
 ### 公众号
-如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
+如果大家想要实时关注我更新的文章以及分享的干货的话,关注我的公众号 **程序员的技术圈子**。
+
+
-
diff --git a/_config.yml b/_config.yml
new file mode 100644
index 0000000..c419263
--- /dev/null
+++ b/_config.yml
@@ -0,0 +1 @@
+theme: jekyll-theme-cayman
\ No newline at end of file
diff --git a/assets/wx.jpg b/assets/wx.jpg
new file mode 100644
index 0000000..3fd7f11
Binary files /dev/null and b/assets/wx.jpg differ
diff --git "a/assets/\347\250\213\345\272\217\345\221\230\346\212\200\346\234\257\345\234\210\345\255\220.jpg" "b/assets/\347\250\213\345\272\217\345\221\230\346\212\200\346\234\257\345\234\210\345\255\220.jpg"
new file mode 100644
index 0000000..8561507
Binary files /dev/null and "b/assets/\347\250\213\345\272\217\345\221\230\346\212\200\346\234\257\345\234\210\345\255\220.jpg" differ
diff --git a/docs/dataStructures-algorithms/Backtracking-NQueens.md b/docs/dataStructures-algorithms/Backtracking-NQueens.md
deleted file mode 100644
index bac262d..0000000
--- a/docs/dataStructures-algorithms/Backtracking-NQueens.md
+++ /dev/null
@@ -1,145 +0,0 @@
-# N皇后
-[51. N皇后](https://leetcode-cn.com/problems/n-queens/)
-### 题目描述
-> n 皇后问题研究的是如何将 n 个皇后放置在 n×n 的棋盘上,并且使皇后彼此之间不能相互攻击。
->
-
->
-上图为 8 皇后问题的一种解法。
->
-给定一个整数 n,返回所有不同的 n 皇后问题的解决方案。
->
-每一种解法包含一个明确的 n 皇后问题的棋子放置方案,该方案中 'Q' 和 '.' 分别代表了皇后和空位。
-
-示例:
-
-```
-输入: 4
-输出: [
- [".Q..", // 解法 1
- "...Q",
- "Q...",
- "..Q."],
-
- ["..Q.", // 解法 2
- "Q...",
- "...Q",
- ".Q.."]
-]
-解释: 4 皇后问题存在两个不同的解法。
-```
-
-### 问题分析
-约束条件为每个棋子所在的行、列、对角线都不能有另一个棋子。
-
-使用一维数组表示一种解法,下标(index)表示行,值(value)表示该行的Q(皇后)在哪一列。
-每行只存储一个元素,然后递归到下一行,这样就不用判断行了,只需要判断列和对角线。
-### Solution1
-当result[row] = column时,即row行的棋子在column列。
-
-对于[0, row-1]的任意一行(i 行),若 row 行的棋子和 i 行的棋子在同一列,则有result[i] == column;
-若 row 行的棋子和 i 行的棋子在同一对角线,等腰直角三角形两直角边相等,即 row - i == Math.abs(result[i] - column)
-
-布尔类型变量 isValid 的作用是剪枝,减少不必要的递归。
-```
-public List
### 公众号
-如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
+如果大家想要实时关注我更新的文章以及分享的干货的话,关注我的公众号 **程序员的技术圈子**。
+
+
-
diff --git a/_config.yml b/_config.yml
new file mode 100644
index 0000000..c419263
--- /dev/null
+++ b/_config.yml
@@ -0,0 +1 @@
+theme: jekyll-theme-cayman
\ No newline at end of file
diff --git a/assets/wx.jpg b/assets/wx.jpg
new file mode 100644
index 0000000..3fd7f11
Binary files /dev/null and b/assets/wx.jpg differ
diff --git "a/assets/\347\250\213\345\272\217\345\221\230\346\212\200\346\234\257\345\234\210\345\255\220.jpg" "b/assets/\347\250\213\345\272\217\345\221\230\346\212\200\346\234\257\345\234\210\345\255\220.jpg"
new file mode 100644
index 0000000..8561507
Binary files /dev/null and "b/assets/\347\250\213\345\272\217\345\221\230\346\212\200\346\234\257\345\234\210\345\255\220.jpg" differ
diff --git a/docs/dataStructures-algorithms/Backtracking-NQueens.md b/docs/dataStructures-algorithms/Backtracking-NQueens.md
deleted file mode 100644
index bac262d..0000000
--- a/docs/dataStructures-algorithms/Backtracking-NQueens.md
+++ /dev/null
@@ -1,145 +0,0 @@
-# N皇后
-[51. N皇后](https://leetcode-cn.com/problems/n-queens/)
-### 题目描述
-> n 皇后问题研究的是如何将 n 个皇后放置在 n×n 的棋盘上,并且使皇后彼此之间不能相互攻击。
->
-
->
-上图为 8 皇后问题的一种解法。
->
-给定一个整数 n,返回所有不同的 n 皇后问题的解决方案。
->
-每一种解法包含一个明确的 n 皇后问题的棋子放置方案,该方案中 'Q' 和 '.' 分别代表了皇后和空位。
-
-示例:
-
-```
-输入: 4
-输出: [
- [".Q..", // 解法 1
- "...Q",
- "Q...",
- "..Q."],
-
- ["..Q.", // 解法 2
- "Q...",
- "...Q",
- ".Q.."]
-]
-解释: 4 皇后问题存在两个不同的解法。
-```
-
-### 问题分析
-约束条件为每个棋子所在的行、列、对角线都不能有另一个棋子。
-
-使用一维数组表示一种解法,下标(index)表示行,值(value)表示该行的Q(皇后)在哪一列。
-每行只存储一个元素,然后递归到下一行,这样就不用判断行了,只需要判断列和对角线。
-### Solution1
-当result[row] = column时,即row行的棋子在column列。
-
-对于[0, row-1]的任意一行(i 行),若 row 行的棋子和 i 行的棋子在同一列,则有result[i] == column;
-若 row 行的棋子和 i 行的棋子在同一对角线,等腰直角三角形两直角边相等,即 row - i == Math.abs(result[i] - column)
-
-布尔类型变量 isValid 的作用是剪枝,减少不必要的递归。
-```
-public List- * As much as is reasonably practical, the hashCode method defined by - * class {@code Object} does return distinct integers for distinct - * objects. (This is typically implemented by converting the internal - * address of the object into an integer, but this implementation - * technique is not required by the - * Java™ programming language.) - * - * @return a hash code value for this object. - * @see java.lang.Object#equals(java.lang.Object) - * @see java.lang.System#identityHashCode - */ - public native int hashCode(); -``` - -散列表存储的是键值对(key-value),它的特点是:能根据“键”快速的检索出对应的“值”。这其中就利用到了散列码!(可以快速找到所需要的对象) - -### 3.2 为什么要有 hashCode - -**我们以“HashSet 如何检查重复”为例子来说明为什么要有 hashCode:** - -当你把对象加入 HashSet 时,HashSet 会先计算对象的 hashcode 值来判断对象加入的位置,同时也会与其他已经加入的对象的 hashcode 值作比较,如果没有相符的 hashcode,HashSet 会假设对象没有重复出现。但是如果发现有相同 hashcode 值的对象,这时会调用 equals()方法来检查 hashcode 相等的对象是否真的相同。如果两者相同,HashSet 就不会让其加入操作成功。如果不同的话,就会重新散列到其他位置。(摘自我的 Java 启蒙书《Head fist java》第二版)。这样我们就大大减少了 equals 的次数,相应就大大提高了执行速度。 - -### 3.3 hashCode()与 equals()的相关规定 - -1. 如果两个对象相等,则 hashcode 一定也是相同的 -2. 两个对象相等,对两个对象分别调用 equals 方法都返回 true -3. 两个对象有相同的 hashcode 值,它们也不一定是相等的 -4. **因此,equals 方法被覆盖过,则 hashCode 方法也必须被覆盖** -5. hashCode()的默认行为是对堆上的对象产生独特值。如果没有重写 hashCode(),则该 class 的两个对象无论如何都不会相等(即使这两个对象指向相同的数据) - -### 3.4 为什么两个对象有相同的 hashcode 值,它们也不一定是相等的? - -在这里解释一位小伙伴的问题。以下内容摘自《Head Fisrt Java》。 - -因为 hashCode() 所使用的杂凑算法也许刚好会让多个对象传回相同的杂凑值。越糟糕的杂凑算法越容易碰撞,但这也与数据值域分布的特性有关(所谓碰撞也就是指的是不同的对象得到相同的 hashCode)。 - -我们刚刚也提到了 HashSet,如果 HashSet 在对比的时候,同样的 hashcode 有多个对象,它会使用 equals() 来判断是否真的相同。也就是说 hashcode 只是用来缩小查找成本。 - -## 四 String 和 StringBuffer、StringBuilder 的区别是什么?String 为什么是不可变的? - -**可变性** - -简单的来说:String 类中使用 final 关键字修饰字符数组来保存字符串,`private final char value[]`,所以 String 对象是不可变的。而 StringBuilder 与 StringBuffer 都继承自 AbstractStringBuilder 类,在 AbstractStringBuilder 中也是使用字符数组保存字符串`char[]value` 但是没有用 final 关键字修饰,所以这两种对象都是可变的。 - -StringBuilder 与 StringBuffer 的构造方法都是调用父类构造方法也就是 AbstractStringBuilder 实现的,大家可以自行查阅源码。 - -AbstractStringBuilder.java - -```java -abstract class AbstractStringBuilder implements Appendable, CharSequence { - char[] value; - int count; - AbstractStringBuilder() { - } - AbstractStringBuilder(int capacity) { - value = new char[capacity]; - } -``` - -**线程安全性** - -String 中的对象是不可变的,也就可以理解为常量,线程安全。AbstractStringBuilder 是 StringBuilder 与 StringBuffer 的公共父类,定义了一些字符串的基本操作,如 expandCapacity、append、insert、indexOf 等公共方法。StringBuffer 对方法加了同步锁或者对调用的方法加了同步锁,所以是线程安全的。StringBuilder 并没有对方法进行加同步锁,所以是非线程安全的。 - -**性能** - -每次对 String 类型进行改变的时候,都会生成一个新的 String 对象,然后将指针指向新的 String 对象。StringBuffer 每次都会对 StringBuffer 对象本身进行操作,而不是生成新的对象并改变对象引用。相同情况下使用 StringBuilder 相比使用 StringBuffer 仅能获得 10%~15% 左右的性能提升,但却要冒多线程不安全的风险。 - -**对于三者使用的总结:** - -1. 操作少量的数据: 适用 String -2. 单线程操作字符串缓冲区下操作大量数据: 适用 StringBuilder -3. 多线程操作字符串缓冲区下操作大量数据: 适用 StringBuffer - -#### String 为什么是不可变的吗? - -简单来说就是 String 类利用了 final 修饰的 char 类型数组存储字符,源码如下图所以: - -```java - /** The value is used for character storage. */ - private final char value[]; -``` - -#### String 真的是不可变的吗? - -我觉得如果别人问这个问题的话,回答不可变就可以了。 -下面只是给大家看两个有代表性的例子: - -**1) String 不可变但不代表引用不可以变** - -```java - String str = "Hello"; - str = str + " World"; - System.out.println("str=" + str); -``` - -结果: - -``` -str=Hello World -``` - -解析: - -实际上,原来 String 的内容是不变的,只是 str 由原来指向"Hello"的内存地址转为指向"Hello World"的内存地址而已,也就是说多开辟了一块内存区域给"Hello World"字符串。 - -**2) 通过反射是可以修改所谓的“不可变”对象** - -```java - // 创建字符串"Hello World", 并赋给引用s - String s = "Hello World"; - - System.out.println("s = " + s); // Hello World - - // 获取String类中的value字段 - Field valueFieldOfString = String.class.getDeclaredField("value"); - - // 改变value属性的访问权限 - valueFieldOfString.setAccessible(true); - - // 获取s对象上的value属性的值 - char[] value = (char[]) valueFieldOfString.get(s); - - // 改变value所引用的数组中的第5个字符 - value[5] = '_'; - - System.out.println("s = " + s); // Hello_World -``` - -结果: - -``` -s = Hello World -s = Hello_World -``` - -解析: - -用反射可以访问私有成员, 然后反射出 String 对象中的 value 属性, 进而改变通过获得的 value 引用改变数组的结构。但是一般我们不会这么做,这里只是简单提一下有这个东西。 - -## 五 什么是反射机制?反射机制的应用场景有哪些? - -### 5.1 反射机制介绍 - -JAVA 反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为 java 语言的反射机制。 - -### 5.2 静态编译和动态编译 - -- **静态编译:**在编译时确定类型,绑定对象 -- **动态编译:**运行时确定类型,绑定对象 - -### 5.3 反射机制优缺点 - -- **优点:** 运行期类型的判断,动态加载类,提高代码灵活度。 -- **缺点:** 性能瓶颈:反射相当于一系列解释操作,通知 JVM 要做的事情,性能比直接的 java 代码要慢很多。 - -### 5.4 反射的应用场景 - -**反射是框架设计的灵魂。** - -在我们平时的项目开发过程中,基本上很少会直接使用到反射机制,但这不能说明反射机制没有用,实际上有很多设计、开发都与反射机制有关,例如模块化的开发,通过反射去调用对应的字节码;动态代理设计模式也采用了反射机制,还有我们日常使用的 Spring/Hibernate 等框架也大量使用到了反射机制。 - -举例:① 我们在使用 JDBC 连接数据库时使用 `Class.forName()`通过反射加载数据库的驱动程序;②Spring 框架也用到很多反射机制,最经典的就是 xml 的配置模式。Spring 通过 XML 配置模式装载 Bean 的过程:1) 将程序内所有 XML 或 Properties 配置文件加载入内存中; -2)Java 类里面解析 xml 或 properties 里面的内容,得到对应实体类的字节码字符串以及相关的属性信息; 3)使用反射机制,根据这个字符串获得某个类的 Class 实例; 4)动态配置实例的属性 - -**推荐阅读:** - -- [Reflection:Java 反射机制的应用场景](https://segmentfault.com/a/1190000010162647?utm_source=tuicool&utm_medium=referral "Reflection:Java反射机制的应用场景") -- [Java 基础之—反射(非常重要)](https://blog.csdn.net/sinat_38259539/article/details/71799078 "Java基础之—反射(非常重要)") - -## 六 什么是 JDK?什么是 JRE?什么是 JVM?三者之间的联系与区别 - -### 6.1 JVM - -Java 虚拟机(JVM)是运行 Java 字节码的虚拟机。JVM 有针对不同系统的特定实现(Windows,Linux,macOS),目的是使用相同的字节码,它们都会给出相同的结果。 - -**什么是字节码?采用字节码的好处是什么?** - -> 在 Java 中,JVM 可以理解的代码就叫做`字节码`(即扩展名为 `.class` 的文件),它不面向任何特定的处理器,只面向虚拟机。Java 语言通过字节码的方式,在一定程度上解决了传统解释型语言执行效率低的问题,同时又保留了解释型语言可移植的特点。所以 Java 程序运行时比较高效,而且,由于字节码并不针对一种特定的机器,因此,Java 程序无须重新编译便可在多种不同操作系统的计算机上运行。 - -**Java 程序从源代码到运行一般有下面 3 步:** - - - -我们需要格外注意的是 .class->机器码 这一步。在这一步 JVM 类加载器首先加载字节码文件,然后通过解释器逐行解释执行,这种方式的执行速度会相对比较慢。而且,有些方法和代码块是经常需要被调用的(也就是所谓的热点代码),所以后面引进了 JIT 编译器,而 JIT 属于运行时编译。当 JIT 编译器完成第一次编译后,其会将字节码对应的机器码保存下来,下次可以直接使用。而我们知道,机器码的运行效率肯定是高于 Java 解释器的。这也解释了我们为什么经常会说 Java 是编译与解释共存的语言。 - -> HotSpot 采用了惰性评估(Lazy Evaluation)的做法,根据二八定律,消耗大部分系统资源的只有那一小部分的代码(热点代码),而这也就是 JIT 所需要编译的部分。JVM 会根据代码每次被执行的情况收集信息并相应地做出一些优化,因此执行的次数越多,它的速度就越快。JDK 9 引入了一种新的编译模式 AOT(Ahead of Time Compilation),它是直接将字节码编译成机器码,这样就避免了 JIT 预热等各方面的开销。JDK 支持分层编译和 AOT 协作使用。但是 ,AOT 编译器的编译质量是肯定比不上 JIT 编译器的。 - -**总结:** - -Java 虚拟机(JVM)是运行 Java 字节码的虚拟机。JVM 有针对不同系统的特定实现(Windows,Linux,macOS),目的是使用相同的字节码,它们都会给出相同的结果。字节码和不同系统的 JVM 实现是 Java 语言“一次编译,随处可以运行”的关键所在。 - -### 6.2 JDK 和 JRE - -JDK 是 Java Development Kit,它是功能齐全的 Java SDK。它拥有 JRE 所拥有的一切,还有编译器(javac)和工具(如 javadoc 和 jdb)。它能够创建和编译程序。 - -JRE 是 Java 运行时环境。它是运行已编译 Java 程序所需的所有内容的集合,包括 Java 虚拟机(JVM),Java 类库,java 命令和其他的一些基础构件。但是,它不能用于创建新程序。 - -如果你只是为了运行一下 Java 程序的话,那么你只需要安装 JRE 就可以了。如果你需要进行一些 Java 编程方面的工作,那么你就需要安装 JDK 了。但是,这不是绝对的。有时,即使您不打算在计算机上进行任何 Java 开发,仍然需要安装 JDK。例如,如果要使用 JSP 部署 Web 应用程序,那么从技术上讲,您只是在应用程序服务器中运行 Java 程序。那你为什么需要 JDK 呢?因为应用程序服务器会将 JSP 转换为 Java servlet,并且需要使用 JDK 来编译 servlet。 - -## 七 什么是字节码?采用字节码的最大好处是什么? - -**先看下 java 中的编译器和解释器:** - -Java 中引入了虚拟机的概念,即在机器和编译程序之间加入了一层抽象的虚拟的机器。这台虚拟的机器在任何平台上都提供给编译程序一个的共同的接口。编译程序只需要面向虚拟机,生成虚拟机能够理解的代码,然后由解释器来将虚拟机代码转换为特定系统的机器码执行。在 Java 中,这种供虚拟机理解的代码叫做`字节码`(即扩展名为`.class`的文件),它不面向任何特定的处理器,只面向虚拟机。每一种平台的解释器是不同的,但是实现的虚拟机是相同的。Java 源程序经过编译器编译后变成字节码,字节码由虚拟机解释执行,虚拟机将每一条要执行的字节码送给解释器,解释器将其翻译成特定机器上的机器码,然后在特定的机器上运行。这也就是解释了 Java 的编译与解释并存的特点。 - -Java 源代码---->编译器---->jvm 可执行的 Java 字节码(即虚拟指令)---->jvm---->jvm 中解释器----->机器可执行的二进制机器码---->程序运行。 - -**采用字节码的好处:** - -Java 语言通过字节码的方式,在一定程度上解决了传统解释型语言执行效率低的问题,同时又保留了解释型语言可移植的特点。所以 Java 程序运行时比较高效,而且,由于字节码并不专对一种特定的机器,因此,Java 程序无须重新编译便可在多种不同的计算机上运行。 - -## 八 接口和抽象类的区别是什么? - -1. 接口的方法默认是 public,所有方法在接口中不能有实现,抽象类可以有非抽象的方法 -2. 接口中的实例变量默认是 final 类型的,而抽象类中则不一定 -3. 一个类可以实现多个接口,但最多只能实现一个抽象类 -4. 一个类实现接口的话要实现接口的所有方法,而抽象类不一定 -5. 接口不能用 new 实例化,但可以声明,但是必须引用一个实现该接口的对象 从设计层面来说,抽象是对类的抽象,是一种模板设计,接口是行为的抽象,是一种行为的规范。 - -注意:Java8 后接口可以有默认实现( default )。 - -## 九 重载和重写的区别 - -### 重载 - -发生在同一个类中,方法名必须相同,参数类型不同、个数不同、顺序不同,方法返回值和访问修饰符可以不同。 - -下面是《Java 核心技术》对重载这个概念的介绍: - - - -### 重写 - -重写是子类对父类的允许访问的方法的实现过程进行重新编写,发生在子类中,方法名、参数列表必须相同,返回值范围小于等于父类,抛出的异常范围小于等于父类,访问修饰符范围大于等于父类。另外,如果父类方法访问修饰符为 private 则子类就不能重写该方法。**也就是说方法提供的行为改变,而方法的外貌并没有改变。** - -## 十. Java 面向对象编程三大特性: 封装 继承 多态 - -### 封装 - -封装把一个对象的属性私有化,同时提供一些可以被外界访问的属性的方法,如果属性不想被外界访问,我们大可不必提供方法给外界访问。但是如果一个类没有提供给外界访问的方法,那么这个类也没有什么意义了。 - -### 继承 - -继承是使用已存在的类的定义作为基础建立新类的技术,新类的定义可以增加新的数据或新的功能,也可以用父类的功能,但不能选择性地继承父类。通过使用继承我们能够非常方便地复用以前的代码。 - -**关于继承如下 3 点请记住:** - -1. 子类拥有父类对象所有的属性和方法(包括私有属性和私有方法),但是父类中的私有属性和方法子类是无法访问,**只是拥有**。 -2. 子类可以拥有自己属性和方法,即子类可以对父类进行扩展。 -3. 子类可以用自己的方式实现父类的方法。(以后介绍)。 - -### 多态 - -所谓多态就是指程序中定义的引用变量所指向的具体类型和通过该引用变量发出的方法调用在编程时并不确定,而是在程序运行期间才确定,即一个引用变量到底会指向哪个类的实例对象,该引用变量发出的方法调用到底是哪个类中实现的方法,必须在由程序运行期间才能决定。 - -在 Java 中有两种形式可以实现多态:继承(多个子类对同一方法的重写)和接口(实现接口并覆盖接口中同一方法)。 - -## 十一. 什么是线程和进程? - -### 11.1 何为进程? - -进程是程序的一次执行过程,是系统运行程序的基本单位,因此进程是动态的。系统运行一个程序即是一个进程从创建,运行到消亡的过程。 - -在 Java 中,当我们启动 main 函数时其实就是启动了一个 JVM 的进程,而 main 函数所在的线程就是这个进程中的一个线程,也称主线程。 - -如下图所示,在 windows 中通过查看任务管理器的方式,我们就可以清楚看到 window 当前运行的进程(.exe 文件的运行)。 - - - -### 11.2 何为线程? - -线程与进程相似,但线程是一个比进程更小的执行单位。一个进程在其执行的过程中可以产生多个线程。与进程不同的是同类的多个线程共享进程的**堆**和**方法区**资源,但每个线程有自己的**程序计数器**、**虚拟机栈**和**本地方法栈**,所以系统在产生一个线程,或是在各个线程之间作切换工作时,负担要比进程小得多,也正因为如此,线程也被称为轻量级进程。 - -Java 程序天生就是多线程程序,我们可以通过 JMX 来看一下一个普通的 Java 程序有哪些线程,代码如下。 - -```java -public class MultiThread { - public static void main(String[] args) { - // 获取 Java 线程管理 MXBean - ThreadMXBean threadMXBean = ManagementFactory.getThreadMXBean(); - // 不需要获取同步的 monitor 和 synchronizer 信息,仅获取线程和线程堆栈信息 - ThreadInfo[] threadInfos = threadMXBean.dumpAllThreads(false, false); - // 遍历线程信息,仅打印线程 ID 和线程名称信息 - for (ThreadInfo threadInfo : threadInfos) { - System.out.println("[" + threadInfo.getThreadId() + "] " + threadInfo.getThreadName()); - } - } -} -``` - -上述程序输出如下(输出内容可能不同,不用太纠结下面每个线程的作用,只用知道 main 线程执行 main 方法即可): - -``` -[5] Attach Listener //添加事件 -[4] Signal Dispatcher // 分发处理给 JVM 信号的线程 -[3] Finalizer //调用对象 finalize 方法的线程 -[2] Reference Handler //清除 reference 线程 -[1] main //main 线程,程序入口 -``` - -从上面的输出内容可以看出:**一个 Java 程序的运行是 main 线程和多个其他线程同时运行**。 - -## 十二. 请简要描述线程与进程的关系,区别及优缺点? - -**从 JVM 角度说进程和线程之间的关系** - -### 12.1 图解进程和线程的关系 - -下图是 Java 内存区域,通过下图我们从 JVM 的角度来说一下线程和进程之间的关系。如果你对 Java 内存区域 (运行时数据区) 这部分知识不太了解的话可以阅读一下这篇文章:[《可能是把 Java 内存区域讲的最清楚的一篇文章》](https://github.com/Snailclimb/JavaGuide/blob/3965c02cc0f294b0bd3580df4868d5e396959e2e/Java%E7%9B%B8%E5%85%B3/%E5%8F%AF%E8%83%BD%E6%98%AF%E6%8A%8AJava%E5%86%85%E5%AD%98%E5%8C%BA%E5%9F%9F%E8%AE%B2%E7%9A%84%E6%9C%80%E6%B8%85%E6%A5%9A%E7%9A%84%E4%B8%80%E7%AF%87%E6%96%87%E7%AB%A0.md "《可能是把 Java 内存区域讲的最清楚的一篇文章》") - -
 -
- -
-**简单示意图:**
-
-
-**简单示意图:**
- -
-- 客户端–发送带有 SYN 标志的数据包–一次握手–服务端
-- 服务端–发送带有 SYN/ACK 标志的数据包–二次握手–客户端
-- 客户端–发送带有带有 ACK 标志的数据包–三次握手–服务端
-
-#### 为什么要三次握手
-
-**三次握手的目的是建立可靠的通信信道,说到通讯,简单来说就是数据的发送与接收,而三次握手最主要的目的就是双方确认自己与对方的发送与接收是正常的。**
-
-第一次握手:Client 什么都不能确认;Server 确认了对方发送正常,自己接收正常。
-
-第二次握手:Client 确认了:自己发送、接收正常,对方发送、接收正常;Server 确认了:自己接收正常,对方发送正常
-
-第三次握手:Client 确认了:自己发送、接收正常,对方发送、接收正常;Server 确认了:自己发送、接收正常,对方发送、接收正常
-
-所以三次握手就能确认双发收发功能都正常,缺一不可。
-
-#### 为什么要传回 SYN
-
-接收端传回发送端所发送的 SYN 是为了告诉发送端,我接收到的信息确实就是你所发送的信号了。
-
-> SYN 是 TCP/IP 建立连接时使用的握手信号。在客户机和服务器之间建立正常的 TCP 网络连接时,客户机首先发出一个 SYN 消息,服务器使用 SYN-ACK 应答表示接收到了这个消息,最后客户机再以 ACK(Acknowledgement[汉译:确认字符 ,在数据通信传输中,接收站发给发送站的一种传输控制字符。它表示确认发来的数据已经接受无误。 ])消息响应。这样在客户机和服务器之间才能建立起可靠的 TCP 连接,数据才可以在客户机和服务器之间传递。
-
-#### 传了 SYN,为啥还要传 ACK
-
-双方通信无误必须是两者互相发送信息都无误。传了 SYN,证明发送方(主动关闭方)到接收方(被动关闭方)的通道没有问题,但是接收方到发送方的通道还需要 ACK 信号来进行验证。
-
-断开一个 TCP 连接则需要“四次挥手”:
-
-- 客户端-发送一个 FIN,用来关闭客户端到服务器的数据传送
-- 服务器-收到这个 FIN,它发回一 个 ACK,确认序号为收到的序号加 1 。和 SYN 一样,一个 FIN 将占用一个序号
-- 服务器-关闭与客户端的连接,发送一个 FIN 给客户端
-- 客户端-发回 ACK 报文确认,并将确认序号设置为收到序号加 1
-
-#### 为什么要四次挥手
-
-任何一方都可以在数据传送结束后发出连接释放的通知,待对方确认后进入半关闭状态。当另一方也没有数据再发送的时候,则发出连接释放通知,对方确认后就完全关闭了 TCP 连接。
-
-举个例子:A 和 B 打电话,通话即将结束后,A 说“我没啥要说的了”,B 回答“我知道了”,但是 B 可能还会有要说的话,A 不能要求 B 跟着自己的节奏结束通话,于是 B 可能又巴拉巴拉说了一通,最后 B 说“我说完了”,A 回答“知道了”,这样通话才算结束。
-
-上面讲的比较概括,推荐一篇讲的比较细致的文章:[https://blog.csdn.net/qzcsu/article/details/72861891](https://blog.csdn.net/qzcsu/article/details/72861891 "https://blog.csdn.net/qzcsu/article/details/72861891")
-
-## 5. IP 地址与 MAC 地址的区别
-
-参考:[https://blog.csdn.net/guoweimelon/article/details/50858597](https://blog.csdn.net/guoweimelon/article/details/50858597 "https://blog.csdn.net/guoweimelon/article/details/50858597")
-
-IP 地址是指互联网协议地址(Internet Protocol Address)IP Address 的缩写。IP 地址是 IP 协议提供的一种统一的地址格式,它为互联网上的每一个网络和每一台主机分配一个逻辑地址,以此来屏蔽物理地址的差异。
-
-MAC 地址又称为物理地址、硬件地址,用来定义网络设备的位置。网卡的物理地址通常是由网卡生产厂家写入网卡的,具有全球唯一性。MAC 地址用于在网络中唯一标示一个网卡,一台电脑会有一或多个网卡,每个网卡都需要有一个唯一的 MAC 地址。
-
-## 6. HTTP 请求,响应报文格式
-
-HTTP 请求报文主要由请求行、请求头部、请求正文 3 部分组成
-
-HTTP 响应报文主要由状态行、响应头部、响应正文 3 部分组成
-
-详细内容可以参考:[https://blog.csdn.net/a19881029/article/details/14002273](https://blog.csdn.net/a19881029/article/details/14002273 "https://blog.csdn.net/a19881029/article/details/14002273")
-
-## 7. 为什么要使用索引?索引这么多优点,为什么不对表中的每一个列创建一个索引呢?索引是如何提高查询速度的?说一下使用索引的注意事项?Mysql 索引主要使用的两种数据结构?什么是覆盖索引?
-
-**为什么要使用索引?**
-
-1. 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
-2. 可以大大加快 数据的检索速度(大大减少的检索的数据量), 这也是创建索引的最主要的原因。
-3. 帮助服务器避免排序和临时表
-4. 将随机 IO 变为顺序 IO
-5. 可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
-
-**索引这么多优点,为什么不对表中的每一个列创建一个索引呢?**
-
-1. 当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
-2. 索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大。
-3. 创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
-
-**索引是如何提高查询速度的?**
-
-将无序的数据变成相对有序的数据(就像查目录一样)
-
-**说一下使用索引的注意事项**
-
-1. 避免 where 子句中对字段施加函数,这会造成无法命中索引。
-2. 在使用 InnoDB 时使用与业务无关的自增主键作为主键,即使用逻辑主键,而不要使用业务主键。
-3. 将打算加索引的列设置为 NOT NULL ,否则将导致引擎放弃使用索引而进行全表扫描
-4. 删除长期未使用的索引,不用的索引的存在会造成不必要的性能损耗 MySQL 5.7 可以通过查询 sys 库的 schema_unused_indexes 视图来查询哪些索引从未被使用
-5. 在使用 limit offset 查询缓慢时,可以借助索引来提高性能
-
-**Mysql 索引主要使用的哪两种数据结构?**
-
-- 哈希索引:对于哈希索引来说,底层的数据结构就是哈希表,因此在绝大多数需求为单条记录查询的时候,可以选择哈希索引,查询性能最快;其余大部分场景,建议选择 BTree 索引。
-- BTree 索引:Mysql 的 BTree 索引使用的是 B 树中的 B+Tree。但对于主要的两种存储引擎(MyISAM 和 InnoDB)的实现方式是不同的。
-
-更多关于索引的内容可以查看我的这篇文章:[【思维导图-索引篇】搞定数据库索引就是这么简单](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484486&idx=1&sn=215450f11e042bca8a58eac9f4a97686&chksm=fd985227caefdb3117b8375f150676f5824aa20d1ebfdbcfb93ff06e23e26efbafae6cf6b48e&token=1990180468&lang=zh_CN#rd)
-
-**什么是覆盖索引?**
-
-如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称
-之为“覆盖索引”。我们知道在 InnoDB 存储引擎中,如果不是主键索引,叶子节点存储的是主键+列值。最终还是要“回表”,也就是要通过主键再查找一次,这样就会比较慢。覆盖索引就是把要查询出的列和索引是对应的,不做回表操作!
-
-## 8. 进程与线程的区别是什么?进程间的几种通信方式说一下?线程间的几种通信方式知道不?
-
-**进程与线程的区别是什么?**
-
-线程与进程相似,但线程是一个比进程更小的执行单位。一个进程在其执行的过程中可以产生多个线程。与进程不同的是同类的多个线程共享同一块内存空间和一组系统资源,所以系统在产生一个线程,或是在各个线程之间作切换工作时,负担要比进程小得多,也正因为如此,线程也被称为轻量级进程。另外,也正是因为共享资源,所以线程中执行时一般都要进行同步和互斥。总的来说,进程和线程的主要差别在于它们是不同的操作系统资源管理方式。
-
-**进程间的几种通信方式说一下?**
-
-1. **管道(pipe)**:管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有血缘关系的进程间使用。进程的血缘关系通常指父子进程关系。管道分为 pipe(无名管道)和 fifo(命名管道)两种,有名管道也是半双工的通信方式,但是它允许无亲缘关系进程间通信。
-2. **信号量(semophore)**:信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它通常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
-3. **消息队列(message queue)**:消息队列是由消息组成的链表,存放在内核中 并由消息队列标识符标识。消息队列克服了信号传递信息少,管道只能承载无格式字节流以及缓冲区大小受限等缺点。消息队列与管道通信相比,其优势是对每个消息指定特定的消息类型,接收的时候不需要按照队列次序,而是可以根据自定义条件接收特定类型的消息。
-4. **信号(signal)**:信号是一种比较复杂的通信方式,用于通知接收进程某一事件已经发生。
-5. **共享内存(shared memory)**:共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问,共享内存是最快的 IPC 方式,它是针对其他进程间的通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号量配合使用,来实现进程间的同步和通信。
-6. **套接字(socket)**:socket,即套接字是一种通信机制,凭借这种机制,客户/服务器(即要进行通信的进程)系统的开发工作既可以在本地单机上进行,也可以跨网络进行。也就是说它可以让不在同一台计算机但通过网络连接计算机上的进程进行通信。也因为这样,套接字明确地将客户端和服务器区分开来。
-
-**线程间的几种通信方式知道不?**
-
-1、锁机制
-
-- 互斥锁:提供了以排它方式阻止数据结构被并发修改的方法。
-- 读写锁:允许多个线程同时读共享数据,而对写操作互斥。
-- 条件变量:可以以原子的方式阻塞进程,直到某个特定条件为真为止。对条件测试是在互斥锁的保护下进行的。条件变量始终与互斥锁一起使用。
-
-2、信号量机制:包括无名线程信号量与有名线程信号量
-
-3、信号机制:类似于进程间的信号处理。
-
-线程间通信的主要目的是用于线程同步,所以线程没有象进程通信中用于数据交换的通信机制。
-
-## 9. 为什么要用单例模式?手写几种线程安全的单例模式?
-
-**简单来说使用单例模式可以带来下面几个好处:**
-
-- 对于频繁使用的对象,可以省略创建对象所花费的时间,这对于那些重量级对象而言,是非常可观的一笔系统开销;
-- 由于 new 操作的次数减少,因而对系统内存的使用频率也会降低,这将减轻 GC 压力,缩短 GC 停顿时间。
-
-**懒汉式(双重检查加锁版本)**
-
-```java
-public class Singleton {
-
- //volatile保证,当uniqueInstance变量被初始化成Singleton实例时,多个线程可以正确处理uniqueInstance变量
- private volatile static Singleton uniqueInstance;
- private Singleton() {
- }
- public static Singleton getInstance() {
- //检查实例,如果不存在,就进入同步代码块
- if (uniqueInstance == null) {
- //只有第一次才彻底执行这里的代码
- synchronized(Singleton.class) {
- //进入同步代码块后,再检查一次,如果仍是null,才创建实例
- if (uniqueInstance == null) {
- uniqueInstance = new Singleton();
- }
- }
- }
- return uniqueInstance;
- }
-}
-```
-
-**静态内部类方式**
-
-静态内部实现的单例是懒加载的且线程安全。
-
-只有通过显式调用 getInstance 方法时,才会显式装载 SingletonHolder 类,从而实例化 instance(只有第一次使用这个单例的实例的时候才加载,同时不会有线程安全问题)。
-
-```java
-public class Singleton {
- private static class SingletonHolder {
- private static final Singleton INSTANCE = new Singleton();
- }
- private Singleton (){}
- public static final Singleton getInstance() {
- return SingletonHolder.INSTANCE;
- }
-}
-```
-
-## 10. 简单介绍一下 bean;知道 Spring 的 bean 的作用域与生命周期吗?
-
-在 Spring 中,那些组成应用程序的主体及由 Spring IOC 容器所管理的对象,被称之为 bean。简单地讲,bean 就是由 IOC 容器初始化、装配及管理的对象,除此之外,bean 就与应用程序中的其他对象没有什么区别了。而 bean 的定义以及 bean 相互间的依赖关系将通过配置元数据来描述。
-
-Spring 中的 bean 默认都是单例的,这些单例 Bean 在多线程程序下如何保证线程安全呢? 例如对于 Web 应用来说,Web 容器对于每个用户请求都创建一个单独的 Sevlet 线程来处理请求,引入 Spring 框架之后,每个 Action 都是单例的,那么对于 Spring 托管的单例 Service Bean,如何保证其安全呢? Spring 的单例是基于 BeanFactory 也就是 Spring 容器的,单例 Bean 在此容器内只有一个,Java 的单例是基于 JVM,每个 JVM 内只有一个实例。
-
-
-
-Spring 的 bean 的生命周期以及更多内容可以查看:[一文轻松搞懂 Spring 中 bean 的作用域与生命周期](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484400&idx=2&sn=7201eb365102fce017f89cb3527fb0bc&chksm=fd985591caefdc872a2fac897288119f94c345e4e12150774f960bf5f816b79e4b9b46be3d7f&token=1990180468&lang=zh_CN#rd)
-
-## 11. Spring 中的事务传播行为了解吗?TransactionDefinition 接口中哪五个表示隔离级别的常量?
-
-#### 事务传播行为
-
-事务传播行为(为了解决业务层方法之间互相调用的事务问题):
-当事务方法被另一个事务方法调用时,必须指定事务应该如何传播。例如:方法可能继续在现有事务中运行,也可能开启一个新事务,并在自己的事务中运行。在 TransactionDefinition 定义中包括了如下几个表示传播行为的常量:
-
-**支持当前事务的情况:**
-
-- TransactionDefinition.PROPAGATION_REQUIRED: 如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。
-- TransactionDefinition.PROPAGATION_SUPPORTS: 如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。
-- TransactionDefinition.PROPAGATION_MANDATORY: 如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。(mandatory:强制性)
-
-**不支持当前事务的情况:**
-
-- TransactionDefinition.PROPAGATION_REQUIRES_NEW: 创建一个新的事务,如果当前存在事务,则把当前事务挂起。
-- TransactionDefinition.PROPAGATION_NOT_SUPPORTED: 以非事务方式运行,如果当前存在事务,则把当前事务挂起。
-- TransactionDefinition.PROPAGATION_NEVER: 以非事务方式运行,如果当前存在事务,则抛出异常。
-
-**其他情况:**
-
-- TransactionDefinition.PROPAGATION_NESTED: 如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于 TransactionDefinition.PROPAGATION_REQUIRED。
-
-#### 隔离级别
-
-TransactionDefinition 接口中定义了五个表示隔离级别的常量:
-
-- **TransactionDefinition.ISOLATION_DEFAULT:** 使用后端数据库默认的隔离级别,Mysql 默认采用的 REPEATABLE_READ 隔离级别 Oracle 默认采用的 READ_COMMITTED 隔离级别.
-- **TransactionDefinition.ISOLATION_READ_UNCOMMITTED:** 最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读
-- **TransactionDefinition.ISOLATION_READ_COMMITTED:** 允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生
-- **TransactionDefinition.ISOLATION_REPEATABLE_READ:** 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
-- **TransactionDefinition.ISOLATION_SERIALIZABLE:** 最高的隔离级别,完全服从 ACID 的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。但是这将严重影响程序的性能。通常情况下也不会用到该级别。
-
-## 12. SpringMVC 原理了解吗?
-
-
-
-客户端发送请求-> 前端控制器 DispatcherServlet 接受客户端请求 -> 找到处理器映射 HandlerMapping 解析请求对应的 Handler-> HandlerAdapter 会根据 Handler 来调用真正的处理器处理请求,并处理相应的业务逻辑 -> 处理器返回一个模型视图 ModelAndView -> 视图解析器进行解析 -> 返回一个视图对象->前端控制器 DispatcherServlet 渲染数据(Model)->将得到视图对象返回给用户
-
-关于 SpringMVC 原理更多内容可以查看我的这篇文章:[SpringMVC 工作原理详解](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484496&idx=1&sn=5472ffa687fe4a05f8900d8ee6726de4&chksm=fd985231caefdb27fc75b44ecf76b6f43e4617e0b01b3c040f8b8fab32e51dfa5118eed1d6ad&token=1990180468&lang=zh_CN#rd)
-
-## 13. Spring AOP IOC 实现原理
-
-过了秋招挺长一段时间了,说实话我自己也忘了如何简要概括 Spring AOP IOC 实现原理,就在网上找了一个较为简洁的答案,下面分享给各位。
-
-**IOC:** 控制反转也叫依赖注入。IOC 利用 java 反射机制,AOP 利用代理模式。IOC 概念看似很抽象,但是很容易理解。说简单点就是将对象交给容器管理,你只需要在 spring 配置文件中配置对应的 bean 以及设置相关的属性,让 spring 容器来生成类的实例对象以及管理对象。在 spring 容器启动的时候,spring 会把你在配置文件中配置的 bean 都初始化好,然后在你需要调用的时候,就把它已经初始化好的那些 bean 分配给你需要调用这些 bean 的类。
-
-**AOP:** 面向切面编程。(Aspect-Oriented Programming) 。AOP 可以说是对 OOP 的补充和完善。OOP 引入封装、继承和多态性等概念来建立一种对象层次结构,用以模拟公共行为的一个集合。实现 AOP 的技术,主要分为两大类:一是采用动态代理技术,利用截取消息的方式,对该消息进行装饰,以取代原有对象行为的执行;二是采用静态织入的方式,引入特定的语法创建“方面”,从而使得编译器可以在编译期间织入有关“方面”的代码,属于静态代理。
-
-# 二 进阶篇
-
-## 1 消息队列 MQ 的套路
-
-消息队列/消息中间件应该是 Java 程序员必备的一个技能了,如果你之前没接触过消息队列的话,建议先去百度一下某某消息队列入门,然后花 2 个小时就差不多可以学会任何一种消息队列的使用了。如果说仅仅学会使用是万万不够的,在实际生产环境还要考虑消息丢失等等情况。关于消息队列面试相关的问题,推荐大家也可以看一下视频《Java 工程师面试突击第 1 季-中华石杉老师》,如果大家没有资源的话,可以在我的公众号“Java 面试通关手册”后台回复关键字“1”即可!
-
-### 1.1 介绍一下消息队列 MQ 的应用场景/使用消息队列的好处
-
-面试官一般会先问你这个问题,预热一下,看你知道消息队列不,一般在第一面的时候面试官可能只会问消息队列 MQ 的应用场景/使用消息队列的好处、使用消息队列会带来什么问题、消息队列的技术选型这几个问题,不会太深究下去,在后面的第二轮/第三轮技术面试中可能会深入问一下。
-
-**《大型网站技术架构》第四章和第七章均有提到消息队列对应用性能及扩展性的提升。**
-
-#### 1)通过异步处理提高系统性能
-
-
-如上图,**在不使用消息队列服务器的时候,用户的请求数据直接写入数据库,在高并发的情况下数据库压力剧增,使得响应速度变慢。但是在使用消息队列之后,用户的请求数据发送给消息队列之后立即 返回,再由消息队列的消费者进程从消息队列中获取数据,异步写入数据库。由于消息队列服务器处理速度快于数据库(消息队列也比数据库有更好的伸缩性),因此响应速度得到大幅改善。**
-
-通过以上分析我们可以得出**消息队列具有很好的削峰作用的功能**——即**通过异步处理,将短时间高并发产生的事务消息存储在消息队列中,从而削平高峰期的并发事务。** 举例:在电子商务一些秒杀、促销活动中,合理使用消息队列可以有效抵御促销活动刚开始大量订单涌入对系统的冲击。如下图所示:
-
-因为**用户请求数据写入消息队列之后就立即返回给用户了,但是请求数据在后续的业务校验、写数据库等操作中可能失败**。因此使用消息队列进行异步处理之后,需要**适当修改业务流程进行配合**,比如**用户在提交订单之后,订单数据写入消息队列,不能立即返回用户订单提交成功,需要在消息队列的订单消费者进程真正处理完该订单之后,甚至出库后,再通过电子邮件或短信通知用户订单成功**,以免交易纠纷。这就类似我们平时手机订火车票和电影票。
-
-#### 2)降低系统耦合性
-
-我们知道模块分布式部署以后聚合方式通常有两种:1.**分布式消息队列**和 2.**分布式服务**。
-
-> **先来简单说一下分布式服务:**
-
-目前使用比较多的用来构建**SOA(Service Oriented Architecture 面向服务体系结构)**的**分布式服务框架**是阿里巴巴开源的**Dubbo**。如果想深入了解 Dubbo 的可以看我写的关于 Dubbo 的这一篇文章:**《高性能优秀的服务框架-dubbo 介绍》**:[https://juejin.im/post/5acadeb1f265da2375072f9c](https://juejin.im/post/5acadeb1f265da2375072f9c "https://juejin.im/post/5acadeb1f265da2375072f9c")
-
-> **再来谈我们的分布式消息队列:**
-
-我们知道如果模块之间不存在直接调用,那么新增模块或者修改模块就对其他模块影响较小,这样系统的可扩展性无疑更好一些。
-
-我们最常见的**事件驱动架构**类似生产者消费者模式,在大型网站中通常用利用消息队列实现事件驱动结构。如下图所示:
-
-
-**消息队列使利用发布-订阅模式工作,消息发送者(生产者)发布消息,一个或多个消息接受者(消费者)订阅消息。** 从上图可以看到**消息发送者(生产者)和消息接受者(消费者)之间没有直接耦合**,消息发送者将消息发送至分布式消息队列即结束对消息的处理,消息接受者从分布式消息队列获取该消息后进行后续处理,并不需要知道该消息从何而来。**对新增业务,只要对该类消息感兴趣,即可订阅该消息,对原有系统和业务没有任何影响,从而实现网站业务的可扩展性设计**。
-
-消息接受者对消息进行过滤、处理、包装后,构造成一个新的消息类型,将消息继续发送出去,等待其他消息接受者订阅该消息。因此基于事件(消息对象)驱动的业务架构可以是一系列流程。
-
-**另外为了避免消息队列服务器宕机造成消息丢失,会将成功发送到消息队列的消息存储在消息生产者服务器上,等消息真正被消费者服务器处理后才删除消息。在消息队列服务器宕机后,生产者服务器会选择分布式消息队列服务器集群中的其他服务器发布消息。**
-
-**备注:** 不要认为消息队列只能利用发布-订阅模式工作,只不过在解耦这个特定业务环境下是使用发布-订阅模式的,**比如在我们的 ActiveMQ 消息队列中还有点对点工作模式**,具体的会在后面的文章给大家详细介绍,这一篇文章主要还是让大家对消息队列有一个更透彻的了解。
-
-> 这个问题一般会在上一个问题问完之后,紧接着被问到。“使用消息队列会带来什么问题?”这个问题要引起重视,一般我们都会考虑使用消息队列会带来的好处而忽略它带来的问题!
-
-### 1.2 那么使用消息队列会带来什么问题?考虑过这些问题吗?
-
-- **系统可用性降低:** 系统可用性在某种程度上降低,为什么这样说呢?在加入 MQ 之前,你不用考虑消息丢失或者说 MQ 挂掉等等的情况,但是,引入 MQ 之后你就需要去考虑了!
-- **系统复杂性提高:** 加入 MQ 之后,你需要保证消息没有被重复消费、处理消息丢失的情况、保证消息传递的顺序性等等问题!
-- **一致性问题:** 我上面讲了消息队列可以实现异步,消息队列带来的异步确实可以提高系统响应速度。但是,万一消息的真正消费者并没有正确消费消息怎么办?这样就会导致数据不一致的情况了!
-
-> 了解下面这个问题是为了我们更好的进行技术选型!该部分摘自:《Java 工程师面试突击第 1 季-中华石杉老师》,如果大家没有资源的话,可以在我的公众号“Java 面试通关手册”后台回复关键字“1”即可!
-
-### 1.3 介绍一下你知道哪几种消息队列,该如何选择呢?
-
-| 特性 | ActiveMQ | RabbitMQ | RocketMQ | Kafka |
-| :----------------------- | -----------------------------------------------------------: | -----------------------------------------------------------: | -----------------------------------------------------------: | -----------------------------------------------------------: |
-| 单机吞吐量 | 万级,吞吐量比 RocketMQ 和 Kafka 要低了一个数量级 | 万级,吞吐量比 RocketMQ 和 Kafka 要低了一个数量级 | 10 万级,RocketMQ 也是可以支撑高吞吐的一种 MQ | 10 万级别,这是 kafka 最大的优点,就是吞吐量高。一般配合大数据类的系统来进行实时数据计算、日志采集等场景 |
-| topic 数量对吞吐量的影响 | | | topic 可以达到几百,几千个的级别,吞吐量会有较小幅度的下降这是 RocketMQ 的一大优势,在同等机器下,可以支撑大量的 topic | topic 从几十个到几百个的时候,吞吐量会大幅度下降。所以在同等机器下,kafka 尽量保证 topic 数量不要过多。如果要支撑大规模 topic,需要增加更多的机器资源 |
-| 可用性 | 高,基于主从架构实现高可用性 | 高,基于主从架构实现高可用性 | 非常高,分布式架构 | 非常高,kafka 是分布式的,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用 |
-| 消息可靠性 | 有较低的概率丢失数据 | | 经过参数优化配置,可以做到 0 丢失 | 经过参数优化配置,消息可以做到 0 丢失 |
-| 时效性 | ms 级 | 微秒级,这是 rabbitmq 的一大特点,延迟是最低的 | ms 级 | 延迟在 ms 级以内 |
-| 功能支持 | MQ 领域的功能极其完备 | 基于 erlang 开发,所以并发能力很强,性能极其好,延时很低 | MQ 功能较为完善,还是分布式的,扩展性好 | 功能较为简单,主要支持简单的 MQ 功能,在大数据领域的实时计算以及日志采集被大规模使用,是事实上的标准 |
-| 优劣势总结 | 非常成熟,功能强大,在业内大量的公司以及项目中都有应用。偶尔会有较低概率丢失消息,而且现在社区以及国内应用都越来越少,官方社区现在对 ActiveMQ 5.x 维护越来越少,几个月才发布一个版本而且确实主要是基于解耦和异步来用的,较少在大规模吞吐的场景中使用 | erlang 语言开发,性能极其好,延时很低;吞吐量到万级,MQ 功能比较完备而且开源提供的管理界面非常棒,用起来很好用。社区相对比较活跃,几乎每个月都发布几个版本分在国内一些互联网公司近几年用 rabbitmq 也比较多一些但是问题也是显而易见的,RabbitMQ 确实吞吐量会低一些,这是因为他做的实现机制比较重。而且 erlang 开发,国内有几个公司有实力做 erlang 源码级别的研究和定制?如果说你没这个实力的话,确实偶尔会有一些问题,你很难去看懂源码,你公司对这个东西的掌控很弱,基本职能依赖于开源社区的快速维护和修复 bug。而且 rabbitmq 集群动态扩展会很麻烦,不过这个我觉得还好。其实主要是 erlang 语言本身带来的问题。很难读源码,很难定制和掌控。 | 接口简单易用,而且毕竟在阿里大规模应用过,有阿里品牌保障。日处理消息上百亿之多,可以做到大规模吞吐,性能也非常好,分布式扩展也很方便,社区维护还可以,可靠性和可用性都是 ok 的,还可以支撑大规模的 topic 数量,支持复杂 MQ 业务场景。而且一个很大的优势在于,阿里出品都是 java 系的,我们可以自己阅读源码,定制自己公司的 MQ,可以掌控。社区活跃度相对较为一般,不过也还可以,文档相对来说简单一些,然后接口这块不是按照标准 JMS 规范走的有些系统要迁移需要修改大量代码。还有就是阿里出台的技术,你得做好这个技术万一被抛弃,社区黄掉的风险,那如果你们公司有技术实力我觉得用 RocketMQ 挺好的 | kafka 的特点其实很明显,就是仅仅提供较少的核心功能,但是提供超高的吞吐量,ms 级的延迟,极高的可用性以及可靠性,而且分布式可以任意扩展。同时 kafka 最好是支撑较少的 topic 数量即可,保证其超高吞吐量。而且 kafka 唯一的一点劣势是有可能消息重复消费,那么对数据准确性会造成极其轻微的影响,在大数据领域中以及日志采集中,这点轻微影响可以忽略这个特性天然适合大数据实时计算以及日志收集。 |
-
-> 这部分内容,我这里不给出答案,大家可以自行根据自己学习的消息队列查阅相关内容,我可能会在后面的文章中介绍到这部分内容。另外,下面这些问题在视频《Java 工程师面试突击第 1 季-中华石杉老师》中都有提到,如果大家没有资源的话,可以在我的公众号“Java 面试通关手册”后台回复关键字“1”即可!
-
-### 1.4 关于消息队列其他一些常见的问题展望
-
-1. 引入消息队列之后如何保证高可用性?
-2. 如何保证消息不被重复消费呢?
-3. 如何保证消息的可靠性传输(如何处理消息丢失的问题)?
-4. 我该怎么保证从消息队列里拿到的数据按顺序执行?
-5. 如何解决消息队列的延时以及过期失效问题?消息队列满了以后该怎么处理?有几百万消息持续积压几小时,说说怎么解决?
-6. 如果让你来开发一个消息队列中间件,你会怎么设计架构?
-
-## 2 谈谈 InnoDB 和 MyIsam 两者的区别
-
-### 2.1 两者的对比
-
-1. **count 运算上的区别:** 因为 MyISAM 缓存有表 meta-data(行数等),因此在做 COUNT(\*)时对于一个结构很好的查询是不需要消耗多少资源的。而对于 InnoDB 来说,则没有这种缓存
-2. **是否支持事务和崩溃后的安全恢复:** MyISAM 强调的是性能,每次查询具有原子性,其执行速度比 InnoDB 类型更快,但是不提供事务支持。但是 InnoDB 提供事务支持,外部键等高级数据库功能。 具有事务(commit)、回滚(rollback)和崩溃修复能力(crash recovery capabilities)的事务安全(transaction-safe (ACID compliant))型表。
-3. **是否支持外键:** MyISAM 不支持,而 InnoDB 支持。
-
-### 2.2 关于两者的总结
-
-MyISAM 更适合读密集的表,而 InnoDB 更适合写密集的表。 在数据库做主从分离的情况下,经常选择 MyISAM 作为主库的存储引擎。
-
-一般来说,如果需要事务支持,并且有较高的并发读取频率(MyISAM 的表锁的粒度太大,所以当该表写并发量较高时,要等待的查询就会很多了),InnoDB 是不错的选择。如果你的数据量很大(MyISAM 支持压缩特性可以减少磁盘的空间占用),而且不需要支持事务时,MyISAM 是最好的选择。
-
-## 3 聊聊 Java 中的集合吧!
-
-### 3.1 Arraylist 与 LinkedList 有什么不同?(注意加上从数据结构分析的内容)
-
-- **1. 是否保证线程安全:** ArrayList 和 LinkedList 都是不同步的,也就是不保证线程安全;
-- **2. 底层数据结构:** Arraylist 底层使用的是 Object 数组;LinkedList 底层使用的是双向链表数据结构(注意双向链表和双向循环链表的区别:);
-- **3. 插入和删除是否受元素位置的影响:** ① **ArrayList 采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。** 比如:执行`add(E e)`方法的时候, ArrayList 会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是 O(1)。但是如果要在指定位置 i 插入和删除元素的话(`add(int index, E element)`)时间复杂度就为 O(n-i)。因为在进行上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执行向后位/向前移一位的操作。 ② **LinkedList 采用链表存储,所以插入,删除元素时间复杂度不受元素位置的影响,都是近似 O(1) 而数组为近似 O(n) 。**
-- **4. 是否支持快速随机访问:** LinkedList 不支持高效的随机元素访问,而 ArrayList 支持。快速随机访问就是通过元素的序号快速获取元素对象(对应于`get(int index)`方法)。
-- **5. 内存空间占用:** ArrayList 的空 间浪费主要体现在在 list 列表的结尾会预留一定的容量空间,而 LinkedList 的空间花费则体现在它的每一个元素都需要消耗比 ArrayList 更多的空间(因为要存放直接后继和直接前驱以及数据)。
-
-**补充内容:RandomAccess 接口**
-
-```java
-public interface RandomAccess {
-}
-```
-
-查看源码我们发现实际上 RandomAccess 接口中什么都没有定义。所以,在我看来 RandomAccess 接口不过是一个标识罢了。标识什么? 标识实现这个接口的类具有随机访问功能。
-
-在 binarySearch() 方法中,它要判断传入的 list 是否 RamdomAccess 的实例,如果是,调用 indexedBinarySearch() 方法,如果不是,那么调用 iteratorBinarySearch() 方法
-
-```java
- public static
-
-- 客户端–发送带有 SYN 标志的数据包–一次握手–服务端
-- 服务端–发送带有 SYN/ACK 标志的数据包–二次握手–客户端
-- 客户端–发送带有带有 ACK 标志的数据包–三次握手–服务端
-
-#### 为什么要三次握手
-
-**三次握手的目的是建立可靠的通信信道,说到通讯,简单来说就是数据的发送与接收,而三次握手最主要的目的就是双方确认自己与对方的发送与接收是正常的。**
-
-第一次握手:Client 什么都不能确认;Server 确认了对方发送正常,自己接收正常。
-
-第二次握手:Client 确认了:自己发送、接收正常,对方发送、接收正常;Server 确认了:自己接收正常,对方发送正常
-
-第三次握手:Client 确认了:自己发送、接收正常,对方发送、接收正常;Server 确认了:自己发送、接收正常,对方发送、接收正常
-
-所以三次握手就能确认双发收发功能都正常,缺一不可。
-
-#### 为什么要传回 SYN
-
-接收端传回发送端所发送的 SYN 是为了告诉发送端,我接收到的信息确实就是你所发送的信号了。
-
-> SYN 是 TCP/IP 建立连接时使用的握手信号。在客户机和服务器之间建立正常的 TCP 网络连接时,客户机首先发出一个 SYN 消息,服务器使用 SYN-ACK 应答表示接收到了这个消息,最后客户机再以 ACK(Acknowledgement[汉译:确认字符 ,在数据通信传输中,接收站发给发送站的一种传输控制字符。它表示确认发来的数据已经接受无误。 ])消息响应。这样在客户机和服务器之间才能建立起可靠的 TCP 连接,数据才可以在客户机和服务器之间传递。
-
-#### 传了 SYN,为啥还要传 ACK
-
-双方通信无误必须是两者互相发送信息都无误。传了 SYN,证明发送方(主动关闭方)到接收方(被动关闭方)的通道没有问题,但是接收方到发送方的通道还需要 ACK 信号来进行验证。
-
-断开一个 TCP 连接则需要“四次挥手”:
-
-- 客户端-发送一个 FIN,用来关闭客户端到服务器的数据传送
-- 服务器-收到这个 FIN,它发回一 个 ACK,确认序号为收到的序号加 1 。和 SYN 一样,一个 FIN 将占用一个序号
-- 服务器-关闭与客户端的连接,发送一个 FIN 给客户端
-- 客户端-发回 ACK 报文确认,并将确认序号设置为收到序号加 1
-
-#### 为什么要四次挥手
-
-任何一方都可以在数据传送结束后发出连接释放的通知,待对方确认后进入半关闭状态。当另一方也没有数据再发送的时候,则发出连接释放通知,对方确认后就完全关闭了 TCP 连接。
-
-举个例子:A 和 B 打电话,通话即将结束后,A 说“我没啥要说的了”,B 回答“我知道了”,但是 B 可能还会有要说的话,A 不能要求 B 跟着自己的节奏结束通话,于是 B 可能又巴拉巴拉说了一通,最后 B 说“我说完了”,A 回答“知道了”,这样通话才算结束。
-
-上面讲的比较概括,推荐一篇讲的比较细致的文章:[https://blog.csdn.net/qzcsu/article/details/72861891](https://blog.csdn.net/qzcsu/article/details/72861891 "https://blog.csdn.net/qzcsu/article/details/72861891")
-
-## 5. IP 地址与 MAC 地址的区别
-
-参考:[https://blog.csdn.net/guoweimelon/article/details/50858597](https://blog.csdn.net/guoweimelon/article/details/50858597 "https://blog.csdn.net/guoweimelon/article/details/50858597")
-
-IP 地址是指互联网协议地址(Internet Protocol Address)IP Address 的缩写。IP 地址是 IP 协议提供的一种统一的地址格式,它为互联网上的每一个网络和每一台主机分配一个逻辑地址,以此来屏蔽物理地址的差异。
-
-MAC 地址又称为物理地址、硬件地址,用来定义网络设备的位置。网卡的物理地址通常是由网卡生产厂家写入网卡的,具有全球唯一性。MAC 地址用于在网络中唯一标示一个网卡,一台电脑会有一或多个网卡,每个网卡都需要有一个唯一的 MAC 地址。
-
-## 6. HTTP 请求,响应报文格式
-
-HTTP 请求报文主要由请求行、请求头部、请求正文 3 部分组成
-
-HTTP 响应报文主要由状态行、响应头部、响应正文 3 部分组成
-
-详细内容可以参考:[https://blog.csdn.net/a19881029/article/details/14002273](https://blog.csdn.net/a19881029/article/details/14002273 "https://blog.csdn.net/a19881029/article/details/14002273")
-
-## 7. 为什么要使用索引?索引这么多优点,为什么不对表中的每一个列创建一个索引呢?索引是如何提高查询速度的?说一下使用索引的注意事项?Mysql 索引主要使用的两种数据结构?什么是覆盖索引?
-
-**为什么要使用索引?**
-
-1. 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
-2. 可以大大加快 数据的检索速度(大大减少的检索的数据量), 这也是创建索引的最主要的原因。
-3. 帮助服务器避免排序和临时表
-4. 将随机 IO 变为顺序 IO
-5. 可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
-
-**索引这么多优点,为什么不对表中的每一个列创建一个索引呢?**
-
-1. 当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
-2. 索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大。
-3. 创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
-
-**索引是如何提高查询速度的?**
-
-将无序的数据变成相对有序的数据(就像查目录一样)
-
-**说一下使用索引的注意事项**
-
-1. 避免 where 子句中对字段施加函数,这会造成无法命中索引。
-2. 在使用 InnoDB 时使用与业务无关的自增主键作为主键,即使用逻辑主键,而不要使用业务主键。
-3. 将打算加索引的列设置为 NOT NULL ,否则将导致引擎放弃使用索引而进行全表扫描
-4. 删除长期未使用的索引,不用的索引的存在会造成不必要的性能损耗 MySQL 5.7 可以通过查询 sys 库的 schema_unused_indexes 视图来查询哪些索引从未被使用
-5. 在使用 limit offset 查询缓慢时,可以借助索引来提高性能
-
-**Mysql 索引主要使用的哪两种数据结构?**
-
-- 哈希索引:对于哈希索引来说,底层的数据结构就是哈希表,因此在绝大多数需求为单条记录查询的时候,可以选择哈希索引,查询性能最快;其余大部分场景,建议选择 BTree 索引。
-- BTree 索引:Mysql 的 BTree 索引使用的是 B 树中的 B+Tree。但对于主要的两种存储引擎(MyISAM 和 InnoDB)的实现方式是不同的。
-
-更多关于索引的内容可以查看我的这篇文章:[【思维导图-索引篇】搞定数据库索引就是这么简单](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484486&idx=1&sn=215450f11e042bca8a58eac9f4a97686&chksm=fd985227caefdb3117b8375f150676f5824aa20d1ebfdbcfb93ff06e23e26efbafae6cf6b48e&token=1990180468&lang=zh_CN#rd)
-
-**什么是覆盖索引?**
-
-如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称
-之为“覆盖索引”。我们知道在 InnoDB 存储引擎中,如果不是主键索引,叶子节点存储的是主键+列值。最终还是要“回表”,也就是要通过主键再查找一次,这样就会比较慢。覆盖索引就是把要查询出的列和索引是对应的,不做回表操作!
-
-## 8. 进程与线程的区别是什么?进程间的几种通信方式说一下?线程间的几种通信方式知道不?
-
-**进程与线程的区别是什么?**
-
-线程与进程相似,但线程是一个比进程更小的执行单位。一个进程在其执行的过程中可以产生多个线程。与进程不同的是同类的多个线程共享同一块内存空间和一组系统资源,所以系统在产生一个线程,或是在各个线程之间作切换工作时,负担要比进程小得多,也正因为如此,线程也被称为轻量级进程。另外,也正是因为共享资源,所以线程中执行时一般都要进行同步和互斥。总的来说,进程和线程的主要差别在于它们是不同的操作系统资源管理方式。
-
-**进程间的几种通信方式说一下?**
-
-1. **管道(pipe)**:管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有血缘关系的进程间使用。进程的血缘关系通常指父子进程关系。管道分为 pipe(无名管道)和 fifo(命名管道)两种,有名管道也是半双工的通信方式,但是它允许无亲缘关系进程间通信。
-2. **信号量(semophore)**:信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它通常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
-3. **消息队列(message queue)**:消息队列是由消息组成的链表,存放在内核中 并由消息队列标识符标识。消息队列克服了信号传递信息少,管道只能承载无格式字节流以及缓冲区大小受限等缺点。消息队列与管道通信相比,其优势是对每个消息指定特定的消息类型,接收的时候不需要按照队列次序,而是可以根据自定义条件接收特定类型的消息。
-4. **信号(signal)**:信号是一种比较复杂的通信方式,用于通知接收进程某一事件已经发生。
-5. **共享内存(shared memory)**:共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问,共享内存是最快的 IPC 方式,它是针对其他进程间的通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号量配合使用,来实现进程间的同步和通信。
-6. **套接字(socket)**:socket,即套接字是一种通信机制,凭借这种机制,客户/服务器(即要进行通信的进程)系统的开发工作既可以在本地单机上进行,也可以跨网络进行。也就是说它可以让不在同一台计算机但通过网络连接计算机上的进程进行通信。也因为这样,套接字明确地将客户端和服务器区分开来。
-
-**线程间的几种通信方式知道不?**
-
-1、锁机制
-
-- 互斥锁:提供了以排它方式阻止数据结构被并发修改的方法。
-- 读写锁:允许多个线程同时读共享数据,而对写操作互斥。
-- 条件变量:可以以原子的方式阻塞进程,直到某个特定条件为真为止。对条件测试是在互斥锁的保护下进行的。条件变量始终与互斥锁一起使用。
-
-2、信号量机制:包括无名线程信号量与有名线程信号量
-
-3、信号机制:类似于进程间的信号处理。
-
-线程间通信的主要目的是用于线程同步,所以线程没有象进程通信中用于数据交换的通信机制。
-
-## 9. 为什么要用单例模式?手写几种线程安全的单例模式?
-
-**简单来说使用单例模式可以带来下面几个好处:**
-
-- 对于频繁使用的对象,可以省略创建对象所花费的时间,这对于那些重量级对象而言,是非常可观的一笔系统开销;
-- 由于 new 操作的次数减少,因而对系统内存的使用频率也会降低,这将减轻 GC 压力,缩短 GC 停顿时间。
-
-**懒汉式(双重检查加锁版本)**
-
-```java
-public class Singleton {
-
- //volatile保证,当uniqueInstance变量被初始化成Singleton实例时,多个线程可以正确处理uniqueInstance变量
- private volatile static Singleton uniqueInstance;
- private Singleton() {
- }
- public static Singleton getInstance() {
- //检查实例,如果不存在,就进入同步代码块
- if (uniqueInstance == null) {
- //只有第一次才彻底执行这里的代码
- synchronized(Singleton.class) {
- //进入同步代码块后,再检查一次,如果仍是null,才创建实例
- if (uniqueInstance == null) {
- uniqueInstance = new Singleton();
- }
- }
- }
- return uniqueInstance;
- }
-}
-```
-
-**静态内部类方式**
-
-静态内部实现的单例是懒加载的且线程安全。
-
-只有通过显式调用 getInstance 方法时,才会显式装载 SingletonHolder 类,从而实例化 instance(只有第一次使用这个单例的实例的时候才加载,同时不会有线程安全问题)。
-
-```java
-public class Singleton {
- private static class SingletonHolder {
- private static final Singleton INSTANCE = new Singleton();
- }
- private Singleton (){}
- public static final Singleton getInstance() {
- return SingletonHolder.INSTANCE;
- }
-}
-```
-
-## 10. 简单介绍一下 bean;知道 Spring 的 bean 的作用域与生命周期吗?
-
-在 Spring 中,那些组成应用程序的主体及由 Spring IOC 容器所管理的对象,被称之为 bean。简单地讲,bean 就是由 IOC 容器初始化、装配及管理的对象,除此之外,bean 就与应用程序中的其他对象没有什么区别了。而 bean 的定义以及 bean 相互间的依赖关系将通过配置元数据来描述。
-
-Spring 中的 bean 默认都是单例的,这些单例 Bean 在多线程程序下如何保证线程安全呢? 例如对于 Web 应用来说,Web 容器对于每个用户请求都创建一个单独的 Sevlet 线程来处理请求,引入 Spring 框架之后,每个 Action 都是单例的,那么对于 Spring 托管的单例 Service Bean,如何保证其安全呢? Spring 的单例是基于 BeanFactory 也就是 Spring 容器的,单例 Bean 在此容器内只有一个,Java 的单例是基于 JVM,每个 JVM 内只有一个实例。
-
-
-
-Spring 的 bean 的生命周期以及更多内容可以查看:[一文轻松搞懂 Spring 中 bean 的作用域与生命周期](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484400&idx=2&sn=7201eb365102fce017f89cb3527fb0bc&chksm=fd985591caefdc872a2fac897288119f94c345e4e12150774f960bf5f816b79e4b9b46be3d7f&token=1990180468&lang=zh_CN#rd)
-
-## 11. Spring 中的事务传播行为了解吗?TransactionDefinition 接口中哪五个表示隔离级别的常量?
-
-#### 事务传播行为
-
-事务传播行为(为了解决业务层方法之间互相调用的事务问题):
-当事务方法被另一个事务方法调用时,必须指定事务应该如何传播。例如:方法可能继续在现有事务中运行,也可能开启一个新事务,并在自己的事务中运行。在 TransactionDefinition 定义中包括了如下几个表示传播行为的常量:
-
-**支持当前事务的情况:**
-
-- TransactionDefinition.PROPAGATION_REQUIRED: 如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。
-- TransactionDefinition.PROPAGATION_SUPPORTS: 如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。
-- TransactionDefinition.PROPAGATION_MANDATORY: 如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。(mandatory:强制性)
-
-**不支持当前事务的情况:**
-
-- TransactionDefinition.PROPAGATION_REQUIRES_NEW: 创建一个新的事务,如果当前存在事务,则把当前事务挂起。
-- TransactionDefinition.PROPAGATION_NOT_SUPPORTED: 以非事务方式运行,如果当前存在事务,则把当前事务挂起。
-- TransactionDefinition.PROPAGATION_NEVER: 以非事务方式运行,如果当前存在事务,则抛出异常。
-
-**其他情况:**
-
-- TransactionDefinition.PROPAGATION_NESTED: 如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于 TransactionDefinition.PROPAGATION_REQUIRED。
-
-#### 隔离级别
-
-TransactionDefinition 接口中定义了五个表示隔离级别的常量:
-
-- **TransactionDefinition.ISOLATION_DEFAULT:** 使用后端数据库默认的隔离级别,Mysql 默认采用的 REPEATABLE_READ 隔离级别 Oracle 默认采用的 READ_COMMITTED 隔离级别.
-- **TransactionDefinition.ISOLATION_READ_UNCOMMITTED:** 最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读
-- **TransactionDefinition.ISOLATION_READ_COMMITTED:** 允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生
-- **TransactionDefinition.ISOLATION_REPEATABLE_READ:** 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
-- **TransactionDefinition.ISOLATION_SERIALIZABLE:** 最高的隔离级别,完全服从 ACID 的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。但是这将严重影响程序的性能。通常情况下也不会用到该级别。
-
-## 12. SpringMVC 原理了解吗?
-
-
-
-客户端发送请求-> 前端控制器 DispatcherServlet 接受客户端请求 -> 找到处理器映射 HandlerMapping 解析请求对应的 Handler-> HandlerAdapter 会根据 Handler 来调用真正的处理器处理请求,并处理相应的业务逻辑 -> 处理器返回一个模型视图 ModelAndView -> 视图解析器进行解析 -> 返回一个视图对象->前端控制器 DispatcherServlet 渲染数据(Model)->将得到视图对象返回给用户
-
-关于 SpringMVC 原理更多内容可以查看我的这篇文章:[SpringMVC 工作原理详解](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484496&idx=1&sn=5472ffa687fe4a05f8900d8ee6726de4&chksm=fd985231caefdb27fc75b44ecf76b6f43e4617e0b01b3c040f8b8fab32e51dfa5118eed1d6ad&token=1990180468&lang=zh_CN#rd)
-
-## 13. Spring AOP IOC 实现原理
-
-过了秋招挺长一段时间了,说实话我自己也忘了如何简要概括 Spring AOP IOC 实现原理,就在网上找了一个较为简洁的答案,下面分享给各位。
-
-**IOC:** 控制反转也叫依赖注入。IOC 利用 java 反射机制,AOP 利用代理模式。IOC 概念看似很抽象,但是很容易理解。说简单点就是将对象交给容器管理,你只需要在 spring 配置文件中配置对应的 bean 以及设置相关的属性,让 spring 容器来生成类的实例对象以及管理对象。在 spring 容器启动的时候,spring 会把你在配置文件中配置的 bean 都初始化好,然后在你需要调用的时候,就把它已经初始化好的那些 bean 分配给你需要调用这些 bean 的类。
-
-**AOP:** 面向切面编程。(Aspect-Oriented Programming) 。AOP 可以说是对 OOP 的补充和完善。OOP 引入封装、继承和多态性等概念来建立一种对象层次结构,用以模拟公共行为的一个集合。实现 AOP 的技术,主要分为两大类:一是采用动态代理技术,利用截取消息的方式,对该消息进行装饰,以取代原有对象行为的执行;二是采用静态织入的方式,引入特定的语法创建“方面”,从而使得编译器可以在编译期间织入有关“方面”的代码,属于静态代理。
-
-# 二 进阶篇
-
-## 1 消息队列 MQ 的套路
-
-消息队列/消息中间件应该是 Java 程序员必备的一个技能了,如果你之前没接触过消息队列的话,建议先去百度一下某某消息队列入门,然后花 2 个小时就差不多可以学会任何一种消息队列的使用了。如果说仅仅学会使用是万万不够的,在实际生产环境还要考虑消息丢失等等情况。关于消息队列面试相关的问题,推荐大家也可以看一下视频《Java 工程师面试突击第 1 季-中华石杉老师》,如果大家没有资源的话,可以在我的公众号“Java 面试通关手册”后台回复关键字“1”即可!
-
-### 1.1 介绍一下消息队列 MQ 的应用场景/使用消息队列的好处
-
-面试官一般会先问你这个问题,预热一下,看你知道消息队列不,一般在第一面的时候面试官可能只会问消息队列 MQ 的应用场景/使用消息队列的好处、使用消息队列会带来什么问题、消息队列的技术选型这几个问题,不会太深究下去,在后面的第二轮/第三轮技术面试中可能会深入问一下。
-
-**《大型网站技术架构》第四章和第七章均有提到消息队列对应用性能及扩展性的提升。**
-
-#### 1)通过异步处理提高系统性能
-
-
-如上图,**在不使用消息队列服务器的时候,用户的请求数据直接写入数据库,在高并发的情况下数据库压力剧增,使得响应速度变慢。但是在使用消息队列之后,用户的请求数据发送给消息队列之后立即 返回,再由消息队列的消费者进程从消息队列中获取数据,异步写入数据库。由于消息队列服务器处理速度快于数据库(消息队列也比数据库有更好的伸缩性),因此响应速度得到大幅改善。**
-
-通过以上分析我们可以得出**消息队列具有很好的削峰作用的功能**——即**通过异步处理,将短时间高并发产生的事务消息存储在消息队列中,从而削平高峰期的并发事务。** 举例:在电子商务一些秒杀、促销活动中,合理使用消息队列可以有效抵御促销活动刚开始大量订单涌入对系统的冲击。如下图所示:
-
-因为**用户请求数据写入消息队列之后就立即返回给用户了,但是请求数据在后续的业务校验、写数据库等操作中可能失败**。因此使用消息队列进行异步处理之后,需要**适当修改业务流程进行配合**,比如**用户在提交订单之后,订单数据写入消息队列,不能立即返回用户订单提交成功,需要在消息队列的订单消费者进程真正处理完该订单之后,甚至出库后,再通过电子邮件或短信通知用户订单成功**,以免交易纠纷。这就类似我们平时手机订火车票和电影票。
-
-#### 2)降低系统耦合性
-
-我们知道模块分布式部署以后聚合方式通常有两种:1.**分布式消息队列**和 2.**分布式服务**。
-
-> **先来简单说一下分布式服务:**
-
-目前使用比较多的用来构建**SOA(Service Oriented Architecture 面向服务体系结构)**的**分布式服务框架**是阿里巴巴开源的**Dubbo**。如果想深入了解 Dubbo 的可以看我写的关于 Dubbo 的这一篇文章:**《高性能优秀的服务框架-dubbo 介绍》**:[https://juejin.im/post/5acadeb1f265da2375072f9c](https://juejin.im/post/5acadeb1f265da2375072f9c "https://juejin.im/post/5acadeb1f265da2375072f9c")
-
-> **再来谈我们的分布式消息队列:**
-
-我们知道如果模块之间不存在直接调用,那么新增模块或者修改模块就对其他模块影响较小,这样系统的可扩展性无疑更好一些。
-
-我们最常见的**事件驱动架构**类似生产者消费者模式,在大型网站中通常用利用消息队列实现事件驱动结构。如下图所示:
-
-
-**消息队列使利用发布-订阅模式工作,消息发送者(生产者)发布消息,一个或多个消息接受者(消费者)订阅消息。** 从上图可以看到**消息发送者(生产者)和消息接受者(消费者)之间没有直接耦合**,消息发送者将消息发送至分布式消息队列即结束对消息的处理,消息接受者从分布式消息队列获取该消息后进行后续处理,并不需要知道该消息从何而来。**对新增业务,只要对该类消息感兴趣,即可订阅该消息,对原有系统和业务没有任何影响,从而实现网站业务的可扩展性设计**。
-
-消息接受者对消息进行过滤、处理、包装后,构造成一个新的消息类型,将消息继续发送出去,等待其他消息接受者订阅该消息。因此基于事件(消息对象)驱动的业务架构可以是一系列流程。
-
-**另外为了避免消息队列服务器宕机造成消息丢失,会将成功发送到消息队列的消息存储在消息生产者服务器上,等消息真正被消费者服务器处理后才删除消息。在消息队列服务器宕机后,生产者服务器会选择分布式消息队列服务器集群中的其他服务器发布消息。**
-
-**备注:** 不要认为消息队列只能利用发布-订阅模式工作,只不过在解耦这个特定业务环境下是使用发布-订阅模式的,**比如在我们的 ActiveMQ 消息队列中还有点对点工作模式**,具体的会在后面的文章给大家详细介绍,这一篇文章主要还是让大家对消息队列有一个更透彻的了解。
-
-> 这个问题一般会在上一个问题问完之后,紧接着被问到。“使用消息队列会带来什么问题?”这个问题要引起重视,一般我们都会考虑使用消息队列会带来的好处而忽略它带来的问题!
-
-### 1.2 那么使用消息队列会带来什么问题?考虑过这些问题吗?
-
-- **系统可用性降低:** 系统可用性在某种程度上降低,为什么这样说呢?在加入 MQ 之前,你不用考虑消息丢失或者说 MQ 挂掉等等的情况,但是,引入 MQ 之后你就需要去考虑了!
-- **系统复杂性提高:** 加入 MQ 之后,你需要保证消息没有被重复消费、处理消息丢失的情况、保证消息传递的顺序性等等问题!
-- **一致性问题:** 我上面讲了消息队列可以实现异步,消息队列带来的异步确实可以提高系统响应速度。但是,万一消息的真正消费者并没有正确消费消息怎么办?这样就会导致数据不一致的情况了!
-
-> 了解下面这个问题是为了我们更好的进行技术选型!该部分摘自:《Java 工程师面试突击第 1 季-中华石杉老师》,如果大家没有资源的话,可以在我的公众号“Java 面试通关手册”后台回复关键字“1”即可!
-
-### 1.3 介绍一下你知道哪几种消息队列,该如何选择呢?
-
-| 特性 | ActiveMQ | RabbitMQ | RocketMQ | Kafka |
-| :----------------------- | -----------------------------------------------------------: | -----------------------------------------------------------: | -----------------------------------------------------------: | -----------------------------------------------------------: |
-| 单机吞吐量 | 万级,吞吐量比 RocketMQ 和 Kafka 要低了一个数量级 | 万级,吞吐量比 RocketMQ 和 Kafka 要低了一个数量级 | 10 万级,RocketMQ 也是可以支撑高吞吐的一种 MQ | 10 万级别,这是 kafka 最大的优点,就是吞吐量高。一般配合大数据类的系统来进行实时数据计算、日志采集等场景 |
-| topic 数量对吞吐量的影响 | | | topic 可以达到几百,几千个的级别,吞吐量会有较小幅度的下降这是 RocketMQ 的一大优势,在同等机器下,可以支撑大量的 topic | topic 从几十个到几百个的时候,吞吐量会大幅度下降。所以在同等机器下,kafka 尽量保证 topic 数量不要过多。如果要支撑大规模 topic,需要增加更多的机器资源 |
-| 可用性 | 高,基于主从架构实现高可用性 | 高,基于主从架构实现高可用性 | 非常高,分布式架构 | 非常高,kafka 是分布式的,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用 |
-| 消息可靠性 | 有较低的概率丢失数据 | | 经过参数优化配置,可以做到 0 丢失 | 经过参数优化配置,消息可以做到 0 丢失 |
-| 时效性 | ms 级 | 微秒级,这是 rabbitmq 的一大特点,延迟是最低的 | ms 级 | 延迟在 ms 级以内 |
-| 功能支持 | MQ 领域的功能极其完备 | 基于 erlang 开发,所以并发能力很强,性能极其好,延时很低 | MQ 功能较为完善,还是分布式的,扩展性好 | 功能较为简单,主要支持简单的 MQ 功能,在大数据领域的实时计算以及日志采集被大规模使用,是事实上的标准 |
-| 优劣势总结 | 非常成熟,功能强大,在业内大量的公司以及项目中都有应用。偶尔会有较低概率丢失消息,而且现在社区以及国内应用都越来越少,官方社区现在对 ActiveMQ 5.x 维护越来越少,几个月才发布一个版本而且确实主要是基于解耦和异步来用的,较少在大规模吞吐的场景中使用 | erlang 语言开发,性能极其好,延时很低;吞吐量到万级,MQ 功能比较完备而且开源提供的管理界面非常棒,用起来很好用。社区相对比较活跃,几乎每个月都发布几个版本分在国内一些互联网公司近几年用 rabbitmq 也比较多一些但是问题也是显而易见的,RabbitMQ 确实吞吐量会低一些,这是因为他做的实现机制比较重。而且 erlang 开发,国内有几个公司有实力做 erlang 源码级别的研究和定制?如果说你没这个实力的话,确实偶尔会有一些问题,你很难去看懂源码,你公司对这个东西的掌控很弱,基本职能依赖于开源社区的快速维护和修复 bug。而且 rabbitmq 集群动态扩展会很麻烦,不过这个我觉得还好。其实主要是 erlang 语言本身带来的问题。很难读源码,很难定制和掌控。 | 接口简单易用,而且毕竟在阿里大规模应用过,有阿里品牌保障。日处理消息上百亿之多,可以做到大规模吞吐,性能也非常好,分布式扩展也很方便,社区维护还可以,可靠性和可用性都是 ok 的,还可以支撑大规模的 topic 数量,支持复杂 MQ 业务场景。而且一个很大的优势在于,阿里出品都是 java 系的,我们可以自己阅读源码,定制自己公司的 MQ,可以掌控。社区活跃度相对较为一般,不过也还可以,文档相对来说简单一些,然后接口这块不是按照标准 JMS 规范走的有些系统要迁移需要修改大量代码。还有就是阿里出台的技术,你得做好这个技术万一被抛弃,社区黄掉的风险,那如果你们公司有技术实力我觉得用 RocketMQ 挺好的 | kafka 的特点其实很明显,就是仅仅提供较少的核心功能,但是提供超高的吞吐量,ms 级的延迟,极高的可用性以及可靠性,而且分布式可以任意扩展。同时 kafka 最好是支撑较少的 topic 数量即可,保证其超高吞吐量。而且 kafka 唯一的一点劣势是有可能消息重复消费,那么对数据准确性会造成极其轻微的影响,在大数据领域中以及日志采集中,这点轻微影响可以忽略这个特性天然适合大数据实时计算以及日志收集。 |
-
-> 这部分内容,我这里不给出答案,大家可以自行根据自己学习的消息队列查阅相关内容,我可能会在后面的文章中介绍到这部分内容。另外,下面这些问题在视频《Java 工程师面试突击第 1 季-中华石杉老师》中都有提到,如果大家没有资源的话,可以在我的公众号“Java 面试通关手册”后台回复关键字“1”即可!
-
-### 1.4 关于消息队列其他一些常见的问题展望
-
-1. 引入消息队列之后如何保证高可用性?
-2. 如何保证消息不被重复消费呢?
-3. 如何保证消息的可靠性传输(如何处理消息丢失的问题)?
-4. 我该怎么保证从消息队列里拿到的数据按顺序执行?
-5. 如何解决消息队列的延时以及过期失效问题?消息队列满了以后该怎么处理?有几百万消息持续积压几小时,说说怎么解决?
-6. 如果让你来开发一个消息队列中间件,你会怎么设计架构?
-
-## 2 谈谈 InnoDB 和 MyIsam 两者的区别
-
-### 2.1 两者的对比
-
-1. **count 运算上的区别:** 因为 MyISAM 缓存有表 meta-data(行数等),因此在做 COUNT(\*)时对于一个结构很好的查询是不需要消耗多少资源的。而对于 InnoDB 来说,则没有这种缓存
-2. **是否支持事务和崩溃后的安全恢复:** MyISAM 强调的是性能,每次查询具有原子性,其执行速度比 InnoDB 类型更快,但是不提供事务支持。但是 InnoDB 提供事务支持,外部键等高级数据库功能。 具有事务(commit)、回滚(rollback)和崩溃修复能力(crash recovery capabilities)的事务安全(transaction-safe (ACID compliant))型表。
-3. **是否支持外键:** MyISAM 不支持,而 InnoDB 支持。
-
-### 2.2 关于两者的总结
-
-MyISAM 更适合读密集的表,而 InnoDB 更适合写密集的表。 在数据库做主从分离的情况下,经常选择 MyISAM 作为主库的存储引擎。
-
-一般来说,如果需要事务支持,并且有较高的并发读取频率(MyISAM 的表锁的粒度太大,所以当该表写并发量较高时,要等待的查询就会很多了),InnoDB 是不错的选择。如果你的数据量很大(MyISAM 支持压缩特性可以减少磁盘的空间占用),而且不需要支持事务时,MyISAM 是最好的选择。
-
-## 3 聊聊 Java 中的集合吧!
-
-### 3.1 Arraylist 与 LinkedList 有什么不同?(注意加上从数据结构分析的内容)
-
-- **1. 是否保证线程安全:** ArrayList 和 LinkedList 都是不同步的,也就是不保证线程安全;
-- **2. 底层数据结构:** Arraylist 底层使用的是 Object 数组;LinkedList 底层使用的是双向链表数据结构(注意双向链表和双向循环链表的区别:);
-- **3. 插入和删除是否受元素位置的影响:** ① **ArrayList 采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。** 比如:执行`add(E e)`方法的时候, ArrayList 会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是 O(1)。但是如果要在指定位置 i 插入和删除元素的话(`add(int index, E element)`)时间复杂度就为 O(n-i)。因为在进行上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执行向后位/向前移一位的操作。 ② **LinkedList 采用链表存储,所以插入,删除元素时间复杂度不受元素位置的影响,都是近似 O(1) 而数组为近似 O(n) 。**
-- **4. 是否支持快速随机访问:** LinkedList 不支持高效的随机元素访问,而 ArrayList 支持。快速随机访问就是通过元素的序号快速获取元素对象(对应于`get(int index)`方法)。
-- **5. 内存空间占用:** ArrayList 的空 间浪费主要体现在在 list 列表的结尾会预留一定的容量空间,而 LinkedList 的空间花费则体现在它的每一个元素都需要消耗比 ArrayList 更多的空间(因为要存放直接后继和直接前驱以及数据)。
-
-**补充内容:RandomAccess 接口**
-
-```java
-public interface RandomAccess {
-}
-```
-
-查看源码我们发现实际上 RandomAccess 接口中什么都没有定义。所以,在我看来 RandomAccess 接口不过是一个标识罢了。标识什么? 标识实现这个接口的类具有随机访问功能。
-
-在 binarySearch() 方法中,它要判断传入的 list 是否 RamdomAccess 的实例,如果是,调用 indexedBinarySearch() 方法,如果不是,那么调用 iteratorBinarySearch() 方法
-
-```java
- public static  -
-做过分布式电商系统的一定很熟悉上面的架构图(目前比较流行的是微服务架构,但是如果你有分布式开发经验也是非常加分的!)。
-
-**面试官:** 简单介绍一下你做的这个系统吧!
-
-**我:** 我一本正经的对着我刚刚画的商城架构图开始了满嘴造火箭的讲起来:
-
-> 本系统主要分为展示层、服务层和持久层这三层。表现层顾名思义主要就是为了用来展示,比如我们的后台管理系统的页面、商城首页的页面、搜索系统的页面等等,这一层都只是作为展示,并没有提供任何服务。
->
-> 展示层和服务层一般是部署在不同的机器上来提高并发量和扩展性,那么展示层和服务层怎样才能交互呢?在本系统中我们使用 Dubbo 来进行服务治理。Dubbo 是一款高性能、轻量级的开源 Java RPC 框架。Dubbo 在本系统的主要作用就是提供远程 RPC 调用。在本系统中服务层的信息通过 Dubbo 注册给 ZooKeeper,表现层通过 Dubbo 去 ZooKeeper 中获取服务的相关信息。Zookeeper 的作用仅仅是存放提供服务的服务器的地址和一些服务的相关信息,实现 RPC 远程调用功能的还是 Dubbo。如果需要引用到某个服务的时候,我们只需要在配置文件中配置相关信息就可以在代码中直接使用了,就像调用本地方法一样。假如说某个服务的使用量增加时,我们只用为这单个服务增加服务器,而不需要为整个系统添加服务。
->
-> 另外,本系统的数据库使用的是常用的 MySQL,并且用到了数据库中间件 MyCat。另外,本系统还用到 redis 内存数据库来作为缓存来提高系统的反应速度。假如用户第一次访问数据库中的某些数据,这个过程会比较慢,因为是从硬盘上读取的。将该用户访问的数据存在数缓存中,这样下一次再访问这些数据的时候就可以直接从缓存中获取了。操作缓存就是直接操作内存,所以速度相当快。
->
-> 系统还用到了 Elasticsearch 来提供搜索功能。使用 Elasticsearch 我们可以非常方便的为我们的商城系统添加必备的搜索功能,并且使用 Elasticsearch 还能提供其它非常实用的功能,并且很容易扩展。
-
-**面试官:** 我看你的系统里面还用到了消息队列,能说说为什么要用它吗?
-
-**我:**
-
-> 使用消息队列主要是为了:
->
-> 1. 减少响应所需时间和削峰。
-> 2. 降低系统耦合性(解耦/提升系统可扩展性)。
-
-**面试官:** 你这说的太简单了!能不能稍微详细一点,最好能画图给我解释一下。
-
-**我:** 内心 os:"都 2019 年了,大部分面试者都能对消息队列的为系统带来的这两个好处倒背如流了,如果你想走的更远就要别别人懂的更深一点!"
-
-> 当我们不使用消息队列的时候,所有的用户的请求会直接落到服务器,然后通过数据库或者缓存响应。假如在高并发的场景下,如果没有缓存或者数据库承受不了这么大的压力的话,就会造成响应速度缓慢,甚至造成数据库宕机。但是,在使用消息队列之后,用户的请求数据发送给了消息队列之后就可以立即返回,再由消息队列的消费者进程从消息队列中获取数据,异步写入数据库,不过要确保消息不被重复消费还要考虑到消息丢失问题。由于消息队列服务器处理速度快于数据库,因此响应速度得到大幅改善。
->
-> 文字 is too 空洞,直接上图吧!下图展示了使用消息前后系统处理用户请求的对比(ps:我自己都被我画的这个图美到了,如果你也觉得这张图好看的话麻烦来个素质三连!)。
->
-> 
->
-> 通过以上分析我们可以得出**消息队列具有很好的削峰作用的功能**——即**通过异步处理,将短时间高并发产生的事务消息存储在消息队列中,从而削平高峰期的并发事务。** 举例:在电子商务一些秒杀、促销活动中,合理使用消息队列可以有效抵御促销活动刚开始大量订单涌入对系统的冲击。如下图所示:
->
-> 
->
-> 使用消息队列还可以降低系统耦合性。我们知道如果模块之间不存在直接调用,那么新增模块或者修改模块就对其他模块影响较小,这样系统的可扩展性无疑更好一些。还是直接上图吧:
->
-> 
->
-> 生产者(客户端)发送消息到消息队列中去,接受者(服务端)处理消息,需要消费的系统直接去消息队列取消息进行消费即可而不需要和其他系统有耦合, 这显然也提高了系统的扩展性。
-
-**面试官:** 你觉得它有什么缺点吗?或者说怎么考虑用不用消息队列?
-
-**我:** 内心 os: "面试官真鸡贼!这不是勾引我上钩么?还好我准备充分。"
-
-> 我觉得可以从下面几个方面来说:
->
-> 1. **系统可用性降低:** 系统可用性在某种程度上降低,为什么这样说呢?在加入 MQ 之前,你不用考虑消息丢失或者说 MQ 挂掉等等的情况,但是,引入 MQ 之后你就需要去考虑了!
-> 2. **系统复杂性提高:** 加入 MQ 之后,你需要保证消息没有被重复消费、处理消息丢失的情况、保证消息传递的顺序性等等问题!
-> 3. **一致性问题:** 我上面讲了消息队列可以实现异步,消息队列带来的异步确实可以提高系统响应速度。但是,万一消息的真正消费者并没有正确消费消息怎么办?这样就会导致数据不一致的情况了!
-
-**面试官**:做项目的过程中遇到了什么问题吗?解决了吗?如果解决的话是如何解决的呢?
-
-**我** : 内心 os: "做的过程中好像也没有遇到什么问题啊!怎么办?怎么办?突然想到可以说我在使用 Redis 过程中遇到的问题,毕竟我对 Redis 还算熟悉嘛,**把面试官往这个方向吸引**,准没错。"
-
-> 我在使用 Redis 对常用数据进行缓冲的过程中出现了缓存穿透问题。然后,我通过谷歌搜索相关的解决方案来解决的。
-
-**面试官:** 你还知道缓存穿透啊?不错啊!来说说什么是缓存穿透以及你最后的解决办法。
-
-**我:** 我先来谈谈什么是缓存穿透吧!
-
-> 缓存穿透说简单点就是大量请求的 key 根本不存在于缓存中,导致请求直接到了数据库上,根本没有经过缓存这一层。举个例子:某个黑客故意制造我们缓存中不存在的 key 发起大量请求,导致大量请求落到数据库。
->
-> 总结一下就是:
->
-> 1. 缓存层不命中。
-> 2. 存储层不命中,不将空结果写回缓存。
-> 3. 返回空结果给客户端。
->
-> 一般 MySQL 默认的最大连接数在 150 左右,这个可以通过 `show variables like '%max_connections%';`命令来查看。最大连接数一个还只是一个指标,cpu,内存,磁盘,网络等物理条件都是其运行指标,这些指标都会限制其并发能力!所以,一般 3000 的并发请求就能打死大部分数据库了。
-
-**面试官:** 小伙子不错啊!还准备问你:“为什么 3000 的并发能把支持最大连接数 4000 数据库压死?”想不到你自己就提前回答了!不错!
-
-**我:** 别夸了!别夸了!我再来说说我知道的一些解决办法以及我最后采用的方案吧!您帮忙看看有没有问题。
-
-> 最基本的就是首先做好参数校验,一些不合法的参数请求直接抛出异常信息返回给客户端。比如查询的数据库 id 不能小于 0、传入的邮箱格式不对的时候直接返回错误消息给客户端等等。
->
-> 参数校验通过的情况还是会出现缓存穿透,我们还可以通过以下几个方案来解决这个问题:
->
-> **1)缓存无效 key** : 如果缓存和数据库都查不到某个 key 的数据就写一个到 redis 中去并设置过期时间,具体命令如下:`SET key value EX 10086`。这种方式可以解决请求的 key 变化不频繁的情况,如何黑客恶意攻击,每次构建的不同的请求 key,会导致 redis 中缓存大量无效的 key 。很明显,这种方案并不能从根本上解决此问题。如果非要用这种方式来解决穿透问题的话,尽量将无效的 key 的过期时间设置短一点比如 1 分钟。
->
-> 另外,这里多说一嘴,一般情况下我们是这样设计 key 的: `表名:列名:主键名:主键值`。
->
-> **2)布隆过滤器:** 布隆过滤器是一个非常神奇的数据结构,通过它我们可以非常方便地判断一个给定数据是否存在于海量数据中。我们需要的就是判断 key 是否合法,有没有感觉布隆过滤器就是我们想要找的那个“人”。
-
-**面试官:** 不错不错!你还知道布隆过滤器啊!来给我谈一谈。
-
-**我:** 内心 os:“如果你准备过海量数据处理的面试题,你一定对:“如何确定一个数字是否在于包含大量数字的数字集中(数字集很大,5 亿以上!)?”这个题目很了解了!解决这道题目就要用到布隆过滤器。”
-
-> 布隆过滤器在针对海量数据去重或者验证数据合法性的时候非常有用。**布隆过滤器的本质实际上是 “位(bit)数组”,也就是说每一个存入布隆过滤器的数据都只占一位。相比于我们平时常用的的 List、Map 、Set 等数据结构,它占用空间更少并且效率更高,但是缺点是其返回的结果是概率性的,而不是非常准确的。**
->
-> **当一个元素加入布隆过滤器中的时候,会进行如下操作:**
->
-> 1. 使用布隆过滤器中的哈希函数对元素值进行计算,得到哈希值(有几个哈希函数得到几个哈希值)。
-> 2. 根据得到的哈希值,在位数组中把对应下标的值置为 1。
->
-> **当我们需要判断一个元素是否存在于布隆过滤器的时候,会进行如下操作:**
->
-> 1. 对给定元素再次进行相同的哈希计算;
-> 2. 得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。
->
-> 举个简单的例子:
->
-> 
->
-> 如图所示,当字符串存储要加入到布隆过滤器中时,该字符串首先由多个哈希函数生成不同的哈希值,然后在对应的位数组的下表的元素设置为 1(当位数组初始化时 ,所有位置均为 0)。当第二次存储相同字符串时,因为先前的对应位置已设置为 1,所以很容易知道此值已经存在(去重非常方便)。
->
-> 如果我们需要判断某个字符串是否在布隆过滤器中时,只需要对给定字符串再次进行相同的哈希计算,得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。
->
-> **不同的字符串可能哈希出来的位置相同,这种情况我们可以适当增加位数组大小或者调整我们的哈希函数。**
->
-> 综上,我们可以得出:**布隆过滤器说某个元素存在,小概率会误判。布隆过滤器说某个元素不在,那么这个元素一定不在。**
-
-**面试官:** 看来你对布隆过滤器了解的还挺不错的嘛!那你快说说你最后是怎么利用它来解决缓存穿透的。
-
-**我:** 知道了布隆过滤器的原理就之后就很容易做了。我是利用 Redis 布隆过滤器来做的。我把所有可能存在的请求的值都存放在布隆过滤器中,当用户请求过来,我会先判断用户发来的请求的值是否存在于布隆过滤器中。不存在的话,直接返回请求参数错误信息给客户端,存在的话才会走下面的流程。总结一下就是下面这张图(这张图片不是我画的,为了省事直接在网上找的):
-
-
-
-做过分布式电商系统的一定很熟悉上面的架构图(目前比较流行的是微服务架构,但是如果你有分布式开发经验也是非常加分的!)。
-
-**面试官:** 简单介绍一下你做的这个系统吧!
-
-**我:** 我一本正经的对着我刚刚画的商城架构图开始了满嘴造火箭的讲起来:
-
-> 本系统主要分为展示层、服务层和持久层这三层。表现层顾名思义主要就是为了用来展示,比如我们的后台管理系统的页面、商城首页的页面、搜索系统的页面等等,这一层都只是作为展示,并没有提供任何服务。
->
-> 展示层和服务层一般是部署在不同的机器上来提高并发量和扩展性,那么展示层和服务层怎样才能交互呢?在本系统中我们使用 Dubbo 来进行服务治理。Dubbo 是一款高性能、轻量级的开源 Java RPC 框架。Dubbo 在本系统的主要作用就是提供远程 RPC 调用。在本系统中服务层的信息通过 Dubbo 注册给 ZooKeeper,表现层通过 Dubbo 去 ZooKeeper 中获取服务的相关信息。Zookeeper 的作用仅仅是存放提供服务的服务器的地址和一些服务的相关信息,实现 RPC 远程调用功能的还是 Dubbo。如果需要引用到某个服务的时候,我们只需要在配置文件中配置相关信息就可以在代码中直接使用了,就像调用本地方法一样。假如说某个服务的使用量增加时,我们只用为这单个服务增加服务器,而不需要为整个系统添加服务。
->
-> 另外,本系统的数据库使用的是常用的 MySQL,并且用到了数据库中间件 MyCat。另外,本系统还用到 redis 内存数据库来作为缓存来提高系统的反应速度。假如用户第一次访问数据库中的某些数据,这个过程会比较慢,因为是从硬盘上读取的。将该用户访问的数据存在数缓存中,这样下一次再访问这些数据的时候就可以直接从缓存中获取了。操作缓存就是直接操作内存,所以速度相当快。
->
-> 系统还用到了 Elasticsearch 来提供搜索功能。使用 Elasticsearch 我们可以非常方便的为我们的商城系统添加必备的搜索功能,并且使用 Elasticsearch 还能提供其它非常实用的功能,并且很容易扩展。
-
-**面试官:** 我看你的系统里面还用到了消息队列,能说说为什么要用它吗?
-
-**我:**
-
-> 使用消息队列主要是为了:
->
-> 1. 减少响应所需时间和削峰。
-> 2. 降低系统耦合性(解耦/提升系统可扩展性)。
-
-**面试官:** 你这说的太简单了!能不能稍微详细一点,最好能画图给我解释一下。
-
-**我:** 内心 os:"都 2019 年了,大部分面试者都能对消息队列的为系统带来的这两个好处倒背如流了,如果你想走的更远就要别别人懂的更深一点!"
-
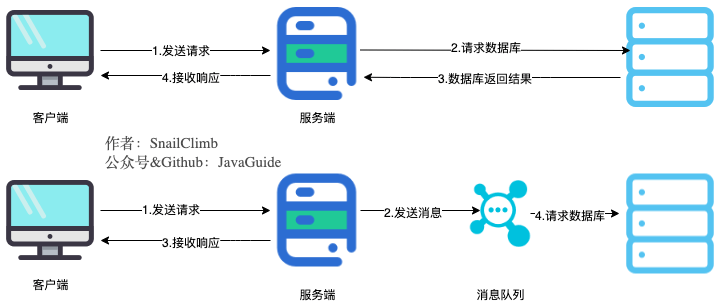
-> 当我们不使用消息队列的时候,所有的用户的请求会直接落到服务器,然后通过数据库或者缓存响应。假如在高并发的场景下,如果没有缓存或者数据库承受不了这么大的压力的话,就会造成响应速度缓慢,甚至造成数据库宕机。但是,在使用消息队列之后,用户的请求数据发送给了消息队列之后就可以立即返回,再由消息队列的消费者进程从消息队列中获取数据,异步写入数据库,不过要确保消息不被重复消费还要考虑到消息丢失问题。由于消息队列服务器处理速度快于数据库,因此响应速度得到大幅改善。
->
-> 文字 is too 空洞,直接上图吧!下图展示了使用消息前后系统处理用户请求的对比(ps:我自己都被我画的这个图美到了,如果你也觉得这张图好看的话麻烦来个素质三连!)。
->
-> 
->
-> 通过以上分析我们可以得出**消息队列具有很好的削峰作用的功能**——即**通过异步处理,将短时间高并发产生的事务消息存储在消息队列中,从而削平高峰期的并发事务。** 举例:在电子商务一些秒杀、促销活动中,合理使用消息队列可以有效抵御促销活动刚开始大量订单涌入对系统的冲击。如下图所示:
->
-> 
->
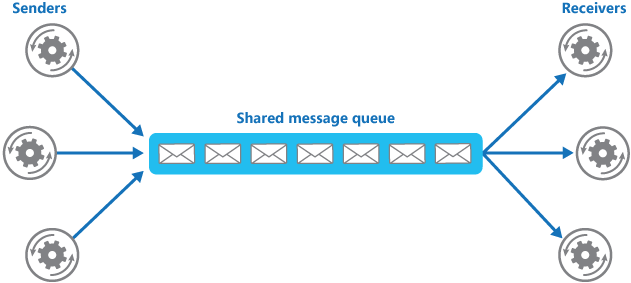
-> 使用消息队列还可以降低系统耦合性。我们知道如果模块之间不存在直接调用,那么新增模块或者修改模块就对其他模块影响较小,这样系统的可扩展性无疑更好一些。还是直接上图吧:
->
-> 
->
-> 生产者(客户端)发送消息到消息队列中去,接受者(服务端)处理消息,需要消费的系统直接去消息队列取消息进行消费即可而不需要和其他系统有耦合, 这显然也提高了系统的扩展性。
-
-**面试官:** 你觉得它有什么缺点吗?或者说怎么考虑用不用消息队列?
-
-**我:** 内心 os: "面试官真鸡贼!这不是勾引我上钩么?还好我准备充分。"
-
-> 我觉得可以从下面几个方面来说:
->
-> 1. **系统可用性降低:** 系统可用性在某种程度上降低,为什么这样说呢?在加入 MQ 之前,你不用考虑消息丢失或者说 MQ 挂掉等等的情况,但是,引入 MQ 之后你就需要去考虑了!
-> 2. **系统复杂性提高:** 加入 MQ 之后,你需要保证消息没有被重复消费、处理消息丢失的情况、保证消息传递的顺序性等等问题!
-> 3. **一致性问题:** 我上面讲了消息队列可以实现异步,消息队列带来的异步确实可以提高系统响应速度。但是,万一消息的真正消费者并没有正确消费消息怎么办?这样就会导致数据不一致的情况了!
-
-**面试官**:做项目的过程中遇到了什么问题吗?解决了吗?如果解决的话是如何解决的呢?
-
-**我** : 内心 os: "做的过程中好像也没有遇到什么问题啊!怎么办?怎么办?突然想到可以说我在使用 Redis 过程中遇到的问题,毕竟我对 Redis 还算熟悉嘛,**把面试官往这个方向吸引**,准没错。"
-
-> 我在使用 Redis 对常用数据进行缓冲的过程中出现了缓存穿透问题。然后,我通过谷歌搜索相关的解决方案来解决的。
-
-**面试官:** 你还知道缓存穿透啊?不错啊!来说说什么是缓存穿透以及你最后的解决办法。
-
-**我:** 我先来谈谈什么是缓存穿透吧!
-
-> 缓存穿透说简单点就是大量请求的 key 根本不存在于缓存中,导致请求直接到了数据库上,根本没有经过缓存这一层。举个例子:某个黑客故意制造我们缓存中不存在的 key 发起大量请求,导致大量请求落到数据库。
->
-> 总结一下就是:
->
-> 1. 缓存层不命中。
-> 2. 存储层不命中,不将空结果写回缓存。
-> 3. 返回空结果给客户端。
->
-> 一般 MySQL 默认的最大连接数在 150 左右,这个可以通过 `show variables like '%max_connections%';`命令来查看。最大连接数一个还只是一个指标,cpu,内存,磁盘,网络等物理条件都是其运行指标,这些指标都会限制其并发能力!所以,一般 3000 的并发请求就能打死大部分数据库了。
-
-**面试官:** 小伙子不错啊!还准备问你:“为什么 3000 的并发能把支持最大连接数 4000 数据库压死?”想不到你自己就提前回答了!不错!
-
-**我:** 别夸了!别夸了!我再来说说我知道的一些解决办法以及我最后采用的方案吧!您帮忙看看有没有问题。
-
-> 最基本的就是首先做好参数校验,一些不合法的参数请求直接抛出异常信息返回给客户端。比如查询的数据库 id 不能小于 0、传入的邮箱格式不对的时候直接返回错误消息给客户端等等。
->
-> 参数校验通过的情况还是会出现缓存穿透,我们还可以通过以下几个方案来解决这个问题:
->
-> **1)缓存无效 key** : 如果缓存和数据库都查不到某个 key 的数据就写一个到 redis 中去并设置过期时间,具体命令如下:`SET key value EX 10086`。这种方式可以解决请求的 key 变化不频繁的情况,如何黑客恶意攻击,每次构建的不同的请求 key,会导致 redis 中缓存大量无效的 key 。很明显,这种方案并不能从根本上解决此问题。如果非要用这种方式来解决穿透问题的话,尽量将无效的 key 的过期时间设置短一点比如 1 分钟。
->
-> 另外,这里多说一嘴,一般情况下我们是这样设计 key 的: `表名:列名:主键名:主键值`。
->
-> **2)布隆过滤器:** 布隆过滤器是一个非常神奇的数据结构,通过它我们可以非常方便地判断一个给定数据是否存在于海量数据中。我们需要的就是判断 key 是否合法,有没有感觉布隆过滤器就是我们想要找的那个“人”。
-
-**面试官:** 不错不错!你还知道布隆过滤器啊!来给我谈一谈。
-
-**我:** 内心 os:“如果你准备过海量数据处理的面试题,你一定对:“如何确定一个数字是否在于包含大量数字的数字集中(数字集很大,5 亿以上!)?”这个题目很了解了!解决这道题目就要用到布隆过滤器。”
-
-> 布隆过滤器在针对海量数据去重或者验证数据合法性的时候非常有用。**布隆过滤器的本质实际上是 “位(bit)数组”,也就是说每一个存入布隆过滤器的数据都只占一位。相比于我们平时常用的的 List、Map 、Set 等数据结构,它占用空间更少并且效率更高,但是缺点是其返回的结果是概率性的,而不是非常准确的。**
->
-> **当一个元素加入布隆过滤器中的时候,会进行如下操作:**
->
-> 1. 使用布隆过滤器中的哈希函数对元素值进行计算,得到哈希值(有几个哈希函数得到几个哈希值)。
-> 2. 根据得到的哈希值,在位数组中把对应下标的值置为 1。
->
-> **当我们需要判断一个元素是否存在于布隆过滤器的时候,会进行如下操作:**
->
-> 1. 对给定元素再次进行相同的哈希计算;
-> 2. 得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。
->
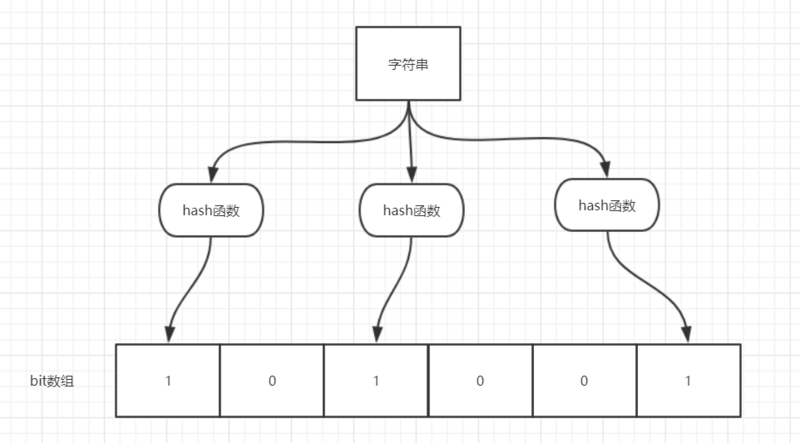
-> 举个简单的例子:
->
-> 
->
-> 如图所示,当字符串存储要加入到布隆过滤器中时,该字符串首先由多个哈希函数生成不同的哈希值,然后在对应的位数组的下表的元素设置为 1(当位数组初始化时 ,所有位置均为 0)。当第二次存储相同字符串时,因为先前的对应位置已设置为 1,所以很容易知道此值已经存在(去重非常方便)。
->
-> 如果我们需要判断某个字符串是否在布隆过滤器中时,只需要对给定字符串再次进行相同的哈希计算,得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。
->
-> **不同的字符串可能哈希出来的位置相同,这种情况我们可以适当增加位数组大小或者调整我们的哈希函数。**
->
-> 综上,我们可以得出:**布隆过滤器说某个元素存在,小概率会误判。布隆过滤器说某个元素不在,那么这个元素一定不在。**
-
-**面试官:** 看来你对布隆过滤器了解的还挺不错的嘛!那你快说说你最后是怎么利用它来解决缓存穿透的。
-
-**我:** 知道了布隆过滤器的原理就之后就很容易做了。我是利用 Redis 布隆过滤器来做的。我把所有可能存在的请求的值都存放在布隆过滤器中,当用户请求过来,我会先判断用户发来的请求的值是否存在于布隆过滤器中。不存在的话,直接返回请求参数错误信息给客户端,存在的话才会走下面的流程。总结一下就是下面这张图(这张图片不是我画的,为了省事直接在网上找的):
-
- -
-更多关于布隆过滤器的内容可以看我的这篇原创:[《不了解布隆过滤器?一文给你整的明明白白!》](https://github.com/Snailclimb/JavaGuide/blob/master/docs/dataStructures-algorithms/data-structure/bloom-filter.md "《不了解布隆过滤器?一文给你整的明明白白!》") ,强烈推荐,个人感觉网上应该找不到总结的这么明明白白的文章了。
-
-**面试官:** 好了好了。项目就暂时问到这里吧!下面有一些比较基础的问题我简单地问一下你。内心 os: 难不成这家伙满口高并发,连最基础的东西都不会吧!
-
-**我:** 好的好的!没问题!
-
-**面试官:** 浏览器输入 URL 发生了什么?
-
-**我:** 内心 os:“很常问的一个问题,建议拿小本本记好了!另外,百度好像最喜欢问这个问题,去百度面试可要提前备好这道题的功课哦!相似问题:打开一个网页,整个过程会使用哪些协议?”。
-
-> 图解(图片来源:《图解 HTTP》):
->
->
-
-更多关于布隆过滤器的内容可以看我的这篇原创:[《不了解布隆过滤器?一文给你整的明明白白!》](https://github.com/Snailclimb/JavaGuide/blob/master/docs/dataStructures-algorithms/data-structure/bloom-filter.md "《不了解布隆过滤器?一文给你整的明明白白!》") ,强烈推荐,个人感觉网上应该找不到总结的这么明明白白的文章了。
-
-**面试官:** 好了好了。项目就暂时问到这里吧!下面有一些比较基础的问题我简单地问一下你。内心 os: 难不成这家伙满口高并发,连最基础的东西都不会吧!
-
-**我:** 好的好的!没问题!
-
-**面试官:** 浏览器输入 URL 发生了什么?
-
-**我:** 内心 os:“很常问的一个问题,建议拿小本本记好了!另外,百度好像最喜欢问这个问题,去百度面试可要提前备好这道题的功课哦!相似问题:打开一个网页,整个过程会使用哪些协议?”。
-
-> 图解(图片来源:《图解 HTTP》):
->
->  ->
-> 总体来说分为以下几个过程:
->
-> 1. DNS 解析
-> 2. TCP 连接
-> 3. 发送 HTTP 请求
-> 4. 服务器处理请求并返回 HTTP 报文
-> 5. 浏览器解析渲染页面
-> 6. 连接结束
->
-> 具体可以参考下面这篇文章:
->
-> - [https://segmentfault.com/a/1190000006879700](https://segmentfault.com/a/1190000006879700 "https://segmentfault.com/a/1190000006879700")
-
-**面试官:** TCP 和 UDP 区别?
-
-**我:**
-
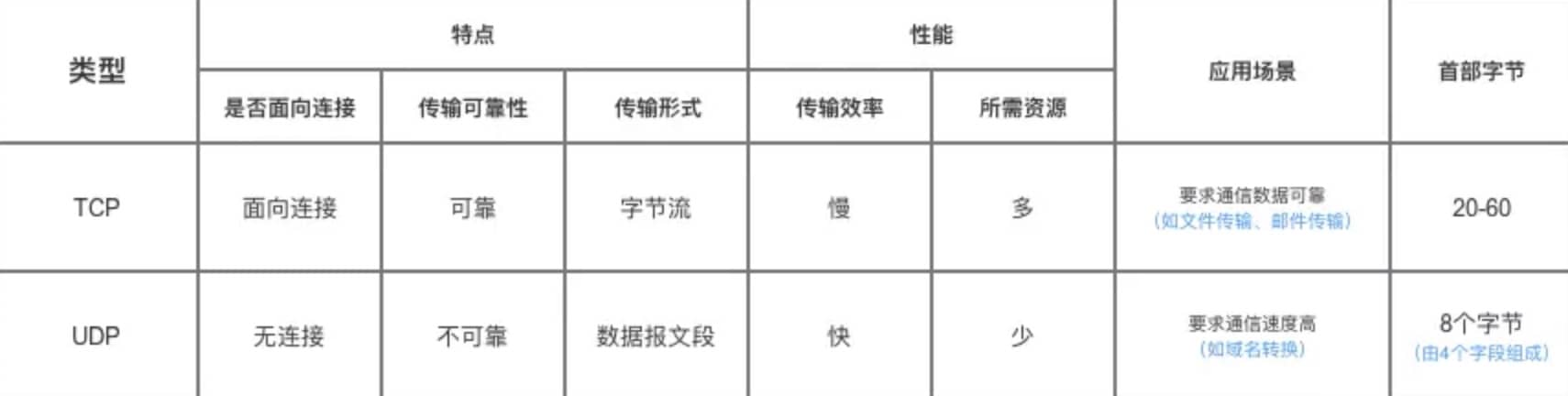
-> 
->
-> UDP 在传送数据之前不需要先建立连接,远地主机在收到 UDP 报文后,不需要给出任何确认。虽然 UDP 不提供可靠交付,但在某些情况下 UDP 确是一种最有效的工作方式(一般用于即时通信),比如: QQ 语音、 QQ 视频 、直播等等
->
-> TCP 提供面向连接的服务。在传送数据之前必须先建立连接,数据传送结束后要释放连接。 TCP 不提供广播或多播服务。由于 TCP 要提供可靠的,面向连接的传输服务(TCP 的可靠体现在 TCP 在传递数据之前,会有三次握手来建立连接,而且在数据传递时,有确认、窗口、重传、拥塞控制机制,在数据传完后,还会断开连接用来节约系统资源),这一难以避免增加了许多开销,如确认,流量控制,计时器以及连接管理等。这不仅使协议数据单元的首部增大很多,还要占用许多处理机资源。TCP 一般用于文件传输、发送和接收邮件、远程登录等场景。
-
-**面试官:** TCP 如何保证传输可靠性?
-
-**我:**
-
-> 1. 应用数据被分割成 TCP 认为最适合发送的数据块。
-> 2. TCP 给发送的每一个包进行编号,接收方对数据包进行排序,把有序数据传送给应用层。
-> 3. **校验和:** TCP 将保持它首部和数据的检验和。这是一个端到端的检验和,目的是检测数据在传输过程中的任何变化。如果收到段的检验和有差错,TCP 将丢弃这个报文段和不确认收到此报文段。
-> 4. TCP 的接收端会丢弃重复的数据。
-> 5. **流量控制:** TCP 连接的每一方都有固定大小的缓冲空间,TCP 的接收端只允许发送端发送接收端缓冲区能接纳的数据。当接收方来不及处理发送方的数据,能提示发送方降低发送的速率,防止包丢失。TCP 使用的流量控制协议是可变大小的滑动窗口协议。 (TCP 利用滑动窗口实现流量控制)
-> 6. **拥塞控制:** 当网络拥塞时,减少数据的发送。
-> 7. **ARQ 协议:** 也是为了实现可靠传输的,它的基本原理就是每发完一个分组就停止发送,等待对方确认。在收到确认后再发下一个分组。
-> 8. **超时重传:** 当 TCP 发出一个段后,它启动一个定时器,等待目的端确认收到这个报文段。如果不能及时收到一个确认,将重发这个报文段。
-
-**面试官:** 我再来问你一些 Java 基础的问题吧!小伙子。
-
-**我:** 好的。(内心 os:“你尽管来!”)
-
-**面试官:** 既然有了字节流,为什么还要有字符流?
-
-我:内心 os :“问题本质想问:**不管是文件读写还是网络发送接收,信息的最小存储单元都是字节,那为什么 I/O 流操作要分为字节流操作和字符流操作呢?**”
-
-> 字符流是由 Java 虚拟机将字节转换得到的,问题就出在这个过程还算是非常耗时,并且,如果我们不知道编码类型就很容易出现乱码问题。所以, I/O 流就干脆提供了一个直接操作字符的接口,方便我们平时对字符进行流操作。如果音频文件、图片等媒体文件用字节流比较好,如果涉及到字符的话使用字符流比较好。
-
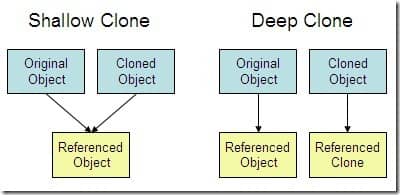
-**面试官**:深拷贝 和 浅拷贝有啥区别呢?
-
-**我:**
-
-> 1. **浅拷贝**:对基本数据类型进行值传递,对引用数据类型进行引用传递般的拷贝,此为浅拷贝。
-> 2. **深拷贝**:对基本数据类型进行值传递,对引用数据类型,创建一个新的对象,并复制其内容,此为深拷贝。
->
-> 
-
-**面试官:** 好的!面试结束。小伙子可以的!回家等通知吧!
-
-**我:** 好的好的!辛苦您了!
diff --git "a/docs/essential-content-for-interview/\346\211\213\346\212\212\346\211\213\346\225\231\344\275\240\347\224\250Markdown\345\206\231\344\270\200\344\273\275\351\253\230\350\264\250\351\207\217\347\232\204\347\256\200\345\216\206.md" "b/docs/essential-content-for-interview/\346\211\213\346\212\212\346\211\213\346\225\231\344\275\240\347\224\250Markdown\345\206\231\344\270\200\344\273\275\351\253\230\350\264\250\351\207\217\347\232\204\347\256\200\345\216\206.md"
deleted file mode 100644
index 9cb2811..0000000
--- "a/docs/essential-content-for-interview/\346\211\213\346\212\212\346\211\213\346\225\231\344\275\240\347\224\250Markdown\345\206\231\344\270\200\344\273\275\351\253\230\350\264\250\351\207\217\347\232\204\347\256\200\345\216\206.md"
+++ /dev/null
@@ -1,93 +0,0 @@
-## Markdown 简历模板样式一览
-
-**可以看到我把联系方式放在第一位,因为公司一般会与你联系,所以把联系方式放在第一位也是为了方便联系考虑。**
-
-## 为什么要用 Markdown 写简历?
-
-Markdown 语法简单,易于上手。使用正确的 Markdown 语言写出来的简历不论是在排版还是格式上都比较干净,易于阅读。另外,使用 Markdown 写简历也会给面试官一种你比较专业的感觉。
-
-除了这些,我觉得使用 Markdown 写简历可以很方便将其与PDF、HTML、PNG格式之间转换。后面我会介绍到转换方法,只需要一条命令你就可以实现 Markdown 到 PDF、HTML 与 PNG之间的无缝切换。
-
-> 下面的一些内容我在之前的一篇文章中已经提到过,这里再说一遍,最后会分享如何实现Markdown 到 PDF、HTML、PNG格式之间转换。
-
-## 为什么说简历很重要?
-
-假如你是网申,你的简历必然会经过HR的筛选,一张简历HR可能也就花费10秒钟看一下,然后HR就会决定你这一关是Fail还是Pass。
-
-假如你是内推,如果你的简历没有什么优势的话,就算是内推你的人再用心,也无能为力。
-
-另外,就算你通过了筛选,后面的面试中,面试官也会根据你的简历来判断你究竟是否值得他花费很多时间去面试。
-
-## 写简历的两大法则
-
-目前写简历的方式有两种普遍被认可,一种是 STAR, 一种是 FAB。
-
-**STAR法则(Situation Task Action Result):**
-
-- **Situation:** 事情是在什么情况下发生;
-- **Task::** 你是如何明确你的任务的;
-- **Action:** 针对这样的情况分析,你采用了什么行动方式;
-- **Result:** 结果怎样,在这样的情况下你学习到了什么。
-
-**FAB 法则(Feature Advantage Benefit):**
-
-- **Feature:** 是什么;
-- **Advantage:** 比别人好在哪些地方;
-- **Benefit:** 如果雇佣你,招聘方会得到什么好处。
-
-## 项目经历怎么写?
-简历上有一两个项目经历很正常,但是真正能把项目经历很好的展示给面试官的非常少。对于项目经历大家可以考虑从如下几点来写:
-
-1. 对项目整体设计的一个感受
-2. 在这个项目中你负责了什么、做了什么、担任了什么角色
-3. 从这个项目中你学会了那些东西,使用到了那些技术,学会了那些新技术的使用
-4. 另外项目描述中,最好可以体现自己的综合素质,比如你是如何协调项目组成员协同开发的或者在遇到某一个棘手的问题的时候你是如何解决的。
-
-## 专业技能该怎么写?
-先问一下你自己会什么,然后看看你意向的公司需要什么。一般HR可能并不太懂技术,所以他在筛选简历的时候可能就盯着你专业技能的关键词来看。对于公司有要求而你不会的技能,你可以花几天时间学习一下,然后在简历上可以写上自己了解这个技能。比如你可以这样写:
-
-- Dubbo:精通
-- Spring:精通
-- Docker:掌握
-- SOA分布式开发 :掌握
-- Spring Cloud:了解
-
-## 简历模板分享
-
-**开源程序员简历模板**: [https://github.com/geekcompany/ResumeSample](https://github.com/geekcompany/ResumeSample)(包括PHP程序员简历模板、iOS程序员简历模板、Android程序员简历模板、Web前端程序员简历模板、Java程序员简历模板、C/C++程序员简历模板、NodeJS程序员简历模板、架构师简历模板以及通用程序员简历模板)
-
-**上述简历模板的改进版本:** [https://github.com/Snailclimb/Java-Guide/blob/master/面试必备/简历模板.md](https://github.com/Snailclimb/Java-Guide/blob/master/面试必备/简历模板.md)
-
-## 其他的一些小tips
-
-1. 尽量避免主观表述,少一点语义模糊的形容词,尽量要简洁明了,逻辑结构清晰。
-2. 注意排版(不需要花花绿绿的),尽量使用Markdown语法。
-3. 如果自己有博客或者个人技术栈点的话,写上去会为你加分很多。
-4. 如果自己的Github比较活跃的话,写上去也会为你加分很多。
-5. 注意简历真实性,一定不要写自己不会的东西,或者带有欺骗性的内容
-6. 项目经历建议以时间倒序排序,另外项目经历不在于多,而在于有亮点。
-7. 如果内容过多的话,不需要非把内容压缩到一页,保持排版干净整洁就可以了。
-8. 简历最后最好能加上:“感谢您花时间阅读我的简历,期待能有机会和您共事。”这句话,显的你会很有礼貌。
-
-
-> 我们刚刚讲了很多关于如何写简历的内容并且分享了一份 Markdown 格式的简历文档。下面我们来看看如何实现 Markdown 到 HTML格式、PNG格式之间转换。
-## Markdown 到 HTML格式、PNG格式之间转换
-
-网上很难找到一个比较方便并且效果好的转换方法,最后我是通过 Visual Studio Code 的 Markdown PDF 插件完美解决了这个问题!
-
-### 安装 Markdown PDF 插件
-
-**① 打开Visual Studio Code ,按快捷键 F1,选择安装扩展选项**
-
-
-
-**② 搜索 “Markdown PDF” 插件并安装 ,然后重启**
-
-
-
-### 使用方法
-
-随便打开一份 Markdown 文件 点击F1,然后输入export即可!
-
-
-
diff --git "a/docs/essential-content-for-interview/\347\256\200\345\216\206\346\250\241\346\235\277.md" "b/docs/essential-content-for-interview/\347\256\200\345\216\206\346\250\241\346\235\277.md"
deleted file mode 100644
index 2a7a043..0000000
--- "a/docs/essential-content-for-interview/\347\256\200\345\216\206\346\250\241\346\235\277.md"
+++ /dev/null
@@ -1,79 +0,0 @@
-# 联系方式
-
-- 手机:
-- Email:
-- 微信:
-
-# 个人信息
-
- - 姓名/性别/出生日期
- - 本科/xxx计算机系xxx专业/英语六级
- - 技术博客:[http://snailclimb.top/](http://snailclimb.top/)
- - 荣誉奖励:获得了什么奖(获奖时间)
- - Github:[https://github.com/Snailclimb ](https://github.com/Snailclimb)
- - Github Resume: [http://resume.github.io/?Snailclimb](http://resume.github.io/?Snailclimb)
- - 期望职位:Java 研发程序员/大数据工程师(Java后台开发为首选)
- - 期望城市:xxx城市
-
-
-# 项目经历
-
-## xxx项目
-
-### 项目描述
-
-介绍该项目是做什么的、使用到了什么技术以及你对项目整体设计的一个感受
-
-### 责任描述
-
-主要可以从下面三点来写:
-
-1. 在这个项目中你负责了什么、做了什么、担任了什么角色
-2. 从这个项目中你学会了那些东西,使用到了那些技术,学会了那些新技术的使用
-3. 另外项目描述中,最好可以体现自己的综合素质,比如你是如何协调项目组成员协同开发的或者在遇到某一个棘手的问题的时候你是如何解决的。
-
-# 开源项目和技术文章
-
-## 开源项目
-
-- [Java-Guide](https://github.com/Snailclimb/Java-Guide) :一份涵盖大部分Java程序员所需要掌握的核心知识。Star:3.9K; Fork:0.9k。
-
-
-## 技术文章推荐
-
-- [可能是把Java内存区域讲的最清楚的一篇文章](https://juejin.im/post/5b7d69e4e51d4538ca5730cb)
-- [搞定JVM垃圾回收就是这么简单](https://juejin.im/post/5b85ea54e51d4538dd08f601)
-- [前端&后端程序员必备的Linux基础知识](https://juejin.im/post/5b3b19856fb9a04fa42f8c71)
-- [可能是把Docker的概念讲的最清楚的一篇文章](https://juejin.im/post/5b260ec26fb9a00e8e4b031a)
-
-
-# 校园经历(可选)
-
-## 2016-2017
-
-担任学校社团-致深社副会长,主要负责团队每周活动的组建以及每周例会的主持。
-
-## 2017-2018
- 担任学校传媒组织:“长江大学在线信息传媒”的副站长以及安卓组成员。主要负责每周例会主持、活动策划以及学校校园通APP的研发工作。
-
-
-# 技能清单
-
-以下均为我熟练使用的技能
-
-- Web开发:PHP/Hack/Node
-- Web框架:ThinkPHP/Yaf/Yii/Lavarel/LazyPHP
-- 前端框架:Bootstrap/AngularJS/EmberJS/HTML5/Cocos2dJS/ionic
-- 前端工具:Bower/Gulp/SaSS/LeSS/PhoneGap
-- 数据库相关:MySQL/PgSQL/PDO/SQLite
-- 版本管理、文档和自动化部署工具:Svn/Git/PHPDoc/Phing/Composer
-- 单元测试:PHPUnit/SimpleTest/Qunit
-- 云和开放平台:SAE/BAE/AWS/微博开放平台/微信应用开发
-
-# 自我评价(可选)
-
-自我发挥。切记不要过度自夸!!!
-
-
-### 感谢您花时间阅读我的简历,期待能有机会和您共事。
-
diff --git "a/docs/essential-content-for-interview/\351\235\242\350\257\225\345\277\205\345\244\207\344\271\213\344\271\220\350\247\202\351\224\201\344\270\216\346\202\262\350\247\202\351\224\201.md" "b/docs/essential-content-for-interview/\351\235\242\350\257\225\345\277\205\345\244\207\344\271\213\344\271\220\350\247\202\351\224\201\344\270\216\346\202\262\350\247\202\351\224\201.md"
deleted file mode 100644
index 00aaecd..0000000
--- "a/docs/essential-content-for-interview/\351\235\242\350\257\225\345\277\205\345\244\207\344\271\213\344\271\220\350\247\202\351\224\201\344\270\216\346\202\262\350\247\202\351\224\201.md"
+++ /dev/null
@@ -1,115 +0,0 @@
-点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java面试突击》以及Java工程师必备学习资源。
-
-
-
-- [何谓悲观锁与乐观锁](#何谓悲观锁与乐观锁)
- - [悲观锁](#悲观锁)
- - [乐观锁](#乐观锁)
- - [两种锁的使用场景](#两种锁的使用场景)
-- [乐观锁常见的两种实现方式](#乐观锁常见的两种实现方式)
- - [1. 版本号机制](#1-版本号机制)
- - [2. CAS算法](#2-cas算法)
-- [乐观锁的缺点](#乐观锁的缺点)
- - [1 ABA 问题](#1-aba-问题)
- - [2 循环时间长开销大](#2-循环时间长开销大)
- - [3 只能保证一个共享变量的原子操作](#3-只能保证一个共享变量的原子操作)
-- [CAS与synchronized的使用情景](#cas与synchronized的使用情景)
-
-
-
-### 何谓悲观锁与乐观锁
-
-> 乐观锁对应于生活中乐观的人总是想着事情往好的方向发展,悲观锁对应于生活中悲观的人总是想着事情往坏的方向发展。这两种人各有优缺点,不能不以场景而定说一种人好于另外一种人。
-
-#### 悲观锁
-
-总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁(**共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程**)。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。Java中`synchronized`和`ReentrantLock`等独占锁就是悲观锁思想的实现。
-
-
-#### 乐观锁
-
-总是假设最好的情况,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号机制和CAS算法实现。**乐观锁适用于多读的应用类型,这样可以提高吞吐量**,像数据库提供的类似于**write_condition机制**,其实都是提供的乐观锁。在Java中`java.util.concurrent.atomic`包下面的原子变量类就是使用了乐观锁的一种实现方式**CAS**实现的。
-
-#### 两种锁的使用场景
-
-从上面对两种锁的介绍,我们知道两种锁各有优缺点,不可认为一种好于另一种,像**乐观锁适用于写比较少的情况下(多读场景)**,即冲突真的很少发生的时候,这样可以省去了锁的开销,加大了系统的整个吞吐量。但如果是多写的情况,一般会经常产生冲突,这就会导致上层应用会不断的进行retry,这样反倒是降低了性能,所以**一般多写的场景下用悲观锁就比较合适。**
-
-
-### 乐观锁常见的两种实现方式
-
-> **乐观锁一般会使用版本号机制或CAS算法实现。**
-
-#### 1. 版本号机制
-
-一般是在数据表中加上一个数据版本号version字段,表示数据被修改的次数,当数据被修改时,version值会加一。当线程A要更新数据值时,在读取数据的同时也会读取version值,在提交更新时,若刚才读取到的version值为当前数据库中的version值相等时才更新,否则重试更新操作,直到更新成功。
-
-**举一个简单的例子:**
-假设数据库中帐户信息表中有一个 version 字段,当前值为 1 ;而当前帐户余额字段( balance )为 $100 。
-
-1. 操作员 A 此时将其读出( version=1 ),并从其帐户余额中扣除 $50( $100-$50 )。
-2. 在操作员 A 操作的过程中,操作员B 也读入此用户信息( version=1 ),并从其帐户余额中扣除 $20 ( $100-$20 )。
-3. 操作员 A 完成了修改工作,将数据版本号加一( version=2 ),连同帐户扣除后余额( balance=$50 ),提交至数据库更新,此时由于提交数据版本大于数据库记录当前版本,数据被更新,数据库记录 version 更新为 2 。
-4. 操作员 B 完成了操作,也将版本号加一( version=2 )试图向数据库提交数据( balance=$80 ),但此时比对数据库记录版本时发现,操作员 B 提交的数据版本号为 2 ,数据库记录当前版本也为 2 ,不满足 “ 提交版本必须大于记录当前版本才能执行更新 “ 的乐观锁策略,因此,操作员 B 的提交被驳回。
-
-这样,就避免了操作员 B 用基于 version=1 的旧数据修改的结果覆盖操作员A 的操作结果的可能。
-
-#### 2. CAS算法
-
-即**compare and swap(比较与交换)**,是一种有名的**无锁算法**。无锁编程,即不使用锁的情况下实现多线程之间的变量同步,也就是在没有线程被阻塞的情况下实现变量的同步,所以也叫非阻塞同步(Non-blocking Synchronization)。**CAS算法**涉及到三个操作数
-
-- 需要读写的内存值 V
-- 进行比较的值 A
-- 拟写入的新值 B
-
-当且仅当 V 的值等于 A时,CAS通过原子方式用新值B来更新V的值,否则不会执行任何操作(比较和替换是一个原子操作)。一般情况下是一个**自旋操作**,即**不断的重试**。
-
-关于自旋锁,大家可以看一下这篇文章,非常不错:[《
-面试必备之深入理解自旋锁》](https://blog.csdn.net/qq_34337272/article/details/81252853)
-
-### 乐观锁的缺点
-
-> ABA 问题是乐观锁一个常见的问题
-
-#### 1 ABA 问题
-
-如果一个变量V初次读取的时候是A值,并且在准备赋值的时候检查到它仍然是A值,那我们就能说明它的值没有被其他线程修改过了吗?很明显是不能的,因为在这段时间它的值可能被改为其他值,然后又改回A,那CAS操作就会误认为它从来没有被修改过。这个问题被称为CAS操作的 **"ABA"问题。**
-
-JDK 1.5 以后的 `AtomicStampedReference 类`就提供了此种能力,其中的 `compareAndSet 方法`就是首先检查当前引用是否等于预期引用,并且当前标志是否等于预期标志,如果全部相等,则以原子方式将该引用和该标志的值设置为给定的更新值。
-
-#### 2 循环时间长开销大
-**自旋CAS(也就是不成功就一直循环执行直到成功)如果长时间不成功,会给CPU带来非常大的执行开销。** 如果JVM能支持处理器提供的pause指令那么效率会有一定的提升,pause指令有两个作用,第一它可以延迟流水线执行指令(de-pipeline),使CPU不会消耗过多的执行资源,延迟的时间取决于具体实现的版本,在一些处理器上延迟时间是零。第二它可以避免在退出循环的时候因内存顺序冲突(memory order violation)而引起CPU流水线被清空(CPU pipeline flush),从而提高CPU的执行效率。
-
-#### 3 只能保证一个共享变量的原子操作
-
-CAS 只对单个共享变量有效,当操作涉及跨多个共享变量时 CAS 无效。但是从 JDK 1.5开始,提供了`AtomicReference类`来保证引用对象之间的原子性,你可以把多个变量放在一个对象里来进行 CAS 操作.所以我们可以使用锁或者利用`AtomicReference类`把多个共享变量合并成一个共享变量来操作。
-
-### CAS与synchronized的使用情景
-
-> **简单的来说CAS适用于写比较少的情况下(多读场景,冲突一般较少),synchronized适用于写比较多的情况下(多写场景,冲突一般较多)**
-
-1. 对于资源竞争较少(线程冲突较轻)的情况,使用synchronized同步锁进行线程阻塞和唤醒切换以及用户态内核态间的切换操作额外浪费消耗cpu资源;而CAS基于硬件实现,不需要进入内核,不需要切换线程,操作自旋几率较少,因此可以获得更高的性能。
-2. 对于资源竞争严重(线程冲突严重)的情况,CAS自旋的概率会比较大,从而浪费更多的CPU资源,效率低于synchronized。
-
-补充: Java并发编程这个领域中synchronized关键字一直都是元老级的角色,很久之前很多人都会称它为 **“重量级锁”** 。但是,在JavaSE 1.6之后进行了主要包括为了减少获得锁和释放锁带来的性能消耗而引入的 **偏向锁** 和 **轻量级锁** 以及其它**各种优化**之后变得在某些情况下并不是那么重了。synchronized的底层实现主要依靠 **Lock-Free** 的队列,基本思路是 **自旋后阻塞**,**竞争切换后继续竞争锁**,**稍微牺牲了公平性,但获得了高吞吐量**。在线程冲突较少的情况下,可以获得和CAS类似的性能;而线程冲突严重的情况下,性能远高于CAS。
-
-## 公众号
-
-如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
-
-**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"面试突击"** 即可免费领取!
-
-**Java工程师必备学习资源:** 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
-
-
-
-
-
-
-
-
-
-
-
-
-
-
diff --git "a/docs/golang/\351\235\242\350\257\225\351\242\230/golang\351\235\242\350\257\225\351\242\230\346\225\264\347\220\206-\345\276\256\344\277\241\345\256\214\346\225\264.md" "b/docs/golang/\351\235\242\350\257\225\351\242\230/golang\351\235\242\350\257\225\351\242\230\346\225\264\347\220\206-\345\276\256\344\277\241\345\256\214\346\225\264.md"
new file mode 100644
index 0000000..e65120c
--- /dev/null
+++ "b/docs/golang/\351\235\242\350\257\225\351\242\230/golang\351\235\242\350\257\225\351\242\230\346\225\264\347\220\206-\345\276\256\344\277\241\345\256\214\346\225\264.md"
@@ -0,0 +1,836 @@
+> ❝
+>
+> 原文: https://zhuanlan.zhihu.com/p/519979757,作者:沪猿小韩。为适于阅读,部分样式及内容有做简单修改。
+>
+> ❞
+
+# 前言
+
+文章部分题目来源于网络,答案系个人结合5月份面试了近30家公司整理所得,最后附录参考原文链接,如有遗漏的原文出处请联系本人。不对之处望批评指正,答案需要加上自己的思考,最好是代码实践下。
+
+参与过面试的企业有:zg人寿,睿科lun,qi猫,yun汉商城,zi节跳动,特斯la,虾P,chuan音,qi安信,ai立信等大大小小企业近30家,BAT简历都过不了。
+
+## 面试建议
+
+### 技术部分
+
+1)算法部分,刷LeetCode就完事了,这是一个长期的过程,短期突击没啥效果,因为题目太多了。
+
+2)语言基础,细分为:
+
+* golang基础及原理,就是本文主要内容了;
+* mysql基础及原理;
+* redis基础及原理;
+* kafka或其他消息中间件(如果没用过,需要了解大概的底层原理及结构);
+* linux常用的命令,比如定时脚本几个参数时间分别代表啥,文件权限需要搞清楚,进程内存占用命令;小公司还要懂一些前端的知识,因为他们希望你什么都会。
+
+3)项目经验,可以搞一个基于gin的后端接口服务的web框架,一般会问你怎么实现的;以及微服务了解一下。
+
+### 非技术部分
+
+1)因为上海5月份居家办公,远程面试,这些题目准备一份,遇到卡壳的题目完全可以参考你准备好的答案,因为视频面试你眼睛是看着面试官还是题目是不太容易区分的(把题目窗口置顶)。
+
+2)HR面也可以完全准备一份可能问到的问题的答案,并不是说你不会回答,而是会让你的表达更顺畅,其次也说明你是有备而来的,我在某拉公司面试就吃了这个亏,技术通过,HR说我的表达能力不行(后续我也会把这个模板分享出来,感谢我媳妇充当面试官,以及指导如何高情商的回答HR的问题)。
+
+3)可以自己录音面试回答,看看自己的语气、音量,顺畅度,如果自己听了都不舒服,面试官可能也不舒服。
+
+## 一、基础部分
+
+#### 1、golang 中 make 和 new 的区别?(基本必问)
+
+共同点:给变量分配内存
+
+不同点:
+
+* 作用变量类型不同,new给string,int和数组分配内存,make给切片,map,channel分配内存;
+
+* 返回类型不一样,new返回指向变量的指针,make返回变量本身;
+
+* new 分配的空间被清零。make 分配空间后,会进行初始化;
+
+* 字节的面试官还说了另外一个区别,就是分配的位置,在堆上还是在栈上?这块我比较模糊,大家可以自己探究下,我搜索出来的答案是golang会弱化分配的位置的概念,因为编译的时候会自动内存逃逸处理,懂的大佬帮忙补充下:make、new内存分配是在堆上还是在栈上?
+
+#### string 底层数据结构
+
+```go
+// from: string.go 在GoLand IDE中双击shift快速找到
+type stringStruct struct {
+ array unsafe.Pointer // 指向一个 [len]byte 的数组
+ length int // 长度
+}
+```
+
+#### []string 和 []byte 的区别
+
+string
+
+1 .是一个指针,指向某个数组的首地址
+[]byte
+
+1 .是一个切片slice。一个封装了数组的结构体
+2 .slice结构
+```go
+type slice struct {
+ array unsafe.Pointer
+ len int
+ cap int
+```
+使用场景
+
+1 .想要在本身原地修改,就只能使用[]byte
+2 .string不能为nil,想要返回nil表达特殊含义,只能使用[]byte
+3 .string可以直接比较,而[]byte不可以,所以[]byte不可以当map的key值。
+4 .因为无法修改string中的某个字符,需要粒度小到操作一个字符时,用[]byte
+5 .[]byte切片这么灵活,想要用切片的特性就用[]byte
+6 .需要大量字符串处理的时候用[]byte,性能好很多
+区别
+
+1 .string的指针指向的内容是不可以改变的,所以每次更改一次字符串,都需要重新分配内存。之前的内存还需要GC收回,这是导致string效率底下的根本原因
+2 .如果我们保存的字符在 ASCII 表的,比如[0-1, a-z,A-Z..]直接可以保存到 byte
+3 .如果我们保存的字符对应码值大于 255,这时我们可以考虑使用 int 类型保存
+
+#### 2、数组和切片的区别 (基本必问)
+
+相同点:
+
+* 只能存储一组相同类型的数据结构
+
+* 都是通过下标来访问,并且有容量长度,长度通过 len 获取,容量通过 cap 获取
+
+区别:
+
+* 数组是定长,访问和复制不能超过数组定义的长度,否则就会下标越界,切片长度和容量可以自动扩容
+
+* 数组是值类型,切片是引用类型,每个切片都引用了一个底层数组,切片本身不能存储任何数据,都是这底层数组存储数据,所以修改切片的时候修改的是底层数组中的数据。切片一旦扩容,指向一个新的底层数组,内存地址也就随之改变
+
+简洁的回答:
+
+1)定义方式不一样 2)初始化方式不一样,数组需要指定大小,大小不改变 3)函数的传递方式不一样,数组传递的是值,切片传的是地址。
+
+数组的定义
+
+```go
+var a1 [3]int
+
+var a2 [...]int{1,2,3}
+```
+
+切片的定义
+
+```go
+var a1 []int
+
+var a2 :=make([]int,3,5)
+```
+
+数组的初始化
+
+```go
+a1 := [...]int{1,2,3}
+
+a2 := [5]int{1,2,3}
+```
+
+切片的初始化
+
+```go
+b:= make([]int,3,5)
+```
+#### 3、for range 的时候它的地址会发生变化么?
+
+答:在 `for a,b := range c` 遍历中, a 和 b 在内存中只会存在一份,即之后每次循环时遍历到的数据都是以值覆盖的方式赋给 a 和 b,a,b 的内存地址始终不变。由于有这个特性,**「for 循环里面如果开协程,不要直接把 a 或者 b 的地址传给协程」**。解决办法:在每次循环时,创建一个临时变量。
+
+#### 4、go defer,多个 defer 的顺序,defer 在什么时机会修改返回值?
+
+作用:defer延迟函数,释放资源,收尾工作;如释放锁,关闭文件,关闭链接;捕获panic;
+
+避坑指南:defer函数紧跟在资源打开后面,否则defer可能得不到执行,导致内存泄露。
+
+多个 defer 调用顺序是 LIFO(后入先出),defer后的操作可以理解为压入栈中
+
+解析:函数的 return 语句并不是原子级的,实际上 return 语句只代理汇编指令 ret。defer 语句是在返回前执行,所以返回过程是:「设置返回值—>执行defer—>ret」。defer可以修改函数最终返回值,修改时机:有名返回值或者函数返回指针 参考:[Go高阶指南07,一文搞懂 defer 实现原理)](https://mp.weixin.qq.com/s?__biz=Mzk0NzI3Mjk1Mg==&mid=2247484683&idx=1&sn=262b205caeef06489e5ac8cf84d44112&chksm=c378289cf40fa18aef1d26e1437232b6b20a2f1f7129951d3b094eefa04007ee3fcd0af4655f&token=1319045915&lang=zh_CN&scene=21#wechat_redirect)
+
+有名返回值
+
+```go
+func b() (i int) {
+ defer func() {
+ i++
+ fmt.Println("defer2:", i)
+ }()
+ defer func() {
+ i++
+ fmt.Println("defer1:", i)
+ }()
+ return i //或者直接写成return
+}
+func main() {
+ fmt.Println("return:", b())
+}
+
+//运行结果:
+//defer1: 1
+//defer2: 2
+//return: 2
+```
+
+函数返回指针
+
+```go
+func c() *int {
+ var i int
+ defer func() {
+ i++
+ fmt.Println("defer2:", i)
+ }()
+ defer func() {
+ i++
+ fmt.Println("defer1:", i)
+ }()
+ return &i
+}
+func main() {
+ fmt.Println("return:", *(c()))
+}
+
+//运行结果:
+//defer1: 1
+//defer2: 2
+//return: 2
+```
+#### 5、uint 类型溢出问题
+
+超过最大存储值如uint8最大是255
+
+var a uint8 =255
+
+var b uint8 =1
+
+a+b = 0总之类型溢出会出现难以意料的事
+
+
+#### 6、能介绍下 rune 类型吗?
+
+相当int32
+
+golang中的字符串底层实现是通过byte数组的,中文字符在unicode下占2个字节,在utf-8编码下占3个字节,而golang默认编码正好是utf-8
+
+byte 等同于int8,常用来处理ascii字符
+
+rune 等同于int32,常用来处理unicode或utf-8字符
+
+
+#### 7、 golang 中解析 tag 是怎么实现的?反射原理是什么?(中高级肯定会问,比较难,需要自己多去总结)
+
+参考如下连接golang中struct关于反射tag (https://blog.csdn.net/paladinosment/article/details/42570937)
+
+```go
+type User struct {
+ name string `json:name-field`
+ age int
+}
+func main() {
+ user := &User{"John Doe The Fourth", 20}
+
+ field, ok := reflect.TypeOf(user).Elem().FieldByName("name")
+ if !ok {
+ panic("Field not found")
+ }
+ fmt.Println(getStructTag(field))
+}
+
+func getStructTag(f reflect.StructField) string {
+ return string(f.Tag)
+}
+```
+
+o 中解析的 tag 是通过反射实现的,反射是指计算机程序在运行时(Run time)可以访问、检测和修改它本身状态或行为的一种能力或动态知道给定数据对象的类型和结构,并有机会修改它。反射将接口变量转换成反射对象 Type 和 Value;反射可以通过反射对象 Value 还原成原先的接口变量;反射可以用来修改一个变量的值,前提是这个值可以被修改;tag是啥:结构体支持标记,name string `json:name-field` 就是 `json:name-field` 这部分
+
+gorm json yaml gRPC protobuf gin.Bind()都是通过反射来实现的
+
+#### 8、调用函数传入结构体时,应该传值还是指针?(Golang 都是传值)
+
+Go 的函数参数传递都是值传递。所谓值传递:指在调用函数时将实际参数复制一份传递到函数中,这样在函数中如果对参数进行修改,将不会影响到实际参数。参数传递还有引用传递,所谓引用传递是指在调用函数时将实际参数的地址传递到函数中,那么在函数中对参数所进行的修改,将影响到实际参数
+
+因为 Go 里面的 map,slice,chan 是引用类型。变量区分值类型和引用类型。
+所谓值类型:变量和变量的值存在同一个位置。
+所谓引用类型:变量和变量的值是不同的位置,变量的值存储的是对值的引用。
+但并不是 map,slice,chan 的所有的变量在函数内都能被修改,不同数据类型的底层存储结构和实现可能不太一样,情况也就不一样。
+
+#### 9、讲讲 Go 的 slice 底层数据结构和一些特性?
+
+答:Go 的 slice 底层数据结构是由一个 array 指针指向底层数组,len 表示切片长度,cap 表示切片容量。slice 的主要实现是扩容。对于 append 向 slice 添加元素时,假如 slice 容量够用,则追加新元素进去,slice.len++,返回原来的 slice。当原容量不够,则 slice 先扩容,扩容之后 slice 得到新的 slice,将元素追加进新的 slice,slice.len++,返回新的 slice。对于切片的扩容规则:当切片比较小时(容量小于 1024),则采用较大的扩容倍速进行扩容(新的扩容会是原来的 2 倍),避免频繁扩容,从而减少内存分配的次数和数据拷贝的代价。当切片较大的时(原来的 slice 的容量大于或者等于 1024),采用较小的扩容倍速(新的扩容将扩大大于或者等于原来 1.25 倍),主要避免空间浪费,网上其实很多总结的是 1.25 倍,那是在不考虑内存对齐的情况下,实际上还要考虑内存对齐,扩容是大于或者等于 1.25 倍。
+
+(关于刚才问的 slice 为什么传到函数内可能被修改,如果 slice 在函数内没有出现扩容,函数外和函数内 slice 变量指向是同一个数组,则函数内复制的 slice 变量值出现更改,函数外这个 slice 变量值也会被修改。如果 slice 在函数内出现扩容,则函数内变量的值会新生成一个数组(也就是新的 slice,而函数外的 slice 指向的还是原来的 slice,则函数内的修改不会影响函数外的 slice。)
+
+#### 10、讲讲 Go 的 select 底层数据结构和一些特性?(难点,没有项目经常可能说不清,面试一般会问你项目中怎么使用select)
+
+答:go 的 select 为 golang 提供了多路 IO 复用机制,和其他 IO 复用一样,用于检测是否有读写事件是否 ready。linux 的系统 IO 模型有 select,poll,epoll,go 的 select 和 linux 系统 select 非常相似。
+
+select 结构组成主要是由 case 语句和执行的函数组成 select 实现的多路复用是:每个线程或者进程都先到注册和接受的 channel(装置)注册,然后阻塞,然后只有一个线程在运输,当注册的线程和进程准备好数据后,装置会根据注册的信息得到相应的数据。
+
+select 的特性
+
+* select 操作至少要有一个 case 语句,出现读写 nil 的 channel 该分支会忽略,在 nil 的 channel 上操作则会报错。
+* select 仅支持管道,而且是单协程操作。
+* 每个 case 语句仅能处理一个管道,要么读要么写。
+* 多个 case 语句的执行顺序是随机的。
+* 存在 default 语句,select 将不会阻塞,但是存在 default 会影响性能。
+
+- select 和 channel 的使用场景:https://blog.csdn.net/u011240877/article/details/123611525
+
+#### 11、讲讲 Go 的 defer 底层数据结构和一些特性?
+
+答:每个 defer 语句都对应一个_defer 实例,多个实例使用指针连接起来形成一个单连表,保存在 gotoutine 数据结构中,每次插入_defer 实例,均插入到链表的头部,函数结束再一次从头部取出,从而形成后进先出的效果。
+
+defer 的规则总结:
+
+* 延迟函数的参数是 defer 语句出现的时候就已经确定了的。
+* 延迟函数执行按照后进先出的顺序执行,即先出现的 defer 最后执行。
+* 延迟函数可能操作主函数的返回值。
+* 申请资源后立即使用 defer 关闭资源是个好习惯。
+
+#### 12、单引号,双引号,反引号的区别?
+
+单引号,表示byte类型或rune类型,对应 uint8和int32类型,默认是 rune 类型。byte用来强调数据是raw data,而不是数字;而rune用来表示Unicode的code point。
+
+双引号,才是字符串,实际上是字符数组。可以用索引号访问某字节,也可以用len()函数来获取字符串所占的字节长度。
+
+反引号,表示字符串字面量,但不支持任何转义序列。字面量 raw literal string 的意思是,你定义时写的啥样,它就啥样,你有换行,它就换行。你写转义字符,它也就展示转义字符。
+
+# 二、map相关
+
+#### 1、map 使用注意的点,是否并发安全?
+
+map的类型是map[key],key类型的ke必须是可比较的,通常情况,会选择内建的基本类型,比如整数、字符串做key的类型。如果要使用struct作为key,要保证struct对象在逻辑上是不可变的。在Go语言中,map[key]函数返回结果可以是一个值,也可以是两个值。map是无序的,如果我们想要保证遍历map时元素有序,可以使用辅助的数据结构,例如orderedmap。
+
+第一,一定要先初始化,否则panic
+
+第二,map类型是容易发生并发访问问题的。不注意就容易发生程序运行时并发读写导致的panic。Go语言内建的map对象不是线程安全的,并发读写的时候运行时会有检查,遇到并发问题就会导致panic。
+
+#### 2、map 循环是有序的还是无序的?
+
+无序的, map 因扩张⽽重新哈希时,各键值项存储位置都可能会发生改变,顺序自然也没法保证了,所以官方避免大家依赖顺序,直接打乱处理。就是 for range map 在开始处理循环逻辑的时候,就做了随机播种
+
+#### 3、 map 中删除一个 key,它的内存会释放么?(常问)
+
+如果删除的元素是值类型,如int,float,bool,string以及数组和struct,map的内存不会自动释放
+
+如果删除的元素是引用类型,如指针,slice,map,chan等,map的内存会自动释放,但释放的内存是子元素应用类型的内存占用
+
+将map设置为nil后,内存被回收。
+
+这个问题还需要大家去搜索下答案,我记得有不一样的说法,谨慎采用本题答案。
+
+#### 4、怎么处理对 map 进行并发访问?有没有其他方案?区别是什么?
+
+方式一、使用内置sync.Map,详细参考#### golang sync.map 原理和使用 #### (https://yebd1h.smartapps.cn/pages/blog/index?_swebFromHost=baiduboxapp&blogId=114628932&_swebfr=1)
+
+方式二、使用读写锁实现并发安全mapgolang线程安全map (https://yebd1h.smartapps.cn/pages/blog/index?_swebFromHost=baiduboxapp&blogId=123259483&_swebfr=1)
+
+#### 5、 nil map 和空 map 有何不同?
+
+1. 可以对未初始化的map进行取值,但取出来的东西是空:
+
+```go
+var m1 map[string]string
+
+fmt.Println(m1["1"])
+```
+
+1. 不能对未初始化的map进行赋值,这样将会抛出一个异常:
+
+```go
+var m1 map[string]string
+
+m1["1"] = "1"
+
+panic: assignment to entry in nil map
+```
+
+1. 通过fmt打印map时,空map和nil map结果是一样的,都为map[]。所以,这个时候别断定map是空还是nil,而应该通过map == nil来判断。
+ nil map 未初始化,空map是长度为空
+
+#### 6、map 的数据结构是什么?是怎么实现扩容?
+
+答:golang 中 map 是一个 kv 对集合。底层使用 hash table,用链表来解决冲突 ,出现冲突时,不是每一个 key 都申请一个结构通过链表串起来,而是以 bmap 为最小粒度挂载,一个 bmap 可以放 8 个 kv。在哈希函数的选择上,会在程序启动时,检测 cpu 是否支持 aes,如果支持,则使用 aes hash,否则使用 memhash。每个 map 的底层结构是 hmap,是有若干个结构为 bmap 的 bucket 组成的数组。每个 bucket 底层都采用链表结构。
+
+hmap 的结构如下:
+
+```go
+type hmap struct {
+ count int // 元素个数
+ flags uint8
+ B uint8 // 扩容常量相关字段B是buckets数组的长度的对数 2^B
+ noverflow uint16 // 溢出的bucket个数
+ hash0 uint32 // hash seed
+ buckets unsafe.Pointer // buckets 数组指针
+ oldbuckets unsafe.Pointer // 结构扩容的时候用于赋值的buckets数组
+ nevacuate uintptr // 搬迁进度
+ extra *mapextra // 用于扩容的指针
+}
+```
+
+map 的容量大小
+
+底层调用 makemap 函数,计算得到合适的 B,map 容量最多可容纳 6.52^B 个元素,6.5 为装载因子阈值常量。装载因子的计算公式是:装载因子=填入表中的元素个数/散列表的长度,装载因子越大,说明空闲位置越少,冲突越多,散列表的性能会下降。底层调用 makemap 函数,计算得到合适的 B,map 容量最多可容纳 6.52^B 个元素,6.5 为装载因子阈值常量。装载因子的计算公式是:装载因子=填入表中的元素个数/散列表的长度,装载因子越大,说明空闲位置越少,冲突越多,散列表的性能会下降。
+
+触发 map 扩容的条件
+
+* 装载因子超过阈值,源码里定义的阈值是 6.5。
+* overflow 的 bucket 数量过多 map 的 bucket 定位和 key 的定位高八位用于定位 bucket,低八位用于定位 key,快速试错后再进行完整对比。
+
+#### 7、slices能作为map类型的key吗?
+
+当时被问得一脸懵逼,其实是这个问题的变种:golang 哪些类型可以作为map key?
+
+答案是:在golang规范中,可比较的类型都可以作为map key;这个问题又延伸到在:golang规范中,哪些数据类型可以比较?
+
+不能作为map key 的类型包括:
+
+slices maps functions
+
+# 三、context相关
+
+#### 1、context 结构是什么样的?context 使用场景和用途?
+
+(难,也常常问你项目中怎么用,光靠记答案很难让面试官满意,反正有各种结合实际的问题)
+
+参考链接:go context详解 (https://www.cnblogs.com/juanmaofeifei/p/14439957.html)
+
+答:Go 的 Context 的数据结构包含 Deadline,Done,Err,Value,Deadline 方法返回一个 time.Time,表示当前 Context 应该结束的时间,ok 则表示有结束时间,Done 方法当 Context 被取消或者超时时候返回的一个 close 的 channel,告诉给 context 相关的函数要停止当前工作然后返回了,Err 表示 context 被取消的原因,Value 方法表示 context 实现共享数据存储的地方,是协程安全的。context 在业务中是经常被使用的,
+
+其主要的应用 :
+
+1:上下文控制,2:多个 goroutine 之间的数据交互等,3:超时控制:到某个时间点超时,过多久超时。
+
+# 四、channel相关
+
+#### 1、channel 是否线程安全?锁用在什么地方?
+
+
+
+#### 2、go channel 的底层实现原理 (数据结构)
+
+
+
+底层结构需要描述出来,这个简单,buf,发送队列,接收队列,lock。
+
+#### 3、nil、关闭的 channel、有数据的 channel,再进行读、写、关闭会怎么样?(各类变种题型,重要)
+
+
+
+还要去了解一下单向channel,如只读或者只写通道常见的异常问题,这块还需要大家自己总结总结,有懂的大佬也可以评论发送答案。
+
+#### 4、向 channel 发送数据和从 channel 读数据的流程是什么样的?
+
+发送流程:
+
+
+
+接收流程:
+
+这个没啥好说的,底层原理,1、2、3描述出来,保证面试官满意。具体的文字描述下面一题有,channel的概念多且复杂,脑海中有个总分的概念,否则你说的再多,面试官也抓不住你说的重点,等于白说。问题5已经为大家总结好了。
+
+#### 5、讲讲 Go 的 chan 底层数据结构和主要使用场景
+
+答:channel 的数据结构包含 qccount 当前队列中剩余元素个数,dataqsiz 环形队列长度,即可以存放的元素个数,buf 环形队列指针,elemsize 每个元素的大小,closed 标识关闭状态,elemtype 元素类型,sendx 队列下表,指示元素写入时存放到队列中的位置,recv 队列下表,指示元素从队列的该位置读出。recvq 等待读消息的 goroutine 队列,sendq 等待写消息的 goroutine 队列,lock 互斥锁,chan 不允许并发读写。
+
+无缓冲和有缓冲区别:管道没有缓冲区,从管道读数据会阻塞,直到有协程向管道中写入数据。同样,向管道写入数据也会阻塞,直到有协程从管道读取数据。管道有缓冲区但缓冲区没有数据,从管道读取数据也会阻塞,直到协程写入数据,如果管道满了,写数据也会阻塞,直到协程从缓冲区读取数据。
+
+channel 的一些特点 1)、读写值 nil 管道会永久阻塞 2)、关闭的管道读数据仍然可以读数据 3)、往关闭的管道写数据会 panic 4)、关闭为 nil 的管道 panic 5)、关闭已经关闭的管道 panic
+
+向 channel 写数据的流程:如果等待接收队列 recvq 不为空,说明缓冲区中没有数据或者没有缓冲区,此时直接从 recvq 取出 G,并把数据写入,最后把该 G 唤醒,结束发送过程;如果缓冲区中有空余位置,将数据写入缓冲区,结束发送过程;如果缓冲区中没有空余位置,将待发送数据写入 G,将当前 G 加入 sendq,进入睡眠,等待被读 goroutine 唤醒;
+
+向 channel 读数据的流程:如果等待发送队列 sendq 不为空,且没有缓冲区,直接从 sendq 中取出 G,把 G 中数据读出,最后把 G 唤醒,结束读取过程;如果等待发送队列 sendq 不为空,此时说明缓冲区已满,从缓冲区中首部读出数据,把 G 中数据写入缓冲区尾部,把 G 唤醒,结束读取过程;如果缓冲区中有数据,则从缓冲区取出数据,结束读取过程;将当前 goroutine 加入 recvq,进入睡眠,等待被写 goroutine 唤醒;
+
+使用场景:消息传递、消息过滤,信号广播,事件订阅与广播,请求、响应转发,任务分发,结果汇总,并发控制,限流,同步与异步
+
+# 五、GMP相关
+
+#### 1、什么是 GMP?(必问)
+
+答:G 代表着 goroutine,P 代表着上下文处理器,M 代表 thread 线程,在 GPM 模型,有一个全局队列(Global Queue):存放等待运行的 G,还有一个 P 的本地队列:也是存放等待运行的 G,但数量有限,不超过 256 个。GPM 的调度流程从 go func()开始创建一个 goroutine,新建的 goroutine 优先保存在 P 的本地队列中,如果 P 的本地队列已经满了,则会保存到全局队列中。M 会从 P 的队列中取一个可执行状态的 G 来执行,如果 P 的本地队列为空,就会从其他的 MP 组合偷取一个可执行的 G 来执行,当 M 执行某一个 G 时候发生系统调用或者阻塞,M 阻塞,如果这个时候 G 在执行,runtime 会把这个线程 M 从 P 中摘除,然后创建一个新的操作系统线程来服务于这个 P,当 M 系统调用结束时,这个 G 会尝试获取一个空闲的 P 来执行,并放入到这个 P 的本地队列,如果这个线程 M 变成休眠状态,加入到空闲线程中,然后整个 G 就会被放入到全局队列中。
+
+关于 G,P,M 的个数问题,G 的个数理论上是无限制的,但是受内存限制,P 的数量一般建议是逻辑 CPU 数量的 2 倍,M 的数据默认启动的时候是 10000,内核很难支持这么多线程数,所以整个限制客户忽略,M 一般不做设置,设置好 P,M 一般都是要大于 P。
+
+#### 2、进程、线程、协程有什么区别?(必问)
+
+进程:是应用程序的启动实例,每个进程都有独立的内存空间,不同的进程通过进程间的通信方式来通信。
+
+线程:从属于进程,每个进程至少包含一个线程,线程是 CPU 调度的基本单位,多个线程之间可以共享进程的资源并通过共享内存等线程间的通信方式来通信。
+
+协程:为轻量级线程,与线程相比,协程不受操作系统的调度,协程的调度器由用户应用程序提供,协程调度器按照调度策略把协程调度到线程中运行
+
+#### 3、抢占式调度是如何抢占的?
+
+基于协作式抢占
+
+基于信号量抢占
+
+就像操作系统要负责线程的调度一样,Go的runtime要负责goroutine的调度。现代操作系统调度线程都是抢占式的,我们不能依赖用户代码主动让出CPU,或者因为IO、锁等待而让出,这样会造成调度的不公平。基于经典的时间片算法,当线程的时间片用完之后,会被时钟中断给打断,调度器会将当前线程的执行上下文进行保存,然后恢复下一个线程的上下文,分配新的时间片令其开始执行。这种抢占对于线程本身是无感知的,系统底层支持,不需要开发人员特殊处理。
+
+基于时间片的抢占式调度有个明显的优点,能够避免CPU资源持续被少数线程占用,从而使其他线程长时间处于饥饿状态。goroutine的调度器也用到了时间片算法,但是和操作系统的线程调度还是有些区别的,因为整个Go程序都是运行在用户态的,所以不能像操作系统那样利用时钟中断来打断运行中的goroutine。也得益于完全在用户态实现,goroutine的调度切换更加轻量。
+
+上面这两段文字只是对调度的一个概括,具体的协作式调度、信号量调度大家还需要去详细了解,这偏底层了,大厂或者中高级开发会问。(字节就问了)
+
+#### 4、M 和 P 的数量问题?
+
+p默认cpu内核数
+
+M与P的数量没有绝对关系,一个M阻塞,P就会去创建或者切换另一个M,所以,即使P的默认数量是1,也有可能会创建很多个M出来
+
+【Go语言调度模型G、M、P的数量多少合适?】
+
+详细参考这篇文章Go语言调度模型G、M、P的数量多少合适? (https://zoyi14.smartapps.cn/pages/note/index?_swebFromHost=baiduboxapp&origin=share&slug=1a50330adf1b&_swebfr=1)
+
+GMP数量这一块,结论很好记,没用项目经验的话,问了项目中怎么用可能容易卡壳。
+
+# 六、锁相关
+
+#### 1、除了 mutex 以外还有哪些方式安全读写共享变量?
+
+* 将共享变量的读写放到一个 goroutine 中,其它 goroutine 通过 channel 进行读写操作。
+
+* 可以用个数为 1 的信号量(semaphore)实现互斥
+
+* 通过 Mutex 锁实现
+
+#### 2、Go 如何实现原子操作?
+
+答:原子操作就是不可中断的操作,外界是看不到原子操作的中间状态,要么看到原子操作已经完成,要么看到原子操作已经结束。在某个值的原子操作执行的过程中,CPU 绝对不会再去执行其他针对该值的操作,那么其他操作也是原子操作。
+
+Go 语言的标准库代码包 sync/atomic 提供了原子的读取(Load 为前缀的函数)或写入(Store 为前缀的函数)某个值(这里细节还要多去查查资料)。
+
+原子操作与互斥锁的区别
+
+* 互斥锁是一种数据结构,用来让一个线程执行程序的关键部分,完成互斥的多个操作。
+* 原子操作是针对某个值的单个互斥操作。
+* Mutex 是悲观锁还是乐观锁?悲观锁、乐观锁是什么?
+
+悲观锁
+
+悲观锁:当要对数据库中的一条数据进行修改的时候,为了避免同时被其他人修改,最好的办法就是直接对该数据进行加锁以防止并发。这种借助数据库锁机制,在修改数据之前先锁定,再修改的方式被称之为悲观并发控制【Pessimistic Concurrency Control,缩写“PCC”,又名“悲观锁”】。
+
+乐观锁
+
+乐观锁是相对悲观锁而言的,乐观锁假设数据一般情况不会造成冲突,所以在数据进行提交更新的时候,才会正式对数据的冲突与否进行检测,如果冲突,则返回给用户异常信息,让用户决定如何去做。乐观锁适用于读多写少的场景,这样可以提高程序的吞吐量
+
+#### 4、Mutex 有几种模式?
+
+1. 正常模式
+
+当前的mutex只有一个goruntine来获取,那么没有竞争,直接返回。新的goruntine进来,如果当前mutex已经被获取了,则该goruntine进入一个先入先出的waiter队列,在mutex被释放后,waiter按照先进先出的方式获取锁。该goruntine会处于自旋状态(不挂起,继续占有cpu)。新的goruntine进来,mutex处于空闲状态,将参与竞争。新来的 goroutine 有先天的优势,它们正在 CPU 中运行,可能它们的数量还不少,所以,在高并发情况下,被唤醒的 waiter 可能比较悲剧地获取不到锁,这时,它会被插入到队列的前面。如果 waiter 获取不到锁的时间超过阈值 1 毫秒,那么,这个 Mutex 就进入到了饥饿模式。
+
+1. 饥饿模式
+
+在饥饿模式下,Mutex 的拥有者将直接把锁交给队列最前面的 waiter。新来的 goroutine 不会尝试获取锁,即使看起来锁没有被持有,它也不会去抢,也不会 spin(自旋),它会乖乖地加入到等待队列的尾部。如果拥有 Mutex 的 waiter 发现下面两种情况的其中之一,它就会把这个 Mutex 转换成正常模式:
+
+此 waiter 已经是队列中的最后一个 waiter 了,没有其它的等待锁的 goroutine 了;此 waiter 的等待时间小于 1 毫秒。
+
+#### 5、goroutine 的自旋占用资源如何解决
+
+自旋锁是指当一个线程在获取锁的时候,如果锁已经被其他线程获取,那么该线程将循环等待,然后不断地判断是否能够被成功获取,直到获取到锁才会退出循环。
+
+自旋的条件如下:
+
+* 还没自旋超过 4 次,
+* 多核处理器,
+* GOMAXPROCS > 1,
+* p 上本地 goroutine 队列为空。
+
+mutex 会让当前的 goroutine 去空转 CPU,在空转完后再次调用 CAS 方法去尝试性的占有锁资源,直到不满足自旋条件,则最终会加入到等待队列里。
+
+# 七、并发相关
+
+#### 1、怎么控制并发数?
+
+1. 有缓冲通道
+
+根据通道中没有数据时读取操作陷入阻塞和通道已满时继续写入操作陷入阻塞的特性,正好实现控制并发数量。
+
+```go
+func main() {
+ count := 10 // 最大支持并发
+ sum := 100 // 任务总数
+ wg := sync.WaitGroup{} //控制主协程等待所有子协程执行完之后再退出。
+
+ c := make(chan struct{}, count) // 控制任务并发的chan
+ defer close(c)
+
+ for i:=0; i
->
-> 总体来说分为以下几个过程:
->
-> 1. DNS 解析
-> 2. TCP 连接
-> 3. 发送 HTTP 请求
-> 4. 服务器处理请求并返回 HTTP 报文
-> 5. 浏览器解析渲染页面
-> 6. 连接结束
->
-> 具体可以参考下面这篇文章:
->
-> - [https://segmentfault.com/a/1190000006879700](https://segmentfault.com/a/1190000006879700 "https://segmentfault.com/a/1190000006879700")
-
-**面试官:** TCP 和 UDP 区别?
-
-**我:**
-
-> 
->
-> UDP 在传送数据之前不需要先建立连接,远地主机在收到 UDP 报文后,不需要给出任何确认。虽然 UDP 不提供可靠交付,但在某些情况下 UDP 确是一种最有效的工作方式(一般用于即时通信),比如: QQ 语音、 QQ 视频 、直播等等
->
-> TCP 提供面向连接的服务。在传送数据之前必须先建立连接,数据传送结束后要释放连接。 TCP 不提供广播或多播服务。由于 TCP 要提供可靠的,面向连接的传输服务(TCP 的可靠体现在 TCP 在传递数据之前,会有三次握手来建立连接,而且在数据传递时,有确认、窗口、重传、拥塞控制机制,在数据传完后,还会断开连接用来节约系统资源),这一难以避免增加了许多开销,如确认,流量控制,计时器以及连接管理等。这不仅使协议数据单元的首部增大很多,还要占用许多处理机资源。TCP 一般用于文件传输、发送和接收邮件、远程登录等场景。
-
-**面试官:** TCP 如何保证传输可靠性?
-
-**我:**
-
-> 1. 应用数据被分割成 TCP 认为最适合发送的数据块。
-> 2. TCP 给发送的每一个包进行编号,接收方对数据包进行排序,把有序数据传送给应用层。
-> 3. **校验和:** TCP 将保持它首部和数据的检验和。这是一个端到端的检验和,目的是检测数据在传输过程中的任何变化。如果收到段的检验和有差错,TCP 将丢弃这个报文段和不确认收到此报文段。
-> 4. TCP 的接收端会丢弃重复的数据。
-> 5. **流量控制:** TCP 连接的每一方都有固定大小的缓冲空间,TCP 的接收端只允许发送端发送接收端缓冲区能接纳的数据。当接收方来不及处理发送方的数据,能提示发送方降低发送的速率,防止包丢失。TCP 使用的流量控制协议是可变大小的滑动窗口协议。 (TCP 利用滑动窗口实现流量控制)
-> 6. **拥塞控制:** 当网络拥塞时,减少数据的发送。
-> 7. **ARQ 协议:** 也是为了实现可靠传输的,它的基本原理就是每发完一个分组就停止发送,等待对方确认。在收到确认后再发下一个分组。
-> 8. **超时重传:** 当 TCP 发出一个段后,它启动一个定时器,等待目的端确认收到这个报文段。如果不能及时收到一个确认,将重发这个报文段。
-
-**面试官:** 我再来问你一些 Java 基础的问题吧!小伙子。
-
-**我:** 好的。(内心 os:“你尽管来!”)
-
-**面试官:** 既然有了字节流,为什么还要有字符流?
-
-我:内心 os :“问题本质想问:**不管是文件读写还是网络发送接收,信息的最小存储单元都是字节,那为什么 I/O 流操作要分为字节流操作和字符流操作呢?**”
-
-> 字符流是由 Java 虚拟机将字节转换得到的,问题就出在这个过程还算是非常耗时,并且,如果我们不知道编码类型就很容易出现乱码问题。所以, I/O 流就干脆提供了一个直接操作字符的接口,方便我们平时对字符进行流操作。如果音频文件、图片等媒体文件用字节流比较好,如果涉及到字符的话使用字符流比较好。
-
-**面试官**:深拷贝 和 浅拷贝有啥区别呢?
-
-**我:**
-
-> 1. **浅拷贝**:对基本数据类型进行值传递,对引用数据类型进行引用传递般的拷贝,此为浅拷贝。
-> 2. **深拷贝**:对基本数据类型进行值传递,对引用数据类型,创建一个新的对象,并复制其内容,此为深拷贝。
->
-> 
-
-**面试官:** 好的!面试结束。小伙子可以的!回家等通知吧!
-
-**我:** 好的好的!辛苦您了!
diff --git "a/docs/essential-content-for-interview/\346\211\213\346\212\212\346\211\213\346\225\231\344\275\240\347\224\250Markdown\345\206\231\344\270\200\344\273\275\351\253\230\350\264\250\351\207\217\347\232\204\347\256\200\345\216\206.md" "b/docs/essential-content-for-interview/\346\211\213\346\212\212\346\211\213\346\225\231\344\275\240\347\224\250Markdown\345\206\231\344\270\200\344\273\275\351\253\230\350\264\250\351\207\217\347\232\204\347\256\200\345\216\206.md"
deleted file mode 100644
index 9cb2811..0000000
--- "a/docs/essential-content-for-interview/\346\211\213\346\212\212\346\211\213\346\225\231\344\275\240\347\224\250Markdown\345\206\231\344\270\200\344\273\275\351\253\230\350\264\250\351\207\217\347\232\204\347\256\200\345\216\206.md"
+++ /dev/null
@@ -1,93 +0,0 @@
-## Markdown 简历模板样式一览
-
-**可以看到我把联系方式放在第一位,因为公司一般会与你联系,所以把联系方式放在第一位也是为了方便联系考虑。**
-
-## 为什么要用 Markdown 写简历?
-
-Markdown 语法简单,易于上手。使用正确的 Markdown 语言写出来的简历不论是在排版还是格式上都比较干净,易于阅读。另外,使用 Markdown 写简历也会给面试官一种你比较专业的感觉。
-
-除了这些,我觉得使用 Markdown 写简历可以很方便将其与PDF、HTML、PNG格式之间转换。后面我会介绍到转换方法,只需要一条命令你就可以实现 Markdown 到 PDF、HTML 与 PNG之间的无缝切换。
-
-> 下面的一些内容我在之前的一篇文章中已经提到过,这里再说一遍,最后会分享如何实现Markdown 到 PDF、HTML、PNG格式之间转换。
-
-## 为什么说简历很重要?
-
-假如你是网申,你的简历必然会经过HR的筛选,一张简历HR可能也就花费10秒钟看一下,然后HR就会决定你这一关是Fail还是Pass。
-
-假如你是内推,如果你的简历没有什么优势的话,就算是内推你的人再用心,也无能为力。
-
-另外,就算你通过了筛选,后面的面试中,面试官也会根据你的简历来判断你究竟是否值得他花费很多时间去面试。
-
-## 写简历的两大法则
-
-目前写简历的方式有两种普遍被认可,一种是 STAR, 一种是 FAB。
-
-**STAR法则(Situation Task Action Result):**
-
-- **Situation:** 事情是在什么情况下发生;
-- **Task::** 你是如何明确你的任务的;
-- **Action:** 针对这样的情况分析,你采用了什么行动方式;
-- **Result:** 结果怎样,在这样的情况下你学习到了什么。
-
-**FAB 法则(Feature Advantage Benefit):**
-
-- **Feature:** 是什么;
-- **Advantage:** 比别人好在哪些地方;
-- **Benefit:** 如果雇佣你,招聘方会得到什么好处。
-
-## 项目经历怎么写?
-简历上有一两个项目经历很正常,但是真正能把项目经历很好的展示给面试官的非常少。对于项目经历大家可以考虑从如下几点来写:
-
-1. 对项目整体设计的一个感受
-2. 在这个项目中你负责了什么、做了什么、担任了什么角色
-3. 从这个项目中你学会了那些东西,使用到了那些技术,学会了那些新技术的使用
-4. 另外项目描述中,最好可以体现自己的综合素质,比如你是如何协调项目组成员协同开发的或者在遇到某一个棘手的问题的时候你是如何解决的。
-
-## 专业技能该怎么写?
-先问一下你自己会什么,然后看看你意向的公司需要什么。一般HR可能并不太懂技术,所以他在筛选简历的时候可能就盯着你专业技能的关键词来看。对于公司有要求而你不会的技能,你可以花几天时间学习一下,然后在简历上可以写上自己了解这个技能。比如你可以这样写:
-
-- Dubbo:精通
-- Spring:精通
-- Docker:掌握
-- SOA分布式开发 :掌握
-- Spring Cloud:了解
-
-## 简历模板分享
-
-**开源程序员简历模板**: [https://github.com/geekcompany/ResumeSample](https://github.com/geekcompany/ResumeSample)(包括PHP程序员简历模板、iOS程序员简历模板、Android程序员简历模板、Web前端程序员简历模板、Java程序员简历模板、C/C++程序员简历模板、NodeJS程序员简历模板、架构师简历模板以及通用程序员简历模板)
-
-**上述简历模板的改进版本:** [https://github.com/Snailclimb/Java-Guide/blob/master/面试必备/简历模板.md](https://github.com/Snailclimb/Java-Guide/blob/master/面试必备/简历模板.md)
-
-## 其他的一些小tips
-
-1. 尽量避免主观表述,少一点语义模糊的形容词,尽量要简洁明了,逻辑结构清晰。
-2. 注意排版(不需要花花绿绿的),尽量使用Markdown语法。
-3. 如果自己有博客或者个人技术栈点的话,写上去会为你加分很多。
-4. 如果自己的Github比较活跃的话,写上去也会为你加分很多。
-5. 注意简历真实性,一定不要写自己不会的东西,或者带有欺骗性的内容
-6. 项目经历建议以时间倒序排序,另外项目经历不在于多,而在于有亮点。
-7. 如果内容过多的话,不需要非把内容压缩到一页,保持排版干净整洁就可以了。
-8. 简历最后最好能加上:“感谢您花时间阅读我的简历,期待能有机会和您共事。”这句话,显的你会很有礼貌。
-
-
-> 我们刚刚讲了很多关于如何写简历的内容并且分享了一份 Markdown 格式的简历文档。下面我们来看看如何实现 Markdown 到 HTML格式、PNG格式之间转换。
-## Markdown 到 HTML格式、PNG格式之间转换
-
-网上很难找到一个比较方便并且效果好的转换方法,最后我是通过 Visual Studio Code 的 Markdown PDF 插件完美解决了这个问题!
-
-### 安装 Markdown PDF 插件
-
-**① 打开Visual Studio Code ,按快捷键 F1,选择安装扩展选项**
-
-
-
-**② 搜索 “Markdown PDF” 插件并安装 ,然后重启**
-
-
-
-### 使用方法
-
-随便打开一份 Markdown 文件 点击F1,然后输入export即可!
-
-
-
diff --git "a/docs/essential-content-for-interview/\347\256\200\345\216\206\346\250\241\346\235\277.md" "b/docs/essential-content-for-interview/\347\256\200\345\216\206\346\250\241\346\235\277.md"
deleted file mode 100644
index 2a7a043..0000000
--- "a/docs/essential-content-for-interview/\347\256\200\345\216\206\346\250\241\346\235\277.md"
+++ /dev/null
@@ -1,79 +0,0 @@
-# 联系方式
-
-- 手机:
-- Email:
-- 微信:
-
-# 个人信息
-
- - 姓名/性别/出生日期
- - 本科/xxx计算机系xxx专业/英语六级
- - 技术博客:[http://snailclimb.top/](http://snailclimb.top/)
- - 荣誉奖励:获得了什么奖(获奖时间)
- - Github:[https://github.com/Snailclimb ](https://github.com/Snailclimb)
- - Github Resume: [http://resume.github.io/?Snailclimb](http://resume.github.io/?Snailclimb)
- - 期望职位:Java 研发程序员/大数据工程师(Java后台开发为首选)
- - 期望城市:xxx城市
-
-
-# 项目经历
-
-## xxx项目
-
-### 项目描述
-
-介绍该项目是做什么的、使用到了什么技术以及你对项目整体设计的一个感受
-
-### 责任描述
-
-主要可以从下面三点来写:
-
-1. 在这个项目中你负责了什么、做了什么、担任了什么角色
-2. 从这个项目中你学会了那些东西,使用到了那些技术,学会了那些新技术的使用
-3. 另外项目描述中,最好可以体现自己的综合素质,比如你是如何协调项目组成员协同开发的或者在遇到某一个棘手的问题的时候你是如何解决的。
-
-# 开源项目和技术文章
-
-## 开源项目
-
-- [Java-Guide](https://github.com/Snailclimb/Java-Guide) :一份涵盖大部分Java程序员所需要掌握的核心知识。Star:3.9K; Fork:0.9k。
-
-
-## 技术文章推荐
-
-- [可能是把Java内存区域讲的最清楚的一篇文章](https://juejin.im/post/5b7d69e4e51d4538ca5730cb)
-- [搞定JVM垃圾回收就是这么简单](https://juejin.im/post/5b85ea54e51d4538dd08f601)
-- [前端&后端程序员必备的Linux基础知识](https://juejin.im/post/5b3b19856fb9a04fa42f8c71)
-- [可能是把Docker的概念讲的最清楚的一篇文章](https://juejin.im/post/5b260ec26fb9a00e8e4b031a)
-
-
-# 校园经历(可选)
-
-## 2016-2017
-
-担任学校社团-致深社副会长,主要负责团队每周活动的组建以及每周例会的主持。
-
-## 2017-2018
- 担任学校传媒组织:“长江大学在线信息传媒”的副站长以及安卓组成员。主要负责每周例会主持、活动策划以及学校校园通APP的研发工作。
-
-
-# 技能清单
-
-以下均为我熟练使用的技能
-
-- Web开发:PHP/Hack/Node
-- Web框架:ThinkPHP/Yaf/Yii/Lavarel/LazyPHP
-- 前端框架:Bootstrap/AngularJS/EmberJS/HTML5/Cocos2dJS/ionic
-- 前端工具:Bower/Gulp/SaSS/LeSS/PhoneGap
-- 数据库相关:MySQL/PgSQL/PDO/SQLite
-- 版本管理、文档和自动化部署工具:Svn/Git/PHPDoc/Phing/Composer
-- 单元测试:PHPUnit/SimpleTest/Qunit
-- 云和开放平台:SAE/BAE/AWS/微博开放平台/微信应用开发
-
-# 自我评价(可选)
-
-自我发挥。切记不要过度自夸!!!
-
-
-### 感谢您花时间阅读我的简历,期待能有机会和您共事。
-
diff --git "a/docs/essential-content-for-interview/\351\235\242\350\257\225\345\277\205\345\244\207\344\271\213\344\271\220\350\247\202\351\224\201\344\270\216\346\202\262\350\247\202\351\224\201.md" "b/docs/essential-content-for-interview/\351\235\242\350\257\225\345\277\205\345\244\207\344\271\213\344\271\220\350\247\202\351\224\201\344\270\216\346\202\262\350\247\202\351\224\201.md"
deleted file mode 100644
index 00aaecd..0000000
--- "a/docs/essential-content-for-interview/\351\235\242\350\257\225\345\277\205\345\244\207\344\271\213\344\271\220\350\247\202\351\224\201\344\270\216\346\202\262\350\247\202\351\224\201.md"
+++ /dev/null
@@ -1,115 +0,0 @@
-点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java面试突击》以及Java工程师必备学习资源。
-
-
-
-- [何谓悲观锁与乐观锁](#何谓悲观锁与乐观锁)
- - [悲观锁](#悲观锁)
- - [乐观锁](#乐观锁)
- - [两种锁的使用场景](#两种锁的使用场景)
-- [乐观锁常见的两种实现方式](#乐观锁常见的两种实现方式)
- - [1. 版本号机制](#1-版本号机制)
- - [2. CAS算法](#2-cas算法)
-- [乐观锁的缺点](#乐观锁的缺点)
- - [1 ABA 问题](#1-aba-问题)
- - [2 循环时间长开销大](#2-循环时间长开销大)
- - [3 只能保证一个共享变量的原子操作](#3-只能保证一个共享变量的原子操作)
-- [CAS与synchronized的使用情景](#cas与synchronized的使用情景)
-
-
-
-### 何谓悲观锁与乐观锁
-
-> 乐观锁对应于生活中乐观的人总是想着事情往好的方向发展,悲观锁对应于生活中悲观的人总是想着事情往坏的方向发展。这两种人各有优缺点,不能不以场景而定说一种人好于另外一种人。
-
-#### 悲观锁
-
-总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁(**共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程**)。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。Java中`synchronized`和`ReentrantLock`等独占锁就是悲观锁思想的实现。
-
-
-#### 乐观锁
-
-总是假设最好的情况,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号机制和CAS算法实现。**乐观锁适用于多读的应用类型,这样可以提高吞吐量**,像数据库提供的类似于**write_condition机制**,其实都是提供的乐观锁。在Java中`java.util.concurrent.atomic`包下面的原子变量类就是使用了乐观锁的一种实现方式**CAS**实现的。
-
-#### 两种锁的使用场景
-
-从上面对两种锁的介绍,我们知道两种锁各有优缺点,不可认为一种好于另一种,像**乐观锁适用于写比较少的情况下(多读场景)**,即冲突真的很少发生的时候,这样可以省去了锁的开销,加大了系统的整个吞吐量。但如果是多写的情况,一般会经常产生冲突,这就会导致上层应用会不断的进行retry,这样反倒是降低了性能,所以**一般多写的场景下用悲观锁就比较合适。**
-
-
-### 乐观锁常见的两种实现方式
-
-> **乐观锁一般会使用版本号机制或CAS算法实现。**
-
-#### 1. 版本号机制
-
-一般是在数据表中加上一个数据版本号version字段,表示数据被修改的次数,当数据被修改时,version值会加一。当线程A要更新数据值时,在读取数据的同时也会读取version值,在提交更新时,若刚才读取到的version值为当前数据库中的version值相等时才更新,否则重试更新操作,直到更新成功。
-
-**举一个简单的例子:**
-假设数据库中帐户信息表中有一个 version 字段,当前值为 1 ;而当前帐户余额字段( balance )为 $100 。
-
-1. 操作员 A 此时将其读出( version=1 ),并从其帐户余额中扣除 $50( $100-$50 )。
-2. 在操作员 A 操作的过程中,操作员B 也读入此用户信息( version=1 ),并从其帐户余额中扣除 $20 ( $100-$20 )。
-3. 操作员 A 完成了修改工作,将数据版本号加一( version=2 ),连同帐户扣除后余额( balance=$50 ),提交至数据库更新,此时由于提交数据版本大于数据库记录当前版本,数据被更新,数据库记录 version 更新为 2 。
-4. 操作员 B 完成了操作,也将版本号加一( version=2 )试图向数据库提交数据( balance=$80 ),但此时比对数据库记录版本时发现,操作员 B 提交的数据版本号为 2 ,数据库记录当前版本也为 2 ,不满足 “ 提交版本必须大于记录当前版本才能执行更新 “ 的乐观锁策略,因此,操作员 B 的提交被驳回。
-
-这样,就避免了操作员 B 用基于 version=1 的旧数据修改的结果覆盖操作员A 的操作结果的可能。
-
-#### 2. CAS算法
-
-即**compare and swap(比较与交换)**,是一种有名的**无锁算法**。无锁编程,即不使用锁的情况下实现多线程之间的变量同步,也就是在没有线程被阻塞的情况下实现变量的同步,所以也叫非阻塞同步(Non-blocking Synchronization)。**CAS算法**涉及到三个操作数
-
-- 需要读写的内存值 V
-- 进行比较的值 A
-- 拟写入的新值 B
-
-当且仅当 V 的值等于 A时,CAS通过原子方式用新值B来更新V的值,否则不会执行任何操作(比较和替换是一个原子操作)。一般情况下是一个**自旋操作**,即**不断的重试**。
-
-关于自旋锁,大家可以看一下这篇文章,非常不错:[《
-面试必备之深入理解自旋锁》](https://blog.csdn.net/qq_34337272/article/details/81252853)
-
-### 乐观锁的缺点
-
-> ABA 问题是乐观锁一个常见的问题
-
-#### 1 ABA 问题
-
-如果一个变量V初次读取的时候是A值,并且在准备赋值的时候检查到它仍然是A值,那我们就能说明它的值没有被其他线程修改过了吗?很明显是不能的,因为在这段时间它的值可能被改为其他值,然后又改回A,那CAS操作就会误认为它从来没有被修改过。这个问题被称为CAS操作的 **"ABA"问题。**
-
-JDK 1.5 以后的 `AtomicStampedReference 类`就提供了此种能力,其中的 `compareAndSet 方法`就是首先检查当前引用是否等于预期引用,并且当前标志是否等于预期标志,如果全部相等,则以原子方式将该引用和该标志的值设置为给定的更新值。
-
-#### 2 循环时间长开销大
-**自旋CAS(也就是不成功就一直循环执行直到成功)如果长时间不成功,会给CPU带来非常大的执行开销。** 如果JVM能支持处理器提供的pause指令那么效率会有一定的提升,pause指令有两个作用,第一它可以延迟流水线执行指令(de-pipeline),使CPU不会消耗过多的执行资源,延迟的时间取决于具体实现的版本,在一些处理器上延迟时间是零。第二它可以避免在退出循环的时候因内存顺序冲突(memory order violation)而引起CPU流水线被清空(CPU pipeline flush),从而提高CPU的执行效率。
-
-#### 3 只能保证一个共享变量的原子操作
-
-CAS 只对单个共享变量有效,当操作涉及跨多个共享变量时 CAS 无效。但是从 JDK 1.5开始,提供了`AtomicReference类`来保证引用对象之间的原子性,你可以把多个变量放在一个对象里来进行 CAS 操作.所以我们可以使用锁或者利用`AtomicReference类`把多个共享变量合并成一个共享变量来操作。
-
-### CAS与synchronized的使用情景
-
-> **简单的来说CAS适用于写比较少的情况下(多读场景,冲突一般较少),synchronized适用于写比较多的情况下(多写场景,冲突一般较多)**
-
-1. 对于资源竞争较少(线程冲突较轻)的情况,使用synchronized同步锁进行线程阻塞和唤醒切换以及用户态内核态间的切换操作额外浪费消耗cpu资源;而CAS基于硬件实现,不需要进入内核,不需要切换线程,操作自旋几率较少,因此可以获得更高的性能。
-2. 对于资源竞争严重(线程冲突严重)的情况,CAS自旋的概率会比较大,从而浪费更多的CPU资源,效率低于synchronized。
-
-补充: Java并发编程这个领域中synchronized关键字一直都是元老级的角色,很久之前很多人都会称它为 **“重量级锁”** 。但是,在JavaSE 1.6之后进行了主要包括为了减少获得锁和释放锁带来的性能消耗而引入的 **偏向锁** 和 **轻量级锁** 以及其它**各种优化**之后变得在某些情况下并不是那么重了。synchronized的底层实现主要依靠 **Lock-Free** 的队列,基本思路是 **自旋后阻塞**,**竞争切换后继续竞争锁**,**稍微牺牲了公平性,但获得了高吞吐量**。在线程冲突较少的情况下,可以获得和CAS类似的性能;而线程冲突严重的情况下,性能远高于CAS。
-
-## 公众号
-
-如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
-
-**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"面试突击"** 即可免费领取!
-
-**Java工程师必备学习资源:** 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
-
-
-
-
-
-
-
-
-
-
-
-
-
-
diff --git "a/docs/golang/\351\235\242\350\257\225\351\242\230/golang\351\235\242\350\257\225\351\242\230\346\225\264\347\220\206-\345\276\256\344\277\241\345\256\214\346\225\264.md" "b/docs/golang/\351\235\242\350\257\225\351\242\230/golang\351\235\242\350\257\225\351\242\230\346\225\264\347\220\206-\345\276\256\344\277\241\345\256\214\346\225\264.md"
new file mode 100644
index 0000000..e65120c
--- /dev/null
+++ "b/docs/golang/\351\235\242\350\257\225\351\242\230/golang\351\235\242\350\257\225\351\242\230\346\225\264\347\220\206-\345\276\256\344\277\241\345\256\214\346\225\264.md"
@@ -0,0 +1,836 @@
+> ❝
+>
+> 原文: https://zhuanlan.zhihu.com/p/519979757,作者:沪猿小韩。为适于阅读,部分样式及内容有做简单修改。
+>
+> ❞
+
+# 前言
+
+文章部分题目来源于网络,答案系个人结合5月份面试了近30家公司整理所得,最后附录参考原文链接,如有遗漏的原文出处请联系本人。不对之处望批评指正,答案需要加上自己的思考,最好是代码实践下。
+
+参与过面试的企业有:zg人寿,睿科lun,qi猫,yun汉商城,zi节跳动,特斯la,虾P,chuan音,qi安信,ai立信等大大小小企业近30家,BAT简历都过不了。
+
+## 面试建议
+
+### 技术部分
+
+1)算法部分,刷LeetCode就完事了,这是一个长期的过程,短期突击没啥效果,因为题目太多了。
+
+2)语言基础,细分为:
+
+* golang基础及原理,就是本文主要内容了;
+* mysql基础及原理;
+* redis基础及原理;
+* kafka或其他消息中间件(如果没用过,需要了解大概的底层原理及结构);
+* linux常用的命令,比如定时脚本几个参数时间分别代表啥,文件权限需要搞清楚,进程内存占用命令;小公司还要懂一些前端的知识,因为他们希望你什么都会。
+
+3)项目经验,可以搞一个基于gin的后端接口服务的web框架,一般会问你怎么实现的;以及微服务了解一下。
+
+### 非技术部分
+
+1)因为上海5月份居家办公,远程面试,这些题目准备一份,遇到卡壳的题目完全可以参考你准备好的答案,因为视频面试你眼睛是看着面试官还是题目是不太容易区分的(把题目窗口置顶)。
+
+2)HR面也可以完全准备一份可能问到的问题的答案,并不是说你不会回答,而是会让你的表达更顺畅,其次也说明你是有备而来的,我在某拉公司面试就吃了这个亏,技术通过,HR说我的表达能力不行(后续我也会把这个模板分享出来,感谢我媳妇充当面试官,以及指导如何高情商的回答HR的问题)。
+
+3)可以自己录音面试回答,看看自己的语气、音量,顺畅度,如果自己听了都不舒服,面试官可能也不舒服。
+
+## 一、基础部分
+
+#### 1、golang 中 make 和 new 的区别?(基本必问)
+
+共同点:给变量分配内存
+
+不同点:
+
+* 作用变量类型不同,new给string,int和数组分配内存,make给切片,map,channel分配内存;
+
+* 返回类型不一样,new返回指向变量的指针,make返回变量本身;
+
+* new 分配的空间被清零。make 分配空间后,会进行初始化;
+
+* 字节的面试官还说了另外一个区别,就是分配的位置,在堆上还是在栈上?这块我比较模糊,大家可以自己探究下,我搜索出来的答案是golang会弱化分配的位置的概念,因为编译的时候会自动内存逃逸处理,懂的大佬帮忙补充下:make、new内存分配是在堆上还是在栈上?
+
+#### string 底层数据结构
+
+```go
+// from: string.go 在GoLand IDE中双击shift快速找到
+type stringStruct struct {
+ array unsafe.Pointer // 指向一个 [len]byte 的数组
+ length int // 长度
+}
+```
+
+#### []string 和 []byte 的区别
+
+string
+
+1 .是一个指针,指向某个数组的首地址
+[]byte
+
+1 .是一个切片slice。一个封装了数组的结构体
+2 .slice结构
+```go
+type slice struct {
+ array unsafe.Pointer
+ len int
+ cap int
+```
+使用场景
+
+1 .想要在本身原地修改,就只能使用[]byte
+2 .string不能为nil,想要返回nil表达特殊含义,只能使用[]byte
+3 .string可以直接比较,而[]byte不可以,所以[]byte不可以当map的key值。
+4 .因为无法修改string中的某个字符,需要粒度小到操作一个字符时,用[]byte
+5 .[]byte切片这么灵活,想要用切片的特性就用[]byte
+6 .需要大量字符串处理的时候用[]byte,性能好很多
+区别
+
+1 .string的指针指向的内容是不可以改变的,所以每次更改一次字符串,都需要重新分配内存。之前的内存还需要GC收回,这是导致string效率底下的根本原因
+2 .如果我们保存的字符在 ASCII 表的,比如[0-1, a-z,A-Z..]直接可以保存到 byte
+3 .如果我们保存的字符对应码值大于 255,这时我们可以考虑使用 int 类型保存
+
+#### 2、数组和切片的区别 (基本必问)
+
+相同点:
+
+* 只能存储一组相同类型的数据结构
+
+* 都是通过下标来访问,并且有容量长度,长度通过 len 获取,容量通过 cap 获取
+
+区别:
+
+* 数组是定长,访问和复制不能超过数组定义的长度,否则就会下标越界,切片长度和容量可以自动扩容
+
+* 数组是值类型,切片是引用类型,每个切片都引用了一个底层数组,切片本身不能存储任何数据,都是这底层数组存储数据,所以修改切片的时候修改的是底层数组中的数据。切片一旦扩容,指向一个新的底层数组,内存地址也就随之改变
+
+简洁的回答:
+
+1)定义方式不一样 2)初始化方式不一样,数组需要指定大小,大小不改变 3)函数的传递方式不一样,数组传递的是值,切片传的是地址。
+
+数组的定义
+
+```go
+var a1 [3]int
+
+var a2 [...]int{1,2,3}
+```
+
+切片的定义
+
+```go
+var a1 []int
+
+var a2 :=make([]int,3,5)
+```
+
+数组的初始化
+
+```go
+a1 := [...]int{1,2,3}
+
+a2 := [5]int{1,2,3}
+```
+
+切片的初始化
+
+```go
+b:= make([]int,3,5)
+```
+#### 3、for range 的时候它的地址会发生变化么?
+
+答:在 `for a,b := range c` 遍历中, a 和 b 在内存中只会存在一份,即之后每次循环时遍历到的数据都是以值覆盖的方式赋给 a 和 b,a,b 的内存地址始终不变。由于有这个特性,**「for 循环里面如果开协程,不要直接把 a 或者 b 的地址传给协程」**。解决办法:在每次循环时,创建一个临时变量。
+
+#### 4、go defer,多个 defer 的顺序,defer 在什么时机会修改返回值?
+
+作用:defer延迟函数,释放资源,收尾工作;如释放锁,关闭文件,关闭链接;捕获panic;
+
+避坑指南:defer函数紧跟在资源打开后面,否则defer可能得不到执行,导致内存泄露。
+
+多个 defer 调用顺序是 LIFO(后入先出),defer后的操作可以理解为压入栈中
+
+解析:函数的 return 语句并不是原子级的,实际上 return 语句只代理汇编指令 ret。defer 语句是在返回前执行,所以返回过程是:「设置返回值—>执行defer—>ret」。defer可以修改函数最终返回值,修改时机:有名返回值或者函数返回指针 参考:[Go高阶指南07,一文搞懂 defer 实现原理)](https://mp.weixin.qq.com/s?__biz=Mzk0NzI3Mjk1Mg==&mid=2247484683&idx=1&sn=262b205caeef06489e5ac8cf84d44112&chksm=c378289cf40fa18aef1d26e1437232b6b20a2f1f7129951d3b094eefa04007ee3fcd0af4655f&token=1319045915&lang=zh_CN&scene=21#wechat_redirect)
+
+有名返回值
+
+```go
+func b() (i int) {
+ defer func() {
+ i++
+ fmt.Println("defer2:", i)
+ }()
+ defer func() {
+ i++
+ fmt.Println("defer1:", i)
+ }()
+ return i //或者直接写成return
+}
+func main() {
+ fmt.Println("return:", b())
+}
+
+//运行结果:
+//defer1: 1
+//defer2: 2
+//return: 2
+```
+
+函数返回指针
+
+```go
+func c() *int {
+ var i int
+ defer func() {
+ i++
+ fmt.Println("defer2:", i)
+ }()
+ defer func() {
+ i++
+ fmt.Println("defer1:", i)
+ }()
+ return &i
+}
+func main() {
+ fmt.Println("return:", *(c()))
+}
+
+//运行结果:
+//defer1: 1
+//defer2: 2
+//return: 2
+```
+#### 5、uint 类型溢出问题
+
+超过最大存储值如uint8最大是255
+
+var a uint8 =255
+
+var b uint8 =1
+
+a+b = 0总之类型溢出会出现难以意料的事
+
+
+#### 6、能介绍下 rune 类型吗?
+
+相当int32
+
+golang中的字符串底层实现是通过byte数组的,中文字符在unicode下占2个字节,在utf-8编码下占3个字节,而golang默认编码正好是utf-8
+
+byte 等同于int8,常用来处理ascii字符
+
+rune 等同于int32,常用来处理unicode或utf-8字符
+
+
+#### 7、 golang 中解析 tag 是怎么实现的?反射原理是什么?(中高级肯定会问,比较难,需要自己多去总结)
+
+参考如下连接golang中struct关于反射tag (https://blog.csdn.net/paladinosment/article/details/42570937)
+
+```go
+type User struct {
+ name string `json:name-field`
+ age int
+}
+func main() {
+ user := &User{"John Doe The Fourth", 20}
+
+ field, ok := reflect.TypeOf(user).Elem().FieldByName("name")
+ if !ok {
+ panic("Field not found")
+ }
+ fmt.Println(getStructTag(field))
+}
+
+func getStructTag(f reflect.StructField) string {
+ return string(f.Tag)
+}
+```
+
+o 中解析的 tag 是通过反射实现的,反射是指计算机程序在运行时(Run time)可以访问、检测和修改它本身状态或行为的一种能力或动态知道给定数据对象的类型和结构,并有机会修改它。反射将接口变量转换成反射对象 Type 和 Value;反射可以通过反射对象 Value 还原成原先的接口变量;反射可以用来修改一个变量的值,前提是这个值可以被修改;tag是啥:结构体支持标记,name string `json:name-field` 就是 `json:name-field` 这部分
+
+gorm json yaml gRPC protobuf gin.Bind()都是通过反射来实现的
+
+#### 8、调用函数传入结构体时,应该传值还是指针?(Golang 都是传值)
+
+Go 的函数参数传递都是值传递。所谓值传递:指在调用函数时将实际参数复制一份传递到函数中,这样在函数中如果对参数进行修改,将不会影响到实际参数。参数传递还有引用传递,所谓引用传递是指在调用函数时将实际参数的地址传递到函数中,那么在函数中对参数所进行的修改,将影响到实际参数
+
+因为 Go 里面的 map,slice,chan 是引用类型。变量区分值类型和引用类型。
+所谓值类型:变量和变量的值存在同一个位置。
+所谓引用类型:变量和变量的值是不同的位置,变量的值存储的是对值的引用。
+但并不是 map,slice,chan 的所有的变量在函数内都能被修改,不同数据类型的底层存储结构和实现可能不太一样,情况也就不一样。
+
+#### 9、讲讲 Go 的 slice 底层数据结构和一些特性?
+
+答:Go 的 slice 底层数据结构是由一个 array 指针指向底层数组,len 表示切片长度,cap 表示切片容量。slice 的主要实现是扩容。对于 append 向 slice 添加元素时,假如 slice 容量够用,则追加新元素进去,slice.len++,返回原来的 slice。当原容量不够,则 slice 先扩容,扩容之后 slice 得到新的 slice,将元素追加进新的 slice,slice.len++,返回新的 slice。对于切片的扩容规则:当切片比较小时(容量小于 1024),则采用较大的扩容倍速进行扩容(新的扩容会是原来的 2 倍),避免频繁扩容,从而减少内存分配的次数和数据拷贝的代价。当切片较大的时(原来的 slice 的容量大于或者等于 1024),采用较小的扩容倍速(新的扩容将扩大大于或者等于原来 1.25 倍),主要避免空间浪费,网上其实很多总结的是 1.25 倍,那是在不考虑内存对齐的情况下,实际上还要考虑内存对齐,扩容是大于或者等于 1.25 倍。
+
+(关于刚才问的 slice 为什么传到函数内可能被修改,如果 slice 在函数内没有出现扩容,函数外和函数内 slice 变量指向是同一个数组,则函数内复制的 slice 变量值出现更改,函数外这个 slice 变量值也会被修改。如果 slice 在函数内出现扩容,则函数内变量的值会新生成一个数组(也就是新的 slice,而函数外的 slice 指向的还是原来的 slice,则函数内的修改不会影响函数外的 slice。)
+
+#### 10、讲讲 Go 的 select 底层数据结构和一些特性?(难点,没有项目经常可能说不清,面试一般会问你项目中怎么使用select)
+
+答:go 的 select 为 golang 提供了多路 IO 复用机制,和其他 IO 复用一样,用于检测是否有读写事件是否 ready。linux 的系统 IO 模型有 select,poll,epoll,go 的 select 和 linux 系统 select 非常相似。
+
+select 结构组成主要是由 case 语句和执行的函数组成 select 实现的多路复用是:每个线程或者进程都先到注册和接受的 channel(装置)注册,然后阻塞,然后只有一个线程在运输,当注册的线程和进程准备好数据后,装置会根据注册的信息得到相应的数据。
+
+select 的特性
+
+* select 操作至少要有一个 case 语句,出现读写 nil 的 channel 该分支会忽略,在 nil 的 channel 上操作则会报错。
+* select 仅支持管道,而且是单协程操作。
+* 每个 case 语句仅能处理一个管道,要么读要么写。
+* 多个 case 语句的执行顺序是随机的。
+* 存在 default 语句,select 将不会阻塞,但是存在 default 会影响性能。
+
+- select 和 channel 的使用场景:https://blog.csdn.net/u011240877/article/details/123611525
+
+#### 11、讲讲 Go 的 defer 底层数据结构和一些特性?
+
+答:每个 defer 语句都对应一个_defer 实例,多个实例使用指针连接起来形成一个单连表,保存在 gotoutine 数据结构中,每次插入_defer 实例,均插入到链表的头部,函数结束再一次从头部取出,从而形成后进先出的效果。
+
+defer 的规则总结:
+
+* 延迟函数的参数是 defer 语句出现的时候就已经确定了的。
+* 延迟函数执行按照后进先出的顺序执行,即先出现的 defer 最后执行。
+* 延迟函数可能操作主函数的返回值。
+* 申请资源后立即使用 defer 关闭资源是个好习惯。
+
+#### 12、单引号,双引号,反引号的区别?
+
+单引号,表示byte类型或rune类型,对应 uint8和int32类型,默认是 rune 类型。byte用来强调数据是raw data,而不是数字;而rune用来表示Unicode的code point。
+
+双引号,才是字符串,实际上是字符数组。可以用索引号访问某字节,也可以用len()函数来获取字符串所占的字节长度。
+
+反引号,表示字符串字面量,但不支持任何转义序列。字面量 raw literal string 的意思是,你定义时写的啥样,它就啥样,你有换行,它就换行。你写转义字符,它也就展示转义字符。
+
+# 二、map相关
+
+#### 1、map 使用注意的点,是否并发安全?
+
+map的类型是map[key],key类型的ke必须是可比较的,通常情况,会选择内建的基本类型,比如整数、字符串做key的类型。如果要使用struct作为key,要保证struct对象在逻辑上是不可变的。在Go语言中,map[key]函数返回结果可以是一个值,也可以是两个值。map是无序的,如果我们想要保证遍历map时元素有序,可以使用辅助的数据结构,例如orderedmap。
+
+第一,一定要先初始化,否则panic
+
+第二,map类型是容易发生并发访问问题的。不注意就容易发生程序运行时并发读写导致的panic。Go语言内建的map对象不是线程安全的,并发读写的时候运行时会有检查,遇到并发问题就会导致panic。
+
+#### 2、map 循环是有序的还是无序的?
+
+无序的, map 因扩张⽽重新哈希时,各键值项存储位置都可能会发生改变,顺序自然也没法保证了,所以官方避免大家依赖顺序,直接打乱处理。就是 for range map 在开始处理循环逻辑的时候,就做了随机播种
+
+#### 3、 map 中删除一个 key,它的内存会释放么?(常问)
+
+如果删除的元素是值类型,如int,float,bool,string以及数组和struct,map的内存不会自动释放
+
+如果删除的元素是引用类型,如指针,slice,map,chan等,map的内存会自动释放,但释放的内存是子元素应用类型的内存占用
+
+将map设置为nil后,内存被回收。
+
+这个问题还需要大家去搜索下答案,我记得有不一样的说法,谨慎采用本题答案。
+
+#### 4、怎么处理对 map 进行并发访问?有没有其他方案?区别是什么?
+
+方式一、使用内置sync.Map,详细参考#### golang sync.map 原理和使用 #### (https://yebd1h.smartapps.cn/pages/blog/index?_swebFromHost=baiduboxapp&blogId=114628932&_swebfr=1)
+
+方式二、使用读写锁实现并发安全mapgolang线程安全map (https://yebd1h.smartapps.cn/pages/blog/index?_swebFromHost=baiduboxapp&blogId=123259483&_swebfr=1)
+
+#### 5、 nil map 和空 map 有何不同?
+
+1. 可以对未初始化的map进行取值,但取出来的东西是空:
+
+```go
+var m1 map[string]string
+
+fmt.Println(m1["1"])
+```
+
+1. 不能对未初始化的map进行赋值,这样将会抛出一个异常:
+
+```go
+var m1 map[string]string
+
+m1["1"] = "1"
+
+panic: assignment to entry in nil map
+```
+
+1. 通过fmt打印map时,空map和nil map结果是一样的,都为map[]。所以,这个时候别断定map是空还是nil,而应该通过map == nil来判断。
+ nil map 未初始化,空map是长度为空
+
+#### 6、map 的数据结构是什么?是怎么实现扩容?
+
+答:golang 中 map 是一个 kv 对集合。底层使用 hash table,用链表来解决冲突 ,出现冲突时,不是每一个 key 都申请一个结构通过链表串起来,而是以 bmap 为最小粒度挂载,一个 bmap 可以放 8 个 kv。在哈希函数的选择上,会在程序启动时,检测 cpu 是否支持 aes,如果支持,则使用 aes hash,否则使用 memhash。每个 map 的底层结构是 hmap,是有若干个结构为 bmap 的 bucket 组成的数组。每个 bucket 底层都采用链表结构。
+
+hmap 的结构如下:
+
+```go
+type hmap struct {
+ count int // 元素个数
+ flags uint8
+ B uint8 // 扩容常量相关字段B是buckets数组的长度的对数 2^B
+ noverflow uint16 // 溢出的bucket个数
+ hash0 uint32 // hash seed
+ buckets unsafe.Pointer // buckets 数组指针
+ oldbuckets unsafe.Pointer // 结构扩容的时候用于赋值的buckets数组
+ nevacuate uintptr // 搬迁进度
+ extra *mapextra // 用于扩容的指针
+}
+```
+
+map 的容量大小
+
+底层调用 makemap 函数,计算得到合适的 B,map 容量最多可容纳 6.52^B 个元素,6.5 为装载因子阈值常量。装载因子的计算公式是:装载因子=填入表中的元素个数/散列表的长度,装载因子越大,说明空闲位置越少,冲突越多,散列表的性能会下降。底层调用 makemap 函数,计算得到合适的 B,map 容量最多可容纳 6.52^B 个元素,6.5 为装载因子阈值常量。装载因子的计算公式是:装载因子=填入表中的元素个数/散列表的长度,装载因子越大,说明空闲位置越少,冲突越多,散列表的性能会下降。
+
+触发 map 扩容的条件
+
+* 装载因子超过阈值,源码里定义的阈值是 6.5。
+* overflow 的 bucket 数量过多 map 的 bucket 定位和 key 的定位高八位用于定位 bucket,低八位用于定位 key,快速试错后再进行完整对比。
+
+#### 7、slices能作为map类型的key吗?
+
+当时被问得一脸懵逼,其实是这个问题的变种:golang 哪些类型可以作为map key?
+
+答案是:在golang规范中,可比较的类型都可以作为map key;这个问题又延伸到在:golang规范中,哪些数据类型可以比较?
+
+不能作为map key 的类型包括:
+
+slices maps functions
+
+# 三、context相关
+
+#### 1、context 结构是什么样的?context 使用场景和用途?
+
+(难,也常常问你项目中怎么用,光靠记答案很难让面试官满意,反正有各种结合实际的问题)
+
+参考链接:go context详解 (https://www.cnblogs.com/juanmaofeifei/p/14439957.html)
+
+答:Go 的 Context 的数据结构包含 Deadline,Done,Err,Value,Deadline 方法返回一个 time.Time,表示当前 Context 应该结束的时间,ok 则表示有结束时间,Done 方法当 Context 被取消或者超时时候返回的一个 close 的 channel,告诉给 context 相关的函数要停止当前工作然后返回了,Err 表示 context 被取消的原因,Value 方法表示 context 实现共享数据存储的地方,是协程安全的。context 在业务中是经常被使用的,
+
+其主要的应用 :
+
+1:上下文控制,2:多个 goroutine 之间的数据交互等,3:超时控制:到某个时间点超时,过多久超时。
+
+# 四、channel相关
+
+#### 1、channel 是否线程安全?锁用在什么地方?
+
+
+
+#### 2、go channel 的底层实现原理 (数据结构)
+
+
+
+底层结构需要描述出来,这个简单,buf,发送队列,接收队列,lock。
+
+#### 3、nil、关闭的 channel、有数据的 channel,再进行读、写、关闭会怎么样?(各类变种题型,重要)
+
+
+
+还要去了解一下单向channel,如只读或者只写通道常见的异常问题,这块还需要大家自己总结总结,有懂的大佬也可以评论发送答案。
+
+#### 4、向 channel 发送数据和从 channel 读数据的流程是什么样的?
+
+发送流程:
+
+
+
+接收流程:
+
+这个没啥好说的,底层原理,1、2、3描述出来,保证面试官满意。具体的文字描述下面一题有,channel的概念多且复杂,脑海中有个总分的概念,否则你说的再多,面试官也抓不住你说的重点,等于白说。问题5已经为大家总结好了。
+
+#### 5、讲讲 Go 的 chan 底层数据结构和主要使用场景
+
+答:channel 的数据结构包含 qccount 当前队列中剩余元素个数,dataqsiz 环形队列长度,即可以存放的元素个数,buf 环形队列指针,elemsize 每个元素的大小,closed 标识关闭状态,elemtype 元素类型,sendx 队列下表,指示元素写入时存放到队列中的位置,recv 队列下表,指示元素从队列的该位置读出。recvq 等待读消息的 goroutine 队列,sendq 等待写消息的 goroutine 队列,lock 互斥锁,chan 不允许并发读写。
+
+无缓冲和有缓冲区别:管道没有缓冲区,从管道读数据会阻塞,直到有协程向管道中写入数据。同样,向管道写入数据也会阻塞,直到有协程从管道读取数据。管道有缓冲区但缓冲区没有数据,从管道读取数据也会阻塞,直到协程写入数据,如果管道满了,写数据也会阻塞,直到协程从缓冲区读取数据。
+
+channel 的一些特点 1)、读写值 nil 管道会永久阻塞 2)、关闭的管道读数据仍然可以读数据 3)、往关闭的管道写数据会 panic 4)、关闭为 nil 的管道 panic 5)、关闭已经关闭的管道 panic
+
+向 channel 写数据的流程:如果等待接收队列 recvq 不为空,说明缓冲区中没有数据或者没有缓冲区,此时直接从 recvq 取出 G,并把数据写入,最后把该 G 唤醒,结束发送过程;如果缓冲区中有空余位置,将数据写入缓冲区,结束发送过程;如果缓冲区中没有空余位置,将待发送数据写入 G,将当前 G 加入 sendq,进入睡眠,等待被读 goroutine 唤醒;
+
+向 channel 读数据的流程:如果等待发送队列 sendq 不为空,且没有缓冲区,直接从 sendq 中取出 G,把 G 中数据读出,最后把 G 唤醒,结束读取过程;如果等待发送队列 sendq 不为空,此时说明缓冲区已满,从缓冲区中首部读出数据,把 G 中数据写入缓冲区尾部,把 G 唤醒,结束读取过程;如果缓冲区中有数据,则从缓冲区取出数据,结束读取过程;将当前 goroutine 加入 recvq,进入睡眠,等待被写 goroutine 唤醒;
+
+使用场景:消息传递、消息过滤,信号广播,事件订阅与广播,请求、响应转发,任务分发,结果汇总,并发控制,限流,同步与异步
+
+# 五、GMP相关
+
+#### 1、什么是 GMP?(必问)
+
+答:G 代表着 goroutine,P 代表着上下文处理器,M 代表 thread 线程,在 GPM 模型,有一个全局队列(Global Queue):存放等待运行的 G,还有一个 P 的本地队列:也是存放等待运行的 G,但数量有限,不超过 256 个。GPM 的调度流程从 go func()开始创建一个 goroutine,新建的 goroutine 优先保存在 P 的本地队列中,如果 P 的本地队列已经满了,则会保存到全局队列中。M 会从 P 的队列中取一个可执行状态的 G 来执行,如果 P 的本地队列为空,就会从其他的 MP 组合偷取一个可执行的 G 来执行,当 M 执行某一个 G 时候发生系统调用或者阻塞,M 阻塞,如果这个时候 G 在执行,runtime 会把这个线程 M 从 P 中摘除,然后创建一个新的操作系统线程来服务于这个 P,当 M 系统调用结束时,这个 G 会尝试获取一个空闲的 P 来执行,并放入到这个 P 的本地队列,如果这个线程 M 变成休眠状态,加入到空闲线程中,然后整个 G 就会被放入到全局队列中。
+
+关于 G,P,M 的个数问题,G 的个数理论上是无限制的,但是受内存限制,P 的数量一般建议是逻辑 CPU 数量的 2 倍,M 的数据默认启动的时候是 10000,内核很难支持这么多线程数,所以整个限制客户忽略,M 一般不做设置,设置好 P,M 一般都是要大于 P。
+
+#### 2、进程、线程、协程有什么区别?(必问)
+
+进程:是应用程序的启动实例,每个进程都有独立的内存空间,不同的进程通过进程间的通信方式来通信。
+
+线程:从属于进程,每个进程至少包含一个线程,线程是 CPU 调度的基本单位,多个线程之间可以共享进程的资源并通过共享内存等线程间的通信方式来通信。
+
+协程:为轻量级线程,与线程相比,协程不受操作系统的调度,协程的调度器由用户应用程序提供,协程调度器按照调度策略把协程调度到线程中运行
+
+#### 3、抢占式调度是如何抢占的?
+
+基于协作式抢占
+
+基于信号量抢占
+
+就像操作系统要负责线程的调度一样,Go的runtime要负责goroutine的调度。现代操作系统调度线程都是抢占式的,我们不能依赖用户代码主动让出CPU,或者因为IO、锁等待而让出,这样会造成调度的不公平。基于经典的时间片算法,当线程的时间片用完之后,会被时钟中断给打断,调度器会将当前线程的执行上下文进行保存,然后恢复下一个线程的上下文,分配新的时间片令其开始执行。这种抢占对于线程本身是无感知的,系统底层支持,不需要开发人员特殊处理。
+
+基于时间片的抢占式调度有个明显的优点,能够避免CPU资源持续被少数线程占用,从而使其他线程长时间处于饥饿状态。goroutine的调度器也用到了时间片算法,但是和操作系统的线程调度还是有些区别的,因为整个Go程序都是运行在用户态的,所以不能像操作系统那样利用时钟中断来打断运行中的goroutine。也得益于完全在用户态实现,goroutine的调度切换更加轻量。
+
+上面这两段文字只是对调度的一个概括,具体的协作式调度、信号量调度大家还需要去详细了解,这偏底层了,大厂或者中高级开发会问。(字节就问了)
+
+#### 4、M 和 P 的数量问题?
+
+p默认cpu内核数
+
+M与P的数量没有绝对关系,一个M阻塞,P就会去创建或者切换另一个M,所以,即使P的默认数量是1,也有可能会创建很多个M出来
+
+【Go语言调度模型G、M、P的数量多少合适?】
+
+详细参考这篇文章Go语言调度模型G、M、P的数量多少合适? (https://zoyi14.smartapps.cn/pages/note/index?_swebFromHost=baiduboxapp&origin=share&slug=1a50330adf1b&_swebfr=1)
+
+GMP数量这一块,结论很好记,没用项目经验的话,问了项目中怎么用可能容易卡壳。
+
+# 六、锁相关
+
+#### 1、除了 mutex 以外还有哪些方式安全读写共享变量?
+
+* 将共享变量的读写放到一个 goroutine 中,其它 goroutine 通过 channel 进行读写操作。
+
+* 可以用个数为 1 的信号量(semaphore)实现互斥
+
+* 通过 Mutex 锁实现
+
+#### 2、Go 如何实现原子操作?
+
+答:原子操作就是不可中断的操作,外界是看不到原子操作的中间状态,要么看到原子操作已经完成,要么看到原子操作已经结束。在某个值的原子操作执行的过程中,CPU 绝对不会再去执行其他针对该值的操作,那么其他操作也是原子操作。
+
+Go 语言的标准库代码包 sync/atomic 提供了原子的读取(Load 为前缀的函数)或写入(Store 为前缀的函数)某个值(这里细节还要多去查查资料)。
+
+原子操作与互斥锁的区别
+
+* 互斥锁是一种数据结构,用来让一个线程执行程序的关键部分,完成互斥的多个操作。
+* 原子操作是针对某个值的单个互斥操作。
+* Mutex 是悲观锁还是乐观锁?悲观锁、乐观锁是什么?
+
+悲观锁
+
+悲观锁:当要对数据库中的一条数据进行修改的时候,为了避免同时被其他人修改,最好的办法就是直接对该数据进行加锁以防止并发。这种借助数据库锁机制,在修改数据之前先锁定,再修改的方式被称之为悲观并发控制【Pessimistic Concurrency Control,缩写“PCC”,又名“悲观锁”】。
+
+乐观锁
+
+乐观锁是相对悲观锁而言的,乐观锁假设数据一般情况不会造成冲突,所以在数据进行提交更新的时候,才会正式对数据的冲突与否进行检测,如果冲突,则返回给用户异常信息,让用户决定如何去做。乐观锁适用于读多写少的场景,这样可以提高程序的吞吐量
+
+#### 4、Mutex 有几种模式?
+
+1. 正常模式
+
+当前的mutex只有一个goruntine来获取,那么没有竞争,直接返回。新的goruntine进来,如果当前mutex已经被获取了,则该goruntine进入一个先入先出的waiter队列,在mutex被释放后,waiter按照先进先出的方式获取锁。该goruntine会处于自旋状态(不挂起,继续占有cpu)。新的goruntine进来,mutex处于空闲状态,将参与竞争。新来的 goroutine 有先天的优势,它们正在 CPU 中运行,可能它们的数量还不少,所以,在高并发情况下,被唤醒的 waiter 可能比较悲剧地获取不到锁,这时,它会被插入到队列的前面。如果 waiter 获取不到锁的时间超过阈值 1 毫秒,那么,这个 Mutex 就进入到了饥饿模式。
+
+1. 饥饿模式
+
+在饥饿模式下,Mutex 的拥有者将直接把锁交给队列最前面的 waiter。新来的 goroutine 不会尝试获取锁,即使看起来锁没有被持有,它也不会去抢,也不会 spin(自旋),它会乖乖地加入到等待队列的尾部。如果拥有 Mutex 的 waiter 发现下面两种情况的其中之一,它就会把这个 Mutex 转换成正常模式:
+
+此 waiter 已经是队列中的最后一个 waiter 了,没有其它的等待锁的 goroutine 了;此 waiter 的等待时间小于 1 毫秒。
+
+#### 5、goroutine 的自旋占用资源如何解决
+
+自旋锁是指当一个线程在获取锁的时候,如果锁已经被其他线程获取,那么该线程将循环等待,然后不断地判断是否能够被成功获取,直到获取到锁才会退出循环。
+
+自旋的条件如下:
+
+* 还没自旋超过 4 次,
+* 多核处理器,
+* GOMAXPROCS > 1,
+* p 上本地 goroutine 队列为空。
+
+mutex 会让当前的 goroutine 去空转 CPU,在空转完后再次调用 CAS 方法去尝试性的占有锁资源,直到不满足自旋条件,则最终会加入到等待队列里。
+
+# 七、并发相关
+
+#### 1、怎么控制并发数?
+
+1. 有缓冲通道
+
+根据通道中没有数据时读取操作陷入阻塞和通道已满时继续写入操作陷入阻塞的特性,正好实现控制并发数量。
+
+```go
+func main() {
+ count := 10 // 最大支持并发
+ sum := 100 // 任务总数
+ wg := sync.WaitGroup{} //控制主协程等待所有子协程执行完之后再退出。
+
+ c := make(chan struct{}, count) // 控制任务并发的chan
+ defer close(c)
+
+ for i:=0; i@SpringBootApplication
+ public class Springboot0101QuickstartApplication {
+
+ public static void main(String[] args) {
+ ConfigurableApplicationContext ctx = SpringApplication.run(Springboot0101QuickstartApplication.class, args);
+ //获取bean对象
+ BookController bean = ctx.getBean(BookController.class);
+ System.out.println("bean======>" + bean);
+ }
+ }
+
+ SpringBoot的引导类是Boot工程的执行入口,运行main方法就可以启动项目
+
+ SpringBoot工程运行后初始化Spring容器,扫描引导类所在包加载bean
+
+### 1.4、内置Tomcat
+
+
+
+* Jetty比Tomcat更轻量级,可扩展性更强(相较于Tomcat),谷歌应用引擎(GAE)已经全面切换为Jetty
+
+* 内置服务器
+
+ tomcat(默认) apache出品,粉丝多,应用面广,负载了若干较重的组件
+
+ jetty 更轻量级,负载性能远不及tomcat
+
+ undertow undertow,负载性能勉强跑赢tomcat
+
+## 2、Rest风格
+
+### 2.1、什么是Rest
+
+1. 什么是 rest :
+
+ REST(Representational State Transfer)表现形式状态转换
+
+ 传统风格资源描述形式
+ http://localhost/user/getById?id=1 (得到id为1的用户)
+ http://localhost/user/saveUser (保存用户)
+
+ REST风格描述形式
+ http://localhost/user/1 (得到id为1的用户)
+ http://localhost/user (保存用户)
+
+2. 优点:
+
+ 隐藏资源的访问行为, 无法通过地址得知对资源是何种操作
+ 书写简化
+
+3. 按照REST风格访问资源时使用行为动作区分对资源进行了何种操作
+
+ GET 用来获取资源,POST 用来新建资源,PUT 用来更新资源,DELETE 用来删除资源
+
+ http://localhost/users 查询全部用户信息 GET (查询)
+ http://localhost/users/1 查询指定用户信息 GET (查询)
+ http://localhost/users 添加用户信息 POST (新增/保存)
+ http://localhost/users 修改用户信息 PUT (修改/更新)
+ http://localhost/users/1 删除用户信息 DELETE (删除)
+
+注意:
+
+上述行为是约定方式,约定不是规范,可以打破,所以称REST风格,而不是REST规范
+描述模块的名称通常使用复数,也就是加s的格式描述,表示此类资源,而非单个资源,例如: users、
+
+1. 根据REST风格对资源进行访问称为**RESTful**
+
+### 2.2、Rest入门案例
+
+步骤:
+
+①设定http请求动作(动词)
+
+使用 @RequestMapping 注解的 method 属性声明请求的方式
+
+使用 @RequestBody 注解 获取请求体内容。直接使用得到是 key=value&key=value…结构的数据。get 请求方式不适用。
+
+使用@ResponseBody 注解实现将 controller 方法返回对象转换为 json 响应给客户端。
+
+@RequestMapping(value=“/users”,method=RequestMethod.POST)
+
+
+
+②:设定请求参数(路径变量)
+
+使用`@PathVariable` 用于绑定 url 中的占位符。例如:请求 url 中 /delete/`{id}`,这个`{id}`就是 url 占位符。
+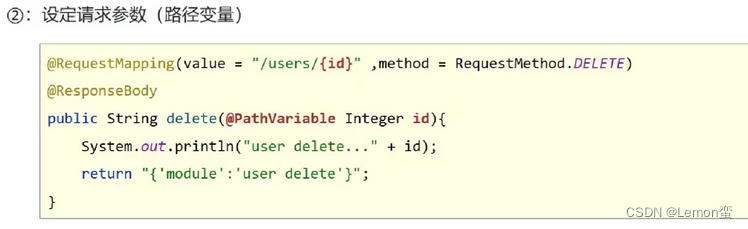
+
+@RequestMapping
+
+![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HhzZsWGO-1657811363433)(SpringBoot.assets/image-20220312164532116.png)]](https://img-blog.csdnimg.cn/7fb5465b71a346d4b2e8920493c5e36c.png)
+
+@PathVariable
+
+![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Yaepxdng-1657811363434)(SpringBoot.assets/image-20220312164552778.png)]](https://img-blog.csdnimg.cn/a9c22e3367a7480ea219baaa21de868e.png)
+
+@RequestBody @RequestParam @PathVariable
+
+
+### 2.3、Restful快速开发
+
+使用 `@RestController` 注解开发 RESTful 风格
+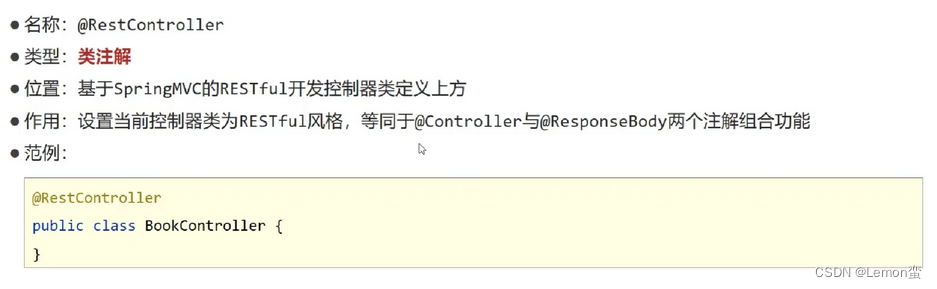
+
+使用 @GetMapping @PostMapping @PutMapping @DeleteMapping 简化 `@RequestMapping` 注解开发
+
+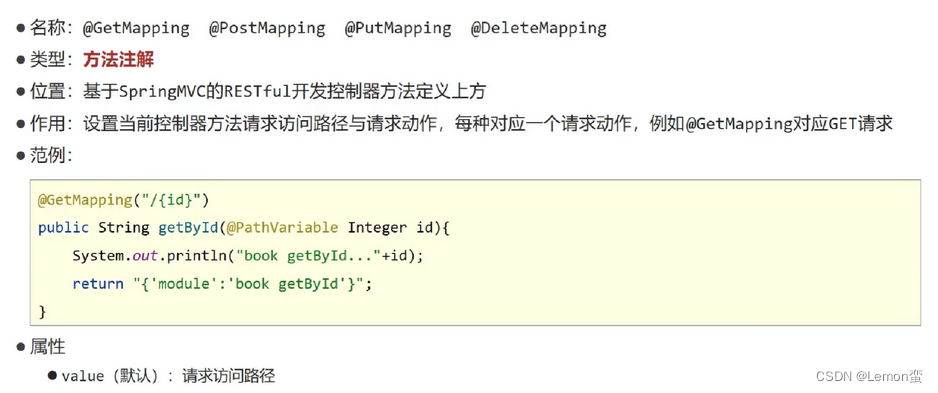
+
+### 3、配置文档
+
+### 3.1、基础配置
+
+1. 修改配置
+ 修改服务器端口
+ server.port=80
+ 关闭运行日志图标(banner)
+ spring.main.banner-mode=off
+ 设置日志相关
+ logging.level.root=debug
+
+# 服务器端口配置
+server.port=80
+
+# 修改banner
+# spring.main.banner-mode=off
+# spring.banner.image.location=logo.png
+
+# 日志
+logging.level.root=info
+
+1. SpringBoot内置属性查询
+ https://docs.spring.io/spring-boot/docs/current/reference/html/application-properties.html#application-properties
+ 官方文档中参考文档第一项:Application Propertie
+
+### 3.2、配置文件类型
+
+* 配置文件格式
+ 
+
+* SpringBoot提供了多种属性配置方式
+
+ application.properties
+
+ server.port=80
+
+ application.yml
+
+ server:
+ port: 81
+
+ application.yaml
+
+ server:
+ port: 82
+
+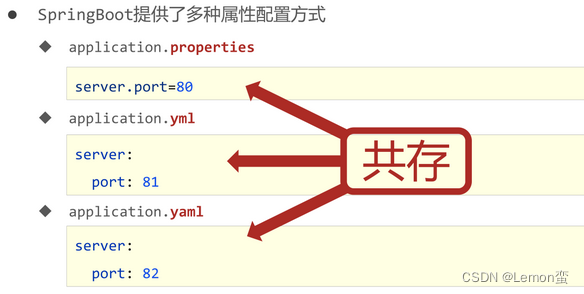
+
+### 3.3、配置文件加载优先级
+
+* SpringBoot配置文件加载顺序
+ application.properties > application.yml > application.yaml
+* 常用配置文件种类
+ application.yml
+
+### 3.4、yaml数据格式
+
+yaml
+
+YAML(YAML Ain’t Markup Language),一种数据序列化格式
+
+优点:
+ 容易阅读
+ 容易与脚本语言交互
+ 以数据为核心,重数据轻格式
+
+YAML文件扩展名
+ .yml(主流)
+ .yaml
+
+yaml语法规则
+基本语法
+
+key: value -> value 前面一定要有空格
+大小写敏感
+属性层级关系使用多行描述,每行结尾使用冒号结束
+使用缩进表示层级关系,同层级左侧对齐,只允许使用空格(不允许使用Tab键)
+属性值前面添加空格(属性名与属性值之间使用冒号+空格作为分隔)
+# 表示注释
+核心规则:数据前面要加空格与冒号隔开 server:
+ servlet:
+ context-path: /hello
+ port: 82
+### 数据类型
+
+* 字面值表示方式
+ 
+
+# 字面值表示方式
+
+boolean: TRUE #TRUE,true,True,FALSE,false , False 均可
+float: 3.14 #6.8523015e+5 # 支持科学计数法
+int: 123 #0b1010_0111_0100_1010_1110 # 支持二进制、八进制、十六进制
+# null: ~ # 使用 ~ 表示 null
+string: HelloWorld # 字符串可以直接书写
+string2: "Hello World" # 可以使用双引号包裹特殊字符
+date: 2018-02-17 # 日期必须使用 yyyy-MM-dd 格式
+datetime: 2018-02-17T15:02:31+08:00 # 时间和日期之间使用 T 连接,最后使用 + 代表时区
+
+* 数组表示方式:在属性名书写位置的下方使用减号作为数据开始符号,每行书写一个数据,减号与数据间空格分隔
+
+
+
+subject:
+ - Java
+ - 前端
+ - 大数据
+
+enterprise:
+ name: zhangsan
+ age: 16
+
+subject2:
+ - Java
+ - 前端
+ - 大数据
+likes: [王者荣耀,刺激战场] # 数组书写缩略格式
+
+users: # 对象数组格式
+ - name: Tom
+ age: 4
+
+ - name: Jerry
+ age: 5
+users2: # 对象数组格式二
+ -
+ name: Tom
+ age: 4
+ -
+ name: Jerry
+ age: 5
+
+# 对象数组缩略格式
+users3: [ { name:Tom , age:4 } , { name:Jerry , age:5 } ]
+### 3.5、读取yaml单一属性数据
+
+* 使用@Value读取单个数据,属性名引用方式:${一级属性名.二级属性名……}
+ 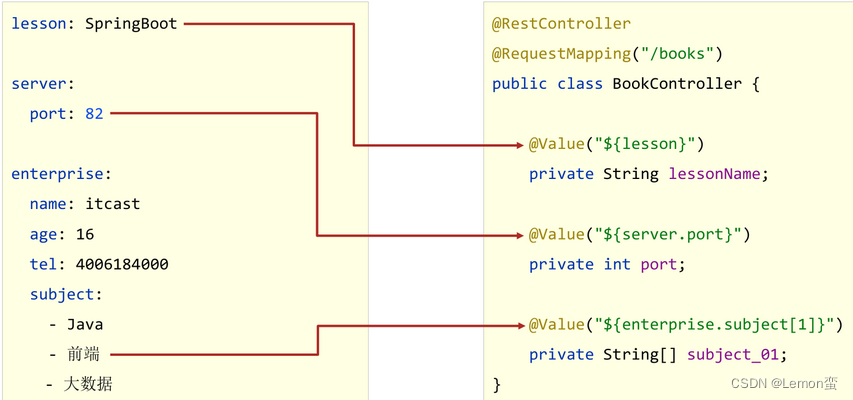
+
+ @Value("${country}")
+ private String country1;
+
+ @Value("${user.age}")
+ private String age1;
+
+ @Value("${likes[1]}")
+ private String likes1;
+
+ @Value("${users[1].name}")
+ private String name1;
+
+ @GetMapping
+ public String getById() {
+ System.out.println("springboot is running2...");
+ System.out.println("country1=>" + country1);
+ System.out.println("age1=>" + age1);
+ System.out.println("likes1=>" + likes1);
+ System.out.println("name1=>" + name1);
+ return "springboot is running2...";
+ }
+### 3.6、yaml文件中的变量应用
+
+* 在配置文件中可以使用属性名引用方式引用属性
+ 
+ 
+
+* 属性值中如果出现转移字符,需要使用双引号包裹
+
+ lesson: "Spring\tboot\nlesson"
+
+### 3.7、读取yaml全部属性数据
+
+* 封装全部数据到Environment对象
+* 注意 要导这个 包
+* **import org.springframework.core.env.Environment**
+ 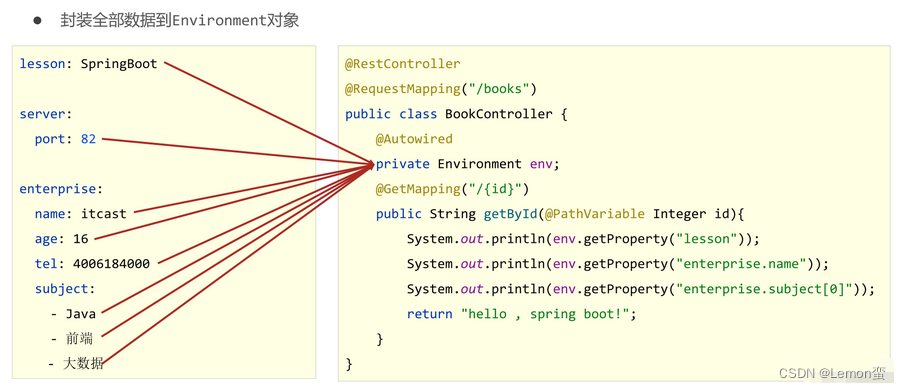
+ 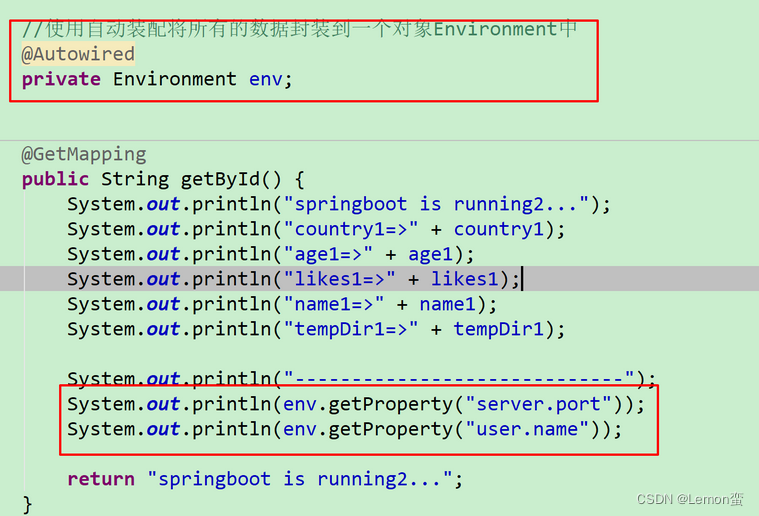
+
+### 3.8、读取yaml应用类型属性数据
+
+* 自定义对象封装指定数据
+
+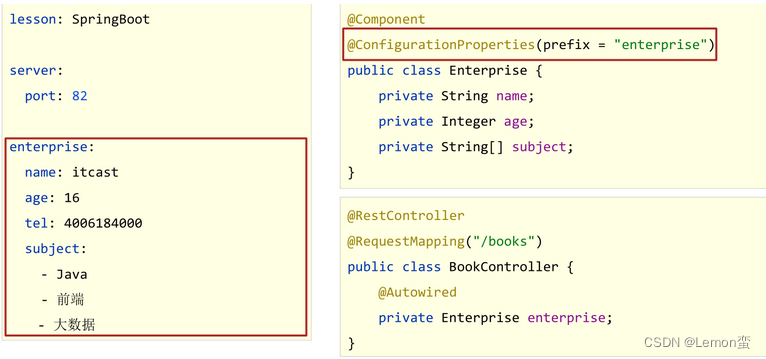
+
+* 自定义对象封装指定数据的作用
+ 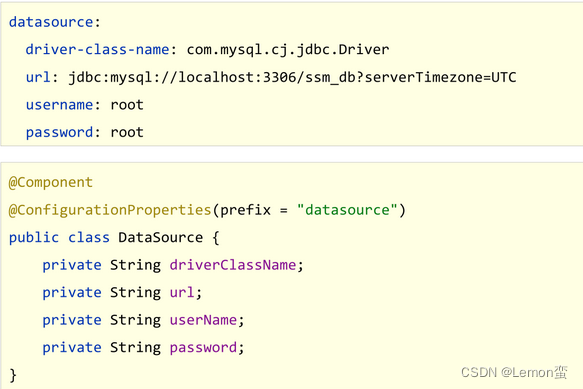
+
+# 创建类,用于封装下面的数据
+# 由spring帮我们去加载数据到对象中,一定要告诉spring加载这组信息
+# 使用时候从spring中直接获取信息使用
+
+datasource:
+ driver: com.mysql.jdbc.Driver
+ url: jdbc:mysql://localhost/springboot_db
+ username: root
+ password: root666123 //1.定义数据模型封装yaml文件中对应的数据
+//2.定义为spring管控的bean
+@Component
+//3.指定加载的数据
+@ConfigurationProperties(prefix = "datasource")
+public class MyDataSource {
+
+ private String driver;
+ private String url;
+ private String username;
+ private String password;
+
+ //省略get/set/tostring 方法
+}
+
+使用自动装配封装指定数据
+
+ @Autowired
+ private MyDataSource myDataSource;
+
+输出查看
+
+System.out.println(myDataSource);
+## 4、SpringBoot整合JUnit
+
+### 4.1、整合JUnit
+
+* 添加Junit的起步依赖 Spring Initializr 创建时自带
+
+
+
+ org.springframework.boot
+ spring-boot-starter-test
+ test
+
+* SpringBoot整合JUnit
+
+ @SpringBootTest
+ class Springboot07JunitApplicationTests {
+ @Autowired
+ private BookService bookService;
+ @Test
+ public void testSave(){
+ bookService.save();
+ }
+ }
+* @SpringBootTest
+ 名称:@SpringBootTest
+ 类型:测试类注解
+ 位置:测试类定义上方
+ 作用:设置JUnit加载的SpringBoot启动类
+ 范例:
+
+ @SpringBootTest
+ class Springboot05JUnitApplicationTests {}
+
+### 4.2、整合JUnit——classes属性
+
+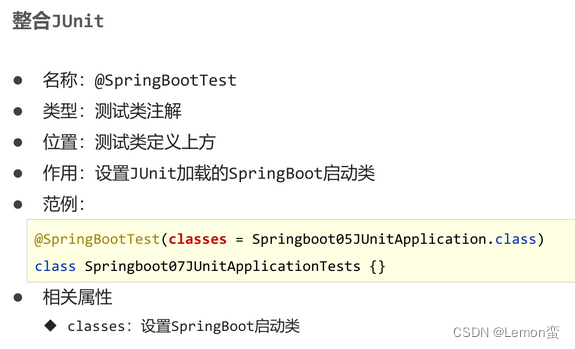
+
+@SpringBootTest(classes = Springboot04JunitApplication.class)
+//@ContextConfiguration(classes = Springboot04JunitApplication.class)
+class Springboot04JunitApplicationTests {
+ //1.注入你要测试的对象
+ @Autowired
+ private BookDao bookDao;
+
+ @Test
+ void contextLoads() {
+ //2.执行要测试的对象对应的方法
+ bookDao.save();
+ System.out.println("two...");
+ }
+}
+
+注意:
+
+* 如果测试类在SpringBoot启动类的包或子包中,可以省略启动类的设置,也就是省略classes的设定
+
+## 5、SpringBoot整合MyBatis、MyBatisPlus
+
+### 5.1、整合MyBatis
+
+①:创建新模块,选择Spring初始化,并配置模块相关基础信息
+
+②:选择当前模块需要使用的技术集(MyBatis、MySQL)
+
+③:设置数据源参数
+
+#DB Configuration:
+spring:
+ datasource:
+ driver-class-name: com.mysql.cj.jdbc.Driver
+ url: jdbc:mysql://localhost:3306/springboot_db
+ username: root
+ password: 123456
+
+④:创建user表
+在 springboot_db 数据库中创建 user 表
+
+-- ----------------------------
+-- Table structure for `user`
+-- ----------------------------
+DROP TABLE IF EXISTS `user`;
+CREATE TABLE `user` (
+ `id` int(11) NOT NULL AUTO_INCREMENT,
+ `username` varchar(50) DEFAULT NULL,
+ `password` varchar(50) DEFAULT NULL,
+ `name` varchar(50) DEFAULT NULL,
+ PRIMARY KEY (`id`)
+) ENGINE=InnoDB AUTO_INCREMENT=10 DEFAULT CHARSET=utf8;
+
+-- ----------------------------
+-- Records of user
+-- ----------------------------
+INSERT INTO `user` VALUES ('1', 'zhangsan', '123', '张三');
+INSERT INTO `user` VALUES ('2', 'lisi', '123', '李四');
+
+⑤:创建实体Bean
+
+public class User {
+ // 主键
+ private Long id;
+ // 用户名
+ private String username;
+ // 密码
+ private String password;
+ // 姓名
+ private String name;
+
+ //此处省略getter,setter,toString方法 .. ..
+
+}
+
+⑥: 定义数据层接口与映射配置
+
+@Mapper
+public interface UserDao {
+
+ @Select("select * from user")
+ public List getAll();
+}
+
+⑦:测试类中注入dao接口,测试功能
+
+@SpringBootTest
+class Springboot05MybatisApplicationTests {
+
+ @Autowired
+ private UserDao userDao;
+
+ @Test
+ void contextLoads() {
+ List userList = userDao.getAll();
+ System.out.println(userList);
+ }
+
+}
+
+⑧:运行如下
+
+[User{id=1, username='zhangsan', password='123', name='张三'}, User{id=2, username='lisi', password='123', name='李四'}]
+### 5.2、常见问题处理
+
+SpringBoot版本低于2.4.3(不含),Mysql驱动版本大于8.0时,需要在url连接串中配置时区
+
+jdbc:mysql://localhost:3306/springboot_db?serverTimezone=UTC
+
+或在MySQL数据库端配置时区解决此问题
+
+1.MySQL 8.X驱动强制要求设置时区
+
+修改url,添加serverTimezone设定
+修改MySQL数据库配置(略)
+
+2.驱动类过时,提醒更换为com.mysql.cj.jdbc.Driver
+
+### 5.3、整合MyBatisPlus
+
+①:手动添加SpringBoot整合MyBatis-Plus的坐标,可以通过mvnrepository获取
+
+
+ com.baomidou
+ mybatis-plus-boot-starter
+ 3.4.3
+ @Mapper
+public interface UserDao extends BaseMapper {
+
+}
+
+③:其他同SpringBoot整合MyBatis
+(略)
+
+④:测试类中注入dao接口,测试功能
+
+@SpringBootTest
+class Springboot06MybatisPlusApplicationTests {
+
+ @Autowired
+ private UserDao userDao;
+
+ @Test
+ void contextLoads() {
+ List users = userDao.selectList(null);
+ System.out.println(users);
+ }
+
+}
+
+⑤: 运行如下:
+
+[User{id=1, username='zhangsan', password='123', name='张三'}, User{id=2, username='lisi', password='123', name='李四'}]
+
+注意: 如果你的数据库表有前缀要在 application.yml 添加如下配制
+
+#设置Mp相关的配置
+mybatis-plus:
+ global-config:
+ db-config:
+ table-prefix: tbl_
+### 6、SpringBoot整合Druid
+
+①: 导入Druid对应的starter
+
+
+ com.alibaba
+ druid-spring-boot-starter
+ 1.2.6
+ #DB Configuration:
+spring:
+ datasource:
+ driver-class-name: com.mysql.cj.jdbc.Driver
+ url: jdbc:mysql://localhost:3306/springboot_db?serverTimezone=UTC
+ username: root
+ password: Lemon
+ type: com.alibaba.druid.pool.DruidDataSource
+
+②: 指定数据源类型 (这种方式只需导入一个 Druid 的坐标)
+
+spring:
+ datasource:
+ druid:
+ driver-class-name: com.mysql.cj.jdbc.Driver
+ url: jdbc:mysql://localhost:3306/springboot_db?serverTimezone=UTC
+ username: root
+ password: 123456
+
+或者 变更Druid的配置方式(推荐) 这种方式需要导入 Druid对应的starter
+
+## 7、SSMP
+
+### 7.1、数据配置
+
+1\. 案例实现方案分析
+ 实体类开发————使用Lombok快速制作实体类
+ Dao开发————整合MyBatisPlus,制作数据层测试类
+ Service开发————基于MyBatisPlus进行增量开发,制作业务层测试类
+ Controller开发————基于Restful开发,使用PostMan测试接口功能
+ Controller开发————前后端开发协议制作
+ 页面开发————基于VUE+ElementUI制作,前后端联调,页面数据处理,页面消息处理
+ 列表、新增、修改、删除、分页、查询
+ 项目异常处理
+ 按条件查询————页面功能调整、Controller修正功能、Service修正功能
+2\. SSMP案例制作流程解析
+ 先开发基础CRUD功能,做一层测一层
+ 调通页面,确认异步提交成功后,制作所有功能
+ 添加分页功能与查询功能 DROP TABLE IF EXISTS `tbl_book`;
+CREATE TABLE `tbl_book` (
+ `id` int(11) NOT NULL AUTO_INCREMENT,
+ `type` varchar(20) DEFAULT NULL,
+ `name` varchar(50) DEFAULT NULL,
+ `description` varchar(255) DEFAULT NULL,
+ PRIMARY KEY (`id`)
+) ENGINE=InnoDB AUTO_INCREMENT=13 DEFAULT CHARSET=utf8;
+
+-- ----------------------------
+-- Records of tbl_book
+-- ----------------------------
+INSERT INTO `tbl_book` VALUES ('1', '计算机理论', 'Spring实战第5版', 'Spring入门经典教程,深入理解Spring原理技术内幕');
+INSERT INTO `tbl_book` VALUES ('2', '计算机理论', 'Spring 5核心原理与30个类手写实战', '十年沉淀之作,写Spring精华思想');
+INSERT INTO `tbl_book` VALUES ('3', '计算机理论', 'Spring 5设计模式', '深入Spring源码剖析Spring源码中蕴含的10大设计模式');
+INSERT INTO `tbl_book` VALUES ('4', '计算机理论', 'Spring MVC+ MyBatis开发从入门到项目实战', '全方位解析面向Web应用的轻量级框架,带你成为Spring MVC开发高手');
+INSERT INTO `tbl_book` VALUES ('5', '计算机理论', '轻量级Java Web企业应用实战', '源码级剖析Spring框架,适合已掌握Java基础的读者');
+INSERT INTO `tbl_book` VALUES ('6', '计算机理论', 'Java核心技术卷|基础知识(原书第11版)', 'Core Java第11版,Jolt大奖获奖作品,针对Java SE9、10、 11全面更新');
+INSERT INTO `tbl_book` VALUES ('7', '计算机理论', '深入理解Java虚拟机', '5个维度全面剖析JVM,面试知识点全覆盖');
+INSERT INTO `tbl_book` VALUES ('8', '计算机理论', 'Java编程思想(第4版)', 'Java学习必读经典殿堂级著作!赢得了全球程序员的广泛赞誉');
+INSERT INTO `tbl_book` VALUES ('9', '计算机理论', '零基础学Java (全彩版)', '零基础自学编程的入门]图书,由浅入深,详解Java语言的编程思想和核心技术');
+INSERT INTO `tbl_book` VALUES ('10', '市场营销', '直播就该这么做:主播高效沟通实战指南', '李子柒、李佳琦、薇娅成长为网红的秘密都在书中');
+INSERT INTO `tbl_book` VALUES ('11', '市场营销', '直播销讲实战一本通', '和秋叶一起学系列网络营销书籍');
+INSERT INTO `tbl_book` VALUES ('12', '市场营销', '直播带货:淘宝、天猫直播从新手到高手', '一本教你如何玩转直播的书, 10堂课轻松实现带货月入3W+');
+
+ org.springframework.boot
+ spring-boot-starter-web
+
+
+
+ mysql
+ mysql-connector-java
+ runtime
+
+
+
+ com.baomidou
+ mybatis-plus-boot-starter
+ 3.4.3
+
+
+
+ com.alibaba
+ druid-spring-boot-starter
+ 1.2.6
+
+
+
+ org.springframework.boot
+ spring-boot-starter-test
+ test
+
+
+
+
+ org.projectlombok
+ lombok
+
+
+
+ com.baomidou
+ mybatis-plus-boot-starter
+ 3.4.3
+
+
+
+ com.alibaba
+ druid-spring-boot-starter
+ 1.2.6
+
+
+ server:
+ port: 80
+# druid 数据源配制
+spring:
+ datasource:
+ druid:
+ driver-class-name: com.mysql.cj.jdbc.Driver
+ url: jdbc:mysql://localhost:3306/springboot?serverTimezone=UTC
+ username: root
+ password: Lemon
+
+# mybatis-plus
+mybatis-plus:
+ global-config:
+ db-config:
+ table-prefix: tbl_
+ id-type: auto # 主键策略
+
+Book.class
+
+@Data
+public class Book {
+ private Integer id;
+ private String type;
+ private String name;
+ private String description;
+}
+
+BookDao.class
+
+@Mapper
+public interface BookDao extends BaseMapper {
+
+ /**
+ * 查询一个
+ * 这是 Mybatis 开发
+ * @param id
+ * @return
+ */
+ @Select("select * from tbl_book where id = #{id}")
+ Book getById(Integer id);
+}
+
+测试类
+
+@SpringBootTest
+public class BookDaoTestCase {
+
+ @Autowired
+ private BookDao bookDao;
+
+ @Test
+ void testGetById() {
+ System.out.println(bookDao.getById(1));
+ System.out.println(bookDao.selectById(1));
+ }
+
+ @Test
+ void testSave() {
+ Book book = new Book();
+ book.setType("测试数据123");
+ book.setName("测试数据123");
+ book.setDescription("测试数据123");
+ bookDao.insert(book);
+ }
+
+ @Test
+ void testUpdate() {
+ Book book = new Book();
+ book.setId(13);
+ book.setType("测试数据asfd");
+ book.setName("测试数据123");
+ book.setDescription("测试数据123");
+ bookDao.updateById(book);
+ }
+
+ @Test
+ void testDelete() {
+ bookDao.deleteById(13);
+ }
+
+ @Test
+ void testGetAll() {
+ System.out.println(bookDao.selectList(null));
+ }
+
+ @Test
+ void testGetPage() {
+ }
+
+ @Test
+ void testGetBy() {
+ }
+}
+
+开启MybatisPlus运行日志
+
+# mybatis-plus
+mybatis-plus:
+ global-config:
+ db-config:
+ table-prefix: tbl_
+ id-type: auto # 主键策略
+ configuration:
+ # 开启MyBatisPlus的日志
+ log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
+### 7.2、分页
+
+分页操作需要设定分页对象IPage
+
+@Test
+void testGetPage() {
+ IPage page = new Page(1, 5);
+ bookDao.selectPage(page, null);
+}
+
+* IPage对象中封装了分页操作中的所有数据
+
+ 数据
+
+ 当前页码值
+
+ 每页数据总量
+
+ 最大页码值
+
+ 数据总量
+
+* 分页操作是在MyBatisPlus的常规操作基础上增强得到,内部是动态的拼写SQL语句,因此需要增强对应的功能
+
+使用MyBatisPlus拦截器实现
+
+@Configuration
+public class MybatisPlusConfig {
+
+ @Bean
+ public MybatisPlusInterceptor mybatisPlusInterceptor() {
+ //1\. 定义 Mp 拦截器
+ MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
+ //2\. 添加具体的拦截器 分页拦截器
+ interceptor.addInnerInterceptor(new PaginationInnerInterceptor());
+ return interceptor;
+ }
+}
+
+测试
+
+@Test
+void testGetPage() {
+ IPage page = new Page(1, 5);
+ bookDao.selectPage(page, null);
+ System.out.println(page.getCurrent());
+ System.out.println(page.getSize());
+ System.out.println(page.getPages());
+ System.out.println(page.getTotal());
+ System.out.println(page.getRecords());
+}
+### 7.3、数据层标准开发
+
+* 使用QueryWrapper对象封装查询条件,推荐使用LambdaQueryWrapper对象,所有查询操作封装成方法调用
+
+@Test
+void testGetBy2() {
+ LambdaQueryWrapper lambdaQueryWrapper = new LambdaQueryWrapper<>();
+ lambdaQueryWrapper.like(Book::getName, "Spring");
+ bookDao.selectList(lambdaQueryWrapper);
+} @Test
+void testGetBy() {
+ QueryWrapper queryWrapper = new QueryWrapper<>();
+ queryWrapper.like("name", "Spring");
+ bookDao.selectList(queryWrapper);
+}
+
+* 支持动态拼写查询条件
+
+@Test
+void testGetBy2() {
+ String name = "1";
+ LambdaQueryWrapper lambdaQueryWrapper = new LambdaQueryWrapper<>();
+ //if (name != null) lambdaQueryWrapper.like(Book::getName,name);
+ lambdaQueryWrapper.like(Strings.isNotEmpty(name), Book::getName, name);
+ bookDao.selectList(lambdaQueryWrapper);
+}
+### 7.4、业务层标准开发(基础CRUD)
+
+* Service层接口定义与数据层接口定义具有较大区别,不要混用
+ selectByUserNameAndPassword(String username,String password); 数据层接口
+ login(String username,String password); Service层接口
+
+* 接口定义
+
+ public interface BookService {
+
+ Boolean save(Book book);
+
+ Boolean update(Book book);
+
+ Boolean delete(Integer id);
+
+ Book getById(Integer id);
+
+ List getAll();
+
+ IPage getPage(int currentPage,int pageSize);
+ }
+* 实现类定义
+
+@Service
+public class BookServiceImpl implements BookService {
+
+ @Autowired
+ private BookDao bookDao;
+
+ @Override
+ public Boolean save(Book book) {
+ return bookDao.insert(book) > 0;
+ }
+
+ @Override
+ public Boolean update(Book book) {
+ return bookDao.updateById(book) > 0;
+ }
+
+ @Override
+ public Boolean delete(Integer id) {
+ return bookDao.deleteById(id) > 0;
+ }
+
+ @Override
+ public Book getById(Integer id) {
+ return bookDao.selectById(id);
+ }
+
+ @Override
+ public List getAll() {
+ return bookDao.selectList(null);
+ }
+
+ @Override
+ public IPage getPage(int currentPage, int pageSize) {
+ IPage page = new Page(currentPage, pageSize);
+ bookDao.selectPage(page, null);
+ return page;
+ }
+}
+
+* 测试类定义
+
+@SpringBootTest
+public class BookServiceTestCase {
+
+ @Autowired
+ private BookService bookService;
+
+ @Test
+ void testGetById() {
+ System.out.println(bookService.getById(4));
+ }
+
+ @Test
+ void testSave() {
+ Book book = new Book();
+ book.setType("测试数据123");
+ book.setName("测试数据123");
+ book.setDescription("测试数据123");
+ bookService.save(book);
+ }
+
+ @Test
+ void testUpdate() {
+ Book book = new Book();
+ book.setId(14);
+ book.setType("测试数据asfd");
+ book.setName("测试数据123");
+ book.setDescription("测试数据123");
+ bookService.update(book);
+ }
+
+ @Test
+ void testDelete() {
+ bookService.delete(14);
+ }
+
+ @Test
+ void testGetAll() {
+ System.out.println(bookService.getAll());
+ }
+
+ @Test
+ void testGetPage() {
+ IPage page = bookService.getPage(2, 5);
+ System.out.println(page.getCurrent());
+ System.out.println(page.getSize());
+ System.out.println(page.getPages());
+ System.out.println(page.getTotal());
+ System.out.println(page.getRecords());
+ }
+}
+### 7.5、业务层快速开发(基于MyBatisPlus构建)
+
+* 快速开发方案
+
+ 使用MyBatisPlus提供有业务层通用接口(ISerivce)与业务层通用实现类(ServiceImplpublic interface IBookService extends IService {
+}
+
+* 接口追加功能
+
+public interface IBookService extends IService {
+
+ // 追加的操作与原始操作通过名称区分,功能类似
+ Boolean delete(Integer id);
+
+ Boolean insert(Book book);
+
+ Boolean modify(Book book);
+
+ Book get(Integer id);
+}
+
+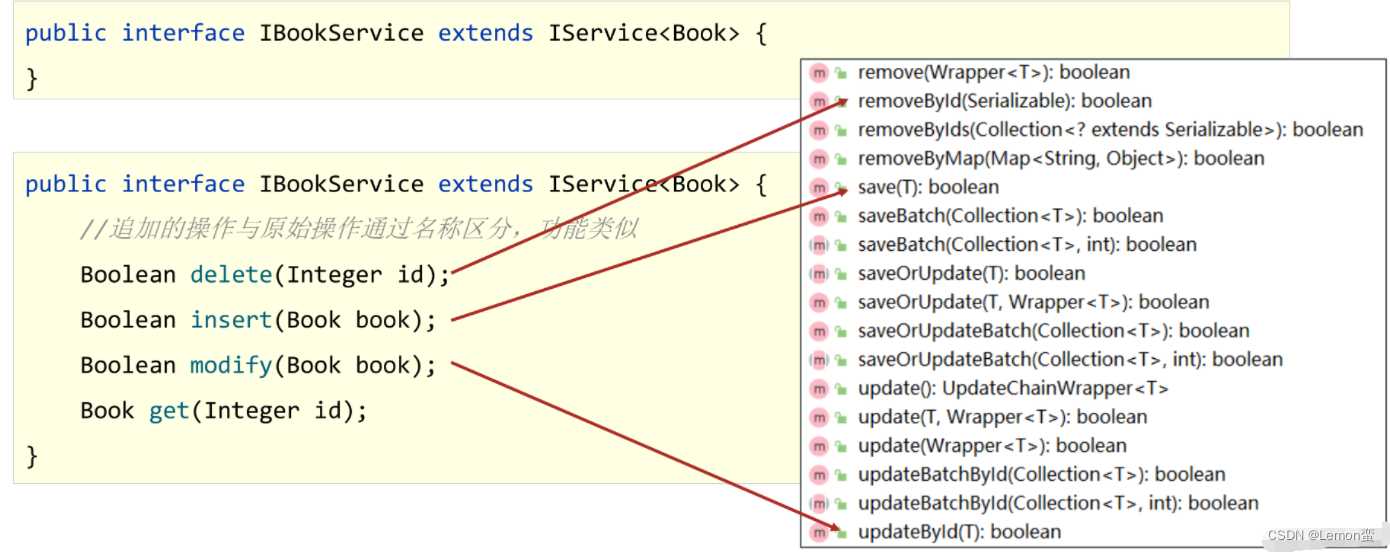
+
+* 实现类定义
+
+@Service
+public class BookServiceImpl extends ServiceImpl implements IBookService {
+}
+
+* 实现类追加功能
+
+@Service
+public class BookServiceImpl extends ServiceImpl implements IBookService {
+
+ @Autowired
+ private BookDao bookDao;
+
+ public Boolean insert(Book book) {
+ return bookDao.insert(book) > 0;
+ }
+
+ public Boolean modify(Book book) {
+ return bookDao.updateById(book) > 0;
+ }
+
+ public Boolean delete(Integer id) {
+ return bookDao.deleteById(id) > 0;
+ }
+
+ public Book get(Integer id) {
+ return bookDao.selectById(id);
+ }
+}
+
+* 测试类定义
+
+@SpringBootTest
+public class BookServiceTest {
+
+ @Autowired
+ private IBookService bookService;
+
+ @Test
+ void testGetById() {
+ System.out.println(bookService.getById(4));
+ }
+
+ @Test
+ void testSave() {
+ Book book = new Book();
+ book.setType("测试数据123");
+ book.setName("测试数据123");
+ book.setDescription("测试数据123");
+ bookService.save(book);
+ }
+
+ @Test
+ void testUpdate() {
+ Book book = new Book();
+ book.setId(14);
+ book.setType("===========");
+ book.setName("测试数据123");
+ book.setDescription("测试数据123");
+ bookService.updateById(book);
+ }
+
+ @Test
+ void testDelete() {
+ bookService.removeById(14);
+ }
+
+ @Test
+ void testGetAll() {
+ System.out.println(bookService.list());
+ }
+
+ @Test
+ void testGetPage() {
+ IPage page = new Page<>(2, 5);
+ bookService.page(page);
+ System.out.println(page.getCurrent());
+ System.out.println(page.getSize());
+ System.out.println(page.getPages());
+ System.out.println(page.getTotal());
+ System.out.println(page.getRecords());
+ }
+}
+### 7.7、表现层标准开发
+
+* 基于Restful进行表现层接口开发
+* 使用Postman测试表现层接口功能
+
+@RestController
+@RequestMapping("/books")
+public class BookController {
+
+ @Autowired
+ private IBookService bookService;
+
+ @GetMapping
+ public List getAll() {
+ return bookService.list();
+ }
+
+ @PostMapping
+ public Boolean save(@RequestBody Book book) {
+ return bookService.save(book);
+ }
+
+ @PutMapping
+ public Boolean update(@RequestBody Book book) {
+ return bookService.modify(book);
+ }
+
+ @DeleteMapping("{id}")
+ public Boolean delete(@PathVariable Integer id) {
+ return bookService.delete(id);
+ }
+
+ @GetMapping("{id}")
+ public Book getById(@PathVariable Integer id) {
+ return bookService.getById(id);
+ }
+
+ @GetMapping("{currentPage}/{pageSize}")
+ public IPage getPage(@PathVariable Integer currentPage, @PathVariable int pageSize) {
+ return bookService.getPage(currentPage, pageSize);
+ }
+
+}
+
+添加 分页的业务层方法
+
+IBookService
+
+ IPage getPage(int currentPage,int pageSize);
+
+BookServiceImpl
+
+@Override
+public IPage getPage(int currentPage, int pageSize) {
+
+ IPage page = new Page(currentPage, pageSize);
+ bookDao.selectPage(page, null);
+
+ return page;
+}
+
+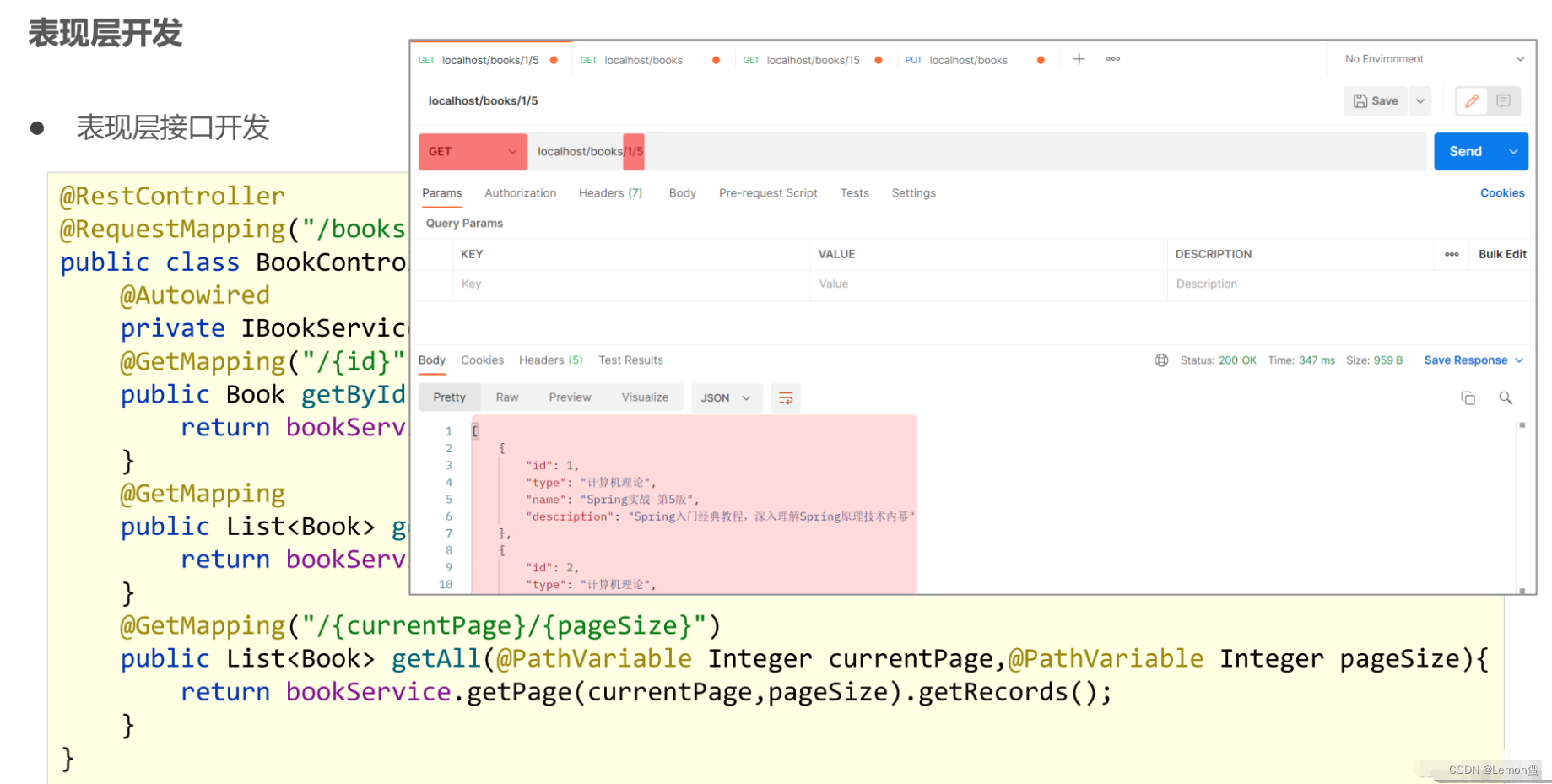
+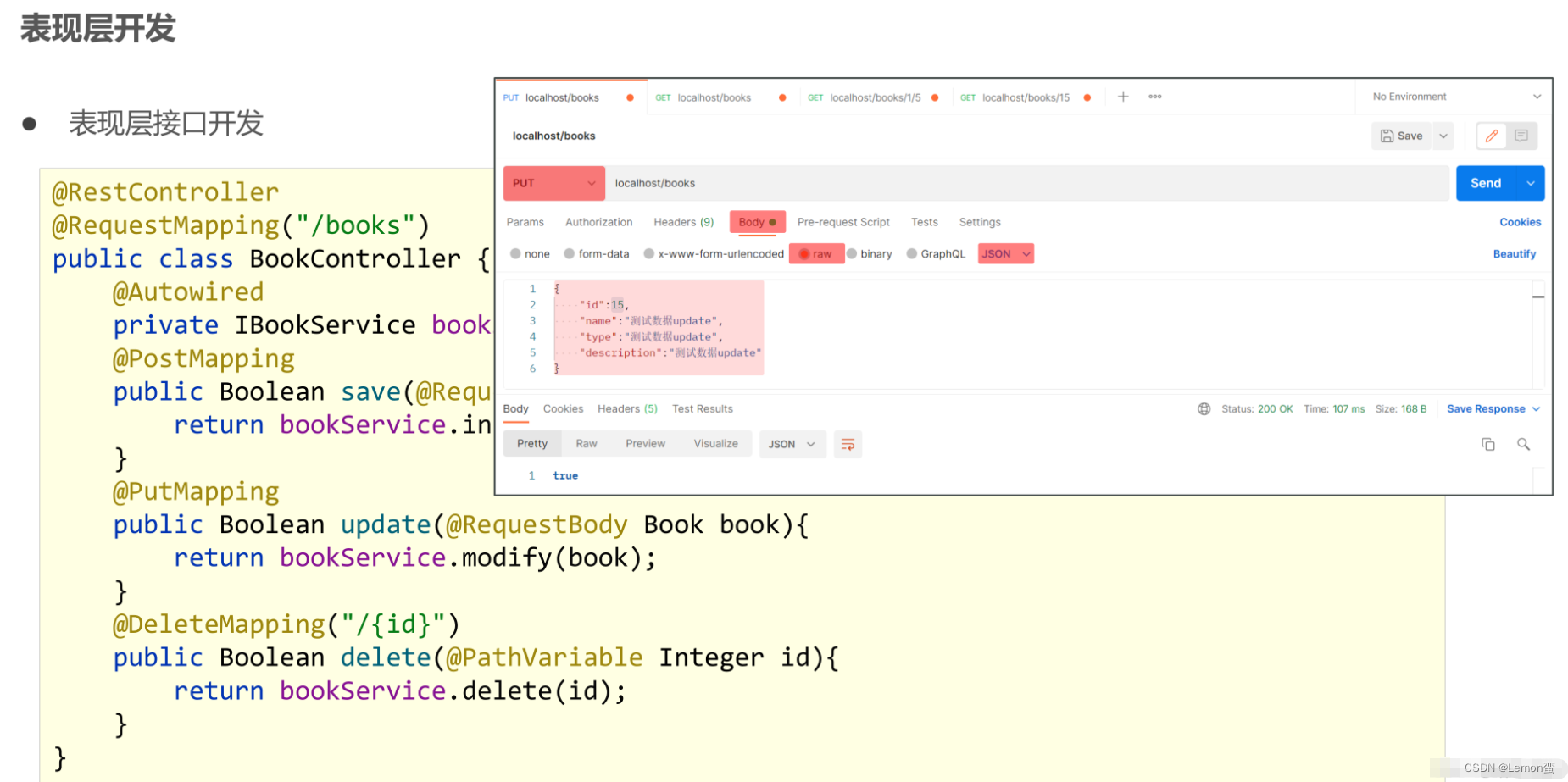
+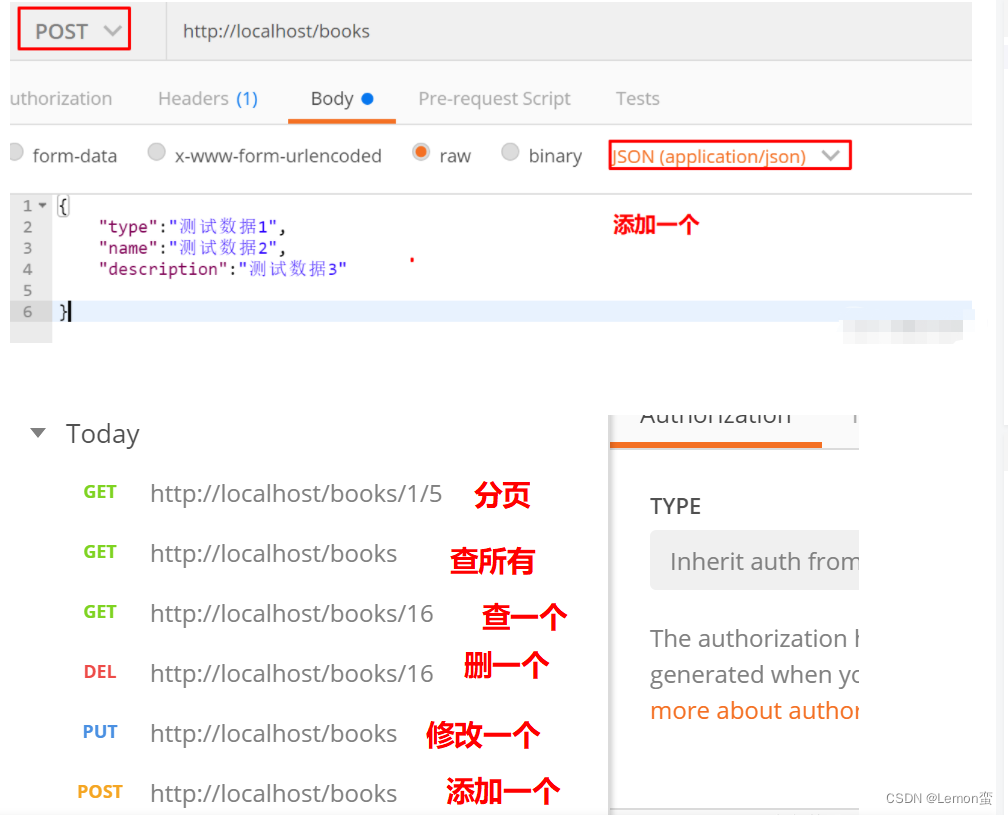
+
+### 7.8、表现层数据一致性处理(R对象)
+
+统一格式
+
+
+
+
+* 设计表现层返回结果的模型类,用于后端与前端进行数据格式统一,也称为**前后端数据协议**
+
+@Data
+public class R {
+ private Boolean flag;
+ private Object data;
+
+ public R() {
+ }
+
+ /**
+ * 不返回数据的构造方法
+ *
+ * @param flag
+ */
+ public R(Boolean flag) {
+ this.flag = flag;
+ }
+
+ /**
+ * 返回数据的构造方法
+ *
+ * @param flag
+ * @param data
+ */
+ public R(Boolean flag, Object data) {
+ this.flag = flag;
+ this.data = data;
+ }
+}
+
+* 表现层接口统一返回值类型结果
+
+@RestController
+@RequestMapping("/books")
+public class BookController {
+
+ @Autowired
+ private IBookService bookService;
+
+ @GetMapping
+ public R getAll() {
+ return new R(true, bookService.list());
+ }
+
+ @PostMapping
+ public R save(@RequestBody Book book) {
+ return new R(bookService.save(book));
+
+ }
+
+ @PutMapping
+ public R update(@RequestBody Book book) {
+ return new R(bookService.modify(book));
+ }
+
+ @DeleteMapping("{id}")
+ public R delete(@PathVariable Integer id) {
+ return new R(bookService.delete(id));
+ }
+
+ @GetMapping("{id}")
+ public R getById(@PathVariable Integer id) {
+ return new R(true, bookService.getById(id));
+ }
+
+ @GetMapping("{currentPage}/{pageSize}")
+ public R getPage(@PathVariable Integer currentPage, @PathVariable int pageSize) {
+ return new R(true, bookService.getPage(currentPage, pageSize));
+ }
+
+}
+
+
+
+**前端部分省略**
+
+## 8、Springboot工程打包与运行
+
+### 8.1、程序为什么要打包
+
+将程序部署在独立的服务器上
+
+
+### 8.2、SpringBoot项目快速启动(Windows版)
+
+步骤
+
+①:对SpringBoot项目打包(执行[Maven](https://so.csdn.net/so/search?q=Maven&spm=1001.2101.3001.7020)构建指令package)
+执行 package 打包命令之前 先执行 **mvn clean** 删除 target 目录及内容
+
+mvn package
+
+![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Eg4DFXqd-1657811363451)(SpringBoot.assets/image-20220317212408717.png)]](https://img-blog.csdnimg.cn/a19f1b3a110349cd9e16dbbd229ded5e.png)
+
+打包完成 生成对应的 jar 文件
+
+
+可能出现的问题: IDEA下 执行 Maven 命令控制台中文乱码
+Ctr+Alt+S 打开设置,在Build,Execution ,Deployment找到Build Tools下Maven项下的Runner ,在VM Options 添加
+-Dfile.encoding=GB2312 ,点击OK。
+![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Z5rHQGqK-1657811363452)(SpringBoot.assets/image-20220317212514627.png)]](https://img-blog.csdnimg.cn/74c0cddee08a4766bf1390fb3f7fac3f.png)
+
+②:运行项目(执行启动指令) java -jar <打包文件名>
+
+java –jar springboot.jar
+
+注意事项:
+jar支持命令行启动需要依赖maven插件支持,请确认打包时是否具有SpringBoot对应的maven插件
+
+
+
+
+ org.springframework.boot
+ spring-boot-maven-plugin
+
+
+
+
+
+ org.springframework.boot
+ spring-boot-maven-plugin
+
+
+ Manifest-Version: 1.0
+Implementation-Title: springboot_08_ssmp
+Implementation-Version: 0.0.1-SNAPSHOT
+Build-Jdk-Spec: 1.8
+Created-By: Maven Jar Plugin 3.2.0
+
+基于spring-boot-maven-plugin打包的工程
+
+Manifest-Version: 1.0
+Spring-Boot-Classpath-Index: BOOT-INF/classpath.idx
+Implementation-Title: springboot_08_ssmp
+Implementation-Version: 0.0.1-SNAPSHOT
+Spring-Boot-Layers-Index: BOOT-INF/layers.idx
+Start-Class: com.example.SSMPApplication 启动类
+Spring-Boot-Classes: BOOT-INF/classes/
+Spring-Boot-Lib: BOOT-INF/lib/
+Build-Jdk-Spec: 1.8
+Spring-Boot-Version: 2.5.6
+Created-By: Maven Jar Plugin 3.2.0
+Main-Class: org.springframework.boot.loader.JarLauncher jar启动器
+
+命令行启动常见问题及解决方案
+
+* Windonws端口被占用
+
+# 查询端口
+netstat -ano
+# 查询指定端口
+netstat -ano |findstr "端口号"
+# 根据进程PID查询进程名称
+tasklist |findstr "进程PID号"
+# 根据PID杀死任务
+taskkill /F /PID "进程PID号"
+# 根据进程名称杀死任务
+taskkill -f -t -im "进程名称"
+### 8.4、Boot工程快速启动
+
+
+
+* 基于Linux(CenterOS7)
+
+* 安装JDK,且版本不低于打包时使用的JDK版本
+
+ * 可以使用 yum 安装
+* 安装 MySQL
+
+ * 可以参考: https://blog.csdn.net/qq_42324086/article/details/120579197
+* 安装包保存在/usr/local/自定义目录中或$HOME下
+
+* 其他操作参照Windows版进行
+
+**启动成功无法访问**
+
+添加 80 端口
+
+* 添加 端口
+
+firewall-cmd --zone=public --permanent --add-port=80/tcp
+
+重启
+
+systemctl restart firewalld
+
+后台启动命令
+
+nohup java -jar springboot_08_ssmp-0.0.1-SNAPSHOT.jar > server.log 2>&1 &
+
+停止服务
+
+* ps -ef | grep “java -jar”
+* kill -9 PID
+* cat server.log (查看日志)
+
+[root@cjbCentos01 app]# ps -ef | grep "java -jar"
+UID PID PPID C STIME TTY TIME CMD
+root 6848 6021 7 14:45 pts/2 00:00:19 java -jar springboot_08_ssmp-0.0.1-SNAPSHOT.jar
+root 6919 6021 0 14:49 pts/2 00:00:00 grep --color=auto java -jar
+[root@cjbCentos01 app]# kill -9 6848
+[root@cjbCentos01 app]# ps -ef | grep "java -jar"
+root 7016 6021 0 14:52 pts/2 00:00:00 grep --color=auto java -jar
+[1]+ 已杀死 nohup java -jar springboot_08_ssmp-0.0.1-SNAPSHOT.jar > server.log 2>&1
+[root@cjbCentos01 app]#
+### 8.6、临时属性
+
+#### 8.6.1、临时属性
+
+
+
+* 带属性数启动SpringBoot
+
+java -jar springboot_08_ssmp-0.0.1-SNAPSHOT.jar --server.port=8080
+
+* 携带多个属性启动SpringBoot,属性间使用空格分隔
+
+属性加载优先顺序
+
+1. 参看 https://docs.spring.io/spring-boot/docs/current/reference/html/spring-boot-features.html#boot-features-external-config
+ 
+
+#### 8.6.2、开发环境
+
+
+
+* 带属性启动SpringBoot程序,为程序添加运行属性
+ 
+ 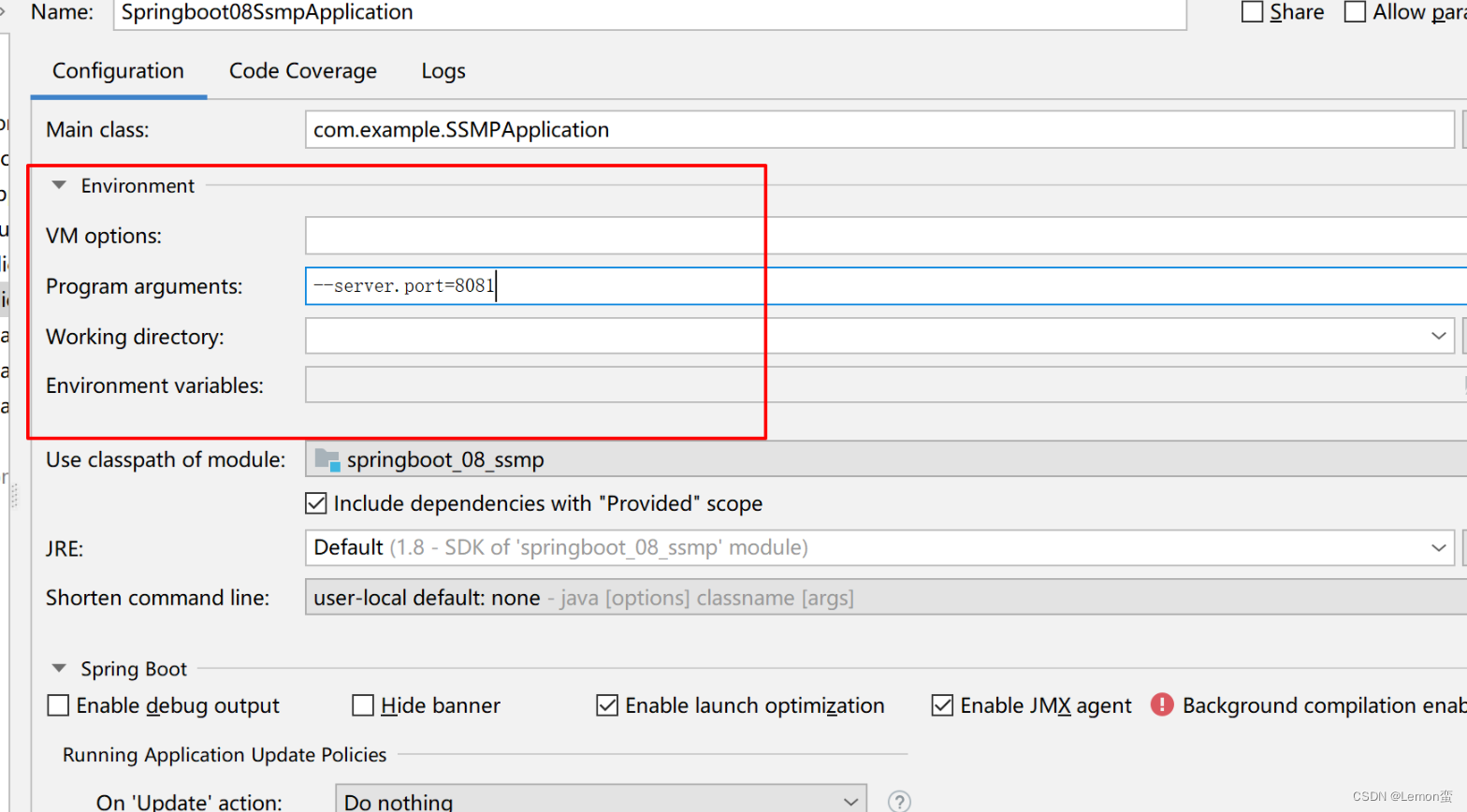
+
+在启动类中 main 可以通过 System.out.println(Arrays.toString(args)); 查看配制的属性
+
+通过编程形式带参数启动SpringBoot程序,为程序添加运行参数
+
+public static void main(String[] args) {
+ String[] arg = new String[1];
+ arg[0] = "--server.port=8080";
+ SpringApplication.run(SSMPApplication.class, arg);
+}
+
+不携带参数启动SpringBoot程序
+
+public static void main(String[] args) {
+ //可以在启动boot程序时断开读取外部临时配置对应的入口,也就是去掉读取外部参数的形参
+ SpringApplication.run(SSMPApplication.class);
+}
+### 8.7、配置环境
+
+
+
+#### 8.7.1、配置文件分类
+
+* SpringBoot中4级配置文件
+
+ * 1级:file :config/application.yml 【最高】
+
+ * 2级:file :application.yml
+
+ * 3级:classpath:config/application.yml
+
+ * 4级:classpath:application.yml 【最低】
+
+* 作用:
+
+ * 1级与2级留做系统打包后设置通用属性,1级常用于运维经理进行线上整体项目部署方案调控
+
+ * 3级与4级用于系统开发阶段设置通用属性,3级常用于项目经理进行整体项目属性调控
+
+#### 8.7.2、自定义配置文件
+
+
+
+通过启动参数加载配置文件(无需书写配置文件扩展名) --spring.config.name=eban
+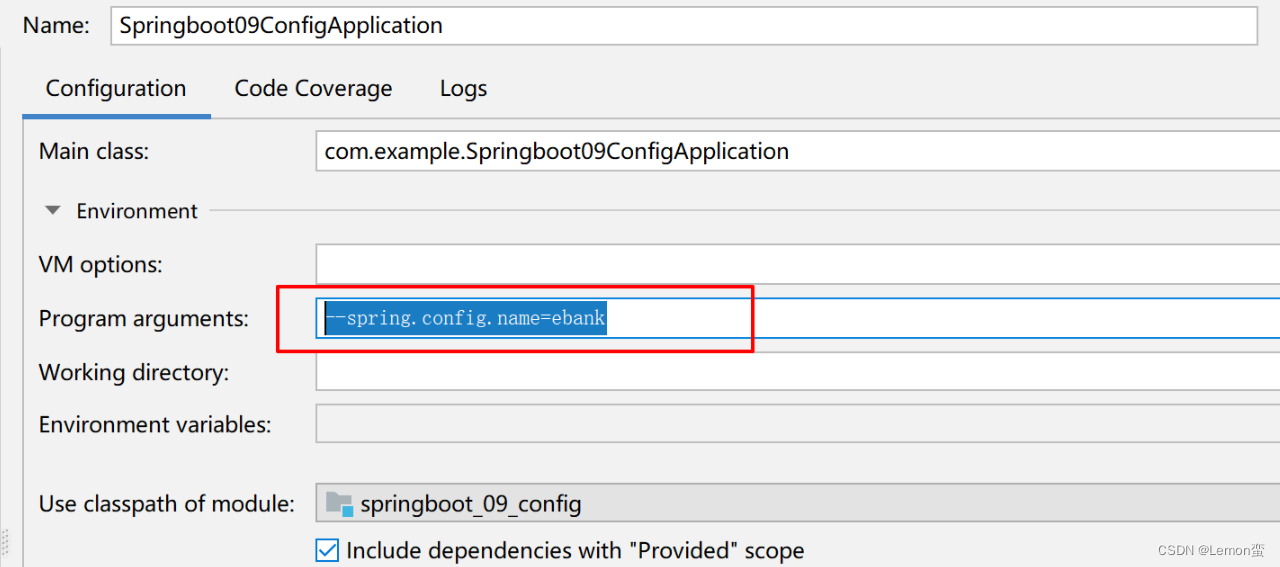
+
+properties与yml文件格式均支持
+
+* 通过启动参数加载指定文件路径下的配置文件 --spring.config.location=classpath:/ebank.yml
+ 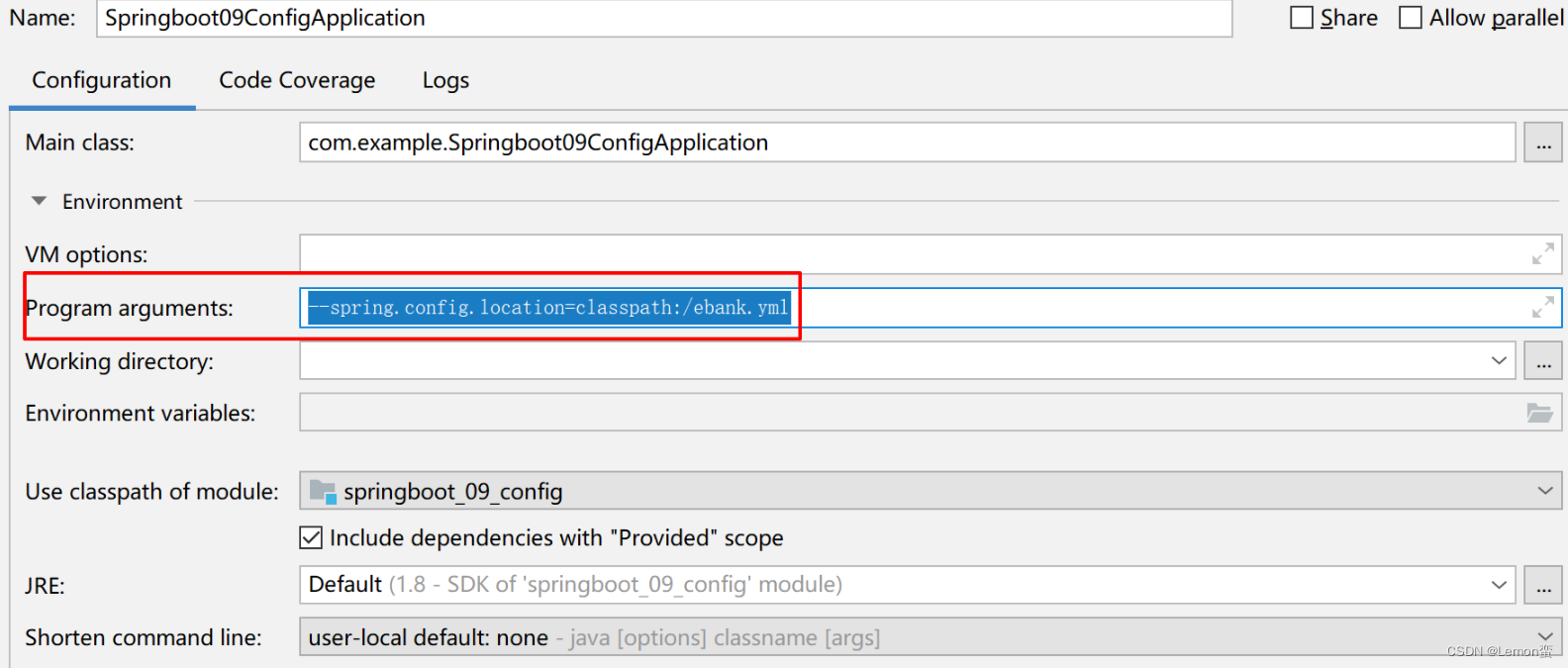
+
+properties与yml文件格式均支持
+
+* 通过启动参数加载指定文件路径下的配置文件时可以加载多个配置,后面的会覆盖前面的
+
+--spring.config.location=classpath:/ebank.yml,classpath:/ebank-server.yml
+
+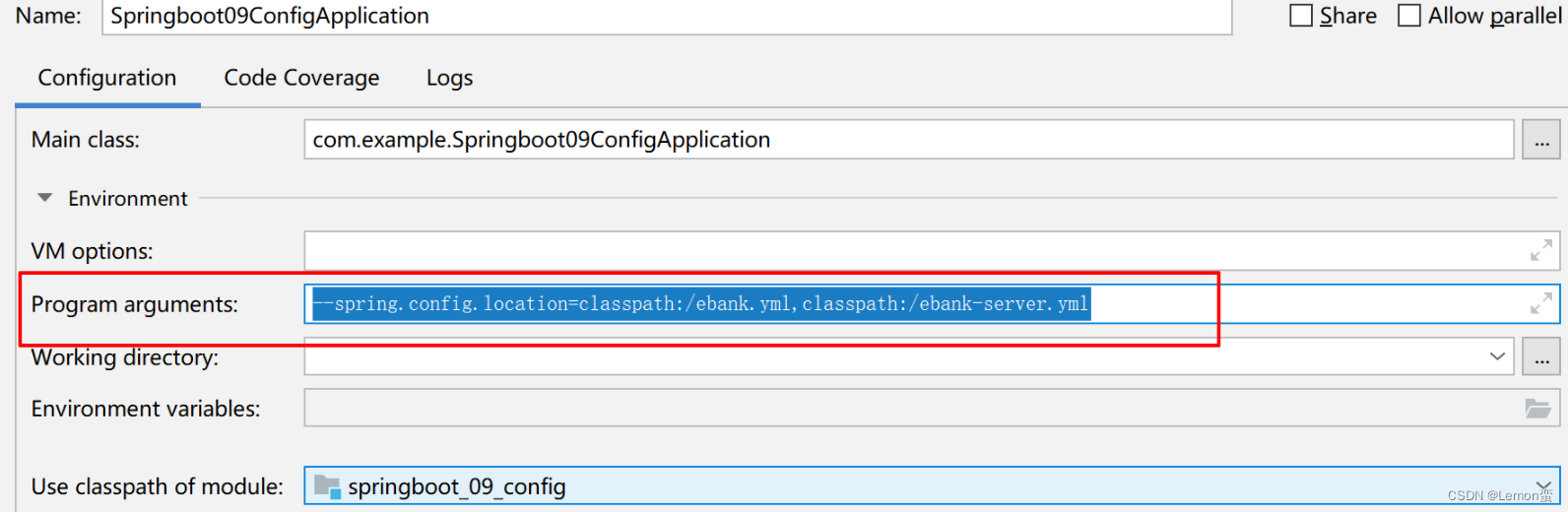
+
+注意事项:
+多配置文件常用于将配置进行分类,进行独立管理,或将可选配置单独制作便于上线更新维护
+
+自定义配置文件——重要说明
+
+* 单服务器项目:使用自定义配置文件需求较低
+
+* 多服务器项目:使用自定义配置文件需求较高,将所有配置放置在一个目录中,统一管理
+
+* 基于SpringCloud技术,所有的服务器将不再设置配置文件,而是通过配置中心进行设定,动态加载配置信息
+
+#### 8.7.3、多环境开发(yaml)
+
+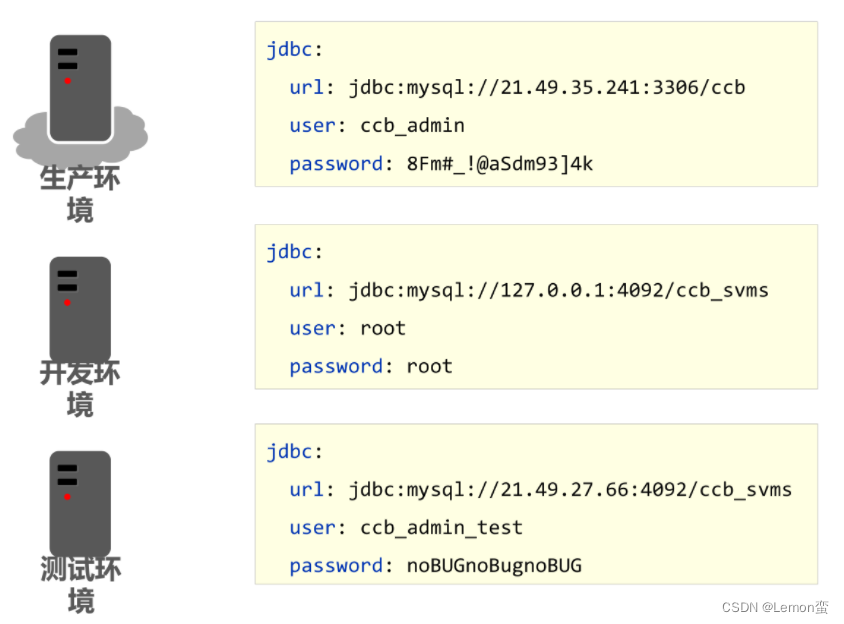
+
+
+
+#应用环境
+#公共配制
+spring:
+ profiles:
+ active: dev
+
+#设置环境
+#开发环境
+---
+spring:
+ config:
+ activate:
+ on-profile: dev
+server:
+ port: 81
+
+#生产环境
+---
+spring:
+ profiles: pro
+server:
+ port: 80
+
+#测试环境
+---
+spring:
+ profiles: test
+server:
+ port: 82
+#### 8.7.4、多环境开发文件(yaml)
+
+
+
+多环境开发(YAML版)多配置文件格式
+主启动配置文件application.yml
+
+#应用环境
+#公共配制
+spring:
+ profiles:
+ active: test
+
+环境分类配置文件application-pro.yml
+
+server:
+ port: 81
+
+环境分类配置文件application-dev.yml
+
+server:
+ port: 82
+
+环境分类配置文件application-test.yml
+
+server:
+ port: 83
+#### 8.7.5、多环境分组管理
+
+* 根据功能对配置文件中的信息进行拆分,并制作成独立的配置文件,命名规则如下
+
+ * application-devDB.yml
+
+ * application-devRedis.yml
+
+ * application-devMVC.yml
+
+* 使用include属性在激活指定环境的情况下,同时对多个环境进行加载使其生效,多个环境间使用逗号分隔
+
+ spring:
+ profiles:
+ active: dev
+ include: devDB,devMVC
+
+ 注意事项:
+ **当主环境dev与其他环境有相同属性时,主环境属性生效;其他环境中有相同属性时,最后加载的环境属性生效**
+
+ The following profiles are active: devDB,devMVC,dev
+* 从Spring2.4版开始使用group属性替代include属性,降低了配置书写量
+
+* 使用**group**属性定义多种主环境与子环境的包含关系
+
+spring:
+ profiles:
+ active: dev
+ group:
+ "dev": devDB,devMVC
+ "pro": proDB,proMVC
+ "test": testDB,testRedis,testMVC
+
+注意事项:
+**使用group属性,会覆盖 主环境dev (active) 的内容,最后加载的环境属性生效**
+
+The following profiles are active: dev,devDB,devMVC
+#### 8.7.6、多环境开发控制
+
+
+Maven与SpringBoot多环境兼容
+①:Maven中设置多环境属性
+
+
+
+
+ dev_env
+
+ dev
+
+
+ true
+
+
+
+ pro_env
+
+ pro
+
+
+
+
+ test_env
+
+ test
+
+
+
+
+②:SpringBoot中引用Maven属性
+
+spring:
+ profiles:
+ active: @profile.active@
+ group:
+ "dev": devDB,devMVC
+ "pro": proDB,proMVC
+
+
+
+③:执行Maven打包指令,并在生成的boot打包文件.jar文件中查看对应信息
+问题:**修改pom.xml 文件后,启动没有生效 手动 compile 即可**
+
+
+或者 设置 IDEA进行自动编译
+
+
+## 9、日志
+
+### 9.1、日志基础操作
+
+日志(log)作用
+
+1. 编程期调试代码
+2. 运营期记录信息
+ * 记录日常运营重要信息(峰值流量、平均响应时长……)
+ * 记录应用报错信息(错误堆栈)
+ * 记录运维过程数据(扩容、宕机、报警……)
+
+代码中使用日志工具记录日志
+
+* 先引入 Lombok 工具类
+
+
+
+ org.projectlombok
+ lombok
+
+
+ ①:添加日志记录操作
+
+ @RestController
+ @RequestMapping("/books")
+ public class BookController {
+ private static final Logger log = LoggerFactory.getLogger(BookController.class);
+
+ @GetMapping
+ public String getById() {
+ System.out.println("springboot is running...");
+ log.debug("debug ...");
+ log.info("info ...");
+ log.warn("warn ...");
+ log.error("error ...");
+ return "springboot is running...";
+ }
+ }
+* 日志级别
+
+TRACE:运行堆栈信息,使用率低
+DEBUG:程序员调试代码使用
+INFO:记录运维过程数据
+WARN:记录运维过程报警数据
+ERROR:记录错误堆栈信息
+FATAL:灾难信息,合并计入ERRO
+
+②:设置日志输出级别
+
+# 开启 debug 模式,输出调试信息,常用于检查系统运行状况
+debug: true
+# 设置日志级别, root 表示根节点,即整体应用日志级别
+logging:
+ level:
+ root: debug
+
+③:设置日志组,控制指定包对应的日志输出级别,也可以直接控制指定包对应的日志输出级别
+
+logging:
+ # 设置分组
+ group:
+ # 自定义组名,设置当前组中所包含的包
+ ebank: com.example.controller,com.example.service,com.example.dao
+ iservice: com.alibaba
+ level:
+ root: info
+ # 设置某个包的日志级别
+# com.example.controller: debug
+ # 为对应组设置日志级别
+ ebank: warn
+### 9.2、快速创建日志对象
+
+* 使用lombok提供的注解@Slf4j简化开发,减少日志对象的声明操作
+
+ @Slf4j
+ //Rest模式
+ @RestController
+ @RequestMapping("/books")
+ public class BookController {
+
+ @GetMapping
+ public String getById(){
+ System.out.println("springboot is running...2");
+
+ log.debug("debug...");
+ log.info("info...");
+ log.warn("warn...");
+ log.error("error...");
+
+ return "springboot is running...2";
+ }
+
+ }
+
+### 9.3、日志输出格式控制
+
+
+
+* PID:进程ID,用于表明当前操作所处的进程,当多服务同时记录日志时,该值可用于协助程序员调试程序
+* 所属类/接口名:当前显示信息为SpringBoot重写后的信息,名称过长时,简化包名书写为首字母,甚至直接删除
+* 设置日志输出格式
+
+logging:
+ pattern:
+ console: "%d - %m%n"
+
+%d:日期
+%m:消息
+%n:换行
+
+
+logging:
+pattern:
+# console: "%d - %m%n"
+console: "%d %clr(%5p) --- [%16t] %clr(%-40.40c){cyan} : %m %n"
+### 9.4、文件记录日志
+
+* 设置日志文件
+
+logging:
+ file:
+ name: server.log
+
+* 日志文件详细配置
+
+logging:
+ file:
+ name: server.log
+ logback:
+ rollingpolicy:
+ max-file-size: 4KB
+ file-name-pattern: server.%d{yyyy-MM-dd}.%i.log
+
+
+
+## 10、热部署
+
+
+ org.springframework.boot
+ spring-boot-devtools
+ true
+ spring:
+ # 热部署范围配置
+ devtools:
+ restart:
+ # 设置不参与热部署的文件和文件夹(即修改后不重启)
+ exclude: static/**,public/**,config/application.yml
+ #是否可用
+ enabled: false
+
+如果配置文件比较多的时候找热部署对应配置比较麻烦,可以在`springboot`启动类的main方法中设置,此处设置的优先级将比配置文件高,一定会生效。
+
+System.setProperty("spring.devtools.restart.enabled", "false");
+## 11、属性绑定
+
+1. 先在要配置的类上面加@Component注解将该类交由spring容器管理;
+2. `@ConfigurationProperties(prefix="xxx")`,xxx跟application.yml配置文件中的属性对应;
+3. 如果多个配置类想统一管理也可以通过`@EnableConfigurationProperties({xxx.class, yyy.class})`的方式完成配置,不过该注解会与@Component配置发生冲突,二选一即可;
+4. 第三方类对象想通过配置进行属性注入,可以通过创建一个方法,在方法体上加@Bean和`@ConfigurationProperties(prefix="xxx")`注解,然后方法返回这个第三方对象的方式。
+5. 使用`@ConfigurationProperties(prefix="xxx")`注解后idea工具会报一个警告Spring Boot Configuration Annotation Processor not configured
+
+@ConfigurationProperties(prefix="xxx")
+@Data
+public class ServerConfig {
+ private String inAddress;
+ private int port;
+ private long timeout;
+}
+
+`@ConfigurationProperties`绑定属性支持属性名宽松绑定,又叫松散绑定。
+
+比如要将`ServerConfig.class`作为配置类,并通过配置文件`application.yml`绑定属性
+
+ServerConfig.class serverConfig:
+ # ipAddress: 192.168.0.1 # 驼峰模式
+ # ipaddress: 192.168.0.1
+ # IPADDRESS: 192.168.0.1
+ ip-address: 192.168.0.1 # 主流配置方式,烤肉串模式
+ # ip_address: 192.168.0.1 # 下划线模式
+ # IP_ADDRESS: 192.168.0.1 # 常量模式
+ # ip_Add_rEss: 192.168.0.1
+ # ipaddress: 192.168.0.1
+ port: 8888
+ timeout: -1
+
+以ipAddress属性为例,上面的多种配置方式皆可生效,这就是松散绑定。而@Value不支持松散绑定,必须一一对应。
+
+`@ConfigurationProperties(prefix="serverconfig")`中的prefix的值为serverconfig或者server-config,如果是serverConfig就会报错,这与松散绑定的前缀命名规范有关:仅能使用纯小写字母、数字、中划线作为合法的字符
+
+## 12、常用计量单位应用
+
+//@Component
+@ConfigurationProperties(prefix = "server-config")
+@Data
+public class ServerConfig {
+ private String ipAddress;
+ private int port;
+ @DurationUnit(ChronoUnit.MINUTES)
+ private Duration timeout;
+
+ @DataSizeUnit(DataUnit.MEGABYTES)
+ private DataSize dataSize;
+}
+
+引入`Bean`属性校验框架的步骤:
+
+1. 在`pom.xml`中添加`JSR303`规范和`hibernate`校验框架的依赖:
+
+
+
+ javax.validation
+ validation-api
+
+
+
+ org.hibernate.validator
+ hibernate-validator
+
+
+1. 在要校验的类上加`@Validated`注解
+
+2. 设置具体的校验规则,如:`@Max(value=8888, message="最大值不能超过8888")`
+
+@ConfigurationProperties(prefix = "server-config")
+@Data
+// 2.开启对当前bean的属性注入校验
+@Validated
+public class ServerConfig {
+ private String ipAddress;
+ // 设置具体的规则
+ @Max(value = 8888, message = "最大值不能超过8888")
+ @Min(value = 1000, message = "最小值不能低于1000")
+ private int port;
+ @DurationUnit(ChronoUnit.MINUTES)
+ private Duration timeout;
+
+ @DataSizeUnit(DataUnit.MEGABYTES)
+ private DataSize dataSize;
+}
+
+进制转换中的一些问题:
+
+如`application.yml`文件中对数据库有如下配置:
+
+datasource:
+ driverClassName: com.mysql.cj.jdbc.Driver123
+ # 不加引号读取的时候默认解析为了8进制数,转成十进制就是87
+ # 所以想让这里正确识别,需要加上引号
+ # password: 0127
+ password: "0127"
+## 13、测试类
+
+### 13.1、加载专用属性
+
+@SpringBootTest注解中可以设置properties和args属性,这里的args属性的作用跟idea工具中自带的程序参数类似,只不过这里的配置是源码级别的,会随着源码的移动而跟随,而idea中的程序参数的配置会丢失。并且这里的args属性的配置的作用范围比较小,仅在当前测试类生效。
+
+application.yml
+
+test:
+ prop: testValue // properties属性可以为当前测试用例添加临时的属性配置
+//@SpringBootTest(properties = {"test.prop=testValue1"})
+// args属性可以为当前测试用例添加临时的命令行参数
+//@SpringBootTest(args = {"--test.prop=testValue2"})
+// 优先级排序: args > properties > 配置文件
+@SpringBootTest(args = {"--test.prop=testValue2"}, properties = {"test.prop=testValue1"})
+class PropertiesAndArgsTest {
+ @Value("${test.prop}")
+ private String prop;
+ @Test
+ public void testProperties() {
+ System.out.println("prop = " + prop);
+ }
+}
+### 13.2、加载专用类
+
+某些测试类中需要用到第三方的类,而其他测试类则不需要用到,这里可以在类上加载`@Import({xxx.class, yyy.class})`
+
+@RestController
+@RequestMapping("/books")
+public class BookController {
+ /*@GetMapping("/{id}")
+ public String getById(@PathVariable int id) {
+ System.out.println("id = " + id);
+ return "getById...";
+ }*/
+
+ @GetMapping("/{id}")
+ public Book getById(@PathVariable int id) {
+ System.out.println("id = " + id);
+ Book book = new Book();
+ book.setId(5);
+ book.setName("springboot");
+ book.setType("springboot");
+ book.setDescription("springboot");
+ return book;
+ }
+}
+
+相应测试类
+
+@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT)
+// 开启虚拟mvc调用
+@AutoConfigureMockMvc
+public class WebTest {
+ @Test
+ public void testRandomPort() {
+ }
+
+ @Test
+ public void testWeb(@Autowired MockMvc mvc) throws Exception {
+ // 创建虚拟请求,当前访问 /books
+ MockHttpServletRequestBuilder builder = MockMvcRequestBuilders.get("/books/5");
+ mvc.perform(builder);
+ }
+
+ @Test
+ public void testStatus(@Autowired MockMvc mvc) throws Exception {
+ MockHttpServletRequestBuilder builder = MockMvcRequestBuilders.get("/books1/6");
+ ResultActions action = mvc.perform(builder);
+ // 设定预期值,与真实值进行比较,成功测试通过,失败测试不通过
+ // 定义本次调用的预期值
+ StatusResultMatchers srm = MockMvcResultMatchers.status();
+ // 预计本次调用成功的状态码:200
+ ResultMatcher ok = srm.isOk();
+ // 添加预计值到本次调用过程中进行匹配
+ action.andExpect(ok);
+ }
+
+ @Test
+ public void testBody(@Autowired MockMvc mvc) throws Exception {
+ MockHttpServletRequestBuilder builder = MockMvcRequestBuilders.get("/books/6");
+ ResultActions action = mvc.perform(builder);
+ // 设定预期值,与真实值进行比较,成功测试通过,失败测试不通过
+ // 定义本次调用的预期值
+ ContentResultMatchers crm = MockMvcResultMatchers.content();
+ // 预计本次调用成功的状态码:200
+ ResultMatcher rm = crm.string("getById...");
+ // 添加预计值到本次调用过程中进行匹配
+ action.andExpect(rm);
+ }
+
+ @Test
+ public void testJson(@Autowired MockMvc mvc) throws Exception {
+ MockHttpServletRequestBuilder builder = MockMvcRequestBuilders.get("/books/7");
+ ResultActions action = mvc.perform(builder);
+ // 设定预期值,与真实值进行比较,成功测试通过,失败测试不通过
+ // 定义本次调用的预期值
+ ContentResultMatchers jsonMatcher = MockMvcResultMatchers.content();
+ ResultMatcher rm = jsonMatcher.json("{\"id\":5,\"name\":\"springboot\",\"type\":\"springboot\",\"description\":\"springboot1\"}");
+ action.andExpect(rm);
+ }
+
+ @Test
+ public void testContentType(@Autowired MockMvc mvc) throws Exception {
+ MockHttpServletRequestBuilder builder = MockMvcRequestBuilders.get("/books/7");
+ ResultActions action = mvc.perform(builder);
+ // 设定预期值,与真实值进行比较,成功测试通过,失败测试不通过
+ // 定义本次调用的预期值
+ HeaderResultMatchers hrm = MockMvcResultMatchers.header();
+ ResultMatcher rm = hrm.string("Content-Type", "application/json");
+ action.andExpect(rm);
+ }
+
+ @Test
+ // 完整测试
+ public void testGetById(@Autowired MockMvc mvc) throws Exception {
+ MockHttpServletRequestBuilder builder = MockMvcRequestBuilders.get("/books/8");
+ ResultActions action = mvc.perform(builder);
+
+ // 1、比较状态码
+ StatusResultMatchers statusResultMatchers = MockMvcResultMatchers.status();
+ ResultMatcher statusResultMatcher = statusResultMatchers.isOk();
+ action.andExpect(statusResultMatcher);
+
+ // 2、比较返回值类型
+ HeaderResultMatchers headerResultMatchers = MockMvcResultMatchers.header();
+ ResultMatcher headerResultMatcher = headerResultMatchers.string("Content-Type", "application/json");
+ action.andExpect(headerResultMatcher);
+
+ /// 3、比较json返回值
+ ContentResultMatchers contentResultMatchers = MockMvcResultMatchers.content();
+ ResultMatcher jsonResultMatcher = contentResultMatchers.json("{\"id\":5,\"name\":\"springboot\",\"type\":\"springboot\",\"description\":\"springboot\"}");
+ action.andExpect(jsonResultMatcher);
+ }
+}
+### 13.3、业务层测试事务回滚
+
+* 为测试用例添加事务,SpringBoot会对测试用例对应的事务提交操作进行回滚
+
+ @SpringBootTest
+ @Transactional public class DaoTest {
+ @Autowired
+ private BookService bookService; }
+* l如果想在测试用例中提交事务,可以通过@Rollback注解设置
+
+ @SpringBootTest
+ @Transactional
+ @Rollback(false)
+ public class DaoTest {
+ }
+
+### 13.4、测试用例数据设定
+
+* 测试用例数据通常采用随机值进行测试,使用SpringBoot提供的随机数为其赋值
+
+testcast:
+ book:
+ id: ${random.int} # 随机整数
+ id2: ${random.int(10)} # 10以内随机数
+ type: ${random.int(10,20)} # 10到20随机数
+ uuid: ${random.uuid} # 随机uuid
+ name: ${random.value} # 随机字符串,MD5字符串,32位
+ publishTime: ${random.long} # 随机整数(long范围) u${random.int}表示随机整数
+
+u${random.int(10)}表示10以内的随机数
+
+u${random.int(10,20)}表示10到20的随机数
+
+u其中()可以是任意字符,例如[],!!均可
+## 14、数据层解决方案
+
+### 14.1、SQL
+
+现有数据层解决方案技术选型
+
+Druid + MyBatis-Plus + MySQL
+
+* 数据源:DruidDataSource
+* 持久化技术:MyBatis-Plus / MyBatis
+* 数据库:MySQL
+
+格式一:
+
+spring:
+ datasource:
+ driver-class-name: com.mysql.cj.jdbc.Driver
+ url: jdbc:mysql://localhost:3306/ssm_db?serverTimezone=UTC
+ username: root
+ password: root
+
+格式二:
+
+spring:
+ datasource:
+ druid:
+ driver-class-name: com.mysql.cj.jdbc.Driver
+ url: jdbc:mysql://localhost:3306/ssm_db?serverTimezone=UTC
+ username: root
+ password: root
+
+* SpringBoot提供了3种内嵌的数据源对象供开发者选择
+ * HikariCP
+ * Tomcat提供DataSource
+ * Commons DBCP
+
+spring:
+ datasource:
+ driver-class-name: com.mysql.cj.jdbc.Driver
+ url: jdbc:mysql://localhost:3306/ssm_db?serverTimezone=UTC
+ username: root
+ password: root spring:
+ datasource:
+ druid:
+ driver-class-name: com.mysql.cj.jdbc.Driver
+ url: jdbc:mysql://localhost:3306/ssm_db?serverTimezone=UTC
+ username: root
+ password: root
+
+* SpringBoot提供了3种内嵌的数据源对象供开发者选择
+
+ * HikariCP:默认内置数据源对象
+
+ * Tomcat提供DataSource:HikariCP不可用的情况下,且在web环境中,将使用tomcat服务器配置的数据源对象
+
+ * Commons DBCP:Hikari不可用,tomcat数据源也不可用,将使用dbcp数据源
+
+* 通用配置无法设置具体的数据源配置信息,仅提供基本的连接相关配置,如需配置,在下一级配置中设置具体设定
+
+spring:
+ datasource:
+ driver-class-name: com.mysql.cj.jdbc.Driver
+ url: jdbc:mysql://localhost:3306/ssm_db
+ username: root
+ password: root
+ hikari:
+ maximum-pool-size: 50
+
+* 内置持久化解决方案——JdbcTemplate
+
+@SpringBootTest
+class Springboot15SqlApplicationTests {
+ @Autowired
+ private JdbcTemplate jdbcTemplate;
+ @Test
+ void testJdbc(){
+ String sql = "select * from tbl_book where id = 1";
+ List query = jdbcTemplate.query(sql, new RowMapper() {
+ @Override
+ public Book mapRow(ResultSet rs, int rowNum) throws SQLException {
+ Book temp = new Book();
+ temp.setId(rs.getInt("id"));
+ temp.setName(rs.getString("name"));
+ temp.setType(rs.getString("type"));
+ temp.setDescription(rs.getString("description"));
+ return temp;
+ }
+ });
+ System.out.println(query);
+ }
+}
+ org.springframework.boot
+ spring-boot-starter-jdbc
+ spring:
+ jdbc:
+ template:
+ query-timeout: -1 # 查询超时时间
+ max-rows: 500 # 最大行数
+ fetch-size: -1 # 缓存行数
+
+* SpringBoot提供了3种内嵌数据库供开发者选择,提高开发测试效率
+
+ * H2
+ * HSQL
+ * Derby
+* 导入H2相关坐标
+
+
+ org.springframework.boot
+ spring-boot-starter-data-jpa
+
+
+ com.h2database
+ h2
+ runtime
+ server:
+ port: 80
+spring:
+ h2:
+ console:
+ path: /h2
+ enabled: true
+
+访问用户名sa,默认密码123456
+
+操作数据库(创建表)
+
+create table tbl_book (id int,name varchar,type varchar,description varchar) #设置访问数据源
+server:
+ port: 80
+spring:
+ datasource:
+ driver-class-name: org.h2.Driver
+ url: jdbc:h2:~/test
+ username: sa
+ password: 123456
+h2:
+ console:
+ path: /h2
+ enabled: true
+
+H2数据库控制台仅用于开发阶段,线上项目请务必关闭控制台功能
+
+server:
+ port: 80
+spring:
+ h2:
+ console:
+ path: /h2
+ enabled: false
+
+SpringBoot可以根据url地址自动识别数据库种类,在保障驱动类存在的情况下,可以省略配置
+
+server:
+ port: 80
+spring:
+ datasource:
+# driver-class-name: org.h2.Driver
+ url: jdbc:h2:~/test
+ username: sa
+ password: 123456
+ h2:
+ console:
+ path: /h2
+ enabled: true
+
+
+
+### 14.2、MongoDB
+
+MongoDB是一个开源、高性能、无模式的文档型数据库。NoSQL数据库产品中的一种,是最像关系型数据库的非关系型数据库
+
+
+#### 14.2.1、MongoDB的使用
+
+* Windows版Mongo下载
+
+https://www.mongodb.com/try/download
+
+* Windows版Mongo安装
+
+解压缩后设置数据目录
+
+* Windows版Mongo启动
+
+服务端启动
+
+在bin目录下
+
+`mongod --dbpath=..\data\db`
+
+客户端启动
+
+`mongo --host=127.0.0.1 --port=27017`
+
+#### 14.2.2、MongoDB可视化客户端
+
+
+
+* 新增
+
+ `db.集合名称.insert/save/insertOne(文档)`
+
+* 修改
+
+ `db.集合名称.remove(条件)`
+
+* 删除
+
+ `db.集合名称.update(条件,{操作种类:{文档}})`
+ 
+ 
+
+#### 14.2.3、Springboot集成MongoDB
+
+导入MongoDB驱动
+
+
+ org.springframework.boot
+ spring-boot-starter-data-mongodb
+ spring:
+ data:
+ mongodb:
+ uri: mongodb://localhost/itheima
+
+客户端读写MongoDB
+
+@Test
+void testSave(@Autowired MongoTemplate mongoTemplate){
+ Book book = new Book();
+ book.setId(1);
+ book.setType("springboot");
+ book.setName("springboot");
+ book.setDescription("springboot");
+ mongoTemplate.save(book);
+}
+@Test
+void testFind(@Autowired MongoTemplate mongoTemplate){
+ List all = mongoTemplate.findAll(Book.class);
+ System.out.println(all);
+}
+### 14.3、ElasticSearch(ES)
+
+Elasticsearch是一个分布式全文搜索引擎
+
+
+
+
+
+#### 14.3.1、ES下载
+
+* Windows版ES下载
+
+[https://](https://www.elastic.co/cn/downloads/elasticsearch)[www.elastic.co/cn/downloads/elasticsearch](https://www.elastic.co/cn/downloads/elasticsearch)
+
+* Windows版ES安装与启动
+
+运行:`elasticsearch.bat`
+
+#### 14.3.2、ES索引、分词器
+
+* 创建/查询/删除索引
+
+put:`http://localhost:9200/books`
+
+get:`http://localhost:9200/books`
+
+delete:`http://localhost:9200/books`
+
+* IK分词器
+
+ 下载:https://github.com/medcl/elasticsearch-analysis-ik/releases
+
+* 创建索引并指定规则
+
+{
+ "mappings":{
+ "properties":{
+ "id":{
+ "type":"keyword"
+ },
+ "name":{
+ "type":"text", "analyzer":"ik_max_word", "copy_to":"all"
+ },
+ "type":{
+ "type":"keyword"
+ },
+ "description":{
+ "type":"text", "analyzer":"ik_max_word", "copy_to":"all"
+ },
+ "all":{
+ "type":"text", "analyzer":"ik_max_word"
+ }
+ }
+ }
+}
+#### 14.3.3、文档操作(增删改查)
+
+* 创建文档
+
+ post:`http://localhost:9200/books/_doc`(使用系统生成的id)
+
+ post:`http://localhost:9200/books/_create/1`(使用指定id)
+
+ post:`http://localhost:9200/books/_doc/1`(使用指定id,不存在创建,存在更新,版本递增)
+
+ {
+ "name":"springboot",
+ "type":"springboot",
+ "description":"springboot"
+ }
+* 查询文档
+
+ get:`http://localhost:9200/books/_doc/1`
+
+ get:`http://localhost:9200/books/_search`
+
+* 条件查询
+
+ get:`http://localhost:9200/books/_search?q=name:springboot`
+
+* 删除文档
+
+ delete:`http://localhost:9200/books/_doc/1`
+
+* 修改文档(全量修改)
+
+ put:`http://localhost:9200/books/_doc/1`
+
+ {
+ "name":"springboot",
+ "type":"springboot",
+ "description":"springboot"
+ }
+* 修改文档(部分修改)
+
+ post:`http://localhost:9200/books/_update/1`
+
+ {
+ "doc":{
+ "name":"springboot"
+ }
+ }
+
+#### 14.3.4、Springboot集成ES
+
+* 导入坐标
+
+
+ org.springframework.boot
+ spring-boot-starter-data-elasticsearch
+ spring:
+ elasticsearch:
+ rest:
+ uris: http://localhost:9200
+* 客户端
+
+ @SpringBootTest
+ class Springboot18EsApplicationTests {
+ @Autowired
+ private ElasticsearchRestTemplate template;
+ }
+* SpringBoot平台并没有跟随ES的更新速度进行同步更新,ES提供了High Level Client操作ES
+
+ 导入坐标
+
+
+ org.elasticsearch.client
+ elasticsearch-rest-high-level-client
+ @Test
+ void test() throws IOException {
+ HttpHost host = HttpHost.create("http://localhost:9200");
+ RestClientBuilder builder = RestClient.builder(host);
+ RestHighLevelClient client = new RestHighLevelClient(builder);
+ //客户端操作
+ CreateIndexRequest request = new CreateIndexRequest("books");
+ //获取操作索引的客户端对象,调用创建索引操作
+ client.indices().create(request, RequestOptions.DEFAULT);
+ //关闭客户端
+ client.close();
+ }
+* 客户端改进
+
+ @SpringBootTest
+ class Springboot18EsApplicationTests {
+ @Autowired
+ private BookDao bookDao;
+ @Autowired
+ RestHighLevelClient client;
+ @BeforeEach
+ void setUp() {
+ this.client = new RestHighLevelClient(RestClient.builder(HttpHost.create("http://localhost:9200")));
+ }
+ @AfterEach
+ void tearDown() throws IOException {
+ this.client.close();
+ }
+ @Test
+ void test() throws IOException {
+ //客户端操作
+ CreateIndexRequest request = new CreateIndexRequest("books");
+ //获取操作索引的客户端对象,调用创建索引操作
+ client.indices().create(request, RequestOptions.DEFAULT);
+ }
+ }
+
+#### 14.3.5、索引
+
+* 创建索引
+
+ //创建索引
+ @Test
+ void testCreateIndexByIK() throws IOException {
+ HttpHost host = HttpHost.create("http://localhost:9200");
+ RestClientBuilder builder = RestClient.builder(host);
+ RestHighLevelClient client = new RestHighLevelClient(builder);
+ //客户端操作
+ CreateIndexRequest request = new CreateIndexRequest("books");
+ //设置要执行操作
+ String json = "";
+ //设置请求参数,参数类型json数据
+ request.source(json,XContentType.JSON);
+ //获取操作索引的客户端对象,调用创建索引操作
+ client.indices().create(request, RequestOptions.DEFAULT);
+ //关闭客户端
+ client.close();
+ } String json = "{\n" +
+ " \"mappings\":{\n" +
+ " \"properties\":{\n" +
+ " \"id\":{\n" +
+ " \"type\":\"keyword\"\n" +
+ " },\n" +
+ " \"name\":{\n" +
+ " \"type\":\"text\",\n" +
+ " \"analyzer\":\"ik_max_word\",\n" +
+ " \"copy_to\":\"all\"\n" +
+ " },\n" +
+ " \"type\":{\n" +
+ " \"type\":\"keyword\"\n" +
+ " },\n" +
+ " \"description\":{\n" +
+ " \"type\":\"text\",\n" +
+ " \"analyzer\":\"ik_max_word\",\n" +
+ " \"copy_to\":\"all\"\n" +
+ " },\n" +
+ " \"all\":{\n" +
+ " \"type\":\"text\",\n" +
+ " \"analyzer\":\"ik_max_word\"\n" +
+ " }\n" +
+ " }\n" +
+ " }\n" +
+ "}";
+* 添加文档
+
+ //添加文档
+ @Test
+ void testCreateDoc() throws IOException {
+ Book book = bookDao.selectById(1);
+ IndexRequest request = new IndexRequest("books").id(book.getId().toString());
+ String json = JSON.toJSONString(book);
+ request.source(json,XContentType.JSON);
+ client.index(request, RequestOptions.DEFAULT);
+ }
+* 批量添加文档
+
+ //批量添加文档
+ @Test
+ void testCreateDocAll() throws IOException {
+ List bookList = bookDao.selectList(null);
+ BulkRequest bulk = new BulkRequest();
+ for (Book book : bookList) {
+ IndexRequest request = new IndexRequest("books").id(book.getId().toString());
+ String json = JSON.toJSONString(book);
+ request.source(json,XContentType.JSON);
+ bulk.add(request);
+ }
+ client.bulk(bulk,RequestOptions.DEFAULT);
+ }
+* 按id查询文档
+
+ @Test
+ void testGet() throws IOException {
+ GetRequest request = new GetRequest("books","1");
+ GetResponse response = client.get(request, RequestOptions.DEFAULT);
+ String json = response.getSourceAsString();
+ System.out.println(json);
+ }
+* 按条件查询文档
+
+@Test
+void testSearch() throws IOException {
+ SearchRequest request = new SearchRequest("books");
+ SearchSourceBuilder builder = new SearchSourceBuilder();
+ builder.query(QueryBuilders.termQuery("all",“java"));
+ request.source(builder);
+ SearchResponse response = client.search(request, RequestOptions.DEFAULT);
+ SearchHits hits = response.getHits();
+ for (SearchHit hit : hits) {
+ String source = hit.getSourceAsString();
+ Book book = JSON.parseObject(source, Book.class);
+ System.out.println(book);
+ }
+}
+## 15、缓存
+
+### 15.1、缓存简介
+
+缓存是一种介于数据永久存储介质与数据应用之间的数据临时存储介质
+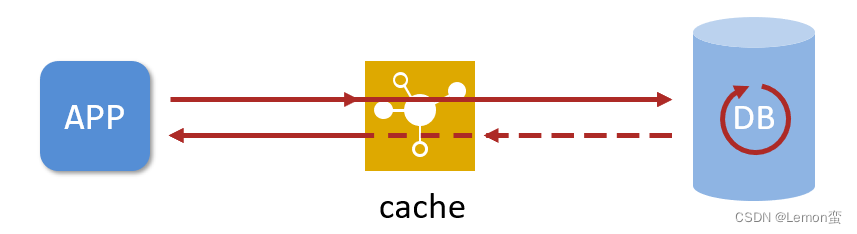
+
+* 缓存是一种介于数据永久存储介质与数据应用之间的数据临时存储介质
+
+* 使用缓存可以有效的减少低速数据读取过程的次数(例如磁盘IO),提高系统性能
+
+* 缓存不仅可以用于提高永久性存储介质的数据读取效率,还可以提供临时的数据存储空间
+ 
+
+* SpringBoot提供了缓存技术,方便缓存使用
+
+### 15.2、缓存使用
+
+* 启用缓存
+
+* 设置进入缓存的数据
+
+* 设置读取缓存的数据
+
+* 导入缓存技术对应的starter
+
+
+ org.springframework.boot
+ spring-boot-starter-cache
+ @SpringBootApplication
+ @EnableCaching
+ public class Springboot19CacheApplication {
+ public static void main(String[] args) {
+ SpringApplication.run(Springboot19CacheApplication.class, args);
+ }
+ }
+* 设置当前操作的结果数据进入缓存
+
+@Cacheable(value="cacheSpace",key="#id")
+public Book getById(Integer id) {
+ return bookDao.selectById(id);
+}
+### 15.3、其他缓存
+
+* SpringBoot提供的缓存技术除了提供默认的缓存方案,还可以对其他缓存技术进行整合,统一接口,方便缓存技术的开发与管理
+ * Generic
+ * JCache
+ * **Ehcache**
+ * Hazelcast
+ * Infinispan
+ * Couchbase
+ * **Redis**
+ * Caffeine
+ * Simple(默认)
+ * **memcached**
+ * jetcache(阿里)
+
+### 15.4、缓存使用案例——手机验证码
+
+* 需求
+
+ * 输入手机号获取验证码,组织文档以短信形式发送给用户(页面模拟)
+
+ * 输入手机号和验证码验证结果
+
+* 需求分析
+
+ * 提供controller,传入手机号,业务层通过手机号计算出独有的6位验证码数据,存入缓存后返回此数据
+
+ * 提供controller,传入手机号与验证码,业务层通过手机号从缓存中读取验证码与输入验证码进行比对,返回比对结果
+
+#### 15.4.1、Cache
+
+* 开启缓存
+
+ @SpringBootApplication
+ @EnableCaching
+ public class Springboot19CacheApplication {
+ public static void main(String[] args) {
+ SpringApplication.run(Springboot19CacheApplication.class, args);
+ }
+ }
+* 业务层接口
+
+ public interface SMSCodeService {
+ /**
+ * 传入手机号获取验证码,存入缓存
+ * @param tele
+ * @return
+ */
+ String sendCodeToSMS(String tele);
+
+ /**
+ * 传入手机号与验证码,校验匹配是否成功
+ * @param smsCode
+ * @return
+ */
+ boolean checkCode(SMSCode smsCode);
+ }
+* 业务层设置获取验证码操作,并存储缓存,手机号为key,验证码为value
+
+ @Autowired
+ private CodeUtils codeUtils;
+ @CachePut(value = "smsCode",key="#tele")
+ public String sendCodeToSMS(String tele) {
+ String code = codeUtils.generator(tele);
+ return code;
+ }
+* 业务层设置校验验证码操作,校验码通过缓存读取,返回校验结果
+
+ @Autowired
+ private CodeUtils codeUtils;
+ public boolean checkCode(SMSCode smsCode) {
+ //取出内存中的验证码与传递过来的验证码比对,如果相同,返回true
+ String code = smsCode.getCode();
+ String cacheCode = codeUtils.get(smsCode.getTele());
+ return code.equals(cacheCode);
+ } @Component
+ public class CodeUtils {
+ @Cacheable(value = "smsCode",key="#tele")
+ public String get(String tele){
+ return null;
+ }
+ }
+
+#### 15.4.2、Ehcache
+
+* 加入Ehcache坐标(缓存供应商实现)
+
+
+ net.sf.ehcache
+ ehcache
+ spring:
+ cache:
+ type: ehcache
+ ehcache:
+ config: ehcache.xml
+* 提供ehcache配置文件ehcache.xml
+
+
+
+
+
+
+
+
+
+
+
+
+
+#### 15.4.3、Redis
+
+* 加入Redis坐标(缓存供应商实现)
+
+
+ org.springframework.boot
+ spring-boot-starter-data-redis
+ spring:
+ redis:
+ host: localhost
+ port: 6379
+ cache:
+ type: redis
+* 设置Redis相关配置
+
+ spring:
+ redis:
+ host: localhost
+ port: 6379
+ cache:
+ type: redis
+ redis:
+ use-key-prefix: true # 是否使用前缀名(系统定义前缀名)
+ key-prefix: sms_ # 追加自定义前缀名
+ time-to-live: 10s # 有效时长
+ cache-null-values: false # 是否允许存储空值
+
+#### 15.4.4、memcached
+
+* 下载memcached
+
+* 地址:https://www.runoob.com/memcached/window-install-memcached.html
+
+* 安装memcached
+
+ * 使用管理员身份运行cmd指令
+
+ * 安装
+
+ `memcached.exe -d install`
+
+* 运行
+
+ * 启动服务
+
+ `memcached.exe -d start`
+
+ * 定制服务
+
+ `memcached.exe -d stop`
+
+* memcached客户端选择
+
+ * Memcached Client for Java:最早期客户端,稳定可靠,用户群广
+ * SpyMemcached:效率更高
+ * Xmemcached:并发处理更好
+* SpringBoot未提供对memcached的整合,需要使用硬编码方式实现客户端初始化管理
+
+* 加入Xmemcached坐标(缓存供应商实现)
+
+
+ com.googlecode.xmemcached
+ xmemcached
+ 2.4.7
+ memcached:
+ # memcached服务器地址
+ servers: localhost:11211
+ # 连接池的数量
+ poolSize: 10
+ # 设置默认操作超时
+ opTimeout: 3000
+* 创建读取属性配置信息类,加载配置
+
+ @Component
+ @ConfigurationProperties(prefix = "memcached")
+ @Data
+ public class XMemcachedProperties {
+ private String servers;
+ private Integer poolSize;
+ private Long opTimeout;
+ }
+* 创建客户端配置类
+
+ @Configuration
+ public class XMemcachedConfig {
+ @Autowired
+ private XMemcachedProperties xMemcachedProperties;
+ @Bean
+ public MemcachedClient getMemcachedClinet() throws IOException {
+ MemcachedClientBuilder builder = new XMemcachedClientBuilder(xMemcachedProperties.getServers());
+ MemcachedClient memcachedClient = builder.build();
+ return memcachedClient;
+ }
+ }
+* 配置memcached属性
+
+ @Service
+ public class SMSCodeServiceMemcacheImpl implements SMSCodeService {
+ @Autowired
+ private CodeUtils codeUtils;
+ @Autowired
+ private MemcachedClient memcachedClient;
+ @Override
+ public String sendCodeToSMS(String tele) {
+ String code = this.codeUtils.generator(tele);
+ //将数据加入memcache
+ try {
+ memcachedClient.set(tele,0,code); // key,timeout,value
+ } catch (Exception e) {
+ e.printStackTrace();
+ }
+ return code;
+ }
+ } @Service
+ public class SMSCodeServiceMemcacheImpl implements SMSCodeService {
+ @Autowired
+ private CodeUtils codeUtils;
+ @Autowired
+ private MemcachedClient memcachedClient;
+ @Override
+ public boolean checkCode(CodeMsg codeMsg) {
+ String value = null;
+ try {
+ value = memcachedClient.get(codeMsg.getTele()).toString();
+ } catch (Exception e) {
+ e.printStackTrace();
+ }
+ return codeMsg.getCode().equals(value);
+ }
+ }
+
+#### 15.4.5、jetcache
+
+* jetCache对SpringCache进行了封装,在原有功能基础上实现了多级缓存、缓存统计、自动刷新、异步调用、数据报表等功能
+
+* jetCache设定了本地缓存与远程缓存的多级缓存解决方案
+
+ * 本地缓存(local)
+
+ * LinkedHashMap
+ * Caffeine
+ * 远程缓存(remote)
+
+ * Redis
+ * Tair
+* 加入jetcache坐标
+
+
+ com.alicp.jetcache
+ jetcache-starter-redis
+ 2.6.2
+ jetcache:
+ remote:
+ default:
+ type: redis
+ host: localhost
+ port: 6379
+ poolConfig:
+ maxTotal: 50 jetcache:
+ remote:
+ default:
+ type: redis
+ host: localhost
+ port: 6379
+ poolConfig:
+ maxTotal: 50
+ sms:
+ type: redis
+ host: localhost
+ port: 6379
+ poolConfig:
+ maxTotal: 50
+* 配置**本地**缓存必要属性
+
+ jetcache:
+ local:
+ default:
+ type: linkedhashmap
+ keyConvertor: fastjson
+* 配置范例
+
+ jetcache:
+ statIntervalMinutes: 15
+ areaInCacheName: false
+ local:
+ default:
+ type: linkedhashmap
+ keyConvertor: fastjson
+ limit: 100
+ remote:
+ default:
+ host: localhost
+ port: 6379
+ type: redis
+ keyConvertor: fastjson
+ valueEncoder: java
+ valueDecoder: java
+ poolConfig:
+ minIdle: 5
+ maxIdle: 20
+ maxTotal: 50
+* 配置属性说明
+ 
+
+* 开启jetcache注解支持
+
+ @SpringBootApplication
+ @EnableCreateCacheAnnotation
+ public class Springboot19CacheApplication {
+ public static void main(String[] args) {
+ SpringApplication.run(Springboot19CacheApplication.class, args);
+ }
+ }
+* 声明缓存对象
+
+ @Service
+ public class SMSCodeServiceImpl implements SMSCodeService {
+ @Autowired
+ private CodeUtils codeUtils;
+ @CreateCache(name = "smsCache", expire = 3600)
+ private Cache jetSMSCache;
+ }
+* 操作缓存
+
+ @Service
+ public class SMSCodeServiceImpl implements SMSCodeService {
+ @Override
+ public String sendCodeToSMS(String tele) {
+ String code = this.codeUtils.generator(tele);
+ jetSMSCache.put(tele,code);
+ return code;
+ }
+ @Override
+ public boolean checkCode(CodeMsg codeMsg) {
+ String value = jetSMSCache.get(codeMsg.getTele());
+ return codeMsg.getCode().equals(value);
+ }
+ }
+* 启用方法注解
+
+ @SpringBootApplication
+ @EnableCreateCacheAnnotation
+ @EnableMethodCache(basePackages = "com.itheima")
+ public class Springboot20JetCacheApplication {
+ public static void main(String[] args) {
+ SpringApplication.run(Springboot20JetCacheApplication.class, args);
+ }
+ }
+* 使用方法注解操作缓存
+
+ @Service
+ public class BookServiceImpl implements BookService {
+ @Autowired
+ private BookDao bookDao;
+ @Cached(name = "smsCache_", key = "#id", expire = 3600)
+ @CacheRefresh(refresh = 10,timeUnit = TimeUnit.SECONDS)
+ public Book getById(Integer id) {
+ return bookDao.selectById(id);
+ }
+ } @Service
+ public class BookServiceImpl implements BookService {
+
+ @CacheUpdate(name = "smsCache_", key = "#book.id", value = "#book")
+ public boolean update(Book book) {
+ return bookDao.updateById(book) > 0;
+ }
+
+ @CacheInvalidate(name = "smsCache_", key = "#id")
+ public boolean delete(Integer id) {
+ return bookDao.deleteById(id) > 0;
+ }
+ }
+* 缓存对象必须保障可序列化
+
+ @Data
+ public class Book implements Serializable {
+ } jetcache:
+ remote:
+ default:
+ type: redis
+ keyConvertor: fastjson
+ valueEncoder: java
+ valueDecoder: java
+* 查看缓存统计报告
+
+ jetcache:
+ statIntervalMinutes: 15
+
+#### 15.4.6、j2cache
+
+* j2cache是一个缓存整合框架,可以提供缓存的整合方案,使各种缓存搭配使用,自身不提供缓存功能
+
+* 基于 ehcache + redis 进行整合
+
+* 加入j2cache坐标,加入整合缓存的坐标
+
+
+ net.oschina.j2cache
+ j2cache-spring-boot2-starter
+ 2.8.0-release
+
+
+ net.oschina.j2cache
+ j2cache-core
+ 2.8.4-release
+
+
+ net.sf.ehcache
+ ehcache
+ j2cache:
+ config-location: j2cache.properties
+* 配置一级缓存与二级缓存以及一级缓存数据到二级缓存的发送方式(j2cache.properties)
+
+ # 配置1级缓存
+ j2cache.L1.provider_class = ehcache
+ ehcache.configXml = ehcache.xml
+
+ # 配置1级缓存数据到2级缓存的广播方式:可以使用redis提供的消息订阅模式,也可以使用jgroups多播实现
+ j2cache.broadcast = net.oschina.j2cache.cache.support.redis.SpringRedisPubSubPolicy
+
+ # 配置2级缓存
+ j2cache.L2.provider_class = net.oschina.j2cache.cache.support.redis.SpringRedisProvider
+ j2cache.L2.config_section = redis
+ redis.hosts = localhost:6379
+* 设置使用缓存
+
+ @Service
+ public class SMSCodeServiceImpl implements SMSCodeService {
+ @Autowired
+ private CodeUtils codeUtils;
+ @Autowired
+ private CacheChannel cacheChannel;
+ } @Service
+ public class SMSCodeServiceImpl implements SMSCodeService {
+ @Override
+ public String sendCodeToSMS(String tele) {
+ String code = codeUtils.generator(tele);
+ cacheChannel.set("sms",tele,code);
+ return code;
+ }
+ @Override
+ public boolean checkCode(SMSCode smsCode) {
+ String code = cacheChannel.get("sms",smsCode.getTele()).asString();
+ return smsCode.getCode().equals(code);
+ }
+ }
+
+## 16、定时
+
+任务
+
+* 定时任务是企业级应用中的常见操作
+
+ * 年度报表
+ * 缓存统计报告
+ * … …
+* 市面上流行的定时任务技术
+
+ * Quartz
+ * Spring Task
+
+### 16.1、SpringBoot整合Quartz
+
+* 相关概念
+
+ * 工作(Job):用于定义具体执行的工作
+ * 工作明细(JobDetail):用于描述定时工作相关的信息
+ * 触发器(Trigger):用于描述触发工作的规则,通常使用cron表达式定义调度规则
+ * 调度器(Scheduler):描述了工作明细与触发器的对应关系
+* 导入SpringBoot整合quartz的坐标
+
+
+ org.springframework.boot
+ spring-boot-starter-quartz
+ public class QuartzTaskBean extends QuartzJobBean {
+ @Override
+ protected void executeInternal(JobExecutionContext context) throws JobExecutionException {
+ System.out.println(“quartz job run... ");
+ }
+ }
+* 定义工作明细与触发器,并绑定对应关系
+
+ @Configuration
+ public class QuartzConfig {
+ @Bean
+ public JobDetail printJobDetail(){
+ return JobBuilder.newJob(QuartzTaskBean.class).storeDurably().build();
+ }
+ @Bean
+ public Trigger printJobTrigger() {
+ CronScheduleBuilder cronScheduleBuilder = CronScheduleBuilder.cronSchedule("0/3 * * * * ?");
+ return TriggerBuilder.newTrigger().forJob(printJobDetail())
+ .withSchedule(cronScheduleBuilder).build();
+ }
+ }
+
+### 16.2、Spring Task
+
+* 开启定时任务功能
+
+ @SpringBootApplication
+ @EnableScheduling
+ public class Springboot22TaskApplication {
+ public static void main(String[] args) {
+ SpringApplication.run(Springboot22TaskApplication.class, args);
+ }
+ }
+* 设置定时执行的任务,并设定执行周期
+
+ @Component
+ public class ScheduledBean {
+ @Scheduled(cron = "0/5 * * * * ?")
+ public void printLog(){
+ System.out.println(Thread.currentThread().getName()+":run...");
+ }
+ }
+* 定时任务相关配置
+
+ spring:
+ task:
+ scheduling:
+ # 任务调度线程池大小 默认 1
+ pool:
+ size: 1
+ # 调度线程名称前缀 默认 scheduling-
+ thread-name-prefix: ssm_
+ shutdown:
+ # 线程池关闭时等待所有任务完成
+ await-termination: false
+ # 调度线程关闭前最大等待时间,确保最后一定关闭
+ await-termination-period: 10s
+
+### 16.3、SpringBoot整合JavaMail
+
+* SMTP(Simple Mail Transfer Protocol):简单邮件传输协议,用于**发送**电子邮件的传输协议
+
+* POP3(Post Office Protocol - Version 3):用于**接收**电子邮件的标准协议
+
+* IMAP(Internet Mail Access Protocol):互联网消息协议,是POP3的替代协议
+
+* 导入SpringBoot整合JavaMail的坐标
+
+
+ org.springframework.boot
+ spring-boot-starter-mail
+ spring:
+ mail:
+ host: smtp.qq.com
+ username: *********@qq.com
+ password: *********
+
+
+
+* 开启定时任务功能
+
+ @Service
+ public class SendMailServiceImpl implements SendMailService {
+ private String from = “********@qq.com"; // 发送人
+ private String to = "********@126.com"; // 接收人
+ private String subject = "测试邮件"; // 邮件主题
+ private String text = "测试邮件正文"; // 邮件内容
+ }
+* 开启定时任务功能
+
+ @Service
+ public class SendMailServiceImpl implements SendMailService {
+ @Autowired
+ private JavaMailSender javaMailSender;
+ @Override
+ public void sendMail() {
+ SimpleMailMessage mailMessage = new SimpleMailMessage();
+ mailMessage.setFrom(from);
+ mailMessage.setTo(to);
+ mailMessage.setSubject(subject);
+ mailMessage.setText(text);
+ javaMailSender.send(mailMessage);
+ }
+ }
+* 附件与HTML文本支持
+
+ private String text = "传智教育";
+ @Override
+ public void sendMail() {
+ try {
+ MimeMessage mimeMessage = javaMailSender.createMimeMessage();
+ MimeMessageHelper mimeMessageHelper = new MimeMessageHelper(mimeMessage,true);
+ mimeMessageHelper.setFrom(from);
+ mimeMessageHelper.setTo(to);
+ mimeMessageHelper.setSubject(subject);
+ mimeMessageHelper.setText(text,true);
+ File file = new File("logo.png");
+ mimeMessageHelper.addAttachment("美图.png",file);
+ javaMailSender.send(mimeMessage);
+ } catch (Exception e) {
+ e.printStackTrace();
+ }
+ }
+
+## 17、消息
+
+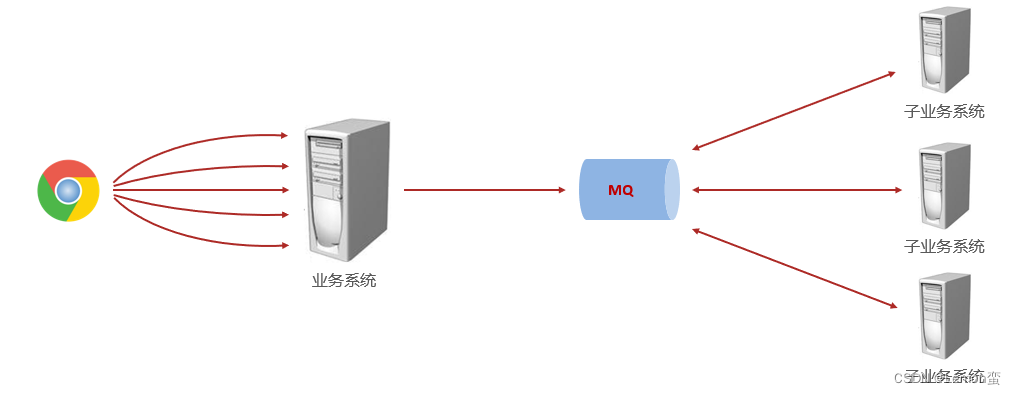
+
+* 企业级应用中广泛使用的三种异步消息传递技术
+ * JMS
+ * AMQP
+ * MQTT
+
+### 17.1、JMS
+
+* JMS(Java Message Service):一个规范,等同于JDBC规范,提供了与消息服务相关的API接口
+
+* JMS消息模型
+
+ * peer-2-peer:点对点模型,消息发送到一个队列中,队列保存消息。队列的消息只能被一个消费者消费,或超时
+ * **pub**lish-**sub**scribe:发布订阅模型,消息可以被多个消费者消费,生产者和消费者完全独立,不需要感知对方的存在
+* JMS消息种类
+
+ * TextMessage
+ * MapMessage
+ * **BytesMessage**
+ * StreamMessage
+ * ObjectMessage
+ * Message (只有消息头和属性)
+* JMS实现:ActiveMQ、Redis、HornetMQ、RabbitMQ、RocketMQ(没有完全遵守JMS规范
+
+### 17.2、AMQP
+
+* AMQP(advanced message queuing protocol):一种协议(高级消息队列协议,也是消息代理规范),规范了网络交换的数据格式,兼容JMS
+
+* 优点:具有跨平台性,服务器供应商,生产者,消费者可以使用不同的语言来实现
+
+* AMQP消息模型
+
+ * direct exchange
+ * fanout exchange
+ * topic exchange
+ * headers exchange
+ * system exchange
+* AMQP消息种类:byte[]
+
+* AMQP实现:RabbitMQ、StormMQ、RocketMQ
+
+### 17.3、MQTT
+
+* MQTT(Message Queueing Telemetry Transport)消息队列遥测传输,专为小设备设计,是物联网(IOT)生态系统中主要成分之一
+
+### 17.4、Kafka
+
+* Kafka,一种高吞吐量的分布式发布订阅消息系统,提供实时消息功能。
+
+### 17.5、消息案例
+
+* 购物订单业务
+ * 登录状态检测
+ * 生成主单
+ * 生成子单
+ * 库存检测与变更
+ * 积分变更
+ * 支付
+ * 短信通知(异步)
+ * 购物车维护
+ * 运单信息初始化
+ * 商品库存维护
+ * 会员维护
+ * …
+
+### 17.6、ActiveMQ
+
+* 下载地址:[https://activemq.apache.org/components/classic/download](https://activemq.apache.org/components/classic/download/)[/](https://activemq.apache.org/components/classic/download/)
+
+* 安装:解压缩
+
+* 启动服务
+
+ `activemq.bat`
+
+* 访问服务器
+
+ `http://127.0.0.1:8161/`
+
+ * 服务端口:61616,管理后台端口:8161
+ * 用户名&密码:**admin**
+
+#### 17.6.1、SpringBoot整合ActiveMQ
+
+* 导入SpringBoot整合ActiveMQ坐标
+
+
+ org.springframework.boot
+ spring-boot-starter-activemq
+ spring:
+ activemq:
+ broker-url: tcp://localhost:61616
+ jms:
+ pub-sub-domain: true
+ template:
+ default-destination: itheima
+* 生产与消费消息(使用默认消息存储队列)
+
+ @Service
+ public class MessageServiceActivemqImpl implements MessageService {
+ @Autowired
+ private JmsMessagingTemplate jmsMessagingTemplate;
+ public void sendMessage(String id) {
+ System.out.println("使用Active将待发送短信的订单纳入处理队列,id:"+id);
+ jmsMessagingTemplate.convertAndSend(id);
+ }
+ public String doMessage() {
+ return jmsMessagingTemplate.receiveAndConvert(String.class);
+ }
+ }
+* 生产与消费消息(指定消息存储队列)
+
+ @Service
+ public class MessageServiceActivemqImpl implements MessageService {
+ @Autowired
+ private JmsMessagingTemplate jmsMessagingTemplate;
+
+ public void sendMessage(String id) {
+ System.out.println("使用Active将待发送短信的订单纳入处理队列,id:"+id);
+ jmsMessagingTemplate.convertAndSend("order.sm.queue.id",id);
+ }
+ public String doMessage() {
+ return jmsMessagingTemplate.receiveAndConvert("order.sm.queue.id",String.class);
+ }
+ }
+* 使用消息监听器对消息队列监听
+
+ @Component
+ public class MessageListener {
+ @JmsListener(destination = "order.sm.queue.id")
+ public void receive(String id){
+ System.out.println("已完成短信发送业务,id:"+id);
+ }
+ }
+* 流程性业务消息消费完转入下一个消息队列
+
+ @Component
+ public class MessageListener {
+ @JmsListener(destination = "order.sm.queue.id")
+ @SendTo("order.other.queue.id")
+ public String receive(String id){
+ System.out.println("已完成短信发送业务,id:"+id);
+ return "new:"+id;
+ }
+ }
+
+### 17.7、RabbitMQ
+
+* RabbitMQ基于Erlang语言编写,需要安装Erlang
+
+* Erlang
+
+ * 下载地址:[https](https://www.erlang.org/downloads)[😕/www.erlang.org/downloads](https://www.erlang.org/downloads)
+ * 安装:一键傻瓜式安装,安装完毕需要重启,需要依赖Windows组件
+ * 环境变量配置
+ * ERLANG_HOME
+ * PATH
+* 下载地址:[https://](https://rabbitmq.com/install-windows.html)[rabbitmq.com/install-windows.html](https://rabbitmq.com/install-windows.html)
+
+* 安装:一键傻瓜式安装
+
+* 启动服务
+
+ `rabbitmq-service.bat start`
+
+* 关闭服务
+
+ `rabbitmq-service.bat stop`
+
+* 查看服务状态
+
+ `rabbitmqctl status`
+
+* 服务管理可视化(插件形式)
+
+* 查看已安装的插件列表
+
+* 开启服务管理插件
+
+ `rabbitmq-plugins.bat enable rabbitmq_management`
+
+* 访问服务器
+
+ `http://localhost:15672`
+
+ * 服务端口:5672,管理后台端口:15672
+ * 用户名&密码:**guest**
+
+#### 17.7.1、SpringBoot整合RabbitMQ
+
+* 导入SpringBoot整合RabbitMQ坐标
+
+
+ org.springframework.boot
+ spring-boot-starter-amqp
+ spring:
+ rabbitmq:
+ host: localhost
+ port: 5672
+* 定义消息队列(direct)
+
+ @Configuration
+ public class RabbitDirectConfig {
+ @Bean
+ public Queue queue(){
+ return new Queue("simple_queue");
+ }
+ } @Configuration
+ public class RabbitDirectConfig {
+ @Bean
+ public Queue queue(){
+ // durable:是否持久化,默认false
+ // exclusive:是否当前连接专用,默认false,连接关闭后队列即被删除
+ // autoDelete:是否自动删除,当生产者或消费者不再使用此队列,自动删除
+ return new Queue("simple_queue",true,false,false);
+ }
+ } @Configuration
+ public class RabbitDirectConfig {
+ @Bean
+ public Queue directQueue(){
+ return new Queue("direct_queue");
+ }
+ @Bean
+ public Queue directQueue2(){
+ return new Queue("direct_queue2");
+ }
+ @Bean
+ public DirectExchange directExchange(){
+ return new DirectExchange("directExchange");
+ }
+ @Bean
+ public Binding bindingDirect(){
+ return BindingBuilder.bind(directQueue()).to(directExchange()).with("direct");
+ }
+ @Bean
+ public Binding bindingDirect2(){
+ return BindingBuilder.bind(directQueue2()).to(directExchange()).with("direct2");
+ }
+ }
+* 生产与消费消息(direct)
+
+ @Service
+ public class MessageServiceRabbitmqDirectImpl implements MessageService {
+ @Autowired
+ private AmqpTemplate amqpTemplate;
+ @Override
+ public void sendMessage(String id) {
+ System.out.println("使用Rabbitmq将待发送短信的订单纳入处理队列,id:"+id);
+ amqpTemplate.convertAndSend("directExchange","direct",id);
+ }
+ }
+* 使用消息监听器对消息队列监听(direct)
+
+ @Component
+ public class RabbitMessageListener {
+ @RabbitListener(queues = "direct_queue")
+ public void receive(String id){
+ System.out.println("已完成短信发送业务,id:"+id);
+ }
+ }
+* 使用多消息监听器对消息队列监听进行消息轮循处理(direct)
+
+ @Component
+ public class RabbitMessageListener2 {
+ @RabbitListener(queues = "direct_queue")
+ public void receive(String id){
+ System.out.println("已完成短信发送业务(two),id:"+id);
+ }
+ }
+* 定义消息队列(topic)
+
+ @Configuration
+ public class RabbitTopicConfig {
+ @Bean
+ public Queue topicQueue(){ return new Queue("topic_queue"); }
+ @Bean
+ public Queue topicQueue2(){ return new Queue("topic_queue2"); }
+ @Bean
+ public TopicExchange topicExchange(){
+ return new TopicExchange("topicExchange");
+ }
+ @Bean
+ public Binding bindingTopic(){
+ return BindingBuilder.bind(topicQueue()).to(topicExchange()).with("topic.*.*");
+ }
+ @Bean
+ public Binding bindingTopic2(){
+ return BindingBuilder.bind(topicQueue2()).to(topicExchange()).with("topic.#");
+ }
+ }
+* 绑定键匹配规则
+
+ * `*`(星号): 用来表示一个单词 ,且该单词是必须出现的
+ * `#`(井号): 用来表示任意数量
+
+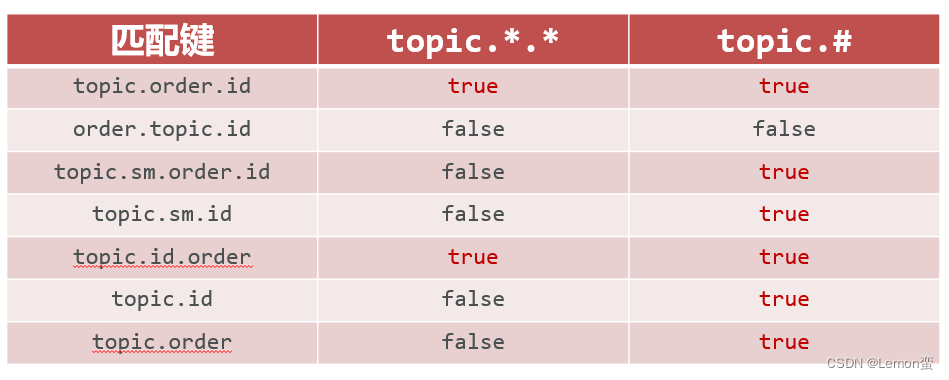
+
+* 生产与消费消息(topic)
+
+ @Service
+ public class MessageServiceRabbitmqTopicmpl implements MessageService {
+ @Autowired
+ private AmqpTemplate amqpTemplate;
+ @Override
+ public void sendMessage(String id) {
+ System.out.println("使用Rabbitmq将待发送短信的订单纳入处理队列,id:"+id);
+ amqpTemplate.convertAndSend("topicExchange","topic.order.id",id);
+ }
+ }
+* 使用消息监听器对消息队列监听(topic)
+
+ @Component
+ public class RabbitTopicMessageListener {
+ @RabbitListener(queues = "topic_queue")
+ public void receive(String id){
+ System.out.println("已完成短信发送业务,id:"+id);
+ }
+ @RabbitListener(queues = "topic_queue2")
+ public void receive2(String id){
+ System.out.println("已完成短信发送业务(two),id:"+id);
+ }
+ }
+
+### 17.8、RocketMQ
+
+* 下载地址:[https://rocketmq.apache.org](https://rocketmq.apache.org/)[/](https://rocketmq.apache.org/)
+
+* 安装:解压缩
+
+ * 默认服务端口:9876
+* 环境变量配置
+
+* ROCKETMQ_HOME
+
+* PATH
+
+* NAMESRV_ADDR (建议): 127.0.0.1:9876
+
+* 命名服务器与broker
+ 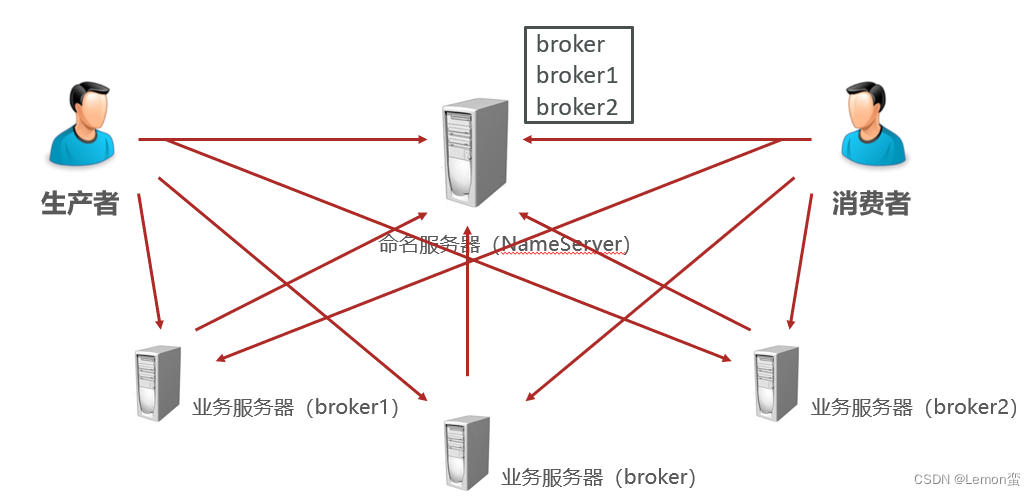
+
+* 启动命名服务器
+
+ `mqnamesrv`
+
+* 启动broker
+
+ `mqbroker`
+
+* 服务器功能测试:生产者
+
+ `tools org.apache.rocketmq.example.quickstart.Producer`
+
+* 服务器功能测试:消费者
+
+ `tools org.apache.rocketmq.example.quickstart.Consumer`
+
+#### 17.8.1、SpringBoot整合RocketMQ
+
+* 导入SpringBoot整合RocketMQ坐标
+
+
+ org.apache.rocketmq
+ rocketmq-spring-boot-starter
+ 2.2.1
+ rocketmq:
+ name-server: localhost:9876
+ producer:
+ group: group_rocketmq
+* 生产消息
+
+ @Service
+ public class MessageServiceRocketmqImpl implements MessageService {
+ @Autowired
+ private RocketMQTemplate rocketMQTemplate;
+ @Override
+ public void sendMessage(String id) {
+ rocketMQTemplate.convertAndSend("order_sm_id",id);
+ System.out.println("使用Rabbitmq将待发送短信的订单纳入处理队列,id:"+id);
+ }
+ }
+* 生产异步消息
+
+ @Service
+ public class MessageServiceRocketmqImpl implements MessageService {
+ @Autowired
+ private RocketMQTemplate rocketMQTemplate;
+ @Override
+ public void sendMessage(String id) {
+ SendCallback callback = new SendCallback() {
+ @Override
+ public void onSuccess(SendResult sendResult) {
+ System.out.println("消息发送成功");
+ }
+ @Override
+ public void onException(Throwable throwable) {
+ System.out.println("消息发送失败!!!!!!!!!!!");
+ }
+ };
+ System.out.println("使用Rabbitmq将待发送短信的订单纳入处理队列,id:"+id);
+ rocketMQTemplate.asyncSend("order_sm_id",id,callback);
+ }
+ }
+* 使用消息监听器对消息队列监听
+
+ @Component
+ @RocketMQMessageListener(topic="order_sm_id",consumerGroup = "group_rocketmq")
+ public class RocketmqMessageListener implements RocketMQListener {
+ @Override
+ public void onMessage(String id) {
+ System.out.println("已完成短信发送业务,id:"+id);
+ }
+ }
+
+### 17.9、Kafka
+
+* 下载地址:[https://](https://kafka.apache.org/downloads)[kafka.apache.org/downloads](https://kafka.apache.org/downloads)
+
+* windows 系统下3.0.0版本存在BUG,建议使用2.X版本
+
+* 安装:解压缩
+
+* 启动zookeeper
+
+ `zookeeper-server-start.bat ..\..\config\zookeeper.properties`
+
+ * 默认端口:2181
+* 启动kafka
+
+ `kafka-server-start.bat ..\..\config\server.properties`
+
+ * 默认端口:9092
+* 创建topic
+
+ `kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic itheima`
+
+* 查看topic
+
+ `kafka-topics.bat --zookeeper 127.0.0.1:2181 --list`
+
+* 删除topic
+
+ `kafka-topics.bat --delete --zookeeper localhost:2181 --topic itheima`
+
+* 生产者功能测试
+
+ `kafka-console-producer.bat --broker-list localhost:9092 --topic itheima`
+
+* 消费者功能测试
+
+ `kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic itheima --from-beginning`
+
+#### 17.9.1、SpringBoot整合Kafka
+
+* 导入SpringBoot整合Kafka坐标
+
+
+ org.springframework.kafka
+ spring-kafka
+ spring:
+ kafka:
+ bootstrap-servers: localhost:9092
+ consumer:
+ group-id: order
+* 生产消息
+
+ @Service
+ public class MessageServiceKafkaImpl implements MessageService {
+ @Autowired
+ private KafkaTemplate kafkaTemplate;
+ @Override
+ public void sendMessage(String id) {
+ System.out.println("使用Kafka将待发送短信的订单纳入处理队列,id:"+id);
+ kafkaTemplate.send("kafka_topic",id); }
+ }
+* 使用消息监听器对消息队列监听
+
+ @Component
+ public class KafkaMessageListener{
+ @KafkaListener(topics = {"kafka_topic"})
+ public void onMessage(ConsumerRecord record) {
+ System.out.println("已完成短信发送业务,id:"+record.value());
+ }
+ }
+
+## 18、监控
+
+### 18.1、简介
+
+监控的意义:
+
+* 监控服务状态是否宕机
+* 监控服务运行指标(内存、虚拟机、线程、请求等)
+* 监控日志
+* 管理服务(服务下线)
+
+监控的实施方式:
+
+* 显示监控信息的服务器:用于获取服务信息,并显示对应的信息
+* 运行的服务:启动时主动上报,告知监控服务器自己需要受到监控
+ 
+
+### 18.2、可视化监控平台
+
+* Spring Boot Admin,开源社区项目,用于管理和监控SpringBoot应用程序。 客户端注册到服务端后,通过HTTP请求方式,服务端定期从客户端获取对应的信息,并通过UI界面展示对应信息。
+
+* Admin服务端
+
+
+ 2.5.4
+
+
+
+ de.codecentric
+ spring-boot-admin-starter-server
+
+
+
+
+
+ de.codecentric
+ spring-boot-admin-dependencies
+ ${spring-boot-admin.version}
+ pom
+ import
+
+
+
+ 2.5.4
+
+
+
+ de.codecentric
+ spring-boot-admin-starter-client
+
+
+
+
+
+ de.codecentric
+ spring-boot-admin-dependencies
+ ${spring-boot-admin.version}
+ pom
+ import
+
+
+
+ de.codecentric
+ spring-boot-admin-starter-server
+ 2.5.4
+
+ de.codecentric
+ spring-boot-admin-starter-client
+ 2.5.4
+ server:
+ port: 8080
+* 设置启用Spring-Admin
+
+ @SpringBootApplication
+ @EnableAdminServer
+ public class Springboot25ActuatorServerApplication {
+ public static void main(String[] args) {
+ SpringApplication.run(Springboot25ActuatorServerApplication.class, args);
+ }
+ }
+* Admin客户端
+
+ spring:
+ boot:
+ admin:
+ client:
+ url: http://localhost:8080
+ management:
+ endpoint:
+ health:
+ show-details: always
+ endpoints:
+ web:
+ exposure:
+ include: "*"
+
+
+
+### 18.3、监控原理
+
+* Actuator提供了SpringBoot生产就绪功能,通过端点的配置与访问,获取端点信息
+
+* 端点描述了一组监控信息,SpringBoot提供了多个内置端点,也可以根据需要自定义端点信息
+
+* 访问当前应用所有端点信息:**/actuator**
+
+* 访问端点详细信息:/actuator**/****端点名称**
+ 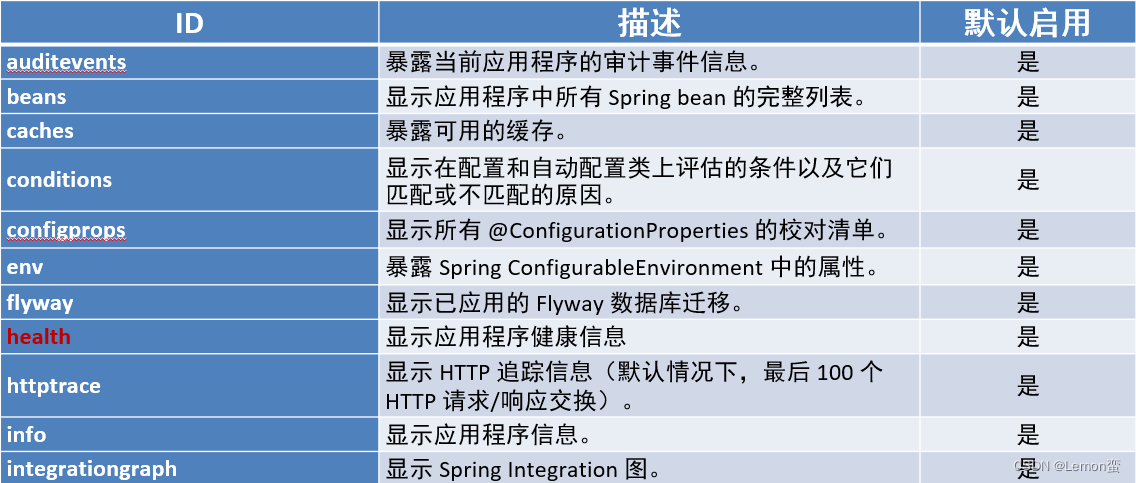
+
+
+
+* Web程序专用端点
+ 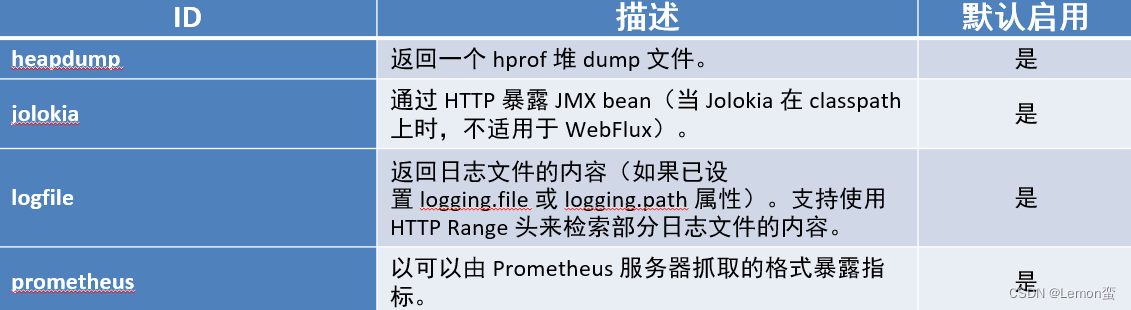
+
+* 启用指定端点
+
+ management:
+ endpoint:
+ health: # 端点名称
+ enabled: true show-details: always beans: # 端点名称 enabled: true
+* 启用所有端点
+
+ management:
+ endpoints:
+ enabled-by-default: true
+* 暴露端点功能
+
+ * 端点中包含的信息存在敏感信息,需要对外暴露端点功能时手动设定指定端点信息
+ 
+ 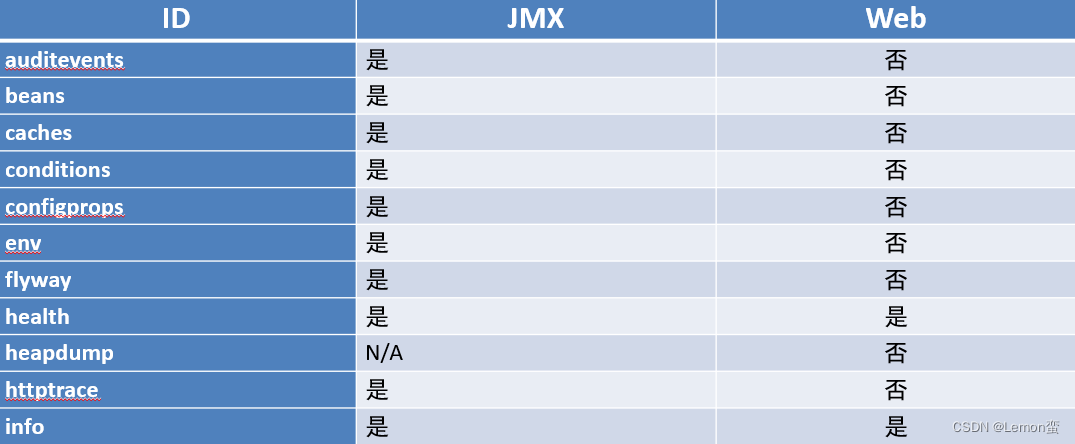
+ 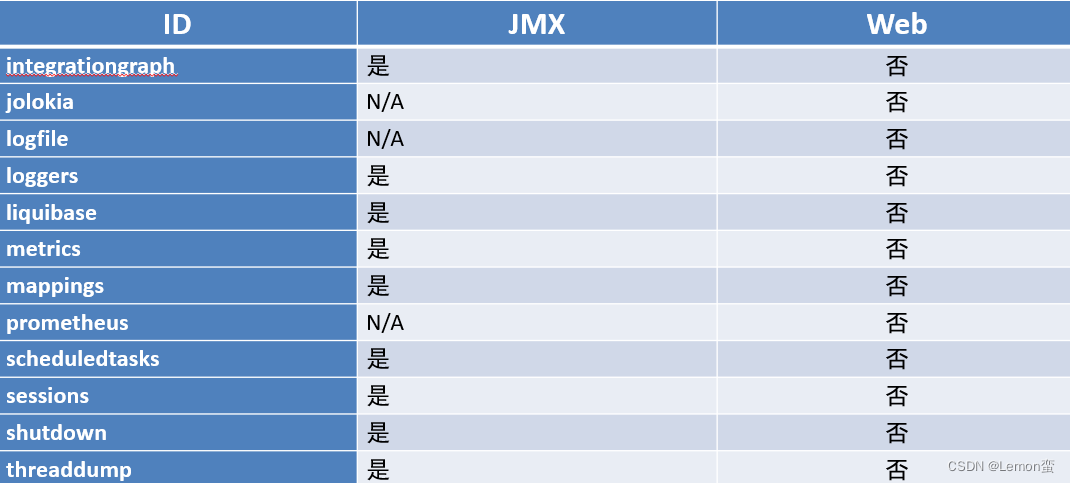
+
+### 18.4、自定义监控指标
+
+* 为info端点添加自定义指标
+
+ info:
+ appName: @project.artifactId@
+ version: @project.version@
+ author: itheima @Component
+ public class AppInfoContributor implements InfoContributor {
+ @Override
+ public void contribute(Info.Builder builder) {
+ Map infoMap = new HashMap<>();
+ infoMap.put("buildTime","2006");
+ builder.withDetail("runTime",System.currentTimeMillis())
+ .withDetail("company","传智教育");
+ builder.withDetails(infoMap);
+ }
+ }
+* 为Health端点添加自定义指标
+
+ @Component
+ public class AppHealthContributor extends AbstractHealthIndicator {
+ @Override
+ protected void doHealthCheck(Health.Builder builder) throws Exception {
+ boolean condition = true;
+ if(condition){
+ Map infoMap = new HashMap<>();
+ infoMap.put("buildTime","2006");
+ builder.withDetail("runTime",System.currentTimeMillis())
+ .withDetail("company","传智教育");
+ builder.withDetails(infoMap);
+ builder.status(Status.UP);
+ }else{
+ builder.status(Status.DOWN);
+ }
+ }
+ }
+* 为Metrics端点添加自定义指标
+
+ @Service
+ public class BookServiceImpl extends ServiceImpl implements IBookService {
+ private Counter counter;
+ public BookServiceImpl(MeterRegistry meterRegistry){
+ counter = meterRegistry.counter("用户付费操作次数:");
+ }
+ @Override
+ public boolean delete(Integer id) {
+ counter.increment();
+ return bookDao.deleteById(id) > 0;
+ }
+ }
+* 自定义端点
+
+ @Component
+ @Endpoint(id="pay")
+ public class PayEndPoint {
+ @ReadOperation
+ public Object getPay(){
+ //调用业务操作,获取支付相关信息结果,最终return出去
+ Map payMap = new HashMap();
+ payMap.put("level 1",103);
+ payMap.put("level 2",315);
+ payMap.put("level 3",666);
+ return payMap;
+ }
+ }
+
+pom
+import
+
+ - Admin客户端
+
+```xml
+
+ 2.5.4
+
+
+
+ de.codecentric
+ spring-boot-admin-starter-client
+
+
+
+
+
+ de.codecentric
+ spring-boot-admin-dependencies
+ ${spring-boot-admin.version}
+ pom
+ import
+
+
+
+
+* Admin服务端
+
+
+ de.codecentric
+ spring-boot-admin-starter-server
+ 2.5.4
+
+ de.codecentric
+ spring-boot-admin-starter-client
+ 2.5.4
+ server:
+ port: 8080
+* 设置启用Spring-Admin
+
+ @SpringBootApplication
+ @EnableAdminServer
+ public class Springboot25ActuatorServerApplication {
+ public static void main(String[] args) {
+ SpringApplication.run(Springboot25ActuatorServerApplication.class, args);
+ }
+ }
+* Admin客户端
+
+ spring:
+ boot:
+ admin:
+ client:
+ url: http://localhost:8080
+ management:
+ endpoint:
+ health:
+ show-details: always
+ endpoints:
+ web:
+ exposure:
+ include: "*"
+
+ [外链图片转存中…(img-cXWfQSEx-1657811363485)]
+
+### 18.3、监控原理
+
+* Actuator提供了SpringBoot生产就绪功能,通过端点的配置与访问,获取端点信息
+
+* 端点描述了一组监控信息,SpringBoot提供了多个内置端点,也可以根据需要自定义端点信息
+
+* 访问当前应用所有端点信息:**/actuator**
+
+* 访问端点详细信息:/actuator**/****端点名称**
+
+ [外链图片转存中…(img-KSdMaD18-1657811363486)]
+
+ [外链图片转存中…(img-UlUbALwe-1657811363487)]
+
+* Web程序专用端点
+
+ [外链图片转存中…(img-maGlhCAb-1657811363487)]
+
+* 启用指定端点
+
+ management:
+ endpoint:
+ health: # 端点名称
+ enabled: true show-details: always beans: # 端点名称 enabled: true
+* 启用所有端点
+
+ management:
+ endpoints:
+ enabled-by-default: true
+* 暴露端点功能
+
+ * 端点中包含的信息存在敏感信息,需要对外暴露端点功能时手动设定指定端点信息
+
+ [外链图片转存中…(img-6UeTKYgJ-1657811363488)]
+
+[外链图片转存中…(img-bLPYJP4S-1657811363489)]
+
+[外链图片转存中…(img-RwCI70cm-1657811363490)]
+
+### 18.4、自定义监控指标
+
+* 为info端点添加自定义指标
+
+ info:
+ appName: @project.artifactId@
+ version: @project.version@
+ author: itheima @Component
+ public class AppInfoContributor implements InfoContributor {
+ @Override
+ public void contribute(Info.Builder builder) {
+ Map infoMap = new HashMap<>();
+ infoMap.put("buildTime","2006");
+ builder.withDetail("runTime",System.currentTimeMillis())
+ .withDetail("company","传智教育");
+ builder.withDetails(infoMap);
+ }
+ }
+* 为Health端点添加自定义指标
+
+ @Component
+ public class AppHealthContributor extends AbstractHealthIndicator {
+ @Override
+ protected void doHealthCheck(Health.Builder builder) throws Exception {
+ boolean condition = true;
+ if(condition){
+ Map infoMap = new HashMap<>();
+ infoMap.put("buildTime","2006");
+ builder.withDetail("runTime",System.currentTimeMillis())
+ .withDetail("company","传智教育");
+ builder.withDetails(infoMap);
+ builder.status(Status.UP);
+ }else{
+ builder.status(Status.DOWN);
+ }
+ }
+ }
+* 为Metrics端点添加自定义指标
+
+ @Service
+ public class BookServiceImpl extends ServiceImpl implements IBookService {
+ private Counter counter;
+ public BookServiceImpl(MeterRegistry meterRegistry){
+ counter = meterRegistry.counter("用户付费操作次数:");
+ }
+ @Override
+ public boolean delete(Integer id) {
+ counter.increment();
+ return bookDao.deleteById(id) > 0;
+ }
+ }
+* 自定义端点
+
+ @Component
+ @Endpoint(id="pay")
+ public class PayEndPoint {
+ @ReadOperation
+ public Object getPay(){
+ //调用业务操作,获取支付相关信息结果,最终return出去
+ Map payMap = new HashMap();
+ payMap.put("level 1",103);
+ payMap.put("level 2",315);
+ payMap.put("level 3",666);
+ return payMap;
+ }
+ }
\ No newline at end of file
diff --git "a/docs/interview-experience/\345\220\204\345\244\247\345\205\254\345\217\270\351\235\242\347\273\217.md" "b/docs/interview-experience/\345\220\204\345\244\247\345\205\254\345\217\270\351\235\242\347\273\217.md"
index 03ebf3e..1c0fbd0 100644
--- "a/docs/interview-experience/\345\220\204\345\244\247\345\205\254\345\217\270\351\235\242\347\273\217.md"
+++ "b/docs/interview-experience/\345\220\204\345\244\247\345\205\254\345\217\270\351\235\242\347\273\217.md"
@@ -1,3 +1,49 @@
+# 京东
+
+### 京东一面
+
+1、Java中的乐观锁悲观锁
+
+https://segmentfault.com/a/1190000016611415
+
+2、单点登录
+3、集合的问题
+4、反转链表
+5、二分查找
+6、堆排序
+7、JUC
+8、Java中如何实现线程安全
+9、ArrayList和linkedList区别
+10、数组和链表区别
+11、volitale
+
+### 秋招一面
+
+1、数据库死锁及解决方案
+
+https://blog.csdn.net/cbjcry/article/details/84920174
+
+
+2、数据库分库分表后的分页查询及相关操作怎么解决
+
+https://crossoverjie.top/2019/07/24/framework-design/sharding-db-03/
+https://juejin.im/entry/6844903478171533320
+https://tech.meituan.com/2016/11/18/dianping-order-db-sharding.html
+
+
+### 秋招二面
+
+1、UML
+https://www.jianshu.com/p/28200121a33d
+2、超时确认,快速重传原理,快速重传重传几次,3次
+https://blog.csdn.net/u010710458/article/details/79968648
+https://www.cnblogs.com/postw/p/9678454.html
+3、singleThreadThreadPool相对于ThreadPoolExecutor的优势
+4、可重复读机制
+https://www.pianshen.com/article/11361872925/
+
+
+
# 阿里
- [阿里社招四面(分布式)](https://www.nowcoder.com/discuss/349542)
@@ -19,6 +65,18 @@
8、maven:如何查找重复的jar包问题
9、单点登录如何做的,如果保证安全性
+**缺点**:linux实战的不懂
+
+### 钉钉二面
+
+1、项目有什么难点:应该不管是什么项目都是数据库优化跟JVM问题排查
+2、操作系统内存交换方式
+3、tcp7层模型
+4、平时学习方法
+5、自己博客写的好的进行介绍
+
+**缺点**:重点不突出、操作系统不清楚。
+
# 腾讯
@@ -77,6 +135,36 @@
# 头条
+### 一面
+
+1、多线程调度原理
+https://zhuanlan.zhihu.com/p/58846439
+2、select、poll、epoll
+3、多线程原理与操作系统
+https://www.zhihu.com/question/25527028
+4、redis的单线程模型:单核会有多线程切换吗
+https://blog.csdn.net/qq_27185561/article/details/82900426
+5、算法、算法、算法、算法。
+6、线程池用到的数据结构
+7、最长上升子序列的个数
+8、为什么myisam快:非聚集索引,B+树,为什么用B+树和B树的区别。为什么B+树IO次数少
+9、MyISAM与InnoDB 的区别
+https://www.cnblogs.com/fwqblogs/p/6645274.html
+10、事务隔离级别:可重复读会发生幻读吗?会
+
+### 二面
+
+1、hashmap解决冲突方法
+2、hashmap扩容机制
+3、jvm的jstack作用
+4、最长不重复子串
+5、https
+
+
+
+
+
+
# 拼多多
@@ -133,6 +221,14 @@ https://www.cnblogs.com/JackPn/p/9386182.html
# 快手
+1、项目
+2、两数之和等于target
+3、http介绍
+4、输入网址的过程
+5、dubbo原理
+6、http和dubbo协议的区别
+
+**缺点**:写算法还不熟练
#### Tip:本来有很多我准备的资料的,但是都是外链,或者不合适的分享方式,所以大家去公众号回复【资料】好了。
diff --git "a/docs/interview-experience/\351\235\242\350\257\225\345\270\270\350\247\201\347\237\245\350\257\206.md" "b/docs/interview-experience/\351\235\242\350\257\225\345\270\270\350\247\201\347\237\245\350\257\206.md"
deleted file mode 100644
index d5c41a0..0000000
--- "a/docs/interview-experience/\351\235\242\350\257\225\345\270\270\350\247\201\347\237\245\350\257\206.md"
+++ /dev/null
@@ -1,90 +0,0 @@
-# 阿里
-
-linux进程结构
-linux文件系统
-linux统计文件数量
-spingioc,springaop中的cglib动态
-shell脚本
-webLogic知道不? 与tomcat区别?
-webservice
-HashMap链表转红黑树是怎么实现的
-进程通信
-散列表(哈希表)
-Java中pv操作实现时用的类
-说一下TCP/IP的状态转移
-说一下NIO
-线程通信
-写过异步的代码吗
-拜占庭算法的理解?
-红黑树么,在插入上有什么优化?
-resetful风格
-分布式rpc调度过程中要注意的问题
-hashmap并发读写死循环问题
-快排时间复杂度?最好什么情况,最坏什么情况?有什么改进方案?
-HashMap get和put源码,为什么红黑而非平衡树?
-分布式系统CAP理论,重点解释分区容错性的意义
-对虚拟内存的理解
-三个线程如何实现交替打印ABC
-线程池中LinkedBlockingQueue满了的话,线程会怎么样
-HashMap和ConcurrentHashMap哪个效率更高?为什么?
-mybatis如何进行类型转换
-myql间歇锁的实现原理
-future的底层实现异步原理
-rpc原理
-多个服务端上下线怎么感知
-降级处理hystrix了解过么
-redis的热点key问题
-一致性哈希
-ClassLoader原理和应用
-注解的原理
-
-
-
-# 腾讯
-
-
-
-# 百度
-
-
-
-# 滴滴
-
-
-
-# 头条
-
-
-
-# 拼多多
-
-
-
-# 美团
-
-
-
-# 小米
-
-
-
-# 网易
-
-
-
-# 华为
-
-
-#### Tip:本来有很多我准备的资料的,但是都是外链,或者不合适的分享方式,所以大家去公众号回复【资料】好了。
-
-
-
-现在免费送给大家,在我的公众号 **好好学java** 回复 **资料** 即可获取。
-
-有收获?希望老铁们来个三连击,给更多的人看到这篇文章
-
-1、老铁们,关注我的原创微信公众号「**好好学java**」,专注于Java、数据结构和算法、微服务、中间件等技术分享,保证你看完有所收获。
-
-
-
-2、给俺一个 **star** 呗,可以让更多的人看到这篇文章,顺便激励下我继续写作,嘻嘻。
\ No newline at end of file
diff --git "a/docs/interview-experience/\351\235\242\350\257\225\345\270\270\350\247\201\351\227\256\351\242\230\345\210\206\347\261\273\346\261\207\346\200\273.md" "b/docs/interview-experience/\351\235\242\350\257\225\345\270\270\350\247\201\351\227\256\351\242\230\345\210\206\347\261\273\346\261\207\346\200\273.md"
index 7857062..5c926ef 100644
--- "a/docs/interview-experience/\351\235\242\350\257\225\345\270\270\350\247\201\351\227\256\351\242\230\345\210\206\347\261\273\346\261\207\346\200\273.md"
+++ "b/docs/interview-experience/\351\235\242\350\257\225\345\270\270\350\247\201\351\227\256\351\242\230\345\210\206\347\261\273\346\261\207\346\200\273.md"
@@ -1,96 +1,398 @@
-# Java基础
-#### 反射在jvm层面的实现
+
+
+
+
+- [一 Java基础](#一-java基础)
+ - [一致性hash算法](#一致性hash算法)
+ - [sleep和wait](#sleep和wait)
+ - [强软弱虚引用](#强软弱虚引用)
+ - [Arrays.sort原理](#arrayssort原理)
+ - [创建对象的方式](#创建对象的方式)
+ - [若hashcode方法永远返回1会产生什么结果](#若hashcode方法永远返回1会产生什么结果)
+ - [解决hash冲突的三种方法](#解决hash冲突的三种方法)
+ - [为什么要重写hashCode()方法和equals()方法以及如何进行重写](#为什么要重写hashcode方法和equals方法以及如何进行重写)
+ - [动态代理](#动态代理)
+ - [sleep和wait的区别](#sleep和wait的区别)
+ - [java 地址和值传递的例子](#java-地址和值传递的例子)
+ - [Java序列化](#java序列化)
+ - [java NIO,java 多线程、线程池,java 网络编程解决并发量](#java-niojava-多线程-线程池java-网络编程解决并发量)
+ - [JDBC 连接的过程 ,手写 jdbc 连接过程](#jdbc-连接的过程-手写-jdbc-连接过程)
+ - [说出三个遇到过的程序报异常的情况](#说出三个遇到过的程序报异常的情况)
+ - [socket 是靠什么协议支持的](#socket-是靠什么协议支持的)
+ - [java io 用到什么设计模式](#java-io-用到什么设计模式)
+ - [serviable 的序列化,其中 uuid 的作用](#serviable-的序列化其中-uuid-的作用)
+ - [什么情景下会用到反射](#什么情景下会用到反射)
+ - [浅克隆与深克隆有什么区别,如何实现深克隆](#浅克隆与深克隆有什么区别如何实现深克隆)
+ - [反射能够使用私有的方法属性吗和底层原理?](#反射能够使用私有的方法属性吗和底层原理)
+ - [处理器指令优化有些什么考虑?](#处理器指令优化有些什么考虑)
+ - [object 对象的常用方法](#object-对象的常用方法)
+ - [Stack 和 ArrayList 的区别](#stack-和-arraylist-的区别)
+ - [statement 和 prestatement 的区别](#statement-和-prestatement-的区别)
+ - [手写模拟实现一个阻塞队列](#手写模拟实现一个阻塞队列)
+ - [util 包下有哪几种接口](#util-包下有哪几种接口)
+ - [很常见的 Nullpointerexception ,你是怎么排查的,怎么解决的;](#很常见的-nullpointerexception-你是怎么排查的怎么解决的)
+ - [静态内部类和非静态内部类的区别是什么?](#静态内部类和非静态内部类的区别是什么)
+ - [怎么创建静态内部类和非静态内部类?](#怎么创建静态内部类和非静态内部类)
+ - [Xml 解析方式,原理优缺点](#xml-解析方式原理优缺点)
+ - [静态变量和全局变量的区别](#静态变量和全局变量的区别)
+- [二 Java集合](#二-java集合)
+ - [hashmap的jdk1.7和jdk1.8区别](#hashmap的jdk17和jdk18区别)
+ - [concurrenthashmap的jdk1.7和jdk1.8区别](#concurrenthashmap的jdk17和jdk18区别)
+ - [HashMap 实现原理,扩容因子过大过小的缺点,扩容过程 采用什么方法能保证每个 bucket 中的数据更均匀 解决冲突的方式,还有没有其他方式(全域哈希)](#hashmap-实现原理扩容因子过大过小的缺点扩容过程-采用什么方法能保证每个-bucket-中的数据更均匀-解决冲突的方式还有没有其他方式全域哈希)
+ - [Collection 集合类中只能在 Iterator 中删除元素的原因](#collection-集合类中只能在-iterator-中删除元素的原因)
+ - [ArrayList、LinkedList、Vector](#arraylist-linkedlist-vector)
+ - [还了解除 util 其他包下的 List 吗?](#还了解除-util-其他包下的-list-吗)
+ - [CopyOnWriteArrayList](#copyonwritearraylist)
+ - [ConcurrentHashMap 和 LinkedHashMap 差异和适用情形](#concurrenthashmap-和-linkedhashmap-差异和适用情形)
+ - [ConcurrentHashMap分段锁是如何实现,ConcurrentHashmap jdk1.8 访问的时候是怎么加锁的,插入的时候是怎么加锁的 访问不加 锁插入的时候对头结点加锁](#concurrenthashmap分段锁是如何实现concurrenthashmap-jdk18-访问的时候是怎么加锁的插入的时候是怎么加锁的-访问不加-锁插入的时候对头结点加锁)
+ - [ArrayDeque 的使用场景](#arraydeque-的使用场景)
+ - [ArrayBlockingQueue 源码](#arrayblockingqueue-源码)
+ - [hashmap 和 treemap 的区别](#hashmap-和-treemap-的区别)
+ - [hashmap](#hashmap)
+ - [treemap](#treemap)
+ - [rehash 过程](#rehash-过程)
+ - [HashMap 的负载因子,为什么容量为2^n](#hashmap-的负载因子为什么容量为2n)
+ - [list,map,set 之间的区别](#listmapset-之间的区别)
+ - [什么时候会用到 HashMap](#什么时候会用到-hashmap)
+ - [常见的线程安全的集合类](#常见的线程安全的集合类)
+- [三 JVM](#三-jvm)
+ - [反射在jvm层面的实现](#反射在jvm层面的实现)
+ - [jvm的方法区存什么?](#jvm的方法区存什么)
+ - [JDK1.8 JVM方法区变成了什么,为什么这样做](#jdk18-jvm方法区变成了什么为什么这样做)
+ - [oom出现的原因](#oom出现的原因)
+ - [Class.forName和ClassLoader的区别](#classforname和classloader的区别)
+ - [java对象信息分配](#java对象信息分配)
+ - [java虚拟机ZGC详解](#java虚拟机zgc详解)
+ - [java虚拟机CMS详解](#java虚拟机cms详解)
+ - [java虚拟机G1详解](#java虚拟机g1详解)
+ - [JVM tomcat 容器启动,jvm 加载情况描述](#jvm-tomcat-容器启动jvm-加载情况描述)
+- [四 多线程并发](#四-多线程并发)
+ - [volitale使用场景](#volitale使用场景)
+ - [可重入锁,实现原理](#可重入锁实现原理)
+ - [Java 无锁原理](#java-无锁原理)
+ - [讲讲多线程,多线程的同步方法](#讲讲多线程多线程的同步方法)
+ - [synchronized原理](#synchronized原理)
+ - [reetrantlock](#reetrantlock)
+ - [java 线程安全都体现在哪些方面](#java-线程安全都体现在哪些方面)
+ - [如果维护线程安全 如果想实现一个线程安全的队列,可以怎么实现?](#如果维护线程安全-如果想实现一个线程安全的队列可以怎么实现)
+ - [Java多线程通信方式](#java多线程通信方式)
+ - [CountDownLatch、CyclicBarrier、Semaphore 用法总结](#countdownlatch-cyclicbarrier-semaphore-用法总结)
+ - [juc下的内容](#juc下的内容)
+ - [AOS等并发相关面试题](#aos等并发相关面试题)
+ - [threadlocal](#threadlocal)
+ - [java 线程池达到提交上限的具体情况 ,线程池用法,Java 多线程,线程池有哪几类,每一类的差别](#java-线程池达到提交上限的具体情况-线程池用法java-多线程线程池有哪几类每一类的差别)
+ - [要你设计的话,如何实现一个线程池](#要你设计的话如何实现一个线程池)
+ - [线程池的类型,固定大小的线程池内部是如何实现的,等待队列是用了哪一个队列实现 线程池种类和工作流程](#线程池的类型固定大小的线程池内部是如何实现的等待队列是用了哪一个队列实现-线程池种类和工作流程)
+ - [线程池使用了什么设计模式](#线程池使用了什么设计模式)
+ - [线程池使用时一般要考虑哪些问题](#线程池使用时一般要考虑哪些问题)
+ - [线程池的配置](#线程池的配置)
+ - [Excutor 以及 Connector 的配置](#excutor-以及-connector-的配置)
+- [五 Java框架(ssm)](#五-java框架ssm)
+- [hibernate](#hibernate)
+ - [Hibernate 的生成策略](#hibernate-的生成策略)
+ - [Hibernate 与 Mybatis 区别](#hibernate-与-mybatis-区别)
+ - [Mybatis原理](#mybatis原理)
+ - [mybatis执行select的过程](#mybatis执行select的过程)
+ - [mybatis有哪些executors](#mybatis有哪些executors)
+ - [mybatis插件原理](#mybatis插件原理)
+ - [mybatis二级缓存](#mybatis二级缓存)
+- [spring&springmvc](#springspringmvc)
+ - [spring中的设计模式](#spring中的设计模式)
+ - [spring中bean的作用域](#spring中bean的作用域)
+ - [BeanFactory和FactoryBean区别](#beanfactory和factorybean区别)
+ - [aspect的种类](#aspect的种类)
+ - [spring aop的实际应用](#spring-aop的实际应用)
+ - [spring实现多线程安全](#spring实现多线程安全)
+ - [spring的bean的高并发安全问题](#spring的bean的高并发安全问题)
+ - [ioc aop总结(概述性)](#ioc-aop总结概述性)
+ - [Spring 的加载流程,Spring 的源码中 Bean 的构造的流程](#spring-的加载流程spring-的源码中-bean-的构造的流程)
+ - [Spring 事务源码,IOC 源码,AOP 源码](#spring-事务源码ioc-源码aop-源码)
+ - [spring 的作用及理解 事务怎么配置](#spring-的作用及理解-事务怎么配置)
+ - [spring事务失效情况](#spring事务失效情况)
+ - [Spring 的 annotation 如何实现](#spring-的-annotation-如何实现)
+ - [SpringMVC 工作原理](#springmvc-工作原理)
+ - [了解 SpringMVC 与 Struct2 区别](#了解-springmvc-与-struct2-区别)
+ - [springMVC 和 spring 是什么关系](#springmvc-和-spring-是什么关系)
+ - [项目中 Spring 的 IOC 和 AOP 具体怎么使用的](#项目中-spring-的-ioc-和-aop-具体怎么使用的)
+ - [spring mvc 底层实现原理](#spring-mvc-底层实现原理)
+ - [动态代理的原理](#动态代理的原理)
+ - [如果使用 spring mvc,那 post 请求跟 put 请求有什么区别啊; 然后开始问 springmvc:描述从 tomcat 开始到 springmvc 返回到前端显示的整个流程,接着问 springmvc 中的 handlerMapping 的内部实现,然后又问 spring 中从载入 xml 文件到 getbean 整个流程,描述一遍](#如果使用-spring-mvc那-post-请求跟-put-请求有什么区别啊-然后开始问-springmvc描述从-tomcat-开始到-springmvc-返回到前端显示的整个流程接着问-springmvc-中的-handlermapping-的内部实现然后又问-spring-中从载入-xml-文件到-getbean-整个流程描述一遍)
+- [六 微服务(springboot等)](#六-微服务springboot等)
+ - [springboot](#springboot)
+ - [springcloud](#springcloud)
+- [七 数据结构](#七-数据结构)
+ - [二叉树相关](#二叉树相关)
+ - [红黑树](#红黑树)
+- [八 数据库](#八-数据库)
+- [MySQL](#mysql)
+ - [数据库死锁问题](#数据库死锁问题)
+ - [hash索引和B+树索引的区别](#hash索引和b树索引的区别)
+ - [可重复的原理MVCC](#可重复的原理mvcc)
+ - [count(1)、count(*)、count(列名)](#count1-count-count列名)
+ - [mysql的undo、redo、binlog的区别](#mysql的undo-redo-binlog的区别)
+ - [explain解释](#explain解释)
+ - [mysql分页查询优化](#mysql分页查询优化)
+ - [sql注入](#sql注入)
+ - [为什么用B+树](#为什么用b树)
+ - [sql执行流程](#sql执行流程)
+ - [聚集索引与非聚集索引](#聚集索引与非聚集索引)
+ - [覆盖索引](#覆盖索引)
+ - [sql总结](#sql总结)
+ - [有人建议给每张表都建一个自增主键,这样做有什么优点跟缺点](#有人建议给每张表都建一个自增主键这样做有什么优点跟缺点)
+ - [对 MySQL 的了解,和 oracle 的区别](#对-mysql-的了解和-oracle-的区别)
+ - [500万数字排序,内存只能容纳5万个,如何排序,如何优化?](#500万数字排序内存只能容纳5万个如何排序如何优化)
+ - [平时怎么写数据库的模糊查询(由字典树扯到模糊查询,前缀查询,例如“abc%”,还是索引策略的问题)](#平时怎么写数据库的模糊查询由字典树扯到模糊查询前缀查询例如abc还是索引策略的问题)
+ - [数据库里有 10000000 条用户信息,需要给每位用户发送信息(必须发送成功),要求节省内存](#数据库里有-10000000-条用户信息需要给每位用户发送信息必须发送成功要求节省内存)
+ - [项目中如何实现事务](#项目中如何实现事务)
+ - [数据库设计一般设计成第几范式](#数据库设计一般设计成第几范式)
+ - [mysql 用的什么版本 5.7 跟 5.6 有啥区别](#mysql-用的什么版本-57-跟-56-有啥区别)
+ - [提升 MySQL 安全性](#提升-mysql-安全性)
+ - [问了一个这样的表(三个字段:姓名,id,分数)要求查出平均分大于 80 的 id 然后分数降序排序,然后经过提示用聚合函数 avg。](#问了一个这样的表三个字段姓名id分数要求查出平均分大于-80-的-id-然后分数降序排序然后经过提示用聚合函数-avg)
+ - [为什么 mysql 事务能保证失败回滚](#为什么-mysql-事务能保证失败回滚)
+ - [主键索引底层的实现原理](#主键索引底层的实现原理)
+ - [经典的01索引问题?](#经典的01索引问题)
+ - [如何在长文本中快捷的筛选出你的名字?](#如何在长文本中快捷的筛选出你的名字)
+ - [多列索引及最左前缀原则和其他使用场景](#多列索引及最左前缀原则和其他使用场景)
+ - [事务隔离级别](#事务隔离级别)
+ - [索引的最左前缀原则](#索引的最左前缀原则)
+ - [数据库悲观锁怎么实现的](#数据库悲观锁怎么实现的)
+ - [建表的原则](#建表的原则)
+ - [索引的内涵和用法](#索引的内涵和用法)
+ - [给了两条 SQL 语句,让根据这两条语句建索引(个人想法:主要考虑复合索引只能匹配前缀列的特点)](#给了两条-sql-语句让根据这两条语句建索引个人想法主要考虑复合索引只能匹配前缀列的特点)
+ - [那么我们来聊一下数据库。A 和 B 两个表做等值连接(Inner join) 怎么优化](#那么我们来聊一下数据库a-和-b-两个表做等值连接inner-join-怎么优化)
+ - [数据库连接池的理解和优化](#数据库连接池的理解和优化)
+ - [Sql语句分组排序](#sql语句分组排序)
+ - [SQL语句的5个连接概念](#sql语句的5个连接概念)
+ - [数据库优化和架构(主要是主从分离和分库分表相关)](#数据库优化和架构主要是主从分离和分库分表相关)
+ - [分库分表](#分库分表)
+ - [跨库join实现](#跨库join实现)
+ - [探讨主从分离和分库分表相关](#探讨主从分离和分库分表相关)
+ - [数据库中间件](#数据库中间件)
+ - [读写分离在中间件的实现](#读写分离在中间件的实现)
+ - [限流 and 熔断](#限流-and-熔断)
+ - [行锁适用场景](#行锁适用场景)
+- [Redis](#redis)
+ - [redis为什么快?](#redis为什么快)
+ - [Redis 数据结构原理](#redis-数据结构原理)
+ - [Redis 持久化机制](#redis-持久化机制)
+ - [Redis 的一致性哈希算法](#redis-的一致性哈希算法)
+ - [redis了解多少](#redis了解多少)
+ - [redis五种数据类型,当散列类型的 value 值非常大的时候怎么进行压缩](#redis五种数据类型当散列类型的-value-值非常大的时候怎么进行压缩)
+ - [用redis怎么实现摇一摇与附近的人功能](#用redis怎么实现摇一摇与附近的人功能)
+ - [redis 主从复制过程](#redis-主从复制过程)
+ - [Redis 如何解决 key 冲突](#redis-如何解决-key-冲突)
+ - [redis 是怎么存储数据的](#redis-是怎么存储数据的)
+ - [redis 使用场景](#redis-使用场景)
+- [九 计算机网络](#九-计算机网络)
+ - [cookie 禁用怎么办](#cookie-禁用怎么办)
+ - [Netty new 实例化过程](#netty-new-实例化过程)
+ - [socket 实现过程,具体用的方法;怎么实现异步 socket.](#socket-实现过程具体用的方法怎么实现异步-socket)
+ - [浏览器的缓存机制](#浏览器的缓存机制)
+ - [http相关问题](#http相关问题)
+ - [TCP三次握手第三次握手时ACK丢失怎么办](#tcp三次握手第三次握手时ack丢失怎么办)
+ - [dns属于udp还是tcp,原因](#dns属于udp还是tcp原因)
+ - [http的幂等性](#http的幂等性)
+ - [建立连接的过程客户端跟服务端会交换什么信息(参考 TCP 报文结构)](#建立连接的过程客户端跟服务端会交换什么信息参考-tcp-报文结构)
+ - [丢包如何解决重传的消耗](#丢包如何解决重传的消耗)
+ - [traceroute 实现原理](#traceroute-实现原理)
+ - [IO多路复用](#io多路复用)
+ - [select 和 poll 区别?](#select-和-poll-区别)
+ - [在不使用 WebSocket 情况下怎么实现服务器推送的一种方法](#在不使用-websocket-情况下怎么实现服务器推送的一种方法)
+ - [可以使用客户端定时刷新请求或者和 TCP 保持心跳连接实现。](#可以使用客户端定时刷新请求或者和-tcp-保持心跳连接实现)
+ - [查看磁盘读写吞吐量?](#查看磁盘读写吞吐量)
+ - [PING 位于哪一层](#ping-位于哪一层)
+ - [网络重定向,说下流程](#网络重定向说下流程)
+ - [controller 怎么处理的请求:路由](#controller-怎么处理的请求路由)
+ - [IP 地址分为几类,每类都代表什么,私网是哪些](#ip-地址分为几类每类都代表什么私网是哪些)
+- [十 操作系统](#十-操作系统)
+ - [Java I/O 底层细节,注意是底层细节,而不是怎么用](#java-io-底层细节注意是底层细节而不是怎么用)
+ - [Java IO 模型(BIO,NIO 等) ,Tomcat 用的哪一种模型](#java-io-模型bionio-等-tomcat-用的哪一种模型)
+ - [当获取第一个获取锁之后,条件不满足需要释放锁应当怎么做?](#当获取第一个获取锁之后条件不满足需要释放锁应当怎么做)
+ - [手写一个线程安全的生产者与消费者。](#手写一个线程安全的生产者与消费者)
+ - [进程和线程调度方法](#进程和线程调度方法)
+- [linux](#linux)
+ - [linux查找命令](#linux查找命令)
+ - [项目部署常见linux命令](#项目部署常见linux命令)
+ - [进程文件里有哪些信息](#进程文件里有哪些信息)
+ - [sed 和 awk 的区别](#sed-和-awk-的区别)
+ - [linux查看进程并杀死的命令](#linux查看进程并杀死的命令)
+ - [有一个文件被锁住,如何查看锁住它的线程?](#有一个文件被锁住如何查看锁住它的线程)
+ - [如何查看一个文件第100行到150行的内容](#如何查看一个文件第100行到150行的内容)
+ - [如何查看进程消耗的资源](#如何查看进程消耗的资源)
+ - [如何查看每个进程下的线程?](#如何查看每个进程下的线程)
+ - [linux 如何查找文件](#linux-如何查找文件)
+ - [select epoll等问题](#select-epoll等问题)
+- [十一 框架其他](#十一-框架其他)
+ - [Servlet 的 Filter 用的什么设计模式](#servlet-的-filter-用的什么设计模式)
+ - [zookeeper 的常用功能,自己用它来做什么](#zookeeper-的常用功能自己用它来做什么)
+ - [redis 的操作是不是原子操作](#redis-的操作是不是原子操作)
+ - [秒杀业务场景设计](#秒杀业务场景设计)
+ - [如何设计淘宝秒杀系统(重点关注架构,比如数据一致性,数据库集群一致性哈希,缓存, 分库分表等等)](#如何设计淘宝秒杀系统重点关注架构比如数据一致性数据库集群一致性哈希缓存-分库分表等等)
+ - [对后台的优化有了解吗?比如负载均衡](#对后台的优化有了解吗比如负载均衡)
+ - [对 Restful 了解 Restful 的认识,优点,以及和 soap 的区别](#对-restful-了解-restful-的认识优点以及和-soap-的区别)
+ - [lrucache 的基本原理](#lrucache-的基本原理)
+- [十二 设计模式](#十二-设计模式)
+ - [Java常见设计模式](#java常见设计模式)
+- [十三 分布式](#十三-分布式)
+ - [dubbo中的dubbo协议和http协议有什么区别?](#dubbo中的dubbo协议和http协议有什么区别)
+ - [负载均衡](#负载均衡)
+ - [分布式锁的实现方式及优缺点](#分布式锁的实现方式及优缺点)
+ - [CAP](#cap)
+ - [如何实现分布式缓存](#如何实现分布式缓存)
+- [十四 其他](#十四-其他)
+ - [Java 8 函数式编程 回调函数](#java-8-函数式编程-回调函数)
+ - [函数式编程,面向对象之间区别](#函数式编程面向对象之间区别)
+ - [Java 8 中 stream 迭代的优势和区别?](#java-8-中-stream-迭代的优势和区别)
+ - [同步等于可见性吗?](#同步等于可见性吗)
+ - [git底层数据结构](#git底层数据结构)
+ - [安全加密](#安全加密)
+ - [web安全问题](#web安全问题)
+
+
+
+
+### 一 Java基础
+
+#### 一致性hash算法
+
+https://blog.csdn.net/qq_40551994/article/details/100991581
+
+#### sleep和wait
+
+https://blog.csdn.net/qq_20009015/article/details/89980966
+https://blog.csdn.net/lengyue309/article/details/79639245
+
+#### 强软弱虚引用
+
+https://blog.csdn.net/junjunba2689/article/details/80601729
+
+#### Arrays.sort原理
+
+https://www.cnblogs.com/baichunyu/p/11935995.html
+
+#### 创建对象的方式
+
+https://blog.csdn.net/w410589502/article/details/56489294
-https://www.jianshu.com/p/b6cb4c694951
+#### 若hashcode方法永远返回1会产生什么结果
-#### mysql语句分别会加什么锁
+https://blog.csdn.net/cnq2328/article/details/50436175
-https://blog.csdn.net/iceman1952/article/details/85504278
+#### 解决hash冲突的三种方法
-#### 若hashcode方法永远返回1会产生什么结果
+https://blog.csdn.net/qq_32595453/article/details/80660676
-https://blog.csdn.net/cnq2328/article/details/50436175
+#### 为什么要重写hashCode()方法和equals()方法以及如何进行重写
-#### jvm的方法区存什么?
+https://blog.csdn.net/xlgen157387/article/details/63683882
-https://www.jianshu.com/p/10584345b10a
+#### 动态代理
-#### Class.forName和ClassLoader的区别
+https://segmentfault.com/a/1190000011291179
-https://blog.csdn.net/qq_27093465/article/details/52262340
+#### sleep和wait的区别
-#### java对象信息分配
+https://blog.csdn.net/u012050154/article/details/50903326
-https://blog.csdn.net/u014520047/article/details/81940447
+#### java 地址和值传递的例子
-#### java虚拟机ZGC详解
+https://www.cnblogs.com/zhangyu317/p/11226105.html
-https://vimsky.com/article/4162.html
+#### Java序列化
-#### java虚拟机CMS详解
+https://juejin.im/post/5ce3cdc8e51d45777b1a3cdf
-https://juejin.im/post/5c7262a15188252f30484351
+#### java NIO,java 多线程、线程池,java 网络编程解决并发量
-#### java虚拟机G1详解
+Java Nio使用:https://blog.csdn.net/forezp/article/details/88414741
+Java Nio原理:https://www.cnblogs.com/crazymakercircle/p/10225159.html
+线程池:http://cmsblogs.com/?p=2448
+为什么nio快:https://blog.csdn.net/yaogao000/article/details/47972143
-https://zhuanlan.zhihu.com/p/59861022
+#### JDBC 连接的过程 ,手写 jdbc 连接过程
-#### 解决hash冲突的三种方法
+https://blog.csdn.net/qq_44971038/article/details/103204217
-https://blog.csdn.net/qq_32595453/article/details/80660676
+#### 说出三个遇到过的程序报异常的情况
-#### 为什么要重写hashCode()方法和equals()方法以及如何进行重写
+https://www.cnblogs.com/winnie-man/p/10471338.html
-https://blog.csdn.net/xlgen157387/article/details/63683882
+#### socket 是靠什么协议支持的
-#### 动态代理
+TCP/IP,协议。socket用于 通信,在实际应用中有im等,因此需要可靠的网络协议,UDP则是不可靠的协议,且服务端与客户端不链接,UDP用于广播,视频流等
-- https://segmentfault.com/a/1190000011291179
+#### java io 用到什么设计模式
-#### 红黑树
+装饰模式和适配器模式
-- https://zhuanlan.zhihu.com/p/31805309
+#### serviable 的序列化,其中 uuid 的作用
-#### hashmap的jdk1.7和jdk1.8区别
+相当于快递的打包和拆包,里面的东西要保持一致,不能人为的去改变他,不然就交易不成功。序列化与反序列化也是一样,而版本号的存在就是要是里面内容要是不一致,不然就报错。像一个防伪码一样。
-- https://juejin.im/post/5aa5d8d26fb9a028d2079264
+#### 什么情景下会用到反射
-- https://blog.csdn.net/qq_36520235/article/details/82417949
+注解、Spring 配置文件、动态代理、jdbc
-#### concurrenthashmap的jdk1.7和jdk1.8区别
+#### 浅克隆与深克隆有什么区别,如何实现深克隆
-- [面试题](https://juejin.im/post/5df8d7346fb9a015ff64eaf9)
+浅拷贝:仅仅克隆基本类型变量,而不克隆引用类型的变量
+深克隆:既克隆基本类型变量,也克隆引用类型变量
+1.浅克隆:只复制基本类型的数据,引用类型的数据只复制了引用的地址,引用的对象并没有复制,在新的对象中修改引用类型的数据会影响原对象中的引用。直接使用clone方法,再嵌套的还是浅克隆,因为有些引用类型不能直接克隆。
+2.深克隆:是在引用类型的类中也实现了clone,是clone的嵌套,并且在clone方法中又对没有clone方法的引用类型又做差异化复制,克隆后的对象与原对象之间完全不会影响,但是内容完全相同。
-#### Java I/O 底层细节,注意是底层细节,而不是怎么用
+#### 反射能够使用私有的方法属性吗和底层原理?
-可以从Java IO底层、JavaIO模型(阻塞、异步等)
+https://blog.51cto.com/4247649/2109128
-https://www.cnblogs.com/crazymakercircle/p/10225159.html
+#### 处理器指令优化有些什么考虑?
-#### 如何实现分布式缓存
+禁止重排序
-redis如何实现分布式缓存
-https://stor.51cto.com/art/201912/607229.htm
+#### object 对象的常用方法
-#### 浏览器的缓存机制
+#### Stack 和 ArrayList 的区别
-说明计算机网络的知识还没有记住
+#### statement 和 prestatement 的区别
-https://www.cnblogs.com/yangyangxxb/p/10218871.html
+1、Statement用于执行静态SQL语句,在执行时,必须指定一个事先准备好的SQL语句。
+2、PrepareStatement是预编译的SQL语句对象,sql语句被预编译并保存在对象中。被封装的sql语句代表某一类操作,语句中可以包含动态参数“?”,在执行时可以为“?”动态设置参数值。
+3、使用PrepareStatement对象执行sql时,sql被数据库进行解析和编译,然后被放到命令缓冲区,每当执行同一个PrepareStatement对象时,它就会被解析一次,但不会被再次编译。在缓冲区可以发现预编译的命令,并且可以重用。
+4、PrepareStatement可以减少编译次数提高数据库性能。
-#### JVM tomcat 容器启动,jvm 加载情况描述
+#### 手写模拟实现一个阻塞队列
-- tomcat请求流程:http://objcoding.com/2017/06/12/Tomcat-structure-and-processing-request-process/
+https://www.cnblogs.com/keeya/p/9713686.html
-其实就是jvm的类加载情况,非常相似
-- https://blog.csdn.net/lduzhenlin/article/details/83013143
-- https://blog.csdn.net/xlgen157387/article/details/53521928
+#### util 包下有哪几种接口
-#### 当获取第一个获取锁之后,条件不满足需要释放锁应当怎么做?
+#### 很常见的 Nullpointerexception ,你是怎么排查的,怎么解决的;
-https://www.jianshu.com/p/eb112b25b848
+#### 静态内部类和非静态内部类的区别是什么?
+
+#### 怎么创建静态内部类和非静态内部类?
+
+https://blog.csdn.net/qq_38366777/article/details/78088386
+
+#### Xml 解析方式,原理优缺点
+
+https://segmentfault.com/a/1190000013504078?utm_source=tag-newest
+
+#### 静态变量和全局变量的区别
+
+
+### 二 Java集合
+
+#### hashmap的jdk1.7和jdk1.8区别
+
+https://juejin.im/post/5aa5d8d26fb9a028d2079264
+
+https://blog.csdn.net/qq_36520235/article/details/82417949
+
+#### concurrenthashmap的jdk1.7和jdk1.8区别
+
+https://juejin.im/post/5df8d7346fb9a015ff64eaf9
#### HashMap 实现原理,扩容因子过大过小的缺点,扩容过程 采用什么方法能保证每个 bucket 中的数据更均匀 解决冲突的方式,还有没有其他方式(全域哈希)
@@ -109,49 +411,35 @@ https://www.cnblogs.com/peizhe123/p/5790252.html
更加详细的解释
https://blog.csdn.net/yanshuanche3765/article/details/78917507
-#### java 地址和值传递的例子
-
-https://www.cnblogs.com/zhangyu317/p/11226105.html
-
-#### java NIO,java 多线程、线程池,java 网络编程解决并发量
+#### ArrayList、LinkedList、Vector
-- Java Nio使用:https://blog.csdn.net/forezp/article/details/88414741
-- Java Nio原理:https://www.cnblogs.com/crazymakercircle/p/10225159.html
-- 线程池:http://cmsblogs.com/?p=2448
-- 为什么nio快:https://blog.csdn.net/yaogao000/article/details/47972143
+https://blog.csdn.net/zhangqiluGrubby/article/details/72870493
-#### 手写一个线程安全的生产者与消费者。
+##### 还了解除 util 其他包下的 List 吗?
-- https://www.cnblogs.com/jun-ma/p/11843394.html
-- https://blog.csdn.net/Virgil_K2017/article/details/89283946
+##### CopyOnWriteArrayList
+(1)CopyOnWriteArrayList使用ReentrantLock重入锁加锁,保证线程安全;
+(2)CopyOnWriteArrayList的写操作都要先拷贝一份新数组,在新数组中做修改,修改完了再用新数组替换老数组,所以空间复杂度是O(n),性能比较低下;
+(3)CopyOnWriteArrayList的读操作支持随机访问,时间复杂度为O(1);
+(4)CopyOnWriteArrayList采用读写分离的思想,读操作不加锁,写操作加锁,且写操作占用较大内存空间,所以适用于读多写少的场合;
+(5)CopyOnWriteArrayList只保证最终一致性,不保证实时一致性;
#### ConcurrentHashMap 和 LinkedHashMap 差异和适用情形
哈希表的原理:https://blog.csdn.net/yyyljw/article/details/80903391
可以以下方面进行回答
-
(1)使用的数据结构?
-
(2)添加元素、删除元素的基本逻辑?
-
(3)是否是fail-fast的?
-
(4)是否需要扩容?扩容规则?
-
(5)是否有序?是按插入顺序还是自然顺序还是访问顺序?
-
(6)是否线程安全?
-
(7)使用的锁?
-
(8)优点?缺点?
-
(9)适用的场景?
-
(10)时间复杂度?
-
(11)空间复杂度?
#### ConcurrentHashMap分段锁是如何实现,ConcurrentHashmap jdk1.8 访问的时候是怎么加锁的,插入的时候是怎么加锁的 访问不加 锁插入的时候对头结点加锁
@@ -164,18 +452,6 @@ jdk1.8;https://blog.csdn.net/weixin_42130471/article/details/89813248
2、线程不是安全的
3、可以用来实现栈
-#### JDBC 连接的过程 ,手写 jdbc 连接过程
-
-https://blog.csdn.net/qq_44971038/article/details/103204217
-
-#### 可重入锁,实现原理
-
-ReetrantLock:https://www.jianshu.com/p/f8f6ac49830e
-
-#### Java IO 模型(BIO,NIO 等) ,Tomcat 用的哪一种模型
-
-tomcat支持:https://blog.csdn.net/fd2025/article/details/80007435
-
#### ArrayBlockingQueue 源码
http://cmsblogs.com/?p=4755
@@ -185,16 +461,6 @@ http://cmsblogs.com/?p=4755
(3)入队和出队各定义了四组方法为满足不同的用途;
(4)利用重入锁和两个条件保证并发安全:lock、notEmpty、notFull
-#### 多进程和多线程的区别
-
-#### 说出三个遇到过的程序报异常的情况
-
-https://www.cnblogs.com/winnie-man/p/10471338.html
-
-#### Java 无锁原理
-
-https://blog.csdn.net/qq_39291929/article/details/81501829
-
#### hashmap 和 treemap 的区别
http://cmsblogs.com/?p=4743
@@ -223,151 +489,111 @@ http://cmsblogs.com/?p=4743
https://www.jianshu.com/p/dde9b12343c1
-#### 网络编程的 accept 和 connect
-
#### HashMap 的负载因子,为什么容量为2^n
HashMap为了存取高效,要尽量较少碰撞,就是要尽量把数据分配均匀,每个链表长度大致相同,这个实现就在把数据存到哪个链表中的算法; 这个算法实际就是取模,hash%length,计算机中直接求余效率不如位移运算,源码中做了优化hash&(length-1), hash%length==hash&(length-1)的前提是length是2的n次方; 为什么这样能均匀分布减少碰撞呢?2的n次方实际就是1后面n个0,2的n次方-1 实际就是n个1; 例如长度为9时候,3&(9-1)=0 2&(9-1)=0 ,都在0上,碰撞了; 例如长度为8时候,3&(8-1)=3 2&(8-1)=2 ,不同位置上,不碰撞; 其实就是按位“与”的时候,每一位都能 &1 ,也就是和1111……1111111进行与运算
-#### try catch finally 可不可以没有 catch(try return,finally return)
-
-#### mapreduce 流程,如何保证 reduce 接受的数据没有丢失,数据如何去重,mapreduce 原理,partion 发生在什么阶段
-
-#### 直接写一个 java 程序,统计 IP 地址的次数
-
-#### 讲讲多线程,多线程的同步方法
-
-1、synchronized
-2、reetrantlock
-
#### list,map,set 之间的区别
https://blog.csdn.net/u012102104/article/details/79235938
-#### socket 是靠什么协议支持的
-
-TCP/IP,协议。socket用于 通信,在实际应用中有im等,因此需要可靠的网络协议,UDP则是不可靠的协议,且服务端与客户端不链接,UDP用于广播,视频流等
-
-#### java io 用到什么设计模式
-
-装饰模式和适配器模式
-
-#### serviable 的序列化,其中 uuid 的作用
-
-相当于快递的打包和拆包,里面的东西要保持一致,不能人为的去改变他,不然就交易不成功。序列化与反序列化也是一样,而版本号的存在就是要是里面内容要是不一致,不然就报错。像一个防伪码一样。
-
#### 什么时候会用到 HashMap
-#### 什么情景下会用到反射
+#### 常见的线程安全的集合类
-注解、Spring 配置文件、动态代理、jdbc
-#### 浅克隆与深克隆有什么区别,如何实现深克隆
+### 三 JVM
-浅拷贝:仅仅克隆基本类型变量,而不克隆引用类型的变量
-深克隆:既克隆基本类型变量,也克隆引用类型变量
+#### 反射在jvm层面的实现
-1.浅克隆:只复制基本类型的数据,引用类型的数据只复制了引用的地址,引用的对象并没有复制,在新的对象中修改引用类型的数据会影响原对象中的引用。直接使用clone方法,再嵌套的还是浅克隆,因为有些引用类型不能直接克隆。
-2.深克隆:是在引用类型的类中也实现了clone,是clone的嵌套,并且在clone方法中又对没有clone方法的引用类型又做差异化复制,克隆后的对象与原对象之间完全不会影响,但是内容完全相同。
+https://www.jianshu.com/p/b6cb4c694951
+#### jvm的方法区存什么?
-##### 常见的线程安全的集合类
+https://www.jianshu.com/p/10584345b10a
-##### Java 8 函数式编程 回调函数
+#### JDK1.8 JVM方法区变成了什么,为什么这样做
-#### 函数式编程,面向对象之间区别
+https://blog.csdn.net/u011665991/article/details/107141348/
-#### Java 8 中 stream 迭代的优势和区别?
+#### oom出现的原因
-#### 同步等于可见性吗?
+https://blog.csdn.net/iteye_9584/article/details/82583093
-保证了可见性不等于正确同步,因为还有原子性没考虑。
+#### Class.forName和ClassLoader的区别
-#### 还了解除 util 其他包下的 List 吗?
+https://blog.csdn.net/qq_27093465/article/details/52262340
-##### CopyOnWriteArrayList
+#### java对象信息分配
-(1)CopyOnWriteArrayList使用ReentrantLock重入锁加锁,保证线程安全;
-(2)CopyOnWriteArrayList的写操作都要先拷贝一份新数组,在新数组中做修改,修改完了再用新数组替换老数组,所以空间复杂度是O(n),性能比较低下;
-(3)CopyOnWriteArrayList的读操作支持随机访问,时间复杂度为O(1);
-(4)CopyOnWriteArrayList采用读写分离的思想,读操作不加锁,写操作加锁,且写操作占用较大内存空间,所以适用于读多写少的场合;
-(5)CopyOnWriteArrayList只保证最终一致性,不保证实时一致性;
+https://blog.csdn.net/u014520047/article/details/81940447
-#### 反射能够使用私有的方法属性吗和底层原理?
+#### java虚拟机ZGC详解
-https://blog.51cto.com/4247649/2109128
+https://vimsky.com/article/4162.html
-#### 处理器指令优化有些什么考虑?
+#### java虚拟机CMS详解
-禁止重排序
+https://juejin.im/post/5c7262a15188252f30484351
-#### object 对象的常用方法
+#### java虚拟机G1详解
-#### Stack 和 ArrayList 的区别
+https://zhuanlan.zhihu.com/p/59861022
-#### statement 和 prestatement 的区别
+#### JVM tomcat 容器启动,jvm 加载情况描述
-1、Statement用于执行静态SQL语句,在执行时,必须指定一个事先准备好的SQL语句。
-2、PrepareStatement是预编译的SQL语句对象,sql语句被预编译并保存在对象中。被封装的sql语句代表某一类操作,语句中可以包含动态参数“?”,在执行时可以为“?”动态设置参数值。
-3、使用PrepareStatement对象执行sql时,sql被数据库进行解析和编译,然后被放到命令缓冲区,每当执行同一个PrepareStatement对象时,它就会被解析一次,但不会被再次编译。在缓冲区可以发现预编译的命令,并且可以重用。
-4、PrepareStatement可以减少编译次数提高数据库性能。
+tomcat请求流程:http://objcoding.com/2017/06/12/Tomcat-structure-and-processing-request-process/
-#### 手写模拟实现一个阻塞队列
+其实就是jvm的类加载情况,非常相似
+https://blog.csdn.net/lduzhenlin/article/details/83013143
+https://blog.csdn.net/xlgen157387/article/details/53521928
-https://www.cnblogs.com/keeya/p/9713686.html
+### 四 多线程并发
-#### 怎么使用父类的方法
+#### volitale使用场景
-#### util 包下有哪几种接口
+https://blog.csdn.net/vking_wang/article/details/9982709
-#### cookie 禁用怎么办
+#### 可重入锁,实现原理
-https://segmentfault.com/q/1010000007715137
+ReetrantLock:https://www.jianshu.com/p/f8f6ac49830e
-- Netty new 实例化过程
+#### Java 无锁原理
-#### socket 实现过程,具体用的方法;怎么实现异步 socket.
+https://blog.csdn.net/qq_39291929/article/details/81501829
-https://blog.csdn.net/charjay_lin/article/details/81810922
+#### 讲讲多线程,多线程的同步方法
+
+#### synchronized原理
-- 很常见的 Nullpointerexception ,你是怎么排查的,怎么解决的;
+https://www.jianshu.com/p/d53bf830fa09
-#### Binder 的原理
+#### reetrantlock
#### java 线程安全都体现在哪些方面
#### 如果维护线程安全 如果想实现一个线程安全的队列,可以怎么实现?
-JUC 包里的 ArrayBlockingQueue 还有 LinkedBlockingQueue 啥的又结合源码说了一 通。
-
-#### 静态内部类和非静态内部类的区别是什么?
-
-#### 怎么创建静态内部类和非静态内部类?
+JUC 包里的 ArrayBlockingQueue 还有 LinkedBlockingQueue 啥的又结合源码说了一通。
-https://blog.csdn.net/qq_38366777/article/details/78088386
-
-#### 断点续传的原理
-
-#### Xml 解析方式,原理优缺点
+#### Java多线程通信方式
-####
-
-https://segmentfault.com/a/1190000013504078?utm_source=tag-newest
-
-#### 静态变量和全局变量的区别
+https://blog.csdn.net/u011514810/article/details/77131296
+https://blog.csdn.net/xiaokang123456kao/article/details/77331878
+#### CountDownLatch、CyclicBarrier、Semaphore 用法总结
-### Java多线程
+https://segmentfault.com/a/1190000012234469
-#### CountDownLatch、CyclicBarrier、Semaphore 用法总结
+#### juc下的内容
-- https://segmentfault.com/a/1190000012234469
+https://blog.csdn.net/sixabs/article/details/98471709
#### AOS等并发相关面试题
-- https://cloud.tencent.com/developer/article/1471770
-- https://zhuanlan.zhihu.com/p/96544118
-- https://zhuanlan.zhihu.com/p/48295486
+https://cloud.tencent.com/developer/article/1471770
+https://zhuanlan.zhihu.com/p/96544118
+https://zhuanlan.zhihu.com/p/48295486
#### threadlocal
https://juejin.im/post/5ac2eb52518825555e5e06ee
@@ -399,263 +625,216 @@ https://juejin.im/post/5d1882b1f265da1ba84aa676#heading-14
https://www.cnblogs.com/kismetv/p/7806063.html
-### spring&springmvc
-
-面试题:
-https://mp.weixin.qq.com/s/2Y5X11TycreHgO0R3agK2A
-https://mp.weixin.qq.com/s/IdjCxumDleLqdU8MgQnrLQ
-
-#### ioc aop总结(概述性)
-
-https://juejin.im/post/5b040cf66fb9a07ab7748c8b
-https://juejin.im/post/5b06bf2df265da0de2574ee1
-
-#### Spring 的加载流程,Spring 的源码中 Bean 的构造的流程
-
-spring ioc系列文章:http://cmsblogs.com/?p=2806
-- 加载流程(概述):https://www.jianshu.com/p/5fd1922ccab1
-- 循环依赖问题:https://blog.csdn.net/u010853261/article/details/77940767
-
-
-#### Spring 事务源码,IOC 源码,AOP 源码
-
-https://juejin.im/post/5c525968e51d453f5e6b744b
-
-ioc、aop系列源码:
-https://segmentfault.com/a/1190000015319623
-http://www.tianxiaobo.com/2018/05/30/Spring-IOC-%E5%AE%B9%E5%99%A8%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90%E7%B3%BB%E5%88%97%E6%96%87%E7%AB%A0%E5%AF%BC%E8%AF%BB/
+### 五 Java框架(ssm)
-#### spring 的作用及理解 事务怎么配置
-
-https://www.jianshu.com/p/e7d59ebf41a3
-
-#### Spring 的 annotation 如何实现
-https://segmentfault.com/a/1190000013258647
-
-#### SpringMVC 工作原理
-
-https://blog.csdn.net/cswhale/article/details/16941281
-
-#### 了解 SpringMVC 与 Struct2 区别
-
-https://blog.csdn.net/chenleixing/article/details/44570681
-
-#### springMVC 和 spring 是什么关系
-
-
-#### 项目中 Spring 的 IOC 和 AOP 具体怎么使用的
-
-- https://www.cnblogs.com/xdp-gacl/p/4249939.html
-- https://juejin.im/post/5b06bf2df265da0de2574ee1
-
-#### spring mvc 底层实现原理
-
-https://blog.csdn.net/weixin_42323802/article/details/84038765
-
-#### 动态代理的原理
-
-https://juejin.im/post/5a3284a75188252970793195
-
-#### 如果使用 spring mvc,那 post 请求跟 put 请求有什么区别啊; 然后开始问 springmvc:描述从 tomcat 开始到 springmvc 返回到前端显示的整个流程,接着问 springmvc 中的 handlerMapping 的内部实现,然后又问 spring 中从载入 xml 文件到 getbean 整个流程,描述一遍
-
-### springboot & springcloud
-
-#### springboot
-
-- [springboot面试题](https://mp.weixin.qq.com/s/id0Ga1OC4D3Hu6lkzc9hRg)
-- [springboot面试题2](https://mp.weixin.qq.com/s/XGIErbCx2i6Y8vBgw1gq_Q)
-
-#### springcloud
+### hibernate
-- [springcloudm面试题](https://mp.weixin.qq.com/s/CYfLA9s9zhwcIwJjMFXhQQ)
+#### Hibernate 的生成策略
+主要说了 native 、uuid
+https://blog.csdn.net/itmyhome1990/article/details/54863822
-### servlet
+#### Hibernate 与 Mybatis 区别
-#### Servlet 知道是做什么的吗?和 JSP 有什么联系?
+https://blog.csdn.net/wangpeng047/article/details/17038659
-jsp就是在html里面写java代码,servlet就是在java里面写html代码…其实jsp经过容器解释之后就是servlet.只是我们自己写代码的时候尽量能让它们各司其职,jsp更注重前端显示,servlet更注重模型和业务逻辑。不要写出万能的jsp或servlet来即可。
+#### Mybatis原理
-作者:知乎用户
-链接:https://www.zhihu.com/question/37962386/answer/74906895
+https://www.javazhiyin.com/34438.html
+#### mybatis执行select的过程
-#### JSP 的运行原理?
+https://www.jianshu.com/p/ae2bda8f9d84
+https://blog.csdn.net/qwesxd/article/details/90049863
-jsp/servlet原理:https://www.jianshu.com/p/93736c3b448b
+#### mybatis有哪些executors
-#### JSP 属于 Java 中 的吗?
+https://blog.csdn.net/weixin_42495773/article/details/106799280
+https://blog.csdn.net/weixin_34025051/article/details/92405286
-#### Servlet 是线程安全
+#### mybatis插件原理
-https://blog.csdn.net/qq_24145735/article/details/52433096
-https://www.cnblogs.com/chanshuyi/p/5052426.html
+https://www.cnblogs.com/qdhxhz/p/11390778.html
-#### servlet 是单例
-#### servlet 和 filter 的区别。
+#### mybatis二级缓存
-https://blog.csdn.net/weixin_42669555/article/details/81049423
+https://blog.csdn.net/csdnliuxin123524/article/details/78874261
-#### servlet jsp tomcat常见面试题
-https://juejin.im/post/5a75ab4b6fb9a063592ba9db
-https://blog.csdn.net/shxz130/article/details/39735373
+### spring&springmvc
+面试题:
+https://mp.weixin.qq.com/s/2Y5X11TycreHgO0R3agK2A
+https://mp.weixin.qq.com/s/IdjCxumDleLqdU8MgQnrLQ
+#### spring中的设计模式
-### hibernate
+https://juejin.im/post/5ce69379e51d455d877e0ca0
-#### Hibernate 的生成策略
+#### spring中bean的作用域
-主要说了 native 、uuid
+https://blog.csdn.net/weidaoyouwen/article/details/80503575
-https://blog.csdn.net/itmyhome1990/article/details/54863822
+#### BeanFactory和FactoryBean区别
-#### Hibernate 与 Mybatis 区别
+https://blog.csdn.net/weixin_38361347/article/details/92852611
-- https://blog.csdn.net/wangpeng047/article/details/17038659
+#### aspect的种类
-#### Mybatis原理
+https://blog.csdn.net/StubbornAccepted/article/details/70767014
-- https://www.javazhiyin.com/34438.html
+#### spring aop的实际应用
-### Redis
+https://blog.csdn.net/zzh_spring/article/details/107207025
-- Redis 数据结构
+#### spring实现多线程安全
-- Redis 持久化机制
+https://www.cnblogs.com/tiancai/p/9627109.html
-- Redis 的一致性哈希算法
+#### spring的bean的高并发安全问题
-- redis了解多少
+https://blog.csdn.net/songzehao/article/details/103365494/
-- redis五种数据类型,当散列类型的 value 值非常大的时候怎么进行压缩
+#### ioc aop总结(概述性)
-#### 用redis怎么实现摇一摇与附近的人功能
+https://juejin.im/post/5b040cf66fb9a07ab7748c8b
+https://juejin.im/post/5b06bf2df265da0de2574ee1
-https://blog.csdn.net/smartwu_sir/article/details/80254733
+#### Spring 的加载流程,Spring 的源码中 Bean 的构造的流程
-- redis 主从复制过程
+spring ioc系列文章:http://cmsblogs.com/?p=2806
+加载流程(概述):https://www.jianshu.com/p/5fd1922ccab1
+循环依赖问题:https://blog.csdn.net/u010853261/article/details/77940767
+https://blog.csdn.net/a15119273009/article/details/108007864
-- Redis 如何解决 key 冲突
-- redis 是怎么存储数据的
+#### Spring 事务源码,IOC 源码,AOP 源码
-- redis 使用场景
+https://juejin.im/post/5c525968e51d453f5e6b744b
-### 框架其他
+ioc、aop系列源码:
+https://segmentfault.com/a/1190000015319623
+http://www.tianxiaobo.com/2018/05/30/Spring-IOC-%E5%AE%B9%E5%99%A8%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90%E7%B3%BB%E5%88%97%E6%96%87%E7%AB%A0%E5%AF%BC%E8%AF%BB/
-#### Servlet 的 Filter 用的什么设计模式
+#### spring 的作用及理解 事务怎么配置
-https://www.jianshu.com/p/e4197a54828d
+https://www.jianshu.com/p/e7d59ebf41a3
-- zookeeper 的常用功能,自己用它来做什么
+#### spring事务失效情况
+https://blog.csdn.net/luo4105/article/details/79733338
-#### ibatis 是怎么实现映射的,它的映射原理是什么
+#### Spring 的 annotation 如何实现
+https://segmentfault.com/a/1190000013258647
-mybatis面试题:https://zhuanlan.zhihu.com/p/44464109
+#### SpringMVC 工作原理
-#### redis 的操作是不是原子操作
+https://blog.csdn.net/cswhale/article/details/16941281
-https://juejin.im/entry/58f9e22044d9040069d40dca
+#### 了解 SpringMVC 与 Struct2 区别
-#### 秒杀业务场景设计
+https://blog.csdn.net/chenleixing/article/details/44570681
-- WebSocket 长连接问题
+#### springMVC 和 spring 是什么关系
-- 如何设计淘宝秒杀系统(重点关注架构,比如数据一致性,数据库集群一致性哈希,缓存, 分库分表等等)
-- List 接口去实例化一个它的实现类(ArrayList)以及直接用 ArrayList 去 new 一个该类的对 象,这两种方式有什么区别
+#### 项目中 Spring 的 IOC 和 AOP 具体怎么使用的
-#### Tomcat 关注哪些参数 (tomcat调优)
+https://www.cnblogs.com/xdp-gacl/p/4249939.html
+https://juejin.im/post/5b06bf2df265da0de2574ee1
-https://juejin.im/post/5ac034f351882548fe4a4383
+#### spring mvc 底层实现原理
-https://testerhome.com/topics/16082
+https://blog.csdn.net/weixin_42323802/article/details/84038765
+#### 动态代理的原理
-- 对后台的优化有了解吗?比如负载均衡
+https://juejin.im/post/5a3284a75188252970793195
-我给面试官说了 Ngix+Tomcat 负载均 衡,异步处理(消息缓冲服务器),缓存(Redis, Memcache), NoSQL,数据库优化,存储索引优化
+#### 如果使用 spring mvc,那 post 请求跟 put 请求有什么区别啊; 然后开始问 springmvc:描述从 tomcat 开始到 springmvc 返回到前端显示的整个流程,接着问 springmvc 中的 handlerMapping 的内部实现,然后又问 spring 中从载入 xml 文件到 getbean 整个流程,描述一遍
-#### 对 Restful 了解 Restful 的认识,优点,以及和 soap 的区别
+### 六 微服务(springboot等)
-https://www.ruanyifeng.com/blog/2011/09/restful.html
+#### springboot
-- lrucache 的基本原理
+[springboot面试题](https://mp.weixin.qq.com/s/id0Ga1OC4D3Hu6lkzc9hRg)
+[springboot面试题2](https://mp.weixin.qq.com/s/XGIErbCx2i6Y8vBgw1gq_Q)
+#### springcloud
-### 设计模式
+[springcloud面试题](https://mp.weixin.qq.com/s/CYfLA9s9zhwcIwJjMFXhQQ)
-#### Java常见设计模式
-- https://www.jianshu.com/p/61b67ca754a3
+### 七 数据结构
-- 单例模式(双检锁模式)、简单工厂、观察者模式、适配器模式、职责链模式等等
+#### 二叉树相关
-- 享元模式模式 选两个画下 UML 图
+https://www.jianshu.com/p/655d83f9ba7b
+https://www.jianshu.com/p/ff4b93b088eb
-- 手写单例
+#### 红黑树
-写的是静态内部类的单例,然后他问我这个地方为什么用 private,这儿为啥用 static, 这就考察你的基本功啦
+https://www.jianshu.com/p/e136ec79235c
+https://zhuanlan.zhihu.com/p/31805309
-- 静态类与单例模式的区别
-- 单例模式 double check 单例模式都有什么,都是否线程安全,怎么改进(从 synchronized 到 双重检验锁 到 枚举 Enum)
-- 基本的设计模式及其核心思想
+### 八 数据库
-- 来,我们写一个单例模式的实现
+### MySQL
-这里有一个深坑,详情请见《 JVM 》 第 370 页
+#### 数据库死锁问题
+https://blog.csdn.net/cbjcry/article/details/84920174
-- 基本的设计原则
+#### hash索引和B+树索引的区别
-如果有人问你接口里的属性为什么都是 final static 的,记得和他聊一聊设计原则。
+https://www.cnblogs.com/heiming/p/5865101.html
+#### 可重复的原理MVCC
-### 数据库
+https://www.cnblogs.com/wade-luffy/p/8686883.html
+https://blog.csdn.net/weixin_42041027/article/details/100587435
+https://www.jianshu.com/p/8845ddca3b23
#### count(1)、count(*)、count(列名)
-- https://blog.csdn.net/iFuMI/article/details/77920767
+https://blog.csdn.net/iFuMI/article/details/77920767
#### mysql的undo、redo、binlog的区别
-- https://mp.weixin.qq.com/s/0z6GmUp0Lb1hDUo0EyYiUg
+https://mp.weixin.qq.com/s/0z6GmUp0Lb1hDUo0EyYiUg
#### explain解释
-- https://segmentfault.com/a/1190000010293791
+https://segmentfault.com/a/1190000010293791
#### mysql分页查询优化
-- https://blog.csdn.net/hanchao5272/article/details/102790490
+https://blog.csdn.net/hanchao5272/article/details/102790490
#### sql注入
-- https://blog.csdn.net/github_36032947/article/details/78442189
+https://blog.csdn.net/github_36032947/article/details/78442189
#### 为什么用B+树
-- https://blog.csdn.net/xlgen157387/article/details/79450295
+https://blog.csdn.net/xlgen157387/article/details/79450295
#### sql执行流程
-- https://juejin.im/post/5b7036de6fb9a009c40997eb
+https://juejin.im/post/5b7036de6fb9a009c40997eb
#### 聚集索引与非聚集索引
-- https://juejin.im/post/5cdd701ee51d453a36384939
+https://juejin.im/post/5cdd701ee51d453a36384939
#### 覆盖索引
-- https://www.jianshu.com/p/77eaad62f974
+https://www.jianshu.com/p/77eaad62f974
#### sql总结
@@ -669,62 +848,55 @@ https://blog.csdn.net/yixuandong9010/article/details/72286029
https://juejin.im/post/5cbdbb455188250ab224802d
-
#### 500万数字排序,内存只能容纳5万个,如何排序,如何优化?
参考文章:https://juejin.im/entry/5a27cb796fb9a045104a5e8c
-- 平时怎么写数据库的模糊查询(由字典树扯到模糊查询,前缀查询,例如“abc%”,还是索引策略的问题)
+#### 平时怎么写数据库的模糊查询(由字典树扯到模糊查询,前缀查询,例如“abc%”,还是索引策略的问题)
-- 数据库里有 10000000 条用户信息,需要给每位用户发送信息(必须发送成功),要求节省内存
+#### 数据库里有 10000000 条用户信息,需要给每位用户发送信息(必须发送成功),要求节省内存
-- 项目中如何实现事务
+#### 项目中如何实现事务
#### 数据库设计一般设计成第几范式
https://blog.csdn.net/hsd2012/article/details/51018631
-- mysql 用的什么版本 5.7 跟 5.6 有啥区别
+#### mysql 用的什么版本 5.7 跟 5.6 有啥区别
#### 提升 MySQL 安全性
https://blog.csdn.net/listen_for/article/details/53907270
-- 问了一个这样的表(三个字段:姓名,id,分数)要求查出平均分大于 80 的 id 然后分数降序排序,然后经过提示用聚合函数 avg。
+#### 问了一个这样的表(三个字段:姓名,id,分数)要求查出平均分大于 80 的 id 然后分数降序排序,然后经过提示用聚合函数 avg。
select id from table group by id having avg(score) > 80 order by avg(score) desc。
-- 为什么 mysql 事务能保证失败回滚
-
-
-#### 一道算法题,在一个整形数组中,找出第三大的数,注意时间效率 (使用堆)
-
+#### 为什么 mysql 事务能保证失败回滚
-
-- 主键索引底层的实现原理
+#### 主键索引底层的实现原理
B+树
-- 经典的01索引问题?
+#### 经典的01索引问题?
-- 如何在长文本中快捷的筛选出你的名字?
+#### 如何在长文本中快捷的筛选出你的名字?
全文索引
-- 多列索引及最左前缀原则和其他使用场景
+#### 多列索引及最左前缀原则和其他使用场景
-- 事务隔离级别
+#### 事务隔离级别
-- 索引的最左前缀原则
+#### 索引的最左前缀原则
-- 数据库悲观锁怎么实现的
+#### 数据库悲观锁怎么实现的
https://www.jianshu.com/p/f5ff017db62a
-- 建表的原则
-
-- 索引的内涵和用法
+#### 建表的原则
+#### 索引的内涵和用法
-- 给了两条 SQL 语句,让根据这两条语句建索引(个人想法:主要考虑复合索引只能匹配前缀列的特点)
+#### 给了两条 SQL 语句,让根据这两条语句建索引(个人想法:主要考虑复合索引只能匹配前缀列的特点)
#### 那么我们来聊一下数据库。A 和 B 两个表做等值连接(Inner join) 怎么优化
@@ -735,29 +907,80 @@ https://blog.csdn.net/hguisu/article/details/5731880
#### 数据库连接池的理解和优化
-- Sql 语句 分组排序
+#### Sql语句分组排序
-- SQL 语句的 5 个连接概念
+#### SQL语句的5个连接概念
-- 数据库优化和架构(主要是主从分离和分库分表相关)
+#### 数据库优化和架构(主要是主从分离和分库分表相关)
-分库分表
+#### 分库分表
-- 跨库join实现
+#### 跨库join实现
-- 探讨主从分离和分库分表相关
+#### 探讨主从分离和分库分表相关
-- 数据库中间件
+#### 数据库中间件
-- 读写分离在中间件的实现
+#### 读写分离在中间件的实现
-- 限流 and 熔断
+#### 限流 and 熔断
#### 行锁适用场景
https://cloud.tencent.com/developer/article/1104098
-### 计算机网络
+
+### Redis
+
+#### redis为什么快?
+
+https://zhuanlan.zhihu.com/p/57089960
+
+#### Redis 数据结构原理
+
+https://blog.csdn.net/jackFXX/article/details/82318080
+
+#### Redis 持久化机制
+
+#### Redis 的一致性哈希算法
+
+#### redis了解多少
+
+#### redis五种数据类型,当散列类型的 value 值非常大的时候怎么进行压缩
+
+#### 用redis怎么实现摇一摇与附近的人功能
+
+https://blog.csdn.net/smartwu_sir/article/details/80254733
+
+#### redis 主从复制过程
+
+#### Redis 如何解决 key 冲突
+
+#### redis 是怎么存储数据的
+
+#### redis 使用场景
+
+### 九 计算机网络
+
+#### cookie 禁用怎么办
+
+https://segmentfault.com/q/1010000007715137
+
+#### Netty new 实例化过程
+
+#### socket 实现过程,具体用的方法;怎么实现异步 socket.
+
+https://blog.csdn.net/charjay_lin/article/details/81810922
+
+#### 浏览器的缓存机制
+
+说明计算机网络的知识还没有记住
+
+https://www.cnblogs.com/yangyangxxb/p/10218871.html
+
+#### http相关问题
+
+https://mp.weixin.qq.com/s/xSGD3rWdboeeQvaS8jEchw
#### TCP三次握手第三次握手时ACK丢失怎么办
@@ -765,13 +988,13 @@ https://www.cnblogs.com/wuyepeng/p/9801470.html
#### dns属于udp还是tcp,原因
-- https://www.zhihu.com/question/310145373
+https://www.zhihu.com/question/310145373
#### http的幂等性
-- https://www.cnblogs.com/weidagang2046/archive/2011/06/04/idempotence.html
+https://www.cnblogs.com/weidagang2046/archive/2011/06/04/idempotence.html
-- 建立连接的过程客户端跟服务端会交换什么信息(参考 TCP 报文结构)
+#### 建立连接的过程客户端跟服务端会交换什么信息(参考 TCP 报文结构)
#### 丢包如何解决重传的消耗
@@ -783,7 +1006,7 @@ https://zhuanlan.zhihu.com/p/36811672
#### IO多路复用
-- https://sanyuesha.com/python-server-tutorial/book/ch05.html
+https://sanyuesha.com/python-server-tutorial/book/ch05.html
#### select 和 poll 区别?
@@ -793,7 +1016,7 @@ https://zhuanlan.zhihu.com/p/36811672
服务器推送:https://juejin.im/post/5c20e5766fb9a049b13e387b
-可以使用客户端定时刷新请求或者和 TCP 保持心跳连接实现。
+#### 可以使用客户端定时刷新请求或者和 TCP 保持心跳连接实现。
#### 查看磁盘读写吞吐量?
@@ -807,27 +1030,51 @@ https://www.cnblogs.com/ggjucheng/archive/2013/01/13/2858810.html
https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Redirections
-- controller 怎么处理的请求:路由
+#### controller 怎么处理的请求:路由
#### IP 地址分为几类,每类都代表什么,私网是哪些
https://zhuanlan.zhihu.com/p/54593244
+
+### 十 操作系统
+
+#### Java I/O 底层细节,注意是底层细节,而不是怎么用
+
+可以从Java IO底层、JavaIO模型(阻塞、异步等)
+https://www.cnblogs.com/crazymakercircle/p/10225159.html
+
+#### Java IO 模型(BIO,NIO 等) ,Tomcat 用的哪一种模型
+
+tomcat支持:https://blog.csdn.net/fd2025/article/details/80007435
+
+#### 当获取第一个获取锁之后,条件不满足需要释放锁应当怎么做?
+
+https://www.jianshu.com/p/eb112b25b848
+
+#### 手写一个线程安全的生产者与消费者。
+
+https://blog.csdn.net/u010983881/article/details/78554671
+
+#### 进程和线程调度方法
+
+https://www.jianshu.com/p/91c8600cb2ae
+
### linux
#### linux查找命令
-- https://blog.51cto.com/whylinux/2043871
+https://blog.51cto.com/whylinux/2043871
#### 项目部署常见linux命令
-- https://blog.csdn.net/u010938610/article/details/79625988
+https://blog.csdn.net/u010938610/article/details/79625988
-- 进程文件里有哪些信息
+#### 进程文件里有哪些信息
#### sed 和 awk 的区别
-- awk用法:https://www.cnblogs.com/isykw/p/6258781.html
+awk用法:https://www.cnblogs.com/isykw/p/6258781.html
其实sed和awk都是每次读入一行来处理的,区别是:sed 适合简单的文本替换和搜索;而awk除了自动给你分列之外,里面丰富的函数大大增强了awk的功能。数据统计,正则表达式搜索,逻辑处理,前后置脚本等。因此基本上sed能做的,awk可以全部完成并且做的更好。
@@ -838,8 +1085,6 @@ https://zhuanlan.zhihu.com/p/54593244
https://blog.csdn.net/qingmu0803/article/details/38271077
-
-
#### 有一个文件被锁住,如何查看锁住它的线程?
#### 如何查看一个文件第100行到150行的内容
@@ -852,7 +1097,7 @@ https://www.cnblogs.com/freeweb/p/5407105.html
https://blog.csdn.net/inuyashaw/article/details/55095545
-- linux 如何查找文件
+#### linux 如何查找文件
linux命令:https://juejin.im/post/5d3857eaf265da1bd04f2437
@@ -860,91 +1105,93 @@ linux命令:https://juejin.im/post/5d3857eaf265da1bd04f2437
https://juejin.im/post/5b624f4d518825068302aee9#heading-13
-### 安全加密
-
-- http://www.ruanyifeng.com/blog/2011/08/what_is_a_digital_signature.html
-- https://yq.aliyun.com/articles/54155
+### 十一 框架其他
-#### web安全问题
+#### Servlet 的 Filter 用的什么设计模式
-https://juejin.im/post/5da44c5de51d45783a772a22
+https://www.jianshu.com/p/e4197a54828d
-### 分布式
+#### zookeeper 的常用功能,自己用它来做什么
-#### dubbo中的dubbo协议和http协议有什么区别?
+#### redis 的操作是不是原子操作
-- https://blog.csdn.net/wjw_77/article/details/99696757
+https://juejin.im/entry/58f9e22044d9040069d40dca
-### 项目及规划
+#### 秒杀业务场景设计
-1. 对你来说影响最大的一个项目(该面试中有关项目问题都针对该项目展开)?
+#### 如何设计淘宝秒杀系统(重点关注架构,比如数据一致性,数据库集群一致性哈希,缓存, 分库分表等等)
-2. 项目哪一部分最难攻克?如何攻克?
-个人建议:大家一定要选自己印象最深的项目回答,首先按模块,然后组成 人员,最后你在项目中的角色和发挥 的作用。全程组织好语言,最好不要有停顿,面试官可以 看出你对项目的熟悉程度
+#### 对后台的优化有了解吗?比如负载均衡
-3. 你觉得你在项目运行过程中作为组长是否最大限度发挥了组员的优势?具体事例?
+我给面试官说了 Ngix+Tomcat 负载均 衡,异步处理(消息缓冲服务器),缓存(Redis, Memcache), NoSQL,数据库优化,存储索引优化
-4. 职业规划,今天想发展的工作方向
-5. 项目里我遇到过的最大的困难是什么
+#### 对 Restful 了解 Restful 的认识,优点,以及和 soap 的区别
-6. 实验室的新来的研一,你会给他们什么学习上的建议,例如对于内核源码的枯 燥如何克服
+https://www.ruanyifeng.com/blog/2011/09/restful.html
-7. 如何协调团队中多人的工作
+#### lrucache 的基本原理
-8. 当团队中有某人的任务没有完成的很好,如何处理
-9. 平时看些什么书,技术 综合
+### 十二 设计模式
-10. 项目解决的什么问题 用到了哪些技术
+#### Java常见设计模式
-11. 怎么预防 bug 日志 jvm 异常信息 如何找问题的根源(统计表格)
+- https://www.jianshu.com/p/61b67ca754a3
+- 单例模式(双检锁模式)、简单工厂、观察者模式、适配器模式、职责链模式等等
+- 享元模式模式 选两个画下 UML 图
+- 手写单例
+写的是静态内部类的单例,然后他问我这个地方为什么用 private,这儿为啥用 static, 这就考察你的基本功啦
+- 静态类与单例模式的区别
+- 单例模式 double check 单例模式都有什么,都是否线程安全,怎么改进(从 synchronized 到 双重检验锁 到 枚举 Enum)
+- 基本的设计模式及其核心思想
+- 来,我们写一个单例模式的实现
-12. 你是怎么学习的,说完会让举个例子
+### 十三 分布式
-13. 实习投了哪几个公司?为什么,原因
+#### dubbo中的dubbo协议和http协议有什么区别?
-14. 最得意的项目是什么?为什么?(回答因为项目对实际作用大,并得到认可)
+https://blog.csdn.net/wjw_77/article/details/99696757
-15. 最得意的项目内容,讲了会
+#### 负载均衡
-16. 你简历上写的是最想去的部门不是我们部门,来我们部门的话对你有影响麽?
+https://juejin.im/post/5b39eea0e51d4558c1010e36
-17. 你除了在学校还有哪些方式去获取知识和技术?
+#### 分布式锁的实现方式及优缺点
-18. 你了解阿里文化和阿里开源吗?
+https://zhuanlan.zhihu.com/p/62158041
-19. 遇到困难解决问题的思路?
+#### CAP
-20. 我觉得最成功的一件事了
+https://www.jianshu.com/p/8025e3346734
-我说能说几件吗,说了我大学明白明白了 自己想干什么,选择了自己喜欢的事,大学里学会了和自己相处,自己一个人的 时候也不会感觉无聊,精神世界比较丰富,坚持锻炼,健身,有个很不错的身体, 然后顿了顿笑着说,说,有一个对我很好的女朋友算吗?
+#### 如何实现分布式缓存
-21. 压力大的时候怎么调整?多个任务冲突了你怎么协调的?
+redis如何实现分布式缓存
+https://stor.51cto.com/art/201912/607229.htm
-22. 家里有几个孩子,父母对你来北京有什么看法?
+### 十四 其他
-23. 职业生涯规划
+##### Java 8 函数式编程 回调函数
-24. 你在什么情况下可能会离职
+#### 函数式编程,面向对象之间区别
-25. 对你影响最大的人
+#### Java 8 中 stream 迭代的优势和区别?
-26. 1. 优点 3 个,以及缺点 2. 说说你应聘这个岗位的优势 3. 说说家庭 4. 为什么 想来网易,用过网易的哪些产品,对比下有什么好的地方 5. 投递了哪些公司,对第一份工 作怎么看待
+#### 同步等于可见性吗?
-27. 为什么要选择互联网(楼主偏底层的)
+保证了可见性不等于正确同步,因为还有原子性没考虑。
-28. 为什么来网易(看你如何夸)
+#### git底层数据结构
-29. 在校期间怎样学习
+https://blog.csdn.net/leo187/article/details/106233706
-30. 经常逛的技术性网站有哪些?
+#### 安全加密
-31. 举出你在开发过程中遇到的原先不知道的 bug, 通过各种方式定位 bug 并最终 成功解决的例子
+http://www.ruanyifeng.com/blog/2011/08/what_is_a_digital_signature.html
+https://yq.aliyun.com/articles/54155
-32. 举出一个例子说明你的自学能力 7 次面试记录,除了京东基本上也都走到了很后面的阶段。硬要说经验可能有三点:
+#### web安全问题
-- 不会就不会。我比较爽快,如果遇到的不会的甚至是不确定的,都直接说:“对不起, 我答不上来”之类的。
-- 一技之长。中间件和架构相关的实习经历,让我基本上和面试官都可以聊的很多, 也可以看到,我整个过程没有多少算法题。是因为面试官和你聊完项目就知道你能 做事了。其实,面试官很不愿意出算法题的(BAT 那个档次除外),你能和他扯技 术他当然高兴了。关键很多人只会算法(逃)。
-- 基础非常重要。面试官只要问 Java 相关的基础,我都有自信让一般的面试官感觉 惊讶,甚至学到新知识
\ No newline at end of file
+https://juejin.im/post/5da44c5de51d45783a772a22
diff --git "a/docs/interview/\345\267\262\346\212\225\345\205\254\345\217\270\346\203\205\345\206\265.md" "b/docs/interview/\345\267\262\346\212\225\345\205\254\345\217\270\346\203\205\345\206\265.md"
index c1bb8fe..3ca1b9c 100644
--- "a/docs/interview/\345\267\262\346\212\225\345\205\254\345\217\270\346\203\205\345\206\265.md"
+++ "b/docs/interview/\345\267\262\346\212\225\345\205\254\345\217\270\346\203\205\345\206\265.md"
@@ -5,7 +5,7 @@
|蘑菇街|http://job.mogujie.com/#/candidate/perfectInfo | | offer |
|虎牙| | | 不匹配 |
|远景|https://campus.envisioncn.com/ | | 笔试 |
-|阿里钉钉| https://campus.alibaba.com/myJobApply.htm?saveResume=yes&t=1584782560963 |https://www.nowcoder.com/discuss/368915?type=0&order=0&pos=25&page=3| 一面 |
+|阿里钉钉| https://campus.alibaba.com/myJobApply.htm?saveResume=yes&t=1584782560963 |https://www.nowcoder.com/discuss/368915?type=0&order=0&pos=25&page=3| 二面 |
|阿里新零售| |https://www.nowcoder.com/discuss/374171?type=0&order=0&pos=35&page=1 https://www.nowcoder.com/discuss/372118?type=0&order=0&pos=80&page=2| |
|深信服| |https://www.nowcoder.com/discuss/369399?type=0&order=0&pos=40&page=6| |
|CVTE| |https://www.nowcoder.com/discuss/368463?type=0&order=0&pos=87&page=3| 已投 |
@@ -15,13 +15,13 @@
|拼多多| https://pinduoduo.zhiye.com/Portal/Apply/Index | https://www.nowcoder.com/discuss/393350?type=post&order=time&pos=&page=8 | 已投 |
|腾讯| https://join.qq.com/center.php |https://www.nowcoder.com/discuss/377813?type=post&order=time&pos=&page=1| offer |
|猿辅导| https://app.mokahr.com/m/candidate/applications/deliver-query/fenbi |https://www.nowcoder.com/discuss/375610?type=0&order=0&pos=95&page=2| 已投 |
-|斗鱼| https://app.mokahr.com/m/candidate/applications/deliver-query/douyu |https://www.nowcoder.com/discuss/375180?type=0&order=0&pos=158&page=1| 笔试 |
+|斗鱼| https://app.mokahr.com/m/candidate/applications/deliver-query/douyu |https://www.nowcoder.com/discuss/375180?type=0&order=0&pos=158&page=1| 一面挂 |
|淘宝技术部| |https://www.nowcoder.com/discuss/374655?type=0&order=0&pos=165&page=6| |
|字节跳动| https://job.bytedance.com/user https://job.bytedance.com/referral/pc/position/application?lightning=1&token=MzsxNTg0MTU2NDIxMDIzOzY2ODgyMjg1NzI1Mjk3MjI4ODM7MA/profile/ |https://www.nowcoder.com/discuss/381888?type=post&order=time&pos=&page=2| 已投 |
|陌陌| | 来自内推军 |已投|
|网易| http://gzgame.campus.163.com/applyPosition.do?&lan=zh |https://www.nowcoder.com/discuss/373132?type=post&order=create&pos=&page=1 一姐| 已投|
|百度| https://talent.baidu.com/external/baidu/index.html#/individualCenter |https://www.nowcoder.com/discuss/376515?type=post&order=time&pos=&page=1| 已投 |
-|京东| http://campus.jd.com/web/resume/resume_index?fxType=0 |https://www.nowcoder.com/discuss/372978?type=post&order=time&pos=&page=4| 已投 |
+|京东| http://campus.jd.com/web/resume/resume_index?fxType=0 |https://www.nowcoder.com/discuss/372978?type=post&order=time&pos=&page=4| 二面挂 |
|爱奇艺| | | |
|科大讯飞| | | |
|度小满| | https://www.nowcoder.com/discuss/387950?type=post&order=time&pos=&page=13 | 已投 |
\ No newline at end of file
diff --git "a/docs/interview/\350\207\252\346\210\221\344\273\213\347\273\215\345\222\214\351\241\271\347\233\256\344\273\213\347\273\215.md" "b/docs/interview/\350\207\252\346\210\221\344\273\213\347\273\215\345\222\214\351\241\271\347\233\256\344\273\213\347\273\215.md"
index 374650b..3825b52 100644
--- "a/docs/interview/\350\207\252\346\210\221\344\273\213\347\273\215\345\222\214\351\241\271\347\233\256\344\273\213\347\273\215.md"
+++ "b/docs/interview/\350\207\252\346\210\221\344\273\213\347\273\215\345\222\214\351\241\271\347\233\256\344\273\213\347\273\215.md"
@@ -35,20 +35,8 @@
4、对数据库性能进行调优
5、开发抢购活动功能模块(业务需求)
-### 北京项目介绍
-这个项目的背景是,现在深空探索的研究越来越热,这个项目就是研究及开发脉冲星导航的相关问题,而脉冲星导航的能够解决深空探索航天器的位置问题,这个就是北京项目的研究目标。
-
-脉冲星是一颗稳定的中子星,能够发出稳定的脉冲波,通过接收脉冲星发出来的脉冲波,可以确定航天器在太空中的位置。
-
-而我在北京的工作是:
-1、开发一个软件
-2、实现相关算法对航天器上的部件精度进行控制
-3、航天器相关的数据进行数据显示
-4、近地卫星轨道5星编队仿真实现
-
-
-2019年5月–2019年9月,在####实习,参加了脉冲星导航的项目开发工作。项目的背景是,现在深空探索的研究越来越热,这个项目就是研究及开发脉冲星导航的相关问题,而脉冲星导航的能够解决深空探索航天器的位置问题,这个就是项目的研究目标。
+2019年5月–2019年9月,在中国空间技术研究院钱学森空间技术实验室实习,参加了脉冲星导航的项目开发工作。项目的背景是,现在深空探索的研究越来越热,这个项目就是研究及开发脉冲星导航的相关问题,而脉冲星导航的能够解决深空探索航天器的位置问题,这个就是项目的研究目标。
负责工作:
1、开发一个脉冲星导航仿真软件
2、实现相关算法对航天器上的部件精度进行控制
@@ -69,4 +57,6 @@

-2、给俺一个 **star** 呗,可以让更多的人看到这篇文章,顺便激励下我继续写作,嘻嘻。
\ No newline at end of file
+2、给俺一个 **star** 呗,可以让更多的人看到这篇文章,顺便激励下我继续写作,嘻嘻。
+
+
diff --git a/docs/java/BIO-NIO-AIO.md b/docs/java/BIO-NIO-AIO.md
deleted file mode 100644
index 36aac43..0000000
--- a/docs/java/BIO-NIO-AIO.md
+++ /dev/null
@@ -1,346 +0,0 @@
-熟练掌握 BIO,NIO,AIO 的基本概念以及一些常见问题是你准备面试的过程中不可或缺的一部分,另外这些知识点也是你学习 Netty 的基础。
-
-
-
-- [BIO,NIO,AIO 总结](#bionioaio-总结)
- - [1. BIO \(Blocking I/O\)](#1-bio-blocking-io)
- - [1.1 传统 BIO](#11-传统-bio)
- - [1.2 伪异步 IO](#12-伪异步-io)
- - [1.3 代码示例](#13-代码示例)
- - [1.4 总结](#14-总结)
- - [2. NIO \(New I/O\)](#2-nio-new-io)
- - [2.1 NIO 简介](#21-nio-简介)
- - [2.2 NIO的特性/NIO与IO区别](#22-nio的特性nio与io区别)
- - [1)Non-blocking IO(非阻塞IO)](#1non-blocking-io(非阻塞io))
- - [2)Buffer\(缓冲区\)](#2buffer缓冲区)
- - [3)Channel \(通道\)](#3channel-通道)
- - [4)Selectors\(选择器\)](#4selectors选择器)
- - [2.3 NIO 读数据和写数据方式](#23-nio-读数据和写数据方式)
- - [2.4 NIO核心组件简单介绍](#24-nio核心组件简单介绍)
- - [2.5 代码示例](#25-代码示例)
- - [3. AIO \(Asynchronous I/O\)](#3-aio-asynchronous-io)
- - [参考](#参考)
-
-
-
-
-# BIO,NIO,AIO 总结
-
- Java 中的 BIO、NIO和 AIO 理解为是 Java 语言对操作系统的各种 IO 模型的封装。程序员在使用这些 API 的时候,不需要关心操作系统层面的知识,也不需要根据不同操作系统编写不同的代码。只需要使用Java的API就可以了。
-
-在讲 BIO,NIO,AIO 之前先来回顾一下这样几个概念:同步与异步,阻塞与非阻塞。
-
-**同步与异步**
-
-- **同步:** 同步就是发起一个调用后,被调用者未处理完请求之前,调用不返回。
-- **异步:** 异步就是发起一个调用后,立刻得到被调用者的回应表示已接收到请求,但是被调用者并没有返回结果,此时我们可以处理其他的请求,被调用者通常依靠事件,回调等机制来通知调用者其返回结果。
-
-同步和异步的区别最大在于异步的话调用者不需要等待处理结果,被调用者会通过回调等机制来通知调用者其返回结果。
-
-**阻塞和非阻塞**
-
-- **阻塞:** 阻塞就是发起一个请求,调用者一直等待请求结果返回,也就是当前线程会被挂起,无法从事其他任务,只有当条件就绪才能继续。
-- **非阻塞:** 非阻塞就是发起一个请求,调用者不用一直等着结果返回,可以先去干其他事情。
-
-举个生活中简单的例子,你妈妈让你烧水,小时候你比较笨啊,在那里傻等着水开(**同步阻塞**)。等你稍微再长大一点,你知道每次烧水的空隙可以去干点其他事,然后只需要时不时来看看水开了没有(**同步非阻塞**)。后来,你们家用上了水开了会发出声音的壶,这样你就只需要听到响声后就知道水开了,在这期间你可以随便干自己的事情,你需要去倒水了(**异步非阻塞**)。
-
-
-## 1. BIO (Blocking I/O)
-
-同步阻塞I/O模式,数据的读取写入必须阻塞在一个线程内等待其完成。
-
-### 1.1 传统 BIO
-
-BIO通信(一请求一应答)模型图如下(图源网络,原出处不明):
-
-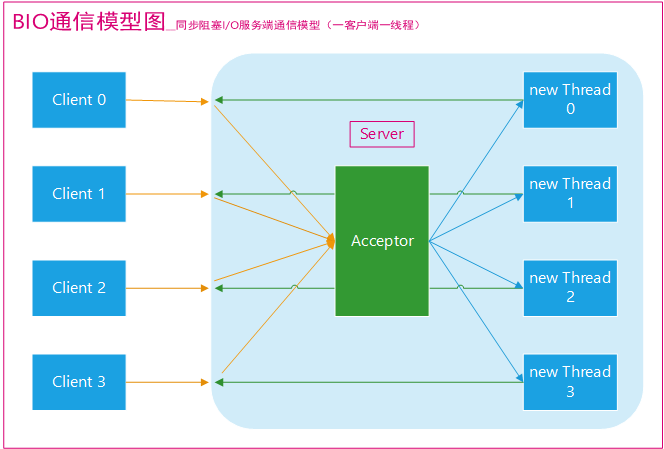
-
-采用 **BIO 通信模型** 的服务端,通常由一个独立的 Acceptor 线程负责监听客户端的连接。我们一般通过在`while(true)` 循环中服务端会调用 `accept()` 方法等待接收客户端的连接的方式监听请求,请求一旦接收到一个连接请求,就可以建立通信套接字在这个通信套接字上进行读写操作,此时不能再接收其他客户端连接请求,只能等待同当前连接的客户端的操作执行完成, 不过可以通过多线程来支持多个客户端的连接,如上图所示。
-
-如果要让 **BIO 通信模型** 能够同时处理多个客户端请求,就必须使用多线程(主要原因是`socket.accept()`、`socket.read()`、`socket.write()` 涉及的三个主要函数都是同步阻塞的),也就是说它在接收到客户端连接请求之后为每个客户端创建一个新的线程进行链路处理,处理完成之后,通过输出流返回应答给客户端,线程销毁。这就是典型的 **一请求一应答通信模型** 。我们可以设想一下如果这个连接不做任何事情的话就会造成不必要的线程开销,不过可以通过 **线程池机制** 改善,线程池还可以让线程的创建和回收成本相对较低。使用`FixedThreadPool` 可以有效的控制了线程的最大数量,保证了系统有限的资源的控制,实现了N(客户端请求数量):M(处理客户端请求的线程数量)的伪异步I/O模型(N 可以远远大于 M),下面一节"伪异步 BIO"中会详细介绍到。
-
-**我们再设想一下当客户端并发访问量增加后这种模型会出现什么问题?**
-
-在 Java 虚拟机中,线程是宝贵的资源,线程的创建和销毁成本很高,除此之外,线程的切换成本也是很高的。尤其在 Linux 这样的操作系统中,线程本质上就是一个进程,创建和销毁线程都是重量级的系统函数。如果并发访问量增加会导致线程数急剧膨胀可能会导致线程堆栈溢出、创建新线程失败等问题,最终导致进程宕机或者僵死,不能对外提供服务。
-
-### 1.2 伪异步 IO
-
-为了解决同步阻塞I/O面临的一个链路需要一个线程处理的问题,后来有人对它的线程模型进行了优化一一一后端通过一个线程池来处理多个客户端的请求接入,形成客户端个数M:线程池最大线程数N的比例关系,其中M可以远远大于N.通过线程池可以灵活地调配线程资源,设置线程的最大值,防止由于海量并发接入导致线程耗尽。
-
-伪异步IO模型图(图源网络,原出处不明):
-
-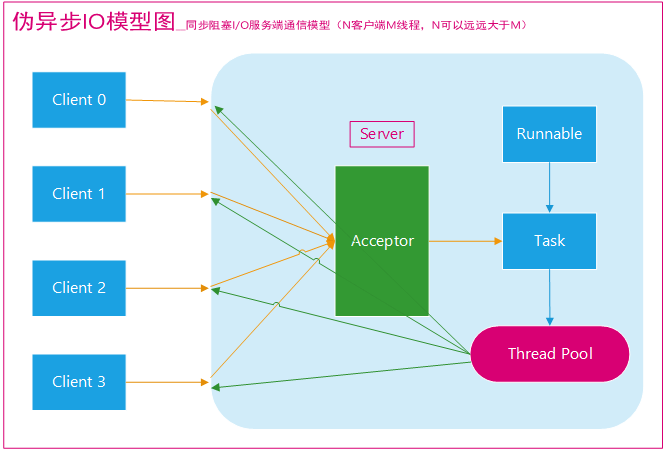
-
-采用线程池和任务队列可以实现一种叫做伪异步的 I/O 通信框架,它的模型图如上图所示。当有新的客户端接入时,将客户端的 Socket 封装成一个Task(该任务实现java.lang.Runnable接口)投递到后端的线程池中进行处理,JDK 的线程池维护一个消息队列和 N 个活跃线程,对消息队列中的任务进行处理。由于线程池可以设置消息队列的大小和最大线程数,因此,它的资源占用是可控的,无论多少个客户端并发访问,都不会导致资源的耗尽和宕机。
-
-伪异步I/O通信框架采用了线程池实现,因此避免了为每个请求都创建一个独立线程造成的线程资源耗尽问题。不过因为它的底层仍然是同步阻塞的BIO模型,因此无法从根本上解决问题。
-
-### 1.3 代码示例
-
-下面代码中演示了BIO通信(一请求一应答)模型。我们会在客户端创建多个线程依次连接服务端并向其发送"当前时间+:hello world",服务端会为每个客户端线程创建一个线程来处理。代码示例出自闪电侠的博客,原地址如下:
-
-[https://www.jianshu.com/p/a4e03835921a](https://www.jianshu.com/p/a4e03835921a)
-
-**客户端**
-
-```java
-/**
- *
- * @author 闪电侠
- * @date 2018年10月14日
- * @Description:客户端
- */
-public class IOClient {
-
- public static void main(String[] args) {
- // TODO 创建多个线程,模拟多个客户端连接服务端
- new Thread(() -> {
- try {
- Socket socket = new Socket("127.0.0.1", 3333);
- while (true) {
- try {
- socket.getOutputStream().write((new Date() + ": hello world").getBytes());
- Thread.sleep(2000);
- } catch (Exception e) {
- }
- }
- } catch (IOException e) {
- }
- }).start();
-
- }
-
-}
-
-```
-
-**服务端**
-
-```java
-/**
- * @author 闪电侠
- * @date 2018年10月14日
- * @Description: 服务端
- */
-public class IOServer {
-
- public static void main(String[] args) throws IOException {
- // TODO 服务端处理客户端连接请求
- ServerSocket serverSocket = new ServerSocket(3333);
-
- // 接收到客户端连接请求之后为每个客户端创建一个新的线程进行链路处理
- new Thread(() -> {
- while (true) {
- try {
- // 阻塞方法获取新的连接
- Socket socket = serverSocket.accept();
-
- // 每一个新的连接都创建一个线程,负责读取数据
- new Thread(() -> {
- try {
- int len;
- byte[] data = new byte[1024];
- InputStream inputStream = socket.getInputStream();
- // 按字节流方式读取数据
- while ((len = inputStream.read(data)) != -1) {
- System.out.println(new String(data, 0, len));
- }
- } catch (IOException e) {
- }
- }).start();
-
- } catch (IOException e) {
- }
-
- }
- }).start();
-
- }
-
-}
-```
-
-### 1.4 总结
-
-在活动连接数不是特别高(小于单机1000)的情况下,这种模型是比较不错的,可以让每一个连接专注于自己的 I/O 并且编程模型简单,也不用过多考虑系统的过载、限流等问题。线程池本身就是一个天然的漏斗,可以缓冲一些系统处理不了的连接或请求。但是,当面对十万甚至百万级连接的时候,传统的 BIO 模型是无能为力的。因此,我们需要一种更高效的 I/O 处理模型来应对更高的并发量。
-
-
-
-## 2. NIO (New I/O)
-
-### 2.1 NIO 简介
-
- NIO是一种同步非阻塞的I/O模型,在Java 1.4 中引入了 NIO 框架,对应 java.nio 包,提供了 Channel , Selector,Buffer等抽象。
-
-NIO中的N可以理解为Non-blocking,不单纯是New。它支持面向缓冲的,基于通道的I/O操作方法。 NIO提供了与传统BIO模型中的 `Socket` 和 `ServerSocket` 相对应的 `SocketChannel` 和 `ServerSocketChannel` 两种不同的套接字通道实现,两种通道都支持阻塞和非阻塞两种模式。阻塞模式使用就像传统中的支持一样,比较简单,但是性能和可靠性都不好;非阻塞模式正好与之相反。对于低负载、低并发的应用程序,可以使用同步阻塞I/O来提升开发速率和更好的维护性;对于高负载、高并发的(网络)应用,应使用 NIO 的非阻塞模式来开发。
-
-### 2.2 NIO的特性/NIO与IO区别
-
-如果是在面试中回答这个问题,我觉得首先肯定要从 NIO 流是非阻塞 IO 而 IO 流是阻塞 IO 说起。然后,可以从 NIO 的3个核心组件/特性为 NIO 带来的一些改进来分析。如果,你把这些都回答上了我觉得你对于 NIO 就有了更为深入一点的认识,面试官问到你这个问题,你也能很轻松的回答上来了。
-
-#### 1)Non-blocking IO(非阻塞IO)
-
-**IO流是阻塞的,NIO流是不阻塞的。**
-
-Java NIO使我们可以进行非阻塞IO操作。比如说,单线程中从通道读取数据到buffer,同时可以继续做别的事情,当数据读取到buffer中后,线程再继续处理数据。写数据也是一样的。另外,非阻塞写也是如此。一个线程请求写入一些数据到某通道,但不需要等待它完全写入,这个线程同时可以去做别的事情。
-
-Java IO的各种流是阻塞的。这意味着,当一个线程调用 `read()` 或 `write()` 时,该线程被阻塞,直到有一些数据被读取,或数据完全写入。该线程在此期间不能再干任何事情了
-
-#### 2)Buffer(缓冲区)
-
-**IO 面向流(Stream oriented),而 NIO 面向缓冲区(Buffer oriented)。**
-
-Buffer是一个对象,它包含一些要写入或者要读出的数据。在NIO类库中加入Buffer对象,体现了新库与原I/O的一个重要区别。在面向流的I/O中·可以将数据直接写入或者将数据直接读到 Stream 对象中。虽然 Stream 中也有 Buffer 开头的扩展类,但只是流的包装类,还是从流读到缓冲区,而 NIO 却是直接读到 Buffer 中进行操作。
-
-在NIO厍中,所有数据都是用缓冲区处理的。在读取数据时,它是直接读到缓冲区中的; 在写入数据时,写入到缓冲区中。任何时候访问NIO中的数据,都是通过缓冲区进行操作。
-
-最常用的缓冲区是 ByteBuffer,一个 ByteBuffer 提供了一组功能用于操作 byte 数组。除了ByteBuffer,还有其他的一些缓冲区,事实上,每一种Java基本类型(除了Boolean类型)都对应有一种缓冲区。
-
-#### 3)Channel (通道)
-
-NIO 通过Channel(通道) 进行读写。
-
-通道是双向的,可读也可写,而流的读写是单向的。无论读写,通道只能和Buffer交互。因为 Buffer,通道可以异步地读写。
-
-#### 4)Selector (选择器)
-
-NIO有选择器,而IO没有。
-
-选择器用于使用单个线程处理多个通道。因此,它需要较少的线程来处理这些通道。线程之间的切换对于操作系统来说是昂贵的。 因此,为了提高系统效率选择器是有用的。
-
-
-
-### 2.3 NIO 读数据和写数据方式
-通常来说NIO中的所有IO都是从 Channel(通道) 开始的。
-
-- 从通道进行数据读取 :创建一个缓冲区,然后请求通道读取数据。
-- 从通道进行数据写入 :创建一个缓冲区,填充数据,并要求通道写入数据。
-
-数据读取和写入操作图示:
-
-
-
-
-### 2.4 NIO核心组件简单介绍
-
-NIO 包含下面几个核心的组件:
-
-- Channel(通道)
-- Buffer(缓冲区)
-- Selector(选择器)
-
-整个NIO体系包含的类远远不止这三个,只能说这三个是NIO体系的“核心API”。我们上面已经对这三个概念进行了基本的阐述,这里就不多做解释了。
-
-### 2.5 代码示例
-
-代码示例出自闪电侠的博客,原地址如下:
-
-[https://www.jianshu.com/p/a4e03835921a](https://www.jianshu.com/p/a4e03835921a)
-
-客户端 IOClient.java 的代码不变,我们对服务端使用 NIO 进行改造。以下代码较多而且逻辑比较复杂,大家看看就好。
-
-```java
-/**
- *
- * @author 闪电侠
- * @date 2019年2月21日
- * @Description: NIO 改造后的服务端
- */
-public class NIOServer {
- public static void main(String[] args) throws IOException {
- // 1. serverSelector负责轮询是否有新的连接,服务端监测到新的连接之后,不再创建一个新的线程,
- // 而是直接将新连接绑定到clientSelector上,这样就不用 IO 模型中 1w 个 while 循环在死等
- Selector serverSelector = Selector.open();
- // 2. clientSelector负责轮询连接是否有数据可读
- Selector clientSelector = Selector.open();
-
- new Thread(() -> {
- try {
- // 对应IO编程中服务端启动
- ServerSocketChannel listenerChannel = ServerSocketChannel.open();
- listenerChannel.socket().bind(new InetSocketAddress(3333));
- listenerChannel.configureBlocking(false);
- listenerChannel.register(serverSelector, SelectionKey.OP_ACCEPT);
-
- while (true) {
- // 监测是否有新的连接,这里的1指的是阻塞的时间为 1ms
- if (serverSelector.select(1) > 0) {
- Set