272\214\345\210\206\346\237\245\346\211\276/1.jpg" differ
diff --git "a/pictures/\344\272\214\345\210\206\346\237\245\346\211\276/2.jpg" "b/pictures/\344\272\214\345\210\206\346\237\245\346\211\276/2.jpg"
new file mode 100644
index 0000000000..6865c24b13
Binary files /dev/null and "b/pictures/\344\272\214\345\210\206\346\237\245\346\211\276/2.jpg" differ
diff --git "a/pictures/\344\272\214\345\210\206\346\237\245\346\211\276/3.jpg" "b/pictures/\344\272\214\345\210\206\346\237\245\346\211\276/3.jpg"
new file mode 100644
index 0000000000..a360ba8767
Binary files /dev/null and "b/pictures/\344\272\214\345\210\206\346\237\245\346\211\276/3.jpg" differ
diff --git "a/pictures/\344\272\214\345\210\206\346\237\245\346\211\276/4.jpg" "b/pictures/\344\272\214\345\210\206\346\237\245\346\211\276/4.jpg"
new file mode 100644
index 0000000000..35e46116bf
Binary files /dev/null and "b/pictures/\344\272\214\345\210\206\346\237\245\346\211\276/4.jpg" differ
diff --git "a/pictures/\344\272\214\345\210\206\346\237\245\346\211\276/binarySearch1.png" "b/pictures/\344\272\214\345\210\206\346\237\245\346\211\276/binarySearch1.png"
index 911bde51e7..d5a410abcd 100644
Binary files "a/pictures/\344\272\214\345\210\206\346\237\245\346\211\276/binarySearch1.png" and "b/pictures/\344\272\214\345\210\206\346\237\245\346\211\276/binarySearch1.png" differ
diff --git "a/pictures/\344\272\214\345\210\206\346\237\245\346\211\276/binarySearch2.png" "b/pictures/\344\272\214\345\210\206\346\237\245\346\211\276/binarySearch2.png"
index d6ca59b939..abff601aba 100644
Binary files "a/pictures/\344\272\214\345\210\206\346\237\245\346\211\276/binarySearch2.png" and "b/pictures/\344\272\214\345\210\206\346\237\245\346\211\276/binarySearch2.png" differ
diff --git "a/pictures/\344\272\214\345\210\206\346\237\245\346\211\276/poem.png" "b/pictures/\344\272\214\345\210\206\346\237\245\346\211\276/poem.png"
new file mode 100644
index 0000000000..6262c33549
Binary files /dev/null and "b/pictures/\344\272\214\345\210\206\346\237\245\346\211\276/poem.png" differ
diff --git "a/pictures/\344\275\215\346\223\215\344\275\234/1.png" "b/pictures/\344\275\215\346\223\215\344\275\234/1.png"
index 89bfd0cef5..c4463610a4 100644
Binary files "a/pictures/\344\275\215\346\223\215\344\275\234/1.png" and "b/pictures/\344\275\215\346\223\215\344\275\234/1.png" differ
diff --git "a/pictures/\344\275\215\346\223\215\344\275\234/title.png" "b/pictures/\344\275\215\346\223\215\344\275\234/title.png"
index 9b961475cc..953f1c3a86 100644
Binary files "a/pictures/\344\275\215\346\223\215\344\275\234/title.png" and "b/pictures/\344\275\215\346\223\215\344\275\234/title.png" differ
diff --git "a/pictures/\344\277\241\345\260\201\345\265\214\345\245\227/0.jpg" "b/pictures/\344\277\241\345\260\201\345\265\214\345\245\227/0.jpg"
index 3a19e9d3ef..48728e408c 100644
Binary files "a/pictures/\344\277\241\345\260\201\345\265\214\345\245\227/0.jpg" and "b/pictures/\344\277\241\345\260\201\345\265\214\345\245\227/0.jpg" differ
diff --git "a/pictures/\344\277\241\345\260\201\345\265\214\345\245\227/1.jpg" "b/pictures/\344\277\241\345\260\201\345\265\214\345\245\227/1.jpg"
index 337378019b..df0cc5fb3a 100644
Binary files "a/pictures/\344\277\241\345\260\201\345\265\214\345\245\227/1.jpg" and "b/pictures/\344\277\241\345\260\201\345\265\214\345\245\227/1.jpg" differ
diff --git "a/pictures/\344\277\241\345\260\201\345\265\214\345\245\227/2.jpg" "b/pictures/\344\277\241\345\260\201\345\265\214\345\245\227/2.jpg"
index 5c9d52b608..4e256327c4 100644
Binary files "a/pictures/\344\277\241\345\260\201\345\265\214\345\245\227/2.jpg" and "b/pictures/\344\277\241\345\260\201\345\265\214\345\245\227/2.jpg" differ
diff --git "a/pictures/\344\277\241\345\260\201\345\265\214\345\245\227/title.png" "b/pictures/\344\277\241\345\260\201\345\265\214\345\245\227/title.png"
index 771fa0c075..fbd9329141 100644
Binary files "a/pictures/\344\277\241\345\260\201\345\265\214\345\245\227/title.png" and "b/pictures/\344\277\241\345\260\201\345\265\214\345\245\227/title.png" differ
diff --git "a/pictures/\345\205\250\345\256\266\346\241\266.jpg" "b/pictures/\345\205\250\345\256\266\346\241\266.jpg"
new file mode 100644
index 0000000000..b97e4cbb4b
Binary files /dev/null and "b/pictures/\345\205\250\345\256\266\346\241\266.jpg" differ
diff --git "a/pictures/\345\211\215\347\274\200\345\222\214/1.jpg" "b/pictures/\345\211\215\347\274\200\345\222\214/1.jpg"
index 5c748457ee..3b1c46fbb7 100644
Binary files "a/pictures/\345\211\215\347\274\200\345\222\214/1.jpg" and "b/pictures/\345\211\215\347\274\200\345\222\214/1.jpg" differ
diff --git "a/pictures/\345\211\215\347\274\200\345\222\214/2.jpg" "b/pictures/\345\211\215\347\274\200\345\222\214/2.jpg"
index b0e9993d39..1306f903f3 100644
Binary files "a/pictures/\345\211\215\347\274\200\345\222\214/2.jpg" and "b/pictures/\345\211\215\347\274\200\345\222\214/2.jpg" differ
diff --git "a/pictures/\345\211\215\347\274\200\345\222\214/title.png" "b/pictures/\345\211\215\347\274\200\345\222\214/title.png"
index 9e52a72f6a..cb19e8180f 100644
Binary files "a/pictures/\345\211\215\347\274\200\345\222\214/title.png" and "b/pictures/\345\211\215\347\274\200\345\222\214/title.png" differ
diff --git "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/coindp.png" "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/coindp.png"
index 0b06a4f426..0d1b8a0a12 100644
Binary files "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/coindp.png" and "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/coindp.png" differ
diff --git "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/coinfunc.png" "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/coinfunc.png"
index a07c92ec8c..26e6460f53 100644
Binary files "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/coinfunc.png" and "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/coinfunc.png" differ
diff --git "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/cointree.png" "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/cointree.png"
index 6a57937cb7..26c978a9c6 100644
Binary files "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/cointree.png" and "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/cointree.png" differ
diff --git "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/fibdp.png" "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/fibdp.png"
index 986b4d21b2..f121f029fd 100644
Binary files "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/fibdp.png" and "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/fibdp.png" differ
diff --git "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/fibfunc.png" "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/fibfunc.png"
index a1044f232c..8657eae81b 100644
Binary files "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/fibfunc.png" and "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/fibfunc.png" differ
diff --git "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/fibmemo.png" "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/fibmemo.png"
index 536a793923..359d1b0cc5 100644
Binary files "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/fibmemo.png" and "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/fibmemo.png" differ
diff --git "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/fibtree.png" "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/fibtree.png"
index dc5bf5732d..b5e6f028ca 100644
Binary files "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/fibtree.png" and "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/fibtree.png" differ
diff --git "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/img_20190514_013033.441.png" "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/img_20190514_013033.441.png"
index a1044f232c..8657eae81b 100644
Binary files "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/img_20190514_013033.441.png" and "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/img_20190514_013033.441.png" differ
diff --git "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/img_20190514_013830.397.png" "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/img_20190514_013830.397.png"
index a07c92ec8c..26e6460f53 100644
Binary files "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/img_20190514_013830.397.png" and "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/img_20190514_013830.397.png" differ
diff --git "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/ink-image (1).png" "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/ink-image (1).png"
index 536a793923..359d1b0cc5 100644
Binary files "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/ink-image (1).png" and "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/ink-image (1).png" differ
diff --git "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/ink-image (2).png" "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/ink-image (2).png"
index 986b4d21b2..f121f029fd 100644
Binary files "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/ink-image (2).png" and "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/ink-image (2).png" differ
diff --git "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/ink-image (3).png" "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/ink-image (3).png"
index 6a57937cb7..26c978a9c6 100644
Binary files "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/ink-image (3).png" and "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/ink-image (3).png" differ
diff --git "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/ink-image (4).png" "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/ink-image (4).png"
index 0b06a4f426..0d1b8a0a12 100644
Binary files "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/ink-image (4).png" and "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/ink-image (4).png" differ
diff --git "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/ink-image.png" "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/ink-image.png"
index dc5bf5732d..b5e6f028ca 100644
Binary files "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/ink-image.png" and "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243/ink-image.png" differ
diff --git "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/1.jpg" "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/1.jpg"
index 6178c1abf4..b4732ffc9d 100644
Binary files "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/1.jpg" and "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/1.jpg" differ
diff --git "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/2.jpg" "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/2.jpg"
index 229d05bd79..386669df9b 100644
Binary files "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/2.jpg" and "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/2.jpg" differ
diff --git "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/3.jpg" "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/3.jpg"
index 9ce9c1bdd5..3d543edccc 100644
Binary files "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/3.jpg" and "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/3.jpg" differ
diff --git "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/4.jpg" "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/4.jpg"
index 6946a5546b..58e2a3a53a 100644
Binary files "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/4.jpg" and "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/4.jpg" differ
diff --git "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/5.jpg" "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/5.jpg"
index 1d8af7a881..64100c8440 100644
Binary files "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/5.jpg" and "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/5.jpg" differ
diff --git "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/6.jpg" "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/6.jpg"
index b57a81ecc9..fbd22932b8 100644
Binary files "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/6.jpg" and "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/6.jpg" differ
diff --git "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/coin.png" "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/coin.png"
index 2b2bdf99cb..2b99fb680c 100644
Binary files "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/coin.png" and "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/coin.png" differ
diff --git "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/fib.png" "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/fib.png"
index f122fd8df5..c90a9c6473 100644
Binary files "a/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/fib.png" and "b/pictures/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266/fib.png" differ
diff --git "a/pictures/\345\215\225\350\260\203\346\240\210/1.png" "b/pictures/\345\215\225\350\260\203\346\240\210/1.png"
index a3729004bb..1a2575d094 100644
Binary files "a/pictures/\345\215\225\350\260\203\346\240\210/1.png" and "b/pictures/\345\215\225\350\260\203\346\240\210/1.png" differ
diff --git "a/pictures/\345\215\225\350\260\203\346\240\210/2.png" "b/pictures/\345\215\225\350\260\203\346\240\210/2.png"
index bdc7ea6b48..aa6635831b 100644
Binary files "a/pictures/\345\215\225\350\260\203\346\240\210/2.png" and "b/pictures/\345\215\225\350\260\203\346\240\210/2.png" differ
diff --git "a/pictures/\345\215\225\350\260\203\346\240\210/3.png" "b/pictures/\345\215\225\350\260\203\346\240\210/3.png"
index 71d78b84ea..4d067ce487 100644
Binary files "a/pictures/\345\215\225\350\260\203\346\240\210/3.png" and "b/pictures/\345\215\225\350\260\203\346\240\210/3.png" differ
diff --git "a/pictures/\345\215\225\350\260\203\351\230\237\345\210\227/1.png" "b/pictures/\345\215\225\350\260\203\351\230\237\345\210\227/1.png"
index ce6d3f1daa..131253f93e 100644
Binary files "a/pictures/\345\215\225\350\260\203\351\230\237\345\210\227/1.png" and "b/pictures/\345\215\225\350\260\203\351\230\237\345\210\227/1.png" differ
diff --git "a/pictures/\345\215\225\350\260\203\351\230\237\345\210\227/2.png" "b/pictures/\345\215\225\350\260\203\351\230\237\345\210\227/2.png"
index ab02276bdc..49e658cd4c 100644
Binary files "a/pictures/\345\215\225\350\260\203\351\230\237\345\210\227/2.png" and "b/pictures/\345\215\225\350\260\203\351\230\237\345\210\227/2.png" differ
diff --git "a/pictures/\345\215\225\350\260\203\351\230\237\345\210\227/3.png" "b/pictures/\345\215\225\350\260\203\351\230\237\345\210\227/3.png"
index 4a8bf8743f..500cf80a8e 100644
Binary files "a/pictures/\345\215\225\350\260\203\351\230\237\345\210\227/3.png" and "b/pictures/\345\215\225\350\260\203\351\230\237\345\210\227/3.png" differ
diff --git "a/pictures/\345\215\225\350\260\203\351\230\237\345\210\227/title.png" "b/pictures/\345\215\225\350\260\203\351\230\237\345\210\227/title.png"
index 62b1f9d26a..13e2a28f5e 100644
Binary files "a/pictures/\345\215\225\350\260\203\351\230\237\345\210\227/title.png" and "b/pictures/\345\215\225\350\260\203\351\230\237\345\210\227/title.png" differ
diff --git "a/pictures/\345\215\232\345\274\210\351\227\256\351\242\230/1.png" "b/pictures/\345\215\232\345\274\210\351\227\256\351\242\230/1.png"
index 10426deb7d..965db46ef9 100644
Binary files "a/pictures/\345\215\232\345\274\210\351\227\256\351\242\230/1.png" and "b/pictures/\345\215\232\345\274\210\351\227\256\351\242\230/1.png" differ
diff --git "a/pictures/\345\215\232\345\274\210\351\227\256\351\242\230/2.png" "b/pictures/\345\215\232\345\274\210\351\227\256\351\242\230/2.png"
index 1f0efb0b7d..5205c28ad1 100644
Binary files "a/pictures/\345\215\232\345\274\210\351\227\256\351\242\230/2.png" and "b/pictures/\345\215\232\345\274\210\351\227\256\351\242\230/2.png" differ
diff --git "a/pictures/\345\215\232\345\274\210\351\227\256\351\242\230/3.png" "b/pictures/\345\215\232\345\274\210\351\227\256\351\242\230/3.png"
index 1c7a3be316..469f3835f5 100644
Binary files "a/pictures/\345\215\232\345\274\210\351\227\256\351\242\230/3.png" and "b/pictures/\345\215\232\345\274\210\351\227\256\351\242\230/3.png" differ
diff --git "a/pictures/\345\215\232\345\274\210\351\227\256\351\242\230/4.png" "b/pictures/\345\215\232\345\274\210\351\227\256\351\242\230/4.png"
index 137f39b556..0929ea854d 100644
Binary files "a/pictures/\345\215\232\345\274\210\351\227\256\351\242\230/4.png" and "b/pictures/\345\215\232\345\274\210\351\227\256\351\242\230/4.png" differ
diff --git "a/pictures/\345\217\214\346\214\207\351\222\210/1.png" "b/pictures/\345\217\214\346\214\207\351\222\210/1.png"
index a5aa914f25..c1fe49a237 100644
Binary files "a/pictures/\345\217\214\346\214\207\351\222\210/1.png" and "b/pictures/\345\217\214\346\214\207\351\222\210/1.png" differ
diff --git "a/pictures/\345\217\214\346\214\207\351\222\210/2.png" "b/pictures/\345\217\214\346\214\207\351\222\210/2.png"
index 6c829a2055..7d7bd77193 100644
Binary files "a/pictures/\345\217\214\346\214\207\351\222\210/2.png" and "b/pictures/\345\217\214\346\214\207\351\222\210/2.png" differ
diff --git "a/pictures/\345\217\214\346\214\207\351\222\210/3.png" "b/pictures/\345\217\214\346\214\207\351\222\210/3.png"
index 5d1f57e8ec..de27d35383 100644
Binary files "a/pictures/\345\217\214\346\214\207\351\222\210/3.png" and "b/pictures/\345\217\214\346\214\207\351\222\210/3.png" differ
diff --git "a/pictures/\345\217\214\346\214\207\351\222\210/center.png" "b/pictures/\345\217\214\346\214\207\351\222\210/center.png"
index 487902356b..586e6e38fc 100644
Binary files "a/pictures/\345\217\214\346\214\207\351\222\210/center.png" and "b/pictures/\345\217\214\346\214\207\351\222\210/center.png" differ
diff --git "a/pictures/\345\217\214\346\214\207\351\222\210/title.png" "b/pictures/\345\217\214\346\214\207\351\222\210/title.png"
index 280d516953..ff32a9c7e5 100644
Binary files "a/pictures/\345\217\214\346\214\207\351\222\210/title.png" and "b/pictures/\345\217\214\346\214\207\351\222\210/title.png" differ
diff --git "a/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/1.jpg" "b/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/1.jpg"
index 151357e5b9..b9fff89cb1 100644
Binary files "a/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/1.jpg" and "b/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/1.jpg" differ
diff --git "a/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/2.jpg" "b/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/2.jpg"
index d50918c554..c244744301 100644
Binary files "a/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/2.jpg" and "b/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/2.jpg" differ
diff --git "a/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/3.jpg" "b/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/3.jpg"
index ff2be512a6..be3eed15a2 100644
Binary files "a/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/3.jpg" and "b/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/3.jpg" differ
diff --git "a/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/4.jpg" "b/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/4.jpg"
index acfb32e827..bc1a5fa325 100644
Binary files "a/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/4.jpg" and "b/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/4.jpg" differ
diff --git "a/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/5.jpg" "b/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/5.jpg"
index c3a5537c85..69362da683 100644
Binary files "a/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/5.jpg" and "b/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/5.jpg" differ
diff --git "a/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/6.jpg" "b/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/6.jpg"
index a29283ca33..df31967e27 100644
Binary files "a/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/6.jpg" and "b/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/6.jpg" differ
diff --git "a/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/7.jpg" "b/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/7.jpg"
index 1faecf7542..f962eeb29e 100644
Binary files "a/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/7.jpg" and "b/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/7.jpg" differ
diff --git "a/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/title.png" "b/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/title.png"
index 5a411d6c50..915c1a33d1 100644
Binary files "a/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/title.png" and "b/pictures/\345\217\215\350\275\254\351\223\276\350\241\250/title.png" differ
diff --git "a/pictures/\345\233\236\346\226\207/title.png" "b/pictures/\345\233\236\346\226\207/title.png"
index 5c6e77d9e6..3ec4774981 100644
Binary files "a/pictures/\345\233\236\346\226\207/title.png" and "b/pictures/\345\233\236\346\226\207/title.png" differ
diff --git "a/pictures/\345\233\236\346\226\207\351\223\276\350\241\250/1.jpg" "b/pictures/\345\233\236\346\226\207\351\223\276\350\241\250/1.jpg"
index be6f1d165f..e3f9643f57 100644
Binary files "a/pictures/\345\233\236\346\226\207\351\223\276\350\241\250/1.jpg" and "b/pictures/\345\233\236\346\226\207\351\223\276\350\241\250/1.jpg" differ
diff --git "a/pictures/\345\233\236\346\226\207\351\223\276\350\241\250/2.jpg" "b/pictures/\345\233\236\346\226\207\351\223\276\350\241\250/2.jpg"
index 217a7c9f4c..828ec0ae41 100644
Binary files "a/pictures/\345\233\236\346\226\207\351\223\276\350\241\250/2.jpg" and "b/pictures/\345\233\236\346\226\207\351\223\276\350\241\250/2.jpg" differ
diff --git "a/pictures/\345\233\236\346\226\207\351\223\276\350\241\250/3.jpg" "b/pictures/\345\233\236\346\226\207\351\223\276\350\241\250/3.jpg"
index fbe86512b8..b5162e61ba 100644
Binary files "a/pictures/\345\233\236\346\226\207\351\223\276\350\241\250/3.jpg" and "b/pictures/\345\233\236\346\226\207\351\223\276\350\241\250/3.jpg" differ
diff --git "a/pictures/\345\233\236\346\226\207\351\223\276\350\241\250/4.jpg" "b/pictures/\345\233\236\346\226\207\351\223\276\350\241\250/4.jpg"
index 47589f384f..679314382f 100644
Binary files "a/pictures/\345\233\236\346\226\207\351\223\276\350\241\250/4.jpg" and "b/pictures/\345\233\236\346\226\207\351\223\276\350\241\250/4.jpg" differ
diff --git "a/pictures/\345\255\220\345\272\217\345\210\227/1.jpg" "b/pictures/\345\255\220\345\272\217\345\210\227/1.jpg"
index a936d379e3..580a9bcc9b 100644
Binary files "a/pictures/\345\255\220\345\272\217\345\210\227/1.jpg" and "b/pictures/\345\255\220\345\272\217\345\210\227/1.jpg" differ
diff --git "a/pictures/\345\255\220\345\272\217\345\210\227/2.jpg" "b/pictures/\345\255\220\345\272\217\345\210\227/2.jpg"
index 21a0244d0b..92993c52d1 100644
Binary files "a/pictures/\345\255\220\345\272\217\345\210\227/2.jpg" and "b/pictures/\345\255\220\345\272\217\345\210\227/2.jpg" differ
diff --git "a/pictures/\345\255\220\345\272\217\345\210\227/3.jpg" "b/pictures/\345\255\220\345\272\217\345\210\227/3.jpg"
index b46eb2f158..b54b6cdd81 100644
Binary files "a/pictures/\345\255\220\345\272\217\345\210\227/3.jpg" and "b/pictures/\345\255\220\345\272\217\345\210\227/3.jpg" differ
diff --git "a/pictures/\345\255\220\351\233\206/1.jpg" "b/pictures/\345\255\220\351\233\206/1.jpg"
index af13075733..85e712e3a3 100644
Binary files "a/pictures/\345\255\220\351\233\206/1.jpg" and "b/pictures/\345\255\220\351\233\206/1.jpg" differ
diff --git "a/pictures/\345\255\220\351\233\206/2.jpg" "b/pictures/\345\255\220\351\233\206/2.jpg"
index 8a0341aa1e..b02026d8f2 100644
Binary files "a/pictures/\345\255\220\351\233\206/2.jpg" and "b/pictures/\345\255\220\351\233\206/2.jpg" differ
diff --git "a/pictures/\345\255\220\351\233\206/3.jpg" "b/pictures/\345\255\220\351\233\206/3.jpg"
index e9ad4c34f5..0b34ef306f 100644
Binary files "a/pictures/\345\255\220\351\233\206/3.jpg" and "b/pictures/\345\255\220\351\233\206/3.jpg" differ
diff --git "a/pictures/\345\255\227\347\254\246\344\270\262\344\271\230\346\263\225/1.jpg" "b/pictures/\345\255\227\347\254\246\344\270\262\344\271\230\346\263\225/1.jpg"
index 01f78f5fac..d771001d86 100644
Binary files "a/pictures/\345\255\227\347\254\246\344\270\262\344\271\230\346\263\225/1.jpg" and "b/pictures/\345\255\227\347\254\246\344\270\262\344\271\230\346\263\225/1.jpg" differ
diff --git "a/pictures/\345\255\227\347\254\246\344\270\262\344\271\230\346\263\225/2.jpg" "b/pictures/\345\255\227\347\254\246\344\270\262\344\271\230\346\263\225/2.jpg"
index c71e96dbf5..0e3f07f896 100644
Binary files "a/pictures/\345\255\227\347\254\246\344\270\262\344\271\230\346\263\225/2.jpg" and "b/pictures/\345\255\227\347\254\246\344\270\262\344\271\230\346\263\225/2.jpg" differ
diff --git "a/pictures/\345\255\227\347\254\246\344\270\262\344\271\230\346\263\225/3.jpg" "b/pictures/\345\255\227\347\254\246\344\270\262\344\271\230\346\263\225/3.jpg"
index 6e3fa2e6b2..9fd5077199 100644
Binary files "a/pictures/\345\255\227\347\254\246\344\270\262\344\271\230\346\263\225/3.jpg" and "b/pictures/\345\255\227\347\254\246\344\270\262\344\271\230\346\263\225/3.jpg" differ
diff --git "a/pictures/\345\255\227\347\254\246\344\270\262\344\271\230\346\263\225/6.jpg" "b/pictures/\345\255\227\347\254\246\344\270\262\344\271\230\346\263\225/6.jpg"
index 221176e91e..b873dd7a50 100644
Binary files "a/pictures/\345\255\227\347\254\246\344\270\262\344\271\230\346\263\225/6.jpg" and "b/pictures/\345\255\227\347\254\246\344\270\262\344\271\230\346\263\225/6.jpg" differ
diff --git "a/pictures/\345\255\227\347\254\246\344\270\262\344\271\230\346\263\225/title.png" "b/pictures/\345\255\227\347\254\246\344\270\262\344\271\230\346\263\225/title.png"
index 7866cff6f1..e9cf410f06 100644
Binary files "a/pictures/\345\255\227\347\254\246\344\270\262\344\271\230\346\263\225/title.png" and "b/pictures/\345\255\227\347\254\246\344\270\262\344\271\230\346\263\225/title.png" differ
diff --git "a/pictures/\345\257\206\347\240\201\346\212\200\346\234\257/1.jpg" "b/pictures/\345\257\206\347\240\201\346\212\200\346\234\257/1.jpg"
index 1770e44e90..dacbb65bd2 100644
Binary files "a/pictures/\345\257\206\347\240\201\346\212\200\346\234\257/1.jpg" and "b/pictures/\345\257\206\347\240\201\346\212\200\346\234\257/1.jpg" differ
diff --git "a/pictures/\345\257\206\347\240\201\346\212\200\346\234\257/2.jpg" "b/pictures/\345\257\206\347\240\201\346\212\200\346\234\257/2.jpg"
index 16086b9803..e6d28f0ef1 100644
Binary files "a/pictures/\345\257\206\347\240\201\346\212\200\346\234\257/2.jpg" and "b/pictures/\345\257\206\347\240\201\346\212\200\346\234\257/2.jpg" differ
diff --git "a/pictures/\345\257\206\347\240\201\346\212\200\346\234\257/3.jpg" "b/pictures/\345\257\206\347\240\201\346\212\200\346\234\257/3.jpg"
index 8ab2b8f11c..b5fc5e217c 100644
Binary files "a/pictures/\345\257\206\347\240\201\346\212\200\346\234\257/3.jpg" and "b/pictures/\345\257\206\347\240\201\346\212\200\346\234\257/3.jpg" differ
diff --git "a/pictures/\345\257\206\347\240\201\346\212\200\346\234\257/4.jpg" "b/pictures/\345\257\206\347\240\201\346\212\200\346\234\257/4.jpg"
index 0c86ab9765..09989d4013 100644
Binary files "a/pictures/\345\257\206\347\240\201\346\212\200\346\234\257/4.jpg" and "b/pictures/\345\257\206\347\240\201\346\212\200\346\234\257/4.jpg" differ
diff --git "a/pictures/\345\257\206\347\240\201\346\212\200\346\234\257/5.jpg" "b/pictures/\345\257\206\347\240\201\346\212\200\346\234\257/5.jpg"
index e5cd2b74d9..27b67d7c43 100644
Binary files "a/pictures/\345\257\206\347\240\201\346\212\200\346\234\257/5.jpg" and "b/pictures/\345\257\206\347\240\201\346\212\200\346\234\257/5.jpg" differ
diff --git "a/pictures/\345\257\206\347\240\201\346\212\200\346\234\257/6.jpg" "b/pictures/\345\257\206\347\240\201\346\212\200\346\234\257/6.jpg"
index e78fa6f9eb..e99f74dfb8 100644
Binary files "a/pictures/\345\257\206\347\240\201\346\212\200\346\234\257/6.jpg" and "b/pictures/\345\257\206\347\240\201\346\212\200\346\234\257/6.jpg" differ
diff --git "a/pictures/\345\257\206\347\240\201\346\212\200\346\234\257/7.jpg" "b/pictures/\345\257\206\347\240\201\346\212\200\346\234\257/7.jpg"
index 76dced4d54..a368d636db 100644
Binary files "a/pictures/\345\257\206\347\240\201\346\212\200\346\234\257/7.jpg" and "b/pictures/\345\257\206\347\240\201\346\212\200\346\234\257/7.jpg" differ
diff --git "a/pictures/\345\272\247\344\275\215\350\260\203\345\272\246/1.jpg" "b/pictures/\345\272\247\344\275\215\350\260\203\345\272\246/1.jpg"
index 6971d39a64..a0c943df93 100644
Binary files "a/pictures/\345\272\247\344\275\215\350\260\203\345\272\246/1.jpg" and "b/pictures/\345\272\247\344\275\215\350\260\203\345\272\246/1.jpg" differ
diff --git "a/pictures/\345\272\247\344\275\215\350\260\203\345\272\246/2.jpg" "b/pictures/\345\272\247\344\275\215\350\260\203\345\272\246/2.jpg"
index 3025b3d386..b0d46a2c8d 100644
Binary files "a/pictures/\345\272\247\344\275\215\350\260\203\345\272\246/2.jpg" and "b/pictures/\345\272\247\344\275\215\350\260\203\345\272\246/2.jpg" differ
diff --git "a/pictures/\345\272\247\344\275\215\350\260\203\345\272\246/3.jpg" "b/pictures/\345\272\247\344\275\215\350\260\203\345\272\246/3.jpg"
index 4eaa1c7c3b..159b32bfdd 100644
Binary files "a/pictures/\345\272\247\344\275\215\350\260\203\345\272\246/3.jpg" and "b/pictures/\345\272\247\344\275\215\350\260\203\345\272\246/3.jpg" differ
diff --git "a/pictures/\345\272\247\344\275\215\350\260\203\345\272\246/4.jpg" "b/pictures/\345\272\247\344\275\215\350\260\203\345\272\246/4.jpg"
index 96fb8b964c..1eb30ff5c9 100644
Binary files "a/pictures/\345\272\247\344\275\215\350\260\203\345\272\246/4.jpg" and "b/pictures/\345\272\247\344\275\215\350\260\203\345\272\246/4.jpg" differ
diff --git "a/pictures/\345\272\247\344\275\215\350\260\203\345\272\246/5.jpg" "b/pictures/\345\272\247\344\275\215\350\260\203\345\272\246/5.jpg"
index 0ead3214e1..f88315e344 100644
Binary files "a/pictures/\345\272\247\344\275\215\350\260\203\345\272\246/5.jpg" and "b/pictures/\345\272\247\344\275\215\350\260\203\345\272\246/5.jpg" differ
diff --git "a/pictures/\345\272\247\344\275\215\350\260\203\345\272\246/6.jpg" "b/pictures/\345\272\247\344\275\215\350\260\203\345\272\246/6.jpg"
index c9ce5a42a9..1095324265 100644
Binary files "a/pictures/\345\272\247\344\275\215\350\260\203\345\272\246/6.jpg" and "b/pictures/\345\272\247\344\275\215\350\260\203\345\272\246/6.jpg" differ
diff --git "a/pictures/\345\272\247\344\275\215\350\260\203\345\272\246/7.jpg" "b/pictures/\345\272\247\344\275\215\350\260\203\345\272\246/7.jpg"
index e4c2fbc0e4..0c22c5375c 100644
Binary files "a/pictures/\345\272\247\344\275\215\350\260\203\345\272\246/7.jpg" and "b/pictures/\345\272\247\344\275\215\350\260\203\345\272\246/7.jpg" differ
diff --git "a/pictures/\346\211\224\351\270\241\350\233\213/1.jpg" "b/pictures/\346\211\224\351\270\241\350\233\213/1.jpg"
index d711bb29af..0bc912961b 100644
Binary files "a/pictures/\346\211\224\351\270\241\350\233\213/1.jpg" and "b/pictures/\346\211\224\351\270\241\350\233\213/1.jpg" differ
diff --git "a/pictures/\346\211\224\351\270\241\350\233\213/2.jpg" "b/pictures/\346\211\224\351\270\241\350\233\213/2.jpg"
index 72748efb91..5f7f9edf58 100644
Binary files "a/pictures/\346\211\224\351\270\241\350\233\213/2.jpg" and "b/pictures/\346\211\224\351\270\241\350\233\213/2.jpg" differ
diff --git "a/pictures/\346\211\224\351\270\241\350\233\213/3.jpg" "b/pictures/\346\211\224\351\270\241\350\233\213/3.jpg"
index 5ba41f1e4f..069d53cfb2 100644
Binary files "a/pictures/\346\211\224\351\270\241\350\233\213/3.jpg" and "b/pictures/\346\211\224\351\270\241\350\233\213/3.jpg" differ
diff --git "a/pictures/\346\211\224\351\270\241\350\233\213/dp.png" "b/pictures/\346\211\224\351\270\241\350\233\213/dp.png"
index aa8ff334c8..70169d3d52 100644
Binary files "a/pictures/\346\211\224\351\270\241\350\233\213/dp.png" and "b/pictures/\346\211\224\351\270\241\350\233\213/dp.png" differ
diff --git "a/pictures/\346\216\245\351\233\250\346\260\264/0.jpg" "b/pictures/\346\216\245\351\233\250\346\260\264/0.jpg"
index 2d2e1cb645..ec17d57f58 100644
Binary files "a/pictures/\346\216\245\351\233\250\346\260\264/0.jpg" and "b/pictures/\346\216\245\351\233\250\346\260\264/0.jpg" differ
diff --git "a/pictures/\346\216\245\351\233\250\346\260\264/1.jpg" "b/pictures/\346\216\245\351\233\250\346\260\264/1.jpg"
index 6e5196cadf..03e5217171 100644
Binary files "a/pictures/\346\216\245\351\233\250\346\260\264/1.jpg" and "b/pictures/\346\216\245\351\233\250\346\260\264/1.jpg" differ
diff --git "a/pictures/\346\216\245\351\233\250\346\260\264/2.jpg" "b/pictures/\346\216\245\351\233\250\346\260\264/2.jpg"
index 5aa7684553..839a8bf812 100644
Binary files "a/pictures/\346\216\245\351\233\250\346\260\264/2.jpg" and "b/pictures/\346\216\245\351\233\250\346\260\264/2.jpg" differ
diff --git "a/pictures/\346\216\245\351\233\250\346\260\264/3.jpg" "b/pictures/\346\216\245\351\233\250\346\260\264/3.jpg"
index 5f74da29ac..a48dc5afcc 100644
Binary files "a/pictures/\346\216\245\351\233\250\346\260\264/3.jpg" and "b/pictures/\346\216\245\351\233\250\346\260\264/3.jpg" differ
diff --git "a/pictures/\346\216\245\351\233\250\346\260\264/4.jpg" "b/pictures/\346\216\245\351\233\250\346\260\264/4.jpg"
index 953add1171..f97488589e 100644
Binary files "a/pictures/\346\216\245\351\233\250\346\260\264/4.jpg" and "b/pictures/\346\216\245\351\233\250\346\260\264/4.jpg" differ
diff --git "a/pictures/\346\216\245\351\233\250\346\260\264/5.jpg" "b/pictures/\346\216\245\351\233\250\346\260\264/5.jpg"
index 9d53111988..718509a03f 100644
Binary files "a/pictures/\346\216\245\351\233\250\346\260\264/5.jpg" and "b/pictures/\346\216\245\351\233\250\346\260\264/5.jpg" differ
diff --git "a/pictures/\346\216\245\351\233\250\346\260\264/title.png" "b/pictures/\346\216\245\351\233\250\346\260\264/title.png"
index f4c908625f..177355ac2b 100644
Binary files "a/pictures/\346\216\245\351\233\250\346\260\264/title.png" and "b/pictures/\346\216\245\351\233\250\346\260\264/title.png" differ
diff --git "a/pictures/\346\225\260\347\273\204\344\272\244\346\215\242/ink-image (1).png" "b/pictures/\346\225\260\347\273\204\344\272\244\346\215\242/ink-image (1).png"
index 650f77d1fe..db21abcfb6 100644
Binary files "a/pictures/\346\225\260\347\273\204\344\272\244\346\215\242/ink-image (1).png" and "b/pictures/\346\225\260\347\273\204\344\272\244\346\215\242/ink-image (1).png" differ
diff --git "a/pictures/\346\225\260\347\273\204\344\272\244\346\215\242/ink-image (2).png" "b/pictures/\346\225\260\347\273\204\344\272\244\346\215\242/ink-image (2).png"
index 4ceccb84f1..213ad2a38a 100644
Binary files "a/pictures/\346\225\260\347\273\204\344\272\244\346\215\242/ink-image (2).png" and "b/pictures/\346\225\260\347\273\204\344\272\244\346\215\242/ink-image (2).png" differ
diff --git "a/pictures/\346\225\260\347\273\204\344\272\244\346\215\242/ink-image (3).png" "b/pictures/\346\225\260\347\273\204\344\272\244\346\215\242/ink-image (3).png"
index 931f98e23b..1c9989acf3 100644
Binary files "a/pictures/\346\225\260\347\273\204\344\272\244\346\215\242/ink-image (3).png" and "b/pictures/\346\225\260\347\273\204\344\272\244\346\215\242/ink-image (3).png" differ
diff --git "a/pictures/\346\225\260\347\273\204\344\272\244\346\215\242/ink-image.png" "b/pictures/\346\225\260\347\273\204\344\272\244\346\215\242/ink-image.png"
index 0fda0bf947..e1a1afa3fc 100644
Binary files "a/pictures/\346\225\260\347\273\204\344\272\244\346\215\242/ink-image.png" and "b/pictures/\346\225\260\347\273\204\344\272\244\346\215\242/ink-image.png" differ
diff --git "a/pictures/\346\234\200\344\274\230\345\255\220\347\273\223\346\236\204/1.jpg" "b/pictures/\346\234\200\344\274\230\345\255\220\347\273\223\346\236\204/1.jpg"
index e20dafac67..a8cc3f4cbe 100644
Binary files "a/pictures/\346\234\200\344\274\230\345\255\220\347\273\223\346\236\204/1.jpg" and "b/pictures/\346\234\200\344\274\230\345\255\220\347\273\223\346\236\204/1.jpg" differ
diff --git "a/pictures/\346\234\200\351\225\277\345\233\236\346\226\207\345\255\220\345\272\217\345\210\227/1.jpg" "b/pictures/\346\234\200\351\225\277\345\233\236\346\226\207\345\255\220\345\272\217\345\210\227/1.jpg"
index c15af92ce7..7e3281a560 100644
Binary files "a/pictures/\346\234\200\351\225\277\345\233\236\346\226\207\345\255\220\345\272\217\345\210\227/1.jpg" and "b/pictures/\346\234\200\351\225\277\345\233\236\346\226\207\345\255\220\345\272\217\345\210\227/1.jpg" differ
diff --git "a/pictures/\346\234\200\351\225\277\345\233\236\346\226\207\345\255\220\345\272\217\345\210\227/2.jpg" "b/pictures/\346\234\200\351\225\277\345\233\236\346\226\207\345\255\220\345\272\217\345\210\227/2.jpg"
index 541665ce23..9f0baa5a8d 100644
Binary files "a/pictures/\346\234\200\351\225\277\345\233\236\346\226\207\345\255\220\345\272\217\345\210\227/2.jpg" and "b/pictures/\346\234\200\351\225\277\345\233\236\346\226\207\345\255\220\345\272\217\345\210\227/2.jpg" differ
diff --git "a/pictures/\346\234\200\351\225\277\345\233\236\346\226\207\345\255\220\345\272\217\345\210\227/3.jpg" "b/pictures/\346\234\200\351\225\277\345\233\236\346\226\207\345\255\220\345\272\217\345\210\227/3.jpg"
index ac73079c07..aafb4d028e 100644
Binary files "a/pictures/\346\234\200\351\225\277\345\233\236\346\226\207\345\255\220\345\272\217\345\210\227/3.jpg" and "b/pictures/\346\234\200\351\225\277\345\233\236\346\226\207\345\255\220\345\272\217\345\210\227/3.jpg" differ
diff --git "a/pictures/\346\234\200\351\225\277\345\233\236\346\226\207\345\255\220\345\272\217\345\210\227/4.jpg" "b/pictures/\346\234\200\351\225\277\345\233\236\346\226\207\345\255\220\345\272\217\345\210\227/4.jpg"
index e78e87866e..843ffacd36 100644
Binary files "a/pictures/\346\234\200\351\225\277\345\233\236\346\226\207\345\255\220\345\272\217\345\210\227/4.jpg" and "b/pictures/\346\234\200\351\225\277\345\233\236\346\226\207\345\255\220\345\272\217\345\210\227/4.jpg" differ
diff --git "a/pictures/\346\234\200\351\225\277\345\233\236\346\226\207\345\255\220\345\272\217\345\210\227/5.jpg" "b/pictures/\346\234\200\351\225\277\345\233\236\346\226\207\345\255\220\345\272\217\345\210\227/5.jpg"
index d9211a9b39..1dc29efc2b 100644
Binary files "a/pictures/\346\234\200\351\225\277\345\233\236\346\226\207\345\255\220\345\272\217\345\210\227/5.jpg" and "b/pictures/\346\234\200\351\225\277\345\233\236\346\226\207\345\255\220\345\272\217\345\210\227/5.jpg" differ
diff --git "a/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/1.jpeg" "b/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/1.jpeg"
index 6af4e101f6..3640ab127d 100644
Binary files "a/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/1.jpeg" and "b/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/1.jpeg" differ
diff --git "a/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/2.jpeg" "b/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/2.jpeg"
index 8dbbbe94c7..c96ed6399b 100644
Binary files "a/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/2.jpeg" and "b/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/2.jpeg" differ
diff --git "a/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/3.jpeg" "b/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/3.jpeg"
index 5cb141327d..4490d13fdd 100644
Binary files "a/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/3.jpeg" and "b/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/3.jpeg" differ
diff --git "a/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/poker1.jpeg" "b/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/poker1.jpeg"
index 1560d39ebd..093306bee4 100644
Binary files "a/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/poker1.jpeg" and "b/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/poker1.jpeg" differ
diff --git "a/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/poker2.jpeg" "b/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/poker2.jpeg"
index e4e5bd433e..2ad0c604ab 100644
Binary files "a/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/poker2.jpeg" and "b/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/poker2.jpeg" differ
diff --git "a/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/poker3.jpeg" "b/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/poker3.jpeg"
index c1b979816d..efa99bd717 100644
Binary files "a/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/poker3.jpeg" and "b/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/poker3.jpeg" differ
diff --git "a/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/poker4.jpeg" "b/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/poker4.jpeg"
index 429a23120c..ba781198ca 100644
Binary files "a/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/poker4.jpeg" and "b/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/poker4.jpeg" differ
diff --git "a/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/title.png" "b/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/title.png"
index 820075da24..65c3aa9222 100644
Binary files "a/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/title.png" and "b/pictures/\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227/title.png" differ
diff --git "a/pictures/\346\234\211\345\272\217\346\225\260\347\273\204\345\216\273\351\207\215/title.png" "b/pictures/\346\234\211\345\272\217\346\225\260\347\273\204\345\216\273\351\207\215/title.png"
index 47c0ab0faf..5b986b9d0d 100644
Binary files "a/pictures/\346\234\211\345\272\217\346\225\260\347\273\204\345\216\273\351\207\215/title.png" and "b/pictures/\346\234\211\345\272\217\346\225\260\347\273\204\345\216\273\351\207\215/title.png" differ
diff --git "a/pictures/\346\240\210\351\230\237\345\210\227/1.jpg" "b/pictures/\346\240\210\351\230\237\345\210\227/1.jpg"
index c2788a7ffe..cb72cc5f72 100644
Binary files "a/pictures/\346\240\210\351\230\237\345\210\227/1.jpg" and "b/pictures/\346\240\210\351\230\237\345\210\227/1.jpg" differ
diff --git "a/pictures/\346\240\210\351\230\237\345\210\227/2.jpg" "b/pictures/\346\240\210\351\230\237\345\210\227/2.jpg"
index 6eafa08bdd..982c344fd3 100644
Binary files "a/pictures/\346\240\210\351\230\237\345\210\227/2.jpg" and "b/pictures/\346\240\210\351\230\237\345\210\227/2.jpg" differ
diff --git "a/pictures/\346\240\210\351\230\237\345\210\227/3.jpg" "b/pictures/\346\240\210\351\230\237\345\210\227/3.jpg"
index 1b59b8d2c4..ae9a8ef8d7 100644
Binary files "a/pictures/\346\240\210\351\230\237\345\210\227/3.jpg" and "b/pictures/\346\240\210\351\230\237\345\210\227/3.jpg" differ
diff --git "a/pictures/\346\240\210\351\230\237\345\210\227/4.jpg" "b/pictures/\346\240\210\351\230\237\345\210\227/4.jpg"
index 7d2c558b5b..e29c85ea55 100644
Binary files "a/pictures/\346\240\210\351\230\237\345\210\227/4.jpg" and "b/pictures/\346\240\210\351\230\237\345\210\227/4.jpg" differ
diff --git "a/pictures/\346\240\210\351\230\237\345\210\227/5.jpg" "b/pictures/\346\240\210\351\230\237\345\210\227/5.jpg"
index 5b47d0eb82..d19d22355b 100644
Binary files "a/pictures/\346\240\210\351\230\237\345\210\227/5.jpg" and "b/pictures/\346\240\210\351\230\237\345\210\227/5.jpg" differ
diff --git "a/pictures/\346\240\210\351\230\237\345\210\227/6.jpg" "b/pictures/\346\240\210\351\230\237\345\210\227/6.jpg"
index 60a6f2d042..891301d6ef 100644
Binary files "a/pictures/\346\240\210\351\230\237\345\210\227/6.jpg" and "b/pictures/\346\240\210\351\230\237\345\210\227/6.jpg" differ
diff --git "a/pictures/\346\246\202\347\216\207\351\227\256\351\242\230/p.png" "b/pictures/\346\246\202\347\216\207\351\227\256\351\242\230/p.png"
index 794f5a5cc5..959c02bb27 100644
Binary files "a/pictures/\346\246\202\347\216\207\351\227\256\351\242\230/p.png" and "b/pictures/\346\246\202\347\216\207\351\227\256\351\242\230/p.png" differ
diff --git "a/pictures/\346\246\202\347\216\207\351\227\256\351\242\230/sanmen.png" "b/pictures/\346\246\202\347\216\207\351\227\256\351\242\230/sanmen.png"
index daf212d629..121a3cfd14 100644
Binary files "a/pictures/\346\246\202\347\216\207\351\227\256\351\242\230/sanmen.png" and "b/pictures/\346\246\202\347\216\207\351\227\256\351\242\230/sanmen.png" differ
diff --git "a/pictures/\346\246\202\347\216\207\351\227\256\351\242\230/tree.png" "b/pictures/\346\246\202\347\216\207\351\227\256\351\242\230/tree.png"
index 0b59308f5b..98c51178da 100644
Binary files "a/pictures/\346\246\202\347\216\207\351\227\256\351\242\230/tree.png" and "b/pictures/\346\246\202\347\216\207\351\227\256\351\242\230/tree.png" differ
diff --git "a/pictures/\346\255\243\345\210\231/1.jpeg" "b/pictures/\346\255\243\345\210\231/1.jpeg"
new file mode 100644
index 0000000000..e5977fcae6
Binary files /dev/null and "b/pictures/\346\255\243\345\210\231/1.jpeg" differ
diff --git "a/pictures/\346\255\243\345\210\231/2.jpeg" "b/pictures/\346\255\243\345\210\231/2.jpeg"
new file mode 100644
index 0000000000..f3fa3711a5
Binary files /dev/null and "b/pictures/\346\255\243\345\210\231/2.jpeg" differ
diff --git "a/pictures/\346\255\243\345\210\231/3.jpeg" "b/pictures/\346\255\243\345\210\231/3.jpeg"
new file mode 100644
index 0000000000..11d9838ddc
Binary files /dev/null and "b/pictures/\346\255\243\345\210\231/3.jpeg" differ
diff --git "a/pictures/\346\255\243\345\210\231/4.jpeg" "b/pictures/\346\255\243\345\210\231/4.jpeg"
new file mode 100644
index 0000000000..24de168927
Binary files /dev/null and "b/pictures/\346\255\243\345\210\231/4.jpeg" differ
diff --git "a/pictures/\346\255\243\345\210\231/example.png" "b/pictures/\346\255\243\345\210\231/example.png"
index 3646b16793..9eaace9963 100644
Binary files "a/pictures/\346\255\243\345\210\231/example.png" and "b/pictures/\346\255\243\345\210\231/example.png" differ
diff --git "a/pictures/\346\255\243\345\210\231/title.png" "b/pictures/\346\255\243\345\210\231/title.png"
index 2423900773..6debfa67d6 100644
Binary files "a/pictures/\346\255\243\345\210\231/title.png" and "b/pictures/\346\255\243\345\210\231/title.png" differ
diff --git "a/pictures/\346\264\227\347\211\214\347\256\227\346\263\225/1.png" "b/pictures/\346\264\227\347\211\214\347\256\227\346\263\225/1.png"
index d85e0093d3..1414c8c4dc 100644
Binary files "a/pictures/\346\264\227\347\211\214\347\256\227\346\263\225/1.png" and "b/pictures/\346\264\227\347\211\214\347\256\227\346\263\225/1.png" differ
diff --git "a/pictures/\346\264\227\347\211\214\347\256\227\346\263\225/2.png" "b/pictures/\346\264\227\347\211\214\347\256\227\346\263\225/2.png"
index 0536a15701..9f769de386 100644
Binary files "a/pictures/\346\264\227\347\211\214\347\256\227\346\263\225/2.png" and "b/pictures/\346\264\227\347\211\214\347\256\227\346\263\225/2.png" differ
diff --git "a/pictures/\346\264\227\347\211\214\347\256\227\346\263\225/3.png" "b/pictures/\346\264\227\347\211\214\347\256\227\346\263\225/3.png"
index d9fbe24d5d..157d082613 100644
Binary files "a/pictures/\346\264\227\347\211\214\347\256\227\346\263\225/3.png" and "b/pictures/\346\264\227\347\211\214\347\256\227\346\263\225/3.png" differ
diff --git "a/pictures/\346\264\227\347\211\214\347\256\227\346\263\225/4.png" "b/pictures/\346\264\227\347\211\214\347\256\227\346\263\225/4.png"
index 0547caaeeb..06f0c04092 100644
Binary files "a/pictures/\346\264\227\347\211\214\347\256\227\346\263\225/4.png" and "b/pictures/\346\264\227\347\211\214\347\256\227\346\263\225/4.png" differ
diff --git "a/pictures/\346\264\227\347\211\214\347\256\227\346\263\225/5.jpg" "b/pictures/\346\264\227\347\211\214\347\256\227\346\263\225/5.jpg"
index af797bacc6..0a1f94a022 100644
Binary files "a/pictures/\346\264\227\347\211\214\347\256\227\346\263\225/5.jpg" and "b/pictures/\346\264\227\347\211\214\347\256\227\346\263\225/5.jpg" differ
diff --git "a/pictures/\346\264\227\347\211\214\347\256\227\346\263\225/6.png" "b/pictures/\346\264\227\347\211\214\347\256\227\346\263\225/6.png"
index e6be333570..44c2c35a80 100644
Binary files "a/pictures/\346\264\227\347\211\214\347\256\227\346\263\225/6.png" and "b/pictures/\346\264\227\347\211\214\347\256\227\346\263\225/6.png" differ
diff --git "a/pictures/\346\273\221\345\212\250\347\252\227\345\217\243/0.png" "b/pictures/\346\273\221\345\212\250\347\252\227\345\217\243/0.png"
index ad4ff28c15..974e71fc83 100644
Binary files "a/pictures/\346\273\221\345\212\250\347\252\227\345\217\243/0.png" and "b/pictures/\346\273\221\345\212\250\347\252\227\345\217\243/0.png" differ
diff --git "a/pictures/\346\273\221\345\212\250\347\252\227\345\217\243/1.png" "b/pictures/\346\273\221\345\212\250\347\252\227\345\217\243/1.png"
index 0825d34608..2967070a4a 100644
Binary files "a/pictures/\346\273\221\345\212\250\347\252\227\345\217\243/1.png" and "b/pictures/\346\273\221\345\212\250\347\252\227\345\217\243/1.png" differ
diff --git "a/pictures/\346\273\221\345\212\250\347\252\227\345\217\243/2.png" "b/pictures/\346\273\221\345\212\250\347\252\227\345\217\243/2.png"
index 04d583c605..95bfa5c2fe 100644
Binary files "a/pictures/\346\273\221\345\212\250\347\252\227\345\217\243/2.png" and "b/pictures/\346\273\221\345\212\250\347\252\227\345\217\243/2.png" differ
diff --git "a/pictures/\346\273\221\345\212\250\347\252\227\345\217\243/3.png" "b/pictures/\346\273\221\345\212\250\347\252\227\345\217\243/3.png"
index e07f12455e..65b5510a3e 100644
Binary files "a/pictures/\346\273\221\345\212\250\347\252\227\345\217\243/3.png" and "b/pictures/\346\273\221\345\212\250\347\252\227\345\217\243/3.png" differ
diff --git "a/pictures/\346\273\221\345\212\250\347\252\227\345\217\243/title1.png" "b/pictures/\346\273\221\345\212\250\347\252\227\345\217\243/title1.png"
index c84081f9c5..3d5d2bc76c 100644
Binary files "a/pictures/\346\273\221\345\212\250\347\252\227\345\217\243/title1.png" and "b/pictures/\346\273\221\345\212\250\347\252\227\345\217\243/title1.png" differ
diff --git "a/pictures/\346\273\221\345\212\250\347\252\227\345\217\243/title2.png" "b/pictures/\346\273\221\345\212\250\347\252\227\345\217\243/title2.png"
index cb33c71545..ce357d5db2 100644
Binary files "a/pictures/\346\273\221\345\212\250\347\252\227\345\217\243/title2.png" and "b/pictures/\346\273\221\345\212\250\347\252\227\345\217\243/title2.png" differ
diff --git "a/pictures/\346\273\221\345\212\250\347\252\227\345\217\243/title3.png" "b/pictures/\346\273\221\345\212\250\347\252\227\345\217\243/title3.png"
index 9a1ad10542..0de1770c3f 100644
Binary files "a/pictures/\346\273\221\345\212\250\347\252\227\345\217\243/title3.png" and "b/pictures/\346\273\221\345\212\250\347\252\227\345\217\243/title3.png" differ
diff --git "a/pictures/\347\274\272\345\244\261\345\205\203\347\264\240/1.jpg" "b/pictures/\347\274\272\345\244\261\345\205\203\347\264\240/1.jpg"
index 7bbc566938..180b57081a 100644
Binary files "a/pictures/\347\274\272\345\244\261\345\205\203\347\264\240/1.jpg" and "b/pictures/\347\274\272\345\244\261\345\205\203\347\264\240/1.jpg" differ
diff --git "a/pictures/\347\274\272\345\244\261\345\205\203\347\264\240/2.jpg" "b/pictures/\347\274\272\345\244\261\345\205\203\347\264\240/2.jpg"
index 7458897d9f..44e1b8076e 100644
Binary files "a/pictures/\347\274\272\345\244\261\345\205\203\347\264\240/2.jpg" and "b/pictures/\347\274\272\345\244\261\345\205\203\347\264\240/2.jpg" differ
diff --git "a/pictures/\347\274\272\345\244\261\345\205\203\347\264\240/3.jpg" "b/pictures/\347\274\272\345\244\261\345\205\203\347\264\240/3.jpg"
index 6114a5fc3a..bec62f3fff 100644
Binary files "a/pictures/\347\274\272\345\244\261\345\205\203\347\264\240/3.jpg" and "b/pictures/\347\274\272\345\244\261\345\205\203\347\264\240/3.jpg" differ
diff --git "a/pictures/\347\274\272\345\244\261\345\205\203\347\264\240/title.png" "b/pictures/\347\274\272\345\244\261\345\205\203\347\264\240/title.png"
index 18065d570d..4b2eff0e45 100644
Binary files "a/pictures/\347\274\272\345\244\261\345\205\203\347\264\240/title.png" and "b/pictures/\347\274\272\345\244\261\345\205\203\347\264\240/title.png" differ
diff --git "a/pictures/\347\274\272\345\244\261\345\205\203\347\264\240/xor.png" "b/pictures/\347\274\272\345\244\261\345\205\203\347\264\240/xor.png"
index 20d360007c..1cd5e85a6f 100644
Binary files "a/pictures/\347\274\272\345\244\261\345\205\203\347\264\240/xor.png" and "b/pictures/\347\274\272\345\244\261\345\205\203\347\264\240/xor.png" differ
diff --git "a/pictures/\350\202\241\347\245\250\351\227\256\351\242\230/1.png" "b/pictures/\350\202\241\347\245\250\351\227\256\351\242\230/1.png"
index db1b56a9ef..298b497197 100644
Binary files "a/pictures/\350\202\241\347\245\250\351\227\256\351\242\230/1.png" and "b/pictures/\350\202\241\347\245\250\351\227\256\351\242\230/1.png" differ
diff --git "a/pictures/\350\202\241\347\245\250\351\227\256\351\242\230/title.png" "b/pictures/\350\202\241\347\245\250\351\227\256\351\242\230/title.png"
index 44406abe31..f2f9779541 100644
Binary files "a/pictures/\350\202\241\347\245\250\351\227\256\351\242\230/title.png" and "b/pictures/\350\202\241\347\245\250\351\227\256\351\242\230/title.png" differ
diff --git "a/pictures/\350\256\276\350\256\241Twitter/design.png" "b/pictures/\350\256\276\350\256\241Twitter/design.png"
index 623b58242b..2427a47e3f 100644
Binary files "a/pictures/\350\256\276\350\256\241Twitter/design.png" and "b/pictures/\350\256\276\350\256\241Twitter/design.png" differ
diff --git "a/pictures/\350\256\276\350\256\241Twitter/tweet.jpg" "b/pictures/\350\256\276\350\256\241Twitter/tweet.jpg"
index 89b5bfe2c1..cee1199abd 100644
Binary files "a/pictures/\350\256\276\350\256\241Twitter/tweet.jpg" and "b/pictures/\350\256\276\350\256\241Twitter/tweet.jpg" differ
diff --git "a/pictures/\350\256\276\350\256\241Twitter/user.jpg" "b/pictures/\350\256\276\350\256\241Twitter/user.jpg"
index 0471ec44b6..dce6b67e0a 100644
Binary files "a/pictures/\350\256\276\350\256\241Twitter/user.jpg" and "b/pictures/\350\256\276\350\256\241Twitter/user.jpg" differ
diff --git a/starHistory.jpg b/starHistory.jpg
new file mode 100644
index 0000000000..2847906b4b
Binary files /dev/null and b/starHistory.jpg differ
diff --git a/starHistory.png b/starHistory.png
new file mode 100644
index 0000000000..340e80263c
Binary files /dev/null and b/starHistory.png differ
diff --git "a/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/LCS.md" "b/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/LCS.md"
new file mode 100644
index 0000000000..253d6f1239
--- /dev/null
+++ "b/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/LCS.md"
@@ -0,0 +1,408 @@
+# 经典动态规划:最长公共子序列
+
+
+
+
+
+**通知:为满足广大读者的需求,网站上架 [速成目录](https://labuladong.online/algo/intro/quick-learning-plan/),如有需要可以看下,谢谢大家的支持~另外,建议你在我的 [网站](https://labuladong.online/algo/) 学习文章,体验更好。**
+
+
+
+读完本文,你不仅学会了算法套路,还可以顺便解决如下题目:
+
+| LeetCode | 力扣 | 难度 |
+| :----: | :----: | :----: |
+| [1143. Longest Common Subsequence](https://leetcode.com/problems/longest-common-subsequence/) | [1143. 最长公共子序列](https://leetcode.cn/problems/longest-common-subsequence/) | 🟠 |
+| [583. Delete Operation for Two Strings](https://leetcode.com/problems/delete-operation-for-two-strings/) | [583. 两个字符串的删除操作](https://leetcode.cn/problems/delete-operation-for-two-strings/) | 🟠 |
+| [712. Minimum ASCII Delete Sum for Two Strings](https://leetcode.com/problems/minimum-ascii-delete-sum-for-two-strings/) | [712. 两个字符串的最小ASCII删除和](https://leetcode.cn/problems/minimum-ascii-delete-sum-for-two-strings/) | 🟠 |
+
+**-----------**
+
+
+
+> [!NOTE]
+> 阅读本文前,你需要先学习:
+>
+> - [动态规划核心框架](https://labuladong.online/algo/essential-technique/dynamic-programming-framework/)
+
+不知道大家做算法题有什么感觉,我总结出来做算法题的技巧就是,把大的问题细化到一个点,先研究在这个小的点上如何解决问题,然后再通过递归/迭代的方式扩展到整个问题。
+
+比如说我们前文 [手把手带你刷二叉树第三期](https://labuladong.online/algo/data-structure/binary-tree-part3/),解决二叉树的题目,我们就会把整个问题细化到某一个节点上,想象自己站在某个节点上,需要做什么,然后套二叉树递归框架就行了。
+
+动态规划系列问题也是一样,尤其是子序列相关的问题。**本文从「最长公共子序列问题」展开,总结三道子序列问题**,解这道题仔细讲讲这种子序列问题的套路,你就能感受到这种思维方式了。
+
+## 最长公共子序列
+
+计算最长公共子序列(Longest Common Subsequence,简称 LCS)是一道经典的动态规划题目,力扣第 1143 题「最长公共子序列」就是这个问题:
+
+给你输入两个字符串 `s1` 和 `s2`,请你找出他们俩的最长公共子序列,返回这个子序列的长度。函数签名如下:
+
+```java
+int longestCommonSubsequence(String s1, String s2);
+```
+
+比如说输入 `s1 = "zabcde", s2 = "acez"`,它俩的最长公共子序列是 `lcs = "ace"`,长度为 3,所以算法返回 3。
+
+如果没有做过这道题,一个最简单的暴力算法就是,把 `s1` 和 `s2` 的所有子序列都穷举出来,然后看看有没有公共的,然后在所有公共子序列里面再寻找一个长度最大的。
+
+显然,这种思路的复杂度非常高,你要穷举出所有子序列,这个复杂度就是指数级的,肯定不实际。
+
+正确的思路是不要考虑整个字符串,而是细化到 `s1` 和 `s2` 的每个字符。前文 [子序列解题模板](https://labuladong.online/algo/dynamic-programming/subsequence-problem/) 中总结的一个规律:
+
+
+
+
+
+
+
+**对于两个字符串求子序列的问题,都是用两个指针 `i` 和 `j` 分别在两个字符串上移动,大概率是动态规划思路**。
+
+最长公共子序列的问题也可以遵循这个规律,我们可以先写一个 `dp` 函数:
+
+```java
+// 定义:计算 s1[i..] 和 s2[j..] 的最长公共子序列长度
+int dp(String s1, int i, String s2, int j)
+```
+
+根据这个 `dp` 函数的定义,那么我们想要的答案就是 `dp(s1, 0, s2, 0)`,且 base case 就是 `i == len(s1)` 或 `j == len(s2)` 时,因为这时候 `s1[i..]` 或 `s2[j..]` 就相当于空串了,最长公共子序列的长度显然是 0:
+
+```java
+int longestCommonSubsequence(String s1, String s2) {
+ return dp(s1, 0, s2, 0);
+}
+
+// 定义:计算 s1[i..] 和 s2[j..] 的最长公共子序列长度
+int dp(String s1, int i, String s2, int j) {
+ // base case
+ if (i == s1.length() || j == s2.length()) {
+ return 0;
+ }
+ // ...
+}
+```
+
+**接下来,咱不要看 `s1` 和 `s2` 两个字符串,而是要具体到每一个字符,思考每个字符该做什么**。
+
+
+
+我们只看 `s1[i]` 和 `s2[j]`,**如果 `s1[i] == s2[j]`,说明这个字符一定在 `lcs` 中**:
+
+
+
+这样,就找到了一个 `lcs` 中的字符,根据 `dp` 函数的定义,我们可以完善一下代码:
+
+```java
+// 定义:计算 s1[i..] 和 s2[j..] 的最长公共子序列长度
+int dp(String s1, int i, String s2, int j) {
+ if (s1.charAt(i) == s2.charAt(j)) {
+ // s1[i] 和 s2[j] 必然在 lcs 中,
+ // 加上 s1[i+1..] 和 s2[j+1..] 中的 lcs 长度,就是答案
+ return 1 + dp(s1, i + 1, s2, j + 1);
+ } else {
+ // ...
+ }
+}
+```
+
+刚才说的 `s1[i] == s2[j]` 的情况,但如果 `s1[i] != s2[j]`,应该怎么办呢?
+
+**`s1[i] != s2[j]` 意味着,`s1[i]` 和 `s2[j]` 中至少有一个字符不在 `lcs` 中**:
+
+
+
+如上图,总共可能有三种情况,我怎么知道具体是那种情况呢?
+
+其实我们也不知道,那就把这三种情况的答案都算出来,取其中结果最大的那个呗,因为题目让我们算「最长」公共子序列的长度嘛。
+
+这三种情况的答案怎么算?回想一下我们的 `dp` 函数定义,不就是专门为了计算它们而设计的嘛!
+
+代码可以再进一步:
+
+```java
+// 定义:计算 s1[i..] 和 s2[j..] 的最长公共子序列长度
+int dp(String s1, int i, String s2, int j) {
+ if (s1.charAt(i) == s2.charAt(j)) {
+ return 1 + dp(s1, i + 1, s2, j + 1);
+ } else {
+ // s1[i] 和 s2[j] 中至少有一个字符不在 lcs 中,
+ // 穷举三种情况的结果,取其中的最大结果
+ return max(
+ // 情况一、s1[i] 不在 lcs 中
+ dp(s1, i + 1, s2, j),
+ // 情况二、s2[j] 不在 lcs 中
+ dp(s1, i, s2, j + 1),
+ // 情况三、都不在 lcs 中
+ dp(s1, i + 1, s2, j + 1)
+ );
+ }
+}
+```
+
+这里就已经非常接近我们的最终答案了,**还有一个小的优化,情况三「`s1[i]` 和 `s2[j]` 都不在 lcs 中」其实可以直接忽略**。
+
+因为我们在求最大值嘛,情况三在计算 `s1[i+1..]` 和 `s2[j+1..]` 的 `lcs` 长度,这个长度肯定是小于等于情况二 `s1[i..]` 和 `s2[j+1..]` 中的 `lcs` 长度的,因为 `s1[i+1..]` 比 `s1[i..]` 短嘛,那从这里面算出的 `lcs` 当然也不可能更长嘛。
+
+同理,情况三的结果肯定也小于等于情况一。**说白了,情况三被情况一和情况二包含了**,所以我们可以直接忽略掉情况三,完整代码如下:
+
+```java
+class Solution {
+ // 备忘录,消除重叠子问题
+ int[][] memo;
+
+ // 主函数
+ public int longestCommonSubsequence(String s1, String s2) {
+ int m = s1.length(), n = s2.length();
+ // 备忘录值为 -1 代表未曾计算
+ memo = new int[m][n];
+ for (int[] row : memo)
+ Arrays.fill(row, -1);
+ // 计算 s1[0..] 和 s2[0..] 的 lcs 长度
+ return dp(s1, 0, s2, 0);
+ }
+
+ // 定义:计算 s1[i..] 和 s2[j..] 的最长公共子序列长度
+ int dp(String s1, int i, String s2, int j) {
+ // base case
+ if (i == s1.length() || j == s2.length()) {
+ return 0;
+ }
+ // 如果之前计算过,则直接返回备忘录中的答案
+ if (memo[i][j] != -1) {
+ return memo[i][j];
+ }
+ // 根据 s1[i] 和 s2[j] 的情况做选择
+ if (s1.charAt(i) == s2.charAt(j)) {
+ // s1[i] 和 s2[j] 必然在 lcs 中
+ memo[i][j] = 1 + dp(s1, i + 1, s2, j + 1);
+ } else {
+ // s1[i] 和 s2[j] 至少有一个不在 lcs 中
+ memo[i][j] = Math.max(
+ dp(s1, i + 1, s2, j),
+ dp(s1, i, s2, j + 1)
+ );
+ }
+ return memo[i][j];
+ }
+}
+```
+
+以上思路完全就是按照我们之前的爆文 [动态规划套路框架](https://labuladong.online/algo/essential-technique/dynamic-programming-framework/) 来的,应该是很容易理解的。至于为什么要加 `memo` 备忘录,我们之前写过很多次,为了照顾新来的读者,这里再简单重复一下,首先抽象出我们核心 `dp` 函数的递归框架:
+
+```java
+int dp(int i, int j) {
+ dp(i + 1, j + 1); // #1
+ dp(i, j + 1); // #2
+ dp(i + 1, j); // #3
+}
+```
+
+你看,假设我想从 `dp(i, j)` 转移到 `dp(i+1, j+1)`,有不止一种方式,可以直接走 `#1`,也可以走 `#2 -> #3`,也可以走 `#3 -> #2`。
+
+这就是重叠子问题,如果我们不用 `memo` 备忘录消除子问题,那么 `dp(i+1, j+1)` 就会被多次计算,这是没有必要的。
+
+至此,最长公共子序列问题就完全解决了,用的是自顶向下带备忘录的动态规划思路,我们当然也可以使用自底向上的迭代的动态规划思路,和我们的递归思路一样,关键是如何定义 `dp` 数组,我这里也写一下自底向上的解法吧:
+
+```java
+class Solution {
+ public int longestCommonSubsequence(String s1, String s2) {
+ int m = s1.length(), n = s2.length();
+ int[][] dp = new int[m + 1][n + 1];
+ // 定义:s1[0..i-1] 和 s2[0..j-1] 的 lcs 长度为 dp[i][j]
+ // 目标:s1[0..m-1] 和 s2[0..n-1] 的 lcs 长度,即 dp[m][n]
+ // base case: dp[0][..] = dp[..][0] = 0
+
+ for (int i = 1; i <= m; i++) {
+ for (int j = 1; j <= n; j++) {
+ // 现在 i 和 j 从 1 开始,所以要减一
+ if (s1.charAt(i - 1) == s2.charAt(j - 1)) {
+ // s1[i-1] 和 s2[j-1] 必然在 lcs 中
+ dp[i][j] = 1 + dp[i - 1][j - 1];
+ } else {
+ // s1[i-1] 和 s2[j-1] 至少有一个不在 lcs 中
+ dp[i][j] = Math.max(dp[i][j - 1], dp[i - 1][j]);
+ }
+ }
+ }
+
+ return dp[m][n];
+ }
+}
+```
+
+
+
+
+
+
+🍭 代码可视化动画🍭
+
+
+
+
+
+
+
+自底向上的解法中 `dp` 数组定义的方式和我们的递归解法有一点差异,而且由于数组索引从 0 开始,有索引偏移,不过思路和我们的递归解法完全相同,如果你看懂了递归解法,这个解法应该不难理解。
+
+另外,自底向上的解法可以通过我们前文讲过的 [动态规划空间压缩技巧](https://labuladong.online/algo/dynamic-programming/space-optimization/) 来进行优化,把空间复杂度压缩为 O(N),这里由于篇幅所限,就不展开了。
+
+下面,来看两道和最长公共子序列相似的两道题目。
+
+## 字符串的删除操作
+
+这是力扣第 583 题「两个字符串的删除操作」,看下题目:
+
+给定两个单词 `s1` 和 `s2` ,返回使得 `s1` 和 `s2` 相同所需的最小步数。每步可以删除任意一个字符串中的一个字符。
+
+函数签名如下:
+
+```java
+int minDistance(String s1, String s2);
+```
+
+比如输入 `s1 = "sea" s2 = "eat"`,算法返回 2,第一步将 `"sea"` 变为 `"ea"` ,第二步将 `"eat"` 变为 `"ea"`。
+
+题目让我们计算将两个字符串变得相同的最少删除次数,那我们可以思考一下,最后这两个字符串会被删成什么样子?
+
+删除的结果不就是它俩的最长公共子序列嘛!
+
+那么,要计算删除的次数,就可以通过最长公共子序列的长度推导出来:
+
+```java
+int minDistance(String s1, String s2) {
+ int m = s1.length(), n = s2.length();
+ // 复用前文计算 lcs 长度的函数
+ int lcs = longestCommonSubsequence(s1, s2);
+ return m - lcs + n - lcs;
+}
+```
+
+这道题就解决了!
+
+## 最小 ASCII 删除和
+
+这是力扣第 712 题「两个字符串的最小 ASCII 删除和」,题目和上一道题目类似,只不过上道题要求删除次数最小化,这道题要求删掉的字符 ASCII 码之和最小化。
+
+函数签名如下:
+
+```java
+int minimumDeleteSum(String s1, String s2)
+```
+
+比如输入 `s1 = "sea", s2 = "eat"`,算法返回 231。
+
+因为在 `"sea"` 中删除 `"s"`,在 `"eat"` 中删除 `"t"`,可使得两个字符串相等,且删掉字符的 ASCII 码之和最小,即 `s(115) + t(116) = 231`。
+
+**这道题不能直接复用计算最长公共子序列的函数,但是可以依照之前的思路,稍微修改 base case 和状态转移部分即可直接写出解法代码**:
+
+```java
+class Solution {
+ // 备忘录
+ int memo[][];
+ // 主函数
+ public int minimumDeleteSum(String s1, String s2) {
+ int m = s1.length(), n = s2.length();
+ // 备忘录值为 -1 代表未曾计算
+ memo = new int[m][n];
+ for (int[] row : memo)
+ Arrays.fill(row, -1);
+
+ return dp(s1, 0, s2, 0);
+ }
+
+ // 定义:将 s1[i..] 和 s2[j..] 删除成相同字符串,
+ // 最小的 ASCII 码之和为 dp(s1, i, s2, j)。
+ int dp(String s1, int i, String s2, int j) {
+ int res = 0;
+ // base case
+ if (i == s1.length()) {
+ // 如果 s1 到头了,那么 s2 剩下的都得删除
+ for (; j < s2.length(); j++)
+ res += s2.charAt(j);
+ return res;
+ }
+ if (j == s2.length()) {
+ // 如果 s2 到头了,那么 s1 剩下的都得删除
+ for (; i < s1.length(); i++)
+ res += s1.charAt(i);
+ return res;
+ }
+
+ if (memo[i][j] != -1) {
+ return memo[i][j];
+ }
+
+ if (s1.charAt(i) == s2.charAt(j)) {
+ // s1[i] 和 s2[j] 都是在 lcs 中的,不用删除
+ memo[i][j] = dp(s1, i + 1, s2, j + 1);
+ } else {
+ // s1[i] 和 s2[j] 至少有一个不在 lcs 中,删一个
+ memo[i][j] = Math.min(
+ s1.charAt(i) + dp(s1, i + 1, s2, j),
+ s2.charAt(j) + dp(s1, i, s2, j + 1)
+ );
+ }
+ return memo[i][j];
+ }
+}
+```
+
+
+
+
+
+
+🍭 代码可视化动画🍭
+
+
+
+
+
+
+
+base case 有一定区别,计算 `lcs` 长度时,如果一个字符串为空,那么 `lcs` 长度必然是 0;但是这道题如果一个字符串为空,另一个字符串必然要被全部删除,所以需要计算另一个字符串所有字符的 ASCII 码之和。
+
+关于状态转移,当 `s1[i]` 和 `s2[j]` 相同时不需要删除,不同时需要删除,所以可以利用 `dp` 函数计算两种情况,得出最优的结果。其他的大同小异,就不具体展开了。
+
+至此,三道子序列问题就解决完了,关键在于将问题细化到字符,根据每两个字符是否相同来判断他们是否在结果子序列中,从而避免了对所有子序列进行穷举。
+
+这也算是在两个字符串中求子序列的常用思路吧,建议好好体会,多多练习~
+
+
+
+
+
+
+
+
+
+引用本文的文章
+
+ - [动态规划之子序列问题解题模板](https://labuladong.online/algo/dynamic-programming/subsequence-problem/)
+
+
+
+
+
+
+
+
+引用本文的题目
+
+安装 [我的 Chrome 刷题插件](https://labuladong.online/algo/intro/chrome/) 点开下列题目可直接查看解题思路:
+
+| LeetCode | 力扣 | 难度 |
+| :----: | :----: | :----: |
+| [97. Interleaving String](https://leetcode.com/problems/interleaving-string/?show=1) | [97. 交错字符串](https://leetcode.cn/problems/interleaving-string/?show=1) | 🟠 |
+| - | [剑指 Offer II 095. 最长公共子序列](https://leetcode.cn/problems/qJnOS7/?show=1) | 🟠 |
+
+
+
+
+
+
+**_____________**
+
+
+
+
\ No newline at end of file
diff --git "a/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/README.md" "b/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/README.md"
index 5075ab2b62..8dae5afb4b 100644
--- "a/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/README.md"
+++ "b/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/README.md"
@@ -8,6 +8,6 @@
这就是思维模式的框架,**本章都会按照以上的模式来解决问题,辅助读者养成这种模式思维**,有了方向遇到问题就不会抓瞎,足以解决一般的动态规划问题。
-欢迎关注我的公众号 labuladong,方便获得最新的优质文章:
+欢迎关注我的公众号 labuladong,查看全部文章:

\ No newline at end of file
diff --git "a/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\345\212\250\346\200\201\350\247\204\345\210\222\344\271\213KMP\345\255\227\347\254\246\345\214\271\351\205\215\347\256\227\346\263\225.md" "b/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\345\212\250\346\200\201\350\247\204\345\210\222\344\271\213KMP\345\255\227\347\254\246\345\214\271\351\205\215\347\256\227\346\263\225.md"
index 7276292f5e..a6991d3049 100644
--- "a/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\345\212\250\346\200\201\350\247\204\345\210\222\344\271\213KMP\345\255\227\347\254\246\345\214\271\351\205\215\347\256\227\346\263\225.md"
+++ "b/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\345\212\250\346\200\201\350\247\204\345\210\222\344\271\213KMP\345\255\227\347\254\246\345\214\271\351\205\215\347\256\227\346\263\225.md"
@@ -1,5 +1,32 @@
# 动态规划之KMP字符匹配算法
+
+ +
+
+
+ +
+ +
+
+
+
+
+**通知:[新版网站会员](https://labuladong.online/algo/intro/site-vip/) 即将涨价;已支持老用户续费~另外,建议你在我的 [网站](https://labuladong.online/algo/) 学习文章,体验更好。**
+
+
+
+读完本文,你不仅学会了算法套路,还可以顺便解决如下题目:
+
+| LeetCode | 力扣 | 难度 |
+| :----: | :----: | :----: |
+| [28. Find the Index of the First Occurrence in a String](https://leetcode.com/problems/find-the-index-of-the-first-occurrence-in-a-string/) | [28. 找出字符串中第一个匹配项的下标](https://leetcode.cn/problems/find-the-index-of-the-first-occurrence-in-a-string/) | 🟠
+
+**-----------**
+
+::: tip
+
+阅读本文之前,建议你先学习一下另一种字符串匹配算法:[Rabin Karp 字符匹配算法](https://labuladong.online/algo/practice-in-action/rabinkarp/)。
+
+:::
+
KMP 算法(Knuth-Morris-Pratt 算法)是一个著名的字符串匹配算法,效率很高,但是确实有点复杂。
很多读者抱怨 KMP 算法无法理解,这很正常,想到大学教材上关于 KMP 算法的讲解,也不知道有多少未来的 Knuth、Morris、Pratt 被提前劝退了。有一些优秀的同学通过手推 KMP 算法的过程来辅助理解该算法,这是一种办法,不过本文要从逻辑层面帮助读者理解算法的原理。十行代码之间,KMP 灰飞烟灭。
@@ -10,14 +37,19 @@ KMP 算法(Knuth-Morris-Pratt 算法)是一个著名的字符串匹配算法
读者见过的 KMP 算法应该是,一波诡异的操作处理 `pat` 后形成一个一维的数组 `next`,然后根据这个数组经过又一波复杂操作去匹配 `txt`。时间复杂度 O(N),空间复杂度 O(M)。其实它这个 `next` 数组就相当于 `dp` 数组,其中元素的含义跟 `pat` 的前缀和后缀有关,判定规则比较复杂,不好理解。**本文则用一个二维的 `dp` 数组(但空间复杂度还是 O(M)),重新定义其中元素的含义,使得代码长度大大减少,可解释性大大提高**。
-PS:本文的代码参考《算法4》,原代码使用的数组名称是 `dfa`(确定有限状态机),因为我们的公众号之前有一系列动态规划的文章,就不说这么高大上的名词了,我对书中代码进行了一点修改,并沿用 `dp` 数组的名称。
+::: note
+
+本文的代码参考《算法4》,原代码使用的数组名称是 `dfa`(确定有限状态机),因为我们的公众号之前有一系列动态规划的文章,就不说这么高大上的名词了,我对书中代码进行了一点修改,并沿用 `dp` 数组的名称。
+
+:::
### 一、KMP 算法概述
首先还是简单介绍一下 KMP 算法和暴力匹配算法的不同在哪里,难点在哪里,和动态规划有啥关系。
-暴力的字符串匹配算法很容易写,看一下它的运行逻辑:
+力扣第 28 题「实现 strStr」就是字符串匹配问题,暴力的字符串匹配算法很容易写,看一下它的运行逻辑:
+
```java
// 暴力匹配(伪码)
int search(String pat, String txt) {
@@ -37,21 +69,21 @@ int search(String pat, String txt) {
}
```
-对于暴力算法,如果出现不匹配字符,同时回退 `txt` 和 `pat` 的指针,嵌套 for 循环,时间复杂度 $O(MN)$,空间复杂度$O(1)$。最主要的问题是,如果字符串中重复的字符比较多,该算法就显得很蠢。
+对于暴力算法,如果出现不匹配字符,同时回退 `txt` 和 `pat` 的指针,嵌套 for 循环,时间复杂度 `O(MN)`,空间复杂度`O(1)`。最主要的问题是,如果字符串中重复的字符比较多,该算法就显得很蠢。
-比如 txt = "aaacaaab" pat = "aaab":
+比如 `txt = "aaacaaab", pat = "aaab"`:
-
+
很明显,`pat` 中根本没有字符 c,根本没必要回退指针 `i`,暴力解法明显多做了很多不必要的操作。
KMP 算法的不同之处在于,它会花费空间来记录一些信息,在上述情况中就会显得很聪明:
-
+
-再比如类似的 txt = "aaaaaaab" pat = "aaab",暴力解法还会和上面那个例子一样蠢蠢地回退指针 `i`,而 KMP 算法又会耍聪明:
+再比如类似的 `txt = "aaaaaaab", pat = "aaab"`,暴力解法还会和上面那个例子一样蠢蠢地回退指针 `i`,而 KMP 算法又会耍聪明:
-
+
因为 KMP 算法知道字符 b 之前的字符 a 都是匹配的,所以每次只需要比较字符 b 是否被匹配就行了。
@@ -74,24 +106,29 @@ pat = "aaab"
只不过对于 `txt1` 的下面这个即将出现的未匹配情况:
-
+
`dp` 数组指示 `pat` 这样移动:
-
+
+
+::: note
+
+这个`j` 不要理解为索引,它的含义更准确地说应该是**状态**(state),所以它会出现这个奇怪的位置,后文会详述。
-PS:这个`j` 不要理解为索引,它的含义更准确地说应该是**状态**(state),所以它会出现这个奇怪的位置,后文会详述。
+:::
而对于 `txt2` 的下面这个即将出现的未匹配情况:
-
+
`dp` 数组指示 `pat` 这样移动:
-
+
明白了 `dp` 数组只和 `pat` 有关,那么我们这样设计 KMP 算法就会比较漂亮:
+
```java
public class KMP {
private int[][] dp;
@@ -122,46 +159,45 @@ int pos2 = kmp.search("aaaaaaab"); //4
为什么说 KMP 算法和状态机有关呢?是这样的,我们可以认为 `pat` 的匹配就是状态的转移。比如当 pat = "ABABC":
-
+
如上图,圆圈内的数字就是状态,状态 0 是起始状态,状态 5(`pat.length`)是终止状态。开始匹配时 `pat` 处于起始状态,一旦转移到终止状态,就说明在 `txt` 中找到了 `pat`。比如说当前处于状态 2,就说明字符 "AB" 被匹配:
-
+
另外,处于不同状态时,`pat` 状态转移的行为也不同。比如说假设现在匹配到了状态 4,如果遇到字符 A 就应该转移到状态 3,遇到字符 C 就应该转移到状态 5,如果遇到字符 B 就应该转移到状态 0:
-
+
具体什么意思呢,我们来一个个举例看看。用变量 `j` 表示指向当前状态的指针,当前 `pat` 匹配到了状态 4:
-
+
如果遇到了字符 "A",根据箭头指示,转移到状态 3 是最聪明的:
-
+
如果遇到了字符 "B",根据箭头指示,只能转移到状态 0(一夜回到解放前):
-
+
如果遇到了字符 "C",根据箭头指示,应该转移到终止状态 5,这也就意味着匹配完成:
-
-
+
当然了,还可能遇到其他字符,比如 Z,但是显然应该转移到起始状态 0,因为 `pat` 中根本都没有字符 Z:
-
+
这里为了清晰起见,我们画状态图时就把其他字符转移到状态 0 的箭头省略,只画 `pat` 中出现的字符的状态转移:
-
+
KMP 算法最关键的步骤就是构造这个状态转移图。**要确定状态转移的行为,得明确两个变量,一个是当前的匹配状态,另一个是遇到的字符**;确定了这两个变量后,就可以知道这个情况下应该转移到哪个状态。
下面看一下 KMP 算法根据这幅状态转移图匹配字符串 `txt` 的过程:
-
+
**请记住这个 GIF 的匹配过程,这就是 KMP 算法的核心逻辑**!
@@ -184,6 +220,7 @@ pat 应该转移到状态 2
根据我们这个 dp 数组的定义和刚才状态转移的过程,我们可以先写出 KMP 算法的 search 函数代码:
+
```java
public int search(String txt) {
int M = pat.length();
@@ -216,29 +253,29 @@ for 0 <= j < M: # 状态
这个 next 状态应该怎么求呢?显然,**如果遇到的字符 `c` 和 `pat[j]` 匹配的话**,状态就应该向前推进一个,也就是说 `next = j + 1`,我们不妨称这种情况为**状态推进**:
-
+
**如果字符 `c` 和 `pat[j]` 不匹配的话**,状态就要回退(或者原地不动),我们不妨称这种情况为**状态重启**:
-
+
那么,如何得知在哪个状态重启呢?解答这个问题之前,我们再定义一个名字:**影子状态**(我编的名字),用变量 `X` 表示。**所谓影子状态,就是和当前状态具有相同的前缀**。比如下面这种情况:
-
+
当前状态 `j = 4`,其影子状态为 `X = 2`,它们都有相同的前缀 "AB"。因为状态 `X` 和状态 `j` 存在相同的前缀,所以当状态 `j` 准备进行状态重启的时候(遇到的字符 `c` 和 `pat[j]` 不匹配),可以通过 `X` 的状态转移图来获得**最近的重启位置**。
比如说刚才的情况,如果状态 `j` 遇到一个字符 "A",应该转移到哪里呢?首先只有遇到 "C" 才能推进状态,遇到 "A" 显然只能进行状态重启。**状态 `j` 会把这个字符委托给状态 `X` 处理,也就是 `dp[j]['A'] = dp[X]['A']`**:
-
+
为什么这样可以呢?因为:既然 `j` 这边已经确定字符 "A" 无法推进状态,**只能回退**,而且 KMP 就是要**尽可能少的回退**,以免多余的计算。那么 `j` 就可以去问问和自己具有相同前缀的 `X`,如果 `X` 遇见 "A" 可以进行「状态推进」,那就转移过去,因为这样回退最少。
-
+
当然,如果遇到的字符是 "B",状态 `X` 也不能进行「状态推进」,只能回退,`j` 只要跟着 `X` 指引的方向回退就行了:
-
+
你也许会问,这个 `X` 怎么知道遇到字符 "B" 要回退到状态 0 呢?因为 `X` 永远跟在 `j` 的身后,状态 `X` 如何转移,在之前就已经算出来了。动态规划算法不就是利用过去的结果解决现在的问题吗?
@@ -261,6 +298,7 @@ for 0 <= j < M:
如果之前的内容你都能理解,恭喜你,现在就剩下一个问题:影子状态 `X` 是如何得到的呢?下面先直接看完整代码吧。
+
```java
public class KMP {
private int[][] dp;
@@ -332,10 +370,11 @@ for (int i = 0; i < N; i++) {
下面来看一下状态转移图的完整构造过程,你就能理解状态 `X` 作用之精妙了:
-
+
至此,KMP 算法的核心终于写完啦啦啦啦!看下 KMP 算法的完整代码吧:
+
```java
public class KMP {
private int[][] dp;
@@ -399,12 +438,149 @@ public class KMP {
KMP 算法也就是动态规划那点事,我们的公众号文章目录有一系列专门讲动态规划的,而且都是按照一套框架来的,无非就是描述问题逻辑,明确 `dp` 数组含义,定义 base case 这点破事。希望这篇文章能让大家对动态规划有更深的理解。
-**致力于把算法讲清楚!欢迎关注我的微信公众号 labuladong,查看更多通俗易懂的文章**:
-
-[上一篇:贪心算法之区间调度问题](../动态规划系列/贪心算法之区间调度问题.md)
+
+
+引用本文的文章
+
+ - [我的刷题心得:算法的本质](https://labuladong.online/algo/essential-technique/algorithm-summary/)
+ - [滑动窗口算法延伸:Rabin Karp 字符匹配算法](https://labuladong.online/algo/practice-in-action/rabinkarp/)
+
+
+
+
+
+
+
+**_____________**
+
+**《labuladong 的算法笔记》已经出版,关注公众号查看详情;后台回复「**全家桶**」可下载配套 PDF 和刷题全家桶**:
+
+
+
+======其他语言代码======
+
+[28.实现 strStr()](https://leetcode-cn.com/problems/implement-strstr)
+
+### python
+
+[MoguCloud](https://github.com/MoguCloud) 提供 实现 strStr() 的 Python 完整代码:
+
+```python
+class Solution:
+ def strStr(self, haystack: str, needle: str) -> int:
+ # 边界条件判断
+ if not needle:
+ return 0
+ pat = needle
+ txt = haystack
+
+ M = len(pat)
+ # dp[状态][字符] = 下个状态
+ dp = [[0 for _ in range(256)] for _ in pat]
+ # base case
+ dp[0][ord(pat[0])] = 1
+ # 影子状态 X 初始化为 0
+ X = 0
+ for j in range(1, M):
+ for c in range(256):
+ dp[j][c] = dp[X][c]
+ dp[j][ord(pat[j])] = j + 1
+ # 更新影子状态
+ X = dp[X][ord(pat[j])]
+
+ N = len(txt)
+ # pat 初始状态为 0
+ j = 0
+ for i in range(N):
+ # 计算 pat 的下一个状态
+ j = dp[j][ord(txt[i])]
+ # 到达终止态,返回结果
+ if j == M:
+ return i - M + 1
+ # 没到达终止态,匹配失败
+ return -1
+```
+
+
+
+### javascript
+
+```js
+class KMP {
+ constructor(pat) {
+ this.pat = pat;
+ let m = pat.length;
+
+ // dp[状态][字符] = 下个状态 初始化一个m*256的整数矩阵
+ this.dp = new Array(m);
+ for (let i = 0; i < m; i++) {
+ this.dp[i] = new Array(256);
+ this.dp[i].fill(0, 0, 256);
+ }
+
+ // base case
+ this.dp[0][this.pat[0].charCodeAt()] = 1;
+
+ // 影子状态X 初始为0
+ let x = 0;
+
+ // 构建状态转移图
+ for (let j = 1; j < m; j++) {
+ for (let c = 0; c < 256; c++) {
+ this.dp[j][c] = this.dp[x][c];
+ }
+
+ // dp[][对应的ASCII码]
+ this.dp[j][this.pat[j].charCodeAt()] = j + 1;
+
+ // 更新影子状态
+ x = this.dp[x][this.pat[j].charCodeAt()]
+ }
+ }
+
+ search(txt) {
+
+ let m = this.pat.length;
+ let n = txt.length;
+
+ // pat的初始态为0
+ let j = 0;
+ for (let i = 0; i < n; i++) {
+ // 计算pat的下一个状态
+ j = this.dp[j][txt[i].charCodeAt()];
+
+ // 到达终止态 返回结果
+ if (j === m) return i - m + 1;
+ }
+
+ // 没到终止态 匹配失败
+ return -1;
+ }
+
+}
+
+/**
+ * @param {string} haystack
+ * @param {string} needle
+ * @return {number}
+ */
+var strStr = function(haystack, needle) {
+ if(haystack === ""){
+ if(needle !== ""){
+ return -1;
+ }
+ return 0;
+ }
+
+ if(needle === ""){
+ return 0;
+ }
+ let kmp = new KMP(needle);
+ return kmp.search(haystack)
+};
+```
+
-[下一篇:团灭 LeetCode 股票买卖问题](../动态规划系列/团灭股票问题.md)
-[目录](../README.md#目录)
\ No newline at end of file
diff --git "a/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\345\212\250\346\200\201\350\247\204\345\210\222\344\271\213\345\215\232\345\274\210\351\227\256\351\242\230.md" "b/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\345\212\250\346\200\201\350\247\204\345\210\222\344\271\213\345\215\232\345\274\210\351\227\256\351\242\230.md"
index 9c869039ec..d3c64f5d6a 100644
--- "a/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\345\212\250\346\200\201\350\247\204\345\210\222\344\271\213\345\215\232\345\274\210\351\227\256\351\242\230.md"
+++ "b/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\345\212\250\346\200\201\350\247\204\345\210\222\344\271\213\345\215\232\345\274\210\351\227\256\351\242\230.md"
@@ -1,32 +1,89 @@
-# 动态规划之博弈问题
+# 经典动态规划:博弈问题
-上一篇文章 [几道智力题](../高频面试系列/一行代码解决的智力题.md) 中讨论到一个有趣的「石头游戏」,通过题目的限制条件,这个游戏是先手必胜的。但是智力题终究是智力题,真正的算法问题肯定不会是投机取巧能搞定的。所以,本文就借石头游戏来讲讲「假设两个人都足够聪明,最后谁会获胜」这一类问题该如何用动态规划算法解决。
-博弈类问题的套路都差不多,下文举例讲解,其核心思路是在二维 dp 的基础上使用元组分别存储两个人的博弈结果。掌握了这个技巧以后,别人再问你什么俩海盗分宝石,俩人拿硬币的问题,你就告诉别人:我懒得想,直接给你写个算法算一下得了。
-我们「石头游戏」改的更具有一般性:
+
-你和你的朋友面前有一排石头堆,用一个数组 piles 表示,piles[i] 表示第 i 堆石子有多少个。你们轮流拿石头,一次拿一堆,但是只能拿走最左边或者最右边的石头堆。所有石头被拿完后,谁拥有的石头多,谁获胜。
+**通知:为满足广大读者的需求,网站上架 [速成目录](https://labuladong.online/algo/intro/quick-learning-plan/),如有需要可以看下,谢谢大家的支持~另外,建议你在我的 [网站](https://labuladong.online/algo/) 学习文章,体验更好。**
+
+
+
+读完本文,你不仅学会了算法套路,还可以顺便解决如下题目:
+
+| LeetCode | 力扣 | 难度 |
+| :----: | :----: | :----: |
+| [486. Predict the Winner](https://leetcode.com/problems/predict-the-winner/) | [486. 预测赢家](https://leetcode.cn/problems/predict-the-winner/) | 🟠 |
+| [877. Stone Game](https://leetcode.com/problems/stone-game/) | [877. 石子游戏](https://leetcode.cn/problems/stone-game/) | 🟠 |
+
+**-----------**
+
+
+
+> [!NOTE]
+> 阅读本文前,你需要先学习:
+>
+> - [动态规划核心框架](https://labuladong.online/algo/essential-technique/dynamic-programming-framework/)
+
+上一篇文章 [几道智力题](https://labuladong.online/algo/frequency-interview/one-line-solutions/) 中讨论到一个有趣的「石头游戏」,通过题目的限制条件,这个游戏是先手必胜的。但是智力题终究是智力题,真正的算法问题肯定不会是投机取巧能搞定的。所以,本文就借石头游戏来讲讲「假设两个人都足够聪明,最后谁会获胜」这一类问题该如何用动态规划算法解决。
+
+博弈类问题的套路都差不多,下文参考 [这个 YouTube 视频](https://www.youtube.com/watch?v=WxpIHvsu1RI) 的思路讲解,其核心思路是在二维 dp 的基础上使用元组分别存储两个人的博弈结果。掌握了这个技巧以后,别人再问你什么俩海盗分宝石,俩人拿硬币的问题,你就告诉别人:我懒得想,直接给你写个算法算一下得了。
+
+
+
+
+
+
+
+我们把力扣第 877 题「石头游戏」改的更具有一般性:
+
+你和你的朋友面前有一排石头堆,用一个数组 `piles` 表示,`piles[i]` 表示第 `i` 堆石子有多少个。你们轮流拿石头,一次拿一堆,但是只能拿走最左边或者最右边的石头堆。所有石头被拿完后,谁拥有的石头多,谁获胜。
石头的堆数可以是任意正整数,石头的总数也可以是任意正整数,这样就能打破先手必胜的局面了。比如有三堆石头 `piles = [1, 100, 3]`,先手不管拿 1 还是 3,能够决定胜负的 100 都会被后手拿走,后手会获胜。
-**假设两人都很聪明**,请你设计一个算法,返回先手和后手的最后得分(石头总数)之差。比如上面那个例子,先手能获得 4 分,后手会获得 100 分,你的算法应该返回 -96。
+**假设两人都很聪明**,请你写一个 `stoneGame` 函数,返回先手和后手的最后得分(石头总数)之差。比如上面那个例子,先手能获得 4 分,后手会获得 100 分,你的算法应该返回 -96:
+
+```java
+int stoneGame(int[] nums);
+```
+
+这样推广之后就变成了一道难度比较高的动态规划问题了,力扣第 486 题「预测赢家」就是一道类似的问题:
+
+
+
+函数签名如下:
+
+```java
+boolean predictTheWinner(int[] nums);
+```
+
+那么如果有了一个计算先手和后手分差的 `stoneGame` 函数,这道题的解法就直接出来了:
+
+```java
+public boolean predictTheWinner(int[] nums) {
+ // 先手的分数大于等于后手,则能赢
+ return stoneGame(nums) >= 0;
+}
+```
+
+这个 `stoneGame` 函数怎么写呢?博弈问题的难点在于,两个人要轮流进行选择,而且都贼精明,应该如何编程表示这个过程呢?其实不难,还是按照 [动态规划核心框架](https://labuladong.online/algo/essential-technique/dynamic-programming-framework/) 中强调多次的套路,首先明确 `dp` 数组的含义,然后只要找到「状态」和「选择」,一切就水到渠成了。
+
+## 一、定义 `dp` 数组的含义
+
+定义 `dp` 数组的含义是很有技术含量的,同一问题可能有多种定义方法,不同的定义会引出不同的状态转移方程,不过只要逻辑没有问题,最终都能得到相同的答案。
-这样推广之后,这个问题算是一道 Hard 的动态规划问题了。**博弈问题的难点在于,两个人要轮流进行选择,而且都贼精明,应该如何编程表示这个过程呢?**
+我建议不要迷恋那些看起来很牛逼,代码很短小的解法思路,最好是稳一点,采取可解释性最好,最容易推广的解法思路。本文就给出一种博弈问题的通用设计框架。
-还是强调多次的套路,首先明确 dp 数组的含义,然后和股票买卖系列问题类似,只要找到「状态」和「选择」,一切就水到渠成了。
+介绍 `dp` 数组的含义之前,我们先看一下 `dp` 数组最终的样子:
+
+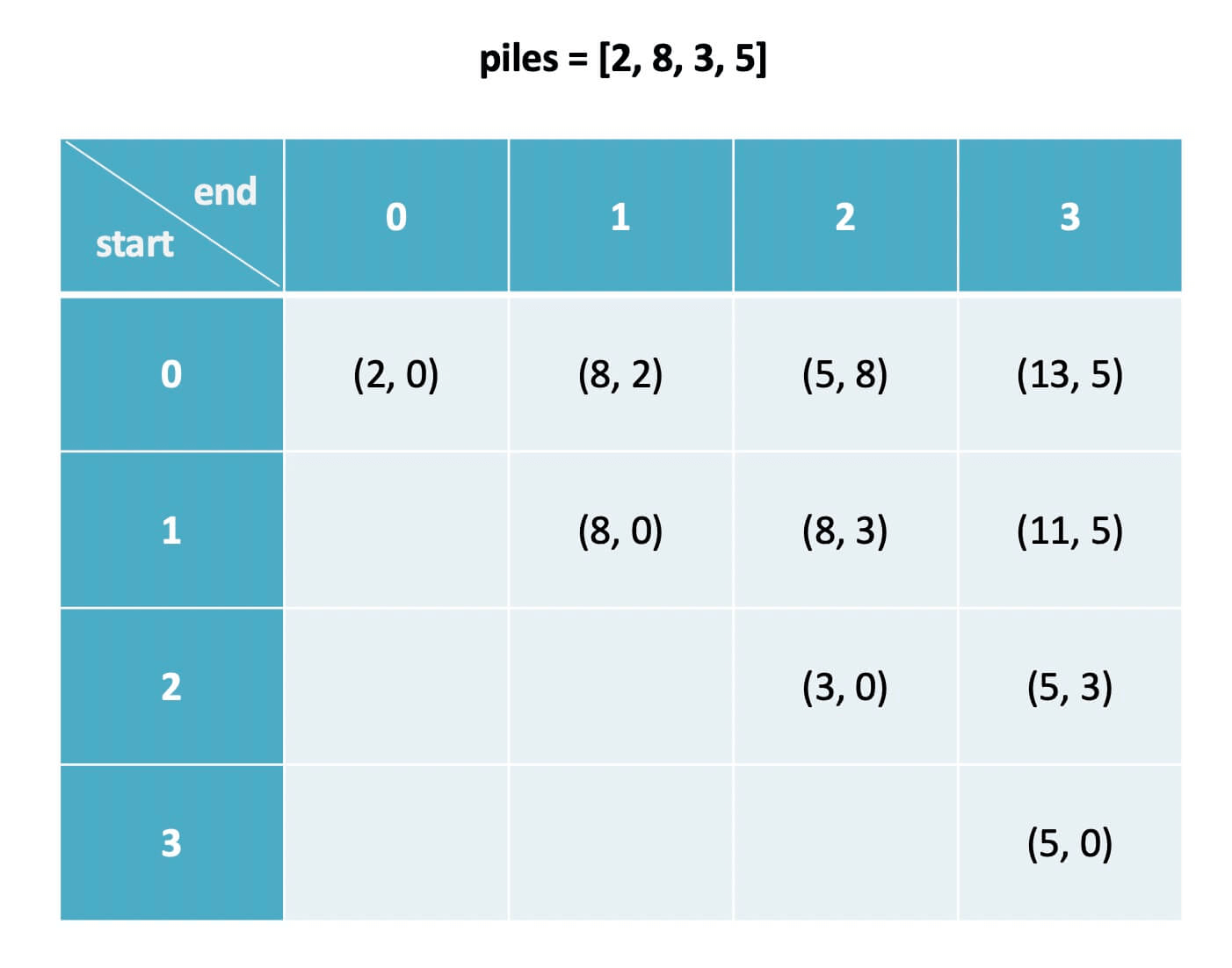
+
+下文讲解时,认为元组是包含 `first` 和 `second` 属性的一个类,而且为了节省篇幅,将这两个属性简写为 `fir` 和 `sec`。比如按上图的数据,我们说 `dp[1][3].fir = 11`,`dp[0][1].sec = 2`。
-### 一、定义 dp 数组的含义
-定义 dp 数组的含义是很有技术含量的,同一问题可能有多种定义方法,不同的定义会引出不同的状态转移方程,不过只要逻辑没有问题,最终都能得到相同的答案。
-我建议不要迷恋那些看起来很牛逼,代码很短小的奇技淫巧,最好是稳一点,采取可解释性最好,最容易推广的设计思路。本文就给出一种博弈问题的通用设计框架。
-介绍 dp 数组的含义之前,我们先看一下 dp 数组最终的样子:
-
-下文讲解时,认为元组是包含 first 和 second 属性的一个类,而且为了节省篇幅,将这两个属性简写为 fir 和 sec。比如按上图的数据,我们说 `dp[1][3].fir = 10`,`dp[0][1].sec = 3`。
先回答几个读者可能提出的问题:
@@ -34,22 +91,27 @@
**以下是对 dp 数组含义的解释:**
-```python
-dp[i][j].fir 表示,对于 piles[i...j] 这部分石头堆,先手能获得的最高分数。
-dp[i][j].sec 表示,对于 piles[i...j] 这部分石头堆,后手能获得的最高分数。
+`dp[i][j].fir = x` 表示,对于 `piles[i...j]` 这部分石头堆,先手能获得的最高分数为 `x`。
-举例理解一下,假设 piles = [3, 9, 1, 2],索引从 0 开始
-dp[0][1].fir = 9 意味着:面对石头堆 [3, 9],先手最终能够获得 9 分。
-dp[1][3].sec = 2 意味着:面对石头堆 [9, 1, 2],后手最终能够获得 2 分。
-```
+`dp[i][j].sec = y` 表示,对于 `piles[i...j]` 这部分石头堆,后手能获得的最高分数为 `y`。
+
+举例理解一下,假设 `piles = [2, 8, 3, 5]`,索引从 0 开始,那么:
-我们想求的答案是先手和后手最终分数之差,按照这个定义也就是 $dp[0][n-1].fir - dp[0][n-1].sec$,即面对整个 piles,先手的最优得分和后手的最优得分之差。
+`dp[0][1].fir = 8` 意味着:面对石头堆 `[2, 8]`,先手最多能够获得 8 分;`dp[1][3].sec = 5` 意味着:面对石头堆 `[8, 3, 5]`,后手最多能够获得 5 分。
-### 二、状态转移方程
+我们想求的答案是先手和后手最终分数之差,按照这个定义也就是 `dp[0][n-1].fir - dp[0][n-1].sec`,即面对整个 `piles`,先手的最优得分和后手的最优得分之差。
+
+
+
+
+
+
+
+## 二、状态转移方程
写状态转移方程很简单,首先要找到所有「状态」和每个状态可以做的「选择」,然后择优。
-根据前面对 dp 数组的定义,**状态显然有三个:开始的索引 i,结束的索引 j,当前轮到的人。**
+根据前面对 `dp` 数组的定义,**状态显然有三个:开始的索引 `i`,结束的索引 `j`,当前轮到的人。**
```python
dp[i][j][fir or sec]
@@ -66,35 +128,48 @@ for 0 <= i < n:
for j <= i < n:
for who in {fir, sec}:
dp[i][j][who] = max(left, right)
-
```
-上面的伪码是动态规划的一个大致的框架,股票系列问题中也有类似的伪码。这道题的难点在于,两人是交替进行选择的,也就是说先手的选择会对后手有影响,这怎么表达出来呢?
+上面的伪码是动态规划的一个大致的框架,这道题的难点在于,两人足够聪明,而且是交替进行选择的,也就是说先手的选择会对后手有影响,这怎么表达出来呢?
+
+根据我们对 `dp` 数组的定义,很容易解决这个难点,**写出状态转移方程**:
+
+
+
-根据我们对 dp 数组的定义,很容易解决这个难点,**写出状态转移方程:**
```python
dp[i][j].fir = max(piles[i] + dp[i+1][j].sec, piles[j] + dp[i][j-1].sec)
-dp[i][j].fir = max( 选择最左边的石头堆 , 选择最右边的石头堆 )
+dp[i][j].fir = max( 选择最左边的石头堆 , 选择最右边的石头堆 )
# 解释:我作为先手,面对 piles[i...j] 时,有两种选择:
-# 要么我选择最左边的那一堆石头,然后面对 piles[i+1...j]
-# 但是此时轮到对方,相当于我变成了后手;
-# 要么我选择最右边的那一堆石头,然后面对 piles[i...j-1]
-# 但是此时轮到对方,相当于我变成了后手。
+
+# 要么我选择最左边的那一堆石头 piles[i],局面变成了 piles[i+1...j],
+# 然后轮到对方选了,我变成了后手,此时我作为后手的最优得分是 dp[i+1][j].sec
+
+# 要么我选择最右边的那一堆石头 piles[j],局面变成了 piles[i...j-1]
+# 然后轮到对方选了,我变成了后手,此时我作为后手的最优得分是 dp[i][j-1].sec
if 先手选择左边:
dp[i][j].sec = dp[i+1][j].fir
if 先手选择右边:
dp[i][j].sec = dp[i][j-1].fir
# 解释:我作为后手,要等先手先选择,有两种情况:
+
# 如果先手选择了最左边那堆,给我剩下了 piles[i+1...j]
-# 此时轮到我,我变成了先手;
+# 此时轮到我,我变成了先手,此时的最优得分是 dp[i+1][j].fir
+
# 如果先手选择了最右边那堆,给我剩下了 piles[i...j-1]
-# 此时轮到我,我变成了先手。
+# 此时轮到我,我变成了先手,此时的最优得分是 dp[i][j-1].fir
```
+
+
根据 dp 数组的定义,我们也可以找出 **base case**,也就是最简单的情况:
+
+
+
+
```python
dp[i][j].fir = piles[i]
dp[i][j].sec = 0
@@ -104,20 +179,27 @@ dp[i][j].sec = 0
# 后手没有石头拿了,得分为 0
```
-
+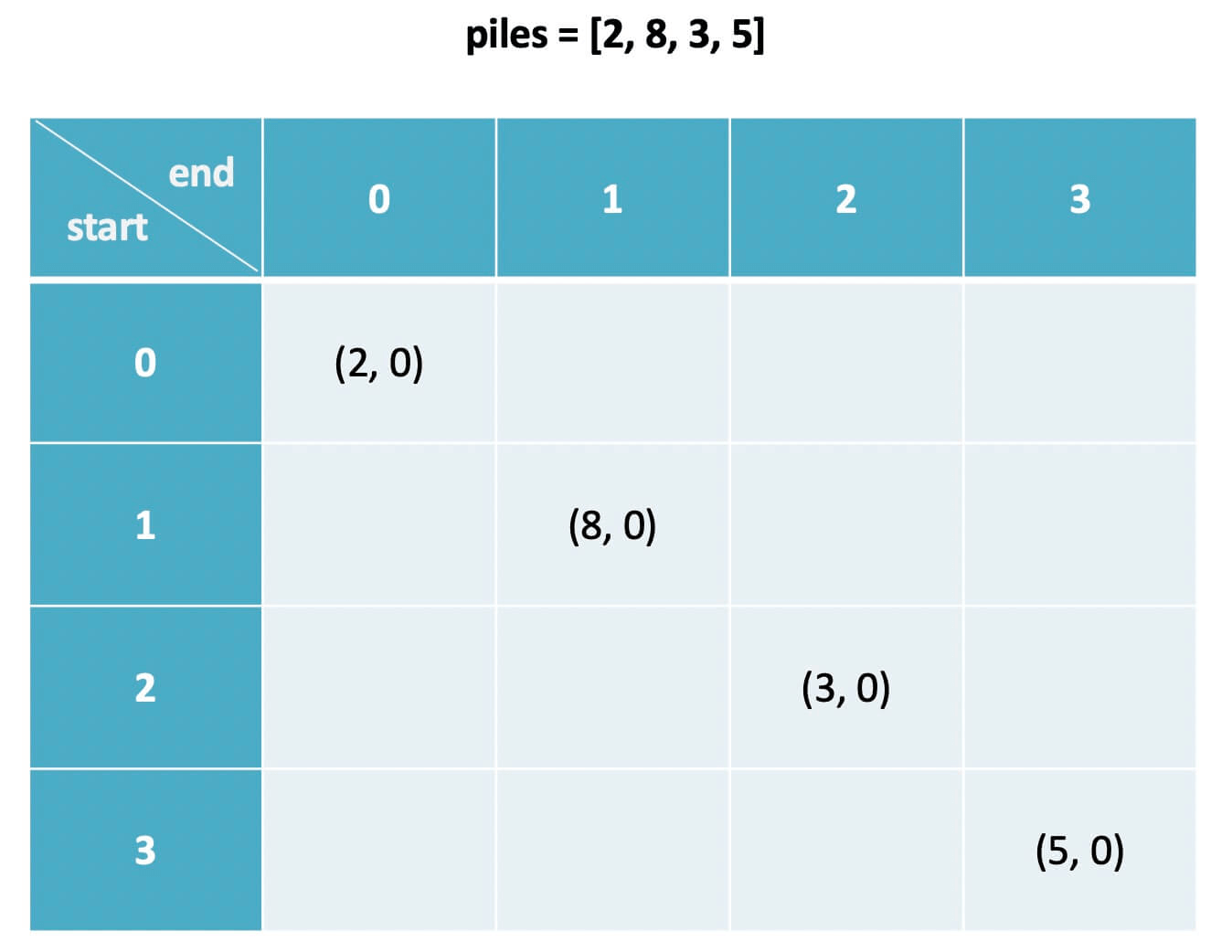
+
-这里需要注意一点,我们发现 base case 是斜着的,而且我们推算 dp[i][j] 时需要用到 dp[i+1][j] 和 dp[i][j-1]:
-
+这里需要注意一点,我们发现 base case 是斜着的,而且我们推算 `dp[i][j]` 时需要用到 `dp[i+1][j]` 和 `dp[i][j-1]`:
-所以说算法不能简单的一行一行遍历 dp 数组,**而要斜着遍历数组:**
+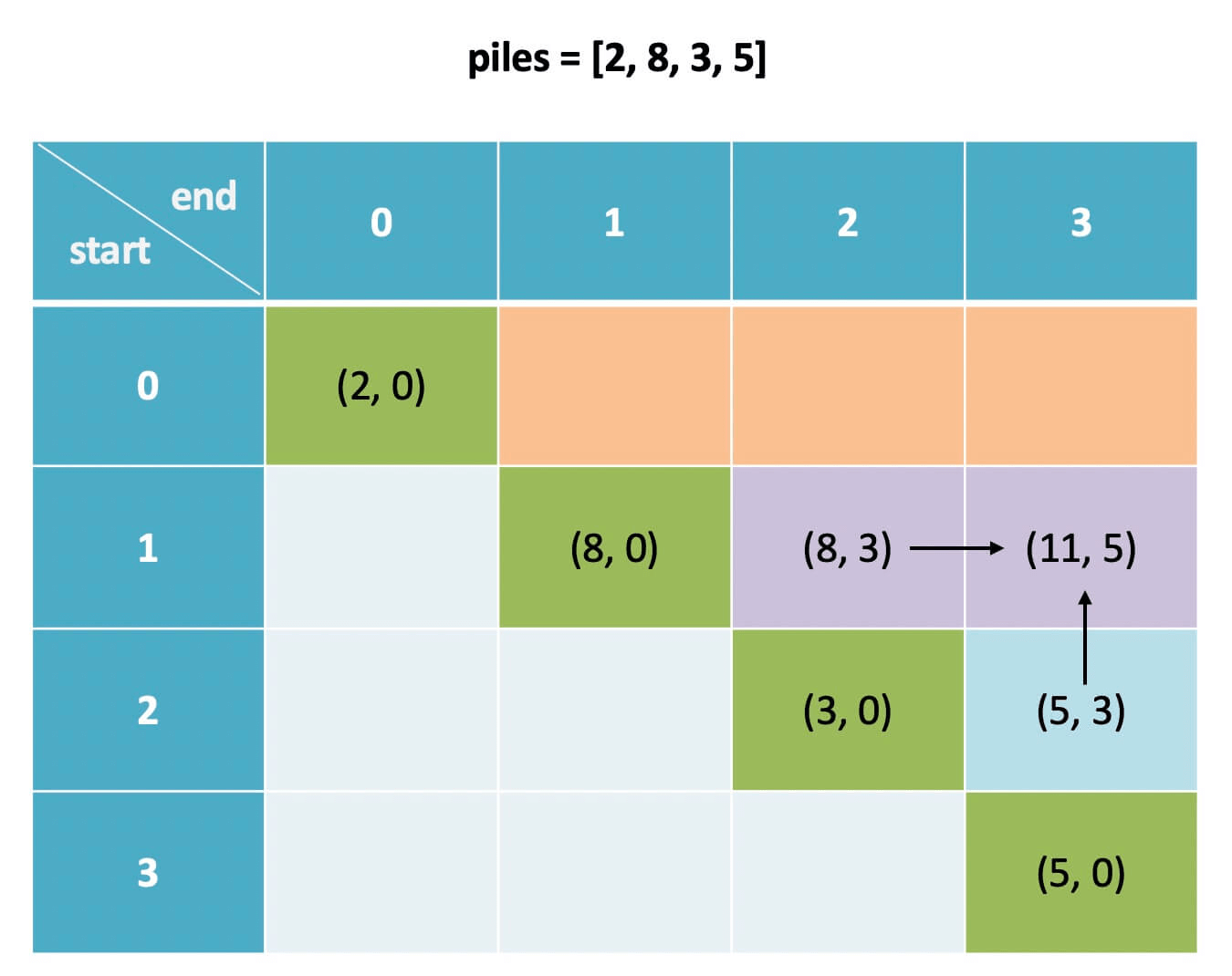
-
+根据前文 [动态规划答疑篇](https://labuladong.online/algo/dynamic-programming/faq-summary/) 判断 `dp` 数组遍历方向的原则,算法应该倒着遍历 `dp` 数组:
-说实话,斜着遍历二维数组说起来容易,你还真不一定能想出来怎么实现,不信你思考一下?这么巧妙的状态转移方程都列出来了,要是不会写代码实现,那真的很尴尬了。
+```java
+for (int i = n - 2; i >= 0; i--) {
+ for (int j = i + 1; j < n; j++) {
+ dp[i][j] = ...
+ }
+}
+```
+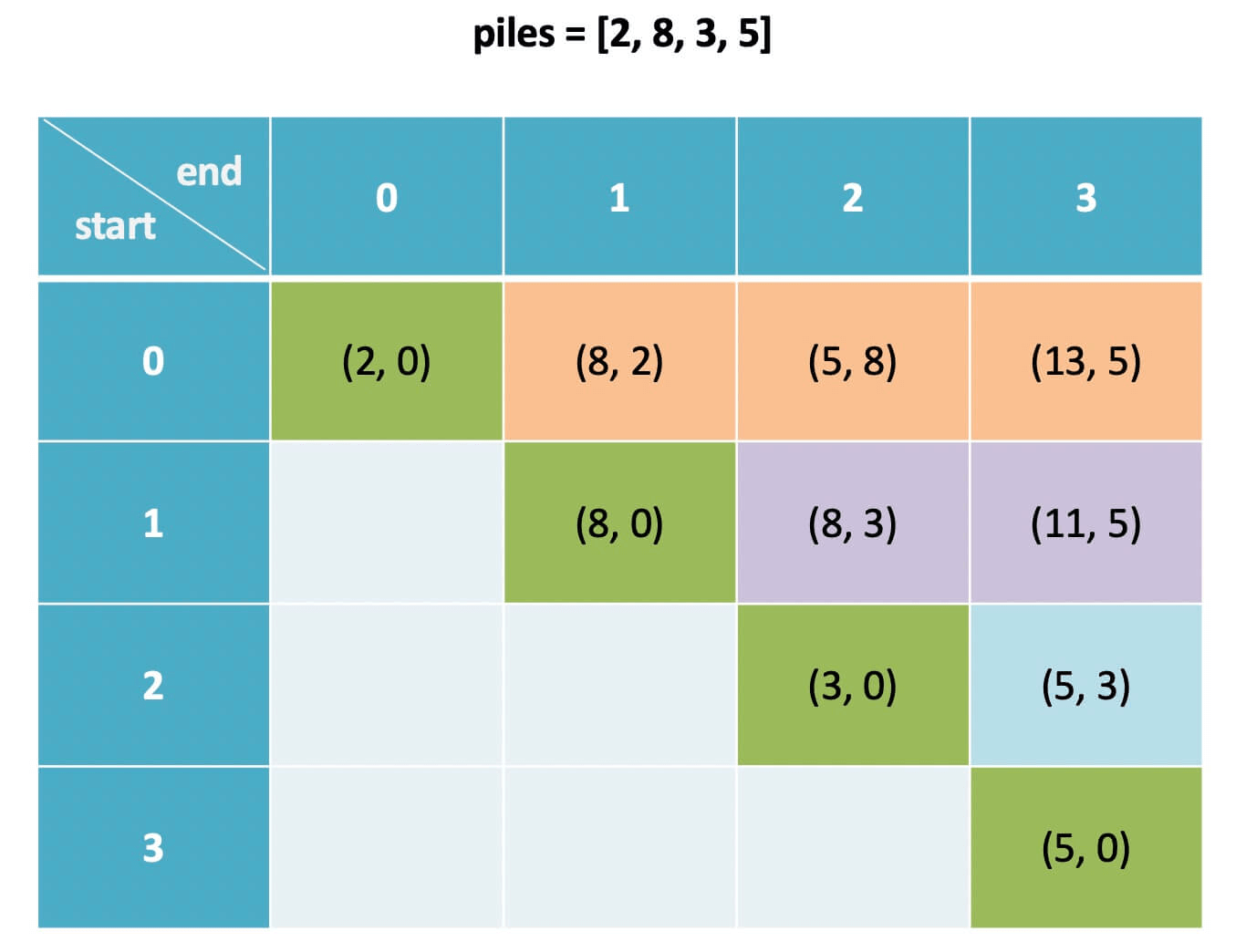
-### 三、代码实现
+## 三、代码实现
如何实现这个 fir 和 sec 元组呢,你可以用 python,自带元组类型;或者使用 C++ 的 pair 容器;或者用一个三维数组 `dp[n][n][2]`,最后一个维度就相当于元组;或者我们自己写一个 Pair 类:
@@ -131,10 +213,10 @@ class Pair {
}
```
-然后直接把我们的状态转移方程翻译成代码即可,可以注意一下斜着遍历数组的技巧:
+然后直接把我们的状态转移方程翻译成代码即可,注意我们要倒着遍历数组:
```java
-/* 返回游戏最后先手和后手的得分之差 */
+// 返回游戏最后先手和后手的得分之差
int stoneGame(int[] piles) {
int n = piles.length;
// 初始化 dp 数组
@@ -147,14 +229,15 @@ int stoneGame(int[] piles) {
dp[i][i].fir = piles[i];
dp[i][i].sec = 0;
}
- // 斜着遍历数组
- for (int l = 2; l <= n; l++) {
- for (int i = 0; i <= n - l; i++) {
- int j = l + i - 1;
+
+ // 倒着遍历数组
+ for (int i = n - 2; i >= 0; i--) {
+ for (int j = i + 1; j < n; j++) {
// 先手选择最左边或最右边的分数
int left = piles[i] + dp[i+1][j].sec;
int right = piles[j] + dp[i][j-1].sec;
// 套用状态转移方程
+ // 先手肯定会选择更大的结果,后手的选择随之改变
if (left > right) {
dp[i][j].fir = left;
dp[i][j].sec = dp[i+1][j].fir;
@@ -171,24 +254,36 @@ int stoneGame(int[] piles) {
动态规划解法,如果没有状态转移方程指导,绝对是一头雾水,但是根据前面的详细解释,读者应该可以清晰理解这一大段代码的含义。
-而且,注意到计算 `dp[i][j]` 只依赖其左边和下边的元素,所以说肯定有优化空间,转换成一维 dp,想象一下把二维平面压扁,也就是投影到一维。但是,一维 dp 比较复杂,可解释性很差,大家就不必浪费这个时间去理解了。
+而且,注意到计算 `dp[i][j]` 只依赖其左边和下边的元素,所以说肯定有优化空间,转换成一维 dp,想象一下把二维平面压扁,也就是投影到一维。但是,一维 `dp` 比较复杂,可解释性比较差,大家就不必浪费这个时间去理解了。
-### 四、最后总结
+## 四、最后总结
本文给出了解决博弈问题的动态规划解法。博弈问题的前提一般都是在两个聪明人之间进行,编程描述这种游戏的一般方法是二维 dp 数组,数组中通过元组分别表示两人的最优决策。
-之所以这样设计,是因为先手在做出选择之后,就成了后手,后手在对方做完选择后,就变成了先手。这种角色转换使得我们可以重用之前的结果,典型的动态规划标志。
+之所以这样设计,是因为先手在做出选择之后,就成了后手,后手在对方做完选择后,就变成了先手。**这种角色转换使得我们可以重用之前的结果,典型的动态规划标志**。
+
+读到这里的朋友应该能理解算法解决博弈问题的套路了。学习算法,一定要注重算法的模板框架,而不是一些看起来牛逼的思路,也不要奢求上来就写一个最优的解法。不要舍不得多用空间,不要过早尝试优化,不要惧怕多维数组。`dp` 数组就是存储信息避免重复计算的,随便用,直到咱满意为止。
+
+
+
+
+
+
+
+
+
+引用本文的文章
+
+ - [贪心算法之区间调度问题](https://labuladong.online/algo/frequency-interview/interval-scheduling/)
+
+
+
-读到这里的朋友应该能理解算法解决博弈问题的套路了。学习算法,一定要注重算法的模板框架,而不是一些看起来牛逼的思路,也不要奢求上来就写一个最优的解法。不要舍不得多用空间,不要过早尝试优化,不要惧怕多维数组。dp 数组就是存储信息避免重复计算的,随便用,直到咱满意为止。
-希望本文对你有帮助。
-**致力于把算法讲清楚!欢迎关注我的微信公众号 labuladong,查看更多通俗易懂的文章**:
-
+**_____________**
-[上一篇:动态规划之子序列问题解题模板](../动态规划系列/子序列问题模板.md)
-[下一篇:贪心算法之区间调度问题](../动态规划系列/贪心算法之区间调度问题.md)
-[目录](../README.md#目录)
\ No newline at end of file
+
\ No newline at end of file
diff --git "a/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\345\212\250\346\200\201\350\247\204\345\210\222\344\271\213\345\233\233\351\224\256\351\224\256\347\233\230.md" "b/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\345\212\250\346\200\201\350\247\204\345\210\222\344\271\213\345\233\233\351\224\256\351\224\256\347\233\230.md"
index 2605d4c9f2..b6a5a79cf6 100644
--- "a/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\345\212\250\346\200\201\350\247\204\345\210\222\344\271\213\345\233\233\351\224\256\351\224\256\347\233\230.md"
+++ "b/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\345\212\250\346\200\201\350\247\204\345\210\222\344\271\213\345\233\233\351\224\256\351\224\256\347\233\230.md"
@@ -1,12 +1,58 @@
# 动态规划之四键键盘
-四键键盘问题很有意思,而且可以明显感受到:对 dp 数组的不同定义需要完全不同的逻辑,从而产生完全不同的解法。
+
+
+
+
+
+
+
+
+
+**通知:[新版网站会员](https://labuladong.online/algo/intro/site-vip/) 即将涨价;已支持老用户续费~另外,建议你在我的 [网站](https://labuladong.online/algo/) 学习文章,体验更好。**
+
+
+
+读完本文,你不仅学会了算法套路,还可以顺便解决如下题目:
+
+| LeetCode | 力扣 | 难度 |
+| :----: | :----: | :----: |
+| [651. 4 Keys Keyboard](https://leetcode.com/problems/4-keys-keyboard/)🔒 | [651. 4键键盘](https://leetcode.cn/problems/4-keys-keyboard/)🔒 | 🟠
+
+**-----------**
+
+力扣第 651 题「四键键盘」很有意思,而且可以明显感受到:对 `dp` 数组的不同定义需要完全不同的逻辑,从而产生完全不同的解法。
首先看一下题目:
-
+假设你有一个特殊的键盘,上面只有四个键,它们分别是:
-如何在 N 次敲击按钮后得到最多的 A?我们穷举呗,每次有对于每次按键,我们可以穷举四种可能,很明显就是一个动态规划问题。
+1、`A` 键:在屏幕上打印一个 `A`。
+
+2、`Ctrl-A` 键:选中整个屏幕。
+
+3、`Ctrl-C` 键:复制选中的区域到缓冲区。
+
+4、`Ctrl-V` 键:将缓冲区的内容输入到光标所在的屏幕上。
+
+这就和我们平时使用的全选复制粘贴功能完全相同嘛,只不过题目把 `Ctrl` 的组合键视为了一个键。现在要求你只能进行 `N` 次操作,请你计算屏幕上最多能显示多少个 `A`?
+
+函数签名如下:
+
+
+```java
+int maxA(int N);
+```
+
+比如说输入 `N = 3`,算法返回 3,因为连按 3 次 `A` 键是最优的方案。
+
+如果输入是 `N = 7`,则算法返回 9,最优的操作序列如下:
+
+`A`, `A`, `A`, `Ctrl-A`, `Ctrl-C`, `Ctrl-V`, `Ctrl-V`
+
+可以得到 9 个 `A`。
+
+如何在 `N` 次敲击按钮后得到最多的 `A`?我们穷举呗,每次有对于每次按键,我们可以穷举四种可能,很明显就是一个动态规划问题。
### 第一种思路
@@ -39,6 +85,7 @@ dp(n - 2, a_num, a_num) # C-A C-C
这样可以看到问题的规模 `n` 在不断减小,肯定可以到达 `n = 0` 的 base case,所以这个思路是正确的:
+
```python
def maxA(N: int) -> int:
@@ -60,6 +107,7 @@ def maxA(N: int) -> int:
这个解法应该很好理解,因为语义明确。下面就继续走流程,用备忘录消除一下重叠子问题:
+
```python
def maxA(N: int) -> int:
# 备忘录
@@ -87,7 +135,7 @@ dp[n][a_num][copy]
# 状态的总数(时空复杂度)就是这个三维数组的体积
```
-我们知道变量 `n` 最多为 `N`,但是 `a_num` 和 `copy` 最多为多少我们很难计算,复杂度起码也有 O(N^3) 把。所以这个算法并不好,复杂度太高,且已经无法优化了。
+我们知道变量 `n` 最多为 `N`,但是 `a_num` 和 `copy` 最多为多少我们很难计算,复杂度起码也有 O(N^3) 吧。所以这个算法并不好,复杂度太高,且已经无法优化了。
这也就说明,我们这样定义「状态」是不太优秀的,下面我们换一种定义 dp 的思路。
@@ -124,7 +172,8 @@ dp[i] = dp[i - 1] + 1;
但是,如果要按 `C-V`,还要考虑之前是在哪里 `C-A C-C` 的。
**刚才说了,最优的操作序列一定是 `C-A C-C` 接着若干 `C-V`,所以我们用一个变量 `j` 作为若干 `C-V` 的起点**。那么 `j` 之前的 2 个操作就应该是 `C-A C-C` 了:
-
+
+
```java
public int maxA(int N) {
int[] dp = new int[N + 1];
@@ -145,7 +194,7 @@ public int maxA(int N) {
其中 `j` 变量减 2 是给 `C-A C-C` 留下操作数,看个图就明白了:
-
+
这样,此算法就完成了,时间复杂度 O(N^2),空间复杂度 O(N),这种解法应该是比较高效的了。
@@ -168,13 +217,81 @@ def dp(n, a_num, copy):
根据这个事实,我们重新定义了状态,重新寻找了状态转移,从逻辑上减少了无效的子问题个数,从而提高了算法的效率。
-坚持原创高质量文章,致力于把算法问题讲清楚,欢迎关注我的公众号 labuladong 获取最新文章:
-
+
+
+引用本文的文章
+
+ - [一个方法团灭 LeetCode 打家劫舍问题](https://labuladong.online/algo/dynamic-programming/house-robber/)
+ - [最优子结构原理和 dp 数组遍历方向](https://labuladong.online/algo/dynamic-programming/faq-summary/)
+
+
+
+
+
+
+
+**_____________**
-[上一篇:团灭 LeetCode 打家劫舍问题](../动态规划系列/抢房子.md)
+**《labuladong 的算法笔记》已经出版,关注公众号查看详情;后台回复「**全家桶**」可下载配套 PDF 和刷题全家桶**:
-[下一篇:动态规划之正则表达](../动态规划系列/动态规划之正则表达.md)
+
+
+======其他语言代码======
+
+### javascript
+
+[651.四键键盘](https://leetcode-cn.com/problems/4-keys-keyboard)
+
+**1、第一种思路**
+
+```js
+let maxA = function (N) {
+ // 备忘录
+ let memo = {}
+
+ let dp = function (n, a_num, copy) {
+ if (n <= 0) {
+ return a_num;
+ }
+
+ let key = n + ',' + a_num + ',' + copy
+ // 避免计算重叠子问题
+ if (memo[key] !== undefined) {
+ return memo[key]
+ }
+
+ memo[key] = Math.max(
+ dp(n - 1, a_num + 1, copy), // A
+ dp(n - 1, a_num + copy, copy), // C-V
+ dp(n - 2, a_num, a_num) // C-A C-C
+ )
+
+ return memo[key]
+ }
+
+ return dp(N, 0, 0)
+}
+```
+
+**2、第二种思路**
+
+```js
+var maxA = function (N) {
+ let dp = new Array(N + 1);
+ dp[0] = 0;
+ for (let i = 1; i <= N; i++) {
+ // 按A键盘
+ dp[i] = dp[i - 1] + 1;
+ for (let j = 2; j < i; j++) {
+ // 全选 & 复制 dp[j-2],连续粘贴 i - j 次
+ // 屏幕上共 dp[j - 2] * (i - j + 1) 个 A
+ dp[i] = Math.max(dp[i], dp[j - 2] * (i - (j - 2) - 1));
+ }
+ }
+ // N 次按键之后最多有几个 A?
+ return dp[N];
+}
+```
-[目录](../README.md#目录)
\ No newline at end of file
diff --git "a/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\345\212\250\346\200\201\350\247\204\345\210\222\344\271\213\346\255\243\345\210\231\350\241\250\350\276\276.md" "b/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\345\212\250\346\200\201\350\247\204\345\210\222\344\271\213\346\255\243\345\210\231\350\241\250\350\276\276.md"
index 605bccc2c9..bad9314251 100644
--- "a/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\345\212\250\346\200\201\350\247\204\345\210\222\344\271\213\346\255\243\345\210\231\350\241\250\350\276\276.md"
+++ "b/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\345\212\250\346\200\201\350\247\204\345\210\222\344\271\213\346\255\243\345\210\231\350\241\250\350\276\276.md"
@@ -1,177 +1,379 @@
-# 动态规划之正则表达
+# 经典动态规划:正则表达式
-之前的文章「动态规划详解」收到了普遍的好评,今天写一个动态规划的实际应用:正则表达式。如果有读者对「动态规划」还不了解,建议先看一下上面那篇文章。
-正则表达式匹配是一个很精妙的算法,而且难度也不小。本文主要写两个正则符号的算法实现:点号「.」和星号「*」,如果你用过正则表达式,应该明白他们的用法,不明白也没关系,等会会介绍。文章的最后,介绍了一种快速看出重叠子问题的技巧。
-本文还有一个重要目的,就是教会读者如何设计算法。我们平时看别人的解法,直接看到一个面面俱到的完整答案,总觉得无法理解,以至觉得问题太难,自己太菜。我力求向读者展示,算法的设计是一个螺旋上升、逐步求精的过程,绝不是一步到位就能写出正确算法。本文会带你解决这个较为复杂的问题,让你明白如何化繁为简,逐个击破,从最简单的框架搭建出最终的答案。
+
-前文无数次强调的框架思维,就是在这种设计过程中逐步培养的。下面进入正题,首先看一下题目:
+**通知:为满足广大读者的需求,网站上架 [速成目录](https://labuladong.online/algo/intro/quick-learning-plan/),如有需要可以看下,谢谢大家的支持~另外,建议你在我的 [网站](https://labuladong.online/algo/) 学习文章,体验更好。**
-
-### 一、热身
-第一步,我们暂时不管正则符号,如果是两个普通的字符串进行比较,如何进行匹配?我想这个算法应该谁都会写:
+读完本文,你不仅学会了算法套路,还可以顺便解决如下题目:
-```cpp
-bool isMatch(string text, string pattern) {
- if (text.size() != pattern.size())
- return false;
- for (int j = 0; j < pattern.size(); j++) {
- if (pattern[j] != text[j])
+| LeetCode | 力扣 | 难度 |
+| :----: | :----: | :----: |
+| [10. Regular Expression Matching](https://leetcode.com/problems/regular-expression-matching/) | [10. 正则表达式匹配](https://leetcode.cn/problems/regular-expression-matching/) | 🔴 |
+
+**-----------**
+
+
+
+> [!NOTE]
+> 阅读本文前,你需要先学习:
+>
+> - [动态规划核心框架](https://labuladong.online/algo/essential-technique/dynamic-programming-framework/)
+> - [经典动态规划:编辑距离](https://labuladong.online/algo/dynamic-programming/edit-distance/)
+
+正则表达式是一个非常强力的工具,本文就来具体看一看正则表达式的底层原理是什么。力扣第 10 题「正则表达式匹配」就要求我们实现一个简单的正则匹配算法,包括「.」通配符和「*」通配符。
+
+这两个通配符是最常用的,其中点号「.」可以匹配任意一个字符,星号「*」可以让之前的那个字符重复任意次数(包括 0 次)。
+
+比如说模式串 `".a*b"` 就可以匹配文本 `"zaaab"`,也可以匹配 `"cb"`;模式串 `"a..b"` 可以匹配文本 `"amnb"`;而模式串 `".*"` 就比较牛逼了,它可以匹配任何文本。
+
+题目会给我们输入两个字符串 `s` 和 `p`,`s` 代表文本,`p` 代表模式串,请你判断模式串 `p` 是否可以匹配文本 `s`。我们可以假设模式串只包含小写字母和上述两种通配符且一定合法,不会出现 `*a` 或者 `b**` 这种不合法的模式串,
+
+函数签名如下:
+
+```java
+boolean isMatch(string s, string p);
+```
+
+对于我们将要实现的这个正则表达式,难点在那里呢?
+
+点号通配符其实很好实现,`s` 中的任何字符,只要遇到 `.` 通配符,无脑匹配就完事了。主要是这个星号通配符不好实现,一旦遇到 `*` 通配符,前面的那个字符可以选择重复一次,可以重复多次,也可以一次都不出现,这该怎么办?
+
+对于这个问题,答案很简单,对于所有可能出现的情况,全部穷举一遍,只要有一种情况可以完成匹配,就认为 `p` 可以匹配 `s`。那么一旦涉及两个字符串的穷举,我们就应该条件反射地想到动态规划的技巧了。
+
+## 一、思路分析
+
+我们先脑补一下,`s` 和 `p` 相互匹配的过程大致是,两个指针 `i, j` 分别在 `s` 和 `p` 上移动,如果最后两个指针都能移动到字符串的末尾,那么久匹配成功,反之则匹配失败。
+
+**如果不考虑 `*` 通配符,面对两个待匹配字符 `s[i]` 和 `p[j]`,我们唯一能做的就是看他俩是否匹配**:
+
+```java
+boolean isMatch(String s, String p) {
+ int i = 0, j = 0;
+ while (i < s.length() && j < p.length()) {
+ // 「.」通配符就是万金油
+ if (s.charAt(i) == p.charAt(j) || p.charAt(j) == '.') {
+ // 匹配,接着匹配 s[i+1..] 和 p[j+1..]
+ i++; j++;
+ } else {
+ // 不匹配
return false;
+ }
}
- return true;
+ return i == j;
}
```
-然后,我稍微改造一下上面的代码,略微复杂了一点,但意思还是一样的,很容易理解吧:
+那么考虑一下,如果加入 `*` 通配符,局面就会稍微复杂一些,不过只要分情况来分析,也不难理解。
-```cpp
-bool isMatch(string text, string pattern) {
- int i = 0; // text 的索引位置
- int j = 0; // pattern 的索引位置
- while (j < pattern.size()) {
- if (i >= text.size())
- return false;
- if (pattern[j++] != text[i++])
- return false;
+**当 `p[j + 1]` 为 `*` 通配符时,我们分情况讨论下**:
+
+1、如果 `s[i] == p[j]`,那么有两种情况:
+
+1.1 `p[j]` 有可能会匹配多个字符,比如 `s = "aaa", p = "a*"`,那么 `p[0]` 会通过 `*` 匹配 3 个字符 `"a"`。
+
+1.2 `p[i]` 也有可能匹配 0 个字符,比如 `s = "aa", p = "a*aa"`,由于后面的字符可以匹配 `s`,所以 `p[0]` 只能匹配 0 次。
+
+2、如果 `s[i] != p[j]`,只有一种情况:
+
+`p[j]` 只能匹配 0 次,然后看下一个字符是否能和 `s[i]` 匹配。比如说 `s = "aa", p = "b*aa"`,此时 `p[0]` 只能匹配 0 次。
+
+综上,可以把之前的代码针对 `*` 通配符进行一下改造:
+
+```java
+if (s.charAt(i) == p.charAt(j) || p.charAt(j) == '.') {
+ // 匹配
+ if (j < p.length() - 1 && p.charAt(j + 1) == '*') {
+ // 有 * 通配符,可以匹配 0 次或多次
+ } else {
+ // 无 * 通配符,老老实实匹配 1 次
+ i++; j++;
+ }
+} else {
+ // 不匹配
+ if (j < p.length() - 1 && p.charAt(j + 1) == '*') {
+ // 有 * 通配符,只能匹配 0 次
+ } else {
+ // 无 * 通配符,匹配无法进行下去了
+ return false;
}
- // 相等则说明完成匹配
- return j == text.size();
}
```
-如上改写,是为了将这个算法改造成递归算法(伪码):
+整体的思路已经很清晰了,但现在的问题是,遇到 `*` 通配符时,到底应该匹配 0 次还是匹配多次?多次是几次?
-```python
-def isMatch(text, pattern) -> bool:
- if pattern is empty: return (text is empty?)
- first_match = (text not empty) and pattern[0] == text[0]
- return first_match and isMatch(text[1:], pattern[1:])
-```
+你看,这就是一个做「选择」的问题,要把所有可能的选择都穷举一遍才能得出结果。动态规划算法的核心就是「状态」和「选择」,**「状态」无非就是 `i` 和 `j` 两个指针的位置,「选择」就是 `p[j]` 选择匹配几个字符**。
+
+## 二、动态规划解法
+
+根据「状态」,我们可以定义一个 `dp` 函数:
-如果你能够理解这段代码,恭喜你,你的递归思想已经到位,正则表达式算法虽然有点复杂,其实是基于这段递归代码逐步改造而成的。
-### 二、处理点号「.」通配符
-点号可以匹配任意一个字符,万金油嘛,其实是最简单的,稍加改造即可:
-```python
-def isMatch(text, pattern) -> bool:
- if not pattern: return not text
- first_match = bool(text) and pattern[0] in {text[0], '.'}
- return first_match and isMatch(text[1:], pattern[1:])
+
+```java
+boolean dp(String s, int i, String p, int j);
```
-### 三、处理「*」通配符
-星号通配符可以让前一个字符重复任意次数,包括零次。那到底是重复几次呢?这似乎有点困难,不过不要着急,我们起码可以把框架的搭建再进一步:
-```python
-def isMatch(text, pattern) -> bool:
- if not pattern: return not text
- first_match = bool(text) and pattern[0] in {text[0], '.'}
- if len(pattern) >= 2 and pattern[1] == '*':
- # 发现 '*' 通配符
- else:
- return first_match and isMatch(text[1:], pattern[1:])
+`dp` 函数的定义如下:
+
+**若 `dp(s, i, p, j) = true`,则表示 `s[i..]` 可以匹配 `p[j..]`;若 `dp(s, i, p, j) = false`,则表示 `s[i..]` 无法匹配 `p[j..]`**。
+
+根据这个定义,我们想要的答案就是 `i = 0, j = 0` 时 `dp` 函数的结果,所以可以这样使用这个 `dp` 函数:
+
+```java
+boolean isMatch(String s, String p) {
+ // 指针 i,j 从索引 0 开始移动
+ return dp(s, 0, p, 0);
+}
```
-星号前面的那个字符到底要重复几次呢?这需要计算机暴力穷举来算,假设重复 N 次吧。前文多次强调过,写递归的技巧是管好当下,之后的事抛给递归。具体到这里,不管 N 是多少,当前的选择只有两个:匹配 0 次、匹配 1 次。所以可以这样处理:
+可以根据之前的代码写出 `dp` 函数的主要逻辑:
+
+```java
+// dp 函数的核心逻辑(伪码)
+// 定义:函数返回 s[i..] 是否能匹配 p[j..]
+boolean dp(String s, int i, String p, int j) {
+ if (s.charAt(i) == p.charAt(j) || p.charAt(j) == '.') {
+ // 匹配
+ if (j < p.length() - 1 && p.charAt(j + 1) == '*') {
+ // 1.1 通配符匹配 0 次或多次
+ return dp(s, i, p, j + 2) || dp(s, i + 1, p, j);
+ } else {
+ // 1.2 常规匹配 1 次
+ return dp(s, i + 1, p, j + 1);
+ }
+ } else {
+ // 不匹配
+ if (j < p.length() - 1 && p.charAt(j + 1) == '*') {
+ // 2.1 通配符匹配 0 次
+ return dp(s, i, p, j + 2);
+ } else {
+ // 2.2 无法继续匹配
+ return false;
+ }
+ }
+}
+```
+
+**根据 `dp` 函数的定义**,这几种情况都很好解释:
+
+**1.1 通配符匹配 0 次或多次**
+
+将 `j` 加 2,`i` 不变,含义就是直接跳过 `p[j]` 和之后的通配符,即通配符匹配 0 次。
+
+即便 `s[i] == p[j]`,依然可能出现这种情况,如下图:
+
+
+
+将 `i` 加 1,`j` 不变,含义就是 `p[j]` 匹配了 `s[i]`,但 `p[j]` 还可以继续匹配,即通配符匹配多次的情况:
+
+
+
+两种情况只要有一种可以完成匹配即可,所以对上面两种情况求或运算。
+
+**1.2 常规匹配 1 次**
+
+由于这个条件分支是无 `*` 的常规匹配,那么如果 `s[i] == p[j]`,就是 `i` 和 `j` 分别加一:
+
+
-```py
-if len(pattern) >= 2 and pattern[1] == '*':
- return isMatch(text, pattern[2:]) or \
- first_match and isMatch(text[1:], pattern)
-# 解释:如果发现有字符和 '*' 结合,
- # 或者匹配该字符 0 次,然后跳过该字符和 '*'
- # 或者当 pattern[0] 和 text[0] 匹配后,移动 text
+**2.1 通配符匹配 0 次**
+
+类似情况 1.1,将 `j` 加 2,`i` 不变:
+
+
+
+**2.2 如果没有 `*` 通配符,也无法匹配,那只能说明匹配失败了**
+
+
+
+看图理解应该很容易了,现在可以思考一下 `dp` 函数的 base case:
+
+**一个 base case 是 `j == p.length()` 时**,按照 `dp` 函数的定义,这意味着模式串 `p` 已经被匹配完了,那么应该看看文本串 `s` 匹配到哪里了,如果 `s` 也恰好被匹配完,则说明匹配成功:
+
+
+
+
+
+```java
+if (j == p.length()) {
+ return i == s.length();
+}
```
-可以看到,我们是通过保留 pattern 中的「\*」,同时向后推移 text,来实现「*」将字符重复匹配多次的功能。举个简单的例子就能理解这个逻辑了。假设 `pattern = a*`, `text = aaa`,画个图看看匹配过程:
-
-
-
-至此,正则表达式算法就基本完成了,
-
-### 四、动态规划
-
-我选择使用「备忘录」递归的方法来降低复杂度。有了暴力解法,优化的过程及其简单,就是使用两个变量 i, j 记录当前匹配到的位置,从而避免使用子字符串切片,并且将 i, j 存入备忘录,避免重复计算即可。
-
-我将暴力解法和优化解法放在一起,方便你对比,你可以发现优化解法无非就是把暴力解法「翻译」了一遍,加了个 memo 作为备忘录,仅此而已。
-
-```py
-# 带备忘录的递归
-def isMatch(text, pattern) -> bool:
- memo = dict() # 备忘录
- def dp(i, j):
- if (i, j) in memo: return memo[(i, j)]
- if j == len(pattern): return i == len(text)
-
- first = i < len(text) and pattern[j] in {text[i], '.'}
-
- if j <= len(pattern) - 2 and pattern[j + 1] == '*':
- ans = dp(i, j + 2) or \
- first and dp(i + 1, j)
- else:
- ans = first and dp(i + 1, j + 1)
-
- memo[(i, j)] = ans
- return ans
-
- return dp(0, 0)
-
-# 暴力递归
-def isMatch(text, pattern) -> bool:
- if not pattern: return not text
-
- first = bool(text) and pattern[0] in {text[0], '.'}
-
- if len(pattern) >= 2 and pattern[1] == '*':
- return isMatch(text, pattern[2:]) or \
- first and isMatch(text[1:], pattern)
- else:
- return first and isMatch(text[1:], pattern[1:])
+
+
+
+**另一个 base case 是 `i == s.length()` 时**,按照 `dp` 函数的定义,这种情况意味着文本串 `s` 已经全部被匹配了,那么是不是只要简单地检查一下 `p` 是否也匹配完就行了呢?
+
+
+
+
+
+```java
+if (i == s.length()) {
+ // 这样行吗?
+ return j == p.length();
+}
```
-**有的读者也许会问,你怎么知道这个问题是个动态规划问题呢,你怎么知道它就存在「重叠子问题」呢,这似乎不容易看出来呀?**
-解答这个问题,最直观的应该是随便假设一个输入,然后画递归树,肯定是可以发现相同节点的。这属于定量分析,其实不用这么麻烦,下面我来教你定性分析,一眼就能看出「重叠子问题」性质。
-先拿最简单的斐波那契数列举例,我们抽象出递归算法的框架:
+**这是不正确的,此时并不能根据 `j` 是否等于 `p.length()` 来判断是否完成匹配,只要 `p[j..]` 能够匹配空串,就可以算完成匹配**。比如说 `s = "a", p = "ab*c*"`,当 `i` 走到 `s` 末尾的时候,`j` 并没有走到 `p` 的末尾,但是 `p` 依然可以匹配 `s`。
+
+所以我们可以写出如下代码:
+
+```java
+int m = s.length(), n = p.length();
+
+if (i == s.length()) {
+ // 如果能匹配空串,一定是字符和 * 成对儿出现
+ if ((n - j) % 2 == 1) {
+ return false;
+ }
+ // 检查是否为 x*y*z* 这种形式
+ for (; j + 1 < p.length(); j += 2) {
+ if (p.charAt(j + 1) != '*') {
+ return false;
+ }
+ }
+ return true;
+}
+```
+
+根据以上思路,就可以写出完整的代码:
+
+```java
+class Solution {
+ // 备忘录
+ int[][] memo;
+
+ public boolean isMatch(String s, String p) {
+ int m = s.length(), n = p.length();
+ memo = new int[m][n];
+ for (int[] row : memo) {
+ Arrays.fill(row, -1);
+ }
+ // 指针 i,j 从索引 0 开始移动
+ return dp(s, 0, p, 0);
+ }
-```py
-def fib(n):
- fib(n - 1) #1
- fib(n - 2) #2
+ // 计算 p[j..] 是否匹配 s[i..]
+ boolean dp(String s, int i, String p, int j) {
+ int m = s.length(), n = p.length();
+ // base case
+ if (j == n) {
+ return i == m;
+ }
+ if (i == m) {
+ if ((n - j) % 2 == 1) {
+ return false;
+ }
+ for (; j + 1 < n; j += 2) {
+ if (p.charAt(j + 1) != '*') {
+ return false;
+ }
+ }
+ return true;
+ }
+
+ // 查备忘录,防止重复计算
+ if (memo[i][j] != -1) {
+ return memo[i][j] == 1;
+ }
+
+ boolean res = false;
+
+ if (s.charAt(i) == p.charAt(j) || p.charAt(j) == '.') {
+ if (j < n - 1 && p.charAt(j + 1) == '*') {
+ res = dp(s, i, p, j + 2) || dp(s, i + 1, p, j);
+ } else {
+ res = dp(s, i + 1, p, j + 1);
+ }
+ } else {
+ if (j < n - 1 && p.charAt(j + 1) == '*') {
+ res = dp(s, i, p, j + 2);
+ } else {
+ res = false;
+ }
+ }
+ // 将当前结果记入备忘录
+ memo[i][j] = res ? 1 : 0;
+ return res;
+ }
+}
```
-看着这个框架,请问原问题 f(n) 如何触达子问题 f(n - 2) ?有两种路径,一是 f(n) -> #1 -> #1, 二是 f(n) -> #2。前者经过两次递归,后者进过一次递归而已。两条不同的计算路径都到达了同一个问题,这就是「重叠子问题」,而且可以肯定的是,**只要你发现一条重复路径,这样的重复路径一定存在千万条,意味着巨量子问题重叠。**
-同理,对于本问题,我们依然先抽象出算法框架:
+
+
+
+
+🍭 代码可视化动画🍭
+
+
+
+
+
+
+
+代码中用了一个哈希表 `memo` 消除重叠子问题。如何一眼看出重叠子问题?可以参考前文 [动态规划系列答疑](https://labuladong.online/algo/dynamic-programming/faq-summary/) 中所讲的技巧,抽出正则表达算法的递归框架:
-```py
-def dp(i, j):
- dp(i, j + 2) #1
- dp(i + 1, j) #2
- dp(i + 1, j + 1) #3
+```java
+boolean dp(String s, int i, String p, int j) {
+ dp(s, i, p, j + 2); // 1
+ dp(s, i + 1, p, j); // 2
+ dp(s, i + 1, p, j + 1); // 3
+ dp(s, i, p, j + 2); // 4
+}
```
-提出类似的问题,请问如何从原问题 dp(i, j) 触达子问题 dp(i + 2, j + 2) ?至少有两种路径,一是 dp(i, j) -> #3 -> #3,二是 dp(i, j) -> #1 -> #2 -> #2。因此,本问题一定存在重叠子问题,一定需要动态规划的优化技巧来处理。
+如果让你从 `dp(s, i, p, j)` 得到 `dp(s, i+2, p, j+2)`,至少有两条路径:`1 -> 2 -> 2` 和 `3 -> 3`。这就说明 `(i+2, j+2)` 这个状态的计算必然存在重复,也就说明存在重叠子问题,我们需要用备忘录消除重叠子问题,提高效率。
+
+动态规划的时间复杂度为「状态的总数」*「每次递归花费的时间」,本题中状态的总数当然就是 `i` 和 `j` 的组合,也就是 `M * N`(`M` 为 `s` 的长度,`N` 为 `p` 的长度);递归函数 `dp` 中没有循环(base case 中的不考虑,因为 base case 的触发次数有限),所以一次递归花费的时间为常数。二者相乘,总的时间复杂度为 $O(MN)$。
+
+空间复杂度很简单,就是备忘录 `memo` 的大小,即 $O(MN)$。
+
+
+
+
+
+
+
+
+
+引用本文的文章
+
+ - [最优子结构原理和 dp 数组遍历方向](https://labuladong.online/algo/dynamic-programming/faq-summary/)
+
+
+
+
+
+
+
+
+引用本文的题目
-### 五、最后总结
+安装 [我的 Chrome 刷题插件](https://labuladong.online/algo/intro/chrome/) 点开下列题目可直接查看解题思路:
-通过本文,你深入理解了正则表达式的两种常用通配符的算法实现。其实点号「.」的实现及其简单,关键是星号「*」的实现需要用到动态规划技巧,稍微复杂些,但是也架不住我们对问题的层层拆解,逐个击破。另外,你掌握了一种快速分析「重叠子问题」性质的技巧,可以快速判断一个问题是否可以使用动态规划套路解决。
+| LeetCode | 力扣 | 难度 |
+| :----: | :----: | :----: |
+| - | [剑指 Offer 19. 正则表达式匹配](https://leetcode.cn/problems/zheng-ze-biao-da-shi-pi-pei-lcof/?show=1) | 🔴 |
-回顾整个解题过程,你应该能够体会到算法设计的流程:从简单的类似问题入手,给基本的框架逐渐组装新的逻辑,最终成为一个比较复杂、精巧的算法。所以说,读者不必畏惧一些比较复杂的算法问题,多思考多类比,再高大上的算法在你眼里也不过一个脆皮。
+
+
-如果本文对你有帮助,欢迎关注我的公众号 labuladong,致力于把算法问题讲清楚~
+**_____________**
-[上一篇:动态规划之四键键盘](../动态规划系列/动态规划之四键键盘.md)
-[下一篇:最长公共子序列](../动态规划系列/最长公共子序列.md)
-[目录](../README.md#目录)
\ No newline at end of file
+
\ No newline at end of file
diff --git "a/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\345\212\250\346\200\201\350\247\204\345\210\222\350\256\276\350\256\241\357\274\232\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227.md" "b/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\345\212\250\346\200\201\350\247\204\345\210\222\350\256\276\350\256\241\357\274\232\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227.md"
index ccb36f4561..ac5a4f7939 100644
--- "a/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\345\212\250\346\200\201\350\247\204\345\210\222\350\256\276\350\256\241\357\274\232\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227.md"
+++ "b/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\345\212\250\346\200\201\350\247\204\345\210\222\350\256\276\350\256\241\357\274\232\346\234\200\351\225\277\351\200\222\345\242\236\345\255\220\345\272\217\345\210\227.md"
@@ -1,194 +1,428 @@
# 动态规划设计:最长递增子序列
-很多读者反应,就算看了前文[动态规划详解](动态规划详解进阶.md),了解了动态规划的套路,也不会写状态转移方程,没有思路,怎么办?本文就借助「最长递增子序列」来讲一种设计动态规划的通用技巧:数学归纳思想。
-最长递增子序列(Longest Increasing Subsequence,简写 LIS)是比较经典的一个问题,比较容易想到的是动态规划解法,时间复杂度 O(N^2),我们借这个问题来由浅入深讲解如何写动态规划。比较难想到的是利用二分查找,时间复杂度是 O(NlogN),我们通过一种简单的纸牌游戏来辅助理解这种巧妙的解法。
-先看一下题目,很容易理解:
+
-
+**通知:为满足广大读者的需求,网站上架 [速成目录](https://labuladong.online/algo/intro/quick-learning-plan/),如有需要可以看下,谢谢大家的支持~另外,建议你在我的 [网站](https://labuladong.online/algo/) 学习文章,体验更好。**
-注意「子序列」和「子串」这两个名词的区别,子串一定是连续的,而子序列不一定是连续的。下面先来一步一步设计动态规划算法解决这个问题。
-### 一、动态规划解法
+
+读完本文,你不仅学会了算法套路,还可以顺便解决如下题目:
+
+| LeetCode | 力扣 | 难度 |
+| :----: | :----: | :----: |
+| [300. Longest Increasing Subsequence](https://leetcode.com/problems/longest-increasing-subsequence/) | [300. 最长递增子序列](https://leetcode.cn/problems/longest-increasing-subsequence/) | 🟠 |
+| [354. Russian Doll Envelopes](https://leetcode.com/problems/russian-doll-envelopes/) | [354. 俄罗斯套娃信封问题](https://leetcode.cn/problems/russian-doll-envelopes/) | 🔴 |
+
+**-----------**
+
+
+
+> [!NOTE]
+> 阅读本文前,你需要先学习:
+>
+> - [动态规划核心框架](https://labuladong.online/algo/essential-technique/dynamic-programming-framework/)
+
+
+也许有读者看了前文 [动态规划详解](https://labuladong.online/algo/essential-technique/dynamic-programming-framework/),学会了动态规划的套路:找到了问题的「状态」,明确了 `dp` 数组/函数的含义,定义了 base case;但是不知道如何确定「选择」,也就是找不到状态转移的关系,依然写不出动态规划解法,怎么办?
+
+不要担心,动态规划的难点本来就在于寻找正确的状态转移方程,本文就借助经典的「最长递增子序列问题」来讲一讲设计动态规划的通用技巧:**数学归纳思想**。
+
+最长递增子序列(Longest Increasing Subsequence,简写 LIS)是非常经典的一个算法问题,比较容易想到的是动态规划解法,时间复杂度 O(N^2),我们借这个问题来由浅入深讲解如何找状态转移方程,如何写出动态规划解法。比较难想到的是利用二分查找,时间复杂度是 O(NlogN),我们通过一种简单的纸牌游戏来辅助理解这种巧妙的解法。
+
+力扣第 300 题「最长递增子序列」就是这个问题:
+
+
+
+
+
+
+
+```java
+// 函数签名
+int lengthOfLIS(int[] nums);
+```
+
+比如说输入 `nums=[10,9,2,5,3,7,101,18]`,其中最长的递增子序列是 `[2,3,7,101]`,所以算法的输出应该是 4。
+
+注意「子序列」和「子串」这两个名词的区别,子串一定是连续的,而子序列不一定是连续的。下面先来设计动态规划算法解决这个问题。
+
+## 一、动态规划解法
动态规划的核心设计思想是数学归纳法。
-相信大家对数学归纳法都不陌生,高中就学过,而且思路很简单。比如我们想证明一个数学结论,那么我们先假设这个结论在 $k [!NOTE]
+> 为什么这样定义呢?这是解决子序列问题的一个套路,后文 [动态规划之子序列问题解题模板](https://labuladong.online/algo/dynamic-programming/subsequence-problem/) 总结了几种常见套路。你读完本章所有的动态规划问题,就会发现 `dp` 数组的定义方法也就那几种。
-
+根据这个定义,我们就可以推出 base case:`dp[i]` 初始值为 1,因为以 `nums[i]` 结尾的最长递增子序列起码要包含它自己。
+举两个例子:
-
+
-算法演进的过程是这样的,:
+这个 GIF 展示了算法演进的过程:
-
+
根据这个定义,我们的最终结果(子序列的最大长度)应该是 dp 数组中的最大值。
+
+
+
+
```java
int res = 0;
-for (int i = 0; i < dp.size(); i++) {
+for (int i = 0; i < dp.length; i++) {
res = Math.max(res, dp[i]);
}
return res;
```
-读者也许会问,刚才这个过程中每个 dp[i] 的结果是我们肉眼看出来的,我们应该怎么设计算法逻辑来正确计算每个 dp[i] 呢?
-这就是动态规划的重头戏了,要思考如何进行状态转移,这里就可以使用数学归纳的思想:
-我们已经知道了 $dp[0...4]$ 的所有结果,我们如何通过这些已知结果推出 $dp[5]$ 呢?
+读者也许会问,刚才的算法演进过程中每个 `dp[i]` 的结果是我们肉眼看出来的,我们应该怎么设计算法逻辑来正确计算每个 `dp[i]` 呢?
+
+这就是动态规划的重头戏,如何设计算法逻辑进行状态转移,才能正确运行呢?这里需要使用数学归纳的思想:
+
+**假设我们已经知道了 `dp[0..4]` 的所有结果,我们如何通过这些已知结果推出 `dp[5]` 呢**?
+
+
+
+根据刚才我们对 `dp` 数组的定义,现在想求 `dp[5]` 的值,也就是想求以 `nums[5]` 为结尾的最长递增子序列。
+
+**`nums[5] = 3`,既然是递增子序列,我们只要找到前面那些结尾比 3 小的子序列,然后把 3 接到这些子序列末尾,就可以形成一个新的递增子序列,而且这个新的子序列长度加一**。
-
+`nums[5]` 前面有哪些元素小于 `nums[5]`?这个好算,用 for 循环比较一波就能把这些元素找出来。
-根据刚才我们对 dp 数组的定义,现在想求 dp[5] 的值,也就是想求以 nums[5] 为结尾的最长递增子序列。
+以这些元素为结尾的最长递增子序列的长度是多少?回顾一下我们对 `dp` 数组的定义,它记录的正是以每个元素为末尾的最长递增子序列的长度。
-nums[5] = 3,既然是递增子序列,我们只要找到前面那些结尾比 3 小的子序列,然后把 3 接到最后,就可以形成一个新的递增子序列,而且这个新的子序列长度加一。
+以我们举的例子来说,`nums[0]` 和 `nums[4]` 都是小于 `nums[5]` 的,然后对比 `dp[0]` 和 `dp[4]` 的值,我们让 `nums[5]` 和更长的递增子序列结合,得出 `dp[5] = 3`:
-当然,可能形成很多种新的子序列,但是我们只要最长的,把最长子序列的长度作为 dp[5] 的值即可。
-
+
+
+
+
```java
for (int j = 0; j < i; j++) {
- if (nums[i] > nums[j])
+ if (nums[i] > nums[j]) {
dp[i] = Math.max(dp[i], dp[j] + 1);
+ }
}
```
-这段代码的逻辑就可以算出 dp[5]。到这里,这道算法题我们就基本做完了。读者也许会问,我们刚才只是算了 dp[5] 呀,dp[4], dp[3] 这些怎么算呢?
-类似数学归纳法,你已经可以算出 dp[5] 了,其他的就都可以算出来:
+
+当 `i = 5` 时,这段代码的逻辑就可以算出 `dp[5]`。其实到这里,这道算法题我们就基本做完了。
+
+读者也许会问,我们刚才只是算了 `dp[5]` 呀,`dp[4]`, `dp[3]` 这些怎么算呢?类似数学归纳法,你已经可以算出 `dp[5]` 了,其他的就都可以算出来:
+
+
+
+
```java
for (int i = 0; i < nums.length; i++) {
for (int j = 0; j < i; j++) {
- if (nums[i] > nums[j])
+ // 寻找 nums[0..i-1] 中比 nums[i] 小的元素
+ if (nums[i] > nums[j]) {
+ // 把 nums[i] 接在后面,即可形成长度为 dp[j] + 1,
+ // 且以 nums[i] 为结尾的递增子序列
dp[i] = Math.max(dp[i], dp[j] + 1);
+ }
}
}
```
-还有一个细节问题,dp 数组应该全部初始化为 1,因为子序列最少也要包含自己,所以长度最小为 1。下面我们看一下完整代码:
+
+
+结合我们刚才说的 base case,下面我们看一下完整代码:
```java
-public int lengthOfLIS(int[] nums) {
- int[] dp = new int[nums.length];
- // dp 数组全都初始化为 1
- Arrays.fill(dp, 1);
- for (int i = 0; i < nums.length; i++) {
- for (int j = 0; j < i; j++) {
- if (nums[i] > nums[j])
- dp[i] = Math.max(dp[i], dp[j] + 1);
+class Solution {
+ public int lengthOfLIS(int[] nums) {
+ // 定义:dp[i] 表示以 nums[i] 这个数结尾的最长递增子序列的长度
+ int[] dp = new int[nums.length];
+ // base case:dp 数组全都初始化为 1
+ Arrays.fill(dp, 1);
+ for (int i = 0; i < nums.length; i++) {
+ for (int j = 0; j < i; j++) {
+ if (nums[i] > nums[j]) {
+ dp[i] = Math.max(dp[i], dp[j] + 1);
+ }
+ }
}
+
+ int res = 0;
+ for (int i = 0; i < dp.length; i++) {
+ res = Math.max(res, dp[i]);
+ }
+ return res;
}
-
- int res = 0;
- for (int i = 0; i < dp.length; i++) {
- res = Math.max(res, dp[i]);
- }
- return res;
}
```
-至此,这道题就解决了,时间复杂度 O(N^2)。总结一下动态规划的设计流程:
-首先明确 dp 数组所存数据的含义。这步很重要,如果不得当或者不够清晰,会阻碍之后的步骤。
+
+
+
+
+🎃 代码可视化动画🎃
+
+
+
+
+
+
+
+至此,这道题就解决了,时间复杂度 $O(N^2)$。总结一下如何找到动态规划的状态转移关系:
+
+1、明确 `dp` 数组的定义。这一步对于任何动态规划问题都很重要,如果不得当或者不够清晰,会阻碍之后的步骤。
+
+2、根据 `dp` 数组的定义,运用数学归纳法的思想,假设 `dp[0...i-1]` 都已知,想办法求出 `dp[i]`,一旦这一步完成,整个题目基本就解决了。
+
+但如果无法完成这一步,很可能就是 `dp` 数组的定义不够恰当,需要重新定义 `dp` 数组的含义;或者可能是 `dp` 数组存储的信息还不够,不足以推出下一步的答案,需要把 `dp` 数组扩大成二维数组甚至三维数组。
+
+目前的解法是标准的动态规划,但对最长递增子序列问题来说,这个解法不是最优的,可能无法通过所有测试用例了,下面讲讲更高效的解法。
-然后根据 dp 数组的定义,运用数学归纳法的思想,假设 $dp[0...i-1]$ 都已知,想办法求出 $dp[i]$,一旦这一步完成,整个题目基本就解决了。
-但如果无法完成这一步,很可能就是 dp 数组的定义不够恰当,需要重新定义 dp 数组的含义;或者可能是 dp 数组存储的信息还不够,不足以推出下一步的答案,需要把 dp 数组扩大成二维数组甚至三维数组。
-最后想一想问题的 base case 是什么,以此来初始化 dp 数组,以保证算法正确运行。
-### 二、二分查找解法
-这个解法的时间复杂度会将为 O(NlogN),但是说实话,正常人基本想不到这种解法(也许玩过某些纸牌游戏的人可以想出来)。所以如果大家了解一下就好,正常情况下能够给出动态规划解法就已经很不错了。
+
+
+## 二、二分查找解法
+
+这个解法的时间复杂度为 $O(NlogN)$,但是说实话,正常人基本想不到这种解法(也许玩过某些纸牌游戏的人可以想出来)。所以大家了解一下就好,正常情况下能够给出动态规划解法就已经很不错了。
根据题目的意思,我都很难想象这个问题竟然能和二分查找扯上关系。其实最长递增子序列和一种叫做 patience game 的纸牌游戏有关,甚至有一种排序方法就叫做 patience sorting(耐心排序)。
-为了简单期间,后文跳过所有数学证明,通过一个简化的例子来理解一下思路。
+为了简单起见,后文跳过所有数学证明,通过一个简化的例子来理解一下算法思路。
首先,给你一排扑克牌,我们像遍历数组那样从左到右一张一张处理这些扑克牌,最终要把这些牌分成若干堆。
-
+
+
+
+
+
+
-处理这些扑克牌要遵循以下规则:
-只能把点数小的牌压到点数比它大的牌上。如果当前牌点数较大没有可以放置的堆,则新建一个堆,把这张牌放进去。如果当前牌有多个堆可供选择,则选择最左边的堆放置。
+**处理这些扑克牌要遵循以下规则**:
-比如说上述的扑克牌最终会被分成这样 5 堆(我们认为 A 的值是最大的,而不是 1)。
+只能把点数小的牌压到点数比它大的牌上;如果当前牌点数较大没有可以放置的堆,则新建一个堆,把这张牌放进去;如果当前牌有多个堆可供选择,则选择最左边的那一堆放置。
-
+比如说上述的扑克牌最终会被分成这样 5 堆(我们认为纸牌 A 的牌面是最大的,纸牌 2 的牌面是最小的)。
+
+
为什么遇到多个可选择堆的时候要放到最左边的堆上呢?因为这样可以保证牌堆顶的牌有序(2, 4, 7, 8, Q),证明略。
-
+
按照上述规则执行,可以算出最长递增子序列,牌的堆数就是最长递增子序列的长度,证明略。
-
+
-我们只要把处理扑克牌的过程编程写出来即可。每次处理一张扑克牌不是要找一个合适的牌堆顶来放吗,牌堆顶的牌不是有序吗,这就能用到二分查找了:用二分查找来搜索当前牌应放置的位置。
+我们只要把处理扑克牌的过程编程写出来即可。每次处理一张扑克牌不是要找一个合适的牌堆顶来放吗,牌堆顶的牌不是**有序**吗,这就能用到二分查找了:用二分查找来搜索当前牌应放置的位置。
-PS:旧文[二分查找算法详解](../算法思维系列/二分查找详解.md)详细介绍了二分查找的细节及变体,这里就完美应用上了。如果没读过强烈建议阅读。
+> [!TIP]
+> 前文 [二分查找算法详解](https://labuladong.online/algo/essential-technique/binary-search-framework/) 详细介绍了二分查找的细节及变体,这里就完美应用上了,如果没读过强烈建议阅读。
```java
-public int lengthOfLIS(int[] nums) {
- int[] top = new int[nums.length];
- // 牌堆数初始化为 0
- int piles = 0;
- for (int i = 0; i < nums.length; i++) {
- // 要处理的扑克牌
- int poker = nums[i];
-
- /***** 搜索左侧边界的二分查找 *****/
- int left = 0, right = piles;
- while (left < right) {
- int mid = (left + right) / 2;
- if (top[mid] > poker) {
- right = mid;
- } else if (top[mid] < poker) {
- left = mid + 1;
- } else {
- right = mid;
+class Solution {
+ public int lengthOfLIS(int[] nums) {
+ int[] top = new int[nums.length];
+ // 牌堆数初始化为 0
+ int piles = 0;
+ for (int i = 0; i < nums.length; i++) {
+ // 要处理的扑克牌
+ int poker = nums[i];
+
+ // ***** 搜索左侧边界的二分查找 *****
+ int left = 0, right = piles;
+ while (left < right) {
+ int mid = (left + right) / 2;
+ if (top[mid] > poker) {
+ right = mid;
+ } else if (top[mid] < poker) {
+ left = mid + 1;
+ } else {
+ right = mid;
+ }
}
+ // *********************************
+
+ // 没找到合适的牌堆,新建一堆
+ if (left == piles) piles++;
+ // 把这张牌放到牌堆顶
+ top[left] = poker;
}
- /*********************************/
-
- // 没找到合适的牌堆,新建一堆
- if (left == piles) piles++;
- // 把这张牌放到牌堆顶
- top[left] = poker;
+ // 牌堆数就是 LIS 长度
+ return piles;
}
- // 牌堆数就是 LIS 长度
- return piles;
}
```
+
+
+
+
+
+🍭 代码可视化动画🍭
+
+
+
+
+
+
+
至此,二分查找的解法也讲解完毕。
这个解法确实很难想到。首先涉及数学证明,谁能想到按照这些规则执行,就能得到最长递增子序列呢?其次还有二分查找的运用,要是对二分查找的细节不清楚,给了思路也很难写对。
所以,这个方法作为思维拓展好了。但动态规划的设计方法应该完全理解:假设之前的答案已知,利用数学归纳的思想正确进行状态的推演转移,最终得到答案。
-坚持原创高质量文章,致力于把算法问题讲清楚,欢迎关注我的公众号 labuladong 获取最新文章:
-
-[上一篇:动态规划答疑篇](../动态规划系列/最优子结构.md)
-[下一篇:编辑距离](../动态规划系列/编辑距离.md)
-[目录](../README.md#目录)
\ No newline at end of file
+
+## 三、拓展到二维
+
+我们看一个经常出现在生活中的有趣问题,力扣第 354 题「俄罗斯套娃信封问题」,先看下题目:
+
+
+
+**这道题目其实是最长递增子序列的一个变种,因为每次合法的嵌套是大的套小的,相当于在二维平面中找一个最长递增的子序列,其长度就是最多能嵌套的信封个数**。
+
+前面说的标准 LIS 算法只能在一维数组中寻找最长子序列,而我们的信封是由 `(w, h)` 这样的二维数对形式表示的,如何把 LIS 算法运用过来呢?
+
+
+
+读者也许会想,通过 `w × h` 计算面积,然后对面积进行标准的 LIS 算法。但是稍加思考就会发现这样不行,比如 `1 × 10` 大于 `3 × 3`,但是显然这样的两个信封是无法互相嵌套的。
+
+
+
+
+
+
+
+这道题的解法比较巧妙:
+
+**先对宽度 `w` 进行升序排序,如果遇到 `w` 相同的情况,则按照高度 `h` 降序排序;之后把所有的 `h` 作为一个数组,在这个数组上计算 LIS 的长度就是答案**。
+
+画个图理解一下,先对这些数对进行排序:
+
+
+
+然后在 `h` 上寻找最长递增子序列,这个子序列就是最优的嵌套方案:
+
+
+
+**那么为什么这样就可以找到可以互相嵌套的信封序列呢**?稍微思考一下就明白了:
+
+首先,对宽度 `w` 从小到大排序,确保了 `w` 这个维度可以互相嵌套,所以我们只需要专注高度 `h` 这个维度能够互相嵌套即可。
+
+其次,两个 `w` 相同的信封不能相互包含,所以对于宽度 `w` 相同的信封,对高度 `h` 进行降序排序,保证二维 LIS 中不存在多个 `w` 相同的信封(因为题目说了长宽相同也无法嵌套)。
+
+下面看解法代码:
+
+```java
+class Solution {
+ // envelopes = [[w, h], [w, h]...]
+ public int maxEnvelopes(int[][] envelopes) {
+ int n = envelopes.length;
+ // 按宽度升序排列,如果宽度一样,则按高度降序排列
+ Arrays.sort(envelopes, (int[] a, int[] b) -> {
+ return a[0] == b[0] ?
+ b[1] - a[1] : a[0] - b[0];
+ });
+ // 对高度数组寻找 LIS
+ int[] height = new int[n];
+ for (int i = 0; i < n; i++)
+ height[i] = envelopes[i][1];
+
+ return lengthOfLIS(height);
+ }
+
+ int lengthOfLIS(int[] nums) {
+ // 见前文
+ }
+}
+```
+
+
+
+
+
+
+🌟 代码可视化动画🌟
+
+
+
+
+
+
+
+为了复用之前的函数,我将代码分为了两个函数,你也可以合并代码,节省下 `height` 数组的空间。
+
+由于增加了测试用例,这里必须使用二分搜索版的 `lengthOfLIS` 函数才能通过所有测试用例。这样的话算法的时间复杂度为 $O(NlogN)$,因为排序和计算 LIS 各需要 $O(NlogN)$ 的时间,加到一起还是 $O(NlogN)$;空间复杂度为 $O(N)$,因为计算 LIS 的函数中需要一个 `top` 数组。
+
+
+
+
+
+
+
+
+
+引用本文的文章
+
+ - [【强化练习】单调队列的通用实现及经典习题](https://labuladong.online/algo/problem-set/monotonic-queue/)
+ - [动态规划之子序列问题解题模板](https://labuladong.online/algo/dynamic-programming/subsequence-problem/)
+ - [动态规划穷举的两种视角](https://labuladong.online/algo/dynamic-programming/two-views-of-dp/)
+ - [动态规划设计:最大子数组](https://labuladong.online/algo/dynamic-programming/maximum-subarray/)
+ - [学习数据结构和算法的框架思维](https://labuladong.online/algo/essential-technique/algorithm-summary/)
+ - [最优子结构原理和 dp 数组遍历方向](https://labuladong.online/algo/dynamic-programming/faq-summary/)
+
+
+
+
+
+
+
+
+引用本文的题目
+
+安装 [我的 Chrome 刷题插件](https://labuladong.online/algo/intro/chrome/) 点开下列题目可直接查看解题思路:
+
+| LeetCode | 力扣 | 难度 |
+| :----: | :----: | :----: |
+| [1425. Constrained Subsequence Sum](https://leetcode.com/problems/constrained-subsequence-sum/?show=1) | [1425. 带限制的子序列和](https://leetcode.cn/problems/constrained-subsequence-sum/?show=1) | 🔴 |
+| [256. Paint House](https://leetcode.com/problems/paint-house/?show=1)🔒 | [256. 粉刷房子](https://leetcode.cn/problems/paint-house/?show=1)🔒 | 🟠 |
+| [368. Largest Divisible Subset](https://leetcode.com/problems/largest-divisible-subset/?show=1) | [368. 最大整除子集](https://leetcode.cn/problems/largest-divisible-subset/?show=1) | 🟠 |
+| - | [剑指 Offer II 091. 粉刷房子](https://leetcode.cn/problems/JEj789/?show=1) | 🟠 |
+
+
+
+
+
+
+**_____________**
+
+
+
+
\ No newline at end of file
diff --git "a/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266.md" "b/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266.md"
index 6fc27cef57..95feea2b83 100644
--- "a/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266.md"
+++ "b/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\345\212\250\346\200\201\350\247\204\345\210\222\350\257\246\350\247\243\350\277\233\351\230\266.md"
@@ -1,162 +1,324 @@
-# 动态规划详解
+# 动态规划解题套路框架
-这篇文章是我们号半年前一篇 200 多赞赏的成名之作「动态规划详解」的进阶版。由于账号迁移的原因,旧文无法被搜索到,所以我润色了本文,并添加了更多干货内容,希望本文成为解决动态规划的一部「指导方针」。
-再说句题外话,我们的公众号开号至今写了起码十几篇文章拆解动态规划问题,我都整理到了公众号菜单的「文章目录」中,**它们都提到了动态规划的解题框架思维,本文就系统总结一下**。这段时间本人也从非科班小白成长到刷通半个 LeetCode,所以我总结的套路可能不适合各路大神,但是应该适合大众,毕竟我自己也是一路摸爬滚打过来的。
-算法技巧就那几个套路,如果你心里有数,就会轻松很多,本文就来扒一扒动态规划的裤子,形成一套解决这类问题的思维框架。废话不多说了,上干货。
+
-**动态规划问题的一般形式就是求最值**。动态规划其实是运筹学的一种最优化方法,只不过在计算机问题上应用比较多,比如说让你求**最长**递增子序列呀,**最小**编辑距离呀等等。
+**通知:为满足广大读者的需求,网站上架 [速成目录](https://labuladong.online/algo/intro/quick-learning-plan/),如有需要可以看下,谢谢大家的支持~另外,建议你在我的 [网站](https://labuladong.online/algo/) 学习文章,体验更好。**
+
+
+
+读完本文,你不仅学会了算法套路,还可以顺便解决如下题目:
+
+| LeetCode | 力扣 | 难度 |
+| :----: | :----: | :----: |
+| [322. Coin Change](https://leetcode.com/problems/coin-change/) | [322. 零钱兑换](https://leetcode.cn/problems/coin-change/) | 🟠 |
+| [509. Fibonacci Number](https://leetcode.com/problems/fibonacci-number/) | [509. 斐波那契数](https://leetcode.cn/problems/fibonacci-number/) | 🟢 |
+
+**-----------**
+
+
+
+> [!NOTE]
+> 阅读本文前,你需要先学习:
+>
+> - [二叉树的遍历框架](https://labuladong.online/algo/data-structure-basic/binary-tree-traverse-basic/)
+> - [多叉树结构及遍历框架](https://labuladong.online/algo/data-structure-basic/n-ary-tree-traverse-basic/)
+
+> tip:本文有视频版:[动态规划框架套路详解](https://www.bilibili.com/video/BV1XV411Y7oE)。建议关注我的 B 站账号,我会用视频领读的方式带大家学习那些稍有难度的算法技巧。
+
+
+
+这篇文章是我多年前一篇 200 多赞赏的 [动态规划详解](https://mp.weixin.qq.com/s/1V3aHVonWBEXlNUvK3S28w) 的进阶版,我添加了更多干货内容,希望本文成为解决动态规划的一部「指导方针」。
+
+动态规划问题(Dynamic Programming)应该是很多读者头疼的,不过这类问题也是最具有技巧性,最有意思的。本书使用了整整一个章节专门来写这个算法,动态规划的重要性也可见一斑。
+
+本文解决几个问题:
+
+动态规划是什么?解决动态规划问题有什么技巧?如何学习动态规划?
+
+刷题刷多了就会发现,算法技巧就那几个套路,我们后续的动态规划系列章节,都在使用本文的解题框架思维,如果你心里有数,就会轻松很多。所以本文放在第一章,希望能够成为解决动态规划问题的一部指导方针,下面上干货。
+
+首先,**动态规划问题的一般形式就是求最值**。动态规划其实是运筹学的一种最优化方法,只不过在计算机问题上应用比较多,比如说让你求最长递增子序列呀,最小编辑距离呀等等。
既然是要求最值,核心问题是什么呢?**求解动态规划的核心问题是穷举**。因为要求最值,肯定要把所有可行的答案穷举出来,然后在其中找最值呗。
-动态规划就这么简单,就是穷举就完事了?我看到的动态规划问题都很难啊!
+动态规划这么简单,就是穷举就完事了?我看到的动态规划问题都很难啊!
+
-首先,动态规划的穷举有点特别,因为这类问题**存在「重叠子问题」**,如果暴力穷举的话效率会极其低下,所以需要「备忘录」或者「DP table」来优化穷举过程,避免不必要的计算。
-而且,动态规划问题一定会**具备「最优子结构」**,才能通过子问题的最值得到原问题的最值。
-另外,虽然动态规划的核心思想就是穷举求最值,但是问题可以千变万化,穷举所有可行解其实并不是一件容易的事,只有列出**正确的「状态转移方程**」才能正确地穷举。
-以上提到的重叠子问题、最优子结构、状态转移方程就是动态规划三要素。具体什么意思等会会举例详解,但是在实际的算法问题中,**写出状态转移方程是最困难的**,这也就是为什么很多朋友觉得动态规划问题困难的原因,我来提供我研究出来的一个思维框架,辅助你思考状态转移方程:
-明确「状态」 -> 定义 dp 数组/函数的含义 -> 明确「选择」-> 明确 base case。
-下面通过斐波那契数列问题和凑零钱问题来详解动态规划的基本原理。前者主要是让你明白什么是重叠子问题(斐波那契数列严格来说不是动态规划问题),后者主要举集中于如何列出状态转移方程。
+首先,虽然动态规划的核心思想就是穷举求最值,但是问题可以千变万化,穷举所有可行解其实并不是一件容易的事,需要你熟练掌握递归思维,只有列出**正确的「状态转移方程」**,才能正确地穷举。而且,你需要判断算法问题是否**具备「最优子结构」**,是否能够通过子问题的最值得到原问题的最值。另外,动态规划问题**存在「重叠子问题」**,如果暴力穷举的话效率会很低,所以需要你使用「备忘录」或者「DP table」来优化穷举过程,避免不必要的计算。
-请读者不要嫌弃这个例子简单,**只有简单的例子才能让你把精力充分集中在算法背后的通用思想和技巧上,而不会被那些隐晦的细节问题搞的莫名其妙**。想要困难的例子,历史文章里有的是。
+以上提到的重叠子问题、最优子结构、状态转移方程就是动态规划三要素。具体什么意思等会会举例详解,但是在实际的算法问题中,写出状态转移方程是最困难的,这也就是为什么很多朋友觉得动态规划问题困难的原因,我来提供我总结的一个思维框架,辅助你思考状态转移方程:
-### 一、斐波那契数列
+**明确「状态」-> 明确「选择」 -> 定义 `dp` 数组/函数的含义**。
-**1、暴力递归**
+按上面的套路走,最后的解法代码就会是如下的框架:
+
+
+
+
+
+
+
+```python
+# 自顶向下递归的动态规划
+def dp(状态1, 状态2, ...):
+ for 选择 in 所有可能的选择:
+ # 此时的状态已经因为做了选择而改变
+ result = 求最值(result, dp(状态1, 状态2, ...))
+ return result
+
+# 自底向上迭代的动态规划
+# 初始化 base case
+dp[0][0][...] = base case
+# 进行状态转移
+for 状态1 in 状态1的所有取值:
+ for 状态2 in 状态2的所有取值:
+ for ...
+ dp[状态1][状态2][...] = 求最值(选择1,选择2...)
+```
+
+下面通过斐波那契数列问题和凑零钱问题来详解动态规划的基本原理。前者主要是让你明白什么是重叠子问题(斐波那契数列没有求最值,所以严格来说不是动态规划问题),后者主要举集中于如何列出状态转移方程。
+
+## 一、斐波那契数列
+
+力扣第 509 题「斐波那契数」就是这个问题,请读者不要嫌弃这个例子简单,**只有简单的例子才能让你把精力充分集中在算法背后的通用思想和技巧上,而不会被那些隐晦的细节问题搞的莫名其妙**。想要困难的例子,接下来的动态规划系列里有的是。
+
+### 暴力递归
斐波那契数列的数学形式就是递归的,写成代码就是这样:
-```cpp
+```java
int fib(int N) {
if (N == 1 || N == 2) return 1;
return fib(N - 1) + fib(N - 2);
}
```
-这个不用多说了,学校老师讲递归的时候似乎都是拿这个举例。我们也知道这样写代码虽然简洁易懂,但是十分低效,低效在哪里?假设 n = 20,请画出递归树。
-PS:但凡遇到需要递归的问题,最好都画出递归树,这对你分析算法的复杂度,寻找算法低效的原因都有巨大帮助。
+
+
+
+
+🌈 代码可视化动画🌈
+
+
+
+
+
+
+
+这个不用多说了,学校老师讲递归的时候似乎都是拿这个举例。我们也知道这样写代码虽然简洁易懂,但是十分低效,低效在哪里?假设 n = 20,请画出递归树:
-
+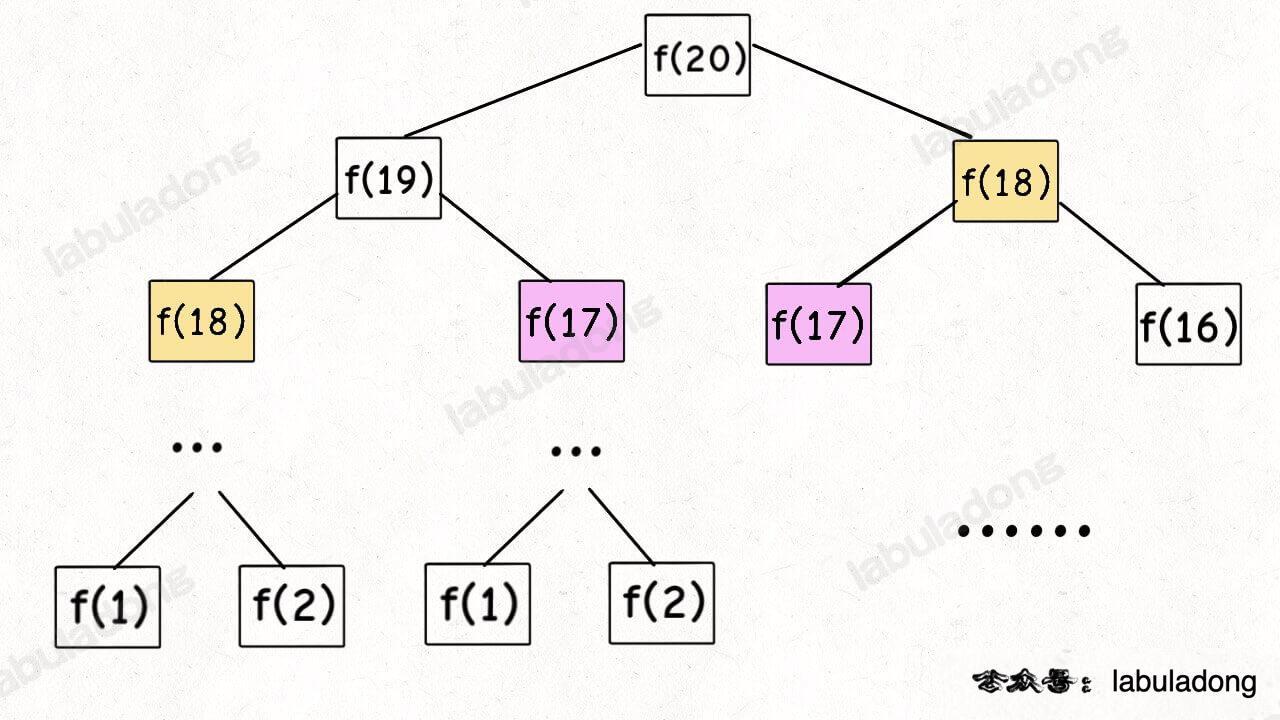
+
+> [!TIP]
+> 但凡遇到需要递归的问题,最好都画出递归树,这对你分析算法的复杂度,寻找算法低效的原因都有巨大帮助。
这个递归树怎么理解?就是说想要计算原问题 `f(20)`,我就得先计算出子问题 `f(19)` 和 `f(18)`,然后要计算 `f(19)`,我就要先算出子问题 `f(18)` 和 `f(17)`,以此类推。最后遇到 `f(1)` 或者 `f(2)` 的时候,结果已知,就能直接返回结果,递归树不再向下生长了。
-**递归算法的时间复杂度怎么计算?子问题个数乘以解决一个子问题需要的时间。**
+**递归算法的时间复杂度怎么计算?就是用子问题个数乘以解决一个子问题需要的时间**。
-子问题个数,即递归树中节点的总数。显然二叉树节点总数为指数级别,所以子问题个数为 O(2^n)。
+首先计算子问题个数,即递归树中节点的总数。显然二叉树节点总数为指数级别,所以子问题个数为 O(2^n)。
-解决一个子问题的时间,在本算法中,没有循环,只有 f(n - 1) + f(n - 2) 一个加法操作,时间为 O(1)。
+然后计算解决一个子问题的时间,在本算法中,没有循环,只有 `f(n - 1) + f(n - 2)` 一个加法操作,时间为 O(1)。
-所以,这个算法的时间复杂度为 O(2^n),指数级别,爆炸。
+所以,这个算法的时间复杂度为二者相乘,即 O(2^n),指数级别,爆炸。
观察递归树,很明显发现了算法低效的原因:存在大量重复计算,比如 `f(18)` 被计算了两次,而且你可以看到,以 `f(18)` 为根的这个递归树体量巨大,多算一遍,会耗费巨大的时间。更何况,还不止 `f(18)` 这一个节点被重复计算,所以这个算法及其低效。
这就是动态规划问题的第一个性质:**重叠子问题**。下面,我们想办法解决这个问题。
-**2、带备忘录的递归解法**
+
+
+
+
+
+
+### 带备忘录的递归解法
明确了问题,其实就已经把问题解决了一半。即然耗时的原因是重复计算,那么我们可以造一个「备忘录」,每次算出某个子问题的答案后别急着返回,先记到「备忘录」里再返回;每次遇到一个子问题先去「备忘录」里查一查,如果发现之前已经解决过这个问题了,直接把答案拿出来用,不要再耗时去计算了。
一般使用一个数组充当这个「备忘录」,当然你也可以使用哈希表(字典),思想都是一样的。
-```cpp
+```java
int fib(int N) {
- if (N < 1) return 0;
// 备忘录全初始化为 0
- vector memo(N + 1, 0);
- // 初始化最简情况
- return helper(memo, N);
+ int[] memo = new int[N + 1];
+ // 进行带备忘录的递归
+ return dp(memo, N);
}
-
-int helper(vector& memo, int n) {
- // base case
- if (n == 1 || n == 2) return 1;
- // 已经计算过
+
+// 带着备忘录进行递归
+int dp(int[] memo, int n) {
+ // base case
+ if (n == 0 || n == 1) return n;
+ // 已经计算过,不用再计算了
if (memo[n] != 0) return memo[n];
- memo[n] = helper(memo, n - 1) +
- helper(memo, n - 2);
+ memo[n] = dp(memo, n - 1) + dp(memo, n - 2);
return memo[n];
}
```
+
+
+
+
+
+🌈 代码可视化动画🌈
+
+
+
+
+
+
+
现在,画出递归树,你就知道「备忘录」到底做了什么。
-
+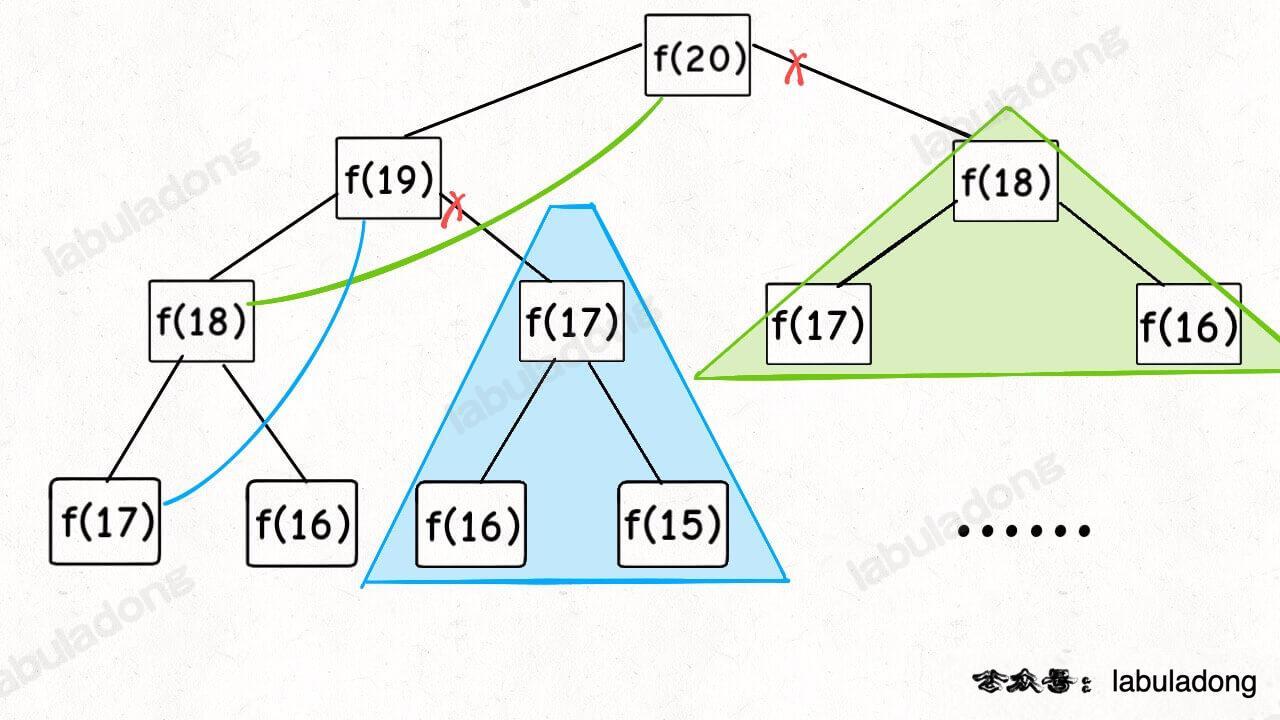
实际上,带「备忘录」的递归算法,把一棵存在巨量冗余的递归树通过「剪枝」,改造成了一幅不存在冗余的递归图,极大减少了子问题(即递归图中节点)的个数。
-
+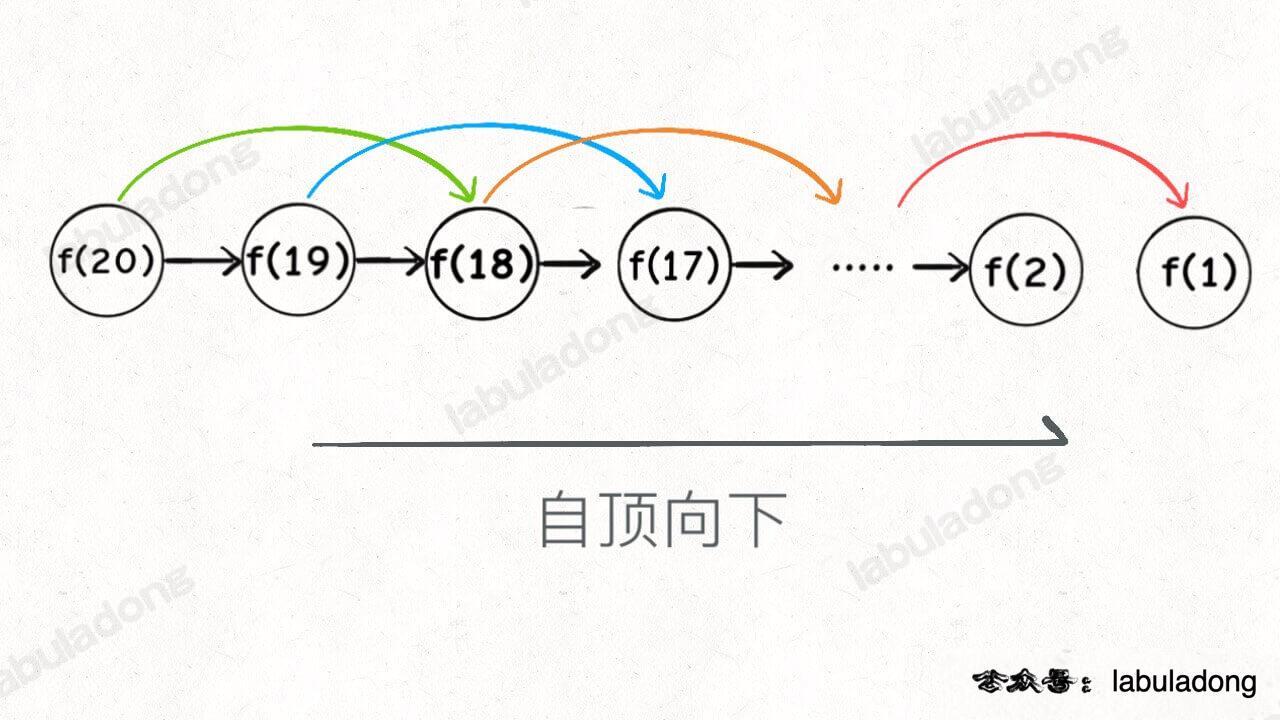
-递归算法的时间复杂度怎么算?子问题个数乘以解决一个子问题需要的时间。
+**递归算法的时间复杂度怎么计算?就是用子问题个数乘以解决一个子问题需要的时间**。
子问题个数,即图中节点的总数,由于本算法不存在冗余计算,子问题就是 `f(1)`, `f(2)`, `f(3)` ... `f(20)`,数量和输入规模 n = 20 成正比,所以子问题个数为 O(n)。
解决一个子问题的时间,同上,没有什么循环,时间为 O(1)。
-所以,本算法的时间复杂度是 O(n)。比起暴力算法,是降维打击。
+所以,本算法的时间复杂度是 O(n),比起暴力算法,是降维打击。
+
+
+
+
-至此,带备忘录的递归解法的效率已经和迭代的动态规划解法一样了。实际上,这种解法和迭代的动态规划已经差不多了,只不过这种方法叫做「自顶向下」,动态规划叫做「自底向上」。
-啥叫「自顶向下」?注意我们刚才画的递归树(或者说图),是从上向下延伸,都是从一个规模较大的原问题比如说 `f(20)`,向下逐渐分解规模,直到 `f(1)` 和 `f(2)` 触底,然后逐层返回答案,这就叫「自顶向下」。
-啥叫「自底向上」?反过来,我们直接从最底下,最简单,问题规模最小的 `f(1)` 和 `f(2)` 开始往上推,直到推到我们想要的答案 `f(20)`,这就是动态规划的思路,这也是为什么动态规划一般都脱离了递归,而是由循环迭代完成计算。
+至此,带备忘录的递归解法的效率已经和迭代的动态规划解法一样了。实际上,这种解法和常见的动态规划解法已经差不多了,只不过这种解法是「自顶向下」进行「递归」求解,我们更常见的动态规划代码是「自底向上」进行「递推」求解。
-**3、dp 数组的迭代解法**
+啥叫「自顶向下」?注意我们刚才画的递归树(或者说图),是从上向下延伸,都是从一个规模较大的原问题比如说 `f(20)`,向下逐渐分解规模,直到 `f(1)` 和 `f(2)` 这两个 base case,然后逐层返回答案,这就叫「自顶向下」。
-有了上一步「备忘录」的启发,我们可以把这个「备忘录」独立出来成为一张表,就叫做 DP table 吧,在这张表上完成「自底向上」的推算岂不美哉!
+啥叫「自底向上」?反过来,我们直接从最底下、最简单、问题规模最小、已知结果的 `f(1)` 和 `f(2)`(base case)开始往上推,直到推到我们想要的答案 `f(20)`。这就是「递推」的思路,这也是动态规划一般都脱离了递归,而是由循环迭代完成计算的原因。
-```cpp
+### `dp` 数组的迭代(递推)解法
+
+有了上一步「备忘录」的启发,我们可以把这个「备忘录」独立出来成为一张表,通常叫做 DP table,在这张表上完成「自底向上」的推算岂不美哉!
+
+```java
int fib(int N) {
- vector dp(N + 1, 0);
+ if (N == 0) return 0;
+ int[] dp = new int[N + 1];
// base case
- dp[1] = dp[2] = 1;
- for (int i = 3; i <= N; i++)
+ dp[0] = 0; dp[1] = 1;
+ // 状态转移
+ for (int i = 2; i <= N; i++) {
dp[i] = dp[i - 1] + dp[i - 2];
+ }
+
return dp[N];
}
```
-
-画个图就很好理解了,而且你发现这个 DP table 特别像之前那个「剪枝」后的结果,只是反过来算而已。实际上,带备忘录的递归解法中的「备忘录」,最终完成后就是这个 DP table,所以说这两种解法其实是差不多的,大部分情况下,效率也基本相同。
+
+
+
+
+🌟 代码可视化动画🌟
+
+
+
+
+
+
+
+画个图就很好理解了,而且你发现这个 DP table 特别像之前那个「剪枝」后的结果,只是反过来算而已:
+
+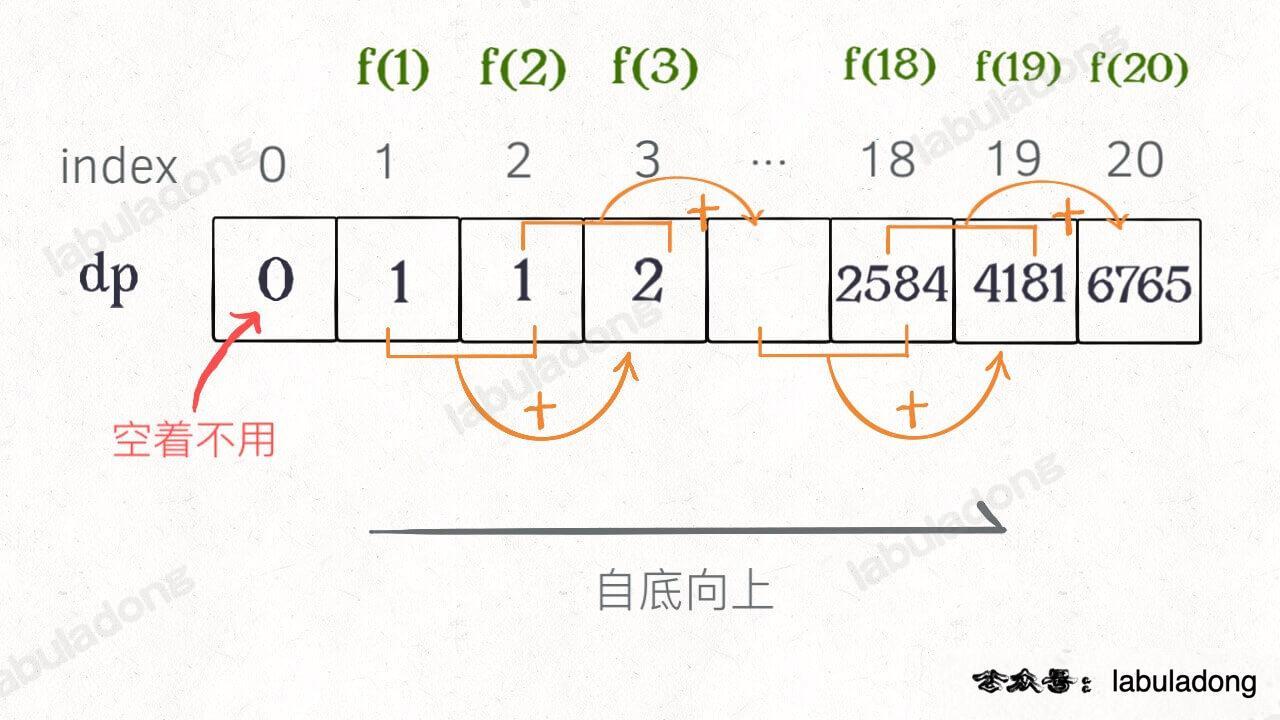
+
+实际上,带备忘录的递归解法中的那个「备忘录」`memo` 数组,最终完成后就是这个解法中的 `dp` 数组,你对比一下可视化面板中两个算法执行的过程可以更直观地看出它俩的联系。
+
+所以说自顶向下、自底向上两种解法本质其实是差不多的,大部分情况下,效率也基本相同。
+
+
+
+
+
+
+
+### 拓展延伸
这里,引出「状态转移方程」这个名词,实际上就是描述问题结构的数学形式:
-
+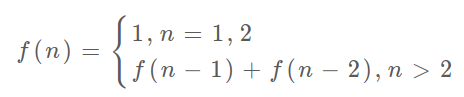
+
+为啥叫「状态转移方程」?其实就是为了听起来高端。
+
+`f(n)` 的函数参数会不断变化,所以你把参数 `n` 想做一个状态,这个状态 `n` 是由状态 `n - 1` 和状态 `n - 2` 转移(相加)而来,这就叫状态转移,仅此而已。
+
+你会发现,上面的几种解法中的所有操作,例如 `return f(n - 1) + f(n - 2)`,`dp[i] = dp[i - 1] + dp[i - 2]`,以及对备忘录或 DP table 的初始化操作,都是围绕这个方程式的不同表现形式。
+
+可见列出「状态转移方程」的重要性,它是解决问题的核心,而且很容易发现,其实状态转移方程直接代表着暴力解法。
-为啥叫「状态转移方程」?为了听起来高端。你把 f(n) 想做一个状态 n,这个状态 n 是由状态 n - 1 和状态 n - 2 相加转移而来,这就叫状态转移,仅此而已。
+**千万不要看不起暴力解,动态规划问题最困难的就是写出这个暴力解,即状态转移方程**。
-你会发现,上面的几种解法中的所有操作,例如 return f(n - 1) + f(n - 2),dp[i] = dp[i - 1] + dp[i - 2],以及对备忘录或 DP table 的初始化操作,都是围绕这个方程式的不同表现形式。可见列出「状态转移方程」的重要性,它是解决问题的核心。很容易发现,其实状态转移方程直接代表着暴力解法。
+只要写出暴力解,优化方法无非是用备忘录或者 DP table,再无奥妙可言。
-**千万不要看不起暴力解,动态规划问题最困难的就是写出状态转移方程**,即这个暴力解。优化方法无非是用备忘录或者 DP table,再无奥妙可言。
+这个例子的最后,讲一个细节优化。
-这个例子的最后,讲一个细节优化。细心的读者会发现,根据斐波那契数列的状态转移方程,当前状态只和之前的两个状态有关,其实并不需要那么长的一个 DP table 来存储所有的状态,只要想办法存储之前的两个状态就行了。所以,可以进一步优化,把空间复杂度降为 O(1):
+细心的读者会发现,根据斐波那契数列的状态转移方程,当前状态 `n` 只和之前的 `n-1, n-2` 两个状态有关,其实并不需要那么长的一个 DP table 来存储所有的状态,只要想办法存储之前的两个状态就行了。
-```cpp
+所以,可以进一步优化,把空间复杂度降为 O(1)。这也就是我们最常见的计算斐波那契数的算法:
+
+```java
int fib(int n) {
- if (n == 2 || n == 1)
- return 1;
- int prev = 1, curr = 1;
- for (int i = 3; i <= n; i++) {
- int sum = prev + curr;
- prev = curr;
- curr = sum;
+ if (n == 0 || n == 1) {
+ // base case
+ return n;
}
- return curr;
+ // 分别代表 dp[i - 1] 和 dp[i - 2]
+ int dp_i_1 = 1, dp_i_2 = 0;
+ for (int i = 2; i <= n; i++) {
+ // dp[i] = dp[i - 1] + dp[i - 2];
+ int dp_i = dp_i_1 + dp_i_2;
+ // 滚动更新
+ dp_i_2 = dp_i_1;
+ dp_i_1 = dp_i;
+ }
+ return dp_i_1;
}
```
-有人会问,动态规划的另一个重要特性「最优子结构」,怎么没有涉及?下面会涉及。斐波那契数列的例子严格来说不算动态规划,因为没有涉及求最值,以上旨在演示算法设计螺旋上升的过程。下面,看第二个例子,凑零钱问题。
-### 二、凑零钱问题
+
+
+
+
+🌟 代码可视化动画🌟
+
+
+
+
+
-先看下题目:给你 `k` 种面值的硬币,面值分别为 `c1, c2 ... ck`,每种硬币的数量无限,再给一个总金额 `amount`,问你**最少**需要几枚硬币凑出这个金额,如果不可能凑出,算法返回 -1 。算法的函数签名如下:
+
+这一般是动态规划问题的最后一步优化,如果我们发现每次状态转移只需要 DP table 中的一部分,那么可以尝试缩小 DP table 的大小,只记录必要的数据,从而降低空间复杂度。
+
+上述例子就相当于把 DP table 的大小从 `n` 缩小到 2,即把空间复杂度下降了一个量级。我会在后文 [对动态规划发动降维打击](https://labuladong.online/algo/dynamic-programming/space-optimization/) 进一步讲解这个压缩空间复杂度的技巧,一般来说用来把一个二维的 DP table 压缩成一维,即把空间复杂度从 O(n^2) 压缩到 O(n)。
+
+有人会问,动态规划的另一个重要特性「最优子结构」,怎么没有涉及?下面会涉及。斐波那契数列的例子严格来说不算动态规划,因为没有涉及求最值,以上旨在说明重叠子问题的消除方法,演示得到最优解法逐步求精的过程。下面,看第二个例子,凑零钱问题。
+
+## 二、凑零钱问题
+
+这是力扣第 322 题「零钱兑换」:
+
+给你 `k` 种面值的硬币,面值分别为 `c1, c2 ... ck`,每种硬币的数量无限,再给一个总金额 `amount`,问你**最少**需要几枚硬币凑出这个金额,如果不可能凑出,算法返回 -1 。算法的函数签名如下:
```java
// coins 中是可选硬币面值,amount 是目标金额
@@ -165,152 +327,329 @@ int coinChange(int[] coins, int amount);
比如说 `k = 3`,面值分别为 1,2,5,总金额 `amount = 11`。那么最少需要 3 枚硬币凑出,即 11 = 5 + 5 + 1。
-你认为计算机应该如何解决这个问题?显然,就是把所有肯能的凑硬币方法都穷举出来,然后找找看最少需要多少枚硬币。
+你认为计算机应该如何解决这个问题?显然,就是把所有可能的凑硬币方法都穷举出来,然后找找看最少需要多少枚硬币。
-**1、暴力递归**
+### 暴力递归
首先,这个问题是动态规划问题,因为它具有「最优子结构」的。**要符合「最优子结构」,子问题间必须互相独立**。啥叫相互独立?你肯定不想看数学证明,我用一个直观的例子来讲解。
-比如说,你的原问题是考出最高的总成绩,那么你的子问题就是要把语文考到最高,数学考到最高…… 为了每门课考到最高,你要把每门课相应的选择题分数拿到最高,填空题分数拿到最高…… 当然,最终就是你每门课都是满分,这就是最高的总成绩。
+比如说,假设你考试,每门科目的成绩都是互相独立的。你的原问题是考出最高的总成绩,那么你的子问题就是要把语文考到最高,数学考到最高…… 为了每门课考到最高,你要把每门课相应的选择题分数拿到最高,填空题分数拿到最高…… 当然,最终就是你每门课都是满分,这就是最高的总成绩。
-得到了正确的结果:最高的总成绩就是总分。因为这个过程符合最优子结构,“每门科目考到最高”这些子问题是互相独立,互不干扰的。
+得到了正确的结果:最高的总成绩就是总分。因为这个过程符合最优子结构,「每门科目考到最高」这些子问题是互相独立,互不干扰的。
-但是,如果加一个条件:你的语文成绩和数学成绩会互相制约,此消彼长。这样的话,显然你能考到的最高总成绩就达不到总分了,按刚才那个思路就会得到错误的结果。因为子问题并不独立,语文数学成绩无法同时最优,所以最优子结构被破坏。
+但是,如果加一个条件:你的语文成绩和数学成绩会互相制约,不能同时达到满分,数学分数高,语文分数就会降低,反之亦然。
-回到凑零钱问题,为什么说它符合最优子结构呢?比如你想求 `amount = 11` 时的最少硬币数(原问题),如果你知道凑出 `amount = 10` 的最少硬币数(子问题),你只需要把子问题的答案加一(再选一枚面值为 1 的硬币)就是原问题的答案,因为硬币的数量是没有限制的,子问题之间没有相互制,是互相独立的。
+这样的话,显然你能考到的最高总成绩就达不到总分了,按刚才那个思路就会得到错误的结果。因为「每门科目考到最高」的子问题并不独立,语文数学成绩户互相影响,无法同时最优,所以最优子结构被破坏。
-那么,既然知道了这是个动态规划问题,就要思考**如何列出正确的状态转移方程**?
+回到凑零钱问题,为什么说它符合最优子结构呢?假设你有面值为 `1, 2, 5` 的硬币,你想求 `amount = 11` 时的最少硬币数(原问题),如果你知道凑出 `amount = 10, 9, 6` 的最少硬币数(子问题),你只需要把子问题的答案加一(再选一枚面值为 `1, 2, 5` 的硬币),求个最小值,就是原问题的答案。因为硬币的数量是没有限制的,所以子问题之间没有相互制,是互相独立的。
-**先确定「状态」**,也就是原问题和子问题中变化的变量。由于硬币数量无限,所以唯一的状态就是目标金额 `amount`。
-**然后确定 `dp` 函数的定义**:当前的目标金额是 `n`,至少需要 `dp(n)` 个硬币凑出该金额。
-**然后确定「选择」并择优**,也就是对于每个状态,可以做出什么选择改变当前状态。具体到这个问题,无论当的目标金额是多少,选择就是从面额列表 `coins` 中选择一个硬币,然后目标金额就会减少:
-```python
-# 伪码框架
-def coinChange(coins: List[int], amount: int):
- # 定义:要凑出金额 n,至少要 dp(n) 个硬币
- def dp(n):
- # 做选择,选择需要硬币最少的那个结果
- for coin in coins:
- res = min(res, 1 + dp(n - coin))
- return res
- # 我们要求的问题是 dp(amount)
- return dp(amount)
+
+
+
+> [!TIP]
+> 关于最优子结构的问题,后文 [动态规划答疑篇](https://labuladong.online/algo/dynamic-programming/faq-summary/) 还会再举例探讨。
+
+那么,既然知道了这是个动态规划问题,就要思考如何列出正确的状态转移方程?
+
+**1、确定「状态」,也就是原问题和子问题中会变化的变量**。由于硬币数量无限,硬币的面额也是题目给定的,只有目标金额会不断地向 base case 靠近,所以唯一的「状态」就是目标金额 `amount`。
+
+**2、确定「选择」,也就是导致「状态」产生变化的行为**。目标金额为什么变化呢,因为你在选择硬币,你每选择一枚硬币,就相当于减少了目标金额。所以说所有硬币的面值,就是你的「选择」。
+
+**3、明确 `dp` 函数/数组的定义**。我们这里讲的是自顶向下的解法,所以会有一个递归的 `dp` 函数,一般来说函数的参数就是状态转移中会变化的量,也就是上面说到的「状态」;函数的返回值就是题目要求我们计算的量。就本题来说,状态只有一个,即「目标金额」,题目要求我们计算凑出目标金额所需的最少硬币数量。
+
+**所以我们可以这样定义 `dp` 函数:`dp(n)` 表示,输入一个目标金额 `n`,返回凑出目标金额 `n` 所需的最少硬币数量**。
+
+那么根据这个定义,我们的最终答案就是 `dp(amount)` 的返回值。
+
+搞清楚上面这几个关键点,解法的伪码就可以写出来了:
+
+```java
+// 伪码框架
+int coinChange(int[] coins, int amount) {
+ // 题目要求的最终结果是 dp(amount)
+ return dp(coins, amount);
+}
+
+// 定义:要凑出金额 n,至少要 dp(coins, n) 个硬币
+int dp(int[] coins, int n) {
+ // 做选择,选择需要硬币最少的那个结果
+ for (int coin : coins) {
+ res = min(res, 1 + dp(coins, n - coin));
+ }
+ return res;
+}
```
-**最后明确 base case**,显然目标金额为 0 时,所需硬币数量为 0;当目标金额小于 0 时,无解,返回 -1:
+根据伪码,我们加上 base case 即可得到最终的答案。显然目标金额为 0 时,所需硬币数量为 0;当目标金额小于 0 时,无解,返回 -1:
-```python
-def coinChange(coins: List[int], amount: int):
-
- def dp(n):
- # base case
- if n == 0: return 0
- if n < 0: return -1
- # 求最小值,所以初始化为正无穷
- res = float('INF')
- for coin in coins:
- subproblem = dp(n - coin)
- # 子问题无解,跳过
- if subproblem == -1: continue
- res = min(res, 1 + subproblem)
-
- return res if res != float('INF') else -1
-
- return dp(amount)
+```java
+class Solution {
+ public int coinChange(int[] coins, int amount) {
+ // 题目要求的最终结果是 dp(amount)
+ return dp(coins, amount);
+ }
+
+ // 定义:要凑出金额 n,至少要 dp(coins, n) 个硬币
+ int dp(int[] coins, int amount) {
+ // base case
+ if (amount == 0) return 0;
+ if (amount < 0) return -1;
+
+ int res = Integer.MAX_VALUE;
+ for (int coin : coins) {
+ // 计算子问题的结果
+ int subProblem = dp(coins, amount - coin);
+ // 子问题无解则跳过
+ if (subProblem == -1) continue;
+ // 在子问题中选择最优解,然后加一
+ res = Math.min(res, subProblem + 1);
+ }
+
+ return res == Integer.MAX_VALUE ? -1 : res;
+ }
+}
```
+> [!NOTE]
+> 这里 `coinChange` 和 `dp` 函数的签名完全一样,所以理论上不需要额外写一个 `dp` 函数。但为了后文讲解方便,这里还是另写一个 `dp` 函数来实现主要逻辑。
+>
+> 另外,我经常看到有读者留言问,子问题的结果为什么要加 1(`subProblem + 1`),而不是加硬币金额之类的。我这里统一提示一下,动态规划问题的关键是 `dp` 函数/数组的定义,你这个函数的返回值代表什么?你回过头去搞清楚这一点,然后就知道为什么要给子问题的返回值加 1 了。
+
+
+
+
+
+
+🎃 代码可视化动画🎃
+
+
+
+
+
至此,状态转移方程其实已经完成了,以上算法已经是暴力解法了,以上代码的数学形式就是状态转移方程:
-
+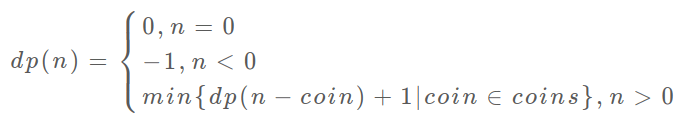
至此,这个问题其实就解决了,只不过需要消除一下重叠子问题,比如 `amount = 11, coins = {1,2,5}` 时画出递归树看看:
-
+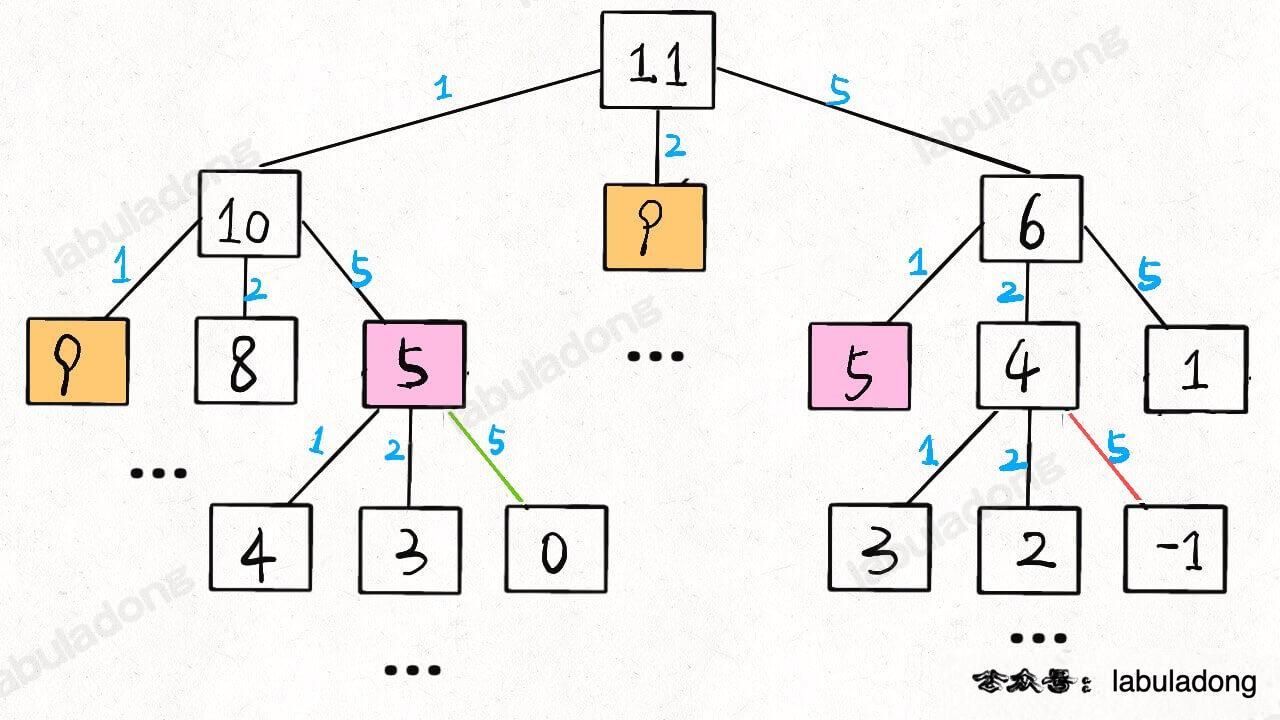
-**时间复杂度分析:子问题总数 x 每个子问题的时间**。
+**递归算法的时间复杂度分析:子问题总数 x 解决每个子问题所需的时间**。
-子问题总数为递归树节点个数,这个比较难看出来,是 O(n^k),总之是指数级别的。每个子问题中含有一个 for 循环,复杂度为 O(k)。所以总时间复杂度为 O(k * n^k),指数级别。
+子问题总数为递归树的节点个数,但算法会进行剪枝,剪枝的时机和题目给定的具体硬币面额有关,所以可以想象,这棵树生长的并不规则,确切算出树上有多少节点是比较困难的。对于这种情况,我们一般的做法是按照最坏的情况估算一个时间复杂度的上界。
-**2、带备忘录的递归**
+假设目标金额为 `n`,给定的硬币个数为 `k`,那么递归树最坏情况下高度为 `n`(全用面额为 1 的硬币),然后再假设这是一棵满 `k` 叉树,则节点的总数在 `k^n` 这个数量级。
-只需要稍加修改,就可以通过备忘录消除子问题:
+接下来看每个子问题的复杂度,由于每次递归包含一个 for 循环,复杂度为 $O(k)$,相乘得到总时间复杂度为 $O(k^n)$,指数级别。
-```python
-def coinChange(coins: List[int], amount: int):
- # 备忘录
- memo = dict()
- def dp(n):
- # 查备忘录,避免重复计算
- if n in memo: return memo[n]
-
- if n == 0: return 0
- if n < 0: return -1
- res = float('INF')
- for coin in coins:
- subproblem = dp(n - coin)
- if subproblem == -1: continue
- res = min(res, 1 + subproblem)
-
- # 记入备忘录
- memo[n] = res if res != float('INF') else -1
- return memo[n]
-
- return dp(amount)
-```
+### 带备忘录的递归
-不画图了,很显然「备忘录」大大减小了子问题数目,完全消除了子问题的冗余,所以子问题总数不会超过金额数 n,即子问题数目为 O(n)。处理一个子问题的时间不变,仍是 O(k),所以总的时间复杂度是 O(kn)。
+类似之前斐波那契数列的例子,只需要稍加修改,就可以通过备忘录消除子问题:
-**3、dp 数组的迭代解法**
+```java
+class Solution {
+ int[] memo;
-当然,我们也可以自底向上使用 dp table 来消除重叠子问题,`dp` 数组的定义和刚才 `dp` 函数类似,定义也是一样的:
+ public int coinChange(int[] coins, int amount) {
+ memo = new int[amount + 1];
+ // 备忘录初始化为一个不会被取到的特殊值,代表还未被计算
+ Arrays.fill(memo, -666);
-**`dp[i] = x` 表示,当目标金额为 `i` 时,至少需要 `x` 枚硬币**。
+ return dp(coins, amount);
+ }
-```cpp
-int coinChange(vector& coins, int amount) {
- // 数组大小为 amount + 1,初始值也为 amount + 1
- vector dp(amount + 1, amount + 1);
- // base case
- dp[0] = 0;
- for (int i = 0; i < dp.size(); i++) {
- // 内层 for 在求所有子问题 + 1 的最小值
+ int dp(int[] coins, int amount) {
+ if (amount == 0) return 0;
+ if (amount < 0) return -1;
+ // 查备忘录,防止重复计算
+ if (memo[amount] != -666)
+ return memo[amount];
+
+ int res = Integer.MAX_VALUE;
for (int coin : coins) {
- // 子问题无解,跳过
- if (i - coin < 0) continue;
- dp[i] = min(dp[i], 1 + dp[i - coin]);
+ // 计算子问题的结果
+ int subProblem = dp(coins, amount - coin);
+ // 子问题无解则跳过
+ if (subProblem == -1) continue;
+ // 在子问题中选择最优解,然后加一
+ res = Math.min(res, subProblem + 1);
}
+ // 把计算结果存入备忘录
+ memo[amount] = (res == Integer.MAX_VALUE) ? -1 : res;
+ return memo[amount];
}
- return (dp[amount] == amount + 1) ? -1 : dp[amount];
}
```
-
-PS:为啥 `dp` 数组初始化为 `amount + 1` 呢,因为凑成 `amount` 金额的硬币数最多只可能等于 `amount`(全用 1 元面值的硬币),所以初始化为 `amount + 1` 就相当于初始化为正无穷,便于后续取最小值。
+
+
+
+
+🥳 代码可视化动画🥳
+
+
+
+
-### 三、最后总结
-第一个斐波那契数列的问题,解释了如何通过「备忘录」或者「dp table」的方法来优化递归树,并且明确了这两种方法本质上是一样的,只是自顶向下和自底向上的不同而已。
-第二个凑零钱的问题,展示了如何流程化确定「状态转移方程」,只要通过状态转移方程写出暴力递归解,剩下的也就是优化递归树,消除重叠子问题而已。
+不画图了,很显然「备忘录」大大减小了子问题数目,完全消除了子问题的冗余,所以子问题总数不会超过金额数 `n`,即子问题数目为 $O(n)$。处理一个子问题的时间不变,仍是 $O(k)$,所以总的时间复杂度是 $O(kn)$。
-如果你不太了解动态规划,还能看到这里,真得给你鼓掌,相信你已经掌握了这个算法的设计技巧。
+### dp 数组的迭代解法
-**计算机解决问题其实没有任何奇技淫巧,它唯一的解决办法就是穷举**,穷举所有可能性。算法设计无非就是先思考“如何穷举”,然后再追求“如何聪明地穷举”。
+当然,我们也可以自底向上使用 dp table 来消除重叠子问题,关于「状态」「选择」和 base case 与之前没有区别,`dp` 数组的定义和刚才 `dp` 函数类似,也是把「状态」,也就是目标金额作为变量。不过 `dp` 函数体现在函数参数,而 `dp` 数组体现在数组索引:
-列出动态转移方程,就是在解决“如何穷举”的问题。之所以说它难,一是因为很多穷举需要递归实现,二是因为有的问题本身的解空间复杂,不那么容易穷举完整。
+**`dp` 数组的定义:当目标金额为 `i` 时,至少需要 `dp[i]` 枚硬币凑出**。
-备忘录、DP table 就是在追求“如何聪明地穷举”。用空间换时间的思路,是降低时间复杂度的不二法门,除此之外,试问,还能玩出啥花活?
+根据我们文章开头给出的动态规划代码框架可以写出如下解法:
-**致力于把算法讲清楚!欢迎关注我的微信公众号 labuladong,查看更多通俗易懂的文章**:
+```java
+class Solution {
+ public int coinChange(int[] coins, int amount) {
+ int[] dp = new int[amount + 1];
+ // 数组大小为 amount + 1,初始值也为 amount + 1
+ Arrays.fill(dp, amount + 1);
+
+ // base case
+ dp[0] = 0;
+ // 外层 for 循环在遍历所有状态的所有取值
+ for (int i = 0; i < dp.length; i++) {
+ // 内层 for 循环在求所有选择的最小值
+ for (int coin : coins) {
+ // 子问题无解,跳过
+ if (i - coin < 0) {
+ continue;
+ }
+ dp[i] = Math.min(dp[i], 1 + dp[i - coin]);
+ }
+ }
+ return (dp[amount] == amount + 1) ? -1 : dp[amount];
+ }
+}
+```
-
+> [!NOTE]
+> 为啥 `dp` 数组中的值都初始化为 `amount + 1` 呢,因为凑成 `amount` 金额的硬币数最多只可能等于 `amount`(全用 1 元面值的硬币),所以初始化为 `amount + 1` 就相当于初始化为正无穷,便于后续取最小值。为啥不直接初始化为 int 型的最大值 `Integer.MAX_VALUE` 呢?因为后面有 `dp[i - coin] + 1`,这就会导致整型溢出。
-[上一篇:学习数据结构和算法读什么书](../算法思维系列/为什么推荐算法4.md)
+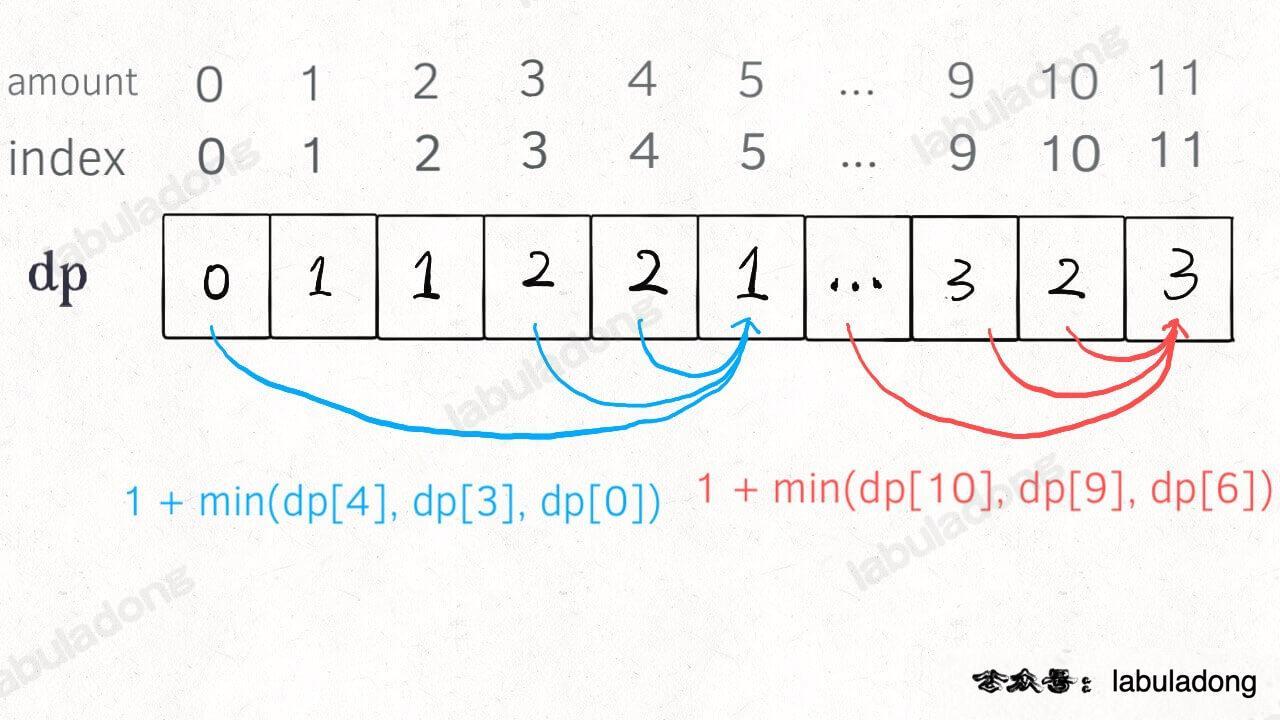
-[下一篇:动态规划答疑篇](../动态规划系列/最优子结构.md)
+## 三、最后总结
+
+第一个斐波那契数列的问题,解释了如何通过「备忘录」或者「dp table」的方法来优化递归树,并且明确了这两种方法本质上是一样的,只是自顶向下和自底向上的不同而已。
+
+第二个凑零钱的问题,展示了如何流程化确定「状态转移方程」,只要通过状态转移方程写出暴力递归解,剩下的也就是优化递归树,消除重叠子问题而已。
+
+如果你不太了解动态规划,还能看到这里,真得给你鼓掌,相信你已经掌握了这个算法的设计技巧。
+
+**计算机解决问题其实没有任何特殊的技巧,它唯一的解决办法就是穷举**,穷举所有可能性。算法设计无非就是先思考“如何穷举”,然后再追求“如何聪明地穷举”。
+
+列出状态转移方程,就是在解决“如何穷举”的问题。之所以说它难,一是因为很多穷举需要递归实现,二是因为有的问题本身的解空间复杂,不那么容易穷举完整。
+
+备忘录、DP table 就是在追求“如何聪明地穷举”。用空间换时间的思路,是降低时间复杂度的不二法门,除此之外,试问,还能玩出啥花活?
-[目录](../README.md#目录)
\ No newline at end of file
+之后我们会有一章专门讲解动态规划问题,如果有任何问题都可以随时回来重读本文,希望读者在阅读每个题目和解法时,多往「状态」和「选择」上靠,才能对这套框架产生自己的理解,运用自如。
+
+
+
+
+
+
+
+
+
+引用本文的文章
+
+ - [base case 和备忘录的初始值怎么定?](https://labuladong.online/algo/dynamic-programming/memo-fundamental/)
+ - [【强化练习】BFS 经典习题 II](https://labuladong.online/algo/problem-set/bfs-ii/)
+ - [【强化练习】二分搜索算法经典习题](https://labuladong.online/algo/problem-set/binary-search/)
+ - [【强化练习】单调队列的通用实现及经典习题](https://labuladong.online/algo/problem-set/monotonic-queue/)
+ - [【强化练习】同时运用两种思维解题](https://labuladong.online/algo/problem-set/binary-tree-combine-two-view/)
+ - [【强化练习】数学技巧相关习题](https://labuladong.online/algo/problem-set/math-tricks/)
+ - [一个方法团灭 LeetCode 打家劫舍问题](https://labuladong.online/algo/dynamic-programming/house-robber/)
+ - [一个方法团灭 LeetCode 股票买卖问题](https://labuladong.online/algo/dynamic-programming/stock-problem-summary/)
+ - [二叉树基础及常见类型](https://labuladong.online/algo/data-structure-basic/binary-tree-basic/)
+ - [二叉树系列算法核心纲领](https://labuladong.online/algo/essential-technique/binary-tree-summary/)
+ - [分治算法解题套路框架](https://labuladong.online/algo/essential-technique/divide-and-conquer/)
+ - [动态规划之子序列问题解题模板](https://labuladong.online/algo/dynamic-programming/subsequence-problem/)
+ - [动态规划之最小路径和](https://labuladong.online/algo/dynamic-programming/minimum-path-sum/)
+ - [动态规划和回溯算法的思维转换](https://labuladong.online/algo/dynamic-programming/word-break/)
+ - [动态规划帮我通关了《辐射4》](https://labuladong.online/algo/dynamic-programming/freedom-trail/)
+ - [动态规划帮我通关了《魔塔》](https://labuladong.online/algo/dynamic-programming/magic-tower/)
+ - [动态规划穷举的两种视角](https://labuladong.online/algo/dynamic-programming/two-views-of-dp/)
+ - [动态规划设计:最大子数组](https://labuladong.online/algo/dynamic-programming/maximum-subarray/)
+ - [动态规划设计:最长递增子序列](https://labuladong.online/algo/dynamic-programming/longest-increasing-subsequence/)
+ - [学习数据结构和算法的框架思维](https://labuladong.online/algo/essential-technique/algorithm-summary/)
+ - [对动态规划进行降维打击](https://labuladong.online/algo/dynamic-programming/space-optimization/)
+ - [拓展:归并排序详解及应用](https://labuladong.online/algo/practice-in-action/merge-sort/)
+ - [旅游省钱大法:加权最短路径](https://labuladong.online/algo/dynamic-programming/cheap-travel/)
+ - [最优子结构原理和 dp 数组遍历方向](https://labuladong.online/algo/dynamic-programming/faq-summary/)
+ - [算法学习和心流体验](https://labuladong.online/algo/fname.html?fname=心流)
+ - [算法时空复杂度分析实用指南](https://labuladong.online/algo/essential-technique/complexity-analysis/)
+ - [算法笔试「骗分」套路](https://labuladong.online/algo/other-skills/tips-in-exam/)
+ - [经典动态规划:0-1 背包问题](https://labuladong.online/algo/dynamic-programming/knapsack1/)
+ - [经典动态规划:博弈问题](https://labuladong.online/algo/dynamic-programming/game-theory/)
+ - [经典动态规划:子集背包问题](https://labuladong.online/algo/dynamic-programming/knapsack2/)
+ - [经典动态规划:完全背包问题](https://labuladong.online/algo/dynamic-programming/knapsack3/)
+ - [经典动态规划:戳气球](https://labuladong.online/algo/dynamic-programming/burst-balloons/)
+ - [经典动态规划:最长公共子序列](https://labuladong.online/algo/dynamic-programming/longest-common-subsequence/)
+ - [经典动态规划:正则表达式](https://labuladong.online/algo/dynamic-programming/regular-expression-matching/)
+ - [经典动态规划:编辑距离](https://labuladong.online/algo/dynamic-programming/edit-distance/)
+ - [经典动态规划:高楼扔鸡蛋](https://labuladong.online/algo/dynamic-programming/egg-drop/)
+ - [老司机加油算法](https://labuladong.online/algo/frequency-interview/gas-station-greedy/)
+ - [背包问题的变体:目标和](https://labuladong.online/algo/dynamic-programming/target-sum/)
+ - [贪心算法解题套路框架](https://labuladong.online/algo/essential-technique/greedy/)
+
+
+
+
+
+
+
+
+引用本文的题目
+
+安装 [我的 Chrome 刷题插件](https://labuladong.online/algo/intro/chrome/) 点开下列题目可直接查看解题思路:
+
+| LeetCode | 力扣 | 难度 |
+| :----: | :----: | :----: |
+| [111. Minimum Depth of Binary Tree](https://leetcode.com/problems/minimum-depth-of-binary-tree/?show=1) | [111. 二叉树的最小深度](https://leetcode.cn/problems/minimum-depth-of-binary-tree/?show=1) | 🟢 |
+| [112. Path Sum](https://leetcode.com/problems/path-sum/?show=1) | [112. 路径总和](https://leetcode.cn/problems/path-sum/?show=1) | 🟢 |
+| [115. Distinct Subsequences](https://leetcode.com/problems/distinct-subsequences/?show=1) | [115. 不同的子序列](https://leetcode.cn/problems/distinct-subsequences/?show=1) | 🔴 |
+| [139. Word Break](https://leetcode.com/problems/word-break/?show=1) | [139. 单词拆分](https://leetcode.cn/problems/word-break/?show=1) | 🟠 |
+| [1696. Jump Game VI](https://leetcode.com/problems/jump-game-vi/?show=1) | [1696. 跳跃游戏 VI](https://leetcode.cn/problems/jump-game-vi/?show=1) | 🟠 |
+| [221. Maximal Square](https://leetcode.com/problems/maximal-square/?show=1) | [221. 最大正方形](https://leetcode.cn/problems/maximal-square/?show=1) | 🟠 |
+| [240. Search a 2D Matrix II](https://leetcode.com/problems/search-a-2d-matrix-ii/?show=1) | [240. 搜索二维矩阵 II](https://leetcode.cn/problems/search-a-2d-matrix-ii/?show=1) | 🟠 |
+| [256. Paint House](https://leetcode.com/problems/paint-house/?show=1)🔒 | [256. 粉刷房子](https://leetcode.cn/problems/paint-house/?show=1)🔒 | 🟠 |
+| [279. Perfect Squares](https://leetcode.com/problems/perfect-squares/?show=1) | [279. 完全平方数](https://leetcode.cn/problems/perfect-squares/?show=1) | 🟠 |
+| [343. Integer Break](https://leetcode.com/problems/integer-break/?show=1) | [343. 整数拆分](https://leetcode.cn/problems/integer-break/?show=1) | 🟠 |
+| [365. Water and Jug Problem](https://leetcode.com/problems/water-and-jug-problem/?show=1) | [365. 水壶问题](https://leetcode.cn/problems/water-and-jug-problem/?show=1) | 🟠 |
+| [542. 01 Matrix](https://leetcode.com/problems/01-matrix/?show=1) | [542. 01 矩阵](https://leetcode.cn/problems/01-matrix/?show=1) | 🟠 |
+| [576. Out of Boundary Paths](https://leetcode.com/problems/out-of-boundary-paths/?show=1) | [576. 出界的路径数](https://leetcode.cn/problems/out-of-boundary-paths/?show=1) | 🟠 |
+| [62. Unique Paths](https://leetcode.com/problems/unique-paths/?show=1) | [62. 不同路径](https://leetcode.cn/problems/unique-paths/?show=1) | 🟠 |
+| [63. Unique Paths II](https://leetcode.com/problems/unique-paths-ii/?show=1) | [63. 不同路径 II](https://leetcode.cn/problems/unique-paths-ii/?show=1) | 🟠 |
+| [70. Climbing Stairs](https://leetcode.com/problems/climbing-stairs/?show=1) | [70. 爬楼梯](https://leetcode.cn/problems/climbing-stairs/?show=1) | 🟢 |
+| [91. Decode Ways](https://leetcode.com/problems/decode-ways/?show=1) | [91. 解码方法](https://leetcode.cn/problems/decode-ways/?show=1) | 🟠 |
+| - | [剑指 Offer 04. 二维数组中的查找](https://leetcode.cn/problems/er-wei-shu-zu-zhong-de-cha-zhao-lcof/?show=1) | 🟠 |
+| - | [剑指 Offer 10- I. 斐波那契数列](https://leetcode.cn/problems/fei-bo-na-qi-shu-lie-lcof/?show=1) | 🟢 |
+| - | [剑指 Offer 10- II. 青蛙跳台阶问题](https://leetcode.cn/problems/qing-wa-tiao-tai-jie-wen-ti-lcof/?show=1) | 🟢 |
+| - | [剑指 Offer 14- I. 剪绳子](https://leetcode.cn/problems/jian-sheng-zi-lcof/?show=1) | 🟠 |
+| - | [剑指 Offer 46. 把数字翻译成字符串](https://leetcode.cn/problems/ba-shu-zi-fan-yi-cheng-zi-fu-chuan-lcof/?show=1) | 🟠 |
+| - | [剑指 Offer II 091. 粉刷房子](https://leetcode.cn/problems/JEj789/?show=1) | 🟠 |
+| - | [剑指 Offer II 097. 子序列的数目](https://leetcode.cn/problems/21dk04/?show=1) | 🔴 |
+| - | [剑指 Offer II 098. 路径的数目](https://leetcode.cn/problems/2AoeFn/?show=1) | 🟠 |
+| - | [剑指 Offer II 103. 最少的硬币数目](https://leetcode.cn/problems/gaM7Ch/?show=1) | 🟠 |
+
+
+
+
+
+
+**_____________**
+
+
+
+
\ No newline at end of file
diff --git "a/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\345\215\225\350\257\215\346\213\274\346\216\245.md" "b/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\345\215\225\350\257\215\346\213\274\346\216\245.md"
new file mode 100644
index 0000000000..cba8ca949b
--- /dev/null
+++ "b/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\345\215\225\350\257\215\346\213\274\346\216\245.md"
@@ -0,0 +1,571 @@
+# 动态规划和回溯算法的思维转换
+
+
+
+
+
+**通知:为满足广大读者的需求,网站上架 [速成目录](https://labuladong.online/algo/intro/quick-learning-plan/),如有需要可以看下,谢谢大家的支持~另外,建议你在我的 [网站](https://labuladong.online/algo/) 学习文章,体验更好。**
+
+
+
+读完本文,你不仅学会了算法套路,还可以顺便解决如下题目:
+
+| LeetCode | 力扣 | 难度 |
+| :----: | :----: | :----: |
+| [139. Word Break](https://leetcode.com/problems/word-break/) | [139. 单词拆分](https://leetcode.cn/problems/word-break/) | 🟠 |
+| [140. Word Break II](https://leetcode.com/problems/word-break-ii/) | [140. 单词拆分 II](https://leetcode.cn/problems/word-break-ii/) | 🔴 |
+
+**-----------**
+
+
+
+> [!NOTE]
+> 阅读本文前,你需要先学习:
+>
+> - [二叉树系列算法(纲领篇)](https://labuladong.online/algo/essential-technique/binary-tree-summary/)
+> - [动态规划核心框架](https://labuladong.online/algo/essential-technique/dynamic-programming-framework/)
+
+之前 [手把手带你刷二叉树(纲领篇)](https://labuladong.online/algo/essential-technique/binary-tree-summary/) 把递归穷举划分为「遍历」和「分解问题」两种思路,其中「遍历」的思路扩展延伸一下就是 [回溯算法](https://labuladong.online/algo/essential-technique/backtrack-framework/),「分解问题」的思路可以扩展成 [动态规划算法](https://labuladong.online/algo/essential-technique/dynamic-programming-framework/)。
+
+这种思维转换不止局限于二叉树相关的算法,本文就跳出二叉树类型问题,来看看实际算法题中如何把问题抽象成树形结构,见招拆招逐步优化,从而进行「遍历」和「分解问题」的思维转换,从回溯算法顺滑地切换到动态规划算法。
+
+先说句题外话,前文 [动态规划核心框架详解](https://labuladong.online/algo/essential-technique/dynamic-programming-framework/) 说,**标准的动态规划问题一定是求最值的**,因为动态规划类型问题有一个性质叫做「最优子结构」,即从子问题的最优解推导出原问题的最优解。
+
+但在我们平常的语境中,就算不是求最值的题目,只要看见使用备忘录消除重叠子问题,我们一般都称它为动态规划算法。严格来讲这是不符合动态规划问题的定义的,说这种解法叫做「带备忘录的 DFS 算法」可能更准确些。不过咱也不用太纠结这种名词层面的细节,既然大家叫的顺口,就叫它动态规划也无妨。
+
+本文讲解的两道题目也不是求最值的,但依然会把他们的解法称为动态规划解法,这里提前跟大家说下这个变通,免得严谨的读者疑惑。其他不多说了,直接看题目吧。
+
+
+
+
+
+## 单词拆分 I
+
+
+
+首先看下力扣第 139 题「单词拆分」:
+
+
+
+函数签名如下:
+
+```java
+boolean wordBreak(String s, List wordDict);
+```
+
+这是一道非常高频的面试题,我们来思考下如何通过「遍历」和「分解问题」的思路来解决它。
+
+### 遍历的思路(回溯解法)
+
+**先说说「遍历」的思路,也就是用回溯算法解决本题**。回溯算法最经典的应用就是排列组合相关的问题了,不难发现这道题换个说法也可以变成一个排列问题:
+
+现在给你一个不包含重复单词的单词列表 `wordDict` 和一个字符串 `s`,请你判断是否可以从 `wordDict` 中选出若干单词的排列(可以重复挑选)构成字符串 `s`。
+
+这就是前文 [回溯算法秒杀排列组合问题的九种变体](https://labuladong.online/algo/essential-technique/permutation-combination-subset-all-in-one/) 中讲到的最后一种变体:元素无重可复选的排列问题,前文我写了一个 `permuteRepeat` 函数,代码如下:
+
+```java
+class Solution {
+ List> res = new LinkedList<>();
+ LinkedList track = new LinkedList<>();
+
+ // 元素无重可复选的全排列
+ public List> permuteRepeat(int[] nums) {
+ backtrack(nums);
+ return res;
+ }
+
+ // 回溯算法核心函数
+ void backtrack(int[] nums) {
+ // base case,到达叶子节点
+ if (track.size() == nums.length) {
+ // 收集根到叶子节点路径上的值
+ res.add(new LinkedList(track));
+ return;
+ }
+
+ // 回溯算法标准框架
+ for (int i = 0; i < nums.length; i++) {
+ // 做选择
+ track.add(nums[i]);
+ // 进入下一层回溯树
+ backtrack(nums);
+ // 取消选择
+ track.removeLast();
+ }
+ }
+}
+```
+
+给这个函数输入 `nums = [1,2,3]`,输出是 3^3 = 27 种可能的组合:
+
+
+
+
+
+```java
+[
+ [1,1,1],[1,1,2],[1,1,3],[1,2,1],[1,2,2],[1,2,3],[1,3,1],[1,3,2],[1,3,3],
+ [2,1,1],[2,1,2],[2,1,3],[2,2,1],[2,2,2],[2,2,3],[2,3,1],[2,3,2],[2,3,3],
+ [3,1,1],[3,1,2],[3,1,3],[3,2,1],[3,2,2],[3,2,3],[3,3,1],[3,3,2],[3,3,3]
+]
+```
+
+
+
+这段代码实际上就是遍历一棵高度为 `N + 1` 的满 `N` 叉树(`N` 为 `nums` 的长度),其中根到叶子的每条路径上的元素就是一个排列结果:
+
+
+
+类比一下,本文讲的这道题也有异曲同工之妙,假设 `wordDict = ["a", "aa", "ab"], s = "aaab"`,想用 `wordDict` 中的单词拼出 `s`,其实也面对着类似的一棵 `M` 叉树,`M` 为 `wordDict` 中单词的个数,**你需要做的就是站在回溯树的每个节点上,看看哪个单词能够匹配 `s[i..]` 的前缀,从而判断应该往哪条树枝上走**:
+
+
+
+然后,按照前文 [回溯算法框架详解](https://labuladong.online/algo/essential-technique/backtrack-framework/) 所说,你把 `backtrack` 函数理解成在回溯树上游走的一个指针,维护每个节点上的变量 `i`,即可遍历整棵回溯树,寻找出匹配 `s` 的组合。
+
+回溯算法解法代码如下:
+
+```java
+class Solution {
+ List wordDict;
+ // 记录是否找到一个合法的答案
+ boolean found = false;
+ // 记录回溯算法的路径
+ LinkedList track = new LinkedList<>();
+
+ // 主函数
+ public boolean wordBreak(String s, List wordDict) {
+ this.wordDict = wordDict;
+ // 执行回溯算法穷举所有可能的组合
+ backtrack(s, 0);
+ return found;
+ }
+
+ // 回溯算法框架
+ void backtrack(String s, int i) {
+ // base case
+ if (found) {
+ // 如果已经找到答案,就不要再递归搜索了
+ return;
+ }
+ if (i == s.length()) {
+ // 整个 s 都被匹配完成,找到一个合法答案
+ found = true;
+ return;
+ }
+
+ // 回溯算法框架
+ for (String word : wordDict) {
+ // 看看哪个单词能够匹配 s[i..] 的前缀
+ int len = word.length();
+ if (i + len <= s.length()
+ && s.substring(i, i + len).equals(word)) {
+ // 找到一个单词匹配 s[i..i+len)
+ // 做选择
+ track.addLast(word);
+ // 进入回溯树的下一层,继续匹配 s[i+len..]
+ backtrack(s, i + len);
+ // 撤销选择
+ track.removeLast();
+ }
+ }
+ }
+}
+```
+
+这段代码就是严格按照回溯算法框架写出来的,应该不难理解,但这段代码无法通过所有测试用例,我们按照 [算法时空复杂度使用指南](https://labuladong.online/algo/essential-technique/complexity-analysis/) 中讲到的方法来分析一下它的时间复杂度。
+
+递归函数的时间复杂度的粗略估算方法就是用递归函数调用次数(递归树的节点数) x 递归函数本身的复杂度。对于这道题来说,递归树的每个节点其实就是对 `s` 进行的一次切割,那么最坏情况下 `s` 能有多少种切割呢?长度为 `N` 的字符串 `s` 中共有 `N - 1` 个「缝隙」可供切割,每个缝隙可以选择「切」或者「不切」,所以 `s` 最多有 $O(2^N)$ 种切割方式,即递归树上最多有 $O(2^N)$ 个节点。
+
+当然,实际情况可定会好一些,毕竟存在剪枝逻辑,但从最坏复杂度的角度来看,递归树的节点个数确实是指数级别的。
+
+那么 `backtrack` 函数本身的时间复杂度是多少呢?主要的时间消耗是遍历 `wordDict` 寻找匹配 `s[i..]` 的前缀的单词:
+
+```java
+// 遍历 wordDict 的所有单词
+for (String word : wordDict) {
+ // 看看哪个单词能够匹配 s[i..] 的前缀
+ int len = word.length();
+ if (i + len <= s.length()
+ && s.substring(i, i + len).equals(word)) {
+ // 找到一个单词匹配 s[i..i+len)
+ // ...
+ }
+}
+```
+
+设 `wordDict` 的长度为 `M`,字符串 `s` 的长度为 `N`,那么这段代码的最坏时间复杂度是 $O(MN)$(for 循环 $O(M)$,Java 的 `substring` 方法 $O(N)$),所以总的时间复杂度是 $O(2^N * MN)$。
+
+这里顺便说一个细节优化,其实你也可以反过来,通过穷举 `s[i..]` 的前缀去判断 `wordDict` 中是否有对应的单词:
+
+```java
+// 注意,要转化成哈希集合,提高 contains 方法的效率
+HashSet wordDict = new HashSet<>(wordDict);
+
+// 遍历 s[i..] 的所有前缀
+for (int len = 1; i + len <= s.length(); len++) {
+ // 看看 wordDict 中是否有单词能匹配 s[i..] 的前缀
+ String prefix = s.substring(i, i + len);
+ if (wordDict.contains(prefix)) {
+ // 找到一个单词匹配 s[i..i+len)
+ // ...
+ }
+}
+```
+
+这段代码和刚才那段代码的结果是一样的,但这段代码的时间复杂度变成了 $O(N^2)$,和刚才的代码不同。
+
+到底哪样子好呢?这要看题目给的数据范围。本题说了 `1 <= s.length <= 300, 1 <= wordDict.length <= 1000`,所以 $O(N^2)$ 的结果较小,这段代码的实际运行效率应该稍微高一些,这个是一个细节的优化,你可以自己做一下,我就不写了。
+
+不过即便你优化这段代码,总的时间复杂度依然是指数级的 $O(2^N * N^2)$,是无法通过所有测试用例的,那么问题出在哪里呢?
+
+比如输入 `wordDict = ["a", "aa", "b"], s = "aaab"`,你注意回溯算法穷举时会存在重复的情况:
+
+
+
+图中标红的这两部分,虽然经历了不同的切分,但是切分得出的结果是相同的 `"aab"`,所以这两个节点下面的子树也是重复的,即存在冗余计算,这也是这个算法复杂度为指数级别的原因。
+
+### 利用后序位置优化
+
+不管是什么算法,消除冗余计算的方法就是加备忘录。回溯算法也可以加备忘录,我们可以称之为「剪枝」,即把冗余的子树给它剪掉。
+
+就比如面对这个 `"aab"` 子串的局面,我希望让备忘录告诉我,这个 `"aab"` 到底能不能被成功切分?如果之前尝试过不能切分的话,我就直接跳过,不用遍历子树去穷举切分了,从而优化效率。如果之前尝试过能成功切分的话,那也不关备忘录什么事情了,因为 `found == true` 本身就是个 base case,整个递归都会被终止。
+
+正如 [二叉树/递归系列算法通用心法](https://labuladong.online/algo/essential-technique/binary-tree-summary/) 对前序/后序位置的分析,要想让备忘录做到这一点,需要在后序位置上更新备忘录,因为这个 `"aab"` 其实是一棵子树,对吧?**你需要在遍历完子树的时候,在备忘录中记录下该子树是否可以被成功切分**。
+
+回溯函数 `backtrack` 为遍历而生,本身没有返回值,即没有从子树传递回来的信息。但针对这道题,我们还是有办法的,因为这不是有个外部变量 `found` 吗?这个变量就可以告诉我们子树是否能够成功切分:
+
+**如果 `found` 为 false,说明还没找到一个成功的切分,也就间接说明当前子树不能成功切分**。此时我们可以在备忘录里面记一笔,从而消除掉冗余的穷举。
+
+具体到代码上,只需稍加修改,即可实现备忘录功能,为了节约篇幅,我只给出修改的部分,:
+
+```java
+class Solution {
+ // 备忘录,存储不能切分的子串(子树),从而避免重复计算
+ HashSet memo = new HashSet<>();
+
+ // ...
+
+ void backtrack(String s, int i) {
+ if (found) {
+ return;
+ }
+ if (i == s.length()) {
+ found = true;
+ return;
+ }
+
+ // 新增的剪枝逻辑,查询子串(子树)是否已经计算过
+ String suffix = s.substring(i);
+ if (memo.contains(suffix)) {
+ // 当前子串(子树)不能被切分,就不用继续递归了
+ return;
+ }
+
+ for (String word : wordDict) {
+ // ...
+ }
+
+ // 后序位置,将不能切分的子串(子树)记录到备忘录
+ if (!found) {
+ memo.add(suffix);
+ }
+ }
+}
+```
+
+### 分解问题的思路(动态规划)
+
+上面能用回溯算法解决这个问题,其实还是这道题比较简单,我们可以借助 `found` 变量在后序位置更新备忘录,你会看到后面讲的单词拆分 II 就不能这么搞了。
+
+要在后序位置更新备忘录存储子树的答案,一般还是要借助递归函数的返回值,因此还是要用「分解问题」的思维模式。
+
+我们刚才以排列组合的视角思考这个问题,现在我们换一种视角,思考一下是否能够把原问题分解成规模更小,结构相同的子问题,然后通过子问题的结果计算原问题的结果。
+
+对于输入的字符串 `s`,如果我能够从单词列表 `wordDict` 中找到一个单词匹配 `s` 的前缀 `s[0..k]`,那么只要我能拼出 `s[k+1..]`,就一定能拼出整个 `s`。换句话说,我把规模较大的原问题 `wordBreak(s[0..])` 分解成了规模较小的子问题 `wordBreak(s[k+1..])`,然后通过子问题的解反推出原问题的解。
+
+有了这个思路就可以定义一个 `dp` 函数,并给出该函数的定义:
+
+```java
+// 定义:返回 s[i..] 是否能够被拼出
+int dp(String s, int i);
+
+// 计算整个 s 是否能被拼出,调用 dp(s, 0)
+```
+
+有了这个函数定义,就可以把刚才的逻辑大致翻译成伪码:
+
+```java
+List wordDict;
+
+// 定义:返回 s[i..] 是否能够被拼出
+int dp(String s, int i) {
+ // base case,s[i..] 是空串
+ if (i == s.length()) {
+ return true;
+ }
+ // 遍历 wordDict,看看哪些单词是 s[i..] 的前缀
+ for (Strnig word : wordDict) {
+ // word 是 s[i..] 的前缀
+ if (s.substring(i).startsWith(word)) {
+ int len = word.length();
+ // 只要 s[i+len..] 可以被拼出,s[i..] 就能被拼出
+ if (dp(s, i + len) == true) {
+ return true;
+ }
+ }
+ }
+ // 所有单词都尝试过,无法拼出整个 s
+ return false;
+}
+```
+
+类似之前讲的回溯算法,`dp` 函数中的 for 循环也可以优化一下:
+
+```java
+// 注意,用哈希集合快速判断元素是否存在
+HashSet wordDict;
+
+// 定义:返回 s[i..] 是否能够被拼出
+int dp(String s, int i) {
+ // base case,s[i..] 是空串
+ if (i == s.length()) {
+ return true;
+ }
+
+ // 遍历 s[i..] 的所有前缀,看看哪些前缀存在 wordDict 中
+ for (int len = 1; i + len <= s.length(); len++) {
+ // wordDict 中存在 s[i..len)
+ if (wordDict.contains(s.substring(i, i + len))) {
+ // 只要 s[i+len..] 可以被拼出,s[i..] 就能被拼出
+ if (dp(s, i + len) == true) {
+ return true;
+ }
+ }
+ }
+ // 所有单词都尝试过,无法拼出整个 s
+ return false;
+}
+```
+
+对于这个 `dp` 函数,指针 `i` 的位置就是「状态」,所以我们可以通过添加备忘录的方式优化效率,避免对相同的子问题进行冗余计算。最终的解法代码如下:
+
+```java
+class Solution {
+ // 用哈希集合方便快速判断是否存在
+ HashSet wordDict;
+ // 备忘录,-1 代表未计算,0 代表无法凑出,1 代表可以凑出
+ int[] memo;
+
+ // 主函数
+ public boolean wordBreak(String s, List wordDict) {
+ // 转化为哈希集合,快速判断元素是否存在
+ this.wordDict = new HashSet<>(wordDict);
+ // 备忘录初始化为 -1
+ this.memo = new int[s.length()];
+ Arrays.fill(memo, -1);
+ return dp(s, 0);
+ }
+
+ // 定义:s[i..] 是否能够被拼出
+ boolean dp(String s, int i) {
+ // base case
+ if (i == s.length()) {
+ return true;
+ }
+ // 防止冗余计算
+ if (memo[i] != -1) {
+ return memo[i] == 0 ? false : true;
+ }
+
+ // 遍历 s[i..] 的所有前缀
+ for (int len = 1; i + len <= s.length(); len++) {
+ // 看看哪些前缀存在 wordDict 中
+ String prefix = s.substring(i, i + len);
+ if (wordDict.contains(prefix)) {
+ // 找到一个单词匹配 s[i..i+len)
+ // 只要 s[i+len..] 可以被拼出,s[i..] 就能被拼出
+ boolean subProblem = dp(s, i + len);
+ if (subProblem == true) {
+ memo[i] = 1;
+ return true;
+ }
+ }
+ }
+ // s[i..] 无法被拼出
+ memo[i] = 0;
+ return false;
+ }
+}
+```
+
+> [!TIP]
+> 注意到计算 `prefix` 的过程中,我们是直接调用编程语言提供的子串截取函数,这个函数的时间复杂度是 $O(N)$。不难发现截取子串的开始索引是固定的 `i`,结束索引是递增的 `j`,所以我们手动维护这个 `prefix` 子串,避免调用子串截取函数,进一步提高效率。这个小优化就留给你来做吧。
+
+
+
+
+
+
+🌈 代码可视化动画🌈
+
+
+
+
+
+这个解法能够通过所有测试用例,我们根据 [算法时空复杂度使用指南](https://labuladong.online/algo/essential-technique/complexity-analysis/) 来算一下它的时间复杂度:
+
+因为有备忘录的辅助,消除了递归树上的重复节点,使得递归函数的调用次数从指数级别降低为状态的个数 $O(N)$,函数本身的复杂度还是 $O(N^2)$,所以总的时间复杂度是 $O(N^3)$,相较回溯算法的效率有大幅提升。
+
+## 单词拆分 II
+
+有了上一道题的铺垫,力扣第 140 题「单词拆分 II」就容易多了,先看下题目:
+
+
+
+相较上一题,这道题不是单单问你 `s` 是否能被拼出,还要问你是怎么拼的,其实只要把之前的解法稍微改一改就可以解决这道题。
+
+### 遍历的思路(回溯算法)
+
+上一道题的回溯算法维护一个 `found` 变量,只要找到一种拼接方案就提前结束遍历回溯树,那么在这道题中我们不要提前结束遍历,并把所有可行的拼接方案收集起来就能得到答案:
+
+```java
+class Solution {
+ // 记录结果
+ List res = new LinkedList<>();
+ // 记录回溯算法的路径
+ LinkedList track = new LinkedList<>();
+ List wordDict;
+
+ // 主函数
+ public List wordBreak(String s, List wordDict) {
+ this.wordDict = wordDict;
+ // 执行回溯算法穷举所有可能的组合
+ backtrack(s, 0);
+ return res;
+ }
+
+ // 回溯算法框架
+ void backtrack(String s, int i) {
+ // base case
+ if (i == s.length()) {
+ // 找到一个合法组合拼出整个 s,转化成字符串
+ res.add(String.join(" ", track));
+ return;
+ }
+
+ // 回溯算法框架
+ for (String word : wordDict) {
+ // 看看哪个单词能够匹配 s[i..] 的前缀
+ int len = word.length();
+ if (i + len <= s.length()
+ && s.substring(i, i + len).equals(word)) {
+ // 找到一个单词匹配 s[i..i+len)
+ // 做选择
+ track.addLast(word);
+ // 进入回溯树的下一层,继续匹配 s[i+len..]
+ backtrack(s, i + len);
+ // 撤销选择
+ track.removeLast();
+ }
+ }
+ }
+}
+```
+
+这个解法的时间复杂度和前一道题类似,依然是 $O(2^N * MN)$,但由于这道题给的数据规模较小,所以可以通过所有测试用例。
+
+### 是否可以利用后序位置优化?
+
+和之前类似,这个解法还是有优化空间的,依然是这种情况:
+
+
+
+对于重复的子树,依然会造成没有必要的重复遍历,我们依然可以通过备忘录的方式进行优化,即可以在备忘录缓存子串 `"aab"` 的切分结果,避免重复遍历相同的子树。
+
+但用回溯算法就不好加备忘录了,因为回溯算法的 `track` 变量仅维护了从根节点到当前节点走过的路径,并没有记录子树的信息。
+
+所以,这种题目想要消除重叠子问题的话一般要用分解问题的思路,利用函数返回值来更新备忘录。
+
+### 分级问题的思路(动态规划)
+
+这个问题也可以用分解问题的思维解决,把上一道题的 `dp` 函数稍作修改即可:
+
+```java
+class Solution {
+ HashSet wordDict;
+ // 备忘录
+ List[] memo;
+
+ public List wordBreak(String s, List wordDict) {
+ this.wordDict = new HashSet<>(wordDict);
+ memo = new List[s.length()];
+ return dp(s, 0);
+ }
+
+ // 定义:返回用 wordDict 构成 s[i..] 的所有可能
+ List dp(String s, int i) {
+ List res = new LinkedList<>();
+ if (i == s.length()) {
+ res.add("");
+ return res;
+ }
+ // 防止冗余计算
+ if (memo[i] != null) {
+ return memo[i];
+ }
+
+ // 遍历 s[i..] 的所有前缀
+ for (int len = 1; i + len <= s.length(); len++) {
+ // 看看哪些前缀存在 wordDict 中
+ String prefix = s.substring(i, i + len);
+ if (wordDict.contains(prefix)) {
+ // 找到一个单词匹配 s[i..i+len)
+ List subProblem = dp(s, i + len);
+ // 构成 s[i+len..] 的所有组合加上 prefix
+ // 就是构成构成 s[i] 的所有组合
+ for (String sub : subProblem) {
+ if (sub.isEmpty()) {
+ // 防止多余的空格
+ res.add(prefix);
+ } else {
+ res.add(prefix + " " + sub);
+ }
+ }
+ }
+ }
+ // 存入备忘录
+ memo[i] = res;
+
+ return res;
+ }
+}
+```
+
+
+
+
+
+
+🎃 代码可视化动画🎃
+
+
+
+
+
+这个解法依然用备忘录消除了重叠子问题,所以 `dp` 函数递归调用的次数减少为 $O(N)$,但 `dp` 函数本身的时间复杂度上升了,因为 `subProblem` 是一个子集列表,它的长度是指数级的。
+
+再加上拼接字符串的效率并不高,且还要消耗备忘录去存储所有子问题的结果,所以从 Big O 的角度来分析,这个算法的时间复杂度并不比回溯算法低,依然是指数级别;但这个解法确实消除了重叠子问题,所以是要比回溯算法高明一些。
+
+综上,我们处理排列组合问题时一般使用回溯算法去「遍历」回溯树,而不用「分解问题」的思路去处理,因为存储子问题的结果就需要大量的时间和空间,除非重叠子问题的数量较多的极端情况,否则得不偿失。
+
+以上就是本文的全部内容,希望你能对回溯思路和分解问题的思路有更深刻的理解。
+
+
+
+
+
+**_____________**
+
+
+
+
\ No newline at end of file
diff --git "a/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\345\233\242\347\201\255\350\202\241\347\245\250\351\227\256\351\242\230.md" "b/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\345\233\242\347\201\255\350\202\241\347\245\250\351\227\256\351\242\230.md"
index 6b5ec28bdb..ff4cd9c9be 100644
--- "a/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\345\233\242\347\201\255\350\202\241\347\245\250\351\227\256\351\242\230.md"
+++ "b/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\345\233\242\347\201\255\350\202\241\347\245\250\351\227\256\351\242\230.md"
@@ -1,47 +1,85 @@
-# 团灭 LeetCode 股票买卖问题
+# 一个方法团灭 LeetCode 股票买卖问题
-很多读者抱怨 LeetCode 的股票系列问题奇技淫巧太多,如果面试真的遇到这类问题,基本不会想到那些巧妙的办法,怎么办?**所以本文拒绝奇技淫巧,而是稳扎稳打,只用一种通用方法解决所用问题,以不变应万变**。
-这篇文章用状态机的技巧来解决,可以全部提交通过。不要觉得这个名词高大上,文学词汇而已,实际上就是 DP table,看一眼就明白了。
-PS:本文参考自[英文版 LeetCode 的一篇题解](https://leetcode.com/problems/best-time-to-buy-and-sell-stock/discuss/39038)。
+
+
+**通知:为满足广大读者的需求,网站上架 [速成目录](https://labuladong.online/algo/intro/quick-learning-plan/),如有需要可以看下,谢谢大家的支持~另外,建议你在我的 [网站](https://labuladong.online/algo/) 学习文章,体验更好。**
+
+
+
+读完本文,你不仅学会了算法套路,还可以顺便解决如下题目:
+
+| LeetCode | 力扣 | 难度 |
+| :----: | :----: | :----: |
+| [121. Best Time to Buy and Sell Stock](https://leetcode.com/problems/best-time-to-buy-and-sell-stock/) | [121. 买卖股票的最佳时机](https://leetcode.cn/problems/best-time-to-buy-and-sell-stock/) | 🟢 |
+| [122. Best Time to Buy and Sell Stock II](https://leetcode.com/problems/best-time-to-buy-and-sell-stock-ii/) | [122. 买卖股票的最佳时机 II](https://leetcode.cn/problems/best-time-to-buy-and-sell-stock-ii/) | 🟠 |
+| [123. Best Time to Buy and Sell Stock III](https://leetcode.com/problems/best-time-to-buy-and-sell-stock-iii/) | [123. 买卖股票的最佳时机 III](https://leetcode.cn/problems/best-time-to-buy-and-sell-stock-iii/) | 🔴 |
+| [188. Best Time to Buy and Sell Stock IV](https://leetcode.com/problems/best-time-to-buy-and-sell-stock-iv/) | [188. 买卖股票的最佳时机 IV](https://leetcode.cn/problems/best-time-to-buy-and-sell-stock-iv/) | 🔴 |
+| [309. Best Time to Buy and Sell Stock with Cooldown](https://leetcode.com/problems/best-time-to-buy-and-sell-stock-with-cooldown/) | [309. 最佳买卖股票时机含冷冻期](https://leetcode.cn/problems/best-time-to-buy-and-sell-stock-with-cooldown/) | 🟠 |
+| [714. Best Time to Buy and Sell Stock with Transaction Fee](https://leetcode.com/problems/best-time-to-buy-and-sell-stock-with-transaction-fee/) | [714. 买卖股票的最佳时机含手续费](https://leetcode.cn/problems/best-time-to-buy-and-sell-stock-with-transaction-fee/) | 🟠 |
+
+**-----------**
+
+
+
+> [!NOTE]
+> 阅读本文前,你需要先学习:
+>
+> - [动态规划核心框架](https://labuladong.online/algo/essential-technique/dynamic-programming-framework/)
+
+很多读者抱怨力扣上的股票系列问题的解法太多,如果面试真的遇到这类问题,基本不会想到那些巧妙的办法,怎么办?**所以本文不讲那些过于巧妙的思路,而是稳扎稳打,只用一种通用方法解决所有问题,以不变应万变**。
+
+这篇文章参考 [英文版高赞题解](https://leetcode.com/problems/best-time-to-buy-and-sell-stock-with-transaction-fee/discuss/108870/Most-consistent-ways-of-dealing-with-the-series-of-stock-problems) 的思路,用状态机的技巧来解决,可以全部提交通过。不要觉得这个名词高大上,文学词汇而已,实际上就是 DP table,看一眼就明白了。
先随便抽出一道题,看看别人的解法:
-```cpp
-int maxProfit(vector& prices) {
+
+
+
+
+```java
+int maxProfit(int[] prices) {
if(prices.empty()) return 0;
- int s1=-prices[0],s2=INT_MIN,s3=INT_MIN,s4=INT_MIN;
-
- for(int i=1;i
+
+第一题是只进行一次交易,相当于 `k = 1`;第二题是不限交易次数,相当于 `k = +infinity`(正无穷);第三题是只进行 2 次交易,相当于 `k = 2`;剩下两道也是不限次数,但是加了交易「冷冻期」和「手续费」的额外条件,其实就是第二题的变种,都很容易处理。
+
+下面言归正传,开始解题。
+
-
-第一题是只进行一次交易,相当于 k = 1;第二题是不限交易次数,相当于 k = +infinity(正无穷);第三题是只进行 2 次交易,相当于 k = 2;剩下两道也是不限次数,但是加了交易「冷冻期」和「手续费」的额外条件,其实就是第二题的变种,都很容易处理。
-如果你还不熟悉题目,可以去 LeetCode 查看这些题目的内容,本文为了节省篇幅,就不列举这些题目的具体内容了。下面言归正传,开始解题。
-**一、穷举框架**
-首先,还是一样的思路:如何穷举?这里的穷举思路和上篇文章递归的思想不太一样。
-递归其实是符合我们思考的逻辑的,一步步推进,遇到无法解决的就丢给递归,一不小心就做出来了,可读性还很好。缺点就是一旦出错,你也不容易找到错误出现的原因。比如上篇文章的递归解法,肯定还有计算冗余,但确实不容易找到。
+## 一、穷举框架
-而这里,我们不用递归思想进行穷举,而是利用「状态」进行穷举。我们具体到每一天,看看总共有几种可能的「状态」,再找出每个「状态」对应的「选择」。我们要穷举所有「状态」,穷举的目的是根据对应的「选择」更新状态。听起来抽象,你只要记住「状态」和「选择」两个词就行,下面实操一下就很容易明白了。
+首先,还是一样的思路:如何穷举?
+
+[动态规划核心套路](https://labuladong.online/algo/essential-technique/dynamic-programming-framework/) 说过,动态规划算法本质上就是穷举「状态」,然后在「选择」中选择最优解。
+
+那么对于这道题,我们具体到每一天,看看总共有几种可能的「状态」,再找出每个「状态」对应的「选择」。我们要穷举所有「状态」,穷举的目的是根据对应的「选择」更新状态。听起来抽象,你只要记住「状态」和「选择」两个词就行,下面实操一下就很容易明白了。
```python
for 状态1 in 状态1的所有取值:
@@ -50,14 +88,27 @@ for 状态1 in 状态1的所有取值:
dp[状态1][状态2][...] = 择优(选择1,选择2...)
```
-比如说这个问题,**每天都有三种「选择」**:买入、卖出、无操作,我们用 buy, sell, rest 表示这三种选择。但问题是,并不是每天都可以任意选择这三种选择的,因为 sell 必须在 buy 之后,buy 必须在 sell 之后。那么 rest 操作还应该分两种状态,一种是 buy 之后的 rest(持有了股票),一种是 sell 之后的 rest(没有持有股票)。而且别忘了,我们还有交易次数 k 的限制,就是说你 buy 还只能在 k > 0 的前提下操作。
+比如说这个问题,**每天都有三种「选择」**:买入、卖出、无操作,我们用 `buy`, `sell`, `rest` 表示这三种选择。
+
+但问题是,并不是每天都可以任意选择这三种选择的,因为 `sell` 必须在 `buy` 之后,`buy` 必须在 `sell` 之后。那么 `rest` 操作还应该分两种状态,一种是 `buy` 之后的 `rest`(持有了股票),一种是 `sell` 之后的 `rest`(没有持有股票)。而且别忘了,我们还有交易次数 `k` 的限制,就是说你 `buy` 还只能在 `k > 0` 的前提下操作。
+
+> [!NOTE]
+> 注意我在本文会频繁使用「交易」这个词,**我们把一次买入和一次卖出定义为一次「交易」**。
+
+
+
-很复杂对吧,不要怕,我们现在的目的只是穷举,你有再多的状态,老夫要做的就是一把梭全部列举出来。**这个问题的「状态」有三个**,第一个是天数,第二个是允许交易的最大次数,第三个是当前的持有状态(即之前说的 rest 的状态,我们不妨用 1 表示持有,0 表示没有持有)。然后我们用一个三维数组就可以装下这几种状态的全部组合:
+
+
+
+很复杂对吧,不要怕,我们现在的目的只是穷举,你有再多的状态,老夫要做的就是一把梭全部列举出来。
+
+**这个问题的「状态」有三个**,第一个是天数,第二个是允许交易的最大次数,第三个是当前的持有状态(即之前说的 `rest` 的状态,我们不妨用 1 表示持有,0 表示没有持有)。然后我们用一个三维数组就可以装下这几种状态的全部组合:
```python
dp[i][k][0 or 1]
-0 <= i <= n-1, 1 <= k <= K
-n 为天数,大 K 为最多交易数
+0 <= i <= n - 1, 1 <= k <= K
+n 为天数,大 K 为交易数的上限,0 和 1 代表是否持有股票。
此问题共 n × K × 2 种状态,全部穷举就能搞定。
for 0 <= i < n:
@@ -68,54 +119,90 @@ for 0 <= i < n:
而且我们可以用自然语言描述出每一个状态的含义,比如说 `dp[3][2][1]` 的含义就是:今天是第三天,我现在手上持有着股票,至今最多进行 2 次交易。再比如 `dp[2][3][0]` 的含义:今天是第二天,我现在手上没有持有股票,至今最多进行 3 次交易。很容易理解,对吧?
-我们想求的最终答案是 dp[n - 1][K][0],即最后一天,最多允许 K 次交易,最多获得多少利润。读者可能问为什么不是 dp[n - 1][K][1]?因为 [1] 代表手上还持有股票,[0] 表示手上的股票已经卖出去了,很显然后者得到的利润一定大于前者。
+我们想求的最终答案是 `dp[n - 1][K][0]`,即最后一天,最多允许 `K` 次交易,最多获得多少利润。
+
+读者可能问为什么不是 `dp[n - 1][K][1]`?因为 `dp[n - 1][K][1]` 代表到最后一天手上还持有股票,`dp[n - 1][K][0]` 表示最后一天手上的股票已经卖出去了,很显然后者得到的利润一定大于前者。
记住如何解释「状态」,一旦你觉得哪里不好理解,把它翻译成自然语言就容易理解了。
-**二、状态转移框架**
-现在,我们完成了「状态」的穷举,我们开始思考每种「状态」有哪些「选择」,应该如何更新「状态」。只看「持有状态」,可以画个状态转移图。
-
+
+
+
+
+## 二、状态转移框架
+
+现在,我们完成了「状态」的穷举,我们开始思考每种「状态」有哪些「选择」,应该如何更新「状态」。
+
+只看「持有状态」,可以画个状态转移图:
+
+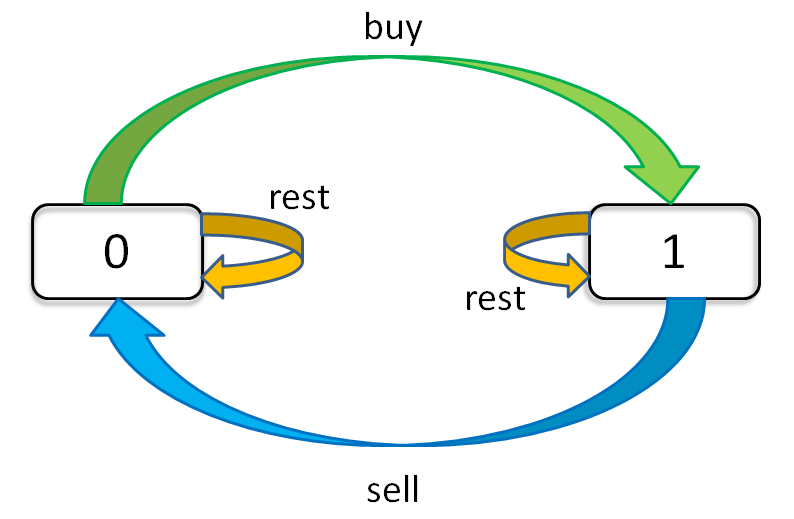
通过这个图可以很清楚地看到,每种状态(0 和 1)是如何转移而来的。根据这个图,我们来写一下状态转移方程:
-```
+```python
dp[i][k][0] = max(dp[i-1][k][0], dp[i-1][k][1] + prices[i])
- max( 选择 rest , 选择 sell )
+ max( 今天选择 rest, 今天选择 sell )
+```
-解释:今天我没有持有股票,有两种可能:
-要么是我昨天就没有持有,然后今天选择 rest,所以我今天还是没有持有;
-要么是我昨天持有股票,但是今天我 sell 了,所以我今天没有持有股票了。
+解释:今天我没有持有股票,有两种可能,我从这两种可能中求最大利润:
-dp[i][k][1] = max(dp[i-1][k][1], dp[i-1][k-1][0] - prices[i])
- max( 选择 rest , 选择 buy )
+1、我昨天就没有持有,且截至昨天最大交易次数限制为 `k`;然后我今天选择 `rest`,所以我今天还是没有持有,最大交易次数限制依然为 `k`。
+
+2、我昨天持有股票,且截至昨天最大交易次数限制为 `k`;但是今天我 `sell` 了,所以我今天没有持有股票了,最大交易次数限制依然为 `k`。
-解释:今天我持有着股票,有两种可能:
-要么我昨天就持有着股票,然后今天选择 rest,所以我今天还持有着股票;
-要么我昨天本没有持有,但今天我选择 buy,所以今天我就持有股票了。
+```python
+dp[i][k][1] = max(dp[i-1][k][1], dp[i-1][k-1][0] - prices[i])
+ max( 今天选择 rest, 今天选择 buy )
```
-这个解释应该很清楚了,如果 buy,就要从利润中减去 prices[i],如果 sell,就要给利润增加 prices[i]。今天的最大利润就是这两种可能选择中较大的那个。而且注意 k 的限制,我们在选择 buy 的时候,把 k 减小了 1,很好理解吧,当然你也可以在 sell 的时候减 1,一样的。
+解释:今天我持有着股票,最大交易次数限制为 `k`,那么对于昨天来说,有两种可能,我从这两种可能中求最大利润:
-现在,我们已经完成了动态规划中最困难的一步:状态转移方程。**如果之前的内容你都可以理解,那么你已经可以秒杀所有问题了,只要套这个框架就行了。**不过还差最后一点点,就是定义 base case,即最简单的情况。
-```
-dp[-1][k][0] = 0
-解释:因为 i 是从 0 开始的,所以 i = -1 意味着还没有开始,这时候的利润当然是 0 。
-dp[-1][k][1] = -infinity
-解释:还没开始的时候,是不可能持有股票的,用负无穷表示这种不可能。
-dp[i][0][0] = 0
-解释:因为 k 是从 1 开始的,所以 k = 0 意味着根本不允许交易,这时候利润当然是 0 。
-dp[i][0][1] = -infinity
-解释:不允许交易的情况下,是不可能持有股票的,用负无穷表示这种不可能。
+1、我昨天就持有着股票,且截至昨天最大交易次数限制为 `k`;然后今天选择 `rest`,所以我今天还持有着股票,最大交易次数限制依然为 `k`。
+
+2、我昨天本没有持有,且截至昨天最大交易次数限制为 `k - 1`;但今天我选择 `buy`,所以今天我就持有股票了,最大交易次数限制为 `k`。
+
+> [!NOTE]
+> 这里着重提醒一下,**时刻牢记「状态」的定义**,状态 `k` 的定义并不是「已进行的交易次数」,而是「最大交易次数的上限限制」。如果确定今天进行一次交易,且要保证截至今天最大交易次数上限为 `k`,那么昨天的最大交易次数上限必须是 `k - 1`。举个具体的例子,比方说要求你的银行卡里今天至少有 100 块钱,且你确定你今天可以赚 10 块钱,那么你就要保证昨天的银行卡要至少剩下 90 块钱。
+
+这个解释应该很清楚了,如果 `buy`,就要从利润中减去 `prices[i]`,如果 `sell`,就要给利润增加 `prices[i]`。今天的最大利润就是这两种可能选择中较大的那个。
+
+注意 `k` 的限制,在选择 `buy` 的时候相当于开启了一次交易,那么对于昨天来说,交易次数的上限 `k` 应该减小 1。
+
+> [!NOTE]
+> 这里补充修正一点,以前我以为在 `sell` 的时候给 `k` 减小 1 和在 `buy` 的时候给 `k` 减小 1 是等效的,但细心的读者向我提出质疑,经过深入思考我发现前者确实是错误的,因为交易是从 `buy` 开始,如果 `buy` 的选择不改变交易次数 `k` 的话,会出现交易次数超出限制的的错误。
+
+
+
+
+
+
+
+现在,我们已经完成了动态规划中最困难的一步:状态转移方程。**如果之前的内容你都可以理解,那么你已经可以秒杀所有问题了,只要套这个框架就行了**。不过还差最后一点点,就是定义 base case,即最简单的情况。
+
+```python
+dp[-1][...][0] = 0
+解释:因为 i 是从 0 开始的,所以 i = -1 意味着还没有开始,这时候的利润当然是 0。
+
+dp[-1][...][1] = -infinity
+解释:还没开始的时候,是不可能持有股票的。
+因为我们的算法要求一个最大值,所以初始值设为一个最小值,方便取最大值。
+
+dp[...][0][0] = 0
+解释:因为 k 是从 1 开始的,所以 k = 0 意味着根本不允许交易,这时候利润当然是 0。
+
+dp[...][0][1] = -infinity
+解释:不允许交易的情况下,是不可能持有股票的。
+因为我们的算法要求一个最大值,所以初始值设为一个最小值,方便取最大值。
```
把上面的状态转移方程总结一下:
-```
+```python
base case:
-dp[-1][k][0] = dp[i][0][0] = 0
-dp[-1][k][1] = dp[i][0][1] = -infinity
+dp[-1][...][0] = dp[...][0][0] = 0
+dp[-1][...][1] = dp[...][0][1] = -infinity
状态转移方程:
dp[i][k][0] = max(dp[i-1][k][0], dp[i-1][k][1] + prices[i])
@@ -124,13 +211,23 @@ dp[i][k][1] = max(dp[i-1][k][1], dp[i-1][k-1][0] - prices[i])
读者可能会问,这个数组索引是 -1 怎么编程表示出来呢,负无穷怎么表示呢?这都是细节问题,有很多方法实现。现在完整的框架已经完成,下面开始具体化。
-**三、秒杀题目**
-**第一题,k = 1**
+
+
+
+
+
+## 三、秒杀题目
+
+### 121. 买卖股票的最佳时机
+
+**第一题,先说力扣第 121 题「买卖股票的最佳时机」,相当于 `k = 1` 的情况**:
+
+
直接套状态转移方程,根据 base case,可以做一些化简:
-```
+```python
dp[i][1][0] = max(dp[i-1][1][0], dp[i-1][1][1] + prices[i])
dp[i][1][1] = max(dp[i-1][1][1], dp[i-1][0][0] - prices[i])
= max(dp[i-1][1][1], -prices[i])
@@ -154,34 +251,58 @@ for (int i = 0; i < n; i++) {
return dp[n - 1][0];
```
-显然 i = 0 时 dp[i-1] 是不合法的。这是因为我们没有对 i 的 base case 进行处理。可以这样处理:
+显然 `i = 0` 时 `i - 1` 是不合法的索引,这是因为我们没有对 `i` 的 base case 进行处理,可以这样给一个特化处理:
+
+
+
+
```java
-for (int i = 0; i < n; i++) {
- if (i - 1 == -1) {
- dp[i][0] = 0;
- // 解释:
- // dp[i][0]
- // = max(dp[-1][0], dp[-1][1] + prices[i])
- // = max(0, -infinity + prices[i]) = 0
- dp[i][1] = -prices[i];
- //解释:
- // dp[i][1]
- // = max(dp[-1][1], dp[-1][0] - prices[i])
- // = max(-infinity, 0 - prices[i])
- // = -prices[i]
- continue;
- }
- dp[i][0] = Math.max(dp[i-1][0], dp[i-1][1] + prices[i]);
- dp[i][1] = Math.max(dp[i-1][1], -prices[i]);
+if (i - 1 == -1) {
+ dp[i][0] = 0;
+ // 根据状态转移方程可得:
+ // dp[i][0]
+ // = max(dp[-1][0], dp[-1][1] + prices[i])
+ // = max(0, -infinity + prices[i]) = 0
+ // = max(dp[-1][0], dp[-1][1] + prices[i])
+ // = max(0, -infinity + prices[i]) = 0
+
+ dp[i][1] = -prices[i];
+ // 根据状态转移方程可得:
+ // dp[i][1]
+ // = max(dp[-1][1], dp[-1][0] - prices[i])
+ // = max(-infinity, 0 - prices[i])
+ // = -prices[i]
+ // = max(dp[-1][1], dp[-1][0] - prices[i])
+ // = max(-infinity, 0 - prices[i])
+ // = -prices[i]
+ continue;
}
-return dp[n - 1][0];
```
-第一题就解决了,但是这样处理 base case 很麻烦,而且注意一下状态转移方程,新状态只和相邻的一个状态有关,其实不用整个 dp 数组,只需要一个变量储存相邻的那个状态就足够了,这样可以把空间复杂度降到 O(1):
+
+
+第一题就解决了,但是这样处理 base case 很麻烦,而且注意一下状态转移方程,新状态只和相邻的一个状态有关,所以可以用前文 [动态规划的降维打击:空间压缩技巧](https://labuladong.online/algo/dynamic-programming/space-optimization/),不需要用整个 `dp` 数组,只需要一个变量储存相邻的那个状态就足够了,这样可以把空间复杂度降到 O(1):
```java
-// k == 1
+// 原始版本
+int maxProfit_k_1(int[] prices) {
+ int n = prices.length;
+ int[][] dp = new int[n][2];
+ for (int i = 0; i < n; i++) {
+ if (i - 1 == -1) {
+ // base case
+ dp[i][0] = 0;
+ dp[i][1] = -prices[i];
+ continue;
+ }
+ dp[i][0] = Math.max(dp[i-1][0], dp[i-1][1] + prices[i]);
+ dp[i][1] = Math.max(dp[i-1][1], -prices[i]);
+ }
+ return dp[n - 1][0];
+}
+
+// 空间复杂度优化版本
int maxProfit_k_1(int[] prices) {
int n = prices.length;
// base case: dp[-1][0] = 0, dp[-1][1] = -infinity
@@ -196,11 +317,28 @@ int maxProfit_k_1(int[] prices) {
}
```
-两种方式都是一样的,不过这种编程方法简洁很多。但是如果没有前面状态转移方程的引导,是肯定看不懂的。后续的题目,我主要写这种空间复杂度 O(1) 的解法。
-**第二题,k = +infinity**
+
+
+
+
+🍭 代码可视化动画🍭
+
+
+
+
+
+两种方式都是一样的,不过这种编程方法简洁很多,但是如果没有前面状态转移方程的引导,是肯定看不懂的。后续的题目,你可以对比一下如何把 `dp` 数组的空间优化掉。
+
+### 122. 买卖股票的最佳时机 II
+
+**第二题,看一下力扣第 122 题「买卖股票的最佳时机 II」,也就是 `k` 为正无穷的情况**:
-如果 k 为正无穷,那么就可以认为 k 和 k - 1 是一样的。可以这样改写框架:
+
+
+题目还专门强调可以在同一天出售,但我觉得这个条件纯属多余,如果当天买当天卖,那利润当然就是 0,这不是和没有进行交易是一样的吗?这道题的特点在于没有给出交易总数 `k` 的限制,也就相当于 `k` 为正无穷。
+
+如果 `k` 为正无穷,那么就可以认为 `k` 和 `k - 1` 是一样的。可以这样改写框架:
```python
dp[i][k][0] = max(dp[i-1][k][0], dp[i-1][k][1] + prices[i])
@@ -215,6 +353,24 @@ dp[i][1] = max(dp[i-1][1], dp[i-1][0] - prices[i])
直接翻译成代码:
```java
+// 原始版本
+int maxProfit_k_inf(int[] prices) {
+ int n = prices.length;
+ int[][] dp = new int[n][2];
+ for (int i = 0; i < n; i++) {
+ if (i - 1 == -1) {
+ // base case
+ dp[i][0] = 0;
+ dp[i][1] = -prices[i];
+ continue;
+ }
+ dp[i][0] = Math.max(dp[i-1][0], dp[i-1][1] + prices[i]);
+ dp[i][1] = Math.max(dp[i-1][1], dp[i-1][0] - prices[i]);
+ }
+ return dp[n - 1][0];
+}
+
+// 空间复杂度优化版本
int maxProfit_k_inf(int[] prices) {
int n = prices.length;
int dp_i_0 = 0, dp_i_1 = Integer.MIN_VALUE;
@@ -227,11 +383,26 @@ int maxProfit_k_inf(int[] prices) {
}
```
-**第三题,k = +infinity with cooldown**
-每次 sell 之后要等一天才能继续交易。只要把这个特点融入上一题的状态转移方程即可:
+
+
+
+
+🌟 代码可视化动画🌟
+
+
+
+
-```
+### 309. 最佳买卖股票时机含冷冻期
+
+**第三题,看力扣第 309 题「最佳买卖股票时机含冷冻期」,也就是 `k` 为正无穷,但含有交易冷冻期的情况**:
+
+
+
+和上一道题一样的,只不过每次 `sell` 之后要等一天才能继续交易,只要把这个特点融入上一题的状态转移方程即可:
+
+```python
dp[i][0] = max(dp[i-1][0], dp[i-1][1] + prices[i])
dp[i][1] = max(dp[i-1][1], dp[i-2][0] - prices[i])
解释:第 i 天选择 buy 的时候,要从 i-2 的状态转移,而不是 i-1 。
@@ -240,10 +411,40 @@ dp[i][1] = max(dp[i-1][1], dp[i-2][0] - prices[i])
翻译成代码:
```java
+// 原始版本
+int maxProfit_with_cool(int[] prices) {
+ int n = prices.length;
+ int[][] dp = new int[n][2];
+ for (int i = 0; i < n; i++) {
+ if (i - 1 == -1) {
+ // base case 1
+ dp[i][0] = 0;
+ dp[i][1] = -prices[i];
+ continue;
+ }
+ if (i - 2 == -1) {
+ // base case 2
+ dp[i][0] = Math.max(dp[i-1][0], dp[i-1][1] + prices[i]);
+ // i - 2 小于 0 时根据状态转移方程推出对应 base case
+ dp[i][1] = Math.max(dp[i-1][1], -prices[i]);
+ // dp[i][1]
+ // = max(dp[i-1][1], dp[-1][0] - prices[i])
+ // = max(dp[i-1][1], 0 - prices[i])
+ // = max(dp[i-1][1], -prices[i])
+ continue;
+ }
+ dp[i][0] = Math.max(dp[i-1][0], dp[i-1][1] + prices[i]);
+ dp[i][1] = Math.max(dp[i-1][1], dp[i-2][0] - prices[i]);
+ }
+ return dp[n - 1][0];
+}
+
+// 空间复杂度优化版本
int maxProfit_with_cool(int[] prices) {
int n = prices.length;
int dp_i_0 = 0, dp_i_1 = Integer.MIN_VALUE;
- int dp_pre_0 = 0; // 代表 dp[i-2][0]
+ // 代表 dp[i-2][0]
+ int dp_pre_0 = 0;
for (int i = 0; i < n; i++) {
int temp = dp_i_0;
dp_i_0 = Math.max(dp_i_0, dp_i_1 + prices[i]);
@@ -254,20 +455,63 @@ int maxProfit_with_cool(int[] prices) {
}
```
-**第四题,k = +infinity with fee**
-每次交易要支付手续费,只要把手续费从利润中减去即可。改写方程:
+
+
+
+
+🌈 代码可视化动画🌈
+
+
+
+
-```
+### 714. 买卖股票的最佳时机含手续费
+
+
+
+**第四题,看力扣第 714 题「买卖股票的最佳时机含手续费」,也就是 `k` 为正无穷且考虑交易手续费的情况**:
+
+
+
+每次交易要支付手续费,只要把手续费从利润中减去即可,改写方程:
+
+```python
dp[i][0] = max(dp[i-1][0], dp[i-1][1] + prices[i])
dp[i][1] = max(dp[i-1][1], dp[i-1][0] - prices[i] - fee)
解释:相当于买入股票的价格升高了。
在第一个式子里减也是一样的,相当于卖出股票的价格减小了。
```
-直接翻译成代码:
+> [!NOTE]
+> 如果直接把 `fee` 放在第一个式子里减,会有一些测试用例无法通过,错误原因是整型溢出而不是思路问题。一种解决方案是把代码中的 `int` 类型都改成 `long` 类型,避免 `int` 的整型溢出。
+
+直接翻译成代码,注意状态转移方程改变后 base case 也要做出对应改变:
```java
+// 原始版本
+int maxProfit_with_fee(int[] prices, int fee) {
+ int n = prices.length;
+ int[][] dp = new int[n][2];
+ for (int i = 0; i < n; i++) {
+ if (i - 1 == -1) {
+ // base case
+ dp[i][0] = 0;
+ dp[i][1] = -prices[i] - fee;
+ // dp[i][1]
+ // = max(dp[i - 1][1], dp[i - 1][0] - prices[i] - fee)
+ // = max(dp[-1][1], dp[-1][0] - prices[i] - fee)
+ // = max(-inf, 0 - prices[i] - fee)
+ // = -prices[i] - fee
+ continue;
+ }
+ dp[i][0] = Math.max(dp[i - 1][0], dp[i - 1][1] + prices[i]);
+ dp[i][1] = Math.max(dp[i - 1][1], dp[i - 1][0] - prices[i] - fee);
+ }
+ return dp[n - 1][0];
+}
+
+// 空间复杂度优化版本
int maxProfit_with_fee(int[] prices, int fee) {
int n = prices.length;
int dp_i_0 = 0, dp_i_1 = Integer.MIN_VALUE;
@@ -280,14 +524,31 @@ int maxProfit_with_fee(int[] prices, int fee) {
}
```
-**第五题,k = 2**
-k = 2 和前面题目的情况稍微不同,因为上面的情况都和 k 的关系不太大。要么 k 是正无穷,状态转移和 k 没关系了;要么 k = 1,跟 k = 0 这个 base case 挨得近,最后也没有存在感。
+
+
+
+
+🌈 代码可视化动画🌈
+
+
+
+
+
-这道题 k = 2 和后面要讲的 k 是任意正整数的情况中,对 k 的处理就凸显出来了。我们直接写代码,边写边分析原因。
+
+### 123. 买卖股票的最佳时机 III
+
+**第五题,看力扣第 123 题「买卖股票的最佳时机 III」,也就是 `k = 2` 的情况**:
+
+
+
+`k = 2` 和前面题目的情况稍微不同,因为上面的情况都和 `k` 的关系不太大:要么 `k` 是正无穷,状态转移和 `k` 没关系了;要么 `k = 1`,跟 `k = 0` 这个 base case 挨得近,最后也没有存在感。
+
+这道题 `k = 2` 和后面要讲的 `k` 是任意正整数的情况中,对 `k` 的处理就凸显出来了,我们直接写代码,边写边分析原因。
```java
-原始的动态转移方程,没有可化简的地方
+原始的状态转移方程,没有可化简的地方
dp[i][k][0] = max(dp[i-1][k][0], dp[i-1][k][1] + prices[i])
dp[i][k][1] = max(dp[i-1][k][1], dp[i-1][k-1][0] - prices[i])
```
@@ -297,8 +558,13 @@ dp[i][k][1] = max(dp[i-1][k][1], dp[i-1][k-1][0] - prices[i])
```java
int k = 2;
int[][][] dp = new int[n][k + 1][2];
-for (int i = 0; i < n; i++)
- if (i - 1 == -1) { /* 处理一下 base case*/ }
+for (int i = 0; i < n; i++) {
+ if (i - 1 == -1) {
+ // 处理 base case
+ dp[i][k][0] = 0;
+ dp[i][k][1] = -prices[i];
+ continue;
+ }
dp[i][k][0] = Math.max(dp[i-1][k][0], dp[i-1][k][1] + prices[i]);
dp[i][k][1] = Math.max(dp[i-1][k][1], dp[i-1][k-1][0] - prices[i]);
}
@@ -307,37 +573,80 @@ return dp[n - 1][k][0];
为什么错误?我这不是照着状态转移方程写的吗?
-还记得前面总结的「穷举框架」吗?就是说我们必须穷举所有状态。其实我们之前的解法,都在穷举所有状态,只是之前的题目中 k 都被化简掉了。比如说第一题,k = 1:
+还记得前面总结的「穷举框架」吗?就是说我们必须穷举所有状态。其实我们之前的解法,都在穷举所有状态,只是之前的题目中 `k` 都被化简掉了。
-「代码截图」
-
-这道题由于没有消掉 k 的影响,所以必须要对 k 进行穷举:
+比如说第一题,`k = 1` 时的代码框架:
```java
-int max_k = 2;
-int[][][] dp = new int[n][max_k + 1][2];
+int n = prices.length;
+int[][] dp = new int[n][2];
for (int i = 0; i < n; i++) {
- for (int k = max_k; k >= 1; k--) {
- if (i - 1 == -1) { /*处理 base case */ }
- dp[i][k][0] = max(dp[i-1][k][0], dp[i-1][k][1] + prices[i]);
- dp[i][k][1] = max(dp[i-1][k][1], dp[i-1][k-1][0] - prices[i]);
+ dp[i][0] = Math.max(dp[i-1][0], dp[i-1][1] + prices[i]);
+ dp[i][1] = Math.max(dp[i-1][1], -prices[i]);
+}
+return dp[n - 1][0];
+```
+
+但当 `k = 2` 时,由于没有消掉 `k` 的影响,所以必须要对 `k` 进行穷举:
+
+```java
+// 原始版本
+int maxProfit_k_2(int[] prices) {
+ int max_k = 2, n = prices.length;
+ int[][][] dp = new int[n][max_k + 1][2];
+ for (int i = 0; i < n; i++) {
+ for (int k = max_k; k >= 1; k--) {
+ if (i - 1 == -1) {
+ // 处理 base case
+ dp[i][k][0] = 0;
+ dp[i][k][1] = -prices[i];
+ continue;
+ }
+ dp[i][k][0] = Math.max(dp[i-1][k][0], dp[i-1][k][1] + prices[i]);
+ dp[i][k][1] = Math.max(dp[i-1][k][1], dp[i-1][k-1][0] - prices[i]);
+ }
}
+ // 穷举了 n × max_k × 2 个状态,正确。
+ return dp[n - 1][max_k][0];
}
-// 穷举了 n × max_k × 2 个状态,正确。
-return dp[n - 1][max_k][0];
```
-如果你不理解,可以返回第一点「穷举框架」重新阅读体会一下。
-这里 k 取值范围比较小,所以可以不用 for 循环,直接把 k = 1 和 2 的情况全部列举出来也可以:
+
+
+
+
+🍭 代码可视化动画🍭
+
+
+
+
+
+
+
+> [!NOTE]
+> **这里肯定会有读者疑惑,`k` 的 base case 是 0,按理说应该从 `k = 1, k++` 这样穷举状态 `k` 才对?而且如果你真的这样从小到大遍历 `k`,提交发现也是可以的**。
+
+这个疑问很正确,因为我们前文 [动态规划答疑篇](https://labuladong.online/algo/dynamic-programming/faq-summary/) 有介绍 `dp` 数组的遍历顺序是怎么确定的,主要是根据 base case,以 base case 为起点,逐步向结果靠近。
+
+但为什么我从大到小遍历 `k` 也可以正确提交呢?因为你注意看,`dp[i][k][..]` 不会依赖 `dp[i][k - 1][..]`,而是依赖 `dp[i - 1][k - 1][..]`,而 `dp[i - 1][..][..]`,都是已经计算出来的,所以不管你是 `k = max_k, k--`,还是 `k = 1, k++`,都是可以得出正确答案的。
+
+那为什么我使用 `k = max_k, k--` 的方式呢?因为这样符合语义:
+
+你买股票,初始的「状态」是什么?应该是从第 0 天开始,而且还没有进行过买卖,所以最大交易次数限制 `k` 应该是 `max_k`;而随着「状态」的推移,你会进行交易,那么交易次数上限 `k` 应该不断减少,这样一想,`k = max_k, k--` 的方式是比较合乎实际场景的。
+
+当然,这里 `k` 取值范围比较小,所以也可以不用 for 循环,直接把 k = 1 和 2 的情况全部列举出来也可以:
```java
-dp[i][2][0] = max(dp[i-1][2][0], dp[i-1][2][1] + prices[i])
-dp[i][2][1] = max(dp[i-1][2][1], dp[i-1][1][0] - prices[i])
-dp[i][1][0] = max(dp[i-1][1][0], dp[i-1][1][1] + prices[i])
-dp[i][1][1] = max(dp[i-1][1][1], -prices[i])
+// 状态转移方程:
+// dp[i][2][0] = max(dp[i-1][2][0], dp[i-1][2][1] + prices[i])
+// dp[i][2][1] = max(dp[i-1][2][1], dp[i-1][1][0] - prices[i])
+// dp[i][1][0] = max(dp[i-1][1][0], dp[i-1][1][1] + prices[i])
+// dp[i][1][1] = max(dp[i-1][1][1], -prices[i])
+// 空间复杂度优化版本
int maxProfit_k_2(int[] prices) {
+ // base case
int dp_i10 = 0, dp_i11 = Integer.MIN_VALUE;
int dp_i20 = 0, dp_i21 = Integer.MIN_VALUE;
for (int price : prices) {
@@ -350,50 +659,202 @@ int maxProfit_k_2(int[] prices) {
}
```
-有状态转移方程和含义明确的变量名指导,相信你很容易看懂。其实我们可以故弄玄虚,把上述四个变量换成 a, b, c, d。这样当别人看到你的代码时就会大惊失色,对你肃然起敬。
+有状态转移方程和含义明确的变量名指导,相信你很容易看懂。其实我们可以故弄玄虚,把上述四个变量换成 `a, b, c, d`。这样当别人看到你的代码时就会大惊失色,对你肃然起敬。
+
+### 188. 买卖股票的最佳时机 IV
+
+第六题,看力扣第 188 题「买卖股票的最佳时机 IV」,即 `k` 可以是题目给定的任何数的情况:
-**第六题,k = any integer**
+
-有了上一题 k = 2 的铺垫,这题应该和上一题的第一个解法没啥区别。但是出现了一个超内存的错误,原来是传入的 k 值会非常大,dp 数组太大了。现在想想,交易次数 k 最多有多大呢?
+有了上一题 `k = 2` 的铺垫,这题应该和上一题的第一个解法没啥区别,你把上一题的 `k = 2` 换成题目输入的 `k` 就行了。
-一次交易由买入和卖出构成,至少需要两天。所以说有效的限制 k 应该不超过 n/2,如果超过,就没有约束作用了,相当于 k = +infinity。这种情况是之前解决过的。
+但试一下发现会出一个内存超限的错误,原来是传入的 `k` 值会非常大,`dp` 数组太大了。那么现在想想,交易次数 `k` 最多有多大呢?
-直接把之前的代码重用:
+一次交易由买入和卖出构成,至少需要两天。所以说有效的限制 `k` 应该不超过 `n/2`,如果超过,就没有约束作用了,相当于 `k` 没有限制的情况,而这种情况是之前解决过的。
+
+所以我们可以直接把之前的代码重用:
```java
int maxProfit_k_any(int max_k, int[] prices) {
int n = prices.length;
- if (max_k > n / 2)
+ if (n <= 0) {
+ return 0;
+ }
+ if (max_k > n / 2) {
+ // 复用之前交易次数 k 没有限制的情况
return maxProfit_k_inf(prices);
+ }
+ // base case:
+ // dp[-1][...][0] = dp[...][0][0] = 0
+ // dp[-1][...][1] = dp[...][0][1] = -infinity
int[][][] dp = new int[n][max_k + 1][2];
+ // k = 0 时的 base case
+ for (int i = 0; i < n; i++) {
+ dp[i][0][1] = Integer.MIN_VALUE;
+ dp[i][0][0] = 0;
+ }
+
for (int i = 0; i < n; i++)
for (int k = max_k; k >= 1; k--) {
- if (i - 1 == -1) { /* 处理 base case */ }
- dp[i][k][0] = max(dp[i-1][k][0], dp[i-1][k][1] + prices[i]);
- dp[i][k][1] = max(dp[i-1][k][1], dp[i-1][k-1][0] - prices[i]);
+ if (i - 1 == -1) {
+ // 处理 i = -1 时的 base case
+ dp[i][k][0] = 0;
+ dp[i][k][1] = -prices[i];
+ continue;
+ }
+ dp[i][k][0] = Math.max(dp[i-1][k][0], dp[i-1][k][1] + prices[i]);
+ dp[i][k][1] = Math.max(dp[i-1][k][1], dp[i-1][k-1][0] - prices[i]);
}
return dp[n - 1][max_k][0];
}
```
+
+
+
+
+
+🌟 代码可视化动画🌟
+
+
+
+
+
+
+
至此,6 道题目通过一个状态转移方程全部解决。
+## 万法归一
+
+如果你能看到这里,已经可以给你鼓掌了,初次理解如此复杂的动态规划问题想必消耗了你不少的脑细胞,不过这是值得的,股票系列问题已经属于动态规划问题中较困难的了,如果这些题你都能搞懂,试问,其他那些虾兵蟹将又何足道哉?
+
+**现在你已经过了九九八十一难中的前八十难,最后我还要再难为你一下,请你实现如下函数**:
+
+```java
+int maxProfit_all_in_one(int max_k, int[] prices, int cooldown, int fee);
+```
+
+输入股票价格数组 `prices`,你最多进行 `max_k` 次交易,每次交易需要额外消耗 `fee` 的手续费,而且每次交易之后需要经过 `cooldown` 天的冷冻期才能进行下一次交易,请你计算并返回可以获得的最大利润。
+
+怎么样,有没有被吓到?如果你直接给别人出一道这样的题目,估计对方要当场吐血,不过我们这样一步步做过来,你应该很容易发现这道题目就是之前我们探讨的几种情况的组合体嘛。
+
+所以,我们只要把之前实现的几种代码掺和到一块,**在 base case 和状态转移方程中同时加上 `cooldown` 和 `fee` 的约束就行了**:
+
+```java
+// 同时考虑交易次数的限制、冷冻期和手续费
+int maxProfit_all_in_one(int max_k, int[] prices, int cooldown, int fee) {
+ int n = prices.length;
+ if (n <= 0) {
+ return 0;
+ }
+ if (max_k > n / 2) {
+ // 交易次数 k 没有限制的情况
+ return maxProfit_k_inf(prices, cooldown, fee);
+ }
+
+ int[][][] dp = new int[n][max_k + 1][2];
+ // k = 0 时的 base case
+ for (int i = 0; i < n; i++) {
+ dp[i][0][1] = Integer.MIN_VALUE;
+ dp[i][0][0] = 0;
+ }
+
+ for (int i = 0; i < n; i++)
+ for (int k = max_k; k >= 1; k--) {
+ if (i - 1 == -1) {
+ // base case 1
+ dp[i][k][0] = 0;
+ dp[i][k][1] = -prices[i] - fee;
+ continue;
+ }
+
+ // 包含 cooldown 的 base case
+ if (i - cooldown - 1 < 0) {
+ // base case 2
+ dp[i][k][0] = Math.max(dp[i-1][k][0], dp[i-1][k][1] + prices[i]);
+ // 别忘了减 fee
+ dp[i][k][1] = Math.max(dp[i-1][k][1], -prices[i] - fee);
+ continue;
+ }
+ dp[i][k][0] = Math.max(dp[i-1][k][0], dp[i-1][k][1] + prices[i]);
+ // 同时考虑 cooldown 和 fee
+ dp[i][k][1] = Math.max(dp[i-1][k][1], dp[i-cooldown-1][k-1][0] - prices[i] - fee);
+ }
+ return dp[n - 1][max_k][0];
+}
+
+// k 无限制,包含手续费和冷冻期
+int maxProfit_k_inf(int[] prices, int cooldown, int fee) {
+ int n = prices.length;
+ int[][] dp = new int[n][2];
+ for (int i = 0; i < n; i++) {
+ if (i - 1 == -1) {
+ // base case 1
+ dp[i][0] = 0;
+ dp[i][1] = -prices[i] - fee;
+ continue;
+ }
+
+ // 包含 cooldown 的 base case
+ if (i - cooldown - 1 < 0) {
+ // base case 2
+ dp[i][0] = Math.max(dp[i-1][0], dp[i-1][1] + prices[i]);
+ // 别忘了减 fee
+ dp[i][1] = Math.max(dp[i-1][1], -prices[i] - fee);
+ continue;
+ }
+ dp[i][0] = Math.max(dp[i - 1][0], dp[i - 1][1] + prices[i]);
+ // 同时考虑 cooldown 和 fee
+ dp[i][1] = Math.max(dp[i - 1][1], dp[i - cooldown - 1][0] - prices[i] - fee);
+ }
+ return dp[n - 1][0];
+}
+```
+
+你可以用这个 `maxProfit_all_in_one` 函数去完成之前讲的 6 道题目,因为我们无法对 `dp` 数组进行优化,所以执行效率上不是最优的,但正确性上肯定是没有问题的。
+
+最后总结一下吧,本文给大家讲了如何通过状态转移的方法解决复杂的问题,用一个状态转移方程秒杀了 6 道股票买卖问题,现在回头去看,其实也不算那么可怕对吧?
+
+关键就在于列举出所有可能的「状态」,然后想想怎么穷举更新这些「状态」。一般用一个多维 `dp` 数组储存这些状态,从 base case 开始向后推进,推进到最后的状态,就是我们想要的答案。想想这个过程,你是不是有点理解「动态规划」这个名词的意义了呢?
+
+具体到股票买卖问题,我们发现了三个状态,使用了一个三维数组,无非还是穷举 + 更新,不过我们可以说的高大上一点,这叫「三维 DP」,听起来是不是很厉害?
+
+
+
+
+
+
+
+
+
+引用本文的文章
+
+ - [最优子结构原理和 dp 数组遍历方向](https://labuladong.online/algo/dynamic-programming/faq-summary/)
+
+
+
+
+
+
+
+
+引用本文的题目
-**四、最后总结**
+安装 [我的 Chrome 刷题插件](https://labuladong.online/algo/intro/chrome/) 点开下列题目可直接查看解题思路:
-本文给大家讲了如何通过状态转移的方法解决复杂的问题,用一个状态转移方程秒杀了 6 道股票买卖问题,现在想想,其实也不算难对吧?这已经属于动态规划问题中较困难的了。
+| LeetCode | 力扣 | 难度 |
+| :----: | :----: | :----: |
+| - | [剑指 Offer 63. 股票的最大利润](https://leetcode.cn/problems/gu-piao-de-zui-da-li-run-lcof/?show=1) | 🟠 |
-关键就在于列举出所有可能的「状态」,然后想想怎么穷举更新这些「状态」。一般用一个多维 dp 数组储存这些状态,从 base case 开始向后推进,推进到最后的状态,就是我们想要的答案。想想这个过程,你是不是有点理解「动态规划」这个名词的意义了呢?
+
+
-具体到股票买卖问题,我们发现了三个状态,使用了一个三维数组,无非还是穷举 + 更新,不过我们可以说的高大上一点,这叫「三维 DP」,怕不怕?这个大实话一说,立刻显得你高人一等,名利双收有没有,所以给个在看/分享吧,鼓励一下我。
-**致力于把算法讲清楚!欢迎关注我的微信公众号 labuladong,查看更多通俗易懂的文章**:
-
+**_____________**
-[上一篇:动态规划之KMP字符匹配算法](../动态规划系列/动态规划之KMP字符匹配算法.md)
-[下一篇:团灭 LeetCode 打家劫舍问题](../动态规划系列/抢房子.md)
-[目录](../README.md#目录)
\ No newline at end of file
+
\ No newline at end of file
diff --git "a/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\345\255\220\345\272\217\345\210\227\351\227\256\351\242\230\346\250\241\346\235\277.md" "b/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\345\255\220\345\272\217\345\210\227\351\227\256\351\242\230\346\250\241\346\235\277.md"
index 39917bb8e7..9b7fb43724 100644
--- "a/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\345\255\220\345\272\217\345\210\227\351\227\256\351\242\230\346\250\241\346\235\277.md"
+++ "b/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\345\255\220\345\272\217\345\210\227\351\227\256\351\242\230\346\250\241\346\235\277.md"
@@ -1,20 +1,50 @@
# 动态规划之子序列问题解题模板
+
+
+
+
+**通知:为满足广大读者的需求,网站上架 [速成目录](https://labuladong.online/algo/intro/quick-learning-plan/),如有需要可以看下,谢谢大家的支持~另外,建议你在我的 [网站](https://labuladong.online/algo/) 学习文章,体验更好。**
+
+
+
+读完本文,你不仅学会了算法套路,还可以顺便解决如下题目:
+
+| LeetCode | 力扣 | 难度 |
+| :----: | :----: | :----: |
+| [1312. Minimum Insertion Steps to Make a String Palindrome](https://leetcode.com/problems/minimum-insertion-steps-to-make-a-string-palindrome/) | [1312. 让字符串成为回文串的最少插入次数](https://leetcode.cn/problems/minimum-insertion-steps-to-make-a-string-palindrome/) | 🔴 |
+| [516. Longest Palindromic Subsequence](https://leetcode.com/problems/longest-palindromic-subsequence/) | [516. 最长回文子序列](https://leetcode.cn/problems/longest-palindromic-subsequence/) | 🟠 |
+
+**-----------**
+
+
+
+> [!NOTE]
+> 阅读本文前,你需要先学习:
+>
+> - [动态规划核心框架](https://labuladong.online/algo/essential-technique/dynamic-programming-framework/)
+
子序列问题是常见的算法问题,而且并不好解决。
首先,子序列问题本身就相对子串、子数组更困难一些,因为前者是不连续的序列,而后两者是连续的,就算穷举你都不一定会,更别说求解相关的算法问题了。
-而且,子序列问题很可能涉及到两个字符串,比如前文「最长公共子序列」,如果没有一定的处理经验,真的不容易想出来。所以本文就来扒一扒子序列问题的套路,其实就有两种模板,相关问题只要往这两种思路上想,十拿九稳。
+而且,子序列问题很可能涉及到两个字符串,比如前文 [最长公共子序列](https://labuladong.online/algo/dynamic-programming/longest-common-subsequence/),如果没有一定的处理经验,真的不容易想出来。所以本文就来扒一扒子序列问题的套路,其实就有两种模板,相关问题只要往这两种思路上想,十拿九稳。
一般来说,这类问题都是让你求一个**最长子序列**,因为最短子序列就是一个字符嘛,没啥可问的。一旦涉及到子序列和最值,那几乎可以肯定,**考察的是动态规划技巧,时间复杂度一般都是 O(n^2)**。
原因很简单,你想想一个字符串,它的子序列有多少种可能?起码是指数级的吧,这种情况下,不用动态规划技巧,还想怎么着?
-既然要用动态规划,那就要定义 dp 数组,找状态转移关系。我们说的两种思路模板,就是 dp 数组的定义思路。不同的问题可能需要不同的 dp 数组定义来解决。
+既然要用动态规划,那就要定义 `dp` 数组,找状态转移关系。我们说的两种思路模板,就是 `dp` 数组的定义思路。不同的问题可能需要不同的 `dp` 数组定义来解决。
-### 一、两种思路
+## 一、两种思路
-**1、第一种思路模板是一个一维的 dp 数组**:
+
+
+
+
+
+
+**1、第一种思路模板是一个一维的 `dp` 数组**:
```java
int n = array.length;
@@ -27,13 +57,15 @@ for (int i = 1; i < n; i++) {
}
```
-举个我们写过的例子「最长递增子序列」,在这个思路中 dp 数组的定义是:
+比如我们写过的 [最长递增子序列](https://labuladong.online/algo/dynamic-programming/longest-increasing-subsequence/) 和 [最大子数组和](https://labuladong.online/algo/dynamic-programming/maximum-subarray/) 都是这个思路。
-**在子数组 `array[0..i]` 中,我们要求的子序列(最长递增子序列)的长度是 `dp[i]`**。
+在这个思路中 `dp` 数组的定义是:
+
+**在子数组 `arr[0..i]` 中,以 `arr[i]` 结尾的子序列的长度是 `dp[i]`**。
为啥最长递增子序列需要这种思路呢?前文说得很清楚了,因为这样符合归纳法,可以找到状态转移的关系,这里就不具体展开了。
-**2、第二种思路模板是一个二维的 dp 数组**:
+**2、第二种思路模板是一个二维的 `dp` 数组**:
```java
int n = arr.length;
@@ -49,46 +81,54 @@ for (int i = 0; i < n; i++) {
}
```
-这种思路运用相对更多一些,尤其是涉及两个字符串/数组的子序列,比如前文讲的「最长公共子序列」。本思路中 dp 数组含义又分为「只涉及一个字符串」和「涉及两个字符串」两种情况。
+这种思路运用相对更多一些,尤其是涉及两个字符串/数组的子序列时,比如前文讲的 [最长公共子序列](https://labuladong.online/algo/dynamic-programming/longest-common-subsequence/) 和 [编辑距离](https://labuladong.online/algo/dynamic-programming/edit-distance/);这种思路也可以用于只涉及一个字符串/数组的情景,比如本文讲的回文子序列问题。
-**2.1 涉及两个字符串/数组时**(比如最长公共子序列),dp 数组的含义如下:
+**2.1 涉及两个字符串/数组的场景**,`dp` 数组的定义如下:
-**在子数组 `arr1[0..i]` 和子数组 `arr2[0..j]` 中,我们要求的子序列(最长公共子序列)长度为 `dp[i][j]`**。
+**在子数组 `arr1[0..i]` 和子数组 `arr2[0..j]` 中,我们要求的子序列长度为 `dp[i][j]`**。
-**2.2 只涉及一个字符串/数组时**(比如本文要讲的最长回文子序列),dp 数组的含义如下:
+**2.2 只涉及一个字符串/数组的场景**,`dp` 数组的定义如下:
-**在子数组 `array[i..j]` 中,我们要求的子序列(最长回文子序列)的长度为 `dp[i][j]`**。
+**在子数组 `array[i..j]` 中,我们要求的子序列的长度为 `dp[i][j]`**。
-第一种情况可以参考这两篇旧文:「编辑距离」「公共子序列」
+下面就看看最长回文子序列问题,详解一下第二种情况下如何使用动态规划。
-下面就借最长回文子序列这个问题,详解一下第二种情况下如何使用动态规划。
+## 二、最长回文子序列
-### 二、最长回文子序列
+之前解决了 [最长回文子串](https://labuladong.online/algo/essential-technique/array-two-pointers-summary/) 的问题,这次提升难度,看看力扣第 516 题「最长回文子序列」,求最长回文子序列的长度:
-之前解决了「最长回文子串」的问题,这次提升难度,求最长回文子序列的长度:
+输入一个字符串 `s`,请你找出 `s` 中的最长回文子序列长度,函数签名如下:
-
+```java
+int longestPalindromeSubseq(String s);
+```
-我们说这个问题对 dp 数组的定义是:**在子串 `s[i..j]` 中,最长回文子序列的长度为 `dp[i][j]`**。一定要记住这个定义才能理解算法。
+比如说输入 `s = "aecda"`,算法返回 3,因为最长回文子序列是 `"aca"`,长度为 3。
-为啥这个问题要这样定义二维的 dp 数组呢?我们前文多次提到,**找状态转移需要归纳思维,说白了就是如何从已知的结果推出未知的部分**,这样定义容易归纳,容易发现状态转移关系。
+我们对 `dp` 数组的定义是:**在子串 `s[i..j]` 中,最长回文子序列的长度为 `dp[i][j]`**。一定要记住这个定义才能理解算法。
+
+为啥这个问题要这样定义二维的 `dp` 数组呢?我在 [最长递增子序列](https://labuladong.online/algo/dynamic-programming/longest-increasing-subsequence/) 提到,找状态转移需要归纳思维,说白了就是如何从已知的结果推出未知的部分。而这样定义能够进行归纳,容易发现状态转移关系。
具体来说,如果我们想求 `dp[i][j]`,假设你知道了子问题 `dp[i+1][j-1]` 的结果(`s[i+1..j-1]` 中最长回文子序列的长度),你是否能想办法算出 `dp[i][j]` 的值(`s[i..j]` 中,最长回文子序列的长度)呢?
-
+
可以!这取决于 `s[i]` 和 `s[j]` 的字符:
**如果它俩相等**,那么它俩加上 `s[i+1..j-1]` 中的最长回文子序列就是 `s[i..j]` 的最长回文子序列:
-
+
**如果它俩不相等**,说明它俩**不可能同时**出现在 `s[i..j]` 的最长回文子序列中,那么把它俩**分别**加入 `s[i+1..j-1]` 中,看看哪个子串产生的回文子序列更长即可:
-
+
以上两种情况写成代码就是这样:
+
+
+
+
```java
if (s[i] == s[j])
// 它俩一定在最长回文子序列中
@@ -98,55 +138,189 @@ else
dp[i][j] = max(dp[i + 1][j], dp[i][j - 1]);
```
+
+
至此,状态转移方程就写出来了,根据 dp 数组的定义,我们要求的就是 `dp[0][n - 1]`,也就是整个 `s` 的最长回文子序列的长度。
-### 三、代码实现
+## 三、代码实现
首先明确一下 base case,如果只有一个字符,显然最长回文子序列长度是 1,也就是 `dp[i][j] = 1 (i == j)`。
因为 `i` 肯定小于等于 `j`,所以对于那些 `i > j` 的位置,根本不存在什么子序列,应该初始化为 0。
-另外,看看刚才写的状态转移方程,想求 `dp[i][j]` 需要知道 `dp[i+1][j-1]`,`dp[i+1][j]`,`dp[i][j-1]` 这三个位置;再看看我们确定的 base case,填入 dp 数组之后是这样:
+另外,看看刚才写的状态转移方程,想求 `dp[i][j]` 需要知道 `dp[i+1][j-1]`,`dp[i+1][j]`,`dp[i][j-1]` 这三个位置;再看看我们确定的 base case,填入 `dp` 数组之后是这样:
-
+
**为了保证每次计算 `dp[i][j]`,左下右方向的位置已经被计算出来,只能斜着遍历或者反着遍历**:
-
+
+
+> [!TIP]
+> 关于 `dp` 数组的遍历方向,详情见 [动态规划答疑篇](https://labuladong.online/algo/dynamic-programming/faq-summary/)。
我选择反着遍历,代码如下:
-```cpp
-int longestPalindromeSubseq(string s) {
- int n = s.size();
- // dp 数组全部初始化为 0
- vector> dp(n, vector(n, 0));
- // base case
- for (int i = 0; i < n; i++)
- dp[i][i] = 1;
- // 反着遍历保证正确的状态转移
- for (int i = n - 1; i >= 0; i--) {
- for (int j = i + 1; j < n; j++) {
- // 状态转移方程
- if (s[i] == s[j])
- dp[i][j] = dp[i + 1][j - 1] + 2;
- else
- dp[i][j] = max(dp[i + 1][j], dp[i][j - 1]);
+```java
+class Solution {
+ public int longestPalindromeSubseq(String s) {
+ int n = s.length();
+ // dp 数组全部初始化为 0
+ int[][] dp = new int[n][n];
+ // base case
+ for (int i = 0; i < n; i++) {
+ dp[i][i] = 1;
+ }
+ // 反着遍历保证正确的状态转移
+ for (int i = n - 1; i >= 0; i--) {
+ for (int j = i + 1; j < n; j++) {
+ // 状态转移方程
+ if (s.charAt(i) == s.charAt(j)) {
+ dp[i][j] = dp[i + 1][j - 1] + 2;
+ } else {
+ dp[i][j] = Math.max(dp[i + 1][j], dp[i][j - 1]);
+ }
+ }
}
+ // 整个 s 的最长回文子串长度
+ return dp[0][n - 1];
}
- // 整个 s 的最长回文子串长度
- return dp[0][n - 1];
}
```
+
+
+
+
+
+🥳 代码可视化动画🥳
+
+
+
+
+
+
+
至此,最长回文子序列的问题就解决了。
-**致力于把算法讲清楚!欢迎关注我的微信公众号 labuladong,查看更多通俗易懂的文章**:
+## 四、拓展延伸
+
+虽然回文相关的问题没有什么特别广泛的使用场景,但是你会算最长回文子序列之后,一些类似的题目也可以顺手做掉。
+
+比如力扣第 1312 题「计算让字符串成为回文串的最少插入次数」:
+
+输入一个字符串 `s`,你可以在字符串的任意位置插入任意字符。如果要把 `s` 变成回文串,请你计算最少要进行多少次插入?
+
+函数签名如下:
+
+```java
+int minInsertions(String s);
+```
+
+比如说输入 `s = "abcea"`,算法返回 2,因为可以给 `s` 插入 2 个字符变成回文串 `"abeceba"` 或者 `"aebcbea"`。如果输入 `s = "aba"`,则算法返回 0,因为 `s` 已经是回文串,不用插入任何字符。
+
+这也是一道单字符串的子序列问题,所以我们也可以使用一个二维 `dp` 数组,其中 `dp[i][j]` 的定义如下:
+
+**对字符串 `s[i..j]`,最少需要进行 `dp[i][j]` 次插入才能变成回文串**。
+
+根据 `dp` 数组的定义,base case 就是 `dp[i][i] = 0`,因为单个字符本身就是回文串,不需要插入。
+
+然后使用数学归纳法,假设已经计算出了子问题 `dp[i+1][j-1]` 的值了,思考如何推出 `dp[i][j]` 的值:
+
+
+
+实际上和最长回文子序列问题的状态转移方程非常类似,这里也分两种情况:
+
+
+
+
+
+```java
+if (s[i] == s[j]) {
+ // 不需要插入任何字符
+ dp[i][j] = dp[i + 1][j - 1];
+} else {
+ // 把 s[i+1..j] 和 s[i..j-1] 变成回文串,选插入次数较少的
+ // 然后还要再插入一个 s[i] 或 s[j],使 s[i..j] 配成回文串
+ dp[i][j] = min(dp[i + 1][j], dp[i][j - 1]) + 1;
+}
+```
+
+
+
+最后,我们依然采取倒着遍历 `dp` 数组的方式,写出代码:
+
+```java
+class Solution {
+ public int minInsertions(String s) {
+ int n = s.length();
+ // dp[i][j] 表示把字符串 s[i..j] 变成回文串的最少插入次数
+ // dp 数组全部初始化为 0
+ int[][] dp = new int[n][n];
+ // 反着遍历保证正确的状态转移
+ for (int i = n - 1; i >= 0; i--) {
+ for (int j = i + 1; j < n; j++) {
+ // 状态转移方程
+ if (s.charAt(i) == s.charAt(j)) {
+ dp[i][j] = dp[i + 1][j - 1];
+ } else {
+ dp[i][j] = Math.min(dp[i + 1][j], dp[i][j - 1]) + 1;
+ }
+ }
+ }
+ // 整个 s 的最少插入次数
+ return dp[0][n - 1];
+ }
+}
+```
+
+至此,这道题也使用子序列解题模板解决了,整体逻辑和最长回文子序列非常相似,那么这个问题是否可以直接复用回文子序列的解法呢?
+
+其实是可以的,我们甚至都不用写状态转移方程,你仔细想想:
+
+**我先算出字符串 `s` 中的最长回文子序列,那些不在最长回文子序列中的字符,不就是需要插入的字符吗**?
+
+所以这道题可以直接复用之前实现的 `longestPalindromeSubseq` 函数:
+
+```java
+class Solution {
+ // 计算把 s 变成回文串的最少插入次数
+ public int minInsertions(String s) {
+ return s.length() - longestPalindromeSubseq(s);
+ }
+
+ // 计算 s 中的最长回文子序列长度
+ int longestPalindromeSubseq(String s) {
+ // 见上文
+ }
+}
+```
+
+好了,子序列相关的算法就讲到这里,希望对你有启发。
+
+
+
+
+
+
+
+
+
+引用本文的文章
+
+ - [动态规划设计:最长递增子序列](https://labuladong.online/algo/dynamic-programming/longest-increasing-subsequence/)
+ - [对动态规划进行降维打击](https://labuladong.online/algo/dynamic-programming/space-optimization/)
+ - [最优子结构原理和 dp 数组遍历方向](https://labuladong.online/algo/dynamic-programming/faq-summary/)
+ - [经典动态规划:最长公共子序列](https://labuladong.online/algo/dynamic-programming/longest-common-subsequence/)
+
+
+
+
+
+
-
+**_____________**
-[上一篇:经典动态规划问题:高楼扔鸡蛋(进阶)](../动态规划系列/高楼扔鸡蛋进阶.md)
-[下一篇:动态规划之博弈问题](../动态规划系列/动态规划之博弈问题.md)
-[目录](../README.md#目录)
\ No newline at end of file
+
\ No newline at end of file
diff --git "a/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\346\212\242\346\210\277\345\255\220.md" "b/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\346\212\242\346\210\277\345\255\220.md"
index eeefc0190d..3b27313c5a 100644
--- "a/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\346\212\242\346\210\277\345\255\220.md"
+++ "b/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\346\212\242\346\210\277\345\255\220.md"
@@ -1,20 +1,58 @@
-# 团灭 LeetCode 打家劫舍问题
+# 一个方法团灭 LeetCode 打家劫舍问题
-有读者私下问我 LeetCode 「打家劫舍」系列问题(英文版叫 House Robber)怎么做,我发现这一系列题目的点赞非常之高,是比较有代表性和技巧性的动态规划题目,今天就来聊聊这道题目。
-打家劫舍系列总共有三道,难度设计非常合理,层层递进。第一道是比较标准的动态规划问题,而第二道融入了环形数组的条件,第三道更绝,把动态规划的自底向上和自顶向下解法和二叉树结合起来,我认为很有启发性。如果没做过的朋友,建议学习一下。
+
+
+
+**通知:为满足广大读者的需求,网站上架 [速成目录](https://labuladong.online/algo/intro/quick-learning-plan/),如有需要可以看下,谢谢大家的支持~另外,建议你在我的 [网站](https://labuladong.online/algo/) 学习文章,体验更好。**
+
+
+
+读完本文,你不仅学会了算法套路,还可以顺便解决如下题目:
+
+| LeetCode | 力扣 | 难度 |
+| :----: | :----: | :----: |
+| [198. House Robber](https://leetcode.com/problems/house-robber/) | [198. 打家劫舍](https://leetcode.cn/problems/house-robber/) | 🟠 |
+| [213. House Robber II](https://leetcode.com/problems/house-robber-ii/) | [213. 打家劫舍 II](https://leetcode.cn/problems/house-robber-ii/) | 🟠 |
+| [337. House Robber III](https://leetcode.com/problems/house-robber-iii/) | [337. 打家劫舍 III](https://leetcode.cn/problems/house-robber-iii/) | 🟠 |
+
+**-----------**
+
+
+
+> [!NOTE]
+> 阅读本文前,你需要先学习:
+>
+> - [二叉树系列算法(纲领篇)](https://labuladong.online/algo/essential-technique/binary-tree-summary/)
+> - [动态规划核心框架](https://labuladong.online/algo/essential-technique/dynamic-programming-framework/)
+
+今天来讲「打家劫舍」系列问题(英文版叫 House Robber),这个系列是比较有代表性和技巧性的动态规划题目。
+
+打家劫舍系列总共有三道,难度设计比较合理,层层递进。第一道是比较标准的动态规划问题,而第二道融入了环形数组的条件,第三道更绝,把动态规划的自底向上和自顶向下解法和二叉树结合起来,我认为很有启发性。
下面,我们从第一道开始分析。
-### House Robber I
+## 打家劫舍 I
+
+力扣第 198 题「打家劫舍」的题目如下:
-
+街上有一排房屋,用一个包含非负整数的数组 `nums` 表示,每个元素 `nums[i]` 代表第 `i` 间房子中的现金数额。现在你是一名专业盗贼,你希望**尽可能多**的盗窃这些房子中的现金,但是,**相邻的房子不能被同时盗窃**,否则会触发报警器,你就凉凉了。
+
+请你写一个算法,计算在不触动报警器的前提下,最多能够盗窃多少现金呢?函数签名如下:
```java
-public int rob(int[] nums);
+int rob(int[] nums);
```
-题目很容易理解,而且动态规划的特征很明显。我们前文「动态规划详解」做过总结,**解决动态规划问题就是找「状态」和「选择」,仅此而已**。
+比如说输入 `nums=[2,1,7,9,3,1]`,算法返回 12,小偷可以盗窃 `nums[0], nums[3], nums[5]` 三个房屋,得到的现金之和为 2 + 9 + 1 = 12,是最优的选择。
+
+题目很容易理解,而且动态规划的特征很明显。我们前文 [动态规划详解](https://labuladong.online/algo/essential-technique/dynamic-programming-framework/) 做过总结,**解决动态规划问题就是找「状态」和「选择」,仅此而已**。
+
+
+
+
+
+
假想你就是这个专业强盗,从左到右走过这一排房子,在每间房子前都有两种**选择**:抢或者不抢。
@@ -26,213 +64,301 @@ public int rob(int[] nums);
以上的逻辑很简单吧,其实已经明确了「状态」和「选择」:**你面前房子的索引就是状态,抢和不抢就是选择**。
-
+
在两个选择中,每次都选更大的结果,最后得到的就是最多能抢到的 money:
```java
-// 主函数
-public int rob(int[] nums) {
- return dp(nums, 0);
-}
-// 返回 nums[start..] 能抢到的最大值
-private int dp(int[] nums, int start) {
- if (start >= nums.length) {
- return 0;
+class Solution {
+ // 主函数
+ public int rob(int[] nums) {
+ return dp(nums, 0);
+ }
+
+ // 定义:返回 nums[start..] 能抢到的最大值
+ private int dp(int[] nums, int start) {
+ if (start >= nums.length) {
+ return 0;
+ }
+
+ int res = Math.max(
+ // 不抢,去下家
+ dp(nums, start + 1),
+ // 抢,去下下家
+ nums[start] + dp(nums, start + 2)
+ );
+ return res;
}
-
- int res = Math.max(
- // 不抢,去下家
- dp(nums, start + 1),
- // 抢,去下下家
- nums[start] + dp(nums, start + 2)
- );
- return res;
}
```
明确了状态转移,就可以发现对于同一 `start` 位置,是存在重叠子问题的,比如下图:
-
+
盗贼有多种选择可以走到这个位置,如果每次到这都进入递归,岂不是浪费时间?所以说存在重叠子问题,可以用备忘录进行优化:
```java
-private int[] memo;
-// 主函数
-public int rob(int[] nums) {
- // 初始化备忘录
- memo = new int[nums.length];
- Arrays.fill(memo, -1);
- // 强盗从第 0 间房子开始抢劫
- return dp(nums, 0);
-}
+class Solution {
+
+ private int[] memo;
+ // 主函数
+ public int rob(int[] nums) {
+ // 初始化备忘录
+ memo = new int[nums.length];
+ Arrays.fill(memo, -1);
+ // 强盗从第 0 间房子开始抢劫
+ return dp(nums, 0);
+ }
-// 返回 dp[start..] 能抢到的最大值
-private int dp(int[] nums, int start) {
- if (start >= nums.length) {
- return 0;
+ // 定义:返回 dp[start..] 能抢到的最大值
+ private int dp(int[] nums, int start) {
+ if (start >= nums.length) {
+ return 0;
+ }
+ // 避免重复计算
+ if (memo[start] != -1) return memo[start];
+
+ int res = Math.max(
+ dp(nums, start + 1),
+ dp(nums, start + 2) + nums[start]
+ );
+ // 记入备忘录
+ memo[start] = res;
+ return res;
}
- // 避免重复计算
- if (memo[start] != -1) return memo[start];
-
- int res = Math.max(dp(nums, start + 1),
- nums[start] + dp(nums, start + 2));
- // 记入备忘录
- memo[start] = res;
- return res;
}
```
+
+
+
+
+
+🎃 代码可视化动画🎃
+
+
+
+
+
+
+
这就是自顶向下的动态规划解法,我们也可以略作修改,写出**自底向上**的解法:
```java
- int rob(int[] nums) {
- int n = nums.length;
- // dp[i] = x 表示:
- // 从第 i 间房子开始抢劫,最多能抢到的钱为 x
- // base case: dp[n] = 0
- int[] dp = new int[n + 2];
- for (int i = n - 1; i >= 0; i--) {
- dp[i] = Math.max(dp[i + 1], nums[i] + dp[i + 2]);
+class Solution {
+ public int rob(int[] nums) {
+ int n = nums.length;
+ // dp[i] = x 表示:
+ // 从第 i 间房子开始抢劫,最多能抢到的钱为 x
+ // base case: dp[n] = 0
+ int[] dp = new int[n + 2];
+ for (int i = n - 1; i >= 0; i--) {
+ dp[i] = Math.max(dp[i + 1], nums[i] + dp[i + 2]);
+ }
+ return dp[0];
}
- return dp[0];
}
```
我们又发现状态转移只和 `dp[i]` 最近的两个状态有关,所以可以进一步优化,将空间复杂度降低到 O(1)。
```java
-int rob(int[] nums) {
- int n = nums.length;
- // 记录 dp[i+1] 和 dp[i+2]
- int dp_i_1 = 0, dp_i_2 = 0;
- // 记录 dp[i]
- int dp_i = 0;
- for (int i = n - 1; i >= 0; i--) {
- dp_i = Math.max(dp_i_1, nums[i] + dp_i_2);
- dp_i_2 = dp_i_1;
- dp_i_1 = dp_i;
+class Solution {
+ public int rob(int[] nums) {
+ int n = nums.length;
+ // 记录 dp[i+1] 和 dp[i+2]
+ int dp_i_1 = 0, dp_i_2 = 0;
+ // 记录 dp[i]
+ int dp_i = 0;
+ for (int i = n - 1; i >= 0; i--) {
+ dp_i = Math.max(dp_i_1, nums[i] + dp_i_2);
+ dp_i_2 = dp_i_1;
+ dp_i_1 = dp_i;
+ }
+ return dp_i;
}
- return dp_i;
}
```
-以上的流程,在我们「动态规划详解」中详细解释过,相信大家都能手到擒来了。我认为很有意思的是这个问题的 follow up,需要基于我们现在的思路做一些巧妙的应变。
+以上的流程,在我们 [动态规划详解](https://labuladong.online/algo/essential-technique/dynamic-programming-framework/) 中详细解释过,相信大家都能手到擒来了。我认为很有意思的是这个问题的 follow up,需要基于我们现在的思路做一些巧妙的应变。
-### House Robber II
+## 打家劫舍 II
-这道题目和第一道描述基本一样,强盗依然不能抢劫相邻的房子,输入依然是一个数组,但是告诉你**这些房子不是一排,而是围成了一个圈**。
+力扣第 213 题「打家劫舍 II」和上一道题描述基本一样,强盗依然不能抢劫相邻的房子,输入依然是一个数组,但是告诉你**这些房子不是一排,而是围成了一个圈**。
也就是说,现在第一间房子和最后一间房子也相当于是相邻的,不能同时抢。比如说输入数组 `nums=[2,3,2]`,算法返回的结果应该是 3 而不是 4,因为开头和结尾不能同时被抢。
-这个约束条件看起来应该不难解决,我们前文「单调栈解决 Next Greater Number」说过一种解决环形数组的方案,那么在这个问题上怎么处理呢?
+这个约束条件看起来应该不难解决,我们前文 [单调栈问题汇总](https://labuladong.online/algo/data-structure/monotonic-stack/) 说过一种解决环形数组的方案,那么在这个问题上怎么处理呢?
首先,首尾房间不能同时被抢,那么只可能有三种不同情况:要么都不被抢;要么第一间房子被抢最后一间不抢;要么最后一间房子被抢第一间不抢。
-
+
-那就简单了啊,这三种情况,那种的结果最大,就是最终答案呗!不过,其实我们不需要比较三种情况,只要比较情况二和情况三就行了,**因为这两种情况对于房子的选择余地比情况一大呀,房子里的钱数都是非负数,所以选择余地大,最优决策结果肯定不会小**。
+那就简单了啊,这三种情况,哪种的结果最大,就是最终答案呗!不过,其实我们不需要比较三种情况,只要比较情况二和情况三就行了,**因为这两种情况对于房子的选择余地比情况一大呀,房子里的钱数都是非负数,所以选择余地大,最优决策结果肯定不会小**。
所以只需对之前的解法稍作修改即可:
```java
-public int rob(int[] nums) {
- int n = nums.length;
- if (n == 1) return nums[0];
- return Math.max(robRange(nums, 0, n - 2),
- robRange(nums, 1, n - 1));
-}
+class Solution {
+ public int rob(int[] nums) {
+ int n = nums.length;
+ if (n == 1) return nums[0];
+ return Math.max(robRange(nums, 0, n - 2),
+ robRange(nums, 1, n - 1));
+ }
-// 仅计算闭区间 [start,end] 的最优结果
-int robRange(int[] nums, int start, int end) {
- int n = nums.length;
- int dp_i_1 = 0, dp_i_2 = 0;
- int dp_i = 0;
- for (int i = end; i >= start; i--) {
- dp_i = Math.max(dp_i_1, nums[i] + dp_i_2);
- dp_i_2 = dp_i_1;
- dp_i_1 = dp_i;
+ // 定义:返回闭区间 [start,end] 能抢到的最大值
+ int robRange(int[] nums, int start, int end) {
+ int n = nums.length;
+ int dp_i_1 = 0, dp_i_2 = 0;
+ int dp_i = 0;
+ for (int i = end; i >= start; i--) {
+ dp_i = Math.max(dp_i_1, nums[i] + dp_i_2);
+ dp_i_2 = dp_i_1;
+ dp_i_1 = dp_i;
+ }
+ return dp_i;
}
- return dp_i;
}
```
至此,第二问也解决了。
-### House Robber III
+## 打家劫舍 III
-第三题又想法设法地变花样了,此强盗发现现在面对的房子不是一排,不是一圈,而是一棵二叉树!房子在二叉树的节点上,相连的两个房子不能同时被抢劫,果然是传说中的高智商犯罪:
+力扣第 337 题「打家劫舍 III」又想法设法地变花样了,此强盗发现现在面对的房子不是一排,不是一圈,而是一棵二叉树!房子在二叉树的节点上,相连的两个房子不能同时被抢劫,果然是传说中的高智商犯罪。函数的签名如下:
-
+```java
+int rob(TreeNode root);
+```
+
+比如说输入为下图这样一棵二叉树:
+
+```
+ 3
+ / \
+ 2 3
+ \ \
+ 3 1
+```
+
+算法应该返回 7,因为抢劫第一层和第三层的房子可以得到最高金额 3 + 3 + 1 = 7。
+
+如果输入为下图这棵二叉树:
+
+```
+ 3
+ / \
+ 4 5
+ / \ \
+ 1 3 1
+```
+
+那么算法应该返回 9,如果抢劫第二层的房子可以获得最高金额 4 + 5 = 9。
整体的思路完全没变,还是做抢或者不抢的选择,去收益较大的选择。甚至我们可以直接按这个套路写出代码:
```java
-Map memo = new HashMap<>();
-public int rob(TreeNode root) {
- if (root == null) return 0;
- // 利用备忘录消除重叠子问题
- if (memo.containsKey(root))
- return memo.get(root);
- // 抢,然后去下下家
- int do_it = root.val
- + (root.left == null ?
- 0 : rob(root.left.left) + rob(root.left.right))
- + (root.right == null ?
- 0 : rob(root.right.left) + rob(root.right.right));
- // 不抢,然后去下家
- int not_do = rob(root.left) + rob(root.right);
-
- int res = Math.max(do_it, not_do);
- memo.put(root, res);
- return res;
+class Solution {
+ Map memo = new HashMap<>();
+ public int rob(TreeNode root) {
+ if (root == null) return 0;
+ // 利用备忘录消除重叠子问题
+ if (memo.containsKey(root))
+ return memo.get(root);
+ // 抢,然后去下下家
+ int do_it = root.val
+ + (root.left == null ?
+ 0 : rob(root.left.left) + rob(root.left.right))
+ + (root.right == null ?
+ 0 : rob(root.right.left) + rob(root.right.right));
+ // 不抢,然后去下家
+ int not_do = rob(root.left) + rob(root.right);
+
+ int res = Math.max(do_it, not_do);
+ memo.put(root, res);
+ return res;
+ }
}
```
-这道题就解决了,时间复杂度 O(N),`N` 为数的节点数。
-但是这道题让我觉得巧妙的点在于,还有更漂亮的解法。比如下面是我在评论区看到的一个解法:
+
+
+
+
+👾 代码可视化动画👾
+
+
+
+
+
+
+
+分析下时间复杂度,虽然看这个递归结构似乎是一棵四叉树,但实际上由于备忘录的优化,递归函数做的事情就是还是遍历每个节点,不会多次进入同一个节点,所以时间复杂度是还是 $O(N)$,`N` 为树的节点数。空间复杂度是备忘录的大小,即 $O(N)$。
+
+如果对时间/空间复杂度分析有困惑,可以参考 [时空复杂度分析实用指南](https://labuladong.online/algo/essential-technique/complexity-analysis/)。
+
+但是这道题巧妙的点在于,还有更漂亮的解法。比如一个读者评论了这样一个解法:
```java
-int rob(TreeNode root) {
- int[] res = dp(root);
- return Math.max(res[0], res[1]);
-}
+class Solution {
+ int rob(TreeNode root) {
+ int[] res = dp(root);
+ return Math.max(res[0], res[1]);
+ }
-/* 返回一个大小为 2 的数组 arr
-arr[0] 表示不抢 root 的话,得到的最大钱数
-arr[1] 表示抢 root 的话,得到的最大钱数 */
-int[] dp(TreeNode root) {
- if (root == null)
- return new int[]{0, 0};
- int[] left = dp(root.left);
- int[] right = dp(root.right);
- // 抢,下家就不能抢了
- int rob = root.val + left[0] + right[0];
- // 不抢,下家可抢可不抢,取决于收益大小
- int not_rob = Math.max(left[0], left[1])
- + Math.max(right[0], right[1]);
-
- return new int[]{not_rob, rob};
+ // 返回一个大小为 2 的数组 arr
+ // arr[0] 表示不抢 root 的话,得到的最大钱数
+ // arr[1] 表示抢 root 的话,得到的最大钱数
+ int[] dp(TreeNode root) {
+ if (root == null)
+ return new int[]{0, 0};
+ int[] left = dp(root.left);
+ int[] right = dp(root.right);
+ // 抢,下家就不能抢了
+ int rob = root.val + left[0] + right[0];
+ // 不抢,下家可抢可不抢,取决于收益大小
+ int not_rob = Math.max(left[0], left[1])
+ + Math.max(right[0], right[1]);
+
+ return new int[]{not_rob, rob};
+ }
}
```
-时间复杂度 O(N),空间复杂度只有递归函数堆栈所需的空间,不需要备忘录的额外空间。
+时间复杂度还是 $O(N)$,空间复杂度只有递归函数堆栈所需的空间,即树的高度 $O(H)$,不需要备忘录的额外空间。
-你看他和我们的思路不一样,修改了递归函数的定义,略微修改了思路,使得逻辑自洽,依然得到了正确的答案,而且代码更漂亮。这就是我们前文「不同定义产生不同解法」所说过的动态规划问题的一个特性。
+你看他和我们的思路不一样,修改了递归函数的定义,略微修改了思路,使得逻辑自洽,依然得到了正确的答案,而且代码更漂亮。这就是我们前文 [二叉树思维(纲领篇)](https://labuladong.online/algo/essential-technique/binary-tree-summary/) 中讲到的后序位置的妙用。
实际上,这个解法比我们的解法运行时间要快得多,虽然算法分析层面时间复杂度是相同的。原因在于此解法没有使用额外的备忘录,减少了数据操作的复杂性,所以实际运行效率会快。
-坚持原创高质量文章,致力于把算法问题讲清楚,欢迎关注我的公众号 labuladong 获取最新文章:
-
-[上一篇:团灭 LeetCode 股票买卖问题](../动态规划系列/团灭股票问题.md)
-[下一篇:动态规划之四键键盘](../动态规划系列/动态规划之四键键盘.md)
-[目录](../README.md#目录)
\ No newline at end of file
+
+
+引用本文的题目
+
+安装 [我的 Chrome 刷题插件](https://labuladong.online/algo/intro/chrome/) 点开下列题目可直接查看解题思路:
+
+| LeetCode | 力扣 | 难度 |
+| :----: | :----: | :----: |
+| - | [剑指 Offer II 089. 房屋偷盗](https://leetcode.cn/problems/Gu0c2T/?show=1) | 🟠 |
+| - | [剑指 Offer II 090. 环形房屋偷盗](https://leetcode.cn/problems/PzWKhm/?show=1) | 🟠 |
+
+
+
+
+
+
+**_____________**
+
+
+
+
\ No newline at end of file
diff --git "a/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\346\234\200\344\274\230\345\255\220\347\273\223\346\236\204.md" "b/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\346\234\200\344\274\230\345\255\220\347\273\223\346\236\204.md"
index 21871b7a1a..bf32b7aed7 100644
--- "a/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\346\234\200\344\274\230\345\255\220\347\273\223\346\236\204.md"
+++ "b/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\346\234\200\344\274\230\345\255\220\347\273\223\346\236\204.md"
@@ -1,12 +1,45 @@
-# 动态规划答疑篇
+# 最优子结构原理和 dp 数组遍历方向
-这篇文章就给你讲明白两个问题:
+
+
+
+
+**通知:为满足广大读者的需求,网站上架 [速成目录](https://labuladong.online/algo/intro/quick-learning-plan/),如有需要可以看下,谢谢大家的支持~另外,建议你在我的 [网站](https://labuladong.online/algo/) 学习文章,体验更好。**
+
+
+
+**-----------**
+
+
+
+> [!NOTE]
+> 阅读本文前,你需要先学习:
+>
+> - [动态规划核心框架](https://labuladong.online/algo/essential-technique/dynamic-programming-framework/)
+
+> tip:本文有视频版:[动态规划详解进阶](https://www.bilibili.com/video/BV1uv411W73P/)。建议关注我的 B 站账号,我会用视频领读的方式带大家学习那些稍有难度的算法技巧。
+
+
+
+本文是旧文 [动态规划答疑篇](https://mp.weixin.qq.com/s/qvlfyKBiXVX7CCwWFR-XKg) 的修订版,根据我的不断学习总结以及读者的评论反馈,我给扩展了更多内容,力求使本文成为继 [动态规划核心套路框架](https://labuladong.online/algo/essential-technique/dynamic-programming-framework/) 之后的一篇全面答疑文章。以下是正文。
+
+这篇文章就给你讲明白以下几个问题:
1、到底什么才叫「最优子结构」,和动态规划什么关系。
-2、为什么动态规划遍历 `dp` 数组的方式五花八门,有的正着遍历,有的倒着遍历,有的斜着遍历。
+2、如何判断一个问题是动态规划问题,即如何看出是否存在重叠子问题。
+
+3、为什么经常看到将 `dp` 数组的大小设置为 `n + 1` 而不是 `n`。
+
+4、为什么动态规划遍历 `dp` 数组的方式五花八门,有的正着遍历,有的倒着遍历,有的斜着遍历。
+
+
+
-### 一、最优子结构详解
+
+
+
+## 一、最优子结构详解
「最优子结构」是某些问题的一种特定性质,并不是动态规划问题专有的。也就是说,很多问题其实都具有最优子结构,只是其中大部分不具有重叠子问题,所以我们不把它们归为动态规划系列问题而已。
@@ -18,10 +51,14 @@
再举个例子:假设你们学校有 10 个班,你已知每个班的最大分数差(最高分和最低分的差值)。那么现在我让你计算全校学生中的最大分数差,你会不会算?可以想办法算,但是肯定不能通过已知的这 10 个班的最大分数差推到出来。因为这 10 个班的最大分数差不一定就包含全校学生的最大分数差,比如全校的最大分数差可能是 3 班的最高分和 6 班的最低分之差。
-这次我给你提出的问题就**不符合最优子结构**,因为你没办通过每个班的最优值推出全校的最优值,没办法通过子问题的最优值推出规模更大的问题的最优值。前文「动态规划详解」说过,想满足最优子结,子问题之间必须互相独立。全校的最大分数差可能出现在两个班之间,显然子问题不独立,所以这个问题本身不符合最优子结构。
+这次我给你提出的问题就**不符合最优子结构**,因为你没办通过每个班的最优值推出全校的最优值,没办法通过子问题的最优值推出规模更大的问题的最优值。前文 [动态规划详解](https://labuladong.online/algo/essential-technique/dynamic-programming-framework/) 说过,想满足最优子结,子问题之间必须互相独立。全校的最大分数差可能出现在两个班之间,显然子问题不独立,所以这个问题本身不符合最优子结构。
**那么遇到这种最优子结构失效情况,怎么办?策略是:改造问题**。对于最大分数差这个问题,我们不是没办法利用已知的每个班的分数差吗,那我只能这样写一段暴力代码:
+
+
+
+
```java
int result = 0;
for (Student a : school) {
@@ -33,11 +70,13 @@ for (Student a : school) {
return result;
```
+
+
改造问题,也就是把问题等价转化:最大分数差,不就等价于最高分数和最低分数的差么,那不就是要求最高和最低分数么,不就是我们讨论的第一个问题么,不就具有最优子结构了么?那现在改变思路,借助最优子结构解决最值问题,再回过头解决最大分数差问题,是不是就高效多了?
当然,上面这个例子太简单了,不过请读者回顾一下,我们做动态规划问题,是不是一直在求各种最值,本质跟我们举的例子没啥区别,无非需要处理一下重叠子问题。
-前文「不同定义不同解法」和「高楼扔鸡蛋进阶」就展示了如何改造问题,不同的最优子结构,可能导致不同的解法和效率。
+前文 [高楼扔鸡蛋问题](https://labuladong.online/algo/dynamic-programming/egg-drop/) 就展示了如何改造问题,不同的最优子结构,可能导致不同的解法和效率。
再举个常见但也十分简单的例子,求一棵二叉树的最大值,不难吧(简单起见,假设节点中的值都是非负数):
@@ -57,14 +96,235 @@ int maxVal(TreeNode root) {
动态规划不就是从最简单的 base case 往后推导吗,可以想象成一个链式反应,以小博大。但只有符合最优子结构的问题,才有发生这种链式反应的性质。
-找最优子结构的过程,其实就是证明状态转移方程正确性的过程,方程符合最优子结构就可以写暴力解了,写出暴力解就可以看出有没有重叠子问题了,有则优化,无则 OK。这也是套路,经常刷题的朋友应该能体会。
+找最优子结构的过程,其实就是证明状态转移方程正确性的过程,方程符合最优子结构就可以写暴力解了,写出暴力解就可以看出有没有重叠子问题了,有则优化,无则 OK。这也是套路,经常刷题的读者应该能体会。
+
+这里就不举那些正宗动态规划的例子了,读者可以翻翻历史文章,看看状态转移是如何遵循最优子结构的,这个话题就聊到这,下面再来看其他的动态规划迷惑行为。
+
+
+
+
+
+
+
+## 二、如何一眼看出重叠子问题
+
+经常有读者说:
+
+看了前文 [动态规划核心套路](https://labuladong.online/algo/essential-technique/dynamic-programming-framework/),我知道了如何一步步优化动态规划问题;
-这里就不举那些正宗动态规划的例子了,读者可以翻翻历史文章,看看状态转移是如何遵循最优子结构的,这个话题就聊到这,下面再来看另外个动态规划迷惑行为。
+看了前文 [动态规划设计:数学归纳法](https://labuladong.online/algo/dynamic-programming/longest-increasing-subsequence/),我知道了利用数学归纳法写出暴力解(状态转移方程)。
-### 二、dp 数组的遍历方向
+**但就算我写出了暴力解,我很难判断这个解法是否存在重叠子问题**,从而无法确定是否可以运用备忘录等方法去优化算法效率。
+
+对于这个问题,其实我在动态规划系列的文章中写过几次,在这里再统一总结一下吧。
+
+**首先,最简单粗暴的方式就是画图,把递归树画出来,看看有没有重复的节点**。
+
+比如最简单的例子,[动态规划核心套路](https://labuladong.online/algo/essential-technique/dynamic-programming-framework/) 中斐波那契数列的递归树:
+
+
+
+这棵递归树很明显存在重复的节点,所以我们可以通过备忘录避免冗余计算。
+
+但毕竟斐波那契数列问题太简单了,实际的动态规划问题比较复杂,比如二维甚至三维的动态规划,当然也可以画递归树,但不免有些复杂。
+
+比如在 [最小路径和问题](https://labuladong.online/algo/dynamic-programming/minimum-path-sum/) 中,我们写出了这样一个暴力解法:
+
+```java
+int dp(int[][] grid, int i, int j) {
+ if (i == 0 && j == 0) {
+ return grid[0][0];
+ }
+ if (i < 0 || j < 0) {
+ return Integer.MAX_VALUE;
+ }
+
+ return Math.min(
+ dp(grid, i - 1, j),
+ dp(grid, i, j - 1)
+ ) + grid[i][j];
+}
+```
+
+你不需要读过前文,光看这个函数代码就能看出来,该函数递归过程中参数 `i, j` 在不断变化,即「状态」是 `(i, j)` 的值,你是否可以判断这个解法是否存在重叠子问题呢?
+
+假设输入的 `i = 8, j = 7`,二维状态的递归树如下图,显然出现了重叠子问题:
+
+
+
+**但稍加思考就可以知道,其实根本没必要画图,可以通过递归框架直接判断是否存在重叠子问题**。
+
+具体操作就是直接删掉代码细节,抽象出该解法的递归框架:
+
+
+
+
+
+```java
+int dp(int[][] grid, int i, int j) {
+ dp(grid, i - 1, j), // #1
+ dp(grid, i, j - 1) // #2
+}
+```
+
+
+
+可以看到 `i, j` 的值在不断减小,那么我问你一个问题:如果我想从状态 `(i, j)` 转移到 `(i-1, j-1)`,有几种路径?
+
+显然有两种路径,可以是 `(i, j) -> #1 -> #2` 或者 `(i, j) -> #2 -> #1`,不止一种,说明 `(i-1, j-1)` 会被多次计算,所以一定存在重叠子问题。
+
+再举个稍微复杂的例子,前文 [正则表达式问题](https://labuladong.online/algo/dynamic-programming/regular-expression-matching/) 的暴力解代码:
+
+```java
+boolean dp(String s, int i, String p, int j) {
+ int m = s.length(), n = p.length();
+ // base case
+ if (j == n) {
+ return i == m;
+ }
+ if (i == m) {
+ if ((n - j) % 2 == 1) {
+ return false;
+ }
+ for (; j + 1 < n; j += 2) {
+ if (p.charAt(j + 1) != '*') {
+ return false;
+ }
+ }
+ return true;
+ }
+
+ boolean res = false;
+
+ if (s.charAt(i) == p.charAt(j) || p.charAt(j) == '.') {
+ if (j < n - 1 && p.charAt(j + 1) == '*') {
+ res = dp(s, i, p, j + 2) || dp(s, i + 1, p, j);
+ } else {
+ res = dp(s, i + 1, p, j + 1);
+ }
+ } else {
+ if (j < n - 1 && p.charAt(j + 1) == '*') {
+ res = dp(s, i, p, j + 2);
+ } else {
+ res = false;
+ }
+ }
+
+ return res;
+}
+```
+
+代码有些复杂对吧,如果画图的话有些麻烦,但我们不画图,直接忽略所有细节代码和条件分支,只抽象出递归框架:
+
+```java
+boolean dp(String s, int i, String p, int j) {
+ dp(s, i, p, j + 2); // #1
+ dp(s, i + 1, p, j); // #2
+ dp(s, i + 1, p, j + 1); // #3
+}
+```
+
+和上一题一样,这个解法的「状态」也是 `(i, j)` 的值,那么我继续问你问题:如果我想从状态 `(i, j)` 转移到 `(i+2, j+2)`,有几种路径?
+
+显然,至少有两条路径:`(i, j) -> #1 -> #2 -> #2` 和 `(i, j) -> #3 -> #3`,这就说明这个解法存在巨量重叠子问题。
+
+所以,不用画图就知道这个解法也存在重叠子问题,需要用备忘录技巧去优化。
+
+## 三、dp 数组的大小设置
+
+比如说前文 [编辑距离问题](https://labuladong.online/algo/dynamic-programming/edit-distance/),我首先讲的是自顶向下的递归解法,实现了这样一个 `dp` 函数:
+
+```java
+class Solution {
+ public int minDistance(String s1, String s2) {
+ int m = s1.length(), n = s2.length();
+ // 按照 dp 函数的定义,计算 s1 和 s2 的最小编辑距离
+ return dp(s1, m - 1, s2, n - 1);
+ }
+
+ // 定义:s1[0..i] 和 s2[0..j] 的最小编辑距离是 dp(s1, i, s2, j)
+ int dp(String s1, int i, String s2, int j) {
+ // 处理 base case
+ if (i == -1) {
+ return j + 1;
+ }
+ if (j == -1) {
+ return i + 1;
+ }
+
+ // 进行状态转移
+ if (s1.charAt(i) == s2.charAt(j)) {
+ return dp(s1, i - 1, s2, j - 1);
+ } else {
+ return min(
+ dp(s1, i, s2, j - 1) + 1,
+ dp(s1, i - 1, s2, j) + 1,
+ dp(s1, i - 1, s2, j - 1) + 1
+ );
+ }
+ }
+
+ int min(int a, int b, int c) {
+ return Math.min(a, Math.min(b, c));
+ }
+}
+```
+
+然后改造成了自底向上的迭代解法:
+
+```java
+class Solution {
+ public int minDistance(String s1, String s2) {
+ int m = s1.length(), n = s2.length();
+ // 定义:s1[0..i] 和 s2[0..j] 的最小编辑距离是 dp[i+1][j+1]
+ int[][] dp = new int[m + 1][n + 1];
+ // 初始化 base case
+ for (int i = 1; i <= m; i++)
+ dp[i][0] = i;
+ for (int j = 1; j <= n; j++)
+ dp[0][j] = j;
+
+ // 自底向上求解
+ for (int i = 1; i <= m; i++) {
+ for (int j = 1; j <= n; j++) {
+ // 进行状态转移
+ if (s1.charAt(i-1) == s2.charAt(j-1)) {
+ dp[i][j] = dp[i - 1][j - 1];
+ } else {
+ dp[i][j] = min(
+ dp[i - 1][j] + 1,
+ dp[i][j - 1] + 1,
+ dp[i - 1][j - 1] + 1
+ );
+ }
+ }
+ }
+ // 按照 dp 数组的定义,存储 s1 和 s2 的最小编辑距离
+ return dp[m][n];
+ }
+}
+```
+
+这两种解法思路是完全相同的,但就有读者提问,为什么迭代解法中的 `dp` 数组初始化大小要设置为 `int[m+1][n+1]`?为什么 `s1[0..i]` 和 `s2[0..j]` 的最小编辑距离要存储在 `dp[i+1][j+1]` 中,有一位索引偏移?
+
+能不能模仿 `dp` 函数的定义,把 `dp` 数组初始化为 `int[m][n]`,然后让 `s1[0..i]` 和 `s2[0..j]` 的最小编辑距离要存储在 `dp[i][j]` 中?
+
+**理论上,你怎么定义都可以,只要根据定义处理好 base case 就可以**。
+
+你看 `dp` 函数的定义,`dp(s1, i, s2, j)` 计算 `s1[0..i]` 和 `s2[0..j]` 的编辑距离,那么 `i, j` 等于 -1 时代表空串的 base case,所以函数开头处理了这两种特殊情况。
+
+再看 `dp` 数组,你当然也可以定义 `dp[i][j]` 存储 `s1[0..i]` 和 `s2[0..j]` 的编辑距离,但问题是 base case 怎么搞?索引怎么能是 -1 呢?
+
+所以我们把 `dp` 数组初始化为 `int[m+1][n+1]`,让索引整体偏移一位,把索引 0 留出来作为 base case 表示空串,然后定义 `dp[i+1][j+1]` 存储 `s1[0..i]` 和 `s2[0..j]` 的编辑距离。
+
+## 四、dp 数组的遍历方向
我相信读者做动态规问题时,肯定会对 `dp` 数组的遍历顺序有些头疼。我们拿二维 `dp` 数组来举例,有时候我们是正向遍历:
+
+
+
+
```java
int[][] dp = new int[m][n];
for (int i = 0; i < m; i++)
@@ -72,16 +332,28 @@ for (int i = 0; i < m; i++)
// 计算 dp[i][j]
```
+
+
有时候我们反向遍历:
+
+
+
+
```java
for (int i = m - 1; i >= 0; i--)
for (int j = n - 1; j >= 0; j--)
// 计算 dp[i][j]
```
+
+
有时候可能会斜向遍历:
+
+
+
+
```java
// 斜着遍历数组
for (int l = 2; l <= n; l++) {
@@ -92,22 +364,28 @@ for (int l = 2; l <= n; l++) {
}
```
-甚至更让人迷惑的是,有时候发现正向反向遍历都可以得到正确答案,比如我们在「团灭股票问题」中有的地方就正反皆可。
-那么,如果仔细观察的话可以发现其中的原因的。你只要把住两点就行了:
+
+甚至更让人迷惑的是,有时候发现正向反向遍历都可以得到正确答案,比如我们在 [团灭股票问题](https://labuladong.online/algo/dynamic-programming/stock-problem-summary/) 中有的地方就正反皆可。
+
+如果仔细观察的话可以发现其中的原因,你只要把住两点就行了:
**1、遍历的过程中,所需的状态必须是已经计算出来的**。
-**2、遍历的终点必须是存储结果的那个位置**。
+**2、遍历结束后,存储结果的那个位置必须已经被计算出来**。
-下面来距离解释上面两个原则是什么意思。
+下面来具体解释上面两个原则是什么意思。
-比如编辑距离这个经典的问题,详解见前文「编辑距离详解」,我们通过对 `dp` 数组的定义,确定了 base case 是 `dp[..][0]` 和 `dp[0][..]`,最终答案是 `dp[m][n]`;而且我们通过状态转移方程知道 `dp[i][j]` 需要从 `dp[i-1][j]`, `dp[i][j-1]`, `dp[i-1][j-1]` 转移而来,如下图:
+比如 [编辑距离](https://labuladong.online/algo/dynamic-programming/edit-distance/) 这个经典的问题,我们通过对 `dp` 数组的定义,确定了 base case 是 `dp[..][0]` 和 `dp[0][..]`,最终答案是 `dp[m][n]`;而且我们通过状态转移方程知道 `dp[i][j]` 需要从 `dp[i-1][j]`, `dp[i][j-1]`, `dp[i-1][j-1]` 转移而来,如下图:
-
+
那么,参考刚才说的两条原则,你该怎么遍历 `dp` 数组?肯定是正向遍历:
+
+
+
+
```java
for (int i = 1; i < m; i++)
for (int j = 1; j < n; j++)
@@ -115,26 +393,71 @@ for (int i = 1; i < m; i++)
// 计算 dp[i][j]
```
+
+
因为,这样每一步迭代的左边、上边、左上边的位置都是 base case 或者之前计算过的,而且最终结束在我们想要的答案 `dp[m][n]`。
-再举一例,回文子序列问题,详见前文「子序列问题模板」,我们通过过对 `dp` 数组的定义,确定了 base case 处在中间的对角线,`dp[i][j]` 需要从 `dp[i+1][j]`, `dp[i][j-1]`, `dp[i+1][j-1]` 转移而来,想要求的最终答案是 `dp[0][n-1]`,如下图:
+再举一例,回文子序列问题,详见前文 [子序列问题模板](https://labuladong.online/algo/dynamic-programming/subsequence-problem/),我们通过过对 `dp` 数组的定义,确定了 base case 处在中间的对角线,`dp[i][j]` 需要从 `dp[i+1][j]`, `dp[i][j-1]`, `dp[i+1][j-1]` 转移而来,想要求的最终答案是 `dp[0][n-1]`,如下图:
-
+
这种情况根据刚才的两个原则,就可以有两种正确的遍历方式:
-
+
-要么从左至右斜着遍历,要么从下向上从左到右遍历,这样才能保证每次 `dp[i][j]` 的左边、下边、左下边已经计算完毕,得到正确结果。
+要么从左上至右下斜着遍历,要么从下向上从左到右遍历,这样才能保证每次 `dp[i][j]` 的左边、下边、左下边已经计算完毕,得到正确结果。
现在,你应该理解了这两个原则,主要就是看 base case 和最终结果的存储位置,保证遍历过程中使用的数据都是计算完毕的就行,有时候确实存在多种方法可以得到正确答案,可根据个人口味自行选择。
-**致力于把算法讲清楚!欢迎关注我的微信公众号 labuladong,查看更多通俗易懂的文章**:
-
-[上一篇:动态规划解题框架](../动态规划系列/动态规划详解进阶.md)
-[下一篇:回溯算法解题框架](../算法思维系列/回溯算法详解修订版.md)
-[目录](../README.md#目录)
\ No newline at end of file
+
+
+
+
+引用本文的文章
+
+ - [一个方法团灭 LeetCode 股票买卖问题](https://labuladong.online/algo/dynamic-programming/stock-problem-summary/)
+ - [动态规划之子序列问题解题模板](https://labuladong.online/algo/dynamic-programming/subsequence-problem/)
+ - [动态规划解题套路框架](https://labuladong.online/algo/essential-technique/dynamic-programming-framework/)
+ - [经典动态规划:博弈问题](https://labuladong.online/algo/dynamic-programming/game-theory/)
+ - [经典动态规划:戳气球](https://labuladong.online/algo/dynamic-programming/burst-balloons/)
+ - [经典动态规划:正则表达式](https://labuladong.online/algo/dynamic-programming/regular-expression-matching/)
+ - [经典动态规划:编辑距离](https://labuladong.online/algo/dynamic-programming/edit-distance/)
+
+
+
+
+
+
+
+
+引用本文的题目
+
+安装 [我的 Chrome 刷题插件](https://labuladong.online/algo/intro/chrome/) 点开下列题目可直接查看解题思路:
+
+| LeetCode | 力扣 | 难度 |
+| :----: | :----: | :----: |
+| [115. Distinct Subsequences](https://leetcode.com/problems/distinct-subsequences/?show=1) | [115. 不同的子序列](https://leetcode.cn/problems/distinct-subsequences/?show=1) | 🔴 |
+| [139. Word Break](https://leetcode.com/problems/word-break/?show=1) | [139. 单词拆分](https://leetcode.cn/problems/word-break/?show=1) | 🟠 |
+| [221. Maximal Square](https://leetcode.com/problems/maximal-square/?show=1) | [221. 最大正方形](https://leetcode.cn/problems/maximal-square/?show=1) | 🟠 |
+| [256. Paint House](https://leetcode.com/problems/paint-house/?show=1)🔒 | [256. 粉刷房子](https://leetcode.cn/problems/paint-house/?show=1)🔒 | 🟠 |
+| [343. Integer Break](https://leetcode.com/problems/integer-break/?show=1) | [343. 整数拆分](https://leetcode.cn/problems/integer-break/?show=1) | 🟠 |
+| [576. Out of Boundary Paths](https://leetcode.com/problems/out-of-boundary-paths/?show=1) | [576. 出界的路径数](https://leetcode.cn/problems/out-of-boundary-paths/?show=1) | 🟠 |
+| [63. Unique Paths II](https://leetcode.com/problems/unique-paths-ii/?show=1) | [63. 不同路径 II](https://leetcode.cn/problems/unique-paths-ii/?show=1) | 🟠 |
+| [91. Decode Ways](https://leetcode.com/problems/decode-ways/?show=1) | [91. 解码方法](https://leetcode.cn/problems/decode-ways/?show=1) | 🟠 |
+| - | [剑指 Offer II 091. 粉刷房子](https://leetcode.cn/problems/JEj789/?show=1) | 🟠 |
+| - | [剑指 Offer II 097. 子序列的数目](https://leetcode.cn/problems/21dk04/?show=1) | 🔴 |
+
+
+
+
+
+
+**_____________**
+
+
+
+
\ No newline at end of file
diff --git "a/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\346\234\200\351\225\277\345\205\254\345\205\261\345\255\220\345\272\217\345\210\227.md" "b/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\346\234\200\351\225\277\345\205\254\345\205\261\345\255\220\345\272\217\345\210\227.md"
deleted file mode 100644
index 98b06af07a..0000000000
--- "a/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\346\234\200\351\225\277\345\205\254\345\205\261\345\255\220\345\272\217\345\210\227.md"
+++ /dev/null
@@ -1,129 +0,0 @@
-# 最长公共子序列
-
-最长公共子序列(Longest Common Subsequence,简称 LCS)是一道非常经典的面试题目,因为它的解法是典型的二维动态规划,大部分比较困难的字符串问题都和这个问题一个套路,比如说编辑距离。而且,这个算法稍加改造就可以用于解决其他问题,所以说 LCS 算法是值得掌握的。
-
-题目就是让我们求两个字符串的 LCS 长度:
-
-```
-输入: str1 = "abcde", str2 = "ace"
-输出: 3
-解释: 最长公共子序列是 "ace",它的长度是 3
-```
-
-肯定有读者会问,为啥这个问题就是动态规划来解决呢?因为子序列类型的问题,穷举出所有可能的结果都不容易,而动态规划算法做的就是穷举 + 剪枝,它俩天生一对儿。所以可以说只要涉及子序列问题,十有八九都需要动态规划来解决,往这方面考虑就对了。
-
-下面就来手把手分析一下,这道题目如何用动态规划技巧解决。
-
-### 一、动态规划思路
-
-**第一步,一定要明确 `dp` 数组的含义**。对于两个字符串的动态规划问题,套路是通用的。
-
-比如说对于字符串 `s1` 和 `s2`,一般来说都要构造一个这样的 DP table:
-
-
-
-为了方便理解此表,我们暂时认为索引是从 1 开始的,待会的代码中只要稍作调整即可。其中,`dp[i][j]` 的含义是:对于 `s1[1..i]` 和 `s2[1..j]`,它们的 LCS 长度是 `dp[i][j]`。
-
-比如上图的例子,d[2][4] 的含义就是:对于 `"ac"` 和 `"babc"`,它们的 LCS 长度是 2。我们最终想得到的答案应该是 `dp[3][6]`。
-
-**第二步,定义 base case。**
-
-我们专门让索引为 0 的行和列表示空串,`dp[0][..]` 和 `dp[..][0]` 都应该初始化为 0,这就是 base case。
-
-比如说,按照刚才 dp 数组的定义,`dp[0][3]=0` 的含义是:对于字符串 `""` 和 `"bab"`,其 LCS 的长度为 0。因为有一个字符串是空串,它们的最长公共子序列的长度显然应该是 0。
-
-**第三步,找状态转移方程。**
-
-这是动态规划最难的一步,不过好在这种字符串问题的套路都差不多,权且借这道题来聊聊处理这类问题的思路。
-
-状态转移说简单些就是做选择,比如说这个问题,是求 `s1` 和 `s2` 的最长公共子序列,不妨称这个子序列为 `lcs`。那么对于 `s1` 和 `s2` 中的每个字符,有什么选择?很简单,两种选择,要么在 `lcs` 中,要么不在。
-
-
-
-这个「在」和「不在」就是选择,关键是,应该如何选择呢?这个需要动点脑筋:如果某个字符应该在 `lcs` 中,那么这个字符肯定同时存在于 `s1` 和 `s2` 中,因为 `lcs` 是最长**公共**子序列嘛。所以本题的思路是这样:
-
-用两个指针 `i` 和 `j` 从后往前遍历 `s1` 和 `s2`,如果 `s1[i]==s2[j]`,那么这个字符**一定在 `lcs` 中**;否则的话,`s1[i]` 和 `s2[j]` 这两个字符**至少有一个不在 `lcs` 中**,需要丢弃一个。先看一下递归解法,比较容易理解:
-
-```python
-def longestCommonSubsequence(str1, str2) -> int:
- def dp(i, j):
- # 空串的 base case
- if i == -1 or j == -1:
- return 0
- if str1[i] == str2[j]:
- # 这边找到一个 lcs 的元素,继续往前找
- return dp(i - 1, j - 1) + 1
- else:
- # 谁能让 lcs 最长,就听谁的
- return max(dp(i-1, j), dp(i, j-1))
-
- # i 和 j 初始化为最后一个索引
- return dp(len(str1)-1, len(str2)-1)
-```
-
-对于第一种情况,找到一个 `lcs` 中的字符,同时将 `i` `j` 向前移动一位,并给 `lcs` 的长度加一;对于后者,则尝试两种情况,取更大的结果。
-
-其实这段代码就是暴力解法,我们可以通过备忘录或者 DP table 来优化时间复杂度,比如通过前文描述的 DP table 来解决:
-
-```python
-def longestCommonSubsequence(str1, str2) -> int:
- m, n = len(str1), len(str2)
- # 构建 DP table 和 base case
- dp = [[0] * (n + 1) for _ in range(m + 1)]
- # 进行状态转移
- for i in range(1, m + 1):
- for j in range(1, n + 1):
- if str1[i - 1] == str2[j - 1]:
- # 找到一个 lcs 中的字符
- dp[i][j] = 1 + dp[i-1][j-1]
- else:
- dp[i][j] = max(dp[i-1][j], dp[i][j-1])
-
- return dp[-1][-1]
-```
-
-### 二、疑难解答
-
-对于 `s1[i]` 和 `s2[j]` 不相等的情况,**至少有一个**字符不在 `lcs` 中,会不会两个字符都不在呢?比如下面这种情况:
-
-
-
-所以代码是不是应该考虑这种情况,改成这样:
-
-```python
-if str1[i - 1] == str2[j - 1]:
- # ...
-else:
- dp[i][j] = max(dp[i-1][j],
- dp[i][j-1],
- dp[i-1][j-1])
-```
-
-我一开始也有这种怀疑,其实可以这样改,也能得到正确答案,但是多此一举,因为 `dp[i-1][j-1]` 永远是三者中最小的,max 根本不可能取到它。
-
-原因在于我们对 dp 数组的定义:对于 `s1[1..i]` 和 `s2[1..j]`,它们的 LCS 长度是 `dp[i][j]`。
-
-
-
-这样一看,显然 `dp[i-1][j-1]` 对应的 `lcs` 长度不可能比前两种情况大,所以没有必要参与比较。
-
-### 三、总结
-
-对于两个字符串的动态规划问题,一般来说都是像本文一样定义 DP table,因为这样定义有一个好处,就是容易写出状态转移方程,`dp[i][j]` 的状态可以通过之前的状态推导出来:
-
-
-
-找状态转移方程的方法是,思考每个状态有哪些「选择」,只要我们能用正确的逻辑做出正确的选择,算法就能够正确运行。
-
-
-
-坚持原创高质量文章,致力于把算法问题讲清楚,欢迎关注我的公众号 labuladong 获取最新文章:
-
-
-
-
-[上一篇:动态规划之正则表达](../动态规划系列/动态规划之正则表达.md)
-
-[下一篇:学习算法和刷题的思路指南](../算法思维系列/学习数据结构和算法的高效方法.md)
-
-[目录](../README.md#目录)
\ No newline at end of file
diff --git "a/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\347\212\266\346\200\201\345\216\213\347\274\251\346\212\200\345\267\247.md" "b/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\347\212\266\346\200\201\345\216\213\347\274\251\346\212\200\345\267\247.md"
new file mode 100644
index 0000000000..3c0c09a2bb
--- /dev/null
+++ "b/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\347\212\266\346\200\201\345\216\213\347\274\251\346\212\200\345\267\247.md"
@@ -0,0 +1,319 @@
+# 对动态规划进行降维打击
+
+
+
+
+
+**通知:为满足广大读者的需求,网站上架 [速成目录](https://labuladong.online/algo/intro/quick-learning-plan/),如有需要可以看下,谢谢大家的支持~另外,建议你在我的 [网站](https://labuladong.online/algo/) 学习文章,体验更好。**
+
+
+
+**-----------**
+
+
+
+> [!NOTE]
+> 阅读本文前,你需要先学习:
+>
+> - [动态规划核心框架](https://labuladong.online/algo/essential-technique/dynamic-programming-framework/)
+
+> [!NOTE]
+> 空间压缩并不难,主要用来优化某些动态规划问题的空间复杂度。但是一般的笔试中对空间的要求并不高,即便不使用这个优化技巧也能通过,所以我个人认为状态压缩并不是必须掌握的技巧,有兴趣的读者可以仔细学习理解一下。
+
+我们号之前写过十几篇动态规划文章,可以说动态规划技巧对于算法效率的提升非常可观,一般来说都能把指数级和阶乘级时间复杂度的算法优化成 O(N^2),堪称算法界的二向箔,把各路魑魅魍魉统统打成二次元。
+
+但是,动态规划求解的过程中也是可以进行阶段性优化的,如果你认真观察某些动态规划问题的状态转移方程,就能够把它们解法的空间复杂度进一步降低,由 O(N^2) 降低到 O(N)。
+
+
+
+
+
+
+
+> [!NOTE]
+> 之前我在本文中误用了「状态压缩」这个词,有读者指出「状态压缩」这个词的含义是把多个状态通过二进制运算用一个整数表示出来,从而减少 `dp` 数组的维度。而本文描述的优化方式是通过观察状态转移方程的依赖关系,从而减少 `dp` 数组的维度,确实和「状态压缩」有所区别。所以严谨起见,我把原来文章中的「状态压缩」都改为了「空间压缩」,避免名词的误用。
+
+能够使用空间压缩技巧的动态规划都是二维 `dp` 问题,**你看它的状态转移方程,如果计算状态 `dp[i][j]` 需要的都是 `dp[i][j]` 相邻的状态,那么就可以使用空间压缩技巧**,将二维的 `dp` 数组转化成一维,将空间复杂度从 O(N^2) 降低到 O(N)。
+
+什么叫「和 `dp[i][j]` 相邻的状态」呢,比如前文 [最长回文子序列](https://labuladong.online/algo/dynamic-programming/subsequence-problem/) 中,最终的代码如下:
+
+```java
+int longestPalindromeSubseq(String s) {
+ int n = s.length();
+ // dp 数组全部初始化为 0
+ int[][] dp = new int[n][n];
+ // base case
+ for (int i = 0; i < n; i++) {
+ dp[i][i] = 1;
+ }
+ // 反着遍历保证正确的状态转移
+ for (int i = n - 1; i >= 0; i--) {
+ for (int j = i + 1; j < n; j++) {
+ // 状态转移方程
+ if (s.charAt(i) == s.charAt(j)) {
+ dp[i][j] = dp[i + 1][j - 1] + 2;
+ } else {
+ dp[i][j] = Math.max(dp[i + 1][j], dp[i][j - 1]);
+ }
+ }
+ }
+ // 整个 s 的最长回文子串长度
+ return dp[0][n - 1];
+}
+```
+
+> [!TIP]
+> 我们本文不探讨如何推状态转移方程,只探讨对二维 DP 问题进行空间压缩的技巧。技巧都是通用的,所以如果你没看过前文,不明白这段代码的逻辑也无妨,完全不会阻碍你学会空间压缩。
+
+你看我们对 `dp[i][j]` 的更新,其实只依赖于 `dp[i+1][j-1], dp[i][j-1], dp[i+1][j]` 这三个状态:
+
+
+
+这就叫和 `dp[i][j]` 相邻,反正你计算 `dp[i][j]` 只需要这三个相邻状态,其实根本不需要那么大一个二维的 dp table 对不对?**空间压缩的核心思路就是,将二维数组「投影」到一维数组**:
+
+
+
+「投影」这个词应该比较形象吧,说白了就是希望让一维数组发挥原来二维数组的作用。
+
+思路很直观,但是也有一个明显的问题,图中 `dp[i][j-1]` 和 `dp[i+1][j-1]` 这两个状态处在同一列,而一维数组中只能容下一个,那么他俩投影到一维必然有一个会被另一个覆盖掉,我还怎么计算 `dp[i][j]` 呢?
+
+这就是空间压缩的难点,下面就来分析解决这个问题,还是拿「最长回文子序列」问题举例,它的状态转移方程主要逻辑就是如下这段代码:
+
+
+
+
+
+```java
+for (int i = n - 2; i >= 0; i--) {
+ for (int j = i + 1; j < n; j++) {
+ // 状态转移方程
+ if (s.charAt(i) == s.charAt(j)) {
+ dp[i][j] = dp[i + 1][j - 1] + 2;
+ } else {
+ dp[i][j] = Math.max(dp[i + 1][j], dp[i][j - 1]);
+ }
+ }
+}
+```
+
+
+
+回想上面的图,「投影」其实就是把多行变成一行,所以想把二维 `dp` 数组压缩成一维,一般来说是把第一个维度,也就是 `i` 这个维度去掉,只剩下 `j` 这个维度。**压缩后的一维 `dp` 数组就是之前二维 `dp` 数组的 `dp[i][..]` 那一行**。
+
+我们先将上述代码进行改造,直接无脑去掉 `i` 这个维度,把 `dp` 数组变成一维:
+
+
+
+
+
+```java
+for (int i = n - 2; i >= 0; i--) {
+ for (int j = i + 1; j < n; j++) {
+ // 在这里,一维 dp 数组中的数是什么?
+ if (s.charAt(i) == s.charAt(j)) {
+ dp[j] = dp[j - 1] + 2;
+ } else {
+ dp[j] = Math.max(dp[j], dp[j - 1]);
+ }
+ }
+}
+```
+
+
+
+上述代码的一维 `dp` 数组只能表示二维 `dp` 数组的一行 `dp[i][..]`。但是我们想得到 `dp[i+1][j-1], dp[i][j-1], dp[i+1][j]` 这几个必要的的值进行状态转移。
+
+因此,我们要先来思考两个问题:
+
+1、在对 `dp[j]` 赋新值之前,`dp[j]` 对应着二维 `dp` 数组中的什么位置?
+
+2、`dp[j-1]` 对应着二维 `dp` 数组中的什么位置?
+
+**对于问题 1,在对 `dp[j]` 赋新值之前,`dp[j]` 的值就是外层 for 循环上一次迭代算出来的值,也就是对应二维 `dp` 数组中 `dp[i+1][j]` 的位置**。
+
+**对于问题 2,`dp[j-1]` 的值就是内层 for 循环上一次迭代算出来的值,也就是对应二维 `dp` 数组中 `dp[i][j-1]` 的位置**。
+
+那么问题已经解决了一大半了,只剩下二维 `dp` 数组中的 `dp[i+1][j-1]` 这个状态我们不能直接从一维 `dp` 数组中得到:
+
+
+
+
+
+```java
+for (int i = n - 2; i >= 0; i--) {
+ for (int j = i + 1; j < n; j++) {
+ if (s.charAt(i) == s.charAt(j)) {
+ // dp[i][j] = dp[i+1][j-1] + 2;
+ dp[j] = ?? + 2;
+ } else {
+ // dp[i][j] = max(dp[i+1][j], dp[i][j-1]);
+ dp[j] = Math.max(dp[j], dp[j - 1]);
+ }
+ }
+}
+```
+
+
+
+因为 for 循环遍历 `i` 和 `j` 的顺序为从左向右,从下向上,所以可以发现,在更新一维 `dp` 数组的时候,`dp[i+1][j-1]` 会被 `dp[i][j-1]` 覆盖掉,图中标出了这四个位置被遍历到的次序:
+
+
+
+**那么如果我们想得到 `dp[i+1][j-1]`,就必须在它被覆盖之前用一个临时变量 `temp` 把它存起来,并把这个变量的值保留到计算 `dp[i][j]` 的时候**。为了达到这个目的,结合上图,我们可以这样写代码:
+
+
+
+
+
+```java
+for (int i = n - 2; i >= 0; i--) {
+ // 存储 dp[i+1][j-1] 的变量
+ int pre = 0;
+ for (int j = i + 1; j < n; j++) {
+ int temp = dp[j];
+ if (s.charAt(i) == s.charAt(j)) {
+ // dp[i][j] = dp[i+1][j-1] + 2;
+ dp[j] = pre + 2;
+ } else {
+ dp[j] = Math.max(dp[j], dp[j - 1]);
+ }
+ // 到下一轮循环,pre 就是 dp[i+1][j-1] 了
+ pre = temp;
+ }
+}
+```
+
+
+
+别小看这段代码,这是一维 `dp` 最精妙的地方,会者不难,难者不会。为了清晰起见,我用具体的数值来拆解这个逻辑:
+
+假设现在 `i = 5, j = 7` 且 `s[5] == s[7]`,那么现在会进入下面这个逻辑对吧:
+
+
+
+
+
+```java
+for (int i = 5; i--) {
+ for (int j = 7; j++) {
+ if (s[5] == s[7]) {
+ // dp[5][7] = dp[i+1][j-1] + 2;
+ dp[7] = pre + 2;
+ }
+ }
+}
+```
+
+
+
+我问你这个 `pre` 变量是什么?是内层 for 循环上一次迭代的 `temp` 值。
+
+那我再问你**内层** for 循环上一次迭代的 `temp` 值是什么?是 `dp[j-1]` 也就是 `dp[6]`,但请注意,这是**外层** for 循环**上一次迭代**对应的 `dp[6]`,不是现在的 `dp[6]`。
+
+这个要对应二维数组的索引来理解。你现在的 `dp[6]` 是二维 `dp` 数组中的 `dp[i][6] = dp[5][6]`,而人家这个 `temp` 是二维 `dp` 数组中的 `dp[i+1][6] = dp[6][6]`。
+
+也就是说,`pre` 变量就是 `dp[i+1][j-1] = dp[6][6]`,也就是我们想要的结果。
+
+那么现在我们成功对状态转移方程进行了降维打击,算是最硬的的骨头啃掉了,但注意到我们还有 base case 要处理呀:
+
+```java
+// dp 数组全部初始化为 0
+int[][] dp = new int[n][n];
+// base case
+for (int i = 0; i < n; i++) {
+ dp[i][i] = 1;
+}
+```
+
+如何把 base case 也打成一维呢?很简单,记住空间压缩就是投影,我们把 base case 投影到一维看看:
+
+
+
+二维 `dp` 数组中的 base case 全都落入了一维 `dp` 数组,不存在冲突和覆盖,所以说我们直接这样写代码就行了:
+
+```java
+// base case:一维 dp 数组全部初始化为 1
+int[] dp = new int[n];
+Arrays.fill(dp, 1);
+```
+
+至此,我们把 base case 和状态转移方程都进行了降维,实际上已经写出完整代码了:
+
+```java
+class Solution {
+ public int longestPalindromeSubseq(String s) {
+ int n = s.length();
+ // base case:一维 dp 数组全部初始化为 1
+ int[] dp = new int[n];
+ Arrays.fill(dp, 1);
+
+ for (int i = n - 2; i >= 0; i--) {
+ int pre = 0;
+ for (int j = i + 1; j < n; j++) {
+ int temp = dp[j];
+ // 状态转移方程
+ if (s.charAt(i) == s.charAt(j))
+ dp[j] = pre + 2;
+ else
+ dp[j] = Math.max(dp[j], dp[j - 1]);
+ pre = temp;
+ }
+ }
+ return dp[n - 1];
+ }
+}
+```
+
+本文就结束了,不过空间压缩技巧再牛逼,也是基于常规动态规划思路之上的。
+
+你也看到了,使用空间压缩技巧对二维 `dp` 数组进行降维打击之后,解法代码的可读性变得非常差了,如果直接看这种解法,任何人都是一脸懵逼的。算法的优化就是这么一个过程,先写出可读性很好的暴力递归算法,然后尝试运用动态规划技巧优化重叠子问题,最后尝试用空间压缩技巧优化空间复杂度。
+
+也就是说,你最起码能够熟练运用我们前文 [动态规划框架套路详解](https://labuladong.online/algo/essential-technique/dynamic-programming-framework/) 的套路找出状态转移方程,写出一个正确的动态规划解法,然后才有可能观察状态转移的情况,分析是否可能使用空间压缩技巧来优化。
+
+希望读者能够稳扎稳打,层层递进,对于这种比较极限的优化,不做也罢。毕竟套路存于心,走遍天下都不怕!
+
+
+
+
+
+
+
+
+
+引用本文的文章
+
+ - [一个方法团灭 LeetCode 股票买卖问题](https://labuladong.online/algo/dynamic-programming/stock-problem-summary/)
+ - [动态规划之最小路径和](https://labuladong.online/algo/dynamic-programming/minimum-path-sum/)
+ - [动态规划解题套路框架](https://labuladong.online/algo/essential-technique/dynamic-programming-framework/)
+ - [动态规划设计:最大子数组](https://labuladong.online/algo/dynamic-programming/maximum-subarray/)
+ - [学习数据结构和算法的框架思维](https://labuladong.online/algo/essential-technique/algorithm-summary/)
+ - [经典动态规划:子集背包问题](https://labuladong.online/algo/dynamic-programming/knapsack2/)
+ - [经典动态规划:完全背包问题](https://labuladong.online/algo/dynamic-programming/knapsack3/)
+ - [经典动态规划:最长公共子序列](https://labuladong.online/algo/dynamic-programming/longest-common-subsequence/)
+ - [经典动态规划:高楼扔鸡蛋](https://labuladong.online/algo/dynamic-programming/egg-drop/)
+
+
+
+
+
+
+
+
+引用本文的题目
+
+安装 [我的 Chrome 刷题插件](https://labuladong.online/algo/intro/chrome/) 点开下列题目可直接查看解题思路:
+
+| LeetCode | 力扣 | 难度 |
+| :----: | :----: | :----: |
+| [63. Unique Paths II](https://leetcode.com/problems/unique-paths-ii/?show=1) | [63. 不同路径 II](https://leetcode.cn/problems/unique-paths-ii/?show=1) | 🟠 |
+
+
+
+
+
+
+**_____________**
+
+
+
+
\ No newline at end of file
diff --git "a/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\347\274\226\350\276\221\350\267\235\347\246\273.md" "b/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\347\274\226\350\276\221\350\267\235\347\246\273.md"
index 4e4146bb39..75691018f9 100644
--- "a/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\347\274\226\350\276\221\350\267\235\347\246\273.md"
+++ "b/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\347\274\226\350\276\221\350\267\235\347\246\273.md"
@@ -1,47 +1,103 @@
-# 编辑距离
+# 经典动态规划:编辑距离
-前几天看了一份鹅场的面试题,算法部分大半是动态规划,最后一题就是写一个计算编辑距离的函数,今天就专门写一篇文章来探讨一下这个问题。
-我个人很喜欢编辑距离这个问题,因为它看起来十分困难,解法却出奇得简单漂亮,而且它是少有的比较实用的算法(是的,我承认很多算法问题都不太实用)。下面先来看下题目:
-
+
-为什么说这个问题难呢,因为显而易见,它就是难,让人手足无措,望而生畏。
+**通知:为满足广大读者的需求,网站上架 [速成目录](https://labuladong.online/algo/intro/quick-learning-plan/),如有需要可以看下,谢谢大家的支持~另外,建议你在我的 [网站](https://labuladong.online/algo/) 学习文章,体验更好。**
-为什么说它实用呢,因为前几天我就在日常生活中用到了这个算法。之前有一篇公众号文章由于疏忽,写错位了一段内容,我决定修改这部分内容让逻辑通顺。但是公众号文章最多只能修改 20 个字,且只支持增、删、替换操作(跟编辑距离问题一模一样),于是我就用算法求出了一个最优方案,只用了 16 步就完成了修改。
+
+
+读完本文,你不仅学会了算法套路,还可以顺便解决如下题目:
+
+| LeetCode | 力扣 | 难度 |
+| :----: | :----: | :----: |
+| [72. Edit Distance](https://leetcode.com/problems/edit-distance/) | [72. 编辑距离](https://leetcode.cn/problems/edit-distance/) | 🔴 |
+
+**-----------**
+
+
+
+> [!NOTE]
+> 阅读本文前,你需要先学习:
+>
+> - [二叉树系列算法(纲领篇)](https://labuladong.online/algo/essential-technique/binary-tree-summary/)
+> - [动态规划核心框架](https://labuladong.online/algo/essential-technique/dynamic-programming-framework/)
+
+
+> tip:本文有视频版:[编辑距离详解动态规划](https://www.bilibili.com/video/BV1uv411W73P/)。建议关注我的 B 站账号,我会用视频领读的方式带大家学习那些稍有难度的算法技巧。
+
+
+
+前几天看了一份鹅厂的面试题,算法部分大半是动态规划,最后一题就是写一个计算编辑距离的函数,今天就专门写一篇文章来探讨一下这个问题。
+
+力扣第 72 题「编辑距离」就是这个问题,先看下题目:
+
+
+
+
+
+
+
+```java
+// 函数签名如下
+int minDistance(String s1, String s2)
+```
+
+对于没有接触过动态规划问题的读者来说,这道题还是有一定难度的,是不是感觉完全无从下手?
+
+但这个问题本身还是比较实用的,我曾经就在日常生活中用到过这个算法。之前有一篇公众号文章由于疏忽,写错位了一段内容,我决定修改这部分内容让逻辑通顺。但是公众号文章最多只能修改 20 个字,且只支持增、删、替换操作(跟编辑距离问题一模一样),于是我就用算法求出了一个最优方案,只用了 16 步就完成了修改。
再比如高大上一点的应用,DNA 序列是由 A,G,C,T 组成的序列,可以类比成字符串。编辑距离可以衡量两个 DNA 序列的相似度,编辑距离越小,说明这两段 DNA 越相似,说不定这俩 DNA 的主人是远古近亲啥的。
下面言归正传,详细讲解一下编辑距离该怎么算,相信本文会让你有收获。
-### 一、思路
+
+
+
+
+
+
+## 一、思路
编辑距离问题就是给我们两个字符串 `s1` 和 `s2`,只能用三种操作,让我们把 `s1` 变成 `s2`,求最少的操作数。需要明确的是,不管是把 `s1` 变成 `s2` 还是反过来,结果都是一样的,所以后文就以 `s1` 变成 `s2` 举例。
-前文「最长公共子序列」说过,**解决两个字符串的动态规划问题,一般都是用两个指针 `i,j` 分别指向两个字符串的最后,然后一步步往前走,缩小问题的规模**。
+> [!TIP]
+> 解决两个字符串的动态规划问题,一般都是用两个指针 `i, j` 分别指向两个字符串的头部或尾部,然后尝试写状态转移方程。
+>
+> 比方说让 `i, j` 分别指向两个字符串的尾部,把 `dp[i], dp[j]` 定义为 `s1[0..i], s2[0..j]` 子串的编辑距离,那么 `i, j` 一步步往前移动的过程,就是问题规模(子串长度)逐步减小的过程。
+>
+> 当然,你想让让 `i, j` 分别指向字符串头部,然后一步步往后移动也可以,本质上并无区别,只要改一下 `dp` 函数/数组的定义即可。
-设两个字符串分别为 "rad" 和 "apple",为了把 `s1` 变成 `s2`,算法会这样进行:
+设两个字符串分别为 `"rad"` 和 `"apple"`,让 `i, j` 两个指针分别指向 `s1, s2` 的尾部,为了把 `s1` 变成 `s2`,算法会这样进行:
-
-
+
+
+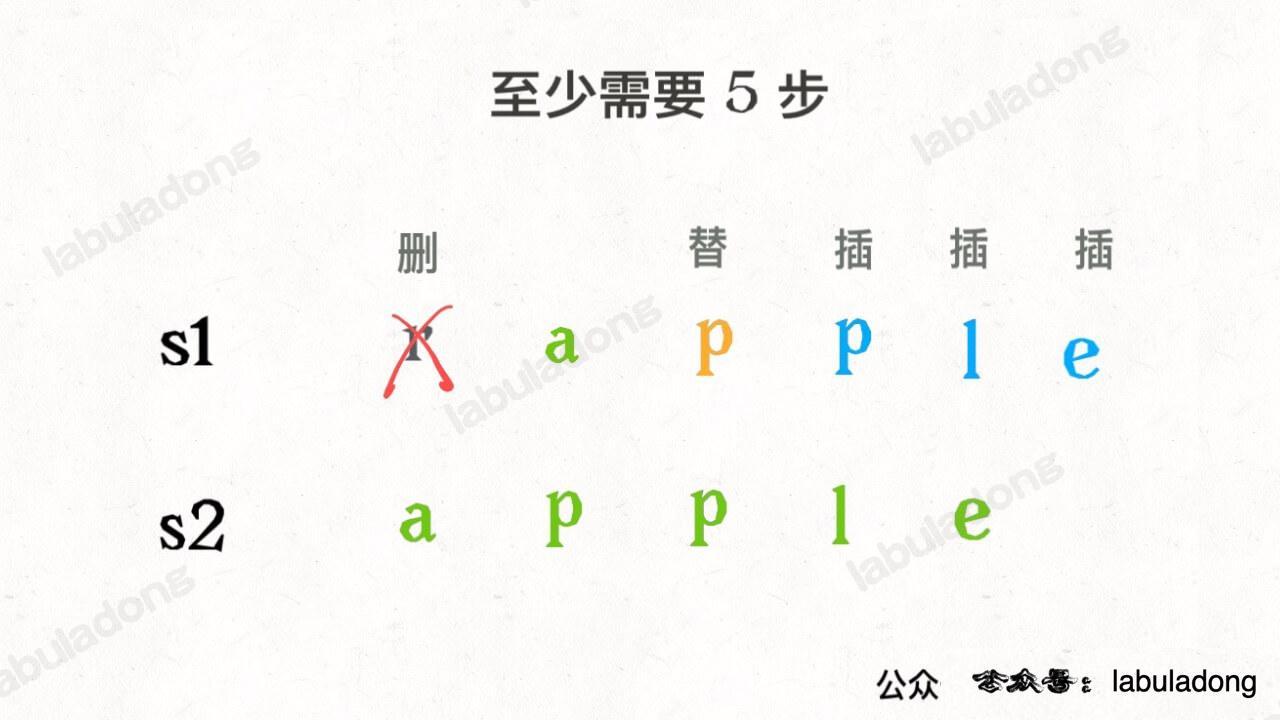
请记住这个 GIF 过程,这样就能算出编辑距离。关键在于如何做出正确的操作,稍后会讲。
根据上面的 GIF,可以发现操作不只有三个,其实还有第四个操作,就是什么都不要做(skip)。比如这个情况:
-
+
-因为这两个字符本来就相同,为了使编辑距离最小,显然不应该对它们有任何操作,直接往前移动 `i,j` 即可。
+因为这两个字符本来就相同,为了使编辑距离最小,显然不应该对它们有任何操作,直接往前移动 `i, j` 即可。
还有一个很容易处理的情况,就是 `j` 走完 `s2` 时,如果 `i` 还没走完 `s1`,那么只能用删除操作把 `s1` 缩短为 `s2`。比如这个情况:
-
+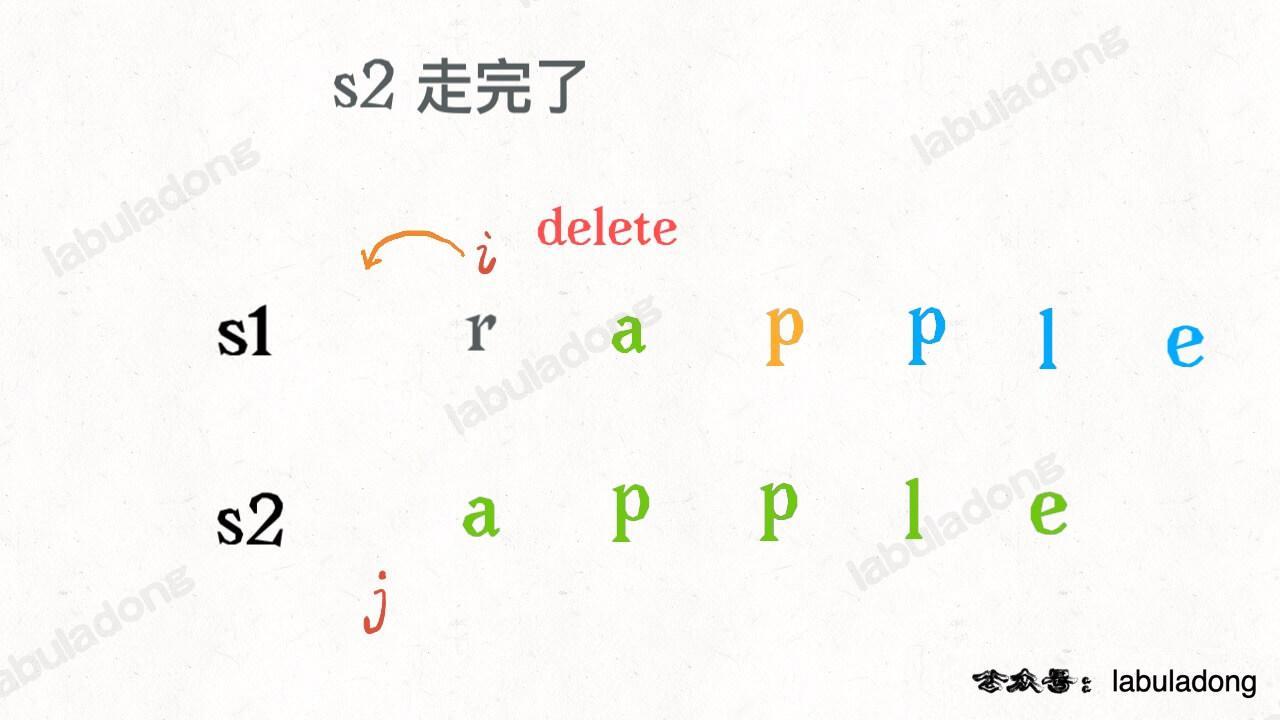
类似的,如果 `i` 走完 `s1` 时 `j` 还没走完了 `s2`,那就只能用插入操作把 `s2` 剩下的字符全部插入 `s1`。等会会看到,这两种情况就是算法的 **base case**。
-下面详解一下如何将思路转换成代码,坐稳,要发车了。
+下面详解一下如何将思路转换成代码。
+
+
-### 二、代码详解
+
+
+
+
+## 二、代码详解
先梳理一下之前的思路:
@@ -60,43 +116,57 @@ else:
替换(replace)
```
-有这个框架,问题就已经解决了。读者也许会问,这个「三选一」到底该怎么选择呢?很简单,全试一遍,哪个操作最后得到的编辑距离最小,就选谁。这里需要递归技巧,理解需要点技巧,先看下代码:
-
-```python
-def minDistance(s1, s2) -> int:
+有这个框架,问题就已经解决了。读者也许会问,这个「三选一」到底该怎么选择呢?很简单,全试一遍,哪个操作最后得到的编辑距离最小,就选谁。这里需要递归技巧,先看下暴力解法代码:
- def dp(i, j):
- # base case
- if i == -1: return j + 1
- if j == -1: return i + 1
-
- if s1[i] == s2[j]:
- return dp(i - 1, j - 1) # 啥都不做
- else:
- return min(
- dp(i, j - 1) + 1, # 插入
- dp(i - 1, j) + 1, # 删除
- dp(i - 1, j - 1) + 1 # 替换
- )
-
- # i,j 初始化指向最后一个索引
- return dp(len(s1) - 1, len(s2) - 1)
+```java
+class Solution {
+ public int minDistance(String s1, String s2) {
+ int m = s1.length(), n = s2.length();
+ // i,j 初始化指向最后一个索引
+ return dp(s1, m - 1, s2, n - 1);
+ }
+
+ // 定义:返回 s1[0..i] 和 s2[0..j] 的最小编辑距离
+ int dp(String s1, int i, String s2, int j) {
+ // base case
+ if (i == -1) return j + 1;
+ if (j == -1) return i + 1;
+
+ if (s1.charAt(i) == s2.charAt(j)) {
+ // 啥都不做
+ return dp(s1, i - 1, s2, j - 1);
+ }
+ return min(
+ // 插入
+ dp(s1, i, s2, j - 1) + 1,
+ // 删除
+ dp(s1, i - 1, s2, j) + 1,
+ // 替换
+ dp(s1, i - 1, s2, j - 1) + 1
+ );
+ }
+
+ int min(int a, int b, int c) {
+ return Math.min(a, Math.min(b, c));
+ }
+}
```
下面来详细解释一下这段递归代码,base case 应该不用解释了,主要解释一下递归部分。
-都说递归代码的可解释性很好,这是有道理的,只要理解函数的定义,就能很清楚地理解算法的逻辑。我们这里 dp(i, j) 函数的定义是这样的:
+都说递归代码的可解释性很好,这是有道理的,只要理解函数的定义,就能很清楚地理解算法的逻辑。我们这里 `dp` 函数的定义是这样的:
-```python
-def dp(i, j) -> int
-# 返回 s1[0..i] 和 s2[0..j] 的最小编辑距离
+```java
+// 定义:返回 s1[0..i] 和 s2[0..j] 的最小编辑距离
+int dp(String s1, int i, String s2, int j)
```
**记住这个定义**之后,先来看这段代码:
```python
if s1[i] == s2[j]:
- return dp(i - 1, j - 1) # 啥都不做
+ # 啥都不做
+ return dp(s1, i - 1, s2, j - 1)
# 解释:
# 本来就相等,不需要任何操作
# s1[0..i] 和 s2[0..j] 的最小编辑距离等于
@@ -104,129 +174,187 @@ if s1[i] == s2[j]:
# 也就是说 dp(i, j) 等于 dp(i-1, j-1)
```
-如果 `s1[i]!=s2[j]`,就要对三个操作递归了,稍微需要点思考:
+如果 `s1[i] != s2[j]`,就要对三个操作递归了,稍微需要点思考:
```python
-dp(i, j - 1) + 1, # 插入
+# 插入
+dp(s1, i, s2, j - 1) + 1,
# 解释:
# 我直接在 s1[i] 插入一个和 s2[j] 一样的字符
# 那么 s2[j] 就被匹配了,前移 j,继续跟 i 对比
# 别忘了操作数加一
```
-
+
```python
-dp(i - 1, j) + 1, # 删除
+# 删除
+dp(s1, i - 1, s2, j) + 1,
# 解释:
# 我直接把 s[i] 这个字符删掉
# 前移 i,继续跟 j 对比
# 操作数加一
```
-
+
```python
-dp(i - 1, j - 1) + 1 # 替换
+# 替换
+dp(s1, i - 1, s2, j - 1) + 1
# 解释:
# 我直接把 s1[i] 替换成 s2[j],这样它俩就匹配了
# 同时前移 i,j 继续对比
# 操作数加一
```
-
+
+
+
现在,你应该完全理解这段短小精悍的代码了。还有点小问题就是,这个解法是暴力解法,存在重叠子问题,需要用动态规划技巧来优化。
-**怎么能一眼看出存在重叠子问题呢**?前文「动态规划之正则表达式」有提过,这里再简单提一下,需要抽象出本文算法的递归框架:
+**怎么能一眼看出存在重叠子问题呢**?我在 [动态规划答疑篇](https://labuladong.online/algo/dynamic-programming/faq-summary/) 有讲过,这里再简单提一下,需要抽象出本文算法的递归框架:
-```python
-def dp(i, j):
- dp(i - 1, j - 1) #1
- dp(i, j - 1) #2
- dp(i - 1, j) #3
+```java
+int dp(i, j) {
+ dp(i - 1, j - 1); // #1
+ dp(i, j - 1); // #2
+ dp(i - 1, j); // #3
+}
```
对于子问题 `dp(i-1, j-1)`,如何通过原问题 `dp(i, j)` 得到呢?有不止一条路径,比如 `dp(i, j) -> #1` 和 `dp(i, j) -> #2 -> #3`。一旦发现一条重复路径,就说明存在巨量重复路径,也就是重叠子问题。
-### 三、动态规划优化
+## 三、动态规划优化
-对于重叠子问题呢,前文「动态规划详解」详细介绍过,优化方法无非是备忘录或者 DP table。
+对于重叠子问题呢,前文 [动态规划详解](https://labuladong.online/algo/essential-technique/dynamic-programming-framework/) 详细介绍过,优化方法无非是给递归解法加备忘录,或者把动态规划过程用 DP table 迭代实现,下面逐个来讲。
-备忘录很好加,原来的代码稍加修改即可:
+### 备忘录解法
-```python
-def minDistance(s1, s2) -> int:
+既然暴力递归解法都写出来了,备忘录是很容易加的,原来的代码稍加修改即可:
- memo = dict() # 备忘录
- def dp(i, j):
- if (i, j) in memo:
- return memo[(i, j)]
- ...
+```java
+class Solution {
+ // 备忘录
+ int[][] memo;
- if s1[i] == s2[j]:
- memo[(i, j)] = ...
- else:
- memo[(i, j)] = ...
- return memo[(i, j)]
-
- return dp(len(s1) - 1, len(s2) - 1)
+ public int minDistance(String s1, String s2) {
+ int m = s1.length(), n = s2.length();
+ // 备忘录初始化为特殊值,代表还未计算
+ memo = new int[m][n];
+ for (int[] row : memo) {
+ Arrays.fill(row, -1);
+ }
+ return dp(s1, m - 1, s2, n - 1);
+ }
+
+ int dp(String s1, int i, String s2, int j) {
+ if (i == -1) return j + 1;
+ if (j == -1) return i + 1;
+ // 查备忘录,避免重叠子问题
+ if (memo[i][j] != -1) {
+ return memo[i][j];
+ }
+ // 状态转移,结果存入备忘录
+ if (s1.charAt(i) == s2.charAt(j)) {
+ memo[i][j] = dp(s1, i - 1, s2, j - 1);
+ } else {
+ memo[i][j] = min(
+ dp(s1, i, s2, j - 1) + 1,
+ dp(s1, i - 1, s2, j) + 1,
+ dp(s1, i - 1, s2, j - 1) + 1
+ );
+ }
+ return memo[i][j];
+ }
+
+ int min(int a, int b, int c) {
+ return Math.min(a, Math.min(b, c));
+ }
+}
```
-**主要说下 DP table 的解法**:
+### DP table 解法
-首先明确 dp 数组的含义,dp 数组是一个二维数组,长这样:
+主要说下 DP table 的解法,我们需要定义一个 `dp` 数组,然后在这个数组上执行状态转移方程。
+
+首先明确 `dp` 数组的含义,由于本题有两个状态(索引 `i` 和 `j`),所以`dp` 数组是一个二维数组,大概长这样:
+
+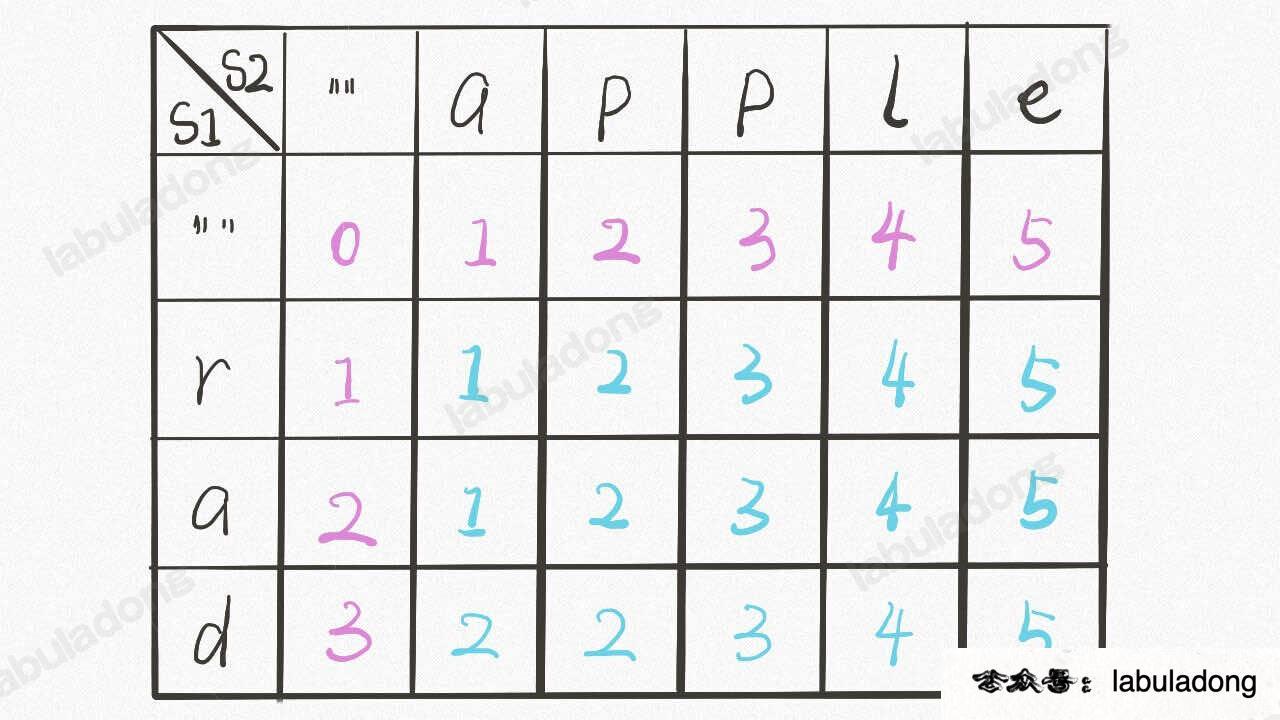
+
+状态转移和递归解法相同,`dp[..][0]` 和 `dp[0][..]` 对应 base case,`dp[i][j]` 的含义和之前 `dp` 函数的定义类似:
-
-有了之前递归解法的铺垫,应该很容易理解。`dp[..][0]` 和 `dp[0][..]` 对应 base case,`dp[i][j]` 的含义和之前的 dp 函数类似:
-```python
-def dp(i, j) -> int
-# 返回 s1[0..i] 和 s2[0..j] 的最小编辑距离
+
+
+```java
+int dp(String s1, int i, String s2, int j)
+// 返回 s1[0..i] 和 s2[0..j] 的最小编辑距离
dp[i-1][j-1]
-# 存储 s1[0..i] 和 s2[0..j] 的最小编辑距离
+// 存储 s1[0..i] 和 s2[0..j] 的最小编辑距离
```
-dp 函数的 base case 是 `i,j` 等于 -1,而数组索引至少是 0,所以 dp 数组会偏移一位。
-既然 dp 数组和递归 dp 函数含义一样,也就可以直接套用之前的思路写代码,**唯一不同的是,DP table 是自底向上求解,递归解法是自顶向下求解**:
+
+`dp` 函数的 base case 是 `i, j` 等于 -1,而数组索引至少是 0,所以 `dp` 数组会偏移一位。
+
+既然 `dp` 数组和递归 `dp` 函数含义一样,也就可以直接套用之前的思路写代码,**唯一不同的是,递归解法是自顶向下求解(从原问题开始,逐步分解到 base case),DP table 是自底向上求解(从 base case 开始,向原问题推演)**:
```java
-int minDistance(String s1, String s2) {
- int m = s1.length(), n = s2.length();
- int[][] dp = new int[m + 1][n + 1];
- // base case
- for (int i = 1; i <= m; i++)
- dp[i][0] = i;
- for (int j = 1; j <= n; j++)
- dp[0][j] = j;
- // 自底向上求解
- for (int i = 1; i <= m; i++)
+class Solution {
+ public int minDistance(String s1, String s2) {
+ int m = s1.length(), n = s2.length();
+ // 定义:s1[0..i] 和 s2[0..j] 的最小编辑距离是 dp[i+1][j+1]
+ int[][] dp = new int[m + 1][n + 1];
+ // base case
+ for (int i = 1; i <= m; i++)
+ dp[i][0] = i;
for (int j = 1; j <= n; j++)
- if (s1.charAt(i-1) == s2.charAt(j-1))
- dp[i][j] = dp[i - 1][j - 1];
- else
- dp[i][j] = min(
- dp[i - 1][j] + 1,
- dp[i][j - 1] + 1,
- dp[i-1][j-1] + 1
- );
- // 储存着整个 s1 和 s2 的最小编辑距离
- return dp[m][n];
-}
-
-int min(int a, int b, int c) {
- return Math.min(a, Math.min(b, c));
+ dp[0][j] = j;
+ // 自底向上求解
+ for (int i = 1; i <= m; i++) {
+ for (int j = 1; j <= n; j++) {
+ if (s1.charAt(i-1) == s2.charAt(j-1)) {
+ dp[i][j] = dp[i - 1][j - 1];
+ } else {
+ dp[i][j] = min(
+ dp[i - 1][j] + 1,
+ dp[i][j - 1] + 1,
+ dp[i - 1][j - 1] + 1
+ );
+ }
+ }
+ }
+ // 储存着整个 s1 和 s2 的最小编辑距离
+ return dp[m][n];
+ }
+
+ int min(int a, int b, int c) {
+ return Math.min(a, Math.min(b, c));
+ }
}
```
-### 三、扩展延伸
+
+
+
+
+
+🎃 代码可视化动画🎃
+
+
+
+
+
+
+
+## 四、扩展延伸
一般来说,处理两个字符串的动态规划问题,都是按本文的思路处理,建立 DP table。为什么呢,因为易于找出状态转移的关系,比如编辑距离的 DP table:
-
+
还有一个细节,既然每个 `dp[i][j]` 只和它附近的三个状态有关,空间复杂度是可以压缩成 $O(min(M, N))$ 的(M,N 是两个字符串的长度)。不难,但是可解释性大大降低,读者可以自己尝试优化一下。
@@ -252,18 +380,151 @@ class Node {
我们的最终结果不是 `dp[m][n]` 吗,这里的 `val` 存着最小编辑距离,`choice` 存着最后一个操作,比如说是插入操作,那么就可以左移一格:
-
+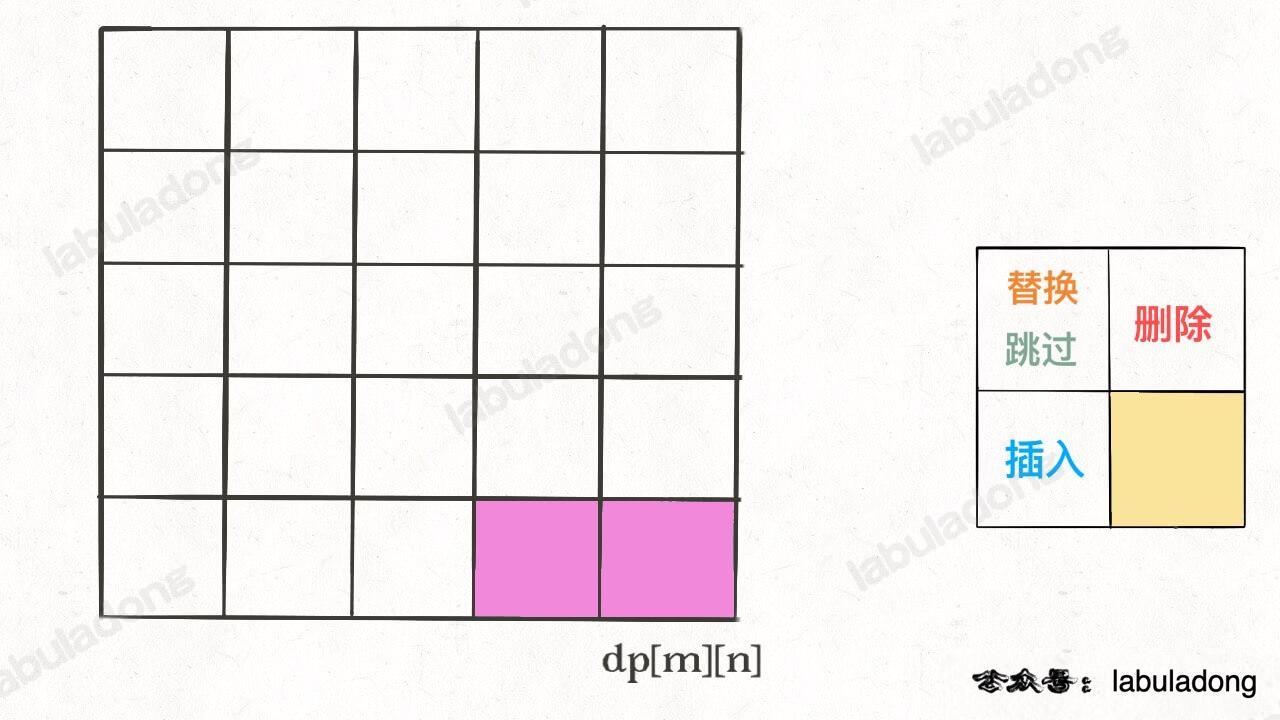
重复此过程,可以一步步回到起点 `dp[0][0]`,形成一条路径,按这条路径上的操作进行编辑,就是最佳方案。
-
+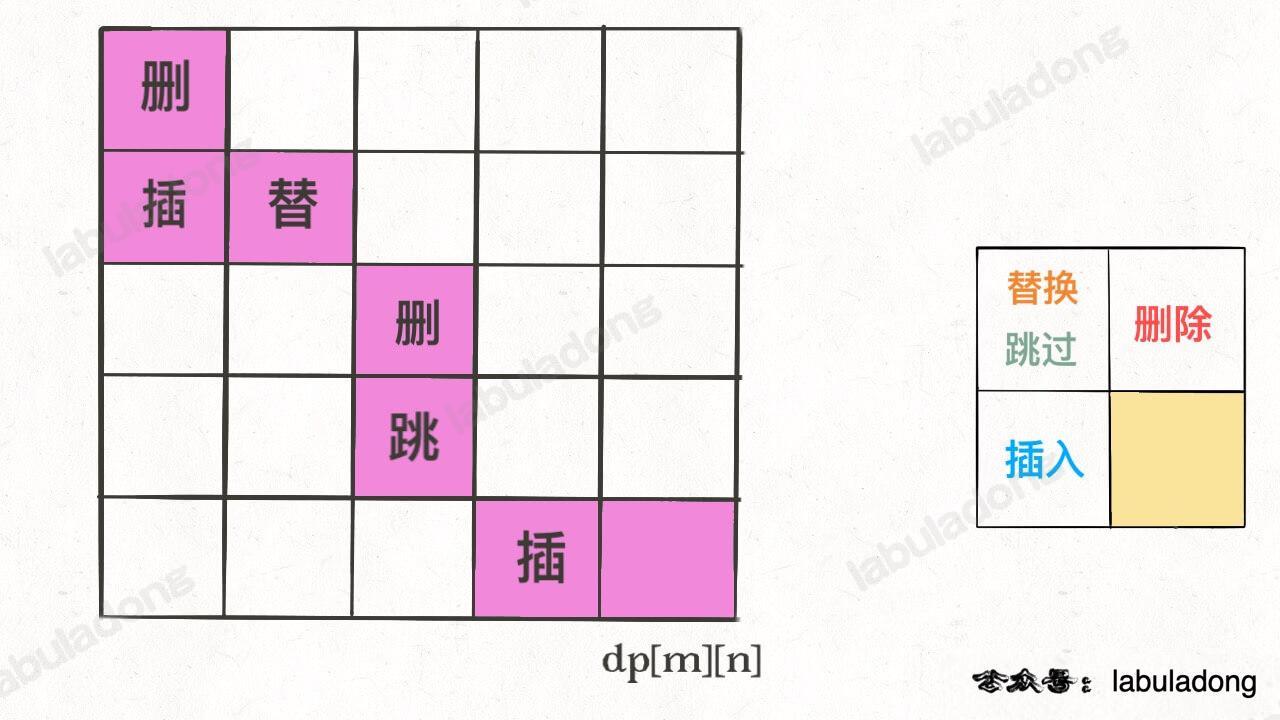
+
+应大家的要求,我把这个思路也写出来,你可以自己运行试一下:
+
+```java
+int minDistance(String s1, String s2) {
+ int m = s1.length(), n = s2.length();
+ Node[][] dp = new Node[m + 1][n + 1];
+ // base case
+ for (int i = 0; i <= m; i++) {
+ // s1 转化成 s2 只需要删除一个字符
+ dp[i][0] = new Node(i, 2);
+ }
+ for (int j = 1; j <= n; j++) {
+ // s1 转化成 s2 只需要插入一个字符
+ dp[0][j] = new Node(j, 1);
+ }
+ // 状态转移方程
+ for (int i = 1; i <= m; i++) {
+ for (int j = 1; j <= n; j++) {
+ if (s1.charAt(i-1) == s2.charAt(j-1)){
+ // 如果两个字符相同,则什么都不需要做
+ Node node = dp[i - 1][j - 1];
+ dp[i][j] = new Node(node.val, 0);
+ } else {
+ // 否则,记录代价最小的操作
+ dp[i][j] = minNode(
+ dp[i - 1][j],
+ dp[i][j - 1],
+ dp[i-1][j-1]
+ );
+ // 并且将编辑距离加一
+ dp[i][j].val++;
+ }
+ }
+ }
+ // 根据 dp table 反推具体操作过程并打印
+ printResult(dp, s1, s2);
+ return dp[m][n].val;
+}
+
+// 计算 delete, insert, replace 中代价最小的操作
+Node minNode(Node a, Node b, Node c) {
+ Node res = new Node(a.val, 2);
+
+ if (res.val > b.val) {
+ res.val = b.val;
+ res.choice = 1;
+ }
+ if (res.val > c.val) {
+ res.val = c.val;
+ res.choice = 3;
+ }
+ return res;
+}
+```
+
+最后,`printResult` 函数反推结果并把具体的操作打印出来:
+
+```java
+void printResult(Node[][] dp, String s1, String s2) {
+ int rows = dp.length;
+ int cols = dp[0].length;
+ int i = rows - 1, j = cols - 1;
+ System.out.println("Change s1=" + s1 + " to s2=" + s2 + ":\n");
+ while (i != 0 && j != 0) {
+ char c1 = s1.charAt(i - 1);
+ char c2 = s2.charAt(j - 1);
+ int choice = dp[i][j].choice;
+ System.out.print("s1[" + (i - 1) + "]:");
+ switch (choice) {
+ case 0:
+ // 跳过,则两个指针同时前进
+ System.out.println("skip '" + c1 + "'");
+ i--; j--;
+ break;
+ case 1:
+ // 将 s2[j] 插入 s1[i],则 s2 指针前进
+ System.out.println("insert '" + c2 + "'");
+ j--;
+ break;
+ case 2:
+ // 将 s1[i] 删除,则 s1 指针前进
+ System.out.println("delete '" + c1 + "'");
+ i--;
+ break;
+ case 3:
+ // 将 s1[i] 替换成 s2[j],则两个指针同时前进
+ System.out.println(
+ "replace '" + c1 + "'" + " with '" + c2 + "'");
+ i--; j--;
+ break;
+ }
+ }
+ // 如果 s1 还没有走完,则剩下的都是需要删除的
+ while (i > 0) {
+ System.out.print("s1[" + (i - 1) + "]:");
+ System.out.println("delete '" + s1.charAt(i - 1) + "'");
+ i--;
+ }
+ // 如果 s2 还没有走完,则剩下的都是需要插入 s1 的
+ while (j > 0) {
+ System.out.print("s1[0]:");
+ System.out.println("insert '" + s2.charAt(j - 1) + "'");
+ j--;
+ }
+}
+```
+
+
+
+
+
+引用本文的文章
+
+ - [动态规划之子序列问题解题模板](https://labuladong.online/algo/dynamic-programming/subsequence-problem/)
+ - [最优子结构原理和 dp 数组遍历方向](https://labuladong.online/algo/dynamic-programming/faq-summary/)
+ - [经典动态规划:正则表达式](https://labuladong.online/algo/dynamic-programming/regular-expression-matching/)
+
+
+
+
+
+
+
+
+引用本文的题目
+
+安装 [我的 Chrome 刷题插件](https://labuladong.online/algo/intro/chrome/) 点开下列题目可直接查看解题思路:
+
+| LeetCode | 力扣 | 难度 |
+| :----: | :----: | :----: |
+| [97. Interleaving String](https://leetcode.com/problems/interleaving-string/?show=1) | [97. 交错字符串](https://leetcode.cn/problems/interleaving-string/?show=1) | 🟠 |
+
+
+
+
-以上就是编辑距离算法的全部内容,如果本文对你有帮助,**欢迎关注我的公众号 labuladong,致力于把算法问题讲清楚**~
-
+**_____________**
-[上一篇:动态规划设计:最长递增子序列](../动态规划系列/动态规划设计:最长递增子序列.md)
-[下一篇:经典动态规划问题:高楼扔鸡蛋](../动态规划系列/高楼扔鸡蛋问题.md)
-[目录](../README.md#目录)
\ No newline at end of file
+
\ No newline at end of file
diff --git "a/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\350\203\214\345\214\205\351\227\256\351\242\230.md" "b/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\350\203\214\345\214\205\351\227\256\351\242\230.md"
new file mode 100644
index 0000000000..faff96106c
--- /dev/null
+++ "b/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\350\203\214\345\214\205\351\227\256\351\242\230.md"
@@ -0,0 +1,225 @@
+# 经典动态规划:0-1 背包问题
+
+
+
+
+
+**通知:为满足广大读者的需求,网站上架 [速成目录](https://labuladong.online/algo/intro/quick-learning-plan/),如有需要可以看下,谢谢大家的支持~另外,建议你在我的 [网站](https://labuladong.online/algo/) 学习文章,体验更好。**
+
+
+
+**-----------**
+
+
+
+> [!NOTE]
+> 阅读本文前,你需要先学习:
+>
+> - [动态规划核心框架](https://labuladong.online/algo/essential-technique/dynamic-programming-framework/)
+
+> tip:本文有视频版:[0-1背包问题详解](https://www.bilibili.com/video/BV15B4y1P7X7/)。建议关注我的 B 站账号,我会用视频领读的方式带大家学习那些稍有难度的算法技巧。
+
+
+
+后台天天有人问背包问题,这个问题其实不难,借助动态规划的思维框架,无非还是状态 + 选择,没啥特别之处。今天就来说一下背包问题吧,就讨论最常见的 0-1 背包问题。描述:
+
+给你一个可装载重量为 `W` 的背包和 `N` 个物品,每个物品有重量和价值两个属性。其中第 `i` 个物品的重量为 `wt[i]`,价值为 `val[i]`。现在让你用这个背包装物品,每个物品只能用一次,在不超过背包容量的前提下,最多能装的价值是多少?
+
+
+
+举个简单的例子,输入如下:
+
+```py
+N = 3, W = 4
+wt = [2, 1, 3]
+val = [4, 2, 3]
+```
+
+算法返回 6,选择前两件物品装进背包,总重量 3 小于 `W`,可以获得最大价值 6。
+
+题目就是这么简单,一个典型的动态规划问题。这个题目中的物品不可以分割,要么装进包里,要么不装,不能说切成两块装一半。这就是 0-1 背包这个名词的来历。
+
+解决这个问题没有什么排序之类巧妙的方法,只能穷举所有可能,根据我们 [动态规划详解](https://labuladong.online/algo/essential-technique/dynamic-programming-framework/) 中的套路,直接走流程就行了。
+
+
+
+
+
+
+
+## 动规标准套路
+
+看来每篇动态规划文章都得重复一遍套路,历史文章中的动态规划问题都是按照下面的套路来的。
+
+**第一步要明确两点,「状态」和「选择」**。
+
+先说状态,如何才能描述一个问题局面?只要给几个物品和一个背包的容量限制,就形成了一个背包问题呀。**所以状态有两个,就是「背包的容量」和「可选择的物品」**。
+
+再说选择,也很容易想到啊,对于每件物品,你能选择什么?**选择就是「装进背包」或者「不装进背包」嘛**。
+
+明白了状态和选择,动态规划问题基本上就解决了,对于自底向上的思考方式,代码的一般框架是这样:
+
+```python
+for 状态1 in 状态1的所有取值:
+ for 状态2 in 状态2的所有取值:
+ for ...
+ dp[状态1][状态2][...] = 择优(选择1,选择2...)
+```
+
+**第二步要明确 `dp` 数组的定义**。
+
+首先看看刚才找到的「状态」,有两个,也就是说我们需要一个二维 `dp` 数组。
+
+`dp[i][w]` 的定义如下:对于前 `i` 个物品,当前背包的容量为 `w`,这种情况下可以装的最大价值是 `dp[i][w]`。
+
+比如说,如果 `dp[3][5] = 6`,其含义为:对于给定的一系列物品中,若只对前 3 个物品进行选择,当背包容量为 5 时,最多可以装下的价值为 6。
+
+
+
+
+
+
+
+> [!NOTE]
+> 为什么要这么定义?因为这样可以找到状态转移关系,或者说这就是背包问题的特殊定义方式,你当做套路记下来就行,未来遇到动态规划相关问题,都可以这样定义试一试。
+
+根据这个定义,我们想求的最终答案就是 `dp[N][W]`。base case 就是 `dp[0][..] = dp[..][0] = 0`,因为没有物品或者背包没有空间的时候,能装的最大价值就是 0。
+
+细化上面的框架:
+
+```python
+int[][] dp[N+1][W+1]
+dp[0][..] = 0
+dp[..][0] = 0
+
+for i in [1..N]:
+ for w in [1..W]:
+ dp[i][w] = max(
+ 把物品 i 装进背包,
+ 不把物品 i 装进背包
+ )
+return dp[N][W]
+```
+
+**第三步,根据「选择」,思考状态转移的逻辑**。
+
+简单说就是,上面伪码中「把物品 `i` 装进背包」和「不把物品 `i` 装进背包」怎么用代码体现出来呢?
+
+这就要结合对 `dp` 数组的定义,看看这两种选择会对状态产生什么影响:
+
+
+
+
+
+
+
+先重申一下刚才我们的 `dp` 数组的定义:
+
+`dp[i][w]` 表示:对于前 `i` 个物品(从 1 开始计数),当前背包的容量为 `w` 时,这种情况下可以装下的最大价值是 `dp[i][w]`。
+
+**如果你没有把这第 `i` 个物品装入背包**,那么很显然,最大价值 `dp[i][w]` 应该等于 `dp[i-1][w]`,继承之前的结果。
+
+**如果你把这第 `i` 个物品装入了背包**,那么 `dp[i][w]` 应该等于 `val[i-1] + dp[i-1][w - wt[i-1]]`。
+
+首先,由于数组索引从 0 开始,而我们定义中的 `i` 是从 1 开始计数的,所以 `val[i-1]` 和 `wt[i-1]` 表示第 `i` 个物品的价值和重量。
+
+你如果选择将第 `i` 个物品装进背包,那么第 `i` 个物品的价值 `val[i-1]` 肯定就到手了,接下来你就要在剩余容量 `w - wt[i-1]` 的限制下,在前 `i - 1` 个物品中挑选,求最大价值,即 `dp[i-1][w - wt[i-1]]`。
+
+综上就是两种选择,我们都已经分析完毕,也就是写出来了状态转移方程,可以进一步细化代码:
+
+```python
+for i in [1..N]:
+ for w in [1..W]:
+ dp[i][w] = max(
+ dp[i-1][w],
+ dp[i-1][w - wt[i-1]] + val[i-1]
+ )
+return dp[N][W]
+```
+
+**最后一步,把伪码翻译成代码,处理一些边界情况**。
+
+我用 Java 写的代码,把上面的思路完全翻译了一遍,并且处理了 `w - wt[i-1]` 可能小于 0 导致数组索引越界的问题:
+
+```java
+int knapsack(int W, int N, int[] wt, int[] val) {
+ assert N == wt.length;
+ // base case 已初始化
+ int[][] dp = new int[N + 1][W + 1];
+ for (int i = 1; i <= N; i++) {
+ for (int w = 1; w <= W; w++) {
+ if (w - wt[i - 1] < 0) {
+ // 这种情况下只能选择不装入背包
+ dp[i][w] = dp[i - 1][w];
+ } else {
+ // 装入或者不装入背包,择优
+ dp[i][w] = Math.max(
+ dp[i - 1][w - wt[i-1]] + val[i-1],
+ dp[i - 1][w]
+ );
+ }
+ }
+ }
+
+ return dp[N][W];
+}
+```
+
+
+
+
+
+
+👾 代码可视化动画👾
+
+
+
+
+
+
+
+> [!NOTE]
+> 其实函数签名中的物品数量 `N` 就是 `wt` 数组的长度,所以实际上这个参数 `N` 是多此一举的。但为了体现原汁原味的 0-1 背包问题,我就带上这个参数 `N` 了,你自己写的话可以省略。
+
+至此,背包问题就解决了,相比而言,我觉得这是比较简单的动态规划问题,因为状态转移的推导比较自然,基本上你明确了 `dp` 数组的定义,就可以理所当然地确定状态转移了。
+
+
+
+
+
+
+
+
+
+引用本文的文章
+
+ - [扫描线技巧:安排会议室](https://labuladong.online/algo/frequency-interview/scan-line-technique/)
+ - [经典动态规划:子集背包问题](https://labuladong.online/algo/dynamic-programming/knapsack2/)
+ - [经典动态规划:完全背包问题](https://labuladong.online/algo/dynamic-programming/knapsack3/)
+ - [背包问题的变体:目标和](https://labuladong.online/algo/dynamic-programming/target-sum/)
+
+
+
+
+
+
+
+
+引用本文的题目
+
+安装 [我的 Chrome 刷题插件](https://labuladong.online/algo/intro/chrome/) 点开下列题目可直接查看解题思路:
+
+| LeetCode | 力扣 | 难度 |
+| :----: | :----: | :----: |
+| [1235. Maximum Profit in Job Scheduling](https://leetcode.com/problems/maximum-profit-in-job-scheduling/?show=1) | [1235. 规划兼职工作](https://leetcode.cn/problems/maximum-profit-in-job-scheduling/?show=1) | 🔴 |
+
+
+
+
+
+
+**_____________**
+
+
+
+
\ No newline at end of file
diff --git "a/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\350\264\252\345\277\203\347\256\227\346\263\225\344\271\213\345\214\272\351\227\264\350\260\203\345\272\246\351\227\256\351\242\230.md" "b/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\350\264\252\345\277\203\347\256\227\346\263\225\344\271\213\345\214\272\351\227\264\350\260\203\345\272\246\351\227\256\351\242\230.md"
index 889cd26cd4..f03859a7c4 100644
--- "a/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\350\264\252\345\277\203\347\256\227\346\263\225\344\271\213\345\214\272\351\227\264\350\260\203\345\272\246\351\227\256\351\242\230.md"
+++ "b/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\350\264\252\345\277\203\347\256\227\346\263\225\344\271\213\345\214\272\351\227\264\350\260\203\345\272\246\351\227\256\351\242\230.md"
@@ -1,5 +1,24 @@
# 贪心算法之区间调度问题
+
+
+
+
+**通知:为满足广大读者的需求,网站上架 [速成目录](https://labuladong.online/algo/intro/quick-learning-plan/),如有需要可以看下,谢谢大家的支持~另外,建议你在我的 [网站](https://labuladong.online/algo/) 学习文章,体验更好。**
+
+
+
+读完本文,你不仅学会了算法套路,还可以顺便解决如下题目:
+
+| LeetCode | 力扣 | 难度 |
+| :----: | :----: | :----: |
+| [435. Non-overlapping Intervals](https://leetcode.com/problems/non-overlapping-intervals/) | [435. 无重叠区间](https://leetcode.cn/problems/non-overlapping-intervals/) | 🟠 |
+| [452. Minimum Number of Arrows to Burst Balloons](https://leetcode.com/problems/minimum-number-of-arrows-to-burst-balloons/) | [452. 用最少数量的箭引爆气球](https://leetcode.cn/problems/minimum-number-of-arrows-to-burst-balloons/) | 🟠 |
+
+**-----------**
+
+
+
什么是贪心算法呢?贪心算法可以认为是动态规划算法的一个特例,相比动态规划,使用贪心算法需要满足更多的条件(贪心选择性质),但是效率比动态规划要高。
比如说一个算法问题使用暴力解法需要指数级时间,如果能使用动态规划消除重叠子问题,就可以降到多项式级别的时间,如果满足贪心选择性质,那么可以进一步降低时间复杂度,达到线性级别的。
@@ -8,21 +27,29 @@
比如你面前放着 100 张人民币,你只能拿十张,怎么才能拿最多的面额?显然每次选择剩下钞票中面值最大的一张,最后你的选择一定是最优的。
-然而,大部分问题明显不具有贪心选择性质。比如打斗地主,对手出对儿三,按照贪心策略,你应该出尽可能小的牌刚好压制住对方,但现实情况我们甚至可能会出王炸。这种情况就不能用贪心算法,而得使用动态规划解决,参见前文「动态规划解决博弈问题」。
+然而,大部分问题明显不具有贪心选择性质。比如打斗地主,对手出对儿三,按照贪心策略,你应该出尽可能小的牌刚好压制住对方,但现实情况我们甚至可能会出王炸。这种情况就不能用贪心算法,而得使用动态规划解决,参见前文 [动态规划解决博弈问题](https://labuladong.online/algo/dynamic-programming/game-theory/)。
+
+## 一、问题概述
-### 一、问题概述
+言归正传,本文解决一个很经典的贪心算法问题 Interval Scheduling(区间调度问题),也就是力扣第 435 题「无重叠区间」:
-言归正传,本文解决一个很经典的贪心算法问题 Interval Scheduling(区间调度问题)。给你很多形如 `[start, end]` 的闭区间,请你设计一个算法,**算出这些区间中最多有几个互不相交的区间**。
+给你很多形如 `[start, end]` 的闭区间,请你设计一个算法,**算出这些区间中最多有几个互不相交的区间**。
```java
-int intervalSchedule(int[][] intvs) {}
+int intervalSchedule(int[][] intvs);
```
举个例子,`intvs = [[1,3], [2,4], [3,6]]`,这些区间最多有 2 个区间互不相交,即 `[[1,3], [3,6]]`,你的算法应该返回 2。注意边界相同并不算相交。
-这个问题在生活中的应用广泛,比如你今天有好几个活动,每个活动都可以用区间 `[start, end]` 表示开始和结束的时间,请问你今天**最多能参加几个活动呢?**显然你一个人不能同时参加两个活动,所以说这个问题就是求这些时间区间的最大不相交子集。
+这个问题在生活中的应用广泛,比如你今天有好几个活动,每个活动都可以用区间 `[start, end]` 表示开始和结束的时间,请问你今天**最多能参加几个活动呢**?显然你一个人不能同时参加两个活动,所以说这个问题就是求这些时间区间的最大不相交子集。
-### 二、贪心解法
+
+
+
+
+
+
+## 二、贪心解法
这个问题有许多看起来不错的贪心思路,却都不能得到正确答案。比如说:
@@ -30,100 +57,163 @@ int intervalSchedule(int[][] intvs) {}
正确的思路其实很简单,可以分为以下三步:
-1. 从区间集合 intvs 中选择一个区间 x,这个 x 是在当前所有区间中**结束最早的**(end 最小)。
-2. 把所有与 x 区间相交的区间从区间集合 intvs 中删除。
-3. 重复步骤 1 和 2,直到 intvs 为空为止。之前选出的那些 x 就是最大不相交子集。
+1、从区间集合 `intvs` 中选择一个区间 `x`,这个 `x` 是在当前所有区间中**结束最早的**(`end` 最小)。
-把这个思路实现成算法的话,可以按每个区间的 `end` 数值升序排序,因为这样处理之后实现步骤 1 和步骤 2 都方便很多:
+2、把所有与 `x` 区间相交的区间从区间集合 `intvs` 中删除。
-
+3、重复步骤 1 和 2,直到 `intvs` 为空为止。之前选出的那些 `x` 就是最大不相交子集。
-现在来实现算法,对于步骤 1,由于我们预先按照 `end` 排了序,所以选择 x 是很容易的。关键在于,如何去除与 x 相交的区间,选择下一轮循环的 x 呢?
+把这个思路实现成算法的话,可以按每个区间的 `end` 数值升序排序,因为这样处理之后实现步骤 1 和步骤 2 都方便很多,如下 GIF 所示:
-**由于我们事先排了序**,不难发现所有与 x 相交的区间必然会与 x 的 `end` 相交;如果一个区间不想与 x 的 `end` 相交,它的 `start` 必须要大于(或等于)x 的 `end`:
+
-
+现在来实现算法,对于步骤 1,由于我们预先按照 `end` 排了序,所以选择 `x` 是很容易的。关键在于,如何去除与 `x` 相交的区间,选择下一轮循环的 `x` 呢?
+
+**由于我们事先排了序**,不难发现所有与 `x` 相交的区间必然会与 `x` 的 `end` 相交;如果一个区间不想与 `x` 的 `end` 相交,它的 `start` 必须要大于(或等于)`x` 的 `end`:
+
+
看下代码:
```java
-public int intervalSchedule(int[][] intvs) {
- if (intvs.length == 0) return 0;
- // 按 end 升序排序
- Arrays.sort(intvs, new Comparator() {
- public int compare(int[] a, int[] b) {
- return a[1] - b[1];
- }
- });
- // 至少有一个区间不相交
- int count = 1;
- // 排序后,第一个区间就是 x
- int x_end = intvs[0][1];
- for (int[] interval : intvs) {
- int start = interval[0];
- if (start >= x_end) {
- // 找到下一个选择的区间了
- count++;
- x_end = interval[1];
+class Solution {
+ public int intervalSchedule(int[][] intvs) {
+ if (intvs.length == 0) return 0;
+ // 按 end 升序排序
+ Arrays.sort(intvs, (a, b) -> Integer.compare(a[1], b[1]));
+ // 至少有一个区间不相交
+ int count = 1;
+ // 排序后,第一个区间就是 x
+ int x_end = intvs[0][1];
+ for (int[] interval : intvs) {
+ int start = interval[0];
+ if (start >= x_end) {
+ // 找到下一个选择的区间了
+ count++;
+ x_end = interval[1];
+ }
}
+ return count;
}
- return count;
}
```
-### 三、应用举例
+## 三、应用举例
+
+下面再举例几道具体的题目应用一下区间调度算法。
+
+首先是力扣第 435 题「无重叠区间」问题:
+
+输入一个区间的集合,请你计算,要想使其中的区间都互不重叠,至少需要移除几个区间?函数签名如下:
-下面举例几道 LeetCode 题目应用一下区间调度算法。
+```java
+int eraseOverlapIntervals(int[][] intvs);
+```
-第 435 题,无重叠区间:
+其中,可以假设输入的区间的终点总是大于起点,另外边界相等的区间只算接触,但并不算相互重叠。
-
+比如说输入是 `intvs = [[1,2],[2,3],[3,4],[1,3]]`,算法返回 1,因为只要移除 `[1,3]` 后,剩下的区间就没有重叠了。
我们已经会求最多有几个区间不会重叠了,那么剩下的不就是至少需要去除的区间吗?
```java
-int eraseOverlapIntervals(int[][] intervals) {
- int n = intervals.length;
- return n - intervalSchedule(intervals);
+class Solution {
+ public int eraseOverlapIntervals(int[][] intvs) {
+ int n = intvs.length;
+ return n - intervalSchedule(intvs);
+ }
+
+ private int intervalSchedule(int[][] intvs) {
+ // 见上文
+ }
}
```
-第 452 题,用最少的箭头射爆气球:
-
+
+
+
+
+🍭 代码可视化动画🍭
+
+
+
+
+
+
+
+再说说力扣第 452 题「用最少的箭头射爆气球」,我来描述一下题目:
+
+假设在二维平面上有很多圆形的气球,这些圆形投影到 x 轴上会形成一个个区间对吧。那么给你输入这些区间,你沿着 x 轴前进,可以垂直向上射箭,请问你至少要射几箭才能把这些气球全部射爆呢?
+
+函数签名如下:
+
+```java
+int findMinArrowShots(int[][] intvs);
+```
+
+比如说输入为 `[[10,16],[2,8],[1,6],[7,12]]`,算法应该返回 2,因为我们可以在 `x` 为 6 的地方射一箭,射爆 `[2,8]` 和 `[1,6]` 两个气球,然后在 `x` 为 10,11 或 12 的地方射一箭,射爆 `[10,16]` 和 `[7,12]` 两个气球。
其实稍微思考一下,这个问题和区间调度算法一模一样!如果最多有 `n` 个不重叠的区间,那么就至少需要 `n` 个箭头穿透所有区间:
-
+
只是有一点不一样,在 `intervalSchedule` 算法中,如果两个区间的边界触碰,不算重叠;而按照这道题目的描述,箭头如果碰到气球的边界气球也会爆炸,所以说相当于区间的边界触碰也算重叠:
-
+
所以只要将之前的算法稍作修改,就是这道题目的答案:
```java
-int findMinArrowShots(int[][] intvs) {
- // ...
-
- for (int[] interval : intvs) {
- int start = interval[0];
- // 把 >= 改成 > 就行了
- if (start > x_end) {
- count++;
- x_end = interval[1];
+class Solution {
+ public int findMinArrowShots(int[][] intvs) {
+ if (intvs.length == 0) return 0;
+ Arrays.sort(intvs, (a, b) -> Integer.compare(a[1], b[1]));
+ int count = 1;
+ int x_end = intvs[0][1];
+
+ for (int[] interval : intvs) {
+ int start = interval[0];
+ // 把 >= 改成 > 就行了
+ if (start > x_end) {
+ count++;
+ x_end = interval[1];
+ }
}
+ return count;
}
- return count;
}
```
-这么做的原因也不难理解,因为现在边界接触也算重叠,所以 `start == x_end` 时不能更新 x。
-如果本文对你有帮助,欢迎关注我的公众号 labuladong,致力于把算法问题讲清楚~
+
+
+
+
+🌈 代码可视化动画🌈
+
+
+
+
+
+
+
+
+
+引用本文的文章
+
+ - [一个方法解决三道区间问题](https://labuladong.online/algo/practice-in-action/interval-problem-summary/)
+ - [剪视频剪出一个贪心算法](https://labuladong.online/algo/frequency-interview/cut-video/)
+ - [扫描线技巧:安排会议室](https://labuladong.online/algo/frequency-interview/scan-line-technique/)
+
+
+
+
+
+
+
+**_____________**
-[上一篇:动态规划之博弈问题](../动态规划系列/动态规划之博弈问题.md)
-[下一篇:动态规划之KMP字符匹配算法](../动态规划系列/动态规划之KMP字符匹配算法.md)
-[目录](../README.md#目录)
\ No newline at end of file
+
\ No newline at end of file
diff --git "a/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\351\253\230\346\245\274\346\211\224\351\270\241\350\233\213\350\277\233\351\230\266.md" "b/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\351\253\230\346\245\274\346\211\224\351\270\241\350\233\213\350\277\233\351\230\266.md"
deleted file mode 100644
index 50ff9efecc..0000000000
--- "a/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\351\253\230\346\245\274\346\211\224\351\270\241\350\233\213\350\277\233\351\230\266.md"
+++ /dev/null
@@ -1,275 +0,0 @@
-# 经典动态规划问题:高楼扔鸡蛋(进阶)
-
-上篇文章聊了高楼扔鸡蛋问题,讲了一种效率不是很高,但是较为容易理解的动态规划解法。后台很多读者问如何更高效地解决这个问题,今天就谈两种思路,来优化一下这个问题,分别是二分查找优化和重新定义状态转移。
-
-如果还不知道高楼扔鸡蛋问题的读者可以看下「经典动态规划:高楼扔鸡蛋」,那篇文章详解了题目的含义和基本的动态规划解题思路,请确保理解前文,因为今天的优化都是基于这个基本解法的。
-
-二分搜索的优化思路也许是我们可以尽力尝试写出的,而修改状态转移的解法可能是不容易想到的,可以借此见识一下动态规划算法设计的玄妙,当做思维拓展。
-
-### 二分搜索优化
-
-之前提到过这个解法,核心是因为状态转移方程的单调性,这里可以具体展开看看。
-
-首先简述一下原始动态规划的思路:
-
-1、暴力穷举尝试在所有楼层 `1 <= i <= N` 扔鸡蛋,每次选择尝试次数**最少**的那一层;
-
-2、每次扔鸡蛋有两种可能,要么碎,要么没碎;
-
-3、如果鸡蛋碎了,`F` 应该在第 `i` 层下面,否则,`F` 应该在第 `i` 层上面;
-
-4、鸡蛋是碎了还是没碎,取决于哪种情况下尝试次数**更多**,因为我们想求的是最坏情况下的结果。
-
-核心的状态转移代码是这段:
-
-```python
-# 当前状态为 K 个鸡蛋,面对 N 层楼
-# 返回这个状态下的最优结果
-def dp(K, N):
- for 1 <= i <= N:
- # 最坏情况下的最少扔鸡蛋次数
- res = min(res,
- max(
- dp(K - 1, i - 1), # 碎
- dp(K, N - i) # 没碎
- ) + 1 # 在第 i 楼扔了一次
- )
- return res
-```
-
-这个 for 循环就是下面这个状态转移方程的具体代码实现:
-
-$$ dp(K, N) = \min_{0 <= i <= N}\{\max\{dp(K - 1, i - 1), dp(K, N - i)\} + 1\}$$
-
-如果能够理解这个状态转移方程,那么就很容易理解二分查找的优化思路。
-
-首先我们根据 `dp(K, N)` 数组的定义(有 `K` 个鸡蛋面对 `N` 层楼,最少需要扔几次),**很容易知道 `K` 固定时,这个函数随着 `N` 的增加一定是单调递增的**,无论你策略多聪明,楼层增加测试次数一定要增加。
-
-那么注意 `dp(K - 1, i - 1)` 和 `dp(K, N - i)` 这两个函数,其中 `i` 是从 1 到 `N` 单增的,如果我们固定 `K` 和 `N`,**把这两个函数看做关于 `i` 的函数,前者随着 `i` 的增加应该也是单调递增的,而后者随着 `i` 的增加应该是单调递减的**:
-
-
-
-这时候求二者的较大值,再求这些最大值之中的最小值,其实就是求这两条直线交点,也就是红色折线的最低点嘛。
-
-我们前文「二分查找只能用来查找元素吗」讲过,二分查找的运用很广泛,形如下面这种形式的 for 循环代码:
-
-```java
-for (int i = 0; i < n; i++) {
- if (isOK(i))
- return i;
-}
-```
-
-都很有可能可以运用二分查找来优化线性搜索的复杂度,回顾这两个 `dp` 函数的曲线,我们要找的最低点其实就是这种情况:
-
-```java
-for (int i = 1; i <= N; i++) {
- if (dp(K - 1, i - 1) == dp(K, N - i))
- return dp(K, N - i);
-}
-```
-
-熟悉二分搜索的同学肯定敏感地想到了,这不就是相当于求 Valley(山谷)值嘛,可以用二分查找来快速寻找这个点的,直接看代码吧,整体的思路还是一样,只是加快了搜索速度:
-
-```python
-def superEggDrop(self, K: int, N: int) -> int:
-
- memo = dict()
- def dp(K, N):
- if K == 1: return N
- if N == 0: return 0
- if (K, N) in memo:
- return memo[(K, N)]
-
- # for 1 <= i <= N:
- # res = min(res,
- # max(
- # dp(K - 1, i - 1),
- # dp(K, N - i)
- # ) + 1
- # )
-
- res = float('INF')
- # 用二分搜索代替线性搜索
- lo, hi = 1, N
- while lo <= hi:
- mid = (lo + hi) // 2
- broken = dp(K - 1, mid - 1) # 碎
- not_broken = dp(K, N - mid) # 没碎
- # res = min(max(碎,没碎) + 1)
- if broken > not_broken:
- hi = mid - 1
- res = min(res, broken + 1)
- else:
- lo = mid + 1
- res = min(res, not_broken + 1)
-
- memo[(K, N)] = res
- return res
-
- return dp(K, N)
-```
-
-这个算法的时间复杂度是多少呢?**动态规划算法的时间复杂度就是子问题个数 × 函数本身的复杂度**。
-
-函数本身的复杂度就是忽略递归部分的复杂度,这里 `dp` 函数中用了一个二分搜索,所以函数本身的复杂度是 O(logN)。
-
-子问题个数也就是不同状态组合的总数,显然是两个状态的乘积,也就是 O(KN)。
-
-所以算法的总时间复杂度是 O(K\*N\*logN), 空间复杂度 O(KN)。效率上比之前的算法 O(KN^2) 要高效一些。
-
-### 重新定义状态转移
-
-前文「不同定义有不同解法」就提过,找动态规划的状态转移本就是见仁见智,比较玄学的事情,不同的状态定义可以衍生出不同的解法,其解法和复杂程度都可能有巨大差异。这里就是一个很好的例子。
-
-再回顾一下我们之前定义的 `dp` 数组含义:
-
-```python
-def dp(k, n) -> int
-# 当前状态为 k 个鸡蛋,面对 n 层楼
-# 返回这个状态下最少的扔鸡蛋次数
-```
-
-用 dp 数组表示的话也是一样的:
-
-```python
-dp[k][n] = m
-# 当前状态为 k 个鸡蛋,面对 n 层楼
-# 这个状态下最少的扔鸡蛋次数为 m
-```
-
-按照这个定义,就是**确定当前的鸡蛋个数和面对的楼层数,就知道最小扔鸡蛋次数**。最终我们想要的答案就是 `dp(K, N)` 的结果。
-
-这种思路下,肯定要穷举所有可能的扔法的,用二分搜索优化也只是做了「剪枝」,减小了搜索空间,但本质思路没有变,还是穷举。
-
-现在,我们稍微修改 `dp` 数组的定义,**确定当前的鸡蛋个数和最多允许的扔鸡蛋次数,就知道能够确定 `F` 的最高楼层数**。具体来说是这个意思:
-
-```python
-dp[k][m] = n
-# 当前有 k 个鸡蛋,可以尝试扔 m 次鸡蛋
-# 这个状态下,最坏情况下最多能确切测试一栋 n 层的楼
-
-# 比如说 dp[1][7] = 7 表示:
-# 现在有 1 个鸡蛋,允许你扔 7 次;
-# 这个状态下最多给你 7 层楼,
-# 使得你可以确定楼层 F 使得鸡蛋恰好摔不碎
-# (一层一层线性探查嘛)
-```
-
-这其实就是我们原始思路的一个「反向」版本,我们先不管这种思路的状态转移怎么写,先来思考一下这种定义之下,最终想求的答案是什么?
-
-我们最终要求的其实是扔鸡蛋次数 `m`,但是这时候 `m` 在状态之中而不是 `dp` 数组的结果,可以这样处理:
-
-```java
-int superEggDrop(int K, int N) {
-
- int m = 0;
- while (dp[K][m] < N) {
- m++;
- // 状态转移...
- }
- return m;
-}
-```
-
-题目不是**给你 `K` 鸡蛋,`N` 层楼,让你求最坏情况下最少的测试次数 `m`** 吗?`while` 循环结束的条件是 `dp[K][m] == N`,也就是**给你 `K` 个鸡蛋,测试 `m` 次,最坏情况下最多能测试 `N` 层楼**。
-
-注意看这两段描述,是完全一样的!所以说这样组织代码是正确的,关键就是状态转移方程怎么找呢?还得从我们原始的思路开始讲。之前的解法配了这样图帮助大家理解状态转移思路:
-
-
-
-这个图描述的仅仅是某一个楼层 `i`,原始解法还得线性或者二分扫描所有楼层,要求最大值、最小值。但是现在这种 `dp` 定义根本不需要这些了,基于下面两个事实:
-
-**1、无论你在哪层楼扔鸡蛋,鸡蛋只可能摔碎或者没摔碎,碎了的话就测楼下,没碎的话就测楼上**。
-
-**2、无论你上楼还是下楼,总的楼层数 = 楼上的楼层数 + 楼下的楼层数 + 1(当前这层楼)**。
-
-根据这个特点,可以写出下面的状态转移方程:
-
-`dp[k][m] = dp[k][m - 1] + dp[k - 1][m - 1] + 1`
-
-**`dp[k][m - 1]` 就是楼上的楼层数**,因为鸡蛋个数 `k` 不变,也就是鸡蛋没碎,扔鸡蛋次数 `m` 减一;
-
-**`dp[k - 1][m - 1]` 就是楼下的楼层数**,因为鸡蛋个数 `k` 减一,也就是鸡蛋碎了,同时扔鸡蛋次数 `m` 减一。
-
-PS:这个 `m` 为什么要减一而不是加一?之前定义得很清楚,这个 `m` 是一个允许的次数上界,而不是扔了几次。
-
-
-
-至此,整个思路就完成了,只要把状态转移方程填进框架即可:
-
-```java
-int superEggDrop(int K, int N) {
- // m 最多不会超过 N 次(线性扫描)
- int[][] dp = new int[K + 1][N + 1];
- // base case:
- // dp[0][..] = 0
- // dp[..][0] = 0
- // Java 默认初始化数组都为 0
- int m = 0;
- while (dp[K][m] < N) {
- m++;
- for (int k = 1; k <= K; k++)
- dp[k][m] = dp[k][m - 1] + dp[k - 1][m - 1] + 1;
- }
- return m;
-}
-```
-
-如果你还觉得这段代码有点难以理解,其实它就等同于这样写:
-
-```java
-for (int m = 1; dp[K][m] < N; m++)
- for (int k = 1; k <= K; k++)
- dp[k][m] = dp[k][m - 1] + dp[k - 1][m - 1] + 1;
-```
-
-看到这种代码形式就熟悉多了吧,因为我们要求的不是 `dp` 数组里的值,而是某个符合条件的索引 `m`,所以用 `while` 循环来找到这个 `m` 而已。
-
-这个算法的时间复杂度是多少?很明显就是两个嵌套循环的复杂度 O(KN)。
-
-另外注意到 `dp[m][k]` 转移只和左边和左上的两个状态有关,所以很容易优化成一维 `dp` 数组,这里就不写了。
-
-### 还可以再优化
-
-再往下就要用一些数学方法了,不具体展开,就简单提一下思路吧。
-
-在刚才的思路之上,**注意函数 `dp(m, k)` 是随着 `m` 单增的,因为鸡蛋个数 `k` 不变时,允许的测试次数越多,可测试的楼层就越高**。
-
-这里又可以借助二分搜索算法快速逼近 `dp[K][m] == N` 这个终止条件,时间复杂度进一步下降为 O(KlogN),我们可以设 `g(k, m) =`……
-
-算了算了,打住吧。我觉得我们能够写出 O(K\*N\*logN) 的二分优化算法就行了,后面的这些解法呢,听个响鼓个掌就行了,把欲望限制在能力的范围之内才能拥有快乐!
-
-不过可以肯定的是,根据二分搜索代替线性扫描 `m` 的取值,代码的大致框架肯定是修改穷举 `m` 的 for 循环:
-
-```java
-// 把线性搜索改成二分搜索
-// for (int m = 1; dp[K][m] < N; m++)
-int lo = 1, hi = N;
-while (lo < hi) {
- int mid = (lo + hi) / 2;
- if (... < N) {
- lo = ...
- } else {
- hi = ...
- }
-
- for (int k = 1; k <= K; k++)
- // 状态转移方程
-}
-```
-
-简单总结一下吧,第一个二分优化是利用了 `dp` 函数的单调性,用二分查找技巧快速搜索答案;第二种优化是巧妙地修改了状态转移方程,简化了求解了流程,但相应的,解题逻辑比较难以想到;后续还可以用一些数学方法和二分搜索进一步优化第二种解法,不过看了看镜子中的发量,算了。
-
-本文终,希望对你有一点启发。
-
-坚持原创高质量文章,致力于把算法问题讲清楚,欢迎关注我的公众号 labuladong 获取最新文章:
-
-
-
-
-[上一篇:经典动态规划问题:高楼扔鸡蛋](../动态规划系列/高楼扔鸡蛋问题.md)
-
-[下一篇:动态规划之子序列问题解题模板](../动态规划系列/子序列问题模板.md)
-
-[目录](../README.md#目录)
\ No newline at end of file
diff --git "a/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\351\253\230\346\245\274\346\211\224\351\270\241\350\233\213\351\227\256\351\242\230.md" "b/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\351\253\230\346\245\274\346\211\224\351\270\241\350\233\213\351\227\256\351\242\230.md"
index 6fc72e09e6..56fa24f9ec 100644
--- "a/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\351\253\230\346\245\274\346\211\224\351\270\241\350\233\213\351\227\256\351\242\230.md"
+++ "b/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\351\253\230\346\245\274\346\211\224\351\270\241\350\233\213\351\227\256\351\242\230.md"
@@ -1,14 +1,45 @@
-# 经典动态规划问题:高楼扔鸡蛋
+# 经典动态规划:高楼扔鸡蛋
-今天要聊一个很经典的算法问题,若干层楼,若干个鸡蛋,让你算出最少的尝试次数,找到鸡蛋恰好摔不碎的那层楼。国内大厂以及谷歌脸书面试都经常考察这道题,只不过他们觉得扔鸡蛋太浪费,改成扔杯子,扔破碗什么的。
-具体的问题等会再说,但是这道题的解法技巧很多,光动态规划就好几种效率不同的思路,最后还有一种极其高效数学解法。秉承咱们号一贯的作风,拒绝奇技淫巧,拒绝过于诡异的技巧,因为这些技巧无法举一反三,学了也不划算。
+
+
+
+**通知:为满足广大读者的需求,网站上架 [速成目录](https://labuladong.online/algo/intro/quick-learning-plan/),如有需要可以看下,谢谢大家的支持~另外,建议你在我的 [网站](https://labuladong.online/algo/) 学习文章,体验更好。**
+
+
+
+读完本文,你不仅学会了算法套路,还可以顺便解决如下题目:
+
+| LeetCode | 力扣 | 难度 |
+| :----: | :----: | :----: |
+| [887. Super Egg Drop](https://leetcode.com/problems/super-egg-drop/) | [887. 鸡蛋掉落](https://leetcode.cn/problems/super-egg-drop/) | 🔴 |
+
+**-----------**
+
+
+
+> [!NOTE]
+> 阅读本文前,你需要先学习:
+>
+> - [动态规划核心框架](https://labuladong.online/algo/essential-technique/dynamic-programming-framework/)
+
+本文要聊一个很经典的算法问题,若干层楼,若干个鸡蛋,让你算出最少的尝试次数,找到鸡蛋恰好摔不碎的那层楼。国内大厂以及谷歌脸书面试都经常考察这道题,只不过他们觉得扔鸡蛋太浪费,改成扔杯子,扔破碗什么的。
+
+具体的问题等会再说,但是这道题的解法技巧很多,光动态规划就好几种效率不同的思路,最后还有一种极其高效数学解法。秉承本书一贯的作风,拒绝过于诡异的技巧,因为这些技巧无法举一反三,学了也不划算。
下面就来用我们一直强调的动态规划通用思路来研究一下这道题。
-### 一、解析题目
-题目是这样:你面前有一栋从 1 到 `N` 共 `N` 层的楼,然后给你 `K` 个鸡蛋(`K` 至少为 1)。现在确定这栋楼存在楼层 `0 <= F <= N`,在这层楼将鸡蛋扔下去,鸡蛋**恰好没摔碎**(高于 `F` 的楼层都会碎,低于 `F` 的楼层都不会碎)。现在问你,**最坏**情况下,你**至少**要扔几次鸡蛋,才能**确定**这个楼层 `F` 呢?
+
+
+
+
+
+## 一、解析题目
+
+这是力扣第 887 题「鸡蛋掉落」,我描述一下题目:
+
+你面前有一栋从 1 到 `N` 共 `N` 层的楼,然后给你 `K` 个鸡蛋(`K` 至少为 1)。现在确定这栋楼存在楼层 `0 <= F <= N`,在这层楼将鸡蛋扔下去,鸡蛋**恰好没摔碎**(高于 `F` 的楼层都会碎,低于 `F` 的楼层都不会碎,如果鸡蛋没有碎,可以捡回来继续扔)。现在问你,**最坏**情况下,你**至少**要扔几次鸡蛋,才能**确定**这个楼层 `F` 呢?
也就是让你找摔不碎鸡蛋的最高楼层 `F`,但什么叫「最坏情况」下「至少」要扔几次呢?我们分别举个例子就明白了。
@@ -30,23 +61,33 @@
以这种策略,**最坏**情况应该是试到第 7 层鸡蛋还没碎(`F = 7`),或者鸡蛋一直碎到第 1 层(`F = 0`)。然而无论那种最坏情况,只需要试 `log7` 向上取整等于 3 次,比刚才尝试 7 次要少,这就是所谓的**至少**要扔几次。
-PS:这有点像 Big O 表示法计算算法的复杂度。
+
+
+
+
+
实际上,如果不限制鸡蛋个数的话,二分思路显然可以得到最少尝试的次数,但问题是,**现在给你了鸡蛋个数的限制 `K`,直接使用二分思路就不行了**。
-比如说只给你 1 个鸡蛋,7 层楼,你敢用二分吗?你直接去第 4 层扔一下,如果鸡蛋没碎还好,但如果碎了你就没有鸡蛋继续测试了,无法确定鸡蛋恰好摔不碎的楼层 `F` 了。这种情况下只能用线性扫描的方法,算法返回结果应该是 7。
+比如说只给你 1 个鸡蛋,7 层楼,你敢用二分吗?你直接去第 4 层扔一下,如果鸡蛋没碎还好,你可以把鸡蛋捡起来再去更高的楼层尝试;但如果碎了,你就没有鸡蛋继续测试了,无法确定鸡蛋恰好摔不碎的楼层 `F` 了。
+
+其实这种情况下只能用线性扫描的方法,从下往上一层层尝试扔鸡蛋,那么最坏情况下需要扔 7 次,算法返回结果应该是 7。
有的读者也许会有这种想法:二分查找排除楼层的速度无疑是最快的,那干脆先用二分查找,等到只剩 1 个鸡蛋的时候再执行线性扫描,这样得到的结果是不是就是最少的扔鸡蛋次数呢?
很遗憾,并不是,比如说把楼层变高一些,100 层,给你 2 个鸡蛋,你在 50 层扔一下,碎了,那就只能线性扫描 1~49 层了,最坏情况下要扔 50 次。
-如果不要「二分」,变成「五分」「十分」都会大幅减少最坏情况下的尝试次数。比方说第一个鸡蛋每隔十层楼扔,在哪里碎了第二个鸡蛋一个个线性扫描,总共不会超过 20 次。
-
-最优解其实是 14 次。最优策略非常多,而且并没有什么规律可言。
+如果不要「二分」,变成「五分」「十分」都会大幅减少最坏情况下的尝试次数。比方说第一个鸡蛋每隔十层楼扔,在哪里碎了第二个鸡蛋一个个线性扫描,总共不会超过 20 次。最优解其实是 14 次。最优策略非常多,而且并没有什么规律可言。
说了这么多废话,就是确保大家理解了题目的意思,而且认识到这个题目确实复杂,就连我们手算都不容易,如何用算法解决呢?
-### 二、思路分析
+
+
+
+
+
+
+## 二、思路分析
对动态规划问题,直接套我们以前多次强调的框架即可:这个问题有什么「状态」,有什么「选择」,然后穷举。
@@ -55,17 +96,25 @@ PS:这有点像 Big O 表示法计算算法的复杂度。
**「选择」其实就是去选择哪层楼扔鸡蛋**。回顾刚才的线性扫描和二分思路,二分查找每次选择到楼层区间的中间去扔鸡蛋,而线性扫描选择一层层向上测试。不同的选择会造成状态的转移。
现在明确了「状态」和「选择」,**动态规划的基本思路就形成了**:肯定是个二维的 `dp` 数组或者带有两个状态参数的 `dp` 函数来表示状态转移;外加一个 for 循环来遍历所有选择,择最优的选择更新状态:
-
-```python
-# 当前状态为 K 个鸡蛋,面对 N 层楼
-# 返回这个状态下的最优结果
-def dp(K, N):
- int res
- for 1 <= i <= N:
- res = min(res, 这次在第 i 层楼扔鸡蛋)
- return res
+
+
+
+
+
+```java
+// 定义:当前状态为 K 个鸡蛋,面对 N 层楼
+// 返回这个状态下最少的扔鸡蛋次数
+int dp(int K, int N) {
+ int res;
+ for (int i = 1; i <= N; i++) {
+ res = Math.min(res, 这次在第 i 层楼扔鸡蛋);
+ }
+ return res;
+}
```
+
+
这段伪码还没有展示递归和状态转移,不过大致的算法框架已经完成了。
我们选择在第 `i` 层楼扔了鸡蛋之后,可能出现两种情况:鸡蛋碎了,鸡蛋没碎。**注意,这时候状态转移就来了**:
@@ -74,164 +123,431 @@ def dp(K, N):
**如果鸡蛋没碎**,那么鸡蛋的个数 `K` 不变,搜索的楼层区间应该从 `[1..N]` 变为 `[i+1..N]` 共 `N-i` 层楼。
-
+
-PS:细心的读者可能会问,在第i层楼扔鸡蛋如果没碎,楼层的搜索区间缩小至上面的楼层,是不是应该包含第i层楼呀?不必,因为已经包含了。开头说了 F 是可以等于 0 的,向上递归后,第i层楼其实就相当于第 0 层,可以被取到,所以说并没有错误。
+> [!NOTE]
+> 细心的读者可能会问,在第 `i` 层楼扔鸡蛋如果没碎,楼层的搜索区间缩小至上面的楼层,是不是应该包含第 `i` 层楼呀?不必,因为已经包含了。开头说了 `F` 是可以等于 0 的,向上递归后,第 `i` 层楼其实就相当于第 0 层,可以被取到,所以说并没有错误。
因为我们要求的是**最坏情况**下扔鸡蛋的次数,所以鸡蛋在第 `i` 层楼碎没碎,取决于那种情况的结果**更大**:
-```python
-def dp(K, N):
+
+
+
+
+```java
+int dp(int K, int N):
for 1 <= i <= N:
- # 最坏情况下的最少扔鸡蛋次数
- res = min(res,
- max(
- dp(K - 1, i - 1), # 碎
- dp(K, N - i) # 没碎
- ) + 1 # 在第 i 楼扔了一次
- )
+ // 最坏情况下的最少扔鸡蛋次数
+ res = min(res, max(
+ // 碎
+ dp(K - 1, i - 1),
+ // 没碎
+ dp(K, N - i),
+ ) + 1
+ // 在第 i 楼扔了一次,所以加一
+ )
return res
```
-递归的 base case 很容易理解:当楼层数 `N` 等于 0 时,显然不需要扔鸡蛋;当鸡蛋数 `K` 为 1 时,显然只能线性扫描所有楼层:
+递归的 base case 很容易理解,当楼层数 `N` 等于 0 时,显然不需要扔鸡蛋;当鸡蛋数 `K` 为 1 时,显然只能线性扫描所有楼层:
-```python
-def dp(K, N):
- if K == 1: return N
- if N == 0: return 0
- ...
+```java
+int dp(int K, int N) {
+ // base case
+ if (K == 1) return N;
+ if (N == 0) return 0;
+ // ...
+}
```
+
+
至此,其实这道题就解决了!只要添加一个备忘录消除重叠子问题即可:
-```python
-def superEggDrop(K: int, N: int):
-
- memo = dict()
- def dp(K, N) -> int:
- # base case
- if K == 1: return N
- if N == 0: return 0
- # 避免重复计算
- if (K, N) in memo:
- return memo[(K, N)]
-
- res = float('INF')
- # 穷举所有可能的选择
- for i in range(1, N + 1):
- res = min(res,
- max(
- dp(K, N - i),
- dp(K - 1, i - 1)
- ) + 1
- )
- # 记入备忘录
- memo[(K, N)] = res
- return res
-
- return dp(K, N)
+```java
+class Solution {
+ // 备忘录
+ int[][] memo;
+
+ public int superEggDrop(int K, int N) {
+ // m 最多不会超过 N 次(线性扫描)
+ memo = new int[K + 1][N + 1];
+ for (int[] row : memo) {
+ Arrays.fill(row, -666);
+ }
+ return dp(K, N);
+ }
+
+ // 定义:手握 K 个鸡蛋,面对 N 层楼,最少的扔鸡蛋次数为 dp(K, N)
+ int dp(int K, int N) {
+ // base case
+ if (K == 1) return N;
+ if (N == 0) return 0;
+
+ // 查备忘录避免冗余计算
+ if (memo[K][N] != -666) {
+ return memo[K][N];
+ }
+ // 状态转移方程
+ int res = Integer.MAX_VALUE;
+ for (int i = 1; i <= N; i++) {
+ // 在所有楼层进行尝试,取最少扔鸡蛋次数
+ res = Math.min(
+ res,
+ // 碎和没碎取最坏情况
+ Math.max(dp(K, N - i), dp(K - 1, i - 1)) + 1
+ );
+ }
+ // 结果存入备忘录
+ memo[K][N] = res;
+ return res;
+ }
+}
```
这个算法的时间复杂度是多少呢?**动态规划算法的时间复杂度就是子问题个数 × 函数本身的复杂度**。
函数本身的复杂度就是忽略递归部分的复杂度,这里 `dp` 函数中有一个 for 循环,所以函数本身的复杂度是 O(N)。
-子问题个数也就是不同状态组合的总数,显然是两个状态的乘积,也就是 O(KN)。
-
-所以算法的总时间复杂度是 O(K*N^2), 空间复杂度 O(KN)。
-
-### 三、疑难解答
+子问题个数也就是不同状态组合的总数,显然是两个状态的乘积,也就是 O(KN)。所以算法的总时间复杂度是 O(K*N^2), 空间复杂度 O(KN)。
这个问题很复杂,但是算法代码却十分简洁,这就是动态规划的特性,穷举加备忘录/DP table 优化,真的没啥新意。
-首先,有读者可能不理解代码中为什么用一个 for 循环遍历楼层 `[1..N]`,也许会把这个逻辑和之前探讨的线性扫描混为一谈。其实不是的,**这只是在做一次「选择」**。
+有读者可能不理解代码中为什么用一个 for 循环遍历楼层 `[1..N]`,也许会把这个逻辑和之前探讨的线性扫描混为一谈。其实不是的,**这只是在做一次「选择」**。
-比方说你有 2 个鸡蛋,面对 10 层楼,你**这次**选择去哪一层楼扔呢?不知道,那就把这 10 层楼全试一遍。至于下次怎么选择不用你操心,有正确的状态转移,递归会算出每个选择的代价,我们取最优的那个就是最优解。
+比方说你有 2 个鸡蛋,面对 10 层楼,你**这次**选择去哪一层楼扔呢?不知道,那就把这 10 层楼全试一遍。至于下次怎么选择不用你操心,有正确的状态转移,递归算法会把每个选择的代价都算出来,我们取最优的那个就是最优解。
另外,这个问题还有更好的解法,比如修改代码中的 for 循环为二分搜索,可以将时间复杂度降为 O(K\*N\*logN);再改进动态规划解法可以进一步降为 O(KN);使用数学方法解决,时间复杂度达到最优 O(K*logN),空间复杂度达到 O(1)。
二分的解法也有点误导性,你很可能以为它跟我们之前讨论的二分思路扔鸡蛋有关系,实际上没有半毛钱关系。能用二分搜索是因为状态转移方程的函数图像具有单调性,可以快速找到最值。
-简单介绍一下二分查找的优化吧,其实只是在优化这段代码:
+接下来我们看一看如何优化。
-```python
-def dp(K, N):
+
+
+
+
+
+
+## 三、二分搜索优化
+
+二分搜索的优化的核心是状态转移方程的单调性,首先简述一下原始动态规划的思路:
+
+1、暴力穷举尝试在所有楼层 `1 <= i <= N` 扔鸡蛋,每次选择尝试次数**最少**的那一层;
+
+2、每次扔鸡蛋有两种可能,要么碎,要么没碎;
+
+3、如果鸡蛋碎了,`F` 应该在第 `i` 层下面,否则,`F` 应该在第 `i` 层上面;
+
+4、鸡蛋是碎了还是没碎,取决于哪种情况下尝试次数**更多**,因为我们想求的是最坏情况下的结果。
+
+核心的状态转移代码是这段:
+
+
+
+
+
+```java
+// 当前状态为 K 个鸡蛋,面对 N 层楼
+// 返回这个状态下的最优结果
+int dp(int K, int N):
for 1 <= i <= N:
- # 最坏情况下的最少扔鸡蛋次数
- res = min(res,
- max(
- dp(K - 1, i - 1), # 碎
- dp(K, N - i) # 没碎
- ) + 1 # 在第 i 楼扔了一次
- )
+ // 最坏情况下的最少扔鸡蛋次数
+ res = min(res, max(
+ // 碎
+ dp(K - 1, i - 1),
+ // 没碎
+ dp(K, N - i),
+ ) + 1
+ // 在第 i 楼扔了一次,所以加一
+ )
return res
```
+
+
这个 for 循环就是下面这个状态转移方程的具体代码实现:
-$$ dp(K, N) = \min_{0 <= i <= N}\{\max\{dp(K - 1, i - 1), dp(K, N - i)\} + 1\}$$
+
-首先我们根据 `dp(K, N)` 数组的定义(有 `K` 个鸡蛋面对 `N` 层楼,最少需要扔几次),**很容易知道 `K` 固定时,这个函数一定是单调递增的**,无论你策略多聪明,楼层增加测试次数一定要增加。
+如果能够理解这个状态转移方程,那么就很容易理解二分查找的优化思路。
+
+首先我们根据 `dp(K, N)` 数组的定义(有 `K` 个鸡蛋面对 `N` 层楼,最少需要扔几次),**很容易知道 `K` 固定时,这个函数随着 `N` 的增加一定是单调递增的**,无论你策略多聪明,楼层增加测试次数一定要增加。
那么注意 `dp(K - 1, i - 1)` 和 `dp(K, N - i)` 这两个函数,其中 `i` 是从 1 到 `N` 单增的,如果我们固定 `K` 和 `N`,**把这两个函数看做关于 `i` 的函数,前者随着 `i` 的增加应该也是单调递增的,而后者随着 `i` 的增加应该是单调递减的**:
-
+
-这时候求二者的较大值,再求这些最大值之中的最小值,其实就是求这个交点嘛,熟悉二分搜索的同学肯定敏感地想到了,这不就是相当于求 Valley(山谷)值嘛,可以用二分查找来快速寻找这个点的。
+这时候求二者的较大值,再求这些最大值之中的最小值,其实就是求这两条直线交点,也就是红色折线的最低点嘛。
-直接贴一下代码吧,思路还是完全一样的:
+我们前文 [二分查找的运用技巧](https://labuladong.online/algo/frequency-interview/binary-search-in-action/) 讲过,二分查找的运用很广泛,只要能够找到具有单调性的函数关系,都很有可能可以运用二分查找来优化线性搜索的复杂度。回顾这两个 `dp` 函数的曲线,我们要找的最低点其实就是这种情况:
+
+```java
+for (int i = 1; i <= N; i++) {
+ if (dp(K - 1, i - 1) == dp(K, N - i))
+ return dp(K, N - i);
+}
+```
+
+熟悉二分搜索的同学肯定敏感地想到了,这不就是相当于求 Valley(山谷)值嘛,可以用二分查找来快速寻找这个点的,直接看代码吧,将 `dp` 函数的线性搜索改造成了二分搜索,加快了搜索速度:
+
+```java
+class Solution {
+ // 备忘录
+ int[][] memo;
+
+ public int superEggDrop(int K, int N) {
+ // m 最多不会超过 N 次(线性扫描)
+ memo = new int[K + 1][N + 1];
+ for (int[] row : memo) {
+ Arrays.fill(row, -666);
+ }
+ return dp(K, N);
+ }
+
+ // 定义:手握 K 个鸡蛋,面对 N 层楼,最少的扔鸡蛋次数为 dp(K, N)
+ int dp(int K, int N) {
+ // base case
+ if (K == 1) return N;
+ if (N == 0) return 0;
+
+ // 查备忘录避免冗余计算
+ if (memo[K][N] != -666) {
+ return memo[K][N];
+ }
+
+ // for (int i = 1; i <= N; i++) {
+ // res = Math.min(
+ // res,
+ // Math.max(dp(K, N - i), dp(K - 1, i - 1)) + 1
+ // );
+ // }
+
+ // 用二分搜索代替线性搜索
+ int res = Integer.MAX_VALUE;
+ int lo = 1, hi = N;
+ while (lo <= hi) {
+ int mid = lo + (hi - lo) / 2;
+ // 鸡蛋在第 mid 层碎了和没碎两种情况
+ int broken = dp(K - 1, mid - 1);
+ int not_broken = dp(K, N - mid);
+ // res = min(max(碎,没碎) + 1)
+ if (broken > not_broken) {
+ hi = mid - 1;
+ res = Math.min(res, broken + 1);
+ } else {
+ lo = mid + 1;
+ res = Math.min(res, not_broken + 1);
+ }
+ }
+ memo[K][N] = res;
+ return res;
+ }
+}
+```
+
+这个算法的时间复杂度是多少呢?**动态规划算法的时间复杂度就是子问题个数 × 函数本身的复杂度**。
+
+函数本身的复杂度就是忽略递归部分的复杂度,这里 `dp` 函数中用了一个二分搜索,所以函数本身的复杂度是 O(logN)。
+
+子问题个数也就是不同状态组合的总数,显然是两个状态的乘积,也就是 O(KN)。
+
+所以算法的总时间复杂度是 O(KNlogN), 空间复杂度 O(KN)。效率上比之前的算法 O(KN^2) 要高效一些。
+
+## 四、重新定义状态转移
+
+找动态规划的状态转移本就是见仁见智,比较玄学的事情,不同的状态定义可以衍生出不同的解法,其解法和复杂程度都可能有巨大差异,这里就是一个很好的例子。
+
+再回顾一下我们之前定义的 `dp` 数组含义:
+
+
+
+
+
+```java
+int dp(int k, int n)
+// 当前状态为 k 个鸡蛋,面对 n 层楼
+// 返回这个状态下最少的扔鸡蛋次数
+```
+
+用 `dp` 数组表示的话也是一样的:
+
+```java
+dp[k][n] = m
+// 当前状态为 k 个鸡蛋,面对 n 层楼
+// 这个状态下最少的扔鸡蛋次数为 m
+```
+
+
+
+按照这个定义,就是**确定当前的鸡蛋个数和面对的楼层数,就知道最小扔鸡蛋次数**。最终我们想要的答案就是 `dp(K, N)` 的结果。
+
+这种思路下,肯定要穷举所有可能的扔法的,用二分搜索优化也只是做了「剪枝」,减小了搜索空间,但本质思路没有变,还是穷举。
+
+现在,我们稍微修改 `dp` 数组的定义,**确定当前的鸡蛋个数和最多允许的扔鸡蛋次数,就知道能够确定 `F` 的最高楼层数**。具体来说是这个意思:
+
+
+
+
+
+```java
+dp[k][m] = n
+// 当前有 k 个鸡蛋,可以尝试扔 m 次鸡蛋
+// 这个状态下,最坏情况下最多能确切测试一栋 n 层的楼
+
+// 比如说 dp[1][7] = 7 表示:
+// 现在有 1 个鸡蛋,允许你扔 7 次;
+// 这个状态下最多给你 7 层楼,
+// 使得你可以确定楼层 F 使得鸡蛋恰好摔不碎
+// (一层一层线性探查嘛)
+```
+
+
+
+这其实就是我们原始思路的一个「反向」版本,我们先不管这种思路的状态转移怎么写,先来思考一下这种定义之下,最终想求的答案是什么?
+
+我们最终要求的其实是扔鸡蛋次数 `m`,但是这时候 `m` 在状态之中而不是 `dp` 数组的结果,可以这样处理:
+
+```java
+int superEggDrop(int K, int N) {
+
+ int m = 0;
+ while (dp[K][m] < N) {
+ m++;
+ // 状态转移...
+ }
+ return m;
+}
+```
+
+题目不是**给你 `K` 鸡蛋,`N` 层楼,让你求最坏情况下最少的测试次数 `m`** 吗?`while` 循环结束的条件是 `dp[K][m] == N`,也就是**给你 `K` 个鸡蛋,测试 `m` 次,最坏情况下最多能测试 `N` 层楼**。
+
+注意看这两段描述,是完全一样的!所以说这样组织代码是正确的,关键就是状态转移方程怎么找呢?还得从我们原始的思路开始讲。之前的解法配了这样图帮助大家理解状态转移思路:
+
+
+
+这个图描述的仅仅是某一个楼层 `i`,原始解法还得线性或者二分扫描所有楼层,要求最大值、最小值。但是现在这种 `dp` 定义根本不需要这些了,基于下面两个事实:
+
+**1、无论你在哪层楼扔鸡蛋,鸡蛋只可能摔碎或者没摔碎,碎了的话就测楼下,没碎的话就测楼上**。
+
+**2、无论你上楼还是下楼,总的楼层数 = 楼上的楼层数 + 楼下的楼层数 + 1(当前这层楼)**。
+
+根据这个特点,可以写出下面的状态转移方程:
```python
-def superEggDrop(self, K: int, N: int) -> int:
-
- memo = dict()
- def dp(K, N):
- if K == 1: return N
- if N == 0: return 0
- if (K, N) in memo:
- return memo[(K, N)]
-
- # for 1 <= i <= N:
- # res = min(res,
- # max(
- # dp(K - 1, i - 1),
- # dp(K, N - i)
- # ) + 1
- # )
-
- res = float('INF')
- # 用二分搜索代替线性搜索
- lo, hi = 1, N
- while lo <= hi:
- mid = (lo + hi) // 2
- broken = dp(K - 1, mid - 1) # 碎
- not_broken = dp(K, N - mid) # 没碎
- # res = min(max(碎,没碎) + 1)
- if broken > not_broken:
- hi = mid - 1
- res = min(res, broken + 1)
- else:
- lo = mid + 1
- res = min(res, not_broken + 1)
-
- memo[(K, N)] = res
- return res
+dp[k][m] = dp[k][m - 1] + dp[k - 1][m - 1] + 1
+```
+
+**`dp[k][m - 1]` 就是楼上的楼层数**,因为鸡蛋个数 `k` 不变,也就是鸡蛋没碎,扔鸡蛋次数 `m` 减一;
+
+**`dp[k - 1][m - 1]` 就是楼下的楼层数**,因为鸡蛋个数 `k` 减一,也就是鸡蛋碎了,同时扔鸡蛋次数 `m` 减一。
+
+> [!NOTE]
+> 这个 `m` 为什么要减一而不是加一?之前定义得很清楚,这个 `m` 是一个允许扔鸡蛋的次数上界,而不是扔了几次。
+
+
+
+至此,整个思路就完成了,只要把状态转移方程填进框架即可:
+
+```java
+class Solution {
+ public int superEggDrop(int K, int N) {
+ // m 最多不会超过 N 次(线性扫描)
+ int[][] dp = new int[K + 1][N + 1];
+ // base case:
+ // dp[0][..] = 0
+ // dp[..][0] = 0
+ // Java 默认初始化数组都为 0
+ int m = 0;
+ while (dp[K][m] < N) {
+ m++;
+ for (int k = 1; k <= K; k++)
+ dp[k][m] = dp[k][m - 1] + dp[k - 1][m - 1] + 1;
+ }
+ return m;
+ }
+}
+```
+
+
+
+
+
+
+👾 代码可视化动画👾
+
+
+
+
+
+
+
+如果你还觉得这段代码有点难以理解,其实它就等同于这样写:
+
+```java
+for (int m = 1; dp[K][m] < N; m++)
+ for (int k = 1; k <= K; k++)
+ dp[k][m] = dp[k][m - 1] + dp[k - 1][m - 1] + 1;
+```
+
+看到这种代码形式就熟悉多了吧,因为我们要求的不是 `dp` 数组里的值,而是某个符合条件的索引 `m`,所以用 `while` 循环来找到这个 `m` 而已。
+
+这个算法的时间复杂度是多少?很明显就是两个嵌套循环的复杂度 O(KN)。
+
+另外注意到 `dp[m][k]` 转移只和左边和左上的两个状态有关,可以根据前文 [动态规划的空间压缩技巧](https://labuladong.online/algo/dynamic-programming/space-optimization/) 优化成一维 `dp` 数组,这里就不写了。
+
+## 五、还可以再优化
+
+再往下还可以继续优化,我就不具体展开了,仅仅简单提一下思路吧。
+
+在刚才的思路之上,**注意函数 `dp(m, k)` 是随着 `m` 单增的,因为鸡蛋个数 `k` 不变时,允许的测试次数越多,可测试的楼层就越高**。
+
+这里又可以借助二分搜索算法快速逼近 `dp[K][m] == N` 这个终止条件,时间复杂度进一步下降为 O(KlogN)。不过我觉得我们能够写出 O(K\*N\*logN) 的二分优化算法就行了,后面的这些解法呢,我认为不太有必要掌握,把欲望限制在能力的范围之内才能拥有快乐!
+
+不过可以肯定的是,根据二分搜索代替线性扫描 `m` 的取值,代码的大致框架肯定是修改穷举 `m` 的 while 循环:
+
+```java
+// 把线性搜索改成二分搜索
+// for (int m = 1; dp[K][m] < N; m++)
+int lo = 1, hi = N;
+while (lo < hi) {
+ int mid = (lo + hi) / 2;
+ if (... < N) {
+ lo = ...
+ } else {
+ hi = ...
+ }
- return dp(K, N)
+ for (int k = 1; k <= K; k++) {
+ // 状态转移方程
+ }
+}
```
-这里就不展开其他解法了,留在下一篇文章 [高楼扔鸡蛋进阶](高楼扔鸡蛋进阶.md)
+简单总结一下吧,第一个二分优化是利用了 `dp` 函数的单调性,用二分查找技巧快速搜索答案;第二种优化是巧妙地修改了状态转移方程,简化了求解了流程,但相应的,解题逻辑比较难以想到;后续还可以用一些数学方法和二分搜索进一步优化第二种解法,不过不太值得掌握。
+
+
+
+
+
+
+
+
+
+引用本文的文章
+
+ - [实际运用二分搜索时的思维框架](https://labuladong.online/algo/frequency-interview/binary-search-in-action/)
+ - [最优子结构原理和 dp 数组遍历方向](https://labuladong.online/algo/dynamic-programming/faq-summary/)
+ - [经典动态规划:戳气球](https://labuladong.online/algo/dynamic-programming/burst-balloons/)
+
+
+
-我觉得吧,我们这种解法就够了:找状态,做选择,足够清晰易懂,可流程化,可举一反三。掌握这套框架学有余力的话,再去考虑那些奇技淫巧也不迟。
-最后预告一下,《动态规划详解(修订版)》和《回溯算法详解(修订版)》已经动笔了,教大家用模板的力量来对抗变化无穷的算法题,敬请期待。
-**致力于把算法讲清楚!欢迎关注我的微信公众号 labuladong,查看更多通俗易懂的文章**:
-
+**_____________**
-[上一篇:编辑距离](../动态规划系列/编辑距离.md)
-[下一篇:经典动态规划问题:高楼扔鸡蛋(进阶)](../动态规划系列/高楼扔鸡蛋进阶.md)
-[目录](../README.md#目录)
\ No newline at end of file
+
\ No newline at end of file
diff --git "a/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\351\255\224\345\241\224.md" "b/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\351\255\224\345\241\224.md"
new file mode 100644
index 0000000000..c8353f7f5a
--- /dev/null
+++ "b/\345\212\250\346\200\201\350\247\204\345\210\222\347\263\273\345\210\227/\351\255\224\345\241\224.md"
@@ -0,0 +1,262 @@
+# 动态规划帮我通关了《魔塔》
+
+
+
+
+
+**通知:为满足广大读者的需求,网站上架 [速成目录](https://labuladong.online/algo/intro/quick-learning-plan/),如有需要可以看下,谢谢大家的支持~另外,建议你在我的 [网站](https://labuladong.online/algo/) 学习文章,体验更好。**
+
+
+
+读完本文,你不仅学会了算法套路,还可以顺便解决如下题目:
+
+| LeetCode | 力扣 | 难度 |
+| :----: | :----: | :----: |
+| [174. Dungeon Game](https://leetcode.com/problems/dungeon-game/) | [174. 地下城游戏](https://leetcode.cn/problems/dungeon-game/) | 🔴 |
+
+**-----------**
+
+
+
+> [!NOTE]
+> 阅读本文前,你需要先学习:
+>
+> - [动态规划核心框架](https://labuladong.online/algo/essential-technique/dynamic-programming-framework/)
+
+「魔塔」是一款经典的地牢类游戏,碰怪物要掉血,吃血瓶能加血,你要收集钥匙,一层一层上楼,最后救出美丽的公主。
+
+现在手机上仍然可以玩这个游戏:
+
+
+
+嗯,相信这款游戏承包了不少人的童年回忆,记得小时候,一个人拿着游戏机玩,两三个人围在左右指手画脚,这导致玩游戏的人体验极差,而左右的人异常快乐 😂
+
+力扣第 174 题「地下城游戏」是一道类似的题目:
+
+
+
+**简单说,就是问你至少需要多少初始生命值,能够让骑士从最左上角移动到最右下角,且任何时候生命值都要大于 0**。
+
+函数签名如下:
+
+```java
+int calculateMinimumHP(int[][] grid);
+```
+
+上篇文章 [最小路径和](https://labuladong.online/algo/dynamic-programming/minimum-path-sum/) 写过类似的问题,问你从左上角到右下角的最小路径和是多少。
+
+我们做算法题一定要尝试举一反三,感觉今天这道题和最小路径和有点关系对吧?
+
+想要最小化骑士的初始生命值,是不是意味着要最大化骑士行进路线上的血瓶?是不是相当于求「最大路径和」?是不是可以直接套用计算「最小路径和」的思路?
+
+但是稍加思考,发现这个推论并不成立,吃到最多的血瓶,并不一定就能获得最小的初始生命值。
+
+比如如下这种情况,如果想要吃到最多的血瓶获得「最大路径和」,应该按照下图箭头所示的路径,初始生命值需要 11:
+
+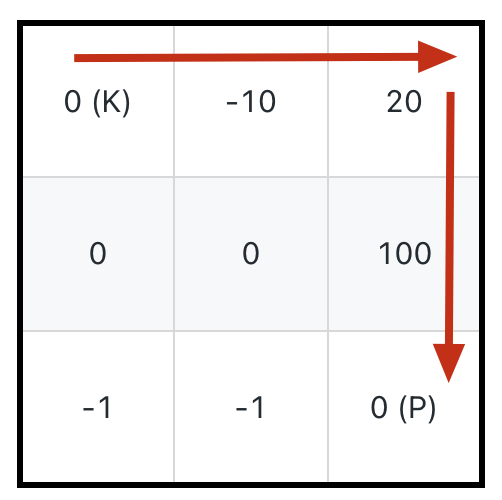
+
+但也很容易看到,正确的答案应该是下图箭头所示的路径,初始生命值只需要 1:
+
+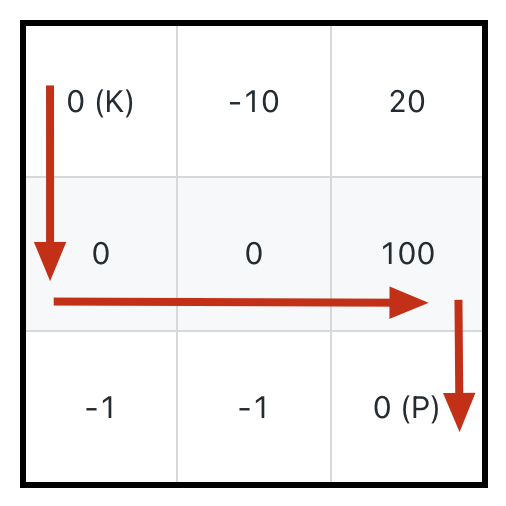
+
+**所以,关键不在于吃最多的血瓶,而是在于如何损失最少的生命值**。
+
+这类求最值的问题,肯定要借助动态规划技巧,要合理设计 `dp` 数组/函数的定义。类比前文 [最小路径和问题](https://labuladong.online/algo/dynamic-programming/minimum-path-sum/),`dp` 函数签名肯定长这样:
+
+```java
+int dp(int[][] grid, int i, int j);
+```
+
+但是这道题对 `dp` 函数的定义比较有意思,按照常理,这个 `dp` 函数的定义应该是:
+
+**从左上角(`grid[0][0]`)走到 `grid[i][j]` 至少需要 `dp(grid, i, j)` 的生命值**。
+
+这样定义的话,base case 就是 `i, j` 都等于 0 的时候,我们可以这样写代码:
+
+```java
+int calculateMinimumHP(int[][] grid) {
+ int m = grid.length;
+ int n = grid[0].length;
+ // 我们想计算左上角到右下角所需的最小生命值
+ return dp(grid, m - 1, n - 1);
+}
+
+int dp(int[][] grid, int i, int j) {
+ // base case
+ if (i == 0 && j == 0) {
+ // 保证骑士落地不死就行了
+ return grid[i][j] > 0 ? 1 : -grid[i][j] + 1;
+ }
+ ...
+}
+```
+
+> [!NOTE]
+> 为了简洁,之后 `dp(grid, i, j)` 就简写为 `dp(i, j)`,大家理解就好。
+
+接下来我们需要找状态转移了,还记得如何找状态转移方程吗?我们这样定义 `dp` 函数能否正确进行状态转移呢?
+
+我们希望 `dp(i, j)` 能够通过 `dp(i-1, j)` 和 `dp(i, j-1)` 推导出来,这样就能不断逼近 base case,也就能够正确进行状态转移。
+
+具体来说,「到达 `A` 的最小生命值」应该能够由「到达 `B` 的最小生命值」和「到达 `C` 的最小生命值」推导出来:
+
+
+
+**但问题是,能推出来么?实际上是不能的**。
+
+因为按照 `dp` 函数的定义,你只知道「能够从左上角到达 `B` 的最小生命值」,但并不知道「到达 `B` 时的生命值」。
+
+「到达 `B` 时的生命值」是进行状态转移的必要参考,我给你举个例子你就明白了,假设下图这种情况:
+
+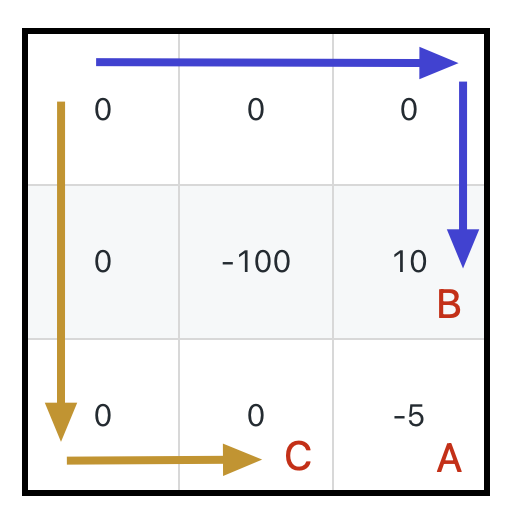
+
+你说这种情况下,骑士救公主的最优路线是什么?
+
+显然是按照图中蓝色的线走到 `B`,最后走到 `A` 对吧,这样初始血量只需要 1 就可以;如果走黄色箭头这条路,先走到 `C` 然后走到 `A`,初始血量至少需要 6。
+
+为什么会这样呢?骑士走到 `B` 和 `C` 的最少初始血量都是 1,为什么最后是从 `B` 走到 `A`,而不是从 `C` 走到 `A` 呢?
+
+因为骑士走到 `B` 的时候生命值为 11,而走到 `C` 的时候生命值依然是 1。
+
+如果骑士执意要通过 `C` 走到 `A`,那么初始血量必须加到 6 点才行;而如果通过 `B` 走到 `A`,初始血量为 1 就够了,因为路上吃到血瓶了,生命值足够抗 `A` 上面怪物的伤害。
+
+这下应该说的很清楚了,再回顾我们对 `dp` 函数的定义,上图的情况,算法只知道 `dp(1, 2) = dp(2, 1) = 1`,都是一样的,怎么做出正确的决策,计算出 `dp(2, 2)` 呢?
+
+**所以说,我们之前对 `dp` 数组的定义是错误的,信息量不足,算法无法做出正确的状态转移**。
+
+正确的做法需要反向思考,依然是如下的 `dp` 函数:
+
+```java
+int dp(int[][] grid, int i, int j);
+```
+
+但是我们要修改 `dp` 函数的定义:
+
+**从 `grid[i][j]` 到达终点(右下角)所需的最少生命值是 `dp(grid, i, j)`**。
+
+那么可以这样写代码:
+
+```java
+int calculateMinimumHP(int[][] grid) {
+ // 我们想计算左上角到右下角所需的最小生命值
+ return dp(grid, 0, 0);
+}
+
+int dp(int[][] grid, int i, int j) {
+ int m = grid.length;
+ int n = grid[0].length;
+ // base case
+ if (i == m - 1 && j == n - 1) {
+ return grid[i][j] >= 0 ? 1 : -grid[i][j] + 1;
+ }
+ ...
+}
+```
+
+根据新的 `dp` 函数定义和 base case,我们想求 `dp(0, 0)`,那就应该试图通过 `dp(i, j+1)` 和 `dp(i+1, j)` 推导出 `dp(i, j)`,这样才能不断逼近 base case,正确进行状态转移。
+
+具体来说,「从 `A` 到达右下角的最少生命值」应该由「从 `B` 到达右下角的最少生命值」和「从 `C` 到达右下角的最少生命值」推导出来:
+
+
+
+能不能推导出来呢?这次是可以的,假设 `dp(0, 1) = 5, dp(1, 0) = 4`,那么可以肯定要从 `A` 走向 `C`,因为 4 小于 5 嘛。
+
+那么怎么推出 `dp(0, 0)` 是多少呢?
+
+假设 `A` 的值为 1,既然知道下一步要往 `C` 走,且 `dp(1, 0) = 4` 意味着走到 `grid[1][0]` 的时候至少要有 4 点生命值,那么就可以确定骑士出现在 `A` 点时需要 4 - 1 = 3 点初始生命值,对吧。
+
+那如果 `A` 的值为 10,落地就能捡到一个大血瓶,超出了后续需求,4 - 10 = -6 意味着骑士的初始生命值为负数,这显然不可以,骑士的生命值小于 1 就挂了,所以这种情况下骑士的初始生命值应该是 1。
+
+综上,状态转移方程已经推出来了:
+
+
+
+
+
+```java
+int res = min(
+ dp(i + 1, j),
+ dp(i, j + 1)
+) - grid[i][j];
+
+dp(i, j) = res <= 0 ? 1 : res;
+```
+
+根据这个核心逻辑,加一个备忘录消除重叠子问题,就可以直接写出最终的代码了:
+
+```java
+class Solution {
+ // 主函数
+ public int calculateMinimumHP(int[][] grid) {
+ int m = grid.length;
+ int n = grid[0].length;
+ // 备忘录中都初始化为 -1
+ memo = new int[m][n];
+ for (int[] row : memo) {
+ Arrays.fill(row, -1);
+ }
+
+ return dp(grid, 0, 0);
+ }
+
+ // 备忘录,消除重叠子问题
+ int[][] memo;
+
+ // 定义:从 (i, j) 到达右下角,需要的初始血量至少是多少
+ int dp(int[][] grid, int i, int j) {
+ int m = grid.length;
+ int n = grid[0].length;
+ // base case
+ if (i == m - 1 && j == n - 1) {
+ return grid[i][j] >= 0 ? 1 : -grid[i][j] + 1;
+ }
+ if (i == m || j == n) {
+ return Integer.MAX_VALUE;
+ }
+ // 避免重复计算
+ if (memo[i][j] != -1) {
+ return memo[i][j];
+ }
+ // 状态转移逻辑
+ int res = Math.min(
+ dp(grid, i, j + 1),
+ dp(grid, i + 1, j)
+ ) - grid[i][j];
+ // 骑士的生命值至少为 1
+ memo[i][j] = res <= 0 ? 1 : res;
+
+ return memo[i][j];
+ }
+}
+```
+
+
+
+
+
+
+👾 代码可视化动画👾
+
+
+
+
+
+
+
+这就是自顶向下带备忘录的动态规划解法,参考前文 [动态规划套路详解](https://labuladong.online/algo/essential-technique/dynamic-programming-framework/) 很容易就可以改写成 `dp` 数组的迭代解法,这里就不写了,读者可以尝试自己写一写。
+
+这道题的核心是定义 `dp` 函数,找到正确的状态转移方程,从而计算出正确的答案。
+
+
+
+
+
+
+
+
+
+**_____________**
+
+
+
+
\ No newline at end of file
diff --git "a/\345\244\232\350\257\255\350\250\200\350\247\243\346\263\225\344\273\243\347\240\201/contribution-guide.md" "b/\345\244\232\350\257\255\350\250\200\350\247\243\346\263\225\344\273\243\347\240\201/contribution-guide.md"
new file mode 100644
index 0000000000..0336bb3d4c
--- /dev/null
+++ "b/\345\244\232\350\257\255\350\250\200\350\247\243\346\263\225\344\273\243\347\240\201/contribution-guide.md"
@@ -0,0 +1,74 @@
+# 修正 labuladong 刷题插件中的错误
+
+## 背景
+
+为了帮助大家更好地学习算法,我之前写了很多算法教程,并开发了一系列刷题插件,统称为《labuladong 的刷题全家桶》,详情见 [这里](https://labuladong.github.io/article/fname.html?fname=全家桶简介)。
+
+在我的教程和插件中的解法主要使用的是 Java 语言,原因是 Java 这门语言中规中矩,就算之前没有接触过,也能比较容易看懂逻辑。不过现在这不是 chatGPT 横空出世了嘛,我就借助 chatGPT 把我的解法改写成多种语言,希望对不同技术背景的小伙伴更加友好。
+
+chatGPT 的改写效果还是非常不错的,不过难免还是存在一些错误,所以我希望能够和大家一起来修正这些错误。
+
+## 如何反馈错误
+
+如果你发现某些解法代码不能通过力扣的所有测试用例(一般都是 chatGPT 改写的解法代码会出现这种情况,我的解法代码都是通过测试才发布的),可以 [点这里](https://github.com/labuladong/fucking-algorithm/issues/new?assignees=&labels=code+bug&template=bug_report.yml&title=%5Bbug%5D%5B%7B%E8%BF%99%E9%87%8C%E6%9B%BF%E6%8D%A2%E4%B8%BA%E5%87%BA%E9%94%99%E7%9A%84%E7%BC%96%E7%A8%8B%E8%AF%AD%E8%A8%80%7D%5D+%7B%E8%BF%99%E9%87%8C%E6%9B%BF%E6%8D%A2%E4%B8%BA%E5%87%BA%E9%94%99%E7%9A%84%E5%8A%9B%E6%89%A3%E9%A2%98%E7%9B%AE%E6%A0%87%E8%AF%86%E7%AC%A6%7D+) 按照模板提交 issue,我和其他小伙伴会提交 PR 修复这些错误。
+
+## 如何修正错误
+
+首先,感谢你愿意为我的插件提供的解法代码纠错,你向本仓库提交 PR 修复错误后,你将成为本仓库的 contributor,出现在仓库首页的贡献者列表中。本仓库已经获得了 115k star,你的贡献将会被许多人看到。
+
+修复代码很简单,所有多语言解法代码都存储在 [多语言解法代码/solution_code.md](https://github.com/labuladong/fucking-algorithm/blob/master/%E5%A4%9A%E8%AF%AD%E8%A8%80%E8%A7%A3%E6%B3%95%E4%BB%A3%E7%A0%81/solution_code.md) 中,你只要修改这个文件就行了。其内容的组织形如如下:
+
+
+ https://leetcode.cn/problems/xxx 的多语言解法👇
+
+ ```cpp
+ class Solution {
+ public:
+ int xxx() {
+ // ...
+ }
+ };
+ ```
+
+ ```java
+ class Solution {
+ public int xxx() {
+ // ...
+ }
+ }
+ ```
+
+ ```python
+ class Solution:
+ def xxx(self):
+ # ...
+ ```
+
+ ```javascript
+ var xxx = function() {
+ // ...
+ }
+ ```
+
+ ```go
+ func xxx() {
+ // ...
+ }
+ ```
+
+ https://leetcode.cn/problems/xxx 的多语言解法👆
+
+
+比如你想修改 [https://leetcode-cn.com/problems/longest-palindromic-substring/](https://leetcode-cn.com/problems/longest-palindromic-substring/) 的 JavaScript 解法,你可以在 [多语言解法代码/solution_code.md](https://github.com/labuladong/fucking-algorithm/blob/master/%E5%A4%9A%E8%AF%AD%E8%A8%80%E8%A7%A3%E6%B3%95%E4%BB%A3%E7%A0%81/solution_code.md) 中搜索 `longest-palindromic-substring` 关键词,即可找到这道题的多语言解法,然后修改 JavaScript 对应的解法代码,提交 PR 即可。
+
+我的插件会自动拉取这个文件的最新内容,所以你的 PR 被合进 master 分支后,插件中的内容修改也会生效。
+
+## 提交 PR 的要求
+
+1、你的 PR 必须是针对 [多语言解法代码/solution_code.md](https://github.com/labuladong/fucking-algorithm/blob/master/%E5%A4%9A%E8%AF%AD%E8%A8%80%E8%A7%A3%E6%B3%95%E4%BB%A3%E7%A0%81/solution_code.md) 文件中代码部分的修改,不要修改其他文件和其他内容。
+
+2、把我的解法翻译成多语言的目的是帮助不同背景的小伙伴理解算法思维,所以你修改的代码可以不是效率最优的,但应该尽可能和我的解法思路保持一致,且包含我的解法中的完整注释。
+
+3、你的 PR 描述中需要包含代码通过所有测试用例截图。PR 标题的格式为 `[fix][{lang}] {slug}`,其中 `{lang}` 需要替换为你修复的解法语言,比如 `[fix][cpp]`,`{slug}` 需要替换为你修复的题目的标识符(题目 URL 的最后一部分),比如 [https://leetcode.cn/problems/search-a-2d-matrix/](https://leetcode.cn/problems/search-a-2d-matrix/) 这道题的标识符就是 `search-a-2d-matrix`。
+
+**你可以查看这个 PR 作为案例**:https://github.com/labuladong/fucking-algorithm/pull/1112
\ No newline at end of file
diff --git "a/\345\244\232\350\257\255\350\250\200\350\247\243\346\263\225\344\273\243\347\240\201/solution_code.md" "b/\345\244\232\350\257\255\350\250\200\350\247\243\346\263\225\344\273\243\347\240\201/solution_code.md"
new file mode 100644
index 0000000000..900137b7e7
--- /dev/null
+++ "b/\345\244\232\350\257\255\350\250\200\350\247\243\346\263\225\344\273\243\347\240\201/solution_code.md"
@@ -0,0 +1,72142 @@
+https://leetcode.cn/problems/01-matrix 的多语言解法👇
+
+```cpp
+// by chatGPT (cpp)
+class Solution {
+public:
+ vector> updateMatrix(vector>& mat) {
+ int m = mat.size(), n = mat[0].size();
+ // 记录答案的结果数组
+ vector> res(m, vector(n, -1));
+ // 初始化队列,把那些值为 0 的坐标放到队列里
+ queue> q;
+ for (int i = 0; i < m; i++) {
+ for (int j = 0; j < n; j++) {
+ if (mat[i][j] == 0) {
+ q.push({i, j});
+ res[i][j] = 0;
+ }
+ }
+ }
+ // 执行 BFS 算法框架,从值为 0 的坐标开始向四周扩散
+ vector> dirs{{0, 1}, {0, -1}, {1, 0}, {-1, 0}};
+ while (!q.empty()) {
+ auto cur = q.front();
+ q.pop();
+ int x = cur.first, y = cur.second;
+ // 向四周扩散
+ for (auto& dir : dirs) {
+ int nextX = x + dir[0];
+ int nextY = y + dir[1];
+ // 确保相邻的这个坐标没有越界且之前未被计算过
+ if (nextX >= 0 && nextX < m && nextY >= 0 && nextY < n
+ && res[nextX][nextY] == -1) {
+ q.push({nextX, nextY});
+ // 从 mat[x][y] 走到 mat[nextX][nextY] 需要一步
+ res[nextX][nextY] = res[x][y] + 1;
+ }
+ }
+ }
+
+ return res;
+ }
+};
+```
+
+```go
+// by chatGPT (go)
+func updateMatrix(mat [][]int) [][]int {
+ m, n := len(mat), len(mat[0])
+ // 记录答案的结果数组
+ res := make([][]int, m)
+ for i := range res {
+ res[i] = make([]int, n)
+ for j := range res[i] {
+ res[i][j] = -1
+ }
+ }
+ // 初始化队列,把那些值为 0 的坐标放到队列里
+ q := make([][2]int, 0)
+ for i := 0; i < m; i++ {
+ for j := 0; j < n; j++ {
+ if mat[i][j] == 0 {
+ q = append(q, [2]int{i, j})
+ res[i][j] = 0
+ }
+ }
+ }
+ // 执行 BFS 算法框架,从值为 0 的坐标开始向四周扩散
+ dirs := [][]int{{0, 1}, {0, -1}, {1, 0}, {-1, 0}}
+ for len(q) > 0 {
+ cur := q[0]
+ q = q[1:]
+ x, y := cur[0], cur[1]
+ // 向四周扩散
+ for _, dir := range dirs {
+ nextX, nextY := x+dir[0], y+dir[1]
+ // 确保相邻的这个坐标没有越界且之前未被计算过
+ if nextX >= 0 && nextX < m && nextY >= 0 && nextY < n && res[nextX][nextY] == -1 {
+ q = append(q, [2]int{nextX, nextY})
+ // 从 mat[x][y] 走到 mat[nextX][nextY] 需要一步
+ res[nextX][nextY] = res[x][y] + 1
+ }
+ }
+ }
+
+ return res
+}
+```
+
+```java
+// by labuladong (java)
+class Solution {
+ public int[][] updateMatrix(int[][] mat) {
+ int m = mat.length, n = mat[0].length;
+ // 记录答案的结果数组
+ int[][] res = new int[m][n];
+ // 初始化全部填充特殊值 -1,代表未计算,
+ // 待会可以用来判断坐标是否已经计算过,避免重复遍历
+ for (int[] row : res) {
+ Arrays.fill(row, -1);
+ }
+
+ Queue q = new LinkedList<>();
+ // 初始化队列,把那些值为 0 的坐标放到队列里
+ for (int i = 0; i < m; i++) {
+ for (int j = 0; j < n; j++) {
+ if (mat[i][j] == 0) {
+ q.offer(new int[]{i, j});
+ res[i][j] = 0;
+ }
+ }
+ }
+ // 执行 BFS 算法框架,从值为 0 的坐标开始向四周扩散
+ int[][] dirs = new int[][]{{0, 1}, {0, -1}, {1, 0}, {-1, 0}};
+ while (!q.isEmpty()) {
+ int[] cur = q.poll();
+ int x = cur[0], y = cur[1];
+ // 向四周扩散
+ for (int i = 0; i < 4; i++) {
+ int nextX = x + dirs[i][0];
+ int nextY = y + dirs[i][1];
+ // 确保相邻的这个坐标没有越界且之前未被计算过
+ if (nextX >= 0 && nextX < m && nextY >= 0 && nextY < n
+ && res[nextX][nextY] == -1) {
+ q.offer(new int[]{nextX, nextY});
+ // 从 mat[x][y] 走到 mat[nextX][nextY] 需要一步
+ res[nextX][nextY] = res[x][y] + 1;
+ }
+ }
+ }
+
+ return res;
+ }
+}
+```
+
+```javascript
+// by chatGPT (javascript)
+function updateMatrix(mat) {
+ const m = mat.length, n = mat[0].length;
+ // 记录答案的结果数组
+ const res = new Array(m).fill().map(() => new Array(n).fill(-1));
+
+ const q = [];
+ // 初始化队列,把那些值为 0 的坐标放到队列里
+ for (let i = 0; i < m; i++) {
+ for (let j = 0; j < n; j++) {
+ if (mat[i][j] === 0) {
+ q.push([i, j]);
+ res[i][j] = 0;
+ }
+ }
+ }
+ // 执行 BFS 算法框架,从值为 0 的坐标开始向四周扩散
+ const dirs = [[0, 1], [0, -1], [1, 0], [-1, 0]];
+ while (q.length) {
+ const cur = q.shift();
+ const x = cur[0], y = cur[1];
+ // 向四周扩散
+ for (let i = 0; i < 4; i++) {
+ const nextX = x + dirs[i][0];
+ const nextY = y + dirs[i][1];
+ // 确保相邻的这个坐标没有越界且之前未被计算过
+ if (nextX >= 0 && nextX < m && nextY >= 0 && nextY < n
+ && res[nextX][nextY] === -1) {
+ q.push([nextX, nextY]);
+ // 从 mat[x][y] 走到 mat[nextX][nextY] 需要一步
+ res[nextX][nextY] = res[x][y] + 1;
+ }
+ }
+ }
+
+ return res;
+}
+```
+
+```python
+# by chatGPT (python)
+from collections import deque
+
+class Solution:
+ def updateMatrix(self, mat: List[List[int]]) -> List[List[int]]:
+ m, n = len(mat), len(mat[0])
+ # 记录答案的结果数组
+ res = [[-1] * n for _ in range(m)]
+
+ q = deque()
+ # 初始化队列,把那些值为 0 的坐标放到队列里
+ for i in range(m):
+ for j in range(n):
+ if mat[i][j] == 0:
+ q.append((i, j))
+ res[i][j] = 0
+
+ # 执行 BFS 算法框架,从值为 0 的坐标开始向四周扩散
+ dirs = [[0, 1], [0, -1], [1, 0], [-1, 0]]
+ while q:
+ x, y = q.popleft()
+ # 向四周扩散
+ for dx, dy in dirs:
+ nextX, nextY = x + dx, y + dy
+ # 确保相邻的这个坐标没有越界且之前未被计算过
+ if 0 <= nextX < m and 0 <= nextY < n and res[nextX][nextY] == -1:
+ q.append((nextX, nextY))
+ # 从 mat[x][y] 走到 mat[nextX][nextY] 需要一步
+ res[nextX][nextY] = res[x][y] + 1
+
+ return res
+```
+
+https://leetcode.cn/problems/01-matrix 的多语言解法👆
+
+https://leetcode.cn/problems/0i0mDW 的多语言解法👇
+
+```cpp
+// by chatGPT (cpp)
+class Solution {
+public:
+ int memo[201][201];
+
+ int minPathSum(vector>& grid) {
+ int m = grid.size();
+ int n = grid[0].size();
+ // 构造备忘录,初始值全部设为 -1
+ memset(memo, -1, sizeof(memo));
+
+ return dp(grid, m - 1, n - 1);
+ }
+
+ int dp(vector>& grid, int i, int j) {
+ // base case
+ if (i == 0 && j == 0) {
+ return grid[0][0];
+ }
+ if (i < 0 || j < 0) {
+ return INT_MAX;
+ }
+ // 避免重复计算
+ if (memo[i][j] != -1) {
+ return memo[i][j];
+ }
+ // 将计算结果记入备忘录
+ memo[i][j] = min(
+ dp(grid, i - 1, j),
+ dp(grid, i, j - 1)
+ ) + grid[i][j];
+
+ return memo[i][j];
+ }
+};
+```
+
+```go
+// by chatGPT (go)
+func minPathSum(grid [][]int) int {
+ m := len(grid)
+ n := len(grid[0])
+ // 构造备忘录,初始值全部设为 -1
+ memo := make([][]int, m)
+ for i := 0; i < m; i++ {
+ memo[i] = make([]int, n)
+ for j := 0; j < n; j++ {
+ memo[i][j] = -1
+ }
+ }
+
+ return dp(grid, m - 1, n - 1, memo)
+}
+
+func dp(grid [][]int, i int, j int, memo [][]int) int {
+ // base case
+ if i == 0 && j == 0 {
+ return grid[0][0]
+ }
+ if i < 0 || j < 0 {
+ return math.MaxInt32
+ }
+ // 避免重复计算
+ if memo[i][j] != -1 {
+ return memo[i][j]
+ }
+ // 将计算结果记入备忘录
+ left := dp(grid, i - 1, j, memo)
+ up := dp(grid, i, j - 1, memo)
+ curr := grid[i][j] + min(left, up)
+ memo[i][j] = curr
+ return curr
+}
+
+func min(a, b int) int {
+ if a < b {
+ return a
+ }
+ return b
+}
+```
+
+```java
+// by labuladong (java)
+class Solution {
+ int[][] memo;
+
+ public int minPathSum(int[][] grid) {
+ int m = grid.length;
+ int n = grid[0].length;
+ // 构造备忘录,初始值全部设为 -1
+ memo = new int[m][n];
+ for (int[] row : memo)
+ Arrays.fill(row, -1);
+
+ return dp(grid, m - 1, n - 1);
+ }
+
+ int dp(int[][] grid, int i, int j) {
+ // base case
+ if (i == 0 && j == 0) {
+ return grid[0][0];
+ }
+ if (i < 0 || j < 0) {
+ return Integer.MAX_VALUE;
+ }
+ // 避免重复计算
+ if (memo[i][j] != -1) {
+ return memo[i][j];
+ }
+ // 将计算结果记入备忘录
+ memo[i][j] = Math.min(
+ dp(grid, i - 1, j),
+ dp(grid, i, j - 1)
+ ) + grid[i][j];
+
+ return memo[i][j];
+ }
+}
+```
+
+```javascript
+// by chatGPT (javascript)
+var minPathSum = function(grid) {
+ var m = grid.length;
+ var n = grid[0].length;
+ // 构造备忘录,初始值全部设为 -1
+ var memo = new Array(m);
+ for (var i = 0; i < memo.length; i++) {
+ memo[i] = new Array(n);
+ memo[i].fill(-1);
+ }
+
+ return dp(grid, m - 1, n - 1, memo);
+};
+
+function dp(grid, i, j, memo) {
+ // base case
+ if (i == 0 && j == 0) {
+ return grid[0][0];
+ }
+ if (i < 0 || j < 0) {
+ return Number.MAX_VALUE;
+ }
+ // 避免重复计算
+ if (memo[i][j] != -1) {
+ return memo[i][j];
+ }
+ // 将计算结果记入备忘录
+ memo[i][j] = Math.min(
+ dp(grid, i - 1, j, memo),
+ dp(grid, i, j - 1, memo)
+ ) + grid[i][j];
+
+ return memo[i][j];
+}
+```
+
+```python
+# by chatGPT (python)
+class Solution:
+ def __init__(self):
+ self.memo = None
+
+ def minPathSum(self, grid: List[List[int]]) -> int:
+ m = len(grid)
+ n = len(grid[0])
+ # 构造备忘录,初始值全部设为 -1
+ self.memo = [[-1 for _ in range(n)] for _ in range(m)]
+
+ return self.dp(grid, m - 1, n - 1)
+
+ def dp(self, grid: List[List[int]], i: int, j: int) -> int:
+ # base case
+ if i == 0 and j == 0:
+ return grid[0][0]
+ if i < 0 or j < 0:
+ return float('inf')
+ # 避免重复计算
+ if self.memo[i][j] != -1:
+ return self.memo[i][j]
+ # 将计算结果记入备忘录
+ self.memo[i][j] = min(
+ self.dp(grid, i - 1, j),
+ self.dp(grid, i, j - 1)
+ ) + grid[i][j]
+
+ return self.memo[i][j]
+```
+
+https://leetcode.cn/problems/0i0mDW 的多语言解法👆
+
+https://leetcode.cn/problems/1fGaJU 的多语言解法👇
+
+```cpp
+// by labuladong (cpp)
+class Solution {
+ public:
+ vector> threeSum(vector& nums) {
+ sort(nums.begin(), nums.end());
+ // n 为 3,从 nums[0] 开始计算和为 0 的三元组
+ return nSumTarget(nums, 3, 0, 0);
+ }
+
+ /* 注意:调用这个函数之前一定要先给 nums 排序 */
+ // n 填写想求的是几数之和,start 从哪个索引开始计算(一般填 0),target 填想凑出的目标和
+ vector> nSumTarget(
+ vector& nums, int n, int start, int target) {
+
+ int sz = nums.size();
+ vector> res;
+ // 至少是 2Sum,且数组大小不应该小于 n
+ if (n < 2 || sz < n) return res;
+ // 2Sum 是 base case
+ if (n == 2) {
+ // 双指针那一套操作
+ int lo = start, hi = sz - 1;
+ while (lo < hi) {
+ int sum = nums[lo] + nums[hi];
+ int left = nums[lo], right = nums[hi];
+ if (sum < target) {
+ while (lo < hi && nums[lo] == left) lo++;
+ } else if (sum > target) {
+ while (lo < hi && nums[hi] == right) hi--;
+ } else {
+ res.push_back({left, right});
+ while (lo < hi && nums[lo] == left) lo++;
+ while (lo < hi && nums[hi] == right) hi--;
+ }
+ }
+ } else {
+ // n > 2 时,递归计算 (n-1)Sum 的结果
+ for (int i = start; i < sz; i++) {
+ vector>
+ sub = nSumTarget(nums, n - 1, i + 1, target - nums[i]);
+ for (vector& arr : sub) {
+ // (n-1)Sum 加上 nums[i] 就是 nSum
+ arr.push_back(nums[i]);
+ res.push_back(arr);
+ }
+ while (i < sz - 1 && nums[i] == nums[i + 1]) i++;
+ }
+ }
+ return res;
+ }
+};
+```
+
+```go
+// by chatGPT (go)
+func threeSum(nums []int) [][]int {
+ sort.Ints(nums)
+ // n 为 3,从 nums[0] 开始计算和为 0 的三元组
+ return nSumTarget(nums, 3, 0, 0)
+}
+
+/* 注意:调用这个函数之前一定要先给 nums 排序 */
+// n 填写想求的是几数之和,start 从哪个索引开始计算(一般填 0),target 填想凑出的目标和
+func nSumTarget(nums []int, n int, start int, target int) [][]int {
+ sz := len(nums)
+ var res [][]int
+ // 至少是 2Sum,且数组大小不应该小于 n
+ if n < 2 || sz < n {
+ return res
+ }
+ // 2Sum 是 base case
+ if n == 2 {
+ // 双指针那一套操作
+ lo, hi := start, sz-1
+ for lo < hi {
+ sum := nums[lo] + nums[hi]
+ left, right := nums[lo], nums[hi]
+ if sum < target {
+ for lo < hi && nums[lo] == left {
+ lo++
+ }
+ } else if sum > target {
+ for lo < hi && nums[hi] == right {
+ hi--
+ }
+ } else {
+ res = append(res, []int{left, right})
+ for lo < hi && nums[lo] == left {
+ lo++
+ }
+ for lo < hi && nums[hi] == right {
+ hi--
+ }
+ }
+ }
+ } else {
+ // n > 2 时,递归计算 (n-1)Sum 的结果
+ for i := start; i < sz; i++ {
+ sub := nSumTarget(nums, n-1, i+1, target-nums[i])
+ for _, arr := range sub {
+ // (n-1)Sum 加上 nums[i] 就是 nSum
+ arr = append(arr, nums[i])
+ res = append(res, arr)
+ }
+ for i < sz-1 && nums[i] == nums[i+1] {
+ i++
+ }
+ }
+ }
+ return res
+}
+```
+
+```java
+// by chatGPT (java)
+class Solution {
+ public List> threeSum(int[] nums) {
+ Arrays.sort(nums);
+ // n 为 3,从 nums[0] 开始计算和为 0 的三元组
+ return nSumTarget(nums, 3, 0, 0);
+ }
+
+ /* 注意:调用这个函数之前一定要先给 nums 排序 */
+ // n 填写想求的是几数之和,start 从哪个索引开始计算(一般填 0),target 填想凑出的目标和
+ public List> nSumTarget(
+ int[] nums, int n, int start, int target) {
+
+ int sz = nums.length;
+ List> res = new ArrayList<>();
+ // 至少是 2Sum,且数组大小不应该小于 n
+ if (n < 2 || sz < n) return res;
+ // 2Sum 是 base case
+ if (n == 2) {
+ // 双指针那一套操作
+ int lo = start, hi = sz - 1;
+ while (lo < hi) {
+ int sum = nums[lo] + nums[hi];
+ int left = nums[lo], right = nums[hi];
+ if (sum < target) {
+ while (lo < hi && nums[lo] == left) lo++;
+ } else if (sum > target) {
+ while (lo < hi && nums[hi] == right) hi--;
+ } else {
+ List triplet = new ArrayList<>();
+ triplet.add(left);
+ triplet.add(right);
+ res.add(triplet);
+ while (lo < hi && nums[lo] == left) lo++;
+ while (lo < hi && nums[hi] == right) hi--;
+ }
+ }
+ } else {
+ // n > 2 时,递归计算 (n-1)Sum 的结果
+ for (int i = start; i < sz; i++) {
+ List> sub =
+ nSumTarget(nums, n - 1, i + 1, target - nums[i]);
+ for (List arr : sub) {
+ // (n-1)Sum 加上 nums[i] 就是 nSum
+ arr.add(nums[i]);
+ res.add(arr);
+ }
+ while (i < sz - 1 && nums[i] == nums[i + 1]) i++;
+ }
+ }
+ return res;
+ }
+}
+```
+
+```javascript
+// by chatGPT (javascript)
+var threeSum = function(nums) {
+ nums.sort((a, b) => a - b);
+ // n 为 3,从 nums[0] 开始计算和为 0 的三元组
+ return nSumTarget(nums, 3, 0, 0);
+};
+
+/* 注意:调用这个函数之前一定要先给 nums 排序 */
+// n 填写想求的是几数之和,start 从哪个索引开始计算(一般填 0),target 填想凑出的目标和
+var nSumTarget = function(nums, n, start, target) {
+ var sz = nums.length;
+ var res = [];
+ // 至少是 2Sum,且数组大小不应该小于 n
+ if (n < 2 || sz < n) return res;
+ // 2Sum 是 base case
+ if (n === 2) {
+ // 双指针那一套操作
+ var lo = start, hi = sz - 1;
+ while (lo < hi) {
+ var sum = nums[lo] + nums[hi];
+ var left = nums[lo], right = nums[hi];
+ if (sum < target) {
+ while (lo < hi && nums[lo] === left) lo++;
+ } else if (sum > target) {
+ while (lo < hi && nums[hi] === right) hi--;
+ } else {
+ res.push([left, right]);
+ while (lo < hi && nums[lo] === left) lo++;
+ while (lo < hi && nums[hi] === right) hi--;
+ }
+ }
+ } else {
+ // n > 2 时,递归计算 (n-1)Sum 的结果
+ for (var i = start; i < sz; i++) {
+ var sub = nSumTarget(nums, n - 1, i + 1, target - nums[i]);
+ for (var j = 0; j < sub.length; j++) {
+ // (n-1)Sum 加上 nums[i] 就是 nSum
+ sub[j].push(nums[i]);
+ res.push(sub[j]);
+ }
+ while (i < sz - 1 && nums[i] === nums[i + 1]) i++;
+ }
+ }
+ return res;
+};
+```
+
+```python
+# by chatGPT (python)
+class Solution:
+ def threeSum(self, nums: List[int]) -> List[List[int]]:
+ nums.sort()
+ # n 为 3,从 nums[0] 开始计算和为 0 的三元组
+ return self.nSumTarget(nums, 3, 0, 0)
+
+ # 注意:调用这个函数之前一定要先给 nums 排序
+ # n 填写想求的是几数之和,start 从哪个索引开始计算(一般填 0),target 填想凑出的目标和
+ def nSumTarget(self, nums: List[int], n: int, start: int, target: int) -> List[List[int]]:
+ sz = len(nums)
+ res = []
+ # 至少是 2Sum,且数组大小不应该小于 n
+ if n < 2 or sz < n:
+ return res
+ # 2Sum 是 base case
+ if n == 2:
+ # 双指针那一套操作
+ lo, hi = start, sz - 1
+ while lo < hi:
+ _sum = nums[lo] + nums[hi]
+ left, right = nums[lo], nums[hi]
+ if _sum < target:
+ while lo < hi and nums[lo] == left:
+ lo += 1
+ elif _sum > target:
+ while lo < hi and nums[hi] == right:
+ hi -= 1
+ else:
+ res.append([left, right])
+ while lo < hi and nums[lo] == left:
+ lo += 1
+ while lo < hi and nums[hi] == right:
+ hi -= 1
+ else:
+ # n > 2 时,递归计算 (n-1)Sum 的结果
+ for i in range(start, sz):
+ if i > start and nums[i] == nums[i - 1]:
+ continue
+ sub = self.nSumTarget(nums, n - 1, i + 1, target - nums[i])
+ for arr in sub:
+ # (n-1)Sum 加上 nums[i] 就是 nSum
+ arr.append(nums[i])
+ res.append(arr)
+ return res
+```
+
+https://leetcode.cn/problems/1fGaJU 的多语言解法👆
+
+https://leetcode.cn/problems/2AoeFn 的多语言解法👇
+
+```cpp
+// by chatGPT (cpp)
+class Solution {
+public:
+ // 备忘录
+ int memo[100][100];
+
+ int uniquePaths(int m, int n) {
+ memset(memo, 0, sizeof(memo));
+ return dp(m - 1, n - 1);
+ }
+
+ // 定义:从 (0, 0) 到 (x, y) 有 dp(x, y) 条路径
+ int dp(int x, int y) {
+ // base case
+ if (x == 0 && y == 0) {
+ return 1;
+ }
+ if (x < 0 || y < 0) {
+ return 0;
+ }
+ // 避免冗余计算
+ if (memo[x][y] > 0) {
+ return memo[x][y];
+ }
+ // 状态转移方程:
+ // 到达 (x, y) 的路径数等于到达 (x - 1, y) 和 (x, y - 1) 路径数之和
+ memo[x][y] = dp(x - 1, y) + dp(x, y - 1);
+ return memo[x][y];
+ }
+};
+```
+
+```go
+// by chatGPT (go)
+func uniquePaths(m int, n int) int {
+ // 备忘录
+ memo := make([][]int, m)
+ for i := range memo {
+ memo[i] = make([]int, n)
+ }
+ return dp(m-1, n-1, memo)
+}
+
+// 定义:从 (0, 0) 到 (x, y) 有 dp(x, y) 条路径
+func dp(x int, y int, memo [][]int) int {
+ // base case
+ if x == 0 && y == 0 {
+ return 1
+ }
+ if x < 0 || y < 0 {
+ return 0
+ }
+ // 避免冗余计算
+ if memo[x][y] > 0 {
+ return memo[x][y]
+ }
+ // 状态转移方程:
+ // 到达 (x, y) 的路径数等于到达 (x - 1, y) 和 (x, y - 1) 路径数之和
+ memo[x][y] = dp(x-1, y, memo) + dp(x, y-1, memo)
+ return memo[x][y]
+}
+```
+
+```java
+// by labuladong (java)
+class Solution {
+ // 备忘录
+ int[][] memo;
+
+ public int uniquePaths(int m, int n) {
+ memo = new int[m][n];
+ return dp(m - 1, n - 1);
+ }
+
+ // 定义:从 (0, 0) 到 (x, y) 有 dp(x, y) 条路径
+ int dp(int x, int y) {
+ // base case
+ if (x == 0 && y == 0) {
+ return 1;
+ }
+ if (x < 0 || y < 0) {
+ return 0;
+ }
+ // 避免冗余计算
+ if (memo[x][y] > 0) {
+ return memo[x][y];
+ }
+ // 状态转移方程:
+ // 到达 (x, y) 的路径数等于到达 (x - 1, y) 和 (x, y - 1) 路径数之和
+ memo[x][y] = dp(x - 1, y) + dp(x, y - 1);
+ return memo[x][y];
+ }
+}
+```
+
+```javascript
+// by chatGPT (javascript)
+var uniquePaths = function(m, n) {
+ // 备忘录
+ let memo = new Array(m).fill().map(() => new Array(n).fill(0));
+
+ // 定义:从 (0, 0) 到 (x, y) 有 dp(x, y) 条路径
+ var dp = function(x, y) {
+ // base case
+ if (x === 0 && y === 0) {
+ return 1;
+ }
+ if (x < 0 || y < 0) {
+ return 0;
+ }
+ // 避免冗余计算
+ if (memo[x][y] > 0) {
+ return memo[x][y];
+ }
+ // 状态转移方程:
+ // 到达 (x, y) 的路径数等于到达 (x - 1, y) 和 (x, y - 1) 路径数之和
+ memo[x][y] = dp(x - 1, y) + dp(x, y - 1);
+ return memo[x][y];
+ };
+
+ return dp(m - 1, n - 1);
+};
+```
+
+```python
+# by chatGPT (python)
+class Solution:
+ def __init__(self):
+ self.memo = None
+
+ def uniquePaths(self, m: int, n: int) -> int:
+ self.memo = [[0] * n for _ in range(m)]
+ return self.dp(m-1, n-1)
+
+ def dp(self, x: int, y: int) -> int:
+ # base case
+ if x == 0 and y == 0:
+ return 1
+ if x < 0 or y < 0:
+ return 0
+ # 避免冗余计算
+ if self.memo[x][y] > 0:
+ return self.memo[x][y]
+ # 状态转移方程:
+ # 到达 (x, y) 的路径数等于到达 (x - 1, y) 和 (x, y - 1) 路径数之和
+ self.memo[x][y] = self.dp(x - 1, y) + self.dp(x, y - 1)
+ return self.memo[x][y]
+```
+
+https://leetcode.cn/problems/2AoeFn 的多语言解法👆
+
+https://leetcode.cn/problems/3sum 的多语言解法👇
+
+```cpp
+// by labuladong (cpp)
+class Solution {
+ public:
+ vector> threeSum(vector& nums) {
+ sort(nums.begin(), nums.end());
+ // n 为 3,从 nums[0] 开始计算和为 0 的三元组
+ return nSumTarget(nums, 3, 0, 0);
+ }
+
+ /* 注意:调用这个函数之前一定要先给 nums 排序 */
+ // n 填写想求的是几数之和,start 从哪个索引开始计算(一般填 0),target 填想凑出的目标和
+ vector> nSumTarget(
+ vector& nums, int n, int start, int target) {
+
+ int sz = nums.size();
+ vector> res;
+ // 至少是 2Sum,且数组大小不应该小于 n
+ if (n < 2 || sz < n) return res;
+ // 2Sum 是 base case
+ if (n == 2) {
+ // 双指针那一套操作
+ int lo = start, hi = sz - 1;
+ while (lo < hi) {
+ int sum = nums[lo] + nums[hi];
+ int left = nums[lo], right = nums[hi];
+ if (sum < target) {
+ while (lo < hi && nums[lo] == left) lo++;
+ } else if (sum > target) {
+ while (lo < hi && nums[hi] == right) hi--;
+ } else {
+ res.push_back({left, right});
+ while (lo < hi && nums[lo] == left) lo++;
+ while (lo < hi && nums[hi] == right) hi--;
+ }
+ }
+ } else {
+ // n > 2 时,递归计算 (n-1)Sum 的结果
+ for (int i = start; i < sz; i++) {
+ vector>
+ sub = nSumTarget(nums, n - 1, i + 1, target - nums[i]);
+ for (vector& arr : sub) {
+ // (n-1)Sum 加上 nums[i] 就是 nSum
+ arr.push_back(nums[i]);
+ res.push_back(arr);
+ }
+ while (i < sz - 1 && nums[i] == nums[i + 1]) i++;
+ }
+ }
+ return res;
+ }
+};
+```
+
+```go
+// by chatGPT (go)
+func threeSum(nums []int) [][]int {
+ sort.Ints(nums)
+ // n 为 3,从 nums[0] 开始计算和为 0 的三元组
+ return nSumTarget(nums, 3, 0, 0)
+}
+
+/* 注意:调用这个函数之前一定要先给 nums 排序 */
+// n 填写想求的是几数之和,start 从哪个索引开始计算(一般填 0),target 填想凑出的目标和
+func nSumTarget(nums []int, n int, start int, target int) [][]int {
+ sz := len(nums)
+ var res [][]int
+ // 至少是 2Sum,且数组大小不应该小于 n
+ if n < 2 || sz < n {
+ return res
+ }
+ // 2Sum 是 base case
+ if n == 2 {
+ // 双指针那一套操作
+ lo, hi := start, sz-1
+ for lo < hi {
+ sum := nums[lo] + nums[hi]
+ left, right := nums[lo], nums[hi]
+ if sum < target {
+ for lo < hi && nums[lo] == left {
+ lo++
+ }
+ } else if sum > target {
+ for lo < hi && nums[hi] == right {
+ hi--
+ }
+ } else {
+ res = append(res, []int{left, right})
+ for lo < hi && nums[lo] == left {
+ lo++
+ }
+ for lo < hi && nums[hi] == right {
+ hi--
+ }
+ }
+ }
+ } else {
+ // n > 2 时,递归计算 (n-1)Sum 的结果
+ for i := start; i < sz; i++ {
+ sub := nSumTarget(nums, n-1, i+1, target-nums[i])
+ for _, arr := range sub {
+ // (n-1)Sum 加上 nums[i] 就是 nSum
+ arr = append(arr, nums[i])
+ res = append(res, arr)
+ }
+ for i < sz-1 && nums[i] == nums[i+1] {
+ i++
+ }
+ }
+ }
+ return res
+}
+```
+
+```java
+// by chatGPT (java)
+class Solution {
+ public List> threeSum(int[] nums) {
+ Arrays.sort(nums);
+ // n 为 3,从 nums[0] 开始计算和为 0 的三元组
+ return nSumTarget(nums, 3, 0, 0);
+ }
+
+ /* 注意:调用这个函数之前一定要先给 nums 排序 */
+ // n 填写想求的是几数之和,start 从哪个索引开始计算(一般填 0),target 填想凑出的目标和
+ public List> nSumTarget(
+ int[] nums, int n, int start, int target) {
+
+ int sz = nums.length;
+ List> res = new ArrayList<>();
+ // 至少是 2Sum,且数组大小不应该小于 n
+ if (n < 2 || sz < n) return res;
+ // 2Sum 是 base case
+ if (n == 2) {
+ // 双指针那一套操作
+ int lo = start, hi = sz - 1;
+ while (lo < hi) {
+ int sum = nums[lo] + nums[hi];
+ int left = nums[lo], right = nums[hi];
+ if (sum < target) {
+ while (lo < hi && nums[lo] == left) lo++;
+ } else if (sum > target) {
+ while (lo < hi && nums[hi] == right) hi--;
+ } else {
+ res.add(new ArrayList<>(Arrays.asList(left, right)));
+ while (lo < hi && nums[lo] == left) lo++;
+ while (lo < hi && nums[hi] == right) hi--;
+ }
+ }
+ } else {
+ // n > 2 时,递归计算 (n-1)Sum 的结果
+ for (int i = start; i < sz; i++) {
+ List>
+ sub = nSumTarget(nums, n - 1, i + 1, target - nums[i]);
+ for (List arr : sub) {
+ // (n-1)Sum 加上 nums[i] 就是 nSum
+ arr.add(nums[i]);
+ res.add(arr);
+ }
+ while (i < sz - 1 && nums[i] == nums[i + 1]) i++;
+ }
+ }
+ return res;
+ }
+}
+```
+
+```javascript
+// by chatGPT (javascript)
+var threeSum = function(nums) {
+ nums.sort((a, b) => a - b);
+ // n 为 3,从 nums[0] 开始计算和为 0 的三元组
+ return nSumTarget(nums, 3, 0, 0);
+}
+
+/* 注意:调用这个函数之前一定要先给 nums 排序 */
+// n 填写想求的是几数之和,start 从哪个索引开始计算(一般填 0),target 填想凑出的目标和
+var nSumTarget = function(nums, n, start, target) {
+ var sz = nums.length;
+ var res = [];
+ // 至少是 2Sum,且数组大小不应该小于 n
+ if (n < 2 || sz < n) return res;
+ // 2Sum 是 base case
+ if (n == 2) {
+ // 双指针那一套操作
+ var lo = start, hi = sz - 1;
+ while (lo < hi) {
+ var sum = nums[lo] + nums[hi];
+ var left = nums[lo], right = nums[hi];
+ if (sum < target) {
+ while (lo < hi && nums[lo] == left) lo++;
+ } else if (sum > target) {
+ while (lo < hi && nums[hi] == right) hi--;
+ } else {
+ res.push([left, right]);
+ while (lo < hi && nums[lo] == left) lo++;
+ while (lo < hi && nums[hi] == right) hi--;
+ }
+ }
+ } else {
+ // n > 2 时,递归计算 (n-1)Sum 的结果
+ for (var i = start; i < sz; i++) {
+ var sub = nSumTarget(nums, n - 1, i + 1, target - nums[i]);
+ for (var j = 0; j < sub.length; j++) {
+ // (n-1)Sum 加上 nums[i] 就是 nSum
+ sub[j].push(nums[i]);
+ res.push(sub[j]);
+ }
+ while (i < sz - 1 && nums[i] == nums[i + 1]) i++;
+ }
+ }
+ return res;
+};
+```
+
+```python
+# by chatGPT (python)
+class Solution:
+ def threeSum(self, nums: List[int]) -> List[List[int]]:
+ nums.sort()
+ # n 为 3,从 nums[0] 开始计算和为 0 的三元组
+ return self.nSumTarget(nums, 3, 0, 0)
+
+ # 注意:调用这个函数之前一定要先给 nums 排序
+ # n 填写想求的是几数之和,start 从哪个索引开始计算(一般填 0),target 填想凑出的目标和
+ def nSumTarget(self, nums: List[int], n: int, start: int, target: int) -> List[List[int]]:
+ sz = len(nums)
+ res = []
+ # 至少是 2Sum,且数组大小不应该小于 n
+ if n < 2 or sz < n:
+ return res
+ # 2Sum 是 base case
+ if n == 2:
+ # 双指针那一套操作
+ lo, hi = start, sz - 1
+ while lo < hi:
+ s = nums[lo] + nums[hi]
+ left, right = nums[lo], nums[hi]
+ if s < target:
+ while lo < hi and nums[lo] == left:
+ lo += 1
+ elif s > target:
+ while lo < hi and nums[hi] == right:
+ hi -= 1
+ else:
+ res.append([left, right])
+ while lo < hi and nums[lo] == left:
+ lo += 1
+ while lo < hi and nums[hi] == right:
+ hi -= 1
+ else:
+ # n > 2 时,递归计算 (n-1)Sum 的结果
+ for i in range(start, sz):
+ sub = self.nSumTarget(nums, n - 1, i + 1, target - nums[i])
+ for arr in sub:
+ # (n-1)Sum 加上 nums[i] 就是 nSum
+ arr.append(nums[i])
+ res.append(arr)
+ while i < sz - 1 and nums[i] == nums[i + 1]:
+ i += 1
+ return res
+```
+
+https://leetcode.cn/problems/3sum 的多语言解法👆
+
+https://leetcode.cn/problems/3sum-closest 的多语言解法👇
+
+```cpp
+// by chatGPT (cpp)
+class Solution {
+public:
+ int threeSumClosest(vector& nums, int target) {
+ if (nums.size() < 3) {
+ return 0;
+ }
+ // 别忘了要先排序数组
+ sort(nums.begin(), nums.end());
+ // 记录三数之和与目标值的偏差
+ int delta = INT_MAX;
+ for (int i = 0; i < nums.size() - 2; i++) {
+ // 固定 nums[i] 为三数之和中的第一个数,
+ // 然后对 nums[i+1..] 搜索接近 target - nums[i] 的两数之和
+ int sum = nums[i] + twoSumClosest(nums, i + 1, target - nums[i]);
+ if (abs(delta) > abs(target - sum)) {
+ delta = target - sum;
+ }
+ }
+ return target - delta;
+ }
+
+ // 在 nums[start..] 搜索最接近 target 的两数之和
+ int twoSumClosest(vector& nums, int start, int target) {
+ int lo = start, hi = nums.size() - 1;
+ // 记录两数之和与目标值的偏差
+ int delta = INT_MAX;
+ while (lo < hi) {
+ int sum = nums[lo] + nums[hi];
+ if (abs(delta) > abs(target - sum)) {
+ delta = target - sum;
+ }
+ if (sum < target) {
+ lo++;
+ } else {
+ hi--;
+ }
+ }
+ return target - delta;
+ }
+};
+```
+
+```go
+// by chatGPT (go)
+func threeSumClosest(nums []int, target int) int {
+ if len(nums) < 3 {
+ return 0
+ }
+ // 先排序数组
+ sort.Ints(nums)
+ // 记录三数之和与目标值的偏差
+ delta := math.MaxInt32
+ for i := 0; i < len(nums)-2; i++ {
+ // 固定 nums[i] 为三数之和中的第一个数,
+ // 然后对 nums[i+1..] 搜索接近 target - nums[i] 的两数之和
+ sum := nums[i] + twoSumClosest(nums, i+1, target-nums[i])
+ if int(math.Abs(float64(delta))) > int(math.Abs(float64(target-sum))) {
+ delta = target - sum
+ }
+ }
+ return target - delta
+}
+
+// 在 nums[start..] 搜索最接近 target 的两数之和
+func twoSumClosest(nums []int, start int, target int) int {
+ lo, hi := start, len(nums)-1
+ // 记录两数之和与目标值的偏差
+ delta := math.MaxInt32
+ for lo < hi {
+ sum := nums[lo] + nums[hi]
+ if int(math.Abs(float64(delta))) > int(math.Abs(float64(target-sum))) {
+ delta = target - sum
+ }
+ if sum < target {
+ lo++
+ } else {
+ hi--
+ }
+ }
+ return target - delta
+}
+```
+
+```java
+// by labuladong (java)
+class Solution {
+ public int threeSumClosest(int[] nums, int target) {
+ if (nums.length < 3) {
+ return 0;
+ }
+ // 别忘了要先排序数组
+ Arrays.sort(nums);
+ // 记录三数之和与目标值的偏差
+ int delta = Integer.MAX_VALUE;
+ for (int i = 0; i < nums.length - 2; i++) {
+ // 固定 nums[i] 为三数之和中的第一个数,
+ // 然后对 nums[i+1..] 搜索接近 target - nums[i] 的两数之和
+ int sum = nums[i] + twoSumClosest(nums, i + 1, target - nums[i]);
+ if (Math.abs(delta) > Math.abs(target - sum)) {
+ delta = target - sum;
+ }
+ }
+ return target - delta;
+ }
+
+ // 在 nums[start..] 搜索最接近 target 的两数之和
+ int twoSumClosest(int[] nums, int start, int target) {
+ int lo = start, hi = nums.length - 1;
+ // 记录两数之和与目标值的偏差
+ int delta = Integer.MAX_VALUE;
+ while (lo < hi) {
+ int sum = nums[lo] + nums[hi];
+ if (Math.abs(delta) > Math.abs(target - sum)) {
+ delta = target - sum;
+ }
+ if (sum < target) {
+ lo++;
+ } else {
+ hi--;
+ }
+ }
+ return target - delta;
+ }
+}
+```
+
+```javascript
+// by chatGPT (javascript)
+var threeSumClosest = function(nums, target) {
+ if (nums.length < 3) {
+ return 0;
+ }
+ // 别忘了要先排序数组
+ nums.sort(function(a, b) {
+ return a - b;
+ });
+ // 记录三数之和与目标值的偏差
+ var delta = Number.MAX_SAFE_INTEGER;
+ for (var i = 0; i < nums.length - 2; i++) {
+ // 固定 nums[i] 为三数之和中的第一个数,
+ // 然后对 nums[i+1..] 搜索接近 target - nums[i] 的两数之和
+ var sum = nums[i] + twoSumClosest(nums, i + 1, target - nums[i]);
+ if (Math.abs(delta) > Math.abs(target - sum)) {
+ delta = target - sum;
+ }
+ }
+ return target - delta;
+};
+
+// 在 nums[start..] 搜索最接近 target 的两数之和
+var twoSumClosest = function(nums, start, target) {
+ var lo = start, hi = nums.length - 1;
+ // 记录两数之和与目标值的偏差
+ var delta = Number.MAX_SAFE_INTEGER;
+ while (lo < hi) {
+ var sum = nums[lo] + nums[hi];
+ if (Math.abs(delta) > Math.abs(target - sum)) {
+ delta = target - sum;
+ }
+ if (sum < target) {
+ lo++;
+ } else {
+ hi--;
+ }
+ }
+ return target - delta;
+};
+```
+
+```python
+# by chatGPT (python)
+class Solution:
+ def threeSumClosest(self, nums: List[int], target: int) -> int:
+ if len(nums) < 3:
+ return 0
+ # 别忘了要先排序数组
+ nums.sort()
+ # 记录三数之和与目标值的偏差
+ delta = float('inf')
+ for i in range(len(nums) - 2):
+ # 固定 nums[i] 为三数之和中的第一个数,
+ # 然后对 nums[i+1..] 搜索接近 target - nums[i] 的两数之和
+ sum_ = nums[i] + self.twoSumClosest(nums, i + 1, target - nums[i])
+ if abs(delta) > abs(target - sum_):
+ delta = target - sum_
+ return target - delta
+
+ # 在 nums[start..] 搜索最接近 target 的两数之和
+ def twoSumClosest(self, nums: List[int], start: int, target: int) -> int:
+ lo, hi = start, len(nums) - 1
+ # 记录两数之和与目标值的偏差
+ delta = float('inf')
+ while lo < hi:
+ sum_ = nums[lo] + nums[hi]
+ if abs(delta) > abs(target - sum_):
+ delta = target - sum_
+ if sum_ < target:
+ lo += 1
+ else:
+ hi -= 1
+ return target - delta
+```
+
+https://leetcode.cn/problems/3sum-closest 的多语言解法👆
+
+https://leetcode.cn/problems/3sum-smaller 的多语言解法👇
+
+```cpp
+// by chatGPT (cpp)
+class Solution {
+public:
+ int threeSumSmaller(vector& nums, int target) {
+ if (nums.size() < 3) {
+ return 0;
+ }
+ // 别忘了要先排序数组
+ sort(nums.begin(), nums.end());
+ int res = 0;
+ for (int i = 0; i < nums.size() - 2; i++) {
+ // 固定 nums[i] 为三数之和中的第一个数,
+ // 然后对 nums[i+1..] 搜索小于 target - nums[i] 的两数之和个数
+ res += twoSumSmaller(nums, i + 1, target - nums[i]);
+ }
+ return res;
+ }
+
+ // 在 nums[start..] 搜索小于 target 的两数之和个数
+ int twoSumSmaller(vector& nums, int start, int target) {
+ int lo = start, hi = nums.size() - 1;
+ int count = 0;
+ while (lo < hi) {
+ if (nums[lo] + nums[hi] < target) {
+ // nums[lo] 和 nums[lo+1..hi]
+ // 中的任一元素之和都小于 target
+ count += hi - lo;
+ lo++;
+ } else {
+ hi--;
+ }
+ }
+ return count;
+ }
+};
+```
+
+```go
+// by chatGPT (go)
+func threeSumSmaller(nums []int, target int) int {
+ if len(nums) < 3 {
+ return 0
+ }
+ // 别忘了要先排序数组
+ sort.Ints(nums)
+ res := 0
+ for i := 0; i < len(nums) - 2; i++ {
+ // 固定 nums[i] 为三数之和中的第一个数,
+ // 然后对 nums[i+1..] 搜索小于 target - nums[i] 的两数之和个数
+ res += twoSumSmaller(nums, i + 1, target - nums[i])
+ }
+ return res
+}
+
+// 在 nums[start..] 搜索小于 target 的两数之和个数
+func twoSumSmaller(nums []int, start int, target int) int {
+ lo, hi := start, len(nums) - 1
+ count := 0
+ for lo < hi {
+ if nums[lo] + nums[hi] < target {
+ // nums[lo] 和 nums[lo+1..hi]
+ // 中的任一元素之和都小于 target
+ count += hi - lo
+ lo++
+ } else {
+ hi--
+ }
+ }
+ return count
+}
+```
+
+```java
+// by labuladong (java)
+class Solution {
+ public int threeSumSmaller(int[] nums, int target) {
+ if (nums.length < 3) {
+ return 0;
+ }
+ // 别忘了要先排序数组
+ Arrays.sort(nums);
+ int res = 0;
+ for (int i = 0; i < nums.length - 2; i++) {
+ // 固定 nums[i] 为三数之和中的第一个数,
+ // 然后对 nums[i+1..] 搜索小于 target - nums[i] 的两数之和个数
+ res += twoSumSmaller(nums, i + 1, target - nums[i]);
+ }
+ return res;
+ }
+
+ // 在 nums[start..] 搜索小于 target 的两数之和个数
+ int twoSumSmaller(int[] nums, int start, int target) {
+ int lo = start, hi = nums.length - 1;
+ int count = 0;
+ while (lo < hi) {
+ if (nums[lo] + nums[hi] < target) {
+ // nums[lo] 和 nums[lo+1..hi]
+ // 中的任一元素之和都小于 target
+ count += hi - lo;
+ lo++;
+ } else {
+ hi--;
+ }
+ }
+ return count;
+ }
+}
+```
+
+```javascript
+// by chatGPT (javascript)
+var threeSumSmaller = function(nums, target) {
+ // 如果数组长度小于3,返回0
+ if(nums.length < 3) {
+ return 0;
+ }
+ // 将数组升序排序
+ nums.sort(function(a,b) {return a - b;});
+ // 定义变量res,初始化为0
+ var res = 0;
+ // 枚举第一个元素
+ for (var i = 0; i < nums.length - 2; i++) {
+ // 对第一个元素之后的元素搜索两数之和小于target-nums[i]的个数
+ res += twoSumSmaller(nums, i + 1, target - nums[i]);
+ }
+ // 返回答案
+ return res;
+
+ // 搜索nums[start..]内两数之和小于target的个数
+ function twoSumSmaller(nums, start, target) {
+ var lo = start, hi = nums.length - 1;
+ var count = 0;
+ while (lo < hi) {
+ // 如果nums[lo] + nums[hi] < target,这时nums[lo]和nums[lo + 1..hi]中任意一个数与nums[hi]相加都会小于target
+ if (nums[lo] + nums[hi] < target) {
+ // 计算加入nums[lo]时小于target的两数之和的个数,并将lo移动一位
+ count += hi - lo;
+ lo++;
+ } else {
+ // 如果nums[lo] + nums[hi] >= target,则将hi往前一位
+ hi--;
+ }
+ }
+ // 返回小于target的两数之和的个数
+ return count;
+ }
+};
+```
+
+```python
+# by chatGPT (python)
+class Solution:
+ def threeSumSmaller(self, nums: List[int], target: int) -> int:
+ if len(nums) < 3:
+ return 0
+ nums.sort()
+ res = 0
+ for i in range(len(nums) - 2):
+ # 固定 nums[i] 为三数之和中的第一个数,
+ # 然后对 nums[i+1..] 搜索小于 target - nums[i] 的两数之和个数
+ res += self.twoSumSmaller(nums, i + 1, target - nums[i])
+ return res
+
+ def twoSumSmaller(self, nums: List[int], start: int, target: int) -> int:
+ lo = start
+ hi = len(nums) - 1
+ count = 0
+ while lo < hi:
+ if nums[lo] + nums[hi] < target:
+ # nums[lo] 和 nums[lo+1..hi]
+ # 中的任一元素之和都小于 target
+ count += hi - lo
+ lo += 1
+ else:
+ hi -= 1
+ return count
+```
+
+https://leetcode.cn/problems/3sum-smaller 的多语言解法👆
+
+https://leetcode.cn/problems/3u1WK4 的多语言解法👇
+
+```cpp
+// by chatGPT (cpp)
+class Solution {
+public:
+ ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {
+ // p1 指向 A 链表头结点,p2 指向 B 链表头结点
+ ListNode *p1 = headA, *p2 = headB;
+ while (p1 != p2) {
+ // p1 走一步,如果走到 A 链表末尾,转到 B 链表
+ if (p1 == nullptr) p1 = headB;
+ else p1 = p1->next;
+ // p2 走一步,如果走到 B 链表末尾,转到 A 链表
+ if (p2 == nullptr) p2 = headA;
+ else p2 = p2->next;
+ }
+ return p1;
+ }
+};
+```
+
+```go
+// by chatGPT (go)
+func getIntersectionNode(headA, headB *ListNode) *ListNode {
+ // p1 指向 A 链表头结点,p2 指向 B 链表头结点
+ p1, p2 := headA, headB
+ for p1 != p2 {
+ // p1 走一步,如果走到 A 链表末尾,转到 B 链表
+ if p1 == nil {
+ p1 = headB
+ } else {
+ p1 = p1.Next
+ }
+ // p2 走一步,如果走到 B 链表末尾,转到 A 链表
+ if p2 == nil {
+ p2 = headA
+ } else {
+ p2 = p2.Next
+ }
+ }
+ return p1
+}
+```
+
+```java
+// by labuladong (java)
+public class Solution {
+ public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
+ // p1 指向 A 链表头结点,p2 指向 B 链表头结点
+ ListNode p1 = headA, p2 = headB;
+ while (p1 != p2) {
+ // p1 走一步,如果走到 A 链表末尾,转到 B 链表
+ if (p1 == null) p1 = headB;
+ else p1 = p1.next;
+ // p2 走一步,如果走到 B 链表末尾,转到 A 链表
+ if (p2 == null) p2 = headA;
+ else p2 = p2.next;
+ }
+ return p1;
+ }
+}
+```
+
+```javascript
+// by chatGPT (javascript)
+var getIntersectionNode = function(headA, headB) {
+ // p1 指向 A 链表头结点,p2 指向 B 链表头结点
+ let p1 = headA, p2 = headB;
+ while (p1 !== p2) {
+ // p1 走一步,如果走到 A 链表末尾,转到 B 链表
+ if (p1 === null) p1 = headB;
+ else p1 = p1.next;
+ // p2 走一步,如果走到 B 链表末尾,转到 A 链表
+ if (p2 === null) p2 = headA;
+ else p2 = p2.next;
+ }
+ return p1;
+};
+```
+
+```python
+# by chatGPT (python)
+class Solution:
+ def getIntersectionNode(self, headA: ListNode, headB: ListNode) -> ListNode:
+ # p1 指向 A 链表头结点,p2 指向 B 链表头结点
+ p1, p2 = headA, headB
+ while p1 != p2:
+ # p1 走一步,如果走到 A 链表末尾,转到 B 链表
+ if p1 is None:
+ p1 = headB
+ else:
+ p1 = p1.next
+ # p2 走一步,如果走到 B 链表末尾,转到 A 链表
+ if p2 is None:
+ p2 = headA
+ else:
+ p2 = p2.next
+ return p1
+```
+
+https://leetcode.cn/problems/3u1WK4 的多语言解法👆
+
+https://leetcode.cn/problems/4sum 的多语言解法👇
+
+```cpp
+// by labuladong (cpp)
+class Solution {
+ public:
+ vector> fourSum(vector& nums, int target) {
+ sort(nums.begin(), nums.end());
+ // n 为 4,从 nums[0] 开始计算和为 target 的四元组
+ return nSumTarget(nums, 4, 0, target);
+ }
+
+ /* 注意:调用这个函数之前一定要先给 nums 排序 */
+ // n 填写想求的是几数之和,start 从哪个索引开始计算(一般填 0),target 填想凑出的目标和
+ vector> nSumTarget(
+ vector& nums, int n, int start, int target) {
+
+ int sz = nums.size();
+ vector> res;
+ // 至少是 2Sum,且数组大小不应该小于 n
+ if (n < 2 || sz < n) return res;
+ // 2Sum 是 base case
+ if (n == 2) {
+ // 双指针那一套操作
+ int lo = start, hi = sz - 1;
+ while (lo < hi) {
+ int sum = nums[lo] + nums[hi];
+ int left = nums[lo], right = nums[hi];
+ if (sum < target) {
+ while (lo < hi && nums[lo] == left) lo++;
+ } else if (sum > target) {
+ while (lo < hi && nums[hi] == right) hi--;
+ } else {
+ res.push_back({left, right});
+ while (lo < hi && nums[lo] == left) lo++;
+ while (lo < hi && nums[hi] == right) hi--;
+ }
+ }
+ } else {
+ // n > 2 时,递归计算 (n-1)Sum 的结果
+ for (int i = start; i < sz; i++) {
+ vector>
+ sub = nSumTarget(nums, n - 1, i + 1, target - nums[i]);
+ for (vector& arr : sub) {
+ // (n-1)Sum 加上 nums[i] 就是 nSum
+ arr.push_back(nums[i]);
+ res.push_back(arr);
+ }
+ while (i < sz - 1 && nums[i] == nums[i + 1]) i++;
+ }
+ }
+ return res;
+ }
+};
+```
+
+```go
+// by chatGPT (go)
+func fourSum(nums []int, target int) [][]int {
+ sort.Ints(nums)
+ // n 为 4,从 nums[0] 开始计算和为 target 的四元组
+ return nSumTarget(nums, 4, 0, target)
+}
+
+/* 注意:调用这个函数之前一定要先给 nums 排序 */
+// n 填写想求的是几数之和,start 从哪个索引开始计算(一般填 0),target 填想凑出的目标和
+func nSumTarget(nums []int, n, start, target int) [][]int {
+ sz := len(nums)
+ res := [][]int{}
+ // 至少是 2Sum,且数组大小不应该小于 n
+ if n < 2 || sz < n {
+ return res
+ }
+ // 2Sum 是 base case
+ if n == 2 {
+ // 双指针那一套操作
+ lo, hi := start, sz-1
+ for lo < hi {
+ sum := nums[lo] + nums[hi]
+ left, right := nums[lo], nums[hi]
+ if sum < target {
+ for lo < hi && nums[lo] == left {
+ lo++
+ }
+ } else if sum > target {
+ for lo < hi && nums[hi] == right {
+ hi--
+ }
+ } else {
+ res = append(res, []int{left, right})
+ for lo < hi && nums[lo] == left {
+ lo++
+ }
+ for lo < hi && nums[hi] == right {
+ hi--
+ }
+ }
+ }
+ } else {
+ // n > 2 时,递归计算 (n-1)Sum 的结果
+ for i := start; i < sz; i++ {
+ sub := nSumTarget(nums, n-1, i+1, target-nums[i])
+ for _, arr := range sub {
+ // (n-1)Sum 加上 nums[i] 就是 nSum
+ arr = append(arr, nums[i])
+ res = append(res, arr)
+ }
+ for i < sz-1 && nums[i] == nums[i+1] {
+ i++
+ }
+ }
+ }
+ return res
+}
+```
+
+```java
+// by chatGPT (java)
+class Solution {
+ public List> fourSum(int[] nums, int target) {
+ Arrays.sort(nums);
+ // n 为 4,从 nums[0] 开始计算和为 target 的四元组
+ return nSumTarget(nums, 4, 0, target);
+ }
+
+ /* 注意:调用这个函数之前一定要先给 nums 排序 */
+ // n 填写想求的是几数之和,start 从哪个索引开始计算(一般填 0),target 填想凑出的目标和
+ private List> nSumTarget(int[] nums, int n, int start, int target) {
+ int sz = nums.length;
+ List> res = new ArrayList<>();
+ // 至少是 2Sum,且数组大小不应该小于 n
+ if (n < 2 || sz < n) return res;
+ // 2Sum 是 base case
+ if (n == 2) {
+ // 双指针那一套操作
+ int lo = start, hi = sz - 1;
+ while (lo < hi) {
+ int sum = nums[lo] + nums[hi];
+ int left = nums[lo], right = nums[hi];
+ if (sum < target) {
+ while (lo < hi && nums[lo] == left) lo++;
+ } else if (sum > target) {
+ while (lo < hi && nums[hi] == right) hi--;
+ } else {
+ res.add(new ArrayList<>(Arrays.asList(left, right)));
+ while (lo < hi && nums[lo] == left) lo++;
+ while (lo < hi && nums[hi] == right) hi--;
+ }
+ }
+ } else {
+ // n > 2 时,递归计算 (n-1)Sum 的结果
+ for (int i = start; i < sz; i++) {
+ List> sub = nSumTarget(nums, n - 1, i + 1, target - nums[i]);
+ for (List arr : sub) {
+ // (n-1)Sum 加上 nums[i] 就是 nSum
+ arr.add(nums[i]);
+ res.add(arr);
+ }
+ while (i < sz - 1 && nums[i] == nums[i + 1]) i++;
+ }
+ }
+ return res;
+ }
+}
+```
+
+```javascript
+// by chatGPT (javascript)
+var fourSum = function(nums, target) {
+ nums.sort((a, b) => a - b);
+ // n 为 4,从 nums[0] 开始计算和为 target 的四元组
+ return nSumTarget(nums, 4, 0, target);
+};
+
+/* 注意:调用这个函数之前一定要先给 nums 排序 */
+// n 填写想求的是几数之和,start 从哪个索引开始计算(一般填 0),target 填想凑出的目标和
+var nSumTarget = function(nums, n, start, target) {
+ var sz = nums.length;
+ var res = [];
+ // 至少是 2Sum,且数组大小不应该小于 n
+ if (n < 2 || sz < n) return res;
+ // 2Sum 是 base case
+ if (n === 2) {
+ // 双指针那一套操作
+ var lo = start, hi = sz - 1;
+ while (lo < hi) {
+ var sum = nums[lo] + nums[hi];
+ var left = nums[lo], right = nums[hi];
+ if (sum < target) {
+ while (lo < hi && nums[lo] === left) lo++;
+ } else if (sum > target) {
+ while (lo < hi && nums[hi] === right) hi--;
+ } else {
+ res.push([left, right]);
+ while (lo < hi && nums[lo] === left) lo++;
+ while (lo < hi && nums[hi] === right) hi--;
+ }
+ }
+ } else {
+ // n > 2 时,递归计算 (n-1)Sum 的结果
+ for (var i = start; i < sz; i++) {
+ var sub = nSumTarget(nums, n - 1, i + 1, target - nums[i]);
+ for (var arr of sub) {
+ // (n-1)Sum 加上 nums[i] 就是 nSum
+ arr.push(nums[i]);
+ res.push(arr);
+ }
+ while (i < sz - 1 && nums[i] === nums[i + 1]) i++;
+ }
+ }
+ return res;
+};
+```
+
+```python
+# by chatGPT (python)
+class Solution:
+ def fourSum(self, nums: List[int], target: int) -> List[List[int]]:
+ nums.sort()
+ # n 为 4,从 nums[0] 开始计算和为 target 的四元组
+ return self.nSumTarget(nums, 4, 0, target)
+
+ # 注意:调用这个函数之前一定要先给 nums 排序
+ # n 填写想求的是几数之和,start 从哪个索引开始计算(一般填 0),target 填想凑出的目标和
+ def nSumTarget(self, nums: List[int], n: int, start: int, target: int) -> List[List[int]]:
+ sz = len(nums)
+ res = []
+ # 至少是 2Sum,且数组大小不应该小于 n
+ if n < 2 or sz < n:
+ return res
+ # 2Sum 是 base case
+ if n == 2:
+ # 双指针那一套操作
+ lo, hi = start, sz - 1
+ while lo < hi:
+ s = nums[lo] + nums[hi]
+ left, right = nums[lo], nums[hi]
+ if s < target:
+ while lo < hi and nums[lo] == left:
+ lo += 1
+ elif s > target:
+ while lo < hi and nums[hi] == right:
+ hi -= 1
+ else:
+ res.append([left, right])
+ while lo < hi and nums[lo] == left:
+ lo += 1
+ while lo < hi and nums[hi] == right:
+ hi -= 1
+ else:
+ # n > 2 时,递归计算 (n-1)Sum 的结果
+ for i in range(start, sz):
+ sub = self.nSumTarget(nums, n - 1, i + 1, target - nums[i])
+ for arr in sub:
+ # (n-1)Sum 加上 nums[i] 就是 nSum
+ arr.append(nums[i])
+ res.append(arr)
+ while i < sz - 1 and nums[i] == nums[i + 1]:
+ i += 1
+ return res
+```
+
+https://leetcode.cn/problems/4sum 的多语言解法👆
+
+https://leetcode.cn/problems/8Zf90G 的多语言解法👇
+
+```cpp
+// by chatGPT (cpp)
+class Solution {
+public:
+ int evalRPN(vector& tokens) {
+ stack stk;
+ for (const auto& token : tokens) {
+ if (string("+-*/").find(token) != string::npos) {
+ // 是个运算符,从栈顶拿出两个数字进行运算,运算结果入栈
+ int a = stk.top();
+ stk.pop();
+ int b = stk.top();
+ stk.pop();
+ switch (token[0]) {
+ case '+':
+ stk.push(b + a);
+ break;
+ case '*':
+ stk.push(b * a);
+ break;
+ // 对于减法和除法,顺序别搞反了,第二个数是被除(减)数
+ case '-':
+ stk.push(b - a);
+ break;
+ case '/':
+ stk.push(b / a);
+ break;
+ }
+ } else {
+ // 是个数字,直接入栈即可
+ stk.push(stoi(token));
+ }
+ }
+ // 最后栈中剩下一个数字,即是计算结果
+ return stk.top();
+ }
+};
+```
+
+```go
+// by chatGPT (go)
+func evalRPN(tokens []string) int {
+ stk := make([]int, 0)
+ for _, token := range tokens {
+ if strings.Contains("+-*/", token) {
+ // 是个运算符,从栈顶拿出两个数字进行运算,运算结果入栈
+ a, b := stk[len(stk)-1], stk[len(stk)-2]
+ stk = stk[:len(stk)-2]
+ switch token {
+ case "+":
+ stk = append(stk, a+b)
+ case "*":
+ stk = append(stk, a*b)
+ // 对于减法和除法,顺序别搞反了,第二个数是被除(减)数
+ case "-":
+ stk = append(stk, b-a)
+ case "/":
+ stk = append(stk, b/a)
+ }
+ } else {
+ // 是个数字,直接入栈即可
+ num, _ := strconv.Atoi(token)
+ stk = append(stk, num)
+ }
+ }
+ // 最后栈中剩下一个数字,即是计算结果
+ return stk[0]
+}
+```
+
+```java
+// by labuladong (java)
+class Solution {
+ public int evalRPN(String[] tokens) {
+ Stack stk = new Stack<>();
+ for (String token : tokens) {
+ if ("+-*/".contains(token)) {
+ // 是个运算符,从栈顶拿出两个数字进行运算,运算结果入栈
+ int a = stk.pop(), b = stk.pop();
+ switch (token) {
+ case "+":
+ stk.push(a + b);
+ break;
+ case "*":
+ stk.push(a * b);
+ break;
+ // 对于减法和除法,顺序别搞反了,第二个数是被除(减)数
+ case "-":
+ stk.push(b - a);
+ break;
+ case "/":
+ stk.push(b / a);
+ break;
+ }
+ } else {
+ // 是个数字,直接入栈即可
+ stk.push(Integer.parseInt(token));
+ }
+ }
+ // 最后栈中剩下一个数字,即是计算结果
+ return stk.pop();
+ }
+}
+```
+
+```javascript
+// by chatGPT (javascript)
+var evalRPN = function(tokens) {
+ let stk = [];
+ for (let i = 0; i < tokens.length; i++) {
+ let token = tokens[i];
+ if ("+-*/".includes(token)) {
+ // 是个运算符,从栈顶拿出两个数字进行运算,运算结果入栈
+ let a = stk.pop(), b = stk.pop();
+ switch (token) {
+ case "+":
+ stk.push(a + b);
+ break;
+ case "*":
+ stk.push(a * b);
+ break;
+ // 对于减法和除法,顺序别搞反了,第二个数是被除(减)数
+ case "-":
+ stk.push(b - a);
+ break;
+ case "/":
+ stk.push(parseInt(b / a));
+ break;
+ }
+ } else {
+ // 是个数字,直接入栈即可
+ stk.push(parseInt(token));
+ }
+ }
+ // 最后栈中剩下一个数字,即是计算结果
+ return stk.pop();
+};
+```
+
+```python
+# by chatGPT (python)
+class Solution:
+ def evalRPN(self, tokens: List[str]) -> int:
+ stk = []
+ for token in tokens:
+ if token in "+-*/":
+ # 是个运算符,从栈顶拿出两个数字进行运算,运算结果入栈
+ a = stk.pop()
+ b = stk.pop()
+ if token == "+":
+ stk.append(a + b)
+ elif token == "-":
+ stk.append(b - a)
+ elif token == "*":
+ stk.append(a * b)
+ else: # token == "/"
+ stk.append(int(b / a))
+ else:
+ # 是个数字,直接入栈即可
+ stk.append(int(token))
+ # 最后栈中剩下一个数字,即是计算结果
+ return stk.pop()
+```
+
+https://leetcode.cn/problems/8Zf90G 的多语言解法👆
+
+https://leetcode.cn/problems/B1IidL 的多语言解法👇
+
+```cpp
+// by chatGPT (cpp)
+class Solution {
+public:
+ int peakIndexInMountainArray(vector& nums) {
+ // 取两端都闭的二分搜索
+ int left = 0, right = nums.size() - 1;
+ // 因为题目必然有解,所以设置 left == right 为结束条件
+ while (left < right) {
+ int mid = left + (right - left) / 2;
+ if (nums[mid] > nums[mid + 1]) {
+ // mid 本身就是峰值或其左侧有一个峰值
+ right = mid;
+ } else {
+ // mid 右侧有一个峰值
+ left = mid + 1;
+ }
+ }
+ return left;
+ }
+};
+```
+
+```go
+// by chatGPT (go)
+func peakIndexInMountainArray(nums []int) int {
+ // 取两端都闭的二分搜索
+ left, right := 0, len(nums)-1
+ // 因为题目必然有解,所以设置 left == right 为结束条件
+ for left < right {
+ mid := left + (right-left)/2
+ if nums[mid] > nums[mid+1] {
+ // mid 本身就是峰值或其左侧有一个峰值
+ right = mid
+ } else {
+ // mid 右侧有一个峰值
+ left = mid + 1
+ }
+ }
+ return left
+}
+```
+
+```java
+// by labuladong (java)
+class Solution {
+ public int peakIndexInMountainArray(int[] nums) {
+ // 取两端都闭的二分搜索
+ int left = 0, right = nums.length - 1;
+ // 因为题目必然有解,所以设置 left == right 为结束条件
+ while (left < right) {
+ int mid = left + (right - left) / 2;
+ if (nums[mid] > nums[mid + 1]) {
+ // mid 本身就是峰值或其左侧有一个峰值
+ right = mid;
+ } else {
+ // mid 右侧有一个峰值
+ left = mid + 1;
+ }
+ }
+ return left;
+ }
+}
+```
+
+```javascript
+// by chatGPT (javascript)
+var peakIndexInMountainArray = function(nums) {
+ // 取两端都闭的二分搜索
+ let left = 0, right = nums.length - 1;
+ // 因为题目必然有解,所以设置 left == right 为结束条件
+ while (left < right) {
+ let mid = left + Math.floor((right - left) / 2);
+ if (nums[mid] > nums[mid + 1]) {
+ // mid 本身就是峰值或其左侧有一个峰值
+ right = mid;
+ } else {
+ // mid 右侧有一个峰值
+ left = mid + 1;
+ }
+ }
+ return left;
+};
+```
+
+```python
+# by chatGPT (python)
+class Solution:
+ def peakIndexInMountainArray(self, nums: List[int]) -> int:
+ # 取两端都闭的二分搜索
+ left, right = 0, len(nums) - 1
+ # 因为题目必然有解,所以设置 left == right 为结束条件
+ while left < right:
+ mid = left + (right - left) // 2
+ if nums[mid] > nums[mid + 1]:
+ # mid 本身就是峰值或其左侧有一个峰值
+ right = mid
+ else:
+ # mid 右侧有一个峰值
+ left = mid + 1
+ return left
+```
+
+https://leetcode.cn/problems/B1IidL 的多语言解法👆
+
+https://leetcode.cn/problems/FortPu 的多语言解法👇
+
+```cpp
+// by labuladong (cpp)
+class RandomizedSet {
+ public:
+ // 存储元素的值
+ vector nums;
+ // 记录每个元素对应在 nums 中的索引
+ unordered_map valToIndex;
+
+ bool insert(int val) {
+ // 若 val 已存在,不用再插入
+ if (valToIndex.count(val)) {
+ return false;
+ }
+ // 若 val 不存在,插入到 nums 尾部,
+ // 并记录 val 对应的索引值
+ valToIndex[val] = nums.size();
+ nums.push_back(val);
+ return true;
+ }
+
+ bool remove(int val) {
+ // 若 val 不存在,不用再删除
+ if (!valToIndex.count(val)) {
+ return false;
+ }
+ // 先拿到 val 的索引
+ int index = valToIndex[val];
+ // 将最后一个元素对应的索引修改为 index
+ valToIndex[nums.back()] = index;
+ // 交换 val 和最后一个元素
+ swap(nums[index], nums.back());
+ // 在数组中删除元素 val
+ nums.pop_back();
+ // 删除元素 val 对应的索引
+ valToIndex.erase(val);
+ return true;
+ }
+
+ int getRandom() {
+ // 随机获取 nums 中的一个元素
+ return nums[rand() % nums.size()];
+ }
+};
+```
+
+```go
+// by chatGPT (go)
+// 定义结构体
+type RandomizedSet struct {
+ // 存储元素的值
+ nums []int
+ // 记录每个元素对应在 nums 中的索引
+ valToIndex map[int]int
+}
+
+// 插入操作
+func (r *RandomizedSet) insert(val int) bool {
+ // 若 val 已存在,不用再插入
+ if _, ok := r.valToIndex[val]; ok {
+ return false
+ }
+ // 若 val 不存在,插入到 nums 尾部,
+ // 并记录 val 对应的索引值
+ r.valToIndex[val] = len(r.nums)
+ r.nums = append(r.nums, val)
+ return true
+}
+
+// 删除操作
+func (r *RandomizedSet) remove(val int) bool {
+ // 若 val 不存在,不用再删除
+ if _, ok := r.valToIndex[val]; !ok {
+ return false
+ }
+ // 先拿到 val 的索引
+ index := r.valToIndex[val]
+ // 将最后一个元素对应的索引修改为 index
+ r.valToIndex[r.nums[len(r.nums)-1]] = index
+ // 交换 val 和最后一个元素
+ r.nums[index], r.nums[len(r.nums)-1] = r.nums[len(r.nums)-1], r.nums[index]
+ // 在数组中删除元素 val
+ r.nums = r.nums[:len(r.nums)-1]
+ // 删除元素 val 对应的索引
+ delete(r.valToIndex, val)
+ return true
+}
+
+// 随机获取元素
+func (r *RandomizedSet) getRandom() int {
+ // 随机获取 nums 中的一个元素
+ return r.nums[rand.Intn(len(r.nums))]
+}
+```
+
+```java
+// by chatGPT (java)
+class RandomizedSet {
+ // 存储元素的值
+ List nums;
+ // 记录每个元素对应在 nums 中的索引
+ Map valToIndex;
+
+ public boolean insert(int val) {
+ // 若 val 已存在,不用再插入
+ if (valToIndex.containsKey(val)) {
+ return false;
+ }
+ // 若 val 不存在,插入到 nums 尾部,
+ // 并记录 val 对应的索引值
+ valToIndex.put(val, nums.size());
+ nums.add(val);
+ return true;
+ }
+
+ public boolean remove(int val) {
+ // 若 val 不存在,不用再删除
+ if (!valToIndex.containsKey(val)) {
+ return false;
+ }
+ // 先拿到 val 的索引
+ int index = valToIndex.get(val);
+ // 将最后一个元素对应的索引修改为 index
+ valToIndex.put(nums.get(nums.size()-1), index);
+ // 交换 val 和最后一个元素
+ Collections.swap(nums, index, nums.size()-1);
+ // 在数组中删除元素 val
+ nums.remove(nums.size()-1);
+ // 删除元素 val 对应的索引
+ valToIndex.remove(val);
+ return true;
+ }
+
+ public int getRandom() {
+ // 随机获取 nums 中的一个元素
+ return nums.get((int)(Math.random() * nums.size()));
+ }
+}
+```
+
+```javascript
+// by chatGPT (javascript)
+/**
+ * Initialize your data structure here.
+ */
+var RandomizedSet = function() {
+ // 存储元素的值
+ this.nums = [];
+ // 记录每个元素对应在 nums 中的索引
+ this.valToIndex = new Map();
+};
+
+/**
+ * Inserts a value to the set. Returns true if the set did not already contain the specified element.
+ * @param {number} val
+ * @return {boolean}
+ */
+RandomizedSet.prototype.insert = function(val) {
+ // 若 val 已存在,不用再插入
+ if (this.valToIndex.has(val)) {
+ return false;
+ }
+ // 若 val 不存在,插入到 nums 尾部,
+ // 并记录 val 对应的索引值
+ this.valToIndex.set(val, this.nums.length);
+ this.nums.push(val);
+ return true;
+};
+
+/**
+ * Removes a value from the set. Returns true if the set contained the specified element.
+ * @param {number} val
+ * @return {boolean}
+ */
+RandomizedSet.prototype.remove = function(val) {
+ // 若 val 不存在,不用再删除
+ if (!this.valToIndex.has(val)) {
+ return false;
+ }
+ // 先拿到 val 的索引
+ const index = this.valToIndex.get(val);
+ // 将最后一个元素对应的索引修改为 index
+ this.valToIndex.set(this.nums[this.nums.length - 1], index);
+ // 交换 val 和最后一个元素
+ [this.nums[index], this.nums[this.nums.length - 1]] = [this.nums[this.nums.length - 1], this.nums[index]];
+ // 在数组中删除元素 val
+ this.nums.pop();
+ // 删除元素 val 对应的索引
+ this.valToIndex.delete(val);
+ return true;
+};
+
+/**
+ * Get a random element from the set.
+ * @return {number}
+ */
+RandomizedSet.prototype.getRandom = function() {
+ // 随机获取 nums 中的一个元素
+ return this.nums[Math.floor(Math.random() * this.nums.length)];
+};
+```
+
+```python
+# by chatGPT (python)
+class RandomizedSet:
+ def __init__(self):
+ # 存储元素的值
+ self.nums = []
+ # 记录每个元素对应在 nums 中的索引
+ self.valToIndex = {}
+
+ def insert(self, val: int) -> bool:
+ # 若 val 已存在,不用再插入
+ if val in self.valToIndex:
+ return False
+ # 若 val 不存在,插入到 nums 尾部,
+ # 并记录 val 对应的索引值
+ self.valToIndex[val] = len(self.nums)
+ self.nums.append(val)
+ return True
+
+ def remove(self, val: int) -> bool:
+ # 若 val 不存在,不用再删除
+ if val not in self.valToIndex:
+ return False
+ # 先拿到 val 的索引
+ index = self.valToIndex[val]
+ # 将最后一个元素对应的索引修改为 index
+ self.valToIndex[self.nums[-1]] = index
+ # 交换 val 和最后一个元素
+ self.nums[index], self.nums[-1] = self.nums[-1], self.nums[index]
+ # 在数组中删除元素 val
+ self.nums.pop()
+ # 删除元素 val 对应的索引
+ self.valToIndex.pop(val)
+ return True
+
+ def getRandom(self) -> int:
+ # 随机获取 nums 中的一个元素
+ return self.nums[random.randint(0, len(self.nums) - 1)]
+```
+
+https://leetcode.cn/problems/FortPu 的多语言解法👆
+
+https://leetcode.cn/problems/Gu0c2T 的多语言解法👇
+
+```cpp
+// by chatGPT (cpp)
+class Solution {
+private:
+ // 备忘录
+ vector memo;
+ // dp 函数
+ int dp(vector& nums, int start) {
+ if (start >= nums.size()) {
+ return 0;
+ }
+ // 避免重复计算
+ if (memo[start] != -1) {
+ return memo[start];
+ }
+ int res = max(dp(nums, start + 1),
+ nums[start] + dp(nums, start + 2));
+ // 记入备忘录
+ memo[start] = res;
+ return res;
+ }
+
+public:
+ // 主函数
+ int rob(vector& nums) {
+ // 初始化备忘录
+ memo.resize(nums.size(), -1);
+ // 强盗从第 0 间房子开始抢劫
+ return dp(nums, 0);
+ }
+};
+```
+
+```go
+// by chatGPT (go)
+import (
+ "fmt"
+)
+
+func rob(nums []int) int {
+ // 初始化备忘录
+ memo := make([]int, len(nums))
+ for i := 0; i < len(memo); i++ {
+ memo[i] = -1
+ }
+ // 强盗从第 0 间房子开始抢劫
+ return dp(nums, 0, memo)
+}
+
+// 返回 dp[start..] 能抢到的最大值
+func dp(nums []int, start int, memo []int) int {
+ if start >= len(nums) {
+ return 0
+ }
+ // 避免重复计算
+ if memo[start] != -1 {
+ return memo[start]
+ }
+
+ res := max(dp(nums, start+1, memo), nums[start]+dp(nums, start+2, memo))
+ // 记入备忘录
+ memo[start] = res
+ return res
+}
+
+func max(x, y int) int {
+ if x > y {
+ return x
+ }
+ return y
+}
+```
+
+```java
+// by labuladong (java)
+class Solution {
+ // 备忘录
+ private int[] memo;
+ // 主函数
+ public int rob(int[] nums) {
+ // 初始化备忘录
+ memo = new int[nums.length];
+ Arrays.fill(memo, -1);
+ // 强盗从第 0 间房子开始抢劫
+ return dp(nums, 0);
+ }
+
+ // 返回 dp[start..] 能抢到的最大值
+ private int dp(int[] nums, int start) {
+ if (start >= nums.length) {
+ return 0;
+ }
+ // 避免重复计算
+ if (memo[start] != -1) return memo[start];
+
+ int res = Math.max(dp(nums, start + 1),
+ nums[start] + dp(nums, start + 2));
+ // 记入备忘录
+ memo[start] = res;
+ return res;
+ }
+}
+```
+
+```javascript
+// by chatGPT (javascript)
+var rob = function(nums) {
+ // 备忘录
+ const memo = new Array(nums.length).fill(-1);
+
+ // 返回 dp[start..] 能抢到的最大值
+ const dp = (start) => {
+ if (start >= nums.length) {
+ return 0;
+ }
+ // 避免重复计算
+ if (memo[start] != -1) return memo[start];
+
+ const res = Math.max(dp(start + 1), nums[start] + dp(start + 2));
+ // 记入备忘录
+ memo[start] = res;
+ return res;
+ }
+
+ // 强盗从第 0 间房子开始抢劫
+ return dp(0);
+};
+```
+
+```python
+# by chatGPT (python)
+class Solution:
+ def __init__(self):
+ # 备忘录
+ self.memo = None
+
+ # 主函数
+ def rob(self, nums: List[int]) -> int:
+ # 初始化备忘录
+ self.memo = [-1] * len(nums)
+ # 强盗从第 0 间房子开始抢劫
+ return self.dp(nums, 0)
+
+ # 返回 dp[start..] 能抢到的最大值
+ def dp(self, nums: List[int], start: int) -> int:
+ if start >= len(nums):
+ return 0
+ # 避免重复计算
+ if self.memo[start] != -1:
+ return self.memo[start]
+ res = max(self.dp(nums, start + 1),
+ nums[start] + self.dp(nums, start + 2))
+ # 记入备忘录
+ self.memo[start] = res
+ return res
+```
+
+https://leetcode.cn/problems/Gu0c2T 的多语言解法👆
+
+https://leetcode.cn/problems/IDBivT 的多语言解法👇
+
+```cpp
+// by labuladong (cpp)
+class Solution {
+ public:
+ vector generateParenthesis(int n) {
+ if (n == 0) return {};
+ // 记录所有合法的括号组合
+ vector res;
+ // 回溯过程中的路径
+ string track;
+ // 可用的左括号和右括号数量初始化为 n
+ backtrack(n, n, track, res);
+ return res;
+ }
+
+ // 可用的左括号数量为 left 个,可用的右括号数量为 rgiht 个
+ void backtrack(int left, int right,
+ string& track, vector& res) {
+ // 若左括号剩下的多,说明不合法
+ if (right < left) return;
+ // 数量小于 0 肯定是不合法的
+ if (left < 0 || right < 0) return;
+ // 当所有括号都恰好用完时,得到一个合法的括号组合
+ if (left == 0 && right == 0) {
+ res.push_back(track);
+ return;
+ }
+
+ // 尝试放一个左括号
+ track.push_back('('); // 选择
+ backtrack(left - 1, right, track, res);
+ track.pop_back(); // 撤消选择
+
+ // 尝试放一个右括号
+ track.push_back(')'); // 选择
+ backtrack(left, right - 1, track, res);
+ track.pop_back(); // 撤消选择
+ }
+}
+```
+
+```go
+// by chatGPT (go)
+func generateParenthesis(n int) []string {
+ if n == 0 {
+ return []string{}
+ }
+ // 记录所有合法的括号组合
+ var res []string
+ // 回溯过程中的路径
+ var track string
+ // 可用的左括号和右括号数量初始化为 n
+ backtrack(n, n, &track, &res)
+ return res
+}
+
+// 可用的左括号数量为 left 个,可用的右括号数量为 right 个
+func backtrack(left, right int, track *string, res *[]string) {
+ // 若左括号剩下的多,说明不合法
+ if right < left {
+ return
+ }
+ // 数量小于 0 肯定是不合法的
+ if left < 0 || right < 0 {
+ return
+ }
+ // 当所有括号都恰好用完时,得到一个合法的括号组合
+ if left == 0 && right == 0 {
+ *res = append(*res, *track)
+ return
+ }
+
+ // 尝试放一个左括号
+ *track += "(" // 选择
+ backtrack(left-1, right, track, res)
+ *track = (*track)[:len(*track)-1] // 撤消选择
+
+ // 尝试放一个右括号
+ *track += ")" // 选择
+ backtrack(left, right-1, track, res)
+ *track = (*track)[:len(*track)-1] // 撤消选择
+}
+```
+
+```java
+// by chatGPT (java)
+class Solution {
+ public List generateParenthesis(int n) {
+ if (n == 0) return new ArrayList<>();
+ // 记录所有合法的括号组合
+ List res = new ArrayList<>();
+ // 回溯过程中的路径
+ StringBuilder track = new StringBuilder();
+ // 可用的左括号和右括号数量初始化为 n
+ backtrack(n, n, track, res);
+ return res;
+ }
+
+ // 可用的左括号数量为 left 个,可用的右括号数量为 right 个
+ void backtrack(int left, int right,
+ StringBuilder track, List res) {
+ // 若左括号剩下的多,说明不合法
+ if (right < left) return;
+ // 数量小于 0 肯定是不合法的
+ if (left < 0 || right < 0) return;
+ // 当所有括号都恰好用完时,得到一个合法的括号组合
+ if (left == 0 && right == 0) {
+ res.add(track.toString());
+ return;
+ }
+
+ // 尝试放一个左括号
+ track.append('('); // 选择
+ backtrack(left - 1, right, track, res);
+ track.deleteCharAt(track.length() - 1); // 撤消选择
+
+ // 尝试放一个右括号
+ track.append(')'); // 选择
+ backtrack(left, right - 1, track, res);
+ track.deleteCharAt(track.length() - 1); // 撤消选择
+ }
+}
+```
+
+```javascript
+// by chatGPT (javascript)
+var generateParenthesis = function(n) {
+ if (n === 0) return [];
+ // 记录所有合法的括号组合
+ var res = [];
+ // 回溯过程中的路径
+ var track = "";
+ // 可用的左括号和右括号数量初始化为 n
+ backtrack(n, n, track, res);
+ return res;
+};
+
+// 可用的左括号数量为 left 个,可用的右括号数量为 rgiht 个
+var backtrack = function(left, right, track, res) {
+ // 若左括号剩下的多,说明不合法
+ if (right < left) return;
+ // 数量小于 0 肯定是不合法的
+ if (left < 0 || right < 0) return;
+ // 当所有括号都恰好用完时,得到一个合法的括号组合
+ if (left === 0 && right === 0) {
+ res.push(track);
+ return;
+ }
+
+ // 尝试放一个左括号
+ track += '('; // 选择
+ backtrack(left - 1, right, track, res);
+ track = track.substring(0, track.length - 1); // 撤消选择
+
+ // 尝试放一个右括号
+ track += ')'; // 选择
+ backtrack(left, right - 1, track, res);
+ track = track.substring(0, track.length - 1); // 撤消选择
+};
+```
+
+```python
+# by chatGPT (python)
+class Solution:
+ def generateParenthesis(self, n: int) -> List[str]:
+ if n == 0:
+ return []
+ # 记录所有合法的括号组合
+ res = []
+ # 回溯过程中的路径
+ track = ""
+ # 可用的左括号和右括号数量初始化为 n
+ self.backtrack(n, n, track, res)
+ return res
+
+ # 可用的左括号数量为 left 个,可用的右括号数量为 rgiht 个
+ def backtrack(self, left: int, right: int, track: str, res: List[str]) -> None:
+ # 若右括号剩下的多,说明不合法
+ if right < left:
+ return
+ # 数量小于 0 肯定是不合法的
+ if left < 0 or right < 0:
+ return
+ # 当所有括号都恰好用完时,得到一个合法的括号组合
+ if left == 0 and right == 0:
+ res.append(track)
+ return
+
+ # 尝试放一个左括号
+ track += '(' # 选择
+ self.backtrack(left - 1, right, track, res)
+ track = track[:-1] # 撤消选择
+
+ # 尝试放一个右括号
+ track += ')' # 选择
+ self.backtrack(left, right - 1, track, res)
+ track = track[:-1] # 撤消选择
+```
+
+https://leetcode.cn/problems/IDBivT 的多语言解法👆
+
+https://leetcode.cn/problems/M1oyTv 的多语言解法👇
+
+```cpp
+// by labuladong (cpp)
+class Solution {
+ public:
+ string minWindow(string s, string t) {
+ unordered_map need, window;
+ for (char c : t) need[c]++;
+
+ int left = 0, right = 0;
+ int valid = 0;
+ // 记录最小覆盖子串的起始索引及长度
+ int start = 0, len = INT_MAX;
+ /**
+ 
+ */
+ while (right < s.size()) {
+ // c 是将移入窗口的字符
+ char c = s[right];
+ // 右移窗口
+ right++;
+ // 进行窗口内数据的一系列更新
+ if (need.count(c)) {
+ window[c]++;
+ if (window[c] == need[c])
+ valid++;
+ }
+
+ // 判断左侧窗口是否要收缩
+ while (valid == need.size()) {
+ /**
+ 
+ */
+ // 在这里更新最小覆盖子串
+ if (right - left < len) {
+ start = left;
+ len = right - left;
+ }
+ // d 是将移出窗口的字符
+ char d = s[left];
+ // 左移窗口
+ left++;
+ // 进行窗口内数据的一系列更新
+ if (need.count(d)) {
+ if (window[d] == need[d])
+ valid--;
+ window[d]--;
+ }
+ }
+ /**
+ 
+ */
+ }
+ // 返回最小覆盖子串
+ return len == INT_MAX ?
+ "" : s.substr(start, len);
+ }
+};
+```
+
+```go
+// by chatGPT (go)
+func minWindow(s string, t string) string {
+ need := make(map[byte]int)
+ window := make(map[byte]int)
+ for i := 0; i < len(t); i++ {
+ need[t[i]]++
+ }
+
+ left, right, valid := 0, 0, 0
+ // 记录最小覆盖子串的起始索引及长度
+ start, len := 0, math.MaxInt32
+ /**
+ 
+ */
+ for right < len(s) {
+ // c 是将移入窗口的字符
+ c := s[right]
+ // 右移窗口
+ right++
+ // 进行窗口内数据的一系列更新
+ if _, ok := need[c]; ok {
+ window[c]++
+ if window[c] == need[c] {
+ valid++
+ }
+ }
+
+ // 判断左侧窗口是否要收缩
+ for valid == len(need) {
+ /**
+ 
+ */
+ // 在这里更新最小覆盖子串
+ if right-left < len {
+ start = left
+ len = right - left
+ }
+
+ // d 是将移出窗口的字符
+ d := s[left]
+ // 左移窗口
+ left++
+ // 进行窗口内数据的一系列更新
+ if _, ok := need[d]; ok {
+ if window[d] == need[d] {
+ valid--
+ }
+ window[d]--
+ }
+ }
+ /**
+ 
+ */
+ }
+ // 返回最小覆盖子串
+ if len == math.MaxInt32 {
+ return ""
+ }
+ return s[start : start+len]
+}
+```
+
+```java
+// by chatGPT (java)
+class Solution {
+ public String minWindow(String s, String t) {
+ HashMap need = new HashMap<>();
+ HashMap window = new HashMap<>();
+ for (char c : t.toCharArray()) {
+ need.put(c, need.getOrDefault(c, 0) + 1);
+ }
+ int left = 0, right = 0;
+ int valid = 0;
+ // 记录最小覆盖子串的起始索引及长度
+ int start = 0, len = Integer.MAX_VALUE;
+ /**
+ 
+ */
+ while (right < s.length()) {
+ // c 是将移入窗口的字符
+ char c = s.charAt(right);
+ // 右移窗口
+ right++;
+ // 进行窗口内数据的一系列更新
+ if (need.containsKey(c)) {
+ window.put(c, window.getOrDefault(c, 0) + 1);
+ if (window.get(c).equals(need.get(c))) {
+ valid++;
+ }
+ }
+
+ // 判断左侧窗口是否要收缩
+ while (valid == need.size()) {
+ /**
+ 
+ */
+ // 在这里更新最小覆盖子串
+ if (right - left < len) {
+ start = left;
+ len = right - left;
+ }
+ // d 是将移出窗口的字符
+ char d = s.charAt(left);
+ // 左移窗口
+ left++;
+ // 进行窗口内数据的一系列更新
+ if (need.containsKey(d)) {
+ if (window.get(d).equals(need.get(d))) {
+ valid--;
+ }
+ window.put(d, window.get(d) - 1);
+ }
+ }
+ /**
+ 
+ */
+ }
+ // 返回最小覆盖子串
+ return len == Integer.MAX_VALUE ?
+ "" : s.substring(start, start + len);
+ }
+}
+```
+
+```javascript
+// by chatGPT (javascript)
+var minWindow = function(s, t) {
+ var need = new Map();
+ var window = new Map();
+ for (var c of t) {
+ need.set(c, need.has(c) ? need.get(c) + 1 : 1);
+ }
+
+ var left = 0, right = 0;
+ var valid = 0;
+ // 记录最小覆盖子串的起始索引及长度
+ var start = 0, len = Number.MAX_SAFE_INTEGER;
+ /**
+ 
+ */
+ while (right < s.length) {
+ // c 是将移入窗口的字符
+ var c = s[right];
+ // 右移窗口
+ right++;
+ // 进行窗口内数据的一系列更新
+ if (need.has(c)) {
+ window.set(c, window.has(c) ? window.get(c) + 1 : 1);
+ if (window.get(c) === need.get(c))
+ valid++;
+ }
+
+ // 判断左侧窗口是否要收缩
+ while (valid === need.size) {
+ /**
+ 
+ */
+ // 在这里更新最小覆盖子串
+ if (right - left < len) {
+ start = left;
+ len = right - left;
+ }
+ // d 是将移出窗口的字符
+ var d = s[left];
+ // 左移窗口
+ left++;
+ // 进行窗口内数据的一系列更新
+ if (need.has(d)) {
+ if (window.get(d) === need.get(d))
+ valid--;
+ window.set(d, window.get(d) - 1);
+ }
+ }
+ /**
+ 
+ */
+ }
+ // 返回最小覆盖子串
+ return len === Number.MAX_SAFE_INTEGER ?
+ "" : s.substring(start, start + len);
+};
+```
+
+```python
+# by chatGPT (python)
+class Solution:
+ def minWindow(self, s: str, t: str) -> str:
+ from collections import defaultdict
+ need, window = defaultdict(int), defaultdict(int)
+ for c in t:
+ need[c] += 1
+
+ left, right = 0, 0
+ valid = 0
+ # 记录最小覆盖子串的起始索引及长度
+ start, length = 0, float('inf')
+ # 
+ while right < len(s):
+ # c 是将移入窗口的字符
+ c = s[right]
+ # 右移窗口
+ right += 1
+ # 进行窗口内数据的一系列更新
+ if c in need:
+ window[c] += 1
+ if window[c] == need[c]:
+ valid += 1
+
+ # 判断左侧窗口是否要收缩
+ while valid == len(need):
+ # 
+ # 在这里更新最小覆盖子串
+ if right - left < length:
+ start = left
+ length = right - left
+ # d 是将移出窗口的字符
+ d = s[left]
+ # 左移窗口
+ left += 1
+ # 进行窗口内数据的一系列更新
+ if d in need:
+ if window[d] == need[d]:
+ valid -= 1
+ window[d] -= 1
+ # 
+ # 返回最小覆盖子串
+ return '' if length == float('inf') else s[start:start+length]
+```
+
+https://leetcode.cn/problems/M1oyTv 的多语言解法👆
+
+https://leetcode.cn/problems/MPnaiL 的多语言解法👇
+
+```cpp
+// by labuladong (cpp)
+class Solution {
+ public:
+
+ // 判断 s 中是否存在 t 的排列
+ bool checkInclusion(string t, string s) {
+ unordered_map need, window;
+ for (char c : t) need[c]++;
+
+ int left = 0, right = 0;
+ int valid = 0;
+ while (right < s.size()) {
+ char c = s[right];
+ right++;
+ // 进行窗口内数据的一系列更新
+ if (need.count(c)) {
+ window[c]++;
+ if (window[c] == need[c])
+ valid++;
+ }
+
+ // 判断左侧窗口是否要收缩
+ while (right - left >= t.size()) {
+ // 在这里判断是否找到了合法的子串
+ if (valid == need.size())
+ return true;
+ char d = s[left];
+ left++;
+ // 进行窗口内数据的一系列更新
+ if (need.count(d)) {
+ if (window[d] == need[d])
+ valid--;
+ window[d]--;
+ }
+ }
+ }
+ // 未找到符合条件的子串
+ return false;
+ }
+};
+```
+
+```go
+// by chatGPT (go)
+func checkInclusion(t string, s string) bool {
+ need := make(map[byte]int)
+ window := make(map[byte]int)
+ for i := range t {
+ need[t[i]]++
+ }
+
+ left, right := 0, 0
+ valid := 0
+ for right < len(s) {
+ c := s[right]
+ right++
+ // 进行窗口内数据的一系列更新
+ if _, ok := need[c]; ok {
+ window[c]++
+ if window[c] == need[c] {
+ valid++
+ }
+ }
+
+ // 判断左侧窗口是否要收缩
+ for right-left >= len(t) {
+ // 在这里判断是否找到了合法的子串
+ if valid == len(need) {
+ return true
+ }
+ d := s[left]
+ left++
+ // 进行窗口内数据的一系列更新
+ if _, ok := need[d]; ok {
+ if window[d] == need[d] {
+ valid--
+ }
+ window[d]--
+ }
+ }
+ }
+ // 未找到符合条件的子串
+ return false
+}
+```
+
+```java
+// by chatGPT (java)
+class Solution {
+ public boolean checkInclusion(String t, String s) {
+ Map need = new HashMap<>();
+ Map window = new HashMap<>();
+ for (char c : t.toCharArray()) need.put(c, need.getOrDefault(c, 0) + 1);
+
+ int left = 0, right = 0;
+ int valid = 0;
+ while (right < s.length()) {
+ char c = s.charAt(right);
+ right++;
+ // 进行窗口内数据的一系列更新
+ if (need.containsKey(c)) {
+ window.put(c, window.getOrDefault(c, 0) + 1);
+ if (window.get(c).equals(need.get(c)))
+ valid++;
+ }
+
+ // 判断左侧窗口是否要收缩
+ while (right - left >= t.length()) {
+ // 在这里判断是否找到了合法的子串
+ if (valid == need.size())
+ return true;
+ char d = s.charAt(left);
+ left++;
+ // 进行窗口内数据的一系列更新
+ if (need.containsKey(d)) {
+ if (window.get(d).equals(need.get(d)))
+ valid--;
+ window.put(d, window.get(d) - 1);
+ }
+ }
+ }
+ // 未找到符合条件的子串
+ return false;
+ }
+}
+```
+
+```javascript
+// by chatGPT (javascript)
+var checkInclusion = function(t, s) {
+ const need = new Map();
+ const window = new Map();
+ for (let c of t) {
+ need.set(c, (need.get(c) || 0) + 1);
+ }
+
+ let left = 0, right = 0;
+ let valid = 0;
+ while (right < s.length) {
+ const c = s[right];
+ right++;
+ // 进行窗口内数据的一系列更新
+ if (need.has(c)) {
+ window.set(c, (window.get(c) || 0) + 1);
+ if (window.get(c) === need.get(c)) {
+ valid++;
+ }
+ }
+
+ // 判断左侧窗口是否要收缩
+ while (right - left >= t.length) {
+ // 在这里判断是否找到了合法的子串
+ if (valid === need.size) {
+ return true;
+ }
+ const d = s[left];
+ left++;
+ // 进行窗口内数据的一系列更新
+ if (need.has(d)) {
+ if (window.get(d) === need.get(d)) {
+ valid--;
+ }
+ window.set(d, (window.get(d) || 0) - 1);
+ }
+ }
+ }
+ // 未找到符合条件的子串
+ return false;
+};
+```
+
+```python
+# by chatGPT (python)
+class Solution:
+ def checkInclusion(self, t: str, s: str) -> bool:
+ need, window = {}, {}
+ for c in t:
+ need[c] = need.get(c, 0) + 1
+
+ left, right = 0, 0
+ valid = 0
+ while right < len(s):
+ c = s[right]
+ right += 1
+ # 进行窗口内数据的一系列更新
+ if c in need:
+ window[c] = window.get(c, 0) + 1
+ if window[c] == need[c]:
+ valid += 1
+
+ # 判断左侧窗口是否要收缩
+ while right - left >= len(t):
+ # 在这里判断是否找到了合法的子串
+ if valid == len(need):
+ return True
+ d = s[left]
+ left += 1
+ # 进行窗口内数据的一系列更新
+ if d in need:
+ if window[d] == need[d]:
+ valid -= 1
+ window[d] -= 1
+
+ # 未找到符合条件的子串
+ return False
+```
+
+https://leetcode.cn/problems/MPnaiL 的多语言解法👆
+
+https://leetcode.cn/problems/N6YdxV 的多语言解法👇
+
+```cpp
+// by chatGPT (cpp)
+class Solution {
+public:
+ int searchInsert(vector& nums, int target) {
+ return left_bound(nums, target);
+ }
+
+ // 搜索左侧边界的二分算法
+ int left_bound(vector& nums, int target) {
+ if (nums.size() == 0) return -1;
+ int left = 0;
+ int right = nums.size(); // 注意
+
+ while (left < right) { // 注意
+ int mid = left + (right - left) / 2;
+ if (nums[mid] == target) {
+ right = mid;
+ } else if (nums[mid] < target) {
+ left = mid + 1;
+ } else if (nums[mid] > target) {
+ right = mid; // 注意
+ }
+ }
+ return left;
+ }
+};
+```
+
+```go
+// by chatGPT (go)
+func searchInsert(nums []int, target int) int {
+ return leftBound(nums, target)
+}
+
+//搜索左侧边界的二分算法
+func leftBound(nums []int, target int) int {
+ if len(nums) == 0 {
+ return -1
+ }
+ left, right := 0, len(nums)
+
+ for left < right {
+ mid := left + (right - left)/2
+ if nums[mid] == target {
+ right = mid
+ } else if nums[mid] < target {
+ left = mid + 1
+ } else if nums[mid] > target {
+ right = mid
+ }
+ }
+ return left
+}
+```
+
+```java
+// by labuladong (java)
+class Solution {
+ public int searchInsert(int[] nums, int target) {
+ return left_bound(nums, target);
+ }
+
+ // 搜索左侧边界的二分算法
+ int left_bound(int[] nums, int target) {
+ if (nums.length == 0) return -1;
+ int left = 0;
+ int right = nums.length; // 注意
+
+ while (left < right) { // 注意
+ int mid = left + (right - left) / 2;
+ if (nums[mid] == target) {
+ right = mid;
+ } else if (nums[mid] < target) {
+ left = mid + 1;
+ } else if (nums[mid] > target) {
+ right = mid; // 注意
+ }
+ }
+ return left;
+ }
+}
+```
+
+```javascript
+// by chatGPT (javascript)
+var Solution = function() {};
+
+Solution.prototype.searchInsert = function(nums, target) {
+ return this.left_bound(nums, target);
+};
+
+// 搜索左侧边界的二分算法
+Solution.prototype.left_bound = function(nums, target) {
+ if (nums.length == 0) return -1;
+ var left = 0;
+ var right = nums.length; // 注意
+
+ while (left < right) { // 注意
+ var mid = left + Math.floor((right - left) / 2);
+ if (nums[mid] == target) {
+ right = mid;
+ } else if (nums[mid] < target) {
+ left = mid + 1;
+ } else if (nums[mid] > target) {
+ right = mid; // 注意
+ }
+ }
+ return left;
+};
+```
+
+```python
+# by chatGPT (python)
+class Solution:
+ def searchInsert(self, nums: List[int], target: int) -> int:
+ return self.left_bound(nums, target)
+
+ # 搜索左侧边界的二分算法
+ def left_bound(self, nums: List[int], target: int) -> int:
+ if len(nums) == 0:
+ return -1
+ left, right = 0, len(nums) # 注意
+
+ while left < right: # 注意
+ mid = left + (right - left) // 2
+ if nums[mid] == target:
+ right = mid
+ elif nums[mid] < target:
+ left = mid + 1
+ elif nums[mid] > target:
+ right = mid # 注意
+
+ return left
+```
+
+https://leetcode.cn/problems/N6YdxV 的多语言解法👆
+
+https://leetcode.cn/problems/NUPfPr 的多语言解法👇
+
+```cpp
+// by chatGPT (cpp)
+class Solution {
+public:
+ bool canPartition(vector& nums) {
+ int sum = 0;
+ for (int num : nums) sum += num;
+ // 和为奇数时,不可能划分成两个和相等的集合
+ if (sum % 2 != 0) return false;
+ int n = nums.size();
+ sum = sum / 2;
+ vector> dp(n + 1, vector(sum + 1, false));
+ // base case
+ for (int i = 0; i <= n; i++)
+ dp[i][0] = true;
+
+ for (int i = 1; i <= n; i++) {
+ for (int j = 1; j <= sum; j++) {
+ if (j - nums[i - 1] < 0) {
+ // 背包容量不足,不能装入第 i 个物品
+ dp[i][j] = dp[i - 1][j];
+ } else {
+ // 装入或不装入背包
+ dp[i][j] = dp[i - 1][j] || dp[i - 1][j - nums[i - 1]];
+ }
+ }
+ }
+ return dp[n][sum];
+ }
+};
+```
+
+```go
+// by chatGPT (go)
+func canPartition(nums []int) bool {
+ sum := 0
+ for _, num := range nums {
+ sum += num
+ }
+ // 和为奇数时,不可能划分成两个和相等的集合
+ if sum%2 != 0 {
+ return false
+ }
+ n := len(nums)
+ sum = sum / 2
+ dp := make([][]bool, n+1)
+ for i := 0; i <= n; i++ {
+ dp[i] = make([]bool, sum+1)
+ // base case
+ dp[i][0] = true
+ }
+
+ for i := 1; i <= n; i++ {
+ for j := 1; j <= sum; j++ {
+ if j-nums[i-1] < 0 {
+ // 背包容量不足,不能装入第 i 个物品
+ dp[i][j] = dp[i-1][j]
+ } else {
+ // 装入或不装入背包
+ dp[i][j] = dp[i-1][j] || dp[i-1][j-nums[i-1]]
+ }
+ }
+ }
+ return dp[n][sum]
+}
+```
+
+```java
+// by labuladong (java)
+class Solution {
+ public boolean canPartition(int[] nums) {
+ int sum = 0;
+ for (int num : nums) sum += num;
+ // 和为奇数时,不可能划分成两个和相等的集合
+ if (sum % 2 != 0) return false;
+ int n = nums.length;
+ sum = sum / 2;
+ boolean[][] dp = new boolean[n + 1][sum + 1];
+ // base case
+ for (int i = 0; i <= n; i++)
+ dp[i][0] = true;
+
+ for (int i = 1; i <= n; i++) {
+ for (int j = 1; j <= sum; j++) {
+ if (j - nums[i - 1] < 0) {
+ // 背包容量不足,不能装入第 i 个物品
+ dp[i][j] = dp[i - 1][j];
+ } else {
+ // 装入或不装入背包
+ dp[i][j] = dp[i - 1][j] || dp[i - 1][j - nums[i - 1]];
+ }
+ }
+ }
+ return dp[n][sum];
+ }
+}
+```
+
+```javascript
+// by chatGPT (javascript)
+var canPartition = function(nums) {
+ let sum = 0;
+ for (let num of nums) {
+ sum += num;
+ }
+ // 和为奇数时,不可能划分成两个和相等的集合
+ if (sum % 2 !== 0) {
+ return false;
+ }
+ let n = nums.length;
+ sum = sum / 2;
+ let dp = new Array(n + 1).fill(false).map(() => new Array(sum + 1).fill(false));
+ // base case
+ for (let i = 0; i <= n; i++) {
+ dp[i][0] = true;
+ }
+
+ for (let i = 1; i <= n; i++) {
+ for (let j = 1; j <= sum; j++) {
+ if (j - nums[i - 1] < 0) {
+ // 背包容量不足,不能装入第 i 个物品
+ dp[i][j] = dp[i - 1][j];
+ } else {
+ // 装入或不装入背包
+ dp[i][j] = dp[i - 1][j] || dp[i - 1][j - nums[i - 1]];
+ }
+ }
+ }
+ return dp[n][sum];
+};
+```
+
+```python
+# by chatGPT (python)
+class Solution:
+ def canPartition(self, nums: List[int]) -> bool:
+ sum = 0
+ for num in nums:
+ sum += num
+ # 和为奇数时,不可能划分成两个和相等的集合
+ if sum % 2 != 0:
+ return False
+ n = len(nums)
+ sum = sum // 2
+ dp = [[False] * (sum + 1) for _ in range(n + 1)]
+ # base case
+ for i in range(n + 1):
+ dp[i][0] = True
+
+ for i in range(1, n + 1):
+ for j in range(1, sum + 1):
+ if j - nums[i - 1] < 0:
+ # 背包容量不足,不能装入第 i 个物品
+ dp[i][j] = dp[i - 1][j]
+ else:
+ # 装入或不装入背包
+ dp[i][j] = dp[i - 1][j] or dp[i - 1][j - nums[i - 1]]
+ return dp[n][sum]
+```
+
+https://leetcode.cn/problems/NUPfPr 的多语言解法👆
+
+https://leetcode.cn/problems/O4NDxx 的多语言解法👇
+
+```cpp
+// by chatGPT (cpp)
+class NumMatrix {
+private:
+ // preSum[i][j] 记录矩阵 [0, 0, i, j] 的元素和
+ vector> preSum;
+
+public:
+ NumMatrix(vector>& matrix) {
+ int m = matrix.size(), n = matrix[0].size();
+ if (m == 0 || n == 0) return;
+ // 构造前缀和矩阵
+ preSum = vector>(m + 1, vector(n + 1, 0));
+ for (int i = 1; i <= m; i++) {
+ for (int j = 1; j <= n; j++) {
+ // 计算每个矩阵 [0, 0, i, j] 的元素和
+ preSum[i][j] = preSum[i-1][j] + preSum[i][j-1] + matrix[i - 1][j - 1] - preSum[i-1][j-1];
+ }
+ }
+ }
+
+ // 计算子矩阵 [x1, y1, x2, y2] 的元素和
+ int sumRegion(int x1, int y1, int x2, int y2) {
+ // 目标矩阵之和由四个相邻矩阵运算获得
+ return preSum[x2+1][y2+1] - preSum[x1][y2+1] - preSum[x2+1][y1] + preSum[x1][y1];
+ }
+};
+```
+
+```go
+// by chatGPT (go)
+type NumMatrix struct {
+ // preSum[i][j] 记录矩阵 [0, 0, i, j] 的元素和
+ preSum [][]int
+}
+
+func Constructor(matrix [][]int) NumMatrix {
+ m, n := len(matrix), len(matrix[0])
+ if m == 0 || n == 0 {
+ return NumMatrix{}
+ }
+ // 构造前缀和矩阵
+ preSum := make([][]int, m+1)
+ for i := range preSum {
+ preSum[i] = make([]int, n+1)
+ }
+ for i := 1; i <= m; i++ {
+ for j := 1; j <= n; j++ {
+ // 计算每个矩阵 [0, 0, i, j] 的元素和
+ preSum[i][j] = preSum[i-1][j] + preSum[i][j-1] + matrix[i-1][j-1] - preSum[i-1][j-1]
+ }
+ }
+ return NumMatrix{preSum}
+}
+
+// 计算子矩阵 [x1, y1, x2, y2] 的元素和
+func (this *NumMatrix) SumRegion(x1 int, y1 int, x2 int, y2 int) int {
+ // 目标矩阵之和由四个相邻矩阵运算获得
+ return this.preSum[x2+1][y2+1] - this.preSum[x1][y2+1] - this.preSum[x2+1][y1] + this.preSum[x1][y1]
+}
+```
+
+```java
+// by labuladong (java)
+class NumMatrix {
+ // preSum[i][j] 记录矩阵 [0, 0, i-1, j-1] 的元素和
+ private int[][] preSum;
+
+ public NumMatrix(int[][] matrix) {
+ int m = matrix.length, n = matrix[0].length;
+ if (m == 0 || n == 0) return;
+ // 构造前缀和矩阵
+ preSum = new int[m + 1][n + 1];
+ for (int i = 1; i <= m; i++) {
+ for (int j = 1; j <= n; j++) {
+ // 计算每个矩阵 [0, 0, i, j] 的元素和
+ preSum[i][j] = preSum[i-1][j] + preSum[i][j-1] + matrix[i - 1][j - 1] - preSum[i-1][j-1];
+ }
+ }
+ }
+
+ // 计算子矩阵 [x1, y1, x2, y2] 的元素和
+ public int sumRegion(int x1, int y1, int x2, int y2) {
+ // 目标矩阵之和由四个相邻矩阵运算获得
+ return preSum[x2+1][y2+1] - preSum[x1][y2+1] - preSum[x2+1][y1] + preSum[x1][y1];
+ }
+}
+```
+
+```javascript
+// by chatGPT (javascript)
+var NumMatrix = function(matrix) {
+ // preSum[i][j] 记录矩阵 [0, 0, i, j] 的元素和
+ var preSum;
+
+ var m = matrix.length, n = matrix[0].length;
+ if (m == 0 || n == 0) return;
+ // 构造前缀和矩阵
+ preSum = new Array(m + 1);
+ for (var i = 0; i <= m; i++) {
+ preSum[i] = new Array(n + 1).fill(0);
+ }
+ for (var i = 1; i <= m; i++) {
+ for (var j = 1; j <= n; j++) {
+ // 计算每个矩阵 [0, 0, i, j] 的元素和
+ preSum[i][j] = preSum[i-1][j] + preSum[i][j-1] + matrix[i - 1][j - 1] - preSum[i-1][j-1];
+ }
+ }
+
+ // 计算子矩阵 [x1, y1, x2, y2] 的元素和
+ this.sumRegion = function(x1, y1, x2, y2) {
+ // 目标矩阵之和由四个相邻矩阵运算获得
+ return preSum[x2+1][y2+1] - preSum[x1][y2+1] - preSum[x2+1][y1] + preSum[x1][y1];
+ }
+};
+```
+
+```python
+# by chatGPT (python)
+class NumMatrix:
+ def __init__(self, matrix: List[List[int]]):
+ m, n = len(matrix), len(matrix[0])
+ if m == 0 or n == 0:
+ return
+ # 构造前缀和矩阵
+ self.preSum = [[0] * (n + 1) for _ in range(m + 1)]
+ for i in range(1, m + 1):
+ for j in range(1, n + 1):
+ # 计算每个矩阵 [0, 0, i, j] 的元素和
+ self.preSum[i][j] = self.preSum[i - 1][j] + self.preSum[i][j - 1] + matrix[i - 1][j - 1] - self.preSum[i - 1][j - 1]
+
+ # 计算子矩阵 [x1, y1, x2, y2] 的元素和
+ def sumRegion(self, x1: int, y1: int, x2: int, y2: int) -> int:
+ # 目标矩阵之和由四个相邻矩阵运算获得
+ return self.preSum[x2 + 1][y2 + 1] - self.preSum[x1][y2 + 1] - self.preSum[x2 + 1][y1] + self.preSum[x1][y1]
+```
+
+https://leetcode.cn/problems/O4NDxx 的多语言解法👆
+
+https://leetcode.cn/problems/OrIXps 的多语言解法👇
+
+```cpp
+// by chatGPT (cpp)
+class LRUCache {
+ int cap;
+ unordered_map cache;
+ list keys;
+
+public:
+ LRUCache(int capacity) {
+ this->cap = capacity;
+ }
+
+ int get(int key) {
+ auto it = cache.find(key);
+ if (it == cache.end()) {
+ return -1;
+ }
+ // 将 key 变为最近使用
+ makeRecently(key);
+ return it->second;
+ }
+
+ void put(int key, int val) {
+ auto it = cache.find(key);
+ if (it != cache.end()) {
+ // 修改 key 的值
+ it->second = val;
+ // 将 key 变为最近使用
+ makeRecently(key);
+ return;
+ }
+
+ if (cache.size() >= this->cap) {
+ // 链表头部就是最久未使用的 key
+ int oldestKey = keys.front();
+ keys.pop_front();
+ cache.erase(oldestKey);
+ }
+ // 将新的 key 添加链表尾部
+ keys.push_back(key);
+ cache[key] = val;
+ }
+
+private:
+ void makeRecently(int key) {
+ int val = cache[key];
+ // 删除 key,重新插入到队尾
+ keys.remove(key);
+ keys.push_back(key);
+ cache[key] = val;
+ }
+};
+```
+
+```go
+// by chatGPT (go)
+type LRUCache struct {
+ cap int
+ cache map[int]int
+}
+
+// Constructor 创建一个 LRU Cache 实例
+func Constructor(capacity int) LRUCache {
+ return LRUCache{
+ cap: capacity,
+ cache: make(map[int]int),
+ }
+}
+
+// Get 获取一个 key 的值
+func (this *LRUCache) Get(key int) int {
+ if val, ok := this.cache[key]; ok {
+ this.makeRecently(key)
+ return val
+ }
+ return -1
+}
+
+// Put 插入一个 key/value
+func (this *LRUCache) Put(key int, value int) {
+ if _, ok := this.cache[key]; ok {
+ this.cache[key] = value
+ this.makeRecently(key)
+ return
+ }
+ if len(this.cache) >= this.cap {
+ this.removeLeastRecently()
+ }
+ this.cache[key] = value
+}
+
+// makeRecently 将一个元素标记为最近使用的
+func (this *LRUCache) makeRecently(key int) {
+ val := this.cache[key]
+ delete(this.cache, key)
+ this.cache[key] = val
+}
+
+// removeLeastRecently 移除最近未使用的元素
+func (this *LRUCache) removeLeastRecently() {
+ for k := range this.cache {
+ delete(this.cache, k)
+ break
+ }
+}
+```
+
+```java
+// by labuladong (java)
+class LRUCache {
+ int cap;
+ LinkedHashMap cache = new LinkedHashMap<>();
+ public LRUCache(int capacity) {
+ this.cap = capacity;
+ }
+
+ public int get(int key) {
+ if (!cache.containsKey(key)) {
+ return -1;
+ }
+ // 将 key 变为最近使用
+ makeRecently(key);
+ return cache.get(key);
+ }
+
+ public void put(int key, int val) {
+ if (cache.containsKey(key)) {
+ // 修改 key 的值
+ cache.put(key, val);
+ // 将 key 变为最近使用
+ makeRecently(key);
+ return;
+ }
+
+ if (cache.size() >= this.cap) {
+ // 链表头部就是最久未使用的 key
+ int oldestKey = cache.keySet().iterator().next();
+ cache.remove(oldestKey);
+ }
+ // 将新的 key 添加链表尾部
+ cache.put(key, val);
+ }
+
+ private void makeRecently(int key) {
+ int val = cache.get(key);
+ // 删除 key,重新插入到队尾
+ cache.remove(key);
+ cache.put(key, val);
+ }
+}
+```
+
+```javascript
+// by chatGPT (javascript)
+var LRUCache = function(capacity) {
+ this.cap = capacity;
+ this.cache = new Map();
+};
+
+LRUCache.prototype.get = function(key) {
+ if (!this.cache.has(key)) {
+ return -1;
+ }
+ // 将 key 变为最近使用
+ this.makeRecently(key);
+ return this.cache.get(key);
+};
+
+LRUCache.prototype.put = function(key, val) {
+ if (this.cache.has(key)) {
+ // 修改 key 的值
+ this.cache.set(key, val);
+ // 将 key 变为最近使用
+ this.makeRecently(key);
+ return;
+ }
+
+ if (this.cache.size >= this.cap) {
+ // 链表头部就是最久未使用的 key
+ const oldestKey = this.cache.keys().next().value;
+ this.cache.delete(oldestKey);
+ }
+ // 将新的 key 添加链表尾部
+ this.cache.set(key, val);
+};
+
+LRUCache.prototype.makeRecently = function(key) {
+ const val = this.cache.get(key);
+ // 删除 key,重新插入到队尾
+ this.cache.delete(key);
+ this.cache.set(key, val);
+};
+```
+
+```python
+# by chatGPT (python)
+class LRUCache:
+ def __init__(self, capacity: int):
+ self.cap = capacity
+ self.cache = {}
+
+ def get(self, key: int) -> int:
+ if key not in self.cache:
+ return -1
+ # 将 key 变为最近使用
+ self.makeRecently(key)
+ return self.cache[key]
+
+ def put(self, key: int, val: int) -> None:
+ if key in self.cache:
+ # 修改 key 的值
+ self.cache[key] = val
+ # 将 key 变为最近使用
+ self.makeRecently(key)
+ return
+
+ if len(self.cache) >= self.cap:
+ # 链表头部就是最久未使用的 key
+ oldest_key = next(iter(self.cache))
+ self.cache.pop(oldest_key)
+
+ # 将新的 key 添加链表尾部
+ self.cache[key] = val
+
+ def makeRecently(self, key: int) -> None:
+ val = self.cache[key]
+ # 删除 key,重新插入到队尾
+ del self.cache[key]
+ self.cache[key] = val
+```
+
+https://leetcode.cn/problems/OrIXps 的多语言解法👆
+
+https://leetcode.cn/problems/PzWKhm 的多语言解法👇
+
+```cpp
+// by chatGPT (cpp)
+class Solution {
+public:
+ int rob(vector& nums) {
+ int n = nums.size();
+ if (n == 1) return nums[0];
+
+ vector memo1(n, -1);
+ vector memo2(n, -1);
+ // 两次调用使用两个不同的备忘录
+ return max(
+ dp(nums, 0, n - 2, memo1),
+ dp(nums, 1, n - 1, memo2)
+ );
+ }
+
+ // 定义:计算闭区间 [start,end] 的最优结果
+ int dp(vector& nums, int start, int end, vector& memo) {
+ if (start > end) {
+ return 0;
+ }
+
+ if (memo[start] != -1) {
+ return memo[start];
+ }
+ // 状态转移方程
+ int res = max(
+ dp(nums, start + 2, end, memo) + nums[start],
+ dp(nums, start + 1, end, memo)
+ );
+
+ memo[start] = res;
+ return res;
+ }
+};
+```
+
+```go
+// by chatGPT (go)
+import "fmt"
+
+func rob(nums []int) int {
+ n := len(nums)
+ if n == 1 {
+ return nums[0]
+ }
+
+ memo1 := make([]int, n)
+ memo2 := make([]int, n)
+ for i := range memo1 {
+ memo1[i] = -1
+ memo2[i] = -1
+ }
+ // 两次调用使用两个不同的备忘录
+ return max(dp(nums, 0, n - 2, memo1), dp(nums, 1, n - 1, memo2))
+}
+
+// 定义:计算闭区间 [start,end] 的最优结果
+func dp(nums []int, start, end int, memo []int) int {
+ if start > end {
+ return 0
+ }
+
+ if memo[start] != -1 {
+ return memo[start]
+ }
+ // 状态转移方程
+ res := max(dp(nums, start + 2, end, memo) + nums[start], dp(nums, start + 1, end, memo))
+
+ memo[start] = res
+ return res
+}
+
+func max(x, y int) int {
+ if x > y {
+ return x
+ }
+ return y
+}
+```
+
+```java
+// by labuladong (java)
+class Solution {
+
+ public int rob(int[] nums) {
+ int n = nums.length;
+ if (n == 1) return nums[0];
+
+ int[] memo1 = new int[n];
+ int[] memo2 = new int[n];
+ Arrays.fill(memo1, -1);
+ Arrays.fill(memo2, -1);
+ // 两次调用使用两个不同的备忘录
+ return Math.max(
+ dp(nums, 0, n - 2, memo1),
+ dp(nums, 1, n - 1, memo2)
+ );
+ }
+
+ // 定义:计算闭区间 [start,end] 的最优结果
+ int dp(int[] nums, int start, int end, int[] memo) {
+ if (start > end) {
+ return 0;
+ }
+
+ if (memo[start] != -1) {
+ return memo[start];
+ }
+ // 状态转移方程
+ int res = Math.max(
+ dp(nums, start + 2, end, memo) + nums[start],
+ dp(nums, start + 1, end, memo)
+ );
+
+ memo[start] = res;
+ return res;
+ }
+}
+```
+
+```javascript
+// by chatGPT (javascript)
+var rob = function(nums) {
+ const n = nums.length;
+ if (n === 1) return nums[0];
+
+ const memo1 = new Array(n).fill(-1);
+ const memo2 = new Array(n).fill(-1);
+ // 两次调用使用两个不同的备忘录
+ return Math.max(
+ dp(nums, 0, n - 2, memo1),
+ dp(nums, 1, n - 1, memo2)
+ );
+};
+
+// 定义:计算闭区间 [start,end] 的最优结果
+function dp(nums, start, end, memo) {
+ if (start > end) {
+ return 0;
+ }
+
+ if (memo[start] !== -1) {
+ return memo[start];
+ }
+ // 状态转移方程
+ const res = Math.max(
+ dp(nums, start + 2, end, memo) + nums[start],
+ dp(nums, start + 1, end, memo)
+ );
+
+ memo[start] = res;
+ return res;
+}
+```
+
+```python
+# by chatGPT (python)
+class Solution:
+ def rob(self, nums: List[int]) -> int:
+ n = len(nums)
+ if n == 1:
+ return nums[0]
+ memo1 = [-1]*n
+ memo2 = [-1]*n
+ # 两次调用使用两个不同的备忘录
+ return max(
+ self.dp(nums, 0, n-2, memo1),
+ self.dp(nums, 1, n-1, memo2)
+ )
+
+ # 定义:计算闭区间 [start,end] 的最优结果
+ def dp(self, nums: List[int], start: int, end: int, memo: List[int]) -> int:
+ if start > end:
+ return 0
+ if memo[start] != -1:
+ return memo[start]
+ # 状态转移方程
+ res = max(
+ self.dp(nums, start+2, end, memo) + nums[start],
+ self.dp(nums, start+1, end, memo)
+ )
+ memo[start] = res
+ return res
+```
+
+https://leetcode.cn/problems/PzWKhm 的多语言解法👆
+
+https://leetcode.cn/problems/QA2IGt 的多语言解法👇
+
+```cpp
+// by chatGPT (cpp)
+class Solution {
+public:
+ vector findOrder(int numCourses, vector>& prerequisites) {
+ // 建图,和环检测算法相同
+ vector> graph(numCourses);
+ for (auto& edge : prerequisites) {
+ int from = edge[1], to = edge[0];
+ graph[from].push_back(to);
+ }
+ // 计算入度,和环检测算法相同
+ vector indegree(numCourses);
+ for (auto& edge : prerequisites) {
+ int from = edge[1], to = edge[0];
+ indegree[to]++;
+ }
+
+ // 根据入度初始化队列中的节点,和环检测算法相同
+ queue q;
+ for (int i = 0; i < numCourses; i++) {
+ if (indegree[i] == 0) {
+ q.push(i);
+ }
+ }
+
+ // 记录拓扑排序结果
+ vector res(numCourses);
+ // 记录遍历节点的顺序(索引)
+ int count = 0;
+ // 开始执行 BFS 算法
+ while (!q.empty()) {
+ int cur = q.front();
+ q.pop();
+ // 弹出节点的顺序即为拓扑排序结果
+ res[count] = cur;
+ count++;
+ for (int next : graph[cur]) {
+ indegree[next]--;
+ if (indegree[next] == 0) {
+ q.push(next);
+ }
+ }
+ }
+
+ if (count != numCourses) {
+ // 存在环,拓扑排序不存在
+ return {};
+ }
+
+ return res;
+ }
+};
+```
+
+```go
+// by chatGPT (go)
+// 主函数
+func findOrder(numCourses int, prerequisites [][]int) []int {
+ // 建图,和环检测算法相同
+ graph := buildGraph(numCourses, prerequisites)
+ // 计算入度,和环检测算法相同
+ indegree := make([]int, numCourses)
+ for _, edge := range prerequisites {
+ _, to := edge[1], edge[0]
+ indegree[to]++
+ }
+
+ // 根据入度初始化队列中的节点,和环检测算法相同
+ q := make([]int, 0)
+ for i := 0; i < numCourses; i++ {
+ if indegree[i] == 0 {
+ q = append(q, i)
+ }
+ }
+
+ // 记录拓扑排序结果
+ res := make([]int, numCourses)
+ // 记录遍历节点的顺序(索引)
+ count := 0
+ // 开始执行 BFS 算法
+ for len(q) > 0 {
+ cur := q[0]
+ q = q[1:]
+ // 弹出节点的顺序即为拓扑排序结果
+ res[count] = cur
+ count++
+ for _, next := range graph[cur] {
+ indegree[next]--
+ if indegree[next] == 0 {
+ q = append(q, next)
+ }
+ }
+ }
+
+ if count != numCourses {
+ // 存在环,拓扑排序不存在
+ return []int{}
+ }
+
+ return res
+}
+
+// 建图函数
+func buildGraph(numCourses int, prerequisites [][]int) [] []int {
+ // 图中共有 numCourses 个节点
+ graph := make([][]int, numCourses)
+ for i := 0; i < numCourses; i++ {
+ graph[i] = make([]int, 0)
+ }
+ for _, edge := range prerequisites {
+ from, to := edge[1], edge[0]
+ // 修完课程 from 才能修课程 to
+ // 在图中添加一条从 from 指向 to 的有向边
+ graph[from] = append(graph[from], to)
+ }
+ return graph
+}
+```
+
+```java
+// by labuladong (java)
+class Solution {
+ // 主函数
+ public int[] findOrder(int numCourses, int[][] prerequisites) {
+ // 建图,和环检测算法相同
+ List[] graph = buildGraph(numCourses, prerequisites);
+ // 计算入度,和环检测算法相同
+ int[] indegree = new int[numCourses];
+ for (int[] edge : prerequisites) {
+ int from = edge[1], to = edge[0];
+ indegree[to]++;
+ }
+
+ // 根据入度初始化队列中的节点,和环检测算法相同
+ Queue q = new LinkedList<>();
+ for (int i = 0; i < numCourses; i++) {
+ if (indegree[i] == 0) {
+ q.offer(i);
+ /**
+ 
+ */
+ }
+ }
+
+ // 记录拓扑排序结果
+ int[] res = new int[numCourses];
+ // 记录遍历节点的顺序(索引)
+ int count = 0;
+ // 开始执行 BFS 算法
+ while (!q.isEmpty()) {
+ int cur = q.poll();
+ // 弹出节点的顺序即为拓扑排序结果
+ res[count] = cur;
+ count++;
+ for (int next : graph[cur]) {
+ /**
+ 
+ */
+ indegree[next]--;
+ if (indegree[next] == 0) {
+ q.offer(next);
+ }
+ }
+ }
+
+ if (count != numCourses) {
+ // 存在环,拓扑排序不存在
+ return new int[]{};
+ }
+
+ return res;
+ }
+
+ // 建图函数
+ List[] buildGraph(int numCourses, int[][] prerequisites) {
+ // 图中共有 numCourses 个节点
+ List[] graph = new LinkedList[numCourses];
+ for (int i = 0; i < numCourses; i++) {
+ graph[i] = new LinkedList<>();
+ }
+ for (int[] edge : prerequisites) {
+ int from = edge[1], to = edge[0];
+ // 修完课程 from 才能修课程 to
+ // 在图中添加一条从 from 指向 to 的有向边
+ graph[from].add(to);
+ }
+ return graph;
+ }
+}
+```
+
+```javascript
+// by chatGPT (javascript)
+var findOrder = function(numCourses, prerequisites) {
+ // 建图,和环检测算法相同
+ const graph = buildGraph(numCourses, prerequisites);
+ // 计算入度,和环检测算法相同
+ const indegree = new Array(numCourses).fill(0);
+ for (const [from, to] of prerequisites) {
+ indegree[to]++;
+ }
+
+ // 根据入度初始化队列中的节点,和环检测算法相同
+ const q = [];
+ for (let i = 0; i < numCourses; i++) {
+ if (indegree[i] === 0) {
+ q.push(i);
+ /**
+ 
+ */
+ }
+ }
+
+ // 记录拓扑排序结果
+ const res = new Array(numCourses);
+ // 记录遍历节点的顺序(索引)
+ let count = 0;
+ // 开始执行 BFS 算法
+ while (q.length > 0) {
+ const cur = q.shift();
+ // 弹出节点的顺序即为拓扑排序结果
+ res[count] = cur;
+ count++;
+ for (const next of graph[cur]) {
+ /**
+ 
+ */
+ indegree[next]--;
+ if (indegree[next] === 0) {
+ q.push(next);
+ }
+ }
+ }
+
+ if (count !== numCourses) {
+ // 存在环,拓扑排序不存在
+ return [];
+ }
+
+ return res;
+};
+
+// 建图函数
+function buildGraph(numCourses, prerequisites) {
+ // 图中共有 numCourses 个节点
+ const graph = new Array(numCourses).map(() => []);
+ for (const [from, to] of prerequisites) {
+ // 修完课程 from 才能修课程 to
+ // 在图中添加一条从 from 指向 to 的有向边
+ graph[from].push(to);
+ }
+ return graph;
+}
+```
+
+```python
+# by chatGPT (python)
+class Solution:
+ def findOrder(self, numCourses: int, prerequisites: List[List[int]]) -> List[int]:
+ # 建图,和环检测算法相同
+ graph = self.buildGraph(numCourses, prerequisites)
+ # 计算入度,和环检测算法相同
+ indegree = [0] * numCourses
+ for edge in prerequisites:
+ from_, to = edge[1], edge[0]
+ indegree[to] += 1
+
+ # 根据入度初始化队列中的节点,和环检测算法相同
+ q = collections.deque()
+ for i in range(numCourses):
+ if indegree[i] == 0:
+ q.append(i)
+
+ # 记录拓扑排序结果
+ res = [0] * numCourses
+ # 记录遍历节点的顺序(索引)
+ count = 0
+ # 开始执行 BFS 算法
+ while q:
+ cur = q.popleft()
+ # 弹出节点的顺序即为拓扑排序结果
+ res[count] = cur
+ count += 1
+ for next_ in graph[cur]:
+ indegree[next_] -= 1
+ if indegree[next_] == 0:
+ q.append(next_)
+
+ if count != numCourses:
+ # 存在环,拓扑排序不存在
+ return []
+
+ return res
+
+ # 建图函数
+ def buildGraph(self, numCourses: int, prerequisites: List[List[int]]) -> List[List[int]]:
+ # 图中共有 numCourses 个节点
+ graph = [[] for _ in range(numCourses)]
+ for edge in prerequisites:
+ from_, to = edge[1], edge[0]
+ # 修完课程 from 才能修课程 to
+ # 在图中添加一条从 from 指向 to 的有向边
+ graph[from_].append(to)
+ return graph
+```
+
+https://leetcode.cn/problems/QA2IGt 的多语言解法👆
+
+https://leetcode.cn/problems/SLwz0R 的多语言解法👇
+
+```cpp
+// by chatGPT (cpp)
+class Solution {
+public:
+ // 主函数
+ ListNode* removeNthFromEnd(ListNode* head, int n) {
+ // 虚拟头结点
+ ListNode* dummy = new ListNode(-1);
+ dummy->next = head;
+ // 删除倒数第 n 个,要先找倒数第 n + 1 个节点
+ ListNode* x = findFromEnd(dummy, n + 1);
+ // 删掉倒数第 n 个节点
+ x->next = x->next->next;
+ return dummy->next;
+ }
+
+ // 返回链表的倒数第 k 个节点
+ ListNode* findFromEnd(ListNode* head, int k) {
+ ListNode* p1 = head;
+ // p1 先走 k 步
+ for (int i = 0; i < k; i++) {
+ p1 = p1->next;
+ }
+ ListNode* p2 = head;
+ // p1 和 p2 同时走 n - k 步
+ while (p1 != nullptr) {
+ p2 = p2->next;
+ p1 = p1->next;
+ }
+ // p2 现在指向第 n - k 个节点
+ return p2;
+ }
+};
+```
+
+```go
+// by chatGPT (go)
+// removeNthFromEnd 主函数
+func removeNthFromEnd(head *ListNode, n int) *ListNode {
+ // 虚拟头结点
+ dummy := &ListNode{-1, head}
+ // 删除倒数第 n 个,要先找倒数第 n + 1 个节点
+ x := findFromEnd(dummy, n + 1)
+ // 删掉倒数第 n 个节点
+ x.Next = x.Next.Next
+ return dummy.Next
+}
+
+// findFromEnd 返回链表的倒数第 k 个节点
+func findFromEnd(head *ListNode, k int) *ListNode {
+ p1 := head
+ // p1 先走 k 步
+ for i := 0; i < k; i++ {
+ p1 = p1.Next
+ }
+ p2 := head
+ // p1 和 p2 同时走 n - k 步
+ for p1 != nil {
+ p2 = p2.Next
+ p1 = p1.Next
+ }
+ // p2 现在指向第 n - k 个节点
+ return p2
+}
+```
+
+```java
+// by labuladong (java)
+class Solution {
+ // 主函数
+ public ListNode removeNthFromEnd(ListNode head, int n) {
+ // 虚拟头结点
+ ListNode dummy = new ListNode(-1);
+ dummy.next = head;
+ // 删除倒数第 n 个,要先找倒数第 n + 1 个节点
+ ListNode x = findFromEnd(dummy, n + 1);
+ // 删掉倒数第 n 个节点
+ x.next = x.next.next;
+ return dummy.next;
+ }
+
+ // 返回链表的倒数第 k 个节点
+ ListNode findFromEnd(ListNode head, int k) {
+ ListNode p1 = head;
+ // p1 先走 k 步
+ for (int i = 0; i < k; i++) {
+ p1 = p1.next;
+ }
+ ListNode p2 = head;
+ // p1 和 p2 同时走 n - k 步
+ while (p1 != null) {
+ p2 = p2.next;
+ p1 = p1.next;
+ }
+ // p2 现在指向第 n - k 个节点
+ return p2;
+ }
+}
+```
+
+```javascript
+// by chatGPT (javascript)
+var removeNthFromEnd = function(head, n) {
+ // 虚拟头结点
+ var dummy = new ListNode(-1);
+ dummy.next = head;
+ // 删除倒数第 n 个,要先找倒数第 n + 1 个节点
+ var x = findFromEnd(dummy, n + 1);
+ // 删掉倒数第 n 个节点
+ x.next = x.next.next;
+ return dummy.next;
+};
+
+// 返回链表的倒数第 k 个节点
+var findFromEnd = function(head, k) {
+ var p1 = head;
+ // p1 先走 k 步
+ for (var i = 0; i < k; i++) {
+ p1 = p1.next;
+ }
+ var p2 = head;
+ // p1 和 p2 同时走 n - k 步
+ while (p1 != null) {
+ p2 = p2.next;
+ p1 = p1.next;
+ }
+ // p2 现在指向第 n - k 个节点
+ return p2;
+};
+```
+
+```python
+# by chatGPT (python)
+class Solution:
+ def removeNthFromEnd(self, head: ListNode, n: int) -> ListNode:
+ # 虚拟头结点
+ dummy = ListNode(-1)
+ dummy.next = head
+ # 删除倒数第 n 个,要先找倒数第 n + 1 个节点
+ x = self.findFromEnd(dummy, n + 1)
+ # 删掉倒数第 n 个节点
+ x.next = x.next.next
+ return dummy.next
+
+ # 返回链表的倒数第 k 个节点
+ def findFromEnd(self, head: ListNode, k: int) -> ListNode:
+ p1 = head
+ # p1 先走 k 步
+ for i in range(k):
+ p1 = p1.next
+ p2 = head
+ # p1 和 p2 同时走 n - k 步
+ while p1:
+ p2 = p2.next
+ p1 = p1.next
+ # p2 现在指向第 n - k 个节点
+ return p2
+```
+
+https://leetcode.cn/problems/SLwz0R 的多语言解法👆
+
+https://leetcode.cn/problems/SsGoHC 的多语言解法👇
+
+```cpp
+// by chatGPT (cpp)
+class Solution {
+public:
+ vector> merge(vector>& intervals) {
+ vector> res;
+ // 按区间的 start 升序排列
+ sort(intervals.begin(), intervals.end(), [](vector& a, vector& b) {
+ return a[0] < b[0];
+ });
+
+ res.push_back(intervals[0]);
+ for (int i = 1; i < intervals.size(); i++) {
+ vector& curr = intervals[i];
+ // res 中最后一个元素的引用
+ vector& last = res.back();
+ if (curr[0] <= last[1]) {
+ last[1] = max(last[1], curr[1]);
+ } else {
+ // 处理下一个待合并区间
+ res.push_back(curr);
+ }
+ }
+ return res;
+ }
+};
+```
+
+```go
+// by chatGPT (go)
+func merge(intervals [][]int) [][]int {
+ res := [][]int{}
+ // 按区间的 start 升序排列
+ sort.Slice(intervals, func(i, j int) bool {
+ return intervals[i][0] < intervals[j][0]
+ })
+
+ res = append(res, intervals[0])
+ for i := 1; i < len(intervals); i++ {
+ curr := intervals[i]
+ // res 中最后一个元素的引用
+ last := res[len(res)-1]
+ if curr[0] <= last[1] {
+ last[1] = max(last[1], curr[1])
+ } else {
+ // 处理下一个待合并区间
+ res = append(res, curr)
+ }
+ }
+ return res
+}
+
+func max(a, b int) int {
+ if a > b {
+ return a
+ }
+ return b
+}
+```
+
+```java
+// by labuladong (java)
+class Solution {
+ public int[][] merge(int[][] intervals) {
+ LinkedList res = new LinkedList<>();
+ // 按区间的 start 升序排列
+ Arrays.sort(intervals, (a, b) -> {
+ return a[0] - b[0];
+ });
+
+ res.add(intervals[0]);
+ for (int i = 1; i < intervals.length; i++) {
+ int[] curr = intervals[i];
+ // res 中最后一个元素的引用
+ int[] last = res.getLast();
+ if (curr[0] <= last[1]) {
+ last[1] = Math.max(last[1], curr[1]);
+ } else {
+ // 处理下一个待合并区间
+ res.add(curr);
+ }
+ }
+ return res.toArray(new int[0][0]);
+ }
+}
+```
+
+```javascript
+// by chatGPT (javascript)
+var merge = function(intervals) {
+ let res = [];
+ // 按区间的 start 升序排列
+ intervals.sort((a, b) => {
+ return a[0] - b[0];
+ });
+
+ res.push(intervals[0]);
+ for (let i = 1; i < intervals.length; i++) {
+ let curr = intervals[i];
+ // res 中最后一个元素的引用
+ let last = res[res.length - 1];
+ if (curr[0] <= last[1]) {
+ last[1] = Math.max(last[1], curr[1]);
+ } else {
+ // 处理下一个待合并区间
+ res.push(curr);
+ }
+ }
+ return res;
+};
+```
+
+```python
+# by chatGPT (python)
+class Solution:
+ def merge(self, intervals: List[List[int]]) -> List[List[int]]:
+ res = []
+ # 按区间的 start 升序排列
+ intervals.sort(key=lambda x: x[0])
+ res.append(intervals[0])
+ for curr in intervals[1:]:
+ # res 中最后一个元素的引用
+ last = res[-1]
+ if curr[0] <= last[1]:
+ last[1] = max(last[1], curr[1])
+ else:
+ # 处理下一个待合并区间
+ res.append(curr)
+ return res
+```
+
+https://leetcode.cn/problems/SsGoHC 的多语言解法👆
+
+https://leetcode.cn/problems/TVdhkn 的多语言解法👇
+
+```cpp
+// by labuladong (cpp)
+class Solution {
+ public:
+ vector> res;
+ vector> subsets(vector& nums) {
+ // 记录走过的路径
+ vector track;
+ backtrack(nums, 0, track);
+ return res;
+ }
+
+ void backtrack(vector& nums, int start, vector& track) {
+ res.push_back(track);
+ for (int i = start; i < nums.size(); i++) {
+ // 做选择
+ track.push_back(nums[i]);
+ // 回溯
+ backtrack(nums, i + 1, track);
+ // 撤销选择
+ track.pop_back();
+ }
+ }
+};
+```
+
+```go
+// by chatGPT (go)
+// LeetCode Solution for Subsets
+func subsets(nums []int) [][]int {
+ var res [][]int
+ backtrack := func(nums []int, start int, track []int) {
+ tmp := make([]int, len(track))
+ copy(tmp, track)
+ res = append(res, tmp)
+ for i := start; i < len(nums); i++ {
+ // 做选择
+ track = append(track, nums[i])
+ // 回溯
+ backtrack(nums, i+1, track)
+ // 撤销选择
+ track = track[:len(track)-1]
+ }
+ }
+ backtrack(nums, 0, []int{})
+ return res
+}
+```
+
+```java
+// by chatGPT (java)
+class Solution {
+ List> res = new ArrayList<>();
+
+ public List> subsets(int[] nums) {
+ List track = new ArrayList<>();
+ backtrack(nums, 0, track);
+ return res;
+ }
+
+ private void backtrack(int[] nums, int start, List track) {
+ res.add(new ArrayList<>(track));
+ for (int i = start; i < nums.length; i++) {
+ // 做选择
+ track.add(nums[i]);
+ // 回溯
+ backtrack(nums, i + 1, track);
+ // 撤销选择
+ track.remove(track.size() - 1);
+ }
+ }
+}
+```
+
+```javascript
+// by chatGPT (javascript)
+var subsets = function(nums) {
+ // 记录走过的路径
+ var res = [];
+ var backtrack = function(nums, start, track) {
+ res.push(track.slice()); // 添加路径的拷贝
+ for (var i = start; i < nums.length; i++) {
+ // 做选择
+ track.push(nums[i]);
+ // 回溯
+ backtrack(nums, i + 1, track);
+ // 撤销选择
+ track.pop();
+ }
+ }
+ var track = [];
+ backtrack(nums, 0, track);
+ return res;
+};
+```
+
+```python
+# by chatGPT (python)
+class Solution:
+ def __init__(self):
+ self.res = []
+
+ def subsets(self, nums: List[int]) -> List[List[int]]:
+ # 记录走过的路径
+ track = []
+ self.backtrack(nums, 0, track)
+ return self.res
+
+ def backtrack(self, nums: List[int], start: int, track: List[int]) -> None:
+ self.res.append(track[:])
+ for i in range(start, len(nums)):
+ # 做选择
+ track.append(nums[i])
+ # 回溯
+ self.backtrack(nums, i + 1, track)
+ # 撤销选择
+ track.pop()
+```
+
+https://leetcode.cn/problems/TVdhkn 的多语言解法👆
+
+https://leetcode.cn/problems/UHnkqh 的多语言解法👇
+
+```cpp
+// by chatGPT (cpp)
+class Solution {
+public:
+ ListNode* reverseList(ListNode* head) {
+ if (head == nullptr || head->next == nullptr) {
+ return head;
+ }
+ ListNode* last = reverseList(head->next);
+ /**
+ 
+ */
+ head->next->next = head;
+ /**
+ 
+ */
+ head->next = nullptr;
+ /**
+ 
+ */
+ return last;
+ }
+};
+```
+
+```go
+// by chatGPT (go)
+func removeNthFromEnd(head *ListNode, n int) *ListNode {
+ // 哑节点,方便处理删除头节点的情况
+ dummy := &ListNode{Val: 0, Next: head}
+
+ // 快指针先走 n 步
+ fast := head
+ for i := 0; i < n; i++ {
+ fast = fast.Next
+ }
+
+ // 慢指针和快指针一起走,直到快指针到达链表尾部
+ slow := dummy
+ for fast != nil {
+ slow = slow.Next
+ fast = fast.Next
+ }
+
+ // 删除倒数第 n 个节点
+ slow.Next = slow.Next.Next
+
+ // 返回头节点
+ return dummy.Next
+}
+```
+
+```java
+// by labuladong (java)
+class Solution {
+ public ListNode reverseList(ListNode head) {
+ if (head == null || head.next == null) {
+ return head;
+ }
+ ListNode last = reverseList(head.next);
+ /**
+ 
+ */
+ head.next.next = head;
+ /**
+ 
+ */
+ head.next = null;
+ /**
+ 
+ */
+ return last;
+ }
+}
+```
+
+```javascript
+// by chatGPT (javascript)
+/**
+ * 给定一个字符串,请你找出其中不含有重复字符的 最长子串 的长度。
+ *
+ * 示例 1:
+ *
+ * 输入: "abcabcbb"
+ * 输出: 3
+ * 解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。
+ *
+ * 示例 2:
+ *
+ * 输入: "bbbbb"
+ * 输出: 1
+ * 解释: 因为无重复字符的最长子串是 "b",所以其长度为 1。
+ *
+ * 示例 3:
+ *
+ * 输入: "pwwkew"
+ * 输出: 3
+ * 解释: 因为无重复字符的最长子串是 "wke",所以其长度为 3。
+ * 请注意,你的答案必须是 子串 的长度,"pwke" 是一个子序列,不是子串。
+ */
+
+var lengthOfLongestSubstring = function(s) {
+ let n = s.length, ans = 0;
+ let index = new Map(); // 存储字符上一次出现的位置
+ // i为左指针,j为右指针
+ for (let j = 0, i = 0; j < n; j++) {
+ if (index.has(s[j])) {
+ // 如果有重复的字符,移动左指针到上一个同样字符的后一个位置
+ i = Math.max(index.get(s[j]) + 1, i);
+ }
+ ans = Math.max(ans, j - i + 1); // 更新结果
+ index.set(s[j], j); // 更新字符的位置
+ }
+ return ans;
+};
+```
+
+```python
+# by chatGPT (python)
+# 请保留所有中文注释!
+class Solution:
+ def removeNthFromEnd(self, head: ListNode, n: int) -> ListNode:
+ # 新建一个虚拟节点,避免特判头节点的情况
+ dummy = ListNode(0, head)
+ # 快指针先走n步
+ fast = head
+ for i in range(n):
+ fast = fast.next
+ # 慢指针开始走,与快指针保持n步的距离
+ slow = dummy
+ while fast is not None:
+ fast = fast.next
+ slow = slow.next
+ # 此时slow指向的是倒数第n+1个节点,删除下一个节点即可
+ slow.next = slow.next.next
+ return dummy.next
+```
+
+https://leetcode.cn/problems/UHnkqh 的多语言解法👆
+
+https://leetcode.cn/problems/VabMRr 的多语言解法👇
+
+```cpp
+// by labuladong (cpp)
+class Solution {
+ public:
+ vector findAnagrams(string s, string t) {
+ unordered_map need, window;
+ for (char c : t) need[c]++;
+
+ int left = 0, right = 0;
+ int valid = 0;
+ vector res; // 记录结果
+ while (right < s.size()) {
+ char c = s[right];
+ right++;
+ // 进行窗口内数据的一系列更新
+ if (need.count(c)) {
+ window[c]++;
+ if (window[c] == need[c])
+ valid++;
+ }
+ // 判断左侧窗口是否要收缩
+ while (right - left >= t.size()) {
+ // 当窗口符合条件时,把起始索引加入 res
+ if (valid == need.size())
+ res.push_back(left);
+ char d = s[left];
+ left++;
+ // 进行窗口内数据的一系列更新
+ if (need.count(d)) {
+ if (window[d] == need[d])
+ valid--;
+ window[d]--;
+ }
+ }
+ }
+ return res;
+ }
+};
+```
+
+```go
+// by chatGPT (go)
+func findAnagrams(s string, t string) []int {
+ need, window := make(map[byte]int), make(map[byte]int)
+ for i := range t {
+ need[t[i]]++
+ }
+
+ left, right := 0, 0
+ valid := 0
+ var res []int
+ for right < len(s) {
+ c := s[right]
+ right++
+ // 进行窗口内数据的一系列更新
+ update := func(c byte) {
+ if _, ok := need[c]; ok {
+ window[c]++
+ if window[c] == need[c] {
+ valid++
+ }
+ }
+ }
+ update(c)
+ // 判断左侧窗口是否要收缩
+ for right - left >= len(t) {
+ // 当窗口符合条件时,把起始索引加入 res
+ if valid == len(need) {
+ res = append(res, left)
+ }
+ d := s[left]
+ left++
+ // 进行窗口内数据的一系列更新
+ update := func(d byte) {
+ if _, ok := need[d]; ok {
+ if window[d] == need[d] {
+ valid--
+ }
+ window[d]--
+ }
+ }
+ update(d)
+ }
+ }
+ return res
+}
+```
+
+```java
+// by chatGPT (java)
+class Solution {
+ public List findAnagrams(String s, String t) {
+ Map need = new HashMap<>();
+ Map window = new HashMap<>();
+ for (char c : t.toCharArray()) {
+ need.put(c, need.getOrDefault(c, 0) + 1);
+ }
+
+ int left = 0, right = 0, valid = 0;
+ List res = new ArrayList<>(); // 记录结果
+ while (right < s.length()) {
+ char c = s.charAt(right);
+ right++;
+ // 进行窗口内数据的一系列更新
+ if (need.containsKey(c)) {
+ window.put(c, window.getOrDefault(c, 0) + 1);
+ if (window.get(c).equals(need.get(c))) {
+ valid++;
+ }
+ }
+ // 判断左侧窗口是否要收缩
+ while (right - left >= t.length()) {
+ // 当窗口符合条件时,把起始索引加入 res
+ if (valid == need.size()) {
+ res.add(left);
+ }
+ char d = s.charAt(left);
+ left++;
+ // 进行窗口内数据的一系列更新
+ if (need.containsKey(d)) {
+ if (window.get(d).equals(need.get(d))) {
+ valid--;
+ }
+ window.put(d, window.get(d) - 1);
+ }
+ }
+ }
+ return res;
+ }
+}
+```
+
+```javascript
+// by chatGPT (javascript)
+var findAnagrams = function(s, t) {
+ var need = {}, window = {};
+ for (var i = 0; i < t.length; i++) {
+ var c = t[i];
+ need[c] = (need[c] || 0) + 1;
+ }
+
+ var left = 0, right = 0;
+ var valid = 0;
+ var res = [];
+ while (right < s.length) {
+ var c = s[right];
+ right++;
+
+ // 进行窗口内数据的一系列更新
+ if (need.hasOwnProperty(c)) {
+ window[c] = (window[c] || 0) + 1;
+ if (window[c] === need[c])
+ valid++;
+ }
+
+ // 判断左侧窗口是否要收缩
+ while (right - left >= t.length) {
+ // 当窗口符合条件时,把起始索引加入 res
+ if (valid === Object.keys(need).length)
+ res.push(left);
+ var d = s[left];
+ left++;
+
+ // 进行窗口内数据的一系列更新
+ if (need.hasOwnProperty(d)) {
+ if (window[d] === need[d])
+ valid--;
+ window[d]--;
+ }
+ }
+ }
+ return res;
+};
+```
+
+```python
+# by chatGPT (python)
+class Solution:
+ def findAnagrams(self, s: str, t: str) -> List[int]:
+ need, window = {}, {}
+ for c in t:
+ need[c] = need.get(c, 0) + 1 # 统计目标字符串中字符出现次数
+
+ left, right = 0, 0
+ valid = 0
+ res = []
+ while right < len(s):
+ c = s[right] # 移入窗口的字符
+ right += 1
+ # 进行窗口内数据的更新
+ if c in need:
+ window[c] = window.get(c, 0) + 1
+ if window[c] == need[c]:
+ valid += 1
+
+ # 判断左侧窗口是否要收缩
+ while right - left >= len(t):
+ # 当窗口符合条件时,把起始索引加入 res
+ if valid == len(need):
+ res.append(left)
+ d = s[left] # 移出窗口的字符
+ left += 1
+ # 进行窗口内数据的更新
+ if d in need:
+ if window[d] == need[d]:
+ valid -= 1
+ window[d] -= 1
+
+ return res
+```
+
+https://leetcode.cn/problems/VabMRr 的多语言解法👆
+
+https://leetcode.cn/problems/VvJkup 的多语言解法👇
+
+```cpp
+// by chatGPT (cpp)
+class Solution {
+public:
+ vector> res;
+
+ /* 主函数,输入一组不重复的数字,返回它们的全排列 */
+ vector> permute(vector& nums) {
+ // 记录「路径」
+ vector track;
+ // 「路径」中的元素会被标记为 true,避免重复使用
+ vector used(nums.size(), false);
+
+ backtrack(nums, track, used);
+ return res;
+ }
+
+ // 路径:记录在 track 中
+ // 选择列表:nums 中不存在于 track 的那些元素(used[i] 为 false)
+ // 结束条件:nums 中的元素全都在 track 中出现
+ void backtrack(vector& nums, vector& track, vector& used) {
+ // 触发结束条件
+ if (track.size() == nums.size()) {
+ res.push_back(track);
+ return;
+ }
+
+ for (int i = 0; i < nums.size(); i++) {
+ // 排除不合法的选择
+ if (used[i]) {
+ /**
+ 
+ */
+ // nums[i] 已经在 track 中,跳过
+ continue;
+ }
+ // 做选择
+ track.push_back(nums[i]);
+ used[i] = true;
+ // 进入下一层决策树
+ backtrack(nums, track, used);
+ // 取消选择
+ track.pop_back();
+ used[i] = false;
+ }
+ }
+};
+```
+
+```go
+// by chatGPT (go)
+func permute(nums []int) [][]int {
+ res := [][]int{}
+
+ /* backtrack 函数会用到的参数 */
+ var backtrack func(nums, track []int, used []bool)
+ backtrack = func(nums, track []int, used []bool) {
+ // 「取消选择」的过程是撤销上一次的选择,所以不需要结束条件
+ if len(track) == len(nums) {
+ temp := make([]int, len(track))
+ copy(temp, track)
+ res = append(res, temp)
+ return
+ }
+
+ for i := 0; i < len(nums); i++ {
+ // 排除不合法的选择
+ if used[i] {
+ continue
+ }
+ // 做选择
+ track = append(track, nums[i])
+ used[i] = true
+ // 进入下一层决策树
+ backtrack(nums, track, used)
+ // 「取消选择」,进行回溯
+ track = track[:len(track)-1]
+ used[i] = false
+ }
+ }
+
+ backtrack(nums, []int{}, make([]bool, len(nums)))
+ return res
+}
+```
+
+```java
+// by labuladong (java)
+class Solution {
+
+ List> res = new LinkedList<>();
+
+ /* 主函数,输入一组不重复的数字,返回它们的全排列 */
+ List> permute(int[] nums) {
+ // 记录「路径」
+ LinkedList track = new LinkedList<>();
+ // 「路径」中的元素会被标记为 true,避免重复使用
+ boolean[] used = new boolean[nums.length];
+
+ backtrack(nums, track, used);
+ return res;
+ }
+
+ // 路径:记录在 track 中
+ // 选择列表:nums 中不存在于 track 的那些元素(used[i] 为 false)
+ // 结束条件:nums 中的元素全都在 track 中出现
+ void backtrack(int[] nums, LinkedList track, boolean[] used) {
+ // 触发结束条件
+ if (track.size() == nums.length) {
+ res.add(new LinkedList(track));
+ return;
+ }
+
+ for (int i = 0; i < nums.length; i++) {
+ // 排除不合法的选择
+ if (used[i]) {
+ /**
+ 
+ */
+ // nums[i] 已经在 track 中,跳过
+ continue;
+ }
+ // 做选择
+ track.add(nums[i]);
+ used[i] = true;
+ // 进入下一层决策树
+ backtrack(nums, track, used);
+ // 取消选择
+ track.removeLast();
+ used[i] = false;
+ }
+ }
+}
+```
+
+```javascript
+// by chatGPT (javascript)
+var permute = function(nums) {
+ const res = [];
+
+ const backtrack = (track, used) => {
+ if (track.length === nums.length) {
+ res.push([...track]);
+ return;
+ }
+
+ for (let i = 0; i < nums.length; i++) {
+ if (used[i]) {
+ // nums[i] 已经在 track 中,跳过
+ continue;
+ }
+ track.push(nums[i]);
+ used[i] = true;
+ backtrack(track, used);
+ track.pop();
+ used[i] = false;
+ }
+ };
+
+ backtrack([], []);
+ return res;
+};
+```
+
+```python
+# by chatGPT (python)
+class Solution:
+ def __init__(self):
+ self.res = []
+
+ def permute(self, nums: List[int]) -> List[List[int]]:
+ track = []
+ used = [False] * len(nums)
+ self.backtrack(nums, track, used)
+ return self.res
+
+ def backtrack(self, nums: List[int], track: List[int], used: List[bool]) -> None:
+ if len(track) == len(nums):
+ self.res.append(track.copy())
+ return
+
+ for i in range(len(nums)):
+ if used[i]:
+ # nums[i] 已经在 track 中,跳过
+ continue
+ track.append(nums[i])
+ used[i] = True
+ self.backtrack(nums, track, used)
+ track.pop()
+ used[i] = False
+```
+
+https://leetcode.cn/problems/VvJkup 的多语言解法👆
+
+https://leetcode.cn/problems/WhsWhI 的多语言解法👇
+
+```cpp
+// by chatGPT (cpp)
+class Solution {
+public:
+ int longestConsecutive(vector& nums) {
+ // 转化成哈希集合,方便快速查找是否存在某个元素
+ unordered_set set;
+ for (int num : nums) {
+ set.insert(num);
+ }
+
+ int res = 0;
+
+ for (int num : set) {
+ if (set.count(num - 1)) {
+ // num 不是连续子序列的第一个,跳过
+ continue;
+ }
+ // num 是连续子序列的第一个,开始向上计算连续子序列的长度
+ int curNum = num;
+ int curLen = 1;
+
+ while (set.count(curNum + 1)) {
+ curNum += 1;
+ curLen += 1;
+ }
+ // 更新最长连续序列的长度
+ res = max(res, curLen);
+ }
+
+ return res;
+ }
+};
+```
+
+```go
+// by chatGPT (go)
+func longestConsecutive(nums []int) int {
+ // 转化成哈希集合,方便快速查找是否存在某个元素
+ set := make(map[int]bool)
+ for _, num := range nums {
+ set[num] = true
+ }
+
+ res := 0
+
+ for num := range set {
+ if set[num-1] {
+ // num 不是连续子序列的第一个,跳过
+ continue
+ }
+ // num 是连续子序列的第一个,开始向上计算连续子序列的长度
+ curNum := num
+ curLen := 1
+
+ for set[curNum+1] {
+ curNum += 1
+ curLen += 1
+ }
+ // 更新最长连续序列的长度
+ res = max(res, curLen)
+ }
+
+ return res
+}
+
+func max(a, b int) int {
+ if a > b {
+ return a
+ }
+ return b
+}
+```
+
+```java
+// by labuladong (java)
+class Solution {
+ public int longestConsecutive(int[] nums) {
+ // 转化成哈希集合,方便快速查找是否存在某个元素
+ HashSet set = new HashSet();
+ for (int num : nums) {
+ set.add(num);
+ }
+
+ int res = 0;
+
+ for (int num : set) {
+ if (set.contains(num - 1)) {
+ // num 不是连续子序列的第一个,跳过
+ continue;
+ }
+ // num 是连续子序列的第一个,开始向上计算连续子序列的长度
+ int curNum = num;
+ int curLen = 1;
+
+ while (set.contains(curNum + 1)) {
+ curNum += 1;
+ curLen += 1;
+ }
+ // 更新最长连续序列的长度
+ res = Math.max(res, curLen);
+ }
+
+ return res;
+ }
+}
+```
+
+```javascript
+// by chatGPT (javascript)
+var longestConsecutive = function(nums) {
+ // 转化成哈希集合,方便快速查找是否存在某个元素
+ const set = new Set(nums);
+ let res = 0;
+
+ for (const num of set) {
+ if (set.has(num - 1)) {
+ // num 不是连续子序列的第一个,跳过
+ continue;
+ }
+ // num 是连续子序列的第一个,开始向上计算连续子序列的长度
+ let curNum = num;
+ let curLen = 1;
+
+ while (set.has(curNum + 1)) {
+ curNum += 1;
+ curLen += 1;
+ }
+ // 更新最长连续序列的长度
+ res = Math.max(res, curLen);
+ }
+
+ return res;
+};
+```
+
+```python
+# by chatGPT (python)
+class Solution:
+ def longestConsecutive(self, nums: List[int]) -> int:
+ # 转化成哈希集合,方便快速查找是否存在某个元素
+ num_set = set(nums)
+
+ res = 0
+
+ for num in num_set:
+ if num - 1 in num_set:
+ # num 不是连续子序列的第一个,跳过
+ continue
+ # num 是连续子序列的第一个,开始向上计算连续子序列的长度
+ cur_num = num
+ cur_len = 1
+
+ while cur_num + 1 in num_set:
+ cur_num += 1
+ cur_len += 1
+ # 更新最长连续序列的长度
+ res = max(res, cur_len)
+
+ return res
+```
+
+https://leetcode.cn/problems/WhsWhI 的多语言解法👆
+
+https://leetcode.cn/problems/XltzEq 的多语言解法👇
+
+```cpp
+// by chatGPT (cpp)
+class Solution {
+public:
+ bool isPalindrome(string s) {
+ // 先把所有字符转化成小写,并过滤掉空格和标点这类字符
+ string filtered;
+ for (int i = 0; i < s.length(); i++) {
+ char c = s[i];
+ if (isalnum(c)) { // 使用isalnum函数判断是否为字母或数字
+ filtered += tolower(c); // 使用tolower函数将字符转换为小写
+ }
+ }
+
+ // 然后对剩下的这些目标字符执行双指针算法,判断回文串
+ s = filtered;
+ // 一左一右两个指针相向而行
+ int left = 0, right = s.length() - 1;
+ while (left < right) {
+ if (s[left] != s[right]) {
+ return false;
+ }
+ left++;
+ right--;
+ }
+ return true;
+ }
+};
+```
+
+```go
+// by chatGPT (go)
+func isPalindrome(s string) bool {
+ // 先把所有字符转化成小写,并过滤掉空格和标点这类字符
+ sb := strings.Builder{}
+ for _, c := range s {
+ if unicode.IsLetter(c) || unicode.IsDigit(c) {
+ sb.WriteRune(unicode.ToLower(c))
+ }
+ }
+
+ // 然后对剩下的这些目标字符执行双指针算法,判断回文串
+ s = sb.String()
+ // 一左一右两个指针相向而行
+ left, right := 0, len(s)-1
+ for left < right {
+ if s[left] != s[right] {
+ return false
+ }
+ left++
+ right--
+ }
+ return true
+}
+```
+
+```java
+// by labuladong (java)
+class Solution {
+ public boolean isPalindrome(String s) {
+ // 先把所有字符转化成小写,并过滤掉空格和标点这类字符
+ StringBuilder sb = new StringBuilder();
+ for (int i = 0; i < s.length(); i++) {
+ char c = s.charAt(i);
+ if (Character.isLetterOrDigit(c)) {
+ sb.append(Character.toLowerCase(c));
+ }
+ }
+
+ // 然后对剩下的这些目标字符执行双指针算法,判断回文串
+ s = sb.toString();
+ // 一左一右两个指针相向而行
+ int left = 0, right = s.length() - 1;
+ while (left < right) {
+ if (s.charAt(left) != s.charAt(right)) {
+ return false;
+ }
+ left++;
+ right--;
+ }
+ return true;
+ }
+}
+```
+
+```javascript
+// by chatGPT (javascript)
+var isPalindrome = function(s) {
+ // 先把所有字符转化成小写,并过滤掉空格和标点这类字符
+ let sb = '';
+ for (let i = 0; i < s.length; i++) {
+ let c = s.charAt(i);
+ if (/[0-9a-zA-Z]/.test(c)) {
+ sb += c.toLowerCase();
+ }
+ }
+
+ // 然后对剩下的这些目标字符执行双指针算法,判断回文串
+ s = sb;
+ // 一左一右两个指针相向而行
+ let left = 0, right = s.length - 1;
+ while (left < right) {
+ if (s.charAt(left) !== s.charAt(right)) {
+ return false;
+ }
+ left++;
+ right--;
+ }
+ return true;
+}
+```
+
+```python
+# by chatGPT (python)
+class Solution:
+ def isPalindrome(self, s: str) -> bool:
+ # 先把所有字符转化成小写,并过滤掉空格和标点这类字符
+ sb = []
+ for c in s:
+ if c.isalnum():
+ sb.append(c.lower())
+
+ # 然后对剩下的这些目标字符执行双指针算法,判断回文串
+ s = ''.join(sb)
+ # 一左一右两个指针相向而行
+ left, right = 0, len(s) - 1
+ while left < right:
+ if s[left] != s[right]:
+ return False
+ left += 1
+ right -= 1
+ return True
+```
+
+https://leetcode.cn/problems/XltzEq 的多语言解法👆
+
+https://leetcode.cn/problems/YaVDxD 的多语言解法👇
+
+```cpp
+// by chatGPT (cpp)
+class Solution {
+public:
+ int findTargetSumWays(vector& nums, int target) {
+ if (nums.empty()) return 0;
+ return dp(nums, 0, target);
+ }
+
+ // 备忘录
+ unordered_map memo;
+
+ int dp(vector& nums, int i, int remain) {
+ // base case
+ if (i == nums.size()) {
+ if (remain == 0) return 1;
+ return 0;
+ }
+ // 把它俩转成字符串才能作为哈希表的键
+ string key = to_string(i) + "," + to_string(remain);
+ // 避免重复计算
+ if (memo.count(key)) {
+ return memo[key];
+ }
+ // 还是穷举
+ int result = dp(nums, i + 1, remain - nums[i]) + dp(nums, i + 1, remain + nums[i]);
+ // 记入备忘录
+ memo[key] = result;
+ return result;
+ }
+};
+```
+
+```go
+// by chatGPT (go)
+func findTargetSumWays(nums []int, target int) int {
+ if len(nums) == 0 {
+ return 0
+ }
+ //初始化备忘录
+ memo := make(map[string]int)
+ return dp(nums, 0, target, memo)
+}
+
+func dp(nums []int, i int, remain int, memo map[string]int) int {
+ //基本情况
+ if i == len(nums) {
+ if remain == 0 {
+ return 1
+ }
+ return 0
+ }
+ key := fmt.Sprintf("%d,%d", i, remain)
+ //避免重复计算
+ if _, ok := memo[key]; ok {
+ return memo[key]
+ }
+ //穷举
+ result := dp(nums, i+1, remain-nums[i], memo) + dp(nums, i+1, remain+nums[i], memo)
+ //记录结果到备忘录
+ memo[key] = result
+ return result
+}
+```
+
+```java
+// by labuladong (java)
+class Solution {
+ public int findTargetSumWays(int[] nums, int target) {
+ if (nums.length == 0) return 0;
+ return dp(nums, 0, target);
+ }
+
+ // 备忘录
+ HashMap memo = new HashMap<>();
+
+ int dp(int[] nums, int i, int remain) {
+ // base case
+ if (i == nums.length) {
+ if (remain == 0) return 1;
+ return 0;
+ }
+ // 把它俩转成字符串才能作为哈希表的键
+ String key = i + "," + remain;
+ // 避免重复计算
+ if (memo.containsKey(key)) {
+ return memo.get(key);
+ }
+ // 还是穷举
+ int result = dp(nums, i + 1, remain - nums[i]) + dp(nums, i + 1, remain + nums[i]);
+ // 记入备忘录
+ memo.put(key, result);
+ return result;
+ }
+}
+```
+
+```javascript
+// by chatGPT (javascript)
+var findTargetSumWays = function(nums, target) {
+ if (nums.length === 0) return 0;
+ // 备忘录
+ let memo = new Map();
+
+ function dp(nums, i, remain) {
+ // base case
+ if (i === nums.length) {
+ if (remain === 0) return 1;
+ return 0;
+ }
+ // 把它俩转成字符串才能作为哈希表的键
+ let key = i + "," + remain;
+ // 避免重复计算
+ if (memo.has(key)) {
+ return memo.get(key);
+ }
+ // 还是穷举
+ let result = dp(nums, i + 1, remain - nums[i]) + dp(nums, i + 1, remain + nums[i]);
+ // 记入备忘录
+ memo.set(key, result);
+ return result;
+ }
+
+ return dp(nums, 0, target);
+};
+```
+
+```python
+# by chatGPT (python)
+class Solution:
+ def __init__(self):
+ self.memo = {}
+
+ def findTargetSumWays(self, nums: List[int], target: int) -> int:
+ if len(nums) == 0:
+ return 0
+ return self.dp(nums, 0, target)
+
+ def dp(self, nums: List[int], i: int, remain: int) -> int:
+ # base case
+ if i == len(nums):
+ if remain == 0:
+ return 1
+ return 0
+ # 把它俩转成字符串才能作为哈希表的键
+ key = str(i) + "," + str(remain)
+ # 避免重复计算
+ if key in self.memo:
+ return self.memo[key]
+ # 还是穷举
+ result = self.dp(nums, i + 1, remain - nums[i]) + self.dp(nums, i + 1, remain + nums[i])
+ # 记入备忘录
+ self.memo[key] = result
+ return result
+```
+
+https://leetcode.cn/problems/YaVDxD 的多语言解法👆
+
+https://leetcode.cn/problems/Ygoe9J 的多语言解法👇
+
+```cpp
+// by chatGPT (cpp)
+class Solution {
+ vector> res;
+ list track;
+
+public:
+ vector> combinationSum(vector& candidates, int target) {
+ if (candidates.empty()) {
+ return res;
+ }
+ backtrack(candidates, 0, target, 0);
+ return res;
+ }
+
+ // 回溯算法主函数
+ void backtrack(vector& candidates, int start, int target, int sum) {
+ if (sum == target) {
+ // 找到目标和
+ res.push_back(vector(track.begin(), track.end()));
+ return;
+ }
+
+ if (sum > target) {
+ // 超过目标和,直接结束
+ return;
+ }
+
+ // 回溯算法框架
+ for (int i = start; i < candidates.size(); i++) {
+ // 选择 candidates[i]
+ track.push_back(candidates[i]);
+ sum += candidates[i];
+ // 递归遍历下一层回溯树
+ backtrack(candidates, i, target, sum);
+ // 撤销选择 candidates[i]
+ sum -= candidates[i];
+ track.pop_back();
+ }
+ }
+};
+```
+
+```go
+// by chatGPT (go)
+func combinationSum(candidates []int, target int) [][]int {
+ res := [][]int{}
+ if len(candidates) == 0 {
+ return res
+ }
+ backtrack(candidates, []int{}, target, 0, &res)
+ return res
+}
+
+// 回溯算法框架
+func backtrack(candidates []int, path []int, target, sum int, res *[][]int) {
+ if sum == target {
+ // 找到目标和
+ *res = append(*res, append([]int{}, path...))
+ return
+ }
+ if sum > target {
+ // 超过目标和,直接结束
+ return
+ }
+ for i := 0; i < len(candidates); i++ {
+ // 选择 candidates[i]
+ path = append(path, candidates[i])
+ sum += candidates[i]
+ // 递归遍历下一层回溯树
+ backtrack(candidates[i:], path, target, sum, res)
+ // 撤销选择 candidates[i]
+ sum -= candidates[i]
+ path = path[:len(path)-1]
+ }
+}
+```
+
+```java
+// by labuladong (java)
+class Solution {
+ List> res = new LinkedList<>();
+
+ public List> combinationSum(int[] candidates, int target) {
+ if (candidates.length == 0) {
+ return res;
+ }
+ backtrack(candidates, 0, target, 0);
+ return res;
+ }
+
+ // 记录回溯的路径
+ LinkedList track = new LinkedList<>();
+
+ // 回溯算法主函数
+ void backtrack(int[] candidates, int start, int target, int sum) {
+ if (sum == target) {
+ // 找到目标和
+ res.add(new LinkedList<>(track));
+ return;
+ }
+
+ if (sum > target) {
+ // 超过目标和,直接结束
+ return;
+ }
+
+ // 回溯算法框架
+ for (int i = start; i < candidates.length; i++) {
+ // 选择 candidates[i]
+ track.add(candidates[i]);
+ sum += candidates[i];
+ // 递归遍历下一层回溯树
+ backtrack(candidates, i, target, sum);
+ // 撤销选择 candidates[i]
+ sum -= candidates[i];
+ track.removeLast();
+ }
+ }
+}
+```
+
+```javascript
+// by chatGPT (javascript)
+var combinationSum = function(candidates, target) {
+ var res = [];
+ if (candidates.length === 0) {
+ return res;
+ }
+
+ // 记录回溯的路径
+ var track = [];
+
+ // 回溯算法主函数
+ var backtrack = function(candidates, start, target, sum) {
+ if (sum === target) {
+ // 找到目标和
+ res.push([...track]);
+ return;
+ }
+
+ if (sum > target) {
+ // 超过目标和,直接结束
+ return;
+ }
+
+ // 回溯算法框架
+ for (var i = start; i < candidates.length; i++) {
+ // 选择 candidates[i]
+ track.push(candidates[i]);
+ sum += candidates[i];
+ // 递归遍历下一层回溯树
+ backtrack(candidates, i, target, sum);
+ // 撤销选择 candidates[i]
+ sum -= candidates[i];
+ track.pop();
+ }
+ };
+
+ backtrack(candidates, 0, target, 0);
+ return res;
+};
+```
+
+```python
+# by chatGPT (python)
+class Solution:
+ def __init__(self):
+ self.res = []
+ self.track = []
+
+ def combinationSum(self, candidates: List[int], target: int) -> List[List[int]]:
+ if not candidates:
+ return self.res
+ self.backtrack(candidates, 0, target, 0)
+ return self.res
+
+ # 记录回溯的路径
+ def backtrack(self, candidates, start, target, summation):
+ if summation == target:
+ # 找到目标和
+ self.res.append(self.track[:])
+ return
+ if summation > target:
+ # 超过目标和,直接结束
+ return
+ # 回溯算法框架
+ for i in range(start, len(candidates)):
+ # 选择 candidates[i]
+ self.track.append(candidates[i])
+ summation += candidates[i]
+ # 递归遍历下一层回溯树
+ self.backtrack(candidates, i, target, summation)
+ # 撤销选择 candidates[i]
+ summation -= candidates[i]
+ self.track.pop()
+```
+
+https://leetcode.cn/problems/Ygoe9J 的多语言解法👆
+
+https://leetcode.cn/problems/ZL6zAn 的多语言解法👇
+
+```cpp
+// by chatGPT (cpp)
+class Solution {
+public:
+ int maxAreaOfIsland(vector>& grid) {
+ // 记录岛屿的最大面积
+ int res = 0;
+ int m = grid.size(), n = grid[0].size();
+ for (int i = 0; i < m; i++) {
+ for (int j = 0; j < n; j++) {
+ if (grid[i][j] == 1) {
+ // 淹没岛屿,并更新最大岛屿面积
+ res = max(res, dfs(grid, i, j));
+ }
+ }
+ }
+ return res;
+ }
+
+ // 淹没与 (i, j) 相邻的陆地,并返回淹没的陆地面积
+ int dfs(vector>& grid, int i, int j) {
+ int m = grid.size(), n = grid[0].size();
+ if (i < 0 || j < 0 || i >= m || j >= n) {
+ // 超出索引边界
+ return 0;
+ }
+ if (grid[i][j] == 0) {
+ // 已经是海水了
+ return 0;
+ }
+ // 将 (i, j) 变成海水
+ grid[i][j] = 0;
+
+ return dfs(grid, i + 1, j)
+ + dfs(grid, i, j + 1)
+ + dfs(grid, i - 1, j)
+ + dfs(grid, i, j - 1) + 1;
+ }
+};
+```
+
+```go
+// by chatGPT (go)
+// 记录岛屿的最大面积
+func maxAreaOfIsland(grid [][]int) int {
+ res := 0
+ m, n := len(grid), len(grid[0])
+ for i := 0; i < m; i++ {
+ for j := 0; j < n; j++ {
+ if grid[i][j] == 1 {
+ // 淹没岛屿,并更新最大岛屿面积
+ res = max(res, dfs(grid, i, j))
+ }
+ }
+ }
+ return res
+}
+
+// 淹没与 (i, j) 相邻的陆地,并返回淹没的陆地面积
+func dfs(grid [][]int, i, j int) int {
+ m, n := len(grid), len(grid[0])
+ if i < 0 || j < 0 || i >= m || j >= n {
+ // 超出索引边界
+ return 0
+ }
+ if grid[i][j] == 0 {
+ // 已经是海水了
+ return 0
+ }
+ // 将 (i, j) 变成海水
+ grid[i][j] = 0
+
+ return dfs(grid, i+1, j) +
+ dfs(grid, i, j+1) +
+ dfs(grid, i-1, j) +
+ dfs(grid, i, j-1) + 1
+}
+
+func max(a, b int) int {
+ if a > b {
+ return a
+ }
+ return b
+}
+```
+
+```java
+// by labuladong (java)
+class Solution {
+ public int maxAreaOfIsland(int[][] grid) {
+ // 记录岛屿的最大面积
+ int res = 0;
+ int m = grid.length, n = grid[0].length;
+ for (int i = 0; i < m; i++) {
+ for (int j = 0; j < n; j++) {
+ if (grid[i][j] == 1) {
+ // 淹没岛屿,并更新最大岛屿面积
+ res = Math.max(res, dfs(grid, i, j));
+ }
+ }
+ }
+ return res;
+ }
+
+ // 淹没与 (i, j) 相邻的陆地,并返回淹没的陆地面积
+ int dfs(int[][] grid, int i, int j) {
+ int m = grid.length, n = grid[0].length;
+ if (i < 0 || j < 0 || i >= m || j >= n) {
+ // 超出索引边界
+ return 0;
+ }
+ if (grid[i][j] == 0) {
+ // 已经是海水了
+ return 0;
+ }
+ // 将 (i, j) 变成海水
+ grid[i][j] = 0;
+
+ return dfs(grid, i + 1, j)
+ + dfs(grid, i, j + 1)
+ + dfs(grid, i - 1, j)
+ + dfs(grid, i, j - 1) + 1;
+ }
+}
+```
+
+```javascript
+// by chatGPT (javascript)
+var maxAreaOfIsland = function(grid) {
+ let res = 0;
+ let m = grid.length, n = grid[0].length;
+
+ function dfs(grid, i, j) {
+ if (i < 0 || j < 0 || i >= m || j >= n) {
+ // 超出索引边界
+ return 0;
+ }
+ if (grid[i][j] == 0) {
+ // 已经是海水了
+ return 0;
+ }
+ // 将 (i, j) 变成海水
+ grid[i][j] = 0;
+
+ return dfs(grid, i + 1, j)
+ + dfs(grid, i, j + 1)
+ + dfs(grid, i - 1, j)
+ + dfs(grid, i, j - 1) + 1;
+ }
+
+ for (let i = 0; i < m; i++) {
+ for (let j = 0; j < n; j++) {
+ if (grid[i][j] == 1) {
+ res = Math.max(res, dfs(grid, i, j));
+ }
+ }
+ }
+ return res;
+};
+```
+
+```python
+# by chatGPT (python)
+class Solution:
+ def maxAreaOfIsland(self, grid: List[List[int]]) -> int:
+ # 记录岛屿的最大面积
+ res = 0
+ m, n = len(grid), len(grid[0])
+ for i in range(m):
+ for j in range(n):
+ if grid[i][j] == 1:
+ # 淹没岛屿,并更新最大岛屿面积
+ res = max(res, self.dfs(grid, i, j))
+ return res
+
+ # 淹没与 (i, j) 相邻的陆地,并返回淹没的陆地面积
+ def dfs(self, grid: List[List[int]], i: int, j: int) -> int:
+ m, n = len(grid), len(grid[0])
+ if i < 0 or j < 0 or i >= m or j >= n:
+ # 超出索引边界
+ return 0
+ if grid[i][j] == 0:
+ # 已经是海水了
+ return 0
+ # 将 (i, j) 变成海水
+ grid[i][j] = 0
+
+ return (self.dfs(grid, i + 1, j)
+ + self.dfs(grid, i, j + 1)
+ + self.dfs(grid, i - 1, j)
+ + self.dfs(grid, i, j - 1) + 1)
+```
+
+https://leetcode.cn/problems/ZL6zAn 的多语言解法👆
+
+https://leetcode.cn/problems/aMhZSa 的多语言解法👇
+
+```cpp
+// by chatGPT (cpp)
+class Solution {
+public:
+ bool isPalindrome(ListNode* head) {
+ ListNode *slow, *fast;
+ slow = fast = head;
+ while (fast != nullptr && fast->next != nullptr) {
+ slow = slow->next;
+ fast = fast->next->next;
+ }
+
+ if (fast != nullptr)
+ slow = slow->next;
+
+ ListNode *left = head;
+ ListNode *right = reverse(slow);
+ while (right != nullptr) {
+ if (left->val != right->val)
+ return false;
+ left = left->next;
+ right = right->next;
+ }
+
+ return true;
+ }
+
+ ListNode* reverse(ListNode* head) {
+ ListNode *pre = nullptr, *cur = head;
+ while (cur != nullptr) {
+ ListNode *next = cur->next;
+ cur->next = pre;
+ pre = cur;
+ cur = next;
+ }
+ return pre;
+ }
+};
+```
+
+```go
+// by chatGPT (go)
+func isPalindrome(head *ListNode) bool {
+ slow, fast := head, head
+ for fast != nil && fast.Next != nil {
+ slow = slow.Next
+ fast = fast.Next.Next
+ }
+ if fast != nil {
+ slow = slow.Next
+ }
+ left, right := head, reverse(slow)
+ for right != nil {
+ if left.Val != right.Val {
+ return false
+ }
+ left = left.Next
+ right = right.Next
+ }
+ return true
+}
+
+func reverse(head *ListNode) *ListNode {
+ var pre *ListNode
+ cur := head
+ for cur != nil {
+ next := cur.Next
+ cur.Next = pre
+ pre = cur
+ cur = next
+ }
+ return pre
+}
+```
+
+```java
+// by labuladong (java)
+class Solution {
+ public boolean isPalindrome(ListNode head) {
+ ListNode slow, fast;
+ slow = fast = head;
+ while (fast != null && fast.next != null) {
+ slow = slow.next;
+ fast = fast.next.next;
+ }
+
+ if (fast != null)
+ slow = slow.next;
+
+ ListNode left = head;
+ ListNode right = reverse(slow);
+ while (right != null) {
+ if (left.val != right.val)
+ return false;
+ left = left.next;
+ right = right.next;
+ }
+
+ return true;
+ }
+
+ ListNode reverse(ListNode head) {
+ ListNode pre = null, cur = head;
+ while (cur != null) {
+ ListNode next = cur.next;
+ cur.next = pre;
+ pre = cur;
+ cur = next;
+ }
+ return pre;
+ }
+}
+```
+
+```javascript
+// by chatGPT (javascript)
+var isPalindrome = function(head) {
+ let slow, fast;
+ slow = fast = head;
+ while (fast != null && fast.next != null) {
+ slow = slow.next;
+ fast = fast.next.next;
+ }
+
+ if (fast != null)
+ slow = slow.next;
+
+ let left = head;
+ let right = reverse(slow);
+ while (right != null) {
+ if (left.val != right.val)
+ return false;
+ left = left.next;
+ right = right.next;
+ }
+
+ return true;
+};
+
+var reverse = function(head) {
+ let pre = null, cur = head;
+ while (cur != null) {
+ let next = cur.next;
+ cur.next = pre;
+ pre = cur;
+ cur = next;
+ }
+ return pre;
+};
+```
+
+```python
+# by chatGPT (python)
+class Solution:
+ def isPalindrome(self, head: ListNode) -> bool:
+ slow, fast = head, head
+ while fast and fast.next:
+ slow = slow.next
+ fast = fast.next.next
+
+ if fast:
+ slow = slow.next
+
+ left = head
+ right = self.reverse(slow)
+ while right:
+ if left.val != right.val:
+ return False
+ left = left.next
+ right = right.next
+
+ return True
+
+ def reverse(self, head: ListNode) -> ListNode:
+ pre, cur = None, head
+ while cur:
+ nxt = cur.next
+ cur.next = pre
+ pre = cur
+ cur = nxt
+ return pre
+```
+
+https://leetcode.cn/problems/aMhZSa 的多语言解法👆
+
+https://leetcode.cn/problems/add-binary 的多语言解法👇
+
+```cpp
+// by chatGPT (cpp)
+class Solution {
+public:
+ string addBinary(string a, string b) {
+ // 先把输入的这两个二进制串反转,低位放在前面,方便处理进位
+ reverse(a.begin(), a.end());
+ reverse(b.begin(), b.end());
+ // 存储结果
+ string res = "";
+
+ int m = a.size(), n = b.size();
+ // carry 记录进位
+ int carry = 0;
+ int i = 0;
+
+ // 开始类似 [2. 两数相加](#2) 的加法模拟逻辑
+ // 只是这里运算的是二进制字符串
+ while (i < max(m, n) || carry > 0) {
+ int val = carry;
+ val += i < m ? (a[i] - '0') : 0;
+ val += i < n ? (b[i] - '0') : 0;
+ res.push_back(val % 2 + '0');
+ carry = val / 2;
+ i++;
+ }
+
+ reverse(res.begin(), res.end());
+ return res;
+ }
+};
+```
+
+```go
+// by chatGPT (go)
+func addBinary(a string, b string) string {
+ // 先把输入的这两个二进制串反转,低位放在前面,方便处理进位
+ reverse := func(str string) string {
+ reversed := []rune(str)
+ for i, j := 0, len(reversed)-1; i < j; i, j = i+1, j-1 {
+ reversed[i], reversed[j] = reversed[j], reversed[i]
+ }
+ return string(reversed)
+ }
+ a = reverse(a)
+ b = reverse(b)
+ // 存储结果
+ var sb strings.Builder
+
+ m, n := len(a), len(b)
+ // carry 记录进位
+ carry := 0
+ i := 0
+
+ // 开始类似 [2. 两数相加](#2) 的加法模拟逻辑
+ // 只是这里运算的是二进制字符串
+ for i < max(m, n) || carry > 0 {
+ val := carry
+ if i < m {
+ val += int(a[i] - '0')
+ }
+ if i < n {
+ val += int(b[i] - '0')
+ }
+ sb.WriteString(strconv.Itoa(val % 2))
+ carry = val / 2
+ i++
+ }
+
+ return reverse(sb.String())
+}
+
+func max(a, b int) int {
+ if a > b {
+ return a
+ }
+ return b
+}
+```
+
+```java
+// by labuladong (java)
+class Solution {
+ public String addBinary(String a, String b) {
+ // 先把输入的这两个二进制串反转,低位放在前面,方便处理进位
+ a = new StringBuilder(a).reverse().toString();
+ b = new StringBuilder(b).reverse().toString();
+ // 存储结果
+ StringBuilder sb = new StringBuilder();
+
+ int m = a.length(), n = b.length();
+ // carry 记录进位
+ int carry = 0;
+ int i = 0;
+
+ // 开始类似 [2. 两数相加](#2) 的加法模拟逻辑
+ // 只是这里运算的是二进制字符串
+ while (i < Math.max(m, n) || carry > 0) {
+ int val = carry;
+ val += i < m ? (a.charAt(i) - '0') : 0;
+ val += i < n ? (b.charAt(i) - '0') : 0;
+ sb.append(val % 2);
+ carry = val / 2;
+ i++;
+ }
+
+ return sb.reverse().toString();
+ }
+}
+```
+
+```javascript
+// by chatGPT (javascript)
+var addBinary = function(a, b) {
+ // 先把输入的这两个二进制串反转,低位放在前面,方便处理进位
+ a = a.split("").reverse().join("");
+ b = b.split("").reverse().join("");
+ // 存储结果
+ var sb = "";
+
+ var m = a.length, n = b.length;
+ // carry 记录进位
+ var carry = 0;
+ var i = 0;
+
+ // 开始类似 [2. 两数相加](#2) 的加法模拟逻辑
+ // 只是这里运算的是二进制字符串
+ while (i < Math.max(m, n) || carry > 0) {
+ var val = carry;
+ val += i < m ? parseInt(a.charAt(i)) : 0;
+ val += i < n ? parseInt(b.charAt(i)) : 0;
+ sb += (val % 2);
+ carry = Math.floor(val / 2);
+ i++;
+ }
+
+ return sb.split("").reverse().join("");
+};
+```
+
+```python
+# by chatGPT (python)
+class Solution:
+ def addBinary(self, a: str, b: str) -> str:
+ # 先把输入的这两个二进制串反转,低位放在前面,方便处理进位
+ a = a[::-1]
+ b = b[::-1]
+ # 存储结果
+ sb = []
+
+ m, n = len(a), len(b)
+ # carry 记录进位
+ carry = 0
+ i = 0
+
+ # 开始类似 [2. 两数相加](#2) 的加法模拟逻辑
+ # 只是这里运算的是二进制字符串
+ while i < max(m, n) or carry > 0:
+ val = carry
+ val += int(a[i]) if i < m else 0
+ val += int(b[i]) if i < n else 0
+ sb.append(str(val % 2))
+ carry = val // 2
+ i += 1
+
+ return "".join(sb[::-1])
+```
+
+https://leetcode.cn/problems/add-binary 的多语言解法👆
+
+https://leetcode.cn/problems/add-two-numbers 的多语言解法👇
+
+```cpp
+// by chatGPT (cpp)
+class Solution {
+public:
+ ListNode* addTwoNumbers(ListNode* l1, ListNode* l2) {
+ // 在两条链表上的指针
+ ListNode *p1 = l1, *p2 = l2;
+ // 虚拟头结点(构建新链表时的常用技巧)
+ ListNode *dummy = new ListNode(-1);
+ // 指针 p 负责构建新链表
+ ListNode *p = dummy;
+ // 记录进位
+ int carry = 0;
+ // 开始执行加法,两条链表走完且没有进位时才能结束循环
+ while (p1 != nullptr || p2 != nullptr || carry > 0) {
+ // 先加上上次的进位
+ int val = carry;
+ if (p1 != nullptr) {
+ val += p1->val;
+ p1 = p1->next;
+ }
+ if (p2 != nullptr) {
+ val += p2->val;
+ p2 = p2->next;
+ }
+ // 处理进位情况
+ carry = val / 10;
+ val = val % 10;
+ // 构建新节点
+ p->next = new ListNode(val);
+ p = p->next;
+ }
+ // 返回结果链表的头结点(去除虚拟头结点)
+ return dummy->next;
+ }
+};
+```
+
+```go
+// by chatGPT (go)
+func addTwoNumbers(l1 *ListNode, l2 *ListNode) *ListNode {
+ // 在两条链表上的指针
+ p1, p2 := l1, l2
+ // 虚拟头结点(构建新链表时的常用技巧)
+ dummy := &ListNode{-1, nil}
+ // 指针 p 负责构建新链表
+ p := dummy
+ // 记录进位
+ carry := 0
+ // 开始执行加法,两条链表走完且没有进位时才能结束循环
+ for p1 != nil || p2 != nil || carry > 0 {
+ // 先加上上次的进位
+ val := carry
+ if p1 != nil {
+ val += p1.Val
+ p1 = p1.Next
+ }
+ if p2 != nil {
+ val += p2.Val
+ p2 = p2.Next
+ }
+ // 处理进位情况
+ carry = val / 10
+ val = val % 10
+ // 构建新节点
+ p.Next = &ListNode{val, nil}
+ p = p.Next
+ }
+ // 返回结果链表的头结点(去除虚拟头结点)
+ return dummy.Next
+}
+```
+
+```java
+// by labuladong (java)
+class Solution {
+ public ListNode addTwoNumbers(ListNode l1, ListNode l2) {
+ // 在两条链表上的指针
+ ListNode p1 = l1, p2 = l2;
+ // 虚拟头结点(构建新链表时的常用技巧)
+ ListNode dummy = new ListNode(-1);
+ // 指针 p 负责构建新链表
+ ListNode p = dummy;
+ // 记录进位
+ int carry = 0;
+ // 开始执行加法,两条链表走完且没有进位时才能结束循环
+ while (p1 != null || p2 != null || carry > 0) {
+ // 先加上上次的进位
+ int val = carry;
+ if (p1 != null) {
+ val += p1.val;
+ p1 = p1.next;
+ }
+ if (p2 != null) {
+ val += p2.val;
+ p2 = p2.next;
+ }
+ // 处理进位情况
+ carry = val / 10;
+ val = val % 10;
+ // 构建新节点
+ p.next = new ListNode(val);
+ p = p.next;
+ }
+ // 返回结果链表的头结点(去除虚拟头结点)
+ return dummy.next;
+ }
+}
+```
+
+```javascript
+// by chatGPT (javascript)
+var addTwoNumbers = function(l1, l2) {
+ // 在两条链表上的指针
+ let p1 = l1, p2 = l2;
+ // 虚拟头结点(构建新链表时的常用技巧)
+ let dummy = new ListNode(-1);
+ // 指针 p 负责构建新链表
+ let p = dummy;
+ // 记录进位
+ let carry = 0;
+ // 开始执行加法,两条链表走完且没有进位时才能结束循环
+ while (p1 !== null || p2 !== null || carry > 0) {
+ // 先加上上次的进位
+ let val = carry;
+ if (p1 !== null) {
+ val += p1.val;
+ p1 = p1.next;
+ }
+ if (p2 !== null) {
+ val += p2.val;
+ p2 = p2.next;
+ }
+ // 处理进位情况
+ carry = Math.floor(val / 10);
+ val = val % 10;
+ // 构建新节点
+ p.next = new ListNode(val);
+ p = p.next;
+ }
+ // 返回结果链表的头结点(去除虚拟头结点)
+ return dummy.next;
+};
+```
+
+```python
+# by chatGPT (python)
+class Solution:
+ def addTwoNumbers(self, l1: ListNode, l2: ListNode) -> ListNode:
+ # 在两条链表上的指针
+ p1, p2 = l1, l2
+ # 虚拟头结点(构建新链表时的常用技巧)
+ dummy = ListNode(-1)
+ # 指针 p 负责构建新链表
+ p = dummy
+ # 记录进位
+ carry = 0
+ # 开始执行加法,两条链表走完且没有进位时才能结束循环
+ while p1 or p2 or carry:
+ # 先加上上次的进位
+ val = carry
+ if p1:
+ val += p1.val
+ p1 = p1.next
+ if p2:
+ val += p2.val
+ p2 = p2.next
+ # 处理进位情况
+ carry, val = divmod(val, 10)
+ # 构建新节点
+ p.next = ListNode(val)
+ p = p.next
+ # 返回结果链表的头结点(去除虚拟头结点)
+ return dummy.next
+```
+
+https://leetcode.cn/problems/add-two-numbers 的多语言解法👆
+
+https://leetcode.cn/problems/add-two-numbers-ii 的多语言解法👇
+
+```cpp
+// by chatGPT (cpp)
+class Solution {
+public:
+ ListNode* addTwoNumbers(ListNode* l1, ListNode* l2) {
+ // 把链表元素转入栈中
+ stack stk1, stk2;
+ while (l1 != nullptr) {
+ stk1.push(l1->val);
+ l1 = l1->next;
+ }
+ while (l2 != nullptr) {
+ stk2.push(l2->val);
+ l2 = l2->next;
+ }
+
+ // 接下来基本上是复用我在第 2 题的代码逻辑
+ // 注意新节点要直接插入到 dummy 后面
+
+ // 虚拟头结点(构建新链表时的常用技巧)
+ ListNode* dummy = new ListNode(-1);
+
+ // 记录进位
+ int carry = 0;
+ // 开始执行加法,两条链表走完且没有进位时才能结束循环
+ while (!stk1.empty() || !stk2.empty() || carry > 0) {
+ // 先加上上次的进位
+ int val = carry;
+ if (!stk1.empty()) {
+ val += stk1.top();
+ stk1.pop();
+ }
+ if (!stk2.empty()) {
+ val += stk2.top();
+ stk2.pop();
+ }
+ // 处理进位情况
+ carry = val / 10;
+ val = val % 10;
+ // 构建新节点,直接接在 dummy 后面
+ ListNode* newNode = new ListNode(val);
+ newNode->next = dummy->next;
+ dummy->next = newNode;
+ }
+ // 返回结果链表的头结点(去除虚拟头结点)
+ ListNode* result = dummy->next;
+ delete dummy;
+ return result;
+ }
+};
+```
+
+```go
+// by chatGPT (go)
+func addTwoNumbers(l1 *ListNode, l2 *ListNode) *ListNode {
+ // 把链表元素转入栈中
+ stk1 := []int{}
+ for l1 != nil {
+ stk1 = append(stk1, l1.Val)
+ l1 = l1.Next
+ }
+ stk2 := []int{}
+ for l2 != nil {
+ stk2 = append(stk2, l2.Val)
+ l2 = l2.Next
+ }
+
+ // 接下来基本上是复用我在第 2 题的代码逻辑
+ // 注意新节点要直接插入到 dummy 后面
+
+ // 虚拟头结点(构建新链表时的常用技巧)
+ dummy := &ListNode{-1, nil}
+
+ // 记录进位
+ carry := 0
+ // 开始执行加法,两条链表走完且没有进位时才能结束循环
+ for len(stk1) > 0 || len(stk2) > 0 || carry > 0 {
+ // 先加上上次的进位
+ val := carry
+ if len(stk1) > 0 {
+ val += stk1[len(stk1)-1]
+ stk1 = stk1[:len(stk1)-1]
+ }
+ if len(stk2) > 0 {
+ val += stk2[len(stk2)-1]
+ stk2 = stk2[:len(stk2)-1]
+ }
+ // 处理进位情况
+ carry = val / 10
+ val = val % 10
+ // 构建新节点,直接接在 dummy 后面
+ newNode := &ListNode{val, dummy.Next}
+ dummy.Next = newNode
+ }
+ // 返回结果链表的头结点(去除虚拟头结点)
+ return dummy.Next
+}
+```
+
+```java
+// by labuladong (java)
+class Solution {
+ public ListNode addTwoNumbers(ListNode l1, ListNode l2) {
+ // 把链表元素转入栈中
+ Stack stk1 = new Stack<>();
+ while (l1 != null) {
+ stk1.push(l1.val);
+ l1 = l1.next;
+ }
+ Stack stk2 = new Stack<>();
+ while (l2 != null) {
+ stk2.push(l2.val);
+ l2 = l2.next;
+ }
+
+ // 接下来基本上是复用我在第 2 题的代码逻辑
+ // 注意新节点要直接插入到 dummy 后面
+
+ // 虚拟头结点(构建新链表时的常用技巧)
+ ListNode dummy = new ListNode(-1);
+
+ // 记录进位
+ int carry = 0;
+ // 开始执行加法,两条链表走完且没有进位时才能结束循环
+ while (!stk1.isEmpty() || !stk2.isEmpty() || carry > 0) {
+ // 先加上上次的进位
+ int val = carry;
+ if (!stk1.isEmpty()) {
+ val += stk1.pop();
+ }
+ if (!stk2.isEmpty()) {
+ val += stk2.pop();
+ }
+ // 处理进位情况
+ carry = val / 10;
+ val = val % 10;
+ // 构建新节点,直接接在 dummy 后面
+ ListNode newNode = new ListNode(val);
+ newNode.next = dummy.next;
+ dummy.next = newNode;
+ }
+ // 返回结果链表的头结点(去除虚拟头结点)
+ return dummy.next;
+ }
+}
+```
+
+```javascript
+// by chatGPT (javascript)
+var addTwoNumbers = function(l1, l2) {
+ // 把链表元素转入栈中
+ const stk1 = [];
+ while (l1 !== null) {
+ stk1.push(l1.val);
+ l1 = l1.next;
+ }
+ const stk2 = [];
+ while (l2 !== null) {
+ stk2.push(l2.val);
+ l2 = l2.next;
+ }
+
+ // 接下来基本上是复用我在第 2 题的代码逻辑
+ // 注意新节点要直接插入到 dummy 后面
+
+ // 虚拟头结点(构建新链表时的常用技巧)
+ const dummy = new ListNode(-1);
+
+ // 记录进位
+ let carry = 0;
+ // 开始执行加法,两条链表走完且没有进位时才能结束循环
+ while (stk1.length || stk2.length || carry > 0) {
+ // 先加上上次的进位
+ let val = carry;
+ if (stk1.length) {
+ val += stk1.pop();
+ }
+ if (stk2.length) {
+ val += stk2.pop();
+ }
+ // 处理进位情况
+ carry = Math.floor(val / 10);
+ val = val % 10;
+ // 构建新节点,直接接在 dummy 后面
+ const newNode = new ListNode(val);
+ newNode.next = dummy.next;
+ dummy.next = newNode;
+ }
+ // 返回结果链表的头结点(去除虚拟头结点)
+ return dummy.next;
+};
+```
+
+```python
+# by chatGPT (python)
+class Solution:
+ def addTwoNumbers(self, l1: ListNode, l2: ListNode) -> ListNode:
+ # 把链表元素转入栈中
+ stk1 = []
+ while l1:
+ stk1.append(l1.val)
+ l1 = l1.next
+ stk2 = []
+ while l2:
+ stk2.append(l2.val)
+ l2 = l2.next
+
+ # 接下来基本上是复用我在第 2 题的代码逻辑
+ # 注意新节点要直接插入到 dummy 后面
+
+ # 虚拟头结点(构建新链表时的常用技巧)
+ dummy = ListNode(-1)
+
+ # 记录进位
+ carry = 0
+ # 开始执行加法,两条链表走完且没有进位时才能结束循环
+ while stk1 or stk2 or carry > 0:
+ # 先加上上次的进位
+ val = carry
+ if stk1:
+ val += stk1.pop()
+ if stk2:
+ val += stk2.pop()
+ # 处理进位情况
+ carry = val // 10
+ val = val % 10
+ # 构建新节点,直接接在 dummy 后面
+ newNode = ListNode(val)
+ newNode.next = dummy.next
+ dummy.next = newNode
+ # 返回结果链表的头结点(去除虚拟头结点)
+ return dummy.next
+```
+
+https://leetcode.cn/problems/add-two-numbers-ii 的多语言解法👆
+
+https://leetcode.cn/problems/additive-number 的多语言解法👇
+
+```cpp
+// by chatGPT (cpp)
+class Solution {
+public:
+ bool isAdditiveNumber(string num) {
+ // 穷举前两个数字
+ int n = num.size();
+ for (int i = 1; i <= n; i++) {
+ for (int j = i + 1; j <= n; j++) {
+ string first = num.substr(0, i);
+ string second = num.substr(i, j-i);
+ if (isValid(num, first, second)) {
+ return true;
+ }
+ }
+ }
+ return false;
+ }
+
+private:
+ // 定义:num 前两个数字分别是 first 和 second,判断 num 是否满足累加数的性质
+ bool isValid(string num, string first, string second) {
+ if ((first[0] == '0' && first.size() > 1)
+ || (second[0] == '0' && second.size() > 1)) {
+ // 0 开头的数字,只能是 0 本身
+ return false;
+ }
+ string sumStr = strAdd(first, second);
+ string next = num.substr(first.size() + second.size());
+ if (next.find(sumStr) != 0) {
+ // 不满足累加数的性质
+ return false;
+ }
+ if (next == sumStr) {
+ // 已经匹配完整个字符串
+ return true;
+ }
+ // 根据递归函数的定义,继续匹配后面的三个数字,我这里用递归的方式去比较,因为容易写
+ // 你也可以改用迭代写法,一样的
+ return isValid(num.substr(first.size()), second, sumStr);
+ }
+
+ // 模拟加法竖式运算,具体可以看下这道题
+ // https://leetcode-cn.com/problems/add-strings/
+ string strAdd(string a, string b) {
+ int n = a.size(), m = b.size();
+ int i = n - 1, j = m - 1, add = 0;
+ string builder;
+ while (i >= 0 || j >= 0 || add != 0) {
+ int x = i >= 0 ? a[i] - '0' : 0;
+ int y = j >= 0 ? b[j] - '0' : 0;
+ int result = x + y + add;
+ builder.push_back(result % 10 + '0');
+ add = result / 10;
+ i--;
+ j--;
+ }
+ reverse(builder.begin(), builder.end());
+ return builder;
+ }
+};
+```
+
+```go
+// by chatGPT (go)
+import (
+ "strconv"
+ "strings"
+)
+
+// isAdditiveNumber - 穷举前两个数字
+func isAdditiveNumber(num string) bool {
+ n := len(num)
+ for i := 1; i <= n; i++ {
+ for j := i + 1; j <= n; j++ {
+ first := num[:i]
+ second := num[i:j]
+ if isValid(num, first, second) {
+ return true
+ }
+ }
+ }
+ return false
+}
+
+// isValid - 定义:num 前两个数字分别是 first 和 second,判断 num 是否满足累加数的性质
+func isValid(num string, first string, second string) bool {
+ if (strings.HasPrefix(first, "0") && len(first) > 1) ||
+ (strings.HasPrefix(second, "0") && len(second) > 1) {
+ // 0 开头的数字,只能是 0 本身
+ return false
+ }
+ sumStr := strAdd(first, second)
+ next := num[len(first)+len(second):]
+ if !strings.HasPrefix(next, sumStr) {
+ // 不满足累加数的性质
+ return false
+ }
+ if next == sumStr {
+ // 已经匹配完整个字符串
+ return true
+ }
+ // 根据递归函数的定义,继续匹配后面的三个数字,我这里用递归的方式去比较,因为容易写
+ // 你也可以改用迭代写法,一样的
+ return isValid(num[len(first):], second, sumStr)
+}
+
+// strAdd - 模拟加法竖式运算,具体可以看下这道题
+// https://leetcode.cn/problems/add-strings/
+func strAdd(a, b string) string {
+ i, j, carry := len(a)-1, len(b)-1, 0
+ ans := ""
+ for i >= 0 || j >= 0 {
+ x, _ := strconv.Atoi(string(a[i]))
+ y, _ := strconv.Atoi(string(b[j]))
+ sum := x + y + carry
+ tmp := sum % 10
+ carry = sum / 10
+ ans = strconv.Itoa(tmp) + ans
+ i--
+ j--
+ }
+ if carry > 0 {
+ ans = "1" + ans
+ }
+ return ans
+}
+```
+
+```java
+// by labuladong (java)
+class Solution {
+ public boolean isAdditiveNumber(String num) {
+ // 穷举前两个数字
+ int n = num.length();
+ for (int i = 1; i <= n; i++) {
+ // 先穷举第一个数字
+ String first = num.substring(0, i);
+ for (int j = i + 1; j <= n; j++) {
+ // 再穷举第二个数字
+ String second = num.substring(i, j);
+ if (isValid(num, first, second)) {
+ return true;
+ }
+ }
+ }
+ return false;
+ }
+
+ // 定义:num 前两个数字分别是 first 和 second,判断 num 是否满足累加数的性质
+ boolean isValid(String num, String first, String second) {
+ if (first.startsWith("0") && first.length() > 1
+ || second.startsWith("0") && second.length() > 1) {
+ // 0 开头的数字,只能是 0 本身
+ return false;
+ }
+ String sumStr = strAdd(first, second);
+ String next = num.substring(first.length() + second.length());
+ if (!next.startsWith(sumStr)) {
+ // 不满足累加数的性质
+ return false;
+ }
+ if (next.equals(sumStr)) {
+ // 已经匹配完整个字符串
+ return true;
+ }
+ // 根据递归函数的定义,继续匹配后面的三个数字,我这里用递归的方式去比较,因为容易写
+ // 你也可以改用迭代写法,一样的
+ return isValid(num.substring(first.length()), second, sumStr);
+ }
+
+ // 模拟加法竖式运算,具体可以看下这道题
+ // https://leetcode.cn/problems/add-strings/
+ String strAdd(String a, String b) {
+ int n = a.length(), m = b.length();
+ int i = n - 1, j = m - 1, add = 0;
+ StringBuilder builder = new StringBuilder();
+ while (i >= 0 || j >= 0 || add != 0) {
+ int x = i >= 0 ? a.charAt(i) - '0' : 0;
+ int y = j >= 0 ? b.charAt(j) - '0' : 0;
+ int result = x + y + add;
+ builder.append(result % 10);
+ add = result / 10;
+ i--;
+ j--;
+ }
+ return builder.reverse().toString();
+ }
+}
+```
+
+```javascript
+// by chatGPT (javascript)
+var isAdditiveNumber = function(num) {
+ // 穷举前两个数字
+ let n = num.length;
+ for (let i = 1; i <= n; i++) {
+ for (let j = i + 1; j <= n; j++) {
+ let first = num.substring(0, i);
+ let second = num.substring(i, j);
+ if (isValid(num, first, second)) {
+ return true;
+ }
+ }
+ }
+ return false;
+}
+
+var isValid = function(num, first, second) {
+ if ((first.startsWith("0") && first.length > 1)
+ || (second.startsWith("0") && second.length > 1)) {
+ // 0 开头的数字,只能是 0 本身
+ return false;
+ }
+ let sumStr = strAdd(first, second);
+ let next = num.substring(first.length + second.length);
+ if (!next.startsWith(sumStr)) {
+ // 不满足累加数的性质
+ return false;
+ }
+ if (next === sumStr) {
+ // 已经匹配完整个字符串
+ return true;
+ }
+ // 根据递归函数的定义,继续匹配后面的三个数字,我这里用递归的方式去比较,因为容易写
+ // 你也可以改用迭代写法,一样的
+ return isValid(num.substring(first.length), second, sumStr);
+}
+
+var strAdd = function(a, b) {
+ let n = a.length, m = b.length;
+ let i = n - 1, j = m - 1, add = 0;
+ let builder = [];
+ while (i >= 0 || j >= 0 || add != 0) {
+ let x = i >= 0 ? a.charAt(i) - '0' : 0;
+ let y = j >= 0 ? b.charAt(j) - '0' : 0;
+ let result = x + y + add;
+ builder.push(result % 10);
+ add = Math.floor(result / 10);
+ i--;
+ j--;
+ }
+ return builder.reverse().join('');
+}
+```
+
+```python
+# by chatGPT (python)
+class Solution:
+ def isAdditiveNumber(self, num):
+ # 穷举前两个数字
+ n = len(num)
+ for i in range(1, n + 1):
+ for j in range(i + 1, n + 1):
+ first = num[0 : i]
+ second = num[i : j]
+ if self.isValid(num, first, second):
+ return True
+ return False
+
+ def isValid(self, num, first, second):
+ # 定义:num 前两个数字分别是 first 和 second,判断 num 是否满足累加数的性质
+ if (first.startswith("0") and len(first) > 1) or (second.startswith("0") and len(second) > 1):
+ # 0 开头的数字,只能是 0 本身
+ return False
+ sumStr = self.strAdd(first, second)
+ next = num[len(first) + len(second):]
+ if not next.startswith(sumStr):
+ # 不满足累加数的性质
+ return False
+ if next == sumStr:
+ # 已经匹配完整个字符串
+ return True
+ # 根据递归函数的定义,继续匹配后面的三个数字,我这里用递归的方式去比较,因为容易写
+ # 你也可以改用迭代写法,一样的
+ return self.isValid(num[len(first):], second, sumStr)
+
+ def strAdd(self, a, b):
+ # 模拟加法竖式运算,具体可以看下这道题
+ # https://leetcode.cn/problems/add-strings/
+ n, m = len(a), len(b)
+ i, j, add = n - 1, m - 1, 0
+ builder = []
+ while i >= 0 or j >= 0 or add != 0:
+ x = int(a[i]) if i >= 0 else 0
+ y = int(b[j]) if j >= 0 else 0
+ result = x + y + add
+ builder.append(result % 10)
+ add = result // 10
+ i -= 1
+ j -= 1
+ return ''.join(str(i) for i in builder[::-1])
+```
+
+https://leetcode.cn/problems/additive-number 的多语言解法👆
+
+https://leetcode.cn/problems/advantage-shuffle 的多语言解法👇
+
+```cpp
+// by chatGPT (cpp)
+class Solution {
+public:
+ vector advantageCount(vector& nums1, vector& nums2) {
+ int n = nums1.size();
+ // 给 nums2 降序排序
+ priority_queue> maxpq;
+ for (int i = 0; i < n; i++) {
+ maxpq.push({i, nums2[i]});
+ }
+ // 给 nums1 升序排序
+ sort(nums1.begin(), nums1.end());
+
+ // nums1[left] 是最小值,nums1[right] 是最大值
+ int left = 0, right = n - 1;
+ vector res(n);
+
+ while (!maxpq.empty()) {
+ auto [i, maxval] = maxpq.top(); maxpq.pop();
+ // maxval 是 nums2 中的最大值,i 是对应索引
+ if (maxval < nums1[right]) {
+ // 如果 nums1[right] 能胜过 maxval,那就自己上
+ res[i] = nums1[right];
+ right--;
+ } else {
+ // 否则用最小值混一下,养精蓄锐
+ res[i] = nums1[left];
+ left++;
+ }
+ }
+ return res;
+ }
+};
+```
+
+```go
+// by chatGPT (go)
+func advantageCount(nums1 []int, nums2 []int) []int {
+ n := len(nums1)
+ // 给 nums2 降序排序
+ maxpq := make(PriorityQueue, 0)
+ heap.Init(&maxpq)
+ for i := 0; i < n; i++ {
+ heap.Push(&maxpq, []int{i, nums2[i]})
+ }
+ // 给 nums1 升序排序
+ sort.Ints(nums1)
+
+ // nums1[left] 是最小值,nums1[right] 是最大值
+ left, right := 0, n-1
+ res := make([]int, n)
+
+ for maxpq.Len() > 0 {
+ pair := heap.Pop(&maxpq).([]int)
+ // maxval 是 nums2 中的最大值,i 是对应索引
+ i, maxval := pair[0], pair[1]
+ if maxval < nums1[right] {
+ // 如果 nums1[right] 能胜过 maxval,那就自己上
+ res[i] = nums1[right]
+ right--
+ } else {
+ // 否则用最小值混一下,养精蓄锐
+ res[i] = nums1[left]
+ left++
+ }
+ }
+ return res
+}
+
+// 定义一个优先队列类型 PriorityQueue,用于按照指定比较函数排序
+type PriorityQueue [][]int
+
+func (pq PriorityQueue) Len() int {
+ return len(pq)
+}
+
+func (pq PriorityQueue) Less(i, j int) bool {
+ return pq[i][1] > pq[j][1]
+}
+
+func (pq PriorityQueue) Swap(i, j int) {
+ pq[i], pq[j] = pq[j], pq[i]
+}
+
+func (pq *PriorityQueue) Push(x interface{}) {
+ item := x.([]int)
+ *pq = append(*pq, item)
+}
+
+func (pq *PriorityQueue) Pop() interface{} {
+ old := *pq
+ n := len(old)
+ item := old[n-1]
+ *pq = old[0 : n-1]
+ return item
+}
+```
+
+```java
+// by labuladong (java)
+class Solution {
+ public int[] advantageCount(int[] nums1, int[] nums2) {
+ int n = nums1.length;
+ // 给 nums2 降序排序
+ PriorityQueue maxpq = new PriorityQueue<>(
+ (int[] pair1, int[] pair2) -> {
+ return pair2[1] - pair1[1];
+ }
+ );
+ for (int i = 0; i < n; i++) {
+ maxpq.offer(new int[]{i, nums2[i]});
+ }
+ // 给 nums1 升序排序
+ Arrays.sort(nums1);
+
+ // nums1[left] 是最小值,nums1[right] 是最大值
+ int left = 0, right = n - 1;
+ int[] res = new int[n];
+
+ while (!maxpq.isEmpty()) {
+ int[] pair = maxpq.poll();
+ // maxval 是 nums2 中的最大值,i 是对应索引
+ int i = pair[0], maxval = pair[1];
+ if (maxval < nums1[right]) {
+ // 如果 nums1[right] 能胜过 maxval,那就自己上
+ res[i] = nums1[right];
+ right--;
+ } else {
+ // 否则用最小值混一下,养精蓄锐
+ res[i] = nums1[left];
+ left++;
+ }
+ }
+ return res;
+ }
+}
+```
+
+```javascript
+// by chatGPT (javascript)
+var advantageCount = function(nums1, nums2) {
+ var n = nums1.length;
+ //给 nums2 降序排序
+ var maxpq = new PriorityQueue((pair1, pair2) => pair2[1] - pair1[1]);
+ for (var i = 0; i < n; i++) {
+ maxpq.offer([i, nums2[i]]);
+ }
+ //给 nums1 升序排序
+ nums1.sort((a, b) => a - b);
+ // nums1[left] 是最小值,nums1[right] 是最大值
+ var left = 0, right = n - 1;
+ var res = new Array(n);
+
+ while (!maxpq.isEmpty()) {
+ var pair = maxpq.poll();
+ // maxval 是 nums2 中的最大值,i 是对应索引
+ var i = pair[0], maxval = pair[1];
+ if (maxval < nums1[right]) {
+ // 如果 nums1[right] 能胜过 maxval,那就自己上
+ res[i] = nums1[right];
+ right--;
+ } else {
+ // 否则用最小值混一下,养精蓄锐
+ res[i] = nums1[left];
+ left++;
+ }
+ }
+ return res;
+}
+```
+
+```python
+# by chatGPT (python)
+class Solution:
+ def advantageCount(self, nums1: List[int], nums2: List[int]) -> List[int]:
+ n = len(nums1)
+ # 给 nums2 降序排序
+ maxpq = []
+ for i in range(n):
+ maxpq.append([i, nums2[i]])
+ maxpq.sort(key=lambda x: -x[1])
+
+ # 给 nums1 升序排序
+ nums1.sort()
+
+ # nums1[left] 是最小值,nums1[right] 是最大值
+ left, right = 0, n - 1
+ res = [0] * n
+
+ while maxpq:
+ pair = maxpq.pop(0)
+ # maxval 是 nums2 中的最大值,i 是对应索引
+ i, maxval = pair[0], pair[1]
+ if maxval < nums1[right]:
+ # 如果 nums1[right] 能胜过 maxval,那就自己上
+ res[i] = nums1[right]
+ right -= 1
+ else:
+ # 否则用最小值混一下,养精蓄锐
+ res[i] = nums1[left]
+ left += 1
+ return res
+```
+
+https://leetcode.cn/problems/advantage-shuffle 的多语言解法👆
+
+https://leetcode.cn/problems/all-paths-from-source-to-target 的多语言解法👇
+
+```cpp
+// by chatGPT (cpp)
+class Solution {
+ // 记录所有路径
+ vector> res;
+
+public:
+ vector> allPathsSourceTarget(vector>& graph) {
+ deque path;
+ traverse(graph, 0, path);
+ return res;
+ }
+
+ /* 图的遍历框架 */
+ void traverse(vector>& graph, int s, deque& path) {
+
+ // 添加节点 s 到路径
+ path.push_back(s);
+
+ int n = graph.size();
+ if (s == n - 1) {
+ // 到达终点
+ res.push_back(vector(path.begin(), path.end()));
+ path.pop_back();
+ return;
+ }
+
+ // 递归每个相邻节点
+ for (int v : graph[s]) {
+ traverse(graph, v, path);
+ }
+
+ // 从路径移出节点 s
+ path.pop_back();
+ }
+};
+```
+
+```go
+// by chatGPT (go)
+func allPathsSourceTarget(graph [][]int) [][]int {
+ res := [][]int{}
+ path := []int{}
+
+ var traverse func(graph [][]int, s int, path []int)
+ traverse = func(graph [][]int, s int, path []int) {
+ // 添加节点 s 到路径
+ path = append(path, s)
+
+ n := len(graph)
+ if s == n - 1 {
+ // 到达终点
+ tmp := make([]int, len(path))
+ copy(tmp, path)
+ res = append(res, tmp)
+ path = path[:len(path) - 1]
+ return
+ }
+
+ // 递归每个相邻节点
+ for _, v := range graph[s] {
+ traverse(graph, v, path)
+ }
+
+ // 从路径移出节点 s
+ path = path[:len(path) - 1]
+ }
+
+ traverse(graph, 0, path)
+ return res
+}
+```
+
+```java
+// by labuladong (java)
+class Solution {
+ // 记录所有路径
+ List> res = new LinkedList<>();
+
+ public List> allPathsSourceTarget(int[][] graph) {
+ LinkedList path = new LinkedList<>();
+ traverse(graph, 0, path);
+ return res;
+ }
+
+ /* 图的遍历框架 */
+ void traverse(int[][] graph, int s, LinkedList path) {
+
+ // 添加节点 s 到路径
+ path.addLast(s);
+
+ int n = graph.length;
+ if (s == n - 1) {
+ // 到达终点
+ res.add(new LinkedList<>(path));
+ path.removeLast();
+ return;
+ }
+
+ // 递归每个相邻节点
+ for (int v : graph[s]) {
+ traverse(graph, v, path);
+ }
+
+ // 从路径移出节点 s
+ path.removeLast();
+ }
+}
+```
+
+```javascript
+// by chatGPT (javascript)
+var allPathsSourceTarget = function(graph) {
+ // 记录所有路径
+ var res = [];
+
+ var traverse = function(graph, s, path) {
+ // 添加节点 s 到路径
+ path.push(s);
+
+ var n = graph.length;
+ if (s === n - 1) {
+ // 到达终点
+ res.push(path.slice());
+ path.pop();
+ return;
+ }
+
+ // 递归每个相邻节点
+ for (var i = 0; i < graph[s].length; i++) {
+ traverse(graph, graph[s][i], path);
+ }
+
+ // 从路径移出节点 s
+ path.pop();
+ };
+
+ var path = [];
+ traverse(graph, 0, path);
+
+ return res;
+};
+```
+
+```python
+# by chatGPT (python)
+from typing import List
+
+class Solution:
+ def __init__(self):
+ # 记录所有路径
+ self.res = []
+
+ def allPathsSourceTarget(self, graph: List[List[int]]) -> List[List[int]]:
+ path = []
+ self.traverse(graph, 0, path)
+ return self.res
+
+ """ 图的遍历框架 """
+ def traverse(self, graph: List[List[int]], s: int, path: List[int]) -> None:
+ # 添加节点 s 到路径
+ path.append(s)
+
+ n = len(graph)
+ if s == n - 1:
+ # 到达终点
+ self.res.append(path[:])
+ path.pop()
+ return
+
+ # 递归每个相邻节点
+ for v in graph[s]:
+ self.traverse(graph, v, path)
+
+ # 从路径移出节点 s
+ path.pop()
+```
+
+https://leetcode.cn/problems/all-paths-from-source-to-target 的多语言解法👆
+
+https://leetcode.cn/problems/bP4bmD 的多语言解法👇
+
+```cpp
+// by chatGPT (cpp)
+class Solution {
+ // 记录所有路径
+ vector> res;
+
+public:
+ vector> allPathsSourceTarget(vector>& graph) {
+ deque path;
+ traverse(graph, 0, path);
+ return res;
+ }
+
+ /* 图的遍历框架 */
+ void traverse(vector>& graph, int s, deque& path) {
+
+ // 添加节点 s 到路径
+ path.push_back(s);
+
+ int n = graph.size();
+ if (s == n - 1) {
+ // 到达终点
+ res.push_back(vector(path.begin(), path.end()));
+ path.pop_back();
+ return;
+ }
+
+ // 递归每个相邻节点
+ for (int v : graph[s]) {
+ traverse(graph, v, path);
+ }
+
+ // 从路径移出节点 s
+ path.pop_back();
+ }
+};
+```
+
+```go
+// by chatGPT (go)
+func allPathsSourceTarget(graph [][]int) [][]int {
+ // 记录所有路径
+ res := [][]int{}
+ var traverse func(graph [][]int, s int, path []int)
+
+ traverse = func(graph [][]int, s int, path []int) {
+ // 添加节点 s 到路径
+ path = append(path, s)
+
+ n := len(graph)
+ if s == n-1 {
+ // 到达终点
+ tmp := make([]int, len(path))
+ copy(tmp, path)
+ res = append(res, tmp)
+ path = path[:len(path)-1]
+ return
+ }
+
+ // 递归每个相邻节点
+ for _, v := range graph[s] {
+ traverse(graph, v, path)
+ }
+
+ // 从路径移出节点 s
+ path = path[:len(path)-1]
+ }
+
+ path := make([]int, 0)
+ traverse(graph, 0, path)
+ return res
+}
+```
+
+```java
+// by labuladong (java)
+class Solution {
+ // 记录所有路径
+ List> res = new LinkedList<>();
+
+ public List> allPathsSourceTarget(int[][] graph) {
+ LinkedList path = new LinkedList<>();
+ traverse(graph, 0, path);
+ return res;
+ }
+
+ /* 图的遍历框架 */
+ void traverse(int[][] graph, int s, LinkedList path) {
+
+ // 添加节点 s 到路径
+ path.addLast(s);
+
+ int n = graph.length;
+ if (s == n - 1) {
+ // 到达终点
+ res.add(new LinkedList<>(path));
+ path.removeLast();
+ return;
+ }
+
+ // 递归每个相邻节点
+ for (int v : graph[s]) {
+ traverse(graph, v, path);
+ }
+
+ // 从路径移出节点 s
+ path.removeLast();
+ }
+}
+```
+
+```javascript
+// by chatGPT (javascript)
+var allPathsSourceTarget = function(graph) {
+ // 记录所有路径
+ let res = [];
+
+ let traverse = function(graph, s, path) {
+ // 添加节点 s 到路径
+ path.push(s);
+
+ let n = graph.length;
+ if (s == n - 1) {
+ // 到达终点
+ res.push([...path]);
+ path.pop();
+ return;
+ }
+
+ // 递归每个相邻节点
+ for (let v of graph[s]) {
+ traverse(graph, v, path);
+ }
+
+ // 从路径移出节点 s
+ path.pop();
+ };
+
+ let path = [];
+ traverse(graph, 0, path);
+
+ return res;
+};
+```
+
+```python
+# by chatGPT (python)
+class Solution:
+ # 记录所有路径
+ res = []
+
+ def allPathsSourceTarget(self, graph: List[List[int]]) -> List[List[int]]:
+ path = []
+ self.traverse(graph, 0, path)
+ return self.res
+
+ # 图的遍历框架
+ def traverse(self, graph: List[List[int]], s: int, path: List[int]) -> None:
+
+ # 添加节点 s 到路径
+ path.append(s)
+
+ n = len(graph)
+ if s == n - 1:
+ # 到达终点
+ self.res.append(path[:])
+ path.pop()
+ return
+
+ # 递归每个相邻节点
+ for v in graph[s]:
+ self.traverse(graph, v, path)
+
+ # 从路径移出节点 s
+ path.pop()
+```
+
+https://leetcode.cn/problems/bP4bmD 的多语言解法👆
+
+https://leetcode.cn/problems/ba-shu-zi-fan-yi-cheng-zi-fu-chuan-lcof 的多语言解法👇
+
+```cpp
+// by chatGPT (cpp)
+class Solution {
+public:
+ int translateNum(int num) {
+ string s = to_string(num);
+ int n = s.length();
+ if (n < 1) {
+ return 0;
+ }
+ // 定义:dp[i] 表示 s[0..i-1] 的解码方式数量
+ vector dp(n + 1);
+ // base case: s 为空或者 s 只有一个字符的情况
+ dp[0] = 1;
+ dp[1] = 1;
+
+ // 注意 dp 数组和 s 之间的索引偏移一位
+ for (int i = 2; i <= n; i++) {
+ char c = s[i - 1], d = s[i - 2];
+ if ('0' <= c && c <= '9') {
+ // 1. s[i] 本身可以作为一个字母
+ dp[i] += dp[i - 1];
+ }
+ if (d == '1' || d == '2' && c <= '5') {
+ // 2. s[i] 和 s[i - 1] 结合起来表示一个字母
+ dp[i] += dp[i - 2];
+ }
+ }
+ return dp[n];
+ }
+};
+```
+
+```go
+// by chatGPT (go)
+func translateNum(num int) int {
+ s := strconv.Itoa(num)
+ n := len(s)
+ if n < 1 {
+ return 0
+ }
+ // 定义:dp[i] 表示 s[0..i-1] 的解码方式数量
+ dp := make([]int, n+1)
+ // base case: s 为空或者 s 只有一个字符的情况
+ dp[0] = 1
+ dp[1] = 1
+
+ // 注意 dp 数组和 s 之间的索引偏移一位
+ for i := 2; i <= n; i++ {
+ c, d := s[i-1], s[i-2]
+ if '0' <= c && c <= '9' {
+ // 1. s[i] 本身可以作为一个字母
+ dp[i] += dp[i-1]
+ }
+ if (d == '1' || (d == '2' && c <= '5')) {
+ // 2. s[i] 和 s[i - 1] 结合起来表示一个字母
+ dp[i] += dp[i-2]
+ }
+ }
+ return dp[n]
+}
+```
+
+```java
+// by labuladong (java)
+class Solution {
+ public int translateNum(int num) {
+ String s = num + "";
+ int n = s.length();
+ if (n < 1) {
+ return 0;
+ }
+ // 定义:dp[i] 表示 s[0..i-1] 的解码方式数量
+ int[] dp = new int[n + 1];
+ // base case: s 为空或者 s 只有一个字符的情况
+ dp[0] = 1;
+ dp[1] = 1;
+
+ // 注意 dp 数组和 s 之间的索引偏移一位
+ for (int i = 2; i <= n; i++) {
+ char c = s.charAt(i - 1), d = s.charAt(i - 2);
+ if ('0' <= c && c <= '9') {
+ // 1. s[i] 本身可以作为一个字母
+ dp[i] += dp[i - 1];
+ }
+ if (d == '1' || d == '2' && c <= '5') {
+ // 2. s[i] 和 s[i - 1] 结合起来表示一个字母
+ dp[i] += dp[i - 2];
+ }
+ }
+ return dp[n];
+ }
+}
+```
+
+```javascript
+// by chatGPT (javascript)
+var translateNum = function(num) {
+ var s = num.toString();
+ var n = s.length;
+ if (n < 1) {
+ return 0;
+ }
+ // 定义:dp[i] 表示 s[0..i-1] 的解码方式数量
+ var dp = new Array(n + 1).fill(0);
+ // base case: s 为空或者 s 只有一个字符的情况
+ dp[0] = 1;
+ dp[1] = 1;
+
+ // 注意 dp 数组和 s 之间的索引偏移一位
+ for (var i = 2; i <= n; i++) {
+ var c = s.charAt(i - 1), d = s.charAt(i - 2);
+ if ('0' <= c && c <= '9') {
+ // 1. s[i] 本身可以作为一个字母
+ dp[i] += dp[i - 1];
+ }
+ if (d == '1' || d == '2' && c <= '5') {
+ // 2. s[i] 和 s[i - 1] 结合起来表示一个字母
+ dp[i] += dp[i - 2];
+ }
+ }
+ return dp[n];
+};
+```
+
+```python
+# by chatGPT (python)
+class Solution:
+ def translateNum(self, num: int) -> int:
+ s = str(num)
+ n = len(s)
+ if n < 1:
+ return 0
+ # 定义:dp[i] 表示 s[0..i-1] 的解码方式数量
+ dp = [0] * (n + 1)
+ # base case: s 为空或者 s 只有一个字符的情况
+ dp[0] = 1
+ dp[1] = 1
+
+ # 注意 dp 数组和 s 之间的索引偏移一位
+ for i in range(2, n + 1):
+ c = s[i - 1]
+ d = s[i - 2]
+ if '0' <= c <= '9':
+ # 1. s[i] 本身可以作为一个字母
+ dp[i] += dp[i - 1]
+ if d == '1' or (d == '2' and c <= '5'):
+ # 2. s[i] 和 s[i - 1] 结合起来表示一个字母
+ dp[i] += dp[i - 2]
+ return dp[n]
+```
+
+https://leetcode.cn/problems/ba-shu-zi-fan-yi-cheng-zi-fu-chuan-lcof 的多语言解法👆
+
+https://leetcode.cn/problems/ba-shu-zu-pai-cheng-zui-xiao-de-shu-lcof 的多语言解法👇
+
+```cpp
+// by chatGPT (cpp)
+class Solution {
+public:
+ string minNumber(vector& nums) {
+ int n = nums.size();
+ vector strs(n);
+ for (int i = 0; i < n; i++) {
+ strs[i] = to_string(nums[i]);
+ }
+ sort(strs.begin(), strs.end(), [](const string& s1, const string& s2) {
+ // 看看那种拼接方式得到的数字更小,排前面
+ // 不用转成 int 类型,因为字符串的比较算法和正整数的比较算法是一样的
+ // 而且拼接字符串比较长,会导致 int 类型溢出
+ return (s1 + s2) < (s2 + s1);
+ });
+
+ return accumulate(strs.begin(), strs.end(), string(""));
+ }
+};
+```
+
+```go
+// by chatGPT (go)
+func minNumber(nums []int) string {
+ n := len(nums)
+ strs := make([]string, n)
+ for i := 0; i < n; i++ {
+ strs[i] = strconv.Itoa(nums[i])
+ }
+ sort.Slice(strs, func(i, j int) bool {
+ // 看看那种拼接方式得到的数字更小,排前面
+ // 不用转成 int 类型,因为字符串的比较算法和正整数的比较算法是一样的
+ // 而且拼接字符串比较长,会导致 int 类型溢出
+ return strs[i]+strs[j] < strs[j]+strs[i]
+ })
+
+ return strings.Join(strs, "")
+}
+```
+
+```java
+// by labuladong (java)
+class Solution {
+ public String minNumber(int[] nums) {
+ int n = nums.length;
+ String[] strs = new String[n];
+ for (int i = 0; i < n; i++) {
+ strs[i] = Integer.toString(nums[i]);
+ }
+ Arrays.sort(strs, (s1, s2) -> {
+ // 看看那种拼接方式得到的数字更小,排前面
+ // 不用转成 int 类型,因为字符串的比较算法和正整数的比较算法是一样的
+ // 而且拼接字符串比较长,会导致 int 类型溢出
+ return (s1 + s2).compareTo(s2 + s1);
+ });
+
+ return String.join("", strs);
+ }
+}
+```
+
+```javascript
+// by chatGPT (javascript)
+var minNumber = function(nums) {
+ const n = nums.length;
+ const strs = new Array(n);
+ for (let i = 0; i < n; i++) {
+ strs[i] = nums[i].toString();
+ }
+ strs.sort((s1, s2) => {
+ // 看看那种拼接方式得到的数字更小,排前面
+ // 不用转成 int 类型,因为字符串的比较算法和正整数的比较算法是一样的
+ // 而且拼接字符串比较长,会导致 int 类型溢出
+ return (s1 + s2).localeCompare(s2 + s1);
+ });
+
+ return strs.join("");
+}
+```
+
+```python
+# by chatGPT (python)
+class Solution:
+ def minNumber(self, nums: List[int]) -> str:
+ n = len(nums)
+ strs = [str(num) for num in nums]
+
+ def compare(s1: str, s2: str) -> int:
+ # 看看那种拼接方式得到的数字更小,排前面
+ # 不用转成 int 类型,因为字符串的比较算法和正整数的比较算法是一样的
+ # 而且拼接字符串比较长,会导致 int 类型溢出
+ return -1 if s1 + s2 < s2 + s1 else 1
+
+ strs.sort(key=functools.cmp_to_key(compare))
+
+ return ''.join(strs)
+```
+
+https://leetcode.cn/problems/ba-shu-zu-pai-cheng-zui-xiao-de-shu-lcof 的多语言解法👆
+
+https://leetcode.cn/problems/ba-zi-fu-chuan-zhuan-huan-cheng-zheng-shu-lcof 的多语言解法👇
+
+```cpp
+// by chatGPT (cpp)
+class Solution {
+public:
+ int strToInt(string str) {
+ int n = str.length();
+ int i = 0;
+ // 记录正负号
+ int sign = 1;
+ // 用 long 避免 int 溢出
+ long res = 0;
+ // 跳过前导空格
+ while (i < n && str[i] == ' ') {
+ i++;
+ }
+ if (i == n) {
+ return 0;
+ }
+
+ // 记录符号位
+ if (str[i] == '-') {
+ sign = -1;
+ i++;
+ } else if (str[i] == '+') {
+ i++;
+ }
+ if (i == n) {
+ return 0;
+ }
+
+ // 统计数字位
+ while (i < n && '0' <= str[i] && str[i] <= '9') {
+ res = res * 10 + str[i] - '0';
+ if (res > INT_MAX) {
+ break;
+ }
+ i++;
+ }
+ // 如果溢出,强转成 int 就会和真实值不同
+ if ((int) res != res) {
+ return sign == 1 ? INT_MAX : INT_MIN;
+ }
+ return (int) res * sign;
+ }
+};
+```
+
+```go
+// by chatGPT (go)
+func myAtoi(str string) int {
+ n := len(str)
+ i := 0
+ // 记录正负号
+ sign := 1
+ // 用 long 避免 int 溢出
+ var res int64 = 0
+ // 跳过前导空格
+ for i < n && str[i] == ' ' {
+ i++
+ }
+ if i == n {
+ return 0
+ }
+
+ // 记录符号位
+ if str[i] == '-' {
+ sign = -1
+ i++
+ } else if str[i] == '+' {
+ i++
+ }
+ if i == n {
+ return 0
+ }
+
+ // 统计数字位
+ for i < n && '0' <= str[i] && str[i] <= '9' {
+ res = res * 10 + int64(str[i]-'0')
+ if res > math.MaxInt32 {
+ break
+ }
+ i++
+ }
+ // 如果溢出,强转成 int 就会和真实值不同
+ if int(res) != res {
+ if sign == 1 {
+ return math.MaxInt32
+ } else {
+ return math.MinInt32
+ }
+ }
+ return int(res) * sign
+}
+```
+
+```java
+// by labuladong (java)
+class Solution {
+ public int myAtoi(String str) {
+ int n = str.length();
+ int i = 0;
+ // 记录正负号
+ int sign = 1;
+ // 用 long 避免 int 溢出
+ long res = 0;
+ // 跳过前导空格
+ while (i < n && str.charAt(i) == ' ') {
+ i++;
+ }
+ if (i == n) {
+ return 0;
+ }
+
+ // 记录符号位
+ if (str.charAt(i) == '-') {
+ sign = -1;
+ i++;
+ } else if (str.charAt(i) == '+') {
+ i++;
+ }
+ if (i == n) {
+ return 0;
+ }
+
+ // 统计数字位
+ while (i < n && '0' <= str.charAt(i) && str.charAt(i) <= '9') {
+ res = res * 10 + str.charAt(i) - '0';
+ if (res > Integer.MAX_VALUE) {
+ break;
+ }
+ i++;
+ }
+ // 如果溢出,强转成 int 就会和真实值不同
+ if ((int) res != res) {
+ return sign == 1 ? Integer.MAX_VALUE : Integer.MIN_VALUE;
+ }
+ return (int) res * sign;
+ }
+}
+```
+
+```javascript
+// by chatGPT (javascript)
+var myAtoi = function(str) {
+ let n = str.length;
+ let i = 0;
+ // 记录正负号
+ let sign = 1;
+ // 用 BigInt 避免 int 溢出
+ let res = BigInt(0);
+ // 跳过前导空格
+ while (i < n && str[i] === ' ') {
+ i++;
+ }
+ if (i === n) {
+ return 0;
+ }
+
+ // 记录符号位
+ if (str[i] === '-') {
+ sign = -1;
+ i++;
+ } else if (str[i] === '+') {
+ i++;
+ }
+ if (i === n) {
+ return 0;
+ }
+
+ // 统计数字位
+ while (i < n && '0' <= str[i] && str[i] <= '9') {
+ res = res * BigInt(10) + BigInt(str[i].charCodeAt() - '0'.charCodeAt());
+ if (res > BigInt(Number.MAX_VALUE)) {
+ break;
+ }
+ i++;
+ }
+ // 如果溢出,强转成 int 就会和真实值不同
+ if (res > BigInt(Number.MAX_VALUE)) {
+ return sign === 1 ? Number.MAX_VALUE : Number.MIN_VALUE;
+ }
+ return Number(res) * sign;
+};
+```
+
+```python
+# by chatGPT (python)
+class Solution:
+ def myAtoi(self, s: str) -> int:
+ n = len(s)
+ i = 0
+ # 记录正负号
+ sign = 1
+ # 用 long 避免 int 溢出
+ res = 0
+ # 跳过前导空格
+ while i < n and s[i] == ' ':
+ i += 1
+ if i == n:
+ return 0
+
+ # 记录符号位
+ if s[i] == '-':
+ sign = -1
+ i += 1
+ elif s[i] == '+':
+ i += 1
+ if i == n:
+ return 0
+
+ # 统计数字位
+ while i < n and '0' <= s[i] <= '9':
+ res = res * 10 + ord(s[i]) - ord('0')
+ if res > pow(2, 31) - 1:
+ break
+ i += 1
+ # 如果溢出,强转成 int 就会和真实值不同
+ if res != int(res):
+ return sign == 1 and pow(2, 31) - 1 or -pow(2, 31)
+ return int(res) * sign
+```
+
+https://leetcode.cn/problems/ba-zi-fu-chuan-zhuan-huan-cheng-zheng-shu-lcof 的多语言解法👆
+
+https://leetcode.cn/problems/bao-han-minhan-shu-de-zhan-lcof 的多语言解法👇
+
+```cpp
+// by chatGPT (cpp)
+// 原始思路
+class MinStack1 {
+ // 记录栈中的所有元素
+ stack stk;
+ // 阶段性记录栈中的最小元素
+ stack minStk;
+
+public:
+ void push(int val) {
+ stk.push(val);
+ // 维护 minStk 栈顶为全栈最小元素
+ if (minStk.empty() || val <= minStk.top()) {
+ // 新插入的这个元素就是全栈最小的
+ minStk.push(val);
+ }
+ else {
+ // 插入的这个元素比较大
+ minStk.push(minStk.top());
+ }
+ }
+
+ void pop() {
+ stk.pop();
+ minStk.pop();
+ }
+
+ int top() {
+ return stk.top();
+ }
+
+ int getMin() {
+ // minStk 栈顶为全栈最小元素
+ return minStk.top();
+ }
+};
+// 优化版
+class MinStack {
+ // 记录栈中的所有元素
+ stack