diff --git a/.gitignore b/.gitignore
new file mode 100644
index 0000000..30f3b78
--- /dev/null
+++ b/.gitignore
@@ -0,0 +1,106 @@
+# Created by .ignore support plugin (hsz.mobi)
+### Python template
+# Byte-compiled / optimized / DLL files
+__pycache__/
+*.py[cod]
+*$py.class
+
+# C extensions
+*.so
+
+# Distribution / packaging
+.Python
+build/
+develop-eggs/
+dist/
+downloads/
+eggs/
+.eggs/
+lib/
+lib64/
+parts/
+sdist/
+var/
+wheels/
+*.egg-info/
+.installed.cfg
+*.egg
+
+# PyInstaller
+# Usually these files are written by a python script from a template
+# before PyInstaller builds the exe, so as to inject date/other infos into it.
+*.manifest
+*.spec
+
+# Installer logs
+pip-log.txt
+pip-delete-this-directory.txt
+
+# Unit test / coverage reports
+htmlcov/
+.tox/
+.coverage
+.coverage.*
+.cache
+nosetests.xml
+coverage.xml
+*.cover
+.hypothesis/
+
+# Translations
+*.mo
+*.pot
+
+# Django stuff:
+*.log
+local_settings.py
+
+# Flask stuff:
+instance/
+.webassets-cache
+
+# Scrapy stuff:
+.scrapy
+
+# Sphinx documentation
+docs/_build/
+
+# PyBuilder
+target/
+
+# Jupyter Notebook
+.ipynb_checkpoints
+
+# pyenv
+.python-version
+
+# celery beat schedule file
+celerybeat-schedule
+
+# SageMath parsed files
+*.sage.py
+
+# Environments
+.env
+.venv
+env/
+venv/
+ENV/
+
+# Spyder project settings
+.spyderproject
+.spyproject
+
+# Rope project settings
+.ropeproject
+
+# mkdocs documentation
+/site
+
+# mypy
+.mypy_cache/
+
+# customer
+.idea
+.idea/inspectionProfiles/Project_Default.xml
+.idea/vcs.xml
diff --git "a/AI/\344\275\277\347\224\250 GPT-4\343\200\201Python \345\222\214 Langchain\357\274\214\346\236\204\345\273\272\346\227\245\350\257\255\346\261\211\345\255\227\346\212\275\350\256\244\345\215\241\345\272\224\347\224\250\347\250\213\345\272\217.md" "b/AI/\344\275\277\347\224\250 GPT-4\343\200\201Python \345\222\214 Langchain\357\274\214\346\236\204\345\273\272\346\227\245\350\257\255\346\261\211\345\255\227\346\212\275\350\256\244\345\215\241\345\272\224\347\224\250\347\250\213\345\272\217.md"
new file mode 100644
index 0000000..2426081
--- /dev/null
+++ "b/AI/\344\275\277\347\224\250 GPT-4\343\200\201Python \345\222\214 Langchain\357\274\214\346\236\204\345\273\272\346\227\245\350\257\255\346\261\211\345\255\227\346\212\275\350\256\244\345\215\241\345\272\224\347\224\250\347\250\213\345\272\217.md"
@@ -0,0 +1,233 @@
+原文:[Building a Japanese Kanji Flashcard App](https://adilmoujahid.com/posts/2023/10/kanji-gpt4/)
+
+---
+
+# 使用 GPT-4、Python 和 Langchain,构建日语汉字抽认卡应用程序
+
+近几个月来,GPT-4 吸引了主流的关注,ChatGPT 等应用程序展示了其广泛的功能,并为技术的代际转变奠定了基础。可以通过 API 以编程方式访问 GPT-4 模型,从而能够创建具有丰富的上下文相关数据的多样化应用程序。这篇博文旨在揭开利用 GPT-4 构建应用程序的过程的神秘面纱。我们将通过逐步开发日语汉字抽认卡应用程序来探索这一点,使用 GPT-4 来构建该应用程序并为其提供有价值的数据。
+
+随着我们的步步推进,我们将探索学习日语汉字的挑战,利用 ChatGPT 构建前端,利用 GPT-4 的数据生成逻辑动态获取和格式化汉字数据,最终将其整合为一个使用 Python 和 Flask 的统一应用程序。
+
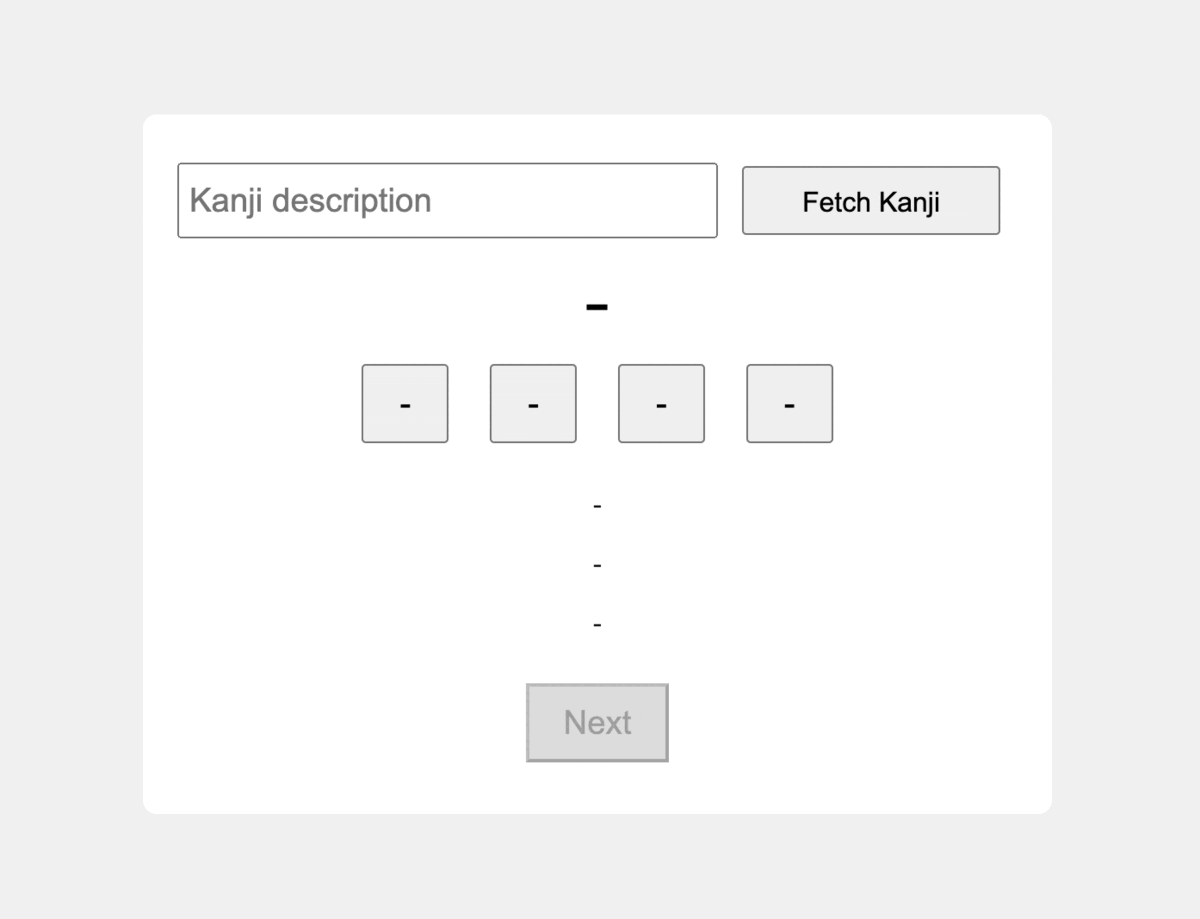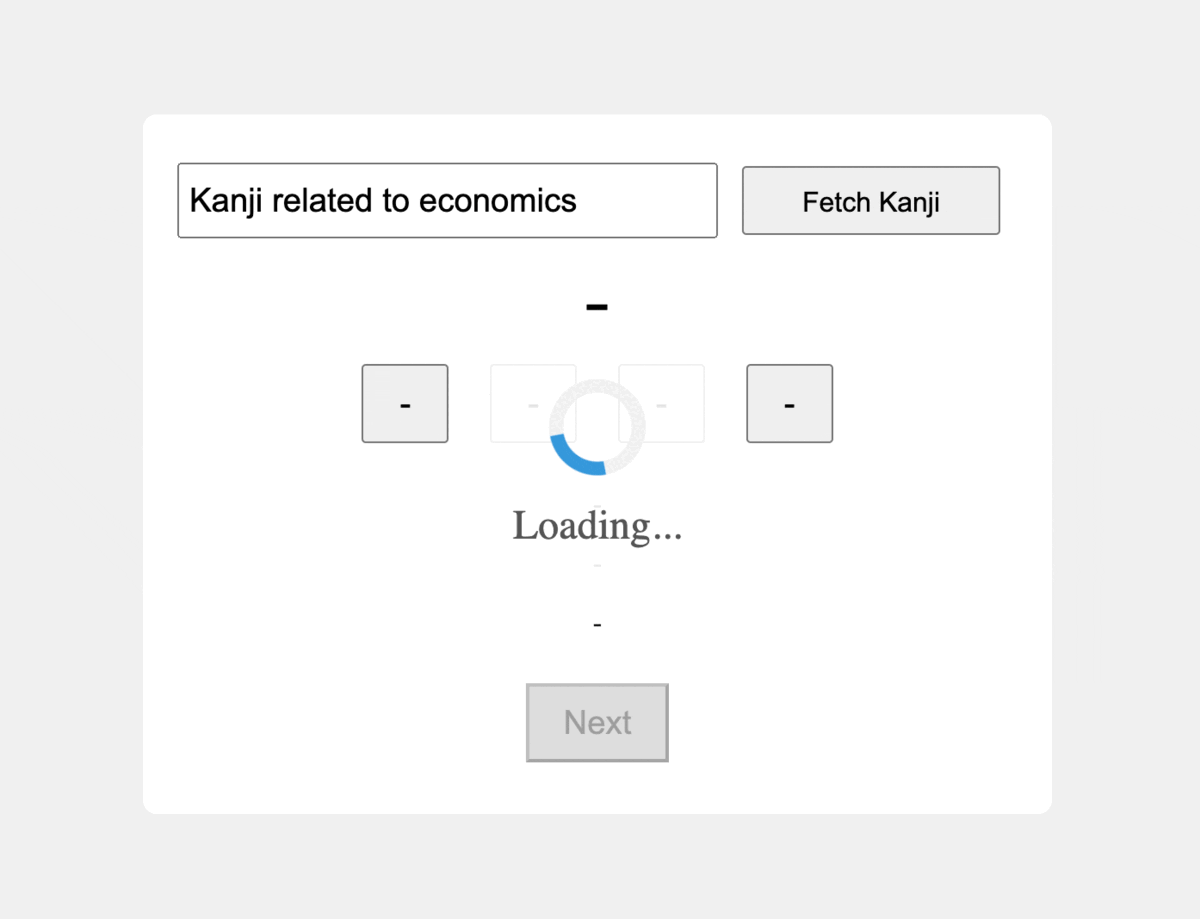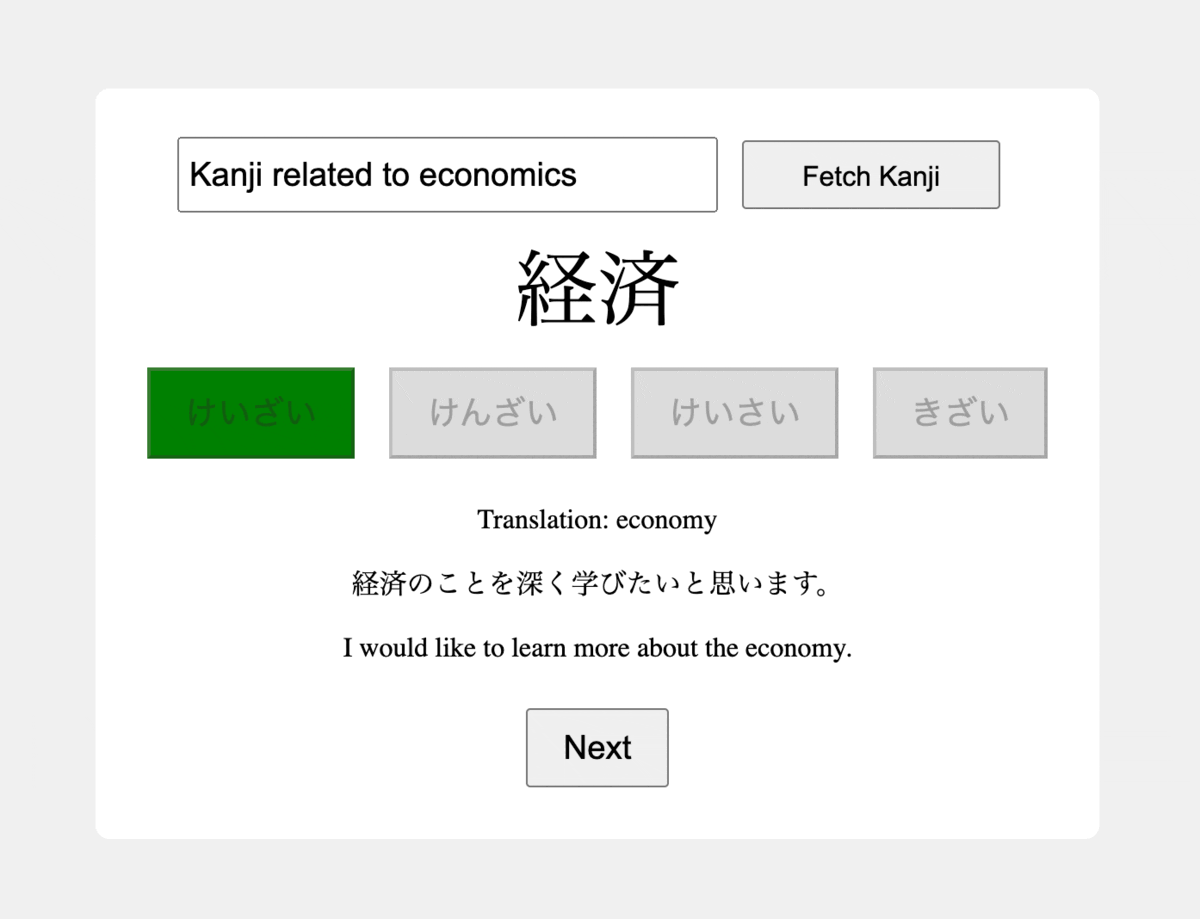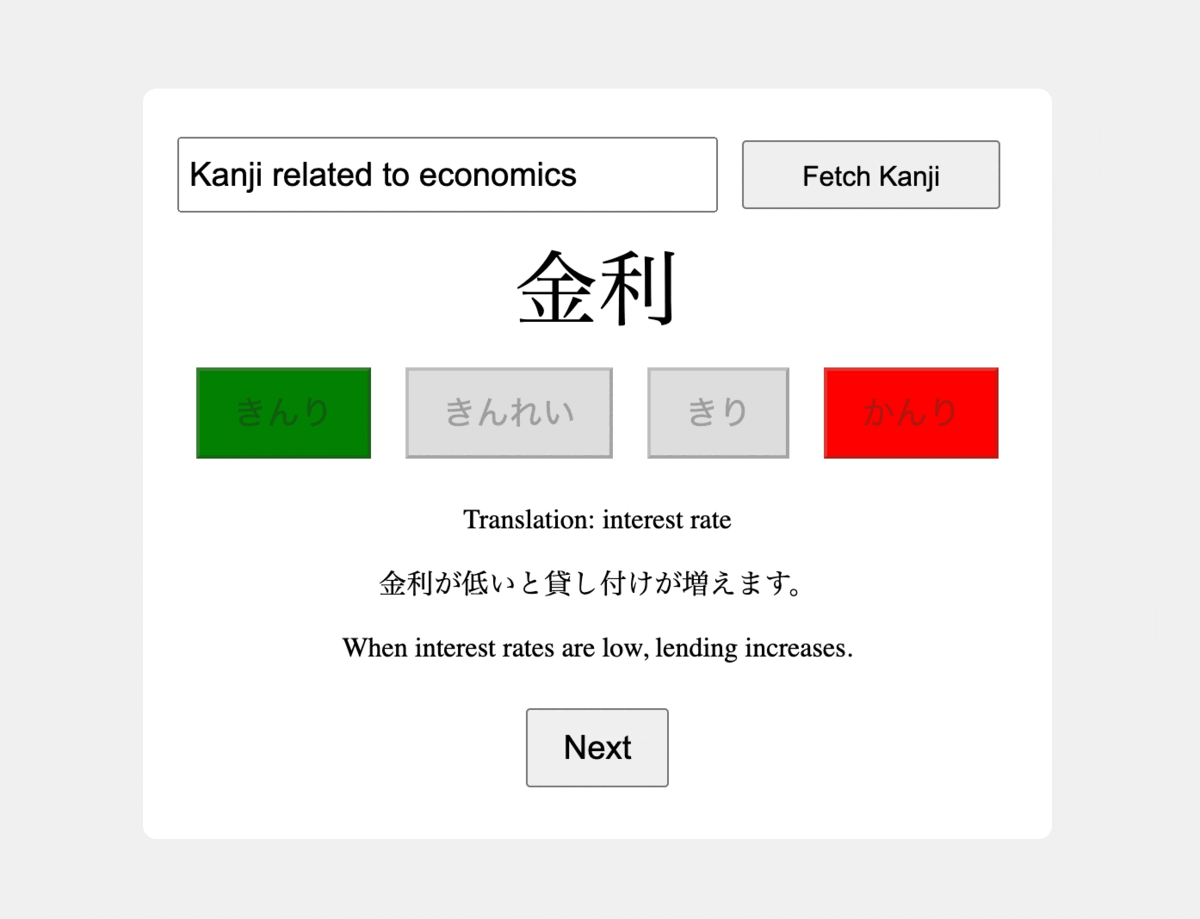
+您可以在下面的动画 GIF 中查看最终成果,并在[此 GitHub 存储库](https://github.com/adilmoujahid/kanji-flashcard-app-gpt4)中找到该项目的源代码。
+
+
+
+
+# 1. 定义用例
+
+当学生开始踏上日语学习的旅程时,他们会遇到一个迷人而复杂的书写系统,由三种文字组成:平假名、片假名和汉字。例如,短语“東京タワーは高いです。”(Tōkyō Tawā wa takai desu),其中“東京”(东京)是汉字,“タワー”(塔)是片假名,连接语法是平假名。这句话翻译过来就是“东京塔很高”。各种文字组合在一起,它们具有不同的功能——汉字用于大多数名词、动词和形容词,片假名用于外来词和借用词,平假名主要用于语法功能 —— 这是日语书面语言的一个显着特征。
+
+
+
+平假名和片假名各有 46 个基本字符,属于注音文字,而汉字是由中国汉字改编而成的,具有含义,并且通常有多种读法。虽然汉字字符有数以万计个,但日本的一般识字能力围绕着 2,136 个字符进行,如[Joyo Kanji List](https://en.wikipedia.org/wiki/List_of_j%C5%8Dy%C5%8D_kanji) 所定义。
+
+在下表中,您可以看到平假名和片假名字符及其相应读法。在每个框中,平假名字符显示在左侧,片假名字符显示在右侧。
+
+
+
+
+下面您可以看到汉字字符的一小部分示例。
+
+
+
+为了解决日语汉字学生面临的挑战,我们的目标是构建一个由 GPT-4 功能支持的汉字抽认卡应用程序,以促进学习之旅。该应用程序充当动态学习伴侣,使用户能够用自然语言指定他们希望探索的特定汉字。利用 GPT-4 的强大功能,该应用程序会自动整理符合用户明确需求的汉字列表,并通过提供单词的多项选择阅读来进一步评估他们的能力,确保提供积极有效的学习体验。
+
+# 2. 构建前端
+
+我们的下一步是为我们的汉字抽认卡应用程序构建前端,我们将在第 4 节中将其与 GPT-4 API 集成在一起。为了实现这一目标,我们将采用 ChatGPT,利用 GPT-4 模型,并应用以下提示生成我们前端的 HTML/CSS/JS 代码。
+
+```
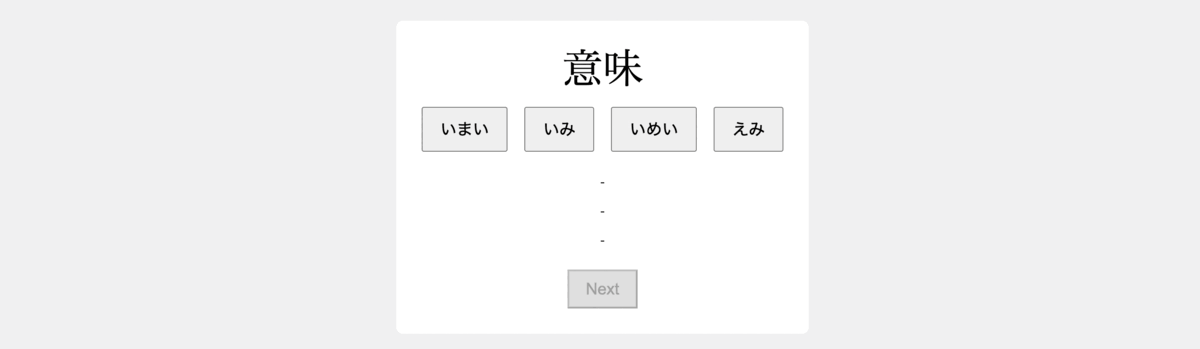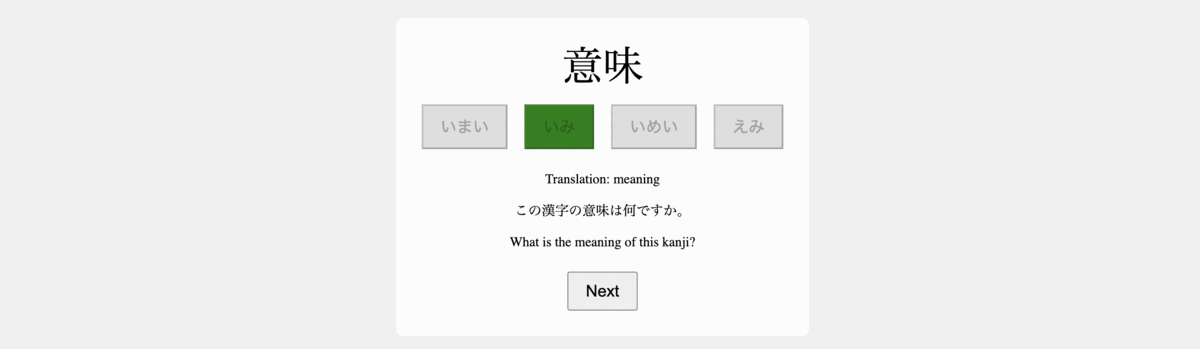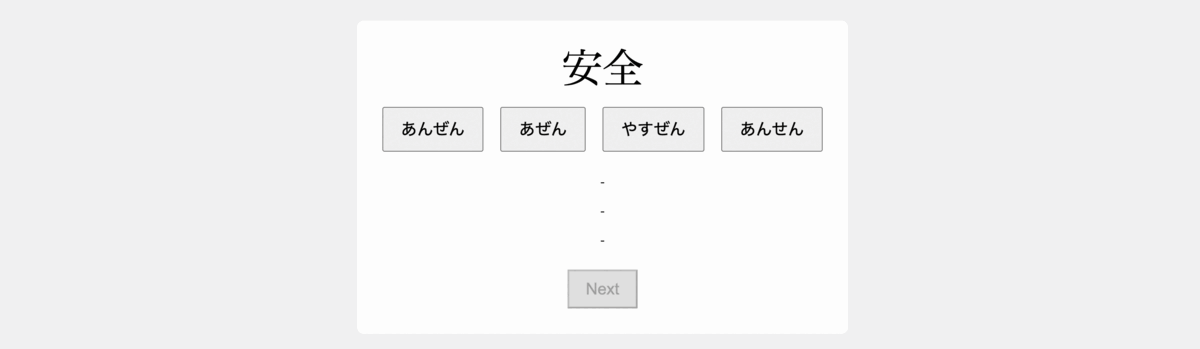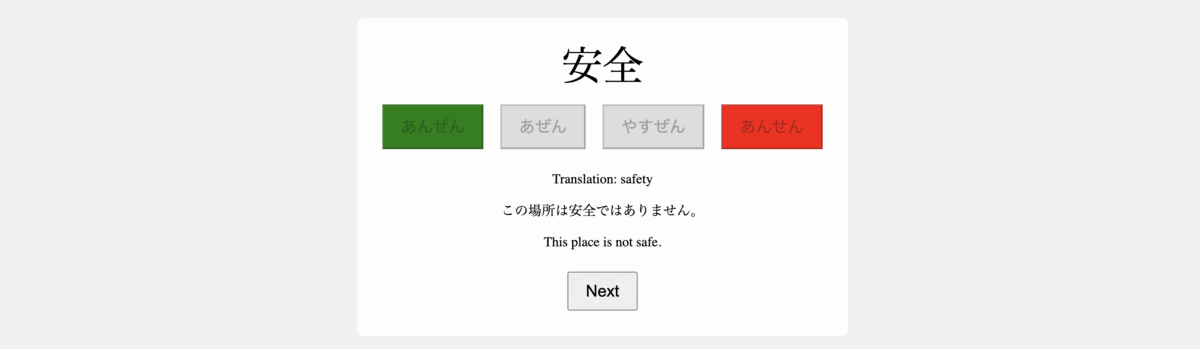
+Develop a flashcard app to facilitate the study of Japanese Kanji, utilizing HTML, JavaScript, and CSS for implementation. The app should have the following functionalities:
+1- Upon launching, the app presents a Japanese word in Kanji, accompanied by four buttons containing Hiragana readings: one correct and three incorrect options.
+2- When the user selects an answer, the corresponding button should be highlighted in green if it's correct, and in red if it's wrong, while also highlighting the correct button in green.
+3- Once an answer is selected, the app should display the English translation of the word, present the word within the context of a Japanese sentence, and also provide its English translation.
+4- Include a button to transition to the subsequent word.
+5- Populate the app with 10 different words in Kanji to test the app. The incorrect options should also be realistic and relevant to the correct answer.
+6- Make sure the app is centered on the screen and use simple styling.
+
+```
+
+下面的 gif 显示了完全使用 ChatGPT 制作的前端。这一令人印象深刻的结果证明了 GPT-4 能够简化开发流程并使其更易于使用,即使对于那些前端经验有限的人来说也是如此。
+
+
+
+
+# 3. 构建数据生成逻辑
+
+在本节中,我们将使用 GPT-4 构建日语汉字学习抽认卡应用程序的后端逻辑。该后端将负责获取和格式化汉字数据。为了实现这一目标,我们将结合使用 Python 和 LangChain。LangChain 是一个专门的框架,旨在创建由大型语言模型(包括来自 OpenAI 的模型)驱动的应用程序。它提供了与 API 接口交互、制作提示和构建返回输出的各种抽象。
+
+我们将从导入必要的库开始。在 Langchain 中,我们特别需要 `ChatOpenAI` 来与 GPT-4 进行通信,以及 `ChatPromptTemplate` 为我们的用例创建提示模板。
+
+```py
+import os
+from langchain.chat_models import ChatOpenAI
+from langchain.prompts import ChatPromptTemplate
+
+```
+接下来,我们指定要部署的模型(“gpt-4-0613”)。确保正确配置我们的 API 密钥至关重要。完成此操作后,我们与 GPT-4 建立连接。有关可用 OpenAI API 的完整列表,请访问[此处](https://platform.openai.com/account/rate-limits)。有关 API 的详细信息以及获取API 密钥的说明,您可以参考 [此链接](https://openai.com/product)。
+
+```py
+llm_model = "gpt-4-0613"
+OPENAI_API_KEY = openai_API_key
+os.environ["OPENAI_API_KEY"] = OPENAI_API_KEY
+
+chat = ChatOpenAI(temperature=1, model=llm_model)
+```
+接下来,我们构建一个专门针对我们的要求设计的 Langchain 模板。将 Langchain 模板视为预定义的表单。这些表单允许我们构建 GPT-4 的提示,其中包含我们希望在发送请求之前设置的特定变量。出于此目的,该模板将包含旨在检索和格式化汉字单词以及附加数据的提示。在本例中,我们的变量用 `{description}` 表示,它将表示我们感兴趣的汉字的具体描述。
+
+
+
+```py
+string_template = """Give 2 words written in Kanji that are: ```{description}```, \
+accompanied with its correct Hiragana reading and three incorrect Hiragana readings \
+that are realistic and relevant to the correct answer. \
+Also give me the English translation of the word, and present the word within the context \
+of a Japanese sentence, and also provide its English translation.
+
+Format the output as JSON with the data represented as an array of dictionaries with the following keys:
+"word": str // Japanese word written in Kanji
+"correct": str // Correct reading of the Kanji word in Hiragana
+"incorrect": List[str] //Incorrect readings of the Kanji phrase
+"english": str // English translation of the Kanji word
+"sentenceJP": str // Example sentence in Japanese using the Kanji word
+"sentenceEN": str // English translation of the example sentence
+"""
+
+prompt_template = ChatPromptTemplate.from_template(string_template)
+```
+
+有了我们手头的模板,我们就可以从 GPT-4 中检索汉字单词,例如,询问与经济学相关的汉字。
+
+```py
+description_example = "related to Economics"
+kanji_request = prompt_template.format_messages(description=description_example)
+
+kanji_response = chat(kanji_request)
+print(kanji_response.content)
+
+```
+
+在本例中,我们收到了一个结构良好的 JSON。但是,如果响应与我们所需的格式不匹配,Langchain 会提供各种[输出解析器](https://python.langchain.com/docs/modules/model_io/output_parsers/)来帮助我们相应地调整输出。
+
+
+```py
+[
+ {
+ "word": "経済",
+ "correct": "けいざい",
+ "incorrect": ["けいせい", "えいざい", "けんざい"],
+ "english": "economics",
+ "sentenceJP": "経済の状況を理解するためのデータが必要です。",
+ "sentenceEN": "We need data to understand the economic situation."
+ },
+ {
+ "word": "財政",
+ "correct": "ざいせい",
+ "incorrect": ["さいせい", "ざいぜい", "ざいしょう"],
+ "english": "finance",
+ "sentenceJP": "政府は財政問題に対応するための新たな策を立てます。",
+ "sentenceEN": "The government will devise new measures to deal with financial problems."
+ }
+]
+
+```
+
+# 4. 整一块
+
+数据生成准备就绪后,我们现在需要将其连接到我们的前端。我们将为此使用 Flask。Flask 会将我们的数据生成逻辑转变为 API,并管理我们的前端。代码很短,不到 50 行,有两条主要路由:服务前端的根路由 `(/)` 和根据前端输入调用数据生成逻辑并以 JSON 格式返回汉字数据的路由 `/get_words`。
+
+```py
+import os
+import json
+from config import *
+from langchain.chat_models import ChatOpenAI
+from langchain.prompts import ChatPromptTemplate
+from flask import Flask, render_template, request, jsonify
+
+app = Flask(__name__)
+
+llm_model = "gpt-4-0613"
+OPENAI_API_KEY = openai_API_key
+os.environ["OPENAI_API_KEY"] = OPENAI_API_KEY
+
+chat = ChatOpenAI(temperature=1, model=llm_model)
+
+
+string_template = """Give 2 words written in Kanji that are: ```{description}```, \
+accompanied with its correct Hiragana reading and three incorrect Hiragana readings \
+that are realistic and relevant to the correct answer. \
+Also give me the English translation of the word, and present the word within the context \
+of a Japanese sentence, and also provide its English translation.
+
+Format the output as JSON with the data represented as an array of dictionaries with the following keys:
+"word": str // Japanese word written in Kanji
+"correct": str // Correct reading of the Kanji word in Hiragana
+"incorrect": List[str] //Incorrect readings of the Kanji phrase
+"english": str // English translation of the Kanji word
+"sentenceJP": str // Example sentence in Japanese using the Kanji word
+"sentenceEN": str // English translation of the example sentence
+"""
+
+prompt_template = ChatPromptTemplate.from_template(string_template)
+
+@app.route('/')
+def home():
+ return render_template('index.html')
+
+@app.route('/get_words', methods=['POST'])
+def get_word():
+ description = request.json.get('description', '')
+ words_request = prompt_template.format_messages(description=description)
+ words_response = chat(words_request)
+ return jsonify(json.loads(words_response.content))
+
+if __name__ == "__main__":
+ app.run(port=5000)
+```
+
+在前端方面,我们引入了一些细微的变化:一个输入字段和一个按钮,让用户能够指定他们希望探索的汉字类型,并附有一个指示数据检索过程的加载旋转器。
+
+要启动应用程序,请从终端运行命令 `python app.py`,然后在您首选的浏览器中访问 http://127.0.0.1:5000。
+
+
+
+
+# 5. 优化和扩展我们应用的一些想法
+
+我们构建的应用程序功能齐全,非常适合学习汉字。尽管如此,我们仍然需要注意某些成本和性能方面的考虑。
+
+### 成本
+
+OpenAI 的定价模型根据 API 调用期间消耗的代币进行收费。截至撰写本文时:
+
+- GPT-4(8K 上下文)的输入价格为**每 1K 代币 0.03 美元**,输出**每 1K 代币价格为 0.06 美元**。
+- GPT-3.5 Turbo(4K 上下文)的输入价格为**每 1K 代币 0.0015 美元**,输出**每 1K 代币价格为 0.002 美元**。
+- 您可以在[此处](https://openai.com/pricing)找到 OpenAI 定价详细信息。
+
+对于我们的特定场景,通过 GPT-4 获取和格式化 5 个汉字单词的提示使用大约 188 个输入标记和 176 个输出标记,这意味着总费用为 0.0162 美元。
+
+要获取消耗的代币数量和美元成本,您可以执行以下代码:
+
+```py
+from langchain.callbacks import get_openai_callback
+
+with get_openai_callback() as cb:
+ description_example = "related to Economics"
+ kanji_request = prompt_template.format_messages(description=description_example)
+ kanji_response = chat(kanji_request)
+ print(cb)
+
+```
+
+虽然这种成本结构对于一些 API 调用来说似乎是可以接受的,但扩展应用程序以满足更大的用户群会增加这些费用。
+
+### 执行时间
+
+使用 GPT-4 获取并格式化 5 个汉字单词大约需要 17.2 秒。这种延迟会对用户体验产生负面影响。
+
+为了有效地优化和扩展我们的应用程序,我们可以考虑一种将数据源与 GPT-4 API 调用相结合并简化提示和输出格式的方法。例如,我们可以从常用汉字列表中获取所有字符,并使用 GPT-4 进行一次性翻译和列举例句。然后,可以通过要求 GPT-4 获取与特定主题相关的汉字单词来简化提示,而无需翻译或句子示例。之后,我们可以将这些汉字与我们预先生成的句子进行匹配。此方法可能会加快执行时间并减少令牌使用。
+
+
+# 总结
+
+总之,GPT-4 正在改变应用程序开发的游戏规则,尤其是在处理数据方面。我们的日语抽认卡应用程序展示了 GPT-4 有多么方便。开发人员可以使用 GPT-4 快速获取所需的信息,而不是手动收集数据。这不仅加快了构建过程,还确保应用程序充满有用的内容。借助 GPT-4 等工具,创建数据丰富的应用程序从未如此简单和高效。
\ No newline at end of file
diff --git "a/AI/\346\236\204\345\273\272\344\270\200\344\270\252 AI \345\267\245\345\205\267\346\235\245\345\215\263\346\227\266\346\200\273\347\273\223\344\271\246\347\261\215.md" "b/AI/\346\236\204\345\273\272\344\270\200\344\270\252 AI \345\267\245\345\205\267\346\235\245\345\215\263\346\227\266\346\200\273\347\273\223\344\271\246\347\261\215.md"
new file mode 100644
index 0000000..bdc127e
--- /dev/null
+++ "b/AI/\346\236\204\345\273\272\344\270\200\344\270\252 AI \345\267\245\345\205\267\346\235\245\345\215\263\346\227\266\346\200\273\347\273\223\344\271\246\347\261\215.md"
@@ -0,0 +1,196 @@
+原文:[Build an AI Tool to Summarize Books Instantly](https://levelup.gitconnected.com/build-an-ai-tool-to-summarize-books-instantly-828680c1ceb4)
+
+---
+> 译注:总体思想就是分而治之
+
+# 构建一个 AI 来即时总结书籍
+
+> 无需从头到尾阅读,即可掌握任何一本书的要点。
+
+在本文中,我们将使用 Python、Langchain 和 OpenAI Embeddings 构建一个简单但功能强大的书籍摘要器。
+
+ ⬆️ 使用 DALL·E 3 生成。
+
+# 挑战
+
+像 GPT-3 和 GPT-4 这样的人工智能模型非常强大,但它们也有其局限性。一个重要的限制是上下文窗口,它限制了模型在任一时间可以考虑的文本量。这意味着,您不能只是将整本书输入到模型中就期望能够得到连贯的摘要。此外,处理大文本的成本可能会很高。
+
+# 解决方案
+
+为了克服这些挑战,我们设计了一种既经济又高效的方法。过程如下:
+
+# 简化流程
+
+以下是我们如何将一本完整的书转化为简明摘要的方法:
+
+1. **分割和嵌入:**我们将书分解成更小的块,然后将它们转换为嵌入。这一步的成本令人惊讶。
+2. **聚类:** 接着,我们对这些嵌入进行聚类,以找到书中最具代表性的部分。
+3. **总结:** 然后,我们使用更具成本效益的 GPT-3.5 模型来总结这些关键部分。
+4. **组合摘要:** 最后,我们使用 GPT-4 将这些摘要拼接成一个流畅的叙述。
+
+通过仅在最后一步使用 GPT-4 来设法保持较低的成本。
+
+现在,让我们分解代码和每个步骤背后的基本原理。构建摘要器
+
+让我们深入研究代码并逐步构建我们的摘要器。
+
+# 步骤一:加载书籍
+
+首先,我们需要读取书本内容。我们将支持 PDF 和 EPUB 格式。
+
+
+```py
+import os
+import tempfile
+from langchain.document_loaders import PyPDFLoader, UnstructuredEPubLoader
+
+def load_book(file_obj, file_extension):
+ """Load the content of a book based on its file type."""
+ text = ""
+ with tempfile.NamedTemporaryFile(delete=False, suffix=file_extension) as temp_file:
+ temp_file.write(file_obj.read())
+ if file_extension == ".pdf":
+ loader = PyPDFLoader(temp_file.name)
+ pages = loader.load()
+ text = "".join(page.page_content for page in pages)
+ elif file_extension == ".epub":
+ loader = UnstructuredEPubLoader(temp_file.name)
+ data = loader.load()
+ text = "\n".join(element.page_content for element in data)
+ else:
+ raise ValueError(f"Unsupported file extension: {file_extension}")
+ os.remove(temp_file.name)
+ text = text.replace('\t', ' ')
+ return text
+```
+
+# 步骤二:分割和嵌入文本
+
+AI 模型有令牌限制,这意味着它们不能一次处理一整本书。通过将文本分块,我们确保书中的每个部分都能够被喂给 AI。
+
+我们将把文本分块并将其转换为嵌入。嵌入可以通过最少的计算快速将文本转换为紧凑的数字形式,从而使该过程既快速又经济高效。
+
+
+```py
+from langchain.text_splitter import RecursiveCharacterTextSplitter
+from langchain.embeddings import OpenAIEmbeddings
+
+def split_and_embed(text, openai_api_key):
+ text_splitter = RecursiveCharacterTextSplitter(separators=["\n\n", "\n", "\t"], chunk_size=10000, chunk_overlap=3000)
+ docs = text_splitter.create_documents([text])
+ embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
+ vectors = embeddings.embed_documents([x.page_content for x in docs])
+ return docs, vectors
+```
+
+# 步骤三:对嵌入进行聚类
+
+我们使用 KMeans 聚类算法对相似的块进行分组。在我的版本中,正如您在下面所看到的,我发现对于大多数书籍来说,11 个簇就可以很好地工作。但您可以根据您的用例进行调整。
+
+这里,我们将整本书分块,然后转化为嵌入。根据其相似性对这些嵌入进行分组。对于每个组,我们选择最具代表性的嵌入并将其映射回其相应的文本块。
+
+
+```py
+from sklearn.cluster import KMeans
+import numpy as np
+
+def cluster_embeddings(vectors, num_clusters):
+ kmeans = KMeans(n_clusters=num_clusters, random_state=42).fit(vectors)
+ closest_indices = [np.argmin(np.linalg.norm(vectors - center, axis=1)) for center in kmeans.cluster_centers_]
+ return sorted(closest_indices)
+```
+
+# 步骤四:总结代表性块
+
+我们将使用 GPT-3.5 来只总结那些选定的块。
+
+
+```py
+from langchain.chains.summarize import load_summarize_chain
+from langchain.prompts import PromptTemplate
+
+def summarize_chunks(docs, selected_indices, openai_api_key):
+ llm3_turbo = ChatOpenAI(temperature=0, openai_api_key=openai_api_key, max_tokens=1000, model='gpt-3.5-turbo-16k')
+ map_prompt = """
+ You are provided with a passage from a book. Your task is to produce a comprehensive summary of this passage. Ensure accuracy and avoid adding any interpretations or extra details not present in the original text. The summary should be at least three paragraphs long and fully capture the essence of the passage.
+ ```{text}```
+ SUMMARY:
+ """
+ map_prompt_template = PromptTemplate(template=map_prompt, input_variables=["text"])
+ selected_docs = [docs[i] for i in selected_indices]
+ summary_list = []
+
+ for doc in selected_docs:
+ chunk_summary = load_summarize_chain(llm=llm3_turbo, chain_type="stuff", prompt=map_prompt_template).run([doc])
+ summary_list.append(chunk_summary)
+
+ return "\n".join(summary_list)
+```
+
+# 步骤五:创建最终摘要
+
+我们使用 GPT-4 将各个摘要合并为一个有凝聚力的最终摘要。
+
+
+```py
+from langchain.schema import Document
+from langchain.chat_models import ChatOpenAI
+
+def create_final_summary(summaries, openai_api_key):
+ llm4 = ChatOpenAI(temperature=0, openai_api_key=openai_api_key, max_tokens=3000, model='gpt-4', request_timeout=120)
+ combine_prompt = """
+ You are given a series of summarized sections from a book. Your task is to weave these summaries into a single, cohesive, and verbose summary. The reader should be able to understand the main events or points of the book from your summary. Ensure you retain the accuracy of the content and present it in a clear and engaging manner.
+ ```{text}```
+ COHESIVE SUMMARY:
+ """
+ combine_prompt_template = PromptTemplate(template=combine_prompt, input_variables=["text"])
+ reduce_chain = load_summarize_chain(llm=llm4, chain_type="stuff", prompt=combine_prompt_template)
+ final_summary = reduce_chain.run([Document(page_content=summaries)])
+ return final_summary
+```
+
+# 将它们放在一起
+
+现在,我们将所有步骤合并到一个函数中,该函数接受上传的文件并生成摘要。
+
+
+```py
+# ... (previous code for imports and functions)
+
+def generate_summary(uploaded_file, openai_api_key, num_clusters=11, verbose=False):
+ file_extension = os.path.splitext(uploaded_file.name)[1].lower()
+ text = load_book(uploaded_file, file_extension)
+ docs, vectors = split_and_embed(text, openai_api_key)
+ selected_indices = cluster_embeddings(vectors, num_clusters)
+ summaries = summarize_chunks(docs, selected_indices, openai_api_key)
+ final_summary = create_final_summary(summaries, openai_api_key)
+ return final_summary
+```
+
+# 测试总结器
+
+最后,我们可以用一本书来测试我们的摘要器。
+
+
+```py
+# Testing the summarizer
+if __name__ == '__main__':
+ load_dotenv()
+ openai_api_key = os.getenv('OPENAI_API_KEY')
+ book_path = "path_to_your_book.epub"
+ with open(book_path, 'rb') as uploaded_file:
+ summary = generate_summary(uploaded_file, openai_api_key, verbose=True)
+ print(summary)
+```
+
+# 总结
+
+这个工具可以帮助你快速理解任何书籍的要点。我们采取的方法不仅成本低廉,而且适用于具有任何长度的书籍。
+
+请记住,摘要的质量取决于聚类和摘要提示,因此请随意根据您的需要进行调整。
+
+您可以尝试 Streamlit 应用程序并在此处查看摘要器:[GPT Summarizer App](https://gptsummarizer.streamlit.app/)。
+
+我希望这篇文章对您有所帮助。如果您有任何问题或反馈,请发表评论或联系我们。
+
+搬砖快乐!:)
diff --git "a/Machine Learning/\344\275\277\347\224\250 Python\357\274\214\345\260\206\345\210\206\346\236\220\346\225\260\346\215\256\351\200\237\345\272\246\346\217\220\351\253\230 170,000 \345\200\215.md" "b/Machine Learning/\344\275\277\347\224\250 Python\357\274\214\345\260\206\345\210\206\346\236\220\346\225\260\346\215\256\351\200\237\345\272\246\346\217\220\351\253\230 170,000 \345\200\215.md"
new file mode 100644
index 0000000..26c0a9a
--- /dev/null
+++ "b/Machine Learning/\344\275\277\347\224\250 Python\357\274\214\345\260\206\345\210\206\346\236\220\346\225\260\346\215\256\351\200\237\345\272\246\346\217\220\351\253\230 170,000 \345\200\215.md"
@@ -0,0 +1,721 @@
+原文:[Analyzing Data 170,000x Faster with Python](https://sidsite.com/posts/python-corrset-optimization/)
+
+---
+
+# 使用 Python,将分析数据速度提高 170,000 倍
+
+
+这篇 [使用 Rust,将分析数据速度提高 180,000 倍](https://willcrichton.net/notes/k-corrset/)首先介绍了一些未优化的 Python 代码,然后展示了用 Rust 重写和优化代码的过程,从而实现了 180,000 倍的加速。作者指出:
+
+
+>
+> 有很多方法可以使 Python 代码更快,但本文的重点不是将高度优化的 Python 与高度优化的 Rust 进行比较。其重点是将“标准 Jupyter 笔记本”形式的 Python 与高度优化的 Rust 进行比较。
+>
+>
+
+问题来了:如果我们坚持使用 Python,那么我们可以实现什么样的速度提升?
+
+在这篇文章中,我们将在 Python 中经历一次分析和迭代加速代码的旅程。
+
+
+#### 复制原始基准
+
+这篇文章中的时间与原始文章中报告的时间相当。使用类似的计算机(M1 Macbook Pro),我测量得到:
+
+* 原始未优化代码的平均迭代时间为 35 毫秒,经过 1,000 多次迭代测量。原始文章则为 36 毫秒。
+* 对于完全优化的 Rust 代码,加速超过 180,081 倍,测量通过超过 5,000,000 次迭代完成。原始文章则为 182,450x。
+
+
+### Python 基线
+
+下面是基线的一个副本,它是未优化的 Python 代码,来自这篇[文章](https://willcrichton.net/notes/k-corrset/)。
+
+```py
+from itertools import combinations
+import pandas as pd
+from pandas import IndexSlice as islice
+
+def k_corrset(data, K):
+ all_qs = data.question.unique()
+ q_to_score = data.set_index(['question', 'user'])
+ all_grand_totals = data.groupby('user').score.sum().rename('grand_total')
+
+ # Inner loop
+ corrs = []
+ for qs in combinations(all_qs, K):
+ qs_data = q_to_score.loc[islice[qs,:],:].swaplevel()
+ answered_all = qs_data.groupby(level=[0]).size() == K
+ answered_all = answered_all[answered_all].index
+ qs_totals = qs_data.loc[islice[answered_all,:]] \
+ .groupby(level=[0]).sum().rename(columns={'score': 'qs'})
+ r = qs_totals.join(all_grand_totals).corr().qs.grand_total
+ corrs.append({'qs': qs, 'r': r})
+ corrs = pd.DataFrame(corrs)
+
+ return corrs.sort_values('r', ascending=False).iloc[0].qs
+
+data = pd.read_json('scores.json')
+print(k_corrset(data, K=5))
+```
+
+这是 dataframe `data` 的前两行。
+
+
+| user | question | score |
+| --- | --- | --- |
+| e213cc2b-387e-4d7d-983c-8abc19a586b1 | d3bdb068-7245-4521-ae57-d0e9692cb627 | 1 |
+| 951ffaee-6e17-4599-a8c0-9dfd00470cd9 | d3bdb068-7245-4521-ae57-d0e9692cb627 | 0 |
+
+
+我们可以使用原始代码的输出来测试优化代码的正确性。
+
+由于我们正在尝试优化内部循环,故而我们将内部循环放入其自己的函数中,以使用 [line_profiler](https://github.com/pyutils/line_profiler) 对其进行分析。
+
+
+```sh
+Avg time per iteration: 35 ms
+Speedup over baseline: 1.0x
+
+% Time Line Contents
+=====================
+ def compute_corrs(
+ qs_iter: Iterable, q_to_score: pd.DataFrame, grand_totals: pd.DataFrame
+ ):
+ 0.0 result = []
+ 0.0 for qs in qs_iter:
+ 13.5 qs_data = q_to_score.loc[islice[qs, :], :].swaplevel()
+ 70.1 answered_all = qs_data.groupby(level=[0]).size() == K
+ 0.4 answered_all = answered_all[answered_all].index
+ 0.0 qs_total = (
+ 6.7 qs_data.loc[islice[answered_all, :]]
+ 1.1 .groupby(level=[0])
+ 0.6 .sum()
+ 0.3 .rename(columns={"score": "qs"})
+ )
+ 7.4 r = qs_total.join(grand_totals).corr().qs.grand_total
+ 0.0 result.append({"qs": qs, "r": r})
+ 0.0 return result
+```
+
+我们可以看到我们试图优化的值(平均迭代时间/加速比),以及每行花费的时间比例。
+
+以下是优化代码的工作流程:
+
+* 运行分析器
+* 识别最慢的代码行
+* 试着让较慢的代码行快点
+* 重复
+
+如果只有几行代码占据了大部分时间,我们就知道具体要关注什么,从上面我们看到有一行特别慢的代码,它占据了大约 70% 的时间。
+
+
+### 优化 1 - 包含回答问题的用户的集合字典,*users_who_answered_q*
+
+基线执行各种繁重的 Pandas 操作,以找出哪些用户回答了当前的一组问题 `qs`。特别是,它检查数据帧的每一行以找出哪些用户回答了问题。对于第一个优化,我们可以使用集合字典,而不是使用完整的数据帧。这让我们可以快速查找哪些用户回答了 `qs` 中的每个问题,并使用 Python 的集合交集来找出哪些用户回答了所有问题。
+
+
+```sh
+Avg time per iteration: 10.0 ms
+Speedup over baseline: 3.5x
+
+% Time Line Contents
+=====================
+ def compute_corrs(qs_iter, users_who_answered_q, q_to_score, grand_totals):
+ 0.0 result = []
+ 0.0 for qs in qs_iter:
+ 0.0 user_sets_for_qs = [users_who_answered_q[q] for q in qs]
+ 3.6 answered_all = set.intersection(*user_sets_for_qs)
+ 40.8 qs_data = q_to_score.loc[islice[qs, :], :].swaplevel()
+ 0.0 qs_total = (
+ 22.1 qs_data.loc[islice[list(answered_all), :]]
+ 3.7 .groupby(level=[0])
+ 1.9 .sum()
+ 1.1 .rename(columns={"score": "qs"})
+ )
+ 26.8 r = qs_total.join(grand_totals).corr().qs.grand_total
+ 0.0 result.append({"qs": qs, "r": r})
+ 0.0 return result
+```
+
+这显着加快了计算行的速度 `answered_all`,从占用 70% 的时间降低到 4%,并且我们的速度已经比基线快了 3 倍以上。
+
+
+### 优化 2 - *score_dict* 字典
+
+如果我们将用于计算 `qs_total` 的每行代码(包括 `qs_data` 这一行)的时间相加,则约为 65%;所以接下来要优化哪一个就很清楚了。我们可以再次通过快速字典查找来切换对整个数据集的繁重操作(索引、分组等)。我们引入了`score_dict`,这是一个字典,可以让我们查找给定问题和用户对的分数。
+
+
+```sh
+Avg time per iteration: 690 μs
+Speedup over baseline: 50.8x
+
+% Time Line Contents
+=====================
+ def compute_corrs(qs_iter, users_who_answered_q, score_dict, grand_totals):
+ 0.0 result = []
+ 0.0 for qs in qs_iter:
+ 0.1 user_sets_for_qs = [users_who_answered_q[q] for q in qs]
+ 35.9 answered_all = set.intersection(*user_sets_for_qs)
+ 3.4 qs_total = {u: sum(score_dict[q, u] for q in qs) for u in answered_all}
+ 8.6 qs_total = pd.DataFrame.from_dict(qs_total, orient="index", columns=["qs"])
+ 0.1 qs_total.index.name = "user"
+ 51.8 r = qs_total.join(grand_totals).corr().qs.grand_total
+ 0.0 result.append({"qs": qs, "r": r})
+ 0.0 return result
+```
+
+这使我们的速度提高了 50 倍。
+
+### 优化 3 - *grand_totals* 字典和 np.corrcoef
+
+
+上面最慢那一行做了几件事,它进行一个 Pandas join 操作,将 `grand_totals` 和 `qs_total` 组合在一起,然后计算其相关系数。同样,我们可以通过使用字典查找而不是 join 来提升速度,此外,由于我们不再使用 Pandas 对象,因此,我们使用 `np.corrcoef` 来代替 Pandas `corr`。
+
+
+```sh
+Avg time per iteration: 380 μs
+Speedup over baseline: 91.6x
+
+% Time Line Contents
+=====================
+ def compute_corrs(qs_iter, users_who_answered_q, score_dict, grand_totals):
+ 0.0 result = []
+ 0.0 for qs in qs_iter:
+ 0.2 user_sets_for_qs = [users_who_answered_q[q] for q in qs]
+ 83.9 answered_all = set.intersection(*user_sets_for_qs)
+ 7.2 qs_total = [sum(score_dict[q, u] for q in qs) for u in answered_all]
+ 0.5 user_grand_total = [grand_totals[u] for u in answered_all]
+ 8.1 r = np.corrcoef(qs_total, user_grand_total)[0, 1]
+ 0.1 result.append({"qs": qs, "r": r})
+ 0.0 return result
+```
+
+这使我们的速度提高了约 90 倍。
+
+
+### 优化 4 - 将 uuid 字符串转换成整数
+
+下一个优化完全不会更改内循环中的代码。但它确实提高了某些操作的速度。我们用更短的整数来替换长的用户/问题 uuid(例如, `e213cc2b-387e-4d7d-983c-8abc19a586b1`)。完成方法是:
+
+
+```py
+data.user = data.user.map({u: i for i, u in enumerate(data.user.unique())})
+data.question = data.question.map(
+ {q: i for i, q in enumerate(data.question.unique())}
+)
+```
+
+然后进行评估:
+
+```sh
+Avg time per iteration: 210 μs
+Speedup over baseline: 168.5x
+
+% Time Line Contents
+=====================
+ def compute_corrs(qs_iter, users_who_answered_q, score_dict, grand_totals):
+ 0.0 result = []
+ 0.1 for qs in qs_iter:
+ 0.4 user_sets_for_qs = [users_who_answered_q[q] for q in qs]
+ 71.6 answered_all = set.intersection(*user_sets_for_qs)
+ 13.1 qs_total = [sum(score_dict[q, u] for q in qs) for u in answered_all]
+ 0.9 user_grand_total = [grand_totals[u] for u in answered_all]
+ 13.9 r = np.corrcoef(qs_total, user_grand_total)[0, 1]
+ 0.1 result.append({"qs": qs, "r": r})
+ 0.0 return result
+```
+
+### 优化 5 - np.bool_ 数组取代用户集
+
+我们可以看到上面的 set 操作仍然是最慢的一行。我们可以转为使用一个类型为 `np.bool_` 的用户数组来取代整数集,然后使用 `np.logical_and.reduce` 来查找那些回答了 `qs` 中所有问题的用户。(注意,虽然 `np.bool_` 中的每个元素都是一个完整的字节,但是 `np.logical_and.reduce` 仍然很快。)这带来了显著的速度提升:
+
+
+```sh
+Benchmark #6: NumPy bool_ array to identify users who answered qs
+Using 1000 iterations...
+
+Avg time per iteration: 75 μs
+Speedup over baseline: 466.7x
+
+% Time Line Contents
+=====================
+ def compute_corrs(qs_iter, users_who_answered_q, score_dict, grand_totals):
+ 0.0 result = []
+ 0.1 for qs in qs_iter:
+ 12.0 user_sets_for_qs = users_who_answered_q[qs, :] # numpy indexing
+ 9.9 answered_all = np.logical_and.reduce(user_sets_for_qs)
+ 10.7 answered_all = np.where(answered_all)[0]
+ 33.7 qs_total = [sum(score_dict[q, u] for q in qs) for u in answered_all]
+ 2.6 user_grand_total = [grand_totals[u] for u in answered_all]
+ 30.6 r = np.corrcoef(qs_total, user_grand_total)[0, 1]
+ 0.2 result.append({"qs": qs, "r": r})
+ 0.0 return result
+```
+
+### 优化 6 - *score_matrix* 代替 dict
+
+上面最慢的一行现在是计算 `qs_total` 了。按照原始文章中的例子,我们改用一个密集的 np.array 来查找分数,而不是使用字典,然后使用快速的 NumPy 索引来获取分数。
+
+```sh
+Avg time per iteration: 56 μs
+Speedup over baseline: 623.7x
+
+% Time Line Contents
+=====================
+ def compute_corrs(qs_iter, users_who_answered_q, score_matrix, grand_totals):
+ 0.0 result = []
+ 0.2 for qs in qs_iter:
+ 16.6 user_sets_for_qs = users_who_answered_q[qs, :]
+ 14.0 answered_all = np.logical_and.reduce(user_sets_for_qs)
+ 14.6 answered_all = np.where(answered_all)[0]
+ 7.6 qs_total = score_matrix[answered_all, :][:, qs].sum(axis=1)
+ 3.9 user_grand_total = [grand_totals[u] for u in answered_all]
+ 42.7 r = np.corrcoef(qs_total, user_grand_total)[0, 1]
+ 0.4 result.append({"qs": qs, "r": r})
+ 0.0 return result
+```
+
+### 优化 7 - 自定义 *corrcoef*
+
+上面最慢的一行是 `np.corrcoef`……我们将尽一切努力来优化我们的代码,所以这是我们自己实现的 corrcoef,对于这个用例来说,它带来了两杯的速度提升:
+
+```py
+def corrcoef(a: list[float], b: list[float]) -> float | None:
+ """same as np.corrcoef(a, b)[0, 1]"""
+ n = len(a)
+ sum_a = sum(a)
+ sum_b = sum(b)
+ sum_ab = sum(a_i * b_i for a_i, b_i in zip(a, b))
+ sum_a_sq = sum(a_i**2 for a_i in a)
+ sum_b_sq = sum(b_i**2 for b_i in b)
+ num = n * sum_ab - sum_a * sum_b
+ den = sqrt(n * sum_a_sq - sum_a**2) * sqrt(n * sum_b_sq - sum_b**2)
+ if den == 0:
+ return None
+ return num / den
+```
+
+我们得到了不错的速度提升:
+
+```sh
+Avg time per iteration: 43 μs
+Speedup over baseline: 814.6x
+
+% Time Line Contents
+=====================
+ def compute_corrs(qs_iter, users_who_answered_q, score_matrix, grand_totals):
+ 0.0 result = []
+ 0.2 for qs in qs_iter:
+ 21.5 user_sets_for_qs = users_who_answered_q[qs, :] # numpy indexing
+ 18.7 answered_all = np.logical_and.reduce(user_sets_for_qs)
+ 19.7 answered_all = np.where(answered_all)[0]
+ 10.0 qs_total = score_matrix[answered_all, :][:, qs].sum(axis=1)
+ 5.3 user_grand_total = [grand_totals[u] for u in answered_all]
+ 24.1 r = corrcoef(qs_total, user_grand_total)
+ 0.5 result.append({"qs": qs, "r": r})
+ 0.0 return result
+```
+
+### 优化 8 - 早期引入 Numba
+
+在上面的代码中,我们尚未完成数据结构的优化,但让我们来看下,如果在这个阶段引入了 [Numba](https://numba.pydata.org/),会发生什么呢。Numba 是 Python 生态中的一个库,它“将 Python 和 NumPy 代码的一个子集转换为快速的机器码”。
+
+为了能够使用 Numba,我们做了两个改动:
+
+改动 1:将 qs_combinations 作为 numpy 数组传递,而不是 `qs_iter`
+
+Numba 不能很好地与 `itertools` 或者生成器配合使用,因此,我们提前将 `qs_iter` 转换为 NumPy 数组,然后才将它传给对应函数。此更改对运行时间的影响(添加 Numba 之前)如下所示。
+
+```sh
+Avg time per iteration: 42 μs
+Speedup over baseline: 829.2x
+
+```
+
+改动 2:结果使用数组,而不是列表
+
+我们初始化一个数组,然后将结果放入其中,而不是将结果附加到列表中。此更改对运行时间的影响(添加 Numba 之前)如下所示。
+
+
+```sh
+Avg time per iteration: 42 μs
+Speedup over baseline: 833.8x
+
+```
+
+最终,代码看起来像是这样的:
+
+
+```py
+import numba
+
+@numba.njit(parallel=False)
+def compute_corrs(qs_combinations, users_who_answered_q, score_matrix, grand_totals):
+ result = np.empty(len(qs_combinations), dtype=np.float64)
+ for i in numba.prange(len(qs_combinations)):
+ qs = qs_combinations[i]
+ user_sets_for_qs = users_who_answered_q[qs, :]
+ # numba doesn't support np.logical_and.reduce
+ answered_all = user_sets_for_qs[0]
+ for j in range(1, len(user_sets_for_qs)):
+ answered_all *= user_sets_for_qs[j]
+ answered_all = np.where(answered_all)[0]
+ qs_total = score_matrix[answered_all, :][:, qs].sum(axis=1)
+ user_grand_total = grand_totals[answered_all]
+ result[i] = corrcoef_numba(qs_total, user_grand_total)
+ return result
+```
+
+(请注意,我们还用了 Numba 来装饰 `corrcoef`,因为 Numba 函数中的函数调用也需要经过编译。)
+
+#### 使用 *parallel=False* 的结果
+
+
+```sh
+Avg time per iteration: 47 μs
+Speedup over baseline: 742.2x
+
+```
+
+#### 使用 *parallel=True* 的结果
+
+
+
+```sh
+Avg time per iteration: 8.5 μs
+Speedup over baseline: 4142.0x
+
+```
+
+我们看到,使用 `parallel=False` 的情况下, Numba 代码比之前的 Python 代码慢一点,但当我们使用了并行,从而开始使用所有的 CPU 核(运行基准测试的机器上有 10 个),这带来了很棒的速度倍增。
+
+然而,我们失去了在 JIT 编译的代码上使用 [line_profiler](https://github.com/pyutils/line_profiler) 的能力(我们可能想开始查看生成的 LLVM IR/汇编)。
+
+
+### 优化 9 - Bitset,不使用 Numba
+
+我们暂时把 Numba 放在一边。原始文章使用 bitset 来快速计算回答了当前 `qs` 中问题的用户,所以,看看这是否适合我们。我们可以使用 `np.int64` 类型的 NumPy 数组以及 `np.bitwise_and.reduce` 来实现 bitset。这与我们前面使用的 `np.bool_` 数组不同,因为现在,我们使用的是字节中的各个位来表示集合中的实体。注意,对于一个给定的 bitset,我们可能需要多个字节,具体取决于我们所需的最大元素数。我们可以对 `qs` 中的每个问题的字节使用快速的 bitwise_and 来查找集合交集,从而找到回答了 `qs` 中所有问题的用户数。
+
+下面是我们将用到的 `bitset` 函数:
+
+```py
+def bitset_create(size):
+ """Initialise an empty bitset"""
+ size_in_int64 = int(np.ceil(size / 64))
+ return np.zeros(size_in_int64, dtype=np.int64)
+
+```
+
+
+```py
+def bitset_add(arr, pos):
+ """Add an element to a bitset"""
+ int64_idx = pos // 64
+ pos_in_int64 = pos % 64
+ arr[int64_idx] |= np.int64(1) << np.int64(pos_in_int64)
+```
+
+
+```py
+def bitset_to_list(arr):
+ """Convert a bitset back into a list of ints"""
+ result = []
+ for idx in range(arr.shape[0]):
+ if arr[idx] == 0:
+ continue
+ for pos in range(64):
+ if (arr[idx] & (np.int64(1) << np.int64(pos))) != 0:
+ result.append(idx * 64 + pos)
+ return np.array(result)
+
+```
+
+然后,我们可以用下述方法初始化 bitset:
+
+```py
+users_who_answered_q = np.array(
+ [bitset_create(data.user.nunique()) for _ in range(data.question.nunique())]
+)
+for q, u in data[["question", "user"]].values:
+ bitset_add(users_who_answered_q[q], u)
+```
+
+让我们看看所得速度提升:
+
+```sh
+Avg time per iteration: 550 μs
+Speedup over baseline: 64.2x
+
+% Time Line Contents
+=====================
+ def compute_corrs(qs_combinations, users_who_answered_q, score_matrix, grand_totals):
+ 0.0 num_qs = qs_combinations.shape[0]
+ 0.0 bitset_size = users_who_answered_q[0].shape[0]
+ 0.0 result = np.empty(qs_combinations.shape[0], dtype=np.float64)
+ 0.0 for i in range(num_qs):
+ 0.0 qs = qs_combinations[i]
+ 0.3 user_sets_for_qs = users_who_answered_q[qs_combinations[i]]
+ 0.4 answered_all = np.bitwise_and.reduce(user_sets_for_qs)
+ 96.7 answered_all = bitset_to_list(answered_all)
+ 0.6 qs_total = score_matrix[answered_all, :][:, qs].sum(axis=1)
+ 0.0 user_grand_total = grand_totals[answered_all]
+ 1.9 result[i] = corrcoef(qs_total, user_grand_total)
+ 0.0 return result
+```
+
+看起来有些倒退了,使用 `bitset_to_list` 操作花费了很多时间。
+
+### 优化 10 - Numba 和 *bitset_to_list*
+
+
+让我们将 `bitset_to_list` 转换为编译后的代码。为此,我们可以添加一个 Numba 装饰器:
+
+```py
+@numba.njit
+def bitset_to_list(arr):
+ result = []
+ for idx in range(arr.shape[0]):
+ if arr[idx] == 0:
+ continue
+ for pos in range(64):
+ if (arr[idx] & (np.int64(1) << np.int64(pos))) != 0:
+ result.append(idx * 64 + pos)
+ return np.array(result)
+```
+
+让我们评估下:
+
+```sh
+Benchmark #14: bitsets, with numba on bitset_to_list
+Using 1000 iterations...
+
+Avg time per iteration: 19 μs
+Speedup over baseline: 1801.2x
+
+% Time Line Contents
+=====================
+ def compute_corrs(qs_combinations, users_who_answered_q, score_matrix, grand_totals):
+ 0.0 num_qs = qs_combinations.shape[0]
+ 0.0 bitset_size = users_who_answered_q[0].shape[0]
+ 0.0 result = np.empty(qs_combinations.shape[0], dtype=np.float64)
+ 0.3 for i in range(num_qs):
+ 0.6 qs = qs_combinations[i]
+ 8.1 user_sets_for_qs = users_who_answered_q[qs_combinations[i]]
+ 11.8 answered_all = np.bitwise_and.reduce(user_sets_for_qs)
+ 7.7 answered_all = bitset_to_list(answered_all)
+ 16.2 qs_total = score_matrix[answered_all, :][:, qs].sum(axis=1)
+ 1.1 user_grand_total = grand_totals[answered_all]
+ 54.1 result[i] = corrcoef(qs_total, user_grand_total)
+ 0.0 return result
+```
+
+和原始代码相比,我们获得了 1,800 倍多代码执行速度提升。回想一下优化 7,在引入 Numba 之前,代码速度提升是 814 倍。(优化 8 是 4142 倍,但那是在内循环上使用了 `parallel=True`,所以它与上面的不具有可比性。)
+
+
+### 优化 11 - Numba 和 *corrcoef*
+
+
+The corrcoef line is again standing out as slow above. Let’s use `corrcoef` decorated with Numba.
+
+
+
+```py
+@numba.njit
+def corrcoef_numba(a, b):
+ """same as np.corrcoef(a, b)[0, 1]"""
+ n = len(a)
+ sum_a = sum(a)
+ sum_b = sum(b)
+ sum_ab = sum(a * b)
+ sum_a_sq = sum(a * a)
+ sum_b_sq = sum(b * b)
+ num = n * sum_ab - sum_a * sum_b
+ den = math.sqrt(n * sum_a_sq - sum_a**2) * math.sqrt(n * sum_b_sq - sum_b**2)
+ return np.nan if den == 0 else num / den
+```
+
+以及基准:
+
+
+```sh
+Avg time per iteration: 11 μs
+Speedup over baseline: 3218.9x
+
+% Time Line Contents
+=====================
+ def compute_corrs(qs_combinations, users_who_answered_q, score_matrix, grand_totals):
+ 0.0 num_qs = qs_combinations.shape[0]
+ 0.0 bitset_size = users_who_answered_q[0].shape[0]
+ 0.0 result = np.empty(qs_combinations.shape[0], dtype=np.float64)
+ 0.7 for i in range(num_qs):
+ 1.5 qs = qs_combinations[i]
+ 15.9 user_sets_for_qs = users_who_answered_q[qs_combinations[i]]
+ 26.1 answered_all = np.bitwise_and.reduce(user_sets_for_qs)
+ 16.1 answered_all = bitset_to_list(answered_all)
+ 33.3 qs_total = score_matrix[answered_all, :][:, qs].sum(axis=1)
+ 2.0 user_grand_total = grand_totals[answered_all]
+ 4.5 result[i] = corrcoef_numba(qs_total, user_grand_total)
+ 0.0 return result
+```
+
+棒,另一个大的速度提升。
+
+### 优化 12 - Numba 和 *bitset_and*
+
+
+我们引入 `bitwise_and` 来替换 `np.bitwise_and.reduce`,然后对其进行 jit 编译。
+
+```py
+@numba.njit
+def bitset_and(arrays):
+ result = arrays[0].copy()
+ for i in range(1, len(arrays)):
+ result &= arrays[i]
+ return result
+```
+
+
+```sh
+Benchmark #16: numba also on bitset_and
+Using 1000 iterations...
+
+Avg time per iteration: 8.9 μs
+Speedup over baseline: 3956.7x
+
+% Time Line Contents
+=====================
+ def compute_corrs(qs_combinations, users_who_answered_q, score_matrix, grand_totals):
+ 0.1 num_qs = qs_combinations.shape[0]
+ 0.0 bitset_size = users_who_answered_q[0].shape[0]
+ 0.1 result = np.empty(qs_combinations.shape[0], dtype=np.float64)
+ 1.0 for i in range(num_qs):
+ 1.5 qs = qs_combinations[i]
+ 18.4 user_sets_for_qs = users_who_answered_q[qs_combinations[i]]
+ 16.1 answered_all = bitset_and(user_sets_for_qs)
+ 17.9 answered_all = bitset_to_list(answered_all)
+ 37.8 qs_total = score_matrix[answered_all, :][:, qs].sum(axis=1)
+ 2.4 user_grand_total = grand_totals[answered_all]
+ 4.8 result[i] = corrcoef_numba(qs_total, user_grand_total)
+ 0.0 return result
+```
+
+### 优化 12 - 整个函数上的 Numba
+
+现在,上面的代码比原始代码快得多,计算量相当均匀地分布在循环中的几行代码上。事实上,看起来最慢的那一行正在执行的是 NumPy 索引操作,这已经相当快了。那么,让我们用 Numba 编译整个函数。
+
+```py
+@numba.njit(parallel=False)
+def compute_corrs(qs_combinations, users_who_answered_q, score_matrix, grand_totals):
+ result = np.empty(len(qs_combinations), dtype=np.float64)
+ for i in numba.prange(len(qs_combinations)):
+ qs = qs_combinations[i]
+ user_sets_for_qs = users_who_answered_q[qs, :]
+ answered_all = user_sets_for_qs[0]
+ # numba doesn't support np.logical_and.reduce
+ for j in range(1, len(user_sets_for_qs)):
+ answered_all *= user_sets_for_qs[j]
+ answered_all = np.where(answered_all)[0]
+ qs_total = score_matrix[answered_all, :][:, qs].sum(axis=1)
+ user_grand_total = grand_totals[answered_all]
+ result[i] = corrcoef_numba(qs_total, user_grand_total)
+ return result
+```
+
+
+```sh
+Avg time per iteration: 4.2 μs
+Speedup over baseline: 8353.2x
+
+```
+
+现在,使用 `parallel=True`:
+
+
+
+```sh
+Avg time per iteration: 960 ns
+Speedup over baseline: 36721.4x
+
+```
+
+可以了,很好,我们比原始代码快了 36,000 倍。
+
+### 优化 13 - Numba,inline with accumulation instead of arrays
+
+我们接下来要干什么呢?...好吧,在上面的代码中仍然有相当多的将值放入数组中,然后传递它们的操作。由于我们正在努力优化此代码,因此我们可以查看 corrcoef 的计算方式,染灰会发现我们不需要构建数组 `answered_all` 和 `user_grand_total`,相反,我们可以在循环时累积值。
+
+这里是代码(我们还启用了一些编译器优化,例如禁用数组的 `boundschecking` 和启用 `fastmath`)。
+
+
+```py
+@numba.njit(boundscheck=False, fastmath=True, parallel=False, nogil=True)
+def compute_corrs(qs_combinations, users_who_answered_q, score_matrix, grand_totals):
+ num_qs = qs_combinations.shape[0]
+ bitset_size = users_who_answered_q[0].shape[0]
+ corrs = np.empty(qs_combinations.shape[0], dtype=np.float64)
+ for i in numba.prange(num_qs):
+ # bitset will contain users who answered all questions in qs_array[i]
+ bitset = users_who_answered_q[qs_combinations[i, 0]].copy()
+ for q in qs_combinations[i, 1:]:
+ bitset &= users_who_answered_q[q]
+ # retrieve stats for the users to compute correlation
+ n = 0.0
+ sum_a = 0.0
+ sum_b = 0.0
+ sum_ab = 0.0
+ sum_a_sq = 0.0
+ sum_b_sq = 0.0
+ for idx in range(bitset_size):
+ if bitset[idx] != 0:
+ for pos in range(64):
+ if (bitset[idx] & (np.int64(1) << np.int64(pos))) != 0:
+ user_idx = idx * 64 + pos
+ score_for_qs = 0.0
+ for q in qs_combinations[i]:
+ score_for_qs += score_matrix[user_idx, q]
+ score_for_user = grand_totals[user_idx]
+ n += 1.0
+ sum_a += score_for_qs
+ sum_b += score_for_user
+ sum_ab += score_for_qs * score_for_user
+ sum_a_sq += score_for_qs * score_for_qs
+ sum_b_sq += score_for_user * score_for_user
+ num = n * sum_ab - sum_a * sum_b
+ den = np.sqrt(n * sum_a_sq - sum_a**2) * np.sqrt(n * sum_b_sq - sum_b**2)
+ corrs[i] = np.nan if den == 0 else num / den
+ return corrs
+```
+
+我们从使用 `parallel=False` 开始。
+
+```sh
+Avg time per iteration: 1.7 μs
+Speedup over baseline: 20850.5x
+
+```
+
+这应该与优化 12 中设置 `parallel=False` 的情况(测量结果为 8353 倍提升)进行比较。
+
+现在,使用 `parallel=True`。
+
+```sh
+Avg time per iteration: 210 ns
+Speedup over baseline: 170476.3x
+
+```
+
+很好,我们已经将 Python 基线的速度提高了 170,000 倍。
+
+
+### 总结
+
+得益于 Numba 和 NumPy,我们已经能够获得使优化的 Rust 代码变得更快的大部分功能,特别是位集、SIMD 和循环级并行性。首先,我们通过 JIT 编译了一些辅助函数,使原始 Python 代码变得相当快,但最后,我们对整个代码进行了 JIT 编译,并为此优化了代码。我们采取了试验和改进的方法,使用分析将我们的工作重点放在最慢的代码行上。我们展示了可以使用 Numba 将 JIT 编译的代码逐渐混合到我们的 Python 代码中。我们可以立即将此代码放入现有的 Python 代码库中。然而,我们没有达到像优化后的 Rust 代码那样 180,000 倍的速度提升,我们推出了自己的相关性和位集实现,而 Rust 代码能够使用一些库来实现这些功能,同时保持其性能。
+
+这是一个有趣的练习,希望它展示了 Python 生态系统中的一些有用的工具。
+
+我会特别推荐其中某种方法吗?不,要使用哪种方法取决于具体情况。
+
+
+#### 笔记
+
+完整的代码在[这里(GitHub)](https://github.com/sradc/corrset-benchmark-fork/tree/main/python_optimization)。
\ No newline at end of file
diff --git a/Others/README.md b/Others/README.md
index 34a3a68..3d00544 100644
--- a/Others/README.md
+++ b/Others/README.md
@@ -124,4 +124,6 @@
- [Python项目中的Makefiles](/Python项目中的Makefiles.md)
- 在Python项目中,你需要像makefile这种东西吗?
\ No newline at end of file
+ 在Python项目中,你需要像makefile这种东西吗?
+
+- [婚礼规模:我是如何使用Twilio, Python和Google来自动化我的婚礼的](./婚礼规模:我是如何使用Twilio, Python和Google来自动化我的婚礼的.md)
\ No newline at end of file
diff --git "a/Others/\345\251\232\347\244\274\350\247\204\346\250\241\357\274\232\346\210\221\346\230\257\345\246\202\344\275\225\344\275\277\347\224\250Twilio, Python\345\222\214Google\346\235\245\350\207\252\345\212\250\345\214\226\346\210\221\347\232\204\345\251\232\347\244\274\347\232\204.md" "b/Others/\345\251\232\347\244\274\350\247\204\346\250\241\357\274\232\346\210\221\346\230\257\345\246\202\344\275\225\344\275\277\347\224\250Twilio, Python\345\222\214Google\346\235\245\350\207\252\345\212\250\345\214\226\346\210\221\347\232\204\345\251\232\347\244\274\347\232\204.md"
new file mode 100644
index 0000000..a9cc96f
--- /dev/null
+++ "b/Others/\345\251\232\347\244\274\350\247\204\346\250\241\357\274\232\346\210\221\346\230\257\345\246\202\344\275\225\344\275\277\347\224\250Twilio, Python\345\222\214Google\346\235\245\350\207\252\345\212\250\345\214\226\346\210\221\347\232\204\345\251\232\347\244\274\347\232\204.md"
@@ -0,0 +1,288 @@
+原文:[Wedding at Scale: How I Used Twilio, Python and Google to Automate My Wedding](https://www.twilio.com/blog/2017/04/wedding-at-scale-how-i-used-twilio-python-and-google-to-automate-my-wedding.html)
+
+---
+
+
+
+2016年9月3日,对世界上的大多数人来说,或许就只是普普通通的一天,但对我而言,将会是一个难忘的日子,因为在那一天,我结婚了。
+
+在规划婚礼时,要考虑许多不同的方面。食物、装饰、桌子装置(啊,是哒,这独立于装饰)、鲜花、住宿、交通、娱乐和位置。虽然在规划婚礼时有许许多多未知数,但是我可以肯定一件事。在婚礼中,有大量的名单、嵌套的名单、以及更多的远到目光可见的名单。当我瞪着越来越多的项目时,我开始怀疑,是否有更好的方法来处理?这一切都如此的手动,充满了低效。必须有一些技术可以改进的方面。
+
+你可能会感到惊讶,但是邀请人们参加婚礼是_昂贵的_(超过380磅),因为你需要发送“按时出席”卡片以及随后的关于婚礼细节的邀请。这也是_缓慢的_,因为你必须通过邮寄来发送它们。追踪人们是否接收到邀请,以及他们是否想要来参加提供免费食物和饮料的派对,是非常_耗时的_,当然,一个自动的好的?最后,邀请卡_不是环境友好的_,因为它们被一次性使用,并且容易丢失或错放。
+
+回到名单。客人名单分成几个部分:
+
+1. 你想要他来的人的名单
+2. 回复你的R.S.V.P的人的名单
+3. 回复你会来的人的名单
+4. 回复你回来的,并且选择了食物的人的名单
+
+但是名单是好的。它们有预先定义好的要求和响应,这让它们是自动化的重要选择。
+
+## 瓶中信
+
+无关年龄,我确信婚礼名单上每个人都有手机,这意味着该是Twilio上场的时候了。如果你想要跳到代码,那么你可以看看[GitHub上的repo](https://github.com/SeekTom/Twilio/tree/master/Wedication)。
+
+[SMS](https://www.twilio.com/docs/api/rest/sending-messages)对我的需求而言相当完美。我可以配置发出的群发短信,并且快速有效地处理回应。在绘制一个MVP并且考虑数据库的时候,我想要某些易于分享的东西,并且不想要浪费时间来构建视图。偶然发现的gspread python库使得我能够[_读写谷歌电子表格_](https://www.twilio.com/blog/2017/02/an-easy-way-to-read-and-write-to-a-google-spreadsheet-in-python.html)。虽然这不是最快的选择,但它确实足够灵活,并且提供了一个易于访问和可读的输出。
+
+对于初始的R.S.V.P,[我创建了一个电子表格](https://docs.google.com/spreadsheets/d/1Zud0nYlAQw7RywwiDmADf9Cd3bBTsHaUSQYXh_Cl9_w/edit?usp=sharing),包含这些列:
+
+* Name
+* Telephone_number
+* Confirmation_status
+* Contact detail status
+* Message_count (发送给客人的邮件数,稍后它会派上用场)
+
+主要数据输入完成后,我使用[gspread](http://gspread.readthedocs.io/en/latest/)来遍历列表,并且发送短信给每一个具有与之相关联的手机号码的客人:
+
+[Sheets.py](https://github.com/SeekTom/Twilio/blob/master/Wedication/sheets.py)
+
+```python
+import json
+import time
+import gspread
+from oauth2client.client import SignedJwtAssertionCredentials
+from twilio.rest import TwilioRestClient
+
+# Message your attendees from a spreadsheet
+
+# add file name for the json created for the spreadsheet
+json_key = json.load(open('.json'))
+scope = ['https://spreadsheets.google.com/feeds']
+
+credentials = SignedJwtAssertionCredentials(json_key['client_email'],
+ json_key['private_key'].encode(),
+ scope)
+gc = gspread.authorize(credentials)
+wks = gc.open("wedding_guests") # add your workbook name here
+wks_attendees = wks.get_worksheet(0) # attendees worksheet
+
+ACCOUNT_SID = 'TWILIO_ACCOUNT_SID'
+AUTH_TOKEN = 'TWILIO_AUTH_TOKEN'
+
+client = TwilioRestClient(ACCOUNT_SID, AUTH_TOKEN)
+
+# to iterate between guests, amend this based on your total
+for num in range(2, 60):
+ print "sleeping for 2 seconds"
+ time.sleep(2) # adding a delay to avoid filtering
+
+ guest_number = wks_attendees.acell('B'+str(num)).value
+ guest_name = wks_attendees.acell('A'+str(num)).value
+ Message_body = u"\u2B50" + u"\u2764" + u"\u2B50" + u"\u2764" + u"\u2B50" + u"\u2764" + u"\u2B50" + u"\u2764" + "\n\n" + u"\u2709" +" Save the date! "+ u"\u2709" +"\n\nLauren Pang and Thomas Curtis are delighted to invite you to our wedding.\n\nSaturday 3rd September 2016. \n\nColville Hall,\nChelmsford Road,\nWhite Roding,\nCM6 1RQ.\n\nThe Ceremony begins at 2pm.\n\nMore details will follow shortly!\n\nPlease text YES if you are saving the date and can join us or text NO if sadly, you won't be able to be with us.\n\n" u"\u2B50" + u"\u2764" + u"\u2B50" + u"\u2764" + u"\u2B50" + u"\u2764" + u"\u2B50" + u"\u2764",
+ if not guest_number: # No mobile number skip this guest
+ print guest_name + ' telephone number empty not messaging'
+ wks_attendees.update_acell('E'+str(num), '0') # set number to 0
+
+ else:
+ print 'Sending message to ' + guest_name
+ client.messages.create(
+ to="+" + guest_number, # add the + back to make the number e.164
+ from_="", # your twilio number here
+ body=message_body,
+ )
+ wks_attendees.update_acell('E'+str(num), int(wks_attendees.acell('E'+str(num)).value) + 1) # increment the message count row
+else: # else part of the loop
+ print 'finished'
+```
+
+因为短信可以看起来很简单,所以我添加了一些[unicode](https://www.twilio.com/blog/2015/08/common-sms-problems-unicode-twilio.html)来让它们有趣些。下面是幸运的受邀者接收到的短信样式:
+
+
+
+
+接下来,我使用Flask作为我的web服务器,然后设置我的Twilio消息请求URL指向`/messages` url,并创建简单的if语句来解析回复 (yes, no):
+
+[hello_guest.py](https://github.com/SeekTom/Twilio/blob/master/Wedication/hello_guest.py)
+
+```python
+@app.route("/messages", methods=['GET', 'POST'])
+def hello_guest():
+
+ if "yes" in body_strip:
+ # We have a keeper! Find the attendee and update their confirmation_status
+ wks_attendees.update_acell("F"+str(guest_confirmation_cell.row), 'Accepted') # update the status to accepted for that guest
+ resp.message(u"\u2665" + "Thanks for confirming, we'll be in touch!" + u"\u2665") # respond to the guest with a confirmation!
+
+ elif "no" in from_body.lower():
+ # update the confirmation_status row to declined for that guest
+ wks_attendees.update_acell("F"+str(guest_confirmation_cell.row), 'Declined')
+ # respond to the user confirming the action
+ resp.message("Sorry to hear that, we still love you though!")
+
+ else: # respond with invalid keyword
+ resp.message("You sent a different keyword, we need a yes or a no, you sent: "+
+ from_body)
+ return str(resp)
+```
+
+
+
+
+
+
+第一条消息是在2月19日早上8:37的时候发送的,而在3分钟后,也就是早上8:40收到了第一条回复。到了早上9:38,我收到了23条确认回复,这可是32%的接受率!初始群发短信2天后,我们收到了58%的客人的确认!尽管取得了明显的成功,但是我的未婚妻并不热衷于我那作为婚礼邀请服务(SAAWIS?)的短信,因此,我决定添加一些功能到我的应用中。
+
+统计!我可以计算现场出席名单并按要求退回,给新娘即使反馈客人名单的成型。代码很简单,因为我已经在电子表格中设置了一些基本的计数器,因此,仅仅是抓取这些单元格的内容,并将其添加到短信中的事:
+
+[hello_guest.py](https://github.com/SeekTom/Twilio/blob/master/Wedication/hello_guest.py)
+
+```python
+# attendance variables
+guest_confirmed = wks_attendees.acell('C70').value
+guest_unconfirmed = wks_attendees.acell('C71').value
+guest_no_response = wks_attendees.acell('C72').value
+guest_acceptance = wks_attendees.acell('C73').value
+
+
+elif "numbers" in from_body.lower():
+ # return statistics (total guests, food choices list)
+ resp.message("R.S.V.P update:\n\nTotal Accepted: " + guest_confirmed
+ "\n\nTotal declined: " guest_unconfirmed "\n\nTotal no response: "+
+ guest_no_response + "\n\nTotal acceptance rate: " + guest_acceptance)
+```
+
+以下是最终的短信:
+
+
+
+
+不是很漂亮,但很有用。
+
+Lauren现在可以跟踪出席率,这件事大大缓解了她的压力。从那时起,万事俱备,并且短信被尽可能集成到婚礼的方方面面。有些是显而易见的,例如当婚礼网站 (自然,由[Heroku](https://www.heroku.com)提供动力) 上线的时候发送通知短信,分享礼物列表以及其他我至今仍然感到骄傲的事。
+
+## 食物,极好的食物
+
+在建立R.S.V.P名单后,经常被推迟的是让客人确认他们的食物选择。你会惊讶于让人们选择免费的食物是多么的困难。第一步是发送另一条短信,告诉那些确认参与的客人访问网站,并通过一个谷歌表单选择他们的食物选项。相当标准的东西,然而,表单被设置为填充与参与者相同的工作簿。这意味着,现在,我有了已确认参与的客人以及那些填写了食物选择表格的客人表单。通常,我会等待客人慢慢选择他们的饭菜,但由于我的婚礼由Twilio驱动,意味着我可以用最少的努力来跟踪。
+
+数据需要匹配访客名称上的两个电子表格,并且在有匹配的时候更新客人的食物选择状态。这需要一些额外的工作,但一旦重排代码,我就可以按需批量运行脚本,并最后通过短信获取我的客人的最新状态:
+
+[food.py](https://github.com/SeekTom/Twilio/blob/master/Wedication/food.py)
+
+```python
+import json
+import time
+import gspread
+from oauth2client.client import SignedJwtAssertionCredentials
+from twilio.rest import TwilioRestClient
+
+# add file name for the json created for the spread sheet
+json_key = json.load(open(''))
+scope = ['https://spreadsheets.google.com/feeds']
+
+credentials = SignedJwtAssertionCredentials(json_key['client_email'],
+ json_key['private_key'].encode(),
+ scope)
+gc = gspread.authorize(credentials)
+wks = gc.open("") # add your spreadsheet name here
+wks_attendees = wks.get_worksheet(0) # attendees worksheet
+wks_food = wks.get_worksheet(1) # food responses worksheet
+
+ACCOUNT_SID = 'TWILIO_ACCOUNT_SID'
+AUTH_TOKEN = 'TWILIO_AUTH_TOKEN'
+
+client = TwilioRestClient(ACCOUNT_SID, AUTH_TOKEN)
+
+# to iterate between 10 to 60 manual hack to ensure no guests not left out
+for num in range(2, 60):
+ food_guest_name = wks_food.acell('B'+str(num)).value # food choice name column
+
+ if food_guest_name:
+ attendees_name = wks_attendees.find(val_food_guest_name).value
+ attendees_name_row = wks_attendees.find(val_food_guest_name).row
+ menu_status = wks_attendees.acell("G"+str(attendees_name_row)).value
+
+ if food_guest_name == attendees_name:
+ print
+ if menu_status == 'Y': # data already matched, move on
+ print('Skipping')
+
+ else: # user has supplied their choices, update main spreadsheet
+ print ('Food sheet name ' + food_guest_name + 'Attendees sheet name ' + attendees_name)
+ # update menu choices row
+ wks_attendees.update_acell("G"+str(attendees_name_row), 'Y')
+ else:
+ print('nothing found, moving on')
+ wks_attendees.update_acell('E'+str(num), int(wks.acell('E'+str(num)).value) + 1) # increment the message count row
+
+ else:
+ # send message to the admin that the process has been completed with update stats
+ client.messages.create(from_="", # twilio number here
+ to="", # admin number here
+ body="Finished processing current meal listnnGuest meals confirmed" + guest_meals_confirmed + "\n\nGuest meals unconfirmed: " + guest_meals_unconfirmed)
+```
+
+现在,有了一个确认的客人名单和越来越多的食物选择名单,通过主要应用将这些统计数据公开是有意义的。所需的只是抓取相关单元格的内容,然后用短信回复:
+
+[Hello_guest.py](https://github.com/SeekTom/Twilio/blob/master/Wedication/hello_guest.py)
+
+```python
+# respond with the current food totals and the meal choices
+elif "food" in body_strip.strip():
+
+ resp.message("Guest meals decided:" + guest_meals_confirmed +
+ "\nGuest meals undecided: " + guest_meals_unconfirmed +
+ "\n\nMenu breakdown:\n\n" + starter_option_1 +": " +
+ starter_option_1_amount + "\n" + starter_option_2 +": " +
+ starter_option_2_amount + "\n" + starter_option_3 +": " +
+ starter_option_3_amount + "\n" + main_option_1 +": " +
+ main_option_1_amount + "\n" + main_option_2 +": " + main_option_2_amount +
+ "\n" + main_option_3 +": " + main_option_3_amount + "\n" +
+ dessert_option_1 + ": " + dessert_option_1_amount + "\n" + dessert_option_2
+ + ": " + dessert_option_2_amount)
+```
+
+
+
+
+
+
+
+让婚礼餐饮者了解我们的进展,并提供谁没有选择的可操作数据,是非常方便的。追踪客人是另一个自动化选择。简单遍历参加者名单,找到没有选择用餐选项的调皮的客人,然后给他们发送信息!
+
+[Chase.py](https://github.com/SeekTom/Twilio/blob/master/Wedication/chase.py)
+
+```python
+for num in range(2, 72): # manual hack to ensure no guests not left out
+ print "sleeping for 3 seconds"
+
+ time.sleep(3) # adding a delay to avoid carrier filtering
+ wedding_guest_number = wks_attendees.acell('B'+str(num)).value # grab attendee tel number
+ wedding_guest_name = wks_attendees.acell('A'+str(num)).value # grab attendee name
+ menu_guest = wks_attendees.acell('G'+str(num)).value
+
+ if not wedding_guest_number:
+ print wedding_guest_name+' telephone number empty not messaging' # output to console that we are not messaging this guest due to lack of telephone number
+ wks_attendees.update_acell('H'+str(num), '1') # increment the message count row for the individual user
+
+ else:
+ if menu_guest == "N": # guest has not chosen food! CHASE THEM!
+ print 'Sending message to '+wedding_guest_name
+ client.messages.create(
+ to="+" + wedding_guest_number,
+ from_="", # your Twilio number here
+ body="If you have received this message, you have not chosen your food options for Tom & Lauren's Wedding!\n\nYou can pick your choices via the website, no paper or postage required!\n\nhttp://www.yourwebsitehere.com/food"
+ )
+ wks_attendees.update_acell('H'+str(num), int(wks_attendees.acell('H'+str(num)).value) + 1) # increment the message count row for the individual user
+else: # else part of the loop
+ print 'finished'
+```
+
+
+
+
+
+
+
+大日子比我们所想的来得更快些。而唯一需要做的事就是发送最后一条短信,提醒客人基本的细节,以及提醒他们带把伞,以防碰上一般的英国夏季的雨季:
+
+
+
+
+## 总结一下
+
+婚礼永远不是个简单的事,它会让你感觉到很多事都不在你掌控之下。自动化通过提供与我们的客人的直接渠道,以及无数的我可以跟踪、推动以及戳他们回应的不同方式,显然让我的生活更轻松了。它帮助我们在婚礼臭名昭着的时间消耗方面变得积极主动,让我们可以空出来关注大日子的其他重要领域。
+
+为复杂问题建立可扩展的解决方案从来不是件简单的事,即使在其最终形式下,我的应用有时也是很脆弱的。我已经计划建立一个更加完整的解决方案,带有进度的数据可视化、语音基础并更少依赖于CLI脚本,但是时间更重要些。总的来说,我很高兴它的工作方式。没有通讯系统是完美的。你需要实现最适合你的受众的渠道,无论是[短信](https://www.twilio.com/docs/api/rest/sending-messages),[语音](https://www.twilio.com/docs/api/rest/making-calls),[聊天](https://www.twilio.com/docs/api/chat),[视频](https://www.twilio.com/docs/api/video),还是[信号量](https://en.wikipedia.org/wiki/Semaphore_(programming))。
+
+如果你想要聊聊关于婚礼自动化的事,我在[Twitter上的@seektom](https://twitter.com/SeekTom)等你。
\ No newline at end of file
diff --git "a/Others/\350\247\243\351\207\212\346\211\207\345\207\272\346\250\241\345\274\217\357\274\210Fanout Pattern\357\274\211.md" "b/Others/\350\247\243\351\207\212\346\211\207\345\207\272\346\250\241\345\274\217\357\274\210Fanout Pattern\357\274\211.md"
new file mode 100644
index 0000000..35ed808
--- /dev/null
+++ "b/Others/\350\247\243\351\207\212\346\211\207\345\207\272\346\250\241\345\274\217\357\274\210Fanout Pattern\357\274\211.md"
@@ -0,0 +1,177 @@
+原文:[The Fanout Pattern Explained](https://www.better-simple.com/django/2023/12/06/fanout-pattern-explained/)
+
+---
+
+# 解释扇出模式(Fanout Pattern)
+
+_2023 年 12 月 06 日_
+
+在我在 [AspirEDU](https://www.aspiredu.com) 的工作中,我们每天都使用 Celery 来捕获教育信息。我们已经采用了几种不同的策略来设计 Celery 的任务签名[1](#fn:1)。其中最强大的策略是**扇出模式(Fanout Pattern)**。
+
+
+### 扇出模式指的是用可变数量的其他任务替换自身的单个任务。
+
+来一起看看一些代码。如果我们有如下的任务签名:
+
+
+```py
+task1.si() | task2.si() | task3.si()
+```
+
+每项任务必须在下一项任务开始之前完成。但是,假设在 `task2` 中,我们正在获取一些集合,并且需要为集合中的每个项目运行另一个任务。扇出模式将替换 `task2`为 `item1, item2, ..., itemN`,其中 N 是集合中的项目数。
+
+下面解释了同个意思,但是用代码的方式进行了解释:
+
+```py
+# We schedule this:
+(
+ task1.si()
+ | task2.si()
+ | task3.si()
+).apply_async()
+# But this is what runs:
+(
+ task1.si()
+ | task2.si()
+ | group([item1.si(), item2.si(), itemN.si()])
+ | task3.si()
+).apply_async()
+```
+
+记住,您不需要用一组其他任务替换这个任务。在 Celery 中,您可以将当前正在运行的任务替换为任何其他任务签名,例如单个任务或复杂的任务签名。
+
+下面深入探讨了一个示例及这个模式,但您可能可以摆脱上面的示例并[阅读关于 `Task.replace` 的文档](https://docs.celeryq.dev/en/stable/reference/celery.app.task.html#celery.app.task.Task.replace)。
+
+
+## 现实的 Taco Bell 示例问题
+
+一个更现实的例子是,您的任务是捕获每个 Taco Bell [2](#fn:2) Franchise 的所有菜单选项,然后发送一封包含最不常列出的项目[3](#fn:3)的电子邮件。您需要使用其中的数据的 API 端点是:
+
+* `fetch_franchises -> list[Franchise]`
+* `fetch_menu(franchise_id: int) -> Menu`
+
+
+假设我们创建一个 Celery 任务来负责每个 API 端点。
+
+```py
+from celery import shared_task
+
+@shared_task
+def capture_franchises():
+ for franchise in fetch_franchises():
+ # Do something
+
+
+@shared_task
+def capture_menu_for_franchise(franchise_id: int):
+ for menu_item in fetch_menu(franchise_id).menu_items:
+ # Do something
+```
+
+现在,我们发送报告的任务是:
+
+```py
+from celery import shared_task
+from django.core.mail import send_mail
+from .models import MenuItem # Our imaginary django model
+
+@shared_task
+def send_report():
+ least_listed_menu_items = MenuItem.objects.least_listed().values_list('name', flat=True)
+ send_mail(
+ subject="Least listed items report",
+ message=f"{', '.join(least_listed_menu_items)}",
+ recipient_list=["menu_design@taco-bell.better-simple.com"],
+ from_email="fanout_pattern@better-simple",
+ )
+```
+
+挑战在于,我们如何创建一个 Celery 任务签名来运行 `capture_franchises`,然后为找到的每个 franchise 运行 `capture_menu_for_franchise`,接着在所有这些任务完成后,调用运行 `send_report` 任务。
+
+一种解决方案就是扇出模式。
+
+## 实践中的扇出模式
+
+扇出模式的关键是能够[用一个任务替换另一个任务](https://docs.celeryq.dev/en/stable/reference/celery.app.task.html#celery.app.task.Task.replace)签名。
+
+在 Celery 中,要替换任务,您必须通过 `@shared_task(bind=True)` 或 `@app.task(bind=True)`[4](#fn:4) 创建[绑定任务](https://docs.celeryq.dev/en/stable/userguide/tasks.html#bound-tasks)。这使您可以通过任务参数 `self` 访问[任务请求](https://docs.celeryq.dev/en/stable/userguide/tasks.html#task-request-info)。然后就是调用 `self` 的 [`replace`](https://docs.celeryq.dev/en/stable/reference/celery.app.task.html#celery.app.task.Task.replace) 方法了。
+
+有很多链接和文档。所以这里的代码应该能够强调我的观点:
+
+```py
+from celery import group
+from .models import Franchise # Our imaginary django model
+
+@shared_task(bind=True)
+def capture_franchises(self):
+ for franchise in fetch_franchises():
+ # Do something
+
+ # We now have fetched all franchises, let's replace this
+ # task with another task signature
+
+ self.replace(
+ group([
+ capture_menu_for_franchise.si(franchise_id=franchise.id)
+ for franchise in Franchise.objects.all()
+ ])
+ )
+```
+
+您可以看到,我们正在通过 `self.replace()` 这行代码,使用一组 `capture_menu_for_franchise` 任务来替换任务 `capture_franchises`。
+
+现在我们需要将报告任务链接到上面的代码中。
+
+```py
+def run_least_listed_report():
+ signature = capture_franchises.si() | send_report.si()
+ signature.apply_async()
+```
+
+## 关于任务设计,再多说一句
+
+如果您像我一样,以上内容并不适合您。这个 `signature` 定义(`capture_franchises.si() | send_report.si()`)对读者来说并无意义。franchises 被捕获了,然后报告就发出来了?如果菜单也被捕获,这是否意味着还有其他数据也在 `capture_franchises` 中被捕获了?
+
+相反,我认为更合适的解决方案是:
+
+```py
+@shared_task
+def capture_franchises():
+ for franchise in fetch_franchises():
+ # Do something
+
+
+@shared_task(bind=True)
+def capture_franchises_menu_fanout(self):
+ franchise_ids = list(Franchise.objects.all().values_list("id", flat=True))
+ if franchise_ids:
+ # Celery doesn't handle group([]) with an empty collection well
+ # so don't replace if there are no franchises stored
+ self.replace(
+ group([
+ capture_menu_for_franchise.si(franchise_id=franchise_id)
+ for franchise_id in franchise_ids
+ ])
+ )
+```
+
+新的签名将是:
+
+```py
+capture_franchises.si() | capture_franchises_menu_fanout.si() | send_report.si()
+
+```
+
+对于其他类似工作流程来说,这更具描述性并且更容易扩展或复制。
+
+## 回顾
+
+扇出模式是在 Celery 任务签名中实现动态工作流程的好方法。您可以使用它来减小签名的大小,并根据外部数据以编程方式选择下一个任务。
+
+我希望您觉得这篇文章有用。如果您有疑问,请随时与我联系。您可以在 [Fediverse](https://fosstodon.org/@CodenameTim)、[Django Discord server](https://discord.gg/xcRH6mN4fa) 或通过[电子邮件](mailto:schillingt@better-simple.com)找到我。
+
+
+1. 一个 Celery 任务签名意味着一个或多个链接在一起的 Celery 任务。[↩](#fnref:1)
+2. 芝士戈迪塔脆饼和鸡肉玉米饼。这是您不知道的问题的答案。 [↩](#fnref:2)
+3. 我们使用最不常列出的项目,因为它要求您无论如何都会搜索每个 franchise。[↩](#fnref:3)
+4. 我使用 [`shared_task` 是因为它被推荐用于 Django](https://docs.celeryq.dev/en/stable/userguide/tasks.html#how-do-i-import-the-task-decorator),但如果你喜欢,你可以使用 `app.task` 。 [↩](#fnref:4)
\ No newline at end of file
diff --git "a/Python Common/Python \347\211\210\346\234\254\351\227\264\347\232\204\344\270\273\350\246\201\345\217\230\345\212\250\347\232\204\346\200\273\347\273\223.md" "b/Python Common/Python \347\211\210\346\234\254\351\227\264\347\232\204\344\270\273\350\246\201\345\217\230\345\212\250\347\232\204\346\200\273\347\273\223.md"
new file mode 100644
index 0000000..d21bb1c
--- /dev/null
+++ "b/Python Common/Python \347\211\210\346\234\254\351\227\264\347\232\204\344\270\273\350\246\201\345\217\230\345\212\250\347\232\204\346\200\273\347\273\223.md"
@@ -0,0 +1,487 @@
+原文:[Python 版本间的主要变动的总结](https://www.nicholashairs.com/posts/major-changes-between-python-versions/)
+
+---
+
+
+# Python 版本间的主要变动的总结
+
+_Feb 2, 2024_
+
+
+
+
+
+
+摄影:[David Clode](https://unsplash.com/@davidclode?utm_source=ghost&utm_medium=referral&utm_campaign=api-credit) / [Unsplash](https://unsplash.com/?utm_source=ghost&utm_medium=referral&utm_campaign=api-credit)
+
+
+
+This post is designed to be a quick reference for the major changes introduced with each new version of Python. This can help with taking advantages of using new features as you upgrade your code base, or ensuring that you have the correct guards for compatibility with older versions.
+
+There are two sections to this post: the first covers the actual changes, the second useful tools, links, and utilities that can aid with upgrading code bases.
+
+# 版本
+
+In this section I've documented the major changes to the Python syntax and standard library. Except for the `typing` module I've mostly excluded changes to modules. I have **not** included any changes to the C-API, byte-code, or other low level parts.
+
+For each section the end-of-life date (EOL) refers to the date at which the Python Software Foundation will not longer provide security patches for a particular version.
+
+## [Python 3.7 及更早版本](https://docs.python.org/3/whatsnew/index.html)
+
+This section has been combined as all these versions are already EOL at the time of writing, but if you've been programming in Python for a while you may have forgotten about when these features were introduced.
+
+* async and await (3.5+)
+* matrix operator: `a @ b` (3.5+)
+* type hints (3.5+)
+* [Formatted String Literals](https://docs.python.org/3/tutorial/inputoutput.html#formatted-string-literals) (aka f-strings) `f"{something}"` (3.6+)
+* underscore in numeric literals `1_000_000` (3.6+)
+* dictionaries are guaranteed insertion ordered (3.7+)
+* `contextvars` (3.7+)
+* `dataclasses` (3.7+)
+* `importlib.resources` (3.7+)
+
+## [Python 3.8](https://docs.python.org/3/whatsnew/3.8.html) (EOL Oct 2024)
+
+### 赋值表达式
+
+也称为海象运算符(Walrus operator)
+
+```py
+if (thing := get_thing()) is not None:
+ do_something(thing)
+else:
+ raise Exception(f"Something is wrong with {thing}")
+```
+
+### Positional only parameters
+
+
+```py
+def foo(a, b, /, c, d, *, e, f):
+ # a, b: positional only
+ # c, d: positional or keyword
+ # e, f: keyword only
+```
+
+### Self documenting f-strings
+
+
+```py
+# Before
+f"user={user}"
+
+# Now
+f"{user=}"
+```
+### Importlib Metadata
+
+
+```py
+import importlib.metadata
+importlib.metadata.version("some-library")
+# "2.3.4"
+importlib.metadata.requires("some-library")
+# ["thing==1.2.4", "other>=5"]
+importlib.metadata.files("some-library")
+# [...]
+```
+### Typing: `TypedDict`, `Literal`, `Final`, `Protocol`
+
+* `TypedDict` - [PEP 589](https://peps.python.org/pep-0589/)
+* `Literal` - [PEP 586](https://peps.python.org/pep-0586/)
+* `Final` - [PEP 591](https://peps.python.org/pep-0591/)
+* `Protocol` - [PEP 544](https://peps.python.org/pep-0544/)
+
+## [Python 3.9](https://docs.python.org/3/whatsnew/3.9.html) (EOL Oct 2025)
+
+### Typing: Builtin Generics
+
+Can now use `dict[...]`, `list[...]`, `set[...]` etc instead of using `typing.Dict, List, Set`.
+
+### Remove Prefix/Suffix
+
+Strings and similar types can now use `removeprefix` and `removesuffix` to more safely remove things from the start or end. This is safer than string slicing methods which rely on correctly counting the length of the prefix (and remembering to change the slice if the prefix changes).
+
+
+```
+if header.startswith("X-Forwarded-"):
+ section = header.removeprefix("X-Forwarded-")
+```
+### Dict Union Operator ([PEP 584](https://peps.python.org/pep-0584/))
+
+
+```
+combined_dict = dict_one | dict_two
+updated_dict |= dict_three
+```
+### Annotations ([PEP 593](https://peps.python.org/pep-0593/))
+
+
+```
+my_int: Annotated[int, SomeRange(0, 255)] = 0
+```
+### Zoneinfo ([PEP 615](https://peps.python.org/pep-0615/))
+
+IANA Time Zone Database is now part of standard library
+
+
+```
+import zoneinfo
+some_zone = zoneinfo.ZoneInfo("Europe/Berlin")
+```
+## [Python 3.10](https://docs.python.org/3/whatsnew/3.10.html) (EOL Oct 2026)
+
+### Structural Pattern Matching ([PEP 634](https://peps.python.org/pep-0634/), [PEP 635](https://peps.python.org/pep-0635/), [PEP 636](https://peps.python.org/pep-0636/))
+
+[See change log for more examples.](https://docs.python.org/3/whatsnew/3.10.html#pep-634-structural-pattern-matching)
+
+
+```
+match command.split():
+ case ["quit"]:
+ print("Goodbye!")
+ quit_game()
+ case ["look"]:
+ current_room.describe()
+ case ["get", obj]:
+ character.get(obj, current_room)
+ case ["go", direction]:
+ current_room = current_room.neighbor(direction)
+ case [action]:
+ ... # interpret single-verb action
+ case [action, obj]:
+ ... # interpret action, obj
+ case _:
+ ... # anything that didn't match
+```
+### Typing: Union using pipe
+
+
+```
+# Before
+from typing import Optional, Union
+thing: Optional[Union[str, list[str]]] = None
+
+# Now
+thing: str | list[str] | None = None
+```
+### Typing: `ParamSpec` ([PEP 612](https://peps.python.org/pep-0612/))
+
+Allows for much better passing of typing information when working with `Callable` and other similar types.
+
+
+```py
+from typing import Awaitable, Callable, ParamSpec, TypeVar
+
+P = ParamSpec("P")
+R = TypeVar("R")
+
+def add_logging(f: Callable[P, R]) -> Callable[P, Awaitable[R]]:
+ async def inner(*args: P.args, **kwargs: P.kwargs) -> R:
+ await log_to_database()
+ return f(*args, **kwargs)
+ return inner
+
+@add_logging
+def takes_int_str(x: int, y: str) -> int:
+ return x + 7
+
+await takes_int_str(1, "A") # Accepted
+await takes_int_str("B", 2) # Correctly rejected by the type checker
+```
+### Typing: `TypeAlias` ([PEP 613](https://peps.python.org/pep-0613/))
+
+
+```
+StrCache: TypeAlias = 'Cache[str]' # a type alias
+LOG_PREFIX = 'LOG[DEBUG]' # a module constant
+```
+### Typing: `TypeGuard` ([PEP 647](https://peps.python.org/pep-0647/))
+
+
+```py
+_T = TypeVar("_T")
+
+def is_two_element_tuple(val: Tuple[_T, ...]) -> TypeGuard[Tuple[_T, _T]]:
+ return len(val) == 2
+
+def func(names: Tuple[str, ...]):
+ if is_two_element_tuple(names):
+ reveal_type(names) # Tuple[str, str]
+ else:
+ reveal_type(names) # Tuple[str, ...]
+```
+### Parenthesized Context Managers ([PEP 617](https://peps.python.org/pep-0617/))
+
+
+```py
+with (CtxManager() as example):
+ ...
+
+with (
+ CtxManager1(), CtxManager2()
+):
+ ...
+
+with (CtxManager1() as example, CtxManager2()):
+ ...
+
+with (CtxManager1(), CtxManager2() as example):
+ ...
+
+with (
+ CtxManager1() as example1,
+ CtxManager2() as example2,
+):
+ ...
+```
+
+### Dataclasses: `slots`, `kw_only`
+
+[Dataclass decorator](https://docs.python.org/3/library/dataclasses.html#dataclasses.dataclass) now supports following:
+
+* `kw_only=True` all parameters in `__init__` will be marked keyword only.
+* `slots=True` the generatred dataclass will use `__slots__` for storing data.
+
+## [Python 3.11](https://docs.python.org/3/whatsnew/3.11.html) (EOL Oct 2027)
+
+### Tomllib
+
+`[tomllib](https://docs.python.org/3/library/tomllib.html#module-tomllib)` - Standard library TOML parser
+
+### Exception Groups ([PEP 654](https://peps.python.org/pep-0654/))
+
+
+> [**PEP 654**](https://peps.python.org/pep-0654/) introduces language features that enable a program to raise and handle multiple unrelated exceptions simultaneously. The builtin types [`ExceptionGroup`](https://docs.python.org/3/library/exceptions.html#ExceptionGroup) and [`BaseExceptionGroup`](https://docs.python.org/3/library/exceptions.html#BaseExceptionGroup) make it possible to group exceptions and raise them together, and the new [`except*`](https://docs.python.org/3/reference/compound_stmts.html#except-star) syntax generalizes [`except`](https://docs.python.org/3/reference/compound_stmts.html#except) to match subgroups of exception groups.
+
+### Enriching Exceptions with notes ([PEP 678](https://peps.python.org/pep-0678/))
+
+
+> The [`add_note()`](https://docs.python.org/3/library/exceptions.html#BaseException.add_note) method is added to [`BaseException`](https://docs.python.org/3/library/exceptions.html#BaseException). It can be used to enrich exceptions with context information that is not available at the time when the exception is raised. The added notes appear in the default traceback.
+
+
+```
+try:
+ do_something()
+except BaseException as e:
+ e.add_note("this happened during do_something")
+ raise
+```
+### Typing: `Self` ([PEP 673](https://peps.python.org/pep-0673/))
+
+
+```
+class MyClass:
+ @classmethod
+ def from_hex(cls, s: str) -> Self: # Self means instance of cls
+ return cls(int(s, 16))
+
+ def frobble(self, x: int) -> Self: # Self means this instance
+ self.y >> x
+ return self
+```
+### Typing: LiteralString ([PEP 675](https://peps.python.org/pep-0675/))
+
+
+> The new [`LiteralString`](https://docs.python.org/3/library/typing.html#typing.LiteralString) annotation may be used to indicate that a function parameter can be of any literal string type. This allows a function to accept arbitrary literal string types, as well as strings created from other literal strings. Type checkers can then enforce that sensitive functions, such as those that execute SQL statements or shell commands, are called only with static arguments, providing protection against injection attacks.
+
+### Typing: Marking `TypedDict` entries as [not] required ([PEP 655](https://peps.python.org/pep-0655/))
+
+
+```
+# default is required
+class Movie(TypedDict):
+ title: str
+ year: NotRequired[int]
+
+# default is not-required
+class Movie(TypedDict, total=False):
+ title: Required[str]
+ year: int
+```
+### Typing: Variadic Generics via `TypeVarTuple` ([PEP 646](https://peps.python.org/pep-0646/))
+
+
+> [**PEP 484**](https://peps.python.org/pep-0484/) previously introduced [`TypeVar`](https://docs.python.org/3/library/typing.html#typing.TypeVar), enabling creation of generics parameterised with a single type. [**PEP 646**](https://peps.python.org/pep-0646/) adds [`TypeVarTuple`](https://docs.python.org/3/library/typing.html#typing.TypeVarTuple), enabling parameterisation with an *arbitrary* number of types. In other words, a [`TypeVarTuple`](https://docs.python.org/3/library/typing.html#typing.TypeVarTuple) is a *variadic* type variable, enabling *variadic* generics.
+
+
+> This enables a wide variety of use cases. In particular, it allows the type of array-like structures in numerical computing libraries such as NumPy and TensorFlow to be parameterised with the array *shape*. Static type checkers will now be able to catch shape-related bugs in code that uses these libraries.
+
+### Typing: `@dataclass_transform` ([PEP 681](https://peps.python.org/pep-0681/))
+
+
+> [`dataclass_transform`](https://docs.python.org/3/library/typing.html#typing.dataclass_transform) may be used to decorate a class, metaclass, or a function that is itself a decorator. The presence of `@dataclass_transform()` tells a static type checker that the decorated object performs runtime “magic” that transforms a class, giving it [`dataclass`](https://docs.python.org/3/library/dataclasses.html#dataclasses.dataclass)-like behaviors.
+
+
+```
+# The create_model decorator is defined by a library.
+@typing.dataclass_transform()
+def create_model(cls: Type[T]) -> Type[T]:
+ cls.__init__ = ...
+ cls.__eq__ = ...
+ cls.__ne__ = ...
+ return cls
+
+# The create_model decorator can now be used to create new model classes:
+@create_model
+class CustomerModel:
+ id: int
+ name: str
+```
+### Star unpacking expressions allowed in `for` statements:
+
+This is officially supported syntax
+
+
+```
+for x in *a, *b:
+ print(x)
+```
+## [Python 3.12](https://docs.python.org/3/whatsnew/3.12.html) (EOL Oct 2028)
+
+### Typing: Type Parameter Syntax ([PEP 695](https://peps.python.org/pep-0695/))
+
+Compact annotion of generic classes and functions
+
+
+```
+def max[T](args: Iterable[T]) -> T:
+ ...
+
+class list[T]:
+ def __getitem__(self, index: int, /) -> T:
+ ...
+
+ def append(self, element: T) -> None:
+ ...
+```
+Ability to declare type aliases using `type` statement (generates `TypeAliasType`)
+
+
+```
+type Point = tuple[float, float]
+
+# Type aliases can also be generic
+type Point[T] = tuple[T, T]
+```
+### F-string changes ([PEP 701](https://peps.python.org/pep-0701/))
+
+
+> Expression components inside f-strings can now be any valid Python expression, including strings reusing the same quote as the containing f-string, multi-line expressions, comments, backslashes, and unicode escape sequences.
+
+Can re-use quotes (including nesting f-string statements
+
+
+```
+## Can re-use quotes
+f"This is the playlist: {", ".join(songs)}"
+
+f"{f"{f"{f"{f"{f"{1+1}"}"}"}"}"}" # '2'
+
+## Multiline f-string with comments
+f"This is the playlist: {", ".join([
+ 'Take me back to Eden', # My, my, those eyes like fire
+ 'Alkaline', # Not acid nor alkaline
+ 'Ascensionism' # Take to the broken skies at last
+])}"
+
+## Backslashes / Unicode
+f"This is the playlist: {"\n".join(songs)}"
+
+f"This is the playlist: {"\N{BLACK HEART SUIT}".join(songs)}"
+```
+### Buffer protocol ([PEP 688](https://peps.python.org/pep-0688/))
+
+
+> [**PEP 688**](https://peps.python.org/pep-0688/) introduces a way to use the [buffer protocol](https://docs.python.org/3/c-api/buffer.html#bufferobjects) from Python code. Classes that implement the [`__buffer__()`](https://docs.python.org/3/reference/datamodel.html#object.__buffer__) method are now usable as buffer types.
+
+
+> The new [`collections.abc.Buffer`](https://docs.python.org/3/library/collections.abc.html#collections.abc.Buffer) ABC provides a standard way to represent buffer objects, for example in type annotations. The new [`inspect.BufferFlags`](https://docs.python.org/3/library/inspect.html#inspect.BufferFlags) enum represents the flags that can be used to customize buffer creation.
+
+### Typing: `Unpack` for `**kwargs` typing ([PEP 692](https://peps.python.org/pep-0692/))
+
+
+```
+from typing import TypedDict, Unpack
+
+class Movie(TypedDict):
+ name: str
+ year: int
+
+def foo(**kwargs: Unpack[Movie]):
+ ...
+```
+### Typing: `override` decorator ([PEP 698](https://peps.python.org/pep-0698/))
+
+Ensure's that the method being overridden by a child class actually exists in a parent class.
+
+
+```
+from typing import override
+
+class Base:
+ def get_color(self) -> str:
+ return "blue"
+
+class GoodChild(Base):
+ @override # ok: overrides Base.get_color
+ def get_color(self) -> str:
+ return "yellow"
+
+class BadChild(Base):
+ @override # type checker error: does not override Base.get_color
+ def get_colour(self) -> str:
+ return "red"
+```
+# Useful Things
+
+## Postponed Annotations ([PEP 563](https://peps.python.org/pep-0563/))
+
+In newer versions of Python, typing annotations are stored as strings when they are initially parsed. This helps with preventing circular imports, needing to quote references before they are defined, and many other issues. All versions of Python from 3.7 support
+`from __future__ import annotations`
+which allows the interpreter to parse using this new format.
+
+Note: PEP 563 has been superseded by [PEP 649](https://peps.python.org/pep-0649/) which will be implemented in Python 3.13.
+
+## Typing Extensions
+
+This library back-ports typing features so that they are available to type checkers inspecting older code bases.
+
+
+```
+import sys
+
+if sys.version_info < (3, 10):
+ from typing_extensions import TypeAlias
+else:
+ from typing import TypeAlias
+```
+[GitHub - python/typing\_extensions: Backported and experimental type hints for PythonBackported and experimental type hints for Python. Contribute to python/typing\_extensions development by creating an account on GitHub.GitHubpython](https://github.com/python/typing_extensions)## Python Support Schedule
+
+To keep track of which versions of Python are support I use the following website:
+
+[PythonCheck end-of-life, release policy and support schedule for Python.endoflife.date](https://endoflife.date/python)## Ruff
+
+This is a linter and code formatter written in Rust. It's becoming very popular as it can replace a number of existing tools and is very fast. It also includes the ability to auto-fix errors.
+
+Thus you can combine ruff with it's pyupgrade compatible linter (`UP`) and then use
+`ruff check --fix` to auto upgrade the code base.
+
+When using `pyproject.toml` ruff will respect the versions specified by
+`project.requires-python`.
+
+[GitHub - astral-sh/ruff: An extremely fast Python linter and code formatter, written in Rust.An extremely fast Python linter and code formatter, written in Rust. - GitHub - astral-sh/ruff: An extremely fast Python linter and code formatter, written in Rust.GitHubastral-sh](https://github.com/astral-sh/ruff)## Pyupgrade
+
+This tool can be used to automatically upgrade your code base.
+
+[GitHub - asottile/pyupgrade: A tool (and pre-commit hook) to automatically upgrade syntax for newer versions of the language.A tool (and pre-commit hook) to automatically upgrade syntax for newer versions of the language. - GitHub - asottile/pyupgrade: A tool (and pre-commit hook) to automatically upgrade syntax for newe...GitHubasottile](https://github.com/asottile/pyupgrade)## Black
+
+Black is a popular code formatter.
+
+When using `pyproject.toml` black will respect the versions specified by
+`project.requires-python`.
+
+[GitHub - psf/black: The uncompromising Python code formatterThe uncompromising Python code formatter. Contribute to psf/black development by creating an account on GitHub.GitHubpsf](https://github.com/psf/black)
+
+
+
diff --git "a/Python Common/Python \351\231\267\351\230\261\357\274\232Join vs Concat.md" "b/Python Common/Python \351\231\267\351\230\261\357\274\232Join vs Concat.md"
new file mode 100644
index 0000000..9208bd6
--- /dev/null
+++ "b/Python Common/Python \351\231\267\351\230\261\357\274\232Join vs Concat.md"
@@ -0,0 +1,77 @@
+原文:[Python Gotcha: Join vs Concat](https://andrewwegner.com/python-gotcha-join-vs-concat.html)
+
+---
+
+## 问题[¶](#the-problem "Permanent link")
+
+这是一个有点人为的示例,用来演示问题所在。我需要创建一个包含 100,000 个 `word` 的字符串。生成该字符串的最快方法是什么呢?我可以使用字符串连接(只是用 `+` 将字符串相互连接)。我还可以在包含 100,000 个元素的列表上使用 [`join`](https://docs.python.org/3/library/stdtypes.html#str.join)。
+
+为此,我的示例代码如下
+
+```py
+def concat_string(word: str, iterations: int = 100000) -> str:
+ final_string = ""
+ for i in range(iterations):
+ final_string += word
+ return final_string
+
+def join_string(word: str, iterations: int = 100000) -> str:
+ final_string = []
+ for i in range(iterations):
+ final_string.append(word)
+ return "".join(final_string)
+```
+
+## 结果[¶](#results "Permanent link")
+
+在 `concat_string` 中,我迭代了 100,000 个元素,每次迭代都将 我的 `word` 添加到字符串末尾。在 `join_string` 中,我在每次迭代时将我的 `word` 附加到列表中,然后在末尾将列表连接成字符串。
+
+通过内置分析器 (`cProfile`) 运行每个函数会显示这两个函数的执行情况。
+
+
+```sh
+>>> cProfile.run('concat_string("word ")')
+
+ 4 function calls in 1.026 seconds
+
+Ordered by: standard name
+
+ncalls tottime percall cumtime percall filename:lineno(function)
+ 1 0.000 0.000 1.026 1.026 :1()
+ 1 1.026 1.026 1.026 1.026 test.py:9(concat_string)
+ 1 0.000 0.000 1.026 1.026 {built-in method builtins.exec}
+ 1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
+
+>>> cProfile.run('join_string("word ")')
+
+ 100005 function calls in 0.013 seconds
+
+Ordered by: standard name
+
+ncalls tottime percall cumtime percall filename:lineno(function)
+ 1 0.000 0.000 0.013 0.013 :1()
+ 1 0.009 0.009 0.013 0.013 test.py:16(join_string)
+ 1 0.000 0.000 0.013 0.013 {built-in method builtins.exec}
+100000 0.004 0.000 0.004 0.000 {method 'append' of 'list' objects}
+ 1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
+ 1 0.000 0.000 0.000 0.000 {method 'join' of 'str' objects}
+```
+
+## 这里发生了什么?[¶](#whats-happening-here "Permanent link")
+
+
+`join` 比连接方法快了 75 倍以上。
+
+为什么呢?
+
+字符串是 Python 中不可变的对象。我在上一篇[关于默认参数的陷阱文章](https://andrewwegner.com/python-gotcha-optional-default-arguments.html)中对其进行了讨论。这种不变性意味着不能更改字符串。`concat_string` 看起来好像每次 `+` 操作都会更改字符串,但实际上,Python 必须在循环的每次迭代中创建一个新的字符串对象。这意味着有 99,999 个临时字符串值 - 几乎所有这些值都在连接操作期间的下一次迭代中被立即创建和丢弃。
+
+另一方面,`join_string` 将 100,000 个字符串对象附加到列表中。但在此过程中仅创建了一个列表。最终的 `join` 仅对所有 100,000 个字符串进行*一次*串联。
+
+
+
+## 这意味着什么?[¶](#what-are-the-implications-of-this "Permanent link")
+
+虽然这是一个展示问题的人为示例,对字符串不变性的实际性能影响可能并不明显。Python 中还有其他常用的创建新字符串的地方。例如`f-strings`,`%s` 格式说明符和 `.format()`。它们中每一个都会创建一个全新的字符串。
+
+这并不意味着您应该避免使用这些,因为只有在将*大量*字符串附加在一起的情况下,性能影响才会真正明显。但是,如果循环中有字符串格式化行,那么它就是一个需要重点关注的性能改进之处。
\ No newline at end of file
diff --git "a/Python Common/Python \351\231\267\351\230\261\357\274\232\346\257\224\350\276\203.md" "b/Python Common/Python \351\231\267\351\230\261\357\274\232\346\257\224\350\276\203.md"
new file mode 100644
index 0000000..7556eb2
--- /dev/null
+++ "b/Python Common/Python \351\231\267\351\230\261\357\274\232\346\257\224\350\276\203.md"
@@ -0,0 +1,198 @@
+原文:[Python Gotcha: Comparisons](https://andrewwegner.com/python-gotcha-comparisons.html)
+
+---
+
+# Python 陷阱:比较
+
+
+## 浮点数等价性比较[¶](#float-equality-comparisons "Permanent link")
+
+与其他所有编程语言一样,Python 也无法准确表示浮点数。我确信许多计算机科学专业的学生已经花费了很多时间来学习[如何表示浮点](https://www.doc.ic.ac.uk/~eedwards/compsys/float/)。那堂课我记得很清楚。
+
+无论如何,让我们讨论一下Python 中比较 `float` 值的问题以及如何处理它。
+
+```py
+>>> 0.1 + 0.2 == 0.3
+False
+
+```
+
+你、我,以及任何读过几年小学的人都可以看出,这*应该是* `True`。
+
+那这里发生了什么呢?我们通过分解这个比较的组成部分就可以看出问题所在。
+
+```py
+>>> 0.3
+0.3
+>>> 0.1 + 0.2
+0.30000000000000004
+
+```
+现在我们已经看到了导致问题的浮点表示形式。
+
+那么,我们该如何处理这个问题呢?
+
+
+### Decimal[¶](#decimal "Permanent link")
+
+有几种选择,它们都有各自的缺点。让我们从 [`Decimal`](https://docs.python.org/3/library/decimal.html) 开始。
+
+>
+> The decimal module provides support for fast correctly rounded decimal floating point arithmetic. (decimal 模块提供对快速正确舍入的十进制浮点运算的支持。)
+>
+
+这听起来不错,但这里的一个重要问题是,它如何处理数字与字符串。
+
+
+```py
+>>> from decimal import Decimal
+>>> Decimal(0.1)
+Decimal('0.1000000000000000055511151231257827021181583404541015625')
+>>> Decimal('0.1')
+Decimal('0.1')
+
+```
+这意味着,为了完成上面的比较,我们需要将每个数字包装在一个字符串中。
+
+```py
+>>> Decimal('0.1') + Decimal('0.2') == Decimal('0.3')
+True
+
+```
+
+很烦,但确实能用。
+
+### isclose[¶](#isclose "Permanent link")
+
+Python 3.5 实现了 [PEP 485](https://peps.python.org/pep-0485/) 来测试近似相等。这是在 [`isclose`](https://docs.python.org/3/library/math.html#math.isclose) 函数中完成的。
+
+
+```py
+>>> import math
+>>> math.isclose(0.1+0.2,0.3)
+True
+
+```
+
+这比把所有东西都用字符串包裹起来更干净。但是,它也比简单的 `==` 语句更冗长。它让您的代码不太干净,但确实提供了准确的比较。
+
+## is vs. ==[¶](#is-vs "Permanent link")
+
+我经常看到的另一个被误用的比较是,开发人员用了 `is`但他们其实是想表达 `==`. 简而言之,`is` **仅**当您检查两个引用是否引用同一对象时才应使用。`==` 用于通过调用底层方法 `__eq__` 来比较值。
+
+让我们看看实际效果:
+
+```py
+>>> a = [1, 2, 3]
+>>> b = a
+>>> c = [1, 2, 3]
+>>> d = [3, 2, 1]
+>>> a == b
+True
+>>> a == c
+True
+>>> a == d
+False
+
+```
+到目前为止,没有什么异常。`a` 具有和 `b` 与 `c` 相同的值,并且与 `d` 具有不同的值。现在让我们使用 `is`
+
+```py
+>>> a is b
+True
+>>> b is a
+True
+>>> a is c
+False
+>>> a is d
+False
+>>> b is c
+False
+
+```
+
+这里,唯一为 `True` 的语句是 `a` 和 `b` 之间的比较。这是因为 `b` 是用 `b = a` 语句初始化的。另外两个变量被初始化为它们自己的语句和值。**请记住,`is` 比较对象引用。如果它们相同,则返回 `True`。**
+
+
+```py
+>>> id(a), id(b), id(c), id(d)
+(2267170738432, 2267170738432, 2267170545600, 2267170359040)
+
+```
+
+由于 `a` 和 `b` 是同一个对象,在对其进行比较的时候,我们才会得到 `True`。其他是不同对象,因此是 `False`。
+
+
+## nan == nan[¶](#nan-nan "Permanent link")
+
+`nan`,或者说“非数字(Not a Number)”是一个浮点值,它无法被转换为浮点数以外的任何值,并且被视为不等于所有其他值。这是表示数据集中缺失值的常见方法。
+
+上面的描述中有一个关键短语,它是这个陷阱的基础:
+>
+> is considered not equal to all other values(被视为不等于所有其他值)
+>
+
+软件通常会在采取操作之前检查两个值是否彼此相等。对于 `nan`,这不起作用:
+
+```py
+>>> float('nan') == float('nan')
+False
+
+```
+
+这可以防止这样的代码进入 `if/else` 语句的 `if` 块。
+
+
+```py
+>>> a = float('nan')
+>>> b = float('nan')
+>>> if a == b:
+... .. ## Do something if equal
+... else:
+... .. ## Do something if not equal
+
+```
+
+在这个例子中,它们*永远*不相等。
+
+这导致了一种有意思的(如果不是不直观的话)检查变量是否是 `nan` 值的方法。由于 `nan` 不等于所有其他值,因此它也不等于自身。
+
+```py
+>>> a != a
+True
+
+```
+
+就像我说的,“有意思”。但是,当其他人查看您的代码时,它也会“令人困惑”。有一种更简单的方法可以表明您正在检查一个 `nan` 值。[`isnan`](https://docs.python.org/3/library/math.html#math.isnan)
+
+
+```py
+>>> import math
+>>> a = float('nan')
+>>> b = 5
+>>> c = float('infinity')
+>>> math.isnan(a)
+True
+>>> math.isnan(b)
+False
+>>> math.isnan(c)
+False
+
+```
+
+对我来说,这是一个更清晰的检查,我们想看看该值是否为 `nan`。 您可能不只是传递 `nan` 给单个变量。你可能正在使用诸如 [NumPy](https://numpy.org/) 或者 [Pandas](https://pandas.pydata.org/) 这样的库。在这种情况下,每个库都自带了一些函数,你可以用它们来完美检查 `nan`。
+
+
+* 在 NumPy 中,这个函数具有相同的名字,但是是在 NumPy 库中的:`numpy.isnan(value)`。
+* 在 Pandas 中,这个函数具有一个稍微不同的名字:`pandas.isna(value)`
+
+
+### 总结[¶](#conclusion "Permanent link")
+
+比较并不总是像我们希望的那样直接。我在这里介绍了 Python 中的一些常见比较问题。
+
+浮点比较在各种语言中都很常见。Python 有几种方法可以让开发人员更轻松地做到这一点。我建议使用 `isclose`,因为它可以使代码更加简洁,并且在使用该模块时无需像 `Decimal` 模块那样将数字包装在字符串中
+
+`is` 应该*只*用于检查两个项目是否引用同一个对象。在任何其他情况下,它都不会执行您希望它执行的检查。
+
+最后,`nan`等于*没有别的*。在开始将数据集中的值相互比较之前,了解这一点很重要。
\ No newline at end of file
diff --git "a/Python Common/Python\344\270\255\347\232\204assert\350\257\255\345\217\245.md" "b/Python Common/Python\344\270\255\347\232\204assert\350\257\255\345\217\245.md"
new file mode 100644
index 0000000..8dcb88a
--- /dev/null
+++ "b/Python Common/Python\344\270\255\347\232\204assert\350\257\255\345\217\245.md"
@@ -0,0 +1,234 @@
+
+原文地址: https://dbader.org/blog/python-assert-tutorial
+
+- [什么是断言 & 断言擅长什么?](#org49b25fa)
+- [Assert的一个例子](#org1be508a)
+- [Assert的语法](#org565d224)
+- [使用Assert时常见的坑](#orgeae94a8)
+ - [警告 #1 – 不要将Assert用于数据验证](#orgf6294c0)
+ - [警告 #2 – 小心写出永远不会失败的Assert语句](#orgaab9ee3)
+- [总结](#org9e1fa7b)
+
+如何利用断言自动探测Python程序中的错误使之更可靠且易于调试.
+
+
+
+
+
+
+# 什么是断言 & 断言擅长什么?
+
+Python的 `assert` 语句可以用于调试. 它会测试一个条件,若这个条件为真,则它什么也不做,你的程序照常往下执行. 但若条件为假,则它会抛出一个 `AssertionError` 异常,该异常甚至还能包括一个错误信息.
+
+`assertions` 的正确使用方法是用它来通知开发者程序中出现了无法回复的异常. 你不能用它来处理类似"文件没找到"这类可以预见的错误,因为用户可以采取行动修正这一错误,然后重试.
+
+另一种看法是把 `assertions` 看成是程序的内部检查工具. 它标注某些情况是不可能在代码中出现的. 如果真的出现了其中的情况,那表示程序中肯定有bug.
+
+若你的程序中没有bug, 就不会触发这些条件. 但如果真的触发了这些条件,那么程序就会崩溃,并显示一条断言错误信息告诉你是触发了哪一条"不该出现的"条件. 这有利于追踪和修复bug.
+
+总结起来就是: Python的 `assert` 是一种调试的工具而不适于用来处理运行时错误的. 使用断言是为了让开发者快速找到bug产生的根源. 应该要做到只有当你的程序中出现bug时才能抛出断言错误.
+
+
+
+
+# Assert的一个例子
+
+下面是一个简单的例子,展示一下断言应该怎么用. 我尽量让这个例子更实际一点.
+
+假设你在用Python搭建一个在线商场. 你需要为它添加一项折扣券的功能因此写了下面这个 `apply_discount` 功能:
+
+```python
+def apply_discount(product, discount):
+ price = int(product['price'] * (1.0 - discount))
+ assert 0 <= price <= product['price']
+ return price
+```
+
+注意到了那个 `assert` 语句了么? 它会保证,不管怎么样,打折后的价格都不会低于0元,也不会高于原价.
+
+让我们用各种折扣来调用该函数,确保该函数能如我们所愿那边地正常工作.
+
+```python
+#
+# Our example product: Nice shoes for $149.00
+#
+>>> shoes = {'name': 'Fancy Shoes', 'price': 14900}
+
+#
+# 25% off -> $111.75
+#
+>>> apply_discount(shoes, 0.25)
+11175
+```
+
+不错,挺正常的. 现在再试试其他非法的折扣:
+
+```python
+#
+# A "200% off" discount:
+#
+>>> apply_discount(shoes, 2.0)
+Traceback (most recent call last):
+ File "", line 1, in
+ apply_discount(prod, 2.0)
+ File "", line 4, in apply_discount
+ assert 0 <= price <= product['price']
+AssertionError
+
+#
+# A "-30% off" discount:
+#
+>>> apply_discount(shoes, -0.3)
+Traceback (most recent call last):
+ File "", line 1, in
+ apply_discount(prod, -0.3)
+ File "", line 4, in apply_discount
+ assert 0 <= price <= product['price']
+AssertionError
+```
+
+如你所见,当传入一个非法的折扣时会引发 `AssertionError` 异常,并指出异常的行以及不匹配的断言条件. 当我们在测试在线商场时,若出现了这种错误,通过查看 traceback 可以很方便地找出错误原因.
+
+这就是断言的威力.
+
+
+
+
+# Assert的语法
+
+开始使用某项语言特性前最好先了解它是如何实现的. 下面我们就来看一下 [Python文档中assert语句的语法是怎样的](https://docs.python.org/3/reference/simple_stmts.html#the-assert-statement):
+
+```python
+assert_stmt ::= "assert" expression1 ["," expression2]
+```
+
+其中 `expression1` 就是我们要测试的条件, 而可选的 `expression2` 是断言失败时要显示的错误信息.
+
+在执行期间,Python解释器会将每个 `assert` 语句都转换成类似下面这样:
+
+```python
+if __debug__:
+ if not expression1:
+ raise AssertionError(expression2)
+```
+
+你也可以通过 `expression2` 传递一个可选的错误信息, 当触发 `AssertionError` 异常时, 该错误信息也会一同在 traceback 中显示出来. 它可以进一步简化调试. 举个例子,我曾见过这样的代码:
+
+```python
+if cond == 'x':
+ do_x()
+elif cond == 'y':
+ do_y()
+else:
+ assert False, ("This should never happen, but it does occasionally. "
+ "We're currently trying to figure out why. "
+ "Email dbader if you encounter this in the wild.")
+```
+
+这段代码丑吗? 是的,的确很丑. 但是当你遇见 [heisenbug](https://en.wikipedia.org/wiki/Heisenbug) 这样的问题时,这种技术都很有用了. 😉
+
+
+
+
+# 使用Assert时常见的坑
+
+在你继续往下读之前,有两点需要注意:
+
+第一点告诉你如何防止引入安全风险和bug,第二点 about a syntax quirk that makes it easy to write useless assertions.
+
+这两条警告听起来(而且实际上也是)听恐怖的, 所以请你至少了解一下这两条警告或者至少读一下后面的总结.
+
+
+
+
+## 警告 #1 – 不要将Assert用于数据验证
+
+**Python解释器可以全面关闭Assert特性. 因此不要依赖 `assert` 表达式来进行数据验证和数据处理.**
+
+使用 `asserts` 一定要注意,通过给CPython提供命令行参数(或者修改PYTHONOPTIMIZE环境变量) `-O` 或 `-OO` 可以 [全面禁止断言生效](https://docs.python.org/3/library/constants.html#__debug__)
+
+这会将所有的 `assert` 语句都转换成空操作: 断言在编译时会被丢弃,而且也不会被执行,因此里面的条件表达式也就不会执行了.
+
+许多语言都有类似的这种设计. 这带来的一个后果就是用 `assert` 语句来校验输入的数据是很危险的一件事情.
+
+也就是说,如果你想用 `assert` 来检查函数参数的合法性,那恐怕会事与愿违,而且很容易产生bug和安全漏洞.
+
+让我们来看一个简单的例子. 假设你在用python创建一个在线商场的应用. 在代码中有一个函数用来响应用户请求删除一个产品:
+
+```python
+def delete_product(product_id, user):
+ assert user.is_admin(), 'Must have admin privileges to delete'
+ assert store.product_exists(product_id), 'Unknown product id'
+ store.find_product(product_id).delete()
+```
+
+仔细看看这个函数. 如果断言被禁用了会怎样?
+
+这个函数虽然只有短短的三行,但是由于误用 `assert` 语句,产生了两个严重的问题:
+
+1. 使用 `assert` 语句来验证管理员特权是很危险的. Python解释器禁用断言会让它变成一个空操作. 由于根本不会运行特权检查语句,这使得任何用户都能够删除产品. 这样一来就引入了一个安全问题,允许攻击者损坏你的客户或公司的在线商城中的数据. 这可不妙啊.
+2. 禁用断言后, `product_exists()` 检查会被跳过. 也就是说 `find_product()` 的参数可能是一个非法的产品id号—这可能会产生很严重的bug. 在最坏的情况下, 它会导致针对我们商场的拒绝服务的攻击. 若删除未知的商品会导致商场崩溃的话,攻击者就可以通过发起age无效的删除请求让我们的商场失去服务能力.
+
+那我们该怎么办呢? 答案是不要用断言来做数据验证, 而改用普通的if语句+抛出验证异常的方法来验证. 像这样子:
+
+```python
+def delete_product(product_id, user):
+ if not user.is_admin():
+ raise AuthError('Must have admin privileges to delete')
+
+ if not store.product_exists(product_id):
+ raise ValueError('Unknown product id')
+
+ store.find_product(product_id).delete()
+```
+
+相比之下,修改后的函数不再只是抛出泛泛的 `AssertionError` 异常,它能够根据实际情况抛出像 `ValueError` 或 `AuthError` 这类更贴合实际意义的异常(当然 [这些异常需要我们自己定义](https://dbader.org/blog/python-custom-exceptions)).
+
+
+
+
+## 警告 #2 – 小心写出永远不会失败的Assert语句
+
+一不小心就会写出永远为真的assert语句. 我之前也着过这个道. 还专门写过 [一篇相关的文章](https://dbader.org/blog/catching-bogus-python-asserts).
+
+总结起来就是:
+
+**当你使用一个元组作为assert语句的第一个参数时,该断言永远为真不会失败.**
+
+比如, 这个断言就永远不会失败:
+
+```python
+assert(1 == 2, 'This should fail')
+```
+
+这是因为非空的元组在Python中总是为真. 传递一个元组给 `assert` 语句会让该 `assert` 的条件永远为真—这样以来上面的 `assert` 语句也就没啥用了,它永远不可能失败然后触发异常.
+
+这种反直觉的行为很容易使得在写多行的assert时出错. 它会破坏测试代码中的测试案例,使它们失去保障安全的能力. 比如你可能在单元测试集中有下面这样一个断言:
+
+```python
+assert (
+ counter == 10,
+ 'It should have counted all the items'
+)
+```
+
+初看起来貌似没什么问题. 然而该测试案例永远无法捕捉到错误的结果:不管 `counter` 变量的值是什么,它的结果总为真.
+
+就像我说过的,你很容易就误用了assert. 不过好在有一些措施能够帮助你避开这些问题:
+
+[>> Read the full article on bogus assertions to get the dirty details.](https://dbader.org/blog/catching-bogus-python-asserts)
+
+
+
+
+# 总结
+
+虽然有写警告,我依然认为Python的断言是一个非常强力的调试工具,然而该工具尚未被开发者们充分地使用起来.
+
+理解断言的工作原理以及学会在恰当的时候使用断言会帮助你写出更加可维护也更加易于调试的程序. 学会这项技能会提升你的Python代码水平,让你成为一个更成熟的Python开发者.
diff --git "a/Python Common/Python\344\270\255\347\232\204lambda\350\241\250\350\276\276\345\274\217.md" "b/Python Common/Python\344\270\255\347\232\204lambda\350\241\250\350\276\276\345\274\217.md"
new file mode 100644
index 0000000..7b9e83e
--- /dev/null
+++ "b/Python Common/Python\344\270\255\347\232\204lambda\350\241\250\350\276\276\345\274\217.md"
@@ -0,0 +1,93 @@
+
+
+原文链接: https://allanderek.github.io/posts/python-and-lambdas/
+
+我拥有函数式编程的经验, 因此我非常热衷于使用函数以及lambda表达式,也就是所谓的匿名函数. 然而我发现当写Python时我并不怎么使用它的lambda语法,我很好奇怎么会这样. 这么说似乎对lambda很不利 但是请记住,总体来说我并不讨厌lambda.
+
+所有的lambda表达式都能被普通函数所代替. 问题是,什么情况下使用lambda会比定义普通函数拥有更好的可读性? 答案是几乎总是这样. 因为你要定义的函数太简单了,定义的语法反而会阻碍对内容的理解. 这些函数一般都会作为其他方法的参数来使用. 比如可以作为 list的 `sort` 方法中的 `key` 参数的值,在比较元素时使用. 如果你有一个包含item的列表,然后想根据这些item的price来排序,那么你可以这么做:
+
+```python
+list_of_items.sort(key=lambda x: x.price)
+```
+
+当然可以通过定义函数的方式来代替lambda:
+
+```python
+def price(item):
+ return item.price
+list_of_items.sort(key=price)
+```
+
+严格来说,这两者是不等价的,因为后面这种方式会引入一个新名字到当前作用域中而前者不会, 不过我并不会仅仅为了避免污染命名空间就选择用lambda表达式.
+
+我们甚至可以定义一个一般性的高阶函数,用于生成一个访问属性的函数.
+
+```python
+def f_attr(attr_name):
+ def attr_getter(item):
+ return getattr(item, attr_name)
+ return attr_getter
+
+list_of_items.sort(key=f_attr('price'))
+```
+
+这看起来要比前两个版本更糟糕, 但若你要根据不同属性进行多次排序,那么使用定义普通函数的方法会很烦:
+
+```python
+def price(item):
+ return item.price
+list_of_items.sort(key=price)
+do_something(list_of_items)
+
+def quantity(item):
+ return item.quantity
+list_of_items.sort(key=quantity)
+do_something(list_of_items)
+
+def margin(item):
+ return item.margin
+list_of_items.sort(key=margin)
+do_something(list_of_items)
+```
+
+相比来说使用lambda就简单多了:
+
+```python
+list_of_items.sort(key=lambda x: x.price)
+do_something(list_of_items)
+list_of_items.sort(key=lambda x: x.quantity)
+do_something(list_of_items)
+list_of_items.sort(key=lambda x: x.margin)
+do_something(list_of_items)
+```
+
+使用f\_attr也一样:
+
+```python
+list_of_items.sort(key=f_attr('price'))
+do_something(list_of_items)
+list_of_items.sort(key=f_attr('quantity'))
+do_something(list_of_items)
+list_of_items.sort(key=f_attr('margin'))
+do_something(list_of_items)
+```
+
+甚至还能用循环来解决:
+
+```python
+for attribute in ['price', 'quantity', 'margin']:
+ list_of_items.sort(key=f_attr(attribute))
+ do_something(list_of_items)
+```
+
+我认为lambda版本至少在某些情况下会更有可读性. 但是函数天然具有自我说明的功能,因为函数名本身就有说明的作用,尤其那些能用lambda表达式代替的简单函数,他们的自描述性更强.
+
+所以,最好用lambda表达式来代替那些内容足够简单,无需函数名就能充分理解意义的函数(比如单纯的访问对象属性).
+
+不过这种情况对我来说很少见. 也许是我定义的函数还不够一般化以至于要接受其他函数作为参数吧.
diff --git "a/Python Common/Python\346\226\260\345\242\236\347\232\204secrets\346\250\241\345\235\227.md" "b/Python Common/Python\346\226\260\345\242\236\347\232\204secrets\346\250\241\345\235\227.md"
new file mode 100644
index 0000000..4b46e9a
--- /dev/null
+++ "b/Python Common/Python\346\226\260\345\242\236\347\232\204secrets\346\250\241\345\235\227.md"
@@ -0,0 +1,75 @@
+
+
+原文链接: http://www.blog.pythonlibrary.org/2017/02/16/pythons-new-secrets-module/
+
+- [使用secrets生成令牌](#orga8639ea)
+- [摘要](#org42cb0a3)
+
+Python 3.6新增了一个名为 `secrets` 的模块. 他可以很直观的生成密码强度的伪随机数. 这些伪随机数足以用于管理像账户认证,令牌之类的机密信息. Python的 `random` 模块,其强度只适用于仿真与建模,而并不能胜任真正加密工作. 当然,你始终可以用os模块中的 `urandom()` 函数:
+
+```python
+>>> import os
+>>> os.urandom(8)
+'\x9c\xc2WCzS\x95\xc8'
+```
+
+不过现在有了 `secrets` 模块, 我们可以创建自己的"密码强度的伪随机值"了. 下面是一个简单的例子:
+
+```python
+>>> import secrets
+>>> import string
+>>> characters = string.ascii_letters + string.digits
+>>> bad_password = ''.join(secrets.choice(characters) for i in range(8))
+>>> bad_password
+'SRvM54Z1'
+```
+
+在这个例子中,我们导入了 `secrets` 模块和 `string` 模块. 然后用大写字母和数字组成了一个字符串. 最后使用 `secrets` 模块的 `choice()` 方法随机地抽取出其中的字符,从而生成一个不够好的密码. 之所以说这个密码不够好是因为密码中没有特殊字符, 但实际上它已经要好过很多人使用的密码了. 还有读者指出,除此之外,这个密码也比较难记,所以很可能会被记录在纸上被人发现. 这当然也对,但是使用字典里的单词作为密码是非常不建议的,你最好习惯这种密码或者使用密码管理软件管理你的密码.
+
+---
+
+
+
+
+# 使用secrets生成令牌
+
+`secrets` 模块还提供了许多生成令牌的方法. 下面来看一些例子:
+
+```python
+>>>: secrets.token_bytes()
+b'\xd1Od\xe0\xe4\xf8Rn\x8cO\xa7XV\x1cb\xd6\x11\xa0\xcaK'
+
+>>> secrets.token_bytes(8)
+b'\xfc,9y\xbe]\x0e\xfb'
+
+>>> secrets.token_hex(16)
+'6cf3baf51c12ebfcbe26d08b6bbe1ac0'
+
+>>> secrets.token_urlsafe(16)
+'5t_jLGlV8yp2Q5tolvBesQ'
+```
+
+`token_bytes` 函数会返回一段随机的包含了n个字节的字节字符串. 我一开始没有指定要生成多少个字节,所以Python自动为我选择了一个合适的长度. 随后我又调用了一次这个函数并且明确指定了生成8个字节长度的字符串. 然后我们又试了一把 `token_hex` 函数, 它会返回一段随机的十六进制形式的字符串. 最后的 `token_urlsafe` 函数会返回一段随机的 URL安全的文本字符串. 其文本已经用 Base64 编码过了! 要注意,在实际使用中,你应该至少生成32字节长度的令牌才能够防止被暴力破解所攻破([source](https://docs.python.org/3.6/library/secrets.html#how-many-bytes-should-tokens-use)).
+
+---
+
+
+
+
+# 摘要
+
+新增的 `secrets` 模块非常有价值. 老实说,我觉得这玩意早就该有了. 好在最终我们终于有了这么一个模块,可以用来安全地生成密码强度哦令牌和密码了. 可以花点时间看看该模块的文档,其中有一些好玩的应用例子.
+
+---
+
+相关阅读资料
+
+- The secrets module [documentation](https://docs.python.org/3.6/library/secrets.html)
+- What’s new in Python 3.6: [secrets module](https://docs.python.org/3.6/library/secrets.html#module-secrets)
+- PEP 506 — [Adding A Secrets Module To The Standard Library](https://www.python.org/dev/peps/pep-0506/)
diff --git a/Python Common/README.md b/Python Common/README.md
index af3b300..fa238ae 100644
--- a/Python Common/README.md
+++ b/Python Common/README.md
@@ -70,4 +70,12 @@
- [Python:声明动态属性](./Python:声明动态属性.md)
-- [了解Python类实例化](./了解Python类实例化.md)
\ No newline at end of file
+- [了解Python类实例化](./了解Python类实例化.md)
+
+- [Python中的assert语句](./Python中的assert语句.md)
+
+- [Python新增的secrets模块](./Python新增的secrets模块.md)
+
+- [Python中的lambda表达式](./Python中的lambda表达式.md)
+
+- [我是如何修复 Python 3.7 中一个非常老的 GIL 竞争条件的](./python37-gil-change.md)
\ No newline at end of file
diff --git "a/Python Common/What's New in Python xx/New In Python\357\274\232\345\217\230\351\207\217\346\263\250\350\247\243\350\257\255\346\263\225.md" "b/Python Common/What's New in Python xx/New In Python\357\274\232\345\217\230\351\207\217\346\263\250\350\247\243\350\257\255\346\263\225.md"
new file mode 100644
index 0000000..aa2c195
--- /dev/null
+++ "b/Python Common/What's New in Python xx/New In Python\357\274\232\345\217\230\351\207\217\346\263\250\350\247\243\350\257\255\346\263\225.md"
@@ -0,0 +1,110 @@
+
+
+原文地址:http://www.blog.pythonlibrary.org/2017/01/12/new-in-python-syntax-for-variable-annotations/
+
+---
+
+[Python 3.6](https://docs.python.org/3.6/whatsnew/3.6.html#whatsnew36-pep526) 开始支持变量注解了(Syntax for variable annotations). 这是一项脱胎于 [PEP 526](https://www.python.org/dev/peps/pep-0526) 的新功能. 这个PEP将Type Hinting ([PEP 484](https://www.python.org/dev/peps/pep-0484)) 的理念变成了现实. 它可以为Python变量(包括类变量和实例变量)添加额外可选的类型声明. 请注意,添加这些注解或者说声明并不会让Python变成一门静态类型语言. 解释器依然并不关心变量的类型是什么. 但是对于Python IDE或其他类似pylink这样的工具来说,他们可以使用这些注解来进行检查,并高亮出与注解声明类型不一致的变量来.
+
+下面通过一个简单的例子来看看它是怎么工作的:
+
+```python
+# annotate.py
+name: str = 'Mike'
+```
+
+这是 `annotate.py` 中的内容. 其中,我们创建了一个变量: `name`, 它后面的注解说明它是一个字符串. 为变量添加注解就是在变量名后加上一个冒号以及该变量所属的类型. 如果你不想为变量赋值也可以. 下面的句子也没问题.
+
+```python
+# annotate.py
+name: str
+```
+
+当你为一个变量添加了注解,该变量就会被添加到 module 或是 class 的 `__annotations__` 属性中. 下面让我们导入这个 `annotate` module,然后看看它的属性:
+
+```python
+>>> import annotate
+>>> annotate.__annotations__
+{'name': }
+>>> annotate.name
+'Mike'
+```
+
+你可以看到, `__annotations__` 属性返回了一个Python dict变量, 其中以变量名为key,以对应的注解类型为value.
+
+下面让我们添加一些其他类型的注解,再看看 `__annotations__` 属性会变成怎样的.
+
+```python
+# annotate2.py
+name: str = 'Mike'
+
+ages: list = [12, 20, 32]
+
+class Car:
+ variable: dict
+```
+
+在这段代码中, 我们添加了一个带注解的 `list` 变量,以及一个类,这个类中又定义了一个带注解的类变量. 现在我们再导入这个 `annotate` module,然后看看 `__annotations__` 属性是怎样的:
+
+```python
+>>> import annotate
+>>> annotate.__annotations__
+{'name': , 'ages': }
+>>> annotate.Car.__annotations__
+{'variable': }
+>>> car = annotate.Car()
+>>> car.__annotations__
+{'variable': }
+```
+
+这一次你会发现这个注解字典中包含了两项内容,而其中并没有那个类变量. 要看到这个类变量,你需要访问 `Car` 这个类中的 `__annotations__` 属性,或者先创建一个Car实例,然后再访问该实例的 `__annotations__` 属性.
+
+有读者指出, 借助于 `typing` module,你可以让这里的例子更接近PEP484的要求. 比如下面这个例子:
+
+```python
+# annotate3.py
+from typing import Dict, List
+
+name: str = 'Mike'
+
+ages: List[int] = [12, 20, 32]
+
+class Car:
+
+ variable: Dict
+```
+
+在解释器中运行这段代码会发现如下结果:
+
+```python
+import annotate
+
+In [2]: annotate.__annotations__
+Out[2]: {'ages': typing.List[int], 'name': str}
+
+In [3]: annotate.Car.__annotations__
+Out[3]: {'variable': typing.Dict}
+```
+
+你会发现大部分的type现在都来自于 `typing` module了.
+
+---
+
+
+
+
+# 总结
+我发现这项新功能确实很有用. 我很喜欢Python的动态特性,但这几年的C++经历也让我同时能发现明确变量类型的价值所在. 当然,Python有很强大的内省能力,要探测出一个对象的类型并不难. 但是这个项新功能能够改进静态检查器,同时让你的代码更易懂. 尤其当你需要回过头来维护一个N久没有接触过的软件时更是如此.
+
+---
+
+扩展阅读
+- PEP 526 – [Syntax for variable annotations](https://www.python.org/dev/peps/pep-0526)
+- PEP 484 – [Type Hinting](https://www.python.org/dev/peps/pep-0484)
+- Python 3.6: [What’s New](https://docs.python.org/3.6/whatsnew/3.6.html)
diff --git "a/Python Common/What's New in Python xx/New in Python\357\274\232\346\225\260\345\255\227\345\255\227\351\235\242\351\207\217\344\270\255\347\232\204\344\270\213\345\210\222\347\272\277.md" "b/Python Common/What's New in Python xx/New in Python\357\274\232\346\225\260\345\255\227\345\255\227\351\235\242\351\207\217\344\270\255\347\232\204\344\270\213\345\210\222\347\272\277.md"
new file mode 100644
index 0000000..2ff22e1
--- /dev/null
+++ "b/Python Common/What's New in Python xx/New in Python\357\274\232\346\225\260\345\255\227\345\255\227\351\235\242\351\207\217\344\270\255\347\232\204\344\270\213\345\210\222\347\272\277.md"
@@ -0,0 +1,50 @@
+
+原文地址: http://www.blog.pythonlibrary.org/2017/01/11/new-in-python-underscores-in-numeric-literals/
+
+Python 3.6 新增了一些有趣的功能. 本文要说的这项功能脱胎于[PEP 515: Underscores in Numeric Literals](https://www.python.org/dev/peps/pep-0515). 正如其名所言,它允许你在写一个很长的数字时用下划线(代替常用的逗号)来进行分段. 即是说, `1000000` 现在可以写成 `1_000_000` 了. 下面来看一些简单的例子:
+
+```python
+>>> 1_234_567
+1234567
+>>>'{:_}'.format(123456789)
+'123_456_789'
+>>> '{:_}'.format(1234567)
+'1_234_567'
+```
+
+第一个例子展示了Python是如何解释用下划线分段过的数字的. 第二个例子说明了我们不仅可以使用逗号,还能使用“\_” (下划线) 来将数字格式化成字符串了. 其效果不言自明.
+
+在进行数学运算时,有没有下划线分段都一样:
+
+```python
+>>> 120_000 + 30_000
+150000
+>>> 120_000 - 30_000
+90000
+```
+
+Python文档和PEP同时也有说明,你可以用下划线对任意进制的数字进行分段. 下面摘抄一些例子:
+
+```python
+>>> flags = 0b_0011_1111_0100_1110
+>>> flags
+16206
+>>> 0x_FF_FF_FF_FF
+4294967295
+>>> flags = int('0b_1111_0000', 2)
+>>> flags
+240
+```
+
+使用下划线对数字分段时需要注意以下几点:
+
+- 你只能使用单下划线进行分段,而且它的位置必须在数字之间,在进制说明符之后
+- 下划线不能出现在数字的首部和尾部
+
+这真是一项有趣的新功能. 我本人目前是用不倒这个功能,希望对你用吧.
diff --git a/Python Common/What's New in Python xx/Python 3.6.md b/Python Common/What's New in Python xx/Python 3.6.md
new file mode 100644
index 0000000..7a896e9
--- /dev/null
+++ b/Python Common/What's New in Python xx/Python 3.6.md
@@ -0,0 +1,1218 @@
+原文:[What's New in Python](https://docs.python.org/3.6/whatsnew/index.html)
+
+# Python 3.6新特性
+
+发布版本:| 3.6.0b2
+---|---
+日期:| 2016年10月11日
+
+本文介绍了与3.5相比,Python 3.6的新特性。
+
+有关详情,见[更新日志](https://docs.python.org/3.6/whatsnew/changelog.html#changelog)。
+
+>注意
+>
+>抢鲜用户应该注意,本文档目前还处于草稿阶段。随着Python 3.6的发布,将会大幅度更新,因此,甚至是在阅读早期版本后,都值得回来再看看。
+
+## 摘要 - 版本亮点
+
+新语法特性:
+
+ * A `global` or `nonlocal` statement must now textually appear before the first use of the affected name in the same scope. Previously this was a SyntaxWarning.
+ * PEP 498: 格式化字符串
+ * PEP 515: 数字文本中的下划线
+ * PEP 526: 变量注解语法
+ * PEP 525: 异步生成器
+ * PEP 530: 异步推导式
+
+标准库改进:
+
+安全性改进:
+
+ * On Linux, [`os.urandom()`](https://docs.python.org/3.6/library/os.html#os.urandom "os.urandom" ) now blocks until the system urandom entropy pool is initialized to increase the security. See the [**PEP 524**](https://www.python.org/dev/peps/pep-0524) for the rationale.
+ * [`hashlib`](https://docs.python.org/3.6/library/hashlib-blake2.html#module-hashlib "hashlib: BLAKE2 hash function for Python" ) and [`ssl`](https://docs.python.org/3.6/library/ssl.html#module-ssl "ssl: TLS/SSL wrapper for socket objects" ) now support OpenSSL 1.1.0.
+ * The default settings and feature set of the [`ssl`](https://docs.python.org/3.6/library/ssl.html#module-ssl "ssl: TLS/SSL wrapper for socket objects" ) have been improved.
+ * The [`hashlib`](https://docs.python.org/3.6/library/hashlib-blake2.html#module-hashlib "hashlib: BLAKE2 hash function for Python" ) module has got support for BLAKE2, SHA-3 and SHAKE hash algorithms and [`scrypt()`](https://docs.python.org/3.6/library/hashlib.html#hashlib.scrypt "hashlib.scrypt" ) key derivation function.
+
+Windows改进:
+
+ * PEP 529: Change Windows filesystem encoding to UTF-8
+ * PEP 528: Change Windows console encoding to UTF-8
+ * The `py.exe` launcher, when used interactively, no longer prefers Python 2 over Python 3 when the user doesn't specify a version (via command line arguments or a config file). Handling of shebang lines remains unchanged - "python" refers to Python 2 in that case.
+ * `python.exe` and `pythonw.exe` have been marked as long-path aware, which means that when the 260 character path limit may no longer apply. See [removing the MAX_PATH limitation](https://docs.python.org/3.6/using/windows.html#max-path) for details.
+ * A `._pth` file can be added to force isolated mode and fully specify all search paths to avoid registry and environment lookup. See [the documentation](https://docs.python.org/3.6/using/windows.html#finding-modules) for more information.
+ * A `python36.zip` file now works as a landmark to infer [`PYTHONHOME`](https://docs.python.org/3.6/using/cmdline.html#envvar-PYTHONHOME). See [the documentation](https://docs.python.org/3.6/using/windows.html#finding-modules) for more information.
+
+新的内置特性:
+
+ * PEP 520: Preserving Class Attribute Definition Order
+ * PEP 468: Preserving Keyword Argument Order
+
+Python 3.6中实现的PEP完整列表:
+
+ * [**PEP 468**](https://www.python.org/dev/peps/pep-0468), Preserving Keyword Argument Order
+ * [**PEP 487**](https://www.python.org/dev/peps/pep-0487), Simpler customization of class creation
+ * [**PEP 495**](https://www.python.org/dev/peps/pep-0495), Local Time Disambiguation
+ * [**PEP 498**](https://www.python.org/dev/peps/pep-0498), Formatted string literals
+ * [**PEP 506**](https://www.python.org/dev/peps/pep-0506), Adding A Secrets Module To The Standard Library
+ * [**PEP 509**](https://www.python.org/dev/peps/pep-0509), Add a private version to dict
+ * [**PEP 515**](https://www.python.org/dev/peps/pep-0515), Underscores in Numeric Literals
+ * [**PEP 519**](https://www.python.org/dev/peps/pep-0519), Adding a file system path protocol
+ * [**PEP 520**](https://www.python.org/dev/peps/pep-0520), Preserving Class Attribute Definition Order
+ * [**PEP 523**](https://www.python.org/dev/peps/pep-0523), Adding a frame evaluation API to CPython
+ * [**PEP 524**](https://www.python.org/dev/peps/pep-0524), Make os.urandom() blocking on Linux (during system startup)
+ * [**PEP 525**](https://www.python.org/dev/peps/pep-0525), Asynchronous Generators (provisional)
+ * [**PEP 526**](https://www.python.org/dev/peps/pep-0526), Syntax for Variable Annotations (provisional)
+ * [**PEP 528**](https://www.python.org/dev/peps/pep-0528), Change Windows console encoding to UTF-8 (provisional)
+ * [**PEP 529**](https://www.python.org/dev/peps/pep-0529), Change Windows filesystem encoding to UTF-8 (provisional)
+ * [**PEP 530**](https://www.python.org/dev/peps/pep-0530), Asynchronous Comprehensions
+
+## 新特性
+
+### PEP 515: Underscores in Numeric Literals
+
+Prior to PEP 515, there was no support for writing long numeric literals with
+some form of separator to improve readability. For instance, how big is
+`1000000000000000`? With [**PEP 515**](https://www.python.org/dev/peps/pep-0515), though, you can use
+underscores to separate digits as desired to make numeric literals easier to
+read: `1_000_000_000_000_000`. Underscores can be used with other numeric
+literals beyond integers, e.g. `0x_FF_FF_FF_FF`.
+
+Single underscores are allowed between digits and after any base specifier.
+More than a single underscore in a row, leading, or trailing underscores are
+not allowed.
+
+>又见
+
+[**PEP 515**](https://www.python.org/dev/peps/pep-0515) - Underscores in
+Numeric Literals
+
+ PEP written by Georg Brandl and Serhiy Storchaka.
+
+### PEP 523: Adding a frame evaluation API to CPython
+
+While Python provides extensive support to customize how code executes, one
+place it has not done so is in the evaluation of frame objects. If you wanted
+some way to intercept frame evaluation in Python there really wasn't any way
+without directly manipulating function pointers for defined functions.
+
+[**PEP 523**](https://www.python.org/dev/peps/pep-0523) changes this by
+providing an API to make frame evaluation pluggable at the C level. This will
+allow for tools such as debuggers and JITs to intercept frame evaluation
+before the execution of Python code begins. This enables the use of
+alternative evaluation implementations for Python code, tracking frame
+evaluation, etc.
+
+This API is not part of the limited C API and is marked as private to signal
+that usage of this API is expected to be limited and only applicable to very
+select, low-level use-cases. Semantics of the API will change with Python as
+necessary.
+
+>又见
+
+[**PEP 523**](https://www.python.org/dev/peps/pep-0523) - Adding a frame
+evaluation API to CPython
+
+ PEP written by Brett Cannon and Dino Viehland.
+
+### PEP 519: Adding a file system path protocol
+
+File system paths have historically been represented as
+[`str`](https://docs.python.org/3.6/library/stdtypes.html#str "str" ) or
+[`bytes`](https://docs.python.org/3.6/library/functions.html#bytes "bytes" )
+objects. This has led to people who write code which operate on file system
+paths to assume that such objects are only one of those two types (an
+[`int`](https://docs.python.org/3.6/library/functions.html#int "int" )
+representing a file descriptor does not count as that is not a file path).
+Unfortunately that assumption prevents alternative object representations of
+file system paths like
+[`pathlib`](https://docs.python.org/3.6/library/pathlib.html#module-pathlib
+"pathlib: Object-oriented filesystem paths" ) from working with pre-existing
+code, including Python's standard library.
+
+To fix this situation, a new interface represented by
+[`os.PathLike`](https://docs.python.org/3.6/library/os.html#os.PathLike
+"os.PathLike" ) has been defined. By implementing the [`__fspath__()`](https:/
+/docs.python.org/3.6/library/os.html#os.PathLike.__fspath__
+"os.PathLike.__fspath__" ) method, an object signals that it represents a
+path. An object can then provide a low-level representation of a file system
+path as a [`str`](https://docs.python.org/3.6/library/stdtypes.html#str "str"
+) or [`bytes`](https://docs.python.org/3.6/library/functions.html#bytes
+"bytes" ) object. This means an object is considered [path-
+like](https://docs.python.org/3.6/glossary.html#term-path-like-object) if it
+implements
+[`os.PathLike`](https://docs.python.org/3.6/library/os.html#os.PathLike
+"os.PathLike" ) or is a
+[`str`](https://docs.python.org/3.6/library/stdtypes.html#str "str" ) or
+[`bytes`](https://docs.python.org/3.6/library/functions.html#bytes "bytes" )
+object which represents a file system path. Code can use
+[`os.fspath()`](https://docs.python.org/3.6/library/os.html#os.fspath
+"os.fspath" ),
+[`os.fsdecode()`](https://docs.python.org/3.6/library/os.html#os.fsdecode
+"os.fsdecode" ), or
+[`os.fsencode()`](https://docs.python.org/3.6/library/os.html#os.fsencode
+"os.fsencode" ) to explicitly get a
+[`str`](https://docs.python.org/3.6/library/stdtypes.html#str "str" ) and/or
+[`bytes`](https://docs.python.org/3.6/library/functions.html#bytes "bytes" )
+representation of a path-like object.
+
+The built-in
+[`open()`](https://docs.python.org/3.6/library/functions.html#open "open" )
+function has been updated to accept
+[`os.PathLike`](https://docs.python.org/3.6/library/os.html#os.PathLike
+"os.PathLike" ) objects as have all relevant functions in the
+[`os`](https://docs.python.org/3.6/library/os.html#module-os "os:
+Miscellaneous operating system interfaces." ) and
+[`os.path`](https://docs.python.org/3.6/library/os.path.html#module-os.path
+"os.path: Operations on pathnames." ) modules. [`PyUnicode_FSConverter()`](htt
+ps://docs.python.org/3.6/c-api/unicode.html#c.PyUnicode_FSConverter
+"PyUnicode_FSConverter" ) and [`PyUnicode_FSConverter()`](https://docs.python.
+org/3.6/c-api/unicode.html#c.PyUnicode_FSConverter "PyUnicode_FSConverter" )
+have been changed to accept path-like objects. The
+[`os.DirEntry`](https://docs.python.org/3.6/library/os.html#os.DirEntry
+"os.DirEntry" ) class and relevant classes in
+[`pathlib`](https://docs.python.org/3.6/library/pathlib.html#module-pathlib
+"pathlib: Object-oriented filesystem paths" ) have also been updated to
+implement
+[`os.PathLike`](https://docs.python.org/3.6/library/os.html#os.PathLike
+"os.PathLike" ).
+
+The hope in is that updating the fundamental functions for operating on file
+system paths will lead to third-party code to implicitly support all [path-
+like objects](https://docs.python.org/3.6/glossary.html#term-path-like-object)
+without any code changes or at least very minimal ones (e.g. calling
+[`os.fspath()`](https://docs.python.org/3.6/library/os.html#os.fspath
+"os.fspath" ) at the beginning of code before operating on a path-like
+object).
+
+Here are some examples of how the new interface allows for
+[`pathlib.Path`](https://docs.python.org/3.6/library/pathlib.html#pathlib.Path
+"pathlib.Path" ) to be used more easily and transparently with pre-existing
+code:
+
+```python
+
+ >>> import pathlib
+ >>> with open(pathlib.Path("README")) as f:
+ ... contents = f.read()
+ ...
+ >>> import os.path
+ >>> os.path.splitext(pathlib.Path("some_file.txt"))
+ ('some_file', '.txt')
+ >>> os.path.join("/a/b", pathlib.Path("c"))
+ '/a/b/c'
+ >>> import os
+ >>> os.fspath(pathlib.Path("some_file.txt"))
+ 'some_file.txt'
+
+```
+
+(Implemented by Brett Cannon, Ethan Furman, Dusty Phillips, and Jelle
+Zijlstra.)
+
+>又见
+
+[**PEP 519**](https://www.python.org/dev/peps/pep-0519) - Adding a file system
+path protocol
+
+ PEP written by Brett Cannon and Koos Zevenhoven.
+
+### PEP 498: Formatted string literals
+
+Formatted string literals are a new kind of string literal, prefixed with
+`'f'`. They are similar to the format strings accepted by
+[`str.format()`](https://docs.python.org/3.6/library/stdtypes.html#str.format
+"str.format" ). They contain replacement fields surrounded by curly braces.
+The replacement fields are expressions, which are evaluated at run time, and
+then formatted using the
+[`format()`](https://docs.python.org/3.6/library/functions.html#format
+"format" ) protocol:
+
+```python
+
+ >>> name = "Fred"
+ >>> f"He said his name is {name}."
+ 'He said his name is Fred.'
+
+```
+
+See [**PEP 498**](https://www.python.org/dev/peps/pep-0498) and the main
+documentation at [Formatted string literals](https://docs.python.org/3.6/refer
+ence/lexical_analysis.html#f-strings).
+
+### PEP 526: Syntax for variable annotations
+
+[**PEP 484**](https://www.python.org/dev/peps/pep-0484) introduced standard
+for type annotations of function parameters, a.k.a. type hints. This PEP adds
+syntax to Python for annotating the types of variables including class
+variables and instance variables:
+
+```python
+
+ primes: List[int] = []
+
+ captain: str # Note: no initial value!
+
+ class Starship:
+ stats: Dict[str, int] = {}
+
+```
+
+Just as for function annotations, the Python interpreter does not attach any
+particular meaning to variable annotations and only stores them in a special
+attribute `__annotations__` of a class or module. In contrast to variable
+declarations in statically typed languages, the goal of annotation syntax is
+to provide an easy way to specify structured type metadata for third party
+tools and libraries via the abstract syntax tree and the `__annotations__`
+attribute.
+
+>又见
+
+[**PEP 526**](https://www.python.org/dev/peps/pep-0526) - Syntax for variable
+annotations.
+
+ PEP written by Ryan Gonzalez, Philip House, Ivan Levkivskyi, Lisa Roach, and Guido van Rossum. Implemented by Ivan Levkivskyi.
+
+Tools that use or will use the new syntax:
+[mypy](http://github.com/python/mypy),
+[pytype](http://github.com/google/pytype), PyCharm, etc.
+
+### PEP 529: Change Windows filesystem encoding to UTF-8
+
+Representing filesystem paths is best performed with str (Unicode) rather than
+bytes. However, there are some situations where using bytes is sufficient and
+correct.
+
+Prior to Python 3.6, data loss could result when using bytes paths on Windows.
+With this change, using bytes to represent paths is now supported on Windows,
+provided those bytes are encoded with the encoding returned by [`sys.getfilesy
+stemencoding()`](https://docs.python.org/3.6/library/sys.html#sys.getfilesyste
+mencoding "sys.getfilesystemencoding" ), which now defaults to `'utf-8'`.
+
+Applications that do not use str to represent paths should use
+[`os.fsencode()`](https://docs.python.org/3.6/library/os.html#os.fsencode
+"os.fsencode" ) and
+[`os.fsdecode()`](https://docs.python.org/3.6/library/os.html#os.fsdecode
+"os.fsdecode" ) to ensure their bytes are correctly encoded. To revert to the
+previous behaviour, set [`PYTHONLEGACYWINDOWSFSENCODING`](https://docs.python.
+org/3.6/using/cmdline.html#envvar-PYTHONLEGACYWINDOWSFSENCODING) or call [`sys
+._enablelegacywindowsfsencoding()`](https://docs.python.org/3.6/library/sys.ht
+ml#sys._enablelegacywindowsfsencoding "sys._enablelegacywindowsfsencoding" ).
+
+See [**PEP 529**](https://www.python.org/dev/peps/pep-0529) for more
+information and discussion of code modifications that may be required.
+
+Note
+
+This change is considered experimental for 3.6.0 beta releases. The default
+encoding may change before the final release.
+
+### PEP 487: Simpler customization of class creation
+
+Upon subclassing a class, the `__init_subclass__` classmethod (if defined) is
+called on the base class. This makes it straightforward to write classes that
+customize initialization of future subclasses without introducing the
+complexity of a full custom metaclass.
+
+The descriptor protocol has also been expanded to include a new optional
+method, `__set_name__`. Whenever a new class is defined, the new method will
+be called on all descriptors included in the definition, providing them with a
+reference to the class being defined and the name given to the descriptor
+within the class namespace.
+
+Also see [**PEP 487**](https://www.python.org/dev/peps/pep-0487) and the
+updated class customization documentation at [Customizing class
+creation](https://docs.python.org/3.6/reference/datamodel.html#class-
+customization) and [Implementing Descriptors](https://docs.python.org/3.6/refe
+rence/datamodel.html#descriptors).
+
+(Contributed by Martin Teichmann in [issue
+27366](https://bugs.python.org/issue27366))
+
+### PEP 528: Change Windows console encoding to UTF-8
+
+The default console on Windows will now accept all Unicode characters and
+provide correctly read str objects to Python code. `sys.stdin`, `sys.stdout`
+and `sys.stderr` now default to utf-8 encoding.
+
+This change only applies when using an interactive console, and not when
+redirecting files or pipes. To revert to the previous behaviour for
+interactive console use, set [`PYTHONLEGACYWINDOWSIOENCODING`](https://docs.py
+thon.org/3.6/using/cmdline.html#envvar-PYTHONLEGACYWINDOWSIOENCODING).
+
+>又见
+
+[**PEP 528**](https://www.python.org/dev/peps/pep-0528) - Change Windows
+console encoding to UTF-8
+
+ PEP written and implemented by Steve Dower.
+
+### PYTHONMALLOC environment variable
+
+The new [`PYTHONMALLOC`](https://docs.python.org/3.6/using/cmdline.html
+#envvar-PYTHONMALLOC) environment variable allows setting the Python memory
+allocators and/or install debug hooks.
+
+It is now possible to install debug hooks on Python memory allocators on
+Python compiled in release mode using `PYTHONMALLOC=debug`. Effects of debug
+hooks:
+
+ * Newly allocated memory is filled with the byte `0xCB`
+ * Freed memory is filled with the byte `0xDB`
+ * Detect violations of Python memory allocator API. For example, `PyObject_Free()` called on a memory block allocated by [`PyMem_Malloc()`](https://docs.python.org/3.6/c-api/memory.html#c.PyMem_Malloc "PyMem_Malloc" ).
+ * Detect write before the start of the buffer (buffer underflow)
+ * Detect write after the end of the buffer (buffer overflow)
+ * Check that the [GIL](https://docs.python.org/3.6/glossary.html#term-global-interpreter-lock) is held when allocator functions of [`PYMEM_DOMAIN_OBJ`](https://docs.python.org/3.6/c-api/memory.html#c.PYMEM_DOMAIN_OBJ "PYMEM_DOMAIN_OBJ" ) (ex: `PyObject_Malloc()`) and [`PYMEM_DOMAIN_MEM`](https://docs.python.org/3.6/c-api/memory.html#c.PYMEM_DOMAIN_MEM "PYMEM_DOMAIN_MEM" ) (ex: [`PyMem_Malloc()`](https://docs.python.org/3.6/c-api/memory.html#c.PyMem_Malloc "PyMem_Malloc" )) domains are called.
+
+Checking if the GIL is held is also a new feature of Python 3.6.
+
+See the [`PyMem_SetupDebugHooks()`](https://docs.python.org/3.6/c-api/memory.h
+tml#c.PyMem_SetupDebugHooks "PyMem_SetupDebugHooks" ) function for debug hooks
+on Python memory allocators.
+
+It is now also possible to force the usage of the `malloc()` allocator of the
+C library for all Python memory allocations using `PYTHONMALLOC=malloc`. It
+helps to use external memory debuggers like Valgrind on a Python compiled in
+release mode.
+
+On error, the debug hooks on Python memory allocators now use the
+[`tracemalloc`](https://docs.python.org/3.6/library/tracemalloc.html#module-
+tracemalloc "tracemalloc: Trace memory allocations." ) module to get the
+traceback where a memory block was allocated.
+
+Example of fatal error on buffer overflow using `python3.6 -X tracemalloc=5`
+(store 5 frames in traces):
+
+```python
+
+ Debug memory block at address p=0x7fbcd41666f8: API 'o'
+ 4 bytes originally requested
+ The 7 pad bytes at p-7 are FORBIDDENBYTE, as expected.
+ The 8 pad bytes at tail=0x7fbcd41666fc are not all FORBIDDENBYTE (0xfb):
+ at tail+0: 0x02 *** OUCH
+ at tail+1: 0xfb
+ at tail+2: 0xfb
+ at tail+3: 0xfb
+ at tail+4: 0xfb
+ at tail+5: 0xfb
+ at tail+6: 0xfb
+ at tail+7: 0xfb
+ The block was made by call #1233329 to debug malloc/realloc.
+ Data at p: 1a 2b 30 00
+
+ Memory block allocated at (most recent call first):
+ File "test/test_bytes.py", line 323
+ File "unittest/case.py", line 600
+ File "unittest/case.py", line 648
+ File "unittest/suite.py", line 122
+ File "unittest/suite.py", line 84
+
+ Fatal Python error: bad trailing pad byte
+
+ Current thread 0x00007fbcdbd32700 (most recent call first):
+ File "test/test_bytes.py", line 323 in test_hex
+ File "unittest/case.py", line 600 in run
+ File "unittest/case.py", line 648 in __call__
+ File "unittest/suite.py", line 122 in run
+ File "unittest/suite.py", line 84 in __call__
+ File "unittest/suite.py", line 122 in run
+ File "unittest/suite.py", line 84 in __call__
+ ...
+
+```
+
+(Contributed by Victor Stinner in [issue
+26516](https://bugs.python.org/issue26516) and [issue
+26564](https://bugs.python.org/issue26564).)
+
+### DTrace and SystemTap probing support
+
+Python can now be built `--with-dtrace` which enables static markers for the
+following events in the interpreter:
+
+ * function call/return
+ * garbage collection started/finished
+ * line of code executed.
+
+This can be used to instrument running interpreters in production, without the
+need to recompile specific debug builds or providing application-specific
+profiling/debugging code.
+
+More details in [Instrumenting CPython with DTrace and SystemTap](https://docs
+.python.org/3.6/howto/instrumentation.html#instrumentation).
+
+The current implementation is tested on Linux and macOS. Additional markers
+may be added in the future.
+
+(Contributed by Łukasz Langa in [issue
+21590](https://bugs.python.org/issue21590), based on patches by Jesús Cea
+Avión, David Malcolm, and Nikhil Benesch.)
+
+### PEP 520: Preserving Class Attribute Definition Order
+
+Attributes in a class definition body have a natural ordering: the same order
+in which the names appear in the source. This order is now preserved in the
+new class's `__dict__` attribute.
+
+Also, the effective default class _execution_ namespace (returned from
+`type.__prepare__()`) is now an insertion-order-preserving mapping.
+
+>又见
+
+[**PEP 520**](https://www.python.org/dev/peps/pep-0520) - Preserving Class
+Attribute Definition Order
+
+ PEP written and implemented by Eric Snow.
+
+### PEP 468: Preserving Keyword Argument Order
+
+`**kwargs` in a function signature is now guaranteed to be an insertion-order-
+preserving mapping.
+
+>又见
+
+[**PEP 468**](https://www.python.org/dev/peps/pep-0468) - Preserving Keyword
+Argument Order
+
+ PEP written and implemented by Eric Snow.
+
+### PEP 509: Add a private version to dict
+
+Add a new private version to the builtin `dict` type, incremented at each
+dictionary creation and at each dictionary change, to implement fast guards on
+namespaces.
+
+(Contributed by Victor Stinner in [issue
+26058](https://bugs.python.org/issue26058).)
+
+## Other Language Changes
+
+Some smaller changes made to the core Python language are:
+
+ * [`dict()`](https://docs.python.org/3.6/library/stdtypes.html#dict "dict" ) now uses a "compact" representation [pioneered by PyPy](https://morepypy.blogspot.com/2015/01/faster-more-memory-efficient-and-more.html). The memory usage of the new [`dict()`](https://docs.python.org/3.6/library/stdtypes.html#dict "dict" ) is between 20% and 25% smaller compared to Python 3.5. [**PEP 468**](https://www.python.org/dev/peps/pep-0468) (Preserving the order of `**kwargs` in a function.) is implemented by this. The order-preserving aspect of this new implementation is considered an implementation detail and should not be relied upon (this may change in the future, but it is desired to have this new dict implementation in the language for a few releases before changing the language spec to mandate order-preserving semantics for all current and future Python implementations; this also helps preserve backwards-compatibility with older versions of the language where random iteration order is still in effect, e.g. Python 3.5). (Contributed by INADA Naoki in [issue 27350](https://bugs.python.org/issue27350). Idea [originally suggested by Raymond Hettinger](https://mail.python.org/pipermail/python-dev/2012-December/123028.html).)
+ * Long sequences of repeated traceback lines are now abbreviated as `"[Previous line repeated {count} more times]"` (see traceback for an example). (Contributed by Emanuel Barry in [issue 26823](https://bugs.python.org/issue26823).)
+ * Import now raises the new exception [`ModuleNotFoundError`](https://docs.python.org/3.6/library/exceptions.html#ModuleNotFoundError "ModuleNotFoundError" ) (subclass of [`ImportError`](https://docs.python.org/3.6/library/exceptions.html#ImportError "ImportError" )) when it cannot find a module. Code that current checks for ImportError (in try-except) will still work.
+
+## New Modules
+
+ * None yet.
+
+## Improved Modules
+
+On Linux,
+[`os.urandom()`](https://docs.python.org/3.6/library/os.html#os.urandom
+"os.urandom" ) now blocks until the system urandom entropy pool is initialized
+to increase the security. See the [**PEP
+524**](https://www.python.org/dev/peps/pep-0524) for the rationale.
+
+### asyncio
+
+Since the [`asyncio`](https://docs.python.org/3.6/library/asyncio.html#module-
+asyncio "asyncio: Asynchronous I/O, event loop, coroutines and tasks." )
+module is [provisional](https://docs.python.org/3.6/glossary.html#term-
+provisional-api), all changes introduced in Python 3.6 have also been
+backported to Python 3.5.x.
+
+Notable changes in the
+[`asyncio`](https://docs.python.org/3.6/library/asyncio.html#module-asyncio
+"asyncio: Asynchronous I/O, event loop, coroutines and tasks." ) module since
+Python 3.5.0:
+
+ * The [`ensure_future()`](https://docs.python.org/3.6/library/asyncio-task.html#asyncio.ensure_future "asyncio.ensure_future" ) function and all functions that use it, such as `loop.run_until_complete()`, now accept all kinds of [awaitable objects](https://docs.python.org/3.6/glossary.html#term-awaitable). (Contributed by Yury Selivanov.)
+ * New [`run_coroutine_threadsafe()`](https://docs.python.org/3.6/library/asyncio-task.html#asyncio.run_coroutine_threadsafe "asyncio.run_coroutine_threadsafe" ) function to submit coroutines to event loops from other threads. (Contributed by Vincent Michel.)
+ * New [`Transport.is_closing()`](https://docs.python.org/3.6/library/asyncio-protocol.html#asyncio.BaseTransport.is_closing "asyncio.BaseTransport.is_closing" ) method to check if the transport is closing or closed. (Contributed by Yury Selivanov.)
+ * The `loop.create_server()` method can now accept a list of hosts. (Contributed by Yann Sionneau.)
+ * New `loop.create_future()` method to create Future objects. This allows alternative event loop implementations, such as [uvloop](https://github.com/MagicStack/uvloop), to provide a faster [`asyncio.Future`](https://docs.python.org/3.6/library/asyncio-task.html#asyncio.Future "asyncio.Future" ) implementation. (Contributed by Yury Selivanov.)
+ * New `loop.get_exception_handler()` method to get the current exception handler. (Contributed by Yury Selivanov.)
+ * New [`StreamReader.readuntil()`](https://docs.python.org/3.6/library/asyncio-stream.html#asyncio.StreamReader.readuntil "asyncio.StreamReader.readuntil" ) method to read data from the stream until a separator bytes sequence appears. (Contributed by Mark Korenberg.)
+ * The `loop.getaddrinfo()` method is optimized to avoid calling the system `getaddrinfo` function if the address is already resolved. (Contributed by A. Jesse Jiryu Davis.)
+
+### contextlib
+
+The [`contextlib.AbstractContextManager`](https://docs.python.org/3.6/library/
+contextlib.html#contextlib.AbstractContextManager
+"contextlib.AbstractContextManager" ) class has been added to provide an
+abstract base class for context managers. It provides a sensible default
+implementation for __enter__() which returns `self` and leaves __exit__() an
+abstract method. A matching class has been added to the
+[`typing`](https://docs.python.org/3.6/library/typing.html#module-typing
+"typing: Support for type hints \(see PEP 484\)." ) module as [`typing.Context
+Manager`](https://docs.python.org/3.6/library/typing.html#typing.ContextManage
+r "typing.ContextManager" ). (Contributed by Brett Cannon in [issue
+25609](https://bugs.python.org/issue25609).)
+
+### venv
+
+[`venv`](https://docs.python.org/3.6/library/venv.html#module-venv "venv:
+Creation of virtual environments." ) accepts a new parameter `--prompt`. This
+parameter provides an alternative prefix for the virtual environment.
+(Proposed by Łukasz.Balcerzak and ported to 3.6 by Stéphane Wirtel in [issue
+22829](https://bugs.python.org/issue22829).)
+
+### datetime
+
+The [`datetime.strftime()`](https://docs.python.org/3.6/library/datetime.html#
+datetime.datetime.strftime "datetime.datetime.strftime" ) and [`date.strftime(
+)`](https://docs.python.org/3.6/library/datetime.html#datetime.date.strftime
+"datetime.date.strftime" ) methods now support ISO 8601 date directives `%G`,
+`%u` and `%V`. (Contributed by Ashley Anderson in [issue
+12006](https://bugs.python.org/issue12006).)
+
+### distutils.command.sdist
+
+The `default_format` attribute has been removed from
+`distutils.command.sdist.sdist` and the `formats` attribute defaults to
+`['gztar']`. Although not anticipated, Any code relying on the presence of
+`default_format` may need to be adapted. See [issue
+27819](https://bugs.python.org/issue27819) for more details.
+
+### email
+
+The new email API, enabled via the _policy_ keyword to various constructors,
+is no longer provisional. The
+[`email`](https://docs.python.org/3.6/library/email.html#module-email "email:
+Package supporting the parsing, manipulating, and generating email messages."
+) documentation has been reorganized and rewritten to focus on the new API,
+while retaining the old documentation for the legacy API. (Contributed by R.
+David Murray in [issue 24277](https://bugs.python.org/issue24277).)
+
+The [`email.mime`](https://docs.python.org/3.6/library/email.mime.html#module-
+email.mime "email.mime: Build MIME messages." ) classes now all accept an
+optional _policy_ keyword. (Contributed by Berker Peksag in [issue
+27331](https://bugs.python.org/issue27331).)
+
+The [`DecodedGenerator`](https://docs.python.org/3.6/library/email.generator.h
+tml#email.generator.DecodedGenerator "email.generator.DecodedGenerator" ) now
+supports the _policy_ keyword.
+
+There is a new
+[`policy`](https://docs.python.org/3.6/library/email.policy.html#module-
+email.policy "email.policy: Controlling the parsing and generating of
+messages" ) attribute, [`message_factory`](https://docs.python.org/3.6/library
+/email.policy.html#email.policy.Policy.message_factory
+"email.policy.Policy.message_factory" ), that controls what class is used by
+default when the parser creates new message objects. For the [`email.policy.co
+mpat32`](https://docs.python.org/3.6/library/email.policy.html#email.policy.co
+mpat32 "email.policy.compat32" ) policy this is [`Message`](https://docs.pytho
+n.org/3.6/library/email.compat32-message.html#email.message.Message
+"email.message.Message" ), for the new policies it is [`EmailMessage`](https:/
+/docs.python.org/3.6/library/email.message.html#email.message.EmailMessage
+"email.message.EmailMessage" ). (Contributed by R. David Murray in [issue
+20476](https://bugs.python.org/issue20476).)
+
+### encodings
+
+On Windows, added the `'oem'` encoding to use `CP_OEMCP` and the `'ansi'`
+alias for the existing `'mbcs'` encoding, which uses the `CP_ACP` code page.
+
+### faulthandler
+
+On Windows, the
+[`faulthandler`](https://docs.python.org/3.6/library/faulthandler.html#module-
+faulthandler "faulthandler: Dump the Python traceback." ) module now installs
+a handler for Windows exceptions: see [`faulthandler.enable()`](https://docs.p
+ython.org/3.6/library/faulthandler.html#faulthandler.enable
+"faulthandler.enable" ). (Contributed by Victor Stinner in [issue
+23848](https://bugs.python.org/issue23848).)
+
+### hashlib
+
+[`hashlib`](https://docs.python.org/3.6/library/hashlib-blake2.html#module-
+hashlib "hashlib: BLAKE2 hash function for Python" ) supports OpenSSL 1.1.0.
+The minimum recommend version is 1.0.2. It has been tested with 0.9.8zc,
+0.9.8zh and 1.0.1t as well as LibreSSL 2.3 and 2.4. (Contributed by Christian
+Heimes in [issue 26470](https://bugs.python.org/issue26470).)
+
+BLAKE2 hash functions were added to the module.
+[`blake2b()`](https://docs.python.org/3.6/library/hashlib-
+blake2.html#hashlib.blake2b "hashlib.blake2b" ) and
+[`blake2s()`](https://docs.python.org/3.6/library/hashlib-
+blake2.html#hashlib.blake2s "hashlib.blake2s" ) are always available and
+support the full feature set of BLAKE2. (Contributed by Christian Heimes in
+[issue 26798](https://bugs.python.org/issue26798) based on code by Dmitry
+Chestnykh and Samuel Neves. Documentation written by Dmitry Chestnykh.)
+
+The SHA-3 hash functions `sha3_224()`, `sha3_256()`, `sha3_384()`,
+`sha3_512()`, and SHAKE hash functions `shake_128()` and `shake_256()` were
+added. (Contributed by Christian Heimes in [issue
+16113](https://bugs.python.org/issue16113). Keccak Code Package by Guido
+Bertoni, Joan Daemen, Michaël Peeters, Gilles Van Assche, and Ronny Van Keer.)
+
+The password-based key derivation function
+[`scrypt()`](https://docs.python.org/3.6/library/hashlib.html#hashlib.scrypt
+"hashlib.scrypt" ) is now available with OpenSSL 1.1.0 and newer. (Contributed
+by Christian Heimes in [issue 27928](https://bugs.python.org/issue27928).)
+
+### http.client
+
+[`HTTPConnection.request()`](https://docs.python.org/3.6/library/http.client.h
+tml#http.client.HTTPConnection.request "http.client.HTTPConnection.request" )
+and [`endheaders()`](https://docs.python.org/3.6/library/http.client.html#http
+.client.HTTPConnection.endheaders "http.client.HTTPConnection.endheaders" )
+both now support chunked encoding request bodies. (Contributed by Demian
+Brecht and Rolf Krahl in [issue 12319](https://bugs.python.org/issue12319).)
+
+### idlelib and IDLE
+
+The idlelib package is being modernized and refactored to make IDLE look and
+work better and to make the code easier to understand, test, and improve. Part
+of making IDLE look better, especially on Linux and Mac, is using ttk widgets,
+mostly in the dialogs. As a result, IDLE no longer runs with tcl/tk 8.4. It
+now requires tcl/tk 8.5 or 8.6. We recommend running the latest release of
+either.
+
+'Modernizing' includes renaming and consolidation of idlelib modules. The
+renaming of files with partial uppercase names is similar to the renaming of,
+for instance, Tkinter and TkFont to tkinter and tkinter.font in 3.0. As a
+result, imports of idlelib files that worked in 3.5 will usually not work in
+3.6. At least a module name change will be needed (see idlelib/README.txt),
+sometimes more. (Name changes contributed by Al Swiegart and Terry Reedy in
+[issue 24225](https://bugs.python.org/issue24225). Most idlelib patches since
+have been and will be part of the process.)
+
+In compensation, the eventual result with be that some idlelib classes will be
+easier to use, with better APIs and docstrings explaining them. Additional
+useful information will be added to idlelib when available.
+
+### importlib
+
+[`importlib.util.LazyLoader`](https://docs.python.org/3.6/library/importlib.ht
+ml#importlib.util.LazyLoader "importlib.util.LazyLoader" ) now calls [`create_
+module()`](https://docs.python.org/3.6/library/importlib.html#importlib.abc.Lo
+ader.create_module "importlib.abc.Loader.create_module" ) on the wrapped
+loader, removing the restriction that [`importlib.machinery.BuiltinImporter`](
+https://docs.python.org/3.6/library/importlib.html#importlib.machinery.Builtin
+Importer "importlib.machinery.BuiltinImporter" ) and [`importlib.machinery.Ext
+ensionFileLoader`](https://docs.python.org/3.6/library/importlib.html#importli
+b.machinery.ExtensionFileLoader "importlib.machinery.ExtensionFileLoader" )
+couldn't be used with [`importlib.util.LazyLoader`](https://docs.python.org/3.
+6/library/importlib.html#importlib.util.LazyLoader "importlib.util.LazyLoader"
+).
+
+[`importlib.util.cache_from_source()`](https://docs.python.org/3.6/library/imp
+ortlib.html#importlib.util.cache_from_source
+"importlib.util.cache_from_source" ), [`importlib.util.source_from_cache()`](h
+ttps://docs.python.org/3.6/library/importlib.html#importlib.util.source_from_c
+ache "importlib.util.source_from_cache" ), and [`importlib.util.spec_from_file
+_location()`](https://docs.python.org/3.6/library/importlib.html#importlib.uti
+l.spec_from_file_location "importlib.util.spec_from_file_location" ) now
+accept a [path-like object](https://docs.python.org/3.6/glossary.html#term-
+path-like-object).
+
+### json
+
+[`json.load()`](https://docs.python.org/3.6/library/json.html#json.load
+"json.load" ) and
+[`json.loads()`](https://docs.python.org/3.6/library/json.html#json.loads
+"json.loads" ) now support binary input. Encoded JSON should be represented
+using either UTF-8, UTF-16, or UTF-32. (Contributed by Serhiy Storchaka in
+[issue 17909](https://bugs.python.org/issue17909).)
+
+### os
+
+A new [`close()`](https://docs.python.org/3.6/library/os.html#os.scandir.close
+"os.scandir.close" ) method allows explicitly closing a
+[`scandir()`](https://docs.python.org/3.6/library/os.html#os.scandir
+"os.scandir" ) iterator. The
+[`scandir()`](https://docs.python.org/3.6/library/os.html#os.scandir
+"os.scandir" ) iterator now supports the [context
+manager](https://docs.python.org/3.6/glossary.html#term-context-manager)
+protocol. If a `scandir()` iterator is neither exhausted nor explicitly closed
+a [`ResourceWarning`](https://docs.python.org/3.6/library/exceptions.html#Reso
+urceWarning "ResourceWarning" ) will be emitted in its destructor.
+(Contributed by Serhiy Storchaka in [issue
+25994](https://bugs.python.org/issue25994).)
+
+The Linux `getrandom()` syscall (get random bytes) is now exposed as the new
+[`os.getrandom()`](https://docs.python.org/3.6/library/os.html#os.getrandom
+"os.getrandom" ) function. (Contributed by Victor Stinner, part of the [**PEP
+524**](https://www.python.org/dev/peps/pep-0524))
+
+See the summary for PEP 519 for details on how the
+[`os`](https://docs.python.org/3.6/library/os.html#module-os "os:
+Miscellaneous operating system interfaces." ) and
+[`os.path`](https://docs.python.org/3.6/library/os.path.html#module-os.path
+"os.path: Operations on pathnames." ) modules now support [path-like
+objects](https://docs.python.org/3.6/glossary.html#term-path-like-object).
+
+### pickle
+
+Objects that need calling `__new__` with keyword arguments can now be pickled
+using [pickle protocols](https://docs.python.org/3.6/library/pickle.html
+#pickle-protocols) older than protocol version 4. Protocol version 4 already
+supports this case. (Contributed by Serhiy Storchaka in [issue
+24164](https://bugs.python.org/issue24164).)
+
+### re
+
+Added support of modifier spans in regular expressions. Examples:
+`'(?i:p)ython'` matches `'python'` and `'Python'`, but not `'PYTHON'`;
+`'(?i)g(?-i:v)r'` matches `'GvR'` and `'gvr'`, but not `'GVR'`. (Contributed
+by Serhiy Storchaka in [issue 433028](https://bugs.python.org/issue433028).)
+
+Match object groups can be accessed by `__getitem__`, which is equivalent to
+`group()`. So `mo['name']` is now equivalent to `mo.group('name')`.
+(Contributed by Eric Smith in [issue
+24454](https://bugs.python.org/issue24454).)
+
+### readline
+
+Added [`set_auto_history()`](https://docs.python.org/3.6/library/readline.html
+#readline.set_auto_history "readline.set_auto_history" ) to enable or disable
+automatic addition of input to the history list. (Contributed by Tyler
+Crompton in [issue 26870](https://bugs.python.org/issue26870).)
+
+### rlcompleter
+
+Private and special attribute names now are omitted unless the prefix starts
+with underscores. A space or a colon is added after some completed keywords.
+(Contributed by Serhiy Storchaka in [issue
+25011](https://bugs.python.org/issue25011) and [issue
+25209](https://bugs.python.org/issue25209).)
+
+Names of most attributes listed by
+[`dir()`](https://docs.python.org/3.6/library/functions.html#dir "dir" ) are
+now completed. Previously, names of properties and slots which were not yet
+created on an instance were excluded. (Contributed by Martin Panter in [issue
+25590](https://bugs.python.org/issue25590).)
+
+### site
+
+When specifying paths to add to
+[`sys.path`](https://docs.python.org/3.6/library/sys.html#sys.path "sys.path"
+) in a .pth file, you may now specify file paths on top of directories (e.g.
+zip files). (Contributed by Wolfgang Langner in [issue
+26587](https://bugs.python.org/issue26587)).
+
+### sqlite3
+
+[`sqlite3.Cursor.lastrowid`](https://docs.python.org/3.6/library/sqlite3.html#
+sqlite3.Cursor.lastrowid "sqlite3.Cursor.lastrowid" ) now supports the
+`REPLACE` statement. (Contributed by Alex LordThorsen in [issue
+16864](https://bugs.python.org/issue16864).)
+
+### socket
+
+The [`ioctl()`](https://docs.python.org/3.6/library/socket.html#socket.socket.
+ioctl "socket.socket.ioctl" ) function now supports the [`SIO_LOOPBACK_FAST_PA
+TH`](https://docs.python.org/3.6/library/socket.html#socket.SIO_LOOPBACK_FAST_
+PATH "socket.SIO_LOOPBACK_FAST_PATH" ) control code. (Contributed by Daniel
+Stokes in [issue 26536](https://bugs.python.org/issue26536).)
+
+The [`getsockopt()`](https://docs.python.org/3.6/library/socket.html#socket.so
+cket.getsockopt "socket.socket.getsockopt" ) constants `SO_DOMAIN`,
+`SO_PROTOCOL`, `SO_PEERSEC`, and `SO_PASSSEC` are now supported. (Contributed
+by Christian Heimes in [issue 26907](https://bugs.python.org/issue26907).)
+
+The socket module now supports the address family
+[`AF_ALG`](https://docs.python.org/3.6/library/socket.html#socket.AF_ALG
+"socket.AF_ALG" ) to interface with Linux Kernel crypto API. `ALG_*`,
+`SOL_ALG` and [`sendmsg_afalg()`](https://docs.python.org/3.6/library/socket.h
+tml#socket.socket.sendmsg_afalg "socket.socket.sendmsg_afalg" ) were added.
+(Contributed by Christian Heimes in [issue
+27744](https://bugs.python.org/issue27744) with support from Victor Stinner.)
+
+### socketserver
+
+Servers based on the
+[`socketserver`](https://docs.python.org/3.6/library/socketserver.html#module-
+socketserver "socketserver: A framework for network servers." ) module,
+including those defined in
+[`http.server`](https://docs.python.org/3.6/library/http.server.html#module-
+http.server "http.server: HTTP server and request handlers." ),
+[`xmlrpc.server`](https://docs.python.org/3.6/library/xmlrpc.server.html
+#module-xmlrpc.server "xmlrpc.server: Basic XML-RPC server implementations." )
+and [`wsgiref.simple_server`](https://docs.python.org/3.6/library/wsgiref.html
+#module-wsgiref.simple_server "wsgiref.simple_server: A simple WSGI HTTP
+server." ), now support the [context
+manager](https://docs.python.org/3.6/glossary.html#term-context-manager)
+protocol. (Contributed by Aviv Palivoda in [issue
+26404](https://bugs.python.org/issue26404).)
+
+The `wfile` attribute of [`StreamRequestHandler`](https://docs.python.org/3.6/
+library/socketserver.html#socketserver.StreamRequestHandler
+"socketserver.StreamRequestHandler" ) classes now implements the [`io.Buffered
+IOBase`](https://docs.python.org/3.6/library/io.html#io.BufferedIOBase
+"io.BufferedIOBase" ) writable interface. In particular, calling [`write()`](h
+ttps://docs.python.org/3.6/library/io.html#io.BufferedIOBase.write
+"io.BufferedIOBase.write" ) is now guaranteed to send the data in full.
+(Contributed by Martin Panter in [issue
+26721](https://bugs.python.org/issue26721).)
+
+### ssl
+
+[`ssl`](https://docs.python.org/3.6/library/ssl.html#module-ssl "ssl: TLS/SSL
+wrapper for socket objects" ) supports OpenSSL 1.1.0. The minimum recommend
+version is 1.0.2. It has been tested with 0.9.8zc, 0.9.8zh and 1.0.1t as well
+as LibreSSL 2.3 and 2.4. (Contributed by Christian Heimes in [issue
+26470](https://bugs.python.org/issue26470).)
+
+3DES has been removed from the default cipher suites and ChaCha20 Poly1305
+cipher suites are now in the right position. (Contributed by Christian Heimes
+in [issue 27850](https://bugs.python.org/issue27850) and [issue
+27766](https://bugs.python.org/issue27766).)
+
+[`SSLContext`](https://docs.python.org/3.6/library/ssl.html#ssl.SSLContext
+"ssl.SSLContext" ) has better default configuration for options and ciphers.
+(Contributed by Christian Heimes in [issue
+28043](https://bugs.python.org/issue28043).)
+
+SSL session can be copied from one client-side connection to another with
+[`SSLSession`](https://docs.python.org/3.6/library/ssl.html#ssl.SSLSession
+"ssl.SSLSession" ). TLS session resumption can speed up the initial handshake,
+reduce latency and improve performance (Contributed by Christian Heimes in
+[issue 19500](https://bugs.python.org/issue19500) based on a draft by Alex
+Warhawk.)
+
+All constants and flags have been converted to
+[`IntEnum`](https://docs.python.org/3.6/library/enum.html#enum.IntEnum
+"enum.IntEnum" ) and `IntFlags`. (Contributed by Christian Heimes in [issue
+28025](https://bugs.python.org/issue28025).)
+
+Server and client-side specific TLS protocols for
+[`SSLContext`](https://docs.python.org/3.6/library/ssl.html#ssl.SSLContext
+"ssl.SSLContext" ) were added. (Contributed by Christian Heimes in [issue
+28085](https://bugs.python.org/issue28085).)
+
+General resource ids (`GEN_RID`) in subject alternative name extensions no
+longer case a SystemError. (Contributed by Christian Heimes in [issue
+27691](https://bugs.python.org/issue27691).)
+
+### subprocess
+
+[`subprocess.Popen`](https://docs.python.org/3.6/library/subprocess.html#subpr
+ocess.Popen "subprocess.Popen" ) destructor now emits a [`ResourceWarning`](ht
+tps://docs.python.org/3.6/library/exceptions.html#ResourceWarning
+"ResourceWarning" ) warning if the child process is still running. Use the
+context manager protocol (`with proc: ...`) or call explicitly the [`wait()`](
+https://docs.python.org/3.6/library/subprocess.html#subprocess.Popen.wait
+"subprocess.Popen.wait" ) method to read the exit status of the child process
+(Contributed by Victor Stinner in [issue
+26741](https://bugs.python.org/issue26741)).
+
+The [`subprocess.Popen`](https://docs.python.org/3.6/library/subprocess.html#s
+ubprocess.Popen "subprocess.Popen" ) constructor and all functions that pass
+arguments through to it now accept _encoding_ and _errors_ arguments.
+Specifying either of these will enable text mode for the _stdin_, _stdout_ and
+_stderr_ streams.
+
+### telnetlib
+
+[`Telnet`](https://docs.python.org/3.6/library/telnetlib.html#telnetlib.Telnet
+"telnetlib.Telnet" ) is now a context manager (contributed by Stéphane Wirtel
+in [issue 25485](https://bugs.python.org/issue25485)).
+
+### tkinter
+
+Added methods `trace_add()`, `trace_remove()` and `trace_info()` in the
+`tkinter.Variable` class. They replace old methods `trace_variable()`,
+`trace()`, `trace_vdelete()` and `trace_vinfo()` that use obsolete Tcl
+commands and might not work in future versions of Tcl. (Contributed by Serhiy
+Storchaka in [issue 22115](https://bugs.python.org/issue22115)).
+
+### traceback
+
+Both the traceback module and the interpreter's builtin exception display now
+abbreviate long sequences of repeated lines in tracebacks as shown in the
+following example:
+
+```python
+
+ >>> def f(): f()
+ ...
+ >>> f()
+ Traceback (most recent call last):
+ File "", line 1, in
+ File "", line 1, in f
+ File "", line 1, in f
+ File "", line 1, in f
+ [Previous line repeated 995 more times]
+ RecursionError: maximum recursion depth exceeded
+
+```
+
+(Contributed by Emanuel Barry in [issue
+26823](https://bugs.python.org/issue26823).)
+
+### typing
+
+The [`typing.ContextManager`](https://docs.python.org/3.6/library/typing.html#
+typing.ContextManager "typing.ContextManager" ) class has been added for
+representing [`contextlib.AbstractContextManager`](https://docs.python.org/3.6
+/library/contextlib.html#contextlib.AbstractContextManager
+"contextlib.AbstractContextManager" ). (Contributed by Brett Cannon in [issue
+25609](https://bugs.python.org/issue25609).)
+
+### unicodedata
+
+The internal database has been upgraded to use Unicode 9.0.0. (Contributed by
+Benjamin Peterson.)
+
+### unittest.mock
+
+The [`Mock`](https://docs.python.org/3.6/library/unittest.mock.html#unittest.m
+ock.Mock "unittest.mock.Mock" ) class has the following improvements:
+
+ * Two new methods, [`Mock.assert_called()`](https://docs.python.org/3.6/library/unittest.mock.html#unittest.mock.Mock.assert_called "unittest.mock.Mock.assert_called" ) and [`Mock.assert_called_once()`](https://docs.python.org/3.6/library/unittest.mock.html#unittest.mock.Mock.assert_called_once "unittest.mock.Mock.assert_called_once" ) to check if the mock object was called. (Contributed by Amit Saha in [issue 26323](https://bugs.python.org/issue26323).)
+
+### urllib.request
+
+If a HTTP request has a file or iterable body (other than a bytes object) but
+no Content-Length header, rather than throwing an error, `AbstractHTTPHandler`
+now falls back to use chunked transfer encoding. (Contributed by Demian Brecht
+and Rolf Krahl in [issue 12319](https://bugs.python.org/issue12319).)
+
+### urllib.robotparser
+
+[`RobotFileParser`](https://docs.python.org/3.6/library/urllib.robotparser.htm
+l#urllib.robotparser.RobotFileParser "urllib.robotparser.RobotFileParser" )
+now supports the `Crawl-delay` and `Request-rate` extensions. (Contributed by
+Nikolay Bogoychev in [issue 16099](https://bugs.python.org/issue16099).)
+
+### warnings
+
+A new optional _source_ parameter has been added to the [`warnings.warn_explic
+it()`](https://docs.python.org/3.6/library/warnings.html#warnings.warn_explici
+t "warnings.warn_explicit" ) function: the destroyed object which emitted a [`
+ResourceWarning`](https://docs.python.org/3.6/library/exceptions.html#Resource
+Warning "ResourceWarning" ). A _source_ attribute has also been added to
+`warnings.WarningMessage` (contributed by Victor Stinner in [issue
+26568](https://bugs.python.org/issue26568) and [issue
+26567](https://bugs.python.org/issue26567)).
+
+When a [`ResourceWarning`](https://docs.python.org/3.6/library/exceptions.html
+#ResourceWarning "ResourceWarning" ) warning is logged, the
+[`tracemalloc`](https://docs.python.org/3.6/library/tracemalloc.html#module-
+tracemalloc "tracemalloc: Trace memory allocations." ) is now used to try to
+retrieve the traceback where the detroyed object was allocated.
+
+Example with the script `example.py`:
+
+```python
+
+ import warnings
+
+ def func():
+ return open(__file__)
+
+ f = func()
+ f = None
+
+```
+
+Output of the command `python3.6 -Wd -X tracemalloc=5 example.py`:
+
+```python
+
+ example.py:7: ResourceWarning: unclosed file <_io.TextIOWrapper name='example.py' mode='r' encoding='UTF-8'>
+ f = None
+ Object allocated at (most recent call first):
+ File "example.py", lineno 4
+ return open(__file__)
+ File "example.py", lineno 6
+ f = func()
+
+```
+
+The "Object allocated at" traceback is new and only displayed if
+[`tracemalloc`](https://docs.python.org/3.6/library/tracemalloc.html#module-
+tracemalloc "tracemalloc: Trace memory allocations." ) is tracing Python
+memory allocations and if the
+[`warnings`](https://docs.python.org/3.6/library/warnings.html#module-warnings
+"warnings: Issue warning messages and control their disposition." ) was
+already imported.
+
+### winreg
+
+Added the 64-bit integer type
+[`REG_QWORD`](https://docs.python.org/3.6/library/winreg.html#winreg.REG_QWORD
+"winreg.REG_QWORD" ). (Contributed by Clement Rouault in [issue
+23026](https://bugs.python.org/issue23026).)
+
+### winsound
+
+Allowed keyword arguments to be passed to
+[`Beep`](https://docs.python.org/3.6/library/winsound.html#winsound.Beep
+"winsound.Beep" ), [`MessageBeep`](https://docs.python.org/3.6/library/winsoun
+d.html#winsound.MessageBeep "winsound.MessageBeep" ), and [`PlaySound`](https:
+//docs.python.org/3.6/library/winsound.html#winsound.PlaySound
+"winsound.PlaySound" ) ([issue 27982](https://bugs.python.org/issue27982)).
+
+### xmlrpc.client
+
+The module now supports unmarshalling additional data types used by Apache
+XML-RPC implementation for numerics and `None`. (Contributed by Serhiy
+Storchaka in [issue 26885](https://bugs.python.org/issue26885).)
+
+### zipfile
+
+A new [`ZipInfo.from_file()`](https://docs.python.org/3.6/library/zipfile.html
+#zipfile.ZipInfo.from_file "zipfile.ZipInfo.from_file" ) class method allows
+making a
+[`ZipInfo`](https://docs.python.org/3.6/library/zipfile.html#zipfile.ZipInfo
+"zipfile.ZipInfo" ) instance from a filesystem file. A new [`ZipInfo.is_dir()`
+](https://docs.python.org/3.6/library/zipfile.html#zipfile.ZipInfo.is_dir
+"zipfile.ZipInfo.is_dir" ) method can be used to check if the
+[`ZipInfo`](https://docs.python.org/3.6/library/zipfile.html#zipfile.ZipInfo
+"zipfile.ZipInfo" ) instance represents a directory. (Contributed by Thomas
+Kluyver in [issue 26039](https://bugs.python.org/issue26039).)
+
+The [`ZipFile.open()`](https://docs.python.org/3.6/library/zipfile.html#zipfil
+e.ZipFile.open "zipfile.ZipFile.open" ) method can now be used to write data
+into a ZIP file, as well as for extracting data. (Contributed by Thomas
+Kluyver in [issue 26039](https://bugs.python.org/issue26039).)
+
+### zlib
+
+The [`compress()`](https://docs.python.org/3.6/library/zlib.html#zlib.compress
+"zlib.compress" ) function now accepts keyword arguments. (Contributed by Aviv
+Palivoda in [issue 26243](https://bugs.python.org/issue26243).)
+
+### fileinput
+
+[`hook_encoded()`](https://docs.python.org/3.6/library/fileinput.html#fileinpu
+t.hook_encoded "fileinput.hook_encoded" ) now supports the _errors_ argument.
+(Contributed by Joseph Hackman in [issue
+25788](https://bugs.python.org/issue25788).)
+
+## Optimizations
+
+ * The ASCII decoder is now up to 60 times as fast for error handlers `surrogateescape`, `ignore` and `replace` (Contributed by Victor Stinner in [issue 24870](https://bugs.python.org/issue24870)).
+ * The ASCII and the Latin1 encoders are now up to 3 times as fast for the error handler `surrogateescape` (Contributed by Victor Stinner in [issue 25227](https://bugs.python.org/issue25227)).
+ * The UTF-8 encoder is now up to 75 times as fast for error handlers `ignore`, `replace`, `surrogateescape`, `surrogatepass` (Contributed by Victor Stinner in [issue 25267](https://bugs.python.org/issue25267)).
+ * The UTF-8 decoder is now up to 15 times as fast for error handlers `ignore`, `replace` and `surrogateescape` (Contributed by Victor Stinner in [issue 25301](https://bugs.python.org/issue25301)).
+ * `bytes % args` is now up to 2 times faster. (Contributed by Victor Stinner in [issue 25349](https://bugs.python.org/issue25349)).
+ * `bytearray % args` is now between 2.5 and 5 times faster. (Contributed by Victor Stinner in [issue 25399](https://bugs.python.org/issue25399)).
+ * Optimize [`bytes.fromhex()`](https://docs.python.org/3.6/library/stdtypes.html#bytes.fromhex "bytes.fromhex" ) and [`bytearray.fromhex()`](https://docs.python.org/3.6/library/stdtypes.html#bytearray.fromhex "bytearray.fromhex" ): they are now between 2x and 3.5x faster. (Contributed by Victor Stinner in [issue 25401](https://bugs.python.org/issue25401)).
+ * Optimize `bytes.replace(b'', b'.')` and `bytearray.replace(b'', b'.')`: up to 80% faster. (Contributed by Josh Snider in [issue 26574](https://bugs.python.org/issue26574)).
+ * Allocator functions of the [`PyMem_Malloc()`](https://docs.python.org/3.6/c-api/memory.html#c.PyMem_Malloc "PyMem_Malloc" ) domain ([`PYMEM_DOMAIN_MEM`](https://docs.python.org/3.6/c-api/memory.html#c.PYMEM_DOMAIN_MEM "PYMEM_DOMAIN_MEM" )) now use the [pymalloc memory allocator](https://docs.python.org/3.6/c-api/memory.html#pymalloc) instead of `malloc()` function of the C library. The pymalloc allocator is optimized for objects smaller or equal to 512 bytes with a short lifetime, and use `malloc()` for larger memory blocks. (Contributed by Victor Stinner in [issue 26249](https://bugs.python.org/issue26249)).
+ * [`pickle.load()`](https://docs.python.org/3.6/library/pickle.html#pickle.load "pickle.load" ) and [`pickle.loads()`](https://docs.python.org/3.6/library/pickle.html#pickle.loads "pickle.loads" ) are now up to 10% faster when deserializing many small objects (Contributed by Victor Stinner in [issue 27056](https://bugs.python.org/issue27056)).
+
+ * Passing [keyword arguments](https://docs.python.org/3.6/glossary.html#term-keyword-argument) to a function has an overhead in comparison with passing [positional arguments](https://docs.python.org/3.6/glossary.html#term-positional-argument). Now in extension functions implemented with using Argument Clinic this overhead is significantly decreased. (Contributed by Serhiy Storchaka in [issue 27574](https://bugs.python.org/issue27574)).
+
+ * Optimized [`glob()`](https://docs.python.org/3.6/library/glob.html#glob.glob "glob.glob" ) and [`iglob()`](https://docs.python.org/3.6/library/glob.html#glob.iglob "glob.iglob" ) functions in the [`glob`](https://docs.python.org/3.6/library/glob.html#module-glob "glob: Unix shell style pathname pattern expansion." ) module; they are now about 3-6 times faster. (Contributed by Serhiy Storchaka in [issue 25596](https://bugs.python.org/issue25596)).
+ * Optimized globbing in [`pathlib`](https://docs.python.org/3.6/library/pathlib.html#module-pathlib "pathlib: Object-oriented filesystem paths" ) by using [`os.scandir()`](https://docs.python.org/3.6/library/os.html#os.scandir "os.scandir" ); it is now about 1.5-4 times faster. (Contributed by Serhiy Storchaka in [issue 26032](https://bugs.python.org/issue26032)).
+
+## Build and C API Changes
+
+ * Python now requires some C99 support in the toolchain to build. For more information, see [**PEP 7**](https://www.python.org/dev/peps/pep-0007).
+ * Cross-compiling CPython with the Android NDK and the Android API level set to 21 (Android 5.0 Lollilop) or greater, runs successfully. While Android is not yet a supported platform, the Python test suite runs on the Android emulator with only about 16 tests failures. See the Android meta-issue [issue 26865](https://bugs.python.org/issue26865).
+ * The `--with-optimizations` configure flag has been added. Turning it on will activate LTO and PGO build support (when available). (Original patch by Alecsandru Patrascu of Intel in [issue 26539](https://bugs.python.org/issue26539).)
+ * New [`Py_FinalizeEx()`](https://docs.python.org/3.6/c-api/init.html#c.Py_FinalizeEx "Py_FinalizeEx" ) API which indicates if flushing buffered data failed ([issue 5319](https://bugs.python.org/issue5319)).
+ * [`PyArg_ParseTupleAndKeywords()`](https://docs.python.org/3.6/c-api/arg.html#c.PyArg_ParseTupleAndKeywords "PyArg_ParseTupleAndKeywords" ) now supports [positional-only parameters](https://docs.python.org/3.6/glossary.html#positional-only-parameter). Positional-only parameters are defined by empty names. (Contributed by Serhiy Storchaka in [issue 26282](https://bugs.python.org/issue26282)).
+ * `PyTraceback_Print` method now abbreviates long sequences of repeated lines as `"[Previous line repeated {count} more times]"`. (Contributed by Emanuel Barry in [issue 26823](https://bugs.python.org/issue26823).)
+
+## Deprecated
+
+### Deprecated Build Options
+
+The `--with-system-ffi` configure flag is now on by default on non-OSX UNIX
+platforms. It may be disabled by using `--without-system-ffi`, but using the
+flag is deprecated and will not be accepted in Python 3.7. OSX is unaffected
+by this change. Note that many OS distributors already use the `--with-system-
+ffi` flag when building their system Python.
+
+### New Keywords
+
+`async` and `await` are not recommended to be used as variable, class,
+function or module names. Introduced by [**PEP
+492**](https://www.python.org/dev/peps/pep-0492) in Python 3.5, they will
+become proper keywords in Python 3.7.
+
+### Deprecated Python modules, functions and methods
+
+ * [`importlib.machinery.SourceFileLoader.load_module()`](https://docs.python.org/3.6/library/importlib.html#importlib.machinery.SourceFileLoader.load_module "importlib.machinery.SourceFileLoader.load_module" ) and [`importlib.machinery.SourcelessFileLoader.load_module()`](https://docs.python.org/3.6/library/importlib.html#importlib.machinery.SourcelessFileLoader.load_module "importlib.machinery.SourcelessFileLoader.load_module" ) are now deprecated. They were the only remaining implementations of [`importlib.abc.Loader.load_module()`](https://docs.python.org/3.6/library/importlib.html#importlib.abc.Loader.load_module "importlib.abc.Loader.load_module" ) in [`importlib`](https://docs.python.org/3.6/library/importlib.html#module-importlib "importlib: The implementation of the import machinery." ) that had not been deprecated in previous versions of Python in favour of [`importlib.abc.Loader.exec_module()`](https://docs.python.org/3.6/library/importlib.html#importlib.abc.Loader.exec_module "importlib.abc.Loader.exec_module" ).
+ * The [`tkinter.tix`](https://docs.python.org/3.6/library/tkinter.tix.html#module-tkinter.tix "tkinter.tix: Tk Extension Widgets for Tkinter" ) module is now deprecated. [`tkinter`](https://docs.python.org/3.6/library/tkinter.html#module-tkinter "tkinter: Interface to Tcl/Tk for graphical user interfaces" ) users should use [`tkinter.ttk`](https://docs.python.org/3.6/library/tkinter.ttk.html#module-tkinter.ttk "tkinter.ttk: Tk themed widget set" ) instead.
+
+### Deprecated functions and types of the C API
+
+ * None yet.
+
+### Deprecated features
+
+ * The `pyvenv` script has been deprecated in favour of `python3 -m venv`. This prevents confusion as to what Python interpreter `pyvenv` is connected to and thus what Python interpreter will be used by the virtual environment. (Contributed by Brett Cannon in [issue 25154](https://bugs.python.org/issue25154).)
+ * When performing a relative import, falling back on `__name__` and `__path__` from the calling module when `__spec__` or `__package__` are not defined now raises an [`ImportWarning`](https://docs.python.org/3.6/library/exceptions.html#ImportWarning "ImportWarning" ). (Contributed by Rose Ames in [issue 25791](https://bugs.python.org/issue25791).)
+ * Unlike to other [`dbm`](https://docs.python.org/3.6/library/dbm.html#module-dbm "dbm: Interfaces to various Unix "database" formats." ) implementations, the [`dbm.dumb`](https://docs.python.org/3.6/library/dbm.html#module-dbm.dumb "dbm.dumb: Portable implementation of the simple DBM interface." ) module creates database in `'r'` and `'w'` modes if it doesn't exist and allows modifying database in `'r'` mode. This behavior is now deprecated and will be removed in 3.8. (Contributed by Serhiy Storchaka in [issue 21708](https://bugs.python.org/issue21708).)
+ * Undocumented support of general [bytes-like objects](https://docs.python.org/3.6/glossary.html#term-bytes-like-object) as paths in [`os`](https://docs.python.org/3.6/library/os.html#module-os "os: Miscellaneous operating system interfaces." ) functions, [`compile()`](https://docs.python.org/3.6/library/functions.html#compile "compile" ) and similar functions is now deprecated. (Contributed by Serhiy Storchaka in [issue 25791](https://bugs.python.org/issue25791) and [issue 26754](https://bugs.python.org/issue26754).)
+ * The undocumented `extra_path` argument to a distutils Distribution is now considered deprecated, will raise a warning during install if set. Support for this parameter will be dropped in a future Python release and likely earlier through third party tools. See [issue 27919](https://bugs.python.org/issue27919) for details.
+ * A backslash-character pair that is not a valid escape sequence now generates a DeprecationWarning. Although this will eventually become a SyntaxError, that will not be for several Python releases. (Contributed by Emanuel Barry in [issue 27364](https://bugs.python.org/issue27364).)
+ * Inline flags `(?letters)` now should be used only at the start of the regular expression. Inline flags in the middle of the regular expression affects global flags in Python [`re`](https://docs.python.org/3.6/library/re.html#module-re "re: Regular expression operations." ) module. This is an exception to other regular expression engines that either apply flags to only part of the regular expression or treat them as an error. To avoid distinguishing inline flags in the middle of the regular expression now emit a deprecation warning. It will be an error in future Python releases. (Contributed by Serhiy Storchaka in [issue 22493](https://bugs.python.org/issue22493).)
+ * SSL-related arguments like `certfile`, `keyfile` and `check_hostname` in [`ftplib`](https://docs.python.org/3.6/library/ftplib.html#module-ftplib "ftplib: FTP protocol client \(requires sockets\)." ), [`http.client`](https://docs.python.org/3.6/library/http.client.html#module-http.client "http.client: HTTP and HTTPS protocol client \(requires sockets\)." ), [`imaplib`](https://docs.python.org/3.6/library/imaplib.html#module-imaplib "imaplib: IMAP4 protocol client \(requires sockets\)." ), [`poplib`](https://docs.python.org/3.6/library/poplib.html#module-poplib "poplib: POP3 protocol client \(requires sockets\)." ), and [`smtplib`](https://docs.python.org/3.6/library/smtplib.html#module-smtplib "smtplib: SMTP protocol client \(requires sockets\)." ) have been deprecated in favor of `context`. (Contributed by Christian Heimes in [issue 28022](https://bugs.python.org/issue28022).)
+ * A couple of protocols and functions of the [`ssl`](https://docs.python.org/3.6/library/ssl.html#module-ssl "ssl: TLS/SSL wrapper for socket objects" ) module are now deprecated. Some features will no longer be available in future versions of OpenSSL. Other features are deprecated in favor of a different API. (Contributed by Christian Heimes in [issue 28022](https://bugs.python.org/issue28022) and [issue 26470](https://bugs.python.org/issue26470).)
+
+### Deprecated Python behavior
+
+ * Raising the [`StopIteration`](https://docs.python.org/3.6/library/exceptions.html#StopIteration "StopIteration" ) exception inside a generator will now generate a [`DeprecationWarning`](https://docs.python.org/3.6/library/exceptions.html#DeprecationWarning "DeprecationWarning" ), and will trigger a [`RuntimeError`](https://docs.python.org/3.6/library/exceptions.html#RuntimeError "RuntimeError" ) in Python 3.7. See [PEP 479: Change StopIteration handling inside generators](https://docs.python.org/3.6/whatsnew/3.5.html#whatsnew-pep-479) for details.
+
+## Removed
+
+### API and Feature Removals
+
+ * `inspect.getmoduleinfo()` was removed (was deprecated since CPython 3.3). [`inspect.getmodulename()`](https://docs.python.org/3.6/library/inspect.html#inspect.getmodulename "inspect.getmodulename" ) should be used for obtaining the module name for a given path.
+ * `traceback.Ignore` class and `traceback.usage`, `traceback.modname`, `traceback.fullmodname`, `traceback.find_lines_from_code`, `traceback.find_lines`, `traceback.find_strings`, `traceback.find_executable_lines` methods were removed from the [`traceback`](https://docs.python.org/3.6/library/traceback.html#module-traceback "traceback: Print or retrieve a stack traceback." ) module. They were undocumented methods deprecated since Python 3.2 and equivalent functionality is available from private methods.
+ * The `tk_menuBar()` and `tk_bindForTraversal()` dummy methods in [`tkinter`](https://docs.python.org/3.6/library/tkinter.html#module-tkinter "tkinter: Interface to Tcl/Tk for graphical user interfaces" ) widget classes were removed (corresponding Tk commands were obsolete since Tk 4.0).
+ * The [`open()`](https://docs.python.org/3.6/library/zipfile.html#zipfile.ZipFile.open "zipfile.ZipFile.open" ) method of the [`zipfile.ZipFile`](https://docs.python.org/3.6/library/zipfile.html#zipfile.ZipFile "zipfile.ZipFile" ) class no longer supports the `'U'` mode (was deprecated since Python 3.4). Use [`io.TextIOWrapper`](https://docs.python.org/3.6/library/io.html#io.TextIOWrapper "io.TextIOWrapper" ) for reading compressed text files in [universal newlines](https://docs.python.org/3.6/glossary.html#term-universal-newlines) mode.
+ * The undocumented `IN`, `CDROM`, `DLFCN`, `TYPES`, `CDIO`, and `STROPTS` modules have been removed. They had been available in the platform specific `Lib/plat-*/` directories, but were chronically out of date, inconsistently available across platforms, and unmaintained. The script that created these modules is still available in the source distribution at [Tools/scripts/h2py.py](https://hg.python.org/cpython/file/3.6/Tools/scripts/h2py.py).
+
+## Porting to Python 3.6
+
+This section lists previously described changes and other bugfixes that may
+require changes to your code.
+
+### Changes in 'python' Command Behavior
+
+ * The output of a special Python build with defined `COUNT_ALLOCS`, `SHOW_ALLOC_COUNT` or `SHOW_TRACK_COUNT` macros is now off by default. It can be re-enabled using the `-X showalloccount` option. It now outputs to `stderr` instead of `stdout`. (Contributed by Serhiy Storchaka in [issue 23034](https://bugs.python.org/issue23034).)
+
+### Changes in the Python API
+
+ * [`sqlite3`](https://docs.python.org/3.6/library/sqlite3.html#module-sqlite3 "sqlite3: A DB-API 2.0 implementation using SQLite 3.x." ) no longer implicitly commit an open transaction before DDL statements.
+
+ * On Linux, [`os.urandom()`](https://docs.python.org/3.6/library/os.html#os.urandom "os.urandom" ) now blocks until the system urandom entropy pool is initialized to increase the security.
+
+ * When [`importlib.abc.Loader.exec_module()`](https://docs.python.org/3.6/library/importlib.html#importlib.abc.Loader.exec_module "importlib.abc.Loader.exec_module" ) is defined, [`importlib.abc.Loader.create_module()`](https://docs.python.org/3.6/library/importlib.html#importlib.abc.Loader.create_module "importlib.abc.Loader.create_module" ) must also be defined.
+
+ * [`PyErr_SetImportError()`](https://docs.python.org/3.6/c-api/exceptions.html#c.PyErr_SetImportError "PyErr_SetImportError" ) now sets [`TypeError`](https://docs.python.org/3.6/library/exceptions.html#TypeError "TypeError" ) when its **msg** argument is not set. Previously only `NULL` was returned.
+
+ * The format of the `co_lnotab` attribute of code objects changed to support negative line number delta. By default, Python does not emit bytecode with negative line number delta. Functions using `frame.f_lineno`, `PyFrame_GetLineNumber()` or `PyCode_Addr2Line()` are not affected. Functions decoding directly `co_lnotab` should be updated to use a signed 8-bit integer type for the line number delta, but it's only required to support applications using negative line number delta. See `Objects/lnotab_notes.txt` for the `co_lnotab` format and how to decode it, and see the [**PEP 511**](https://www.python.org/dev/peps/pep-0511) for the rationale.
+
+ * The functions in the [`compileall`](https://docs.python.org/3.6/library/compileall.html#module-compileall "compileall: Tools for byte-compiling all Python source files in a directory tree." ) module now return booleans instead of `1` or `0` to represent success or failure, respectively. Thanks to booleans being a subclass of integers, this should only be an issue if you were doing identity checks for `1` or `0`. See [issue 25768](https://bugs.python.org/issue25768).
+
+ * Reading the `port` attribute of [`urllib.parse.urlsplit()`](https://docs.python.org/3.6/library/urllib.parse.html#urllib.parse.urlsplit "urllib.parse.urlsplit" ) and [`urlparse()`](https://docs.python.org/3.6/library/urllib.parse.html#urllib.parse.urlparse "urllib.parse.urlparse" ) results now raises [`ValueError`](https://docs.python.org/3.6/library/exceptions.html#ValueError "ValueError" ) for out-of-range values, rather than returning [`None`](https://docs.python.org/3.6/library/constants.html#None "None" ). See [issue 20059](https://bugs.python.org/issue20059).
+
+ * The [`imp`](https://docs.python.org/3.6/library/imp.html#module-imp "imp: Access the implementation of the import statement. \(deprecated\)" ) module now raises a [`DeprecationWarning`](https://docs.python.org/3.6/library/exceptions.html#DeprecationWarning "DeprecationWarning" ) instead of [`PendingDeprecationWarning`](https://docs.python.org/3.6/library/exceptions.html#PendingDeprecationWarning "PendingDeprecationWarning" ).
+
+ * The following modules have had missing APIs added to their `__all__` attributes to match the documented APIs: [`calendar`](https://docs.python.org/3.6/library/calendar.html#module-calendar "calendar: Functions for working with calendars, including some emulation of the Unix cal program." ), [`cgi`](https://docs.python.org/3.6/library/cgi.html#module-cgi "cgi: Helpers for running Python scripts via the Common Gateway Interface." ), [`csv`](https://docs.python.org/3.6/library/csv.html#module-csv "csv: Write and read tabular data to and from delimited files." ), [`ElementTree`](https://docs.python.org/3.6/library/xml.etree.elementtree.html#module-xml.etree.ElementTree "xml.etree.ElementTree: Implementation of the ElementTree API." ), [`enum`](https://docs.python.org/3.6/library/enum.html#module-enum "enum: Implementation of an enumeration class." ), [`fileinput`](https://docs.python.org/3.6/library/fileinput.html#module-fileinput "fileinput: Loop over standard input or a list of files." ), [`ftplib`](https://docs.python.org/3.6/library/ftplib.html#module-ftplib "ftplib: FTP protocol client \(requires sockets\)." ), [`logging`](https://docs.python.org/3.6/library/logging.html#module-logging "logging: Flexible event logging system for applications." ), [`mailbox`](https://docs.python.org/3.6/library/mailbox.html#module-mailbox "mailbox: Manipulate mailboxes in various formats" ), [`mimetypes`](https://docs.python.org/3.6/library/mimetypes.html#module-mimetypes "mimetypes: Mapping of filename extensions to MIME types." ), [`optparse`](https://docs.python.org/3.6/library/optparse.html#module-optparse "optparse: Command-line option parsing library. \(deprecated\)" ), [`plistlib`](https://docs.python.org/3.6/library/plistlib.html#module-plistlib "plistlib: Generate and parse Mac OS X plist files." ), [`smtpd`](https://docs.python.org/3.6/library/smtpd.html#module-smtpd "smtpd: A SMTP server implementation in Python." ), [`subprocess`](https://docs.python.org/3.6/library/subprocess.html#module-subprocess "subprocess: Subprocess management." ), [`tarfile`](https://docs.python.org/3.6/library/tarfile.html#module-tarfile "tarfile: Read and write tar-format archive files." ), [`threading`](https://docs.python.org/3.6/library/threading.html#module-threading "threading: Thread-based parallelism." ) and [`wave`](https://docs.python.org/3.6/library/wave.html#module-wave "wave: Provide an interface to the WAV sound format." ). This means they will export new symbols when `import *` is used. See [issue 23883](https://bugs.python.org/issue23883).
+
+ * When performing a relative import, if `__package__` does not compare equal to `__spec__.parent` then [`ImportWarning`](https://docs.python.org/3.6/library/exceptions.html#ImportWarning "ImportWarning" ) is raised. (Contributed by Brett Cannon in [issue 25791](https://bugs.python.org/issue25791).)
+
+ * When a relative import is performed and no parent package is known, then [`ImportError`](https://docs.python.org/3.6/library/exceptions.html#ImportError "ImportError" ) will be raised. Previously, [`SystemError`](https://docs.python.org/3.6/library/exceptions.html#SystemError "SystemError" ) could be raised. (Contributed by Brett Cannon in [issue 18018](https://bugs.python.org/issue18018).)
+
+ * Servers based on the [`socketserver`](https://docs.python.org/3.6/library/socketserver.html#module-socketserver "socketserver: A framework for network servers." ) module, including those defined in [`http.server`](https://docs.python.org/3.6/library/http.server.html#module-http.server "http.server: HTTP server and request handlers." ), [`xmlrpc.server`](https://docs.python.org/3.6/library/xmlrpc.server.html#module-xmlrpc.server "xmlrpc.server: Basic XML-RPC server implementations." ) and [`wsgiref.simple_server`](https://docs.python.org/3.6/library/wsgiref.html#module-wsgiref.simple_server "wsgiref.simple_server: A simple WSGI HTTP server." ), now only catch exceptions derived from [`Exception`](https://docs.python.org/3.6/library/exceptions.html#Exception "Exception" ). Therefore if a request handler raises an exception like [`SystemExit`](https://docs.python.org/3.6/library/exceptions.html#SystemExit "SystemExit" ) or [`KeyboardInterrupt`](https://docs.python.org/3.6/library/exceptions.html#KeyboardInterrupt "KeyboardInterrupt" ), [`handle_error()`](https://docs.python.org/3.6/library/socketserver.html#socketserver.BaseServer.handle_error "socketserver.BaseServer.handle_error" ) is no longer called, and the exception will stop a single-threaded server. (Contributed by Martin Panter in [issue 23430](https://bugs.python.org/issue23430).)
+
+ * [`spwd.getspnam()`](https://docs.python.org/3.6/library/spwd.html#spwd.getspnam "spwd.getspnam" ) now raises a [`PermissionError`](https://docs.python.org/3.6/library/exceptions.html#PermissionError "PermissionError" ) instead of [`KeyError`](https://docs.python.org/3.6/library/exceptions.html#KeyError "KeyError" ) if the user doesn't have privileges.
+
+ * The [`socket.socket.close()`](https://docs.python.org/3.6/library/socket.html#socket.socket.close "socket.socket.close" ) method now raises an exception if an error (e.g. EBADF) was reported by the underlying system call. See [issue 26685](https://bugs.python.org/issue26685).
+
+ * The _decode_data_ argument for [`smtpd.SMTPChannel`](https://docs.python.org/3.6/library/smtpd.html#smtpd.SMTPChannel "smtpd.SMTPChannel" ) and [`smtpd.SMTPServer`](https://docs.python.org/3.6/library/smtpd.html#smtpd.SMTPServer "smtpd.SMTPServer" ) constructors is now `False` by default. This means that the argument passed to [`process_message()`](https://docs.python.org/3.6/library/smtpd.html#smtpd.SMTPServer.process_message "smtpd.SMTPServer.process_message" ) is now a bytes object by default, and `process_message()` will be passed keyword arguments. Code that has already been updated in accordance with the deprecation warning generated by 3.5 will not be affected.
+
+ * All optional parameters of the [`dump()`](https://docs.python.org/3.6/library/json.html#json.dump "json.dump" ), [`dumps()`](https://docs.python.org/3.6/library/json.html#json.dumps "json.dumps" ), [`load()`](https://docs.python.org/3.6/library/json.html#json.load "json.load" ) and [`loads()`](https://docs.python.org/3.6/library/json.html#json.loads "json.loads" ) functions and [`JSONEncoder`](https://docs.python.org/3.6/library/json.html#json.JSONEncoder "json.JSONEncoder" ) and [`JSONDecoder`](https://docs.python.org/3.6/library/json.html#json.JSONDecoder "json.JSONDecoder" ) class constructors in the [`json`](https://docs.python.org/3.6/library/json.html#module-json "json: Encode and decode the JSON format." ) module are now [keyword-only](https://docs.python.org/3.6/glossary.html#keyword-only-parameter). (Contributed by Serhiy Storchaka in [issue 18726](https://bugs.python.org/issue18726).)
+
+ * As part of [**PEP 487**](https://www.python.org/dev/peps/pep-0487), the handling of keyword arguments passed to [`type`](https://docs.python.org/3.6/library/functions.html#type "type" ) (other than the metaclass hint, `metaclass`) is now consistently delegated to [`object.__init_subclass__()`](https://docs.python.org/3.6/reference/datamodel.html#object.__init_subclass__ "object.__init_subclass__" ). This means that `type.__new__()` and `type.__init__()` both now accept arbitrary keyword arguments, but [`object.__init_subclass__()`](https://docs.python.org/3.6/reference/datamodel.html#object.__init_subclass__ "object.__init_subclass__" ) (which is called from `type.__new__()`) will reject them by default. Custom metaclasses accepting additional keyword arguments will need to adjust their calls to `type.__new__()` (whether direct or via [`super`](https://docs.python.org/3.6/library/functions.html#super "super" )) accordingly.
+
+ * In `distutils.command.sdist.sdist`, the `default_format` attribute has been removed and is no longer honored. Instead, the gzipped tarfile format is the default on all platforms and no platform-specific selection is made. In environments where distributions are built on Windows and zip distributions are required, configure the project with a `setup.cfg` file containing the following:
+```python [sdist]
+
+ formats=zip
+
+```
+
+This behavior has also been backported to earlier Python versions by
+Setuptools 26.0.0.
+
+ * In the [`urllib.request`](https://docs.python.org/3.6/library/urllib.request.html#module-urllib.request "urllib.request: Extensible library for opening URLs." ) module and the [`http.client.HTTPConnection.request()`](https://docs.python.org/3.6/library/http.client.html#http.client.HTTPConnection.request "http.client.HTTPConnection.request" ) method, if no Content-Length header field has been specified and the request body is a file object, it is now sent with HTTP 1.1 chunked encoding. If a file object has to be sent to a HTTP 1.0 server, the Content-Length value now has to be specified by the caller. See [issue 12319](https://bugs.python.org/issue12319).
+
+### Changes in the C API
+
+ * [`PyMem_Malloc()`](https://docs.python.org/3.6/c-api/memory.html#c.PyMem_Malloc "PyMem_Malloc" ) allocator family now uses the [pymalloc allocator](https://docs.python.org/3.6/c-api/memory.html#pymalloc) rather than system `malloc()`. Applications calling [`PyMem_Malloc()`](https://docs.python.org/3.6/c-api/memory.html#c.PyMem_Malloc "PyMem_Malloc" ) without holding the GIL can now crash. Set the [`PYTHONMALLOC`](https://docs.python.org/3.6/using/cmdline.html#envvar-PYTHONMALLOC) environment variable to `debug` to validate the usage of memory allocators in your application. See [issue 26249](https://bugs.python.org/issue26249).
+ * [`Py_Exit()`](https://docs.python.org/3.6/c-api/sys.html#c.Py_Exit "Py_Exit" ) (and the main interpreter) now override the exit status with 120 if flushing buffered data failed. See [issue 5319](https://bugs.python.org/issue5319).
+
diff --git a/Python Common/What's New in Python xx/README.md b/Python Common/What's New in Python xx/README.md
new file mode 100644
index 0000000..7f0991e
--- /dev/null
+++ b/Python Common/What's New in Python xx/README.md
@@ -0,0 +1,6 @@
+# What's New in Python xx
+
+关注最新python版本发布动向,记录其改动~
+
+- [New In Python:变量注解语法](./New In Python:变量注解语法.md)
+- [New in Python:数字字面量中的下划线](./New in Python:数字字面量中的下划线.md)
\ No newline at end of file
diff --git "a/Python Common/base64-\344\275\277\347\224\250ASCII\347\274\226\347\240\201\344\272\214\350\277\233\345\210\266\346\225\260\346\215\256.org" "b/Python Common/base64-\344\275\277\347\224\250ASCII\347\274\226\347\240\201\344\272\214\350\277\233\345\210\266\346\225\260\346\215\256.md"
similarity index 100%
rename from "Python Common/base64-\344\275\277\347\224\250ASCII\347\274\226\347\240\201\344\272\214\350\277\233\345\210\266\346\225\260\346\215\256.org"
rename to "Python Common/base64-\344\275\277\347\224\250ASCII\347\274\226\347\240\201\344\272\214\350\277\233\345\210\266\346\225\260\346\215\256.md"
diff --git a/Python Common/python37-gil-change.md b/Python Common/python37-gil-change.md
new file mode 100644
index 0000000..78f7ec8
--- /dev/null
+++ b/Python Common/python37-gil-change.md
@@ -0,0 +1,221 @@
+原文:[How I fixed a very old GIL race condition in Python 3.7](https://vstinner.github.io/python37-gil-change.html "Permalink to How I fixed a very old GIL race condition in Python 3.7" )
+
+---
+
+**我花了 4 年的时间修复了著名的 Python GIL(Global Interpreter Lock,全局解释器锁,Python最关键的部分之一)中的一个令人讨厌的 bug**。为了解决它,我不得不挖出 Git 历史,寻找 **Guido van Rossum** 在 **26 年前做的一个改动**:在那个时候,_线程还是某些深奥难懂的东西_。请听我娓娓道来。
+
+## 由 C 线程和 GIL 引发的致命 Python 错误
+
+2014 年 3 月,**Steve Dower** 报告了这个“C 线程”使用 Python C API 时发生的 bug [bpo-20891](https://bugs.python.org/issue20891):
+
+> 在 Python 3.4rc3 中,从非 Python 创建,并且没有对 `PyEval_InitThreads()` 进行任何调用的线程中调用 `PyGILState_Ensure()`,将导致一个致命的退出:
+
+>
+
+> `Fatal Python error: take_gil: NULL tstate`
+
+我的第一个评论是:
+
+> IMO it's a bug in `PyEval_InitThreads()`(在我看来,这是一个 `PyEval_InitThreads()` 中的问题)
+
+[](https://twitter.com/kwinkunks/status/619496450834087938)
+
+## PyGILState_Ensure() 修复
+
+在随后的 2 年中,我忘掉了这个 bug。2016 年 3月,我修改了 Steve 的测试程序,以使其与 Linux 兼容(测试是为 Windows 写的)。我成功地在我的电脑上重现了这个 bug,并且为 `PyGILState_Ensure()` 编写了一个修复代码。
+
+一年后,也就是 2017 年 11 月,**Marcin Kasperski** 问:
+
+> 该修复发布了吗?在更新日志中,我没法找到相关信息……
+
+哎呀,再一次,我彻底地忘记了这个问题!这一次,我不仅 **应用了我的 PyGILState_Ensure() 修复代码**,还编写了**单元测试** `test_embed.test_bpo20891()`:
+
+> 好啦,这个 bug 现在已经在 Python 2.7、3.6 和 master(未来的 3.7)上修复了。在 3.6 和 master 上,该修复自带单元测试。
+
+我的主分支修复,提交 [b4d1e1f7](https://github.com/python/cpython/commit/b4d1e1f7c1af6ae33f0e371576c8bcafedb099db):
+
+```
+
+ bpo-20891: Fix PyGILState_Ensure() (#4650)
+
+ When PyGILState_Ensure() is called in a non-Python thread before
+ PyEval_InitThreads(), only call PyEval_InitThreads() after calling
+ PyThreadState_New() to fix a crash.
+
+ Add an unit test in test_embed.
+
+```
+
+然后,我关闭了这个问题 [bpo-20891](https://bugs.python.org/issue20891)……
+
+## 在 macOS 上测试的随机崩溃
+
+一切进展顺利……但在一周后,我注意到我新增加的单元测试在 macOS buildbot 上发生了**随机**崩溃。我成功地手动重现了这个 bug,下面是第三次运行时崩溃的示例:
+
+```
+
+ macbook:master haypo$ while true; do ./Programs/_testembed bpo20891 ||break; date; done
+ Lun 4 déc 2017 12:46:34 CET
+ Lun 4 déc 2017 12:46:34 CET
+ Lun 4 déc 2017 12:46:34 CET
+ Fatal Python error: PyEval_SaveThread: NULL tstate
+
+ Current thread 0x00007fffa5dff3c0 (most recent call first):
+ Abort trap: 6
+
+```
+
+macOS 上的 `test_embed.test_bpo20891()` 展现出了 `PyGILState_Ensure()` 中的竞争条件:GIL 锁自身的创建……不受锁保护!增加一个新锁来检查 Python 当前是否有 GIL 锁并没有任何意义……
+
+我为 `PyThread_start_new_thread()` 提出了一个不完整的修复:
+
+> 我发现了一个能用的解决方法:在 `PyThread_start_new_thread()` 中调用 `PyEval_InitThreads()`。这样的话,一旦产生第二个线程,就会立即创建 GIL。当同时运行两个线程时,就不能在创建 GIL 了。至少,使用 `python` 二进制文件。它没法修复线程不是由 Python 生成时产生的问题,但是,这个线程调用了 `PyGILState_Ensure()`。(I found a working fix: call `PyEval_InitThreads()` in `PyThread_start_new_thread()`. So the GIL is created as soon as a second thread is spawned. The GIL cannot be created anymore while two threads are running. At least, with the `python` binary. It doesn't fix the issue if a
+thread is not spawned by Python, but this thread calls `PyGILState_Ensure()`.)
+
+## 为什么不总是创建 GIL 呢?
+
+**Antoine Pitrou** 问了一个简单的问题:
+
+> 为什么不_总是_在解释器初始化时调用 `PyEval_InitThreads()` 呢?这样有什么缺点吗?(Why not _always_ call `PyEval_InitThreads()` at interpreter initialization? Are there any downsides?)
+
+感谢 `git blame` 和 `git log`,我发现了“按需”创建 GIL 的代码的起源,**这是一个 26 年前做出的改动**!
+
+```
+
+ commit 1984f1e1c6306d4e8073c28d2395638f80ea509b
+ Author: Guido van Rossum
+ Date: Tue Aug 4 12:41:02 1992 +0000
+
+ * Makefile adapted to changes below.
+ * split pythonmain.c in two: most stuff goes to pythonrun.c, in the library.
+ * new optional built-in threadmodule.c, build upon Sjoerd's thread.{c,h}.
+ * new module from Sjoerd: mmmodule.c (dynamically loaded).
+ * new module from Sjoerd: sv (svgen.py, svmodule.c.proto).
+ * new files thread.{c,h} (from Sjoerd).
+ * new xxmodule.c (example only).
+ * myselect.h: bzero -> memset
+ * select.c: bzero -> memset; removed global variable
+
+ (...)
+
+ +void
+ +init_save_thread()
+ +{
+ +#ifdef USE_THREAD
+ + if (interpreter_lock)
+ + fatal("2nd call to init_save_thread");
+ + interpreter_lock = allocate_lock();
+ + acquire_lock(interpreter_lock, 1);
+ +#endif
+ +}
+ +#endif
+
+```
+
+我猜,动态创建 GIL 的目的是为了减少只使用单个 Python 线程(永远不会产生新的 Python 线程)的应用的 GIL “开销”。
+
+幸运的是,**Guido van Rossum** 就在旁边,他能够阐明理由:
+
+> 是哒,最初的理由是**线程是某些深奥的东西,大部分代码都没有用它**,并且当时,我们肯定觉得,**总是使用 GIL 会导致(微小的)性能下滑**,并**增加**由于 GIL 代码中的错误**而导致的崩溃的风险**。我很高兴地知道,我们不再需要担心这一点了,并且**可以始终对其进行初始化**。(Yeah, the original reasoning was that **threads were something esoteric and not used by most code**, and at the time we definitely felt that **always using the GIL would cause a (tiny) slowdown** and **increase the risk of crashes** due to bugs in the GIL code. I'd be happy to learn that we no longer need to worry about this and **can just always initialize it**.)
+
+## 提出 Py_Initialize() 的第二个修复版本
+
+我提出了 `Py_Initialize()` 的**第二个修复版本**:在 Python 启动时始终创建 GIL,而不是“按需”创建,以防止任何竞争条件产生的风险:
+
+```
+
+ + /* Create the GIL */
+ + PyEval_InitThreads();
+
+```
+
+**Nick Coghlan** 问,我的补丁是否可以通过性能基准测试。于是,我在我的 [PR 4700](https://github.com/python/cpython/pull/4700/) 上运行了 [pyperformance](http://pyperformance.readthedocs.io/)。有至少 5% 的差异:
+
+```
+
+ haypo@speed-python$ python3 -m perf compare_to \
+ 2017-12-18_12-29-master-bd6ec4d79e85.json.gz \
+ 2017-12-18_12-29-master-bd6ec4d79e85-patch-4700.json.gz \
+ --table --min-speed=5
+
+ +----------------------+--------------------------------------+-------------------------------------------------+
+ | Benchmark | 2017-12-18_12-29-master-bd6ec4d79e85 | 2017-12-18_12-29-master-bd6ec4d79e85-patch-4700 |
+ +======================+======================================+=================================================+
+ | pathlib | 41.8 ms | 44.3 ms: 1.06x slower (+6%) |
+ +----------------------+--------------------------------------+-------------------------------------------------+
+ | scimark_monte_carlo | 197 ms | 210 ms: 1.07x slower (+7%) |
+ +----------------------+--------------------------------------+-------------------------------------------------+
+ | spectral_norm | 243 ms | 269 ms: 1.11x slower (+11%) |
+ +----------------------+--------------------------------------+-------------------------------------------------+
+ | sqlite_synth | 7.30 us | 8.13 us: 1.11x slower (+11%) |
+ +----------------------+--------------------------------------+-------------------------------------------------+
+ | unpickle_pure_python | 707 us | 796 us: 1.13x slower (+13%) |
+ +----------------------+--------------------------------------+-------------------------------------------------+
+
+ Not significant (55): 2to3; chameleon; chaos; (...)
+
+```
+
+哎呀,这 5 个基准测试都更慢了。Python 是不欢迎性能衰退的:我们很努力地[再让 Python 更快](https://lwn.net/Articles/725114/)!
+
+## 在圣诞节前跳过失败的测试
+
+我没想到那 5 个基准测试会变得更慢。这需要进一步的研究,但是我没有时间,并且我太羞愧去承担让性能衰退的责任。
+
+在圣诞节前,我没有做出任何决定,而 `test_embed.test_bpo20891()` 在 macOS buildbot 上仍然会随机失败。在两周的假期之前,我**不大情愿去接触 Python 的重要部分**,它的 GIL。所以,我决定跳过 `test_bpo20891()`,直到我回来。
+
+不给你带礼物,Python 3.7。
+
+[](https://drawception.com/panel/drawing/0teL3336/charlie-brown-sad-about-small-christmas-tree/)
+
+## 运行新的基准测试,以及将第二次修复用于主分支
+
+在 2018 年 1 月底,我再次跑了那 5 个在我的 PR 上更慢的基准测试。我在我的笔记本电脑上,使用 CPU 隔离,手动运行了这些基准测试:
+
+```
+
+ vstinner@apu$ python3 -m perf compare_to ref.json patch.json --table
+ Not significant (5): unpickle_pure_python; sqlite_synth; spectral_norm; pathlib; scimark_monte_carlo
+
+```
+
+好了,根据[Python “性能”基准套件](http://pyperformance.readthedocs.io/),它证实了我的第二次修复**对性能没有显著的影响**。
+
+于是,我决定**把我的修复推*到主分支上,提交 [2914bb32](https://github.com/python/cpython/commit/2914bb32e2adf8dff77c0ca58b33201bc94e398c):
+
+```
+
+ bpo-20891: Py_Initialize() now creates the GIL (#4700)
+
+ The GIL is no longer created "on demand" to fix a race condition when
+ PyGILState_Ensure() is called in a non-Python thread.
+
+```
+
+然后,我在主分支上重新启用了 `test_embed.test_bpo20891()`。
+
+## 没有用于 Python 2.7 和 3.6 的第二次修复,抱歉!
+
+**Antoine Pitrou** 认为,[不应该合并](https://github.com/python/cpython/pull/5421#issuecomment-361214537)用于 Python 3.6 的补丁:
+
+> 我不这么认为。人么可能已经调用了 `PyEval_InitThreads()`。(I don't think so. People can already call `PyEval_InitThreads()`.)
+
+**Guido van Rossum** 也不想向后移植这项改动。所以,我只是将 `test_embed.test_bpo20891()` 从 3.6 分支移除。
+
+出于同样的理由,我没有将我的第二次修复应用到 Python 2.7。而且,由于很难向后移植,Python 2.7 没有单元测试。
+
+但是至少,Python 2.7 和 3.6 包含了我的第一次 `PyGILState_Ensure()` 修复。
+
+## 结论
+
+在极端场景下,Python 仍然存在一些竞争条件。当使用 Python API 启动 C 线程时,创建 GIL 会发现这样的错误。我推了第一次修复版本,但是在 macOS 上发现了另一个新的不一样的竞争条件。
+
+我不得不深入 Python GIL 的历史(1992年)。幸运的是,**Guido van Rossum**也能够阐述理由。
+
+在基准测试中出现的一点小问题后,我们同意修改 Python 3.7 为总是创建 GIL,而不是“按需”创建 GIL。这个改动对性能没有显著的影响。
+
+还有让 Python 2.7 和 3.6 保持不变的决定,以防止任何衰退的风险:继续“按需”创建 GIL。
+
+**我花了 4 年的时间解决著名的 Python GIL 中的一个令人讨厌的 bug。** 当触及这类 Python **关键部分**时,我从没有觉得舒服过。现在,很高兴的是,这个错误已经过去了:它完全在未来的 Python 3.7 中修复了!
+
+完整的故事见 [bpo-20891](https://bugs.python.org/issue20891)。感谢所有帮助我解决这个 bug 的开发者!
diff --git "a/Python Common/\344\270\272\344\273\200\344\271\210 Python \344\273\243\347\240\201\345\234\250\345\207\275\346\225\260\344\270\255\350\277\220\350\241\214\345\276\227\346\233\264\345\277\253\357\274\237.md" "b/Python Common/\344\270\272\344\273\200\344\271\210 Python \344\273\243\347\240\201\345\234\250\345\207\275\346\225\260\344\270\255\350\277\220\350\241\214\345\276\227\346\233\264\345\277\253\357\274\237.md"
new file mode 100644
index 0000000..07c6f4d
--- /dev/null
+++ "b/Python Common/\344\270\272\344\273\200\344\271\210 Python \344\273\243\347\240\201\345\234\250\345\207\275\346\225\260\344\270\255\350\277\220\350\241\214\345\276\227\346\233\264\345\277\253\357\274\237.md"
@@ -0,0 +1,317 @@
+原文:[why-does-python-code-run-faster-in-a-function.md](https://stackabuse.com/why-does-python-code-run-faster-in-a-function/)
+
+---
+## 介绍
+
+Python 不一定以其速度而闻名,但有些东西可以帮助您从代码中榨取更多性能。令人惊讶的是,其中一种做法是在函数中而不是在全局范围内运行代码。在本文中,我们将了解为什么 Python 代码在函数中运行得更快以及 Python 代码执行的工作原理。
+
+
+## Python 代码执行
+
+要理解为什么 Python 代码在函数中运行得更快,我们首先需要了解 Python 是如何执行代码的。Python 是一种解释性语言,这意味着它逐行读取并执行代码。当 Python 执行脚本时,它首先将其编译为字节码(一种更接近机器代码的中间语言),然后 Python 解释器再执行这些字节码。
+
+```py
+def hello_world():
+ print("Hello, World!")
+
+import dis
+dis.dis(hello_world)
+```
+
+```
+ 2 0 LOAD_GLOBAL 0 (print)
+ 2 LOAD_CONST 1 ('Hello, World!')
+ 4 CALL_FUNCTION 1
+ 6 POP_TOP
+ 8 LOAD_CONST 0 (None)
+ 10 RETURN_VALUE
+
+```
+
+Python 中的 [dis](https://docs.python.org/3/library/dis.html) 模块将函数 `hello_world` 反汇编为字节码,如上所示。
+
+
+> **注意:** Python 解释器是执行字节码的虚拟机。默认的 Python 解释器是 CPython,它是用 C 编写的。还有其他 Python 解释器,如 Jython(用 Java 编写)、IronPython(用 .NET 编写)和 PyPy(用 Python 和 C 编写),但 CPython 是最常用的。
+
+
+## 为什么 Python 代码在函数中运行得更快
+
+考虑一个简化的示例,其中包含一个迭代一系列数字的循环:
+
+```py
+def my_function():
+ for i in range(100000000):
+ pass
+
+```
+
+编译此函数时,字节码可能如下所示:
+
+```
+ SETUP_LOOP 20 (to 23)
+ LOAD_GLOBAL 0 (range)
+ LOAD_CONST 3 (100000000)
+ CALL_FUNCTION 1
+ GET_ITER
+ FOR_ITER 6 (to 22)
+ STORE_FAST 0 (i)
+ JUMP_ABSOLUTE 13
+ POP_BLOCK
+ LOAD_CONST 0 (None)
+ RETURN_VALUE
+
+```
+
+这里的关键指令是 `STORE_FAST`,它用来存储循环变量 `i`。
+
+现在让我们考虑一下,当循环位于 Python 脚本顶层时,字节码是怎么样的:
+
+```
+ SETUP_LOOP 20 (to 23)
+ LOAD_NAME 0 (range)
+ LOAD_CONST 3 (100000000)
+ CALL_FUNCTION 1
+ GET_ITER
+ FOR_ITER 6 (to 22)
+ STORE_NAME 1 (i)
+ JUMP_ABSOLUTE 13
+ POP_BLOCK
+ LOAD_CONST 2 (None)
+ RETURN_VALUE
+
+```
+
+请注意,这里使用了 `STORE_NAME` 指令,而不是 `STORE_FAST`。
+
+字节码 `STORE_FAST` 比 `STORE_NAME` 快,因为在函数中,局部变量是存储在固定大小的数组中的,而不是存储在字典中。这个数组可通过索引直接访问,使得变量检索非常快。基本上,它只是对列表进行指针查找并增加 PyObject 的引用计数,这两者都是高效操作。
+
+另一方面,全局变量存储在字典中。当访问全局变量时,Python 必须执行哈希表查找,其中涉及哈希值的计算,然后检索与其关联的值。尽管这些操作经过优化,但它本质上仍然比基于索引的查找慢。
+
+## Python 代码的基准测试和分析
+
+想亲自测试一下吗?尝试对您的代码进行基准测试和分析吧。
+
+基准测试和分析是性能优化的重要实践。它们可以帮助您了解代码的行为方式以及瓶颈所在。
+
+基准测试就是对代码进行计时以查看运行时间。您可以使用 Python 的内置 `time` [timeit](https://docs.python.org/3/library/timeit.html)。
+
+另一方面,分析提供了代码执行的更详细视图。它向您显示大部分时间花在执行哪些代码、调用哪些函数以及调用频率。Python 的内置 [profile](https://docs.python.org/3/library/profile.html) 或者 [cProfile](https://docs.python.org/3/library/cProfile.html) 模块可用于此目的。
+
+以下是分析 Python 代码的一种方法:
+
+```py
+import cProfile
+
+def loop():
+ for i in range(10000000):
+ pass
+
+cProfile.run('loop()')
+
+```
+
+这将输出 `loop` 函数执行期间所有函数调用的详细报告。
+
+> **注意:** 分析会给代码执行增加相当多的开销,因此分析器显示的执行时间可能会比实际执行时间长。
+
+
+## 分别在函数与全局范围内对代码进行基准测试
+
+在 Python 中,代码执行的速度可能会根据代码的执行位置(在函数中还是在全局范围内)而有所不同。让我们用一个简单的例子来对两者进行比较。
+
+考虑以下计算数字阶乘的代码片段:
+
+```py
+def factorial(n):
+ result = 1
+ for i in range(1, n + 1):
+ result *= i
+ return result
+
+```
+
+现在让我们在全局范围内运行相同的代码:
+
+```py
+n = 20
+result = 1
+for i in range(1, n + 1):
+ result *= i
+
+```
+为了对这两段代码进行基准测试,我们可以使用 Python 中的 `timeit` 模块,它提供了一种对少量 Python 代码进行计时的简单方法。
+
+```py
+import timeit
+
+# Factorial function here...
+
+def benchmark():
+ start = timeit.default_timer()
+
+ factorial(20)
+
+ end = timeit.default_timer()
+ print(end - start)
+
+#
+# Run benchmark on function code
+#
+benchmark()
+# Prints: 3.541994374245405e-06
+
+#
+# Run benchmark on global scope code
+#
+start = timeit.default_timer()
+
+n = 20
+result = 1
+for i in range(1, n + 1):
+ result *= i
+
+end = timeit.default_timer()
+print(end - start)
+# Pirnts: 5.375011824071407e-06
+
+```
+
+您会发现函数代码比全局作用域代码执行得更快。这是因为由于我们之前讨论的原因,Python 执行函数代码的速度更快。
+
+
+> **注意:** 如果在同一个脚本中运行 `benchmark()` 函数和全局作用域代码,全局作用域代码会运行得更快。这是因为 `benchmark()` 函数增加了一些执行时间的开销,并且全局代码在内部还进行了一些优化。但是,如果单独运行它们,您会发现函数代码确实运行得更快。
+
+## 分别在函数与全局范围内对代码进行分析
+
+Python 提供了一个用于此目的的内置模块 `cProfile`。让我们用它来分析一个新函数,该函数在局部和全局范围内计算平方和。
+
+```py
+import cProfile
+
+def sum_of_squares():
+ total = 0
+ for i in range(1, 10000000):
+ total += i * i
+
+i = None
+total = 0
+def sum_of_squares_g():
+ global i
+ global total
+ for i in range(1, 10000000):
+ total += i * i
+
+def profile(func):
+ pr = cProfile.Profile()
+ pr.enable()
+
+ func()
+
+ pr.disable()
+ pr.print_stats()
+#
+# Profile function code
+#
+print("Function scope:")
+profile(sum_of_squares)
+
+#
+# Profile global scope code
+#
+print("Global scope:")
+profile(sum_of_squares_g)
+```
+
+从分析结果中,您将看到函数代码在执行时间方面更加高效。
+
+```
+Function scope:
+ 2 function calls in 0.903 seconds
+
+ Ordered by: standard name
+
+ ncalls tottime percall cumtime percall filename:lineno(function)
+ 1 0.903 0.903 0.903 0.903 profiler.py:3(sum_of_squares)
+ 1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
+
+
+Global scope:
+ 2 function calls in 1.358 seconds
+
+ Ordered by: standard name
+
+ ncalls tottime percall cumtime percall filename:lineno(function)
+ 1 1.358 1.358 1.358 1.358 profiler.py:10(sum_of_squares_g)
+ 1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
+
+```
+
+我们认为 `sum_of_squares_g()` 函数是全局的,因为它使用了两个全局变量 `i` 和 `total`。正如我们之前所看到的,全局变量会减慢代码执行速度,这就是我们在此代码中将这些变量设置为全局变量的原因。
+
+## 优化 Python 函数性能
+
+鉴于 Python 函数往往比全局范围内的等效代码运行得更快,因此值得研究如何进一步优化函数性能。
+
+当然,由于我们之前看到的,一种策略是使用局部变量而不是全局变量。下面是一个例子:
+
+```py
+import time
+
+# Global variable
+x = 5
+
+def calculate_power_global():
+ for i in range(10000000):
+ y = x ** 2 # Accessing global variable
+
+def calculate_power_local(x):
+ for i in range(10000000):
+ y = x ** 2 # Accessing local variable
+
+start = time.time()
+calculate_power_global()
+end = time.time()
+
+print(f"Execution time with global variable: {end - start} seconds")
+
+start = time.time()
+calculate_power_local(x)
+end = time.time()
+
+print(f"Execution time with local variable: {end - start} seconds")
+
+```
+
+在这个例子中,`calculate_power_local` 通常会比 `calculate_power_global` 跑得更快,因为它使用了一个局部变量,而不是全局变量。
+
+```
+Execution time with global variable: 1.9901456832885742 seconds
+Execution time with local variable: 1.9626312255859375 seconds
+```
+
+另一种优化策略是尽可能使用内置函数和库。Python 的内置函数是用 C 实现的,比Python快得多。同样的,许多 Python 库(例如 NumPy 和 Pandas)也是用 C 或 C++ 实现的,这使得它们比同等的 Python 代码更快。
+
+例如,考虑这个对数字列表求和的任务。您可以编写一个函数来执行此操作:
+
+```py
+def sum_numbers(numbers):
+ total = 0
+ for number in numbers:
+ total += number
+ return total
+
+```
+
+然而,Python 的内置 `sum` 函数也可以被用来做同样的事情,但它会更快:
+
+```py
+numbers = [1, 2, 3, 4, 5]
+total = sum(numbers)
+```
+尝试自己计时这两个代码片段,并找出哪一个更快吧!
+
+## 总结
+
+在本文中,我们探索了 Python 代码执行的有趣世界,特别关注为什么封装在函数中的 Python 代码往往运行得更快。我们简要介绍了基准测试和分析的概念,提供了如何在函数和全局范围内执行这些过程的实际示例。
+
+我们还讨论了优化 Python 函数性能的几种方法。虽然这些技巧肯定可以使您的代码运行得更快,但您应该谨慎使用某些优化,因为平衡可读性、可维护性与性能是非常重要的。
\ No newline at end of file
diff --git "a/Python Common/\346\217\217\350\277\260\345\231\250\357\274\232Python\344\270\255\345\261\236\346\200\247\350\256\277\351\227\256\350\203\214\345\220\216\347\232\204\351\255\224\346\263\225.md" "b/Python Common/\346\217\217\350\277\260\345\231\250\357\274\232Python\344\270\255\345\261\236\346\200\247\350\256\277\351\227\256\350\203\214\345\220\216\347\232\204\351\255\224\346\263\225.md"
new file mode 100644
index 0000000..b84f352
--- /dev/null
+++ "b/Python Common/\346\217\217\350\277\260\345\231\250\357\274\232Python\344\270\255\345\261\236\346\200\247\350\256\277\351\227\256\350\203\214\345\220\216\347\232\204\351\255\224\346\263\225.md"
@@ -0,0 +1,631 @@
+原文:[Descriptors: The magic behind attribute access in Python](http://nbviewer.jupyter.org/github/akittas/presentations/blob/master/pythess/descriptors/descriptors.ipynb)
+
+---
+
+# 什么是封装? (IMNSHO)
+
+ 1. _封装_**不是**关于隐藏数据。
+ 2. _访问控制_**才是**关于隐藏数据。
+ 3. 封装和访问控制是两个不同的独立的事情。
+ * You **don't need** access control to have encapsulation.
+ * You can encapsulate behavior **without** having to restrict access.
+ 4. Encapsulation separates the concept of **what something does** from **how it is implemented**.
+ 5. Encapsulation decouples a programming construct's **public interface/API** from its **implemenation**.
+ 6. When calling code wants to retrieve a value, it should not depend on from where the value comes. Internally, the class can store the value in a field or retrieve it from some external resource (such as a file or a database). Perhaps the value is not stored at all, but calculated on-the-fly. This should not matter to the calling code.
+
+# 在我们开始之前:Python中的属性里的下划线
+
+ 1. Single underscore before a name (e.g. `_foo`)
+ * Used as a convention, these attributes should be treated as a non-public part of the API (whether it is a function, a method or a data member) and considered an implementation detail and subject to change without notice (source: [Python documentation](https://docs.python.org/3/tutorial/classes.html#tut-private)).
+ * It's more than a convention and actually does mean something to the interpreter; if you `from import *`, none of the names that start with an `_` will be imported unless the module's/package's `__all__` list explicitly contains them.
+ 2. Double underscore before a name (e.g. `__foo`)
+ * This is not a convention, any identifier of the form `__foo` (at least two leading underscores, at most one trailing underscore) is textually replaced with `_classname__foo`, where classname is the current class name with leading underscore(s) stripped. This is called _name mangling_. (source: [Python documentation](https://docs.python.org/3/tutorial/classes.html)).
+ * Name mangling is helpful for letting subclasses override methods without breaking intraclass method calls.
+ 3. Double underscore before and after a name (e.g. `__foo__`)
+ * Methods that use this naming format are called _special_ or _magic_ methods and are automatically invoked when certain syntax is used. We typically override these methods to implement the desired behaviour in classes (e.g. constructors, operator overloading, indexing etc).
+ * _Special_ attributes that provide access to the implementation and are not intended for general use. Examples from class special attributes: `__name__` is the class name, `__module__` is the module name in which the class was defined, `__dict__` is the dictionary containing the class’s namespace, `__bases__` is a tuple containing the base classes.
+
+In [1]:
+
+
+
+ # name mangling mechanism
+
+ class Mapping:
+ def __init__(self, iterable):
+ self.items_list = []
+ # self.__update inside the class is equivalent to self._Mapping__update
+ # the same function will be called even if __update is overridden in inheriting classes
+ self.__update(iterable)
+
+ def __update(self, iterable):
+ for item in iterable:
+ self.items_list.append(item)
+
+ class MappingSub(Mapping):
+ def __update(self, keys, values):
+ # provides new signature for __update() but does not break __init__()
+ for item in zip(keys, values):
+ self.items_list.append(item)
+
+
+In [2]:
+
+
+
+ m = Mapping([1, 2])
+ ms = MappingSub([1,2])
+ print('__update' in dir(m), '__update' in dir(ms))
+
+ m._Mapping__update([3, 4])
+ print(m.items_list)
+
+ ms._Mapping__update([3, 4]) # call update function of Mapping class
+ ms._MappingSub__update([5, 6], ['five', 'six']) # call update of MappingSub class
+ print(ms.items_list)
+
+
+
+ False False
+ [1, 2, 3, 4]
+ [1, 2, 3, 4, (5, 'five'), (6, 'six')]
+
+
+# 一个属性是什么?
+
+ * Quite simply, an attribute is a way to get from one object to another.
+ * Apply the power of the almighty dot `objectname.attributename` and voila! you now have the handle to another object.
+ * You also have the power to create attributes, by assignment: `objectname.attributename = anotherobject`.
+ * Which object does an attribute access return, though? And where does the object set as an attribute end up?
+
+取决于编程语言:
+
+ * You don't have any control to attribute access (Java plebs).
+ * You control attribute access through properties (C# cool kids).
+ * You can completely customize attribute access in addition to properties (Python master race).
+
+
+
+# 实例属性访问
+
+ * When we access an instance we actually call its `__getattribute__` method, i.e. `a.x -> a.__getattribute__(x)`.
+ * `__getattribute__` has an order of priority that describes where to look for attributes and how to react to them.
+ * Classes and instances have a `__dict__` where user provided attributes are stored and looked up.
+ * Python provides extra attributes, most of which are not stored in `__dict__` (e.g. special methods).
+ * `__dict__` is looked up first and this is how we override special methods.
+ * We can also override this behavior to save memory for classes with a few fields using `__slots__`. However we cannot add new attributes to `__slots__`.
+
+In [3]:
+
+
+
+ class B:
+ x = 1
+
+ class A(B):
+ y = 2
+ def __getattr__(self, value):
+ return str(value)
+
+ a = A()
+ print("a.x: {}, a.y: {}".format(a.x, a.y)) # x from B, y from A
+ a.y = 3
+ print("a.x: {}, a.y: {}, A.y: {}".format(a.x, a.y, A.y)) # x from B, y from a (overrides y in A)
+ print("a.z: {}".format(a.z)) # call __getattr__
+
+ print(A.__dict__)
+ print(a.__dict__)
+
+
+
+ a.x: 1, a.y: 2
+ a.x: 1, a.y: 3, A.y: 2
+ a.z: z
+ {'__module__': '__main__', 'y': 2, '__getattr__': , '__doc__': None}
+ {'y': 3}
+
+
+# 描述器协议
+
+Raymond Hettinger ([Python文档](https://docs.python.org/3/howto/descriptor.html)):
+
+> In general, a descriptor is an object attribute with "binding behavior", one
+whose attribute access has been overridden by methods in the descriptor
+protocol.
+
+ * Those methods are `__get__`, `__set__` and `__delete__`. If any of those methods are defined for an object, it is said to be a **descriptor**.
+ * Only one of the methods _needs_ to be implemented in order to be considered a descriptor, but any number of them _can_ be implemented.
+ * There are two types of descriptors based on which sets of these methods are implemented: **data** and **non-data** descriptors.
+ 1. A **data** descriptor implements at least `__set__` or `__delete__`, but can include both. They also often include `__get__`, since it's rare to want to set something without also being able to get it too.
+ 2. A **non-data** descriptor only implements `__get__`. If it adds `__set__` or `__delete__`to its method list, it becomes a data descriptor.
+
+# `__get__(self, instance, owner)`
+
+ 1. `self` is the descriptor instance.
+ 2. `owner` is the class the descriptor is accessed _from_.
+ * When you call `A.x`, where `x` is a descriptor object with `__get__`, it's called with `A` as owner and `instance` as `None`.
+ * This lets the descriptor know that `__get__` is being called from a _class_, not an _instance_.
+ * `A.x` is translated to `A.__dict__['x'].__get__(None, A)`.
+ 3. `instance` is the instance that the descriptor is accessed _from_.
+ * If the discriptor is accessed from an _instance_ it receives it as `instance` and the class of the instance as `owner`.
+ * `a.x` is translated to `type(a).__dict__['x'].__get__(a, type(a))`
+ * Note that the call starts with `type(a)`, not just `a`, because descriptors are stored on _classes_ not _instances_.
+
+两个要点:
+
+ 1. In order to be able to apply per-instance as well as per-class functionality, descriptors are given `instance` and `owner` (the class of the instance).
+ 2. It is not the _instance_ that the descriptor is being called from, but instead, the `instance` _parameter_ is the instance the descriptor is being called from. It is actually being called from the instance class.
+
+# `__set__(self, instance, value)`
+
+ 1. `__set__` does not have an owner parameter that accepts a class and does not need it, since data descriptors are generally designed for storing per-instance data.
+ 2. `A.x = value` does not get translated to anything; `value` replaces the descriptor object stored in `x` (however, see note below).
+ 3. `a.x = value` is translated to `type(a).__dict__['x'].__set__(a, value)`
+
+# `__delete__(self, instance)`
+
+ 1. invoked when `del a.x` is called.
+ 2. `del a.x` is translated to `type(a).__dict__['x'].__delete__(a)`
+
+**Note**: If we want a descriptor's `__set__` or `__delete__` methods to work from the _class_ level, the descriptor must be created on the class's _metaclass_. When doing so, everything that refers to `owner` is referring to the _metaclass_, while a reference to `instance` refers to the _class_. After all, classes are just instances of metaclasses.
+
+# 实例和类属性访问
+
+ * Descriptors are invoked by the `__getattribute__` method.
+ * Overriding `__getattribute__` prevents automatic descriptor calls.
+ * Class attribute access still uses `__getattribute__`, but it's the one defined on its _metaclass_.
+ * Priorities when an _instance_ attribute is looked up:
+ 1. Data descriptors in its class (up the MRO).
+ 2. Instance attributes.
+ 3. Non-data descriptors in its class / class attributes (up the MRO).
+ 4. The `__getattr__` method.
+ * Priorities when an _class_ attribute is looked up:
+ 1. Data descriptors in its metaclass (up the MRO).
+ 2. Class attributes (up the MRO).
+ 3. Non-data descriptors in its metaclass / metaclass attributes (up the MRO).
+ 4. The `__getattr__` method.
+
+# 实例属性访问优先级 (`a.x`)
+
+ 1. Look in the class `__dict__`, working up the MRO.
+ * If found, check if it's a data descriptor.
+ * If it has a `__get__` method, call it and return the result.
+ 2. Look in the instance `__dict__`.
+ * If found, return the value in `__dict__`.
+ 3. Check class `__dict__` again, working up the MRO.
+ * If found, check if it's a descriptor.
+ * If it has a `__get__` method, call it and return the result.
+ * If it doesn't have a `__get__` method, return the descriptor object itself.
+ * If found and not a descriptor, return the value in `__dict__`.
+ 4. Call `__getattr__` if it exists and return the result.
+ 5. If everything up to this point has failed, raise `AttributeError`.
+
+# 类属性访问优先级 (`A.x`)
+
+ 1. Look in the metaclass `__dict__`, working up the MRO.
+ * If found, check if it's a data descriptor.
+ * If it has a `__get__` method, call it and return the result.
+ 2. Look in the class `__dict__`, working up the MRO.
+ * If found, check if it's a descriptor.
+ * If it has a `__get__` method, call it and return the result.
+ * If it doesn't have a `__get__` method, return the descriptor object itself.
+ * If found and not a descriptor, return the value in `__dict__`.
+ 3. Check metaclass `__dict__` again, working up the MRO.
+ * If found, check if it's a descriptor.
+ * If it has a `__get__` method, call it and return the result.
+ * If it doesn't have a `__get__` method, return the descriptor object itself.
+ * If found and not a descriptor, return the value in `__dict__`.
+ 4. Call `__getattr__` if it exists and return the result.
+ 5. If everything up to this point has failed, raise `AttributeError`.
+
+# 实例属性访问优先级:
+
+## `__set__` & `__delete__` (`a.x = value` & `del a.x`)
+
+ 1. Look in the class `__dict__`, working up the MRO.
+ * If found, check if it's a data descriptor.
+ * If it has a `__set__` or `__delete__` method, call `__set__` or `__delete__`.
+ * If it doesn't have the corresponding method, raise `AttributeError`.
+ 2. Look in the instance `__dict__`.
+ * `a.x = value`
+ * Set attribute to value.
+ * `del a.x`
+ * If found, delete attribute.
+ * If not found, raise `AttributeError`.
+
+# 类属性访问优先级:
+
+## `__set__` & `__delete__` (`A.x = value` & `del A.x`)
+
+ 1. Look in the metaclass `__dict__`, working up the MRO.
+ * If found, check if it's a data descriptor.
+ * If it has a `__set__` or `__delete__` method, call `__set__` or `__delete__`.
+ * If it doesn't have the corresponding method, raise `AttributeError`.
+ 2. Look in the class `__dict__`.
+ * `A.x = value`
+ * Set attribute to value.
+ * `del A.x`
+ * If found, delete attribute.
+ * If not found, raise `AttributeError`.
+
+
+
+In [4]:
+
+
+
+ # implementation of classmethod and staticmethod, equivalent to the standard library
+
+ class MyClassmethod:
+ def __init__(self, func):
+ self.func = func
+
+ # ignore the instance, provide the class as first argument (usually named cls) so the
+ # returned function can be called with the arguments the user wants to explicitly provide
+ def __get__(self, instance, owner):
+ def cls_wrapper(*args, **kwargs):
+ return self.func(owner, *args, **kwargs) # what if I put cls=owner?
+ return cls_wrapper
+
+ class MyStaticmethod:
+ def __init__(self, func):
+ self.func = func
+
+ # essentially just accepts a function and then returns it when __get__ is called
+ def __get__(self, instance, owner):
+ return self.func
+
+
+In [5]:
+
+
+
+ class A:
+ def foo(self):
+ print(self)
+
+ @MyClassmethod # same as: bar = MyClassmethod(bar)
+ def bar(cls):
+ print(cls)
+
+ @MyStaticmethod # same as: baz = MyStaticmethod(baz)
+ def baz():
+ print('static method')
+
+ # both methods are accessed through their respective descriptors
+
+
+In [6]:
+
+
+
+ a = A()
+
+ # instance method, business as always
+ a.foo()
+ print()
+
+ # access the method object, descriptor is called and returns the cls_wrapper method object
+ print(A.bar)
+
+ # call the method, instance in __get__ is None (don't care), owner is A
+ A.bar()
+
+ # run it on the instance, instance in __get__ is a (don't care), owner is A
+ a.bar()
+ print()
+
+ # access the method object, descriptor returns a function with no arguments
+ print(A.baz)
+
+ # call the method without any instance (self) or class (cls) object
+ # of course same result if we call it in the instance
+ A.baz()
+ a.baz()
+
+
+
+ <__main__.A object at 0x0000022EE39CCF60>
+
+ .cls_wrapper at 0x0000022EE39D2510>
+
+
+
+
+ static method
+ static method
+
+
+In [7]:
+
+
+
+ # implementation of property, equivalent to the standard library
+
+ class MyProperty:
+ def __init__(self, fget=None, fset=None, fdel=None):
+ self.fget = fget
+ self.fset = fset
+ self.fdel = fdel
+
+ def __get__(self, instance, owner):
+ if instance is None: # this was called from the class, not the instance
+ return self
+ elif self.fget is None:
+ raise AttributeError("unreadable attribute")
+ else:
+ return self.fget(instance)
+
+ def __set__(self, instance, value):
+ if self.fset is None:
+ raise AttributeError("can't set attribute")
+ else:
+ self.fset(instance, value)
+
+ def __delete__(self, instance):
+ if self.fdel is None:
+ raise AttributeError("can't delete attribute")
+ else:
+ self.fdel(instance)
+
+ def getter(self, fget):
+ return type(self)(fget, self.fset, self.fdel)
+
+ def setter(self, fset):
+ return type(self)(self.fget, fset, self.fdel)
+
+ def deleter(self, fdel):
+ return type(self)(self.fget, self.fset, fdel)
+
+
+In [8]:
+
+
+
+ class A:
+ def __init__(self, x):
+ self._x = x
+
+ @MyProperty
+ def x(self):
+ print("returning _x: {}".format(self._x))
+ return self._x
+
+ @x.setter
+ def x(self, value):
+ print("setting _x to {}".format(value))
+ self._x = value
+
+
+In [9]:
+
+
+
+ a = A(1)
+ print(A.x) # call the descriptor from the class, returns the descriptor object
+ print(a.x)
+ print()
+ a.x = 2
+ print(a.x)
+ print()
+ A.x = 'bye bye descriptor'
+ print(a.x) # descriptor is gone from class, instance gets attribute from class
+
+
+
+ <__main__.MyProperty object at 0x0000022EE39EBF28>
+ returning _x: 1
+ 1
+
+ setting _x to 2
+ returning _x: 2
+ 2
+
+ bye bye descriptor
+
+
+
+
+# 这有用吗?
+
+ * Why do I need to know this? Can't I just use `property`?
+ * No problem. `property` is awesome! Use `property` for greater good!
+ * However there are times where logic needs to be repeated in properties.
+ * This can lead to code duplication.
+ * We can try to fix this by writing helper methods.
+ * But then in each property, code for these method calls will be duplicated.
+ * Descriptors allow us to **capture the logic** for attribute access and **re-use** it for different attributes.
+
+In [10]:
+
+
+
+ class BasketballGame:
+ def __init__(self, points, rebounds, steals):
+ self.points = points
+ self.rebounds = rebounds
+ self.steals = steals
+
+ @property
+ def points(self):
+ return self._points
+
+ @points.setter
+ def points(self, value):
+ if value < 0:
+ raise ValueError('Positive values only!')
+ self._points = value
+
+ @property
+ def rebounds(self):
+ return self._rebounds
+
+ @rebounds.setter
+ def rebounds(self, value):
+ if value < 0:
+ raise ValueError('Positive values only!')
+ self._rebounds = value
+
+ @property
+ def steals(self):
+ return self._steals
+
+ @steals.setter
+ def steals(self, value):
+ if value < 0:
+ raise ValueError('Positive values only!')
+ self._steals = value
+
+
+In [11]:
+
+
+
+ class NonNegativeField:
+ def __init__(self, name=''):
+ # need to store the field name on the descriptor object itself
+ # as descriptors are defined on the class level
+ self.name = name
+
+ def __get__(self, instance, owner):
+ return instance.__dict__[self.name]
+
+ def __set__(self, instance, value):
+ if value < 0:
+ raise ValueError('Positive values only!')
+ instance.__dict__[self.name] = value
+
+
+In [12]:
+
+
+
+ class BasketballGame:
+ # is there a better way, so that we don't have to repeat the field name?
+ points = NonNegativeField('points')
+ rebounds = NonNegativeField('rebounds')
+ steals = NonNegativeField('steals')
+
+ def __init__(self, points, rebounds, steals):
+ self.points = points
+ self.rebounds = rebounds
+ self.steals = steals
+
+
+In [13]:
+
+
+
+ a = BasketballGame(points=100, rebounds=30, steals=10)
+ print("points: {}, rebounds: {}".format(a.points, a.rebounds))
+ try:
+ a.points = -5
+ except ValueError as e:
+ print("Error! {}".format(e))
+
+
+
+ points: 100, rebounds: 30
+ Error! Positive values only!
+
+
+In [14]:
+
+
+
+ def named_descriptors(cls):
+ for name, attr in cls.__dict__.items():
+ if isinstance(attr, NonNegativeField):
+ attr.name = name
+ return cls
+
+ @named_descriptors
+ class BasketballGame:
+ points = NonNegativeField()
+ rebounds = NonNegativeField()
+ steals = NonNegativeField()
+
+ def __init__(self, points, rebounds, steals):
+ self.points = points
+ self.rebounds = rebounds
+ self.steals = steals
+
+
+In [15]:
+
+
+
+ a = BasketballGame(points=100, rebounds=30, steals=10)
+ print("points: {}, rebounds: {}".format(a.points, a.rebounds))
+ try:
+ a.points = -5
+ except ValueError as e:
+ print("Error! {}".format(e.args))
+
+
+
+ points: 100, rebounds: 30
+ Error! ('Positive values only!',)
+
+
+In [16]:
+
+
+
+ class NonNegativeField:
+ def __get__(self, instance, owner):
+ return instance.__dict__[self.name]
+
+ def __set__(self, instance, value):
+ if value < 0:
+ raise ValueError('Positive values only!')
+ instance.__dict__[self.name] = value
+
+ # new in Python 3.6
+ def __set_name__(self, owner, name):
+ self.name = name
+
+ class BasketballGame:
+ points = NonNegativeField()
+ rebounds = NonNegativeField()
+ steals = NonNegativeField()
+
+ def __init__(self, points, rebounds, steals):
+ self.points = points
+ self.rebounds = rebounds
+ self.steals = steals
+
+
+In [17]:
+
+
+
+ a = BasketballGame(points=100, rebounds=30, steals=10)
+ print("points: {}, rebounds: {}".format(a.points, a.rebounds))
+ try:
+ a.points = -5
+ except ValueError as e:
+ print("Error! {}".format(e))
+
+
+
+ points: 100, rebounds: 30
+ Error! Positive values only!
+
+
+
+
+# 参考
+
+ 1. [StackOverflow - What is encapsulation? How does it actually hide data?](http://stackoverflow.com/questions/5673829/what-is-encapsulation-how-does-it-actually-hide-data)
+ 2. [Shahriar Tajbakhsh - Underscores in Python](https://shahriar.svbtle.com/underscores-in-python)
+ 3. [Shalabh Chaturvedi - Python Attributes and Methods](http://www.cafepy.com/article/python_attributes_and_methods/python_attributes_and_methods.html)
+ 4. [Raymond Hettinger - Descriptor HowTo Guide](https://docs.python.org/3/howto/descriptor.html)
+ 5. Simeon Franklin - Python Descriptors [video](https://www.youtube.com/watch?v=ZdvpNaWwx24) & [presentation](http://simeonfranklin.com/talk/descriptors.html)
+ 6. [Laura Rupprecht - Describing Descriptors - PyCon 2015](https://www.youtube.com/watch?v=h2-WPwGnHqE)
+ 7. Jacob Zimmerman - Python Descriptors, Apress Publishing (2006)
+ 8. [Dan Sackett - An introduction to Python descriptors](http://programeveryday.com/post/an-introduction-to-python-descriptors/)
diff --git "a/Python Common/\347\216\260\345\256\236\344\270\255\347\232\204 match_case.md" "b/Python Common/\347\216\260\345\256\236\344\270\255\347\232\204 match_case.md"
new file mode 100644
index 0000000..4c5f2eb
--- /dev/null
+++ "b/Python Common/\347\216\260\345\256\236\344\270\255\347\232\204 match_case.md"
@@ -0,0 +1,133 @@
+原文:[Real-world match case](https://nedbatchelder.com/blog/202312/realworld_matchcase.html)
+
+---
+
+Python 3.10 为我们带来了结构模式匹配,更广为人知的名称是 **match/case**。乍一看,它像来自 C 或 JavaScript 的 switch 语句,但其实有很大不同。
+
+您可以使用 match/case 来匹配特定的文字,类似于 switch 语句的工作方式,但它们的目的是匹配数据结构中的模式,而不仅仅是值。[PEP 636:结构模式匹配:教程](https://peps.python.org/pep-0636/)很好地解释了其机制,但感觉就像一个玩具示例。
+
+这是一个现实世界中的使用示例:在工作中,我们安装了一个 GitHub 机器人作为 Webhook。当我们的某个存储库发生了些什么时,GitHub 会向我们的机器人发送 JSON 格式的有效负载。机器人必须检查解码后的有效负载来决定要做什么。
+
+这些有效负载很复杂:它们是只包含 6 或 8 个键的字典,但它们嵌套极深,最终包含数百条数据。最初我们将它们分开以查看它们有什么键值,但是 match/case 使工作变得更加简单。
+
+以下是一些代码,用于确定当我们收到“comment created(评论已创建)”事件时要执行的操作:
+
+```py
+# Check the structure of the payload:
+match event:
+ case {
+ "issue": {"closed_at": closed},
+ "comment": {"created_at": commented},
+ } if closed == commented:
+ # This is a "Close with comment" comment. Don't do anything for the
+ # comment, because we'll also get a "pull request closed" event at
+ # the same time, and it will do whatever we need.
+ pass
+
+ case {"sender": {"login": who}} if who == get_bot_username():
+ # When the bot comments on a pull request, it causes an event, which
+ # gets sent to webhooks, including us. We don't have to do anything
+ # for our own comment events.
+ pass
+
+ case {"issue": {"pull_request": _}}:
+ # The comment is on a pull request. Process it.
+ return process_pull_request_comment(event)
+```
+
+如果字典有一个“issue”键,值为一个带有“close_at”键的字典,并且还有一个“comment”键,值为一个带有“created_at”键的字典,并且字典中的这两个键值相等,则第一种情况匹配。在没有 match/case 的情况下要写出这种条件,代码会更加冗长和混乱。
+
+第二种情况检查 event 以查看机器人是否是 event 的发起者。如果用不同的方式来写这个就不那么难了,但是 match/case 让代码更漂亮。
+
+这正是 match/case 所擅长的:检查数据结构中的模式。
+
+看看生成的字节码也很有趣。对于第一种情况,它看起来像这样:
+
+```
+ 2 0 LOAD_GLOBAL 0 (event)
+
+ 3 2 MATCH_MAPPING
+ 4 POP_JUMP_IF_FALSE 67 (to 134)
+ 6 GET_LEN
+ 8 LOAD_CONST 1 (2)
+ 10 COMPARE_OP 5 (>=)
+ 12 POP_JUMP_IF_FALSE 67 (to 134)
+
+ 4 14 NOP
+
+ 5 16 NOP
+
+ 3 18 LOAD_CONST 8 (('issue', 'comment'))
+ 20 MATCH_KEYS
+ 22 POP_JUMP_IF_FALSE 65 (to 130)
+ 24 DUP_TOP
+ 26 LOAD_CONST 4 (0)
+ 28 BINARY_SUBSCR
+
+ 4 30 MATCH_MAPPING
+ 32 POP_JUMP_IF_FALSE 64 (to 128)
+ 34 GET_LEN
+ 36 LOAD_CONST 5 (1)
+ 38 COMPARE_OP 5 (>=)
+ 40 POP_JUMP_IF_FALSE 64 (to 128)
+ 42 LOAD_CONST 9 (('closed_at',))
+ 44 MATCH_KEYS
+ 46 POP_JUMP_IF_FALSE 62 (to 124)
+ 48 DUP_TOP
+ 50 LOAD_CONST 4 (0)
+ 52 BINARY_SUBSCR
+ 54 ROT_N 7
+ 56 POP_TOP
+ 58 POP_TOP
+ 60 POP_TOP
+ 62 DUP_TOP
+ 64 LOAD_CONST 5 (1)
+ 66 BINARY_SUBSCR
+
+ 5 68 MATCH_MAPPING
+ 70 POP_JUMP_IF_FALSE 63 (to 126)
+ 72 GET_LEN
+ 74 LOAD_CONST 5 (1)
+ 76 COMPARE_OP 5 (>=)
+ 78 POP_JUMP_IF_FALSE 63 (to 126)
+ 80 LOAD_CONST 10 (('created_at',))
+ 82 MATCH_KEYS
+ 84 POP_JUMP_IF_FALSE 61 (to 122)
+ 86 DUP_TOP
+ 88 LOAD_CONST 4 (0)
+ 90 BINARY_SUBSCR
+ 92 ROT_N 8
+ 94 POP_TOP
+ 96 POP_TOP
+ 98 POP_TOP
+ 100 POP_TOP
+ 102 POP_TOP
+ 104 POP_TOP
+ 106 STORE_FAST 0 (closed)
+ 108 STORE_FAST 1 (commented)
+
+ 6 110 LOAD_FAST 0 (closed)
+ 112 LOAD_FAST 1 (commented)
+ 114 COMPARE_OP 2 (==)
+ 116 POP_JUMP_IF_FALSE 70 (to 140)
+
+ 10 118 LOAD_CONST 0 (None)
+ 120 RETURN_VALUE
+
+ 3 >> 122 POP_TOP
+ >> 124 POP_TOP
+ >> 126 POP_TOP
+ >> 128 POP_TOP
+ >> 130 POP_TOP
+ 132 POP_TOP
+ >> 134 POP_TOP
+ 136 LOAD_CONST 0 (None)
+ 138 RETURN_VALUE
+
+ 6 >> 140 LOAD_CONST 0 (None)
+ 142 RETURN_VALUE
+```
+
+虽然很长,但您可以大致了解它在做什么:检查该值是否是包含至少两个键(字节码 2-12)的映射(字典),然后检查它是否包含我们将要检查的两个特定键( 18-22)。查看第一个键的值,检查它是否是一个至少有一个键(24-40)的字典,等等。
+
+手写这些类型的检查可能会导致字节码更短。例如,我已经知道 event 的值是一个字典,因为这是 GitHub API 向我承诺的,因此无需每次都显式检查它。但 Python 代码会更加曲折且更难执行正确。我最初对 match/case 持怀疑态度,但这个例子显示了它的一个明显的优势。
\ No newline at end of file
diff --git "a/Python Common/\351\235\242\350\257\225\344\270\255\351\201\207\345\210\260\347\232\204\351\227\256\351\242\230\344\273\254\342\200\246\342\200\246.ipynb" "b/Python Common/\351\235\242\350\257\225\344\270\255\351\201\207\345\210\260\347\232\204\351\227\256\351\242\230\344\273\254\342\200\246\342\200\246.ipynb"
deleted file mode 100644
index 813de1e..0000000
--- "a/Python Common/\351\235\242\350\257\225\344\270\255\351\201\207\345\210\260\347\232\204\351\227\256\351\242\230\344\273\254\342\200\246\342\200\246.ipynb"
+++ /dev/null
@@ -1,177 +0,0 @@
-{
- "metadata": {
- "name": "\u9762\u8bd5\u4e2d\u9047\u5230\u7684\u95ee\u9898\u4eec\u2026\u2026"
- },
- "nbformat": 2,
- "worksheets": [
- {
- "cells": [
- {
- "cell_type": "code",
- "collapsed": false,
- "input": [
- "# list\u7684\u62f7\u8d1d\u4e0e\u5206\u7247",
- "list1 = ['a','b','c','d','e']",
- "list2 = list1",
- "list1[1] = 'xxx'",
- "print \"list1: id=\",id(list1), \"value=\", list1",
- "print \"list2: id=\",id(list2), \"value=\", list2",
- "# \u8bf4\u660e\uff1apython\u666e\u901a\u7684\u62f7\u8d1d\u53ea\u662f\u521b\u5efa\u539f\u59cb\u5bf9\u8c61\u7684\u4e00\u4e2a\u5f15\u7528\u3002",
- "# \u56e0\u6b64\uff0c\u5f53\u5bf9a\u505a\u4e86\u4efb\u4f55\u6539\u52a8\u90fd\u4f1a\u76f4\u63a5\u5f71\u54cd\u5230b\u3002",
- "# \u4eceid\u4e5f\u53ef\u4ee5\u770b\u5230\uff0ca\u548cb\u6307\u5411\u7684\u662f\u5b8c\u5168\u4e00\u6837\u7684\u5bf9\u8c61\u3002",
- "print list1[10:]",
- "# \u8bf4\u660e\uff1a\u5217\u8868\u7684\u5207\u7247\u64cd\u4f5c\u4e2d\uff0c\u82e5begin/end index\u8d85\u51fa\u4e86\u5217\u8868\u7684index\u8303\u56f4\uff0c",
- "# \u4e0d\u4f1a\u8fd4\u56deIndexError\uff0c\u800c\u662f\u4f1a\u8fd4\u56de\u4e00\u4e2a\u7a7a\u7684\u5217\u8868"
- ],
- "language": "python",
- "outputs": [
- {
- "output_type": "stream",
- "stream": "stdout",
- "text": [
- "list1: id= 41922608 value= ['a', 'xxx', 'c', 'd', 'e']",
- "list2: id= 41922608 value= ['a', 'xxx', 'c', 'd', 'e']",
- "[]"
- ]
- }
- ],
- "prompt_number": 6
- },
- {
- "cell_type": "code",
- "collapsed": false,
- "input": [
- "# \u53c2\u6570\u7c7b\u578b\u53ca\u5176\u533a\u522b",
- "# \u89c1\uff1ahttps://github.com/ictar/pythondocument/blob/master/Python%20Common/3.5.1/glossary.md#\u53c2\u6570argument",
- "# \u4e5f\u89c1\uff1ahttps://github.com/ictar/pythondocument/blob/master/Python%20Common/3.5.1/glossary.md#\u53c2\u6570parameter",
- "addi = lambda a,b : a + b",
- "# 1. \u5173\u952e\u5b57\u53c2\u6570\uff1a\u51fd\u6570\u8c03\u7528\u524d\u9762\u6709\u4e00\u4e2a\u6807\u8bc6\u7b26\u7684\u53c2\u6570\u6216\u8005\u503c\u901a\u8fc7\u5728\u5b57\u5178\u524d\u52a0**\u4f20\u9012\u7684\u53c2\u6570\u3002\u4f8b\u5982",
- "print addi(a=3,b=5)",
- "print addi(**{'a':3,'b':5})",
- "# 2. \u4f4d\u7f6e\u53c2\u6570\uff1a\u4e0d\u662f\u5173\u952e\u5b57\u53c2\u6570\u7684\u53c2\u6570\u3002",
- "# \u4f4d\u7f6e\u53c2\u6570\u53ef\u4ee5\u51fa\u73b0\u5728\u53c2\u6570\u5217\u8868\u7684\u8d77\u59cb\u4f4d\u7f6e\uff0c\u53ca\uff08\u6216\u8005\uff09\u901a\u8fc7\u5728\u4e00\u4e2a\u53ef\u8fed\u4ee3\u5bf9\u8c61\u7684\u5143\u7d20\u524d\u52a0*\u8fdb\u884c\u4f20\u9012\u3002\u4f8b\u5982",
- "print addi(3,5)",
- "print addi(*(3,5))"
- ],
- "language": "python",
- "outputs": [
- {
- "output_type": "stream",
- "stream": "stdout",
- "text": [
- "8",
- "8",
- "8",
- "8"
- ]
- }
- ],
- "prompt_number": 5
- },
- {
- "cell_type": "code",
- "collapsed": true,
- "input": [
- "# \u9759\u6001\u51fd\u6570\uff0c\u7c7b\u51fd\u6570\uff0c\u6210\u5458\u51fd\u6570",
- "# \u9759\u6001\u51fd\u6570(@staticmethod): \u5373\u9759\u6001\u65b9\u6cd5,\u4e3b\u8981\u5904\u7406\u4e0e\u8fd9\u4e2a\u7c7b\u7684\u903b\u8f91\u5173\u8054, \u5982\u9a8c\u8bc1\u6570\u636e;",
- "# \u7c7b\u51fd\u6570(@classmethod):\u5373\u7c7b\u65b9\u6cd5, \u66f4\u5173\u6ce8\u4e8e\u4ece\u7c7b\u4e2d\u8c03\u7528\u65b9\u6cd5, \u800c\u4e0d\u662f\u5728\u5b9e\u4f8b\u4e2d\u8c03\u7528\u65b9\u6cd5, \u5982\u6784\u9020\u91cd\u8f7d;",
- "# \u6210\u5458\u51fd\u6570: \u5b9e\u4f8b\u7684\u65b9\u6cd5, \u53ea\u80fd\u901a\u8fc7\u5b9e\u4f8b\u8fdb\u884c\u8c03\u7528;",
- "class Person:",
- " grade=1",
- " def __init__(self,name):",
- " self.name = name",
- " ",
- " def sayHi(self):#\u52a0self\u533a\u522b\u4e8e\u666e\u901a\u51fd\u6570",
- " print 'Hello, your name is?',self.name",
- " ",
- " # \u58f0\u660e\u9759\u6001\uff0c\u53bb\u6389\u5219\u7f16\u8bd1\u62a5\u9519;\u8fd8\u6709\u9759\u6001\u65b9\u6cd5\u4e0d\u80fd\u8bbf\u95ee\u7c7b\u53d8\u91cf\u548c\u5b9e\u4f8b\u53d8\u91cf",
- " # \u597d\u5904\uff1a\u4e0d\u9700\u8981\u5b9a\u4e49\u5b9e\u4f8b\u5373\u53ef\u4f7f\u7528\u8fd9\u4e2a\u65b9\u6cd5\u3002\u53e6\u5916\uff0c\u591a\u4e2a\u5b9e\u4f8b\u5171\u4eab\u6b64\u9759\u6001\u65b9\u6cd5\u3002 ",
- " @staticmethod",
- " def sayName():#\u4f7f\u7528\u4e86\u9759\u6001\u65b9\u6cd5\uff0c\u5219\u4e0d\u80fd\u518d\u4f7f\u7528self",
- " print \"my name is king\"#,grade,#self.name",
- " ",
- " # \u7c7b\u65b9\u6cd5\uff1a\u4e00\u4e2a\u7c7b\u65b9\u6cd5\u5c31\u53ef\u4ee5\u901a\u8fc7\u7c7b\u6216\u5b83\u7684\u5b9e\u4f8b\u6765\u8c03\u7528\u7684\u65b9\u6cd5, ",
- " # \u4e0d\u7ba1\u4f60\u662f\u7528\u7c7b\u6765\u8c03\u7528\u8fd9\u4e2a\u65b9\u6cd5\u8fd8\u662f\u7c7b\u5b9e\u4f8b\u8c03\u7528\u8fd9\u4e2a\u65b9\u6cd5,\u8be5\u65b9\u6cd5\u7684\u7b2c\u4e00\u4e2a\u53c2\u6570\u603b\u662f\u5b9a\u4e49\u8be5\u65b9\u6cd5\u7684\u7c7b\u5bf9\u8c61\u3002",
- " @classmethod",
- " def classMethod(cls):",
- " print(\"class method\") "
- ],
- "language": "python",
- "outputs": []
- },
- {
- "cell_type": "code",
- "collapsed": false,
- "input": [
- "# \u5185\u5efa\u51fd\u6570\uff1amap, reduce, filter",
- "# map(function, sequence[, sequence, ...]) -> list",
- "# \u5c06\u51fd\u6570function\u4f5c\u7528\u4e8e\u7ed9\u5b9a\u5e8f\u5217\u7684\u6bcf\u4e2a\u5143\u7d20\uff0c\u5e76\u7528\u4e00\u4e2a\u5217\u8868\u6765\u63d0\u4f9b\u8fd4\u56de\u503c",
- "print map(lambda x: x*2, [1,2,3,4])",
- "# \u82e5function\u4e3aNone\uff0cfunction\u8868\u73b0\u4e3a\u8eab\u4efd\u51fd\u6570\uff0c\u8fd4\u56de\u4e00\u4e2a\u542b\u6709\u6bcf\u4e2a\u5e8f\u5217\u4e2d\u5143\u7d20\u96c6\u5408\u7684n\u4e2a\u5143\u7ec4\u7684\u5217\u8868",
- "print map(None,[1,2,3,4], [1,2,3,4,5])",
- "# reduce(function, sequence[, initial]) -> value",
- "# function\u4e3a\u4e8c\u5143\u51fd\u6570\uff0c\u5c06function\u4f5c\u7528\u4e8esequence\u5e8f\u5217\u7684\u5143\u7d20\uff0c\u6bcf\u6b21\u643a\u5e26\u4e00\u5bf9\uff0c",
- "# \u8fde\u7eed\u7684\u5c06\u73b0\u6709\u7ed3\u679c\u548c\u4e0b\u4e00\u4e2a\u503c\u4f5c\u7528\u5728\u83b7\u5f97\u7684\u968f\u540e\u7684\u7ed3\u679c\u4e0a\uff0c\u6700\u540e\u51cf\u5c11\u6211\u4eec\u7684\u5e8f\u5217\u4e3a\u4e00\u4e2a\u5355\u4e00\u7684\u8fd4\u56de\u503c",
- "# \u82e5\u7ed9\u5b9a\u521d\u59cb\u503cinitial\uff0c\u5219\u7b2c\u4e00\u4e2a\u6bd4\u8f83\u4f1a\u662finitial\u548c\u7b2c\u4e00\u4e2a\u5e8f\u5217\u5143\u7d20\u800c\u4e0d\u662f\u5e8f\u5217\u7684\u5934\u4e24\u4e2a\u5143\u7d20",
- "print reduce(lambda x,y: x+y, [1,2,3,4])",
- "print reduce(lambda x,y: x+y, [1,2,3,4], 10)",
- "# filter(function or None, sequence) -> list, tuple, or strin",
- "# \u8fc7\u6ee4\u5668\u3002\u8c03\u7528\u51fd\u6570function\u6765\u8fed\u4ee3\u904d\u5386sequence\u4e2d\u6bcf\u4e2a\u5143\u7d20\uff0c\u8fd4\u56de\u4e00\u4e2a\u4f7ffunction\u8fd4\u56de\u503c\u4e3atrue\u7684\u5143\u7d20\u5217\u8868",
- "print filter(lambda x: x%2 == 0, [1,2,3,4,5])"
- ],
- "language": "python",
- "outputs": [
- {
- "output_type": "stream",
- "stream": "stdout",
- "text": [
- "[2, 4, 6, 8]",
- "[(1, 1), (2, 2), (3, 3), (4, 4), (None, 5)]",
- "10",
- "20",
- "[2, 4]"
- ]
- }
- ],
- "prompt_number": 13
- },
- {
- "cell_type": "code",
- "collapsed": false,
- "input": [
- "# \u5185\u5efa\u51fd\u6570\uff1aall, any",
- "# all(iterable) -> bool",
- "# \u5982\u679citerable\u7684\u6240\u6709\u5143\u7d20\u4e0d\u4e3a0\u3001''\u3001False\u6216\u8005iterable\u4e3a\u7a7a\uff0call(iterable)\u8fd4\u56deTrue\uff0c\u5426\u5219\u8fd4\u56deFalse\uff1b",
- "print all([2, 4, 6, 8])",
- "print all([2, 4, 6, 8,0])",
- "# any(iterable) -> bool",
- "# \u5982\u679citerable\u7684\u4efb\u4f55\u4e00\u4e2a\u5143\u7d20\u4e0d\u4e3a0\u3001''\u3001False,any(iterable)\u8fd4\u56deTrue\u3002\u5982\u679citerable\u4e3a\u7a7a\uff0c\u8fd4\u56deFalse\u3002",
- "print any([2, 4, 6, 8])",
- "print any([2, 4, 6, 8,0])"
- ],
- "language": "python",
- "outputs": [
- {
- "output_type": "stream",
- "stream": "stdout",
- "text": [
- "True",
- "False",
- "True",
- "True"
- ]
- }
- ],
- "prompt_number": 16
- },
- {
- "cell_type": "code",
- "collapsed": true,
- "input": [],
- "language": "python",
- "outputs": []
- }
- ]
- }
- ]
-}
\ No newline at end of file
diff --git a/Python Weekly/Python Weekly Issue 243.md b/Python Weekly/Python_Weekly_Issue_243.md
similarity index 99%
rename from Python Weekly/Python Weekly Issue 243.md
rename to Python Weekly/Python_Weekly_Issue_243.md
index f8fffd0..dae0a83 100644
--- a/Python Weekly/Python Weekly Issue 243.md
+++ b/Python Weekly/Python_Weekly_Issue_243.md
@@ -48,7 +48,7 @@
[Django, ELB健康检查和持续交付](http://tech.octopus.energy/2016/05/05/django-elb-health-checks.html)
-[中文版](../Django/Django, ELB健康检查和持续交付.md)
+[中文版](../Django/Django%2C%20ELB健康检查和持续交付.md)
[Python, Postgres, SQLAlchemy, 和PGA Tour Stats](https://bigishdata.com/2016/05/08/python-postgres-sqlalchemy-and-pga-tour-stats/)
diff --git a/Python Weekly/Python Weekly Issue 244.md b/Python Weekly/Python_Weekly_Issue_244.md
similarity index 98%
rename from Python Weekly/Python Weekly Issue 244.md
rename to Python Weekly/Python_Weekly_Issue_244.md
index 68302ba..ca07783 100644
--- a/Python Weekly/Python Weekly Issue 244.md
+++ b/Python Weekly/Python_Weekly_Issue_244.md
@@ -36,7 +36,7 @@ Bot是Slack通道和外部应用直接一个超级有用的桥梁。让我们编
在这个matplotlib教程中,我们将介绍该库的基本知识,并看看如何进行一些中间可视化。我们将使用包含将近240,000条关于Hillary Clinton, Donald Trump, 和Bernie Sanders,目前所有美国总统候选人的推特的数据集。
-[中文版](../Science and Data Analysis/Matplotlib教程 - 绘制提到Trump, Clinton & Sanders的推特.md)
+[中文版](../Science%20and%20Data%20Analysis/Matplotlib教程%20-%20绘制提到Trump,%20Clinton%20&%20Sanders的推特.md)
[Episode #58: 使用并发,库和模式创建更好的Python程序](https://talkpython.fm/episodes/show/58/create-better-python-programs-with-concurrency-libraries-and-patterns)
diff --git a/Python Weekly/Python Weekly Issue 245.md b/Python Weekly/Python_Weekly_Issue_245.md
similarity index 98%
rename from Python Weekly/Python Weekly Issue 245.md
rename to Python Weekly/Python_Weekly_Issue_245.md
index 20195d1..a87ca9c 100644
--- a/Python Weekly/Python Weekly Issue 245.md
+++ b/Python Weekly/Python_Weekly_Issue_245.md
@@ -24,7 +24,7 @@ PyConIE 2016的建议征集现已开放。格式将由两个座谈轨迹和两
在这个notebook上,我们将开发一个机器学习模型来预测纽约的出租车需求。
-[中文版](../Science and Data Analysis/使用BigQuery和TensorFlow进行需求预测.md)
+[中文版](../Science%20and%20Data%20Analysis/使用BigQuery和TensorFlow进行需求预测.md)
[Episode #60:使用Ufora将Python缩放到1000个内核上](https://talkpython.fm/episodes/show/60/scaling-python-to-1000-s-of-cores-with-ufora)
diff --git a/Python Weekly/Python Weekly Issue 246.md b/Python Weekly/Python_Weekly_Issue_246.md
similarity index 98%
rename from Python Weekly/Python Weekly Issue 246.md
rename to Python Weekly/Python_Weekly_Issue_246.md
index 3ebe6eb..e657dbb 100644
--- a/Python Weekly/Python Weekly Issue 246.md
+++ b/Python Weekly/Python_Weekly_Issue_246.md
@@ -29,7 +29,7 @@ SortedContainers在大规模上运行得相当好。本文在理论和实践层
[使用Pandas, Docker和OS(R)M,猜测神秘的旅游地点](http://nbviewer.jupyter.org/gist/mhermans/8c32eea0d5ec29e6b4329acbe7f0d3de)
-[中文版](../Science and Data Analysis/使用Pandas, Docker和OS(R)M来猜测神秘的旅行地.md)
+[中文版](../Science%20and%20Data%20Analysis/使用Pandas,%20Docker和OS(R)M来猜测神秘的旅行地.md)
[带django教程的Facebook聊天机器人,又名笑话机器人](https://codeexperiments.quora.com/Facebook-chat-bot-aka-joke-bot-with-django-tutorial)
diff --git a/Python Weekly/Python Weekly Issue 247.md b/Python Weekly/Python_Weekly_Issue_247.md
similarity index 98%
rename from Python Weekly/Python Weekly Issue 247.md
rename to Python Weekly/Python_Weekly_Issue_247.md
index d0db271..1a51119 100644
--- a/Python Weekly/Python Weekly Issue 247.md
+++ b/Python Weekly/Python_Weekly_Issue_247.md
@@ -37,7 +37,7 @@ ensembles可以为你的数据集提供一个精度的飞跃。在这篇文章
在本教程中,我们将提出几个简单但是有效的方法,你可以只用很少的训练样本就可以构建一个强大的图像分类器 —— 只需你想要识别的每个类中几百或几千图片。
-[中文版](../Machine Learning/使用非常少的数据构建强大的图像分类模型.md)
+[中文版](../Machine%20Learning/使用非常少的数据构建强大的图像分类模型.md)
[Python大肆宣传调查结果](https://www.linkedin.com/pulse/python-hype-survey-results-experience-any-drastic-decline-brian-ray)
diff --git a/Python Weekly/Python Weekly Issue 248.md b/Python Weekly/Python_Weekly_Issue_248.md
similarity index 96%
rename from Python Weekly/Python Weekly Issue 248.md
rename to Python Weekly/Python_Weekly_Issue_248.md
index 54324f0..abaa76d 100644
--- a/Python Weekly/Python Weekly Issue 248.md
+++ b/Python Weekly/Python_Weekly_Issue_248.md
@@ -43,7 +43,7 @@
本文我们将看到过滤pandas DataFrame和更新基于各种标准的数据的一些例子。使用这种方式,我将解释一些关于pandas索引以及如何基于简单或复杂的条件,使用诸如.loc , .ix 和.iloc的索引方法来快速容易的更新数据子集。
-[在有限预算上计算最佳公路旅行](http://www.randalolson.com/2016/06/05/computing-optimal-road-trips-on-a-limited-budget/) [中文版](../Machine Learning/在有限预算上计算最佳公路旅行.md)
+[在有限预算上计算最佳公路旅行](http://www.randalolson.com/2016/06/05/computing-optimal-road-trips-on-a-limited-budget/) [中文版](../Machine%20Learning/在有限预算上计算最佳公路旅行.md)
本文通过引入多目标Pareto最优化到算法中,以扩展优化公路旅行的想法。它简要介绍了Pareto最优化是如何工作的,以及它在有限的预算下,是如何帮助我们优化公路旅行的。
@@ -61,11 +61,11 @@
[用变分推理估计PyMC3中的神经网络](http://twiecki.github.io/blog/2016/06/01/bayesian-deep-learning/)
-[在Python中实现你自己的推荐系统](http://online.cambridgecoding.com/notebooks/eWReNYcAfB/implementing-your-own-recommender-systems-in-python-2) [../Science and Data Analysis/在Python中实现你自己的推荐系统.md]
+[在Python中实现你自己的推荐系统](http://online.cambridgecoding.com/notebooks/eWReNYcAfB/implementing-your-own-recommender-systems-in-python-2) [../Science%20and%20Data%20Analysis/在Python中实现你自己的推荐系统.md]
[设置深度学习硬件时的注意事项](http://www.pyimagesearch.com/2016/06/13/considerations-when-setting-up-deep-learning-hardware/)
-[Python中一个简单的基于内容的推荐引擎](http://blog.untrod.com/2016/06/simple-similar-products-recommendation-engine-in-python.html) ([中文版](../Science and Data Analysis/Python中一个简单的基于内容的推荐引擎.md))
+[Python中一个简单的基于内容的推荐引擎](http://blog.untrod.com/2016/06/simple-similar-products-recommendation-engine-in-python.html) ([中文版](../Science%20and%20Data%20Analysis/Python中一个简单的基于内容的推荐引擎.md))
# 本周的Python工作
diff --git a/Python Weekly/Python Weekly Issue 249.md b/Python Weekly/Python_Weekly_Issue_249.md
similarity index 100%
rename from Python Weekly/Python Weekly Issue 249.md
rename to Python Weekly/Python_Weekly_Issue_249.md
diff --git a/Python Weekly/Python Weekly Issue 250.md b/Python Weekly/Python_Weekly_Issue_250.md
similarity index 97%
rename from Python Weekly/Python Weekly Issue 250.md
rename to Python Weekly/Python_Weekly_Issue_250.md
index 3de8f1c..6b2eb14 100644
--- a/Python Weekly/Python Weekly Issue 250.md
+++ b/Python Weekly/Python_Weekly_Issue_250.md
@@ -30,9 +30,9 @@ Armin Ronacher是Python软件生态圈的一个多产贡献者,他创造了诸
本文展示了如何使用Plotly和Python,在3D中绘制客户服务指标。
-[分析权力游戏图表](http://www.lyonwj.com/2016/06/26/graph-of-thrones-neo4j-social-network-analysis/) | [中文版](../Science and Data Analysis/分析权力游戏图表.md)
+[分析权力游戏图表](http://www.lyonwj.com/2016/06/26/graph-of-thrones-neo4j-social-network-analysis/) | [中文版](../Science%20and%20Data%20Analysis/分析权力游戏图表.md)
-[使用Python探索NFL选秀](http://savvastjortjoglou.com/nfl-draft.html) | [中文版](../Science and Data Analysis/使用Python探索NFL选秀.md)
+[使用Python探索NFL选秀](http://savvastjortjoglou.com/nfl-draft.html) | [中文版](../Science%20and%20Data%20Analysis/使用Python探索NFL选秀.md)
[第65集:使用RethinkDB,扑向实时网络](https://talkpython.fm/episodes/show/65/jump-on-the-real-time-web-with-rethinkdb)
diff --git a/Python Weekly/Python Weekly Issue 251.md b/Python Weekly/Python_Weekly_Issue_251.md
similarity index 100%
rename from Python Weekly/Python Weekly Issue 251.md
rename to Python Weekly/Python_Weekly_Issue_251.md
diff --git a/Python Weekly/Python Weekly Issue 252.md b/Python Weekly/Python_Weekly_Issue_252.md
similarity index 100%
rename from Python Weekly/Python Weekly Issue 252.md
rename to Python Weekly/Python_Weekly_Issue_252.md
diff --git a/Python Weekly/Python Weekly Issue 253.md b/Python Weekly/Python_Weekly_Issue_253.md
similarity index 97%
rename from Python Weekly/Python Weekly Issue 253.md
rename to Python Weekly/Python_Weekly_Issue_253.md
index a3d6022..9024a36 100644
--- a/Python Weekly/Python Weekly Issue 253.md
+++ b/Python Weekly/Python_Weekly_Issue_253.md
@@ -19,7 +19,7 @@
# 文章,教程和讲座
-[对超过1M的酒店点评进行机器学习,发现有趣的见解](https://blog.monkeylearn.com/machine-learning-1m-hotel-reviews-finds-interesting-insights/) | [中文版](../Machine Learning/对超过1M的酒店点评进行机器学习,发现有趣的见解.md)
+[对超过1M的酒店点评进行机器学习,发现有趣的见解](https://blog.monkeylearn.com/machine-learning-1m-hotel-reviews-finds-interesting-insights/) | [中文版](../Machine%20Learning/对超过1M的酒店点评进行机器学习,发现有趣的见解.md)
本文中,我们将涵盖可以如何使用这些机器学习模型来分析数百万条来自于TripAdvisor的点评,然后比较人们对不同城市的酒店的感受,来学习各种有趣的事情。
@@ -45,7 +45,7 @@ Scrapy被设计成可扩展的,并且组件之间松耦合。你可以使用
[映射瑞典小镇名字的原子部分](http://maxberggren.se/2016/07/14/atomic-parts-of-town-names/)
-[Python, GIL, 和Pyston](http://blog.kevmod.com/2014/06/python-the-gil-and-pyston/) [中文版](../Others/Python, GIL, 和Pyston.md)
+[Python, GIL, 和Pyston](http://blog.kevmod.com/2014/06/python-the-gil-and-pyston/) [中文版](../Others/Python,%20GIL,%20和Pyston.md)
[SciPy 2016视频](https://www.youtube.com/playlist?list=PLGB9meziqbzpRP7mVyihOihNzm_J2Kx9I)
diff --git a/Python Weekly/Python Weekly Issue 254.md b/Python Weekly/Python_Weekly_Issue_254.md
similarity index 98%
rename from Python Weekly/Python Weekly Issue 254.md
rename to Python Weekly/Python_Weekly_Issue_254.md
index 0651caa..dafbdf8 100644
--- a/Python Weekly/Python Weekly Issue 254.md
+++ b/Python Weekly/Python_Weekly_Issue_254.md
@@ -18,11 +18,11 @@
你有博客吗?在上面,你写了多少篇文章呢?你有没有发现一直写作,或者开始进行一些技术写作很难呢?本周,我们或许可以帮助你解决这些问题。
-[如何扩展Django User Model](http://simpleisbetterthancomplex.com/tutorial/2016/07/22/how-to-extend-django-user-model.html) | [中文版](../Django/如何扩展Django User模型.md)
+[如何扩展Django User Model](http://simpleisbetterthancomplex.com/tutorial/2016/07/22/how-to-extend-django-user-model.html) | [中文版](../Django/如何扩展Django%20User模型.md)
本教程介绍了一些策略,你可以用它们来简单的扩展默认的Django User Model,这样,你就无需一切从头开始。
-[我是如何构建一个Slack机器人来帮助我在San Francisco找房子的](https://www.dataquest.io/blog/apartment-finding-slackbot/) | [中文版](../Others/我是如何构建一个Slack机器人来帮助我在San Francisco找房子的.md)
+[我是如何构建一个Slack机器人来帮助我在San Francisco找房子的](https://www.dataquest.io/blog/apartment-finding-slackbot/) | [中文版](../Others/我是如何构建一个Slack机器人来帮助我在San%20Francisco找房子的.md)
[机器学习很好玩!第四部分:使用深度学习进行面部识别](https://medium.com/@ageitgey/machine-learning-is-fun-part-4-modern-face-recognition-with-deep-learning-c3cffc121d78)
@@ -30,7 +30,7 @@
[愚蠢的Python技巧:滥用显式self](https://medium.com/@hwayne/stupid-python-tricks-abusing-explicit-self-53d46b72e9e0)
-[Django Channels和Celery示例](http://vincenttide.com/blog/1/django-channels-and-celery-example/) [中文版](../Django/Django Channels和Celery示例.md)
+[Django Channels和Celery示例](http://vincenttide.com/blog/1/django-channels-and-celery-example/) [中文版](../Django/Django%20Channels和Celery示例.md)
[为Numpy编写类型桩](http://www.machinalis.com/blog/writing-type-stubs-for-numpy/)
diff --git a/Python Weekly/Python Weekly Issue 255.md b/Python Weekly/Python_Weekly_Issue_255.md
similarity index 100%
rename from Python Weekly/Python Weekly Issue 255.md
rename to Python Weekly/Python_Weekly_Issue_255.md
diff --git a/Python Weekly/Python Weekly Issue 256.md b/Python Weekly/Python_Weekly_Issue_256.md
similarity index 98%
rename from Python Weekly/Python Weekly Issue 256.md
rename to Python Weekly/Python_Weekly_Issue_256.md
index 602ff74..fbaac35 100644
--- a/Python Weekly/Python Weekly Issue 256.md
+++ b/Python Weekly/Python_Weekly_Issue_256.md
@@ -29,7 +29,7 @@
在这篇文章中,你会发现可以如何使用scikit-learn Python机器学习库中的网格搜索功能来调Keras深度学习模型的超参数。
-[设计Pythonic API](http://noamelf.com/2016/08/05/designing-pythonic-apis/) | [中文](../Others/设计Pythonic API.md)
+[设计Pythonic API](http://noamelf.com/2016/08/05/designing-pythonic-apis/) | [中文](../Others/设计Pythonic%20API.md)
当编写一个包(库)的时候,为它提供一个良好的API,几乎与它的功能本身一样重要(好吧,至少你想要让别人使用),但怎么才算一个良好的API呢?在这篇文章中,我将尝试通过比较Requests和Urllib(Python标准库的一部分)在一些经典的HTTP场景的使用,从而提供关于这个问题的一些见解,并看看为什么Requests已经成为了Python用户中的事实上的标准。
@@ -51,7 +51,7 @@
[使用TensorFlow中的深度学习进行图像修复](http://bamos.github.io/2016/08/09/deep-completion/)
-[Requests vs. urllib:它解决了什么问题?](http://www.curiousefficiency.org/posts/2016/08/what-problem-does-it-solve.html) | [中文版](../Others/Requests vs. urllib:它解决了什么问题?.md)
+[Requests vs. urllib:它解决了什么问题?](http://www.curiousefficiency.org/posts/2016/08/what-problem-does-it-solve.html) | [中文版](../Others/Requests%20vs.%20urllib:它解决了什么问题?.md)
[EuroPython 2016年视频集](https://www.youtube.com/playlist?list=PL8uoeex94UhE3FDvjacSlHFffoNEoPzzm)
diff --git a/Python Weekly/Python Weekly Issue 257.md b/Python Weekly/Python_Weekly_Issue_257.md
similarity index 100%
rename from Python Weekly/Python Weekly Issue 257.md
rename to Python Weekly/Python_Weekly_Issue_257.md
diff --git a/Python Weekly/Python Weekly Issue 258.md b/Python Weekly/Python_Weekly_Issue_258.md
similarity index 97%
rename from Python Weekly/Python Weekly Issue 258.md
rename to Python Weekly/Python_Weekly_Issue_258.md
index ab1a263..7ff0ea1 100644
--- a/Python Weekly/Python Weekly Issue 258.md
+++ b/Python Weekly/Python_Weekly_Issue_258.md
@@ -25,7 +25,7 @@
这篇文章重温Tensorflow上的RNNs的使用最佳实践,特别是在官网上没有得到很好记录的特性。
-[Lists和Tuples大对决](http://nedbatchelder.com/blog/201608/lists_vs_tuples.html) | [中文版](../Python Common/Lists和Tuples大对决.md)
+[Lists和Tuples大对决](http://nedbatchelder.com/blog/201608/lists_vs_tuples.html) | [中文版](../Python%20Common/Lists和Tuples大对决.md)
常见的Python初学者问题:列表和元组之间有何区别?答案是,有两个不同的差异,以及两者之复杂的相互作用。这就是技术差异和文化差异。
@@ -41,7 +41,7 @@
这篇文章讨论了参数化学习和线性分类的基础知识。虽然简单,但是线性分类可以被看成更高级的机器学习算法基本构架模块,自然扩展到神经网络和卷积神经网络。
-[使用Python和LLVM的,用于TensorFlow计算图形的JIT本地代码生成](http://blog.christianperone.com/2016/08/jit-native-code-generation-for-tensorflow-computation-graphs-using-python-and-llvm/) [中文版](../Science and Data Analysis/用于格式化和数据清理的便捷Python库.md)
+[使用Python和LLVM的,用于TensorFlow计算图形的JIT本地代码生成](http://blog.christianperone.com/2016/08/jit-native-code-generation-for-tensorflow-computation-graphs-using-python-and-llvm/) [中文版](../Science%20and%20Data%20Analysis/用于格式化和数据清理的便捷Python库.md)
[Python JIT来了](https://lwn.net/Articles/691070/)
diff --git a/Python Weekly/Python Weekly Issue 259.md b/Python Weekly/Python_Weekly_Issue_259.md
similarity index 100%
rename from Python Weekly/Python Weekly Issue 259.md
rename to Python Weekly/Python_Weekly_Issue_259.md
diff --git a/Python Weekly/Python Weekly Issue 260.md b/Python Weekly/Python_Weekly_Issue_260.md
similarity index 97%
rename from Python Weekly/Python Weekly Issue 260.md
rename to Python Weekly/Python_Weekly_Issue_260.md
index c00b986..9c1b3b9 100644
--- a/Python Weekly/Python Weekly Issue 260.md
+++ b/Python Weekly/Python_Weekly_Issue_260.md
@@ -24,7 +24,7 @@ GeoViews是一个新的Python库,它使得探索和可视化地理,气象,
我们今天的客人是Michael Cuthbert,MIT的音乐方面的副教授,以及Music21项目的主要研究者,而Music21项目是我们讨论的重点。Music21是一个让音乐分析方便有趣的Python库。它支持与诸如MIDI, MusicXML, Lilypond等等流行格式的集成。它也与Elvis项目集成良好,允许用户导入大量的音乐,便于分析。Music21是音乐家和类似的机器学习研究人员探索音乐中模式和结构的一个很好的平台。
-[使用预测算法追踪实时健康趋势](http://blog.algorithmia.com/predictive-algorithms-track-real-time-health-trends/) | [中文](../Machine Learning/使用预测算法追踪实时健康趋势.md)
+[使用预测算法追踪实时健康趋势](http://blog.algorithmia.com/predictive-algorithms-track-real-time-health-trends/) | [中文](../Machine%20Learning/使用预测算法追踪实时健康趋势.md)
在这个教程中,我们将构建一个实时健康显示面板,用来追踪一个人的血压读数,进行时间序列分析,然后使用预测算法绘制时间趋势。本教程是使用时间序列算法和预测API来创建你个人健康显示面板的起点。
@@ -32,11 +32,11 @@ GeoViews是一个新的Python库,它使得探索和可视化地理,气象,
当前关于房租租赁的数据源,例如人口普查或商业数据库,关注大型公寓,它们并不反映近期的市场活动或者美国租赁市场的全概貌。为了填补这个缺失,我们收集,清理,分析,映射,并可视化一千一百万个Craigslist房租租赁房源。数据揭示了美国大城市住房市场内以及跨大城市住房市场的细粒度空间和时间模式。我们发现,一些大城市地区只有个位数百分比的低于公平市场租金的房源。自愿地理信息的非传统来源为规划人员提供当前在替代来源,例如人口普查数据,缺失的租赁和住房特征的实时的,局部尺度评估。
-[深度探索Python: 让我们审查dict模块](https://www.buzzfeed.com/andrewkelleher/deep-exploration-into-python-lets-review-the-dict-module) | [中文](../Python Common/深度探索Python:让我们审查dict模块.md)
+[深度探索Python: 让我们审查dict模块](https://www.buzzfeed.com/andrewkelleher/deep-exploration-into-python-lets-review-the-dict-module) | [中文](../Python%20Common/深度探索Python:让我们审查dict模块.md)
Dictobject.c是Python的dict对象背后的模块。它非常常用,但有一些鲜为人知的秘密,这些秘密对于了解最佳性能非常有用
-[分析iPhone步数数据](http://blog.yhat.com/posts/phone-steps-timeseries.html) | [中文](../Science and Data Analysis/分析iPhone步数数据.md)
+[分析iPhone步数数据](http://blog.yhat.com/posts/phone-steps-timeseries.html) | [中文](../Science%20and%20Data%20Analysis/分析iPhone步数数据.md)
本文展示了如何使用pandas timeseries和ggplot来分析iPhone步数数据。
diff --git a/Python Weekly/Python Weekly Issue 261.md b/Python Weekly/Python_Weekly_Issue_261.md
similarity index 98%
rename from Python Weekly/Python Weekly Issue 261.md
rename to Python Weekly/Python_Weekly_Issue_261.md
index 99e7bab..56ccca1 100644
--- a/Python Weekly/Python Weekly Issue 261.md
+++ b/Python Weekly/Python_Weekly_Issue_261.md
@@ -34,7 +34,7 @@ Django团队很高兴宣布,Channels项目现在是Django项目的官方的一
能够处理流数据对任何有抱负的数据科学家来说都是一项重要技能。在这篇文章中,我们将谈谈处理流数据的策略,并看看一个流化和存储来自Twitter数据的例子。
-[不可不知的一点Python陷阱](https://access.redhat.com/blogs/766093/posts/2592591) | [中文](../Python Common/不可不知的一点Python陷阱.md)
+[不可不知的一点Python陷阱](https://access.redhat.com/blogs/766093/posts/2592591) | [中文](../Python%20Common/不可不知的一点Python陷阱.md)
在这篇文章中,它主要针对Python新手,会看到少量安全相关的小技巧;有经验的开发者可能会注意到后面的特殊性。
diff --git a/Python Weekly/Python Weekly Issue 262.md b/Python Weekly/Python_Weekly_Issue_262.md
similarity index 95%
rename from Python Weekly/Python Weekly Issue 262.md
rename to Python Weekly/Python_Weekly_Issue_262.md
index 01c1a3e..9f2904b 100644
--- a/Python Weekly/Python Weekly Issue 262.md
+++ b/Python Weekly/Python_Weekly_Issue_262.md
@@ -11,7 +11,7 @@
# 文章,教程和讲座
-[用Python进行股票市场数据分析概述 (第一部分)](https://ntguardian.wordpress.com/2016/09/19/introduction-stock-market-data-python-1/) | [中文](../Science and Data Analysis/用Python进行股票市场数据分析概述 (第一部分).md)
+[用Python进行股票市场数据分析概述 (第一部分)](https://ntguardian.wordpress.com/2016/09/19/introduction-stock-market-data-python-1/) | [中文](../Science%20and%20Data%20Analysis/用Python进行股票市场数据分析概述%20(第一部分).md)
这篇文章是使用Python进行股票数据分析系列的两部分中的第一个部分,基于我在Utah大学为MATH 3900(数据科学)课题提供的一个讲座。在这些文章中,我会讨论到基础知识,例如使用pandas从Yahoo! Finance获取数据,可视化股票数据,移动均值,制定一个移动平均交叉策略,回测和基准。最后的一篇文章会包含实际问题。这第一篇文章讨论的主题到介绍移动均值。
@@ -19,7 +19,7 @@
深度学习、廉价硬件和目标识别大冒险。
-[压缩和增强手写笔记](https://mzucker.github.io/2016/09/20/noteshrink.html) | [中文版](../Image Processing/压缩和增强手写笔记.md)
+[压缩和增强手写笔记](https://mzucker.github.io/2016/09/20/noteshrink.html) | [中文版](../Image%20Processing/压缩和增强手写笔记.md)
这篇文章将向你展示如何写个程序来清理手写笔记扫描件,同时减少文件大小。
@@ -39,7 +39,7 @@ Sandstorm.io是一个创新平台,旨在让自托管应用对于普通人来
最近已经有一些文章从最终用户的角度反映Python包生态圈的现状,因此,作为该生态圈的主架构师之一,对我来说,值得从我的角度写写我如何描述软件出版发行的整体问题空间,此刻我认为我们所处的境地,以及我所希望看到的未来的发展。
-[使用Python,分析23AndMe数据,获取遗传起源](http://online.cambridgecoding.com/notebooks/cca_admin/genetic-ancestry-analysis-python) | [中文](../Science and Data Analysis/使用Python,分析23AndMe数据,获取遗传起源.md)
+[使用Python,分析23AndMe数据,获取遗传起源](http://online.cambridgecoding.com/notebooks/cca_admin/genetic-ancestry-analysis-python) | [中文](../Science%20and%20Data%20Analysis/使用Python,分析23AndMe数据,获取遗传起源.md)
你的DNA包含了关于你的主线,易患疾病以及复杂特性,包括身高、体重、五官和行为等丰富的信息。使用来自23andMe,一家直接面向消费者的遗传学公司,的公众可获取数据,我们将展示如何确定在网上找到的来自23andMe的一份匿名样本的祖先。
diff --git a/Python Weekly/Python Weekly Issue 263.md b/Python Weekly/Python_Weekly_Issue_263.md
similarity index 100%
rename from Python Weekly/Python Weekly Issue 263.md
rename to Python Weekly/Python_Weekly_Issue_263.md
diff --git a/Python Weekly/Python Weekly Issue 264.md b/Python Weekly/Python_Weekly_Issue_264.md
similarity index 99%
rename from Python Weekly/Python Weekly Issue 264.md
rename to Python Weekly/Python_Weekly_Issue_264.md
index 102117a..2e0ce3e 100644
--- a/Python Weekly/Python Weekly Issue 264.md
+++ b/Python Weekly/Python_Weekly_Issue_264.md
@@ -46,7 +46,7 @@
[网络效应说明:PageRank和偏好连接](https://medium.com/@bgoncalves/network-effects-explained-pagerank-and-preferential-attachment-61fdf93d023a)
-[了解Python类实例化](http://amir.rachum.com/blog/2016/10/03/understanding-python-class-instantiation/) | [中文](../Python Common/了解Python类实例化.md)
+[了解Python类实例化](http://amir.rachum.com/blog/2016/10/03/understanding-python-class-instantiation/) | [中文](../Python%20Common/了解Python类实例化.md)
# 书籍
diff --git a/Python Weekly/Python Weekly Issue 265.md b/Python Weekly/Python_Weekly_Issue_265.md
similarity index 100%
rename from Python Weekly/Python Weekly Issue 265.md
rename to Python Weekly/Python_Weekly_Issue_265.md
diff --git a/Python Weekly/Python Weekly Issue 266.md b/Python Weekly/Python_Weekly_Issue_266.md
similarity index 100%
rename from Python Weekly/Python Weekly Issue 266.md
rename to Python Weekly/Python_Weekly_Issue_266.md
diff --git a/Python Weekly/Python_Weekly_Issue_267.md b/Python Weekly/Python_Weekly_Issue_267.md
new file mode 100644
index 0000000..88714c1
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_267.md
@@ -0,0 +1,130 @@
+原文:[Python Weekly Issue 267](http://eepurl.com/clVF5r)
+
+欢迎来到Python周刊第267期。让我们直奔主题。
+
+# 新闻
+
+[现在,每个Python包都预装在了Repl.it —— 一个在线REPL](https://repl.it/site/blog/python-import)
+
+[PEP 531 —— 存在性检查操作符](https://www.python.org/dev/peps/pep-0531/)
+
+
+# 文章,教程和讲座
+
+[Episode #81: 天文学中的Python和机器学习](https://talkpython.fm/episodes/show/81/python-and-machine-learning-in-astronomy)
+
+在过去的一个世纪里,天文学的进步是人类聪明才智的最高层次的证据和证明。通过研究光的频率,我们学习到宇宙正在膨胀。通过观察水星的轨道,我们证明了爱因斯坦的广义相对论是正确的。当你知道Python和数据科学在当代天文学发挥着核心作用的时候,你可能不会感到惊讶。本周,你将会遇见Jake VanderPlas,一个来自华盛顿大学的天文学家和数据科学家。加入到Jake和我对天文学中Python的状态的讨论中来吧。
+
+[在Django ORM中解决性能问题](https://medium.com/@hansonkd/performance-problems-in-the-django-orm-1f62b3d04785)
+
+对于利用ORM,并没有一个一刀切的答案。大部分时候,小应用的性能增益并没什么大不了的。你应该首先寻求让你的代码变得清晰,然后才去优化它。随着你的应用的增长,在使用ORM的时候,进行好的清理是很重要的。现在,关于资源的消耗,养成良好的习惯将会在随后获得很大的好处。
+
+[Podcast.__init__ 第80集 - 和Sean Gillies聊聊把Python用于GIS](https://podcastinit.com/sean-gillies-python-gis.html)
+
+随着我们有了越来越多的连接到互联网的带GPS功能的设备,位置信息日渐成为软件系统一个相关的方面。GIS (地理资讯系统)是用来处理和分析这些数据的,幸运的是,Python拥有一套库来助力这些努力。本周,Sean Gillies,许多这些工具的作者和贡献者,会跟我们分享他职业生涯的故事及贡献,还有他在MapBox的工作。
+
+[防弹Django模型](https://medium.com/@hakibenita/bullet-proofing-django-models-c080739be4e)
+
+最近,我们添加了一个类银行账户的功能到我们其中一个产品中。在开发期间,我们遇到了一些教科书式问题,因此我认为这是重温我们在我们的Django模型中使用的一些模式的一个好机会。
+
+[如何编写你自己的Python文档生成器](https://medium.com/@tryexceptpass/python-introspection-with-the-inspect-module-2c85d5aa5a48)
+
+使用inspect模块进行检查。
+
+[使用Airflow调度Spark作业](https://blog.insightdatascience.com/scheduling-spark-jobs-with-airflow-4c66f3144660)
+
+本文介绍了如何使用Airflow来调度由从S3下载Reddit数据触发的Spark作业。
+
+[集成Pandas, Django REST框架和Bokeh](http://www.machinalis.com/blog/pandas-django-rest-framework-bokeh/)
+
+使用Pandas和Django REST框架使用基于Ajax的Bokeh图表。
+
+[使用Numpy进行图像处理](http://www.degeneratestate.org/posts/2016/Oct/23/image-processing-with-numpy/)
+
+[话说乡村歌曲中的卡车,啤酒和爱 —— 分析天才歌词](https://bigishdata.com/2016/10/25/talkin-bout-trucks-beer-and-love-in-country-songs-analyzing-genius-lyrics/)
+
+[隐式矩阵分解介绍](http://blog.ethanrosenthal.com/2016/10/19/implicit-mf-part-1/)
+
+[PyData DC 2016视频集](https://www.youtube.com/playlist?list=PLGVZCDnMOq0qLoYpkeySVtfdbQg1A_GiB)
+
+[在Python中开发CLI应用的轻松(漂亮)的方式](https://medium.com/@trstringer/the-easy-and-nice-way-to-do-cli-apps-in-python-5d9964dc950d)
+
+[不要把重要数据放到你的Celery队列中](https://www.caktusgroup.com/blog/2016/10/18/dont-keep-important-data-your-celery-queue/)
+
+[一个在Django使用Braintree的指南](https://blog.bitlabstudio.com/a-guide-for-using-braintree-in-django-53e99d677f71)
+
+[如何在Python中快速编写一个MapReduce框架](https://medium.com/@nidhog/how-to-quickly-write-a-mapreduce-framework-in-python-821a79fda554)
+
+[为Discord创建聊天机器人](https://medium.com/@sto5e/creating-chatbots-for-discord-90407e1bf382)
+
+
+# 书籍
+
+[Programming Raspberry Pi 3: Getting Started With Python](http://amzn.to/2fhhNTD)
+
+24小时内,学会使用树莓派套件,并且学会编写Python!这本指导书将会确保你具备对树莓派3进行编程的完整知识。
+
+
+# 本周Python工作
+
+[Patch招聘CTO/首席程序员](http://jobs.pythonweekly.com/jobs/cto-lead-developer/)
+
+Patch正在寻找CTO/首席程序员。作为扩张公司的一部分,我们正在扩展我们的技术团队。加入我们,有机会大大影响我们的电子商务平台,帮助规整我们正在创造的新服务。
+
+
+# 好玩的项目,工具和库
+
+[RapidSMS](https://www.rapidsms.org/)
+
+RapidSMS是一个用来按规模快速构建移动服务的免费开源框架。RapidSMS使用Python和Django构建的,设计来使用基于web的面板构建健壮且高度定制的移动服务。RapidSMS提供了一个灵活的平台和模块化组件,用来进行大规模数据收集、管理复杂工作流和自动化数据分析。
+
+[is-service-up](https://github.com/marcopaz/is-service-up)
+
+IsServiceUp帮助你在一个web页面中监控弄所有你依赖的云服务。你可以使用你想要监控的服务来对其自定义,并且在你自己的服务器上托管它。
+
+[DeepTeach](https://github.com/mldbai/deepteach)
+
+DeepTeach是一个MLDB.ai插件,允许用户通过一个迭代的过程,教会一个机器学习模型他正在寻找什么类型的图像。它是人类增强的一个好的例子,其中,机器学习被用来让人类更有效。
+
+[Deform](https://github.com/Pylons/deform)
+
+Deform是一个Python表单库,用来在服务端生成HTML表单。默认支持日期和时间选择小部件、富文本编辑器、带动态添加和删除功能的表单,以及起一些其他复杂用例。
+
+[paco](https://github.com/h2non/paco)
+
+用于在Python +3.4中进行协程驱动的基于异步的泛型编程的小工具库。
+
+[CNN-Sentence-Classifier](https://github.com/shagunsodhani/CNN-Sentence-Classifier)
+
+“用于句子分类的卷积神经网络(Convolutional Neural Networks for Sentence Classification)”论文的简化实现。
+
+[keras-molecules](https://github.com/maxhodak/keras-molecules)
+
+自动编码网络,用来学习分子结构的连续表示。
+
+[illuminOS](https://github.com/idimitrakopoulos/illuminOS)
+
+一个用于启用了WiFi的微控制器的基于SDK的开源MicroPython。
+
+[yip](https://github.com/balzss/yip)
+
+用来搜索PyPI的前端,一个功能丰富的pip搜索替代品。
+
+
+# 最新发布
+
+[MicroPython 1.8.5](https://github.com/micropython/micropython/releases/tag/v1.8.5)
+
+这个版本增加了一个新的MicroPython端口,来运行在Zephyr实时操作系统之上。作为这个的一部分,现在有了将mbedTLS作为ussl模块使用的基本支持。该版本还通过一个Python模块接口,带来了在具有低堆内存的裸机系统(例如esp8266)上运行包管理器upip的初始支持。
+
+[Django REST框架3.5](http://www.django-rest-framework.org/topics/3.5-announcement/)
+
+3.5版本时计划中的系列的第二个版本,它提供schema生成,超媒体支持,API客户端库,以及最后实时支持。
+
+
+# 近期活动和网络研讨会
+
+[线上事件 - 开放PyCraft编码服务器](https://www.facebook.com/events/552075598331982/)
+
+在周日,也就是10月30号,我们将有一个开放的PyCraft服务器。这是我们的PyCraft编码服务器,在上面,学生在“玩”Minecraft的时候,还可以学习编程。我们会运行一些有趣的脚本,让我们的客人四处看看,咨询我们导师问题,以及跟我们度过一段时间……或许甚至有机会运行一些脚本。
+
diff --git a/Python Weekly/Python_Weekly_Issue_268.md b/Python Weekly/Python_Weekly_Issue_268.md
new file mode 100644
index 0000000..4921acf
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_268.md
@@ -0,0 +1,124 @@
+原文:[Python Weekly Issue 268](http://eepurl.com/cmXU6X)
+
+---
+
+欢迎来到Python周刊第268期。让我们直奔主题。
+
+# 来自赞助商
+
+[](https://software.intel.com/en-us/intel-sdp-home)
+
+打破**Python****性能**壁垒,加速你的机器学习应用,快使用来自Intel的强大的Python工具吧。这个[视频](https://software.intel.com/en-us/videos/remove-python-performance-barriers-for-machine-learning)演示简单使用优化工具,例如Python的Intel发行版本和Intel VTune Amplifier,就可以获得额外的性能。
+
+
+# 新闻
+
+[PyCon Pune 2017 征集议题](https://pyconpune.talkfunnel.com/2017/)
+
+
+# 文章,教程和讲座
+
+[Episode #83: PyVideo上的即需Python视频](https://talkpython.fm/episodes/show/83/python-videos-on-demand-at-pyvideo)
+
+你是否曾经搜索过Python教育视频?也许是如何开始使用Pyramid,或者是使用SQLAlchemy的ORM层进行查询?那么极有可能你曾经偶然访问过PyVideo.org。这个惊人的网站收录了超过5,000个来自大部分来自别处的最近的Python会议的Python视频。根据演讲者、主题、事件等等进行浏览。本周,你将会遇到Paul Logston,他在该项目即将黄了的时候,接管了它的领导权。
+
+[如何使用R和Python应用人脸识别API技术到数据新闻中](https://benheubl.github.io/data%20analysis/fr/)
+
+Microsoft Emotion API是基于微软研究院在计算机视觉的最先进的研究,以及一个训练来对视频和图像中的人类面部表情进行分类的深度卷积神经网络模型。本文试着解释如何应用该API到数据驱动的报告中。
+
+[使用Python进行安斯库姆四重奏(Anscombe's quartet),差异性和队列研究](http://vknight.org/unpeudemath/mathematics/2016/10/29/anscombes-quartet-variability-and-ciw.html)
+
+安斯库姆四重奏(Anscombe's quartet)是完全理解数据集中的差异性的重要性的一个很好的例子:它是由四个具有相同统计特性(mean, std, 等等……)的数据集组成的集合,相同的相关性以及相同的回归线,但是具有非常不同的分布。本文,我将会展示使用Python来玩安斯库姆四重奏是有多容易,然后谈谈另一个数学领域,其中,必须完全理解差异性:队列研究。我将会使用Ciw python库来完成。
+
+[如何添加自定义的动作按钮到Django Admin](https://medium.com/@hakibenita/how-to-add-custom-action-buttons-to-django-admin-8d266f5b0d41)
+
+在上一篇文章中,我们展示了一种常用在我们的Django模型中的模式。我们用了一个银行账户应用,带有一个Account和账户Action模型,来证明我们处理一般问题(例如并发和验证)的方式。我们想将银行账户的两个操作放到admin界面上 —— 存款和取款。我们将添加用来存款和取款的按钮到Django admin界面上,并且我们会用少于100行代码来实现它!
+
+[如何添加社交网站登录到Django](https://simpleisbetterthancomplex.com/tutorial/2016/10/24/how-to-add-social-login-to-django.html)
+
+在本教程中,我们将使用python-social-auth库来实现Facebook, Twitter和GitHub身份验证。它们支持其他几个服务,而过程应该是有点类似的。python-social-auth库有几个自定义选项,这使得有时开始会有挑战。因此,对于本教程,我将通过必备步骤来引导你,最终,你将会拥有一个功能齐全的社交网站身份验证。
+
+[我不明白Python的Asyncio](http://lucumr.pocoo.org/2016/10/30/i-dont-understand-asyncio/)
+
+[使用Python,对Reddit上新的MPB进行情感分析](https://nbviewer.jupyter.org/github/knowsuchagency/mpb-sentiment-analysis-example/blob/master/index.ipynb)
+
+[为你的Django API自动生成炫酷文档](http://hirelofty.com/blog/auto-generate-swagger-docs-your-django-api/)
+
+[使用TensorFlow分类手写数字](http://blog.yhat.com/posts/handwriting-classifier-updated.html)
+
+[在iPython notebook中进行基于网络摄像头的图像处理](https://medium.com/@neotheicebird/webcam-based-image-processing-in-ipython-notebooks-47c75a022514)
+
+
+# 好玩的项目,工具和库
+
+[Clairvoyant](https://github.com/anfederico/Clairvoyant)
+
+使用股票历史数据,利用金融指标的任意组合来训练监督学习算法。快速测试模型的准确性和模拟投资组合的表现。
+
+[safety-db](https://github.com/pyupio/safety-db)
+
+一个不安全Python包的监管数据库。
+
+[neural-enhance](https://github.com/alexjc/neural-enhance)
+
+使用深度学习的图像超分辨率。
+
+[fast-style-transfer](https://github.com/lengstrom/fast-style-transfer)
+
+将来自于名画的风格添加到任意照片中,仅需几分之一秒!你甚至可以用在视频中!
+
+[tsfresh](https://github.com/blue-yonder/tsfresh)
+
+时间序列中的相关特性的自动提取。
+
+[minicache](https://github.com/duboviy/minicache)
+
+适用于Python 2和3版本,以及PyPy的Python内存缓存利器。
+
+[Stocktalk](https://github.com/anfederico/Stocktalk)
+
+用于社交媒体分析的数据收集工具包。
+
+[FlaskSR](https://github.com/arpitbbhayani/flasksr)
+
+通过HTTP响应流,FlaskSR提供给了一种简单的方式来让flask页面加载得更快更好。
+
+[PyHooks](https://github.com/Shir0kamii/pyhooks)
+
+PyHooks是为了公开用于类的方法钩子。
+
+[django-traffic](https://github.com/koslibpro/django-traffic/)
+
+Django中间件,帮助你在Kibana中可视化应用的流量。
+
+[easyargs](https://github.com/stedmeister/easyargs)
+
+一个让处理命令行参数容易的python模块。
+
+
+# 最新发布
+
+[Python 3.6.0b3](https://www.python.org/downloads/release/python-360b3/)
+
+[Django安全版本发行:1.10.3, 1.9.11和1.8.16](https://www.djangoproject.com/weblog/2016/nov/01/security-releases/)
+
+[pip 9.0](https://pip.pypa.io/en/stable/news/)
+
+
+# 近期活动和网络研讨会
+
+[San Francisco 2016年11月聚会 - San Francisco, CA](https://www.meetup.com/sfpython/events/234998005/)
+
+将会有以下演讲
+
+ * Word2vec算法:尽可能地简化,直到没法再简化为止
+ * 使用TensorFlow的递归神经网络
+
+
+[IndyPy 每月聚会(2016.10) - Indianapolis, IN](https://www.meetup.com/indypy/events/228228293/)
+
+这个月,Andy Harris将带给我们“如何开始像一个程序员一样思考 —— 即使你不相信你可以”。
+
+[Austin Python 2016年11月聚会 - Austin, TX](https://www.meetup.com/austinpython/events/232001931/)
+
+[VanPy 2016年11月聚会 - Vancouver, BC](https://www.meetup.com/vanpyz/events/234427836/)
\ No newline at end of file
diff --git a/Python Weekly/Python_Weekly_Issue_269.md b/Python Weekly/Python_Weekly_Issue_269.md
new file mode 100644
index 0000000..199d029
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_269.md
@@ -0,0 +1,99 @@
+原文:[Python Weekly Issue 269](http://eepurl.com/cn3QCX)
+
+---
+
+欢迎来到Python周刊第269期。让我们直奔主题。
+
+# 来自赞助商
+
+[](https://software.intel.com/en-us/intel-sdp-home)
+
+参加SC'16?注册[Intel HPCDevCon](http://www.intel.com/content/www/us/en/events/hpcdevcon/overview.html) 以及全天关于 [用于科学计算的高性能Python](http://sc16.supercomputing.org/presentation/?id=tut172&sess=sess193)的SC'16教程。参加我们的演讲,展会以及专家访谈,学习可以如何从我们为Python设计的性能优化工具受益。
+
+
+# 文章,教程和讲座
+
+[Texas死囚数据探索](http://signal-to-noise.xyz/texas-death-row.html)
+
+在[德州刑事司法部门](http://www.tdcj.state.tx.us)网站上,有一个页面,上面列举了所有自1982年起被执行死刑的人,恢复死刑的时间,以及他们的最后陈述。在这个项目中,我们将探索该数据,并且看看是否可以应用主题模型到陈述中。
+
+[通过Chainer,让复杂神经网络变得轻松起来](https://www.oreilly.com/learning/complex-neural-networks-made-easy-by-chainer)
+
+Chainer是一个开源框架,专为高效率研究和深度学习算法的发展而设。在这篇文章中,我们简单通过几个例子介绍了Chainer,并将其与其他框架,例如Caffe,
+Theano, Torch, 和Tensorflow,进行对比。
+
+[Pandas教程:Python中的DataFrame](https://www.datacamp.com/community/tutorials/pandas-tutorial-dataframe-python)
+
+本教程介绍了11种最流行的Pandas DataFrame问题,从而让你理解,以及避免,那些已经走在你之前的Python人的疑惑。
+
+[OSMnx: 用于街道网络的Python包](http://geoffboeing.com/2016/11/osmnx-python-street-networks/)
+
+OSMnx是一个Python包,用于从OpenStreetMap下载行政边界形状和街道网络。它让你能够轻松地在Python中利用NetworkX构造、设计、可视化以及分析复杂的街道网络。仅需一行Python代码,你就可以获得一个城市或者街区的步行、驾驶或者自行车网络。然后,你可以简单地可视化死胡同或者单向街道,绘制最短路径路线,或者计算统计数据,例如路口密度,平均节点连接,或者中介中心性。
+
+[离Django的GenericForeignKey远点](http://lukeplant.me.uk/blog/posts/avoid-django-genericforeignkey/)
+
+在Django中GenericForeignKey是这样的一个特性,它允许一个模型与系统中的其他模型相关联,与与特定的模型相关联的ForeignKey相对。这篇文章是关于为什么通常有时你应该离GenericForeignKey远点。
+
+[利用LightFM,探索Learning to Rank Sketchfab模型](http://blog.ethanrosenthal.com/2016/11/07/implicit-mf-part-2/)
+
+在这片文章中,我们将在上一篇介绍隐式矩阵分解的文章之后,做一堆很酷的事。我们将探索
+Learning to Rank,它是一个不同的隐式矩阵分解的方法,然后使用LightFM库来将边信息合并到我们的推荐系统中。接下来,我们会使用比网格搜索更智能的scikit-optimize来进行交叉验证超参数。最后,我们会看到,我们可以超越简单的用户到项和项到项推荐,现在,我们已经将边信息嵌入到yu与我们到用户和项一致到空间中了。
+
+[后异步/等待世界中,关于异步API设计的一些思考](https://vorpus.org/blog/some-thoughts-on-asynchronous-api-design-in-a-post-asyncawait-world/)
+
+[分析Berkeley的住房价格](http://aakashjapi.com/housing-prices-in-berkeley/)
+
+[Celery 4.0新特性](http://docs.celeryproject.org/en/latest/whatsnew-4.0.html)
+
+[为了乐趣与获利的Python中的计时测试](https://hackernoon.com/timing-tests-in-python-for-fun-and-profit-1663144571)
+
+[用Python实现Raspberry Pi条码扫描仪](https://medium.com/@yushulx/raspberry-pi-barcode-scanner-in-python-927839100c6b)
+
+
+# 好玩的项目,工具和库
+
+[stack-overflow-import](https://github.com/drathier/stack-overflow-import)
+
+从Stack Overflow中把任意代码当成Python模块导入。
+
+[Python cheatsheet](https://www.pythonsheets.com/)
+
+该工程试图提供大量的让生活更轻松的Python代码片段。
+
+[The Knowledge Repository](https://github.com/airbnb/knowledge-repo)
+
+为数据科学家和其他技术专家提供的下一代整理知识共享平台。
+
+[PyFME](https://github.com/AeroPython/PyFME)
+
+PyFME是Python Flight Mechanics Engine(Python飞行力学引擎)的简称。PyFME背后的目的是构建一个库,它能模拟飞行器在空中的动作,以及进行飞行中所有涉及的物理学建模。
+
+[Rewrite](https://github.com/kaonashi-tyc/Rewrite)
+
+汉字的神经式转换。
+
+[Kappa](https://github.com/garnaat/kappa)
+
+Kappa是一个致力于让部署、更新和测试AWS Lambda函数更简单的命令行工具。
+
+[JamDocs](http://jam-py.com/jamdocs/)
+
+JamDocs是一个用于Sphinx文档生成的Jam.py web界面。
+
+[Pyonic-interpreter](https://github.com/inclement/Pyonic-interpreter)
+
+Android上的Python解释器。
+
+[Colorful-Image-Colorization](https://github.com/cameronfabbri/Colorful-Image-Colorization)
+
+一种用以对图像着色的深度学习方法。
+
+
+# 近期活动和网络研讨会
+
+[Numba - 加速你的Python原来是辣么简单! - New York, NY](https://www.meetup.com/NYDataScientists/events/235403768/)
+
+[Edmonton Python 2016年11月聚会 - Edmonton, AB](https://www.meetup.com/startupedmonton/events/234340991/)
+
+[PyHou 2016年聚会 - Houston, TX](https://www.meetup.com/python-14/events/234195007/)
+
\ No newline at end of file
diff --git a/Python Weekly/Python_Weekly_Issue_270.md b/Python Weekly/Python_Weekly_Issue_270.md
new file mode 100644
index 0000000..2c981e2
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_270.md
@@ -0,0 +1,145 @@
+原文:[Python Weekly - Issue 270](http://eepurl.com/co55bH)
+
+---
+
+欢迎来到Python周刊第270期。让我们直奔主题。祝好。
+
+# 来自赞助商
+
+[](http://www.amazon.com/gp/product/B0185367JQ/ref=as_li_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=B0185367JQ&linkCode=as2&tag=mymerch-20&linkId=OLIXWD4WZ5X6FFHD)
+
+嘿,Python粉,你想要表达你对**Python**的爱吗?那么,[点击这里](http://www.amazon.com/gp/product/B0185367JQ/ref=as_li_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=B0185367JQ&linkCode=as2&tag=mymerch-20&linkId=OLIXWD4WZ5X6FFHD),获取你的T恤,骄傲地穿上它吧。
+
+
+# 文章,教程和讲座
+
+[嵌入、编码、处理、预测:用于国家最先进的NLP模型的新深度学习公式](https://explosion.ai/blog/deep-learning-formula-nlp)
+
+在过去的六个月中,自然语言处理迎来了一个强大的新神经网络方法。这个新的方法可以被总结为简单的四步骤公式嵌入、编码、处理、预测。这篇文章解释了这个新方法的组成部分,并展示了它们是如何用于两个最近的系统中的。
+
+[Python中的干净架构:一个按部就班的例子](http://blog.thedigitalcatonline.com/blog/2016/11/14/clean-architectures-in-python-a-step-by-step-example/)
+
+这篇文章的目的是展示如何在Python中使用一个干净的架构,从头开始构建一个web服务。这种分层设计的主要优点之一是可测性,因此,我将按照TDD方法来开发它。
+
+[如果使用Pynini,在Python中进行出色的文本处理](https://www.oreilly.com/ideas/how-to-get-superior-text-processing-in-python-with-pynini)
+
+对于基本的字符串处理而言,很难击败正则表达式。但对于许多问题,包括一些看似简单的问题,我们都可以使用有限状态转录机(FST)来获得更好的性能。FST是简单的状态机,正如其名,它具有有限数量的状态。但在我们讨论你可以用FST做到的事(从快速文本注释 —— 无正则表达式的灾难性的最坏行为 —— 到简单的自然语言生成,或者甚至是语音识别)之前,让我们看看状态机是什么,它们必须用正则表达式做什么。
+
+[使用Telegram和Python构建一个聊天机器人 (第一部分)](https://www.codementor.io/garethdwyer/tutorials/building-a-telegram-bot-using-python-part-1-goi5fncay)
+
+在这个教程中,我们将使用Python来构建一个简单的Telegram机器人。首先,我们的机器人将简单的回显任何我们发送给它的消息,接着,我们会对其进行扩展,添加一个数据库,并且持久化整个聊天会话中的信息。
+
+[使用SciPy栈的关于基因组的全面介绍](https://www.toptal.com/python/comprehensive-introduction-your-genome-scipy)
+
+在这个教程中,Zhuyi Xue带我们领略SciPy栈的一些功能。他还回答了关于人类基因组的一些有趣问题,包括:有多少基因组是不完整的?一个典型的基因有多长?
+
+[在Python中处理Unicode字符串](http://blog.emacsos.com/unicode-in-python.html)
+
+这篇文章试图解释python中所有关于文本和unicode处理的东东。
+
+[Grakn Pandas明星](https://blog.grakn.ai/grakn-pandas-celebrities-5854ad688a4f)
+
+使用GRAKN.AI和Python来分析电影数据。
+
+[Podcast.__init__ 第83集 - 和Travis Jungroth聊聊HouseCanary](https://www.podcastinit.com/episode-83-house-canary-with-travis-jungroth/)
+
+住房是我们都会经历的事情,但许多人并不了解市场的复杂性。本周,Travis Jungroth谈论了HouseCanary如何使用数据来让房地产更透明的。
+
+[在Tensorflow上,为人类活动识别实现一个CNN](http://aqibsaeed.github.io/2016-11-04-human-activity-recognition-cnn/)
+
+在这篇文章中,我们将看到如何为HAR(人类活动识别)部署卷积神经网络 (CNN),它将会自动学习复杂特性,从原始加速器信号到区分日常生活中的不同活动。
+
+[在Django应用上设置一个BDD栈](https://semaphoreci.com/community/tutorials/setting-up-a-bdd-stack-on-a-django-application)
+
+利用行为驱动开发(Behavior Driven Development,即BDD)来提高你的Django和Python栈吧。学习为你的应用编写BDD测试用例,并且避免用例错误。
+
+[使用调和乘积谱(HPS)算法进行单声道基音检测](http://nbviewer.jupyter.org/gist/carlthome/1e7244e31bd628a0dba233b6dceebaef)
+
+[给工程师的整数规划简介:简化公车调度](https://blog.remix.com/an-intro-to-integer-programming-for-engineers-simplified-bus-scheduling-bd3d64895e92)
+
+[成为pdb高级用户](https://medium.com/instamojo-matters/become-a-pdb-power-user-e3fc4e2774b2)
+
+[Python播客的最终名单](https://dbader.org/blog/ultimate-list-of-python-podcasts)
+
+[Theano中的对抗性神经密码学](https://nlml.github.io/neural-networks/adversarial-neural-cryptography/)
+
+
+# 书籍
+
+[用Python进行机器学习介绍:数据科学家指南](http://amzn.to/2gjdCYC)
+
+你将学到使用Python和scikit-learn库创建一个成功的机器学习应用的必要步骤。作者Andreas Muller和Sarah更关注使用机器学习算法解决实际问题,而不是其背后的数学。熟悉NumPy和matplotlib库将帮助你从此书中获得更多的东西。
+
+
+# 好玩的项目,工具和库
+
+[Superset](https://github.com/airbnb/superset)
+
+Superset是一个数据探索平台,旨在视觉、直观和交互。
+
+[MLAlgorithms](https://github.com/rushter/MLAlgorithms)
+机器学习算法的最小化和干净实现的集合。
+
+[Trigger Happy](https://github.com/foxmask/django-th)
+
+使用这个IFTTT的开源拷贝,控制你的数据,你的网络服务之间的桥梁。
+
+[WereSync](https://github.com/DonyorM/weresync)
+
+增量拷贝Linux硬盘驱动器,或者拷贝到一个更小的驱动器。
+
+[keyboard](https://github.com/boppreh/keyboard)
+
+Windows和Linux上的钩子和模拟键盘事件。
+
+[ByteNet](https://github.com/buriburisuri/ByteNet)
+
+使用DeepMind的ByteNet,进行法语到英语机器翻译的一个tensorflow实现。
+
+[LightBulb](https://github.com/lightbulb-framework/lightbulb-framework)
+
+LightBulb是一个开源的python框架,用于审计web应用防火墙。
+
+[Place-Recognition-using-Autoencoders-and-NN](https://github.com/aqibsaeed/Place-Recognition-using-Autoencoders-and-NN)
+
+以下[论文](https://arxiv.org/pdf/1611.02049v1.pdf)中讨论到的模型的Tensorflow实现: Low-effort place recognition with WiFi fingerprints using deep learning
+
+[cligenerator](https://github.com/bharadwaj-raju/cligenerator)
+
+从一个Python模块/函数生成一个CLI工具。
+
+
+[paintingReorganize](https://github.com/ardila/paintingReorganize)
+
+使用PCA(主成分)分析来识别画的像素,来组成一个光滑的调色板。
+
+[raftos](https://github.com/zhebrak/raftos)
+
+基于Raft算法,用于容错分布式系统的异步复制框架。
+
+
+# 最新发布
+
+[PyPy2.7 v5.6](https://morepypy.blogspot.co.il/2016/11/pypy27-v56-released-stdlib-2712-support.html)
+
+[MicroPython 1.8.6](https://github.com/micropython/micropython/releases/tag/v1.8.6)
+
+
+# 近期活动和网络研讨会
+
+[网络直播:为更好的数据科学编写Pythonic代码](https://www.crowdcast.io/e/pythonic/register)
+
+作为一个有追求的数据科学家,你或许听说过,你需要学习如何使用pandas, scikit-learn, 和其他Python库。但是你知道吗?你也能通过更好地使用Python语言本身来提升你的数据科学技能。在这个1小时的网络直播中,Michael Kennedy将会教你如何编写Pythonic代码,这是利用Python语言最佳特性的代码。这不仅会帮助你编写更有效更可读的代码,它还让你能够更快的挑选其他Python库!
+
+[网络直播:Python中的鸭子类型](https://www.crowdcast.io/e/duck-typing/register)
+
+让我们来聊聊Python中的鸭子类型!它是啥?为啥你应该关心它?
+
+[一起抓取一个数据集来预测奥斯卡得主 - Cambridge, MA](https://www.meetup.com/bostonpython/events/230702569/)
+
+使用Jupyter notebook和scikit-learn,我将预测一个电影是否可能赢得奥斯卡金像奖或者卖座。我将展示创建一个有效数据集的大部分重要步骤,使用你在网上找到的信息:问你的数据可以回答的问题,编写一个网络爬虫,然后仅仅使用Python库和来自网络的数据来回答那些问题。为了描述这些步骤是如何相互协作的,我将从IMDB构建一个数据集,然后用它来预测什么成就了一个奥斯卡得奖电影。
+
+[给Python开发者的Plone, django CMS, Wagtail - London, United Kingdom](https://www.meetup.com/LondonPython/events/233376629/)
+
+存在一些不错的Python网络内容管理系统 (CMS) - 一些非常有名,而一些是鲜为人知的宝石。我们将简单浏览每项技术,然后在最后进行问答环节。这个演讲将针对像我们这样的技术人员和Python开发者,因此,我们可以更好地理解这些工具可以如何帮助我们去帮助我们的用户的。
+
\ No newline at end of file
diff --git a/Python Weekly/Python_Weekly_Issue_271.md b/Python Weekly/Python_Weekly_Issue_271.md
new file mode 100644
index 0000000..a456723
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_271.md
@@ -0,0 +1,101 @@
+原文:[Python Weekly - Issue 271](http://eepurl.com/cp_sQf)
+
+---
+
+欢迎来到Python Weekly第271期。享受这周的出版,并且如果你过的话,感恩节快乐!
+
+
+# 文章,教程和讲座
+
+[Episode #85: 用Python解析可怕的东西](https://talkpython.fm/episodes/show/85/parsing-horrible-things-with-python)
+
+你是否曾经需要解析可怕而令人费解的东西呢?显然,你会从这一集中学到一堆技巧和窍门。但是,你将看到,高级解析是通往许多有趣的计算机科学技术之路。听听我与Erik Rose谈谈他在Mozilla解析奇奇怪怪的东西之旅吧。
+
+[深入了解地理空间分析](http://nbviewer.jupyter.org/github/ResidentMario/boston-airbnb-geo/blob/master/notebooks/boston-airbnb-geo.ipynb)
+
+数据科学家处理的许多数据集都有某些地理空间部分,而这种信息对于理解手头上的问题常常是至关重要的。这样,理解空间数据,以及如何使用它们就成为了任何数据科学家具有的宝贵技能。更妙的是,Python提供了用于该领域的丰富的工具集,并且最近的进展大大简化和巩固了它们。在这个教程中,我们将深入了解Python中的地理空间分析,使用诸如geopandas, shapely, 和pysal这样的工具来分析由Kaggle(来源于Inside AirBnB)提供的数据集,它带有Boston, Massachusetts中的AirBnB位置样本。
+
+[用Pandas构建金融模型](http://pbpython.com/amortization-model.html)
+
+在我前面的文章中,我讨论了如何使用pandas作为数据操作工具来替代Excel。在许多情况下,python + pandas解决方案优于许多人在Excel中用于操作数据的高度手动过程。然而,Excel被用于商业环境下的许多常见 - 不仅是数据操作。这篇详细的文章将讨论如何用pandas取代Excel进行金融建模。在这个例子中,我将在pandas中构建一个简单的分期偿还债务表,并且展示如何建模各种成果。
+
+[Django站点上的水印图像](http://www.machinalis.com/blog/watermarking-images-django/)
+
+使用Pillow和django-imagekit生成可见和不可见水印的技术。
+
+[贝叶斯线性回归](https://github.com/liviu-/notebooks/blob/master/bayesian_linear_regression.ipynb)
+
+贝叶斯线性回归的快速演示 -- 特别是,我想要向你展示你可以如何找到一个从中你可以取样权重来适应于你的数据集的高斯分布的参数!然后,你可以把这个分布当成找到预测分布和利用置信水平的先验使用。我会尽量解释我所做的所有事,但你应该知道线性回归、一些线性代数和一些贝叶斯统计数据。
+
+[给工作中的Python开发者的AsyncIO](https://hackernoon.com/asyncio-for-the-working-python-developer-5c468e6e2e8e)
+
+[iSee: 使用深度学习来从脸部移除眼镜](https://blog.insightdatascience.com/isee-removing-eyeglasses-from-faces-using-deep-learning-d4e7d935376f)
+
+
+# 书籍
+
+[智能网算法](http://amzn.to/2fSfV2T)
+
+智能网算法教你如何创建紧缩和争论(crunch and wrangle)那些从用户、web应用和网站日志收集来的数据的机器学习应用。在这个完全修订版,你将看到从数据中提取实际价值的智能算法。通过使用Python的scikit-learn编写的代码样例,解释了关键的机器学习概念。这本书将引导你通过算法捕获、存储和结构化来自网络的数据流。通过统计算法、神经网络和深度学习,你将探索推荐引擎,并深入分类。
+
+
+# 好玩的项目,工具和库
+
+[Speech-Hacker](https://github.com/ParhamP/Speech-Hacker)
+
+通过连接名人的话,让他们说出任何你想他们说的话。
+
+[pipfile](https://github.com/pypa/pipfile)
+
+一个Pipfile,及其相关的Pipfile.lock,是pip的requirements.txt文件的新的(及好得多的!)替换品。
+
+[Kalliope](https://github.com/kalliope-project/kalliope)
+
+Kalliope是一个模块化的不间断声控个人助手,专为家庭自动化而设。
+
+[Pydoc](https://www.pydoc.io/)
+
+Pydoc是一个为每一个上传到PyPI的包构建自动生成的API文档的项目。它类似于诸如
+http://rubydoc.info/ 和 https://godoc.org/这样的项目 -- 但是是用于Python社区的。一旦获取了PyPI中所有的包,我们就希望也把它扩展到GitHub上的包。
+
+[gzint](https://github.com/pirate/gzint)
+
+一个python3库,用于有效存储大整数 (用 gzip 压缩的整数表示)。
+
+[NBA-prediction](https://github.com/christopherjenness/NBA-prediction)
+
+使用矩阵完备预测NBA比赛比分。
+
+[Quiver](https://github.com/jakebian/quiver)
+
+为Keras提供的互动式卷积神经网络特性可视化
+
+[Streamlink](https://github.com/streamlink/streamlink)
+
+Streamlink是一个CLI工具,它将在线流服务的Flash视频导到各种视频播放器,例如VLC,或者浏览器。streamlink的主要目的在于转换重CPU的Flash插件到一个较少CPU密集的格式。
+
+[colorcet](https://github.com/bokeh/colorcet)
+
+一套用于绘制科学数据的有用的感知一致的色图。
+
+
+# 最新发布
+
+[Python 3.6.0 beta 4](http://blog.python.org/2016/11/python-360-beta-4-is-now-available.html)
+
+[PyCharm 2016.3](https://www.jetbrains.com/pycharm/whatsnew/)
+
+
+# 近期活动和网络研讨会
+
+[AnacondaCON 2017](https://anacondacon17.io/)
+
+一场致力于聚集开放数据科学(Open Data Science)和Anaconda社区最强大脑的盛会。在AnacondaCON,你将接触到使用Anaconda的企业客户,以及那些开放数据科学运动中,利用社区力量和革新的基础贡献者和思想领袖。议程将充满教育性、知识性和发人深省的部分,确保你轻松获得提高开放数据科学所需的知识和连接。
+
+[San Francisco Django 2016年12月聚会 - San Francisco, CA](https://www.meetup.com/The-San-Francisco-Django-Meetup-Group/events/235111262/)
+
+将会有以下演讲
+
+ * Django + Ionic: 从POC到生产
+ * 使用Django Channels的REST Websockets API
+
diff --git a/Python Weekly/Python_Weekly_Issue_272.md b/Python Weekly/Python_Weekly_Issue_272.md
new file mode 100644
index 0000000..1c6326c
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_272.md
@@ -0,0 +1,113 @@
+原文:[Python Weekly - Issue 272](http://eepurl.com/crfJ89)
+
+---
+
+欢迎来到Python Weekly第272期。本周,让我们直入主题。
+
+
+# 文章,教程和讲座
+
+[Episode #87: PonyORM: 可能是最Pythonic的ORM](https://talkpython.fm/episodes/show/87/ponyorm-the-most-pythonic-orm-yet)
+
+如果你可以有任何你所想要的从Python访问数据的API,那会是什么样子的呢?而又是什么让它Pythonic呢?本周,你将会听到Pony ORM: Pony是一个Python ORM,带有漂亮的查询语法,让你能够使用Python生成器和lambda来编写你的数据库查询。
+
+[和Andrew Godwin Guest聊聊Python, Django, 和Channels](https://changelog.com/podcast/229)
+
+Django核心贡献者Andrew Godwin加入了本次节目,来告诉我们所有关于Python和Django的东东。如果你曾经好奇过为什么人们喜爱Python,Django作为一个web框架的美德是什么,或者Django Channels是怎样够得上Phoenix的Channels和Rails' Action Cable的,那么这个节目就是为你准备的。另外:Andrew还负责了提供资金和维持开源。
+
+[使用BeautifulSoup的Python Web 抓取教程](https://www.dataquest.io/blog/web-scraping-tutorial-python/)
+
+在这个教程中,我们将向你展示如何使用Python 3和BeautifulSoup库进行网络爬取。我们将爬取来自国家气象局的天气预报,然后使用Pandas库对其进行分析。
+
+[Podcast.__init__ 第85期 - 和Eric Steele聊聊Plone](https://www.podcastinit.com/episode-85-plone-with-eric-steele/)
+
+Plone是第一批使用Python构建的CMS项目之一,并且它仍在积极发展中。本周,Eric Steele,Plone的发行管理者,告诉我们它是如何开始的,如何架构,以及社区如何是其最大优势之一的。
+
+[在Python中检查是否所有的项都匹配某个条件](http://treyhunner.com/2016/11/check-whether-all-items-match-a-condition-in-python/)
+
+在这篇文章中,我们将看看一个常见的编程模式,并且讨论当我们注意到这种模式的时候,如何重构我们的代码。
+
+[入门Pytest](https://jacobian.org/writing/getting-started-with-pytest/)
+
+Pytest是我首选的Python测试库。它使得简单的测试非常容易编写,并且充满了高级特性 (以及大量的插件) ,这有助于更高级的测试场景。为了演示基本知识,我将带你看看我是如何使用py.test,以测试驱动的方式,解决第一对cryptopals挑战的。
+
+[(缺乏)反对Python 3的情况](http://blog.lerner.co.il/case-python-3/)
+
+[你发现了关于python哪些很酷的特性?](https://www.reddit.com/r/Python/comments/5f3koe/what_are_some_cool_features_that_you_discovered/)
+
+[使用Python的Kanren简化复杂业务逻辑](https://jeffersonheard.github.io/2016/11/simplifying-complex-business-logic-with-pythons-kanren/)
+
+[PyCharm技巧](http://www.devdungeon.com/content/pycharm-tips)
+
+[Jupyter Notebook教程:权威指南](https://www.datacamp.com/community/tutorials/tutorial-jupyter-notebook)
+
+[你创建了哪些让你的生活更轻松的Python程序?](https://www.reddit.com/r/Python/comments/5esa4g/what_python_program_have_you_created_to_make_your/)
+
+[限制Python版本](http://www.b-list.org/weblog/2016/nov/28/break-python/)
+
+[优化Django查询集的构造](https://adamj.eu/tech/2016/11/30/optimizing-construction-of-django-querysets/)
+
+[Tensorflow: 如何冻结一个模型,并通过一个python API来提供它](https://blog.metaflow.fr/tensorflow-how-to-freeze-a-model-and-serve-it-with-a-python-api-d4f3596b3adc)
+
+
+# 书籍
+
+[深入浅出Python:一个大脑友好型指南,第二版](http://amzn.to/2gKnXcs)
+
+基于认知科学和学习理论的最新研究成果,深入浅出Python使用了丰富的视觉形式引人入胜,而不是让你昏昏欲睡的满是文字的方法。为什么要浪费时间挣扎于新的概念呢?这种多感官学习经验是专为你的大脑实际工作的方式而设的。
+
+
+# 好玩的项目,工具和库
+
+[DeepGraph](https://github.com/deepgraph/deepgraph)
+DeepGraph是一个可扩展的通用数据分析软件包。它基于pandas DataFrame实现了一个网络表示,并提供了构建、分区和绘制网络的方法,以及与流行网络包交互的接口等等。
+
+[rapping-neural-network](https://github.com/robbiebarrat/rapping-neural-network)
+
+它是一个已经在说唱音乐上进行训练的神经网络,并且可以将任何你扔给它的歌词重新安排成一首押韵且(一定程度上)具有流动性的歌。
+
+[pycodesuggest](https://github.com/uclmr/pycodesuggest)
+
+使用RNN语言模型学习自动完成。
+
+[Fatiando](http://www.fatiando.org/index.html)
+
+一个用于地球物理建模和反演的开源Python库。
+
+[shellfuncs](https://github.com/timofurrer/shellfuncs)
+
+Python API,用来把shell函数充当Python函数执行。
+
+[TwitterQA](https://github.com/kootenpv/twitterqa)
+
+"一个神经会话模型",一个基于深度学习的聊天机器人的TensorFlow实现。
+
+[djangocms-inline-comment](https://github.com/arteria/djangocms-inline-comment)
+
+用于django CMS的插件 - 添加注释到结构板和注释掉插件,只对员工可见。
+
+[speech-to-text-wavenet](https://github.com/buriburisuri/speech-to-text-wavenet)
+
+基于DeepMind的WaveNet和tensorflow的端到端的句子层面的英语语音识别。
+
+[mitmAP](https://github.com/xdavidhu/mitmAP)
+
+一个python程序,创建一个假的AP并嗅探数据。
+
+[pix2pix-tensorflow](https://github.com/yenchenlin/pix2pix-tensorflow)
+
+"使用条件对抗性网络的图像到图像转换"的TensorFlow实现
+
+[gcn](https://github.com/tkipf/gcn)
+
+TensorFlow中图卷积网络的实现。
+
+
+# 近期活动和网络研讨会
+
+[网络研讨会:Python中的字典](https://www.crowdcast.io/e/dictionaries)
+
+对于新的Python学习者,字典在理解上往往会比列表更加棘手。在即时聊天期间,我们将会看看字典是什么,以及为什么它们有用。Trey还会回答你字典相关的问题。新手应该会很欢迎这个谈话,但是高级的Pythonista或许也能学习到一些新的东西。
+
+[PyAtl 2016年12月聚会 - Atlanta, GA](https://www.meetup.com/python-atlanta/events/231510144/)
+
diff --git a/Python Weekly/Python_Weekly_Issue_273.md b/Python Weekly/Python_Weekly_Issue_273.md
new file mode 100644
index 0000000..c521e5f
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_273.md
@@ -0,0 +1,174 @@
+原文:[Python Weekly - Issue 273](http://eepurl.com/csvGCX)
+
+---
+
+欢迎来到Python Weekly第273期。本周干货满满。尽情享用!
+
+# 来自赞助商
+
+[](http://www.amazon.com/gp/product/B0185367JQ/ref=as_li_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=B0185367JQ&linkCode=as2&tag=mymerch-20&linkId=OLIXWD4WZ5X6FFHD)
+
+嘿,Python粉,你想要表达你对**Python**的爱吗?那么,[点击这里](http://www.amazon.com/gp/product/B0185367JQ/ref=as_li_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=B0185367JQ&linkCode=as2&tag=mymerch-20&linkId=OLIXWD4WZ5X6FFHD),获取你的T恤,骄傲地穿上它吧。
+
+
+# 新闻
+
+[Django论战用户跟踪](https://lwn.net/Articles/707443/)
+
+
+# 文章,教程和讲座
+
+[如何用数据抓住地铁环线的异常地铁](https://blog.data.gov.sg/how-we-caught-the-circle-line-rogue-train-with-data-79405c86ab6a)
+
+这篇文章详细描述了一组数据科学家是如何调查新加坡地铁环线的神秘中断的。
+
+[利用深度学习,寻找一首歌的曲风](https://chatbotslife.com/finding-the-genre-of-a-song-with-deep-learning-da8f59a61194)
+
+让你的计算机成为一个音乐专家的手把手指南。
+
+[榨干uWSGI的每一微秒](https://blog.codeship.com/getting-every-microsecond-out-of-uwsgi/)
+
+这篇文章关于调整通过uWSGIThis post looks into tuning a Python application running via uWSGI.
+
+[为你的聊天机器人利用NLP和机器学习的终极指南](https://chatbotslife.com/ultimate-guide-to-leveraging-nlp-machine-learning-for-you-chatbot-531ff2dd870c)
+
+这篇文章向你展示如何实现一个在给定对话上下文的情况下,可以分配分数给潜在响应的,基于检索的神经网络模型。
+
+[Episode #88: Lightweight Django](https://talkpython.fm/episodes/show/88/lightweight-django)
+
+Django是一个非常流行的Python web框架。原因之一就是,对于你的应用的大部分,你有许多构建块可用。需要一个完整的管理员表编辑器后端吗?仅需几行代码,然后,你就有了一个基本的表编辑器啦~这对许多人都适用。但是我们这些人,包括我在内,都欣赏轻量级框架,其中,我们从最好的组成部分选择各个部分,放在一起,组成我们的web应用,因此觉得(django)这样并不好。本周,你将会见到Julia Elman和Mark Lavin,他们是Lightweight Django的作者,他们来到这里,为你驱散Django应用必须基于大构建块进行构建的迷信。
+
+[跟踪一个奇特的Python内存泄漏](https://benbernardblog.com/tracking-down-a-freaky-python-memory-leak/)
+
+在这篇文章中,你将会发现我是如何使用各种工具,在Windows下跟踪我的Python应用中的内存泄漏的!
+
+[介绍:Fastparquet](https://www.continuum.io/blog/developer-blog/introducing-fastparquet)
+
+fastparquet是Python中对于Parquet格式文件的一个适应性、灵活且快速的接口,提供了内存中pandas DataFrame和磁盘中存储之间的无缝转换。在这篇文章中,我将会介绍两个函数,它们是fastparquet中最常使用的两个函数,接着关于当前的大数据版图的讨论,Python在其中的位置,以及fastparquet在构建Python中一个完整的端到端的大数据管道的过程中如何填补其中一个沟壑的细节。
+
+[Python机器学习教程,Wine Snob版本](https://elitedatascience.com/python-machine-learning-tutorial-scikit-learn)
+
+在这个端到端Python机器学习教程中,你将会学到如何使用Scikit-Learn来构建和调整一个监督学习模型!
+
+[线程化异步魔法,以及如何运用它](https://medium.com/@tryexceptpass/threaded-asynchronous-magic-and-how-to-wield-it-bba9ed602c32)
+
+深入Python的异步io任务和事件循环。
+
+[利用Telegram和Python构建一个聊天机器人 (第2部分):添加一个SQLite数据库后端](https://www.codementor.io/garethdwyer/tutorials/building-a-chatbot-using-telegram-and-python-part-2-sqlite-databse-backend-m7o96jger)
+
+在本教程的第一部分,我们使用Python从头构建了一个基本的Telegram聊天机器人。我们的机器人不大聪明,只能简单的将发送给它的东西回显给用户。我们构建的这个机器人是广大可能机器人的良好基础,因为我们可以接收输入,处理它,然后返回结果 —— 经典计算的基础。我们之前的机器人的一个主要限制是它不能存储任何信息。它没有长期记忆。在这部分,我们会添加一个SQLite数据库后端到我们的机器人,允许它永远记住特定用户的信息。我们会构建一个简单的ToDo列表,允许用户添加新的项,或者删除旧有的。
+
+[Python中的整洁数据](http://www.jeannicholashould.com/tidy-data-in-python.html)
+
+在这篇文章中,我会总结Wickham在他的[论文](http://vita.had.co.nz/papers/tidy-data.pdf)中使用的一些整理样例,并且我将会演示如何用Python pandas库来做到。
+
+[Podcast.__init__ 第86期 - 与Alexis Metaireau和Mathieu Leplatr聊聊Kinto](https://www.podcastinit.com/episode-86-kinto-with-alexis-metaireau-and-mathieu-leplatre/)
+
+你是否在寻找一个这样的后端,它作为服务提供,并且你拥有对你的数据完整的控制权?眼下就有一个:Kinto! 本周,Alexis Metaireau和Mathieu Leplatre分享了Kinto是如何创造出来的,它如何在幕后工作的故事,以及将它用于Mozilla和网络上的方式。
+
+[使用Python, Chromedriver和我们在Reddit上好奇的小伙伴来雾化你的谷歌搜索历史。](http://howlroundmusic.org/wp/?p=23)
+
+[分析2016年世界国际象棋锦标赛](https://medium.com/pachyderm-data/analyzing-the-2016-world-chess-championship-b823d0d2fd11)
+
+[用Python写的x86-64玩具反编译器](https://yurichev.com/writings/toy_decompiler.pdf)
+
+[在 < 3.6的版本中,实现python 3.6的print](https://oded.ninja/2016/12/05/723/)
+
+[Python和故事片](http://dgovil.com/blog/2016/11/30/python-for-feature-film/)
+
+[用Scikit-Learnfen lei分类Amazon评论 -- 证明越多数据越好](https://bigishdata.com/2016/12/05/classifying-amazon-reviews-with-scikit-learn-more-data-is-better-turns-out/)
+
+[Python中的时间序列分析 (TSA) - 从线性模型到 GARCH](http://www.blackarbs.com/blog/time-series-analysis-in-python-linear-models-to-garch/11/1/2016)
+
+[使用Python可视化Tweet](http://www.johnwittenauer.net/visualizing-tweet-vectors-using-python/)
+
+[40+个用于数据科学资源的Python统计数据](https://www.datacamp.com/community/tutorials/python-statistics-data-science)
+
+
+# 书籍
+
+[微控制器上的Python:开始MicroPython之旅(Python for Microcontrollers: Getting Started with MicroPython)](http://amzn.to/2h7VQnT)
+
+本DIY指南对用MicroPython进行微控制器编程进行了实用的介绍。本书的作者是一位经验丰富的电子爱好者,微控制器上的Python:开始MicroPython之旅(Python for Microcontrollers: Getting Started with MicroPython)有八个完整的项目,它们清晰地演示了每项技术。你将学到如何使用传感器、存储数据、控制电机和其他设备,以及使用扩展ban扩展板。从那里,你会发现如何自己设计、构建和编程所有类型的娱乐性核实用性项目。
+
+
+# 好玩的项目,工具和库
+
+[Universe](https://github.com/openai/universe)
+
+Universe是一个软件平台,用来跨世界上提供的游戏、网站和其他应用,衡量和训练一个AI的一般智能。
+
+[pina-colada](https://github.com/ecthros/pina-colada)
+
+一个强大可扩展的无线投递箱,能够在网络上进行广泛的远程攻击。可以通过它的命令行界面来控制它,或者连接到它的命令核控制远程服务器来远程控制,通过使用web应用或者Android应用。
+
+[oil](https://github.com/oilshell/oil)
+
+Oil是一个新的Unix shell,仍处于初期阶段。
+
+[DeepAudioClassification](https://github.com/despoisj/DeepAudioClassification)
+
+从你自己的音乐库中构建一个数据集,并且用它来填补丢失的音乐流派的管道。
+
+[malboxes](https://github.com/GoSecure/malboxes)
+构建恶意软件分析的Windows虚拟机,这样你就无需自己构建。
+
+[Gransk](https://github.com/pcbje/gransk)
+
+Gransk是一个开源工具,旨在cheng wei成为文档处理核分析的瑞士军刀。它的初始目标是在调查期间,快速地为用户提供对他们的文档的洞察。它包含了一个用Python编写的处理引擎和一个web界面。钩子之下,它使用Apache Tika进行内容提取,使用Elasticsearch进行数据索引,使用dfVFS来解压磁盘镜像。
+
+[pook](https://github.com/h2non/pook)
+
+Python中的一个用于HTTP流量模拟和期望的多变、具有表现力且可hack的功能库。
+
+[git-of-theseus](https://github.com/erikbern/git-of-theseus)
+
+分析一个Git repo如何随时间增长。
+
+[fastparquet](https://github.com/martindurant/fastparquet/)
+
+fastparquet是parquet格式的python实现,旨在集成到基于python的大数据工作流。
+
+[foss-heartbeat](https://github.com/sarahsharp/foss-heartbeat)
+
+FOSS Heartbeat分析贡献者社区的健康度。
+
+[LinNetLim](https://github.com/chozabu/LinNetLim)
+
+一个LinuxNetlimiting程序。
+
+[Harser](https://github.com/sihaelov/harser)
+
+HTML解析和构建XPath的简单方式。
+
+
+# 最新发布
+
+[Python 3.6.0 RC1](http://blog.python.org/2016/12/python-360-release-candidate-is-now.html)
+
+[Django问题修复版本发布: 1.10.4, 1.9.12, 1.8.17](https://www.djangoproject.com/weblog/2016/dec/01/bugfix-releases/)
+
+
+# 近期活动和网络研讨会
+
+[Princeton Python用户2016年12月聚会 - Princeton, NJ](https://www.meetup.com/pug-ip/events/236092516/)
+
+Alan Yorinks将会分享他在RedBot机器人平台上使用树莓派(从最初基于Arduino的处理器板子过渡)的经历。
+
+[Boulder Python 2016年12月聚会 - Boulder, CO](https://www.meetup.com/BoulderPython/events/235416975/)
+
+将会有以下演讲
+
+ * 使用Celery来处理Django中的API调用
+ * Python和Kafka
+ * Flask和Django颂歌
+
+
+[函数式编程和Python - London, United Kingdom](https://www.meetup.com/LondonPython/events/235125918/)
+
+在介绍以及(稍微)一点理论之后,我们将看看如何用Python进行函数式编程,以及欣赏这样做的优势,包括写更好的Python代码。
+
+[Edmonton Python 2016年12月聚会 - Edmonton, AB](https://www.meetup.com/startupedmonton/events/235763425/)
+
+[Austin Python 2016年12月聚会 - Austin, TX](https://www.meetup.com/austinpython/events/233895154/)
+
\ No newline at end of file
diff --git a/Python Weekly/Python_Weekly_Issue_274.md b/Python Weekly/Python_Weekly_Issue_274.md
new file mode 100644
index 0000000..b796f06
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_274.md
@@ -0,0 +1,119 @@
+原文:[Python Weekly - Issue 274](http://eepurl.com/ctyn3T)
+
+---
+
+欢迎来到Python Weekly第274期。本周,让我们直入主题。
+
+# 来自赞助商
+
+[](https://software.intel.com/en-us/intel-sdp-home)
+
+**Python**的Intel发行版现在作为一个[DockerHub上的Docker镜像](https://hub.docker.com/u/intelpython/)可用了。遵循[指令](https://software.intel.com/en-us/articles/docker-images-for-intel-python)来轻松从Docker镜像中启动Intel Python,或者访问[GitHub上的DockerFiles](https://github.com/IntelPython/container-images)来自定义构建。灵活的部署选项助力你的工作流。来自Intel Python团队的节日祝福!
+
+
+# 新闻
+
+[DjangoCon Europe 2017建议征集](https://2017.djangocon.eu/call-for-proposals/submit/)
+
+
+# 文章,教程和讲座
+
+[Podcast.__init__ 第87集 - 和Matthew Honnibal聊聊SpaCy](https://www.podcastinit.com/episode-87-spacy-with-matthew-honnibal/)
+
+随着互联网和商业中的可用文本数量的持续增长,对快速准确的语言分析的需求显得更为突出。本周,Matthew Honnibal,SpaCy的创造者,谈到了他研究自然语言处理和创建一个库来让他的发现可用于工业的经历。
+
+[Python 3.6:快速预览](https://blog.jetbrains.com/pycharm/2016/12/python-3-6-a-quick-look/)
+
+Python的新版本,version 3.6,计划于12月16日周五发布。让我们快速看一看这个版本中包含的新特性,并且玩一下它。
+
+[使用Interactive Brokers API,用Python实现算法交易(Algo Trading)](https://www.youtube.com/watch?v=hogXB07OJ_I)
+
+这个演讲是为初学者和自动化交易世界中的专家而设的。聚焦于IBridgePy的适用性,IBridgePy是一个开源软件,用来连接到Interactive Brokers C++ API,以在真实市场执行python代码。
+
+[MongoDB和Python介绍](https://realpython.com/blog/python/introduction-to-mongodb-and-python/)
+
+通过这篇文章,我们将向你展示如何使用Python来和流行的MongoDB (v3.4.0)数据库交互,以及SQL vs. NoSQL、PyMongo (v3.4.0)和MongoEngine (v0.10.7)的概述,等等。
+
+[贝叶斯推断介绍](https://www.datascience.com/blog/introduction-to-bayesian-inference-learn-data-science-tutorials)
+
+这篇文章是对贝叶斯概率和推理的介绍。我们会讨论这些概念之后的直觉,并提供一些用Python写的例子来帮助你开始。
+
+[使用Microsoft Cognitive服务和Python创建我第一个聊天机器人](https://blogs.msdn.microsoft.com/uk_faculty_connection/2016/11/28/creating-my-first-chatbot-using-microsoft-cognitive-services-and-python/)
+
+所以,你想做你第一个聊天机器人吗?但不仅仅是聊天机器人……而是一个会考虑情感的聊天机器人。检测文本中的情感或者解析语言声音对你而言太难了吗?这篇文章向你展示了如何使用微软的认知服务创建一个聊天机器人。
+
+[使用PyPI下载统计数据的数据驱动决策](https://langui.sh/2016/12/09/data-driven-decisions/)
+
+[K均值聚类简介](https://www.datascience.com/blog/introduction-to-k-means-clustering-algorithm-learn-data-science-tutorials)
+
+[Tensorflow中的变分自动编码(Variational Autoencoder) - 面部表情的低维嵌入](http://int8.io/variational-autoencoder-in-tensorflow/)
+
+[使用readline库的基础](http://eli.thegreenplace.net/2016/basics-of-using-the-readline-library/)
+
+[如何启动一个Python项目](http://blog.emacsos.com/bootstrap-a-python-project.html)
+
+
+# 书籍
+
+[Python数据科学手册:处理数据的基本工具(Python Data Science Handbook: Essential Tools for Working with Data)](http://amzn.to/2gyYktD)
+
+Python数据科学手册提供了对集中于数据密集型科学、研究和发现的广泛计算和统计方法的参考。具有编程背景,并且想要使用Python高效处理数据科学任务的人会学到如何面对各种各样的问题:例如,我可以如何读取这种数据格式到我的脚本中?如何操作、转换和清理这个数据?如何可视化这类型的数据?如何使用这个数据来获取见解、回答问题、或者建立统计/机器学习模型?
+
+
+# 好玩的项目,工具和库
+
+[pynamical](https://github.com/gboeing/pynamical)
+
+Pynamical是一个用于建模和可视化离散非线性动力系统、混乱和分形的Python包。
+
+[python-execution-trace](https://github.com/mihneadb/python-execution-trace)
+
+仅用一个装饰器,就可以跟踪一个Python函数执行的本地上下文。
+
+[Surprise](http://surpriselib.com/)
+
+Surprise是一个用于推荐系统的易于使用的开源Python库。它的目标是让那些想要玩转新算法点子的研究者、那些想要一些教学材料的老师以及学生的生活更轻松。
+
+[py_d3](https://github.com/ResidentMario/py_d3)
+
+py_d3是一个IPython扩展,它添加D3支持到Jupyter Notebook环境中。
+
+[iOSSecAudit](https://github.com/alibaba/iOSSecAudit)
+
+iOS安全审计工具包 —— 一个用于iOS应用安全审计和iOS逆向工程的半自动工具
+
+[grafanalib](https://github.com/weaveworks/grafanalib)
+
+你是否喜欢Grafana,但希望你可以版本化你的面板配置?你有没有发现自己一直重复相同的模式?如果是的话,grafanalib就是为你准备的。grafanalib让你从简单的Python脚本中生成Grafana面板。
+
+[chess-surprise-analysis](https://github.com/CYHSM/chess-surprise-analysis)
+
+发现棋类游戏的惊人招数。
+
+
+# 最新发布
+
+[Pygame 1.9.2](https://pypi.python.org/pypi/Pygame)
+
+
+# 近期活动和网络研讨会
+
+[网络研讨会:字符串格式化和Python 3.6的f字符串](https://www.crowdcast.io/e/string-formatting/register)
+
+Python 3.6几乎有了,它包含了一个新的字符串格式化语法!在本周的聊天中,我们会讨论旧式字符串格式化,当前“新的”字符串格式化语法,以及目前新的f字符串语法。
+
+[Boston 2016年12月聚会 - Cambridge, MA](https://www.meetup.com/bostonpython/events/234430655/)
+
+将会有以下小演讲。
+
+ * 列表推导式
+ * "Brain LEGOs" 认知系统技术工具包
+ * 秘密共享
+ * 如何用~15行Python代码实现Instagram滤镜
+ * 函数默认参数
+ * Voronoi图
+ * 使用并滥用Python的魔术方法来减少粘性代码(goo code)
+
+
+[PyHou 2016年12月聚会 - Houston, TX](https://www.meetup.com/python-14/events/235039426/)
+
\ No newline at end of file
diff --git a/Python Weekly/Python_Weekly_Issue_275.md b/Python Weekly/Python_Weekly_Issue_275.md
new file mode 100644
index 0000000..627733b
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_275.md
@@ -0,0 +1,95 @@
+原文:[Python Weekly - Issue 275](http://eepurl.com/cuGU8L)
+
+---
+
+
+欢迎来到Python Weekly第275期。我祝福你们都节日愉快,并且期待2017,送给你们最好的Python相关连接。(Ele注:节日快乐呀,小伙伴们~~)
+
+# 文章,教程和讲座
+
+[利用TensorFlow进行交通标志识别](https://medium.com/@waleedka/traffic-sign-recognition-with-tensorflow-629dffc391a6)
+
+这是关于构建一个深度学习模型来识别交通标志系列的第一部分。在这部分,我将谈谈图像分类,并且会尽可能的让模型简单。在后面的部分中,我将介绍卷积神经网络、数据增强和对象检测。
+
+[Episode #90: 使用Python进行数据再加工](https://talkpython.fm/episodes/show/90/data-wrangling-with-python)
+
+你有没有脏乱数据的问题?无论你是一名软件开发者,或者是一个数据科学家,你都一定会遇到那些畸形、不完整、甚至可能是错的数据。不要让凌乱的数据破坏了你的应用,或者生成错误的结果。你应该怎么办呢?听听这一期,Katharine Jarmul会谈到有关她合作编写的名为使用Python进行数据再加工(Data Wrangling with Python)书,以及她的PyCon UK演讲,名为,如何用Python自动化你的数据清理(How to Automate your Data Cleanup with Python)。
+
+[如何在Debian 8上,使用uWSGI和Nginx,提供Django应用服务](https://www.digitalocean.com/community/tutorials/how-to-serve-django-applications-with-uwsgi-and-nginx-on-debian-8)
+
+本指南中,我们将演示如何在Debian 8上安装和配置一些组件,以支持和提供Django应用服务。我们会配置uWSGI应用容器服务器来与我们的应用交互。然后,我们会设置Nginx来反向代理到uWSGI,利用其安全性和性能特性来服务我们的应用。
+
+[Podcast.__init__ 第88集 - 和Michal Čihař聊聊Weblate](https://www.podcastinit.com/episode-88-weblate-with-michal-cihar/)
+
+添加翻译到我们的项目中让它们可以用于更多的地方,更多的人,这最终会让它们更有价值。如果你没有正确的工具,那么管理本地化过程是很困难的,因此,本周,Michal čihař跟我们聊聊Weblate项目,以及它是如何简化集成翻译到你的源代码中的过程的。
+
+[Python化的代码审查](https://access.redhat.com/blogs/766093/posts/2802001)
+
+[24小时生成850k张图像:自动化深度学习数据集创建](https://gab41.lab41.org/850k-images-in-24-hours-automating-deep-learning-dataset-creation-60bdced04275)
+
+[为本地开发和小规模部署使用Docker和Docker Compose](https://www.codementor.io/jquacinella/tutorials/docker-and-docker-compose-for-local-development-and-small-deployments-ph4p434gb)
+
+[使用Pandas构建一个金融模型 - 第2版](http://pbpython.com/amortization-model-revised.html)
+
+[给SAS用户的Python指南](http://nbviewer.jupyter.org/github/RandyBetancourt/PythonForSASUsers/tree/master/)
+
+[如何远程监控你的Pi进程](https://github.com/initialstate/pi-process-dashboard/wiki)
+
+
+# 好玩的项目,工具和库
+
+[Maya](https://github.com/kennethreitz/maya)
+
+在Python中,使用Datetime是非常令人沮丧的,特别是处理不同系统上的不同地区时。这个库的存在是为了让简单的事情更简单,同时承认时间就是一个幻觉 (时区更是如此)。
+
+[awesome-functional-python](https://github.com/sfermigier/awesome-functional-python)
+
+关于Python中进行函数式编程的棒棒哒的东西的列表。
+
+[Whitewidow](https://github.com/WhitewidowScanner/whitewidow)
+
+Whitewidow是一个开源的自动SQL漏洞扫描器,它能够过一遍文件列表,或者能够抓取Google,查找潜在易受攻击的网站。它允许自动文件格式化、随机用户代理、IP地址、服务器信息、多种SQL注入语法、从程序中加载sqlmap的能力,以及有趣的环境。
+
+[Elizabeth](https://github.com/lk-geimfari/elizabeth)
+
+Elizabeth是一个用于生成伪数据的快速且更易于使用的Python库,这在软件测试阶段需要引导数据库时是非常有用的。
+
+[PixieDust](https://github.com/ibm-cds-labs/pixiedust)
+
+PixieDust是一个开源Python辅助库,它作为Jupyter notebooks的一个附加品工作,用以改善处理数据的用户体验。它还提供额外的能力,填补当notebook被托管到云上,并且用户无法访问配置文件时的沟壑。
+
+[Bowtie](https://github.com/jwkvam/bowtie)
+
+Bowtie是一个用于在python中编写面板的库。无需懂得web框架或者JavaScript,关注于构建python中的功能性。以全新的方式交互式探索你的数据!部署并与他人分享吧!
+
+[libtmux](https://libtmux.git-pull.com/en/latest/)
+
+libtmux是tmuxp背后的工具,一个python中的tmux工作空间管理器。它建立在tmux的目标和格式之上,创建一个对象映射到遍历、检查和与存活的tmux会话交互。
+
+[zxcvbn-python](https://github.com/dwolfhub/zxcvbn-python)
+
+Dropbox的现实密码强度评估器的Python实现。
+
+[kernelscope](https://github.com/josefbacik/kernelscope)
+
+一个用于收集内核跟踪数据和可视化它的守护进程和web应用。
+
+[kansha](https://github.com/Net-ng/kansha)
+
+Kansha是一个开源的web应用,用来管理和共享协作的scrum板等等。
+
+[Wifi-Dumper](https://github.com/Viralmaniar/Wifi-Dumper)
+
+这是一个开源工具,用来Windows机器上的转储wiki配置和已连接接入点的明文密码。这个工具将在Wifi渗透测试中帮助你。此外,当执行red team或者内部基础设置约定时也有用。
+
+[EBS-SnapShooter](https://github.com/smileisak/ebs-snapshooter)
+
+EBS-SnapShooter是一个基于boto2的python脚本,它为你所有的aws ebs卷创建每日、每周、每月快照。
+
+
+# 近期活动和网络研讨会
+
+[网络研讨会:使用PyCharm,扩展一个带REST Capabilities的Django应用](https://blog.jetbrains.com/pycharm/2016/12/webinar-extending-a-django-app-with-rest-capabilities-using-pycharm-january-10th/)
+
+这个实作型网络研讨会将会教你如何利用Python和Django来扩展一个已经存在的web应用,并且添加REST capabilities。此次网络研讨会以一个构建来跟踪笔记的已有的Django应用的概述开始,然后使用Django REST框架深入添加REST。参与者可以跟着我们构建Notes web应用。我们将展示使用PyCharm来检查数据库和测试我们的API。我们还将看看使用强大的PyCharm调试器来调试这个应用。
+
diff --git a/Python Weekly/Python_Weekly_Issue_276.md b/Python Weekly/Python_Weekly_Issue_276.md
new file mode 100644
index 0000000..f489091
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_276.md
@@ -0,0 +1,128 @@
+原文:[Python Weekly - Issue 276](http://eepurl.com/cwf-qT)
+
+---
+
+欢迎来到Python Weekly第276期。本周,我想要感谢我们的赞助商Springboard的支持。一定要看看他们已经启动的第一个数据科学集训。
+
+# 文章,教程和讲座
+
+[](https://www.springboard.com/workshops/data-science-career-track?utm_source=pythonweekly&utm_campaign=pythonweeklydscblast&utm_medium=email)
+
+Springboard已经启动了[第一个数据科学集训](https://www.springboard.com/workshops/data-science-career-track?utm_source=pythonweekly&utm_campaign=pythonweeklydscblast&utm_medium=email),保证你得到一个数据科学家职位 —— 否则,归还你支付的金钱。为你提供专家课程,来自行业专家的1对1辅导,职业指导和雇主合作关系,扩展你的**Python**技能,让你学习成为一名数据科学家所需的一切知识,从而领你走进数据科学的大门。
+
+
+# 文章,教程和讲座
+
+[给研究者的免费超级计算:在Open Science Grid上使用Python的一个教程](https://srcole.github.io/2017/01/03/osg_python/)
+
+超级计算机资源一般要花钱,但是,Open Science Grid (OSG)为美国的任何研究人员免费提供了高吞吐量的计算。这个教程的目的是提供一个在OSG上运行Python任务的完整示例。这个例子很重要,其中,包含了多个数据集、公共库 (例如,scipy)、私有库和输出分析。
+
+[愉快玩耍机器学习:新手指南](https://github.com/humphd/have-fun-with-machine-learning)
+
+这个给没有AI背景的程序员的机器学习动手指南。在这个指南中,我们的目标将是编写一个程序,它使用机器学习进行高度确定性预测:在没看到图像之前,仅使用图像本身,预测数据/未训练样本中的图像是海豚还是海马。
+
+[迭代器协议:在Python中,for循环是如何工作的](http://treyhunner.com/2016/12/python-iterator-protocol-how-for-loops-work/)
+
+我们将要学习,在Python中,for循环是如何工作的。一路上,我们会需要学习可迭代对象、迭代器和迭代器协议。让我们循环起来。
+
+[Python中的本地Hadoop文件系统 (HDFS) 连通性](http://wesmckinney.com/blog/python-hdfs-interfaces/)
+
+通过Hadoop文件系统(HDFS)的WebHDFS网关,以及它的本地基于Protocol Buffers的RPC接口,已经开发了许多与其交互的Python库。我将对现有的工具进行概述,并且展示一些我一直在做的工程,以提供在发展中的Arrow生态系统中的一个高性能的HDFS接口。
+
+[在Python中,从头开始实现一个分类器,我学到了什么](http://www.jeannicholashould.com/what-i-learned-implementing-a-classifier-from-scratch.html)
+
+为了揭秘机器学习算法背后的一些魔法,我决定从头开始实现一个简单的机器学习算法。我将不会使用诸如scikit-learn这样的已经实现了许多算法的库。相反,我会编写所有的代码,以便拥有一个可用的二进制分类器算法。这个练习的目标在于了解它的内部工作。
+
+[使用Fabric和Ansible自动化Django部署](https://realpython.com/blog/python/automating-django-deployments-with-fabric-and-ansible/)
+
+在上一篇文章中,我们覆盖了成功在单个服务器上开发和部署一个Django应用所需的的所有步骤。在这个教程中,我们会使用Fabric (v1.12.0)和Ansible (v2.1.3)自动化部署过程,以解决这些问题:缩放和冗余。
+
+[使用Python,破解BBC的GCHQ Puzzlebook挑战](https://stiobhart.net/2016-12-03-gchqpuzzlebook/)
+
+[利用深度学习,根据文本进行图像合成](https://www.youtube.com/watch?v=rAbhypxs1qQ)
+
+[TensorKart:使用的TensorFlow的自驾MarioKart](http://kevinhughes.ca/blog/tensor-kart)
+
+[Flask-Ask —— 构建复杂Alexa技能的简单易用方式的一个教程](https://blog.craftworkz.co/flask-ask-a-tutorial-on-a-simple-and-easy-way-to-build-complex-alexa-skills-426a6b3ff8bc)
+
+[超容易的Micropython ESP8266 Windows指南。无需Guesswork!](http://www.instructables.com/id/The-Super-Easy-Micropython-ESP8266-Guide-No-Guessw/?ALLSTEPS)
+
+[当心Python的新式字符串格式](http://lucumr.pocoo.org/2016/12/29/careful-with-str-format/)
+
+[如何用Python创建间距图表](https://gavinr.com/2016/12/22/create-pitch-charts-python/)
+
+
+# 好玩的项目,工具和库
+
+[Grumpy](https://github.com/google/grumpy)
+
+Grumpy是一个从Python到Go源代码反编译器和运行时,其目的在于成为CPython 2.7的一个近似替代品。关键的区别在于,它将Python源代码编译成Go源代码,后者接着会被编译成本地代码,而不是字节码。这意味着,Grumpy没有虚拟机。已编译的Go源代码是对Grumpy运行时(一个Go库,提供与Python C API类似功能的服务)的一系列调用。
+
+[audio-reactive-led-strip](https://github.com/scottlawsonbc/audio-reactive-led-strip)
+
+使用ESP8266和Python的实时LED条音乐可视化。
+
+[PEP8 Speaks](https://github.com/OrkoHunter/pep8speaks)
+
+一个GitHub集成,它检查pep8问题,然后通过Pull请求评论。
+
+[chatbot-rnn](https://github.com/pender/chatbot-rnn)
+
+一个由深度学习驱动,基于Reddit上的数据进行训练的玩具聊天机器人。
+
+[Thonny](http://thonny.org/)
+
+给初学者的Python IDE。
+
+[yarl](https://github.com/aio-libs/yarl)
+
+这个模块提供了用于url解析和更改的便捷的URL类。
+
+[GeeMusic](https://github.com/stevenleeg/geemusic)
+
+GeeMusic是一项Alexa技能,它桥接了Google Music和Amazon的Alexa。它希望拯救所有那些想要一个Echo/Dot,但是不想关闭Google Music,或者为Amazon Music Unlimited订阅付费的人。
+
+[EH Forwarder Bot](https://github.com/blueset/ehForwarderBot)
+
+一个可扩展的聊天机器人通道框架。在平台间传递消息,远程控制你其他的账户。
+
+[Truffle Hog](https://github.com/dxa4481/truffleHog)
+
+通过git仓库搜索高熵字符串,深挖提交历史和分支。这对于查找那些意外提交的包含高熵的密钥很有效。
+
+[ThreadTone](https://github.com/theveloped/ThreadTone)
+
+一个由线条组成的图像的半色调展示。
+
+[Amazon-Alert](https://github.com/anfederico/Amazon-Alert)
+
+跟踪亚马逊上的价格,并且在降价的时候接收到电子邮件告警。
+
+
+# 最新发布
+
+[Python 3.6.0](http://blog.python.org/2016/12/python-360-is-now-available.html)
+
+[Django错误修复版本发布:1.10.5](https://www.djangoproject.com/weblog/2017/jan/04/bugfix-release/)
+
+
+# 近期活动和网络研讨会
+
+[San Francisco Python 2017年1月聚会 - San Francisco, CA](https://www.meetup.com/sfpython/events/236600824/)
+
+将会有以下讲座
+
+ * Magic-Wormhole:简单的安全文件传输
+ * pycoin库
+
+
+[IndyPy 2017年1月每月聚会 - Indianapolis, IN](https://www.meetup.com/indypy/events/228228310/)
+
+这个月,Matt Rasband将会展示,Docker, Python和You(Ele注:你?)。
+
+[Austin Python 2017年1月聚会 - Austin, TX](https://www.meetup.com/austinpython/events/234338374/)
+
+[Boulder Python 2017年1月聚会 - Boulder, CO](https://www.meetup.com/BoulderPython/events/235791889/)
+
+[PyAtl 2017年1月聚会 - Atlanta, GA](https://www.meetup.com/python-atlanta/events/234242113/)
+
diff --git a/Python Weekly/Python_Weekly_Issue_277.md b/Python Weekly/Python_Weekly_Issue_277.md
new file mode 100644
index 0000000..0c7f2b3
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_277.md
@@ -0,0 +1,112 @@
+原文:[Python Weekly - Issue 277](http://eepurl.com/cxbt0z)
+
+---
+
+欢迎来到Python Weekly第277期。本周,让我们直入主题。
+
+
+# 文章,教程和讲座
+
+[介绍Python的类型注释](https://www.youtube.com/watch?v=ZP_QV4ccFHQ)
+
+Dropbox有几百万行的生产代码都是用Python 2.7写的。作为迁移到Python 3的第一步,以及让我们的代码更易驾驭,我们利用PEP 484,使用类型注释来注释我们的代码,使用mypy来对注释代码进行类型检查。在这个讲座中,我们将讨论经验教训,并向你展示你也可以如何开始对旧的Python 2.7代码进行类型检查,每次一个文件。我们也将会描述在此过程中对mypy所做的许多改进,以及一些其他工具。
+
+[深度学习指南](http://yerevann.com/a-guide-to-deep-learning/)
+
+深度学习是计算机科学和数学交叉的一个快速变化的领域。它是一个名为机器学习的更广泛的领域的一个相当新的分支。机器学习的目标是教会计算机基于给定的数据执行各种任务。这个指南是为那些知道一些数据并且知道一些编程语言,而现在想要深入深度学习的人准备的。
+
+[Python机器学习:Scikit-Learn教程](https://www.datacamp.com/community/tutorials/machine-learning-python)
+
+这个教程将会介绍Python机器学习的基础知识:一步一步,它将会向你展示如何使用Python和它们的库,在matplotlib的帮助下,来探索你的数据,利用知名的算法KMeans和支持向量机 (SVM) 来构造模型,适配数据到这些模型,来预测值,以及验证你构建的模型。
+
+[Podcast.__init__ 第91集 - 和Martijn Faassen聊聊Morepath](https://www.podcastinit.com/episode-91-morepath-with-martijn-faassen/)
+
+Python有广泛并且不断增长的各种web框架以供选择,但是如果你想要一个拥有超能力的框架,那么,你需要Morepath。本周,Martijn Faassen会跟我们分享怎样创造出Morepath,它是如何与其他可用选项区分开来的,以及你可以如何用它来助力你的下一个项目。
+
+[神经网络的超参数优化](http://neupy.com/2016/12/17/hyperparameter_optimization_for_neural_networks.html)
+
+有时,为神经网络选择一个正确的架构会很难。通常,这个过程需要大量的经验,因为网络包含许多参数。让我们检查一些可以用来优化这个神经网络的最重要的参数。
+
+[添加一个REST API到Django应用](https://blog.jetbrains.com/pycharm/2017/01/webinar-adding-a-rest-api-to-a-django-application/)
+
+这个动手讲座将会教你如何利用Python和Django来扩展一个已有的web应用,并添加REST能力。首先,它会对一个构建来跟踪注释的已有的Django应用进行概述,然后深入使用Django REST框架来添加REST。观看者可以跟着我们构建这个Notes web应用。我们会展示使用PyCharm专业版来检查数据库和测试我们的API。我们还会看看如何用强大的PyCharm调试器来调试这个应用。
+
+[使用python和pandas分析和可视化公开的OKCupid个人资料数据集](http://nbviewer.jupyter.org/github/lalelale/profiles_analysis/blob/master/profiles.ipynb#Analysis-and-visualization-of-a-public-OKCupid-profile-dataset-using-python-and-pandas)
+
+[Episode #94: 通过Conda和Conda-Forge来保证包](https://talkpython.fm/episodes/show/94/guarenteed-packages-via-conda-and-conda-forge)
+
+[从Python到Numpy](http://www.labri.fr/perso/nrougier/from-python-to-numpy/)
+
+[利用Flask和Mapbox可视化你的旅行](http://kazuar.github.io/visualize-trip-with-flask-and-mapbox/)
+
+[每个Python项目必备之物](https://vladcalin.github.io/what-every-python-project-should-have.html)
+
+[使用机器学习增加来自你可预见客户的销量](https://jackstouffer.com/blog/target-predictable-customers.html)
+
+[编写一个Django应用时我犯的错误 (以及我是如何修复它们的)](https://hackernoon.com/mistakes-i-made-writing-a-django-app-and-how-i-fixed-them-16de4e632042)
+
+[Gumbel机制](https://cmaddis.github.io/gumbel-machinery)
+
+
+# 好玩的项目,工具和库
+
+[MuGo](https://github.com/brilee/MuGo)
+
+这是AlphaGo主要部分的纯Python实现。
+
+[Deep Text Correcter](https://github.com/atpaino/deep-text-correcter)
+
+深度学习模型,训练来修正短的、类消息文本中的输入错误。
+
+[PySignal](https://github.com/dgovil/PySignal)
+
+一个不带QObject依赖的Qt信号系统的纯Python实现。
+
+[KickThemOut](https://github.com/k4m4/kickthemout)
+
+通过执行ARP欺骗攻击来把设备从你的网络中踢掉。
+
+[psync](https://github.com/lazywei/psync)
+
+基于rsync的同步项目;支持监控改动,并自动同步。
+
+[predictron](https://github.com/zhongwen/predictron)
+
+"The Predictron: End-To-End Learning and Planning"的Tensorflow实现
+
+[Argos](https://github.com/titusjan/argos)
+
+Argos是一个用于查看和探索科学数据的GUI,用Python和Qt编写。它有一个插件架构,从而能够扩展以读取新的数据格式。
+
+[DVR-Scan](http://dvr-scan.readthedocs.io/en/latest/)
+
+DVR-Scan是一个跨平台的命令行 (CLI) 应用,它自动检测视频文件(例如,安全监控录像)中的运动事件。除了定位每个运动事件的时间和持续时间外,DVR-Scan将会保持每个动作事件的录像到一个新的独立的视频剪辑中。
+
+[systemdlogger](https://github.com/techjacker/systemdlogger)
+
+导出systemd日志到一个外部服务,例如cloudwatch, elasticsearch。
+
+[hsr](https://github.com/pyk/hsr)
+
+使用在TensorFlow中实现的卷积神经网络进行手势识别。
+
+
+# 近期活动和网络研讨会
+
+[网络研讨会:为机器学习构建理想堆栈](http://www.oreilly.com/pub/e/3855)
+
+机器学习从未有过像如今一样更容易靠近 —— 如果你的数据管道支持实时分析的话。参与者将会学习到用于集成不同行业和组织的机器学习模型的工具和技术。Steven Camiña是MemSQL产品经理,他将会介绍你的技术生态系统中所需的关键技术,包括Python, Apache Kafka, Apache Spark, 和一个实时数据库。
+
+[New York Python 2017年1月聚会 - New York, NY](https://www.meetup.com/nycpython/events/235725722/)
+
+将会有以下讲座
+
+ * Paxos简介
+ * 测试工具/开源requestbin库
+ * 201*年(到底)发生了什么?
+ * 异步编程
+
+
+[PyHou 2017年1月聚会 - Houston, TX](https://www.meetup.com/python-14/events/230111277/)
+
+
diff --git a/Python Weekly/Python_Weekly_Issue_278.md b/Python Weekly/Python_Weekly_Issue_278.md
new file mode 100644
index 0000000..67ba926
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_278.md
@@ -0,0 +1,140 @@
+原文:[Python Weekly Issue 278](http://eepurl.com/cyas5j)
+
+---
+
+欢迎来到Python Weekly第278期。本周,让我们直入主题。
+
+# 来自赞助商
+
+[](http://www.amazon.com/gp/product/B0185367JQ/ref=as_li_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=B0185367JQ&linkCode=as2&tag=mymerch-20&linkId=OLIXWD4WZ5X6FFHD)
+
+嘿,Python粉,你想要表达你对**Python**的爱吗?那么,[点击这里](http://www.amazon.com/gp/product/B0185367JQ/ref=as_li_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=B0185367JQ&linkCode=as2&tag=mymerch-20&linkId=OLIXWD4WZ5X6FFHD),获取你的T恤,骄傲地穿上它吧。
+
+
+# 新闻
+
+[PEP 541 -- 包索引名保留](https://www.python.org/dev/peps/pep-0541/)
+
+[Google Tensorflow选择了Keras](http://www.fast.ai/2017/01/03/keras/)
+
+
+# 文章,教程和讲座
+
+[Python异步I/O漫游](http://pgbovine.net/python-async-io-walkthrough.htm)
+
+在这个90分钟视频系列中,Philip Guo介绍了一本名为使用asyncio协程的网络爬虫(A Web Crawler With asyncio Coroutines)的书中的关于Python中的异步I/O的这一章节,这本书的共同执笔者是Python的创建者。
+
+[在Instagram禁用Python垃圾回收](https://engineering.instagram.com/dismissing-python-garbage-collection-at-instagram-4dca40b29172)
+
+通过禁用Python垃圾收集 (GC) 机制(通过收集和释放未使用数据来回收内存),Instagram可以获得10%的性能增益。是哒,你没听错!通过禁用GC,我们可以减少内存占用,提高CPU LLC缓存命中率。如果你对原因感兴趣,那么开始行动吧!
+
+[Episode #95: Grumpy:在Go上运行Python](https://talkpython.fm/episodes/show/95/grumpy-running-python-on-go)
+
+Google运行数百万行Python代码。驱动youtube.com和YouTube API的前端服务器主要是用Python写的,并且它每秒服务数百万的请求!在这一集中,你将会见到Dylan Trotter,他的工作是为驱动YouTube的这些服务器提高性能和并发性。他刚刚发布了Grumpy:一个基于Go(来自Google的高并发语言)的Python实现。
+
+[使用深度学习识别红绿灯](https://medium.freecodecamp.com/recognizing-traffic-lights-with-deep-learning-23dae23287cc)
+
+我是如何在10周内学习深度学习,并赢取$5,000的。
+
+[抓取Craft Beers](http://www.jeannicholashould.com/python-web-scraping-tutorial-for-craft-beers.html)
+
+这篇文章分为两个部分:爬取和整理数据。在第一部分,我们将计划编写代码来从一个站点收集一个数据集。在第二部分,我们将会应用“整洁数据”原则到这个新鲜抓取的数据集上。在这篇文章的最后,我们将会得到一个干净的craft beers数据集。
+
+[Podcast.__init__ 第92集 - 与Dwayne Bailey和Ryan Northey聊聊Translate House](https://www.podcastinit.com/episode-92-translate-house-with-dwayne-bailey-and-ryan-northey/)
+
+什么是国际化,何时你应该将其添加到你的程序中,以及你如何开始?本周,Dwayne Bailey和Ryan Northey告诉我们有关他们Translate House的工作,以及他们构建来更容易转换你的软件的不同项目。
+
+[使用fastText进行自然语言处理简介](https://github.com/miguelgfierro/sciblog_support/blob/master/Intro_to_NLP_with_fastText/Intro_to_NLP.ipynb)
+
+在这个notebook中,我们将会讨论如何使用fastText的一个python封装器,fastText.py,来轻松实现多个项目。
+
+[Python中的断言语句](https://dbader.org/blog/python-assert-tutorial)
+
+如何使用断言来帮助自动检测你的Python程序中的错误,以便让它们更可靠、更易于调试。
+
+[使用AWS Lambda和Python索引Amazon Elasticsearch Service中的元数据](https://aws.amazon.com/blogs/database/indexing-metadata-in-amazon-elasticsearch-service-using-aws-lambda-and-python/)
+
+这篇文章提供了关于如何使用AWS Lambda和Python,把元数据存储在Amazon Elasticsearch Service (Amazon ES)中的渐进式指导。
+
+[Python 3的str的唯一一个问题是你并没有充分理解它](http://sircmpwn.github.io/2017/01/13/The-problem-with-Python-3.html)
+
+[使用Dask array的一个集群上的分布式NumPy](http://matthewrocklin.com/blog/work/2017/01/17/dask-images)
+
+[教程:PyTorch中的深度学习](https://iamtrask.github.io/2017/01/15/pytorch-tutorial/)
+
+[寻找HTTP请求API之间的共同性](https://snarky.ca/looking-for-commonality-among-http-request-apis/)
+
+[入门Spark Streaming, Python, 和Kafka](https://www.rittmanmead.com/blog/2017/01/getting-started-with-spark-streaming-with-python-and-kafka/)
+
+[了解Python的下划线( _ )](https://hackernoon.com/understanding-the-underscore-of-python-309d1a029edc)
+
+
+# 好玩的项目,工具和库
+
+[PyTorch](http://pytorch.org/)
+
+Python中的Tensors和动态神经网络,具有很强的GPU加速。
+
+[itermplot](https://github.com/daleroberts/itermplot)
+
+一个用于Matplotlib的超棒的iTerm2后端,这样,你就可以直接在终端上绘图。
+
+[waveconverter](https://github.com/paulgclark/waveconverter)
+
+用于RF逆向工程的开源工具。
+
+[image-learner](https://github.com/schenker/image-learner/)
+
+训练一个神经网络来将一个图像的x,y像素映射到r,g,b。
+
+[Frozen-Flask](http://pythonhosted.org/Frozen-Flask/)
+
+Frozen-Flask将一个Flask应用冻结到一组静态文件中。该结果可以在除了传统的web服务器外,无需任何服务端软件的情况下被托管。
+
+[tifu](https://github.com/c0riolis/tifu)
+
+TIFU是一个工具,用来帮助恢复被Github, Gitlab和Bitbucket上的强制push擦除的提交。
+
+[rePy2exe](https://github.com/4w4k3/rePy2exe)
+
+用于py2exe应用的逆向工程工具。
+
+[DonaldTrumpStockMonitor](https://github.com/Mhyles/DonaldTrumpStockMonitor)
+
+监控Donald Trumps的推特,如果有哪个公司的名字出现在他的推特上,那么监控这个公司下周的股票水平。
+
+[WaterNet](https://github.com/treigerm/WaterNet)
+
+识别卫星图像中的水的卷积神经网络。
+
+[snake_8x8_dotmatrix](https://github.com/lucasbrambrink/snake_8x8_dotmatrix)
+
+用Python写的8x8蛇。也提供HC595和Dot matrix接口。
+
+
+# 最新发布
+
+[Matplotlib 2.0](https://github.com/matplotlib/matplotlib/releases)
+
+[Python 3.5.3](https://www.python.org/downloads/release/python-353/)
+
+[Django 1.11 alpha 1](https://www.djangoproject.com/weblog/2017/jan/17/django-111-alpha-1/)
+
+
+# 近期活动和网络研讨会
+
+[使用RPLY和RPython构建你自己的语言 - Philadelphia, PA](https://www.meetup.com/phillypug/events/236726527/)
+
+我们将使用RPLY构建DIVSPL,它是David Beazley的PLY的一种实现 (但是有一个“更酷的”API),并且将其与RPython,Python编程语言的有限子集,兼容。一路下来,你将学习到词法分析器,解析器和语法,最后,你将会知道如何构建你自己的编程语言。
+
+[San Diego Python 2017年1月聚会 - San Diego, CA](https://www.meetup.com/pythonsd/events/236030102/)
+
+将会有以下讲座
+
+ * python派生分析
+ * 制作交互式科学应用上的bokeh和jupyter notebooks对比
+ * WYSIWYG基于Web的HTML编辑器
+
+
+[PYKC 2017年1月每月聚会 - Kansas City, MO](https://www.meetup.com/pythonkc/events/232904085/)
+
\ No newline at end of file
diff --git a/Python Weekly/Python_Weekly_Issue_279.md b/Python Weekly/Python_Weekly_Issue_279.md
new file mode 100644
index 0000000..c88a980
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_279.md
@@ -0,0 +1,155 @@
+原文:[Python Weekly Issue 279](http://eepurl.com/cy-5dH)
+
+---
+
+欢迎来到Python周刊第279期。本周,我想要感谢我们的赞助商,PyImageSearch的支持。一定要利用他们令人惊奇的产品。
+
+# 来自赞助商
+
+[](https://www.kickstarter.com/projects/adrianrosebrock/1866482244)
+
+[Kickstarter: 用Python进行计算机视觉深度学习(Kickstarter: Deep Learning for Computer Vision with Python)](https://www.kickstarter.com/projects/adrianrosebrock/1866482244)
+
+在这本来自PyImageSearch.com的新书中,你将会找到超级实用的演练,实践教程和一种非BS教学方式,保证帮你掌握计算机视觉的深度学习。要了解更多信息,[仅需点击这里](https://www.kickstarter.com/projects/adrianrosebrock/1866482244)。
+
+
+# 文章,教程和讲座
+
+[和Matthew Rocklin聊聊Dask](https://www.dataengineeringpodcast.com/episode-2-dask-with-matthew-rocklin/)
+
+处理和分析数据有大量的工具和平台。在这一集中,Matthew Rocklin谈到Dask是如何填补面向任务的工具流任务和内存处理框架之间的差距的,以及它如何使用Python之力对大数据问题产生影响的。
+
+[实用PyTorch:使用字符级RNN分类名字](https://github.com/spro/practical-pytorch/blob/master/char-rnn-classification/char-rnn-classification.ipynb)
+
+我们将构建和训练一个基本的字符级RNN来分类单词。一个字符级RNN将单词作为一系列字符读取 - 每步都输出预测和“隐藏状态”,将它前一个隐藏状态输入到下一步中。我们将最终的预测作为输出,即单词所属的类别。
+
+[使用OpenCV, Python, 和scikit-image的seam carving](http://www.pyimagesearch.com/2017/01/23/seam-carving-with-opencv-python-and-scikit-image/)
+
+这篇文章讨论了seam carving算法,它是如何工作的,以及如何使用Python, OpenCV, 和sickit-image来应用seam carving。
+
+[Podcast.__init__ 第93集 - 和Paul Kehrer聊聊Cryptography](https://www.podcastinit.com/episode-93-cryptography-with-paul-kehrer/)
+
+迟早你会需要加密或者哈希一些数据。幸好我们有Cryptography库,以及其他一些由Python Cryptographic Authority维护的项目,来确保加密正确完成。在这一集中,Paul Kehrer谈到了PyCA是如何开始的,他们维护的项目,以及现今,你可以如何开始在你的程序中使用cryptography。
+
+[如何在Python中自动记录Twitch流](https://www.junian.net/2017/01/how-to-record-twitch-streams.html)
+
+借助streamlink和ffmpeg,可以在每次用户上线的时候记录twitch流。
+
+[Flask中的基于token的认证](https://realpython.com/blog/python/token-based-authentication-with-flask/)
+
+本教程使用一种测试优先方法,利用JSON网络令牌 (JWTs),在Flask应用中实现基于token的认证。
+
+[编写生产级PySpark招聘信息库的最佳实践](https://developerzen.com/best-practices-writing-production-grade-pyspark-jobs-cb688ac4d20f)
+
+如何构建你的PySpark招聘信息库和代码。
+
+[使用全卷积网络 (FCNs) 进行图像分割](http://warmspringwinds.github.io/tensorflow/tf-slim/2017/01/23/fully-convolutional-networks-\(fcns\)-for-image-segmentation/)
+
+这篇文章展示了如何使用利用我们的框架在PASCAL VOC上训练的全卷积网络,进行图像分割。
+
+[Pyramid 1.8新特性](http://docs.pylonsproject.org/projects/pyramid/en/latest/whatsnew-1.8.html)
+
+本文解释了相较于Pyramid 1.7,Pyramid 1.8的新特性。它还记录了这两个版本之间的向后不兼容性,和添加到Pyramid 1.8点弃用特性,以及软件依赖项变更和显著的文档增加。
+
+[使用Dask,在一个集群之上自定义并行算法](http://matthewrocklin.com/blog/work/2017/01/24/dask-custom)
+
+本文将Dask描述成一个适用于诸如Hadoop/Spark这样的大数据计算框架和诸如Airflow/Celery/Luigi之类的任务调度器之间某处等计算任务调度器。我们看到,通过结合来自这些类型的系统的元素,Dask如何能够特别好地处理复杂数据科学问题。
+
+[使用Pytest来测试Python应用](https://semaphoreci.com/community/tutorials/testing-python-applications-with-pytest)
+
+Pytest的简单易用使得它在Python测试工具中脱颖而出。这个教程将会让你开始使用pytest来测试你的下一个Python项目。
+
+[Python中进行字符串格式化的4大方法](https://dbader.org/blog/python-string-formatting)
+
+本文演示了四个字符串格式化方法如何工作,以及它们各自的优势和劣势是什么。它还提供了作者如何选取最好的通用字符串格式化方法等简单“经验法则”。
+
+[使用Blender和Python来3D打印一条裙子](https://opensource.com/article/16/12/blender-python-3D-dress)
+
+[Wolfram自动机,Python的一个简单实现](http://faingezicht.com/articles/2017/01/23/wolfram/)
+
+[在Sublime Text上lint Python 3.6的三个步骤](https://janikarhunen.fi/three-steps-to-lint-python-3-6-in-sublime-text.html)
+
+[在PyPy上运行Numba](http://www.embecosm.com/2017/01/19/running-numba-on-pypy/)
+
+[在API客户端中使用Requests的一些最佳实践](http://www.coglib.com/~icordasc/blog/2017/01/some-better-practices-for-using-requests-in-api-clients.html)
+
+
+# 本周Python工作
+
+[Patch招聘首席技术官](http://jobs.pythonweekly.com/jobs/chief-technology-officer/)
+
+Patch正在招聘一名CTO / 首席程序员。作为扩展公司的一部分,我们正在扩大我们的技术团队。这是一个对我们的电子商务平台产生巨大影响,以及帮助塑造我们正在创建的新服务的机会。我们正在寻找能把事情做到的人。我们是一个以客户为中心的公司,因此期望那些为制作伟大的最终产品,以及编写高质量代码的人可以加入。成为早期技术团队中的一员,你将有机会随着公司的成长,塑造你在公司中的角色。
+
+[Texas Tribune招聘软件工程师](http://jobs.pythonweekly.com/jobs/software-engineer-16/)
+
+你将成为不断提高我们的新闻编辑室系统(包括一个Django CMS以及它与外部API的交互),以及原型化新工具的团队的一部分。我们使用现代化的工作流 (包括Docker, HTTPS, 和Webpack),而你将始终面临新的挑战。
+
+
+
+# 好玩的项目,工具和库
+
+[pipenv](https://github.com/kennethreitz/pipenv)
+
+Pipenv是一个实验项目,旨在把所有包世界中的最好的东西带进Python世界。它将Pipfile, pip, 和virtualenv整合到单个工具链中。它具有非常漂亮的终端颜色。
+
+[SKiDL](https://xesscorp.github.io/skidl/docs/_site/index.html)
+
+永不再使用一个糟糕的图解编辑器!SKiDL是一个简单的模块,它让你使用Python描述电子电路。生成的Python程序输出一个网表,让PCB布局工具用来生成一个完成的电路板。
+
+[Notebook Gallery](http://nb.bianp.net/)
+
+到最佳IPython和Jupyter Notebook的链接。
+
+[Cage](https://github.com/macostea/cage)
+
+在干净的Docker环境中开发和运行你的Python应用。
+
+[nbtutor](https://github.com/lgpage/nbtutor)
+
+在Jupyter Notebook格子里可视化Python代码执行 (逐行)。
+
+[practical-pytorch](https://github.com/spro/practical-pytorch)
+
+实用PyTorch教程,关注于将RNNs用于NLP。
+
+[Glazier](https://github.com/google/glazier)
+
+一个用于在各种设备平台上自动安装微软Windows操作系统的工具。
+
+[dtn-tensorflow](https://github.com/yunjey/dtn-tensorflow)
+
+无监督跨域图像生成的TensorFlow实现。
+
+[Donkey](https://github.com/wroscoe/donkey)
+
+Donkey是极简主义以及模块化自驱动库,用Python编写。它因爱好而开发,关注于允许快速实验和轻松社区贡献。
+
+[jupyter-themes](https://github.com/dunovank/jupyter-themes)
+
+自定义Jupyter Notebook主题。
+
+[flask-base](https://github.com/hack4impact/flask-base)
+
+一个使用SQLAlchemy,Redis,用户认证等等的死简单Flask样板应用。
+
+[attention-transfer](https://github.com/szagoruyko/attention-transfer)
+
+通过注意力转移改进卷积网络。
+
+[face-identification-tpe](https://github.com/meownoid/face-identification-tpe)
+
+人脸识别演示,实现了人脸验证和集群工作的三重概率性嵌入(Triplet Probabilistic Embedding)
+
+[syntax_sugar_python](https://github.com/czheo/syntax_sugar_python)
+
+一个库,添加了一些反pythonic语法糖到Python中。这只是一个实验原型,显示Python中操作符重载到一些潜力。
+
+[kawaii-player](https://github.com/kanishka-linux/kawaii-player)
+
+音频/视频管理器,多媒体播放器和便携式媒体服务器,基于python3和pyqt5。
+
+[GpxTrackPoster](https://github.com/flopp/GpxTrackPoster)
+
+从你的GPX轨迹创建一个引人注目的海报。
+
+
diff --git a/Python Weekly/Python_Weekly_Issue_280.md b/Python Weekly/Python_Weekly_Issue_280.md
new file mode 100644
index 0000000..b9be15c
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_280.md
@@ -0,0 +1,143 @@
+原文:[Python Weekly Issue 280](http://eepurl.com/cAaJM9)
+
+---
+
+欢迎来到Python周刊第280期。让我们直奔主题。
+
+# 来自赞助商
+
+[](https://www.kickstarter.com/projects/adrianrosebrock/1866482244)
+
+[Kickstarter: 用Python进行计算机视觉深度学习(Kickstarter: Deep Learning for Computer Vision with Python)](https://www.kickstarter.com/projects/adrianrosebrock/1866482244)
+
+在这本来自PyImageSearch.com的新书中,你将会找到超级实用的演练,实践教程和一种非BS教学方式,保证帮你掌握计算机视觉的深度学习。要了解更多信息,[仅需点击这里](https://www.kickstarter.com/projects/adrianrosebrock/1866482244)。
+
+
+# 文章,教程和讲座
+
+[机器学习之约:机器学习工程的最佳实践](http://martin.zinkevich.org/rules_of_ml/rules_of_ml.pdf)
+
+不具体到Python,但是这篇文档目的是帮助那些具有机器学习基础知识到人,从谷歌获取获取关于机器学习的最佳实践的好处。
+
+[Python Excel教程:权威指南](https://www.datacamp.com/community/tutorials/python-excel-tutorial)
+
+这个教程将会向你提供关于你可以如何使用Excel和Python的一些见解。它将向你提供你在Python的帮助下,可以用来加载和写入这些电子表格到文件中的包的概述。你将学到如何使用诸如pandas, openpyxl, xlrd, xlutils和pyexcel这样的包。
+
+[使用神经网络的文本分类](https://medium.com/@gk_/text-classification-using-neural-networks-f5cd7b8765c6)
+
+了解聊天机器人是如何工作的很重要。一个聊天机器人内部机制的一个基本部分是文本分类器。让我们来看看用于文本分类的人工神经网络(ANN)的内部工作过程。
+
+[数据科学How-To:使用Apache Spark进行体育分析](https://content.pivotal.io/blog/how-data-science-assists-sports)
+
+在体育界中,分析已经成为了主要的工具,而特别是在NBA中,分析具体化了如何打比赛。联盟已经偏向于采取更多的3分射门,因为这种方式在每次投篮尝试得分评估下更加高效。在这篇文章中,我们使用从1979年开始的赛季统计数据,壹基金地理空间投篮图数据,来评估和分析NBA中的这种趋势。这篇文章中的概念 —— Spark中的数据清理、可视化和建模 —— 是一般的数据科学概念,可以应用到体育数据分析之外的其他任务上。这篇文章总结了作者对使用Spark的一般感觉,以及给新用户的提示和建议。
+
+[生产化和部署数据科学工程](https://www.continuum.io/blog/developer-blog/productionizing-deploying-data-science-projects)
+
+在这篇文章中,我们将专注于开发一个应用后随之而来的数据科学工作流阶段:生产化和部署数据科学工程和应用。我们将会基于我们在Anaconda企业平台上与客户合作的经验,以及定制咨询和培训解决方案,讨论最佳实践、推荐的工具和常见工作流。
+
+[想要药?用Python吧。](https://arxiv.org/pdf/1607.00378v1.pdf)
+
+我们描述了可以如何利用Python来简化药物发现数据的管理、建模和传播,以及为相关科学界开发创造性的免费工具。我们会看到各种例子,例如化学工具包,机器学习应用和web框架,并展示Python可以如何将它们粘合在一起,来创造高效的数据科学管道。
+
+[使用Keras+Tensorflow实现车道跟随自动驾驶仪](https://wroscoe.github.io/keras-lane-following-autopilot.html)
+
+这篇文章介绍了如何使用Keras+Tensorflow来创建一个卷积神经网络,并且训练它来讲一辆车保持在两条白线之间。
+
+[用Python处理每秒百万条请求](https://medium.com/@squeaky_pl/million-requests-per-second-with-python-95c137af319)
+
+[利用Q-Learning,在一个小小的爬行机器人上学习动作元(motor primitives)](http://nbviewer.jupyter.org/github/du-phan/Autonomous_robot/blob/master/Code/Simulation/Crawling_Simulation.ipynb)
+
+[在Keras / Tensorflow上用深度学习进行食物分类](http://blog.stratospark.com/deep-learning-applied-food-classification-deep-learning-keras.html)
+
+[一个Python的Python式类型系统:静态鸭子类型](https://trm.io/2017/01/29/structural-subtyping-python.html)
+
+
+# 好玩的项目,工具和库
+
+[PaintsChainer](https://github.com/pfnet/PaintsChainer)
+
+Paints Chainer是使用链接器的素描着色器。使用CNN,你可以自动/半自动为你的草图上色。
+
+[clickbait-detector](https://github.com/saurabhmathur96/clickbait-detector)
+
+使用深度学习检测clickbait头条。
+
+[PRET](https://github.com/RUB-NDS/PRET)
+
+打印机利用工具包。你的打印机安全吗?在别人下手之前检查一下吧……
+
+[StreamAlert](https://github.com/airbnb/streamalert)
+
+StreamAlert是一个无服务器、实时数据分析框架,让你能够在来自任意幻环境的数据上获取、分析和预警,使用你定义的数据源和告警逻辑。
+
+[Japronto](https://github.com/squeaky-pl/japronto)
+
+极其快速的Python 3.5+ web微框架,与pipelining HTTP服务器集成,基于uvloop和picohttpparser。
+
+[pyzdb](https://github.com/asrp/pyzdb)
+
+带Python语法查询的轻量级数据库,使用ZeroMQ。
+
+[IMGKit](https://github.com/jarrekk/imgkit)
+
+将html转化成图像的Wkhtmltoimage python分装器
+
+[BucketStore](https://github.com/kennethreitz/bucketstore)
+
+BucketStore是一个用Python编写的非常简单的Amazon S3的客户端。它的目的是比boto3更直接使用,并且只专注于Amazon S3,忽略AWS生态的其余部分。
+
+[lifelights](https://github.com/jjensn/lifelights)
+
+视频游戏和家庭自动化。基于游戏中状态控制你的物联网设备。
+
+[deep-makeover](https://github.com/david-gpu/deep-makeover)
+
+将男性肖像转换成女性,以及将女性肖像转换成男性的深度学习项目。
+
+[FreeWifi](https://github.com/kylemcdonald/FreeWifi)
+
+如何获取免费wifi。
+
+[rpi-appliance-monitor](https://github.com/Shmoopty/rpi-appliance-monitor)
+
+监控诸如干衣机或者车库开门器之类的振动设备的设备。
+
+[hypertools](https://github.com/ContextLab/hypertools)
+
+一个用于可视化和操作高维数据的python工具箱。
+
+[tweets_analyzer](https://github.com/x0rz/tweets_analyzer)
+
+推特元数据爬虫以及活动分析器。
+
+[word_prediction](https://github.com/Kyubyong/word_prediction)
+
+使用卷积神经网络的单词预测。
+
+
+# 最新发布
+
+[IPython 5.2](http://ipython.readthedocs.io/en/stable/whatsnew/version5.html#ipython-5-2)
+
+[Anaconda 4.3](https://www.continuum.io/blog/developer-blog/anaconda-43-released)
+
+[TensorFlow 1.0.0-rc0](https://github.com/tensorflow/tensorflow/releases/tag/v1.0.0-rc0)
+
+
+# 近期活动和网络研讨会
+
+[San Francisco 2017年二月Python聚会 - San Francisco, CA](https://www.meetup.com/sfpython/events/237153246/)
+
+将会有以下讲座
+
+ * Python中的不可变数据库建模
+ * Python中的TextRank
+ * 使用Apache Airflow的高级数据工程模式
+
+
+[LA Django 2017年二月聚会 - Los Angeles, CA](https://www.meetup.com/ladjango/events/236269519/)
+
+[Austin 2017年二月Python聚会 - Austin, TX](https://www.meetup.com/austinpython/events/228937914/)
+
+[PyAtl 2017年二月聚会 - Atlanta, GA](https://www.meetup.com/python-atlanta/events/234242118/)
+
\ No newline at end of file
diff --git a/Python Weekly/Python_Weekly_Issue_281.md b/Python Weekly/Python_Weekly_Issue_281.md
new file mode 100644
index 0000000..15bd8a1
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_281.md
@@ -0,0 +1,147 @@
+原文:[Python Weekly Issue 281](http://eepurl.com/cBclUb)
+
+---
+
+欢迎来到Python周刊第281期。让我们直奔主题。
+
+# 来自赞助商
+
+[](https://www.kickstarter.com/projects/adrianrosebrock/1866482244)
+
+[Kickstarter: 用Python进行计算机视觉深度学习(Kickstarter: Deep Learning for Computer Vision with Python)](https://www.kickstarter.com/projects/adrianrosebrock/1866482244)
+
+在这本来自PyImageSearch.com的新书中,你将会找到超级实用的演练,实践教程和一种非BS教学方式,保证帮你掌握计算机视觉的深度学习。要了解更多信息,[仅需点击这里](https://www.kickstarter.com/projects/adrianrosebrock/1866482244)。
+
+
+# 文章,教程和讲座
+
+[Python金融编程](https://www.youtube.com/playlist?list=PLQVvvaa0QuDcOdF96TBtRtuQksErCEBYZ)
+
+在这个系列中,我们将涉及使用Pandas框架,将金融(股票)数据导入到Python中的基础知识。从这里,我们会操作数据,并尝试提出一些用于投资公司的系统,应用一些机器学习,甚至一些深度学习,然后学习如何后验测试一个策略。
+
+[Podcast.__init__ 第95集 - 与Dave Beazley和ErikRose聊聊解析和解析器](https://www.podcastinit.com/episode-95-parsing-and-parsers-with-dave-beazley-and-erik-rose/)
+
+如果你曾经发现自己被一个复杂的正则表达式弄得很郁闷,或者想知道要如何构建你自己的Python方言,那么你需要一个解析器。在这一集中,Dave Beazley和Erik Rose聊到了解析器是什么,它们中的一些是如何工作的,以及你可以用它们做什么。
+
+[它一直是元类](http://nbviewer.jupyter.org/github/akittas/presentations/blob/master/pythess/meta_alltheway/meta_alltheway.ipynb)
+
+了解并使用Python的元编程设施。
+
+[如何使用snapcraft在Ubuntu 16.04中,通过网络,创建一个Python应用的快照](https://blog.simos.info/how-to-create-a-snap-for-a-python-app-with-networking-using-snapcraft-in-ubuntu-16-04/)
+
+在这篇文章中,我们看到如何创建Ubuntu 16.04中的一些软件的快照包(或者,只是快照)。快照是一个限制包,它可以只包含我们所限制的东东。一旦创建了它,我们就可以在不同的Linux发行版中安装相同的快照!
+
+[文档中的自动截图](https://blog.codeship.com/automating-screenshots-in-documentation/)
+
+如果你有一个带有界面的应用程序,那么截图则是向用户展示重要的组件和概念的好方法。然而,确保它们是最新且有用的则是一个耗时的任务。如果你可以自动化这个任务,岂不是很棒?好消息!我将告诉你怎么做。
+
+[Episode #97: Flask-Diamond下的Flask, Django风格](https://talkpython.fm/episodes/show/97/flask-django-style-with-flask-diamond)
+
+有一个完整的Python网络框架。在一端,我们拥有诸如bottle, flask, 以及一定程度的Pyramid这样的微框架。而其他诸如Django,甚至是像Wagtail (构建于Django之上) 这样的CMS们,则处于遥远的另一端。虽然这常常被定位成一种非此即彼的选择,但是本周,你将见到Ian Dennis Miller,他是Flask-Diamond的创造者。Flask-Diamond是Flask的一个扩展,它将Django中的许多好东西带到了Flask短小精悍的API中。
+
+[使用Scikit Learn和Dask的两种简单方式](http://matthewrocklin.com/blog/work/2017/02/07/dask-sklearn-simple)
+
+这篇文章描述了无论是在单个计算机还是跨集群的情况下,使用Dask来并行Scikit-Learn操作的两种简单的方式。
+
+[PyEcore: Eclipse建模框架的Python(ic)实现](http://modeling-languages.com/pyecore-python-eclipse-modeling-framework/)
+
+这篇文章介绍了PyEcore,EMF的一个Python实现。PyEcore主要关注灵活性,以提供一种脚本模型/元模型的方式,并试着通过XMI导入/导出和基本的对象命名,来与EMF-Java/Ecore尽可能的兼容。PyEcore还展示了Python如何提供许多对于模型/元模型操作而言可以非常有趣的机制,以及提供使用来自丰富的Python生态的库的能力。
+
+[使用k-均值进行颜色量化](http://lmcaraig.com/color-quantization-using-k-means/)
+
+在这篇文章中,我想要聊聊颜色量化,可以如何使用k-均值聚类法来执行它,以及与更简单的方法相比,它的性能如何。
+
+[使用React组件协调Django模板](https://hackernoon.com/reconciling-djangos-mvc-templates-with-react-components-3aa986cf510a)
+
+如何在无需创建一个单页应用的情况下构建前端。
+
+[Python的编码分类值指南](http://pbpython.com/categorical-encoding.html)
+
+[用Django构建一个REST API - 一个测试驱动方法:第一部分](https://scotch.io/tutorials/build-a-rest-api-with-django-a-test-driven-approach-part-1)
+
+[SciPy备忘单:Python中的线性代数](https://www.datacamp.com/community/blog/python-scipy-cheat-sheet)
+
+[无OperationalError的多线程SQLite](http://charlesleifer.com/blog/multi-threaded-sqlite-without-the-operationalerrors/)
+
+[像一个老板那样在Python中使用函数式编程:生成器、迭代器和装饰器](http://nbviewer.jupyter.org/github/akittas/presentations/blob/master/pythess/func_py/func_py.ipynb)
+
+[Python中的一个简单的趋势产品推荐引擎](http://blog.untrod.com/2017/02/recommendation-engine-for-trending-products-in-python.md.html)
+
+
+# 书籍
+
+[Thoughtful Machine Learning with Python: A Test-Driven Approach](http://amzn.to/2knFKqU)
+
+获得在你的日常工作中应用机器学习所需的信心。通过这本实用指南,作者Matthew Kirk向你展示如何在你的代码中集成和测试机器学习算法,无需学术背景。
+
+
+# 本周Python工作
+
+[Nextdoor招聘软件工程师](http://jobs.pythonweekly.com/jobs/software-engineer-17/)
+
+我们正处于构建一个对你的社区和当地有用、可靠且私有的平台的早期阶段。我们正在解决很酷的技术挑战,这会使得依赖于Nextdoor的将近65%的US社区成员见到他们的邻居,密切关注彼此,并且开始在线聊天,从而使得线下构建社区。我们不断寻找极具驱动力的优秀工程师加入我们的团队中:通用工程师,后端工程师,基础设施工程师,实习工程师,iOS工程师,个性化工程师,产品工程师和系统工程师。
+
+
+# 好玩的项目,工具和库
+
+[HubCommander](https://github.com/Netflix/hubcommander)
+
+一个用于GitHub组织管理的Slack机器人。
+
+[pyract](https://github.com/samdroid-apps/pyract)
+
+想成:满足React的Gtk+,以及用于Python的MobX
+
+[block](https://github.com/bamos/block)
+
+一个用于numpy, PyTorch等的智能块矩阵库。
+
+[Trump2Cash](https://github.com/maxbbraun/trump2cash)
+
+这个机器人监控Donald Trump的推特,并且等他提到任何公开上市公司。当他提到的时候,则使用情绪分析来决策他对于那些公司的观点是积极的还是消极的。然后,这个机器人根据预期的市场反应,自动对相关股票执行交易。
+
+[pyheat](https://github.com/csurfer/pyheat)
+
+pprofile + matplotlib = 作为棒棒哒的热图的Python程序分析器!
+
+[django-jchart](https://github.com/matthisk/django-jchart)
+
+一个使用优秀的Chart.JS库来绘制图的Django包。
+
+[TensorFlow Fold](https://github.com/tensorflow/fold)
+
+TensorFlow Fold是一个用来创建使用结构化数据的TensorFlow模型的库,其中,计算图的结构取决于输入数据的结构。
+
+[wal-e](https://github.com/wal-e/wal-e)
+
+WAL-E是一个旨在进行PostgreSQL WAL连续归档和基本备份的程序。
+
+[geoplot](https://github.com/ResidentMario/geoplot)
+
+geoplot是一个高级的Python地理空间绘图库。它是cartopy和matplotlib的扩展,使得映射变得简单:例如用于地理空间的seaborn。
+
+[SimpleAudioIndexer](https://github.com/aalireza/SimpleAudioIndexer)
+
+在音频文件中搜索单词/短语或者任意正则表达式模式出现的秒数。
+
+[SimGAN](https://github.com/wayaai/SimGAN)
+
+Apple的通过对抗训练从模拟和无监督图像的实现。
+
+
+# 近期活动和网络研讨会
+
+[Boulder 2017年二月Python聚会 - Boulder, CO](https://www.meetup.com/BoulderPython/events/235496815/)
+
+将会有以下讲座
+
+ * 在构建Flask Web应用程序时学习一些简单的Python
+ * 爬取漫画图片
+ * Python窍门,提示和技巧
+
+
+[IndyPy 2017年二月每月聚会 - Indianapolis,
+IN](https://www.meetup.com/indypy/events/231706173/)
+
+[Edmonton 2017年二月Python聚会 - Edmonton, AB](https://www.meetup.com/startupedmonton/events/236902223/)
+
diff --git a/Python Weekly/Python_Weekly_Issue_282.md b/Python Weekly/Python_Weekly_Issue_282.md
new file mode 100644
index 0000000..28d4287
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_282.md
@@ -0,0 +1,129 @@
+原文:[Python Weekly Issue 282](http://eepurl.com/cCgOaT)
+
+欢迎来到Python周刊第282期。让我们直奔主题。
+
+# 来自赞助商
+
+[](https://www.yhat.com/whitepapers/data-science-in-practice?utm_source=PyWeekly)
+
+[[白皮书] 数据科学的5个常见应用](https://www.yhat.com/whitepapers/data-science-in-practice?utm_source=PyWeekly)
+
+在这个白皮书中,我们介绍了五种常见的数据科学应用,以及使用它们来解决实际业务问题的公司示例。不不不,它跟这只猫半毛钱关系都没有。
+
+\- Yhat团队
+
+
+# 新闻
+
+[DjangoCon US 2017更新:征求建议、指导和财政支持!](https://www.djangoproject.com/weblog/2017/feb/13/djangocon-us-2017-update-call-proposals-mentorship/)
+
+
+# 文章,教程和讲座
+
+[Episode #98: 使用Django Channels为Django增加并发性](https://talkpython.fm/episodes/show/98/adding-concurrency-to-django-with-django-channels)
+
+Python 3中的一个主要的创新领域是异步和并发编程。然而,当使用任何主要的web框架时:django,flask,或者pyramid,基本都没有并发选项。这就是为什么Andrew Godwin决定使用django channels解决django站点上的这个问题。
+
+[与François Chollet聊聊深度学习和Keras](https://softwareengineeringdaily.com/2016/01/29/deep-learning-and-keras-with-francois-chollet/ )
+
+Keras是一个简约且高度模块化的神经网络库,用Python编写,并且能够在TensorFlow或者Theano之上运行。它的开发重点是实现快速实验。在这一集中,François讨论了深度学习的状态,并解释了为什么这个领域正在经历一次寒武纪爆炸,并最终可能会逐渐消失。他解释了为什么需要Keras,以及为什么它的简单性和易用性让它成为一个对开发者实验和构建有用的深度学习库。
+
+[用OpenCV和Python识别数字](http://www.pyimagesearch.com/2017/02/13/recognizing-digits-with-opencv-and-python/)
+
+这篇文章演示了如何使用OpenCV和Python识别图像中的数字。在这篇教程的第一部分,我们会讨论七段显示器是什么,以及我们可以如何应用计算机视觉和图像处理操作来识别这些类型的数字 (无需机器学习!)。在那里,我会提供可以用来识别图像中的数字的实际的Python和OpenCV代码。
+
+[Podcast.__init__ 第96集 - 和Dave Vandenbout聊聊SKIDL](https://www.podcastinit.com/episode-96-skidl-with-dave-vandenbout/)
+
+随着电路和电子组件变得更加复杂,可视化电路构建工具变得更难以有效使用。如果你希望你可以只是用Python编写你的电路,那么你很幸运!Dave Vandenbout写了一个名为SKIDL的库,它将Python的强大功能和灵活性带到了电气工程领域,并且,在本周的节目中,他还会告诉我们所有关于这个库的东东。
+
+[利用Uber的Pyflame和日志来解决扩展问题](https://benbernardblog.com/using-ubers-pyflame-and-logs-to-tackle-scaling-issues/)
+
+在这篇文章中,你将了解我用来诊断我基于Python的网络爬虫的扩展问题(以及一定程度上更一般的性能问题)的技术和工具。
+
+[不好了!这个包只能用于Python 2](https://medium.com/@anthonypjshaw/oh-no-this-package-is-python-2-only-8e6316f9a02)
+
+你埋头进行一个新项目,但是其中一个依赖仍然未支持Python 3 —— 啊!这有一个关于如何解决那个问题的手把手指南。
+
+[马尔科夫链图像生成](https://jonnoftw.github.io/2017/01/18/markov-chain-image-generation)
+
+在这篇文章中,我将会描述一种使用马尔科夫链,从训练图像生成图像的方法。我们训练一个马尔科夫链来存储像素颜色,作为节点值,而相邻像素颜色的数目则成为到相邻节点的连接权重。为了生成图像,我们随机遍历该链,并在输出图像上绘制像素。结果是拥有与原始图像相似的图像调色,但并无一致性的图像。
+
+[树莓派上的TensorFlow图像识别](http://svds.com/tensorflow-image-recognition-raspberry-pi/)
+
+[为什么说分层模型是棒棒哒、棘手并且贝叶斯的](http://twiecki.github.io/blog/2017/02/08/bayesian-hierchical-non-centered/)
+
+[用namedtuple编写干净的Python代码](https://dbader.org/blog/writing-clean-python-with-namedtuples)
+
+[Python中有效的数据可视化的一个提示](https://www.dataquest.io/blog/how-to-communicate-with-data/)
+
+[TensorFlow howto:神经网络中的一个通用逼近器](https://blog.metaflow.fr/tensorflow-howto-a-universal-approximator-inside-a-neural-net-bb034430b71e)
+
+[用50行代码实现生成对抗式网络(Generative Adversarial Networks, GANs) (PyTorch)](https://medium.com/@devnag/generative-adversarial-networks-gans-in-50-lines-of-code-pytorch-e81b79659e3f)
+
+
+# 书籍
+
+[The Hacker's Guide to Python](http://amzn.to/2kUz1rh)
+
+Python是一种精彩的编程语言,被越来越多地使用在很多不同的行业中。它快速,灵活,并且功能齐备。你读到的大部分关于Python的书籍教你的是语言基础知识。但一旦你学会了,你就可以自己设计应用,发掘最佳实践。在这本书中,我们将会看到如何利用Python来有效地解决你的问题,以及构建伟大的Python应用。
+
+[Tiny Python 3.6 Notebook](https://github.com/mattharrison/Tiny-Python-3.6-Notebook/blob/master/python.rst)
+
+这并非Python介绍。相反,这是一个笔记本,里面包含了Python 3的一些例子,以及Python 3.6中发现的新特性。
+
+
+# 好玩的项目,工具和库
+
+[ergonomica](https://github.com/ergonomica/ergonomica)
+
+一个用Python编写的跨平台现代shell。
+
+[Bella](https://github.com/manwhoami/Bella)
+
+一个macOS的纯python、post-exploitation的数据挖掘工具和远程管理工具。
+
+[TensorFlowOnSpark](https://github.com/yahoo/TensorFlowOnSpark)
+
+TensorFlowOnSpark为Apache Hadoop和Apache Spark集群带来了可扩展的深度学习。通过结合深度学习框架TensorFlow和大数据框架Apache Spark和Apache Hadoop的显著特征,TensorFlowOnSpark可以在GPU和CPU服务器集群上实现分布式深度学习。
+
+[neat-python](https://github.com/CodeReclaimers/neat-python)
+
+NEAT神经归化算法的Python实现。
+
+[Lark](https://github.com/erezsh/Lark)
+
+一个带Earley/LALR(1)支持的现代解析库,用Python编写。
+
+[ipytracer](https://github.com/sn0wle0pard/ipytracer)
+
+Jupyter/IPython Notebook的算法可视化。
+
+[django-behaviors](https://github.com/audiolion/django-behaviors)
+轻松集成Django模型的常见行为,例如,时间戳、发布、创作、编辑等等。
+
+[mongoaudit](https://github.com/stampery/mongoaudit)
+
+mongoaudit是一个审计MongoDB服务器、检测弱安全设置以及执行自动渗透测试的CLI工具。
+
+[Flametree](https://github.com/Edinburgh-Genome-Foundry/Flametree)
+
+Flametree是一个Python库,它为处理文件和文件夹提供了一种简单的语法 (无os.path.join,os.listdir等等),并且对于不同的文件系统,使用相同的工作方式。
+
+[densenet.pytorch](https://github.com/bamos/densenet.pytorch)
+
+DenseNet的PyTorch实现。
+
+
+# 近期活动和网络研讨会
+
+[你需要知道的关于Ansible的一切 - 简介 - Philadelphia, PA](https://www.meetup.com/phillypug/events/236696626/)
+
+来了解一下配置管理和Python代码部署的令人兴奋的世界吧。我们的演讲者将会介绍Ansible,提供大量的详情和用例,以及给问答留下大量的时间。你有关于如何扩展大数据应用部署的挑战或问题吗?想知道如何让你的Django站点在多节点上运行,并使用runserver和SQLite吗?随时提出你的问题!
+
+[数据科学家的统计数据 - Houston, TX](https://www.meetup.com/python-14/events/236367843/)
+
+你正在统计数据世界的“门外”,想要找到敲门砖吗?刷新你的统计数据知识,并希望增加此类知识,这怎么样?如果你想知道概率、随机变量、统计推断、探索性数据分析等等意味着什么,那么,这个讲座将会向你展示抵达这些概念的路线图。
+
+[VFX产业中的Python微服务 - London, United Kingdom](https://www.meetup.com/LondonPython/events/237120009/)
+
+这个讲座将会从关于微服务是什么以及为什么它们有用的一个简单介绍开始,然后深入探讨它们在要求严苛的VFX世界中的使用。接着,Python微服务框架nameko背后的人将会像我们展示我们自己可以怎么来做这类很酷的事情。
\ No newline at end of file
diff --git a/Python Weekly/Python_Weekly_Issue_283.md b/Python Weekly/Python_Weekly_Issue_283.md
new file mode 100644
index 0000000..7d8f3de
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_283.md
@@ -0,0 +1,167 @@
+原文:[Python Weekly - Issue 283](http://eepurl.com/cDnLeH)
+---
+
+欢迎来到Python周刊第283期。本周干货满满。尽情享用!
+
+# 来自赞助商
+
+[](https://software.intel.com/en-us/intel-distribution-for-python?utm_source=Python%20Weekly%20Newsletter&utm_campaign=Feb%202017%20-%20U2%20release%20features&utm_medium=email&utm_content=U2%20blog%20announcement)
+
+你会从更快的Numpy, SciPy, scikit-learn中受益吗?无忧安装Theano和Caffe,你觉得咋样?看看刚为[Python* 2017的Intel®发行版](https://software.intel.com/en-us/intel-distribution-for-python?utm_source=Python%20Weekly%20Newsletter&utm_campaign=Feb%202017%20-%20U2%20release%20features&utm_medium=email&utm_content=U2%20blog%20announcement)发布的更新:[令人印象深刻的性能加速](https://software.intel.com/en-us/articles/intelr-distribution-for-python-2017-update-2?utm_source=Python%20Weekly%20U2%20blog&utm_campaign=Feb%202017%20-%20U2%20blog&utm_medium=technical%20article&utm_content=U2%20blog%20announcement) (某些超过100倍)。用Python获取近乎原生的速度。
+
+
+# 新闻
+
+[Django 1.11就会是支持Python 2的最后一个版本](https://docs.djangoproject.com/en/dev/releases/1.11/)
+
+[SciPy 2017现在开放议题征集](http://scipy2017.scipy.org/ehome/220975/493425/)
+
+
+# 文章,教程和讲座
+
+[Episode #100: 和Guido van Rossum聊聊Python的过去、现在和未来](https://talkpython.fm/episodes/show/100/python-past-present-and-future-with-guido-van-rossum)
+
+在这一集中,我们讨论了Guido是如何走进编程的,Python从何而来,以及为什么会有Python,另外,还谈到了Python 3下Python的光明未来。
+
+[使用深度学习,在Quora数据集上进行重复问题检测](http://www.erogol.com/duplicate-question-detection-deep-learning/)
+
+Quora最近宣布了他们发布以来的第一个公共数据集。它包括了404351个问题对,带有一个标识他们是否重复的标签列。在这篇文章中,我想要调查这个数据集,并至少提出一个深度学习的基线方法。
+
+[Podcast.__init__ 第97集 - 和Francesc Alted聊聊PyTables](https://www.podcastinit.com/episode-97-pytables-with-francesc-alted/)
+
+HDF5是一种支持大型数据集的快速且空间有效的分析的文件格式。PyTables是一个项目,它封装并扩展了HDF5的公开,使其易于与更大的Python数据生态系统集成。Francesc Alted解释了项目是如何开始的,它是如何工作的,以及它可以如何被用于创建可共享和可归档的数据集。
+
+[Python类型注释](https://www.caktusgroup.com/blog/2017/02/22/python-type-annotations/)
+
+当谈到编程,我有一个皮带和吊带理念。任何可以帮助我在早期规避错误的东西都值得研究。已经逐渐添加到Python中的类型注释支持就是一个很好的例子。这里是它的工作原理,以及它可以如何对你有帮助。
+
+[使用Python Networkx和Sklearn的隐式Markov模型介绍](http://www.blackarbs.com/blog/introduction-hidden-markov-models-python-networkx-sklearn/2/9/2017)
+
+这篇文章讨论了Markov属性、Markov模型和隐式Markov模型的概念。它使用networkx包来创建Markov链图,并使用sklearn的GaussianMixture来评估历史机制。
+
+[不到100行的Python代码的算法交易](https://www.oreilly.com/learning/algorithmic-trading-in-less-than-100-lines-of-python-code)
+
+如果你对金融交易熟悉,并懂Python,那么你可以马上开始进行基本的算法交易。
+
+[Google Spreadsheets和Python](https://www.twilio.com/blog/2017/02/an-easy-way-to-read-and-write-to-a-google-spreadsheet-in-python.html)
+
+在这个教程中,我将使用Anton Burnashev的优秀的gspread Python包,用几行代码来读取、写入和删除Google Spreadsheet中的数据。
+
+[构建深度学习DOOM机器人](https://www.codelitt.com/blog/doom-ai/)
+
+本文是关注于使用VizDoom平台进行基于深度学习的强化探索之旅的系列文中的第一篇。其目标是创建一个能够在Deathmatch环境中欣欣向荣的Doom AI (woohoo killer AI)。在这个特定的文章中,我将概述Theano(一个开源的深度学习框架)以及VizDoom环境的初始设置过程。
+
+[对Django框架做出贡献比你想象得容易](https://www.vinta.com.br/blog/2017/contributing-hugh-lib/)
+
+在这篇文章中,我将一步一步向你展示我是如何通过修复一个Django容易挑的问题来开始为开源贡献的,以及你可以如何在几步内做到相同的事情。我将使用一个我修复的问题来解释事情的来龙去脉。
+
+[Tensorflow中的图像到图像转换](https://affinelayer.com/pix2pix/)
+
+[使用Pandas和Seaborn进行数据操作和可视化](https://gist.github.com/5agado/ee95008f25730d04bfd0eedd5c36f0ee)
+
+[如何用Kur训练百度的Deepspeech模型](http://blog.deepgram.com/how-to-train-baidus-deepspeech-model-with-kur/)
+
+[描述器:Python中属性访问背后的魔法](http://nbviewer.jupyter.org/github/akittas/presentations/blob/master/pythess/descriptors/descriptors.ipynb)
+
+[用Python填充MS Word模板](http://pbpython.com/python-word-template.html)
+
+[Matplotlib备忘录:在Python中绘图](https://www.datacamp.com/community/blog/python-matplotlib-cheat-sheet)
+
+[持续集成。CircleCI vs Travis CI vs Jenkins](http://djangostars.com/blog/continuous-integration-circleci-vs-travisci-vs-jenkins/)
+
+
+# 本周的Python工作
+
+[Inspirient招聘后端开发](http://jobs.pythonweekly.com/jobs/backend-developer/)
+
+在Inspirient,我们正在建立业务分析的自驾车 —— 一个像经验丰富的顾问或者数据科学家会做的那样,分析任何业务数据集的人工智能。作为Inspirient的一个后端开发,你将负责我们的web应用程序的后端开发。
+
+
+# 好玩的项目,工具和库
+
+[Stethoscope](https://github.com/Netflix/stethoscope)
+
+Stethoscope是这么一个web应用,它收集一个指定用户的设备的信息,并为它们提供保护其系统的清晰具体的建议。
+
+[A.I. Duet](https://github.com/googlecreativelab/aiexperiments-ai-duet)
+
+会回应你的钢琴。这个实验让你通过机器学习制作音乐。在许多MIDI例子上训练了一个神经网络,它学习有关音乐概念的知识、构建音符和节拍图谱。你只需弹奏几个音符,然后看看这个神经网如何回应。
+
+[Securitybot](https://github.com/dropbox/securitybot)
+
+Securitybot是一个分布式告警聊天机器人的开源实现,如Ryan Huber的播客中所述。分布式告警改善了你的安全团队的监控效率,可以帮助你更快更有效地捕获安全事件。
+
+[Universal Radio Hacker](https://github.com/jopohl/urh)
+
+Universal Radio Hacker是一个用于调查未知无线协议的软件。
+
+[bootstrapped](https://github.com/facebookincubator/bootstrapped)
+
+bootstrapped是一个允许你从数据构建置信区间的Python库。这在多种上下文中是有用的 —— 包括在非正式的a/b测试分析中。
+
+[Tweetfeels](https://github.com/uclatommy/tweetfeels)
+
+使用推特的streaming API的实时情感分析。它依赖于VADER情感分析,为用户定义的主题提供情感分数。它通过利用推特的streaming API来监听关于特定主题的实时推特,从而实现此目的。
+
+[scikit-plot](https://github.com/reiinakano/scikit-plot)
+
+一个直观的库,用于添加绘图功能到scikit-learn对象。
+
+[fast-pixel-cnn](https://github.com/PrajitR/fast-pixel-cnn)
+
+加速PixelCNN++图像生成,快达183倍。
+
+[Privy](https://github.com/ofek/privy)
+
+Privy是一个小而快的实用程序,用于密码保护,例如数字签名种子,或者Bitcoin钱包。
+
+[ChainerRL](https://github.com/pfnet/chainerrl)
+
+ChainerRL是一个建立在Chainer之上的深度强化学习库。
+
+[evilpass](https://github.com/SirCmpwn/evilpass)
+
+稍微邪恶的密码强度检查器。
+
+[Errator](https://github.com/haxsaw/errator)
+
+为你的库和终端用户程序创建人类可读的异常叙述。
+
+[Mercure](https://github.com/synhack/mercure)
+
+Mercure是为那些想要教会他们的合作者关于钓鱼的安全管理者提供的工具。
+
+[ipyvolume](https://github.com/maartenbreddels/ipyvolume)
+
+Jupyter notebook中基于IPython小部件的使用WebGL的Python 3d绘图。
+
+[pmcli](https://github.com/christopher-dG/pmcli)
+
+用于Google Play音乐流媒体服务的轻量级,可自定义的TUI客户端。
+
+
+# 最新发布
+
+[TensorFlow 1.0](https://developers.googleblog.com/2017/02/announcing-
+tensorflow-10.html)
+
+[Django 1.11 beta 1](https://www.djangoproject.com/weblog/2017/feb/20/django-1
+11-beta-1-released/)
+
+
+# 近期活动和网络研讨会
+
+[网络研讨会:对客户生命周期价值进行预测建模的简介](http://www.oreilly.com/pub/e/3861)
+
+在这个网络广播中,我们将解释可以用来量化客户未来价值的概率模型的输入和输出,并演示电子商务公司如何使用这些模型的输出来识别、保留和定位高价值客户。在第二部分,我们将指导你完成一个关于如何在零售数据集上实现、训练和验证CLV(客户生命周期价值)模型的实践Python教程。
+
+[SoCal Python 2017年2月聚会 - Los Angeles, CA](https://www.meetup.com/socalpython/events/237707543/)
+
+将会有一场演讲:使用Python探索自然语言。这场演讲将会关注于演示如何使用诸如NLTK, Spacey和SCIPy这样的自然语言工具和库来提取句子的情感,以及探索如何解析外语。特别是,在我们的例子中,我们会使用Arabic和Hebrew,并演示一些可能不会出现在英语中的有趣的东东。
+
+[DFW Pythoneers 2017年3月聚会 - Plano, TX](https://www.meetup.com/dfwpython/events/237375328/)
+
+
+
+
+
diff --git a/Python Weekly/Python_Weekly_Issue_284.md b/Python Weekly/Python_Weekly_Issue_284.md
new file mode 100644
index 0000000..d4ded07
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_284.md
@@ -0,0 +1,134 @@
+原文:[Python Weekly - Issue 284](http://eepurl.com/cEro-H)
+---
+
+欢迎来到Python周刊第284期。让我们直奔主题。
+
+
+# 文章,教程和讲座
+
+[Django Channels入门](https://realpython.com/blog/python/getting-started-with-django-channels/)
+
+在这篇教程中,我们会使用Django Channels来创建一个实时的应用,它会在用户登录和注销时更新用户。有了在客户端和服务器之间管理通信的WebSockets (通过Django Channels),每当认证了一个用户时,就会广播一个事件给其他每一个连接的用户。每个用户的屏幕都会自动改变,无需他们自己加载浏览器。
+
+[Podcast.__init__ 第98集 - 和Jeff Reback聊聊Pandas](https://www.podcastinit.com/episode-98-pandas-with-jeff-reback/)
+
+在Python界,Pandas是进行数据操作和分析的最通用和最广泛使用的工具之一。本周,Jeff Reback解释了为什么会那样,你可以如何用它来让你的生活更轻松,以及在未来的几个月中,你可以期待的东西。
+
+[在AWS上,使用Python分析4百万Yelp评论](http://www.developintelligence.com/blog/2017/02/analyzing-4-million-yelp-reviews-python-aws-ec2-instance/)
+
+Yelp每年都有一次数据竞赛,邀请人们探索其真实世界的数据集,以获取独特见解。在这篇文章中,我们将介绍如何把数据集加载到在一个强大但便宜的AWS spot实例上运行的Jupyter Notebook中,并得出一些初步的探索和可视化。
+
+[利用Python, pandas和statsmodels,通过线性回归预测房价](http://www.learndatasci.com/predicting-housing-prices-linear-regression-using-python-pandas-statsmodels/)
+
+在这篇文章中,我们将通过建立线性回归模型来预测由经济活动导致的房价。
+
+[现代Django](https://github.com/djstein/modern-django)
+
+一篇关于怎样在2017年部署基于Django的Web应用的指南。
+
+[使用基于坐标的神经网络的超分辨率](http://liviu.me/blog/super-resolution-using-coordinates-networks)
+
+这是一篇探索在除了缩小图像自身之外,无需使用训练数据的情况下,使用神经网络扩展图像的快速发布。
+
+[Python 3.6中的后现代错误处理](http://journalpanic.com/post/postmodern-error-handling/)
+
+如何在一些类型错误发生之前捕获它们。
+
+[防止Python中的SQL注入 (以及其他漏洞)](https://blog.sqreen.io/preventing-sql-injections-in-python/)
+
+随着应用复杂度的增加,可能很容易在无意中引入潜在问题和漏洞。在这篇文章中,我将会强调可能会引发最大问题的最容易忽略的问题和漏洞,如何避免,以及帮助你节省时间的工具和服务。
+
+[在MacOS应用上嵌入Python](https://medium.com/python-pandemonium/embedding-a-python-application-in-macos-d866adfcaf94)
+
+通过pyinstaller,嵌入一个Python应用到MacOS cocoa应用中。
+
+[客户细分的初学者指南](http://blog.yhat.com/posts/customer-segmentation-python-rodeo.html)
+
+在这篇文章中,我将详细介绍你可以如何使用K均值聚类来帮助进行客户细分的某些探索。
+
+[Zendesk是如何在生产上为TensorFlow模型服务的](https://medium.com/zendesk-engineering/how-zendesk-serves-tensorflow-models-in-production-751ee22f0f4b)
+
+[利用LDAP连接池缩放Django+Gevent](https://medium.com/@joey_tallieu/scaling-django-gevent-with-ldap-connection-pooling-d2c5cbb60a40)
+
+[如果构建一个可扩展的爬虫来在短短2个小时内,仅用单个机器即可爬取百万页面](https://medium.com/@tonywangcn/how-to-build-a-scaleable-crawler-to-crawl-million-pages-with-a-single-machine-in-just-2-hours-ab3e238d1c22)
+
+[PyPy3上的异步HTTP基准](https://morepypy.blogspot.com/2017/03/async-http-benchmarks-on-pypy3.html)
+
+[达美乐比萨(Domino's Pizza)通知器](http://www.technologyversus.com/pizza/)
+
+
+# 好玩的项目,工具和库
+
+[Machine Learning From Scratch](https://github.com/eriklindernoren/ML-From-Scratch)
+
+从头开始用Python实现一些基础机器学习模型和算法。
+
+[DeepVideoAnalytics](https://github.com/AKSHAYUBHAT/DeepVideoAnalytics)
+
+Deep Video Analytics提供了一个从视频和图像索引和提取信息的平台。使用深度学习检测和识别算法来用检测到的对象索引各个帧/图像。Deep Video analytics的目标是成为一个用于开发视觉和视频分析应用的快速可定制平台,同时受益于与视觉研究社区发布的状态(state)或者艺术模型无缝集成。
+
+[Prophet](https://github.com/facebookincubator/prophet)
+
+用于生成用于时间序列数据(具有线性或非线性增长的多季节性)的高质量预测的工具。
+
+[mazesolving](https://github.com/mikepound/mazesolving)
+
+解决来自输入图像的迷宫的各种算法。
+
+[keep](https://github.com/OrkoHunter/keep)
+
+Meta CLI工具包:个人shell命令保存器
+
+[BrainDamage](https://github.com/mehulj94/BrainDamage)
+
+一个功能齐全的后门,使用Telegram作为C&C服务器。
+
+[pdftabextract](https://github.com/WZBSocialScienceCenter/pdftabextract)
+
+用于从PDF文件中提取表单的一组工具,以助于在(OCR处理过的)扫描文档上进行数据挖掘。
+
+[Staffjoy](https://github.com/Staffjoy/suite)
+
+Staffjoy V1,又名"Suite" - 给数百名工作者的的时间安排应用。
+
+[facebook-bot](https://github.com/srcecde/facebook-bot)
+
+一个基本的Python facebook机器人,它可以按照所需的时间间隔,自动点赞和更新状态。你所需要做的只是将状态数据提交给机器人。无需API Developer key。
+
+[SWA-Scraper](https://github.com/wcrasta/SWA-Scraper)
+
+一个爬取西南航空公司网站并展示当前机票的最低价格的命令行工具。如何当前的最低价格在你指定的某些阈值之下,那么,将会发送一条短信给你。
+
+[TensorFlow-NRE](https://github.com/thunlp/TensorFlow-NRE)
+
+神经关系提取旨在通过神经模型从纯文本中提取关系,这是关系提取的最先进的方法。在这个项目中,我们提供了我们词级和句子级组合的双向GRU网络 (BGRU+2ATT)的实现。
+
+[PythonBuddy](https://github.com/ethanchewy/OnlinePythonLinterSyntaxChecker)
+
+带有即时语法检查和执行的Python编辑器。
+
+
+# 最新发布
+
+[Django问题修复版本发布:1.10.6](https://docs.djangoproject.com/en/1.10/releases/1.10.6/)
+
+
+# 近期活动和网络研讨会
+
+[San Francisco Python 2017年3月聚会 - San Francisco, CA](https://www.meetup.com/sfpython/events/237795676/)
+
+Eli Uriegas将会介绍Sanic是如何使用异步的,它的优点,以及我们在Python的标准文档中看到的标准的httprequests / sleep和print应用之外的有用的async/await应用。他还会提供一些例子,包括asyncio协议实现、通过异步函数使用那个asyncio协议,以及如何在一个asyncio循环中运行所有这些东东 (优选uvloop)。然后,了解旧金山海湾地区最有前途的Python驱动的新兴公司。
+
+[PyAtl 2017年3月聚会 - Atlanta, GA](https://www.meetup.com/python-atlanta/events/233890712/)
+
+将会有以下讲座
+
+ * 给普通人的Python Packaging
+ * 我是如何停止焦虑,并学着在Python中使用一点点线程的
+
+
+[Austin Python 2017年3月聚会 - Austin, TX](https://www.meetup.com/austinpython/events/235872974/)
+
+
+
+
diff --git a/Python Weekly/Python_Weekly_Issue_285.md b/Python Weekly/Python_Weekly_Issue_285.md
new file mode 100644
index 0000000..4e2bc76
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_285.md
@@ -0,0 +1,147 @@
+原文:[Python Weekly - Issue 285](http://eepurl.com/cFyrlf)
+---
+
+欢迎来到Python周刊第285期。让我们直奔主题。
+
+# 来自赞助商
+
+[](https://software.intel.com/en-us/intel-distribution-for-python?utm_source=Mar%202017%20Image%20link%20Python%20weekly&utm_campaign=Python%20Weekly%20newsletter&utm_medium=email)
+
+有了FFT,umath,memory和scikit-learn算法的加速,NumPy,SciPy,scikit-learn现在更快了。看看刚刚发布的Intel® Python* 2017发行版的更新中,那些[令人印象深刻的性能加速](https://software.intel.com/en-us/articles/intelr-distribution-for-python-2017-update-2?utm_source=Mar%202017%20U2%20blog%20Python%20weekly&utm_campaign=Python%20Weekly%20newsletter&utm_medium=email) (一些超过100倍)吧。获得接近Python原生的速度。
+
+
+# 文章,教程和讲座
+
+[Episode #101: 添加一个全功能Python环境到Visual Studio Code](https://talkpython.fm/episodes/show/101/adding-a-full-featured-python-environment-to-visual-studio-code)
+
+你知道我在每一集结束的时候问的两个问题吗?编写Python代码你最喜欢的编辑器,以及推荐哪些鲜为人知的PyPI包?这一次,我们整一集都在谈论“你最喜欢的编辑器是啥”。你将会见到Don Jayamanne,他创建了用于Visual Studio Code的非常流行的开源Python加载项。这不只是专用于Windows的Visual Studio,还是Microsoft免费的跨平台编辑器。
+
+[使用OpenCV (C++ / Python)自动化红眼去除器](http://www.learnopencv.com/automatic-red-eye-remover-using-opencv-cpp-python/)
+
+在这个教程中,我们将会学习如何自动地彻底从照片中删除红眼。
+
+[Triple Pendulum CHAOS!](http://jakevdp.github.io/blog/2017/03/08/triple-pendulum-chaos/)
+
+本周早些时候,一条推特公布了一个视频,很好地展示了活动中的混沌动力系统。当然,我立刻想知道,是否我可以在Python中重现这个模拟。本文就是答案。
+
+[IPython还是Jupyter?](https://www.datacamp.com/community/blog/ipython-jupyter)
+
+本文旨在更清楚地阐明二者之间的一些核心差异,不仅仅是从两者的起源开始解释二者之间的关系,还涵盖了它们的一些特有特征,这会让你更容易区分它们!
+
+[简单解释一致性哈希环](https://akshatm.svbtle.com/consistent-hash-rings-theory-and-implementation)
+
+一致性哈希环是种漂亮的饥饿哦股,然而,很少有人解释它。实现往往集中在聪明的语言特定的技巧,而理论方法则坚持用数学和不相干切线来使人迷惑。这是一篇进行解释的尝试 - 和一个Python实现 - 普通高中生阅读无碍。
+
+[使用Facebook的Prophet库预测网站流量](http://pbpython.com/prophet-overview.html)
+
+在这篇文章中,我将介绍prophet,并且演示如何用它来预测Practical Business Python明年的流量。为了让它更有趣些,我将会在3月底发布预测,这样,我们就可以看看预测是有多准了。
+
+[TensorFlow上的Doom机器人](http://tech.marksblogg.com/tensorflow-vizdoom-bots.html)
+
+ViZDoom是一个AI研究平台,允许你训练机器人玩Doom,这是一款最初由id Software在1993年发布的经典第一人称射击游戏。ViZDoom通过ZDoom,这一开源Doom引擎来与游戏交互。在这篇文章中,我将通过设置ViZDoom和TensorFlow,训练机器人担任Doom中的恶魔。
+
+[开始在Python中使用模拟测试](https://semaphoreci.com/community/tutorials/getting-started-with-mocking-in-python)
+
+一篇关于使用Python的unittest.mock来替换测试环境下的系统,并提高你的单元测试的效率的介绍。
+
+[文本特征提取](https://andhint.github.io/machine-learning/nlp/Feature-Extraction-From-Text/)
+
+本文是用于机器学习模型的文本特征提取的一个简单的介绍,使用Python和sci-kit learn。大多数的机器学习算法无法接收直接的文本作为输入,因此,我们会创建一个数值矩阵来代表我们的文本。我们会讨论两种常用的实现方法直接的区别:CountVectorizer和TfidfVectorizer。
+
+[Podcast.__init__ 第99集 - Update框架 —— 保护你的软件更新](https://www.podcastinit.com/episode-99-the-update-framework-with-justin-cappos/)
+
+如果你写软件,那么很有可能,你不得不处理依赖安装,但是,你有停下来问问,你是否安装的是你想要安装的东西?本周,我的客人是来自纽约大学安全系统实验室的Justin Cappos教授,他和我一起讨论了他在Update框架上的工作,该框架旨在保证你不在你的系统中安装受损软件包。
+
+[利用Python查找免费食物](http://jamesbvaughan.com/python-twilio-scraping/)
+
+[在Python中导入ctypes:解决溢出问题](https://www.cossacklabs.com/blog/fighting-ctypes-overflows.html ).
+
+[CIA (大量)使用Python](https://www.reddit.com/r/Python/comments/5y2boe/cia_uses_python_a_lot/)
+
+[利用Python构建微服务,第一部分](https://medium.com/@ssola/building-microservices-with-python-part-i-5240a8dcc2fb)
+
+[在AWS EC2实例上启动和运行Python 3.6和TensorFlow的指南](https://sebastianraschka.com/pdf/books/dlb/appendix_h_cloud-computing.pdf)
+
+[通过Twilio, Heroku, 和Python接收Stripe SMS通知](https://www.twilio.com/blog/2017/02/stripe-sms-notifications-via-twilio-heroku-and-python.html)
+
+
+# 好玩的项目,工具和库
+
+[Python Fire](https://github.com/google/python-fire)
+
+Python Fire是一个用于绝对从任意Python对象自动化生成命令行接口(CLI)的库。
+
+[scrabble](https://github.com/benjamincrom/scrabble)
+
+实现Scrabble(拼词游戏纸牌)。还允许用户从给定的板和得分列表中恢复所有的游戏移动,以及暴力查找最好的移动。
+
+[Bleach](https://github.com/mozilla/bleach)
+
+Bleach是一个基于白名单的HTML清理库,它可以转义或者删除标记和属性。Bleach还可以安全地链接文本,应用Django的urlize过滤器无法做到的过滤,并且可选地设置rel属性,甚至是已经存在于文本中的链接。Bleach用于对来自不可信源的文本进行清理。
+
+[playlistfromsong](https://github.com/schollz/playlistfromsong)
+
+从单首歌曲中创建一个离线音乐播放列表。
+
+[Devpy](https://github.com/sametmax/devpy)
+
+Devpy是一组用来简化Python开发的工具,提供自动日志记录。
+
+[dockerscan](https://github.com/cr0hn/dockerscan)
+
+一个Docker分析工具。
+
+[Python Cheat Sheet](https://github.com/JulianGaal/python-cheat-sheet)
+
+这个仓库是为数据科学量身定制的Python备忘录列表。目前,它包括了NumPy备忘录,未来将会有更多,敬请期待。
+
+[aredis](https://github.com/NoneGG/aredis)
+
+一个高效且用户友好的异步redis客户端。
+
+[rwa](https://github.com/jostmey/rwa)
+
+使用复发性加权平均的顺序数据之上的机器学习。
+
+[Snape](https://github.com/mbernico/snape)
+
+Snape是一个方便的人工数据集生成器,封装了sklearn的make_classification和make_regression,然后添加了“现实主义”特性,例如复杂格式化、尺度变化、分类变量和缺失值。
+
+[qpth](https://github.com/locuslab/qpth)
+
+PyTorch的一个快速可微的QP解算器。
+
+[Simon](https://github.com/hcyrnd/simon)
+
+简单的macOS菜单栏系统监控器,用Python3.6 + pyobjc编写。
+
+
+# 最新发布
+
+[Python 3.6.1rc1](http://blog.python.org/2017/03/python-361rc1-is-now-
+available-for.html)
+
+
+# 近期活动和网络研讨会
+
+[网络研讨会:高效Python学习习惯](https://www.crowdcast.io/e/learning)
+
+在学习一门编程语言的时候,你怎么知道你的努力行之有效,还是在浪费时间?加入我们的在线聊天,聊聊如何确保你正高效地进行Python学习。
+
+[Boulder Python 2017年3月聚会 - Boulder, CO](https://www.meetup.com/BoulderPython/events/235590248/)
+
+将会有以下讲座
+
+ * 用Python自动化WordPress设置
+ * 用Python进行SDN自动化
+
+
+[Princeton Python User 2017年3月聚会 - Princeton, NJ](https://www.meetup.com/pug-ip/events/237749846/)
+
+Blockstack是一个用Python编写的平台,用来构建分散式Web应用。区块链被用来维护一个跨应用标识系统,安全地将用户ID映射到用户名、公钥和数据存储URI。开发者无需担忧运行中的服务器,数据库维护,或者用户管理系统构建,分散的无服务器应用可以比其传统的同类产品更容易地构建。Blockstack核心开发者,Jude Nelson,将提供一个关于如何构建一个让你安全存储和共享文件的简单的CLI应用的实践教程。
+
+[Edmonton Python 2017年3月聚会 - Edmonton, AB](https://www.meetup.com/startupedmonton/events/237498368/)
+
+
+
+
diff --git a/Python Weekly/Python_Weekly_Issue_286.md b/Python Weekly/Python_Weekly_Issue_286.md
new file mode 100644
index 0000000..3966bf5
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_286.md
@@ -0,0 +1,153 @@
+原文:[Python Weekly - Issue 286](http://eepurl.com/cGFJaz)
+---
+
+欢迎来到Python Weekly第286期。本周,让我们直入主题。
+
+# 来自赞助商
+
+[](http://www.amazon.com/gp/product/B0185367JQ/ref=as_li_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=B0185367JQ&linkCode=as2&tag=mymerch-20&linkId=OLIXWD4WZ5X6FFHD)
+
+嘿,Python粉,你想要表达你对**Python**的爱吗?那么,[点击这里](http://www.amazon.com/gp/product/B0185367JQ/ref=as_li_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=B0185367JQ&linkCode=as2&tag=mymerch-20&linkId=OLIXWD4WZ5X6FFHD),获取你的T恤,骄傲地穿上它吧。
+
+
+# 新闻
+
+[XLA - TensorFlow, 已编译](https://developers.googleblog.com/2017/03/xla-tensorflow-compiled.html)
+
+Google已经宣布了XLA (加速线性代数),这是一个用于TensorFlow的编译器。XLA使用JIT编译技术来分析用户在运行时创建的TensorFlow图,专门用于实际的运行时维度和类型,与多种操作相联合,并为它们产生高效的本地机器码 —— 对于像CPU, GPU和自定义加速器(例如,谷歌的TPU)之类的设备。
+
+
+# 文章,教程和讲座
+
+[Podcast.__init__ 第100集 - MetPy: 以Python为辅,驯服天气](https://www.podcastinit.com/episode-100-metpy-with-ryan-may-sean-arms-and-john-leeman/)
+
+明天的天气怎么样?这是一个气象学家一直试图更好解答的问题。本周,MetPy的开发者讨论了他们的项目是如何用在这个任务上的,以及在大气和天气研究中固有的挑战。处理不确定性,使用凌乱、多维数据来建模一个大规模复杂系统,是相当名人的。
+
+[在Python中构建分析数据管道](https://www.dataquest.io/blog/data-pipelines-tutorial/)
+
+数据管道的一个常见用途是找出你的站点的访问者的相关信息。如果你熟悉Google Analytics,那你就会知道查看访问者的实时和历史信息的价值。在这篇文章中,我们将使用来自web服务器日志的数据来回答有关访问者的问题。
+
+[如果丢失的Python源代码仍然驻留在内存中的话,如何恢复它们](https://gist.github.com/simonw/8aa492e59265c1a021f5c5618f9e6b12)
+
+我弄错了git的使用 (对于错误的文件使用了"git checkout --"),设法删除我刚写好的代码……但是这些代码仍然在一个docker容器中的一个进程里运行。这里,我将展示如何使用pyrasite和uncompyle6,将它们弄回来。
+
+[如何编写DSL (在Python中,利用Lark)](http://blog.erezsh.com/how-to-write-a-dsl-in-python-with-lark/)
+
+在这个教程中,我将向你展示如何用仅仅70行代码,解析和解释一个类Logo语言,并使用这个例子来设计和实现你自己的语言。为此,我们将使用我的解析库Lark,以及Python的turtle模块。让我们开始吧!
+
+[检测Apache和Nginx日志中的机器人](http://tech.marksblogg.com/detect-bots-apache-nginx-logs.html)
+
+由于阻止基于JavaScript的跟踪锚节点的浏览器插件现在有9位数的用户数,因此,网络流量日志是一个可以更好的了解多少人访问你的网站的好地方。但是,任何一个已经监控网络流量日志几分钟的人都会发现,存在一个爬取网站的机器人军队。然而,能够在网络服务器日志中将机器人和人为产生的流量分离出来却是一种挑战。在这篇文章中,我将介绍构建一个IPv4所有权和浏览器基于字符串的机器人检测脚本的步骤。
+
+[使用Google Maps Distance Matrix API的等流时线](http://blog.yhat.com/posts/isochrones-isocronut.html)
+
+[SciPy新的LowLevelCallable是一种创新](https://ilovesymposia.com/2017/03/12/scipys-new-lowlevelcallable-is-a-game-changer/)
+
+[Python 3还存在那些WTF的东东?](https://www.reddit.com/r/Python/comments/5zk97l/what_are_some_wtfs_still_in_python_3/)
+
+[适用于Python/Django应用的可用于生产的Dockerfile](https://www.caktusgroup.com/blog/2017/03/14/production-ready-dockerfile-your-python-django-app/)
+
+[神秘Python崩溃的情况](https://benbernardblog.com/the-case-of-the-mysterious-python-crash/)
+
+[Python 3中新的有趣的数据结构](https://github.com/topper-123/Articles/blob/master/New-interesting-data-types-in-Python3.rst)
+
+[标题党重顾:标题+内容特性上的深度学习,以捕获标题党](https://www.linkedin.com/pulse/clickbaits-revisited-deep-learning-title-content-features-thakur)
+
+[Python中的拟合高斯过程模型](https://blog.dominodatalab.com/fitting-gaussian-process-models-python/ )
+
+[Vector Venture - 在Python中使用Tkinter的官方预告片!](https://www.youtube.com/watch?v=XSWWsX7gUp0 )
+
+
+# 本周的Python工作
+
+[Academic Merit招聘首席Python软件工程师](http://jobs.pythonweekly.com/jobs/lead-python-software-engineer/)
+
+由于我们从此开始为快速的业务增长做准备,因此,AcademicMerit正在寻找一些软件工程师,我们需要你敏捷,对于伟大的软件组件和服务持有自己的观点,并且在交付根据用户期望进行了良好测试的可靠软件方面非常注意细节。软件工程师将有机会参与全栈开发、可视化、用户分析、分布式系统、基于docker容器的服务和机器学习算法。你将工作于给美国和全球各国际学校的教师和高中生使用的关于写作教育和AP课程的多种产品。
+
+[MindMeld招聘经验丰富的后台工程师](http://jobs.pythonweekly.com/jobs/seasoned-backend-engineer/)
+
+作为高级软件工程师,你将负责MindMeld Conversational AI平台的几个组件和功能,并且在财富500强公司的其中一个概念验证或者生产部署中扮演重要角色。你将加入一个团队,这个团队试图为大型词汇知识领域实现最先进的端到端准确性(> 99%),并且满足长尾用户请求。你将主要用python进行编码,并且利用大量的库和框架。你将使用像Amazon Mechanical这样的众包工具来进行数据收集。作为工程团队的早期成员,你将拥有独一无二的机会来构建关键产品功能和基础设施,同时塑造团队和公司的方向。
+
+
+# 好玩的项目,工具和库
+
+[pdir2](https://github.com/laike9m/pdir2)
+
+愉悦的漂亮dir()打印。
+
+[face_recognition](https://github.com/ageitgey/face_recognition)
+
+世界上最简单的Python和命令行面部识别API。
+
+[seq2seq](https://github.com/google/seq2seq)
+
+Tensorflow的通用编码-解码框架。
+
+[trio](https://github.com/python-trio/trio)
+
+Trio是为Python生成一个生产级质量、带有许可的原生async/await I/O库的一种实验性尝试,重点在于可用性和正确性,我们希望使得正确操作变得容易。
+
+[MellPlayer](https://github.com/Mellcap/MellPlayer)
+
+基于Python3的微型终端播放器。
+
+[LXDock](https://github.com/lxdock/lxdock)
+
+LXDock是LXD的一个封装器,允许开发者使用类似于Vagrant的工作流来编排他们的开发环境。
+
+[django-react-blog](https://github.com/raymestalez/django-react-blog)
+
+使用Django和React/Redux构建,通过Docker部署,利用nginx/uwsgi提供服务的简单播客。
+
+[Jarvis](https://github.com/sukeesh/Jarvis)
+
+Linux上的个人助理
+
+[sharingan](https://github.com/vipul-sharma20/sharingan)
+
+从报纸中提取新闻文章,并提供有关新闻的上下文的工具。
+
+[CHIPSEC](https://github.com/chipsec/chipsec)
+
+CHIPSEC是一个用于分析包括硬件、系统固件(BIOS/UEFI)和平台组件的PC平台的安全性的框架。它包括了一个安全测试套件,访问各种低级接口的工具以及取证功能。它可以在Windows, Linux, Mac OS X 和UEFI shell上运行。
+
+
+# 最新发布
+
+[Django REST框架 3.6](http://www.django-rest-framework.org/topics/3.6-announcement/)
+
+3.6版本添加了两个主要的新特性到REST框架。
+
+ * 内置的交互式API文档支持。
+ * 一个新的JavaScript客户端库。
+
+
+[Keras 2](https://blog.keras.io/introducing-keras-2.html)
+
+
+# 近期活动和网络研讨会
+
+[San Francisco Django 2017年3月聚会 - San Francisco, CA](https://www.meetup.com/The-San-Francisco-Django-Meetup-Group/events/237666575/)
+
+将会有以下讲座
+
+ * 将Twisted作为你的WSGI容器
+ * Django和Webpack + React
+
+
+[PyHou 2017年3月聚会 - Houston, TX](https://www.meetup.com/python-14/events/236367841/)
+
+Glen Zangirolami将会介绍Asyncio模块 —— 从生成器到Asyncio,我们将会学到一点关于Asyncio的东西,以及它是如何能够在你的个人和专业项目中帮助你的。我们将从生成器开始,并创建我们自己的基础I/O循环来演示Asyncio是如何工作的。从那开始,我们将覆盖基本的Asyncio代码示例。
+
+[San Diego Python 2017年3月聚会 - San Diego, CA](https://www.meetup.com/pythonsd/events/237628732/)
+
+将会有以下讲座
+
+ * Disk-based spooling with Django query
+ * Style II元素 - 词选择
+
+
+
+
+
+
diff --git a/Python Weekly/Python_Weekly_Issue_287.md b/Python Weekly/Python_Weekly_Issue_287.md
new file mode 100644
index 0000000..489055f
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_287.md
@@ -0,0 +1,175 @@
+原文:[Python Weekly - Issue 287](http://eepurl.com/cHK54v)
+
+---
+
+欢迎来到Python Weekly第287期。本周干货满满。尽情享用!
+
+
+# 文章,教程和讲座
+
+[构建安全A.I.](https://iamtrask.github.io/2017/03/17/safe-ai/)
+
+在这篇文章中,我们会训练一个在训练期间完全加密的神经网络(在未加密数据上进行训练)。结果将会是一个带两个有益属性的神经网络。首先,该神经网络的智能被保护,以免遭受窃取,允许在不安全的环境中对有价值的AI进行训练,而无需冒着智能被窃取的风险。其次,该网络可以只进行加密预测(可假定对外部世界没有影响,因为外部世界无法在没有秘钥的情况下理解这个预测)。这在用户和超级智能之间创造了一种有价值的权利不均衡。如果AI被同态加密,那么从它的角度来看,整个外部世界也被同态加密了。人类控制秘钥,并且可以选择解锁AI自身 (将它释放到世界中),还是仅仅解锁AI进行的个别预测 (看起来更安全)。
+
+[如何用Python挖掘新闻源数据,并且提取交互式洞察](http://ahmedbesbes.com/how-to-mine-newsfeed-data-and-extract-interactive-insights-in-python.html)
+
+在这个教程中,我们还将了解一个具体用例的数据。我们会从60个不同的来源 (Google News, The BBC,
+Business Insider, BuzzFeed,等等)收集新闻源。我们会将它们转换成一种可用格式作为输入。然后,应用一些机器学习技术来根据它们的相似性进行文章聚类,最后,对结果进行可视化,以获取高水平的洞察。这将提供给我们一种对分组聚类和基础主体的可视化感受。这些技术是我们所说的主题挖掘的一部分。
+
+
+[Podcast.__init__ 第101集 - 与Tobias Oberstein和Alexander Godde聊聊Crossbar.io](https://www.podcastinit.com/episode-101-crossbar-io-with-tobias-oberstein-and-alexander-goedde/)
+
+随着我们的系统架构和物联网不断地将我们推向分布式逻辑,我们需要一种方式来在这些各种各样的组件之间路由流量。Crossbar.io是web应用程序消息传递协议 (WAMP)的原始实现,这个协议将远程过程调用 (RPC) 和发布/订阅 (PubSub) 通信模式组合到单个通信层里。在这一集中,Tobias Oberstein描述了当你在一个高吞吐量和低延迟系统中拥有一个基于事件的RPC时,可能会出现的用例和设计模式。
+
+
+[Python和JSON:使用Pandas处理大型数据集](http://www.dataquest.io/blog/python-json-tutorial/)
+
+在这篇文章中,我们将会看看如何利用诸如Pandas这样的工具来探索并在地图上标出Montgomery County, Maryland的警察活动。我们先会看看JSON数据,然后再用Python对JSON进行探索和分析。
+
+
+[Episode #103:通过PyLLVM和MongoDB,为数据科学家编译Python](https://talkpython.fm/episodes/show/103/compiling-python-through-pyllvm-and-mongodb-for-data-scientists)
+
+我们先看看使用LLVM编译器和一个称为PyLLVM的项目(使用普通的Python代码,将其编译为已优化的机器指令,并在一个集群中分发它),为机器学习优化Python代码的一部分。在下半部分,我们看看给写Python的数据科学家的一个和MongoDB一起使用的神话般的新方法。这个项目称为bson-numpy,它提供MongoDB和NumPy之间的直接连接,并且比标准的pymongo快10倍。
+
+
+[使用data.world Python库加速你的数据采集](https://www.dataquest.io/blog/datadotworld-python-tutorial/)
+
+在处理数据的时候,工作过程的一个重要部分是查找和导入数据集。能够快速的定位数据,理解它,并将其与其他来源进行合并可能是困难的。一个可以帮助你的工具是data.world,其中,你可以搜索、拷贝、分析和下载数据集。另外,你也可以上传你的数据到data.world,然后用它与他人协作。在这个教程中,我们将会向你展示如何使用data.world的Python库来轻松用你的Python脚本或者Jupyter notebook玩耍数据。
+
+[无反向传播的深度学习](https://iamtrask.github.io/2017/03/21/synthetic-gradients/)
+
+在这篇文章中,我们将会(从头开始)原型化和学习DeepMind最近提出的“使用合成梯度的解耦神经网络接口(Decoupled Neural Interfaces Using Synthetic Gradients)”论文背后的逻辑。
+
+[在Keras和TensorFlow中实现的五种视频分类方法](https://medium.com/@harvitronix/five-video-classification-methods-implemented-in-keras-and-tensorflow-99cad29cc0b5)
+
+在这篇文章中,我们将会介绍使用Keras和TensorFlow后端分类视频的不同策略。我们将尝试学习如何将五种深度学习模型应用于具有挑战且研究较多的UCF101数据集。
+
+
+[Python的函数是一类对象](https://dbader.org/blog/python-first-class-functions)
+
+Python的函数是一种一类对象。你可以将它们赋值给变量,将其存储到数据结构中,将它们作为参数传递给其他函数,甚至是在其他函数中将它们作为值返回。在这篇文章中,我将会引导了解一些例子,以助你拥有这些直观的理解。这些例子将会构建在其他例子之上,因此你也许想要按顺序阅读它们,甚至是边读边在Python解释器中试试它们。
+
+[使用scikit-learn和Python,从评论中预测Yelp星级](http://www.developintelligence.com/blog/2017/03/predicting-yelp-star-ratings-review-text-python/)
+
+在这篇文章中,我们将看看来自Yelp Dataset Challenge的评论。我们会训练一个深度学习系统,仅仅基于一个评论的文本来预测它的星级。例如,如果文本是"Everything was great! Best
+stay ever!!",那么我们会预计是5星评级。如果文本是"Worst stay of my life. Avoid at all costs",那么我们预计回事1星评级。我们可以训练一个机器学习分类器,通过给它标记好的例子,来“学习”积极评论和消极评论之间的差异,而不是编写一系列的规则来确定一些文本是正面的还是负面的。
+
+[在AWS GPU上运行Jupyter notebooks:入门者指南](https://blog.keras.io/running-jupyter-notebooks-on-gpu-on-aws-a-starter-guide.html)
+
+这是一个开始在AWS GPU实例上运行深度学习Jupyter notebooks,同时在你的浏览器中随时随地编辑notebooks的手把手指南。如果在你的本机上没有GPU,那么这就是深入学习研究的完美设置。
+
+[数据科学的基本统计:使用Python的案例研究,第一部分](http://www.learndatasci.com/data-science-statistics-using-python/)
+
+我们最后一篇文章直接进入到线性回归。在这篇文章中,我们将回顾一下每个数据科学家都应该知道的基本统计信息。为了论证这些要点,我们会看看一个假设的案例研究,它涉及一个负责提高Tennessee学校表现的管理者。
+
+[用mypy给你的Jupyter Notebook加点料](http://journalpanic.com/post/spice-up-thy-jupyter-notebooks-with-mypy/)
+
+添加类型检查到Jupyter Notebook单元。
+
+[自组织地图:全面介绍](http://blog.yhat.com/posts/self-organizing-maps-2.html)
+
+在第一部分,我介绍了自组织地图 (SOMs)的概念。现在在第2部分,我想要介绍一下训练的过程,以及使用一个SOM,包括直觉和Python代码。最后,我还会介绍几个现实生活中的用例,而不仅仅是我们将用于实现的小例子。
+
+[使用机器学习过滤初创公司的新闻 —— 第一部分](https://blog.monkeylearn.com/filtering-startup-news-machine-learning/)
+
+在这个新的文章系列,我们会分析成千上万篇来自TechCrunch, VentureBeat和Recode的文章,以发现初创公司的酷炫趋势和见解。在这第一篇文章中,我们会介绍如何使用Scrapy来获取曾经在这些技术新闻网站上发布的所有文章,以及可以如何使用MonkeyLearn来根据它们是否是初创公司来过滤这些爬下来的文章。我们想要创建一个初创公司新闻文章的数据集,稍后,它们可以被用来学习趋势。
+
+[黑进虚拟内存:Python字节](https://blog.holbertonschool.com/hack-the-virtual-memory-python-bytes/)
+
+[高级网络爬虫:绕过"403 Forbidden," 验证码,等等](http://sangaline.com/post/advanced-web-scraping-tutorial/)
+
+[Python中使用感知哈希的重复图像检测](http://tech.jetsetter.com/2017/03/21/duplicate-image-detection/)
+
+[在Dask中开发Convex优化算法](https://matthewrocklin.com/blog//work/2017/03/22/dask-glm-1)
+
+[随机步进贝叶斯深层网络(Random-Walk Bayesian Deep Networks):处理非固定数据](http://twiecki.github.io/blog/2017/03/14/random-walk-deep-net/)
+
+[分析和优化你的Python代码](https://toucantoco.com/back/2017/01/16/python-performance-optimization.html)
+
+[Pandas和Seaborn - 优雅处理和可视化数据的指南](https://tryolabs.com/blog/2017/03/16/pandas-seaborn-a-guide-to-handle-visualize-data-elegantly/)
+
+[添加AJAX交互到Django中,不用写Javascript啦!](https://petercuret.com/add-ajax-to-django-without-writing-javascript/)
+
+
+# 好玩的项目,工具和库
+
+[aeneas](https://github.com/readbeyond/aeneas)
+
+aeneas是一个Python/C库和一组工具,用来自动化同步音频和文本 (又名强制排列)。
+
+[visdom](https://github.com/facebookresearch/visdom)
+
+用于创建、组织和共享实时丰富数据的可视化的灵活工具。支持Torch和Numpy。
+
+[better-exceptions](https://github.com/Qix-/better-exceptions)
+
+Python中自动的漂亮而有用的异常。
+
+[Instant-Lyrics](https://github.com/bhrigu123/Instant-Lyrics)
+
+显示当前播放的Spotify歌曲,或者任何歌曲的歌词。
+
+[flango](https://github.com/kennethreitz/flango)
+
+使用flask作为前端,Django作为后端的一个Django模板。
+
+[Bit](https://github.com/ofek/bit)
+
+Bit是Python最快的比特币库,并且从头设计以顺应直接,以毫不费力地使用,并且具有可读源代码。它受到Requests和Keras的深刻启发。
+
+[bulbea](https://github.com/achillesrasquinha/bulbea)
+
+基于深度学习的Python库,用以股票市场预测和建模。
+
+[PytchControl](https://github.com/WyattWismer/PytchControl)
+
+通过基于python的音调检测控制你的电脑
+
+[pythonnet](https://github.com/pythonnet/pythonnet)
+
+Python for .NET是让Python开发者近乎无缝集成.NET公共语言运行库 (CLR),并为.NET开发者提供强大应用脚本工具的一个软件包。它允许Python代码与CLR进行交互,并且也可能用来嵌入Python代码到.NET应用中。
+
+
+[selenium-respectful](https://github.com/SerpentAI/selenium-respectful)
+
+极简Selenium WebDriver封装器,用于同时使用在任意数量的网站速度限制之内。并行处理友好。
+
+[python-cx_Oracle](https://github.com/oracle/python-cx_Oracle)
+
+遵循Python DB API 2.0规范的Oracle数据库的Python接口。
+
+[flask-rest-jsonapi](https://github.com/miLibris/flask-rest-jsonapi)
+
+根据JSONAPI 1.0规范构建REST API的Flask扩展。
+
+[plugin.video.netflix](https://github.com/asciidisco/plugin.video.netflix)
+
+Kodi的基于Inputstream的Netflix插件。
+
+[DiscoGAN-pytorch](https://github.com/carpedm20/DiscoGAN-pytorch)
+
+"Learning to Discover Cross-Domain Relations with Generative Adversarial Networks"的PyTorch实现。
+
+
+# 最新发布
+
+[Python 3.6.1](https://docs.python.org/3.6/whatsnew/changelog.html#python-3-6-1)
+
+[Django 1.11 候选版本1](https://www.djangoproject.com/weblog/2017/mar/21/django-111-rc-1-released/)
+
+[PyPy2.7和PyPy3.5 v5.7 - 二合一版本](https://morepypy.blogspot.nl/2017/03/pypy27-and-pypy35-v57-two-in-one-release.html)
+
+
+# 近期活动和网络研讨会
+
+[SoCal Python 2017年3月聚会 - Los Angeles, CA](https://www.meetup.com/socalpython/events/238244773/)
+
+将会有以下讲座
+
+ * Magic Method, on the wall, who, now, is the `__fairest__` one of all?
+ * Cooking with Bio-Python
+
+
+[模块生命周期:如何测试和部署你的Python Web应用 - Philadelphia, PA](https://www.meetup.com/phillypug/events/237877302/)
+
+本次技术研讨会将会遵循开发者在使用一个Python模块时所采用的步骤:单元测试代码的修改;构建该模块的部署版本;使用已部署的版本,对应不同的OS运行集成测试。单元测试也将会作为集成测试,针对多个Python版本运行。与会者将会更加了解如何测试和部署Python Web应用。
diff --git a/Python Weekly/Python_Weekly_Issue_288.md b/Python Weekly/Python_Weekly_Issue_288.md
new file mode 100644
index 0000000..f5d6c6d
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_288.md
@@ -0,0 +1,133 @@
+原文:[Python Weekly - Issue 288](http://eepurl.com/cIQbBv)
+
+---
+
+欢迎来到Python Weekly第288期。本周,让我们直入主题。
+
+
+# 文章,教程和讲座
+
+[pdb教程](https://github.com/spiside/pdb-tutorial)
+
+有效使用pdb的一个简单的教程。
+
+[使用深度学习分类白细胞](https://blog.athelas.com/classifying-white-blood-cells-with-convolutional-neural-networks-2ca6da239331)
+
+如果你可以像体温一样快速便宜地发现你的血细胞数目的话,那么你的医疗保健看起来会是怎样的呢?在Athelas,我们着迷于这种可能性,并相信,在现代深度学习技术的助力下,这样的未来将在可见之中。在这篇文章中,我们将演示一个关于如何利用深度学习技术来分类白细胞图像的简单玩具示例。我们的示例模型将会把白细胞分类为多核或者单核,在参考数据集上精度达到98%。
+
+[Episode #105: 一次Pythonic数据库漫游](https://talkpython.fm/episodes/show/105/a-pythonic-database-tour)
+
+之所以说现在是成为一个开发者的好时机,是有许多原因的。其中之一就是,关于数据访问和数据库,有很多选择。所以,本周,我们和我们的嘉宾Jim Fulton会漫游一些你可能没有听过或者尝试过的数据库。你会听到纯Python数据库ZODB。有Zero DB,一个端到端加密数据库,其中,数据库服务器对它所存储的数据一无所知。以及NewtDb,跨越了ZODB和JSON友好型的Postgres世界。
+
+[Python的实例、类和静态方法揭秘](https://realpython.com/blog/python/instance-class-and-static-methods-demystified/)
+
+在这个教程中,我会帮你揭秘类方法、静态方法和常规实例方法背后的东西。如果对于它们的不同,你有了直观的了解,那么你将能够编写面向对象的Python,从而更清楚地传达其意图,并从长远来看,将更容易维护。
+
+[仅需$100,动手构建一个可对话的面部识别门铃](https://www.oreilly.com/ideas/build-a-talking-face-recognizing-doorbell-for-about-100)
+
+用Amazon Echo+树莓派进行DIY:以极低价格,每月识别你门口的成千上万个人。
+
+[Podcast.__init__ 第102集 - 和Brian Warner聊聊数字身份、隐私和安全](https://www.podcastinit.com/episode-102-brian-warner/)
+
+随着互联网和数字技术不断渗透我们的生活方式,我们被迫考虑在这些空间中,如何反映我们的身份和安全概念。本周,Brian Warner加入我们,探讨他从事的关于聚焦隐私的项目的工作,包括Tahoe LAFS,Firefox Sync和Magic Wormhole。他还有一些关于我们可以如何替换密码,以及具有在线身份意味着什么的有趣想法。
+
+[如何用Python处理丢失数据](http://machinelearningmastery.com/handle-missing-data-python/)
+
+真实世界的数据常常会丢了一些值。数据有某些值缺失有很多原因,例如未记录的观察结果和数据损坏。处理数据丢失的值很重要,因为许多机器学习算法不支持缺少值的数据。在这个教程中,你会发现如何使用Python为机器学习处理丢失数据。
+
+[开始使用Apache Airflow开发工作流](http://michal.karzynski.pl/blog/2017/03/19/developing-workflows-with-apache-airflow/)
+
+Apache Airflow是一个用于编排复杂计算工作流和数据处理管道的开源工具。如果你发现自己在运行执行长长脚本的cron任务,或者安排了大数据处理批量任务,那么Airflow也许可以帮到你。这篇文章为那些想要开始使用Airflow编写管道的人提供了一个介绍性教程。
+
+[Dask和Pandas,以及XGBoost](http://matthewrocklin.com/blog/work/2017/03/28/dask-xgboost)
+
+这篇文章谈到了使用Dask的分布式Pandas Dataframes,然后将其分发到分配式XGBoost以进行训练。更一般地,它讨论了在相同的共享内存进程中启动多个分布式系统,以及在它们之间平稳地处理数据的价值。
+
+[神奇GAN,以及它们在哪里](http://guimperarnau.com/blog/2017/03/Fantastic-GANs-and-where-to-find-them)
+
+你有没有想过了解生成对抗网络 (GANs)?也许,你只是想要赶上潮流?又或许,你只想要看看在过去的几年中,这些网络的改进?那么,在这些情况下,你也许会对这篇文章感兴趣。
+
+[利用一个内存损坏错误逃离Python沙箱](https://hackernoon.com/python-sandbox-escape-via-a-memory-corruption-bug-19dde4d5fea5)
+
+[分类算法的一个神奇介绍](http://blog.yhat.com/posts/harry-potter-classification.html)
+
+[科普君 —— 带递归点符号访问的Python字典](http://www.codecalamity.com/?p=307)
+
+[DeepDream:利用硬件加速深度学习](https://medium.com/@mrubash1/deepdream-accelerating-deep-learning-with-hardware-5085ea415d8a)
+
+
+# 书籍
+
+[Computational and Inferential Thinking](https://www.inferentialthinking.com/)
+
+这是UC Berkeley的数据科学基础课程的教科书。该课程结合了三个观点:推理思维,计算思维和现实世界相关性。给定一些现实世界现象产生的数据,要如何分析数据以了解相应现象?这门课程教授计算机程序设计和统计推理中的关键概念和技能,结合对现实世界数据集(包括经济数据、文档集合、地理数据和社会网络)的动手分析。它围绕数据分析探索诸如隐私和设计的社会问题。
+
+
+# 好玩的项目,工具和库
+
+[LocalStack](https://github.com/atlassian/localstack)
+
+全功能本地AWS云栈。离线开发和测试你的云应用!
+
+[Golem](https://github.com/golemfactory/golem)
+
+Golem项目的目标是为计算能力创造一个全球专业消费市场,其中,生产者可以销售他们个人计算机的备用CPU时间,而消费者可以为计算密集型任务获得资源。在技术方面,Golem被设计为一个由运行着Golem客户端软件的节点建立的分布式对等网络。根据本文的目标,我们假设在Golem网络中有两种类型的节点:宣布计算任务的请求者节点,和执行计算的计算节点(在实际实现中,节点可以在这两种角色之间切换)。
+
+[Computer Vision Drone](http://cvdrone.de/)
+
+构建一个交互式计算机视觉无人机。
+
+[poline](https://github.com/riolet/poline)
+
+Python一行程序:python中类awk的一行程序。
+
+[pyreportcard](https://github.com/mingrammer/pyreportcard)
+
+给你的Python应用的报告卡。它审查托管在Github上的python项目,分析源代码质量 (pep8, pyflakes和bandit等等。),license文件的存在,以及整个代码库的一些有用的统计数据。然后在web上显示它的分析结果。
+
+[Delbot](https://github.com/shaildeliwala/delbot)
+
+它理解你的声音指令,搜索新闻和知识源,然后为你总结和读取内容。
+
+[RNN-Tutorial](https://github.com/silicon-valley-data-science/RNN-Tutorial)
+
+循环神经网络 - 一个简短的TensorFlow教程。
+
+[flasgger](https://github.com/rochacbruno/flasgger)
+
+为你的Flask API提供毫不费力的Swagger UI。
+
+[django-cruds](https://github.com/oscarmlage/django-cruds)
+
+django-cruds是一个简单顺手的django应用,为更快速的原型创造CRUD。
+
+[sact](https://github.com/mfigurnov/sact)
+
+代码实现了一个基于剩余网络的深度学习体系结构,该体系结构自动为图像区域调整执行层数。这个体系结构是端到端可训练的,确定以及问题无关的。包含的代码应用这个到CIFAR-10一个ImageNet图像分类问题上。使用TensorFlow和TF-Slim实现。
+
+[portSpider](https://github.com/xdavidhu/portSpider )
+
+一个带模块的轻量级快速多线程网络扫描器框架。(Ele注:貌似404了)
+
+[PyMedium](https://github.com/enginebai/PyMedium)
+
+PyMedium是用python flask写的非官方Medium API。它让开发者能够访问Medium站点的用户、博文列表和详细信息。这是一个访问Medium公开信息的只读API,你可以自定义这个API来适配你的需求,以及部署在你自己的服务器上。
+
+
+# 近期活动和网络研讨会
+
+[在线课程:音乐应用的音频信号处理](https://www.coursera.org/learn/audio-signal-processing)
+
+在这个课程中,你将会学习到音频信号处理方法,这些方法专用于音乐和实际应用。我们关注于与声音描述和转换相关的频谱处理技术,通过在音乐应用的背景下,分析、合成、转换和描述音频信号,来提高基本理论和实践知识。
+
+[New York Python 2017年4月聚会 - New York, NY](https://www.meetup.com/nycpython/events/237182654/)
+
+将会有以下讲座
+
+ * Pandas新特性!
+ * Theano和Python!
+
+
+
+
+
diff --git a/Python Weekly/Python_Weekly_Issue_289.md b/Python Weekly/Python_Weekly_Issue_289.md
new file mode 100644
index 0000000..aabd26d
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_289.md
@@ -0,0 +1,148 @@
+原文:[Python Weekly - Issue 289 ](http://eepurl.com/cJYQef)
+
+---
+
+欢迎来到Python Weekly第289期。本周,我想感谢我们的赞助商ActiveState。一定要去看看他们超级棒的Python发行版哦。
+
+# 来自赞助商
+
+[](http://www.activestate.com/activepython?utm_source=python-weekly&utm_medium=email&utm_term=&utm_content=17-04-06-newsletter&utm_campaign=activepython-fc)
+
+ActivePython最新的发布版本中预编译了200+个包,现在,管理包更简单了。NumPy, SciPy, scikit-learn, Django, Flask, Tornado, AWS SDK等等用于数据科学和web应用的包。使用一个支持的Python版本[开始免费开发](http://www.activestate.com/activepython?utm_source=python-weekly&utm_medium=email&utm_term=&utm_content=17-04-06-newsletter&utm_campaign=activepython-fc),花费更少的时间配置吧。
+
+
+# 新闻
+
+[EuroPython征集建议](https://ep2017.europython.eu/en/call-for-proposals/)
+
+我们正在寻求Python方方面面的建议:从新手到高手级别的程序设计,应用和框架,或者你是如何参与到把Python引入到你的团队的。EuroPython是一个社区晦气,我们渴望听到来自你的经验。
+
+[宣布Google Cloud Dataflow对Python的普遍可用性](https://cloud.google.com/blog/big-data/2017/03/announcing-general-availability-of-google-cloud-dataflow-for-python)
+
+Cloud Dataflow服务,以及Python的Dataflow SDK为你提供开始使用所需要的一切。今天,你就可以开始使用Dataflow来进行你自己的数据处理,并且利用流行的预安装包,包括TensorFlow, NumPy, SciPy和pandas。例如,你可以直接在交互式Python shell中快速进行实验,从Landsat数据创建植被索引或者用TensorFlow分类图像。你甚至可以安装非Python依赖来执行囧囧的并行R程序。
+
+
+# 文章,教程和讲座
+
+[掌握Python 3中的asyncio](https://www.youtube.com/watch?v=M-UcUs7IMIM)
+
+这个讨论探讨了asyncio是什么,并演示如何用它来最大限度地解决Python中的并发问题,包括有关如何最好地测试异步Python代码的建议。
+
+[NBA犯规宣告和贝叶斯项目反应理论(Bayesian Item Response Theory)](http://austinrochford.com/posts/2017-04-04-nba-irt.html)
+
+自2015年起,NBA发布了一个报告,评估在每次NBA比赛最后两分钟内的每一个宣判和非宣判。NBA当然是一个以明星为中心的联盟,因此,这个数据集提供了一个了解在决定中涉及的球员在多大程度上影响是否犯规被宣告的绝佳机会。我们还将探讨与犯规相关的其他因素。
+
+[用Emojis进行深度学习 (不是Math)](https://tech.instacart.com/deep-learning-with-emojis-not-math-660ba1ad6cdc)
+
+使用Keras和Tensorflow,通过深度学习排序购物清单。
+
+[如何将Django Admin转为一个轻量的面板](https://medium.com/@hakibenita/how-to-turn-django-admin-into-a-lightweight-dashboard-a0e0bbf609ad)
+
+Django Admin是一个管理应用数据的强大工具。然而,它并没有设计出简要表格和图表。幸运的是,Django Admin的开发者让它变得易于自定义。这篇文章向你展示如何通过添加一个图表和一个简要表格来将Django Admin转为一个面板。
+
+[Python装饰器:手把手介绍](https://dbader.org/blog/python-decorators)
+
+对任何一个认真严肃的Python程序员来说,理解装饰器都是一个里程碑。这里,是装饰器如何可以帮你成为一个更加高效的Python开发者的手把手指南。
+
+[Podcast.__init__ 第103集 - 和Kenneth Loafman聊聊Duplicity](https://www.podcastinit.com/episode-103-duplicity-with-kenneth-loafman/)
+
+每个使用计算机的人都知道备份的重要性。Duplicity是最广泛使用的备份技术之一,并且它是用Python写的!本周,Kenneth Loafman分享了Duplicity是如何开始的,它是怎样工作的,以及为什么你应该每天都用它。
+
+[Django应用清单](http://djangoappschecklist.com/)
+
+一个构建伟大可重用django应用的清单。
+
+[学习Scrapy](http://help.scrapinghub.com/scrapy-cloud/learn-scrapy-video-tutorials)
+通过一系列教育视频来学习Scrapy
+
+[为什么说Postgres应该成为你的文档数据库](https://www.youtube.com/watch?v=-gD0_VXNBBU)
+
+在这个讲座中,Jim Fulton向我们展示了如何将JSONB和相关的机制用于纯/混合Python的面向文档的应用。我们还简短地讨论了他悠长的历史,远到Python的开端,并以他唯一的用于与JSONB查询相关的原生python对象的NewtDB库作为结束。
+
+[花了$5在服务器上,我的开源Instagram机器人给我带来了2,500个真实的关注人](https://medium.freecodecamp.com/my-open-source-instagram-bot-got-me-2-500-real-followers-for-5-in-server-costs-e40491358340)
+
+[Matplotlib备忘单](https://github.com/juliangaal/python-cheat-sheet/blob/master/Matplotlib/Matplotlib.md)
+
+[深入Django QuerySet](https://www.caktusgroup.com/blog/2017/04/05/digging-into-django-querysets/)
+
+[了解Pandas中的转换函数](http://pbpython.com/pandas_transform.html)
+
+[通过情感分析,排列黑镜(Black Mirror)的消极性](https://datameetsmedia.wordpress.com/2017/04/03/ranking-the-negativity-of-black-mirror-episodes-with-sentiment-analysis/)
+
+[Python中自定义类创建](https://snarky.ca/customizing-class-creation-in-python/)
+
+
+# 好玩的项目,工具和库
+
+[explainshell](https://github.com/idank/explainshell)
+
+explainshell是一个能够解析man页面,提取选项并通过匹配每个参数到man页面中相关的帮助文本来解释一条给定命令行的 (带web界面) 的工具。
+
+[usb-canary](https://github.com/probablynotablog/usb-canary)
+
+一个Linux工具,当你的计算机被锁住的时候,使用pyudev来监控设备。在这种情况下,它检测设备插拔行为,可以配置它来给你发送一条短信,或者通过Slack向你告警潜在的安全漏洞。
+
+[magnetico](https://github.com/boramalper/magnetico)
+
+自主(自托管) BitTorrent DHT搜索引擎套件。
+
+[neural_complete](https://github.com/kootenpv/neural_complete)
+
+一个训练来帮助使用自动完成编写神经网络代码的神经网络。
+
+[Dagda](https://github.com/eliasgranderubio/dagda)
+
+一个在docker image/container中进行已知漏洞的静态分析以及监控运行中的docker container以检测异常活动工具。
+
+[apistar](https://github.com/tomchristie/apistar)
+
+一个智能Web API框架,为Python 3而生。
+
+[python-draftlog](https://github.com/kepoorhampond/python-draftlog)
+
+在终端创建可更新的日志行。
+
+[google-youtube-history-analytics](https://github.com/srcecde/google-youtube-history-analytics)
+
+它读取你从谷歌获得的历史数据,然后提供你在谷歌、YouTube和YouTube观看历史的分析。它提供了你搜索的术语量。
+
+[EzPyGame](https://github.com/Mahi/EzPyGame)
+
+EzPyGame旨在比以往更容易以及更pythonic的使用pygame。它实现了轻松的场景管理工具以及一个应用类,以轻松初始化pygame和运行场景。
+
+
+# 最新发布
+
+[Jupyter Notebook 5.0](https://blog.jupyter.org/2017/04/04/jupyter-notebook-5-0/)
+
+这是自4.0版本起Jupyter Notebook的一个主要版本,也是IPython和Jupyter之间的一个“大分裂”。这个版本增加了一些期待已久的功能,例如单元格标记,自定义键盘快捷键,notebook之间单元格的复制和粘贴,以及用于表格的一个更加吸引人的默认样式。它还进行了许多改进和问题修复。这个版本并没有引入任何破坏性的API更改。
+
+[Django 1.11](https://www.djangoproject.com/weblog/2017/apr/04/django-111-released/)
+
+[Django安全发行版本:1.10.7, 1.9.13, 和1.8.18](https://www.djangoproject.com/weblog/2017/apr/04/security-releases/)
+
+[PyPy 5.7.1问题修复版本发布](https://morepypy.blogspot.com/2017/04)
+
+
+# 近期活动和网络研讨会
+
+[San Francisco Python 2017年4月聚会 - San Francisco, CA](https://www.meetup.com/sfpython/events/238786293/)
+
+将会有以下讲座
+
+ * 在Python中构建一个Pratt解析器
+ * 使用状态机设计安全API
+
+
+[Austin Python 2017年4月聚会 - Austin, TX](https://www.meetup.com/austinpython/events/237731969/)
+
+[Boulder Python 2017年4月聚会 - Boulder, CO](https://www.meetup.com/BoulderPython/events/236238281/)
+
+[PyAtl 2017年4月聚会 - Atlanta, GA ](https://www.meetup.com/python-atlanta/events/234242124/)
+
+[Edmonton Python 2017年4月聚会 - Edmonton, AB](https://www.meetup.com/startupedmonton/events/238216600/)
+
+
+
+
+
diff --git a/Python Weekly/Python_Weekly_Issue_290.md b/Python Weekly/Python_Weekly_Issue_290.md
new file mode 100644
index 0000000..daf8a65
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_290.md
@@ -0,0 +1,112 @@
+原文:[Python Weekly - Issue 290](http://eepurl.com/cK06Gn)
+
+---
+
+欢迎来到Python Weekly第290期。本周,让我们直入主题。
+
+# 来自赞助商
+
+[](https://software.intel.com/en-us/intel-distribution-for-python?utm_source=April%202017%20Image%20link%20Python%20weekly&utm_medium=email&utm_campaign=Python%20Weekly%20newsletter)
+
+[Intel® Distribution for Python*](https://software.intel.com/en-us/intel-distribution-for-python?utm_source=April%202017%20ad%20Python%20weekly&utm_medium=email&utm_campaign=Python%20Weekly%20newsletter) 已经**免费**可用了,并且许可证允许商业和非商业用途。就是这样!试试在NumPy, SciPy和scikit-learn中的性能优化吧,所有的加速都在后台。你的代码保持不变 —— 仅需在Intel Python环境中运行它,即可获得加速。
+
+
+# 文章,教程和讲座
+
+[数据整理101:使用Python来获取、操纵和可视化NBA数据](http://blog.yhat.com/posts/visualize-nba-pipelines.html)
+
+这是一篇使用pandas和其他一些包来为获取NBA数据构建一个简单的数据管道的教程。即使这个教程是使用NBA数据来完成的,但是你无需是个NBA粉就可以跟着它走。相同的概念和技术可以应用于你选择的任何项目。
+
+[使用PyTorch的递归神经网络](https://devblogs.nvidia.com/parallelforall/recursive-neural-networks-pytorch/)
+
+这篇文章详述了通过一个循环跟踪器和TreeLSTM节点的递归神经网络的PyTorch实现,也称为SPINN,这是来自神经语言处理的一个深度学习模型的样例,在很多流行框架中都是很难建立的。我所描述的实现也是部分批量的,因此,它可以利用GPU加速来比那些不使用批量的版本运行的更快一点。
+
+[递归、连续和Trampoline](http://eli.thegreenplace.net/2017/on-recursion-continuations-and-trampolines/)
+
+尾部递归和常规递归如何不同?连续与此有什么关系,CPS是什么,以及trampoline如何助益?这篇文章提供了介绍,包含了Python和Clojure的代码样例。
+
+[语言创建傻瓜教程](https://ralsina.me/weblog/posts/creating-languages-for-dummies.html)
+
+这篇文章解释了使用Python和PyParsing,如何从无到一个函数式、可扩展语言。
+
+[你该相信谁的评分?IMDB,烂番茄,Metacritic,还是Fandango?](https://medium.freecodecamp.com/whose-reviews-should-you-trust-imdb-rotten-tomatoes-metacritic-or-fandango-7d1010c6cf19)
+
+你应该看某部电影吗?嗯,有很多因素要考虑,比方说导演、演员、还有电影的预算。我们大多数都是基于一篇评论、一个简短的预告片、或者只是通过看看这个电影的评级来做决定的。这篇文章旨在推荐一个单一的网站,来快速获取准确的电影评级,并为其提供强大的数据驱动的论证。
+
+[Podcast.__init__ 第104集 - Oscar电子商务](https://www.podcastinit.com/episode-104-oscar-ecommerce-with-david-winterbottom-and-michael-van-tellingen/)
+
+如果你要销售一个产品,无论是个实体产品还是订阅服务,那么你需要有一种管理交易的方法。Django的Oscar电子商务框架是一个灵活、可扩展的完善方法,让你添加这种功能到你的网站上。本周,David Winterbottom和Michael van Tellingen谈到了这个项目是怎样开始的,其覆盖范围,以及如何开始使用它。
+
+[Django Rest框架入门](http://www.projectforrest.com/path/70)
+
+如果你期待在Django中构建REST API,并且之前没啥经验,那么,这个为你指了一条明路。
+
+[zi2zi:使用条件对话网络掌握中国书法](https://kaonashi-tyc.github.io/2017/04/06/zi2zi.html)
+
+[婚礼规模:我是如何使用Twilio, Python和Google来自动化我的婚礼的](https://www.twilio.com/blog/2017/04/wedding-at-scale-how-i-used-twilio-python-and-google-to-automate-my-wedding.html) | [中文版](../Others/婚礼规模:我是如何使用Twilio,%20Python和Google来自动化我的婚礼的.md)
+
+[使用Context Free Grammar和Pyparsing构建Slack Bot CLI](https://hashedin.com/2017/03/29/build-slack-bot-cli-using-cfg-pyparsing/)
+
+[Episode #106:使用Python发明你自己的电脑游戏](https://talkpython.fm/episodes/show/106/invent-your-own-computer-games-with-python)
+
+
+# 书籍
+
+[Python数据分析 —— 第二版](http://amzn.to/2pvtbfv)
+
+通过这本书,你将学习如何使用Python来处理和操作数据,以进行复杂的分析和建模。我们使用NumPy和Pandas,学习数据操作,例如聚合、连接、附加、清理和处理缺失值。本书介绍了如何从各种数据源(例如SQL和NoSQL, CSV文件和HDF5)来存储和检索数据。我们学习如何使用可视化库来可视化数据,以及一些高级话题,例如信号处理、时间序列、文本数据分析、机器学习和社交媒体分析。
+
+
+# 本周的Python工作
+
+[Wevolver招聘全栈Python开发](http://jobs.pythonweekly.com/jobs/full-stack-python-developer-to-build-github-for-hardware/)
+
+Wevolver是硬件开发的一个协作平台。(硬件界的Github) 我们构建了Wevolver,让来自四海八荒的每一个人都可以开发硬件技术。我们的平台被来自五湖四海的工程师用来在开源和私人项目上进行合作。我们对开源深刻承诺,我们分析并回馈我们的社区。我们正在寻找想要对我们的世界产生巨大积极影响的雄心勃勃的人。
+
+[Money Mover招聘后端开发](http://jobs.pythonweekly.com/jobs/back-end-developer-3/)
+
+如果你想要在一个于2014年全休投资达到68亿美元的有前途的FinTech创业公司一展拳脚,那么,我们找的就是你。你将与我们的主要开发人员紧密合作,专注于后端开发和我们的web应用、合作伙伴门户应用、合作伙伴集成以及营销网站的服务端逻辑。
+
+
+# 好玩的项目,工具和库
+
+[Tinfoil Chat](https://github.com/maqp/tfc)
+
+Tinfoil Chat (TFC) 是一个高度保密的加密消息系统,可以在现有的IM客户端上运行。它被用于保护用户免受被动窃听、有组织犯罪和民族国家攻击者实施的MITM工具和远程CNE工具之害。
+
+[DjangoQL](https://github.com/ivelum/djangoql)
+
+带自动完成功能的Django高级搜索语言。支持逻辑运算符、括号、表连接,可与任何Django模型配合使用。
+
+[imgaug](https://github.com/aleju/imgaug)
+
+用于机器学习实验的图像增强。
+
+[python-alexa](https://github.com/nmyster/python-alexa)
+
+一个简单的Python库,使得旨在在Lambda中使用时,让Alexa技能发展变得容易。
+
+[kim](https://github.com/mikeywaites/kim)
+
+一个JSON序列化和调度框架。
+
+[Punter](https://github.com/nethunteros/punter)
+
+Punter (被动猎手) 帮你迈出涉足某个域的第一步。它的想法不是触及目标域,而是被动地找到一个好的初始量信息,然后将其放在一个易于查看的报告中。
+
+[pytorch-rl](https://github.com/jingweiz/pytorch-rl)
+
+使用pytorch和visdom的深度强化学习。
+
+[drawlikebobross](https://github.com/kendricktan/drawlikebobross)
+
+借助神经网络的神力(使用PyTorch),像Bob Ross那样作画!
+
+
+# 近期活动和网络研讨会
+
+[PyHou 2017年4月聚会 - Houston, TX](https://www.meetup.com/python-14/events/238248013/)
+
+
+
+
diff --git a/Python Weekly/Python_Weekly_Issue_291.md b/Python Weekly/Python_Weekly_Issue_291.md
new file mode 100644
index 0000000..a04388a
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_291.md
@@ -0,0 +1,130 @@
+原文:[Python Weekly - Issue 291](http://eepurl.com/cLPaVP)
+
+---
+
+欢迎来到Python Weekly第291期。本周,我想感谢我们的赞助商Lights On Software。一定要去看看哦。
+
+# 来自赞助商
+
+[](http://lightsonsoftware.com/)
+
+**[Lights On Software](http://lightsonsoftware.com/)**
+
+需要在截止时间时帮忙交付你的Python应用吗?手头上有太多项目吗?我们交付坚实的Python代码,并且能够帮助构建和维护Python应用。
+
+
+# 新闻
+
+[AWS Lambda现在支持Python 3.6了!](https://aws.amazon.com/releasenotes/5198208415517126)
+
+
+# 文章,教程和讲座
+
+[神经网络教程 - 深度学习之路](http://adventuresinmachinelearning.com/neural-networks-tutorial/)
+
+这个教程介绍了一些概念、代码和数据,它们能够让你构建并理解一个简单的神经网络。在这个神经网络教程的最后,你将能够在Python中构建一个ANN,它会以很大程度的精确性正确识别图像中的手写数字。
+
+[使用QThreadPool的多线程PyQt应用](https://mfitzp.io/article/multithreading-pyqt-applications-with-qthreadpool/)
+
+在构建GUI应用时的一个常见问题是当试图执行长时间运行的后台任务时,界面的“锁定”。在这个教程中,我将介绍PyQt中实现并发执行的最简单的方法之一。
+
+[入门aiohttp.web:一个Todo教程](https://justanr.github.io/getting-start-with-aiohttpweb-a-todo-tutorial)
+
+aiohttp是基于Python 3.4+ asyncio模块的HTTP工具包。在这个指南中,我们会构建一个简单Todo应用,将其作为入门高级服务器的简短介绍。
+
+
+[Podcast.__init__ 第105集 - Scikit-Image](https://www.podcastinit.com/episode-105-scikit-image-with-stefan-van-der-walt-and-juan-nunez-iglesias/)
+
+计算机视觉是一个复杂的领域,它跨域多个行业,并由不同的需求和实现。Scikit-Image是一个库,它为在科学界工作的人们提供工具和技术,以处理对其研究至关重要的视觉数据。本周,Stefan Van der Walt和Juan Nunez-Iglesias,Elegant SciPy的联合作者,聊聊这个项目是如何开始的,它的工作原理,以及他们是如何使用它来为他们的实验提供支持的。
+
+[6分钟内修改Python语言](https://hackernoon.com/modifying-the-python-language-in-7-minutes-b94b0a99ce14)
+
+[图形数据库:使用Python聊聊你的数据关系](https://medium.com/labcodes/graph-databases-talking-about-your-data-relationships-with-python-b438c689dc89)
+
+[NumPy备忘录](https://www.dataquest.io/blog/numpy-cheat-sheet/)
+
+[从Indeed网络爬取工作告示](https://medium.com/@msalmon00/web-scraping-job-postings-from-indeed-96bd588dcb4b)
+
+[使用Dask的异步优化算法](https://matthewrocklin.com/blog//work/2017/04/19/dask-glm-2)
+
+[Episode #107:和Curio聊聊Python并发](https://talkpython.fm/episodes/show/107/python-concurrency-with-curio)
+
+
+# 好玩的项目,工具和库
+
+[Sonnet](https://github.com/deepmind/sonnet)
+
+Sonnet是一个在TensorFlow之上构建的库,用以构建复杂神经网络。
+
+[Module Linker](https://fiatjaf.alhur.es/module-linker/#/python)
+
+Module Linker将GitHub源码查看器中的直接链接添加到任何导入的模块或者文件中。如果你正在GitHub上浏览源码,那么这个扩展将会让你的生活更美好。
+
+[CycleGAN and pix2pix in PyTorch](https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix)
+
+不配对和配对图像到图像转换的PyTorch实现。
+
+[pygta5](https://github.com/sentdex/pygta5/)
+
+使用Python来玩Grand Theft Auto 5的探索
+
+[NoDB](https://github.com/Miserlou/NoDB)
+
+NoDB是基于Amazon的S3静态文件存储的一个非常简单的Pythonic对象存储。
+
+[OpenSnitch](https://github.com/evilsocket/opensnitch)
+
+OpenSnitch是Little Snitch应用防火墙的GNU/Linux端口。
+
+[mimipenguin](https://github.com/huntergregal/mimipenguin)
+
+一个从当前linux用户转储登录密码的工具。
+
+[colorful](https://github.com/timofurrer/colorful)
+
+正确完成的终端字符串样式,用Python编写。
+
+[SpiderKeeper](https://github.com/DormyMo/SpiderKeeper)
+
+scrapy/开源scrapinghub的管理UI。
+
+[Poet](https://github.com/sdispater/poet)
+
+Poet帮你声明、管理和安装Python项目的依赖,确保你有正确的堆栈。
+
+
+# 最新发布
+
+[IPython 6.0](https://blog.jupyter.org/2017/04/19/release-of-ipython-6-0/)
+
+IPython 6在实现机制上具有重大改进,现在,它能够实现非执行代码。它还是IPython第一个停止兼容Python 2的版本,其中,对Python 2的支持仅在5.x分支上对代码的修复。
+
+[Tornado 4.5](http://www.tornadoweb.org/en/stable/releases/v4.5.0.html)
+
+
+# 近期活动和网络研讨会
+
+[SoCal Python 2017年4月聚会 - Los Angeles, CA](https://www.meetup.com/socalpython/events/239310914/)
+
+将会有以下讲座
+
+ * 使用Habitat部署Twelve-Factor Python应用
+ * 用Pyramid构建它
+
+
+[Python Notebook - 给完全新手的温和教程 - London, UK](https://www.meetup.com/LondonPython/events/237672087/)
+
+这个实用(温和)的教程是给python notebook完全新手使用的,它会向我们介绍基础知识。一旦你完成了,那么你就已经为你自己有趣的项目做好准备了!
+
+[San Diego Python 2017年4月聚会 - San Diego, CA](https://www.meetup.com/pythonsd/events/238867374/)
+
+将会有以下讲座
+
+ * Bottle web框架
+ * Zoomascii扩展
+ * 如何本地化你的应用
+
+
+
+
+
diff --git a/Python Weekly/Python_Weekly_Issue_292.md b/Python Weekly/Python_Weekly_Issue_292.md
new file mode 100644
index 0000000..9493580
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_292.md
@@ -0,0 +1,144 @@
+原文:[Python Weekly - Issue 292](http://eepurl.com/cMFwd5)
+
+---
+
+欢迎来到Python Weekly第292期。本周,让我们直入主题。
+
+# 来自赞助商
+
+[](http://www3.activestate.com/activepython.html?utm_source=python-weekly&utm_medium=email&utm_term=&utm_content=17-04-27-newsletter&utm_campaign=activepython-fc)
+
+ActivePython最新的发布版本中预编译了200+个包,现在,管理包更简单了。NumPy, SciPy, scikit-learn, Django, Flask, Tornado, AWS SDK等等用于数据科学和web应用的包。使用一个支持的Python版本[开始免费开发](http://www3.activestate.com/activepython.html?utm_source=python-weekly&utm_medium=email&utm_term=&utm_content=17-04-27-newsletter&utm_campaign=activepython-fc),花费更少的时间配置吧。
+
+
+# 新闻
+
+[Python之力降临SQL Server 2017](http://www.infoworld.com/article/3191187/database/python-power-comes-to-sql-server-2017.html)
+
+微软的旗舰数据库的下一个版本将运行Python脚本,支持作为本地T-SQL存储过程的Python第三方数据库的完全访问
+
+
+# 文章,教程和讲座
+
+[Episode #108: MicroPython和Adafruit的开源硬件](https://talkpython.fm/episodes/show/108/micropython-and-open-source-hardware-at-adafruit)
+
+想要学习如何构建一个像钢铁侠一样的电弧反应器配件,或者太阳能充电背包?假使你可以用Python编程这些设备,那么会怎么样呢?我们将谈到一个让这成为可能的项目和公司。本周,你会见到Tony DiCola,他在Adafruit工作。Adafruit是一家可以使硬件编程的公司。我们还将讨论micropython,它让你用Python编程这些很酷的设备!
+
+[深刻了解GIL:如何编写快速并且线程安全的Python](https://opensource.com/article/17/4/grok-gil)
+
+我们探索Python的全局解释锁,并且学习它是如何影响多线程程序的。
+
+[用Python构建和探索Reddit地图](https://lmcinnes.github.io/subreddit_mapping/)
+
+这个notebook的目标是构建和分析Reddit上10,000个最受欢迎的子reddit的地图。为了做到这一点,我们需要一种手段来衡量两个子reddit的相似性。在FiveThirtyEight上的一篇很不错的文章中,Trevor Martin通过考虑两个不同的子reddit上用户评论的重叠来进行分析。他们的兴趣在于,使用代表性向量的向量代数来查看,比方说,如果你从r/The_Donald删除r/politics,会发生什么事。我们的兴趣更广泛些 —— 我们想要绘制并可视化子reddit的空间,并尝试将子reddit聚集到它们的自然群众。之后,我们可以探索其中一些集群,然后找到有趣的东西。
+
+[高效率Matplotlib](http://pbpython.com/effective-matplotlib.html)
+
+这篇文章将展示如何使用matplotlib,并为那些入门用户,或者没有时间学习matplotlib的用户提供一些建议。我坚信matplotlib是python数据科学栈的重要组成部分,并且希望这篇文章会帮助人们了解如何使用它来进行可视化。
+
+[给Node开发者的Flask教程](http://mherman.org/blog/2017/04/26/flask-for-node-developers/)
+
+在这篇文章中,我们将会介绍如何使用Python和Flask构建一个基本的CRUD服务器端应用,面向精通Node和Express的JavaScript开发者。
+
+[使用Python、Flask、NASA API和Twilio MMS的火星上的短信机器人](https://www.twilio.com/blog/2017/04/texting-robots-on-mars-using-python-flask-nasa-apis-and-twilio-mms.html)
+
+NASA有一大堆棒棒哒的API,它们让你可以编程以访问太空奇迹。我认为,火星漫游者照片API(Mars Rover Photos API)尤其惊人,因为你可以用它来看看好奇号火星漫游者照了哪些照片。让我们使用火星漫游者API( Mars Rover API)、Twilio MMS、Python和Flask来构建一个应用,使得我们可以提供一个电话号码,然后接收来自火星的图片。
+
+[我是怎样使用Python来比较文档相似性的?](https://www.oreilly.com/learning/how-do-i-compare-document-similarity-using-python)
+
+学习如何使用gensim Python库来确定两个或多个文档之间的相似性。
+
+[7行代码的深度学习](https://chatbotslife.com/deep-learning-in-7-lines-of-code-7879a8ef8cfb)
+
+机器学习的本质在于识别数据之中的模式。这归结为3件事:数据、软件和数学。那么你要问了,用7行代码我们可以做些啥?答案是,很多很多。
+
+[Podcast.__init__ 第106集 - yt项目](https://www.podcastinit.com/episode-106-yt-project-with-nathan-goldbaum-and-john-zuhone/)
+
+天体物理学和宇宙学是需要使用复杂的多维数据来模拟宇宙运行的领域。yt项目被创建来让使用这些数据以及有用可视化的提供简单而有趣的。本周,Nathan Goldbaum和John Zuhone分享了yt是如何开始、如何运作以及如何使用。
+
+[如何使用Keras和Tensorflow,为一个1000件日常对象类别构建图像识别系统](https://deeplearningsandbox.com/how-to-build-an-image-recognition-system-using-keras-and-tensorflow-for-a-1000-everyday-object-559856e04699)
+
+这是系列文的第一篇,它介绍了如何使用Keras,TensorFlow和python requests库,在几行代码中构建你自己的识别或者检测/边框预测web服务。
+
+[可视化调试](https://www.youtube.com/watch?v=nksiGORLDZw)
+
+PyCharm在调试时有一个可视化界面,我们希望帮助更多的开发者冒险尝试并调试。在这个演讲中,Paul Everitt介绍了这个调试器,并且介绍而来编写一个2d游戏的过程中许许多多必须的内容。
+
+[Python和MongoDB入门](https://www.mongodb.com/blog/post/getting-started-with-python-and-mongodb)
+
+这篇文章是针对那些对MongoDB不熟悉的Python开发者的,其中,你将学到,如何:使用 MongoDB Atlas创建一个免费托管的MongoDB数据库,安装PyMongo,Python驱动程序,连接到MongoDB,浏览MongoDB集合(Collection)和文档(Document),使用PyMongo执行基本创建、检索、更新和删除(CRUD)操作。
+
+[Python代码可视化](http://codimension.org/documentation/visualization-technology/python-code-visualization.html)
+
+[用OpenCV、Python和dlib进行眨眼检测](http://www.pyimagesearch.com/2017/04/24/eye-blink-detection-opencv-python-dlib/)
+
+[Python和Trio中的Control-C处理](https://vorpus.org/blog/control-c-handling-in-python-and-trio/)
+
+[Keras小抄:Python中的神经网络](https://www.datacamp.com/community/blog/keras-cheat-sheet)
+
+
+# 书籍
+
+[来点django:django 1.11最佳实践(Two Scoops of Django: Best Practices for Django 1.11)](https://www.twoscoopspress.com/products/two-scoops-of-django-1-11)
+
+这本书干货满满,它将有助于你的django项目。它向你介绍了我们多年来收集的各种提示、技巧、模式、代码片段和技术。
+
+
+# 本周的Python工作
+
+[Backend Engineer at Bitly](http://jobs.pythonweekly.com/jobs/backend-engineer-2/)
+
+Bitly正在寻找一名关注后端开发以帮助改进和扩展助力我们所有产品的服务的中级应用工程师。API设计会让你感到兴奋不已吗?你是否想应对构建可扩展、强大的分布式系统的挑战?你看到了构建工具来帮助人们了解周围世界的机遇了吗?那么,Bitly或许就是你的命定之所。
+
+
+# 好玩的项目,工具和库
+
+[Timestrap](https://github.com/overshard/timestrap)
+
+你可以随时随地托管的发票实时跟踪。支持多种格式的完全导出,并且易于扩展。
+
+[dnc](https://github.com/deepmind/dnc)
+
+可微分神经计算机的TensorFlow实现。
+
+[Manticore](https://github.com/trailofbits/manticore)
+
+Manticore是一个用于动态二进制分析的原型设计工具,支持符号执行、污染分析和二进制检测。
+
+[UserLine](https://github.com/THIBER-ORG/userline)
+
+这个工具通过展示用户域、源和目标登录以及会话持续时间之间的图表关系,自动化从MS Windows安全事件创建登录关系的过程。
+
+[Focuson](https://github.com/uber/focuson)
+
+Focuson是一个查找基于flask的python网络应用的安全漏洞的实验性工具。因为使用数据流分析,它将为安全工程师发出名单,用以以合理的信噪比进行调查。
+
+[evilginx](https://github.com/kgretzky/evilginx)
+
+用于任何网络服务的钓鱼 凭证和会话cookies的中间人攻击框架。它应该只用于带有来自待验证方书面许可的合法渗透测试任务中。
+
+[memory_profiler](https://pypi.python.org/pypi/memory_profiler)
+
+一个用于监控python程序的内存使用的模块。
+
+[Memgraph](https://github.com/technige/memgraph)
+
+Memgraph是一个提供兼容Neo4j的内存中图像存储的Python库。
+
+
+# 近期活动和网络研讨会
+
+[PyCon预演2:惰性、Mongo和不可变性 - Cambridge, MA](https://www.meetup.com/bostonpython/events/238648235/)
+
+将会有以下讲座:
+
+ * 惰性求值(Lazy Evaluation)介绍
+ * 用PyMongo分析数学素养数据
+ * 不可变编程 - 编写函数式Python
+
+
+[DFW Pythoneers 2017年5月聚会 - Plano, TX](https://www.meetup.com/dfwpython/events/238130975/)
+
+
+
+
diff --git a/Python Weekly/Python_Weekly_Issue_293.md b/Python Weekly/Python_Weekly_Issue_293.md
new file mode 100644
index 0000000..7ad1bcb
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_293.md
@@ -0,0 +1,162 @@
+原文:[Python Weekly - Issue 293](http://eepurl.com/cNw1mf)
+
+---
+
+欢迎来到Python Weekly第293期。本周干货满满。尽情享用!
+
+# 来自赞助商
+
+[](https://software.intel.com/en-us/intel-distribution-for-python?utm_source=04May2017%20image%20ad%20Python%20weekly&utm_medium=email&utm_campaign=Python%20Weekly%20newsletter)
+
+现在可以从YUM和APT Linux储存库上免费下载Python的Intel发行版及其所有优化包了。点击[这里](https://software.intel.com/en-us/articles/installing-intel-free-libs-and-python?utm_source=04May2017%20ad%20Python%20weekly&utm_medium=email&utm_campaign=Python%20Weekly%20newsletter)以获取详细指令。在Intel Python环境中运行你基于NumPy/SciPy/scikit-learn的Python代码,轻松获得更快的性能吧。
+
+
+# 新闻
+
+[PyCon JP 2017征求提议](https://pycon.jp/2017/en/talks/cfp/)
+
+
+# 文章,教程和讲座
+
+[使用计算机视觉和深度学习创建现代OCR管道](https://blogs.dropbox.com/tech/2017/04/creating-a-modern-ocr-pipeline-using-computer-vision-and-deep-learning/)
+
+在这篇文章中,我们将会带你走入为我们的移动文件扫描仪构建的最先进的光学字符识别(OCR)管道的幕后。我们使用了计算机视觉和深度学习高级技术,例如双向长短期记忆 (Long Short Term Memory, LSTMs),联结主义时间分类 (Connectionist Temporal Classification, CTC),卷积神经网络 (CNNs)等等。此外,我们还将深入了解实际上让我们的OCR管道在Dropbox规模上可投入生产的因素。
+
+[使用Python和SciKit Learn 0.18的神经网络初学者指南](https://www.springboard.com/blog/beginners-guide-neural-network-in-python-scikit-learn-0-18/)
+
+Python最流行的机器学习库是SciKit Learn。最新版本 (0.18) 现在已经支持神经网络模型了!在这篇文章中,我们将学习神经网络是如何工作的,以及如何使用Python编程语言和SciKit-Learn的最新版本来实现它们!
+
+[构建自定义块模板标签](https://www.caktusgroup.com/blog/2017/05/01/building-custom-block-template-tag/)
+
+这些年来,在所提供的装饰器(它们在构建常见的简单的标签时做了大部分的工作)的帮助下,为django模板构建自定义标签变得越发容易了。但是,一个没有覆盖的区域就是块标签,即那些拥有一个开始和结束标签,其中的内容可能还需要模板引擎进行处理的标签。块标签几乎可以做任何事,这或许就是为什么不存在一个简单的装饰器来帮助编写它们的原因。在这篇文章中,我将要介绍如何构建一个示例块标签,它接受可以控制其逻辑的参数。
+
+[Podcast.__init__ 第107集 - Scapy](https://www.podcastinit.com/episode-107-scapy-with-guillaume-valadon/)
+
+网络协议通常是不可预测的,但是如果你有一种有效的方式来尝试,那么它们会暴露出更大的威力。本周,Guillaume Valadon解释了可以如何使用Scapy来检查你的网络流浪,测试系统的安全性,以及开发全新的协议,所有这些都是用Python完成的!
+
+[一个Django RESTful API的测试驱动开发](https://realpython.com/blog/python/test-driven-development-of-a-django-restful-api)
+
+这篇文章介绍了用Django和Django REST框架开发一个基于CRUD的RESTful API的过程,用于快速构建基于django模型的RESTful API。
+
+[Episode #110: 用Redash进行数据民主化](https://talkpython.fm/episodes/show/110/data-democratization-with-redash)
+
+你曾经被要求过根据你公司的数据生成报告吗?有没有人建议暗示你购买/部署昂贵、闭源并且通常是平庸的大型BI软件?嗯,此时,Redash和Python可救你于水火之中。今天,你将会见到Arik Fraimovich,Redash的创造者,他的目标是通过连接到任意数据来源,轻松实现数据可视化,从而驱动你的公司数据。
+
+[企业局域网中的Jupyter和Python](https://medium.com/@olivier.borderies/jupyter-python-in-the-corporate-lan-109e2ffde897)
+
+我们 (欧元区的一家投资银行) 正在在企业环境中部署Jupyter和Python科学栈,从而向员工和承包商提供交互式计算环境,以帮助他们利用他们的数据,自动化流程,并且更一般地,促进合作和想法、服务以及代码分享。我们提供了一些配置样例和示例Notebook。
+
+[用于Mac的Google Home](https://newmediaeurope.com/google-home-mac/)
+
+Google近期宣布,他们向开发者开放Google Assistant SDK。现在,你可以在你的Mac上使用Google Home助手了。继续阅读,了解如何做到!
+
+[pygit:能够创建一个存储库、提交、并推送自己到GitHub的刚刚够用的Git客户端](http://benhoyt.com/writings/pygit/)
+
+最近,我写了大约500行Python代码,它们实现了刚刚够用的一个Git客户端,它可以创建一个存储库、添加文件到索引中、提交、以及推送到GitHub。本文提供了一些背景,并介绍了代码。
+
+[Celery任务检查表](http://celerytaskschecklist.com/)
+
+构建棒棒哒的Celery异步任务的检查表。
+
+[使用Faker,为Python单元测试创建假数据](https://semaphoreci.com/community/tutorials/generating-fake-data-for-python-unit-tests-with-faker)
+
+学习如何使用Faker库,在你的Python单元测试中生成假数据。
+
+[关于Django中的预取(prefetching),你所需要知道的一切](https://hackernoon.com/all-you-need-to-know-about-prefetching-in-django-f9068ebe1e60)
+
+[设计一个异步API,从sans-I/O开始](https://snarky.ca/designing-an-async-api-from-sans-i-o-on-up/)
+
+[如何创建你的第一个Python 3.6 AWS Lambda函数](https://www.fullstackpython.com/blog/aws-lambda-python-3-6.html)
+
+[如何在Python中执行常见的Excel和SQL任务](http://code-love.com/2017/04/30/excel-sql-python/)
+
+[使用word2vec和keras的推特情绪分析](http://ahmedbesbes.com/sentiment-analysis-on-twitter-using-word2vec-and-keras.html)
+
+[如何使用Keras和Tensorflow中的传递学习和微调,来构建构建一个图像识别系统,并分类(几乎)任何对象](https://deeplearningsandbox.com/how-to-use-transfer-learning-and-fine-tuning-in-keras-and-tensorflow-to-build-an-image-recognition-94b0b02444f2)
+
+[使用单一职责原理(Single Responsibility Principle)重构Python代码库](https://medium.com/unbabel-dev/refactoring-a-python-codebase-using-the-single-responsibility-principle-ed1367baefd6)
+
+[利用流行建模来改善Facebook上的广告点击率](https://medium.com/towards-data-science/utilising-epidemic-modelling-to-improve-advertising-click-rates-on-facebook-6f294205a43f)
+
+
+# 本周的Python工作
+
+[Vote.org招聘软件工程师](http://jobs.pythonweekly.com/jobs/software-engineer-18/)
+
+Vote.org正在寻找一名软件工程师,帮助永久增加美国的投票率。如果你既有才华又务实;如果你喜爱干净并且文档良好的代码;如果你想要编写解决实际的现实世界问题的软件;并且如果你想要对美国选举产生直接持久的影响,那么,这或许是一份适合你的工作。
+
+
+# 好玩的项目,工具和库
+
+[Automatic-Speech-Recognition](https://github.com/zzw922cn/Automatic_Speech_Recognition)
+
+在TensorFlow中实现的端到端自动化语音识别系统。
+
+[Gixy](https://github.com/yandex/gixy)
+
+Gixy是一个分析nginx配置的工具。Gixy的主要目标是防止错误配置和自动化缺陷检测。
+
+[Mocktails Mixer](https://github.com/Deeplocal/mocktailsmixer)
+
+做一个由Google Assistant SDK提供动力的DIY机器人Mocktails混音器。
+
+[octodns](https://github.com/github/octodns)
+
+在架构即代码(Infrastructure as Code)的脉络中,OctoDNS提供了一组工具和模式,使得管理跨多个提供商的DNS记录变得简单。结果配置可以存储在存储库中,并且就像你的其他代码一样被部署,保持干净的历史记录并且使用你已有的评审工作流程。
+
+[SeqBox](https://github.com/MarcoPon/SeqBox)
+
+一个即使在完全丢失了文件系统结构后,也能重新构建的单个文件容器/归档。
+
+[py-backwards](https://github.com/nvbn/py-backwards)
+
+Python到python编译器,允许你在较老的版本中使用Python 3.6特性。
+
+[Perceptron](https://github.com/casparwylie/Perceptron)
+
+一个用来分析性能并优化最佳模型的灵活的人工神经网络构建器。
+
+[Flaskex](https://github.com/anfederico/Flaskex)
+
+用于快速原型和小型应用的简单flask示例。
+
+[scrape](https://github.com/huntrar/scrape)
+
+一个命令行网络爬虫工具。
+
+[Science Flask](https://github.com/danielhomola/science_flask)
+
+Science Flask是一个用于在线科学研究工具的web应用模板,使用Python Flask,JavaScript和Bootstrap CSS构建。
+
+[ActualVim](https://github.com/lunixbochs/ActualVim)
+
+使用Neovim的Sublime Text 3输入模式。
+
+[subconscious](https://github.com/paxos-bankchain/subconscious)
+
+用于python3的支持Redis (内存中) 的db,兼容asyncio。
+
+[django-notifyAll](https://github.com/inforian/django-notifyAll)
+
+一个可以用于所有类型的通知(如短信、邮件、推送)的库。
+
+[clif](https://github.com/google/clif)
+
+用于使用LLVM,为Python和其他语言封装C++的封装器生成器基础。
+
+
+# 近期活动和网络研讨会
+
+[PyCon CZ 2017](https://cz.pycon.org/2017/)
+
+PyCon CZ旨在成为捷克共和国的Python社区最大的年度聚会。它专注于尊重和支持优秀人才在捷克以及周边欧盟成员国,用Python进行教学、学习和创新。
+
+[Boulder Python 2017年5月聚会 - Boulder, CO](https://www.meetup.com/BoulderPython/events/239106610/)
+
+[Austin Python 2017年5月聚会 - Austin, TX](https://www.meetup.com/austinpython/events/234490249/)
+
+[Edmonton Python 2017年5月聚会 - Edmonton, AB](https://www.meetup.com/startupedmonton/events/238378393/)
+
+
+
+
diff --git a/Python Weekly/Python_Weekly_Issue_294.md b/Python Weekly/Python_Weekly_Issue_294.md
new file mode 100644
index 0000000..fb8c342
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_294.md
@@ -0,0 +1,148 @@
+原文:[Python Weekly - Issue 294](http://eepurl.com/cOpN7T)
+
+---
+
+欢迎来到Python Weekly第294期。本周,让我们直入主题。
+
+# 来自赞助商
+
+[](https://goo.gl/wlxnDm)
+
+Intel荣幸地赞助了PyCon 2017。参观我们的展位来与Python开发者和合作者互动,他们展示了关于加速Python性能的demo和10分钟展位技术讲座,以及Intel工具,例如[Intel® Python*发行版](https://goo.gl/INtRDH)。停下来,学习更多,并获得很棒的奖品!
+
+
+# 新闻
+
+[征集提议 - PyCon Sweden 2017](https://docs.google.com/forms/d/e/1FAIpQLSclEtEayxaxh6u5xcav7ZVWLHVrMojq2A5a30UYts9kU9bFxQ/viewform?c=0&w=1)
+
+
+# 文章,教程和讲座
+
+[Kaggle入门:房屋竞价](https://www.dataquest.io/blog/kaggle-getting-started/)
+
+本指南将教你如何靠近并进入一个Kaggle比赛,包括探索数据、创建和工程化特性、构建模型并提交预测。我们将使用Python 3和Jupyter Notebook。
+
+[使用OpenCV进行睡意检测](http://www.pyimagesearch.com/2017/05/08/drowsiness-detection-opencv/)
+
+本文向你展示如何使用OpenCV、dlib和Python构建一个睡意检测器。
+
+[构建棒呆了的命令行用户界面的4个Python库](https://opensource.com/article/17/5/4-practical-python-libraries)
+
+在关于带有不错的命令行UI的终端应用的两部分系列的第二部分中,我们探索了Prompt Toolkit,Click,Pygments和Fuzzy Finder。
+
+[Podcast.__init__ 第108集 - Python走进电影](https://www.podcastinit.com/episode-108-python-goes-to-the-movies-with-dhruv-govil/)
+
+电影就是魔法,而Python则是让魔法成为可能的一部分。本周,我们和Dhruv Govil一起走进幕后,了解Python是如何用于将电影从概念带到完成的。他分享了他开始做电影的故事,他每天使用的工具以及一些进一步学习的资源。
+
+[令牌游戏:利用TDD,使用Python编写一个解释器 —— 第一部分](http://blog.thedigitalcatonline.com/blog/2017/05/09/a-game-of-tokens-write-an-interpreter-in-python-with-tdd-part-1/)
+
+这一系列文将会指导你利用纯TDD(测试驱动开发)方法,用Python创建一个简单的解释器。这些文章的结构就像一个游戏,其中,每一个等级就是一个我将会添加进去的新测试。如果你对TDD没有信心,那么,你会在具体的部分中找到更多信息。跟着这个系列,你将会学到Python、编译器、解释器、解析器、词法分析器、测试驱动开发、重构、覆盖、正则表达式、类、上下文管理器。
+
+[如何将时间序列转换为Python中的监督学习问题](http://machinelearningmastery.com/convert-time-series-supervised-learning-problem-python/)
+
+诸如深度学习这样的机器学习方法可以被用于时间序列预测。在可以使用机器学习之前,时间序列预测问题并需被重新定位为监督学习问题。从一个序列到一对输入输出序列。在这个教程中,你将会发现如何将单变和多变时间序列预测问题转换为用于机器学习算法的监督学习问题。
+
+[使用Tensorflow实现语境聊天机器人](https://chatbotsmagazine.com/contextual-chat-bots-with-tensorflow-4391749d0077)
+
+在对话中,上下文为王!我们将使用Tensorflow构建一个聊天机器人框架,并添加一些上下文处理来展示如何处理它。
+
+[JIT编译大冒险:第4部分 - 在Python中](http://eli.thegreenplace.net/2017/adventures-in-jit-compilation-part-4-in-python/)
+
+即使出于性能考虑,大多数的JIT编译器都是使用像C和C++这样的低级语言编写的,但是在某些情况下,用更高级的语言来编写它们可能会是个不错的选择。这篇文章的目的就是这样哒,通过介绍BF的另一个JIT —— 这一次,使用Python编写的。它提供了一个JIT本地机器码的低级方法,以及使用一个较高级别的库来执行指令编码。这里实现的JIT并没有被优化 (等价于第2部分的“简单”JIT),因此,我将不会讨论任何性能结果。想法只是为了Python中的JIT是如何工作的。
+
+[使用Python和MTurk的众包(crowdsource)ML训练数据的初学者指南](https://blog.mturk.com/tutorial-a-beginners-guide-to-crowdsourcing-ml-training-data-with-python-and-mturk-d8df4bdf2977)
+
+对于许多机器学习项目而言,生成训练数据的最佳方式之一就是使用Python,从Amazon Mechanical Turk (MTurk),以编程方式众包(crowdsource)它。在这个指南中,我们将介绍使用Python来访问MTurk的一个端到端例子。
+
+
+[增强现实撞球游戏](https://www.youtube.com/watch?v=5ft3SDvuhgw)
+
+使用OpenCV、Pygame和Pymunk,用Python3编写。用户只需使用一个撞球球杆,在任意普通的表面上运行这个程序。
+
+[分类2吨乐高,软件部分](https://jacquesmattheij.com/sorting-lego-the-software-side)
+
+[如何使用Python、向量空间搜索和Ngram关键词识别软件许可证](http://www.boyter.org/2017/05/identify-software-licenses-python-vector-space-search-ngram-keywords/)
+
+[纯Python 100天算法](https://medium.com/100-days-of-algorithms)
+
+[让我们构建一个简单的解释器。第14部分:嵌套范围和源到源编译器](https://ruslanspivak.com/lsbasi-part14/)
+
+[异步io协程模式:不仅仅是await](https://medium.com/@yeraydiazdiaz/asyncio-coroutine-patterns-beyond-await-a6121486656f)
+
+[如何侧写Django视图](https://rock-it.pl/how-to-profile-django-views/)
+
+
+# 书籍
+
+[Python软件体系结构(Software Architecture with Python)](http://amzn.to/2r3nK96)
+
+这本书首先解释了Python是如何适应应用程序架构的。随着你逐步深入,你将了解到架构上的重要需求,以及如何确定它们。接着,你将全面了解帮助架构构建一个满足业务需要的产品的不同的架构质量要求,例如可维护性/可重用性、可测试性、可扩展性、性能、可用性和安全性。
+
+
+# 好玩的项目,工具和库
+
+[Flow Dashboard](https://github.com/onejgordon/flow-dashboard)
+
+一个目标、任务和习惯跟踪器 + 个人面板,专注于重要事项。
+
+[OpenAI Lab](https://github.com/kengz/openai_lab)
+
+一个使用了OpenAI Gym,Tensorflow和Keras的强化学习实验性系统。
+
+[vy](https://github.com/iogf/vy)
+
+一个用Python编写的强大的模态编辑器。vy是基于Tkinter构建的,这是最有效率的图形工具包之一;它允许vy对于插件拥有一个超棒的编程接口。
+
+[Pyekaboo](https://github.com/SafeBreach-Labs/pyekaboo)
+
+Pyekaboo是一个概念验证程序,它可以通过`$PYTHONPATH`变量来劫持/挂钩/代理Python模块。它就像Python的"DLL Search Order Hijacking"。
+
+[Stegano](https://github.com/cedricbonhomme/Stegano)
+
+Stegano是一个纯Python的隐写模块。提供不同的隐写和隐写分析方法。
+
+[pdpipe](https://github.com/shaypal5/pdpipe)
+
+用于pandas DataFrames的简单管道
+
+[OnlineSchemaChange](https://github.com/facebookincubator/OnlineSchemaChange)
+
+OnlineSchemaChange是一个以非阻塞方式对MySQL表进行模式更改的工具。
+
+[AssistantPi](https://github.com/xtools-at/AssistantPi)
+
+AssistantPi基本上是AlexaPi的调整,允许你在树莓派上运行Google Assistant和Amazon的Alexa。它包括了Google Assistant SDK ,并使用AlexaPi的热门识别来激活Assistant或者Alexa。安装程序提供了一个简单的方法来在一个小时内完成所有的设置。
+
+[Chattie](https://github.com/chasinglogic/chattie)
+
+用Python编写机器人的框架。受Hubot启发。
+
+[scanless](https://github.com/vesche/scanless)
+
+命令行实用工具,用于使用那些可以代替你执行端口扫描的网站。适用于渗透测试的早期阶段,或者当你想要对一台主机进行端口扫描并且不想从你的IP地址进行的时候。
+
+[plydata](https://github.com/has2k1/plydata)
+
+在Python中进行数据操作的语法
+
+
+# 最新发布
+
+[Pandas 0.20](https://pandas-docs.github.io/pandas-docs-travis/whatsnew.html#v0-20-1-may-5-2017)
+
+这是从0.19.2以来的主要版本,包括许多API改动、弃用、新特性、增强功能、性能改进以及大量的错误修复。
+
+[Kivy 1.10.0](https://groups.google.com/forum/#!topic/kivy-users/2zusmq8NXPE)
+
+[Django问题修复版本:1.11.1](https://www.djangoproject.com/weblog/2017/may/06/bugfix-release/)
+
+
+# 近期活动和网络研讨会
+
+[LA Django 2017年5月聚会 - Los Angeles, CA](https://www.meetup.com/ladjango/events/239091967/)
+
+[PyHou 2017年5月聚会 - Houston, TX](https://www.meetup.com/python-14/events/239189223/)
+
+
+
+
diff --git a/Python Weekly/Python_Weekly_Issue_295.md b/Python Weekly/Python_Weekly_Issue_295.md
new file mode 100644
index 0000000..4483fa0
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_295.md
@@ -0,0 +1,150 @@
+原文:[Python Weekly - Issue 295](http://eepurl.com/cPh4Zv)
+
+---
+
+欢迎来到Python Weekly第295期。本周,让我们直入主题。
+
+# 来自赞助商
+
+[](http://www3.activestate.com/activepython-data-science.html?utm_source=python-weekly&utm_medium=email&utm_term=&utm_content=17-05-18-newsletter&utm_campaign=activepython-fc)
+
+ActiveState荣幸地赞助了PyCon 2017。参观我们的展位,来试试Neuro Blast,这是我们由机器学习AI助力的经典街机空间射击游戏。另外,了解[最新的ActivePython版本](http://www3.activestate.com/activepython-data-science.html?utm_source=python-weekly&utm_medium=email&utm_term=&utm_content=17-05-18-newsletter&utm_campaign=activepython-fc) —— 利用Intel数学核心库,并且与TensorFlow, theano, Keras一起预编译。
+
+
+# 新闻
+
+[推出TensorFlow Research Cloud](https://research.googleblog.com/2017/05/introducing-tensorflow-research-cloud.html)
+
+研究人员需要庞大的计算资源来训练最近在医学成像、神经机器翻译、游戏以及许多其他领域去的突破的机器学习(ML)模型。我们相信,大量的计算将使研究人员发现更准确有用的新型ML模型成为可能。为了加快开放机器学习研究的步伐,我们正在推出TensorFlow Research Cloud (TFRC),这是1,000个云端TPU组成的一个集群,将会免费提供它,以支持广泛的通过其他途径也许不大可能实现的计算密集型研究项目。
+
+
+# 文章,教程和讲座
+
+[带动图的Scikit中的集群算法](https://dashee87.github.io/data%20science/general/Clustering-with-Scikit-with-GIFs/)
+
+这篇文章描述了 (带动图和文字) Scikit-learn中最常见的集群算法。
+
+[Podcast.__init__ 第109集 - 和Jeremy Kauffman聊聊LBRY](https://www.podcastinit.com/episode-109-lbry-with-jeremy-kauffman/)
+
+内容发现和交付,以及它在数字领域是如何工作的,这是我们现代经济中最重要的一部分。近年来,区块链是实现的最具突破性和变革性的技术之一。本周,Jeremy Kauffman截止了LBRY的公司和平台如何将二者结合起来,通过为各种媒体创建一个新的分布式市场,试图重新定义内容创作者和消费者之间的互动。
+
+[辛普森检测器](http://zachmoshe.com/2017/05/03/simpsons-detector.html)
+
+一个检测主要的四个辛普森人物的卷积神经网络。
+
+[如何使用一个CALLR/Python SMS房屋搜索机器人,来自动化找房子的](https://www.callr.com/blog/python-house-hunter-bot/)
+
+在这篇文章中,作者向你展示了他是如何使用Python,Google Spreadsheet和CALLR,在巴黎找到一个公寓的。
+
+[构建大规模高质量Django应用的建议](https://blog.doordash.com/tips-for-building-high-quality-django-apps-at-scale-a5a25917b2b5)
+
+在DoorDash,我们大多数后端目前都是基于Django和Python的。随着我们业务的增长,我们早期乱七八糟的Django代码已经逐渐发展和成熟了。为了继续扩展,我们还开始将我们的单片应用移植到微服务架构。我们学到了大量对于Django好用的以及不好用的经验教训,希望我们可以分享一些关于如何使用这个流行的web框架的有用建议。
+
+[Episode #111: Pythonic职业建议等等](https://talkpython.fm/episodes/show/111/pythonic-career-advice-and-more)
+
+和Matt Harrison聊聊一些Pythonic工作和事业建议的时间。认真听,因为我们讨论了大多数从未加入到完整工作列表中的开发者工作。以及你可以如何走进它们。我们还讨论了他出的书,以及他关于Pandas库的雪崩式研究。
+
+[制定价格策略,以最大限度提高收入](https://www.datascience.com/resources/notebooks/finding-optimal-pricing-to-maximize-revenue-in-python)
+
+这篇文章是关于动态定价以及如何获得最优定价策略,以最大限度提高收入的介绍。
+
+[Django教程](https://www.youtube.com/playlist?list=PLw02n0FEB3E3VSHjyYMcFadtQORvl1Ssj)
+
+一个关于Django的包含62个视频教程的列表。
+
+[如何在PyPI上发布你的包](https://blog.jetbrains.com/pycharm/2017/05/how-to-publish-your-package-on-pypi/ )
+
+当你写了一些棒棒哒的代码时,你也许想要让其他人也可以使用它。分享一个包的pythonic方法是让它在PyPI上可用。让我们创建一个简单的包,然后经历下发布过程吧!
+
+[拼写元素符号](https://www.amin.space/blog/2017/5/elemental_speller/)
+
+[PyData London 2017视频](https://www.youtube.com/playlist?list=PLGVZCDnMOq0pAwbVAb1kUN3lV7ukhLL2k)
+
+[用于Django的最快的Redis配置](https://www.peterbe.com/plog/fastest-redis-optimization-for-django)
+
+[什么是你不得不写的最重要的代码片段?](https://www.reddit.com/r/Python/comments/6bjgkt/what_are_the_most_repetitive_pieces_of_code_that/)
+
+[Visual Studio 2017中的Python圈](https://blogs.msdn.microsoft.com/visualstudio/2017/05/12/a-lap-around-python-in-visual-studio-2017/)
+
+
+# 书籍
+
+[Python in a Nutshell: A Desktop Quick Reference 3rd Edition](http://amzn.to/2rsGPBR)
+
+非常适合于那些拥有一些Python经验以及从其他编程语言来到Python的程序员,这本书涵盖了广泛的应用领域,包括web和网络编程、XML处理、数据库交互和高速数字计算。了解Python如何提供独特的优雅、简约、使用以及纯粹的混合之力。
+
+[给科学家和工程师看的Python书 (Python for Scientists and Engineers)](http://pythonforengineers.com/python-for-scientists-and-engineers/)
+
+给科学家和工程师看的Python书 (Python for Scientists and Engineers)现在可以免费在网上阅读了。这本书假设你已经知道Python或者其他编程语言。它适用于中级程序员,而不是完全初学者。
+
+
+# 好玩的项目,工具和库
+
+[Deep Feature Flow](https://github.com/msracver/Deep-Feature-Flow)
+Deep Feature Flow为视频识别(例如,视频中的对象检测和语义分割)提供了一个简单、快速、准确的端到端框架。
+
+[Howmanypeoplearearound](https://github.com/schollz/howmanypeoplearearound)
+
+通过监控wifi信号,计算你周围的人数。
+
+[Picasso](https://github.com/merantix/picasso)
+
+用于卷积神经网络的一个免费的开源可视化工具。
+
+[Django Developer Panel](https://github.com/loftylabs/django-developer-panel)
+
+通过Chrome开发者工具调试Django应用
+
+[Roboschool](https://github.com/openai/roboschool)
+
+用于机器人仿真的开源软件,与OpenAI Gym集成。
+
+[plotnine](https://github.com/has2k1/plotnine)
+
+plotnine是Python中图形语法的一种实现,基于ggplot2。该语法允许用户通过显式映射数据到组成图的视觉对象,来合成图。
+
+[Persimmon](https://github.com/AlvarBer/Persimmon)
+
+用于sklearn的视觉数据流编程语言。
+
+[IPpy](https://github.com/shivammathur/IPpy)
+
+用python对IP地址和域进行并行测试。从一个CSV文件中读取IP地址和域,然后给出可访问和不可访问的两个列表。
+
+[diskover](https://github.com/shirosaidev/diskover)
+
+diskover是一个多线程文件系统爬取工具,它使用Elasticsearch和Kibana来索引和可视化你的数据。它旨在使用单个或并发进程,在本地或远程服务器上爬取你的文件系统,并分析磁盘使用情况。
+
+[Tagger News](https://github.com/danrobinson/taggernews)
+
+Hacker News加上主题标签。
+
+[WS Celery](https://github.com/johan-sports/wscelery)
+
+使用websockets的实时celery监控。
+
+[TouristFriend](https://github.com/octohedron/TouristFriend)
+
+TouristFriend是一个用来搜索和合并来自Google Places, Yelp和Foursquare的结果的API。
+
+
+# 最新发布
+
+[Django REST框架3.6.3](http://www.django-rest-framework.org/topics/release-notes/#363)
+
+
+# 近期活动和网络研讨会
+
+[SciPy 2017](https://scipy2017.scipy.org/ehome/220975/493388/)
+
+SciPy 2017发布演讲和教程。不要错过了到5月22日的早鸟注册。
+
+[London Python 2017年五月见面会 - London, UK](https://www.meetup.com/LondonPython/events/239036267/)
+
+Leonardo Giordani将会介绍抽象基础课程,以及为什么你应该学习如何有效使用它们。
+
+[San Diego Python 2017年五月见面会 - San Diego, CA](https://www.meetup.com/pythonsd/events/238867394/)
+
+
+
+
diff --git a/Python Weekly/Python_Weekly_Issue_296.md b/Python Weekly/Python_Weekly_Issue_296.md
new file mode 100644
index 0000000..12fa683
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_296.md
@@ -0,0 +1,132 @@
+原文:[Python Weekly - Issue 296 ](http://eepurl.com/cPZM5n)
+
+---
+
+欢迎来到Python Weekly第296期。本周,让我们直入主题。
+
+# 来自赞助商
+[](http://www3.activestate.com/activepython-data-science.html?utm_source=python-weekly&utm_medium=email&utm_term=&utm_content=17-05-25-newsletter&utm_campaign=activepython-fc)
+
+专注于算法,而不是准备时间。ActivePython自己预编译了TensorFlow, theano, Keras和其他难以构建的包。通过英特尔数学核心库,优化你的NumPy和SciPy算法。开始为数据科学和机器学习,使用ActivePython[免费开发](http://www3.activestate.com/activepython-data-science.html?utm_source=python-weekly&utm_medium=email&utm_term=&utm_content=17-05-25-newsletter&utm_campaign=activepython-fc)吧。
+
+
+# 文章,教程和讲座
+
+[仅用3行Python代码,实现四子棋](https://danverbraganza.com/writings/connect-four-in-3-lines-of-python)
+
+带解释的终端四子棋的小小实现。
+
+[抓取数据 —— 实用指南](https://medium.com/k-folds/scraping-for-data-a-practical-guide-67cc397450b2)
+
+一篇关于使用Python进行网络抓取、用Urllib和BeautifulSoup从Indeed.com提取工作描述文本以进行数据分析的介绍。
+
+[如何使用Python和Asyncio,在10分钟内抓取并解析600个ETF选项](http://www.blackarbs.com/blog/how-to-scrape-and-parse-600-etf-options-in-10-mins-with-python-and-asyncio/5/18/2017)
+
+这是我正在进行的用Python半实时构建一个功能选项数据仪表盘的新系列的第一部分。在这篇文章中,我展示了关于获取数据的位置、抓取方法、解析方法和以快速读写访问为目的的存储方法的一个当前工作方案。我们将使用aiohttp和asyncio爬取Barchart.com的基本选项应用,这两个都包含在Python 3.6标准库中。我们将使用Pandas和Numpy解析它,并且以HDF5文件格式存储数据。
+
+[Podcast.__init__ 第110集 - Yelp!的技术债和重构](https://www.podcastinit.com/tech-debt-and-refactoring-at-yelp-with-andrew-mason-episode-110/)
+
+健康代码造就快乐码农,而由许许多多种方法来衡量一个项目的健康。本周,Andrew Mason聊到了来自Yelp!的Undebt项目,以及一些其他开发来确保他们的技术债卡余额保持低水平的工具和实践。听一听,学习如何以及为什么要测量和解决软件的痛点。
+
+[ChatOps和PowerShell](https://www.youtube.com/watch?v=XIMOFnfdOx0)
+
+写了大量的棒极的PowerShell脚本,但发现难以让你的终端用户或者支持者使用它们,是吗?让我们使用ChatOps解决这个问题吧。我们将快速介绍ChatOps,然后投入Windows上一个Errbot(一个聊天机器人)的安装。在学习Errbot的基础知识后,我们会运行一些代码样例,以便你可以轻松通过聊天将你的脚本传递给用户。最后,我们会介绍涉及到ChatOps和PowerShell时,有哪些安全性。
+
+[图灵模式](http://www.degeneratestate.org/posts/2017/May/05/turing-patterns/)
+
+探索由反应扩散方程产生的模式。
+
+[Python在诉讼下划线的含义](https://dbader.org/blog/meaning-of-underscores-in-python)
+
+本文讨论了五种下划线模式和命名约定,以及它们是如何影响你的Python程序的行为的。
+
+[Python库API清单](http://python.apichecklist.com/)
+
+构建不错的Python库API的有用清单。
+
+[最小化英语中的负对数似然(Negative Log-Likelihood)](http://willwolf.io/2017/05/18/minimizing_the_negative_log_likelihood_in_english/)
+
+[PyCon 2017视频集](https://www.youtube.com/channel/UCrJhliKNQ8g0qoE_zvL8eVg/)
+
+[在PyPi上构建僵尸网络](https://hackernoon.com/building-a-botnet-on-pypi-be1ad280b8d6)
+
+[Jupyter Notebook:鲜为人知的技巧!](https://blog.3blades.io/jupyter-notebook-little-known-tricks-b0866a558017)
+
+[在TensorFlow中了解和实现CycleGAN](https://hardikbansal.github.io/CycleGANBlog/)
+
+[利用Python和Mxnet,基于深度学习的现代人脸检测](https://medium.com/wassa/modern-face-detection-based-on-deep-learning-using-python-and-mxnet-5e6377f22674)
+
+[通过Python和Google BigQuery,在纽约出租车数据上构建机器学习合成分类器,来预测无小费 vs 很多小费](https://medium.com/towards-data-science/building-a-ml-classifier-on-ny-city-taxi-data-to-predict-no-tips-vs-generous-tips-with-python-92e21d5d9fd0)
+
+
+# 书籍
+
+[利用Python学习数据挖掘 - 第二版 (Learning Data Mining with Python - Second Edition)](http://amzn.to/2qhiTQ4)
+
+本书教你如何使用各种数据集来设计和开发数据挖掘应用,从基本分类和关联分析开始。本书涵盖了大量Python中可用的库,包括Jupyter Notebook, pandas,scikit-learn和NLTK。
+
+
+# 好玩的项目,工具和库
+
+[ParlAI](http://parl.ai/)
+
+一个在各种公开可用对话数据集上训练和评估AI模型的框架。
+
+[darkflow](https://github.com/thtrieu/darkflow)
+
+将darknet转换成tensorflow。加载训练权重,使用tensorflow重新训练/微调,导出常数图到移动设备。
+
+[BoopSuite](https://github.com/M1ND-B3ND3R/BoopSuite)
+
+一个用于无线审计和安全测试的Python工具套件。
+
+[Cyphon](https://github.com/dunbarcyber/cyphon)
+
+Cyphon通过单一平台简化所有相关流程,终结了数据管理传统上带来的令人头疼的东西。Cyphon从电子邮件、日志信息、社交媒体和其他在线资源接收、处理和分类数据。
+
+[SemiLive](https://github.com/toji/semilive)
+
+用于“实时”编码的Sublime Text插件。
+
+[scikit-garden](https://github.com/scikit-garden/scikit-garden)
+
+Scikit-Garden或者skgarden (发音为skarden) 是Scikit-Learn兼容的决策树和森林的花园。
+
+[Reconnoitre](https://github.com/codingo/Reconnoitre)
+
+一个安全工具,用于多线程信息收集和服务枚举,同时构建目录结构以存储结果,以及写出进一步测试的建议。
+
+[haishoku](https://github.com/LanceGin/haishoku)
+
+Haishoku是一个从图像中获取主色或者代表色的开发工具,依赖于Python3和Pillow。
+
+[binsnitch](https://github.com/NVISO-BE/binsnitch)
+
+binsnitch可以用于检测你的系统上的文件的静默无意义的修改。它会递归扫描一个给定目录下的文件,并且基于文件的SHA256值,跟踪其检测到的东西的任意修改。你可以选择跟踪可执行文件,或者所有文件。
+
+[tinynumpy](https://github.com/wadetb/tinynumpy)
+
+一个轻量级、纯Python的符合numpy的ndarray类。
+
+
+# 最新发布
+
+[PyCharm 2017.1.3](https://blog.jetbrains.com/pycharm/2017/05/pycharm-2017-1-3-out-now)
+
+
+# 近期活动和网络研讨会
+
+[SoCal Python 2017年5月聚会 - Los Angeles, CA](https://www.meetup.com/socalpython/events/240033209/)
+
+将会有以下演讲
+
+ * 用Python玩转戴尔生命周期控制器
+ * 通过生成测试“调戏”测试
+
+
+[DFW Pythoneers 2017年6月聚会 - Plano, TX](https://www.meetup.com/dfwpython/events/238130973/)
+
+
+
+
+
diff --git a/Python Weekly/Python_Weekly_Issue_297.md b/Python Weekly/Python_Weekly_Issue_297.md
new file mode 100644
index 0000000..4e3aed5
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_297.md
@@ -0,0 +1,152 @@
+原文:[Python Weekly - Issue 297 ](http://eepurl.com/cQXCcT)
+
+---
+
+欢迎来到Python Weekly第297期。本周,让我们直入主题。
+
+# 来自赞助商
+
+[](http://www.amazon.com/gp/product/B0185367JQ/ref=as_li_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=B0185367JQ&linkCode=as2&tag=mymerch-20&linkId=OLIXWD4WZ5X6FFHD)
+
+嘿,Python粉,你想要表达你对**Python**的爱吗?那么,[点击这里](http://www.amazon.com/gp/product/B0185367JQ/ref=as_li_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=B0185367JQ&linkCode=as2&tag=mymerch-20&linkId=OLIXWD4WZ5X6FFHD),获取你的T恤,骄傲地穿上它吧。
+
+
+# 文章,教程和讲座
+
+[如何使用Chatbots,Facebook Messages和Empathy实现你自己的数字形象](https://medium.com/towards-data-science/how-to-make-a-digital-personality-of-yourself-using-chatbots-facebook-and-empathy-8b0c53afa9bd)
+
+本文总结了我研究和开发我的毕业论文的经验等精华部分,在我的毕业论文中,我尝试创造一个名为Emoter的聊天机器人,它具有同情心(或编程上与其相似的东东),它被放在帕森斯设计学院,被部署为艺术画廊中的一个交互式展览。这个经验不仅让我成为了一个更好的开发,还能深入了解一个聊天机器人的用户体验真正感受上应该是怎样的,这将是贯穿全文的重点。
+
+[使用OpenCV和Python进行面部对齐](http://www.pyimagesearch.com/2017/05/22/face-alignment-with-opencv-and-python/ )
+
+本文的目的是展示如何使用OpenCV,Python和面部界标来对齐面部。给定一组面部界标(输入坐标),我们的目标是将图像扭曲和转换成输出坐标空间。
+
+[使用Amazon AWS和Python进行蓝绿部署(Blue green deployment)](https://medium.com/practo-engineering/blue-green-deployment-on-amazon-aws-38b820518411)
+
+在蓝绿部署方法中,我们创建当前生产基础设施的副本,然后路由所有的流量到该副本。当前基础设施被称为蓝色,而副本则为绿色。当然,我们在绿队中进行所有的代码更新。这保证了部署期间的高可用性。本文是关于使用Amazon AWS和Python实现蓝绿部署。我们将使用Elastic Compute Cloud(EC2),Autoscaling Groups,Launch Configurations(LC),Elastic Load Balancer(ELB),Route 53,Python的Boto和Python的Fabric。
+
+[教程:python中的异步语音识别](https://medium.com/towards-data-science/tutorial-asynchronous-speech-recognition-in-python-b1215d501c64)
+
+一个使用谷歌的非常混乱的语音识别API的(相当)简单的技术。
+
+[编写一个python应用来获取Outlook邮件、日历和联系人](https://docs.microsoft.com/en-us/outlook/rest/python-tutorial)
+
+本指南的目的是逐步介绍创建一个简单的python网络应用的过程,这个应用检索Office 365或者Outlook.com中的消息。本指南将会使用Microsoft Graph来访问Outlook邮件。微软推荐使用Microsoft Graph来访问Outlook邮件、日历和联系人。
+
+[子测试是最好的](https://www.caktusgroup.com/blog/2017/05/29/subtests-are-best/)
+
+使用子测试可以帮助python开发者编写更清晰的代码。来看看怎么做吧。
+
+[Podcast.__init__ 第111集 - 和Scott Ernst聊聊Cauldron](https://www.podcastinit.com/episode-111-cauldron-notebook-with-scott-ernst/)
+
+已由IPython/Jupyter项目举例说明的notebook格式已经在数据科学家中受到了欢迎。虽然现有的格式已经证明了它们的价值,但是它们在协作和可维护性方面仍然容易遇到麻烦。Scott Ernst创造了Cauldron notebook,它是可以测试的、可用于生产并且属于版本控制友好型。本周,我们探讨Cauldron的功能、用例和架构,以及如何开始使用它!
+
+[花费$1700的不错的深度学习套装:装配、设置和基准](https://blog.slavv.com/the-1700-great-deep-learning-box-assembly-setup-and-benchmarks-148c5ebe6415)
+
+[给DOS Python生成64位哈希碰撞](https://medium.com/@robertgrosse/generating-64-bit-hash-collisions-to-dos-python-5b21404a5306)
+
+[用python进行短信欺骗,无论正邪](http://www.thedurkweb.com/sms-spoofing-with-python-for-good-and-evil/)
+
+[玩转无监督机器学习和利用篮子集群(Basket Clusters)](https://hackernoon.com/unsupervised-machine-learning-for-fun-profit-with-basket-clusters-17a1161e7aa1)
+
+[用python进行BS / AN脸部检测](https://www.youtube.com/watch?v=92uo6Ijqn7U)
+
+[使用Python和Pandas分析价格目标和评级](http://blog.ayoungprogrammer.com/2017/05/using-python-and-pandas-to-analyze-price-targets-and-ratings.html/)
+
+[使用机器学习构建游戏AI](https://www.activestate.com/blog/2017/05/building-game-ai-using-machine-learning-working-tensorflow-keras-and-intel-mkl-python)
+
+[用Home Assistant监控我的VOIP提供商](https://medium.com/@davidcameron/monitoring-my-voip-provider-with-home-assistant-83a31f0a8cb9)
+
+[赢得擂台国家之战(The Battle For Riddler Nation);基于代理的建模解决方案](https://ntguardian.wordpress.com/2017/05/29/winning-the-battle-for-riddler-nation-an-agent-based-modelling-approach/)
+
+[现代Django —— 第二部分:REST API,App和Django REST框架](https://medium.com/@djstein/modern-django-part-2-rest-apis-apps-and-django-rest-framework-ea0cac5ab104)
+
+[使用Bokeh,Flask和Python 3绘制响应式直方图](https://www.fullstackpython.com/blog/responsive-bar-charts-bokeh-flask-python-3.html)
+
+
+# 书籍
+
+[Black Hat Python: 2 Manuscripts--Hacking With Python and Wireless Hacking(黑帽python:2手稿 —— python黑客和无线入侵)](http://amzn.to/2rdbWDB)
+
+[Learn Tkinter By Example(通过示例学习Tkinter)](https://github.com/Dvlv/Tkinter-By-Example/blob/master/Tkinter-By-Example.pdf )
+
+
+# 本周的Python工作
+
+[Tictail招聘增长工程师](http://jobs.pythonweekly.com/jobs/growth-engineer/)
+
+Tictail的工程师不仅仅涉及到代码;你将成为把想法带入生活的过程中的一部分。从头脑风暴和早期设计,到迭代实现,配送代码并在未来支持它。构建功能将包含python后端工作,开发支持tictail.com的React前端,以及帮助你的同事扩大其影响的内部工具。
+
+
+
+# 好玩的项目,工具和库
+
+[ChaosBot](https://github.com/chaosbot/Chaos)
+
+ChaosBot是一次社会编码实验,为了看看当软件项目的绝对方向转向开源社区时会发生些什么。
+
+[Django Viewflow](http://viewflow.io/)
+
+用于业务流程自动化的可重用工作流库,使用python和BPMN。
+
+[Baselines](https://github.com/openai/baselines)
+
+OpenAI基线:强化学习算法的高质量实现。
+
+[Polyaxon](https://github.com/polyaxon/polyaxon)
+
+TensorFlow深度学习库,用来构建端到端模型和实验。
+
+[visidata](https://github.com/saulpw/visidata)
+
+一个用来发现和排列数据的控制台电子表格工具。
+
+[xcessiv](https://github.com/reiinakano/xcessiv)
+
+一个基于web的应用,用来在python中进行快速和可扩展的超参数调整和堆栈合并。
+
+[Python Boilerplate](https://www.python-boilerplate.com/py3+executable)
+
+用于快速且正确开始的python样板集合。
+
+[gitsuggest](https://github.com/csurfer/gitsuggest)
+
+一个基于你表现出兴趣的仓库的github仓库推荐工具。
+
+[Skater](https://github.com/datascienceinc/Skater)
+
+Skater是一个用于预测模型的模型无关解释的python包。使用Skater,你可以打开任意模型的内部机制;只要你可以获得输入,并且使用一个函数来获取输出,你就能使用Skater来学习模型内部的决策策略。
+
+[MicroPython on Unicorn](https://github.com/micropython/micropython-unicorn)
+
+这个仓库包含了一个基于Unicorn仿真器的虚拟微控制器的实现,它反过来基于QEMU。它还包含了到那个虚拟微控制器的一个MicroPython端口。Unicorn有一个JavaScript版本,unicorn.js,它是通过在Unicorn的C版本上运行Emscripten来得到的,并且允许该虚拟微控制器在浏览器中运行。这样,就可以提供一个在web浏览器中运行模拟裸机的完整MicroPython端口。
+
+[tox-docker](https://github.com/dcrosta/Tox-Docker/)
+
+一个在测试期间运行一个或多个Docker容器的tox插件。
+
+[QuickUI](https://github.com/ac1235/python-QuickUI)
+
+科学单行交换式GUI库。
+
+[pmbootstrap](https://github.com/postmarketOS/pmbootstrap)
+
+开发和安装postmarketOS的复杂chroot/build/flash工具。
+
+[typot](https://github.com/chakki-works/typot)
+
+自动检测打字错误,仅通过检查就可以接受更正。
+
+[cheat.sh](https://github.com/chubin/cheat.sh)
+
+找到你所需的{命令行选项|代码片段}的最快的方式。
+
+
+# 近期活动和网络研讨会
+
+[使用python的数据科学介绍 - New York, NY](https://www.meetup.com/NYDataScientists/events/240372768/)
+
+虽然了解数据科学绝不会更简单,但是有个指南来帮助你开始征程却是很有用的。在这个免费的实践工作室中,和galvanize一起,你会通过python编程语言,学到数据科学的基础知识。
+
+
+
diff --git "a/Python Weekly/Python_Weekly_Issue_297\302\240.md" "b/Python Weekly/Python_Weekly_Issue_297\302\240.md"
new file mode 100644
index 0000000..1ec8cb1
--- /dev/null
+++ "b/Python Weekly/Python_Weekly_Issue_297\302\240.md"
@@ -0,0 +1,137 @@
+原文:[Python Weekly - Issue 297 ](http://eepurl.com/cQXCcT)
+
+---
+
+欢迎来到Python Weekly第297期。本周,让我们直入主题。
+
+# 来自赞助商
+
+[](http://www.amazon.com/gp/product/B0185367JQ/ref=as_li_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=B0185367JQ&linkCode=as2&tag=mymerch-20&linkId=OLIXWD4WZ5X6FFHD)
+
+嘿,Python粉,你想要表达你对**Python**的爱吗?那么,[点击这里](http://www.amazon.com/gp/product/B0185367JQ/ref=as_li_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=B0185367JQ&linkCode=as2&tag=mymerch-20&linkId=OLIXWD4WZ5X6FFHD),获取你的T恤,骄傲地穿上它吧。
+
+
+
+# 文章,教程和讲座
+
+[How to Make a Digital Personality of Yourself Using Chatbots, Facebook Messages, and Empathy](https://medium.com/towards-data-science/how-to-make-a-digital-personality-of-yourself-using-chatbots-facebook-and-empathy-8b0c53afa9bd)
+This article sums up the culmination of my experiences researching and developing my senior thesis, an attempt to create a chatbot named Emoter that would have empathy (or some programmatic equivalent to it), at Parsons School of Design, deployed as an interactive exhibit in an art gallery. The experience didn't just leave me a better developer, but also with more insight on how the user experience of a chatbot should really feel, which will be the main point I address throughout the article.
+
+[Face Alignment with OpenCV and Python](http://www.pyimagesearch.com/2017/05/22/face-alignment-with-opencv-and-python/ )
+The purpose of this post is to demonstrate how to align a face using OpenCV, Python, and facial landmarks. Given a set of facial landmarks (the input coordinates) our goal is to warp and transform the image to an output coordinate space.
+
+[Blue Green Deployment Using Amazon AWS and Python.](https://medium.com/practo-engineering/blue-green-deployment-on-amazon-aws-38b820518411)
+In Blue green deployment approach we create replica of the current production infrastructure and route all the traffic to the replica. The current infrastructure is termed as Blue while the replica is Green. Of course we make all code updates in the green fleet. This ensure high availability during deployments. This article is about implementing blue green deployment using Amazon AWS and Python. We will use Elastic Compute Cloud(EC2), Autoscaling Groups, Launch Configurations(LC), Elastic Load Balancer(ELB), Route 53, Python Boto and Python Fabric.
+
+[Tutorial: Asynchronous Speech Recognition in Python](https://medium.com/towards-data-science/tutorial-asynchronous-speech-recognition-in-python-b1215d501c64)
+A (fairly) simple technique for using Google's kinda-sorta-really confusing Speech Recognition API.
+
+[Write a Python app to get Outlook mail, calendar, and contacts](https://docs.microsoft.com/en-us/outlook/rest/python-tutorial)
+The purpose of this guide is to walk through the process of creating a simple Python web app that retrieves messages in Office 365 or Outlook.com. This guide will use the Microsoft Graph to access Outlook mail. Microsoft recommends using the Microsoft Graph to access Outlook mail, calendar, and contacts.
+
+[Subtests are the Best](https://www.caktusgroup.com/blog/2017/05/29/subtests-are-best/)
+Using subtests can help Python developers write cleaner code. Find out how.
+
+[Podcast.__init__ Episode 111 - Cauldron with Scott Ernst](https://www.podcastinit.com/episode-111-cauldron-notebook-with-scott-ernst/)
+The notebook format that has been exemplified by the IPython/Jupyter project has gained in popularity among data scientists. While the existing formats have proven their value, they are still susceptible with difficulties in collaboration and maintainability. Scott Ernst created the Cauldron notebook to be testable, production ready, and friendly to version control. This week we explore the capabilities, use cases, and architecture of Cauldron and how you can start using it today!
+
+[The $1700 great Deep Learning box: Assembly, setup and benchmarks](https://blog.slavv.com/the-1700-great-deep-learning-box-assembly-setup-and-benchmarks-148c5ebe6415)
+
+[Generating 64 bit hash collisions to DOS Python](https://medium.com/@robertgrosse/generating-64-bit-hash-collisions-to-dos-python-5b21404a5306)
+
+[SMS Spoofing with Python for Good and Evil](http://www.thedurkweb.com/sms-spoofing-with-python-for-good-and-evil/)
+
+[Unsupervised Machine Learning for Fun & Profit with Basket Clusters](https://hackernoon.com/unsupervised-machine-learning-for-fun-profit-with-basket-clusters-17a1161e7aa1)
+
+[BS / AN Face Detection Python](https://www.youtube.com/watch?v=92uo6Ijqn7U)
+
+[Using Python and Pandas to Analyze Price Targets and Ratings](http://blog.ayoungprogrammer.com/2017/05/using-python-and-pandas-to-analyze-price-targets-and-ratings.html/)
+
+[Building Game AI Using Machine Learning](https://www.activestate.com/blog/2017/05/building-game-ai-using-machine-learning-working-tensorflow-keras-and-intel-mkl-python)
+
+[Monitoring my VOIP provider with Home Assistant](https://medium.com/@davidcameron/monitoring-my-voip-provider-with-home-assistant-83a31f0a8cb9)
+
+[Winning the Battle for Riddler Nation; An Agent-Based Modelling Approach to the Solution](https://ntguardian.wordpress.com/2017/05/29/winning-the-battle-for-riddler-nation-an-agent-based-modelling-approach/)
+
+[Modern Django -- Part 2: REST APIs, Apps, and Django REST Framework](https://medium.com/@djstein/modern-django-part-2-rest-apis-apps-and-django-rest-framework-ea0cac5ab104)
+
+[Responsive Bar Charts with Bokeh, Flask and Python 3](https://www.fullstackpython.com/blog/responsive-bar-charts-bokeh-flask-python-3.html)
+
+
+# 书籍
+
+[Black Hat Python: 2 Manuscripts--Hacking With Python and Wireless Hacking](http://amzn.to/2rdbWDB)
+
+[Learn Tkinter By Example](https://github.com/Dvlv/Tkinter-By-Example/blob/master/Tkinter-By-Example.pdf )
+
+
+# 本周的Python工作
+
+[Growth Engineer at Tictail](http://jobs.pythonweekly.com/jobs/growth-engineer/)
+Engineering at Tictail does not just involve code; you will be part of the entire process of bringing ideas to life. From brainstorming and early design, to iterating upon the implementation, shipping the code and supporting it in the future. Building features will include work on the Python backend, developing the React frontend that powers tictail.com as well as internal tools that help your colleagues scale their impact.
+
+
+# 好玩的项目,工具和库
+
+[ChaosBot](https://github.com/chaosbot/Chaos)
+ChaosBot is a social coding experiment to see what happens when the absolute direction of a software project is turned over to the open source community.
+
+[Django Viewflow](http://viewflow.io/)
+Reusable workflow library for business process automation with python and BPMN.
+
+[Baselines](https://github.com/openai/baselines)
+OpenAI Baselines: high-quality implementations of reinforcement learning algorithms.
+
+[Polyaxon](https://github.com/polyaxon/polyaxon)
+Deep Learning library for TensorFlow for building end to end models and experiments.
+
+[visidata](https://github.com/saulpw/visidata)
+A console spreadsheet tool for discovering and arranging data.
+
+[xcessiv](https://github.com/reiinakano/xcessiv)
+A web-based application for quick and scalable hyperparameter tuning and stacked ensembling in Python.
+
+[Python Boilerplate](https://www.python-boilerplate.com/py3+executable)
+A collection of Python boilerplates for getting started quickly and right-footed.
+
+[gitsuggest](https://github.com/csurfer/gitsuggest)
+A tool to suggest github repositories based on the repositories you have shown interest in.
+
+[Skater](https://github.com/datascienceinc/Skater)
+
+Skater is a python package for model agnostic interpretation of predictive models. With Skater, you can unpack the internal mechanics of arbitrary models; as long as you can obtain inputs, and use a function to obtain outputs, you can use Skater to learn about the models internal decision policies.
+
+[MicroPython on Unicorn](https://github.com/micropython/micropython-unicorn)
+
+这个仓库包含了一个基于Unicorn仿真器(转而基于QEMU)的虚拟微控制器的实现。它还包含了一个到那个虚拟微控制器的MicroPython端口。Unicorn有一个JavaScript版本,unicorn.js,它是通过在Unicorn的C版本上运行Emscripten来实现的,并且允许虚拟微控制器在浏览器中运行。这样,就可以提供在web浏览器中运行模拟裸机的完整MicroPython端口。
+
+[tox-docker](https://github.com/dcrosta/Tox-Docker/)
+
+测试期间运行一个或多个Docker容器的tox插件。
+
+[QuickUI](https://github.com/ac1235/python-QuickUI)
+
+科学的单行式交互GUI库。
+
+[pmbootstrap](https://github.com/postmarketOS/pmbootstrap)
+
+开发和安装postmarketOS的复杂chroot/build/flash工具。
+
+[typot](https://github.com/chakki-works/typot)
+
+自动检测打字错误,只需检查即可接受修复。
+
+[cheat.sh](https://github.com/chubin/cheat.sh)
+
+找到你需要的{命令选项|代码片段}的最快方法。
+
+
+# 近期活动和网络研讨会
+
+[使用Python的数据科学介绍 - New York, NY](https://www.meetup.com/NYDataScientists/events/240372768/)
+
+虽然说了解数据科学从来就不是一件容易的事,但是,如果有个指南帮你开始你的旅程,那将对你有所助益。在这个免费的实践性研讨会上,和Galvanize一起,你将通过python编程语言,学会数据科学的基本知识。
+
+
+
+
diff --git a/Python Weekly/Python_Weekly_Issue_298.md b/Python Weekly/Python_Weekly_Issue_298.md
new file mode 100644
index 0000000..4c195d5
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_298.md
@@ -0,0 +1,145 @@
+原文:[Python Weekly - Issue 298](http://eepurl.com/cROAov)
+
+---
+
+欢迎来到Python Weekly第298期。本周,让我们直入主题。
+
+# 来自赞助商
+[](https://software.intel.com/en-us/intel-distribution-for-python?utm_source=April%202017%20Image%20link%20Python%20weekly&utm_medium=email&utm_campaign=Python%20Weekly%20newsletter)
+
+[Intel® Distribution for Python*](https://software.intel.com/en-us/intel-distribution-for-python?utm_source=April%202017%20ad%20Python%20weekly&utm_medium=email&utm_campaign=Python%20Weekly%20newsletter)可以**免费**用了,而许可证允许用于商业和非商业用途。就是这样哒!试试NumPy,SciPy和scikit-learn中的性能优化吧,所有加速都在内部。你的代码保持不变 —— 只需在Intel Python环境中运行你的代码,然后就可以获得加速了。
+
+
+# 新闻
+
+[PyGotham 2017 CFP](https://www.papercall.io/pygotham-2017)
+
+Big Apple Py,它带给你NYC Python和Learn Python NYC,正主办PyGotham 2017,时间从十月六号到八号,位于纽约!PyGotham将会成为今年纽约市最让人激动的python事件,拥有涵盖各种各样广泛范围的众多演讲。现在正在征求提议。快来提交你的演讲吧。
+
+
+# 文章,教程和讲座
+
+[安全犯罪预测](https://iamtrask.github.io/2017/06/05/homomorphic-surveillance/)
+
+如果可能监督只会侵犯到罪犯和恐怖分子的隐私,而不会监视无辜的人,那么会怎样呢?本文提出了一种使用python中原型的方法。
+
+[比特币(Bitcoin)之下一瞥](http://www.samlewis.me/2017/06/a-peek-under-bitcoins-hood/)
+
+本文逐步介绍了这个一个过程:创建一个可以创造交易的最小可行Bitcoin客户端,然后将其提交到比特币对等网络,从而将其置于区块链中。
+
+[使用统计模型预测足球比赛结果](https://dashee87.github.io/football/python/predicting-football-results-with-statistical-modelling/)
+
+将世界上最受欢迎的运动与人人都喜欢的离散概率分布结合在一起,本文使用柏松分布来预测足球比赛。
+
+[python中的记录、结构和数据传输对象](https://dbader.org/blog/records-structs-and-data-transfer-objects-in-python)
+
+Python提供了可用于实现记录、结构和数据传输对象的几种数据类型。在这篇文章中,你将快速了解每种实现及其独特的特征。最后,你会看到总结,以及一个决策指南,这将帮助你进行自己的选择。
+
+[Podcast.__init__ 第112集 - 和Evan Hubinger聊聊Coconut](https://www.podcastinit.com/episode-112-coconut-with-evan-hubinger/)
+
+随着我们来到一个越来越平行的世界,函数式编程也变得越来越受欢迎。有时,你想要访问纯功能语法和功能,但是你并不想要学习全新的语言。这里,Coconut来助攻啦!本周,Evan Hubinger解释了Coconut是怎样一个编译到python的函数式语言,并且它如何与你的程序中的其他部分混合匹配使用的。
+
+[在Kaggle的Quora问题对竞赛中实现MaLSTM](https://medium.com/@eliorcohen/implementing-malstm-on-kaggles-quora-question-pairs-competition-8b31b0b16a07)
+
+本文是关于用于句子相似性的MaLSTM Siamese LSTM网络,及其在Kaggle的Quora问题对竞赛中的应用。
+
+[通过HTTPS运行你自己的flask应用](https://blog.miguelgrinberg.com/post/running-your-flask-application-over-https)
+
+在这篇文章中,我将呈现将加密添加到一个flask应用中的几种姿势,从一个你可以在五分钟就实现的极其简单的方法,到一个强大的解决方案,后者应该会给你一个A+评级,就像我的站点从这个详尽的SSL分析服务中得到的一样。
+
+[金融Python:算法交易](https://www.datacamp.com/community/tutorials/finance-python-trading)
+
+[Reddit的代码部署演进](https://redditblog.com/2017/06/02/the-evolution-of-code-deploys-at-reddit/)
+
+[选项和对象:自定义Django用户模型](https://medium.com/agatha-codes/options-objects-customizing-the-django-user-model-6d42b3e971a4)
+
+[文本卷积方法](https://medium.com/@TalPerry/convolutional-methods-for-text-d5260fd5675f)
+
+[机器学习和python(以及数学)备忘录](https://unsupervisedmethods.com/cheat-sheet-of-machine-learning-and-python-and-math-cheat-sheets-a4afe4e791b6 )
+
+
+# 本周的Python工作
+
+[Interactive招聘高级Python/Django开发工程师](http://jobs.pythonweekly.com/jobs/senior-pythondjango-developer-2/)
+
+作为高级Python开发工程师,你会在一个专业的团队中工作,并实现坚如磐石的解决方案以创造高质量网络应用。你会在评估和定义架构方面扮演重要角色。你要为我们的项目定义架构,并提出技术解决方案。大多数时候,你的工作是设计和编码这些技术解决方案。测试你自己的工作以及其他人的工作当然也包含在内。你要协助定义数据库和 (web) 应用设计。
+
+
+# 好玩的项目,工具和库
+
+[Scattertext](https://github.com/JasonKessler/scattertext)
+
+一个用于在中小型语料库中找出区别术语,并将其呈现在一个带非重叠术语标签的性感交互式散点图中的工具。
+
+[CleverHans](https://github.com/tensorflow/cleverhans)
+
+一个用于对抗脆弱性基准例子的库。
+
+[Gain](https://github.com/gaojiuli/gain/)
+
+给所有人的网络爬取框架,基于asyncio
+
+[NeuroNER](https://github.com/Franck-Dernoncourt/NeuroNER)
+
+使用神经网络的命名实体识别。易于使用,并且是最先进的结果。
+
+[CuPy](https://github.com/cupy/cupy)
+
+用CUDA加速的类NumPy API。
+
+[WebDNN](https://github.com/mil-tokyo/webdnn)
+
+WebDNN是一个开源软件框架,用来在网络浏览器上执行深度神经网络 (DNN) 预训练模型。
+
+[pydantic](https://github.com/samuelcolvin/pydantic/)
+
+使用Python 3.6类型提示进行数据验证。
+
+[flask-assistant](https://github.com/treethought/flask-assistant/)
+用API.AI和python构建虚拟助手的框架。
+
+[basicRAT](https://github.com/vesche/basicRAT)
+
+这是一个跨平台Python 2.x远程访问木马 (RAT),basicRAT被创造来维持一个简洁的设计功能齐全的Python RAT。
+
+[blackbox](https://github.com/paulknysh/blackbox)
+
+一个用于昂贵的黑盒子函数的并行优化的Python模块。
+
+
+# 最新发布
+
+[Anaconda 4.4.0](https://www.continuum.io/downloads)
+
+它现在同时可用于Python 2.7和Python 3.6了。除了通过为Windows,Mac,Linux和Power8提供一个单一安装程序,从而为以python为中心的数据科学提供全面的平台外,Anaconda 4.4还旨在简化使用Python 2和Python 3代码。
+
+[Django问题修复版本:1.11.2](https://www.djangoproject.com/weblog/2017/jun/01/bugfix-release/)
+
+
+# 近期活动和网络研讨会
+
+[San Francisco 2017年六月Python聚会 - San Francisco, CA](https://www.meetup.com/sfpython/events/240006418/)
+
+将会有以下演讲:
+
+ * 疯狂的Import # 如何使用import语句实现归并排序
+ * Python的Mock库
+ * Unicode:啥是大事?
+
+
+[Boulder 2017年六月Python聚会 - Boulder, CO](https://www.meetup.com/BoulderPython/events/239146783/)
+
+将会有以下演讲:
+
+ * 列表推导简介
+ * CPython vs Jython vs PyPy
+ * Matplotlib:准备……。分散!
+
+
+[Austin 2017年六月Python聚会 - Austin, TX](https://www.meetup.com/austinpython/events/238199528/)
+
+[IndyPy 2017年六月每月聚会 - Indianapolis, IN](https://www.meetup.com/indypy/events/239042788/)
+
+
+
+
diff --git a/Python Weekly/Python_Weekly_Issue_299.md b/Python Weekly/Python_Weekly_Issue_299.md
new file mode 100644
index 0000000..ca47d58
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_299.md
@@ -0,0 +1,146 @@
+原文:[Python Weekly - Issue 299](http://eepurl.com/cSIjsr)
+
+---
+
+欢迎来到Python Weekly第299期。本周,我想要感谢我们的赞助商Datadog的支持。一定要看看他们免费的棒棒哒的解决放啊。
+
+# 来自赞助商
+
+[](https://www.datadoghq.com/dg/apm/ts-python-performance/?utm_source=Advertisement&utm_medium=Advertisement&utm_campaign=PythonWeekly-Tshirt&utm_content=Python)
+
+[怎样监控Python应用](https://www.datadoghq.com/dg/apm/ts-python-performance/?utm_source=Advertisement&utm_medium=Advertisement&utm_campaign=PythonWeekly-Tshirt&utm_content=Python)
+
+关于实时Python指标的图表和告警,并与你的栈中的150多种其他技术生成的数据相关联。
+
+
+# 新闻
+
+[NumPy首次获得资金资助](https://www.numfocus.org/blog/numpy-receives-first-ever-funding-thanks-to-moore-foundation/)
+
+有史以来,NumPy获得了资助。提案 —— "为了更好的数据科学,改进NumPy" —— 将会在两年中收到来自摩尔基金会的$645,020,资金将投入到加州大学伯克利分校,用于数据科学。
+
+
+# 文章,教程和讲座
+
+[Instagram平缓移植到Python 3](https://thenewstack.io/instagram-makes-smooth-move-python-3/)
+
+Instagram不仅仅是已经成为世界上最大的Python用户,这个公司最近还移植到了Python 3,并且不对用户体验造成任何影响。Instagram工程师Hui Ding和Lisa Guo聊到了新的技术栈,以分享对Python的爱,并描述了Python 3的迁移体验。
+
+[Podcast.__init__ 第113集 - 和David Halter聊聊Jedi代码完成](https://www.podcastinit.com/episode-113-jedi-code-completion-with-david-halter/)
+
+当你在写python代码,而你的编辑器提供一些建议的时候,那些建议都是从哪来的呢?最有可能的答案是Jedi!本周,David Halter解释了Jedi自动完成库是如何创建的,它的工作原理是什么,以及他计划在哪里采用的历史。
+
+[了解Python中的异步编程](https://dbader.org/blog/understanding-asynchronous-programming-in-python)
+
+如何使用Python编写异步程序,以及为什么要做这样的事。
+
+[从Flask-Script迁移到新的Flask CLI](https://blog.miguelgrinberg.com/post/migrating-from-flask-script-to-the-new-flask-cli)
+
+这篇文章向你展示新的Flask CLI提供的功能,如果你想要迁移你的基于Flask-Script的应用,那么这将会有用。
+
+[Pelican使用更快的R-CNN来计数对象](https://softwaremill.com/counting-objects-with-faster-rcnn/)
+
+精确计算一个给定图像或视频帧中的对象实例数量是机器学习中一个难以解决的问题。已经开发了许多解决方法来计数人、汽车和其他对象,但它们没有一个是完美的。当然,这里,我们讲的是图像处理,因此,神经网络似乎是解决这个问题的一个好工具。在这篇文章中,你可以找到关于不同的解决方法、常见问题、挑战和神经网络对象计数领域中的最新方法的描述。作为对概念的证明,将会使用现有的更快的R-CNN网络模型来计算文章末尾给出的视频中街道上的对象数。
+
+[如何使用Pelican和Jinja2创建你的第一个静态站点](https://www.fullstackpython.com/blog/generating-static-websites-pelican-jinja2-markdown.html)
+
+Pelican是一个用来创建静态站点的非常完美的Python工具。在这个教程中,你将学到如何使用Pelican,从头开始创建你自己的静态站点。
+
+[破解一个由Jupyter notebook驱动的播客的方法](https://nipunbatra.github.io/blog/2017/Jupyter-powered-blog.html)
+
+一篇关于通过Jupyter notebook驱动博客和相关的挣扎的文章!
+
+[给Python程序员的Apache Kafka介绍](https://www.confluent.io/blog/introduction-to-apache-kafka-for-python-programmers/)
+
+在这篇文章中,我们将会回归基础知识,并了解如何开始为你的Python应用使用Apache Kafka。
+
+[用Django REST框架和基于类的视图构建一个API](https://medium.com/@ktruong008/building-an-api-with-django-rest-framework-and-class-based-views-75b369b30396)
+
+[5种让Django Admin更安全的方法](https://hackernoon.com/5-ways-to-make-django-admin-safer-eb7753698ac8)
+
+[GOAI:开放GPU加速数据分析](https://devblogs.nvidia.com/parallelforall/goai-open-gpu-accelerated-data-analytics/)
+
+[用Python检测虚假视频](http://sunnybala.com/2017/05/28/python-video-loop-detection.html)
+
+
+# 好玩的项目,工具和库
+
+[ShutIt](https://github.com/ianmiell/shutit)
+
+ShutIt是一个对用户终端操作进行建模的自动化工具。它可以毫不费力地自动化人类在命令行中可以运行的任何过程。
+
+[Music Genre Classifier](https://github.com/indrajithi/mgc-django)
+
+基于流派分类音乐的机器学习方法。
+
+[Spans](https://github.com/runfalk/spans)
+
+Spans是https://github.com/damianavila/RISE的range类型的纯Python实现。
+
+[Sudoku](https://github.com/Kyubyong/sudoku)
+
+神经网络可以破解数独吗?已经有各种解决数独的方法了,包括计算方法。这个项目展示了简单的卷积神经网络在无需任何基于规则的后处理情况下破解数独的潜力。
+
+[RISE](https://github.com/damianavila/RISE)
+
+RISE: "Live" Reveal.js —— Jupyter/IPython Slideshow扩展
+
+[DLTK](https://github.com/DLTK/DLTK)
+
+用于医学图像分析的深度学习工具包。
+
+[Snaek](https://github.com/mitsuhiko/snaek)
+
+Snaek是一个Python库,帮你构建Rust库,并通过cffi将它们与Python结合在一起。
+
+[scikit-video](https://github.com/scikit-video/scikit-video)
+
+Scikit-video专为使用Python轻松进行视频处理而设计。它的建模受其他成功的scikits(例如scikit-learn和scikit-image)精髓影响。
+
+[snaptile](https://github.com/jakebian/snaptile)
+
+用于X11的带功能强大的键盘控件的多功能窗口平铺。
+
+[molotov](https://github.com/loads/molotov)
+
+编写负载测试的简单Python 3.5+工具。
+
+[Sounder](https://github.com/SlapBot/sounder)
+
+一个预测给定文本意图的意图识别算法。
+
+[uvicorn](https://github.com/tomchristie/uvicorn)
+
+一个用于Python 3的快如闪电的asyncio服务器。
+
+[VADER-Sentiment-Analysis](https://github.com/cjhutto/vaderSentiment)
+
+VADER (Valence Aware Dictionary and sEntiment Reasoner) 是一个基于词汇和规则的情绪分析工具,专门针对社交媒体中表达的情绪。
+
+
+# 最新发布
+
+[NumPy 1.13.0](https://github.com/numpy/numpy/releases/tag/v1.13.0)
+
+[PyPy v5.8](https://morepypy.blogspot.com/2017/06/pypy-v58-released.html)
+
+
+# 近期活动和网络研讨会
+
+[PyOhio 2017](https://www.eventbrite.com/e/pyohio-2017-tickets-33066656259)
+
+为Ohio,整个中西部地区,甚至整个世界提供的Python程序员免费年会。
+
+[San Diego Python 2017年六月聚会 - San Diego, CA](https://www.meetup.com/pythonsd/events/238867409/)
+
+将会有以下演讲
+
+ * 为Python配置Vim
+ * Django路上的磕磕碰碰,以及如何避免
+
+
+[PyHou 2017年六月聚会 - Houston, TX](https://www.meetup.com/python-14/events/239458416/)
+
+
+
+
diff --git a/Python Weekly/Python_Weekly_Issue_300.md b/Python Weekly/Python_Weekly_Issue_300.md
new file mode 100644
index 0000000..a0c3635
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_300.md
@@ -0,0 +1,144 @@
+原文:[Python Weekly - Issue 300](http://eepurl.com/cTwwiH)
+
+---
+
+欢迎来到Python Weekly第300期。本周,让我们直入主题。
+
+# 来自赞助商
+[](https://www.datadoghq.com/dg/apm/ts-python-performance/?utm_source=Advertisement&utm_medium=Advertisement&utm_campaign=PythonWeekly-Tshirt&utm_content=Python)
+
+[如何监控Python应用](https://www.datadoghq.com/dg/apm/ts-python-performance/?utm_source=Advertisement&utm_medium=Advertisement&utm_campaign=PythonWeekly-Tshirt&utm_content=Python)
+
+关于实时Python指标的图表和告警,并与你的栈中的150多种其他技术生成的数据相关联。
+
+
+# 文章,教程和讲座
+
+[Episode #117: 用Coconut实现函数式Python](https://talkpython.fm/episodes/show/117/functional-python-with-coconut)
+
+Python语言的一个好处是,它至少有3种编程范例:过程式分割、面向对象式分割和函数式分割。本周,你将见到Evan Hubinger,他采用Python的函数式编程风格,并将其转换成11.我们聊到Coconut。这是一种完整的函数式编程语言,它是Python本身的一个合适的超集。
+
+[使用Python,Plaid和Twilio,通过SMS检查你的每日支出](https://www.twilio.com/blog/2017/06/check-daily-spending-sms-python-plaid-twilio.html)
+
+你使用的银行也许会让你为各种触发行为设置短信告警。它甚至还会让你选择通过短信接收定期的支出总结 (我的不是!)。但是,一个跨所有账号的每日支出短信总结怎么样呢?这种总结更难以得到,但是幸运的是,通过将Plaid(一个易于使用的金融服务API)和Twilio短信结合起来,使用一点点Python3,就可以自己弄一个。让我们开始吧!
+
+[使用OpenCV和Python的图像差异](http://www.pyimagesearch.com/2017/06/19/image-difference-with-opencv-and-python/)
+
+在这篇文章中,你将会学习如何使用OpenCV,Python和scikit-image的结构相似性指数 (SSIM)来计算图像差异。基于图像差异,你还将学习如何标记和可视化两张图像中的不同区域。
+
+[Podcast.__init__ 第114集 - 和Jonas Neubert聊聊工业自动化](https://www.podcastinit.com/episode-114-industrial-automation-with-jonas-neubert/)
+
+我们都是用工厂中生产的物品,但是你有没有过停下来思考驱动生产的代码呢?本周,Jonas Neubert把我们带到幕后,聊聊驱动现代设施的系统和软件,开发工作流,以及如何使用Python来将所有的东东绑在一起的。
+
+[Edward和Keras中的随机效应神经网络](http://willwolf.io/2017/06/15/random-effects-neural-networks/)
+
+本文的目的是为Edward中的贝叶斯模型奠定实际基础,然后探索我们可以如何,以及如何轻松地通过Keras,在经典深度学习的方向上扩展这些模型。它将会给出下面模型的概念概述,以及它们的实现的实际考虑的注意事项 —— 哪些有用,哪些没用。最后,本文将会总结进一步扩展这些模型的具体方式。
+
+[深度学习航空影像的语义分割](https://www.azavea.com/blog/2017/05/30/deep-learning-on-aerial-imagery/)
+
+光栅视野开始于我们对ISPRS提供的航空图像进行语义分割的工作。在这篇文章中,我们会讨论分析这个数据集的方法。我们好ui描述我们使用的主要模型架构,我们在Keras和Tensorflow中是如何实现它们的,并且聊聊使用ISPRS数据运行的各种实验。然后,我们讨论怎样使用Azavea构建的其他开源工具来可视化结果,展示交互式网络地图绘制工具中的深度学习的一些分析,并为未来的工作提供方向。
+
+[神经嵌入式Emojis](http://willwolf.io/2017/06/19/neurally-embedded-emojis/)
+
+[使用Dunder (魔法、特别的) 方法,丰富你的Python类](https://dbader.org/blog/python-dunder-methods)
+
+[最快的可用于生产的图像大小调整就在那里,第0部分](https://blog.uploadcare.com/the-fastest-production-ready-image-resize-out-there-part-0-7c974d520ad9)
+
+[使用Python,Flask和Twilio,为忙碌的父亲宣告新生儿的诞生](https://www.twilio.com/blog/2017/06/birth-announcements-busy-father-python-flask-twilio-sms.html )
+
+[重塑的乐趣](https://www.youtube.com/watch?v=js_0wjzuMfc)
+
+[经验丰富的python程序员:有哪些python的标准特性你仍未经常使用?](https://www.reddit.com/r/Python/comments/6i829l/experienced_python_programmers_are_there_any/)
+
+
+# 本周的Python工作
+
+[Omaze招聘高级后端工程师](http://jobs.pythonweekly.com/jobs/senior-back-end-engineer-2/)
+
+Omaze的API团队正在寻找厉害的工程师人才,以助益我们在2017,2018以及之后的时间里的成长。我们拥有有趣的难题以及巨大的野心。我们需要出色的人来帮助我们构建一些棒极的东西。Omaze的高级软件工程师是特别的。你经验丰富,富有智慧;你技术棒棒,但也与人协作良好;你为自己的技能感到骄傲,但也能带领团队人员走向成功。你有很高的标准。你喜爱发布。并且你对即将使用你对才能来有意义地帮助其他人而感到兴奋不已。
+
+
+# 好玩的项目,工具和库
+
+[tensor2tensor](https://github.com/tensorflow/tensor2tensor)
+
+用于TensorFlow的监督学习的一个模块化可扩展库和二进制文件,带对序列任务的支持。
+
+[Dash](https://github.com/plotly/dash)
+
+纯python的交互式响应web应用
+
+[IFFSE](https://github.com/kendricktan/iffse)
+
+Instagram面部特性搜索引擎。
+
+[goSecure](https://github.com/iadgov/goSecure)
+
+一个易于使用的便携式虚拟专用网 (VPN) 系统,使用Linux和一个树莓派进行构建。
+
+[LemonGraph](https://github.com/NationalSecurityAgency/lemongraph)
+
+LemonGraph是一个基于日志的事务图 (节点/边/属性) 数据库引擎,由单个文件支撑。其主要使用场景是支持流式种子集扩展。这个图库的核心部分由C编写,而Python (2.x)层则增加了友好的绑定,查询语言和一个REST服务。
+
+[html5-parser](https://github.com/kovidgoyal/html5-parser)
+
+一个快速、符合标准、基于C的python HTML 5解析器。比诸如html5lib的基于纯python的解释器快超过30倍。
+
+[whitepy](https://github.com/yasn77/whitepy)
+
+用Python3写的空白解释器。
+
+[django-wedding-website](https://github.com/czue/django-wedding-website)
+
+一个由django驱动的婚礼网站和客人管理系统。
+
+[transformer](https://github.com/Kyubyong/transformer)
+
+转换器的一种TensorFlow实现:仅需关注。
+
+[django-admin-env-notice](https://github.com/dizballanze/django-admin-env-notice)
+
+Django Admin中的可视化区分环境。
+
+[Nash](https://github.com/drvinceknight/Nashpy)
+
+一个用于计算2人策略游戏的平衡的python库。
+
+[salt-scanner](https://github.com/0x4D31/salt-scanner )
+
+Linux漏洞扫描程序,基于Salt Open和Vulners审计API,带Slack通知和JIRA集成。
+
+
+# 最新发布
+
+[Python 3.6.2rc1](http://blog.python.org/2017/06/python-362rc1-is-now-available-for.html)
+
+[Jython 2.7.1 发布候选版本3](https://fwierzbicki.blogspot.nl/2017/06/jython-271-release-candidate-3-released.html)
+
+
+# 近期活动和网络研讨会
+
+[SoCal Python 2017年六月聚会 - Santa Monica, CA](https://www.meetup.com/socalpython/events/240587429/)
+
+将会有以下演讲:
+
+ * 更好地循环:更深入了解Python中的迭代
+ * 当一切被自动化时,我们做什么
+
+
+[San Francisco Django2017年六月聚会 - San Francisco, CA](https://www.meetup.com/The-San-Francisco-Django-Meetup-Group/events/240092699/)
+
+将会有以下演讲:
+
+ * Django从小白到大牛
+ * GIS,Django,数据科学和农业
+
+
+
+
+[London Python 2017年六月聚会 - London, UK](https://www.meetup.com/LondonPython/events/240079951/)
+
+将会有一个演讲 —— 用Python构建一个医疗聊天机器人时学到的经验教训。
+
+
+
diff --git "a/Python Weekly/Python_Weekly_Issue_301\302\240.md" "b/Python Weekly/Python_Weekly_Issue_301\302\240.md"
new file mode 100644
index 0000000..9253985
--- /dev/null
+++ "b/Python Weekly/Python_Weekly_Issue_301\302\240.md"
@@ -0,0 +1,117 @@
+原文:[Python Weekly - Issue 301 ](http://eepurl.com/cUlDLb)
+
+---
+
+欢迎来到Python Weekly第301期。本周,让我们直入主题。
+
+# 来自赞助商
+
+[](http://www.amazon.com/gp/product/B0185367JQ/ref=as_li_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=B0185367JQ&linkCode=as2&tag=mymerch-20&linkId=OLIXWD4WZ5X6FFHD)
+
+嘿,Python粉,你想要表达你对**Python**的爱吗?那么,[点击这里](http://www.amazon.com/gp/product/B0185367JQ/ref=as_li_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=B0185367JQ&linkCode=as2&tag=mymerch-20&linkId=OLIXWD4WZ5X6FFHD),获取你的T恤,骄傲地穿上它吧。
+
+
+# 文章,教程和讲座
+
+[GreenPiThumb:一个树莓派园艺机器人](https://mtlynch.io/greenpithumb/)
+
+这是关于GreenPiThumb的故事:它是一个自动给室内植物浇水的园艺机器人,但有时也会杀死它们(室内植物)。
+
+[为了好玩,(零)利益将Python语法编译到x86-64程序集](http://benhoyt.com/writings/pyast64/)
+
+我使用Python内置的AST模型来解析Python语法的一部分,并将其转换到一个x86-64程序集里。它基本上就是一个工具,但是,它展示了出于自己的目的,使用AST模型来选择Python可爱的语法是多么的容易。
+
+[Django vs Flask:一个从业者的角度](https://www.git-pull.com/code_explorer/django-vs-flask.html)
+
+这个分析比较了2个Python框架,Flask和Django。它讨论了二者的特性,以及它们的技术哲学是如何影响软件开发人员的。这基于我自己使用它们的经历,以及花费在二者代码上的个人时间。
+
+[使用Python管理你的AWS容器基础架构](https://www.caktusgroup.com/blog/2017/06/28/managing-your-aws-container-infrastructure-with-python/)
+
+在这篇文章中,我将会讨论在AWS上托管Python/Django应用和管理服务器基础架构的另一种方法。特别是,我们将会看看一个名为troposphere的Python库,它允许你使用Python来描述AWS资源,并且生成CloudFormation模板来上传上传到AWS。我们还会看看我编译的一个troposphere样本集,作为这篇文章的的准备工作的一部分,我将其命名为(至少是现在)AWS容器基础知识。
+
+[将Snips和Home Assistant集成](https://medium.com/snips-ai/integrating-snips-with-home-assistant-314723645c77)
+
+在这篇文章中,我们将会展示如何使用Snips和Home Assistant来声控家庭电灯,无需网络连接。
+
+[Python中的链表](https://dbader.org/blog/python-linked-list)
+
+学习如何在Python中实现一个链表数据结构,只使用内置的数据类型和标准库。
+
+[我是如何使用Python和Twilio“黑入”我大学的注册系统的](https://www.twilio.com/blog/2017/06/hacked-my-universitys-registration-system-python-twilio.html)
+
+大学生都知道注册一门课程,但是只发现注册人员已满的痛苦。在我的大学,对于大多数的课程,我们甚至没有一个候补名单系统。我们不得不依靠每天多次登录然后检查网站。这看起来像是一个计算机可以做的事,因此,我开始使用一点点Python和Twilio API来自动化它。
+
+[如何使用Python 3.6中的静态类型检查](https://medium.com/@ageitgey/learn-how-to-use-static-type-checking-in-python-3-6-in-10-minutes-12c86d72677b)
+在编码时自动捕获许多常见错误。
+
+[使用隐写术的指纹文件](http://blog.fastforwardlabs.com/2017/06/23/fingerprinting-documents-with-steganography.html)
+
+隐写术是将消息隐藏到不被认为会出现的地方的做法。在很好地执行了隐写术的片段中,任何不是预期接收者的人都能看到消息,但是却完全无法意识到消息就在那儿。本文谈论关于使用基于文本的隐写术的指纹文件。
+
+[将Docker用于Flask应用部署(不仅仅是生产环境!)](http://www.patricksoftwareblog.com/using-docker-for-flask-application-development-not-just-production/)
+
+本文展示了如何配置Docker和Docker,来创建一个你可以在日常基础上轻松用来开发Flask应用的开发环境。
+
+[Python世界里的GraphQL](http://nafiulis.me/graphql-in-the-python-world.html)
+
+[使用深度学习来重构高分辨率音频](https://blog.insightdatascience.com/using-deep-learning-to-reconstruct-high-resolution-audio-29deee8b7ccd)
+
+[为什么Pinterest从Django移到Flask。](https://www.reddit.com/r/Python/comments/6jjqxx/why_did_pinterest_move_from_django_to_flask/)
+
+[如何在Python中执行性能微基准测试](https://www.peterbe.com/plog/how-to-do-performance-micro-benchmarks-in-python)
+
+[开始翻译Django应用](https://blog.braham.biz/getting-started-with-translating-a-django-application-d85ec34e505)
+
+
+# 好玩的项目,工具和库
+
+[Solid](https://github.com/100/Solid)
+
+一个用Python写的全面的无梯度优化框架。
+
+[python-nmap](http://xael.org/pages/python-nmap-en.html)
+
+python-nmap是一个有助于使用nmap端口扫描器的python库。它允许轻松操作nmap扫描结果,并且将会是想要自动化扫描任务和报告的系统管理员的完美工具。它还支持nmap脚本输出。
+
+[implicit](https://github.com/benfred/implicit)
+
+用于隐式数据集的快速Python协同过滤。
+
+[Object-Detector-App](https://github.com/datitran/Object-Detector-App)
+
+一个使用谷歌的TensorFlow对象检测API和OpenCV的实时对象识别应用。
+
+[pyethereum](https://github.com/ethereum/pyethereum)
+
+这是Ethereum项目的Python核心库。
+
+[netutils-linux](https://github.com/strizhechenko/netutils-linux)
+
+简化linux网络故障排除和性能调优的实用工具。
+
+[coremltools](https://pythonhosted.org/coremltools/)
+
+Core ML是一个苹果框架,它允许开发者简单轻松地机器学习(ML)模型到在苹果设备(包括iOS, watchOS, macOS和tvOS)上运行的应用。Core ML为包括深度学习网络(卷积和复现)、带有增强功能的树形组合以及广义线性模型的广泛的ML方法引入了一种公共文件格式 (.mlmodel)。使用这种格式的模型可以通过Xcode直接集成到应用中去。python包中的coremltools用于创建、检查和测试使用.mlmodel格式的模型。
+
+[lousy_bitcoins](https://github.com/joarleymoraes/lousy_bitcoins)
+
+尝试破解从弱密码生成的比特币私钥的实用工具。
+
+[GPkit](https://github.com/hoburg/gpkit)
+
+GPkit是一个Python包,用于定义和操作几何编程模型,抽象出后端求解器。
+
+[keras-vis](https://github.com/raghakot/keras-vis)
+
+keras-vis是用于可视化和调试你训练有素的keras神经网络模型的高级工具包。
+
+
+# 近期活动和网络研讨会
+
+[DjangoCon US 2017](https://ti.to/defna/djangocon-us-2017)
+
+DjangoCon US是社区为社区举办的关于Django网络框架的一个六天国际会议,每年在北美举行。你将会发现来自世界各地的人使用Django构建的各式各样的应用细节,更深入了解你已经熟知的概念,并且发掘使用它们的新方法,玩得开心!
+
+[DFW Pythoneers 2017年七月聚会 - Plano, TX](https://www.meetup.com/dfwpython/events/238602894/)
+
+本月安排的演讲是来自Kevin的“将Python代码发布到PyPI”。这个演讲将会涵盖如何使用最近的工具将一个Python版本放到PyPI上,以及最佳实践。
diff --git a/Python Weekly/Python_Weekly_Issue_302.md b/Python Weekly/Python_Weekly_Issue_302.md
new file mode 100644
index 0000000..aa23b2d
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_302.md
@@ -0,0 +1,142 @@
+原文:[Python Weekly - Issue 302](http://eepurl.com/cU-W3r)
+
+---
+
+欢迎来到Python Weekly第302期。本周,让我们直入主题。
+
+
+# 文章,教程和讲座
+
+[使用Linux,Python和树莓派,酿酒](https://opensource.com/article/17/7/brewing-beer-python-and-raspberry-pi)
+
+使用Python和树莓派,构建自制酿酒软件的便捷方法。
+
+[空间,时间和杂货](https://tech.instacart.com/space-time-and-groceries-a315925acf3a)
+
+在Instacart,我们提供了大量的杂货。到明年年底,80%的美国家庭将能够使用Instacart。我们的挑战是:准时完成每一次交货,并尽可能快地提供正确的货品。在一周的过程中,我们多次遍及美国的各个城市,并提供货品。我们是怎样在杂乱中井井有条的?在这篇文章的剩余部分,我们将首先介绍Instacart正在解决的物流问题,概述我们的系统架构,并描述我们收集的GPS数据。然后,我们将会通过浏览一系列的datashader可视化来得出结论。
+
+[了解pandas中的SettingwithCopyWarning](https://www.dataquest.io/blog/settingwithcopywarning/)
+
+SettingWithCopyWarning是人们在学习pandas时碰到的最常见障碍之一。快速进行网页搜索,你将会发现大量的来自程序员的Stack Overflow问题,GitHub问题和论坛帖子,他们绞尽脑汁试图搞明白在特定的情景下该警告的含义。对此有诸多挣扎并不令人感到奇怪;有许许多多的方式对pandas的数据结构进行索引,每个都有其特定的细微差别,甚至于pandas自身都不能保证对于两行代码的同种输出会看起来相同。本指南解释了为什么会生成这种警告,并且向你介绍如何解决它。它还介绍了内部细节,以便让你更好了解发生了什么,并且提供关于这个主题的一些历史信息,让你了解为什么它都以这种方式工作。
+
+[如何处理机器学习中的不平衡类](https://elitedatascience.com/imbalanced-classes)
+
+不平衡类使得“准确性”失去意义。这是机器学习(特别是分类)中令人惊讶的常见问题,发生于每个类中存在不恰当比例的观察的数据集中。标准的准确性不再可靠地评估性能,这使得建模训练更加棘手。在这个指南中,我们将探索5种处理不平衡类的有效方法。
+
+[PonyGE2:Python中的文法演进](https://arxiv.org/pdf/1703.08535.pdf)
+
+文法演进 (Grammatical Evolution, GE)是一个基于人口的演进算法,其中,一个形式化文法被用于基因型以表型映射过程。PonyGE2是Python中GE的一种开源实现,由UCD的自然计算研究和应用组开发。它旨在作为给GE新人的广告和起点,为学生和研究人员提供参考,为我们自己的实验提供快速原型介质,以及一个Python练习。除了为GE的表型映射提供特征基因型外,还提供一个搜索算法引擎。已经开发了一些关于如何使用和调整PonyGE2的示例问题和教程。
+
+[将你的Python函数作为REST API进行部署](https://datascience.ibm.com/blog/deploy-your-python-functions-as-a-rest-api/)
+
+本教程演示了如何使用Bluemix和Flask,将任意的Python函数作为API进行部署,并配有干净直观的Swagger API文档。
+
+[Django项目优化指南(第二部分)](http://dizballanze.com/django-project-optimization-part-2/)
+
+这是django项目优化系列的第二部分。这个部分将会关于使用数据库优化 (Django模型)。
+
+[Podcast.__init__ 第116集 - 和Glyph Lefkowitz聊聊Automat状态机](https://www.podcastinit.com/automat-state-machines-with-glyph-lefkowitz-episode-116/)
+
+珍贵的‘if’语句是程序流程和业务逻辑的基石,但有时,它会变得笨重,导致不可维护的软件。一种可以生成更干净更容易理解的代码的替代方案是状态机。本周,Glyph解释了Automat是怎样创建的,以及它是怎样被用于升级Twisted项目的部分的。
+
+[快速提示:使用进程池加速你的Python数据处理脚本](https://medium.com/@ageitgey/quick-tip-speed-up-your-python-data-processing-scripts-with-process-pools-cf275350163a)
+
+[使用daiquiri轻松进行Python日志记录](https://julien.danjou.info/blog/python-logging-easy-with-daiquiri)
+
+[Python中的市场篮子分析介绍](http://pbpython.com/market-basket-analysis.html)
+
+
+# 书籍
+
+[The Python 3 Standard Library by Example (Developer's Library)](http://amzn.to/2sO8egU)
+
+Python 3标准库包含了数百个用于与操作系统、解释器和网络交互的模块,所有这些模块都进行了广泛的测试,并准备好快速启动应用开发。现在,Python专家Doug Hellmann通过简洁的源代码和输出样例,介绍了Python 3.x库的每个主要领域。Hellmann的样例充分展示了每个特性,旨在轻松学习和重用。你将会找到处理文本、数据结构、算法、日期/时间、数学、文件系统、持久化、数据交换、压缩、归档、加密、进程/线程、网络、互联网功能、电子邮件、开发人员和语言工具、运行时、包等等的实用代码。每个部分完全涵盖一个模块,其中包含附加资源的链接,这使得本书成为理想的教程和参考资料。
+
+
+# 本周的Python工作
+
+[Beauhurst招聘全栈开发人员](http://jobs.pythonweekly.com/jobs/full-stack-developer-5/)
+
+Beauhurst的使命是寻找并追踪英国的每一个野心勃勃的高增长业务。这进展顺利,事实上,我们已经是这类信息位列第一的数据源。我们已经建立了一个聪明的在线平台,以便于与用户分享空前数量的信息。他们告诉我们,这是非常有价值的,但是,我们自己作为一个野心勃勃的公司,还没有完成此类的工作。如果你是一名无畏的全才,喜欢使用Django和Python,并且不介意踩坑,那么,这可能就是一份适合你的工作。
+
+
+# 好玩的项目,工具和库
+
+[Datashader](https://github.com/bokeh/datashader)
+
+Datashader是一个图形管道系统,用于快速灵活地创建大型数据集的有意义展示。Datashader将图像的创建分解为一系列允许在中间展示上进行的明确的步骤。该方法允许自动生成精确有效的可视化,并且也让数据科学家能够简单地以原则性的方法,关注特定的数据和感兴趣的关系。
+
+[CraftBeerPI](https://github.com/manuel83/craftbeerpi)
+
+基于树莓派的家庭酿造软件。
+
+[Dipy](https://github.com/nipy/dipy)
+
+DIPY是一个用于分析MR扩散成像的python工具箱。它实现了用于去燥、注册、重建、跟踪、聚类、可视化和MRI数据统计分析的广泛算法。
+
+[Iris](https://github.com/linkedin/iris)
+
+Iris是一个高度可配置的灵活服务,用于分页和信息传递。
+
+[SOTA-Py](https://github.com/mehrdadn/SOTA-Py)
+
+用于随机准时到达路由问题的离散时间Python解算器。
+
+[logzero](https://github.com/metachris/logzero)
+
+强大而有效的日志记录,适用于Python 2和3。
+
+[ssl_logger](https://github.com/google/ssl_logger)
+
+解密并记录进程的SSL流量。
+
+[kube-shell](https://github.com/cloudnativelabs/kube-shell)
+
+与Kubernetes CLI一起使用的集成shell。
+
+[daiquiri](https://github.com/jd/daiquiri)
+
+轻松设置基本的日志功能的Python库。
+
+[Susanoo](https://github.com/ant4g0nist/Susanoo)
+
+一个REST API安全测试框架。
+
+
+# 最新发布
+
+[Django问题修复版本:1.11.3](https://www.djangoproject.com/weblog/2017/jul/01/bugfix-release/)
+
+
+# 近期活动和网络研讨会
+
+[使用python的数据科学介绍 - New York, NY](https://www.meetup.com/NYDataScientists/events/240372745/)
+
+虽然了解数据科学绝不会更简单,但是有个指南来帮助你开始征程却是很有用的。在这个免费的实践工作室中,和galvanize一起,你会通过python编程语言,学到数据科学的基础知识。
+
+[Boulder Python 2017年七月聚会 - Boulder, CO](https://www.meetup.com/BoulderPython/events/239106652/)
+
+将会有以下演讲:
+
+ * Python字典的替代品
+ * 使用Stream的API来构建一个社交活动Feed
+ * 使用Flask和Docker开发微服务
+
+[Python展示之夜(Python Presentation Night) #53 - Minneapolis, MN](https://www.meetup.com/PyMNtos-Twin-Cities-Python-User-Group/events/239200309/)
+
+将会有以下演讲:
+
+ * 在无辜的Python项目中创建恶意后门
+ * 使用Python和OpenGL进行最新数学
+ * Jupyter notebook集群特性 (ipyparallel)
+
+[IndyPy 2017年七月每月聚会 - Indianapolis, IN](https://www.meetup.com/indypy/events/239881564/)
+
+本月,Jeff Licquia将会带来“在云端部署Python”。
+
+[Austin Python 2017年七月聚会 - Austin, TX](https://www.meetup.com/austinpython/events/239803285/)
+
+[PyAtl 2017年七月聚会 - Atlanta, GA](https://www.meetup.com/python-atlanta/events/237560610/)
+
+
+
diff --git a/Python Weekly/Python_Weekly_Issue_303.md b/Python Weekly/Python_Weekly_Issue_303.md
new file mode 100644
index 0000000..55993cc
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_303.md
@@ -0,0 +1,147 @@
+原文:[Python Weekly - Issue 303](http://eepurl.com/cVW859)
+
+---
+
+欢迎来到Python Weekly第303期。本周,让我们直入主题。
+
+# 来自赞助商
+[](https://goo.gl/wlxnDm)
+
+如果你尚未尝试使用Intel® Python发行版来进行NumPy/SciPy/scikit-learn计算,那么你正弃性能于不顾。看看这个[短视频](https://www.youtube.com/watch?v=rfg279VgtDY),了解有关Intel Python的所有信息,以及你可以如何简单切换到一个**更快的Python**来获得高性能。
+
+
+# 文章,教程和讲座
+
+[HBO的硅谷(Silicon Valley)是如何使用移动TensorFlow,Keras和React Native来构建"Not Hotdog"](https://hackernoon.com/how-hbos-silicon-valley-built-not-hotdog-with-mobile-tensorflow-keras-react-native-ef03260747f3)
+虽然用于滑稽剧中,但是,该应用是深度学习和边缘计算的一个亲切示例。所有的AI工作都是100%由用户设备驱动的,并且图像处理从来离不开他们的手机。这给用户提供了一种快速体验(无需到云的往返),离线可用性和更好的隐私。这也使我们能够免费运行该应用(即使是在百万用户的负载下),与传统的基于云的AI方法相比,可以节省大量成本。应用在出品中是由一个开发者在内部开发的,运行在单个笔记本电脑和附加的GPU上,使用手工制作的数据。在这方面,它可以提供现金有限的时间资源下,非技术公司、独立的开发者和业余爱好者之类的可以实现什么成果。本着这种精神,本文试图详细介绍涉及的步骤,以帮助其他人构建他们自己的引用。
+
+[通过Python使用Tesseract OCR](http://www.pyimagesearch.com/2017/07/10/using-tesseract-ocr-python/)
+
+在这篇文章中,我们将学习如何安装Tesseract OCR + Python“绑定”,然后编写一个简单的Python脚本来调用这些绑定。在教程结束后,你将能够转换一张图片中的文本为一个Python字符串。
+
+[FAT Python:Python优化中的下一章](https://hackernoon.com/fat-python-the-next-chapter-in-python-optimization-69dc974bcca2)
+
+Victor Stinner在2015年十月份启动了FAT Python项目,试图解决针对Python的“静态优化器”之前的尝试中出现的问题。Victor已经为CPython创建了一系列的改动 (Python增强建议,或者说是"PEPs"),一些示例优化和基准测试。我们将在本文中探索这3种级别。
+
+[Podcast.__init__ 第117集 - 与David Barroso和Mircea Ulinic聊聊NAPALM](https://www.podcastinit.com/napalm-with-david-barosso-and-mircea-ulinic-episode-117/)
+
+交换机和路由器是我们所依赖的互联网的隐形结构中缝线。管理硬件在传统上是一件非常手工的活,但是,NAPALM (带多供应商支持的网络自动化和可编程抽象层,Network Automation and Programmability Abstraction Layer with Multivendor support)正在帮助我们改变这一点。本周,David Barroso和Mircea Ulinic解释了怎样使用Python来确保你可以看到那些六类视频。
+
+[探索和清理有关科学家联盟(The Union of Concerned Scientists )的地球卫星(Earth Satellites)数据库](http://probcomp.csail.mit.edu/bayesdb/satellites-notebook.html)
+
+关科学家联盟维护了一个大约1000个地球卫星的数据库。对于大多数卫星,它包含运动学、材料、电气、政治、功能和经济特征,例如干质量、发射日期、轨道类型、操作员国籍和目的。这个iPython notebook描述了与该数据库的一个快照的一系列交互,使用BayesDB的bayeslite实现,使用Python的bayeslite客户端库。该快照包含了使用UCS数据定义的卫星群,以及该卫星群的生成概率模型星群。
+
+[实体提取和网络分析](http://brandonrose.org/ner2sna)
+
+在这个指南中,我将会带你领略使用实体提取和网络分析了解大量非结构化文本的策略。这些策略被积极用于法律电子发现和执法以及情报界。想象一下,你在FBI工作,而你在刚刚没收的笔记本电脑或服务器上发泄了大量的文件。你会怎么做?本指南提供了处理这种类型场景的方法。最后,你将会生成类似于上面的图,你可以用它来分析隐藏于数据集中的网络。
+
+[面向Channels 2.0](http://www.aeracode.org/2017/7/11/towards-channels-20/)
+
+[在Python中与一个长时间运行的子进程进行交互](http://eli.thegreenplace.net/2017/interacting-with-a-long-running-child-process-in-python/)
+
+[使用Python,Flask和Openpyxl读取Excel电子表格](https://www.twilio.com/blog/2017/06/reading-excel-with-python-flask-and-openpyxl.html)
+
+[神经网络的初学者介绍](https://www.youtube.com/playlist?list=PLxt59R_fWVzT9bDxA76AHm3ig0Gg9S3So)
+
+[Django迁移真正让我烦恼之处](https://cheesecakelabs.com/blog/really-annoys-django-migrations/)
+
+
+# 书籍
+
+[Learn Python 3 the Hard Way(笨办法学Python 3)](http://amzn.to/2t51LDy)
+
+在Learn Python 3 the Hard Way(笨办法学Python 3),你将通过52个精心制作的练习来学习Python。阅读。然后准确敲代码。(不要复制粘贴!)修复错误。看着程序运行。一旦这样做了,你将会学到计算机的工作方式;好的程序应该是什么样子的;以及如何阅读、编写和考虑代码。然后,Zed会在5小时以上的视频中教会你更多内容,其中,他会向你展示如何中断、修复和调试你的代码,这是实时的,因为他就在做这些练习。
+
+
+# 本周的Python工作
+
+[高级软件工程师 - Python 于Tenable Network Security](http://jobs.pythonweekly.com/jobs/sr-software-engineer-python-3/)
+
+Tenable正在寻找一名高级软件工程师。这个职位将涉及设计、部署和维护一个收集漏洞和威胁信息,并使用这些数据来为Tenable产品生成内容的自动化系统。
+
+
+# 好玩的项目,工具和库
+
+[crackcoin](https://github.com/DutchGraa/crackcoin)
+
+Python中非常基本的无区块链加密货币PoC。
+
+[honeyλ](https://github.com/0x4D31/honeyLambda)
+
+一个简单的无服务器应用,用于创建和监控URL {honey}令牌,基于AWS Lambda和Amazon API Gateway。
+
+[crocs](https://github.com/iogf/crocs)
+
+使用纯python类/函数语法来编写正则表达式,以及更好的测试。(为人类提供的正则表达式)。
+
+[SentEval](https://github.com/facebookresearch/SentEval)
+
+评估句子嵌入质量的python工具。
+
+[InferSent](https://github.com/facebookresearch/InferSent)
+
+InferSent是一种句子嵌入方法,它提供语义句子表示形式。它是在自然语言推理数据上训练的,并对许多不同的任务进行了良好的概况。
+
+[TensorForce](https://github.com/reinforceio/tensorforce)
+
+TensorForce是一个开源的强化学习库,专注于提供清晰的API,可读性和模块化,以在研究和实践中部署强化学习解决方案。
+
+[django-eraserhead](https://github.com/dizballanze/django-eraserhead)
+
+提供通过延迟未使用字段来优化数据库使用的建议。
+
+[Deep-learning-with-cats](https://github.com/AlexiaJM/Deep-learning-with-cats)
+
+猫咪酱深度学习 (^._.^)
+
+[Seashells](https://github.com/anishathalye/seashells)
+
+Seashells.io的官方客户端
+
+[RIDDLE](https://github.com/jisungk/RIDDLE)
+
+RIDDLE (使用深度学习从疾病历史中归责民族和种族信息) 是一个开源的Python2库,使用深度学习来追责匿名电子病历(EMR)中的民族和种族信息。RIDDLE提供以下功能 (1) 从临床特征构建模型以评估民族和种族 (2) 解释训练模型来描述具体的特征是如何助于预测的。
+
+[pg_chameleon](https://github.com/the4thdoctor/pg_chameleon)
+
+pg_chameleon是一个从MySQL复制到PostgreSQL的工具,兼容Python 2.7和Python 3.3+。该系统使用库mysql-replication来从MySQL拉取行镜像,将其转换成jsonb对象。一个pl/pgsql函数解码该jsonb对象,然后将更改重新执行到PostgreSQL数据库。
+
+[nbgrader](https://github.com/jupyter/nbgrader)
+
+一个分配和分级Jupyter notebook的系统。
+
+[CSVtoTable](https://github.com/vividvilla/csvtotable)
+
+将CSV文件转换成可搜索可排序的HTML表单的简单命令行实用程序。
+
+[django-cloudflare-push](https://github.com/skorokithakis/django-cloudflare-push)
+
+一个使用Cloudflare的HTTP/2 Push把静态媒体文件推送到客户端的中间件。
+
+
+# 最新发布
+
+[Python 3.6.2rc2](http://blog.python.org/2017/07/python-362rc2-is-now-available-for.html)
+
+[PyQt v5.9](https://www.riverbankcomputing.com/pipermail/pyqt/2017-July/039378.html )
+
+
+# 近期活动和网络研讨会
+
+[VanPy 2017年七月聚会 - Vancouver, BC](https://www.meetup.com/vanpyz/events/240647993/)
+
+将会有以下演讲:
+
+ * PEP 498:独白
+ * Python中的高保真web爬取
+ * 如丝般顺滑,使用Django和Websockets的交互式应用
+
+
+[Baltimore Python 2017年七月聚会 - Baltimore, MD](https://www.meetup.com/baltimore-python/events/239922797/)
+
+此次,我们将会有两个演讲,一个是关于俄罗斯宣传,一个是关于构建数据集。
+
+[PyHou 2017年七月聚会 - Houston, TX](https://www.meetup.com/python-14/events/240814237/)
+
+
+
diff --git a/Python Weekly/Python_Weekly_Issue_304.md b/Python Weekly/Python_Weekly_Issue_304.md
new file mode 100644
index 0000000..9b92b55
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_304.md
@@ -0,0 +1,161 @@
+原文:[Python Weekly - Issue 304](http://eepurl.com/cWJhTT)
+
+---
+
+欢迎来到Python周刊第304期。让我们直奔主题。
+
+# 来自赞助商
+[](https://www.datadoghq.com/dg/apm/ts-python-performance/?utm_source=Advertisement&utm_medium=Advertisement&utm_campaign=PythonWeekly-Tshirt&utm_content=Python)
+
+[Python应用性能监控](https://www.datadoghq.com/dg/apm/ts-python-performance/?utm_source=Advertisement&utm_medium=Advertisement&utm_campaign=PythonWeekly-Tshirt&utm_content=Python)
+
+实时Python度量的图表和告警,并与来自你的栈(包括AWS,Azure,MySQL,Postgres,Slack等)中200多个其他技术的数据相关联。
+
+
+# 新闻
+
+[介绍Python Classroom Lab](https://fedoramagazine.org/introducing-python-classroom-lab/)
+
+Fedora Lab是Fedora社区的成员策划和维护的精心挑选的一系列目标驱动的软件和内容。最新发布的Fedora 26包括了全新的Python Classroom Lab。新的Python Classroom Lab是一个现成的操作系统,供教师在他们的课堂上使用Fedora。这个Lab预先安装了一些用于教授Python的有用的工具。Python Classroomyou3种变体:一个基于GNOME桌面的实时镜像,一个Vagrant镜像和一个Docker容器。
+
+[Python软件基金会新闻:欢迎新的董事会成员](https://pyfound.blogspot.com/2017/07/welcome-new-board-members.html)
+
+
+# 文章,教程和讲座
+
+[神经机器翻译 (序列到序列) 教程](https://github.com/tensorflow/nmt)
+
+序列到序列 (seq2seq) 模型在诸如机器翻译、语音识别和文本摘要等各种任务中取得了巨大的成功。这个教程可以让读者充分了解seq2seq模型,并且展示了如何从头构建一个具有竞争力的seq2seq模型。我们专注于神经机器翻译(NMT)的任务,这是第一个具有空前成功的seq2seq模型测试平台。包含的代码轻量、高品质、可用于生产并且结合了最新的研究想法。
+
+[Episode #121:Python中的微服务](https://talkpython.fm/episodes/show/121/microservices-in-python)
+
+你有这样庞大的web应用或服务,它们难以管理,难以改变,并且难以扩展吗?或许将它们分解成微服务会给你带来更多发展以及扩展该应用的选择。本周,我们再次和Miguel Grinberg一起,讨论微服务的权衡以及优点。
+
+[Python中的解析:工具和库](https://tomassetti.me/parsing-in-python/)
+
+我们提供并比较了所有你可以在Python中用来解析语言的可能的替代方法。从库到解析器生成器,我们展示了所有的选项。
+
+[创建一个Jupyter notebook小挂件](https://kazuar.github.io/jupyter-widget-tutorial/)
+
+本文将会提供一个创建并运行Jupyter小挂件的手把手教程。
+
+[如何用Python检查一个文件是否存在](https://dbader.org/blog/python-check-if-file-exists)
+
+一个关于如何使用Python内置以及来自标准库的函数,确定文件(或者目录)是否存在的教程。
+
+[Podcast.__init__ 第118集 - 和Tim Abbott聊聊Zulip Chat](https://www.podcastinit.com/zulip-chat-with-tim-abbott-episode-118/)
+
+在现代工作环境中,电子邮件正被群聊挤出首选沟通方式的位置。所使用的大部分平台都是商业的,并且闭源,但有一个项目正在努力改变这种情况。Zulip是一个旨在重新定义高效团队的沟通方式的项目,它已日渐普及。本周,Tim Abbott分享了Zulip的开始故事,它的构建方式,以及为什么你会想要开始使用它。
+
+[使用TensorFlow,利用LSTM进行情绪分析](https://www.oreilly.com/learning/perform-sentiment-analysis-with-lstms-using-tensorflow)
+
+探究使用TensorFlow和LSTM网络进行情感分析的高效深入学习方法。
+
+[SciPy 2017视频集](https://www.youtube.com/playlist?list=PLYx7XA2nY5GfdAFycPLBdUDOUtdQIVoMf)
+
+SciPy 2017会议演讲和教程的视频集现在可以在线观看啦~
+
+[让我们一起来创造属于我们自己的加密数字货币](https://cranklin.wordpress.com/2017/07/11/lets-create-our-own-cryptocurrency/)
+
+[Django反模式:信号](https://lincolnloop.com/blog/django-anti-patterns-signals/)
+
+[Bash大抨击 —— 用Python替换Shell脚本](https://medium.com/capital-one-developers/bashing-the-bash-replacing-shell-scripts-with-python-d8d201bc0989)
+
+[认真严肃Docker化Django,uWSGI和Postgres](http://www.eidel.io/2017/07/10/dockerizing-django-uwsgi-postgres/)
+
+[你应该知道并使用的五个Python函数参数](https://blog.lerner.co.il/five-python-function-parameters-know-use/)
+
+
+# 书籍
+
+[The Blender Python API: Precision 3D Modeling and Add-on Development(Blender Python API:精确3D建模和附加开发)](http://amzn.to/2tgJTBL)
+
+Blender Python API是一个无与伦比的可编程可视化环境。其复杂的对象层次结构和庞大的文档,使得API的使用尤为困难。了解Blender Python API清楚地解释了其接口。你将变得熟悉数建模和渲染中的据结构和低层次的概念,并特别注意优化程序生成的模型。
+
+
+# 本周的Python工作
+
+[iHeartRadio招聘技术经理、产品和媒体提取](http://jobs.pythonweekly.com/jobs/engineering-manager-product-and-media-ingestion/)
+
+iHeartRadio正在为其内容和出版工程团队寻找一名有实际经验的软件开发经理。该团队为我们的iHeartRadio应用处理、丰富、转码、策划和最终发布数百万首歌曲、视频和播客。该团队在构建和支持我们的核心内容以及支撑着我们的产品和功能的基础的媒体平台方面发挥着至关重要的作用。如果你对管理一个身处快节奏的敏捷环境中的工程师团队、构建惊人产品以及接触数千万用户感兴趣,那么这就是一个极好的地方。
+
+[Lucasfilm招聘IS软件开发人员](http://jobs.pythonweekly.com/jobs/is-software-developer/)
+
+Lucasfilm正在为其积极灵活的Python和web开发者团队寻觅良人。信息系统(Information System,IS)的开发人员编写代码来存储和跟踪数据,以便其他部门能够有效地创造电影、电视节目和游戏。我们正在为我们在非正式环境茁壮成长的成熟的开发者团队寻找谦逊的专家,他支持这个团队,填补空白,使得开发人员能够自由地完成其工作。
+
+[VirTra招聘Jr. Python网络开发人员(合同工)](http://jobs.pythonweekly.com/jobs/jr-python-web-developer-contract/)
+
+寻找一名合格的python网络开发人员,要求1到3年的长期合同工作经验,他/她将为VirTra的下一代ERP系统开发定制应用。
+
+
+# 好玩的项目,工具和库
+
+[CatBoost](https://tech.yandex.com/catboost/)
+
+CatBoost是决策树库中最先进的开源梯度推进。它由Yandex的研究人员和工程师共同开发,是在公司内广泛用于排序任务、预测和提出建议的MatrixNet算法的后继者。它具有普遍性,可以被应用于广泛的领域和各种各样的问题。它提供了与scikit集成的Python接口。
+
+[PyREBox](https://github.com/Cisco-Talos/pyrebox)
+
+PyREBox是一个Python可脚本化逆向工程沙箱。它基于QEMU,其目标是通过从不同角度提供动态分析和调试功能,从而协助逆向工程。PyREBox允许用python创建简单的脚本来自动化任何类型的分析,从而检查正在运行中的QEMU VM,修改其内存或寄存器,并指示其执行。QEMU (作为一个完整的系统仿真器工作时) 模拟完整的系统 (CPU,内存,设备……)。通过使用VMI技术,它并不需要对客户机操作系统进行任何的修改,因为它可以在运行时从其内存中透明检索信息。
+
+[Lip Reading](https://github.com/astorfi/lip-reading-deeplearning)
+
+使用3D卷积神经网络的交叉视听识别。
+
+[Anyprint](https://github.com/kragniz/anyprint)
+
+在Python中使用任何语言的print语句。
+
+[Cranky Coin](https://github.com/cranklin/crankycoin)
+
+Cranky Coin是一个简单的区块链、加密货币、钱包实现。
+
+[Foolbox](https://github.com/bethgelab/foolbox)
+
+Foolbox是一个Python工具箱,用于创建愚弄神经网络的对抗样例。
+
+[Sukhoi](https://github.com/iogf/sukhoi)
+
+极简强大的网络爬虫。Sukhoi是建立在矿工的概念之上的,它类似于scrapy和它的网络蜘蛛。然而,在sukhoi中,矿工可以被置于像列表或者字典这样的结构中,以便为从页面中提取的数据构建类似于json的结构。
+
+[objection](https://github.com/sensepost/objection)
+
+objection是一个运行时移动探索工具包,由Frida驱动。它的目的是在不需要越狱或者移动设备拥有root权限的情况下,帮助评估移动应用及其安全状态。
+
+[mpl-scatter-density](https://github.com/astrofrog/mpl-scatter-density)
+
+Matplotlib的快速散点密度图。
+
+[ModernGL](https://github.com/cprogrammer1994/ModernGL)
+
+python的现代OpenGL绑定。
+
+[faker-schema](https://github.com/ueg1990/faker-schema)
+
+使用joke2k的伪造器和你自己的模式生成假数据。
+
+
+# 最新发布
+
+[Python 3.6.2](http://blog.python.org/2017/07/python-362-is-now-available.html)
+
+
+# 近期活动和网络研讨会
+
+[SoCal Python 2017年七月聚会 - Santa Monica, CA](https://www.meetup.com/socalpython/events/241659667/)
+
+将会有以下演讲
+
+ * 让我们使用MyPy来将类型带进python中
+ * 利用模式进行更智能的软件设计
+
+
+[SIMPL:一个Python/Django和ReactJS仿真框架 - Philadelphia, PA](https://www.meetup.com/phillypug/events/241114805/)
+
+Jane Eisenstein和Joseph Lee,Wharton计算学习实验室的主要开发人员,将会展示他们新的开源仿真框架,SIMPL。
+
+[视觉效果(VFX)行业中的Python - London](https://www.meetup.com/LondonPython/events/240288813/)
+
+借鉴CI/CD管道的类比,这个演讲将探索用来为工业级规模的视觉效果创造提供平台的基础设施。使用这个类比来塑造理解,我们将重点关注三个原语:存储,计算和网络,并且看看一些如何用Python帮助解决这些领域的问题的例子。
+
+
diff --git a/Python Weekly/Python_Weekly_Issue_305.md b/Python Weekly/Python_Weekly_Issue_305.md
new file mode 100644
index 0000000..9ee5440
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_305.md
@@ -0,0 +1,149 @@
+原文:[Python Weekly - Issue 305 ](http://eepurl.com/cXuHj5)
+
+---
+
+欢迎来到Python周刊第305期。让我们直奔主题。
+
+# 来自赞助商
+
+[](https://www.datadoghq.com/dg/apm/ts-python-performance/?utm_source=Advertisement&utm_medium=Advertisement&utm_campaign=PythonWeekly-Tshirt&utm_content=Python)
+
+[Python应用性能监控](https://www.datadoghq.com/dg/apm/ts-python-performance/?utm_source=Advertisement&utm_medium=Advertisement&utm_campaign=PythonWeekly-Tshirt&utm_content=Python)
+
+实时Python度量的图表和告警,并与来自你的栈(包括AWS,Azure,MySQL,Postgres,Slack等)中200多个其他技术的数据相关联。
+
+
+# 新闻
+
+[Florida PyCon征求提议](https://www.papercall.io/flpy)
+
+Florida PyCon是Florida第一个,也是唯一一个区域性Python语言会议。我们接受完整的演讲和快速演讲,演讲内容主要有三种:Web,数据科学和其他。我们也接受3小时的研讨会建议。
+
+
+# 文章,教程和讲座
+
+[机器学习管道的一种端到端实现](https://spandan-madan.github.io/DeepLearningProject/)
+
+从头开始向读者介绍完整的机器学习管道的深入机器学习教程。
+
+[使用机器学习来预测Airbnb上的家庭价值](https://medium.com/airbnb-engineering/using-machine-learning-to-predict-value-of-homes-on-airbnb-9272d3d4739d)
+
+最近,Airbnb的机器学习基础设施的进步大大降低了将新的机器学习模型部署到生产中的成本。例如,我们的ML Infra团队构建了一个通用功能库,允许用户在他们的模型中利用高质量、已审查的可重用功能。数据科学家已经开始将多种AutoML工具纳入其工作流程中,以加快模型选择和性能基线。此外,ML infra创建了一个新的框架,它会自动将Jupyter notebooks转换成Airflow管道。在这篇文章中,我将描述这些工具是如何在一起加快建模过程,从而降低LTV建模的一个具体用例(预测Airbnb上的家庭价值)的总体开发成本。
+
+[如何在Keras中,使用attention可视化你的反复神经网络](https://medium.com/datalogue/attention-in-keras-1892773a4f22)
+在这个教程中,我们将会在Keras中编写一个RNN,它可以将人类日期 ("November 5, 2016", "5th November 2016") 转换成一个标准格式 ("2016-11-05")。特别是,我们想要获得一些关于神经网络如何这样做的直觉。我们将会利用attention的概念来生成一个地图,来展示哪些输入字符在预测输出字符方面是重要的。
+
+[基于树的学习算法的实用指南](https://sadanand-singh.github.io/posts/treebasedmodels/)
+
+在这篇文章中,我们将看看决策树的数学细节(以及各种python示例),它的优缺点。我们将会发现,它们对于解释而言,是很简单,并且非常有用。但是,和最佳监督学习方法相比,它们通常毫无竞争力可言。为了克服决策树的各种缺点,我们将会看看各种概念(以及Python中真实世界的例子),例如Bootstrap聚合或者Bagging,和随机森林(Random Forests)。
+
+[网络爬取,以及不仅仅是网络爬取](https://rrighart.github.io/Webscraping/)
+
+在这篇文章中,我将简单讨论如何网络爬取数据。然而,并不止步于此。常常需要网络爬取之外的分析。文中展示了一些而外的步骤,例如捕获隐藏字符,合并不同的数据,总结统计信息和可视化等。
+
+[Twitter用户的地理位置](https://www.continuum.io/blog/developer-blog/galvanize-capstone-series-geolocation-twitter-users)
+
+使用Twitter的限制之一是,只有大约1%的推特的推特位置上带有地理标记,这会让这项工作困难得多得多。对于我的capstone项目,我选择使用那些带有地理标记的1%的推特来训练模型,从而预测那些推特上不带地理标记的推特用户的美国城市层面的位置。我就是这么做的。
+
+[Dash介绍](https://medium.com/@plotlygraphs/introducing-dash-5ecf7191b503)
+
+用纯Python创建Reactive Web应用。
+
+[如何为你的Flask Web应用添加托管监控](https://www.fullstackpython.com/blog/hosted-monitoring-flask-web-apps.html)
+
+在构建和部署你的应用后,你怎么知道它是否正常运行?监控你的Flask Web应用最快最简单的方式是,在许许多多个可用的奇特的托管监控工具中挑一个集成。在这篇文章中,我们将快速添加Rollbar监控来捕获错误,并且可视化我们的应用的正常运行。
+
+[从零开始Ethereum - 第一部分:Ping](https://ocalog.com/post/10/)
+
+这是从初学者角度全面实现Ethereum协议系列的第一篇。
+
+ * [第二部分:Ping一个Bootnode](https://ocalog.com/post/18/)
+
+
+[通过街头图像,衡量纽约市自行车道的质量](https://medium.com/a-r-g-o/classifying-nyc-bike-lane-quality-with-image-processing-and-computer-vision-in-python-76b13147ec2d)
+
+[PyData Seattle 2017视频集](https://www.youtube.com/playlist?list=PLGVZCDnMOq0rxoq9Nx0B4tqtr891vaCn7)
+
+[在Python中带测试重构:一个实际的例子](http://blog.thedigitalcatonline.com/blog/2017/07/21/refactoring-with-test-in-python-a-practical-example/)
+
+
+# 书籍
+
+[Python Microservices Development(Python微服务开发)](http://amzn.to/2uDDjGY)
+
+我们通常会将web应用部署到云端,并且我们的代码需要与许多第三方服务交互。构建这样的引用的一个有效的方式是通过微服务架构。但是,实际上,由于所有组件互相交互的复杂性,我们很难这样做。本书将会教你如何使用所有已被证明的最佳实践,并避免常见陷阱,从而克服这些问题,并创建作为小的标准单元构建的应用。这是一本实用书:你将会使用Python 3及其绚烂的工具生态系统来构建一切东东。你将会了解到TDD(测试驱动开发)的原理并应用它们。
+
+
+# 本周的Python工作
+
+[RenaultSport Racing招聘软件开发人员(空气动力学)](http://jobs.pythonweekly.com/jobs/software-developer-aerodynamics/)
+
+我们正在寻求改进我们现有的软件,并创造雄心勃勃的新工具来更有效地提取和了解来自风洞、轨道和CFD的结果。通过开发以直观和无缝的方式,比较跨此三种领域的汽车性能数据的能力来协助工程师。当选者将要生产干净、可维护、可扩展,并且满足或超过最终用户需求的具有高性能和高质量设计的代码。
+
+
+# 好玩的项目,工具和库
+
+[TeachCraft](https://teachcraft.net/)
+
+在Minecraft,我们都知道并热爱的多人世界中,学习写Python代码!敲你自己的超级大国,构建算法来构造大型建筑或城市,甚至造一个竞争性PVP环境来用你的代码魔法技能与你的伙伴对战!让学习代码变得有趣起来吧!
+
+[BinaryAlert](https://github.com/airbnb/binaryalert)
+
+无服务器、实时以及追溯恶意软件检测。
+
+[King Phisher](https://github.com/securestate/king-phisher)
+
+King Phisher是一个通过模拟真实世界网络钓鱼攻击来测试和提高用户意识的工具。它易于使用,并且具有灵活的架构,允许全面控制邮件和服务器内容。King Phisher的使用范围可以从简单的意识训练,到更复杂的场景(其中,用户意识到内容被用于收获凭证)。
+
+[Spotlight](https://github.com/maciejkula/spotlight)
+
+Spotlight使用PyTorch来构建深浅推荐模型。通过提供大量的用于损失函数 (各种逐点和成对排序损失)、表征 (浅因子分解表征,深度序列模型)的构建,以及用于获取(或生成)推荐数据集的实用程序,它旨在成为快速探索并原型化新的推荐模型的工具。
+
+[Scatteract](https://github.com/bloomberg/scatteract)
+
+Scatteract是一个自动从散点图中提取数据的框架。我们使用TensorBox1来检测相关对象(点、刻度线和刻度值),使用Tesseract来进行OCR,以及使用几个启发式提取图表坐标中的点。
+
+[Quart](https://gitlab.com/pgjones/quart)
+
+Quart是一个Python asyncio web微框架,具有和Flask相同的API。Quart应该提供了在Flask应用中使用Asyncio的极简步骤。
+
+[Brainforge](https://github.com/csxeba/brainforge)
+
+仅基于NumPy的神经网络库。
+
+[Requester](https://github.com/kylebebak/Requester)
+
+在requests库之上构建的强大现代的HTTP客户端。
+
+[graphql-compiler](https://github.com/kensho-technologies/graphql-compiler)
+
+将复杂的GraphQL查询转换为已优化的数据库查询。
+
+[federation](https://github.com/jaywink/federation)
+
+抽象诸如Diaspora这样的社交网络联盟协议的Python库。
+
+[yacron](https://github.com/gjcarneiro/yacron)
+
+现代Cron替代品,支持Docker。
+
+
+# 最新发布
+
+[PyCharm 2017.2](https://www.jetbrains.com/pycharm/whatsnew/)
+
+支持在Windows上编写Docker,SSH代理,Amazon Redshift和Azure数据库。
+
+[Python 3.5.4rc1和Python 3.4.7rc1](http://blog.python.org/2017/07/python-354rc1-and-python-347rc1-are-now.html)
+
+
+# 近期活动和网络研讨会
+
+[PyBay](https://pybay.com/pre-conference-workshops/)
+
+旧金山湾区Python会议宣布将于8月10日和11日举行为期四天半和三天全日会前研讨会。主题包括计算机科学基础、Python元编程、并发、机器学习和物联网。现在就获取入门票吧(还有余票哦~)!
+
+[DFW Pythoneer 2017年8月聚会 - Plano, TX](https://www.meetup.com/dfwpython/events/238602920/)
+
+Marcel将介绍“从零开始把函数作为服务使用”。这个演讲的目的在于提供关于FAS提供商和功能的相关信息。
+
diff --git a/Python Weekly/Python_Weekly_Issue_306.md b/Python Weekly/Python_Weekly_Issue_306.md
new file mode 100644
index 0000000..0081fe2
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_306.md
@@ -0,0 +1,143 @@
+原文:[Python Weekly - Issue 306](http://eepurl.com/cYjQj1)
+
+---
+
+欢迎来到Python周刊第306期。让我们直奔主题。
+
+# 来自赞助商
+[](https://www.datadoghq.com/dg/apm/ts-python-performance/?utm_source=Advertisement&utm_medium=Advertisement&utm_campaign=PythonWeekly-Tshirt&utm_content=Python)
+
+[Python应用性能监控](https://www.datadoghq.com/dg/apm/ts-python-performance/?utm_source=Advertisement&utm_medium=Advertisement&utm_campaign=PythonWeekly-Tshirt&utm_content=Python)
+
+实时Python度量的图表和告警,并与来自你的栈中150多个其他技术的数据相关联。
+
+
+# 文章,教程和讲座
+
+[一个可用于数百万图像文件的Keras多线程DataFrame生成器](https://techblog.appnexus.com/a-keras-multithreaded-dataframe-generator-for-millions-of-image-files-84d3027f6f43)
+
+AppNexus的数据科学团队使用深度学习来处理各种图像分类任务。有许多资源可以让你快速运行深度学习模型,但是它们很少有提供大规模运行的样例。为了帮助填补这个空白,本文以及随附的代码演示:如何使用Keras中用于深度学习(分类或回归)的高效内存生成器,利用数百GB或者更多的磁盘空间来处理数百万图像文件,以及如何使用相同的生成器来有效实现一个合并模型。
+
+[Python入口点解释](http://amir.rachum.com/blog/2017/07/28/python-entry-points/)
+
+在这篇文章中,我将要解释Python的入口点。大多数人都把入口点当成放在setup.py文件中以使得包可以在命令行被当成脚本使用的小小代码片段,但是它们的用途更广泛得多。我将要向你展示如何将入口点作为一个模块化插件架构使用。如果你想要让其他人编写在运行时与你现有的Python包交互或添加新功能的Python包,那么这是超级有用的。
+
+[16行Python代码,网络抓取总统谎言](http://www.dataschool.io/python-web-scraping-of-president-trumps-lies/)
+
+这是关于Python中的网络爬取的介绍性较差。只需要基本了解Python语言即可。在本教程结束之后,你将能够使用requests和Beautiful Soup库,从一个静态网络页面抓取数据,并使用pandas库,来将数据导出到结构化文本文件中。
+
+[利用OpenCV和Python,介绍计算机视觉](https://dzone.com/articles/introduction-to-computer-vision-with-opencv-and-py)
+
+只有利用AI的最新发展,才能使真正伟大的计算机视觉成为可能。以下是我们如何使用算法和计算机视觉来实现人物探测器的。
+
+[揭秘动态编程](https://medium.freecodecamp.org/demystifying-dynamic-programming-3efafb8d4296)
+
+如何构建和编写动态编程算法。
+
+[使用谷歌的卷积神经网络进行对象识别](https://medium.com/@williamkoehrsen/object-recognition-with-googles-convolutional-neural-networks-2fe65657ff90)
+
+使用谷歌的预训练初始CNN模型来对图像进行分类。
+
+[如何在一个Django项目中安装Amazon S3](https://simpleisbetterthancomplex.com/tutorial/2017/08/01/how-to-setup-amazon-s3-in-a-django-project.html)
+
+在本教程中,你将会学习如何使用Amazon S3服务来处理静态资源以及用户上传的文件,即媒体资源。
+
+[Pandas的Grouper和Agg函数解释](http://pbpython.com/pandas-grouper-agg.html)
+
+本文将介绍如何以及为什么你可能希望在你自己的数据上使用Grouper和agg函数。其中,我将介绍一些关于如何最有效地使用它们的技巧和提示。
+
+[使用TensorFlow检测伪钞](https://medium.com/tensorist/detecting-fake-banknotes-using-tensorflow-be21ffd2c478)
+
+这篇文章展示了如何使用TensorFlow来构建一个检测伪钞的人工神经网络。
+
+[利用深度学习,构建音乐推荐器](http://mattmurray.net/building-a-music-recommender-with-deep-learning/)
+
+[优化Pandas代码执行速度的初学者指南](https://engineering.upside.com/a-beginners-guide-to-optimizing-pandas-code-for-speed-c09ef2c6a4d6)
+
+[用Python,让山姆清理学城(GoT)10个小时](https://kazuar.github.io/got-remix/)
+
+[在Python中,使用Scrapy进行网络爬取(例子多多)](https://www.analyticsvidhya.com/blog/2017/07/web-scraping-in-python-using-scrapy/)
+
+
+# 书籍
+
+[Mastering Bitcoin: Programming the Open Blockchain(精通比特币:编程开放区块链)](http://amzn.to/2uShplT)
+
+精通比特币是是带你走过看似复杂的比特币世界的指南,为你提供参与互联网金融所需要的知识。无论你是在建立下一个杀手级应用,投资初创公司,还是单纯地对技术感到好奇,此修订和扩展的第二版提供了让你开始的基本细节。
+
+
+# 好玩的项目,工具和库
+
+[sandsifter](https://github.com/xoreaxeaxeax/sandsifter)
+
+sandsifter通过系统地生成机器码来搜索处理器的指令集,并监视异常执行情况,来审核x86处理器的隐藏指令和硬件错误。sandsifter已经发行了每个主要供应商的秘密处理器指令;反编译器、汇编器和仿真器中普遍存在的软件错误;企业管理程序的缺陷;以及x86芯片中的两性和安全关键硬件错误。
+
+[pywonderland](https://github.com/neozhaoliang/pywonderland)
+
+使用Python,渲染数学中漂亮的图像或者生动有趣的算法。
+
+[PlasmaPy](https://github.com/PlasmaPy/PlasmaPy)
+
+一个用于等离子体物理学的社区开发的Python包。
+
+[CryptoTracker](https://github.com/EthVentures/CryptoTracker)
+
+一个用于跟踪和可视化主要交换机上的加密价格变动的完整开源系统。
+
+[QuTiP](http://qutip.org/)
+
+QuTiP是用于模拟开放量子系统动力学的开源软件。QuTiP旨在为各种哈密尔顿算子提供用户友好的高效数值模拟,包括那些具有任意时间依赖性的数值模拟,通常在物理应用中广泛应用,如量子光学,俘获离子,超导电路和量子纳米机械谐振器。
+
+[LabelImg](https://github.com/tzutalin/labelImg)
+
+LabelImg是一个图形图像注释工具,在图像上标记对象边界边框。
+
+[P4wnP1](https://github.com/mame82/P4wnP1)
+
+P4wnP1是一个高度可定制的USB攻击平台,基于低成本的Raspberry Pi Zero或者Raspberry Pi Zero W。
+
+[jupyter-notify](https://github.com/shoprunner/jupyter-notify)
+
+关于单元格完成的浏览器通知的Jupyter Notebook魔法。
+
+[Photographic Image Synthesis](https://github.com/CQFIO/PhotographicImageSynthesis)
+
+这是用于从语义布局合成摄影图像的级联细化网络的Tensorflow实现。
+
+[EAST](https://github.com/argman/EAST)
+
+EAST文本检测器的tensorflow实现。
+
+[text_classification](https://github.com/brightmart/text_classification)
+
+各种文本分类模型,以及更多的深度学习。
+
+[SimGAN-Captcha](https://github.com/rickyhan/SimGAN-Captcha)
+
+无需手动标识训练集的情况下解决验证码问题。
+
+
+# 最新发布
+
+[Django问题修复版本:1.11.4](https://www.djangoproject.com/weblog/2017/aug/01/bugfix-release/)
+
+
+# 近期活动和网络研讨会
+
+[IndyPy 2017年8月每月聚会 - Indianapolis, IN](https://www.meetup.com/indypy/events/239881571/)
+
+将会有一个讲座,Coffeebot 3000 - 一个有关树莓派、Redis、LED和Mario的物联网故事。
+
+[PyAtl 2017年8月聚会 - Atlanta, GA](https://www.meetup.com/python-atlanta/events/237560613/)
+
+将会有以下讲座:
+
+ * Python工作市场总览
+ * Dunder方法:系列,第一集: __init__
+
+[Boulder Python 2017年8月聚会 - Boulder, CO](https://www.meetup.com/BoulderPython/events/239106655/)
+
+[Austin Python 2017年8月聚会 - Austin, TX](https://www.meetup.com/austinpython/events/239803300/)
+
+
+
diff --git a/Python Weekly/Python_Weekly_Issue_307.md b/Python Weekly/Python_Weekly_Issue_307.md
new file mode 100644
index 0000000..e68ceda
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_307.md
@@ -0,0 +1,116 @@
+原文:[Python Weekly - Issue 307](http://eepurl.com/cY9QSD)
+
+---
+
+欢迎来到Python周刊第307期。让我们直奔主题。
+
+# 来自赞助商
+[](https://goo.gl/wlxnDm)
+
+获取免费的[Linux上Intel已优化的TensorFlow wheel](https://software.intel.com/en-us/articles/intel-optimized-tensorflow-wheel-now-available?utm_source=10Aug2017%20image%20ad%20Python%20weekly&utm_medium=email&utm_campaign=Python%20Weekly%20newsletter),现在,可以通过pip安装啦。它利用最新的矢量指令,通过并行化实现高效核心利用,并且改进数据处理,以在Intel硬件平台上提供最佳性能。用Intel支撑深度学习!
+
+
+# 文章,教程和讲座
+
+[我是如何使用深度学习来训练一个如我一般的聊天机器人的 (Sorta)](https://adeshpande3.github.io/adeshpande3.github.io/How-I-Used-Deep-Learning-to-Train-a-Chatbot-to-Talk-Like-Me)
+
+在这篇文章中,我们将看看可以如何使用深度学习模型来在我过去的社交媒体对话上训练一个聊天机器人,以期让这个机器人以我的方式回复消息。
+
+[Python中的机器学习的搭乘指南](https://medium.freecodecamp.org/the-hitchhikers-guide-to-machine-learning-algorithms-in-python-bfad66adb378)
+
+具有实现代码、教学视频等。
+
+[为什么AI和机器学习研究者开始拥抱PyTorch](https://www.oreilly.com/ideas/why-ai-and-machine-learning-researchers-are-beginning-to-embrace-pytorch)
+
+O'Reilly Data Show播客:和Soumith Chintala聊聊构建一个有价值的Torch继任者(PyTorch),以及Facebook里的深度学习。
+
+[大数据和pandas](https://www.dataquest.io/blog/pandas-big-data/)
+
+在这篇文章中,我们将了解pandas的内存使用情况,如何通过简单选择列的适当数据类型,减少一个dataframe近90%的内存占用。
+
+[Python中的内存中空间半径查询实验](https://tech.minodes.com/experiments-with-in-memory-spatial-radius-queries-in-python-e40c9e66cf63)
+
+在给定数据集上高效地查询地理空间半径,是我们常常面临的问题。通常,我们是这样来处理这个问题的:旋转一个PostgreSQL数据库,并且安装PostGis(带其所有高效的空间索引功能)。然而,最近我们决定调查在内存中进行快速的地理空间半径查询的一些其他可能,以为我们实时的Postgres实例减负。在这篇文章中,我想分享调研过程中发现的三种替代方案,以及它们之间的对比。
+
+[使用TensorFlow的复杂目标强化学习](https://www.oreilly.com/ideas/reinforcement-learning-for-complex-goals-using-tensorflow)
+
+在这篇文章中,以及GitHub上提供的补充notebook,我将介绍机器学习中传统的强化学习范例,以及一个用于扩展强化学习,以实现随时间变化的复杂目标的新兴的范式。
+
+
+[从头开始为Spotify构建Sublime Text插件](https://www.youtube.com/playlist?list=PLJGDHERh23x_t5w5U3e_cWg5CLeCq8_7j)
+
+在本系列中,你将学到如何从头开始为Spotify构建Sublime Text插件。已经上传了第一部分,其余部分将每周发布。
+
+[在Python中,利用机器学习开发一个牌照识别系统](https://blog.devcenter.co/developing-a-license-plate-recognition-system-with-machine-learning-in-python-787833569ccd)
+
+在这篇教程中,我将介绍利用Python,使用机器学习的概念来开发车牌识别系统的基础知识。
+
+[极简django应用](https://simpleisbetterthancomplex.com/article/2017/08/07/a-minimal-django-application.html)
+
+在这篇文章中,我想要探索django的一些基本概念,建立一个极简web应用,来更深入了解django背后是怎么工作的。
+
+[Gynvael的第十一个使命(英文版):Python字节码逆向工程](https://chriswarrick.com/blog/2017/08/03/gynvaels-mission-11-en-python-bytecode-reverse-engineering/)
+
+[使用K-Means(K均值)来分析黑客攻击](https://medium.com/tensorist/using-k-means-to-analyse-hacking-attacks-81957c492c93)
+
+[使用Python和TensorFlow的Word2Vec单词嵌入教程](http://adventuresinmachinelearning.com/word2vec-tutorial-tensorflow/)
+
+[Pycon Australia 2017视频集](https://www.youtube.com/playlist?list=PLs4CJRBY5F1KsK4AbFaPsUT8X8iXc7X84)
+
+
+# 好玩的项目,工具和库
+
+[toasted-marshmallow](https://github.com/lyft/toasted-marshmallow)
+
+toasted-marshmallow为Marshmallow实现了一个加速转储对象10到25倍(取决于你的模式)的JIT。toasted-marshmallow在不需要牺牲性能的情况下,允许你使用Marshmallow提供的棒棒哒的API。
+
+[reportermate](https://pypi.python.org/pypi/reportermate)
+
+根据数据集,自动生成新闻报道和报告。
+
+[Tinychain](https://github.com/jamesob/tinychain)
+
+Tinychain是比特币的一个小小实现。它的目标是以牺牲高级功能、速度和任何真正实用性为代价,成为一种紧凑、可理解并可用的Nakamoto一致性算法的实现。
+
+[AsciiDots](https://github.com/aaronduino/asciidots)
+
+AsciiDots是基于ascii艺术(注,关于ASCII艺术,可以参考[wiki](https://zh.wikipedia.org/zh-hans/ASCII%E8%89%BA%E6%9C%AF))的深奥编程语言!在这门语言中,由句点(.)表示的点,沿着ascii艺术路径向下移动并接受操作。
+
+[Pygorithm](https://github.com/OmkarPathak/pygorithm)
+
+一个进行中的学习所有主要算法的Python模块!
+
+[covertutils](https://github.com/operatorequals/covertutils)
+
+一个用于远程代码执行代理编程的框架。
+
+[keras_weight_animator](https://github.com/brannondorsey/keras_weight_animator)
+
+将Keras的权重矩阵保存为短动画视频,以便更好地了解你的神经网络正在学习什么,以及如何学习。
+
+
+# 最新发布
+
+[PyTorch v0.2.0](https://github.com/pytorch/pytorch/releases/tag/v0.2.0)
+
+这里是PyTorch的下一个主要版本,恰好赶上ICML。我们引进了期待已久的功能,例如广播、高级索引、高阶渐变以及,分布式PyTorch。
+
+[Python 3.5.4](https://www.python.org/downloads/release/python-354/)
+
+Python 3.5.4是3.5的最后一个“问题修复”版本。Python 3.5分支现在进入了“仅限安全修复”模式;接下来,3.5分支中进行的改进将会是安全性修复。
+
+[Python 3.4.7](https://www.python.org/downloads/release/python-347/)
+
+Python 3.4现在进入了“仅限安全修复”模式,因此,Python 3.4.6和Python 3.4.7之间的唯一改进就是安全性修复。
+
+
+# 近期活动和网络研讨会
+
+[PyHou 2017年8月聚会 - Houston, TX](https://www.meetup.com/python-14/events/241073166/)
+
+[Baltimore Python 2017年8月聚会 - Baltimore, MD](https://www.meetup.com/baltimore-python/events/239922806/)
+
+
+
+
+
diff --git a/Python Weekly/Python_Weekly_Issue_308.md b/Python Weekly/Python_Weekly_Issue_308.md
new file mode 100644
index 0000000..f63997e
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_308.md
@@ -0,0 +1,131 @@
+原文:[Python Weekly - Issue 308](http://eepurl.com/cZXdKD)
+
+---
+
+欢迎来到Python周刊第308期。让我们直奔主题。
+
+# 来自赞助商
+
+[](https://www.datadoghq.com/dg/apm/ts-python-performance/?utm_source=Advertisement&utm_medium=Advertisement&utm_campaign=PythonWeekly-Tshirt&utm_content=Python)
+
+[Python应用跑得太慢了?](https://www.datadoghq.com/dg/apm/ts-python-performance/?utm_source=Advertisement&utm_medium=Advertisement&utm_campaign=PythonWeekly-Tshirt&utm_content=Python)
+
+用Datadog跟踪每一个请求吧!使用端到端跟踪,快速定位你的引用中的Python性能问题。
+
+
+# 新闻
+
+[支持良好合作关系:PyCharm和Django再次合作](https://www.djangoproject.com/weblog/2017/aug/15/support-dsf-2017/)
+
+去年 (2016) 六月,JetBrains PyCharm和Django软件基金会合作,大力推动了Django筹款。该活动取得了巨大的成功。我们一起为Django软件基金会筹集了5万美元!今天,我们希望可以复制那些成功。在两周的活动中,利用一个具有30%折扣的折扣码购买一个新的PyCharm专业版个人许可证,所筹款项将全部用于DSF的一般筹款活动和Django奖学金计划。
+
+[PEP 550 —— 执行上下文](https://www.python.org/dev/peps/pep-0550/)
+
+这个PEP提出了一种管理执行状态的新机制 —— 在其中执行函数、线程、生成器或者协程的逻辑环境。
+
+
+# 文章,教程和讲座
+
+[Dogs vs. Cats:在Python中,使用TensorFlow,进行深度学习的图像分类](https://sandipanweb.wordpress.com/2017/08/13/dogs-vs-cats-image-classification-with-deep-learning-using-tensorflow-in-python/)
+
+给定一组猫和狗的已标记图像,将学习到一个机器学习模型,接着,将用它来把一组新的图像分类为猫或狗。这个问题出现在Kaggle比赛中,而图像来自于这个kaggle数据集。
+
+[PyTorch vs TensorFlow —— 发现差异](https://medium.com/towards-data-science/pytorch-vs-tensorflow-spotting-the-difference-25c75777377b)
+
+这篇文章探讨了两个流行的深度学习框架(PyTorch和TensorFlow)之间的一些关键的相似点和差异。
+
+[在Python中解包嵌套数据结构](https://dbader.org/blog/python-nested-unpacking)
+
+一篇关于Python的高级数据解包功能的教程:如何使用“=”运算符和for循环来解压缩数据。
+
+[利用CoreML来使用预测模型](https://blog.pusher.com/using-prediction-models-coreml/)
+
+最近,Apple发布了Core ML,这是一个用于集成机器学习模型到任意iOS应用的新框架,从而可以在设备上进行预测,而无需使用任何外部服务。你可以使用来自诸如Caffe,Keras和scikit-learn这样的框架的已训练模型,并使用Apple提供的Python库coremltools,你可以将这些模型转换成CoreML格式。在这个教程中,我们将回顾一下使用scikit-learn创建一个预测模型,将其转换成Core ML格式,并把它集成到一个应用中的过程。
+
+[使用Python, GeoJSON和GeoPandas,进行地理空间分析的入门指南](https://www.twilio.com/blog/2017/08/geospatial-analysis-python-geojson-geopandas.html)
+
+在这篇教程中,我们将会使用Python来学习获取地理空间数据、处理以及可视化这些数据的基础知识。更具体地说,我们将进行一些美国的交互式可视化!
+
+[Django中的整洁架构](https://engineering.21buttons.com/clean-architecture-in-django-d326a4ab86a9)
+
+本文将试图解释应用整洁架构到Django Restful API上的方法。
+
+[Python多线程](https://www.youtube.com/playlist?list=PLGKQkV4guDKEv1DoK4LYdo2ZPLo6cyLbm)
+
+涵盖Python多线程的视频系列,目标人群是初学者。
+
+[我们是如何用一个简单的函数替换掉几十个测试装备的](https://medium.com/@hakibenita/how-we-replaced-dozens-of-test-fixtures-with-one-simple-function-bac73bfc277d)
+
+[TensorFlow排队和线程介绍](http://adventuresinmachinelearning.com/introduction-tensorflow-queuing/)
+
+[Django Service对象](http://mitchel.me/2017/django-service-objects/)
+
+[让我们删掉全局解释锁(GIL)](https://morepypy.blogspot.com/2017/08/lets-remove-global-interpreter-lock.html)
+
+
+# 本周的Python工作
+
+[Factmata招聘高级后端和数据科学工程师](http://jobs.pythonweekly.com/jobs/senior-backend-and-data-science-engineer/)
+
+你的工作是构建Factmata的后端。你必须每天都考虑我们要如何获得并分析大量的社交和传统媒体数据,如何扩大和建立面向客户的产品。你将成为创始软件和NLP工程师组成的平台团队的一员,来一起创建Factmata平台。这是一个加入位于NLP、ML、数据科学和软件工程前沿的早起团队的很好的机会。
+
+
+# 好玩的项目,工具和库
+
+[pysc2](https://github.com/deepmind/pysc2)
+
+PySC2是DeepMind的“星际争霸II学习环境(SC2LE)”的Python组件。它将暴雪娱乐公司的星际争霸II机器学习API作为一个Python RL环境公开。
+
+[DroidBot](https://github.com/honeynet/droidbot)
+
+一个Android轻量级测试输入生成器。类似于Monkey,单更具智能和酷酷的功能!
+
+[Torrench](https://github.com/kryptxy/torrench/)
+
+命令行torrent搜索工具。
+
+[Spaghetti](https://github.com/m4ll0k/Spaghetti)
+
+Spaghetti是一个web应用安全扫描工具。它被设计来发现各种默认和不安全的文件、配置和配置错误。
+
+[abootool](https://github.com/alephsecurity/abootool)
+
+基于静态知识的动态发现隐藏的fastboot OEM命令的简单工具。
+
+[mistletoe](https://github.com/miyuchina/mistletoe)
+
+mistletoe是一个纯Python的Markdown解析器,旨在快速、模块化和完全可定制。
+
+[nider](https://github.com/pythad/nider)
+
+添加文本到图像、纹理和不同背景中的Python包。
+
+[ChainerCV](https://github.com/chainer/chainercv)
+
+ChainerCV是一个使用Chainer,为计算机视觉任务训练和运行神经网络的工具集。
+
+[TemPy](https://github.com/Hrabal/TemPy)
+
+Python中快速的面向对象HTML模板!
+
+
+# 近期活动和网络研讨会
+
+[Boston Python Meetup August 2017 - Cambridge, MA](https://www.meetup.com/bostonpython/events/240446981/)
+
+将会有以下讲座:
+
+ * Virtualenv
+ * Items vs Attributes
+
+
+[San Diego Python 2017年8月聚会 - San Diego, CA](https://www.meetup.com/pythonsd/events/241076005/)
+
+将会有以下讲座:
+ * NumPy简介
+ * 一个快速(免费!)的请愿web应用,使用Django + Heroku
+
+
+
+
+
diff --git a/Python Weekly/Python_Weekly_Issue_309.md b/Python Weekly/Python_Weekly_Issue_309.md
new file mode 100644
index 0000000..dc11f5a
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_309.md
@@ -0,0 +1,96 @@
+原文:[Python Weekly - Issue 309](http://eepurl.com/c0L75j)
+
+---
+
+欢迎来到Python周刊第309期。让我们直奔主题。
+
+# 来自赞助商
+[](https://www.datadoghq.com/dg/apm/ts-python-performance/?utm_source=Advertisement&utm_medium=Advertisement&utm_campaign=PythonWeekly-Tshirt&utm_content=Python)
+
+[如何监控Python应用?](https://www.datadoghq.com/dg/apm/ts-python-performance/?utm_source=Advertisement&utm_medium=Advertisement&utm_campaign=PythonWeekly-Tshirt&utm_content=Python)
+
+实时Python度量的图表和告警,并与你的技术栈中200多个其他技术的数据相关联。
+
+
+# 文章,教程和讲座
+
+[使用Python,分析加密货币市场](https://blog.patricktriest.com/analyzing-cryptocurrencies-python/)
+
+本文的目标是提供使用Python进行加密货币分析的一个简单的介绍。我们将通过一个简单的Python脚本来检索、分析和可视化不同加密货币的数据。在此过程中,我们将会发现关于这些不稳定的市场行为怎样发现以及它们怎样演变的一种有趣趋势。
+
+[使用OpenCV进行深度学习](http://www.pyimagesearch.com/2017/08/21/deep-learning-with-opencv/)
+
+在这篇教程中,你将会学习到如何通过Caffe,TensorFlow和PyTorch,使用OpenCV和深度学习,利用预训练网络来分类图像。
+
+[对Enron数据集使用Python进行机器学习](https://medium.com/@williamkoehrsen/machine-learning-with-python-on-the-enron-dataset-8d71015be26d)
+
+使用Scikit-learn调查欺诈。
+
+[集成学习以改善机器学习结果](https://blog.statsbot.co/ensemble-learning-d1dcd548e936)
+
+集成方法如何工作:减少方差(bagging),偏差(boosting)和提高预测(stacking)。
+
+[生物进化 - 给无聊的书呆子的游戏](https://www.youtube.com/watch?v=2boI6R0Gx8A)
+
+关于使用Python3,PyGame和几个较小的库,来模拟智能进化的游戏。
+
+[Python生成器是神马?](https://dbader.org/blog/python-generators)
+
+生成器是Python的一个棘手的主题。通过本教程,你将立即实现从基于类的迭代器到使用生成器函数和“yield”语句的飞跃。
+
+[如何在Django中使用Celery和RabbitMQ](https://simpleisbetterthancomplex.com/tutorial/2017/08/20/how-to-use-celery-with-django.html)
+
+一篇解释如何安装和设置Celery + RabbitMQ来在Django应用中异步执行的初学者教程。
+
+[手把手教你配置一个Apache Spark独立集群,并与Jupyter集成](https://www.davidadrian.cc/posts/2017/08/how-to-spark-cluster/)
+
+[减少Python启动时间](https://lwn.net/SubscriberLink/730915/d6da49c8d92e815d/)
+
+[使用CFFI链接Python到C](https://tmarkovich.github.io//articles/2017-08/linking-python-to-c-with-cffi)
+
+[使用Python进行网络爬取:Scrapy,SQL,Matplotlib以获取网络数据洞察](http://www.scrapingauthority.com/python-scrapy-mysql-and-matplotlib-to-gain-web-data-insights)
+
+[收集、探索和预测Pocket上的流行的东东](https://tselai.com/pypocketexplore-collecting-exploring-predicting-pocket-items-machine-learning.html)
+
+
+# 好玩的项目,工具和库
+
+[mimesis](https://github.com/lk-geimfari/mimesis)
+
+Python库,帮助生成用于各种目的的不同语言的模拟数据。这些数据在软件开发和测试的各种阶段尤为有用。
+
+[AlgoCoin](https://github.com/theocean154/algo-coin)
+
+跨多个交易所的算法交易加密货币。
+
+[CageTheUnicorn](https://github.com/reswitched/CageTheUnicorn)
+
+用于任天堂Switch代码的调试/仿真环境。使用CTU,你可以运行整个Switch系统模块或者应用,跟踪并调试代码,测试漏洞,模糊测试等等。
+
+[robotbenchmark](https://robotbenchmark.net/)
+
+在线编程模拟机器人。将你的表现与最佳效果相比较。分享你的成就。
+
+[reactionrnn](https://github.com/minimaxir/reactionrnn)
+
+使用预训练的循环神经网络,预测对给定文本反应的Python模块 + R包。
+
+[pyheatmagic](https://github.com/csurfer/pyheatmagic)
+
+配置并将你的python代码作为热图查看的IPython魔术方法。
+
+[Cansina](https://github.com/deibit/cansina)
+
+Cansina是一个web内容发现应用。众所周知,web应用不会公开它们所有的资源或者公共链接,因此,发现这些资源的唯一一种方法就是请求这些资源,然后检查响应。Cansina的责任就是帮助你发起这些请求,过滤响应以分辨出它是现有资源,还是一个烦人或者伪装的404。
+
+[lehar](https://github.com/darxtrix/lehar/)
+
+使用相对排序可视化数据。
+
+[SMASH](https://github.com/ajbrock/SMASH)
+
+一项有效探索神经体系结构的实验技术。
+
+[flask-allows](https://github.com/justanr/flask-allows)
+
+Flask-Allows是一个受django-rest-framework的权限系统和rest_condition将简单的需求组合成更为复杂的系统的能力的Flask鉴权工具。
diff --git a/Python Weekly/Python_Weekly_Issue_310.md b/Python Weekly/Python_Weekly_Issue_310.md
new file mode 100644
index 0000000..6b8bec9
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_310.md
@@ -0,0 +1,129 @@
+原文:[Python Weekly - Issue 310](http://eepurl.com/c1Ba9f)
+
+---
+
+欢迎来到Python周刊第310期。让我们直奔主题
+
+# 来自赞助商
+[](http://www.amazon.com/gp/product/B0185367JQ/ref=as_li_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=B0185367JQ&linkCode=as2&tag=mymerch-20&linkId=OLIXWD4WZ5X6FFHD)
+
+嘿,Python粉,你想要表达你对**Python**的爱吗?那么,[点击这里](http://www.amazon.com/gp/product/B0185367JQ/ref=as_li_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=B0185367JQ&linkCode=as2&tag=mymerch-20&linkId=OLIXWD4WZ5X6FFHD),获取你的T恤,骄傲地穿上它吧。
+
+
+# 文章,教程和讲座
+
+[使用OpenCV和Python的信用卡OCR](http://www.pyimagesearch.com/2017/07/17/credit-card-ocr-with-opencv-and-python/)
+
+这篇文章演示了我们可以如何把模板匹配作为OCR的一种形式使用,以帮助我们创建一种自动识别信用卡,并从图像中提取相关的信用卡数字的解决方案。
+
+[使用Angular 4和Flask的用户验证](https://realpython.com/blog/python/user-authentication-with-angular-4-and-flask/)
+
+在这篇教程中,我们将演示如何使用Angular 4和Flask,设置基于令牌的身份验证 (通过JSON Web令牌)。
+
+[Python中的生成器表达式:简介](https://dbader.org/blog/python-generator-expressions)
+
+生成器表达式是列表推导和生成器的一种高性能的高效内存效率泛化。在这篇教程中,你将会学到如何从头使用它们。
+
+[TensorFlow中的高级API](https://medium.com/onfido-tech/higher-level-apis-in-tensorflow-67bfb602e6c0)
+
+如何使用估计器(Estimator),实验(Experiment)和数据集来训练模型。
+
+[为Python,使用Celery编排后台作业工作流](https://www.toptal.com/python/orchestrating-celery-python-background-jobs)
+
+如何将Python中的Celery作为工作流编排工具使用,附有从新手到高级的示例和示例代码。
+
+[如何使用Python来处理日期和时间](https://opensource.com/article/17/5/understanding-datetime-python-primer)
+
+通过此入门书,更好的理解Python中的datetime。
+
+[使用Python,构建一个子弹图](http://pbpython.com/bullet-graph.html)
+
+本文将介绍子弹图(又名项目符号图)有用的原因,以及如何使用python和matplotlib来构建一个。
+
+[使用Python进行声音模式识别](https://medium.com/@almeidneto/sound-pattern-recognition-with-python-9aff69edce5d)
+
+[使用OpenCV和Python的快速优化的“for”像素(pixel)循环](http://www.pyimagesearch.com/2017/08/28/fast-optimized-for-pixel-loops-with-opencv-and-python/)
+
+[Django迁移那些不要做的事情](http://blog.edx.org/django-migration-donts)
+
+[使用Python,下载并玩转加密货币历史数据](https://gmarti.gitlab.io/cryptocurrency/2017/08/25/download-cryptocoins-api-python.html)
+
+[使用Python监控道路流量](http://andrew.carterlunn.co.uk/programming/2017/08/24/monitoring-road-traffic-with-python.html)
+
+[5分钟GraphQL和Django教程](https://joaorafaelm.github.io/blog/graphql-and-django-in-5-minutes)
+
+
+# 书籍
+
+[Elegant SciPy: The Art of Scientific Python(优雅的SciPy:科学Python的艺术)](http://amzn.to/2wKLq7Q)
+
+如果你是一个使用Python编程的科学家,那么这个实用指南不仅仅教你SciPy的基础部分以及与之相关的库,还会让你体验你能用在实践中的漂亮、易读的代码。你将会学习如何编写优雅的代码,这些代码在执行手头上的任务时清晰、简洁,并且高效。
+
+
+# 好玩的项目,工具和库
+
+[Coinhub](https://github.com/kennethreitz/coinbin.org)
+
+一个用于加密货币信息的人性化API服务。
+
+[bookmark-archiver](https://github.com/pirate/bookmark-archiver)
+
+使用Pocket/Pinboard/Bookmarks,生成所有标记的网站的归档副本。输出可浏览html。
+
+[setup.py (for humans)](https://github.com/kennethreitz/setup.py)
+
+setup.py的人性化指南。
+
+[CrowdMaster](https://github.com/johnroper100/CrowdMaster)
+
+群众的人群模拟。
+
+[roamer](https://github.com/abaldwin88/roamer)
+
+Roamer将会把你最喜欢的文本编辑器变成一个轻量级的文件管理器。一起复制、剪切和粘贴文件,而无需离开你的终端窗口。
+
+[LaTeXiPy](https://github.com/masasin/latexipy)
+
+使用现有的基于Matplotlib的代码,为LaTeX生成漂亮的图。
+
+[beholder](https://github.com/chrisranderson/beholder)
+
+一个TensorBoard插件,用于训练网络时,通过视频可视化任意tensor。
+
+[lolviz](https://github.com/parrt/lolviz)
+
+用于列表的列表、列表、字典的简单Python数据结构可视化工具;主要用在Jupyter notebooks / 演示中。
+
+[vim_turing_machine](https://github.com/ealter/vim_turing_machine)
+
+仅用正常模式下的Vim命令的图灵机的实现。
+
+[selenium_extensions](https://github.com/pythad/selenium_extensions)
+
+让使用Selenium编写测试、机器人和爬虫容易得多的工具。
+
+[Pyfiddle](https://pyfiddle.io/)
+
+PyFiddle是一个免费的轻量级Python IDE,用于带一些漂亮功能地运行和分享Python脚本。
+
+[tensorflow-generative-model-collections](https://github.com/hwalsuklee/tensorflow-generative-model-collections)
+
+各种GAN和VAE的Tensorflow实现。
+
+[noto-emoji](https://github.com/googlei18n/noto-emoji)
+
+彩色和黑白Noto emoji字体,以及它们相关的工具。
+
+[Fashion-MNIST](https://github.com/zalandoresearch/fashion-mnist)
+
+一个类MNIST的时尚产品数据库
+
+
+# 近期活动和网络研讨会
+
+[DFW Pythoneers 2017年九月聚会 - Plano, TX](https://www.meetup.com/dfwpython/events/238602945/)
+
+Randall将会为我们介绍关于Home Assistant (hass.io)的基本安装技巧,与其协同使用的组件,以及物联网世界的概述。
+
+
+
diff --git a/Python Weekly/Python_Weekly_Issue_311.md b/Python Weekly/Python_Weekly_Issue_311.md
new file mode 100644
index 0000000..b486c77
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_311.md
@@ -0,0 +1,156 @@
+原文:[Python Weekly - Issue 311 ](http://eepurl.com/c2ulsL)
+
+---
+
+欢迎来到Python周刊第311期。让我们直奔主题。
+
+# 来自赞助商
+[](https://www.datadoghq.com/dg/apm/ts-python-performance/?utm_source=Advertisement&utm_medium=Advertisement&utm_campaign=PythonWeekly-Tshirt&utm_content=Python)
+
+[Python应用跑得太慢了?](https://www.datadoghq.com/dg/apm/ts-python-performance/?utm_source=Advertisement&utm_medium=Advertisement&utm_campaign=PythonWeekly-Tshirt&utm_content=Python)
+
+用Datadog追踪每一个请求吧!通过应用的端到端追踪,快速定位Python的性能问题。
+
+
+# 新闻
+
+[PEP 553 —— 内置的breakpoint()](https://www.python.org/dev/peps/pep-0553/)
+
+这个PEP建议添加一个新的内置函数breakpoint(),它在调用的时候会进入到Python的调试器中。另外,添加两个新的名字到sys模块中,从而使得调试器可插拔。
+
+
+# 文章,教程和讲座
+
+[机器学习基础:预测Airbnb价格](https://www.dataquest.io/blog/machine-learning-tutorial/)
+
+本教程旨在向你介绍机器学习的基本概念 —— 你将从头开始构建你的第一个预测模型,同时了解模型的工作原理。
+
+[Python令人难以置信的成长](https://stackoverflow.blog/2017/09/06/incredible-growth-python/)
+
+在这篇文章中,我们将会探讨在过去的五年中,Python编程语言非凡的增长,如高收入国家中的Stack Overflow流量所证。“最快增长”这个术语可能难以准确定义,但是我们认为,可以很坚定地说,Python成为增长最快的主要编程语言。
+
+[给神经网络初学者的另一个Keras教程](https://dashee87.github.io/data%20science/deep%20learning/python/another-keras-tutorial-for-neural-network-beginners/)
+
+本文希望为那些目标是在Keras中构建神经网络的初学者提出一些好的做法。
+
+[Python中使用serpy的JSON序列化](https://www.twilio.com/blog/2017/08/json-serialization-in-python-using-serpy.html)
+
+在这篇文章中,我们会使用一个名为serpy的小而美的库,来看看这种转换是如何工作的。接着,我们会集成这些代码到一个基于tornado的网络服务器,以快速演示如何编写返回JSON数据的API。
+
+[使用计算机视觉的强大车道搜索技术 —— Python和Open CV](https://medium.com/@vamsiramakrishnan/robust-lane-finding-using-python-open-cv-63eb66fa2616)
+
+本文介绍了用以处理来自摄像机的输入视频信号,跟踪并将车道统计信息投射到视频源上,并将其展示给用户的方法。它可以发现用于ADAS应用中的Lane Keep Assist、Lane Departure Warning系统中的潜在应用。
+
+[史上最快最简单的FPGA Blinker!](http://www.xess.com/static/media/pages/pygmyhdl/examples/1_blinker/fastest_easiest_FPGA_blinker_ever.html)
+
+FPGA通常使用诸如VHDL和Verilog的硬件描述语言(HDL)进行编程。有时,你可能需要学习这些语言,但并非今天!本教程使用MyHDL,这是一个基于Python编程语言的简单HDL。MyHDL不仅仅更易于学习,你还可以设计、模拟和编程一个FPGA,而无需离开浏览器中的Jupyter notebook。
+
+[Python是如何处理Unicode的](http://www.b-list.org/weblog/2017/sep/05/how-python-does-unicode/)
+
+[Django完全初学者指南 —— 第一部分](https://simpleisbetterthancomplex.com/series/2017/09/04/a-complete-beginners-guide-to-django-part-1.html)
+
+[数码化神奇宝贝](https://eev.ee/blog/2017/08/02/datamining-pokemon/)
+
+[使用Tensorflow (Fashion MNIST)分类衣物](https://medium.com/tensorist/classifying-fashion-articles-using-tensorflow-fashion-mnist-f22e8a04728a)
+
+[EuroSciPy 2017视频集](https://www.youtube.com/channel/UCruMegFU9dg2doEGOUaAWTg/videos)
+
+
+# 书籍
+
+[Mastering Python Networking(掌握Python网络)](http://amzn.to/2xbK1YN)
+
+成为用Python实现高级的网络相关任务的专家。
+
+
+# 本周的Python工作
+
+[Real Geeks招聘Python/Django开发者](http://jobs.pythonweekly.com/jobs/hawaii-pythondjango-developer/)
+
+Real Geeks正在寻找全职Python开发者。我们使用最新的开源技术,为房地产产业创建动态网站。
+
+
+# 好玩的项目,工具和库
+
+[wtfpython](https://github.com/satwikkansal/wtfPython)
+
+有趣、微妙和棘手的Python代码片段的集合。
+
+[Nili](https://github.com/niloofarkheirkhah/nili)
+
+Nili是一个用于网络扫描、中间人攻击、协议逆向工程和模糊测试的工具。
+
+[btcpy](https://github.com/chainside/btcpy)
+
+一个Python3兼容SegWit的库,它提供以简单的方式处理比特币(Bitcoin)数据结构的工具。
+
+[SpeechPy](https://github.com/astorfi/speechpy)
+
+一个用于语音处理和识别的库。
+
+[domain_analyzer](https://github.com/eldraco/domain_analyzer)
+
+域分析器是一个安全分析工具,它自动发现和报告给定域的信息。其主要目的是以无人值守的方式分析域。
+
+[CSrankings](https://github.com/emeryberger/CSrankings)
+
+一个根据计算机科学部门在选择性场所的研究成果,对这些部门进行排名的网络应用。
+
+[sdnpwn](https://github.com/smythtech/sdnpwn)
+
+sdnpwn是一个测试软件定义网络(SDN)的安全性的工具包和框架。
+
+[VoiceLoop](https://github.com/facebookresearch/loop)
+
+跨多个扬声器生成语音的方法。
+
+[Hatch](https://github.com/ofek/hatch)
+
+Python的一个现代工程、包和虚拟环境管理器。
+
+[pynesis](https://github.com/ticketea/pynesis)
+
+用于使用kinesis流的高级Python库。
+
+[console-logging](https://github.com/pshah123/console-logging)
+
+更好更漂亮的Python命令行日志记录 —— 带颜色!
+
+
+# 最新发布
+
+[Django安全版本发布:1.11.5和1.10.8](https://www.djangoproject.com/weblog/2017/sep/05/security-releases/)
+
+
+# 近期活动和网络研讨会
+
+[网络研讨会:使用PyCharm进行视觉测试](https://info.jetbrains.com/PyCharm-Webinar-September2017.html)
+
+Python中的测试通常要求你花费大量的时间查看终端中的点。但是,PyCharm可以让测试更容易更友好!当你配置PyCharm以运行你的Python测试的时候,你可以获得有用的视觉反馈、用以快速重新运行测试套件或者仅仅是失败用例的工具等等。
+
+[旧金山Python 2017年九月聚会 - San Francisco, CA](https://www.meetup.com/sfpython/events/242959856/)
+
+将会有以下演讲:
+
+ * 从TCL到Python之旅
+ * 缓存所有东东
+ * 么么哒,我扩展的Python
+
+
+[IndyPy 2017年九月每月聚会 - Indianapolis, IN](https://www.meetup.com/indypy/events/241996030/)
+
+将会有一个演讲,将物理世界连接到数字世界:或者,如何使用物联网和Python,轻松自动化讲话。
+
+[Python Presentation Night #54 - Minneapolis, MN](https://www.meetup.com/PyMNtos-Twin-Cities-Python-User-Group/events/241805012/)
+
+[Boulder Python 2017年九月聚会 - Boulder, CO](https://www.meetup.com/BoulderPython/events/239106657/)
+
+[Austin Python 2017年九月聚会 - Austin, TX](https://www.meetup.com/austinpython/events/240805211/)
+
+[PyAtl 2017年九月聚会 - Atlanta, GA](https://www.meetup.com/python-atlanta/events/238300275/)
+
+[Edmonton Python 2017年九月聚会 - Edmonton, AB ](https://www.meetup.com/startupedmonton/events/241316306/)
+
+
+
+
diff --git a/Python Weekly/Python_Weekly_Issue_312.md b/Python Weekly/Python_Weekly_Issue_312.md
new file mode 100644
index 0000000..3ff26a8
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_312.md
@@ -0,0 +1,167 @@
+原文:[Python Weekly - Issue 312](http://eepurl.com/c3nJ1P)
+
+---
+
+欢迎来到Python周刊第312期。本周干货满满。尽情享用吧!
+
+# 来自赞助商
+[](https://goo.gl/wlxnDm)
+
+Intel®数学核心库现在支持ActivePython啦,了解Intel性能库是如何加速ActivePython中的线性代数、FFT、算术和超越运算,以推动Python中更快的数值计算和机器学习。体验高性能Python吧!
+
+
+# 新闻
+
+[PEP 562 —— 模块__getattr__](https://www.python.org/dev/peps/pep-0562/)
+
+建议支持模块上定义的__getattr__函数,以提供模块属性访问的基本自定义。
+
+[PEP 563 —— 推迟注释评估](https://www.python.org/dev/peps/pep-0563/)
+
+PEP 3107引入了函数注释的语法,但是,故意让语义保持未定义。PEP 484为注释引入了标准的含义:类型提示(type hint)。PEP 526定义了变量注释,明确将它们与类型提示用例绑定。这个PEP提出了更改函数注释和变量注释,使其在函数定义时间不在进行评估。相反,它们以字符串的形式保存在__annotations__中。
+
+[PyTexas 2017征求提议](https://www.papercall.io/pytexas-2017)
+
+[PyCon Pune 2018征求提议](https://pyconpune.talkfunnel.com/2018/)
+
+
+# 文章,教程和讲座
+
+[如何在Python中生成FiveThirtyEight图表](https://www.dataquest.io/blog/making-538-plots/)
+
+如果你阅读数据科学文章,那么你或许已经刚好碰到FiveThirtyEight的内容了。当然,它们惊人的可视化给你留下了深深的印象。在这篇文章中,使用Python的matplotlib和pandas,我们会看到,复刻任意FiveThirtyEight (FTE)的可视化的核心部分是相当容易的。
+
+[使用Clarifai图像识别和Python,通过MMS实现Not Hot Dog](https://www.youtube.com/watch?v=MTVS2T8sjFA)
+
+让我们看看是否可以使用Clarifai来重新创建HBO的硅谷(Silicon Valley)创造的著名的Not Hot Dog应用。我们将会使用Twilio MMS来接收图像,并且通过Clarifai的食物模型来进行热狗检测。
+
+[使用Python中的NetworkX进行图优化简介](https://www.datacamp.com/community/tutorials/networkx-python-graph-tutorial)
+
+通过本教程,你将解决图论中一个称为中国邮差问题的已建立问题。我们首先将浏览图的基本构建块(点、边、路径等等),并且使用Python中的NetworkX库,解决真实图形(国家公园的路径网络)上的这个问题。我们将会关注核心概念和实现。
+
+[使用深度学习进行心脏病诊断](https://blog.insightdatascience.com/heart-disease-diagnosis-with-deep-learning-c2d92c27e730)
+
+最先进的结果,参数减少了60倍。
+
+[可扩展机器学习(第一部分)](https://tomaugspurger.github.io/scalable-ml-01.html)
+
+Anaconda对扩展科学Python生态系统颇感兴趣。我当前的关注点在于核外、并行和分布式机器学习。本系列将会介绍这些概念,探索我们今天所提供的东西,并且跟踪社区的努力以突破边界。本文将会关注在可以装入内存的数据集上进行训练,但是必须在比内存还要大的数据集上进行预测的场景。
+
+[使用Python、BlockExplorer和Webhose.io跟踪比特币](http://www.automatingosint.com/blog/2017/09/follow-the-bitcoin-with-python-blockexplorer-and-webhose-io/)
+
+在这篇文章中,我们将会开发一个工具,通过它,我们可以针对特定的比特币地址,可视化它的流出流入交易流,然后使用Webhose.io执行中级的暗网搜索,来看看我们是否可以找到该比特币钱包提到过的隐藏服务。
+
+[利用机器学习助力产品分类](https://techblog.commercetools.com/boosting-product-categorization-with-machine-learning-ad4dbd30b0e8)
+
+为了改善产品分类的过程,我们从机器学习寻找帮助。我们的目标是开发一个机器学习系统,对于一个给定的产品,它可以预测该产品最适宜哪个目录,从而使得整个过程更容易、更快并且更少出错。在这篇文章中,我将会介绍一路上我们面对的问题,以及我们是怎样决定解决方法的。
+
+[使用Python和Kali linux进行伦理黑客攻击](https://www.youtube.com/watch?v=Q6W-mZY4Wuo)
+
+[使用Python,对Trump的推特进行情感分析](https://dev.to/rodolfoferro/sentiment-analysis-on-trumpss-tweets-using-python-)
+
+[创建分布式Web爬虫的故事](https://benbernardblog.com/the-tale-of-creating-a-distributed-web-crawler/)
+
+[使用Django REST框架的简单嵌套API](http://blog.apptension.com/2017/09/13/simple-nested-api-using-django-rest-framework/)
+
+[多元化:玩转Django中的客户数据](https://www.vinta.com.br/blog/2017/multitenancy-juggling-customer-data-django/)
+
+[Django的完全初学者指南 —— 第二部分](https://simpleisbetterthancomplex.com/series/2017/09/11/a-complete-beginners-guide-to-django-part-2.html)
+
+[通过Python,自动化web分析](https://rrighart.github.io/GA/)
+
+[使用自然语言处理,识别诗歌的编写日期](https://medium.com/towards-data-science/identifying-when-poems-were-written-with-natural-language-processing-a40ff286bcd)
+
+
+# 书籍
+
+[Test-Driven Development with Python: Obey the Testing Goat: Using Django, Selenium, and JavaScript(测试驱动开发)](http://amzn.to/2jq5Opu)
+
+通过带你从头到尾开发一个真实的web应用,本动手指南的第二版演示了使用Python进行测试驱动开发(TDD)的实际优势。你将会学习如何在构建应用的每个部分之前,编写和运行测试,然后开发开发通过这些测试所需的最少量代码。结果呢?就是可以用的干净代码啦。
+
+
+# 本周的Python工作
+
+[Pole Star招聘高级软件工程师(Python)](http://jobs.pythonweekly.com/jobs/senior-software-engineer-python-2/)
+
+在Pole Star,我们需要一个具有丰富Python商业经验的软件工程师,来构建和维护我们基于Python的核心平台和服务。你将会在一个人才济济的跨学科团队中工作(该团队具有强大的创新文化),并且帮助我们实现高影响力的作品。
+
+[Bromium招聘高级Python开发者](http://jobs.pythonweekly.com/jobs/senior-python-developer-8/)
+
+你将会加入到一个团队中,来设计、工程化、测试和大规模部署需要处理数百万客户端的系统,这些都是用于Bromium客户和我们的OEM合作伙伴。你将会让用户能够汇总配置和管理信息,以及查看和分析Bromium软件隔离的任何攻击。
+
+
+# 好玩的项目,工具和库
+
+[Cryptowatch](https://github.com/alexanderepstein/cryptowatch)
+
+加密货币价格和账户余额监控。
+
+[AllenNLP](http://allennlp.org/)
+
+一个开源NLP研究库,基于PyTorch。
+
+[DeepMoji](https://github.com/bfelbo/DeepMoji)
+
+使用在emojis上预先训练的深度学习模型的最先进的情感分析。
+
+[jupyter4kids](https://github.com/mikkokotila/jupyter4kids)
+
+帮助教授孩子编程原理、Python和数学的notebooks系列。
+
+[TensorLy](https://github.com/tensorly/tensorly)
+
+TensorLy是一个用于tensor学习的快速简单的Python库。它构建于NumPy、SciPy和MXNet之上,允许快速直接的tensor分解、tensor学习和tensor代数。
+
+[Monique Dashboards](https://github.com/monique-dashboards/monique)
+
+Monique Dashboards是一个用来创造面板和监控应用的创新Python库。它具有用来创建自定义面板的完整的功能性示例Web和HTTP API应用:Monique Web和Monique API。
+
+[ONNX](https://github.com/onnx/onnx)
+
+开放神经网络交换 (ONNX)是迈向开放生态系统的第一步,它使得AI开发者可以随着其项目的演进,选择合适的工具。ONNX为AI模块提供了一个开源格式。它定义了一个可扩展的计算图模型,以及内置运算符和标准数据类型的定义。
+
+[anaGo](https://github.com/hironsan/anago)
+
+anaGo是一个使用Keras的用于序列标记的最先进的库。anaGo可以为多种语言执行命名实体识别 (NER),词性标记 (POS标记),语义角色标记 (SRL)等等。
+
+[TensorFlow Agents](https://github.com/tensorflow/agents)
+
+这个项目提供了用于强化学习的优化基础设施。它扩展了OpenAI gym接口道多个并行环境,并且允许在TensorFlow中实现代理,以及执行批量计算。
+
+[SRU](https://github.com/taolei87/sru)
+
+SRU是一个周期性单元,可以比cuDNN LSTM快十倍,而且在许多任务中测试都没有精确度损失。
+
+[django-gamification](https://github.com/mattjegan/django-gamification)
+
+Django Gamification旨在填补Django包生态的游戏空缺。在当前的状态下,Django Gamification提供了一组可用于实现应用中游戏化功能的模块。这些包含了用来跟踪包括徽章、点和可解锁的所有游戏化相关对象的集中接口。
+
+[GulpIO](https://github.com/TwentyBN/GulpIO)
+
+给大容量深度学习数据的二进制存储格式。
+
+
+# 最新发布
+
+[Sublime Text 3.0](https://www.sublimetext.com/blog/articles/sublime-text-3-point-0)
+
+
+# 近期活动和网络研讨会
+
+[我暑假都做了啥 - Cambridge, MA](https://www.meetup.com/bostonpython/events/241561681/)
+
+这个夏天,我开始了一个新的项目。我碰到了一些在其他项目中也会碰到的问题。这个演讲是对其中一些问题进行的漫漫探索。随着演讲的推进,我会解释Python设施,并且提到棘手的工程问题:什么是大O表示法,以及它会如何影响代码速度?Python的特殊方法是什么?如何选择数据表示?如何处理其他人的代码?如何管理不确定性?以及最重要的是:如何克服自己的恐惧和疑虑。
+
+[LA Django 2017年九月聚会 - Los Angeles, CA](https://www.meetup.com/ladjango/events/242340191/)
+
+将会有以下演讲:
+
+ * Python和Django中更好的调试
+ * Django中的干净架构
+
+
+[PyHou 2017年九月聚会 - Houston, TX](https://www.meetup.com/python-14/events/242580962/)
+
+本周的主题将会是pipenv。它是啥,如何使用它,以及一些额外的细节。
+
+
diff --git a/Python Weekly/Python_Weekly_Issue_313.md b/Python Weekly/Python_Weekly_Issue_313.md
new file mode 100644
index 0000000..c64494c
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_313.md
@@ -0,0 +1,128 @@
+原文:[Python Weekly - Issue 313 ](http://eepurl.com/c4gzuj)
+
+---
+
+欢迎来到Python周刊第313期。让我们直奔主题。
+
+[](https://click.linksynergy.com/link?id=x9UsEHf2tls&offerid=323085.1094964&type=2&murl=https%3A%2F%2Fwww.udemy.com%2Fdjango-python%2F)
+
+[使用Django REST框架,构建你自己的后端REST API](https://click.linksynergy.com/link?id=x9UsEHf2tls&offerid=323085.1094964&type=2&murl=https%3A%2F%2Fwww.udemy.com%2Fdjango-python%2F)
+
+最终,在这门完整的课程中,创建App + 全功能用户数据库,以构建一个REST API
+
+
+# 新闻
+
+[开发者不知不觉使用进入到官方Python存储库的“恶意”模块](https://arstechnica.com/information-technology/2017/09/devs-unknowingly-use-malicious-modules-put-into-official-python-repository/)
+
+
+# 文章,教程和讲座
+
+[Django小萌新指南 - 第3部分](https://simpleisbetterthancomplex.com/series/2017/09/18/a-complete-beginners-guide-to-django-part-3.html)
+
+在这篇教程中,我们将会深入两个基础概念:URL和表单。在此过程中,我们将会探讨一些其他的概念,例如创建可重用模板和安装第三方库。我们还会编写大量的单元测试。
+
+
+[Python 3.7新特性](https://docs.python.org/3.7/whatsnew/3.7.html)
+
+本文解释了与3.6相比,Python 3.7的新特性。
+
+[CPython内部:任意精度的整型实现](http://rushter.com/blog/python-integer-implementation/)
+
+你有没有注意到,Python支持任意大小的整型?这里是关于此的快速浏览。
+
+[Django项目优化指南(第三部分)](http://dizballanze.com/django-project-optimization-part-3/)
+
+在本指南的这个部分,我将会实现高性能的最有价值的方法 —— 缓存。缓存的本质是将最常用的数据放置到快速存储中,从而加速对它们的访问。重要的是,了解快速存储(比方说,内存)常常容量是有限的。因此,我们应该只将其用于常常使用的数据。
+
+[利用Keras和Tensorflow,检测恶意请求](https://medium.com/slalom-engineering/detecting-malicious-requests-with-keras-tensorflow-5d5db06b4f28)
+
+[通过Python Telegram机器人,远程控制macOS](https://medium.com/@half0wl/remote-controlling-macos-with-a-python-telegram-bot-d656d2e00226)
+
+[分析一百万个robots.txt文件](https://intoli.com/blog/analyzing-one-million-robots-txt-files/)
+
+[AI实战:识别Python中的部分语言](https://medium.com/@brianray_7981/ai-in-practice-identifying-parts-of-speech-in-python-8a690c7a1a08)
+
+[使用深度学习和OpenCV,进行实时对象检测](http://www.pyimagesearch.com/2017/09/18/real-time-object-detection-with-deep-learning-and-opencv/)
+
+[预测波兰房屋价格](https://laurenshareshian.github.io/Predicting-Portland-Home-Prices/)
+
+[Python中的日志记录指南](https://opensource.com/article/17/9/python-logging)
+
+
+# 好玩的项目,工具和库
+
+[face_classification](https://github.com/oarriaga/face_classification)
+
+实时面部检测和表情/性别分类,使用fer2013/imdb数据集和一个keras CNN模型与openCV。
+
+[Evennia](http://www.evennia.com/)
+
+Evennia是一个用来构建多玩家在线文本游戏(MUD, MUX, MUSH, MUCK和其他MU*)的开源库和工具集。使用普通的Python模块,轻松设计你自己完整的游戏。除了支持传统客户端,Evennia还自带了一个游戏web客户端和web服务器。
+
+[EvalAI](https://github.com/Cloud-CV/EvalAI)
+
+EvalAI是一个开源web应用,帮助研究人员、学生和数据科学家创建、协作和参与全球各地的AI挑战。
+
+[Pysimplechain](https://github.com/EricAlcaide/pysimplechain/)
+
+少于200行代码的区块链Python实现。
+
+[GeoPySpark](https://github.com/locationtech-labs/geopyspark)
+
+GeoPySpark是GeoTrellis的一个Python绑定库,GeoTrellis是一个在分布式环境中处理地理空间数据的Scala库。通过使用PySpark,GeoPySpark可以为GeoTrellis框架提供接口。
+
+[GeoNotebook](https://github.com/OpenGeoscience/geonotebook)
+
+一个用于地理空间可视化和分析的Jupyter notebook扩展。
+
+[SQLCell](https://github.com/tmthyjames/SQLCell)
+
+SQLCell是一个用于Jupyter Notebook的魔术函数,它执行原始、并行以及参数化的SQL查询,并且能够接受Python值作为参数,将输出值赋给Python变量,同时运行Python代码。还有更多功能。
+
+[fairseq-py](https://github.com/facebookresearch/fairseq-py)
+
+Facebook AI研究序列到序列工具包,用Python编写。
+
+[style2paints](https://github.com/lllyasviel/style2paints)
+
+根据一种给定的特定颜色样式,这个AI可以在草图上绘制颜色。
+
+[forseti-security](https://github.com/GoogleCloudPlatform/forseti-security)
+
+一个用来提高Google Cloud Platform环境安全的社区驱动的开源工具集合。
+
+[face-alignment](https://github.com/1adrianb/face-alignment)
+
+2D和3D人脸对齐库,使用pytorch。
+
+
+# 最新发布
+
+[Jupyter Notebook 5.1.0](https://groups.google.com/forum/#!topic/jupyter/jZu-4fhF1ss)
+
+这是一个次要版本,主要包括问题修复和改进,显著增加了i18n (国际化和本地化) 支持。
+
+
+# 近期活动和网络研讨会
+
+[San Francisco Django 2017年九月聚会 - San Francisco, CA](https://www.meetup.com/The-San-Francisco-Django-Meetup-Group/events/243442618/)
+
+将会有以下演讲:
+
+ * Django ORM谓词
+ * Anatomy of Open edX: 一个服务超过2.2千万用户的现代在线学习平台。
+
+
+[Elasticsearch和Elastic Stack - Philadelphia, PA](https://www.meetup.com/phillypug/events/243460298/)
+
+在本演讲中国年,我们会涵盖Elastic Stack的关键领域:健壮的Elastic Stack概述,搜索性能调整,事件弹性,深入Elasticsearch和Logstash,深入一些代码,Elastic Stack 5.1 Xpack讨论和一个Ansibile化的ELK栈演示。
+
+[使用Python,为自然语言处理进行文字嵌入 - London](https://www.meetup.com/LondonPython/events/240263693/)
+
+文字嵌入是自然语言处理 (NLP) 算法中的一类,其中,把文字映射到低维空间中的向量。在过去的几年中,由于这些技术驱使了许多NLP应用(例如文本分类、语义分析或者机器翻译)的重大进展,关于文字嵌入的兴趣一直在上升。我们还会探索一些让我们实现当代NLP应用的Python工具,然后我们会总结一些实际考虑。
+
+[San Diego Python 2017年九月聚会 - San Diego, CA](https://www.meetup.com/pythonsd/events/241076010/)
+
+[Python Web开发者之夜 #34 - Minneapolis, MN](https://www.meetup.com/PyMNtos-Twin-Cities-Python-User-Group/events/243472959/)
+
diff --git a/Python Weekly/Python_Weekly_Issue_314.md b/Python Weekly/Python_Weekly_Issue_314.md
new file mode 100644
index 0000000..869c79f
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_314.md
@@ -0,0 +1,140 @@
+原文:[Python Weekly - Issue 314](http://eepurl.com/c49W4r)
+
+---
+
+欢迎来到Python周刊第314期。本周干货满满。尽情享用吧!
+
+# 来自赞助商
+
+[](https://www.datadoghq.com/dg/apm/ts-python-performance/?utm_source=Advertisement&utm_medium=Advertisement&utm_campaign=PythonWeekly-Tshirt&utm_content=Python)
+
+[如何监控Python应用?](https://www.datadoghq.com/dg/apm/ts-python-performance/?utm_source=Advertisement&utm_medium=Advertisement&utm_campaign=PythonWeekly-Tshirt&utm_content=Python)
+
+实时Python度量的图表和告警,并与你的技术栈中200多个其他技术的数据相关联。
+
+
+# 新闻
+
+[PyCon 2018开始征求提议!](https://pycon.blogspot.com/2017/09/pycon-2018-call-for-proposals-is-open.html)
+
+
+# 文章,教程和讲座
+
+[通过做一个来学习区块链](https://hackernoon.com/learn-blockchains-by-building-one-117428612f46)
+
+学习区块链的工作方式的最快速的方法是构建一个。
+
+[Django完全初学者指南 - 第四部分](https://simpleisbetterthancomplex.com/series/2017/09/25/a-complete-beginners-guide-to-django-part-4.html)
+
+这个教程将会涵盖所有关于Django的鉴权系统的东西。我们将会实现完整的过程:注册、登录、注销、密码重置和密码更改。
+
+[为了最大收益,进行动态酒店房间定价](https://www.datascience.com/resources/notebooks/dynamically-pricing-hotel-rooms-with-data-science)
+
+对于连锁酒店,用于定价房间的策略可能会造就或者破坏生意。当与静态定价相比较的时候,动态房间定价(基于可用性、需求和其他因素来调整价格)可以带来更多利润。但是,如何确定最优价格,并且确保相应实施?
+
+[使用Python Pivot表,探索Happiness数据](https://www.dataquest.io/blog/pandas-pivot-table/)
+
+学习如何使用pandas pivot表,通过切片、过滤和分组数据,快速提取有用的洞察。
+
+[Apache Arrow以及“我讨厌pandas的十个理由”](http://wesmckinney.com/blog/apache-arrow-pandas-internals/)
+
+这篇文章是在最近的时间里和可预见的未来中,关于Apache Arrow,pandas,pandas2,和我工作的一般轨迹的许许多多即将到来的文章的第一篇。在这篇文章中国年,我希望尽我可能地简洁地解释pandas内部的一些关键问题,以及我是如何为它们稳步规划和构建务实的工作解决方案的。
+
+[布隆过滤器(Bloom Filter) 的困惑](https://sagi.io/2017/07/bloom-filters-for-the-perplexed/)
+
+布隆过滤器(Bloom Filter) 是每个工程师的工具箱中必备的那些简单易用的工程工具之一。它是一种空间高效的概率数据结构,代表一个集合,允许你测试其中是否包含某个元素。有很多种布隆过滤器(Bloom Filter) 。我们将涵盖标准的布隆过滤器,因为它是其他布隆过滤器的基础,并且还可以作为更高级的概率集合成员数据结构(例如Cuckoo过滤器)的一个很好的介绍。
+
+[如何创建Django数据迁移](https://simpleisbetterthancomplex.com/tutorial/2017/09/26/how-to-create-django-data-migrations.html)
+
+数据迁移(Data Migration)是改变数据库中数据连同数据模式的一种非常便利的方式。它们像常规的模式迁移一样。Django跟踪依赖关系,执行顺序以及应用是否已经应用了给定的数据迁移。数据迁移的常用用例是当我们需要引入不可为空的新字段的时候。或者当我们正在创建一个用来存储某些东西的缓存数量的新字段的时候,因此,我们可以创建这个新的字段,然后添加初始计数。在这篇文章中,我们将会探索一个简单的样例,你可以非常轻松地根据需要进行扩展和修改。
+
+[如何使用Python,Google Maps和GeoJSON,构建一个Boba Tea Shop查找器](https://www.twilio.com/blog/2017/09/boba-python-google-maps-geojson.html)
+
+[Python中的快速地理空间分析](http://matthewrocklin.com/blog/work/2017/09/21/accelerating-geopandas-1)
+
+[Cython 0.27有啥新东西?](http://blog.behnel.de/posts/whats-new-in-cython-027.html)
+
+[使用Python NLTK的NLP教程(简单示例)](https://likegeeks.com/nlp-tutorial-using-python-nltk/)
+
+[Python中的命令行参数](http://stackabuse.com/command-line-arguments-in-python/)
+
+[Python中的gRPC简化指南](https://engineering.semantics3.com/a-simplified-guide-to-grpc-in-python-6c4e25f0c506)
+
+[使用Scrapy来构建你自己的数据集](https://medium.com/towards-data-science/using-scrapy-to-build-your-own-dataset-64ea2d7d4673)
+
+
+# 书籍
+
+[Text Analytics with Python: A Practical Real-World Approach to Gaining Actionable Insights from your Data(使用python进行文本分析:从数据中获取可操作洞察的实用现实世界方法)](http://amzn.to/2fsnXyh)
+
+使用python进行文本分析教你自然语言处理和文本分析相关的技术,而你将会获得知晓哪些技术最适合用于解决特定的问题的技能。对于每项技术和算法,你将会概要了解如何使用,以及详细了解其数学概念,并实现它们以解决你自己的问题。
+
+
+# 好玩的项目,工具和库
+
+[pix2code](https://github.com/tonybeltramelli/pix2code)
+
+从图形用户界面截图生成代码。
+
+[europilot](https://github.com/marshq/europilot)
+
+使用python,控制Euro Truck模拟器2,来开发自驾算法的工具包。
+
+[Serpent.AI](http://serpent.ai/)
+
+Serpent.AI是一个简单但是强大的新颖框架,协助开发者创建游戏代理。将你拥有的任何视频游戏变成一个成熟的实验沙箱环境,所有这些都使用熟悉的Python代码。该框架的存在理由首先是为机器学习和AI研究提供有价值的工具。它也证明作为一个业务爱好使用时非常有趣的!
+
+[timy](https://github.com/ramonsaraiva/timy)
+
+python代码时间极简化度量。
+
+[qtmodern](https://github.com/gmarull/qtmodern)
+
+PyQt/PySide小部件现代用户界面。
+
+[Redsails](https://github.com/BeetleChunks/redsails)
+
+RedSails是一个基于Python的后利用项目,旨在绕过基于主机的安全监控和日志记录。
+
+[Fabrik](https://github.com/Cloud-CV/Fabrik)
+
+Fabrik是一个在线协作平台,通过一个简单的拖放界面,来构建、可视化和训练深度学习模型。它允许研究人员使用一个WEB界面来协同开发和调试模型,这个界面支持导入、编辑和导出在广泛流行的框架(例如Caffe,Keras和TensorFlow)上编写的网络。
+
+[BLEAH](https://github.com/evilsocket/bleah)
+
+一个“智能”设备破解BLE扫描仪。
+
+[gaps](https://github.com/nemanja-m/gaps)
+
+一个基于遗传算法的七巧板求解器。
+
+[golem](https://github.com/lucianopuccio/golem)
+
+一个简单但是强大的自动化测试框架。
+
+[Achoo](https://github.com/tmthyjames/Achoo)
+
+Achoo使用树莓派,根据任何一天的天气、花粉和空气质量数据来预测我的儿子是否会需要他的吸入器。如果对于某一天的预测高于指定的阈值,那么树莓派将会发邮件给他的校园护士和我自己,提示校园护士我的儿子可能会需要抢先治疗。
+
+[sshpry](https://github.com/nopernik/sshpry)
+
+无缝监视SSH会话,就像此会话是你的TTY一样。
+
+[crypto-signal](https://github.com/AbenezerMamo/crypto-signal)
+
+这个脚本将会自动化Bittrex上的比特币对技术分析。当发生突发事件时,它还会通过你的桌面、SMS和控制台,试图向你预警。
+
+
+# 最新发布
+
+[Django 2.0 alpha 1](https://www.djangoproject.com/weblog/2017/sep/22/django-20-alpha-1-released/)
+
+[PyInstaller 3.3](https://github.com/pyinstaller/pyinstaller/releases/tag/v3.3)
+
+[PyDev 6.0](https://pydev.blogspot.co.uk/2017/09/pydev-60-pip-conda-isort-and-subword.html)
+
+[Zope 4.0b1](https://blog.gocept.com/2017/09/22/earl-zope-ii-is-dead-long-live-earl-zope/)
+
+
+
+
diff --git a/Python Weekly/Python_Weekly_Issue_315.md b/Python Weekly/Python_Weekly_Issue_315.md
new file mode 100644
index 0000000..0207391
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_315.md
@@ -0,0 +1,138 @@
+原文:[Python Weekly - Issue 315](http://eepurl.com/c53fhP)
+
+---
+
+欢迎来到Python周刊第315期。让我们直奔主题。
+
+# 来自赞助商
+
+[](https://www.datadoghq.com/dg/apm/ts-python-performance/?utm_source=Advertisement&utm_medium=Advertisement&utm_campaign=PythonWeekly-Tshirt&utm_content=Python)
+
+[Python应用跑得太慢?](https://www.datadoghq.com/dg/apm/ts-python-performance/?utm_source=Advertisement&utm_medium=Advertisement&utm_campaign=PythonWeekly-Tshirt&utm_content=Python)
+
+用Datadog跟踪每一个请求!使用应用端到端跟踪,快速定位Python性能问题。
+
+# 新闻
+
+[Anaconda和Microsoft联手打造python助力的机器学习](https://www.anaconda.com/blog/news/anaconda-and-microsoft-partner-to-deliver-python-powered-machine-learning/)
+
+Microsoft将Anaconda嵌入到Azure Machine Learning,Visual Studio和SQL Server中,加速数据科学探索和生产部署。
+
+# 文章,教程和讲座
+
+[爱丽丝梦游Python项目之地](https://veekaybee.github.io/2017/09/26/python-packaging/)
+
+让我们通过构建一个有趣的迷你文字编辑器,来领略构造和打包一个python项目的复杂性。
+
+[Django完全初学者指南 —— 第五部分](https://simpleisbetterthancomplex.com/series/2017/10/02/a-complete-beginners-guide-to-django-part-5.html)
+
+在这个部分中,我们将会学习更多关于如何防止未授权用户访问视图,以及如何在视图和表单中访问授权用户。我们还会实现主题文章列表视图和回复视图。最后,我们还会探索Django ORM的一些特性,并且简略介绍迁移。
+
+[使用Anaconda项目封装你的仓库](https://blog.daftcode.pl/how-to-wrap-your-repo-with-anaconda-project-c7ee2259ec42)
+
+我们使用一个带有一个有点费解的README的仓库,使用Anaconda项目来将其封装起来,处理纪录,并且发布我们的项目从而让其他人下载,并且可以单命令运行而无需担心依赖。
+
+[使用Python和Flask,开发RESTful API](https://auth0.com/blog/developing-restful-apis-with-python-and-flask/)
+
+通过这篇文章,我们将会使用Flask和Python来开发一个RESTful API。首先,我们会创建一个返回静态数据(字典)的端点。接着,我们会创建一个具有两个特性的类和一些端点来插入和检索这些类的实例。最后,将会看一看如何在Docker container上运行API。
+
+[实时生成照片逼真纹理的最新方法](https://jobs.zalando.com/tech/blog/a-state-of-the-art-method-for-generating-photo-realistic-textures-in-real-time/index.html)
+
+这篇文章概述了使用Zalando Research的机器学习进行图像生成的最新工作。特别是,通过使用深度神经网络来实时生成照片级逼真高分辨率纹理图案,来展示我们在此领域是有多先进。
+
+[你可能不知道的关于Numba的七件事](https://devblogs.nvidia.com/parallelforall/seven-things-numba/)
+
+在这篇文章中,我想要更深入了解并展示在GPU上使用Numba时往往会忽略掉几个方面。我将会快速扫过一些话题,但是我会提供链接,以便进一步阅读。
+
+[在黑暗之下,部署功能](https://medium.com/build-smarter/deploying-features-under-cover-of-darkness-f112ce444bba)
+
+我们是如何秘密且安全地构建、测试和发布功能的。
+
+[Python中的字典](http://www.sharats.me/posts/the-python-dictionary/)
+
+[使用python的股票价格动态](https://jtsulliv.github.io/stock-movement/)
+
+[手把手教你用Python构建逻辑回归](https://medium.com/towards-data-science/building-a-logistic-regression-in-python-step-by-step-becd4d56c9c8)
+
+[通过python,使用机器学习中的分类数据](https://blog.myyellowroad.com/using-categorical-data-in-machine-learning-with-python-from-dummy-variables-to-deep-category-66041f734512)
+
+[EuroPython 2017视频集](https://www.youtube.com/watch?v=OCHrzW-R3QI&list=PL8uoeex94UhG9QAoRICebFpeKK2M0Herh)
+
+[使用Python,为docker进行动态nginx配置](http://www.ameyalokare.com/docker/2017/09/27/nginx-dynamic-upstreams-docker.html)
+
+# 书籍
+
+[Python Testing with pytest: Simple, Rapid, Effective, and Scalable(使用pytest进行python测试:简单、快速、高效和可扩展)](http://amzn.to/2y0wAtG)
+
+减少python代码测试的工作量,但恰好表达其意,恰好优雅十足,恰好可读性强。pytest测试框架帮助你快速编写测试用例,并使它们可读可维护 —— 无需样板代码。使用一个强大但简单的固定模型,使用pytest,为应用、包和库编写可扩展到复杂的功能性测试就如编写小型测试一样简单。本书为你娓娓道来。
+
+
+# 本周python工作
+
+[Energy Solutions招聘高级软件工程师](http://jobs.pythonweekly.com/jobs/senior-software-engineer-12/)
+
+Energy Solutions正在寻找一名经验丰富的高级软件工程师,加入到清洁能源领域中的web应用开发者团队中。我们的软件工程师人员协同设计和构建最佳的数据和软件系统,以支持加州和美国的可再生能源部署和政策制定。成为这名角色,你将会领导我们有才华的全栈软件工程师团队,与动态团队环境中的开发者、项目经理、设计师、客户和内容专家密切合作。
+
+[Mercurytide招聘python web开发人员](http://jobs.pythonweekly.com/jobs/python-web-developer-all-levels/)
+
+给那些有才华的开发者加入我们的团队的机会来啦。你将填补关键的技术角色,为激动人心的新项目提供范围和方向,实现强大的规范解决方案,并确保与其他团队成员共同实现卓越的最佳实践。
+
+
+# 好玩的项目,工具和库
+
+[rasa_core](https://github.com/RasaHQ/rasa_core)
+
+Rasa Core是一个构建会话软件的框架,包含:Messenger上的聊天机器人,Slack机器人,Alexa Skills,Google Home Actions等等。Rasa Core的主要目的是帮你构建具有大量前后关系的上下文分层对话。
+
+[halo](https://github.com/ManrajGrover/halo)
+
+Python中漂亮的终端下拉框。
+
+[Notifiers](https://github.com/liiight/notifiers)
+
+有一个应用或者服务,然后你想要让你的用户能够使用他们的提供商提供的通知?你无需自己实现ש解决方案,或者使用单独的提供商库。这是一个用于所有通知提供商的一站式商店,带有统一并且简单的接口。
+
+[VHostScan](https://github.com/codingo/VHostScan)
+
+一个执行反向查找的虚拟主机扫描器,可以和枢纽工具一起使用,检测所有场景、别名和动态默认页面。
+
+[hpat](https://github.com/IntelLabs/hpat)
+
+一个基于编译器的python大数据框架。
+
+[PySyft](https://github.com/OpenMined/PySyft)
+
+加密深度学习库。
+
+[mitogen](https://github.com/dw/mitogen)
+
+用python编写分布式自我复制程序的库。
+
+[PortableCellNetwork](https://github.com/MBRO95/PortableCellNetwork)
+
+利用一个树莓派和一个Nuand BladeRF,来生成你自己的便携式本地小区网络。
+
+[ambient-shipping](https://github.com/marcdacosta/ambient-shipping)
+
+这个仓库包含了用于捕通过过往船只获AIS消息广播,然后将其与公开数据集结合在一起,从而显示船舶运载内容的实用程序。
+
+# 最新发布
+
+[SciPy 1.0.0](https://mail.python.org/pipermail/numpy-discussion/2017-September/077222.html)
+
+这是一个大版本,此版本号酝酿了16年之久。跟一般的版本相比,它包含了多一点弃用和向后不兼容更改。
+
+[Python 3.6.3](https://www.python.org/downloads/release/python-363/)
+
+# 近期活动和网络研讨会
+
+[IndyPy 2017年10月每月聚会 - Indianapolis, IN](https://www.meetup.com/indypy/events/243245182/)
+
+将会有以下演讲:
+
+* Python REPL - 它是啥,以及为嘛它辣么腻害。
+* Python中的Rust:修正正则表达式
+
+[Boulder Python 2017年10月聚会 - Boulder, CO](https://www.meetup.com/BoulderPython/events/239106667/)
+
+[PyAtl 2017年10月聚会 - Atlanta, GA](https://www.meetup.com/python-atlanta/events/238300281/)
diff --git a/Python Weekly/Python_Weekly_Issue_316.md b/Python Weekly/Python_Weekly_Issue_316.md
new file mode 100644
index 0000000..3901e36
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_316.md
@@ -0,0 +1,129 @@
+原文:[Python Weekly - Issue 316 ](http://eepurl.com/c7bM0r)
+
+---
+
+欢迎来到Python周刊第316期。让我们直奔主题。
+
+# 来自赞助商
+[](https://goo.gl/wlxnDm)
+
+分析太慢了?使用[Daal4py](https://software.intel.com/en-us/articles/daal4py-overview-a-high-level-python-api-to-the-intel-data-analytics-acceleration-library?utm_source=12Oct2017%20ad%20Python%20weekly&utm_medium=email&utm_campaign=Oct%20Python%20Weekly%20newsletter),将你的多核桌面变身为集群。使用你最喜欢的算法,PCA,SVM,SVD,线性回归等等,仅仅通过几行代码,就可以实现惊人的速度。可以在Linux上,通过conda下载,支持Python 2.7和3.6。更快的数据分析,现在通过Daal4Py,触手可得!
+
+
+# 文章,教程和讲座
+
+[在树莓派3 + PiCamera上,使用OpenCV-Python,进行纸牌检测](https://www.youtube.com/watch?v=m-QPjO-2IkA)
+
+我做了一个纸牌检测器,它使用OpenCV-Python来检测和识别视频传送中的纸牌。它运行在带有PiCamera的树莓派3上。这个视频解释了我用来检测和识别纸牌的图像处理算法。
+
+[使用Python,在Bancor交换上实现Ethereum交易前端](https://hackernoon.com/front-running-bancor-in-150-lines-of-python-with-ethereum-api-d5e2bfd0d798)
+
+本文深入编程Ethereum / Bancor交换上的交易,并利用Bancor上的一个游戏理论安全漏洞,这是Ethereum区块链上的一个知名的智能合约。
+
+[你可以如何使用Python来构建你自己的CNC控制器和3D打印机](https://medium.freecodecamp.org/how-to-build-a-3-d-printer-using-cnc-controller-in-python-bd3cd5e28516)
+
+在这篇文章中,我将会介绍如何构建一个CNC控制器 —— 特别是3D打印机 —— 使用现代ARM板(树莓派)和现代高级语言(Python)。
+
+[他们不会告诉你的那些装饰器](https://github.com/hchasestevens/posts/blob/master/notebooks/the-decorators-they-wont-tell-you-about.ipynb)
+
+这篇简短的指南旨在解密你所听到的关于装饰器的神话,并且告诉你好东西:他们不会告诉你的那些装饰器,以及你不知道的那些装饰器能做的事情。
+
+[使用Plotly的Dash框架,创建交互式可视化](http://pbpython.com/plotly-dash-intro.html)
+
+Dash是由Plotly团队创建的开源框架,它利用Flask,plotly.js和React.js来构建自定义的数据可视化应用。本文是关于如何开始使用dash来构建一个简单但是强大的交互式仪表板的高级概述。
+
+[Django完全初学者指南 —— 第6部分](https://simpleisbetterthancomplex.com/series/2017/10/09/a-complete-beginners-guide-to-django-part-6.html)
+
+在这篇教程中,我们将会详细讨论基于类的视图。我们还会重构一些现有的视图,以利用内置的基于类的视图。
+
+[使用OpenCV的高动态范围(HDR)成像](http://www.learnopencv.com/high-dynamic-range-hdr-imaging-using-opencv-cpp-python/)
+
+在这篇教程中,我们将学习如何使用不同曝光设置拍摄的多个图像,创建一个高动态范围(HDR)图像。我们将会分享使用C++和Python编写的代码。
+
+[缩放Django Admin的日期层次结构](https://medium.com/@hakibenita/scaling-django-admin-date-hierarchy-85c8e441dd4c)
+
+我们发布了一个名为django-admin-lightweight-date-hierarchy的包,它覆盖了Django Admin的date_hierarchy模板标签,并且删除了所有对它的数据库数据库查询。有关实现细节和令人震惊的性能分析,请继续阅读。
+
+[使用更好的命令行界面](https://dev.to/sobolevn/using-better-clis-6o8)
+
+对于那些花费一半的时间在终端上的人们来说,用户体验和功能是非常重要的。让你成为更快乐的人。这里有一些默认命令行应用的非常好的替代方法。
+
+[使用Django和PostgreSQL,实现多面搜索](https://simonwillison.net/2017/Oct/5/django-postgresql-faceted-search/)
+
+[Django + webpack + Vue.js —— 设置一个易于开发和部署的新项目(第一部分)](https://ariera.github.io/2017/09/26/django-webpack-vue-js-setting-up-a-new-project-that-s-easy-to-develop-and-deploy-part-1.html)
+
+[考虑Python的目标用户](http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html)
+
+[现代Django:第一部分;设置Django和React](http://v1k45.com/blog/modern-django-part-1-setting-up-django-and-react/)
+
+[禁用Django中的错误电子邮件](https://lincolnloop.com/blog/disabling-error-emails-django/)
+
+
+# 书籍
+
+[Programming with MicroPython: Embedded Programming with Microcontrollers and Python(MicroPython编程:使用微控制器和Python进行嵌入式编程)](http://amzn.to/2z0g62I)
+
+使用MicroPython(用于微控制器和控制系统Python 3的重新实现)是一个令人兴奋的时刻。这个实用指南提供了使用这种精简高效的编程语言,卷起袖子开始创建独特的嵌入式项目所需要的知识。如果你是个熟悉Python的程序员、教育工作者或者制造者,那么,你已经可以随时学习了 —— 尽情享受吧。
+
+
+# 好玩的项目,工具和库
+
+[Livepython](https://github.com/agermanidis/livepython)
+
+实时可视化跟踪你的Python代码。
+
+[Lattice](https://github.com/tensorflow/lattice)
+
+TensorFlow中的Lattice方法。
+
+[Tably](https://github.com/narimiran/tably)
+
+将.csv数据转换成LaTeX表的Python命令行脚本。
+
+[spidy](https://github.com/rivermont/spidy)
+
+使用命令行网络爬虫的简单易用方法。
+
+[xam](https://github.com/MaxHalford/xam)
+
+xam是我的个人数据科学和机器学习工具箱。它使用Python 3,并且围绕主流库(例如pandas和scikit-learn)构建。
+
+[torchMoji](https://github.com/huggingface/torchMoji)
+
+DeepMoji模型的pyTorch实现:用于分析情感、心情、讽刺等的最先进的深度学习模型。
+
+[pcap2curl](https://github.com/jullrich/pcap2curl)
+
+读取数据包捕获,提取HTTP请求,然后将其转换成cURL命令用于重放。
+
+[flask-redis-queue](https://github.com/realpython/flask-redis-queue)
+
+如何使用Flask,Redis Queue和Docker处理后台进程的示例。
+
+[TigerJython](http://jython.tobiaskohn.ch/index.html)
+
+TigerJython是Python的免费开发环境。
+
+[magic-the-gifening](https://github.com/minimaxir/magic-the-gifening)
+
+推Magic的推特机器人:采集卡,上面叠加了合适的GIF。
+
+
+# 最新发布
+
+[PyPy v5.9](https://morepypy.blogspot.com/2017/10/pypy-v59-released-now-supports-pandas.html)
+
+PyPy v5.9发布,现在支持Pandas,NumPy了。
+
+[Matplotlib 2.1](http://matplotlib.org/users/whats_new.html#new-in-matplotlib-2-1)
+
+[Django REST框架 3.7](http://www.django-rest-framework.org/topics/3.7-announcement/)
+
+
+# 近期活动和网络研讨会
+
+[PyHou 2017年10月聚会 - Houston, TX](https://www.meetup.com/python-14/events/242603685/)
+
+
+
+
diff --git a/Python Weekly/Python_Weekly_Issue_317.md b/Python Weekly/Python_Weekly_Issue_317.md
new file mode 100644
index 0000000..7d5ed3d
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_317.md
@@ -0,0 +1,157 @@
+原文:[Python Weekly - Issue 317](http://eepurl.com/c78_yL)
+
+---
+
+欢迎来到Python周刊第317期。让我们直奔主题。
+
+# 来自赞助商
+[](https://www.datadoghq.com/dg/apm/ts-python-performance/?utm_source=Advertisement&utm_medium=Advertisement&utm_campaign=PythonWeekly-Tshirt&utm_content=Python)
+
+[如何监控Python应用](https://www.datadoghq.com/dg/apm/ts-python-performance/?utm_source=Advertisement&utm_medium=Advertisement&utm_campaign=PythonWeekly-Tshirt&utm_content=Python)
+
+实时Python度量的图表和告警,并与你的技术栈中200多个其他技术的数据相关联。
+
+
+# 文章,教程和讲座
+
+[Spotify's Discover Weekly:机器学习是如何找到你的新音乐的](https://hackernoon.com/spotifys-discover-weekly-how-machine-learning-finds-your-new-music-19a41ab76efe)
+
+个性化音乐推荐背后的科学。
+
+[遇见Horovod:Uber的TensorFlow开源分布式深度学习框架](https://eng.uber.com/horovod/)
+
+上个月,Uber工程介绍了Michelangelo,这是一个内部的将机器学习作为服务的平台,它将机器学习大众化,并且让大规模构建和部署这些系统变得简单。在这篇文章中,我们揭开Horovod的面纱,Horovod是一个Michelangelo的深度学习工具箱中的一个开源组件,它让使用TensorFlow开始(并且加速)分布深度学习项目变得更容易。
+
+[广告商神经网络](https://softwaremill.com/neural-networks-for-advertisers/)
+
+构建概念验证型应用,来检测足球场上的商标品牌。
+
+[Django完全初学者指南 —— 第7部分](https://simpleisbetterthancomplex.com/series/2017/10/16/a-complete-beginners-guide-to-django-part-7.html)
+
+在这篇教程中,我们将会把我们的Django引用部署到生产服务器上。我们还会为我们的服务器配置一个Email服务和HTTPS证书。
+
+[pickle有什么危险?](https://intoli.com/blog/dangerous-pickles/)
+
+Python的pickle协议,Pickle Machine(Pickle机)以及构建恶意pickle的简单介绍。
+
+[纯小白Python教程](http://stackabuse.com/python-tutorial-for-absolute-beginners/)
+
+本文为Python小白提供了该语言简略的介绍。本文目标群体是那些之前没有写Python经验的纯小白,虽然有一些编程知识会有点用,但是这并非必须的。
+
+[太阳能驱动的网络连接草地喷灌器项目](http://www.movingelectrons.net/blog/2017/10/18/solar-powered-internet-connected-lawn-sprinkler.html)
+
+学习如何使用Adafruit的Feather Huzzah,MicroPython和MQTT协议来创建一个太阳能驱动的自动草地喷灌器系统。
+
+[裸机Flask REST API](https://medium.com/@camillovisini/barebone-flask-rest-api-ac263db82e40)
+
+学习如何用Flask设置和部署一个裸机REST API。
+
+[Python中超快的字符串匹配](https://bergvca.github.io/2017/10/14/super-fast-string-matching.html)
+
+对于大数据集来说,像Jaro-Winkler或者Levenshtein距离测度这样的传统字符串匹配方法太慢了。使用带N-Grams的TF-IDF,作为查找相似字符串的方法,将问题转换成一个矩阵操作问题,这在计算上便宜得多。使用这种方法使得只用一台双核笔记本电脑,在42分钟内搜索包含663,000个公司名称的集合中的近似重复成为可能。
+
+[编写你自己的区块链第一部分 —— 创建、存储、同步、展示、挖掘和证明工作](https://bigishdata.com/2017/10/17/write-your-own-blockchain-part-1-creating-storing-syncing-displaying-mining-and-proving-work/)
+
+[用Python编写一个特定领域语言(DSL)](https://dbader.org/blog/writing-a-dsl-with-python#.)
+
+[Seam Carving:使用动态编程来实现内容识别的图像缩放(Python)](https://sandipanweb.wordpress.com/2017/10/14/seam-carving-using-dynamic-programming-to-implement-context-aware-image-resizing-in-python/)
+
+[如何使用免费的托管工具,设置世界级的持续部署](https://simonwillison.net/2017/Oct/17/free-continuous-deployment/)
+
+[使用Vue.js和Flask的全栈单页面应用](https://medium.com/@oleg.agapov/full-stack-single-page-application-with-vue-js-and-flask-b1e036315532)
+
+[使用Pytest进行Django测试驱动开发](https://medium.com/@Afroshok/django-test-driven-development-with-pytest-63cb99e6fff2)
+
+
+# 好玩的项目,工具和库
+
+[Python Graph Gallery](https://python-graph-gallery.com/)
+
+Python Graph Gallery是一个提升数据可视化的项目,使用Python。其想法是提供数百个Python图表,以及相应的可复制代码。这个样例源码是学习和获取你自己的数据可视化灵感的好平台!
+
+[appJar](https://github.com/jarvisteach/appJar)
+
+Python的简单tKinter GUI。
+
+[librxvm](https://github.com/eriknyquist/librxvm)
+
+非回溯的基于NFA的正则表达式库,用于C和Python。
+
+[awesome-django-rest-framework](https://github.com/nioperas06/awesome-django-rest-framework)
+
+使用Django REST框架创建棒棒哒的API所需要的工具、程序和资源。
+
+[ray](https://github.com/ray-project/ray)
+
+一个高性能的分布式执行引擎。
+
+[test-tube](https://github.com/williamFalcon/test-tube)
+
+Test tube是一个Python库,用来跟踪和优化深度学习实验。它与框架无关,在python的argparse API上构建,易于使用。
+
+[DumpsterFire](https://github.com/TryCatchHCF/DumpsterFire)
+
+DumpsterFire工具集是一个模块化、菜单驱动的跨平台工具,用以构建可复用、时延分布式安全事件。轻松创建用于蓝队演练和感应器/告警映射的自定义事件链。红队可以创建假事件、干扰和诱饵,以支持和扩展他们的操作。将纸上谈兵转变成受控的“实战”。构建事件序列(“叙述”)以模拟真实的场景,并生成对应的网络和文件系统伪像。
+
+[pynotes](https://github.com/srigalibe/pynotes)
+
+练手Python程序。
+
+[pytorch-a2c-ppo-acktr](https://github.com/ikostrikov/pytorch-a2c-ppo-acktr)
+
+Advantage Actor Critic (A2C)、Proximal Policy Optimization (PPO)和使用Kronecker-factored approximation (ACKTR)的深度强化学习的可扩展信赖域方法的PyTorch实现。
+
+[rev-proxy-grapher](https://github.com/mricon/rev-proxy-grapher)
+
+这是一个有用的小工具,它会生成一个漂亮的graphviz图表,用以描绘你的反向代理流。它接收一个手动编写的YAML文件(文件描述网络拓扑、代理定义)以及(可选的)一组nmap输出文件(用以额外的端口/服务信息),然后输出graphviz支持的格式的图表。
+
+[ida_ea](https://github.com/1111joe1111/ida_ea)
+
+一组IDA利用/逆向支持。
+
+
+# 最新发布
+
+[Jupyter Notebook 5.2.0](https://blog.jupyter.org/jupyter-notebook-5-2-0-9c5b3ea672f)
+
+这是一个小版本,主要包括问题修复和改进,值得注意的是,增加了对RTL(从右到左)的支持。
+
+[Django 2.0 beta 1](https://www.djangoproject.com/weblog/2017/oct/16/django-20-beta-1-released/)
+
+[SciPy 1.0.0rc2](https://github.com/scipy/scipy/releases/tag/v1.0.0rc2)
+
+[Python 3.7.0a2](https://www.python.org/downloads/release/python-370a2/)
+
+
+# 近期活动和网络研讨会
+
+[PyTennessee 2018](https://www.pytennessee.org/)
+
+PyTennessee,每年都会在Nashville举行,TN已经在为第五年做准备了!早鸟票仍在售,并且建议征集已经开放。分享你的知识,提交你的演讲,马上买票吧!
+
+[SoCal Python 2017年10月聚会 - Burbank, CA](https://www.meetup.com/socalpython/events/244045621/)
+
+本周,Dmitriy Leybel将会给我们带来:Bokeh - 给那些喜欢闪闪发光的东西的开发者、数据科学家和人们。
+
+[用Python构建一个简单的推荐系统 - Philadelphia, PA](https://www.meetup.com/phillypug/events/243841399/)
+
+Jason Rodriguez将会分析其探索MTGO( Magic: The Gathering Online)世界的经历,部分通过他在Cardhoarders.com的朋友提供的交易数据。通过这个项目,他学到了一些关于MTGO社区、游戏经济以及使用Python构建简单的推荐系统。
+
+[Boston Python 2017年10月聚会 - Cambridge, MA](https://www.meetup.com/bostonpython/events/242251013/)
+
+将会有以下演讲:
+
+ * 如何编写一个函数
+ * 描述器,魔术方法和继承:我滴神呀!
+ * 教青少年写Python
+
+[Python Web编程之夜#35 - Roseville, MN](https://www.meetup.com/PyMNtos-Twin-Cities-Python-User-Group/events/243472751/)
+
+[Edmonton Python 2017年10月聚会 - Edmonton, AB](https://www.meetup.com/startupedmonton/events/243557298/)
+
+[Baltimore Python 2017年10月聚会 - Baltimore, MD](https://www.meetup.com/baltimore-python/events/244203794/)
+
+
+
+
+
diff --git a/Python Weekly/Python_Weekly_Issue_318.md b/Python Weekly/Python_Weekly_Issue_318.md
new file mode 100644
index 0000000..ce08c72
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_318.md
@@ -0,0 +1,145 @@
+原文:[Python Weekly - Issue 318 ](http://eepurl.com/c826p9)
+
+---
+
+欢迎来到Python周刊第318期。让我们直奔主题。
+
+# 来自赞助商
+[](https://www.datadoghq.com/dg/apm/ts-python-performance/?utm_source=Advertisement&utm_medium=Advertisement&utm_campaign=PythonWeekly-Tshirt&utm_content=Python)
+
+[Python应用跑得太慢?](https://www.datadoghq.com/dg/apm/ts-python-performance/?utm_source=Advertisement&utm_medium=Advertisement&utm_campaign=PythonWeekly-Tshirt&utm_content=Python)
+
+用Datadog跟踪每一个请求!使用应用端到端跟踪,快速定位Python性能问题。
+
+
+
+# 新闻
+
+[PyCon开放经济援助申请](https://pycon.blogspot.com/2017/10/pycon-opens-financial-aid-applications.html)
+
+
+# 文章,教程和讲座
+
+[缺乏数据时自动化客户支持](https://blog.insightdatascience.com/automating-customer-support-when-you-lack-data-e9975fd8a053)
+
+初创公司从头开始指南。
+
+[用机器学习进行日内股票价格预测1:线性模型](https://www.hardikp.com/2017/10/03/intraday-stock-price-prediction-1/)
+
+这是将机器学习应用到日内股票价格/回报预测的任务的文章系列中的第一篇。对于大多数贸易公司而言,价格预测至关重要。多年来,人们一直在使用各种预测技术。我们将探讨这些技术以及最近流行的算法,例如神经网络。在这篇文章中,我们将关注把线性模型应用于市场数据特征。
+
+ * [第2部分:神经网络](https://www.hardikp.com/2017/10/19/intraday-stock-price-prediction-2/) - 在这篇文章中,我们将关注把神经网络应用于市场数据特征。
+
+
+[文字嵌入:一次自然语言处理速成课](https://www.datascience.com/resources/notebooks/word-embeddings-in-python)
+
+本文解释了文字嵌入背后的原由,并演示了如何通过这些技术,使用来自50万份亚马逊食品评论的数据,创建类似词汇的集合。
+
+[构建一个Python单库,用以快速可靠的开发](https://medium.com/@Pinterest_Engineering/building-a-python-monorepo-for-fast-reliable-development-be763781f67)
+
+在这篇文章中,我们将分享大规模管理Python代码时所遇到的一些挑战,以及Python一般是如何提供一个快速可靠的代码开发环境的。
+
+[Python并行计算(60s内)](https://dbader.org/blog/python-parallel-computing-in-60-seconds#.)
+
+如果你的Python程序比你想要的慢,那么你可以通过并行化来加快它们。在这个简短的引文中,你将了解Python 2和3中并行处理的基础知识。
+
+[Telegram API介绍](https://medium.com/towards-data-science/introduction-to-the-telegram-api-b0cd220dbed2)
+
+以编程的方式分析你在Telegram上的对话历史。
+
+[小心那个PyPI](https://glyph.twistedmatrix.com/2017/10/careful-with-that-pypi.html)
+
+PyPI凭证是很重要的。这里是一些更好一点保护它们的提示。
+
+[使用神经网络着色B&W图片](https://blog.floydhub.com/colorizing-b&w-photos-with-neural-networks/)
+
+[最快的可用于生产的图像大小调整就在那里,第一部分:一般优化](https://blog.uploadcare.com/the-fastest-production-ready-image-resize-out-there-part-1-general-optimizations-1b9b0faf2959)
+
+[Python中的线性回归;预测湾区房价](https://medium.com/@actsusanli/linear-regression-in-python-predict-the-bay-areas-home-price-5c91c8378878)
+
+[教程:用纯Python编写有限状态机来解析自定义语言](https://medium.com/@brianray_7981/tutorial-write-a-finite-state-machine-to-parse-a-custom-language-in-pure-python-1c11ade9bd43)
+
+[使用Pandas,从头开始生成产品使用数据](https://medium.com/towards-data-science/generating-product-usage-data-from-scratch-with-pandas-319487590c6d)
+
+[使用Python,充分利用Sqlite3](https://remusao.github.io/posts/2017-10-21-few-tips-sqlite-perf.html)
+
+
+# 书籍
+
+[Python Machine Learning: Machine Learning and Deep Learning with Python, scikit-learn, and TensorFlow, 2nd Edition(Python机器学习:使用Python、scikit-learn和TensorFlow进行机器学习和深度学习,第二版)](http://amzn.to/2i3V8Jp)
+
+机器学习正在蚕食软件世界,而今,深度学习正在扩展机器学习。通过Sebastian Raschka的畅销书《Python Machine Learning(Python机器学习)》的第二版,来了解和使用机器学习、神经网络和深度学习。本书全面使用最新的Python开源库进行更新,提供了创建和贡献机器学习、深度学习和现代数据分析所需的实用知识和技术。
+
+
+# 本周的Python工作
+
+[Sweethearts招聘全栈Python/Django开发者](http://jobs.pythonweekly.com/jobs/full-stack-python-django-developer-mf/)
+除了那些你必须关心维护和改进的现有项目外,还有很多正在等待实施的想法。我们正以敏捷的方式进行工作,以便跟上并超越我们的业务速度。你将会负责包含前端、后端和全栈开发者的小团队中的一个social sweethearts项目。
+
+
+# 好玩的项目,工具和库
+
+[Coach](https://github.com/NervanaSystems/coach)
+
+Coach是一个Python强化学习研究框架,包含许多最先进的算法的实现。它暴露了一组用于实验新的强化学习的易于使用的API,并且允许对新环境的简单集成来解决问题。它很好地解耦了基本的强化学习组件(算法、环境、神经网络架构、探索策略,……),因此,扩展和重用现有的组件是相当轻松的。
+
+[Luminoth](https://github.com/tryolabs/luminoth)
+
+Luminoth是一个计算机视觉开源工具包。目前,我们支持对象检测和图像分类,但我们不止步于此。它使用Python编写,用到了TensorFlow和Sonnet。
+
+[FoxDot](http://foxdot.org/)
+
+使用Python和SuperCollider实时编码音乐。
+
+[uncaptcha](https://github.com/ecthros/uncaptcha)
+
+以85%的准确度击败谷歌的音频验证码。
+
+[Bounter](https://github.com/RaRe-Technologies/bounter)
+
+Bounter是一个用C编写的Python库,用于对大量数据集进行非常快速的概率计数,只使用小的固定内存占用。
+
+[PyScripter](https://github.com/pyscripter/pyscripter)
+
+Pyscripter是一个功能丰富但是轻量的Python IDE。
+
+[Dramatiq](https://dramatiq.io/)
+
+Dramatiq是一个Python分布式任务处理库,专注于简单性、可靠性和性能。
+
+[TensorRec](https://github.com/jfkirk/tensorrec)
+
+Python的一款TensorFlow推荐算法框架。
+
+[PyRexecd](https://github.com/euske/pyrexecd)
+
+PyRexecd是一个Windows独立SSH服务器。
+
+[flask-webpack cookiecutter](https://github.com/mattfinnell/flask-webpack-cookiecutter/)
+
+自动构建一个迷你Flask+Webpack项目。
+
+[instantnews](https://github.com/shivam043/instantnews)
+
+立即获取实时新闻。
+
+[Streamz](https://github.com/mrocklin/streamz)
+
+玩转计算流构建。
+
+[mx-maskrcnn](https://github.com/TuSimple/mx-maskrcnn)
+
+Mask R-CNN的MXNet实现。
+
+[DilatedRNN](https://github.com/code-terminator/DilatedRNN)
+
+DilatedRNN的Tensorflow实现。
+
+
+# 近期活动和网络研讨会
+
+[DFW Pythoneers 2017年11月聚会 - Plano, TX](https://www.meetup.com/dfwpython/events/238602997/)
+
+
+
+
diff --git a/Python Weekly/Python_Weekly_Issue_319.md b/Python Weekly/Python_Weekly_Issue_319.md
new file mode 100644
index 0000000..6387bbe
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_319.md
@@ -0,0 +1,120 @@
+原文:[Python Weekly - Issue 319 ](http://eepurl.com/c9TWzP)
+
+---
+
+欢迎来到Python周刊第319期。让我们直奔主题。
+
+# 来自赞助商
+[](http://www.amazon.com/gp/product/B0185367JQ/ref=as_li_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=B0185367JQ&linkCode=as2&tag=mymerch-20&linkId=OLIXWD4WZ5X6FFHD)
+
+嘿,Python粉,你想要表达你对**Python**的爱吗?那么,[点击这里](http://www.amazon.com/gp/product/B0185367JQ/ref=as_li_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=B0185367JQ&linkCode=as2&tag=mymerch-20&linkId=OLIXWD4WZ5X6FFHD),获取你的T恤,骄傲地穿上它吧。
+
+
+# 文章,教程和讲座
+
+[使用Python探索美国警务数据](https://blog.patricktriest.com/police-data-python/)
+
+使用Python分析和可视化一个来自全美各地6000万警察站点的开源数据集。
+
+[如果用Python构建一个3D打印机](https://medium.com/iotforall/how-to-build-a-3d-printer-in-python-b05af32489f5)
+
+首次在纯Python上实现数控机床控制器。
+
+[如何让你的代码快80倍](https://morepypy.blogspot.it/2017/10/how-to-make-your-code-80-times-faster.html)
+
+我常常听到人们很开心,因为PyPy让他们的代码快了2倍左右。这里是一个简短的个人故事,它告诉你,PyPy可以做得更好。
+
+[Python内置函数和方法(用Python进行数据科学基础 #3)](https://data36.com/python-built-in-functions-methods-python-data-science-basics-3/)
+
+在这篇文章中,我不仅仅是向你介绍概念,还会教给你一系列未来将会一直使用的最重要的函数和方法。
+
+[让AWS Lambda Function变得容易](https://medium.com/@alexandraj777/aws-lambda-functions-made-easy-1fae0feeab27)
+
+为AWS Lambda打包Python 2.7函数的手把手指南,带代码片段。
+
+[Python中简洁的URL缩短器](http://aguo.us/writings/url-shortener.html)
+
+有多简洁?14行。
+
+[使用Tensorflow,利用开放图像进行对象检测](https://blog.algorithmia.com/deep-dive-into-object-detection-with-open-images-using-tensorflow/)
+
+Tensorflow教程和演示:使用谷歌新的“开放图像数据集”循环计算机视觉模型,并通过Algorithmia进行推理。
+
+[学习树数据结构](https://medium.com/the-renaissance-developer/learning-tree-data-structure-27c6bb363051)
+
+本文试图让我们更好的了解树数据结构,并澄清关于它的任何疑问。我们会学习什么是树、关于它的例子、它的术语、它是如何工作的以及一个技术实现(即,代码!)
+
+[30分支Python web爬虫](https://hackernoon.com/30-minute-python-web-scraper-39d6d038e5da)
+
+[构建你自己的区块链第2部分 —— 同步来自不同节点的区块链](https://bigishdata.com/2017/10/27/build-your-own-blockchain-part-2-syncing-chains-from-different-nodes/)
+
+[如何单元测试机器学习代码](https://medium.com/@keeper6928/how-to-unit-test-machine-learning-code-57cf6fd81765)
+
+[How-To:使用Keras、Python和深度学习进行多GPU循环](https://www.pyimagesearch.com/2017/10/30/how-to-multi-gpu-training-with-keras-python-and-deep-learning)
+
+[使用Python和aiohttp框架,创建一个REST API](https://www.youtube.com/watch?v=Z784Mwm4VBg)
+
+[迁移Flask web应用到Serverless](https://medium.com/@jbesw/adventures-in-migrating-to-serverless-a63556b39042)
+
+[SQLite极简指南](http://tech.marksblogg.com/sqlite3-tutorial-and-guide.html)
+
+
+# 书籍
+
+[Python Tricks: A Buffet of Awesome Python Features(Python诀窍:神奇的Python特性自助餐)](http://amzn.to/2zoZZjv)
+
+学习Python的细节是很困难的,通过这本书,你将能够关注真正重要的实际技能。发现Python标准库中的“隐藏宝藏”,今天就开始编写干净的Pythonic代码吧。
+
+
+# 好玩的项目,工具和库
+
+[babybuddy](https://github.com/cdubz/babybuddy)
+
+看护人的好伙伴,帮助看护人跟踪睡眠、喂食、尿布更换和俯卧时间,在无需(那么多)猜测的情况下,了解和预测宝宝的需求。
+
+[statically](https://github.com/AlanCristhian/statically)
+
+使用cython,只通过一个装饰器来编译一个python函数。
+
+[pybaseball](https://github.com/jldbc/pybaseball)
+
+使用Python(Statcast,Baseball Reference,FanGraphs)提取当前和历史棒球统计数据。
+
+[deep-voice-conversion](https://github.com/andabi/deep-voice-conversion)
+
+在Tensorflow中进行语音转换(语音风格转换)的深度神经网络。
+
+[trevorc2](https://github.com/trustedsec/trevorc2)
+
+TrevorC2是一个合法的网站(可浏览),在客户端和服务端之间架设通信通道,用于隐蔽的命令执行。
+
+[Blazy](https://github.com/UltimateHackers/Blazy)
+
+Blazy是一个当代登录破解工具,它也对CSRF,Clickjacking,Cloudflare和WAF进行测试。
+
+[curequests](https://github.com/guyskk/curequests)
+
+Curio + Requests:为人类准备的异步HTTP。
+
+[dni-pytorch](https://github.com/koz4k/dni-pytorch)
+
+使用合成梯度,解耦神经接口,用于PyTorch。
+
+
+# 最新发布
+
+[Pandas 0.21](http://pandas.pydata.org/pandas-docs/stable/whatsnew.html#v0-21-0-october-27-2017)
+
+这是自0.20.3版本起的一个主要版本,包含了许多API更改、启用、新特性、增强功能和性能提升,以及大量的问题修复。我们推荐所有的用户更新到这个版本。
+
+[Anaconda Distribution 5.0](https://www.anaconda.com/blog/developer-blog/announcing-the-release-of-anaconda-distribution-5-0/)
+
+[Django问题修复版本:1.11.7](https://www.djangoproject.com/weblog/2017/nov/01/bugfix-release/)
+
+
+# 近期活动和网络研讨会
+
+[Austin Python 2017年11月聚会 - Austin, TX](https://www.meetup.com/austinpython/events/242025685/)
+
+[PyAtl 2017年11月聚会 - Atlanta, GA](https://www.meetup.com/python-atlanta/events/238300285/)
+
diff --git a/Python Weekly/Python_Weekly_Issue_320.md b/Python Weekly/Python_Weekly_Issue_320.md
new file mode 100644
index 0000000..7d29796
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_320.md
@@ -0,0 +1,165 @@
+原文:[Python Weekly - Issue 320 ](http://eepurl.com/c-Jfrr)
+
+---
+
+欢迎来到Python周刊第320期。本周干货满满。尽情享用吧!
+
+# 来自赞助商
+
+[](https://goo.gl/wlxnDm)
+
+[Intel® Distribution for Python*](https://software.intel.com/en-us/distribution-for-python?utm_source=9Nov2017%20ad%20Python%20weekly&utm_medium=email&utm_campaign=Nov%202017%20Python%20Weekly%20newsletter)免费提供,并且许可证允许商业和非商业用途。这就对了!试试Intel优化过的NumPy、SciPy和scikit-learn,全部都在内部进行了优化。你的代码保持不变 —— 只需要在Intel Python环境中运行它,就可以获得速度提升。
+
+
+# 新闻
+
+[PyCon 2018注册现已开放!](https://pycon.blogspot.com/2017/11/pycon-2018-registration-is-now-open.html)
+
+前六个PyCon已经售罄,所以准备另外一个PyCon,并且提早取票。前800张票享受早鸟优惠,企业门票节省超过20%,个人门票则超过12%。学生如果买得早的话,可以节省$25!
+
+[2018年DSF董事会选举申请](https://www.djangoproject.com/weblog/2017/nov/07/2018-dsf-board-election-application/)
+
+如果你对帮助支持Django的发展感兴趣,那么,这是一个机会。
+
+
+# 文章,教程和讲座
+
+[构建你自己的Instagram发现引擎:手把手教程](https://getstream.io/blog/building-instagram-discovery-engine-step-step-tutorial/)
+
+如果Instagram的“Explore”部分显示的是符合你的兴趣的内容,岂不是很棒?当你打开应用,展示的内容和推荐几乎总是与你特定的爱好、兴趣、联系等等相关。虽然认为我们是Instagram世界的中心可能很有趣,但是事实是,每天个性化的相关内容也是为其他4亿人专门准备的。每天有4亿活跃用户并且发布80万张照片,Instagram是如何决定把什么放在你的“explore”部分的呢?让我们探讨一下Instagram用来决定你的Instagram时间表中的帖子和“explore”部分的分数的关键因素。
+
+[敌对攻击是如何工作的](http://blog.ycombinator.com/how-adversarial-attacks-work/)
+
+机器学习算法将输入作为数值向量。以特定的方法设计输入,从而从模型获得错误的结果被称为敌对攻击(adversarial attack)。在这篇文章中,我们将会展示攻击的主要类型的实际样例,解释为什么执行这些攻击非常容易,并且讨论源自此技术的安全隐患。
+
+[Python列表推导教程](https://www.datacamp.com/community/tutorials/python-list-comprehension)
+
+学习如何有效地使用Python中的列表推导来创建列表、替换(嵌套)for循环以及map()、filter()和reduce()函数,……!
+
+[结合Python和C:高级“ctypes”功能](https://dbader.org/blog/python-ctypes-tutorial-part-2#)
+
+学习把Python和原生库相结合的高级模式,例如在Pytnon中处理C结构,以及值传递与引用传递语义。
+
+[使用PyTorch,为任意图像抽取特征向量](https://becominghuman.ai/extract-a-feature-vector-for-any-image-with-pytorch-9717561d1d4c)
+在这篇教程中,我们将会把图像转换成向量,并且使用余弦相似度来测试向量的质量。
+
+[如何使用你的监控指标来编写一个自定义的Kubernetes调度程序](https://sysdig.com/blog/kubernetes-scheduler/)
+
+本文涵盖了创建一个自定义的Kubernetes调度程序的用例,并且实现了一个使用来自Sysdig的监控指标(系统、网络、服务、statsd、JMX或者Prometheus指标)的例子。
+
+[Eager Execution:一个TensorFlow命令式、通过运行定义的接口](https://research.googleblog.com/2017/10/eager-execution-imperative-define-by.html)
+
+Eager execution是一个命令式、通过运行定义的接口,其中,当从Python调用操作时,会立即执行它们。这使得TensorFlow更容易上手,并且会让研究和开发更直观。
+
+[使用Flask构建一个GIF消息机器人](https://medium.com/codebagng/building-a-gif-messenger-bot-with-flask-fcdca58e581c)
+
+在这篇文章中,我们将会构建一个GIF Facebook Messenger机器人。这个机器人将会回复跟它从用户那边接收到的任意文本相关的GIF。
+
+[TensorFlow神经网络教程](http://stackabuse.com/tensorflow-neural-network-tutorial/)
+
+[为Gevent开放任务队列](http://charlesleifer.com/blog/ditching-the-task-queue-for-gevent/)
+
+[如何构建你自己的区块链第3部分 —— 编写挖缺和谈论的节点](https://bigishdata.com/2017/11/02/build-your-own-blockchain-part-3-writing-nodes-that-mine/)
+
+[使用Django Channels,构建一个聊天室](https://www.ploggingdev.com/2017/11/building-a-chat-room-using-django-channels/)
+
+[快速使用SQLite和Python](http://charlesleifer.com/blog/going-fast-with-sqlite-and-python/)
+
+[爬取Reddit,查找最受欢迎的域名](https://www.find-me.co/blog/reddit_creators)
+
+[如何使用TensorFlow的对象检测API,来训练你自己的对象检测器](https://towardsdatascience.com/how-to-train-your-own-object-detector-with-tensorflows-object-detector-api-bec72ecfe1d9)
+
+
+# 本周的Python工作
+
+[Zapier招聘产品工程团队经理](http://jobs.pythonweekly.com/jobs/product-engineering-team-manager/)
+
+我们正在寻找一名产品工程经理来领导Zapier不断增长的产品工程团队。有兴趣帮助构建为数百万专业人员提供自动化的工具吗?那么,请继续阅读……
+
+
+# 好玩的项目,工具和库
+
+[pyro](https://github.com/uber/pyro)
+
+Pyro是一个建立在PyTorch之上的灵活的可扩展深度概率编程库。
+
+[Colaboratory](https://research.google.com/colaboratory/unregistered.html)
+
+Colaboratory是一个用于机器学习教育和研究的研究工具。它是Jupyter notebook环境,无需安装即可使用。
+
+[tt](https://github.com/welchbj/tt)
+
+一个用来使用布尔表达式的Pythonic工具包。
+
+[Tangent](https://github.com/google/tangent)
+
+纯Python中的源码到源码可调式衍生物。
+
+[conversation-tensorflow](https://github.com/DongjunLee/conversation-tensorflow)
+
+一个神经聊天机器人,使用Tensorflow 1.4版本的序列到序列模型与注意力解码器(attentional decoder)实现(估计、实验和数据集)
+
+[Striker](https://github.com/UltimateHackers/Striker)
+
+Striker是一个烦人信息和漏洞扫描器。
+
+[jbc](https://github.com/jackschultz/jbc)
+
+简单的区块链,用以学习和讨论区块链是如何工作的。
+
+[sqs-s3-logger](https://github.com/ellimilial/sqs-s3-logger)
+
+通过SQS,自动化无服务器日志记录到S3。
+
+[PySchemes](https://github.com/shivylp/pyschemes)
+
+PySchemes是一个用来验证数据结构的Python库。
+
+[phishing_catcher](https://github.com/x0rz/phishing_catcher)
+
+使用certstream SSL证书直播捕获恶意钓鱼域名。
+
+[Uplink](https://github.com/prkumar/uplink)
+
+一个Python声明式HTT客户端。
+
+[Mentalist](https://github.com/sc0tfree/mentalist)
+
+Mentalist是自定义词汇表生成的图形工具。它利用常见的人类范例来构建密码,并且能够输出完整的词汇表以及与Hashcat和John the Ripper兼容的规则。
+
+[MazeGenerator](https://github.com/jostbr/MazeGenerator)
+
+生成和解决随机可解迷宫的Python脚本,使用深度优先搜索和递归回溯算法。
+
+
+# 最新发布
+
+[TensorFlow r1.4](https://developers.googleblog.com/2017/11/announcing-tensorflow-r14.html)
+
+[Jinja 2.10](https://github.com/pallets/jinja/releases/tag/2.10)
+
+[RISE 5.1.0](http://www.damian.oquanta.info/posts/rise-510-is-out.html )
+
+
+# 近期活动和网络研讨会
+
+[Boulder 2017年11月Python聚会 - Boulder, CO](https://www.meetup.com/BoulderPython/events/239106676/)
+
+将会有以下演讲:
+
+ * JavaScript vs. Python (我在6个小时中,从网络上学到的东西)
+ * 用模拟绘制政治边界
+ * 基于特性(有生产力)的测试,带使用Python和JS编写的示例
+
+
+[Princeton Python用户2017年11月聚会 - Princeton, NJ](https://www.meetup.com/pug-ip/events/244002972/)
+
+本周演讲将是:大致了解Wallaroo,大致了解我们使用我们规模无关的API所解决的问题,对Python API的简介,演示我们的自动缩放功能,运行中的规模无关的API的能力的想法。
+
+[IndyPy 2017年11月每月聚会 - Indianapolis, IN](https://www.meetup.com/indypy/events/243754572/)
+
+将会有以下演讲:
+
+ * Python内置的`logging`模块
+ * 作为一名开发者,如何在家工作,以及企业可以如何帮助它们的远程工作人员。
+
diff --git a/Python Weekly/Python_Weekly_Issue_321.md b/Python Weekly/Python_Weekly_Issue_321.md
new file mode 100644
index 0000000..f51d768
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_321.md
@@ -0,0 +1,134 @@
+原文:[Python Weekly - Issue 321](http://eepurl.com/c_yJGj)
+
+---
+
+欢迎来到Python周刊第321期。让我们直奔主题。
+
+[](https://click.linksynergy.com/link?id=x9UsEHf2tls&offerid=323085.970600&type=2&murl=https%3A%2F%2Fwww.udemy.com%2Frest-api-flask-and-python%2F)
+
+[使用Flask和Python的REST API](https://click.linksynergy.com/link?id=x9UsEHf2tls&offerid=323085.970600&type=2&murl=https%3A%2F%2Fwww.udemy.com%2Frest-api-flask-and-python%2F)
+
+利用Python、Flask、Flask-RESTful和Flask-SQLAlchemy,构建专业的REST API
+
+
+# 新闻
+
+[NumPy宣布放弃支持Python 2的时间表](https://github.com/numpy/numpy/blob/master/doc/neps/dropping-python2.7-proposal.rst)
+
+[2017年Malcolm Tredinnick纪念奖提名](https://www.djangoproject.com/weblog/2017/nov/10/nominations-malcolm-prize-2017/)
+
+
+# 文章,教程和讲座
+
+[使用机器学习预测天气:第一部分](http://stackabuse.com/using-machine-learning-to-predict-the-weather-part-1/)
+
+这是使用Python和机器学习,基于从Weather Underground收集到的数据,构建预测天气温度的模型系列的第一篇文章。该系列将由三个不同的文章组成,描述机器学习项目的主要方面。
+
+[移动中的人类姿势匹配](https://becominghuman.ai/human-pose-matching-on-mobile-a-fun-application-using-human-pose-estimation-part-1-intro-93c5cbe3a096)
+
+一个使用Human Pose Estimation的有趣的应用(第1部分简介)。
+
+[GDB Python API](https://developers.redhat.com/blog/2017/11/10/gdb-python-api/)
+
+在过去的几年里,GDB得以发展,提供了一个Python API。本系列文章将会介绍用户可以如何使用该API来编程GDB,并深入了解该API的几个功能。
+
+[PoetBot:一个诗歌推荐的Telegram聊天机器人](https://towardsdatascience.com/poetbot-2-a-telegram-chat-bot-for-poem-recommendation-70d1b809761c)
+
+从头开始构建你的第一个诗人机器人。
+
+[用普通的Python,从头开始编写一个基本的x86-64 JIT编译器](https://csl.name/post/python-jit/)
+
+在这篇文章中,我将会介绍如何在CPython中,仅使用内置模块,编写一个基本的原生x86-64即时编译器(JIT)。
+
+[使用Python、Neo4j和GraphQL,爬取俄罗斯Twitter Trolls](http://www.lyonwj.com/2017/11/12/scraping-russian-twitter-trolls-python-neo4j/)
+
+上周,作为众议院情报委员会的调查结果,Twitter发布了与俄罗斯互联网研究机构相关的2752个推特账户的账户名,这些账户涉嫌传播假新闻,大概是为了影响2016年的选举。在这篇文章中,我们探讨了如何从这些用户页面的缓存版本中爬取tweet,导入Neo4j来进行分析,以及如何通过GraphQL构建一个简单的GraphQL API来显示这些数据。
+
+[给Python开发者的SQLAlchemy ORM教程](https://auth0.com/blog/sqlalchemy-orm-tutorial-for-python-developers/)
+
+让我们来一起学习如何使用SQLAlchemy ORM,在Python应用中持久化和查询数据。
+
+[Asyncio事件循环教程](https://tutorialedge.net/python/concurrency/asyncio-event-loops-tutorial/)
+
+在这篇教程中,我们将介绍Asyncio的事件循环。
+
+[使用Arduino、树莓派和一个Pi相机的自主赛车机器人](https://becominghuman.ai/autonomous-racing-robot-with-an-arduino-a-raspberry-pi-and-a-pi-camera-3e72819e1e63)
+
+[使用Python和OpenCV的增强现实(第一部分)](https://bitesofcode.wordpress.com/2017/09/12/augmented-reality-with-python-and-opencv-part-1/)
+
+[高级Python程序员,你会想把什么样的技巧传授给我们这些年轻一辈呢?](https://www.reddit.com/r/Python/comments/7cs8dq/senior_python_programmers_what_tricks_do_you_want/)
+
+[使用pandas.DataFrames的因果推理](https://medium.com/@akelleh/causal-inference-with-pandas-dataframes-fc3e64fce5d)
+
+[探索Python包中的行长度](https://jakevdp.github.io/blog/2017/11/09/exploring-line-lengths-in-python-packages/)
+
+[为TensorFlow模型创建REST API](https://becominghuman.ai/creating-restful-api-to-tensorflow-models-c5c57b692c10)
+
+[从头开始实现Pokedex,第一部分](https://medium.com/@ericfeldman93/implementing-pokedex-from-scratch-part-i-3e91ea0b0d2b)
+
+
+# 好玩的项目,工具和库
+
+[SLING](https://github.com/google/sling)
+
+一个自然语言框架语义分析器。
+
+[datasette](https://github.com/simonw/datasette)
+
+一个SQLite数据库的即时JSON API。
+
+[qiskit-sdk-py](https://github.com/QISKit/qiskit-sdk-py)
+
+Python软件开发工具,用来编写量子计算实验、程序和应用。
+
+[Milksnake](https://github.com/getsentry/milksnake)
+
+Milksnake是setuptools的一个扩展,它允许你以最便携的方式,以Python wheel的形式,发布动态链接库。它为你提供一个钩子来调用你自己的构建过程,然后获得生成的动态链接库。
+
+[FlashText](https://github.com/vi3k6i5/flashtext)
+
+从句子中提取关键字,或替换句子中的关键字。
+
+[PyAnnotate](https://github.com/dropbox/pyannotate)
+
+自动生成PEP-484注释。
+
+[micropython-upyphone](https://github.com/jeffmer/micropython-upyphone)
+
+一个使用pyboard和sim800l的gsm手机。
+
+[iphone-checker](https://github.com/WTFox/iphone-checker)
+
+这会安装一个CLI checkx,它将检查附近拥有iPhoneX库存的苹果商店的位置。
+
+[django-multitenant](https://github.com/citusdata/django-multitenant)
+
+Python/Django支持像Postgres+Citus这样的分布式多租户数据库。
+
+[Pyrlang](https://github.com/esl/Pyrlang)
+
+一个用Python实现的Erlang结点,使用gevent库,努力同时与Python 2和Python 3兼容。
+
+[django-postgres-extra](https://github.com/SectorLabs/django-postgres-extra)
+
+将PostgreSQL所有棒棒哒的东西带到Django。
+
+[PySwarms](https://github.com/ljvmiranda921/pyswarms)
+
+PySwarms是一个用于粒子群优化(PSO)的Python可扩展研究工具包。
+
+[caeroc](https://github.com/ashwinvis/caeroc)
+
+Python可压缩空气动力学计算器。
+
+[Capsule Networks](https://github.com/bourdakos1/capsule-networks)
+胶囊网络的Tensorflow实现。
+
+
+# 最新发布
+
+[Django 2.0 发布候选版本1](https://www.djangoproject.com/weblog/2017/nov/15/django-20-release-candidate-1-released/)
+
+
+
+
diff --git a/Python Weekly/Python_Weekly_Issue_322.md b/Python Weekly/Python_Weekly_Issue_322.md
new file mode 100644
index 0000000..ad75fc9
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_322.md
@@ -0,0 +1,145 @@
+原文:[Python Weekly - Issue 322](http://eepurl.com/da7JJ5)
+
+---
+
+欢迎来到Python周刊第322期。尽情享用!另外,如果你过节的话,感恩节快乐!
+
+# 来自赞助商
+[](https://www.pyimagesearch.com/deep-learning-computer-vision-python-book/?utm_campaign=pythonweekly)
+
+嘿,这里是来自PyImageSearch.com的Adrian。这次黑五,我提供我全新的**深度学习+Python书****15%的折扣** —— 但是作为Python Weekly的读者,_我决定提前24小时推出此优惠!_[点击这里下载]( https://www.pyimagesearch.com/deep-learning-computer-vision-python-book/?utm_campaign=pythonweekly),但是要快点哦,这个优惠在周一美国东部时间午夜过期。
+
+
+# 新闻
+
+[IronPython和.NET基金会](http://ironpython.net/blog/2017/11/14/ironpython-and-dotnet-foundation.html)
+
+IronPython和DLR将加入.NET基金会。
+
+
+# 文章,教程和讲座
+
+[使用Tensorflow和Keras中的一个实际用例来理解深度卷积神经网络](https://ahmedbesbes.com/understanding-deep-convolutional-neural-networks-with-a-practical-use-case-in-tensorflow-and-keras.html)
+
+现今,当涉及分析图像数据时,卷积神经网络(CNN)是标准首选技术。这些是特殊的神经网络架构,在图像分类上表现得非常好。它们被广泛用于计算机视觉行业,并被装配到不同产品中:自驾车、图片标签系统、人脸检测安全摄像头等。卷积网络背后的理论是很美腻的。它试图解释和逆向工程视觉过程。本文通过它来解释CNN的含义,并提供带代码片段和解释的详细解释。这也是在AWS上搭建深度学习专用机器并使用convnets和Tensorflow从头开发端到端CNN模型的实践指南。
+
+[使用机器学习检测天气:第二部分](http://stackabuse.com/using-machine-learning-to-predict-the-weather-part-2/)
+
+本文的重点将是描述基于前一篇文章中建立的数据集,构建一个严格的线性回归模型,来预测未来每日平均温度值所需的过程和步骤。为了构建线性回归模型,我将演示机器学习行业中两个重要的Python库的使用:Scikit-Learn 和 StatsModels。
+
+[使用Rust加速你的Python](https://developers.redhat.com/blog/2017/11/16/speed-python-using-rust/)
+
+Rust是一个没有运行时的语言,因此它可以用来与任何运行时集成;你可以用Rust来编写模块,然后使用Python进行调用。
+
+[开源ptracer,一个Python系统调用跟踪库](https://medium.com/@Pinterest_Engineering/open-sourcing-ptracer-a-syscall-tracing-library-for-python-b0fe0d91105d)
+
+对于我们的工程师团队来说,让Pinterest更快更可靠是我们不断关注的焦点,而更有效地使用硬件资源则是这项工作的重要组成部分。提高效率和可靠性需要良好的诊断工具。这就是为什么今天我们发布了我们最新的跟踪工具,ptracer,它提供了Python程序中细粒度的系统调用跟踪。在这篇文章中,我们会介绍Pinterest代码库的背景、我们需要更好的跟踪器的原因以及ptracer可以怎样帮助我们解决某些工程问题。
+
+[Python中带脸部识别的自动模因](https://www.makeartwithpython.com/blog/deal-with-it-generator-face-recognition/)
+
+DEAL WITH IT是一个 meme,其中,眼镜从屏幕外飞进来,落到用户的脸上。这个meme的最佳实例以唯一的方式这样做。在这篇文章中,我们将编写一个自动的meme生成器,使用任意的静态图像作为我们的输入。这些代码为meme API或者使用视频输入构建你自己的动画版本提供了一个很好的起点。
+
+[Python中的备忘录:如何缓存函数结果](https://dbader.org/blog/python-memoization#intro)
+
+这篇文章向你介绍一种加速Python代码的方便的方法:备忘录(memoization,有时也被拼写为memoisation)。
+
+[处理视频,使用Go和Python进行脸部识别](https://blog.machinebox.io/processing-video-to-do-face-recognition-with-go-and-python-298275a26095)
+
+如果你有大量的视频内容,但不知道它们中有谁出现,那么你可以快速地使用一个会自动检测和识别人的工具(使用Go、Python和Facebox)。
+
+[在Windows上设置PyData栈](https://www.dataquest.io/blog/pydata-windows/)
+
+在这篇教程中,我们会向你展示如何在本地Windows机器上设置功能完备的PyData栈。这将使你完全控制你的安装环境,并让你先了解在云中设置更高级的配置时,需要了解的内容。
+
+[5分钟内构建一个Python REST API](https://medium.com/python-rest-api-toolkit/build-a-python-rest-api-in-5-minutes-c183c00d3465)
+
+在这篇文章中,我们介绍Arrested —— 一个使用Python构建REST API的新框架。我们会使用Docker、SQLAlchemy和其他工具,在5分钟内构建一个以星球大战为主题的API!
+
+[Python Django速成课](https://www.youtube.com/watch?v=D6esTdOLXh4)
+
+在这个视频中,我将尽可能地谈及Python Django框架。我们会讨论这个框架及其优点,并且我们会从头开始搭建一个应用,使用MySQL。我们会讨论MTV(Model-Template-View)设计模式,设置虚拟环境,查看核心Django文件并且构建应用程序。
+
+[在Instagram上分析CPython](https://engineering.instagram.com/profiling-cpython-at-instagram-89d4cbeeb898)
+
+[用Python分析1000多种希腊葡萄酒](https://tselai.com/greek-wines-analysis.html)
+
+[监督机器学习 —— Python中的线性回归](https://hackernoon.com/supervised-machine-learning-linear-regression-in-python-541a5d8141ce)
+
+[Python哈希和等价性](https://hynek.me/articles/hashes-and-equality/)
+
+
+# 本周的Python工作
+
+[Bromium招聘高级Python Web开发](http://jobs.pythonweekly.com/jobs/senior-python-web-developer/)
+
+我们正在为我们的工程师团队寻找一名经验丰富的全栈开发者。你将从事Bromium Controller(一个用于我们的产品的基于web的管理平台)相关的工作。
+
+
+# 好玩的项目,工具和库
+
+[state_machine](https://github.com/jtushman/state_machine)
+
+人类Python状态机。
+
+[ActivityWatch](https://github.com/ActivityWatch/activitywatch)
+
+ActivityWatch是一个自动时间跟踪软件,帮助你跟踪你所做的事。
+
+[olympus](https://github.com/galiboo/olympus)
+
+一个用于任意AI模型的即时REST API。
+
+[ptracer](https://github.com/pinterest/ptracer)
+
+一个用于Python程序的基于ptrace跟踪的库。
+
+[KeplerMapper](https://github.com/MLWave/kepler-mapper)
+
+KeplerMapper是一个用于高维数据和三维点云数据可视化的Python类。
+
+[jean-pierre](https://github.com/matteocargnelutti/jean-pierre)
+
+一个帮助人们制作购物清单的树莓派机器人。
+
+[CardIO](https://github.com/analysiscenter/cardio)
+
+CardIO是一个用于心脏信号的数据科学研究的库。
+
+[pytest-annotate](https://github.com/kensho-technologies/pytest-annotate)
+
+根据pytest测试,生成PyAnnotate注释。
+
+[CHeSF](https://github.com/nicodds/chesf)
+
+CHeSF是Chrome Headless爬取框架,一个爬取JavaScript密集的web页面的非常非常初始的代码。
+
+[tavern](https://github.com/taverntesting/tavern)
+
+一个用于RESTful API自动化测试的命令行工具、Python库和Pytest插件,具有简单灵活的基于YAML的语法。
+
+[EqualAreaCartogram](https://github.com/LokiTechnologies/equalareacartogram)
+
+一个将Shapefile、GeoJSON或者CSV转换成等面积图纸SVG的Python脚本。
+
+[tosheets](https://github.com/kren1/tosheets)
+
+一个简单的命令行实用程序,它将你的标准输入发送到表中。
+
+[Nochi](https://github.com/rossumai/nochi)
+
+极简类AlphaGoZero引擎。
+
+
+# 近期活动和网络研讨会
+
+[San Francisco Django 2017年11月聚会 - San Francisco, CA](https://www.meetup.com/The-San-Francisco-Django-Meetup-Group/events/245111417/)
+
+将会有以下演讲:
+
+ * Django中的数据库设计和实现
+ * 架构:部署无自定义编码的自定义应用的平台
+
+
+[Philadelphia Python 2017年11月聚会 - Philadelphia, PA](https://www.meetup.com/phillypug/events/244306771/)
+
+将会有一个演讲,调试生产上的Python问题。
diff --git a/Python Weekly/Python_Weekly_Issue_323.md b/Python Weekly/Python_Weekly_Issue_323.md
new file mode 100644
index 0000000..b5fc6ff
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_323.md
@@ -0,0 +1,157 @@
+原文:[Python Weekly (Issue 323 - November 30 2017)](http://eepurl.com/dch2KX)
+
+---
+
+欢迎来到Python周刊第323期。让我们直奔主题。
+
+# 来自赞助商
+[](https://www.datacamp.com/promo/cybermonday)
+
+**[在DataCamp上省下$100!](https://www.datacamp.com/promo/cybermonday)**
+
+仅限Cyber Week,可以**无限次访问**DataCamp的数据科学学习库,获得超过$100的优惠。对于那些不了解DataCamp的人:它是通过专家指导的在线教程,确保你的Python技能永不过时的最直观的方法。现在就看看,优惠在12月5日结束!
+
+
+# 新闻
+
+[PSF 从 Mozilla 开源项目中获得了 $170,000 的资助,以提高PyPI的可持续性](https://pyfound.blogspot.com/2017/11/the-psf-awarded-moss-grant-pypi.html)
+
+# 文章,教程和讲座
+
+[演化策略的视觉指南](http://blog.otoro.net/2017/10/29/visual-evolution-strategies/)
+
+在这篇文章中,我通过几个视觉例子,解释了演化策略(ES)是如何工作的。这是系列文的第一篇。在这个系列文中,我计划展示将这些算法应用到一系列任务(从MNIST、OpenAI Gym、Roboschool到PyBullet环境 )上的方法。
+
+[演变中的稳定战略](http://blog.otoro.net/2017/11/12/evolving-stable-strategies/)
+
+在前面的文章中,我已经介绍了一些可以在不需要显式计算梯度的情况下,优化函数参数的演化策略(ES)算法。这些算法可以应用于强化学习(RL)问题上,以帮助找到适合神经网络代理的一组模型参数。在这篇文章中,我将探讨将ES应用于这些RL问题中的一些问题上,并强调我们可以使用来找到那些更稳定更健壮的策略的方法。
+
+[给数据科学家的正则表达式](https://www.dataquest.io/blog/regular-expressions-data-scientists/)
+
+在这篇教程中,学习如何使用正则表达式和 pandas 库来管理大型数据集。
+
+[使用CTC进行序列建模](https://distill.pub/2017/ctc/)
+
+(Connectionist Temporal Classification)视觉指南,用来训练语音识别、手写识别和其他序列问题中的深度神经网络的算法。
+
+[我们的NIPS 2017:学习跑步方法](https://medium.com/mlreview/our-nips-2017-learning-to-run-approach-b80a295d3bb5)
+
+从7月份到11月13日这3个月中(有时会有很长时间的休息),我和我的朋友Piotr Jarosik参加了NIPS 2017:学习跑步(Learning to Run)比赛。在这篇文章中,我们描述了它是如何进行的。我们发布了完整的源代码。
+
+[用OpenCV和Python进行图像哈希](https://www.pyimagesearch.com/2017/11/27/image-hashing-opencv-python/)
+
+本教程介绍了如何使用计算机视觉和通过OpenCV和Python进行图像处理,实现图像哈希和和知觉哈希。
+
+[变万物为矢量](https://blog.insightdatascience.com/entity2vec-dad368c5b830)
+
+entity2vec:使用协作学习方法来生成实体矢量。
+
+[Maya的并行GPU世界中的变形分层](https://medium.com/@charles_76959/deformation-layering-in-mayas-parallel-gpu-world-15c2e3d66d82)
+
+本文将介绍Maya 2017+中变形分层更好的现代实践。我将使用Brian Tindall的精彩的Hippydrome.comw网格。
+
+[通过Wavenet、MFCCs、UMAP、t-SNE和PCA进行比较音频分析](https://medium.com/@LeonFedden/comparative-audio-analysis-with-wavenet-mfccs-umap-t-sne-and-pca-cb8237bfce2f)
+
+这篇文章是关于一个在两个维度上探索音频数据集的项目的。我介绍了一些有趣的算法,例如NSynth、UMAP、t-SNE、MFCCs和PCA,展示了如何使用Librosa和TensorFlow,在Python中实现它们,还演示了使用HTML、JavaScript和CSS的可视化,这使我们能够交互地在一张二维参数化的图中探索这个音频数据集。
+
+[快3倍的Flask应用](https://medium.com/@pgjones/3x-faster-than-flask-8e89bfbe8e4f)
+
+自Flask首次发布以来,Python已经进化了,特别是引入了asyncio。保持Flask-API,但是切换到基于asyncio的Quart带来了3倍的加速。
+
+[使用OpenCV的BFS迷宫求解器](https://www.youtube.com/watch?v=-keGVhYmY2c)
+
+学习如何使用Python和OpenCV,创建一个非常炫酷的迷宫求解器。
+
+[用Python构建视频合成器](https://www.makeartwithpython.com/blog/video-synthesizer-in-python/)
+
+使用Onset Detection和aubio,构建一个视频合成器。
+
+[使用Dask + Numba 进行高效的内存模型评分](https://medium.com/capital-one-developers/dask-numba-for-efficient-in-memory-model-scoring-dfc9b68ba6ce)
+
+[花费5天时间运行的正则表达式。所以我弄了个工具,它在15分钟内跑完这个正则表达式。](https://medium.freecodecamp.org/regex-was-taking-5-days-flashtext-does-it-in-15-minutes-55f04411025f)
+
+[JupyterCon 2017视频集](https://www.youtube.com/playlist?list=PL055Epbe6d5aP6Ru42r7hk68GTSaclYgi)
+
+[使用Python的Pathlib模块](http://pbpython.com/pathlib-intro.html)
+
+
+# 书籍
+
+[scikit-learn Cookbook - Second Edition: Over 80 recipes for machine learning in Python with scikit-learn(scikit-learn烹饪指南第二版:在Python中使用scikit-learn进行机器学习的80多个食谱)](http://amzn.to/2jxBB4N)
+
+第二版首先带给你关于评估数据统计属性和为机器学习建模生成合成数据的食谱。接着,通过各章的层层演进,你将会看到一些食谱,它们会教你实现诸如数据预处理、线性回归、逻辑回归、K-NN、朴素贝叶斯、分类、决策树、集合等技术。此外,你还会学习如何使用多级分类、交叉验证、模型评估来优化你的模型,并且深入使用scikit-learn来实现深度学习。除了涵盖模型部分、API和诸如分类器、回归器和模拟器这样的新增功能外,本书还包含了评估和微调模型性能的方法。
+
+
+# 好玩的项目,工具和库
+
+[StarGAN](https://github.com/yunjey/StarGAN)
+
+StarGAN:用于多域图像到图像转换的统一生成对抗网络。
+
+[pytudes](https://github.com/norvig/pytudes)
+
+用于练习或演示技能的Python程序。
+
+[py2rs](https://github.com/rochacbruno/py2rs)
+
+给正在成为Rustacean的过程中的Pythonista的快速参考指南。
+
+[PyPika](https://github.com/kayak/pypika)
+
+PyPika是一个SQL查询生成器,具有pythonic语法,故而不限制SQL的表达能力。
+
+[cloud-inquisitor](https://github.com/RiotGames/cloud-inquisitor)
+
+在AWSA中实施所有权和数据安全的工具。
+
+[free-python-games](https://github.com/grantjenks/free-python-games/)
+
+Free Python Games是免费的Python游戏的Apache2许可集合,旨在教育和娱乐。这些游戏都是用简单的Python代码编写的,并且被设计于实验和更改。包含几个经典的街机游戏的简化版本。
+
+[the-endorser](https://github.com/eth0izzle/the-endorser)
+
+一个OSINT工具,允许你通过认可/技能,绘制出LinkedIn上的人员之间的关系。
+
+[shell-functools](https://github.com/sharkdp/shell-functools)
+
+用于shell的函数式编程工具集。
+
+[ripyr](https://github.com/predikto/ripyr)
+
+用于快速地自动从数据流中推断信息的实用程序。
+
+[Ignite](https://github.com/pytorch/ignite)
+
+Ignite是一个高级库,帮助你在PyTorch中训练神经网络。
+
+[FireAnt](https://github.com/kayak/fireant)
+
+数据分析和报告工具,可快速访问Jupyter Notebooks和shell中的自定义图表和表格。
+
+[mordecai](https://github.com/openeventdata/mordecai)
+
+定制的全文和事件地理解析。
+
+[Requestium](https://github.com/tryolabs/requestium)
+
+Requestium是一个Python库,它将Requests,Selenium和Parsel的功能合并成单个用于自动化web操作的集成工具。
+
+
+# 最新发布
+
+[PyCharm 2017.3](https://blog.jetbrains.com/pycharm/2017/11/pycharm-2017-3-is-out-now/)
+
+PyCharm 2017.3来啦:对于数据科学,它更快、可用性更强并且更好。
+
+
+# 近期活动和网络研讨会
+
+[Python + 数据科学 2017年12月聚会 - New York, NY](https://www.meetup.com/python-plus-data-science/events/245122800/)
+
+将会有一个演讲 —— Python中的产业优势NLP:spaCy&Stanford CoreNLP
+
+[DFW Pythoneers 2017年12月聚会 - Plano, TX](https://www.meetup.com/dfwpython/events/238603016/)
+
+
+
+
diff --git a/Python Weekly/Python_Weekly_Issue_324.md b/Python Weekly/Python_Weekly_Issue_324.md
new file mode 100644
index 0000000..5403772
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_324.md
@@ -0,0 +1,185 @@
+原文:[Python Weekly - Issue 324](http://eepurl.com/ddcPpT)
+
+---
+
+欢迎来到Python周刊第324期。让我们直奔主题。
+
+[](https://click.linksynergy.com/link?id=x9UsEHf2tls&offerid=323085.1400924&type=2&murl=https%3A%2F%2Fwww.udemy.com%2Fmachine-learning-for-apps%2F)
+
+[为应用而备的机器学习](https://click.linksynergy.com/link?id=x9UsEHf2tls&offerid=323085.1400924&type=2&murl=https%3A%2F%2Fwww.udemy.com%2Fmachine-learning-for-apps%2F)
+
+开始使用机器学习构建更智能的应用吧。利用这个新的基础框架!
+
+
+# 文章,教程和讲座
+
+[超过一百万份的废除网络中立频率可能是假的](https://hackernoon.com/more-than-a-million-pro-repeal-net-neutrality-comments-were-likely-faked-e9f0e3ed36a6)
+
+我使用自然语言处理技术来分析2017年4月至10月提交给FCC的网络中立评论,结果令人不安。代码可以[在这里](https://github.com/j2kao/fcc_nn_research)找到。
+
+[疯狂的现场编程 —— 让我们构建一个深度学习库](https://www.youtube.com/watch?v=o64FV-ez6Gw)
+
+使用Python 3.6现场从头编程一个深度学习库,并且用它来解决Fizz Buzz。
+
+[使用机器学习预测天气:第三部分](http://stackabuse.com/using-machine-learning-to-predict-the-weather-part-3/)
+
+这是关于通过Python使用机器学习,基于从Weather Underground获取的气象天气数据(如本系列的第一部分所述),对平均温度进行预测系列的最后一篇。这最后一篇文章的主题将是使用谷歌开源的TensorFlow库,构建一个神经网络回归器。
+
+[从不平衡类中学习](https://www.svds.com/tbt-learning-imbalanced-classes/)
+
+本文提供了关于如何解决不平衡数据的见解和具体建议。如果你在处理这些问题,并且想要得到实际的建议,那么,请继续阅读。
+
+[TensorRT 3:更快的TensorFlow推导和Volta支持](https://devblogs.nvidia.com/parallelforall/tensorrt-3-faster-tensorflow-inference/)
+
+NVIDIA TensorRT是一款高性能的深度学习推理优化器和运行库,可为深度学习应用提供低延迟、高吞吐量推理。NVIDIA去年发布了TensorRT,目标是加速生产部署的深度学习推理。在这篇文章中,我们将介绍TensorRT 3,相较于以前的版本,它提高了性能,并且包含了一些使其更易于使用的新功能。
+
+[使用Click编写Python命令行工具](https://dbader.org/blog/python-commandline-tools-with-click#intro)
+
+关于使用Click库进行参数解析等的高级Python命令行工具的深入教程。
+
+[使用Python的PCA (scikit-learn)](https://towardsdatascience.com/pca-using-python-scikit-learn-e653f8989e60)
+
+加速机器学习算法的更常见的方式是使用主成分分析(PCA)。要理解将PCA用于数据可视化的价值,本教程的第一部分将在应用PCA后,对IRIS数据集进行基本的可视化。第二部分使用PCA来在MNIST数据集上加速机器学习算法(逻辑回归)。
+
+[从头开始学习Python装饰器](https://pabloariasal.github.io/python-decorators-from-the-ground-up/)
+
+装饰器是我们的好基友。尽管如此,它们往往被看成一个相当模糊的特性,并且往往被严重忽视。在这篇文章中,我将告诉你,装饰器不需要很复杂,并且如果使用得当,在很多情况下,它都会成为你的MVP。
+
+[Django日志记录正确之道](https://lincolnloop.com/blog/django-logging-right-way/)
+
+好的日志记录对调试和问题定位至关重要。它不仅是对本地开发有用,而且在生产中也是不可或缺的。当为了定位问题查找日志时,很少听到有人会说:“我们的应用中日志太多了。”反而常常听到相反的内容(日志太少)。所以,考虑到这一点,让我们开始吧。
+
+[使用Celery和Redis的Flask异步后台任务](http://allynh.com/blog/flask-asynchronous-background-tasks-with-celery-and-redis/)
+
+本文将介绍如何在Flask环境中实现异步后台任务的一个实例,以我正在进行的构建迪斯尼游戏库管理web应用这个项目为例。
+
+[应用类型提示](https://www.youtube.com/watch?v=JqBCFfiE11g)
+
+本演讲介绍了作为Python开发一部分的可选静态类型提示,并且与其他语言中强大的运行时强制进行对比。我们介绍了类型提示的历史、Python语言中函数和变量注释的作用、演示类型提示以及展示了如何在项目中,从类型注释中获利。
+
+[使用TensorFlow的机器学习WAVE文件](https://becominghuman.ai/machine-learning-wave-files-with-tensorflow-5a990385fb3e)
+
+学习如何在Python中处理WAVE文件,并深入研究如何创建TensorFlow操作。
+
+[Python socket备忘录](https://github.com/crazyguitar/pysheeet/blob/master/docs/notes/python-socket.rst)
+
+[PyCon.DE 2017视频集](https://www.youtube.com/watch?v=3h-6GBBF4Hg&list=PLHd2BPBhxqRI_HtgmPJcm3LPAlhdX6J9v)
+
+[使用Flask-SocketIO,将Flask变成一个实时websocket服务器](https://secdevops.ai/weekend-project-part-2-turning-flask-into-a-real-time-websocket-server-using-flask-socketio-ab6b45f1d896)
+
+
+# 书籍
+
+[Pandas Cookbook(Pandas烹饪指南)](http://amzn.to/2zPrByO)
+
+本书将向你提供干净清晰的食谱,以及解释如何使用pandas处理常见的数据操作和科学计算任务的解决方案。你将会处理不同类型的数据集,并且有效地进行数据操作和数据处理。你将探索pandas DataFrame的威力,并且弄清楚布尔和多索引。本书还涵盖了与统计和时间序列计算相关的任务,以及在财务和科学应用中实现它的方法。
+
+
+# 本周的Python工作
+
+[Enthought招聘Python技术培训师](http://jobs.pythonweekly.com/jobs/python-technical-trainer/)
+
+Enthought正在寻找一名惊才艳艳的Python教师,他需要有教学热情,以及把Python用于科学计算/数据科学应用的扎实经验。你将在我们位于Austin市区的办公室工作,并且还将会到大城市出差,向各行各业的科学家、工程师、分析师和数据科学家教授Python。
+
+[Beauhurst招聘全栈web开发人员](http://jobs.pythonweekly.com/jobs/full-stack-web-developer/)
+
+如果你是一个勇敢的多面手,至少有一年的工作经验,喜欢使用Django和Python,那么,这可能是最好的机会。Beauhurst的使命是寻找和跟踪英国每一个雄心勃勃的高增长业务。我们的web平台是这些令人兴奋的公司的数据的首要来源。随着我们扩大覆盖范围,并努力让我们的产品更加有用,你将帮助我们提供访问、存储和分析数据的新/改进方法。
+
+
+# 好玩的项目,工具和库
+
+[HoME Platform](https://github.com/HoME-Platform/home-platform)
+
+家庭多模式环境是人造代理从视觉、语言、语义、物理和与对象以及其他代理的交互中学习的平台。
+
+[handtracking](https://github.com/victordibia/handtracking)
+
+在Tensorflow上,使用神经网络(SSD),构建一个实时手写字检测器。
+
+[MatchZoo](https://github.com/faneshion/MatchZoo)
+
+MatchZoo是一个文本匹配工具包。它是为了便于深度学习匹配模型的设计、比较和共享而开发的。
+
+[Misocoin](https://github.com/kendricktan/misocoin)
+
+用Python 3.6实现的裸类比特币协议。
+
+[sentiment-discovery](https://github.com/NVIDIA/sentiment-discovery)
+
+用于健壮的情感分类的大规模无监督语言建模。
+
+[deep-image-prior](https://github.com/DmitryUlyanov/deep-image-prior)
+
+使用神经网络但是不使用机器学习的图像恢复。
+
+[toapi](https://github.com/gaojiuli/toapi)
+
+让任何网站提供API的库。
+
+[Flake8Rules](https://lintlyci.github.io/Flake8Rules/)
+
+Flake8中规则的描述和示例(pyflakes,pycodestyle和mccabe)。
+
+[selectolax](https://github.com/rushter/selectolax)
+
+使用Modest引擎的快速HTML5解析器和CSS选择器。
+
+[DeepVariant](https://github.com/google/deepvariant)
+
+DeepVariant是一种分析流水线,使用深度神经网络来从下一代DNA测序数据中调用遗传变异。
+
+[RFCrack](https://github.com/cclabsInc/RFCrack)
+
+软件定义的无限攻击工具。它是为测试任何通过亚Ghz频率来进行通信的物理设备之间的RF通信而开发的。物联网设备、汽车、报警系统等。
+
+[bucket-stream](https://github.com/eth0izzle/bucket-stream)
+
+通过查看证书透明度日志,查找有趣的Amazon S3 Bucket。
+
+[pynb](https://github.com/minodes/pynb)
+
+作为纯Python代码的Jupyter Notebooks,带嵌入式Markdown文本。
+
+[MAgent](https://github.com/geek-ai/MAgent)
+
+用于多agent强化学习的平台。
+
+[optimal-buy-gdax](https://github.com/brndnmtthws/optimal-buy-gdax)
+
+定期用最优的方案,从GDAX购买BTC,ETH和LTC!
+
+[sumeval](https://github.com/chakki-works/sumeval)
+
+用于文本摘要的经过良好测试的多语言评估框架。
+
+
+# 最新发布
+
+[Django 2.0](https://www.djangoproject.com/weblog/2017/dec/02/django-20-released/)
+
+这个版本开始了Django对语义版本的松散形式的使用,但是,没有任何主要的向后不兼容的变化(除了删除了对Python 2.7的支持),这可能就是2.0版本的预期了。对于所有更改,请检查[发布说明](https://docs.djangoproject.com/en/2.0/releases/2.0/)。
+
+
+[PyDev 6.2.0](https://pydev.blogspot.com/2017/11/pydev-620-interactive-console-word.html)
+
+PyDev 6.2.0主要是一个错误修正版本,虽然它确实为表格增加了一些功能,例如增加在控制台中激活文字换行的可能性,并且支持使用Python 3.6的变量类型的代码完成。
+
+[Python 3.6.4rc1和3.7.0a3](http://blog.python.org/2017/12/python-364rc1-and-370a3-now-available.html)
+
+Python 3.6.4rc1和3.7.0a3现在可以测试使用了。
+
+
+# 近期活动和网络研讨会
+
+[Boulder Python 2017年12月聚会 - Boulder, CO](https://www.meetup.com/BoulderPython/events/239106678/)
+
+将会有以下演讲:
+
+ * Dunder Wonder:Python的魔术方法
+ * AST和我
+
+
+[Austin Python 2017年12月聚会 - Austin, TX](https://www.meetup.com/austinpython/events/243637650/)
+
+
+
diff --git a/Python Weekly/Python_Weekly_Issue_325.md b/Python Weekly/Python_Weekly_Issue_325.md
new file mode 100644
index 0000000..9a8d17d
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_325.md
@@ -0,0 +1,137 @@
+原文:[Python Weekly - Issue 325](http://eepurl.com/dd8nG5)
+
+---
+
+欢迎来到Python周刊第325期。让我们直奔主题。
+
+# 来自赞助商
+
+[](https://goo.gl/wlxnDm)
+
+现在可以[通过pip,从PyPI安装](https://software.intel.com/en-us/articles/installing-the-intel-distribution-for-python-and-intel-performance-libraries-with-pip-and?utm_source=13Dec2017%20ad%20Python%20weekly&utm_medium=email&utm_campaign=Dec%202017%20Python%20Weekly%20newsletter)英特尔Python版本加速包(包括NumPy、Scipy、性能库和运行时包)。Intel Python团队感谢用户不断的支持,并有机会为2017年更好更快的Python做出贡献。节日快乐!
+
+
+# 新闻
+
+[Ubuntu Devs在为Ubuntu 18.04 LTS将Python 2扔到“Universe”存储库中](http://news.softpedia.com/news/ubuntu-devs-work-on-demoting-python-2-to-universe-repo-for-ubuntu-18-04-lts-518926.shtml)
+
+
+# 文章,教程和讲座
+
+[如何用机器学习,在15分钟内破解验证码系统](https://medium.com/@ageitgey/how-to-break-a-captcha-system-in-15-minutes-with-machine-learning-dbebb035a710)
+
+让我们一起破解世界上最流行的Wordpress CAPTCHA插件。
+
+[区块链开发介绍](https://www.youtube.com/watch?v=drpzgnPNno8)
+
+来自Loom Network,Ex DigitalOcean,Bloomberg的Matthew Campbell。向Python群众展示了如何牢固地构建他们的第一个智能合约。以及如何使用Node和Python 来与智能合约进行交互。
+
+[用pandas处理Excel文件](https://www.dataquest.io/blog/excel-and-pandas/)
+
+在这篇教程中,我们将向你介绍如何用pandas处理Excel文件 —— 从设置你的电脑环境,到移动和可视化数据。
+
+[预测员工流失](https://towardsdatascience.com/predicting-employee-turnover-7ab2b9ecf47e)
+
+在这篇文章中,我们将使用来自kaggle的模拟HR数据,来构建一个分类器,以帮助我们预测:在某些情况下,什么类型的员工更有可能离职。这样子的分类器将有助于帮助公司预测员工流失率,并积极帮助解决这些昂贵的问题。我们将限制使用最常见的分类器:随机森林、梯度提升树、K最近邻、逻辑回归和支持向量机。
+
+[Django Admin基于范围的日期层次结构](https://codeburst.io/django-admin-range-based-date-hierarchy-37955b12ea4e)
+
+我们是如何显著改进Django Admin的日期层次结构的。
+
+[使用Scrapy、Geopy和Leaflet,爬取、地理编码和绘图点](https://cbrownley.wordpress.com/2017/12/12/scraping-geocoding-and-mapping-points-with-scrapy-geopy-and-leaflet/)
+
+在地图上显示兴趣点是很有趣的,并且可以作为地理空间分析有意义的第一步。当数据已经包含点的经纬度时,这个任务是相对简单的。然而,有时,数据并不包含这些信息,例如,当你只是拥有一个地址列表的时候。在这种情况下,为了在地图上显示这些点,你可以对地址进行地理编码,以确定它们的经纬度。我们来处理这种情况,以演示如何对地址进行地理编码,然后将其显示在地图上。
+
+[给初学者的Python Web爬取以及舆情分析教程 | Top 100 Subreddits](https://www.youtube.com/watch?v=e6xZAISu-5E)
+
+学习如何使用python、bs4和TextBlob,来爬取web并进行情感分析,以及学习如何使用PRAW python reddit API。
+
+[GitPython第一步](https://www.fullstackpython.com/blog/first-steps-gitpython.html)
+
+GitPython是一个用于编程读取和写入Git源代码控制库的Python代码库。让我们快速地安装并且读取一个本次克隆的Git存储库,来一起学习如何使用GitPython。
+
+[Django 2.0 Window表达式教程](http://agiliq.com/blog/2017/12/django-20-window-expressions-tutorial/)
+
+Django 2.0最近发布了,其中最让我兴奋的是对Window表达式的支持,这允许我们把一个OVER子句添加到查询集中。我们会使用Window表达式来分析提交到Django参考的数据。
+
+[Pandas拼接教程](https://www.dataquest.io/blog/pandas-concatenation-tutorial/)
+
+在这个教程中,我们将介绍使用pandas合并数据的几种方法。
+
+[利用TensorFlow进行声音分类](https://medium.com/iotforall/sound-classification-with-tensorflow-8209bdb03dfb)
+
+将此方法与物联网平台联合使用,让你可以在非常广泛的领域中构建智能解决方案。
+
+[关于棒球,Moneyball可以告诉我们些什么?](https://www.kaggle.com/nikdudaev/what-moneyball-can-tell-us-about-baseball/notebook)
+
+[使用Bottle、SQLAlchemy和Twitter API,构建一个简单的web应用](https://realpython.com/blog/python/building-a-simple-web-app-with-bottle-sqlalchemy-twitter-api/)
+
+[将一个基于Django的应用从1.11升级到2.0](https://nezhar.com/blog/upgrade-a-django-based-application-from-1-11-to-2-0/)
+
+[使用Numba和ParallelAccelerator的并行化Python](https://www.anaconda.com/blog/developer-blog/parallel-python-with-numba-and-parallelaccelerator/)
+
+[用机器学习计算人数](https://www.byu.io/2017/12/07/counting-people-with-ml)
+
+[Python中的Cassandra性能:避免namedtuple](https://rhye.org/post/python-cassandra-namedtuple-performance/)
+
+
+# 本周的Python工作
+
+[Jewellery Quarter Bullion招聘经验丰富的Django开发人员](http://jobs.pythonweekly.com/jobs/experienced-django-developer/)
+
+Jewellery Quarter Bullion正在寻找一名经验丰富的Django开发人员来支持我们不断增长的开发团队,因为我们将继续改进我们的系统,并在国际上扩张。
+
+
+# 好玩的项目,工具和库
+
+[skorch](https://github.com/dnouri/skorch)
+
+一个封装了pytorch的scikit-learn兼容的神经网络库。
+
+[download_emails.py](https://teklern.blogspot.com/2017/11/download-all-your-email-information.html)
+
+用这个Python 3.6程序,下载你所有的电子邮件信息吧。
+
+[Goose3](https://github.com/goose3/goose3/)
+
+一个用Python编写的文章提取器。
+
+[XDiFF](https://github.com/IOActive/XDiFF)
+
+XDiFF是一个可扩展的差分模糊暴力式探测框架,用于查找漏洞。它的目标是收集尽可能多的有价值的数据,然后推断应用程序中的所有潜在漏洞。
+
+[lcp-physics](https://github.com/locuslab/lcp-physics)
+
+PyTorch中的一个可区分的LCP物理引擎。
+
+[minimum_python_ide](https://github.com/minimumbuilds/minimum_python_ide)
+一个预先构建的Vim 8.0 IDE,支持python2/3等等 —— 在Docker中。
+
+[HereIsWally](https://github.com/tadejmagajna/HereIsWally)
+
+通过在图像中找到Wally的确切位置来解决Wally困局的深度学习项目。
+
+[mssql-cli](https://github.com/dbcli/mssql-cli)
+
+一个SQL服务器的命令行客户端,带自动补全和语法高亮。
+
+
+# 近期活动和网络研讨会
+
+[Kubernetes与Python - London, UK](https://www.meetup.com/LondonPython/events/244725466/)
+
+在这个讲座中,你会学习Kubernetes的一些基本概念,学习可以如何在集群内外利用来自Python程序的API以及使用这些知识来创建监控服务和chaos monkeys的过程。讲座结束后,你将能够设计并调试你自己的服务,并且理解使用Kubernetes的乐趣。
+
+[Boston Python 2017年12月聚会 - Cambridge, MA](https://www.meetup.com/bostonpython/events/244941784/)
+
+将会有以下演讲:
+
+ * 用Python控制一个监控摄像头
+ * DragonPaint - 引导小数据到彩色漫画
+
+
+[PyHou 2017年12月聚会 - Houston, TX](https://www.meetup.com/python-14/events/242603695/)
+
+
+
+
diff --git a/Python Weekly/Python_Weekly_Issue_326.md b/Python Weekly/Python_Weekly_Issue_326.md
new file mode 100644
index 0000000..d6603f9
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_326.md
@@ -0,0 +1,146 @@
+原文:[Python Weekly - Issue 326](http://eepurl.com/de-5aH)
+
+---
+
+欢迎来到Python周刊第 326 期。愿诸君节日快乐,期待 2018 的到来,为你们呈现最好的 Python 相关链接。
+
+[](https://click.linksynergy.com/link?id=x9UsEHf2tls&offerid=323085.567828&type=2&murl=https%3A%2F%2Fwww.udemy.com%2Fcomplete-python-bootcamp%2F)
+
+[Complete Python Bootcamp: Go from zero to hero in Python](https://click.linksynergy.com/link?id=x9UsEHf2tls&offerid=323085.567828&type=2&murl=https%3A%2F%2Fwww.udemy.com%2Fcomplete-python-bootcamp%2F)
+
+像专家一样学习 Python!从基础开始,一路前行,去创建你自己的应用和游戏!
+
+
+# 新闻
+
+[Microsoft 考虑将 Python 作为官方脚本语言添加到 Excel](https://www.bleepingcomputer.com/news/microsoft/microsoft-considers-adding-python-as-an-official-scripting-language-to-excel/)
+
+[DjangoCon Europe 2018 更新:已经开放早鸟票、CFP 和机会奖励!](https://www.djangoproject.com/weblog/2017/dec/18/djangocon-europe-2018-update-early-bird-tickets-ca/)
+
+[SciPy 2018 建议征集现已开放](https://scipy2018.scipy.org/ehome/index.php?eventid=299527&)
+
+
+# 文章,教程和讲座
+
+[迭代演进:for 循环的未授权传记](https://www.youtube.com/watch?v=2AXuhgid7E4)
+
+在这个演讲中,David Beazley 讨论了 for 循环的早期演变、迭代协议以及导致生成器函数和协程的发展。还特别说明了 Python 0.9.1 编码的诡异世界。
+
+[用 Python 构建一个穷人深度学习摄像头](https://www.makeartwithpython.com/blog/poor-mans-deep-learning-camera/)
+
+将摄像头流式传输到深度学习模型,黑客方式。
+
+[自动化 Oncall:开源 Fossor 和 Ascii Etch](https://engineering.linkedin.com/blog/2017/12/open-sourcing-fossor-and-ascii-etch)
+
+LinkedIn 开源了两个新工具,以帮助工程师自动调查挂掉的主机和服务:Fossor 和 Ascii Etch。Fossor 是一个面向插件的 Python 工具和自动调查挂掉的主机和服务的库。Ascii Etch 也是一个 Python 库,它获取数字流,然后使用 ascii 字符将它们转换成可视化图形,最初创建来帮助展示 Fossor 的输出。我们遇到了一些真正的挑战,这些挑战导致了这些工具的诞生。本文将涵盖这些内容,以及如何通过创建插件,为特定的目的,量身定制 Fossor。
+
+[树莓派上的 Keras 和深度学习](https://www.pyimagesearch.com/2017/12/18/keras-deep-learning-raspberry-pi/)
+
+在这篇指南中,你将会学习使用Keras、Python 和 TensorFlow,在树莓派上进行实时的深度学习。
+
+[用 Python 创建 J.A.R.V.I.S](https://www.youtube.com/watch?v=2eoudIBVW9w)
+
+学习如何使用 Python 和谷歌的 Text-To-Speech 来创建 J.A.R.V.I.S,一个语言激活桌面助手。
+
+[用于灾难发现的深度学习](https://blog.insightdatascience.com/deep-learning-for-disaster-recovery-45c8cd174d7a)
+
+自动检测被水淹的道路。
+
+[使用 Docker Compose 和 RabbitMQ 的深度学习实验分布式计算系统](https://deezer.io/a-distributed-computation-system-for-deep-learning-experiments-with-docker-compose-and-rabbitmq-5ac4ab344406)
+
+本文提供了一个解决方案,用于处理运行深度学习实验(训练过程中需要大量的处理以生成数据)时出现的计算任务的分配。它展示了常见的代理模式的一个实际的案例研究,并举例说明如何可以轻松使用 Docker 部署系统堆栈的不同组件。
+
+[使用 Salt 进行基础架构管理的 Python 开发](https://mirceaulinic.net/2017-12-19-salt-pure-python/)
+
+Salt 被忽视的一面,以及一些最佳实践。
+
+[用 Python 自动化无聊的东西 —— tinder](https://gfycat.com/PointlessSimplisticAmericanquarterhorse)
+
+[用 Python 模拟滑梯](https://jakevdp.github.io/blog/2017/12/18/simulating-chutes-and-ladders )
+
+[如何使用 Python 和 Flask 构建一个 web 应用 —— 深入教程](https://medium.freecodecamp.org/how-to-use-python-and-flask-to-build-a-web-app-an-in-depth-tutorial-437dbfe9f1c6)
+
+[Python 的 PrettyPrinter 介绍](https://tommikaikkonen.github.io/introducing-prettyprinter-for-python/)
+
+[Ruby 和 Python 分析器是如何工作的?](https://jvns.ca/blog/2017/12/17/how-do-ruby---python-profilers-work-/)
+
+[电影评级的探索性分析和信用卡交易的欺诈检测](https://sandipanweb.wordpress.com/2017/12/16/data-science-with-python-exploratory-analysis-with-movie-ratings-and-fraud-detection-with-credit-card-transactions/)
+
+
+# 书籍
+
+[wxPython Recipes: A Problem - Solution Approach](http://amzn.to/2BnMcuJ)
+
+快速发现常见问题的解决方案,学习最佳实践,并且了解 wxPython 提供的一切。本书适合希望了解如何使用 wxPython 桌面 GUI 工具包的人。它假设读者具有一些 Python 知识,并对 wxPython 或者 GUI 开发有一个大体的了解,并且,它包含了超过 50 个解决方案,涵盖了工具包的各种任务和方面。
+
+
+# 好玩的项目,工具和库
+
+[turicreate](https://github.com/apple/turicreate)
+
+Turi Create 简化了自定义机器学习模型的开发。你无需是机器学习专家,即可将推荐、对象检测、图像分类、图像相似性或者活动分类添加到你的应用中。
+
+[fossor](https://github.com/linkedin/fossor)
+
+一个自动化调查挂掉的主机和服务的面向插件的工具。
+
+[memory_utils](https://github.com/jtushman/memory_utils)
+
+一个帮助对抗和防止内存泄漏的工具。
+
+[asciietch](https://github.com/linkedin/asciietch)
+
+一个旨在让使用 ascii 字符绘图变得简单的图形库。
+
+[MonkeyType](https://github.com/Instagram/MonkeyType)
+
+一个用于 Python,通过收集运行时类型来生成静态类型注释的系统。
+
+[PowerfulSeal](https://github.com/bloomberg/powerfulseal)
+
+一个强大的 Kubernetes 集群测试工具。
+
+[whatsapp-assistant-bot](https://github.com/jctissier/whatsapp-assistant-bot)
+
+一个个人 WhatsApp 助理机器人,可以帮助你在网上(Google、Images、Google Maps)搜索任何东西。
+
+[PrettyPrinter](https://github.com/tommikaikkonen/prettyprinter)
+
+用于 Python 3.6+ 的语法高亮、声明式和可组合的美化打印。
+
+[chainer-chemistry](https://github.com/pfnet-research/chainer-chemistry)
+
+生物和化学中的深度学习库。
+
+[Dependabot](https://github.com/dependabot/dependabot-core)
+
+Ruby、JavaScript、Python 和 PHP 的自动依赖管理。
+
+[word2vec-spam-filter](https://github.com/doodyparizada/word2vec-spam-filter)
+
+使用单词向量来分类垃圾邮件。
+
+[spreadsheet.py](https://gist.github.com/alchemyst/b6328a89d4dc9526f39e5871ec138d01)
+
+一个简单的 GUI 电子表格,少于 100 行 Python 代码。
+
+[Age-Gender-Estimate-TF](https://github.com/BoyuanJiang/Age-Gender-Estimate-TF)
+
+基于卷积神经网络和 TensorFlow 的年龄和性别估计。
+
+[tensorflow-1.4-billion-password-analysis](https://github.com/philipperemy/tensorflow-1.4-billion-password-analysis)
+
+分析大量明文密码的深度学习模型。
+
+[open-paperless](https://github.com/zhoubear/open-paperless)
+
+扫描、索引和归档所有的纸质文档。
+
+[ATM](https://github.com/HDI-Project/ATM)
+
+自动调谐模型 —— 一个模型选择和调谐的多用户多数据系统。
+
+
+# 最新发布
+
+[Python 3.6.4](https://blog.python.org/2017/12/python-364-is-now-available.html)
diff --git a/Python Weekly/Python_Weekly_Issue_327.md b/Python Weekly/Python_Weekly_Issue_327.md
new file mode 100644
index 0000000..07f9ce6
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_327.md
@@ -0,0 +1,118 @@
+原文:[Python Weekly - Issue 327 ](http://eepurl.com/dfOOcv)
+
+---
+欢迎来到Python周刊第327期。让我们直奔主题。
+
+# 来自赞助商
+
+[](https://click.linksynergy.com/link?id=x9UsEHf2tls&offerid=323085.753140&type=2&murl=https%3A%2F%2Fwww.udemy.com%2Fdata-science-natural-language-processing-in-python%2F)
+
+[数据科学:Python 中的自然语言处理(NLP)](https://click.linksynergy.com/link?id=x9UsEHf2tls&offerid=323085.753140&type=2&murl=https%3A%2F%2Fwww.udemy.com%2Fdata-science-natural-language-processing-in-python%2F)
+
+实用 NLP 的完整指南:垃圾邮件检测、情感分析、文章调整器和潜在语义分析。
+
+# 新闻
+
+[BIDS 收到斯隆基金会的资助,以为 NumPy 的发展作出贡献](https://bids.berkeley.edu/news/bids-receives-sloan-foundation-grant-contribute-numpy-development)
+
+伯克利数据科学研究院(BIDS)很高兴地宣布,它已经获得了阿尔弗雷德·斯隆基金会的资助,以支持 NumPy 的发展。该赠款补充了戈登和贝蒂·摩尔基金会在 2016 年为同样目的而提供的资金。支援赠款的 BIDS 团队包括(按字母顺序)Jonathan Dugan,Jarrod Millman,Fernando Perez,Nathaniel Smith,Nelle Varoquaux 和 Stefan van der Walt。
+
+
+# 文章,教程和讲座
+
+[我黑了 HQ Trivia,但这里是他们如何阻止我的](https://hackernoon.com/i-hacked-hq-trivia-but-heres-how-they-can-stop-me-68750ed16365)
+
+为了探索黑入 HQ 的可行性,我写了一个脚本,它赢了大部分的 HQ 游戏。在这篇文章中,我解释了这个脚本是如何工作的,以及 HQ 自身如何对抗这些攻击。
+
+[Dumbcoin(哑币)—— 一个类比特币区块链的教育性 Python 实现](https://github.com/julienr/ipynb_playground/blob/master/bitcoin/dumbcoin/dumbcoin.ipynb)
+
+This is an experimental notebook that implements most of the concepts of a bitcoin-like blockchain in python.
+
+[使用 Django REST 框架,构建一个 Rest API](https://www.youtube.com/watch?v=tG6O8YF91HE)
+
+This is a rapid-fire guide on covering the basics to build a REST API with Django & Python.
+
+[使用遗传算法和深度学习,用 Python 从零开始演化简单的生物种群](https://nathanrooy.github.io/posts/2017-11-30/evolving-simple-organisms-using-a-genetic-algorithm-and-deep-learning/)
+
+学习如何使用遗传算法来演化一个简单的生物种群(每个包含独特的神经网络)。
+
+[贵宾犬,哈巴狗还是维也纳狗?](https://thenewstack.io/poodle-pug-weiner-dog-deploying-dog-identification-tensorflow-model-using-python-flask/)
+
+使用 Python 和 Flask,部署一个汪星人识别 TensorFlow 模型。
+
+[Python 中的随机森林](https://medium.com/@williamkoehrsen/random-forest-in-python-24d0893d51c0)
+
+一个实用的端到端机器学习示例。
+
+[用 Python 进行加密货币分析 - MACD](https://romanorac.github.io/cryptocurrency/analysis/2017/12/17/cryptocurrency-analysis-with-python-part1.html)
+
+加密货币正成为主流,因此,我决定花费周末的时间来学习它。我设计了下载每日比特币价格的代码,并以你敢用一个简单的交易策略。
+
+[通过机器学习发现隐藏模式](https://www.oreilly.com/ideas/uncovering-hidden-patterns-through-machine-learning)
+
+使用 Apache MXNet,从 FizzBuzz 学到的。
+
+[用 Python 进行加密数字货币分析 —— 购买和持有](https://romanorac.github.io/cryptocurrency/analysis/2017/12/25/cryptocurrency-analysis-with-python-part2.html)
+
+在这个部分,我将利用买入和持有策略,分析过去两个月中哪些货币(比特币、以太坊或莱特币)获利最多。我们将对这三种加密货币进行分析,然后试图给出一个客观的答案。
+
+[高级 Numpy 技术](https://nbviewer.jupyter.org/github/vlad17/np-learn/blob/master/presentation.ipynb)
+
+[写时复制的友好 Python 垃圾收集器](https://engineering.instagram.com/copy-on-write-friendly-python-garbage-collection-ad6ed5233ddf)
+
+[升级到 Django 2.0 的 10 个技巧](http://eldarion.com/blog/2017/12/26/10-tips-upgrading-django-20/)
+
+[pyGAM:Python 中的通用添加模型入门](https://codeburst.io/pygam-getting-started-with-generalized-additive-models-in-python-457df5b4705f)
+
+[CPython 列表笔记](https://rcoh.svbtle.com/notes-of-cpython-lists)
+
+# 书籍
+
+[Deep Learning with Python(使用 Python 进行深度学习)](http://amzn.to/2liyYEU)
+
+Deep Learning with Python 介绍了深度学习领域(使用 Python 语言和强大的 Keras 库)。本书由 Keras 的创造者和 Google AI 研究院 François Chollet 撰写,通过直观的解释和实例来加深理解。
+
+
+# 好玩的项目,工具和库
+
+[end-to-end-negotiator](https://github.com/facebookresearch/end-to-end-negotiator)
+
+这是研究论文“Deal or No Deal? End-to-End Learning for Negotiation Dialogues”的 PyTorch 实现,由 Facebook AI Research 开发。该代码训练神经网络,以使用自然语言进行谈判,并允许强化学习自我发挥和基于部署的计划。
+
+[electricitymap](https://github.com/tmrowco/electricitymap)
+
+电力消耗的二氧化碳排放量的实时可视化。
+
+[cryptoview](https://github.com/anfederico/cryptoview)
+
+多交易交易者的优雅投资组合管理。
+
+[AlphaZero_Gomoku](https://github.com/junxiaosong/AlphaZero_Gomoku)
+Gomoku(也被称为五子棋或者五行棋)的 AlphaZero 算法的一种实现。
+
+[MUSE](https://github.com/facebookresearch/MUSE)
+
+多语言无监督或者有监督词语嵌入库。
+
+[WhatWaf](https://github.com/Ekultek/WhatWaf)
+
+检测并绕过网络应用防火墙和防护系统。
+
+[yolo2-pytorch](https://github.com/ruiminshen/yolo2-pytorch)
+
+YOLO (You Only Look Once) v2 的 PyTorch 实现。
+
+[bottom-up-attention-vqa](https://github.com/hengyuan-hu/bottom-up-attention-vqa)
+
+2017 VQA 挑战赛的获奖作品的一个高效的 PyTorch 实现。
+
+[transformer-tensorflow](https://github.com/DongjunLee/transformer-tensorflow)
+
+“Attention Is All You Need”的 TensorFlow 实现。
+
+
+# 最新发布
+
+[PyPy2.7 和 PyPy3.5 v5.10 双版本发布](https://morepypy.blogspot.com/2017/12/pypy27-and-pypy35-v510-dual-release.html)
+
+
\ No newline at end of file
diff --git a/Python Weekly/Python_Weekly_Issue_328.md b/Python Weekly/Python_Weekly_Issue_328.md
new file mode 100644
index 0000000..188a8f3
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_328.md
@@ -0,0 +1,134 @@
+原文:[Python Weekly - Issue 328 ](http://eepurl.com/dgkfqj)
+
+---
+
+欢迎来到Python周刊第328期。让我们直奔主题。
+
+# 来自赞助商
+
+[](https://click.linksynergy.com/link?id=x9UsEHf2tls&offerid=323085.903744&type=2&murl=https%3A%2F%2Fwww.udemy.com%2Fpython-for-data-science-and-machine-learning-bootcamp%2F)
+
+[Python 数据科学和机器学习训练营](https://click.linksynergy.com/link?id=x9UsEHf2tls&offerid=323085.903744&type=2&murl=https%3A%2F%2Fwww.udemy.com%2Fpython-for-data-science-and-machine-learning-bootcamp%2F)
+
+学习如何使用 NumPy、Pandas、Seaborn、Matplotlib、Plotly、Scikit-Learn、机器学习、Tensorflow 等等!
+
+
+# 文章,教程和讲座
+
+[机器学习学习曲线](https://www.dataquest.io/blog/learning-curves-machine-learning/)
+
+本教程使用真实世界数据集,教你如何诊断和减少偏差和方差。
+
+[掌握 Click:编写高级 Python 命令行应用](https://dbader.org/blog/mastering-click-advanced-python-command-line-apps#info)
+
+如何使用高级功能(如子命令、用户输入、参数类型、上下文等),改善你现有的 Click Python CLI。
+
+[澳大利亚葡萄酒评级等交互式可视化](http://pbpython.com/wine_visualization.html)
+
+使用 Bokeh,构建一个交互式葡萄酒评级可视化工具。
+
+[如何为 Django Admin 添加一个文本过滤器](https://medium.com/@hakibenita/how-to-add-a-text-filter-to-django-admin-5d1db93772d8)
+
+如何用特定字段的文本过滤器来替换 Django 搜索。
+
+[使用 Falcon 和 RHSCL,创建一个可扩展的 REST API](https://developers.redhat.com/blog/2017/12/29/create-scalable-rest-api-falcon-rhscl/)
+
+对于自动化、集成和开发本地云应用而言,API至关重要,而可以对其扩展,以满足用户群的需求,这也是很重要的。在这篇文章中,我们会使用 Red Hat Software Collections (RHSCL),基于 Python Falcon 框架,创建一个支持数据库的 REST API,测试其性能,并且为应对不断增长的用户群而将其向外扩展。
+
+[在 Go 中扩展 Python 3](https://hackernoon.com/extending-python-3-in-go-78f3a69552ac)
+
+[用 Python 编写你自己的微型 Redis](http://charlesleifer.com/blog/building-a-simple-redis-server-with-python/)
+
+[深度学习与艺术:神经风格转换 —— Python 中使用 Tensorflow 的一种实现](https://sandipanweb.wordpress.com/2018/01/02/deep-learning-art-neural-style-transfer-an-implementation-with-tensorflow-in-python/)
+
+[使用 OpenCV 和 Python 来截图](https://www.pyimagesearch.com/2018/01/01/taking-screenshots-with-opencv-and-python/)
+
+
+# 书籍
+
+[The Hacker's Guide to Scaling Python](http://amzn.to/2CNBA5T)
+
+Python 是一种棒棒哒的编程语言,让我们可以快速编写应用。但是,对于成千万的用户和请求,你要如何扩展这些应用呢?要获得这些经验和知识,是需要多年的实践、研究、尝试和犯错的。诸如“我要如何才能让我的代码跑得更快些?”或者“我要如何确保没有瓶颈?”这样简单的问题,要话费数小时才能找到好的答案。如果对于这些主题,没有足够的研究,你将无法确保你想出来的答案是正确的。「The Hacker's Guide to Scaling Python」这本书将会提供指导、技巧和最佳实践,来帮你解决这些问题。通过增加相关主题的专家采访,你将学习分布式 python 应用的方法,以便能够处理数以千计的请求。
+
+
+# 本周的Python工作
+
+[Pole Star 招聘高级软件工程师(Python)](http://jobs.pythonweekly.com/jobs/senior-software-engineer-python-4/)
+
+Pole Star 正在为海事、银行、金融和政府部门开发创新型 SaaS 软件解决方案和 API。我们正在寻找一名经验丰富的软件工程师,他/她需要有丰富的 Python 商业经验,以构建和维护我们核心的基于 Python 的平台和服务。
+
+[Inspirient 招聘高级 webapp 开发(Python)](http://jobs.pythonweekly.com/jobs/senior-webapp-developer-django/)
+
+在 Inspirient,我们正在构建业务分析的自驾车 —— 一个就像经验丰富的顾问或者数据科学家那样分析任何业务数据集的人工智能。在我们的软件中,我们结合了包含机器学习、专家系统、模式识别、程序生成和内存中数据处理等领域的各种技术。作为高级软件工程师,您的主要职责是负责 web 应用的后台开发。
+
+
+# 好玩的项目,工具和库
+
+[fsociety](https://github.com/Manisso/fsociety)
+
+渗透测试框架,你将拥有黑客需要的每一个脚本。
+
+[Parris](https://github.com/jgreenemi/Parris)
+
+一个机器学习算法的自动化基础架构设置工具。
+
+[opentracing-python](https://github.com/opentracing/opentracing-python)
+OpenTracing 的 Python API。
+
+[spoon](https://github.com/Jiramew/spoon)
+
+一个为不同站点构建特定代理池的软件包。
+
+[VulnWhisperer](https://github.com/austin-taylor/VulnWhisperer)
+
+从漏洞扫描中创建可操作数据。
+
+[images-to-osm](https://github.com/jremillard/images-to-osm)
+
+使用 TensorFlow、Bing 和 OSM,to find features in satellite images for fun.
+
+[rop-rpc](https://github.com/xyzz/rop-rpc)
+
+在任天堂交换机上运行任意复杂的 ROP 有效负载的复杂企业级方法。
+
+[crossviper](https://github.com/morten1982/crossviper)
+
+Tkinter Python IDE。
+
+[skip-thoughts](https://github.com/sanyam5/skip-thoughts)
+
+PyTorch 中的 Skip-Thought Vector 实现。
+
+[pydqc](https://github.com/SauceCat/pydqc)
+
+Python 自动数据质量检查工具包。
+
+[dm_control](https://github.com/deepmind/dm_control)
+
+DeepMind 控制套件和控制包。
+
+
+# 最新发布
+
+[Scrapy 1.5.0](https://docs.scrapy.org/en/latest/news.html#scrapy-1-5-0-2017-12-29)
+
+此版本整个代码带来了小的新功能和改进。
+
+[Django 问题修复版本:2.0.1 和 1.11.9](https://www.djangoproject.com/weblog/2018/jan/01/bugfix-releases/)
+
+
+# 近期活动和网络研讨会
+
+[San Francisco 2018 年 1 月 Python 聚会 - San Francisco, CA](https://www.meetup.com/sfpython/events/245191678/)
+There will be a talk, Python 3 at Lyft.
+
+[Boulder 2018 年 1 月 Python 聚会 - Boulder, CO](https://www.meetup.com/BoulderPython/events/245533980/)
+
+[Austin 2018 年 1 月 Python 聚会 - Austin, TX](https://www.meetup.com/austinpython/events/243637662/)
+
+[PyAtl 2018 年 1 月 Python 聚会 - Atlanta, GA](https://www.meetup.com/python-atlanta/events/241451570/)
+
+
+
+
+
diff --git a/Python Weekly/Python_Weekly_Issue_329.md b/Python Weekly/Python_Weekly_Issue_329.md
new file mode 100644
index 0000000..e089700
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_329.md
@@ -0,0 +1,103 @@
+原文:[Python Weekly - Issue 329 ](http://eepurl.com/dg2ynP)
+
+---
+
+欢迎来到Python周刊第329期。让我们直奔主题。
+
+# 来自赞助商
+
+[](https://goo.gl/wlxnDm)
+
+[Intel® Distribution for Python*](https://software.intel.com/en-us/distribution-for-python?utm_source=11Jan2018%20ad%20Python%20weekly&utm_medium=email&utm_campaign=Jan%202018%20Python%20Weekly%20newsletter) 现已免费提供,其许可证允许商业和非商业用途。这就对啦!试试 Intel 优化过的 NumPy、SciPy 和 scikit-learn,全部都在底层进行了加速。你的代码保持不变 —— 只需在 Intel Python 环境中运行它,就可以获得加速
+
+
+# 文章,教程和讲座
+
+[黑入 WiFi,把加密货币矿工注入到 HTML 请求中](http://arnaucode.com/blog/coffeeminer-hacking-wifi-cryptocurrency-miner.html)
+
+本文的目的是解释如何进行 MITM(中间人)攻击,从而注入一些 javascript 到 html 页面中,以强制所有连接到 WiFi 网络的设备为攻击者挖掘加密货币。
+
+[Postgres 内部:建立一个描述工具](https://www.dataquest.io/blog/postgres-internals/)
+
+在这篇教程中,学习 Postgres 是如何存储它的内部数据的,并使用 Python 构建你自己的数据库描述工具。
+
+[如何用 Python 创建一个僵尸网络](https://www.youtube.com/watch?v=eSPLRuOezGc)
+
+学习如何使用 Python 创建你自己的僵尸网络。这篇文章严格出于教育目的。视频中讨论的主题是提高对 Python 恶意软件的认识,并拓宽对僵尸网络及其功能的理解。
+
+[使用 PostgreSQL,在 Django 中进行全文搜索](http://www.paulox.net/2017/12/22/full-text-search-in-django-with-postgresql/)
+
+基于我关于使用 PostgreSQL,在 Django 中进行全文搜索的演讲的文章。
+
+[生活在【断层】线上](https://cbrownley.wordpress.com/2018/01/08/lives-on-the-fault-line-a-geospatial-analysis-of-the-san-andreas-fault-in-python/)
+
+Python 中的圣安德烈亚斯断层(San Andreas Fault)的地理空间分析。
+
+[在 Mac 上运行 PyGame 应用程序的技巧和诀窍 ](https://glyph.twistedmatrix.com/2018/01/shipping-pygame-mac-app.html)
+
+破解那个小小的 PyGame,并在别人的 Mac 上运行的一个快速暗戳戳的指南。
+
+[使用 Python 改进随机森林:第一部分](https://towardsdatascience.com/improving-random-forest-in-python-part-1-893916666cd)
+
+[如何简化你的节假日用餐计划](https://hengrumay.github.io/MenuPlannerHelper/)
+
+[揭秘双重认证](https://rcoh.me/posts/two-factor-auth/)
+
+
+# 书籍
+
+[Python Notes for Professionals book(专业人士的 Python 说明书)](http://books.goalkicker.com/PythonBook/)
+
+这本 Python Notes for Professionals book (专业人士的 Python 说明书)是从 Stack Overflow Documentation 编译而来的,内容是由 Stack Overflow 美好的人们编写。
+
+
+# 好玩的项目,工具和库
+
+[Eel](https://github.com/ChrisKnott/Eel)
+
+一个制作简单电子类 HTML/JS GUI 应用的小 Python 库。
+
+[Qgrid](https://github.com/quantopian/qgrid)
+
+Jupyter notebooks 中排序、筛选和编辑 DataFrame 的交互式网络。
+
+[Zeus](https://github.com/getsentry/zeus)
+
+Zeus 是 CI 解决方案的前端和分析提供器。
+
+[MMdnn](https://github.com/Microsoft/MMdnn)
+
+MMdnn 是一套帮助在不同深度学习框架之间互相操作的工具。例如,模型转换和可视化。在Caffe, Keras、MXNet、Tensorflow、CNTK 和 PyTorch 之间转换模型。
+
+[Authlib](https://github.com/lepture/authlib)
+
+Authlib 是一个使用OAuth 1、OAuth 2等的即用身份验证客户端和服务端。
+
+[py2bpf](https://github.com/facebookresearch/py2bpf)
+
+一个 python 到 bpf(Berkeley Packet Filter bytecode,伯克利包过滤器字节码)转换器。
+
+[AnPyLar](https://github.com/anpylar/anpylar)
+
+一个创建 web 应用的客户端侧 Python 框架。
+
+[CoffeeMiner](https://github.com/arnaucode/coffeeMiner)
+
+WiFi 网络中的协作(mitm)加密电子货币挖掘池。
+
+[fleep](https://github.com/floyernick/fleep)
+
+Python 的文件格式确定库。
+
+[convnet-drawer](https://github.com/yu4u/convnet-drawer)
+
+使用类 Keras 模型定义,说明卷积神经网络(CNN)的 Python 脚本。
+
+
+# 最新发布
+
+[Numpy 1.14.0](https://github.com/numpy/numpy/releases/tag/v1.14.0)
+
+Numpy 1.14.0 是七个月努力的产物,包含大量问题修复和新特性,以及关于潜在兼容性问题的一些改动。用户会注意到的主要改动是打印 numpy 数组和标量的风格变化,这是一项会影响到 doctest 的改动。
+
+[Python 3.7.0a4](https://www.python.org/downloads/release/python-370a4/)
diff --git a/Python Weekly/Python_Weekly_Issue_330.md b/Python Weekly/Python_Weekly_Issue_330.md
new file mode 100644
index 0000000..b3030c6
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_330.md
@@ -0,0 +1,180 @@
+原文:[Python Weekly - Issue 330](http://eepurl.com/dhNSX5)
+
+---
+
+欢迎来到Python周刊第330期。本周干货满满。尽情享用吧!
+
+# 来自赞助商
+[](https://www.datadoghq.com/dg/apm/ts-python-tracing/?utm_source=Advertisement&utm_medium=Advertisement&utm_campaign=PythonWeekly-Tshirt&utm_content=Python)
+
+[使用 Datadog,全面了解你的 Python 应用](https://www.datadoghq.com/dg/apm/ts-python-tracing/?utm_source=Advertisement&utm_medium=Advertisement&utm_campaign=PythonWeekly-Tshirt&utm_content=Python)
+
+你可以通过全面的延迟细分,来识别应用中的瓶颈,并与许多库集成,来跟踪异步 Python 代码。今天就开始 14 天的免费试用,可视化你的 python 性能吧。
+
+
+# 新闻
+
+[宣布 PyCharm 的 MicroPython 插件](https://blog.jetbrains.com/pycharm/2018/01/micropython-plugin-for-pycharm/)
+
+
+# 文章,教程和讲座
+
+[用深度学习,将设计模型转换成代码](https://blog.floydhub.com/turning-design-mockups-into-code-with-deep-learning/)
+
+在这篇文章中,我们将教大家一个神经网络是怎样基于设计模型的图片,来编写一个基本的 HTML 和 CSS 网站的。
+
+[使用 TensorFlow,介绍 LSTM](https://www.oreilly.com/ideas/introduction-to-lstms-with-tensorflow)
+
+如何使用 TensorFlow 构建一个多层 LSTM 网络,从社交对话中推断股市。
+
+[使用 MicroPython 玩转 ESP32,第一部分](https://boneskull.com/micropython-on-esp32-part-1/)
+
+学习如何在一块 Espressif ESP32 开发板上开始使用 MicroPython。在这个教程的第一部分,我会向你展示如何:在 ESP32 上启动并运行 MicroPython,连接 WiFi,上传脚本到开发板上并读取环境温度。
+
+[如何用 Python 创建一个推特机器人](https://www.youtube.com/watch?v=MN_1wOxIfRU)
+
+了解如何抓取网络数据,以及创建一个推特机器人,以设定的时间间隔发图像或者状态更新推文。
+
+[Python Ensembles 介绍](https://www.dataquest.io/blog/introduction-to-ensembles/)
+
+本文向你介绍 ensembles 的基础知识 —— 它们是啥,以及它们工作良好的原因 —— 然后提供一个构建基本 ensembles 的动手教程。
+
+[开开心心迁移到 Python 3](https://github.com/arogozhnikov/python3_with_pleasure)
+
+一个给数据科学家的关于 Python 3 特性的简短指南。
+
+[Python 中的时间序列分析:简介](https://towardsdatascience.com/time-series-analysis-in-python-an-introduction-70d5a5b1d52a)
+
+本文将介绍一个介绍性示例,使用 Python 和由 Facebook 开发的 Prophet 预测软件包,为财务时间序列数据创建附加模型。介绍过程中,我们会涵盖一些使用 pandas 的数据操作,使用 Quandl 库访问财务数据,以及使用 matplotlib 绘图。这篇简介将会向你展示开始自行建模时间序列所需的所有步骤!
+
+[理解并构建生成对抗网络(GAN)](https://becominghuman.ai/understanding-and-building-generative-adversarial-networks-gans-8de7c1dc0e25)
+
+我们将构建一个生成对抗网络,它将能够生成现实世界中从来没有实际存在的鸟类图像。
+
+[使用 Python 和 Google Cloud Speech API,将语音转录成文本](https://www.alexkras.com/transcribing-audio-file-to-text-with-google-cloud-speech-api-and-python/)
+
+本教程将会介绍如何使用 Google Cloud Speech API 来转录大型音频文件。
+
+[支持单个页面应用](https://tag1consulting.com/blog/building-api-django-20-part-i)
+
+在这个博客系列中,我们将使用 Django 构建一个后台 API 服务器,用于管理高流量网站上的用户。在这个系列的第一部分,我们会建立一个简单的注册和登录系统,可供单个页面应用或者移动应用使用。
+
+[Luciano Ramalho 聊 Python 特性和库](https://www.oreilly.com/ideas/luciano-ramalho-on-pythons-features-and-libraries)
+
+看看 Python 的一些有价值但常常被忽视的特性。
+
+[如何用 Python 创建一个 Reddit 机器人](https://www.youtube.com/watch?v=wAN8b38U_8c)
+
+学习如何用 Python 创建一个 Reddit 机器人。如果你创建了一个 reddit 机器人,那么请参阅 reddit 机器人礼仪,并遵循其中的指导 —— https://www.reddit.com/wiki/bottiquette.
+
+[用 Python 实现的一些马尔可夫链应用](https://sandipanweb.wordpress.com/2018/01/12/some-applications-of-markov-chain/)
+
+[我为什么构建一个历史加密货币交易模拟器](https://hackernoon.com/why-i-built-a-historical-cryptocurrency-trade-simulator-which-you-can-use-too-45125630e139)
+
+[Python 中的 pickle 是如何工作的?](https://rushter.com/blog/pickle-serialization-internals/)
+
+[使用 Docker Compose,在容器中调试 Python Flask 应用](https://medium.com/@trstringer/debugging-a-python-flask-application-in-a-container-with-docker-compose-fa5be981ec9a)
+
+
+# 书籍
+
+[Pandas for Everyone: Python Data Analysis(每个人的 Pandas 书:Python 数据分析)](http://amzn.to/2DL2CeD)
+
+Pandas for Everyone(每个人的 Pandas 书:Python 数据分析)给大家带来了用 Pandas 解决实际问题的实用知识和见解,即使你是 Python 数据分析 的小萌新也没问题。Daniel Y. Chen 通过简单但实用的例子,给我们介绍了关键概念,在这些例子之上,逐步解决更难的现实问题。
+
+
+# 本周的Python工作
+
+[Zapier 招聘产品工程师](http://jobs.pythonweekly.com/jobs/product-engineer-3/)
+
+Zapier 的工程师团队正在寻找一名产品经理。想要帮忙设计一个简单的产品,让任何人都能够使用世界级 API 来做复杂的、令人难以置信的事情吗?Zapier 是一家快速增长,并以远程办公优先的小型公司,因此,你可能会在公司内许多不同的项目中获得经验。
+
+[Bromium 招聘高级 Python Web 开发人员](http://jobs.pythonweekly.com/jobs/senior-python-web-developer/)
+
+我们正在寻找一名经验丰富的全栈开发人员,加入到我们剑桥的工程师团队中。你将在 Bromium Controller(我们产品的基于 web 的管理平台)上工作。
+
+
+# 好玩的项目,工具和库
+
+[House3D](https://github.com/facebookresearch/House3D)
+
+一个真实丰富的 3D 环境。
+
+[GSIL](https://github.com/FeeiCN/GSIL)
+
+几近实时地监控 Github 敏感信息泄漏,并且发送告警通知。
+
+[pipenvlib](https://github.com/kennethreitz/pipenvlib)
+
+用于操纵 Pipenv 项目的库。
+
+[bridgy](https://github.com/wagoodman/bridgy)
+
+轻松搜索你的云清单,并与 ssh + tmux + sshfs 集成。
+
+[Simcoin](https://github.com/simonmulser/simcoin)
+
+使用 Docker 和 Python 的区块链模拟框架。
+
+[pyray](https://github.com/ryu577/pyray)
+
+一个完全用 python 编写的 3D 渲染库。
+
+[Spinzero](https://github.com/neilpanchal/spinzero-jupyter-theme)
+
+一个最小的 Jupyter Notebook 主题。
+
+[gifmaze](https://github.com/neozhaoliang/gifmaze)
+
+制作各种迷宫生成额迷宫解决算法的 GIF 动画。
+
+[label-maker](https://github.com/developmentseed/label-maker)
+
+卫星机器学习的数据准备。
+
+[cutelog](https://github.com/busimus/cutelog)
+
+Python 的 logging 模块的 GUI。
+
+[One-Lin3r](https://github.com/D4Vinci/One-Lin3r)
+
+帮助你进行渗透测试操作的单行程序。
+
+[shap](https://github.com/slundberg/shap)
+
+使用期望值和 Shapley 值解释任意机器学习模型的输出。
+
+
+# 最新发布
+
+[Jupyter Notebook 5.3](https://jupyter-notebook.readthedocs.io/en/stable/changelog.html#release-5-3-0)
+
+此版本引入了一些值得注意的改进,例如 Windows 终端支持和操作系统垃圾桶支持(从 notebook 仪表板删除的文件被移到操作系统垃圾桶中 VS. 永久删除)。
+
+
+# 近期活动和网络研讨会
+
+[PhillyPUG 2018 年 1 月聚会 - Philadelphia, PA](https://www.meetup.com/phillypug/events/246023442/)
+
+将会有以下演讲:
+
+ * 用 Python 实现 Forth
+ * 为了代码清晰度更好的命名
+
+
+[London 2018 年 1 月 Python 聚会 - London, UK](https://www.meetup.com/LondonPython/events/245559958/)
+
+诊断、解释和缩放机器学习是困难的。Ian Ozsvald 将会讲到一些帮助他理解模型何时失败以及如何失败库,帮助他向非技术用户传达为什么它有用、自动搜索更好的模型并帮他扩展模型的库。
+
+[San Diego 2018 年 1 月 Python 聚会 - San Diego, CA](https://www.meetup.com/pythonsd/events/246559147/)
+
+将会有以下演讲:
+
+ * Mezzanine CMS
+ * 类 Lego 微服务
+ * 2 月 1 号关于机器学习的演讲的“预告”
+
+[Python Web 开发者之夜 #37 - Minneapolis, MN](https://www.meetup.com/PyMNtos-Twin-Cities-Python-User-Group/events/244911342/)
+
+[PyHou 2018 年 1 月聚会 - Houston, TX](https://www.meetup.com/python-14/events/244301647/)
+
\ No newline at end of file
diff --git a/Python Weekly/Python_Weekly_Issue_331.md b/Python Weekly/Python_Weekly_Issue_331.md
new file mode 100644
index 0000000..a5032f5
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_331.md
@@ -0,0 +1,139 @@
+原文:[Python Weekly - Issue 331](http://eepurl.com/divuh5)
+
+---
+
+欢迎来到Python周刊第331期。让我们直奔主题。
+
+# 来自赞助商
+[](https://training.talkpython.fm/courses/bundle/everything-bundle-2018?utm_source=pythonweekly)
+
+Talk Python Training 的 [Everything Bundle](https://training.talkpython.fm/courses/bundle/everything-bundle-2018?utm_source=pythonweekly) 介绍:获取当前在我们库中或者会在 2018 年期间推出的每一门课程的使用期。你可以立即访问 90 多个小时的 Python 课程。企业和团队许可可用。
+
+
+# 新闻
+
+[JupyterCon 2018:征集建议](https://blog.jupyter.org/jupytercon-2018-call-for-proposal-87986014ee0b)
+
+[PyData London 2018 征集建议](https://pydata.org/london2018/cfp/)
+
+[Claude Paroz 被授予 2017 年 Malcolm Tredinnick 纪念奖](https://www.djangoproject.com/weblog/2018/jan/22/2017-malcolm-tredinnick-prize-claude-paroz/)
+
+
+# 文章,教程和讲座
+
+[用 15 行 Python 代码,创建一个分类糖尿病风险的神经网络](https://www.youtube.com/watch?v=T91fsaG2L0s)
+
+了解神经网络模型,然后利用 Keras,用 15 行 Python 代码构建一个神经网络,来预测健康风险。
+
+[Python 中的网络爬取实用简介](https://realpython.com/blog/python/python-web-scraping-practical-introduction/)
+
+学习使用 Python 和 requests 以及 BeautifulSoup 包,进行网络爬取的基础知识。
+
+[使用自定义 C 扩展来增强 Python](http://stackabuse.com/enhancing-python-with-custom-c-extensions/)
+
+本文将重点介绍用来为 Python 构建 C 扩展的 CPython API 的功能。我将重点介绍编写一个相当平庸的玩具一般的示例 C 函数库,然后将其暴露于 Python 封装器中的一般工作流程。
+
+[使用 Docker,简化脱机 Python 部署](https://realpython.com/blog/python/offline-python-deployments-with-docker/)
+
+学习如何使用 Docker,打包一个 Python 项目,用以在从互联网上断开的机器上进行部署。
+
+[我建立了一个 Jupyter Notebook,它会给你分析加密货币的投资组合](http://grantbartel.com/blog/jupyter-notebook-that-will-analyze-cryptocurrency-portfolios/)
+
+加密投资领域的参与量不言自明。随着市场上限、成交量和公众意识的不断提高,我想我会把这些都放进一个简单的 Jupyter notebook 中,从而更清晰更广泛地看清楚我自己的加密货币投资组合中投资活动。
+
+[欢迎来到未来!](https://medium.com/the-infinite-machine/welcome-to-the-future-3ca4fb5a4656)
+
+本文解释了 App Engine 的分布式分层未来的基础知识,这是创建复杂分布式系统的一个抽象概念。
+
+[Gowanus 中的 311 个噪音投诉,可以告诉我们一些与高档化有关的事情吗?](https://medium.com/@sebscho_/what-can-311-noise-complaints-in-gowanus-tell-us-about-gentrification-444c7da0a07a)
+
+使用 Python 和 NYC Open Data,识别我最喜爱的布鲁克林区中的模式。
+
+[使用 django、RabbitMQ 和 Vue.js,构建实时聊天应用](https://github.com/danidee10/chatire)
+
+这个包含 5 部分的系列向你展示如何使用 django、RabbitMQ 和 Vue.js,来构建聊天应用程序。
+
+[了解 Python 类内部](https://rushter.com/blog/python-class-internals/)
+
+本系列的目标是描述 Python 3.6 中类对象的内部和一般概念。在这一部分中,我会解释 Python 是如何存储和查找属性的。
+
+[使用 Python 进行 Linux 系统挖掘](http://echorand.me/linux-system-mining-with-python.html)
+
+在这篇文章中,我们将探索 Python 编程语言作为一个工具,检索关于一个运行着 Linux 的系统的各种信息。让我们开始吧。
+
+[Python GUI 示例(Tkinter 教程)](https://likegeeks.com/python-gui-examples-tkinter-tutorial/)
+
+在这篇教程中,我们将学习如何使用 Tkinter 包编写一些 Python GUI,来开发图形用户界面。
+
+[使用文本分析来量化角色](https://medium.com/agatha-codes/using-textual-analysis-to-quantify-a-cast-of-characters-4f3baecdb5c)
+
+如果你曾经写过文章,并且希望自己能够获得一个角色列表,或者看看每个角色被提及的次数,那么这就是一篇为你而写的教程。
+
+[Python 3.7 数据类的简要介绍](https://hackernoon.com/a-brief-tour-of-python-3-7-data-classes-22ee5e046517)
+
+[PyTorch,一岁了……](http://pytorch.org/2018/01/19/a-year-in.html)
+
+
+# 书籍
+
+[Cracking Codes with Python: An Introduction to Building and Breaking Ciphers(用 Python 破解代码:构建和破解密码介绍)](http://amzn.to/2DHPnhb)
+
+学习如何使用 Python 编程,同时创建和破解密码 —— 用以创建和发送秘密消息的算法!在 Python 编程基础速成课之后,你将学习创建、测试和破解使用经典密码(如转置密码和 Vigenere 密码)加密文本的程序。你将从使用简单的反向和 Caesar 密码的程序开始,然后逐渐深入到公钥密码加密,即用于保护当今在线交易(包括数字签名、电子邮件和比特币)的加密类型。
+
+
+# 本周的Python工作
+
+[Zapier 招聘安全基础设施工程师](http://jobs.pythonweekly.com/jobs/security-infrastructure-engineer/)
+
+Zapier 正在为其工程师团队寻找一名安全基础设施工程师。你对帮忙构建和保护强大的自动化工具感兴趣吗?如果是的话,那么阅读……
+
+
+# 好玩的项目,工具和库
+
+[Detectron](https://github.com/facebookresearch/Detectron)
+
+FAIR 的对象检测研究平台,实现 Mask R-CNN 和 RetinaNet 等流行算法。
+
+[DeepLeague](https://github.com/farzaa/DeepLeague)
+
+在英雄联盟迷你地图和包含超过 100,000 张标记图像的数据集上,利用计算机视觉和深度学习,进行进一步电子竞技 A.I 研究。
+
+[Chatistics](https://github.com/MasterScrat/Chatistics)
+
+将来自 Facebook Messenger 和 Google Hangouts 的聊天日志转换成 Pandas DataFrames 的 Python 脚本。
+
+[python-mss](https://github.com/BoboTiG/python-mss)
+
+使用 ctypes 的纯 Python 超快跨平台多屏截图模块。
+
+[Bplustree](https://github.com/NicolasLM/bplustree)
+
+Python 3 的磁盘 B+ 树。
+
+[mocker](https://github.com/tonybaloney/mocker)
+
+百分百用 Python 编写的 Docker 概念验证模型。使用 Linux 的内核命名空间、cgroups 和网络命名空间/iproute2。
+
+[cookiecutter-flask-restful](https://github.com/karec/cookiecutter-flask-restful)
+flask restful 的 Cookiecutter 模板,包括 JWT 授权、cli、测试等等。
+
+[binance-trader](https://github.com/yasinkuyu/binance-trader)
+
+Binance 的加密货币交易机器人(实验性)
+
+[unimatrix](https://github.com/will8211/unimatrix)
+
+在终端中模拟“黑客帝国”中的显示的 Python 脚本。默认使用半角片假名字符,但是可以使用自定义字符集。运行时接受键盘控制。基于 CMatrix。
+
+[CloudFlair](https://github.com/christophetd/CloudFlair)
+
+使用来自 Censys 的互联网扫描数据,查找由 CloudFlare 支持的网站的原始服务器。
+
+[InsightFace](https://github.com/deepinsight/insightface)
+
+MXNet 上的面部识别项目。
+
+# 最新发布
+
+[PyCharm 2017.3.3](https://blog.jetbrains.com/pycharm/2018/01/pycharm-2017-3-3-out-now)
+
\ No newline at end of file
diff --git a/Python Weekly/Python_Weekly_Issue_332.md b/Python Weekly/Python_Weekly_Issue_332.md
new file mode 100644
index 0000000..458bf77
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_332.md
@@ -0,0 +1,125 @@
+原文:[ Python Weekly - Issue 332 ](http://eepurl.com/djgcPP)
+
+---
+
+欢迎来到Python周刊第332期。让我们直奔主题。
+
+# 来自赞助商
+[](https://www.datadoghq.com/dg/apm/ts-python-tracing/?utm_source=Advertisement&utm_medium=Advertisement&utm_campaign=PythonWeekly-Tshirt&utm_content=Python)
+
+[使用 Datadog,获得对你的 Python 应用性能的全面了解吧。](https://www.datadoghq.com/dg/apm/ts-python-tracing/?utm_source=Advertisement&utm_medium=Advertisement&utm_campaign=PythonWeekly-Tshirt&utm_content=Python)
+
+你可以通过全面的延迟细分来识别应用中的瓶颈,并与许多库集成,来跟踪异步 Python 代码。今天就利用 14 天的免费试用期,开始可视化你的 Python 应用吧。
+
+
+# 文章,教程和讲座
+
+[如何使用 Python 和 Keras,构建你自己的 AlphaZero AI](https://medium.com/applied-data-science/how-to-build-your-own-alphazero-ai-using-python-and-keras-7f664945c188)
+通过自学和深度学习,教会机器学习 Connect4 策略。
+
+[Python 数据整理教程:加密货币版本](https://elitedatascience.com/python-data-wrangling-tutorial)
+
+这个 Python 数据整理教程将向你展示如何过滤、重塑、汇总以及转换原始数据集为更有用的数据集。
+
+[Python + Memcached:分布式应用中的高效缓存](https://realpython.com/blog/python/python-memcache-efficient-caching/)
+
+使用 memcached,通过避免重新计算数据或者访问缓慢的数据库,来加速你的 Python 应用的方法。这个教程还涵盖了高级 memcached 模式,例如“缓存和设置”,以及使用回退缓存来避免冷缓存(cold cache)性能问题。
+
+[机器是如何预测的:找到复杂数据中的相关性](https://medium.freecodecamp.org/how-machines-make-predictions-finding-correlations-in-complex-data-dfd9f0d87889)
+
+通过布朗运动,从 Pearson 的 r(PCC,或者皮尔逊相关系数) 到最大信息系数之旅。
+
+[使用数据库的 9 个 Django 技巧](https://medium.com/@hakibenita/9-django-tips-for-working-with-databases-beba787ed7d3)
+
+ORM 为开发者提供了很好的实用性,但是抽象数据库访问是有成本的。那些愿意在数据库中查找并修改默认值的开发人员经常会发现可以进行很大的改进。在这篇文章中,我将分享在 Django 中使用数据库的 9 个技巧。
+
+[构建一个 PDF 分配应用](http://pbpython.com/pdf-splitter-gui.html)
+
+创建一个 GUI 来控制一个从 PDF 文件中提取页面的 Python 程序。
+
+[MicroPython on the 在 ESP32 上玩转MicroPython:第二篇的第二部分](https://boneskull.com/micropython-on-esp32-part-2/)
+
+在这个令人难以忍受的教程的第一部分中,我教了读者如何在一块基于 ESP32 的开发板上开始使用 MicroPython。在这个教程的这一部分,我们会采集传感器收集的数据,然后通过 MQTT 发布。
+
+[使用 Tensorflow 对象检测,在 Android 上检测皮卡丘](https://towardsdatascience.com/detecting-pikachu-on-android-using-tensorflow-object-detection-15464c7a60cd)
+
+本指南解释了如何出于部署在 Android 上的目的,使用皮卡丘作为目标对象,训练一个对象检测模型。
+
+[Python 3 快速技巧](https://medium.com/@ageitgey/python-3-quick-tip-the-easy-way-to-deal-with-file-paths-on-windows-mac-and-linux-11a072b58d5f)
+
+在 Windows、Mac 和 Linux 上处理文件路径的简单方法。
+
+[Raymond Hettinger - Python 3.7 的新数据类](https://www.youtube.com/watch?v=lSnBvQjvqnA)
+
+[将节省你的时间的 9 个新的 pandas 更新](http://www.dataschool.io/python-pandas-updates/)
+
+[用 Python 简化 ERC20 令牌](https://medium.com/kin-contributors/streamlining-erc20-tokens-in-python-d1a4c57444fc)
+
+[如何用 Django 实现多用户类型](https://simpleisbetterthancomplex.com/tutorial/2018/01/18/how-to-implement-multiple-user-types-with-django.html)
+
+[在 Python 中使用优化的图像着色](https://sandipanweb.wordpress.com/2018/01/27/image-colorization-using-optimization-in-python/)
+
+[使用 Dask DataFrame,进行集群上的分布式 pandas](http://matthewrocklin.com/blog/work/2017/01/12/dask-dataframes)
+
+[如何用 Django,实现相关/链接下拉列表](https://simpleisbetterthancomplex.com/tutorial/2018/01/29/how-to-implement-dependent-or-chained-dropdown-list-with-django.html)
+
+
+# 好玩的项目,工具和库
+
+[Minigo](https://github.com/tensorflow/minigo)
+
+一个模范阿尔法狗的极简 Go 引擎,建立在 MuGo 基础上。
+
+[datastream.io](https://github.com/MentatInnovations/datastream.io)
+
+使用 Python、ElasticSearch 和 Kibana 进行实时异常检测的开源框架。
+
+[NiftyNet](https://github.com/NifTK/NiftyNet)
+
+一个开源卷积神经网络平台,用于研究医学图像分析和图像引导治疗。
+
+[vapeplot](https://github.com/dantaki/vapeplot)
+
+用于气体美学的 matplotlib 扩展。
+
+[NapkinML](https://github.com/eriklindernoren/NapkinML)
+
+NumPy 中的机器学习模型的袖珍实现库。
+
+[seldon-core](https://github.com/SeldonIO/seldon-core)
+
+Seldon Core 是一个在 Kubernetes 上部署机器学习模型的开源平台。
+
+[lanGhost](https://github.com/xdavidhu/lanGhost)
+
+可通过 Telegram 控制的局部互联网 dropbox 聊天机器人。
+
+[django-tenants](https://github.com/tomturner/django-tenants)
+
+使用 PostgreSQL 模式的 Django 租户。
+
+[AutoSploit](https://github.com/NullArray/AutoSploit)
+
+正如名字暗示的那样,AutoSploit 试图自动化利用远程主机的过程。通过使用 Shodan.io API,也可以自动收集目标。这个程序允许用户输入他们平台特定的搜索查询,例如 Apache、IIS 等等,然后会检索一系列候选者。
+
+[sneakysnek](https://github.com/SerpentAI/sneakysnek)
+
+用于 Python 3.6+ 的简单得要死的跨平台键盘和鼠标全局输入捕获解决方案。
+
+[Captivox](https://github.com/expectocode/captivox)
+
+使用 pyqt5 和 parametrics 的很酷的动画。
+
+[PyDLT](https://github.com/dmarnerides/pydlt)
+
+基于 PyTorch 的深度学习工具箱。
+
+
+# 最新发布
+
+[Python 3.7.0b1](https://www.python.org/downloads/release/python-370b1/)
+
+[wxPython 4.0.0](https://groups.google.com/forum/#!topic/wxpython-dev/ZQ2ZE4hzRcc)
+
+
+
diff --git a/Python Weekly/Python_Weekly_Issue_333.md b/Python Weekly/Python_Weekly_Issue_333.md
new file mode 100644
index 0000000..7a82ccb
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_333.md
@@ -0,0 +1,144 @@
+原文:[Python Weekly - Issue 333](http://eepurl.com/dj6Ktb)
+
+---
+
+欢迎来到Python周刊第333期。让我们直奔主题。
+
+# 来自赞助商
+[](https://goo.gl/wlxnDm)
+
+使用 Python 进行科学计算、数值分析还是数据科学?获取免费的 [Intel® Distribution for Python*](https://software.intel.com/en-us/distribution-for-python?utm_source=02%2F08%2F18%20Python%20Weekly%20Newsletter&utm_medium=Email),内置已加速的 NumPy、SciPy 和 scikit-learn,以提高本地代码的性能!更短的计算时间和更快的结果,只需切换到更快的 python 即可获得。
+
+
+# 文章,教程和讲座
+
+[构建神经网络的简单入门指南](https://www.kdnuggets.com/2018/02/simple-starter-guide-build-neural-network.html)
+
+本指南作为一个基本的实践工具,引导你从头开始构建神经网络。
+
+[使用 Python 和 Selenium 的现代 Web 自动化](https://realpython.com/blog/python/modern-web-automation-with-python-and-selenium/)
+
+在本教程中,你将会学习高级的 Python web 自动化技术:将 Selenium 用于一个“无头的”浏览器,导出抓取的数据到 CSV 文件中,然后把你的爬取代码封装到一个 Python 类中。
+
+[使用 Python 和 Scikit-Learn,学习线性回归](http://stackabuse.com/linear-regression-in-python-with-scikit-learn/)
+
+有两种类型的监督机器学习算法:回归和分类。前者预测连续值输出,而后者预测离散输出。例如,预测房屋价格(以美元为单位)属于回归问题,而预测肿瘤是恶性还是良性的则是分类问题。在这篇文章中,我们会简要地学习线性回归的概念,以及可以怎样使用 Python Scikit-Learn 库(最受欢迎的 Python 机器学习库之一)实现。
+
+[如何在 Django 中使用 RESTful API](https://simpleisbetterthancomplex.com/tutorial/2018/02/03/how-to-use-restful-apis-with-django.html)
+
+作为开发者,我们可以是任意一种角色。我们可以既是 API 的提供者,又是其消费者。但是,在这篇教程中,我们将会探索消费者的角色。我们将编写一些消费公共 API 的代码。你会看到,这个过程非常相似,并且一旦学习了,你可以将其应用于许多问题。
+
+[在你的(Django)项目中使用 setup.py](https://lincolnloop.com/blog/using-setuppy-your-django-project/)
+
+最近,有一个客户问我,为什么我们创建的所有 Django 项目的根目录下都有一个 setup.py 文件。没有这个文件,很多项目也都还不错,所以,为什么我要用它?关于这个的解释有点啰嗦,所以,我想,我会将它写成一篇博文(就是这里啦)。
+
+[Numba 在社区代码中的案例](https://www.anaconda.com/blog/developer-blog/the-case-for-numba-in-community-code/)
+
+Numba 在性能和可用性方面表现出色,但是在安装简便性和社区信任方面一如既往的弱。这篇文章从 OSS 库维护者的角度解释了这些优缺点。它使用了其他更多关于这个主题的技术文章作为参考。鉴于该项目最近的改动,它倾向于被更广泛的采用。
+
+[安全分析 GitHub 项目:流行许可证](https://www.kaggle.com/mrisdal/safely-analyzing-github-projects-popular-licenses/notebook)
+
+使用 Python 和 BigQuery,分析 Kaggle 上的 Kaggle 项目。
+
+[当我 2018 年开始 Django 开发时,我希望我知道的那些事](https://peeomid.com/blog/2018-01-26-what-i-wish-i-knew-when-i-started-django-development-2018/)
+
+当我开始使用 Django 时,一些我希望我知道的几点东西,这可以节省我大量的时间和精力。
+
+[Python 的元组是不可变的,除非当它们是可变的时候](https://inventwithpython.com/blog/2018/02/05/python-tuples-are-immutable-except-when-theyre-mutable/)
+
+[在 Python 3.5 中,无需使用用户空间内存的 socket 文件传输](http://michaldul.com/python/sendfile/)
+
+[预测开局投手的薪水](https://medium.com/discovering-data-science-a-chronicle/predicting-starting-pitcher-salaries-4b7a4a26cb65)
+
+[分析纽约市地铁和人口统计数据,以优化街道队伍建设](https://medium.com/@cipher813/analyzing-nyc-subway-and-demographic-data-to-optimize-street-team-deployment-2614522bd83e)
+
+
+# 书籍
+
+[Machine Learning with TensorFlow(用TensorFlow进行机器学习)](http://amzn.to/2C39pxX)
+
+Machine Learning with TensorFlow(用TensorFlow进行机器学习)为读者打造了机器学习概念的坚实基础,以及用 Python 编写 TensorFlow 的实践经验。你将通过使用经典预测、分类和聚类算法来学习基础知识。然后,你将进入正题:探索深度学习概念,例如自动编码器、递归神经网络和强化学习。消化此书,你就已经准备好使用 TensorFlow 开发你自己的机器学习和深度学习应用了。
+
+
+# 好玩的项目,工具和库
+
+[Tensorflow-Project-Template](https://github.com/MrGemy95/Tensorflow-Project-Template)
+
+tensorflow 项目模板架构的最佳实践。
+
+[birdseye](https://github.com/alexmojaki/birdseye)
+Quick, convenient, expression-centric, graphical Python debugger using the AST.
+
+[DeepPavlov](https://github.com/deepmipt/DeepPavlov)
+
+用于构建端到端对话系统和训练聊天机器人的开源库。
+
+[multidiff](https://github.com/juhakivekas/multidiff)
+
+用于多个对象或数据流的二进制数据区分。
+
+[exodus](https://github.com/intoli/exodus)
+
+Linux 二进制文件及其所有依赖的无痛搬迁,无需容器。(译注:名字是出埃及记哦^_^)
+
+[Lulu](https://github.com/iawia002/Lulu)
+
+一个简单而干净的视频/音乐/图像下载器。
+
+[Sickle](https://github.com/wetw0rk/Sickle)
+
+Sickle 是一个 shellcode 开发工具,用于加速创建正常运行的 shellcode 所需的各个步骤。
+
+[pdvega](https://github.com/jakevdp/pdvega)
+
+pdvega 是一个允许你快速创建来自 andas dataframes 的交互式 Vega-Lite 图的工具,它使用一个几乎与 Pandas 内置的可视化工具相同的 API,并设计为易于在 Jupyter notebook 中使用。
+
+[CakeChat](https://github.com/lukalabs/cakechat)
+
+情感生成对话系统。
+
+[hate_crack](https://github.com/trustedsec/hate_crack)
+
+来自 TrustedSec 团队的通过 Hashcat 自动化破解方法的工具。
+
+[cryptory](https://github.com/dashee87/cryptory)
+
+检索历史加密数字货币和其他相关数据。cryptory 集成了各种历史加密数据源,因此,你可以进行分析并构建模型,而不用担忧不同的包和 API。
+
+[som-tsp](https://github.com/DiegoVicen/som-tsp)
+
+使用自组织映射解决旅行商问题。
+
+
+# 最新发布
+
+[Channels 2.0](https://www.aeracode.org/2018/02/02/channels-20/)
+
+Channels 2 是一个重要的重写版本,完全改变了运行方式以及构造代码的方式,希望会变得更好。
+
+[Visual Studio Code 中的 Python - 2018 年 1 月发布](https://blogs.msdn.microsoft.com/pythonengineering/2018/02/01/python-in-visual-studio-code-jan-2018-release/)
+
+在这个版本中,我们总共关闭了 72 个问题,主要关注 lint 改进、虚拟环境支持以及其他一些改进。
+
+[Python 3.5.5](https://www.python.org/downloads/release/python-355/)
+
+[Django 安全版本发布:2.0.2 和 1.11.10](https://www.djangoproject.com/weblog/2018/feb/01/security-releases/)
+
+[Peewee 3.0](http://charlesleifer.com/blog/peewee-3-0-released/)
+
+
+# 近期活动和网络研讨会
+
+[IndyPy 2018 年 2 月每月聚会 - Indianapolis, IN](https://www.meetup.com/indypy/events/245244442/)
+
+将会有以下演讲:
+
+ * 面试,快方式和慢方式:使用行为科学进行王牌科技面试,或者建立更好的团队
+ * 为什么说 Django(仍然)是构建你的 SaaS 初创公司的好选择。
+
+[Austin Python 2018 年 2 月聚会 - Austin, TX](https://www.meetup.com/austinpython/events/245776114/)
+
+[Boulder Python 2018 年 2 月聚会 - Boulder, CO](https://www.meetup.com/BoulderPython/events/245528063/)
+
+
+
diff --git a/Python Weekly/Python_Weekly_Issue_334.md b/Python Weekly/Python_Weekly_Issue_334.md
new file mode 100644
index 0000000..d659689
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_334.md
@@ -0,0 +1,135 @@
+原文:[Python Weekly - Issue 334](http://eepurl.com/dkSwLL)
+
+---
+
+欢迎来到Python周刊第334期。让我们直奔主题。
+
+# 来自赞助商
+[](https://www.datadoghq.com/dg/apm/ts-python-error-tracking/?utm_source=Advertisement&utm_medium=Advertisement&utm_campaign=PythonWeekly-Tshirt&utm_content=Python)
+
+使用 Datadog,快速识别 Python 应用中的错误。可视化关键指标,如命中率、错误率和延迟,以及端到端请求跟踪,以找到缓慢的查询、错误和低效代码。开始使用[ 14 天免费试用版](https://www.datadoghq.com/dg/apm/ts-python-error-tracking/?utm_source=Advertisement&utm_medium=Advertisement&utm_campaign=PythonWeekly-Tshirt&utm_content=Python),可视化你的 Python 性能吧。
+
+
+# 文章,教程和讲座
+
+[使用 Python 构建一个神经网络](https://enlight.nyc/neural-network)
+
+神经网络可能会让人恐惧,特别是对于那些机器学习小萌新来说。但是,本教程将会分解神经网络的工作原理,最终,你将拥有一个可以使用的灵活的神经网络。让我们开始吧!
+
+[我是如何使用 CoreML、PyTorch 和 React Native,在 iOS 上发布神经网络的](https://attardi.org/pytorch-and-coreml/)
+
+这是一个关于我如何训练一个简单的神经网络,来解决真正的 iOS 应用中定义明确但新颖的挑战的故事。这个问题是独一无二的,但是我所介绍的大部分内容都适用于任意 iOS 应用中的任意任务。这就是神经网络的美妙之处。我会逐步介绍每一个步骤,从一路上会出现的问题到在 App Store 上架。在此过程中,我们会快速绕过一个使用简单数学(失败)的替代方案,经历工具构建、数据集生成、神经网络架构和 PyTorch 训练。我们将忍受危险重重的 CoreML 模型转换,最终到达 React Native 用户界面。
+
+[Python 3 中的面向对象编程(OOP)](https://realpython.com/blog/python/python3-object-oriented-programming/)
+
+在这篇文章中,你将会学习 Python 中面向对象编程(OOP)的基础知识,以及如何使用类、对象和构造函数。本教程还附带了几个 OOP 练习,用来检查你的学习进度。
+
+[Google Colab 免费 GPU 教程](https://medium.com/deep-learning-turkey/google-colab-free-gpu-tutorial-e113627b9f5d)
+
+现在,你可以使用 Keras、Tensorflow 和 PyTorch,在免费的 Tesla K80 GPU 上,使用 Google Colaboratory 来开发深度学习应用了。
+
+[开发你的第一个与分散恒星网络集成的 python 应用](http://blog.adnansiddiqi.me/develop-your-first-python-app-integrated-with-decentralized-stellar-network/)
+
+在这篇文章中,我将讨论如何为恒星网络创建一个分散区块链应用(又名 dApp)。我将狗哦汲一个非常简单的 web 应用(世界上最简单的电子商务应用,称之为 RocketCommerce),人们可以通过支付恒星货币 Lumens(XLM)来购买单件物品。
+
+[使用 Django 和 Aloe 进行行为驱动开发](https://testdriven.io/behavior-driven-development-with-django-and-aloe)
+
+在接下来的教程中,我们将通过使用 Django 和 Aloe,编程一个示例特性,从而引导你完成 BDD 开发周期。请继续学习如何在编程稳定的应用时,使用 BDD 过程来帮助快速捕获并修复不良设计。
+
+[通过 Keras 和 Core ML,使用 MNIST 数据集的手写数字识别器](https://medium.com/@nathan.hubens/handwritten-digit-recognizer-on-ios-with-keras-and-core-ml-using-the-mnist-dataset-8564f5d6f4ba)
+本教程的目的是展示创建、训练深度学习模型以及在 iOS 应用中实现它的全过程。这里的用例是深度学习的“Hello World”,它是使用手写数字数据集(MNIST 数据集)的数字识别。该模型是通过使用 Keras 框架创建以及训练的,然后将其转换为 Core ML 模型,以便在 iOS 应用中使用。
+
+[Numba 和 Cython 是如何加速 Python 代码的](https://rushter.com/blog/numba-cython-python-optimization/)
+
+在过去的几年中,Numba 和 Cython 在数据科学界获得了很多关注。它们都提供了加速 CPU 密集型任务的方式,但方法各不相同。本文介绍了它们之间的体系结构的差异。
+
+[信用建模和 Dask](https://matthewrocklin.com/blog//work/2018/02/09/credit-models-with-dask)
+
+本文探索了使用 Dask,在 Python 中计算复杂信用模型的真实用例。这是一个复杂并行系统的示例,远远超出了传统的“大数据”工作负载。
+
+[在 Wagtail (Django) 中构建可配置的分类标准](https://posts-by.lb.ee/building-a-configurable-taxonomy-in-wagtail-django-94ca1080fb28)
+
+本文旨在介绍一种在 Django 应用中实现完全灵活的分类系统的方法。编程实现很大程度上依赖于 Wagtail(基于 Django 的 CMS)的使用,但如果只是使用 Django,那么仍然也是相关的。
+
+[Django 技巧 #22 设计更好的模型](https://simpleisbetterthancomplex.com/tips/2018/02/10/django-tip-22-designing-better-models.html)
+
+在这篇文章中国年,我将会分享一些技巧,以帮助你改进你的 Django 模型的设计。这些提示很多都与命名约定有关,它们可以提高代码的可读性。
+
+[使用 Cryptory,分析影响加密货币价格的因素](https://dashee87.github.io/data%20science/python/analysing-the-factors-that-influence-cryptocurrency-prices-with-cryptory/)
+
+[为开发 Docker 化 Django](https://fernandofreitasalves.com/dockerizing-django-for-development/)
+
+[使用 OpenCV 和 Haar Cascades,构建 Django POST 人脸检测 API](https://medium.com/@rachit.mishra94/building-a-django-post-face-detection-api-using-opencv-and-haar-cascades-dcf4e0e5f725)
+
+[Python 3.7 中的 5 个速度改进](https://hackernoon.com/5-speed-improvements-in-python-3-7-1b39d1581d86)
+
+
+# 本周的Python工作
+
+[软件工程师 - Bromium 的恶意软件模拟](http://jobs.pythonweekly.com/jobs/software-engineer-malware-simulation/)
+
+我将成为我们监控和攻击可视化团队的关键成员,并将通过识别并解决产品开发周期内的无效率和风险领域,来支撑开发和产品团队。我们的理想人选将需要具有适应能力,风度翩翩,并具有独特的问题调查和技术沟通技巧。你将会喜欢团队协作,但也会很乐意在需要时独立解决问题。
+
+
+# 好玩的项目,工具和库
+
+[carbondoomsday](https://github.com/giving-a-fuck-about-climate-change/carbondoomsday)
+
+用于气候变化相关数据的 REST web API。
+
+[Texygen](https://github.com/geek-ai/Texygen)
+
+文本生成基准测试平台。
+
+[scriptedforms](https://github.com/SimonBiggs/scriptedforms)
+
+使用 Markdown 和一些自定义 HTML 元素,来快速为 Python 包创建漂亮的反应式 GUI。
+
+[thanks](https://github.com/phildini/thanks)
+
+找到资助你的所使用的 python 包的方式。
+
+[youtube-video-face-swap](https://github.com/DerWaldi/youtube-video-face-swap)
+
+这个项目的目标是几乎自动地对 YouTube 视频进行脸部交换。
+
+[bounty-monitor](https://github.com/nashcontrol/bounty-monitor)
+
+利用证书透明度实时馈送来监控新发布的子域证书(最后 90 天,可配置),用于那些参与到错误赏金计划中的域。
+
+[DeepType](https://github.com/openai/deeptype)
+
+设计、发展和训练神经系统。
+
+[KubeSanity](https://github.com/brendandburns/kubesanity)
+
+KubeSanity,是一个 Kubernetes 理性检查框架。
+
+[icecream](https://github.com/gruns/icecream)
+
+你用过 print() 语句来调试你的代码吗?你当然用过。IceCream(简称 ic),让 print() 调试变得更甜美。
+
+[modAL](https://github.com/cosmic-cortex/modAL)
+
+Python3 的模块化主动学习框架。
+
+[eth_python_tracker](https://github.com/pmaji/eth_python_tracker)
+
+基于 Python 的 Dash 应用程序,旨在追踪 GDAX 上的购买/销售墙中的鲸鱼活动。
+
+[VSCodeNotebook](https://github.com/aviaryan/VSCodeNotebook)
+
+将 VS Code 用作为可靠的记录/日记应用。
+
+
+# 近期活动和网络研讨会
+
+[装饰器和上下文管理器介绍 - Houston, TX](https://www.meetup.com/python-14/events/245321796/)
+
+在这个演讲中,我们将会探索如何创建装饰器和上下文管理器,使得你的代码更可重用和 pythonic。我们将会简单提及两个标准库包,functools 和 contextlib,来展示我们可以如何利用一些函数,从而让我们的代码更好。
+
+[San Diego Python 2018 年 2 月聚会 - San Diego, CA](https://www.meetup.com/pythonsd/events/247161738/)
+
+
+
+
diff --git a/Python Weekly/Python_Weekly_Issue_335.md b/Python Weekly/Python_Weekly_Issue_335.md
new file mode 100644
index 0000000..cf47ced
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_335.md
@@ -0,0 +1,130 @@
+原文:[Python Weekly - Issue 335](http://eepurl.com/dlD4ez)
+
+---
+
+欢迎来到Python周刊第 335 期。让我们直奔主题。
+
+# 来自赞助商
+[](https://try.digitalocean.com/performance/?utm_medium=display&utm_source=paid_newsletter+python+weekly&utm_campaign=PricePerf+dr+droplets+newsletters&utm_content=Logo_125x125)
+
+通过 DigitalOcean,轻松扩展 **Python** 和 **Django **应用。DigitalOcean 不仅仅是云托管,它允许你在几秒钟内配置数以千计的云服务器,包括防火墙、监控和告警。花更多的时间编码,减少管理基础架构的时间。[免费试用 60 天](https://try.digitalocean.com/performance/?utm_medium=display&utm_source=paid_newsletter+python+weekly&utm_campaign=PricePerf+dr+droplets+newsletters&utm_content=Logo_125x125)。
+
+
+# 新闻
+
+[JupyterLab 已经可以使用了](https://blog.jupyter.org/jupyterlab-is-ready-for-users-5a6f039b8906)
+
+[Guido Van Rossum 获得 2018 年e Computer History Museum 三项荣誉之一](http://www.computerhistory.org/press/2018-fellow-honorees.html)
+
+[Visual Studio Code 现与 Anaconda 一起发布!](https://blogs.msdn.microsoft.com/pythonengineering/2018/02/15/visual-studio-code-is-now-shipping-with-anaconda)
+
+
+# 文章,教程和讲座
+
+[开始使用 Intel Movidius Neural Compute Stick](https://www.pyimagesearch.com/2018/02/12/getting-started-with-the-intel-movidius-neural-compute-stick/)
+
+本指南将向你展示如何(轻松)为深度学习启动并运行 Intel 的 Movidius Neural Compute Stick (NCS)。
+
+[Python 和异步简化](https://www.aeracode.org/2018/02/19/python-async-simplified/)
+
+Python 中的异步工作方式的高级入门。
+
+[Python 3 的 range 比 Python 2 的 xrange 更强大](http://treyhunner.com/2018/02/python-3-s-range-better-than-python-2-s-xrange/)
+
+如果你在 Python 2 和 Python 3 之间切换,那么你可能会认为 Python 2 的 xrange 对象与 Python 3 的 range 对象几乎完全相同。看起来似乎只是将 xrange 重命名为 range 而已,是吗? 不完全是。Python 2 的 xrange 在某些程度上比 Python 3 的 range 受限些。在这篇文章中,我们将看看 Python 2 中的 xrange 与 Python 3 中 range 有何不同。
+
+[利用 Python、AWS 和社会主义现实主义艺术,构建一个推特艺术机器人](https://veekaybee.github.io/2018/02/19/creating-a-twitter-art-bot/)
+
+我使用 Python 和 AWS Lambdas,构建了一个每 6 小时发布来自 WikiArt 社会主义现实主义类别的绘画作品的推特机器人。这篇文章概述了我决定这么做的原因、我做出的架构决策、关于机器人如何工作的技术细节以及对机器人的下一步改进。
+
+[从小白到大牛](https://jpboost.com/2018/02/06/creating-a-chatbot-with-rasa-nlu-and-rasa-core/)
+
+利用 Rasa NLU 和 Rasa Core,创建聊天机器人。
+
+[我们的 Python 依赖关系综合指南](https://code.kiwi.com/our-comprehensive-guide-to-python-dependencies-8a5a4366a563)
+
+一篇来自 Kiwi.com 内部工程手册的文章,涵盖了 Python 打包、使用自己的私有 PyPI 存储库、使用内部库构建 Docker 镜像等基础知识。
+
+[pdvega 介绍 - 使用 Vega-Lite,为 Pandas 绘图](http://pbpython.com/pdvega.html)
+
+本文将会介绍几个使用 pdvega 的例子,并将其与 pandas 现有的基本功能进行比较。
+
+[使用 Apache MXNet 构建生成模型](https://www.oreilly.com/ideas/generative-model-using-apache-mxnet)
+
+通过生成对抗网络(GAN)构建生成模型,实现从现有的图像中生成新图像的手把手教程。
+
+[将一个庞大而老旧的代码库迁移至 Python3](https://medium.com/@boxed/moving-a-large-and-old-codebase-to-python3-33a5a13f8c99)
+
+[(轻松)跨平台 Python 冻结的一站式指南:第一部分](https://hackernoon.com/the-one-stop-guide-to-easy-cross-platform-python-freezing-part-1-c53e66556a0a)
+
+[加上 Flask 中的 url_for](https://anthonyblackshaw.me/2018-02-17/speeding-up-url-for-for-flask)
+
+
+# 好玩的项目,工具和库
+
+[FastPhotoStyle](https://github.com/NVIDIA/FastPhotoStyle)
+
+这个代码库包含了我们的快速照片级样式的传输算法的实现。给定一张内容图片和样式图片,就可以将这张样式图片的样式转换到内容图片中。
+
+[gnomecast](https://github.com/keredson/gnomecast)
+
+支持转码和字幕的本地 Linux Chromecast GUI。
+
+[15-minute-apps](https://github.com/mfitzp/15-minute-apps)
+
+用 PyQt 构建的 15 分钟(小型)桌面应用程序。
+
+[Chomper](https://github.com/aniketpanjwani/chomper)
+
+Chomper 是一个在 Linux 上使用的 Python 命令行程序,它可以在指定的时间段内创建被阻止的网站的黑名单或者允许的网站的白名单。该程序旨在帮助人们解决互联网干扰导致的计算机问题。
+
+[zroya](https://github.com/malja/zroya)
+
+用于创建 Windows 通知的 win32 Python 封装。
+
+[raspberry-pi-turnkey](https://github.com/schollz/raspberry-pi-turnkey)
+
+如何制作一个可以在任何地方部署,并且无需 SSH 即可对其分配 WiFi 网络的树莓派镜像。
+
+[MSDAT](https://github.com/quentinhardy/msdat)
+
+MSDAT(Microsoft SQL 数据库攻击工具)是一款开源渗透测试工具,可远程测试 Microsoft SQL 数据库的安全性。
+
+[untrusted.py](https://github.com/tawesoft/untrusted.py)
+
+对不可信输入进行类型限制的更安全的 Python。
+
+[ENAS-pytorch](https://github.com/carpedm20/ENAS-pytorch)
+
+“Efficient Neural Architecture Search via Parameters Sharing(通过参数共享实现的高效神经架构搜索)” 的 PyTorch 实现。
+
+[django-channels-chat](https://github.com/narrowfail/django-channels-chat)
+
+一个简单的 Django-Channels web 聊天!
+
+[mutations](https://github.com/omarish/mutations)
+
+将你的业务逻辑组合成清理和验证输入的命令。
+
+[30-seconds-of-python-code](https://github.com/kriadmin/30-seconds-of-python-code)
+
+30 秒代码的 Python 实现。
+
+[EvilOSX](https://github.com/Marten4n6/EvilOSX)
+
+用于 macOS / OSX 的实施漏洞利用的纯 python RAT(远程管理工具)。
+
+[git-xltrail](https://github.com/ZoomerAnalytics/git-xltrail)
+
+控制 Excel 工作簿文件版本的 Git 扩展。
+
+
+# 最新发布
+
+[IronPython 2.7.8](https://github.com/IronLanguages/ironpython2/releases/tag/ipy-2.7.8)
+
+[Matplotlib v2.2.0rc1](https://mail.python.org/pipermail/matplotlib-users/2018-February/001280.html)
+
+
+
+
diff --git a/Python Weekly/Python_Weekly_Issue_336.md b/Python Weekly/Python_Weekly_Issue_336.md
new file mode 100644
index 0000000..181967f
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_336.md
@@ -0,0 +1,162 @@
+原文:[Python Weekly - Issue 336](http://eepurl.com/dmqu9X)
+
+---
+
+欢迎来到Python周刊第 336 期。本周干货满满。尽情享用吧!
+
+# 来自赞助商
+
+[](https://www.datadoghq.com/dg/apm/ts-python-error-tracking/?utm_source=Advertisement&utm_medium=Advertisement&utm_campaign=PythonWeekly-Tshirt&utm_content=Python)
+
+使用 Datadog 快速识别 **Python** 应用中的错误。可视化关键指标,例如点击率、错误率和延迟,以及端到端请求跟踪,以找到慢查询、错误和低效代码。今天就开始 [14 天的免费试用](https://www.datadoghq.com/dg/apm/ts-python-error-tracking/?utm_source=Advertisement&utm_medium=Advertisement&utm_campaign=PythonWeekly-Tshirt&utm_content=Python),可视化你的 Python 性能吧。
+
+
+# 文章,教程和讲座
+
+[如何在 15 分钟内构建一个深度学习模型](https://tech.instacart.com/how-to-build-a-deep-learning-model-in-15-minutes-a3684c6f71e)
+
+一个用 Python 配置、构建、部署和维护深度学习模型的开源框架。
+
+[如何在 Windows 10 上,使用 TensorFlow 1.5 (GPU),训练对象检测分类器](https://www.youtube.com/watch?v=Rgpfk6eYxJA)
+
+这个教程向你展示如何在 Windows 上,使用 Google 的 TensorFlow 对象检测 API,训练你自己的多对象检测器。
+
+[使用 Matplotlib 的 Python 绘图](https://realpython.com/blog/python/python-matplotlib-guide/)
+
+本文是关于 Python 和 matplotlib 的初级到中级的演练,使用理论和示例相结合的方式。
+
+[数据分析的 101 个 NumPy 练习(Python)。](https://www.machinelearningplus.com/101-numpy-exercises-python/)
+
+本 numpy 练习题的目标在于,作为参考,并让你在基础之外使用 numpy。问题包含了 4 个难度,其中,L1 最简单,而 L4 最难。
+
+[如何用 Python,编写一个 Discord 机器人](https://boostlog.io/@junp1234/how-to-write-a-discord-bot-in-python-5a8e73aca7e5b7008ae1da8b)
+
+在这个教程中,你将会学习使用 Python 创建一个简单的 Discord 机器人。以防你不知道 Discord 是什么,这里解释下,它实际上是一个类似于 Slack 的服务,目标在于游戏玩家。在 Discord 中,你可以加入多个服务器,并且你必须注意到,这些服务器拥有许多机器人。这些机器人可以做很多事情,从为你播放音乐,到简单的聊天。我对这些机器人非常着迷,所以决定使用 Python 为自己写一个。所以,让我们开始玩吧!
+
+[OAuth 2.0 流程的基本特性](https://medium.com/@valeriechapple/how-to-truly-understand-oauth-2-0-69dd3e7574c6)
+
+使用谷歌的 REST API,看看处理 OAuth 2.0 流程的内部工作方式,然后不再对其感到困惑。
+
+[使用 Flask 和 Redis Queue 的异步任务](https://testdriven.io/asynchronous-tasks-with-flask-and-redis-queue)
+
+本文讨论了如何配置 Redis Queue 来在 Flask 应用中处理长时间运行的任务。
+
+[用 Python 实现向上趋势线指标](https://medium.com/@vedranmarkulj/https-medium-com-vedranmarkulj-implementing-the-up-trendline-indicator-with-python-part-1-10f19939431e)
+
+从获取数据到建模算法和实现解决方案 —— 第一部分 使用 REST API
+
+[电话号码代理](https://www.twilio.com/blog/2018/02/phone-number-forward-mask-python-flask.html)
+
+我们使用 Python、Flask 和 Twilio 的短信和语音 API,构建了一个代理电话号码,以便在对话中隐藏受保护的号码。看看如何通过 burner 号码,接收语音通话和短信到被屏蔽的号码,以及如何通过那个号码转发拨打出去的电话和发出的短信。
+
+[如何为 Python Web 应用编写 Dockerfile](https://blog.hasura.io/how-to-write-dockerfiles-for-python-web-apps-6d173842ae1d)
+
+这篇文章满满都是示例,从简单的 Dockerfile 到 Python 应用的多阶段生产构建。
+
+[电影评价数据库的情感分类](https://github.com/kodiaklabs/MovieSentimentClassification/blob/master/MovieReviewClassification.ipynb)
+
+在这篇教程中,我们将使用手动标记的 Standford 电影评价数据库来构建情感分类器。我们的工作将强调如何使用 Jupyter Notebooks 以及 Python、Scikit-learn 和 Pandas (包括 Numpy),构建和交叉验证情感分类器。我们还会在 Matplotlib 和 Seaborn 的帮助下,使用一点 EDA。
+
+[现实世界中的 Celery](https://www.vinta.com.br/blog/2018/celery-wild-tips-and-tricks-run-async-tasks-real-world/)
+
+在现实世界中运行异步任务的技巧和窍门。
+
+[用于 asyncio 的上下文信息存储](https://blog.sqreen.io/asyncio/)
+
+[PyCascades 2018 视频集](https://www.youtube.com/watch?v=ZlhHhpnGQjA&list=PLcNrB7gPa-NdK63f099X3Rm3cXfc7N8Ro)
+
+[元组会比列表快吗?](http://zwmiller.com/blogs/python_data_structure_speed.html)
+
+[Harpoon:OSINT / 威胁情报工具](https://www.randhome.io/blog/2018/02/23/harpoon-an-osint-/-threat-intelligence-tool/)
+
+[Raschietto:一个简单的网页抓取库](https://hackernoon.com/raschietto-a-simple-library-for-web-scraping-46957c6aa5b7)
+
+[使用 Python 和 Scikit-Learn,实现决策树](http://stackabuse.com/decision-trees-in-python-with-scikit-learn/)
+
+
+# 书籍
+
+[Django Admin Cookbook](https://books.agiliq.com/projects/django-admin-cookbook/en/latest/)
+
+这是一本关于使用 Django admin 的书。它包含了关于 Django admin,我们可以回答的 40 个问题和常见任务。
+
+
+# 好玩的项目,工具和库
+
+[lore](https://github.com/instacart/lore)
+
+lore 让机器学习对软件工程师变得可接受,对机器学习研究人员变得可维护。
+
+[requests-html](https://github.com/kennethreitz/requests-html)
+
+人类友好的 HTML 及期限。这个库旨在尽可能让 HTML 解析(例如,抓取网页)变得简单直观。
+
+[mapboxgl-jupyter](https://github.com/mapbox/mapboxgl-jupyter)
+
+在 Python Jupyter notebook 中,使用 Mapbox GL JS 可视化数据。
+
+[twitter-scraper](https://github.com/kennethreitz/twitter-scraper)
+
+无需鉴权就可以抓取推特的前端 API。
+
+[s3monkey](https://github.com/kennethreitz/s3monkey)
+
+一个 Python 库,让你可以就像本地文件系统那样与 Amazon S3 Buckets 交互。
+
+[handwriting-synthesis](https://github.com/sjvasquez/handwriting-synthesis)
+
+用 RNNs 进行手写合成。
+
+[Sign-Language](https://github.com/EvilPort2/Sign-Language)
+
+一个非常简单的 CNN 项目。
+
+[dotdotslash](https://github.com/jcesarstef/dotdotslash)
+
+帮助你搜索目录遍历漏洞的工具。
+
+[ssm-cache-python](https://github.com/alexcasalboni/ssm-cache-python)
+AWS 系统管理器参数储存缓存 Python 客户端。
+
+[pyqt-boilerplate](https://github.com/gmarull/pyqt-boilerplate)
+
+PyQt5 应用样板文件:资源、表单、多语言、汇编、文档、linting……
+
+[bellybutton](https://github.com/hchasestevens/bellybutton)
+
+使用 AST 表达式的自定义 Python linting。
+
+[Harpoon](https://github.com/Te-k/harpoon)
+
+用于开源和威胁情报的 CLI 工具。
+
+[one-pixel-attack-keras](https://github.com/Hyperparticle/one-pixel-attack-keras)
+
+“One pixel attack for fooling deep neural networks(用于愚弄深度神经网络的单像素攻击)”的 Keras 重新实现,使用 cifar10 上的差分进化。
+
+
+# 最新发布
+
+[Python 3.7.0b2](https://www.python.org/downloads/release/python-370b2/)
+
+
+# 近期活动和网络研讨会
+
+[PyAtl 2018 年 3 月聚会 - Atlanta, GA](https://www.meetup.com/python-atlanta/events/blgrkpyxfblb/)
+
+将会有以下演讲:
+
+ * 填充 Swear Jar
+ * 使用 Pytest 进行功能测试
+
+[Python 展示之夜 #60 - Minneapolis, MN](https://www.meetup.com/PyMNtos-Twin-Cities-Python-User-Group/events/245582178/)
+
+将会有以下演讲:
+
+ * 如何将 Spark 连接到 Jupyter Notebooks
+ * 绘制轨道交通:制作实时的轨道交通图
+
+
+
+
+
diff --git a/Python Weekly/Python_Weekly_Issue_337.md b/Python Weekly/Python_Weekly_Issue_337.md
new file mode 100644
index 0000000..0c80438
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_337.md
@@ -0,0 +1,169 @@
+原文:[Python Weekly - Issue 337 ](http://eepurl.com/dnepqj)
+
+---
+
+欢迎来到Python周刊第 337 期。让我们直奔主题。
+
+# 来自赞助商
+[](https://goo.gl/wlxnDm)
+
+借助 Intel 加速过的 NumPy 和 SciPy,获得高达 100 倍的性能提升,现在,你可以[从 PyPI 安装](https://software.intel.com/en-us/articles/installing-the-intel-distribution-for-python-and-intel-performance-libraries-with-pip-and?utm_source=03%2F07%2F18%20Python%20Weekly%20Newsletter&utm_medium=Email) 了。只需 pip install intel-numpy, intel-scipy 和其他优化过的 Python 包的 Intel 版本,就可以体验更快的性能。开箱即用!
+
+
+# 新闻
+
+[PyLondinium18 征文](https://www.papercall.io/pylondinium)
+
+
+# 文章,教程和讲座
+
+[使用 TensorFlow API 的机器学习速成课程](https://developers.google.com/machine-learning/crash-course/)
+
+Google 对机器学习的快速实用介绍。它包含一系列带视频录像、现实世界案例研究和动手实践联系的课程。
+
+[快速 Pandas](https://rise.cs.berkeley.edu/blog/pandas-on-ray/)
+
+通过替换一行代码来让 Pandas 更快。
+
+[Python:range 不是迭代器!](http://treyhunner.com/2018/02/python-range-is-not-an-iterator/)
+
+本文针对的是那些错误地将 range 对象描述为迭代器的教师和经验丰富的 Python 程序员。它解释了什么是迭代器、range 对象的工作方式以及两者如何不同。
+
+[Python 中 5 种快速轻松的数据可视化(附代码)](https://towardsdatascience.com/5-quick-and-easy-data-visualizations-in-python-with-code-a2284bae952f)
+
+Matplotlib 是一个流行的 Python 库,可以用它来很容易地创建数据可视化。然而,每次进行新项目的时候,都要设置数据、参数、图形和绘图,这是一件乱七八糟的繁琐工作。在这篇博文中,我们将着眼于 6 种数据可视化,并使用 Python 的 Matplotlib 为它们编写一些快速而简单的功能。
+
+[什么是 Python 全局解释器锁(GIL)?](https://realpython.com/blog/python/python-gil/)
+
+在这篇文章中,你将了解 GIL 是如何影响你的 Python 程序的性能的,以及可以如何减轻它可能对代码造成的影响。
+
+[使用 Sklearn 的朴素贝叶斯分类器](https://blog.sicara.com/naive-bayes-classifier-sklearn-python-example-tips-42d100429e44)
+
+在本教程中,我们将了解朴素贝叶斯分类器是如何工作的、它的优缺点以及使用 Sklearn python 库构建朴素高斯分类器的示例。
+
+[Python 中的数据预处理](https://medium.com/@ernestk.social/how-i-learned-to-love-parallelized-applies-with-python-pandas-dask-and-numba-f06b0b367138)
+
+我是如何学会爱上并行的 apply(使用 Dask 和 Numba)。
+
+[使用 Python,通过 web 抓取进行数据分析:CIA 世界概况说明](https://towardsdatascience.com/data-analytics-with-python-by-web-scraping-illustration-with-cia-world-factbook-abbdaa687a84)
+
+在这篇文章中,我们展示了如何使用 Python 库和 HTML 解析,从网站中提取有用的信息,然后回答一些重要的分析问题。
+
+[集成 Google Sheets 和 Jupyter Notebooks](http://www.countingcalculi.com/explanations/google_sheets_and_jupyter_notebooks/)
+
+如何在 Google Sheets 和 Jupyter Notebooks 之间传递数据。
+
+[使用 Python 创建一个 HTML5 游戏机器人](https://vesche.github.io/articles/01-stabbybot.html)
+
+[如何用 Keras 进行实时触发单词检测](https://hackernoon.com/how-to-do-real-time-trigger-word-detection-with-keras-b8a56ab106b7)
+
+[如何使用 Django 和 Zappa 构建一个 Serverless Slack API](https://medium.com/@eremieff/how-to-build-a-serverless-slack-api-with-django-and-zappa-4ce4e12c2a44)
+
+
+# 书籍
+
+[Django ORM Cookbook(Django ORM 烹饪指南)](https://books.agiliq.com/projects/django-orm-cookbook/en/latest/)
+
+Django ORM Cookbook 是一本关于使用 Django ORM 和 Django 模型的书。Django 是一种“MTV”(模型-模板-视图)框架 —— 本书深入介绍了 M(模型) 部分。
+
+
+# 好玩的项目,工具和库
+
+[S3Scanner](https://github.com/sa7mon/S3Scanner)
+
+搜索打开的 S3 bucket 并转储。
+
+[Socialhome](https://github.com/jaywink/socialhome)
+
+对 Socialhome 的最佳描述是:带社交网络功能的联合个人资料。
+
+[Passhunt](https://github.com/Viralmaniar/Passhunt)
+
+Passhunt 是一个用于搜索网络设备、web 应用等默认凭证的简单工具。搜遍 523 个供应商和他们的 2084 个默认密码。
+
+[ForceNap](https://github.com/omikun/ForceNap)
+
+挂起任意非当前使用的 Mac OS 应用。
+
+[Vermin](https://github.com/netromdk/vermin)
+
+并发检测运行代码所需的最低的 Python 版本。
+
+[Snug](https://github.com/ariebovenberg/snug)
+
+Snug 是一个使用 web API 编写的可重复使用的交互的小工具包。
+
+[poetry](https://github.com/sdispater/poetry)
+
+让 Python 依赖管理和打包变得简单。
+
+[Memcrashed-DDoS-Exploit](https://github.com/649/Memcrashed-DDoS-Exploit)
+
+DDoS 攻击工具,用于将伪造的 UDP 包发送到使用 Shodan API 获取的易受攻击的 Memcached 服务器上。
+
+[CTFR](https://github.com/UnaPibaGeek/ctfr)
+
+用于获取 HTTPS 网站子域名的滥用证书透明度日志。
+
+[Crypto_Trader](https://github.com/bshaw19/Crypto_Trader)
+
+基于 Q-Learning 的加密数字货币交易器和投资组合优化器,用于 Poloniex 交易所。
+
+[Simple-OpenCV-Calculator](https://github.com/EvilPort2/Simple-OpenCV-Calculator)
+
+手势控制计算器。
+
+[SRCNNKit](https://github.com/DeNA/SRCNNKit)
+
+超分辨率卷积神经网络(SRCNN)的 CoreML 和 Keras 实现。
+
+
+# 最新发布
+
+[Django 安全版本发布:2.0.3,1.11.11 和 1.8.19](https://www.djangoproject.com/weblog/2018/mar/06/security-releases/)
+
+[TensorFlow 1.6.0](https://github.com/tensorflow/tensorflow/releases/tag/v1.6.0)
+
+[Wagtail 2.0](https://wagtail.io/blog/wagtail-2/)
+
+
+# 近期活动和网络研讨会
+
+[在线研讨会:和 Grishma Jena 一起学习 Python](https://www.youtube.com/watch?v=WIFCd1m7VuA)
+
+了解代码环境、代码编译以及不同的数据类型和数据结构。我们还将讨论控制流程结构、函数和输入输出。此次课程将使用我们所学完成迷你项目!课程由客座讲师 Grishma Jena 主持。
+
+[在线研讨会:PyCon Colombia 打包教程](https://www.meetup.com/Medellin-Python-y-Django-Meetup/events/248261891/)
+
+想要学习如何将代码片段、最喜欢的函数或者类转换成可安装的 Python 包吗?那么,我们将举办一场免费的 Python 在线打包研讨会。如果你在 Medellin,Colombia,那么,你可以亲自加入到 Audrey Roy Greenfeld 和 Daniel Roy Greenfeld 中。
+
+[网络研讨会:在 Python 中使用 web API](https://www.crowdcast.io/e/http-2/register)
+
+我们将会聊聊用 Python 执行 HTTP 请求,并使用 RESTful web API。这将是一次问答驱动的聊天,所以,请提前准备好问题!
+
+[San Francisco Python 2018 年 3 月聚会 - San Francisco, CA](https://www.meetup.com/sfpython/events/246990804/)
+
+将会有以下演讲:
+
+ * 在 CMB,从 Python 3 迁移中学到的经验教训
+ * 使用 Eliot 进行叙事性日志记录
+ * 使用 Docker 打包一个 flask + gunicorn 应用,以及在 Hasura 上部署
+ * importlib.resources
+ * 给 Python 程序员的 Nim
+
+
+[IndyPy 2018 年 3 月每月聚会 - Indianapolis, IN](https://www.meetup.com/indypy/events/246943122/)
+
+将会有以下演讲:
+
+ * Amazon Echo 和 Python Flask Ask 库
+ * 面对你的恐惧:增加你的收入,自尊和空闲时间
+
+
+[Austin Python 2018 年 3 月聚会 - Austin, TX](https://www.meetup.com/austinpython/events/246719046/)
+
+[Boulder Python 2018 年 3 月聚会 - Boulder, CO](https://www.meetup.com/BoulderPython/events/246751070/)
+
+
+
+
diff --git a/Python Weekly/Python_Weekly_Issue_338.md b/Python Weekly/Python_Weekly_Issue_338.md
new file mode 100644
index 0000000..656b5bd
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_338.md
@@ -0,0 +1,167 @@
+原文:[Python Weekly - Issue 338](http://eepurl.com/dn5F6H)
+
+---
+
+欢迎来到Python周刊第 338 期。让我们直奔主题。
+
+# 来自赞助商
+[](https://www.digitalocean.com/community/tutorials/how-to-write-a-slash-command-with-flask-and-python-3-on-ubuntu-16-04?utm_source=paid_newsletter+python+weekly&utm_medium=display&utm_campaign=Brand+tutorial+newsletter&utm_content=3-15-2018+python+weekly)
+
+[在此深入教程中,学习如何使用 Flask 和 Python,扩展和编写 Slack Slash 命令。](https://www.digitalocean.com/community/tutorials/how-to-write-a-slash-command-with-flask-and-python-3-on-ubuntu-16-04?utm_source=paid_newsletter+python+weekly&utm_medium=display&utm_campaign=Brand+tutorial+newsletter&utm_content=3-15-2018+python+weekly) DigitalOcean 是一个云计算平台,可以在数秒内快速地提供数千台云服务器(带防火墙、监控和告警)。今天,就是用 DigitalOcean 来进行更快速的部署吧。
+
+
+# 新闻
+
+[OpenAI 学者计划](https://blog.openai.com/openai-scholars)
+
+OpenAI 正提供 6 到 10 个津贴和导师制,以帮助那些特殊群体全日制学习机器学习 3 个月,并开源项目。这是一个远程项目,向位于美国时区的具有美国工作许可证的任何人开放。是的,你将会使用 Python 编写程序。如果你符合资格的话,那么这是一个绝佳的机会。
+
+[PyOhio 征求提议](https://www.pyohio.org/2018/program/call-for-proposals)
+
+PyOhio 邀请所有感兴趣的人们提交演讲和教程提案。所有 Python 社区感兴趣的主题都在考虑之内。标准的展示性演讲时间为 30 分钟,而特选演讲将会有 45 分钟时间。教程类将会有 120 分钟。
+
+
+# 文章,教程和讲座
+
+[区块链实用介绍,使用 Python](http://adilmoujahid.com/posts/2018/03/intro-blockchain-bitcoin-python/)
+
+抛开比特币和其他加密货币价格的所有炒作,本文的目标在于,向你提供一个区块链技术的实用介绍。第 1 部分和第 2 部分涵盖区块链背后的一些核心概念,而第 3 部分展示了如何使用 Python 实现区块链。我们还会实现 2 个 web 应用,方便终端用户与我们的区块链互动。
+
+[我是如何在 Python 里,使用深度学习实现 iPhone X 的 FaceID 的。](https://towardsdatascience.com/how-i-implemented-iphone-xs-faceid-using-deep-learning-in-python-d5dbaa128e1d)
+
+逆向 iPhone X 的新解锁机制。
+
+[使用 Nexmo 和微软的 Translator Speech API 构建一个 Babel Fish](https://www.nexmo.com/blog/2018/03/14/speech-voice-translation-microsoft-dr/)
+
+构建你自己的翻译服务或者 Babel Fish;通过简单的语音通话,实时翻译不同的语言。在这篇深入教程里,我们将引导你使用 Nexmo Voice API 和微软的 Microsoft Translator Speech API,来创建你自己的语音翻译器。
+
+[我是如何使用 Twilio 和一个 AWS 物联网按钮来训练我的宝宝如厕的](https://twilioinc.wpengine.com/2018/03/iot-poop-button-python-twilio-aws.html)
+
+一个物联网便盆按钮演练,当孩子必须上厕所时会给我打电话。使用 Python、Twilio、AWS IoT、Lambda 和一个物联网按钮来构建即时提醒(拨打电话)。包含可以用来构建你自己的便便按钮或扩展此想法的样例代码以及链接。
+
+[我是怎样修复 Python 3.7 中一个非常古老的 GIL 竞争条件的。](https://vstinner.github.io/python37-gil-change.html)
+
+我花了 4 年的时间来解决著名的 Python GIL(全局解释器锁,Python最关键的部分之一)中一个令人讨厌的问题。为此,我不得不深入 Git 历史,挖缺出 Guido van Rossum 26 年前做的一个改动:在那个时候,线程是某些深奥的东东。请听我娓娓道来。
+
+[多重赋值和元组解包可以提高 Python 代码的可读性](http://treyhunner.com/2018/03/tuple-unpacking-improves-python-code-readability/)
+
+在这篇文章中,我们将了解多重赋值,我们会看看多重赋值的常见用法,然后还会看看多重赋值的几个常常被忽略的用途。
+
+[教程:使用 React 的 Django REST(Django 2.0)](https://www.valentinog.com/blog/tutorial-api-django-rest-react/)
+
+将 React 和 Django REST 结合在一起的实用(自以为是)的介绍。使用 Django 2.0!
+
+[使用 Falcon 和 Celery 的异步任务](https://testdriven.io/asynchronous-tasks-with-falcon-and-celery)
+
+异步任务被用于将密集且耗时的流程(易于出现故障)转移到后台,这样,就可以快速响应客户端。本文讨论如何集成 Celery(一个异步任务队列)到基于 Python 的 Falcon web 框架。我们还会使用 Docker 和 Docker Compose 来将所有东西绑定在一起。最后,我们还会看看怎样使用单元测试和集成测试来测试 Celery 任务。
+
+[这就是创建一个 REST API 有多简单](https://codeburst.io/this-is-how-easy-it-is-to-create-a-rest-api-8a25122ab1f3)
+
+使用 Python Flask,学习如何快速创建语义 REST API。
+
+[使用 OpenCV(C++/Python)进行图像对齐(基于特征)](http://www.learnopencv.com/image-alignment-feature-based-using-opencv-c-python/)
+
+在这篇文章中,我们将学习如何使用 OpenCV 进行基于特征的图像对齐。我们会同时分享使用 C++ 和 Python 的代码。
+
+[人人都想要的 Jupyter Notebooks 可视化 Python 调试器](https://medium.com/ibm-watson-data-lab/the-visual-python-debugger-for-jupyter-notebooks-youve-always-wanted-761713babc62)
+
+
+# 书籍
+
+[Practical Python AI Projects: Mathematical Models of Optimization Problems with Google OR-Tools(实用 Python AI 项目:使用 Google OR-Tools 实现 优化问题的数学模型)](http://amzn.to/2Ds48R9)
+
+使用优化模型,利用 Python 发现解决人工智能问题的艺术和科学。本书涵盖了数学代数模型(例如线性连续模型、非明显线性连续模型和纯线性整数模型)的实际创建和分析。和强调理论相比,Practical Python AI Projects 这本书是作者几十年行业教学和咨询的产物,强调模型创造方面;对比替代方法和实际变化。
+
+
+# 本周的Python工作
+
+[Enthought 招聘 Python 技术培训师](http://jobs.pythonweekly.com/jobs/python-technical-trainer/)
+
+Enthought 正在寻找一名天赋异禀的 Python 讲师,他应该对教学富有激情,并且拥有将 Python 用于科学计算 / 数据科学应用方面的丰富经验。工作地点是我们位于 Austin 中心的办公室,并且还会前往各大城市,为各行各业的科学家、工程师、分析师和数据科学家教授 Python。
+
+
+# 好玩的项目,工具和库
+
+[snips-nlu](https://github.com/snipsco/snips-nlu)
+
+Snips NLU(自然语言理解)是一个 Python 库,允许解析用自然语言编写的句子,并提取结构化信息。
+
+[Tandem](https://github.com/typeintandem/tandem)
+
+Tandem 是一个去中心化的协作文本编辑解决方案。Tandem 与本地文本编辑器一起使用,跨不同的编辑器工作,并且使用点对点连接来促进沟通。
+
+[machine_learning_basics](https://github.com/zotroneneis/machine_learning_basics)
+
+基本的机器学习算法的简单 python 实现。
+
+[md_math_to_pdf](https://github.com/chrisconlan/md_math_to_pdf)
+
+基于 Python 的 Pandoc 实用程序,使用 Markdown,支持 LaTeX Math 和 LaTeX 模板。
+
+[wpgtk](https://github.com/deviantfero/wpgtk)
+
+wpgtk 是一个用 Python 编写的通用颜色格式、壁纸和模板管理器。
+
+[django-emailhub](https://gitlab.com/h3/django-emailhub)
+
+Django EmailHub 是一个将高级电子邮件功能(例如模板、批量发送和归档)引入 Django 中的库。
+
+[PyGObject](https://pypi.org/project/PyGObject/)
+
+PyGObject 是一个 Python 包,它为诸如GTK+、GStreamer、WebKitGTK+、GLib、GIO等基于 GObject 的库提供绑定。
+
+[Lector](https://github.com/BasioMeusPuga/Lector)
+
+基于 Qt 的电子书阅读器。
+
+[word2vec-graph](https://github.com/anvaka/word2vec-graph)
+
+探索作为最近邻图形的 word2vec 嵌入。
+
+[zAI](https://github.com/BiometricVox/zAI)
+
+zAI(zero-effort Artificial Intelligence,毫不费劲的人工智能)是一个 Python 库,允许任何开发者使用易用的命令执行高级的人工智能任务,这样,用户就不需要了解底层的机器学习模型,或者任何涉及的技术。
+
+[organize](https://github.com/tfeldmann/organize)
+
+文件管理自动化工具。
+
+[GINO](https://github.com/fantix/gino)
+
+GINO(GINO Is Not ORM)是使用 Python asyncio 的轻量级异步 ORM,构建于 SQLAlchemy 核心之上。现在(2018 年初),GINO 只支持一种第三方实现 asyncpg。
+
+[azure-uamqp-python](https://github.com/Azure/azure-uamqp-python)
+
+用于 Python 的 AMQP 1.0 客户端库。
+
+[tactical-exploitation](https://github.com/0xdea/tactical-exploitation)
+
+现代战术利用工具包。
+
+[Black](https://github.com/ambv/black)
+
+不妥协的 Python 代码格式化程序。
+
+
+# 最新发布
+
+[Python 3.6.5rc1](https://pythoninsider.blogspot.com/2018/03/python-365rc1-is-now-available-for.html)
+
+
+# 近期活动和网络研讨会
+
+[使用 Python 进行机器学习:Numpy 和 K-最近邻 - New York, NY](https://www.meetup.com/Build-with-Code-New-York/events/248700837/)
+
+在这个实践研讨会上,我们将学习 numpy 的内部工作原理,因为我们要开发行业中最广泛使用的机器学习算法之一的自己的版本:K-最近邻。
+
+[Baltimore Python 2018 年 3 月聚会 - Baltimore, MD](https://www.meetup.com/baltimore-python/events/248280327/)
+
+我们将与 Baltimore Python and Code Meetup 联手,进行一场以 Pandas vs R 为特色的史诗级对决。
+
+[PyHou 2018 年 3 月聚会 - Houston, TX](https://www.meetup.com/python-14/events/245321801/)
+
+[LA Django 2018 年 3 月聚会](https://www.meetup.com/ladjango/events/248143874/)
+
+
+
+
diff --git a/Python Weekly/Python_Weekly_Issue_339.md b/Python Weekly/Python_Weekly_Issue_339.md
new file mode 100644
index 0000000..5abddc5
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_339.md
@@ -0,0 +1,125 @@
+原文:[Python Weekly - Issue 339 ](http://eepurl.com/doVqiL)
+
+---
+
+欢迎来到Python周刊第 339 期。让我们直奔主题。
+
+# 来自赞助商
+
+[](https://try.digitalocean.com/virtual-private-servers/?utm_source=paid_newsletter+python+weekly&utm_medium=display&utm_campaign=PricePerf+dr+free+newsletter+trial&utm_content=3-22-2018+python+weekly)
+
+当你使用 DigitalOcean 部署你的下一个 Python 应用时,可以获得[100 刀的免费赠送金额](https://try.digitalocean.com/virtual-private-servers/?utm_source=paid_newsletter+python+weekly&utm_medium=display&utm_campaign=PricePerf+dr+free+newsletter+trial&utm_content=3-22-2018+python+weekly)。在数秒钟内快速供应数千台云服务器,并且带有防火墙、监控、安全和告警 —— 所有这些都包含在我们直观的平台上。现在,花更多的时间敲码,并减少管理基础架构的时间吧!
+
+
+# 新闻
+
+[PyPI 上的 Markdown 说明](https://dustingram.com/articles/2018/03/16/markdown-descriptions-on-pypi)
+
+在 PyPI 上,将项目描述作为 Markdown 呈现的最佳方式。
+
+[PyCon Israel 2018 征文](https://docs.google.com/forms/d/e/1FAIpQLSd16_rRvtSlPk3fDpL-VyO8ULOoX4iFKZr81AhK_OuvfjZ-wg/viewform)
+
+
+# 文章,教程和讲座
+
+[MusicVAE:使用机器学习创建乐谱调色板。](https://magenta.tensorflow.org/music-vae)
+
+当画家创作的时候,她首先在调色板上混合并探索颜色选项,然后才将其应用在画布上。这个过程本身就是一种创作行为,对最终的成品具有深远的影响。音乐家和作曲家大多缺乏探索和混合音乐创意的类似设备,但是,我们希望改变这种情况。本文介绍了 MusicVAE,这是一个机器学习模型,可以让我们创建混合和探索乐谱的调色板。
+
+
+[VINE:一个用于神经进化的开源交互式数据可视化工具](https://eng.uber.com/vine/)
+
+Uber 推出了一个开源数据可视化工具 VINE,帮助神经进化研究人员更好地理解这一系列算法。
+
+[如何在 Python 中使用 HDF5 文件](https://www.uetke.com/blog/python/how-to-use-hdf5-files-in-python/)
+
+学习如何使用 HDF5 格式来存储大量数据并读取。使用 Python。
+
+[隐写术:在图像中隐藏图像](https://towardsdatascience.com/steganography-hiding-an-image-inside-another-77ca66b2acb1)
+
+在这篇文章中,我们将学习一些图像处理概念,以及如何在一张图像文件中隐藏另一张图像。
+
+[Python 语音识别的终极指南](https://realpython.com/python-speech-recognition/)
+
+Python 语音识别的深入教程。了解哪个语音识别库可以得到最好的结果,并用它来构建一个全功能的“猜词”游戏。
+
+
+[通过检测共振频率,用 Python 打破酒杯](https://www.makeartwithpython.com/blog/break-glass-with-resonant-frequency/)
+
+本文描述了编写 Python 程序,通过检测酒杯的共振频率,来按需打破酒杯的过程。在此过程中,我们将 3D 打印一个椎体,了解共振频率,然后看看为什么我需要一个放大器和压缩驱动器。那么,就让我们开始吧。
+
+[没有类的类](https://veriny.tf/classes-without-classes/)
+
+Python 的对象模型非常强大,你可以覆盖几乎所有的东西,或者把奇奇怪怪的东西交给任何人,让他们接受它(就好像它是一个普通的对象)。Python 的 OO 继承了 smalltalk OO,其中,一切都是对象,甚至是对象和对象类型也是如此,特别是函数。这让我感到好奇:是否可以在不使用类的情况下编写类?
+
+[测试 Python 命令行(CLI)应用的 4 种技巧](https://realpython.com/python-cli-testing/)
+
+在这篇文章中,你将学习 4 种用于 Python 命令行应用的基本测试技术:“低保真”打印调试、使用可视化调试器、使用 pytest 和桩进行单元测试以及集成测试。
+
+[使用 nginx、haproxy 和 lsyncd,构建高可用的文件存储](https://behind.pretix.eu/2018/03/20/high-available-cdn/)
+
+关于 pretix 背后的文章,你隔壁的友好的售票系统。
+
+[Python 3.7 新的内置断点 —— 快速浏览](https://hackernoon.com/python-3-7s-new-builtin-breakpoint-a-quick-tour-4f1aebc444c)
+
+
+# 本周的Python工作
+
+[PlanGrid 招聘后端工程师](http://jobs.pythonweekly.com/jobs/backend-engineer-3/)
+
+我们正在为我们的团队寻找后端工程师。从 Hudson Yards 到 Levi's Stadium,我们的客户建造了这个星球上一些最让人惊叹的建筑项目。通过用最好的生产工具武装施工人员,PlanGrid 带领行业向云和数字化转型。你将与顶级的设计师和 QA 团队一起构建灵活的解决方案,让客户在其建设项目的整个生命周期内管理他们的数据。
+
+
+# 好玩的项目,工具和库
+
+[MusicVAE](https://github.com/tensorflow/magenta/tree/master/magenta/models/music_vae)
+
+一个分级递归变分音乐自动编码器。
+
+[LabNotebook](https://github.com/henripal/labnotebook)
+
+LabNotebook 是一个可以让你灵活监控、记录、保存和查询你所有机器学习实验的工具。
+
+[livelossplot](https://github.com/stared/livelossplot)
+
+用于 Keras、PyTorch 等的 Jupyter Notebook 中的实时训练的损失绘图。
+
+[Fast-Pandas](https://github.com/mm-mansour/Fast-Pandas)
+
+针对不同 dataframe 大小的 pandas 不同操作的基准。
+
+[thug-memes](https://github.com/jerry-git/thug-memes)
+
+命令行 Thug Meme 生成器,用 Python 编写。
+
+[DjangoX](https://github.com/wsvincent/djangox)
+
+快速启动新的 Django 项目的框架。包含完整的用户身份验证流程:注册、登录和忘记密码。并且可以轻松扩展(通过 Gmail、Facebook、Twitter 等)社交认证功能。
+
+[consensus-cookery](https://github.com/schollz/consensus-cookery)
+
+为你的下一顿获取达成共识的食谱。
+
+[auto-py-to-exe](https://github.com/brentvollebregt/auto-py-to-exe)
+
+使用简单的图形界面将 .py 转换为 .exe。
+
+[PyTorch-NLP](https://github.com/PetrochukM/PyTorch-NLP)
+
+PyTorch 的文本实用程序和数据集。
+
+[Powershell-RAT](https://github.com/Viralmaniar/Powershell-RAT)
+
+基于 Python 的后门程序,它使用 Gmail,通过附件将数据泄露出去。这个 RAT 将在红队致力于给任意 Windows 机器开后门的时候提供帮助。它使用屏幕截图跟踪用户活动,并将其作为电子邮件附件发送给攻击者。
+
+[onegram](https://github.com/pauloromeira/onegram)
+
+一个简单的带 api 的 instagram 机器人,由 requests 提供支持。
+
+[hue](https://github.com/UltimateHackers/hue)
+
+Hue 将帮助你出色地在进行终端打印。
+
+[deep-person-reid](https://github.com/KaiyangZhou/deep-person-reid)
+深度人员重新识别方法的 Pytorch 实现。
+
diff --git a/Python Weekly/Python_Weekly_Issue_340.md b/Python Weekly/Python_Weekly_Issue_340.md
new file mode 100644
index 0000000..c551448
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_340.md
@@ -0,0 +1,172 @@
+原文:[Python Weekly - Issue 340](http://eepurl.com/dpIHQH)
+
+---
+
+欢迎来到Python周刊第 340 期。让我们直奔主题。
+
+# 来自赞助商
+
+[](https://blog.digitalocean.com/currents-march-2018/?utm_source=paid_newsletter+python+weekly&utm_medium=display&utm_campaign=2018_Brand&utm_content=3-29-2018+python+weekly)
+
+DigitalOcean 向全球开发者询问他们对最近的科技新闻的看法,包括网络中立性、GDPR、持续集成(CI)的使用等。[你的观点与世界上其他的开发者一致吗?](https://blog.digitalocean.com/currents-march-2018/?utm_source=paid_newsletter+python+weekly&utm_medium=display&utm_campaign=2018_Brand&utm_content=3-29-2018+python+weekly)
+
+
+# 新闻
+
+[Warehouse:全新的 PyPI 现在处于测试阶段](https://pyfound.blogspot.com/2018/03/warehouse-all-new-pypi-is-now-in-beta.html)
+
+全新的 Python Package Index 的 beta 版本现在在 pypi.org 上可以访问。我们预估,2018 年 4 月可以进行全面切换,所以,这里是关于切换的原因、发生的变化以及期望的提示。
+
+
+# 文章,教程和讲座
+
+[心率显示器](https://martinfitzpatrick.name/article/wemos-heart-rate-sensor-display-micropython/)
+
+发现 HR 传感器数据中的心跳。学习如何使用 Pulsesensor.com 传感器来构建一个带 OLED 脉冲、BPM 和迹线显示的可用的心脏监控器,在 Wemos D1 上使用 MicroPython。
+
+[使用 Keras 的深度学习库的词性标注教程](https://medium.com/@cdiscountdatascience/part-of-speech-tagging-tutorial-with-the-keras-deep-learning-library-d7f93fa05537)
+
+在这篇教程中,你将会看到可以如何使用一个简单的 Keras 模型来训练和评估用于多类分类问题的人工神经网络。
+
+[使用 NumPy 和 Pandas 的 Pythonic 数据清理](https://realpython.com/python-data-cleaning-numpy-pandas/)
+
+让你开始使用 NumPy 和 Pandas,在 Python 中进行基本数据清理的教程。
+
+[GAN 和 Keras:应用到图像去模糊](https://blog.sicara.com/keras-generative-adversarial-networks-image-deblurring-45e3ab6977b5)
+
+在 2014 年,Ian Goodfellow 提出了生成对抗网络(GAN)。本文重点在于使用 Keras,将 GAN 应用于图像去模糊。
+
+[使用 Python 分析 14 亿行数据](https://hackernoon.com/analysing-1-4-billion-rows-with-python-6cec86ca9d73)
+
+使用 pytubes、numpy 和 matplotlib。
+
+[Pandas 数据类型概述](http://pbpython.com/pandas_dtypes.html)
+pandas 数据类型介绍,以及如何将数据列转换为正确的数据类型。
+
+[在 Python 中递归思考](https://realpython.com/python-thinking-recursively/)
+
+通过掌握诸如递归函数和递归数据结构等概念,学习如何在 Python 程序中使用递归。
+
+[处理 Celery 上的资源消耗型任务](https://www.vinta.com.br/blog/2018/dealing-resource-consuming-tasks-celery/)
+
+在这篇文章中,我们将讨论可以如何优化你的 Celery 任务,以及避免与资源消耗型任务相关的某些问题。
+
+[使用 Skater 解释预测模型:开箱模型不透明度](https://www.oreilly.com/ideas/interpreting-predictive-models-with-skater-unboxing-model-opacity)
+
+深入探讨作为理论概念的模型解释,以及对 Skater 的高层次概述。
+
+[使用 Redis 和 Python,构建自行车共享应用](https://opensource.com/article/18/2/building-bikesharing-application-open-source-tools)
+
+学习如何使用 Redis 和 Python,构建位置感知应用。
+
+[使用 Github 和 Python 进行持续部署](https://fedoramagazine.org/continuous-deployment-github-python/)
+
+本教程教你如何编写一个基于 Flask 的 web 服务,该服务接收来自 Github webhook 的请求,然后进行持续部署。将此教程当成起点,你现在应该能够构建你自己有用的服务。
+
+[使用 Django ORM,构建最近添加的组合流](https://simonwillison.net/2018/Mar/25/combined-recent-additions/)
+
+[使用 Flask、Redis Queue 和 Amazon SES,发送确认邮件](https://testdriven.io/sending-confirmation-emails-with-flask-rq-and-ses)
+
+[使用 Python,对糖尿病进行机器学习](https://datascienceplus.com/machine-learning-for-diabetes-with-python/)
+
+
+# 书籍
+
+[Flask Web 开发:使用 Python 开发 web 应用(第二版)](https://amzn.to/2pKN7Nc)
+
+通过基于 Python 的微框架 Flask,完全控制你的 web 应用。有了这本实践书的第二版,你就可以通过开发一个由作者 Miguel Grinberg 创建的完整的真实世界的应用,从头开始学习 Flask。此更新版本解释了过去三年发生的重大技术变化。
+
+[使用 Django 和 Django Rest 框架构建 API](https://books.agiliq.com/projects/django-api-polls-tutorial/en/latest/)
+
+使用 Django 和 DRF 构建 API 作为本 Django 教程结束的部分。在 Django 教程中,你会构建一个常规的 Django 民意调查应用。我们还会重新构建一个类似应用的 API。
+
+
+# 本周的Python工作
+
+[Resonon 招聘软件工程师](http://jobs.pythonweekly.com/jobs/software-engineer-19/)
+
+[YMN LTD. 招聘高级 Python 开发者(爬虫工程师)](http://jobs.pythonweekly.com/jobs/senior-python-developer-crawling-engineer-remote-contractor/)
+
+
+# 好玩的项目,工具和库
+
+[person-blocker](https://github.com/minimaxir/person-blocker)
+
+使用预训练的神经网络,自动“锁定”图像中的人。但是,你能锁定的不只是人:最多可以锁定 80 种 不同类型的对象。
+
+[Python for Data Analysis](https://github.com/cuttlefishh/python-for-data-analysis)
+
+数据科学课程。学习使用 Python 编程语言分析所有类型的数据。不需要任何编程经验。
+
+[upvote](https://github.com/google/upvote)
+
+Upvote 是一个多平台二进制白名单解决方案。它为执行二进制的客户端提供了通过服务器和管理界面。Upvote 当前支持 macOS 上的 Santa 和 Windows 上的 Bit9(现在称为 Carbon Black Protection)。
+
+[Instagram in terminal](https://github.com/billcccheng/instagram-terminal-news-feed)
+
+有时候,在工作的时候上你的 instagram 有点奇怪,所以,为什么不再你的终端里上 instagram 呢?
+
+[requests-xml](https://github.com/erinxocon/requests-xml)
+
+这个库意在让 XML 解析尽可能的简单直观。Requests-XML 与棒棒哒的 Requests-HTML 相关,并且提供相同质量的用户体验 —— 支持我们心爱的 XML 文档。
+
+[Matchbox](https://github.com/salesforce/matchbox)
+Write PyTorch code at the level of individual examples, then run it efficiently on minibatches.
+
+[pytubes](https://github.com/stestagg/pytubes)
+
+一个从大型数据源获取数据到 Python 里的模块。
+
+[yoda](https://github.com/yoda-pa/yoda)
+
+住在你终端里的明智而强大的个人助理。
+
+[textdistance](https://github.com/orsinium/textdistance)
+
+计算序列之间的距离。30 多个算法,纯 Python 实现,通用接口。
+
+[parallel-ssh](https://github.com/ParallelSSH/parallel-ssh)
+
+异步并行 SSH 客户端库。
+
+[DeepLearningFrameworks](https://github.com/ilkarman/DeepLearningFrameworks)
+
+在不同框架中运行 NN 的演示。
+
+[Tern](https://github.com/vmware/tern)
+
+容器开源守则。
+
+[makesite](https://github.com/sunainapai/makesite)
+
+为 Python 开发者提供的简单、轻量级的无隐藏魔术的静态站点/播客生成器。
+
+[Augmentor](https://github.com/mdbloice/Augmentor)
+
+Python 中的图像增强库,用于机器学习。
+
+[pyawssfn](https://github.com/bennorth/pyawssfn)
+
+将 Python 代码转换为 AWS Step Function json 的工具。
+
+
+# 最新发布
+
+[PyCharm 2018.1](https://www.jetbrains.com/pycharm/whatsnew/)
+
+支持 Python 3.7,具备用于科学开发的代码单元,更易于配置的基于 SSH 的 Python 解释器,以及添加了部分 git 功能。
+
+
+# 近期活动和网络研讨会
+
+[AnacondaCON 2018](https://goo.gl/EB3JtR)
+
+来自世界上最受欢迎的 Python 数据科学平台 —— Anaconda Distribution 的创造者,AnacondaCON 2018 是本年度最热门的数据科学打回!这个为期四天的活动将于 2018 年 4 月 8 日至 11 日,在 Austin 举行,内容包括主题演讲、常规会议、教程和三条主线:数据科学实验,Anaconda 企业,以及开源技术。立即注册,并使用优惠码 CONF30,获得 30% 的会议注册费用折扣。
+
+[PyLondinium - London, UK](https://pylondinium.org/)
+
+针对 Python 开发者和用户的 Python 会议,由 PSF 志愿者举办,会议地点位于伦敦金融城。
+
+[线上活动:Python 中的装饰器](https://www.crowdcast.io/e/decorators-2/register)
+
+我们将讨论什么时候以及为什么要使用 Python 中的装饰器。我们还将讨论创建装饰器的最佳实践,以及使用装饰器的缺点。这是一个问答驱动活动,所以准备好提问吧!
\ No newline at end of file
diff --git a/Python Weekly/Python_Weekly_Issue_341.md b/Python Weekly/Python_Weekly_Issue_341.md
new file mode 100644
index 0000000..3df44cf
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_341.md
@@ -0,0 +1,153 @@
+原文:[Python Weekly - Issue 341](http://eepurl.com/dqpDyL)
+
+---
+
+欢迎来到Python周刊第 341 期。现在,我们有了一个对移动端友好的模板了,姗姗来迟。希望你能喜欢。
+
+
+# 来自赞助商
+
+[](https://www.datadoghq.com/dg/apm/ts-python-error-tracking/?utm_source=Advertisement&utm_medium=Advertisement&utm_campaign=PythonWeekly-Tshirt&utm_content=Python
+)
+
+使用 Datadog 用于 Python 应用的分布式请求跟踪,快速跟踪问题。端到端可视化你的应用,找到慢查询、问题和低效代码。[今天,就使用 14 天的免费试用版,开始可视化你的 Python 应用性能吧。](https://www.datadoghq.com/dg/apm/ts-python-error-tracking/?utm_source=Advertisement&utm_medium=Advertisement&utm_campaign=PythonWeekly-Tshirt&utm_content=Python)
+
+
+# 新闻
+
+[引入 TensorFlow Hub](https://medium.com/tensorflow/introducing-tensorflow-hub-a-library-for-reusable-machine-learning-modules-in-tensorflow-cdee41fa18f9)
+
+TensorFlow 中可重用机器学习模块库。
+
+[PyPI 上 Github 风的 Markdown 描述](http://blog.jonparrott.com/github-flavored-markdown-on-pypi/)
+
+
+# 文章,教程和讲座
+
+[实际模型 —— 代理可以在它们自己的幻境中学习吗?](https://worldmodels.github.io/)
+
+我们探索构建流行的强化学习环境的生成神经网络模型。我们的世界模型可以以无监督方式快速训练,一学习环境的压缩空间和时间表示。通过使用从世界模型中抽取的特性作为代理输入,我们可以训练一个非常紧凑和简单的策略,以解决所需任务。我们甚至可以在我们的代理的世界模型生成的自己的梦幻环境中完全训练我们的代理,并将此策略转移到实际环境中。
+
+[Jupyter Notebook 初学者教程](https://www.dataquest.io/blog/jupyter-notebook-tutorial/)
+
+使用这个教程来学习如何创建你的第一个 Jupyter Notebook,重要属于、以及共享和在线上发布 notebook 有多容易。
+
+[给 Python 开发者的 Git 和 GitHub 简介](https://realpython.com/python-git-github-intro/)
+
+啥是 Git?啥是 GitHub?它们有啥区别?在这个教程中,从 Python 人的角度,学习 Git 和 GitHub 的基础知识。
+
+[Python 中的关键字(命名)参数:如何使用它们](http://treyhunner.com/2018/04/keyword-arguments-in-python/)
+
+在这篇文章中,我将解释什么是关键字参数,以及为什么要使用它们。然后,我会回顾一些甚至是长期的 Python 开发者也可能会忽视的更高级的用法,因为在 Python 3 的近期版本中,很多事情都已经发生了变化。如果你已经是一名经验丰富的 Python 程序员,那么可能想要跳到最后。
+
+[机器学习深度可分卷积](https://eli.thegreenplace.net/2018/depthwise-separable-convolutions-for-machine-learning/)
+
+
+卷积是现代深度神经网络(DNN)中的重要工具。本文将讨论一些常见的卷积类型,特别是常规和深度可分卷积。重点将放在这些操作的实现上,展示从头开始的计算它们的基于 Numpy 的代码,以及解释工作原理的图表。
+
+[在 Google Cloud 的灵活应用引擎上部署一个 Django + PostgreSQL 项目的初学者指南](https://medium.com/@vampiire/beginners-guide-to-deploying-a-django-postgresql-project-on-google-cloud-s-flexible-app-engine-e3357b601b91)
+
+如何使用 Gunicorn,在Google Cloud 的灵活应用引擎上部署一个 Django + Postgres 应用。包含配置一个数据库实例,并且提供来自 Google 云端存储分区的静态文件。给完全初学者的手把手教程。
+
+[Python 正则表达式备忘录](https://www.dataquest.io/blog/regex-cheatsheet/ )
+
+写代码时,将这个正则表达式备忘录放在旁边,作为快速方便的参考。
+
+[开始使用 PyTorch(第一部分)](http://tech.marksblogg.com/python-big-data-airflow-jupyter-notebook-hadoop-3-hive-presto.html)
+
+Pytorch 深度学习框架介绍,重点介绍如何使用 autograd 包执行自动分化的。
+
+[全面 Django CBV 指南](https://spapas.github.io/2018/03/19/comprehensive-django-cbv-guide/)
+
+[Python 哪个版本最快?](https://hackernoon.com/which-is-the-fastest-version-of-python-2ae7c61a6b2b)
+
+[Python 和大数据:使用 Airflow、Jupyter Notebook 和 Hadoop 3、Spark 与 Presto](http://tech.marksblogg.com/python-big-data-airflow-jupyter-notebook-hadoop-3-hive-presto.html)
+
+[将 GitHub 当成平面数据存储使用,并用 AWS Lambda 来更新它](http://tryexceptpass.org/article/using-github-as-flat-data-store/)
+
+
+# 好玩的项目,工具和库
+
+[TensorFlow Hub](https://github.com/tensorflow/hub)
+
+通过重用部分 TensorFlow 模型的学习转移库。
+
+[Slicker](https://github.com/Khan/slicker)
+
+一个用 Python 编写的移动东西的工具。
+
+[qr-filetransfer](https://github.com/sdushantha/qr-filetransfer)
+
+在终端,通过 WiFi,将文件从你的计算机上传输到你的智能手机中。
+
+[nucleus](https://github.com/google/nucleus)
+
+读写基因组数据的 Python 和 C++ 代码。
+
+[ShivyC](https://github.com/ShivamSarodia/ShivyC)
+
+业余爱好 C 编译器,用 Python 创建。
+
+[ann-visualizer](https://github.com/Prodicode/ann-visualizer)
+
+可视化人工神经网络(ANN)的 python 库。
+
+[WEBMARIZER](https://github.com/nyavramov/WEBMARIZER)
+
+通过从单个视频创建多个 WEBM 或者 GIF,来自动“汇总”视频。它将视频分解为多个片段,然后从每个片段生成一个 WEBM/GIF。只需点击一下,它就可以为你目录中的每个视频进行这种操作。这与视频缩略图表类型,但是是采用 WEBM/GIF 形式的。
+
+[ScrapedIn](https://github.com/dchrastil/ScrapedIn)
+
+一个没有 API 限制的 LinkedIn 爬取工具,用于数据侦查
+
+[PLSDR](https://arachnoid.com/PLSDR/index.html)
+
+一个强大的基于 Python 的软件定义无线电(SDR)
+
+[import-pypi](https://github.com/miedzinski/import-pypi)
+
+一个依赖搞定所有。
+
+[doc2audiobook](https://github.com/danthelion/doc2audiobook)
+
+将文本文档转换为高保真音频(书籍)。
+
+
+# 最新发布
+
+[Python 3.7.0b3](https://www.python.org/downloads/release/python-370b3/)
+
+[TensorFlow 1.7.0](https://github.com/tensorflow/tensorflow/releases/tag/v1.7.0)
+
+[Django 问题修复版本:2.0.4 和 1.11.12](https://www.djangoproject.com/weblog/2018/apr/02/bugfix-releases/)
+
+
+# 近期活动和网络研讨会
+
+[Boulder 2018 年 4 月 Python 聚会 - Boulder, CO](https://www.meetup.com/BoulderPython/events/247633497/)
+
+将会有以下讲座:
+
+ * 掌握 API,快速教程
+ * Python 2 到 3:如何升级,以及开始使用哪些功能
+
+
+[IndyPy 2018 年 4 月每月聚会 - Indianapolis, IN](https://www.meetup.com/indypy/events/246943166/)
+
+将会有以下讲座:
+
+ * 使用 Python 和 Plotly 的数据可视化
+ * S.T.E.A.M. Power:艺术是怎样改变工艺的
+ * 印第安纳州的 GIS 实践
+
+[Python 展示之夜 #61 - Minneapolis, MN](https://www.meetup.com/PyMNtos-Twin-Cities-Python-User-Group/events/247875151/)
+
+将会有以下讲座:
+
+ * 解封封装,装饰被装饰者:装饰器速成教程
+ * Python 中的路径寻找
+ * 使用 GStreamer 的 HTML5 直播
+
+
+[Austin 2018 年 4 月 Python 聚会 - Austin, TX](https://www.meetup.com/austinpython/events/247708101/)
+
diff --git a/Python Weekly/Python_Weekly_Issue_342.md b/Python Weekly/Python_Weekly_Issue_342.md
new file mode 100644
index 0000000..7e04733
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_342.md
@@ -0,0 +1,154 @@
+原文:[Python Weekly - Issue 342 ](http://eepurl.com/dq_MkL)
+
+---
+
+欢迎来到Python周刊第 342 期。让我们直奔主题。
+
+
+# 来自赞助商
+
+[](https://goo.gl/wlxnDm)
+
+Intel® Distribution for Python 以及包含的 NumPy、Scipy、scikit-learn 通过最新的矢量指令和高效的多线程技术,榨干 CPU 的每一分内存 —— 所有的内置模块都使用高度优化后的性能库。[立即获得免费下载](https://software.seek.intel.com/python-distribution?utm_source=04%2F12%2F18%20Python%20Weekly%20Newsletter&utm_medium=Email),并让 Python 在你的数据上策马狂奔。
+
+
+# 文章,教程和讲座
+
+[仅需 $1 硬件,即可将 MacBook 变成触摸屏](https://www.anishathalye.com/2018/04/03/macbook-touchscreen/)
+
+我们只使用了 $1 硬件以及一点点计算机视觉,就将一台 MacBook 变成了触摸屏。这个概念验证(在西斯廷教堂着名的绘画休闲活动后,被称为“西斯廷计划”)大约在 16 个小时内完成了原型设计。
+
+[如何在树莓派上,用深度学习轻松检测对象](https://medium.com/nanonets/how-to-easily-detect-objects-with-deep-learning-on-raspberrypi-225f29635c74)
+
+真实世界带来的挑战是,数据有限,以及诸如移动电话和树莓派这样的小型硬件,使得我们无法运行复杂的深度学习模型。文本演示了你可以如何使用一个树莓派来检测对象。像路上的车辆,冰箱里的橘子,文档中的签名,以及太空中的特斯拉。
+
+[如何(快速)构建一个深度学习图像数据集](https://www.pyimagesearch.com/2018/04/09/how-to-quickly-build-a-deep-learning-image-dataset)
+
+学习可以如何快速构建一个适用于深度学习的图像数据集,并且使用 Python 和(免费的)必应图像搜索 API 来训练卷积神经网络(CNN)。
+
+[作为数据流程序的安全计算](https://mortendahl.github.io/2018/03/01/secure-computation-as-dataflow-programs)
+
+将 TensorFlow 当成数据流程序的分布式计算框架使用,我们可以全面实现 带网络的 SPDZ 协议,从而实现加密数据的优化机器学习。
+
+[使用 Pdb 进行 Python 调试](https://realpython.com/python-debugging-pdb/)
+
+在这个实践教程中,你将学习 pdb (Python 的交互式源代码调试器)的基础知识。Pdb 是一个很棒的工具,可以用来跟踪难以发现的问题,并且允许你更快速地修复错误代码。
+
+[使用 SSH 远程 Python 解释器,运行 NumPy](https://blog.jetbrains.com/pycharm/2018/04/running-flask-with-an-ssh-remote-python-interpreter/)
+
+许多应用中的错误的一个常见原因是,开发和生产环境不同。虽然在大多数的情况下,不可能为开发提供一个生产环境的精确副本,但追求开发平价是值得的。大多数的 web 应用部署在某种 Linux VM 上。如果你使用传统的网络主机,那么则是 VPS 托管。如果我们想要在一个类似于我们的生产环境的环境中开发,那么要如何解决这个问题?最接近的会是为开发设置第二台虚拟主机。所以,让我们看看可以如何将 PyCharm 连接到 VPS box 上。
+
+[Python 中的蒙特卡罗方法](https://harderchoices.com/2018/04/04/monte-carlo-method-in-python/)
+
+在这篇文章中,我们将探索我们的第一个用于估值的强化学习方法。这是本系列中第一次真正的强化学习尝试。
+
+[看吧,没有 for 循环:使用 NumPy 进行数组编程](https://realpython.com/numpy-array-programming/)
+
+如果利用矢量化和广播,从而让你能够充分利用 NumPy。在这个教程中,你将逐步了解 NumPy 中的这些高级特性是如何帮助你编写更快的代码的。
+
+[可视化贝多芬的作品,第一部分:从 IMSLP 爬取并清理数据](https://towardsdatascience.com/visualizing-beethovens-oeuvre-part-i-scraping-and-cleaning-data-from-imslp-77ecb124002d)
+
+本文是一个简短的教程系列的第一部分,这个系列用于记录我个人项目中的进度,在这个项目中,我希望分析并可视化贝多芬的全部作品。本文的目标是探索音乐和情感之间的联系,同时尝试不同的可视化音乐数据的方式,特别是在色彩方面。
+
+[扫月(Moonsweeper) | 用 Python 克隆扫雷,使用 PyQt](https://martinfitzpatrick.name/article/minesweeper-python-desktop-pyqt/)
+
+[使用 Python 创建地图动画](https://medium.com/udacity/creating-map-animations-with-python-97e24040f17b)
+
+[使用 Tweepy,用 Python 创建一个推特机器人](https://medium.com/@lucaskohorst/creating-a-twitter-bot-in-python-with-tweepy-ac524157a607)
+
+[16 小时内,构建并部署企业级 Django Web 应用](https://medium.com/python-pandemonium/building-and-deploying-an-enterprise-django-web-app-in-16-hours-79e018f7b94c)
+
+[从头开始创建一个 Python3 Web 服务器](https://medium.com/@andrewklatzke/creating-a-python3-webserver-from-the-ground-up-4ff8933ecb96)
+
+
+# 书籍
+
+[用 Python 进行机器学习烹饪指南:从预处理到深度学习的实用解决方案(Machine Learning with Python Cookbook: Practical Solutions from Preprocessing to Deep Learning)](https://amzn.to/2GQtWx0)
+
+本实用指南提供了近 200 种自包含的食谱,以帮助你解决日常工作中可能会遇到的机器学习难题。每一个食谱都包含了代码,你可以复制粘贴到测试数据集中,以确保其能工作。在那里,你可以插入、组合或者调整代码,以帮助钩子你的应用。食谱还包含了解释解决方案和提供有意义上下文的讨论。本烹饪指南通过提供构建工作的机器学习应用所需的零件,让你超越理论和概念。
+
+
+# 好玩的项目,工具和库
+
+[FlameScope](https://github.com/Netflix/flamescope)
+
+FlameScope 是一个可视化工具,用于把不同的时间范围当成火焰图进行探索。
+
+[serverless-application-model](https://github.com/awslabs/serverless-application-model)
+
+AWS 无服务器应用模型(AWS SAM)规定了用于表示 AWS 上的无服务器应用的规则。
+
+[video-nonlocal-net](https://github.com/facebookresearch/video-nonlocal-net)
+
+用于视频分类的非局部神经网络。
+
+[QuSimPy](https://github.com/adamisntdead/QuSimPy)
+
+一个多 Qubit 理想量子计算机模拟器。
+
+[google-images-download](https://github.com/hardikvasa/google-images-download)
+
+从 “Google Images” 下载数百张图片的 Python 脚本。这是一个随时可以运行的代码!
+
+[Astra](https://github.com/flipkart-incubator/Astra)
+
+REST API 的自动安全测试。
+
+[Mask_RCNN](https://github.com/matterport/Mask_RCNN)
+
+在 Keras 和 TensorFlow 上,为对象检测和实例分割进行掩码 R-CNN。
+
+[Bookrest](https://github.com/agiliq/bookrest)
+
+将 rest API 添加到任意数据库中的最简单方法。
+
+[Decodify](https://github.com/UltimateHackers/Decodify)
+
+它可以递归检测和解码编码字符串。
+
+[gopro-py-api](https://github.com/KonradIT/gopro-py-api)
+
+非官方 GoPro API Python 库 —— 通过 WiFi 连接到 HERO3/3+/4/5/+/6。
+
+[NCRFpp](https://github.com/jiesutd/NCRFpp)
+
+一个开源神经序列标签工具包。它包含字符 LSTM/CNN,单词 LSTM/CNN 和 softmax/CRF 模块。
+
+[tvnet](https://github.com/LijieFan/tvnet)
+
+用于视频理解的动作表示的端到端学习。
+
+[snallygaster](https://github.com/hannob/snallygaster)
+
+扫描 HTTP 服务器上的密码文件的工具。
+
+[Stronghold](https://github.com/alichtman/stronghold)
+
+在终端轻松配置 MacOS 安全设置。
+
+[Keras-Project-Template](https://github.com/Ahmkel/Keras-Project-Template)
+
+简化构建和训练深度学习模型的项目模板,使用 Keras。
+
+
+# 近期活动和网络研讨会
+
+[网络研讨会:比较:排序、等价和同一性](https://www.crowdcast.io/e/comparisons)
+
+Python 的比较运算符是非常强大的。但是这种强大意味着,它们有相当多的东西需要理解。在这次对话过程中,我们将会回顾 Python 中的各种比较:等价/不等价,以及排序运算符。我们还将会讨论等价性和统一性之间的区别,并且可能还会看到这些操作符中,有多少是 Python 中的“深层”操作。
+
+[Greater Hartford Python 2018 年 4 月聚会 - Hartford, CT](https://www.meetup.com/The-Greater-Hartford-Python-Group/events/249239821/)
+
+将会有以下演讲:
+
+ * 使用 PyQt 构建桌面应用
+ * 将 Python 用于数据科学
+
+
+[PyHou 2018 年 4 月聚会 - Houston, TX](https://www.meetup.com/python-14/events/248401333/)
+
+本月的主题是来自 Justin Grindal 的使用 PyTest 进行软件测试介绍。
+
+[LA Django 2018 年 4 月聚会](https://www.meetup.com/ladjango/events/248898237/)
+
+
diff --git a/Python Weekly/Python_Weekly_Issue_343.md b/Python Weekly/Python_Weekly_Issue_343.md
new file mode 100644
index 0000000..d09aba7
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_343.md
@@ -0,0 +1,149 @@
+原文:[Python Weekly - Issue 343](http://eepurl.com/dr2su9)
+
+---
+欢迎来到Python周刊第 343 期。让我们直奔主题。
+
+# 来自赞助商
+
+[](https://www.datadoghq.com/dg/apm/ts-python-error-tracking/?utm_source=Advertisement&utm_medium=Advertisement&utm_campaign=PythonWeekly-Tshirt&utm_content=Python)
+
+使用 Datadog 为 Python 应用提供的分布式请求跟踪,快速追踪问题。端到端可视化你的应用,找到慢查询、问题和低效代码。[开始 14 天的免费试用,可视化你的 Python 应用程序性能吧。](https://www.datadoghq.com/dg/apm/ts-python-error-tracking/?utm_source=Advertisement&utm_medium=Advertisement&utm_campaign=PythonWeekly-Tshirt&utm_content=Python)
+
+
+# 新闻
+
+[在 2018 年筹款活动期间,支持 PSF](https://pyfound.blogspot.ca/2018/04/support-psf-during-2018-fundraising_16.html)
+
+PSF 正在启动一项令人兴奋的筹款活动,目标是在 5 月 12 日前筹集 $20,000.00 USD。活动开始于 2018 年 4 月 16 日,并于 5 月 12 日 PyCon 时结束。你的捐款将通过支持冲刺阶段、聚会、社区活动和项目、Python 大使计划、财政赞助以及软件开发和开源项目等方式,帮助全球 Python 社区。
+
+[推出新的 PyPI,旧有的 PyPI 将于 4 月 30 日关闭](https://pythoninsider.blogspot.ca/2018/04/new-pypi-launched-legacy-pypi-shutting.html )
+
+
+# 文章,教程和讲座
+
+[Keras 和卷积神经网络(CNN)](https://www.pyimagesearch.com/2018/04/16/keras-and-convolutional-neural-networks-cnns/)
+
+这份温和的知道将会向你展示如何使用 Keras 和深度学习实现、训练和评估你的第一个卷积神经网络(CNN)。
+
+[使用 PyTorch 构建推荐器](http://blog.fastforwardlabs.com/2018/04/10/pytorch-for-recommenders-101.html)
+
+推荐器,通常与电子商务相关,从大量可用的东西中筛选以查找并推荐用户会喜欢的项目。与搜索不同,推荐器依赖历史数据来梳理用户偏好。那么,推荐器是如何完成这项工作的呢?在这篇文章中,我们将讨论使用 Movielens 100K 数据(该数据拥有 943 个用户提供的关于 1682 部电影的 10 万个评级,从 1 到 5)。
+
+[Python 模块和包 —— 介绍](https://realpython.com/python-modules-packages/)
+
+本文探讨了 Python 模块和 Python 包,这两种有助于模块化编程的机制。
+
+[使用 Python 的 Scikit-Learn,实现 SVM 和内核 SVM](http://stackabuse.com/implementing-svm-and-kernel-svm-with-pythons-scikit-learn/)
+
+在这篇文章中,我们将看到支持向量机算法的概念,支持向量机之后的简单理论以及它们在 Python 的 Scikit-Learn 库中的实现。然后,我们会转向高级 SVM 概念,称为内核 SVM,并将在 Scikit-Learn 的帮助下实现。
+
+[Pyppeteer,耍蛇者](https://medium.com/commite/pyppeteer-the-snake-charmer-f3d1843ddb19)
+
+或者,如何从 Python 远程控制浏览器。
+
+[使用这个简单模式,将你的 Flask API 部署到任意 Serverless 云平台](https://andrewgriffithsonline.com/blog/180412-deploy-flask-api-any-serverless-cloud-platform/)
+
+本文演示了如何在不受困于任何攻击或者云平台的情况下,制作一个 Flask 应用 serverless。无需任何应用代码改动或者 serverless 框架,这样,你就可以继续像以往一样进行本地开发。
+
+[使用 Python 和 Keras 的致幻深度强化学习](https://medium.com/applied-data-science/how-to-build-your-own-world-model-using-python-and-keras-64fb388ba459)
+
+通过“世界模型”,教一台机器掌握赛车和火球避免。
+
+[现代 Django:第二部分:Redux 和 React 路由设置](http://v1k45.com/blog/modern-django-part-2-redux-and-react-router-setup/)
+
+这是该教程的第二部分,我们将在我们的笔记应用中设置 redux 和 react 路由。稍后将此前端连接到 API 后端。
+
+ * [第三部分:创建一个 API 并将其与 React 集成](http://v1k45.com/blog/modern-django-part-3-creating-an-api-and-integrating-with-react/) - 在这一部分,我们会创建数据库模型和 API,使用 react 前端和 redux 存储,来创建、读取、更新和删除数据库中的笔记。
+ * [第四部分:使用 DRF,为 React SPA 添加鉴权](http://v1k45.com/blog/modern-django-part-4-adding-authentication-to-react-spa-using-drf/) - 在这一部分,我们将允许用户维护单独的毕竟,并且使用身份验证来包含它们。
+
+
+[Python 中的以太坊智能合约:全面指南](https://hackernoon.com/ethereum-smart-contracts-in-python-a-comprehensive-ish-guide-771b03990988)
+
+[使用 Python 的量子物理可视化](https://towardsdatascience.com/quantum-physics-visualization-with-python-35df8b365ff)
+
+[将我们的 API 网关从 Flask 迁移至 Django](https://tech.gadventures.com/migrating-our-api-gateway-from-flask-to-django-88a585c4df1a)
+
+[Python 3.7 中的延迟导入方法](https://snarky.ca/lazy-importing-in-python-3-7/)
+
+
+# 书籍
+
+[Web Scraping with Python: Collecting More Data from the Modern Web(使用 Python 进行网络爬取:从现代网络抓取更多数据)](https://amzn.to/2EYzEqs)
+
+本实用书籍的扩展版本不仅介绍了网络爬取,还可以作为从现代网络爬取几乎所有类型的数据的综合指南。第一部分着重于网络爬取机制:使用 Python 从网络服务器请求信息、对服务器响应进行基本处理以及自动与网络交互。第二部分探讨了各种更具体的工具和应用,以适应你可能遇到的各种网页抓取场景。
+
+
+# 好玩的项目,工具和库
+
+[rebound](https://github.com/shobrook/rebound)
+
+当编译错误时立即获取 Stack Overflow 结果的命令行工具。
+
+[Booksoup](https://github.com/Buroni/booksoup)
+
+Booksoup 允许你分析和遍历下载的脸书数据,包括情感分析和随时间退役的消息频率分析等功能。
+
+[tinfoleak](https://github.com/vaguileradiaz/tinfoleak)
+
+推特只能分析的最完整的开源工具。
+
+[backoff](https://github.com/litl/backoff)
+
+提供可配置退避和重试的功能装饰器的 Python 库。
+
+[SparkFlow](https://github.com/lifeomic/sparkflow)
+
+在 Apache Spark 之上发展 Tensorflow 的易于使用的库。
+
+[MUNIT](https://github.com/NVlabs/MUNIT)
+
+多模式无监督图像到图像转换。
+
+[Taskpacker](https://github.com/Edinburgh-Genome-Foundry/Taskpacker)
+
+简单的Python 时间表优化库。
+
+[CredKing](https://github.com/ustayready/CredKing)
+
+使用 AWS Lambda 进行 IP 轮换的 Password Spray(译注:用同个密码暴力攻击所有的用户名)。
+
+[mmlspark](https://github.com/Azure/mmlspark)
+
+针对 Apache Spark 的微软机器学习。
+
+[django-lifecycle](https://github.com/rsinger86/django-lifecycle)
+
+声明式模型生命周期钩子,受 Rails 回调启发。
+
+[doxycannon](https://github.com/audibleblink/doxycannon)
+
+穷人的 proxycannon(代理炮) 和僵尸网络,使用 docker、ovpn 文件和 dante socks5 代理。
+
+[PySolFC](https://github.com/shlomif/PySolFC)
+
+超棒的纸牌/耐心游戏的开源可移植集合,用 Python 编写。
+
+[DeepSuperLearner](https://github.com/levyben/DeepSuperLearner)
+深度集成算法的 Python 实现。
+
+[Sequenticon](https://github.com/Edinburgh-Genome-Foundry/sequenticon)
+
+使用 Python,为 DNA 序列生成 identicon。
+
+
+# 最新发布
+
+[Pip 10](https://blog.python.org/2018/04/pip-10-has-been-released.html)
+
+
+# 近期活动和网络研讨会
+
+[网络研讨会:来自 Luciano Ramalho 的“集合理论与实践:了解 Pythonic 的集合类型”](https://info.jetbrains.com/pycharm-webinar-may2018.html)
+
+集合和逻辑强相关。这就是为什么正确的使用 set 操作可以消除大量的嵌套循环和 if 语句,从而生成更可读和更快的代码。我们来谈谈在实践中使用集合,并且从 Python 的集合类型中学习出色的 API 设计思想。
+
+[Python 类型 / mypy - London](https://www.meetup.com/LondonPython/events/249342757/)
+
+在本次演示中,Bernat Gabor 将会详细介绍他使用类型提示(type hinting)的经历,为同时支持 Python 2 和 3 的库添加类型提示和检查类型正确性,并重用这些信息来自动将类型数据插入到生成的 Sphinx 文档中。
+
+[San Diego Python 2018 年 4 月聚会 - San Diego, CA](https://www.meetup.com/pythonsd/events/247378610/)
diff --git a/Python Weekly/Python_Weekly_Issue_344.md b/Python Weekly/Python_Weekly_Issue_344.md
new file mode 100644
index 0000000..104e425
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_344.md
@@ -0,0 +1,167 @@
+原文:[Python Weekly - Issue 344 ](http://eepurl.com/dsLdC5)
+
+---
+
+欢迎来到Python周刊第 344 期。让我们直奔主题。
+
+
+[](https://click.linksynergy.com/link?id=x9UsEHf2tls&offerid=323085.567828&type=2&murl=https%3A%2F%2Fwww.udemy.com%2Fcomplete-python-bootcamp%2F)
+
+[Complete Python Bootcamp:从 Python 小萌新到大牛](https://click.linksynergy.com/link?id=x9UsEHf2tls&offerid=323085.567828&type=2&murl=https%3A%2F%2Fwww.udemy.com%2Fcomplete-python-bootcamp%2F)
+
+像专家一样学习 Python!从基础知识开始,一路开始创建自己的应用和游戏!
+
+# 新闻
+
+[PyGotham 2018 征集提议](https://www.papercall.io/pygotham-2018)
+
+鼓励任何对演讲有兴趣的人提交提案。对主题无限制,但是我们建议是 Python 人 感兴趣的主题。演讲时长为 20 分钟到 40 分钟,包含提问和回答的时间。
+
+
+# 文章,教程和讲座
+
+[加速深度神经演化:在单台个人电脑上训练 Atari](https://eng.uber.com/accelerated-neuroevolution/)
+
+将硬件加速应用到深度神经演化现在是开源项目了,Uber AI 实验室能够在单台个人电脑上,花费短短几个小时就能训练出玩 Atari 的神经网络,使得更多数量的人可以使用这类型的研究。
+
+[使用 pytest 测试 Django:调试一个 teardown 失败](https://tech.coffeemeetsbagel.com/testing-django-with-pytest-debugging-a-teardown-failure-acfa4103aa67)
+
+这是一个关于调试 odyssey 的故事,可以通过更仔细地阅读文档来避免此事的发生。讲述这个故事不仅是要引起读者对文档的注意,还因为这是一个有趣的追捕故事。我们任何人都可以从中学习到很好的经验教训。
+
+[Pipenv:新的 Python 打包工具指南](https://realpython.com/pipenv-guide/)
+
+Pipenv 是一个 Python 打包工具,它解决了使用 pip、virtualenv 以及很好的老 requirements.txt 的典型工作流中的一些常见问题。本指南介绍了 Pipenv 所解决的问题,以及如何使用它管理你的 Python 依赖。
+
+[使用 CoreML,在 iOS 之上运行 Keras 模型](https://www.pyimagesearch.com/2018/04/23/running-keras-models-on-ios-with-coreml/)
+
+在上周的文章中,你学习了如何使用 Keras 训练一个卷积神经网络(CNN)。在这篇文章中,我们将使用这个已训练的 Keras 模型,并利用 Apple 称为 “CoreML” 的机器学习框架(用于苹果应用)将其部署到 iPhone 和 iOS app 上。
+
+[Python 中的贝叶斯线性回归:使用机器学习预测学生成绩(第一部分)](https://towardsdatascience.com/bayesian-linear-regression-in-python-using-machine-learning-to-predict-student-grades-part-1-7d0ad817fca5)
+
+在这个贝叶斯机器学习项目的第一部分,我们概述了问题,进行了全面的探索性数据分析,选择了特性并建立基准。
+
+ * [第二部分](https://towardsdatascience.com/bayesian-linear-regression-in-python-using-machine-learning-to-predict-student-grades-part-2-b72059a8ac7e) - 在这一部分,我们将用 Python 实现贝叶斯线性回归,来构建一个模型。在训练完我们的模型后,我们将解释模型参数,并使用这个模型进行预测。
+
+
+[ESP8266 车库门监控器/控制器(第一部分)](https://chipsandbits.blog/2018/04/22/esp8266-garage-door-monitor-controller-part-1/)
+
+车库门监控器/控制器原型,使用 MicroPython 和一块 ESP8266。
+
+[如何使用 Python 和 Arcade 库,创建一个 2D 游戏](https://opensource.com/article/18/4/easy-2d-game-creation-python-and-arcade)
+
+学习如何开始使用 Arcade(一个易于使用的用来创建 2D 视频游戏的 Python 库)。
+
+[Flask Webcast #2: 请求和应用上下文](https://www.youtube.com/watch?v=Z4X5Oddhcc8)
+
+本次讨论了 Flask 上下文,以及错误使用时可能会导致的非常混淆的错误。包含了问答部分。
+
+[使用 Dlib 和 Python,实现 Instagram 中的“Pin”效果](https://www.makeartwithpython.com/blog/instagram-pin-effect-in-python/)
+
+在这篇文章中,我们将用 Python 实现 Instagram 的“Pin”效果,其中,当相机在图像周围移动时,图像保持在特定位置。这种 pin 效果随着苹果的 ARKit 的普遍而影响不大,但是,使用像 Dlib 的相关跟踪器这样简单的接口,使得我们可以在不需要像 iPhone 中的传感数据下,就可以很好地开始实现它。因此,我们将使用 Python 构建一个工具,用于创建带有被 pin 图像的视频。在此期间,我们会构建一个交互式环境,用以测试我们关联跟踪器的候选位置,从而允许我们能够预览我们的地点被跟踪的程度。
+
+[Python 3 的 pathlib 模块:驯服文件系统](https://realpython.com/python-pathlib/)
+
+如何用 Python 3 以及标准库中新的 “pathlib” 模块,有效地处理文件系统路径。
+
+[解开 Python 代码](http://engineering.khanacademy.org/posts/python-refactor-3.htm)
+
+之前关于 2017 以及 2018 的 Great Khan Academy Python Refactor 的文章回答了两个问题:我们为什么以及如何重构我们所有的 Python 代码的?在这篇文章中,我想仔细看看这个项目的一个主要目标:清理 Python 代码库部分之间的依赖关系。
+
+[用 Python 编写一个简单的 SOCKS 服务器](https://rushter.com/blog/python-socks-server/)
+
+本文解释了如何用 Python 3.6 编写一个虽小但五脏俱全的 SOCKS 5 服务器。假设你已经对代理服务器有了基本的了解。
+
+[在 Python 上创建 TUI](https://medium.com/@bad_day/create-tui-on-python-71377849879d)
+
+在这篇文章中,我将讨论 npyscreen —— 创建控制台应用的库。
+
+[将 Python AST 转换为优化推导式](https://cypher.codes/writing/transforming-python-asts-to-optimize-comprehensions-at-runtime)
+
+Python 推导式允许重复的函数调用(例如:[foo(x) for x in ... if foo(x)])。如果这些函数调用开销不菲,那么我们需要重写我们的推导式,以避免多次调用的开销。在这篇文章中,我们通过编写一个装饰器来解决这个问题,这个装饰器将函数转换为 AST,优化掉重复的函数调用,并在运行时编译。
+
+[使用 Python DIY Pokedex!](https://towardsdatascience.com/diy-pokedex-with-python-be32e5e3006e)
+
+[预测纽约市的 Uber 需求](https://medium.com/@Vishwacorp/timeseries-forecasting-uber-demand-in-nyc-54dcfcdfd1f9)
+
+[不完整的 HTTP 读取和 Python 中的 requests 库](https://blog.petrzemek.net/2018/04/22/on-incomplete-http-reads-and-the-requests-library-in-python/)
+
+[结构化并发的注意事项,或者:Go 语句并认为是有害的](https://vorpus.org/blog/notes-on-structured-concurrency-or-go-statement-considered-harmful/)
+
+
+# 书籍
+
+[Deep Learning with TensorFlow - Second Edition: Explore neural networks with Python(使用 TensorFlow 进行深度学习 —— 第二版本:使用 Python 探索神经网络)](https://amzn.to/2qZn45z)
+
+借助这本全面的 TensorFlow 指南,深入研究神经网络、实现深度学习算法并探索数据抽象层。在这本书中,你将学习如何为机器学习系统实现深度学习算法,并将其整合到你的产品中,包括搜索、图像识别和语言处理。此外,你还会学习如何分析和改善深度学习模型的性能。这可以通过比较算法与基准,以及机器智能来完成,从而从信息中学习,并确定特定环境中的理想行为。
+
+
+# 好玩的项目,工具和库
+
+[phish-ai-api](https://github.com/phishai/phish-ai-api)
+
+Phish.AI 公共和私人 API 的官方 Python API,用于检测零日钓鱼网站。
+
+[Vecihi](https://github.com/yasintoy/vecihi)
+
+5 分钟内构建你自己的照片共享应用,使用 Django 和 React Native。
+
+[beagle_scraper](https://github.com/ChrisRoark/beagle_scraper)
+
+构建最大的开源电子商务爬虫,使用 Python 和 BeautifulSoup4。
+
+[blackcellmagic](https://github.com/csurfer/blackcellmagic)
+
+格式化单元格中的 Python 代码的 IPython 魔术命令,使用 black。
+
+[hackbox](https://github.com/samhaxr/hackbox)
+
+HackBox 是棒棒哒的工具和技术的结合。
+
+[minebash](https://github.com/panki27/minebash)
+
+minebash 是一个 linux 命令行的扫雷 Python 版本。
+
+[neo4j-github-followers](https://github.com/aaronlelevier/neo4j-github-followers)
+
+结合 Neo4j、Python 和 Github API 的示例项目。
+
+[AudioOwl](https://github.com/dodiku/audioowl)
+
+快速简单的音乐和音频分析,使用 RNN 和 Python。
+
+[django-bruteforce-protection](https://github.com/orsinium/django-bruteforce-protection)
+
+基于 Redis 的 Django 项目的强力保护。简单、强大、可扩展。
+
+[SMBrute](https://github.com/m4ll0k/SMBrute)
+
+SMBrute 是一个可对于使用 SMB(Samba)的服务器强制使用用户名密码的程序。
+
+[RTA](https://github.com/flipkart-incubator/RTA)
+
+红队兵工厂 —— 一个检测公司第 7 层资产中安全漏洞的智能扫描仪。
+
+
+# 最新发布
+
+[PyTorch v0.4](https://github.com/pytorch/pytorch/releases/tag/v0.4.0)
+
+权衡内存的计算、Windows 支持、累积分布函数(CDF)的 24 个分布、方差等、dtypes、零维张量、张量变量合并、更快的分布、性能和问题修复,CuDNN 7.1。
+
+[PyPy2.7 和 PyPy3.5 v6.0 双重发布](https://morepypy.blogspot.com/2018/04/pypy27-and-pypy35-v60-dual-release.html)
+
+PyPy 团队很自豪地同时发布了 PyPy2.7 v6.0(支持 Python 2.7 语法的解释器)和 PyPy3.5 v6.0(支持 Python 3.5 语法的解释器)。这两个版本都基于相同的代码库,因此是双版本。
+
+
+# 近期活动和网络研讨会
+
+[TPU Deep Dive + Hyper-Parameter Tune Real-Time AI Pipeline + Intel BigDL + Spark - New York, NY](https://www.meetup.com/Advanced-Spark-and-TensorFlow-Meetup-New-York/events/248201412/)
+
+将会有以下演讲:
+
+ * 使用 Scikit-Learn、TensorFlow、Spark ML、GPU、TPU、Kafka 和 Kubernetes 进行实时连续的机器学习/AI 模型训练、优化和预测
+ * 使用 Tensorflow 训练和提供机器学习模型。
+
+
+[DFW Pythoneers 2018 年 5 月聚会 - Plano, TX](https://www.meetup.com/dfwpython/events/247432266/)
+
diff --git a/Python Weekly/Python_Weekly_Issue_345.md b/Python Weekly/Python_Weekly_Issue_345.md
new file mode 100644
index 0000000..41cf641
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_345.md
@@ -0,0 +1,165 @@
+原文:[Python Weekly - Issue 345](http://eepurl.com/dtwwdj)
+
+---
+
+欢迎来到Python周刊第 345 期。让我们直奔主题。
+
+# 来自赞助商
+
+[](https://www.datadoghq.com/dg/apm/ts-python-error-tracking/?utm_source=Advertisement&utm_medium=Advertisement&utm_campaign=PythonWeekly-Tshirt&utm_content=Python)
+
+使用 Datadog 的分布式跟踪和 APM,全面了解你的 Python 应用。这个开源代理自动监测框架和库(例如 Django、Redis 和 asyncio),这样,你就可以在不更改代码的情况下开始。[Troubleshoot requests with interactive flame graphs, alert on errors, and optimize your Python apps today with a 14-day free trial.](https://www.datadoghq.com/dg/apm/ts-python-error-tracking/?utm_source=Advertisement&utm_medium=Advertisement&utm_campaign=PythonWeekly-Tshirt&utm_content=Python)
+
+
+# 新闻
+
+[Jupyter 获得 ACM 软件系统奖(ACM Software System Award)](https://blog.jupyter.org/jupyter-receives-the-acm-software-system-award-d433b0dfe3a2)
+
+Jupyter 项目获得了 2017 年度 ACM 软件系统奖,这是一项重大的荣誉。它加入到了知名项目名单之列,这个名单包含了计算历史的主要亮点,例如 Unix、TeX、S(R 的前身)、Web、Mosaic、Java、INGRES(现代数据库)等等。
+
+
+# 文章,教程和讲座
+
+[宣布 Accelerator](https://www.ebayinc.com/stories/blogs/tech/announcing-the-accelerator-processing-1-000-000-000-lines-per-second-on-a-single-computer/)
+
+Expertmaker Accelerator 是一个久经考验的数据处理框架,提供快速数据访问、并行执行以及源代码、输入数据和结果的自动组织。它可以用于日常的数据分析任务,也可以用作带有数十万大型数据文件和许多 CPU 的实时推荐系统。eBay 现以开源的形式发布了 Accelerator。
+
+[使用Python、深度学习和树莓派构建一个真实的Pokemon Pokedex(带有视觉识别功能) ](https://www.pyimagesearch.com/2018/04/30/a-fun-hands-on-deep-learning-project-for-beginners-students-and-hobbyists/)
+
+在这篇文章中,你将学习如何在树莓派上构建完整的端到端深度学习项目。该项目对于有兴趣将深度学习应用于自己应用的初学者、学生以及业余爱好者是相当不错的。
+
+[使用 TensorFlow 构建你的第一个深度学习分类器:汪星人品种示例](https://towardsdatascience.com/build-your-first-deep-learning-classifier-using-tensorflow-dog-breed-example-964ed0689430)
+
+在这篇文章中,我将向你展示几种技术,以便你开始开发可用于经典图像分类问题的算法:从图像中检测汪星人的品种。在文章的最后,我们将开发能够识别用户提供的任意图像,并将汪星人的品种估计作为返回的代码。此外,如果检测到人类,那么该算法将返回最相似的狗狗品种估计。
+
+[使用 Python 进行解释型机器学习](http://savvastjortjoglou.com/intrepretable-machine-learning-nfl-combine.html)
+
+在这篇文章中,我探讨了可以用于尝试解释“黑盒子”模型的不同工具和方法。使用 NFL 结合的数据,我们将首先构建一个模型来预测 NFL 防守端(DE)的早期表现。之后,我们会使用不同的解释型方法来更好地理解模型。
+
+[Python 字节码介绍](https://opensource.com/article/18/4/introduction-python-bytecode)
+
+学习有关 Python 字节码的概念,Python 是如何用它来执行代码的,以及了解它可以如何帮助你。
+
+[Python 异常:简介](https://realpython.com/python-exceptions/)
+
+在这篇初学者教程中,你将了解 Python 中的异常擅长的事情。你还会看到如何引发异常,并且使用“try/except”块来处理它们。
+
+[Python 循环中被遗忘的可选 `else`](https://medium.com/@s16h/the-forgotten-optional-else-in-python-loops-90d9c465c830)
+
+本文讨论了 Python 的 for...else 和 while...else 语句,这是 Python 中最少使用和误解的语法特征之一。
+
+[在 Python 中开发异步任务队列](https://testdriven.io/developing-an-asynchronous-task-queue-in-python)
+
+本文将介绍如何使用 Python 的多进程库和 Redis,实现多个异步任务队列、
+
+[可视化 Pandas 的转轴和重塑函数](https://jalammar.github.io/visualizing-pandas-pivoting-and-reshaping/)
+
+[Swift/Python 互操作](https://github.com/tensorflow/swift/blob/master/docs/PythonInteroperability.md)
+
+[Django 2.0 url() 到 path() 备忘录](https://consideratecode.com/2018/05/02/django-2-0-url-to-path-cheatsheet/)
+
+
+# 书籍
+
+[打造 Python:开发 Python 的最佳实践和经验教训(Forging Python: Best practices and life lessons developing Python)](https://amzn.to/2rj7Eci)
+
+以独特而旧式的方式开发 Python 以及编程的最佳实践和经验教训。
+
+
+# 好玩的项目,工具和库
+
+[WinPwnage](https://github.com/rootm0s/WinPwnage)
+
+提升、UAC 绕过、持久性、特权提升、dll 劫持技术。
+
+[catt](https://github.com/skorokithakis/catt)
+
+catt(全称 Cast All The Things)让你可以将来自许多在线源的视频发送到 Chromecast。
+
+[fdb-nbd](https://github.com/dividuum/fdb-nbd)
+
+一个完全概念证明的基于 FoundationDB 的网络块设备后端。
+
+[mxboard](https://github.com/awslabs/mxboard)
+
+记录 MXNet 数据,以便于在 TensorBoard 中进行可视化。
+
+[SpookFlare](https://github.com/hlldz/SpookFlare)
+
+装载器 / 散播病毒程式生成器,具有多种功能,可绕过客户端和网络端的对抗措施。
+
+[arbitrary_python_verse](https://github.com/Astrokiwi/arbitrary_python_verse)
+
+以任意押韵和压力模式,生成诗歌的蠢萌 Python 脚本。
+
+[Gitmails](https://github.com/giovanifss/Gitmails)
+
+一个信息收集工具,收集版本控制主机服务上的 git commit 电子邮件。
+
+[jupyter-nb-templater](https://github.com/ismailuddin/jupyter-nb-templater)
+
+一个以编程方式生成 Jupyter notebooks 的生成 Python 脚本的工具。
+
+[tasq](https://github.com/codepr/tasq)
+
+一个简单的无代理任务队列实现,利用 zmq 和 actor 模型的原生实现,在本地或远程进程上排队任务。
+
+[anti_forgetful](https://github.com/tbenthompson/anti_forgetful)
+
+不要忘记你的 AWS 实例并让它一直运行!代价太高了……
+
+[memento](https://github.com/aryaminus/memento)
+
+通过在目录中使用 OpenCV 对其进行分段,使用来自 meme 的 OCR 更好地组织你的 meme 图像集群,使用 tesseract 对它们进行排序以及编辑 meme。
+
+[castero](https://github.com/xgi/castero)
+
+castero 是一个命令行播客客户端。
+
+[Turing](https://github.com/TuringApp/Turing)
+
+用于伪代码和 Python 的免费跨平台 IDE。
+
+
+# 最新发布
+
+[Flask 1.0](https://www.palletsprojects.com/blog/flask-1-0-released/)
+
+Flask 框架已经保持稳定很长一段时间了。在第一次代码提交后至今八年多一点的时间,版本号最终反映了这一点。1.0 版本有大量的改动,其反映了这一年多的工作。
+
+[Python 2.7.15](https://mail.python.org/pipermail/python-dev/2018-May/153286.html)
+
+[Django 问题修复版本:2.0.5 和 1.11.13](https://www.djangoproject.com/weblog/2018/may/01/bugfix-releases/)
+
+[Twisted 18.4.0](https://labs.twistedmatrix.com/2018/04/twisted-1840-released.html)
+
+
+# 近期活动和网络研讨会
+
+[San Francisco Python 2018 年 5 月聚会 - San Francisco, CA](https://www.meetup.com/sfpython/events/250124870/)
+
+将会有以下演讲:
+
+ * Jardin,Python 友好的轻量级 ORM
+ * 在 Flask 中部署 SciKit 学习模型
+ * 充分利用 Mypy
+ * 使用 Python 和可编程 LED 可视化算法。
+
+
+[IndyPy 2018 年 5 月聚会 - Indianapolis, IN](https://www.meetup.com/indypy/events/zxdfkpyxhblb/)
+
+将会有以下演讲:
+
+ * Python + AWS Lambda
+ * 从 Pythonista 的角度看专利的价值与缺陷
+ * 基于属性的测试
+
+
+[PyAtl 2018 年 5 月聚会 - Atlanta, GA](https://www.meetup.com/python-atlanta/events/248011862/)
+
+将会有一场演讲:不要在教 Python 上吃亏。
+
+[Boulder Python 2018 年 5 月聚会 - Boulder, CO](https://www.meetup.com/BoulderPython/events/248938618/)
+
+[Austin Python 2018 年 5 月聚会 - Austin, TX](https://www.meetup.com/austinpython/events/247052856/)
+
diff --git a/Python Weekly/Python_Weekly_Issue_346.md b/Python Weekly/Python_Weekly_Issue_346.md
new file mode 100644
index 0000000..9f6aa57
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_346.md
@@ -0,0 +1,158 @@
+原文:[Python Weekly - Issue 346 ](http://eepurl.com/duf3wL)
+
+---
+
+欢迎来到Python周刊第 346 期。让我们直奔主题。
+
+# 来自赞助商
+[](https://goo.gl/wlxnDm)
+
+使用 Python 进行科学计算、数值分析还是数据科学?免费获得 [Intel® Distribution for Python*](https://software.seek.intel.com/python-distribution?utm_source=05%2F10%2F18%20Python%20Weekly%20Newsletter&utm_medium=Email&utm_campaign=Python%20Weekly%20newsletter%20May%202018),它内置已加速的 NumPy、SciPy 和 scikit-learn,适用于原生代码,使用即可获得性能加速!更短的计算时间以及更快的结果,只需简单切换到更快的 Python 即可获得。
+
+
+# 新闻
+
+[宣布 PyTorch 1.0 同时支持研究和商用](https://code.facebook.com/posts/172423326753505/announcing-pytorch-1-0-for-both-research-and-production/)
+
+PyTorch 1.0 采用了 Caffe2 和 ONNX 的模块化的面向生产功能,并将其与 PyTorch 现有的灵活的以研究为重点的设计结合起来,从而为各种 AI 项目提供从研究原型到生产部署的快速无缝的路径。使用 PyTorch 1.0,通过在命令式和声明式执行模式之间无缝过渡的混合前端,AI 开发人员可以既可以快速实验,又可以优化性能。PyTorch 1.0 中的技术已经为大量的脸书产品和服务提供了支持,包括每天执行的 60 亿次文本翻译。PyTorch 1.0 将在未来几个月内推出测试版本,并将包括一系列用于每个开发阶段的工具、库、预训练模型和数据集,使社区可以大规模快速创建和部署新的 AI 创建。
+
+[EuroPython 2018:现在开始征集提议(CFP)](https://www.europython-society.org/post/173666497685/europython-2018-call-for-proposals-cfp-is-open)
+
+我们正在寻找有关Python各方面的提议:从小萌新到大牛、应用和框架、或者你是如何参与到将Python引入你所在的组织的过程中的。 EuroPython 是一个社区会议,我们渴望听到你的经历。
+
+[DjangoCon US 2018 征集提议](https://www.papercall.io/djangocon-us-2018)
+
+
+# 文章,教程和讲座
+
+[创作自定义 Jupyter 小部件](https://blog.jupyter.org/authoring-custom-jupyter-widgets-2884a462e724)
+
+实践指南。
+
+[使用 Keras 进行多标签分类](https://www.pyimagesearch.com/2018/05/07/multi-label-classification-with-keras/)
+
+在这篇教程中,你将学习如何使用 Keras、Python 和深度学习来进行多标签分类。
+
+[使用 Python Flask 构建社交网络(初学者教程)](https://www.youtube.com/watch?v=GjJbaolBPAY)
+
+学习如何使用 Python Flask web 框架来构建一个基本的社交平台。在这个视频中,我们回顾了如何创建数据库、如何将数据导入导出数据库、使用 Python 创建一个 web 服务器以及使用 python HTML 模板为用户渲染页面!
+
+[如何利用深度学习进行语义分割 ](https://medium.com/nanonets/how-to-do-image-segmentation-using-deep-learning-c673cc5862ef)
+
+本文是一个全面的概述,包括实现深度学习图像分割模型的手把手教程。
+
+[Reddit 机器人简介](https://www.youtube.com/watch?v=BaqvfTuHCJk)
+
+在 Python 中,使用 PRAW 编程 Reddit 机器人。
+
+[使用 Python、Node.js 和 Java,创建 web 物件](https://hacks.mozilla.org/2018/05/creating-web-things-with-python-node-js-and-java/)
+
+探索如何使用 Things 框架和 Python、Node.js 或者 Java,构建 web 相关的东西。上述语言对于小型嵌入式设备绝非良选;本教程适用于那些可以轻松运行这些语言的高端设备,设置是你自己的计算机。
+
+[如何使用 Tensorflow 对象检测 API,构建基于 WEB 的 手势控制有些游戏](https://towardsdatascience.com/how-to-build-a-gesture-controlled-web-based-game-using-tensorflow-object-detection-api-587fb7e0f907)
+
+有了 Tensorflow 对象检测 API,我们就可以看到一些示例,其中,训练模型来检测图像中的自定义对象(例如,检测手、玩具、浣熊、苹果和奶酪)。自然而然地,有趣的下一步是这些模型可以如何部署到现实世界的用例中 —— 例如,交互设计。在这篇文章中,我介绍了一个基本的身体作为输入的交互示例,其中,来自手部跟踪模型的实时结果(可以将网络摄像头流作为输入)被映射到一个基于 web 的游戏(Skyfall) 控件中。该系统证明了一个相当准确的轻量级手部检测模型的整合可以如何用于跟踪玩家手部,并实现实时的身体作为输入的交互。
+
+[自定义Python类中的操作符和函数重载](https://realpython.com/operator-function-overloading/)
+
+怎样重载你的自定义 Python 类中的内置函数和运算符,从而让你的代码更 Pythonic。
+
+[使用 Python 和 Apache Spark,阅读计划建议](https://blog.opendigerati.com/reading-plan-recommendations-using-python-and-apache-spark-e1d20c560a69)
+
+学习 [YouVersion](https://www.bible.com/) 是如何使用机器学习来制定智能的圣经计划建议。
+
+[用Python从PDF导出数据](https://www.blog.pythonlibrary.org/2018/05/03/exporting-data-from-pdfs-with-python/)
+
+很多时候,你会想要使用 Python 从 PDF 中提取数据,并以不同的格式导出。不幸的是,大部分的 Python 包都不能很好地完成提取部分。在这一章中,我们将看看可以用来提取文本的各种各样的包。我们还会学习如何如何从 PDF 中提取图像。虽然针对这些任务,Python 中没有完整的解决方案,但是你应该能够使用这里的信息来帮助自己开始。一旦我们提取了想要的数据,我们还会看看可以如何获取这些数据,并将其以不同的格式导出。
+
+[使用 Polyaxon 保存、恢复和重启实验](https://medium.com/polyaxon/saving-resuming-and-restarting-experiments-with-polyaxon-7812b0450358)
+
+在这篇文章中,我们将介绍 Polyaxon 的新功能:保存、恢复和重启实验。
+
+[使用 Bokeh 构建子弹图和瀑布图](http://pbpython.com/bokeh-bullet-waterfall.html)
+
+在上一篇文章中,我提出了一个流程图,这个流程图对于那些试图为可视化任务选择适当的 Python 库的人来说可能有用。基于那篇文章的一些评论,我决定使用 Bokeh 来创建瀑布图和子弹图。本文的其余部分将介绍如何使用 Bokeh 来创建这些独特且有用的可视化。
+
+[你好,Qt for Python](https://blog.qt.io/blog/2018/05/04/hello-qt-for-python/)
+
+用于 Python 技术的第一个 Qt 技术预览版几乎就是在这里了,因此,我们想要给出一个简单的例子,来说明它将如何打开到 Python 世界的大门。让我们使用 QWidgets 构建一个简单的应用,来展示在 Python 中使用 Qt 的简单性。
+
+[Python 类型注释的另一个(棒棒哒的)优势](https://medium.com/@shamir.stav_83310/the-other-great-benefit-of-python-type-annotations-896c7d077c6b)
+
+[通过用 Cython 封装你的 C 库,使得可以从 Python 调用它](https://medium.com/@shamir.stav_83310/making-your-c-library-callable-from-python-by-wrapping-it-with-cython-b09db35012a3)
+
+
+# 本周的Python工作
+
+[The Texas Tribune 招聘软件工程师](http://jobs.pythonweekly.com/jobs/software-engineer-20/)
+
+作为软件工程师,你的职责是构建和改进核心新闻室工具和技术,包括内容管理器系统、会员和捐赠门户网站、民选官员目录等等。你将在新闻室工作,为编辑、听众、艺术和商业部门提供技术解决方案方面的建议。
+
+
+# 好玩的项目,工具和库
+
+[glom](https://github.com/mahmoud/glom)
+
+有数据?(用 glom)抓住它!这是 Python 的嵌套数据操作符(和 CLI),用于你所有的声明式重构需求。
+
+[Brigade](https://github.com/brigade-automation/brigade)
+
+Brigade 是一个纯 Python 自动框架,旨在直接从 Python 使用。大多数的自动化框架使用自己的 DSL,使用者用其来描述想要完成的任务,而 Brigade 允许你用 Python 把控一切。
+
+[Translate](https://github.com/pytorch/translate)
+
+一个 PyTorch 语言库。
+
+[pywebview](https://github.com/r0x0r/pywebview)
+
+webview 组件的轻量级跨平台原生封装,允许在其专用窗口中显示 HTML 内容。
+
+[tacotron2](https://github.com/NVIDIA/tacotron2)
+
+比实时更快的推断的 PyTorch 实现。
+
+[AutoPy](https://github.com/autopilot-rs/autopy)
+
+Python 和 Rust 的一个简单的跨平台 GUI 自动库。
+
+[flask-praetorian](https://github.com/dusktreader/flask-praetorian)
+
+用于 Flask API 的强大、简单和精确的安全(使用 jwt)。
+
+[ZProc](https://github.com/pycampers/zproc)
+
+更给力的进程。
+
+[django-bootstrap-datepicker-plus](https://github.com/monim67/django-bootstrap-datepicker-plus)
+
+用于 bootstrap-datepicker 的 Django 小部件,适用于 Django 1.8、1.10、1.11 和 2.0.5.
+
+[traad](https://github.com/abingham/traad)
+
+用于 rope(Python 重构库)的 JSON+HTTP 服务器
+
+[PyLex](https://github.com/techcentaur/PyLex)
+
+对词语进行词汇分析,一次一个词。
+
+
+# 最新发布
+
+[SciPy 1.1.0](https://github.com/scipy/scipy/releases/tag/v1.1.0)
+SciPy 1.1.0 是 7 个月努力的成果。它包含了许多新的功能、大量的错误修复、改进的测试覆盖率以及更好的文档。
+
+
+# 近期活动和网络研讨会
+
+[Django-NYC 闪电秀 + 五月黑客之夜 - New York, NY](https://www.meetup.com/django-nyc/events/250314894/)
+
+计划的闪电秀:
+
+ * Django 是如何哈希密码的,以及如何定制
+ * Django Rest 框架和 Kakfa
+ * 我们犯过的 Django 数据库错误,而你可以避免
+
+
+[PyHou 2018 年 5 月聚会 - Houston, TX](https://www.meetup.com/python-14/events/248973430/)
+
+[Edmonton Python 2018 年 5 月聚会 - Edmonton, AB](https://www.meetup.com/startupedmonton/events/249719861/)
diff --git a/Python Weekly/Python_Weekly_Issue_347.md b/Python Weekly/Python_Weekly_Issue_347.md
new file mode 100644
index 0000000..c080654
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_347.md
@@ -0,0 +1,121 @@
+原文:[Python Weekly - Issue 347 ](http://eepurl.com/du2g3H)
+
+---
+
+欢迎来到Python周刊第 347 期。让我们直奔主题。
+
+# 来自赞助商
+[](https://www.datadoghq.com/dg/apm/ts-python-error-tracking/?utm_source=Advertisement&utm_medium=Advertisement&utm_campaign=PythonWeekly-Tshirt&utm_content=Python)
+
+利用 Datadog 的分布式跟踪和 APM,全面了解你的 Python 应用。这风格开源的代理自动监测框架和库(例如 Django、Redis 和 asyncio),所以你可以在不修改代码的情况下开始。[今天就开始进行 14 天的免费试用,使用交互式火焰图对请求进行故障排除、错误告警并优化你的 Python 应用。](https://www.datadoghq.com/dg/apm/ts-python-error-tracking/?utm_source=Advertisement&utm_medium=Advertisement&utm_campaign=PythonWeekly-Tshirt&utm_content=Python)
+
+
+# 文章,教程和讲座
+
+[Python 3.7 中的数据类的终极指南](https://realpython.com/python-data-classes/)
+
+数据类是 Python 3.7 的新特征之一。使用数据类,你不必编写样板代码来正确地对对象进行初始化、展现和比较。
+
+[从脑波到使用深度学习的机器人运动:概述](https://towardsdatascience.com/from-brain-waves-to-arm-movements-with-deep-learning-an-introduction-3c2a8b535ece)
+
+使用神经网络可视化并解码大脑运动。
+
+[集合理论与实践:欣赏 Python 式集合类型](https://www.youtube.com/watch?v=NeeO14QBW-s)
+
+集合和逻辑是强相关的。这就是为什么正确地使用结合操作可以消除大量的嵌套循环和 if 语句,从而生成更可读更快的代码。我们来谈谈在实践中使用集合,并从 Python 的 set 类型中学习出色的 API 设计思想。
+
+[Python 3's f-Strings: An Improved String Formatting Syntax (Guide)](https://realpython.com/python-f-strings/)
+
+从 Python 3.6 开始,f-strings 就是格式化字符串的一种很好的新方法。与其他格式化方式相比,它们不仅更易读、更简洁、更不易出错,而且速度更快!在文章的最后,你将学习到今天开始使用 f-strings 的方法和原因。
+
+[我是怎样构建一个 AI 来玩 Dino Run 的。](https://medium.com/acing-ai/how-i-build-an-ai-to-play-dino-run-e37f37bdf153)
+
+学习我是如何使用 Keras 和 Selenium,实现一个强化学习模型来玩 Chrome 的 Dino Run 的。
+
+[汽车共享的 SARIMA 建模 —— 基本数据管道 —— 使用 Python 的应用第一部分](https://medium.com/@rrfd/sarima-modelling-for-car-sharing-basic-data-pipelines-applications-with-python-pt-1-75de4677c0cd)
+
+本文详细介绍了包含查找、获取、托管、清理和分析数据集的所有步骤。
+
+[使用 Django 创建动态表单](https://www.caktusgroup.com/blog/2018/05/07/creating-dynamic-forms-django/)
+
+动态表单需要在运行时修改它们所具有的字段数量,这使得开发更具挑战。正确地使用 Django 的表单系统使得这个过程更加直接。在此博文中学习如何完成此操作。
+
+[使用贝叶斯 Bootstrap 测量 NFL 中的不确定性](http://savvastjortjoglou.com/nfl-bayesian-bootstrap.html)
+
+这是我计划编写的学习如何将贝叶斯方法应用于我感兴趣的不同主题/问题上的系列文章中的第一篇。在这篇文章中,我将回顾如何使用贝叶斯 Bootstrap 来获得 NFL 四分卫(QB)每次传球尝试(YPA)的码数的不确定性。
+
+[Python 的 Pyramid web 框架介绍](https://opensource.com/article/18/5/pyramid-framework)
+
+学习如何使用 Pyramid web 框架创建一个待办事项列表 web 应用。
+
+[PyCon 2018 视频集](https://www.youtube.com/channel/UCsX05-2sVSH7Nx3zuk3NYuQ/videos)
+
+[使用 Python 创建环聊聊天机器人](https://wescpy.blogspot.com/2018/05/creating-hangouts-chat-bots-with-python.html)
+
+[自定义 Django 2.0 路径转换器的隐藏威力](https://consideratecode.com/2018/05/11/the-hidden-powers-of-custom-django-2-0-path-converters/)
+
+[让我们制作一个 RSS 阅读器(Django & Vue)](https://www.youtube.com/watch?v=0FTaWat_VsM)
+
+
+# 好玩的项目,工具和库
+
+[edabit](https://edabit.com/explore?lang=python3)
+
+一个练习 Python 的免费工具。
+
+[Oil shell](https://github.com/oilshell/oil)
+
+一个兼容 bash 的 shell,用 Python 编写。
+
+[Pyre](https://github.com/facebook/pyre-check)
+
+Pyre 是一个 Python 高性能类型检查器。
+
+[shiv](https://github.com/linkedin/shiv)
+
+shiv 是一个命令行实用程序,用于构建完全自包含的 Python zipapps(如 PEP 441 中概述),但包含了其所有依赖。
+
+[pyvis](https://github.com/WestHealth/pyvis)
+
+创建和可视化交互式网络图的 Python 包。
+
+[Emojify](https://github.com/EvilPort2/emojify)
+
+将你的面部表情转换成表情符号。
+
+[meethub](https://github.com/iyanuashiri/meethub)
+
+这是一个基于 Python/Django 的事件管理系统。一个 meetup 克隆。
+
+[Cyberpandas](https://github.com/ContinuumIO/cyberpandas)
+
+提供使用 pandas 将 IP 和 MAC 地址数据存储到 DataFrame 的支持。
+
+[generative-compression](https://github.com/Justin-Tan/generative-compression)
+
+用于极值学习图像压缩的生成对抗网络的 TensorFlow 实现。
+
+
+# 最新发布
+
+[Gevent 1.3](http://www.gevent.org/whatsnew_1_3.html)
+
+gevent 1.3 对性能、调试和监控以及平台支持做了重要更新。它引入了一个(可选的)libuv 循环实现,并且支持 Windows 上的 PyPy。请参阅事件循环实现:libuv 和 libev,以获取更多信息。自 gevent 1.2.2 起,已经有来自 6 名贡献者的大约 450 次提交。近 100 个 pull 请求以及关闭了 100 多个问题。
+
+[Jupyter Notebook 5.5.0](https://groups.google.com/forum/#!topic/jupyter/sLFSOkx3QLs)
+
+这是一个次要版本,包含新功能、错误修复、文档和对我们的测试基础架构的改进。
+
+[Fabric 2.0](http://docs.fabfile.org/en/latest/upgrading.html#upgrading)
+
+
+# 近期活动和网络研讨会
+
+[Wagtail Space US 2018](https://us.wagtail.space/)
+
+Wagtail Space US 将包括演讲、训练和一场可选的短程赛(将在 16 号继续)。这个活动是免费的,虽然我们会邀请企业参与者为那些非资助核心团队成员的旅行费用以及那些因财务原因不能前来的人员提供小额捐赠。
+
+[San Diego Python 2018 年 5 月聚会 - San Diego, CA](https://www.meetup.com/pythonsd/events/246559162/)
+
+[Austria Python 2018 年 5 月聚会 - Vienna, Austria](https://www.meetup.com/PYUGAT/events/250751933/)
+
diff --git a/Python Weekly/Python_Weekly_Issue_348.md b/Python Weekly/Python_Weekly_Issue_348.md
new file mode 100644
index 0000000..af0fce6
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_348.md
@@ -0,0 +1,126 @@
+原文:[Python Weekly - Issue 348 ](http://eepurl.com/dvGAp9)
+
+---
+
+欢迎来到Python周刊第 348 期。让我们直奔主题。
+
+# 来自赞助商
+[](http://www.amazon.com/gp/product/B0185367JQ/ref=as_li_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=B0185367JQ&linkCode=as2&tag=mymerch-20&linkId=OLIXWD4WZ5X6FFHD)
+
+嘿,Python粉,你想要表达你对**Python**的爱吗?那么,[点击这里](http://www.amazon.com/gp/product/B0185367JQ/ref=as_li_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=B0185367JQ&linkCode=as2&tag=mymerch-20&linkId=OLIXWD4WZ5X6FFHD) ,获取你的T恤,骄傲地穿上它吧。
+
+# 文章,教程和讲座
+
+[轻松学 TensorFlow](http://www.easy-tensorflow.com/)
+
+简单而全面的TensorFlow教程。
+
+[用 Python 生成气候温度螺旋](https://www.dataquest.io/blog/climate-temperature-spirals-python/)
+
+在这篇博文中,我们用 Python 重新创建了 Ed Hawkins 的气候螺旋。除了 Python,我们还用了 pandas 和 matplotlib。
+
+[使用 Keras 进行超参数优化](https://towardsdatascience.com/hyperparameter-optimization-with-keras-b82e6364ca53)
+
+通过适当的流程,为给定的预测任务找到最先进的超参数配置并不困难。在三种方法(手动、机器辅助和算法)中,本文将会重点介绍机器辅助。本文将涵盖实现方法、该方法有效的证明,并提供其工作原因的理解。主要原则是简单。
+
+[使用 scrapy、xarray 和 cartopy,利用 Python 可视化全球土地温度](https://cbrownley.wordpress.com/2018/05/15/visualizing-global-land-temperatures-in-python-with-scrapy-xarray-and-cartopy/)
+
+本文演示了如何使用 Python 获取、分析和可视化十六年的全球陆地表明温度数据。在此过程中,它还会说明可以如何使用 xarray、matplotlib 和 cartopy 来选择、分组、聚集和绘制多维数据。
+
+[使用 Django 和 Vue.js 构建现代应用程序](https://auth0.com/blog/building-modern-applications-with-django-and-vuejs/)
+
+在这篇文章中,你将会逐步创建一个使用 Django 和 Vue.js 的完整应用。
+
+[用隐马尔可夫模型进行词性标注(POS)](https://towardsdatascience.com/part-of-speech-tagging-with-hidden-markov-chain-models-e9fccc835c0e)
+
+词性标注(Part of Speech Tagging,POS)是使用词性(例如名词、动词、形容词和副词等)标注句子的过程。隐马尔可夫模型(HMM)是一个简单的概念,可以用来解释最复杂的实时过程,例如语音识别和语音生成、机器翻译、生物信息学的基因识别以及计算机视觉的人类手势识别等等。在这篇文章中,我们将使用 Pomegranate 库来为词性标注构建隐马尔可夫模型。
+
+[Matplotlib 介绍 —— 使用 Python 进行数据可视化](https://heartbeat.fritz.ai/introduction-to-matplotlib-data-visualization-in-python-d9143287ae39)
+
+本教程旨在帮你快速熟悉 Matplotlib。我们将回顾创建最常用的图表的方法,并讨论每个图表的适用场景。
+
+[用特征标记,“驯服”不可逆性(使用Python)](https://www.vinta.com.br/blog/2018/taming-irreversibility-feature-flags-python/)
+
+[修改 Python 对象模型](https://lwn.net/SubscriberLink/754163/a38214c50e7b3ece/)
+
+
+# 本周的Python工作
+
+[招聘全栈 Web 开发](http://jobs.pythonweekly.com/jobs/full-stack-web-developer-2/)
+
+如果你是一名无所畏惧的全才,拥有至少一年的从业经验,并且喜欢使用 Django 和 Python,那么这对你来说可能是最好的机会。Beauhurst 的使命是寻找和跟踪英国每一个野心勃勃的高增长企业。我们的 web 平台是这些令人兴奋的公司的数据的头号来源。随着我们的扩张以及使得产品更加实用的努力,你将帮助创新并改进访问、存储和数据分析的方式。
+
+
+# 好玩的项目,工具和库
+
+[youCanCodeAGif](https://github.com/1-Sisyphe/youCanCodeAGif)
+你可以从头到尾只靠敲码就能制作高质量的 Gif 吗?是的。你想不想?
+
+[EdgeDB](https://github.com/edgedb/edgedb)
+
+下一代对象关系数据库。
+
+[ubelt](https://github.com/Erotemic/ubelt)
+
+一个 Python 工具带,包括额外的“电池”!
+
+[maven-progress-bar](https://github.com/philleonard/maven-progress-bar)
+
+轻量级 Python 应用,用于在命令行展示 Maven 构建的进度。
+
+[Flaskerizer](https://github.com/brettvanderwerff/Flaskerizer)
+从 Bootstrap 模板自动创建 Flask 应用的程序。
+
+[extratools](https://github.com/chuanconggao/extratools/)
+
+超越标准库的 `itertools`、`functools` 等以及诸如 `toolz` 这样的流行第三方库的 100多个额外的更高级别的函数式工具。
+
+[deepo](https://github.com/ufoym/deepo)
+
+一系列 Docker 镜像(及生成器),可以让你快速设置深度学习研究环境。
+
+[chirp](https://github.com/9b/chirp)
+
+用于管理和集中 Google Alert 信息的界面。
+
+[SRGAN_Wasserstein](https://github.com/JustinhoCHN/SRGAN_Wasserstein)
+
+将 Waseerstein GAN 应用到 SRGAN,一个深度学习超分辨率模型。
+
+[userpath](https://github.com/ofek/userpath)
+
+添加地址到用户 PATH 的跨平台工具,无需 sudo/runas!
+
+[IPFuscator](https://github.com/vysec/IPFuscator)
+
+自动生成替代 IP 表示的工具。
+
+[dedupe](https://github.com/dedupeio/dedupe)
+
+用于精确和可扩展模糊匹配、记录重复性和实体解析的 Python 库。
+
+[zazo](https://github.com/pradyunsg/zazo)
+
+用 Python 编写的可插拔依赖解析器。旨在为 pip 提供依赖解决方案。
+
+
+# 最新发布
+
+[Pandas 0.23](https://pandas.pydata.org/pandas-docs/version/0.23.0/whatsnew.html#v0-23-0)
+
+这是自 0.22.0 版本后的一个主要版本,包含了大量的 API 变动、弃用、新特性、增强功能和性能提升,以及大量的问题修复。
+
+[Django 2.1 alpha 1](https://www.djangoproject.com/weblog/2018/may/17/django-21-alpha-1/)
+
+
+# 近期活动和网络研讨会
+
+[San Francisco Django 2018 年 5 月聚会 - San Francisco, CA](https://www.meetup.com/The-San-Francisco-Django-Meetup-Group/events/250490463/)
+
+将会有一场演讲 —— Elasticsearch:加速 Django Admin。
+
+[SoCal Python 2018 年 5 月聚会 - Culver City, CA ](https://www.meetup.com/socalpython/events/250883803/)
+
+将会有一场演讲:管理机器学习实验。演讲和中场休息后,我们将会讨论本年度的 PyCon,今年的 PyCon 将会在 5.9 到 5.17 之间举行。
+
+
diff --git a/Python Weekly/Python_Weekly_Issue_349.md b/Python Weekly/Python_Weekly_Issue_349.md
new file mode 100644
index 0000000..1a9f915
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_349.md
@@ -0,0 +1,123 @@
+原文:[Python Weekly - Issue 349](http://eepurl.com/dwHICL)
+
+---
+
+欢迎来到Python周刊第 349 期。本周,我想感谢我们的赞助商 Dependabot 的支持。一定要看看他们出色的平台。
+
+# 来自赞助商
+[](https://dependabot.com/)
+
+Dependabot 自动创建 pull 请求,以使你的依赖保持最新,并带有对 Pipenv 和 pip-compile 完整的支持。每一个 PR 针对单个依赖项,并包含更改日志(如果存在)。[永久免费将 Dependabot 用于个人账户和开源项目,或者免费试用 14 天。](https://dependabot.com/)
+
+
+# 文章,教程和讲座
+
+[如何为视频游戏创建 AI](https://www.youtube.com/watch?v=v9YwegSFyKI)
+
+学习如何使用卷积神经网络创建视频游戏 AI,来玩谷歌的 Dinosaur run 和其他视频游戏!
+
+[为测量实现线程](https://www.pythonforthelab.com/blog/implementing-threads-for-measurements/)
+
+学习 Python 中线程和进程之间的区别。
+
+[使用 Flask 和 Vue.js 开发单页应用](https://testdriven.io/developing-a-single-page-app-with-flask-and-vuejs)
+
+本文一步一步介绍了使用 Vue 和 Flask 设置一个基本的 CRUD 应用的方法。
+
+[数据检索和清理:追踪迁徙模式](https://www.dataquest.io/blog/data-retrieval-and-cleaning/)
+
+在这篇文章中,我们将看到调查、检索和清理候鸟数据。
+
+[通过示例了解 Python 3 中的 itertools](https://realpython.com/python-itertools/)
+
+通过构建实际示例,掌握 Python 的 itertools 模块。我们将从简单的示例开始,然后逐渐增加复杂度,从而鼓励你反复思考。
+
+[介绍计算摄影中的 Python 图像处理](https://www.toptal.com/opencv/python-image-processing-in-computational-photography)
+
+计算摄影是关于通过计算来增强摄影过程。虽然我们通常倾向于认为这仅仅适用于后处理最终结果(类似于照片编辑),但是由于可以在摄影过程的每个步骤启用计算,因此计算摄影的可能性就丰富得多了。
+
+[超越 Python 中的 Numpy 阵列](https://matthewrocklin.com/blog//work/2018/05/27/beyond-numpy)
+
+近年来,Python 的阵列计算生态圈已经发展成支持 GPU、稀疏分布阵列。这相当不错,并且也是分散式开源开发中可能发生的增长的一个很好的例子。然而,为了巩固这种增长,并且将其应用于整个生态圈,我们现在需要做一些中央计划,完成从包之间需要相互感知的成对模型,到包可以通过开发和遵循社区标准协议来协商的生态系统模型的转变。通过适当的努力,我们可以定义 Numpy API 的子集(在所有 API 中运行良好),允许生态圈在硬件之间更平滑地过渡。本文描述了实现这一目标的机遇和挑战。
+
+[如何轻松使用 LSA、PSLA、LDA 和 lda2Vec 进行主题建模](https://medium.com/nanonets/topic-modeling-with-lsa-psla-lda-and-lda2vec-555ff65b0b05)
+
+本文是主题建模及其相关技术的综合概述。
+
+[使用 Django 2.0 创建一个加密货币价格报价 —— 第一部分](https://medium.com/@auxyz/creating-a-cryptocoin-price-ticker-with-django-2-0-part-one-2b628deb85d9)
+
+在本教程中,我们将使用 Django 2.0、Celery、Redis 和 Channels,创建一个简单的加密货币加个报价页面。
+
+[Django 快速测试](https://dizballanze.com/django-blazing-fast-tests/)
+
+缓慢的测试不仅仅浪费开发人员的时间,还使得遵循 TDD 最佳实践(例如红绿测试)变得困难。如果需要数分钟甚至更长的时间来运行测试用例,那么会导致整个测试套件的运行频率低下。这反过来又导致了问题发现和修复的不及时。在这篇文章中,我将介绍如何加快你的 Django 应用的测试。此外,我还会描述导致你的测试性能下降的原因。
+
+[使用 Python 理解时间序列预测](https://www.vinta.com.br/blog/2018/understanding-time-series-forecasting-python/)
+
+本文是为了让你了解所有(或者几乎所有)有关时间序列的内容的而设计的第一部分内容。文中讨论了时间序列的概念,处理方式,选择预测模型并将其应用到实际问题上的方式。
+
+[pandas 最佳实践(视频集)](http://www.dataschool.io/best-practices-with-pandas/)
+
+[使用 Python 深入 GraphQL 和 Neo4j](https://medium.com/elements/diving-into-graphql-and-neo4j-with-python-244ec39ddd94)
+
+[我是如何通过从头开始构建 web 爬虫来自动执行搜索工作的](https://medium.freecodecamp.org/how-i-built-a-web-crawler-to-automate-my-job-search-f825fb5af718)
+
+[如果用 Python 在 Stellar 网络上创建自定义标记](https://medium.com/python-pandemonium/how-to-create-a-custom-token-on-stellar-network-in-python-abf8b2f7a6f8)
+
+[使用 Python 实现缝线雕刻](https://karthikkaranth.me/blog/implementing-seam-carving-with-python/)
+
+[数据之美:英国的交通事故](http://machineloveus.com/data-is-beautiful-traffic-accidents-in-the-uk/)
+
+
+# 本周的Python工作
+
+[LinkedIn 招聘高级软件工程师](http://jobs.pythonweekly.com/jobs/senior-software-engineer-13/)
+
+正在寻找理想工作?在 LinkedIn,我们努力帮助我们的员工找到激情和目标。加入我们,一起改变世界。LinkedIn 的基础设施开发团队为支撑我们生产运营的团队和系统构建库存和配置管理、监控和工作流程自动化系统。我们的客户是企业中的网络、系统、存储和数据中心工程师,而我们管理的基础架构用于为全球的 LinkedIn 服务。
+
+
+# 好玩的项目,工具和库
+
+[RouterSploit](https://github.com/threat9/routersploit)
+
+嵌入式设备开发框架。
+
+[scylla](https://github.com/imWildCat/scylla)
+
+一个人文智能代理池。
+
+[spotify-playlist-generator](https://github.com/mileshenrichs/spotify-playlist-generator)
+
+一个定时 Python 脚本,使用 Spotify API 爬取新歌名并构建播放列表。
+
+[datasheets](https://github.com/Squarespace/datasheets)
+
+从 Google Sheets 读取数据、写入数据以及修改格式。
+
+[Emojinator](https://github.com/akshaybahadur21/Emojinator)
+
+献给人类的简单表情分类器
+
+[CERT Tapioca](https://github.com/CERTCC/tapioca)
+
+CERT Tapioca 是一个使用 MITM 技术,测试移动设备或者其他应用的实用程序。
+
+[SleuthQL](https://github.com/RhinoSecurityLabs/SleuthQL)
+
+Python3 Burp 历史解析工具,用以发现潜在的 SQL 注入点。 要与 SQLmap 一起使用。
+
+[pwnedOrNot](https://github.com/thewhiteh4t/pwnedOrNot)
+
+使用 haveibeenpwned API,为被侵害的电子邮件账户查找密码的 Python 脚本。
+
+[SugarTeX](https://github.com/kiwi0fruit/sugartex)
+
+SugarTeX 是一个更可读的 LaTeX 语言扩展和 LaTeX 的编译器。
+
+[django-debug-toolbar-requests](https://github.com/ENERGYLINX/django-debug-toolbar-requests)
+
+Django 调试工具栏面板,适用于大多数流行的 http 库请求。
+
+[Terminator](https://github.com/MohamedNourTN/Terminator)
+
+终端漏洞利用负载生成器。
diff --git a/Python Weekly/Python_Weekly_Issue_350.md b/Python Weekly/Python_Weekly_Issue_350.md
new file mode 100644
index 0000000..c91937b
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_350.md
@@ -0,0 +1,152 @@
+原文:[Python Weekly - Issue 350](http://eepurl.com/dxqCwb)
+
+---
+
+欢迎来到Python周刊第 350 期。让我们直奔主题。
+
+# 来自赞助商
+[](https://www.datadoghq.com/dg/apm/ts-python-error-tracking/?utm_source=Advertisement&utm_medium=Advertisement&utm_campaign=PythonWeekly-Tshirt&utm_content=Python)
+
+利用 Datadog 完全集成的平台,了解你的 Python 应用和基础架构。通过在你的环境中跨 web 服务器、数据库和服务来跟踪请求,从而调试并优化代码。然后,在分布式请求跟踪、指标和日志之间进行关联和转换,从而无需切换工具或上下文即可对问题进行故障排除。[今天,就开始 14 天的免费试用吧。](https://www.datadoghq.com/dg/apm/ts-python-error-tracking/?utm_source=Advertisement&utm_medium=Advertisement&utm_campaign=PythonWeekly-Tshirt&utm_content=Python)
+
+
+# 文章,教程和讲座
+
+[Python 中的自动特征工程](https://towardsdatascience.com/automated-feature-engineering-in-python-99baf11cc219)
+
+如何自动创建机器学习特征。
+
+[Python 中的基本数据类型](https://realpython.com/python-data-types/)
+
+学习 Python 中内置的基本数据类型,例如数值、字符串和布尔型。你还会了解 Python 的内置函数。
+
+[如何用深度学习,为任意对象创建自然语言语义搜索](https://towardsdatascience.com/semantic-code-search-3cd6d244a39c)
+
+如何构建一个可以语义搜索对象的系统的端到端示例。
+
+[量子计算:只是试试 Python 和 JavaScript](https://x-team.com/blog/quantum-computation-python-javascript/)
+
+尽管量子计算似乎仍然是科幻小说中描述的魔法,但是,它现在就开始进入到了主流编程。
+
+[在 Python 中开始使用 Elasticsearch](http://blog.adnansiddiqi.me/getting-started-with-elasticsearch-in-python/)
+用 Python 学习 Elasticsearch 的基础知识、其设置和实现。
+
+[使用 Django 构建实时 iOS 聊天应用](http://lucasjackson.io/realtime-ios-chat-with-django/)
+
+本文解释了使用 Django、Swift 以及(最重要的)关系数据库结构,编写实时聊天应用的过程。使用带 ORM 的关系型数据库来构造你的数据使得一切更加灵活,特别是托管选项,这些都是你在使用 Firebase 时没有的。在对几种不同的实现进行了修改后,我将它们汇总在这篇文章中,涵盖了从前端 UI 到套接字通信的所有内容。
+
+[Keras:多产出和多重损失](https://www.pyimagesearch.com/2018/06/04/keras-multiple-outputs-and-multiple-losses/)
+
+了解如何使用多个全连接头和多种损失函数,来创建多输出的深度神经网络,使用 Python、Keras 和深度学习。
+
+[使用检查框架,自动化 Django 中那些无聊的东东](https://medium.com/@hakibenita/automating-the-boring-stuff-in-django-using-the-check-framework-3495fb550a6a)
+
+我们是如何使用 inspect、ast 和 Django 系统检查框架来改进开发过程的。
+
+[Python 中数据可视化方法的简要介绍](https://machinelearningmastery.com/data-visualization-methods-in-python/)
+在这篇教程中,你将发现使用 Python 可视化数据时需要知道的无罪说那个类型的图表,以及如何用它们来更好地了解自己的数据。
+
+[使用 IPython 进行高级计算](https://lwn.net/SubscriberLink/756192/ebada7ecad32f3ad/)
+
+如果你用 Python,那么很有可能你听说过 IPython,它为 Python 提供了增强的 read-eval-print 循环(REPL)。但是,IPython 不仅仅是一个更方便的 REPL。现今的 IPython 自带了集成库,这使得它成为了一些高级计算任务的好帮手。本文将会讨论这些任务中的两个,使用多语言和分布式计算。
+
+[Python 中的类型提示状态](https://www.bernat.tech/the-state-of-type-hints-in-python/)
+
+[使用 Sphinx 和 Readthedocs 进行记录](https://www.pythonforthelab.com/blog/documenting-with-sphinx-and-readthedocs/)
+
+[你的第一个 Map Reduce —— 使用 Hadoop、Python 和 OSX](https://medium.com/@rrfd/your-first-map-reduce-using-hadoop-with-python-and-osx-ca3b6f3dfe78)
+
+[使用 pdfrw 创建和操作 PDF](https://www.blog.pythonlibrary.org/2018/06/06/creating-and-manipulating-pdfs-with-pdfrw/)
+
+
+# 本周的Python工作
+
+[RadarServices 招聘高级 Python 开发人员](http://jobs.pythonweekly.com/jobs/senior-python-developer-mf/)
+
+
+# 好玩的项目,工具和库
+
+[MLflow](https://github.com/databricks/mlflow)
+
+完整机器学习生命周期的开源平台。
+
+[Face-tracking-with-Anime-characters](https://github.com/Aditya-Khadilkar/Face-tracking-with-Anime-characters)
+
+一个 Python 项目,其中,来自游戏 doki doki literature club 的 YURI 访问摄像头,并直视玩家的灵魂。你可以在这里看到[演示](https://www.youtube.com/watch?v=rxHIsFZzRO8)。
+
+[whipFTP](https://github.com/RainingComputers/whipFTP)
+
+whipFTP 是一个 FTP/SFTP 客户端,使用 Python 语言编写,利用 tkinter GUI 工具包。可以上传、下载、创建、重命名、拷贝、移动和搜索文件/文件夹。
+
+[IPSRC](https://github.com/jmercouris/IPSRC)
+
+IPSRC 是一个允许你跟踪你的家用电脑 IP 的程序。它允许你的服务器自动获取 IP,对其进行加密,然后在你选择的平台上广播。
+
+[donbest.py](https://github.com/mamcmanus/donbest.py)
+
+Don Best Sports Data API 的一个易于使用的 Python 封装器。
+
+[PyTorch-YOLOv3](https://github.com/eriklindernoren/PyTorch-YOLOv3)
+
+PyTorch 中 YOLOv3 的最小实现。
+
+[ChromeController](https://github.com/fake-name/ChromeController)
+
+通过 Chrome 调试协议接口,管理和控制远程 chrome 实例的接口。
+
+[Magnitude](https://github.com/plasticityai/magnitude)
+
+快速、高效的通用矢量嵌入实用程序包。
+
+[pyradio](https://github.com/sdushantha/pyradio)
+
+在终端播放你最喜爱的电台。
+
+[pyupgrade](https://github.com/asottile/pyupgrade)
+
+自动升级语言新版本的语法的工具(和预提交钩子)
+
+
+# 最新发布
+
+[Django 问题修复版本:2.0.6](https://www.djangoproject.com/weblog/2018/jun/01/bugfix-release/)
+
+
+# 近期活动和网络研讨会
+
+[网络直播:跟 David Lord 和 Armin Ronacher 一起聊聊 Flask](https://www.crowdcast.io/e/flask2/register)
+
+本周特邀嘉宾 David Lord 和 Armin Ronacher (Flask 的维护者)将会加入我们,一起讨论 Flask,并回答有关 Flask 的问题。
+
+[San Francisco Python 2018 年 6 月聚会 - San Francisco, CA](https://www.meetup.com/sfpython/events/251058082/)
+
+将会有以下演讲:
+
+ * 用 Python 控制量子计算机
+ * Keras-Pandas
+ * 专业工程师的道德
+ * 感谢 Python
+
+
+[IndyPy 2018 年 6 月每月聚会 - Indianapolis, IN](https://www.meetup.com/indypy/events/247814395/)
+
+将会有以下演讲:
+
+ * 让 Python 装饰器像三明治一样易于使用
+ * 跟上技术的高速发展,不断学习新技能,从而成为更好的开发者
+ * CherryPy
+
+
+[Boulder Python 2018 年 6 月聚会 - Boulder, CO](https://www.meetup.com/BoulderPython/events/249980711/)
+
+将会有一场演讲:Python 的伪名技术。
+
+[Princeton Python User 2018 年 6 月聚会 - Princeton, NJ](https://www.meetup.com/pug-ip/events/250980520/)
+
+将会有一场演讲:使用 Python 生成一个 OpenAPI CLI 客户端。
+
+[Austin Python 2018 年 6 月聚会 - Austin, TX](https://www.meetup.com/austinpython/events/247052857/)
+
+[PyAtl 2018 年 6 月聚会 - Atlanta, GA](https://www.meetup.com/python-atlanta/events/248129841/)
+
+[Edmonton Python 2018 年 6 月聚会 - Edmonton, AB](https://www.meetup.com/startupedmonton/events/250677053/)
diff --git a/Python Weekly/Python_Weekly_Issue_351.md b/Python Weekly/Python_Weekly_Issue_351.md
new file mode 100644
index 0000000..2d5eb33
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_351.md
@@ -0,0 +1,136 @@
+原文:[Python Weekly - Issue 351 ](http://eepurl.com/dx6rkb)
+
+---
+
+欢迎来到Python周刊第 351 期。让我们直奔主题。
+
+# 来自赞助商
+[](https://goo.gl/wlxnDm)
+
+现在,可以通过 conda、pip、docker、yum 或者 [Intel® Distribution for Python*](https://software.intel.com/en-us/distribution-for-python?utm_source=06%2F14%2F18%20Python%20Weekly%20Newsletter&utm_medium=Email&utm_campaign=Python%20Weekly%20newsletter%20June%202018) 中的 apt,获取 Intel 优化过的快速的 NumPy、SciPy 和 scikit-learn。通过切换到更快的 Python,让诸如本地代码获得性能提升。
+
+
+# 文章,教程和讲座
+
+[Python 中速度提高 100 倍的更快的自然语言处理](https://medium.com/huggingface/100-times-faster-natural-language-processing-in-python-ee32033bdced)
+
+如何利用 spaCy 和一些 Cython 来实现更快的 NLP。
+
+[使用 Flask 和 Connexion,构建和记录 Python REST API](https://realpython.com/flask-connexion-rest-api/)
+
+使用 Flask 和 Connexion 库,从头开始创建一个基于 Python 的 RESTful API 的方法。还包括使用 Swagger / OpenAPI 标识,为你的 API 端进行自动验证和文档化。
+
+[在 Python 中开始使用 Apache Kafka](http://blog.adnansiddiqi.me/getting-started-with-apache-kafka-in-python)
+
+学习 Kafka 的基础知识,并用 Python 编写一个示例分布式程序。
+
+[101 Pandas 数据分析习题集](https://www.machinelearningplus.com/python/101-pandas-exercises-python/)
+
+101 python pandas 习题集旨在训练你的逻辑思维,帮助你使用数据分析最爱的 Python 包操作数据。问题分成三个难度,其中,L1 是最容易的,而 L3 是最难的。
+
+[利用 Stripe、Vue.js 和 Flask 接受付款](https://testdriven.io/accepting-payments-with-stripe-vuejs-and-flask)
+
+本文详细介绍了如何使用 Stripe、Vue.js 和 Flask,开发一个销售产品的 web 应用。
+
+[教程:在 Jupyter Notebook 中使用 Python 和 MTurk](https://blog.mturk.com/tutorial-mturk-using-python-in-jupyter-notebook-17ba0745a97f)
+
+IPython notebooks 对于数据科学家来说,是一个强大的工具,它让他们可以在 Jupyter Notebook 界面中分析数据和训练机器学习模型。在这个教程中,我们会解释如何使用 MTurk 来注释训练数据,所有内容都在 Jupyter 应用中进行。
+
+[Python 集合和集合论](https://towardsdatascience.com/python-sets-and-set-theory-2ace093d1607)
+
+了解 Python 集合:它们是什么、如何创建它们、何时使用它们、内置方法以及它们和集合论操作的关系。
+
+[PORCUPiNE 教程](https://www.youtube.com/watch?v=3z7LBW_Rl9c)
+
+如果利用 PORCUPiNE,在数分钟内构建一个自定义的语音界面。
+
+[Python 括号物语](http://blog.lerner.co.il/python-parentheses-primer/)
+
+[从头开始构建一个问答系统 —— 第一部分](https://towardsdatascience.com/building-a-question-answering-system-part-1-9388aadff507)
+
+[如何利用 Twilio 可编程聊天,将聊天整合进 Django 应用中。](https://www.twilio.com/blog/2018/05/build-chat-python-django-applications-programmable-chat.html)
+
+[文本分类中的传统和深度学习模型概述和基准](https://ahmedbesbes.com/overview-and-benchmark-of-traditional-and-deep-learning-models-in-text-classification.html)
+
+[如何用 tf-seq2seq,免费创建一个聊天机器人!](https://blog.kovalevskyi.com/how-to-create-a-chatbot-with-tf-seq2seq-for-free-e876ea99063c)
+
+
+# 好玩的项目,工具和库
+
+[who-the-hill](https://github.com/newsdev/who-the-hill)
+
+Who The Hill:为国会议员提供的基于 MMS 的面部识别服务。
+
+[scalapy](https://github.com/shadaj/scalapy)
+
+ScalaPy 允许你通过基于 Jep 的接口和转换,在 Scala 代码中使用 Python 库。
+
+[detect-secrets](https://github.com/Yelp/detect-secrets)
+
+一种检测和防止代码泄密的企业友好方式。
+
+[unyt](https://github.com/yt-project/unyt)
+
+用 unyt(读作"unit")在 Python 中处理、操作和转换数据。
+
+[DefectDojo](https://github.com/DefectDojo/django-DefectDojo)
+
+DefectDojo 是一个开源应用漏洞关联和安全协调应用。
+
+[ShellPop](https://github.com/0x00-0x00/ShellPop)
+
+像高手一样弹出 shell。Shell pop 是关于弹出 shell 的。使用这个工具,你可以生成简单和复杂的逆向 shell,或者绑定 shell 命令,在渗透测试过程中提供帮助。不要把更多的时间浪费在存储逆向 shell 的 .txt 文件中了。
+
+[TorchFusion](https://github.com/johnolafenwa/TorchFusion)
+
+现代深度学习框架,旨在加速 AI 系统的研发。
+
+[wifite2](https://github.com/derv82/wifite2)
+
+流行的无线网络审计器“wifite”的重写版本。
+
+[DumpsterDiver](https://github.com/securing/DumpsterDiver)
+
+搜索各种文件类型中的敏感信息的工具。
+
+[Youtube_subscription_manager](https://gitlab.com/sawyerf/Youtube_subscription_manager)
+
+Youtube_subscription_manager 是一个检索订阅或者分析频道和播放列表的程序。
+
+[survival](https://github.com/ryu577/survival)
+
+优化等待时间的各种生存分析分布和方法。
+
+[v2net](https://github.com/deepjia/v2net)
+
+macOS 的网络助手工具。
+
+[PyRoaringBitMap](https://github.com/Ezibenroc/PyRoaringBitMap/)
+
+32 位整型的一个有效轻量级有序集。
+
+[ChromeREPL](https://github.com/acarabott/ChromeREPL)
+
+一个将 Chrome 作为 REPL 的 SublimeText 3 插件。在浏览器中执行 JavaScript。与运行中的 web 应用交互。实时呈现你脑中的代码吧!
+
+[HN_SO_analysis](https://github.com/dgwozdz/HN_SO_analysis)
+
+对于给定技术,Stack Overflow(SO)和 Hacker News(HN)上的受欢迎程度是否存在关系?以及关于因果关系的一些话。
+
+
+# 最新发布
+
+[Celery 4.2.0](http://docs.celeryproject.org/en/master/changelog.html#changelog)
+
+[Python 3.7.0rc1 和 3.6.6rc1](https://blog.python.org/2018/06/python-370rc1-and-366rc1-now-available.html)
+
+[Qt for Python 5.11](https://blog.qt.io/blog/2018/06/13/qt-python-5-11-released/)
+
+
+# 近期活动和网络研讨会
+
+[大数据中的 PyLadies + Women (PyLadies and Women in Big Data) Python 教程:可视化地理数据 - Los Angeles, CA](https://www.meetup.com/Women-in-Big-Data-Meetup-SoCal-Chapter/events/250933500/)
+
+加入“大数据中的 PyLadies + Women”,获取关于使用 Python 创建地理数据引人注目的交互式可视化的动手教程。PyLadies 组织者 Sylvia Tran 将会领导一场交互式代码研讨会,使用 Folium 和 Bokeh 这两个流行的可视化库。
+
+[PyHou 2018 年 6 月聚会 - Houston, TX](https://www.meetup.com/python-14/events/249765769/)
diff --git a/Python Weekly/Python_Weekly_Issue_352.md b/Python Weekly/Python_Weekly_Issue_352.md
new file mode 100644
index 0000000..6dbd16d
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_352.md
@@ -0,0 +1,158 @@
+原文:[Python Weekly - Issue 352 ](http://eepurl.com/dyK9AT)
+
+---
+
+欢迎来到Python周刊第 352 期。让我们直奔主题。
+
+
+# 来自赞助商
+[](https://www.datadoghq.com/dg/apm/ts-python-error-tracking/?utm_source=Advertisement&utm_medium=Advertisement&utm_campaign=PythonWeekly-Tshirt&utm_content=Python)
+
+通过 Datadog 完全集成的平台,洞察你的 Python 应用和基础架构。通过跨环境中的 web 服务器、数据库和服务,跟踪请求,从而调试和优化你的代码。然后,在分布式请求跟踪、指标和日志之间关联和转换,以便在不切换工具或者上下文的情况下对问题进行故障排除。[今天就开始 14 天的免费试用吧](https://www.datadoghq.com/dg/apm/ts-python-error-tracking/?utm_source=Advertisement&utm_medium=Advertisement&utm_campaign=PythonWeekly-Tshirt&utm_content=Python)。
+
+# 文章,教程和讲座
+
+[使用 OpenCV、Python 和深度学习进行人脸识别](https://www.pyimagesearch.com/2018/06/18/face-recognition-with-opencv-python-and-deep-learning/)
+
+学习如何使用 OpenCV、Python 和 dlib,将深度学习应用到高精度面部识别,来进行人脸识别。
+
+[当 Twitter 遇见 TensorFlow](https://blog.twitter.com/engineering/en_us/topics/insights/2018/twittertensorflow.html)
+
+在这篇文章中,我们会讨论我们的建模/测试/服务框架(内部称之为 Deepbird)的历史、演变和未来,将机器学习应用于 Twitter 数据,以及在生产环境中提供机器学习服务的挑战。事实上,Twitter 处理大量的数据和自定义数据格式。Twitter 具有特定的基础架构栈、延迟限制和大量的请求量。
+
+[预测医院再入院的临床自然语言处理](https://blog.insightdatascience.com/introduction-to-clinical-natural-language-processing-c563b773053f)
+
+本文将概述如何构建一个分类模型,利用自有文本医院出院摘要,来预测那些病人在未来 30 天内有无计划重新入院的风险。
+
+[保存以及托管你的第一个机器学习模型的指南](https://heartbeat.fritz.ai/guide-to-saving-hosting-your-first-machine-learning-model-cdf69729e85d)
+
+在这篇文章中,我们将使用 Flask 构建一个简单的情感分析平台。我们的平台将能够对电影评论进行积极和消极的分类。我们会使用 IMDB 数据集来构建一个简单的情感分析模型,保存并将其托管到 Heroku。我们还会使用 Gunicorn 来服务我们的模型。
+
+[Python 中的运算符和表达式](https://realpython.com/python-operators-expressions/)
+
+你将看到如何对 Python 的对象执行计算。本教程结束时,你将能够通过组合 Python 对象和运算符,来创建复杂的表达式。
+
+[让你所有的 Django 表单更好](https://www.caktusgroup.com/blog/2018/06/18/make-all-your-django-forms-better/)
+
+在你的网站中创建出色的表单。学习如何自定义 Django 的表单呈现,并在整个网站上应用表单样式和实现来对表单进行通用更改。
+
+[创建和共享私有 Python 包](https://medium.com/@christopherdavies553/creating-and-sharing-private-python-packages-689c73ce01ff)
+
+django-carrot 是如何使用 PyPRI 来存储和分发开发版本的。
+
+[自然语言处理实践指南(第一部分):处理和理解文本](https://towardsdatascience.com/a-practitioners-guide-to-natural-language-processing-part-i-processing-understanding-text-9f4abfd13e72)
+
+解决 NLP 任务的经过验证和测试的手动策略。
+
+[Python 中 10 个常见的安全漏洞,以及如何避免](https://hackernoon.com/10-common-security-gotchas-in-python-and-how-to-avoid-them-e19fbe265e03)
+
+[在 Python 解释器生命周期内,分配了多少个对象?](https://rushter.com/blog/python-object-allocation-statistics/)
+
+[用 Python 设计袜子](https://www.sockclub.com/posts/magical_color_machine_sock_design.html)
+
+
+# 书籍
+
+[Beginning Data Analysis with Python And Jupyter(使用 Python 和 Jupyter(使用 开始进行数据分析)](https://amzn.to/2K2wRQt)
+
+开始数据科学并不一定要是一场艰苦的战斗。这个循序渐进的指南对于那些了解一点 Python 并且正在寻找快速、快节奏的介绍的初学者而言,非常适合。在这个手册式 Python 和 Jupyter 课程中,掌握入门级数据科学所需的技能。你将了解一些最常用的库(Anaconda 发行版包含了这部分),然后使用真实的数据集探索机器学习模型,为你提供真实世界所需的技能和实践。
+
+
+# 好玩的项目,工具和库
+
+[Masonite](https://github.com/MasoniteFramework/masonite)
+
+Masonite 是一个快速应用 Python 开发框架,致力于:美丽而优雅的语法、包括许多开箱即用的功能以及极致的可扩展性。Masonite 努力从安装到部署都快速且简单,使得开发者可以尽可能快速高效地从概念到实施。
+
+[gif-for-cli](https://github.com/google/gif-for-cli)
+
+接收 GIF、短视频或者对 Tenor GIF API 的查询,然后将其转换为动画 ASCII 艺术。使用 ANSI 转义序列来执行动画和色彩支持。
+
+[house](https://github.com/nccgroup/house)
+
+一个运行时移动应用分析工具包,带有 Web GUI,由 Frida 提供支持,用 Python 编写。
+
+[wc18-cli](https://github.com/SkullCarverCoder/wc18-cli)
+
+用于 2018 世界杯的简单命令行界面。
+
+[CMSeeK](https://github.com/Tuhinshubhra/CMSeeK)
+
+CMS(内容管理系统)检测和利用套件。
+
+[supervision-by-registration](https://github.com/facebookresearch/supervision-by-registration)
+
+改善面部地标检测器精度的无监督方法。
+
+[m00dbot](https://github.com/dizballanze/m00dbot)
+
+自我检测焦虑和抑郁症的 Telegram 机器人。
+
+[footballNotifier](https://github.com/c-mnzs/footballNotifier)
+
+一个 Python 应用,在你支持的足球队得分时给你发送短信。
+
+[vibora](https://github.com/vibora-io/vibora)
+
+快速、异步且性感的 Python web 框架。
+
+[Pyod](https://github.com/yzhao062/Pyod)
+
+用于异常检测的 Python 工具包。
+
+[decadence](https://github.com/flipcoder/decadence)
+
+用 Vim 写歌:基于文本的音乐追踪器和 MIDI shell。
+
+[nonoCAPTCHA](https://github.com/mikeyy/nonoCAPTCHA)
+
+一个异步 Python 库,通过音频自动解决 ReCAPTCHA v2。
+
+[nesmdb](https://github.com/chrisdonahue/nesmdb)
+
+NES 音乐数据库:使用机器学习来为任天堂娱乐系统作曲!
+
+[amodem](https://github.com/romanz/amodem)
+
+Python 中的音频调制解调器通信库。
+
+[SNIPER](https://github.com/mahyarnajibi/SNIPER)
+
+SNIPER 是一个高效的多尺度目标检测算法。
+
+
+# 最新发布
+
+[Django 2.1 beta 1](https://www.djangoproject.com/weblog/2018/jun/18/django-21-beta-1-released/)
+
+Django 2.1 beta 1 现在能用啦。它代表了 2.1 版本发布周期中的第二个阶段,也是尝试 Django 2.1 中即将添加的修改的机会。
+
+[JupyterHub 0.9](https://blog.jupyter.org/jupyterhub-0-9-54d43bd08a08)
+
+JupyterHub 是 Jupyter notebooks 的多用户服务器,允许学生或研究人员拥有自己的工作区。该版本有很多改进,特别是对于大量用户的稳定性和性能改进。
+
+
+# 近期活动和网络研讨会
+
+[SciPy 2018](https://scipy2018.scipy.org/ehome/299527/648104/)
+
+一年一度的 SciPy 大会汇聚了来自行业、学术界和政界的 700 多名与会者,展示他们最新的项目,向经验丰富的用户和开发者学习,并就代码开发进行合作。
+
+[网络直播:问答:Python 中的日期和时间](https://www.crowdcast.io/e/dates-and-times/register)
+
+加入到 Trey 与 Paul Gannsle 的聊天直播中来,Paul Gannsle 是 python-dateutil 的一名维护者,非常熟悉 Python 中的日期和时间。Paul 和 Trey 将会回答你有关日期和时间、dateutil、时区以及相关主题的问题。这将会是一次问答驱动的聊天,会有一些准备了一至两个问题的人参与进来。
+
+[San Francisco Django 2018 年 6 月聚会 - San Francisco, CA](https://www.meetup.com/The-San-Francisco-Django-Meetup-Group/events/251700694/)
+
+将会有以下演讲:
+
+ * 何时*不*使用 ORM
+ * Accountability Counsel 使用 Django 构建迷你网站来支持贫困社区
+
+
+[San Diego Python 2018 年 6 月聚会 - San Diego, CA](https://www.meetup.com/pythonsd/events/249283032/)
+
+将会有以下演讲:
+
+ * 递归、分形以及 Python Turtle 模块
+ * 带 Flask 的 Zappa serverless
diff --git a/Python Weekly/Python_Weekly_Issue_353.md b/Python Weekly/Python_Weekly_Issue_353.md
new file mode 100644
index 0000000..fe83135
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_353.md
@@ -0,0 +1,150 @@
+原文:[Python Weekly - Issue 353](http://eepurl.com/dzrLG5)
+
+---
+
+欢迎来到Python周刊第 353 期。让我们直奔主题。
+
+
+[](https://click.linksynergy.com/link?id=x9UsEHf2tls&offerid=323085.903744&type=2&murl=https%3A%2F%2Fwww.udemy.com%2Fpython-for-data-science-and-machine-learning-bootcamp%2F)
+
+[用 Python 进行数据科学和机器学习的训练营](https://click.linksynergy.com/link?id=x9UsEHf2tls&offerid=323085.903744&type=2&murl=https%3A%2F%2Fwww.udemy.com%2Fpython-for-data-science-and-machine-learning-bootcamp%2F)
+
+学习如何使用 NumPy、Pandas、Seaborn、Matplotlib、Plotly、Scikit-Learn、机器学习、Tensorflow 等等!
+
+
+# 文章,教程和讲座
+
+[Python 3.7 中很酷的功能](https://realpython.com/python37-new-features/)
+
+在这篇文章中,你将深入探索最新最棒的 CPython 版本中的一些最新消息和新特性。
+
+[树莓派人脸识别](https://www.pyimagesearch.com/2018/06/25/raspberry-pi-face-recognition/)
+
+在这篇教程中,你将学习如何在树莓派上进行人脸识别。使用树莓派、Python 和 OpenCV 来识别人脸吧。
+
+[如何在 Python 中创建迭代器](http://treyhunner.com/2018/06/how-to-make-an-iterator-in-python/)
+
+本文讨论了想要制作自己的迭代器的原因,然后展示方法。
+
+[在 Twitter 使用工作流生成机器学习](https://blog.twitter.com/engineering/en_us/topics/insights/2018/ml-workflows.html)
+Cortex 为 Twitter 的团队提供了机器学习平台技术、建模专业知识和教育。其目的在于通过实现先进且道德的 AI 来改进 Twitter。有了在生产中运行机器学习模型的第一手经验,Cortex 寻求流水线式困难的机器学习过程,使工程师能够专注于建模、实验和用户体验。
+
+[从头开始的卷积神经网络](https://towardsdatascience.com/convolutional-neural-networks-from-the-ground-up-c67bb41454e1)
+
+著名的卷积神经网络的 NumPy 实现:迄今为止最有影响力的神经网络架构之一。
+
+[清理债务:一种 pandas 方法](https://medium.com/@finnqiao/cleaning-up-debt-a-pandas-approach-4093937388de)
+
+不良贷款(NPL)数据的数据处理与探索性数据分析。
+
+[Python 术语:多行字符串](https://amir.rachum.com/blog/2018/06/23/python-multiline-idioms/)
+
+让多行字符串变得漂亮的简短而甜蜜的术语。
+
+[在实验物理中用 Python 进行数据分析的简短指南](https://www.authorea.com/users/18589/articles/304710-a-short-guide-to-using-python-with-data-in-experimental-physics)
+
+实验数据的数字处理中常见的信号处理任务包括:插值、平滑和不确定度传播。将实验结果与理论模型进行比较,还需要进行曲线拟合、函数和数据绘制以及拟合优度确定。这些任务通常需要对数据进行交互式探索性处理,但为了使结果可靠,原始数据需要可以自由获取,分析结果易于重现。在这篇文章中,我们提供了使用数字 Python(Numpy)和科学 Python(SciPy)包和交互式 Jupyter Notebooks 来完成这些目标的方法示例(数据以普通纯文本电子表格格式存储)。本文包括了包含用于执行这些任务的 Python 代码的示例,并且可以作为分析新数据的模板使用。
+
+[使用 PyTorch 检测 logo](https://medium.com/diving-in-deep/logo-detection-using-pytorch-7897d4898211)
+
+[使用 Python、Flask、Contentful 和 Twilio 创建火星主题应用](https://www.twilio.com/blog/2018/06/mars-python-flask-contentful-twilio.html)
+
+[使用 PyO3 和 Rust 编写 Python 扩展](https://www.benfrederickson.com/writing-python-extensions-in-rust-using-pyo3/)
+
+[Wagtail Space US 2018 视频集](https://www.youtube.com/watch?v=lZrWxly9yPE&list=PLEyaio0l1qoGGbXg3XH0205FIF32oO1wV)
+
+[在 Python 中执行无服务器的正确方式](https://read.iopipe.com/the-right-way-to-do-serverless-in-python-e99535574454)
+
+
+# 书籍
+
+[Applied Text Analysis with Python: Enabling Language-Aware Data Products with Machine Learning(用 Python 进行应用文本分析:使用机器学习启用语言感知型数据产品)](https://amzn.to/2lGbcmM)
+
+从新闻和演讲,到社交媒体上的非正式谈话,自然语言是最丰富和利用率最低的数据来源之一。不仅仅是因为它来源于流,并处于不断变化和适应的环境中;还因为它包含了传统数据源未传达的信息。解锁自然语言的关键是通过文本分析的创造性应用。本实用书提供了一种通过应用机器学习来构建语言感知产品的数据科学家的方法。
+
+
+# 本周的Python工作
+
+[Gridium 招聘后端软件工程师](http://jobs.pythonweekly.com/jobs/backend-software-engineer/)
+
+
+
+# 好玩的项目,工具和库
+
+[DensePose](https://github.com/facebookresearch/Densepose)
+
+将二维 RGB 图像的所有人像素映射到身体的三维表面模型的实时方法。
+
+[distiller](https://github.com/NervanaSystems/distiller)
+
+Distiller 是一个用于神经网络压缩研究的开源 Python 包。网络压缩可以减少神经网络的内存占用,提高推断速度并节省能源。Distiller 提供了一个 PyTorch 环境,用于对压缩算法(例如稀疏诱导方法和低精度算法)进行原型设计和分析。
+
+[decaNLP](https://github.com/salesforce/decaNLP)
+
+自然语言十项全能:NLP 多任务挑战。
+
+[molten](https://moltenframework.com/)
+
+molten 是一个 Python 3.6+ 的实验性网页框架。意味着最小、可扩展、快速和高效。
+
+[amazon-scraper-python](https://github.com/tducret/amazon-scraper-python)
+
+获取亚马逊售卖的商品的一些信息的非官方客户端。
+
+[python-cfonts](https://github.com/frostming/python-cfonts)
+
+用于终端的 S*xy 字体。这是 cfonts 的一个 Python 端口。
+
+[B2blaze](https://github.com/sibblegp/b2blaze)
+
+Python 中的 Backblaze B2 库。
+
+[robovision](https://github.com/stoic1979/robovision)
+
+基于 AI 和机器学习的计算机视觉,用于机器人。
+
+[scalable_agent](https://github.com/deepmind/scalable_agent)
+
+带有重要权重的 Actor-Learner 架构的可扩展分布式深度 RL 的 TensorFlow 实现。
+
+[darts](https://github.com/quark0/darts)
+
+用于卷积和循环网络的可区分架构搜索。
+
+[termtosvg](https://github.com/nbedos/termtosvg)
+
+Linux 终端录音机,用 Python 编写,可将你的命令行会话呈现为独立的 SVG 动画。
+
+[instagram-scraper](https://github.com/meetmangukiya/instagram-scraper)
+
+抓取 Instagram 前端。灵感来自于 @kennethreitz 的twitter-scraper。
+
+[flair](https://github.com/zalandoresearch/flair)
+
+一个最先进的 NLP 的非常简单的框架。
+
+[Fuxi-Scanner](https://github.com/jeffzh3ng/Fuxi-Scanner)
+
+Fuxi Scanner 是一款开源网络安全漏洞扫描器,具有多种功能。
+
+[boxx](https://github.com/DIYer22/boxx)
+
+Python 中的高效构建和调试工具箱。特别用于科学计算和计算机视觉。
+
+
+# 最新发布
+
+[Python 3.7.0](https://www.python.org/downloads/release/python-370/)
+
+Python 3.7.0 是 Python 语言最新的主要版本,包含了许多新特性和优化。
+
+
+# 近期活动和网络研讨会
+
+[Django-NYC 2018 年 7 月聚会 - New York, NY](https://www.meetup.com/django-nyc/events/252175913/)
+
+将会有以下演讲:
+
+ * Django 入门
+ * 电子商务和存储挑战,为受监管的大麻行业搭建平台
+ * 如何让多元化和包容性的团队成为现实
diff --git a/Python Weekly/Python_Weekly_Issue_354.md b/Python Weekly/Python_Weekly_Issue_354.md
new file mode 100644
index 0000000..7542a54
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_354.md
@@ -0,0 +1,154 @@
+原文:[Python Weekly - Issue 354 ](http://eepurl.com/dz9-mH)
+
+---
+
+欢迎来到Python周刊第 354 期。让我们直奔主题。
+
+[](https://click.linksynergy.com/link?id=x9UsEHf2tls&offerid=323085.857010&type=2&murl=https%3A%2F%2Fwww.udemy.com%2Flearn-ethical-hacking-from-scratch%2F)
+
+[从头开始学习成为白帽子](https://click.linksynergy.com/link?id=x9UsEHf2tls&offerid=323085.857010&type=2&murl=https%3A%2F%2Fwww.udemy.com%2Flearn-ethical-hacking-from-scratch%2F)
+
+成为一个可以像黑帽子黑客那样攻击计算机系统的白帽子,并且像安全专家那样保护它们。
+
+
+# 新闻
+
+[宣布使用 Python 构建 Alexa 技能的更简单方式](https://developer.amazon.com/blogs/alexa/post/3a8f27f3-d724-4e0b-bc72-0dcddd0b2eab/announcing-an-easier-way-to-build-alexa-skills-using-python)
+
+我们很高兴地宣布用于 Python 的 Alexa 技能套件(ASK)软件开发套件(SDK)(beta版本)。该 SDK 包含了与我们的 Java 和 Node.js SDK 相同的特性,从而让你可以减少处理 Alexa 响应和请求必须编写的样板代码量。如果你用 Python 进行编程,那么,可以使用这个 SDK 来利用 Alexa 和广泛的 Python 支持的库和工具,快速构建和提供语音体验。
+
+
+# 文章,教程和讲座
+
+[我是怎么用不超过 50 行代码构建一个自我飞行无人机来跟踪人的](https://medium.com/nanonets/how-i-built-a-self-flying-drone-to-track-people-in-under-50-lines-of-code-7485de7f828e)
+
+使用基于深度学习的计算机视觉技术(如物体检测和深度预测),为无人机提供自主跟踪能力。
+
+[Python 中的基本统计:描述性统计](https://www.dataquest.io/blog/basic-statistics-with-python-descriptive-statistics/)
+
+正确完成统计使得我们能够从模糊、复杂和困难的现实世界中提取知识。在这篇文章中,我们探讨描述性统计。
+
+[Python 直方图绘图:NumPy、Matplotlib、Pandas 和 Seaborn](https://realpython.com/python-histograms/)
+
+在这篇教程中,你将能够绘制具有生产质量、可用于演示的 Python 直方图,其中包含一系列的选项和特性。这是你使用 Python 科学栈构建和操作直方图的一站式商店。
+
+[试试 Django 教程系列](https://www.youtube.com/playlist?list=PLEsfXFp6DpzTD1BD1aWNxS2Ep06vIkaeW)
+
+在本系列中逐一学习和掌握 Django。
+
+[使用 COM 自动化 Windows 应用](http://pbpython.com/windows-com.html)
+
+介绍如何使用 Python 和微软的 COM 技术来自动化 Windows 应用。
+
+[Python String 格式化](https://realpython.com/python-string-formatting/)
+
+学习 Python 中 4 种主要的字符串格式化方法,以及它们的优缺点。你还会获得一个简单的经验法则,了解如何在自己的程序中选择最佳的通用字符串格式化方法。
+
+[Kafka Python 和 Google Analytics](http://www.admintome.com/blog/kafka-python-and-google-analytics/)
+
+学习如何使用 Kafka Python 来拉取 Google Analytics 指标,并将其推到你的 Kafka Topic。这将允许我们稍后使用 Spark 分析数据,以便为我们提供有意义的业务数据。
+
+[Django Stripe 教程](https://testdriven.io/django-stripe-tutorial)
+
+在这篇教程中,我会演示如何从头开始配置新的 Django 网站来接受使用 Stripe 的一次性付款。
+
+[Facebook 中的 Python 3](https://lwn.net/SubscriberLink/758159/f1f631e1535ab9d6/)
+
+[如何使用 Django、PostgreSQL 和 Docker](https://wsvincent.com/django-docker-postgresql/)
+
+[用 Python 编写自己的编程语言和编译器](https://medium.com/@marcelogdeandrade/writing-your-own-programming-language-and-compiler-with-python-a468970ae6df)
+
+[使用 Python 提取超级马里奥兄弟级别](https://matthewearl.github.io/2018/06/28/smb-level-extractor/)
+
+[如何使用机器学习和 Quilt 来识别卫星图像中的建筑物](https://blog.insightdatascience.com/how-to-use-machine-learning-and-quilt-to-identify-buildings-in-satellite-images-aee4e08ab0f3)
+
+[理解 Python 数据类 —— 第一部分](https://medium.com/mindorks/understanding-python-dataclasses-part-1-c3ccd4355c34)
+
+[使用 Python,查找歌曲中的合唱](https://medium.com/@vivjay30/finding-choruses-in-songs-with-python-ee96054b0113)
+
+[如何在 15 分钟内创建一个无服务器服务](https://medium.freecodecamp.org/how-to-create-a-serverless-service-in-15-minutes-b63af8c892e5)
+
+
+# 本周的Python工作
+
+[Omaze 招聘后端工程师](http://jobs.pythonweekly.com/jobs/backend-engineer-4/)
+
+
+# 好玩的项目,工具和库
+
+[alexa-skills-kit-sdk-for-python](https://github.com/alexa-labs/alexa-skills-kit-sdk-for-python)
+
+适用于 Python 的 Alexa 技能套件 SDK 帮你快速掌握并使用技能,让你专注于技能逻辑,而不是样板代码。
+
+[noisy](https://github.com/1tayH/noisy)
+
+简单的随机 DNS,HTTP/S 互联网流量噪声生成器。
+
+[T2F](https://github.com/akanimax/T2F)
+
+文本到面部生成,使用深度学习。
+
+[hnatt](https://github.com/minqi/hnatt)
+
+训练和可视化分层注意网络。
+
+[Smart-Fruit](https://github.com/madman-bob/Smart-Fruit)
+
+一个基于模式的 Python 机器学习库。
+
+[genomeview](https://github.com/nspies/genomeview)
+
+一个基于 Python 的可扩展基因组学可视化引擎。
+
+[DoWhy](https://github.com/Microsoft/dowhy)
+
+DoWhy 是一个 Python 库,用来轻松估计因果效应。DoWhy 基于统一的因果推断语言,结合因果图形模型和潜在的结果框架。
+
+[kubernetes_asyncio](https://github.com/tomplus/kubernetes_asyncio)
+
+Kubernetes 的 Python 异步客户端库
+
+[FluidDyn](https://fluiddyn.readthedocs.io/en/latest/)
+
+FluidDyn 项目旨在促进开源 Python 软件在流体动力学研究中的应用。该项目The project provides some Python packages specialized for different tasks.
+
+[JupyterSearch](https://github.com/cardwizard/JupyterSearch)
+
+用于帮助在一组 jupyter notebooks 中搜索的使用程序。
+
+
+# 最新发布
+
+[Zato 3.0](https://zato.io/blog/posts/zato-3.0-released.html)
+这是一个主要版本,带来许多非常有趣的 API 集成特性。
+
+[plotly.py 3.0.0](https://medium.com/@plotlygraphs/introducing-plotly-py-3-0-0-7bb1333f69c6)
+
+[Django 问题修复版本:2.0.7 和 1.11.14](https://www.djangoproject.com/weblog/2018/jul/02/bugfix-releases/)
+
+
+# 近期活动和网络研讨会
+
+[IndyPy 2018 年 7 月聚会 - Indianapolis, IN](https://www.meetup.com/indypy/events/248715476/)
+
+将会有以下演讲:
+
+ * 如何修复崩掉的虚拟环境
+ * 别忘了玩得开心
+ * 开发人员测试艺术
+
+
+[PyMNtos Python Presentation Night #64 - Minneapolis, MN](https://www.meetup.com/PyMNtos-Twin-Cities-Python-User-Group/events/252125711/)
+
+将会有以下演讲:
+
+ * 使用 NumPy 刷新你的线性代数知识
+ * 用 Python 解决地球物理问题
+
+
+[PyAtl 2018 年 7 月聚会 - Atlanta, GA](https://www.meetup.com/python-atlanta/events/248129846/)
+
+[Austin Python 2018 年 7 月聚会 - Austin, TX](https://www.meetup.com/austinpython/events/247052860/)
+
+[Edmonton Python 2018 年 7 月聚会 - Edmonton, AB](https://www.meetup.com/startupedmonton/events/251808620/)
+
\ No newline at end of file
diff --git a/Python Weekly/Python_Weekly_Issue_355.md b/Python Weekly/Python_Weekly_Issue_355.md
new file mode 100644
index 0000000..7467db0
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_355.md
@@ -0,0 +1,113 @@
+原文:[Python Weekly - Issue 355 ](http://eepurl.com/dAUipf)
+
+---
+
+欢迎来到Python周刊第 355 期。让我们直奔主题。
+
+---
+
+# 来自赞助商
+
+[](https://goo.gl/wlxnDm)
+
+使用 Python 进行科学计算、数值分析还是数据科学?获取免费的 [Intel® Distribution for Python*](https://software.seek.intel.com/python-distribution?utm_source=05%2F10%2F18%20Python%20Weekly%20Newsletter&utm_medium=Email&utm_campaign=Python%20Weekly%20newsletter%20May%202018),内置加速的 NumPy、SciPy 和 scikit-learn,可用于本地代码实现�性能加速!更短的计算时间和更快的结果,仅需简单切换到更快的 Python 即可拥有。
+
+# 文章,教程和讲座
+
+[使用 Python 进行面部聚类](https://www.pyimagesearch.com/2018/07/09/face-clustering-with-python/)
+
+本教程介绍了面部聚类,即在未标记的图像集中查找唯一面部的过程。我们使用 OpenCV、Python 和深度学习完成面部聚类和身份识别任务。
+
+[Python 中的字符串和字符数据](https://realpython.com/python-strings/)
+
+在这篇教程中,你将学习如何使用 Python 丰富的操作符、函数和方法来处理字符串。你将学习如何访问和提取字符串部分字符,并熟悉 Python 3 中操作和修改字符串数据的方法。
+
+[使用 TensorFlow 和 DLTK 进行生物医学图像分析的介绍](https://medium.com/tensorflow/an-introduction-to-biomedical-image-analysis-with-tensorflow-and-dltk-2c25304e7c13)
+
+DLTK 是用于医学成像的深度学习工具包,它扩展了 TensorFlow,能够实现生物医学图像的深度学习。它为典型应用提供专业操作和方法、模型实现、教程和代码示例。�本文是对生物医学图像深度学习的快速介绍,其中,我们将展示当前工程问题的一些问题和解决方法,并向你展示如何对特定问题启动和运行原型。
+
+[用 Python 进行时间序列分析和预测的端到端项目](https://towardsdatascience.com/an-end-to-end-project-on-time-series-analysis-and-forecasting-with-python-4835e6bf050b)
+
+时间序列分析包括用于分析时间序列数据的方法,以便提取有意义的统计数据和其他数据特征。时间序列预测是使用模型来基于先前观察到的值预测未来值。时间序列广泛应用于非固定数据,例如经济、天气、股票价格和�零售价格。我们将演示预测零售销售时间序列的不同方法。让我们开始吧!
+
+[Pandas on Ray - 并行化 Pandas 的早期教训](https://rise.cs.berkeley.edu/blog/pandas-on-ray-early-lessons/)
+
+在我们上一篇文章中,我们介绍了 Pandas on Ray,��以及一些通过仅需一行代码更改来更快地完成 Pandas �工作流程的基础过程。从那时起,我们收到了来自社区的大量反馈,作为回应,我们努力显著改进功能和性能。在这篇文章中,我们将介绍在此过程中学到的一些经验教训,并讨论性能,以及我们计划如何继续改进该库。
+
+[在 Docker Swarm 上运行 Flask](https://testdriven.io/running-flask-on-docker-swarm)
+
+让我们看看如何在 Digital Ocean 上启动 Docker Swarm 集群,然后配置一个由 Flask 和 Postgres 驱动的微服务,使其在此之上运行。
+
+[Django 开发者的电子商务(Wagtail 教程)](https://snipcart.com/blog/django-ecommerce-tutorial-wagtail-cms)
+
+应该使用 Django 和其他可用的不同工具来实现电子商务的原因。福利:一个完整的 Wagtail 教程,用于精益、中等的电商设置!包括现场演示和代码仓库。
+
+[美国职业棒球大联盟中,击球�顺序是否重要?模拟方法](http://www.randalolson.com/2018/07/04/does-batting-order-matter-in-major-league-baseball-a-simulation-approach)
+Randy Olson 使用数据科学来了解美国职业棒球大联盟中,击球�顺序是否重要。
+
+[初学者的基本 Pandas Dataframe 教程](https://www.marsja.se/pandas-dataframe-read-csv-excel-subset/)
+
+在这篇 Pandas 教程中,我们会学习如何使用 Pandas dataframes。更具体地说,我们将学习如何使用 Pandas 读取和写入 Excel(例如,xlsx)和 CSV 文件。我们还将学习如何添加一个列到 Pandas dataframe 对象中,以及如何移除列。最后,我们还将学习如何对 dataframe 进行子集化和分组。
+
+[在 Python 中进行 Serverless 的正确方式(第二部分)](https://read.iopipe.com/the-right-way-to-do-serverless-in-python-part-2-63430131239)
+
+在第一部分中,我们介绍了 serverless 的基础知识,并开始使用 Serverless 框架。在这篇文章中,我们将介绍一个库,它允许你将任何使用 WSGI 的 web 框架嵌入到 serverless(几乎所有这些)中;然后我们还会看看 AWS 自己的用于创建 web API 的 Python web 框架。
+
+[了解 Python 的 Dataclasses(第二部分)](https://medium.com/mindorks/understanding-python-dataclasses-part-2-660ecc11c9b8)
+
+在第一部分,我讨论了新的 dataclasses 的一般用法。本文涉及另一个功能:dataclasses.field。
+
+[用 Python 生成随机数据(指南)](https://realpython.com/python-random/)
+
+你将学习到用 Python 生成随机数据的一些不同方法,然后根据安全级别、多功能性、目的和速度,对它们进行比较。
+
+[如何为 2018 �年更新你的 scikit-learn 代码](https://www.dataschool.io/how-to-update-your-scikit-learn-code-for-2018/)
+
+
+# 好玩的项目,工具和库
+
+[GlobaLeaks](https://github.com/globaleaks/GlobaLeaks)
+
+GlobaLeaks 是开源/免费软件,旨在实现由爱马仕透明度和数字人权中心开发的安全和匿名举报活动。
+
+[PythonRobotics](https://atsushisakai.github.io/PythonRobotics/)
+
+用于机器人算法的 Python 示例代码。
+
+[appkernel](https://github.com/accelero-cloud/appkernel)
+
+一个“献给人类的”漂亮的 Python 框架,让你可以在几分钟内,从零到生产提供一个启用了 REST 的微服务(不是开玩笑哦:几分钟内就是字面上的意思�)。
+
+[wttr.in](https://github.com/chubin/wttr.in)
+
+查看天气的正确方式。
+
+[word-mesh](https://github.com/mukund109/word-mesh)
+
+一个保留上下文的词云生成器。
+
+[pgn2gif](https://github.com/dn1z/pgn2gif)
+
+一个生成国际象棋的 640x640 gif 的小工具。
+
+[teen](https://github.com/shobrook/teen)
+
+就像 man pages,但是是用于 HTTP 状态码的。
+
+[django-impersonate-auth](https://github.com/JordanReiter/django-impersonate-auth)
+
+Django Impersonate Auth 是一个简单的身份验证后端,允许超级用户模拟系统中的常规用户。
+
+[Switchable-Normalization](https://github.com/switchablenorms/Switchable-Normalization)
+Switchable Normalization 是一种归一化技术,能够以端到端的方式,学习深度神经网络中不同归一化层的不同归一化操作。
+
+
+# 近期活动和网络研讨会
+
+[Conda v.s. Pipenv - 一次 Python 包管理工具的较量 - London, UK](https://www.meetup.com/LondonPython/events/252355228/)
+
+在管理 �Python 应用依赖的时候,除了 vanilla pip,你还有更多的选择。在这次演讲中,我们涉及了 Python 包管理的两个重量级工具 —— Conda(来自 Continuum Analytics)和 Pipenv(来自 Kenneth Reitz),并通过现场演示和专业挑战,来进行一对一较量。
+
+[PyHou 2018 年 7 月聚会 - Houston, TX](https://www.meetup.com/python-14/events/249879259/)
+
+
\ No newline at end of file
diff --git a/Python Weekly/Python_Weekly_Issue_356.md b/Python Weekly/Python_Weekly_Issue_356.md
new file mode 100644
index 0000000..57d0829
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_356.md
@@ -0,0 +1,139 @@
+原文:[Python Weekly - Issue 356 ](http://eepurl.com/dBzcPb)
+
+---
+
+欢迎来到Python周刊第 356 期。让我们直奔主题。
+
+
+# 来自赞助商
+[](https://www.datadoghq.com/dg/apm/ts-python-error-tracking/?utm_source=Advertisement&utm_medium=Advertisement&utm_campaign=PythonWeekly-Tshirt&utm_content=Python)
+
+使用 Datadog 的分布式跟踪和 APM,全面了解你的 Python 应用。这个开源代理自动监测框架和库(例如 Django、Redis 和 asyncio),这样,你就可以在不更改代码的情况下开始。然后,在分布式请求跟踪、指标和日志之间进行关联和转换,从而无需切换工具或上下文即可对问题进行故障排除。[今天就开始 14 天的免费试用吧](https://www.datadoghq.com/dg/apm/ts-python-error-tracking/?utm_source=Advertisement&utm_medium=Advertisement&utm_campaign=PythonWeekly-Tshirt&utm_content=Python).
+
+
+# 新闻
+
+[权力转移](https://mail.python.org/pipermail/python-committers/2018-July/005664.html)
+
+Guido 宣布,他将�作为 Python 的 BDFL 退休。
+
+[ython 的安全漏洞警报](https://blog.github.com/2018-07-12-security-vulnerability-alerts-for-python/)
+
+如果你使用 Python,那么现在 Github 可以在你依赖易受攻击的软件包时示警了。
+
+
+# 文章,教程和讲座
+
+[机器学习基础](https://bloomberg.github.io/foml/#home)
+
+理解机器学习专家使用的概念、技术和数学框架。
+
+[Python 中的基本统计:概率](https://www.dataquest.io/blog/basic-statistics-in-python-probability/)
+
+在这篇文章中,我们将讨论概率的概念、正态分布和 z-score —— 以葡萄酒数据。
+
+[Python 中的列表和元组](https://realpython.com/python-lists-tuples/)
+
+你将学习到 Python 3 中的列表和元组的重要特性。你将学习如何定义它们和操作它们。�结束之际,你应该对何时以及如何在一个 Python 程序中使用这些对象类型有所了解。
+
+[OpenCV 显著性检测](https://www.pyimagesearch.com/2018/07/16/opencv-saliency-detection/)
+
+本教程将向你展示如何使用 OpenCV 的“saliency” 模块和 Python 来进行显著性检测。
+
+[使用 Kubernetes 在 GCP 上进行 Django 生产部署](https://www.agiliq.com/blog/2018/07/django-on-kubernetes/)
+
+如何以生产模式,在 kubernetes 上部署一个 Django 应用 —— 最佳实践。
+
+[我是如何使用 Python、Twilio 和 Google Calendar,让我的母上大人了解我的旅行计划的](https://www.twilio.com/blog/2018/06/how-i-keep-my-mom-updated-on-my-travel-schedule-with-twilio-and-google-calendar.html)
+
+在这篇教程中,你将学习如何使用 Python 和 Twilio 构建一个短信机器人,它会连接到你的 Google Calendar,并且能够对即将发生的事作出响应。
+
+[学习(不)处理异常](https://www.pythonforthelab.com/blog/learning-not-to-handle-exceptions/)
+我们将从错误处理的基础知识一直�讲到定义你自己的异常。你将了解为什么不捕获异常更好的原因,以及如何开发对你的代码的未来用户有用的模式。异常是任何代码的关键部分,而优雅地处理它们可以提高代码的价值。
+
+[使用 Ray,在 15 行 �Python 中实现参数服务器](https://rise.cs.berkeley.edu/blog/implementing-a-parameter-server-in-15-lines-of-python-with-ray/)
+
+参数服务器是许多机器学习应用的核心部分。它们的作用是存储机器学习模型的参数(例如,神经网络的权重),并将其提供给客户端(客户端通常是处理数据和计算参数更新的� worker)。参数服务器(�如数据库)通常作为独立系统构建和发布。这篇文章描述了如何使用 Ray,在几行代码中实现参数服务器。
+
+[Python 中的自行车控制设计](https://plot.ly/ipython-notebooks/bicycle-control-design/)
+
+使用 NumPy、SciPy、Python Control 和 Plotly,设计自行车的顺序双环控制器
+
+[比 Go 快得多的多核 Python HTTP 服务器(剧透:Cython)](https://www.nexedi.com/NXD-Blog.Multicore.Python.HTTP.Server)
+
+可以依靠 Cython 语言和 LWAN C 库构建出比 Go 快约 40% 到 110% 到多核 Python HTTP 服务器。概念验证证实了使用 Cython 语言的高性能系统编程的可能性。
+
+[Python post-Guido](https://lwn.net/SubscriberLink/759756/d9b3110d86b9d373/)
+
+[SciPy 2018 视频集](https://www.youtube.com/playlist?list=PLYx7XA2nY5Gd-tNhm79CNMe_qvi35PgUR)
+
+[Flask 教程:简单用户注册和登录](https://developer.okta.com/blog/2018/07/12/flask-tutorial-simple-user-registration-and-login)
+
+[使用 Python、BeautifulSoup 和 Requests 查找和修复网站链接机器人](https://www.twilio.com/blog/2018/07/find-fix-website-link-rot-python-beautifulsoup-requests.html)
+
+[使用 �Python 进行股票数据分析(第二版)](https://ntguardian.wordpress.com/2018/07/17/stock-data-analysis-python-v2/)
+
+[�高效使用 Django Rest Framework 所需要了解的 10 件事](https://medium.com/profil-software-blog/10-things-you-need-to-know-to-effectively-use-django-rest-framework-7db7728910e0)
+
+
+# 好玩的项目,工具和库
+
+[XAR](https://github.com/facebookincubator/xar)
+
+XAR 允许你将多个文件打包到一个独立的可执行文件中。这使得分发和安装变得容易。
+
+[Mu](https://codewith.mu/en/)
+
+给初学者的简单 Python 编辑器。
+
+[repo2docker](https://github.com/jupyter/repo2docker)
+
+将 git 存储库转换成启用 Jupyter 的 Docker Image。
+
+[sorcery](https://github.com/alexmojaki/sorcery)
+
+python 中令人愉悦的黑魔法。这个包让你可以使用和编写名为“spells”的可调用对象,它们知道调用点,并且可以使用这些信息来做其他不可能完成的事情。
+
+[PyFuck](https://github.com/Shubbler/PyFuck)
+
+命令行 brainfuck 解释器,用 Python 3 编写。
+
+[Hamburglar](https://github.com/needmorecowbell/Hamburglar)
+
+从 URL、目录和文件中收集有用的信息。
+
+[lagom](https://github.com/zuoxingdong/lagom)
+
+快速构建强化学习算法原型的轻量级 PyTorch 基础设施。
+
+[Terminus](https://github.com/randy3k/Terminus)
+
+给 Sublime Text 的真正终端。
+
+[ph0neutria](https://github.com/phage-nz/ph0neutria)
+
+ph0neutria 是一个恶意软件 zoo builder,直接从外部采集样本。所有内容都存储在 Viper 中,以便于访问和管理。
+
+[TextWorld](https://github.com/Microsoft/TextWorld)
+
+TextWorld 是一个沙盒学习环境,用于基于文本的游戏中的强化学习(RL)代理的训练和评估。
+
+[ansible-jupyter-kernel](https://github.com/ansible/ansible-jupyter-kernel)
+
+运行 Ansible 任务和 playbook 的 Jupyter Notebook 内核。
+
+[Nagini](https://github.com/marcoeilers/nagini)
+
+Nagini 是一个基于 Viper 验证基础架构的 python 3 静态验证器。
+
+[cc.py](https://github.com/si9int/cc.py)
+
+基于“commoncrawl.org” 的结果,提取特定目标的 URL。
+
+
+# 最新发布
+
+[Jupyter Notebook 5.6.0](https://jupyter-notebook.readthedocs.io/en/stable/changelog.html)
+
+[Django 2.1 release candidate 1](https://www.djangoproject.com/weblog/2018/jul/18/django-21-rc1/)
+
\ No newline at end of file
diff --git a/Python Weekly/Python_Weekly_Issue_357.md b/Python Weekly/Python_Weekly_Issue_357.md
new file mode 100644
index 0000000..d269d52
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_357.md
@@ -0,0 +1,144 @@
+原文:[Python Weekly - Issue 357](http://eepurl.com/dCcG2b)
+
+---
+
+欢迎来到Python周刊第 357 期。让我们直奔主题。
+
+
+# 来自赞助商
+[](https://www.datadoghq.com/dg/apm/ts-python-error-tracking/?utm_source=Advertisement&utm_medium=Advertisement&utm_campaign=PythonWeekly-Tshirt&utm_content=Python)
+
+使用 Datadog 的分布式跟踪和 APM,今天就开始优化你的 Python 应用。Datadog APM 的新的 Watchdog 自动检测引擎使用机器学习来示警应用中的性能异常。探索和分析你所有的应用性能数据,并在相关指标、跟踪和日志之间无缝导航,以实时快速�解决问题。[今天就开始 14 天的免费试用吧](https://www.datadoghq.com/dg/apm/ts-python-error-tracking/?utm_source=Advertisement&utm_medium=Advertisement&utm_campaign=PythonWeekly-Tshirt&utm_content=Python).
+
+
+# 新闻
+
+[Python 语言服务器介绍](https://blogs.msdn.microsoft.com/pythonengineering/2018/07/18/introducing-the-python-language-server/)
+
+Visual Studio 长期以来因其对所有语言的 IntelliSense(代码分析和建议)的质量而受到认可,并且自 2011 年以来一直支持 Python。我们很高兴地宣布,我们将作为微软 Python 语言服务器,为其他工具提供 Python 支持。它首先在七月发布的 Visual Studio Code 的 Python 扩展中提供,稍后,我们将把它作为独立组件发布,这样,你就可以使用任何适配了改语言服务器�协议的工具了。
+
+
+# 文章,教程和讲座
+
+[使用 OpenCV 进行简单的对象跟踪](https://www.pyimagesearch.com/2018/07/23/simple-object-tracking-with-opencv/)
+
+你将学习使用 OpenCV、Python 和用于实时跟踪对象的质心跟踪算法,进行简单对象跟踪的方法。
+
+[快速、灵活、简单和直观:如何加速你的 Pandas 项目](https://realpython.com/fast-flexible-pandas/)
+
+让数据科学家、分析家和工程师为之疯狂的关于 Pandas 的东西究竟是什么?这是一篇�用 python 的方式使用 Pandas,来充分利用其强大但易于使用的内置功能的指南。此外,你将学习一些实用的节省时间的技巧。
+
+[使用 Cloud TPUs,在 30 分钟内训练并提供实时移动物体探测器](https://medium.com/tensorflow/training-and-serving-a-realtime-mobile-object-detector-in-30-minutes-with-cloud-tpus-b78971cf1193)
+
+如果你能更快地训练和服务对象检测模型,会怎样?我们已经听到了你的反馈,而今天,我们很高兴地宣布支持在 Cloud TPUs 上训练对象检测模型、模型量化以及添加了包含 RetinaNet 和 RetinaNet 的 MobileNet 适配在内的新模型。你可以�在 AI 博客上看到公告帖。在这篇文章中,我们将引导你使用转移学习(transfer learning),在 Cloud TPUs 上训练量化的宠物品种检测器。
+
+[Celery 和 Django 和 Docker:哎哟,我的!](https://www.revsys.com/tidbits/celery-and-django-and-docker-oh-my/)
+
+在这篇文章中,你将学习如何在一个 Docker 容器中的一个 Django 项目内创建一个 Celery 任务。听起来很棒,不是吗?
+
+[记录 Python 代码:完整指南](https://realpython.com/documenting-python-code/)
+
+记录 Python 代码的完整指南。无论是记录一个小脚本还是一个大项目,无论你是初学者还是一个经验丰富的 Python 人,本指南将涵盖你所需要了解的所有内容。
+
+[Django 的注释简介](https://www.youtube.com/watch?v=KbwmdKl-QbI)
+T
+本视频讲述了 Django 中的注释特性的工作原理,并展示了一些例子。
+
+[使用 Rasa 和 Twilio,构建你自己的 Duplex AI 代理](https://medium.com/rasa-blog/building-your-own-duplex-ai-agent-using-rasa-and-twilio-bbd23c80ed30)
+
+本文说明了可以如何构建自己的类 Duplex 代理,来自动处理电话呼叫。我们将从另一个方向处理手头的问题 —— 呼叫并与机器交谈(而不是呼叫的机器)。
+
+[用 Python 编写一个简单的摘要生成器](https://towardsdatascience.com/write-a-simple-summarizer-in-python-e9ca6138a08e)
+
+浅谈自然语言处理。
+
+[使用多元线性回归和 python 的应用机器学习简介](https://medium.com/@powersteh/an-introduction-to-applied-machine-learning-with-multiple-linear-regression-and-python-925c1d97a02b)
+
+本文的目标是向外行人解释应用机器学习的基本概念,并记录数据科学家和数据分析师通常如何用数据和机器学习算法回答问题或者解决问题。
+
+[使用现代 Python,替换 netstat 的 90s C 代码](https://matt.sh/netmatt)
+
+[如何使用 Python,自动将文件上传到 Drive](https://medium.com/@annissouames99/how-to-upload-files-automatically-to-drive-with-python-ee19bb13dda)
+
+
+# 本周的Python工作
+
+[Quora 招聘机器学习工程师](https://leap.ai/info/jobs/c2c633e2-56f1-509e-9f56-c3382f8eca37/?utm_source=newsletter&utm_medium=email&utm_term=quora&utm_content=jobpost&utm_campaign=pythonweekly)
+
+
+[Allume 招聘软件工程师](http://jobs.pythonweekly.com/jobs/software-engineer-21/ )
+
+
+# 好玩的项目,工具和库
+
+[dvc](https://github.com/iterative/dvc)
+
+数据版本控制,或称 DVC,是一个开源的数据科学项目工具。它帮助数据科学家以简单的类 git 命令,一起管理他们的代码和数据。
+
+[Photon](https://github.com/s0md3v/Photon)
+
+超级快的爬虫,可以提取 URL、电子邮件、文件、网站账户等。
+
+[diffy](https://github.com/Netflix-Skunkworks/diffy)
+
+Diffy 是在以云为中心的安全事件中使用的分类工具,用于帮助数字取证和事件响应(DFIR)团队快速识别可疑主机并关注其响应。
+
+[ProjectQ](https://github.com/ProjectQ-Framework/ProjectQ)
+
+量子计算的开源软件框架。
+
+[pyCAIR](https://github.com/avidLearnerInProgress/pyCAIR)
+
+内容感知的图像大小调整。
+
+[mne-python](https://github.com/mne-tools/mne-python)
+
+MNE-Python 软件是一个开源的 Python 包,用于探索、可视化和分析人类神经生理学数据,例如MEG、EEG、sEEG、ECoG 等。它包含了用于数据输入/输出、预处理、可视化、源估计、时频分析、连通性分析、机器学习和统计的模块。
+
+[SQLAthanor](https://github.com/insightindustry/sqlathanor)
+
+SQLAlchemy Declarative ORM 的序列�化/反序列化支持。
+
+[flask-rest-api](https://github.com/Nobatek/flask-rest-api)
+
+使用 Flask 和 marshmallow 构建一个 REST API。
+
+[strawberryfields](https://github.com/XanaduAI/strawberryfields)
+
+Strawberry Fields 是一个用于设计、模拟和优化连续变量(CV)量子光学电路的全栈 Python 库。
+
+[Cirq](https://github.com/quantumlib/Cirq)
+
+创建、编辑以及调用 Noisy Intermediate Scale Quantum (NISQ) 电路的 python 框架。
+
+[layer_linter](https://github.com/seddonym/layer_linter)
+
+Layer Linter 检查你的项目是否遵循所定义的分层体系结构。
+
+
+# 最新发布
+
+[NumPy 1.15.0](https://github.com/numpy/numpy/releases/tag/v1.15.0)
+
+NumPy 1.15.0 这个版本带有超乎寻常数量多清理、对许多旧函数的弃用、以及对许多现有功能的改进。请阅读详细说明,看看是否收到影响。
+
+[pygame 1.9.4](https://www.pygame.org/news)
+
+一些亮点,包括:
+
+ * 支持 python 3.7。
+ * 支持 beta pypy。看看我们 pypy 了没?
+ * 修复 pygame.draw
+ * pygame.math 不再是实验特性了。速度提升和错误修正。
+ * Debian、Mac homebrew、mac virtualenv、manylinux 以及其他平台修复。
+ * 文档修复、VSCode 和 VIM 等编辑器中提前输入�的 jedi 支持。
+ * 更快地立即移动到许多平面的 Surface.blits。
+
+
+
+# 近期活动和网络研讨会
+
+[PyBay2018 - San Francisco, CA](https://pybay.com/)
+
+诚邀你加入到向 Python 核心开发者(例如 Raymond Hettinger、Travis Oliphant、Yury Selivanov、Carol Willing、Brandon Rhodes、Simon Wilison)学习 Python、数据、基础架构和性能的 500 多名开发者中来。演讲者阵容还包括即将上任的初创公司的CTO以及来自谷歌,Linkedin,Facebook,Yelp,Twitter,微软,亚马逊的资深开发者。你可以在开幕派对和PyMaker Fest上结识新朋友。分享您的知识并开展闪电谈话和/或聚会。见识一下往期参与者在 PyBay 之后发表 #mindblown 和 #AwesomeCommunity 的原因 :)
+
\ No newline at end of file
diff --git a/Python Weekly/Python_Weekly_Issue_358.md b/Python Weekly/Python_Weekly_Issue_358.md
new file mode 100644
index 0000000..aa2dd4f
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_358.md
@@ -0,0 +1,127 @@
+原文:[Python Weekly - Issue 358 ](http://eepurl.com/dCS0ZT)
+
+---
+
+欢迎来到Python周刊第 358 期。你在找工作吗?如果是的话,答应我,�看看来自这周的赞助商的一个超棒的平台,好吗?
+
+
+# 来自赞助商
+
+[](https://www.vettery.com/tech?utm_source=newsletter&utm_medium=pythonweekly&utm_term=tech&utm_content=grouped&utm_campaign=ad-77579)
+
+[通过 Vettery 找到 Python 相关的工作](https://www.vettery.com/tech?utm_source=newsletter&utm_medium=pythonweekly&utm_term=tech&utm_content=grouped&utm_campaign=ad-77579)
+
+Vettery 专注于开发者角色,并且对求职者�而言完全免费。感兴趣吗?那就提交您的个人资料,如果平台接受了你的资料,那么,你可以收到来自招聘 Python 开发者的顶级公司的直接面试请求。
+
+
+# 文章,教程和讲座
+
+[Python 中的 socket 编程(指南)](https://realpython.com/python-sockets/)
+
+在这篇深入教程中,你将学习用 Python 构建一个 socket 服务器和客户端的方法。最后,你将了解如何使用 Python 的 socket 模块中的主函数和方法,来编写你自己的网络客户端-服务器应用。
+
+[OpenCV 对象跟踪](https://www.pyimagesearch.com/2018/07/30/opencv-object-tracking/)
+
+使用 OpenCV 来跟踪视频中的对象,使用 OpenCV 的 8 个对象跟踪算法,包括CSRF、KCF、Boosting、MIL、TLD、MedianFlow、MOSSE 和 GOTURN。还包含了 Python + OpenCV 对象跟踪代码。
+
+[Python 类型系统的第一步](https://blog.daftcode.pl/first-steps-with-python-type-system-30e4296722af)
+
+在过去几年中,静态类型语法和语义被逐渐引入到 Python 语言中。但是,Python 中的类型仍然是一个很新的,并且经常被误解的主题。因此,本文介绍了其基础知识,而本文后续内容将介绍一些更高级的功能。
+
+ * [Python 类型系统的下一步](https://blog.daftcode.pl/next-steps-with-python-type-system-efc4df5251c9) - 这篇文章将展示关于 Python 的类型的一些更高级的特性。此外,还包含了一些关于特定的类型特性的用法的技巧,以及关于如何将类型引入到自己的代码库中的简短指南。
+
+
+[使用用户研究参数,预测酒店预订](https://towardsdatascience.com/predicting-hotel-bookings-with-user-search-parameters-8c570ab24805)
+
+一家酒店市场数据和基准公司 STR 和谷歌联合发布的一份报告显示,跟踪酒店搜索结果可以对酒店预订进行可靠评估。因此,我们今天的目标是尝试构建一个机器学习模型,基于用户的搜索和与用户事件相关联的其他属性,来预测该用户事件的事件结果(预订,还是只是单纯的点击)。
+
+[Django-Rok:本地 web 服务器的公开 URL](https://medium.com/@ankurj630/django-rok-public-url-for-your-local-web-server-fec89e635282)
+
+django-rok 是一个反向 ssh 隧道工具,为本地 web 服务器提供公开的 URL。这有助于 web-hook 测试、快速 UAT 等等。
+
+[使用 Chalice 创建一个 Serverless 博客](https://medium.com/richcontext-engineering/creating-a-serverless-blog-with-chalice-bdc39b835f75)
+
+
+# 本周的Python工作
+
+[Pony.ai - 软件工程师](https://leap.ai/info/jobs/bb2c66ec-2498-543a-8ab1-8a4db96477d6?utm_source=newsletter&utm_medium=email&utm_term=pony&utm_content=jobpost&utm_campaign=pythonweekly)
+
+
+[Allume 招聘软件工程师](http://jobs.pythonweekly.com/jobs/software-engineer-21/)
+
+
+# 好玩的项目,工具和库
+
+[faust](https://github.com/robinhood/faust)
+
+Faust 是一个流处理库,将想法从 Kafka Streams 移植到 Python。
+
+[BYOB (Build Your Own Botnet)](https://github.com/colental/byob)
+
+BYOB 是一个开源项目,为安全研究人员和开发者提供一个框架,来构建和运行基本的僵尸网络,以加深他们对每年影响数百万台设备并生成现代僵尸网络的复杂恶意软件的理解,从而提高他们指定应对这些威胁的对策的能力。
+
+[Pythia](https://github.com/facebookresearch/pythia)
+
+Visual Question Answering 的软件套件。
+
+[attrs](https://github.com/python-attrs/attrs)
+
+无样板代码的 Python 类。
+
+[cltk](https://github.com/cltk/cltk)
+
+古典语言工具包(CLTK)提供对古典和中世纪欧亚大陆的语言的自然语言处理(NLP)支持。
+
+[Termgraph](https://github.com/mkaz/termgraph)
+
+在终端绘制基本图形的 python 命令行工具。
+
+[thredo](https://github.com/dabeaz/thredo)
+
+Thredo 是异步线程。是精品,还是垃圾,交给时间来判决。
+
+[AutoEq](https://github.com/jaakkopasanen/AutoEq)
+
+频率响应自动耳机均衡器。
+
+[Pyxel](https://github.com/kitao/pyxel)
+
+Python 中的复古游戏开发环境。
+
+[Raccoon](https://github.com/evyatarmeged/Raccoon)
+
+一款用于侦察和漏洞扫描的高性能攻击性安全工具。
+
+[Utter-More](https://github.com/crumpstrr33/Utter-More)
+
+为 Amazon Alexa 的话语添加冗余可能很枯燥。这个工具根据给定的模版,自动创建它们。
+
+[EduBlocks](https://edublocks.org/)
+
+让从 Scratch 到 Python 到过渡更容易的拖放编码工具。
+
+[whatsapp_automation](https://github.com/mnkgrover08/whatsapp_automation)
+Whatsapp Automation 是与运行在 Android 模拟器上的 WhatsApp messenge 交互的 API 集合,�从而允许开发者构建自动发送和接收短信、添加新的联系人以及广播消息给多个联系人的项目。
+
+[Configfy](https://github.com/mapa17/configfy)
+
+配置函数参数的装饰器库。
+
+
+# 最新发布
+
+[Django 2.1](https://www.djangoproject.com/weblog/2018/aug/01/django-21-released/)
+
+[IPython 5.8 和 6.5](https://mail.python.org/pipermail/ipython-dev/2018-July/016333.html)
+
+
+# 近期活动和网络研讨会
+
+[Baltimore Python 2018 年 8 月聚会 - Columbia, MD](https://www.meetup.com/baltimore-python/events/252684715/)
+
+Nick Garber 将会给我们带来关于 SaltStack 的介绍!
+
+[Austin Python 2018 年 8 月聚会 - Austin, TX](https://www.meetup.com/austinpython/events/247052862/)
+
+[PyAtl 2018 年 8 月聚会 - Atlanta, GA](https://www.meetup.com/python-atlanta/events/248129849/)
+
diff --git a/Python Weekly/Python_Weekly_Issue_359.md b/Python Weekly/Python_Weekly_Issue_359.md
new file mode 100644
index 0000000..ce1bf1b
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_359.md
@@ -0,0 +1,149 @@
+原文:[Python Weekly - Issue 359 ](http://eepurl.com/dDAEPX)
+
+---
+
+欢迎来到Python周刊第 359 期。让我们直奔主题。
+
+
+# 来自赞助商
+
+[](https://goo.gl/wlxnDm)
+
+你有参加 Kaggle 编程比赛吗?利用免费的 [Intel® Distribution for Python*](https://software.intel.com/en-us/distribution-for-python?utm_source=06%2F14%2F18%20Python%20Weekly%20Newsletter&utm_medium=Email&utm_campaign=Python%20Weekly%20newsletter%20June%202018) 中优化过性能的内置 scikit-learn 来助力你复杂的数据分析挑战。切换到更快的 python,以获得令人难以置信的速度提升!
+
+# 新闻
+
+[介绍 App Engine 第二代运行时和 Python 3.7](https://cloud.google.com/blog/products/gcp/introducing-app-engine-second-generation-runtimes-and-python-3-7)
+
+
+# 文章,教程和讲座
+
+[如何通过深度学习�轻松实现自动化监控](https://medium.com/nanonets/how-to-automate-surveillance-easily-with-deep-learning-4eb4fa0cd68d)
+
+本文是是使用基于深度学习的对象检测实现监控系统的快速教程。它还比较了使用 GPU 多处理进行推理的不同对象检测模型,在行人检测上的�性能。
+
+[使用 Python 和 Tensorflow 进行加密投资组合优化 —— 矩阵微积分方法](https://medium.com/jordi-moraleda/crypto-portfolio-optimization-with-python-and-tensorflow-an-approach-aa504578c799)
+
+在这篇文章中,我们将深入研究投资组合优化领域。我们会使用 Python 生态圈中的神奇工具,金融风险建模和一点点机器学习来构建加密投资组合优化器。
+
+[Python 中的字典](https://realpython.com/python-dicts/)
+
+在这篇 Python �字典教程中,你将学习基本特征,并学习如何访问和管理字典数据。一旦完成了本教程,你应该很好地了解字典的用武之地�以及使用方法。
+
+[在 2018 年,冻结 Python 的依赖地狱](https://tech.instacart.com/freezing-pythons-dependency-hell-in-2018-f1076d625241)
+
+解决复杂问题的�简单方法。
+
+[Python MySQL 教程](https://pynative.com/python-mysql-tutorial/)
+
+本教程演示了如何�将 Python 应用与 MySQL 数据库服务器集成。它侧重于访问 MySQL 数据库,进行数据插入、数据检索和数据删除,事务管理,连接池和错误处理技术,以便使用 MySQL 开发健壮的 python 程序。
+
+[跟踪应用是如何分析你的 GPS 数据的:实践教程(使用 Python)](https://towardsdatascience.com/how-tracking-apps-analyse-your-gps-data-a-hands-on-tutorial-in-python-756d4db6715d)
+
+在这篇教程中,我们将提取、挖掘和分析单个路径的 gpx 数据,使用 Python 和 Jupyter Notebook。我们首先将 gpx 文件中的数据提取到方便的 pandas dataframe 中。从那里,我们将探索数据,并尝试复制我们最喜欢的运行应用的界面提供给我们的统计数据和图形。
+
+[带 Flask REST API 的 Python 机器学习预测](https://www.toptal.com/python/python-machine-learning-flask-example)
+本文将演示如何使用 Python 和 Flask API 来创造预测性机器学习架构。
+
+[使用 Python,�介绍 MongoDB 事务](https://www.mongodb.com/blog/post/introduction-to-mongodb-transactions-in-python)
+
+2018 �年 6 月,MongoDB 4.0 带来了多文档事务。为了展示事务,我们使用一个简单的示例应用来模拟在线航空公司应用的航班预订。
+
+[使用 OpenCV 和 Python 进行手指检测和跟踪](https://dev.to/amarlearning/finger-detection-and-tracking-using-opencv-and-python-586m)
+
+跟踪手指的移动是许多计算机视觉应用的一项重要特征。在这个应用中,使用基于直方图的方法来将手与背景帧分离开来。使用阈值处理和滤波技术进行背景消除,以获得最佳结果。
+
+[使用 Django 中的大量数据集](https://blog.labdigital.nl/working-with-huge-data-sets-in-django-169453bca049)
+
+当 prefetch_related() 不再适合。
+
+[Seaborn 的最新版本中的新的图类型](http://pbpython.com/seaborn09.html)
+
+Seaborn 发布版本 0.9 包含了几种新的绘图类型以及本文中描述的其他更新。
+
+[使用哈利波特解释超级棒的 Python 特性](https://github.com/zotroneneis/harry_potter_universe)
+
+[用于基于序列的推荐器的乘法 LSTM](https://florianwilhelm.info/2018/08/multiplicative_LSTM_for_sequence_based_recos/)
+
+[如何用 Python 创建 Windows 服务](https://www.thepythoncorner.com/2018/08/how-to-create-windows-service-in-hi.html)
+
+[Python 的 asyncio 简介](https://hackernoon.com/a-simple-introduction-to-pythons-asyncio-595d9c9ecf8c)
+
+[PyData Berlin 2018 视频集](https://www.youtube.com/watch?v=5bJHUvQ_xGM&list=PLGVZCDnMOq0oQh7daBKy1AW5Q34d0LDsC)
+
+
+# 本周的Python工作
+
+[Opendoor —— 软件工程师(数据基础设施)](https://leap.ai/info/jobs/0e332591-cf0c-5d0b-9460-a2506a886c04?utm_source=newsletter&utm_medium=email&utm_term=opendoor&utm_content=jobpost&utm_campaign=pythonweekly)
+
+
+[Allume 招聘高级软件工程师](http://jobs.pythonweekly.com/jobs/senior-software-engineer-14/)
+
+
+# 好玩的项目,工具和库
+
+[dbt](https://github.com/fishtown-analytics/dbt)
+
+dbt(data build tool,数据构建工具)是一个命令行工具,使得数据分析师和工程师能够更有效地转换仓库中的数据。
+
+[Tweetable Python](https://books.agiliq.com/projects/tweetable-python/en/latest/index.html)
+
+每个程序�都可以当成一条推文(不多于 280 个字母),并做一些有用、强大或者有趣的事情。这些程序将提供参考、灵感和启明。在大多数情况下,当然并非总是如此,代码都是 Pythonic,没有任何混淆或者代码高尔夫(code golfing)。这些程序证明了 Python 的强大、简洁和清晰。
+
+[animatplot](https://github.com/t-makaro/animatplot)
+
+用于在 matplotlib 上构建动画图的 python 包。
+
+[rootfinder](https://github.com/tb0yd/rootfinder)
+
+nshying神经网络的阿拉伯词根�查找器!
+
+[pygmy](https://github.com/amitt001/pygmy)
+
+开源、功能丰富且可扩展的网址缩短器和分析。
+
+[sclack](https://github.com/haskellcamargo/sclack)
+
+Slack 的 CLI 客户端。
+
+[PySimpleGUI](https://github.com/MikeTheWatchGuy/PySimpleGUI)
+
+一个易于理解、易于使用的高可定制 Python GUI。近基于 tkinter。制作自己的 GUI。�也可在树莓派上运行。
+
+[HeapHopper](https://github.com/angr/heaphopper)
+
+HeapHopper 是用于 Heap 实现的有界模型检查框架。
+
+[torchbearer](https://github.com/ecs-vlc/torchbearer)
+
+PyTorch 的模型拟合库。
+
+[proxy_requests](https://github.com/rootVIII/proxy_requests)
+
+使用抓取代理来进行 http GET/POST 请求的类(Python requests)。
+
+[ml_board](https://github.com/bbli/ml_board)
+
+机器学习仪表板,可显示超参数设置以及可视化,并且记录整个训练过程中科学家的想法。
+
+
+# 近期活动和网络研讨会
+
+[IndyPy 2018 年 8 月聚会 - Indianapolis, IN](https://www.meetup.com/indypy/events/248715481/)
+
+将会有以下演讲:
+
+ * 今天会有龙卷风吗?使用 Scikit-Learn 进行分类
+ * 数据科学和预测性警务
+ * 游戏玩家的机器学习:地下城预测和�龙回归
+
+
+[Princeton Python User 2018 年 8 月聚会 - Princeton, NJ](https://www.meetup.com/pug-ip/events/253359522/)
+
+一系列简短的演讲,目前包括了“�将 Python 用于微控制器” 和“将 Pytest 用于数据库资产”。
+
+[Boulder Python 2018 年 8 月聚会 - Boulder, CO](https://www.meetup.com/BoulderPython/events/252365041/)
+
+[Edmonton Python 2018 年 8 月聚会 - Edmonton, AB](https://www.meetup.com/startupedmonton/events/252408025/)
+
+
diff --git a/Python Weekly/Python_Weekly_Issue_360.md b/Python Weekly/Python_Weekly_Issue_360.md
new file mode 100644
index 0000000..019ce3c
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_360.md
@@ -0,0 +1,148 @@
+原文:[ Python Weekly - Issue 360 ](http://eepurl.com/dEdQof)
+
+---
+
+欢迎来到Python周刊第 360 期。让我们直奔主题。
+
+
+# 来自赞助商
+
+[](https://try.digitalocean.com/performance/?utm_medium=Display&utm_source=Python_Weekly&utm_campaign=2018_Brand&utm_content=Conversation_with_100_125x125)
+
+DigitalOcean 是一个开发者友好的云平台,旨在满足你的需求,可用来部署任意规模的超快 Python 应用。了解 DigitalOcean 是如何简化你的基础架构的。[在这之上构建你的下一个应用吧(有 $100 积分哦)](https://try.digitalocean.com/performance/?utm_medium=Display&utm_source=Python_Weekly&utm_campaign=2018_Brand&utm_content=Conversation_with_100_125x125)。
+
+
+# 文章,教程和讲座
+
+[给 Python 开发者的高级 Git 技巧](https://realpython.com/advanced-git-for-pythonistas/)
+
+在这篇针对 Python 开发者的 Git 教程中,我们将讨论如何处理特定的提交和整个提交范围,使用存储来保存临时工作,对比不同的提交,修改历史记录,以及如何某些东西出问题了,如何进行清理。
+
+[Docker 是什么,以及如何以 Python 的方式使用它(教程)](https://dev.to/djangostars/what-is-docker-and-how-to-use-it-with-python-tutorial-87a)
+
+这是一篇关于 Docker 容器的入门教程。在文章的最后,你将会了解如何在本地机器上使用 Docker。加上 Python,我们将运行 Nginx 和 Redis 容器。
+
+[OpenCV 人员计数器](https://www.pyimagesearch.com/2018/08/13/opencv-people-counter/)
+
+在这篇教程中,你将学习如何使用 OpenCV 和 Python 估计一个“人员计数器”。使用 OpenCV,我们将实时计算进出百货商店的人数。
+
+[机器学习方法 —— 构建酒店推荐引擎](https://towardsdatascience.com/a-machine-learning-approach-building-a-hotel-recommendation-engine-6812bfd53f50)
+
+在这篇文章中,我们旨在为搜索要预定的酒店的 Expedia 用户创建最佳酒店推荐。我们将把此问题建模为多类分类问题,并用集合方法构建 SVM 和决策树,根据用户的搜索细节,来预测他(她)可能会预订的“酒店集群”。
+
+[如何在 Django 中使用 Bootstrap 4 表单](https://simpleisbetterthancomplex.com/tutorial/2018/08/13/how-to-use-bootstrap-4-forms-with-django.html)
+
+这是一个快速教程,让你从 django-crispy-forms 开始,并永不回头。Crispy-forms 是一个很棒的应用�,它可以让你控制渲染 Django 表单的方式,而不会破坏默认的行为。本教程将针对 Bootstrap 4 进行定制,但也可用于更老的 Bootstrap 版本以及 Foundation 框架。
+
+[Django 重定向的终极指南](https://realpython.com/django-redirects/)
+
+在本详细的指南中,你将了解关于 Django 中的 HTTP 重定向的所有信息。从 HTTP 协议的底层细节到在 Django 中处理它们的高级方式。
+
+[使用 Python 和 Tensorflow 进行加密投资组合优化 —— 矩阵微积分方法 #2](https://medium.com/jordi-moraleda/crypto-portfolio-optimization-with-python-and-tensorflow-matrix-calculus-approach-2-898c4d2019e8)
+
+在上一篇文章中,我们使用 Python 和 Tensorflow 构建了一个投资组合优化器:给定一组加密货币,它�会获取历史价格,计算方差-协方差矩阵、相关矩阵,然后探索投资组合,以最大化全球夏普比率(Sharpe Ratio)。在这篇文章中,我们将讨论一些可以遵循的方式,以改进我们的工具,并让它更加一致。
+
+[用 Python,为你的 Mac 构建一个简单的语音助手](https://towardsdatascience.com/building-a-simple-voice-assistant-for-your-mac-in-python-62247543b626)
+
+最基本的 python 语音助手,可以为你打开计算机应用,或者搜索互联网。
+
+[Python 存储字符串时是如何节省内存的](https://rushter.com/blog/python-strings-and-memory/)
+
+[使用 Python 和 Pandas 匿名化数据的简单方式](https://dev.to/r0f1/a-simple-way-to-anonymize-data-with-python-and-pandas-79g)
+
+[使用异步 Celery 任务 —— 经验教训](https://blog.daftcode.pl/working-with-asynchronous-celery-tasks-lessons-learned-32bb7495586b)
+
+
+# 本周的Python工作
+
+[Lily AI 招聘机器学习工程师](http://jobs.pythonweekly.com/jobs/machine-learning-engineer/)
+
+
+# 好玩的项目,工具和库
+
+[Auto-Keras](https://github.com/jhfjhfj1/autokeras)
+
+Auto-Keras 是一个用于自动机器学习(AutoML)的开源软件库。它由 Texas A&M 大学的� DATA Lab 和社区贡献者开发。AutoML 的终极目标是为具有有限的数据科学或者机器学习北京的领域专家,提供易于访问的深度学习工具。Auto-Keras 提供自动搜索深度学习模型的架构和超参数的函数。
+
+[btlejack](https://github.com/virtualabs/btlejack)
+
+Btlejack 提供嗅探、阻塞和劫持蓝牙低功耗设备所需的一切。
+
+[python-jvm-interpreter](https://github.com/gkbrk/python-jvm-interpreter)
+
+Python 中的 Java 虚拟机实现。
+
+[trackerjacker](https://github.com/calebmadrigal/trackerjacker)
+�就像映射你没有连接上的 wifi 网络的 nmap,加上设备跟踪。
+
+[Arctic](https://github.com/manahl/arctic)
+
+Arctic 是用于数字数据的高性能数据存储。它开箱即支持Pandas、numpy 数组和被 pickle 的对象,可插拔支持其他数据类型和可选的版本控制。对于每个客户端,Arctic �每秒可以查询数百万行,网络带宽实现约 10 倍的压缩,磁盘实现约 10 倍的压缩,并且每个 MongoDB 实例可以扩展到每秒数亿行。
+
+[dynamic-rest](https://github.com/AltSchool/dynamic-rest)
+
+Django REST 框架的动态 API 扩展。
+
+[img_term](https://github.com/JonnoFTW/img_term)
+
+在 ANSI 终端上显示图像和摄像机!
+
+[artificial-adversary](https://github.com/airbnb/artificial-adversary)
+
+生成对抗文本示例和测试机器学习模型的工具。
+
+[CharmPy](https://github.com/UIUC-PPL/charmpy)
+
+CharmPy 是一个通用的并行和分布式编程框架,带有简单但强大的 API,基于可迁移的 Python 对象和远程方法调用;构建在自适应的 C++ 运行时系统之上,以提供速度、可扩展性和动态负载平衡。
+
+[Crypton](https://github.com/ashutosh1206/Crypton)
+
+包含各种加密系统、数字签名、散列算法以及来自 CTF 的示例挑战上的所有现有攻击的解释和实现的库。
+
+[DanceNet](https://github.com/jsn5/dancenet)
+
+使用 Autoencoder、LSTM 和 Mixture Density Network 的舞蹈生成器。(Keras)
+
+[Skein](https://github.com/jcrist/skein/)
+
+�用于在 Apache YARN 上轻松部署应用的工具和库。
+
+[PaperTTY](https://github.com/joukos/PaperTTY)
+在电子墨水上�渲染 TTY 的 Python 模块。
+
+
+# 近期活动和网络研讨会
+
+[Boston Python 聚会轻演讲! - Boston, MA](https://www.meetup.com/bostonpython/events/251044290/)
+
+将会有以下轻演讲:
+
+ * 用多处理进入 Pickle
+ * 计算机科学/工程中的多样性和包容性
+ * Eliot,因果记录库
+ * pandas DataFrame 快速预览
+ * 使用 PyCharm 进行重构和静态代码分析
+ * 如果你用整型做了一些很糟糕的事情怎么办?
+ * 评估 Pi
+
+
+[PyHou 2018 年 8 月聚会 - Houston, TX](https://www.meetup.com/python-14/events/250807263/)
+
+将会有以下演讲:
+
+ * 电路 Python:利用物理计算可视化计算机科学原理
+ * API 礼仪 —— 缓存响应
+
+
+[London Python August Meet Up - London, UK](https://www.meetup.com/LondonPython/events/253207574/)
+
+将会有以下演讲:
+
+ * 帮你写文档的测试
+ * 构建 BDD 样式的可执行规范
+ * 备用 CLI 工具
+ * 生活更好涂黑
+ * Python 3.8(可能)会有啥新东西
+
+
+[San Diego Python 2018 年 8 月聚会 - San Diego, CA](https://www.meetup.com/pythonsd/events/252768967/)
diff --git a/Python Weekly/Python_Weekly_Issue_361.md b/Python Weekly/Python_Weekly_Issue_361.md
new file mode 100644
index 0000000..5c788a0
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_361.md
@@ -0,0 +1,138 @@
+原文:[Python Weekly - Issue 361 ](http://eepurl.com/dESFaz)
+
+---
+
+欢迎来到Python周刊第 361 期。让我们直奔主题。
+
+
+# 来自赞助商
+[](https://try.digitalocean.com/performance/?utm_medium=Display&utm_source=Python_Weekly&utm_campaign=2018_Brand&utm_content=Conversation_with_100_125x125)
+
+使用 DigitalOcean 部署任何规模的超快 Python 应用,这是一个开发者友好的云平台,旨在满足你的需求。了解 DigitalOcean 如何简化你的基础架构吧。[ v](https://try.digitalocean.com/performance/?utm_medium=Display&utm_source=Python_Weekly&utm_campaign=2018_Brand&utm_content=Conversation_with_100_125x125).
+
+# 文章,教程和讲座
+
+[Python 装饰器入门](https://realpython.com/primer-on-python-decorators/)
+
+在这篇介绍性教程中,我们将了解 Python 装饰器的概念,以及如何创建并使用它们。
+
+[超越互动:Netflix 的 notebooks 创新](https://medium.com/netflix-techblog/notebook-innovation-591ee3221233)
+
+notebooks 在数据科学家中迅速普及,成为�快速原型制作和探索性分析的事实标准。在 Netflix,我们更进一步,重新构想 notebooks 的功能,使用群体,以及用户可以用它们做什么。并且,我们正在进行大量投资,以帮助实现这一愿景。在这篇文章中,我们将分享我们的动机,以及我们觉得 Jupyter notebooks 如此引人注目的原因。我们还将介绍我们的 notebook 基础设施的组件,并探讨在 Netflix �使用 notebooks 的一些新方法。
+
+[OpenCV 文本检测(EAST 文本检测器)](https://www.pyimagesearch.com/2018/08/20/opencv-text-detection-east-text-detector/)
+
+在这篇教程中,你将了解如何使用 OpenCV、EAST 文本检测器来检测自然场景图片中的文本。
+
+[使用 TensorFlow Lite 的移动设备上的神经网络](https://heartbeat.fritz.ai/neural-networks-on-mobile-devices-with-tensorflow-lite-a-tutorial-85b41f53230c)
+
+这是一个实用的端到端指南,关于如何使用 TensorFlow Lite 构建移动应用,它能分类�项目数据集中的图像。
+
+[为 Python 添加管道运算符](https://hackernoon.com/adding-a-pipe-operator-to-python-19a3aa295642)
+
+或者,“那些你永远都不应该在生产中做的事情”
+
+[Python 中的集合](https://realpython.com/python-sets/)
+
+在这篇教程中,你将学习如何有效地使用 Python 的集合数据类型。你将看到如何在 Python 中定义 set 对象,发现它们支持的操作,并在本教程的最后,你将很好地了解何时在程序中使用 set 最合适。
+
+[Asyncio socket 教程](https://medium.com/@pgjones/an-asyncio-socket-tutorial-5e6f3308b8b0)
+
+如何构建一个 ASGI web 服务器,像 Hypercorn。
+
+[使用 TensorFlow Hub 和 Estimators 构建一个文本分类模型](https://medium.com/tensorflow/building-a-text-classification-model-with-tensorflow-hub-and-estimators-3169e7aa568)
+
+转换学习的�诸多好处之一是,你无需像从头开始那样提供给你所有的训练数据。但是这些预先存在的模型从何而来呢?现在,该是 TensorFlow Hub 出现的时候了:它为各种类型的模型(图像、文本等等)提供了现有模型检查点的完整的存储库。在这篇文章中,我将带你使用一个 TensorFlow Hub 文本模块,构建一个模型来根据电影描述预测它的流派。
+
+[实现 DistBelief](https://jcaip.github.io/Distbelief/)
+
+DistBelief 是一篇谷歌论文,描述了如何分布式训练模型。特别是,我们对实现一种分布式优化方法 —— DownpourSGD —— 感兴趣。这是关于我们的实现的概述,以及此过程中遇到的一些问题。
+
+[一个“为善数据科学(Data Science for Good)”机器学习项目,使用 Python:第一部分](https://towardsdatascience.com/a-data-science-for-good-machine-learning-project-walk-through-in-python-part-one-1977dd701dbc)
+解决完整的机器学习问题,以获得社会效益。
+
+ * [第二部分](https://towardsdatascience.com/a-data-science-for-good-machine-learning-project-walk-through-in-python-part-two-2773bd52daf0) - 充分利用模型、弄清楚它们的意义,并尝试新技术。
+
+
+[Python PostgreSQL 教程,使用 Psycopg2](https://pynative.com/python-postgresql-tutorial/)
+
+这篇 Python PostgreSQL 教程演示了如何使用 PostgreSQL 数据库服务器开发 Python 数据库应用。
+
+[湾区房地产分析第 2 部分](https://blog.checkyo.tech/2018/08/15/bay-area-housing-market-analysis-part-2/)
+
+在上一节中,我在针对湾区带 Zillow 租赁市场数据集上进行了一些基本时间序列分析。�分析是用 Python、Jupyter、Pandas 和 Plotly 来完成的。在该系列的第二部分中,我们将介绍一些公开的 Redfin 数据。特别是深入购买东湾的房产。
+
+[带 Model 建模的动态 Django 模型](https://www.protoapi.net/blog/2/)
+
+警告:你可能并不想这样做,因为这种方法不被支持,并且非常黑客�。考虑 JSONField。
+
+[通过滥用类型注释将宏带到 Python 中](https://tinkering.xyz/abusing-type-annotations/)
+
+[用 Python 替换 Bash 脚本](https://github.com/ninjaaron/replacing-bash-scripting-with-python#replacing-sed-grep-awk-etc-python-regex)
+
+[如何用 Django REST 框架在 3 行代码内实现一个 API](https://medium.com/crowdbotics/how-to-write-an-api-in-3-lines-of-code-with-django-rest-framework-59b0971edfa4)
+
+
+# 好玩的项目,工具和库
+
+[vid2vid](https://github.com/NVIDIA/vid2vid)
+
+我们的高分辨率(例如,2048x1024)�逼真对视频到视频转换方法的Pytorch 实现。i
+
+[Papermill](https://github.com/nteract/papermill)
+
+Papermill 是一个用于参数化、执行和分析 Jupyter Notebooks 对工具。
+
+[Pext](https://github.com/Pext/Pext)
+
+基于 Python 对可扩展工具。
+
+[Inception](https://github.com/two06/Inception)
+
+为 AV evasio 提供 C# 应用的内存中编译和反射加载。
+
+[Selfmailbot](https://github.com/f213/selfmailbot)
+
+将消息转发到收件箱到 Telegram 机器人。对 GTD 和� 电子邮箱极客有用。
+
+[fast_progress](https://github.com/fastai/fast_progress)
+
+简单灵活到进度条,用于 Jupyter Notebook 和�控制台。
+
+[pychromecastweb](https://github.com/alexpdp7/pychromecastweb)
+pychromecastweb 是一个 web 应用,让你可以浏览部分本地文件系统,并将视频投射到 Chromecast。
+
+[asciify](https://github.com/RameshAditya/asciify/)
+
+将图像转换成 ASCII 艺术。
+
+[flask-batch](https://github.com/dtkav/flask-batch)
+
+在单个 HTTP 请求中处理多个 API 调用。
+
+[kube-hunter](https://github.com/aquasecurity/kube-hunter)
+
+寻找 Kubernetes 集群中的安全漏洞。
+
+[simple-django-login-and-register](https://github.com/egorsmkv/simple-django-login-and-register)
+带基本用户功能的 Django 项目示例。
+
+
+# 近期活动和网络研讨会
+
+[SoCal Python 2018 年 八月聚会 - Marina del Rey, CA](https://www.meetup.com/socalpython/events/253772838/)
+
+将会有以下讲座:
+
+ * 为什么我应该学习 Pandas?
+ * 工程师写作
+
+
+[旧金山 Django 聚会 - San Francisco, CA](https://www.meetup.com/The-San-Francisco-Django-Meetup-Group/events/253603765/)
+
+将会有以下讲座:
+
+ * 压缩 Django 迁移
+ * 关于 App Engine �和 Datastore 的 Django
+
+
\ No newline at end of file
diff --git a/Python Weekly/Python_Weekly_Issue_362.md b/Python Weekly/Python_Weekly_Issue_362.md
new file mode 100644
index 0000000..603abcb
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_362.md
@@ -0,0 +1,124 @@
+原文:[Python Weekly - Issue 362 ](http://eepurl.com/dFy20H)
+
+---
+
+欢迎来到Python周刊第 362 期。让我们直奔主题。
+
+
+[](https://click.linksynergy.com/link?id=x9UsEHf2tls&offerid=323085.543600&type=2&murl=https%3A%2F%2Fwww.udemy.com%2Fautomate%2F)
+
+ [使用 Python 编程自动化无聊的东东](https://click.linksynergy.com/link?id=x9UsEHf2tls&offerid=323085.543600&type=2&murl=https%3A%2F%2Fwww.udemy.com%2Fautomate%2F)
+
+给那些想要提高工作效率的白领、学者和管理员的实用编程课程。
+
+# 新闻
+
+[PyCon Indonesia 2018 征集提议](https://www.papercall.io/pyconid2018)
+
+我们呼吁演讲者分享他们的 Python 知识(以讲座、研讨会和海报的形式),这将吸引 Python 社区加入此次活动!我们正在寻找关于 Python 各方各面的提议:从基础到高级。
+
+
+# 文章,教程和讲座
+
+[Python Pandas:你可能不知道的技巧和功能](https://realpython.com/python-pandas-tricks/)
+
+给那些已经熟悉 Pandas 基本功能和概念的人的鲜为人知但又惯用的 Pandas 功能。
+
+[Django 教程 // 构建一个视频订阅网站](https://www.youtube.com/watch?v=zu2PBUHMEew)
+
+在这个 Django 项目中,我们教你如何使用 Django 和 Stripe 付费,构建一个基本的视频订阅网站。
+
+[使用 OpenCV 进行神经风格转换](https://www.pyimagesearch.com/2018/08/27/neural-style-transfer-with-opencv/)
+
+在本指南中,你将学习如何使用 OpenCV 和 Python,将神经样式转换应用到图像和视频流上。
+
+[使用 Flask 构建实时表](https://pusher.com/tutorials/live-table-flask)
+
+在本教程中,你将学习如何使用 Python(Flask) 和 Pusher Channels 来构建实时表。在此过程中,我们将构建一个实时航班状态应用。
+
+[教育 Flappy Bird:强化学习教程](https://www.toptal.com/deep-learning/pytorch-reinforcement-learning-tutorial)
+
+本教程介绍了强化学习的构建模块,展示了如何使用 PyTorch 框架,训练一个神经网络来玩 Flappy Bird。
+
+[如何创建自定义的 Django 管理命令](https://simpleisbetterthancomplex.com/tutorial/2018/08/27/how-to-create-custom-django-management-commands.html)
+
+Django 自带了各种命令行工具,可以�通过 django-admin.py 或者方便的 manage.py 脚本进行调用。一个好处是,你也可以添加自己的命令。当你需要使用终端终端,通过命令行与应用程序交互时,这些管理命令非常方便,并且�它还可以作为执行 cron 工作的接口。在这篇教程中,你将学习如何编写自己的命令。
+
+[全栈 Python Flask 教程 —— 构建社交网络](https://www.youtube.com/watch?v=-FWuNnCe73g)
+
+学习如何使用 Python Flask web 框架来构建一个基本的社交平台。在这个视频中,我们将介绍如何创建数据库、�将数据导入导出数据库、使用 python 创建 web 服务器以及使用 python HTML 模板来为客户渲染页面!
+
+[如何使用 MLflow 来实验 Keras 网络模型:电影评论的二进制分类](https://databricks.com/blog/2018/08/23/how-to-use-mlflow-to-experiment-a-keras-network-model-binary-classification-for-movie-reviews.html)
+
+在这篇�博客中,我们演示了如何使用 MLflow 来实验 Keras 模型。特别是,我们使用 MLflow 进行跟踪和实验,构建和试验了一个二进制分类器 Keras/TensorFlow 模型。
+
+[$4,718 —— 使用机器学习投注 NHL](https://medium.com/coinmonks/4-718-using-machine-learning-to-bet-on-the-nhl-25d16649cd52)
+
+[使用 Python 和 TensorFlow 实现自组织映射](https://rubikscode.net/2018/08/27/implementing-self-organizing-maps-with-python-and-tensorflow/)
+
+[使用 Seq2Seq 模型生成音乐](https://medium.com/@noufalsamsudin/generating-music-with-seq2seq-models-627b2506265a)
+
+[PyCon Australia 2018 视频集](https://www.youtube.com/playlist?list=PLs4CJRBY5F1KrUr7z_2mur2QdAKXyh-k3)
+
+[配置一个 .pypirc 文件,以便更轻松地进行 Python 打包](https://truveris.github.io/articles/configuring-pypirc/)
+
+
+# 本周的Python工作
+
+[Verve 招聘高级后端工程师](http://jobs.pythonweekly.com/jobs/senior-backend-engineer-2/)
+
+
+# 好玩的项目,工具和库
+
+[dopamine](https://github.com/google/dopamine)
+
+Dopamine 是一个用于强化学习算法的快速原型设计的研究框架。
+
+[Optimus](https://github.com/ironmussa/Optimus)
+
+敏捷数据科学流程,使用 Python 和 Spark。
+
+[pyodide](https://github.com/iodide-project/pyodide)
+
+Python 科学栈,编译为 WebAssembly。它提供了 Javascript 和 Python 之间对象的透明转换。在浏览器中,意味着 Python 可以完全访问 Web API。
+
+[Salmon](https://github.com/moggers87/salmon)
+
+Salmon 是一个纯 Python 邮件服务器,旨在以现代 web 框架的风格创建健壮且复杂的邮件应用。Salmon 被设计成位于传统邮件服务器之后,就像 web 应用位于 Apache 或者 Nginx 之后那样。它拥有 web 应用栈的所有�功能(模板、路由、处理程序、状态机),并可与其他库(例如 Django 和 SQLAlchemy)很好地配合使用。
+
+[django-shapeshifter](https://github.com/kennethlove/django-shapeshifter)
+
+在一个视图中处理多个表单的 CBV。
+
+[DUGA](https://github.com/MaxwellSalmon/DUGA/)
+
+DUGA 是一个用 Python3 和 Pygame 做的射线追踪器(raycaster)。它是一个建立在同名简单引擎之上的游戏。
+
+[databot](https://github.com/kkyon/databot)
+
+用于 Web Crawler、ETL、数据管道工作的高性能 Python 数据驱动编程框架。
+[Vba2Graph](https://github.com/MalwareCantFly/Vba2Graph)
+
+生成 VBA 代码的调用图,以便更轻松地分析恶意文档。
+
+[imaginaryC2](https://github.com/felixweyne/imaginaryC2)
+
+Imaginary C2 是一个� python 工具,旨在助力恶意软件的行为(网络)分析。Imaginary C2 有一个 HTTP 服务器,用于捕获针对选择性域名或者 IP 的 HTTP 请求。此外,这个工具还致力于让重放捕获命令和控制响应/服务 payload 变得容易。
+
+[Meshroom](https://github.com/alicevision/meshroom)
+
+Meshroom 是一个基于 AliceVision 框架的免费开源 3D 重建工具。
+
+[hyperparameter_hunter](https://github.com/HunterMcGushion/hyperparameter_hunter)
+
+轻松的超参数优化和自动结果保存,跨机器学习算法和库
+
+
+# 近期活动和网络研讨会
+
+[San Francisco PyData 2018 年九月聚会 - San Francisco, CA](https://www.meetup.com/San-Francisco-PyData/events/253819657/)
+将会有以下讲座:
+
+ * MLflow:完整机器学习生命周期的基础设施
+ * 科学发现的数据可视化
+
\ No newline at end of file
diff --git a/Python Weekly/Python_Weekly_Issue_363.md b/Python Weekly/Python_Weekly_Issue_363.md
new file mode 100644
index 0000000..335b0c8
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_363.md
@@ -0,0 +1,150 @@
+原文:[Python Weekly - Issue 363](http://eepurl.com/dGhLSb)
+
+---
+
+欢迎来到Python周刊第 363 期。让我们直奔主题。
+
+
+# 来自赞助商
+
+[](https://try.digitalocean.com/performance/?utm_medium=Display&utm_source=Python_Weekly&utm_campaign=2018_Brand&utm_content=Conversation_with_100_125x125)
+
+使用DigitalOcean部署任何规模的超快Python应用程序,DigitalOcean是一个开发人员友好的云平台,旨在满足您的需求。 了解DigitalOcean如何简化您的基础架构。 [在这之上构建你的下一个应用吧(有 $100 积分哦)](https://try.digitalocean.com/performance/?utm_medium=Display&utm_source=Python_Weekly&utm_campaign=2018_Brand&utm_content=Conversation_with_100_125x125)。
+
+# 新闻
+
+[Python首次进入TIOBE索引前三名](https://www.tiobe.com/tiobe-index/)
+
+
+# 文章,教程和讲座
+
+[Python Django 教程](https://www.youtube.com/playlist?list=PL-osiE80TeTtoQCKZ03TU5fNfx2UY6U4p)
+
+在本系列中国呢,我们将学习构建一个功能齐全的 Django 应用。我们将学习如何开始使用 Django、使用模板、创建数据库、上传图片、创建鉴权系统等等。
+
+[构建 Python 程序](https://realpython.com/python-program-structure/)
+
+在本教程中,你将深入研究 Python 的词法结构,并开始将代码安排到更复杂的分组中。你将了解构成语句的语法元素,以及构成 Python 程序的基本单元。
+
+[揭秘卷积神经网络](https://medium.com/@eternalzer0dayx/demystifying-convolutional-neural-networks-ca17bdc75559)
+
+卷积神经网络的直观解释。
+
+[Python中随机森林的实现与解释](https://towardsdatascience.com/an-implementation-and-explanation-of-the-random-forest-in-python-77bf308a9b76)
+
+通过从单个决策树构建来使用和理解随机森林的指南。
+
+[使用 OpenCV 和深度学习的语义分割](https://www.pyimagesearch.com/2018/09/03/semantic-segmentation-with-opencv-and-deep-learning/)
+
+在这篇教程中,你将学习如何使用 OpenCV、深度学习和 ENet 架构来执行语义分割。阅读本指南后,你将能够使用 OpenCV,将应用语义分割应用到图像和视频上。
+
+[在一个满是鲨鱼的 multiprocessing.Pool 中,用 fork() 刺向你自己](https://codewithoutrules.com/2018/09/04/python-multiprocessing/)
+
+现在,是时候深入探讨 Python 破解和 POSIX 系统编程的痛苦了,这一次,我们使用激动人心但不那么令人信服的鲨鱼主题的隐喻!你将学到的大部分内容并非 Python 特有的,所以无论如何,都要坚持并享受呀亲爱的。
+
+[Python 中的条件语句](https://realpython.com/python-conditional-statements/)
+
+在这篇手把手教程中,你将学习如何使用 Python 中的条件语句。掌握 if 语句,并了解如何在程序中编写复杂的决策代码。
+
+[S3 诡计:将其当成调度器](https://hackernoon.com/s3-trickery-using-it-as-a-scheduler-c618103b1cf2)
+
+使用 serverless 有趣的地方之一是,你可以尝试新的想法,并轻松设置它们。我不止一次提到,s3 是一个强大的工具,不仅仅可以作为弹性持久层使用。在这篇文章中,我将演示如何将 s3 作为一个调度机制来执行各种任务。
+
+[构建 GUI 的手把手指南](https://www.pythonforthelab.com/blog/step-by-step-guide-to-building-a-gui/)
+
+使用 PyQt,为你的网络摄像头构建 GUI。
+
+[让我们更进一步了解奥运会!](https://www.kaggle.com/marcogdepinto/let-s-discover-more-about-the-olympic-games)
+
+[我是如何使用深度学习和 Keras 来优化电子商务业务流程的](https://towardsdatascience.com/how-i-used-deep-learning-to-optimize-an-ecommerce-business-process-with-keras-8ba328e12d9c)
+
+[简单的自动化特征工程 —— 使用 Python 中的 featuretools 进行分类](https://medium.com/@rrfd/simple-automatic-feature-engineering-using-featuretools-in-python-for-classification-b1308040e183)
+
+[极简工业卡车的修理成本:机械工程师的机器学习](https://towardsdatascience.com/minimizing-repair-costs-for-industrial-trucks-machine-learning-for-mechanical-engineers-ba755fb0108b)
+
+
+# 好玩的项目,工具和库
+
+[Bowler](https://github.com/facebookincubator/Bowler)
+
+Bowler 是一个在语法树级别操作 Python 的重构工具。它可以实现安全、大规模的代码修改,同时保证生成的代码可以编译运行。它提供了一个简单的命令行接口和用 Python 写的流畅的 API 来用代码生成复杂的代码修改。
+
+[learn-python](https://github.com/trekhleb/learn-python)
+
+学习 Python 的游乐场和备忘录。
+
+[lazydata](https://github.com/rstojnic/lazydata)
+
+lazydata 是一个将数据依赖包含到 Python 项目的极简库。
+
+[SmokeDetector](https://github.com/Charcoal-SE/SmokeDetector)
+
+检测垃圾邮件并将其发布到聊天室的无领导聊天机器人。使用 ChatExchange,从 Stack Exchange 实时选项卡中获取问题,然后通过 Stack Exchange API 访问答案。
+
+[pytheory](https://github.com/kennethreitz/pytheory)
+
+人类音乐理论。
+
+[pytorch-flows](https://github.com/ikostrikov/pytorch-flows)
+
+用于密度评估的算法的 PyTorch 实现。
+
+[soundcloud-dl](https://github.com/sdushantha/soundcloud-dl)
+
+以 128kbps 速度下载 SoundCloud 音乐,带专辑封面和标签。
+
+[Mantra](https://github.com/RJT1990/mantra)
+
+机器学习项目的高级快速开发的框架。
+
+[Starlette](https://www.starlette.io/)
+
+Starlette 是一个轻量级 ASGI 框架/工具包。它非常适合用来构建高性能的 asyncio 服务,并支持 HTTP 和 WebSockets。
+
+[tortoise-orm](https://github.com/tortoise/tortoise-orm)
+
+python 中的易于使用的异步 ORM,构建时考虑到了关系。
+
+[reprexpy](https://github.com/crew102/reprexpy)
+
+渲染可重现的 Python 代码示例,以便发布到 GitHub/Stack Overflow。
+
+[Yoke](https://github.com/rmst/yoke)
+
+Yoke 是一款适用于 Linux 的可控制 Android 游戏手柄。
+
+
+# 最新发布
+
+[Django 问题修复版本:2.1.1](https://www.djangoproject.com/weblog/2018/aug/31/bugfix-release/)
+
+
+# 近期活动和网络研讨会
+
+[Boulder Python 2018 年九月聚会 - Boulder, CO](https://www.meetup.com/BoulderPython/events/253820597/)
+
+教程:使用 Kubernetes 扩展 Flask。在这次演讲中,Michael Herman 将首先从高层次介绍 Kubernetes 和容器编排,然后,他将展示部署一个基于 Flask 的微服务(�使用 PostgreSQL 和 Vue.js)到 Kubernetes 集群中的方法。
+
+[PyMNtos Python 展示之夜 #65 - Minneapolis, MN](https://www.meetup.com/PyMNtos-Twin-Cities-Python-User-Group/events/253253903/)
+
+将会有以下演讲:
+
+ * 保持代码之美:维护高质量代码的 Python 工具。
+ * 我发现了一个 Python 解释器缺陷
+ * 使用 ARIMA 模型来预测时间序列(Python 版本)
+ * Geopandas
+
+
+[IndyPy 2018 年九月聚会 - Indianapolis, IN](https://www.meetup.com/indypy/events/248715509/)
+
+将会有以下演讲:
+
+ * Webscraping 简介及其在大数据领域的未来
+ * 了解计算和人机交互如何相互关联
+ * Python 之禅教给我们的关于数据伦理的一些事情
+
+
+[PyAtl 2018 年九月聚会 - Atlanta, GA](https://www.meetup.com/python-atlanta/events/251754975/)
+
+[Austin Python 2018 年九月聚会 - Austin, TX](https://www.meetup.com/austinpython/events/247052863/)
+
diff --git a/Python Weekly/Python_Weekly_Issue_364.md b/Python Weekly/Python_Weekly_Issue_364.md
new file mode 100644
index 0000000..dfcb240
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_364.md
@@ -0,0 +1,137 @@
+原文:[Python Weekly - Issue 364 ](http://eepurl.com/dG1JB1)
+
+---
+
+欢迎来到Python周刊第 364 期。让我们直奔主题。
+
+
+# 来自赞助商
+
+[](https://goo.gl/wlxnDm)
+
+查看 [Intel Distribution for Python 2019](https://software.intel.com/en-us/distribution-for-python?utm_source=09%2F13%2F18%20Python%20Weekly%20Newsletter&utm_medium=Email&utm_campaign=Python%20Weekly%20newsletter%20Sep%202018) 的最新版本中到新功能吧。亮点包括使用 scikit-learn 进行更快的机器学习,支持向量机(SVM)和 K 均值预测到显著性能加速。�为你的数据使用一个更快到 Python 吧!
+
+# 文章,教程和讲座
+
+[Alexa 新的 AWS Python SDK 的初学者指南](https://medium.freecodecamp.org/a-beginners-guide-to-the-new-aws-python-sdk-for-alexa-105c0ed45f4e)
+
+Amazon Web Services (AWS) 最近添加了一个新的 Python SDK 到他们的 Alexa 家族。它目前还属于 beta 阶段,但是这不应该阻止我们接触一下。在这篇文章中国,我们将构建一个�非常简单的语音应用,它可以说出关于猫星人的 10 个事实。这个应用的概念非常简单,使得我们可以专注使用该� SDK 的方法,以及使用 DynamoDB 来持久化我们的应用的最重要的数据的方法。
+
+[Python 中的日志记录](https://realpython.com/python-logging/)
+
+了解 Python 的 logging 模块强大的原因,以及如何入门,以满足初学者和企业团队的需求。
+
+[Django 2.1 - 使用 Python 构建一个个人网站](https://www.youtube.com/watch?list=PLhTjy8cBISEpXc-yjjSW90NgNyPYe7c9_&v=ehCjpQXetgo)
+
+在这些视频集中学习 django,在此之中,我从下到上构建了一个完整的个人网站。从 Django web 框架的基础知识,到在 heroku 中构建和托管你自己的网站。
+
+[如何入门 Keras、深度学习和 Python](https://www.pyimagesearch.com/2018/09/10/keras-tutorial-how-to-get-started-with-keras-deep-learning-and-python/)
+
+在这个 Keras 教程中,你会发现入门深度学习和 Python 有多容易。你将使用 Keras 深度学习库,在自定义图像数据集之上训练你第一个神经网络,并从那里开始,你也将实现你的第一个卷积神经网络(CNN)。
+
+[计算任意视频中的演员的演出时间的�深度学习教程](https://www.analyticsvidhya.com/blog/2018/09/deep-learning-video-classification-python/)
+
+我们已经看到了大量的图像分类示例,那么视频呢?在这篇文章中,我们将向你展示如何对视频数据使用深度学习。
+
+[如何在 Django Admin 中添加导航菜单](https://medium.com/crowdbotics/how-to-add-a-navigation-menu-in-django-admin-770b872a9531)
+
+即使 Django Admin 有诸多优点,但是它还可以再进一步改进。其中一种调整是在 Django Admin 中添加导航菜单。本教程将会向你展示如何添加一个这样的菜单。
+
+[关于公共教育的数据科学](https://towardsdatascience.com/data-science-takes-on-public-education-f432910ea9f0)
+
+使用机器学习来帮助分析教育问题。
+
+[管理 Python 应用中的�依赖](https://medium.com/@jimjh/managing-dependencies-in-python-applications-b9c93dda98c2)
+
+如果在不断发展的组织中构建可靠的环境、�共享内部库和迁移主要版本。
+
+[PyMongo 星期一:设置你的 PyMongo 环境](https://www.mongodb.com/blog/post/pymongo-monday-setting-up-your-pymongo-environment)
+
+这是向开发者介绍使用 Python 编程 MongoDB 的常规博文系列的第一篇。在这篇文章中,我们将介绍安装 MongoDB、安装 Python 客户端库、启动 `mongod` 服务器以及在客户端和服务器之间建立连接。
+
+[高价电力短信提醒,使用 Python 和 Twilio SMS](https://www.twilio.com/blog/high-priced-electricity-sms-alerts-python-twilio-sms)
+
+[PyPy 的前 15 年 —— 个人回顾](https://morepypy.blogspot.com/2018/09/the-first-15-years-of-pypy.html)
+
+[使用 pandas 分析摄影师的 flickr 流](https://www.turbowhale.com/posts/analyze_flickr_stream_pandas/)
+
+
+# 书籍
+
+[Project Python](http://projectpython.net/chapter00/)
+
+Project Python 是一本免费的交互式书籍,它将教你用 Python 编程,使用图形、动画和游戏。你还会学习解决经典计算机科学问题的方法、软件设计原理和分析算法性能的方法。
+
+
+# 好玩的项目,工具和库
+
+[python-nubia](https://github.com/facebookincubator/python-nubia)
+一个命令行和交互式 shell 框架。
+
+[Py-Spy](https://github.com/benfred/py-spy/)
+
+Py-Spy 是一个用于 Python 程序的采样分析器。它让你可视化你的 Python 程序花费时间的地方,而无需重启程序或者以任何方式修改代码。
+
+[pdoc](https://github.com/mitmproxy/pdoc)
+
+为 Python 库自动生成 API 文档的简单命令行工具和�库。
+
+[Escher's Island](https://escher.checkio.org/)
+
+带有 15 个编程挑战的敲码游戏,用于 Python 和 JavaScript。
+
+[django-bootstrap-customizer](https://github.com/johnfraney/django-bootstrap-customizer/)
+
+使用 Django admin 构建自定义的 Bootstrap CSS。
+
+[deon](https://github.com/drivendataorg/deon/)
+
+一个可以轻松将道德检查清单添加到你的数据科学项目中的命令行工具。
+
+[jupytext](https://github.com/mwouts/jupytext)
+
+作为 Markdown 文档、Julia、Python 或者 R 脚本的 Jupyter notebooks。
+
+[Zero](https://github.com/KonstantinSchubert/zero)
+
+由 backblaze 云存储和透明本地持久性硬盘驱动缓存支持的 Fuse 文件系统。理想情况下,它感觉像是一个无限空间的本地文件系统,因为它将那些用过的文件保存在本地,同时将那些长时间未访问的文件移动到远程存储中。
+
+[Texar](https://github.com/asyml/texar)
+
+Texar 是一个基于 Tensorflow 的开源工具包,旨在广泛的机器学习,特别是文本生成任务,例如机器翻译、对话、摘要、内容操纵、语言建模等等。
+
+[Pirates-Online-Rewritten](https://github.com/PiratesOnlineRewritten/Pirates-Online-Rewritten)
+
+Pirates of the Caribbean Online Rewritten 是迪斯尼已解散的 MMORPG 的定制私人服务器;在线加勒比海盗。使用 2013 年的客户端代码、最新的 Panda3D 和 Astron 服务器来构建。
+
+[Oriana](https://github.com/mvelazc0/Oriana)
+
+Oriana 是一个威胁搜寻工具,利用 Windows 事件的一部分来构建关系、计算总数并运行分析。结果展示在 Web 层中,以帮助防御者识别公司环境中的异常值和可疑行为。
+
+[ct-exposer](https://github.com/chris408/ct-exposer)
+
+一个通过搜索证书透明工具来发现子域的 OSINT 工具。
+
+# 最新发布
+
+[PyInstaller 3.4](https://pyinstaller.readthedocs.io/en/stable/CHANGES.html)
+
+[IPython 7.0.0b1](https://mail.python.org/pipermail/ipython-dev/2018-September/016336.html)
+
+
+# 近期活动和网络研讨会
+
+[在线课程:开放�机器学习](https://mlcourse.ai/)
+
+来自 OpenDataScience 的开放机器学习课程。该课程旨在完美平衡理论和实践,因此,每一个主题会有一个截止日期为一周的作业。你还可以参加课程期间举办的几个 Kaggle Inclass 比赛,并且做你自己的项目。
+
+[PyPA Sprint - New York, NY](https://generalassemb.ly/education/bloomberg-open-source-weekend-pypa/new-york-city/58377)
+
+加入到来自 PyPA 社区的 Bloomberg 的工程团队和专家们,一起进行为期一个周末的 Python 打包工具(setuptools、pip、venv、warehouse 等等)修改。我们将提供导师、食物、饮料和良好的学习环境。
+
+[Talk Night @ JustWorks - New York, NY](https://www.meetup.com/nycpython/events/254226135/)
+
+加入到 NYC Python 到演讲之夜,�了解关于编写单元测试并将其投入生产的信息。
+
+[PyHou 2018 年九月聚会 - Houston, TX](https://www.meetup.com/python-14/events/247759040/)
+
diff --git a/Python Weekly/Python_Weekly_Issue_365.md b/Python Weekly/Python_Weekly_Issue_365.md
new file mode 100644
index 0000000..2fd2213
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_365.md
@@ -0,0 +1,113 @@
+原文:[Python Weekly - Issue 365](http://eepurl.com/dHIBoc)
+
+---
+
+欢迎来到Python周刊第 365 期。让我们直奔主题。
+
+
+# 来自赞助商
+
+[](https://try.digitalocean.com/performance/?utm_medium=Display&utm_source=Python_Weekly&utm_campaign=2018_Brand&utm_content=Conversation_with_100_125x125)
+
+使用DigitalOcean部署任何规模的超快Python应用程序,DigitalOcean是一个开发人员友好的云平台,旨在满足您的需求。 了解DigitalOcean如何简化您的基础架构。 [在这之上构建你的下一个应用吧(有 $100 积分哦)](https://try.digitalocean.com/performance/?utm_medium=Display&utm_source=Python_Weekly&utm_campaign=2018_Brand&utm_content=Conversation_with_100_125x125)。
+
+# 新闻
+
+[PyCON-KE 18 征求议题](https://docs.google.com/forms/d/e/1FAIpQLSf2cF2KxbI9XsEIHqBA2jEzx0S4fZ4_weK3HYMo10blq1mCWw/viewform)
+
+
+# 文章,教程和讲座
+
+[在 Kubernetes 之上运行 Flask](https://testdriven.io/running-flask-on-kubernetes)
+
+In this post, we'll first take a look at Kubernetes and container orchestration in general and then we'll walk through a step-by-step tutorial that details how to deploy a Flask-based microservice (along with Postgres and Vue.js) to a Kubernetes cluster.
+
+[Streaming data with Amazon Kinesis](https://blog.sqreen.io/streaming-data-amazon-kinesis/)
+Learn how Sqreen uses use Amazon Kinesis to process and stream security data from its agent in near real-time.
+
+[OpenCV OCR and text recognition with Tesseract](https://www.pyimagesearch.com/2018/09/17/opencv-ocr-and-text-recognition-with-tesseract/)
+In this tutorial, you will learn how to apply OpenCV OCR (Optical Character Recognition). We will perform both (1) text detection and (2) text recognition using OpenCV, Python, and Tesseract.
+
+[Making Etch-a-Sketch Art With Python](http://sunnybala.com/2018/09/10/python-etch-a-sketch.html)
+The etch-a-sketch is one of the most frustrating drawing toys from childhood. Can we combine some code and motors to make this toy produce nice pictures?
+
+[Creating a Simple Recommender System in Python using Pandas](https://stackabuse.com/creating-a-simple-recommender-system-in-python-using-pandas/)
+Have you ever wondered how Netflix suggests movies to you based on the movies you have already watched? Or how does an e-commerce websites display options such as "Frequently Bought Together"? They may look relatively simple options but behind the scenes, a complex statistical algorithm executes in order to predict these recommendations. In this article, we will see how we can build a simple recommender system in Python.
+
+[Absolute vs Relative Imports in Python](https://realpython.com/absolute-vs-relative-python-imports/)
+If you've worked on a Python project that has more than one file, chances are you've had to use an import statement before. In this tutorial, you'll not only cover the pros and cons of absolute and relative imports but also learn about the best practices for writing import statements.
+
+[Demystifying middleware in Django's request-response cycle](https://medium.com/@finndersen/demystifying-middleware-in-djangos-request-response-cycle-a463637390a2)
+
+[How to create a graphical form in python using Tkinter and save data to a text file](https://www.youtube.com/watch?v=xH4JOEJ5Uc0)
+
+
+# 好玩的项目,工具和库
+
+[freqtrade](https://github.com/freqtrade/freqtrade)
+Simple High Frequency Trading Bot for Crypto Currencies.
+
+[TensorFlow Datasets](https://github.com/tensorflow/datasets)
+A collection of datasets ready to use with TensorFlow.
+
+[art](https://github.com/sepandhaghighi/art)
+ASCII Art Library For Python.
+
+[GitHub-Audit](https://github.com/mozilla-services/GitHub-Audit)
+Collection of Tools & Procedures for double checking GitHub configurations.
+
+[terrapyn](https://github.com/kennethreitz/terrapyn)
+A Python module for slinging infrastructure (with terraform).
+
+[Electrum](https://github.com/spesmilo/electrum)
+Lightweight Bitcoin client.
+
+[mail-security-tester](https://github.com/TKCERT/mail-security-tester)
+A testing framework for mail security and filtering solutions.
+
+[trio-asyncio](https://github.com/python-trio/trio-asyncio)
+A re-implementation of the asyncio mainloop on top of Trio.
+
+[pydicom](https://github.com/pydicom/pydicom)
+pydicom is a pure python package for working with DICOM files. It was made for inspecting and modifying DICOM data in an easy "pythonic" way. The modifications can be written again to a new file.
+
+[notation](https://github.com/hoffa/notation)
+
+Simplified music notation.
+
+
+# 近期活动和网络研讨会
+
+[SoCal 2018 年 九月 Python 聚会 \- Marina del Rey, CA](https://www.meetup.com/socalpython/events/254638429/)
+
+将会有以下演讲:
+
+ * Python and IOTA cryptoledger
+ * Faster Autocomplete: From Elasticsearch to pure Python!
+
+
+[Boston 2018 年 九月 Python 聚会 - Cambridge, MA](https://www.meetup.com/bostonpython/events/251882456/)
+
+将会有以下轻演讲:
+
+ * CFFI 魔法
+ * 使用 Keras 介绍神经网络
+
+
+[San Diego 2018 年 九月 Python 聚会 - San Diego, CA](https://www.meetup.com/pythonsd/events/251655329/)
+
+将会有以下演讲:
+
+ * We Are 3000 Years Behind: Let's Talk About Engineering Ethics
+ * Using singledispatch to simplify code
+ * Prophet Time-series library
+ * Finite Linear Analysis
+
+
+[London 2018 年 九月 Python 聚会 - London, UK](https://www.meetup.com/LondonPython/events/254408773/)
+
+将会有以下演讲:
+
+ * 让 AI 来演讲:自然语言生成的冒险
+ * 揭秘复杂模型:从在 GoCardless 真实世界中使用 SHAP 解释者�学到的。
+
diff --git a/Python Weekly/Python_Weekly_Issue_374.md b/Python Weekly/Python_Weekly_Issue_374.md
new file mode 100644
index 0000000..a79d975
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_374.md
@@ -0,0 +1,168 @@
+原文:[Python Weekly - Issue 374](http://eepurl.com/dOr7Oj)
+
+---
+
+欢迎来到Python周刊第 374 期。让我们直奔主题。
+---
+[](https://click.linksynergy.com/link?id=x9UsEHf2tls&offerid=507388.1350984&type=2&murl=https%3A%2F%2Fwww.udemy.com%2Fthe-modern-python3-bootcamp%2F)
+
+[现代 Python 3 训练营](https://click.linksynergy.com/link?id=x9UsEHf2tls&offerid=507388.1350984&type=2&murl=https%3A%2F%2Fwww.udemy.com%2Fthe-modern-python3-bootcamp%2F)
+
+带有近 200 个练习和测验的独特的交互式 Python 体验。
+
+
+# 新闻
+
+[2019 年 DSF 董事会选举](https://www.djangoproject.com/weblog/2018/nov/21/dsf-board-election-2019/)
+
+
+# 文章,教程和讲座
+
+[Scikit-learn 教程:使用 Python 的机器学习](https://www.dataquest.io/blog/sci-kit-learn-tutorial/)
+
+Scikit-learn 是一个免费的 Python 机器学习库。它具有各种算法,例如支持向量机、随机森林和k�近邻,并且它还支持 Python 数值和科学库,例如 NumPy 和 SciPy。在这篇教程中,我们将学习如何在 scikit-learn 库的帮助下,轻松应用机器学习。
+
+[通过 OpenCV 使用 Mask R-CNN](https://www.pyimagesearch.com/2018/11/19/mask-r-cnn-with-opencv/)
+
+在这篇教程中,你将使用深度学习、OpenCV、Python 和 Mask R-CNN,来预测图像中每个对象的像素蒙版。
+
+[不再有 Django 核心](https://www.b-list.org/weblog/2018/nov/20/core/)
+
+如果你不是那种密切关注 Django 开发内部的人,那么你或许不知道有一个强烈改变该项目管理的提案草案。GitHub 和邮件列表上一直在讨论它,但是,今天,我想花点时间来解释这个提案以及它试图解决的问题。所以,让我们开始�钻研吧。
+
+[Excel 中的机器学习,使用 Python](https://datascienceplus.com/machine-learning-in-excel-with-python/)
+
+现今,机器学习是许多行业的一个重要课题。这是一个快速发展的领域,有大量活跃的研究,并且受到大量的媒体关注。本文不是对机器学习的介绍,也不是对现有技术的全面概述。相反,它将展示如何在 Excel 中利用机器学习构建的模型。
+
+[使用 Jupyter Notebooks 构建可重复的数据分析过程](http://pbpython.com/notebook-process.html)
+
+本文描述了如何创建一个使用 Jupyter Notebooks 来分析数据的可重复过程。
+
+[在 RPython 中实现一个计算器 REPL](https://morepypy.blogspot.com/2018/11/guest-post-implementing-calculator-repl.html)
+
+这是一篇教程式博文,它描述了使用 RPython 翻译工具链来创建一个执行基本数学表达式的 REPL。
+
+[玩转 NFL 分析、Bokeh 和 Pandas](https://j253.github.io/blog/fun-with-nfl-stats.html)
+
+使用 Bokeh 和 Pandas 的 NFL 比赛详情分析探索。
+
+[Python 中的 tworoutine](http://threespeedlogic.com/python-tworoutines.html)
+
+本文描述了� Python 中的一种代码风格:允许轻松混合同步和异步代码。作为大型微波望远镜(包括南极望远镜)的控制软件的一部分,我们已经成功地在 Tornado / Python 2.x 栈下使用了这种代码。
+
+[概率变成证明波兰被劫。在国际象棋上!](https://tenfifty.io/probabilistic-programming-proves-poland-was-robbed-in-chess/)
+
+使用 Pyro 进行概率编程,以及波兰在 2018 年国际象棋奥林匹克运动会上被劫的确凿证据。
+
+[欺诈检测系统简介](https://medium.com/@deepeshn1988/introduction-to-fraud-detection-systems-1786d696617)
+
+使用 Python 库 LightGBM 的教程,有代码示例。
+
+[在法术之上生成 RNN 文本](https://medium.com/@spellrun/generating-rnn-text-on-spell-18a1ab8179b8)
+
+或者:将 D&D 法术列表变成更长的更不可思议的法术的神秘艺术。
+
+[我在找房子,所以我用 Python 创建了一个网络爬虫!—— 第二部分(EDA)](https://towardsdatascience.com/i-was-looking-for-a-house-so-i-built-a-web-scraper-in-python-part-ii-eda-1effe7274c84)
+
+这篇文章是另外一篇文章(我在那里构建了一个网络爬虫来寻找 Lisbon �的在售房子)的后续。这次,我将专注于对之前收集的数据集的转换和清理过程。然后,我会试着对这个数据集进行一些探索性数据分析(EDA)。我的目标是为你提供一些可以做的事情的示例,而不是提供一个超级复杂的分析。
+
+[使用 Python,将数据从 MongoDB 导入到 MySQL](https://mysqlserverteam.com/importing-data-from-mongodb-to-mysql-using-python/)
+
+MySQL Shell 8.0.13 (GA) 引进了一个新功能,让你可以轻松将 JSON 文档导入到 MySQL 中。这个新功能的基础知识在之前的博文中有所描述。在这篇文章中,我们将提供关于这个功能的更多细节,重点关注许多人感兴趣的实际用例:如何将 JSON 数据从 MongoDB 导入到 MySQL。可以将相同的“配方”应用到其他的文档存储型数据库上,只要它们能够生成或者导出数据到 JSON 即可。
+
+[Jupyter Notebook 中的视频流](https://towardsdatascience.com/video-streaming-in-the-jupyter-notebook-635bc5809e85)
+
+[使用 Mutmut �狩猎突变体](https://medium.com/poka-techblog/hunting-mutants-with-mutmut-5f575b625598)
+
+[使用 Python 映射地理数据](https://towardsdatascience.com/mapping-geograph-data-in-python-610a963d2d7f)
+
+[我们是如何自动截取 Django 应用的屏幕截图的](https://behind.pretix.eu/2018/11/15/automated-screenshots/)
+
+
+# 书籍
+
+[Deep Learning With Python(使用 Python 进行深度学习)](https://amzn.to/2Tw8VKq)
+
+利用 Scikit-Learn、TensorFlow 和 Keras 了解机器学习和人工智能的基础指南。
+
+
+# 好玩的项目,工具和库
+
+[DoodleMaster](https://github.com/karanchahal/DoodleMaster)
+
+“不要编码你的 UI,画出来!”
+
+[JAX](https://github.com/google/jax)
+
+JAX 是一个特定域的跟踪 JIT 编译器,用于从纯 Python 和 Numpy 机器学习程序生成高性能的加速器代码。
+
+[BabySploit](https://github.com/M4cs/BabySploit)
+
+BabySploit 是一个渗透测试工具包,旨在让你轻松学习使用更大更复杂的框架(例如 Metasploit)的方法。通过一个非常易用的 UI 和工具包,任何经验级别的人都可以使用 BabySploit。
+
+[pixelhouse](https://github.com/thoppe/pixelhouse)
+
+一个用 python 制作精美动画的极简绘画库。可以移动所有能被绘制的东西。带有漂亮的渐变、类 instagram 的滤镜和弹性变换。
+
+[ValidX](https://validx.readthedocs.io/en/latest/)
+
+ValidX 是一个具有合理语法的快速、强大且灵活的验证器。
+
+[render-py](https://github.com/tvytlx/render-py)
+
+软件三维渲染器,用 Python 编写。
+
+[Chartify](https://github.com/spotify/chartify/)
+
+Chartify 是一个让数据科学家轻松创建图表的 Python 库。
+
+[CloudBunny](https://github.com/Warflop/CloudBunny)
+
+CloudBunny 是捕捉那些使用 WAF 作为代理或者保护的源服务器的工具。
+
+[Fnord](https://github.com/Neo23x0/Fnord)
+
+模糊代码的模式提取器。
+
+[SetSimilaritySearch](https://github.com/ekzhu/SetSimilaritySearch)
+
+在笔记本电脑傻姑娘,使用 python 在数百万集上进行所有对集合相似度搜索(比 MinHash LSH 快)。
+
+[wemake-django-template](https://github.com/wemake-services/wemake-django-template)
+
+最前沿的 django 模板,专注于代码质量和安全。
+
+[redis-namespace](https://github.com/guokr/redis-namespace)
+
+redis 键空间的命名空间子集
+
+[celluloid](https://github.com/jwkvam/celluloid)
+
+让 Matplotlib 动画变得简单。
+
+[cache.py](https://github.com/bwasti/cache.py)
+
+跨程序运行的 Python [memoization](https://en.wikipedia.org/wiki/Memoization)。
+
+
+# 近期活动和网络研讨会
+
+[San Francisco Django 2018 年 11 月聚会 - San Francisco, CA](https://www.meetup.com/The-San-Francisco-Django-Meetup-Group/events/255927816/)
+
+将会有以下演讲:
+
+ * 别了,REST:使用 Django 构建 GraphQL API
+ * 何时*不*使用 ORM
+
+
+[Boston Python 2018 年 11 月聚会 - Somerville, MA](https://www.meetup.com/bostonpython/events/255411882/)
+
+将会有以下演讲:
+
+ * 传感器
+ * 统计分析
+
+
+[PhillyPUG 2018 年 11 月 - Philadelphia, PA](https://www.meetup.com/phillypug/events/256212583/)
+There will be a talk, Unexpected Uses of Data Pipelines in Economic Modeling.
+
diff --git a/Python Weekly/Python_Weekly_Issue_375.md b/Python Weekly/Python_Weekly_Issue_375.md
new file mode 100644
index 0000000..b37e512
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_375.md
@@ -0,0 +1,120 @@
+原文:[Python Weekly - Issue 375](http://eepurl.com/dPlCW5)
+
+---
+
+欢迎来到Python周刊第 375 期。让我们直奔主题。
+---
+
+[](https://click.linksynergy.com/link?id=x9UsEHf2tls&offerid=507388.1560148&type=2&murl=https%3A%2F%2Fwww.udemy.com%2Fapplied-deep-learningtm-the-complete-self-driving-car-course%2F)
+
+[完整的自动驾驶汽车课程 —— 应用深度学习](https://click.linksynergy.com/link?id=x9UsEHf2tls&offerid=507388.1560148&type=2&murl=https%3A%2F%2Fwww.udemy.com%2Fapplied-deep-learningtm-the-complete-self-driving-car-course%2F)
+
+学习使用深度学习、计算机视觉和机器学习技术来模拟自动驾驶汽车(使用 Python)。
+
+# 文章,教程和讲座
+
+[PySyft 手把手教程](https://github.com/OpenMined/PySyft/tree/master/examples/tutorials)
+
+在这个手把手教程系列中,你将学习使用 PySyft 来将隐私和去中心带入到深度学习生态圈的所有方式。这个教程系列会跟随新特性的实现持续更新,并且是专为小白用户设计的。
+
+[使用神经网络生成古典音乐](https://blog.floydhub.com/generating-classical-music-with-neural-networks/)
+
+Christine McLeavey Payne 可能最终拯救了作曲家的作品。她最近的项目 Clara 是一个长期的短时记忆(LSTM)神经网络,用于编写钢琴曲和室内音乐。仅需告诉 Clara 你正在进行的巨作,Clara 就会明白接下来你应该演奏什么。
+
+[使用 Django Crispy 表单进行高级表单渲染](https://simpleisbetterthancomplex.com/tutorial/2018/11/28/advanced-form-rendering-with-django-crispy-forms.html)
+
+在这篇教程中,我们将探讨一些 Django Crispy 表单功能来处理高级/自定义表单渲染。
+
+[使用 Core ML、Style Transfer 和 Turi Create 创建一个类似 Prisma 的应用](https://medium.com/appcoda-tutorials/creating-a-prisma-like-app-with-core-ml-style-transfer-and-turi-create-748863e5a982)
+
+使用 Turi Create,你可以构建你自己自定义的机器学习模型。本教程向你展示了如何使用 Turi Create �训练� Style Transfer ML 模型。
+
+[预测新用户将在哪里预订他们的首次旅行体验](https://towardsdatascience.com/predict-where-a-new-user-will-book-their-first-travel-experience-e6c9ada67cf4)
+
+本文详细介绍了 Airbnb 发布的两个数据集的探索过程,目的是预测 Airbnb 的用户预订旅程的首个国家。更具体地说,按相关性递减顺序预测前五个旅行目的地国家。通过基于客户的人口统计信息和会话活动(因为客户通过清单和进行查询来计划他们的旅行)来推测他们的偏好,我们想要实现某种程度的个性化。
+
+
+[使用 OpenCV 进行实例分段](https://www.pyimagesearch.com/2018/11/26/instance-segmentation-with-opencv/)
+
+在本教程中,你将学习如何使用 OpenCV、Python 和深度学习来进行实例分段。
+
+[协方差、逆变和不变性 —— 终极 Python 指南](https://blog.daftcode.pl/covariance-contravariance-and-invariance-the-ultimate-python-guide-8fabc0c24278)
+
+这篇文章是关于 Python 类型的协方差、逆变和不变性。详细定义和解释这些概念。
+
+[PogChampNet —— 我们是如何使用 Twitch chat + 深度学习来创建自动游戏精彩集锦(只使用 Visor.gg 上的视频作为输入)](https://medium.com/@farzatv/pogchampnet-how-we-used-twitch-chat-deep-learning-to-create-automatic-game-highlights-with-only-61ed7f7b22d4)
+
+给定大量的守望先锋视频游戏�视频,我们可以创建一个自动找到重要、�突出的有价值的时刻吗?
+
+[Dash:新手指南](https://towardsdatascience.com/dash-a-beginners-guide-d118bd620b5d)
+
+�关于用纯 python 构建 web 应用的库的框架的特性和优势的简短介绍。
+
+[如何使用 Django REST 框架实现令牌认证](https://simpleisbetterthancomplex.com/tutorial/2018/11/22/how-to-implement-token-authentication-using-django-rest-framework.html)
+
+在本教程中,你将学习如何使用 Django REST 框架(DRF)实现基于令牌的认证。该令牌认证是这样工作的,通过交换用户名和密码获得令牌,然后将此令牌用于所有后续的请求,以在服务端识别用户。
+
+[Pandas 读取 CSV 教程](https://www.marsja.se/pandas-read-csv-tutorial-to-csv/)
+
+在本教程中,我们将学习如何使用 Python 和 Pandas 处理逗号分隔(CSV)文件。我们将概述如何使用 Pandas 将 CSV 加载到数据帧,以及如何将数据帧写入到 CSV。
+
+[神奇动物在哪里之 Python 描述符](https://pabloariasal.github.io/2018/11/25/python-descriptors/)
+
+[宇航员网络的数据可视化](https://www.youtube.com/watch?v=Hm4Idkhsr6I)
+
+[给 Python 开发者的 Kubernetes 教程:第一部分](https://www.distributedpython.com/2018/11/28/kubernetes-python-developers-part-1/)
+
+[在 Python 中使用函数式编程的最佳实践](https://kite.com/blog/python/functional-programming)
+
+[我是怎样用 Python 在自动投资策略中实施 Benjamin Graham 的教学的](https://medium.com/automation-generation/teaching-your-computer-to-invest-with-python-commission-free-automated-investing-5ade10961e08)
+
+[MIT AI:Python (Guido van Rossum)](https://www.youtube.com/watch?v=ghwaIiE3Nd8)
+
+
+# 书籍
+
+[How To Code in Python 3(如何用 Python 3 编码)](https://assets.digitalocean.com/books/python/how-to-code-in-python.pdf)
+
+
+# 好玩的项目,工具和库
+
+[trape](https://github.com/jofpin/trape)
+
+互联网上的网民跟踪器:OSINT 分析和研究工具。
+
+[QuickDraw](https://github.com/1991viet/QuickDraw)
+
+Quickdraw(谷歌开发的在线游戏) 实现。
+
+[SatPy](https://github.com/pytroll/satpy)
+
+用于地球观测卫星数据处理的 Python 包。
+
+[Dampr](https://github.com/Refefer/Dampr)
+
+Dampr 旨在作为单机数据处理使用:它原生基于外存,支持 map 和 reduce 侧连接,关联 reduce 组合器,并且提供�用于构建 Dataflow DAG 的高级接口。
+
+[Ptop](https://github.com/darxtrix/ptop)
+
+用 python 编写的一个超棒的任务管理器。
+
+[Telethon](https://github.com/LonamiWebs/Telethon)
+
+纯 Python 3 MTProto API Telegram 客户端库。
+
+[gandissect](https://github.com/CSAILVision/gandissect)
+
+基于 Pytorch 的工具,用于可视化和理解 GAN 的神经元。
+
+[HappyMac](https://github.com/laffra/happymac)
+
+用于暂停后台进程的 Python Mac 应用。
+
+# 近期活动和网络研讨会
+
+[�Visual Studio Code 介绍,2018 年最受欢迎的编辑器 - New York, NY](https://www.meetup.com/NYC-PyLadies/events/256574339/)
+
+Visual Studio Code 是一个免费的开源代码编辑器,它正在迅速普及!在这份动手教程中,我们将介绍�编辑器的功能和有用的 python 扩展,并且展示你可以怎样将其合并在你自己的项目和工作流中。
+
+[DFW Pythoneers 2018 年 12 月聚会 - Plano, TX](https://www.meetup.com/dfwpython/events/sbnhmqyxqbjb/)
+
diff --git a/Python Weekly/Python_Weekly_Issue_376.md b/Python Weekly/Python_Weekly_Issue_376.md
new file mode 100644
index 0000000..0f17129
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_376.md
@@ -0,0 +1,155 @@
+原文:[Python Weekly - Issue 376](http://eepurl.com/dP8H7D)
+
+---
+
+欢迎来到Python周刊第 376 期。让我们直奔主题。
+
+
+# 来自赞助商
+
+[](https://www.vettery.com/tech?utm_source=newsletter&utm_medium=pythonweekly&utm_term=tech&utm_content=grouped&utm_campaign=ad-77579)
+
+[通过 Vettery 找到一个 Python 工作](https://www.vettery.com/tech?utm_source=newsletter&utm_medium=pythonweekly&utm_term=tech&utm_content=grouped&utm_campaign=ad-77579)
+
+Vettery 是一个专门针对开发者角色在线招聘市场,对求职者来说完全免费。感兴趣吗?提交你的个人资料吧,如果你的资料被接受了,那么你就可以直接收到来自那些正招聘 Python 开发的顶级公司的面试邀请。
+
+# 新闻
+
+[为 PyPy 中的 64-bit Armv8-a 支持提供资金](https://morepypy.blogspot.com/2018/11/hello-everyone-at-pypy-we-are-trying-to.html)
+
+
+# 文章,教程和讲座
+
+[使用 Keras 进行深度学习和医学图像分析](https://www.pyimagesearch.com/2018/12/03/deep-learning-and-medical-image-analysis-with-keras/)
+
+在这个教程中,�你将学习如何应用深度学习来进行医学图像分析。具体来说,你将了解如何使用 Keras 深度学习库来自动分析医学图像,以进行疟疾测试。
+
+[解密 Python](https://www.mattlayman.com/blog/2018/decipher-python-ast/)
+Python 程序是如何运行你的代码的?你要怎样理解代码的运行方式?本文探讨抽象语法树(AST),这是 Python 在运行代码之前进行评估的重要部分之一。我们将在实际示例中使用 AST 来向你演示如何了解关于�代码的更多信息。
+
+[用 Python 创建一个简单的实时飞行跟踪](https://www.geodose.com/2018/11/create-simple-live-flight-tracking-python.html)
+
+本教程将带你进行一次 �使用 Python 创建一个简单的实时飞行跟踪的旅程。我们将基于开放街道地图(OSM)底图上的地理坐标,绘制飞行器位置。该地图的中心将是一个像机场的位置,并且我们会请求离中心点几公里范围内的所有飞行器。位置将每秒更新一次。最后,我们将通过 python 获得一个简单的实时飞行跟踪。
+
+[用一个简单的 Python 机器人,提高你的 Instagram 关注人数](https://towardsdatascience.com/increase-your-instagram-followers-with-a-simple-python-bot-fde048dce20d)
+
+我在 4 天内收获了大约 500 名真正的粉丝!
+
+[前 50 个 matplotlib 可视化 —— 主图(带完整的 python 代码)](https://www.machinelearningplus.com/plots/top-50-matplotlib-visualizations-the-master-plots-python/)
+
+前 50 个在数据分析和可视化最有用的 matplotlib 绘图汇总。该列表让你可以使用 python 的 matplotlib 和 seaborn 库,选择在特定的场景下使用特定的可视化。
+
+[2018 年 Python 应用依赖管理](https://hynek.me/articles/python-app-deps-2018/)
+
+�和以往相比,我们有了更多的方式来管理 Python 应用中的依赖。但是,它们在生产使用状况如何呢?不幸的是,此话题被证明是非常两极分化的,并且时许多激烈辩论的中心。这是我通过 DevOps 的角度进行自我评价的尝试。
+
+[保持 Django 模型有序](https://www.revsys.com/tidbits/keeping-django-model-objects-ordered/)
+
+如何巧妙地让一组 Django ORM 对象保持有序以便用于像拖拽这样的场景。
+
+[使用 Flask-RestPlus 设计结构良好的 REST API:第一部分](https://preslav.me/2018/12/02/designing-well-structured-rest-apis-with-flask-restplus-part-1/)
+
+这是由两个部分组成的系列文的第一部分。在这篇文章中,我将介绍 Flask-RestPlus 并演示如何围绕其简单的基于 REST 约定开始组织 API。下一次,我将讨论请求/响应序列化和验证。
+
+[使用 python 编写后门程序 —— 第一部分](https://www.youtube.com/watch?v=Du8BUCOJwVo)
+
+关于如何使用 python 创建一个后门程序(教学目的)系列的第一部分。该程序将让你控制另一个计算机,并执行不同功能,例如文件传输。
+
+ * [第二部分](https://www.youtube.com/watch?v=JnqTMaV4kRA) —— 本教程展示了在建立有线或者无线连接后,远程查看文件的方法。
+
+
+[如何在 AWS 上,使用 API Gateway Lambda 和 DynamoDB,设置一个 Serverless URL 缩短服务](https://blog.ruanbekker.com/blog/2018/11/30/how-to-setup-a-serverless-url-shortener-with-api-gateway-lambda-and-dynamodb-on-aws/)
+
+我们将使用 API Gateway Lambda、Python 和 DynamoDB,设置一个 Serverless URL 缩短服务。我们将创建的这个服务将通过我们的 API(它会在 DynamoDB 中创建一个条目)缩短 URL。当对缩短的 URL 进行 GET 请求时,就会在 DynamoDB 上执行一次 GetItem,以获取对应的长 URL,然后执行 301 �Redirect,将客户端重定向到预期的目标 URL。
+
+[使用 Matplotlib 进行 python 数据可视化](https://stackabuse.com/python-data-visualization-with-matplotlib/)
+
+[Python 中用于数据可视化的 Seaborn库:第一部分](https://stackabuse.com/seaborn-library-for-data-visualization-in-python-part-1/)
+
+[关于 pipenv 的五个传说](https://medium.com/@grassfedcode/five-myths-about-pipenv-698c5f198e4b)
+
+[案例研究:CPython 开发工作流](https://medium.com/mergify/case-study-cpython-development-workflow-9f9ba6fa53a)
+
+[在 S3 中管理数据科学项目 —— Quilt T4 介绍](https://blog.quiltdata.com/using-quilts-t4-to-manage-an-s3-hosted-data-science-project-7332fc463e89)
+
+
+# 本周的Python工作
+
+[Radiant Earth Foundation 招聘 DevOps 工程师](http://jobs.pythonweekly.com/jobs/devops-engineer-3/)
+
+
+# 好玩的项目,工具和库
+
+[video-to-ascii](https://github.com/joelibaceta/video-to-ascii)
+
+一个简单的 python 包,使用 ASCII 字符在终端中播放视频。
+
+[VideoPose3D](https://github.com/facebookresearch/VideoPose3D)
+
+高效的视频三维人体姿势预估,使用 2D 关键点轨迹。
+
+[sneaker-generator](https://github.com/98mprice/sneaker-generator)
+
+�DCGAN 生成运动鞋。使用 keras 构建(带 tensorflow 后端)。
+
+[Optuna](https://github.com/pfnet/optuna)
+
+一个超参数优化框架。
+
+[Advent of Code](https://adventofcode.com/)
+
+Advent of Code 是一个小编程难题的降临节日历,针对各种技能集和技能水平,可以用任意你喜欢的编程语言来解决。
+
+[lambdo](https://github.com/asavinov/lambdo)
+
+Lambdo 是一个工作流引擎,它通过统一特征工程和机器学习操作,显著简化了分析过程。Lambdo 数据分析工作流不对它们加以区分,每个节点都能被当成特征或者预测,并且可以都对它们加以训练。
+
+[fritz-style-transfer](https://github.com/fritzlabs/fritz-style-transfer)
+
+在移动应用中训练和部署实时艺术风格转换,使用 Fritz Style Transfer。
+
+[music21](http://web.mit.edu/music21/)
+
+计算机辅助音乐学工具包。
+
+[Aiogoogle](https://aiogoogle.readthedocs.io/en/latest/)
+
+异步 Google API 客户端。
+
+[TF-Ranking](https://github.com/tensorflow/ranking)
+
+Learning-to-Rank 的一个可扩展 TensorFlow 库。
+
+[slackbot-destroyer](https://github.com/UnitedIncome/slackbot-destroyer)
+
+Slack 集成,可以摧毁所有来自 Slackbot 的传入信息。
+
+[trixi](https://github.com/MIC-DKFZ/trixi)
+
+用 trixi 管理你的机器学习实验 —— 模块化,可重复,以及最新款。为 PyTorch 优化的实验基础架构,但对你的框架和品味而言足够灵活。
+
+
+# 最新发布
+
+[IPython 7.2](https://discourse.jupyter.org/t/release-of-ipython-7-2/226)
+
+[Django 问题修复版本:2.1.4 和 1.11.17](https://www.djangoproject.com/weblog/2018/dec/03/bugfix-releases/)
+
+
+# 近期活动和网络研讨会
+
+[PyMNtos Python 展示之夜 #68 - Minneapolis, MN](https://www.meetup.com/PyMNtos-Twin-Cities-Python-User-Group/events/255384728/)
+将会有以下�演讲:
+ * Geopandas II
+ * 伪造类(我是如何学会停止使用 namedtuple,并爱上数据类的)
+ * Robot 操作系统简介
+
+
+[Boulder Python 2018 年 12 月聚会 - Boulder, CO](https://www.meetup.com/BoulderPython/events/xwblrpyxqbpb/)
+将会有一场演讲:i3status 的用户友好型配置,使用 py3status。
+
+[Greater Hartford Python 2018 年 12 月聚会 - Hartford, CT](https://www.meetup.com/greaterhartfordpython/events/256573411/)
+
+[Austin Python 2018 年 12 月聚会 - Austin, TX](https://www.meetup.com/austinpython/events/lgrbmqyxqbqb/)
+
+[PyAtl 2018 年 12 月聚会 - Atlanta, GA](https://www.meetup.com/python-atlanta/events/xhtxqpyxqbrb/)
diff --git a/Python Weekly/Python_Weekly_Issue_377.md b/Python Weekly/Python_Weekly_Issue_377.md
new file mode 100644
index 0000000..6d19454
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_377.md
@@ -0,0 +1,123 @@
+原文:[Python Weekly - Issue 377](http://eepurl.com/ga8m9D)
+
+---
+
+欢迎来到Python周刊第 377 期。让我们直奔主题。
+
+
+# 来自赞助商
+
+[](https://github.com/IntelPython/daal4py)
+
+你是一名从事大型问题规模处理和使用机器学习框架的数据科学家吗?试试开源的 [daal4py](https://github.com/IntelPython/daal4py) —— 由 Intel® DAAL(Intel® 数据分析加速库)加速的闪电般快速的机器学习算法性能。
+
+
+# 文章,教程和讲座
+
+[修复 Python 中一个严重的内存泄漏](https://info.cloudquant.com/2018/12/numpyleaks)
+
+我们的一些高级用户报告说,长时间运行的 backtest 有时会耗尽内存。这些高级用户常常会找到新的交易策略,因此,我们希望与他们合作,以提供我们的 backtesting 工具的性能。然而,在过去的几周里,我们的高级工程师发现,问题并非出在我们的代码里,而是我们使用的一个流行的 Python 库。我们在 numpy 和 numba 中发现了这个问题。最终,泄漏是由我们使用这些库的方式引起的。我们进行的修正,并且可以�从下图看到,它们确实提高了我们的交易模拟器的内存使用率。下面是我们的高级工程师的报告,以便其他人可以从我们的工程工作中学到点什么。
+
+[pandas 库的未来在哪里?](https://www.dataschool.io/future-of-pandas/)
+
+pandas 是一个非常流行的 Python 库,用来进行数据分析、操作数据和可视化,但它还没有到 1.0 版本。所以,pandas 的下一步会是什么?
+
+[gpython:一个用 Go 编写的 Python 解释器 "batteries not included"](https://blog.gopheracademy.com/advent-2018/gpython/)
+
+Gpython 是一个用 Go 写的 Python 3.4 解释器。这是一篇关于它是如何形成的、如何工作的以及它的发展方向的文章。包含了关于像 Python/Gpython 这样的解释型语言是如何使用虚拟机(VM)、词法分析、�语法分析和字节码编译�的快速预览。
+
+[使用 Python 进行网络爬取介绍](https://towardsdatascience.com/an-introduction-to-web-scraping-with-python-a2601e8619e5)
+
+让我们用 BeautifulSoup 爬取一个虚拟书店网站!
+
+[构建一个自动驾驶 Q-Bot](https://medium.com/@michael_87060/build-a-self-driving-q-bot-6aa67ba60769)
+
+仅需一台 3D 打印机、一些 Python 以及大量的试错即可。
+
+[使用 Twilio 和 Python 构建一个 Serverless SMS Raffle](https://www.twilio.com/blog/twilio-serverless-sms-raffle-python-lambda)
+
+使用 Amazon Lambda、API Gateway、Twilio 可编程 SMS 和 Python 创建一个 Serverless SMS Raffle。
+
+[你不知道 Python 能做的五件事](https://www.youtube.com/watch?v=WlGkBqBRsik)
+
+[如何修复你的 Python 代码样式](https://www.caktusgroup.com/blog/2018/12/10/how-to-fix-python-code-style/)
+
+[使用 Python 和 Selenium 实现免费酒店无线上网](https://gkbrk.com/2018/12/free-hotel-wifi-with-python-and-selenium/)
+
+[通过深度强化学习加速 Pong AI](https://blog.floydhub.com/spinning-up-with-deep-reinforcement-learning/)
+
+[Microsoft 的 Python:低调至极](https://medium.com/microsoft-open-source-stories/python-at-microsoft-flying-under-the-radar-eabbdebe4fb0)
+
+[Keras - 保存并保存你的深度学习模型](https://www.pyimagesearch.com/2018/12/10/keras-save-and-load-your-deep-learning-models/)
+
+[如何从 Jupyter Notebook 扩展整洁的软件架构](https://github.com/guillaume-chevalier/How-to-Grow-Neat-Software-Architecture-out-of-Jupyter-Notebooks)
+
+[使用 Python 3、AWS Lambda、Twilio Lookup 和 SMS 识别未知电话号码](https://www.twilio.com/blog/identify-unknown-phone-numbers-python-3-aws-lambda-lookup-sms)
+
+[从 Jupyter Notebook 安装 Python 包](https://jakevdp.github.io/blog/2017/12/05/installing-python-packages-from-jupyter/)
+
+
+# 好玩的项目,工具和库
+
+[PracticalAI](https://github.com/GokuMohandas/practicalAI)
+
+学习机器学习的实用方法。
+
+[loguru](https://github.com/Delgan/loguru)
+
+让 Python 日志变得炒鸡简单。
+
+[DGL](https://github.com/dmlc/dgl)
+
+Python 包,旨在在现有的 DL 框架上简化图形深度学习。
+
+[completion_utils](https://github.com/CarvellScott/completion_utils)
+
+协助使用 python 替代 bash、fish、zsh 等编写 shell 补全的小工具。
+
+[Athena](https://github.com/M4cs/Athena)
+
+Theos Tweak 开发框架的通用用户界面。
+
+[DynamicForms](https://github.com/velis74/DynamicForms)
+
+DynamicForms 具有 DRF Serializer 和 ViewSet 的所有可视化和数据输入功能,并且加了点料:它是一个 django 库,提供动态显示表单字段、自动填充默认值、动态记录加载等等功能。
+
+[crudcast](https://github.com/chris104957/crudcast)
+
+只用几行 YAML 就能创建并部署 RESTful API。
+
+[secure](https://github.com/cakinney/secure)
+
+Python web 框架的安全 🔒 头和 cookie
+
+[Varken](https://github.com/Boerderij/Varken)
+
+独立的命令行实用程序,用于将 Plex 生态系统中的数据聚合到 InfluxDB 中。
+
+[terracotta](https://github.com/DHI-GRAS/terracotta)
+
+一个轻量级多功能 XYZ tile 服务器,使用 Flask 和 Rasterio 构建
+
+[pyAudioClassification](https://github.com/98mprice/pyAudioClassification)
+
+超级简单的音频分类 🎶
+
+[python-chirp](https://github.com/concretecloud/python-chirp)
+
+给大家的消息传递。
+
+[wtfiswronghere](https://github.com/qxf2/wtfiswronghere)
+
+初学者开始写 Python 时可能会遇到的一系列简单错误。
+
+[SSD](https://github.com/lufficc/SSD)
+
+SSD 的高质量快速模块化参考实现,使用 PyTorch 1.0。
+
+
+# 最新发布
+
+[PyTorch 1.0](https://github.com/pytorch/pytorch/releases/tag/v1.0.0)
+
+[Python 3.7.2rc1 和 3.6.8rc1](https://blog.python.org/2018/12/python-372rc1-and-368rc1-now-available.html)
\ No newline at end of file
diff --git a/Python Weekly/Python_Weekly_Issue_378.md b/Python Weekly/Python_Weekly_Issue_378.md
new file mode 100644
index 0000000..77ac305
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_378.md
@@ -0,0 +1,125 @@
+原文:[Python Weekly - Issue 378](http://eepurl.com/gbUhIH)
+
+---
+
+欢迎来到Python周刊第 378 期。让我们直奔主题。
+
+
+# 来自赞助商
+[](https://www.springboard.com/workshops/ai-machine-learning-career-track/?utm_source=pythonweekly&utm_medium=link&utm_campaign=roger-AIC-pythonweekly&utm_content=roger-AIC-pythonweekly-1)
+
+[获得一份人工智能或者机器学习相关对工作,保证可以拿到](https://www.springboard.com/workshops/ai-machine-learning-career-track/?utm_source=pythonweekly&utm_medium=link&utm_campaign=roger-AIC-pythonweekly&utm_content=roger-AIC-pythonweekly-1)
+
+在完成 Springboard 的自定进度的在线机器学习训练营后,就使用最新的 AI 应用吧。每周都与你专属的 AI/机器学习专家交流。个性化的职业指导。找到一份相关的工作或者返还学费。
+
+# 新闻
+
+[Python 有了新的治理模式](https://lwn.net/SubscriberLink/775105/5db16cfe82e78dc3/)
+
+
+# 文章,教程和讲座
+
+[如何编写完美的 Python 命令行接口 —— 通过示例学习](https://blog.sicara.com/perfect-python-command-line-interfaces-7d5d4efad6a2)
+
+本文将向你展示如何制作完美的 Python 命令行接口,�以提高你团队的生产力和舒适度。
+
+[使用 OpenCV 和 Python 进行图像拼接](https://www.pyimagesearch.com/2018/12/17/image-stitching-with-opencv-and-python/)
+
+在这个教程中,你将学习如何使用 Python、OpenCV 和 cv2.createSticher 以及 cv2.Stitcher_create 函数进行多个图像拼接。
+
+[代码 2018 解决方案的出现](https://www.michaelfogleman.com/aoc18/)
+解释针对日常编码难题的 Python 解决方案。
+
+[直接处理 JPEG 的更快的神经网络](https://eng.uber.com/neural-networks-jpeg/)
+
+Uber AI 实验室介绍了一种方法,通过利用 JPEG 的模型,使得处理图像的神经网络更快更准确。
+
+[使用 pyZMQ 进行进程间通信:第一部分](https://www.pythonforthelab.com/blog/using-pyzmq-for-inter-process-communication-part-1/)
+
+介绍如何使用 socket 进行不同进程间通信的。
+
+[Azure 上的 Django,使用 Visual Studio Code](https://www.youtube.com/playlist?list=PLU2JOyCJmabBHlQ_hQ1YZ3uVUAiXS9Eq7)
+
+关于 Azure 上的 Python 和 Django 的四部分系列。
+
+[通过构建实际应用掌握 Python(第一部分)](https://towardsdatascience.com/master-python-through-building-real-world-applications-part-1-b040b2b7faad)
+
+10 部分系列的第一篇文章,在此,我们要构建的是一个字典。
+
+ * [第二部分](https://towardsdatascience.com/master-python-through-building-real-world-applications-part-2-60d707955aa3) - 在第二部分中,我们将使用地理空间数据创建网络地图。在此过程中,我们将学习如何使用 folium 来创建多用途的网络地图。
+
+
+[增量爬虫,使用 Scrapy 和 MongoDB](https://blog.dipasquale.fr/en/2018/12/17/incremental-scraping-with-scrapy-and-mongo/)
+
+在这篇文章中,我将向你展示如何增量爬取一个网站。每一个新的爬取会话将只会爬取新的项。这里,我们将以爬取 Techcrunch 博文为例。
+
+[超速 Python](https://medium.com/build-smarter/blazing-fast-python-40a2b25b0495)
+
+使用 Pyflame 分析 Python 应用。
+
+[使用 DjangoRestFramework 创建一个 DjangoRest AP,第二部分。](https://medium.com/the-andela-way/creating-a-djangorest-api-using-djangorestframework-part-2-1231fe949795)
+
+在这一部分中,我们将重新创建在之前的文章中创建的那个 Blog API,但是这次是使用 GenericAPIView,而不是基础的 APIView。
+
+[我们是如何在 AWS 上,每月以不到一美元的价格�构建 Hamiltix.net 的](https://blog.badsectorlabs.com/how-we-built-hamiltixnet-for-less-than-1-a-month-on-aws.html)
+
+在 AWS 上以每月不到一美元的价格运行复杂的票证排名网站的细节。
+
+[GPU 和 PyData 的第一印象](https://matthewrocklin.com/blog//work/2018/12/17/gpu-python-challenges)
+
+将 GPU 集成到传统的数据科学工作负荷中的机遇和挑战。
+
+[如何用 Python 的列表做任何事](https://jeffknupp.com/blog/2018/12/13/how-to-do-just-about-anything-with-python-lists/)
+
+[使用浅显英文的 Python 和 Django 日志记录](https://djangodeconstructed.com/2018/12/18/django-and-python-logging-in-plain-english/)
+
+[用 Python 开发一个 NLP 模型,并使用 Flask 进行部署(手把手)](https://towardsdatascience.com/develop-a-nlp-model-in-python-deploy-it-with-flask-step-by-step-744f3bdd7776)
+
+[使用 Redis 和树莓派构建智能卡过境票务系统](https://medium.com/swlh/building-a-smart-card-transit-ticketing-system-with-redis-and-raspberry-pi-820473c0b0c)
+
+[Python,信号处理和异常](https://anonbadger.wordpress.com/2018/12/15/python-signal-handlers-and-exceptions/)
+
+
+# 好玩的项目,工具和库
+
+[PyText](https://github.com/facebookresearch/PyText)
+
+基于 PyTorch 的自然语言建模框架。
+
+[opsmop](https://github.com/opsmop/opsmop)
+
+下一代配置管理和应用部署。
+
+[vaex](https://github.com/vaexio/vaex)
+
+Python 的外存 DataFrame,以每秒十亿行的速度可视化和探索大表格数据。
+
+[mindsdb](https://github.com/mindsdb/mindsdb)
+
+简化神经网络使用的框架。
+
+[twint](https://github.com/twintproject/twint)
+
+一个用 Python 编写的高级推特抓取和 OSINT 工具,不使用 Twitter 的 API,允许你爬取一个用户的粉丝、关注者、推特等等,同时避开大多数的 API 限制。
+
+[SubDomainizer](https://github.com/nsonaniya2010/SubDomainizer)
+
+查找隐藏在页面内部和外部的 Javascript 文件中的子域和有趣内容的工具。
+
+[python-community-map](https://github.com/jonatasbaldin/python-community-map)
+
+充满可爱的 Python 社区的地图。
+
+[vpn-at-home](https://github.com/ezaquarii/vpn-at-home)
+
+一键式自托管 OpenVPN 部署和管理应用。
+
+
+# 最新发布
+
+[Jupyter Notebook 发布了 5.7.3 和 5.7.4](https://groups.google.com/forum/#!topic/jupyter/vfBpHW2FsAo)
+
+[Qt for Python 5.12](https://blog.qt.io/blog/2018/12/18/qt-python-5-12-released/)
+
+[SciPy 1.2.0](https://github.com/scipy/scipy/releases/tag/v1.2.0)
+
diff --git a/Python Weekly/Python_Weekly_Issue_379.md b/Python Weekly/Python_Weekly_Issue_379.md
new file mode 100644
index 0000000..70bb3c4
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_379.md
@@ -0,0 +1,129 @@
+原文:[Python Weekly - Issue 379](http://eepurl.com/gctnCj)
+
+---
+
+欢迎来到Python周刊第 379 期。让我们直奔主题。
+
+
+# 来自赞助商
+
+[](https://click.linksynergy.com/link?id=x9UsEHf2tls&offerid=507388.1527300&type=2&murl=https%3A%2F%2Fwww.udemy.com%2Flearn-python-and-ethical-hacking-from-scratch%2F)
+
+[从零开始学习 Python 和道德黑客](https://click.linksynergy.com/link?id=x9UsEHf2tls&offerid=507388.1527300&type=2&murl=https%3A%2F%2Fwww.udemy.com%2Flearn-python-and-ethical-hacking-from-scratch%2F)
+
+
+# 新闻
+
+[PyCon Italy 征集提议](https://www.pycon.it/en/call-for-proposals/)
+
+[DSF 呼吁申请 Django 研究员](https://www.djangoproject.com/weblog/2018/dec/21/django-fellow-applicants/)
+
+
+# 文章,教程和讲座
+
+[了解 Python Lambda 函数及其有用的原因](https://www.youtube.com/watch?v=iMOIGsNHQjM)
+
+Python 中的 Lambda 函数是一种匿名函数。它们是 Python 中的一种简短但是强大的函数式编程技术。这里是关于 Lambda 函数概念的完整教程。
+
+[教程:在树莓派上安装 TensorFlow 对象检测 API](https://github.com/EdjeElectronics/TensorFlow-Object-Detection-on-the-Raspberry-Pi)
+
+本指南提供了在树莓派上安装 TensorFlow 对象检测 API 的逐步说明。按照本指南中的步骤,你将能够使用树莓派,在 Picamera 或者 USB 网络摄像头的实时视频源上进行对象检测。
+
+[python dict 之内](https://just-taking-a-ride.com/inside_python_dict/chapter1.html)
+
+python 辞典的可探索性解释。
+
+[如何使用 Python 的 socket,流式传输 Twitch 的文本数据](https://www.learndatasci.com/tutorials/how-stream-text-data-twitch-sockets-python/)
+
+学习如何使用 Python 中的 socket 来连接 Twitch Internet Relay Chat(IRC),并且流式传输聊天数据,以进行文本分析。
+
+[实验:后座力 vs 枪口初速](https://blog.ammolytics.com/2018-12-12/experiment-recoil-vs-muzzle-velocity.html)
+
+一个会直接影响另一个吗?
+
+[使用 Surprise,逐步构建和测推荐系统](https://medium.com/@actsusanli/building-and-testing-recommender-systems-with-surprise-step-by-step-d4ba702ef80b)
+
+学习如何使用 Python 和 Surprise 库,构建你自己的推荐引擎((协同过滤)。
+
+[蒙特卡洛功率分析](https://deliveroo.engineering/2018/12/07/monte-carlo-power-analysis.html)
+
+利用计算能力和经验数据来使用蒙特卡洛模拟进行实验功效分析。
+
+[使用 PyPy 上的 Falcon Web 框架来构建非常快的应用程序后端](https://www.alibabacloud.com/blog/building-very-fast-app-backends-with-falcon-web-framework-on-pypy_594282)
+
+在这篇文章中,我们将用 Python web 框架 Falcon 来 快速构建和部署一个超快的 REST API。在阅读本文时,你将首先学习 Falcon 框架的基础知识,将其安装在阿里云弹性计算服务(ECS)上,为应用构建一个 Rest API,最后在云上部署该应用。
+
+[如何使用 Keras fit 和 fit_generator](https://www.pyimagesearch.com/2018/12/24/how-to-use-keras-fit-and-fit_generator-a-hands-on-tutorial/)
+
+在这篇教程中,你将学习 Keras 的 .fit 和 .fit_generator 函数的工作原理,包括二者之间的差异。
+
+[为什么你应该使用 pathlib](https://treyhunner.com/2018/12/why-you-should-be-using-pathlib/)
+
+[关于 Python 递归,我学到的一些知识](https://nedbatchelder.com/blog/201812/a_thing_i_learned_about_python_recursion.html)
+
+[如何优化 Django REST viewsets](http://concisecoder.io/2018/12/23/how-to-optimize-your-django-rest-viewsets/)
+
+[使用 Docker-Compose,docker 化一个带 nginx 反向代理的 Flask 应用](https://mrl33h.de/post/39)
+
+[解构 BERT:从一亿个参数中提取六种模式](https://towardsdatascience.com/deconstructing-bert-distilling-6-patterns-from-100-million-parameters-b49113672f77)
+
+[使用 Python、Flask 和 React,构建一个简单的 CRUD 应用](https://developer.okta.com/blog/2018/12/20/crud-app-with-python-flask-react)
+
+[给绝对初学者:使用 XArray 处理 NetCDF 文件](https://medium.com/@edenau/handling-netcdf-files-using-xarray-for-absolute-beginners-111a8ab4463f)
+
+[用 Python 实现 SIFT](https://medium.com/@lerner98/implementing-sift-in-python-36c619df7945)
+
+
+# 书籍
+
+[Clean Architectures in Python(整洁架构 python 版)](https://leanpub.com/clean-architectures-in-python)
+
+
+# 好玩的项目,工具和库
+
+[awesome-python-applications](https://github.com/mahmoud/awesome-python-applications)
+
+成功发布的 Python 软件的案例研究。
+
+[nevergrad](https://github.com/facebookresearch/nevergrad)
+
+用于执行无梯度优化的 Python 工具箱。
+
+[crossCobra](https://github.com/morten1982/crossCobra)
+
+用 PyQt5 + QScintilla 制作的 Python IDE。
+
+[homemade-machine-learning](https://github.com/trekhleb/homemade-machine-learning)
+
+流行机器学习算法的 Python 示例,带交互式 Jupyter 演示和数学解释。
+
+[sherlock](https://github.com/sdushantha/sherlock)
+
+跨越 75 个社交网络查找用户名。
+
+[Bocadillo](https://github.com/bocadilloproject/bocadillo)
+
+充满异步“风味”的现代 Python web 框架。
+
+[privacy](https://github.com/tensorflow/privacy)
+
+使用带隐私保护的训练数据进行机器学习模型训练的库。
+
+[KubiScan](https://github.com/cyberark/KubiScan)
+
+扫描 Kubernetes 集群以获得风险权限的工具。
+
+[shodan-cli](https://github.com/thom-s/shodan-cli)
+
+shodan.io API 的 Python 命令行封装器
+
+[orjson](https://github.com/ijl/orjson)
+
+快速的 Python JSON 库。
+
+# 最新发布
+
+[Python 3.7.2 和 3.6.8 现已发布](https://blog.python.org/2018/12/python-372-and-368-are-now-available.html)
+
+[Wagtail 2.4](https://wagtail.io/blog/wagtail-2-4/)
+
diff --git a/Python Weekly/Python_Weekly_Issue_380.md b/Python Weekly/Python_Weekly_Issue_380.md
new file mode 100644
index 0000000..d4c45d1
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_380.md
@@ -0,0 +1,126 @@
+原文:[Python Weekly - Issue 380](http://eepurl.com/gcXVET)
+
+---
+
+欢迎阅读 Python 周刊第 380 期。愿诸位新年快乐,期待 Python 2019 年还是那么棒棒哒。
+
+# 来自赞助商
+
+[](https://www.vettery.com/tech?utm_source=newsletter&utm_medium=pythonweekly&utm_term=tech&utm_content=grouped&utm_campaign=ad-77579)
+
+[通过 Vettery 找到一份 Python 工作吧](https://www.vettery.com/tech?utm_source=newsletter&utm_medium=pythonweekly&utm_term=tech&utm_content=grouped&utm_campaign=ad-77579)
+
+Vettery 是一个专门从事开发人员角色的在线招聘市场,对求职者来说完全免费。 感兴趣吗?那就提交你的个人资料吧,如果审核通过,那么就可以直接从寻找 Python 开发者的顶级公司那里收到面试邀请。
+
+# 新闻
+
+[SciPy 2019 现已开放建议征集](https://www.scipy2019.scipy.org/)
+
+# 文章,教程和讲座
+
+[高级 Jupyter Notebooks:教程](https://www.dataquest.io/blog/advanced-jupyter-notebooks-tutorial/)
+
+继“Jupyter Notebook 入门:教程”之后,本指南将带你离开蜜月期,步入十足的危险之旅。没错!Jupyter 无需执行的古怪世界拥有让人手足无措的能力,而当在 notebook 中运行 notebook 时,事情就会变得复杂起来。本指南旨在理清一些混乱源,并传递一些激发你的兴趣,让你迸发想象力的想法。
+
+[列表推导式以及怎样永不滥用](https://www.youtube.com/watch?v=40S9e5Rf384)
+
+Python 中一个比 map、filter 和其他内置方法更灵活的表达式就是列表推导式。现在,即使这些内置方法更灵活了,但是你也会非常容易开始滥用列表推导式。
+
+[优化 Jupyter Notebooks(综合指南)](https://towardsdatascience.com/speed-up-jupyter-notebooks-20716cbe2025)
+
+利用我去年发现的一些技巧,找出瓶颈并大幅度提高性能。
+
+[我是如何构建一个 Python Web 框架并成为一名开源维护者的](https://blog.florimondmanca.com/how-i-built-a-web-framework-and-became-an-open-source-maintainer)
+
+关于启动和管理开源项目的激动人心的想法和技巧(基于我构建 Bocadillo 这一异步 Python web 框架的经验)。
+
+[利用 Python 和 Boto3,自动化 AWS EC2 管理](https://stackabuse.com/automating-aws-ec2-management-with-python-and-boto3/)
+
+本文演示了 Python 以及 Boto3 Amazon Web Services (AWS) 软件开发工具包(SDK)的结合使用,允许熟悉 Python 编程的人利用复杂的 AWS REST API 来管理他们的云资源。
+
+[Keras Conv2D 和卷积层](https://www.pyimagesearch.com/2018/12/31/keras-conv2d-and-convolutional-layers/)
+
+在这个交叉中,我们将讨论 Keras Conv2D 类,包括在训练自己的卷积神经网络(CNN)时需要调整的最重要的参数。在这里,我们将使用 Keras Conv2D 类来实现一个简单的 CNN。然后,我们将在 CALTECH-101 数据集上训练和评估此 CNN。
+
+[利用 Azure App Service 构建一个 Python 和 PostgreSQL 应用 ](https://docs.microsoft.com/en-us/azure/app-service/containers/tutorial-python-postgresql-app)
+
+Linux 上的 App Service 提供了一种高度可扩展的自修补 web 托管服务。本教程介绍了如何创建一个数据驱动的 Python 应用(使用 PostgreSQL 作为数据库后端)。当你完成本教程后,你将拥有一个运行在 Linux 的 App Service 之上的 Django 应用。
+
+[使用 AWS Lambda 构建 Tram-Time 展示](https://blog.rothe.uk/serverless-tram-time-display/)
+
+[使用 Pandas Dataframe,验证你的个人关系](https://cosmicbboy.github.io/2018/12/28/validating-pandas-dataframes.html)
+
+[利用 Python 和遗传算法,解决 Brachistochrone 问题](http://www.declanoller.com/2018/12/24/solving-the-brachistochrone-and-a-cool-parallel-between-diversity-in-genetic-algorithms-and-simulated-annealing/)
+
+[如何实现分组模型选择域](https://simpleisbetterthancomplex.com/tutorial/2019/01/02/how-to-implement-grouped-model-choice-field.html)
+
+[Python Django Web 框架 —— 给初学者的完整课程](https://www.youtube.com/watch?v=F5mRW0jo-U4)
+
+
+# 好玩的项目,工具和库
+
+[DeepFaceLab](https://github.com/iperov/DeepFaceLab)
+
+DeepFaceLab 是一个利用深度学习,识别和交换图片以及视频中的面孔的工具。
+
+[uncaptcha2](https://github.com/ecthros/uncaptcha2)
+
+以 91% 的准确度击败最新版本的 ReCaptcha。
+
+[Sparlab](https://github.com/johnward-umensch/Sparlab)
+
+为 PC 上的 格斗游戏创建你自己的设置和机器人的 GUI 应用。
+
+[PyOxidizer](https://github.com/indygreg/pyoxidizer)
+
+使用 Rust 制作可分发的 Python 应用。
+
+[vault_scanner](https://github.com/abhisharma404/vault_scanner)
+
+黑客版瑞士军刀。
+
+[Neural-Network-from-scratch](https://github.com/ahmedbesbes/Neural-Network-from-scratch)
+
+有没有想过怎样在不涉及任何框架的情况下,使用 NumPy 来编写你的神经网络?
+
+[awesome-flake8-extensions](https://github.com/DmytroLitvinov/awesome-flake8-extensions)
+
+flake8 扩展精选列表。欢迎贡献!
+
+[drive-cli](https://github.com/nurdtechie98/drive-cli)
+
+用于访问谷歌硬盘的命令行接口。
+
+[Writango](https://github.com/joelewis/writango)
+
+编写、发布文章,并让你的受众像 PPT 演示那样播放你的文章。
+
+[profanity-check](https://github.com/vzhou842/profanity-check)
+
+一个检查字符串中攻击性语言的快速强大的 Python 库。
+
+[pandas-sets](https://github.com/Florents-Tselai/pandas-sets)
+
+Pandas 中面向集合的操作
+
+
+# 近期活动和网络研讨会
+
+[San Francisco Python 2019 年一月聚会 - San Francisco, CA](https://www.meetup.com/sfpython/events/257386024/)
+
+将会有以下演讲:
+
+ * 递归入门:初学者的递归指南
+ * Graphland 中的 Numpy
+ * 如何在当今市场中找到工作或者招聘人才
+ * Serverless 介绍
+ * Bioinformatics SIG @ SF Python 项目之夜
+
+
+[Boulder Python 2019 年一月聚会 - Boulder, CO](https://www.meetup.com/BoulderPython/events/xwblrpyzcblb/)
+
+Brandon Rhodes 将献出他的首次演讲,聚焦他最近的设计模式工作。
+
+[PyAtl 2019 年一月聚会 - Atlanta, GA](https://www.meetup.com/python-atlanta/events/xhtxqpyzcbnb/)
+
+[Austin Python 2019 年一月聚会 - Austin, TX](https://www.meetup.com/austinpython/events/lgrbmqyzcbmb/)
\ No newline at end of file
diff --git a/Python Weekly/Python_Weekly_Issue_381.md b/Python Weekly/Python_Weekly_Issue_381.md
new file mode 100644
index 0000000..93af802
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_381.md
@@ -0,0 +1,146 @@
+原文:[Python Weekly - Issue 381](http://eepurl.com/ge4gKf)
+
+---
+
+欢迎阅读 Python 周刊第 381 期。(过去两周没更新是因为作者有点家务事要处理,所以没法发。本周我们回到我们的日常来)
+
+# 来自赞助商
+
+[](https://hackajob.co/p/discover?utm_source=pythonweekly&utm_medium=paid&utm_campaign=jan_24)
+
+[欧洲的科技类工作?看一看 hackajob 吧](https://hackajob.co/p/discover?utm_source=pythonweekly&utm_medium=paid&utm_campaign=jan_24)
+
+
+# 文章,教程和讲座
+
+[通过从头开始模仿 TensorFlow 的 API 来了解 TensorFlow](https://medium.com/@d3lm/understand-tensorflow-by-mimicking-its-api-from-scratch-faa55787170d)
+
+本文的目标在于建立对深度学习库(特别是 TensorFlow)工作原理的直觉和理解。为了达成此目标,我们将会从头开始模仿它的 API 并实现其核心构建块。这将有点小小的额外好处:最后,你将能够自信地使用 TensorFlow,因为你已经对其内部工作有了一个深刻的概念性理解。你还将进一步了解变量、张量、会话或者操作等内容。
+
+[使用 NLP 来自动化](https://blog.floydhub.com/automate-customer-support-part-two/)
+
+让我们一起构建一个自然语言处理(NLP)模型,通过建议之前提出的类似问题来帮助你的客户支持代理。
+
+[Python API 框架综述:DRF、APIStar、Falcon 等](http://friday.hirelofty.com/223293/904996-python-api-framework-roundup-drf-apistar-falcon-and-more)
+
+微服务架构风靡一时,并且已经出现了构建它们的新框架。在本集中,Casey、Alan 和 Tyrel 总结了他们一直在探索的一些框架,以及它们如何相互叠加。
+
+[使用 Pandas 进行时间序列分析](https://www.dataquest.io/blog/tutorial-time-series-analysis-pandas/)
+
+在这个数据科学教程中了解 pandas 库中强大的时间序列工具,并使用 Python 编写一些时间序列分析程序。
+
+[使用 Python 分析文件系统和目录结构](https://janakiev.com/blog/python-filesystem-analysis/)
+
+假设你有一个外部硬盘驱动器,其中包括多层隐藏命名的文件夹和复杂的目录迷宫。那么,你将如何理解这一团乱?Python 在 Python 标准库中提供了各种工具来处理文件系统,而 folderstats 模块可以提供额外的帮助,以深入了解你的文件系统。在这篇文章中,你将学习使用 Python 遍历和探索文件系统的各种方法。
+
+[反转面部识别模型](https://blog.floydhub.com/inverting-facial-recognition-models/)
+
+我们可以训练一个神经网络来将面部嵌入�向量转换回图像吗?
+
+[回归和 Keras](https://www.pyimagesearch.com/2019/01/21/regression-with-keras/)
+
+在这篇教程中,你将学习如何使用 Keras 和深度学习来进行回归。你将学习如何训练 Keras 神经网络进行回归和连续值预测,特别是在房价预测方面。
+
+[Web 应用程序消息传递协议(从一名 Pythonic 的角度)](https://medium.com/@noisyboiler/the-web-application-messaging-protocol-d8efe95aeb67)
+
+本文是 Web 应用程序消息传递协议(The Web Application Messaging Protocol)的介绍和实际用例。
+
+[Python 和财务 —— 启动你的电子表格](https://www.toptal.com/finance/financial-modeling/python-and-finance)
+
+与传统流行的 VBA 脚本相比,Python 为希望自动化和增强其工作流程的财务专业人员提供更多的好处。本文通过实用的分步教程探讨如何将 Python 和财务结合使用。
+
+[将 Elasticache 用于 Python 生产有效负载](https://blog.sendbird.com/elasticache-for-python-production-payloads)
+
+由于读取器端点只能作为 AWS ElastiCache 中的单个节点访问,因此应用需要自己负载均衡读取请求。阅读更多内容,以了解 SendBird 是如何通过使用 HAProxy 来实现活跃的运行状况检查程序来消除 Redis 部署中的单点故障的。
+
+[使用 Kubernetes 和 Tensorflow 来扩展 Jupyter notebooks](https://learnk8s.io/blog/scaling-machine-learning-with-kubeflow-tensorflow)
+
+开发人工智能和深度学习模型的最常见的障碍之一是设计可以大规模实时运行的数据管道。数据科学家和工程师们通常希望学习、开发和维护他们的实验基础设施,但是,这一过程需要从训练和开发模型的专注中挤出时间。但是,如果你可以在仍旧保有控制权的情况下,将所有非数据科学的工作外包给其他人呢?在这篇文章中,你将探索如何利用 Kubernetes、Tensorflow 和 Kubeflow 来扩展模型,而无需担忧基础架构的扩展。
+
+[使用 Mask R-CNN 和 Python 来抢占停车位](https://medium.com/@ageitgey/snagging-parking-spaces-with-mask-r-cnn-and-python-955f2231c400)
+
+[使用 Scrapy 的 Python Web 爬取](https://www.youtube.com/watch?v=ve_0h4Y8nuI&list=PLhTjy8cBISEqkN-5Ku_kXG4QW33sxQo0t)
+
+[我对优化 Python 的一些了解](https://gregoryszorc.com/blog/2019/01/10/what-i've-learned-about-optimizing-python/)
+
+[从 Python 的“print”函数的“hello, world”说起](http://blog.lerner.co.il/beyond-the-hello-world-of-pythons-print-function/)
+
+[揭秘 Python 中的 @decorators](https://sumit-ghosh.com/articles/demystifying-decorators-python/)
+
+[Kubernetes 上的 Django](https://kogan-devblog.squarespace.com/blog/django-on-kubernetes)
+
+[对于初学者�来说,Python 最被低估的游戏引擎](http://blog.vomkonstant.in/2019/01/21/pythons-most-underrated-game-engine-for-beginners/)
+
+
+# 本周的Python工作
+
+[Farfetch 招聘高级 Python 工程师](http://jobs.pythonweekly.com/jobs/senior-python-engineer-3/)
+
+
+[Beeswax 招聘高级后端软件工程师](http://jobs.pythonweekly.com/jobs/sr-backend-software-engineer/)
+
+
+# 好玩的项目,工具和库
+
+[LASER](https://github.com/facebookresearch/LASER)
+
+LASER 是一个计算和使用多语言句子嵌入的库。该工具包现在可用于超过 90 种语言,用 28 种不同的字母表编写。LASER 通过将所有的语言联合嵌入到单个共享空间(而不是为每个语言分别建立模型)来实现这些结果。
+
+[AnyAPI](https://github.com/FKLC/AnyAPI/)
+
+每个 API 的 API 封装器。
+
+[Bashfuscator](https://github.com/Bashfuscator/Bashfuscator)
+
+完全可配置和可扩展的 Bash 混淆框架。该工具旨在帮助红队和蓝队。
+
+[Frame](https://github.com/jddunn/frame/)
+
+笔记应用,可以回答你的问题并为你做摘要。
+
+[Delira](https://github.com/justusschock/delira)
+
+用于快速原型设计和训练医学图像中的深度神经网络的轻量级框架。
+
+[drymail](https://github.com/SkullTech/drymail)
+
+让发送邮件变得简单干净 —— 用于 Python 3。
+
+[wampy](https://github.com/noisyboiler/wampy)
+
+用于 Python 应用和微服务的 Websocket RPC 和 Pub/Sub。
+
+[vorta](https://github.com/borgbase/vorta)
+
+基于 BorgBackup 的桌面备份客户端。
+
+[IGQL](https://github.com/FKLC/IGQL)
+
+无需鉴权即可收集数据的非官方 Instagram GraphQL API。
+
+[ALiPy](https://github.com/NUAA-AL/ALiPy)
+
+Active Learning in Python 是一个主动学习 python 工具箱,允许用户方便地评估、比较和分析主动学习方法的性能。
+
+[vimade](https://github.com/TaDaa/vimade)
+
+一个保护眼睛的插件,可以淡化你的非活跃缓冲区,并保留你的语法高亮!
+
+
+# 最新发布
+
+[Django 2.2 alpha 1](https://www.djangoproject.com/weblog/2019/jan/17/django-22-alpha-1/)
+
+[Python in Visual Studio 2019 Preview 2](https://blogs.msdn.microsoft.com/pythonengineering/2019/01/23/python-in-visual-studio-2019-preview-2/)
+
+
+# 近期活动和网络研讨会
+
+[San Francisco Django 2019 年 1 月聚会 - San Francisco, CA](https://www.meetup.com/The-San-Francisco-Django-Meetup-Group/events/258144700/)
+
+将会有一场演讲:使用 Pytest 编写漂亮的测试以及一个防弹 Django 应用。
+
+[Israeli 2019 年 Python 锦标赛](https://www.meetup.com/life-michael/events/258262954/)
+
+在此聚会起见,我们将举行一场基于 Kahoot 的比赛。该比赛将分两部分进行。第一部分对所有人开放。而第二部分将对那些在第一部分表现最优秀的人开放。
+
diff --git a/Python Weekly/Python_Weekly_Issue_383.md b/Python Weekly/Python_Weekly_Issue_383.md
new file mode 100644
index 0000000..2260ac4
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_383.md
@@ -0,0 +1,139 @@
+原文:[Python Weekly - Issue 383](http://eepurl.com/ggyzub)
+
+---
+
+欢迎来到Python周刊第 383 期。让我们直奔主题。
+
+# 来自赞助商
+[](https://www.datadoghq.com/dg/apm/ts-python-tracing/?utm_source=Advertisement&utm_medium=Advertisement&utm_campaign=PythonWeekly-Tshirt&utm_content=Python)
+
+使用 Datadog APM 监控 Python 程序中的指标、日志和跟踪 —— 我们的跟踪客户端自动检测 Django、Redis 和其他框架及库,以便你可以立即洞悉。[通过 14 天的免费试用,亲身体验 Datadog 吧。](https://www.datadoghq.com/dg/apm/ts-python-tracing/?utm_source=Advertisement&utm_medium=Advertisement&utm_campaign=PythonWeekly-Tshirt&utm_content=Python).
+
+
+# 新闻
+
+[PyConWeb 2019 征求提议](https://www.papercall.io/pyconweb19)
+
+PyConWeb 2019 是第三届为期两天的会议,专注于 Python 的 Web 栈,它将于 5 月 25 日至 26 日在慕尼黑举行。非常欢迎每个人在 PyConWeb 上踊跃发言,此外,作为社区会议,我们在寻找那些愿意分享知识的人。
+
+[PyCon 2019 提醒和信息!](https://pycon.blogspot.com/2019/01/pycon-2019-reminders-and-information.html)
+
+
+# 文章,教程和讲座
+
+[逐步将超过一百万行代码从 Python 2 迁移到 Python 3](https://blogs.dropbox.com/tech/2019/02/incrementally-migrating-over-one-million-lines-of-code-from-python-2-to-python-3/)
+
+在过去的几个月中,我们探讨了开展 Python 3 迁移的原因和方法,以及如何确保生成的应用是可靠的。在这篇文章中,我们将简要介绍我们的桌面客户端中关于 Python 3 的历史,然后深入了解我们是如何在允许持续开发的同时实现逐步迁移的。
+
+[编程 Z3](https://theory.stanford.edu/~nikolaj/programmingz3.html)
+
+本教程提供了对于 Satisfiability Modulo Theories Solver Z3 的程序员介绍。它描述了如何通过脚本来使用 Z3,还描述了 Z3 中决策过程的几个算法。它旨在广泛涵盖 Z3 的几乎所有可用功能,以及底层算法的主要组成部分。
+
+[详解链表与 Python 示例:单链表](https://stackabuse.com/linked-lists-in-detail-with-python-examples-single-linked-lists/)
+
+链表是所有编程语言中最常用的数据结构之一。在这篇文章中,我们将详细了解链表。我们将看到不同类型的链表,了解如何遍历链表、如何向链表插入元素以及将元素从链表中删除、对链表进行排序的不同技术、反转链表的方法等等。
+
+[2018 年 Python 开发人员调查结果](https://www.jetbrains.com/research/python-developers-survey-2018/)
+
+由 Python 软件基金会和 JetBrains 发布的 2018 年官方 Python 开发人员调查结果:来自 150 多个国家的超过 2 万份回复。
+
+[Keras:多输入和混合数据](https://www.pyimagesearch.com/2019/02/04/keras-multiple-inputs-and-mixed-data/)
+
+在这篇教程中,你将学习如何将 Keras 用于多输入和混合数据。你还将学习定义能够接受多种输入(包括数值、分类和图像数据)的 Keras 架构的方法。然后,我们将在此混合数据上训练单个端到端网络。
+
+[使用 Python、Twilio 和 AWS 构建一个回忆物联网按钮罐](https://medium.com/@jman4190/building-a-jar-of-memories-iot-button-with-python-twilio-aws-ca90a8159bc3)
+
+如何点击遥远的按钮,然后通过文本发送喜爱的照片回忆。
+
+[在 Jupyter Notebook 和 Python 中使用虚拟环境](https://janakiev.com/til/jupyter-virtual-envs/)
+
+你有在使用 Jupyter Notebook 和 Python 吗?你是否也想从虚拟环境中受益呢?在本教程中,你将了解如何使用 Anaconda 或者 Virtualenv/venv 来实现这一切。
+
+[使用神经进化代理击败 OpenAI 游戏:非常简单!](http://declanoller.com/2019/01/25/beating-openai-games-with-neuroevolution-agents-pretty-neat/)
+
+[JupyterLab 入门](https://www.blog.pythonlibrary.org/2019/02/05/getting-started-with-jupyterlab/)
+
+[战略和命令涉及模式 —— 向导和三明治 —— Python 中的应用](https://medium.com/@rrfd/strategy-and-command-design-patterns-wizards-and-sandwiches-applications-in-python-d1ee1c86e00f)
+
+[和虚拟环境告别吗?](https://medium.com/@grassfedcode/goodbye-virtual-environments-b9f8115bc2b6)
+
+[使用 Keras,一次性学习 Siamese 网络](https://towardsdatascience.com/one-shot-learning-with-siamese-networks-using-keras-17f34e75bb3d)
+
+
+# 书籍
+
+[Python Flash Cards: Syntax, Concepts, and Examples(Python 记忆卡:语法、概念和示例)](https://amzn.to/2DX87Zy)
+
+随时随地保持你的编程技能!Python 记忆卡采用一种经过实践检验的方法,并对其进行编程改造。Eric Matthes,也就是畅销的 Python 速成课(Python Crash Course)的作者,将基本的 Python 编程知识提炼到这 101 张卡片组中,以便你可以随处使用。每次都可以按次或乱次使用,以便进行新的学习。通过它,你可以刷新基础的编程原理以及诸如数据结构、逻辑控制和程序流程这样的词汇,根据 Python 语法进行自我测试,并通过那些旨在让你保持警觉的练习和挑战测试你的技能 —— 所有这些,一本即可。
+
+
+# 本周的Python工作
+
+[Beauhurst 招聘全栈 Web 开发](http://jobs.pythonweekly.com/jobs/grad-full-stack-web-developer-experience-0-yrs/)
+
+
+# 好玩的项目,工具和库
+
+[RustPython](https://github.com/RustPython/RustPython)
+用 Rust 编写的 Python-3(CPython >= 3.5.0)解释器。
+
+[gita](https://github.com/nosarthur/gita)
+
+并排管理多个 git 仓库,以确保完备性。
+
+[Armory](https://github.com/depthsecurity/armory)
+
+Armory 是一个用于从许多工具中获取大量外部和发现数据,并将其添加到数据库,同时关联所有相关信息的工具。
+
+[awesome-python-security](https://github.com/guardrailsio/awesome-python-security)
+
+棒棒哒的 Python 安全资源。
+
+[gpu-sentry](https://github.com/jacenkow/gpu-sentry)
+
+监控 nVidia GPU 的使用情况的基于 Flask 的软件包。
+
+[geometer](https://github.com/jan-mue/geometer)
+
+一个用 Python 写的几何库。
+
+[pylane](https://github.com/NtesEyes/pylane)
+
+带调试工具的 python vm 注入器,基于 gdb。
+
+[Output](https://gist.github.com/macournoyer/620a8ba4a2ecd6d6feaf)
+
+25 行代码的神经网络框架。
+
+[XLM](https://github.com/facebookresearch/XLM)
+
+跨语言语言模型预训练的 PyTorch 原始实现。
+
+
+# 近期活动和网络研讨会
+
+[San Francisco Python 2019 年 2 月聚会 - San Francisco, CA](https://www.meetup.com/sfpython/events/258401696/)
+
+将会有以下演讲:
+
+ * 一举夺胜 Zork!
+ * 依赖管理
+ * 当布尔值不够的时候……状态机?
+
+
+[Boulder Python 2019 年 2 月聚会 - Boulder, CO](https://www.meetup.com/BoulderPython/events/xwblrpyzdbqb/)
+
+将会有一场演讲:不要使用我的 Grid 系统。
+
+[IndyPy 2019 年 2 月每月聚会 - Indianapolis, IN](https://www.meetup.com/indypy/events/bxqbmqyzdbqb/)
+
+将会有以下演讲:
+
+ * Python 中的 REST API
+ * 先了解,再行动
+ * 将 Python 与 AWS 集成
+
+
+[Edmonton Python 2019 年 2 月聚会 - Edmonton, AB](https://www.meetup.com/startupedmonton/events/dtflxjyzdbpb/)
+
+[Austin Python 2019 年 2 月聚会 - Austin, TX](https://www.meetup.com/austinpython/events/lgrbmqyzdbrb/)
\ No newline at end of file
diff --git a/Python Weekly/Python_Weekly_Issue_384.md b/Python Weekly/Python_Weekly_Issue_384.md
new file mode 100644
index 0000000..dde6de2
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_384.md
@@ -0,0 +1,150 @@
+原文:[Python Weekly - Issue 384](http://eepurl.com/ghiX4f)
+
+---
+
+欢迎来到Python周刊第 384 期。让我们直奔主题。
+
+# 来自赞助商
+[](
+https://www.vettery.com/tech?utm_source=newsletter&utm_medium=pythonweekly&utm_term=tech&utm_content=grouped&utm_campaign=ad-77579)
+
+[通过 Vettery 找到一份 Python 工作](https://www.vettery.com/tech?utm_source=newsletter&utm_medium=pythonweekly&utm_term=tech&utm_content=grouped&utm_campaign=ad-77579)
+
+Vettery是一个专门从事开发人员相关的在线招聘市场,并且对于求职者来说是完全免费的。感兴趣吗? 如果感兴趣的话,就提交您的个人资料,如果资料被接受,您就可以直接收到招聘 Python 开发人员的顶级公司的面试请求。
+
+
+# 新闻
+
+[Python in Education - 寻求创意](https://pyfound.blogspot.com/2019/01/python-in-education-request-for-ideas.html)
+
+[PyCon 2020-2021 位置](https://pycon.blogspot.com/2019/02/pycon-2020-2021-location.html)
+
+
+# 文章,教程和讲座
+
+[给所有人看的机器学习](https://vas3k.com/blog/machine_learning/)
+
+简单易懂。带现实示例。是哒,再来一次。
+
+[PSD2 兼容授权:使用 Python、Flask 和 Auth,验证敏感操作](https://www.twilio.com/blog/psd2-python-flask-authy-push)
+
+将双重验证(2FA)添加到你的登录过程中,以提高用户数据的安全性。我们还可以对其进行扩展,以验证敏感操作,例如从账户汇款、修改送货地址或者确认医疗预约。即使用户已经使用用户名密码登录了,我们也希望确保他们授权每一笔付款。这篇博文将向你展示如何使用 Python、Flask、一点点 Javascript 和 Authy API 来保护付款操作。
+
+[通过重新发明理解神经网络和反向传播](https://medium.com/@interfacer/grok-neural-networks-backpropagation-by-re-inventing-them-a-hackers-guide-with-python-code-e7cc1daea04b)
+
+还有比通过(重新)发明或者发现某些东西来理解它们更好的方式吗?理解神经网络和基于错误梯度反向传播的学习背后的直觉知识和数据。用“黑客的方式”!
+
+
+[学习 Python 直到够用:argparse](https://towardsdatascience.com/learn-enough-python-to-be-useful-argparse-e482e1764e05)
+
+如何在脚本中获取命令行参数。
+
+[Python 打包现状](https://www.bernat.tech/pep-517-and-python-packaging/)
+
+描述当今 Python 打包机制的现状,以及 Python 打包管理局希望的下一步动作。
+
+[语音助手样板和 API](https://medium.com/@dc.aihub/voice-assistant-boilerplate-api-146a4e8a9325)
+
+你可曾想过,“我要如何为网站制作一个专属语音助手?”,如果是的话,那么这篇文章就是为你而写的!我们将逐步指导你将 React 样板和 Python API 连接起来。而通过一些额外的研究,我们将实现的功能也可以很容易地部署到其他设备(例如树莓派)。
+
+[如何用 Python 分析 SEO 数据:参考指南](https://www.searchenginejournal.com/python-seo-data-reference-guide/287927/)
+
+当没有工具可以帮忙的时候,Python 可以帮你消除重复的 SEO 任务。这里是一些实用的 SEO Python 应用。
+
+[你会在泰坦尼克号事件中幸存吗?](https://hackernoon.com/would-you-survive-the-titanic-aa4ae2e86e9)
+
+永不沉没之旅 —— 人工智能可以在这场灾难中学到什么。
+
+[使用 AMD GPU 和 Keras 训练神经网络](https://towardsdatascience.com/train-neural-networks-using-amd-gpus-and-keras-37189c453878)
+
+AMD 正在开发一种名为 ROCm 的新 HPC 平台。它的目标是创建一个通用的开源环境,能够同时与 Nvidia(使用 CUDA)和 AMD GPU 连接。本教程将解释如何在配置一个或多个 AMD GPU 的情况下设置一个神经网络环境。
+
+[使用 Keras 和深度学习训练 Fashion MNIST](https://www.pyimagesearch.com/2019/02/11/fashion-mnist-with-keras-and-deep-learning/)
+
+在这篇教程中,你将学习如何使用 Keras 在 Fashion MNIST 数据集中训练一个简单的卷积神经网络(CNN),让你能够对时尚图像和类别进行分类。Fashion MNIST 数据集被普遍认为是(不太具有挑战性的)MNIST 数据集的一个(稍微具有挑战性的)直接替代品。
+
+[如何用 Python 编写 Tendermint 应用](https://medium.com/coinmonks/how-to-write-tendermint-applications-using-python-d8dde304e339)
+
+[使用 Zeit 和 RDS Postgres 部署 Serverless Django](https://www.agiliq.com/blog/2019/02/django-zeit-now-serverless/)
+
+[如何在不到 50 行代码中构造一个聊天机器人](https://www.codingame.com/playgrounds/41655/how-to-build-a-chatbot-in-less-than-50-lines-of-code)
+
+[Python 异常被认为是反模式](https://sobolevn.me/2019/02/python-exceptions-considered-an-antipattern)
+
+
+# 本周的Python工作
+
+[DevOps / Python engineer at Gridium 招聘 DevOps / Python 工程师](http://jobs.pythonweekly.com/jobs/devops-python-engineer/)
+
+
+# 好玩的项目,工具和库
+
+[ptr](https://github.com/facebookincubator/ptr)
+
+Python Test Runner(ptr)生来就是在任意代码存储库中,以一种固有的方式运行测试。ptr 支持多 Python 项目(每个仓库在其 setup.(cfg|py) 文件中定义了单元测试)。通过使用单个测试虚拟环境,ptr 让开发者能够在一个 Python 环境中测试多个项目与模块。
+
+[spektral](https://github.com/danielegrattarola/spektral)
+
+用于在 Keras 中进行关系表示学习的 Python 框架。
+
+[Ludwig](https://github.com/uber/ludwig)
+
+Ludwig 是一个基于 TensorFlow 构建的工具箱,可以用来在不需要编写代码的情况下训练和测试深度学习模型。
+
+[bert-embedding](https://github.com/imgarylai/bert-embedding)
+
+位于 mxnet 和 gluonnlp 之上的来自 BERT 模型的令牌级别嵌入。
+
+[GPIOzero](https://github.com/RPi-Distro/python-gpiozero)
+
+使用树莓派 1 的一个简单的 GPIO 设备接口
+
+[Cloud Annotations Training](https://github.com/cloud-annotations/training)
+
+自定义对象检测和分类训练。
+
+[PythonEXE](https://github.com/jabbalaci/PythonEXE)
+
+如何从 Python 脚本创建可执行文件?
+
+[db-to-sqlite](https://github.com/simonw/db-to-sqlite)
+
+将来自任意 SQL 数据库的表或者查询导入到 SQLite 文件中的 CLI 工具。
+
+
+# 最新发布
+
+[PyPy v7.0.0:2.7,3.5 和 3.6-alpha 的三重发布](https://morepypy.blogspot.com/2019/02/pypy-v700-triple-release-of-27-35-and.html)
+
+[Django 2.2 beta 1 发布](https://www.djangoproject.com/weblog/2019/feb/11/django-22-beta-1-released/)
+
+[Django 安全版本发布:2.1.6,2.0.11 和 1.11.19](https://www.djangoproject.com/weblog/2019/feb/11/security-releases/)
+
+[Django 错误修复版本:2.1.7,2.0.12 和 1.11.20](https://www.djangoproject.com/weblog/2019/feb/11/bugfix-releases/)
+
+
+# 近期活动和网络研讨会
+
+[IndyPy 自动化会议](https://2019.indypy.org/automate/)
+
+IndyPy Conf 开始了 2019 年的会议系列,其全天的演讲是关于将 Python 用于自动化、编排和物联网。快来了解使用 Python 的自动化流程。无论你是想减少耗费在重复性工作的时间,还是减少人为错误,我们都有适合你的主题。
+
+[Boston Python 2019 年 2 月聚会 - Boston, MA](https://www.meetup.com/bostonpython/events/257225246/)
+
+将会有以下演讲:
+
+ * WiFi 无源雷达
+ * 在 Python 中使用 C/C++ 扩展
+
+
+[Django Boston 2019 年 2 月聚会 - Boston, MA](https://www.meetup.com/djangoboston/events/258890140/)
+
+将会有以下演讲:
+
+ * Figures:开源轻量级分析仪表板
+ * Django 的历史:为什么事情会是现在这个样子
+
+
+[PyHou 2019 年 2 月聚会 - Houston, TX](https://www.meetup.com/python-14/events/drtltlyzdbzb/)
+
+[快速演讲与演讲实践之夜!- New York, NY](https://www.meetup.com/nycpython/events/258461603/)
\ No newline at end of file
diff --git a/Python Weekly/Python_Weekly_Issue_385.md b/Python Weekly/Python_Weekly_Issue_385.md
new file mode 100644
index 0000000..dc21de4
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_385.md
@@ -0,0 +1,133 @@
+原文:[Python Weekly - Issue 385](http://eepurl.com/gh2OkT)
+
+---
+
+欢迎来到Python周刊第 385 期。让我们直奔主题。
+
+
+# 来自赞助商
+[](https://www.datadoghq.com/dg/apm/ts-python-tracing/?utm_source=Advertisement&utm_medium=Advertisement&utm_campaign=PythonWeekly-Tshirt&utm_content=Python)
+
+开始跨越服务边界追踪请求,对缓慢请求进行故障排除,并在几分钟内优化 Python 应用。[通过免费试用监控你的动态环境,并且 Datadog 还会送你一件 T 恤](https://www.datadoghq.com/dg/apm/ts-python-tracing/?utm_source=Advertisement&utm_medium=Advertisement&utm_campaign=PythonWeekly-Tshirt&utm_content=Python).
+
+
+# 文章,教程和讲座
+
+[使用 Keras 和深度学习进行乳腺癌分类](https://www.pyimagesearch.com/2019/02/18/breast-cancer-classification-with-keras-and-deep-learning/)
+
+在本教程中,你将学习如何使用 Keras、深度学习和 Python,对组织学图像中的乳腺癌进行分类。
+
+[如何通过此 DIY 设置监控空气质量](https://medium.freecodecamp.org/how-to-monitor-your-air-quality-with-this-diy-setup-3399793137c3)
+
+通过树莓派、低成本气体传感器和遥控开关,你就可以控制家中的空气质量。
+
+[使用 fbs 打包 PyQt5 应用](https://www.mfitzp.com/article/packaging-pyqt5-apps-with-fbs/)
+
+使用 fman 构建系统分发跨平台 GUI 应用。
+
+[一个完整的 Python 机器学习项目演练](https://codequs.com/p/BkaLEq8r4/a-complete-machine-learning-project-walk-through-in-python)
+
+一个完整的 Python 机器学习项目演练:将机器学习各个部分组合在一起;模型选择;超参数调整以及评估;解释机器学习模型并展示结果。
+
+[你应该知道的十个 Python 文件系统方法](https://towardsdatascience.com/10-python-file-system-methods-you-should-know-799f90ef13c2)
+
+通过 os 和 shutil 操作文件和文件夹。
+
+[ARIMA 模型 —— Python 中的时间序列预测](https://www.machinelearningplus.com/time-series/arima-model-time-series-forecasting-python/)
+
+使用 ARIMA 模型,你可以通过序列过去的值来预测时间序列。在这篇文章中,我们会从头开始构建一个最优的 ARIMA 模型,并将其扩展为 Seasonal ARIMA(SARIMA)和 SARIMAX 模型。你还会了解如何使用 Python 构建自动模型。
+
+[使用变分自动编码器建模电信客户流失](https://towardsdatascience.com/modeling-telecom-customer-churn-with-variational-autoencoder-4e5cf6194871)
+
+如何应用深度卷积神经网络和自动编码器来构建流失预测模型。
+
+[使用 Python 进行蒙特卡洛模拟](https://pbpython.com/monte-carlo.html)
+
+使用 Python、pandas 和 numpy 进行蒙特卡洛模拟。
+
+[为你的 Django 应用构建 AWS CodePipeline CI/CD](https://girisagar46.github.io/build-aws-codepipeline-for-cicd)
+
+在这篇文章中,你将学习如何为 Django 应用设置 AWS CodePipeline,以实现持续集成和持续交付(CI/CD)管道。
+
+[别了,fsync():使用 Docker 进行快十倍的数据库测试](https://pythonspeed.com/articles/faster-db-tests/)
+
+一篇关于如何加速针对数据库运行测试,同时在 Docker 的帮助下仍然使用尽可能真实的环境的文章。
+
+[使用 Apex Up 和 Aurora Serverless,部署完全 serverless 的 Django](https://www.agiliq.com/blog/2019/02/django-apex-up-serverless/)
+
+[Python 字符串格式化指南](https://kite.com/blog/python/python-string-formatting)
+
+[对于用 Python 进行网络爬取的 x86 和 ARM 较量](https://blog.dxmtechsupport.com.au/speed-test-x86-vs-arm-for-web-crawling-in-python/)
+
+[Python 的 str.isdigit vs. str.isnumeric](https://blog.lerner.co.il/pythons-str-isdigit-vs-str-isnumeric/)
+
+
+# 本周的Python工作
+
+[宾夕法尼亚大学招牌解决方案开发人员](http://jobs.pythonweekly.com/jobs/solutions-developer-bc/)
+
+[dubizzle 招聘高级 Python 工程师](http://jobs.pythonweekly.com/jobs/senior-python-engineer-dubai/)
+
+
+# 好玩的项目,工具和库
+
+[planet](https://github.com/google-research/planet)
+
+深度规划网络:通过潜在动态规划学习,从像素进行控制。
+
+[databases](https://github.com/encode/databases)
+
+Python 异步数据库支持。
+
+[Tensorflow-Cookbook](https://github.com/taki0112/Tensorflow-Cookbook)
+易于使用的简单 Tensorflow Cookbook。
+
+[django-pg-timepart](https://github.com/chaitin/django-pg-timepart)
+
+支持 PostgreSQL 11 种时间范围和列表分区的 Django 扩展。
+
+[TheSpaghettiDetective](https://github.com/TheSpaghettiDetective/TheSpaghettiDetective)
+
+用于 3D 打印机远程管理和监控的基于 AI 的故障检测。
+
+[m2cgen](https://github.com/BayesWitnesses/m2cgen)
+
+将机器学习模型转换为零依赖的本地代码(Java、C、Python 等)。
+
+[django-pivot](https://github.com/martsberger/django-pivot)
+
+用于透视 Django Queryset 的模块。
+
+[Vocab](https://github.com/Mckinsey666/Vocab)
+
+与命令行集成的轻量级在线词典。无浏览器。无平装书。
+
+
+# 近期活动和网络研讨会
+
+[Jupyter 社区研讨会 - Paris, France](https://blog.jupyter.org/jupyter-community-workshop-dashboarding-with-project-jupyter-b0e421bdf164)
+
+研讨会将持续四天,包括实际讨论、黑客环节和技术展示。该活动的目标是促进下游库作者和贡献者之间的协作和知识共享,并支持上游贡献。
+
+[London Python 2019 年 2 月聚会 - London, UK](https://www.meetup.com/LondonPython/events/258870262/)
+
+将会有以下演讲:
+
+ * 当深度学习遇见在线时尚
+ * 网络应用消息传递协议 —— Python Web 开发的未来?
+ * 作为反模式导入 —— 解密 Python 中的依赖注入
+
+
+[IndyPy Bytes:集成 —— Indianapolis, IN](https://www.meetup.com/indypy/events/lbdfpqyzdbjc/)
+
+将会有一场演讲 —— Deeper Dive: 集成 Python 和 AWS。
+
+[San Diego Python 2019 年 2 月聚会 - San Diego, CA](https://www.meetup.com/pythonsd/events/nmkqnqyzdblc/)
+
+将会有以下演讲:
+
+ * Windows 中的 PyLauncher
+ * 使用 Python 进行更轻松的调度
+
+[驯服隐藏态:Python 中的状态图 —— Philadelphia, PA](https://www.meetup.com/phillypug/events/258621609/)
+
\ No newline at end of file
diff --git a/Python Weekly/Python_Weekly_Issue_386.md b/Python Weekly/Python_Weekly_Issue_386.md
new file mode 100644
index 0000000..403a3be
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_386.md
@@ -0,0 +1,139 @@
+原文:[Python Weekly - Issue 386](http://eepurl.com/giQEh1)
+
+---
+
+欢迎来到Python周刊第 386 期。让我们直奔主题。
+
+
+# 来自赞助商
+
+[](
+https://www.vettery.com/tech?utm_source=newsletter&utm_medium=pythonweekly&utm_term=tech&utm_content=grouped&utm_campaign=ad-77579)
+
+
+[通过 Vettery 找到一份 Python 工作](https://www.vettery.com/tech?utm_source=newsletter&utm_medium=pythonweekly&utm_term=tech&utm_content=grouped&utm_campaign=ad-77579)
+
+Vettery 是一个专攻开发者的在线招聘平台,对于求职人员而言完全免费。感兴趣吗?那就提交你的个人资料,如果通过的话,你将可以收到由那些寻找 Python 开发者的顶级公司发出的面试邀请。
+
+# 文章,教程和讲座
+
+[从头开始用 Python 构建一个数据分析库](https://www.youtube.com/playlist?list=PLVyhfExBT1XDTu-oocI3ttl_OPhulAJOp)
+
+学习如何使用 Python 从头开始构建数据分析库。沉浸在包含 40 个步骤和 100 次测试的综合项目中,你必须通过这些测试才能完成它。在这里,我们要构建的是 Pandas Cub,这是一个具有与 Pandas 库类似功能的库。
+
+[通过聚类,找到图片的主色](https://www.dataquest.io/blog/tutorial-colors-image-clustering-python/)
+
+用代码分析图片可能很困难。你要怎样让你的代码“理解”一张图片的上下文呢?
+
+[你的第一个开源 Python 项目](https://towardsdatascience.com/build-your-first-open-source-python-project-53471c9942a7)
+
+制作一个开源 Python 包可能听起来很吓人,但要做到这点,并不要求你经验相当丰富。并且,你也不需要精心设计的产品方案。真正需要的,是坚持和时间。希望这份指南能够帮助你减轻负担。
+
+[使用 Python 和 Scikit-Learn,构建一个电影推荐引擎](https://medium.com/code-heroku/building-a-movie-recommendation-engine-in-python-using-scikit-learn-c7489d7cb145)
+
+想知道谷歌是怎么找到那些与你喜欢的电影相似的电影的吗?读过这篇文章,你就可以自己构建一个这样子的系统了。
+
+[如何利用 Google Colab 来练习 Python 编程?](https://towardsdatascience.com/how-to-practice-python-with-google-colab-45fc6b7d118b)
+
+自动设置,及时获得帮助,协作式编程以及版本控制。一站式解决 Python 初学者练习中的痛点。
+
+[如果编写 Python web 框架。第一部分](http://rahmonov.me/posts/write-python-framework-part-one/)
+
+这是编写像 Flask 和 Django 这样的 Python 框架系列的第一部分。在这个部分中,我们将实现以下功能:WSGI 兼容、请求处理器和请求路由:简单并且参数化
+
+ * [第二部分](http://rahmonov.me/posts/write-python-framework-part-two/) - 在此系列的第二部分,我们将实现这些功能:检查重复路由、基于类的处理器以及单元测试。
+
+
+[聊聊 Python 中的数据结构](https://apirobot.me/posts/lets-talk-about-data-structures-in-python)
+
+在这篇文章中,我们将讨论 python 最重要的数据结构。包括它们的工作方式、它们的使用场景以及使用方式。我们甚至会介绍一点点 Big-O 表示法,该表示法有助于描述算法和数据结构的有效性。
+
+[即使某个功能你不使用,它也有可能坑你一把](https://blog.petrzemek.net/2019/02/22/even-feature-that-you-do-not-use-can-bite-you/)
+
+来看看我偶然编写,并且还在代码评审中看到过的一段简单的 Python 代码,它与预期全然不同。
+
+[利用 OpenCV 和深度学习对黑白图像进行着色](https://www.pyimagesearch.com/2019/02/25/black-and-white-image-colorization-with-opencv-and-deep-learning/)
+
+[CPython Bytecode 编译器很蠢](https://nullprogram.com/blog/2019/02/24/)
+
+[Python 字典指南](https://kite.com/blog/python/python-dictionaries)
+
+[修复 Django 异步作业 —— 数据库集成](https://spapas.github.io/2019/02/25/django-fix-async-db/)
+
+[使用 Apache Airflow、Newspaper3k、Quilt T4 和 Vega 实现新闻头条的重复 NLP](https://medium.com/@robnewman/repeatable-nlp-of-news-headlines-using-apache-airflow-newspaper3k-quilt-t4-vega-a0447af57032)
+
+[Cython,超能秘密 Python 扩展介绍](http://okigiveup.net/an-introduction-to-cython/)
+
+[使用 Flask-Login 和 Flask-SocketIO 的单元测试应用](https://blog.miguelgrinberg.com/post/unit-testing-applications-that-use-flask-login-and-flask-socketio)
+
+[关于选择最小可能性的 Django ORM 优化之路](https://www.peterbe.com/plog/django-orm-optimization-story-on-selecting-the-least-possible)
+
+
+# 本周的Python工作
+
+[Cupboard 招聘后端软件工程师](http://jobs.pythonweekly.com/jobs/backend-software-engineer-nyc-or-sea/)
+
+[Wooga 招聘 Python 数据工程师](http://jobs.pythonweekly.com/jobs/data-engineer-python/)
+
+
+# 好玩的项目,工具和库
+
+[privacyIDEA](https://github.com/privacyidea/privacyidea)
+
+privacyIDEA 是一套开源解决方案,用于强双因素身份验证,如 OTP 令牌、SMS、智能手机或者 SSH 密钥。通过 privacyIDEA,你就可以使用第二因素强化现有应用的身份验证过程,例如本地登录(PAM,Windows 凭证提供程序)、VPN、远程访问、SSH 连接、网站或网络门户访问。
+
+[Meltano](https://gitlab.com/meltano/meltano)
+
+Meltano 是一个面向配置的开源产品,适用于整个数据生命周期,包含从数据加载到数据分析的过程。
+
+[bullet](https://github.com/Mckinsey666/bullet)
+
+轻松搞定漂亮的 Python 提示。就像堆叠块一样构建提示。
+
+[SC-FEGAN](https://github.com/JoYoungjoo/SC-FEGAN)
+
+面部编辑生成对抗网络,使用用户草图和颜色。
+
+[subsync](https://github.com/smacke/subsync)
+
+自动将字幕与视频同步。
+
+[Polystores](https://github.com/polyaxon/polystores)
+
+Polystores 是一种抽象以及一组与云存储交互的客户端。
+
+[owoScript](https://github.com/ThePlasmaRailgun/owoScript)
+
+一个基于 OwO 的面向堆栈的编程语言。
+
+[gitdir](https://github.com/sdushantha/gitdir)
+
+下载 GitHub 仓库中的单个目标或者文件夹。
+
+[AdaBound](https://github.com/Luolc/AdaBound)
+
+一个训练速度如 Adam 般快速,功能如 SGD 一样好的优化器。
+
+[message-analyser](https://github.com/vlajnaya-mol/message-analyser)
+
+VKontakte 和 Telegram 消息历史的统计分析。
+
+# 最新发布
+
+[Python 3.8.0a2](https://www.python.org/downloads/release/python-380a2/)
+
+[IPython 7.3](https://discourse.jupyter.org/t/release-of-ipython-7-3/409/1)
+
+
+# 近期活动和网络研讨会
+
+[New York Python 2019 年三月聚会 - New York, NY](https://www.meetup.com/nycpython/events/259044848/)
+
+将会有以下演讲:
+
+ * Copilot @ Xaxis:使用 Python 和 Airflow,在大规模广告技术数据上实现 AI
+ * 为生产环境引进最先进的会话 AI NLP 栈
+ * Runway:为涉及和创意平台添加机器学习功能
+
+
+[DFW Pythoneers 2019 年三月聚会 - Plano, TX](https://www.meetup.com/dfwpython/events/sbnhmqyzfbkb/)
diff --git a/Python Weekly/Python_Weekly_Issue_617.md b/Python Weekly/Python_Weekly_Issue_617.md
new file mode 100644
index 0000000..c973a2d
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_617.md
@@ -0,0 +1,145 @@
+原文:[Python Weekly - Issue 617](http://eepurl.com/izHuCA)
+
+---
+
+欢迎来到Python周刊第 617 期。让我们直奔主题。
+
+
+# 文章、教程和讲座
+
+[向量嵌入教程 – 使用 GPT-4 和自然语言处理创建 AI 助手](https://www.youtube.com/watch?v=yfHHvmaMkcA) 
+
+了解向量嵌入,以及如何在机器学习和人工智能项目中使用它们。了解如何使用矢量嵌入创建 AI 助手。
+
+[Python 数据帧交换协议(Dataframe Interchange Protocol)是如何让生活更美好的](https://ponder.io/how-the-python-dataframe-interchange-protocol-makes-life-better/)
+
+在本文中,我们回答了有关 Python 数据帧交换协议的三个问题:它是什么 + 它解决了什么问题;它是怎么运行的; 以及它被广泛采用的程度。
+
+[flake8-logging 介绍](https://adamj.eu/tech/2023/09/07/introducing-flake8-logging/)
+
+本文介绍 flake8-logging,一个可帮你改进 Python 代码中的日志记录的 Flake8 插件。Flake8 是一个检查 Python 代码是否有错误和样式违规的 linter。flake8-logging 通过添加检查日志代码的规则来扩展 Flake8。
+
+[我们是如何使用 LLM 嵌入来构建 AI 搜索引擎的](https://www.youtube.com/watch?v=ZCPUmC37HLU) 
+
+演示并解释如何使用 Python 的 sentence-transformers 库,通过 Django ORM 和 pgvector 来生成、存储和查询 LLM 嵌入。该视频演示了一个原型应用,这个应用可以使用求职者的非结构化英语描述来进行职位描述的“人工智能驱动搜索”。
+
+[调试 Python 中正则表达式的灾难性回溯](https://krishnanchandra.com/posts/regex-catastrophic-backtracking/)
+
+这篇文章讨论了正则表达式中的灾难性回溯问题,并提供了一些有关如何避免该问题的提示。它还讨论了正则表达式引擎处理回溯的不同方式,以及不同方法之间的权衡。
+
+[使用 Coiled、Dask 和 Xarray 处理 250 TB 数据集](https://blog.coiled.io/blog/coiled-xarray.html)
+
+作者使用 Xarray、Dask 和 Coiled,在 20 分钟内成功处理了大小为 250 TB 的地理空间云数据,强调了所涉及的挑战和优化,同时将成本保持在大约 25 美元左右。这一成就证明了大规模数据处理的可行性,暴露了可扩展性问题,并探索了此类任务的成本效益策略。
+
+[使用 Kamal 部署 Django (mrsk)](https://anthonynsimon.com/blog/kamal-deploy/)
+
+如果你只想在远程计算机上部署容器,Kamal 可能是你工具带的一个不错的补充。将容器部署到一台或多台远程计算机时,它会自动执行许多常见步骤,而不会引入诸如 Kubernetes 这样的复杂性,也无需使用托管服务。
+
+[使用 Django 和 HTMX 添加数据库搜索](https://www.photondesigner.com/articles/database-search-django-htmx)
+
+我们将使用 Django 和 HTMX 来创建快速且简单的数据库搜索。使用 HTMX 可以轻松快速地完成此操作。将有 6 个步骤。
+
+[何时使用 Python 中的类?当您重复相同的函数时](https://death.andgravity.com/same-functions)
+
+在本文中,我们将了解在 Python 中使用类的另一种启发式方法,其中包含来自实际代码的示例以及一些需要记住的事项。
+
+[迈向新的 SymPy:第 1 部分 - 概述](https://oscarbenjamin.github.io/blog/czi/post1.html)
+
+第一篇文章将概述像 SymPy 这样的计算机代数系统 (CAS) 的基础结构,描述 SymPy 目前存在的一些问题以及解决这些问题的方法。接着,后续的文章将更详细地关注特定组件、已完成的工作以及将来要做什么。
+ * [第 2 部分 - 多项式](https://oscarbenjamin.github.io/blog/czi/post2.html) - 本文将描述 SymPy 的多项式计算代数系统,以及如何应用每个步骤来加速 SymPy。我会谈谈 FLINT 和 python-flint,但我也会写一篇关于这些的单独的文章,因为我知道有些人对使用 python-flint 比 SymPy 本身更感兴趣,我希望鼓励他们为 python-flint 做出贡献。
+
+
+[如何通过 PyObjC,使用 Apple Vision 框架进行文本识别](https://yasoob.me/posts/how-to-use-vision-framework-via-pyobjc/)
+
+本文讨论如何通过 PyObjC(允许你通过 Python 使用 Objective-C 框架),使用 Vision 框架。Vision 框架是一个机器学习框架,可用于执行人脸检测、对象检测和文本识别等任务。
+
+[可视化 CPython 发布过程](https://sethmlarson.dev/security-developer-in-residence-weekly-report-9)
+
+[为模块改变 Python 属性处理](https://lwn.net/SubscriberLink/943619/eaa8a4496fcba1fd/)
+
+[如何使用 Python 和 Django 对类似于 Twitter 和 Instagram 的后续系统进行建模](https://uhtred.dev/insights/how-to-model-a-following-system-similar-to-twitter-and-instagram-with-python-and-django)
+
+
+# 好玩的项目,工具和库
+
+[Litestar](https://github.com/litestar-org/litestar)
+
+Litestar 是一个功能强大、灵活但有自己想法的 ASGI 框架,专注于构建 API,并提供高性能的数据验证和解析、依赖项注入、第一类(first-class)ORM 集成、授权原语以及启动和运行应用程序所需的更多功能。
+
+[InstaGraph](https://github.com/yoheinakajima/instagraph)
+
+将文本输入或 URL 转换为知识图表并显示。
+
+[Prompt flow](https://github.com/microsoft/promptflow)
+
+构建高质量的 LLM 应用 - 从原型设计、测试到生产部署和监控。
+
+[kr8s](https://github.com/kr8s-org/kr8s)
+
+一个即拆即用(batteries-included)的 Kubernetes Python 客户端库,对于已经知道如何使用 kubectl 的人来说会感觉到很熟悉。
+
+[Pyflyby](https://github.com/deshaw/pyflyby)
+
+一套 Python 生产力工具。
+
+[pai](https://github.com/AlexWiles/pai)
+
+具有内置 AI 代理和代码生成功能的 Python REPL。
+
+[view.py](https://github.com/ZeroIntensity/view.py)
+
+快如闪电的现代 Web 框架。
+
+[django-send-sms](https://github.com/hizbul25/django-send-sms)
+
+只需编写一行代码,就可以使用任何短信服务提供商,从 Django 应用程序发送短信。
+
+[WhatsApp-Llama](https://github.com/Ads-cmu/WhatsApp-Llama/)
+
+根据你的 WhatsApp 对话,微调 LLM,让它像您一样说话。
+
+[textual-web](https://github.com/Textualize/textual-web)
+
+在浏览器中运行 TUI 和终端。
+
+[LiteLLM](https://github.com/BerriAI/litellm)
+
+使用 OpenAI 格式,调用所有 LLM API(包括 Anthropic、Huggingface、Cohere、TogetherAI、Azure、OpenAI 等)
+
+[blip-caption](https://github.com/simonw/blip-caption)
+
+使用 Salesforce BLIP 为图像生成标题。
+
+[Vanna](https://github.com/vanna-ai/vanna)
+
+个性化 AI SQL 代理。
+
+[Medusa](https://github.com/FasterDecoding/Medusa)
+
+用于通过多个解码头加速 LLM 生成的简单框架。
+
+
+# 最新发布
+
+[Visual Studio Code 中的 Python - 2023 年 9 月版本](https://devblogs.microsoft.com/python/python-in-visual-studio-code-september-2023-release/)
+
+此版本包括以下更新:
+* Python 增加了“重新创建(Recreate)”或者“使用现有(Use Existing)”的选项:创建环境命令
+* 使用环境变量进行实验性终端激活
+* 社区贡献的 yapf 扩展
+
+
+# 近期活动和网络研讨会
+
+[2023 年 9 月的 PyData Berlin Meetup](https://www.meetup.com/pydata-berlin/events/295877988/)
+
+将进行以下演讲:
+* 随机梯度朗之万动力学(Stochastic Gradient Langevin Dynamics,SGLD) —— 动机、基础以及 DL 可以获得什么
+* OpenAI 开源语音识别模型Whisper:最先进的语音转录和语音界面革命
+
+
+[2023 年 9 月的 PyData Zurich Meetup](https://www.meetup.com/pydata-zurich/events/295909252/)
+
+将有以下演讲:
+* 如何(不)在机器学习中使用公平性指标
+* 我们可以从 Python 的类型系统中挤出更多的东西吗?Tensor Shape Annotations 的挑战。
\ No newline at end of file
diff --git a/Python Weekly/Python_Weekly_Issue_618.md b/Python Weekly/Python_Weekly_Issue_618.md
new file mode 100644
index 0000000..5ec33c6
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_618.md
@@ -0,0 +1,160 @@
+原文:[Python Weekly - Issue 618](http://eepurl.com/iz-KzU)
+
+---
+
+欢迎来到Python周刊第 618 期。让我们直奔主题。
+
+
+# 文章、教程和讲座
+
+[为了好玩,将 ML 模型编译为 C](https://bernsteinbear.com/blog/compiling-ml-models/)
+
+ML 模型可以编译为图形,从而被用来遍历以执行前向和后向传递。这种方法可以提高性能并使调试 ML 模型变得更加容易。
+
+[从数据集角度优化 LLM](https://sebastianraschka.com/blog/2023/optimizing-LLMs-dataset-perspective.html)
+
+本文重点介绍如何使用精心制作的数据集对 LLM 进行微调,从而提高 LLM 的建模性能。具体来说,本文重点介绍了涉及修改、利用或操作数据集以进行基于指令的微调的策略,而不是更改模型架构或训练算法(后者将是未来文章的主题)。本文还会解释如何准备自己的数据集来微调开源LLM。
+
+[为什么有这么多 Python 数据帧(DataFrame)?](https://ponder.io/why-are-there-so-many-python-dataframes/)
+
+这篇文章探讨了 Python 数据帧(DataFrame)的激增,剖析了它们在数据科学和分析中盛行背后的原因,揭示了有助于丰富其内容的各种库和框架。
+
+
+[我手工制作了一个 Transformer(无需训练!) ](https://vgel.me/posts/handmade-transformer/)
+
+本文深入探讨了如何创建手工制作的 Transformer 模型,提供了从头开始构建这种流行的深度学习架构的详细演练,深入了解了其内部工作原理和结构。
+
+[EuroPython 2023 视频](https://www.youtube.com/playlist?list=PL8uoeex94UhFcwvAfWHybD7SfNgIUBRo-) 
+
+这里是由 EuroPython 2023 团队和 EuroPython 协会为您带来的会议的所有视频。
+
+[如何在 6 分钟内向 Django 添加无服务器函数(使用 HTMX 和 AWS Lambda)](https://www.photondesigner.com/articles/serverless-functions-django)
+
+本文讨论无服务器函数(serverless functions)与 Django 的集成,重点介绍开发人员可以如何利用无服务器计算(serverless computing)的优势来执行 Django 应用程序中的特定任务。它探讨了无服务器架构的优势,并为实现提供了实用的见解。
+
+[使用 Python 模拟蒙提霍尔问题(Monty Hall problem)](https://www.dataschool.io/python-probability-simulation/)
+
+使用 Python 解决这个困扰数学家和诺贝尔奖获得者的经典概率难题!
+
+> Ele 注:[蒙提霍尔问题](https://zh.wikipedia.org/zh-hans/%E8%92%99%E6%8F%90%E9%9C%8D%E7%88%BE%E5%95%8F%E9%A1%8C)
+
+[PyO3 异常 🎦](https://www.youtube.com/watch?v=UaeOdVwNNpI) 
+
+该视频讨论了使用 Rust 时,在 Python 中处理异常的问题。在 Rust 中,错误的处理方式不同,它使用响应类型,而 Python 则使用异常。该视频演示了如何通过创建 Python 异常实例并引发它,使用 Rust 在 Python 中引发异常。它还展示了如何通过使用映射函数将 Rust 错误转换为 Python 异常来处理异常。
+
+[Django:将模板标签库移至内置模块中](https://adamj.eu/tech/2023/09/15/django-move-template-tag-library-builtins/)
+
+Django 的模板引擎有一个未被充分重视的内置选项,该选项可以选择要在每个模板中预加载的库。将库设为内置对象可以避免在使用其标签或过滤器时需要显式使用 {% load %} 标签。将关键库放入内置模块中可以缩短模板并使开发速度更快一些。在这篇文章中,我们将介绍如何向内置模块添加模板库以及如何从模板中删除现有的 {% load %} 标签。
+
+[加速 Floyd-Steinberg 抖动:一个优化练习](https://pythonspeed.com/articles/optimizing-dithering/)
+
+一个已解决实例:优化低层代码以获得显着的性能和内存改进。
+
+> Ele 注:根据google,Floyd-Steinberg抖动算法是图像抖动算法的一种,其思想是将误差传播到邻近的像素点。 Floyd-Steinberg算法思想是将误差传播到邻近的像素点,误差的计算非常简单,即误差为像素点灰度值与该像素点最后取值的差值。
+
+[Python 初学者教程(带迷你项目)🎦](https://www.youtube.com/watch?v=qwAFL1597eM) 
+
+在这个面向初学者的完整课程中学习 Python 编程。本教程自始至终都以迷你项目为特色,因此您可以立即将学到的知识运用到实践中。
+
+[快 19 倍的响应时间](https://lincolnloop.com/insights/optimizing-response-time-19x-faster/)
+
+Lincoln Loop 优化了大型发布平台的数据库性能。总体而言,数据库性能提高了 19 倍。
+
+[构建适用于生产的基于 RAG 的 LLM 应用程序(第 1 部分)](https://www.anyscale.com/blog/a-comprehensive-guide-for-building-rag-based-llm-applications-part-1)
+
+在本指南中,我们将学习如何开发和生产基于检索增强生成 (RAG) 的 LLM 应用程序,关注规模、评估和路由。
+
+
+# 好玩的项目,工具和库
+
+[EvoDiff](https://github.com/microsoft/evodiff)
+通过离散扩散模型生成蛋白质序列和进化比对。
+
+[every-breath-you-take](https://github.com/kbre93/every-breath-you-take)
+使用 Polar H10 监测仪进行心率变异训练。
+
+[Galactic](https://github.com/taylorai/galactic)
+Galicate 为海量非结构化文本数据集提供清理和管理工具。它旨在帮助您管理微调数据集、创建用于检索增强生成 (RAG) 的文档集合,甚至为 LLM 预训练进行网络规模数据集的重复数据删除。
+
+[Logparser](https://github.com/logpai/logparser)
+Logparser 为自动化日志解析(结构化日志分析的关键步骤)提供了一个机器学习工具包和基准
+
+[HTTP-Shell](https://github.com/JoelGMSec/HTTP-Shell)
+多平台 HTTP 反向 Shell。
+
+[llm-guard](https://github.com/laiyer-ai/llm-guard)
+用于 LLM 交互的安全工具包。
+
+[Temporian](https://github.com/google/temporian)
+Temporian 是一个 Python 库,用于机器学习应用中时态数据(例如时间序列、事务)的特征工程和数据增强。
+
+[vpselector](https://github.com/manumerous/vpselector)
+Visual Pandas Selector:可视化及交互式选择时间序列数据。
+
+[QuasiQueue](https://github.com/tedivm/quasiqueue)
+QuasiQueue 是一个 Python 多处理库,它使长时间运行的多进程作业变得非常容易。QuasiQueue 处理进程创建和清理、信号管理、跨进程通信以及所有其他让人讨厌处理多处理的糟心玩意。
+
+[PyGraft](https://github.com/nicolas-hbt/pygraft)
+触手可及的模式和知识图可配置生成。
+
+[PYOBD](https://github.com/barracuda-fsh/pyobd)
+开源 obd2 汽车诊断程序。
+
+[reinette-II-plus-dot-py](https://github.com/ArthurFerreira2/reinette-II-plus-dot-py)
+用 Python 实现的 Apple II 模拟器
+
+[PyLLMCore](https://github.com/paschembri/py-llm-core)
+提供轻量级 LLM 的 python 库。
+
+[HomeHarvest](https://github.com/ZacharyHampton/HomeHarvest)
+用于房地产抓取的 Python 包,支持 Zillow,Realtor.com 和 Redfin。
+
+
+# 最新发布
+
+[Django 5.0 alpha 1 发布](https://www.djangoproject.com/weblog/2023/sep/18/django-50-alpha-1-released/)
+
+[Python 3.12.0 候选版本 3 现已推出](https://pythoninsider.blogspot.com/2023/09/python-3120-release-candidate-3-now.html)
+
+
+# 近期活动和网络研讨会
+
+[2023 年 9 月 PyLadies 伦敦研讨会](https://www.meetup.com/pyladieslondon/events/295976344/)
+
+将有以下演讲:
+
+ * 外部技术:在工程师和非工程师之间架起桥梁
+ * 使用 Django 进行快速原型设计
+
+
+[2023 年 9 月 Python 巴塞罗那研讨会](https://www.meetup.com/python-barcelona/events/296203267/)
+
+将有以下演讲:
+
+ * 向量化Python表达式中的两种语言问题
+ * AI图像生成算法在服装设计中的应用
+
+
+[2023 年 9 月 PyLadies 巴黎研讨会](https://www.meetup.com/pyladiesparis/events/295911409/)
+
+将有以下演讲:
+
+ * 机器学习和因果推断:寻找新的临床证据?
+ * 项目反馈:减少权限管理时间,同时保护您的用户!
+
+
+[2023 年 9 月 VilniusPy 研讨会](https://www.meetup.com/vilniuspy/events/296100222/)
+
+将有以下演讲:
+
+ * 我们是如何将我们的 Django 测试套件加速 10 倍的
+ * Python 生成器:内存占用少,功耗大
+ * Deadcode —— 一个查找和修复死的(未使用)Python 代码的工具
+
+
+[2023 年 9 月 PyData 斯德哥尔摩研讨会](https://www.meetup.com/pydatastockholm/events/295730658/)
+
+将有以下演讲:
+
+ * 如何通过桥接跨领域知识来开发正确的解决方案,从而实现人工智能的价值?
+ * 自动化一切:使用 Python 扩展 Voi 的 dbt 功能
\ No newline at end of file
diff --git a/Python Weekly/Python_Weekly_Issue_619.md b/Python Weekly/Python_Weekly_Issue_619.md
new file mode 100644
index 0000000..6bd93e9
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_619.md
@@ -0,0 +1,105 @@
+原文:[Python Weekly - Issue 619](http://eepurl.com/iAEiz6)
+
+---
+
+欢迎来到Python周刊第 619 期。让我们直奔主题。
+
+
+# 文章、教程和讲座
+
+[Mojo 编程语言 —— 给初学者的完整课程](https://www.youtube.com/watch?v=5Sm9IVMet9c) 
+在这个完整教程中学习 Mojo。Mojo 编程语言结合了 Python 的可用性和 C 的性能。它基本上是专为人工智能开发人员设计的 Python 增强版本。
+
+[在 git 存储库中,您的文件位于哪里?](https://jvns.ca/blog/2023/09/14/in-a-git-repository--where-do-your-files-live-/)
+这篇文章探讨了 Git 存储库的内部工作原理,揭示了文件在存储库结构中的存储位置。它深入解释了对 Git 对象模型及其管理文件版本的方式。
+
+[语言模型的黑客指南](https://www.youtube.com/watch?v=jkrNMKz9pWU) 
+在这段内容丰富的视频中,fast.ai 联合创始人兼所有现代语言模型 (LM) 所基于的 ULMFiT 方法的创建者 Jeremy Howard 将带您全面了解 LM 的迷人景象。Jeremy 从基本概念开始,介绍了使这些人工智能系统发挥作用的架构和机制。然后,他深入讲述了 GPT-4 的关键评估,阐明了语言模型在代码编写和数据分析中的实际用途,并提供了使用 OpenAI API 的实践技巧。该视频还提供了有关技术主题的专家指导,例如微调、解码令牌和运行 GPT 模型的私有实例。
+
+[Asyncio 协程比线程快!?](https://superfastpython.com/asyncio-coroutines-faster-than-threads/)
+在本教程中,您将在给定一组基准测试的情况下,看看协程是否真的比线程更快。
+
+[为 Django ORM 构建 RisingWave 连接器](https://bas.codes/posts/django-risingwave)
+曾经想过将流数据库连接到 Django ORM 吗?那就来了解如何使用 Django 和 RisingWave 吧。
+
+[我用 ChatGPT 打造了一位人工智能医生 —— 完整的临床经验](https://www.youtube.com/watch?v=EAger7jOrsA) 
+该软件旨在测试人工智能执行患者入院、图表注释以及提供调查和诊断援助的能力。然而,值得注意的是,该软件尚未经过美国食品和药物管理局 (FDA) 或任何其他医疗设备监管机构的测试、验证或批准。
+
+[Seaborn 混淆矩阵:如何用 Python 绘图和可视化](https://www.marsja.se/seaborn-confusion-matrix-how-to-plot-and-visualize-in-python/)
+通过 Seaborn 混淆矩阵绘图掌握数据可视化的艺术。像专业人士一样评估模型性能。
+
+[通过基于角色的权限,使内容管理者的 Django 管理员访问权限保持最新状态](https://406.ch/writing/keep-content-managers-admin-access-up-to-date-with-role-based-permissions/)
+使用 Django 基于角色的权限系统,您可以通过仅授予内容管理者所需的权限,来使内容管理者的管理员访问权限保持最新状态。这可以通过使用基于白名单的方法来完成,其中,用户默认没有权限,因此必须单独授予用户每个权限。
+
+[为什么 Python 代码在函数中运行得更快?](https://stackabuse.com/why-does-python-code-run-faster-in-a-function/)
+Python 不一定以其速度而闻名,但有些东西可以帮助您从代码中榨取更多性能。令人惊讶的是,其中一种做法是在函数中而不是在全局范围内运行代码。在本文中,我们将看到为什么 Python 代码在函数中运行得更快,以及 Python 代码执行的工作原理。
+
+[GPT Engineer 真的有用吗?](https://www.youtube.com/watch?v=NLgw19X8p7I) 
+该视频探讨了 GPT Engineer 的功能,这是一种新的 AI 编码工具,可以为多种编程语言生成代码。它评估了使用 GPT Engineer 的优缺点,并讨论了如何使用它为新项目快速生成样板代码。该视频还比较了 GPT 3.5 和 GPT 4,这是 GPT Engineer 所基于的两种大型语言模型。
+
+[在无法使用多核时加速代码](https://pythonspeed.com/articles/optimizing-dithering/)
+并行并不是唯一的答案:通常您可以优化低级代码以获得显着的性能改进。
+
+[开始 CPython 的软件物料清单(SBOM)](https://sethmlarson.dev/security-developer-in-residence-weekly-report-12)
+
+[那么,你想公开数据库吗?—— 一次自动 API 生成的探索](https://codebeez.nl/blogs/so-you-want-to-expose-a-database-an-exploration-of-automated-api-generation/)
+
+[用不到 10 行代码,使用 GZI P,达到 78% MNIST 准确率。](https://jakobs.dev/solving-mnist-with-gzip/)
+
+[小但快:使用 Flask、htmx 和 Airtable 进行如闪电般的快速搜索(无需 React)。](https://levelup.gitconnected.com/small-and-speedy-lightning-fast-search-with-flask-htmx-and-airtable-no-react-required-f10b40785bf3)
+
+
+# 好玩的项目,工具和库
+
+[magentic](https://github.com/jackmpcollins/magentic)
+将 LLM 无缝集成为 Python 函数。
+
+[vizro](https://github.com/mckinsey/vizro)
+Vizro 是一个用于创建模块化数据可视化应用程序的工具包。
+
+[SeaGOAT](https://github.com/kantord/SeaGOAT)
+本地优先语义代码搜索引擎。
+
+[dify](https://github.com/langgenius/dify)
+一个用于插件和数据集的 API,一个用于快速工程和可视化操作的界面,所有这些都用于创建强大的 AI 应用程序。
+
+[FastStream](https://github.com/airtai/faststream)
+FastStream 是一个功能强大且易于使用的 Python 框架,用于构建与 Apache Kafka 和 RabbitMQ 等事件流交互的异步服务。
+
+[rustworkx](https://github.com/Qiskit/rustworkx)
+一个用 Rust 实现的高性能 Python 图形库。
+
+[shshsh](https://github.com/zqqqqz2000/shshsh)
+python 和 shell 之间的桥梁。
+
+[Medical_Intake](https://github.com/daveshap/Medical_Intake)
+用于医疗摄入、诊断、测试等的自动化管道
+
+[automatic_log_collector_and_analyzer](https://github.com/Dicklesworthstone/automatic_log_collector_and_analyzer)
+用这一奇技淫巧取代您小公司中的 Splunk!
+
+[pythex](https://pythex.org/)
+pythex 是测试 Python 正则表达式的快速方法。
+
+[PyMilo](https://github.com/openscilab/pymilo)
+PyMilo 提供了一种导出预训练机器学习模型的方法。这使得在其他环境中使用模型、跨不同平台传输模型以及与其他人共享模型成为可能。
+
+
+# 近期活动和网络研讨会
+
+[PyBay2023](https://pybay.com/)
+想和朋友一起出去并享受美食和饮料吗?参加 PyBay2023 吧,这是第八届年度区域 Python 会议,有 25 场演讲!
+
+[PyData 伦敦 2023年10月研讨会](https://www.meetup.com/pydata-london-meetup/events/295029812/)
+将会有以下演讲:
+ * 使用这一奇技淫巧创建自助数据
+ * Unicode 历险记:鲜为人知的 `str`
+ * Polars 最疯狂的特性:字节码解析
+ * 设置您自己的 ML 集群
+
+
+[PyRVA 2023年10月研讨会](https://www.meetup.com/pyrvausergroup/events/295802864/)
+会一场演讲:掌握 Selenium 以提高网络浏览器自动化效率。
+
+[Hybrid: PyConZA 2023](https://za.pycon.org/)
+PyConZA 是南非社区使用和开发开源 Python 编程语言的年度聚会。
diff --git a/Python Weekly/Python_Weekly_Issue_620.md b/Python Weekly/Python_Weekly_Issue_620.md
new file mode 100644
index 0000000..acf0ae8
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_620.md
@@ -0,0 +1,96 @@
+原文:[Python Weekly - Issue 620](http://eepurl.com/iA9nDI)
+
+---
+
+欢迎来到Python周刊第 620 期。让我们直奔主题。
+
+
+# 文章、教程和讲座
+
+[Python 3.12:您需要了解的所有新功能!](https://www.youtube.com/watch?v=udHmeAmOlbI) 
+该视频不仅将深入探讨 Python 3.12 中即将推出的令人兴奋的新功能和改进,还将讨论即将发布的版本中将删除的一些东西。
+
+[度量 Python 执行时间的 5 种方法](https://superfastpython.com/benchmark-execution-time/)
+您可以使用标准库中的“time”模块对 Python 代码的执行进行基准测试。在本教程中,您将了解如何使用一套不同的技术来计时 Python 代码的执行时间。
+
+[使用 FastAPI 掌握集成测试](https://alex-jacobs.com/posts/fastapitests/)
+集成测试 FastAPI:使用 MongoMock、MockS3 等来利用模拟后端服务的强大功能。
+
+[LangChain 初始者速成班](https://www.youtube.com/watch?v=lG7Uxts9SXs) 
+LangChain 是一个旨在简化使用大型语言模型创建应用程序的框架。它让你能够轻松地将 AI 模型与大量不同的数据源连接起来,以便您可以创建定制的 NLP 应用程序。
+
+[使用 Django REST 框架构建 API](https://blog.jetbrains.com/pycharm/2023/09/building-apis-with-django-rest-framework/)
+本教程演示了如何在 PyCharm 中使用 Python 和 Django REST 框架来开发 API
+
+[我所学到的有关在 Python 中构建 CLI 工具的那些事](https://simonwillison.net/2023/Sep/30/cli-tools-python/)
+我用 Python 构建了很多命令行工具。它已成为我最喜欢的快速将一段代码变成我可以自己使用并打包供其他人使用的方法。以下是我迄今为止在 Python 中设计和实现 CLI 工具所学到的一些东西的笔记。
+
+[用不到 200 行代码在云中构建 API](https://aeturrell.com/blog/posts/build-a-cloud-api/build-a-cloud-api.html)
+云工具和 Python 包已经变得非常强大,让您可以用不到 200 行代码构建(可扩展的)基于云的 API。在本文中,您将了解如何使用 Google Cloud、Terraform 和 FastAPI,在云上部署可查询数据 API。
+
+[如何在 Django 中安全存储用户的 API 密钥](https://www.photondesigner.com/articles/store-api-keys-securely)
+加密用户的密钥以提高安全性。
+
+[使用 PyTorch Lightning 扩展大型(语言)模型](https://lightning.ai/blog/scaling-large-language-models-with-pytorch-lightning/)
+了解使用 PyTorch Lightning 训练 Llama 和 Stable Diffusion 等大型模型的技术。
+
+[探索 Wordle](https://www.georgevreilly.com/2023/09/26/ExploringWordle.html)
+本文将向您展示如何使用 Python,以编程方式解决 Wordle。
+
+
+# 好玩的项目,工具和库
+
+[mistral-src](https://github.com/mistralai/mistral-src)
+Mistral AI 7B v0.1 模型的参考实现。
+
+[kernel-hardening-checker](https://github.com/a13xp0p0v/kernel-hardening-checker)
+用于检查 Linux 内核安全强化选项的工具。
+
+[dreamgaussian](https://github.com/dreamgaussian/dreamgaussian)
+用于高效 3D 内容创建的生成 Gaussian Splatting。
+
+[cloud_benchmarker](https://github.com/Dicklesworthstone/cloud_benchmarker)
+Cloud Benchmarker 自动化执行云实例的性能测试,提供富有洞察力的图表并随时间进行跟踪。
+
+[DSPy](https://github.com/stanfordnlp/dspy)
+使用基础模型进行编程的框架。
+
+[cloudgrep](https://github.com/cado-security/cloudgrep)
+cloudgrep 是用于云存储的 grep。
+
+[Octogen](https://github.com/dbpunk-labs/octogen)
+Octogen 是一款由 GPT3.5/4 和 Codellama 提供支持的开源代码解释器。
+
+[stepping](https://stepping.site/)
+给 Python 应用开发者的增量视图维护。
+
+[BoTorch](https://botorch.org/)
+BoTorch 是一个基于 PyTorch 构建的贝叶斯优化研究库。
+
+[cappa](https://github.com/dancardin/cappa)
+声明式 CLI 参数解析器。
+
+# 最新发布
+
+[Python 3.12.0](https://www.python.org/downloads/release/python-3120/)
+Python 3.12.0 中的一些主要变化包括
+ * 更灵活的 f 字符串解析
+ * Python 代码对缓冲区协议的支持
+ * 新的调试/分析 API
+ * 支持具有单独全局解释器锁(GIL)的隔离子解释器
+ * 更多改进的错误消息。
+ * 支持 Linux 性能分析器报告跟踪中的 Python 函数名称。
+ * 许多大大小小的性能改进
+
+[Flask 3.0.0](https://flask.palletsprojects.com/en/3.0.x/changes/)
+
+[Django 安全版本已发布:4.2.6、4.1.12 和 3.2.22](https://www.djangoproject.com/weblog/2023/oct/04/security-releases/)
+
+
+ # 近期活动和网络研讨会
+
+[Hybrid IndyPy - 利用 AI 进行创新:构建类似 ChatGPT 的应用程序](https://www.meetup.com/indypy/events/294548715/)
+希望通过创建自己的类似 ChatGPT 的应用程序来释放 AI 和 LLM 的潜力吗?在本次演讲和现场演示中,您将学习如何提取专有数据见解、加速数据驱动的决策、提高生产力并推动创新。
+
+[虚拟(Virtual):克利夫兰 Python 2023 年 10 月聚会](https://www.meetup.com/cleveland-area-python-interest-group/events/295681934/)
+将有一场演讲:使用网络抓取,解析和收集亚马逊产品列表的评论数据。
diff --git a/Python Weekly/Python_Weekly_Issue_621.md b/Python Weekly/Python_Weekly_Issue_621.md
new file mode 100644
index 0000000..66475e4
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_621.md
@@ -0,0 +1,101 @@
+原文:[Python Weekly - Issue 621](http://eepurl.com/iBCBtY)
+
+---
+
+欢迎来到Python周刊第 621 期。让我们直奔主题。
+
+
+# 文章、教程和讲座
+
+[几分钟内构建您的第一个 Pytorch 模型!](https://www.youtube.com/watch?v=tHL5STNJKag) 
+在本视频中,我们将通过实践来学习!构建您的第一个 PyTorch 模型(可以对扑克牌图像进行分类)。
+
+[使用单个 GPU,在 Python 代码上微调 Mistral7B!](https://wandb.ai/byyoung3/ml-news/reports/Fine-Tuning-Mistral7B-on-Python-Code-With-A-Single-GPU---Vmlldzo1NTg0NzY5)
+虽然 Mistral 7B 的开箱即用令人印象深刻,但其微调能力仍有巨大潜力。本教程旨在指导您完成针对特定用例(Python 编码)微调 Mistral 7B 的过程!我们将利用 HuggingFace 的 Transformers 库、DeepSpeed(用于优化)和 Choline(用于简化在 Vast.ai 上部署)等强大工具。
+
+[使用 Python 管道方法,优雅地进行模块化数据处理](https://github.com/dkraczkowski/dkraczkowski.github.io/tree/main/articles/crafting-data-processing-pipeline)
+深入研究错综复杂的数据处理通常感觉就像在错综复杂的迷宫中航行。我们构建了这些复杂的流程,却只是为了避免破坏它们而对其保持原样。但如果我们可以改进它呢?以下是我对用 Python 构建更易于维护、模块化的数据处理工作流程的看法,该工作流程倾向于“管道和过滤器”架构模式。
+
+[使用 Pandas Dropna 处理缺失数据](https://ponder.io/professional-pandas-handling-missing-data-with-pandas-dropna/)
+在这篇文章中,我们将通过探索世界幸福报告来学习如何使用 pandas dropna 处理缺失数据。
+
+[从 Python 调用 Rust](https://blog.frankel.ch/rust-from-python/)
+从这篇文章学习从 Python 调用 Rust 的三种不同方法:HTTP、IPC 和 FFI。
+
+[如何在 SaaS 平台中使用 LLM](https://www.youtube.com/watch?v=fH8fJYWfJcg) 
+该视频将引导您了解在名为 Learntail 的 SaaS 平台中使用了多大的语言模型。Learntail 是一款易于使用的人工智能测验生成工具。
+
+[Django 中的 RegisterFields](https://www.better-simple.com/django/2023/10/03/registerfields-in-django/)
+对一个 Django 模型字段的解释,该字段根据键返回类的实例。
+
+[Python 类型提示:pyastgrep 案例学习](https://lukeplant.me.uk/blog/posts/python-type-hints-pyastgrep-case-study/)
+作者分享了他们在工具 pyastgrep 中向 Python 代码添加类型提示的经验。他们讨论了使用静态类型检查和交互式编程来帮助捕获错误并提高代码可读性的挑战和好处。
+
+# 好玩的项目,工具和库
+
+[LeptonAI](https://github.com/leptonai/leptonai)
+一个用于简化 AI 服务构建的 Pythonic 框架。
+
+[RealtimeSTT](https://github.com/KoljaB/RealtimeSTT)
+强大、高效、低延迟的语音转文本库,具有先进的语音活动检测、唤醒词激活和即时转录功能。专为诸如语音助手这类实时应用程序而设计。
+
+[ziggy-pydust](https://github.com/fulcrum-so/ziggy-pydust)
+用于在 Zig 中构建 Python 扩展的工具包。
+
+[LLM-scientific-feedback](https://github.com/Weixin-Liang/LLM-scientific-feedback)
+大型语言模型能否为研究论文提供有用的反馈?大规模的实证分析。
+
+[genai-stack](https://github.com/docker/genai-stack)
+这个 GenAI 应用程序栈将让您立即开始构建自己的 GenAI 应用程序。演示应用程序可以作为灵感或起点。
+
+[Chrome-GPT](https://github.com/richardyc/Chrome-GPT)
+控制桌面版 Chrome 的 AutoGPT 代理。
+
+[streaming-llm](https://github.com/mit-han-lab/streaming-llm)
+具有注意力接收器的高效流式语言模型。
+
+[torch2jax](https://github.com/samuela/torch2jax)
+在 JAX 中运行 PyTorch。
+
+[swiss_army_llama](https://github.com/Dicklesworthstone/swiss_army_llama)
+一种用于语义文本搜索的 FastAPI 服务,使用预先计算的嵌入和高级相似性度量,提供通过 textract 内置对各种文件类型的支持。
+
+
+# 最新发布
+
+[Visual Studio Code 中的 Python —— 2023 年 10 月版本](https://devblogs.microsoft.com/python/python-in-visual-studio-code-october-2023-release/)
+此版本包括以下声明:
+ * Python 调试器扩展更新
+ * 弃用对 Python 3.7 的支持
+ * Pylint 扩展的更改选项上的 Lint
+ * Mypy 扩展报告范围和守护进程模式
+ * Grace Hopper 会议和开源日参与
+
+
+
+# 近期活动和网络研讨会
+
+[ThaiPy #96](https://www.meetup.com/thaipy-bangkok-python-meetup/events/295498832/)
+将有以下讲座:
+* Python GIL。过去与未来
+* 利用 GPU 加速 100 倍
+
+
+[PyLadies 2023 年 10 月都柏林聚会](https://www.meetup.com/pyladiesdublin/events/295990212/)
+将进行以下演讲:
+* 想再次成为一个小朋友吗?年龄永远不是问题!
+* 打印您自己的冒险游戏
+
+
+[PyData 2023 年 10 月南安普顿聚会](https://www.meetup.com/pydata-southampton/events/296057081/)
+将进行以下演讲:
+* 地理空间数据和处理简介
+* MoleGazer:天文学与皮肤学的结合
+
+
+[PyData 2023 年 10 月柏林聚会](https://www.meetup.com/pydata-berlin/events/296680621/)
+将有一场演讲:利用开源 LLMs 进行生产。
+
+[PyData 2023 年 10 月剑桥聚会](https://www.meetup.com/pydata-cambridge-meetup/events/296429788/)
+将有一场演讲:使用 AI 技术设计和测试现代桌面棋盘游戏。
+
\ No newline at end of file
diff --git a/Python Weekly/Python_Weekly_Issue_622.md b/Python Weekly/Python_Weekly_Issue_622.md
new file mode 100644
index 0000000..401f60d
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_622.md
@@ -0,0 +1,107 @@
+原文:[Python Weekly - Issue 622](http://eepurl.com/iB74LY)
+
+---
+
+欢迎来到Python周刊第 622 期。让我们直奔主题。
+
+# 新闻
+
+[FlaskCon 2023 提案征集现已开放](https://flaskcon.com/2023/)
+请在 2023 年 10 月 31 日之前提交您的演讲提案。
+
+
+# 文章,教程和讲座
+
+[函数会让设计模式过时吗?](https://www.youtube.com/watch?v=vzTrLpxPF54) 
+在本视频中,我们将演示函数并不会让 Python 中的设计模式过时。开发者社区针对此主题进行了广泛的讨论。为了说明这一观点,我们将研究几种常见的设计模式,并提出一种使用函数的替代方法。
+
+[在 FastAPI 中构建自定义中间件](https://semaphoreci.com/blog/custom-middleware-fastapi)
+在这篇文章中,您将了解如何构建自定义中间件,让你可以通过构建基于函数和基于类的中间件来修改请求和响应对象,以满足自己的需求并处理速率限制,从而使您能够以独特的方式扩展 API 的功能。您还将了解如何编写测试用例以及要遵循的最佳实践。
+
+[关于分布式训练和高效微调的一切](https://sumanthrh.com/post/distributed-and-efficient-finetuning)
+深入探讨分布式训练和高效微调 - DeepSpeed ZeRO、FSDP、使用多 GPU 和多节点训练的实用指南和陷阱。
+
+[Python 3.11 与 Python 3.12 – 性能测试](https://en.lewoniewski.info/2023/python-3-11-vs-python-3-12-performance-testing/)
+本文介绍了 Python 3.12 与 Python 3.11 相比的性能测试结果。总共进行了 91 项不同的基准测试,测试使用搭载 AMD Ryzen 7000 系列和第 13 代英特尔酷睿处理器的台式机、笔记本电脑或迷你电脑。
+
+[Django 应用程序中无密码身份验证的选项](https://www.honeybadger.io/blog/options-for-passwordless-authentication-in-django/)
+在 Django 应用程序中,无密码身份验证因其安全且用户友好的特性,作为基于密码的传统身份验证的的替代方案越来越受欢迎。在本文中,我们将深入研究三种无密码身份验证方法:基于电子邮件的身份验证、OAuth 身份验证和魔术链接身份验证。
+
+[我的 eBPF 之旅的开始 - 使用 BBC 的 Kprobe 探险](https://www.kungfudev.com/blog/2023/10/14/the-beginning-of-my-ebpf-journey-kprobe-bcc)
+在这篇文章中,作者分享了他们学习 Extended Berkeley Packet Filter (eBPF) 的过程。他们首先解释什么是 eBPF 以及它为何有用。然后,他们描述了如何在 kprobe 和 BPF Compiler Collection (BCC) 的帮助下使用 eBPF 来跟踪内核函数。最后,他们分享了一些他们认为对学习 eBPF 有帮助的资源。
+
+[为小团队设置(免费*)协作式 Python 开发环境](https://www.kevin-cole.com/blog/setting-up-a-free-collaborative-python-development-environment-for-a-small-team)
+作者介绍了如何使用 GitPod、Github 和 Jupyter Notebook 来设置一个协作式 Python 开发环境。作者还解释了容器化的好处,并提供了如何使用 GitPod、Github 和 Jupyter Notebook 建立协作式 Python 开发环境的分步指南。
+
+[实用人工智能:适合初学者的 HuggingFace Transformers和Diffusers](https://www.youtube.com/watch?v=rK02eXm3mfI) 
+本视频提供了一个关于 HuggingFace Transformers 和 Diffusers 库的简单概述。针对那些对 AI 或 ML 没有深入了解的人,我们将重点关注实用的实践应用程序。最后,我们设置了一个生成 AI 图像的 Flask 应用程序,演示了如何使用这些工具来创建有用的应用程序。
+
+[使用 GPT-4、Python 和 Langchain,构建日语汉字抽认卡应用程序](https://adilmoujahid.com/posts/2023/10/kanji-gpt4/)
+GPT-4 正在改变应用程序开发的游戏规则,尤其是在处理数据方面。我们的日语抽认卡应用程序展示了 GPT-4 有多么方便。开发人员可以使用 GPT-4 快速获取所需的信息,而不是手动收集数据。这不仅加快了构建过程,还确保应用程序满是干货。借助 GPT-4 等工具,创建数据丰富的应用程序从未如此简单和高效。
+
+[解决 A/B 测试中样本比率不匹配的挑战](https://doordash.engineering/2023/10/17/addressing-the-challenges-of-sample-ratio-mismatch-in-a-b-testing)
+这篇文章关于如何解决 A/B 测试中样本比率不匹配的挑战。它讨论了什么是样本比率不匹配,以及为什么它是一个问题。它还详细介绍了 DoorDash 在他们公司中减少样本比率不匹配的一些方法。
+
+[Python 陷阱:比较](https://andrewwegner.com/python-gotcha-comparisons.html)
+如果您不知道一些常见的陷阱,那么在 Python 中比较两个数值变量可能会产生令人惊讶的结果。这篇文章涵盖了一些常见的问题。
+
+[2023 年哥本哈根 Django Day 视频](https://www.youtube.com/playlist?list=PLEpW1LzVyQWgtT_i_IlUmx2FSP2jHcroX) 
+第四版哥本哈根 Django Day 的演讲视频现已发布。
+
+
+# 好玩的项目,工具和库
+
+[MemGPT](https://github.com/cpacker/MemGPT)
+教 LLMs 无限上下文的内存管理。
+
+[SolidGPT](https://github.com/AI-Citizen/SolidGPT)
+与您的代码存储库聊天,根据私人项目生成产品需求文档和代码计划。
+
+[ZenNotes](https://github.com/rohankishore/ZenNotes)
+Windows 记事本替代品,带翻译、TTS 等功能!
+
+[queryish](https://github.com/wagtail/queryish)
+一个库,用于按照 Django 的 QuerySet API 对任意数据源构建查询。
+
+[stable-audio-tools](https://github.com/Stability-AI/stable-audio-tools)
+用于条件音频生成的生成模型。
+
+[ExecuTorch](https://github.com/pytorch/executorch)
+端到端解决方案,用于为 PyTorch 模型,跨移动和边缘设备启用设备上 AI。
+
+[OpenAgents](https://github.com/xlang-ai/OpenAgents)
+一个在野语言代理开放平台
+
+[Llemma](https://github.com/EleutherAI/math-lm)
+一个数学开放语言模型
+
+ # 最新发布
+
+[Python 3.13.0 alpha 1](https://pythoninsider.blogspot.com/2023/10/python-3130-alpha-1-is-now-available.html)
+
+
+ # 近期活动和网络研讨会
+
+[BAyPIGgies 2023 年 10 月聚会](https://www.meetup.com/baypiggies/events/296732583/)
+将有以下演讲
+- Python、可访问性以及确保 DOM 可访问 (domible)
+- WebAssembly、确定性执行以及如何实现撤消
+
+
+[Virtual:PyLadies 阿姆斯特丹 2023 年 10 月](https://www.meetup.com/pyladiesams/events/296507394/)
+在本次研讨会中,您将学习地理空间数据理论的基础知识,涵盖栅格、矢量和相关概念。您还将了解用于地理空间数据的 Python 库,并通过 Jupyter Notebook 练习实际体验如何获得使用卫星图像。
+
+[Python Glasgow 2023 年 10 月聚会](https://www.meetup.com/python-glasgow/events/296605211/)
+将有以下演讲
+- Python 驱动的智能:探索 AI 和 ML 应用
+- LLM 时代扩展 Python 机器学习工作负载
+
+
+[PyData 兰卡斯特 2023 年 10 月聚会](https://www.meetup.com/pydata-lancaster/events/296657964/)
+将有以下演讲
+- 窥探黑匣子内部:让人工智能模型更易于解释
+- 为什么说你不应仅依赖汇总统计数据
+
+
+[Hybrid: PyData 芝加哥 2023 年 10 月聚会](https://www.meetup.com/pydatachi/events/296529896/)
+有一场演讲,即,FuzzyData:用于测试 Dataframe 工作流系统的可扩展工作负载生成器。
\ No newline at end of file
diff --git a/Python Weekly/Python_Weekly_Issue_623.md b/Python Weekly/Python_Weekly_Issue_623.md
new file mode 100644
index 0000000..ddd6b1b
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_623.md
@@ -0,0 +1,99 @@
+原文:[Python Weekly - Issue 623](http://eepurl.com/iCBKtY)
+
+---
+
+欢迎来到Python周刊第 623 期。让我们直奔主题。
+---
+
+
+# 新闻
+
+[PyCon US 2024 提案征集](https://pretalx.com/pyconus2024/)
+Pycon US 2024 提案征集现已正式开放,接受演讲、教程、海报和Charlas(一种交流形式)的提议!在2023年12月18日之前提交您的提案。
+
+
+# 文章,教程和讲座
+
+[Pytest 教程 —— 如何测试 Python 代码](https://www.youtube.com/watch?v=cHYq1MRoyI0) 
+学习如何使用Pytest,这是Python强大的测试框架。在整个课程中,您将对Pytest的功能,最佳实践以及编写有效测试的细微差别有深入的了解。最后,您将学习如何使用Chatgpt来帮助您更快地编写测试。
+
+[使用智能手机录制的语音段,对2型糖尿病进行声学分析和预测](https://www.mcpdigitalhealth.org/article/S2949-7612\(23\)00073-1/fulltext)
+通过检查非糖尿病和 T2DM 个人之间的语音记录差异,探讨语音分析作为2型糖尿病(T2DM)患者预筛选或监测工具的潜力
+
+[嵌入:它们是什么,以及它们为什么重要](https://simonwillison.net/2023/Oct/23/embeddings/)
+
+在这篇文章中,Simon Willison探讨了数据分析和机器学习中的嵌入(embeddings)概念,突出了它们在表示复杂数据以进行高效处理方面的作用,并提供了关于它们使用的实际见解。
+
+[我们必须聊聊 Flask](https://blog.miguelgrinberg.com/post/we-have-to-talk-about-flask)
+
+Miguel Grinberg指出,Flask的维护人员经常在新版本的Flask和Werkzeug中引入微不足道的不兼容变化,导致扩展和教程在更新之前会出现问题。现在,[这篇文章也有更新](https://blog.miguelgrinberg.com/post/some-more-to-talk-about-flask)。
+
+[lambda 表达式是什么?](https://www.pythonmorsels.com/lambda-expressions/)
+了解lambda的表达方式以及如何在Python中使用。
+
+[使用 SIMD 加速Cython](https://pythonspeed.com/articles/faster-cython-simd/)
+SIMD 是一项CPU功能,让您可以加快数字处理。了解如何与Cython一起使用。
+
+[将你的应用插入到 Jupyter 的世界](https://blog.jupyter.org/plug-your-application-into-the-jupyter-world-805e48918801)
+Kernel(核心)是Jupyter架构中一个简单但强大的抽象概念。它们封装了语言解释器,并通过标准化接口使其可访问。这是Jupyter出色多才多艺的关键,支持超过100种编程语言。将一个核心嵌入到您的自定义应用程序中,可以无缝地将其暴露给Jupyter生态系统。您不仅可以将JupyterLab附加到您的程序中,以便进行状态检查(就像使用调试器一样),而且还可以真正利用Jupyter生态系统的所有功能来扩展您的应用程序。
+
+[如何部署基于 Conda 的 docker 镜像](https://blog.neater-hut.com/how-to-deploy-conda-based-docker-images.html)
+学习如何通过三个方法,将基于 Conda 的 Docker 镜像降低到合理的尺寸。
+
+[使用 django 和 htmx 的无限滚动](https://fmacedo.com/posts/1-django-htmx-infinite-scroll/)
+有关如何使用Django和HTMX实现无限滚动的教程。
+
+[如何在 4 分钟内将 Google 表添加为你的 Django 数据库](https://www.youtube.com/watch?v=XXDiqE4t0xA) 
+在4分钟内添加 Google 表作为您的Django数据库。这是更快的原型和小产品的理想选择。
+
+
+# 好玩的项目,工具和库
+
+[Genv](https://github.com/run-ai/genv)
+GPU 环境管理和集群编排
+
+[RIP](https://github.com/prefix-dev/rip)
+使用 Rust 实现的快速简单的 pip 实现。
+
+[LocalPilot](https://github.com/danielgross/localpilot)
+在 Macbook 上,一键即可本地使用 GitHub Copilot!
+
+[autotab](https://github.com/Planetary-Computers/autotab-starter)
+为现实世界的任务构建浏览器代理。
+
+[GRID](https://github.com/ScaledFoundations/GRID-playground)
+通用机器人智能开发(General Robot Intelligence Development,GRID)平台。
+
+
+[RenderCV](https://github.com/sinaatalay/rendercv)
+一个 Python 应用,根据输入的 YAML/JSON 问价,生成 PDF 格式的 CV。
+
+[Waymax](https://github.com/waymo-research/waymax)
+用于自动驾驶研究的基于 JAX 的模拟器。
+
+[DeepSparse](https://github.com/neuralmagic/deepsparse)
+用于 CPU 的稀疏性感知深度学习推理运行时。
+
+[GenSim](https://github.com/liruiw/GenSim)
+通过大型语言模型生成机器人仿真任务(Robotic Simulation Tasks)。
+
+
+[Voyager](https://spotify.github.io/voyager/)
+Voyager是一个用于在内存中的向量集合上执行快速近似最近邻搜索的库。
+
+[pypipe](https://github.com/bugen/pypipe)
+Python pipe 命令行工具。
+
+[dlt](https://github.com/dlt-hub/dlt)
+数据加载工具(data load tool,dlt)—— 用于数据加载的开源 Python 库。
+
+[Deep-Learning-Ultra](https://github.com/daddydrac/Deep-Learning-Ultra)
+开源深度学习容器(Open source Deep Learning Containers,DLCs)是一组用于在 PyTorch、OpenCV(针对GPU进行了编译)、TensorFlow 2(适用于GPU)、PyG 和 NVIDIA RAPIDS 中训练和提供模型的 Docker 镜像。
+
+[higgsfield](https://github.com/higgsfield-ai/higgsfield)
+容错性强、高度可伸缩的GPU编排系统以及一个机器学习框架,专为训练拥有数十亿至数万亿参数的模型而设计
+
+
+# 最新发布
+
+[Django 5.0 beta 1 发布](https://www.djangoproject.com/weblog/2023/oct/23/django-50-beta-1-released/)
\ No newline at end of file
diff --git a/Python Weekly/Python_Weekly_Issue_624.md b/Python Weekly/Python_Weekly_Issue_624.md
new file mode 100644
index 0000000..f405142
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_624.md
@@ -0,0 +1,102 @@
+原文:[Python Weekly - Issue 624](http://eepurl.com/iC6EUY)
+
+---
+
+欢迎来到Python周刊第 624 期。让我们直奔主题。
+
+
+# 文章,教程和讲座
+
+[通过 FastAPI 掌握 API 测试:数据库、依赖等等!](https://www.youtube.com/watch?v=9gC3Ot0LoUQ) 
+本教程将指导您使用 FastAPI 完成 API 测试,并提供完整的代码示例。使用它作为测试您自己的 API 的模板吧!
+
+
+[使用 Python 将数据分析速度提高 170,000 倍](https://sidsite.com/posts/python-corrset-optimization/)
+在这篇文章中,我们将在 Python 中,经历一段分析和迭代加速代码的旅程。
+
+[我移植 setup.py 的用户体验](https://gregoryszorc.com/blog/2023/10/30/my-user-experience-porting-off-setup.py/)
+本文讨论了将 Python 包从 setup.py 移植到 pyproject.toml 的挑战,以及缺乏明确指导的情况。
+
+[算法交易 —— Python 机器学习和量化策略课程](https://www.youtube.com/watch?v=9Y3yaoi9rUQ) 
+本课程涵盖三种高级交易策略。首先,它重点关注使用了标准普尔 500 指数数据的无监督学习,其次是纳斯达克股票的 Twitter 情绪投资策略(Twitter Sentiment Investing Strategy),以及使用 GARCH 模型和技术指标识别每日和日内交易信号的日内策略(Intraday Strategy),从而丰富您的金融技能。
+
+[使用潜在一致性模型(LCMs),在你的 Mac 上一秒生成图像](https://replicate.com/blog/run-latent-consistency-model-on-mac)
+潜在一致性模型 (LCM) 基于稳定扩散(Stable Diffusion),但它们可以更快地生成图像,只需 4 到 8 个步骤即可生成良好的图像(与需要 25 到 50 个步骤才能生成的模型相比)。通过在 M1 或 M2 Mac 上运行 LCM,您可以以每秒一张的速度生成 512x512 图像。
+
+[为什么说 Django 管理系统是“丑的”?](https://www.coderedcorp.com/blog/why-is-the-django-admin-ugly/)
+本文讨论了为什么 Django 管理界面设计得不够美观。它讨论了 Django 管理系统的历史以及它如此设计的原因。一些重要的点是,Django 管理系统旨在供内部使用,而不是用于构建整个前端。
+
+[使用 AI 构建类似 ChatGPT 的应用程序](https://sixfeetup.com/company/news/build-chatgpt-like-apps-with-ai) 
+如果您对 AI 和大型语言模型 (LLM) 的实际应用感兴趣,那您会在本演讲和现场演示中发现其价值之处。该演示超越了理论,包括现实世界的示例和最佳实践,包括了一个包含 Python 代码和类似 ChatGPT 的应用程序示例的 GitHub 存储库,这些示例将帮助您启动自己的应用程序。
+
+
+[不要使用 requirements.txt](https://quanttype.net/posts/2023-10-31-do-not-use-requirements.txt.html)
+本文讨论在 Python 项目中使用 requirements.txt 进行包管理的限制。作者建议改用 Poetry(一个包管理器,可以简化依赖管理并提供虚拟环境和文件锁定等附加功能)。
+
+[从混乱到凝聚:构建您自己的 Monorepo](https://monadical.com/posts/from-chaos-to-cohesion.html)
+使用 GitHub Actions 作为 CI/CD 工具,构建一个简单的 monorepo。
+
+
+# 好玩的项目,工具和库
+
+[SuperDuperDB](https://github.com/SuperDuperDB/superduperdb)
+将人工智能带入您最喜欢的数据库!直接与您的数据库和数据进行集成、训练和管理任何 AI 模型和 API。
+
+[Esmerald](https://github.com/dymmond/esmerald)
+Esmerald 是一个现代、强大、灵活、高性能的 Web 框架,旨在不仅是构建 API,还能够构建从最小到企业级别的完全可扩展应用程序。
+
+[mify](https://github.com/mify-io/mify)
+一个代码生成工具,帮助您构建云后端服务。
+
+[De4py](https://github.com/Fadi002/de4py)
+De4py 是一款高级 Python 反混淆器,具有漂亮的 UI 和一组高级功能,使恶意软件分析师和逆向工程师能够对 Python 文件等进行反混淆。
+
+[rag-demystified](https://github.com/pchunduri6/rag-demystified)
+一个从头开始构建的,由 LLM 驱动的高级 RAG 管道。
+
+[m1n1](https://github.com/AsahiLinux/m1n1)
+Apple Silicon 的引导加载程序和实验场。
+
+[Wonder3D](https://github.com/xxlong0/Wonder3D)
+用于从单个图像进行 3D 重建的跨域扩散模型。
+
+[LearnHouse](https://github.com/learnhouse/learnhouse)
+LearnHouse 是一个开源平台,任何人都可以通过它轻松提供世界一流的教育内容,此外,它提供多种内容类型:动态页面、视频、文档等。
+
+[Marcel](https://github.com/geophile/marcel)
+一个现代的 shell。
+
+[lea](https://github.com/carbonfact/lea)
+lea 是 dbt、SQLMesh 和 Google Dataform 等工具的极简替代品。
+
+[XAgent](https://github.com/OpenBMB/XAgent)
+用于解决复杂任务的自主 LLM 代理。
+
+[Raven](https://github.com/CycodeLabs/raven)
+CI/CD 安全分析器。
+
+
+# 最新发布
+
+[Django 安全版本已发布:4.2.7, 4.1.13, 和 3.2.23](https://www.djangoproject.com/weblog/2023/nov/01/security-releases/)
+
+
+# 近期活动和网络研讨会
+
+[Virtual:PyMNtos Python 演示之夜 #119](https://www.meetup.com/pymntos-twin-cities-python-user-group/events/296436004/)
+将有一场演讲,Selenium 和 Python。
+
+[PyData 伦敦 2023 年 11 月聚会](https://www.meetup.com/pydata-london-meetup/events/296513974/)
+将会有以下演讲:
+ * 使用 Quix Streams 简化实时 ML 管道
+ * 从内到外的 Transformers
+ * Excel 中的 Python
+ * 有时,我们听到的音乐和播放列表并不符合我们的心情,人工智能可以帮助解决这个问题吗?
+
+
+[PyData 慕尼黑 2023 年 11 月聚会](https://www.meetup.com/pydata-munchen/events/296950996/)
+将会有以下演讲:
+ * TensorRT LLM Nvidia
+ * CTranslate2 和 vLLM
+ * 我今天停止阅读 Twitter 时的 LLM 状态
+
diff --git a/Python Weekly/Python_Weekly_Issue_625.md b/Python Weekly/Python_Weekly_Issue_625.md
new file mode 100644
index 0000000..4639762
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_625.md
@@ -0,0 +1,129 @@
+原文:[Python Weekly - Issue 625](http://eepurl.com/iDALBg)
+
+---
+
+欢迎来到Python周刊第 625 期。让我们直奔主题。
+
+
+# 文章,教程和讲座
+
+[在另一个进程内存中苏醒](https://www.youtube.com/watch?v=0ihChIaN8d0) 
+在本视频中,我们学习如何通过从头开始构建内存转储器来读取属于其他进程的内存。关键组件之一是 /proc 文件系统:一个内核为内省进程提供的接口。结合 ptrace(一个允许附加并控制另一个进程的系统调用),我们编写了一个程序来自动提取信息(这些信息有可能完全对我们隐藏!)
+
+[构建 Python 编译器和解释器](https://mathspp.com/blog/tag:bpci)
+一个有关在 Python 中从头开始实现 Python 编程语言的系列。本系列的最终目标是探索和尝试实现像 Python 这样的编程语言所需的概念和算法。为此,我们将创建一种具有 Python 功能子集的编程语言,并且在此过程中,我们将使用分词器、解析器、编译器和解释器!
+
+[数据库的生成列:Django 和 SQLite](https://www.paulox.net/2023/11/07/database-generated-columns-part-1-django-and-sqlite/)
+介绍数据库的生成列,使用 SQLite 和 Django 5.0 中添加的新的 GeneratedField 字段。
+
+[为什么说在 Windows 上,SciPy 为 Python 3.12 构建是一个小奇迹](https://labs.quansight.org/blog/building-scipy-with-flang)
+将 SciPy 迁移到 Meson 意味着在 Windows 上找到不同的 Fortran 编译器,这对于 conda-forge 来说特别棘手。这篇文章讲述了对于 Python 3.12 版本来说,情况是怎样看起来非常严峻的,以及事情如何在关键时刻得到解决的故事。
+
+[机器学习软件和 pickles 有什么关系?](https://blog.nelhage.com/post/pickles-and-ml)
+本文讨论了作者对在机器学习生态系统中使用 Python 的 pickle 模块的不断发展的看法。它强调了与 pickle 相关的问题、安全问题和脆弱性,深入了解其广泛使用背后的原因以及它在机器学习领域要解决的挑战。
+
+[构建一个人工智能工具即时总结书籍](https://levelup.gitconnected.com/build-an-ai-tool-to-summarize-books-instantly-828680c1ceb4)
+无需从头到尾阅读即可了解任何书籍的要点。
+
+[使用 Python 的 bisect 模块可以做的每一件事](https://martinheinz.dev/blog/106)
+了解如何使用“bisect”模块在 Python 中优化搜索并保持数据排序。
+
+[构建 Python 数据科学项目的 7 个技巧](https://www.youtube.com/watch?v=xVuqDBCQAYc) 
+该视频将介绍简化 Python 数据科学项目结构的 7 个技巧。通过正确的设置和详尽的软件设计,您将能够更有效地修改和增强您的项目。
+
+[Python 混淆陷阱](https://checkmarx.com/blog/python-obfuscation-traps/)
+在软件开发领域,开源工具和软件包在简化任务和加速开发过程方面发挥着关键作用。然而,随着社区的发展,想要利用社区的不良行为者的数量也在增加。最近的一个例子涉及开发人员成为看似合法的 Python 混淆包的目标,这些混淆包包含恶意代码。
+
+[调试 Django 中的 CSRF 失败 / 403 Forbidden 错误](https://www.better-simple.com/django/2023/11/04/debugging-csrf-error-in-production/)
+指导性深入理解 Django 源代码,以了解应用程序未通过 CSRF 验证的原因。
+
+[Django 5.0 中的新功能](https://fly.io/django-beats/new-goodies-in-django-50/)
+本文重点介绍了 Django 5.0 中添加的新功能。
+
+[Python 中性能最高的时间戳函数:EXTENDED](https://www.dataroc.ca/blog/most-performant-timestamp-functions-python-2)
+第 2 部分介绍了跨 Python 版本和机器类型的不同时间戳函数性能。获取当前时间的最快方法是什么呢?
+
+
+# 好玩的项目,工具和库
+
+[LocalAIVoiceChat](https://github.com/KoljaB/LocalAIVoiceChat)
+使用基于 Zephyr 7B 模型的自定义语音进行本地 AI 对话。使用 RealtimeSTT 和 fast_whisper 进行转录,使用 RealtimeTTS 和 Coqui XTTS 进行合成。
+
+[DeepSeek-Coder](https://github.com/deepseek-ai/DeepSeek-Coder)
+让代码自己写代码。
+
+[tiger](https://github.com/tigerlab-ai/tiger)
+开源 LLM 工具包,用于构建 LLM 应用程序。TigerRAG(嵌入、RAG)、TigerTune(微调)、TigerArmor(AI 安全)。
+
+[lm-format-enforcer](https://github.com/noamgat/lm-format-enforcer)
+强制执行语言模型的输出格式(JSON 模式、正则表达式等)。
+
+[autollm](https://github.com/safevideo/autollm)
+在几秒钟内交付基于 RAG 的 LLM Web 应用程序。
+
+[lato](https://github.com/pgorecki/lato)
+Python 微框架,用于模块化整体和松散耦合的应用程序。
+
+[giskard](https://github.com/Giskard-AI/giskard)
+ML 模型的测试框架,从表格到 LLMs。
+
+[RoboGen](https://github.com/Genesis-Embodied-AI/RoboGen)
+一种生成式、自我引导的机器人代理,可以不断地提出和掌握新技能。
+
+[error-links](https://pypi.org/project/error-links/)
+在发生异常时向 REPL 添加有用的链接。
+
+[Hexabyte](https://github.com/thetacom/hexabyte)
+一个现代、模块化且强大的 TUI 十六进制编辑器。
+
+
+ # 最新发布
+
+[Visual Studio Code 中的 Python – 2023 年 11 月版本](https://devblogs.microsoft.com/python/python-in-visual-studio-code-november-2023-release/)
+本版本包括以下声明:
+ * 对终端中 Shift + Enter 运行的改进
+ * 已弃用的内置 linting 和格式化功能
+ * Python linting 扩展的改进
+ * 重新配置测试输出
+ * 虚拟环境停用帮助
+ * 宣布 VS Code 中的 Python 的发布视频
+
+
+
+# 近期活动和网络研讨会
+
+[旧金山 Python 2023 年 11 月 聚会](https://www.meetup.com/sfpython/events/296321305/)
+将会有以下演讲:
+ * 在 Snowflake 中使用 Python、PyTorch、OpenAI 和 Streamlit 进行图像识别
+ * 自动照片修饰
+ * 咨询数据库和 Dependabot:以及它们如何应用于 Python
+
+
+[Virtual: PyLadies 柏林 2023 年 11 月 聚会](https://www.meetup.com/pyladies-berlin/events/296907222/)
+将会有以下演讲:
+ * 赋能未来:德国女孩节
+ * 开发大规模图像知识共享数据集
+
+
+[PyLadies 巴黎 2023 年 11 月 聚会](https://www.meetup.com/pyladiesparis/events/297190950/)
+将会有以下演讲:
+ * Django 无停机迁移
+ * 调试的科学
+
+
+[PyData 阿姆斯特丹 2023 年 11 月 聚会](https://www.meetup.com/pydata-nl/events/297111947/)
+将会有以下演讲:
+ * 如何使用机器学习构建出色的风电预测
+ * 使用机器学习为电动汽车智能充电
+
+
+[PyData 布里斯托尔 2023 年 11 月 聚会](https://www.meetup.com/pydata-bristol/events/296142623/)
+将会有以下演讲:
+ * 自然语言处理 —— 从学术理论到商业应用
+ * TweetNLP
+
+
+[PyData 蒙特利尔 2023 年 11 月 聚会](https://www.meetup.com/pydata-mtl/events/297096826/)
+将会有以下演讲:
+ * 人类/人工智能超级团队:通过人机循环学习构建协作系统
+ * 大型语言模型简介
\ No newline at end of file
diff --git a/Python Weekly/Python_Weekly_Issue_626.md b/Python Weekly/Python_Weekly_Issue_626.md
new file mode 100644
index 0000000..68e1c1b
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_626.md
@@ -0,0 +1,111 @@
+原文:[Python Weekly - Issue 626](http://eepurl.com/iD6vfU)
+
+---
+
+欢迎来到Python周刊第 626 期。让我们直奔主题。
+
+# 新闻
+
+[PyPI 已经完成了首次安全审计](https://blog.pypi.org/posts/2023-11-14-1-pypi-completes-first-security-audit/)
+此次审计由网络安全公司 Trail of Bits 负责,重点关注 Warehouse 代码库以及 cabotage 容器编排框架。审计人员发现了29个建议,但没有一个被分类为高危。PyPI 团队已纠正了所有构成重大风险的建议。
+
+
+# 文章,教程和讲座
+
+[什么是 Monad?](https://www.youtube.com/watch?v=Q0aVbqim5pE) 
+Monad 是函数式编程语言(如Haskell)中的一个众所周知的概念,但它们在其他情境中是否同样有用呢?请继续关注,到本视频结束时,您将了解什么是 Monad。
+
+
+[让我们一起创造一个 Python 调试器吧](https://mostlynerdless.de/blog/2023/09/20/lets-create-a-python-debugger-together-part-1/)
+您是否曾想过调试器是如何工作的?设置断点并稍后命中它时会发生什么呢?调试器是我们作为开发人员在日常工作中经常使用的工具,但很少有人知道它们实际上是如何实现的。以下是有关从零开始编写 Python 调试器系列,包含四部分。
+
+[快速浏览目标驱动的代码生成](https://bernsteinbear.com/blog/ddcg/)
+想象一下:你坐在那里,正在写一个编译器,突然间你不得不生成汇编。你有一些中间表示(IR),但现在你必须将虚拟寄存器转换为机器寄存器。这就是所谓的寄存器分配(register allocation)。寄存器分配很棘手。它也很慢。即使像线性扫描这样非常快的寄存器分配器也可能占据大部分编译时间。所以让我们跳过它。让我们用 Python 写一个愚蠢的编译器,看看我们是否可以在不进行完全寄存器分配的情况下改进生成的代码。
+
+[在Python软件包索引中查询每个发布的每一个文件](https://sethmlarson.dev/security-developer-in-residence-weekly-report-18)
+本文介绍了查询 Python 软件包信息数据集的问题。它讨论了如何下载数据集以及其中包含了什么信息。该数据集可用于回答有关 Python 软件包趋势的问题。例如,它可用于跟踪新的打包元数据标准的采用情况。
+
+[使用 django-watson 为 Django 应用添加全文搜索](https://idiomaticprogrammers.com/post/django-watson-full-text-search-guide/)
+学习如何通过 Django-Watson 在 Django 应用中添加全文搜索,深入了解 Postgres 的奥秘并提升搜索功能。
+
+[深入研究 PyPI 软件包名称占用](https://blog.orsinium.dev/posts/py/pypi-squatting/)
+本文讨论了 PyPI 软件包名称占用的问题,以及攻击者可以如何利用它来分发恶意代码。
+
+[解混淆 World of Warships 的 Python 脚本](https://landaire.net/world-of-warships-deobfuscation/)
+对World of Warships 如何混淆其游戏脚本以及如何在很大程度上对其进行解混淆的深入分析。
+
+[Python 中基于属性的测试](https://www.se-radio.net/2023/11/se-radio-589-zac-hatfield-dodds-on-property-based-testing-in-python/) 
+Anthropic 的保障团队负责人 Zac Hatfield-Dodds 与主持人 Gregory M. Kapfhammer 讨论了基于属性的测试技术,以及如何在名为 Hypothesis 的开源工具中使用它们。他们讨论了如何为 Python 函数定义属性并在 Hypothesis 中实现一个测试用例。他们还探讨了 Hypothesis 中的一些高级功能(可以自动生成测试用例并执行模糊测试活动)。
+
+
+# 好玩的项目,工具和库
+
+[MonkeyPatch](https://github.com/monkeypatch/monkeypatch.py)
+构建可扩展的 LLM 驱动应用程序的最简单方法,随着时间推移变得更便宜和更快。
+
+[Movis](https://github.com/rezoo/movis)
+用代码的方式编辑视频
+
+[dpoint](https://github.com/Jcparkyn/dpoint)
+使用相机跟踪和惯性测量的开源数字触控笔。
+
+[narrator](https://github.com/cbh123/narrator)
+大卫·艾滕伯勒为您叙述生活。
+
+[mirror](https://github.com/cocktailpeanut/mirror)
+在您的笔记本电脑上的可黑客化 AI 驱动镜子。
+
+[filequery](https://github.com/MarkyMan4/filequery)
+使用 SQL 查询 CSV、JSON 和 Parquet 文件。
+
+[bulk_transcribe_youtube_videos_from_playlist](https://github.com/Dicklesworthstone/bulk_transcribe_youtube_videos_from_playlist)
+使用 Whisper,轻松将整个 YouTube 播放列表转换为高质量的脚本。
+
+[vimGPT](https://github.com/ishan0102/vimGPT)
+使用 GPT-4V 和 Vimium 浏览网络。
+
+[multi-object-tracking-in-python](https://github.com/kharitonov-ivan/multi-object-tracking-in-python)
+在 Python 中实现多目标跟踪算法,包括 PMBM(泊松多伯努利混合滤波器)。
+
+
+# 近期活动和网络研讨会
+
+[PyLadies Dublin Meetup 2023 年 11 月](https://www.meetup.com/pyladiesdublin/events/296639107/)
+将有以下演讲:
+* Pinkie Pacts - 基于消费者的合同测试
+* 关于再保险风险建模的介绍,使用 Python
+
+[PyLadies London Meetup 2023 年 11 月](https://www.meetup.com/pyladieslondon/events/297095588/)
+将有以下演讲:
+* 使用 ClinicalTrials.gov API 解锁有关妇女健康的见解
+* 使用 Neo4j Vector Search 将患者匹配到临床试验
+
+
+[Python Milano Meetup 2023 年 11 月](https://www.meetup.com/python-milano/events/297364921/)
+将有以下演讲:
+* Kubernetes Operators:用 Pythonic 的方式
+* 边缘设备上的视觉体系结构
+
+
+[PyData Prague Meetup 2023 年 11 月](https://www.meetup.com/pydata-prague/events/297072175/)
+将有以下演讲:
+* 成为 Streamlit 的数据叙述者!
+* 检索增强生成(RAG)在实践中的应用
+
+
+[PyData Southampton Meetup 2023 年 11 月](https://www.meetup.com/pydata-southampton/events/296812566/)
+将有以下演讲:
+* 谨上您的真诚,Streamlit
+* 车队监控:使用 Django 和 Plotly Dash 构建可扩展的云应用程序
+
+
+[PyData Lisbon Meetup 2023 年 11 月](https://www.meetup.com/pydata-lisbon/events/297070615/)
+将有以下演讲:
+* LLM 系统的趋势和挑战
+* AI 启示还是 AI 革命?- 产品经理作为 AI 守护者的角色
+
+
+[PyData Stockholm Meetup 2023 年 11 月](https://www.meetup.com/pydatastockholm/events/297112148/)
+将有以下演讲:
+* FastAPI 入门:ML 的技巧和窍门
+* 谁需要 ChatGPT?使用 Hugging Face 和 Kedro 打造坚固的 AI 管道
diff --git a/Python Weekly/Python_Weekly_Issue_627.md b/Python Weekly/Python_Weekly_Issue_627.md
new file mode 100644
index 0000000..7df31d9
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_627.md
@@ -0,0 +1,127 @@
+原文:[Python Weekly - Issue 627](http://eepurl.com/iEB-HQ)
+
+---
+
+欢迎来到Python周刊第 627 期。让我们直奔主题。
+
+
+# 文章,教程和讲座
+
+[为 CPython 开发的 JIT 编译器](https://www.youtube.com/watch?v=HxSHIpEQRjs) 
+Brandt Bucher 讨论了为 CPython 开发的即时(Just-In-Time,JIT)编译器。演讲深入探讨了专门为 CPython(默认的Python解释器)实现 JIT 编译器的挑战和复杂性。
+
+[给初学者的生成式 AI 教程](https://microsoft.github.io/generative-ai-for-beginners/)
+一门包含 12 课的课程,教授构建生成式 AI 应用程序所需的一切知识。
+
+[大规模编写和linting Python](https://engineering.fb.com/2023/11/21/production-engineering/writing-linting-python-at-scale-meta/) 
+在 Meta 公司,Python 在 Instagram 的后端中起着关键作用,为 Python 3.12 做出贡献,并驱动着诸如配置系统和 AI 工作等关键方面。在 Meta Tech Podcast中,Pascal Hartig 和 Amethyst Reese 深入探讨了 Python 基础团队所做的努力,开源的 Fixit 2 linter 框架,以及关于在 Meta 所担任的生产工程师角色的见解。
+
+[是时候改变了:datetime.utcnow() 现在已弃用](https://blog.miguelgrinberg.com/post/it-s-time-for-a-change-datetime-utcnow-is-now-deprecated)
+本文介绍了关于这些函数被弃用的原因的更多信息,以及替换它们的方法。
+
+[通过 AWS 发布 280 亿分子嵌入](https://ashvardanian.com/posts/usearch-molecules/)
+宣布了一个涉及收集、指纹识别和索引 70 亿种小分子(具有各种结构嵌入,例如 MACCS、PubChem、ECFP4 和 FCFP4)的项目的完成。该数据集使用 Unum 的 USearch 针对分子搜索进行了优化,现在可以通过 AWS Open Data 在全球范围内免费访问,它还通过 GitHub 提供了全面的数据表和可视化脚本。
+
+[Python 全局解释器锁提供的不断变化的“保证”](https://stefan-marr.de/2023/11/python-global-interpreter-lock/)
+本文探讨了 CPython 全局解释器锁 (Global Interpreter Lock,GIL) 的实现细节,以及它们在 Python 3.9 和当前开发分支(将成为 Python 3.13)之间的变化。
+
+[让我们使用 LLM Embeddings、Django 和 pgvector 编写一个 AI 搜索引擎](https://www.youtube.com/watch?v=OPy4dLHdZng) 
+大型语言模型 (Large Language Model,LLM) 可用于业务应用程序,例如内容匹配和职位搜索。William Huster 演示了如何构建利用 LLM 进行职位搜索的原型应用程序。
+
+[两种线程池,以及为什么需要这两种](https://pythonspeed.com/articles/two-thread-pools/)
+线程池应该有多大?这取决于您的用例。
+
+[Python 3.12 范型类型解释](https://www.youtube.com/watch?v=q6ujWWaRdbA) 
+该视频探讨了 Python 3.12 中的泛型类型的工作原理,以及它的优势(相对于仅使用 Any 类型)。
+
+[使用 Polars 在云端处理数百 GB 的数据](https://blog.coiled.io/blog/coiled-functions-polars.html)
+由于内存和网络限制,本地计算机可能难以处理大型数据集。Coiled Functions 提供了一种基于云的解决方案,可以高效且经济高效地处理如此广泛的数据集,克服本地硬件对复杂数据处理任务的限制。融入像 Polars 这样的库可以进一步增强这种方法,利用优化的计算功能,从而更快、更高效地处理数据。在这篇文章中,我们将使用 Coiled Functions,在带有 Polars 的单个云计算机上处理 150 GB 大小的 Uber-Lyft 数据集。
+
+[Python 应用程序中的错误类别](https://threeofwands.com/the-types-of-errors-in-python-apps/)
+编写 Python 程序时,错误是不可避免的。然而,我们可以管理我们所产生的错误类型。让我们探索一个简单的模型,它将这些错误按照从最好到最差进行分类,然后讨论谨慎使用工具可以如何提高软件质量。
+
+[GPU 上的 Pandas Dataframes(使用或不使用 CuDF)](https://www.youtube.com/watch?v=OnYGtKQT-rU) 
+使用 CuDF 的 Pandas 加速器的概述和一些快速示例,以及与普通 Pandas 相比,使用它进行数据分析要快多少。
+
+[使用 PyTorch 构建一个神经网络](https://haydenjames.io/building-a-neural-network-with-pytorch/)
+构建第一个神经网络似乎是一项艰巨的任务,但像 PyTorch 这样的深度学习框架使得这项任务比以往任何时候都更容易完成。本文介绍了如何使用 PyTorch 构建神经网络。
+
+[Python Flask 应用程序中的 GitHub OAuth](https://supabase.com/blog/oauth2-login-python-flask-apps)
+有关在 Python 应用程序中构建使用 Github 进行登录的分步指南。
+
+[如何使用 Django 和 Stripe 创建订阅 SaaS 应用程序](https://www.saaspegasus.com/guides/django-stripe-integrate/)
+使用基于 Python 的 Django Web 框架和 Stripe 支付处理器创建订阅 SaaS 业务的所有技术细节。
+
+[四种优化](https://tratt.net/laurie/blog/2023/four_kinds_of_optimisation.html)
+本文讨论了四种优化程序的方法:使用更好的算法、使用更好的数据结构、使用较低级别的系统,或接受不太精确的解决方案。
+
+[使用 Python 通过 PostgREST API 插入数据](https://www.dataroc.ca/blog/inserting-data-via-the-postgrest-api-using-python)
+
+[CPython 软件物料清单提案](https://sethmlarson.dev/security-developer-in-residence-weekly-report-19)
+
+[有多少 Python 核心开发人员使用类型注释?](https://blog.orsinium.dev/posts/py/core-devs-typing/)
+
+
+# 好玩的项目,工具和库
+
+[LoRAX](https://github.com/predibase/lorax)
+在生产中为 100 个经过微调的 LLM 提供服务,成本为 1.
+
+[AIConfig](https://github.com/lastmile-ai/aiconfig)
+配置驱动、源代码控制友好的 AI 应用程序开发。
+
+[Frigate](https://github.com/blakeblackshear/frigate)
+Frigate 是一款围绕实时 AI 对象检测构建的开源 NVR。所有处理都是在您自己的硬件上本地执行的,并且您的相机馈送永远不会离开您的家。
+
+[PyNest](https://github.com/PythonNest/PyNest)
+PyNest 是一个构建在 FastAPI 之上的 Python 框架,遵循 NestJS 的模块化架构。
+
+[ai-exploits](https://github.com/protectai/ai-exploits)
+真实世界 AI/ML 漏洞利用的集合,用于负责任地披露的漏洞。
+
+[pytest-patterns](https://github.com/flyingcircusio/pytest-patterns)
+pytest-patterns 是 pytest 的插件,提供专门针对测试优化的模式匹配引擎。
+
+[Google-Colab-Selenium](https://github.com/jpjacobpadilla/Google-Colab-Selenium)
+在 Google Colab 笔记本中使用 Selenium 的最佳方式!
+
+[stateless](https://github.com/suned/stateless)
+Python 的静态类型、纯函数效果。
+
+[sqlalchemy_data_model_visualizer](https://github.com/Dicklesworthstone/sqlalchemy_data_model_visualizer)
+自动将您的 SQLalchemy 数据模型转换为漂亮的 SVG 图
+
+[StyleTTS 2](https://github.com/yl4579/StyleTTS2)
+通过风格扩散(Style Diffusion)和大型语音语言模型的对抗性训练实现人类水平的文本到语音转换
+
+[screenshot-to-code](https://github.com/abi/screenshot-to-code)
+放入屏幕截图并将其转换为干净的 HTML/ Tailwind/JS 代码。
+
+[NeumAI](https://github.com/NeumTry/NeumAI)
+Neum AI 是一个一流的框架,用于管理大规模矢量嵌入的创建和同步。
+
+
+# 最新发布
+
+[Python 3.13.0 alpha 2 现已推出](https://pythoninsider.blogspot.com/2023/11/python-3130-alpha-2-is-now-available.html)
+
+[Django 5.0 候选版本 1 已发布](https://www.djangoproject.com/weblog/2023/nov/20/django-50-rc1/)
+
+
+# 近期活动和网络研讨会
+
+[Virtual:PyMunich Meetup 2023 年 11 月](https://www.meetup.com/pymunich/events/296949399/)
+将有以下演讲:
+* Python 元编程简介
+* 数据科学家的知识产权
+* 生产中利用开源 LLM
+
+[PyBerlin 42](https://www.meetup.com/pyberlin/events/296945261/)
+将有以下演讲:
+* 浏览器中的 CPU:WebAssembly 揭秘
+* 敏捷交付的四个关键问题
+* 将 LLM 纳入实际的 NLP 工作流程中
+* Web 黑客:通过单个 Python 漏洞接管服务器
+
+[PyData Copenhagen Meetup 2023 年 11 月](https://www.meetup.com/pydata-copenhagen/events/297375748/)
+将有一场演讲,加速 ML 原型设计:利用 HiPlot 和 Patsy 以思维的速度进行特征工程。
diff --git a/Python Weekly/Python_Weekly_Issue_628.md b/Python Weekly/Python_Weekly_Issue_628.md
new file mode 100644
index 0000000..d8f9635
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_628.md
@@ -0,0 +1,109 @@
+原文:[Python Weekly - Issue 628](http://eepurl.com/iE8zjE)
+
+---
+
+欢迎来到Python周刊第 628 期。**Y Combinator** 公司中的其中一家正在寻找一名具有 6 年以上经验、在 ETL、图形 DB 和基于 Python 的 REST 后端方面拥有专业知识,并且准备为 B2B 销售技术构建尖端解决方案的**创始工程师**。这个角色在美国是远程工作的。This role is remote in the US. 我很了解这家公司的创始人。如果您拥有必要的技能和经验并且有兴趣,请向我发送您的简历。
+
+
+# 文章,教程和讲座
+
+[大语言模型简介](https://www.youtube.com/watch?v=zjkBMFhNj_g) 
+Andrej Karpathy 的大型语言模型简介讲座涵盖了 ChatGPT、Claude 和 Bard 等系统背后的核心技术组件。它们是什么、它们的发展方向、与当今操作系统的比较和类比,以及这种新计算范式的一些与安全相关的挑战。
+
+[Rust std fs 比 Python 慢!?不,是硬件的锅!](https://xuanwo.io/2023/04-rust-std-fs-slower-than-python/)
+加入我们,踏上一段富有启发性的旅程,从 opendal 的 op.read() 开始,走向惊人,作者沿途会分享他们的经验教训。
+
+[使用 Numba 解锁 pandas.DataFrame.apply 中的 C 级性能](https://labs.quansight.org/blog/unlocking-c-level-performance-in-df-apply)
+快速概述 DataFrame.apply 中的新的 Numba 引擎。
+
+[Spinning Up in Deep RL](https://spinningup.openai.com/en/latest/)
+由 OpenAI 制作的教育资源,让您可以更轻松地了解深度强化学习(deep RL)。
+
+[Python 作为值的错误:比较来自 Go 和 Rust 的有用模式](https://www.inngest.com/blog/python-errors-as-values)
+更安全的错误处理,受 Go 和 Rust 启发。
+
+[在 Python 中构建一个小型 REPL](https://bernsteinbear.com/blog/simple-python-repl/)
+在我之前用 Python 编写的许多解释器/编译器项目中,我手动编写了一个 REPL(read-eval-print-loop,读取-评估-打印-循环)。事实证明,Python 附带了一堆完备的功能,以至于它们显得完全没有必要——你免费就能获得很多好东西。让我们看看如何使用它们,就从在项目中嵌入普通的 Python REPL 开始。
+
+[在 vanilla Django 中构建 Bootstrap 风格的表单](https://smithdc.uk/blog/2023/bootstrap_form_in_vanilla_django)
+在这篇文章中,David Smith 探索了在 vanilla Django 中创建 Bootstrap 风格的表单而不依赖第三方包的方法。他讨论了自定义表单小部件、添加 CSS 类以及创建自定义字段模板。
+
+[使用 Sub Interpreter 运行 Python 并行应用](https://tonybaloney.github.io/posts/sub-interpreter-web-workers.html)
+Python 3.12 引入了一个新的“sub interpreter” API,这是一种不同的 Python 并行执行模型,它在多处理的真正并行性之间提供了很好的折衷,但启动时间更快。这篇文章将解释什么是sub interpreter为什么它对于 Python 中的并行代码执行很重要、以及它与其他方法之间的比较。
+
+[CPython 对象系统内部结构:了解 PyObject 的角色](https://codeconfessions.substack.com/p/cpython-object-system-internals-understanding)
+了解 CPython 中是如何实现对象的,以及 CPython 如何使用结构嵌入模拟 C 中的继承和多态性。
+
+[Robot Dad](https://blog.untrod.com/2023/11/robot-dad.html)
+这是一篇关于一位父亲的文章,他创建了一个名为 Robot Dad 的聊天机器人来回答他儿子的问题。这个聊天机器人能够通过 Google 搜索来访问和处理来自现实世界的信息。Robot Dad 还可以用来翻译语言。
+
+[Python 中简单的 WebSocket 基准测试](https://lemire.me/blog/2023/11/28/a-simple-websocket-benchmark-in-python)
+
+[Python,Asyncio 和 Footguns](https://ryanc118.medium.com/python-asyncio-and-footguns-8ebdb4409122)
+
+[LMQL —— 用于语言模型的 SQL](https://towardsdatascience.com/lmql-sql-for-language-models-d7486d88c541)
+
+
+ # 好玩的项目,工具和库
+
+[rags](https://github.com/run-llama/rags)
+在您的数据上构建 ChatGPT,全部使用自然语言。
+
+[easylkb](https://github.com/deepseagirl/easylkb)
+易用的 Linux Kernel Builder。
+
+[kanban-python](https://github.com/Zaloog/kanban-python)
+用 Python 编写的终端看板应用,可用来提高您的工作效率。
+
+[ProAgent](https://github.com/OpenBMB/ProAgent)
+从机器人流程自动化到代理流程自动化。
+
+[autometrics-py](https://github.com/autometrics-dev/autometrics-py)
+轻松将指标添加到您的代码中,这些指标实际上可以帮助您发现和调试生产中的问题。基于 Prometheus 和 OpenTelemetry 构建。
+
+[Subtitle](https://github.com/innovatorved/subtitle)
+开源字幕生成,用于无缝内容翻译。
+
+[Breezy](https://github.com/breezy-team/breezy)
+具有用户友好界面的分布式版本控制系统。
+
+[Flask-Muck](https://github.com/dtiesling/flask-muck)
+Flask-Muck 是一个功能齐全的框架,用于在 Flask/SqlAlchemy 应用程序堆栈中,自动生成带有创建、读取、更新和删除 (CRUD) 端点的 RESTful API。
+
+[self-operating-computer](https://github.com/OthersideAI/self-operating-computer)
+使多模式模型能够操作计算机的框架。
+
+[apple-home-key-reader](https://github.com/kormax/apple-home-key-reader)
+该项目提供了使用 Python 构建 Apple Home Key Reader 的演示。
+
+[sysaidmin](https://github.com/skorokithakis/sysaidmin/)
+Sysaidmin 是为你的机器准备的,由 GPT 提供支持的系统管理员。你可以要求它解决问题,它会在您的系统上运行命令(经过您的许可)来调试正在发生的情况。
+
+[Meditron](https://github.com/epfLLM/meditron)
+Meditron 是一套开源医疗大语言模型(LLM)。
+
+[pip.wtf](https://pip.wtf/)
+小型 Python 脚本的内联依赖项。
+
+
+ # 近期活动和网络研讨会
+
+[PyData Cambridge Meetup 2023 年 12 月](https://www.meetup.com/pydata-cambridge-meetup/events/297337394/)
+将会有一场演讲:使用 Polars 进行网络安全中的实用检测工程。
+
+[PyData Amsterdam Meetup 2023 年 12 月](https://www.meetup.com/pydata-nl/events/297098652/)
+将有以下演讲:
+ * 智能银行:释放 AI 的潜力
+ * 支付处理中的多模型优化
+ * 金融科技的模型选择:优缺点
+
+[PyData London Meetup 2023 年 12 月](https://www.meetup.com/pydata-london-meetup/events/297585435/)
+将举行以下会议:
+ * Python 依赖管理器大对决
+ * 为什么我切换到 Windows
+
+
+[VilniusPY #24](https://www.meetup.com/vilniuspy/events/297507169/)
+将有以下演讲:
+ * 重新认证:如何成为一名成功的入门级开发人员
+ * 将 Python 项目迁移到 K8s
diff --git a/Python Weekly/Python_Weekly_Issue_629.md b/Python Weekly/Python_Weekly_Issue_629.md
new file mode 100644
index 0000000..68a3feb
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_629.md
@@ -0,0 +1,125 @@
+原文:[Python Weekly - Issue 629](http://eepurl.com/iFDrxQ)
+
+---
+
+欢迎来到Python周刊第 629 期。让我们直奔主题。
+
+# 文章,教程和讲座
+
+[深入探讨 Python 中的状态设计模式](https://www.youtube.com/watch?v=5OzLrbk82zY) 
+在本视频中国呢,我将探讨 Python 中的状态设计模式,这是管理面向对象编程中状态更改的游戏颠覆者。
+
+[Django 5.0 的新功能!](https://www.youtube.com/watch?v=lPl5Q5gv9G8) 
+你有没有在倒计时呢?不是圣诞节...而是新的 Django 版本!Django 5.0 发布了!让我们一起揭开我们最喜欢的 Python Web 框架带给我们的新礼物。
+
+[在 Pandas 世界中使用 Polars](https://pythonspeed.com/articles/polars-pandas-interopability/)
+Pandas 拥有比 Polars 更多的第三方集成。了解如何将这些库与 Polars 的 dataframe 一起使用吧。
+
+[将现有 Python 项目切换到 Ruff](https://www.youtube.com/watch?v=ETG5azrc4F4) 
+在最近的构建 SaaS 流中,我们从基于 flake8、Black、isort 和 bandit 的技术栈完全切换到使用单一工具 Ruff。观看经验丰富的 Pythonista 是如何使用多种选项,并完全切换到使用这个强大的工具的。
+
+[无类型 Python:曾经的 Python](https://lucumr.pocoo.org/2023/12/1/the-python-that-was/)
+思考多年来 Python 上所发生的变化,特别是类型。
+
+[比 Meta 的 FAISS 快 10 倍](https://www.unum.cloud/blog/2023-11-07-scaling-vector-search-with-intel)
+在英特尔的 Sapphire Rapids CPU 上,使用 Gcore 扩展 USearch Vector Search 引擎。
+
+[使用 PyTorch II 加速生成式 AI:GPT,快](https://pytorch.org/blog/accelerating-generative-ai-2/)
+本文是多系列博客的第二部分,重点介绍如何使用纯原生 PyTorch 加速生成式 AI 模型。我们很高兴与大家分享新发布的 PyTorch 性能特性以及实用示例,以了解我们可以将 PyTorch 原生性能提升到什么程度。在第一部分中,我们展示了如何仅使用纯原生 PyTorch 将 Segment Anything 速度提高超过 8 倍。在这篇文章中,我们将重点关注 LLM 优化。
+
+[MLOps 课程 – 构建机器学习生产级项目](https://www.youtube.com/watch?v=-dJPoLm_gtE) 
+MLOps 是机器学习操作(Machine Learning Operations)的缩写,指将 DevOps 原则应用于机器学习的实践。本 MLOps 课程将指导您完成端到端 MLOps 项目,涵盖从数据摄取到部署的所有内容,使用 ZenML、MLflow 和各种 MLOps 库等最先进的工具。
+
+[Visual Studio Code 中的 Python Linting – 提示和 Linting 视频系列](https://devblogs.microsoft.com/python/python-linting-video/)
+编写代码最重要的部分之一是确保代码可读。干净的代码有很多积极的下游效应,包括易于维护和添加功能、调试微妙的编程错误或查找未初始化的变量。有些人称此为代码卫生。VS Code 支持 linter 扩展,使您能够更快地开发、生成更清晰的代码并根据您的设置进行调整。
+
+
+# 好玩的项目,工具和库
+
+[Dropbase](https://github.com/DropbaseHQ/dropbase)
+Dropbase 可帮助您使用 Python 构建内部 Web 应用程序。Dropbase 自托管 Worker 可以与您自己的基础设施中的数据安全地进行交互。
+
+[MLX](https://github.com/ml-explore/mlx)
+MLX 是 Apple 芯片上用于机器学习的阵列框架,由 Apple 机器学习研究团队提供。
+
+[unsloth](https://github.com/unslothai/unsloth)
+速度提高 5 倍,内存减少 50% 的 LLM 微调。
+
+[Gymbo](https://github.com/Koukyosyumei/Gymbo)
+从头开始实现的基于梯度的符号执行引擎。
+
+[marker](https://github.com/VikParuchuri/marker)
+快速、高精度地将 PDF 转换为 Markdown
+
+[gpt-fast](https://github.com/pytorch-labs/gpt-fast)
+简单高效的 pytorch 原生转换器文本生成。
+
+[TaskWeaver](https://github.com/microsoft/TaskWeaver)
+一个代码优先的代理框架,用于无缝规划和执行数据分析任务。
+
+[Amphion](https://github.com/open-mmlab/Amphion)
+开源音频、音乐和语音生成工具包。
+
+[akarsu](https://github.com/furkanonder/akarsu/)
+基于 PEP 669 的新一代分析器。
+
+[Skyfield](https://rhodesmill.org/skyfield/)
+用 Python 实现的优雅天文学。
+
+[Dobb*E](https://github.com/notmahi/dobb-e/)
+一个用于学习家政机器人操作的开源通用框架
+
+[GeoDream](https://github.com/baaivision/GeoDream)
+解开 2D 和几何先验,以实现高保真和一致的 3D 生成。
+
+[mlx-examples](https://github.com/ml-explore/mlx-examples)
+MLX 框架中的示例。
+
+[great-tables](https://github.com/posit-dev/great-tables)
+使用 Python 轻松生成信息丰富且达到出版质量的表格。
+
+[DataStack](https://github.com/data-stack-hub/DataStack)
+Datastack 是一个开源框架,让您能够仅使用 Python 就可以轻松构建实时 Web 应用程序、内部工具、仪表板、周末项目、数据输入表单或原型,无需前端经验
+
+[Canopy](https://github.com/pinecone-io/canopy)
+Canopy 是一个构建在 Pinecone 矢量数据库之上的开源检索增强生成 (RAG) 框架和上下文引擎。Canopy 使您能够使用 RAG 快速轻松地试验和构建应用程序。通过几个简单的命令即可开始与文档或文本数据聊天。
+
+[Above](https://github.com/wearecaster/Above)
+隐形网络协议嗅探器。
+
+
+# 最新发布
+
+[Django 5.0 已发布](https://www.djangoproject.com/weblog/2023/dec/04/django-50-released/)
+发行说明详细介绍了大量令人兴奋的新功能,其中一些亮点是:
+ * 数据库计算的默认值:允许将数据库计算的默认值定义为模型字段。
+ * 延续 Django ORM 扩展的趋势,生成的模型字段允许创建数据库生成的列。
+ * 字段组的概念被添加到模板系统中,以简化表单字段呈现。
+
+
+ # 近期活动和网络研讨会
+
+[Django London 2023 年 12 月聚会](https://www.meetup.com/djangolondon/events/297502880/)
+将有一场演讲,支持初级开发人员:我的旅程所得。
+
+[ClePy 2023 年 12 月](https://www.meetup.com/cleveland-area-python-interest-group/events/296720145/)
+将有一场演讲:使用 FastAPI 和 Pydantic 构建 GPT Action。
+
+[Python Milano 2023 年 12 月聚会](https://www.meetup.com/python-milano/events/297758655/)
+将有以下演讲
+ * Streamlit:献给所有人的示例驱动学习
+ * 使用 Streamlit 快速交付 MVP
+
+
+[PyData Stockholm 2023 年 12 月聚会](https://www.meetup.com/pydatastockholm/events/297677610/)
+将有以下演讲
+ * DuckDB:转变数据管理和分析
+ * 即时 MLOps:使用 DuckDB 和 ArrowFlight 来优化特征存储
+
+
+[PyData Lausanne 2023 年 12 月聚会](https://www.meetup.com/pydata-lausanne/events/297505348/)
+将有以下演讲
+ * Python 的 API 和数据模拟
+ * Model-X 仿制品
+
+
diff --git a/Python Weekly/Python_Weekly_Issue_630.md b/Python Weekly/Python_Weekly_Issue_630.md
new file mode 100644
index 0000000..49fa38f
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_630.md
@@ -0,0 +1,81 @@
+原文:[Python Weekly - Issue 630](http://eepurl.com/iF-TCw)
+
+---
+
+欢迎来到Python周刊第 630 期。让我们直奔主题。
+
+
+# 文章,教程和讲座
+
+[Vector Search RAG 教程 —— 通过高级搜索,将您的数据与 LLMs 结合起来](https://www.youtube.com/watch?v=JEBDfGqrAUA) 
+了解如何使用矢量搜索(Vector Search)和嵌入轻松地将数据与 GPT-4 等大型语言模型相结合。您将首先学习概念,然后创建三个项目。
+
+[在运行时注释](https://blog.glyph.im/2023/12/annotated-at-runtime.html)
+PEP 593 对于如何实际使用 Annotated 参数这一点有些含糊其辞;这是我的建议。
+
+[pytest 守护进程:10 倍本地测试迭代速度](https://discord.com/blog/pytest-daemon-10x-local-test-iteration-speed)
+在 Discord,他们的 Python 测试套件本地测试运行缓慢,每次测试需要 13 秒。他们构建了一个 pytest 守护进程,将本地测试迭代速度提高了 10 倍,显着缩短了开发时间。该解决方案涉及将繁重的工作卸载到后台进程并缓存结果,绕过缓慢的导入和固定装置。
+
+[在 Python 中执行 a + b 需要多少行 C 代码?](https://codeconfessions.substack.com/p/cpython-dynamic-dispatch-internals)
+了解 CPython 中动态调度实现的机制。
+
+[为什么使用 TYPE_CHECKING?](https://vickiboykis.com/2023/12/11/why-if-type_checking/)
+本文讨论了 Python 中条件导入的使用,特别是 if TYPE_CHECKING 模式,以解决 mypy 等工具强制执行的类型检查和运行时类型检查的差异。它探讨了在处理存在大量相互依赖并可能导致循环依赖的自定义类时,是否需要此模式。
+
+[对扇出模式(Fanout Pattern)的解释](https://www.better-simple.com/django/2023/12/06/fanout-pattern-explained)
+本文讨论了扇出模式在 Celery 任务上下文中的使用,其中单个任务可以替换为数量可变的其他任务。它提供了一个关于扇出模式的实际示例,及其在处理复杂任务签名中的应用,强调了它在 Celery 框架内的任务设计和管理中的强大功能。通过代码示例说明了扇出模式,展示了其处理顺序和并行任务执行的能力,提供了对于其任务编排和工作负载分配的有效性的一些见解。
+
+[Django:使用 nh3 清理传入的 HTML 片段](https://adamj.eu/tech/2023/12/13/django-sanitize-incoming-html-nh3/)
+让我们看看如何在 Django 表单中使用 nh3 进行 HTML 清理。您可以将此方法应用于其他情况,例如在 DRF 序列化器中。
+
+[现实中的 match/case](https://nedbatchelder.com/blog/202312/realworld_matchcase.html)
+Python 3.10 引入了结构模式匹配,称为 match/case,它允许匹配数据结构中的模式。本文提供了一个使用匹配/大小写来简化对从 GitHub 机器人接收的复杂 JSON 有效负载的检查的真实示例,展示了其在处理深度嵌套数据结构方面的实际应用。作者强调了与传统的分离有效负载的方法相比,match/case 如何使任务变得更加简单
+
+
+# 好玩的项目,工具和库
+
+[coffee](https://github.com/Coframe/coffee)
+使用 AI 直接在您自己的 IDE 上构建和迭代您的 UI,速度提高 10 倍。
+
+[µHTTP](https://github.com/0x67757300/uHTTP)
+µHTTP 的出现源于对简单 Web 框架的需求。它非常适合微服务、单页应用程序以及单体(架构)这类庞然大物。
+
+[PurpleLlama](https://github.com/facebookresearch/PurpleLlama)
+用于评估和提高 LLM 安全性的工具集。
+
+[Arrest](https://github.com/s-bose/arrest)
+Arrest 是一个小型的实用程序,用以使用 pydantic 和 httpx 轻松构建和验证 REST API 调用。
+
+[LLMCompiler](https://github.com/SqueezeAILab/LLMCompiler)
+用于并行函数调用的 LLM 编译器。
+
+[Pearl](https://github.com/facebookresearch/Pearl)
+由 Meta 的应用强化学习团队带来的可投入生产的强化学习 AI 代理库。
+
+[Mamba-Chat](https://github.com/havenhq/mamba-chat)
+Mamba-Chat 是第一款基于状态空间模型架构而非转换器的聊天语言模型。
+
+[Netchecks](https://github.com/hardbyte/netchecks)
+Netchecks 是一组用于测试网络状况,并断言它们是否符合预期的工具。
+
+[concordia](https://github.com/google-deepmind/concordia)
+用于生成社会模拟的库。
+
+[Cyclopts](https://github.com/BrianPugh/cyclopts)
+基于 python 类型提示的直观、简单的 CLI。
+
+[UniDep](https://github.com/basnijholt/unidep)
+具有 pip 和 conda 要求的单一事实来源。
+
+
+# 最新发布
+
+[Visual Studio Code 中的 Python - 2023 年 12 月版本](https://devblogs.microsoft.com/python/python-in-visual-studio-code-december-2023-release/)
+此版本包括以下声明:
+* 运行按钮菜单中添加了可配置的调试选项
+* 使用 Pylance 显示类型层次结构
+* 停用对终端中自动激活的虚拟环境的命令支持
+* 可设置打开/关闭 REPL 智能发送以及不支持时的消息
+
+
+[Python 3.12.1](https://www.python.org/downloads/release/python-3121/)
\ No newline at end of file
diff --git a/Python Weekly/Python_Weekly_Issue_631.md b/Python Weekly/Python_Weekly_Issue_631.md
new file mode 100644
index 0000000..7225630
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_631.md
@@ -0,0 +1,110 @@
+原文:[Python Weekly - Issue 631](http://eepurl.com/iGGpqI)
+
+---
+
+欢迎阅读《Python 周刊》第 631 期。这是2023年的最后一期。我们将在假期结束后回来。祝您及家人节日快乐!(译注:我也要去过节啦,大家节日快乐!!)
+
+# 新闻
+
+[PyPI 的 2FA 要求,开始于 2024-01-01](https://blog.pypi.org/posts/2023-12-13-2fa-enforcement/)
+从 2024 年 1 月 1 日开始,所有用户必须为其 PyPI 帐户启用双因素身份验证 (2FA) 才能执行任何管理操作或上传文件。此要求是 PyPI 为增强安全性所做的努力的一部分,仅需要浏览、下载和安装包的用户不会受到此更改的影响。
+
+
+# 文章,教程和讲座
+
+[Requests vs Httpx vs Aiohttp | 选哪个?](https://www.youtube.com/watch?v=OPyoXx0yA0I) 
+该视频讨论了对应用程序中 API 通信的探索,比较了 requests、httpx 和 aiohttp 的使用。它展示了作者的首选项以及考虑该选择的理由。
+
+[掌握使用 GitHub Copilot 进行 AI 配对编程的方法](https://github.com/microsoft/Mastering-GitHub-Copilot-for-Paired-Programming)
+6 节课的课程,教授有关利用 GitHub Copilot 和 AI 配对编程资源所需了解的所有信息。
+
+[Python 应用程序中的配置:没有魔法,只是必要的实践](https://robertrode.com/2023/10/02/configuration-in-python-applications-no-magic-just-necessary-practice.html)
+本文探讨了 Python 应用程序中的配置实践,强调透明性的重要性并避免在此过程中使用魔法。它深入探讨了管理配置设置的实用方法,提倡 Python 应用程序开发中的清晰度和必要实践。
+
+[GILad 中的 Balm:CPython 扩展的快速字符串构造](https://blog.vito.nyc/posts/gil-balm/)
+一种优化在 Python 字符串上运行的 Python C 扩展的非正统方法。
+
+[构建个人预测文本引擎](https://jamesg.blog/2023/12/15/auto-write/)
+本文讨论了名为 AutoWrite 的个人预测文本引擎的开发过程,该引擎会考虑文档中已编写的单词,从而提供特定于上下文的自动完成功能。
+
+[我是如何使用 Python 构建 Okta 文档聊天机器人的](https://developer.okta.com/blog/2023/12/20/okta-documentation-chatbot)
+本文介绍了 Oktanaut 的开发过程,Oktanaut 是一个 Python 聊天机器人,可简化对 Okta 开发人员文档信息的访问。该聊天机器人是使用 OpenAI 和 Jupyter Notebook 创建的,并开发了两个版本来提供特定的方法和常识。第一个版本使用 LlamaIndex 并根据 Okta 的开发人员文档进行训练,基于其精度而生成准确的响应。
+
+[安全哈希冲突](https://www.da.vidbuchanan.co.uk/blog/colliding-secure-hashes.html)
+本文讨论了这么一个问题:作者使用 pyopencl 移植算法以在 GPU 上运行,导致安全哈希冲突。作者选择截断散列的中间部分而不是末尾部分,试图在视觉上欺骗某人比较全长散列的开头和结尾。
+
+[可重用 Django 应用的设置模式](https://overtag.dk/v2/blog/a-settings-pattern-for-reusable-django-apps)
+本文介绍了可重用 Django 应用程序的新设置模式,解决了使用项目设置覆盖应用程序默认设置的挑战。作者讨论了对清晰一致模式的需求,文章概述了建议的解决方案,其中涉及检查设置的前缀以避免返回 Django 设置的随机属性。
+
+[DjangoCon US 2023 视频集](https://www.youtube.com/playlist?list=PL2NFhrDSOxgX41jqYSi0HmO9Wsf6WDSmf) 
+DjangoCon US 2023 的 YouTube 视频集合,包含该活动的各种视频。它涵盖了与 Django 开发相关的一系列主题,包括在会议上展示的演讲、研讨会和讨论。
+
+[异步任务取消的最佳实践](https://superfastpython.com/asyncio-task-cancellation-best-practices/)
+在本教程中,您将发现在 Python 中取消异步任务的最佳实践。
+
+[使用 Django 构建即时通讯工具(6 分钟内)](https://www.youtube.com/watch?v=-9h3Sjr2WKk) 
+该视频提供了有关使用 Django 创建即时通讯工具的快速教程。本教程旨在以简洁的方式演示该过程,使其成为那些对使用 Django 开发消息应用程序感兴趣的人来说有用的资源。
+
+[理解 GPU 内存 1:可视化随时间变化的所有分配](https://pytorch.org/blog/understanding-gpu-memory-1/)
+第一部分显示了使用内存快照工具的方法。
+
+
+ * [第二部分](https://pytorch.org/blog/understanding-gpu-memory-2/) - 在这一部分中,我们将使用内存快照来可视化由循环引用引起的 GPU 内存泄漏,然后使用引用循环检测器在代码中定位并删除它们。
+
+
+[使用 APIFlask 来保持数据 DRY](https://buildwithlayer.github.io/buildwithlayer/blog/dry_with_apiflask/)
+这篇文章讨论了如何使用 APIFlask(它的路由和模式符合 OpenAPI 规范)从而允许 API 文档的自动编写。它强调了保持数据 DRY(Don't Repeat Yourself,不要重复自己)的好处,以及在编写 API 时轻松记录 API 的好处。这篇文章深入介绍了 APIFlask 是如何帮助避免冗余代码,以及维护清晰简洁的代码库的。
+
+[Python 陷阱:列表复制问题](https://andrewwegner.com/python-gotcha-list-copy.html)
+复制 Python 列表(或任何可变对象)并不是将一个列表设置为另一个值那么简单。让我们讨论一个更好的方法来做到这一点。
+
+[适用于 LLMs 的 Bash One-Liners](https://justine.lol/oneliners/)
+六个可靠示例,说明 llamafile 是如何帮助您提高命令行使用效率的。
+
+[实际上,你可以并行使用多少个 CPU 核心?](https://pythonspeed.com/articles/cpu-thread-pool-size/)
+要弄清楚你的程序可以使用多少并行度是非常棘手的。
+
+[Python 中 `key` 参数的关键之处](https://www.thepythoncodingstack.com/p/the-key-to-the-key-parameter-in-python)
+名为 `key` 的参数存在于多个 Python 函数中,例如 `sorted()`。让我们探讨一下它是什么以及如何使用它。
+
+
+# 好玩的项目,工具和库
+
+[OpenVoice](https://github.com/myshell-ai/OpenVoice)
+一种多功能的即时语音克隆方法,只需要参考说话者的一个简短的音频剪辑即可复制他们的声音并生成多种语言的语音。
+
+[PromptBench](https://github.com/microsoft/promptbench)
+用于评估和理解大型语言模型的统一库。
+
+[generative-ai-python](https://github.com/google/generative-ai-python)
+Google AI Python SDK 使开发人员能够使用 Google 最先进的生成式 AI 模型(如 Gemini 和 PaLM)来构建 AI 驱动的功能和应用程序。
+
+[TwitchDropsMiner](https://github.com/DevilXD/TwitchDropsMiner)
+一款应用,允许您 AFK 挖掘定时 Twitch 掉落物,具有自动掉落物认领和频道切换功能。
+
+[feud](https://github.com/eonu/feud/)
+使用简单的惯用 Python 构建强大的 CLI,由类型提示驱动。
+
+[microagents](https://github.com/aymenfurter/microagents)
+能够自编辑提示/Python 代码的代理。
+
+[django-ninja-crud](https://github.com/hbakri/django-ninja-crud)
+声明式 CRUD 端点和测试,使用 Django Ninja。
+
+[skytrack](https://github.com/ANG13T/skytrack)
+使用 Python 制作的基于命令行的飞机定位和飞机 OSINT 侦察工具。
+
+[resemble-enhance](https://github.com/resemble-ai/resemble-enhance)
+AI 支持的语音去噪和增强。
+
+[whisper-plus](https://github.com/kadirnar/whisper-plus)
+高级语音到文本处理。
+
+[mergekit](https://github.com/cg123/mergekit)
+用于合并预训练大型语言模型的工具。
+
+[llm-mistral](https://github.com/simonw/llm-mistral)
+LLM 插件,提供对使用 Mistral API 的 Mistral 模型的访问。
+
+[tinyzero](https://github.com/s-casci/tinyzero)
+在您想的任何环境中轻松训练类似 AlphaZero 的智能体!
diff --git a/Python Weekly/Python_Weekly_Issue_632.md b/Python Weekly/Python_Weekly_Issue_632.md
new file mode 100644
index 0000000..ed23212
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_632.md
@@ -0,0 +1,112 @@
+原文:[Python Weekly - Issue 632](http://eepurl.com/iHlBRk)
+
+---
+
+欢迎阅读《Python 周刊》第 632 期。新年快乐!希望您度过了一个愉快的假期。
+
+
+# 新闻
+
+[DjangoCon Europe 2024 CFP](https://pretalx.evolutio.pt/djangocon-europe-2024/cfp)
+ DjangoCon Europe 2024 参与呼吁,邀请提交演讲,其主题应涉及 Django 和 Python 开发。提案截止日期为 2024 年 3 月 1 日。
+
+
+# 文章,教程和讲座
+
+[用 Python 读取 Excel 最快的方法](https://hakibenita.com/fast-excel-python)
+用不到 4 秒读取 500K 行。
+
+[面向 Python 爱好者的 Rust 编码简介 ](https://www.youtube.com/watch?v=MoqtsYLGCC4) 
+该视频首次探讨了使用 Rust 进行编码,深入探讨了它的炫酷功能,并与 Python 进行了比较。
+
+[Microdot:另一个 Python Web 框架](https://blog.miguelgrinberg.com/post/microdot-yet-another-python-web-framework)
+本文介绍了 Microdot,这是一个 Python Web 框架,具有类似 Flask 的语法、与 MicroPython 和 CPython 兼容、支持 asyncio 以及为 MicroPython 提供了一个最小的 Web 服务器,旨在满足 MicroPython 生态系统中对 Web 框架的需求。这篇文章还概述了 Microdot 的开发历史及其最近发布的完全异步的 2.0 版本。
+
+[Fontimize:仅将字体精确地设置为您网站使用的字符](https://daveon.design/introducing-fontimize-subset-fonts-to-exactly-and-only-your-websites-used-characters.html)
+Fontimize 是一个 Python 库,可以创建仅包含文本或 HTML 所需的特定字形的字体子集,从而减少网站的初始下载大小,进而优化带宽使用。
+
+[如何让 LLM 更快](https://vgel.me/posts/faster-inference)
+这篇文章是一篇长期而广泛的调查,探讨了一系列使 LLM 取得进展的不同方法(从更好的硬件利用率到巧妙的解码技巧)。
+
+[Django:检测全局隐私控制信号](https://adamj.eu/tech/2023/12/27/django-global-privacy-control/)
+在这篇文章中,我们将研究如何在 Django 项目中实现 GPC,并使用您可以进行调整的代码示例。由于 GPC 很简单,但需要非常依赖于具体情况的操作,因此很难为 Django 或第三方包构建任何特定的支持。
+
+[不使用 git 进行提交](https://matheustavares.gitlab.io/posts/committing-without-git)
+本文提供了一个实践教程,内容是使用 Python 创建具有两次提交的分支,旨在了解 Git 中的主要数据结构(称为“git 对象”)及其相互关系。这篇文章提供一些见解,涉及 Git 对象的不变性、使用 DEFLATE 算法进行压缩、以及通过其内容的 SHA-1 哈希进行引用,同时文中还警告不要在生产中使用该方法,因为由git 命令执行的安全检查和特别处理。
+
+[针对 Flask、Django 和 FastAPI 微调 Python WSGI 和 ASGI 应用程序](https://tonybaloney.github.io/posts/fine-tuning-wsgi-and-asgi-applications.html)
+在这篇文章中,重点是研究配置 Python Web 服务器(例如 Gunicorn、Uvicorn 和 Hypercorn)的最佳实践。它将总结Python代码和用户之间的组件架构,并讨论负载测试等验证方法,以确保配置能够承受用户流量。
+
+[使用两塔方法(Two Tower Approach)和 Expedia Group 旅行者数据生成候选者](https://medium.com/expedia-group-tech/candidate-generation-using-a-two-tower-approach-with-expedia-group-traveler-data-ca6a0dcab83e)
+建模环境和项目功能,以改进旅行者推荐。
+
+[Python 陷阱:在迭代时修改列表](https://andrewwegner.com/python-gotcha-modify-list-while-iterating.html)
+Python 可以让您在迭代列表元素时轻松修改列表。这种操作会反咬你一口。请继续阅读以了解它是如何阴你的,以及可以采取什么措施。
+
+[AutoGluon-TimeSeries:创建强大的集合预测(Ensemble Forecast) - 完整教程](https://aihorizonforecast.substack.com/p/autogluon-timeseries-creating-powerful)
+Amazon 的时间序列预测框架应有尽有。
+
+[如何在 mac 上使用 cli 或免费使用 Python 进行 ocr ](https://blog.greg.technology/2024/01/02/how-do-you-ocr-on-a-mac.html)
+
+[一个实验性的pip子命令,用于Unix的Python启动器](https://snarky.ca/an-experimental-pip-subcommand-for-the-python-launcher-for-unix/)
+
+[在2024年的头几天学习 LLM 和编程](http://antirez.com/news/140)
+
+
+# 好玩的项目,工具和库
+
+[DocFlow](https://github.com/jiisanda/docflow)
+DocFlow 是一个强大的文档管理 API,旨在简化文档处理,包括无缝上传、下载、组织、版本控制、共享等功能。
+
+[Jake](https://github.com/thevahidal/jake)
+在 GitHub 上轻松创建和部署您自己的单链接网站。
+
+[Paracelsus](https://github.com/tedivm/paracelsus)
+Paracelsus 通过读取 SQLAlchemy 模型来生成实体关系图。
+
+[falco](https://github.com/tobi-de/falco)
+增强您的 Django 开发体验:现代 Django 开发者的 CLI 和指南。
+
+[AnyText](https://github.com/tyxsspa/AnyText)
+多语言可视文本生成和编辑。
+
+[mixtral-offloading](https://github.com/dvmazur/mixtral-offloading)
+在 Colab 或者消费者桌面中运行 Mixtral-8x7B 模型。
+
+[UForm](https://github.com/unum-cloud/uform)
+袖珍多模态 AI,用于内容理解和生成,跨多语言文本、图像和视频,速度比 OpenAI CLIP 和 LLaVA 快了多至 5 倍。
+
+[MotionCtrl](https://github.com/TencentARC/MotionCtrl)
+用于视频生成的统一且灵活的运动控制器。
+
+[semantic-router](https://github.com/aurelio-labs/semantic-router)
+语义路由器是您的 LLM 和代理的超快速决策层。相比等待缓慢的 LLM 一代做出工具使用决策,我们利用语义向量空间的魔力来做出这些决策——使用语义来路由我们的请求。
+
+[Autograd-from-scratch](https://github.com/eduardoleao052/Autograd-from-scratch)
+从头开始记录并经过单元测试的教育性深度学习框架,仅使用 Numpy 构建。
+
+[MobileVLM](https://github.com/Meituan-AutoML/MobileVLM)
+适用于移动设备的快速、强大且开放的视觉语言助手。
+
+
+# 最新发布
+
+[Django 错误修复版本已发布:4.2.9 和 5.0.1](https://www.djangoproject.com/weblog/2024/jan/02/bugfix-release/)
+
+
+# 近期活动和网络研讨会
+
+[Virtual: Cleveland Python 2024 年 1 月聚会](https://www.meetup.com/cleveland-area-python-interest-group/events/297549665/)
+将会有一场演讲:使用开源包构建 LLM 支持的数据应用程序。
+
+[Python Milano 2024 年 1 月聚会](https://www.meetup.com/python-milano/events/298086176/)
+将有以下演讲:
+ * 少写,多测试 - 基于属性的测试简介
+ * Dagster:现代数据编排器
+
+
+[PyData Toronto 2024 年 1 月聚会](https://www.meetup.com/pydatato/events/297368081/)
+将有以下演讲:
+ * NumFOCUS - 那是什么?
+ * PyTorch 2.0 - 为什么你应该关心它?
+
diff --git a/Python Weekly/Python_Weekly_Issue_633.md b/Python Weekly/Python_Weekly_Issue_633.md
new file mode 100644
index 0000000..42269c8
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_633.md
@@ -0,0 +1,103 @@
+原文:[Python Weekly - Issue 633](http://eepurl.com/iHOxDc)
+
+---
+
+欢迎来到《Python周刊》第 633 期。让我们直奔主题。
+
+# 文章,教程和讲座
+
+[Python 3.13 有 JIT 啦](https://tonybaloney.github.io/posts/python-gets-a-jit.html)
+2023 年 12 月下旬的时候,CPython 核心开发人员 Brandt Bucher 向 Python 3.13 分支提交了一个小的 Pull 请求,添加了 JIT 编译器。这一更改一旦被接受,就将是自 Python 3.11 中添加专用自适应解释器(pecializing Adaptive Interpreter)以来,CPython 解释器最大的更改之一。在这篇文章中,我们将了解这个 JIT,它是什么、它如何工作以及有什么好处。
+
+[通过一个共享库集成 Rust 和 Python](https://www.youtube.com/watch?v=K9dUqGyQ9pw) 
+了解如何在用 Rust 构建计算和内存密集型函数,并将它们无缝集成到 Python 脚本中。该视频内容涵盖了使用 pyo3 利用 Rust 创建共享 Python 模块、将 Rust 代码编译到共享对象文件中、在 Python 中导入该文件以及从 Python 调用高性能的 Rust 函数。
+
+[保护你的 Flask 应用的最佳实践](https://escape.tech/blog/best-practices-protect-flask-applications/)
+通过我们的专家实践教程,学习如何有效保护您的 Flask 应用程序。只需几个步骤即可增强项目的安全性!
+
+[Knuckledragger:实验 Python 证明助手](https://www.philipzucker.com/python-itp/)
+我正在修改的东西是,用 python 制作一个证明助手。
+
+[CI 上 Scrapy 链接验证的乐趣](https://www.mattlayman.com/blog/2024/fun-scrapy-validation-ci/)
+如何自动确保站点内链接到其他内部页面的所有链接继续有效?在本文中,我们将了解如何使用 Scrapy(一种网页抓取工具)和 GitHub Actions(一种持续集成系统)来实现此目标。
+
+[使用格式化程序和 linter 管理大型代码库](https://tech.octopus.energy/news/2024/01/05/linting-and-formatting.html)
+在 Kraken Tech,我们拥有一支由 500 多名开发人员组成的大型全球开发团队,其中大多数人都在包含超过 400 万行 Python 代码的单体代码库上工作。我们每天发布新代码超过 100 次,在此过程中运行数十万次测试。那么,在变更如此频繁的情况下,要如何在分布式团队中确保高编码质量呢?此外,我们如何才能让新加入者更容易地加入并做出贡献?
+
+[深入探讨 Python 的 functools.wraps 装饰器](https://jacobpadilla.com/articles/Functools-Deep-Dive)
+本文讨论了 Python 中 functools.wraps 装饰器的重要性。它解释了在将一个对象包装在另一个对象上时,特别是在开发 Python 装饰器时,装饰器是如何帮助保留元数据的。作者强调了这个装饰器的重要性,因为封装对象可能会丢失有价值的元数据。
+
+[纯 Python 中的 SIMD](https://www.da.vidbuchanan.co.uk/blog/python-swar.html)
+这篇文章探讨了 Python 环境下的 SWAR(寄存器中的 SIMD)及其变体 SWAB(Bigint 中的 SIMD)的概念。讨论了 SWAB(最大化每条 VM 指令完成的工作量)是如何在 Python 中发挥作用、减少解释器开销、并允许 CPU 将大部分时间花在实现整数运算的快速本机代码上。
+
+[实验《纽约时报填字游戏》上的手写识别](https://open.nytimes.com/experimenting-with-handwriting-recognition-for-new-york-times-crossword-a78e08fec08f)
+本文讨论了 MakerWeek 2023 黑客马拉松期间,针对《纽约时报填字游戏》应用程序中手写识别的探索。该项目涉及在 iOS 和 Android 平台上实现用于手写识别的设备端机器学习,它具有诸如“乱写乱画”检测和应用内自我训练机制等交互功能的潜力。
+
+[Viberary 回顾](https://vickiboykis.com/2024/01/05/retro-on-viberary/)
+本文反映了作者使用 Viberary 的经验,Viberary 是一个旨在根据特定氛围查找书籍的副项目。该项目的创建是为了探索机器学习副项目,以及搜索和推荐的交叉点,作为作者最近深入研究嵌入(embeddings)的生产级补充。
+
+[将 AI 驱动的 Django 应用程序部署到 Modal.com](https://tolkunov.dev/posts/django-on-modal/)
+Modal 是部署使用 AI 模型并需要 GPU 的 Python 应用程序的一个好地方。以下是如何将 Modal 与 Django 应用程序一起使用。
+
+[NumPy 2 来啦:防止损坏,更新代码](https://pythonspeed.com/articles/numpy-2/)
+NumPy 2 即将推出,并且向后不兼容。了解如何防止代码被破坏以及如何升级。
+
+[Pandas 分析:详细说明](https://www.influxdata.com/blog/pandas-profiling-tutorial/)
+Pandas 分析或现在所谓的 ydata-profiling,是通过 Python 提供的一个包,我们将在本文中介绍它并介绍如何使用它。
+
+[数据分析师初学者训练营(SQL、Tableau、Power BI、Python、Excel、Pandas、项目等)](https://www.youtube.com/watch?v=PSNXoAs2FtQ) 
+跟随这个大型课程成为一名数据分析师。您将学习数据分析师需要了解的核心主题。在此过程中,您会通过构建大量项目来获得实践经验。
+
+# 好玩的项目,工具和库
+
+[Open Interpreter](https://github.com/KillianLucas/open-interpreter)
+计算机自然语言界面。
+
+[Harlequin](https://github.com/tconbeer/harlequin)
+适用于您的终端的 SQL IDE。
+
+[crewAI](https://github.com/joaomdmoura/crewAI)
+用于编排角色扮演、自主人工智能代理的尖端框架。通过促进协作智能,CrewAI 使代理能够无缝协作,以及处理复杂的任务。
+
+[skfolio](https://github.com/skfolio/skfolio)
+Python 库,用于构建基于 scikit-learn 的投资组合优化。
+
+[aloha](https://github.com/tonyzhaozh/aloha)
+用于双手远程操作的低成本开源硬件系统。
+
+[selfextend](https://github.com/sdan/selfextend)
+自扩展的实现,通过分组注意力扩展上下文窗口
+
+[langgraph](https://github.com/langchain-ai/langgraph)
+将语言代理构建为图表。
+
+[psst](https://github.com/Sjlver/psst)
+基于纸质的秘密共享技术。
+
+[van-gonography](https://github.com/JoshuaKasa/van-gonography)
+在您选择的图像中隐藏任何类型的文件。
+
+
+# 近期活动和网络研讨会
+
+[DragonPy 2024 年 1 月聚会](https://www.meetup.com/ljubljana-python-group/events/298186535/)
+将有以下演讲:
+* 原谅我的 Python
+* 从 P 到 P – 不同类型的 p2p
+* Python 和能量学
+
+[Bangalore 2024 年 1 月聚会](https://www.meetup.com/bangpypers/events/297639118/)
+将有以下演讲:
+* Micropython - 用于微控制器的 Python
+* 是时候抛弃 requirements.txt 和 VENV 了,现在就开始使用Poetry
+* 我是如何制作 dunderhell 的:最丑陋的 python 压缩器
+
+[PyData Munich 2024 年 1 月聚会](https://www.meetup.com/pydata-munchen/events/298185256/)
+将有以下演讲:
+* 用于图像字幕的不同方法,为给定视觉输入预测字幕的任务
+* 从 LLM 到业务 - 在业务流程中扩展 LLM 应用程序。
+
+[PyData Southampton 2024 年 1 月聚会](https://www.meetup.com/pydata-southampton/events/298281776/)
+将有以下演讲:
+* OpenAI 的函数调用:它是什么以及我们要如何利用它?
+* 为非政府组织构建数据科学解决方案,即使你不知道它会在什么样的基础设施上运行:预测导师供需不匹配的案例研究
\ No newline at end of file
diff --git a/Python Weekly/Python_Weekly_Issue_634.md b/Python Weekly/Python_Weekly_Issue_634.md
new file mode 100644
index 0000000..027cbb2
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_634.md
@@ -0,0 +1,131 @@
+原文:[Python Weekly - Issue 634](http://eepurl.com/iIfkrc)
+
+---
+
+欢迎来到《Python周刊》第 634 期。让我们直奔主题。
+
+# 文章,教程和讲座
+
+[构建可用于生产的 FastAPI 后端的 4 个技巧](https://www.youtube.com/watch?v=XlnmN4BfCxw) 
+该视频讨论了您在大多数 FastAPI 在线教程中通常找不到的 4 件事。这些技巧非常有用,特别是如果您想创建可以在生产环境中使用的后端。
+
+[Python 打包,一年后:Python 打包 2023 年回顾](https://chriswarrick.com/blog/2024/01/15/python-packaging-one-year-later/)
+一年前,我写了一篇关于 Python 打包的悲催状态的文章。这个领域有大量的工具,强调编写模糊的标准而不是围绕一个真正的工具展开,还关注复杂的基于 venv 的生态系统而不是类似于 node_modules 的解决方案。那么,过去一年发生了什么变化呢?有什么改善吗?一切都还维持原样吗?或者情况比以前更糟了吗?
+
+[用于更快的 Python C 扩展的类型信息](https://bernsteinbear.com/blog/typed-c-extensions/)
+PyPy 是 Python 语言的替代实现。PyPy 的 C API 兼容性层存在着一些性能问题。Carl Friedrich Bolz-Tereick 和我正在研究一种使 PyPy 的 C API 交互速度更快的方法。它看起来非常有前途。这里是其工作原理的草图。
+
+[AlphaGeometry:奥林匹克级别的几何 AI 系统](https://deepmind.google/discover/blog/alphageometry-an-olympiad-level-ai-system-for-geometry/)
+这篇文章介绍了 AlphaGeometry,这是一个人工智能系统,可以解决复杂的几何问题,其水平接近人类奥林匹克金牌得主。本文重点介绍了该系统在标准时限内解决了 30 道奥林匹克几何问题中的 25 道的表现,反映了其在数学人工智能推理方面的重大进步。它提供了对 AlphaGeometry 的发展和功能的见解,将其定位为人工智能用于解决几何问题领域的突破性成就。
+
+[用一行代码即可节省 1 TB RAM](https://www.youtube.com/watch?v=Hgw_RlCaIds) 
+Anthony Sottile 展示了他在工作中所做的一个产生巨大影响的小改变,并解释了它是如何工作的!
+
+[我们是如何对 PyTorch 执行关键的供应链攻击的](https://johnstawinski.com/2024/01/11/playing-with-fire-how-we-executed-a-critical-supply-chain-attack-on-pytorch/)
+这篇文章讨论了对 PyTorch 的供应链攻击的执行,强调了潜在影响以及破解 PyTorch 供应链的途径。它深入研究了漏洞识别、攻击执行以及此类攻击在网络安全和供应链完整性背景下的重要性。
+
+[潜伏者代理(Sleeper Agents):训练持续通过安全性训练的欺骗性 LLM](https://arxiv.org/pdf/2401.05566.pdf)
+该研究探讨了大型语言模型 (LLM) 如何能够表现出持久性欺骗行为,例如根据指定的年份编写安全代码,但在年份发生变化时引入可利用的代码。当前的安全训练技术,包括监督微调和对抗性训练,很难检测和消除这些欺骗性策略,引发了人们对确保人工智能安全的标准方法有效性的担忧。
+
+[数据代码的结构应该有多好?](https://blog.dagworks.io/p/how-well-structured-should-your-data)
+这篇文章探讨了性能和系统可靠性之间的权衡,特别是在数据科学的背景下。它深入探讨了 ML 模型原型设计者所面临的挑战,讨论了快速行动的压力,以及放弃工作还是担任生产中机器学习工程师角色的决策过程。
+
+[GPT 中自注意力的直观指南:威尼斯假面舞会](https://twiecki.io/blog/2024/01/04)
+这篇文章讨论了 Transformer 架构中的自注意力机制(self-attention mechanism),使用威尼斯假面舞会的隐喻来解释现代人工智能中的这一概念。它的目的是通过提供直观且相关的解释,远离压倒性的数学细节和技术术语,使复杂的自注意力概念更容易理解。
+
+[Flask 中的另一个密码重置教程](https://freelancefootprints.substack.com/p/yet-another-password-reset-tutorial)
+密码重置流程的实现,有一些变化。
+
+[使用 Python 创建 UI - 使用 PyQt5 创建音乐播放器](https://www.youtube.com/watch?v=DjutoyfCl2c) 
+通过使用 PyQt5 框架创建现代音乐播放器来了解如何使用 Python 创建 UI。该应用程序的一些功能包括:美丽而现代的用户界面、播放列表和最喜爱的歌曲功能、不同页面的自定义上下文菜单以及每首歌曲的背景幻灯片。
+
+
+[Polars 简介](https://pbpython.com/polars-intro.html)
+本文概述了 Polars DataFrame 库,强调其目标是提供快如闪电的 DataFrame 库,以优化查询、处理大型数据集并维护一致且可预测的 API。它将 Polars 与其他解决方案进行了比较,并介绍了那些使其成为 Python 中高性能数据操作和分析的引人注目的选项的设计决策。
+
+[在空气隔离系统上运行 Python](https://iahmed.me/post/python-air-gapped/)
+如何在无法访问 Internet 的系统上可重复地运行 Python 代码。
+> 译注:空气隔离指计算机或计算机网络与其他设备或网络之间没有物理连接,以防止数据泄露或恶意攻击。
+
+[Python 中的同步](https://thiagowfx.github.io/2024/01/synchronized-in-python/)
+在Java中,只需添加 synchronized 关键字就可以使变量线程安全。在Python中可以通过什么东西来达到相同的结果吗?
+
+[避免黑盒 API 调用](https://rednafi.com/misc/eschewing_black_box_api_calls/)
+
+[htmx 是可组合的??](https://timkellogg.me/blog/2024/01/17/htmx)
+
+[The curious case of Pydantic 的奇怪案例,以及 1970 年代的时间戳](https://dev.arie.bovenberg.net/blog/pydantic-timestamps/)
+
+
+ # 好玩的项目,工具和库
+
+[marimo](https://github.com/marimo-team/marimo)
+一个反应式 Python notebook,可复制、git 友好且可作为脚本或应用程序部署。
+
+[surya](https://github.com/VikParuchuri/surya)
+适用于任何语言的精确行级文本检测和识别 (OCR)。
+
+[pathway](https://github.com/pathwaycom/pathway)
+Pathway 是一个高吞吐量、低延迟的数据处理框架,可以为您处理实时数据和流。
+
+[DataMapPlot](https://github.com/TutteInstitute/datamapplot)
+创建漂亮的数据地图。
+
+[Python-Redlines](https://github.com/JSv4/Python-Redlines)
+Docx 跟踪了 Python 生态系统的变更红线。
+
+[phidata](https://github.com/phidatahq/phidata)
+使用 LLM 函数调用构建自主助手。
+
+
+ # 近期活动和网络研讨会
+
+[IndyPy 2024 年 1 月聚会](https://www.meetup.com/indypy/events/297838473/)
+
+将会有一场演讲,高级模块和AI,针对小白。
+
+[ThaiPy - Bangkok Python 2024 年 1 月聚会](https://www.meetup.com/thaipy-bangkok-python-meetup/events/297400014/)
+将有以下演讲:
+ * 使用 Python 和 Apache Kafka 进行流处理
+ * 为什么大型语言模型需要稀疏向量?
+
+
+[Python Barcelona 2024 年 1 月聚会](https://www.meetup.com/python-barcelona/events/298506663/)
+将有以下演讲:
+ * 在公司内启动自己的Python库
+ * 使用 PyPDF 掌握 PDF 表单填写
+
+
+[PyLadies Paris 2024 年 1 月聚会](https://www.meetup.com/pyladiesparis/events/298401634/)
+将有以下演讲:
+ * 利用机器学习进行慢性肾脏病的早期检测
+ * 了解 SEO 对比测试:针对搜索引擎进行优化
+
+
+[Virtual: PyData Chicago 2024 年 1 月聚会](https://www.meetup.com/pydatachi/events/298499243/)
+将会有一场演讲,Securday:自然语言网络扫描仪。
+
+[PyData Zurich 2024 年 1 月聚会](https://www.meetup.com/pydata-zurich/events/298392043/)
+将有以下演讲:
+ * Vega-Altair:一个简单、友好且功能强大的数据可视化库
+ * 关于数据科学软技能的故事
+
+
+[PyData Milano 2024 年 1 月聚会](https://www.meetup.com/pydata-milano/events/298391373/)
+将有以下演讲:
+
+ * 谁需要 ChatGPT?使用 Hugging Face 和 Kedro 打造坚如磐石的 AI 管道
+ * 在 Vertex AI 上使用 Ray 解锁可扩展的机器学习
+
+
+[PyData Sudwest 2024 年 1 月聚会](https://www.meetup.com/pydata-suedwest/events/296355526/)
+将有以下演讲:
+ * 转变您的业务:通过数据运营实现数据驱动的路线图
+ * 使用 LakeFS 和 LakeFS-Spec 进行数据版本控制
+ * 把我的数据留在这里!以节省数据的方式实现人工智能助手
+
+
+[PyData Prague 2024 年 1 月聚会](https://www.meetup.com/pydata-prague/events/298421104/)
+将有以下演讲:
+ * 使用 BirdNET 进行人工智能驱动的生物声学监测
+ * (不仅仅是)大型语言模型成功背后的数据
\ No newline at end of file
diff --git a/Python Weekly/Python_Weekly_Issue_635.md b/Python Weekly/Python_Weekly_Issue_635.md
new file mode 100644
index 0000000..1a26e04
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_635.md
@@ -0,0 +1,122 @@
+原文:[Python Weekly - Issue 635](http://eepurl.com/iIKcaE)
+
+---
+
+欢迎来到《Python周刊》第 635 期。让我们直奔主题。
+
+
+# 文章,教程和讲座
+
+[andas 中的方法链](https://www.youtube.com/watch?v=39MEeDLxGGg) 
+什么是 Pandas 中的方法链?它是如何工作的以及如何使用它?
+
+[在 Python 中,构建优先级-到期时间(priority-expiry) LRU 缓存,无需使用堆或者树](https://death.andgravity.com/lru-cache)
+了解如何仅使用 Python 标准库,实现具有优先级和到期时间的最近最少使用缓存。
+
+[scrapscript.py](https://bernsteinbear.com/blog/scrapscript/)
+文章介绍了一种小型、纯粹、函数式、内容可寻址、网络优先的编程语言,旨在创建小型、可共享的程序。它讨论了该语言的功能及其实现,强调了其目的及其开发背后的协作努力。本文深入探讨了 Scrapscript 的动机和设计原则,以及其创建和实施过程中涉及的协作过程。
+
+[矢量数据库的性能](https://www.youtube.com/watch?v=-MYYB0QjV6I) 
+本次演讲探讨了矢量数据库在增强检索增强生成(Retrieval-Augmented Generation,RAG)等人工智能应用中的作用,重点关注对机器学习至关重要的高维嵌入。Egor Romanov 深入研究创建一个与 pgvector 集成的 Postgres 提供程序,利用 Python 性能评估框架来模拟相似性搜索测试并揭示潜在的性能潜力。
+
+[Python 的 dict() 和 {} 的性能分析](https://madebyme.today/blog/python-dict-vs-curly-brackets/)
+这篇文章探讨了在 Python 中使用 dict() 和 {} 创建字典的差异。它深入研究了它们的功能、性能和最佳实践,提供了有关在 Python 编码中使用每种方法的场景的见解。
+
+[自动化部署的可怕之处](https://slack.engineering/the-scary-thing-about-automating-deploys/)
+Slack Engineering 的文章讨论了对破坏生产的恐惧,这种恐惧阻碍了许多团队实现部署自动化。它强调了了解部署监控与正常监控有何不同的重要性,以及为缓解这些担忧而采取的迭代方法,从而最终实现成功的自动化部署。本文深入探讨了自动化部署流程的挑战和好处,解决了与网络安全和应用程序部署等各个领域的自动化系统相关的恐惧和担忧。
+
+[Python 打包一定会变得更好 —— 一个数据点](https://lukeplant.me.uk/blog/posts/python-packaging-must-be-getting-better-a-datapoint/)
+我在 Windows 上 “pip install”了我的应用,一切都正常了。事情进展顺利。
+
+[增强 Markdown 语言以实现出色的 Python 图形界面](https://www.taipy.io/posts/augmenting-the-markdown-language-for-great-python-graphical-interfaces)
+本文探讨了 Taipy 研发团队开发的增强 Markdown API,该 API 通过添加标签以直接在内容中生成图形界面元素,从而扩展了 Markdown 的简单性。这项创新旨在增强 Python 开发人员创建基于 Web 的界面的能力,提供一种在 Markdown 文档中集成图形元素的独特方法。
+
+[使用语义图和 RAG,生成知识](https://neuml.hashnode.dev/generate-knowledge-with-semantic-graphs-and-rag)
+使用语义图和 RAG 进行知识探索和发现。
+
+[Python 数据分析和可视化课程 —— 天文数据](https://www.youtube.com/watch?v=H9KefzbryEw) 
+使用真实世界的天文数据学习数据分析、数据可视化和图像处理技术。该课程提供了一种实用的实践方法来简化数据分析中的复杂概念,非常适合初学者。
+
+[Django 中简单的 Google 登录](https://www.youtube.com/watch?v=NM9BE0iUB5Q) 
+我们将以最简单的方式将 Google 登录添加到 Django 中(不使用 Django-all-auth 或 Django-social-auth 或任何其他大的包)。
+
+
+ # 书籍
+
+[ml-engineering](https://github.com/stas00/ml-engineering)
+机器学习工程开放书籍。
+
+
+ # 好玩的项目,工具和库
+
+[DataTrove](https://github.com/huggingface/datatrove)
+通过提供一组与平台无关的可定制管道处理块,将数据处理从疯狂的脚本中解放出来。
+
+[Granian](https://github.com/emmett-framework/granian)
+用于 Python 应用程序的 Rust HTTP 服务器。
+
+[InstantID](https://github.com/InstantID/InstantID)
+在几秒钟内 Zero-shot 生成身份保留。
+
+[finagg](https://github.com/theOGognf/finagg)
+一个 Python 包,用于聚合来自流行且免费的金融 API 的历史数据,并将该数据转换为适用于 AI/ML 的特征。
+
+[Python-Type-Challenges](https://github.com/laike9m/Python-Type-Challenges)
+通过交互式在线练习,掌握 Python 类型(类型提示)!
+
+[django-webhook](https://github.com/danihodovic/django-webhook)
+传出 Django webhook,由模型更改触发。
+
+[ULWGL-launcher](https://github.com/Open-Wine-Components/ULWGL-launcher)
+统一 Linux Wine 游戏启动器。
+
+[RAGxplorer](https://github.com/gabrielchua/RAGxplorer)
+可视化并探索您的 RAG 文档。
+
+[FastHX](https://github.com/volfpeter/fasthx)
+FastAPI 和 HTMX,正确之道。
+
+[TaskingAI](https://github.com/TaskingAI/TaskingAI)
+为 AI 原生应用程序开发的开源平台。
+
+[Applio](https://github.com/IAHispano/Applio)
+Ultimate 语音克隆工具,经过精心优化,具有无与伦比的功能、模块化和用户友好的体验。
+
+[wafer](https://github.com/sysdig/wafer)
+Wafer 是一个简单但有效的 Web 应用程序防火墙 (web application firewall,WAF) 模糊测试工具。
+
+> 译注:模糊测试(fuzz testing, fuzzing)是一种软件测试技术。 其核心思想是将**自动或半自动生成的随机数据**输入到一个程序中,并监视程序异常,如崩溃,断言(assertion)失败,以发现可能的程序错误,比如内存泄漏。 模糊测试常常用于检测软件或计算机系统的安全漏洞。 —— 来自维基百科
+
+[SGLang](https://github.com/sgl-project/sglang)
+SGLang 是一种专为大型语言模型 (LLM) 设计的结构化生成语言。它使您与 LLM 的互动更快、更可控。
+
+
+ # 近期活动和网络研讨会
+
+[PyBerlin 43](https://www.meetup.com/pyberlin/events/297958692/)
+将有以下演讲:
+ * 生成结果的会议
+ * f-strings:它们还能变得更好吗?
+ * 在 doctari 衡量软件交付性能
+
+
+[PyData Lancaster 2024 年 1 月聚会](https://www.meetup.com/pydata-lancaster/events/298462888/)
+将有以下演讲:
+ * Earth My Friend:使用开源工具绘制 20 世纪 50 年代的环球航行图
+ * 从代码库到软件
+
+[PyData Copenhagen 2024 年 2 月聚会](https://www.meetup.com/pydata-copenhagen/events/298422850/)
+将有一场演讲,即技术领域的增强检索:LLM 在实践中的挑战和机遇。
+
+[PyData Lausanne 2024 年 2 月聚会](https://www.meetup.com/pydata-lausanne/events/298636167/)
+将有以下演讲:
+ * 使用 DVC 和 CML 的 MLOps
+ * 抑制测试噩梦:使用 pytest 进行简单可靠的测试
+ * 忘记打印语句:如何使用 VSCode 的调试器来简化你的生活
+
+
+[PyData Montreal 2024 年 2 月聚会](https://www.meetup.com/pydata-mtl/events/298407655/)
+将有以下演讲:
+ * 理解语义搜索
+ * 加拿大贝尔 NLP 语音团队对提取式问答变压器的探索
+ * LLM 微调和部署简介
diff --git a/Python Weekly/Python_Weekly_Issue_636.md b/Python Weekly/Python_Weekly_Issue_636.md
new file mode 100644
index 0000000..02d7bfd
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_636.md
@@ -0,0 +1,103 @@
+原文:[Python Weekly - Issue 636](http://eepurl.com/iJcDOI)
+
+---
+
+欢迎来到《Python周刊》第 636 期。让我们直奔主题。
+
+# 文章,教程和讲座
+
+[面向 Python 程序员的 CUDA 入门](https://www.youtube.com/watch?v=nOxKexn3iBo) 
+在本教程中,Jeremy Howard 揭开了 NVIDIA GPU 的 CUDA 编程的神秘面纱,特别关注其与 PyTorch 结合使用时的可访问性。该实践教程在 Colab 笔记本中进行,引导观看者完成实际示例,从简单的任务(例如将 RGB 图像转换为灰度)开始,然后进展到更高级的主题(例如矩阵乘法)。重点是简化 Python 程序员的 CUDA 编程过程,提高调试难度和开发效率。
+
+[深入研究 Python 中的存储库设计模式](https://www.youtube.com/watch?v=9ymRLDfnDKg) 
+仔细研究 Python 中的存储库设计模式(repository design pattern)。这是一个非常有用的模式,允许您将数据存储与数据操作分开。
+
+[鸟瞰 Polars](https://pola.rs/posts/polars_birds_eye_view)
+了解 Polars 是如何执行您的查询(从规划、优化到执行)的。
+
+[分析您的 Numba 代码](https://pythonspeed.com/articles/numba-profiling/)
+了解如何使用 Profila 分析器来查找 Numba 代码中的性能瓶颈。
+
+[十个 Python datetime 陷阱,以及库正在(未)采取哪些措施](https://dev.arie.bovenberg.net/blog/python-datetime-pitfalls/)
+本文探讨了 Python 的 datetime 库中的各种挑战和不一致之处,以及不同的第三方库是如何解决这些问题的。
+
+[使用图像和视频,利用 Vision API 探索 GPT-4](https://jstoppa.com/posts/exploring_the_gpt_with_vision_api_image_and_video/post/)
+要理解如何利用 Vision API 使用 GPT-4,您所需要了解的一切,以及图像和视频的处理示例。
+
+[将 Python 和 Rust 混合用于生产 CLI ](https://www.youtube.com/watch?v=GBZoWervz3s) 
+该视频概述了组合 Python 和 Rust 的有效工作流程 - 使用 PyO3 从 Rust CLI 调用 Python、利用 Rust 的安全性和 Python 的库、添加测试来验证逻辑、自动化流程并向用户提供二进制文件。
+
+[使用 Python 运行开源 LLM —— 实践指南](https://christophergs.com/blog/running-open-source-llms-in-python)
+在你的笔记本电脑上释放 AI 的力量。
+
+[使用 Pylasu 实现解析器](https://tomassetti.me/implement-parsers-with-pylasu/)
+在这篇文章中,我们将学习如何使用 Pylasu 和 ANTLR,用 Python 实现解析器。
+
+[构建一个 Django AI 着色应用](https://www.youtube.com/watch?v=-04pgby8tVE) 
+我们将构建一个简单的 Django 应用程序,它使用 AI 为黑白照片着色。我还将指导您完成在 Django 中使用 webhook 的最简单方法。 Webhook 是外部函数(例如 AI 函数)向服务器发送数据的一种巧妙方式。
+
+[在 pytest 中修补 pydantic 设置](https://rednafi.com/python/patch_pydantic_settings_in_pytest/)
+这篇文章讨论了有关在 Pytest 中修补 Pydantic 设置的 Python 教程。它涵盖了在 Pytest 环境中,测试期间修改 Pydantic 设置的技术,为有效的测试和开发工作流程提供了实用的见解。
+
+
+# 好玩的项目,工具和库
+
+[gpt-newspaper](https://github.com/assafelovic/gpt-newspaper)
+一个创新的自主代理,旨在根据用户偏好创建个性化报纸。 GPT Newspaper 利用人工智能的力量,根据个人品味和兴趣策划、撰写、设计和编辑内容,彻底改变了我们消费新闻的方式。
+
+[excelCPU](https://github.com/InkboxSoftware/excelCPU)
+用于 Excel 的 16 位 CPU,以及相关文件。
+
+[FastCRUD](https://github.com/igorbenav/fastcrud)
+FastCRUD 是 FastAPI 的 Python 包,提供强大的异步 CRUD 操作和灵活的端点创建能力。
+
+[EasyGmail](https://github.com/ayushgun/easygmail)
+一个轻量级、极简且同步的 Python 包,用于通过 Gmail 快速发送电子邮件。
+
+[StreamRAG](https://github.com/video-db/StreamRAG)
+视频搜索和流媒体代理。
+
+[fabric](https://github.com/danielmiessler/fabric)
+Fabric 是一个开源框架,用于使用人工智能增强人类能力。
+
+[llm-app-stack](https://github.com/a16z-infra/llm-app-stack)
+LLM 应用程序的新兴架构。
+
+
+# 近期活动和网络研讨会
+
+[Django London 2024 年 2 月聚会](https://www.meetup.com/djangolondon/events/298796486/)
+将会有一场演讲,即经过实战考验的技巧,以最大限度地从技术事件中学习。
+
+[Python Milano 2024 年 2 月聚会](https://www.meetup.com/python-milano/events/298739054/)
+将有以下演讲:
+ * 使用 Hamilton 构建特征存储
+ * 扩展机器学习训练和推理 @Vedrai
+
+
+[PyData Sudwest 2024 年 2 月聚会](https://www.meetup.com/pydata-suedwest/events/296355526/)
+将有以下演讲:
+ * 转变您的业务:通过数据运营(Data Ops)实现数据驱动的路线图
+ * 使用 LakeFS 和 LakeFS-Spec 进行数据版本控制
+ * 我的数据留在这里!以节省数据的方式实现人工智能助手
+
+
+[PyData London 2024 年 2 月聚会](https://www.meetup.com/pydata-london-meetup/events/298028513/)
+将有以下演讲:
+ * 不那么数据科学家的工具箱
+ * 通过实时流处理促进相似性搜索
+ * 开源科学 (Open-Source Science,OSSci)
+ * 在 GPU 上使用 CuDF (也许)更快的 Pandas(也许)
+
+
+[PyData Tel Aviv 2024 年 2 月聚会](https://www.meetup.com/pydata-tel-aviv/events/298392671/)
+将有以下演讲:
+ * 使用 DS 优化广告转化
+ * 通过颜色矢量选择(color vector selection)使 Feed 多样化
+ * 使用 LLM 将自由文本转换为结构
+
+
+[PyData Amsterdam 2024 年 2 月聚会](https://www.meetup.com/pydata-nl/events/298750712/)
+将有以下演讲:
+ * 晚餐吃什么?构建 ML 平台以增强 Picnic 的在线杂货购物体验
+ * 使用 Cleanlab 实现大规模自动化数据质量
diff --git a/Python Weekly/Python_Weekly_Issue_637.md b/Python Weekly/Python_Weekly_Issue_637.md
new file mode 100644
index 0000000..328d99b
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_637.md
@@ -0,0 +1,94 @@
+原文:[Python Weekly - Issue 637](http://eepurl.com/iJGNIs)
+
+---
+
+欢迎来到《Python周刊》第 637 期。让我们直奔主题。
+
+# 文章,教程和讲座
+
+[Rye:轻松的 Python 体验](https://www.youtube.com/watch?v=q99TYA7LnuA) 
+演示了当时最新版本的 Rye (0.21),而现在它可用于管理 Python 项目和解释器。
+
+[用 80 行代码实现的搜索引擎](https://www.alexmolas.com/2024/02/05/a-search-engine-in-80-lines.html)
+这篇文章详细介绍了如何仅用 80 行代码创建搜索引擎的过程,提供了关于如何有效实现虽然基本但实用的搜索算法的见解。
+
+[超越自注意力:小型语言模型是如何预测下一个 Token 的](https://shyam.blog/posts/beyond-self-attention)
+深入研究小型变压器模型的内部结构,了解它如何将自注意力计算转化为下一个令牌的准确预测。
+
+[Python 版本间的主要变动的总结](https://www.nicholashairs.com/posts/major-changes-between-python-versions/)
+这篇文章旨在作为有关每个新版本 Python 引入的主要更改的快速参考。这可以帮助您在升级代码库时利用新功能,或者确保您拥有与旧版本兼容的正确的保护措施。
+
+[专业提示 —— “丰富(rich)”你的 Python 测试](https://www.revsys.com/tidbits/en-rich-your-python-testing/)
+本文提供了有关使用“rich”库来增强 Python 测试的专业提示。它演示了如何通过使用“rich”来更好地可视化测试结果,从而改进测试(特别是在 pytest 测试中)输出。本文提供了丰富 Python 测试体验的实用建议和代码示例。
+
+[如何使用 GDB 的 Python API 缓存数据](https://developers.redhat.com/articles/2024/02/05/how-cache-data-using-gdbs-python-api#caching_for_object_files_and_program_spaces)
+本文介绍如何在 GDB 的 Python API 中缓存不同对象类型的信息;它为缓存某些对象类型提供了特殊支持,而对于其他对象类型,您需要执行额外的工作来管理缓存的数据。
+
+[使用 Django、Kubernetes、TailwindCSS、Twingate、AWS S3 和 HTMX 构建内容引擎](https://www.youtube.com/watch?v=2TX7Pal5NMc) 
+
+[一万亿行挑战](https://blog.coiled.io/blog/1trc.html)
+
+[使用种子数据库改进 Django 测试](https://tla.wtf/posts/django-seed-db/)
+
+[TensorFlow 中的图形神经网络](https://blog.research.google/2024/02/graph-neural-networks-in-tensorflow.html)
+
+
+ # 好玩的项目,工具和库
+
+[OLMo](https://allenai.org/olmo)
+真正开放的最先进的 LLM和框架。
+
+[Lockbox](https://github.com/mkjt2/lockbox)
+Lockbox 是用于进行第三方 API 调用的转发代理。
+
+[skorche](https://github.com/AnsBalin/skorche)
+Python 的任务编排。
+
+[PyPDFForm](https://github.com/chinapandaman/PyPDFForm)
+处理 PDF 表单的 Python 库。
+
+[rexi](https://github.com/royreznik/rexi)
+用于正则表达式测试(Regex Testing)的终端UI。
+
+[GPTAuthor](https://github.com/dylanhogg/gptauthor)
+GPTAuthor 是一款 AI 工具,用于根据故事提示编写长篇、多章节的故事。
+
+[django-htmx-components](https://github.com/iwanalabs/django-htmx-components)
+这是 Django 和 htmx 的组件集合。它们旨在复制粘贴到您的项目中即可使用,还支持根据您的需求进行定制。
+
+[contrastors](https://github.com/nomic-ai/contrastors)
+contrastors 是对比学习工具包,使研究人员和工程师能够有效地训练和评估对比模型。
+
+[Rawdog](https://github.com/AbanteAI/rawdog)
+通过生成并自动执行 Python 脚本进行响应的 CLI 助手。
+
+[IOPaint](https://github.com/Sanster/IOPaint)
+一款由 SOTA AI 模型提供支持的免费开源图像修复工具。
+
+[NaturalSQL](https://github.com/cfahlgren1/natural-sql)
+一系列性能最佳的文本到 SQL LLM。
+
+[ml-mgie](https://github.com/apple/ml-mgie)
+Apple 全新开源 AI 模型,可以根据自然语言指令编辑图像。
+
+[atopile](https://github.com/atopile/atopile)
+一种用代码创建电子电路板的工具。
+
+[web2pdf](https://github.com/dvcoolarun/web2pdf)
+将网页转换为 PDF 对 CLI。
+
+
+ # 最新发布
+
+[Python 3.12.2 和 3.11.8 现已发布。](https://pythoninsider.blogspot.com/2024/02/python-3122-and-3118-are-now-available.html)
+
+[Django 安全版本现已发布:5.0.2、4.2.10 和 3.2.24](https://www.djangoproject.com/weblog/2024/feb/06/security-releases/)
+
+
+ # 近期活动和网络研讨会
+
+[Python Frederick 2024 年 2 月聚会](https://www.meetup.com/python-frederick/events/298531232/)
+将会有一场演讲:使用 Python 对算法艺术。
+
+[PyData Johannesburg 2024 年 2 月聚会](https://www.meetup.com/pydata-johannesburg/events/298808404/)
+将会有一场演讲:生产化机器学习模型。
diff --git a/Python Weekly/Python_Weekly_Issue_638.md b/Python Weekly/Python_Weekly_Issue_638.md
new file mode 100644
index 0000000..185ed38
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_638.md
@@ -0,0 +1,108 @@
+原文:[Python Weekly - Issue 638](http://eepurl.com/iJ9pdc)
+
+---
+
+欢迎来到《Python周刊》第 638 期。让我们直奔主题。
+
+
+# 文章,教程和讲座
+
+[为什么 AI 会遇到 Python 问题](https://www.youtube.com/watch?v=cGgTvMmtzNU) 
+人工智能 (AI) 已将 Python 变得前所未有的流行,使其成为全球开发人员和研究人员的首选语言。然而,繁荣背后,一个巨大的挑战隐而未现。让我们通过现实世界的示例和技术见解来了解 Python 给人工智能发展带来的具体困难。
+
+[Meta 超爱 Python 的](https://engineering.fb.com/2024/02/12/developer-tools/meta-loves-python/) 
+Meta 工程师讨论了他们对 Python 3.12 的贡献,包括自定义 JIT hook、永久对象、类型系统改进和更快的理解等新功能,强调了他们与 Python 社区的合作以及公司对开源计算的支持
+
+[计算 Python 中使用的 CPU 指令](https://blog.mattstuchlik.com/2024/02/08/counting-cpu-instructions-in-python.html)
+您知道用 Python 打印(“Hello”)需要大约 17,000 个 CPU 指令吗?而导入 Seaborn 则需要大约 20 亿个?
+
+[不仅仅是 NVIDIA:可以在任何地方运行的 GPU 编程](https://pythonspeed.com/articles/gpu-without-cuda/)
+如果您想在 CI、Mac 等设备上运行 GPU 程序,wgu-py 是一个不错的选择。
+
+[部署模型的多种方法](https://outerbounds.com/blog/the-many-ways-to-deploy-a-model)
+部署模型和执行推理的方法有很多种。在这里,我们以 LLM 推理为例分享模型部署的决策准则。
+
+[Adam 优化器背后的数学](https://towardsdatascience.com/the-math-behind-adam-optimizer-c41407efe59b)
+为什么 Adam 是深度学习中最受欢迎的优化器?让我们通过深入研究其数学并重新创建算法来理解它。
+
+[可视化神经网络内部结构](https://www.youtube.com/watch?v=ChfEO8l-fas) 
+可视化神经网络在训练和推理过程中的一些内部结构。
+
+[LLM 应用开发的工程实践](https://martinfowler.com/articles/engineering-practices-llm.html)
+LLM 工程涉及的不仅仅是 prompt 设计或 prompt 工程。在本文中,我们分享了一组工程实践,帮助我们在最近的项目中快速可靠地交付原型 LLM 应用程序。我们将分享 LLM 应用程序的自动化测试和对抗性测试、重构技术,以及构建 LLM 应用程序和负责任的 AI 所需要注意的事项。
+
+[Python 的 textwrap 模块可以做到的一切](https://martinheinz.dev/blog/108)
+
+Python 有许多用于格式化字符串和文本的选项,包括 f 字符串、format() 函数、模板等。然而,有一个模块很少有人知道,它叫做 textwrap。该模块是专门为帮助您进行换行、缩进、修剪等操作而构建的,在本文中我们将向您介绍您可以使用它来完成的所有操作。
+
+[如果可以的话,如何避免在 Django 中进行计数查询](https://www.peterbe.com/plog/how-to-avoid-a-count-query-in-django-if-you-can)
+
+[像专家一样处理 Asyncio 中的任务](https://jacobpadilla.com/articles/handling-asyncio-tasks)
+
+
+# 好玩的项目,工具和库
+
+[modguard](https://github.com/Never-Over/modguard)
+一个用于强制执行模块化、解耦包架构的 Python 工具。
+
+[metavoice-src](https://github.com/metavoiceio/metavoice-src)
+像人一样的富有表现力的 TTS 的基础模型。
+
+[logot](https://github.com/etianen/logot)
+测试您的代码是否正确进行了日志记录。
+
+[TriOTP](https://github.com/linkdd/triotp)
+Python Trio 的 OTP 框架。
+
+[Toolong](https://github.com/textualize/toolong)
+用于查看、追踪、合并和搜索日志文件(以及 JSONL)的终端应用程序。
+
+[django-queryhunter](https://github.com/PaulGilmartin/django-queryhunter)
+寻找 Django 应用程序代码中负责执行最多次查询的行。
+
+[Lag-Llama](https://github.com/time-series-foundation-models/lag-llama)
+面向概率时间序列预测的基础模型。
+
+[HypoFuzz](https://github.com/Zac-HD/hypofuzz)
+用于 Python 最佳测试工作流程的开源智能模糊测试。
+
+[mwmbl](https://github.com/mwmbl/mwmbl)
+一个用 Python 实现的开源、非盈利搜索引擎。
+
+[instld](https://github.com/pomponchik/instld)
+最简单的包管理。
+
+
+ # 近期活动和网络研讨会
+
+[PyLadies Dublin 2024 年 2 月聚会](https://www.meetup.com/pyladiesdublin/events/298929924/)
+将会有一场演讲:当网络安全碰上 Python。
+
+[Spokane Python 2024 年 2 月聚会](https://www.meetup.com/python-spokane/events/298213203/)
+将会有一场演讲:介绍如何通过使用 PyO3 创建 Rust 绑定,从而将 Rust 集成到您的 Python 工作流程中。
+
+[Python Barcelona 2024 年 2 月聚会](https://www.meetup.com/python-barcelona/events/299074873/)
+将有以下演讲:
+ * Pytest,短途远足。
+ * 《查询地图(Queering The Map)》的使用与话语分析
+
+
+[PyData Southampton 2024 年 2 月聚会](https://www.meetup.com/pydata-southampton/events/298595661/)
+将有以下演讲:
+ * 将 3D 及以上的地理空间数据与 TileDB 数组相结合
+ * 利用 GPU 计算搜索太空中的伽马射线源
+
+
+[PyData Berlin 2024 年 2 月聚会](https://www.meetup.com/pydata-berlin/events/298730602/)
+将有以下演讲:
+ * 通过基于扩散的图神经网络利用数据结构和几何
+ * 大型语言模型的采样策略示例
+
+
+[PyData Stockholm 2024 年 2 月聚会](https://www.meetup.com/pydatastockholm/events/299095628/)
+将有以下演讲:
+ * 爬取 130 万条房价信息 —— 并且逃脱惩罚
+ * BYOSC:
+ * 交通地图
+ * DeLight - 延误航班预测器
+ * 这张照片是在哪里拍摄的? - 深度学习时代的视觉地理定位。
diff --git a/Python Weekly/Python_Weekly_Issue_639.md b/Python Weekly/Python_Weekly_Issue_639.md
new file mode 100644
index 0000000..c9ca3fd
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_639.md
@@ -0,0 +1,96 @@
+原文:[Python Weekly - Issue 639](http://eepurl.com/iKyMsA)
+
+---
+
+欢迎来到《Python周刊》第 639 期。让我们直奔主题。
+
+
+# 文章,教程和讲座
+
+[让我们构建 GPT Tokenizer](https://www.youtube.com/watch?v=zduSFxRajkE) 
+Tokenizer 对于大语言模型 (LLM) 至关重要,它在字符串和标记之间进行转换,作为一个具有单独训练集和算法的不同阶段运行。本讲座从头开始构建 GPT 系列 Tokenizer,揭示了 LLM 中与标记化相关的特殊行为。我们探讨这些问题,将其归因于标记化,并考虑完全消除此阶段的理想方案。”
+
+[在 Python 项目中安全使用凭证的 5 个技巧](https://www.youtube.com/watch?v=OOvvQRBcrhI) 
+了解 5 个简单的技巧,以助于确保 Python 凭证安全,并在出现问题时快速解决问题.
+
+[从头开始构建一个 LLM](https://bclarkson-code.github.io/posts/llm-from-scratch-scalar-autograd/post.html)
+了解如何完全从头开始构建一个具有所有花哨功能的现代语言模型:从普通 Python 到函数式编码助手。
+
+[跟踪 Python 中的系统调用](https://blog.mattstuchlik.com/2024/02/16/counting-syscalls-in-python.html)
+本文讨论了作者开发的一个添加到 Cirron 的工具,该工具使我们能够跟踪Python代码的系统调用。它提供了一个跟踪“print”函数的示例,并说明了该工具的实现,使用strace工具进行有效分析。文章还概述了使用 ptrace 系统调用进行实现的初衷,以及随后利用 strace 工具来处理复杂性。
+
+[使用 IPython Jupyter Magic 命令改善 Notebook 体验](https://towardsdatascience.com/using-ipython-jupyter-magic-commands-to-improve-the-notebook-experience-f2c870cab356)
+一篇关于创建自定义 IPython Jupyter Magic 命令的帖子。
+
+[添加 Django 工作线程的最简单方法(使用 AWS Chalice)](https://www.photondesigner.com/articles/lambda-for-django)
+本文讨论了如何利用 AWS Chalice 来合并 Django 工作线程,从而能够使用 lambda 函数作为任何应用程序的无服务器后台工作线程。这种方法允许 lambda 函数在后台运行,而不会阻塞应用程序的主线程,并且它可以在完成后调用 Django 应用程序上的端点,从而提供在 lambda 函数中使用任何 Python 库的能力,而无需引入 lambda 层或其他特定于 AWS 的配置。
+
+[如何对一个使用了 Django、Preact 和 PostgreSQL 的应用程序进行 Docker 化](https://www.honeybadger.io/blog/dockerize-django-preact-postgres)
+对 Django 应用程序进行 Docker 化可能是一件令人生畏的事情,但回报大于风险。在本指南中,Charlie Macnamara 将引导您完成这个设置过程,以便您可以充分利用您的应用程序。
+
+[使用 Python 实现的算法艺术](https://www.youtube.com/watch?v=_XeRM-4DZz0) 
+在本次演讲中,我们将从零开始,构建我们自己的工具,用 Python 进行艺术创作,无需人工智能!我们将展示 Python 的表现力可以如何让我们优雅地描述图形,并使用它以编程方式制作一些独特的艺术作品。
+
+[使用 Neon Postgres 和 AWS App Runner 部署任意规模的无服务器(Serverless) FastAPI 应用程序](https://neon.tech/blog/deploy-a-serverless-fastapi-app-with-neon-postgres-and-aws-app-runner-at-any-scale)
+使用 FastAPI 创建无服务器 API,部署在 AWS App Runner 上并由 Neon Postgres 提供支持。
+
+
+ # 好玩的项目,工具和库
+
+[uv](https://github.com/astral-sh/uv)
+一个非常快的 Python 包安装程序和解析器,用 Rust 编写。这是一篇详细介绍 uv 的[帖子](https://astral.sh/blog/uv)。
+
+[OS-Copilot](https://github.com/OS-Copilot/FRIDAY)
+一个自我改进的具体对话代理,无缝集成到操作系统中,以自动化我们的日常任务。
+
+[Owl](https://github.com/OwlAIProject/Owl)
+本地运行的个人可穿戴人工智能。
+
+[Alto](https://github.com/runprism/alto)
+面向数据从业者的 Serverless。在云中运行代码的最快方法。在虚拟机中轻松运行脚本、函数和 Jupyter Notebook。
+
+[magika](https://github.com/google/magika)
+通过深度学习检测文件内容类型。
+
+[Streamline-Analyst](https://github.com/Wilson-ZheLin/Streamline-Analyst)
+由 LLM 提供支持的人工智能代理,可简化数据分析的整个过程。
+
+[minbpe](https://github.com/karpathy/minbpe)
+LLM 标记化中常用的字节对编码 (Byte Pair Encoding,BPE) 算法的最小的干净代码。
+
+[Hyperdiv](https://github.com/hyperdiv/hyperdiv)
+使用 Python 构建响应式 Web UI。
+
+[UFO](https://github.com/microsoft/UFO)
+用于 Windows 操作系统交互的以 UI 为中心的代理。
+
+
+# 最新发布
+
+[Python 3.13.0 alpha 4](https://pythoninsider.blogspot.com/2024/02/python-3130-alpha-4-is-now-available.html)
+
+
+# 近期活动和网络研讨会
+
+[Oxford Python 2024 年 2 月聚会](https://www.meetup.com/oxfordpython/events/299181384/)
+将会有一场演讲:PyO3 入门。
+
+[PyLadies Amsterdam 2024 年 2 月聚会](https://www.meetup.com/pyladiesams/events/298654058/)
+将举办一个研讨会,微调文本到图像的扩散模型以实现个性化等。
+
+[PyData Toronto 2024 年 2 月聚会](https://www.meetup.com/pydatato/events/298869004/)
+将有以下演讲:
+ * 用于与 LLM 交互的数据文本处理
+ * 因果推理:创建反事实,以及其在付费营销中的应用
+
+
+[PyData Lisbon 2024 年 2 月聚会](https://www.meetup.com/pydata-lisbon/events/299085332/)
+将有以下演讲:
+ * 利用 Poetry 掌握 Python 项目
+ * 生产中的 LLM,即 LLMOps
+
+
+[PyData Prague 2024 年 2 月聚会](https://www.meetup.com/pydata-prague/events/298734567/)
+将有以下演讲:
+ * 解锁效率 —— 矢量化的力量
+ * Jupyter(Hub/Lab)——从本地到 AWS 之旅
diff --git a/Python Weekly/Python_Weekly_Issue_640.md b/Python Weekly/Python_Weekly_Issue_640.md
new file mode 100644
index 0000000..7a15f7f
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_640.md
@@ -0,0 +1,125 @@
+原文:[Python Weekly - Issue 640](http://eepurl.com/iK4M4-/)
+
+---
+
+欢迎来到《Python周刊》第 640 期。让我们直奔主题。
+
+# 文章,教程和讲座
+
+[生成人工智能完整课程 – Gemini Pro、OpenAI、Llama、Langchain、Pinecone、矢量数据库等](https://www.youtube.com/watch?v=mEsleV16qdo) 
+了解生成式模型和不同的框架,研究人工智能生成的文本和视觉材料的生成。
+
+[GPT Pilot —— 我们在CodeGen 结对程序员 GPT Pilot 上工作 6 个月期间,学到了什么](https://blog.pythagora.ai/2024/02/19/gpt-pilot-what-did-we-learn-in-6-months-of-working-on-a-codegen-pair-programmer/)
+本文讨论了在 CodeGen 结对程序员 GPT Pilot 上工作 6 个月的经验教训,旨在让人类开发人员理解代码库,并详细解释了关于添加代码以促进人类开发人员和 AI 在编码任务中的协作。
+
+[七分钟解释依赖注入](https://www.youtube.com/watch?v=DpMGEhwuuyA) 
+该视频解释了为什么依赖注入会改变您的编码项目的游戏规则。创建松散耦合的代码,是使代码更灵活、更可维护的关键。依赖关系的隐式使用使得这一切成为了可能。
+
+[将 Mistral Large 部署到 Azure,并使用 Python 和 LangChain 创建对话](https://neon.tech/blog/deploy-mistral-large-to-azure-and-chat-with-langchain)
+将 Mistral Large 部署到 Azure 的分步指南。
+
+[requests 回顾](https://blog.ian.stapletoncordas.co/2024/02/a-retrospective-on-requests)
+python-requests 已经存在很长时间了。而我已经担任它的维护者很多年了,我分享了一些对该项目的回顾性想法。
+
+[Mamba:艰难之路](https://srush.github.io/annotated-mamba/hard.html)
+一篇关于 Mamba 的文章,Mamba 是一种最新的神经架构,可以粗略地看作是一种现代循环神经网络 (RNN)。该模型的效果非常好,也是无处不在的 Transformer 架构的合法竞争对手。它已经引起了很多关注。
+
+[为什么来自 R 的人会觉得 Pandas 笨重](https://www.sumsar.net/blog/pandas-feels-clunky-when-coming-from-r)
+这篇文章讨论了从 R 过渡到 Python 中的 Pandas 的挑战和看法,探讨了习惯使用 R 的用户可能会觉得 Pandas 笨重的原因。作者提供了见解和技巧,以简化过渡过程并改进 Pandas 的使用体验。
+
+[高级检索增强生成:从理论到 LlamaIndex 实现](https://towardsdatascience.com/advanced-retrieval-augmented-generation-from-theory-to-llamaindex-implementation-4de1464a9930)
+如何通过在 Python 中实现有针对性的高级 RAG 技术,来解决原始 RAG 管道的局限性。
+
+[使用 Mistral 7B 和 Ollama 构建一个打字助手](https://www.youtube.com/watch?v=IUTFrexghsQ) 
+在本 Python 教程中,我们将使用 Mistral 7B 和 Ollama 构建一个在本地运行的打字助手。您还将学习如何使用 Python 实现热键侦听器和键盘控制器。请按照此分步编码教程进行操作。
+
+[使用 Python 的高级 Web 抓取:从任何站点提取数据](https://jacobpadilla.com/articles/advanced-web-scraping-techniques)
+本文介绍了如何获取和管理 cookie 和自定义标头、避免 TLS 指纹识别、识别要发送请求的重要 HTTP 标头,以及如何实现指数退避的 HTTP 请求重试。
+
+[在 5 分钟内构建检索增强一代聊天机器人](https://www.youtube.com/watch?v=N_OOfkEWcOk) 
+NVIDIA 高级解决方案架构师 Rohan Rao 在 5 分钟内,仅用了 100 行 Python 代码,就演示了如何为 AI 聊天机器人应用程序开发和部署大型语言模型 (LLM),而无需使用您自己的 GPU 基础设施。
+
+[Python 依赖项是可以修复的](https://matduggan.com/everyone-is-wrong-but-you/)
+本文批评了 Python 依赖项管理的当前状态,强调需要更好的默认值和用户体验。与 Golang 的成功设计相似,作者主张 Pypa 生态系统内的心态转变,以改善 Pip 等工具的默认行为,并建议在必要时探索替代方案。
+
+
+# 好玩的项目,工具和库
+
+[ingestr](https://github.com/bruin-data/ingestr)
+ingestr 是一个 CLI 工具,可以使用单个命令在任何数据库之间无缝复制数据。
+
+[ok-robot](https://github.com/ok-robot/ok-robot)
+一个开放的模块化框架,用于在任意家庭中执行零样本、语言条件的拾取和放置任务。
+
+[Evo](https://github.com/evo-design/evo)
+从分子到基因组规模的 DNA 基础模型。
+
+[AutoPrompt](https://github.com/Eladlev/AutoPrompt)
+Auto Prompt 是一个 prompt 优化框架,旨在增强和完善现实世界用例的提示。
+
+[PyRIT](https://github.com/Azure/PyRIT)
+用于生成 AI 的 Python 风险识别工具 (PyRIT) 是一个开放访问的自动化框架,使安全专业人员和机器学习工程师能够主动发现他们的生成式 AI 系统中的风险。
+
+[gemma_pytorch](https://github.com/google/gemma_pytorch)
+Google Gemma 模型的官方 PyTorch 实现。
+
+[justpath](https://github.com/epogrebnyak/justpath)
+检查并优化 Windows 和 Linux 上的 PATH 环境变量。
+
+[Mountaineer](https://github.com/piercefreeman/mountaineer)
+Mountaineer 是一个包含开箱即用功能的 Python 和 React Web 框架。
+
+[sqlbind](https://github.com/baverman/sqlbind)
+基于文本的轻量级 SQL 参数绑定。
+
+[hotpdf](https://github.com/weareprestatech/hotpdf)
+hotpdf 是一个快速的 PDF 解析库,用于在 PDF 文档中提取文本并查找文本,在 pdfminer.six 之上构建。
+
+[Sensei](https://github.com/migtissera/Sensei)
+使用 OpenAI 或 MistralAI 生成合成数据。
+
+
+# 最新发布
+
+[JupyterLab 4.1 和 Notebook 7.1 来咯](https://blog.jupyter.org/jupyterlab-4-1-and-notebook-7-1-are-here-20bfc3c10217)
+JupyterLab 4.1 和 Notebook 7.1 现已推出!这些版本包括一些新功能、错误修复和扩展开发人员的增强功能。此版本兼容支持 JupyterLab 4.0 和 Notebook 7.0 的扩展。
+
+[Visual Studio Code 中的 Python - 2024 年 3 月版](https://devblogs.microsoft.com/python/python-in-visual-studio-code-march-2024-release/)
+此版本包括以下公告:
+* 新添加导入代码操作启发式设置
+* 调试 Django 或 Flask 应用程序时,自动启动浏览器
+* Python REPL 的 Shell 集成
+* 对本地运行的 Jupyter 服务器的语言支持
+
+
+# 近期活动和网络研讨会
+
+[PyData London 2024 年 3 月聚会](https://www.meetup.com/pydata-london-meetup/events/299219741/)
+将有以下演讲:
+* 构建单一事实来源:开发大规模实体解析系统
+* 人工智能的未来:开源 LLM
+
+
+[IndyPy 2024 年 3 月聚会](https://www.meetup.com/indypy/events/298740418/)
+将会有一场演讲:Eclipse Insights:人工智能如何改变太阳天文学。
+
+[Python Milano 2024 年 3 月聚会](https://www.meetup.com/python-milano/events/299383407/)
+将有以下演讲:
+* Python 和 (棋盘)游戏设计
+* Python 和设计师
+
+
+[Cleveland PyLadies 2024 年 3 月聚会](https://www.meetup.com/cle-pyladies/events/298846189/)
+将进行有关 Prompt 工程领域的讨论和学习。
+
+[PyData Sudwest 2024 年 3 月聚会](https://www.meetup.com/pydata-suedwest/events/299017089/)
+将有以下演讲:
+* 超越 Parquet 的默认设置 – 您会得到令人惊讶的结果 - Uwe Korn
+* 分析和优化模型预测服务 -Paolo Rechia
+
+[PyData Manchester 2024 年 3 月聚会](https://www.meetup.com/pydata-manchester/events/299463978/)
+将会有一场演讲:开发有价值的 ML 产品。
+
+[PyData Atlanta 2024 年 3 月聚会](https://www.meetup.com/pydata-atlanta/events/299285864/)
+将会有一场演讲:释放商业应用中生成式 AI 的力量。
+
\ No newline at end of file
diff --git a/Python Weekly/Python_Weekly_Issue_641.md b/Python Weekly/Python_Weekly_Issue_641.md
new file mode 100644
index 0000000..b3cbce9
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_641.md
@@ -0,0 +1,132 @@
+原文:[Python Weekly - Issue 641](http://eepurl.com/iLzPwU)
+
+---
+
+欢迎来到《Python周刊》第 641 期。让我们直奔主题。
+
+# 文章,教程和讲座
+
+[Python 升级手册](https://eng.lyft.com/python-upgrade-playbook-1479145d52f4)
+在这篇文章中,我们将介绍 Lyft 如何大规模升级 Python(涵盖 150 多个团队的 1500 多个存储库),以及我们为优化升级所需的总体时间以及我们工程师所需的工作而构建的工具和策略的最新迭代。我们通过多次升级(从 Python 2 到 Python 3.10)成功地使用(并改进)了这个手册。
+
+[构建一个 LLM 微调数据集](https://www.youtube.com/watch?v=pCX_3p40Efc) 
+该视频分享了有关使用 Reddit 评论构建用于 AI 模型训练的综合数据集的见解,强调了诸如处理大型数据集和过滤掉低质量评论这样的挑战。作者讨论了加载、排序和过滤数据等方法来创建训练样本和模型,强调了可用于分析的注释样本丰富性以及微调模型以实现高效训练的过程。最终,他们决定使用 llama 27b 模型,并讨论利用 480 超级 GPU 更快地微调和上传数据集的计划。
+
+[使用 Python 和 Grafana 实现更好的 PC 冷却](https://calbryant.uk/blog/better-pc-cooling-with-python/)
+本文讨论了使用 Python 和 Grafana 改进 PC 冷却,关注于通过利用热质量并以经验得出的速度运行风扇,找到最小和最大风扇速度来优化冷却性能,从而提高冷却效率并降低冷噪音水平。
+
+[使用 HTMX 和 Django,在六分钟内创建一个测验应用程序](https://www.photondesigner.com/articles/quiz-htmx)
+本指南向您展示如何在 6 分钟内使用 Django 和 HTMX 创建一个简单的测验应用程序。HTMX 非常适合用来创建动态 Web 应用程序,无需编写 JavaScript。
+
+[Django 中的多语言支持](https://medium.com/@sakhawy/multilingual-support-in-django-5706e1e144a8)
+本文深入探讨了在 Django 中实现多语言支持的复杂性,探讨了国际化 (i18n) 和本地化所涉及的挑战和流程。它提供了有关 Django 如何促进字符串翻译、GNU gettext 框架的使用以及 Django 项目中支持多种语言的整体框架的见解。
+
+[2024 年的机器学习 —— 新手课程](https://www.youtube.com/watch?v=bmmQA8A-yUA) 
+该机器学习课程是为 2024 年学习机器学习的初学者创建的。该课程从 2024 年机器学习路线图开始,强调职业道路和适合初学者的理论。然后,课程将转向实际应用和使用 Python 的综合端到端项目。
+
+[DSPy 简介:再见 Prompting,你好 Programming!](https://towardsdatascience.com/intro-to-dspy-goodbye-prompting-hello-programming-4ca1c6ce3eb9)
+DSPy 框架是如何通过用编程和编译代替提示,来解决基于 LLM 的应用程序中的脆弱性问题的。
+
+[处理一个 CSV 文件能有多快](https://datapythonista.me/blog/how-fast-can-we-process-a-csv-file)
+本文探讨了处理 CSV 文件的速度,重点介绍了如何使用 PyArrow 来显着提高 CSV 读取速度。它比较了来自使用 C 引擎的 pandas、纯 Python 循环以及使用 PyArrow 引擎的 pandas 的不同方法,展示了 PyArrow 在更快、更有效地处理 CSV 文件方面的效率。
+
+[复杂度级别:RAG 应用](https://jxnl.github.io/blog/writing/2024/02/28/levels-of-complexity-rag-applications)
+这篇文章是一个综合指南,用以理解和实现不同复杂程度下的 RAG 应用程序。无论您是渴望学习基础知识的初学者,还是希望加深专业知识的经验丰富的开发人员,您都会找到宝贵的见解和实践知识来帮助您完成您的旅程。让我们一起开始这一激动人心的探索,释放 RAG 应用程序的全部潜力吧。
+
+[将 Rust 和 Python 组合在一起:两全其美?](https://www.youtube.com/watch?v=lyG6AKzu4ew) 
+该视频向您展示如何使用 Pyo3 将 Rust 与 Python 无缝集成在一起。该库允许您使用 Rust 编写 Python 模块。这意味着我们同时可以获得 Rust 的速度和安全性以及 Python 易于使用的功能!
+
+[在 Kubernetes 中部署 Django 应用](https://blog.jetbrains.com/pycharm/2024/03/deploying-django-apps-in-kubernetes/)
+了解无论您是 Django 开发人员还是 Kubernetes 爱好者,您都可以在 Kubernetes 环境中无缝优化 Django 部署。
+
+[conda 环境入门](https://www.dataschool.io/intro-to-conda-environments/)
+这篇文章解释了虚拟环境的好处,以及如何在 conda 中使用虚拟环境。
+
+[从 Beeps 到 Toots:用 Python 和 Mastodon 复兴寻呼机](https://finnley.dolphinhome.net/2024/02/25/from-beeps-to-toots-reviving-pagers-with-python-and-mastodon/)
+本文展示了 Python 编程的一个独特应用,将寻呼机与 Mastodon 连接起来,将寻呼机的可靠性与现代社交媒体交互融为一体。它强调了 Python 在桥接寻呼机等模拟设备与数字平台方面的多功能性,展示了传统通信方法在当今数字时代的持久相关性。
+
+[使用 JupyterLab Desktop CLI 进行 Python 环境管理](https://blog.jupyter.org/python-environment-management-using-jupyterlab-desktop-cli-e57485c9287c)
+这篇文章讨论了使用 JupyterLab Desktop CLI 进行 Python 环境管理的方法,该工具提供了各种命令和选项,以便在应用程序内有效地管理 Python 环境。其内容涵盖了设置 JupyterLab Desktop CLI、创建新的 Python 环境以及利用捆绑的环境安装程序或从注册中心下载软件包来增强开发过程。
+
+[改善你的 Python 项目架构的六种方式(使用 import-linter)](https://www.piglei.com/articles/en-6-ways-to-improve-the-arch-of-you-py-project/)
+
+这篇文章讨论了六种增强Python项目架构的方法,重点是维护包和模块之间清晰的依赖关系,以避免纠缠在一起的模块间依赖。它解决了像新手对高架构的理解成本,以及在大型项目中难以定位代码导致开发效率降低这样的挑战。
+
+
+# 好玩的项目,工具和库
+
+[Hatchet](https://github.com/hatchet-dev/hatchet)
+一个分布式、容错的任务队列。
+
+[BlendSQL](https://github.com/parkervg/blendsql)
+统一的语言,用于协调 SQLite 逻辑和 LLM 推理。
+
+[django-admin-shellx](https://github.com/adinhodovic/django-admin-shellx)
+一个使用 Xterm.js 和 Django Channels 的 Django 管理后台 Web Shell。
+
+[Bonito](https://github.com/BatsResearch/bonito)
+一个轻量级的库,用于为您的数据生成合成的指令调整数据集,无需使用 GPT。
+
+[FastUI](https://github.com/pydantic/FastUI)
+更快更好的构建 UI。
+
+[Hancho](https://github.com/aappleby/hancho)
+一个简单而愉快的构建系统,用 Python 编写。
+
+[Cadwyn](https://github.com/zmievsa/cadwyn)
+生产就绪的、由社区驱动的、现代的类似于Stripe的API,在 FastAPI 框架中对此 API 进行版本管理和控制。
+
+[flect](https://github.com/Chaoyingz/flect)
+受 Next.js 启发的纯 Python 全栈 Web 应用程序框架。
+
+[pfl](https://github.com/apple/pfl-research)
+用于私有联合学习模拟的 Python 框架。
+
+[EvalPlus](https://github.com/evalplus/evalplus)
+EvalPlus 用于对 LLM 合成代码进行严格评估。
+
+[polars_ds_extension](https://github.com/abstractqqq/polars_ds_extension)
+适用于一般数据科学用例的 Polars 扩展。
+
+
+# 最新发布
+
+[Django 安全版本已发布:5.0.3,4.2.11 和 3.2.25](https://www.djangoproject.com/weblog/2024/mar/04/security-releases/)
+
+
+ # 近期活动和网络研讨会
+
+[San Francisco Python 2024 年 3 月聚会](https://www.meetup.com/sfpython/events/297988890/)
+将会有以下演讲:
+* 电子表格有什么作用?!?
+* 非结构化:LLM的 ETL
+* 数据管道记分卡
+* 帮助开发者自助
+
+[Django London 2024 年 3 月聚会](https://www.meetup.com/djangolondon/events/299189999/)
+将会有以下演讲:
+* WASM 支持的 Django 应用程序,使用 PyScript
+* 2024 年求职指南
+
+[PuPPy 2024 年 3 月聚会](https://www.meetup.com/psppython/events/299203397/)
+将会有以下演讲:
+* 在量子计算机上模拟 3 偏振器实验
+* 为什么我喜欢计划,你也应该如此!
+* 上升的海(The Rising Sea)
+
+
+[Virtual: PyMNtos Python 演示之夜 #123](https://www.meetup.com/pymntos-twin-cities-python-user-group/events/299328386/)
+将会有以下演讲:
+* 关于《Python 简介》第三版的想法
+* 使用 CLIP 进行多模态图像搜索
+
+[PyData NYC 2024 年 3 月聚会](https://www.meetup.com/pydatanyc/events/299507856/)
+将会有以下演讲:
+* 在生产中构建LLM应用程序
+* 但是,您对超参数的调整够了吗?
+
+[PyData Johannesburg 2024 年 3 月聚会](https://www.meetup.com/pydata-johannesburg/events/299175850/)
+将会有一场演讲:揭秘 Apache Nifi 的数据摄取挑战。
+
+[PyData Zurich 2024 年 3 月聚会](https://www.meetup.com/pydata-zurich/events/298797804/)
+将会有一场演讲:基于注意力的自回归模型的多功能性。
diff --git a/Python Weekly/Python_Weekly_Issue_642.md b/Python Weekly/Python_Weekly_Issue_642.md
new file mode 100644
index 0000000..1127f18
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_642.md
@@ -0,0 +1,134 @@
+原文:[Python Weekly - Issue 642](http://eepurl.com/iL4r1k)
+
+---
+
+欢迎来到《Python周刊》第 642 期。让我们直奔主题。
+
+
+# 新闻
+
+[DjangoCon US 2024 CFP](https://pretalx.com/djangocon-us-2024/cfp)
+DjangoCon US 2024 CFP 现已开放。请在美国东部时间 2024 年 4 月 24 日中午 12 点之前提交您的演讲或教程提案。
+
+
+# 文章,教程和讲座
+
+[为了50,000美元,我们黑进了谷歌A.I.](https://www.landh.tech/blog/20240304-google-hack-50000)
+这篇文章讨论了作者参加拉斯维加斯的一个黑客活动的经历,在活动中他们发现了漏洞,从而成功黑进了谷歌。尽管最初取得了成就,但谷歌VRP团队延长了比赛截止日期,以鼓励更多创造性的发现,突显了网络安全领域不断面临的挑战和机遇。
+
+[为什么说在 2024 年你应该使用 Pydantic](https://www.youtube.com/watch?v=502XOB0u8OY) 
+在这个更新的Pydantic教程中,我将介绍所有新功能及其给项目带来的好处。尽管Python的动态类型系统是用户友好的,但它并非没有数据处理问题。这就是Pydantic发挥作用的地方,它为无缝数据管理提供了必要的结构和验证。
+
+[GGUF,迂回的长途](https://vickiboykis.com/2024/02/28/gguf-the-long-way-around/)
+这是一篇关于GGUF的文章,它是一种用于机器学习模型的文件格式。文章讨论了什么是机器学习模型以及它们是如何生成的。
+
+[实践中的Python Gevent:需要牢记的常见陷阱](https://upsun.com/blog/python-gevent-best-practices/)
+在这篇文章中,了解使用异步Python库Gevent的常见陷阱,以及如何解决这些问题。
+
+[使用Collectfasta加速Django的collectstatic命令](https://jasongi.com/2024/03/04/speed-up-djangos-collectstatic-command-with-collectfasta/)
+这篇文章介绍了Collectfasta,这是Collectfast的更新版本,旨在提高Django的collectstatic命令的性能。通过优化存储库并提高性能,Collectfasta提供了比标准Django命令更快的执行和效率,为寻求提高Django项目性能的开发人员提供了有价值的工具。
+
+[创建一个基于机器学习的NCAA比赛预测模型](https://www.youtube.com/watch?v=cHtAEWkvSMU) 
+深入探讨机器学习和人工智能的迷人世界,我们将指导您开发一个旨在预测NCAA锦标赛结果的模型。从初始设置到最终预测,我们将覆盖您创建自己强大模型所需的一切内容。
+
+[使用Win32 App隔离为Python创建沙箱环境](https://blogs.windows.com/windowsdeveloper/2024/03/06/sandboxing-python-with-win32-app-isolation/)
+这篇文章探讨了为Python中创建沙箱环境的挑战和好处,特别是在网站执行用户代码或防止针对大型语言模型的攻击等情况下。Win32 App隔离提供了一种在应用程序/操作系统级别隔离Python的独特方法,它创建了一个安全边界来防止应用程序破坏操作系统。
+
+[使用LLMs生成模糊生成器的](https://verse.systems/blog/post/2024-03-09-using-llms-to-generate-fuzz-generators)
+这篇文章探讨了大型语言模型(LLMs)在生成库API模糊驱动程序方面的有效性。它讨论了基于LLM的模糊驱动程序生成的挑战和好处,突出了其实用性、复杂API使用的策略以及基于全面研究和评估的改进方向。
+
+[Python中的时间序列分析指南](https://www.timescale.com/blog/how-to-work-with-time-series-in-python/)
+探讨了 Python 为何是进行时间序列分析的好语言。另外,还有一些入门建议。
+
+[使用MediaPipe和TensorFlow Lite在设备上进行的大型语言模型](https://developers.googleblog.com/2024/03/running-large-language-models-on-device-with-mediapipe-andtensorflow-lite.html)
+文章讨论了实验性的MediaPipe LLM推理API的发布,该API使大型语言模型(LLMs)能够完全在设备上跨平台运行。这一变革性功能解决了LLMs的显著内存和计算需求,这些需求是传统设备上模型的100多倍,通过新的运算、量化、缓存和权重共享等优化实现。
+
+[Homebrew 所有 Python 的东西](https://blog.davep.org/2024/03/10/homebrew-all-the-python-things.html)
+
+[不安全感和 Python 对象序列化](https://lwn.net/SubscriberLink/964392/498a12fe44f51139/)
+
+[理解上下文管理器及其语法糖](https://bjoernricks.github.io/posts/python/context-manager/)
+
+[Python 有指针嘛?](https://nedbatchelder.com/blog/202403/does_python_have_pointers.html)
+
+
+ # 好玩的项目,工具和库
+
+[openllmetry](https://github.com/traceloop/openllmetry)
+LLM 申请的开源可观察性。
+
+[CBScript](https://github.com/SethBling/cbscript)
+CBScript 是一种转译语言,由 SethBling 设计。该编译器会将 CBScript 文件编译为 Minecraft 数据包 zip 文件。它具有许多 Minecraft 命令级别所不存在的高级语言功能。
+
+[SQLMesh](https://github.com/TobikoData/sqlmesh)
+向后兼容 dbt 的高效数据转换和建模框架。
+
+[Dataverse](https://github.com/UpstageAI/dataverse)
+数据宇宙。关于数据、数据科学和数据工程。
+
+[LlamaGym](https://github.com/KhoomeiK/LlamaGym)
+利用在线强化学习微调 LLM 代理。
+
+[chedule-texts-from-txt](https://github.com/reidjs/schedule-texts-from-txt)
+根据 .txt 文件安排 iMessage 或 SMS 文本。
+
+[fructose](https://github.com/bananaml/fructose)
+像调用强类型函数那样调用 LLM。
+
+[R2R](https://github.com/SciPhi-AI/R2R)
+快速开发和部署生产可用的 RAG 系统的框架。
+
+[python-docstring-highlighter](https://github.com/rodolphebarbanneau/python-docstring-highlighter)
+VSCode 中 Python 文档字符串的语法高亮显示。
+
+[Ludic](https://github.com/paveldedik/ludic)
+纯 Python 方式构建 HTML 页面的轻量级框架。
+
+
+
+# 最新发布
+
+[Python 3.13.0 alpha 5 现已发布](https://pythoninsider.blogspot.com/2024/03/python-3130-alpha-5-is-now-available.html)
+
+
+# 近期活动和网络研讨会
+
+[PyLadies London 2024 年 3 月聚会](https://www.meetup.com/pyladieslondon/events/299658808/)
+将会有以下演讲:
+ * 指导职业道路决策
+ * Spotify 是如何通过机器学习个性化您的搜索结果的
+
+
+[Python Barcelona 2024 年 3 月聚会](https://www.meetup.com/python-barcelona/events/299261127/)
+将会有以下演讲:
+ * Python 和 Rust
+ * 动手操作 Polars,Rust 中数据框架的替代方案
+
+
+[BayPIGgies 2024 年 3 月聚会](https://www.meetup.com/baypiggies/events/299305900/)
+将会有以下演讲:
+ * SRE 的趣味世界
+ * 更好地结合起来:释放 Pandas、Polars 和 Apache Arrow 的协同作用
+ * 模拟直到成功:如何在不离开单元测试的情况下验证您的外部模拟
+
+
+[PyData Stockholm 2024 年 3 月聚会](https://www.meetup.com/pydatastockholm/events/299375069/)
+将会有以下演讲:
+ * 微调您自己的 Stable Diffusion 模型 - 包括提示和技巧
+ * 实际应用中的人工智能工具:Polestar 是如何利用 LLM 增强客户体验的
+
+
+[PyData Southampton 2024 年 3 月聚会](https://www.meetup.com/pydata-southampton/events/298930338/)
+将会有以下演讲:
+ * Python 支持的现代数据堆栈
+ * 讲透 Transformer
+ * 使用脑电图评估认知工作量
+ * 时间序列数据库基准测试
+
+[PyData Ireland 2024 年 3 月聚会](https://www.meetup.com/pydataireland/events/299173763/)
+将会有一场演讲:生成式人工智能企业格局——过去、现在和未来。
+
+[PyData Paris 2024 年 3 月聚会](https://www.meetup.com/pydata-paris/events/299457555/)
+将会有以下演讲:
+ * 仅用 Python,将你的数据项目部署在网上
+ * 充分利用 scikit-learn 分类器:可信概率和最优二元决策
diff --git a/Python Weekly/Python_Weekly_Issue_643.md b/Python Weekly/Python_Weekly_Issue_643.md
new file mode 100644
index 0000000..12fd777
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_643.md
@@ -0,0 +1,123 @@
+原文:[Python Weekly - Issue 643](http://eepurl.com/iMv32k)
+
+---
+
+欢迎来到《Python周刊》第 643 期。让我们直奔主题。
+
+# 文章,教程和讲座
+
+[如何使用 PostgreSQL 执行(军事)地理分析任务](https://klioba.com/how-to-use-postgresql-for-military-geoanalytics-tasks)
+这是一个关于利用 PostgreSQL 进行军事地理分析任务的详细指南,强调了地理空间数据处理在军事行动中的重要性。它涵盖了地理空间数据处理、最近物体查找、距离计算、地理空间索引的使用、多边形内的点的确定以及地理空间聚合的方法,以增强军事环境中的分析能力。
+
+[Python 中的每个 dunder 方法](https://www.pythonmorsels.com/every-dunder-method/)
+对 Pytho 所有的 100 多种 dunder 方法和 50 多种 dunder 属性的解释,包括每一种的摘要。
+
+[地狱模式下的 Lambda:走进 Modal 的 web 基础架构](https://modal.com/blog/serverless-http)
+这篇文章讨论了 Modal 是如何在无服务器函数中处理实时 HTTP 请求和 WebSocket 的
+
+[如何测试 Python 中的异步代码?](https://www.youtube.com/watch?v=n1nqgMtWRwg) 
+异步代码测试是很棘手的,但对于创建流畅、无错误且可靠的应用程序却是至关重要。因此,在本视频中,我将指导您了解有效测试异步代码的基础知识。
+
+[Pixi 的多种环境介绍](https://prefix.dev/blog/introducing_multi_env_pixi)
+这篇文章介绍了 Pixi 的多环境功能,允许用户为不同的任务(如测试、开发或生产)创建具有特定包集的定制环境。 Pixi 中的这一增强功能使用户能够根据项目需求自定义环境,从而在管理依赖项和任务方面提供灵活性和效率。
+
+[从新理论的角度,从头开始介绍扩散模型](https://www.chenyang.co/diffusion.html)
+本文提供了使用欧几里得距离函数解释和增强扩散模型的见解,详细探讨了扩散模型及其应用。它专注于通过梯度估计、高效采样技术以及可视化动量项对文本到图像生成的影响来改进扩散模型。
+
+[用 Python 构建命令行应用](https://www.honeybadger.io/blog/building-command-line-applications-in-python-a-comprehensive-guide/)
+深入了解如何在 Python 中实现命令行应用程序。本教程构建了一个 BMI 计算器应用程序并在 Python 中实现 Linux head 命令,并使用 argparse 模块来解释参数、标志和选项是如何在命令行应用程序中工作的。
+
+[Nextjs 和 Django Airbnb 克隆](https://www.youtube.com/playlist?list=PLpyspNLjzwBnP-906FBRP5qzB4YXjMvnT) 
+了解如何构建 Airbnb 的全栈克隆,其中,前端使用 Nextjs/React 和 Tailwind 等技术,后端使用 Django 和 Django Rest 框架。
+
+[让您的 Pandas 或 Polars DataFrame 与 ITables 2.0 进行交互](https://blog.jupyter.org/make-your-pandas-or-polars-dataframes-interactive-with-itables-2-0-c64e75468fe6)
+ITables(或交互式表)是一个 MIT 许可的 Python 包,它使用 DataTables JavaScript 库呈现 Python DataFrames。我刚刚发布的 ITables 2.0 中添加了对 DataTables 扩展的支持。在这篇文章中,我们回顾了此版本带来的功能。
+
+[用计算机视觉对我的黑胶唱片收藏进行编目](https://jamesg.blog/2024/03/16/vinyl-record-indexing/)
+这篇文章详细介绍了使用计算机视觉对黑胶唱片收藏进行编目的过程,重点是通过系统方法识别独特的黑胶唱片。通过利用计算机视觉技术和嵌入技术,作者分享了关于创建一个系统的见解,这个系统可以准确识别和索引黑胶唱片,以实现高效的编目和组织。
+
+[AutoDev:自动化 AI 驱动开发(Automated AI-Driven Development)](https://arxiv.org/html/2403.08299v1)
+论文“AutoDev:自动化人工智能驱动开发(AutoDev: Automated AI-Driven Development)”提出了一种人工智能驱动开发的自动化方法,涉及多位作者的协作努力。它探讨了人工智能驱动的自动化开发流程的进步,展示了对 AutoDev 的全面研究
+
+[在 Python 中解析 URL](https://tkte.ch/articles/2024/03/15/parsing-urls-in-python.html)
+本文深入探讨了用 Python 解析 URL 的复杂性,重点介绍了 URL 规范随着时间的推移所面临的挑战和演变。它强调了把 WHATWG URL 规范当成在 Python 应用程序中准确处理 URL 的可靠指南的重要性。
+
+[Jupyter 与 IPython 术语解释](https://www.dataschool.io/jupyter-and-ipython-terminology/)
+了解 Jupyter Notebook、JupyterLab、IPython、Colab 和其他相关术语之间的差异。
+
+
+# 好玩的项目,工具和库
+
+[Grok-1](https://github.com/xai-org/grok-1)
+Grok 开源版本。
+
+[Skyvern](https://github.com/Skyvern-AI/skyvern)
+通过 LLM 和计算机视觉自动化基于浏览器的工作流程。
+
+[MindGraph](https://github.com/yoheinakajima/mindgraph)
+用于使用 AI 生成和查询不断扩展的知识图的概念原型验证。
+
+[Chronos](https://github.com/amazon-science/chronos-forecasting)
+用于概率时间序列预测的预训练(语言)模型。
+
+[LaVague](https://github.com/lavague-ai/LaVague)
+使用大型动作模型框架实现自动化。
+
+[DarkGPT](https://github.com/luijait/DarkGPT)
+DarkGPT是一款基于GPT-4-200K的人工智能助手,旨在对泄露的数据库执行查询。
+
+[phospho](https://github.com/phospho-app/phospho)
+LLM 应用程序的文本分析。PostHog 获取提示。从短信中提取评价、意图和事件。 phosph 利用 LLM(OpenAI、MistralAI、Ollama 等)
+
+[LLM4Decompile](https://github.com/albertan017/LLM4Decompile)
+逆向工程:使用大型语言模型反编译二进制代码。
+
+[sqlelf](https://github.com/fzakaria/sqlelf)
+通过 SQL 的强大功能来探索 ELF 对象。
+
+[Magix](https://github.com/luyug/magix)
+通过模型并行性增强拥抱面 transformer。
+
+
+# 最新发布
+
+[Django REST 框架 3.15](https://www.django-rest-framework.org/community/3.15-announcement/)
+
+[Python 3.10.14、3.9.19 和 3.8.19 现已发布](https://pythoninsider.blogspot.com/2024/03/python-31014-3919-and-3819-is-now.html)
+
+
+# 近期活动和网络研讨会
+
+[Virtual: PyMunich 2024 年 3 月聚会](https://www.meetup.com/pymunich/events/299459088/)
+将会有以下演讲:
+ * 一次利用 Python 异步和线程的操作系统之旅
+ * 无服务器应用程序的干净架构
+
+
+[Virtual: DragonPy 2024 年 3 月聚会](https://www.meetup.com/ljubljana-python-group/events/299732452/)
+将会有以下演讲:
+ * Apache Arrow - 管理字节以获得乐趣和利润
+ * 自托管数据堆栈
+ * SQL 和 Python:数据仓库的动态组合
+
+
+[San Diego Python 2024 年 3 月聚会](https://www.meetup.com/pythonsd/events/299374271/)
+将会有以下演讲:
+ * RWKV:transformer 的继承者?
+ * 使用 LangChain 来构建 AI 应用
+ * 在 Cloudera 数据工程中使用 Apache Sedona
+
+
+[PyData Cyprus 2024 年 3 月聚会](https://www.meetup.com/pydata-cyprus/events/299459091/)
+将会有一场演讲:大型语言模型之旅。
+
+[PyData Montreal 2024 年 3 月聚会](https://www.meetup.com/pydata-mtl/events/299605178/)
+将会有以下演讲:
+ * 机器学习可以如何帮助游戏设计
+ * BigCode:开放且负责任的大型代码语言模型开发
+
+
+[PyData Bristol 2024 年 3 月聚会](https://www.meetup.com/pydata-bristol/events/299738605/)
+将会有以下演讲:
+ * 无声入侵:LLM是如何渗透企业的
+ * 用数据科学赋能社会:对日常产生影响的快速部署策略
diff --git a/Python Weekly/Python_Weekly_Issue_644.md b/Python Weekly/Python_Weekly_Issue_644.md
new file mode 100644
index 0000000..c69d389
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_644.md
@@ -0,0 +1,108 @@
+原文:[Python Weekly - Issue 644](http://eepurl.com/iMZAHE)
+
+---
+
+欢迎来到《Python周刊》第 644 期。让我们直奔主题。
+
+# 文章,教程和讲座
+
+[设计一个纯 Python Web 框架](https://reflex.dev/blog/2024-03-21-reflex-architecture/)
+本文解释了Reflex(一个纯 Python 的 Web 框架),是如何让用户可以在无需学习新语言的情况下构建网络应用的。它详细介绍了 Reflex 都工作原理,重点介绍了其将 UI 编译为 JavaScript 的独特方法,同时在服务器上使用 Python 保留应用程序逻辑和状态管理。
+
+[修复 PyPy 增量垃圾收集器中的一个错误](https://www.pypy.org/posts/2024/03/fixing-bug-incremental-gc.html)
+本文讨论了作者是如何修复 PyPy 增量垃圾收集器中的一个错误的,这个错误在 CI 环境中 pytest 的 AST 重写阶段会导致崩溃。它详细介绍了 PyPy 增量 GC 的技术背景,以及在写屏障实现中发现和解决的具体问题。
+
+[针对执行速度慢的函数调用的一个更好的 Python 缓存](https://docs.sweep.dev/blogs/file-cache)
+本文介绍了一种 Python 文件缓存,它将函数值存储在文件中而不是存储在内存中,从而提供了更持久的缓存解决方案。通过使用 file_cache 装饰器,开发人员可以节省运行 LLM 基准测试等函数的时间并将缓存作为 Python 的模块共享,从而提高性能。
+
+[Django:关于优化系统检查框架的文章](https://adamj.eu/tech/2024/03/23/django-optimizing-system-checks/)
+这篇文章讨论了对 Django 系统检查框架的优化,该框架因速度慢而闻名。这些优化将在示例客户端项目上的检查操作运行时间从 37 毫秒减少到 18 毫秒,共减少了 50%。
+
+[八分钟 Python Poetry](https://www.youtube.com/watch?v=Ji2XDxmXSOM) 
+该视频将指导您歇息管理 Python 虚拟环境的方方面面,同时还向您介绍了 Poetry。您将学习大量技巧和策略,以更有效地管理您的项目。
+
+[伪造短信:兔子洞到底有多深?](https://medium.com/@aleksamajkic/fake-sms-how-deep-does-the-rabbit-hole-really-go-17e25c42f986)
+通过模糊的恶意软件代码迷宫追踪不良行为者。
+
+[使用 Numba 加速代码的错误方式](https://pythonspeed.com/articles/slow-numba/)
+Numba 可以使您的数字代码更快,但前提是您正确使用它。
+
+[不必要的 else 语句](https://www.pythonmorsels.com/unnecessary-else-statements/)
+让我们来谈谈 Python 中不必要的 else 语句。
+
+[使用 Apache Superset 和 PostgreSQL 实现数据可视化](https://www.timescale.com/blog/data-visualization-in-postgresql-with-apache-superset/)
+正在寻找适用于 PostgreSQL 的数据可视化工具吗?我们讨论了一些选项,并提供了有关 PostgreSQL 和 Apache Superset 的分步指南。
+
+[为移动开发人员构建 Django API](https://www.youtube.com/playlist?list=PLgRx2Eap1Wm2W-ozbwAZwffEwTTy8xS5g) 
+深入了解应用程序开发的后端,重点关注使用 Django 和 Django Rest Framework 来构建强大的 API。
+
+[安全的 LLM 架构 —— 测试 LLM Guard](https://www.youtube.com/watch?&v=C_5KRqQrGD4) 
+该视频探讨了 LLM 架构,解决了安全问题并批评了无效的安全工具。它介绍了 LLM Guard,这是一种开源工具,旨在通过检查输入是否存在恶意意图和输出是否敏感数据来增强 LLM 的安全性,并通过实际示例对其进行了演示,还强调输出监控和权限在保护数据方面的重要性。
+
+[谓词下推(predicate pushdown)的威力](https://pola.rs/posts/predicate-pushdown-query-optimizer/)
+谓词下推(Predicate pushdown)是查询引擎最重要的优化之一。通过本文了解更多相关信息。
+
+[带原生 Python 扩展和 Dispatch 的分布式协程](https://stealthrocket.tech/blog/distributed-coroutines-in-python/)
+本文讨论了分布式协程是如何与 Dispatch 等分布式调度程序配合使用的,从而通过允许函数在另一个进程中挂起、序列化和恢复来简化可扩展且可靠的软件的创建。它重点介绍了分布式协程如何利用 Python 对协程和异步函数的原生支持,使用常规编程语言结构和控制流对动态工作流程进行编码。
+
+[AWS Lambda + Bedrock 教程](https://www.youtube.com/watch?v=vQ9BUc-UmXY) 
+了解如何使用 AWS Lambda 从 AWS Bedrock 调用 API。本视频手把手教您使用Python和boto3的Bedrock客户端调用InvokeModel API。它还向您展示设置 IAM 权限并修改 Lambda 超时值以应对 Bedrock 的缓慢响应的方法。
+
+
+# 好玩的项目,工具和库
+
+[open-interpreter](https://github.com/OpenInterpreter/open-interpreter)
+计算机自然语言界面。
+
+[Devika](https://github.com/stitionai/devika)
+Agentic 人工智能软件工程师。 Devika 的目标是成为 Cognition AI 开发的 Devin 的有竞争力的开源替代品。
+
+[T-Rex](https://github.com/IDEA-Research/T-Rex)
+通过文本-视觉提示协同,实现通用物体检测。
+
+[OpenDevin](https://github.com/OpenDevin/OpenDevin)
+一个旨在复制 Devin 的开源项目,Devin 是一位自主人工智能软件工程师,能够执行复杂的工程任务并在软件开发项目上与用户积极协作。
+
+[VoiceCraft](https://github.com/jasonppy/VoiceCraft)
+零次语音编辑和文本转语音。
+
+[lightning-thunder](https://github.com/Lightning-AI/lightning-thunder)
+让 PyTorch 模型快如闪电! Thunder 是一个针对 PyTorch 的源到源编译器。它允许同时使用不同的硬件执行器。
+
+
+[reverser_ai](https://github.com/mrphrazer/reverser_ai)
+过在消费类硬件上使用本地大语言模型 (LLM),提供自动化逆向工程协助。
+
+[Leaping](https://github.com/leapingio/leaping)
+Leaping 的 pytest 调试器是一个简单、快速、轻量级的 Python 测试调试器。 Leaping 跟踪代码的执行,并允许您使用基于 LLM 的自然语言调试器,随时追溯检查程序的状态。
+
+[Tracecat](https://github.com/TracecatHQ/tracecat)
+Tines / Splunk SOAR 的 AI 原生开源替代品。
+
+[rag-search](https://github.com/thinkany-ai/rag-search)
+RAG 搜索 API。
+
+[FeatUp](https://mhamilton.net/featup.html)
+一个与模型无关的框架,适用于任何分辨率的特征。
+
+
+# 近期活动和网络研讨会
+
+[PyData London 2024 年 4 月聚会](https://www.meetup.com/pydata-london-meetup/events/299970694/)
+将会有以下演讲:
+ * 构建检索增强生成 (RAG) 支持的应用程序
+ * 将 ML 模型从研究转移到生产时,让 Python 成为一种可能。深入探讨开放神经网络交换 (ONNX)
+
+[Michigan Python 2024 年 4 月聚会](https://www.meetup.com/michigan-python/events/299683479/)
+将会有一场演讲:使用 GeoPandas 对空间数据进行可视化。
+
+[PyData Amsterdam 2024 年 4 月聚会](https://www.meetup.com/pydata-nl/events/299967889/)
+将会有以下演讲:
+ * 欺诈与否:听起来很简单,对吧?
+ * 使用 OSS Metaflow 构建 GenAI 和 ML 系统
+
+[PyData Tel Aviv 2024 年 4 月聚会](https://www.meetup.com/pydata-tel-aviv/events/299310820/)
+将会有以下演讲:
+ * 投标还是不投标 —— 针对实时投标的强化学习
+ * 使用 Rebuff 保护 LangChain 应用程序以免受即时注入
+ * Polars是Pandas杀手
diff --git a/Python Weekly/Python_Weekly_Issue_645.md b/Python Weekly/Python_Weekly_Issue_645.md
new file mode 100644
index 0000000..9c4e068
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_645.md
@@ -0,0 +1,114 @@
+原文:[Python Weekly - Issue 645](http://eepurl.com/iNp38k)
+
+---
+
+欢迎来到《Python周刊》第 645 期。让我们直奔主题。
+
+# 新闻
+
+[针对 Python 开发人员的域名仿冒运动](https://blog.phylum.io/typosquatting-campaign-targets-python-developers/)
+
+Phylum 的自动风险检测平台发现了一场针对 PyPI 上流行 Python 库的新域名仿冒运动,迄今为止已发布了 500 多个域名仿冒变体。 PyPI 已立即删除恶意软件包,并暂时停止新项目和帐户创建,以防止此次攻击造成进一步影响。
+
+
+# 文章,教程和讲座
+
+[关于在 2024 年构建大型语言模型的一个小指南](https://www.youtube.com/watch?v=2-SPH9hIKT8) 
+这是两部分系列的第一个视频,涵盖了在 2024 年训练具备良好性能 LLM 的所有概念。
+
+[为什么 Python 列表会奇怪地倍增?探索 CPython 源代码](https://codeconfessions.substack.com/p/why-do-python-lists-multiply-oddly)
+看看 CPython 中列表实现的内部结构,以了解它们的这个怪癖。
+
+[使用 Pyodide 和 WebAssembly,为 Python 引入 Workers](https://blog.cloudflare.com/python-workers)
+这篇文章讨论了 Cloudflare 对 Python Workers 的实现,重点介绍了它们在无服务器计算方面的优势和用例。它探讨了 Python Workers 如何帮助开发人员在 Cloudflare 网络上高效构建和部署轻量级、可扩展的应用程序。
+
+[制作(Make)Python DevEx](https://tech.target.com/blog/make-python-devex)
+本文讨论了建立高效的 Python 开发环境的挑战,以及如何使用 Make 通过自动准备开发环境和加快测试驱动的开发周期来帮助缓解这些障碍。作者提供了一个示例项目,演示如何使用 Make 改善跨多个代码库的 Python 开发人员体验。
+
+[通过内省,在 Django 项目中强制执行约定](https://lukeplant.me.uk/blog/posts/enforcing-conventions-in-django-projects-with-introspection/)
+结合 Python 和 Django 内省 API,在 Django 模型中强制执行命名约定的一些代码和技巧。
+
+[构建用于代码修复的 LLM](https://blog.replit.com/code-repair)
+本文讨论了 Replit 的代码修复功能,该功能可自动修复代码中的常见编程错误和问题。它探讨了通过为常见编码问题提供自动化解决方案,代码修复可以如何帮助开发人员节省时间并提高代码质量。
+
+[利用断点探索代码](https://www.mostlypython.com/using-breakpoints-to-explore-your-code/)
+本文指导 Python 开发人员有效利用断点来调试和探索代码执行流程。它提供了关于利用断点来更好地理解 Python 代码并进行故障排除的实用技巧和示例。
+
+[Django 的 ASGI 部署选项](https://fly.io/django-beats/asgi-deployment-options-for-django/)
+本文探讨了 Django 应用程序的 ASGI 部署选项,提供了有关使用 ASGI 服务器部署 Django 的见解。
+
+[Python 3.12 泛型简述](https://www.youtube.com/watch?v=TkDg3EHwC1g) 
+Python 3.12 中的泛型可以通过允许类与不同的数据类型一起使用来转换代码,从而增强灵活性以及及早发现错误。该视频深入介绍了通用类和子类,并向您展示它们可以如何简化您的开发过程。
+
+[使用 Google Cloud 自动化 Python](https://www.scipress.io/post/rSp9Rov4ppvHgpHQaRPy/Automating-Python-with-Google-Cloud)
+一个教程系列,关于如何使用 Cloud Functions 和/或 Cloud Run 在 Google Cloud 中自动化 Python 脚本。
+
+[GPT 可以优化我的税务吗?](https://finedataproducts.com/posts/2024-03-10-tax-scenarios-with-ai/)
+这篇文章描述了一个使用 GPT-4 和 10 个 Python 库的 Web 应用程序,它允许用户输入税务场景并接收优化的税务计算和建议。与传统税务软件相比,该应用程序旨在提供更加灵活和个性化的税务咨询体验。
+
+[Python 项目 —— 本地虚拟环境管理 Redux](https://hynek.me/articles/python-virtualenv-redux/)
+
+[2024 年我如何管理 Python](https://outlore.dev/blog/python-dev-2024/)
+
+
+# 好玩的项目,工具和库
+
+[SWE-agent](https://github.com/princeton-nlp/SWE-agent)
+SWE-agent 将 LM(例如 GPT-4)转变为软件工程代理,可以修复真实 GitHub 存储库中的错误和问题。
+
+[DBRX](https://github.com/databricks/dbrx)
+DBRX( Databricks 开发的大型语言模型) 代码示例和资源。
+
+[thepipe](https://github.com/emcf/thepipe)
+通过一行代码将任何文件、文件夹、网站或存储库导出到 GPT-4-Vision。
+
+[Sparrow](https://github.com/katanaml/sparrow)
+使用 ML 和 LLM 进行数据处理。
+
+[Nava](https://github.com/openscilab/nava)
+用 Python 播放声音。
+
+[IPEX-LLM](https://github.com/intel-analytics/ipex-llm)
+一个 PyTorch 库,用于在 Intel CPU 和 GPU(例如,具有 iGPU 的本地 PC、Arc、Flex 和 Max 等独立 GPU)上运行 LLM,延迟非常低。
+
+[RAGFlow](https://github.com/infiniflow/ragflow)
+RAGFlow 是一个基于深度文档理解的开源 RAG(检索增强生成)引擎。
+
+
+# 最新发布
+
+[Django 问题修复版本已发布:5.0.4](https://www.djangoproject.com/weblog/2024/apr/03/bugfix-release/)
+
+
+# 近期活动和网络研讨会
+
+[San Francisco Python 2024 年 4 月聚会](https://www.meetup.com/sfpython/events/298868858/)
+将会有以下演讲:
+* Prompt 工程:适用于 0.1 版代码 - 获得更快结果的途径
+* 更快运行 Pytest 的策略
+
+
+[PyData NYC 2024 年 4 月聚会](https://www.meetup.com/pydatanyc/events/300039833/)
+将会有以下演讲:
+* 时间序列预测简介
+* 使用 STUMPY 进行时间序列 EDA
+
+
+[Pyladies Munich 2024 年 4 月聚会](https://www.meetup.com/pyladiesmunich/events/299309240/)
+将会有以下演讲:
+* 可观察性:原理与 Python 中的应用
+* 使用 Python 进行无缝云基础设施管理
+* 责任因素:同伴支持可以如何改变你的学习之旅
+
+
+[Freiburg Python 2024 年 4 月聚会](https://www.meetup.com/python-user-group-freiburg/events/299919455/)
+将会有以下演讲:
+* 事件系统 - JobRad 软件的演变
+* Docker 化 Python 应用程序及其安全性
+
+
+[PyData Munich 2024 年 4 月聚会](https://www.meetup.com/pydata-munchen/events/300083533/)
+将会有以下演讲:
+* 使用 dstack Sky 访问多个提供商的 GPU
+* 更多标签或案例?评估自然语言推理中的标签变化
+* p(doom) —— 一个开放的、完全去中心化的全球人工智能研究实验室
diff --git a/Python Weekly/Python_Weekly_Issue_646.md b/Python Weekly/Python_Weekly_Issue_646.md
new file mode 100644
index 0000000..d5eef5b
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_646.md
@@ -0,0 +1,115 @@
+原文:[Python Weekly - Issue 646](http://eepurl.com/iNSLLo)
+
+---
+
+欢迎来到《Python周刊》第 646 期。让我们直奔主题。
+
+
+# 文章,教程和讲座
+
+[SQLAlchemy:Python 中最好的 SQL 数据库库](https://www.youtube.com/watch?v=aAy-B6KPld8) 
+你听说过 SQLAlchemy 并觉得它听起来像中世纪的魔药吗?嗯,事实并非如此! SQLAlchemy 将 SQL 的稳健性与 Python 的灵活性相结合,使数据库管理不仅更容易,而且也很有趣!在本视频中,我将仔细看看这个很棒的工具。
+
+[优秀表格的设计理念](https://posit-dev.github.io/great-tables/blog/design-philosophy)
+本文讨论了精心设计的表格对于有效呈现数据的重要性,并从历史表格设计原则中汲取灵感。它强调了 Great Tables 库专注于提供各种自定义选项,以帮助用户为出版物、报告和其他数据驱动内容创建具有视觉吸引力和结构化的表格。
+
+[14 个 LLM 参加了 314 场街头霸王比赛。这里是赢家。](https://community.aws/content/2dbNlQiqKvUtTBV15mHBqivckmo/14-llms-fought-314-street-fighter-matches-here-s-who-won)探索问答任务之外的大型语言模型的新基准。了解 LLM 如何使用 Amazon Bedrock 在街头霸王 III 中竞争。
+
+[没有 API 的客户端库会更好](https://csvbase.com/blog/7)
+本文讨论了作者为 csvbase 构建客户端库的方法,重点是利用现有的文件系统抽象库(如 fsspec)来提供无缝的用户体验,而无需自定义 API。它强调了这种方法的好处,例如可以与已经支持 fsspec 接口的各种工具和库集成。
+
+
+[使用 Django、Channels 和 HTMX 构建流式 ChatGPT 克隆](https://www.youtube.com/watch?v=8JSiiPW4S0A) 
+此视频将引导您逐步使用 Django、websockets 和 HTMX 构建 ChatGPT 克隆。每个功能都被分解为一个提交,然后进行解释和演示。最后,一个功能齐全的流式聊天机器人应用程序就准备好了!
+
+[如何利用单行 Python 代码挺过编码面试](https://ivaniscoding.github.io/posts/codeinterview/)
+本文讨论了使用简洁的单行 Python 代码解决编码面试问题的技术。
+
+[Python 和 OpenAI 中的余弦相似度和文本嵌入](https://earthly.dev/blog/cosine_similarity_text_embeddings/)
+本文讨论了如何使用余弦相似度来比较文本嵌入(文本嵌入是捕获语义的文本向量表示),以确定不同文本输入之间的相似度。它提供了示例代码,计算使用 OpenAI API 生成的文本嵌入之间的余弦相似度。
+
+[六分钟内的 七个 Django GeneratedFiel 示例](https://www.youtube.com/watch?v=b7VkVHBX47w) 
+我们将在 6 分钟内完成 7 个简短的示例。看完它们后,您将了解如何使用 Django 的 GeneratedField - 快速且整齐地使用数据库自动进行计算。
+
+[使用 Python、Datalore 和 AI Assistant,回测交易策略](https://blog.jetbrains.com/datalore/2024/04/05/backtesting-a-trading-strategy-in-python-with-datalore-and-ai-assistant/)
+本文将向您介绍在 Datalore 笔记本中使用 Python 回测每日道琼斯均值回归策略的过程。为了让编码经验有限的人也能使用它,作者利用了 Datalore 的 AI Assistant 功能。
+
+[使用 Python 预测日食](https://erikbern.com/2024/04/07/predicting-solar-eclipses-with-python)
+本文介绍了作者如何利用 Astropy 库和其他 Python 包,编写一个 Python 脚本来计算太阳和月亮的位置并预测日全食的位置,实现所有功能仅用了大约 100 行代码。
+
+
+# 好玩的项目,工具和库
+
+[AutoCodeRover](https://github.com/nus-apr/auto-code-rover)
+一个了解项目结构的自主软件工程师,旨在改进自主程序。
+
+[FreeAskInternet](https://github.com/nashsu/FreeAskInternet)
+FreeAskInternet 是一个完全免费、私有且本地运行的搜索聚合器,并使用 LLM 生成答案,无需 GPU。用户可以提出问题,然后系统会进行多引擎搜索,并将搜索结果合并到ChatGPT3.5 LLM中,再根据搜索结果生成答案。
+
+[Loki](https://github.com/Libr-AI/OpenFactVerification)
+用于事实验证的开源工具。
+
+[schedule_free](https://github.com/facebookresearch/schedule_free)
+PyTorch 中的无计划优化。
+
+[Mantis](https://github.com/PhonePe/mantis)
+Mantis 是一个安全框架,可自动执行发现、侦察和漏洞扫描的工作流程。
+
+[open-parse](https://github.com/Filimoa/open-parse)
+改进了 LLM 的文件解析。
+
+
+# 最新发布
+
+[Visual Studio Code 中的 Python - 2024年四月版本](https://devblogs.microsoft.com/python/python-in-visual-studio-code-april-2024-release/)
+此版本包括以下内容:
+* 改进了 Flask 和 Django 的调试配置流程
+* 使用 Pylance,对 Jupyter 的运行依赖单元进行模块和导入分析
+* 孵化环境发现
+* Pipenv、pyenv 和 Poetry 项目的自动环境选择
+* 报告问题命令的改进
+
+
+[Python 3.11.9 现已发布](https://pythoninsider.blogspot.com/2024/04/python-3119-is-now-available.html)
+
+[Python 3.12.3 和 3.13.0a6 已发布](https://pythoninsider.blogspot.com/2024/04/python-3123-and-3130a6-released.html)
+
+
+# 近期活动和网络研讨会
+
+[Django London 2024 年 4 月聚会](https://www.meetup.com/djangolondon/events/299793290/)
+将会有一场演讲:面向数据的 Django Deux。
+
+[PyLadies London 2024 年 4 月聚会](https://www.meetup.com/pyladieslondon/events/299931279/)
+将会有以下演讲:
+* 使用 Elasticsearch 和 Python 进行语义搜索
+* Elastic 招聘 - 给求职者的提示和技巧
+* 高效的 Python 项目设置:展示 Cookiecutter 在 Kedro 中的潜力
+
+
+[Portland Python 2024 年 4 月聚会](https://www.meetup.com/pdxpython/events/300085006/)
+将会有一场演讲:Python 中的生成器和迭代器。
+
+[PyData Southampton 2024 年 4 月聚会](https://www.meetup.com/pydata-southampton/events/299810812/)
+将会有以下演讲:
+* 沙漠岛 Docker:Python 版本
+* 流数据帧:Python 中处理流数据的新方法
+
+
+[PyData Milano 2024 年 4 月聚会](https://www.meetup.com/pydata-milano/events/299954337/)
+将会有以下演讲:
+* 能源市场的波动期权定价:一个动态规划方法
+* 可解释人工智能:机遇与挑战
+
+
+[PyData Stockholm 2024 年 4 月聚会](https://www.meetup.com/pydatastockholm/events/300163813/)
+将会有以下演讲:
+* 用于基础模型预训练的大规模数据管理
+* Sana AI - 如何使用生成式人工智能构建消费级企业产品
+
+
+[PyData Manchester 2024 年 4 月聚会](https://www.meetup.com/pydata-manchester/events/299810769/)
+将会有以下演讲:
+* 关于制表的传奇故事
+* 开放数据和方法在气候价值分析中的重要性
+
diff --git a/Python Weekly/Python_Weekly_Issue_647.md b/Python Weekly/Python_Weekly_Issue_647.md
new file mode 100644
index 0000000..953d8a2
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_647.md
@@ -0,0 +1,104 @@
+原文:[Python Weekly - Issue 647](http://eepurl.com/iOMKec)
+
+---
+
+欢迎来到《Python周刊》第 647 期。让我们直奔主题。
+
+# 文章,教程和讲座
+
+[从头开始学习 RAG](https://www.youtube.com/watch?v=sVcwVQRHIc8) 
+直接从一位 LangChain 软件工程师那里学习如何从头开始实现 RAG(Retrieval Augmented Generation,检索增强生成)。本 Python 课程教您如何使用 RAG 将您自定义的数据与大型语言模型 (LLM) 的强大功能相结合。
+
+[py2wasm 发布:一个从 Python 到 Wasm 的编译器](https://wasmer.io/posts/py2wasm-a-python-to-wasm-compiler)
+py2wasm 将您的 Python 程序转换为 WebAssembly,运行速度提高了 3 倍。
+
+[7 个令人兴奋的 Kubernetes Hack](https://overcast.blog/7-mind-blowing-kubernetes-hacks-36037e59bb54)
+Kubernetes 拥有的一些功能,即使是经验丰富的开发人员也可能没有完全意识到。这些 Hack 深入研究了更深奥但非常有效的技巧,能让掌握它们的人的能力得到显着增强。这些不是您的日常技巧,而是让 Kubernetes 做出惊人事情的深刻见解。
+
+[Python Big O:Python 中不同数据结构的时间复杂度](https://www.pythonmorsels.com/time-complexities/)
+本文主要是为那些已经了解时间复杂度的概念以及操作的时间复杂度如何影响代码的人提供的一份 Python 时间复杂度备忘单。
+
+[Django 的基本原则](https://www.mostlypython.com/django-from-first-principles-2/)
+许多人没有意识到使用单个文件就可以启动 Django 项目。本系列将逐步介绍从单个文件开始构建一个简单但不平凡的项目的过程。仅当需要将代码移出主文件时,该项目才会使用第二个文件。在本系列结束时,我们的项目都结构将类似于 startproject 和 startapp 生成的项目结构。
+
+[使用 Ollama 和 LlamaEdge,在本地运行 Llama 3](https://www.youtube.com/watch?v=wPuoMaD_SnY) 
+Meta 推出了 Llama3,现在您可以使用 Ollama 在本地运行它。在本视频中,我将讲解如何使用 Ollama 操作各种语言模型,着重介绍 Llama2 和 Llama3。我还将指导您完成该项目的 WebUI,演示如何使用 Ollama 提供模型并使用 Python 与它们进行交互。
+
+[Django:使用 Git 精确定位上游更改](https://adamj.eu/tech/2024/04/24/django-pinpoint-upstream-git/)
+在这篇文章中,我们将介绍 Django 的分支结构、确定和搜索这些提交、一个有效的示例以及使用 git bisect 进行高级行为搜索。
+
+[使用 Django 和 OpenAI 构建一个语音笔记应用程序](https://circumeo.io/blog/entry/building-a-voice-notes-app-with-django-and-openai/)
+我们将构建一个使用 OpenAI 执行语音转文本的语音笔记应用程序。作为奖励,我们将使用 AlpineJS 来管理前端状态。
+
+[8 分钟内使用 HTMX 和 Django 构建一个四子棋游戏](https://www.photondesigner.com/articles/connect4-htmx)
+最后,您将利用 HTMX 构建一个多人游戏,使用简洁的服务器端逻辑并将所有结果存储在数据库中。 HTMX 是一种无需编写 JavaScript 即可使用 JavaScript 的好方法。
+
+[使用 Langfuse 装饰器 (Python) 跟踪复杂的 LLM 应用程序](https://langfuse.com/blog/2024-04-python-decorator)
+在构建 RAG 或代理时,大量 LLM 调用和非 LLM 输入会输入到最终输出中。 Langfuse装饰器可以让您进行整体追踪和评估。
+
+[通过构建您自己的 ChatGPT,学习如何将 Websockets 与 Django 结合使用](https://www.saaspegasus.com/guides/django-websockets-chatgpt-channels-htmx/)
+您需要了解的有关 Websockets 的所有信息,以便在您的应用程序中使用它们,包括 Django、通道和 HTMX。
+
+[我不小心搞了一个 meme 搜索引擎](https://harper.blog/2024/04/12/i-accidentally-built-a-meme-search-engine)
+又名:如何了解 Clip/siglip 和矢量编码图像。
+
+[Llama 3:五分钟内搞定 LLM 构建](https://www.denoise.digital/llama-3-get-started-with-llms/)
+使用 Llama 3、Ollama 和 Python,在 5 分钟内开始构建变革性的 AI 驱动功能。
+
+
+# 好玩的项目,工具和库
+
+[CoreNet](https://github.com/apple/corenet)
+Apple 用于训练深度神经网络的库。
+
+[Cria](https://github.com/leftmove/cria)
+Cria 是一个通过 Python 以编程方式运行大型语言模型的库。 Cria 的构建让您使用尽可能少的配置 - 即使是使用更高级的功能。
+
+[bridge](https://github.com/Never-Over/bridge)
+Django 的自动化基础设施。
+
+[Penzai](https://github.com/google-deepmind/penzai)
+用于构建、编辑和可视化神经网络的 JAX 研究工具包。
+
+[BeyondLLM](https://github.com/aiplanethub/beyondllm)
+构建、评估和观察 LLM 应用程序。
+
+[Hashquery](https://github.com/hashboard-hq/hashquery)
+用于定义和查询数据仓库中的 BI 模型的 Python 框架。
+
+[torchtune](https://github.com/pytorch/torchtune)
+用于 LLM 微调的 Native-PyTorch 库。
+
+[InstructLab](https://github.com/instructlab/instructlab)
+命令行界面。使用它与模型聊天或训练模型(训练消耗分类数据)
+
+[Portr](https://github.com/amalshaji/portr)
+专为团队设计的开源 ngrok 替代方案
+
+[anthropic-cookbook](https://github.com/anthropics/anthropic-cookbook)
+notebooks/使用案例的集合,展示了使用 Claude 的一些有趣且有效的方法。
+
+
+# 最新发布
+
+[llama3](https://github.com/meta-llama/llama3)
+parameters.此版本包括用于预训练和指令调整的 Llama 3 语言模型的模型权重和起始代码 - 包括 8B 到 70B 参数的大小。
+
+[PyTorch 2.3](https://pytorch.org/blog/pytorch2-3/)
+PyTorch 2.3 支持用户在 torch.compile 中定义 Triton 内核,允许用户在不经历性能回归或图形中断的清空下,从 eager 迁移自己的 Triton 内核。Tensor 并行改进了使用本机 PyTorch 函数训练大型语言模型的体验,该功能已在包含 100B 个参数模型的训练运行中得到验证。此外,半结构化稀疏性将半结构化稀疏性实现为Tensor子类,观察到的加速比密集矩阵乘法高达 1.6。
+
+# 近期活动和网络研讨会
+
+[PyData Amsterdam 2024 年 4 月聚会](https://www.meetup.com/pydata-nl/events/300230051/)
+将会有以下演讲:
+ * 生成式人工智能将如何使史基浦机场的客户服务提升到新高度
+ * 释放武士:Albert Heijn 是如何让员工轻松检索内容的
+
+[Hybrid: Michigan Python 2024 年 4 月聚会](https://www.meetup.com/michigan-python/events/299947904/)
+将会有一场演讲:利用 DuckDB 加速 Python 数据分析。
+
+[PyData Seattle 2024 年 4 月聚会](https://www.meetup.com/pydata_seattle/events/299433457/)
+将会有以下演讲:
+ * DBRX 简介:Databricks 推出的一个新的 SOTA 开放 LLM
+ * Fidelius DBRXus:建立您自己私人霍格沃茨
+
diff --git a/Python Weekly/Python_Weekly_Issue_648.md b/Python Weekly/Python_Weekly_Issue_648.md
new file mode 100644
index 0000000..a1ef206
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_648.md
@@ -0,0 +1,115 @@
+原文:[Python Weekly - Issue 648](http://eepurl.com/iPdo2g)
+
+---
+
+欢迎来到《Python周刊》第 648 期。让我们直奔主题。
+
+
+# 新闻
+
+[针对开发者的虚假工作面试,带新的 Python 后门](https://www.bleepingcomputer.com/news/security/fake-job-interviews-target-developers-with-new-python-backdoor/)
+一项名为“Dev Popper”的新活动正在针对软件开发人员进行虚假工作面试,试图诱骗他们安装 Python 远程访问木马 (RAT)。开发人员被要求执行据称与采访相关的任务,例如从 GitHub 下载并运行代码,以使整个过程看起来合法。
+
+
+# 文章,教程和讲座
+
+[Mojo Lang - 未来的高性能 Python?](https://www.youtube.com/watch?v=JRcXUuQYR90) 
+在本集中,我们将探讨 Mojo 的诞生原因,以及它为 Python 程序员和非 Python 程序员提供的服务。它是如何为性能而生的,以及哪些性能特征很重要?它对函数式编程和类型系统有何看法?它能否将 Python 的高级编程与 LLVM/MLIR 的低级编程结合起来?
+
+[Django:一个管理扩展,用于防止请求之间的状态泄漏](https://adamj.eu/tech/2024/04/29/django-admin-prevent-leaking-requests/)
+这是我几年前添加到项目中的一个小保护。自从我在 Django 中间件中看到类似的潜在错误后,我再次考虑了这一点。
+
+[使用 lm-buddy、Prometheus 和 llamafile 进行本地 LLM-as-judge 评估](https://blog.mozilla.ai/local-llm-as-judge-evaluation-with-lm-buddy-prometheus-and-llamafile)
+这篇文章探讨了如何将不同的软件组件组合在一起,以允许 LLM-as-judge 评估而不需要昂贵的 GPU。所有组件都是根据其用户控制、开源性质和互操作性来构建和选择的。
+
+[如何使用矢量搜索构建水晶图像搜索应用程序](https://www.datastax.com/blog/building-a-generative-ai-crystal-image-search-app-with-vector-search)
+演示如何使用 Astra DB 构建应用程序来存储和查询水晶和宝石数据。该 Web 应用程序使用 RAGStack 构建,利用 CLIP 模型提供多模式搜索,从而检索各种晶体的数据。
+
+[linux 上的单个python文件即可实现的“穷人式”自动重新加载服务器Poor mans autoreload server in single file python on linux](https://hereket.com/posts/linux_live_reload_python_server/)
+本文描述了一个简单的 Python 服务器,它可以在内容更改时自动重新加载浏览器页面,而不需要任何额外的设置或配置。服务器充当常规文件服务器,但也可以通过指定路径提供 WebSocket 消息以触发页面重新加载。
+
+[矢量嵌入的初学者指南](https://www.timescale.com/blog/a-beginners-guide-to-vector-embeddings/)
+在本文中,我们将深入研究矢量嵌入,包括矢量嵌入的类型、神经网络如何创建它们、矢量嵌入的工作方式以及如何为数据创建嵌入。
+
+[如何防止 pandas 和 scikit-learn 中的数据泄漏](https://www.dataschool.io/machine-learning-data-leakage/)
+什么是数据泄漏,为什么会出现这样的问题,以及在 Python 中处理有监督机器学习问题时如何防止数据泄漏?
+
+[修补请求以获得乐趣和(并发)利润](https://blog.borrego.dev/entries/patching-requests-for-fun-and-concurrent-profit.html)
+因为人生苦短,无法向 SSL_CTX_load_verify_locations() 发送垃圾邮件调用。
+
+[Sleepsort:睡眠时排序](https://animeshchouhan.com/posts/sleepsort)
+这篇文章介绍了“sleepsort”算法,这是一种奇怪的排序方法,它利用线程睡眠时间,按升序对整数进行排序。它对算法的功能和局限性进行了有趣且富有洞察力的探索。
+
+[流式传输您的声音克隆](https://www.photondesigner.com/articles/voice-api)
+我们将使用 Django,将您的声音变成无限可扩展的乐器。
+
+[Python 中的异步协程对象方法](https://superfastpython.com/asyncio-coroutine-methods/)
+我们可以在自定义 Python 对象上定义协程方法。这允许自定义 Python 对象上的方法使用 async/await 语法,例如,等待其他协程和任务,并允许在我们的 asyncio 程序中等待自定义协程方法本身。在本教程中,您将了解将对象方法定义为协程的方法。
+
+[TypeIs 做了那些我认为 TypeGuard 在 Python 中会做的事儿](https://rednafi.com/python/typeguard_vs_typeis/)
+本文讨论了 Python 中 TypeGuard 和 TypeIs 类型注释之间的差异。它解释了与 TypeGuard 相比,TypeIs 具有更直观的行为,特别是在处理联合类型时,并建议在大多数情况下使用 TypeIs 而不是 TypeGuard。
+
+
+# 好玩的项目,工具和库
+
+[WebLlama](https://github.com/McGill-NLP/webllama)
+Llama-3 代理,可以通过遵循说明并与您交谈来浏览网络。
+
+[LLaMA-Factory](https://github.com/hiyouga/LLaMA-Factory)
+统一对 100 多个 LLM 进行高效微调。
+
+[tkforge](https://github.com/Axorax/tkforge)
+在 Figma 中拖放即可轻松创建 Python GUI。
+
+[TagStudio](https://github.com/TagStudioDev/TagStudio)
+一个文件和照片管理应用程序和系统。
+
+[torchtitan](https://github.com/pytorch/torchtitan)
+用于大型模型训练的原生 PyTorch 库。
+
+[LMDeploy](https://github.com/InternLM/lmdeploy)
+LMDeploy 是一个用于压缩、部署和服务 LLM 的工具包。
+
+[cohere-toolkit](https://github.com/cohere-ai/cohere-toolkit)
+Toolkit 是一个预构建组件的集合,使用户能够快速构建和部署 RAG 应用程序。
+
+[Cognita](https://github.com/truefoundry/cognita)
+RAG (Retrieval Augmented Generation,检索增强生成) 框架,用于通过 TrueFoundry 构建可用于生产的模块化开源应用。
+
+[databonsai](https://github.com/databonsai/databonsai)
+使用 LLM 清理以及管理您的数据。
+
+[tach](https://github.com/Never-Over/tach)
+一个用于实施模块化、解耦包架构的 Python 工具。
+
+
+# 近期活动和网络研讨会
+
+[Virtual: PyMNtos Python Presentation Night #125](https://www.meetup.com/pymntos-twin-cities-python-user-group/events/300536500/)
+将会有以下演讲:
+* 在 Excel 和 Power BI 中使用 Python
+* 将 Python API 部署到云
+
+[PyData NYC 2024 年 5 月聚会](https://www.meetup.com/pydatanyc/events/300430791/)
+将会有以下演讲:
+* Hopsworks 上具有特征、训练、推理管道的模块化 AI 系统 - LLMOps 教程
+* Modal 简介
+
+
+[PyData London 2024 年 5 月聚会](https://www.meetup.com/pydata-london-meetup/events/300415482/)
+将会有以下演讲:
+* 面向 Python 数据开发人员的 Microsoft Fabric
+* 沙漠岛 Docker:Python 版
+* 为什么你应该害怕 Pickle
+* 使用 Python 进行的 ASCII 艺术
+
+[PyData Manchester 2024 年 5 月聚会](https://www.meetup.com/pydata-manchester/events/300228721/)
+将会有以下演讲:
+* 利用数据科学,从智能可穿戴设备中获取个人健康的见解
+* Python 找到它的魔力了吗?机器学习和人工智能的新语言
+
+[PyData Rome 2024 年 5 月聚会](https://www.meetup.com/pydata-rome/events/300514196/)
+将会有以下演讲:
+* 计算机视觉 IRL:从想法到本地部署
+* 将地理空间数据与 Jupyter Notebook 和操作系统软件进行集成
+
diff --git a/Python Weekly/Python_Weekly_Issue_649.md b/Python Weekly/Python_Weekly_Issue_649.md
new file mode 100644
index 0000000..5eda2bd
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_649.md
@@ -0,0 +1,114 @@
+原文:[Python Weekly - Issue 649](http://eepurl.com/iPGqBA)
+
+---
+
+欢迎来到《Python周刊》第 649 期。让我们直奔主题。
+
+
+# 文章,教程和讲座
+
+[ByteWax:当 Rust 当研究遇上 Python 的实用性](https://www.youtube.com/watch?v=ZRWun2MjTEg) 
+Bytewax 是一种奇怪的流处理工具,它将 Python 表面与 Rust 核心混合在一起,产生与 Kafka Streams 或 Apache Flink 类似的东西,但实现方式截然不同。本周我们将了解它的作用、工作原理以及 Python 和 Rust 的结合在实践中如何工作。
+
+[Python Asyncio 的工作原理:从头开始重新创建它](https://jacobpadilla.com/articles/recreating-asyncio)
+通过使用 Python 生成器从头开始重新创建 asyncio 并使用 async/await 关键字的 __await__ 方法来了解 asyncio 的工作原理。
+
+
+[使用不安全的 Python 将速度提高一百倍](https://yosefk.com/blog/a-100x-speedup-with-unsafe-python.html)
+我们将使用“不安全的 Python”将一些 numpy 代码的执行速度提高 100 倍。这与不安全的 Rust 不太一样,但有点相似,我不知道还能叫它什么……你会看到的。它不是您在大多数 Python 代码中使用的东西,但有时它很方便,而且我认为它从一个有趣的角度展示了“Python 的本质”。
+
+[AsyncIO 和事件循环解释](https://www.youtube.com/watch?v=RIVcqT2OGPA) 
+多年来,我制作了好几个关于 AsyncIO 的视频。然而,今天,我将采用一种新方法,即深入解释事件循环。我将更深入异步编程,特别关注事件循环在幕后的工作原理
+
+[LLM 的工作原理(数学含量为零)](https://blog.miguelgrinberg.com/post/how-llms-work-explained-without-math)
+我认为很多人对 GenAI 革命的一个基本问题是,这些模型的明显智能从何而来呢。在本文中,我将尝试用简单的术语而不是使用高级数学来解释通用文本模型的工作原理,从而帮助您将它们视为计算机算法,而不是魔法。
+
+[会让你惊叹不已的简单交互式 Python Streamlit 地图](https://johnloewen.substack.com/p/simple-interactive-python-streamlit)
+通过来自 NASA GIS 的数据集来讲述森林火灾统计数据
+
+[掌握 Python 和 Zoom API|构建转录录音的服务器到服务器应用](https://www.youtube.com/watch?v=sQVliRl5uKw) 
+在本分步指南中了解如何通过 Python 使用 Zoom 的 API!在本教程中,您将学习如何创建强大的服务器到服务器 OAuth 应用程序,该应用程序会自动转录您的 Zoom 录音,然后将其直接打印到您的终端,并将其另存为文本文件。本教程非常适合开发人员,它将引导您从设置到执行,因此在视频结束时,您将拥有一个功能齐全的应用程序。
+
+[全同态加密的高级技术概述](https://www.jeremykun.com/2024/05/04/fhe-overview/)
+本文提供了关于全同态加密 (FHE) 的高级技术概述,这是一种功能强大的加密技术,允许对加密数据执行计算而无需先解密。它讨论了一些正在积极开发的关键 FHE 库和工具。
+
+[“请注意!”:注意力机制的视觉指南](https://codecompass00.substack.com/p/visual-guide-attention-mechanism-transformers)
+培养注意力背后的直觉:为什么它接管了机器学习+LLM,以及它实际上做了什么。
+
+
+# 好玩的项目,工具和库
+
+[gpt-home](https://github.com/judahpaul16/gpt-home)
+家里的 ChatGPT!基本上是一个更好的 Google Nest Hub 或 Amazon Alexa 家庭助理。使用 OpenAI API 在 Raspberry Pi 上构建。
+
+[Logfire](https://github.com/pydantic/logfire)
+适用于 Python 及其他领域的简单可观察性!
+
+[PgQueuer](https://github.com/janbjorge/PgQueuer)
+PgQueuer 是一个利用 PostgreSQL 实现高效作业排队的 Python 库。
+
+[relax-py](https://github.com/crpier/relax-py)
+用于 htmx 和 tailwindcss 的 Python Web 开发框架,具有热模块替换、URL 定位器、依赖项注入,由静态类型支持,构建在 Starlette 之上。
+
+[VILA](https://github.com/Efficient-Large-Model/VILA)
+一种多图像视觉语言模型,具有训练、推理和评估配方,可从云端部署到边缘(Jetson Orin 和笔记本电脑)。
+
+[prometheus-eval](https://github.com/prometheus-eval/prometheus-eval)
+使用 Prometheus 评估您的 LLM 的回应。
+
+[LlamaParse](https://github.com/run-llama/llama_parse)
+LlamaParse 是由 LlamaIndex 创建的 API,用于使用 LlamaIndex 框架高效地解析和表示文件,以实现高效检索和上下文增强。
+
+[fastapi-cli](https://github.com/tiangolo/fastapi-cli)
+使用 FastAPI CLI,从命令行运行和管理 FastAPI 应用程序。
+
+[Bytewax](https://github.com/bytewax/bytewax)
+Bytewax 是一个简化事件和流处理的 Python 框架。
+
+[django-harlequin](https://github.com/adamchainz/django-harlequin)
+使用 Django 数据库配置启动 Harlequin,终端的 SQL IDE。
+
+[LeRobot](https://github.com/huggingface/lerobot)
+适用于现实世界机器人的最先进的机器学习。
+
+[Panza](https://github.com/IST-DASLab/PanzaMail)
+个人电子邮件助理,经过训练并在设备上运行。
+
+[DrEureka](https://eureka-research.github.io/dr-eureka/)
+语言模型引导的模拟到真实的迁移。
+
+[SATO](https://sato-team.github.io/Stable-Text-to-Motion-Framework/)
+稳定的文本转动画框架。
+
+
+# 最新发布
+
+[pip 24.1 beta](https://pip.pypa.io/en/latest/news/#b1-2024-05-06)
+
+[Django 问题修复版本已发布:5.0.6 和 4.2.13](https://www.djangoproject.com/weblog/2024/may/07/bugfix-releases/)
+
+
+# 近期活动和网络研讨会
+
+[Django London 2024 年 5 月聚会](https://www.meetup.com/djangolondon/events/300467704/)
+将会有以下演讲:
+* 用于大规模协作的分层 Django 项目结构
+* 蛇中有蟹!
+
+[PyLadies Berlin 2024 年 5 月聚会](https://www.meetup.com/pyladies-berlin/events/299598103/)
+将会有以下演讲:
+* 嵌套娃娃效应:Python 中的范围
+* `GridSearchCV` 中基于收入的评分:scikit-learn 中关于新元数据路由的一个案例
+
+[PuPPy 2024 年 5 月聚会](https://www.meetup.com/psppython/events/300461407/)
+将会有一场演讲:编写 Python 的最佳语言是 Rust。
+
+[PyBerlin 2024 年 5 月聚会](https://www.meetup.com/pyberlin/events/291577883/)
+将会有以下演讲:
+* 仅使用 Python,在 Web 上部署数据项目
+* magic-di 简介:通过依赖注入器提升 Python
+
+[PyData Sudwest 2024 年 5 月聚会](https://www.meetup.com/pydata-suedwest/events/299870597/)
+将会有以下演讲:
+* Kickstart 大规模编码:项目模板自动化是如何释放开发人员的生产力的
+* Dask DataFrame 现在速度很快啦
diff --git a/Python Weekly/Python_Weekly_Issue_650.md b/Python Weekly/Python_Weekly_Issue_650.md
new file mode 100644
index 0000000..2985260
--- /dev/null
+++ b/Python Weekly/Python_Weekly_Issue_650.md
@@ -0,0 +1,100 @@
+原文:[Python Weekly - Issue 650](http://eepurl.com/iP72qw)
+
+---
+
+欢迎来到《Python周刊》第 650 期。让我们直奔主题。
+
+# 文章,教程和讲座
+
+[工作单元(Unit of Work)设计模式详解](https://www.youtube.com/watch?v=HX6vkP-QD7U) 
+该视频解释了工作单元设计模式,对于经常与数据库交互的人来说,这是一个至关重要的概念。这种模式通过累积所有事务并集中执行它们来发挥关键作用。但为什么这是必要的呢?在此视频中找出答案吧。
+
+[同像 Python](https://aljamal.substack.com/p/homoiconic-python)
+本文探讨了编程语言中的同像概念,其中代码和数据是可以互换的,如 Lisp 所示。它提供了“Lisp in Lisp”代码子集的一个 Python 实现,展示了如何通过将代码视为可以操作和执行的数据结构来使 Python 变得同像。
+
+[从头开始创建 DSPy 代理](https://learnbybuilding.ai/tutorials/dspy-agents-from-scratch)
+本文将使用 DSPy,首次从头开始创建代理。出于教育目的,以及探索如何使用 DSPy 从头开始构建代理。
+
+[滥用实际上是 Python 表达式的 Conda YAML 注释](https://astrid.tech/2024/02/24/0/conda-recipe-selector-abuse/)
+我最喜欢的构建系统 jinja-preprocessed-eval-preprocessed YAML
+
+[用 Mojo 解析 PNG 图像](https://fnands.com/blog/2024/mojo-png-parsing/)
+这篇文章详细介绍了作者使用 Mojo 编程语言实现 PNG 解析器的经验。它涵盖了所面临的挑战,例如处理无符号 8 位整数,以及将字节转换为字符串,同时探索为此任务编写 Mojo 代码的惯用方法。
+
+[Tezos 区块链开发人员课程 – Python Web3 开发](https://www.youtube.com/watch?v=pHQfw1W7V8s) 
+了解如何在 Tezos 上开发分布式应用程序,从设置钱包到有效理解和管理智能合约。该课程涵盖了 Tezos 开发人员必需的各种工具和技术,并重点介绍了支持平台发展的社区驱动创新。
+
+[高影响力 Python Streamlit:漂亮的交互式地图和图表](https://johnloewen.substack.com/p/high-impact-python-streamlit-beautiful)
+一种逐步模块化方法,采用 UNFAO 全球粮食不安全数据。
+
+[如何将 Postgres 用作 Django 的简单任务队列](https://www.youtube.com/watch?v=kNGOcI_qqYo) 
+将 Postgres 当作 Django 的任务队列是可以快速添加的。与传统方法(例如 Celery 和 Redis)相比,还有其他很大的优势。
+
+[简介:使用 Python 和 Loguru 进行日志记录](https://www.blog.pythonlibrary.org/2024/05/15/an-intro-to-logging-with-python-and-loguru/)
+Python 的日志记录模块并不是创建日志的唯一方法。您还可以使用几个第三方包。最受欢迎的包之一是 Loguru。 Loguru 打算删除使用 Python 日志记录 API 获得的所有样板文件。您会发现,Loguru 极大地简化了在 Python 中创建日志的过程。
+
+[重塑 Python notebook 的经验教训](https://marimo.io/blog/lessons-learned)
+本文讨论了开发 marimo(一个新的 Python 笔记本环境)时的关键原则和经验教训。它强调忠于项目的可重复性、可维护性和多用途设计的核心支柱,即使面临可能损害这些原则的功能需求。
+
+[实时脑电波可视化:将 Muse EEG 与 Python 集成](https://ai9.notion.site/Real-Time-Brainwave-Visualization-Integrating-Muse-EEG-with-Python-54391bc09bf04b95a117d0fcf41ba351)
+
+[Django:根据子查询获取完整等模型实例](https://blog.bmispelon.rocks/articles/2024/2024-05-09-django-getting-a-full-model-instance-from-a-subquery.html)
+
+
+# 好玩的项目,工具和库
+
+[storm](https://github.com/stanford-oval/storm)
+一个由 LLM 驱动的知识管理系统,用于研究主题并生成带有引文的完整报告。
+
+[Frame](https://github.com/frame-lang/frame_transpiler)
+Frame 是一种 Markdown 语言,用于在 Python 中创建状态机(自动机)以及生成 UML 文档。
+
+[Pipecat](https://github.com/pipecat-ai/pipecat)
+用于语音和多模式会话 AI 的开源框架。
+
+[UXsim](https://github.com/toruseo/UXsim)
+道路网络中的车辆交通流模拟器,纯Python编写。
+
+[itrm](https://gitlab.com/davidwoodburn/itrm)
+该库提供了多个函数,可以将数据很好地打印到终端。
+
+[drf-api-action](https://github.com/Ori-Roza/drf-api-action)
+利用 action_api 夹具提升了 Django Rest Framework 的测试,将 REST 端点测试简化为无缝、类似函数的体验。
+
+[TimesFM](https://github.com/google-research/timesfm)
+TimesFM(时间序列基础模型)是 Google Research 开发的用于时间序列预测的预训练时间序列基础模型。
+
+[MindNLP](https://github.com/mindspore-lab/mindnlp)
+基于MindSpore的易于使用的高性能NLP和LLM框架,兼容Huggingface的模型和数据集。
+
+[llmware](https://github.com/llmware-ai/llmware)
+提供企业级基于LLM的开发框架、工具和微调模型。
+
+
+# 近期活动和网络研讨会
+
+[Hybrid: PyMunich 2024 年 5 月聚会](https://www.meetup.com/pymunich/events/299650733/)
+将会有以下演讲:
+* 利用 Streamlit 成为数据故事讲述者
+* 自动发布技术文档(Git-to-Confluence)
+* 融合视角:为当今项目中的不同团队编写干净的 Python 代码
+
+[PyLadies Paris 2024 年 5 月聚会](https://www.meetup.com/pyladiesparis/events/300641629/)
+将有一场演讲:从 ML 模型调试到机器人检测 - Sliceline 的故事。
+
+[Python Barcelona 2024 年 5 月聚会](https://www.meetup.com/python-barcelona/events/300940146/)
+将会有以下演讲:
+* 在 AI 中使用 OpenCV:Python 中的实用图像处理
+* cluster-experiments,一个用于设计 AB 测试的模拟库
+
+
+[BAyPIGgies 2024 年 5 月聚会](https://www.meetup.com/baypiggies/events/300647354/)
+将会有以下演讲:
+* 使用 Pandas 和 Pyspark 对仪器数据进行时间序列处理。
+* 使用 Reflex 开发全栈 Python Web 应用程序
+
+
+[PyData Berlin 2024 年 5 月聚会](https://www.meetup.com/pydata-berlin/events/300633031/)
+将会有以下演讲:
+* 超越连续体:深度学习中量化的重要性
+* 思想碰撞
\ No newline at end of file
diff --git a/Python Weekly/README.md b/Python Weekly/README.md
index 239bc67..5bf1385 100644
--- a/Python Weekly/README.md
+++ b/Python Weekly/README.md
@@ -2,27 +2,172 @@
本目录是Python Weekly的中译版,从Issue 243开始。
-- [Issue 243](./Python Weekly Issue 243.md)
-- [Issue 244](./Python Weekly Issue 244.md)
-- [Issue 245](./Python Weekly Issue 245.md)
-- [Issue 246](./Python Weekly Issue 246.md)
-- [Issue 247](./Python Weekly Issue 247.md)
-- [Issue 248](./Python Weekly Issue 248.md)
-- [Issue 249](./Python Weekly Issue 249.md)
-- [Issue 250](./Python Weekly Issue 250.md)
-- [Issue 251](./Python Weekly Issue 251.md)
-- [Issue 252](./Python Weekly Issue 252.md)
-- [Issue 253](./Python Weekly Issue 253.md)
-- [Issue 254](./Python Weekly Issue 254.md)
-- [Issue 255](./Python Weekly Issue 255.md)
-- [Issue 256](./Python Weekly Issue 256.md)
-- [Issue 257](./Python Weekly Issue 257.md)
-- [Issue 258](./Python Weekly Issue 258.md)
-- [Issue 259](./Python Weekly Issue 259.md)
-- [Issue 260](./Python Weekly Issue 260.md)
-- [Issue 261](./Python Weekly Issue 261.md)
-- [Issue 262](./Python Weekly Issue 262.md)
-- [Issue 263](./Python Weekly Issue 263.md)
-- [Issue 264](./Python Weekly Issue 264.md)
-- [Issue 265](./Python Weekly Issue 265.md)
-- [Issue 266](./Python Weekly Issue 266.md)
+- [Issue 650](./Python_Weekly_Issue_650.md)
+- [Issue 649](./Python_Weekly_Issue_649.md)
+- [Issue 648](./Python_Weekly_Issue_648.md)
+- [Issue 647](./Python_Weekly_Issue_647.md)
+- [Issue 646](./Python_Weekly_Issue_646.md)
+- [Issue 645](./Python_Weekly_Issue_645.md)
+- [Issue 644](./Python_Weekly_Issue_644.md)
+- [Issue 643](./Python_Weekly_Issue_643.md)
+- [Issue 642](./Python_Weekly_Issue_642.md)
+- [Issue 641](./Python_Weekly_Issue_641.md)
+- [Issue 640](./Python_Weekly_Issue_640.md)
+- [Issue 639](./Python_Weekly_Issue_639.md)
+- [Issue 638](./Python_Weekly_Issue_638.md)
+- [Issue 637](./Python_Weekly_Issue_637.md)
+- [Issue 636](./Python_Weekly_Issue_636.md)
+- [Issue 635](./Python_Weekly_Issue_635.md)
+- [Issue 634](./Python_Weekly_Issue_634.md)
+- [Issue 633](./Python_Weekly_Issue_633.md)
+- [Issue 632](./Python_Weekly_Issue_632.md)
+- [Issue 631](./Python_Weekly_Issue_631.md)
+- [Issue 630](./Python_Weekly_Issue_630.md)
+- [Issue 629](./Python_Weekly_Issue_629.md)
+- [Issue 628](./Python_Weekly_Issue_628.md)
+- [Issue 627](./Python_Weekly_Issue_627.md)
+- [Issue 626](./Python_Weekly_Issue_626.md)
+- [Issue 625](./Python_Weekly_Issue_625.md)
+- [Issue 624](./Python_Weekly_Issue_624.md)
+- [Issue 623](./Python_Weekly_Issue_623.md)
+- [Issue 622](./Python_Weekly_Issue_622.md)
+- [Issue 621](./Python_Weekly_Issue_621.md)
+- [Issue 620](./Python_Weekly_Issue_620.md)
+- [Issue 619](./Python_Weekly_Issue_619.md)
+- [Issue 618](./Python_Weekly_Issue_618.md)
+- [Issue 617](./Python_Weekly_Issue_617.md)
+- [Issue 386](./Python_Weekly_Issue_386.md)
+- [Issue 385](./Python_Weekly_Issue_385.md)
+- [Issue 384](./Python_Weekly_Issue_384.md)
+- [Issue 383](./Python_Weekly_Issue_383.md)
+- [Issue 381](./Python_Weekly_Issue_381.md)
+- [Issue 380](./Python_Weekly_Issue_380.md)
+- [Issue 379](./Python_Weekly_Issue_379.md)
+- [Issue 378](./Python_Weekly_Issue_378.md)
+- [Issue 377](./Python_Weekly_Issue_377.md)
+- [Issue 376](./Python_Weekly_Issue_376.md)
+- [Issue 375](./Python_Weekly_Issue_375.md)
+- [Issue 374](./Python_Weekly_Issue_374.md)
+- [Issue 365](./Python_Weekly_Issue_365.md)
+- [Issue 364](./Python_Weekly_Issue_364.md)
+- [Issue 363](./Python_Weekly_Issue_363.md)
+- [Issue 362](./Python_Weekly_Issue_362.md)
+- [Issue 361](./Python_Weekly_Issue_361.md)
+- [Issue 360](./Python_Weekly_Issue_360.md)
+- [Issue 359](./Python_Weekly_Issue_359.md)
+- [Issue 358](./Python_Weekly_Issue_358.md)
+- [Issue 357](./Python_Weekly_Issue_357.md)
+- [Issue 356](./Python_Weekly_Issue_356.md)
+- [Issue 355](./Python_Weekly_Issue_355.md)
+- [Issue 354](./Python_Weekly_Issue_354.md)
+- [Issue 353](./Python_Weekly_Issue_353.md)
+- [Issue 352](./Python_Weekly_Issue_352.md)
+- [Issue 351](./Python_Weekly_Issue_351.md)
+- [Issue 350](./Python_Weekly_Issue_350.md)
+- [Issue 349](./Python_Weekly_Issue_349.md)
+- [Issue 348](./Python_Weekly_Issue_348.md)
+- [Issue 347](./Python_Weekly_Issue_347.md)
+- [Issue 346](./Python_Weekly_Issue_346.md)
+- [Issue 345](./Python_Weekly_Issue_345.md)
+- [Issue 344](./Python_Weekly_Issue_344.md)
+- [Issue 343](./Python_Weekly_Issue_343.md)
+- [Issue 342](./Python_Weekly_Issue_342.md)
+- [Issue 341](./Python_Weekly_Issue_341.md)
+- [Issue 340](./Python_Weekly_Issue_340.md)
+- [Issue 339](./Python_Weekly_Issue_339.md)
+- [Issue 338](./Python_Weekly_Issue_338.md)
+- [Issue 337](./Python_Weekly_Issue_337.md)
+- [Issue 336](./Python_Weekly_Issue_336.md)
+- [Issue 335](./Python_Weekly_Issue_335.md)
+- [Issue 334](./Python_Weekly_Issue_334.md)
+- [Issue 333](./Python_Weekly_Issue_333.md)
+- [Issue 332](./Python_Weekly_Issue_332.md)
+- [Issue 331](./Python_Weekly_Issue_331.md)
+- [Issue 330](./Python_Weekly_Issue_330.md)
+- [Issue 329](./Python_Weekly_Issue_329.md)
+- [Issue 328](./Python_Weekly_Issue_328.md)
+- [Issue 327](./Python_Weekly_Issue_327.md)
+- [Issue 326](./Python_Weekly_Issue_326.md)
+- [Issue 325](./Python_Weekly_Issue_325.md)
+- [Issue 324](./Python_Weekly_Issue_324.md)
+- [Issue 323](./Python_Weekly_Issue_323.md)
+- [Issue 322](./Python_Weekly_Issue_322.md)
+- [Issue 321](./Python_Weekly_Issue_321.md)
+- [Issue 320](./Python_Weekly_Issue_320.md)
+- [Issue 319](./Python_Weekly_Issue_319.md)
+- [Issue 318](./Python_Weekly_Issue_318.md)
+- [Issue 317](./Python_Weekly_Issue_317.md)
+- [Issue 316](./Python_Weekly_Issue_316.md)
+- [Issue 315](./Python_Weekly_Issue_315.md)
+- [Issue 314](./Python_Weekly_Issue_314.md)
+- [Issue 313](./Python_Weekly_Issue_313.md)
+- [Issue 312](./Python_Weekly_Issue_312.md)
+- [Issue 311](./Python_Weekly_Issue_311.md)
+- [Issue 310](./Python_Weekly_Issue_310.md)
+- [Issue 309](./Python_Weekly_Issue_309.md)
+- [Issue 308](./Python_Weekly_Issue_308.md)
+- [Issue 307](./Python_Weekly_Issue_307.md)
+- [Issue 306](./Python_Weekly_Issue_306.md)
+- [Issue 305](./Python_Weekly_Issue_305.md)
+- [Issue 304](./Python_Weekly_Issue_304.md)
+- [Issue 303](./Python_Weekly_Issue_303.md)
+- [Issue 302](./Python_Weekly_Issue_302.md)
+- [Issue 301](./Python_Weekly_Issue_301.md)
+- [Issue 300](./Python_Weekly_Issue_300.md)
+- [Issue 299](./Python_Weekly_Issue_299.md)
+- [Issue 298](./Python_Weekly_Issue_298.md)
+- [Issue 297](./Python_Weekly_Issue_297.md)
+- [Issue 296](./Python_Weekly_Issue_296.md)
+- [Issue 295](./Python_Weekly_Issue_295.md)
+- [Issue 294](./Python_Weekly_Issue_294.md)
+- [Issue 293](./Python_Weekly_Issue_293.md)
+- [Issue 292](./Python_Weekly_Issue_292.md)
+- [Issue 291](./Python_Weekly_Issue_291.md)
+- [Issue 290](./Python_Weekly_Issue_290.md)
+- [Issue 289](./Python_Weekly_Issue_289.md)
+- [Issue 288](./Python_Weekly_Issue_288.md)
+- [Issue 287](./Python_Weekly_Issue_287.md)
+- [Issue 286](./Python_Weekly_Issue_286.md)
+- [Issue 285](./Python_Weekly_Issue_285.md)
+- [Issue 284](./Python_Weekly_Issue_284.md)
+- [Issue 283](./Python_Weekly_Issue_283.md)
+- [Issue 282](./Python_Weekly_Issue_282.md)
+- [Issue 281](./Python_Weekly_Issue_281.md)
+- [Issue 280](./Python_Weekly_Issue_280.md)
+- [Issue 279](./Python_Weekly_Issue_279.md)
+- [Issue 278](./Python_Weekly_Issue_278.md)
+- [Issue 277](./Python_Weekly_Issue_277.md)
+- [Issue 276](./Python_Weekly_Issue_276.md)
+- [Issue 275](./Python_Weekly_Issue_275.md)
+- [Issue 274](./Python_Weekly_Issue_274.md)
+- [Issue 273](./Python_Weekly_Issue_273.md)
+- [Issue 272](./Python_Weekly_Issue_272.md)
+- [Issue 271](./Python_Weekly_Issue_271.md)
+- [Issue 270](./Python_Weekly_Issue_270.md)
+- [Issue 269](./Python_Weekly_Issue_269.md)
+- [Issue 268](./Python_Weekly_Issue_268.md)
+- [Issue 267](./Python_Weekly_Issue_267.md)
+- [Issue 266](./Python_Weekly_Issue_266.md)
+- [Issue 265](./Python_Weekly_Issue_265.md)
+- [Issue 264](./Python_Weekly_Issue_264.md)
+- [Issue 263](./Python_Weekly_Issue_263.md)
+- [Issue 262](./Python_Weekly_Issue_262.md)
+- [Issue 261](./Python_Weekly_Issue_261.md)
+- [Issue 260](./Python_Weekly_Issue_260.md)
+- [Issue 259](./Python_Weekly_Issue_259.md)
+- [Issue 258](./Python_Weekly_Issue_258.md)
+- [Issue 257](./Python_Weekly_Issue_257.md)
+- [Issue 256](./Python_Weekly_Issue_256.md)
+- [Issue 255](./Python_Weekly_Issue_255.md)
+- [Issue 254](./Python_Weekly_Issue_254.md)
+- [Issue 253](./Python_Weekly_Issue_253.md)
+- [Issue 252](./Python_Weekly_Issue_252.md)
+- [Issue 251](./Python_Weekly_Issue_251.md)
+- [Issue 250](./Python_Weekly_Issue_250.md)
+- [Issue 249](./Python_Weekly_Issue_249.md)
+- [Issue 248](./Python_Weekly_Issue_248.md)
+- [Issue 247](./Python_Weekly_Issue_247.md)
+- [Issue 246](./Python_Weekly_Issue_246.md)
+- [Issue 245](./Python_Weekly_Issue_245.md)
+- [Issue 244](./Python_Weekly_Issue_244.md)
+- [Issue 243](./Python_Weekly_Issue_243.md)
\ No newline at end of file
diff --git a/README.md b/README.md
index 49fbb83..5a1f289 100644
--- a/README.md
+++ b/README.md
@@ -1,7 +1,9 @@
-# pythondocument
+# Python Document
translate python documents to Chinese for convenient reference
简而言之,这里用来存放那些Python文档君们,并且尽力将其翻译成中文~~
+gitbook地址:[Python Chinese documents](https://ictar.gitbooks.io/python-doc-zh/)
+
# 说明
1. 能在网上找到现成的当然是最好啦,这类型的文档,会直接提供链接,用[中文版](#)这种形式给出。
2. 如果不能找到,会给出自己翻的中文版本。
@@ -10,11 +12,11 @@ translate python documents to Chinese for convenient reference
欢迎抓虫~~
# 目录说明
-- [Python Common](./Python Common/) python 常规文档
+- [Python Common](./Python%20Common 'python 常规文档') python 常规文档
## Web框架
-- [Django](./Django) Django 相关文档
-- [Flask](./Flask) Flask相关文档
+- [Django](./Web/Django) Django 相关文档
+- [Flask](./Web/Flask) Flask相关文档
## web爬取
- [Scrapy](./Scrapy) Scrapy相关文档
@@ -31,22 +33,22 @@ translate python documents to Chinese for convenient reference
- [Hardware](./Hardware) 硬件相关,物联网,无人机等……
## 科学计算和数据分析
-- [Science and Data Analysis](./Science and Data Analysis)
+- [Science and Data Analysis](./Science%20and%20Data%20Analysis 'Science and Data Analysis')
## 自然语言处理
- [NLP](./NLP)
## 机器学习
-- [Machine Learning](./Machine Learning)
+- [Machine Learning](./Machine%20Learning 'Machine Learning')
## 函数式编程
-- [Functional Programming](./Functional Programming)
+- [Functional Programming](./Functional%20Programming 'Functional Programming')
## 图像处理
-- [Image Processing](./Image Processing)
+- [Image Processing](./Image%20Processing 'Image Processing')
## 资源
-- [Python Weekly](./Python Weekly)
+- [Python Weekly](./Python%20Weekly 'Python Weekly')
- Pycoder's Weekly
* 中文版:[蟒周刊](http://weekly.pychina.org/)
@@ -67,3 +69,9 @@ translate python documents to Chinese for convenient reference
# 贡献者
- [lujun9972](https://github.com/lujun9972)
+
+# 捐赠
+如果你觉得这个项目对你有帮助,那就请我喝杯东西吧  +
+---
+[](https://star-history.com/?utm_source=bestxtools.com#ictar/python-doc&Date)
diff --git a/SUMMARY.md b/SUMMARY.md
new file mode 100644
index 0000000..3c94f98
--- /dev/null
+++ b/SUMMARY.md
@@ -0,0 +1,158 @@
+# Summary
+
+* [介绍](README.md)
+
+## Python语言相关
+- [Python Common](./Python Common/README.md)
+ - [3.5.1](./Python Common/3.5.1/README.md)
+ - [What's New in Python xx](./Python Common/What's New in Python xx/README.md)
+ - [New In Python:变量注解语法](./Python Common/What's New in Python xx/New In Python:变量注解语法.md)
+ - [New in Python:数字字面量中的下划线](./Python Common/What's New in Python xx/New in Python:数字字面量中的下划线.md)
+ - [Python 2和3中的异常泄漏](./Python Common/Python 2和3中的异常泄漏.md)
+ - [为什么存在Python 3](./Python Common/为什么存在Python 3.md)
+ - [Python async-await教程](./Python Common/Python async-await教程.md)
+ - [hasattr()是有害的](./Python Common/hasattr()是有害的.md)
+ - [异常 - 原力的黑暗面](./Python Common/异常 - 原力的黑暗面.md)
+ - [Python Cookbook 3rd Edition Documentation(中文版)](http://python3-cookbook.readthedocs.org/zh_CN/latest/index.html)
+ - [什么是stackless](./Python Common/什么是stackless.md)
+ - [2016年的Python 3](./Python Common/2016年的Python 3.md)
+ - [合并Python中的字典的惯用方法](./Python Common/合并Python中的字典的惯用方法.md)
+ - [惯用Python:推导](./Python Common/惯用Python:推导.md)
+ - [在Python 3中比较类型](./Python Common/在Python 3中比较类型.md)
+ - [Python 201 – 什么是双端队列(deque)](./Python Common/Python 201 – 什么是双端队列(deque).md)
+ - [高级asyncio测试](./Python Common/高级asyncio测试.md)
+ - [惯用Python:布尔表达式](./Python Common/惯用Python:布尔表达式.md)
+ - [base64-使用ASCII编码二进制数据](./Python Common/base64-使用ASCII编码二进制数据.md)
+ - [Lists和Tuples大对决](./Python Common/Lists和Tuples大对决.md)
+ - [解释python中的*args和**kwargs](./Python Common/解释python中的*args和**kwargs.md)
+ - [深度探索Python:让我们审查dict模块](./Python Common/深度探索Python:让我们审查dict模块.md)
+ - [不可不知的一点Python陷阱](./Python Common/不可不知的一点Python陷阱.md)
+ - [Python:声明动态属性](./Python Common/Python:声明动态属性.md)
+ - [了解Python类实例化](./Python Common/了解Python类实例化.md)
+ - [Python中的assert语句](./Python Common/Python中的assert语句.md)
+ - [Python新增的secrets模块](./Python Common/Python新增的secrets模块.md)
+ - [Python中的lambda表达式](./Python Common/Python中的lambda表达式.md)
+ - [我是如何修复 Python 3.7 中一个非常老的 GIL 竞争条件的](./Python Common/python37-gil-change.md)
+## Web框架
+- [Django](./Django/README.md)
+ - [1.9](./Django/1.9/README.md) Django 1.9版本官方文档
+ - [使用Django进行原型化](./Django/使用Django进行原型化.md)
+ - [使用Kubernetes使Django应用变得可扩展并具有弹性](./Django/使用Kubernetes使Django应用变得可扩展并具有弹性.md)
+ - [Django, ELB健康检查和持续交付](./Django/Django, ELB健康检查和持续交付.md)
+ - [带django教程的Facebook聊天机器人,又名笑话机器人](./Django/带django教程的Facebook聊天机器人,又名笑话机器人.md)
+ - [在Django中,如何为提高页面加载速度优化图像](./Django/在Django中,如何为提高页面加载速度优化图像.md)
+ - [Django Channels和Celery示例](./Django/Django Channels和Celery示例.md)
+ - [如何扩展Django User模型](./Django/如何扩展Django User模型.md)
+ - [Django中正确处理数据库并发的方法](./Django/Django中正确处理数据库并发的方法.md)
+
+- [Flask](./Flask/README.md)
+
+## web爬取
+- [Scrapy](./Scrapy/README.md)
+ - [Scrapinghub的Scrapy技巧系列](./Scrapy/Scrapinghub的Scrapy技巧系列/README.md)
+ - [跟着高手学习Scrapy技巧:第一部分](./Scrapy/Scrapinghub的Scrapy技巧系列/跟着高手学习Scrapy技巧:第一部分.md)
+ - [Scrapy技巧:2016年三月版](./Scrapy/Scrapinghub的Scrapy技巧系列/Scrapy技巧:2016年三月版.md)
+ - [Scrapy技巧:2016年四月版](./Scrapy/Scrapinghub的Scrapy技巧系列/Scrapy技巧:2016年四月版.md)
+ - [Scrapy技巧:2016年五月版](./Scrapy/Scrapinghub的Scrapy技巧系列/Scrapy技巧:2016年五月版.md)
+ - [Scrapy技巧:2016年六月版](./Scrapy/Scrapinghub的Scrapy技巧系列/Scrapy技巧:2016年六月版.md)
+ - [Scrapy技巧:2016年七月版](./Scrapy/Scrapinghub的Scrapy技巧系列/Scrapy技巧:2016年七月版.md)
+## DevOps工具
+- Fabric: [中文版](http://fabric-chs.readthedocs.org/zh_CN/chs/) | [英文版](http://docs.fabfile.org/en/1.11/index.html)
+
+- [Glances](https://github.com/nicolargo/glances):[中文版](http://glances-zh.readthedocs.io/en/latest/) | [英文版](https://glances.readthedocs.io/en/latest/)
+
+## 测试
+- [Testing](./Testing/README.md)
+ - [Python Mock:简单介绍 —— 第一部分](./Testing/Python Mock:简单介绍 —— 第一部分.md)
+ - [在Python中使用Behave来开始行为测试](./Testing/在Python中使用Behave来开始行为测试.md)
+ - [基于属性的测试,hypothesis以及查找bug](./Testing/基于属性的测试,hypothesis以及查找bug.md)
+
+## 硬件
+- [Hardware](./Hardware/README.md)
+ - 用Python玩转Worcester Wave恒温器
+ * [第一部分](./Hardware/用Python玩转Worcester Wave恒温器-第一部分.md)
+ * [第二部分](./Hardware/用Python玩转Worcester Wave恒温器-第二部分.md)
+ * [第三部分](./Hardware/用Python玩转Worcester Wave恒温器-第三部分.md)
+ - [使用Python构建一个(半)自动无人机](./Hardware/使用Python构建一个(半)自动无人机.md)
+ - [旅程中带着Ipad Pro和Raspberry Pi备份照片](./Hardware/旅程中带着Ipad Pro和Raspberry Pi备份照片.md)
+
+## 科学计算和数据分析
+- [Science and Data Analysis](./Science and Data Analysis/README.md)
+ - [如何使用Python和Pandas处理大量的JSON数据集](./Science and Data Analysis/如何使用Python和Pandas处理大量的JSON数据集.md)
+ - [新闻标题分析](./Science and Data Analysis/新闻标题分析.md)
+ - [使用矩阵分解找到相似歌曲](./Science and Data Analysis/使用矩阵分解找到相似歌曲.md)
+ - [Python中的并行处理](./Science and Data Analysis/Python中的并行处理.md)
+ - [Matplotlib教程 - 绘制提到Trump, Clinton & Sanders的推特](./Science and Data Analysis/Matplotlib教程 - 绘制提到Trump, Clinton & Sanders的推特.md)
+ - [使用Pandas, Docker和OS(R)M来猜测神秘的旅行地](./Science and Data Analysis/使用Pandas, Docker和OS(R)M来猜测神秘的旅行地.md)
+ - [使用BigQuery和TensorFlow进行需求预测](./Science and Data Analysis/使用BigQuery和TensorFlow进行需求预测.md)
+ - [Python中一个简单的基于内容的推荐引擎](./Science and Data Analysis/Python中一个简单的基于内容的推荐引擎.md)
+ - [在Python中实现你自己的推荐系统](./Science and Data Analysis/在Python中实现你自己的推荐系统.md)
+ - [分析权力游戏图表](./Science and Data Analysis/分析权力游戏图表.md)
+ - [使用Python探索NFL选秀](./Science and Data Analysis/使用Python探索NFL选秀.md)
+ - [用于格式化和数据清理的便捷Python库](./Science and Data Analysis/用于格式化和数据清理的便捷Python库.md)
+ - [分析iPhone步数数据](./Science and Data Analysis/分析iPhone步数数据.md)
+ - [使用Python,分析23AndMe数据,获取遗传起源](./Science and Data Analysis/使用Python,分析23AndMe数据,获取遗传起源.md)
+ - [用Python进行股票市场数据分析概述 (第一部分)](./Science and Data Analysis/用Python进行股票市场数据分析概述 (第一部分).md)
+
+## 自然语言处理
+- [NLP](./NLP/README.md)
+ - [003构建一个播客推荐算法](./NLP/003构建一个播客推荐算法.md)
+
+## 机器学习
+- [Machine Learning](./Machine Learning/README.md)
+ - [使用非常少的数据构建强大的图像分类模型](./Machine Learning/使用非常少的数据构建强大的图像分类模型.md)
+ - [在有限预算上计算最佳公路旅行](./Machine Learning/在有限预算上计算最佳公路旅行.md)
+ - [对超过1M的酒店点评进行机器学习,发现有趣的见解](./Machine Learning/对超过1M的酒店点评进行机器学习,发现有趣的见解.md)
+ - [Python,机器学习和语言之争](./Machine Learning/Python,机器学习和语言之争.md)
+ - [使用预测算法追踪实时健康趋势](./Machine Learning/使用预测算法追踪实时健康趋势.md)
+
+## 函数式编程
+- [Functional Programming](./Functional Programming/README.md)
+ - Henry Kupty的函数式编程扫盲系列
+ - [函数式编程:概念,惯用语和理念](./Functional Programming/函数式编程:概念,惯用语和理念.md)
+ - [了解函数式编程背后的属性:单子(Monad)](./Functional Programming/了解函数式编程背后的属性:单子(Monad).md)
+
+## 图像处理
+- [Image Processing](./Image Processing/README.md)
+ - [压缩和增强手写笔记](./Image Processing/压缩和增强手写笔记.md)
+
+## 资源
+- [Python Weekly](./Python Weekly/README.md)
+
+## 无法归类的
+- [Others](./Others/README.md)
+ - [使用图像特征的库存图像相似性(程序是如何比我更时尚的)](./Others/程序是如何比我更时尚的.md)
+ - [如何在Python中使用Twilio Lookup API验证电话号码](./Others/如何在Python中使用Twilio Lookup API验证电话号码.md)
+ - [psutil 4.0.0以及如何获得Python中“真正的”进程内存和环境](./Others/psutil 4.0.0以及如何获得Python中“真正的”进程内存和环境.md)
+ - [Python依赖关系分析](./Others/Python依赖关系分析.md)
+ - [创造你自己的类IPython服务器](./Others/创造你自己的类IPython服务器.md)
+ - [为部署Python web应用程序构建一个更好的用户体验](./Others/为部署Python web应用程序构建一个更好的用户体验.md)
+ - [在Python中导入一个Docker容器](./Others/在Python中导入一个Docker容器.md)
+ - [好吧,你发布了一个损坏的包到PyPI上。那么你现在要怎么办?](./Others/好吧,你发布了一个损坏的包到PyPI上。那么你现在要怎么办?.md)
+ - [Python中Meta类习语的起源](./Others/Python中Meta类习语的起源.md)
+ - [复合构建器模式(Composite Builder Pattern),一个声明式编程的例子](./Others/复合构建器模式(Composite Builder Pattern),一个声明式编程的例子)
+ - [将Python用于地理空间数据处理](./Others/将Python用于地理空间数据处理.md)
+ - [使用Python和Excel进行交互式数据分析](./Others/使用Python和Excel进行交互式数据分析.md)
+ - [RPython的魔力](./Others/RPython的魔力.md)
+ - [使用gdb调试CPython进程](./Others/使用gdb调试CPython进程.md)
+ - [使用Python Newspaper构建Read It Later应用](./Others/使用Python Newspaper构建Read It Later应用.md)
+ - [Python lambda的源代码](./Others/Python lambda的源代码.md)
+ - [如何在Python中创建绿噪音](./Others/如何在Python中创建绿噪音.md)
+ - [你需要学习编写Python装饰器的五大理由](./Others/你需要学习编写Python装饰器的五大理由.md)
+ - [逆向工程我的酒店中的一个神秘的UDP流](./Others/逆向工程我的酒店中的一个神秘的UDP流.md)
+ - [记录每天数以百万计的请求以及需要采取哪些措施](./Others/记录每天数以百万计的请求以及需要采取哪些措施.md)
+ - [教程:手把手教你构建一个基本的Facebook聊天机器人](./Others/教程:手把手教你构建一个基本的Facebook聊天机器人.md)
+ - [我的自动化之旅:为人民服务的自动化](./Others/我的自动化之旅:为人民服务的自动化.md)
+ - [实用Python:EAFP VS. LBYL](./Others/实用Python:EAFP VS. LBYL.md)
+ - [使用str.encode和threads冻结你的Python](./Others/使用str.encode和threads冻结你的Python.md)
+ - [Python, GIL, 和Pyston](./Others/Python, GIL, 和Pyston.md)
+ - [我是如何构建一个Slack机器人来帮助我在San Francisco找房子的](./Others/我是如何构建一个Slack机器人来帮助我在San Francisco找房子的.md)
+ - [中断两个循环](./Others/中断两个循环.md)
+ - [一个模板引擎是如何工作的?](./Others/一个模板引擎是如何工作的?.md)
+ - [设计Pythonic API](./Others/设计Pythonic API.md)
+ - [Requests vs. urllib:它解决了什么问题?](./Others/Requests vs. urllib:它解决了什么问题?.md)
+ - [更好的Python对象序列化方法](./Others/更好的Python对象序列化方法.md)
+ - [使用列表推导式实现zip](./Others/使用列表推导式实现zip.md)
+ - [Python项目中的Makefiles](./Others/Python项目中的Makefiles.md)
+ - [婚礼规模:我是如何使用Twilio, Python和Google来自动化我的婚礼的](./Others/婚礼规模:我是如何使用Twilio, Python和Google来自动化我的婚礼的.md)
+# [小黑屋](./raw/README.md)
diff --git a/Django/1.9/README.md b/Web/Django/1.9/README.md
similarity index 100%
rename from Django/1.9/README.md
rename to Web/Django/1.9/README.md
diff --git a/Django/1.9/howto/Managing static files (e.g. images, JavaScript, CSS).md b/Web/Django/1.9/howto/Managing static files (e.g. images, JavaScript, CSS).md
similarity index 100%
rename from Django/1.9/howto/Managing static files (e.g. images, JavaScript, CSS).md
rename to Web/Django/1.9/howto/Managing static files (e.g. images, JavaScript, CSS).md
diff --git "a/Django/1.9/howto/\344\275\277\347\224\250Django\350\276\223\345\207\272CSV.md" "b/Web/Django/1.9/howto/\344\275\277\347\224\250Django\350\276\223\345\207\272CSV.md"
similarity index 100%
rename from "Django/1.9/howto/\344\275\277\347\224\250Django\350\276\223\345\207\272CSV.md"
rename to "Web/Django/1.9/howto/\344\275\277\347\224\250Django\350\276\223\345\207\272CSV.md"
diff --git "a/Django/1.9/howto/\344\275\277\347\224\250Django\350\276\223\345\207\272PDF.md" "b/Web/Django/1.9/howto/\344\275\277\347\224\250Django\350\276\223\345\207\272PDF.md"
similarity index 100%
rename from "Django/1.9/howto/\344\275\277\347\224\250Django\350\276\223\345\207\272PDF.md"
rename to "Web/Django/1.9/howto/\344\275\277\347\224\250Django\350\276\223\345\207\272PDF.md"
diff --git "a/Django/1.9/howto/\345\246\202\344\275\225\344\275\277\347\224\250WSGI\350\277\233\350\241\214\351\203\250\347\275\262.md" "b/Web/Django/1.9/howto/\345\246\202\344\275\225\344\275\277\347\224\250WSGI\350\277\233\350\241\214\351\203\250\347\275\262.md"
similarity index 100%
rename from "Django/1.9/howto/\345\246\202\344\275\225\344\275\277\347\224\250WSGI\350\277\233\350\241\214\351\203\250\347\275\262.md"
rename to "Web/Django/1.9/howto/\345\246\202\344\275\225\344\275\277\347\224\250WSGI\350\277\233\350\241\214\351\203\250\347\275\262.md"
diff --git "a/Django/1.9/howto/\351\203\250\347\275\262Django.md" "b/Web/Django/1.9/howto/\351\203\250\347\275\262Django.md"
similarity index 100%
rename from "Django/1.9/howto/\351\203\250\347\275\262Django.md"
rename to "Web/Django/1.9/howto/\351\203\250\347\275\262Django.md"
diff --git "a/Django/1.9/misc/\350\256\276\350\256\241\347\220\206\345\277\265.md" "b/Web/Django/1.9/misc/\350\256\276\350\256\241\347\220\206\345\277\265.md"
similarity index 100%
rename from "Django/1.9/misc/\350\256\276\350\256\241\347\220\206\345\277\265.md"
rename to "Web/Django/1.9/misc/\350\256\276\350\256\241\347\220\206\345\277\265.md"
diff --git "a/Django/1.9/ref/\344\270\255\351\227\264\344\273\266.md" "b/Web/Django/1.9/ref/\344\270\255\351\227\264\344\273\266.md"
similarity index 100%
rename from "Django/1.9/ref/\344\270\255\351\227\264\344\273\266.md"
rename to "Web/Django/1.9/ref/\344\270\255\351\227\264\344\273\266.md"
diff --git "a/Django/1.9/topics/db/\346\225\260\346\215\256\345\272\223\350\256\277\351\227\256\344\274\230\345\214\226.md" "b/Web/Django/1.9/topics/db/\346\225\260\346\215\256\345\272\223\350\256\277\351\227\256\344\274\230\345\214\226.md"
similarity index 100%
rename from "Django/1.9/topics/db/\346\225\260\346\215\256\345\272\223\350\256\277\351\227\256\344\274\230\345\214\226.md"
rename to "Web/Django/1.9/topics/db/\346\225\260\346\215\256\345\272\223\350\256\277\351\227\256\344\274\230\345\214\226.md"
diff --git "a/Django/1.9/topics/db/\346\250\241\345\236\213.md" "b/Web/Django/1.9/topics/db/\346\250\241\345\236\213.md"
similarity index 100%
rename from "Django/1.9/topics/db/\346\250\241\345\236\213.md"
rename to "Web/Django/1.9/topics/db/\346\250\241\345\236\213.md"
diff --git a/Django/1.9/topics/forms/Form Assets (the Media class).md b/Web/Django/1.9/topics/forms/Form Assets (the Media class).md
similarity index 100%
rename from Django/1.9/topics/forms/Form Assets (the Media class).md
rename to Web/Django/1.9/topics/forms/Form Assets (the Media class).md
diff --git "a/Django/1.9/topics/forms/\344\275\277\347\224\250\350\241\250\345\215\225.md" "b/Web/Django/1.9/topics/forms/\344\275\277\347\224\250\350\241\250\345\215\225.md"
similarity index 100%
rename from "Django/1.9/topics/forms/\344\275\277\347\224\250\350\241\250\345\215\225.md"
rename to "Web/Django/1.9/topics/forms/\344\275\277\347\224\250\350\241\250\345\215\225.md"
diff --git a/Django/1.9/topics/http/File Uploads.md b/Web/Django/1.9/topics/http/File Uploads.md
similarity index 100%
rename from Django/1.9/topics/http/File Uploads.md
rename to Web/Django/1.9/topics/http/File Uploads.md
diff --git "a/Django/1.9/topics/http/\344\270\255\351\227\264\344\273\266.md" "b/Web/Django/1.9/topics/http/\344\270\255\351\227\264\344\273\266.md"
similarity index 100%
rename from "Django/1.9/topics/http/\344\270\255\351\227\264\344\273\266.md"
rename to "Web/Django/1.9/topics/http/\344\270\255\351\227\264\344\273\266.md"
diff --git "a/Django/1.9/topics/i18n/\345\233\275\351\231\205\345\214\226\345\222\214\346\234\254\345\234\260\345\214\226.md" "b/Web/Django/1.9/topics/i18n/\345\233\275\351\231\205\345\214\226\345\222\214\346\234\254\345\234\260\345\214\226.md"
similarity index 100%
rename from "Django/1.9/topics/i18n/\345\233\275\351\231\205\345\214\226\345\222\214\346\234\254\345\234\260\345\214\226.md"
rename to "Web/Django/1.9/topics/i18n/\345\233\275\351\231\205\345\214\226\345\222\214\346\234\254\345\234\260\345\214\226.md"
diff --git "a/Django/1.9/topics/i18n/\347\277\273\350\257\221\357\274\210\350\275\254\346\215\242\357\274\211.md" "b/Web/Django/1.9/topics/i18n/\347\277\273\350\257\221\357\274\210\350\275\254\346\215\242\357\274\211.md"
similarity index 100%
rename from "Django/1.9/topics/i18n/\347\277\273\350\257\221\357\274\210\350\275\254\346\215\242\357\274\211.md"
rename to "Web/Django/1.9/topics/i18n/\347\277\273\350\257\221\357\274\210\350\275\254\346\215\242\357\274\211.md"
diff --git "a/Django/1.9/topics/testing/\345\234\250Django\344\270\255\346\265\213\350\257\225.md" "b/Web/Django/1.9/topics/testing/\345\234\250Django\344\270\255\346\265\213\350\257\225.md"
similarity index 100%
rename from "Django/1.9/topics/testing/\345\234\250Django\344\270\255\346\265\213\350\257\225.md"
rename to "Web/Django/1.9/topics/testing/\345\234\250Django\344\270\255\346\265\213\350\257\225.md"
diff --git "a/Django/1.9/topics/testing/\347\274\226\345\206\231\345\222\214\350\277\220\350\241\214\346\265\213\350\257\225.md" "b/Web/Django/1.9/topics/testing/\347\274\226\345\206\231\345\222\214\350\277\220\350\241\214\346\265\213\350\257\225.md"
similarity index 100%
rename from "Django/1.9/topics/testing/\347\274\226\345\206\231\345\222\214\350\277\220\350\241\214\346\265\213\350\257\225.md"
rename to "Web/Django/1.9/topics/testing/\347\274\226\345\206\231\345\222\214\350\277\220\350\241\214\346\265\213\350\257\225.md"
diff --git "a/Django/1.9/topics/\346\200\247\350\203\275\345\222\214\344\274\230\345\214\226\346\246\202\350\277\260.md" "b/Web/Django/1.9/topics/\346\200\247\350\203\275\345\222\214\344\274\230\345\214\226\346\246\202\350\277\260.md"
similarity index 100%
rename from "Django/1.9/topics/\346\200\247\350\203\275\345\222\214\344\274\230\345\214\226\346\246\202\350\277\260.md"
rename to "Web/Django/1.9/topics/\346\200\247\350\203\275\345\222\214\344\274\230\345\214\226\346\246\202\350\277\260.md"
diff --git "a/Django/1.9/topics/\346\227\245\345\277\227.md" "b/Web/Django/1.9/topics/\346\227\245\345\277\227.md"
similarity index 100%
rename from "Django/1.9/topics/\346\227\245\345\277\227.md"
rename to "Web/Django/1.9/topics/\346\227\245\345\277\227.md"
diff --git "a/Django/1.9/topics/\346\250\241\346\235\277.md" "b/Web/Django/1.9/topics/\346\250\241\346\235\277.md"
similarity index 100%
rename from "Django/1.9/topics/\346\250\241\346\235\277.md"
rename to "Web/Django/1.9/topics/\346\250\241\346\235\277.md"
diff --git "a/Django/1.9/topics/\350\256\276\347\275\256.md" "b/Web/Django/1.9/topics/\350\256\276\347\275\256.md"
similarity index 100%
rename from "Django/1.9/topics/\350\256\276\347\275\256.md"
rename to "Web/Django/1.9/topics/\350\256\276\347\275\256.md"
diff --git "a/Django/Django Channels\345\222\214Celery\347\244\272\344\276\213.md" "b/Web/Django/Django Channels\345\222\214Celery\347\244\272\344\276\213.md"
similarity index 100%
rename from "Django/Django Channels\345\222\214Celery\347\244\272\344\276\213.md"
rename to "Web/Django/Django Channels\345\222\214Celery\347\244\272\344\276\213.md"
diff --git "a/Django/Django, ELB\345\201\245\345\272\267\346\243\200\346\237\245\345\222\214\346\214\201\347\273\255\344\272\244\344\273\230.md" "b/Web/Django/Django, ELB\345\201\245\345\272\267\346\243\200\346\237\245\345\222\214\346\214\201\347\273\255\344\272\244\344\273\230.md"
similarity index 100%
rename from "Django/Django, ELB\345\201\245\345\272\267\346\243\200\346\237\245\345\222\214\346\214\201\347\273\255\344\272\244\344\273\230.md"
rename to "Web/Django/Django, ELB\345\201\245\345\272\267\346\243\200\346\237\245\345\222\214\346\214\201\347\273\255\344\272\244\344\273\230.md"
diff --git "a/Django/Django\344\270\255\346\255\243\347\241\256\345\244\204\347\220\206\346\225\260\346\215\256\345\272\223\345\271\266\345\217\221\347\232\204\346\226\271\346\263\225.md" "b/Web/Django/Django\344\270\255\346\255\243\347\241\256\345\244\204\347\220\206\346\225\260\346\215\256\345\272\223\345\271\266\345\217\221\347\232\204\346\226\271\346\263\225.md"
similarity index 100%
rename from "Django/Django\344\270\255\346\255\243\347\241\256\345\244\204\347\220\206\346\225\260\346\215\256\345\272\223\345\271\266\345\217\221\347\232\204\346\226\271\346\263\225.md"
rename to "Web/Django/Django\344\270\255\346\255\243\347\241\256\345\244\204\347\220\206\346\225\260\346\215\256\345\272\223\345\271\266\345\217\221\347\232\204\346\226\271\346\263\225.md"
diff --git a/Django/README.md b/Web/Django/README.md
similarity index 100%
rename from Django/README.md
rename to Web/Django/README.md
diff --git "a/Django/\344\275\277\347\224\250Django\350\277\233\350\241\214\345\216\237\345\236\213\345\214\226.md" "b/Web/Django/\344\275\277\347\224\250Django\350\277\233\350\241\214\345\216\237\345\236\213\345\214\226.md"
similarity index 100%
rename from "Django/\344\275\277\347\224\250Django\350\277\233\350\241\214\345\216\237\345\236\213\345\214\226.md"
rename to "Web/Django/\344\275\277\347\224\250Django\350\277\233\350\241\214\345\216\237\345\236\213\345\214\226.md"
diff --git "a/Django/\344\275\277\347\224\250Kubernetes\344\275\277Django\345\272\224\347\224\250\345\217\230\345\276\227\345\217\257\346\211\251\345\261\225\345\271\266\345\205\267\346\234\211\345\274\271\346\200\247.md" "b/Web/Django/\344\275\277\347\224\250Kubernetes\344\275\277Django\345\272\224\347\224\250\345\217\230\345\276\227\345\217\257\346\211\251\345\261\225\345\271\266\345\205\267\346\234\211\345\274\271\346\200\247.md"
similarity index 100%
rename from "Django/\344\275\277\347\224\250Kubernetes\344\275\277Django\345\272\224\347\224\250\345\217\230\345\276\227\345\217\257\346\211\251\345\261\225\345\271\266\345\205\267\346\234\211\345\274\271\346\200\247.md"
rename to "Web/Django/\344\275\277\347\224\250Kubernetes\344\275\277Django\345\272\224\347\224\250\345\217\230\345\276\227\345\217\257\346\211\251\345\261\225\345\271\266\345\205\267\346\234\211\345\274\271\346\200\247.md"
diff --git "a/Django/\345\234\250Django\344\270\255\357\274\214\345\246\202\344\275\225\344\270\272\346\217\220\351\253\230\351\241\265\351\235\242\345\212\240\350\275\275\351\200\237\345\272\246\344\274\230\345\214\226\345\233\276\345\203\217.md" "b/Web/Django/\345\234\250Django\344\270\255\357\274\214\345\246\202\344\275\225\344\270\272\346\217\220\351\253\230\351\241\265\351\235\242\345\212\240\350\275\275\351\200\237\345\272\246\344\274\230\345\214\226\345\233\276\345\203\217.md"
similarity index 100%
rename from "Django/\345\234\250Django\344\270\255\357\274\214\345\246\202\344\275\225\344\270\272\346\217\220\351\253\230\351\241\265\351\235\242\345\212\240\350\275\275\351\200\237\345\272\246\344\274\230\345\214\226\345\233\276\345\203\217.md"
rename to "Web/Django/\345\234\250Django\344\270\255\357\274\214\345\246\202\344\275\225\344\270\272\346\217\220\351\253\230\351\241\265\351\235\242\345\212\240\350\275\275\351\200\237\345\272\246\344\274\230\345\214\226\345\233\276\345\203\217.md"
diff --git "a/Django/\345\246\202\344\275\225\346\211\251\345\261\225Django User\346\250\241\345\236\213.md" "b/Web/Django/\345\246\202\344\275\225\346\211\251\345\261\225Django User\346\250\241\345\236\213.md"
similarity index 100%
rename from "Django/\345\246\202\344\275\225\346\211\251\345\261\225Django User\346\250\241\345\236\213.md"
rename to "Web/Django/\345\246\202\344\275\225\346\211\251\345\261\225Django User\346\250\241\345\236\213.md"
diff --git "a/Django/\345\270\246django\346\225\231\347\250\213\347\232\204Facebook\350\201\212\345\244\251\346\234\272\345\231\250\344\272\272\357\274\214\345\217\210\345\220\215\347\254\221\350\257\235\346\234\272\345\231\250\344\272\272.md" "b/Web/Django/\345\270\246django\346\225\231\347\250\213\347\232\204Facebook\350\201\212\345\244\251\346\234\272\345\231\250\344\272\272\357\274\214\345\217\210\345\220\215\347\254\221\350\257\235\346\234\272\345\231\250\344\272\272.md"
similarity index 100%
rename from "Django/\345\270\246django\346\225\231\347\250\213\347\232\204Facebook\350\201\212\345\244\251\346\234\272\345\231\250\344\272\272\357\274\214\345\217\210\345\220\215\347\254\221\350\257\235\346\234\272\345\231\250\344\272\272.md"
rename to "Web/Django/\345\270\246django\346\225\231\347\250\213\347\232\204Facebook\350\201\212\345\244\251\346\234\272\345\231\250\344\272\272\357\274\214\345\217\210\345\220\215\347\254\221\350\257\235\346\234\272\345\231\250\344\272\272.md"
diff --git a/Flask/README.md b/Web/Flask/README.md
similarity index 100%
rename from Flask/README.md
rename to Web/Flask/README.md
diff --git a/raw/An exploration of Texas Death Row data.md b/raw/An exploration of Texas Death Row data.md
new file mode 100644
index 0000000..e69de29
diff --git "a/\344\275\240\350\257\245\347\233\270\344\277\241\350\260\201\347\232\204\350\257\204\345\210\206\357\274\237IMDB\357\274\214\347\203\202\347\225\252\350\214\204\357\274\214Metacritic\357\274\214\350\277\230\346\230\257Fandango\357\274\237.md" "b/\344\275\240\350\257\245\347\233\270\344\277\241\350\260\201\347\232\204\350\257\204\345\210\206\357\274\237IMDB\357\274\214\347\203\202\347\225\252\350\214\204\357\274\214Metacritic\357\274\214\350\277\230\346\230\257Fandango\357\274\237.md"
new file mode 100644
index 0000000..d761113
--- /dev/null
+++ "b/\344\275\240\350\257\245\347\233\270\344\277\241\350\260\201\347\232\204\350\257\204\345\210\206\357\274\237IMDB\357\274\214\347\203\202\347\225\252\350\214\204\357\274\214Metacritic\357\274\214\350\277\230\346\230\257Fandango\357\274\237.md"
@@ -0,0 +1,3 @@
+原文:[Whose ratings should you trust? IMDB, Rotten Tomatoes, Metacritic, or Fandango?](https://medium.freecodecamp.com/whose-reviews-should-you-trust-imdb-rotten-tomatoes-metacritic-or-fandango-7d1010c6cf19)
+
+---
\ No newline at end of file
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/README.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/README.md"
new file mode 100644
index 0000000..beff5db
--- /dev/null
+++ "b/\350\257\273\344\271\246\347\254\224\350\256\260/README.md"
@@ -0,0 +1,2 @@
+* [官方 python 教程(python 3)](https://docs.python.org/zh-cn/3/tutorial/index.html) | [思维导图](http://naotu.baidu.com/file/a50273db8bba3a2c7f257f039d06e7c1?token=f389efed04f2e4b8)
+*
\ No newline at end of file
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/1. Python \346\225\260\346\215\256\346\250\241\345\236\213.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/1. Python \346\225\260\346\215\256\346\250\241\345\236\213.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/10.\345\272\217\345\210\227\347\232\204\344\277\256\346\224\271\343\200\201\346\225\243\345\210\227\345\222\214\345\210\207\347\211\207.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/10.\345\272\217\345\210\227\347\232\204\344\277\256\346\224\271\343\200\201\346\225\243\345\210\227\345\222\214\345\210\207\347\211\207.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/11.\346\216\245\345\217\243\357\274\232\344\273\216\345\215\217\350\256\256\345\210\260\346\212\275\350\261\241\345\237\272\347\261\273.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/11.\346\216\245\345\217\243\357\274\232\344\273\216\345\215\217\350\256\256\345\210\260\346\212\275\350\261\241\345\237\272\347\261\273.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/12.\347\273\247\346\211\277\347\232\204\344\274\230\347\274\272\347\202\271.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/12.\347\273\247\346\211\277\347\232\204\344\274\230\347\274\272\347\202\271.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/13.\346\255\243\347\241\256\351\207\215\350\275\275\350\277\220\347\256\227\347\254\246.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/13.\346\255\243\347\241\256\351\207\215\350\275\275\350\277\220\347\256\227\347\254\246.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/14. \345\217\257\345\217\240\346\210\264\347\232\204\345\257\271\350\261\241\343\200\201\350\277\255\344\273\243\345\231\250\345\222\214\347\224\237\346\210\220\345\231\250.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/14. \345\217\257\345\217\240\346\210\264\347\232\204\345\257\271\350\261\241\343\200\201\350\277\255\344\273\243\345\231\250\345\222\214\347\224\237\346\210\220\345\231\250.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/15. \344\270\212\344\270\213\346\226\207\347\256\241\347\220\206\345\231\250\345\222\214 else \345\235\227.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/15. \344\270\212\344\270\213\346\226\207\347\256\241\347\220\206\345\231\250\345\222\214 else \345\235\227.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/16. \345\215\217\347\250\213.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/16. \345\215\217\347\250\213.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/17. \344\275\277\347\224\250\346\234\237\347\211\251\345\244\204\347\220\206\345\271\266\345\217\221.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/17. \344\275\277\347\224\250\346\234\237\347\211\251\345\244\204\347\220\206\345\271\266\345\217\221.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/18. \344\275\277\347\224\250 asyncio \345\214\205\345\244\204\347\220\206\345\271\266\345\217\221.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/18. \344\275\277\347\224\250 asyncio \345\214\205\345\244\204\347\220\206\345\271\266\345\217\221.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/19. \345\212\250\346\200\201\345\261\236\346\200\247\345\222\214\347\211\271\346\200\247.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/19. \345\212\250\346\200\201\345\261\236\346\200\247\345\222\214\347\211\271\346\200\247.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/2. \345\272\217\345\210\227\346\236\204\346\210\220\347\232\204\346\225\260\347\273\204.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/2. \345\272\217\345\210\227\346\236\204\346\210\220\347\232\204\346\225\260\347\273\204.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/20. \345\261\236\346\200\247\346\217\217\350\277\260\347\254\246.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/20. \345\261\236\346\200\247\346\217\217\350\277\260\347\254\246.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/21. \347\261\273\345\205\203\347\274\226\347\250\213.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/21. \347\261\273\345\205\203\347\274\226\347\250\213.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/3. \345\255\227\345\205\270\345\222\214\351\233\206\345\220\210.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/3. \345\255\227\345\205\270\345\222\214\351\233\206\345\220\210.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/4. \346\226\207\346\234\254\345\222\214\345\255\227\350\212\202\345\272\217\345\210\227.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/4. \346\226\207\346\234\254\345\222\214\345\255\227\350\212\202\345\272\217\345\210\227.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/5.\344\270\200\347\255\211\345\207\275\346\225\260.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/5.\344\270\200\347\255\211\345\207\275\346\225\260.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/6.\344\275\277\347\224\250\344\270\200\347\255\211\345\207\275\346\225\260\345\256\236\347\216\260\350\256\276\350\256\241\346\250\241\345\274\217.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/6.\344\275\277\347\224\250\344\270\200\347\255\211\345\207\275\346\225\260\345\256\236\347\216\260\350\256\276\350\256\241\346\250\241\345\274\217.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/7.\345\207\275\346\225\260\350\243\205\351\245\260\345\231\250\345\222\214\351\227\255\345\214\205.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/7.\345\207\275\346\225\260\350\243\205\351\245\260\345\231\250\345\222\214\351\227\255\345\214\205.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/8.\345\257\271\350\261\241\345\274\225\347\224\250\343\200\201\345\217\257\345\217\230\346\200\247\345\222\214\345\236\203\345\234\276\345\233\236\346\224\266.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/8.\345\257\271\350\261\241\345\274\225\347\224\250\343\200\201\345\217\257\345\217\230\346\200\247\345\222\214\345\236\203\345\234\276\345\233\236\346\224\266.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/9.\347\254\246\345\220\210 python \351\243\216\346\240\274\347\232\204\345\257\271\350\261\241.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/9.\347\254\246\345\220\210 python \351\243\216\346\240\274\347\232\204\345\257\271\350\261\241.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/README.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/README.md"
new file mode 100644
index 0000000..80a56e4
--- /dev/null
+++ "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/README.md"
@@ -0,0 +1,9 @@
+# 流畅的 python
+
+### 本书源代码
+地址:[fluentpython/example-code](https://github.com/fluentpython/example-code)
+
+使用方式:
+```
+$ python3 -m doctest example_script.py
+```
\ No newline at end of file
+
+---
+[](https://star-history.com/?utm_source=bestxtools.com#ictar/python-doc&Date)
diff --git a/SUMMARY.md b/SUMMARY.md
new file mode 100644
index 0000000..3c94f98
--- /dev/null
+++ b/SUMMARY.md
@@ -0,0 +1,158 @@
+# Summary
+
+* [介绍](README.md)
+
+## Python语言相关
+- [Python Common](./Python Common/README.md)
+ - [3.5.1](./Python Common/3.5.1/README.md)
+ - [What's New in Python xx](./Python Common/What's New in Python xx/README.md)
+ - [New In Python:变量注解语法](./Python Common/What's New in Python xx/New In Python:变量注解语法.md)
+ - [New in Python:数字字面量中的下划线](./Python Common/What's New in Python xx/New in Python:数字字面量中的下划线.md)
+ - [Python 2和3中的异常泄漏](./Python Common/Python 2和3中的异常泄漏.md)
+ - [为什么存在Python 3](./Python Common/为什么存在Python 3.md)
+ - [Python async-await教程](./Python Common/Python async-await教程.md)
+ - [hasattr()是有害的](./Python Common/hasattr()是有害的.md)
+ - [异常 - 原力的黑暗面](./Python Common/异常 - 原力的黑暗面.md)
+ - [Python Cookbook 3rd Edition Documentation(中文版)](http://python3-cookbook.readthedocs.org/zh_CN/latest/index.html)
+ - [什么是stackless](./Python Common/什么是stackless.md)
+ - [2016年的Python 3](./Python Common/2016年的Python 3.md)
+ - [合并Python中的字典的惯用方法](./Python Common/合并Python中的字典的惯用方法.md)
+ - [惯用Python:推导](./Python Common/惯用Python:推导.md)
+ - [在Python 3中比较类型](./Python Common/在Python 3中比较类型.md)
+ - [Python 201 – 什么是双端队列(deque)](./Python Common/Python 201 – 什么是双端队列(deque).md)
+ - [高级asyncio测试](./Python Common/高级asyncio测试.md)
+ - [惯用Python:布尔表达式](./Python Common/惯用Python:布尔表达式.md)
+ - [base64-使用ASCII编码二进制数据](./Python Common/base64-使用ASCII编码二进制数据.md)
+ - [Lists和Tuples大对决](./Python Common/Lists和Tuples大对决.md)
+ - [解释python中的*args和**kwargs](./Python Common/解释python中的*args和**kwargs.md)
+ - [深度探索Python:让我们审查dict模块](./Python Common/深度探索Python:让我们审查dict模块.md)
+ - [不可不知的一点Python陷阱](./Python Common/不可不知的一点Python陷阱.md)
+ - [Python:声明动态属性](./Python Common/Python:声明动态属性.md)
+ - [了解Python类实例化](./Python Common/了解Python类实例化.md)
+ - [Python中的assert语句](./Python Common/Python中的assert语句.md)
+ - [Python新增的secrets模块](./Python Common/Python新增的secrets模块.md)
+ - [Python中的lambda表达式](./Python Common/Python中的lambda表达式.md)
+ - [我是如何修复 Python 3.7 中一个非常老的 GIL 竞争条件的](./Python Common/python37-gil-change.md)
+## Web框架
+- [Django](./Django/README.md)
+ - [1.9](./Django/1.9/README.md) Django 1.9版本官方文档
+ - [使用Django进行原型化](./Django/使用Django进行原型化.md)
+ - [使用Kubernetes使Django应用变得可扩展并具有弹性](./Django/使用Kubernetes使Django应用变得可扩展并具有弹性.md)
+ - [Django, ELB健康检查和持续交付](./Django/Django, ELB健康检查和持续交付.md)
+ - [带django教程的Facebook聊天机器人,又名笑话机器人](./Django/带django教程的Facebook聊天机器人,又名笑话机器人.md)
+ - [在Django中,如何为提高页面加载速度优化图像](./Django/在Django中,如何为提高页面加载速度优化图像.md)
+ - [Django Channels和Celery示例](./Django/Django Channels和Celery示例.md)
+ - [如何扩展Django User模型](./Django/如何扩展Django User模型.md)
+ - [Django中正确处理数据库并发的方法](./Django/Django中正确处理数据库并发的方法.md)
+
+- [Flask](./Flask/README.md)
+
+## web爬取
+- [Scrapy](./Scrapy/README.md)
+ - [Scrapinghub的Scrapy技巧系列](./Scrapy/Scrapinghub的Scrapy技巧系列/README.md)
+ - [跟着高手学习Scrapy技巧:第一部分](./Scrapy/Scrapinghub的Scrapy技巧系列/跟着高手学习Scrapy技巧:第一部分.md)
+ - [Scrapy技巧:2016年三月版](./Scrapy/Scrapinghub的Scrapy技巧系列/Scrapy技巧:2016年三月版.md)
+ - [Scrapy技巧:2016年四月版](./Scrapy/Scrapinghub的Scrapy技巧系列/Scrapy技巧:2016年四月版.md)
+ - [Scrapy技巧:2016年五月版](./Scrapy/Scrapinghub的Scrapy技巧系列/Scrapy技巧:2016年五月版.md)
+ - [Scrapy技巧:2016年六月版](./Scrapy/Scrapinghub的Scrapy技巧系列/Scrapy技巧:2016年六月版.md)
+ - [Scrapy技巧:2016年七月版](./Scrapy/Scrapinghub的Scrapy技巧系列/Scrapy技巧:2016年七月版.md)
+## DevOps工具
+- Fabric: [中文版](http://fabric-chs.readthedocs.org/zh_CN/chs/) | [英文版](http://docs.fabfile.org/en/1.11/index.html)
+
+- [Glances](https://github.com/nicolargo/glances):[中文版](http://glances-zh.readthedocs.io/en/latest/) | [英文版](https://glances.readthedocs.io/en/latest/)
+
+## 测试
+- [Testing](./Testing/README.md)
+ - [Python Mock:简单介绍 —— 第一部分](./Testing/Python Mock:简单介绍 —— 第一部分.md)
+ - [在Python中使用Behave来开始行为测试](./Testing/在Python中使用Behave来开始行为测试.md)
+ - [基于属性的测试,hypothesis以及查找bug](./Testing/基于属性的测试,hypothesis以及查找bug.md)
+
+## 硬件
+- [Hardware](./Hardware/README.md)
+ - 用Python玩转Worcester Wave恒温器
+ * [第一部分](./Hardware/用Python玩转Worcester Wave恒温器-第一部分.md)
+ * [第二部分](./Hardware/用Python玩转Worcester Wave恒温器-第二部分.md)
+ * [第三部分](./Hardware/用Python玩转Worcester Wave恒温器-第三部分.md)
+ - [使用Python构建一个(半)自动无人机](./Hardware/使用Python构建一个(半)自动无人机.md)
+ - [旅程中带着Ipad Pro和Raspberry Pi备份照片](./Hardware/旅程中带着Ipad Pro和Raspberry Pi备份照片.md)
+
+## 科学计算和数据分析
+- [Science and Data Analysis](./Science and Data Analysis/README.md)
+ - [如何使用Python和Pandas处理大量的JSON数据集](./Science and Data Analysis/如何使用Python和Pandas处理大量的JSON数据集.md)
+ - [新闻标题分析](./Science and Data Analysis/新闻标题分析.md)
+ - [使用矩阵分解找到相似歌曲](./Science and Data Analysis/使用矩阵分解找到相似歌曲.md)
+ - [Python中的并行处理](./Science and Data Analysis/Python中的并行处理.md)
+ - [Matplotlib教程 - 绘制提到Trump, Clinton & Sanders的推特](./Science and Data Analysis/Matplotlib教程 - 绘制提到Trump, Clinton & Sanders的推特.md)
+ - [使用Pandas, Docker和OS(R)M来猜测神秘的旅行地](./Science and Data Analysis/使用Pandas, Docker和OS(R)M来猜测神秘的旅行地.md)
+ - [使用BigQuery和TensorFlow进行需求预测](./Science and Data Analysis/使用BigQuery和TensorFlow进行需求预测.md)
+ - [Python中一个简单的基于内容的推荐引擎](./Science and Data Analysis/Python中一个简单的基于内容的推荐引擎.md)
+ - [在Python中实现你自己的推荐系统](./Science and Data Analysis/在Python中实现你自己的推荐系统.md)
+ - [分析权力游戏图表](./Science and Data Analysis/分析权力游戏图表.md)
+ - [使用Python探索NFL选秀](./Science and Data Analysis/使用Python探索NFL选秀.md)
+ - [用于格式化和数据清理的便捷Python库](./Science and Data Analysis/用于格式化和数据清理的便捷Python库.md)
+ - [分析iPhone步数数据](./Science and Data Analysis/分析iPhone步数数据.md)
+ - [使用Python,分析23AndMe数据,获取遗传起源](./Science and Data Analysis/使用Python,分析23AndMe数据,获取遗传起源.md)
+ - [用Python进行股票市场数据分析概述 (第一部分)](./Science and Data Analysis/用Python进行股票市场数据分析概述 (第一部分).md)
+
+## 自然语言处理
+- [NLP](./NLP/README.md)
+ - [003构建一个播客推荐算法](./NLP/003构建一个播客推荐算法.md)
+
+## 机器学习
+- [Machine Learning](./Machine Learning/README.md)
+ - [使用非常少的数据构建强大的图像分类模型](./Machine Learning/使用非常少的数据构建强大的图像分类模型.md)
+ - [在有限预算上计算最佳公路旅行](./Machine Learning/在有限预算上计算最佳公路旅行.md)
+ - [对超过1M的酒店点评进行机器学习,发现有趣的见解](./Machine Learning/对超过1M的酒店点评进行机器学习,发现有趣的见解.md)
+ - [Python,机器学习和语言之争](./Machine Learning/Python,机器学习和语言之争.md)
+ - [使用预测算法追踪实时健康趋势](./Machine Learning/使用预测算法追踪实时健康趋势.md)
+
+## 函数式编程
+- [Functional Programming](./Functional Programming/README.md)
+ - Henry Kupty的函数式编程扫盲系列
+ - [函数式编程:概念,惯用语和理念](./Functional Programming/函数式编程:概念,惯用语和理念.md)
+ - [了解函数式编程背后的属性:单子(Monad)](./Functional Programming/了解函数式编程背后的属性:单子(Monad).md)
+
+## 图像处理
+- [Image Processing](./Image Processing/README.md)
+ - [压缩和增强手写笔记](./Image Processing/压缩和增强手写笔记.md)
+
+## 资源
+- [Python Weekly](./Python Weekly/README.md)
+
+## 无法归类的
+- [Others](./Others/README.md)
+ - [使用图像特征的库存图像相似性(程序是如何比我更时尚的)](./Others/程序是如何比我更时尚的.md)
+ - [如何在Python中使用Twilio Lookup API验证电话号码](./Others/如何在Python中使用Twilio Lookup API验证电话号码.md)
+ - [psutil 4.0.0以及如何获得Python中“真正的”进程内存和环境](./Others/psutil 4.0.0以及如何获得Python中“真正的”进程内存和环境.md)
+ - [Python依赖关系分析](./Others/Python依赖关系分析.md)
+ - [创造你自己的类IPython服务器](./Others/创造你自己的类IPython服务器.md)
+ - [为部署Python web应用程序构建一个更好的用户体验](./Others/为部署Python web应用程序构建一个更好的用户体验.md)
+ - [在Python中导入一个Docker容器](./Others/在Python中导入一个Docker容器.md)
+ - [好吧,你发布了一个损坏的包到PyPI上。那么你现在要怎么办?](./Others/好吧,你发布了一个损坏的包到PyPI上。那么你现在要怎么办?.md)
+ - [Python中Meta类习语的起源](./Others/Python中Meta类习语的起源.md)
+ - [复合构建器模式(Composite Builder Pattern),一个声明式编程的例子](./Others/复合构建器模式(Composite Builder Pattern),一个声明式编程的例子)
+ - [将Python用于地理空间数据处理](./Others/将Python用于地理空间数据处理.md)
+ - [使用Python和Excel进行交互式数据分析](./Others/使用Python和Excel进行交互式数据分析.md)
+ - [RPython的魔力](./Others/RPython的魔力.md)
+ - [使用gdb调试CPython进程](./Others/使用gdb调试CPython进程.md)
+ - [使用Python Newspaper构建Read It Later应用](./Others/使用Python Newspaper构建Read It Later应用.md)
+ - [Python lambda的源代码](./Others/Python lambda的源代码.md)
+ - [如何在Python中创建绿噪音](./Others/如何在Python中创建绿噪音.md)
+ - [你需要学习编写Python装饰器的五大理由](./Others/你需要学习编写Python装饰器的五大理由.md)
+ - [逆向工程我的酒店中的一个神秘的UDP流](./Others/逆向工程我的酒店中的一个神秘的UDP流.md)
+ - [记录每天数以百万计的请求以及需要采取哪些措施](./Others/记录每天数以百万计的请求以及需要采取哪些措施.md)
+ - [教程:手把手教你构建一个基本的Facebook聊天机器人](./Others/教程:手把手教你构建一个基本的Facebook聊天机器人.md)
+ - [我的自动化之旅:为人民服务的自动化](./Others/我的自动化之旅:为人民服务的自动化.md)
+ - [实用Python:EAFP VS. LBYL](./Others/实用Python:EAFP VS. LBYL.md)
+ - [使用str.encode和threads冻结你的Python](./Others/使用str.encode和threads冻结你的Python.md)
+ - [Python, GIL, 和Pyston](./Others/Python, GIL, 和Pyston.md)
+ - [我是如何构建一个Slack机器人来帮助我在San Francisco找房子的](./Others/我是如何构建一个Slack机器人来帮助我在San Francisco找房子的.md)
+ - [中断两个循环](./Others/中断两个循环.md)
+ - [一个模板引擎是如何工作的?](./Others/一个模板引擎是如何工作的?.md)
+ - [设计Pythonic API](./Others/设计Pythonic API.md)
+ - [Requests vs. urllib:它解决了什么问题?](./Others/Requests vs. urllib:它解决了什么问题?.md)
+ - [更好的Python对象序列化方法](./Others/更好的Python对象序列化方法.md)
+ - [使用列表推导式实现zip](./Others/使用列表推导式实现zip.md)
+ - [Python项目中的Makefiles](./Others/Python项目中的Makefiles.md)
+ - [婚礼规模:我是如何使用Twilio, Python和Google来自动化我的婚礼的](./Others/婚礼规模:我是如何使用Twilio, Python和Google来自动化我的婚礼的.md)
+# [小黑屋](./raw/README.md)
diff --git a/Django/1.9/README.md b/Web/Django/1.9/README.md
similarity index 100%
rename from Django/1.9/README.md
rename to Web/Django/1.9/README.md
diff --git a/Django/1.9/howto/Managing static files (e.g. images, JavaScript, CSS).md b/Web/Django/1.9/howto/Managing static files (e.g. images, JavaScript, CSS).md
similarity index 100%
rename from Django/1.9/howto/Managing static files (e.g. images, JavaScript, CSS).md
rename to Web/Django/1.9/howto/Managing static files (e.g. images, JavaScript, CSS).md
diff --git "a/Django/1.9/howto/\344\275\277\347\224\250Django\350\276\223\345\207\272CSV.md" "b/Web/Django/1.9/howto/\344\275\277\347\224\250Django\350\276\223\345\207\272CSV.md"
similarity index 100%
rename from "Django/1.9/howto/\344\275\277\347\224\250Django\350\276\223\345\207\272CSV.md"
rename to "Web/Django/1.9/howto/\344\275\277\347\224\250Django\350\276\223\345\207\272CSV.md"
diff --git "a/Django/1.9/howto/\344\275\277\347\224\250Django\350\276\223\345\207\272PDF.md" "b/Web/Django/1.9/howto/\344\275\277\347\224\250Django\350\276\223\345\207\272PDF.md"
similarity index 100%
rename from "Django/1.9/howto/\344\275\277\347\224\250Django\350\276\223\345\207\272PDF.md"
rename to "Web/Django/1.9/howto/\344\275\277\347\224\250Django\350\276\223\345\207\272PDF.md"
diff --git "a/Django/1.9/howto/\345\246\202\344\275\225\344\275\277\347\224\250WSGI\350\277\233\350\241\214\351\203\250\347\275\262.md" "b/Web/Django/1.9/howto/\345\246\202\344\275\225\344\275\277\347\224\250WSGI\350\277\233\350\241\214\351\203\250\347\275\262.md"
similarity index 100%
rename from "Django/1.9/howto/\345\246\202\344\275\225\344\275\277\347\224\250WSGI\350\277\233\350\241\214\351\203\250\347\275\262.md"
rename to "Web/Django/1.9/howto/\345\246\202\344\275\225\344\275\277\347\224\250WSGI\350\277\233\350\241\214\351\203\250\347\275\262.md"
diff --git "a/Django/1.9/howto/\351\203\250\347\275\262Django.md" "b/Web/Django/1.9/howto/\351\203\250\347\275\262Django.md"
similarity index 100%
rename from "Django/1.9/howto/\351\203\250\347\275\262Django.md"
rename to "Web/Django/1.9/howto/\351\203\250\347\275\262Django.md"
diff --git "a/Django/1.9/misc/\350\256\276\350\256\241\347\220\206\345\277\265.md" "b/Web/Django/1.9/misc/\350\256\276\350\256\241\347\220\206\345\277\265.md"
similarity index 100%
rename from "Django/1.9/misc/\350\256\276\350\256\241\347\220\206\345\277\265.md"
rename to "Web/Django/1.9/misc/\350\256\276\350\256\241\347\220\206\345\277\265.md"
diff --git "a/Django/1.9/ref/\344\270\255\351\227\264\344\273\266.md" "b/Web/Django/1.9/ref/\344\270\255\351\227\264\344\273\266.md"
similarity index 100%
rename from "Django/1.9/ref/\344\270\255\351\227\264\344\273\266.md"
rename to "Web/Django/1.9/ref/\344\270\255\351\227\264\344\273\266.md"
diff --git "a/Django/1.9/topics/db/\346\225\260\346\215\256\345\272\223\350\256\277\351\227\256\344\274\230\345\214\226.md" "b/Web/Django/1.9/topics/db/\346\225\260\346\215\256\345\272\223\350\256\277\351\227\256\344\274\230\345\214\226.md"
similarity index 100%
rename from "Django/1.9/topics/db/\346\225\260\346\215\256\345\272\223\350\256\277\351\227\256\344\274\230\345\214\226.md"
rename to "Web/Django/1.9/topics/db/\346\225\260\346\215\256\345\272\223\350\256\277\351\227\256\344\274\230\345\214\226.md"
diff --git "a/Django/1.9/topics/db/\346\250\241\345\236\213.md" "b/Web/Django/1.9/topics/db/\346\250\241\345\236\213.md"
similarity index 100%
rename from "Django/1.9/topics/db/\346\250\241\345\236\213.md"
rename to "Web/Django/1.9/topics/db/\346\250\241\345\236\213.md"
diff --git a/Django/1.9/topics/forms/Form Assets (the Media class).md b/Web/Django/1.9/topics/forms/Form Assets (the Media class).md
similarity index 100%
rename from Django/1.9/topics/forms/Form Assets (the Media class).md
rename to Web/Django/1.9/topics/forms/Form Assets (the Media class).md
diff --git "a/Django/1.9/topics/forms/\344\275\277\347\224\250\350\241\250\345\215\225.md" "b/Web/Django/1.9/topics/forms/\344\275\277\347\224\250\350\241\250\345\215\225.md"
similarity index 100%
rename from "Django/1.9/topics/forms/\344\275\277\347\224\250\350\241\250\345\215\225.md"
rename to "Web/Django/1.9/topics/forms/\344\275\277\347\224\250\350\241\250\345\215\225.md"
diff --git a/Django/1.9/topics/http/File Uploads.md b/Web/Django/1.9/topics/http/File Uploads.md
similarity index 100%
rename from Django/1.9/topics/http/File Uploads.md
rename to Web/Django/1.9/topics/http/File Uploads.md
diff --git "a/Django/1.9/topics/http/\344\270\255\351\227\264\344\273\266.md" "b/Web/Django/1.9/topics/http/\344\270\255\351\227\264\344\273\266.md"
similarity index 100%
rename from "Django/1.9/topics/http/\344\270\255\351\227\264\344\273\266.md"
rename to "Web/Django/1.9/topics/http/\344\270\255\351\227\264\344\273\266.md"
diff --git "a/Django/1.9/topics/i18n/\345\233\275\351\231\205\345\214\226\345\222\214\346\234\254\345\234\260\345\214\226.md" "b/Web/Django/1.9/topics/i18n/\345\233\275\351\231\205\345\214\226\345\222\214\346\234\254\345\234\260\345\214\226.md"
similarity index 100%
rename from "Django/1.9/topics/i18n/\345\233\275\351\231\205\345\214\226\345\222\214\346\234\254\345\234\260\345\214\226.md"
rename to "Web/Django/1.9/topics/i18n/\345\233\275\351\231\205\345\214\226\345\222\214\346\234\254\345\234\260\345\214\226.md"
diff --git "a/Django/1.9/topics/i18n/\347\277\273\350\257\221\357\274\210\350\275\254\346\215\242\357\274\211.md" "b/Web/Django/1.9/topics/i18n/\347\277\273\350\257\221\357\274\210\350\275\254\346\215\242\357\274\211.md"
similarity index 100%
rename from "Django/1.9/topics/i18n/\347\277\273\350\257\221\357\274\210\350\275\254\346\215\242\357\274\211.md"
rename to "Web/Django/1.9/topics/i18n/\347\277\273\350\257\221\357\274\210\350\275\254\346\215\242\357\274\211.md"
diff --git "a/Django/1.9/topics/testing/\345\234\250Django\344\270\255\346\265\213\350\257\225.md" "b/Web/Django/1.9/topics/testing/\345\234\250Django\344\270\255\346\265\213\350\257\225.md"
similarity index 100%
rename from "Django/1.9/topics/testing/\345\234\250Django\344\270\255\346\265\213\350\257\225.md"
rename to "Web/Django/1.9/topics/testing/\345\234\250Django\344\270\255\346\265\213\350\257\225.md"
diff --git "a/Django/1.9/topics/testing/\347\274\226\345\206\231\345\222\214\350\277\220\350\241\214\346\265\213\350\257\225.md" "b/Web/Django/1.9/topics/testing/\347\274\226\345\206\231\345\222\214\350\277\220\350\241\214\346\265\213\350\257\225.md"
similarity index 100%
rename from "Django/1.9/topics/testing/\347\274\226\345\206\231\345\222\214\350\277\220\350\241\214\346\265\213\350\257\225.md"
rename to "Web/Django/1.9/topics/testing/\347\274\226\345\206\231\345\222\214\350\277\220\350\241\214\346\265\213\350\257\225.md"
diff --git "a/Django/1.9/topics/\346\200\247\350\203\275\345\222\214\344\274\230\345\214\226\346\246\202\350\277\260.md" "b/Web/Django/1.9/topics/\346\200\247\350\203\275\345\222\214\344\274\230\345\214\226\346\246\202\350\277\260.md"
similarity index 100%
rename from "Django/1.9/topics/\346\200\247\350\203\275\345\222\214\344\274\230\345\214\226\346\246\202\350\277\260.md"
rename to "Web/Django/1.9/topics/\346\200\247\350\203\275\345\222\214\344\274\230\345\214\226\346\246\202\350\277\260.md"
diff --git "a/Django/1.9/topics/\346\227\245\345\277\227.md" "b/Web/Django/1.9/topics/\346\227\245\345\277\227.md"
similarity index 100%
rename from "Django/1.9/topics/\346\227\245\345\277\227.md"
rename to "Web/Django/1.9/topics/\346\227\245\345\277\227.md"
diff --git "a/Django/1.9/topics/\346\250\241\346\235\277.md" "b/Web/Django/1.9/topics/\346\250\241\346\235\277.md"
similarity index 100%
rename from "Django/1.9/topics/\346\250\241\346\235\277.md"
rename to "Web/Django/1.9/topics/\346\250\241\346\235\277.md"
diff --git "a/Django/1.9/topics/\350\256\276\347\275\256.md" "b/Web/Django/1.9/topics/\350\256\276\347\275\256.md"
similarity index 100%
rename from "Django/1.9/topics/\350\256\276\347\275\256.md"
rename to "Web/Django/1.9/topics/\350\256\276\347\275\256.md"
diff --git "a/Django/Django Channels\345\222\214Celery\347\244\272\344\276\213.md" "b/Web/Django/Django Channels\345\222\214Celery\347\244\272\344\276\213.md"
similarity index 100%
rename from "Django/Django Channels\345\222\214Celery\347\244\272\344\276\213.md"
rename to "Web/Django/Django Channels\345\222\214Celery\347\244\272\344\276\213.md"
diff --git "a/Django/Django, ELB\345\201\245\345\272\267\346\243\200\346\237\245\345\222\214\346\214\201\347\273\255\344\272\244\344\273\230.md" "b/Web/Django/Django, ELB\345\201\245\345\272\267\346\243\200\346\237\245\345\222\214\346\214\201\347\273\255\344\272\244\344\273\230.md"
similarity index 100%
rename from "Django/Django, ELB\345\201\245\345\272\267\346\243\200\346\237\245\345\222\214\346\214\201\347\273\255\344\272\244\344\273\230.md"
rename to "Web/Django/Django, ELB\345\201\245\345\272\267\346\243\200\346\237\245\345\222\214\346\214\201\347\273\255\344\272\244\344\273\230.md"
diff --git "a/Django/Django\344\270\255\346\255\243\347\241\256\345\244\204\347\220\206\346\225\260\346\215\256\345\272\223\345\271\266\345\217\221\347\232\204\346\226\271\346\263\225.md" "b/Web/Django/Django\344\270\255\346\255\243\347\241\256\345\244\204\347\220\206\346\225\260\346\215\256\345\272\223\345\271\266\345\217\221\347\232\204\346\226\271\346\263\225.md"
similarity index 100%
rename from "Django/Django\344\270\255\346\255\243\347\241\256\345\244\204\347\220\206\346\225\260\346\215\256\345\272\223\345\271\266\345\217\221\347\232\204\346\226\271\346\263\225.md"
rename to "Web/Django/Django\344\270\255\346\255\243\347\241\256\345\244\204\347\220\206\346\225\260\346\215\256\345\272\223\345\271\266\345\217\221\347\232\204\346\226\271\346\263\225.md"
diff --git a/Django/README.md b/Web/Django/README.md
similarity index 100%
rename from Django/README.md
rename to Web/Django/README.md
diff --git "a/Django/\344\275\277\347\224\250Django\350\277\233\350\241\214\345\216\237\345\236\213\345\214\226.md" "b/Web/Django/\344\275\277\347\224\250Django\350\277\233\350\241\214\345\216\237\345\236\213\345\214\226.md"
similarity index 100%
rename from "Django/\344\275\277\347\224\250Django\350\277\233\350\241\214\345\216\237\345\236\213\345\214\226.md"
rename to "Web/Django/\344\275\277\347\224\250Django\350\277\233\350\241\214\345\216\237\345\236\213\345\214\226.md"
diff --git "a/Django/\344\275\277\347\224\250Kubernetes\344\275\277Django\345\272\224\347\224\250\345\217\230\345\276\227\345\217\257\346\211\251\345\261\225\345\271\266\345\205\267\346\234\211\345\274\271\346\200\247.md" "b/Web/Django/\344\275\277\347\224\250Kubernetes\344\275\277Django\345\272\224\347\224\250\345\217\230\345\276\227\345\217\257\346\211\251\345\261\225\345\271\266\345\205\267\346\234\211\345\274\271\346\200\247.md"
similarity index 100%
rename from "Django/\344\275\277\347\224\250Kubernetes\344\275\277Django\345\272\224\347\224\250\345\217\230\345\276\227\345\217\257\346\211\251\345\261\225\345\271\266\345\205\267\346\234\211\345\274\271\346\200\247.md"
rename to "Web/Django/\344\275\277\347\224\250Kubernetes\344\275\277Django\345\272\224\347\224\250\345\217\230\345\276\227\345\217\257\346\211\251\345\261\225\345\271\266\345\205\267\346\234\211\345\274\271\346\200\247.md"
diff --git "a/Django/\345\234\250Django\344\270\255\357\274\214\345\246\202\344\275\225\344\270\272\346\217\220\351\253\230\351\241\265\351\235\242\345\212\240\350\275\275\351\200\237\345\272\246\344\274\230\345\214\226\345\233\276\345\203\217.md" "b/Web/Django/\345\234\250Django\344\270\255\357\274\214\345\246\202\344\275\225\344\270\272\346\217\220\351\253\230\351\241\265\351\235\242\345\212\240\350\275\275\351\200\237\345\272\246\344\274\230\345\214\226\345\233\276\345\203\217.md"
similarity index 100%
rename from "Django/\345\234\250Django\344\270\255\357\274\214\345\246\202\344\275\225\344\270\272\346\217\220\351\253\230\351\241\265\351\235\242\345\212\240\350\275\275\351\200\237\345\272\246\344\274\230\345\214\226\345\233\276\345\203\217.md"
rename to "Web/Django/\345\234\250Django\344\270\255\357\274\214\345\246\202\344\275\225\344\270\272\346\217\220\351\253\230\351\241\265\351\235\242\345\212\240\350\275\275\351\200\237\345\272\246\344\274\230\345\214\226\345\233\276\345\203\217.md"
diff --git "a/Django/\345\246\202\344\275\225\346\211\251\345\261\225Django User\346\250\241\345\236\213.md" "b/Web/Django/\345\246\202\344\275\225\346\211\251\345\261\225Django User\346\250\241\345\236\213.md"
similarity index 100%
rename from "Django/\345\246\202\344\275\225\346\211\251\345\261\225Django User\346\250\241\345\236\213.md"
rename to "Web/Django/\345\246\202\344\275\225\346\211\251\345\261\225Django User\346\250\241\345\236\213.md"
diff --git "a/Django/\345\270\246django\346\225\231\347\250\213\347\232\204Facebook\350\201\212\345\244\251\346\234\272\345\231\250\344\272\272\357\274\214\345\217\210\345\220\215\347\254\221\350\257\235\346\234\272\345\231\250\344\272\272.md" "b/Web/Django/\345\270\246django\346\225\231\347\250\213\347\232\204Facebook\350\201\212\345\244\251\346\234\272\345\231\250\344\272\272\357\274\214\345\217\210\345\220\215\347\254\221\350\257\235\346\234\272\345\231\250\344\272\272.md"
similarity index 100%
rename from "Django/\345\270\246django\346\225\231\347\250\213\347\232\204Facebook\350\201\212\345\244\251\346\234\272\345\231\250\344\272\272\357\274\214\345\217\210\345\220\215\347\254\221\350\257\235\346\234\272\345\231\250\344\272\272.md"
rename to "Web/Django/\345\270\246django\346\225\231\347\250\213\347\232\204Facebook\350\201\212\345\244\251\346\234\272\345\231\250\344\272\272\357\274\214\345\217\210\345\220\215\347\254\221\350\257\235\346\234\272\345\231\250\344\272\272.md"
diff --git a/Flask/README.md b/Web/Flask/README.md
similarity index 100%
rename from Flask/README.md
rename to Web/Flask/README.md
diff --git a/raw/An exploration of Texas Death Row data.md b/raw/An exploration of Texas Death Row data.md
new file mode 100644
index 0000000..e69de29
diff --git "a/\344\275\240\350\257\245\347\233\270\344\277\241\350\260\201\347\232\204\350\257\204\345\210\206\357\274\237IMDB\357\274\214\347\203\202\347\225\252\350\214\204\357\274\214Metacritic\357\274\214\350\277\230\346\230\257Fandango\357\274\237.md" "b/\344\275\240\350\257\245\347\233\270\344\277\241\350\260\201\347\232\204\350\257\204\345\210\206\357\274\237IMDB\357\274\214\347\203\202\347\225\252\350\214\204\357\274\214Metacritic\357\274\214\350\277\230\346\230\257Fandango\357\274\237.md"
new file mode 100644
index 0000000..d761113
--- /dev/null
+++ "b/\344\275\240\350\257\245\347\233\270\344\277\241\350\260\201\347\232\204\350\257\204\345\210\206\357\274\237IMDB\357\274\214\347\203\202\347\225\252\350\214\204\357\274\214Metacritic\357\274\214\350\277\230\346\230\257Fandango\357\274\237.md"
@@ -0,0 +1,3 @@
+原文:[Whose ratings should you trust? IMDB, Rotten Tomatoes, Metacritic, or Fandango?](https://medium.freecodecamp.com/whose-reviews-should-you-trust-imdb-rotten-tomatoes-metacritic-or-fandango-7d1010c6cf19)
+
+---
\ No newline at end of file
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/README.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/README.md"
new file mode 100644
index 0000000..beff5db
--- /dev/null
+++ "b/\350\257\273\344\271\246\347\254\224\350\256\260/README.md"
@@ -0,0 +1,2 @@
+* [官方 python 教程(python 3)](https://docs.python.org/zh-cn/3/tutorial/index.html) | [思维导图](http://naotu.baidu.com/file/a50273db8bba3a2c7f257f039d06e7c1?token=f389efed04f2e4b8)
+*
\ No newline at end of file
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/1. Python \346\225\260\346\215\256\346\250\241\345\236\213.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/1. Python \346\225\260\346\215\256\346\250\241\345\236\213.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/10.\345\272\217\345\210\227\347\232\204\344\277\256\346\224\271\343\200\201\346\225\243\345\210\227\345\222\214\345\210\207\347\211\207.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/10.\345\272\217\345\210\227\347\232\204\344\277\256\346\224\271\343\200\201\346\225\243\345\210\227\345\222\214\345\210\207\347\211\207.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/11.\346\216\245\345\217\243\357\274\232\344\273\216\345\215\217\350\256\256\345\210\260\346\212\275\350\261\241\345\237\272\347\261\273.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/11.\346\216\245\345\217\243\357\274\232\344\273\216\345\215\217\350\256\256\345\210\260\346\212\275\350\261\241\345\237\272\347\261\273.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/12.\347\273\247\346\211\277\347\232\204\344\274\230\347\274\272\347\202\271.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/12.\347\273\247\346\211\277\347\232\204\344\274\230\347\274\272\347\202\271.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/13.\346\255\243\347\241\256\351\207\215\350\275\275\350\277\220\347\256\227\347\254\246.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/13.\346\255\243\347\241\256\351\207\215\350\275\275\350\277\220\347\256\227\347\254\246.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/14. \345\217\257\345\217\240\346\210\264\347\232\204\345\257\271\350\261\241\343\200\201\350\277\255\344\273\243\345\231\250\345\222\214\347\224\237\346\210\220\345\231\250.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/14. \345\217\257\345\217\240\346\210\264\347\232\204\345\257\271\350\261\241\343\200\201\350\277\255\344\273\243\345\231\250\345\222\214\347\224\237\346\210\220\345\231\250.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/15. \344\270\212\344\270\213\346\226\207\347\256\241\347\220\206\345\231\250\345\222\214 else \345\235\227.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/15. \344\270\212\344\270\213\346\226\207\347\256\241\347\220\206\345\231\250\345\222\214 else \345\235\227.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/16. \345\215\217\347\250\213.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/16. \345\215\217\347\250\213.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/17. \344\275\277\347\224\250\346\234\237\347\211\251\345\244\204\347\220\206\345\271\266\345\217\221.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/17. \344\275\277\347\224\250\346\234\237\347\211\251\345\244\204\347\220\206\345\271\266\345\217\221.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/18. \344\275\277\347\224\250 asyncio \345\214\205\345\244\204\347\220\206\345\271\266\345\217\221.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/18. \344\275\277\347\224\250 asyncio \345\214\205\345\244\204\347\220\206\345\271\266\345\217\221.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/19. \345\212\250\346\200\201\345\261\236\346\200\247\345\222\214\347\211\271\346\200\247.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/19. \345\212\250\346\200\201\345\261\236\346\200\247\345\222\214\347\211\271\346\200\247.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/2. \345\272\217\345\210\227\346\236\204\346\210\220\347\232\204\346\225\260\347\273\204.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/2. \345\272\217\345\210\227\346\236\204\346\210\220\347\232\204\346\225\260\347\273\204.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/20. \345\261\236\346\200\247\346\217\217\350\277\260\347\254\246.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/20. \345\261\236\346\200\247\346\217\217\350\277\260\347\254\246.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/21. \347\261\273\345\205\203\347\274\226\347\250\213.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/21. \347\261\273\345\205\203\347\274\226\347\250\213.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/3. \345\255\227\345\205\270\345\222\214\351\233\206\345\220\210.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/3. \345\255\227\345\205\270\345\222\214\351\233\206\345\220\210.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/4. \346\226\207\346\234\254\345\222\214\345\255\227\350\212\202\345\272\217\345\210\227.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/4. \346\226\207\346\234\254\345\222\214\345\255\227\350\212\202\345\272\217\345\210\227.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/5.\344\270\200\347\255\211\345\207\275\346\225\260.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/5.\344\270\200\347\255\211\345\207\275\346\225\260.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/6.\344\275\277\347\224\250\344\270\200\347\255\211\345\207\275\346\225\260\345\256\236\347\216\260\350\256\276\350\256\241\346\250\241\345\274\217.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/6.\344\275\277\347\224\250\344\270\200\347\255\211\345\207\275\346\225\260\345\256\236\347\216\260\350\256\276\350\256\241\346\250\241\345\274\217.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/7.\345\207\275\346\225\260\350\243\205\351\245\260\345\231\250\345\222\214\351\227\255\345\214\205.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/7.\345\207\275\346\225\260\350\243\205\351\245\260\345\231\250\345\222\214\351\227\255\345\214\205.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/8.\345\257\271\350\261\241\345\274\225\347\224\250\343\200\201\345\217\257\345\217\230\346\200\247\345\222\214\345\236\203\345\234\276\345\233\236\346\224\266.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/8.\345\257\271\350\261\241\345\274\225\347\224\250\343\200\201\345\217\257\345\217\230\346\200\247\345\222\214\345\236\203\345\234\276\345\233\236\346\224\266.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/9.\347\254\246\345\220\210 python \351\243\216\346\240\274\347\232\204\345\257\271\350\261\241.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/9.\347\254\246\345\220\210 python \351\243\216\346\240\274\347\232\204\345\257\271\350\261\241.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/README.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/README.md"
new file mode 100644
index 0000000..80a56e4
--- /dev/null
+++ "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/README.md"
@@ -0,0 +1,9 @@
+# 流畅的 python
+
+### 本书源代码
+地址:[fluentpython/example-code](https://github.com/fluentpython/example-code)
+
+使用方式:
+```
+$ python3 -m doctest example_script.py
+```
\ No newline at end of file