diff --git a/.gitignore b/.gitignore
index 496ee2c..6a3e68d 100644
--- a/.gitignore
+++ b/.gitignore
@@ -1 +1 @@
-.DS_Store
\ No newline at end of file
+**/.DS_Store
\ No newline at end of file
diff --git a/2019-COA19/lecture14.md b/2019-COA19/lecture14.md
index 0926624..28820c0 100644
--- a/2019-COA19/lecture14.md
+++ b/2019-COA19/lecture14.md
@@ -1,4 +1,4 @@
-WInstruction Sets
+Instruction Sets
---
diff --git "a/2019-Data-Structure/\346\225\260\346\215\256\347\273\223\346\236\2041-\347\273\252\350\256\272.md" "b/2019-Data-Structure/\346\225\260\346\215\256\347\273\223\346\236\2041-\347\273\252\350\256\272.md"
index f49e875..5c5376e 100644
--- "a/2019-Data-Structure/\346\225\260\346\215\256\347\273\223\346\236\2041-\347\273\252\350\256\272.md"
+++ "b/2019-Data-Structure/\346\225\260\346\215\256\347\273\223\346\236\2041-\347\273\252\350\256\272.md"
@@ -105,12 +105,12 @@
## 2.2. 数据结构
1. 定义:数据结构是描述**数据对象和数据对象之间关系**的统称。
-
+
-2. 数据结构分类:
+1. 数据结构分类:
1. 线性结构
2. 非线性结构
-3. 数据结构涉及三个方面:数据结构是分层的。
+2. 数据结构涉及三个方面:数据结构是分层的。
1. 数据的逻辑结构——从用户视图看,是面向问题的。
2. 数据的物理结构——从具体实现视图看,是面向计算机的。
3. 相关的操作及其实现。
@@ -135,17 +135,17 @@
+ 在内存中读取数据的时候,要注意**大端**形式。(高位在低地址)
+ float是最大约3*1020,参照IEEE754标准
-
+
3. 对于64位系统,字长word是64Byte
4. 数据类型分类
-
+
## 3.2. ADT
1. 是将类型和与这个类型有关的操作集合封装在一起的数据模型。
-
+
## 3.3. OOP
1. 面向对象编程是一种程序编写思想。
@@ -163,7 +163,7 @@
1. objects of same attributes and operates. an instance is an object of the class. different object has different attribute value 一些属性和一些操作的对象。实例这个类的一个对象。不同的对象有着不同的类。
## 3.5. inherit 继承
-
+
## 3.6. 消息和通信
1. 类之间传递消息。
@@ -179,7 +179,7 @@
4. sequence ends(有终点)
3. 程序:是可以用机器处理,并且能够理解程序语言。
-
+
# 5. 数学知识回顾
1. logA不写底数的情况下,默认底数是2
@@ -187,13 +187,13 @@
## 5.1. 同余
1. A≡B(mod N)
-
+
## 5.2. 数学归纳法
-
+
-
+
1. 格式:
1. basis
@@ -211,15 +211,15 @@
1. IntCell(放整数的盒子) —— 不是泛型类。
2. MomoryCell(放任何类型的盒子) —— 泛型类。
-
+
## 7.2. java的private和public
-
+
## 7.3. 构造器
-
+
## 7.4. This关键字
1. java: `This.`
@@ -227,7 +227,7 @@
1. `*This.`:在C++中This是指针,所以要用*变为引用。
2. `This->`:C++
-
+
## 7.5. 类的创建
1. java: `intCell a = new intCell();`
@@ -237,15 +237,15 @@
## 7.6. 静态关键字
-
+
## 7.7. 泛型
-
+
1. java:
2. C++: 用templete
-
+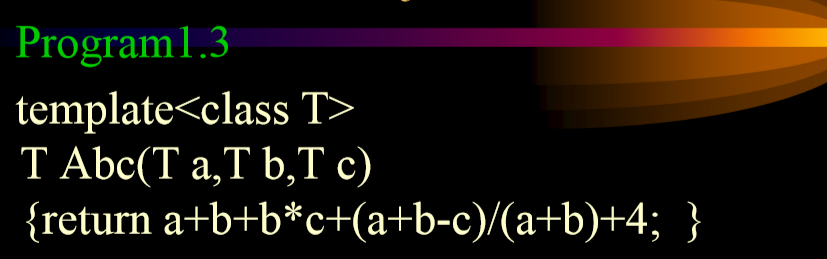
3. 能合在一起的所有的东西,都尽量分离出来,想办法解耦。
+ 出现bug比较好进行修改。
@@ -258,11 +258,11 @@
1. 所有的对象都由基类object派生出来,没有写继承,默认继承自Object。
2. 不能使用基本类型。
-
+
解决类型混乱问题
---
-
+
## 7.8. 接口
1. 接口十分重要
@@ -284,7 +284,7 @@
### 7.9.2. 运行时错误
-
+
### 7.9.3. java异常处理
```java
@@ -297,26 +297,26 @@ try{
}
```
-
+
2. 抛出异常
-
+
## 7.10. 实例
1. 寻找最大值算法:纯白色255,纯黑色000,所以可以用这个算法来找最亮或者最暗的图片。
## 7.11. 输入输出
-
+
1. 可以通过不同的流来进行控制即可。
### 7.11.1. 输入
-
+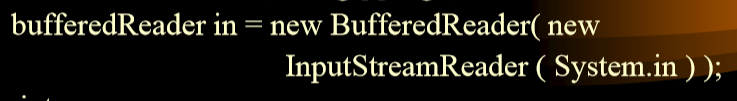
-
+
### 7.11.2. StringTokenizer对象
1. Sometimes we have several items on a line. For instance, suppose each line has two ints. Java provides the StringTokenizer object to separate a String into tokens. 有时我们在一条线上有几样东西。例如,假设每一行有两个int。Java提供StringTokenizer对象来将字符串分隔成标记。
@@ -326,7 +326,7 @@ try{
## 7.12. Sequential Files
-
+
## 7.13. main函数的应用
diff --git "a/2019-Data-Structure/\346\225\260\346\215\256\347\273\223\346\236\2042-algrorithm Analysis.md" "b/2019-Data-Structure/\346\225\260\346\215\256\347\273\223\346\236\2042-algrorithm Analysis.md"
index d02e678..47b9cf0 100644
--- "a/2019-Data-Structure/\346\225\260\346\215\256\347\273\223\346\236\2042-algrorithm Analysis.md"
+++ "b/2019-Data-Structure/\346\225\260\346\215\256\347\273\223\346\236\2042-algrorithm Analysis.md"
@@ -89,14 +89,14 @@
### 2.3.1. 例一
-
+
1. 在调用相应函数之前的空间是不进行计算的,所以数组并没有单独多余输入。
2. a是一个指针。
结果
-
+
1. 例子机器是16个字节
2. S(n):S表示space
@@ -110,11 +110,11 @@
### 2.3.2. 例二
-
+
结果
-
+
1. 只要你写了局部变量,局部变量静态分布,在执行局部之前就已经分配好了而不是等到执行的时候才分配地址。
2. 返回值地址需要被存储(不然无法进行返回)
@@ -126,14 +126,14 @@
1. the amount of time a program needs to run to completion 程序运行完成所需要的时间
2. 编译时间是不计算近时间复杂度,一般来说我们的编译次数是远远小于运行时间,一般只消耗一次。
-
+
## 3.1. 计算程序的时间复杂度
1. 关键的是计数中间的关键的操作个数。
+ 格外重要的是在循环中的操作个数
2. 第一个例子:
-
+
1. 先假设所有的操作都进行计算
+ 1(pos)+1(i)+(n-1)(for): 包含赋值语句,还包括for循环中每次都必须要做的语句。
@@ -154,7 +154,7 @@
## 3.2. 不同情况下的时间复杂度的情况
-
+
### 3.2.1. 最好情况
@@ -166,20 +166,20 @@
### 3.2.3. 最差情况
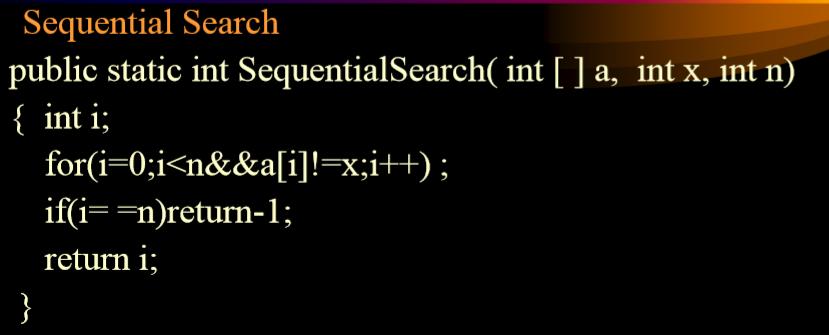
### 3.2.4. 例子
-
+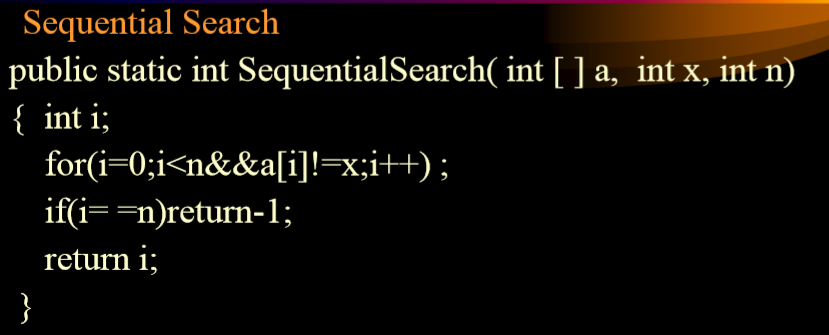
1. 最好情况下:一次性结束,第一次找到
2. 最坏情况下:n次结束,最后一次找到
3. 平均情况下:(n+1)/2,使用算术平均值
-
+
1. 不等概率下如何进行计算?
+ 将对应的位置上的概率加权进行计算。
# 4. 如何统计大规模的算法步数
-
+
1. 使用整形变量count,并且加入到相应的必要的地方进行计数。
2. 为程序加入计数器
@@ -193,7 +193,7 @@
2. 定义:f(n)=O(g(n)) iff positive constant c and n0 exist such that f(n) <=c * g(n) for all n, n>=n0
3. 例子:
-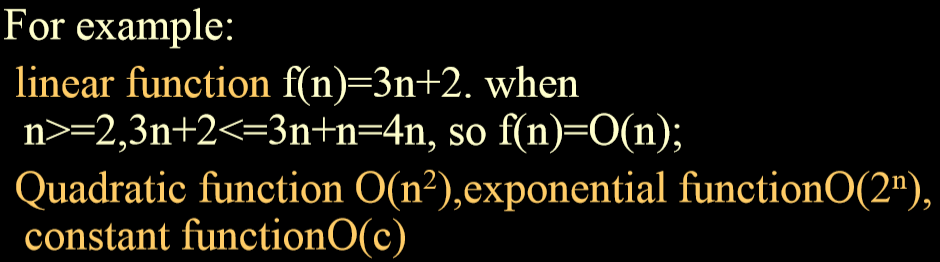
+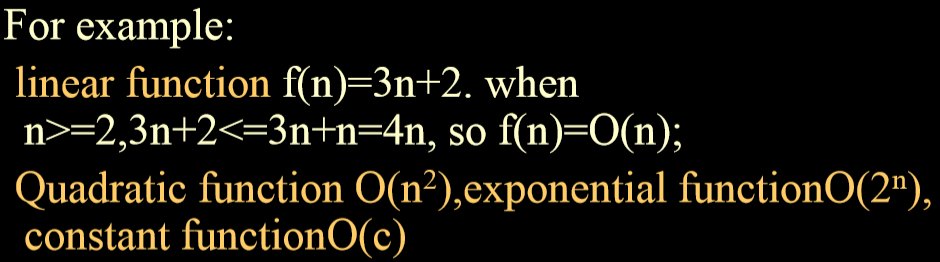
4. 复杂度排序:从小到大
1. O(1)
@@ -319,13 +319,13 @@ public static long gcd( long m, long n ) {
1. 表示的是一个算法的复杂度在数量级上的下界。
2. 定义:is the lower bound analog of the big Oh notation,permits us to bound the value f from below.
-
+
3. 表示的是下限。
## 5.3. Theta θ表示法
-
+
1. 不能向大了写,也不能向小了写。
2. 考试中我们使用的表示法。
\ No newline at end of file
diff --git "a/2019-Data-Structure/\346\225\260\346\215\256\347\273\223\346\236\2043.0-List.md" "b/2019-Data-Structure/\346\225\260\346\215\256\347\273\223\346\236\2043.0-List.md"
index a1d7de4..5445051 100644
--- "a/2019-Data-Structure/\346\225\260\346\215\256\347\273\223\346\236\2043.0-List.md"
+++ "b/2019-Data-Structure/\346\225\260\346\215\256\347\273\223\346\236\2043.0-List.md"
@@ -55,22 +55,22 @@ List
### 1.1.1. 数据对象
-
+
### 1.1.2. 数据结构
-
+
# 2. 线性表
1. 线性表是对象或者值的集合
-
+
2. 以上是需要实现的方法。
## 2.1. 线性表需要实现的方法
-
+
## 2.2. 线性表的不同实现
@@ -263,13 +263,13 @@ public class Polynomial {
## 4.1. 例子
1. 约瑟夫问题
-
+
2. 问题解决:
+ 使用新的单链表来记录。
+ p是最后一个点,降低插入的复杂度
-
+
```java
w = m;
@@ -303,17 +303,17 @@ for( int i = 1; i<= n-1; i++) {
# 5. 多项式问题
## 5.1. 线性表的数组实现
-
+
### 5.1.1. 部分方法
-
+
乘法
---
-
+
## 5.2. 线性表的单链表实现
-
+
### 5.2.1. 多项式相加
1. 存放非零指数的系数与指数,因此没有节点有三个域组成。
@@ -342,20 +342,20 @@ for( int i = 1; i<= n-1; i++) {
# 6. 双向链表
-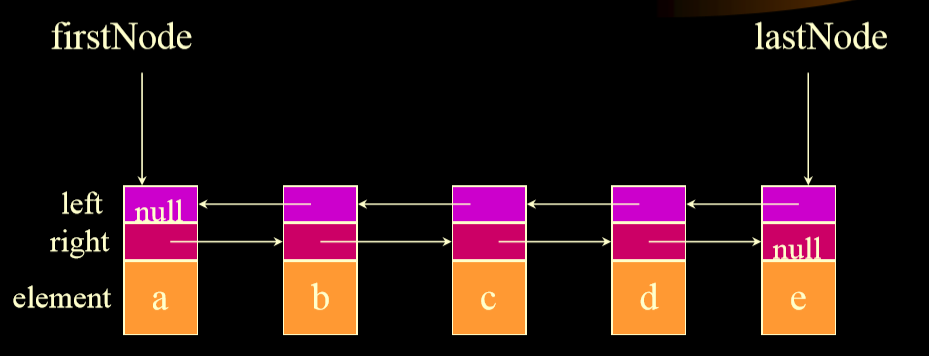
+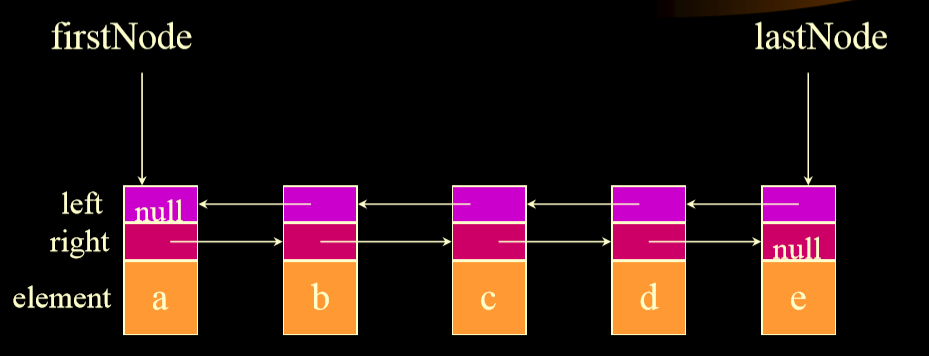
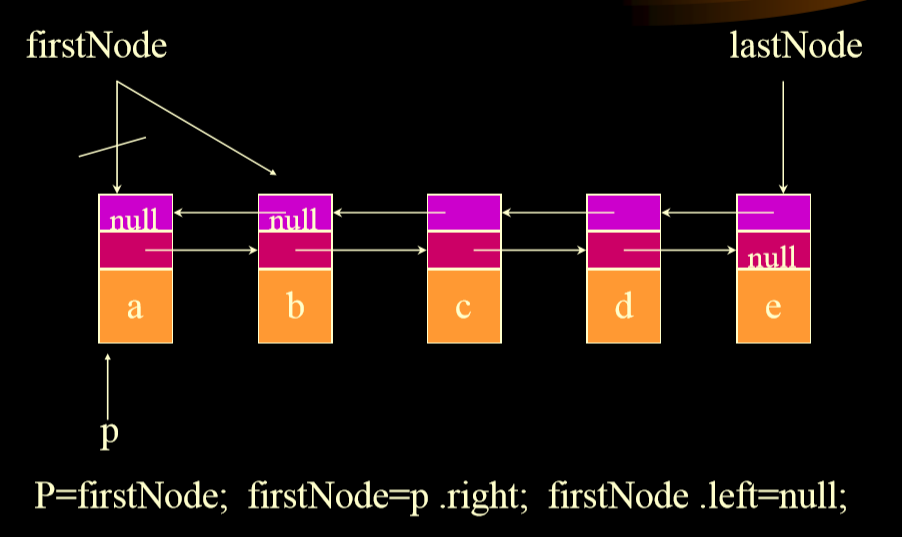
1. 删除开始,删除中间是不同的
## 6.1. 删除
1. 删除第一个节点
-
+
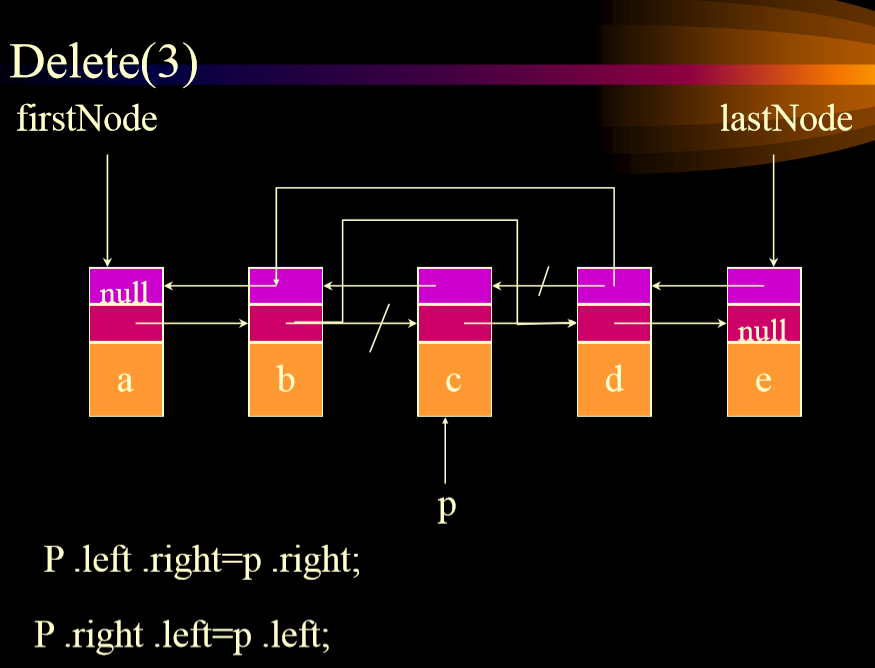
2. 删除中间
-
+
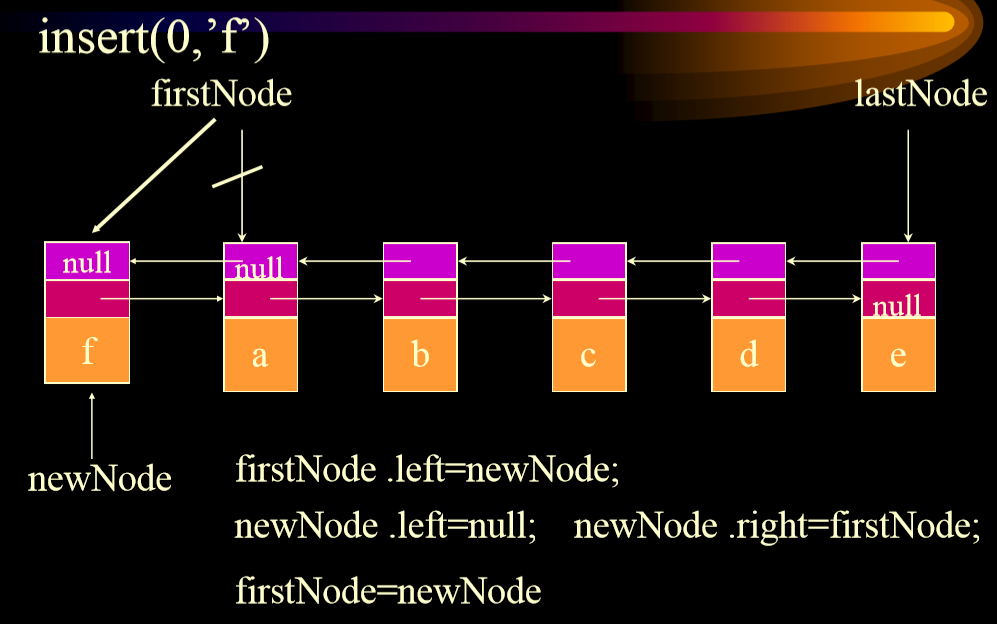
## 6.2. 插入
1. 从头插入
-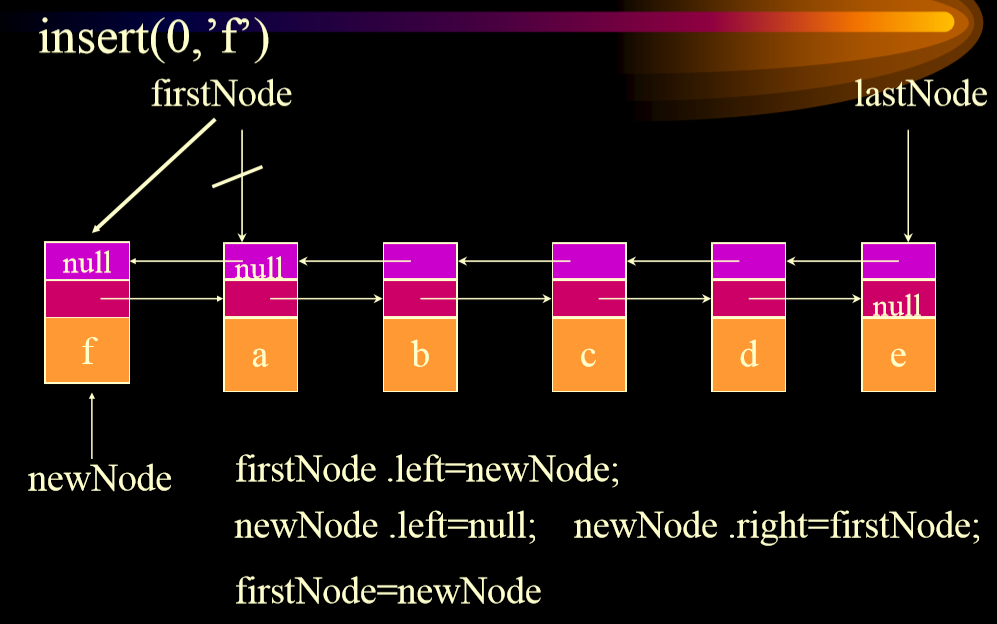
+
2. 从中插入
-
+
## 6.3. 变形:双向循环链表
1. 带表头的双向链表
@@ -368,14 +368,14 @@ for( int i = 1; i<= n-1; i++) {
# 8. 静态链表
1. 静态链表是由数组实现的单链表。
-
+
2. 在系统中,对于系统来说,内存时这样子的被系统管理的。
3. 如果next是0,那么相当于null
## 8.1. 静态链表的实现
-
-
+
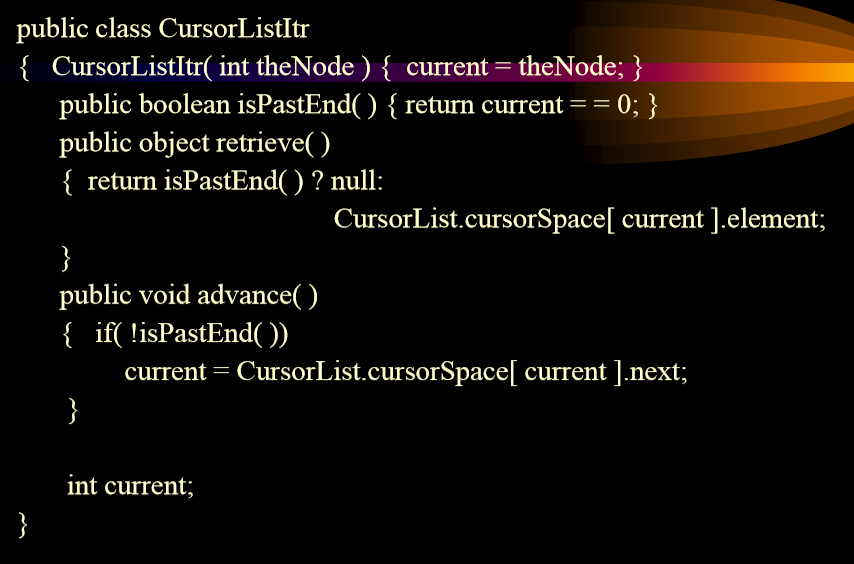
+
## 8.2. 实现代码
```java
diff --git "a/2020-Big-data-analysis/Tec2-\345\256\211\350\243\205Hadoop\345\222\214Spark.md" "b/2020-Big-data-analysis/Tec2-\345\256\211\350\243\205Hadoop\345\222\214Spark.md"
index 4bd96c0..d616ed3 100644
--- "a/2020-Big-data-analysis/Tec2-\345\256\211\350\243\205Hadoop\345\222\214Spark.md"
+++ "b/2020-Big-data-analysis/Tec2-\345\256\211\350\243\205Hadoop\345\222\214Spark.md"
@@ -19,7 +19,7 @@ Tec2-安装Hadoop和Spark
## 3.2. 下载Winutils-3.1.0
1. 因为Hadoop在2.0之前是完全运行在Linux系统上的,所以在之后如果想要在Windows上安装需要我们下载相应的exe才可以。
-2. 下载地址,可以使用fork的方式到自己的仓库然后下载,也可以直接选择下载ZIP文件。
+2. 下载地址,可以使用fork的方式到自己的仓库然后下载,也可以直接选择下载ZIP文件。
## 3.3. 解压Hadoop
1. 将刚刚下载的以tar.gz的文件以**管理员权限**进行解压
diff --git "a/2020-C-plus-plus-advanced-programming/C++-OOP/C++ OOP\345\237\272\347\241\200.md" "b/2020-C-plus-plus-advanced-programming/C++-OOP/C++ OOP\345\237\272\347\241\200.md"
index 3edc8d3..9303573 100644
--- "a/2020-C-plus-plus-advanced-programming/C++-OOP/C++ OOP\345\237\272\347\241\200.md"
+++ "b/2020-C-plus-plus-advanced-programming/C++-OOP/C++ OOP\345\237\272\347\241\200.md"
@@ -2,9 +2,8 @@ C++ 为什么选择OOP
---
OOP是Object Oriented Program
-1. 潘敏学老师邮箱:mxp@nju.edu.cn
-2. 不封装存在很大的安全隐患(数据暴露,可以被直接修改)
-3. 不符合数据类型的定义,使用封装实现OOP
+1. 不封装存在很大的安全隐患(数据暴露,可以被直接修改)
+2. 不符合数据类型的定义,使用封装实现OOP
diff --git "a/2020-Compilation-Principle/Parser4-LR\350\257\255\346\263\225\345\210\206\346\236\220\345\231\250.md" "b/2020-Compilation-Principle/Parser4-LR\350\257\255\346\263\225\345\210\206\346\236\220\345\231\250.md"
index 08068c6..aa964e3 100644
--- "a/2020-Compilation-Principle/Parser4-LR\350\257\255\346\263\225\345\210\206\346\236\220\345\231\250.md"
+++ "b/2020-Compilation-Principle/Parser4-LR\350\257\255\346\263\225\345\210\206\346\236\220\345\231\250.md"
@@ -1,4 +1,3 @@
-
LR语法分析器
---
1. 自顶向下的、不断归约的、基于句柄识别自动机的、适用于LR(∗) 文法的、LR(∗) 语法分析器
diff --git "a/2020-Demand-and-business-model-innovation/\345\225\206\344\270\232\346\250\241\345\274\217/Book5-\346\265\201\347\250\213.md" "b/2020-Demand-and-business-model-innovation/\345\225\206\344\270\232\346\250\241\345\274\217/Book5-\346\265\201\347\250\213.md"
index 46021de..bc867fc 100644
--- "a/2020-Demand-and-business-model-innovation/\345\225\206\344\270\232\346\250\241\345\274\217/Book5-\346\265\201\347\250\213.md"
+++ "b/2020-Demand-and-business-model-innovation/\345\225\206\344\270\232\346\250\241\345\274\217/Book5-\346\265\201\347\250\213.md"
@@ -1,4 +1,4 @@
-s上Book5-流程
+Book5-流程
---
# 1. 商业模式设计流程
diff --git "a/2020-Demand-and-business-model-innovation/\351\234\200\346\261\202/Book5-\347\241\256\345\256\232\351\241\271\347\233\256\347\232\204\345\211\215\346\231\257\345\222\214\350\214\203\345\233\264.md" "b/2020-Demand-and-business-model-innovation/\351\234\200\346\261\202/Book5-\347\241\256\345\256\232\351\241\271\347\233\256\347\232\204\345\211\215\346\231\257\345\222\214\350\214\203\345\233\264.md"
index 854d084..0e53a87 100644
--- "a/2020-Demand-and-business-model-innovation/\351\234\200\346\261\202/Book5-\347\241\256\345\256\232\351\241\271\347\233\256\347\232\204\345\211\215\346\231\257\345\222\214\350\214\203\345\233\264.md"
+++ "b/2020-Demand-and-business-model-innovation/\351\234\200\346\261\202/Book5-\347\241\256\345\256\232\351\241\271\347\233\256\347\232\204\345\211\215\346\231\257\345\222\214\350\214\203\345\233\264.md"
@@ -8,11 +8,6 @@ Book5-确定项目的前景和范围
2. 社区团购:最后一个没有被完全电商化的市场,规模可达万亿。
3. 品控、缺货、退货问题较为明显。
-## 1.2. 华春莹八连问
-1. 诱导式与双筒问题
-2. 封闭问题
-3. 探究式问题与抗辩
-
# 2. 确定项目前景和范围的活动
## 2.1. 为什么要确定项目的前景和范围
diff --git "a/2020-Devops-introduction/\345\215\216\344\270\272Devops\345\256\236\350\267\265\344\271\213\350\267\257.md" "b/2020-Devops-introduction/\345\215\216\344\270\272Devops\345\256\236\350\267\265\344\271\213\350\267\257.md"
deleted file mode 100644
index 5f6f4bc..0000000
--- "a/2020-Devops-introduction/\345\215\216\344\270\272Devops\345\256\236\350\267\265\344\271\213\350\267\257.md"
+++ /dev/null
@@ -1,102 +0,0 @@
-华为Devops实践之路
----
-
-# 1. 姚冬
-
-
-# 2. 敏捷起点
-
-
-1. 安灯绳:避免缺陷流入到下一层
-2. 特斯拉价值:购买的不是你买的时候样子,而是购买了他所配套的一整套服务
-
-# 3. 业界软件阶段
-
-
-# 4. 华为的Devops之路
-
-
-1. 最早是造英雄
-2. 后来人员增加很快
-3. 之后增加了静态检查
-4. 测试工厂:人工智能,智能测试
-
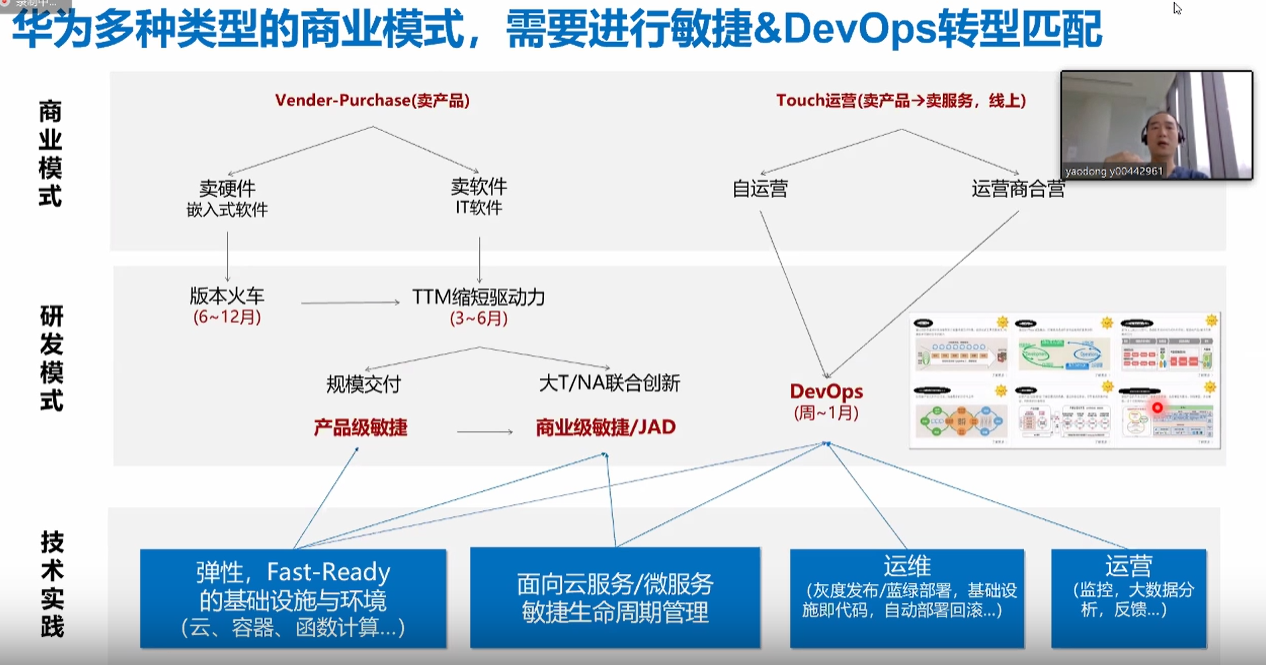
-## 4.1. 华为多种类型商业模式
-
-
-1. 基本有产业全线的东西
-
-## 4.2. 研发交付的核心目的
-
-
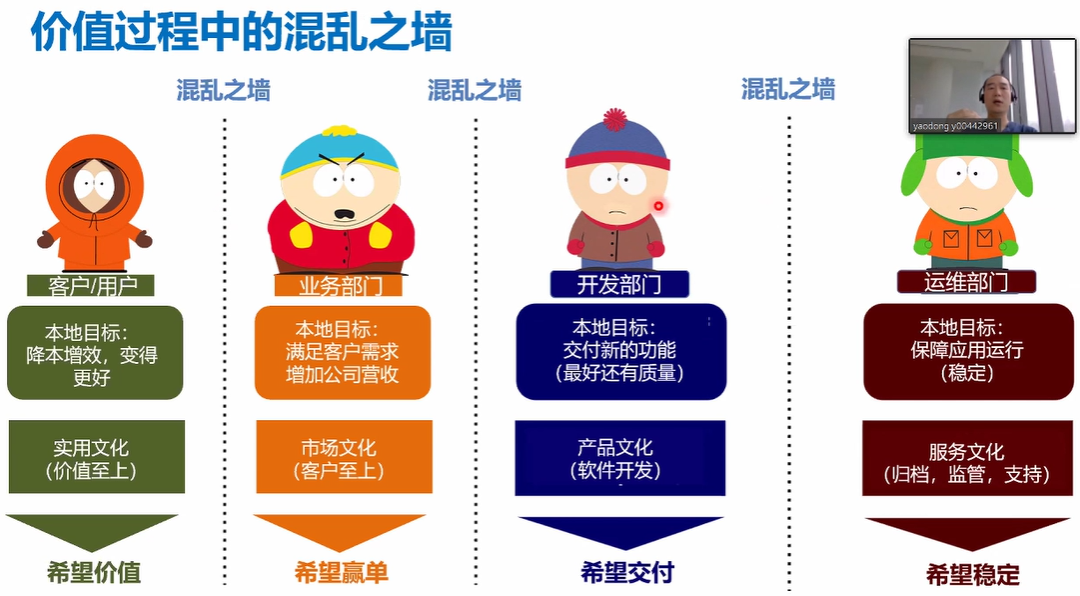
-## 4.3. 价值过程中的混乱之墙
-
-
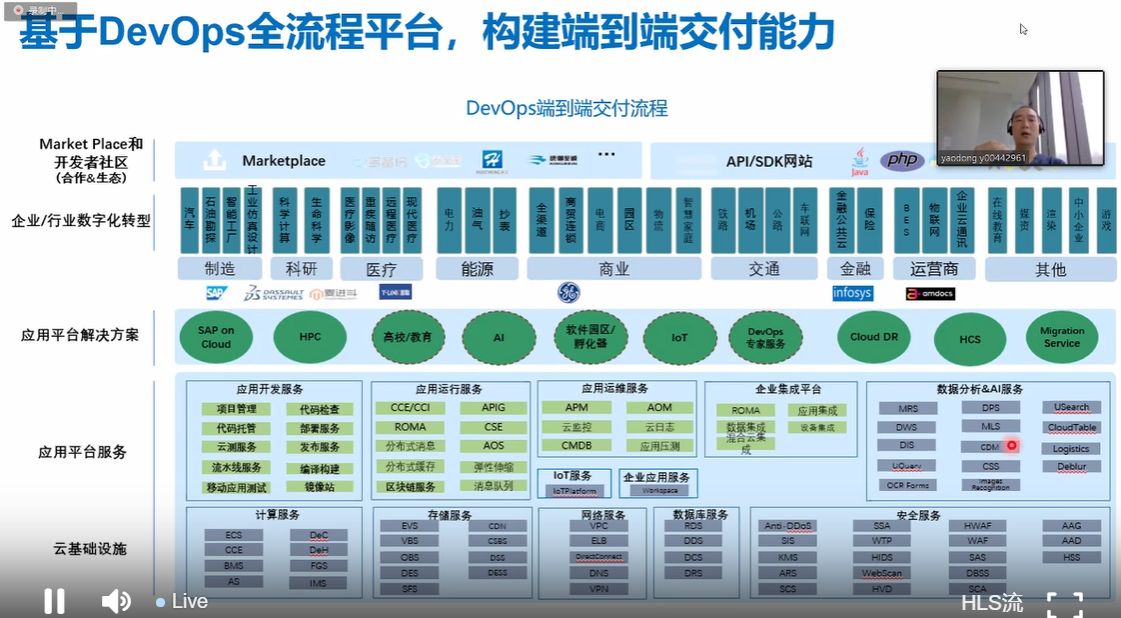
-## 4.4. 华为的技术实现
-
-
-
-
-## 4.5. 漏斗形需求通道消除浪费和风险
-
-
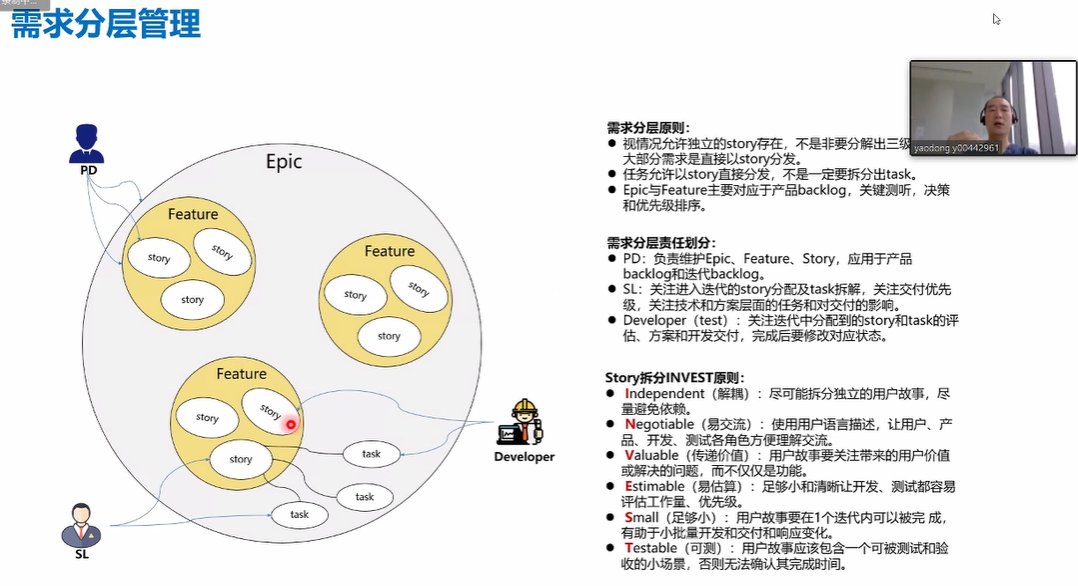
-## 4.6. 需求分层管理
-
-
-## 4.7. 华为敏捷项目管理流程
-
-
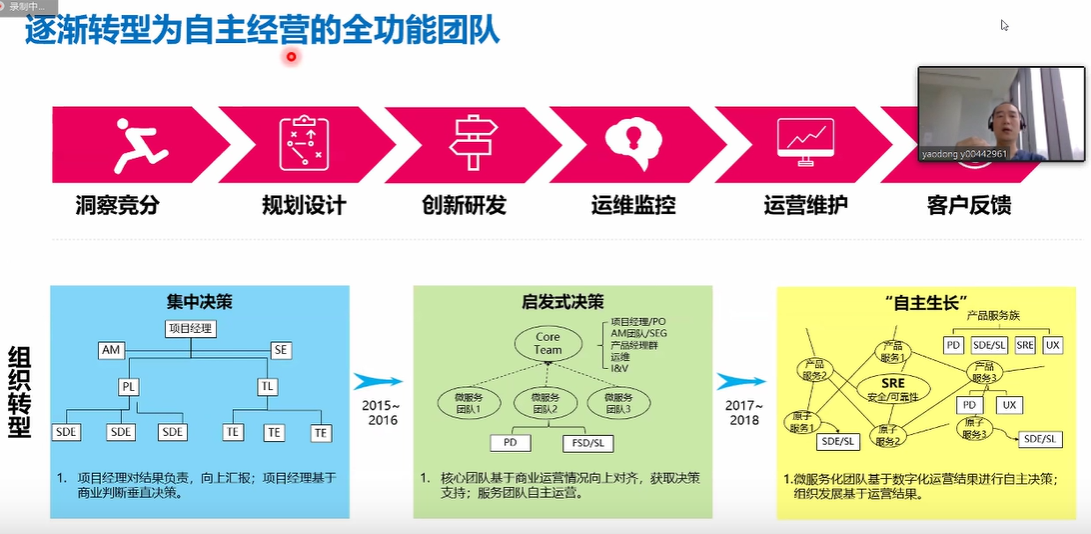
-## 4.8. 逐渐转型为自主经营的全功能团队
-
-
-## 4.9. 康威定律
-
-
-## 4.10. 团队
-1. 全栈铁三角:每个人都应该能做全线的
-
-
-
-## 4.11. Spotify 模式(很好)
-
-
-
-## 4.12. Cloud Native能力构建
-
-
-
-## 4.13. 云原生要素
-
-
-# 5. 测试
-
-## 5.1. 测试金字塔和测试受创面
-
-
-1. 大量的界面测试多
-2. 应该增加写好单元测试
-
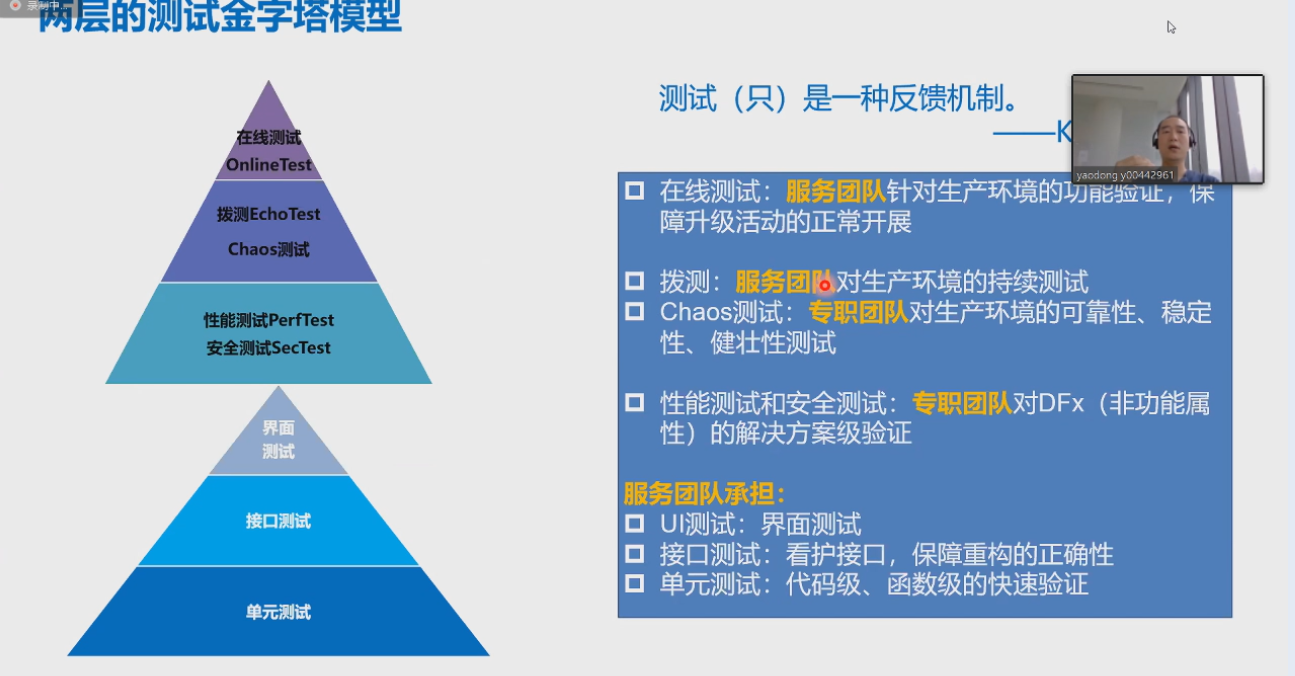
-## 5.2. 两侧的测试金字塔
-
-
-1. 混沌工程(chaos):《混沌工程》
-
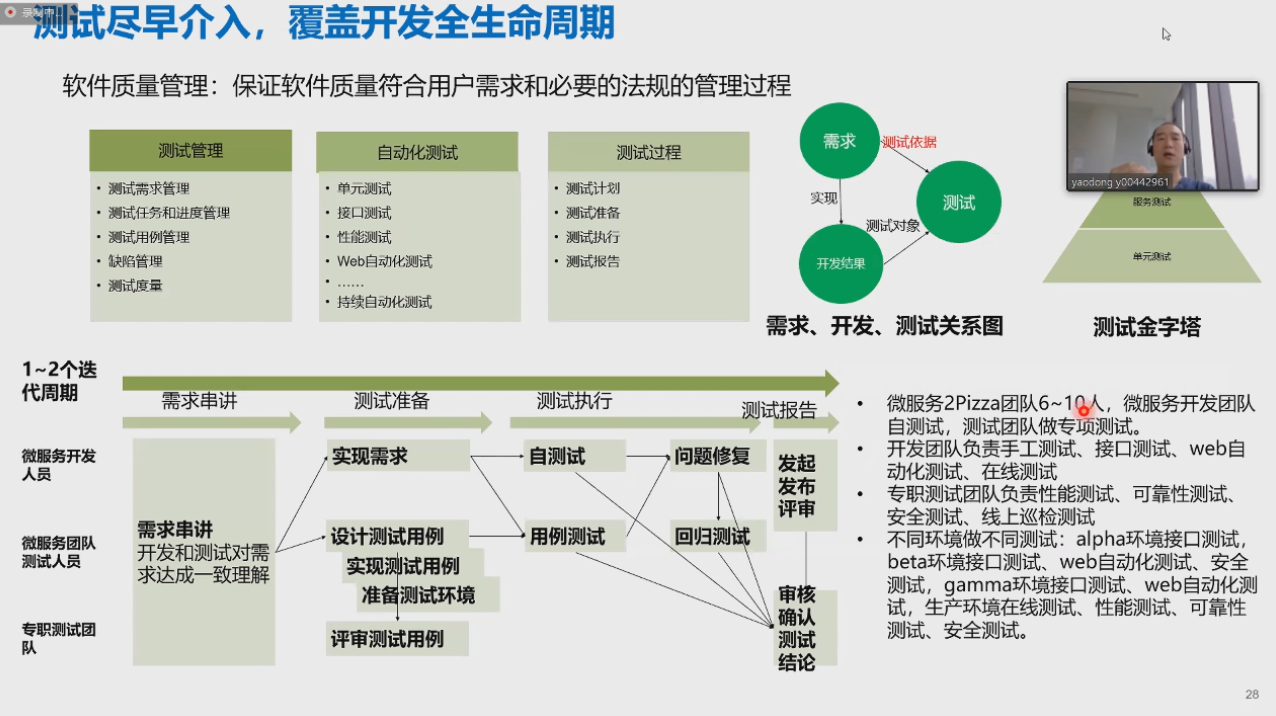
-## 5.3. 测试应该尽早介入
-
-
-
-# 6. Dev实践
-
-
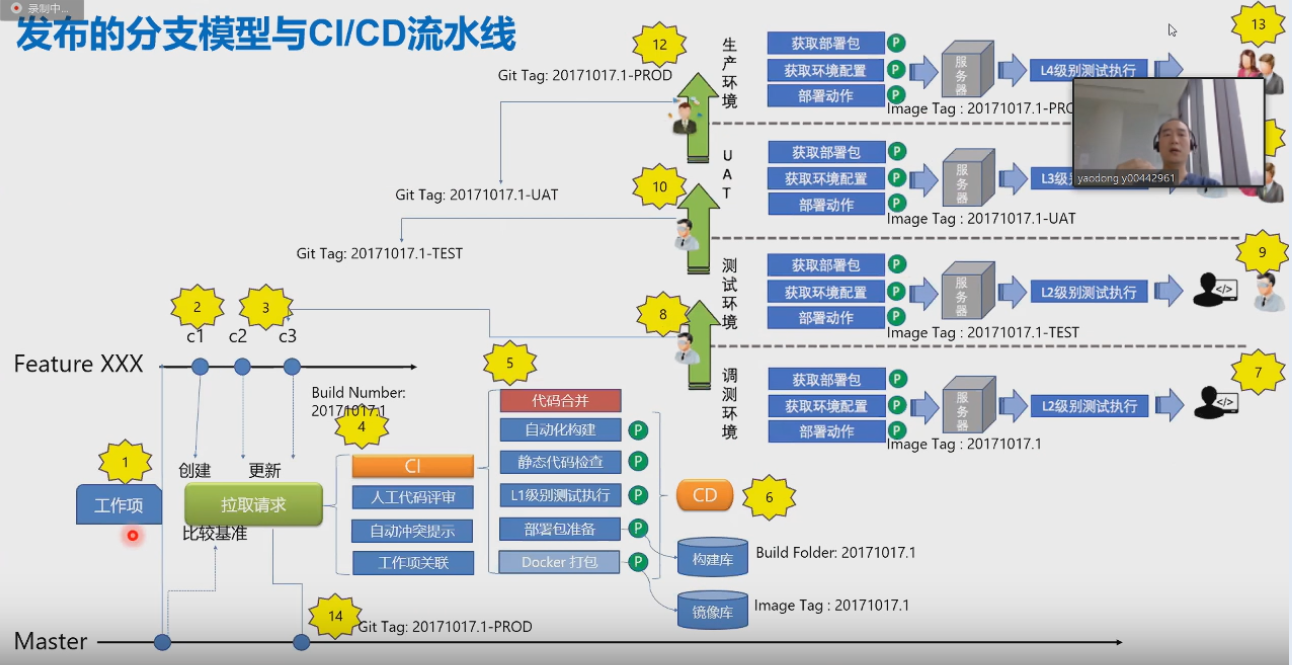
-# 7. CI/CD
-
-
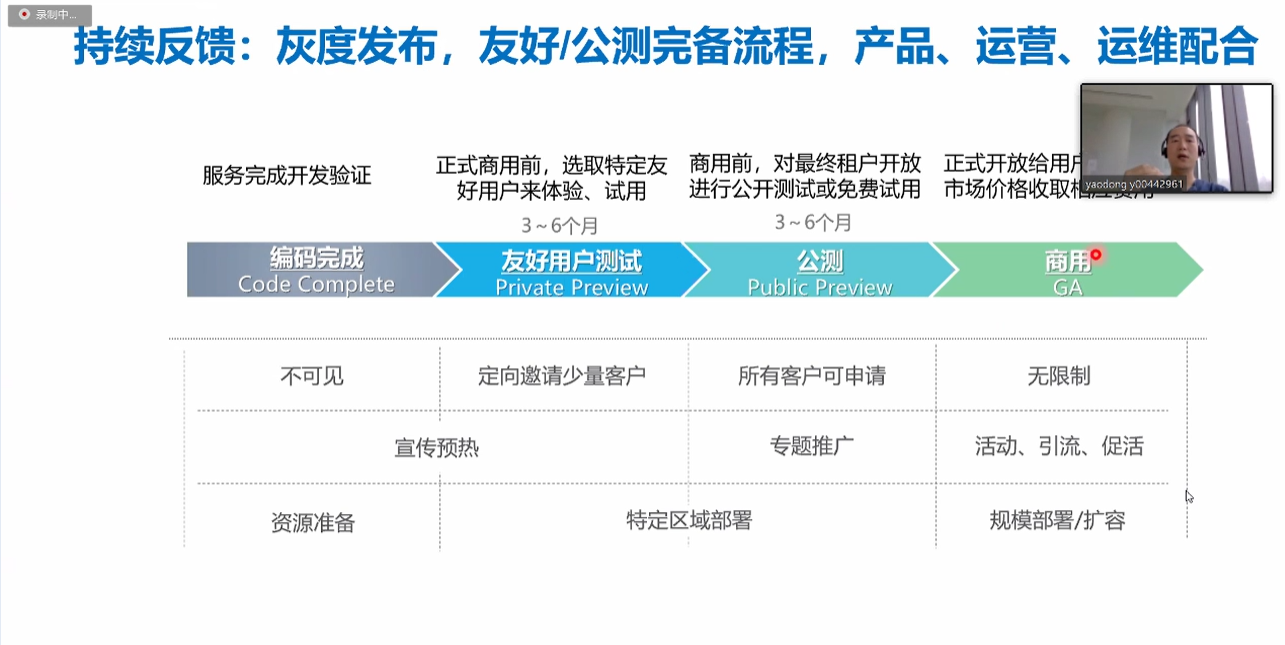
-# 8. 持续反馈:灰度发布
-
-
-1. 首先1%的资源池来进行一次灰度用户
-2. 然后在启动更高级别的灰度
-3. 如果出现问题可以尽快修改
-
-
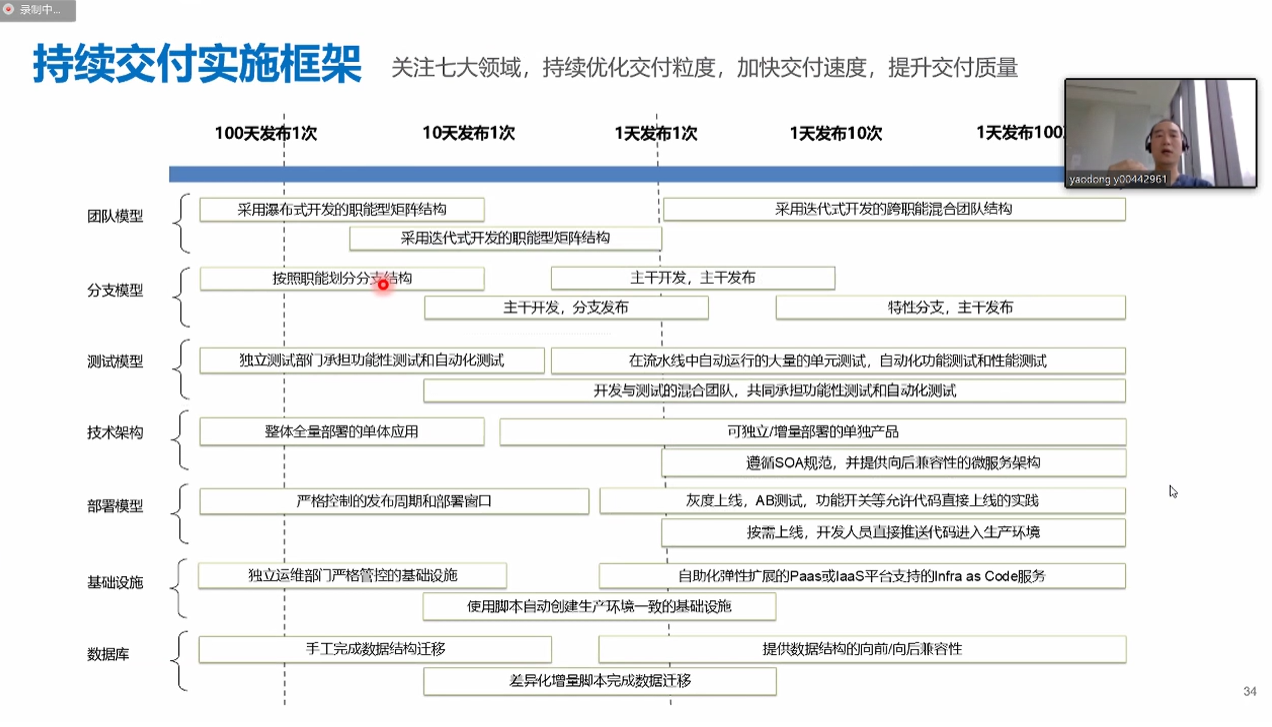
-
diff --git "a/2021-Data-Integration/\345\244\247\346\225\260\346\215\2563.0.md" "b/2021-Data-Integration/\345\244\247\346\225\260\346\215\2563.0.md"
deleted file mode 100644
index 6908459..0000000
--- "a/2021-Data-Integration/\345\244\247\346\225\260\346\215\2563.0.md"
+++ /dev/null
@@ -1,248 +0,0 @@
-大数据3.0:技术的演变历程、发展趋势与应用场景
----
-星环信息科技(上海)有限公司版权所有
-
-# 1. 大数据技术综述
-
-## 1.1. 大数据技术的基本概念
-1. 大数据技术:以**Hadoop**/类Hadoop为代表的**大规模分布式**集群技术**体系**
-2. Hadoop
- 1. 一个**开源**技术体系
- 2. 由国际著名的**Apache软件基金会**主持,起源于Google,由Yahoo、Facebook等国际知名IT公司共同开发
- 3. 通过一系列**大规模分布式集群技术**,实现大数据处理的每个环节(采集 $\rightarrow$ 存储 $\rightarrow$ 管理 $\rightarrow$ 计算 $\rightarrow$ 分析)
- 4. 集群内部、集群之间**精密分工、高度协同**
- 5. 大数据技术体系的**核心和基础**
-
-## 1.2. 大数据技术的演变历程
-
-
-1. 星环在世界上首先提出"Big Data 3.0"概念,并指出其核心就是构建"ABC"深度融合的新型大数据技术体系,并以此为基础,打造覆盖"ABC"全部业务场景的一站式综合平台,以满足客户的多元化、复杂化需求,同时提高用户体验,降低开发、管理和使用复杂度
-2. 星环领先于国内外大数据厂商,率先推出"ABC"融合的平台产品「TDH + Sophon + TDC 」
-
-## 1.3. 大数据技术体系-"ABC"深度融合的3.0技术体系
-
-
-## 1.4. 大数据技术vs 传统数据技术
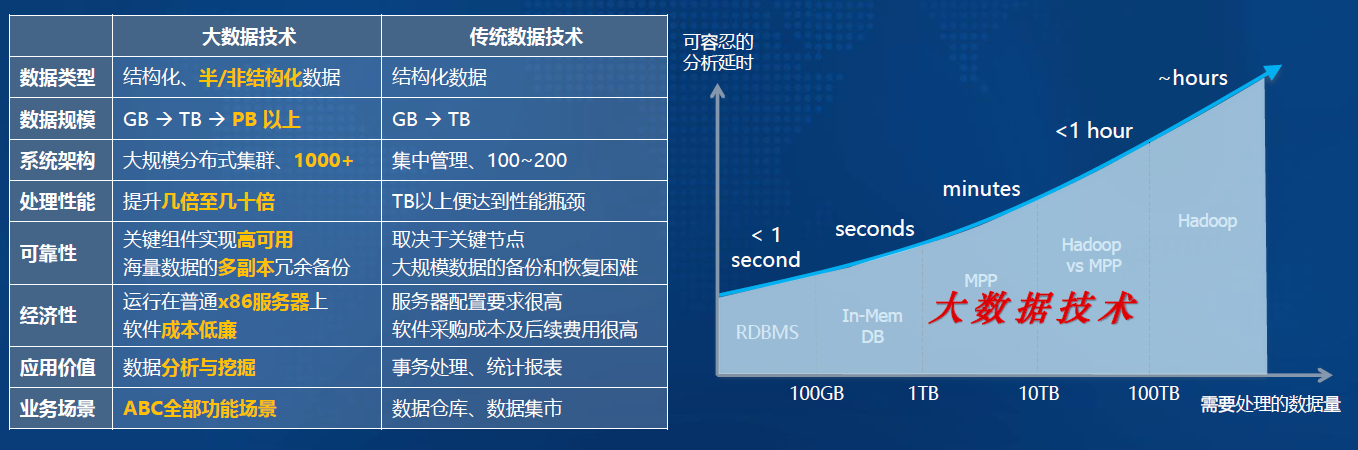
-1. 大数据技术:以Hadoop/类Hadoop为代表的大规模分布式集群技术体系
-2. 传统数据技术:RDBMS(Share-everthing,单机关系数据库)+ RAC(Share-disk,Real Application Cluster/实时应用集群,一库多实例,Oracle RAC)+ MPP(Share-nothing,Massively Parallel Processing/大规模并行处理,分布式关系数据库,Teradata/GreenPlum)
-
-
-
-## 1.5. 大数据技术能做什么-六大功能(场景)
-
-
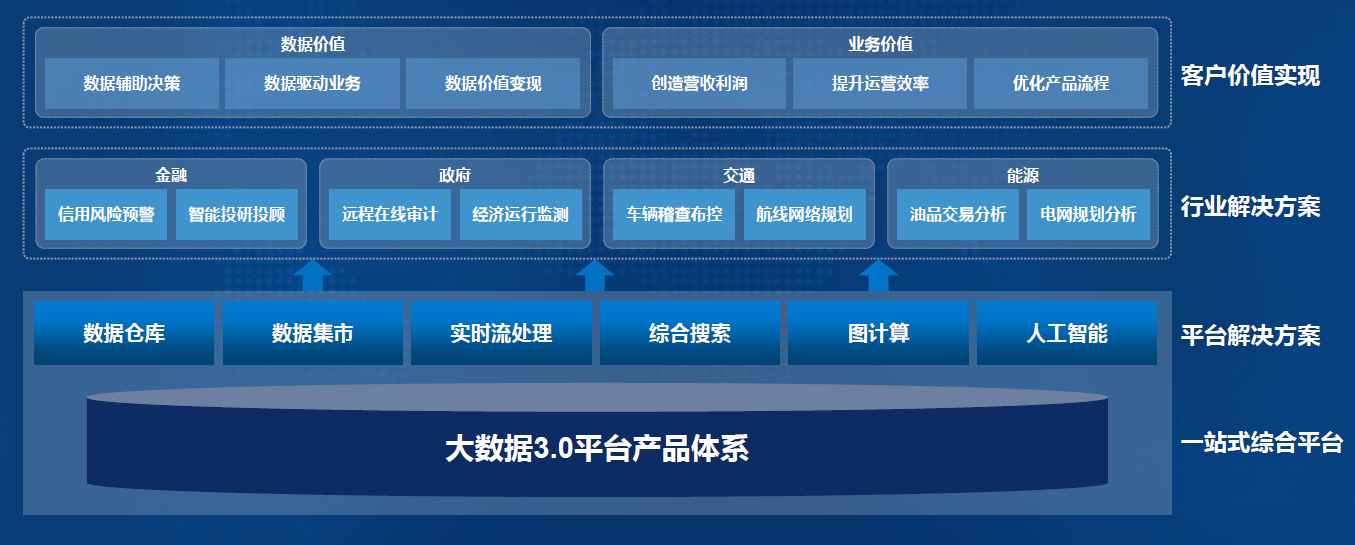
-## 1.6. 大数据技术如何落地-基于产品体系构建3.0融合解决方案
-
-
-## 1.7. Big Data 3.0:大数据技术发展趋势
-
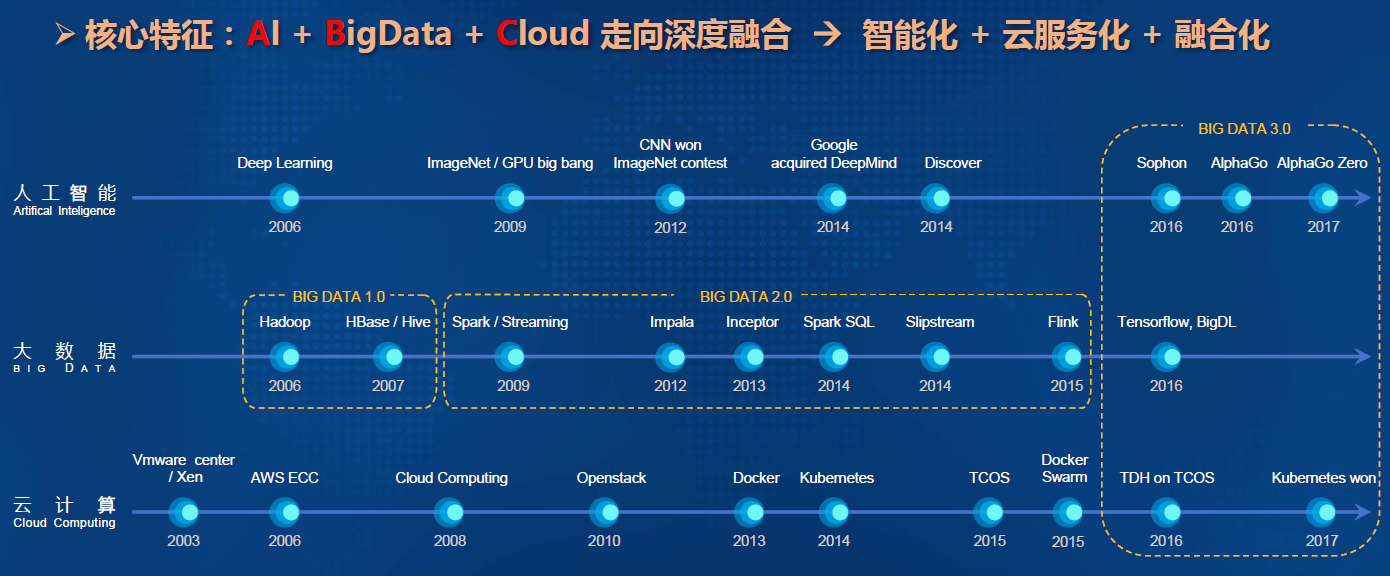
-### 1.7.1. 核心特征
-
-
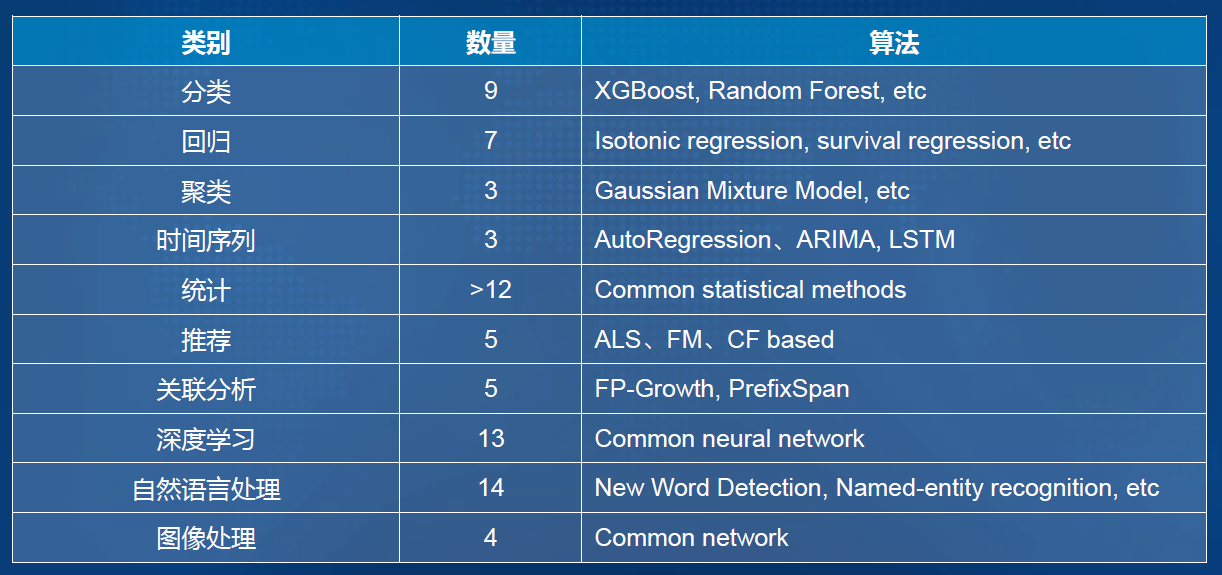
-### 1.7.2. 智能化:分布式人工智能算法
-
-
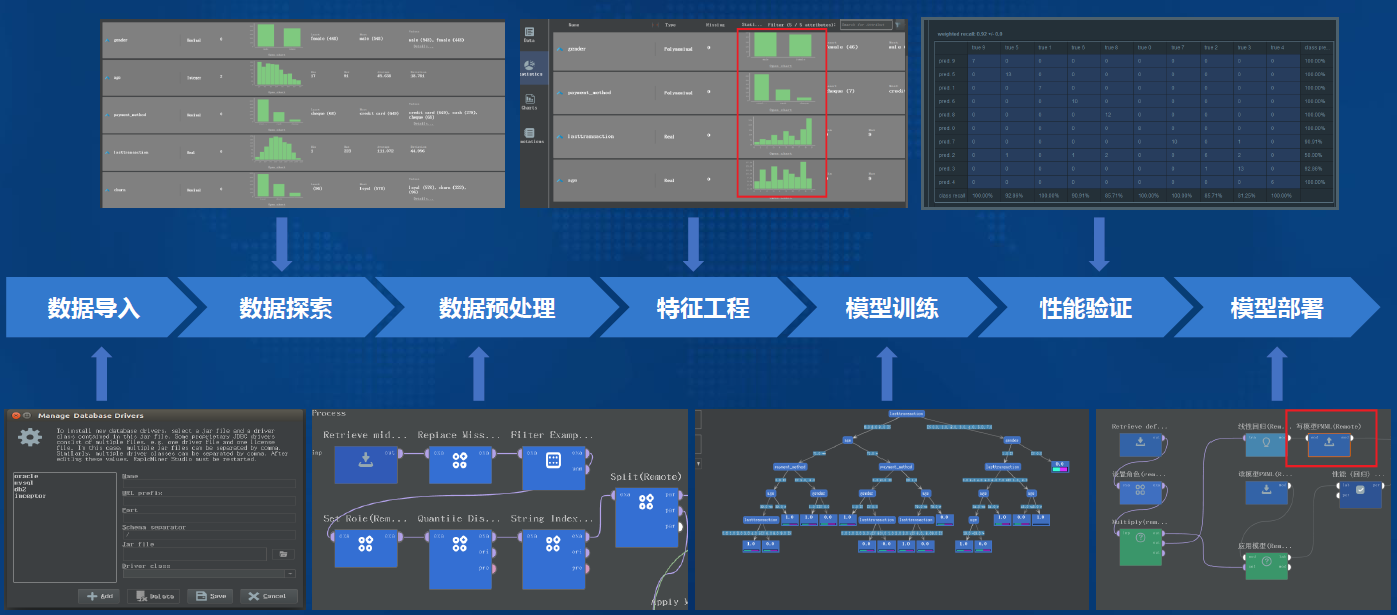
-### 1.7.3. 智能化:机器学习全流程支持
-
-
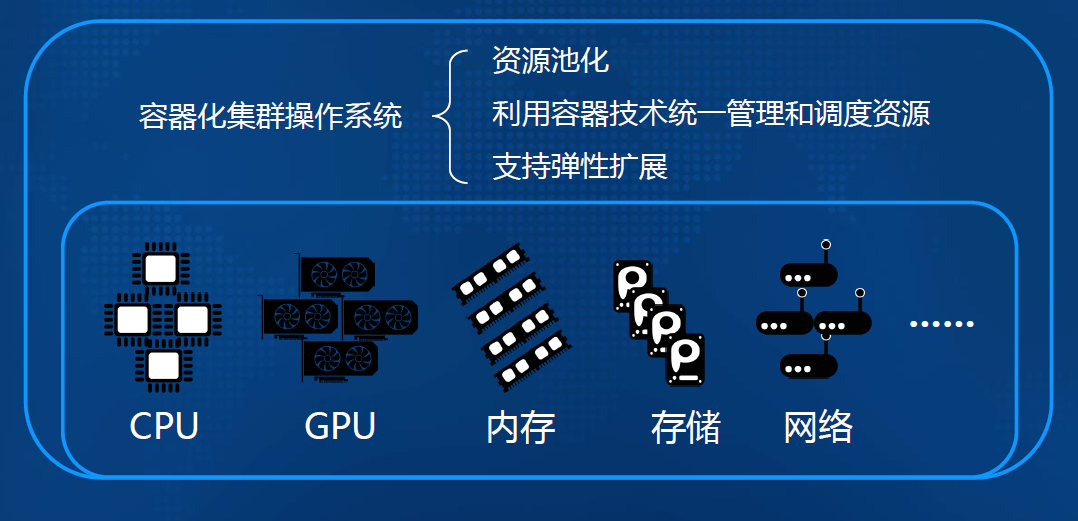
-### 1.7.4. 云服务化:容器化的弹性资源管理和调度,为大数据上云奠定了基础
-
-
-### 1.7.5. 云服务化:在云端提供完整的大数据产品线
-
-
-### 1.7.6. 融合化:平台融合,统一了数据湖、数据仓库和数据集市
-
-
-### 1.7.7. 融合化:服务融合,分析及服务,统一弹性的分析服务调度和管理
-
-
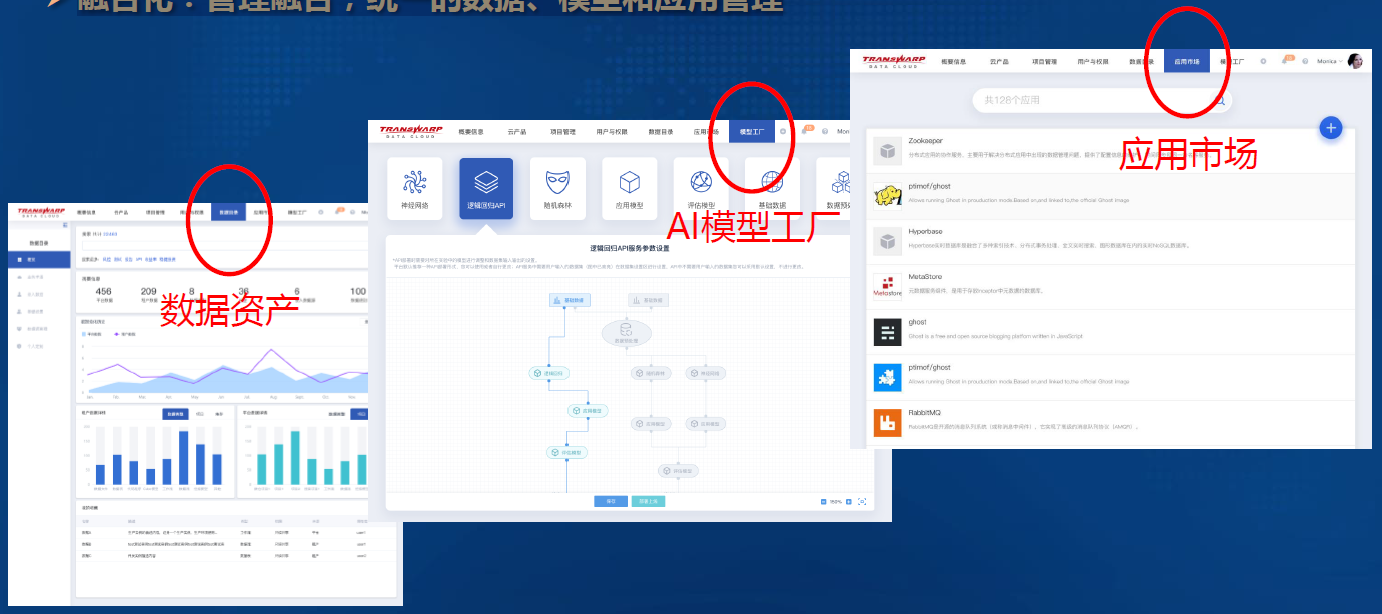
-### 1.7.8. 融合化:管理融合,统一的数据、模型和应用管理
-
-
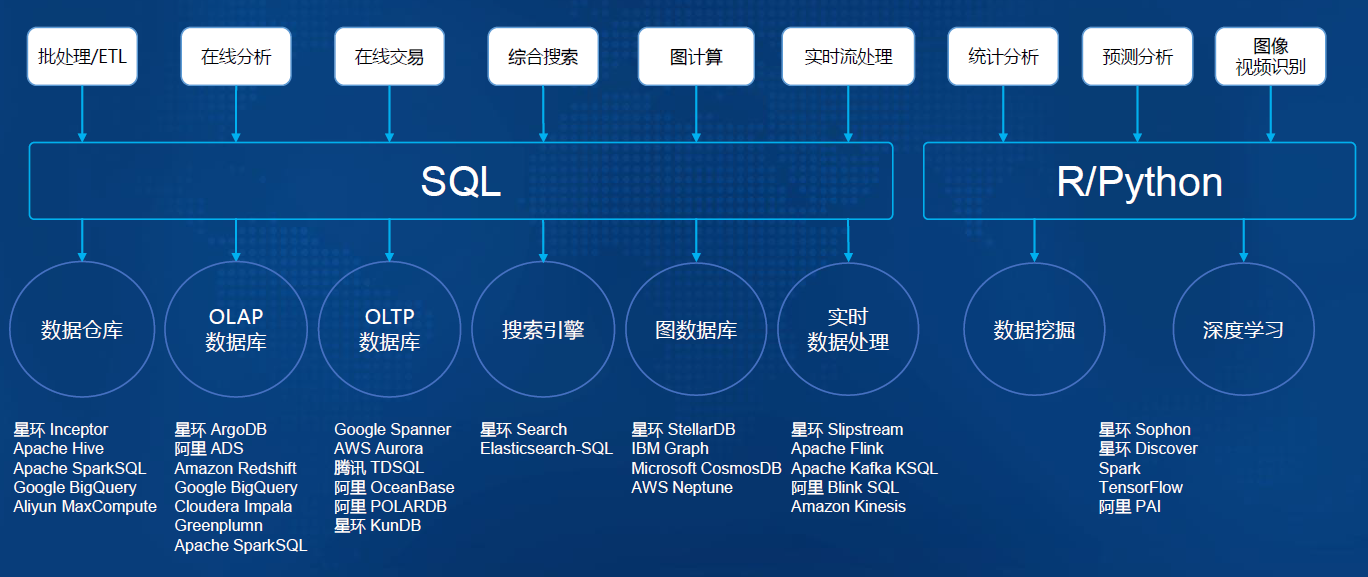
-### 1.7.9. 融合化:开发方式融合,SQL + R/Python
-
-
-### 1.7.10. 融合化:工具融合,完整的BI+AI工具栈,支持数据处理的全生命周期
-
-
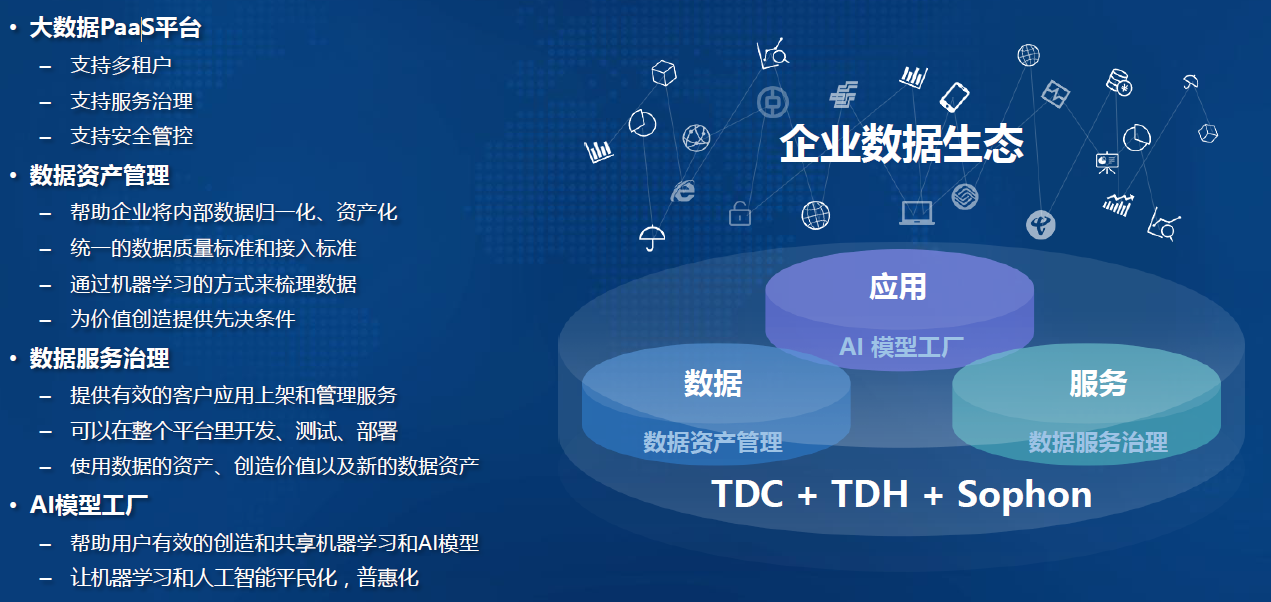
-### 1.7.11. 融合化:数据+ 服务+ 应用融合,三者相互促进,产生闭环,构建企业数据生态
-
-
-# 2. 星环产品体系
-
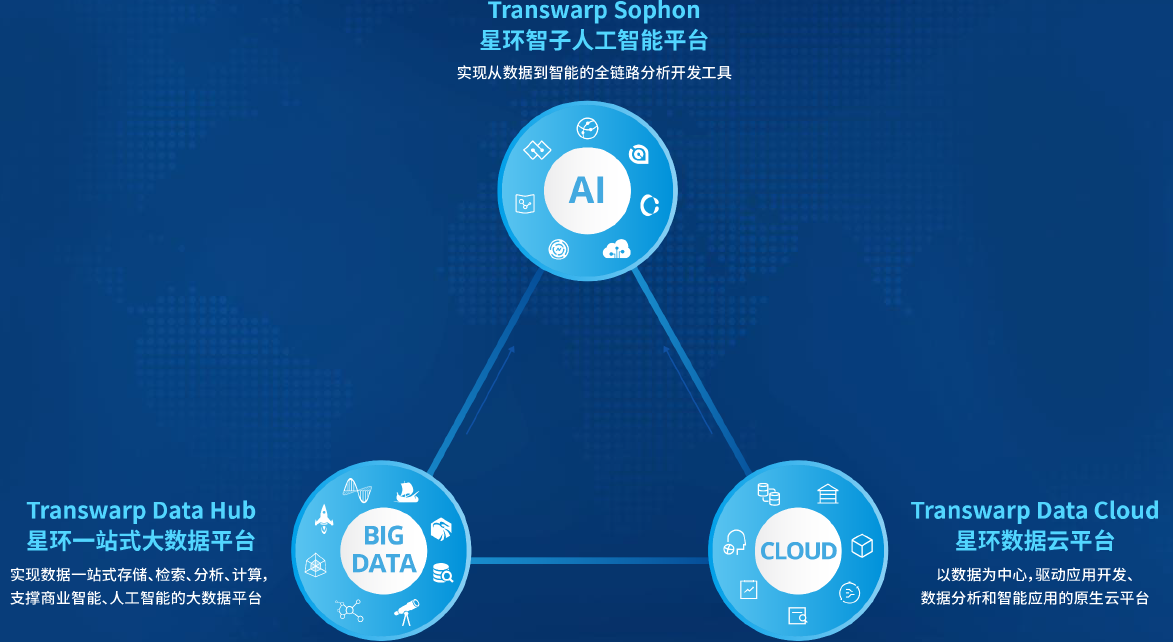
-## 2.1. 星环产品家族(ABC)
-
-
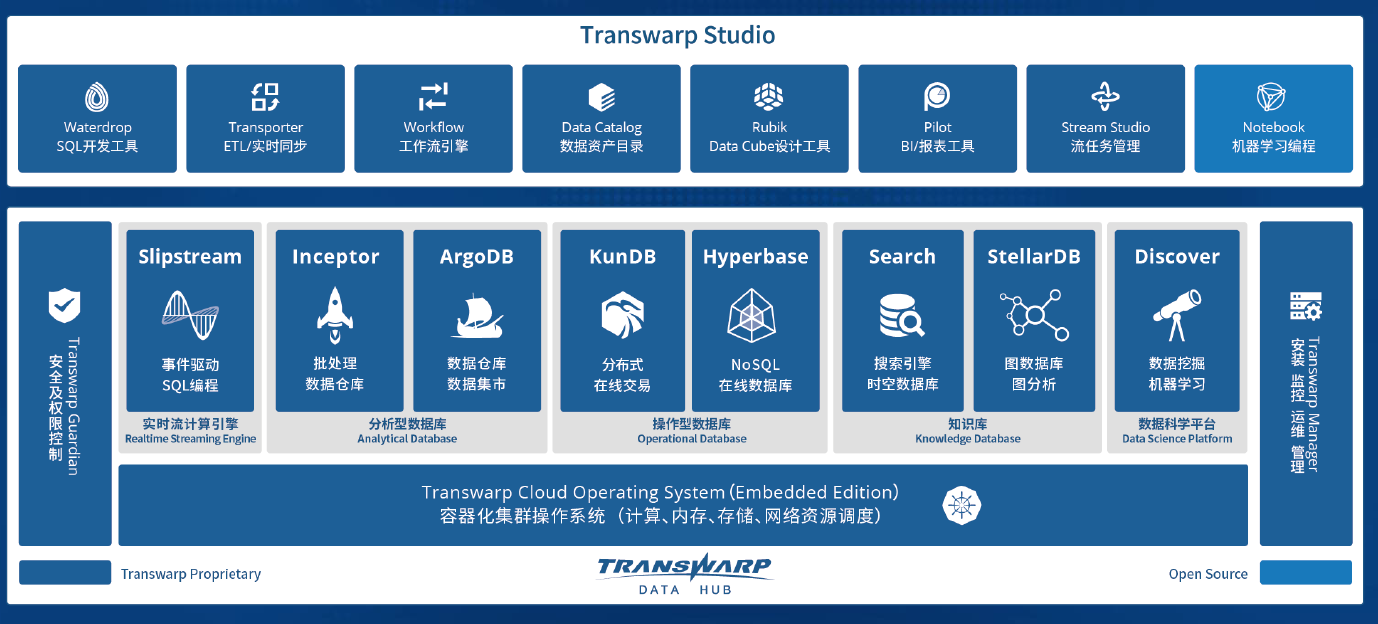
-## 2.2. 星环一站式大数据平台Transwarp Data Hub
-
-
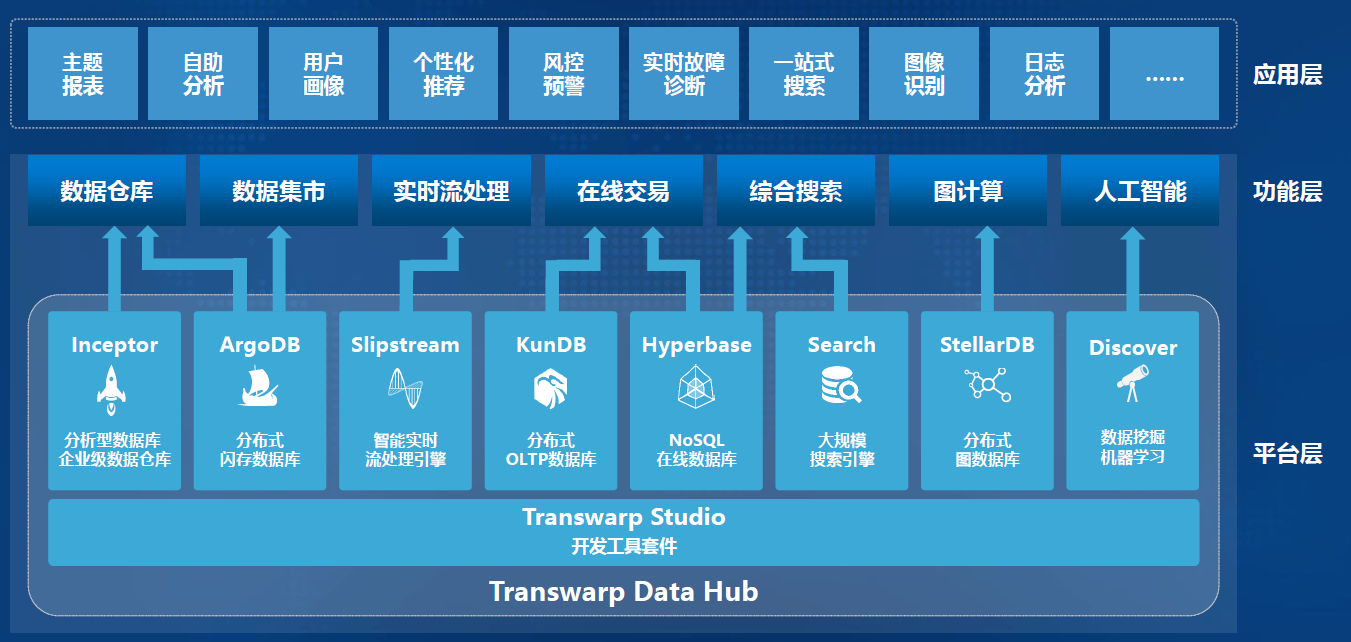
-### 2.2.1. TDH:产品定位
-
-
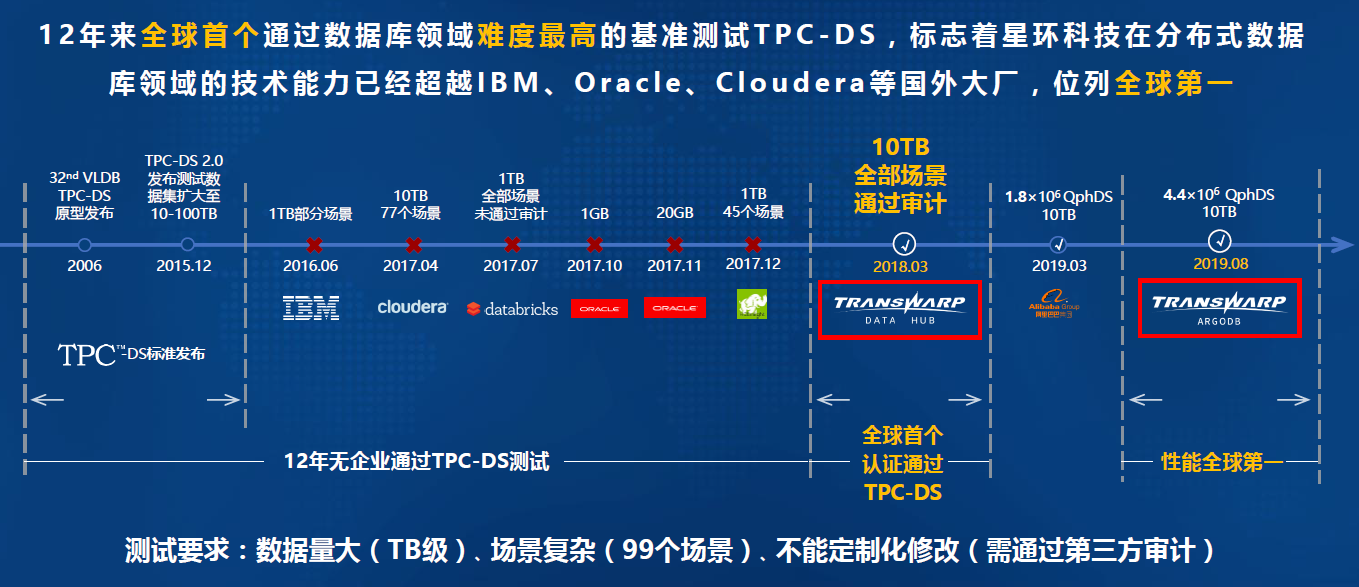
-### 2.2.2. TDH:登顶数据库领域"珠穆朗玛峰",分布式数据库性能全球第一
-
-
-## 2.3. 星环人工智能平台Transwarp Sophon
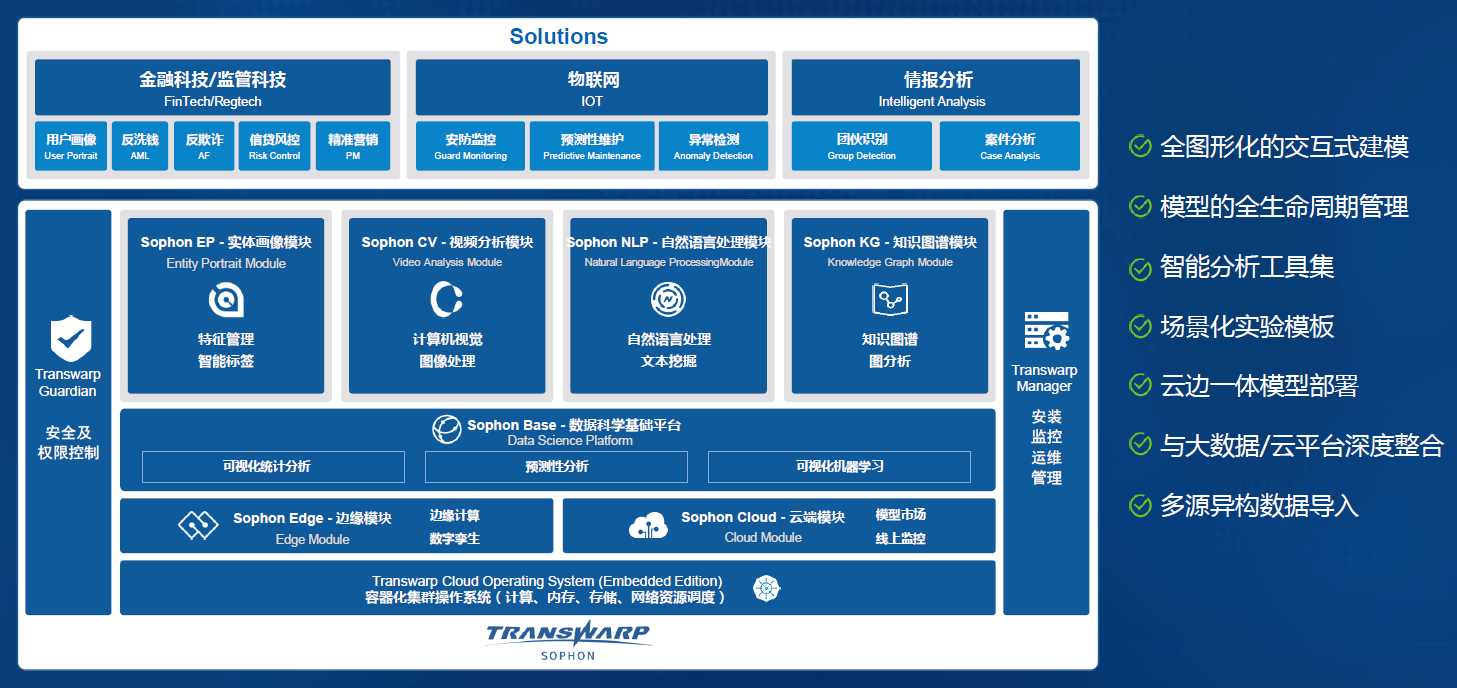
-
-
-1. Sophon 获2018大数据产业峰会唯一AI产品奖
-
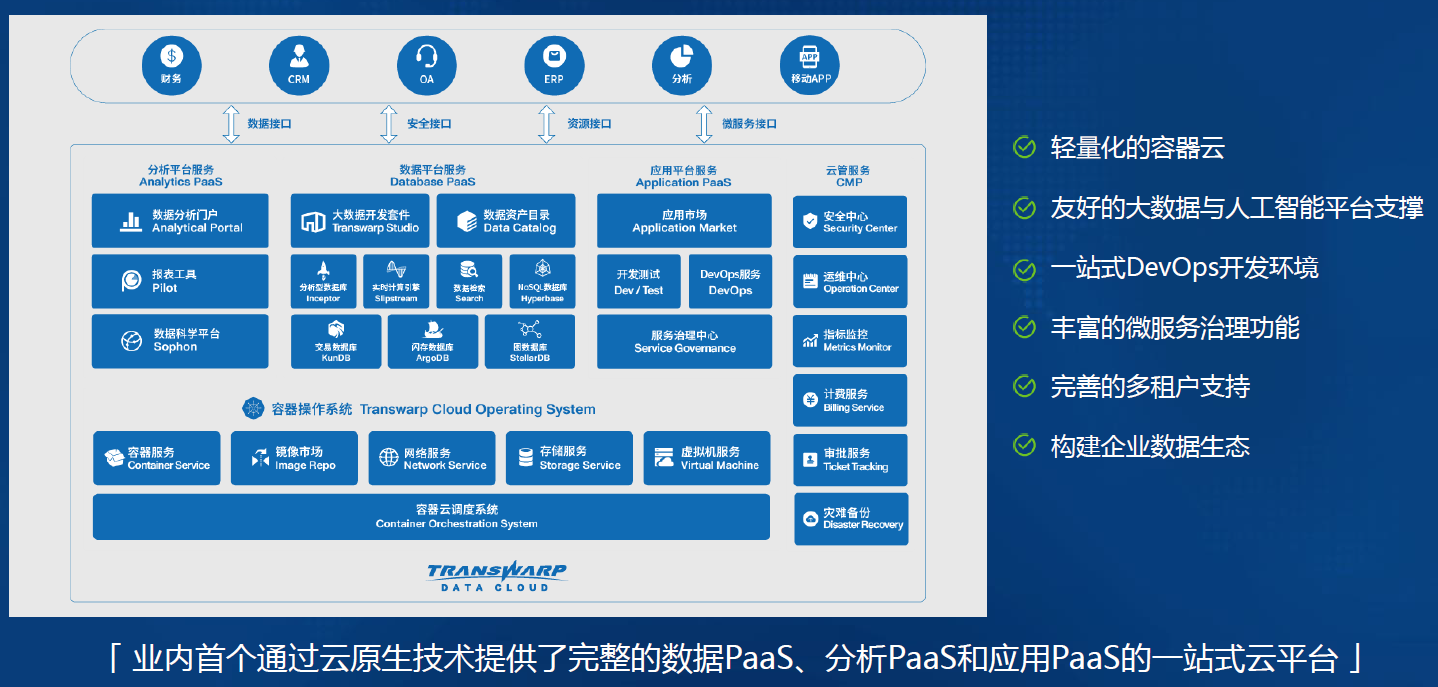
-## 2.4. 星环数据云平台Transwarp Data Cloud
-
-
-## 2.5. 成功替换国外知名基础软件,为国家信息安全保驾护航
-
-
-# 3. 数据仓库案例
-
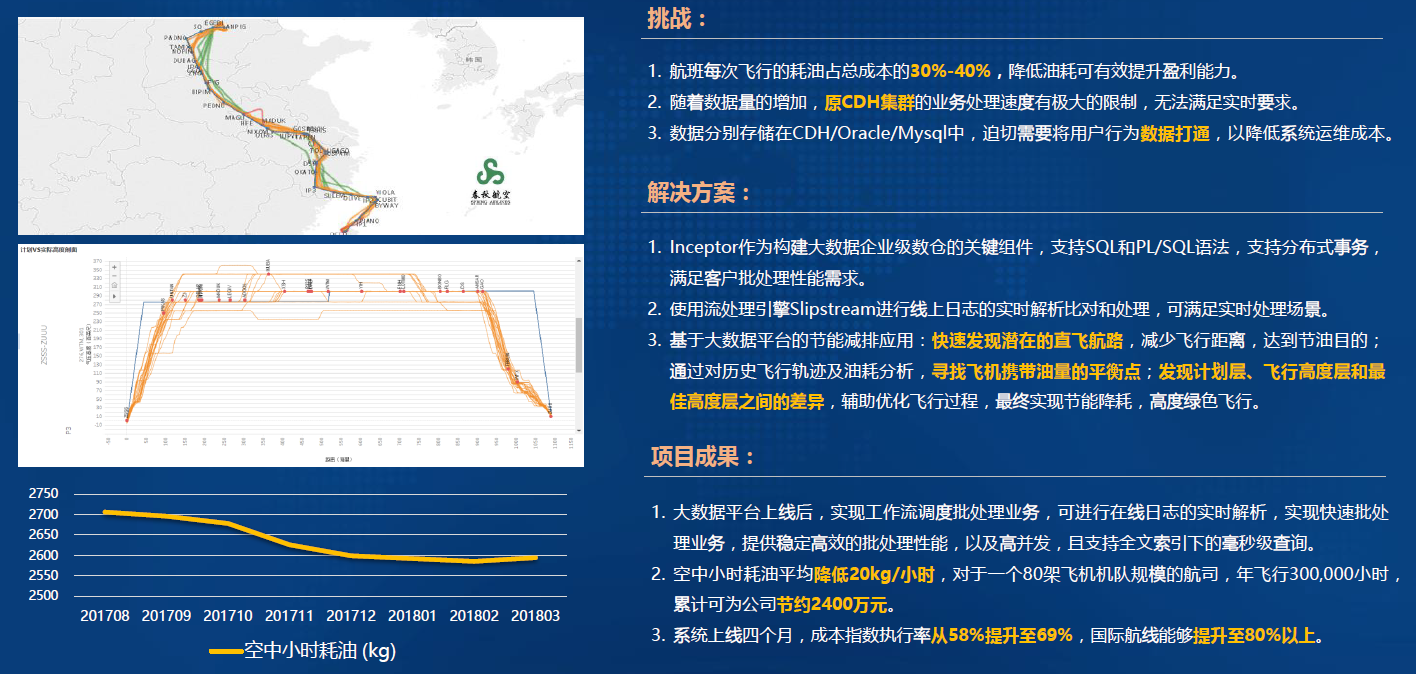
-## 3.1. 交通-春秋航空大数据平台
-
-
-## 3.2. 能源-上海电力智能配用电大数据应系统(863 示范工程)
-
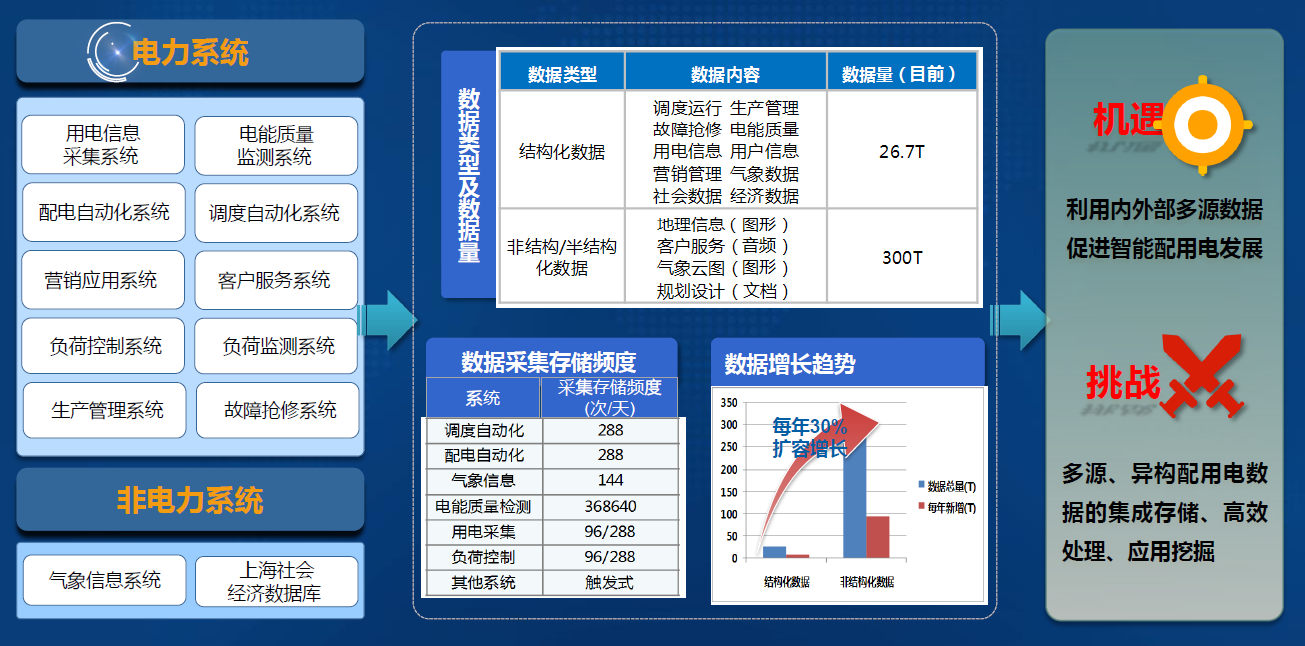
-### 3.2.1. 上海电力大数据的现状与挑战
-
-
-### 3.2.2. 项目来源
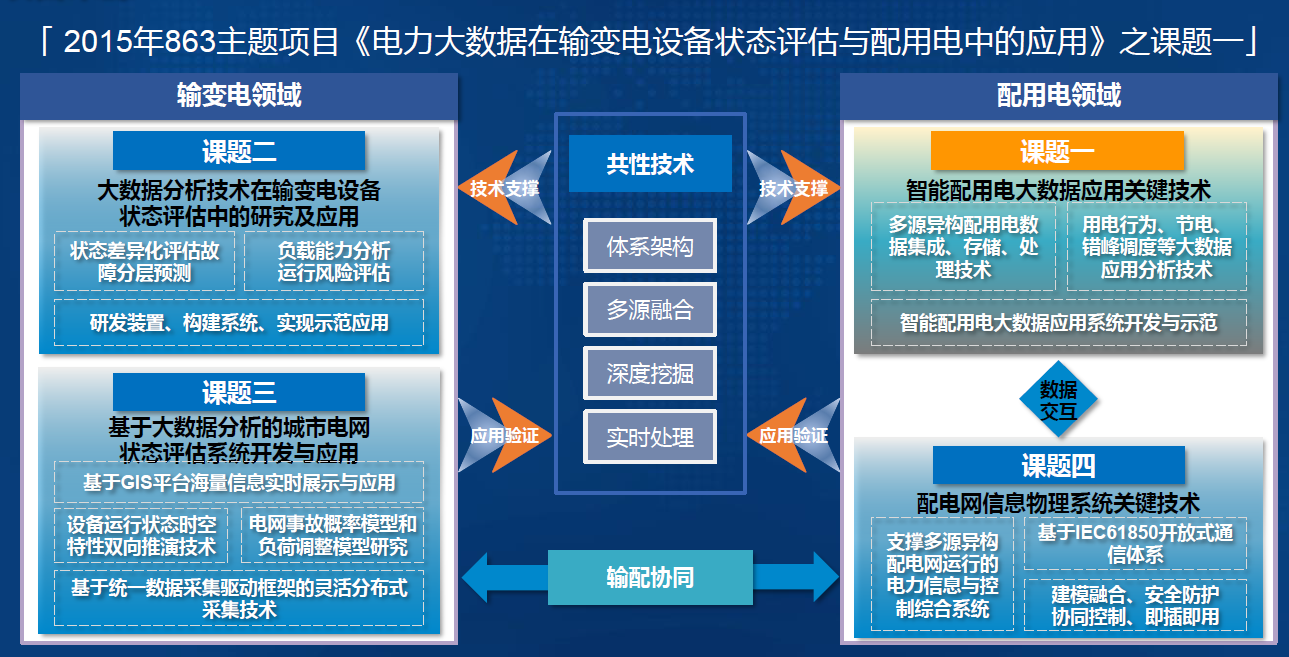
-
-
-### 3.2.3. 建设目标
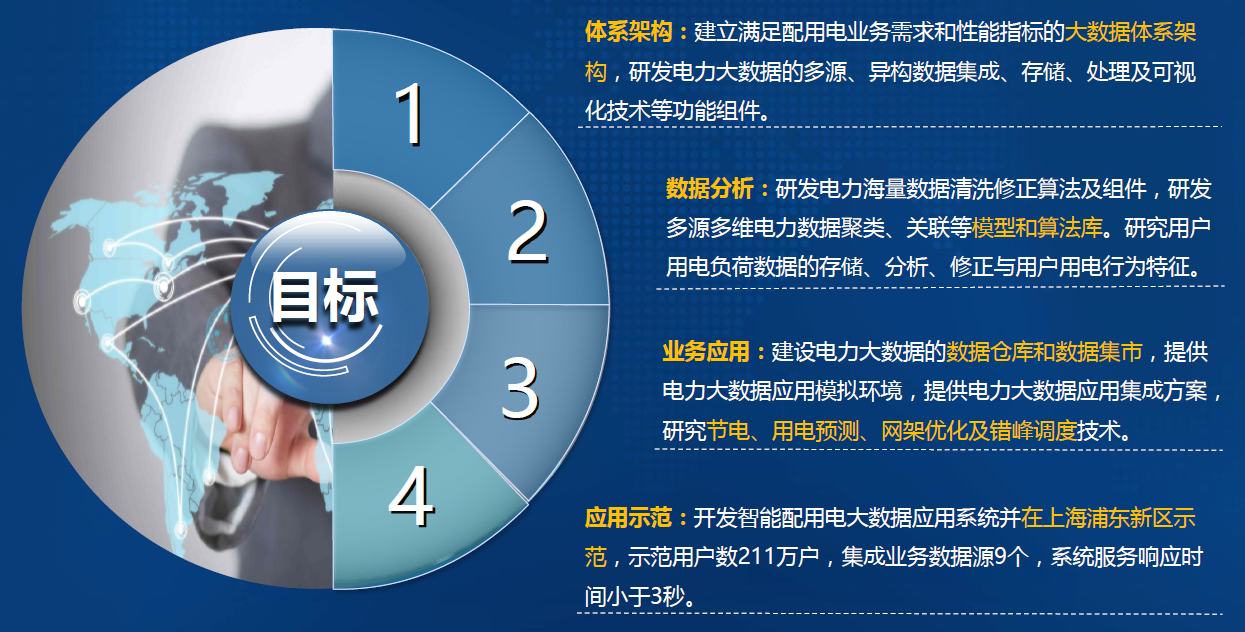
-
-
-### 3.2.4. 总体架构
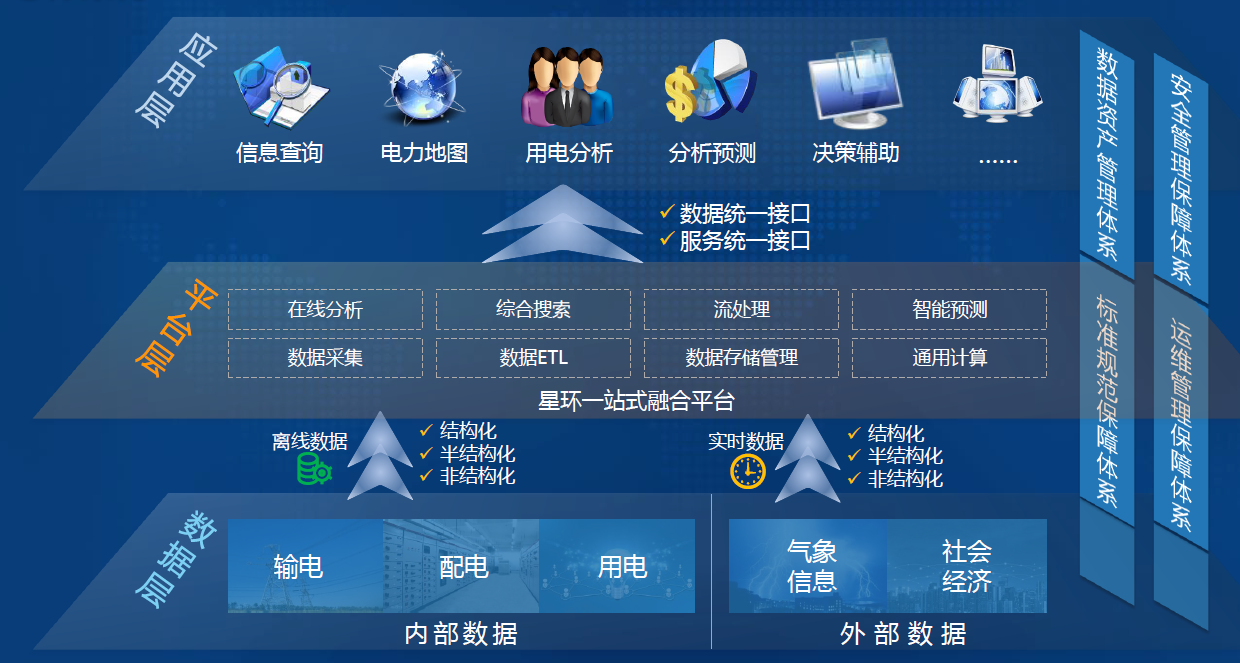
-
-
-### 3.2.5. 技术架构(逻辑数据仓库)
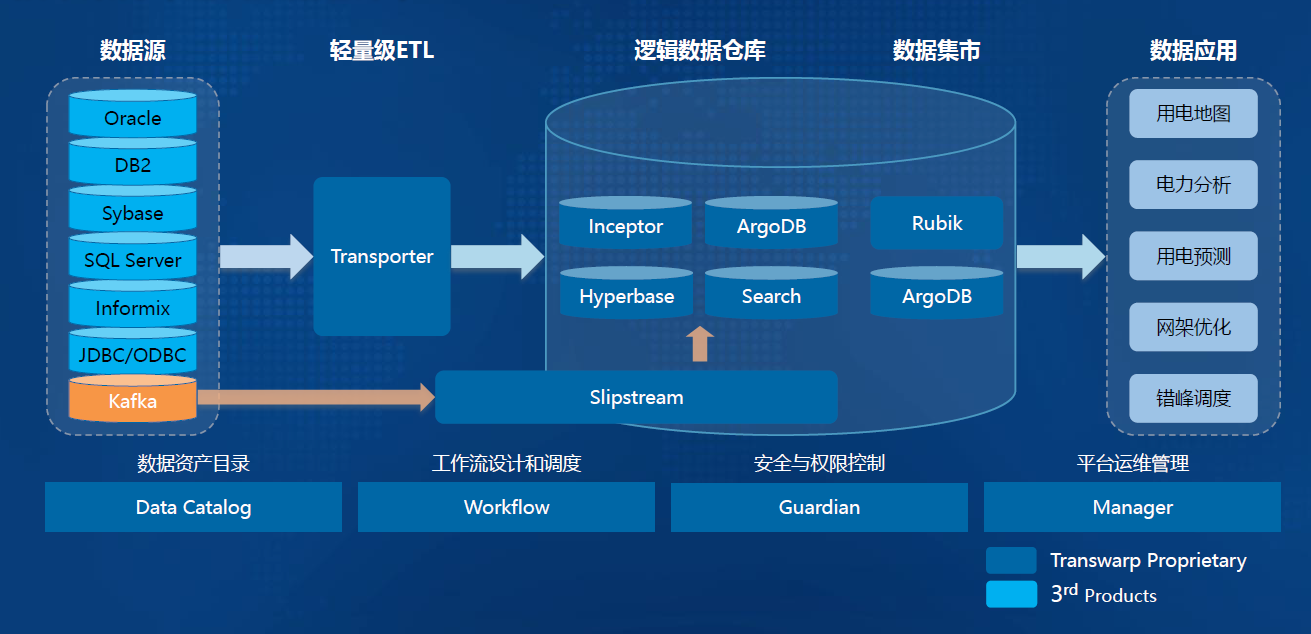
-
-
-### 3.2.6. 项目成果
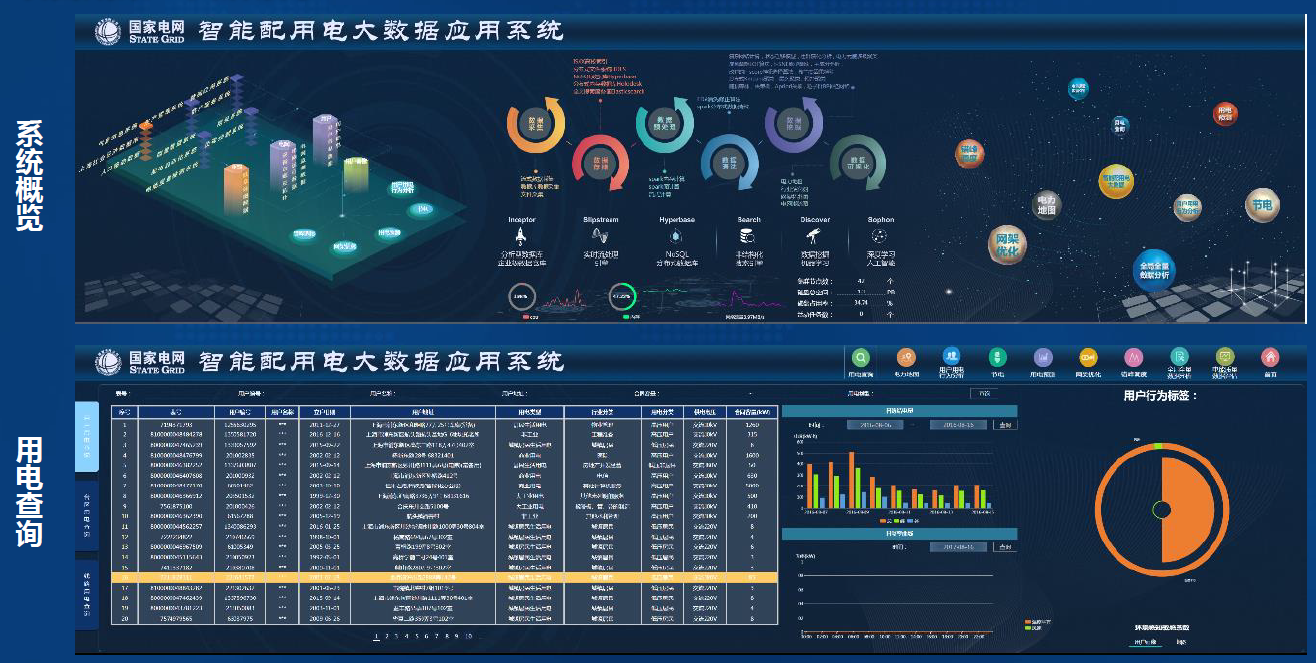
-
-
-# 4. 数据集市案例
-
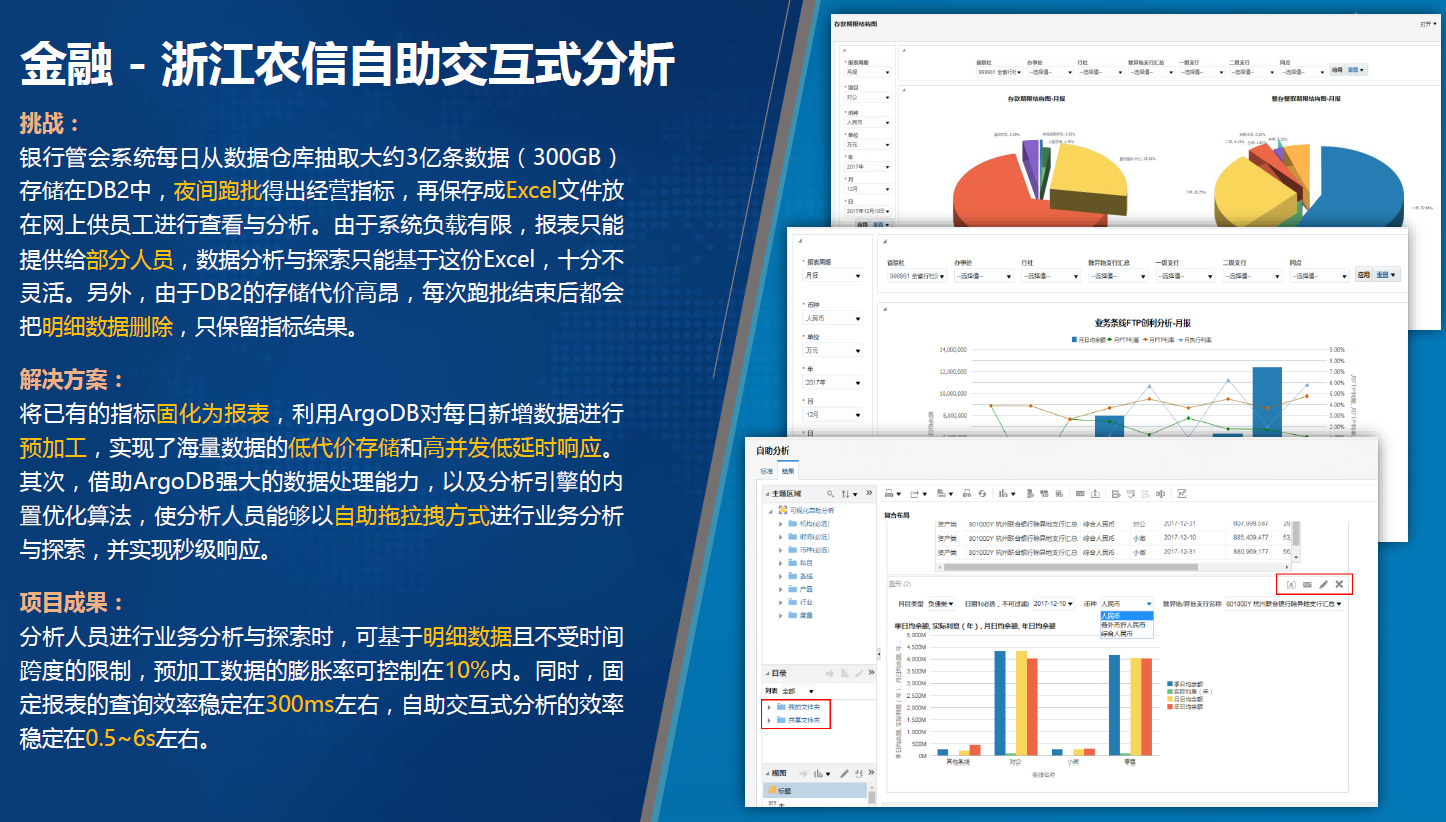
-## 4.1. 金融- 浙江农信自助交互式分析
-
-
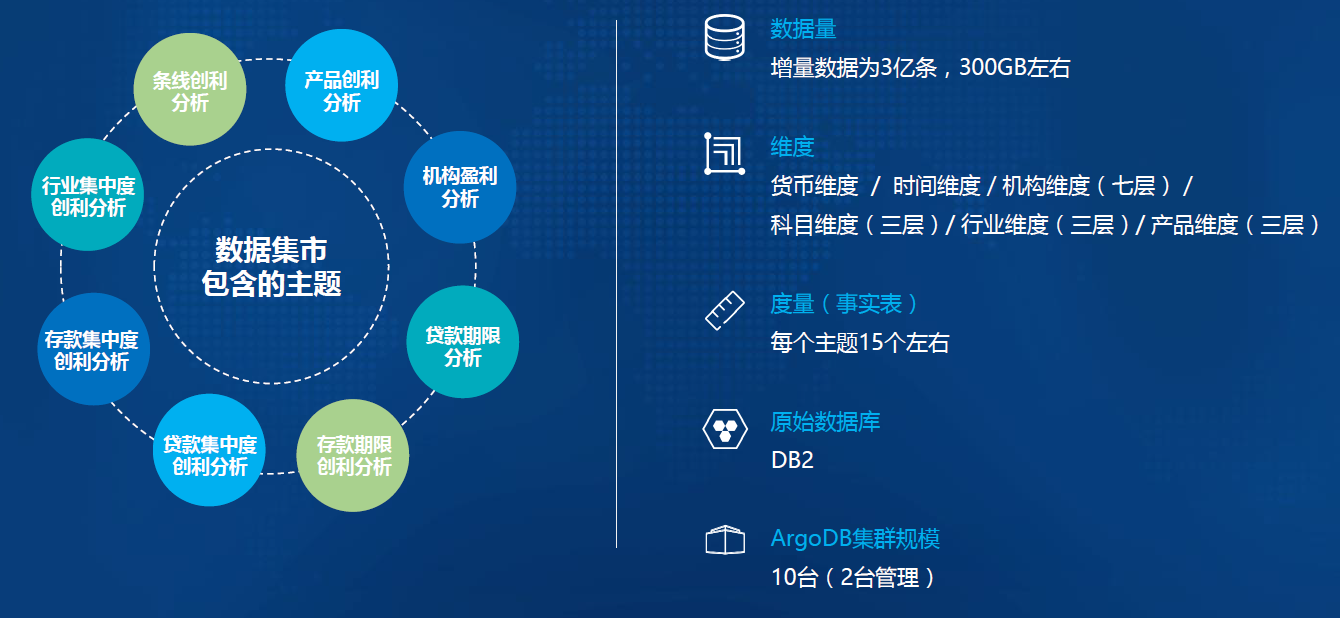
-### 4.1.1. 项目概况
-
-
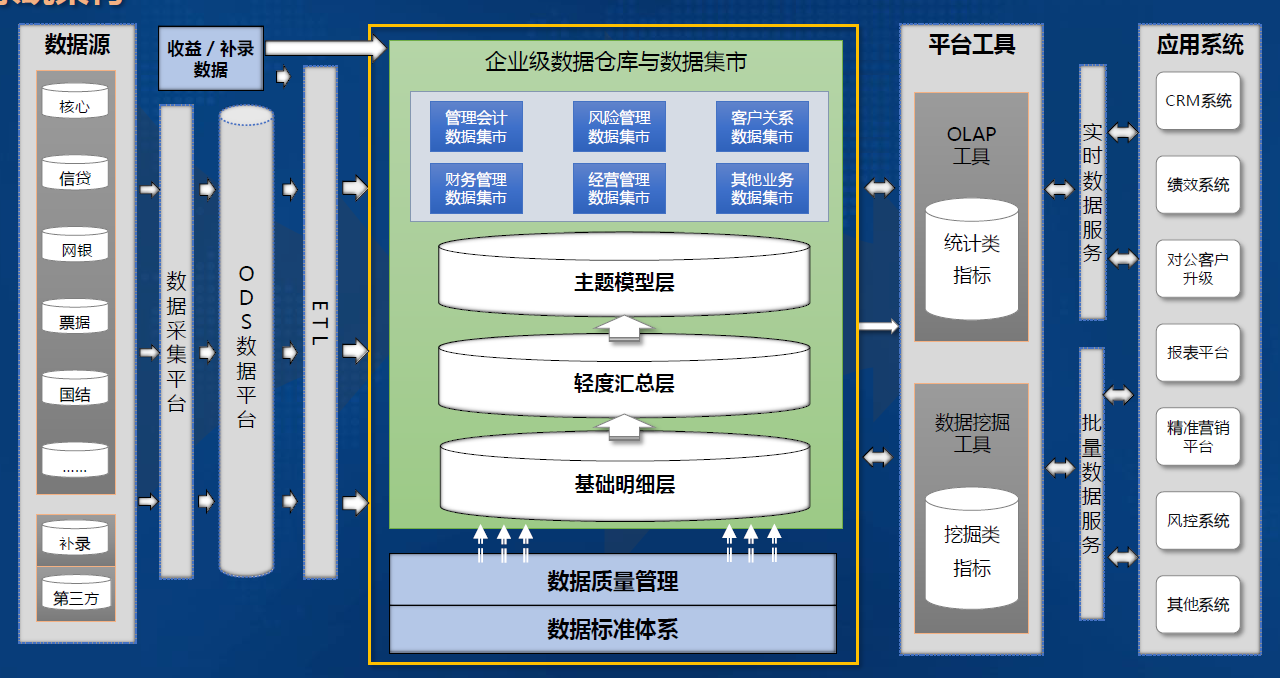
-### 4.1.2. 系统架构
-
-
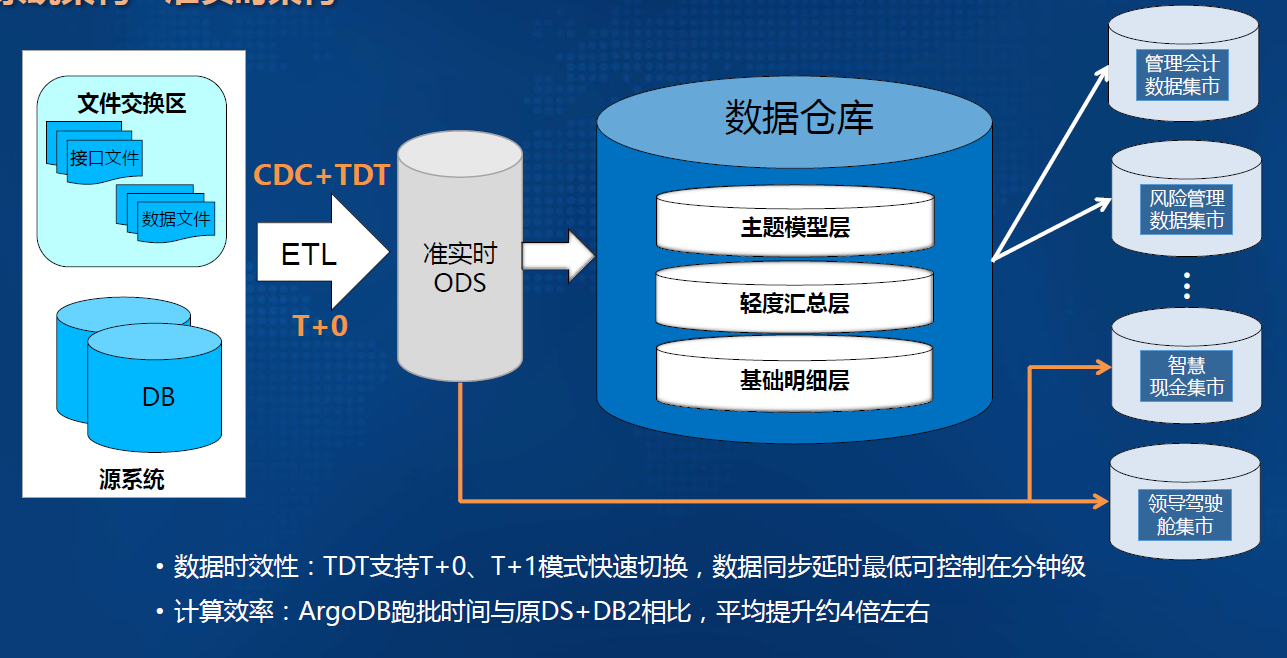
-#### 4.1.2.1. 准实时架构
-
-
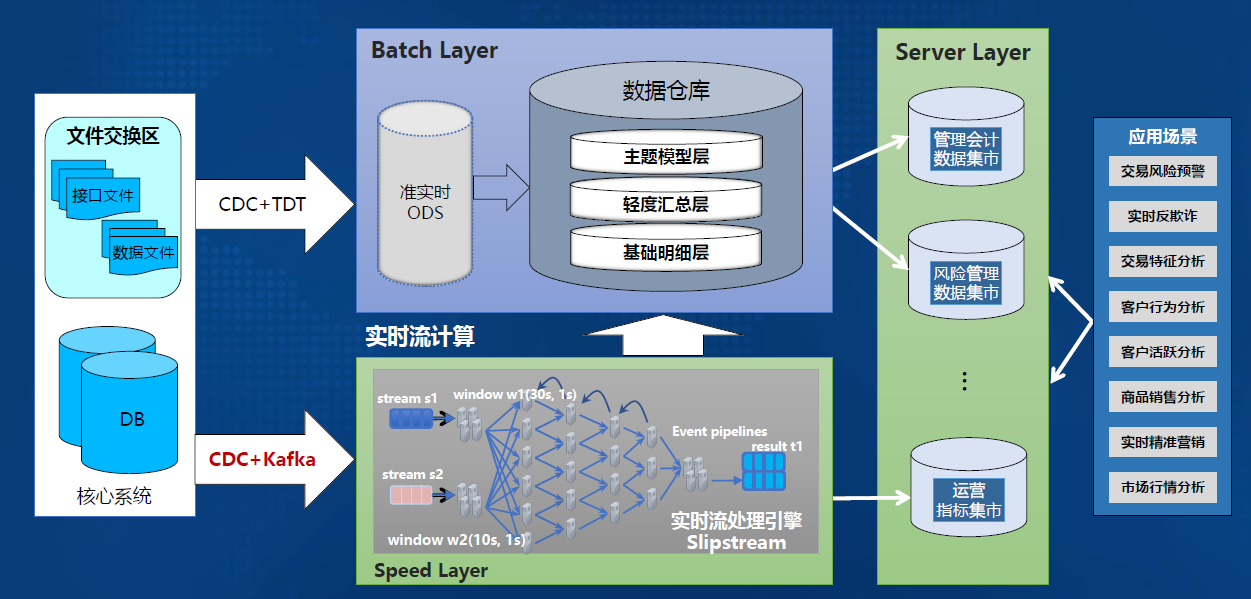
-#### 4.1.2.2. 实时架构
-
-
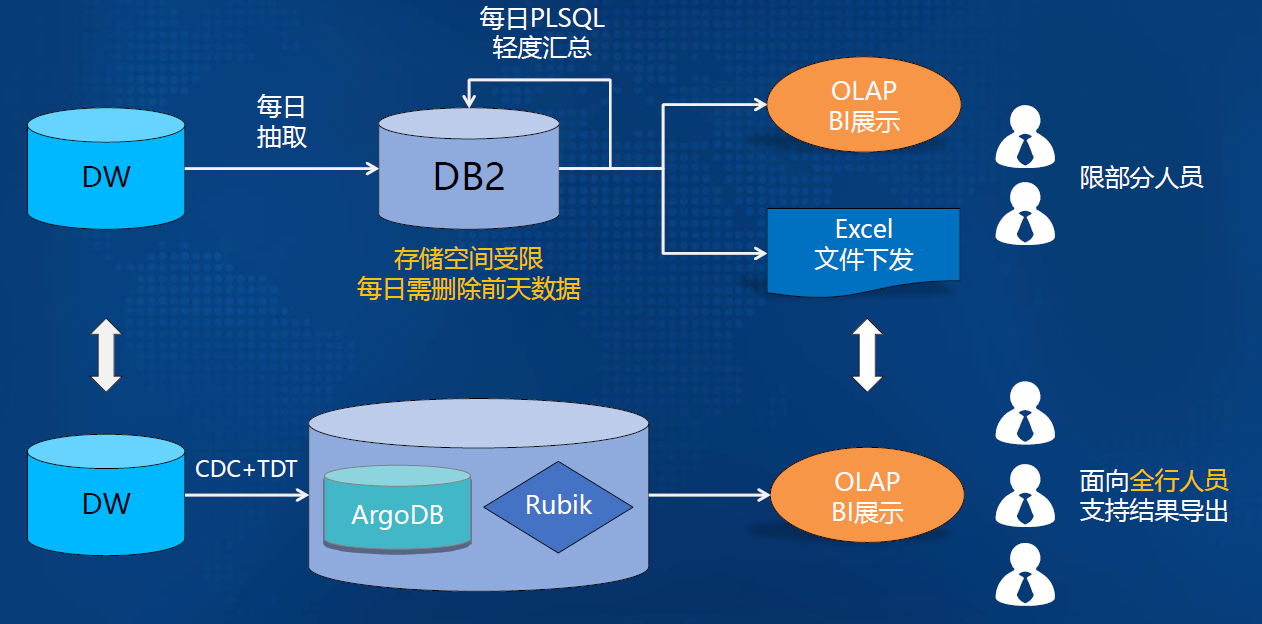
-### 4.1.3. 技术架构
-
-
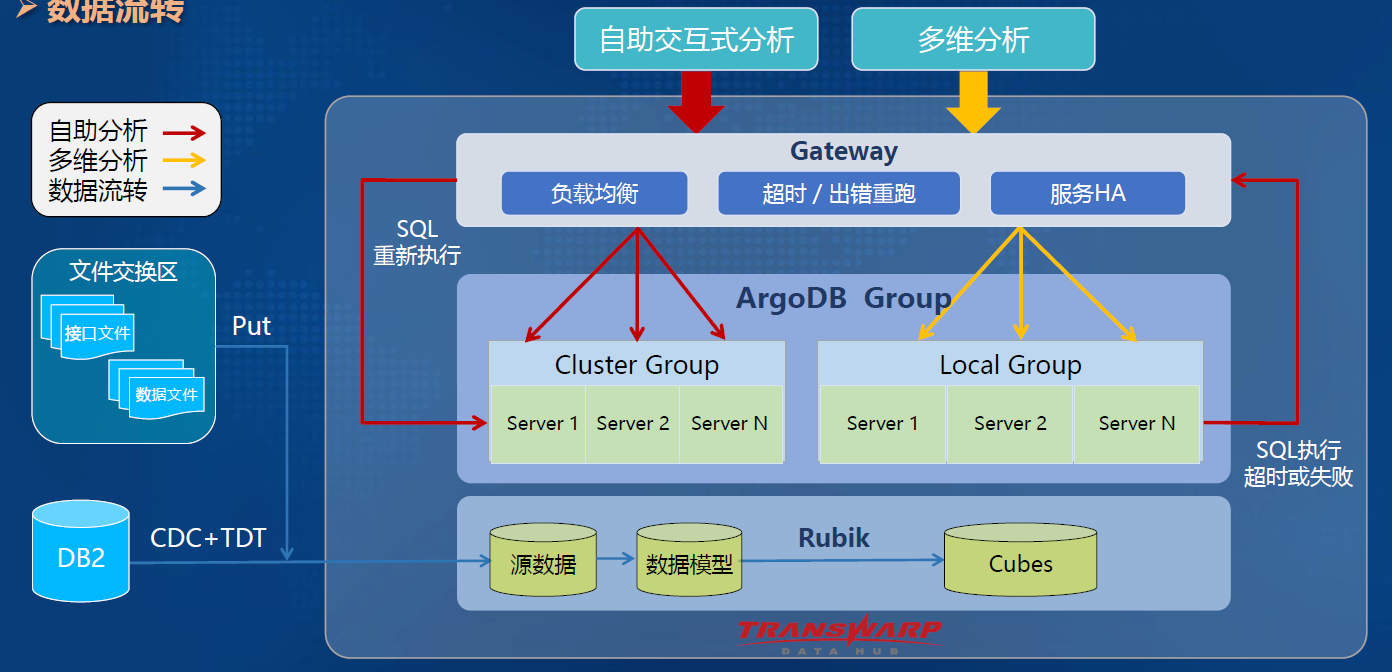
-### 4.1.4. 数据流转
-
-
-### 4.1.5. 平台应用
-
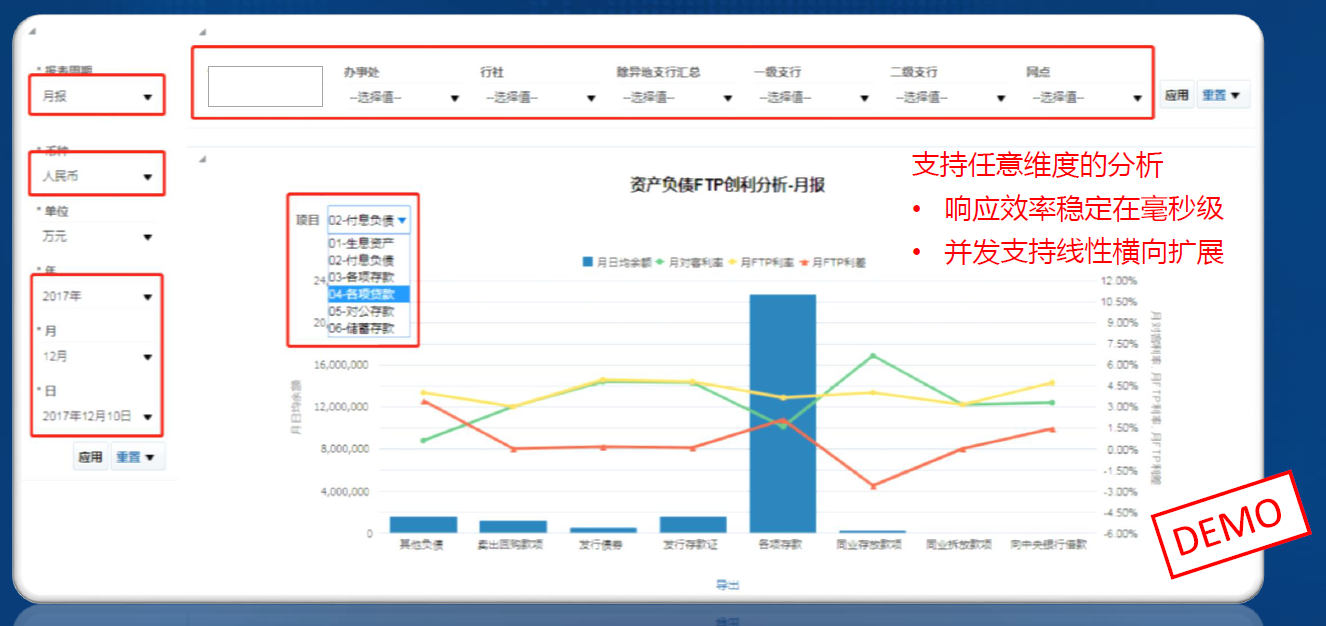
-#### 4.1.5.1. 多维分析
-
-
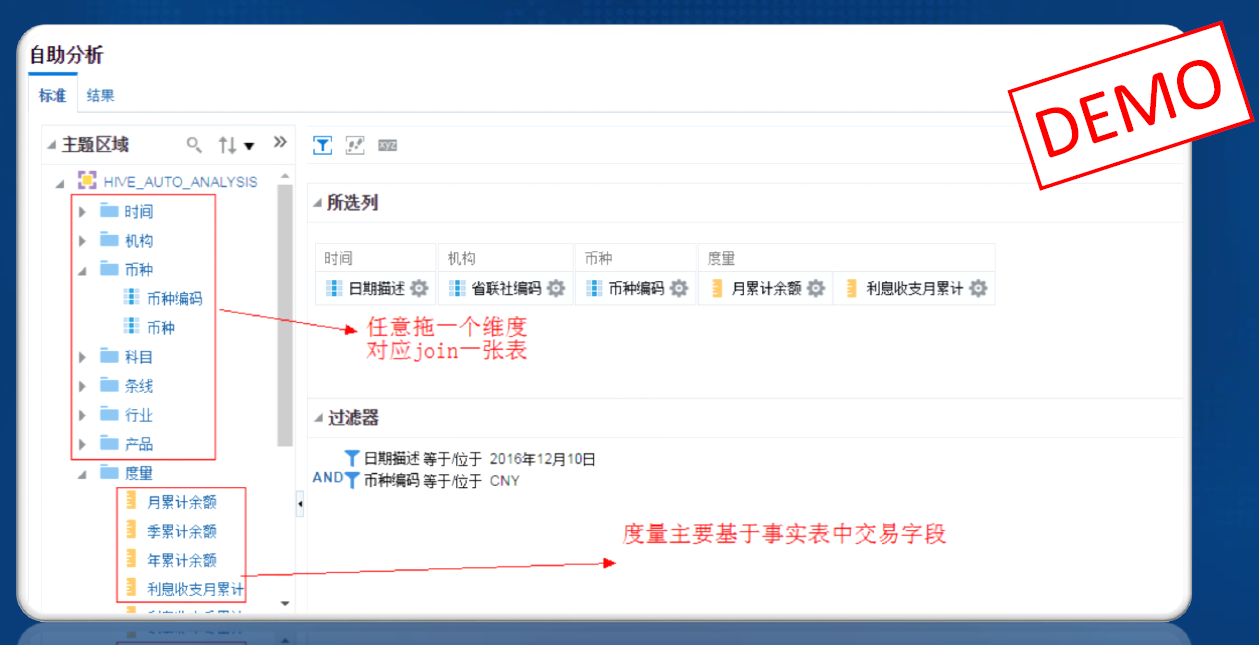
-#### 4.1.5.2. 自助交互式分析
-
-
-#### 4.1.5.3. 领导驾驶舱
-| 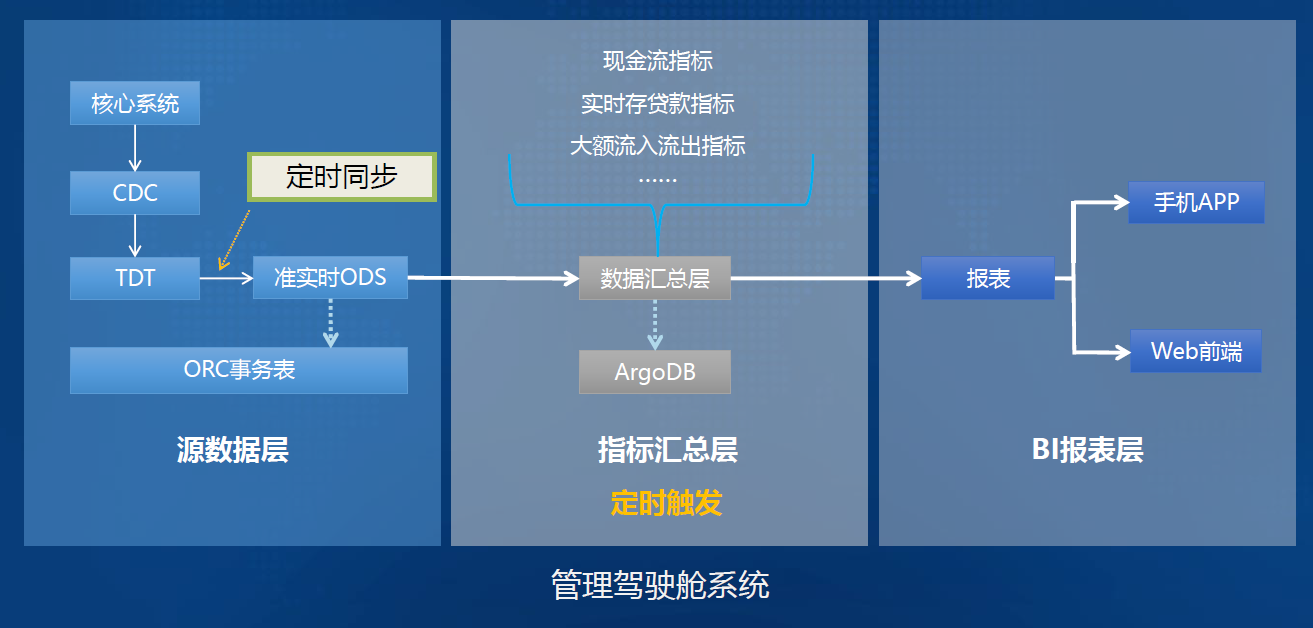 |  |
-| -------------------- | -------------------- |
-
-### 4.1.6. 实施效果
-
-
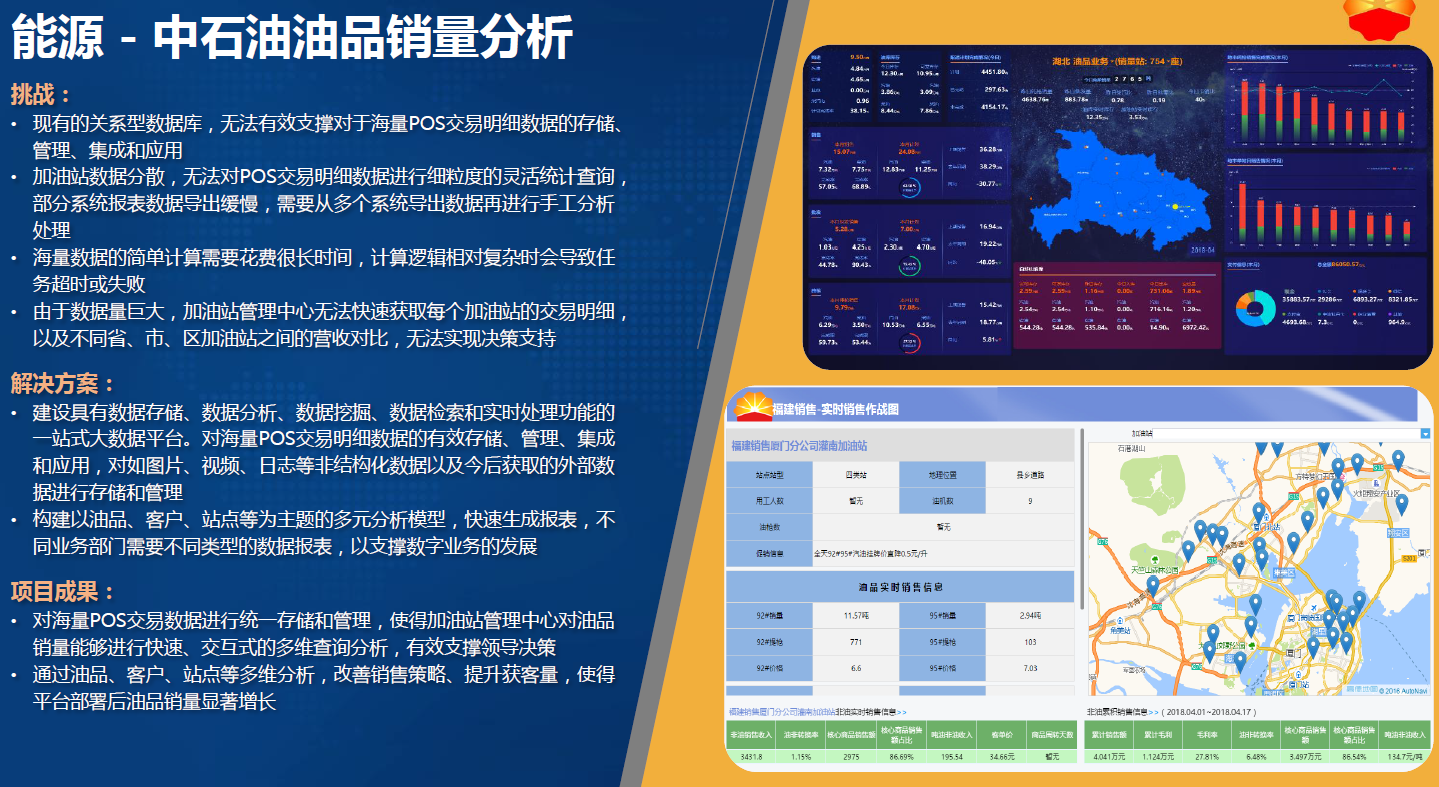
-## 4.2. 能源-中石油油品销量分析
-
-
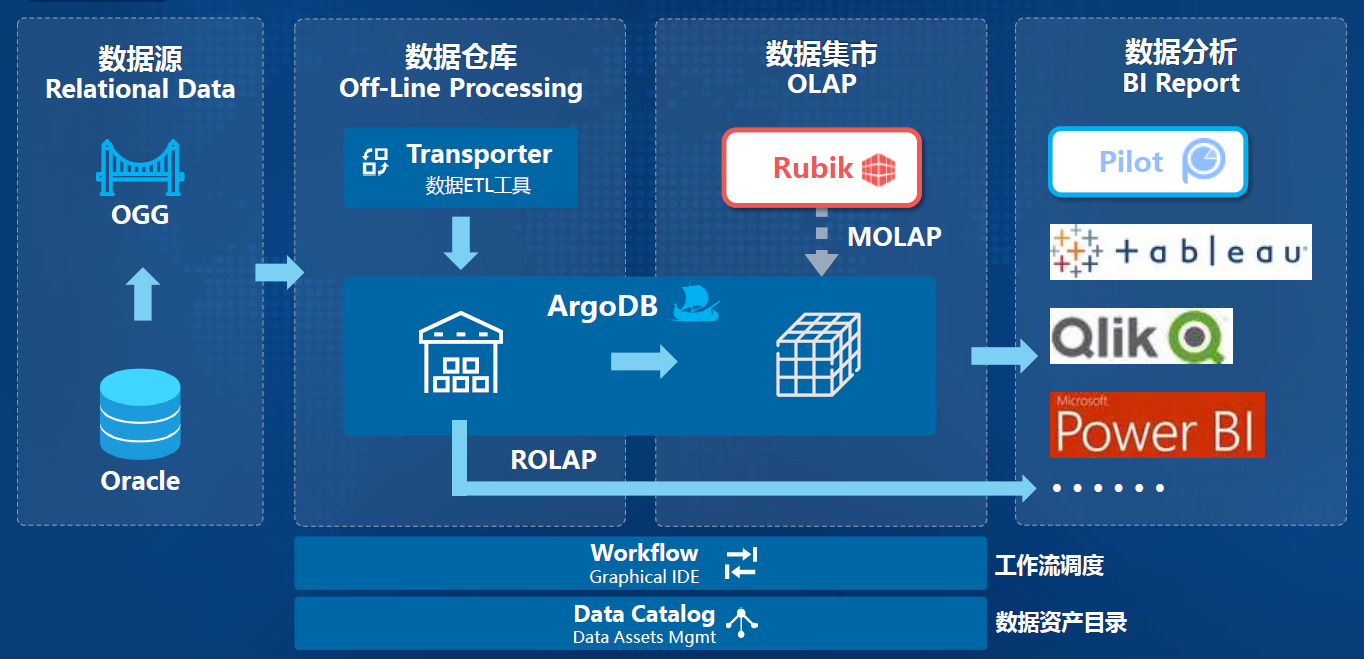
-### 4.2.1. 系统架构
-
-
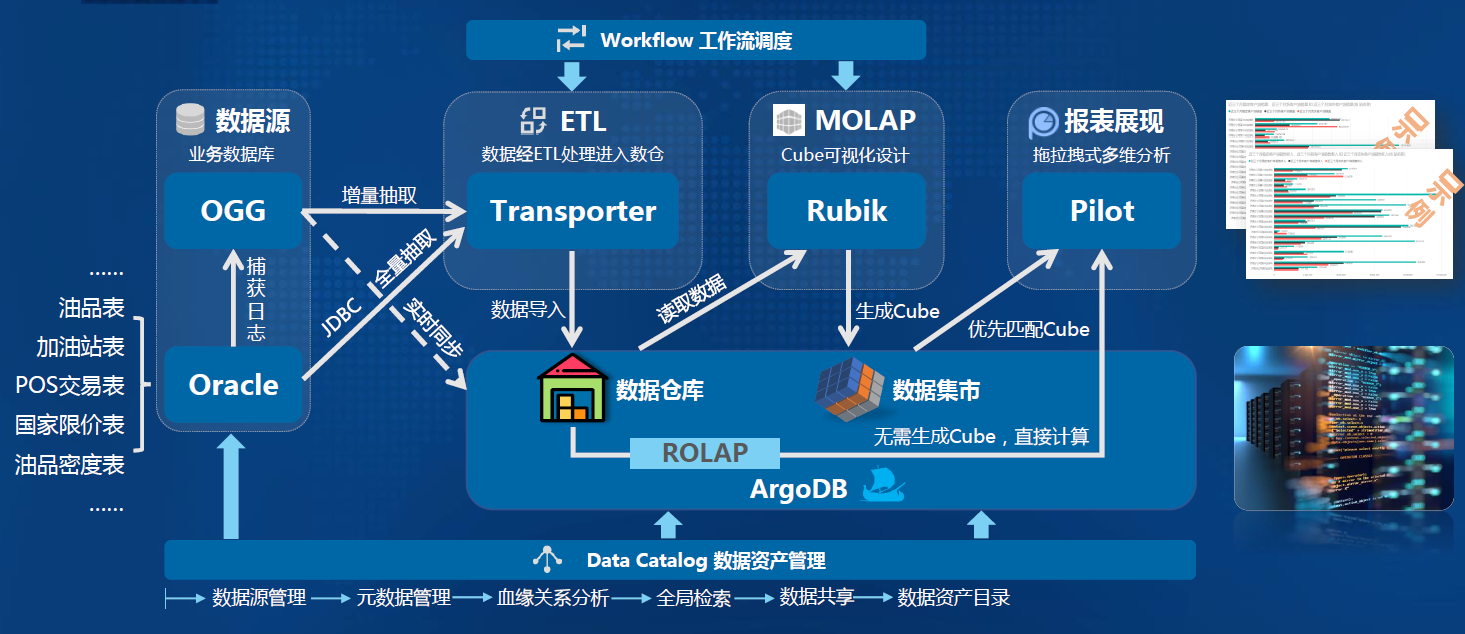
-### 4.2.2. 数据流转
-
-
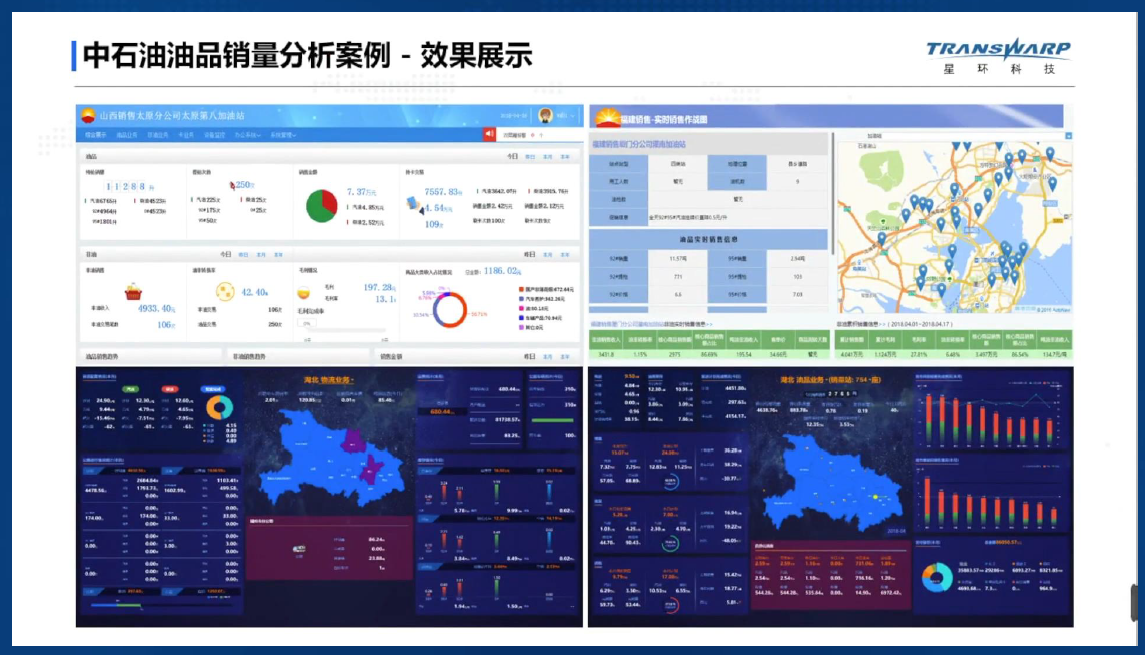
-### 4.2.3. 案例演示
-
-
-# 5. 实时流处理案例
-
-## 5.1. 公安交警-全国公安交通集成指挥平台
-1. 建设背景
- 1. 公路交通"安全防控体系三位一体建设"的重要内容
- 2. 公安交警"科技信息化规划建设的**四大信息平台**"之一
-2. 面临挑战
- 1. 业务:图片和视频数据**实时接入**,同时**实时研判和预警**
- 2. 瓶颈:传统数据处理技术**已无法满足业务对实时性的要求**
-3. 建设目标
- 1. 功能:实现"道路交通态势**智能感知**、交通违法**主动干预**、突发事件**及时处置**、警力科学**部署指挥**"四大业务管理功能
- 2. 体系:构建快速高效的交通指挥体系
- 3. 机制:建立常态实战的新型勤务机制
-4. 建设方案
- 1. 总体:在现有全国机动车缉查布控系统的基础上进行**升级**,按部、省、地市**三级分布建设**,三级平台互联互通,构建全国统一的快速高效的公路交通应急指挥体系
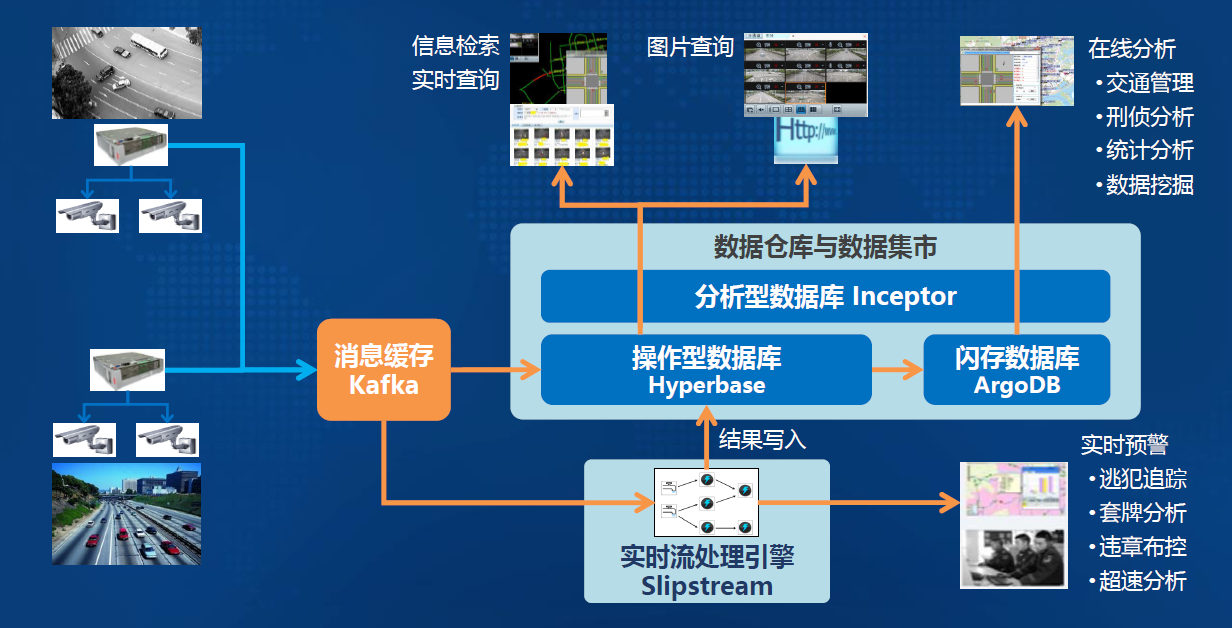
- 2. 技术:基于**星环智能实时流处理解决方案**,利用**高性能流计算引擎Slipstream**,实现交通指挥的复杂、高并发实时业务
-5. 项目成果
- 1. 功能:**秒级响应**过车信息,实现违法车辆发现、缉查布控、区间测速等**实时业务**;同时,实现在线轨迹查询、车辆查获情况分析等**非实时业务**
- 2. 数据:卡口总量近6万个,存量数据为1200亿条,增量数据为3.5亿条/天
- 3. 部署:2017年12月开始在陕西、山东、河南三省试点,2018年逐步推广至全国,目前已在全国十多个省的300多个地级市完成部署(共**300**多套),成为交警日常工作最重要的系统之一
-
-### 5.1.1. 平台架构:基于TDH的新一代交通指挥智能实时流处理架构
-
-
-### 5.1.2. 平台应用:稽查布控
-| 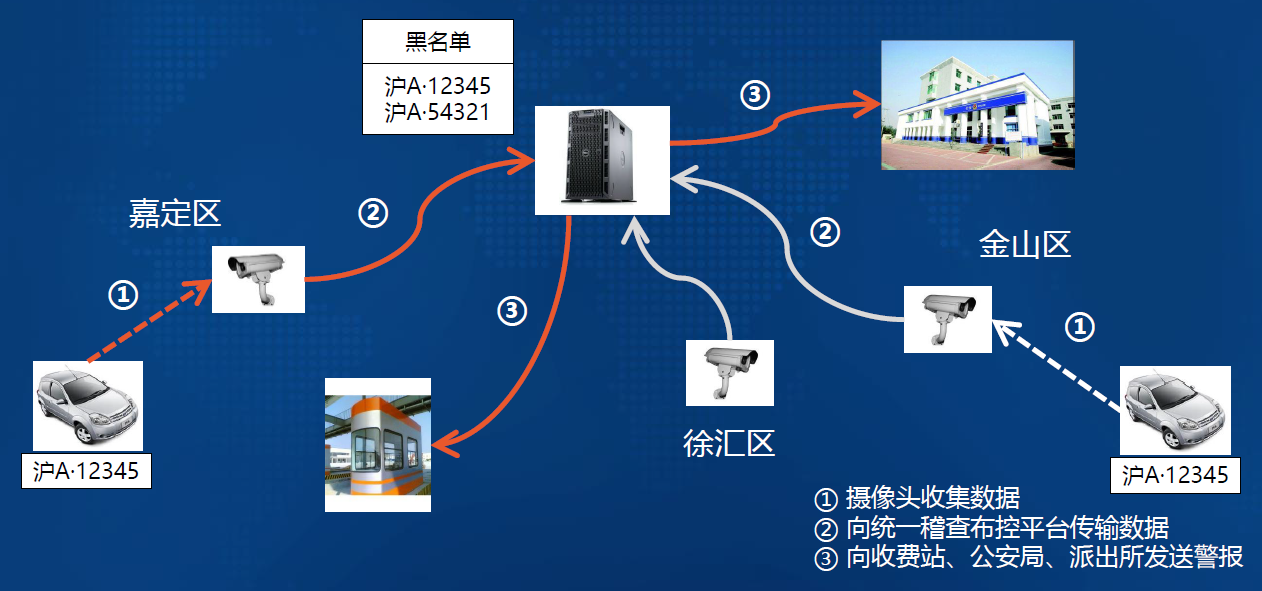 | 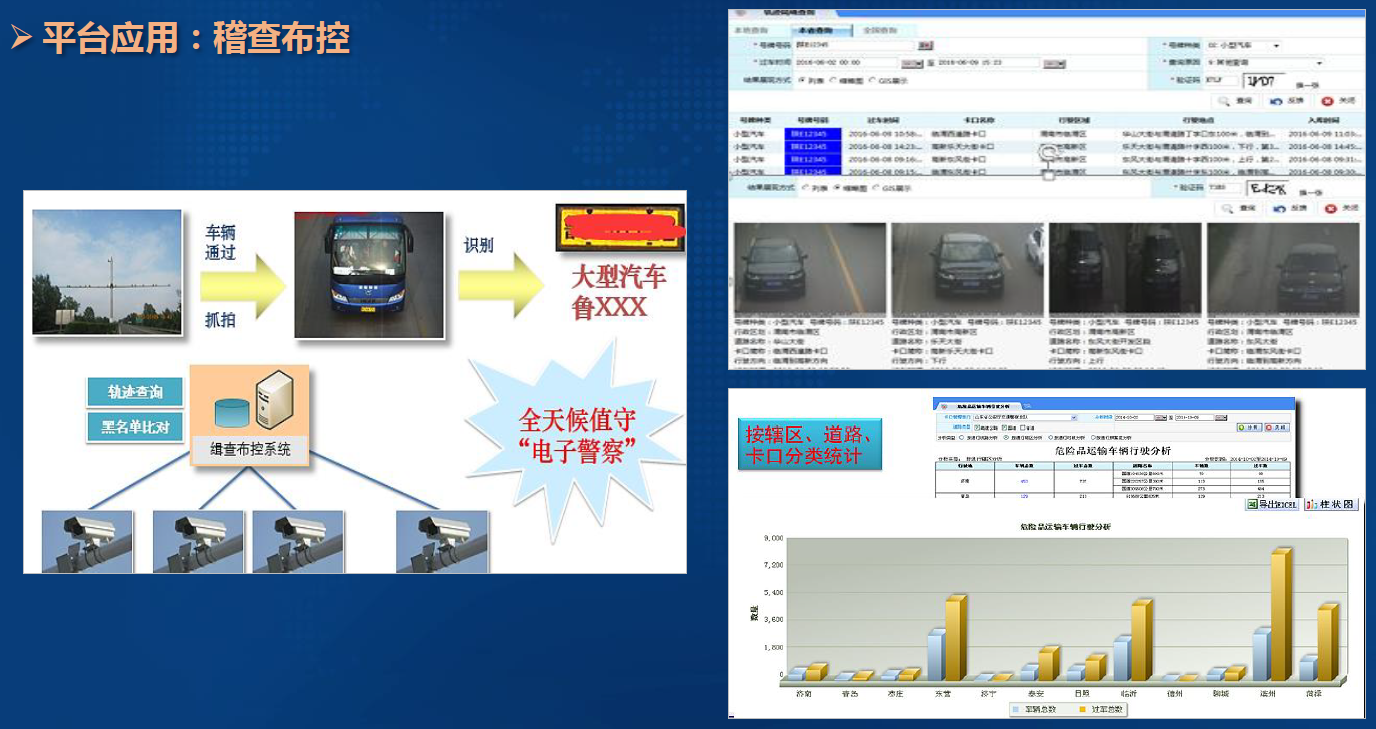 |
-| -------------------- | -------------------- |
-
-## 5.2. 能源-中石油智慧新零售
-1. 挑战:
- 1. 加油站超过70%的消费者是黑箱客户,无法进行消费行为画像和精准营销。因为支付手段的多样性和灵活性造成50%以上加油客户不希望办理预储值卡,积分客户营销基本空白。
- 2. 社会加油站(民营站)因为企业规模限制无法实现多站联动,没有完整的零售平台支持客户精准分析和营销活动。
-2. 解决方案:
- 1. 建设具有数据存储、数据分析、数据挖掘、数据检索和实时处理功能的一体化大数据平台。对POS交易明细等海量数据的有效存储管理、集成和应用,对如图片、视频、日志等非结构化数据以及今后获取的外部数据进行存储和管理。
- 2. 通过机器学习的视频识别结构化算法,每天40万辆车样本的持续训练,实现精准交易信息匹配,消除黑箱客户,聚集忠诚客户。同时开创性地探索了车牌识别与交易信息的匹配算法、车牌/车型识别算法、银行卡交易关联算法和加油站关联算法。
- 3. 构建以卡和车牌为主题的客户、加油站、非油商品的标签体系和多元分析模型。基于多种客户分析模型及推荐算法,通过对客户历史交易数据分析,实现个性化营销推荐。
-3. 项目成果:
- 1. 累积识别车牌数103万个,识别持卡用户44万个,非持卡用户96万个,与车牌关联交易1634万条,商品推荐次数571万次。
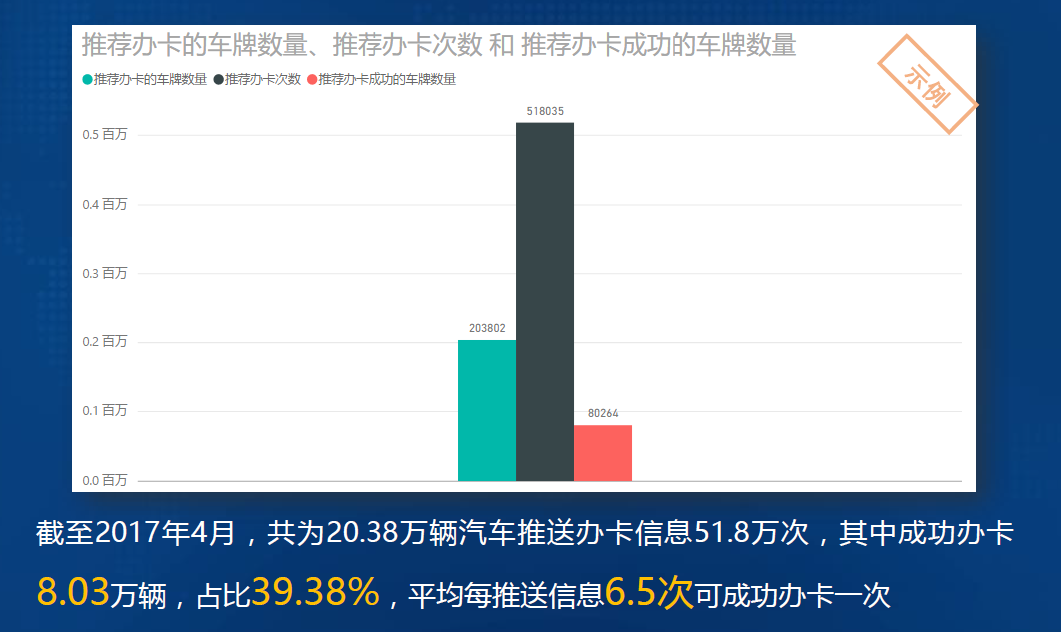
- 2. 截至2017年4月系统共计对20余万辆汽车,推送办卡推荐51万余次。其中成功办卡汽车80264辆,占比39.38%,平均每推送信息6.5次可成功办卡一辆。
-
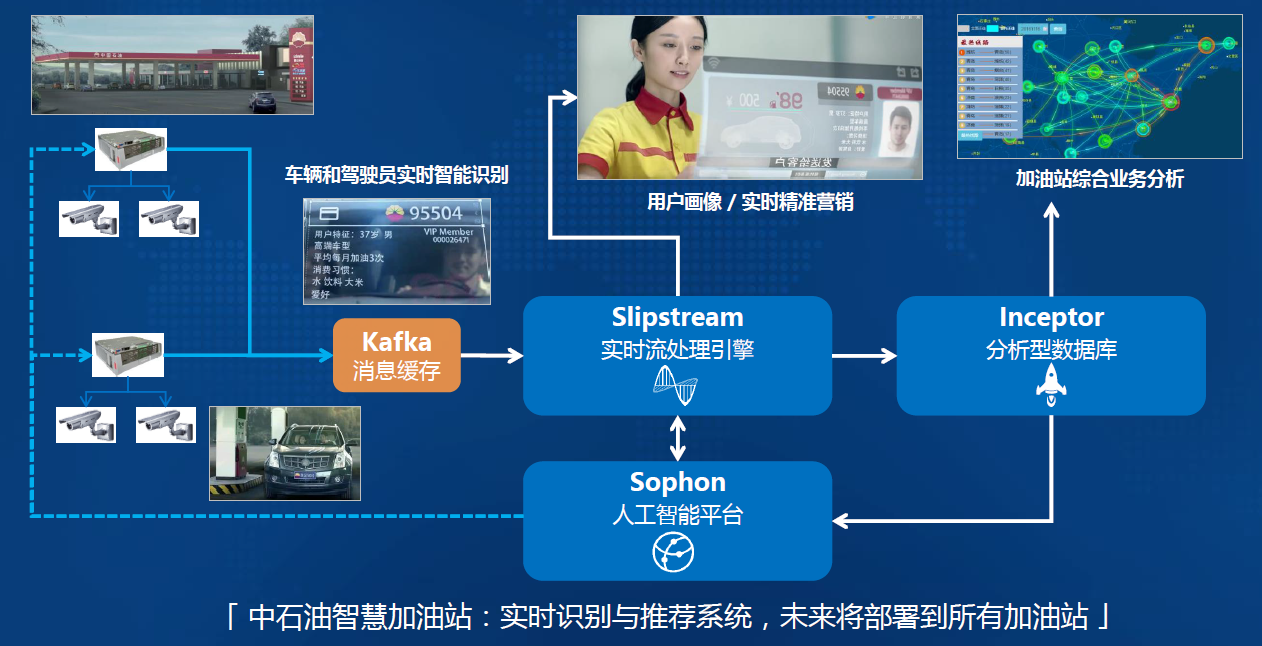
-### 5.2.1. 平台架构:软硬件一体化AI解决方案,实时识别与个性化推荐
-
-
-### 5.2.2. 项目成果
-
-#### 5.2.2.1. 车辆识别
-
-
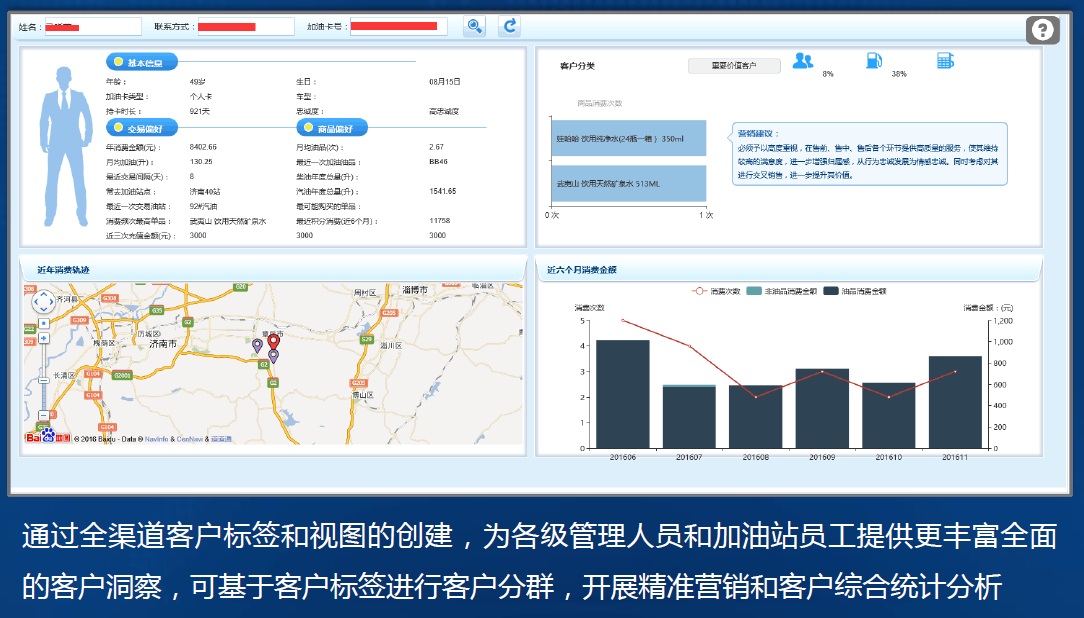
-#### 5.2.2.2. 客户画像
-
-
-#### 5.2.2.3. 办卡推荐量、成功量
-
-
-# 6. 综合搜索案例
-
-## 6.1. 金融监管-福建银监眼
-
-
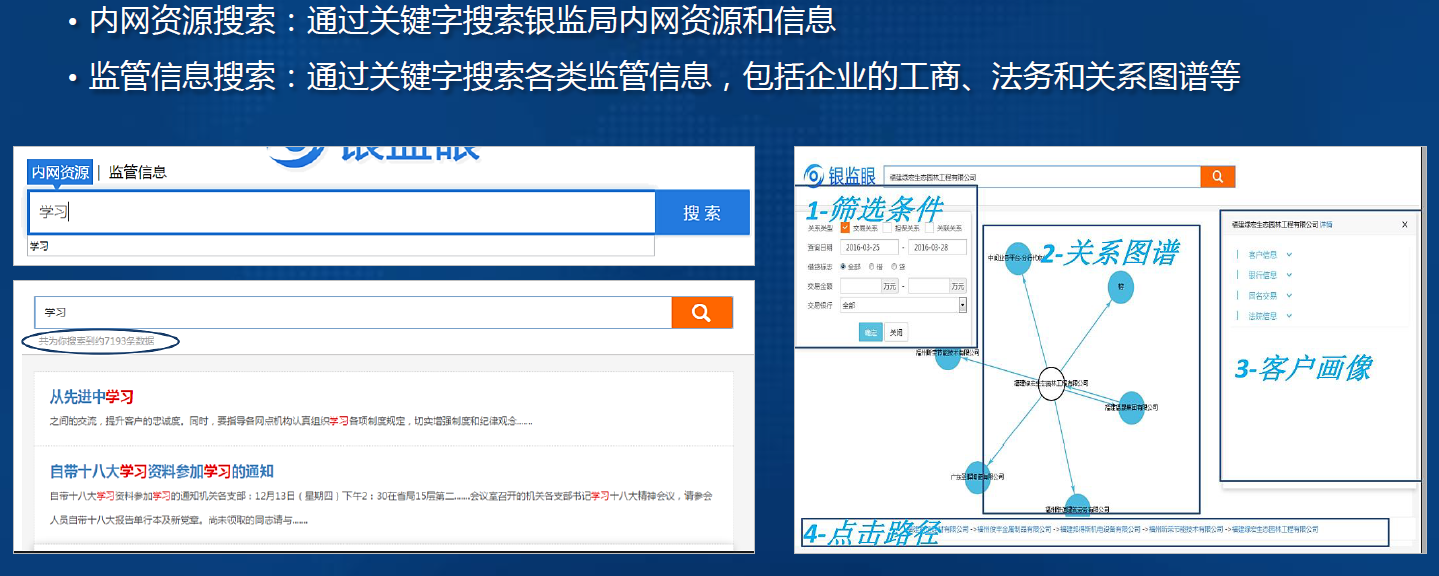
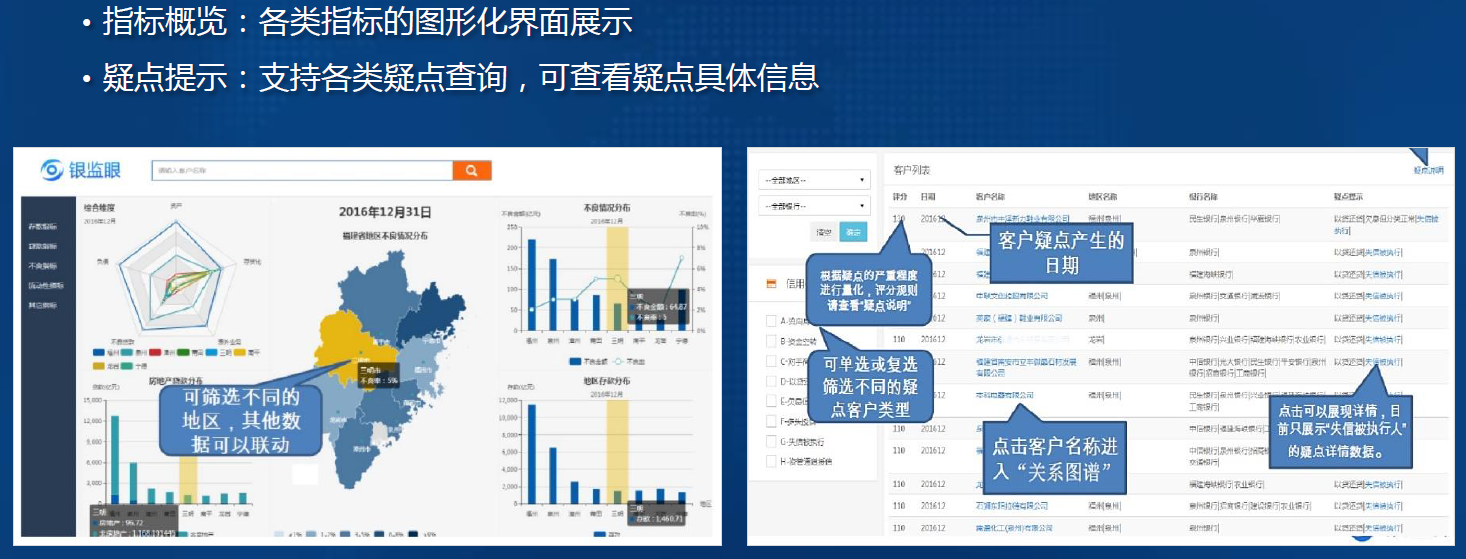
-1. 建设目标
- 1. "银监眼"作为福建银监局业务访问的最主要入口
- 2. 实现内网资源搜索、监管信息搜索、指标概览、疑点提示、担保圈分析等功能
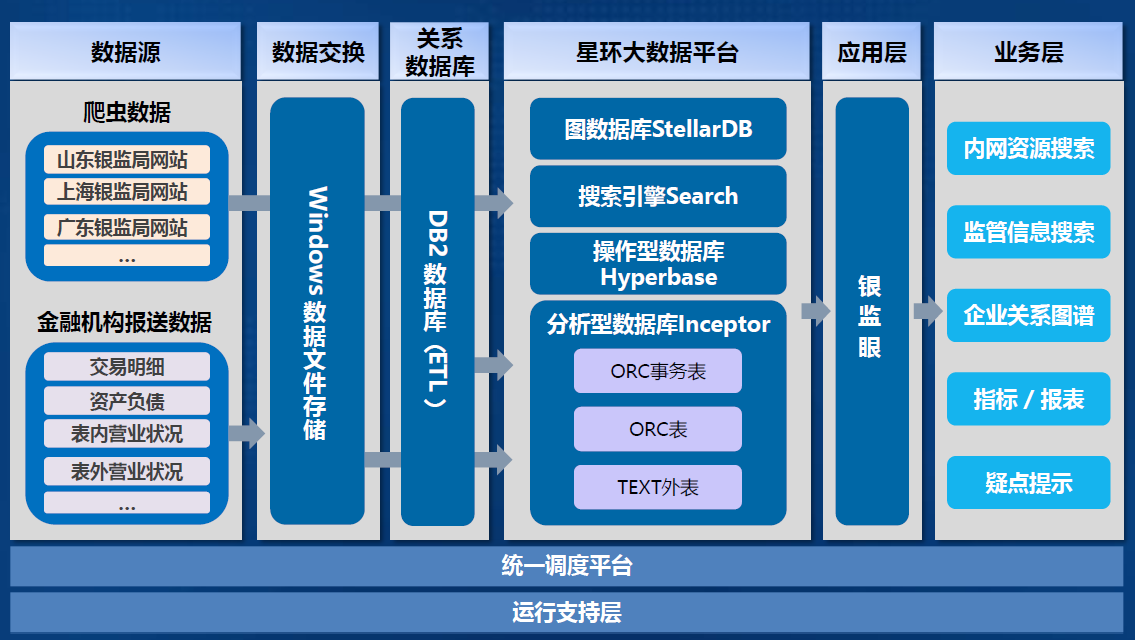
-2. 解决方案
- 1. 金融机构报送数据,经同类归集后,导入分析型数据库Inceptor
- 2. 将业务数据库(DB2)中的指标数据和报表数据导入Inceptor
- 3. 利用爬虫工具,获取全国各省银监局官网数据,将非结构化数据导入操作型数据库Hyperbase,同时将索引存入分布式搜索引擎Search
- 4. 分析企业间担保关系,存入分布式图数据库StellarDB
-
-### 6.1.1. 平台架构
-
-
-### 项目成果
-|  |  |
-| -------------------- | -------------------- |
-|  | |
-
-
diff --git "a/2021-Linux-Programming/Exam1-\351\207\215\347\202\271.md" "b/2021-Linux-Programming/Exam1-\351\207\215\347\202\271.md"
index b7aafe1..68a895c 100644
--- "a/2021-Linux-Programming/Exam1-\351\207\215\347\202\271.md"
+++ "b/2021-Linux-Programming/Exam1-\351\207\215\347\202\271.md"
@@ -177,7 +177,7 @@ make install
1. 标准输入文件(stdin):stdin的文件描述符为0,Unix程序默认从stdin读取数据。
2. 标准输出文件(stdout):stdout的文件描述符为1,Unix程序默认向stdout输出数据。
3. 标准错误文件(stderr):stderr的文件描述符为2,Unix程序会向stderr流中写入错误信息。
-5. 如果希望将stdout和stderr合并后重定向到file,可以这样写:command > file 2 >& 1或command >> file 2>&1,为什么需要将标准错误重定向到标准输出的原因,那就归结为标准错误没有缓冲区,而stdout有。
+5. 如果希望将stdout和stderr合并后重定向到file,可以这样写:`command > file 2>&1` 或`command >> file 2>&1`,为什么需要将标准错误重定向到标准输出的原因,那就归结为标准错误没有缓冲区,而stdout有。
6. 如果希望对stdin和stdout都重定向,可以这样写:command < file1 > file2;command命令将stdin重定向到file1,将stdout重定向到file2。
## 2.4. 管道 掌握
@@ -241,7 +241,7 @@ make install
### 2.8.1. 字符串操作
1. `str1 = str2` 字符串相同则结果真
-2. `str1 != str2` 字符串不先沟通则结果为真
+2. `str1 != str2` 字符串不相同则结果为真
3. `-z str` 字符串为空则结果为真
4. `-n str` 字符串不为空则结果为真
@@ -416,7 +416,8 @@ func para1 para2 # 函数内部调用$1 $2 得不到脚本参数,而是调用
```sh
gcc –o hello hello.c : 将hello.c文件编译成hello的可执行文件
-gcc –c hello.c : 将hello.c文件生成hello.o文件 gcc -E hello.c : 只是激活预处理,不生成文档,需要把它重定向到另外一个文档里
+gcc –c hello.c : 将hello.c文件生成hello.o文件
+gcc -E hello.c : 只是激活预处理,不生成文档,需要把它重定向到另外一个文档里
gcc –S hello.c : 将hello.c文件生成hello.s文件的汇编代码
gcc –pipe –o hello hello.c : 使用管道代替编译中临时文档
gcc hello.c –include /root/hello.h :包含某个代码,简单来说,就是以某个文档,需要另外一个文档的时候,就能够用它设定,功能就相当于在代码中使
@@ -606,7 +607,7 @@ clean:
2. VFS:Virtual File System Switch
| 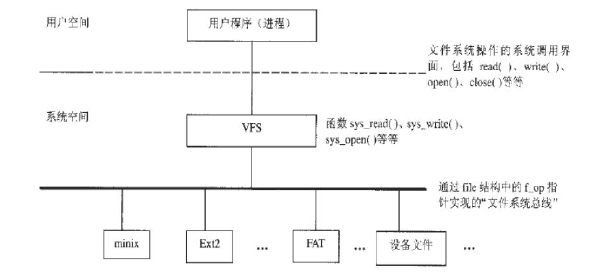 | 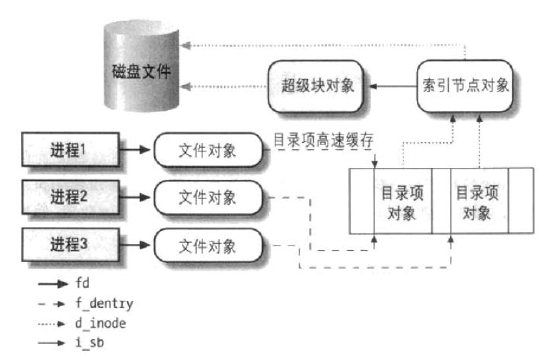 |
-| -------------------- | -------------------- |
+| ------------------------------------------------------------------------------------------ | ------------------------------------------------------------------------------------------ |
### 4.3.2. VFS在系统内建立的四种结构体和含义
1. 超级块(super block):某一个磁盘的某一个分区的文件系统的信息,记录了文件系统类型和参数。
@@ -619,12 +620,12 @@ clean:
1. 不同的文件名对应同一个inode
2. 不能跨越文件系统
3. 对应系统调用link
- 4. ln -s [原文件名] [连接文件名]
+ 4. ln [原文件名] [连接文件名]
2. 软链接
1. 存储被链接文件的文件名(而不是inode)实现链接
2. 可以跨越文件系统
3. 对应系统调用symlink
- 4. ln [原文件名] [连接文件名]
+ 4. ln -s [原文件名] [连接文件名]
## 4.5. 系统调用和C库区别
1. 都以C库函数的形式出现
@@ -706,8 +707,9 @@ int main(){
1. F_DUPDF:复制文件描述符
2. F_GETFD/F_SETFD:获取/设置文件描述符标志,为解决fork子进程执行其他任务(exec等)导致父进程的文件描述符被复制到子进程中,使得对应文件描述符无法被之后需要的进程获取。设置了这个标记后可以使得子进程在执行exce等命令后释放对应的文件描述符资源。
3. F_GETFL/F_SETFL:获得/设置文件状态标志(open/creat中的flags 参数),目前只能更改0_APPEND , 0_ASYNC, 0_DIRECT, 0_NOATIME,O_NONBLOCK
- 4. F_GETOWN/F_SETOWN: 管理1/0可用相关的信号。获得或设置当前文件描述符会接受SIGI0和SIGURG信号的进程或进程组编号F_GETLK/F_SETLK/F_SETLKW: 获得/设置文件锁,设置为F_GETLK时需要传入flock* 指针用于存放最后的锁信息。S_SETLK 需要传入flock *指针表示需要改变的锁的内容,如果不能被设置,则立即返回EAGAIN。
- 5. s_SETLKW同s_SETLK,但是在锁无法设置时会阻塞等待任务完成。
+ 4. F_GETOWN/F_SETOWN: 管理I/O可用相关的信号。获得或设置当前文件描述符会接受SIGI0和SIGURG信号的进程或进程组编号
+ 5. F_GETLK/F_SETLK/F_SETLKW: 获得/设置文件锁,设置为F_GETLK时需要传入flock* 指针用于存放最后的锁信息。S_SETLK 需要传入flock *指针表示需要改变的锁的内容,如果不能被设置,则立即返回EAGAIN。
+ 6. s_SETLKW同s_SETLK,但是在锁无法设置时会阻塞等待任务完成。
#### 4.5.2.4. 头文件``
1. `int stat(const char *filename, struct stat *buf); `
diff --git "a/2021-human-computer-interaction/Lec-2 \344\272\244\344\272\222\350\256\276\350\256\241\347\232\204\345\216\237\345\210\231\345\222\214\346\226\271\346\263\225.md" "b/2021-human-computer-interaction/Lec-2 \344\272\244\344\272\222\350\256\276\350\256\241\347\232\204\345\216\237\345\210\231\345\222\214\346\226\271\346\263\225.md"
index 69e8282..443620f 100644
--- "a/2021-human-computer-interaction/Lec-2 \344\272\244\344\272\222\350\256\276\350\256\241\347\232\204\345\216\237\345\210\231\345\222\214\346\226\271\346\263\225.md"
+++ "b/2021-human-computer-interaction/Lec-2 \344\272\244\344\272\222\350\256\276\350\256\241\347\232\204\345\216\237\345\210\231\345\222\214\346\226\271\346\263\225.md"
@@ -293,7 +293,7 @@
2. 研究表明,能够发现许多可用性问题:**剩下的可以通过简化的边做边说方法来发现**
3. 启发式评估需要有相关的专家用户(不需要找真实的用户),这些专家可以把自己设定为**用户视角**。
4. 为避免个人的偏见,应当让多个不同的人来进行经验性评估。
-5. 被测试的用户:没有用过、有一段时间没有使用的、经常使用的,这个用户群体和想要衡量的指标有关(比如易用性就需要研究有一段时间没有使用的用户)
+5. 被测试的用户:没有用过、有一段时间没有使用的、经常使用的,这个用户群体和想要衡量的指标有关(比如易记性就需要研究有一段时间没有使用的用户)
6. 问题:究竟需要多少个测试专家参与
7. n个测试专家能够发现的可用性问题数量
1. N(1-(1-L)n)
diff --git a/README.md b/README.md
index aee2036..aec7a2a 100644
--- a/README.md
+++ b/README.md
@@ -2,4 +2,4 @@
1. 本仓库中存放了我学习的课程的个人相关课程笔记,对应的笔记在对应的课程的文件夹下。
2. 本仓库中的绝大多数内容来源自课程,我对其结合个人理解进行了一定的整理和加工。
3. 如果内容上有任何不妥,可以提交Issues来告知我,或者提交PR由我完成合并。
-4. 为了方便阅读,我将所有的图片均上传到阿里云,但是在网页端访问仍然可能存在加载失败的问题,建议可以fork仓库后下载到本地进行查看。
+4. 为了方便阅读,我将所有的图片均上传到阿里云,但是在网页端访问仍然可能存在加载失败的问题,建议可以fork仓库后下载到本地进行查看,当然也可以访问我的博客查看:https://SpriCoder.github.io/
\ No newline at end of file