() ;
+ twoStackQueue.appendTail("1") ;
+ twoStackQueue.appendTail("2") ;
+ twoStackQueue.appendTail("3") ;
+ twoStackQueue.appendTail("4") ;
+ twoStackQueue.appendTail("5") ;
+
+
+ int size = twoStackQueue.getSize();
+
+ for (int i = 0; i< size ; i++){
+ LOGGER.info(twoStackQueue.deleteHead());
+ }
+
+ LOGGER.info("========第二次添加=========");
+
+ twoStackQueue.appendTail("6") ;
+
+ size = twoStackQueue.getSize();
+
+ for (int i = 0; i< size ; i++){
+ LOGGER.info(twoStackQueue.deleteHead());
+ }
+ }
+
+}
+```
+# 链表排序
+```java
+/**
+ * 链表排序, 建议使用归并排序,
+ * 问题描述,给定一个Int的链表,要求在时间最优的情况下完成链表元素由大到小的排序,
+ * e.g: 1->5->4->3->2
+ * 排序后结果 5->4->3->2->1
+ *
+ * @author 6563699600@qq.com
+ * @date 6/7/2018 11:42 PM
+ * @since 1.0
+ */
+public class LinkedListMergeSort {
+
+ /**
+ * 定义链表数据结构,包含当前元素,以及当前元素的后续元素指针
+ */
+ final static class Node {
+ int e;
+ Node next;
+
+ public Node() {
+ }
+
+ public Node(int e, Node next) {
+ this.e = e;
+ this.next = next;
+ }
+ }
+
+ public Node mergeSort(Node first, int length) {
+
+ if (length == 1) {
+ return first;
+ } else {
+ Node middle = new Node();
+ Node tmp = first;
+
+ /**
+ * 后期会对这里进行优化,通过一次遍历算出长度和中间元素
+ */
+ for (int i = 0; i < length; i++) {
+ if (i == length / 2) {
+ break;
+ }
+ middle = tmp;
+ tmp = tmp.next;
+ }
+
+ /**
+ * 这里是链表归并时要注意的细节
+ * 在链表进行归并排序过程中,会涉及到将一个链表打散为两个独立的链表,所以需要在中间元素的位置将其后续指针指为null;
+ */
+ Node right = middle.next;
+ middle.next = null;
+
+ Node leftStart = mergeSort(first, length / 2);
+ Node rightStart;
+ if (length % 2 == 0) {
+ rightStart = mergeSort(right, length / 2);
+ } else {
+ rightStart = mergeSort(right, length / 2 + 1);
+ }
+ return mergeList(leftStart, rightStart);
+ }
+ }
+
+ /**
+ * 合并链表,具体的实现细节可参考MergeTwoSortedLists
+ *
+ * @param left
+ * @param right
+ * @return
+ */
+ public Node mergeList(Node left, Node right) {
+
+ Node head = new Node();
+ Node result = head;
+
+ /**
+ * 思想就是两个链表同时遍历,将更的元素插入结果中,同时更更大的元素所属的链表的指针向下移动
+ */
+ while (!(null == left && null == right)) {
+ Node tmp;
+ if (left == null) {
+ result.next = right;
+ break;
+ } else if (right == null) {
+ result.next = left;
+ break;
+ } else if (left.e >= right.e) {
+ tmp = left;
+ result.next = left;
+ result = tmp;
+ left = left.next;
+ } else {
+ tmp = right;
+ result.next = right;
+ result = tmp;
+ right = right.next;
+ }
+ }
+
+ return head.next;
+ }
+
+ public static void main(String[] args) {
+
+ Node head = new Node();
+
+ head.next = new Node(7,
+ new Node(2,
+ new Node(5,
+ new Node(4,
+ new Node(3,
+ new Node(6,
+ new Node(11, null)
+ )
+ )
+ )
+ )
+ )
+ );
+
+ int length = 0;
+
+ for (Node e = head.next; null != e; e = e.next) {
+ length++;
+ }
+
+
+ LinkedListMergeSort sort = new LinkedListMergeSort();
+ head.next = sort.mergeSort(head.next, length);
+
+
+ for (Node n = head.next; n != null; n = n.next) {
+ System.out.println(n.e);
+ }
+
+ }
+}
+```
+# 数组右移 k 次
+```java
+/**
+ * 数组右移K次, 原数组 [1, 2, 3, 4, 5, 6, 7] 右移3次后结果为 [5,6,7,1,2,3,4]
+ *
+ * 基本思路:不开辟新的数组空间的情况下考虑在原属组上进行操作
+ * 1 将数组倒置,这样后k个元素就跑到了数组的前面,然后反转一下即可
+ * 2 同理后 len-k个元素只需要翻转就完成数组的k次移动
+ *
+ * @author 656369960@qq.com
+ * @date 12/7/2018 1:38 PM
+ * @since 1.0
+ */
+public class ArrayKShift {
+
+ public void arrayKShift(int[] array, int k) {
+
+ /**
+ * constrictions
+ */
+
+ if (array == null || 0 == array.length) {
+ return ;
+ }
+
+ k = k % array.length;
+
+ if (0 > k) {
+ return;
+ }
+
+
+ /**
+ * reverse array , e.g: [1, 2, 3 ,4] to [4,3,2,1]
+ */
+
+ for (int i = 0; i < array.length / 2; i++) {
+ int tmp = array[i];
+ array[i] = array[array.length - 1 - i];
+ array[array.length - 1 - i] = tmp;
+ }
+
+ /**
+ * first k element reverse
+ */
+ for (int i = 0; i < k / 2; i++) {
+ int tmp = array[i];
+ array[i] = array[k - 1 - i];
+ array[k - 1 - i] = tmp;
+ }
+
+ /**
+ * last length - k element reverse
+ */
+
+ for (int i = k; i < k + (array.length - k ) / 2; i ++) {
+ int tmp = array[i];
+ array[i] = array[array.length - 1 - i + k];
+ array[array.length - 1 - i + k] = tmp;
+ }
+ }
+
+ public static void main(String[] args) {
+ int[] array = {1, 2, 3 ,4, 5, 6, 7};
+ ArrayKShift shift = new ArrayKShift();
+ shift.arrayKShift(array, 6);
+
+ Arrays.stream(array).forEach(o -> {
+ System.out.println(o);
+ });
+
+ }
+}
+```
+
+# 交替打印奇偶数
+
+## lock 版
+
+```java
+/**
+ * Function: 两个线程交替执行打印 1~100
+ *
+ * lock 版
+ *
+ * @author crossoverJie
+ * Date: 11/02/2018 10:04
+ * @since JDK 1.8
+ */
+public class TwoThread {
+
+ private int start = 1;
+
+ /**
+ * 对 flag 的写入虽然加锁保证了线程安全,但读取的时候由于 不是 volatile 所以可能会读取到旧值
+ *
+ */
+ private volatile boolean flag = false;
+
+ /**
+ * 重入锁
+ */
+ private final static Lock LOCK = new ReentrantLock();
+
+ public static void main(String[] args) {
+ TwoThread twoThread = new TwoThread();
+
+ Thread t1 = new Thread(new OuNum(twoThread));
+ t1.setName("t1");
+
+
+ Thread t2 = new Thread(new JiNum(twoThread));
+ t2.setName("t2");
+
+ t1.start();
+ t2.start();
+ }
+
+ /**
+ * 偶数线程
+ */
+ public static class OuNum implements Runnable {
+
+ private TwoThread number;
+
+ public OuNum(TwoThread number) {
+ this.number = number;
+ }
+
+ @Override
+ public void run() {
+ while (number.start <= 1000) {
+
+ if (number.flag) {
+ try {
+ LOCK.lock();
+ System.out.println(Thread.currentThread().getName() + "+-+" + number.start);
+ number.start++;
+ number.flag = false;
+
+
+ } finally {
+ LOCK.unlock();
+ }
+ }
+ }
+ }
+ }
+
+ /**
+ * 奇数线程
+ */
+ public static class JiNum implements Runnable {
+
+ private TwoThread number;
+
+ public JiNum(TwoThread number) {
+ this.number = number;
+ }
+
+ @Override
+ public void run() {
+ while (number.start <= 1000) {
+
+ if (!number.flag) {
+ try {
+ LOCK.lock();
+ System.out.println(Thread.currentThread().getName() + "+-+" + number.start);
+ number.start++;
+ number.flag = true;
+
+
+ } finally {
+ LOCK.unlock();
+ }
+ }
+ }
+ }
+ }
+}
+```
+
+## 等待通知版
+```java
+/**
+ * Function:两个线程交替执行打印 1~100
+ * 等待通知机制版
+ *
+ * @author crossoverJie
+ * Date: 07/03/2018 13:19
+ * @since JDK 1.8
+ */
+public class TwoThreadWaitNotify {
+
+ private int start = 1;
+
+ private boolean flag = false;
+
+ public static void main(String[] args) {
+ TwoThreadWaitNotify twoThread = new TwoThreadWaitNotify();
+
+ Thread t1 = new Thread(new OuNum(twoThread));
+ t1.setName("t1");
+
+
+ Thread t2 = new Thread(new JiNum(twoThread));
+ t2.setName("t2");
+
+ t1.start();
+ t2.start();
+ }
+
+ /**
+ * 偶数线程
+ */
+ public static class OuNum implements Runnable {
+ private TwoThreadWaitNotify number;
+
+ public OuNum(TwoThreadWaitNotify number) {
+ this.number = number;
+ }
+
+ @Override
+ public void run() {
+
+ while (number.start <= 100) {
+ synchronized (TwoThreadWaitNotify.class) {
+ System.out.println("偶数线程抢到锁了");
+ if (number.flag) {
+ System.out.println(Thread.currentThread().getName() + "+-+偶数" + number.start);
+ number.start++;
+
+ number.flag = false;
+ TwoThreadWaitNotify.class.notify();
+
+ }else {
+ try {
+ TwoThreadWaitNotify.class.wait();
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ }
+ }
+
+ }
+ }
+ }
+
+
+ /**
+ * 奇数线程
+ */
+ public static class JiNum implements Runnable {
+ private TwoThreadWaitNotify number;
+
+ public JiNum(TwoThreadWaitNotify number) {
+ this.number = number;
+ }
+
+ @Override
+ public void run() {
+ while (number.start <= 100) {
+ synchronized (TwoThreadWaitNotify.class) {
+ System.out.println("奇数线程抢到锁了");
+ if (!number.flag) {
+ System.out.println(Thread.currentThread().getName() + "+-+奇数" + number.start);
+ number.start++;
+
+ number.flag = true;
+
+ TwoThreadWaitNotify.class.notify();
+ }else {
+ try {
+ TwoThreadWaitNotify.class.wait();
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ }
+ }
+ }
+ }
+ }
+}
+```
+
+## 非阻塞版
+```java
+/**
+ * Function: 两个线程交替执行打印 1~100
+ *
+ * non blocking 版:
+ * 两个线程轮询volatile变量(flag)
+ * 线程一"看到"flag值为1时执行代码并将flag设置为0,
+ * 线程二"看到"flag值为0时执行代码并将flag设置未1,
+ * 2个线程不断轮询直到满足条件退出
+ *
+ * @author twoyao
+ * Date: 05/07/2018
+ * @since JDK 1.8
+ */
+
+public class TwoThreadNonBlocking implements Runnable {
+
+ /**
+ * 当flag为1时只有奇数线程可以执行,并将其置为0
+ * 当flag为0时只有偶数线程可以执行,并将其置为1
+ */
+ private volatile static int flag = 1;
+
+ private int start;
+ private int end;
+ private String name;
+
+ private TwoThreadNonBlocking(int start, int end, String name) {
+ this.name = name;
+ this.start = start;
+ this.end = end;
+ }
+
+ @Override
+ public void run() {
+ while (start <= end) {
+ int f = flag;
+ if ((start & 0x01) == f) {
+ System.out.println(name + "+-+" + start);
+ start += 2;
+ // 因为只可能同时存在一个线程修改该值,所以不会存在竞争
+ flag ^= 0x1;
+ }
+ }
+ }
+
+
+ public static void main(String[] args) {
+ new Thread(new TwoThreadNonBlocking(1, 100, "t1")).start();
+ new Thread(new TwoThreadNonBlocking(2, 100, "t2")).start();
+ }
+}
+```
\ No newline at end of file
diff --git a/docs/algorithm/consistent-hash-implement.md b/docs/algorithm/consistent-hash-implement.md
new file mode 100644
index 00000000..fb669b4e
--- /dev/null
+++ b/docs/algorithm/consistent-hash-implement.md
@@ -0,0 +1,307 @@
+
+
+
+# 前言
+
+记得一年前分享过一篇[《一致性 Hash 算法分析》](https://crossoverjie.top/2018/01/08/Consistent-Hash/),当时只是分析了这个算法的实现原理、解决了什么问题等。
+
+但没有实际实现一个这样的算法,毕竟要加深印象还得自己撸一遍,于是本次就当前的一个路由需求来着手实现一次。
+
+# 背景
+
+看过[《为自己搭建一个分布式 IM(即时通讯) 系统》](https://crossoverjie.top/2019/01/02/netty/cim01-started/)的朋友应该对其中的登录逻辑有所印象。
+
+
+> 先给新来的朋友简单介绍下 [cim](https://github.com/crossoverJie/cim) 是干啥的:
+
+
+
+其中有一个场景是在客户端登录成功后需要从可用的服务端列表中选择一台服务节点返回给客户端使用。
+
+而这个选择的过程就是一个负载策略的过程;第一版本做的比较简单,默认只支持轮询的方式。
+
+虽然够用,但不够优雅😏。
+
+**因此我的规划是内置多种路由策略供使用者根据自己的场景选择,同时提供简单的 API 供用户自定义自己的路由策略。**
+
+
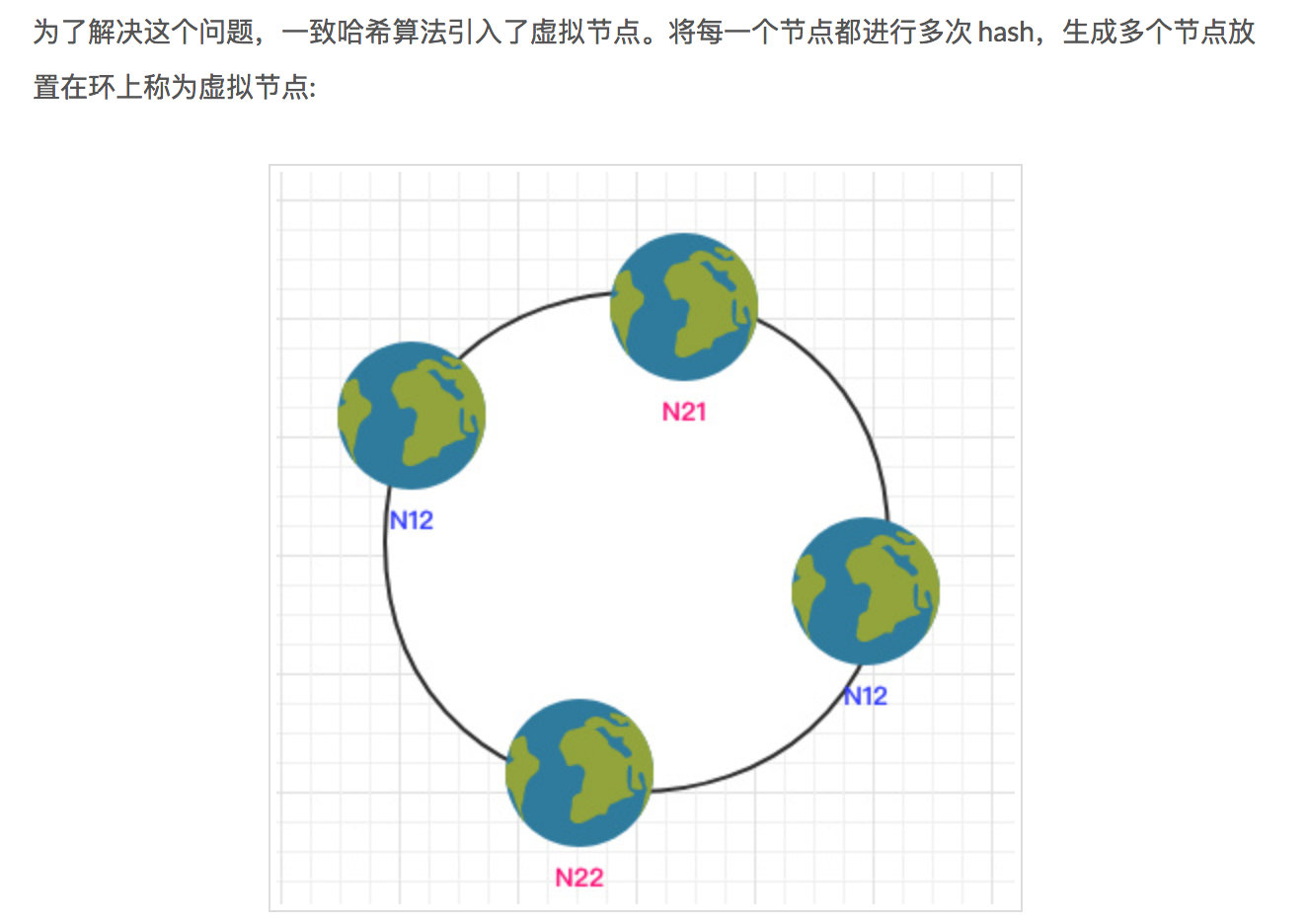
+先来看看一致性 Hash 算法的一些特点:
+
+- 构造一个 `0 ~ 2^32-1` 大小的环。
+- 服务节点经过 hash 之后将自身存放到环中的下标中。
+- 客户端根据自身的某些数据 hash 之后也定位到这个环中。
+- 通过顺时针找到离他最近的一个节点,也就是这次路由的服务节点。
+- 考虑到服务节点的个数以及 hash 算法的问题导致环中的数据分布不均匀时引入了虚拟节点。
+
+
+
+# 自定义有序 Map
+
+根据这些客观条件我们很容易想到通过自定义一个**有序**数组来模拟这个环。
+
+这样我们的流程如下:
+
+1. 初始化一个长度为 N 的数组。
+2. 将服务节点通过 hash 算法得到的正整数,同时将节点自身的数据(hashcode、ip、端口等)存放在这里。
+3. 完成节点存放后将整个数组进行排序(排序算法有多种)。
+4. 客户端获取路由节点时,将自身进行 hash 也得到一个正整数;
+5. 遍历这个数组直到找到一个数据大于等于当前客户端的 hash 值,就将当前节点作为该客户端所路由的节点。
+6. 如果没有发现比客户端大的数据就返回第一个节点(满足环的特性)。
+
+先不考虑排序所消耗的时间,单看这个路由的时间复杂度:
+- 最好是第一次就找到,时间复杂度为`O(1)`。
+- 最差为遍历完数组后才找到,时间复杂度为`O(N)`。
+
+理论讲完了来看看具体实践。
+
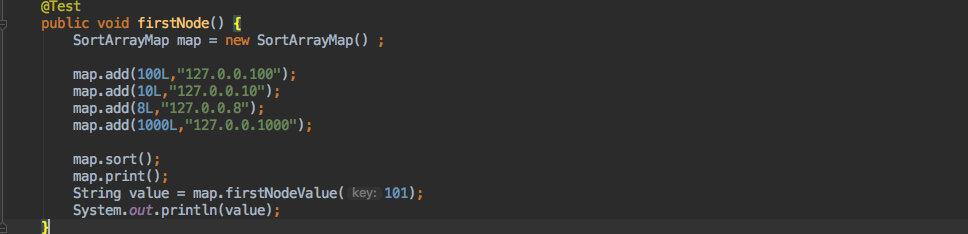
+我自定义了一个类:`SortArrayMap`
+
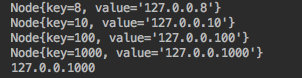
+他的使用方法及结果如下:
+
+
+
+
+
+可见最终会按照 `key` 的大小进行排序,同时传入 `hashcode = 101` 时会按照顺时针找到 `hashcode = 1000` 这个节点进行返回。
+
+----
+下面来看看具体的实现。
+
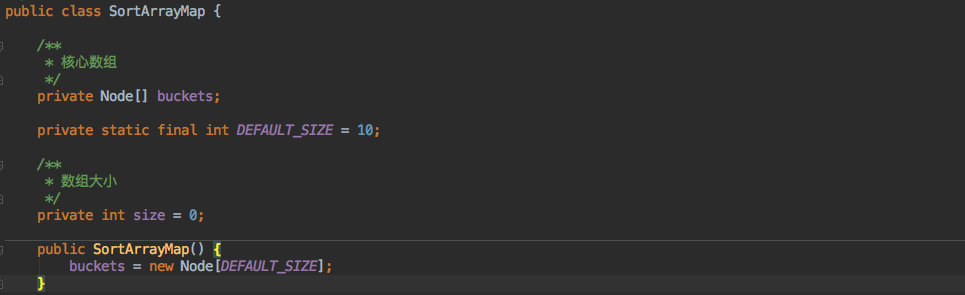
+成员变量和构造函数如下:
+
+
+
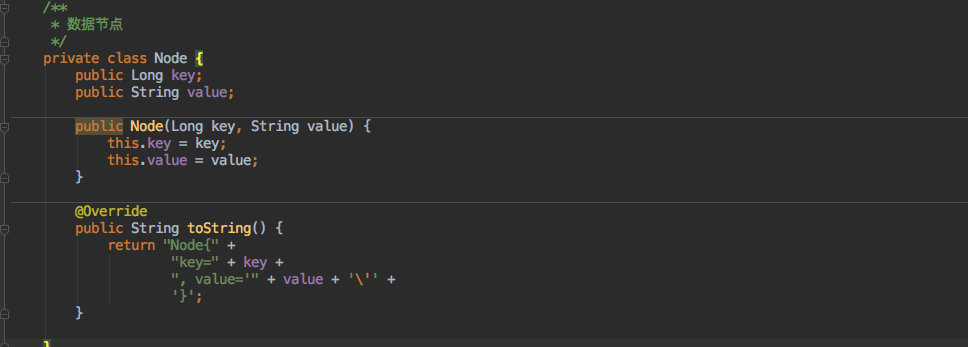
+其中最核心的就是一个 `Node` 数组,用它来存放服务节点的 `hashcode` 以及 `value` 值。
+
+其中的内部类 `Node` 结构如下:
+
+
+
+----
+
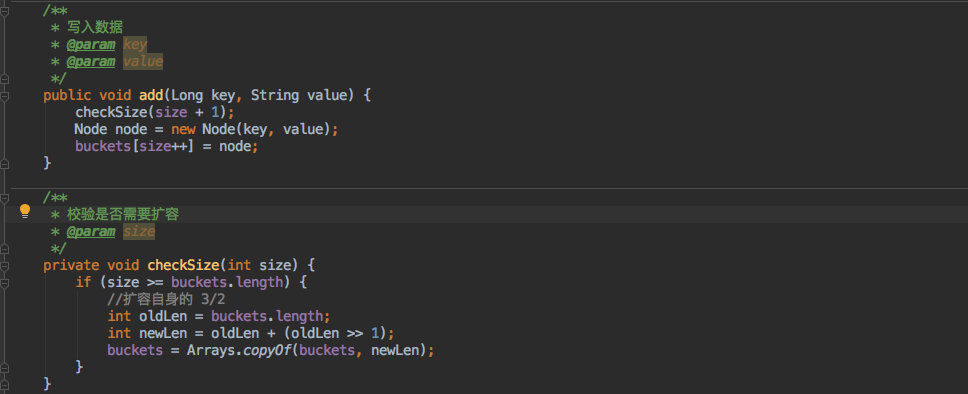
+写入数据的方法如下:
+
+
+
+相信看过 `ArrayList` 的源码应该有印象,这里的写入逻辑和它很像。
+
+- 写入之前判断是否需要扩容,如果需要则复制原来大小的 1.5 倍数组来存放数据。
+- 之后就写入数组,同时数组大小 +1。
+
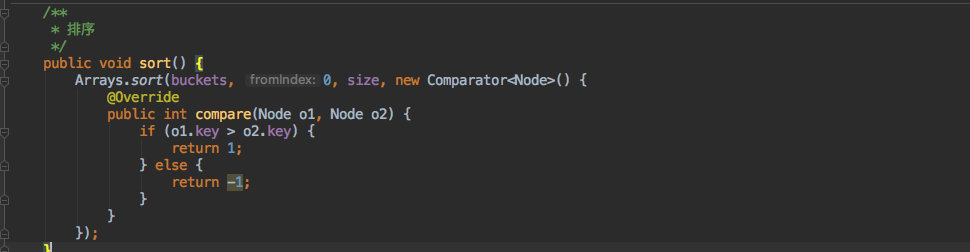
+但是存放时是按照写入顺序存放的,遍历时自然不会有序;因此提供了一个 `Sort` 方法,可以把其中的数据按照 `key` 其实也就是 `hashcode` 进行排序。
+
+
+
+排序也比较简单,使用了 `Arrays` 这个数组工具进行排序,它其实是使用了一个 `TimSort` 的排序算法,效率还是比较高的。
+
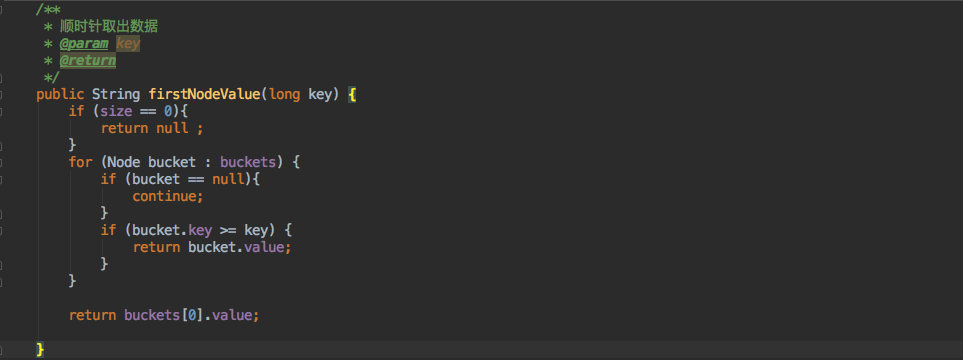
+最后则需要按照一致性 Hash 的标准顺时针查找对应的节点:
+
+
+
+代码还是比较简单清晰的;遍历数组如果找到比当前 key 大的就返回,没有查到就取第一个。
+
+这样就基本实现了一致性 Hash 的要求。
+
+> ps:这里并不包含具体的 hash 方法以及虚拟节点等功能(具体实现请看下文),这个可以由使用者来定,SortArrayMap 可作为一个底层的数据结构,提供有序 Map 的能力,使用场景也不局限于一致性 Hash 算法中。
+
+# TreeMap 实现
+
+`SortArrayMap` 虽说是实现了一致性 hash 的功能,但效率还不够高,主要体现在 `sort` 排序处。
+
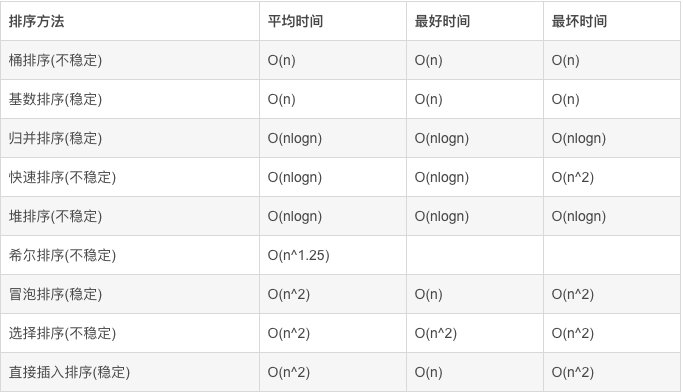
+下图是目前主流排序算法的时间复杂度:
+
+
+
+最好的也就是 `O(N)` 了。
+
+这里完全可以换一个思路,不用对数据进行排序;而是在写入的时候就排好顺序,只是这样会降低写入的效率。
+
+比如二叉查找树,这样的数据结构 `jdk` 里有现成的实现;比如 `TreeMap` 就是使用红黑树来实现的,默认情况下它会对 key 进行自然排序。
+
+---
+
+来看看使用 `TreeMap` 如何来达到同样的效果。
+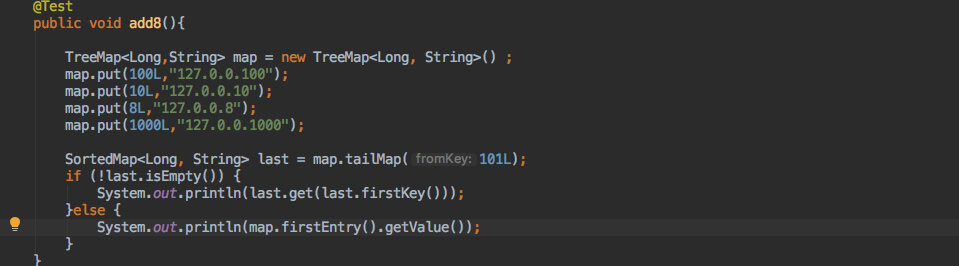
+运行结果:
+
+```
+127.0.0.1000
+```
+
+效果和上文使用 `SortArrayMap` 是一致的。
+
+只使用了 TreeMap 的一些 API:
+
+- 写入数据候,`TreeMap` 可以保证 key 的自然排序。
+- `tailMap` 可以获取比当前 key 大的部分数据。
+- 当这个方法有数据返回时取第一个就是顺时针中的第一个节点了。
+- 如果没有返回那就直接取整个 `Map` 的第一个节点,同样也实现了环形结构。
+
+> ps:这里同样也没有 hash 方法以及虚拟节点(具体实现请看下文),因为 TreeMap 和 SortArrayMap 一样都是作为基础数据结构来使用的。
+
+## 性能对比
+
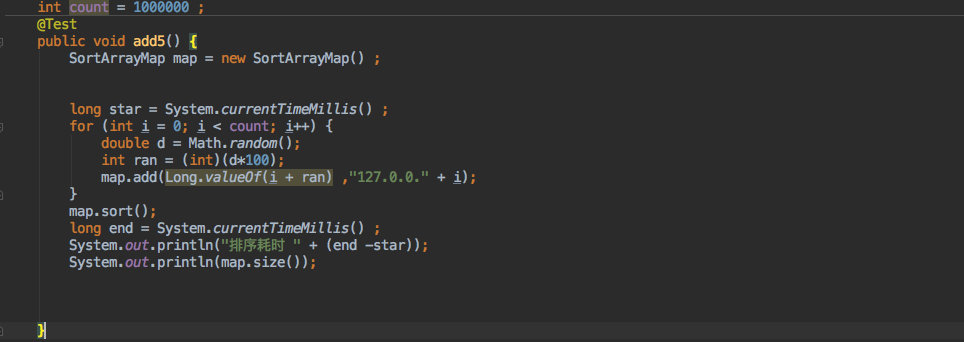
+为了方便大家选择哪一个数据结构,我用 `TreeMap` 和 `SortArrayMap` 分别写入了一百万条数据来对比。
+
+先是 `SortArrayMap`:
+
+
+
+**耗时 2237 毫秒。**
+
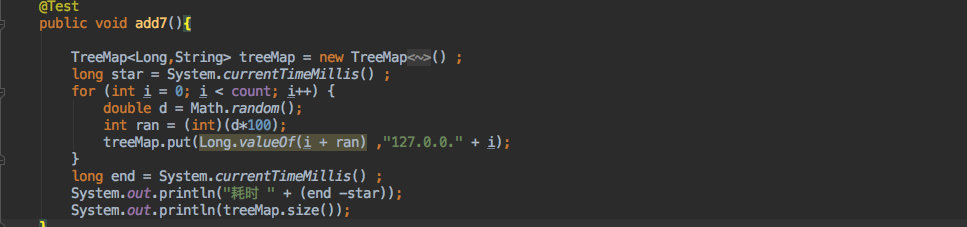
+TreeMap:
+
+
+
+**耗时 1316毫秒。**
+
+结果是快了将近一倍,所以还是推荐使用 `TreeMap` 来进行实现,毕竟它不需要额外的排序损耗。
+
+# cim 中的实际应用
+
+下面来看看在 `cim` 这个应用中是如何具体使用的,其中也包括上文提到的虚拟节点以及 hash 算法。
+
+## 模板方法
+
+在应用的时候考虑到就算是一致性 hash 算法都有多种实现,为了方便其使用者扩展自己的一致性 hash 算法因此我定义了一个抽象类;其中定义了一些模板方法,这样大家只需要在子类中进行不同的实现即可完成自己的算法。
+
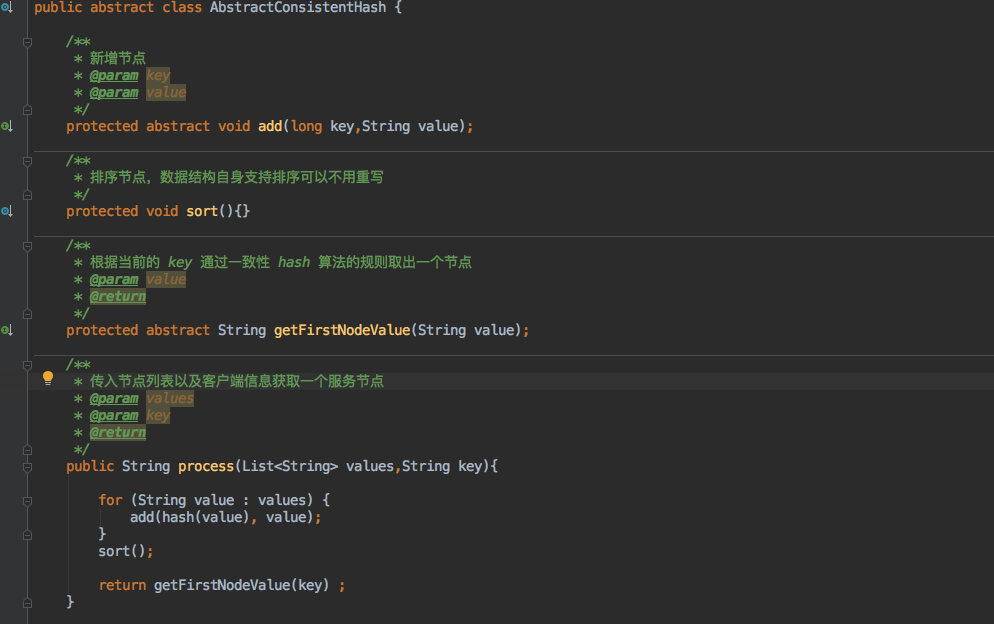
+AbstractConsistentHash,这个抽象类的主要方法如下:
+
+
+
+- `add` 方法自然是写入数据的。
+- `sort` 方法用于排序,但子类也不一定需要重写,比如 `TreeMap` 这样自带排序的容器就不用。
+- `getFirstNodeValue` 获取节点。
+- `process` 则是面向客户端的,最终只需要调用这个方法即可返回一个节点。
+
+
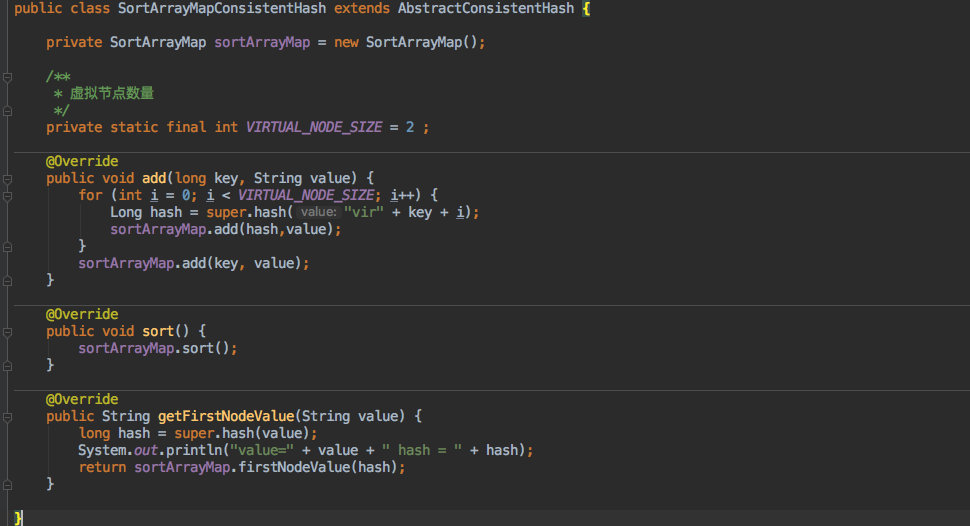
+下面我们来看看利用 `SortArrayMap` 以及 `AbstractConsistentHash` 是如何实现的。
+
+
+
+就是实现了几个抽象方法,逻辑和上文是一样的,只是抽取到了不同的方法中。
+
+只是在 add 方法中新增了几个虚拟节点,相信大家也看得明白。
+
+> 把虚拟节点的控制放到子类而没有放到抽象类中也是为了灵活性考虑,可能不同的实现对虚拟节点的数量要求也不一样,所以不如自定义的好。
+
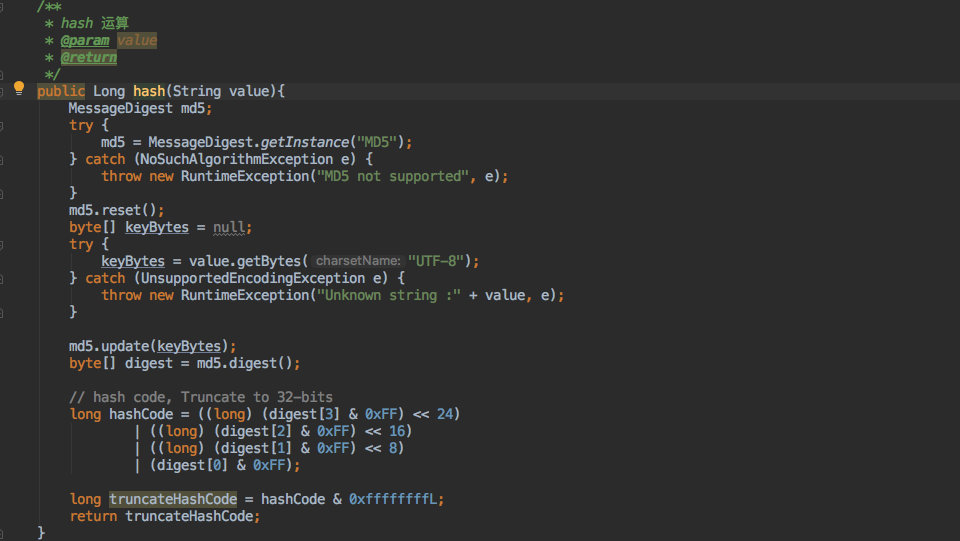
+但是 `hash` 方法确是放到了抽象类中,子类不用重写;因为这是一个基本功能,只需要有一个公共算法可以保证他散列地足够均匀即可。
+
+因此在 `AbstractConsistentHash` 中定义了 hash 方法。
+
+
+
+> 这里的算法摘抄自 xxl_job,网上也有其他不同的实现,比如 `FNV1_32_HASH` 等;实现不同但是目的都一样。
+
+---
+
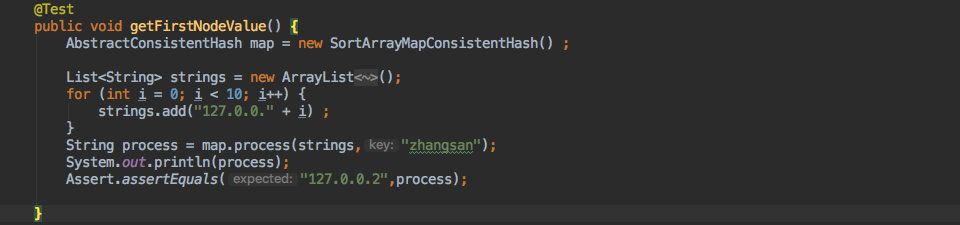
+这样对于使用者来说就非常简单了:
+
+
+
+他只需要构建一个服务列表,然后把当前的客户端信息传入 `process` 方法中即可获得一个一致性 hash 算法的返回。
+
+
+
+---
+
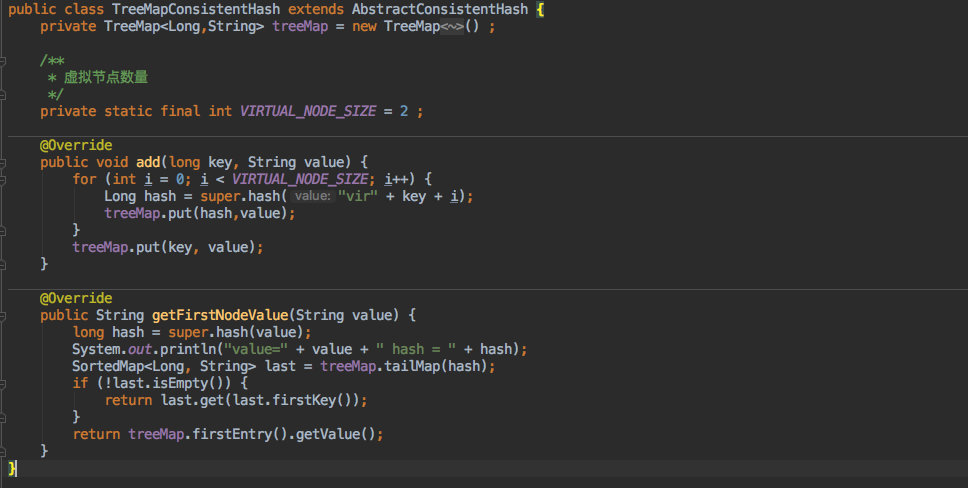
+同样的对于想通过 `TreeMap` 来实现也是一样的套路:
+
+
+
+他这里不需要重写 sort 方法,因为自身写入时已经排好序了。
+
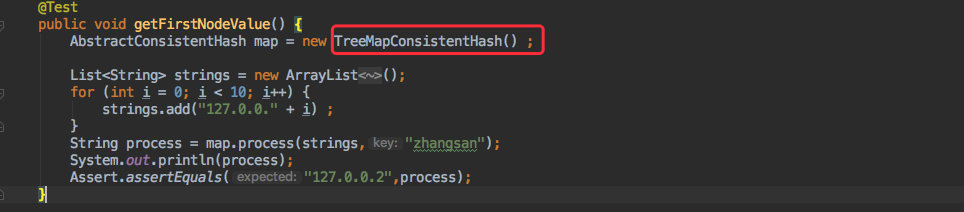
+而在使用时对于客户端来说只需求修改一个实现类,其他的啥都不用改就可以了。
+
+
+
+运行的效果也是一样的。
+
+这样大家想自定义自己的算法时只需要继承 `AbstractConsistentHash` 重写相关方法即可,**客户端代码无须改动。**
+
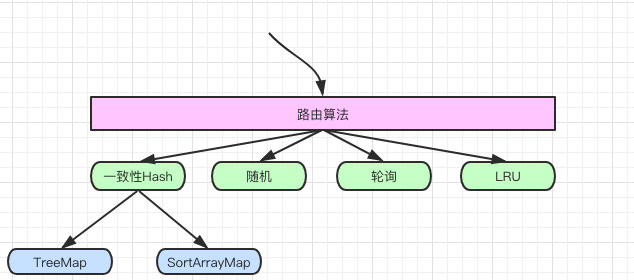
+## 路由算法扩展性
+
+但其实对于 `cim` 来说真正的扩展性是对路由算法来说的,比如它需要支持轮询、hash、一致性hash、随机、LRU等。
+
+只是一致性 hash 也有多种实现,他们的关系就如下图:
+
+
+
+应用还需要满足对这一类路由策略的灵活支持,比如我也想自定义一个随机的策略。
+
+因此定义了一个接口:`RouteHandle`
+
+```java
+public interface RouteHandle {
+
+ /**
+ * 再一批服务器里进行路由
+ * @param values
+ * @param key
+ * @return
+ */
+ String routeServer(List values,String key) ;
+}
+```
+
+其中只有一个方法,也就是路由方法;入参分别是服务列表以及客户端信息即可。
+
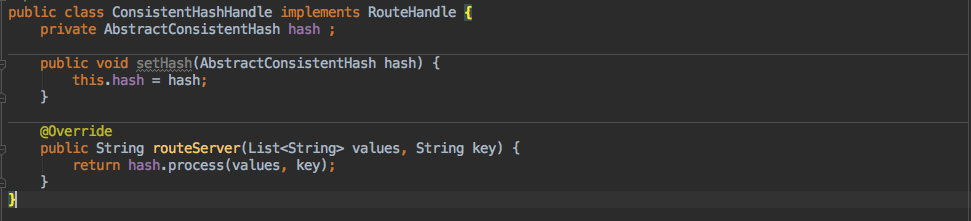
+而对于一致性 hash 算法来说也是只需要实现这个接口,同时在这个接口中选择使用 `SortArrayMapConsistentHash` 还是 `TreeMapConsistentHash` 即可。
+
+
+
+这里还有一个 `setHash` 的方法,入参是 AbstractConsistentHash;这就是用于客户端指定需要使用具体的那种数据结构。
+
+---
+
+而对于之前就存在的轮询策略来说也是同样的实现 `RouteHandle` 接口。
+
+
+
+这里我只是把之前的代码搬过来了而已。
+
+
+接下来看看客户端到底是如何使用以及如何选择使用哪种算法。
+
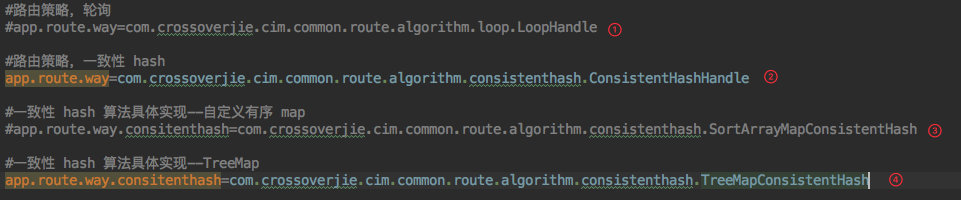
+> 为了使客户端代码几乎不动,我将这个选择的过程放入了配置文件。
+
+
+
+1. 如果想使用原有的轮询策略,就配置实现了 `RouteHandle` 接口的轮询策略的全限定名。
+2. 如果想使用一致性 hash 的策略,也只需要配置实现了 `RouteHandle` 接口的一致性 hash 算法的全限定名。
+3. 当然目前的一致性 hash 也有多种实现,所以一旦配置为一致性 hash 后就需要再加一个配置用于决定使用 `SortArrayMapConsistentHash` 还是 `TreeMapConsistentHash` 或是自定义的其他方案。
+4. 同样的也是需要配置继承了 `AbstractConsistentHash` 的全限定名。
+
+
+不管这里的策略如何改变,在使用处依然保持不变。
+
+只需要注入 `RouteHandle`,调用它的 `routeServer` 方法。
+
+```java
+@Autowired
+private RouteHandle routeHandle ;
+String server = routeHandle.routeServer(serverCache.getAll(),String.valueOf(loginReqVO.getUserId()));
+
+```
+
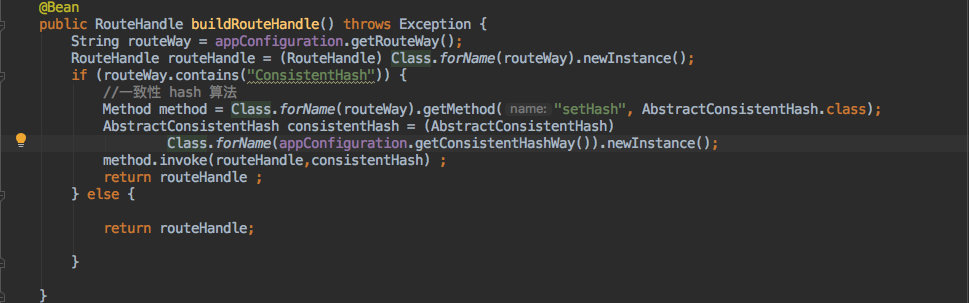
+既然使用了注入,那其实这个策略切换的过程就在创建 `RouteHandle bean` 的时候完成的。
+
+
+
+也比较简单,需要读取之前的配置文件来动态生成具体的实现类,主要是利用反射完成的。
+
+这样处理之后就比较灵活了,比如想新建一个随机的路由策略也是同样的套路;到时候只需要修改配置即可。
+
+> 感兴趣的朋友也可提交 PR 来新增更多的路由策略。
+
+# 总结
+
+希望看到这里的朋友能对这个算法有所理解,同时对一些设计模式在实际的使用也能有所帮助。
+
+相信在金三银四的面试过程中还是能让面试官眼前一亮的,毕竟根据我这段时间的面试过程来看听过这个名词的都在少数😂(可能也是和候选人都在 1~3 年这个层级有关)。
+
+以上所有源码:
+
+[https://github.com/crossoverJie/cim](https://github.com/crossoverJie/cim)
+
+如果本文对你有所帮助还请不吝转发。
diff --git a/docs/algorithm/guava-bloom-filter.md b/docs/algorithm/guava-bloom-filter.md
new file mode 100755
index 00000000..bb705451
--- /dev/null
+++ b/docs/algorithm/guava-bloom-filter.md
@@ -0,0 +1,401 @@
+
+
+
+# 前言
+
+最近有朋友问我这么一个面试题目:
+
+> 现在有一个非常庞大的数据,假设全是 int 类型。现在我给你一个数,你需要告诉我它是否存在其中(尽量高效)。
+
+需求其实很清晰,只是要判断一个数据是否存在即可。
+
+但这里有一个比较重要的前提:**非常庞大的数据**。
+
+
+# 常规实现
+
+先不考虑这个条件,我们脑海中出现的第一种方案是什么?
+
+我想大多数想到的都是用 `HashMap` 来存放数据,因为它的写入查询的效率都比较高。
+
+写入和判断元素是否存在都有对应的 `API`,所以实现起来也比较简单。
+
+为此我写了一个单测,利用 `HashSet` 来存数据(底层也是 `HashMap` );同时为了后面的对比将堆内存写死:
+
+```java
+-Xms64m -Xmx64m -XX:+PrintHeapAtGC -XX:+HeapDumpOnOutOfMemoryError
+```
+
+为了方便调试加入了 `GC` 日志的打印,以及内存溢出后 `Dump` 内存。
+
+```java
+ @Test
+ public void hashMapTest(){
+ long star = System.currentTimeMillis();
+
+ Set hashset = new HashSet<>(100) ;
+ for (int i = 0; i < 100; i++) {
+ hashset.add(i) ;
+ }
+ Assert.assertTrue(hashset.contains(1));
+ Assert.assertTrue(hashset.contains(2));
+ Assert.assertTrue(hashset.contains(3));
+
+ long end = System.currentTimeMillis();
+ System.out.println("执行时间:" + (end - star));
+ }
+```
+
+当我只写入 100 条数据时自然是没有问题的。
+
+还是在这个基础上,写入 1000W 数据试试:
+
+
+
+执行后马上就内存溢出。
+
+
+
+可见在内存有限的情况下我们不能使用这种方式。
+
+实际情况也是如此;既然要判断一个数据是否存在于集合中,考虑的算法的效率以及准确性肯定是要把数据全部 `load` 到内存中的。
+
+
+# Bloom Filter
+
+基于上面分析的条件,要实现这个需求最需要解决的是`如何将庞大的数据 load 到内存中。`
+
+而我们是否可以换种思路,因为只是需要判断数据是否存在,也不是需要把数据查询出来,所以完全没有必要将真正的数据存放进去。
+
+伟大的科学家们已经帮我们想到了这样的需求。
+
+`Burton Howard Bloom` 在 1970 年提出了一个叫做 `Bloom Filter`(中文翻译:布隆过滤)的算法。
+
+它主要就是用于解决判断一个元素是否在一个集合中,但它的优势是只需要占用很小的内存空间以及有着高效的查询效率。
+
+所以在这个场景下在合适不过了。
+
+## Bloom Filter 原理
+
+下面来分析下它的实现原理。
+
+> 官方的说法是:它是一个保存了很长的二级制向量,同时结合 Hash 函数实现的。
+
+听起来比较绕,但是通过一个图就比较容易理解了。
+
+
+
+如图所示:
+
+- 首先需要初始化一个二进制的数组,长度设为 L(图中为 8),同时初始值全为 0 。
+- 当写入一个 `A1=1000` 的数据时,需要进行 H 次 `hash` 函数的运算(这里为 2 次);与 HashMap 有点类似,通过算出的 `HashCode` 与 L 取模后定位到 0、2 处,将该处的值设为 1。
+- `A2=2000` 也是同理计算后将 `4、7` 位置设为 1。
+- 当有一个 `B1=1000` 需要判断是否存在时,也是做两次 Hash 运算,定位到 0、2 处,此时他们的值都为 1 ,所以认为 `B1=1000` 存在于集合中。
+- 当有一个 `B2=3000` 时,也是同理。第一次 Hash 定位到 `index=4` 时,数组中的值为 1,所以再进行第二次 Hash 运算,结果定位到 `index=5` 的值为 0,所以认为 `B2=3000` 不存在于集合中。
+
+整个的写入、查询的流程就是这样,汇总起来就是:
+
+> 对写入的数据做 H 次 hash 运算定位到数组中的位置,同时将数据改为 1 。当有数据查询时也是同样的方式定位到数组中。
+> 一旦其中的有一位为 **0** 则认为数据**肯定不存在于集合**,否则数据**可能存在于集合中**。
+
+所以布隆过滤有以下几个特点:
+
+1. 只要返回数据不存在,则肯定不存在。
+2. 返回数据存在,但只能是大概率存在。
+3. 同时不能清除其中的数据。
+
+第一点应该都能理解,重点解释下 2、3 点。
+
+为什么返回存在的数据却是可能存在呢,这其实也和 `HashMap` 类似。
+
+在有限的数组长度中存放大量的数据,即便是再完美的 Hash 算法也会有冲突,所以有可能两个完全不同的 `A、B` 两个数据最后定位到的位置是一模一样的。
+
+这时拿 B 进行查询时那自然就是误报了。
+
+删除数据也是同理,当我把 B 的数据删除时,其实也相当于是把 A 的数据删掉了,这样也会造成后续的误报。
+
+基于以上的 `Hash` 冲突的前提,所以 `Bloom Filter` 有一定的误报率,这个误报率和 `Hash` 算法的次数 H,以及数组长度 L 都是有关的。
+
+
+# 自己实现一个布隆过滤
+
+算法其实很简单不难理解,于是利用 `Java` 实现了一个简单的雏形。
+
+```java
+public class BloomFilters {
+
+ /**
+ * 数组长度
+ */
+ private int arraySize;
+
+ /**
+ * 数组
+ */
+ private int[] array;
+
+ public BloomFilters(int arraySize) {
+ this.arraySize = arraySize;
+ array = new int[arraySize];
+ }
+
+ /**
+ * 写入数据
+ * @param key
+ */
+ public void add(String key) {
+ int first = hashcode_1(key);
+ int second = hashcode_2(key);
+ int third = hashcode_3(key);
+
+ array[first % arraySize] = 1;
+ array[second % arraySize] = 1;
+ array[third % arraySize] = 1;
+
+ }
+
+ /**
+ * 判断数据是否存在
+ * @param key
+ * @return
+ */
+ public boolean check(String key) {
+ int first = hashcode_1(key);
+ int second = hashcode_2(key);
+ int third = hashcode_3(key);
+
+ int firstIndex = array[first % arraySize];
+ if (firstIndex == 0) {
+ return false;
+ }
+
+ int secondIndex = array[second % arraySize];
+ if (secondIndex == 0) {
+ return false;
+ }
+
+ int thirdIndex = array[third % arraySize];
+ if (thirdIndex == 0) {
+ return false;
+ }
+
+ return true;
+
+ }
+
+
+ /**
+ * hash 算法1
+ * @param key
+ * @return
+ */
+ private int hashcode_1(String key) {
+ int hash = 0;
+ int i;
+ for (i = 0; i < key.length(); ++i) {
+ hash = 33 * hash + key.charAt(i);
+ }
+ return Math.abs(hash);
+ }
+
+ /**
+ * hash 算法2
+ * @param data
+ * @return
+ */
+ private int hashcode_2(String data) {
+ final int p = 16777619;
+ int hash = (int) 2166136261L;
+ for (int i = 0; i < data.length(); i++) {
+ hash = (hash ^ data.charAt(i)) * p;
+ }
+ hash += hash << 13;
+ hash ^= hash >> 7;
+ hash += hash << 3;
+ hash ^= hash >> 17;
+ hash += hash << 5;
+ return Math.abs(hash);
+ }
+
+ /**
+ * hash 算法3
+ * @param key
+ * @return
+ */
+ private int hashcode_3(String key) {
+ int hash, i;
+ for (hash = 0, i = 0; i < key.length(); ++i) {
+ hash += key.charAt(i);
+ hash += (hash << 10);
+ hash ^= (hash >> 6);
+ }
+ hash += (hash << 3);
+ hash ^= (hash >> 11);
+ hash += (hash << 15);
+ return Math.abs(hash);
+ }
+}
+```
+
+1. 首先初始化了一个 int 数组。
+2. 写入数据的时候进行三次 `hash` 运算,同时把对应的位置置为 1。
+3. 查询时同样的三次 `hash` 运算,取到对应的值,一旦值为 0 ,则认为数据不存在。
+
+实现逻辑其实就和上文描述的一样。
+
+下面来测试一下,同样的参数:
+
+```java
+-Xms64m -Xmx64m -XX:+PrintHeapAtGC
+```
+
+```java
+ @Test
+ public void bloomFilterTest(){
+ long star = System.currentTimeMillis();
+ BloomFilters bloomFilters = new BloomFilters(10000000) ;
+ for (int i = 0; i < 10000000; i++) {
+ bloomFilters.add(i + "") ;
+ }
+ Assert.assertTrue(bloomFilters.check(1+""));
+ Assert.assertTrue(bloomFilters.check(2+""));
+ Assert.assertTrue(bloomFilters.check(3+""));
+ Assert.assertTrue(bloomFilters.check(999999+""));
+ Assert.assertFalse(bloomFilters.check(400230340+""));
+ long end = System.currentTimeMillis();
+ System.out.println("执行时间:" + (end - star));
+ }
+```
+
+执行结果如下:
+
+
+
+只花了 3 秒钟就写入了 1000W 的数据同时做出来准确的判断。
+
+---
+
+
+
+当让我把数组长度缩小到了 100W 时就出现了一个误报,`400230340` 这个数明明没在集合里,却返回了存在。
+
+这也体现了 `Bloom Filter` 的误报率。
+
+我们提高数组长度以及 `hash` 计算次数可以降低误报率,但相应的 `CPU、内存`的消耗就会提高;这就需要根据业务需要自行权衡。
+
+
+# Guava 实现
+
+
+
+刚才的方式虽然实现了功能,也满足了大量数据。但其实观察 `GC` 日志非常频繁,同时老年代也使用了 90%,接近崩溃的边缘。
+
+总的来说就是内存利用率做的不好。
+
+其实 Google Guava 库中也实现了该算法,下面来看看业界权威的实现。
+
+```java
+-Xms64m -Xmx64m -XX:+PrintHeapAtGC
+```
+
+---
+
+```java
+ @Test
+ public void guavaTest() {
+ long star = System.currentTimeMillis();
+ BloomFilter filter = BloomFilter.create(
+ Funnels.integerFunnel(),
+ 10000000,
+ 0.01);
+
+ for (int i = 0; i < 10000000; i++) {
+ filter.put(i);
+ }
+
+ Assert.assertTrue(filter.mightContain(1));
+ Assert.assertTrue(filter.mightContain(2));
+ Assert.assertTrue(filter.mightContain(3));
+ Assert.assertFalse(filter.mightContain(10000000));
+ long end = System.currentTimeMillis();
+ System.out.println("执行时间:" + (end - star));
+ }
+```
+
+
+也是同样写入了 1000W 的数据,执行没有问题。
+
+
+
+观察 GC 日志会发现没有一次 `fullGC`,同时老年代的使用率很低。和刚才的一对比这里明显的要好上很多,也可以写入更多的数据。
+
+## 源码分析
+
+那就来看看 `Guava` 它是如何实现的。
+
+构造方法中有两个比较重要的参数,一个是预计存放多少数据,一个是可以接受的误报率。
+我这里的测试 demo 分别是 1000W 以及 0.01。
+
+
+
+`Guava` 会通过你预计的数量以及误报率帮你计算出你应当会使用的数组大小 `numBits` 以及需要计算几次 Hash 函数 `numHashFunctions` 。
+
+这个算法计算规则可以参考维基百科。
+
+### put 写入函数
+
+真正存放数据的 `put` 函数如下:
+
+
+
+- 根据 `murmur3_128` 方法的到一个 128 位长度的 `byte[]`。
+- 分别取高低 8 位的到两个 `hash` 值。
+- 再根据初始化时的到的执行 `hash` 的次数进行 `hash` 运算。
+
+
+```java
+bitsChanged |= bits.set((combinedHash & Long.MAX_VALUE) % bitSize);
+```
+
+其实也是 `hash取模`拿到 `index` 后去赋值 1.
+
+重点是 `bits.set()` 方法。
+
+
+
+其实 set 方法是 `BitArray` 中的一个函数,`BitArray` 就是真正存放数据的底层数据结构。
+
+利用了一个 `long[] data` 来存放数据。
+
+所以 `set()` 时候也是对这个 `data` 做处理。
+
+
+
+- 在 `set` 之前先通过 `get()` 判断这个数据是否存在于集合中,如果已经存在则直接返回告知客户端写入失败。
+- 接下来就是通过位运算进行`位或赋值`。
+- `get()` 方法的计算逻辑和 set 类似,只要判断为 0 就直接返回存在该值。
+
+### mightContain 是否存在函数
+
+
+
+前面几步的逻辑都是类似的,只是调用了刚才的 `get()` 方法判断元素是否存在而已。
+
+
+# 总结
+
+布隆过滤的应用还是蛮多的,比如数据库、爬虫、防缓存击穿等。
+
+特别是需要精确知道某个数据不存在时做点什么事情就非常适合布隆过滤。
+
+这段时间的研究发现算法也挺有意思的,后续应该会继续分享一些类似的内容。
+
+如果对你有帮助那就分享一下吧。
+
+本问的示例代码参考这里:
+
+[https://github.com/crossoverJie/JCSprout](https://github.com/crossoverJie/JCSprout/blob/master/src/test/java/com/crossoverjie/algorithm/BloomFiltersTest.java)
+
+
+
+**你的点赞与分享是对我最大的支持**
diff --git a/docs/architecture-design/Spike.md b/docs/architecture-design/Spike.md
new file mode 100644
index 00000000..35142c69
--- /dev/null
+++ b/docs/architecture-design/Spike.md
@@ -0,0 +1,32 @@
+# 设计一个秒杀系统
+
+**具体实现参考 [秒杀架构实践](architecture-design/seconds-kill.md)**
+
+主要做到以下两点:
+
+- 尽量将请求过滤在上游。
+- 尽可能的利用缓存(大多数场景下都是**查多于写**)。
+
+常用的系统分层结构:
+
+
+
+针对于浏览器端,可以使用 JS 进行请求过滤,比如五秒钟之类只能点一次抢购按钮,五秒钟只能允许请求一次后端服务。(APP 同理)
+
+这样其实就可以过滤掉大部分普通用户。
+
+但是防不住直接抓包循环调用。这种情况可以最简单的处理:在`Web层`通过限制一个 UID 五秒之类的请求服务层的次数(可利用 Redis 实现)。
+
+但如果是真的有 10W 个不同的 UID 来请求,比如黑客抓肉鸡的方式。
+
+这种情况可以在`服务层` 针对于写请求使用请求队列,再通过限流算法([限流算法](https://github.com/crossoverJie/Java-Interview/blob/master/MD/Limiting.md))每秒钟放一部分请求到队列。
+
+对于读请求则尽量使用缓存,可以提前将数据准备好,不管是 `Redis` 还是其他缓存中间件效率都是非常高的。
+
+> ps : 刷新缓存情况,比如库存扣除成功这种情况不用马上刷新缓存,如果库存扣到了 0 再刷新缓存。因为大多数用户都只关心是否有货,并不关心现在还剩余多少。
+
+## 总结
+
+- 如果流量巨大,导致各个层的压力都很大可以适当的加机器横向扩容。如果加不了机器那就只有放弃流量直接返回失败。快速失败非常重要,至少可以保证系统的可用性。
+- 业务分批执行:对于下单、付款等操作可以异步执行提高吞吐率。
+- 主要目的就是尽量少的请求直接访问到 `DB`。
diff --git a/docs/architecture-design/million-sms-push.md b/docs/architecture-design/million-sms-push.md
new file mode 100755
index 00000000..73a5421b
--- /dev/null
+++ b/docs/architecture-design/million-sms-push.md
@@ -0,0 +1,360 @@
+# 设计一个百万级的消息推送系统
+
+
+
+# 前言
+
+首先迟到的祝大家中秋快乐。
+
+最近一周多没有更新了。其实我一直想憋一个大招,分享一些大家感兴趣的干货。
+
+鉴于最近我个人的工作内容,于是利用这三天小长假憋了一个出来(其实是玩了两天🤣)。
+
+
+---
+
+先简单说下本次的主题,由于我最近做的是物联网相关的开发工作,其中就不免会遇到和设备的交互。
+
+最主要的工作就是要有一个系统来支持设备的接入、向设备推送消息;同时还得满足大量设备接入的需求。
+
+所以本次分享的内容不但可以满足物联网领域同时还支持以下场景:
+
+- 基于 `WEB` 的聊天系统(点对点、群聊)。
+- `WEB` 应用中需求服务端推送的场景。
+- 基于 SDK 的消息推送平台。
+
+# 技术选型
+
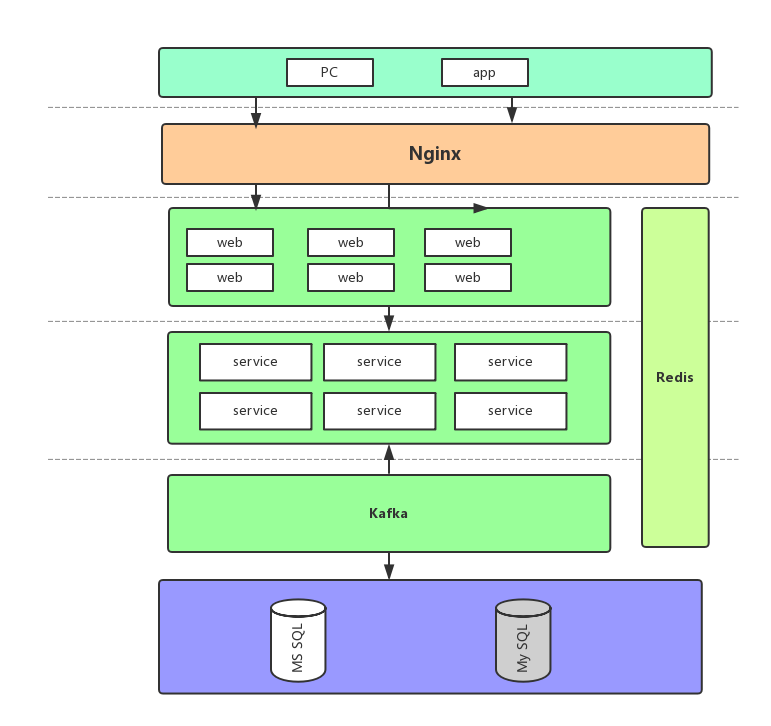
+要满足大量的连接数、同时支持双全工通信,并且性能也得有保障。
+
+在 Java 技术栈中进行选型首先自然是排除掉了传统 `IO`。
+
+那就只有选 NIO 了,在这个层面其实选择也不多,考虑到社区、资料维护等方面最终选择了 Netty。
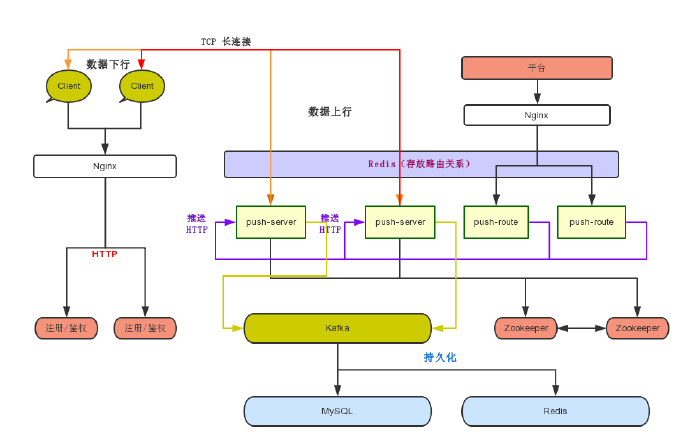
+
+最终的架构图如下:
+
+
+
+
+现在看着蒙没关系,下文一一介绍。
+
+# 协议解析
+
+既然是一个消息系统,那自然得和客户端定义好双方的协议格式。
+
+常见和简单的是 HTTP 协议,但我们的需求中有一项需要是双全工的交互方式,同时 HTTP 更多的是服务于浏览器。我们需要的是一个更加精简的协议,减少许多不必要的数据传输。
+
+因此我觉得最好是在满足业务需求的情况下定制自己的私有协议,在我这个场景下其实有标准的物联网协议。
+
+如果是其他场景可以借鉴现在流行的 `RPC` 框架定制私有协议,使得双方通信更加高效。
+
+不过根据这段时间的经验来看,不管是哪种方式都得在协议中预留安全相关的位置。
+
+协议相关的内容就不过讨论了,更多介绍具体的应用。
+
+# 简单实现
+
+首先考虑如何实现功能,再来思考百万连接的情况。
+
+## 注册鉴权
+
+在做真正的消息上、下行之前首先要考虑的就是鉴权问题。
+
+就像你使用微信一样,第一步怎么也得是登录吧,不能无论是谁都可以直接连接到平台。
+
+所以第一步得是注册才行。
+
+如上面架构图中的 `注册/鉴权` 模块。通常来说都需要客户端通过 `HTTP` 请求传递一个唯一标识,后台鉴权通过之后会响应一个 `token`,并将这个 `token` 和客户端的关系维护到 `Redis` 或者是 DB 中。
+
+客户端将这个 token 也保存到本地,今后的每一次请求都得带上这个 token。一旦这个 token 过期,客户端需要再次请求获取 token。
+
+鉴权通过之后客户端会直接通过`TCP 长连接`到图中的 `push-server` 模块。
+
+这个模块就是真正处理消息的上、下行。
+
+## 保存通道关系
+
+在连接接入之后,真正处理业务之前需要将当前的客户端和 Channel 的关系维护起来。
+
+假设客户端的唯一标识是手机号码,那就需要把手机号码和当前的 Channel 维护到一个 Map 中。
+
+这点和之前 [SpringBoot 整合长连接心跳机制](http://t.cn/EPcNHFZ) 类似。
+
+
+
+同时为了可以通过 Channel 获取到客户端唯一标识(手机号码),还需要在 Channel 中设置对应的属性:
+
+```java
+public static void putClientId(Channel channel, String clientId) {
+ channel.attr(CLIENT_ID).set(clientId);
+}
+```
+
+获取时手机号码时:
+
+```java
+public static String getClientId(Channel channel) {
+ return (String)getAttribute(channel, CLIENT_ID);
+}
+```
+
+这样当我们客户端下线的时便可以记录相关日志:
+
+```java
+String telNo = NettyAttrUtil.getClientId(ctx.channel());
+NettySocketHolder.remove(telNo);
+log.info("客户端下线,TelNo=" + telNo);
+```
+
+> 这里有一点需要注意:存放客户端与 Channel 关系的 Map 最好是预设好大小(避免经常扩容),因为它将是使用最为频繁同时也是占用内存最大的一个对象。
+
+## 消息上行
+
+接下来则是真正的业务数据上传,通常来说第一步是需要判断上传消息输入什么业务类型。
+
+在聊天场景中,有可能上传的是文本、图片、视频等内容。
+
+所以我们得进行区分,来做不同的处理;这就和客户端协商的协议有关了。
+
+- 可以利用消息头中的某个字段进行区分。
+- 更简单的就是一个 `JSON` 消息,拿出一个字段用于区分不同消息。
+
+不管是哪种只有可以区分出来即可。
+
+### 消息解析与业务解耦
+
+消息可以解析之后便是处理业务,比如可以是写入数据库、调用其他接口等。
+
+我们都知道在 Netty 中处理消息一般是在 `channelRead()` 方法中。
+
+
+
+在这里可以解析消息,区分类型。
+
+但如果我们的业务逻辑也写在里面,那这里的内容将是巨多无比。
+
+甚至我们分为好几个开发来处理不同的业务,这样将会出现许多冲突、难以维护等问题。
+
+所以非常有必要将消息解析与业务处理完全分离开来。
+
+
+> 这时面向接口编程就发挥作用了。
+
+这里的核心代码和 [「造个轮子」——cicada(轻量级 WEB 框架)](https://crossoverjie.top/2018/09/03/wheel/cicada1/#%E9%85%8D%E7%BD%AE%E4%B8%9A%E5%8A%A1-Action) 是一致的。
+
+都是先定义一个接口用于处理业务逻辑,然后在解析消息之后通过反射创建具体的对象执行其中的`处理函数`即可。
+
+这样不同的业务、不同的开发人员只需要实现这个接口同时实现自己的业务逻辑即可。
+
+伪代码如下:
+
+
+
+
+
+想要了解 cicada 的具体实现请点击这里:
+
+[https://github.com/TogetherOS/cicada](https://github.com/TogetherOS/cicada)
+
+
+上行还有一点需要注意;由于是基于长连接,所以客户端需要定期发送心跳包用于维护本次连接。同时服务端也会有相应的检查,N 个时间间隔没有收到消息之后将会主动断开连接节省资源。
+
+这点使用一个 `IdleStateHandler` 就可实现,更多内容可以查看 [Netty(一) SpringBoot 整合长连接心跳机制](https://crossoverjie.top/2018/05/24/netty/Netty(1)TCP-Heartbeat/#%E6%9C%8D%E5%8A%A1%E7%AB%AF%E5%BF%83%E8%B7%B3)。
+
+
+
+## 消息下行
+
+有了上行自然也有下行。比如在聊天的场景中,有两个客户端连上了 `push-server`,他们直接需要点对点通信。
+
+这时的流程是:
+
+- A 将消息发送给服务器。
+- 服务器收到消息之后,得知消息是要发送给 B,需要在内存中找到 B 的 Channel。
+- 通过 B 的 Channel 将 A 的消息转发下去。
+
+这就是一个下行的流程。
+
+甚至管理员需要给所有在线用户发送系统通知也是类似:
+
+遍历保存通道关系的 Map,挨个发送消息即可。这也是之前需要存放到 Map 中的主要原因。
+
+伪代码如下:
+
+
+
+具体可以参考:
+
+[https://github.com/crossoverJie/netty-action/](https://github.com/crossoverJie/netty-action/)
+
+
+# 分布式方案
+
+单机版的实现了,现在着重讲讲如何实现百万连接。
+
+百万连接其实只是一个形容词,更多的是想表达如何来实现一个分布式的方案,可以灵活的水平拓展从而能支持更多的连接。
+
+再做这个事前首先得搞清楚我们单机版的能支持多少连接。影响这个的因素就比较多了。
+
+- 服务器自身配置。内存、CPU、网卡、Linux 支持的最大文件打开数等。
+- 应用自身配置,因为 Netty 本身需要依赖于堆外内存,但是 JVM 本身也是需要占用一部分内存的,比如存放通道关系的大 `Map`。这点需要结合自身情况进行调整。
+
+结合以上的情况可以测试出单个节点能支持的最大连接数。
+
+单机无论怎么优化都是有上限的,这也是分布式主要解决的问题。
+
+## 架构介绍
+
+在将具体实现之前首先得讲讲上文贴出的整体架构图。
+
+
+
+先从左边开始。
+
+上文提到的 `注册鉴权` 模块也是集群部署的,通过前置的 Nginx 进行负载。之前也提过了它主要的目的是来做鉴权并返回一个 token 给客户端。
+
+但是 `push-server` 集群之后它又多了一个作用。那就是得返回一台可供当前客户端使用的 `push-server`。
+
+右侧的 `平台` 一般指管理平台,它可以查看当前的实时在线数、给指定客户端推送消息等。
+
+推送消息则需要经过一个推送路由(`push-server`)找到真正的推送节点。
+
+其余的中间件如:Redis、Zookeeper、Kafka、MySQL 都是为了这些功能所准备的,具体看下面的实现。
+
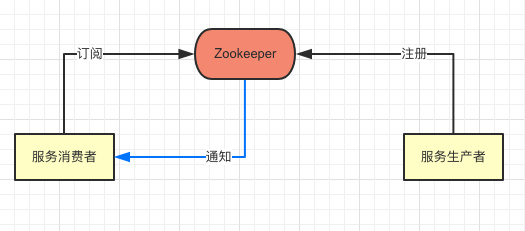
+## 注册发现
+
+首先第一个问题则是 `注册发现`,`push-server` 变为多台之后如何给客户端选择一台可用的节点是第一个需要解决的。
+
+这块的内容其实已经在 [分布式(一) 搞定服务注册与发现](https://crossoverjie.top/2018/08/27/distributed/distributed-discovery-zk/) 中详细讲过了。
+
+所有的 `push-server` 在启动时候需要将自身的信息注册到 Zookeeper 中。
+
+`注册鉴权` 模块会订阅 Zookeeper 中的节点,从而可以获取最新的服务列表。结构如下:
+
+
+
+以下是一些伪代码:
+
+应用启动注册 Zookeeper。
+
+
+
+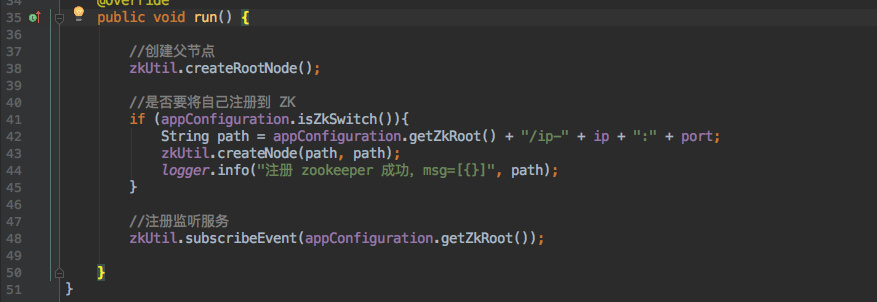
+
+对于`注册鉴权`模块来说只需要订阅这个 Zookeeper 节点:
+
+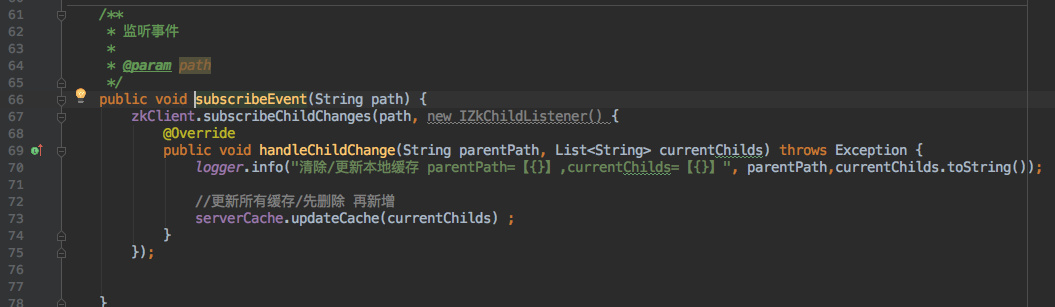
+
+### 路由策略
+
+既然能获取到所有的服务列表,那如何选择一台刚好合适的 `push-server` 给客户端使用呢?
+
+这个过程重点要考虑以下几点:
+
+- 尽量保证各个节点的连接均匀。
+- 增删节点是否要做 Rebalance。
+
+首先保证均衡有以下几种算法:
+
+- 轮询。挨个将各个节点分配给客户端。但会出现新增节点分配不均匀的情况。
+- Hash 取模的方式。类似于 HashMap,但也会出现轮询的问题。当然也可以像 HashMap 那样做一次 Rebalance,让所有的客户端重新连接。不过这样会导致所有的连接出现中断重连,代价有点大。
+- 由于 Hash 取模方式的问题带来了[`一致性 Hash`算法](https://crossoverjie.top/%2F2018%2F01%2F08%2FConsistent-Hash%2F),但依然会有一部分的客户端需要 Rebalance。
+- 权重。可以手动调整各个节点的负载情况,甚至可以做成自动的,基于监控当某些节点负载较高就自动调低权重,负载较低的可以提高权重。
+
+还有一个问题是:
+
+> 当我们在重启部分应用进行升级时,在该节点上的客户端怎么处理?
+
+由于我们有心跳机制,当心跳不通之后就可以认为该节点出现问题了。那就得重新请求`注册鉴权`模块获取一个可用的节点。在弱网情况下同样适用。
+
+如果这时客户端正在发送消息,则需要将消息保存到本地等待获取到新的节点之后再次发送。
+
+## 有状态连接
+
+在这样的场景中不像是 HTTP 那样是无状态的,我们得明确的知道各个客户端和连接的关系。
+
+在上文的单机版中我们将这个关系保存到本地的缓存中,但在分布式环境中显然行不通了。
+
+比如在平台向客户端推送消息的时候,它得首先知道这个客户端的通道保存在哪台节点上。
+
+借助我们以前的经验,这样的问题自然得引入一个第三方中间件用来存放这个关系。
+
+也就是架构图中的存放`路由关系的 Redis`,在客户端接入 `push-server` 时需要将当前客户端唯一标识和服务节点的 `ip+port` 存进 `Redis`。
+
+同时在客户端下线时候得在 Redis 中删掉这个连接关系。
+
+
+> 这样在理想情况下各个节点内存中的 map 关系加起来应该正好等于 Redis 中的数据。
+
+伪代码如下:
+
+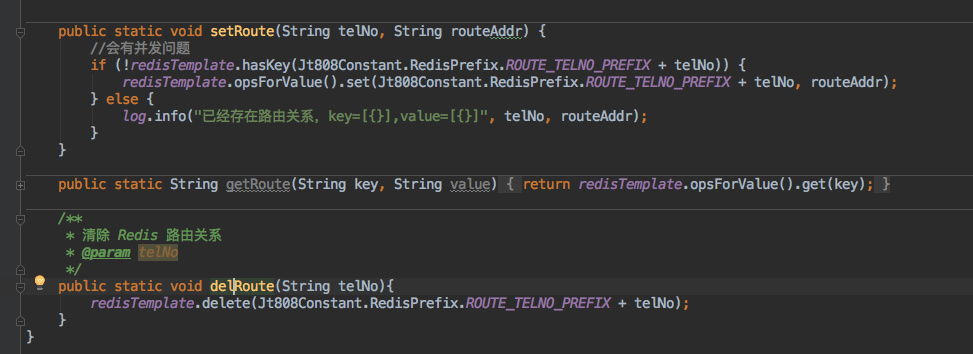
+
+这里存放路由关系的时候会有并发问题,最好是换为一个 `lua` 脚本。
+
+## 推送路由
+
+设想这样一个场景:管理员需要给最近注册的客户端推送一个系统消息会怎么做?
+
+> 结合架构图
+
+假设这批客户端有 10W 个,首先我们需要将这批号码通过`平台`下的 `Nginx` 下发到一个推送路由中。
+
+为了提高效率甚至可以将这批号码再次分散到每个 `push-route` 中。
+
+拿到具体号码之后再根据号码的数量启动多线程的方式去之前的路由 Redis 中获取客户端所对应的 `push-server`。
+
+再通过 HTTP 的方式调用 `push-server` 进行真正的消息下发(Netty 也很好的支持 HTTP 协议)。
+
+推送成功之后需要将结果更新到数据库中,不在线的客户端可以根据业务再次推送等。
+
+## 消息流转
+
+也许有些场景对于客户端上行的消息非常看重,需要做持久化,并且消息量非常大。
+
+在 `push-sever` 做业务显然不合适,这时完全可以选择 Kafka 来解耦。
+
+将所有上行的数据直接往 Kafka 里丢后就不管了。
+
+再由消费程序将数据取出写入数据库中即可。
+
+其实这块内容也很值得讨论,可以先看这篇了解下:[强如 Disruptor 也发生内存溢出?](https://crossoverjie.top/2018/08/29/java-senior/OOM-Disruptor/)
+
+后续谈到 Kafka 再做详细介绍。
+
+# 分布式问题
+
+分布式解决了性能问题但却带来了其他麻烦。
+
+## 应用监控
+
+比如如何知道线上几十个 `push-server` 节点的健康状况?
+
+这时就得监控系统发挥作用了,我们需要知道各个节点当前的内存使用情况、GC。
+
+以及操作系统本身的内存使用,毕竟 Netty 大量使用了堆外内存。
+
+同时需要监控各个节点当前的在线数,以及 Redis 中的在线数。理论上这两个数应该是相等的。
+
+这样也可以知道系统的使用情况,可以灵活的维护这些节点数量。
+
+## 日志处理
+
+日志记录也变得异常重要了,比如哪天反馈有个客户端一直连不上,你得知道问题出在哪里。
+
+
+最好是给每次请求都加上一个 traceID 记录日志,这样就可以通过这个日志在各个节点中查看到底是卡在了哪里。
+
+以及 ELK 这些工具都得用起来才行。
+
+# 总结
+
+本次是结合我日常经验得出的,有些坑可能在工作中并没有踩到,所有还会有一些遗漏的地方。
+
+就目前来看想做一个稳定的推送系统其实是比较麻烦的,其中涉及到的点非常多,只有真正做过之后才会知道。
+
+看完之后觉得有帮助的还请不吝转发分享。
+
+**欢迎关注公众号一起交流:**
+
+
diff --git a/docs/architecture-design/seconds-kill.md b/docs/architecture-design/seconds-kill.md
new file mode 100644
index 00000000..aa8061d7
--- /dev/null
+++ b/docs/architecture-design/seconds-kill.md
@@ -0,0 +1,694 @@
+
+
+## 前言
+
+之前在 [JCSprout](architecture-design/Spike.md) 中提到过秒杀架构的设计,这次基于其中的理论简单实现了一下。
+
+> 本次采用循序渐进的方式逐步提高性能达到并发秒杀的效果,文章较长请准备好瓜子板凳(liushuizhang😂)。
+
+本文所有涉及的代码:
+
+- [https://github.com/crossoverJie/SSM](https://github.com/crossoverJie/SSM)
+- [https://github.com/crossoverJie/distributed-redis-tool](https://github.com/crossoverJie/distributed-redis-tool)
+
+最终架构图:
+
+
+
+
+
+先简单根据这个图谈下请求的流转,因为后面不管怎么改进这个都是没有变的。
+
+- 前端请求进入 `web` 层,对应的代码就是 `controller`。
+- 之后将真正的库存校验、下单等请求发往 `Service` 层(其中 RPC 调用依然采用的 `dubbo`,只是更新为最新版本,本次不会过多讨论 dubbo 相关的细节,有兴趣的可以查看 [基于dubbo的分布式架构](https://crossoverjie.top/%2F2017%2F04%2F07%2FSSM11%2F))。
+- `Service` 层再对数据进行落地,下单完成。
+
+
+## 无限制
+
+其实抛开秒杀这个场景来说正常的一个下单流程可以简单分为以下几步:
+
+- 校验库存
+- 扣库存
+- 创建订单
+- 支付
+
+基于上文的架构所以我们有了以下实现:
+
+先看看实际项目的结构:
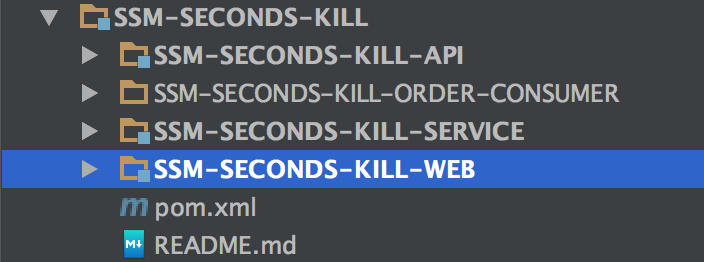
+
+
+
+还是和以前一样:
+
+- 提供出一个 `API` 用于 `Service` 层实现,以及 `web` 层消费。
+- web 层简单来说就是一个 `SpringMVC`。
+- `Service` 层则是真正的数据落地。
+- `SSM-SECONDS-KILL-ORDER-CONSUMER` 则是后文会提到的 `Kafka` 消费。
+
+
+数据库也是只有简单的两张表模拟下单:
+
+```sql
+CREATE TABLE `stock` (
+ `id` int(11) unsigned NOT NULL AUTO_INCREMENT,
+ `name` varchar(50) NOT NULL DEFAULT '' COMMENT '名称',
+ `count` int(11) NOT NULL COMMENT '库存',
+ `sale` int(11) NOT NULL COMMENT '已售',
+ `version` int(11) NOT NULL COMMENT '乐观锁,版本号',
+ PRIMARY KEY (`id`)
+) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;
+
+
+CREATE TABLE `stock_order` (
+ `id` int(11) unsigned NOT NULL AUTO_INCREMENT,
+ `sid` int(11) NOT NULL COMMENT '库存ID',
+ `name` varchar(30) NOT NULL DEFAULT '' COMMENT '商品名称',
+ `create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '创建时间',
+ PRIMARY KEY (`id`)
+) ENGINE=InnoDB AUTO_INCREMENT=55 DEFAULT CHARSET=utf8;
+```
+
+web 层 `controller` 实现:
+
+
+```java
+
+ @Autowired
+ private StockService stockService;
+
+ @Autowired
+ private OrderService orderService;
+
+ @RequestMapping("/createWrongOrder/{sid}")
+ @ResponseBody
+ public String createWrongOrder(@PathVariable int sid) {
+ logger.info("sid=[{}]", sid);
+ int id = 0;
+ try {
+ id = orderService.createWrongOrder(sid);
+ } catch (Exception e) {
+ logger.error("Exception",e);
+ }
+ return String.valueOf(id);
+ }
+```
+
+其中 web 作为一个消费者调用看 `OrderService` 提供出来的 dubbo 服务。
+
+Service 层,`OrderService` 实现:
+
+首先是对 API 的实现(会在 API 提供出接口):
+
+```java
+@Service
+public class OrderServiceImpl implements OrderService {
+
+ @Resource(name = "DBOrderService")
+ private com.crossoverJie.seconds.kill.service.OrderService orderService ;
+
+ @Override
+ public int createWrongOrder(int sid) throws Exception {
+ return orderService.createWrongOrder(sid);
+ }
+}
+```
+
+这里只是简单调用了 `DBOrderService` 中的实现,DBOrderService 才是真正的数据落地,也就是写数据库了。
+
+DBOrderService 实现:
+
+```java
+Transactional(rollbackFor = Exception.class)
+@Service(value = "DBOrderService")
+public class OrderServiceImpl implements OrderService {
+ @Resource(name = "DBStockService")
+ private com.crossoverJie.seconds.kill.service.StockService stockService;
+
+ @Autowired
+ private StockOrderMapper orderMapper;
+
+ @Override
+ public int createWrongOrder(int sid) throws Exception{
+
+ //校验库存
+ Stock stock = checkStock(sid);
+
+ //扣库存
+ saleStock(stock);
+
+ //创建订单
+ int id = createOrder(stock);
+
+ return id;
+ }
+
+ private Stock checkStock(int sid) {
+ Stock stock = stockService.getStockById(sid);
+ if (stock.getSale().equals(stock.getCount())) {
+ throw new RuntimeException("库存不足");
+ }
+ return stock;
+ }
+
+ private int saleStock(Stock stock) {
+ stock.setSale(stock.getSale() + 1);
+ return stockService.updateStockById(stock);
+ }
+
+ private int createOrder(Stock stock) {
+ StockOrder order = new StockOrder();
+ order.setSid(stock.getId());
+ order.setName(stock.getName());
+ int id = orderMapper.insertSelective(order);
+ return id;
+ }
+
+}
+```
+
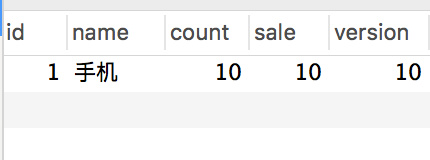
+> 预先初始化了 10 条库存。
+
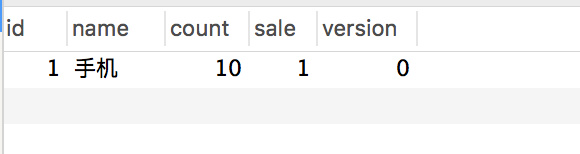
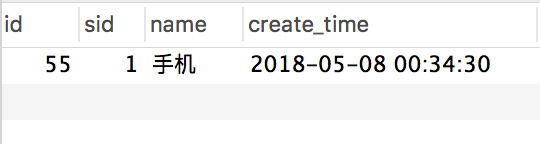
+
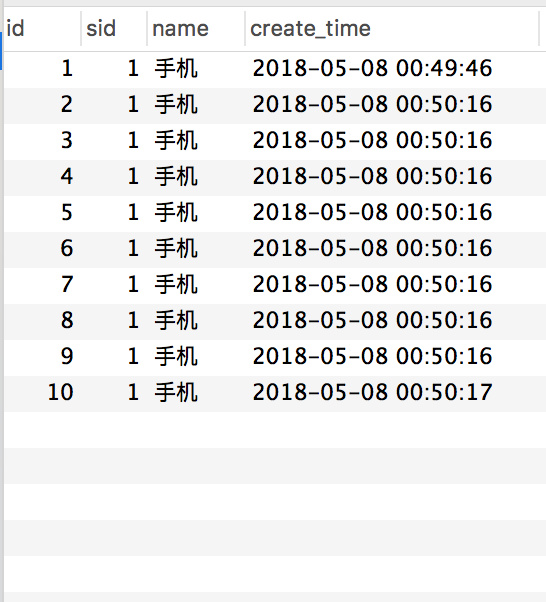
+手动调用下 `createWrongOrder/1` 接口发现:
+
+库存表:
+
+
+订单表:
+
+
+一切看起来都没有问题,数据也正常。
+
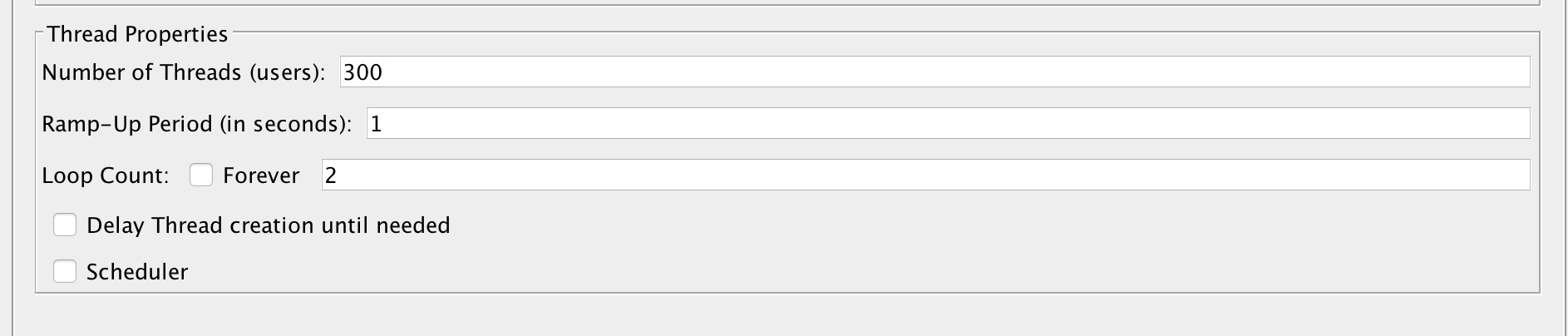
+但是当用 `JMeter` 并发测试时:
+
+
+
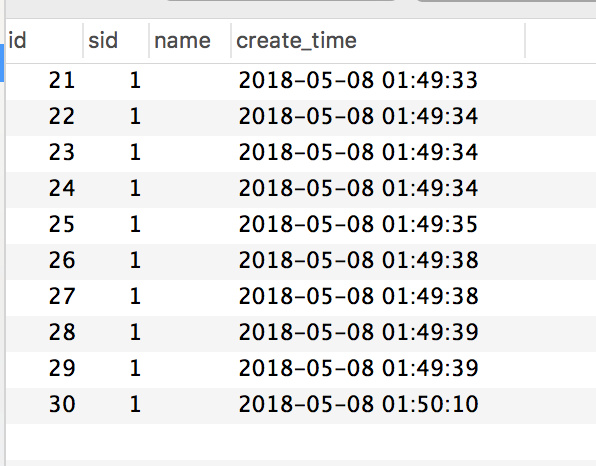
+测试配置是:300个线程并发,测试两轮来看看数据库中的结果:
+
+
+
+
+
+
+
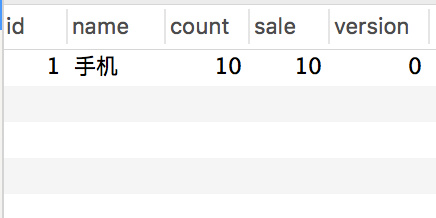
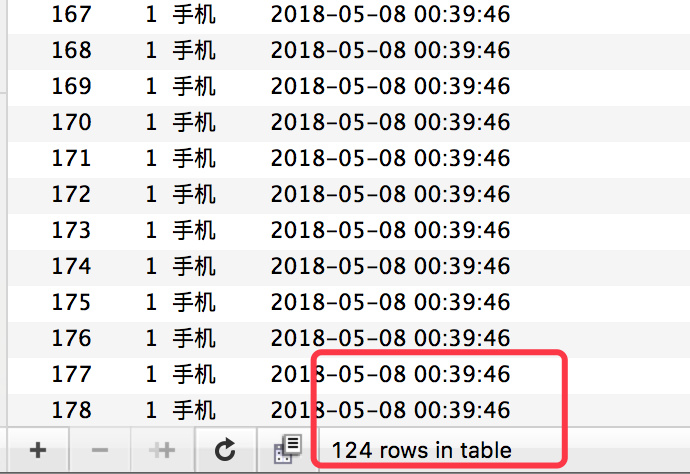
+请求都响应成功,库存确实也扣完了,但是订单却生成了 **124** 条记录。
+
+这显然是典型的超卖现象。
+
+> 其实现在再去手动调用接口会返回库存不足,但为时晚矣。
+
+
+## 乐观锁更新
+
+怎么来避免上述的现象呢?
+
+最简单的做法自然是乐观锁了,这里不过多讨论这个,不熟悉的朋友可以看下[这篇](http://crossoverjie.top/%2F2017%2F07%2F09%2FSSM15%2F)。
+
+来看看具体实现:
+
+> 其实其他的都没怎么改,主要是 Service 层。
+
+```java
+ @Override
+ public int createOptimisticOrder(int sid) throws Exception {
+
+ //校验库存
+ Stock stock = checkStock(sid);
+
+ //乐观锁更新库存
+ saleStockOptimistic(stock);
+
+ //创建订单
+ int id = createOrder(stock);
+
+ return id;
+ }
+
+ private void saleStockOptimistic(Stock stock) {
+ int count = stockService.updateStockByOptimistic(stock);
+ if (count == 0){
+ throw new RuntimeException("并发更新库存失败") ;
+ }
+ }
+```
+
+对应的 XML:
+
+```xml
+
+ update stock
+
+ sale = sale + 1,
+ version = version + 1,
+
+
+ WHERE id = #{id,jdbcType=INTEGER}
+ AND version = #{version,jdbcType=INTEGER}
+
+
+```
+
+同样的测试条件,我们再进行上面的测试 `/createOptimisticOrder/1`:
+
+
+
+
+
+
+
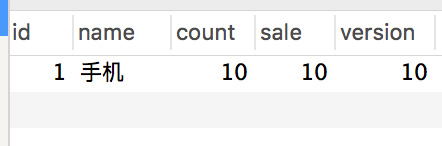
+这次发现无论是库存订单都是 OK 的。
+
+查看日志发现:
+
+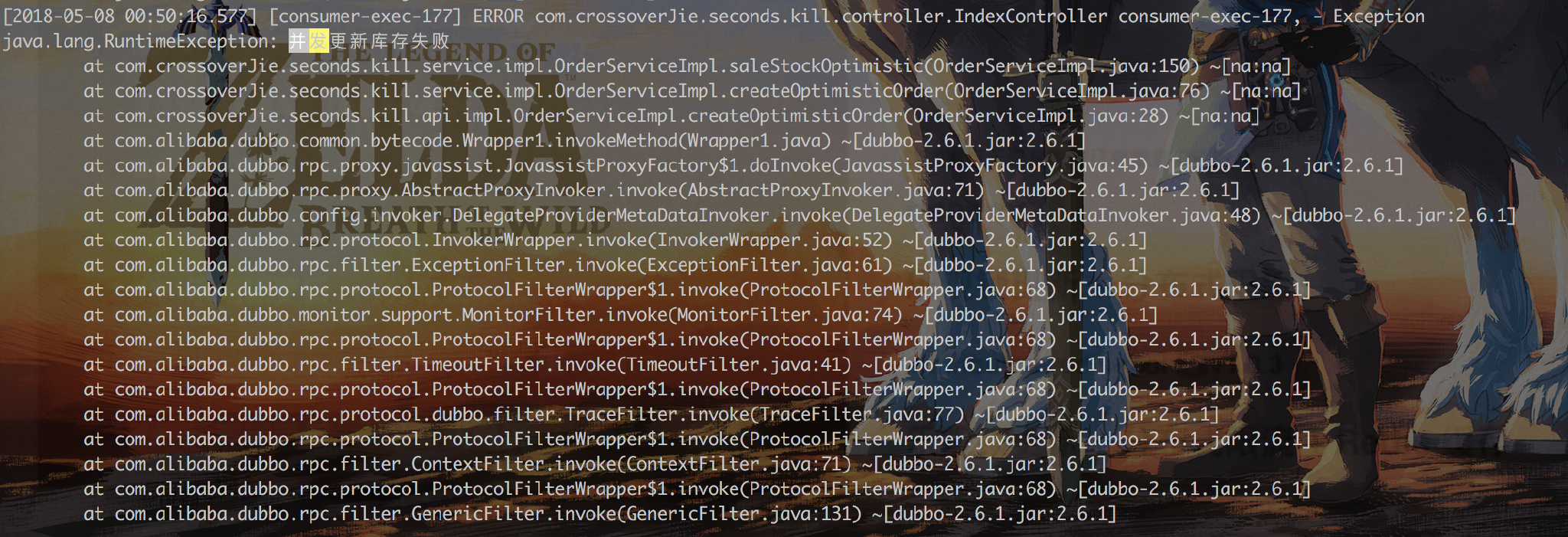
+
+很多并发请求会响应错误,这就达到了效果。
+
+### 提高吞吐量
+
+为了进一步提高秒杀时的吞吐量以及响应效率,这里的 web 和 Service 都进行了横向扩展。
+
+- web 利用 Nginx 进行负载。
+- Service 也是多台应用。
+
+
+
+
+
+再用 JMeter 测试时可以直观的看到效果。
+
+> 由于我是在阿里云的一台小水管服务器进行测试的,加上配置不高、应用都在同一台,所以并没有完全体现出性能上的优势( `Nginx` 做负载转发时候也会增加额外的网络消耗)。
+
+### shell 脚本实现简单的 CI
+
+由于应用多台部署之后,手动发版测试的痛苦相信经历过的都有体会。
+
+这次并没有精力去搭建完整的 CI CD,只是写了一个简单的脚本实现了自动化部署,希望对这方面没有经验的同学带来一点启发:
+
+#### 构建 web
+
+```shell
+#!/bin/bash
+
+# 构建 web 消费者
+
+#read appname
+
+appname="consumer"
+echo "input="$appname
+
+PID=$(ps -ef | grep $appname | grep -v grep | awk '{print $2}')
+
+# 遍历杀掉 pid
+for var in ${PID[@]};
+do
+ echo "loop pid= $var"
+ kill -9 $var
+done
+
+echo "kill $appname success"
+
+cd ..
+
+git pull
+
+cd SSM-SECONDS-KILL
+
+mvn -Dmaven.test.skip=true clean package
+
+echo "build war success"
+
+cp /home/crossoverJie/SSM/SSM-SECONDS-KILL/SSM-SECONDS-KILL-WEB/target/SSM-SECONDS-KILL-WEB-2.2.0-SNAPSHOT.war /home/crossoverJie/tomcat/tomcat-dubbo-consumer-8083/webapps
+echo "cp tomcat-dubbo-consumer-8083/webapps ok!"
+
+cp /home/crossoverJie/SSM/SSM-SECONDS-KILL/SSM-SECONDS-KILL-WEB/target/SSM-SECONDS-KILL-WEB-2.2.0-SNAPSHOT.war /home/crossoverJie/tomcat/tomcat-dubbo-consumer-7083-slave/webapps
+echo "cp tomcat-dubbo-consumer-7083-slave/webapps ok!"
+
+sh /home/crossoverJie/tomcat/tomcat-dubbo-consumer-8083/bin/startup.sh
+echo "tomcat-dubbo-consumer-8083/bin/startup.sh success"
+
+sh /home/crossoverJie/tomcat/tomcat-dubbo-consumer-7083-slave/bin/startup.sh
+echo "tomcat-dubbo-consumer-7083-slave/bin/startup.sh success"
+
+echo "start $appname success"
+```
+
+#### 构建 Service
+
+```shell
+# 构建服务提供者
+
+#read appname
+
+appname="provider"
+
+echo "input="$appname
+
+
+PID=$(ps -ef | grep $appname | grep -v grep | awk '{print $2}')
+
+#if [ $? -eq 0 ]; then
+# echo "process id:$PID"
+#else
+# echo "process $appname not exit"
+# exit
+#fi
+
+# 遍历杀掉 pid
+for var in ${PID[@]};
+do
+ echo "loop pid= $var"
+ kill -9 $var
+done
+
+echo "kill $appname success"
+
+
+cd ..
+
+git pull
+
+cd SSM-SECONDS-KILL
+
+mvn -Dmaven.test.skip=true clean package
+
+echo "build war success"
+
+cp /home/crossoverJie/SSM/SSM-SECONDS-KILL/SSM-SECONDS-KILL-SERVICE/target/SSM-SECONDS-KILL-SERVICE-2.2.0-SNAPSHOT.war /home/crossoverJie/tomcat/tomcat-dubbo-provider-8080/webapps
+
+echo "cp tomcat-dubbo-provider-8080/webapps ok!"
+
+cp /home/crossoverJie/SSM/SSM-SECONDS-KILL/SSM-SECONDS-KILL-SERVICE/target/SSM-SECONDS-KILL-SERVICE-2.2.0-SNAPSHOT.war /home/crossoverJie/tomcat/tomcat-dubbo-provider-7080-slave/webapps
+
+echo "cp tomcat-dubbo-provider-7080-slave/webapps ok!"
+
+sh /home/crossoverJie/tomcat/tomcat-dubbo-provider-8080/bin/startup.sh
+echo "tomcat-dubbo-provider-8080/bin/startup.sh success"
+
+sh /home/crossoverJie/tomcat/tomcat-dubbo-provider-7080-slave/bin/startup.sh
+echo "tomcat-dubbo-provider-8080/bin/startup.sh success"
+
+echo "start $appname success"
+```
+
+之后每当我有更新,只需要执行这两个脚本就可以帮我自动构建。
+
+都是最基础的 Linux 命令,相信大家都看得明白。
+
+
+## 乐观锁更新 + 分布式限流
+
+上文的结果看似没有问题,其实还差得远呢。
+
+这里只是模拟了 300 个并发没有问题,但是当请求达到了 3000 ,3W,300W 呢?
+
+虽说可以横向扩展可以支撑更多的请求。
+
+但是能不能利用最少的资源解决问题呢?
+
+其实仔细分析下会发现:
+
+> 假设我的商品一共只有 10 个库存,那么无论你多少人来买其实最终也最多只有 10 人可以下单成功。
+
+所以其中会有 `99%` 的请求都是无效的。
+
+大家都知道:大多数应用数据库都是压倒骆驼的最后一根稻草。
+
+通过 `Druid` 的监控来看看之前请求数据库的情况:
+
+因为 Service 是两个应用。
+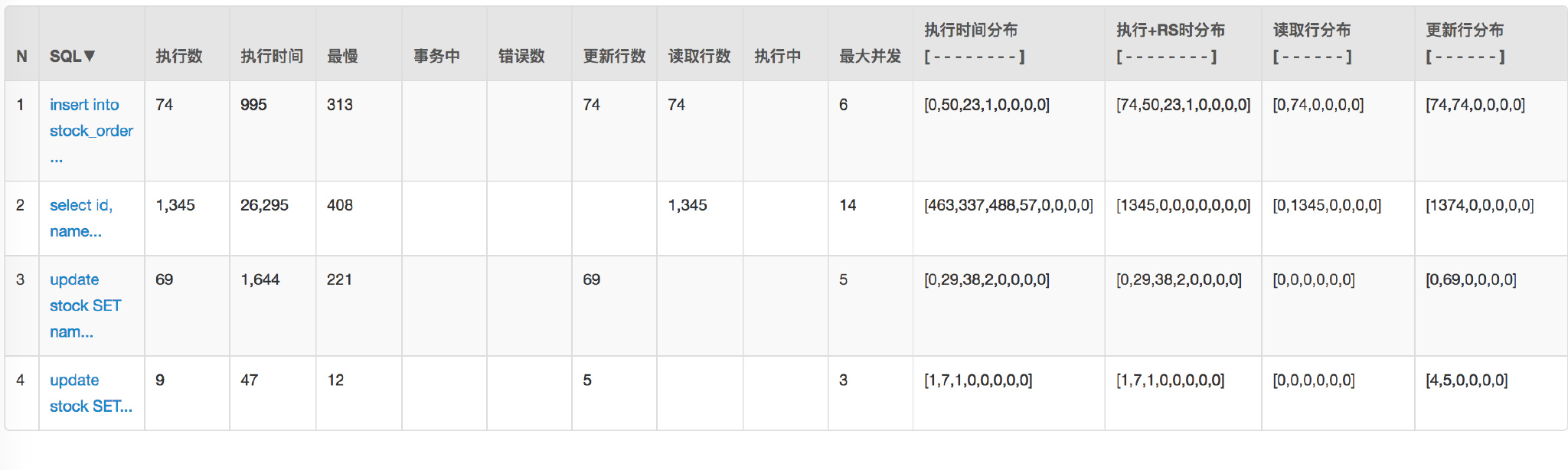
+
+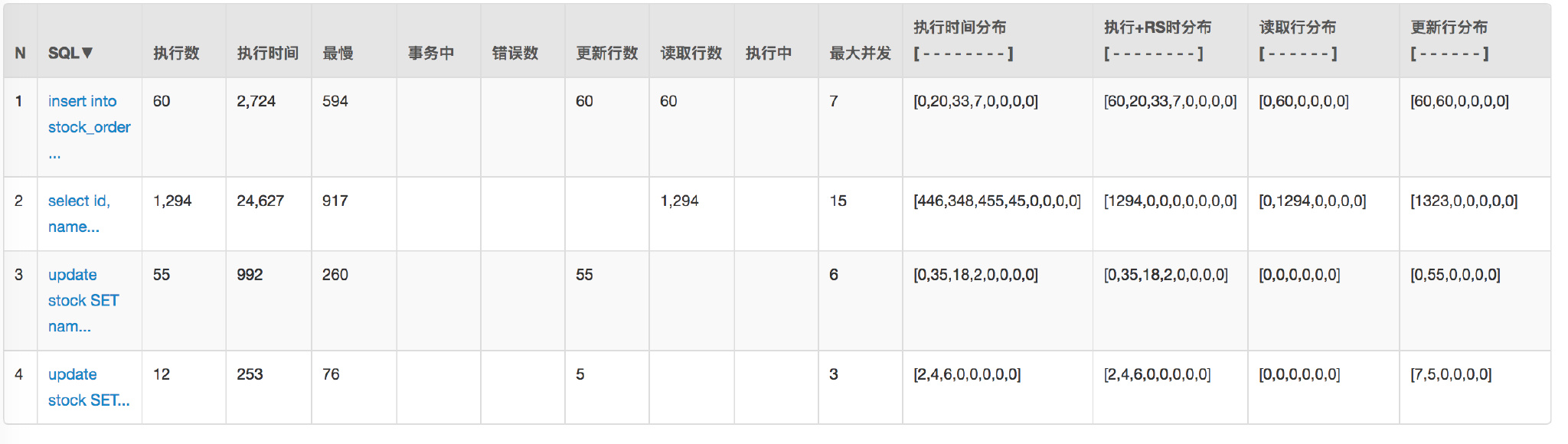
+
+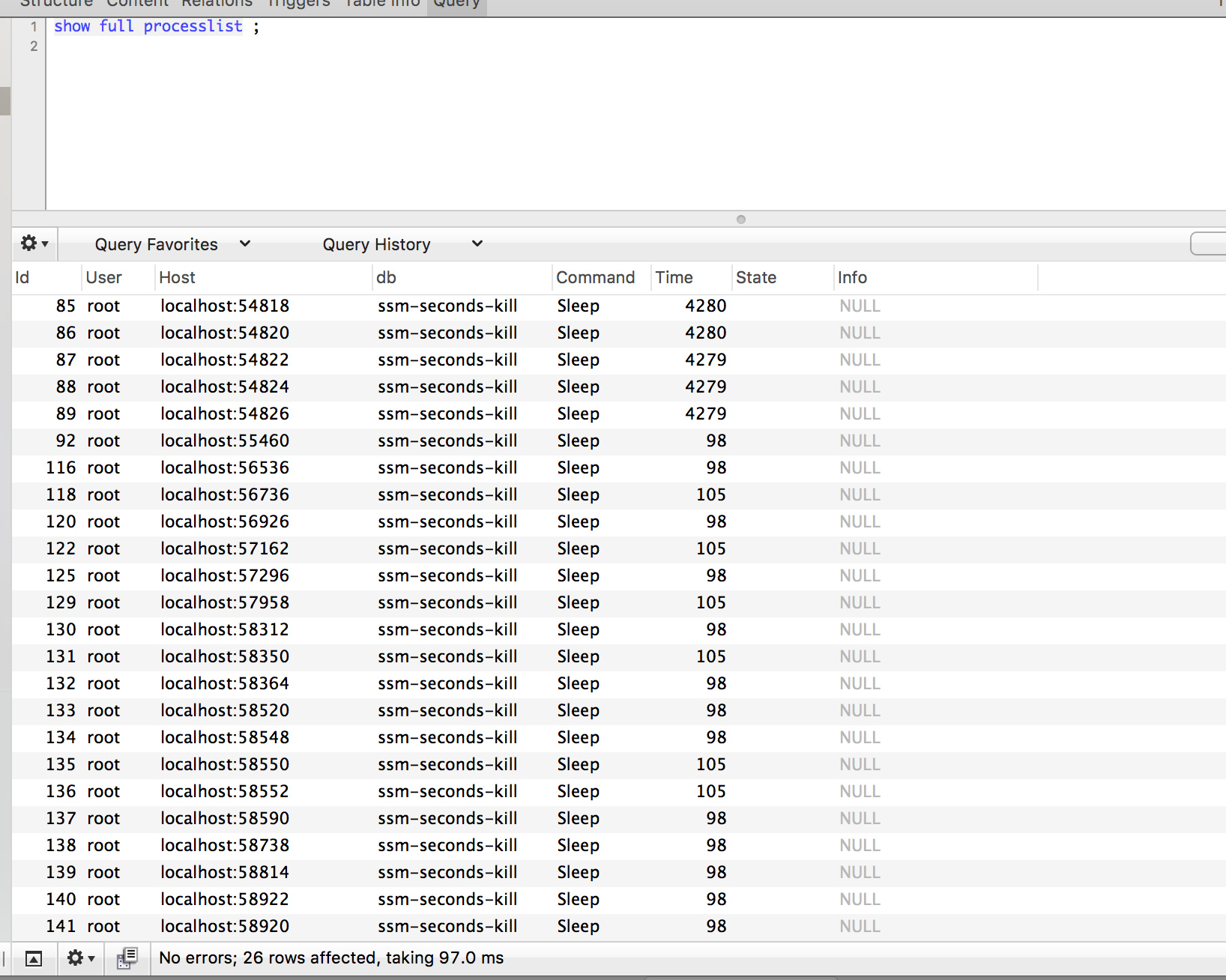
+
+数据库也有 20 多个连接。
+
+怎么样来优化呢?
+其实很容易想到的就是[分布式限流](http://crossoverjie.top/2018/04/28/sbc/sbc7-Distributed-Limit/)。
+
+
+我们将并发控制在一个可控的范围之内,然后快速失败这样就能最大程度的保护系统。
+
+### distributed-redis-tool ⬆️v1.0.3
+
+为此还对 [https://github.com/crossoverJie/distributed-redis-tool](https://github.com/crossoverJie/distributed-redis-tool) 进行了小小的升级。
+
+因为加上该组件之后所有的请求都会经过 Redis,所以对 Redis 资源的使用也是要非常小心。
+
+#### API 更新
+
+修改之后的 API 如下:
+
+```java
+@Configuration
+public class RedisLimitConfig {
+
+ private Logger logger = LoggerFactory.getLogger(RedisLimitConfig.class);
+
+ @Value("${redis.limit}")
+ private int limit;
+
+
+ @Autowired
+ private JedisConnectionFactory jedisConnectionFactory;
+
+ @Bean
+ public RedisLimit build() {
+ RedisLimit redisLimit = new RedisLimit.Builder(jedisConnectionFactory, RedisToolsConstant.SINGLE)
+ .limit(limit)
+ .build();
+
+ return redisLimit;
+ }
+}
+```
+
+这里构建器改用了 `JedisConnectionFactory`,所以得配合 Spring 来一起使用。
+
+并在初始化时显示传入 Redis 是以集群方式部署还是单机(强烈建议集群,限流之后对 Redis 还是有一定的压力)。
+
+##### 限流实现
+
+既然 API 更新了,实现自然也要修改:
+
+```java
+ /**
+ * limit traffic
+ * @return if true
+ */
+ public boolean limit() {
+
+ //get connection
+ Object connection = getConnection();
+
+ Object result = limitRequest(connection);
+
+ if (FAIL_CODE != (Long) result) {
+ return true;
+ } else {
+ return false;
+ }
+ }
+
+ private Object limitRequest(Object connection) {
+ Object result = null;
+ String key = String.valueOf(System.currentTimeMillis() / 1000);
+ if (connection instanceof Jedis){
+ result = ((Jedis)connection).eval(script, Collections.singletonList(key), Collections.singletonList(String.valueOf(limit)));
+ ((Jedis) connection).close();
+ }else {
+ result = ((JedisCluster) connection).eval(script, Collections.singletonList(key), Collections.singletonList(String.valueOf(limit)));
+ try {
+ ((JedisCluster) connection).close();
+ } catch (IOException e) {
+ logger.error("IOException",e);
+ }
+ }
+ return result;
+ }
+
+ private Object getConnection() {
+ Object connection ;
+ if (type == RedisToolsConstant.SINGLE){
+ RedisConnection redisConnection = jedisConnectionFactory.getConnection();
+ connection = redisConnection.getNativeConnection();
+ }else {
+ RedisClusterConnection clusterConnection = jedisConnectionFactory.getClusterConnection();
+ connection = clusterConnection.getNativeConnection() ;
+ }
+ return connection;
+ }
+```
+
+如果是原生的 Spring 应用得采用 `@SpringControllerLimit(errorCode = 200)` 注解。
+
+实际使用如下:
+
+web 端:
+
+```java
+ /**
+ * 乐观锁更新库存 限流
+ * @param sid
+ * @return
+ */
+ @SpringControllerLimit(errorCode = 200)
+ @RequestMapping("/createOptimisticLimitOrder/{sid}")
+ @ResponseBody
+ public String createOptimisticLimitOrder(@PathVariable int sid) {
+ logger.info("sid=[{}]", sid);
+ int id = 0;
+ try {
+ id = orderService.createOptimisticOrder(sid);
+ } catch (Exception e) {
+ logger.error("Exception",e);
+ }
+ return String.valueOf(id);
+ }
+```
+
+Service 端就没什么更新了,依然是采用的乐观锁更新数据库。
+
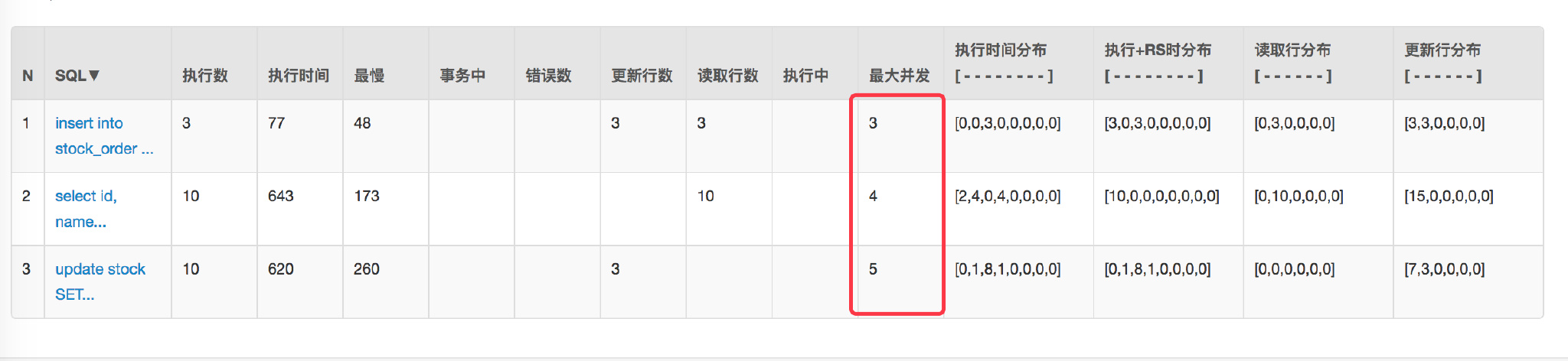
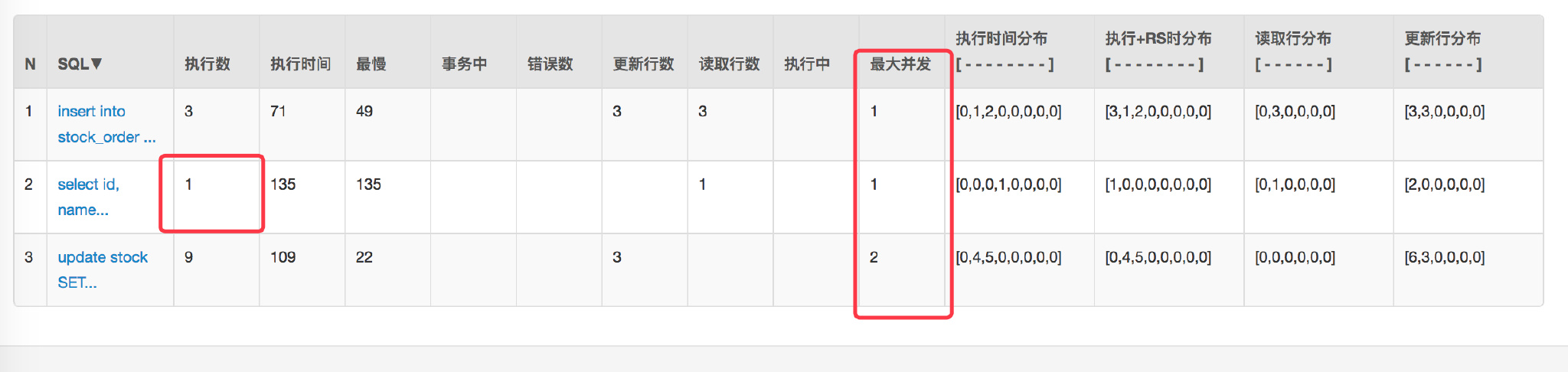
+再压测看下效果 `/createOptimisticLimitOrderByRedis/1`:
+
+
+
+
+
+
+
+
+
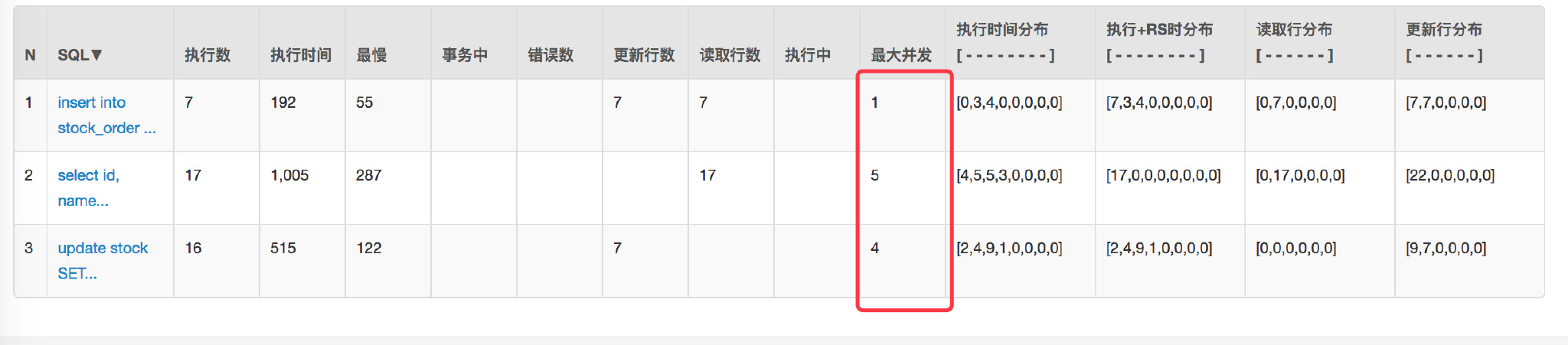
+
+
+首先是看结果没有问题,再看数据库连接以及并发请求数都有**明显的下降**。
+
+
+## 乐观锁更新 + 分布式限流 + Redis 缓存
+
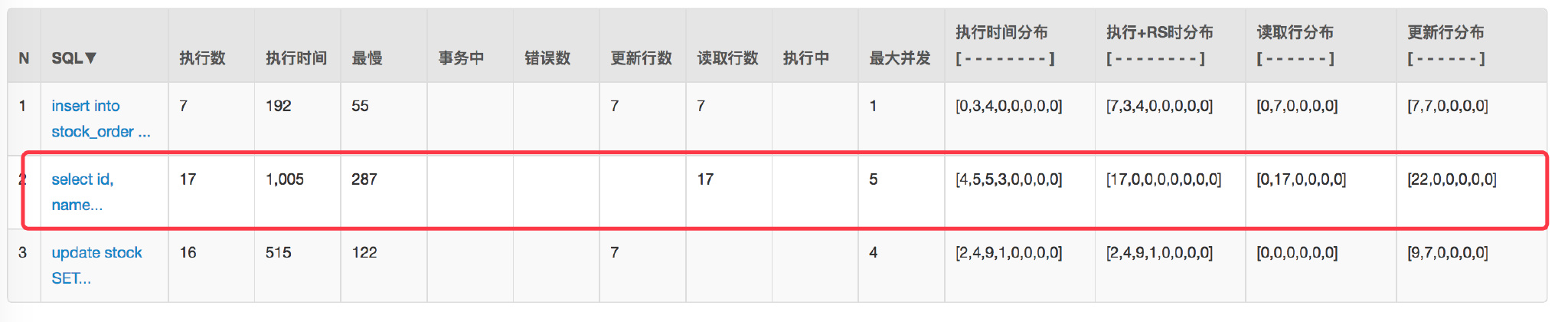
+其实仔细观察 Druid 监控数据发现这个 SQL 被多次查询:
+
+
+
+其实这是实时查询库存的 SQL,主要是为了在每次下单之前判断是否还有库存。
+
+**这也是个优化点**。
+
+这种数据我们完全可以放在内存中,效率比在数据库要高很多。
+
+由于我们的应用是分布式的,所以堆内缓存显然不合适,Redis 就非常适合。
+
+这次主要改造的是 Service 层:
+
+- 每次查询库存时走 Redis。
+- 扣库存时更新 Redis。
+- 需要提前将库存信息写入 Redis(手动或者程序自动都可以)。
+
+主要代码如下:
+
+```java
+ @Override
+ public int createOptimisticOrderUseRedis(int sid) throws Exception {
+ //检验库存,从 Redis 获取
+ Stock stock = checkStockByRedis(sid);
+
+ //乐观锁更新库存 以及更新 Redis
+ saleStockOptimisticByRedis(stock);
+
+ //创建订单
+ int id = createOrder(stock);
+ return id ;
+ }
+
+
+ private Stock checkStockByRedis(int sid) throws Exception {
+ Integer count = Integer.parseInt(redisTemplate.opsForValue().get(RedisKeysConstant.STOCK_COUNT + sid));
+ Integer sale = Integer.parseInt(redisTemplate.opsForValue().get(RedisKeysConstant.STOCK_SALE + sid));
+ if (count.equals(sale)){
+ throw new RuntimeException("库存不足 Redis currentCount=" + sale);
+ }
+ Integer version = Integer.parseInt(redisTemplate.opsForValue().get(RedisKeysConstant.STOCK_VERSION + sid));
+ Stock stock = new Stock() ;
+ stock.setId(sid);
+ stock.setCount(count);
+ stock.setSale(sale);
+ stock.setVersion(version);
+
+ return stock;
+ }
+
+
+ /**
+ * 乐观锁更新数据库 还要更新 Redis
+ * @param stock
+ */
+ private void saleStockOptimisticByRedis(Stock stock) {
+ int count = stockService.updateStockByOptimistic(stock);
+ if (count == 0){
+ throw new RuntimeException("并发更新库存失败") ;
+ }
+ //自增
+ redisTemplate.opsForValue().increment(RedisKeysConstant.STOCK_SALE + stock.getId(),1) ;
+ redisTemplate.opsForValue().increment(RedisKeysConstant.STOCK_VERSION + stock.getId(),1) ;
+ }
+```
+
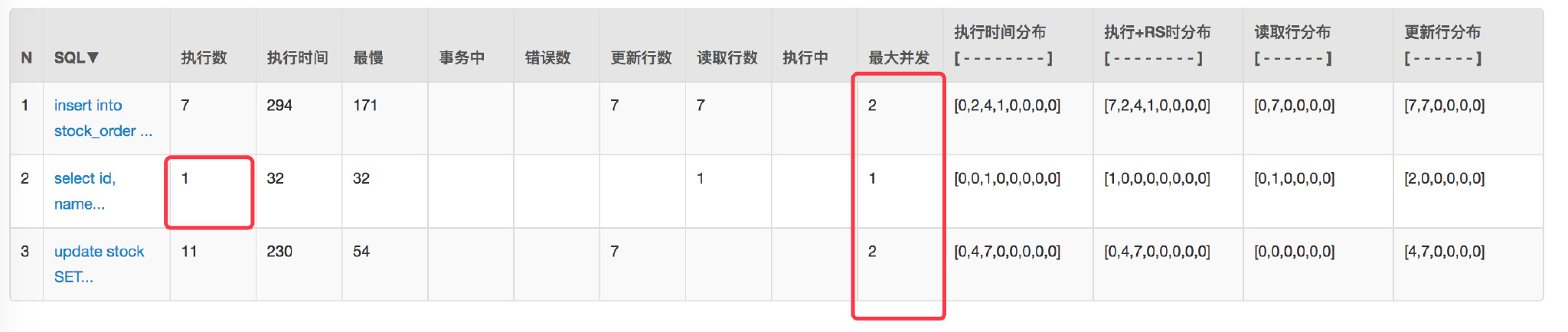
+压测看看实际效果 `/createOptimisticLimitOrderByRedis/1`:
+
+
+
+
+
+
+
+
+
+最后发现数据没问题,数据库的请求与并发也都下来了。
+
+
+
+## 乐观锁更新 + 分布式限流 + Redis 缓存 + Kafka 异步
+
+最后的优化还是想如何来再次提高吞吐量以及性能的。
+
+我们上文所有例子其实都是同步请求,完全可以利用同步转异步来提高性能啊。
+
+这里我们将写订单以及更新库存的操作进行异步化,利用 `Kafka` 来进行解耦和队列的作用。
+
+每当一个请求通过了限流到达了 Service 层通过了库存校验之后就将订单信息发给 Kafka ,这样一个请求就可以直接返回了。
+
+消费程序再对数据进行入库落地。
+
+因为异步了,所以最终需要采取回调或者是其他提醒的方式提醒用户购买完成。
+
+这里代码较多就不贴了,消费程序其实就是把之前的 Service 层的逻辑重写了一遍,不过采用的是 SpringBoot。
+
+感兴趣的朋友可以看下。
+
+[https://github.com/crossoverJie/SSM/tree/master/SSM-SECONDS-KILL/SSM-SECONDS-KILL-ORDER-CONSUMER](https://github.com/crossoverJie/SSM/tree/master/SSM-SECONDS-KILL/SSM-SECONDS-KILL-ORDER-CONSUMER)
+
+
+
+
+## 总结
+
+其实经过上面的一顿优化总结起来无非就是以下几点:
+
+- 尽量将请求拦截在上游。
+- 还可以根据 UID 进行限流。
+- 最大程度的减少请求落到 DB。
+- 多利用缓存。
+- 同步操作异步化。
+- fail fast,尽早失败,保护应用。
+
+码字不易,这应该是我写过字数最多的了,想想当年高中 800 字的作文都憋不出来😂,可想而知是有多难得了。
+
+**以上内容欢迎讨论**。
+
+### 号外
+最近在总结一些 Java 相关的知识点,感兴趣的朋友可以一起维护。
+
+> 地址: [https://github.com/crossoverJie/JCSprout](https://github.com/crossoverJie/JCSprout)
diff --git a/docs/collections/ArrayList.md b/docs/collections/ArrayList.md
new file mode 100644
index 00000000..11bb2ae1
--- /dev/null
+++ b/docs/collections/ArrayList.md
@@ -0,0 +1,151 @@
+# ArrayList/Vector 的底层分析
+
+## ArrayList
+
+`ArrayList` 实现于 `List`、`RandomAccess` 接口。可以插入空数据,也支持随机访问。
+
+`ArrayList `相当于动态数据,其中最重要的两个属性分别是:
+`elementData` 数组,以及 `size` 大小。
+在调用 `add()` 方法的时候:
+```java
+ public boolean add(E e) {
+ ensureCapacityInternal(size + 1); // Increments modCount!!
+ elementData[size++] = e;
+ return true;
+ }
+```
+
+- 首先进行扩容校验。
+- 将插入的值放到尾部,并将 size + 1 。
+
+如果是调用 `add(index,e)` 在指定位置添加的话:
+```java
+ public void add(int index, E element) {
+ rangeCheckForAdd(index);
+
+ ensureCapacityInternal(size + 1); // Increments modCount!!
+ //复制,向后移动
+ System.arraycopy(elementData, index, elementData, index + 1,
+ size - index);
+ elementData[index] = element;
+ size++;
+ }
+```
+
+
+- 也是首先扩容校验。
+- 接着对数据进行复制,目的是把 index 位置空出来放本次插入的数据,并将后面的数据向后移动一个位置。
+
+其实扩容最终调用的代码:
+```java
+ private void grow(int minCapacity) {
+ // overflow-conscious code
+ int oldCapacity = elementData.length;
+ int newCapacity = oldCapacity + (oldCapacity >> 1);
+ if (newCapacity - minCapacity < 0)
+ newCapacity = minCapacity;
+ if (newCapacity - MAX_ARRAY_SIZE > 0)
+ newCapacity = hugeCapacity(minCapacity);
+ // minCapacity is usually close to size, so this is a win:
+ elementData = Arrays.copyOf(elementData, newCapacity);
+ }
+```
+
+也是一个数组复制的过程。
+
+由此可见 `ArrayList` 的主要消耗是数组扩容以及在指定位置添加数据,在日常使用时最好是指定大小,尽量减少扩容。更要减少在指定位置插入数据的操作。
+
+### 序列化
+
+由于 ArrayList 是基于动态数组实现的,所以并不是所有的空间都被使用。因此使用了 `transient` 修饰,可以防止被自动序列化。
+
+```java
+transient Object[] elementData;
+```
+
+因此 ArrayList 自定义了序列化与反序列化:
+
+```java
+ private void writeObject(java.io.ObjectOutputStream s)
+ throws java.io.IOException{
+ // Write out element count, and any hidden stuff
+ int expectedModCount = modCount;
+ s.defaultWriteObject();
+
+ // Write out size as capacity for behavioural compatibility with clone()
+ s.writeInt(size);
+
+ // Write out all elements in the proper order.
+ //只序列化了被使用的数据
+ for (int i=0; i 0) {
+ // be like clone(), allocate array based upon size not capacity
+ ensureCapacityInternal(size);
+
+ Object[] a = elementData;
+ // Read in all elements in the proper order.
+ for (int i=0; i 当对象中自定义了 writeObject 和 readObject 方法时,JVM 会调用这两个自定义方法来实现序列化与反序列化。
+
+
+从实现中可以看出 ArrayList 只序列化了被使用的数据。
+
+
+## Vector
+
+`Vector` 也是实现于 `List` 接口,底层数据结构和 `ArrayList` 类似,也是一个动态数组存放数据。不过是在 `add()` 方法的时候使用 `synchronized` 进行同步写数据,但是开销较大,所以 `Vector` 是一个同步容器并不是一个并发容器。
+
+以下是 `add()` 方法:
+```java
+ public synchronized boolean add(E e) {
+ modCount++;
+ ensureCapacityHelper(elementCount + 1);
+ elementData[elementCount++] = e;
+ return true;
+ }
+```
+
+以及指定位置插入数据:
+```java
+ public void add(int index, E element) {
+ insertElementAt(element, index);
+ }
+ public synchronized void insertElementAt(E obj, int index) {
+ modCount++;
+ if (index > elementCount) {
+ throw new ArrayIndexOutOfBoundsException(index
+ + " > " + elementCount);
+ }
+ ensureCapacityHelper(elementCount + 1);
+ System.arraycopy(elementData, index, elementData, index + 1, elementCount - index);
+ elementData[index] = obj;
+ elementCount++;
+ }
+```
+
+
+
diff --git a/docs/collections/HashMap.md b/docs/collections/HashMap.md
new file mode 100644
index 00000000..a038f075
--- /dev/null
+++ b/docs/collections/HashMap.md
@@ -0,0 +1,77 @@
+**更多 HashMap 与 ConcurrentHashMap 相关请查看[这里](https://crossoverjie.top/2018/07/23/java-senior/ConcurrentHashMap/)。**
+
+# HashMap 底层分析
+
+> 以下基于 JDK1.7 分析。
+
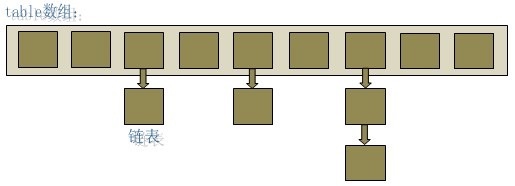
+
+
+如图所示,HashMap 底层是基于数组和链表实现的。其中有两个重要的参数:
+
+- 容量
+- 负载因子
+
+容量的默认大小是 16,负载因子是 0.75,当 `HashMap` 的 `size > 16*0.75` 时就会发生扩容(容量和负载因子都可以自由调整)。
+
+## put 方法
+首先会将传入的 Key 做 `hash` 运算计算出 hashcode,然后根据数组长度取模计算出在数组中的 index 下标。
+
+由于在计算中位运算比取模运算效率高的多,所以 HashMap 规定数组的长度为 `2^n` 。这样用 `2^n - 1` 做位运算与取模效果一致,并且效率还要高出许多。
+
+由于数组的长度有限,所以难免会出现不同的 Key 通过运算得到的 index 相同,这种情况可以利用链表来解决,HashMap 会在 `table[index]`处形成链表,采用头插法将数据插入到链表中。
+
+## get 方法
+
+get 和 put 类似,也是将传入的 Key 计算出 index ,如果该位置上是一个链表就需要遍历整个链表,通过 `key.equals(k)` 来找到对应的元素。
+
+## 遍历方式
+
+
+```java
+ Iterator> entryIterator = map.entrySet().iterator();
+ while (entryIterator.hasNext()) {
+ Map.Entry next = entryIterator.next();
+ System.out.println("key=" + next.getKey() + " value=" + next.getValue());
+ }
+```
+
+```java
+Iterator iterator = map.keySet().iterator();
+ while (iterator.hasNext()){
+ String key = iterator.next();
+ System.out.println("key=" + key + " value=" + map.get(key));
+
+ }
+```
+
+```java
+map.forEach((key,value)->{
+ System.out.println("key=" + key + " value=" + value);
+});
+```
+
+**强烈建议**使用第一种 EntrySet 进行遍历。
+
+第一种可以把 key value 同时取出,第二种还得需要通过 key 取一次 value,效率较低, 第三种需要 `JDK1.8` 以上,通过外层遍历 table,内层遍历链表或红黑树。
+
+
+## notice
+
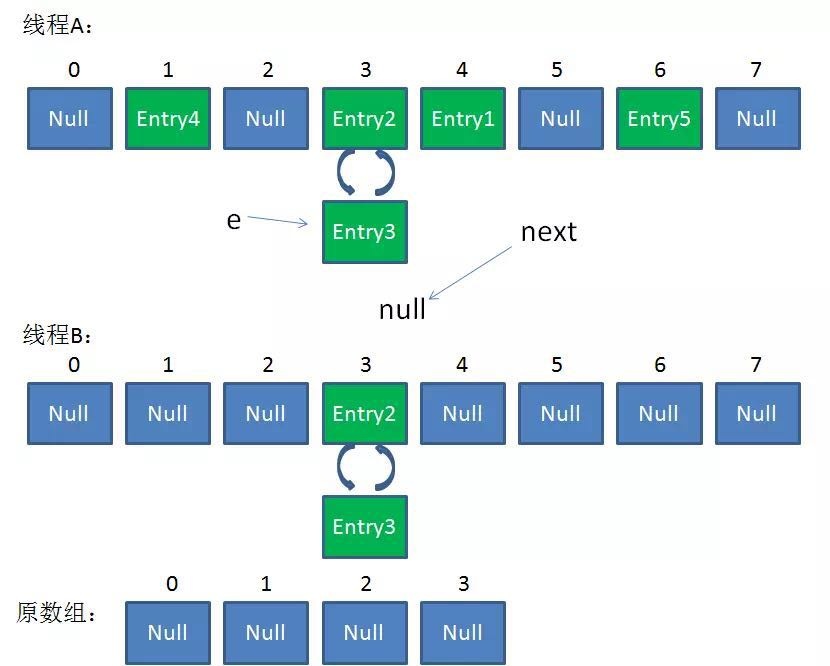
+在并发环境下使用 `HashMap` 容易出现死循环。
+
+并发场景发生扩容,调用 `resize()` 方法里的 `rehash()` 时,容易出现环形链表。这样当获取一个不存在的 `key` 时,计算出的 `index` 正好是环形链表的下标时就会出现死循环。
+
+
+
+> 所以 HashMap 只能在单线程中使用,并且尽量的预设容量,尽可能的减少扩容。
+
+在 `JDK1.8` 中对 `HashMap` 进行了优化:
+当 `hash` 碰撞之后写入链表的长度超过了阈值(默认为8)并且 `table` 的长度不小于64(否则扩容一次)时,链表将会转换为**红黑树**。
+
+假设 `hash` 冲突非常严重,一个数组后面接了很长的链表,此时重新的时间复杂度就是 `O(n)` 。
+
+如果是红黑树,时间复杂度就是 `O(logn)` 。
+
+大大提高了查询效率。
+
+多线程场景下推荐使用 [ConcurrentHashMap](https://github.com/crossoverJie/Java-Interview/blob/master/MD/ConcurrentHashMap.md)。
diff --git a/docs/collections/HashSet.md b/docs/collections/HashSet.md
new file mode 100644
index 00000000..3fd3565e
--- /dev/null
+++ b/docs/collections/HashSet.md
@@ -0,0 +1,49 @@
+# HashSet
+
+`HashSet` 是一个不允许存储重复元素的集合,它的实现比较简单,只要理解了 `HashMap`,`HashSet` 就水到渠成了。
+
+## 成员变量
+首先了解下 `HashSet` 的成员变量:
+
+```java
+ private transient HashMap map;
+
+ // Dummy value to associate with an Object in the backing Map
+ private static final Object PRESENT = new Object();
+```
+
+发现主要就两个变量:
+
+- `map` :用于存放最终数据的。
+- `PRESENT` :是所有写入 map 的 `value` 值。
+
+## 构造函数
+
+```java
+ public HashSet() {
+ map = new HashMap<>();
+ }
+
+ public HashSet(int initialCapacity, float loadFactor) {
+ map = new HashMap<>(initialCapacity, loadFactor);
+ }
+```
+构造函数很简单,利用了 `HashMap` 初始化了 `map` 。
+
+## add
+
+```java
+ public boolean add(E e) {
+ return map.put(e, PRESENT)==null;
+ }
+```
+
+比较关键的就是这个 `add()` 方法。
+可以看出它是将存放的对象当做了 `HashMap` 的健,`value` 都是相同的 `PRESENT` 。由于 `HashMap` 的 `key` 是不能重复的,所以每当有重复的值写入到 `HashSet` 时,`value` 会被覆盖,但 `key` 不会受到影响,这样就保证了 `HashSet` 中只能存放不重复的元素。
+
+## 总结
+
+`HashSet` 的原理比较简单,几乎全部借助于 `HashMap` 来实现的。
+
+所以 `HashMap` 会出现的问题 `HashSet` 依然不能避免。
+
diff --git a/docs/collections/LinkedHashMap.md b/docs/collections/LinkedHashMap.md
new file mode 100644
index 00000000..bbc49c37
--- /dev/null
+++ b/docs/collections/LinkedHashMap.md
@@ -0,0 +1,278 @@
+# LinkedHashMap 底层分析
+
+众所周知 [HashMap](https://github.com/crossoverJie/Java-Interview/blob/master/MD/HashMap.md) 是一个无序的 `Map`,因为每次根据 `key` 的 `hashcode` 映射到 `Entry` 数组上,所以遍历出来的顺序并不是写入的顺序。
+
+因此 JDK 推出一个基于 `HashMap` 但具有顺序的 `LinkedHashMap` 来解决有排序需求的场景。
+
+它的底层是继承于 `HashMap` 实现的,由一个双向链表所构成。
+
+`LinkedHashMap` 的排序方式有两种:
+
+- 根据写入顺序排序。
+- 根据访问顺序排序。
+
+其中根据访问顺序排序时,每次 `get` 都会将访问的值移动到链表末尾,这样重复操作就能得到一个按照访问顺序排序的链表。
+
+## 数据结构
+
+```java
+ @Test
+ public void test(){
+ Map map = new LinkedHashMap();
+ map.put("1",1) ;
+ map.put("2",2) ;
+ map.put("3",3) ;
+ map.put("4",4) ;
+ map.put("5",5) ;
+ System.out.println(map.toString());
+
+ }
+```
+
+调试可以看到 `map` 的组成:
+
+
+
+
+打开源码可以看到:
+
+```java
+ /**
+ * The head of the doubly linked list.
+ */
+ private transient Entry header;
+
+ /**
+ * The iteration ordering method for this linked hash map: true
+ * for access-order, false for insertion-order.
+ *
+ * @serial
+ */
+ private final boolean accessOrder;
+
+ private static class Entry extends HashMap.Entry {
+ // These fields comprise the doubly linked list used for iteration.
+ Entry before, after;
+
+ Entry(int hash, K key, V value, HashMap.Entry next) {
+ super(hash, key, value, next);
+ }
+ }
+```
+
+其中 `Entry` 继承于 `HashMap` 的 `Entry`,并新增了上下节点的指针,也就形成了双向链表。
+
+还有一个 `header` 的成员变量,是这个双向链表的头结点。
+
+上边的 demo 总结成一张图如下:
+
+
+
+第一个类似于 `HashMap` 的结构,利用 `Entry` 中的 `next` 指针进行关联。
+
+下边则是 `LinkedHashMap` 如何达到有序的关键。
+
+就是利用了头节点和其余的各个节点之间通过 `Entry` 中的 `after` 和 `before` 指针进行关联。
+
+
+其中还有一个 `accessOrder` 成员变量,默认是 `false`,默认按照插入顺序排序,为 `true` 时按照访问顺序排序,也可以调用:
+
+```
+ public LinkedHashMap(int initialCapacity,
+ float loadFactor,
+ boolean accessOrder) {
+ super(initialCapacity, loadFactor);
+ this.accessOrder = accessOrder;
+ }
+```
+
+这个构造方法可以显示的传入 `accessOrder `。
+
+
+## 构造方法
+
+`LinkedHashMap` 的构造方法:
+
+```java
+ public LinkedHashMap() {
+ super();
+ accessOrder = false;
+ }
+```
+
+其实就是调用的 `HashMap` 的构造方法:
+
+`HashMap` 实现:
+
+```java
+ public HashMap(int initialCapacity, float loadFactor) {
+ if (initialCapacity < 0)
+ throw new IllegalArgumentException("Illegal initial capacity: " +
+ initialCapacity);
+ if (initialCapacity > MAXIMUM_CAPACITY)
+ initialCapacity = MAXIMUM_CAPACITY;
+ if (loadFactor <= 0 || Float.isNaN(loadFactor))
+ throw new IllegalArgumentException("Illegal load factor: " +
+ loadFactor);
+
+ this.loadFactor = loadFactor;
+ threshold = initialCapacity;
+ //HashMap 只是定义了改方法,具体实现交给了 LinkedHashMap
+ init();
+ }
+```
+
+可以看到里面有一个空的 `init()`,具体是由 `LinkedHashMap` 来实现的:
+
+```java
+ @Override
+ void init() {
+ header = new Entry<>(-1, null, null, null);
+ header.before = header.after = header;
+ }
+```
+其实也就是对 `header` 进行了初始化。
+
+## put() 方法
+
+看 `LinkedHashMap` 的 `put()` 方法之前先看看 `HashMap` 的 `put` 方法:
+
+```
+ public V put(K key, V value) {
+ if (table == EMPTY_TABLE) {
+ inflateTable(threshold);
+ }
+ if (key == null)
+ return putForNullKey(value);
+ int hash = hash(key);
+ int i = indexFor(hash, table.length);
+ for (Entry e = table[i]; e != null; e = e.next) {
+ Object k;
+ if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
+ V oldValue = e.value;
+ e.value = value;
+ //空实现,交给 LinkedHashMap 自己实现
+ e.recordAccess(this);
+ return oldValue;
+ }
+ }
+
+ modCount++;
+ // LinkedHashMap 对其重写
+ addEntry(hash, key, value, i);
+ return null;
+ }
+
+ // LinkedHashMap 对其重写
+ void addEntry(int hash, K key, V value, int bucketIndex) {
+ if ((size >= threshold) && (null != table[bucketIndex])) {
+ resize(2 * table.length);
+ hash = (null != key) ? hash(key) : 0;
+ bucketIndex = indexFor(hash, table.length);
+ }
+
+ createEntry(hash, key, value, bucketIndex);
+ }
+
+ // LinkedHashMap 对其重写
+ void createEntry(int hash, K key, V value, int bucketIndex) {
+ Entry e = table[bucketIndex];
+ table[bucketIndex] = new Entry<>(hash, key, value, e);
+ size++;
+ }
+```
+
+主体的实现都是借助于 `HashMap` 来完成的,只是对其中的 `recordAccess(), addEntry(), createEntry()` 进行了重写。
+
+`LinkedHashMap` 的实现:
+
+```java
+ //就是判断是否是根据访问顺序排序,如果是则需要将当前这个 Entry 移动到链表的末尾
+ void recordAccess(HashMap m) {
+ LinkedHashMap lm = (LinkedHashMap)m;
+ if (lm.accessOrder) {
+ lm.modCount++;
+ remove();
+ addBefore(lm.header);
+ }
+ }
+
+
+ //调用了 HashMap 的实现,并判断是否需要删除最少使用的 Entry(默认不删除)
+ void addEntry(int hash, K key, V value, int bucketIndex) {
+ super.addEntry(hash, key, value, bucketIndex);
+
+ // Remove eldest entry if instructed
+ Entry eldest = header.after;
+ if (removeEldestEntry(eldest)) {
+ removeEntryForKey(eldest.key);
+ }
+ }
+
+ void createEntry(int hash, K key, V value, int bucketIndex) {
+ HashMap.Entry old = table[bucketIndex];
+ Entry e = new Entry<>(hash, key, value, old);
+ //就多了这一步,将新增的 Entry 加入到 header 双向链表中
+ table[bucketIndex] = e;
+ e.addBefore(header);
+ size++;
+ }
+
+ //写入到双向链表中
+ private void addBefore(Entry existingEntry) {
+ after = existingEntry;
+ before = existingEntry.before;
+ before.after = this;
+ after.before = this;
+ }
+
+```
+
+## get 方法
+
+LinkedHashMap 的 `get()` 方法也重写了:
+
+```java
+ public V get(Object key) {
+ Entry e = (Entry)getEntry(key);
+ if (e == null)
+ return null;
+
+ //多了一个判断是否是按照访问顺序排序,是则将当前的 Entry 移动到链表头部。
+ e.recordAccess(this);
+ return e.value;
+ }
+
+ void recordAccess(HashMap m) {
+ LinkedHashMap lm = (LinkedHashMap)m;
+ if (lm.accessOrder) {
+ lm.modCount++;
+
+ //删除
+ remove();
+ //添加到头部
+ addBefore(lm.header);
+ }
+ }
+
+
+```
+
+`clear()` 清空就要比较简单了:
+
+```java
+ //只需要把指针都指向自己即可,原本那些 Entry 没有引用之后就会被 JVM 自动回收。
+ public void clear() {
+ super.clear();
+ header.before = header.after = header;
+ }
+```
+
+
+## 总结
+
+总的来说 `LinkedHashMap` 其实就是对 `HashMap` 进行了拓展,使用了双向链表来保证了顺序性。
+
+因为是继承与 `HashMap` 的,所以一些 `HashMap` 存在的问题 `LinkedHashMap` 也会存在,比如不支持并发等。
+
+
diff --git a/docs/collections/LinkedList.md b/docs/collections/LinkedList.md
new file mode 100644
index 00000000..041f3221
--- /dev/null
+++ b/docs/collections/LinkedList.md
@@ -0,0 +1,67 @@
+# LinkedList 底层分析
+
+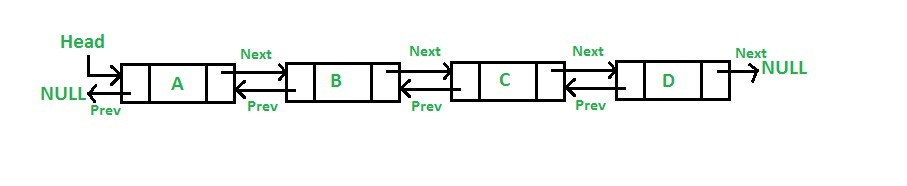
+
+如图所示 `LinkedList` 底层是基于双向链表实现的,也是实现了 `List` 接口,所以也拥有 List 的一些特点(JDK1.7/8 之后取消了循环,修改为双向链表)。
+
+## 新增方法
+
+```java
+ public boolean add(E e) {
+ linkLast(e);
+ return true;
+ }
+ /**
+ * Links e as last element.
+ */
+ void linkLast(E e) {
+ final Node l = last;
+ final Node newNode = new Node<>(l, e, null);
+ last = newNode;
+ if (l == null)
+ first = newNode;
+ else
+ l.next = newNode;
+ size++;
+ modCount++;
+ }
+```
+
+可见每次插入都是移动指针,和 ArrayList 的拷贝数组来说效率要高上不少。
+
+## 查询方法
+
+```java
+ public E get(int index) {
+ checkElementIndex(index);
+ return node(index).item;
+ }
+
+ Node node(int index) {
+ // assert isElementIndex(index);
+
+ if (index < (size >> 1)) {
+ Node x = first;
+ for (int i = 0; i < index; i++)
+ x = x.next;
+ return x;
+ } else {
+ Node x = last;
+ for (int i = size - 1; i > index; i--)
+ x = x.prev;
+ return x;
+ }
+ }
+```
+
+上述代码,利用了双向链表的特性,如果`index`离链表头比较近,就从节点头部遍历。否则就从节点尾部开始遍历。使用空间(双向链表)来换取时间。
+
+- `node()`会以`O(n/2)`的性能去获取一个结点
+ - 如果索引值大于链表大小的一半,那么将从尾结点开始遍历
+
+这样的效率是非常低的,特别是当 index 越接近 size 的中间值时。
+
+总结:
+
+- LinkedList 插入,删除都是移动指针效率很高。
+- 查找需要进行遍历查询,效率较低。
diff --git a/docs/contactme.md b/docs/contactme.md
new file mode 100644
index 00000000..6908d045
--- /dev/null
+++ b/docs/contactme.md
@@ -0,0 +1,33 @@
+# SHOW TIME
+
+> 请科学上网
+
+---
+
+
+
+
+---
+
+
+---
+
+
+
+---
+
+
+
+
+----------
+# CONTACT
+> - [微博](http://weibo.com/crossoverJie "微博")
+> - [GitHub](https://github.com/crossoverJie "github")
+> - [crossoverJie@gmail.com](mailto:crossoverjie@gmail.com)
+
+[](https://jq.qq.com/?_wv=1027&k=5HPYvQk)
+
+**欢迎我的关注公众号一起交流:**
+
+
+
diff --git a/docs/db/DB-split.md b/docs/db/DB-split.md
new file mode 100644
index 00000000..51fccdde
--- /dev/null
+++ b/docs/db/DB-split.md
@@ -0,0 +1,35 @@
+# 数据库水平垂直拆分
+
+当数据库量非常大的时候,DB 已经成为系统瓶颈时就可以考虑进行水平垂直拆分了。
+
+## 水平拆分
+
+一般水平拆分是根据表中的某一字段(通常是主键 ID )取模处理,将一张表的数据拆分到多个表中。这样每张表的表结构是相同的但是数据不同。
+
+不但可以通过 ID 取模分表还可以通过时间分表,比如每月生成一张表。
+按照范围分表也是可行的:一张表只存储 `0~1000W`的数据,超过只就进行分表,这样分表的优点是扩展灵活,但是存在热点数据。
+
+按照取模分表拆分之后我们的查询、修改、删除也都是取模。比如新增一条数据的时候往往需要一张临时表来生成 ID,然后根据生成的 ID 取模计算出需要写入的是哪张表(也可以使用[分布式 ID 生成器](distributed/ID-generator.md)来生成 ID)。
+
+分表之后不能避免的就是查询要比以前复杂,通常不建议 `join` ,一般的做法是做两次查询。
+
+## 垂直拆分
+
+当一张表的字段过多时则可以考虑垂直拆分。
+通常是将一张表的字段才分为主表以及扩展表,使用频次较高的字段在一张表,其余的在一张表。
+
+这里的多表查询也不建议使用 `join` ,依然建议使用两次查询。
+
+## 拆分之后带来的问题
+
+拆分之后由一张表变为了多张表,一个库变为了多个库。最突出的一个问题就是事务如何保证。
+
+### 两段提交
+
+### 最终一致性
+
+如果业务对强一致性要求不是那么高那么最终一致性则是一种比较好的方案。
+
+通常的做法就是补偿,比如 一个业务是 A 调用 B,两个执行成功才算最终成功,当 A 成功之后,B 执行失败如何来通知 A 呢。
+
+比较常见的做法是 失败时 B 通过 MQ 将消息告诉 A,A 再来进行回滚。这种的前提是 A 的回滚操作得是幂等的,不然 B 重复发消息就会出现问题。
\ No newline at end of file
diff --git a/docs/db/MySQL-Index.md b/docs/db/MySQL-Index.md
new file mode 100644
index 00000000..c41f5bff
--- /dev/null
+++ b/docs/db/MySQL-Index.md
@@ -0,0 +1,26 @@
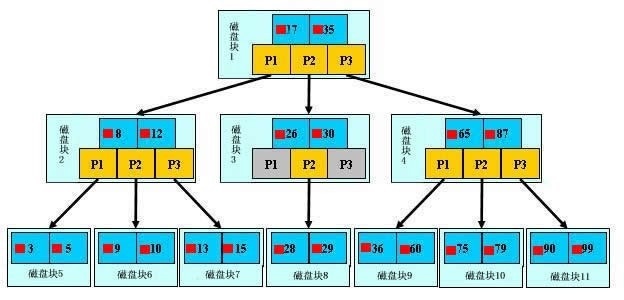
+# MySQL 索引原理
+
+现在互联网应用中对数据库的使用多数都是读较多,比例可以达到 `10:1`。并且数据库在做查询时 `IO` 消耗较大,所以如果能把一次查询的 `IO` 次数控制在常量级那对数据库的性能提升将是非常明显的,因此基于 `B+ Tree` 的索引结构出现了。
+
+
+## B+ Tree 的数据结构
+
+
+
+如图所示是 `B+ Tree` 的数据结构。是由一个一个的磁盘块组成的树形结构,每个磁盘块由数据项和指针组成。
+
+> 所有的数据都是存放在叶子节点,非叶子节点不存放数据。
+
+## 查找过程
+
+以磁盘块1为例,指针 P1 表示小于17的磁盘块,P2 表示在 `17~35` 之间的磁盘块,P3 则表示大于35的磁盘块。
+
+比如要查找数据项99,首先将磁盘块1 load 到内存中,发生 1 次 `IO`。接着通过二分查找发现 99 大于 35,所以找到了 P3 指针。通过P3 指针发生第二次 IO 将磁盘块4加载到内存。再通过二分查找发现大于87,通过 P3 指针发生了第三次 IO 将磁盘块11 加载到内存。最后再通过一次二分查找找到了数据项99。
+
+由此可见,如果一个几百万的数据查询只需要进行三次 IO 即可找到数据,那么整个效率将是非常高的。
+
+观察树的结构,发现查询需要经历几次 IO 是由树的高度来决定的,而树的高度又由磁盘块,数据项的大小决定的。
+
+磁盘块越大,数据项越小那么树的高度就越低。这也就是为什么索引字段要尽可能小的原因。
+
+> 索引使用的一些[原则](db/SQL-optimization.md)。
diff --git a/docs/db/SQL-optimization.md b/docs/db/SQL-optimization.md
new file mode 100644
index 00000000..73e6b456
--- /dev/null
+++ b/docs/db/SQL-optimization.md
@@ -0,0 +1,86 @@
+# SQL 优化
+
+## 负向查询不能使用索引
+
+```sql
+select name from user where id not in (1,3,4);
+```
+应该修改为:
+
+```
+select name from user where id in (2,5,6);
+```
+
+## 前导模糊查询不能使用索引
+如:
+
+```sql
+select name from user where name like '%zhangsan'
+```
+
+非前导则可以:
+```sql
+select name from user where name like 'zhangsan%'
+```
+建议可以考虑使用 `Lucene` 等全文索引工具来代替频繁的模糊查询。
+
+## 数据区分不明显的不建议创建索引
+
+如 user 表中的性别字段,可以明显区分的才建议创建索引,如身份证等字段。
+
+## 字段的默认值不要为 null
+这样会带来和预期不一致的查询结果。
+
+## 在字段上进行计算不能命中索引
+
+```sql
+select name from user where FROM_UNIXTIME(create_time) < CURDATE();
+```
+
+应该修改为:
+
+```sql
+select name from user where create_time < FROM_UNIXTIME(CURDATE());
+```
+
+## 最左前缀问题
+
+如果给 user 表中的 username pwd 字段创建了复合索引那么使用以下SQL 都是可以命中索引:
+
+```sql
+select username from user where username='zhangsan' and pwd ='axsedf1sd'
+
+select username from user where pwd ='axsedf1sd' and username='zhangsan'
+
+select username from user where username='zhangsan'
+```
+
+但是使用
+
+```sql
+select username from user where pwd ='axsedf1sd'
+```
+是不能命中索引的。
+
+## 如果明确知道只有一条记录返回
+
+```sql
+select name from user where username='zhangsan' limit 1
+```
+可以提高效率,可以让数据库停止游标移动。
+
+## 不要让数据库帮我们做强制类型转换
+
+```sql
+select name from user where telno=18722222222
+```
+这样虽然可以查出数据,但是会导致全表扫描。
+
+需要修改为
+```sql
+select name from user where telno='18722222222'
+```
+
+## 如果需要进行 join 的字段两表的字段类型要相同
+
+不然也不会命中索引。
\ No newline at end of file
diff --git a/docs/db/sharding-db.md b/docs/db/sharding-db.md
new file mode 100644
index 00000000..82a8068a
--- /dev/null
+++ b/docs/db/sharding-db.md
@@ -0,0 +1,193 @@
+
+
+# 前言
+
+之前不少人问我“能否分享一些分库分表相关的实践”,其实不是我不分享,而是真的经验不多🤣;和大部分人一样都是停留在理论阶段。
+
+
+不过这次多少有些可以说道了。
+
+先谈谈背景,我们生产数据库随着业务发展量也逐渐起来;好几张单表已经突破**亿级**数据,并且保持每天 200+W 的数据量增加。
+
+而我们有些业务需要进行关联查询、或者是报表统计;在这样的背景下大表的问题更加突出(比如一个查询功能需要跑好几分钟)。
+
+
+
+> 可能很多人会说:为啥单表都过亿了才想方案解决?其实不是不想,而是由于历史原因加上错误预估了数据增长才导致这个局面。总之原因比较复杂,也不是本次讨论的重点。
+
+
+# 临时方案
+
+由于需求紧、人手缺的情况下,整个处理的过程分为几个阶段。
+
+第一阶段应该是去年底,当时运维反应 `MySQL` 所在的主机内存占用很高,整体负载也居高不下,导致整个 MySQL 的吞吐量明显降低(写入、查询数据都明显减慢)。
+
+为此我们找出了数据量最大的几张表,发现大部分数据量在7/8000W 左右,少数的已经突破一亿。
+
+通过业务层面进行分析发现,这些数据多数都是用户产生的一些**日志型数据**,而且这些数据在业务上并不是强相关的,甚至两三个月前的数据其实已经不需要实时查询了。
+
+
+因为接近年底,尽可能的不想去动应用,考虑是否可以在运维层面缓解压力;主要的目的就是把单表的数据量降低。
+
+
+原本是想把两个月之前的数据直接迁移出来放到备份表中,但在准备实施的过程中发现一个大坑。
+
+> 表中没有一个可以排序的索引,导致我们无法快速的筛选出一部分数据!这真是一个深坑,为后面的一些优化埋了个地雷;即便是加索引也需要花几个小时(具体多久没敢在生产测试)。
+
+
+如果我们强行按照时间进行筛选,可能查询出 4000W 的数据就得花上好几个小时;这显然是行不通的。
+
+
+于是我们便想到了一个大胆的想法:这部分数据是否可以直接不要了?
+
+这可能是最有效及最快的方式了,和产品沟通后得知这部分数据真的只是日志型的数据,即便是报表出不来今后补上也是可以的。
+
+于是我们就简单粗暴的做了以下事情:
+
+- 修改原有表的表名,比如加上(`_190416bak`)。
+- 再新建一张和原有表名称相同的表。
+
+
+这样新的数据就写到了新表,同时业务上也是使用的这个数据量较小的新表。
+
+虽说过程不太优雅,但至少是解决了问题同时也给我们做技术改造预留了时间。
+
+# 分表方案
+
+之前的方案虽说可以缓解压力,但不能根本解决问题。
+
+有些业务必须得查询之前的数据,导致之前那招行不通了,所以正好我们就借助这个机会把表分了。
+
+
+我相信大部分人虽说没有做过实际做过分表,但也见过猪跑;网上一搜各种方案层出不穷。
+
+我认为最重要的一点是要结合实际业务找出需要 sharding 的字段,同时还有上线阶段的数据迁移也非常重要。
+
+## 时间
+
+可能大家都会说用 hash 的方式分配得最均匀,但我认为这还是需要使用历史数据的场景才用哈希分表。
+
+
+而对于不需要历史数据的场景,比如业务上只查询近三个月的数据。
+
+这类需求完成可以采取时间分表,按照月份进行划分,这样改动简单,同时对历史数据也比较好迁移。
+
+于是我们首先将这类需求的表筛选出来,按照月份进行拆分,只是在查询的时候拼接好表名即可;也比较好理解。
+
+## 哈希
+
+刚才也提到了:需要根据业务需求进行分表策略。
+
+而一旦所有的数据都有可能查询时,按照时间分表也就行不通了。(也能做,只是如果不是按照时间进行查询时需要遍历所有的表)
+
+因此我们计划采用 `hash` 的方式分表,这算是业界比较主流的方式就不再赘述。
+
+采用哈希时需要将 `sharding` 字段选好,由于我们的业务比较单纯;是一个物联网应用,所有的数据都包含有物联网设备的唯一标识(IMEI),并且这个字段天然的就保持了唯一性;大多数的业务也都是根据这个字段来的,所以它非常适合来做这个 `sharding` 字段。
+
+在做分表之前也调研过 `MyCAT` 及 `sharding-jdbc`(现已升级为 `shardingsphere`),最终考虑到对开发的友好性及不增加运维复杂度还是决定在 jdbc 层 sharding 的方式。
+
+但由于历史原因我们并不太好集成 `sharding-jdbc`,但基于 `sharding` 的特点自己实现了一个分表策略。
+
+这个简单也好理解:
+
+```java
+int index = hash(sharding字段) % 分表数量 ;
+
+select xx from 'busy_'+index where sharding字段 = xxx;
+```
+
+其实就是算出了表名,然后路由过去查询即可。
+
+
+只是我们实现的非常简单:修改了所有的底层查询方法,每个方法都里都做了这样的一个判断。
+
+并没有像 `sharding-jdbc` 一样,代理了数据库的查询方法;其中还要做 `SQL解析-->SQL路由-->执行SQL-->合并结果` 这一系列的流程。
+
+如果自己再做一遍无异于重新造了一个轮子,并且并不专业,只是在现有的技术条件下选择了一个快速实现达成效果的方法。
+
+不过这个过程中我们节省了将 sharding 字段哈希的过程,因为每一个 IMEI 号其实都是一个唯一的整型,直接用它做 mod 运算即可。
+
+
+
+还有一个是需要一个统一的组件生成规则,分表后不能再依赖于单表的字段自增了;方法还是挺多的:
+
+- 比如时间戳+随机数可满足大部分业务。
+- UUID,生成简单,但没法做排序。
+- 雪花算法统一生成主键ID。
+
+大家可以根据自己的实际情况做选择。
+
+# 业务调整
+
+因为我们并没有使用第三方的 sharding-jdbc 组件,所有没有办法做到对代码的低侵入性;每个涉及到分表的业务代码都需要做底层方法的改造(也就是路由到正确的表)。
+
+考虑到后续业务的发展,我们决定将拆分的表分为 64 张;加上后续引入大数据平台足以应对几年的数据增长。
+
+> 这里还有个小细节需要注意:分表的数量需要为 2∧N 次方,因为在取模的这种分表方式下,即便是今后再需要分表影响的数据也会尽量的小。
+
+
+再修改时只能将表名称进行全局搜索,然后加以修改,同时根据修改的方法倒推到表现的业务并记录下来,方便后续回归测试。
+
+---
+
+当然无法避免查询时利用非 sharding 字段导致的全表扫描,这是所有分片后都会遇到的问题。
+
+因此我们在修改分表方法的底层查询时同时也会查看是否有走分片字段,如果不是,那是否可以调整业务。
+
+比如对于一个上亿的数据是否还有必要存在按照分页查询、日期查询?这样的业务是否真的具有意义?
+
+我们尽可能的引导产品按照这样的方式来设计产品或者做出调整。
+
+但对于报表这类的需求确实也没办法,比如统计表中某种类型的数据;这种我们也可以利用多线程的方式去并行查询然后汇总统计来提高查询效率。
+
+
+有时也有一些另类场景:
+
+> 比如一个千万表中有某一特殊类型的数据只占了很小一部分,比如说几千上万条。
+
+
+这时页面上需要对它进行分页查询是比较正常的(比如某种投诉消息,客户需要一条一条的单独处理),但如果我们按照 IMEI 号或者是主键进行分片后再分页查询那就比较蛋疼了。
+
+所以这类型的数据建议单独新建一张表来维护,不要和其他数据混合在一起,这样不管是做分页还是 like 都比较简单和独立。
+
+## 验证
+
+代码改完,开发也单测完成后怎么来验证分表的业务是否正常也比较麻烦。
+
+一个是测试麻烦,再一个是万一哪里改漏了还是查询的原表,但这样在测试环境并不会有异常,一旦上线产生了生产数据到新的 64 张表后想要再修复就比较麻烦了。
+
+所以我们取了个巧,直接将原表的表名修改,比如加一个后缀;这样在测试过程中观察前后台有无报错就比较容易提前发现这个问题。
+
+# 上线流程
+
+测试验收通过后只是分表这个需求的80%,剩下如何上线也是比较头疼。
+
+一旦应用上线后所有的查询、写入、删除都会先走路由然后到达新表;而老数据在原表里是不会发生改变的。
+
+## 数据迁移
+
+所以我们上线前的第一步自然是需要将原有的数据进行迁移,迁移的目的是要分片到新的 64 张表中,这样才会对原有的业务无影响。
+
+
+因此我们需要额外准备一个程序,它需要将老表里的数据按照分片规则复制到新表中;
+
+在我们这个场景下,生产数据有些已经上亿了,这个迁移过程我们在测试环境模拟发现耗时是非常久的。而且我们老表中对于 `create_time` 这样用于筛选数据的字段没有索引(以前的技术债),所以查询起来就更加慢了。
+
+最后没办法,我们只能和产品协商告知用户对于之前产生的数据短期可能会查询不到,这个时间最坏可能会持续几天(我们只能在凌晨迁移,白天会影响到数据库负载)。
+
+
+# 总结
+
+这便是我们这次的分表实践,虽说不少过程都不优雅,但受限于条件也只能折中处理。
+
+但我们后续的计划是,修改我们底层的数据连接(目前是自己封装的一个 jar 包,导致集成 sharding-jdbc 比较麻烦)最终逐渐迁移到 `sharding-jdbc` .
+
+最后得出了几个结论:
+
+- 一个好的产品规划非常有必要,可以在合理的时间对数据处理(不管是分表还是切入归档)。
+- 每张表都需要一个可以用于排序查询的字段(自增ID、创建时间),整个过程由于没有这个字段导致耽搁了很长时间。
+- 分表字段需要谨慎,要全盘的考虑业务情况,尽量避免出现查询扫表的情况。
+
+最后欢迎留言讨论。
+
+**你的点赞与分享是对我最大的支持**
diff --git a/docs/distributed/Cache-design.md b/docs/distributed/Cache-design.md
new file mode 100644
index 00000000..fc26b7a6
--- /dev/null
+++ b/docs/distributed/Cache-design.md
@@ -0,0 +1,45 @@
+# 分布式缓存设计
+
+目前常见的缓存方案都是分层缓存,通常可以分为以下几层:
+
+- `NG` 本地缓存,命中的话直接返回。
+- `NG` 没有命中时则需要查询分布式缓存,如 `Redis` 。
+- 如果分布式缓存没有命中则需要回源到 `Tomcat` 在本地堆进行查询,命中之后异步写回 `Redis` 。
+- 以上都没有命中那就只有从 `DB` 或者是数据源进行查询,并写回到 Redis 中。
+
+
+## 缓存更新的原子性
+
+在写回 Redis 的时候如果是 `Tomcat` 集群,多个进程同时写那很有可能出现脏数据,这时就会出现更新原子性的问题。
+
+可以有以下解决方案:
+- 可以将多个 Tomcat 中的数据写入到 MQ 队列中,由消费者进行单线程更新缓存。
+- 利用[分布式锁](https://github.com/crossoverJie/Java-Interview/blob/master/MD/Java-lock.md#%E5%9F%BA%E4%BA%8E%E6%95%B0%E6%8D%AE%E5%BA%93),只有获取到锁进程才能写数据。
+
+## 如何写缓存
+
+写缓存时也要注意,通常来说分为以下几步:
+
+- 开启事务。
+- 写入 DB 。
+- 提交事务。
+- 写入缓存。
+
+这里可能会存在数据库写入成功但是缓存写入失败的情况,但是也不建议将写入缓存加入到事务中。
+因为写缓存的时候可能会因为网络原因耗时较长,这样会阻塞数据库事务。
+如果对一致性要求不高并且数据量也不大的情况下,可以单独起一个服务来做 DB 和缓存之间的数据同步操作。
+
+更新缓存时也建议做增量更新。
+
+## 负载策略
+
+缓存负载策略一般有以下两种:
+- 轮询机制。
+- 一致哈希算法。
+
+轮询的优点是负载到各个服务器的请求是均匀的,但是如果进行扩容则缓存命中率会下降。
+
+一致哈希的优点是相同的请求会负载到同一台服务器上,命中率不会随着扩容而降低,但是当大流量过来时有可能把服务器拖垮。
+
+所以建议两种方案都采用:
+首先采用一致哈希算法,当流量达到一定的阈值的时候则切换为轮询,这样既能保证缓存命中率,也能提高系统的可用性。
\ No newline at end of file
diff --git a/docs/distributed/Distributed-Limit.md b/docs/distributed/Distributed-Limit.md
new file mode 100644
index 00000000..c69a06fb
--- /dev/null
+++ b/docs/distributed/Distributed-Limit.md
@@ -0,0 +1,483 @@
+
+
+## 前言
+
+本文接着上文[应用限流](http://crossoverjie.top/2017/08/11/sbc4/)进行讨论。
+
+之前谈到的限流方案只能针对于单个 JVM 有效,也就是单机应用。而对于现在普遍的分布式应用也得有一个分布式限流的方案。
+
+基于此尝试写了这个组件:
+
+[https://github.com/crossoverJie/distributed-redis-tool](https://github.com/crossoverJie/distributed-redis-tool)
+
+
+## DEMO
+
+以下采用的是
+
+[https://github.com/crossoverJie/springboot-cloud](https://github.com/crossoverJie/springboot-cloud)
+
+来做演示。
+
+在 Order 应用提供的接口中采取了限流。首先是配置了限流工具的 Bean:
+
+```java
+@Configuration
+public class RedisLimitConfig {
+
+
+ @Value("${redis.limit}")
+ private int limit;
+
+
+ @Autowired
+ private JedisConnectionFactory jedisConnectionFactory;
+
+ @Bean
+ public RedisLimit build() {
+ RedisClusterConnection clusterConnection = jedisConnectionFactory.getClusterConnection();
+ JedisCluster jedisCluster = (JedisCluster) clusterConnection.getNativeConnection();
+ RedisLimit redisLimit = new RedisLimit.Builder<>(jedisCluster)
+ .limit(limit)
+ .build();
+
+ return redisLimit;
+ }
+}
+```
+
+接着在 Controller 使用组件:
+
+```java
+ @Autowired
+ private RedisLimit redisLimit ;
+
+ @Override
+ @CheckReqNo
+ public BaseResponse getOrderNo(@RequestBody OrderNoReqVO orderNoReq) {
+ BaseResponse res = new BaseResponse();
+
+ //限流
+ boolean limit = redisLimit.limit();
+ if (!limit){
+ res.setCode(StatusEnum.REQUEST_LIMIT.getCode());
+ res.setMessage(StatusEnum.REQUEST_LIMIT.getMessage());
+ return res ;
+ }
+
+ res.setReqNo(orderNoReq.getReqNo());
+ if (null == orderNoReq.getAppId()){
+ throw new SBCException(StatusEnum.FAIL);
+ }
+ OrderNoResVO orderNoRes = new OrderNoResVO() ;
+ orderNoRes.setOrderId(DateUtil.getLongTime());
+ res.setCode(StatusEnum.SUCCESS.getCode());
+ res.setMessage(StatusEnum.SUCCESS.getMessage());
+ res.setDataBody(orderNoRes);
+ return res ;
+ }
+
+```
+
+为了方便使用,也提供了注解:
+
+```java
+ @Override
+ @ControllerLimit
+ public BaseResponse getOrderNoLimit(@RequestBody OrderNoReqVO orderNoReq) {
+ BaseResponse res = new BaseResponse();
+ // 业务逻辑
+ return res ;
+ }
+```
+该注解拦截了 http 请求,会再请求达到阈值时直接返回。
+
+普通方法也可使用:
+
+```java
+@CommonLimit
+public void doSomething(){}
+```
+
+会在调用达到阈值时抛出异常。
+
+为了模拟并发,在 [User](https://github.com/crossoverJie/springboot-cloud/blob/master/sbc-user/user/src/main/java/com/crossoverJie/sbcuser/controller/UserController.java#L72-L91) 应用中开启了 10 个线程调用 Order(**限流次数为5**) 接口(也可使用专业的并发测试工具 JMeter 等)。
+
+
+
+```java
+ @Override
+ public BaseResponse getUserByFeign(@RequestBody UserReqVO userReq) {
+ //调用远程服务
+ OrderNoReqVO vo = new OrderNoReqVO();
+ vo.setAppId(1L);
+ vo.setReqNo(userReq.getReqNo());
+
+ for (int i = 0; i < 10; i++) {
+ executorService.execute(new Worker(vo, orderServiceClient));
+ }
+
+ UserRes userRes = new UserRes();
+ userRes.setUserId(123);
+ userRes.setUserName("张三");
+
+ userRes.setReqNo(userReq.getReqNo());
+ userRes.setCode(StatusEnum.SUCCESS.getCode());
+ userRes.setMessage("成功");
+
+ return userRes;
+ }
+
+
+ private static class Worker implements Runnable {
+
+ private OrderNoReqVO vo;
+ private OrderServiceClient orderServiceClient;
+
+ public Worker(OrderNoReqVO vo, OrderServiceClient orderServiceClient) {
+ this.vo = vo;
+ this.orderServiceClient = orderServiceClient;
+ }
+
+ @Override
+ public void run() {
+
+ BaseResponse orderNo = orderServiceClient.getOrderNoCommonLimit(vo);
+ logger.info("远程返回:" + JSON.toJSONString(orderNo));
+
+ }
+ }
+```
+
+> 为了验证分布式效果启动了两个 Order 应用。
+
+
+
+效果如下:
+
+
+
+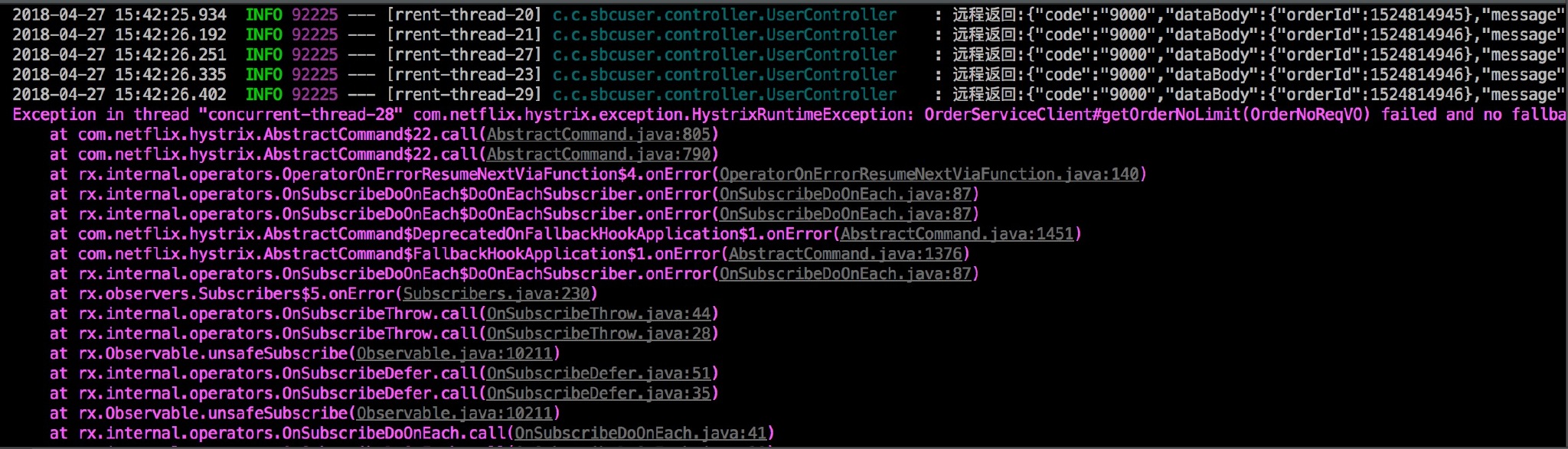
+
+
+
+
+## 实现原理
+实现原理其实很简单。既然要达到分布式全局限流的效果,那自然需要一个第三方组件来记录请求的次数。
+
+其中 Redis 就非常适合这样的场景。
+
+- 每次请求时将当前时间(精确到秒)作为 Key 写入到 Redis 中,超时时间设置为 2 秒,Redis 将该 Key 的值进行自增。
+- 当达到阈值时返回错误。
+- 写入 Redis 的操作用 Lua 脚本来完成,利用 Redis 的单线程机制可以保证每个 Redis 请求的原子性。
+
+Lua 脚本如下:
+
+```lua
+--lua 下标从 1 开始
+-- 限流 key
+local key = KEYS[1]
+-- 限流大小
+local limit = tonumber(ARGV[1])
+
+-- 获取当前流量大小
+local curentLimit = tonumber(redis.call('get', key) or "0")
+
+if curentLimit + 1 > limit then
+ -- 达到限流大小 返回
+ return 0;
+else
+ -- 没有达到阈值 value + 1
+ redis.call("INCRBY", key, 1)
+ redis.call("EXPIRE", key, 2)
+ return curentLimit + 1
+end
+```
+
+Java 中的调用逻辑:
+
+```java
+ public boolean limit() {
+ String key = String.valueOf(System.currentTimeMillis() / 1000);
+ Object result = null;
+ if (jedis instanceof Jedis) {
+ result = ((Jedis) this.jedis).eval(script, Collections.singletonList(key), Collections.singletonList(String.valueOf(limit)));
+ } else if (jedis instanceof JedisCluster) {
+ result = ((JedisCluster) this.jedis).eval(script, Collections.singletonList(key), Collections.singletonList(String.valueOf(limit)));
+ } else {
+ //throw new RuntimeException("instance is error") ;
+ return false;
+ }
+
+ if (FAIL_CODE != (Long) result) {
+ return true;
+ } else {
+ return false;
+ }
+ }
+```
+
+所以只需要在需要限流的地方调用该方法对返回值进行判断即可达到限流的目的。
+
+当然这只是利用 Redis 做了一个粗暴的计数器,如果想实现类似于上文中的令牌桶算法可以基于 Lua 自行实现。
+
+
+### Builder 构建器
+
+在设计这个组件时想尽量的提供给使用者清晰、可读性、不易出错的 API。
+
+> 比如第一步,如何构建一个限流对象。
+
+最常用的方式自然就是构造函数,如果有多个域则可以采用重叠构造器的方式:
+
+```java
+public A(){}
+public A(int a){}
+public A(int a,int b){}
+```
+
+缺点也是显而易见的:如果参数过多会导致难以阅读,甚至如果参数类型一致的情况下客户端颠倒了顺序,但不会引起警告从而出现难以预测的结果。
+
+第二种方案可以采用 JavaBean 模式,利用 `setter` 方法进行构建:
+
+```java
+A a = new A();
+a.setA(a);
+a.setB(b);
+```
+
+这种方式清晰易读,但却容易让对象处于不一致的状态,使对象处于线程不安全的状态。
+
+所以这里采用了第三种创建对象的方式,构建器:
+
+```java
+public class RedisLimit {
+
+ private JedisCommands jedis;
+ private int limit = 200;
+
+ private static final int FAIL_CODE = 0;
+
+ /**
+ * lua script
+ */
+ private String script;
+
+ private RedisLimit(Builder builder) {
+ this.limit = builder.limit ;
+ this.jedis = builder.jedis ;
+ buildScript();
+ }
+
+
+ /**
+ * limit traffic
+ * @return if true
+ */
+ public boolean limit() {
+ String key = String.valueOf(System.currentTimeMillis() / 1000);
+ Object result = null;
+ if (jedis instanceof Jedis) {
+ result = ((Jedis) this.jedis).eval(script, Collections.singletonList(key), Collections.singletonList(String.valueOf(limit)));
+ } else if (jedis instanceof JedisCluster) {
+ result = ((JedisCluster) this.jedis).eval(script, Collections.singletonList(key), Collections.singletonList(String.valueOf(limit)));
+ } else {
+ //throw new RuntimeException("instance is error") ;
+ return false;
+ }
+
+ if (FAIL_CODE != (Long) result) {
+ return true;
+ } else {
+ return false;
+ }
+ }
+
+
+ /**
+ * read lua script
+ */
+ private void buildScript() {
+ script = ScriptUtil.getScript("limit.lua");
+ }
+
+
+ /**
+ * the builder
+ * @param
+ */
+ public static class Builder{
+ private T jedis = null ;
+
+ private int limit = 200;
+
+
+ public Builder(T jedis){
+ this.jedis = jedis ;
+ }
+
+ public Builder limit(int limit){
+ this.limit = limit ;
+ return this;
+ }
+
+ public RedisLimit build(){
+ return new RedisLimit(this) ;
+ }
+
+ }
+}
+```
+
+这样客户端在使用时:
+
+```java
+RedisLimit redisLimit = new RedisLimit.Builder<>(jedisCluster)
+ .limit(limit)
+ .build();
+```
+
+更加的简单直接,并且避免了将创建过程分成了多个子步骤。
+
+这在有多个构造参数,但又不是必选字段时很有作用。
+
+因此顺便将分布式锁的构建器方式也一并更新了:
+
+[https://github.com/crossoverJie/distributed-redis-tool#features](https://github.com/crossoverJie/distributed-redis-tool#features)
+
+> 更多内容可以参考 Effective Java
+
+### API
+
+从上文可以看出,使用过程就是调用 `limit` 方法。
+
+```java
+ //限流
+ boolean limit = redisLimit.limit();
+ if (!limit){
+ //具体限流逻辑
+ }
+```
+
+为了减少侵入性,也为了简化客户端提供了两种注解方式。
+
+#### @ControllerLimit
+
+该注解可以作用于 `@RequestMapping` 修饰的接口中,并会在限流后提供限流响应。
+
+实现如下:
+
+```java
+@Component
+public class WebIntercept extends WebMvcConfigurerAdapter {
+
+ private static Logger logger = LoggerFactory.getLogger(WebIntercept.class);
+
+
+ @Autowired
+ private RedisLimit redisLimit;
+
+ @Override
+ public void addInterceptors(InterceptorRegistry registry) {
+ registry.addInterceptor(new CustomInterceptor())
+ .addPathPatterns("/**");
+ }
+
+
+ private class CustomInterceptor extends HandlerInterceptorAdapter {
+ @Override
+ public boolean preHandle(HttpServletRequest request, HttpServletResponse response,
+ Object handler) throws Exception {
+
+
+ if (redisLimit == null) {
+ throw new NullPointerException("redisLimit is null");
+ }
+
+ if (handler instanceof HandlerMethod) {
+ HandlerMethod method = (HandlerMethod) handler;
+
+ ControllerLimit annotation = method.getMethodAnnotation(ControllerLimit.class);
+ if (annotation == null) {
+ //skip
+ return true;
+ }
+
+ boolean limit = redisLimit.limit();
+ if (!limit) {
+ logger.warn("request has bean limit");
+ response.sendError(500, "request limit");
+ return false;
+ }
+
+ }
+
+ return true;
+
+ }
+ }
+}
+```
+
+其实就是实现了 SpringMVC 中的拦截器,并在拦截过程中判断是否有使用注解,从而调用限流逻辑。
+
+**前提是应用需要扫描到该类,让 Spring 进行管理。**
+
+```java
+@ComponentScan(value = "com.crossoverjie.distributed.intercept")
+```
+
+#### @CommonLimit
+
+当然也可以在普通方法中使用。实现原理则是 Spring AOP (SpringMVC 的拦截器本质也是 AOP)。
+
+```java
+@Aspect
+@Component
+@EnableAspectJAutoProxy(proxyTargetClass = true)
+public class CommonAspect {
+
+ private static Logger logger = LoggerFactory.getLogger(CommonAspect.class);
+
+ @Autowired
+ private RedisLimit redisLimit ;
+
+ @Pointcut("@annotation(com.crossoverjie.distributed.annotation.CommonLimit)")
+ private void check(){}
+
+ @Before("check()")
+ public void before(JoinPoint joinPoint) throws Exception {
+
+ if (redisLimit == null) {
+ throw new NullPointerException("redisLimit is null");
+ }
+
+ boolean limit = redisLimit.limit();
+ if (!limit) {
+ logger.warn("request has bean limit");
+ throw new RuntimeException("request has bean limit") ;
+ }
+
+ }
+}
+```
+
+很简单,也是在拦截过程中调用限流。
+
+当然使用时也得扫描到该包:
+
+```java
+@ComponentScan(value = "com.crossoverjie.distributed.intercept")
+```
+
+### 总结
+
+**限流**在一个高并发大流量的系统中是保护应用的一个利器,成熟的方案也很多,希望对刚了解这一块的朋友提供一些思路。
+
+以上所有的源码:
+
+- [https://github.com/crossoverJie/distributed-redis-tool](https://github.com/crossoverJie/distributed-redis-tool)
+- [https://github.com/crossoverJie/springboot-cloud](https://github.com/crossoverJie/springboot-cloud)
+
+感兴趣的朋友可以点个 Star 或是提交 PR。
+
diff --git a/docs/distributed/ID-generator.md b/docs/distributed/ID-generator.md
new file mode 100644
index 00000000..04a71d93
--- /dev/null
+++ b/docs/distributed/ID-generator.md
@@ -0,0 +1,39 @@
+# 分布式 ID 生成器
+
+一个唯一 ID 在一个分布式系统中是非常重要的一个业务属性,其中包括一些如订单 ID,消息 ID ,会话 ID,他们都有一些共有的特性:
+
+- 全局唯一。
+- 趋势递增。
+
+全局唯一很好理解,目的就是唯一标识某个次请求,某个业务。
+
+通常有以下几种方案:
+
+## 基于数据库
+可以利用 `MySQL` 中的自增属性 `auto_increment` 来生成全局唯一 ID,也能保证趋势递增。
+但这种方式太依赖 DB,如果数据库挂了那就非常容易出问题。
+
+### 水平扩展改进
+但也有改进空间,可以将数据库水平拆分,如果拆为了两个库 A 库和 B 库。
+A 库的递增方式可以是 `0 ,2 ,4 ,6`。B 库则是 `1 ,3 ,5 ,7`。这样的方式可以提高系统可用性,并且 ID 也是趋势递增的。
+
+但也有如下一下问题:
+
+- 想要扩容增加性能变的困难,之前已经定义好了 A B 库递增的步数,新加的数据库不好加入进来,水平扩展困难。
+- 也是强依赖与数据库,并且如果其中一台挂掉了那就不是绝对递增了。
+
+## 本地 UUID 生成
+还可以采用 `UUID` 的方式生成唯一 ID,由于是在本地生成没有了网络之类的消耗,所有效率非常高。
+
+但也有以下几个问题:
+- 生成的 ID 是无序性的,不能做到趋势递增。
+- 由于是字符串并且不是递增,所以不太适合用作主键。
+
+## 采用本地时间
+这种做法非常简单,可以利用本地的毫秒数加上一些业务 ID 来生成唯一ID,这样可以做到趋势递增,并且是在本地生成效率也很高。
+
+但有一个致命的缺点:当并发量足够高的时候**唯一性**就不能保证了。
+
+## Twitter 雪花算法
+
+可以基于 `Twitter` 的 `Snowflake` 算法来实现。它主要是一种划分命名空间的算法,将生成的 ID 按照机器、时间等来进行标志。
\ No newline at end of file
diff --git a/docs/distributed/distributed-lock-redis.md b/docs/distributed/distributed-lock-redis.md
new file mode 100644
index 00000000..b57d052c
--- /dev/null
+++ b/docs/distributed/distributed-lock-redis.md
@@ -0,0 +1,287 @@
+
+
+## 前言
+分布式锁在分布式应用中应用广泛,想要搞懂一个新事物首先得了解它的由来,这样才能更加的理解甚至可以举一反三。
+
+首先谈到分布式锁自然也就联想到分布式应用。
+
+在我们将应用拆分为分布式应用之前的单机系统中,对一些并发场景读取公共资源时如扣库存,卖车票之类的需求可以简单的使用[同步](http://crossoverjie.top/2018/01/14/Synchronize/)或者是[加锁](http://crossoverjie.top/2018/01/25/ReentrantLock/)就可以实现。
+
+但是应用分布式了之后系统由以前的单进程多线程的程序变为了多进程多线程,这时使用以上的解决方案明显就不够了。
+
+
+因此业界常用的解决方案通常是借助于一个第三方组件并利用它自身的排他性来达到多进程的互斥。如:
+
+- 基于 DB 的唯一索引。
+- 基于 ZK 的临时有序节点。
+- 基于 Redis 的 `NX EX` 参数。
+
+这里主要基于 Redis 进行讨论。
+
+
+
+## 实现
+
+既然是选用了 Redis,那么它就得具有排他性才行。同时它最好也有锁的一些基本特性:
+
+- 高性能(加、解锁时高性能)
+- 可以使用阻塞锁与非阻塞锁。
+- 不能出现死锁。
+- 可用性(不能出现节点 down 掉后加锁失败)。
+
+这里利用 `Redis set key` 时的一个 NX 参数可以保证在这个 key 不存在的情况下写入成功。并且再加上 EX 参数可以让该 key 在超时之后自动删除。
+
+所以利用以上两个特性可以保证在同一时刻只会有一个进程获得锁,并且不会出现死锁(最坏的情况就是超时自动删除 key)。
+
+
+### 加锁
+
+实现代码如下:
+
+```java
+
+ private static final String SET_IF_NOT_EXIST = "NX";
+ private static final String SET_WITH_EXPIRE_TIME = "PX";
+
+ public boolean tryLock(String key, String request) {
+ String result = this.jedis.set(LOCK_PREFIX + key, request, SET_IF_NOT_EXIST, SET_WITH_EXPIRE_TIME, 10 * TIME);
+
+ if (LOCK_MSG.equals(result)){
+ return true ;
+ }else {
+ return false ;
+ }
+ }
+```
+
+注意这里使用的 jedis 的
+
+```java
+String set(String key, String value, String nxxx, String expx, long time);
+```
+
+api。
+
+该命令可以保证 NX EX 的原子性。
+
+一定不要把两个命令(NX EX)分开执行,如果在 NX 之后程序出现问题就有可能产生死锁。
+
+#### 阻塞锁
+同时也可以实现一个阻塞锁:
+
+```java
+ //一直阻塞
+ public void lock(String key, String request) throws InterruptedException {
+
+ for (;;){
+ String result = this.jedis.set(LOCK_PREFIX + key, request, SET_IF_NOT_EXIST, SET_WITH_EXPIRE_TIME, 10 * TIME);
+ if (LOCK_MSG.equals(result)){
+ break ;
+ }
+
+ //防止一直消耗 CPU
+ Thread.sleep(DEFAULT_SLEEP_TIME) ;
+ }
+
+ }
+
+ //自定义阻塞时间
+ public boolean lock(String key, String request,int blockTime) throws InterruptedException {
+
+ while (blockTime >= 0){
+
+ String result = this.jedis.set(LOCK_PREFIX + key, request, SET_IF_NOT_EXIST, SET_WITH_EXPIRE_TIME, 10 * TIME);
+ if (LOCK_MSG.equals(result)){
+ return true ;
+ }
+ blockTime -= DEFAULT_SLEEP_TIME ;
+
+ Thread.sleep(DEFAULT_SLEEP_TIME) ;
+ }
+ return false ;
+ }
+
+```
+
+### 解锁
+
+解锁也很简单,其实就是把这个 key 删掉就万事大吉了,比如使用 `del key` 命令。
+
+但现实往往没有那么 easy。
+
+如果进程 A 获取了锁设置了超时时间,但是由于执行周期较长导致到了超时时间之后锁就自动释放了。这时进程 B 获取了该锁执行很快就释放锁。这样就会出现进程 B 将进程 A 的锁释放了。
+
+所以最好的方式是在每次解锁时都需要判断锁**是否是自己**的。
+
+这时就需要结合加锁机制一起实现了。
+
+加锁时需要传递一个参数,将该参数作为这个 key 的 value,这样每次解锁时判断 value 是否相等即可。
+
+所以解锁代码就不能是简单的 `del`了。
+
+```java
+ public boolean unlock(String key,String request){
+ //lua script
+ String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
+
+ Object result = null ;
+ if (jedis instanceof Jedis){
+ result = ((Jedis)this.jedis).eval(script, Collections.singletonList(LOCK_PREFIX + key), Collections.singletonList(request));
+ }else if (jedis instanceof JedisCluster){
+ result = ((JedisCluster)this.jedis).eval(script, Collections.singletonList(LOCK_PREFIX + key), Collections.singletonList(request));
+ }else {
+ //throw new RuntimeException("instance is error") ;
+ return false ;
+ }
+
+ if (UNLOCK_MSG.equals(result)){
+ return true ;
+ }else {
+ return false ;
+ }
+ }
+```
+
+这里使用了一个 `lua` 脚本来判断 value 是否相等,相等才执行 del 命令。
+
+使用 `lua` 也可以保证这里两个操作的原子性。
+
+因此上文提到的四个基本特性也能满足了:
+
+- 使用 Redis 可以保证性能。
+- 阻塞锁与非阻塞锁见上文。
+- 利用超时机制解决了死锁。
+- Redis 支持集群部署提高了可用性。
+
+## 使用
+
+我自己有撸了一个完整的实现,并且已经用于了生产,有兴趣的朋友可以开箱使用:
+
+maven 依赖:
+
+```xml
+
+ top.crossoverjie.opensource
+ distributed-redis-lock
+ 1.0.0
+
+```
+
+配置 bean :
+
+```java
+@Configuration
+public class RedisLockConfig {
+
+ @Bean
+ public RedisLock build(){
+ RedisLock redisLock = new RedisLock() ;
+ HostAndPort hostAndPort = new HostAndPort("127.0.0.1",7000) ;
+ JedisCluster jedisCluster = new JedisCluster(hostAndPort) ;
+ // Jedis 或 JedisCluster 都可以
+ redisLock.setJedisCluster(jedisCluster) ;
+ return redisLock ;
+ }
+
+}
+
+```
+
+使用:
+
+```java
+ @Autowired
+ private RedisLock redisLock ;
+
+ public void use() {
+ String key = "key";
+ String request = UUID.randomUUID().toString();
+ try {
+ boolean locktest = redisLock.tryLock(key, request);
+ if (!locktest) {
+ System.out.println("locked error");
+ return;
+ }
+
+
+ //do something
+
+ } finally {
+ redisLock.unlock(key,request) ;
+ }
+
+ }
+
+```
+
+使用很简单。这里主要是想利用 Spring 来帮我们管理 RedisLock 这个单例的 bean,所以在释放锁的时候需要手动(因为整个上下文只有一个 RedisLock 实例)的传入 key 以及 request(api 看起来不是特别优雅)。
+
+也可以在每次使用锁的时候 new 一个 RedisLock 传入 key 以及 request,这样倒是在解锁时很方便。但是需要自行管理 RedisLock 的实例。各有优劣吧。
+
+项目源码在:
+
+[https://github.com/crossoverJie/distributed-redis-tool](https://github.com/crossoverJie/distributed-redis-tool)
+
+欢迎讨论。
+
+## 单测
+
+在做这个项目的时候让我不得不想提一下**单测**。
+
+因为这个应用是强依赖于第三方组件的(Redis),但是在单测中我们需要排除掉这种依赖。比如其他伙伴 fork 了该项目想在本地跑一遍单测,结果运行不起来:
+
+1. 有可能是 Redis 的 ip、端口和单测里的不一致。
+2. Redis 自身可能也有问题。
+3. 也有可能是该同学的环境中并没有 Redis。
+
+所以最好是要把这些外部不稳定的因素排除掉,单测只测我们写好的代码。
+
+于是就可以引入单测利器 `Mock` 了。
+
+它的想法很简答,就是要把你所依赖的外部资源统统屏蔽掉。如:数据库、外部接口、外部文件等等。
+
+使用方式也挺简单,可以参考该项目的单测:
+
+```java
+ @Test
+ public void tryLock() throws Exception {
+ String key = "test";
+ String request = UUID.randomUUID().toString();
+ Mockito.when(jedisCluster.set(Mockito.anyString(), Mockito.anyString(), Mockito.anyString(),
+ Mockito.anyString(), Mockito.anyLong())).thenReturn("OK");
+
+ boolean locktest = redisLock.tryLock(key, request);
+ System.out.println("locktest=" + locktest);
+
+ Assert.assertTrue(locktest);
+
+ //check
+ Mockito.verify(jedisCluster).set(Mockito.anyString(), Mockito.anyString(), Mockito.anyString(),
+ Mockito.anyString(), Mockito.anyLong());
+ }
+```
+
+这里只是简单演示下,可以的话下次仔细分析分析。
+
+它的原理其实也挺简单,debug 的话可以很直接的看出来:
+
+
+
+这里我们所依赖的 JedisCluster 其实是一个 `cglib 代理对象`。所以也不难想到它是如何工作的。
+
+比如这里我们需要用到 JedisCluster 的 set 函数并需要它的返回值。
+
+Mock 就将该对象代理了,并在实际执行 set 方法后给你返回了一个你自定义的值。
+
+这样我们就可以随心所欲的测试了,**完全把外部依赖所屏蔽了**。
+
+## 总结
+
+至此一个基于 Redis 的分布式锁完成,但是依然有些问题。
+
+- 如在 key 超时之后业务并没有执行完毕但却自动释放锁了,这样就会导致并发问题。
+- 就算 Redis 是集群部署的,如果每个节点都只是 master 没有 slave,那么 master 宕机时该节点上的所有 key 在那一时刻都相当于是释放锁了,这样也会出现并发问题。就算是有 slave 节点,但如果在数据同步到 salve 之前 master 宕机也是会出现上面的问题。
+
+感兴趣的朋友还可以参考 [Redisson](https://github.com/redisson/redisson) 的实现。
+
+
diff --git a/docs/frame/SpringAOP.md b/docs/frame/SpringAOP.md
new file mode 100644
index 00000000..3ebb7f58
--- /dev/null
+++ b/docs/frame/SpringAOP.md
@@ -0,0 +1,224 @@
+# Spring AOP 实现原理
+
+## 静态代理
+
+众所周知 Spring 的 `AOP` 是基于动态代理实现的,谈到动态代理就不得不提下静态代理。实现如下:
+
+假设有一接口 `InterfaceA`:
+
+```java
+public interface InterfaceA{
+ void exec();
+}
+```
+
+其中有实现类 `RealImplement`:
+```java
+public class RealImplement implement InterfaceA{
+ public void exec(){
+ System.out.println("real impl") ;
+ }
+}
+```
+
+这时也有一个代理类 `ProxyImplement` 也实现了 `InterfaceA`:
+```java
+public class ProxyImplement implement InterfaceA{
+ private InterfaceA interface ;
+
+ public ProxyImplement(){
+ interface = new RealImplement() ;
+ }
+
+ public void exec(){
+ System.out.println("dosomethings before);
+ //实际调用
+ interface.exec();
+
+ System.out.println("dosomethings after);
+ }
+
+}
+```
+使用如下:
+```
+public class Main(){
+ public static void main(String[] args){
+ InterfaceA interface = new ProxyImplement() ;
+ interface.exec();
+ }
+}
+```
+可以看出这样的代理方式调用者其实都不知道被代理对象的存在。
+
+## JDK 动态代理
+从静态代理中可以看出: 静态代理只能代理一个具体的类,如果要代理一个接口的多个实现的话需要定义不同的代理类。
+
+需要解决这个问题就可以用到 JDK 的动态代理。
+
+其中有两个非常核心的类:
+
+- `java.lang.reflect.Proxy`类。
+- `java.lang.reflect.InvocationHandle`接口。
+
+`Proxy` 类是用于创建代理对象,而 `InvocationHandler` 接口主要你是来处理执行逻辑。
+
+如下:
+```java
+public class CustomizeHandle implements InvocationHandler {
+ private final static Logger LOGGER = LoggerFactory.getLogger(CustomizeHandle.class);
+
+ private Object target;
+
+ public CustomizeHandle(Class clazz) {
+ try {
+ this.target = clazz.newInstance();
+ } catch (InstantiationException e) {
+ LOGGER.error("InstantiationException", e);
+ } catch (IllegalAccessException e) {
+ LOGGER.error("IllegalAccessException",e);
+ }
+ }
+
+ @Override
+ public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
+
+ before();
+ Object result = method.invoke(target, args);
+ after();
+
+ LOGGER.info("proxy class={}", proxy.getClass());
+ return result;
+ }
+
+
+ private void before() {
+ LOGGER.info("handle before");
+ }
+
+ private void after() {
+ LOGGER.info("handle after");
+ }
+}
+```
+
+其中构造方法传入被代理类的类类型。其实传代理类的实例或者是类类型并没有强制的规定,传类类型的是因为被代理对象应当有代理创建而不应该由调用方创建。
+
+使用方式如下:
+```java
+ @Test
+ public void test(){
+ CustomizeHandle handle = new CustomizeHandle(ISubjectImpl.class) ;
+ ISubject subject = (ISubject) Proxy.newProxyInstance(JDKProxyTest.class.getClassLoader(), new Class[]{ISubject.class}, handle);
+ subject.execute() ;
+ }
+```
+
+首先传入被代理类的类类型构建代理处理器。接着使用 `Proxy` 的`newProxyInstance` 方法动态创建代理类。第一个参数为类加载器,第二个参数为代理类需要实现的接口列表,最后一个则是处理器。
+
+其实代理类是由
+
+
+
+这个方法动态创建出来的。将 proxyClassFile 输出到文件并进行反编译的话就可以的到代理类。
+```java
+ @Test
+ public void clazzTest(){
+ byte[] proxyClassFile = ProxyGenerator.generateProxyClass(
+ "$Proxy1", new Class[]{ISubject.class}, 1);
+ try {
+ FileOutputStream out = new FileOutputStream("/Users/chenjie/Documents/$Proxy1.class") ;
+ out.write(proxyClassFile);
+ out.close();
+ } catch (FileNotFoundException e) {
+ e.printStackTrace();
+ } catch (IOException e) {
+ e.printStackTrace();
+ }
+ }
+```
+
+反编译后结果如下:
+```java
+import com.crossoverjie.proxy.jdk.ISubject;
+import java.lang.reflect.InvocationHandler;
+import java.lang.reflect.Method;
+import java.lang.reflect.Proxy;
+import java.lang.reflect.UndeclaredThrowableException;
+
+public class $Proxy1 extends Proxy implements ISubject {
+ private static Method m1;
+ private static Method m2;
+ private static Method m3;
+ private static Method m0;
+
+ public $Proxy1(InvocationHandler var1) throws {
+ super(var1);
+ }
+
+ public final boolean equals(Object var1) throws {
+ try {
+ return ((Boolean)super.h.invoke(this, m1, new Object[]{var1})).booleanValue();
+ } catch (RuntimeException | Error var3) {
+ throw var3;
+ } catch (Throwable var4) {
+ throw new UndeclaredThrowableException(var4);
+ }
+ }
+
+ public final String toString() throws {
+ try {
+ return (String)super.h.invoke(this, m2, (Object[])null);
+ } catch (RuntimeException | Error var2) {
+ throw var2;
+ } catch (Throwable var3) {
+ throw new UndeclaredThrowableException(var3);
+ }
+ }
+
+ public final void execute() throws {
+ try {
+ super.h.invoke(this, m3, (Object[])null);
+ } catch (RuntimeException | Error var2) {
+ throw var2;
+ } catch (Throwable var3) {
+ throw new UndeclaredThrowableException(var3);
+ }
+ }
+
+ public final int hashCode() throws {
+ try {
+ return ((Integer)super.h.invoke(this, m0, (Object[])null)).intValue();
+ } catch (RuntimeException | Error var2) {
+ throw var2;
+ } catch (Throwable var3) {
+ throw new UndeclaredThrowableException(var3);
+ }
+ }
+
+ static {
+ try {
+ m1 = Class.forName("java.lang.Object").getMethod("equals", new Class[]{Class.forName("java.lang.Object")});
+ m2 = Class.forName("java.lang.Object").getMethod("toString", new Class[0]);
+ m3 = Class.forName("com.crossoverjie.proxy.jdk.ISubject").getMethod("execute", new Class[0]);
+ m0 = Class.forName("java.lang.Object").getMethod("hashCode", new Class[0]);
+ } catch (NoSuchMethodException var2) {
+ throw new NoSuchMethodError(var2.getMessage());
+ } catch (ClassNotFoundException var3) {
+ throw new NoClassDefFoundError(var3.getMessage());
+ }
+ }
+}
+```
+
+可以看到代理类继承了 `Proxy` 类,并实现了 `ISubject` 接口,由此也可以看到 JDK 动态代理为什么需要实现接口,已经继承了 `Proxy`是不能再继承其余类了。
+
+其中实现了 `ISubject` 的 `execute()` 方法,并通过 `InvocationHandler` 中的 `invoke()` 方法来进行调用的。
+
+
+## CGLIB 动态代理
+
+cglib 是对一个小而快的字节码处理框架 `ASM` 的封装。
+他的特点是继承于被代理类,这就要求被代理类不能被 `final` 修饰。
+
+
diff --git a/docs/frame/guava-cache.md b/docs/frame/guava-cache.md
new file mode 100644
index 00000000..8c35b72d
--- /dev/null
+++ b/docs/frame/guava-cache.md
@@ -0,0 +1,518 @@
+
+
+## 前言
+
+Google 出的 [Guava](https://github.com/google/guava) 是 Java 核心增强的库,应用非常广泛。
+
+我平时用的也挺频繁,这次就借助日常使用的 Cache 组件来看看 Google 大牛们是如何设计的。
+
+## 缓存
+
+> 本次主要讨论缓存。
+
+缓存在日常开发中举足轻重,如果你的应用对某类数据有着较高的读取频次,并且改动较小时那就非常适合利用缓存来提高性能。
+
+缓存之所以可以提高性能是因为它的读取效率很高,就像是 CPU 的 `L1、L2、L3` 缓存一样,级别越高相应的读取速度也会越快。
+
+但也不是什么好处都占,读取速度快了但是它的内存更小资源更宝贵,所以我们应当缓存真正需要的数据。
+
+> 其实也就是典型的空间换时间。
+
+下面谈谈 Java 中所用到的缓存。
+
+
+
+### JVM 缓存
+
+首先是 JVM 缓存,也可以认为是堆缓存。
+
+其实就是创建一些全局变量,如 `Map、List` 之类的容器用于存放数据。
+
+这样的优势是使用简单但是也有以下问题:
+
+- 只能显式的写入,清除数据。
+- 不能按照一定的规则淘汰数据,如 `LRU,LFU,FIFO` 等。
+- 清除数据时的回调通知。
+- 其他一些定制功能等。
+
+### Ehcache、Guava Cache
+
+所以出现了一些专门用作 JVM 缓存的开源工具出现了,如本文提到的 Guava Cache。
+
+它具有上文 JVM 缓存不具有的功能,如自动清除数据、多种清除算法、清除回调等。
+
+但也正因为有了这些功能,这样的缓存必然会多出许多东西需要额外维护,自然也就增加了系统的消耗。
+
+### 分布式缓存
+
+刚才提到的两种缓存其实都是堆内缓存,只能在单个节点中使用,这样在分布式场景下就招架不住了。
+
+于是也有了一些缓存中间件,如 Redis、Memcached,在分布式环境下可以共享内存。
+
+具体不在本次的讨论范围。
+
+## Guava Cache 示例
+
+之所以想到 Guava 的 Cache,也是最近在做一个需求,大体如下:
+
+> 从 Kafka 实时读取出应用系统的日志信息,该日志信息包含了应用的健康状况。
+> 如果在时间窗口 N 内发生了 X 次异常信息,相应的我就需要作出反馈(报警、记录日志等)。
+
+对此 Guava 的 Cache 就非常适合,我利用了它的 N 个时间内不写入数据时缓存就清空的特点,在每次读取数据时判断异常信息是否大于 X 即可。
+
+伪代码如下:
+
+```java
+
+ @Value("${alert.in.time:2}")
+ private int time ;
+
+ @Bean
+ public LoadingCache buildCache(){
+ return CacheBuilder.newBuilder()
+ .expireAfterWrite(time, TimeUnit.MINUTES)
+ .build(new CacheLoader() {
+ @Override
+ public AtomicLong load(Long key) throws Exception {
+ return new AtomicLong(0);
+ }
+ });
+ }
+
+
+ /**
+ * 判断是否需要报警
+ */
+ public void checkAlert() {
+ try {
+ if (counter.get(KEY).incrementAndGet() >= limit) {
+ LOGGER.info("***********报警***********");
+
+ //将缓存清空
+ counter.get(KEY).getAndSet(0L);
+ }
+ } catch (ExecutionException e) {
+ LOGGER.error("Exception", e);
+ }
+ }
+```
+
+首先是构建了 LoadingCache 对象,在 N 分钟内不写入数据时就回收缓存(当通过 Key 获取不到缓存时,默认返回 0)。
+
+然后在每次消费时候调用 `checkAlert()` 方法进行校验,这样就可以达到上文的需求。
+
+我们来设想下 Guava 它是如何实现过期自动清除数据,并且是可以按照 LRU 这样的方式清除的。
+
+大胆假设下:
+
+> 内部通过一个队列来维护缓存的顺序,每次访问过的数据移动到队列头部,并且额外开启一个线程来判断数据是否过期,过期就删掉。有点类似于我之前写过的 [动手实现一个 LRU cache](https://crossoverjie.top/%2F2018%2F04%2F07%2Falgorithm%2FLRU-cache%2F)
+
+
+胡适说过:大胆假设小心论证
+
+下面来看看 Guava 到底是怎么实现。
+
+### 原理分析
+
+看原理最好不过是跟代码一步步走了:
+
+示例代码在这里:
+
+[https://github.com/crossoverJie/Java-Interview/blob/master/src/main/java/com/crossoverjie/guava/CacheLoaderTest.java](https://github.com/crossoverJie/Java-Interview/blob/master/src/main/java/com/crossoverjie/guava/CacheLoaderTest.java)
+
+
+
+
+为了能看出 Guava 是怎么删除过期数据的在获取缓存之前休眠了 5 秒钟,达到了超时条件。
+
+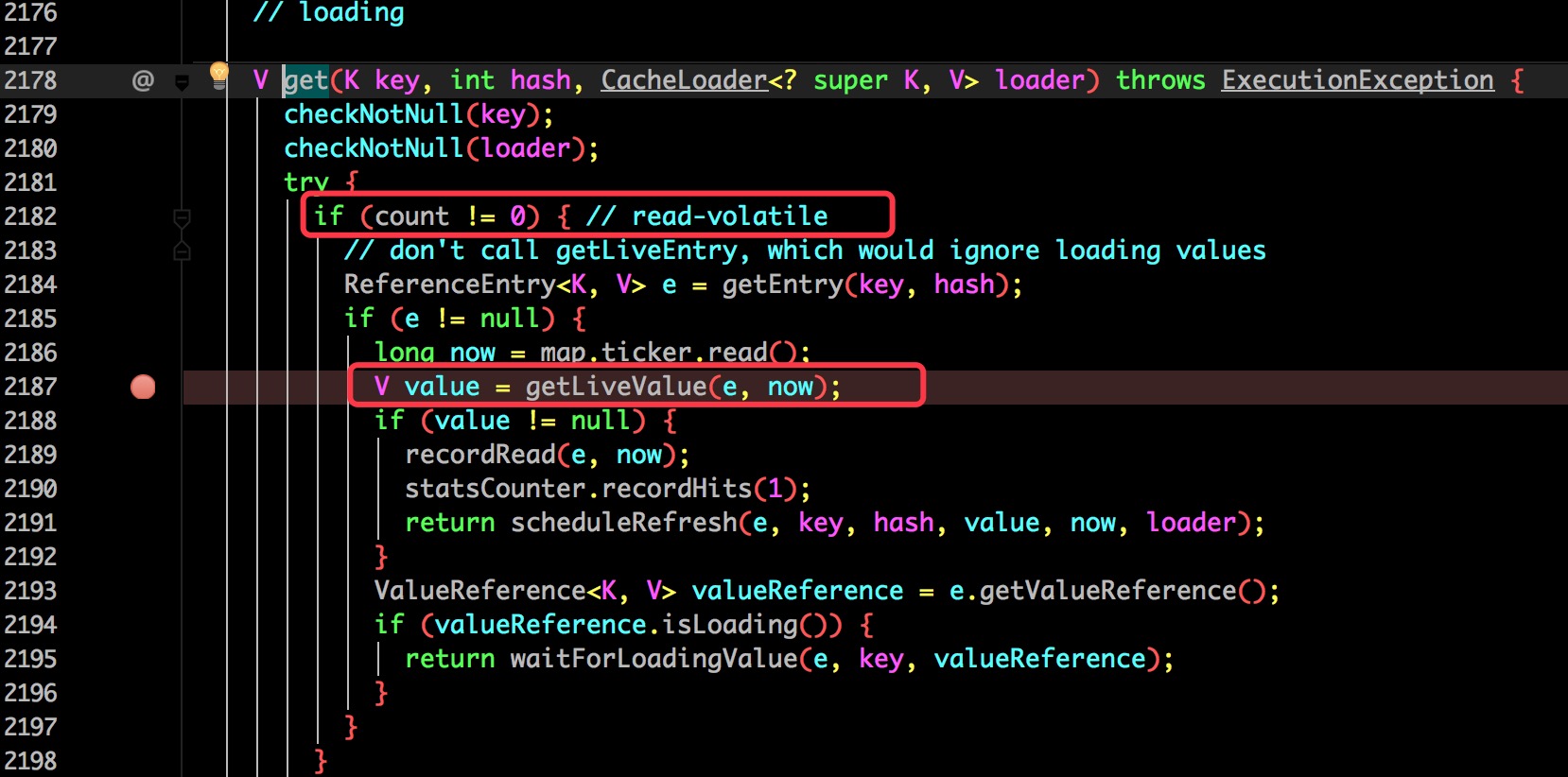
+
+最终会发现在 `com.google.common.cache.LocalCache` 类的 2187 行比较关键。
+
+再跟进去之前第 2182 行会发现先要判断 count 是否大于 0,这个 count 保存的是当前缓存的数量,并用 volatile 修饰保证了可见性。
+
+> 更多关于 volatile 的相关信息可以查看 [你应该知道的 volatile 关键字](https://crossoverjie.top/%2F2018%2F03%2F09%2Fvolatile%2F)
+
+
+接着往下跟到:
+
+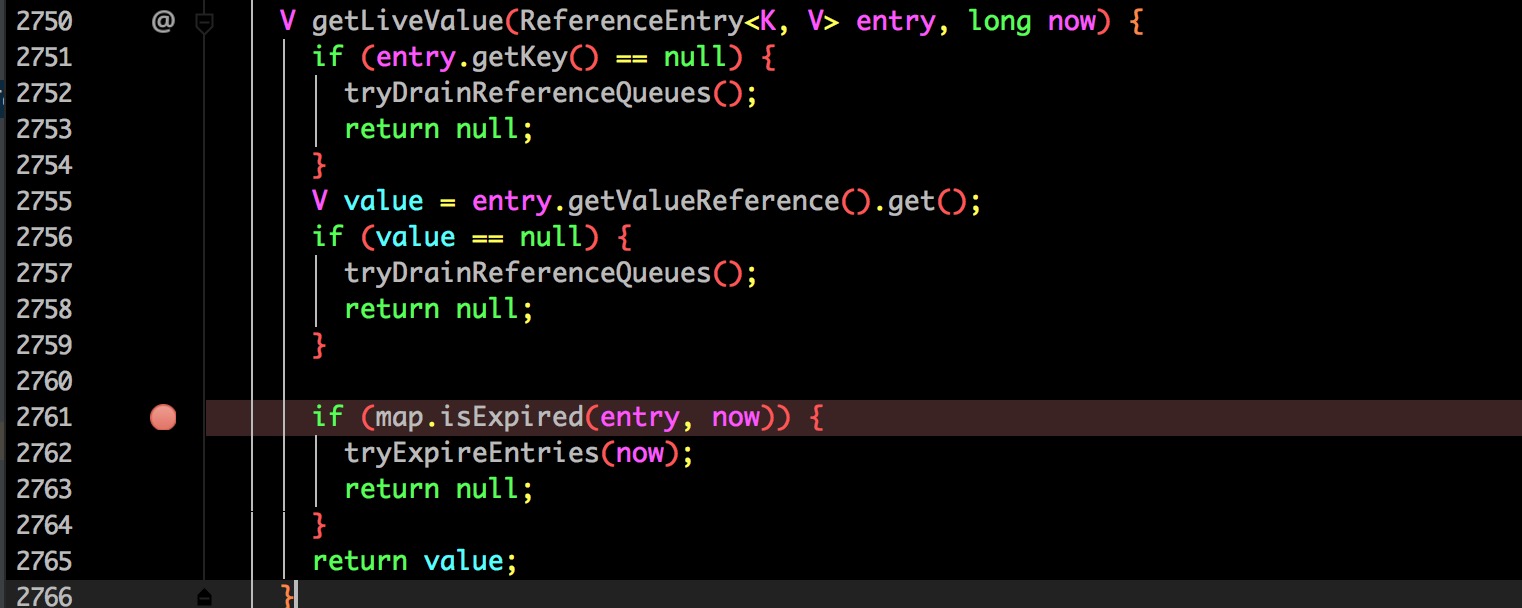
+
+2761 行,根据方法名称可以看出是判断当前的 Entry 是否过期,该 entry 就是通过 key 查询到的。
+
+
+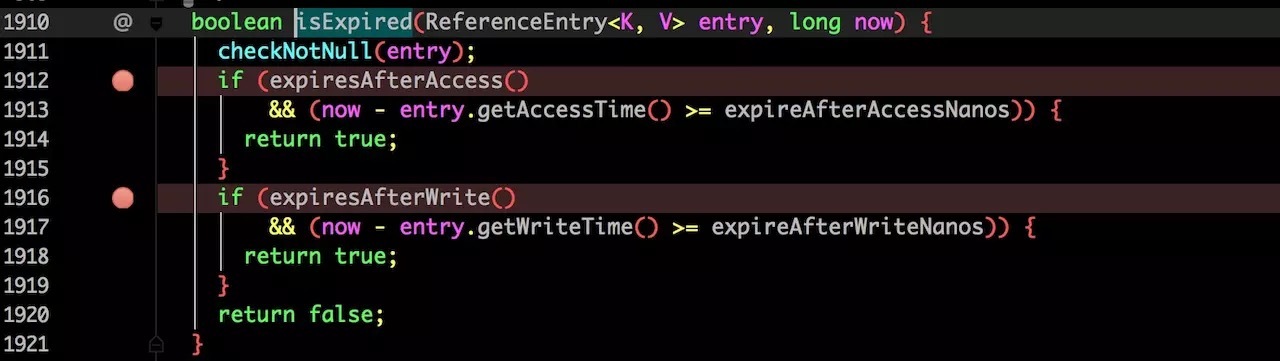
+
+这里就很明显的看出是根据根据构建时指定的过期方式来判断当前 key 是否过期了。
+
+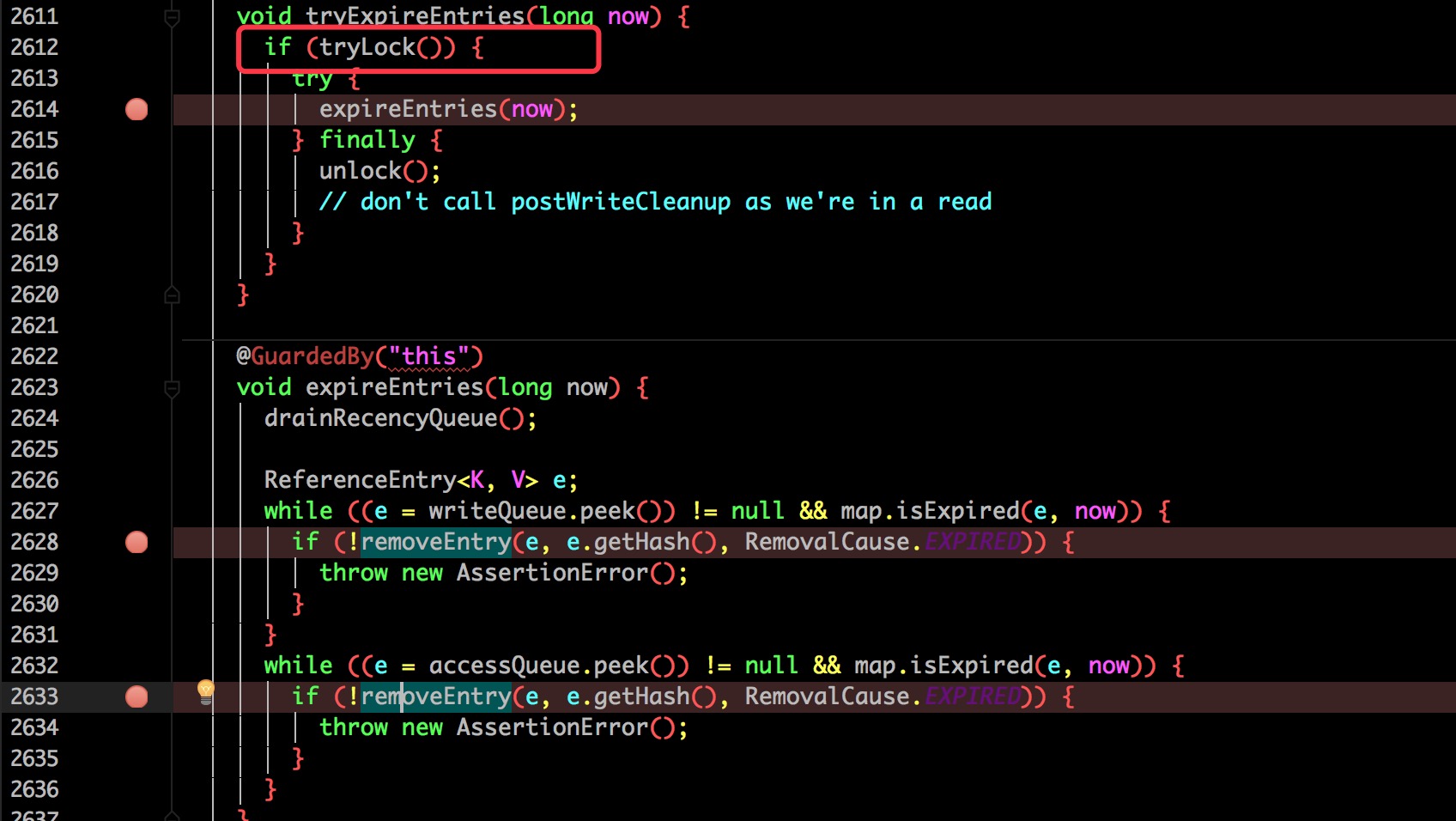
+
+如果过期就往下走,尝试进行过期删除(需要加锁,后面会具体讨论)。
+
+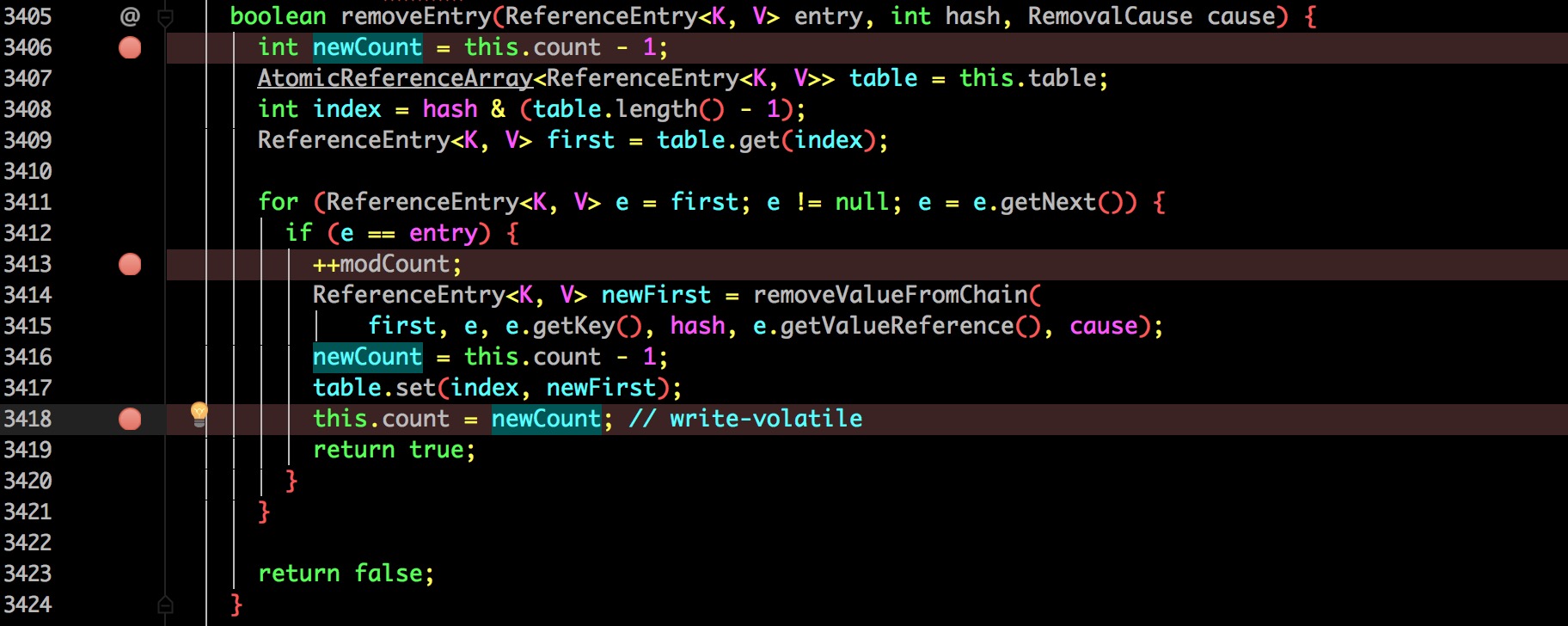
+
+到了这里也很清晰了:
+
+- 获取当前缓存的总数量
+- 自减一(前面获取了锁,所以线程安全)
+- 删除并将更新的总数赋值到 count。
+
+其实大体上就是这个流程,Guava 并没有按照之前猜想的另起一个线程来维护过期数据。
+
+应该是以下原因:
+
+- 新起线程需要资源消耗。
+- 维护过期数据还要获取额外的锁,增加了消耗。
+
+而在查询时候顺带做了这些事情,但是如果该缓存迟迟没有访问也会存在数据不能被回收的情况,不过这对于一个高吞吐的应用来说也不是问题。
+
+## 总结
+
+最后再来总结下 Guava 的 Cache。
+
+其实在上文跟代码时会发现通过一个 key 定位数据时有以下代码:
+
+
+
+如果有看过 [ConcurrentHashMap 的原理](https://github.com/crossoverJie/Java-Interview/blob/master/MD/ConcurrentHashMap.md) 应该会想到这其实非常类似。
+
+其实 Guava Cache 为了满足并发场景的使用,核心的数据结构就是按照 ConcurrentHashMap 来的,这里也是一个 key 定位到一个具体位置的过程。
+
+> 先找到 Segment,再找具体的位置,等于是做了两次 Hash 定位。
+
+上文有一个假设是对的,它内部会维护两个队列 `accessQueue,writeQueue` 用于记录缓存顺序,这样才可以按照顺序淘汰数据(类似于利用 LinkedHashMap 来做 LRU 缓存)。
+
+同时从上文的构建方式来看,它也是[构建者模式](https://crossoverjie.top/2018/04/28/sbc/sbc7-Distributed-Limit/)来创建对象的。
+
+因为作为一个给开发者使用的工具,需要有很多的自定义属性,利用构建则模式再合适不过了。
+
+Guava 其实还有很多东西没谈到,比如它利用 GC 来回收内存,移除数据时的回调通知等。之后再接着讨论。
+
+扫码关注微信公众号,第一时间获取消息。
+
+
+
+## 进一步分析
+
+## 前言
+
+在上文「[Guava 源码分析(Cache 原理)](https://crossoverjie.top/2018/06/13/guava/guava-cache/)」中分析了 `Guava Cache` 的相关原理。
+
+文末提到了**回收机制、移除时间通知**等内容,许多朋友也挺感兴趣,这次就这两个内容再来分析分析。
+
+
+> 在开始之前先补习下 Java 自带的两个特性,Guava 中都有具体的应用。
+
+## Java 中的引用
+
+首先是 Java 中的**引用**。
+
+在之前分享过 JVM 是根据[可达性分析算法](https://github.com/crossoverJie/Java-Interview/blob/master/MD/GarbageCollection.md#%E5%8F%AF%E8%BE%BE%E6%80%A7%E5%88%86%E6%9E%90%E7%AE%97%E6%B3%95)找出需要回收的对象,判断对象的存活状态都和`引用`有关。
+
+在 JDK1.2 之前这点设计的非常简单:一个对象的状态只有**引用**和**没被引用**两种区别。
+
+
+
+这样的划分对垃圾回收不是很友好,因为总有一些对象的状态处于这两之间。
+
+因此 1.2 之后新增了四种状态用于更细粒度的划分引用关系:
+
+- 强引用(Strong Reference):这种对象最为常见,比如 **`A a = new A();`**这就是典型的强引用;这样的强引用关系是不能被垃圾回收的。
+- 软引用(Soft Reference):这样的引用表明一些有用但不是必要的对象,在将发生垃圾回收之前是需要将这样的对象再次回收。
+- 弱引用(Weak Reference):这是一种比软引用还弱的引用关系,也是存放非必须的对象。当垃圾回收时,无论当前内存是否足够,这样的对象都会被回收。
+- 虚引用(Phantom Reference):这是一种最弱的引用关系,甚至没法通过引用来获取对象,它唯一的作用就是在被回收时可以获得通知。
+
+## 事件回调
+
+事件回调其实是一种常见的设计模式,比如之前讲过的 [Netty](https://crossoverjie.top/categories/Netty/) 就使用了这样的设计。
+
+这里采用一个 demo,试下如下功能:
+
+- Caller 向 Notifier 提问。
+- 提问方式是异步,接着做其他事情。
+- Notifier 收到问题执行计算然后回调 Caller 告知结果。
+
+在 Java 中利用接口来实现回调,所以需要定义一个接口:
+
+```java
+public interface CallBackListener {
+
+ /**
+ * 回调通知函数
+ * @param msg
+ */
+ void callBackNotify(String msg) ;
+}
+```
+
+Caller 中调用 Notifier 执行提问,调用时将接口传递过去:
+
+```java
+public class Caller {
+
+ private final static Logger LOGGER = LoggerFactory.getLogger(Caller.class);
+
+ private CallBackListener callBackListener ;
+
+ private Notifier notifier ;
+
+ private String question ;
+
+ /**
+ * 使用
+ */
+ public void call(){
+
+ LOGGER.info("开始提问");
+
+ //新建线程,达到异步效果
+ new Thread(new Runnable() {
+ @Override
+ public void run() {
+ try {
+ notifier.execute(Caller.this,question);
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ }
+ }).start();
+
+ LOGGER.info("提问完毕,我去干其他事了");
+ }
+
+ //隐藏 getter/setter
+
+}
+```
+
+Notifier 收到提问,执行计算(耗时操作),最后做出响应(回调接口,告诉 Caller 结果)。
+
+
+```java
+public class Notifier {
+
+ private final static Logger LOGGER = LoggerFactory.getLogger(Notifier.class);
+
+ public void execute(Caller caller, String msg) throws InterruptedException {
+ LOGGER.info("收到消息=【{}】", msg);
+
+ LOGGER.info("等待响应中。。。。。");
+ TimeUnit.SECONDS.sleep(2);
+
+
+ caller.getCallBackListener().callBackNotify("我在北京!");
+
+ }
+
+}
+```
+
+
+模拟执行:
+
+```java
+ public static void main(String[] args) {
+ Notifier notifier = new Notifier() ;
+
+ Caller caller = new Caller() ;
+ caller.setNotifier(notifier) ;
+ caller.setQuestion("你在哪儿!");
+ caller.setCallBackListener(new CallBackListener() {
+ @Override
+ public void callBackNotify(String msg) {
+ LOGGER.info("回复=【{}】" ,msg);
+ }
+ });
+
+ caller.call();
+ }
+```
+
+最后执行结果:
+
+```log
+2018-07-15 19:52:11.105 [main] INFO c.crossoverjie.guava.callback.Caller - 开始提问
+2018-07-15 19:52:11.118 [main] INFO c.crossoverjie.guava.callback.Caller - 提问完毕,我去干其他事了
+2018-07-15 19:52:11.117 [Thread-0] INFO c.c.guava.callback.Notifier - 收到消息=【你在哪儿!】
+2018-07-15 19:52:11.121 [Thread-0] INFO c.c.guava.callback.Notifier - 等待响应中。。。。。
+2018-07-15 19:52:13.124 [Thread-0] INFO com.crossoverjie.guava.callback.Main - 回复=【我在北京!】
+```
+
+这样一个模拟的异步事件回调就完成了。
+
+## Guava 的用法
+
+Guava 就是利用了上文的两个特性来实现了**引用回收**及**移除通知**。
+
+### 引用
+
+可以在初始化缓存时利用:
+
+- CacheBuilder.weakKeys()
+- CacheBuilder.weakValues()
+- CacheBuilder.softValues()
+
+来自定义键和值的引用关系。
+
+
+
+在上文的分析中可以看出 Cache 中的 `ReferenceEntry` 是类似于 HashMap 的 Entry 存放数据的。
+
+来看看 ReferenceEntry 的定义:
+
+```java
+ interface ReferenceEntry {
+ /**
+ * Returns the value reference from this entry.
+ */
+ ValueReference getValueReference();
+
+ /**
+ * Sets the value reference for this entry.
+ */
+ void setValueReference(ValueReference valueReference);
+
+ /**
+ * Returns the next entry in the chain.
+ */
+ @Nullable
+ ReferenceEntry getNext();
+
+ /**
+ * Returns the entry's hash.
+ */
+ int getHash();
+
+ /**
+ * Returns the key for this entry.
+ */
+ @Nullable
+ K getKey();
+
+ /*
+ * Used by entries that use access order. Access entries are maintained in a doubly-linked list.
+ * New entries are added at the tail of the list at write time; stale entries are expired from
+ * the head of the list.
+ */
+
+ /**
+ * Returns the time that this entry was last accessed, in ns.
+ */
+ long getAccessTime();
+
+ /**
+ * Sets the entry access time in ns.
+ */
+ void setAccessTime(long time);
+}
+```
+
+包含了很多常用的操作,如值引用、键引用、访问时间等。
+
+根据 `ValueReference getValueReference();` 的实现:
+
+
+
+具有强引用和弱引用的不同实现。
+
+key 也是相同的道理:
+
+
+
+当使用这样的构造方式时,弱引用的 key 和 value 都会被垃圾回收。
+
+当然我们也可以显式的回收:
+
+```
+ /**
+ * Discards any cached value for key {@code key}.
+ * 单个回收
+ */
+ void invalidate(Object key);
+
+ /**
+ * Discards any cached values for keys {@code keys}.
+ *
+ * @since 11.0
+ */
+ void invalidateAll(Iterable keys);
+
+ /**
+ * Discards all entries in the cache.
+ */
+ void invalidateAll();
+```
+
+### 回调
+
+改造了之前的例子:
+
+```java
+loadingCache = CacheBuilder.newBuilder()
+ .expireAfterWrite(2, TimeUnit.SECONDS)
+ .removalListener(new RemovalListener() {
+ @Override
+ public void onRemoval(RemovalNotification notification) {
+ LOGGER.info("删除原因={},删除 key={},删除 value={}",notification.getCause(),notification.getKey(),notification.getValue());
+ }
+ })
+ .build(new CacheLoader() {
+ @Override
+ public AtomicLong load(Integer key) throws Exception {
+ return new AtomicLong(0);
+ }
+ });
+```
+
+执行结果:
+
+```log
+2018-07-15 20:41:07.433 [main] INFO c.crossoverjie.guava.CacheLoaderTest - 当前缓存值=0,缓存大小=1
+2018-07-15 20:41:07.442 [main] INFO c.crossoverjie.guava.CacheLoaderTest - 缓存的所有内容={1000=0}
+2018-07-15 20:41:07.443 [main] INFO c.crossoverjie.guava.CacheLoaderTest - job running times=10
+2018-07-15 20:41:10.461 [main] INFO c.crossoverjie.guava.CacheLoaderTest - 删除原因=EXPIRED,删除 key=1000,删除 value=1
+2018-07-15 20:41:10.462 [main] INFO c.crossoverjie.guava.CacheLoaderTest - 当前缓存值=0,缓存大小=1
+2018-07-15 20:41:10.462 [main] INFO c.crossoverjie.guava.CacheLoaderTest - 缓存的所有内容={1000=0}
+```
+
+可以看出当缓存被删除的时候会回调我们自定义的函数,并告知删除原因。
+
+那么 Guava 是如何实现的呢?
+
+
+
+根据 LocalCache 中的 `getLiveValue()` 中判断缓存过期时,跟着这里的调用关系就会一直跟到:
+
+
+
+`removeValueFromChain()` 中的:
+
+
+
+`enqueueNotification()` 方法会将回收的缓存(包含了 key,value)以及回收原因包装成之前定义的事件接口加入到一个**本地队列**中。
+
+
+
+这样一看也没有回调我们初始化时候的事件啊。
+
+不过用过队列的同学应该能猜出,既然这里写入队列,那就肯定就有消费。
+
+我们回到获取缓存的地方:
+
+
+
+在 finally 中执行了 `postReadCleanup()` 方法;其实在这里面就是对刚才的队列进行了消费:
+
+
+
+一直跟进来就会发现这里消费了队列,将之前包装好的移除消息调用了我们自定义的事件,这样就完成了一次事件回调。
+
+## 总结
+
+以上所有源码:
+
+[https://github.com/crossoverJie/Java-Interview/blob/master/src/main/java/com/crossoverjie/guava/callback/Main.java](https://github.com/crossoverJie/Java-Interview/blob/master/src/main/java/com/crossoverjie/guava/callback/Main.java)
+
+通过分析 Guava 的源码可以让我们学习到顶级的设计及实现方式,甚至自己也能尝试编写。
+
+Guava 里还有很多强大的增强实现,值得我们再好好研究。
diff --git a/docs/frame/kafka-consumer.md b/docs/frame/kafka-consumer.md
new file mode 100755
index 00000000..97d8269d
--- /dev/null
+++ b/docs/frame/kafka-consumer.md
@@ -0,0 +1,204 @@
+
+
+
+
+
+# 前言
+
+之前写过一篇[《从源码分析如何优雅的使用 Kafka 生产者》](https://crossoverjie.top/2018/10/11/kafka/kafka-product/) ,有生产者自然也就有消费者。
+
+> 建议对 Kakfa 还比较陌生的朋友可以先看看。
+
+就我的使用经验来说,大部分情况都是处于数据下游的消费者角色。也用 `Kafka` 消费过日均过亿的消息(不得不佩服 Kakfa 的设计),本文将借助我使用 Kakfa 消费数据的经验来聊聊如何高效的消费数据。
+
+
+
+# 单线程消费
+
+以之前生产者中的代码为例,事先准备好了一个 `Topic:data-push`,3个分区。
+
+先往里边发送 100 条消息,没有自定义路由策略,所以消息会均匀的发往三个分区。
+
+先来谈谈最简单的单线程消费,如下图所示:
+
+
+
+由于数据散列在三个不同分区,所以单个线程需要遍历三个分区将数据拉取下来。
+
+单线程消费的示例代码:
+
+
+
+这段代码大家在官网也可以找到:将数据取出放到一个内存缓冲中最后写入数据库的过程。
+
+> 先不讨论其中的 offset 的提交方式。
+
+
+
+
+
+通过消费日志可以看出:
+
+取出的 100 条数据确实是分别遍历了三个分区。
+
+单线程消费虽然简单,但存在以下几个问题:
+
+- 效率低下。如果分区数几十上百个,单线程无法高效的取出数据。
+- 可用性很低。一旦消费线程阻塞,甚至是进程挂掉,那么整个消费程序都将出现问题。
+
+# 多线程消费
+
+既然单线程有诸多问题,那是否可以用多线程来提高效率呢?
+
+在多线程之前不得不将消费模式分为两种进行探讨:消费组、独立消费者。
+
+这两种消费模式对应的处理方式有着很大的不同,所以很有必要单独来讲。
+
+## 独立消费者模式
+
+先从`独立消费者模式`谈起,这种模式相对于消费组来说用的相对小众一些。
+
+看一个简单示例即可知道它的用法:
+
+
+
+> 值得注意的是:独立消费者可以不设置 group.id 属性。
+
+也是发送100条消息,消费结果如下:
+
+
+
+通过 API 可以看出:我们可以手动指定需要消费哪些分区。
+
+比如 `data-push` Topic 有三个分区,我可以手动只消费其中的 1 2 分区,第三个可以视情况来消费。
+
+同时它也支持多线程的方式,每个线程消费指定分区进行消费。
+
+
+
+
+
+为了直观,只发送了 10 条数据。
+
+
+
+根据消费结果可以看出:
+
+c1 线程只取 0 分区;c2 只取 1 分区;c3 只取 2 分区的数据。
+
+甚至我们可以将消费者多进程部署,这样的消费方式如下:
+
+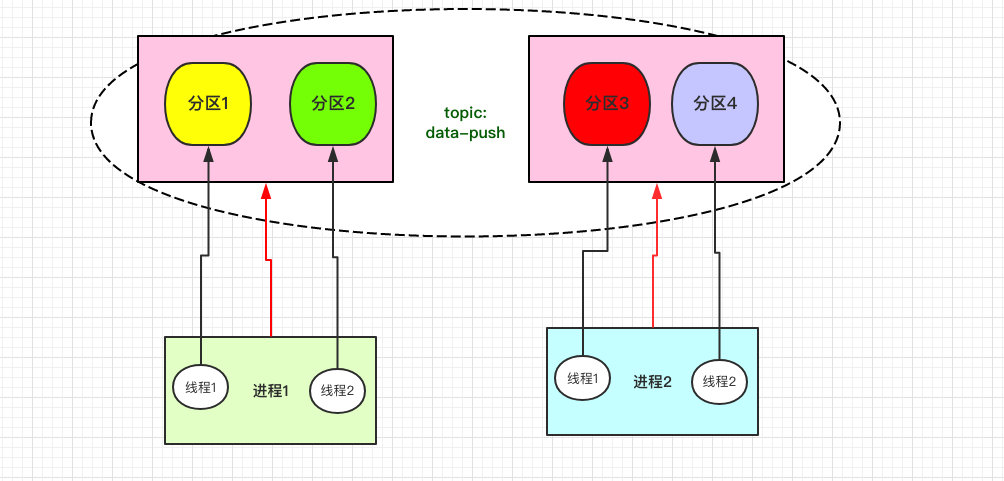
+
+假设 `Topic:data-push` 的分区数为 4 个,那我们就可以按照图中的方式创建两个进程。
+
+每个进程内有两个线程,每个线程再去消费对应的分区。
+
+这样当我们性能不够新增 Topic 的分区数时,消费者这边只需要这样水平扩展即可,非常的灵活。
+
+
+这种自定义分区消费的方式在某些场景下还是适用的,比如生产者每次都将某一类的数据只发往一个分区。这样我们就可以只针对这一个分区消费。
+
+但这种方式有一个问题:可用性不高,当其中一个进程挂掉之后;该进程负责的分区数据没法转移给其他进程处理。
+
+## 消费组模式
+
+消费组模式应当是使用最多的一种消费方式。
+
+我们可以创建 N 个消费者实例(`new KafkaConsumer()`),当这些实例都用同一个 `group.id` 来创建时,他们就属于同一个消费组。
+
+在同一个消费组中的消费实例可以收到消息,但一个分区的消息只会发往一个消费实例。
+
+
+还是借助官方的示例图来更好的理解它。
+
+
+
+某个 Topic 有四个分区 `p0 p1 p2 p3`,同时创建了两个消费组 `groupA,groupB`。
+
+- A 消费组中有两个消费实例 `C1、C2`。
+- B 消费组中有四个消费实例 `C3、C4、C5、C6`。
+
+这样消息是如何划分到每个消费实例的呢?
+
+通过图中可以得知:
+
+- A 组中的 C1 消费了 P0 和 P3 分区;C2 消费 P1、P2 分区。
+- B 组有四个实例,所以每个实例消费一个分区;也就是消费实例和分区是一一对应的。
+
+需要注意的是:
+
+> 这里的消费实例简单的可以理解为 `new KafkaConsumer`,**它和进程没有关系**。
+
+---
+
+比如说某个 Topic 有三个分区,但是我启动了两个进程来消费它。
+
+其中每个进程有两个消费实例,那其实就相当于有四个实例了。
+
+这时可能就会问 4 个实例怎么消费 3 个分区呢?
+
+
+# 消费组自平衡
+
+这个 Kafka 已经帮我做好了,它会来做消费组里的 `Rebalance`。
+
+比如上面的情况,3 个分区却有 4 个消费实例;最终肯定只有三个实例能取到消息。但至于是哪三个呢,这点 Kakfa 会自动帮我们分配好。
+
+看个例子,还在之前的 `data-push` 这个 Topic,其中有三个分区。
+
+当其中一个进程(其中有三个线程,每个线程对应一个消费实例)时,消费结果如下:
+
+
+
+里边的 20 条数据都被这个进程的三个实例消费掉。
+
+这时我新启动了一个进程,程序和上面那个一模一样;这样就相当于有两个进程,同时就是 6 个实例。
+
+我再发送 10 条消息会发现:
+
+进程1 只取到了分区 1 里的两条数据(之前是所有数据都是进程1里的线程获取的)。
+
+
+
+---
+
+同时进程2则消费了剩下的 8 条消息,分别是分区 0、2 的数据(总的还是只有三个实例取到了数据,只是分别在不同的进程里)。
+
+
+
+---
+
+当我关掉进程2,再发送10条数据时会发现所有数据又被进程1里的三个线程消费了。
+
+
+
+通过这些测试相信大家已经可以看到消费组的优势了。
+
+> 我们可以在一个消费组中创建多个消费实例来达到高可用、高容错的特性,不会出现单线程以及独立消费者挂掉之后数据不能消费的情况。同时基于多线程的方式也极大的提高了消费效率。
+
+
+而当新增消费实例或者是消费实例挂掉时 `Kakfa` 会为我们重新分配消费实例与分区的关系就被称为消费组 `Rebalance`。
+
+发生这个的前提条件一般有以下几个:
+
+- 消费组中新增消费实例。
+- 消费组中消费实例 down 掉。
+- 订阅的 Topic 分区数发生变化。
+- 如果是正则订阅 Topic 时,匹配的 Topic 数发生变化也会导致 `Rebalance`。
+
+
+所以推荐使用这样的方式消费数据,同时扩展性也非常好。当性能不足新增分区时只需要启动新的消费实例加入到消费组中即可。
+
+
+# 总结
+
+本次只分享了几个不同消费数据的方式,并没有着重研究消费参数、源码;这些内容感兴趣的话可以在下次分享。
+
+文中提到的部分源码可以在这里查阅:
+
+[https://github.com/crossoverJie/JCSprout](https://github.com/crossoverJie/JCSprout)
+
+
+
+**欢迎关注公众号一起交流:**
diff --git a/docs/frame/kafka-product.md b/docs/frame/kafka-product.md
new file mode 100755
index 00000000..d50364a8
--- /dev/null
+++ b/docs/frame/kafka-product.md
@@ -0,0 +1,324 @@
+
+# 从源码分析如何优雅的使用 Kafka 生产者
+
+
+
+
+# 前言
+
+在上文 [设计一个百万级的消息推送系统](https://crossoverjie.top/2018/09/25/netty/million-sms-push/) 中提到消息流转采用的是 `Kafka` 作为中间件。
+
+其中有朋友咨询在大量消息的情况下 `Kakfa` 是如何保证消息的高效及一致性呢?
+
+正好以这个问题结合 `Kakfa` 的源码讨论下如何正确、高效的发送消息。
+
+> 内容较多,对源码感兴趣的朋友请系好安全带😏(源码基于 `v0.10.0.0` 版本分析)。同时最好是有一定的 Kafka 使用经验,知晓基本的用法。
+
+
+# 简单的消息发送
+
+在分析之前先看一个简单的消息发送是怎么样的。
+
+> 以下代码基于 SpringBoot 构建。
+
+首先创建一个 `org.apache.kafka.clients.producer.Producer` 的 bean。
+
+
+
+主要关注 `bootstrap.servers`,它是必填参数。指的是 Kafka 集群中的 broker 地址,例如 `127.0.0.1:9094`。
+
+> 其余几个参数暂时不做讨论,后文会有详细介绍。
+
+接着注入这个 bean 即可调用它的发送函数发送消息。
+
+
+
+这里我给某一个 Topic 发送了 10W 条数据,运行程序消息正常发送。
+
+但这仅仅只是做到了消息发送,对消息是否成功送达完全没管,等于是纯`异步`的方式。
+
+## 同步
+
+那么我想知道消息到底发送成功没有该怎么办呢?
+
+其实 `Producer` 的 `API` 已经帮我们考虑到了,发送之后只需要调用它的 `get()` 方法即可同步获取发送结果。
+
+
+
+发送结果:
+
+
+
+这样的发送效率其实是比较低下的,因为每次都需要同步等待消息发送的结果。
+
+## 异步
+
+为此我们应当采取异步的方式发送,其实 `send()` 方法默认则是异步的,只要不手动调用 `get()` 方法。
+
+但这样就没法获知发送结果。
+
+所以查看 `send()` 的 API 可以发现还有一个参数。
+
+```java
+Future send(ProducerRecord producer, Callback callback);
+```
+
+`Callback` 是一个回调接口,在消息发送完成之后可以回调我们自定义的实现。
+
+
+
+执行之后的结果:
+
+
+
+同样的也能获取结果,同时发现回调的线程并不是上文同步时的`主线程`,这样也能证明是异步回调的。
+
+同时回调的时候会传递两个参数:
+
+- `RecordMetadata` 和上文一致的消息发送成功后的元数据。
+- `Exception` 消息发送过程中的异常信息。
+
+但是这两个参数并不会同时都有数据,只有发送失败才会有异常信息,同时发送元数据为空。
+
+所以正确的写法应当是:
+
+
+
+> 至于为什么会只有参数一个有值,在下文的源码分析中会一一解释。
+
+
+# 源码分析
+
+现在只掌握了基本的消息发送,想要深刻的理解发送中的一些参数配置还是得源码说了算。
+
+首先还是来谈谈消息发送时的整个流程是怎么样的,`Kafka` 并不是简单的把消息通过网络发送到了 `broker` 中,在 Java 内部还是经过了许多优化和设计。
+
+## 发送流程
+
+为了直观的了解发送的流程,简单的画了几个在发送过程中关键的步骤。
+
+
+
+从上至下依次是:
+
+- 初始化以及真正发送消息的 `kafka-producer-network-thread` IO 线程。
+- 将消息序列化。
+- 得到需要发送的分区。
+- 写入内部的一个缓存区中。
+- 初始化的 IO 线程不断的消费这个缓存来发送消息。
+
+## 步骤解析
+
+接下来详解每个步骤。
+
+### 初始化
+
+
+
+
+调用该构造方法进行初始化时,不止是简单的将基本参数写入 `KafkaProducer`。比较麻烦的是初始化 `Sender` 线程进行缓冲区消费。
+
+初始化 IO 线程处:
+
+
+
+
+可以看到 Sender 线程有需要成员变量,比如:
+
+```
+acks,retries,requestTimeout
+```
+
+等,这些参数会在后文分析。
+
+### 序列化消息
+
+在调用 `send()` 函数后其实第一步就是序列化,毕竟我们的消息需要通过网络才能发送到 Kafka。
+
+
+
+其中的 `valueSerializer.serialize(record.topic(), record.value());` 是一个接口,我们需要在初始化时候指定序列化实现类。
+
+
+
+我们也可以自己实现序列化,只需要实现 `org.apache.kafka.common.serialization.Serializer` 接口即可。
+
+### 路由分区
+
+接下来就是路由分区,通常我们使用的 `Topic` 为了实现扩展性以及高性能都会创建多个分区。
+
+如果是一个分区好说,所有消息都往里面写入即可。
+
+但多个分区就不可避免需要知道写入哪个分区。
+
+通常有三种方式。
+
+#### 指定分区
+
+可以在构建 `ProducerRecord` 为每条消息指定分区。
+
+
+
+这样在路由时会判断是否有指定,有就直接使用该分区。
+
+
+
+这种一般在特殊场景下会使用。
+
+#### 自定义路由策略
+
+
+
+如果没有指定分区,则会调用 `partitioner.partition` 接口执行自定义分区策略。
+
+而我们也只需要自定义一个类实现 `org.apache.kafka.clients.producer.Partitioner` 接口,同时在创建 `KafkaProducer` 实例时配置 `partitioner.class` 参数。
+
+
+
+通常需要自定义分区一般是在想尽量的保证消息的顺序性。
+
+或者是写入某些特有的分区,由特别的消费者来进行处理等。
+
+#### 默认策略
+
+最后一种则是默认的路由策略,如果我们啥都没做就会执行该策略。
+
+该策略也会使得消息分配的比较均匀。
+
+来看看它的实现:
+
+
+
+简单的来说分为以下几步:
+
+- 获取 Topic 分区数。
+- 将内部维护的一个线程安全计数器 +1。
+- 与分区数取模得到分区编号。
+
+其实这就是很典型的轮询算法,所以只要分区数不频繁变动这种方式也会比较均匀。
+
+### 写入内部缓存
+
+在 `send()` 方法拿到分区后会调用一个 `append()` 函数:
+
+
+
+该函数中会调用一个 `getOrCreateDeque()` 写入到一个内部缓存中 `batches`。
+
+
+
+
+### 消费缓存
+
+在最开始初始化的 IO 线程其实是一个守护线程,它会一直消费这些数据。
+
+
+
+通过图中的几个函数会获取到之前写入的数据。这块内容可以不必深究,但其中有个 `completeBatch` 方法却非常关键。
+
+
+
+调用该方法时候肯定已经是消息发送完毕了,所以会调用 `batch.done()` 来完成之前我们在 `send()` 方法中定义的回调接口。
+
+
+
+ > 从这里也可以看出为什么之前说发送完成后元数据和异常信息只会出现一个。
+
+# Producer 参数解析
+
+发送流程讲完了再来看看 `Producer` 中比较重要的几个参数。
+
+## acks
+
+`acks` 是一个影响消息吞吐量的一个关键参数。
+
+
+
+主要有 `[all、-1, 0, 1]` 这几个选项,默认为 1。
+
+由于 `Kafka` 不是采取的主备模式,而是采用类似于 Zookeeper 的主备模式。
+
+> 前提是 `Topic` 配置副本数量 `replica > 1`。
+
+当 `acks = all/-1` 时:
+
+意味着会确保所有的 follower 副本都完成数据的写入才会返回。
+
+这样可以保证消息不会丢失!
+
+> 但同时性能和吞吐量却是最低的。
+
+
+当 `acks = 0` 时:
+
+producer 不会等待副本的任何响应,这样最容易丢失消息但同时性能却是最好的!
+
+当 `acks = 1` 时:
+
+这是一种折中的方案,它会等待副本 Leader 响应,但不会等到 follower 的响应。
+
+一旦 Leader 挂掉消息就会丢失。但性能和消息安全性都得到了一定的保证。
+
+## batch.size
+
+这个参数看名称就知道是内部缓存区的大小限制,对他适当的调大可以提高吞吐量。
+
+但也不能极端,调太大会浪费内存。小了也发挥不了作用,也是一个典型的时间和空间的权衡。
+
+
+
+
+
+上图是几个使用的体现。
+
+
+## retries
+
+`retries` 该参数主要是来做重试使用,当发生一些网络抖动都会造成重试。
+
+这个参数也就是限制重试次数。
+
+但也有一些其他问题。
+
+- 因为是重发所以消息顺序可能不会一致,这也是上文提到就算是一个分区消息也不会是完全顺序的情况。
+- 还是由于网络问题,本来消息已经成功写入了但是没有成功响应给 producer,进行重试时就可能会出现`消息重复`。这种只能是消费者进行幂等处理。
+
+# 高效的发送方式
+
+如果消息量真的非常大,同时又需要尽快的将消息发送到 `Kafka`。一个 `producer` 始终会收到缓存大小等影响。
+
+那是否可以创建多个 `producer` 来进行发送呢?
+
+- 配置一个最大 producer 个数。
+- 发送消息时首先获取一个 `producer`,获取的同时判断是否达到最大上限,没有就新建一个同时保存到内部的 `List` 中,保存时做好同步处理防止并发问题。
+- 获取发送者时可以按照默认的分区策略使用轮询的方式获取(保证使用均匀)。
+
+这样在大量、频繁的消息发送场景中可以提高发送效率减轻单个 `producer` 的压力。
+
+# 关闭 Producer
+
+最后则是 `Producer` 的关闭,Producer 在使用过程中消耗了不少资源(线程、内存、网络等)因此需要显式的关闭从而回收这些资源。
+
+
+
+
+默认的 `close()` 方法和带有超时时间的方法都是在一定的时间后强制关闭。
+
+但在过期之前都会处理完剩余的任务。
+
+所以使用哪一个得视情况而定。
+
+
+# 总结
+
+本文内容较多,从实例和源码的角度分析了 Kafka 生产者。
+
+希望看完的朋友能有收获,同时也欢迎留言讨论。
+
+不出意外下期会讨论 Kafka 消费者。
+
+> 如果对你有帮助还请分享让更多的人看到。
+
+**欢迎关注公众号一起交流:**
+
+ diff --git a/docs/frame/spring-bean-lifecycle.md b/docs/frame/spring-bean-lifecycle.md
new file mode 100644
index 00000000..60f2796a
--- /dev/null
+++ b/docs/frame/spring-bean-lifecycle.md
@@ -0,0 +1,181 @@
+## Spring Bean 生命周期
+
+
+### 前言
+
+Spring Bean 的生命周期在整个 Spring 中占有很重要的位置,掌握这些可以加深对 Spring 的理解。
+
+首先看下生命周期图:
+
+
+
+再谈生命周期之前有一点需要先明确:
+
+> Spring 只帮我们管理单例模式 Bean 的**完整**生命周期,对于 prototype 的 bean ,Spring 在创建好交给使用者之后则不会再管理后续的生命周期。
+
+
+### 注解方式
+
+在 bean 初始化时会经历几个阶段,首先可以使用注解 `@PostConstruct`, `@PreDestroy` 来在 bean 的创建和销毁阶段进行调用:
+
+```java
+@Component
+public class AnnotationBean {
+ private final static Logger LOGGER = LoggerFactory.getLogger(AnnotationBean.class);
+
+ @PostConstruct
+ public void start(){
+ LOGGER.info("AnnotationBean start");
+ }
+
+ @PreDestroy
+ public void destroy(){
+ LOGGER.info("AnnotationBean destroy");
+ }
+}
+```
+
+### InitializingBean, DisposableBean 接口
+
+还可以实现 `InitializingBean,DisposableBean` 这两个接口,也是在初始化以及销毁阶段调用:
+
+```java
+@Service
+public class SpringLifeCycleService implements InitializingBean,DisposableBean{
+ private final static Logger LOGGER = LoggerFactory.getLogger(SpringLifeCycleService.class);
+ @Override
+ public void afterPropertiesSet() throws Exception {
+ LOGGER.info("SpringLifeCycleService start");
+ }
+
+ @Override
+ public void destroy() throws Exception {
+ LOGGER.info("SpringLifeCycleService destroy");
+ }
+}
+```
+
+### 自定义初始化和销毁方法
+
+也可以自定义方法用于在初始化、销毁阶段调用:
+
+```java
+@Configuration
+public class LifeCycleConfig {
+
+
+ @Bean(initMethod = "start", destroyMethod = "destroy")
+ public SpringLifeCycle create(){
+ SpringLifeCycle springLifeCycle = new SpringLifeCycle() ;
+
+ return springLifeCycle ;
+ }
+}
+
+public class SpringLifeCycle{
+
+ private final static Logger LOGGER = LoggerFactory.getLogger(SpringLifeCycle.class);
+ public void start(){
+ LOGGER.info("SpringLifeCycle start");
+ }
+
+
+ public void destroy(){
+ LOGGER.info("SpringLifeCycle destroy");
+ }
+}
+```
+
+以上是在 SpringBoot 中可以这样配置,如果是原始的基于 XML 也是可以使用:
+
+```xml
+
+
+```
+
+来达到同样的效果。
+
+### 实现 *Aware 接口
+
+`*Aware` 接口可以用于在初始化 bean 时获得 Spring 中的一些对象,如获取 `Spring 上下文`等。
+
+```java
+@Component
+public class SpringLifeCycleAware implements ApplicationContextAware {
+ private final static Logger LOGGER = LoggerFactory.getLogger(SpringLifeCycleAware.class);
+
+ private ApplicationContext applicationContext ;
+
+ @Override
+ public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
+ this.applicationContext = applicationContext ;
+ LOGGER.info("SpringLifeCycleAware start");
+ }
+}
+```
+
+这样在 `springLifeCycleAware` 这个 bean 初始化会就会调用 `setApplicationContext` 方法,并可以获得 `applicationContext` 对象。
+
+### BeanPostProcessor 增强处理器
+
+实现 BeanPostProcessor 接口,Spring 中所有 bean 在做初始化时都会调用该接口中的两个方法,可以用于对一些特殊的 bean 进行处理:
+
+```java
+@Component
+public class SpringLifeCycleProcessor implements BeanPostProcessor {
+ private final static Logger LOGGER = LoggerFactory.getLogger(SpringLifeCycleProcessor.class);
+
+ /**
+ * 预初始化 初始化之前调用
+ * @param bean
+ * @param beanName
+ * @return
+ * @throws BeansException
+ */
+ @Override
+ public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
+ if ("annotationBean".equals(beanName)){
+ LOGGER.info("SpringLifeCycleProcessor start beanName={}",beanName);
+ }
+ return bean;
+ }
+
+ /**
+ * 后初始化 bean 初始化完成调用
+ * @param bean
+ * @param beanName
+ * @return
+ * @throws BeansException
+ */
+ @Override
+ public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
+ if ("annotationBean".equals(beanName)){
+ LOGGER.info("SpringLifeCycleProcessor end beanName={}",beanName);
+ }
+ return bean;
+ }
+}
+```
+
+执行之后观察结果:
+
+```
+018-03-21 00:40:24.856 [restartedMain] INFO c.c.s.p.SpringLifeCycleProcessor - SpringLifeCycleProcessor start beanName=annotationBean
+2018-03-21 00:40:24.860 [restartedMain] INFO c.c.spring.annotation.AnnotationBean - AnnotationBean start
+2018-03-21 00:40:24.861 [restartedMain] INFO c.c.s.p.SpringLifeCycleProcessor - SpringLifeCycleProcessor end beanName=annotationBean
+2018-03-21 00:40:24.864 [restartedMain] INFO c.c.s.aware.SpringLifeCycleAware - SpringLifeCycleAware start
+2018-03-21 00:40:24.867 [restartedMain] INFO c.c.s.service.SpringLifeCycleService - SpringLifeCycleService start
+2018-03-21 00:40:24.887 [restartedMain] INFO c.c.spring.SpringLifeCycle - SpringLifeCycle start
+2018-03-21 00:40:25.062 [restartedMain] INFO o.s.b.d.a.OptionalLiveReloadServer - LiveReload server is running on port 35729
+2018-03-21 00:40:25.122 [restartedMain] INFO o.s.j.e.a.AnnotationMBeanExporter - Registering beans for JMX exposure on startup
+2018-03-21 00:40:25.140 [restartedMain] INFO com.crossoverjie.Application - Started Application in 2.309 seconds (JVM running for 3.681)
+2018-03-21 00:40:25.143 [restartedMain] INFO com.crossoverjie.Application - start ok!
+2018-03-21 00:40:25.153 [Thread-8] INFO o.s.c.a.AnnotationConfigApplicationContext - Closing org.springframework.context.annotation.AnnotationConfigApplicationContext@3913adad: startup date [Wed Mar 21 00:40:23 CST 2018]; root of context hierarchy
+2018-03-21 00:40:25.155 [Thread-8] INFO o.s.j.e.a.AnnotationMBeanExporter - Unregistering JMX-exposed beans on shutdown
+2018-03-21 00:40:25.156 [Thread-8] INFO c.c.spring.SpringLifeCycle - SpringLifeCycle destroy
+2018-03-21 00:40:25.156 [Thread-8] INFO c.c.s.service.SpringLifeCycleService - SpringLifeCycleService destroy
+2018-03-21 00:40:25.156 [Thread-8] INFO c.c.spring.annotation.AnnotationBean - AnnotationBean destroy
+```
+
+直到 Spring 上下文销毁时则会调用自定义的销毁方法以及实现了 `DisposableBean` 的 `destroy()` 方法。
+
diff --git a/docs/index.html b/docs/index.html
new file mode 100644
index 00000000..d235b3fc
--- /dev/null
+++ b/docs/index.html
@@ -0,0 +1,43 @@
+
+
+
+
+ JCSprout
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
diff --git a/docs/jvm/ClassLoad.md b/docs/jvm/ClassLoad.md
new file mode 100644
index 00000000..3578ad71
--- /dev/null
+++ b/docs/jvm/ClassLoad.md
@@ -0,0 +1,17 @@
+# 类加载机制
+
+## 双亲委派模型
+
+模型如下图:
+
+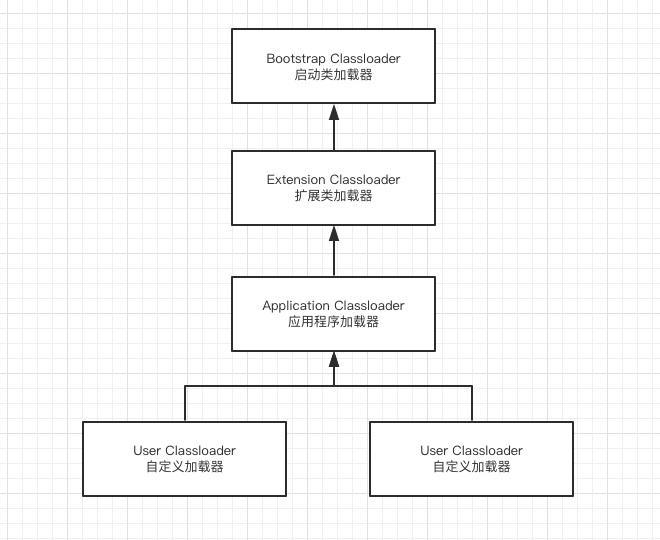
+
+双亲委派模型中除了启动类加载器之外其余都需要有自己的父类加载器
+
+当一个类收到了类加载请求时: 自己不会首先加载,而是委派给父加载器进行加载,每个层次的加载器都是这样。
+
+所以最终每个加载请求都会经过启动类加载器。只有当父类加载返回不能加载时子加载器才会进行加载。
+
+双亲委派的好处 : 由于每个类加载都会经过最顶层的启动类加载器,比如 `java.lang.Object`这样的类在各个类加载器下都是同一个类(只有当两个类是由同一个类加载器加载的才有意义,这两个类才相等。)
+
+如果没有双亲委派模型,由各个类加载器自行加载的话。当用户自己编写了一个 `java.lang.Object`类,那样系统中就会出现多个 `Object`,这样 Java 程序中最基本的行为都无法保证,程序会变的非常混乱。
diff --git a/docs/jvm/GarbageCollection.md b/docs/jvm/GarbageCollection.md
new file mode 100644
index 00000000..eeb3a43a
--- /dev/null
+++ b/docs/jvm/GarbageCollection.md
@@ -0,0 +1,72 @@
+# 垃圾回收
+
+> 垃圾回收主要思考三件事情:
+
+- 哪种内存需要回收?
+- 什么时候回收?
+- 怎么回收?
+
+## 对象是否存活
+
+### 引用计数法
+
+这是一种非常简单易理解的回收算法。每当有一个地方引用一个对象的时候则在引用计数器上 +1,当失效的时候就 -1,无论什么时候计数器为 0 的时候则认为该对象死亡可以回收了。
+
+这种算法虽然简单高效,但是却无法解决**循环引用**的问题,因此 Java 虚拟机并没有采用这种算法。
+
+### 可达性分析算法
+主流的语言其实都是采用可达性分析算法:
+
+可达性算法是通过一个称为 `GC Roots` 的对象向下搜索,整个搜索路径就称为引用链,当一个对象到 `GC Roots` 没有任何引用链 `JVM` 就认为该对象是可以被回收的。
+
+
+
+如图:Object1、2、3、4 都是存活的对象,而 Object5、6、7都是可回收对象。
+
+可以用作 `GC-Roots` 的对象有:
+
+- 方法区中静态变量所引用的对象。
+- 虚拟机栈中所引用的对象。
+
+## 垃圾回收算法
+
+### 标记-清除算法
+
+标记清除算法分为两个步骤,标记和清除。
+首先将**不需要回收的对象**标记起来,然后再清除其余可回收对象。但是存在两个主要的问题:
+- 标记和清除的效率都不高。
+- 清除之后容易出现不连续内存,当需要分配一个较大内存时就不得不需要进行一次垃圾回收。
+
+标记清除过程如下:
+
+
+
+### 复制算法
+
+复制算法是将内存划分为两块大小相等的区域,每次使用时都只用其中一块区域,当发生垃圾回收时会将存活的对象全部复制到未使用的区域,然后对之前的区域进行全部回收。
+
+这样简单高效,而且还不存在标记清除算法中的内存碎片问题,但就是有点浪费内存。
+
+> 在新生代会使用该算法。
+
+新生代中分为一个 `Eden` 区和两个 `Survivor` 区。通常两个区域的比例是 `8:1:1` ,使用时会用到 `Eden` 区和其中一个 `Survivor` 区。当发生回收时则会将还存活的对象从 `Eden` ,`Survivor` 区拷贝到另一个 `Survivor` 区,当该区域内存也不足时则会使用分配担保利用老年代来存放内存。
+
+复制算法过程:
+
+
+
+
+### 标记整理算法
+
+复制算法如果在存活对象较多时效率明显会降低,特别是在老年代中并没有多余的内存区域可以提供内存担保。
+
+所以老年代中使用的时候`标记整理算法`,它的原理和`标记清除算法`类似,只是最后一步的清除改为了将存活对象全部移动到一端,然后再将边界之外的内存全部回收。
+
+
+
+### 分代回收算法
+现代多数的商用 `JVM` 的垃圾收集器都是采用的分代回收算法,和之前所提到的算法并没有新的内容。
+
+只是将 Java 堆分为了新生代和老年代。由于新生代中存活对象较少,所以采用**复制算法**,简单高效。
+
+而老年代中对象较多,并且没有可以担保的内存区域,所以一般采用**标记清除或者是标记整理算法**。
diff --git a/docs/jvm/JVM-concurrent-HashSet-problem.md b/docs/jvm/JVM-concurrent-HashSet-problem.md
new file mode 100755
index 00000000..f834b47a
--- /dev/null
+++ b/docs/jvm/JVM-concurrent-HashSet-problem.md
@@ -0,0 +1,251 @@
+
+
+
+
+# 背景
+
+上午刚到公司,准备开始一天的摸鱼之旅时突然收到了一封监控中心的邮件。
+
+心中暗道不好,因为监控系统从来不会告诉我应用完美无 `bug`,其实系统挺猥琐。
+
+
+
+打开邮件一看,果然告知我有一个应用的线程池队列达到阈值触发了报警。
+
+由于这个应用出问题非常影响用户体验;于是立马让运维保留现场 `dump` 线程和内存同时重启应用,还好重启之后恢复正常。于是开始着手排查问题。
+
+
+
+# 分析
+
+首先了解下这个应用大概是做什么的。
+
+简单来说就是从 `MQ` 中取出数据然后丢到后面的业务线程池中做具体的业务处理。
+
+而报警的队列正好就是这个线程池的队列。
+
+
+
+跟踪代码发现构建线程池的方式如下:
+
+```java
+ThreadPoolExecutor executor = new ThreadPoolExecutor(coreSize, maxSize,
+ 0L, TimeUnit.MILLISECONDS,
+ new LinkedBlockingQueue());;
+ put(poolName,executor);
+```
+
+采用的是默认的 `LinkedBlockingQueue` 并没有指定大小(这也是个坑),于是这个队列的默认大小为 `Integer.MAX_VALUE`。
+
+由于应用已经重启,只能从仅存的线程快照和内存快照进行分析。
+
+
+
+## 内存分析
+
+先利用 `MAT` 分析了内存,的到了如下报告。
+
+
+
+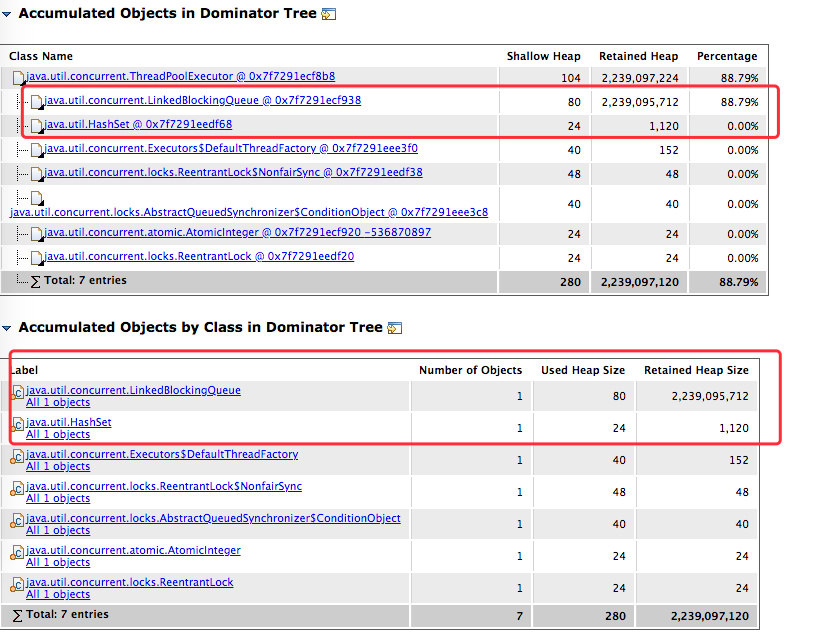
+
+
+
+其中有两个比较大的对象,一个就是之前线程池存放任务的 `LinkedBlockingQueue`,还有一个则是 `HashSet`。
+
+
+
+当然其中队列占用了大量的内存,所以优先查看,`HashSet` 一会儿再看。
+
+
+
+> 由于队列的大小给的够大,所以结合目前的情况来看应当是线程池里的任务处理较慢,导致队列的任务越堆越多,至少这是目前可以得出的结论。
+
+
+
+## 线程分析
+
+再来看看线程的分析,这里利用 [fastthread.io](http://fastthread.io/index.jsp) 这个网站进行线程分析。
+
+因为从表现来看线程池里的任务迟迟没有执行完毕,所以主要看看它们在干嘛。
+
+
+
+正好他们都处于 **RUNNABLE** 状态,同时堆栈如下:
+
+
+
+
+
+发现正好就是在处理上文提到的 `HashSet`,看这个堆栈是在查询 `key` 是否存在。通过查看 312 行的业务代码确实也是如此。
+
+
+
+> 这里的线程名字也是个坑,让我找了好久。
+
+
+
+# 定位
+
+分析了内存和线程的堆栈之后其实已经大概猜出一些问题了。
+
+
+
+这里其实有一个前提忘记讲到:
+
+这个告警是`凌晨三点`发出的邮件,但并没有电话提醒之类的,所以大家都不知道。
+
+到了早上上班时才发现并立即 `dump` 了上面的证据。
+
+
+
+所有有一个很重要的事实:**这几个业务线程在查询 `HashSet` 的时候运行了 6 7 个小时都没有返回**。
+
+
+
+通过之前的监控曲线图也可以看出:
+
+
+
+操作系统在之前一直处于高负载中,直到我们早上看到报警重启之后才降低。
+
+
+
+同时发现这个应用生产上运行的是 `JDK1.7` ,所以我初步认为应该是在查询 key 的时候进入了 `HashMap` 的环形链表导致 `CPU` 高负载同时也进入了死循环。
+
+
+
+为了验证这个问题再次 review 了代码。
+
+
+
+整理之后的伪代码如下:
+
+```java
+//线程池
+private ExecutorService executor;
+
+private Set set = new hashSet();
+
+private void execute(){
+
+ while(true){
+ //从 MQ 中获取数据
+ String key = subMQ();
+ executor.excute(new Worker(key)) ;
+ }
+}
+
+public class Worker extends Thread{
+ private String key ;
+
+ public Worker(String key){
+ this.key = key;
+ }
+
+ @Override
+ private void run(){
+ if(!set.contains(key)){
+
+ //数据库查询
+ if(queryDB(key)){
+ set.add(key);
+ return;
+ }
+ }
+
+ //达到某种条件时清空 set
+ if(flag){
+ set = null ;
+ }
+ }
+}
+```
+
+大致的流程如下:
+
+- 源源不断的从 MQ 中获取数据。
+- 将数据丢到业务线程池中。
+- 判断数据是否已经写入了 `Set`。
+- 没有则查询数据库。
+- 之后写入到 `Set` 中。
+
+
+
+这里有一个很明显的问题,**那就是作为共享资源的 Set 并没有做任何的同步处理**。
+
+这里会有多个线程并发的操作,由于 `HashSet` 其实本质上就是 `HashMap`,所以它肯定是线程不安全的,所以会出现两个问题:
+
+
+
+- Set 中的数据在并发写入时被覆盖导致数据不准确。
+- **会在扩容的时候形成环形链表**。
+
+第一个问题相对于第二个还能接受。
+
+
+
+通过上文的内存分析我们已经知道这个 set 中的数据已经不少了。同时由于初始化时并没有指定大小,仅仅只是默认值,所以在大量的并发写入时候会导致频繁的扩容,而在 1.7 的条件下又可能会形成**环形链表**。
+
+
+
+不巧的是代码中也有查询操作(`contains()`),观察上文的堆栈情况:
+
+
+
+发现是运行在 `HashMap` 的 465 行,来看看 1.7 中那里具体在做什么:
+
+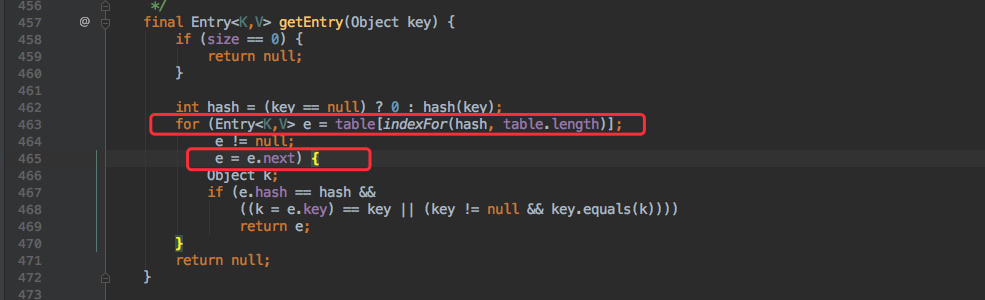
+
+已经很明显了。这里在遍历链表,同时由于形成了环形链表导致这个 `e.next` 永远不为空,所以这个循环也不会退出了。
+
+
+
+到这里其实已经找到问题了,但还有一个疑问是为什么线程池里的任务队列会越堆越多。我第一直觉是任务执行太慢导致的。
+
+
+
+仔细查看了代码发现只有一个地方可能会慢:也就是有一个**数据库的查询**。
+
+
+
+把这个 SQL 拿到生产环境执行发现确实不快,查看索引发现都有命中。
+
+
+
+但我一看表中的数据发现已经快有 **7000W** 的数据了。同时经过运维得知 `MySQL` 那台服务器的 `IO` 压力也比较大。
+
+所以这个原因也比较明显了:
+
+> 由于每消费一条数据都要去查询一次数据库,MySQL 本身压力就比较大,加上数据量也很高所以导致这个 IO 响应较慢,导致整个任务处理的就比较慢了。
+
+但还有一个原因也不能忽视;由于所有的业务线程在某个时间点都进入了死循环,根本没有执行完任务的机会,而后面的数据还在源源不断的进入,所以这个队列只会越堆越多!
+
+
+
+这其实是一个老应用了,可能会有人问为什么之前没出现问题。
+
+这是因为之前数据量都比较少,即使是并发写入也没有出现并发扩容形成环形链表的情况。这段时间业务量的暴增正好把这个隐藏的雷给揪出来了。所以还是得信墨菲他老人家的话。
+
+
+
+# 总结
+
+
+
+至此整个排查结束,而我们后续的调整措施大概如下:
+
+- `HashSet` 不是线程安全的,换为 `ConcurrentHashMap`同时把 `value` 写死一样可以达到 `set` 的效果。
+- 根据我们后面的监控,初始化 `ConcurrentHashMap` 的大小尽量大一些,避免频繁的扩容。
+- `MySQL` 中很多数据都已经不用了,进行冷热处理。尽量降低单表数据量。同时后期考虑分表。
+- 查数据那里调整为查缓存,提高查询效率。
+- 线程池的名称一定得取的有意义,不然是自己给自己增加难度。
+- 根据监控将线程池的队列大小调整为一个具体值,并且要有拒绝策略。
+- 升级到 `JDK1.8`。
+- 再一个是报警邮件酌情考虑为电话通知😂。
+
+
+
+`HashMap` 的死循环问题在网上层出不穷,没想到还真被我遇到了。现在要满足这个条件还是挺少见的,比如 1.8 以下的 `JDK` 这一条可能大多数人就碰不到,正好又证实了一次墨菲定律。
+
+**你的点赞与分享是对我最大的支持**
diff --git a/docs/jvm/MemoryAllocation.md b/docs/jvm/MemoryAllocation.md
new file mode 100644
index 00000000..ce615e40
--- /dev/null
+++ b/docs/jvm/MemoryAllocation.md
@@ -0,0 +1,93 @@
+# Java 运行时的内存划分
+
+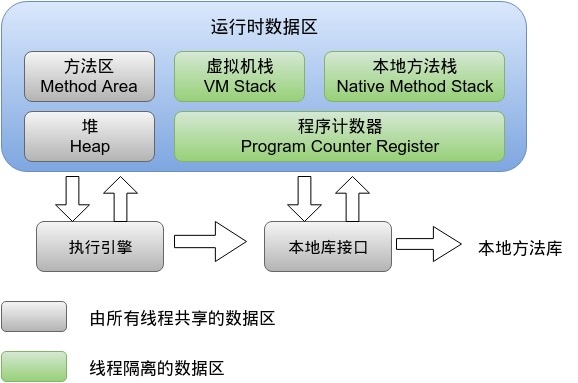
+
+## 程序计数器
+
+记录当前线程所执行的字节码行号,用于获取下一条执行的字节码。
+
+当多线程运行时,每个线程切换后需要知道上一次所运行的状态、位置。由此也可以看出程序计数器是每个线程**私有**的。
+
+
+## 虚拟机栈
+虚拟机栈由一个一个的栈帧组成,栈帧是在每一个方法调用时产生的。
+
+每一个栈帧由`局部变量区`、`操作数栈`等组成。每创建一个栈帧压栈,当一个方法执行完毕之后则出栈。
+
+> - 如果出现方法递归调用出现死循环的话就会造成栈帧过多,最终会抛出 `StackOverflowError`。
+> - 若线程执行过程中栈帧大小超出虚拟机栈限制,则会抛出 `StackOverflowError`。
+> - 若虚拟机栈允许动态扩展,但在尝试扩展时内存不足,或者在为一个新线程初始化新的虚拟机栈时申请不到足够的内存,则会抛出
+ `OutOfMemoryError`。
+
+**这块内存区域也是线程私有的。**
+
+## Java 堆
+`Java` 堆是整个虚拟机所管理的最大内存区域,所有的对象创建都是在这个区域进行内存分配。
+
+可利用参数 `-Xms -Xmx` 进行堆内存控制。
+
+这块区域也是垃圾回收器重点管理的区域,由于大多数垃圾回收器都采用`分代回收算法`,所有堆内存也分为 `新生代`、`老年代`,可以方便垃圾的准确回收。
+
+**这块内存属于线程共享区域。**
+
+## 方法区(JDK1.7)
+
+方法区主要用于存放已经被虚拟机加载的类信息,如`常量,静态变量`。
+这块区域也被称为`永久代`。
+
+可利用参数 `-XX:PermSize -XX:MaxPermSize` 控制初始化方法区和最大方法区大小。
+
+
+
+## 元数据区(JDK1.8)
+
+在 `JDK1.8` 中已经移除了方法区(永久代),并使用了一个元数据区域进行代替(`Metaspace`)。
+
+默认情况下元数据区域会根据使用情况动态调整,避免了在 1.7 中由于加载类过多从而出现 `java.lang.OutOfMemoryError: PermGen`。
+
+但也不能无线扩展,因此可以使用 `-XX:MaxMetaspaceSize`来控制最大内存。
+
+
+
+
+
+## 运行时常量池
+
+运行时常量池是方法区的一部分,其中存放了一些符号引用。当 `new` 一个对象时,会检查这个区域是否有这个符号的引用。
+
+
+
+## 直接内存
+
+
+
+直接内存又称为 `Direct Memory(堆外内存)`,它并不是由 `JVM` 虚拟机所管理的一块内存区域。
+
+有使用过 `Netty` 的朋友应该对这块并内存不陌生,在 `Netty` 中所有的 IO(nio) 操作都会通过 `Native` 函数直接分配堆外内存。
+
+它是通过在堆内存中的 `DirectByteBuffer` 对象操作的堆外内存,避免了堆内存和堆外内存来回复制交换复制,这样的高效操作也称为`零拷贝`。
+
+既然是内存,那也得是可以被回收的。但由于堆外内存不直接受 `JVM` 管理,所以常规 `GC` 操作并不能回收堆外内存。它是借助于老年代产生的 `fullGC` 顺便进行回收。同时也可以显式调用 `System.gc()` 方法进行回收(前提是没有使用 `-XX:+DisableExplicitGC` 参数来禁止该方法)。
+
+**值得注意的是**:由于堆外内存也是内存,是由操作系统管理。如果应用有使用堆外内存则需要平衡虚拟机的堆内存和堆外内存的使用占比。避免出现堆外内存溢出。
+
+## 常用参数
+
+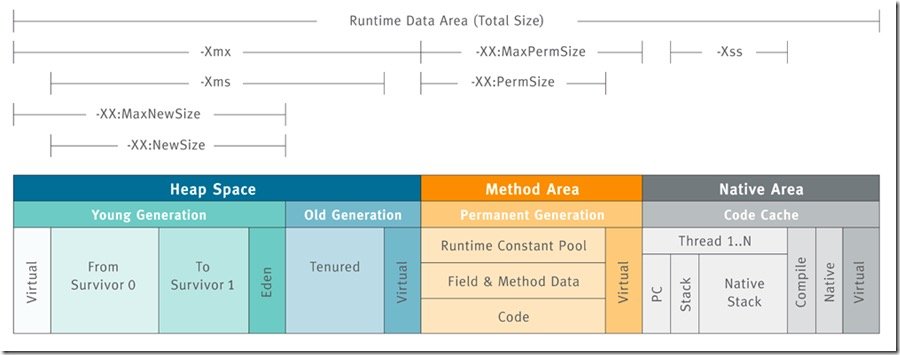
+
+通过上图可以直观的查看各个区域的参数设置。
+
+常见的如下:
+
+- `-Xms64m` 最小堆内存 `64m`.
+- `-Xmx128m` 最大堆内存 `128m`.
+- `-XX:NewSize=30m` 新生代初始化大小为`30m`.
+- `-XX:MaxNewSize=40m` 新生代最大大小为`40m`.
+- `-Xss=256k` 线程栈大小。
+- `-XX:+PrintHeapAtGC` 当发生 GC 时打印内存布局。
+- `-XX:+HeapDumpOnOutOfMemoryError` 发送内存溢出时 dump 内存。
+
+
+新生代和老年代的默认比例为 `1:2`,也就是说新生代占用 `1/3`的堆内存,而老年代占用 `2/3` 的堆内存。
+
+可以通过参数 `-XX:NewRatio=2` 来设置老年代/新生代的比例。
diff --git a/docs/jvm/OOM-Disruptor.md b/docs/jvm/OOM-Disruptor.md
new file mode 100644
index 00000000..c9f32f7b
--- /dev/null
+++ b/docs/jvm/OOM-Disruptor.md
@@ -0,0 +1,125 @@
+
+
+# 前言
+
+`OutOfMemoryError` 问题相信很多朋友都遇到过,相对于常见的业务异常(数组越界、空指针等)来说这类问题是很难定位和解决的。
+
+本文以最近碰到的一次线上内存溢出的定位、解决问题的方式展开;希望能对碰到类似问题的同学带来思路和帮助。
+
+主要从`表现-->排查-->定位-->解决` 四个步骤来分析和解决问题。
+
+
+
+# 表象
+
+最近我们生产上的一个应用不断的爆出内存溢出,并且随着业务量的增长出现的频次越来越高。
+
+该程序的业务逻辑非常简单,就是从 Kafka 中将数据消费下来然后批量的做持久化操作。
+
+而现象则是随着 Kafka 的消息越多,出现的异常的频次就越快。由于当时还有其他工作所以只能让运维做重启,并且监控好堆内存以及 GC 情况。
+
+> 重启大法虽好,可是依然不能根本解决问题。
+
+# 排查
+
+于是我们想根据运维之前收集到的内存数据、GC 日志尝试判断哪里出现问题。
+
+
+
+结果发现老年代的内存使用就算是发生 GC 也一直居高不下,而且随着时间推移也越来越高。
+
+结合 jstat 的日志发现就算是发生了 FGC 老年代也已经回收不了,内存已经到顶。
+
+
+
+甚至有几台应用 FGC 达到了上百次,时间也高的可怕。
+
+这说明应用的内存使用肯定是有问题的,有许多赖皮对象始终回收不掉。
+
+# 定位
+
+由于生产上的内存 dump 文件非常大,达到了几十G。也是由于我们的内存设置太大有关。
+
+所以导致想使用 MAT 分析需要花费大量时间。
+
+因此我们便想是否可以在本地复现,这样就要好定位的多。
+
+为了尽快的复现问题,我将本地应用最大堆内存设置为 150M。
+
+
+然后在消费 Kafka 那里 Mock 为一个 while 循环一直不断的生成数据。
+
+同时当应用启动之后利用 VisualVM 连上应用实时监控内存、GC 的使用情况。
+
+结果跑了 10 几分钟内存使用并没有什么问题。根据图中可以看出,每产生一次 GC 内存都能有效的回收,所以这样并没有复现问题。
+
+
+
+
+没法复现问题就很难定位了。于是我们 review 代码,发现生产的逻辑和我们用 while 循环 Mock 数据还不太一样。
+
+查看生产的日志发现每次从 Kafka 中取出的都是几百条数据,而我们 Mock 时每次只能产生**一条**。
+
+为了尽可能的模拟生产情况便在服务器上跑着一个生产者程序,一直源源不断的向 Kafka 中发送数据。
+
+果然不出意外只跑了一分多钟内存就顶不住了,观察左图发现 GC 的频次非常高,但是内存的回收却是相形见拙。
+
+
+
+同时后台也开始打印内存溢出了,这样便复现出问题。
+
+# 解决
+
+从目前的表现来看就是内存中有许多对象一直存在强引用关系导致得不到回收。
+
+于是便想看看到底是什么对象占用了这么多的内存,利用 VisualVM 的 HeapDump 功能可以立即 dump 出当前应用的内存情况。
+
+
+
+结果发现 `com.lmax.disruptor.RingBuffer` 类型的对象占用了将近 50% 的内存。
+
+看到这个包自然就想到了 `Disruptor` 环形队列。
+
+再次 review 代码发现:从 Kafka 里取出的 700 条数据是直接往 Disruptor 里丢的。
+
+这里也就能说明为什么第一次模拟数据没复现问题了。
+
+模拟的时候是一个对象放进队列里,而生产的情况是 700 条数据放进队列里。这个数据量是 700 倍的差距。
+
+而 Disruptor 作为一个环形队列,再对象没有被覆盖之前是一直存在的。
+
+我也做了一个实验,证明确实如此。
+
+
+
+我设置队列大小为 8 ,从 0~9 往里面写 10 条数据,当写到 8 的时候就会把之前 0 的位置覆盖掉,后面的以此类推(类似于 HashMap 的取模定位)。
+
+所以在生产上假设我们的队列大小是 1024,那么随着系统的运行最终肯定会导致 1024 个位置上装满了对象,而且每个位置是 700 个!
+
+于是查看了生产上 Disruptor 的 RingBuffer 配置,结果是:`1024*1024`。
+
+这个数量级就非常吓人了。
+
+为了验证是否是这个问题,我在本地将该值换为 2 ,一个最小值试试。
+
+同样的 128M 内存,也是通过 Kafka 一直源源不断的取出数据。通过监控如下:
+
+
+
+跑了 20 几分钟系统一切正常,每当一次 GC 都能回收大部分内存,最终呈现锯齿状。
+
+这样问题就找到了,不过生产上这个值具体设置多少还得根据业务情况测试才能知道,但原有的 1024*1024 是绝对不能再使用了。
+
+# 总结
+
+虽然到了最后也就改了一行代码(还没改,直接修改配置),但这排查过程我觉得是有意义的。
+
+也会让大部分觉得 JVM 这样的黑盒难以下手的同学有一个直观的感受。
+
+`同时也得感叹 Disruptor 东西虽好,也不能乱用哦!`
+
+相关演示代码查看:
+
+[https://github.com/crossoverJie/JCSprout/tree/master/src/main/java/com/crossoverjie/disruptor](https://github.com/crossoverJie/JCSprout/tree/master/src/main/java/com/crossoverjie/disruptor)
+
+**你的点赞与转发是最大的支持。**
diff --git a/docs/jvm/OOM-analysis.md b/docs/jvm/OOM-analysis.md
new file mode 100644
index 00000000..dee31454
--- /dev/null
+++ b/docs/jvm/OOM-analysis.md
@@ -0,0 +1,96 @@
+# OOM 分析
+
+## Java 堆内存溢出
+
+在 Java 堆中只要不断的创建对象,并且 `GC-Roots` 到对象之间存在引用链,这样 `JVM` 就不会回收对象。
+
+只要将`-Xms(最小堆)`,`-Xmx(最大堆)` 设置为一样禁止自动扩展堆内存。
+
+
+当使用一个 `while(true)` 循环来不断创建对象就会发生 `OutOfMemory`,还可以使用 `-XX:+HeapDumpOutofMemoryErorr` 当发生 OOM 时会自动 dump 堆栈到文件中。
+
+伪代码:
+
+```java
+ public static void main(String[] args) {
+ List list = new ArrayList<>(10) ;
+ while (true){
+ list.add("1") ;
+ }
+ }
+```
+
+当出现 OOM 时可以通过工具来分析 `GC-Roots` [引用链](https://github.com/crossoverJie/Java-Interview/blob/master/MD/GarbageCollection.md#%E5%8F%AF%E8%BE%BE%E6%80%A7%E5%88%86%E6%9E%90%E7%AE%97%E6%B3%95) ,查看对象和 `GC-Roots` 是如何进行关联的,是否存在对象的生命周期过长,或者是这些对象确实改存在的,那就要考虑将堆内存调大了。
+
+```
+Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
+ at java.util.Arrays.copyOf(Arrays.java:3210)
+ at java.util.Arrays.copyOf(Arrays.java:3181)
+ at java.util.ArrayList.grow(ArrayList.java:261)
+ at java.util.ArrayList.ensureExplicitCapacity(ArrayList.java:235)
+ at java.util.ArrayList.ensureCapacityInternal(ArrayList.java:227)
+ at java.util.ArrayList.add(ArrayList.java:458)
+ at com.crossoverjie.oom.HeapOOM.main(HeapOOM.java:18)
+ at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
+ at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
+ at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
+ at java.lang.reflect.Method.invoke(Method.java:498)
+ at com.intellij.rt.execution.application.AppMain.main(AppMain.java:147)
+
+Process finished with exit code 1
+
+```
+`java.lang.OutOfMemoryError: Java heap space`表示堆内存溢出。
+
+
+
+更多内存溢出相关实战请看这里:[强如 Disruptor 也发生内存溢出?](https://crossoverjie.top/2018/08/29/java-senior/OOM-Disruptor/)
+
+
+
+
+## MetaSpace (元数据) 内存溢出
+
+> `JDK8` 中将永久代移除,使用 `MetaSpace` 来保存类加载之后的类信息,字符串常量池也被移动到 Java 堆。
+
+`PermSize` 和 `MaxPermSize` 已经不能使用了,在 JDK8 中配置这两个参数将会发出警告。
+
+
+JDK 8 中将类信息移到到了本地堆内存(Native Heap)中,将原有的永久代移动到了本地堆中成为 `MetaSpace` ,如果不指定该区域的大小,JVM 将会动态的调整。
+
+可以使用 `-XX:MaxMetaspaceSize=10M` 来限制最大元数据。这样当不停的创建类时将会占满该区域并出现 `OOM`。
+
+```java
+ public static void main(String[] args) {
+ while (true){
+ Enhancer enhancer = new Enhancer() ;
+ enhancer.setSuperclass(HeapOOM.class);
+ enhancer.setUseCache(false) ;
+ enhancer.setCallback(new MethodInterceptor() {
+ @Override
+ public Object intercept(Object o, Method method, Object[] objects, MethodProxy methodProxy) throws Throwable {
+ return methodProxy.invoke(o,objects) ;
+ }
+ });
+ enhancer.create() ;
+
+ }
+ }
+```
+使用 `cglib` 不停的创建新类,最终会抛出:
+```
+Caused by: java.lang.reflect.InvocationTargetException
+ at sun.reflect.GeneratedMethodAccessor1.invoke(Unknown Source)
+ at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
+ at java.lang.reflect.Method.invoke(Method.java:498)
+ at net.sf.cglib.core.ReflectUtils.defineClass(ReflectUtils.java:459)
+ at net.sf.cglib.core.AbstractClassGenerator.generate(AbstractClassGenerator.java:336)
+ ... 11 more
+Caused by: java.lang.OutOfMemoryError: Metaspace
+ at java.lang.ClassLoader.defineClass1(Native Method)
+ at java.lang.ClassLoader.defineClass(ClassLoader.java:763)
+ ... 16 more
+```
+
+注意:这里的 OOM 伴随的是 `java.lang.OutOfMemoryError: Metaspace` 也就是元数据溢出。
+
diff --git a/docs/jvm/cpu-percent-100.md b/docs/jvm/cpu-percent-100.md
new file mode 100755
index 00000000..4c327b5f
--- /dev/null
+++ b/docs/jvm/cpu-percent-100.md
@@ -0,0 +1,152 @@
+
+
+
+
+# 前言
+
+到了年底果然都不太平,最近又收到了运维报警:表示有些服务器负载非常高,让我们定位问题。
+
+还真是想什么来什么,前些天还故意把某些服务器的负载提高([没错,老板让我写个 BUG!](https://crossoverjie.top/2018/12/12/java-senior/java-memary-allocation/)),不过还好是不同的环境互相没有影响。
+
+
+
+
+# 定位问题
+
+拿到问题后首先去服务器上看了看,发现运行的只有我们的 Java 应用。于是先用 `ps` 命令拿到了应用的 `PID`。
+
+接着使用 `top -Hp pid` 将这个进程的线程显示出来。输入大写的 P 可以将线程按照 CPU 使用比例排序,于是得到以下结果。
+
+
+
+果然某些线程的 CPU 使用率非常高。
+
+
+为了方便定位问题我立马使用 `jstack pid > pid.log` 将线程栈 `dump` 到日志文件中。
+
+我在上面 100% 的线程中随机选了一个 `pid=194283` 转换为 16 进制(2f6eb)后在线程快照中查询:
+
+> 因为线程快照中线程 ID 都是16进制存放。
+
+
+
+发现这是 `Disruptor` 的一个堆栈,前段时间正好解决过一个由于 Disruptor 队列引起的一次 [OOM]():[强如 Disruptor 也发生内存溢出?](https://crossoverjie.top/2018/08/29/java-senior/OOM-Disruptor/)
+
+没想到又来一出。
+
+为了更加直观的查看线程的状态信息,我将快照信息上传到专门分析的平台上。
+
+[http://fastthread.io/](http://fastthread.io/)
+
+
+
+其中有一项菜单展示了所有消耗 CPU 的线程,我仔细看了下发现几乎都是和上面的堆栈一样。
+
+也就是说都是 `Disruptor` 队列的堆栈,同时都在执行 `java.lang.Thread.yield` 函数。
+
+众所周知 `yield` 函数会让当前线程让出 `CPU` 资源,再让其他线程来竞争。
+
+根据刚才的线程快照发现处于 `RUNNABLE` 状态并且都在执行 `yield` 函数的线程大概有 30几个。
+
+因此初步判断为大量线程执行 `yield` 函数之后互相竞争导致 CPU 使用率增高,而通过对堆栈发现是和使用 `Disruptor` 有关。
+
+# 解决问题
+
+而后我查看了代码,发现是根据每一个业务场景在内部都会使用 2 个 `Disruptor` 队列来解耦。
+
+假设现在有 7 个业务类型,那就等于是创建 `2*7=14` 个 `Disruptor` 队列,同时每个队列有一个消费者,也就是总共有 14 个消费者(生产环境更多)。
+
+同时发现配置的消费等待策略为 `YieldingWaitStrategy` 这种等待策略确实会执行 yield 来让出 CPU。
+
+代码如下:
+
+
+
+> 初步看来和这个等待策略有很大的关系。
+
+## 本地模拟
+
+为了验证,我在本地创建了 15 个 `Disruptor` 队列同时结合监控观察 CPU 的使用情况。
+
+
+
+
+创建了 15 个 `Disruptor` 队列,同时每个队列都用线程池来往 `Disruptor队列` 里面发送 100W 条数据。
+
+消费程序仅仅只是打印一下。
+
+
+
+跑了一段时间发现 CPU 使用率确实很高。
+
+---
+
+
+
+同时 `dump` 线程发现和生产的现象也是一致的:消费线程都处于 `RUNNABLE` 状态,同时都在执行 `yield`。
+
+通过查询 `Disruptor` 官方文档发现:
+
+
+
+> YieldingWaitStrategy 是一种充分压榨 CPU 的策略,使用`自旋 + yield`的方式来提高性能。
+> 当消费线程(Event Handler threads)的数量小于 CPU 核心数时推荐使用该策略。
+
+---
+
+
+
+同时查阅到其他的等待策略 `BlockingWaitStrategy` (也是默认的策略),它使用的是锁的机制,对 CPU 的使用率不高。
+
+于是在和之前同样的条件下将等待策略换为 `BlockingWaitStrategy`。
+
+
+
+---
+
+
+
+
+和刚才的 CPU 对比会发现到后面使用率的会有明显的降低;同时 dump 线程后会发现大部分线程都处于 waiting 状态。
+
+
+## 优化解决
+
+看样子将等待策略换为 `BlockingWaitStrategy` 可以减缓 CPU 的使用,
+
+但留意到官方对 `YieldingWaitStrategy` 的描述里谈道:
+当消费线程(Event Handler threads)的数量小于 CPU 核心数时推荐使用该策略。
+
+而现有的使用场景很明显消费线程数已经大大的超过了核心 CPU 数了,因为我的使用方式是一个 `Disruptor` 队列一个消费者,所以我将队列调整为只有 1 个再试试(策略依然是 `YieldingWaitStrategy`)。
+
+
+
+
+
+跑了一分钟,发现 CPU 的使用率一直都比较平稳而且不高。
+
+# 总结
+
+所以排查到此可以有一个结论了,想要根本解决这个问题需要将我们现有的业务拆分;现在是一个应用里同时处理了 N 个业务,每个业务都会使用好几个 `Disruptor` 队列。
+
+由于是在一台服务器上运行,所以 CPU 资源都是共享的,这就会导致 CPU 的使用率居高不下。
+
+所以我们的调整方式如下:
+
+- 为了快速缓解这个问题,先将等待策略换为 `BlockingWaitStrategy`,可以有效降低 CPU 的使用率(业务上也还能接受)。
+- 第二步就需要将应用拆分(上文模拟的一个 `Disruptor` 队列),一个应用处理一种业务类型;然后分别单独部署,这样也可以互相隔离互不影响。
+
+当然还有其他的一些优化,因为这也是一个老系统了,这次 dump 线程居然发现创建了 800+ 的线程。
+
+创建线程池的方式也是核心线程数、最大线程数是一样的,导致一些空闲的线程也得不到回收;这样会有很多无意义的资源消耗。
+
+所以也会结合业务将创建线程池的方式调整一下,将线程数降下来,尽量的物尽其用。
+
+
+本文的演示代码已上传至 GitHub:
+
+[https://github.com/crossoverJie/JCSprout](https://github.com/crossoverJie/JCSprout/tree/master/src/main/java/com/crossoverjie/disruptor)
+
+**你的点赞与分享是对我最大的支持**
+
+
diff --git a/docs/jvm/newObject.md b/docs/jvm/newObject.md
new file mode 100644
index 00000000..4542db99
--- /dev/null
+++ b/docs/jvm/newObject.md
@@ -0,0 +1,77 @@
+# 对象的创建与内存分配
+
+
+## 创建对象
+
+当 `JVM` 收到一个 `new` 指令时,会检查指令中的参数在常量池是否有这个符号的引用,还会检查该类是否已经被[加载](https://github.com/crossoverJie/Java-Interview/blob/master/MD/ClassLoad.md)过了,如果没有的话则要进行一次类加载。
+
+接着就是分配内存了,通常有两种方式:
+
+- 指针碰撞
+- 空闲列表
+
+使用指针碰撞的前提是堆内存是**完全工整**的,用过的内存和没用的内存各在一边每次分配的时候只需要将指针向空闲内存一方移动一段和内存大小相等区域即可。
+
+当堆中已经使用的内存和未使用的内存**互相交错**时,指针碰撞的方式就行不通了,这时就需要采用空闲列表的方式。虚拟机会维护一个空闲的列表,用于记录哪些内存是可以进行分配的,分配时直接从可用内存中直接分配即可。
+
+堆中的内存是否工整是有**垃圾收集器**来决定的,如果带有压缩功能的垃圾收集器就是采用指针碰撞的方式来进行内存分配的。
+
+分配内存时也会出现并发问题:
+
+这样可以在创建对象的时候使用 `CAS` 这样的乐观锁来保证。
+
+也可以将内存分配安排在每个线程独有的空间进行,每个线程首先在堆内存中分配一小块内存,称为本地分配缓存(`TLAB : Thread Local Allocation Buffer`)。
+
+分配内存时,只需要在自己的分配缓存中分配即可,由于这个内存区域是线程私有的,所以不会出现并发问题。
+
+可以使用 `-XX:+/-UseTLAB` 参数来设定 `JVM` 是否开启 `TLAB` 。
+
+内存分配之后需要对该对象进行设置,如对象头。对象头的一些应用可以查看 [Synchronize 关键字原理](https://github.com/crossoverJie/Java-Interview/blob/master/MD/Synchronize.md)。
+
+### 对象访问
+
+一个对象被创建之后自然是为了使用,在 `Java` 中是通过栈来引用堆内存中的对象来进行操作的。
+
+对于我们常用的 `HotSpot` 虚拟机来说,这样引用关系是通过直接指针来关联的。
+
+如图:
+
+
+
+这样的好处就是:在 Java 里进行频繁的对象访问可以提升访问速度(相对于使用句柄池来说)。
+
+## 内存分配
+
+
+### Eden 区分配
+简单的来说对象都是在堆内存中分配的,往细一点看则是优先在 `Eden` 区分配。
+
+这里就涉及到堆内存的划分了,为了方便垃圾回收,JVM 将堆内存分为新生代和老年代。
+
+而新生代中又会划分为 `Eden` 区,`from Survivor、to Survivor` 区。
+
+其中 `Eden` 和 `Survivor` 区的比例默认是 `8:1:1`,当然也支持参数调整 `-XX:SurvivorRatio=8`。
+
+当在 `Eden` 区分配内存不足时,则会发生 `minorGC` ,由于 `Java` 对象多数是**朝生夕灭**的特性,所以 `minorGC` 通常会比较频繁,效率也比较高。
+
+当发生 `minorGC` 时,JVM 会根据[复制算法](https://github.com/crossoverJie/Java-Interview/blob/master/MD/GarbageCollection.md#%E5%A4%8D%E5%88%B6%E7%AE%97%E6%B3%95)将存活的对象拷贝到另一个未使用的 `Survivor` 区,如果 `Survivor` 区内存不足时,则会使用分配担保策略将对象移动到老年代中。
+
+谈到 `minorGC` 时,就不得不提到 `fullGC(majorGC)` ,这是指发生在老年代的 `GC` ,不论是效率还是速度都比 `minorGC` 慢的多,回收时还会发生 `stop the world` 使程序发生停顿,所以应当尽量避免发生 `fullGC` 。
+
+### 老年代分配
+
+也有一些情况会导致对象直接在老年代分配,比如当分配一个大对象时(大的数组,很长的字符串),由于 `Eden` 区没有足够大的连续空间来分配时,会导致提前触发一次 `GC`,所以尽量别频繁的创建大对象。
+
+因此 `JVM` 会根据一个阈值来判断大于该阈值对象直接分配到老年代,这样可以避免在新生代频繁的发生 `GC`。
+
+
+对于一些在新生代的老对象 `JVM` 也会根据某种机制移动到老年代中。
+
+JVM 是根据记录对象年龄的方式来判断该对象是否应该移动到老年代,根据新生代的复制算法,当一个对象被移动到 `Survivor` 区之后 JVM 就给该对象的年龄记为1,每当熬过一次 `minorGC` 后对象的年龄就 +1 ,直到达到阈值(默认为15)就移动到老年代中。
+
+> 可以使用 `-XX:MaxTenuringThreshold=15` 来配置这个阈值。
+
+
+## 总结
+
+虽说这些内容略显枯燥,但当应用发生不正常的 `GC` 时,可以方便更快的定位问题。
diff --git a/docs/jvm/volatile.md b/docs/jvm/volatile.md
new file mode 100644
index 00000000..3110e2c6
--- /dev/null
+++ b/docs/jvm/volatile.md
@@ -0,0 +1,218 @@
+# 你应该知道的 volatile 关键字
+
+## 前言
+
+不管是在面试还是实际开发中 `volatile` 都是一个应该掌握的技能。
+
+首先来看看为什么会出现这个关键字。
+
+## 内存可见性
+由于 `Java` 内存模型(`JMM`)规定,所有的变量都存放在主内存中,而每个线程都有着自己的工作内存(高速缓存)。
+
+线程在工作时,需要将主内存中的数据拷贝到工作内存中。这样对数据的任何操作都是基于工作内存(效率提高),并且不能直接操作主内存以及其他线程工作内存中的数据,之后再将更新之后的数据刷新到主内存中。
+
+> 这里所提到的主内存可以简单认为是**堆内存**,而工作内存则可以认为是**栈内存**。
+
+如下图所示:
+
+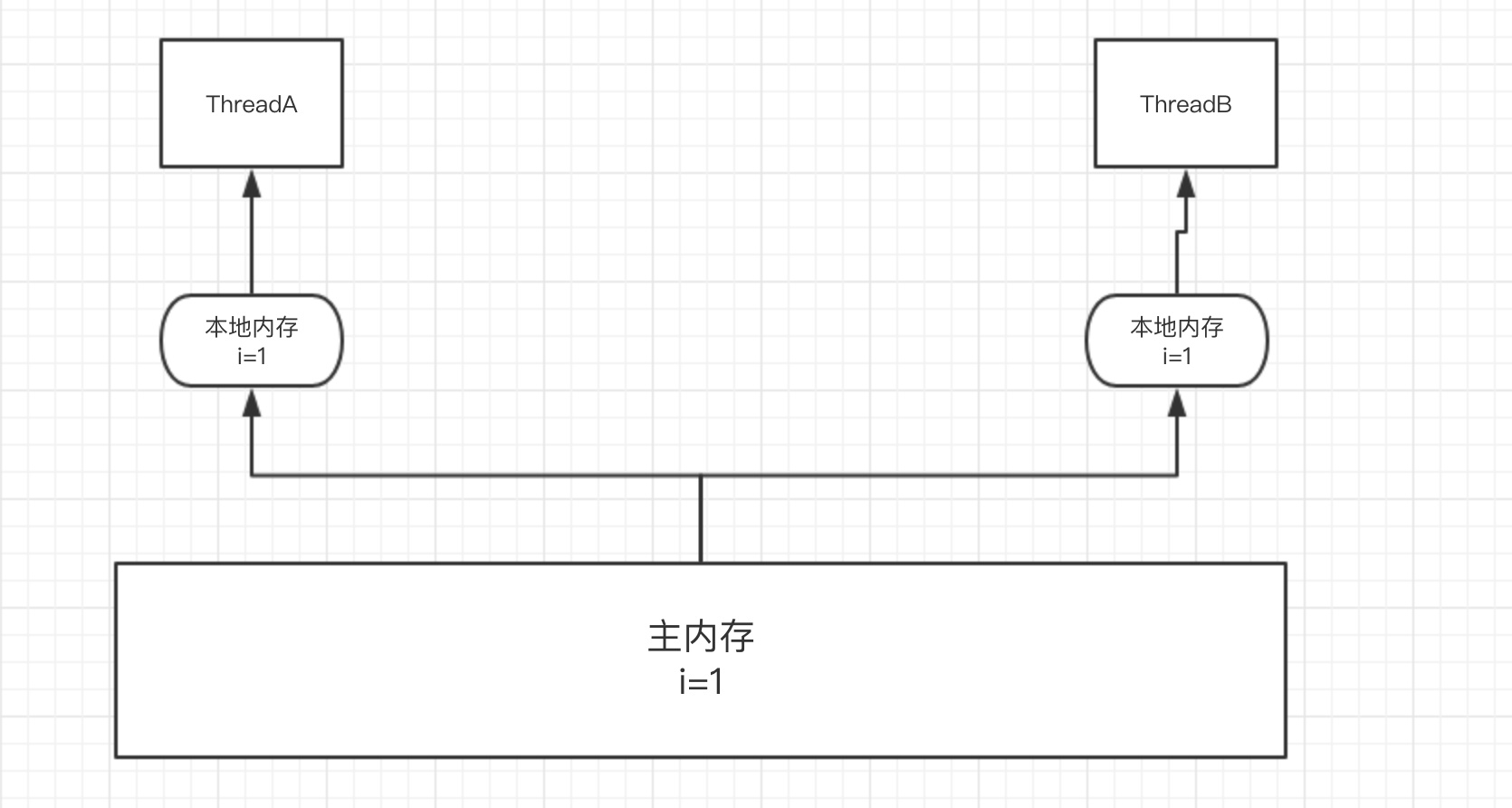
+
+所以在并发运行时可能会出现线程 B 所读取到的数据是线程 A 更新之前的数据。
+
+显然这肯定是会出问题的,因此 `volatile` 的作用出现了:
+
+> 当一个变量被 `volatile` 修饰时,任何线程对它的写操作都会立即刷新到主内存中,并且会强制让缓存了该变量的线程中的数据清空,必须从主内存重新读取最新数据。
+
+*`volatile` 修饰之后并不是让线程直接从主内存中获取数据,依然需要将变量拷贝到工作内存中*。
+
+### 内存可见性的应用
+
+当我们需要在两个线程间依据主内存通信时,通信的那个变量就必须的用 `volatile` 来修饰:
+
+```java
+public class Volatile implements Runnable{
+
+ private static volatile boolean flag = true ;
+
+ @Override
+ public void run() {
+ while (flag){
+ }
+ System.out.println(Thread.currentThread().getName() +"执行完毕");
+ }
+
+ public static void main(String[] args) throws InterruptedException {
+ Volatile aVolatile = new Volatile();
+ new Thread(aVolatile,"thread A").start();
+
+
+ System.out.println("main 线程正在运行") ;
+
+ Scanner sc = new Scanner(System.in);
+ while(sc.hasNext()){
+ String value = sc.next();
+ if(value.equals("1")){
+
+ new Thread(new Runnable() {
+ @Override
+ public void run() {
+ aVolatile.stopThread();
+ }
+ }).start();
+
+ break ;
+ }
+ }
+
+ System.out.println("主线程退出了!");
+
+ }
+
+ private void stopThread(){
+ flag = false ;
+ }
+
+}
+```
+
+主线程在修改了标志位使得线程 A 立即停止,如果没有用 `volatile` 修饰,就有可能出现延迟。
+
+但这里有个误区,这样的使用方式容易给人的感觉是:
+
+> 对 `volatile` 修饰的变量进行并发操作是线程安全的。
+
+这里要重点强调,`volatile` 并**不能**保证线程安全性!
+
+如下程序:
+
+```java
+public class VolatileInc implements Runnable{
+
+ private static volatile int count = 0 ; //使用 volatile 修饰基本数据内存不能保证原子性
+
+ //private static AtomicInteger count = new AtomicInteger() ;
+
+ @Override
+ public void run() {
+ for (int i=0;i<10000 ;i++){
+ count ++ ;
+ //count.incrementAndGet() ;
+ }
+ }
+
+ public static void main(String[] args) throws InterruptedException {
+ VolatileInc volatileInc = new VolatileInc() ;
+ Thread t1 = new Thread(volatileInc,"t1") ;
+ Thread t2 = new Thread(volatileInc,"t2") ;
+ t1.start();
+ //t1.join();
+
+ t2.start();
+ //t2.join();
+ for (int i=0;i<10000 ;i++){
+ count ++ ;
+ //count.incrementAndGet();
+ }
+
+
+ System.out.println("最终Count="+count);
+ }
+}
+```
+
+当我们三个线程(t1,t2,main)同时对一个 `int` 进行累加时会发现最终的值都会小于 30000。
+
+> 这是因为虽然 `volatile` 保证了内存可见性,每个线程拿到的值都是最新值,但 `count ++` 这个操作并不是原子的,这里面涉及到获取值、自增、赋值的操作并不能同时完成。
+>
+
+- 所以想到达到线程安全可以使这三个线程串行执行(其实就是单线程,没有发挥多线程的优势)。
+
+- 也可以使用 `synchronized` 或者是锁的方式来保证原子性。
+
+- 还可以用 `Atomic` 包中 `AtomicInteger` 来替换 `int`,它利用了 `CAS` 算法来保证了原子性。
+
+
+## 指令重排
+
+内存可见性只是 `volatile` 的其中一个语义,它还可以防止 `JVM` 进行指令重排优化。
+
+举一个伪代码:
+
+```java
+int a=10 ;//1
+int b=20 ;//2
+int c= a+b ;//3
+```
+
+一段特别简单的代码,理想情况下它的执行顺序是:`1>2>3`。但有可能经过 JVM 优化之后的执行顺序变为了 `2>1>3`。
+
+可以发现不管 JVM 怎么优化,前提都是保证单线程中最终结果不变的情况下进行的。
+
+可能这里还看不出有什么问题,那看下一段伪代码:
+
+```java
+private static Map value ;
+private static volatile boolean flag = fasle ;
+
+//以下方法发生在线程 A 中 初始化 Map
+public void initMap(){
+ //耗时操作
+ value = getMapValue() ;//1
+ flag = true ;//2
+}
+
+
+//发生在线程 B中 等到 Map 初始化成功进行其他操作
+public void doSomeThing(){
+ while(!flag){
+ sleep() ;
+ }
+ //dosomething
+ doSomeThing(value);
+}
+
+```
+
+这里就能看出问题了,当 `flag` 没有被 `volatile` 修饰时,`JVM` 对 1 和 2 进行重排,导致 `value` 都还没有被初始化就有可能被线程 B 使用了。
+
+所以加上 `volatile` 之后可以防止这样的重排优化,保证业务的正确性。
+### 指令重排的的应用
+
+一个经典的使用场景就是双重懒加载的单例模式了:
+
+```java
+public class Singleton {
+
+ private static volatile Singleton singleton;
+
+ private Singleton() {
+ }
+
+ public static Singleton getInstance() {
+ if (singleton == null) {
+ synchronized (Singleton.class) {
+ if (singleton == null) {
+ //防止指令重排
+ singleton = new Singleton();
+ }
+ }
+ }
+ return singleton;
+ }
+}
+```
+
+这里的 `volatile` 关键字主要是为了防止指令重排。
+
+如果不用 ,`singleton = new Singleton();`,这段代码其实是分为三步:
+- 分配内存空间。(1)
+- 初始化对象。(2)
+- 将 `singleton` 对象指向分配的内存地址。(3)
+
+加上 `volatile` 是为了让以上的三步操作顺序执行,反之有可能第二步在第三步之前被执行就有可能某个线程拿到的单例对象是还没有初始化的,以致于报错。
+
+## 总结
+
+`volatile` 在 `Java` 并发中用的很多,比如像 `Atomic` 包中的 `value`、以及 `AbstractQueuedLongSynchronizer` 中的 `state` 都是被定义为 `volatile` 来用于保证内存可见性。
+
+将这块理解透彻对我们编写并发程序时可以提供很大帮助。
diff --git a/docs/netty/Netty(1)TCP-Heartbeat.md b/docs/netty/Netty(1)TCP-Heartbeat.md
new file mode 100644
index 00000000..e562ecb1
--- /dev/null
+++ b/docs/netty/Netty(1)TCP-Heartbeat.md
@@ -0,0 +1,695 @@
+
+
+
+# 前言
+
+Netty 是一个高性能的 NIO 网络框架,本文基于 SpringBoot 以常见的心跳机制来认识 Netty。
+
+最终能达到的效果:
+
+- 客户端每隔 N 秒检测是否需要发送心跳。
+- 服务端也每隔 N 秒检测是否需要发送心跳。
+- 服务端可以主动 push 消息到客户端。
+- 基于 SpringBoot 监控,可以查看实时连接以及各种应用信息。
+
+效果如下:
+
+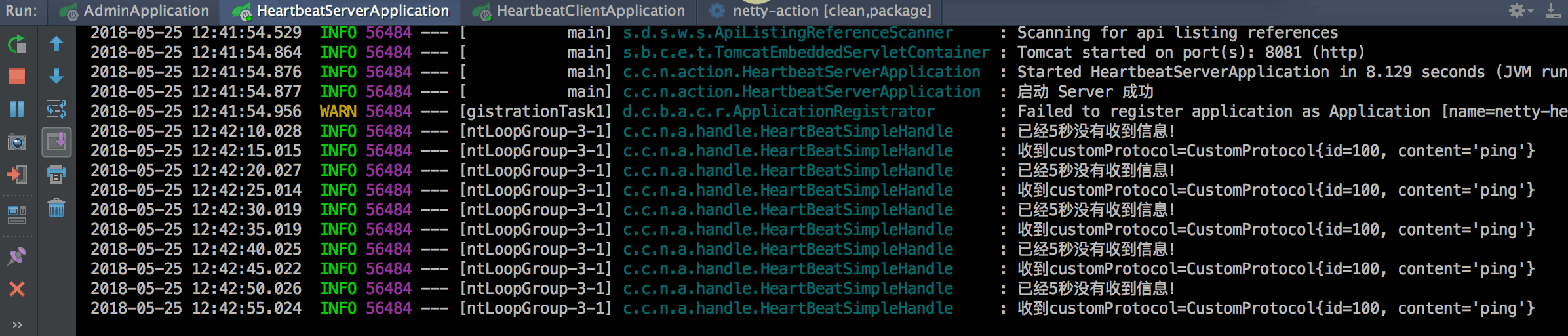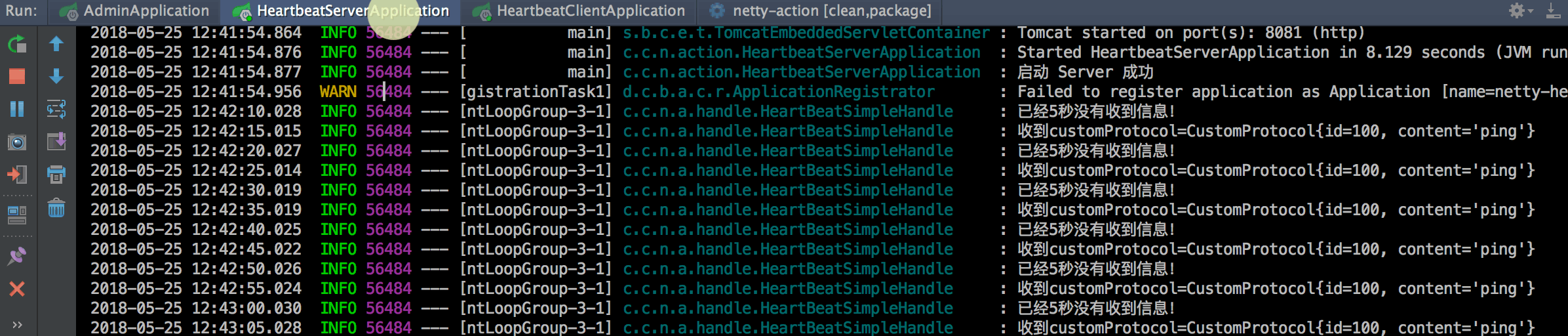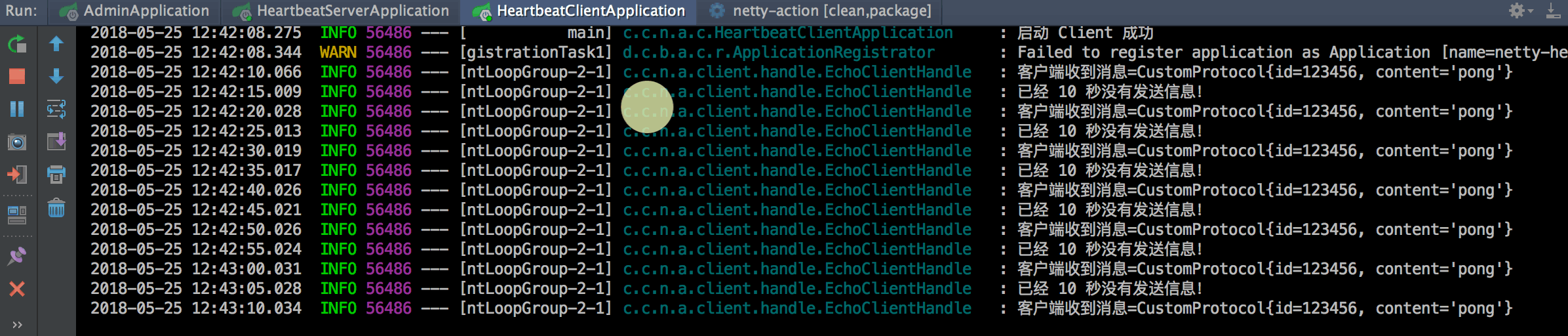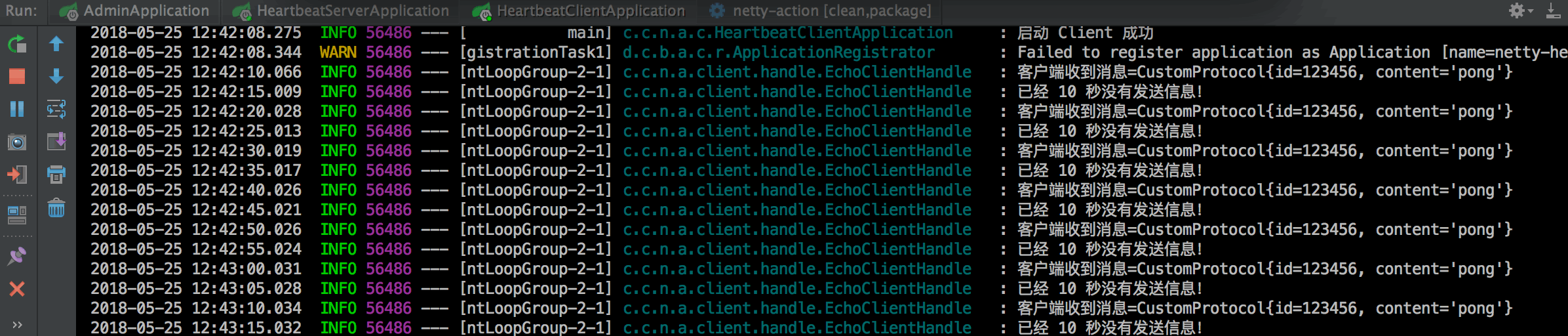
+
+
+
+# IdleStateHandler
+
+Netty 可以使用 IdleStateHandler 来实现连接管理,当连接空闲时间太长(没有发送、接收消息)时则会触发一个事件,我们便可在该事件中实现心跳机制。
+
+## 客户端心跳
+
+当客户端空闲了 N 秒没有给服务端发送消息时会自动发送一个心跳来维持连接。
+
+核心代码代码如下:
+
+```java
+public class EchoClientHandle extends SimpleChannelInboundHandler {
+
+ private final static Logger LOGGER = LoggerFactory.getLogger(EchoClientHandle.class);
+
+
+
+ @Override
+ public void userEventTriggered(ChannelHandlerContext ctx, Object evt) throws Exception {
+
+ if (evt instanceof IdleStateEvent){
+ IdleStateEvent idleStateEvent = (IdleStateEvent) evt ;
+
+ if (idleStateEvent.state() == IdleState.WRITER_IDLE){
+ LOGGER.info("已经 10 秒没有发送信息!");
+ //向服务端发送消息
+ CustomProtocol heartBeat = SpringBeanFactory.getBean("heartBeat", CustomProtocol.class);
+ ctx.writeAndFlush(heartBeat).addListener(ChannelFutureListener.CLOSE_ON_FAILURE) ;
+ }
+
+
+ }
+
+ super.userEventTriggered(ctx, evt);
+ }
+
+
+ @Override
+ protected void channelRead0(ChannelHandlerContext channelHandlerContext, ByteBuf in) throws Exception {
+
+ //从服务端收到消息时被调用
+ LOGGER.info("客户端收到消息={}",in.toString(CharsetUtil.UTF_8)) ;
+
+ }
+}
+```
+
+实现非常简单,只需要在事件回调中发送一个消息即可。
+
+由于整合了 SpringBoot ,所以发送的心跳信息是一个单例的 Bean。
+
+```java
+@Configuration
+public class HeartBeatConfig {
+
+ @Value("${channel.id}")
+ private long id ;
+
+
+ @Bean(value = "heartBeat")
+ public CustomProtocol heartBeat(){
+ return new CustomProtocol(id,"ping") ;
+ }
+}
+```
+
+这里涉及到了自定义协议的内容,请继续查看下文。
+
+当然少不了启动引导:
+
+```java
+@Component
+public class HeartbeatClient {
+
+ private final static Logger LOGGER = LoggerFactory.getLogger(HeartbeatClient.class);
+
+ private EventLoopGroup group = new NioEventLoopGroup();
+
+
+ @Value("${netty.server.port}")
+ private int nettyPort;
+
+ @Value("${netty.server.host}")
+ private String host;
+
+ private SocketChannel channel;
+
+ @PostConstruct
+ public void start() throws InterruptedException {
+ Bootstrap bootstrap = new Bootstrap();
+ bootstrap.group(group)
+ .channel(NioSocketChannel.class)
+ .handler(new CustomerHandleInitializer())
+ ;
+
+ ChannelFuture future = bootstrap.connect(host, nettyPort).sync();
+ if (future.isSuccess()) {
+ LOGGER.info("启动 Netty 成功");
+ }
+ channel = (SocketChannel) future.channel();
+ }
+
+}
+
+public class CustomerHandleInitializer extends ChannelInitializer {
+ @Override
+ protected void initChannel(Channel ch) throws Exception {
+ ch.pipeline()
+ //10 秒没发送消息 将IdleStateHandler 添加到 ChannelPipeline 中
+ .addLast(new IdleStateHandler(0, 10, 0))
+ .addLast(new HeartbeatEncode())
+ .addLast(new EchoClientHandle())
+ ;
+ }
+}
+```
+
+所以当应用启动每隔 10 秒会检测是否发送过消息,不然就会发送心跳信息。
+
+
+
+## 服务端心跳
+
+服务器端的心跳其实也是类似,也需要在 ChannelPipeline 中添加一个 IdleStateHandler 。
+
+```java
+public class HeartBeatSimpleHandle extends SimpleChannelInboundHandler {
+
+ private final static Logger LOGGER = LoggerFactory.getLogger(HeartBeatSimpleHandle.class);
+
+ private static final ByteBuf HEART_BEAT = Unpooled.unreleasableBuffer(Unpooled.copiedBuffer(new CustomProtocol(123456L,"pong").toString(),CharsetUtil.UTF_8));
+
+
+ /**
+ * 取消绑定
+ * @param ctx
+ * @throws Exception
+ */
+ @Override
+ public void channelInactive(ChannelHandlerContext ctx) throws Exception {
+
+ NettySocketHolder.remove((NioSocketChannel) ctx.channel());
+ }
+
+ @Override
+ public void userEventTriggered(ChannelHandlerContext ctx, Object evt) throws Exception {
+
+ if (evt instanceof IdleStateEvent){
+ IdleStateEvent idleStateEvent = (IdleStateEvent) evt ;
+
+ if (idleStateEvent.state() == IdleState.READER_IDLE){
+ LOGGER.info("已经5秒没有收到信息!");
+ //向客户端发送消息
+ ctx.writeAndFlush(HEART_BEAT).addListener(ChannelFutureListener.CLOSE_ON_FAILURE) ;
+ }
+
+
+ }
+
+ super.userEventTriggered(ctx, evt);
+ }
+
+ @Override
+ protected void channelRead0(ChannelHandlerContext ctx, CustomProtocol customProtocol) throws Exception {
+ LOGGER.info("收到customProtocol={}", customProtocol);
+
+ //保存客户端与 Channel 之间的关系
+ NettySocketHolder.put(customProtocol.getId(),(NioSocketChannel)ctx.channel()) ;
+ }
+}
+```
+
+**这里有点需要注意**:
+
+当有多个客户端连上来时,服务端需要区分开,不然响应消息就会发生混乱。
+
+所以每当有个连接上来的时候,我们都将当前的 Channel 与连上的客户端 ID 进行关联(**因此每个连上的客户端 ID 都必须唯一**)。
+
+这里采用了一个 Map 来保存这个关系,并且在断开连接时自动取消这个关联。
+
+```java
+public class NettySocketHolder {
+ private static final Map MAP = new ConcurrentHashMap<>(16);
+
+ public static void put(Long id, NioSocketChannel socketChannel) {
+ MAP.put(id, socketChannel);
+ }
+
+ public static NioSocketChannel get(Long id) {
+ return MAP.get(id);
+ }
+
+ public static Map getMAP() {
+ return MAP;
+ }
+
+ public static void remove(NioSocketChannel nioSocketChannel) {
+ MAP.entrySet().stream().filter(entry -> entry.getValue() == nioSocketChannel).forEach(entry -> MAP.remove(entry.getKey()));
+ }
+}
+```
+
+启动引导程序:
+
+```java
+Component
+public class HeartBeatServer {
+
+ private final static Logger LOGGER = LoggerFactory.getLogger(HeartBeatServer.class);
+
+ private EventLoopGroup boss = new NioEventLoopGroup();
+ private EventLoopGroup work = new NioEventLoopGroup();
+
+
+ @Value("${netty.server.port}")
+ private int nettyPort;
+
+
+ /**
+ * 启动 Netty
+ *
+ * @return
+ * @throws InterruptedException
+ */
+ @PostConstruct
+ public void start() throws InterruptedException {
+
+ ServerBootstrap bootstrap = new ServerBootstrap()
+ .group(boss, work)
+ .channel(NioServerSocketChannel.class)
+ .localAddress(new InetSocketAddress(nettyPort))
+ //保持长连接
+ .childOption(ChannelOption.SO_KEEPALIVE, true)
+ .childHandler(new HeartbeatInitializer());
+
+ ChannelFuture future = bootstrap.bind().sync();
+ if (future.isSuccess()) {
+ LOGGER.info("启动 Netty 成功");
+ }
+ }
+
+
+ /**
+ * 销毁
+ */
+ @PreDestroy
+ public void destroy() {
+ boss.shutdownGracefully().syncUninterruptibly();
+ work.shutdownGracefully().syncUninterruptibly();
+ LOGGER.info("关闭 Netty 成功");
+ }
+}
+
+
+public class HeartbeatInitializer extends ChannelInitializer {
+ @Override
+ protected void initChannel(Channel ch) throws Exception {
+ ch.pipeline()
+ //五秒没有收到消息 将IdleStateHandler 添加到 ChannelPipeline 中
+ .addLast(new IdleStateHandler(5, 0, 0))
+ .addLast(new HeartbeatDecoder())
+ .addLast(new HeartBeatSimpleHandle());
+ }
+}
+```
+
+也是同样将IdleStateHandler 添加到 ChannelPipeline 中,也会有一个定时任务,每5秒校验一次是否有收到消息,否则就主动发送一次请求。
+
+
+
+因为测试是有两个客户端连上所以有两个日志。
+
+## 自定义协议
+
+上文其实都看到了:服务端与客户端采用的是自定义的 POJO 进行通讯的。
+
+所以需要在客户端进行编码,服务端进行解码,也都只需要各自实现一个编解码器即可。
+
+CustomProtocol:
+
+```java
+public class CustomProtocol implements Serializable{
+
+ private static final long serialVersionUID = 4671171056588401542L;
+ private long id ;
+ private String content ;
+ //省略 getter/setter
+}
+```
+
+客户端的编码器:
+
+```java
+public class HeartbeatEncode extends MessageToByteEncoder {
+ @Override
+ protected void encode(ChannelHandlerContext ctx, CustomProtocol msg, ByteBuf out) throws Exception {
+
+ out.writeLong(msg.getId()) ;
+ out.writeBytes(msg.getContent().getBytes()) ;
+
+ }
+}
+```
+
+也就是说消息的前八个字节为 header,剩余的全是 content。
+
+服务端的解码器:
+
+```java
+public class HeartbeatDecoder extends ByteToMessageDecoder {
+ @Override
+ protected void decode(ChannelHandlerContext ctx, ByteBuf in, List
diff --git a/docs/frame/spring-bean-lifecycle.md b/docs/frame/spring-bean-lifecycle.md
new file mode 100644
index 00000000..60f2796a
--- /dev/null
+++ b/docs/frame/spring-bean-lifecycle.md
@@ -0,0 +1,181 @@
+## Spring Bean 生命周期
+
+
+### 前言
+
+Spring Bean 的生命周期在整个 Spring 中占有很重要的位置,掌握这些可以加深对 Spring 的理解。
+
+首先看下生命周期图:
+
+
+
+再谈生命周期之前有一点需要先明确:
+
+> Spring 只帮我们管理单例模式 Bean 的**完整**生命周期,对于 prototype 的 bean ,Spring 在创建好交给使用者之后则不会再管理后续的生命周期。
+
+
+### 注解方式
+
+在 bean 初始化时会经历几个阶段,首先可以使用注解 `@PostConstruct`, `@PreDestroy` 来在 bean 的创建和销毁阶段进行调用:
+
+```java
+@Component
+public class AnnotationBean {
+ private final static Logger LOGGER = LoggerFactory.getLogger(AnnotationBean.class);
+
+ @PostConstruct
+ public void start(){
+ LOGGER.info("AnnotationBean start");
+ }
+
+ @PreDestroy
+ public void destroy(){
+ LOGGER.info("AnnotationBean destroy");
+ }
+}
+```
+
+### InitializingBean, DisposableBean 接口
+
+还可以实现 `InitializingBean,DisposableBean` 这两个接口,也是在初始化以及销毁阶段调用:
+
+```java
+@Service
+public class SpringLifeCycleService implements InitializingBean,DisposableBean{
+ private final static Logger LOGGER = LoggerFactory.getLogger(SpringLifeCycleService.class);
+ @Override
+ public void afterPropertiesSet() throws Exception {
+ LOGGER.info("SpringLifeCycleService start");
+ }
+
+ @Override
+ public void destroy() throws Exception {
+ LOGGER.info("SpringLifeCycleService destroy");
+ }
+}
+```
+
+### 自定义初始化和销毁方法
+
+也可以自定义方法用于在初始化、销毁阶段调用:
+
+```java
+@Configuration
+public class LifeCycleConfig {
+
+
+ @Bean(initMethod = "start", destroyMethod = "destroy")
+ public SpringLifeCycle create(){
+ SpringLifeCycle springLifeCycle = new SpringLifeCycle() ;
+
+ return springLifeCycle ;
+ }
+}
+
+public class SpringLifeCycle{
+
+ private final static Logger LOGGER = LoggerFactory.getLogger(SpringLifeCycle.class);
+ public void start(){
+ LOGGER.info("SpringLifeCycle start");
+ }
+
+
+ public void destroy(){
+ LOGGER.info("SpringLifeCycle destroy");
+ }
+}
+```
+
+以上是在 SpringBoot 中可以这样配置,如果是原始的基于 XML 也是可以使用:
+
+```xml
+
+
+```
+
+来达到同样的效果。
+
+### 实现 *Aware 接口
+
+`*Aware` 接口可以用于在初始化 bean 时获得 Spring 中的一些对象,如获取 `Spring 上下文`等。
+
+```java
+@Component
+public class SpringLifeCycleAware implements ApplicationContextAware {
+ private final static Logger LOGGER = LoggerFactory.getLogger(SpringLifeCycleAware.class);
+
+ private ApplicationContext applicationContext ;
+
+ @Override
+ public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
+ this.applicationContext = applicationContext ;
+ LOGGER.info("SpringLifeCycleAware start");
+ }
+}
+```
+
+这样在 `springLifeCycleAware` 这个 bean 初始化会就会调用 `setApplicationContext` 方法,并可以获得 `applicationContext` 对象。
+
+### BeanPostProcessor 增强处理器
+
+实现 BeanPostProcessor 接口,Spring 中所有 bean 在做初始化时都会调用该接口中的两个方法,可以用于对一些特殊的 bean 进行处理:
+
+```java
+@Component
+public class SpringLifeCycleProcessor implements BeanPostProcessor {
+ private final static Logger LOGGER = LoggerFactory.getLogger(SpringLifeCycleProcessor.class);
+
+ /**
+ * 预初始化 初始化之前调用
+ * @param bean
+ * @param beanName
+ * @return
+ * @throws BeansException
+ */
+ @Override
+ public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
+ if ("annotationBean".equals(beanName)){
+ LOGGER.info("SpringLifeCycleProcessor start beanName={}",beanName);
+ }
+ return bean;
+ }
+
+ /**
+ * 后初始化 bean 初始化完成调用
+ * @param bean
+ * @param beanName
+ * @return
+ * @throws BeansException
+ */
+ @Override
+ public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
+ if ("annotationBean".equals(beanName)){
+ LOGGER.info("SpringLifeCycleProcessor end beanName={}",beanName);
+ }
+ return bean;
+ }
+}
+```
+
+执行之后观察结果:
+
+```
+018-03-21 00:40:24.856 [restartedMain] INFO c.c.s.p.SpringLifeCycleProcessor - SpringLifeCycleProcessor start beanName=annotationBean
+2018-03-21 00:40:24.860 [restartedMain] INFO c.c.spring.annotation.AnnotationBean - AnnotationBean start
+2018-03-21 00:40:24.861 [restartedMain] INFO c.c.s.p.SpringLifeCycleProcessor - SpringLifeCycleProcessor end beanName=annotationBean
+2018-03-21 00:40:24.864 [restartedMain] INFO c.c.s.aware.SpringLifeCycleAware - SpringLifeCycleAware start
+2018-03-21 00:40:24.867 [restartedMain] INFO c.c.s.service.SpringLifeCycleService - SpringLifeCycleService start
+2018-03-21 00:40:24.887 [restartedMain] INFO c.c.spring.SpringLifeCycle - SpringLifeCycle start
+2018-03-21 00:40:25.062 [restartedMain] INFO o.s.b.d.a.OptionalLiveReloadServer - LiveReload server is running on port 35729
+2018-03-21 00:40:25.122 [restartedMain] INFO o.s.j.e.a.AnnotationMBeanExporter - Registering beans for JMX exposure on startup
+2018-03-21 00:40:25.140 [restartedMain] INFO com.crossoverjie.Application - Started Application in 2.309 seconds (JVM running for 3.681)
+2018-03-21 00:40:25.143 [restartedMain] INFO com.crossoverjie.Application - start ok!
+2018-03-21 00:40:25.153 [Thread-8] INFO o.s.c.a.AnnotationConfigApplicationContext - Closing org.springframework.context.annotation.AnnotationConfigApplicationContext@3913adad: startup date [Wed Mar 21 00:40:23 CST 2018]; root of context hierarchy
+2018-03-21 00:40:25.155 [Thread-8] INFO o.s.j.e.a.AnnotationMBeanExporter - Unregistering JMX-exposed beans on shutdown
+2018-03-21 00:40:25.156 [Thread-8] INFO c.c.spring.SpringLifeCycle - SpringLifeCycle destroy
+2018-03-21 00:40:25.156 [Thread-8] INFO c.c.s.service.SpringLifeCycleService - SpringLifeCycleService destroy
+2018-03-21 00:40:25.156 [Thread-8] INFO c.c.spring.annotation.AnnotationBean - AnnotationBean destroy
+```
+
+直到 Spring 上下文销毁时则会调用自定义的销毁方法以及实现了 `DisposableBean` 的 `destroy()` 方法。
+
diff --git a/docs/index.html b/docs/index.html
new file mode 100644
index 00000000..d235b3fc
--- /dev/null
+++ b/docs/index.html
@@ -0,0 +1,43 @@
+
+
+
+
+ JCSprout
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
diff --git a/docs/jvm/ClassLoad.md b/docs/jvm/ClassLoad.md
new file mode 100644
index 00000000..3578ad71
--- /dev/null
+++ b/docs/jvm/ClassLoad.md
@@ -0,0 +1,17 @@
+# 类加载机制
+
+## 双亲委派模型
+
+模型如下图:
+
+
+
+双亲委派模型中除了启动类加载器之外其余都需要有自己的父类加载器
+
+当一个类收到了类加载请求时: 自己不会首先加载,而是委派给父加载器进行加载,每个层次的加载器都是这样。
+
+所以最终每个加载请求都会经过启动类加载器。只有当父类加载返回不能加载时子加载器才会进行加载。
+
+双亲委派的好处 : 由于每个类加载都会经过最顶层的启动类加载器,比如 `java.lang.Object`这样的类在各个类加载器下都是同一个类(只有当两个类是由同一个类加载器加载的才有意义,这两个类才相等。)
+
+如果没有双亲委派模型,由各个类加载器自行加载的话。当用户自己编写了一个 `java.lang.Object`类,那样系统中就会出现多个 `Object`,这样 Java 程序中最基本的行为都无法保证,程序会变的非常混乱。
diff --git a/docs/jvm/GarbageCollection.md b/docs/jvm/GarbageCollection.md
new file mode 100644
index 00000000..eeb3a43a
--- /dev/null
+++ b/docs/jvm/GarbageCollection.md
@@ -0,0 +1,72 @@
+# 垃圾回收
+
+> 垃圾回收主要思考三件事情:
+
+- 哪种内存需要回收?
+- 什么时候回收?
+- 怎么回收?
+
+## 对象是否存活
+
+### 引用计数法
+
+这是一种非常简单易理解的回收算法。每当有一个地方引用一个对象的时候则在引用计数器上 +1,当失效的时候就 -1,无论什么时候计数器为 0 的时候则认为该对象死亡可以回收了。
+
+这种算法虽然简单高效,但是却无法解决**循环引用**的问题,因此 Java 虚拟机并没有采用这种算法。
+
+### 可达性分析算法
+主流的语言其实都是采用可达性分析算法:
+
+可达性算法是通过一个称为 `GC Roots` 的对象向下搜索,整个搜索路径就称为引用链,当一个对象到 `GC Roots` 没有任何引用链 `JVM` 就认为该对象是可以被回收的。
+
+
+
+如图:Object1、2、3、4 都是存活的对象,而 Object5、6、7都是可回收对象。
+
+可以用作 `GC-Roots` 的对象有:
+
+- 方法区中静态变量所引用的对象。
+- 虚拟机栈中所引用的对象。
+
+## 垃圾回收算法
+
+### 标记-清除算法
+
+标记清除算法分为两个步骤,标记和清除。
+首先将**不需要回收的对象**标记起来,然后再清除其余可回收对象。但是存在两个主要的问题:
+- 标记和清除的效率都不高。
+- 清除之后容易出现不连续内存,当需要分配一个较大内存时就不得不需要进行一次垃圾回收。
+
+标记清除过程如下:
+
+
+
+### 复制算法
+
+复制算法是将内存划分为两块大小相等的区域,每次使用时都只用其中一块区域,当发生垃圾回收时会将存活的对象全部复制到未使用的区域,然后对之前的区域进行全部回收。
+
+这样简单高效,而且还不存在标记清除算法中的内存碎片问题,但就是有点浪费内存。
+
+> 在新生代会使用该算法。
+
+新生代中分为一个 `Eden` 区和两个 `Survivor` 区。通常两个区域的比例是 `8:1:1` ,使用时会用到 `Eden` 区和其中一个 `Survivor` 区。当发生回收时则会将还存活的对象从 `Eden` ,`Survivor` 区拷贝到另一个 `Survivor` 区,当该区域内存也不足时则会使用分配担保利用老年代来存放内存。
+
+复制算法过程:
+
+
+
+
+### 标记整理算法
+
+复制算法如果在存活对象较多时效率明显会降低,特别是在老年代中并没有多余的内存区域可以提供内存担保。
+
+所以老年代中使用的时候`标记整理算法`,它的原理和`标记清除算法`类似,只是最后一步的清除改为了将存活对象全部移动到一端,然后再将边界之外的内存全部回收。
+
+
+
+### 分代回收算法
+现代多数的商用 `JVM` 的垃圾收集器都是采用的分代回收算法,和之前所提到的算法并没有新的内容。
+
+只是将 Java 堆分为了新生代和老年代。由于新生代中存活对象较少,所以采用**复制算法**,简单高效。
+
+而老年代中对象较多,并且没有可以担保的内存区域,所以一般采用**标记清除或者是标记整理算法**。
diff --git a/docs/jvm/JVM-concurrent-HashSet-problem.md b/docs/jvm/JVM-concurrent-HashSet-problem.md
new file mode 100755
index 00000000..f834b47a
--- /dev/null
+++ b/docs/jvm/JVM-concurrent-HashSet-problem.md
@@ -0,0 +1,251 @@
+
+
+
+
+# 背景
+
+上午刚到公司,准备开始一天的摸鱼之旅时突然收到了一封监控中心的邮件。
+
+心中暗道不好,因为监控系统从来不会告诉我应用完美无 `bug`,其实系统挺猥琐。
+
+
+
+打开邮件一看,果然告知我有一个应用的线程池队列达到阈值触发了报警。
+
+由于这个应用出问题非常影响用户体验;于是立马让运维保留现场 `dump` 线程和内存同时重启应用,还好重启之后恢复正常。于是开始着手排查问题。
+
+
+
+# 分析
+
+首先了解下这个应用大概是做什么的。
+
+简单来说就是从 `MQ` 中取出数据然后丢到后面的业务线程池中做具体的业务处理。
+
+而报警的队列正好就是这个线程池的队列。
+
+
+
+跟踪代码发现构建线程池的方式如下:
+
+```java
+ThreadPoolExecutor executor = new ThreadPoolExecutor(coreSize, maxSize,
+ 0L, TimeUnit.MILLISECONDS,
+ new LinkedBlockingQueue());;
+ put(poolName,executor);
+```
+
+采用的是默认的 `LinkedBlockingQueue` 并没有指定大小(这也是个坑),于是这个队列的默认大小为 `Integer.MAX_VALUE`。
+
+由于应用已经重启,只能从仅存的线程快照和内存快照进行分析。
+
+
+
+## 内存分析
+
+先利用 `MAT` 分析了内存,的到了如下报告。
+
+
+
+
+
+
+
+其中有两个比较大的对象,一个就是之前线程池存放任务的 `LinkedBlockingQueue`,还有一个则是 `HashSet`。
+
+
+
+当然其中队列占用了大量的内存,所以优先查看,`HashSet` 一会儿再看。
+
+
+
+> 由于队列的大小给的够大,所以结合目前的情况来看应当是线程池里的任务处理较慢,导致队列的任务越堆越多,至少这是目前可以得出的结论。
+
+
+
+## 线程分析
+
+再来看看线程的分析,这里利用 [fastthread.io](http://fastthread.io/index.jsp) 这个网站进行线程分析。
+
+因为从表现来看线程池里的任务迟迟没有执行完毕,所以主要看看它们在干嘛。
+
+
+
+正好他们都处于 **RUNNABLE** 状态,同时堆栈如下:
+
+
+
+
+
+发现正好就是在处理上文提到的 `HashSet`,看这个堆栈是在查询 `key` 是否存在。通过查看 312 行的业务代码确实也是如此。
+
+
+
+> 这里的线程名字也是个坑,让我找了好久。
+
+
+
+# 定位
+
+分析了内存和线程的堆栈之后其实已经大概猜出一些问题了。
+
+
+
+这里其实有一个前提忘记讲到:
+
+这个告警是`凌晨三点`发出的邮件,但并没有电话提醒之类的,所以大家都不知道。
+
+到了早上上班时才发现并立即 `dump` 了上面的证据。
+
+
+
+所有有一个很重要的事实:**这几个业务线程在查询 `HashSet` 的时候运行了 6 7 个小时都没有返回**。
+
+
+
+通过之前的监控曲线图也可以看出:
+
+
+
+操作系统在之前一直处于高负载中,直到我们早上看到报警重启之后才降低。
+
+
+
+同时发现这个应用生产上运行的是 `JDK1.7` ,所以我初步认为应该是在查询 key 的时候进入了 `HashMap` 的环形链表导致 `CPU` 高负载同时也进入了死循环。
+
+
+
+为了验证这个问题再次 review 了代码。
+
+
+
+整理之后的伪代码如下:
+
+```java
+//线程池
+private ExecutorService executor;
+
+private Set set = new hashSet();
+
+private void execute(){
+
+ while(true){
+ //从 MQ 中获取数据
+ String key = subMQ();
+ executor.excute(new Worker(key)) ;
+ }
+}
+
+public class Worker extends Thread{
+ private String key ;
+
+ public Worker(String key){
+ this.key = key;
+ }
+
+ @Override
+ private void run(){
+ if(!set.contains(key)){
+
+ //数据库查询
+ if(queryDB(key)){
+ set.add(key);
+ return;
+ }
+ }
+
+ //达到某种条件时清空 set
+ if(flag){
+ set = null ;
+ }
+ }
+}
+```
+
+大致的流程如下:
+
+- 源源不断的从 MQ 中获取数据。
+- 将数据丢到业务线程池中。
+- 判断数据是否已经写入了 `Set`。
+- 没有则查询数据库。
+- 之后写入到 `Set` 中。
+
+
+
+这里有一个很明显的问题,**那就是作为共享资源的 Set 并没有做任何的同步处理**。
+
+这里会有多个线程并发的操作,由于 `HashSet` 其实本质上就是 `HashMap`,所以它肯定是线程不安全的,所以会出现两个问题:
+
+
+
+- Set 中的数据在并发写入时被覆盖导致数据不准确。
+- **会在扩容的时候形成环形链表**。
+
+第一个问题相对于第二个还能接受。
+
+
+
+通过上文的内存分析我们已经知道这个 set 中的数据已经不少了。同时由于初始化时并没有指定大小,仅仅只是默认值,所以在大量的并发写入时候会导致频繁的扩容,而在 1.7 的条件下又可能会形成**环形链表**。
+
+
+
+不巧的是代码中也有查询操作(`contains()`),观察上文的堆栈情况:
+
+
+
+发现是运行在 `HashMap` 的 465 行,来看看 1.7 中那里具体在做什么:
+
+
+
+已经很明显了。这里在遍历链表,同时由于形成了环形链表导致这个 `e.next` 永远不为空,所以这个循环也不会退出了。
+
+
+
+到这里其实已经找到问题了,但还有一个疑问是为什么线程池里的任务队列会越堆越多。我第一直觉是任务执行太慢导致的。
+
+
+
+仔细查看了代码发现只有一个地方可能会慢:也就是有一个**数据库的查询**。
+
+
+
+把这个 SQL 拿到生产环境执行发现确实不快,查看索引发现都有命中。
+
+
+
+但我一看表中的数据发现已经快有 **7000W** 的数据了。同时经过运维得知 `MySQL` 那台服务器的 `IO` 压力也比较大。
+
+所以这个原因也比较明显了:
+
+> 由于每消费一条数据都要去查询一次数据库,MySQL 本身压力就比较大,加上数据量也很高所以导致这个 IO 响应较慢,导致整个任务处理的就比较慢了。
+
+但还有一个原因也不能忽视;由于所有的业务线程在某个时间点都进入了死循环,根本没有执行完任务的机会,而后面的数据还在源源不断的进入,所以这个队列只会越堆越多!
+
+
+
+这其实是一个老应用了,可能会有人问为什么之前没出现问题。
+
+这是因为之前数据量都比较少,即使是并发写入也没有出现并发扩容形成环形链表的情况。这段时间业务量的暴增正好把这个隐藏的雷给揪出来了。所以还是得信墨菲他老人家的话。
+
+
+
+# 总结
+
+
+
+至此整个排查结束,而我们后续的调整措施大概如下:
+
+- `HashSet` 不是线程安全的,换为 `ConcurrentHashMap`同时把 `value` 写死一样可以达到 `set` 的效果。
+- 根据我们后面的监控,初始化 `ConcurrentHashMap` 的大小尽量大一些,避免频繁的扩容。
+- `MySQL` 中很多数据都已经不用了,进行冷热处理。尽量降低单表数据量。同时后期考虑分表。
+- 查数据那里调整为查缓存,提高查询效率。
+- 线程池的名称一定得取的有意义,不然是自己给自己增加难度。
+- 根据监控将线程池的队列大小调整为一个具体值,并且要有拒绝策略。
+- 升级到 `JDK1.8`。
+- 再一个是报警邮件酌情考虑为电话通知😂。
+
+
+
+`HashMap` 的死循环问题在网上层出不穷,没想到还真被我遇到了。现在要满足这个条件还是挺少见的,比如 1.8 以下的 `JDK` 这一条可能大多数人就碰不到,正好又证实了一次墨菲定律。
+
+**你的点赞与分享是对我最大的支持**
diff --git a/docs/jvm/MemoryAllocation.md b/docs/jvm/MemoryAllocation.md
new file mode 100644
index 00000000..ce615e40
--- /dev/null
+++ b/docs/jvm/MemoryAllocation.md
@@ -0,0 +1,93 @@
+# Java 运行时的内存划分
+
+
+
+## 程序计数器
+
+记录当前线程所执行的字节码行号,用于获取下一条执行的字节码。
+
+当多线程运行时,每个线程切换后需要知道上一次所运行的状态、位置。由此也可以看出程序计数器是每个线程**私有**的。
+
+
+## 虚拟机栈
+虚拟机栈由一个一个的栈帧组成,栈帧是在每一个方法调用时产生的。
+
+每一个栈帧由`局部变量区`、`操作数栈`等组成。每创建一个栈帧压栈,当一个方法执行完毕之后则出栈。
+
+> - 如果出现方法递归调用出现死循环的话就会造成栈帧过多,最终会抛出 `StackOverflowError`。
+> - 若线程执行过程中栈帧大小超出虚拟机栈限制,则会抛出 `StackOverflowError`。
+> - 若虚拟机栈允许动态扩展,但在尝试扩展时内存不足,或者在为一个新线程初始化新的虚拟机栈时申请不到足够的内存,则会抛出
+ `OutOfMemoryError`。
+
+**这块内存区域也是线程私有的。**
+
+## Java 堆
+`Java` 堆是整个虚拟机所管理的最大内存区域,所有的对象创建都是在这个区域进行内存分配。
+
+可利用参数 `-Xms -Xmx` 进行堆内存控制。
+
+这块区域也是垃圾回收器重点管理的区域,由于大多数垃圾回收器都采用`分代回收算法`,所有堆内存也分为 `新生代`、`老年代`,可以方便垃圾的准确回收。
+
+**这块内存属于线程共享区域。**
+
+## 方法区(JDK1.7)
+
+方法区主要用于存放已经被虚拟机加载的类信息,如`常量,静态变量`。
+这块区域也被称为`永久代`。
+
+可利用参数 `-XX:PermSize -XX:MaxPermSize` 控制初始化方法区和最大方法区大小。
+
+
+
+## 元数据区(JDK1.8)
+
+在 `JDK1.8` 中已经移除了方法区(永久代),并使用了一个元数据区域进行代替(`Metaspace`)。
+
+默认情况下元数据区域会根据使用情况动态调整,避免了在 1.7 中由于加载类过多从而出现 `java.lang.OutOfMemoryError: PermGen`。
+
+但也不能无线扩展,因此可以使用 `-XX:MaxMetaspaceSize`来控制最大内存。
+
+
+
+
+
+## 运行时常量池
+
+运行时常量池是方法区的一部分,其中存放了一些符号引用。当 `new` 一个对象时,会检查这个区域是否有这个符号的引用。
+
+
+
+## 直接内存
+
+
+
+直接内存又称为 `Direct Memory(堆外内存)`,它并不是由 `JVM` 虚拟机所管理的一块内存区域。
+
+有使用过 `Netty` 的朋友应该对这块并内存不陌生,在 `Netty` 中所有的 IO(nio) 操作都会通过 `Native` 函数直接分配堆外内存。
+
+它是通过在堆内存中的 `DirectByteBuffer` 对象操作的堆外内存,避免了堆内存和堆外内存来回复制交换复制,这样的高效操作也称为`零拷贝`。
+
+既然是内存,那也得是可以被回收的。但由于堆外内存不直接受 `JVM` 管理,所以常规 `GC` 操作并不能回收堆外内存。它是借助于老年代产生的 `fullGC` 顺便进行回收。同时也可以显式调用 `System.gc()` 方法进行回收(前提是没有使用 `-XX:+DisableExplicitGC` 参数来禁止该方法)。
+
+**值得注意的是**:由于堆外内存也是内存,是由操作系统管理。如果应用有使用堆外内存则需要平衡虚拟机的堆内存和堆外内存的使用占比。避免出现堆外内存溢出。
+
+## 常用参数
+
+
+
+通过上图可以直观的查看各个区域的参数设置。
+
+常见的如下:
+
+- `-Xms64m` 最小堆内存 `64m`.
+- `-Xmx128m` 最大堆内存 `128m`.
+- `-XX:NewSize=30m` 新生代初始化大小为`30m`.
+- `-XX:MaxNewSize=40m` 新生代最大大小为`40m`.
+- `-Xss=256k` 线程栈大小。
+- `-XX:+PrintHeapAtGC` 当发生 GC 时打印内存布局。
+- `-XX:+HeapDumpOnOutOfMemoryError` 发送内存溢出时 dump 内存。
+
+
+新生代和老年代的默认比例为 `1:2`,也就是说新生代占用 `1/3`的堆内存,而老年代占用 `2/3` 的堆内存。
+
+可以通过参数 `-XX:NewRatio=2` 来设置老年代/新生代的比例。
diff --git a/docs/jvm/OOM-Disruptor.md b/docs/jvm/OOM-Disruptor.md
new file mode 100644
index 00000000..c9f32f7b
--- /dev/null
+++ b/docs/jvm/OOM-Disruptor.md
@@ -0,0 +1,125 @@
+
+
+# 前言
+
+`OutOfMemoryError` 问题相信很多朋友都遇到过,相对于常见的业务异常(数组越界、空指针等)来说这类问题是很难定位和解决的。
+
+本文以最近碰到的一次线上内存溢出的定位、解决问题的方式展开;希望能对碰到类似问题的同学带来思路和帮助。
+
+主要从`表现-->排查-->定位-->解决` 四个步骤来分析和解决问题。
+
+
+
+# 表象
+
+最近我们生产上的一个应用不断的爆出内存溢出,并且随着业务量的增长出现的频次越来越高。
+
+该程序的业务逻辑非常简单,就是从 Kafka 中将数据消费下来然后批量的做持久化操作。
+
+而现象则是随着 Kafka 的消息越多,出现的异常的频次就越快。由于当时还有其他工作所以只能让运维做重启,并且监控好堆内存以及 GC 情况。
+
+> 重启大法虽好,可是依然不能根本解决问题。
+
+# 排查
+
+于是我们想根据运维之前收集到的内存数据、GC 日志尝试判断哪里出现问题。
+
+
+
+结果发现老年代的内存使用就算是发生 GC 也一直居高不下,而且随着时间推移也越来越高。
+
+结合 jstat 的日志发现就算是发生了 FGC 老年代也已经回收不了,内存已经到顶。
+
+
+
+甚至有几台应用 FGC 达到了上百次,时间也高的可怕。
+
+这说明应用的内存使用肯定是有问题的,有许多赖皮对象始终回收不掉。
+
+# 定位
+
+由于生产上的内存 dump 文件非常大,达到了几十G。也是由于我们的内存设置太大有关。
+
+所以导致想使用 MAT 分析需要花费大量时间。
+
+因此我们便想是否可以在本地复现,这样就要好定位的多。
+
+为了尽快的复现问题,我将本地应用最大堆内存设置为 150M。
+
+
+然后在消费 Kafka 那里 Mock 为一个 while 循环一直不断的生成数据。
+
+同时当应用启动之后利用 VisualVM 连上应用实时监控内存、GC 的使用情况。
+
+结果跑了 10 几分钟内存使用并没有什么问题。根据图中可以看出,每产生一次 GC 内存都能有效的回收,所以这样并没有复现问题。
+
+
+
+
+没法复现问题就很难定位了。于是我们 review 代码,发现生产的逻辑和我们用 while 循环 Mock 数据还不太一样。
+
+查看生产的日志发现每次从 Kafka 中取出的都是几百条数据,而我们 Mock 时每次只能产生**一条**。
+
+为了尽可能的模拟生产情况便在服务器上跑着一个生产者程序,一直源源不断的向 Kafka 中发送数据。
+
+果然不出意外只跑了一分多钟内存就顶不住了,观察左图发现 GC 的频次非常高,但是内存的回收却是相形见拙。
+
+
+
+同时后台也开始打印内存溢出了,这样便复现出问题。
+
+# 解决
+
+从目前的表现来看就是内存中有许多对象一直存在强引用关系导致得不到回收。
+
+于是便想看看到底是什么对象占用了这么多的内存,利用 VisualVM 的 HeapDump 功能可以立即 dump 出当前应用的内存情况。
+
+
+
+结果发现 `com.lmax.disruptor.RingBuffer` 类型的对象占用了将近 50% 的内存。
+
+看到这个包自然就想到了 `Disruptor` 环形队列。
+
+再次 review 代码发现:从 Kafka 里取出的 700 条数据是直接往 Disruptor 里丢的。
+
+这里也就能说明为什么第一次模拟数据没复现问题了。
+
+模拟的时候是一个对象放进队列里,而生产的情况是 700 条数据放进队列里。这个数据量是 700 倍的差距。
+
+而 Disruptor 作为一个环形队列,再对象没有被覆盖之前是一直存在的。
+
+我也做了一个实验,证明确实如此。
+
+
+
+我设置队列大小为 8 ,从 0~9 往里面写 10 条数据,当写到 8 的时候就会把之前 0 的位置覆盖掉,后面的以此类推(类似于 HashMap 的取模定位)。
+
+所以在生产上假设我们的队列大小是 1024,那么随着系统的运行最终肯定会导致 1024 个位置上装满了对象,而且每个位置是 700 个!
+
+于是查看了生产上 Disruptor 的 RingBuffer 配置,结果是:`1024*1024`。
+
+这个数量级就非常吓人了。
+
+为了验证是否是这个问题,我在本地将该值换为 2 ,一个最小值试试。
+
+同样的 128M 内存,也是通过 Kafka 一直源源不断的取出数据。通过监控如下:
+
+
+
+跑了 20 几分钟系统一切正常,每当一次 GC 都能回收大部分内存,最终呈现锯齿状。
+
+这样问题就找到了,不过生产上这个值具体设置多少还得根据业务情况测试才能知道,但原有的 1024*1024 是绝对不能再使用了。
+
+# 总结
+
+虽然到了最后也就改了一行代码(还没改,直接修改配置),但这排查过程我觉得是有意义的。
+
+也会让大部分觉得 JVM 这样的黑盒难以下手的同学有一个直观的感受。
+
+`同时也得感叹 Disruptor 东西虽好,也不能乱用哦!`
+
+相关演示代码查看:
+
+[https://github.com/crossoverJie/JCSprout/tree/master/src/main/java/com/crossoverjie/disruptor](https://github.com/crossoverJie/JCSprout/tree/master/src/main/java/com/crossoverjie/disruptor)
+
+**你的点赞与转发是最大的支持。**
diff --git a/docs/jvm/OOM-analysis.md b/docs/jvm/OOM-analysis.md
new file mode 100644
index 00000000..dee31454
--- /dev/null
+++ b/docs/jvm/OOM-analysis.md
@@ -0,0 +1,96 @@
+# OOM 分析
+
+## Java 堆内存溢出
+
+在 Java 堆中只要不断的创建对象,并且 `GC-Roots` 到对象之间存在引用链,这样 `JVM` 就不会回收对象。
+
+只要将`-Xms(最小堆)`,`-Xmx(最大堆)` 设置为一样禁止自动扩展堆内存。
+
+
+当使用一个 `while(true)` 循环来不断创建对象就会发生 `OutOfMemory`,还可以使用 `-XX:+HeapDumpOutofMemoryErorr` 当发生 OOM 时会自动 dump 堆栈到文件中。
+
+伪代码:
+
+```java
+ public static void main(String[] args) {
+ List list = new ArrayList<>(10) ;
+ while (true){
+ list.add("1") ;
+ }
+ }
+```
+
+当出现 OOM 时可以通过工具来分析 `GC-Roots` [引用链](https://github.com/crossoverJie/Java-Interview/blob/master/MD/GarbageCollection.md#%E5%8F%AF%E8%BE%BE%E6%80%A7%E5%88%86%E6%9E%90%E7%AE%97%E6%B3%95) ,查看对象和 `GC-Roots` 是如何进行关联的,是否存在对象的生命周期过长,或者是这些对象确实改存在的,那就要考虑将堆内存调大了。
+
+```
+Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
+ at java.util.Arrays.copyOf(Arrays.java:3210)
+ at java.util.Arrays.copyOf(Arrays.java:3181)
+ at java.util.ArrayList.grow(ArrayList.java:261)
+ at java.util.ArrayList.ensureExplicitCapacity(ArrayList.java:235)
+ at java.util.ArrayList.ensureCapacityInternal(ArrayList.java:227)
+ at java.util.ArrayList.add(ArrayList.java:458)
+ at com.crossoverjie.oom.HeapOOM.main(HeapOOM.java:18)
+ at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
+ at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
+ at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
+ at java.lang.reflect.Method.invoke(Method.java:498)
+ at com.intellij.rt.execution.application.AppMain.main(AppMain.java:147)
+
+Process finished with exit code 1
+
+```
+`java.lang.OutOfMemoryError: Java heap space`表示堆内存溢出。
+
+
+
+更多内存溢出相关实战请看这里:[强如 Disruptor 也发生内存溢出?](https://crossoverjie.top/2018/08/29/java-senior/OOM-Disruptor/)
+
+
+
+
+## MetaSpace (元数据) 内存溢出
+
+> `JDK8` 中将永久代移除,使用 `MetaSpace` 来保存类加载之后的类信息,字符串常量池也被移动到 Java 堆。
+
+`PermSize` 和 `MaxPermSize` 已经不能使用了,在 JDK8 中配置这两个参数将会发出警告。
+
+
+JDK 8 中将类信息移到到了本地堆内存(Native Heap)中,将原有的永久代移动到了本地堆中成为 `MetaSpace` ,如果不指定该区域的大小,JVM 将会动态的调整。
+
+可以使用 `-XX:MaxMetaspaceSize=10M` 来限制最大元数据。这样当不停的创建类时将会占满该区域并出现 `OOM`。
+
+```java
+ public static void main(String[] args) {
+ while (true){
+ Enhancer enhancer = new Enhancer() ;
+ enhancer.setSuperclass(HeapOOM.class);
+ enhancer.setUseCache(false) ;
+ enhancer.setCallback(new MethodInterceptor() {
+ @Override
+ public Object intercept(Object o, Method method, Object[] objects, MethodProxy methodProxy) throws Throwable {
+ return methodProxy.invoke(o,objects) ;
+ }
+ });
+ enhancer.create() ;
+
+ }
+ }
+```
+使用 `cglib` 不停的创建新类,最终会抛出:
+```
+Caused by: java.lang.reflect.InvocationTargetException
+ at sun.reflect.GeneratedMethodAccessor1.invoke(Unknown Source)
+ at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
+ at java.lang.reflect.Method.invoke(Method.java:498)
+ at net.sf.cglib.core.ReflectUtils.defineClass(ReflectUtils.java:459)
+ at net.sf.cglib.core.AbstractClassGenerator.generate(AbstractClassGenerator.java:336)
+ ... 11 more
+Caused by: java.lang.OutOfMemoryError: Metaspace
+ at java.lang.ClassLoader.defineClass1(Native Method)
+ at java.lang.ClassLoader.defineClass(ClassLoader.java:763)
+ ... 16 more
+```
+
+注意:这里的 OOM 伴随的是 `java.lang.OutOfMemoryError: Metaspace` 也就是元数据溢出。
+
diff --git a/docs/jvm/cpu-percent-100.md b/docs/jvm/cpu-percent-100.md
new file mode 100755
index 00000000..4c327b5f
--- /dev/null
+++ b/docs/jvm/cpu-percent-100.md
@@ -0,0 +1,152 @@
+
+
+
+
+# 前言
+
+到了年底果然都不太平,最近又收到了运维报警:表示有些服务器负载非常高,让我们定位问题。
+
+还真是想什么来什么,前些天还故意把某些服务器的负载提高([没错,老板让我写个 BUG!](https://crossoverjie.top/2018/12/12/java-senior/java-memary-allocation/)),不过还好是不同的环境互相没有影响。
+
+
+
+
+# 定位问题
+
+拿到问题后首先去服务器上看了看,发现运行的只有我们的 Java 应用。于是先用 `ps` 命令拿到了应用的 `PID`。
+
+接着使用 `top -Hp pid` 将这个进程的线程显示出来。输入大写的 P 可以将线程按照 CPU 使用比例排序,于是得到以下结果。
+
+
+
+果然某些线程的 CPU 使用率非常高。
+
+
+为了方便定位问题我立马使用 `jstack pid > pid.log` 将线程栈 `dump` 到日志文件中。
+
+我在上面 100% 的线程中随机选了一个 `pid=194283` 转换为 16 进制(2f6eb)后在线程快照中查询:
+
+> 因为线程快照中线程 ID 都是16进制存放。
+
+
+
+发现这是 `Disruptor` 的一个堆栈,前段时间正好解决过一个由于 Disruptor 队列引起的一次 [OOM]():[强如 Disruptor 也发生内存溢出?](https://crossoverjie.top/2018/08/29/java-senior/OOM-Disruptor/)
+
+没想到又来一出。
+
+为了更加直观的查看线程的状态信息,我将快照信息上传到专门分析的平台上。
+
+[http://fastthread.io/](http://fastthread.io/)
+
+
+
+其中有一项菜单展示了所有消耗 CPU 的线程,我仔细看了下发现几乎都是和上面的堆栈一样。
+
+也就是说都是 `Disruptor` 队列的堆栈,同时都在执行 `java.lang.Thread.yield` 函数。
+
+众所周知 `yield` 函数会让当前线程让出 `CPU` 资源,再让其他线程来竞争。
+
+根据刚才的线程快照发现处于 `RUNNABLE` 状态并且都在执行 `yield` 函数的线程大概有 30几个。
+
+因此初步判断为大量线程执行 `yield` 函数之后互相竞争导致 CPU 使用率增高,而通过对堆栈发现是和使用 `Disruptor` 有关。
+
+# 解决问题
+
+而后我查看了代码,发现是根据每一个业务场景在内部都会使用 2 个 `Disruptor` 队列来解耦。
+
+假设现在有 7 个业务类型,那就等于是创建 `2*7=14` 个 `Disruptor` 队列,同时每个队列有一个消费者,也就是总共有 14 个消费者(生产环境更多)。
+
+同时发现配置的消费等待策略为 `YieldingWaitStrategy` 这种等待策略确实会执行 yield 来让出 CPU。
+
+代码如下:
+
+
+
+> 初步看来和这个等待策略有很大的关系。
+
+## 本地模拟
+
+为了验证,我在本地创建了 15 个 `Disruptor` 队列同时结合监控观察 CPU 的使用情况。
+
+
+
+
+创建了 15 个 `Disruptor` 队列,同时每个队列都用线程池来往 `Disruptor队列` 里面发送 100W 条数据。
+
+消费程序仅仅只是打印一下。
+
+
+
+跑了一段时间发现 CPU 使用率确实很高。
+
+---
+
+
+
+同时 `dump` 线程发现和生产的现象也是一致的:消费线程都处于 `RUNNABLE` 状态,同时都在执行 `yield`。
+
+通过查询 `Disruptor` 官方文档发现:
+
+
+
+> YieldingWaitStrategy 是一种充分压榨 CPU 的策略,使用`自旋 + yield`的方式来提高性能。
+> 当消费线程(Event Handler threads)的数量小于 CPU 核心数时推荐使用该策略。
+
+---
+
+
+
+同时查阅到其他的等待策略 `BlockingWaitStrategy` (也是默认的策略),它使用的是锁的机制,对 CPU 的使用率不高。
+
+于是在和之前同样的条件下将等待策略换为 `BlockingWaitStrategy`。
+
+
+
+---
+
+
+
+
+和刚才的 CPU 对比会发现到后面使用率的会有明显的降低;同时 dump 线程后会发现大部分线程都处于 waiting 状态。
+
+
+## 优化解决
+
+看样子将等待策略换为 `BlockingWaitStrategy` 可以减缓 CPU 的使用,
+
+但留意到官方对 `YieldingWaitStrategy` 的描述里谈道:
+当消费线程(Event Handler threads)的数量小于 CPU 核心数时推荐使用该策略。
+
+而现有的使用场景很明显消费线程数已经大大的超过了核心 CPU 数了,因为我的使用方式是一个 `Disruptor` 队列一个消费者,所以我将队列调整为只有 1 个再试试(策略依然是 `YieldingWaitStrategy`)。
+
+
+
+
+
+跑了一分钟,发现 CPU 的使用率一直都比较平稳而且不高。
+
+# 总结
+
+所以排查到此可以有一个结论了,想要根本解决这个问题需要将我们现有的业务拆分;现在是一个应用里同时处理了 N 个业务,每个业务都会使用好几个 `Disruptor` 队列。
+
+由于是在一台服务器上运行,所以 CPU 资源都是共享的,这就会导致 CPU 的使用率居高不下。
+
+所以我们的调整方式如下:
+
+- 为了快速缓解这个问题,先将等待策略换为 `BlockingWaitStrategy`,可以有效降低 CPU 的使用率(业务上也还能接受)。
+- 第二步就需要将应用拆分(上文模拟的一个 `Disruptor` 队列),一个应用处理一种业务类型;然后分别单独部署,这样也可以互相隔离互不影响。
+
+当然还有其他的一些优化,因为这也是一个老系统了,这次 dump 线程居然发现创建了 800+ 的线程。
+
+创建线程池的方式也是核心线程数、最大线程数是一样的,导致一些空闲的线程也得不到回收;这样会有很多无意义的资源消耗。
+
+所以也会结合业务将创建线程池的方式调整一下,将线程数降下来,尽量的物尽其用。
+
+
+本文的演示代码已上传至 GitHub:
+
+[https://github.com/crossoverJie/JCSprout](https://github.com/crossoverJie/JCSprout/tree/master/src/main/java/com/crossoverjie/disruptor)
+
+**你的点赞与分享是对我最大的支持**
+
+
diff --git a/docs/jvm/newObject.md b/docs/jvm/newObject.md
new file mode 100644
index 00000000..4542db99
--- /dev/null
+++ b/docs/jvm/newObject.md
@@ -0,0 +1,77 @@
+# 对象的创建与内存分配
+
+
+## 创建对象
+
+当 `JVM` 收到一个 `new` 指令时,会检查指令中的参数在常量池是否有这个符号的引用,还会检查该类是否已经被[加载](https://github.com/crossoverJie/Java-Interview/blob/master/MD/ClassLoad.md)过了,如果没有的话则要进行一次类加载。
+
+接着就是分配内存了,通常有两种方式:
+
+- 指针碰撞
+- 空闲列表
+
+使用指针碰撞的前提是堆内存是**完全工整**的,用过的内存和没用的内存各在一边每次分配的时候只需要将指针向空闲内存一方移动一段和内存大小相等区域即可。
+
+当堆中已经使用的内存和未使用的内存**互相交错**时,指针碰撞的方式就行不通了,这时就需要采用空闲列表的方式。虚拟机会维护一个空闲的列表,用于记录哪些内存是可以进行分配的,分配时直接从可用内存中直接分配即可。
+
+堆中的内存是否工整是有**垃圾收集器**来决定的,如果带有压缩功能的垃圾收集器就是采用指针碰撞的方式来进行内存分配的。
+
+分配内存时也会出现并发问题:
+
+这样可以在创建对象的时候使用 `CAS` 这样的乐观锁来保证。
+
+也可以将内存分配安排在每个线程独有的空间进行,每个线程首先在堆内存中分配一小块内存,称为本地分配缓存(`TLAB : Thread Local Allocation Buffer`)。
+
+分配内存时,只需要在自己的分配缓存中分配即可,由于这个内存区域是线程私有的,所以不会出现并发问题。
+
+可以使用 `-XX:+/-UseTLAB` 参数来设定 `JVM` 是否开启 `TLAB` 。
+
+内存分配之后需要对该对象进行设置,如对象头。对象头的一些应用可以查看 [Synchronize 关键字原理](https://github.com/crossoverJie/Java-Interview/blob/master/MD/Synchronize.md)。
+
+### 对象访问
+
+一个对象被创建之后自然是为了使用,在 `Java` 中是通过栈来引用堆内存中的对象来进行操作的。
+
+对于我们常用的 `HotSpot` 虚拟机来说,这样引用关系是通过直接指针来关联的。
+
+如图:
+
+
+
+这样的好处就是:在 Java 里进行频繁的对象访问可以提升访问速度(相对于使用句柄池来说)。
+
+## 内存分配
+
+
+### Eden 区分配
+简单的来说对象都是在堆内存中分配的,往细一点看则是优先在 `Eden` 区分配。
+
+这里就涉及到堆内存的划分了,为了方便垃圾回收,JVM 将堆内存分为新生代和老年代。
+
+而新生代中又会划分为 `Eden` 区,`from Survivor、to Survivor` 区。
+
+其中 `Eden` 和 `Survivor` 区的比例默认是 `8:1:1`,当然也支持参数调整 `-XX:SurvivorRatio=8`。
+
+当在 `Eden` 区分配内存不足时,则会发生 `minorGC` ,由于 `Java` 对象多数是**朝生夕灭**的特性,所以 `minorGC` 通常会比较频繁,效率也比较高。
+
+当发生 `minorGC` 时,JVM 会根据[复制算法](https://github.com/crossoverJie/Java-Interview/blob/master/MD/GarbageCollection.md#%E5%A4%8D%E5%88%B6%E7%AE%97%E6%B3%95)将存活的对象拷贝到另一个未使用的 `Survivor` 区,如果 `Survivor` 区内存不足时,则会使用分配担保策略将对象移动到老年代中。
+
+谈到 `minorGC` 时,就不得不提到 `fullGC(majorGC)` ,这是指发生在老年代的 `GC` ,不论是效率还是速度都比 `minorGC` 慢的多,回收时还会发生 `stop the world` 使程序发生停顿,所以应当尽量避免发生 `fullGC` 。
+
+### 老年代分配
+
+也有一些情况会导致对象直接在老年代分配,比如当分配一个大对象时(大的数组,很长的字符串),由于 `Eden` 区没有足够大的连续空间来分配时,会导致提前触发一次 `GC`,所以尽量别频繁的创建大对象。
+
+因此 `JVM` 会根据一个阈值来判断大于该阈值对象直接分配到老年代,这样可以避免在新生代频繁的发生 `GC`。
+
+
+对于一些在新生代的老对象 `JVM` 也会根据某种机制移动到老年代中。
+
+JVM 是根据记录对象年龄的方式来判断该对象是否应该移动到老年代,根据新生代的复制算法,当一个对象被移动到 `Survivor` 区之后 JVM 就给该对象的年龄记为1,每当熬过一次 `minorGC` 后对象的年龄就 +1 ,直到达到阈值(默认为15)就移动到老年代中。
+
+> 可以使用 `-XX:MaxTenuringThreshold=15` 来配置这个阈值。
+
+
+## 总结
+
+虽说这些内容略显枯燥,但当应用发生不正常的 `GC` 时,可以方便更快的定位问题。
diff --git a/docs/jvm/volatile.md b/docs/jvm/volatile.md
new file mode 100644
index 00000000..3110e2c6
--- /dev/null
+++ b/docs/jvm/volatile.md
@@ -0,0 +1,218 @@
+# 你应该知道的 volatile 关键字
+
+## 前言
+
+不管是在面试还是实际开发中 `volatile` 都是一个应该掌握的技能。
+
+首先来看看为什么会出现这个关键字。
+
+## 内存可见性
+由于 `Java` 内存模型(`JMM`)规定,所有的变量都存放在主内存中,而每个线程都有着自己的工作内存(高速缓存)。
+
+线程在工作时,需要将主内存中的数据拷贝到工作内存中。这样对数据的任何操作都是基于工作内存(效率提高),并且不能直接操作主内存以及其他线程工作内存中的数据,之后再将更新之后的数据刷新到主内存中。
+
+> 这里所提到的主内存可以简单认为是**堆内存**,而工作内存则可以认为是**栈内存**。
+
+如下图所示:
+
+
+
+所以在并发运行时可能会出现线程 B 所读取到的数据是线程 A 更新之前的数据。
+
+显然这肯定是会出问题的,因此 `volatile` 的作用出现了:
+
+> 当一个变量被 `volatile` 修饰时,任何线程对它的写操作都会立即刷新到主内存中,并且会强制让缓存了该变量的线程中的数据清空,必须从主内存重新读取最新数据。
+
+*`volatile` 修饰之后并不是让线程直接从主内存中获取数据,依然需要将变量拷贝到工作内存中*。
+
+### 内存可见性的应用
+
+当我们需要在两个线程间依据主内存通信时,通信的那个变量就必须的用 `volatile` 来修饰:
+
+```java
+public class Volatile implements Runnable{
+
+ private static volatile boolean flag = true ;
+
+ @Override
+ public void run() {
+ while (flag){
+ }
+ System.out.println(Thread.currentThread().getName() +"执行完毕");
+ }
+
+ public static void main(String[] args) throws InterruptedException {
+ Volatile aVolatile = new Volatile();
+ new Thread(aVolatile,"thread A").start();
+
+
+ System.out.println("main 线程正在运行") ;
+
+ Scanner sc = new Scanner(System.in);
+ while(sc.hasNext()){
+ String value = sc.next();
+ if(value.equals("1")){
+
+ new Thread(new Runnable() {
+ @Override
+ public void run() {
+ aVolatile.stopThread();
+ }
+ }).start();
+
+ break ;
+ }
+ }
+
+ System.out.println("主线程退出了!");
+
+ }
+
+ private void stopThread(){
+ flag = false ;
+ }
+
+}
+```
+
+主线程在修改了标志位使得线程 A 立即停止,如果没有用 `volatile` 修饰,就有可能出现延迟。
+
+但这里有个误区,这样的使用方式容易给人的感觉是:
+
+> 对 `volatile` 修饰的变量进行并发操作是线程安全的。
+
+这里要重点强调,`volatile` 并**不能**保证线程安全性!
+
+如下程序:
+
+```java
+public class VolatileInc implements Runnable{
+
+ private static volatile int count = 0 ; //使用 volatile 修饰基本数据内存不能保证原子性
+
+ //private static AtomicInteger count = new AtomicInteger() ;
+
+ @Override
+ public void run() {
+ for (int i=0;i<10000 ;i++){
+ count ++ ;
+ //count.incrementAndGet() ;
+ }
+ }
+
+ public static void main(String[] args) throws InterruptedException {
+ VolatileInc volatileInc = new VolatileInc() ;
+ Thread t1 = new Thread(volatileInc,"t1") ;
+ Thread t2 = new Thread(volatileInc,"t2") ;
+ t1.start();
+ //t1.join();
+
+ t2.start();
+ //t2.join();
+ for (int i=0;i<10000 ;i++){
+ count ++ ;
+ //count.incrementAndGet();
+ }
+
+
+ System.out.println("最终Count="+count);
+ }
+}
+```
+
+当我们三个线程(t1,t2,main)同时对一个 `int` 进行累加时会发现最终的值都会小于 30000。
+
+> 这是因为虽然 `volatile` 保证了内存可见性,每个线程拿到的值都是最新值,但 `count ++` 这个操作并不是原子的,这里面涉及到获取值、自增、赋值的操作并不能同时完成。
+>
+
+- 所以想到达到线程安全可以使这三个线程串行执行(其实就是单线程,没有发挥多线程的优势)。
+
+- 也可以使用 `synchronized` 或者是锁的方式来保证原子性。
+
+- 还可以用 `Atomic` 包中 `AtomicInteger` 来替换 `int`,它利用了 `CAS` 算法来保证了原子性。
+
+
+## 指令重排
+
+内存可见性只是 `volatile` 的其中一个语义,它还可以防止 `JVM` 进行指令重排优化。
+
+举一个伪代码:
+
+```java
+int a=10 ;//1
+int b=20 ;//2
+int c= a+b ;//3
+```
+
+一段特别简单的代码,理想情况下它的执行顺序是:`1>2>3`。但有可能经过 JVM 优化之后的执行顺序变为了 `2>1>3`。
+
+可以发现不管 JVM 怎么优化,前提都是保证单线程中最终结果不变的情况下进行的。
+
+可能这里还看不出有什么问题,那看下一段伪代码:
+
+```java
+private static Map value ;
+private static volatile boolean flag = fasle ;
+
+//以下方法发生在线程 A 中 初始化 Map
+public void initMap(){
+ //耗时操作
+ value = getMapValue() ;//1
+ flag = true ;//2
+}
+
+
+//发生在线程 B中 等到 Map 初始化成功进行其他操作
+public void doSomeThing(){
+ while(!flag){
+ sleep() ;
+ }
+ //dosomething
+ doSomeThing(value);
+}
+
+```
+
+这里就能看出问题了,当 `flag` 没有被 `volatile` 修饰时,`JVM` 对 1 和 2 进行重排,导致 `value` 都还没有被初始化就有可能被线程 B 使用了。
+
+所以加上 `volatile` 之后可以防止这样的重排优化,保证业务的正确性。
+### 指令重排的的应用
+
+一个经典的使用场景就是双重懒加载的单例模式了:
+
+```java
+public class Singleton {
+
+ private static volatile Singleton singleton;
+
+ private Singleton() {
+ }
+
+ public static Singleton getInstance() {
+ if (singleton == null) {
+ synchronized (Singleton.class) {
+ if (singleton == null) {
+ //防止指令重排
+ singleton = new Singleton();
+ }
+ }
+ }
+ return singleton;
+ }
+}
+```
+
+这里的 `volatile` 关键字主要是为了防止指令重排。
+
+如果不用 ,`singleton = new Singleton();`,这段代码其实是分为三步:
+- 分配内存空间。(1)
+- 初始化对象。(2)
+- 将 `singleton` 对象指向分配的内存地址。(3)
+
+加上 `volatile` 是为了让以上的三步操作顺序执行,反之有可能第二步在第三步之前被执行就有可能某个线程拿到的单例对象是还没有初始化的,以致于报错。
+
+## 总结
+
+`volatile` 在 `Java` 并发中用的很多,比如像 `Atomic` 包中的 `value`、以及 `AbstractQueuedLongSynchronizer` 中的 `state` 都是被定义为 `volatile` 来用于保证内存可见性。
+
+将这块理解透彻对我们编写并发程序时可以提供很大帮助。
diff --git a/docs/netty/Netty(1)TCP-Heartbeat.md b/docs/netty/Netty(1)TCP-Heartbeat.md
new file mode 100644
index 00000000..e562ecb1
--- /dev/null
+++ b/docs/netty/Netty(1)TCP-Heartbeat.md
@@ -0,0 +1,695 @@
+
+
+
+# 前言
+
+Netty 是一个高性能的 NIO 网络框架,本文基于 SpringBoot 以常见的心跳机制来认识 Netty。
+
+最终能达到的效果:
+
+- 客户端每隔 N 秒检测是否需要发送心跳。
+- 服务端也每隔 N 秒检测是否需要发送心跳。
+- 服务端可以主动 push 消息到客户端。
+- 基于 SpringBoot 监控,可以查看实时连接以及各种应用信息。
+
+效果如下:
+
+
+
+
+
+# IdleStateHandler
+
+Netty 可以使用 IdleStateHandler 来实现连接管理,当连接空闲时间太长(没有发送、接收消息)时则会触发一个事件,我们便可在该事件中实现心跳机制。
+
+## 客户端心跳
+
+当客户端空闲了 N 秒没有给服务端发送消息时会自动发送一个心跳来维持连接。
+
+核心代码代码如下:
+
+```java
+public class EchoClientHandle extends SimpleChannelInboundHandler {
+
+ private final static Logger LOGGER = LoggerFactory.getLogger(EchoClientHandle.class);
+
+
+
+ @Override
+ public void userEventTriggered(ChannelHandlerContext ctx, Object evt) throws Exception {
+
+ if (evt instanceof IdleStateEvent){
+ IdleStateEvent idleStateEvent = (IdleStateEvent) evt ;
+
+ if (idleStateEvent.state() == IdleState.WRITER_IDLE){
+ LOGGER.info("已经 10 秒没有发送信息!");
+ //向服务端发送消息
+ CustomProtocol heartBeat = SpringBeanFactory.getBean("heartBeat", CustomProtocol.class);
+ ctx.writeAndFlush(heartBeat).addListener(ChannelFutureListener.CLOSE_ON_FAILURE) ;
+ }
+
+
+ }
+
+ super.userEventTriggered(ctx, evt);
+ }
+
+
+ @Override
+ protected void channelRead0(ChannelHandlerContext channelHandlerContext, ByteBuf in) throws Exception {
+
+ //从服务端收到消息时被调用
+ LOGGER.info("客户端收到消息={}",in.toString(CharsetUtil.UTF_8)) ;
+
+ }
+}
+```
+
+实现非常简单,只需要在事件回调中发送一个消息即可。
+
+由于整合了 SpringBoot ,所以发送的心跳信息是一个单例的 Bean。
+
+```java
+@Configuration
+public class HeartBeatConfig {
+
+ @Value("${channel.id}")
+ private long id ;
+
+
+ @Bean(value = "heartBeat")
+ public CustomProtocol heartBeat(){
+ return new CustomProtocol(id,"ping") ;
+ }
+}
+```
+
+这里涉及到了自定义协议的内容,请继续查看下文。
+
+当然少不了启动引导:
+
+```java
+@Component
+public class HeartbeatClient {
+
+ private final static Logger LOGGER = LoggerFactory.getLogger(HeartbeatClient.class);
+
+ private EventLoopGroup group = new NioEventLoopGroup();
+
+
+ @Value("${netty.server.port}")
+ private int nettyPort;
+
+ @Value("${netty.server.host}")
+ private String host;
+
+ private SocketChannel channel;
+
+ @PostConstruct
+ public void start() throws InterruptedException {
+ Bootstrap bootstrap = new Bootstrap();
+ bootstrap.group(group)
+ .channel(NioSocketChannel.class)
+ .handler(new CustomerHandleInitializer())
+ ;
+
+ ChannelFuture future = bootstrap.connect(host, nettyPort).sync();
+ if (future.isSuccess()) {
+ LOGGER.info("启动 Netty 成功");
+ }
+ channel = (SocketChannel) future.channel();
+ }
+
+}
+
+public class CustomerHandleInitializer extends ChannelInitializer {
+ @Override
+ protected void initChannel(Channel ch) throws Exception {
+ ch.pipeline()
+ //10 秒没发送消息 将IdleStateHandler 添加到 ChannelPipeline 中
+ .addLast(new IdleStateHandler(0, 10, 0))
+ .addLast(new HeartbeatEncode())
+ .addLast(new EchoClientHandle())
+ ;
+ }
+}
+```
+
+所以当应用启动每隔 10 秒会检测是否发送过消息,不然就会发送心跳信息。
+
+
+
+## 服务端心跳
+
+服务器端的心跳其实也是类似,也需要在 ChannelPipeline 中添加一个 IdleStateHandler 。
+
+```java
+public class HeartBeatSimpleHandle extends SimpleChannelInboundHandler {
+
+ private final static Logger LOGGER = LoggerFactory.getLogger(HeartBeatSimpleHandle.class);
+
+ private static final ByteBuf HEART_BEAT = Unpooled.unreleasableBuffer(Unpooled.copiedBuffer(new CustomProtocol(123456L,"pong").toString(),CharsetUtil.UTF_8));
+
+
+ /**
+ * 取消绑定
+ * @param ctx
+ * @throws Exception
+ */
+ @Override
+ public void channelInactive(ChannelHandlerContext ctx) throws Exception {
+
+ NettySocketHolder.remove((NioSocketChannel) ctx.channel());
+ }
+
+ @Override
+ public void userEventTriggered(ChannelHandlerContext ctx, Object evt) throws Exception {
+
+ if (evt instanceof IdleStateEvent){
+ IdleStateEvent idleStateEvent = (IdleStateEvent) evt ;
+
+ if (idleStateEvent.state() == IdleState.READER_IDLE){
+ LOGGER.info("已经5秒没有收到信息!");
+ //向客户端发送消息
+ ctx.writeAndFlush(HEART_BEAT).addListener(ChannelFutureListener.CLOSE_ON_FAILURE) ;
+ }
+
+
+ }
+
+ super.userEventTriggered(ctx, evt);
+ }
+
+ @Override
+ protected void channelRead0(ChannelHandlerContext ctx, CustomProtocol customProtocol) throws Exception {
+ LOGGER.info("收到customProtocol={}", customProtocol);
+
+ //保存客户端与 Channel 之间的关系
+ NettySocketHolder.put(customProtocol.getId(),(NioSocketChannel)ctx.channel()) ;
+ }
+}
+```
+
+**这里有点需要注意**:
+
+当有多个客户端连上来时,服务端需要区分开,不然响应消息就会发生混乱。
+
+所以每当有个连接上来的时候,我们都将当前的 Channel 与连上的客户端 ID 进行关联(**因此每个连上的客户端 ID 都必须唯一**)。
+
+这里采用了一个 Map 来保存这个关系,并且在断开连接时自动取消这个关联。
+
+```java
+public class NettySocketHolder {
+ private static final Map MAP = new ConcurrentHashMap<>(16);
+
+ public static void put(Long id, NioSocketChannel socketChannel) {
+ MAP.put(id, socketChannel);
+ }
+
+ public static NioSocketChannel get(Long id) {
+ return MAP.get(id);
+ }
+
+ public static Map getMAP() {
+ return MAP;
+ }
+
+ public static void remove(NioSocketChannel nioSocketChannel) {
+ MAP.entrySet().stream().filter(entry -> entry.getValue() == nioSocketChannel).forEach(entry -> MAP.remove(entry.getKey()));
+ }
+}
+```
+
+启动引导程序:
+
+```java
+Component
+public class HeartBeatServer {
+
+ private final static Logger LOGGER = LoggerFactory.getLogger(HeartBeatServer.class);
+
+ private EventLoopGroup boss = new NioEventLoopGroup();
+ private EventLoopGroup work = new NioEventLoopGroup();
+
+
+ @Value("${netty.server.port}")
+ private int nettyPort;
+
+
+ /**
+ * 启动 Netty
+ *
+ * @return
+ * @throws InterruptedException
+ */
+ @PostConstruct
+ public void start() throws InterruptedException {
+
+ ServerBootstrap bootstrap = new ServerBootstrap()
+ .group(boss, work)
+ .channel(NioServerSocketChannel.class)
+ .localAddress(new InetSocketAddress(nettyPort))
+ //保持长连接
+ .childOption(ChannelOption.SO_KEEPALIVE, true)
+ .childHandler(new HeartbeatInitializer());
+
+ ChannelFuture future = bootstrap.bind().sync();
+ if (future.isSuccess()) {
+ LOGGER.info("启动 Netty 成功");
+ }
+ }
+
+
+ /**
+ * 销毁
+ */
+ @PreDestroy
+ public void destroy() {
+ boss.shutdownGracefully().syncUninterruptibly();
+ work.shutdownGracefully().syncUninterruptibly();
+ LOGGER.info("关闭 Netty 成功");
+ }
+}
+
+
+public class HeartbeatInitializer extends ChannelInitializer {
+ @Override
+ protected void initChannel(Channel ch) throws Exception {
+ ch.pipeline()
+ //五秒没有收到消息 将IdleStateHandler 添加到 ChannelPipeline 中
+ .addLast(new IdleStateHandler(5, 0, 0))
+ .addLast(new HeartbeatDecoder())
+ .addLast(new HeartBeatSimpleHandle());
+ }
+}
+```
+
+也是同样将IdleStateHandler 添加到 ChannelPipeline 中,也会有一个定时任务,每5秒校验一次是否有收到消息,否则就主动发送一次请求。
+
+
+
+因为测试是有两个客户端连上所以有两个日志。
+
+## 自定义协议
+
+上文其实都看到了:服务端与客户端采用的是自定义的 POJO 进行通讯的。
+
+所以需要在客户端进行编码,服务端进行解码,也都只需要各自实现一个编解码器即可。
+
+CustomProtocol:
+
+```java
+public class CustomProtocol implements Serializable{
+
+ private static final long serialVersionUID = 4671171056588401542L;
+ private long id ;
+ private String content ;
+ //省略 getter/setter
+}
+```
+
+客户端的编码器:
+
+```java
+public class HeartbeatEncode extends MessageToByteEncoder {
+ @Override
+ protected void encode(ChannelHandlerContext ctx, CustomProtocol msg, ByteBuf out) throws Exception {
+
+ out.writeLong(msg.getId()) ;
+ out.writeBytes(msg.getContent().getBytes()) ;
+
+ }
+}
+```
+
+也就是说消息的前八个字节为 header,剩余的全是 content。
+
+服务端的解码器:
+
+```java
+public class HeartbeatDecoder extends ByteToMessageDecoder {
+ @Override
+ protected void decode(ChannelHandlerContext ctx, ByteBuf in, List

 \ No newline at end of file
diff --git a/MD/soft-skills/Interview-experience.md b/MD/soft-skills/Interview-experience.md
new file mode 100644
index 00000000..6c0bd3ba
--- /dev/null
+++ b/MD/soft-skills/Interview-experience.md
@@ -0,0 +1,359 @@
+
+
+## 前言
+
+最近有些朋友在面试阿里,加上 [Java-Interview](https://github.com/crossoverJie/Java-Interview) 项目的原因也有小伙伴和我讨论,近期也在负责部门的招聘,这让我想起年初那段长达三个月的奇葩面试经历🤣。
+
+本来没想拿出来说的,毕竟最后也没成。
+
+但由于那几个月的经历让我了解到了大厂的工作方式、对候选同学的考察重点以及面试官的套路等都有了全新的认识。
+
+当然最重要的是这段时间的查漏补缺也让自己精进不少。
+
+
+先交代下背景吧:
+
+
+从去年 12 月到今年三月底,我前前后后面了阿里三个部门。
+
+其中两个部门通过了技术面试,还有一个跪在了三面。
+
+光看结果还不错,但整个流程堪称曲折。
+
+下面我会尽量描述流程以及大致的面试题目大纲,希望对想要跳槽、正在面试的同学带来点灵感,帮助可能谈不上,但启发还是能有。
+
+以下内容较长,请再次备好瓜子板凳。
+
+
+
+
+## A 部门
+
+首先是第一次机会,去年 12 月份有位大佬加我,后来才知道是一个部门的技术 Leader 在网上看到我的博客,问我想不想来阿里试试。
+
+这时距离上次面阿里也过去一年多了,也想看看现在几斤几两,于是便同意了。
+
+在推荐一周之后收到了杭州打来的电话,说来也巧,那时候我正在机场候机,距离登记还有大概一个小时,心想时间肯定够了。
+
+那是我时隔一年多第一次面试,还是在机场这样嘈杂的环境里。多多少少还是有些紧张。
+
+### 一面
+
+以下是我印象比较深刻的内容:
+
+**面试官:**
+
+谈谈你做过项目中印象较深或自认为做的比较好的地方?
+
+**博主:**
+
+我觉得我在 XX 做的不错,用了 XX 需求实现 XX 功能,性能提高了 N 倍。
+
+**面试官:**
+
+你说使用到了 AOP ,能谈谈它的实现原理嘛?
+
+**博主:**
+
+它是依靠动态代理实现的,动态代理又分为 JDK 自身的以及 CGLIB 。。。。
+
+**面试官:**
+
+嗯,能说说他们的不同及优缺点嘛?
+
+**博主:**
+
+JDK 是基于接口实现,而 CGLIB 继承代理类。。。
+
+就是这样会一直问下去,如果聊的差不多了就开始问一些零散的问题:
+
+- JMM 内存模型,如何划分的?分别存储什么内容?线程安全与否?
+- 类加载机制,谈到双亲委派模型后会问到哪些违反了双亲委派模型?为什么?为什么要双亲委派?好处是什么?
+- 平时怎么使用多线程?有哪些好处?线程池的几个核心参数的意义?
+- 线程间通信的方式?
+- HashMap 的原理?当谈到线程不安全时自然引申出 ConcurrentHashMap ,它的实现原理?
+- 分库分表如何设计?垂直拆分、水平拆分?
+- 业务 ID 的生成规则,有哪些方式?
+- SQL 调优?平时使用数据库有哪些注意点?
+- 当一个应用启动缓慢如何优化?
+
+大概是以上这些,当聊到倒数第二个时我已经登机了。最后不得不提前挂断,结束之前告诉我之后会换一个同事和我沟通,听到这样的回复一面应该是过了,
+后面也确实证实了这点。
+
+### 二面
+
+大概过了一周,二面如期而至。
+
+我听声音很熟,就尝试问下是不是之前一面的面试官,结果真是。
+
+由于二面的面试官临时有事所以他来替一下。于是我赶紧问他能否把之前答的不好的再说说?的到了肯定的答复后开始了我的表演。
+
+有了第一次的经验这一次自然也轻车熟路,原本感觉一切尽在掌握却被告知需要笔试突然被激醒。
+
+笔试是一个在线平台,需要在网页中写代码,会有一个明确的题目:
+
+> 从一个日志文件中根据关键字读取日志,记录出现的次数,最后按照次数排序打印。
+
+在这过程中切记要和面试官多多交流,因为笔试有时间限制,别到最后发现题目理解错了,这就和高考作文写完发现方向错了一样要命。
+
+而且在沟通过程中体现出你解题的思路,即使最终结果不对,但说不定思考的过程很符合面试官的胃口哦。这也和今年的高考改卷一样;过程正确得高分,只有结果得低分。
+
+### 三面
+
+又过了差不多一周的时间接到了三面的电话,一般到了三面会是技术 Leader 之类的角色。
+
+这个过程中不会过多强调技术细节,更多的考察软件能,比如团队协作、学习能力等。
+
+但我记得也问了以下一些技术问题:
+
+- 谈谈你所理解的 HTTP 协议?
+- 对 TCP 的理解?三次握手?滑动窗口?
+- 基本算法,Base64 等。
+- Java 内存模型,Happen Before 的理解。
+
+一周之后我接到了 HR 助理的电话约了和 HRBP 以及产品技术负责人的视频面试。
+
+但是我却没有面下去,具体原因得往下看。
+
+
+## B 部门
+
+在 A 部门三面完成后,我等了差不多一星期,这期间我却收到了一封邮件。
+
+大概内容是他在 GitHub 上看到的我,他们的技术总监对我很感兴趣(我都不敢相信我的眼镜),问我想不想来阿里试试。
+
+我对比了 A B 部门的区别发现 B 部门在做的事情上确实更加有诱惑力,之后我表达了有一个面试正在流程中的顾虑;对方表示可以私下和我快速的进行三面,如果一切没问题再交由我自行选择。至少对双方都是一个双赢嘛。
+
+我想也不亏,并且对方很有诚意,就答应试试;于是便有了下面的面试:
+
+
+### 一面
+
+**面试官:**
+
+对 Java 锁的理解?
+
+**博主:**
+
+我谈到了 synchronize,Lock 接口的应用。
+
+**面试官:**
+
+他们两者的区别以及优缺点呢?
+
+**博主:**
+
+`synchronize` 在 JDK1.6 之前称为重量锁,是通过进出对象监视器来实现同步的;1.6 之后做了 XX 优化。。。
+
+而 `ReentrantLock` 是利用了一个巧妙数据结构实现的,并且加锁解锁是显式的。。。
+
+之后又引申到[分布式锁](https://crossoverjie.top/%2F2018%2F03%2F29%2Fdistributed-lock%2Fdistributed-lock-redis%2F),光这块就聊了差不多半个小时。
+
+之后又聊到了我的[开源项目](https://github.com/crossoverJie):
+- 是如何想做这个项目的?
+- 已经有一些关注了后续是如何规划的?
+- 你今后的学习计划是什么?
+- 平时看哪些书?
+
+之后技术聊的不是很多,但对于个人发展却聊了不少。
+
+
+> 关于锁相关的内容可以参考这里:[ReentrantLock 实现原理](https://crossoverjie.top/%2F2018%2F01%2F25%2FReentrantLock%2F) [synchronize 关键字原理](https://crossoverjie.top/%2F2018%2F01%2F14%2FSynchronize%2F)
+
+
+### 二面
+
+隔了差不多一天的时间,二面很快就来了。
+
+内容不是很多:
+
+- [线程间通信的多种方式](https://crossoverjie.top/%2F2018%2F03%2F16%2Fjava-senior%2Fthread-communication%2F)?
+- 限流算法?单机限流?分布式限流?
+- 提到了 Guava Cache ,了解它的[实现原理](https://crossoverjie.top/2018/06/13/guava/guava-cache/)嘛?
+- 如何定位一个线上问题?
+- CPU 高负载?OOM 排查等?
+
+聊完之后表示第二天应该会有三面。
+
+### 三面
+
+三面的面试官应该是之前邮件中提到的那位总监大佬,以前应该也是一线的技术大牛;聊的问题不是很多:
+
+- 谈谈对 Netty 的理解?
+- Netty 的线程模型?
+- [写一个 LRU 缓存](https://crossoverjie.top/2018/04/07/algorithm/LRU-cache/)。
+
+
+### 笔试
+
+本以为技术面试完了,结果后面告知所有的面试流程都得有笔试了,于是又参与了一次笔试:
+
+> [交替打印奇偶数](https://github.com/crossoverJie/Java-Interview/blob/master/src/main/java/com/crossoverjie/actual/TwoThread.java)
+
+这个相对比较简单,基于锁、等待唤醒机制都是可以的。最后也告知笔试通过。
+
+之后在推荐我的那位大佬的帮助下戏剧般的通过了整个技术轮(真的很感谢他的认可),并且得知这个消息是在我刚好和 A 部门约好视频面试时间之后。
+
+也就意味着我必须**拒掉一个部门!**
+
+没看错,是我要拒掉一个。这对我来说确实太难了,我压根没想过还有两个机会摆在我面前。
+
+最后凭着个人的爱好以及 B 部门的热情我很不好意思的拒掉了 A 部门。。。
+
+
+
+
+### HR 面
+
+在面这之前我从来没有面过这样大厂的 HR 流程,于是疯狂搜索,希望能弥补点经验。
+
+也许这就是乐极生悲吧,我确实猜中了 HR 问的大部分问题,但遗憾的是最终依然没能通过。
+
+后来我在想如果我没有拒掉 A ,会不会结局不一样了?
+
+但现实就是如此,没有那么多假设,并且每个人也得为自己的选择负责!
+
+大概的问题是:
+- 为什么想来阿里?
+- 个人做的最成功最有挑战的事情是什么?
+- 工作中最难忘的经历?
+- 对加入我们团队有何期待?
+
+## C 部门
+
+HR 这关被 Pass 之后没多久我居然又收到了第三个部门的邀约。
+
+说实话当时我是拒绝的,之前经历了将近两个月的时间却没能如愿我内心是崩溃的。
+
+我向联系我的大佬表达了我的想法,他倒觉得我最后被 pass 的原因是个小问题,再尝试的话会有很大的几率通过。
+
+我把这事给朋友说了之后也支持我再试试,反正也没啥损失嘛,而且面试的状态还在。
+
+所以我又被打了鸡血,才有了下面的面试经过:
+
+### 一面
+
+
+**面试官:**
+
+服务化框架的选型和差异?
+
+**博主:**
+
+一起探讨了 SpringCloud、Dubbo、Thrift 的差异,优缺点等。
+
+**面试官:**
+
+[一致性 Hash 算法的原理](https://crossoverjie.top/2018/01/08/Consistent-Hash/)?
+
+**博主:**
+
+将数据 Hash 之后落到一个 `0 ~ 2^32-1` 构成的一个环上。。。。
+
+**面试官:**
+
+谈谈你理解的 Zookeeper?
+
+**博主:**
+
+作为一个分布式协调器。。。
+
+**面试官:**
+
+如何处理 MQ 重复消费?
+
+**博主:**
+
+业务幂等处理。。。。
+
+**面试官:**
+
+客户端负载算法?
+
+**博主:**
+
+轮询、随机、一致性 Hash、故障转移、LRU 等。。
+
+**面试官:**
+
+long 类型的赋值是否是原子的?
+
+**博主:**
+
+不是。。。
+
+**面试官:**
+
+[volatile 关键字的原理及作用?happen Before?](https://crossoverjie.top/2018/03/09/volatile/)
+
+**博主:**
+
+可见性、一致性。。
+
+
+### 二面
+
+一面之后大概一周的时间接到了二面的电话:
+
+原以为会像之前一样直接进入笔试,这次上来先简单聊了下:
+
+- 谈谈对微服务的理解,好处以及弊端?
+- 分布式缓存的设计?热点缓存?
+
+之后才正式进入笔试流程:
+
+> 这次主要考察设计能力,其实就是对设计模式的理解?能否应对后续的扩展性。
+
+笔试完了之后也和面试官交流,原以为会是算法之类的测试,后来得知他能看到前几轮的笔试情况,特地挑的没有做过的方向。
+
+所以大家也不用刻意去押题,总有你想不到的,平时多积累才是硬道理。
+
+### 三面
+
+又过了两周左右,得到 HR 通知;希望能过去杭州参加现场面试。并且阿里包了来回的机票酒店等。
+
+可见阿里对人才渴望还是舍得下成本的。
+
+既然都这样了,就当成一次旅游所以去了一趟杭州。
+
+现场面的时候有别于其他面试,是由两个面试官同时参与:
+
+> 给一个场景,谈谈你的架构方式。
+
+这就对平时的积累要求较高了。
+
+还有一个印象较深的是:
+
+> 在网页上点击一个按钮到服务器的整个流程,尽量完整。
+
+其实之前看过,好像是 Google 的一个面试题。
+
+完了之后让我回去等通知,没有见到 HR 我就知道凉了,果不其然。
+
+## 总结
+
+看到这里的朋友应该都是老铁了,我也把上文提到的大多数面试题整理在了 GitHub:
+
+
+
+厂库地址:
+
+[https://github.com/crossoverJie/JCSprout](https://github.com/crossoverJie/JCSprout)
+
+最后总结下这将近四个月的面试心得:
+
+- 一定要积极的推销自己,像在 A 部门的三面时,由于基础答得不是很好;所以最后我表达了自己的态度,对工作、技术的积极性。让面试官看到你的潜力值得一个 HC 名额。
+- 面试过程中遇到自己的不会的可以主动提出,切不可不懂装懂,这一问就露馅。可以将面试官引导到自己擅长的领域。比如当时我正好研究了锁,所以和面试官一聊就是半小时这就是加分项。
+- 平时要主动积累知识。写博客和参与开源项目就是很好的方式。
+- 博客可以记录自己踩过的坑,加深印象,而且在写的过程中可以查漏补缺,最后把整个知识体系巩固的比较牢固,良好的内容还可以得到意想不到的收获,比如我第一次面试的机会。
+- GitHub 是开发者的一张名片,积极参与开源项目可以和全球大佬头脑风暴,并且在面试过程中绝对是一个加分利器。
+- 面试官一般最后都会问你有什么要问我的?千万不要问一些公司福利待遇之类的问题。可以问下本次面试的表现?还有哪些需要完善的?从而知道自己答得如何也能补全自己。
+
+还有一点:不要在某次面试失利后否定自己,有时真的不是自己能力不行。这个也讲缘分。
+
+**塞翁失马焉知非福**
+
+我就是个例子,虽然最后没能去成阿里,现在在公司也是一个部门的技术负责人,在我们城市还有个窝,温馨的家,和女朋友一起为想要的生活努力奋斗。
+
+
+> 欢迎关注作者公众号于我交流🤗。
\ No newline at end of file
diff --git a/MD/soft-skills/how-to-be-developer.md b/MD/soft-skills/how-to-be-developer.md
new file mode 100644
index 00000000..4bf400f8
--- /dev/null
+++ b/MD/soft-skills/how-to-be-developer.md
@@ -0,0 +1,345 @@
+
+
+## 前言
+
+已经记不清有多少读者问过:
+
+> 博主,你是怎么学习的?像我这样的情况有啥好的建议嘛?
+
+
+也不知道啥时候我居然成人生导师了。当然我不排斥这些问题,和大家交流都是学习的过程。
+
+因此也许诺会准备一篇关于学习方面的文章;所以本文其实准备了很久,篇幅较长,大家耐心看完希望能有收获。
+
+> 以下内容仅代表我从业以来所积累的相关经验,我会从硬技能、软实力这些方面尽量阐述我所认为的 `“不那么差的程序员”` 应当做到哪些技能。
+
+
+
+## 技能树
+
+作为一名码代码的技术工人,怎么说干的还是技术活。
+
+既然是技术活那专业实力就得过硬,下面我会按照相关类别谈谈我们应该掌握哪些。
+
+### 计算机基础
+
+一名和电脑打交道的工种,计算机是我们赖以生存的工具。所以一些基础技能是我们应该和必须掌握的。
+
+> 比如网络相关的知识。
+
+其中就包含了 TCP 协议,它和 UDP 的差异。需要理解 TCP 三次握手的含义,[拆、粘包](http://t.cn/RDYBny8)等问题。
+
+当然上层最常见的 HTTP 也需要了解,甚至是熟悉。
+
+这块推荐[《图解 HTTP》](https://book.douban.com/subject/25863515/)一书。
+
+> 接着是操作系统相关知识。
+
+由于工作后你写的大部分代码都是运行在 Linux 服务器上,所以对于这个看它脸色行事主你也得熟悉才行。
+
+比如进程、线程、内存等概念;服务器常见的命令使用,这个没啥窍门就是得平时多敲敲多总结。
+
+我也是之前兼职了半年运维才算是对这一块比较熟悉。
+
+Linux 这个自然是推荐业界非常出名的[《鸟哥的 Linux 私房菜》](https://book.douban.com/subject/4889838/)。
+
+
+当作为一个初学者学习这些东西时肯定会觉得枯燥乏味,大学一般在讲专业课之前都会有这些基础学科。我相信大部分同学应该都没怎么仔细听讲,因为确实这些东西就算是学会了记熟了也没有太多直接的激励。
+
+但当你工作几年之后会发现,只要你还在做计算机相关的工作,这些都是绕不开的,当哪天这些知识不经意的帮助到你时你会庆幸当初正确的选择。
+
+
+### 数据结构与算法
+
+接下来会谈到另一门枯燥的课程:数据结构。
+
+这块当初在大学时也是最不受待见的一门课程,也是我唯一挂过的科目。
+
+记得当时每次上课老师就让大家用 C 语言练习书上的习题,看着一个个拆开都认识的字母组合在一起就六亲不认我果断选择了放弃。
+
+这也造成现在的我每隔一段时间就要看二叉树、红黑树、栈、队列等知识,加深印象。
+
+算法这个东西我确实没有啥发言权,之前坚持刷了部分 [LeetCode](https://github.com/crossoverJie/leetcode) 的题目也大多停留在初中级。
+
+但像基本的查找、排序算法我觉得还是要会的,不一定要手写出来但要理解其思路。
+
+所以**强烈建议**还在大学同学们积极参与一些 ACM 比赛,绝对是今后的加分利器。
+
+这一块内容可能会在应届生校招时发挥较大作用,在工作中如果你的本职工作是 `Java Web` 开发的话,这一块涉猎的几率还是比较低。
+
+不过一旦你接触到了模型设计、中间件、高效存储、查询等内容这些也是绕不过的坎。
+
+这块内容和上面的计算机基础差不多,对于我们 Java 开发来说我觉得平时除了多刷刷 LeetCode 加深印象之外,在日常开发中每选择一个容器存放数据时想想为什么选它?有没有更好的存储方式?写入、查询效率如何?
+
+同样的坚持下去,今后肯定收货颇丰。
+
+同时推荐[《算法(第4版)》](https://book.douban.com/subject/19952400/)
+
+
+### Java 基础
+
+这里大部分的读者都是 Java 相关,所以这个强相关的技能非常重要。
+
+Java 基础则是走向 Java 高级的必经之路。
+
+这里抛开基本语法不谈,重点讨论实际工作中高频次的东西。
+
+- 基本容器,如:HashMap、ArrayList、HashSet、LinkedList 等,不但要会用还得了解其中的原理。这样才能在不同的场景选择最优的设计。
+- IO、NIO 也是需要掌握。日常开发中大部分是在和磁盘、网络(写日志、数据库、Redis)打交道,这些都是 IO 的过程。
+- 常见的设计模式如:代理、工厂、回调、构建者模式,这对开发灵活、扩展性强的应用有很大帮助。
+- Java 多线程是非常重要的特性,日常开发很多。能理解线程模型、多线程优缺点、以及如何避免。
+- 良好的单测习惯,很多人觉得写单测浪费时间没有意义。但正是有了单测可以提前暴露出许多问题,减少测试返工几率,提高代码质量。
+- 良好的编程规范,这个可以参考《阿里巴巴 Java 开发手册》以及在它基础上优化的[《唯品会 Java 手册》](https://vipshop.github.io/vjtools/#/standard/)
+
+
+> [《Java核心技术·卷 I》](https://book.douban.com/subject/26880667/)值得推荐。
+
+
+### 多线程应用
+
+有了扎实的基础之后来谈谈多线程、并发相关的内容。
+
+想让自己的 title 里加上“高级”两字肯定得经过并发的洗礼。
+
+> 这里谈论的并发主要是指单应用里的场景,多应用的可以看后文的分布式内容。
+
+多线程的出现主要是为了提高 CPU 的利用率、任务的执行效率。但并不是用了多线程就一定能达到这样的效果,因为它同时也带来了一些问题:
+
+- 上下文切换
+- 共享资源
+- 可见性、原子性、有序性等。
+
+一旦使用了多线程那肯定会比单线程的程序要变得复杂和不可控,甚至使用不当还会比单线程慢。所以要考虑清楚是否真的需要多线程。
+
+
+会用了之后也要考虑为啥多线程会出现那样的问题,这时就需要理解内存模型、可见性之类的知识点。
+
+同样的解决方式又有哪些?各自的优缺点也需要掌握。
+
+谈到多线程就不得不提并发包下面的内容 `java.util.concurrent`。
+
+最常用及需要掌握的有:
+
+- 原子类:用于并发场景的原子操作。
+- 队列。常用于解耦,需要了解其实现原理。
+- 并发工具,如 [ConcurrentHashMap](https://crossoverjie.top/2018/07/23/java-senior/ConcurrentHashMap/)、[CountDownLatch](https://crossoverjie.top/%2F2018%2F03%2F16%2Fjava-senior%2Fthread-communication%2F#CountDownLatch-%E5%B9%B6%E5%8F%91%E5%B7%A5%E5%85%B7) 之类的工具使用以及原理。
+- [线程池使用](https://crossoverjie.top/2018/07/29/java-senior/ThreadPool/),以及相关原理。
+- 锁相关内容:[synchronized](https://crossoverjie.top/2018/01/14/Synchronize/)、[ReentrantLock](https://crossoverjie.top/2018/01/25/ReentrantLock/) 的使用及原理。
+
+
+这一块的内容可以然我们知道写 JDK 大牛处理并发的思路,对我们自己编写高质量的多线程程序也有很多帮助。
+
+推荐[《Java 并发编程的艺术》](https://book.douban.com/subject/26591326/)很好的并发入门书籍。
+
+### JVM 虚拟机
+
+想要深入 Java ,JVM 是不可或缺的。对于大部分工作 1~3 年的开发者来说直接接触这一些内容是比较少的。
+
+到了 3~5 年这个阶段就必须得了解了,以下内容我觉得是必须要掌握的:
+
+- JVM 内存划分,[知道哪块内存存放哪些内容](https://crossoverjie.top/%2F2018%2F01%2F18%2FnewObject%2F);线程安全与否;内存不够怎么处理等。
+- 不同情况的[内存溢出、栈溢出](https://github.com/crossoverJie/Java-Interview/blob/master/MD/OOM-analysis.md#oom-%E5%88%86%E6%9E%90),以及定位解决方案。
+- [分代的垃圾回收策略。](https://github.com/crossoverJie/Java-Interview/blob/master/MD/GarbageCollection.md)
+- [线上问题定位及相关解决方案](https://crossoverjie.top/2018/07/08/java-senior/JVM-Troubleshoot/)。
+- 一个类的加载、创建对象、垃圾回收、类卸载的整个过程。
+
+掌握这些内容真的对实际分析问题起到巨大帮助。
+
+> 对此强力推荐[《深入理解Java虚拟机](https://book.douban.com/subject/24722612/)》,这本书反反复复看过好几遍,每个阶段阅读都有不同的收获。
+
+### 数据库
+
+做 WEB 应用开发的同学肯定要和数据库打不少交道,而且通常来说一个系统最先出现瓶颈往往都是数据库,说数据库是压到系统的最后一根稻草一点也不为过。
+
+所以对数据库的掌握也是非常有必要。拿互联网用的较多的 MySQL 数据库为例,一些必须掌握的知识点:
+
+
+- 索引的数据结构及原理、哪些字段应当创建索引。
+- 针对于一个慢 SQL 的优化思路。
+- 数据库水平垂直拆分的方案,需要了解业界常用的 MyCAT、sharding-sphere 等中间件。
+
+常规使用可以参考《阿里巴巴 Java 开发手册》中的数据库章节,想要深入了解 MySQL 那肯定得推荐经典的[《高性能 MySQL》](https://book.douban.com/subject/23008813/)一书了。
+
+### 分布式技术
+
+随着互联网的发展,传统的单体应用越来越不适合现有场景。
+
+因此分布式技术出现了,这块涵盖的内容太多了,经验有限只能列举我日常使用到的一些内容:
+
+- 首先是一些基础理论如:CAP 定理,知道分布式系统会带来的一些问题以及各个应用权衡的方式。
+- 了解近些年大热的微服务相关定义、来源以及对比,有条件的可以阅读 `martin fowler` 的原文 [Microservices](https://martinfowler.com/articles/microservices.html),或者也可以搜索相关的国内翻译。
+- 对 Dubbo、SpringCloud 等分布式框架的使用,最好是要了解原理。
+- 接着要对分布式带来的问题提出解决方案。如[分布式锁](https://crossoverjie.top/2018/03/29/distributed-lock/distributed-lock-redis/)、[分布式限流](https://crossoverjie.top/2018/04/28/sbc/sbc7-Distributed-Limit/)、分布式事务、[分布式缓存](https://github.com/crossoverJie/Java-Interview/blob/master/MD/Cache-design.md)、分布式 ID、消息中间件等。
+- 也要了解一些分布式中的负载算法:权重、Hash、一致性 Hash、故障转移、[LRU](https://crossoverjie.top/2018/04/07/algorithm/LRU-cache/) 等。
+- 最好能做一个实践如:[秒杀架构实践
+ ](https://crossoverjie.top/%2F2018%2F05%2F07%2Fssm%2FSSM18-seconds-kill%2F)
+
+之前有开源一个分布式相关解决组件:
+
+[https://github.com/crossoverJie/distributed-redis-tool](https://github.com/crossoverJie/distributed-redis-tool)
+
+同时推荐一本入门科普[《大型网站技术架构》](https://book.douban.com/subject/25723064/),出版时间有点早,从中可以学习一些思路。
+
+
+### 懂点架构
+
+相信大家都有一个架构师的梦想。
+
+架构师给人的感觉就是画画图纸,搭好架子,下面的人员来添砖加瓦最终产出。
+
+但其实需要的内功也要非常深厚,就上面列举的样样需要掌握,底层到操作系统、算法;上层到应用、框架都需要非常精通。(PPT 架构师除外)
+
+我自身参与架构经验也不多,所以只能提供有限的建议。
+
+首先分布式肯定得掌握,毕竟现在大部分的架构都是基于分布式的。
+
+这其中就得根据 CAP 理论结合项目情况来选择一致性还是可用性,同时如何做好适合现有团队的技术选型。
+
+这里推荐下开涛老师的[《亿级流量网站架构核心技术》](https://book.douban.com/subject/26999243/),列举了很多架构实例,不过网上褒贬不一,但对于刚入门架构的能科普不少知识。
+
+## 如何学习
+
+谈完了技能树,现在来聊聊如何学习,这也是被问的最多的一个话题。
+
+而关于学习讨论的最多的也是看视频还是看书?
+
+### 视频
+
+不得不承认视频是获取知识最便捷的来源,毕竟包含了图、文、声。
+
+大学几年时间其实我也没好好上专业课,我记得真正入门 Java 还是一个暑假花了两个月的时间天天在家里看 ”马士兵“ 老师的视频教程,当时的资源也很老了,记得好像是 07 年出的视频(用的还是 Google )。
+
+那段时间早起晚睡,每天学到东西之后马上实践,心里也很有成就感。后来开学之后一度成为同学们眼中的”学霸“人物。
+
+> 现在打开我 12 年的电脑,硬盘里还躺着好几十 G 的教学视频。
+
+### 看书
+
+工作后时间真的很宝贵,完全没有了学生生涯的想学就学的自由。所以现在我主要知识来源还是书籍。
+
+这些是我最近看的书:
+
+
+
+
+看书又会涉及到电子书和纸质书的区别,我个人比较喜欢纸质书。毕竟我可以方便的记笔记以及可以随时切换章节。最主要的还是从小养成的闻书香的习惯。
+
+
+### 知识付费
+
+近几年知识付费越来越流行,许多大佬也加入了这个行列,人们也逐渐在习惯为知识去付费。
+
+说实话写一好篇文章出一份视频都非常不容易,能有正向的激励,作者才能持续输出更好的内容。
+
+这块我觉得国内做的比较好我也为之付费的有极客时间、大佬的知识星球等。
+
+这三点没有绝对的好坏之分,其实可以看出我刚入门的时候看视频,工作之后看书及知识付费内容。
+
+视频的好处是可以跟着里面老师的思路一步一步往下走,比较有音视频代入感强,就像学校老师讲课一样。
+
+但由于内容较长使读者没法知晓其中的重点,甚至都不敢快进生怕错过了哪个重要知识,现在由于 IT 越来越火,网上的视频也很多导致质量参差不齐也不成体系。
+
+而看书可以选择性的浏览自己感兴趣的章节,费解的内容也方便反复阅读
+
+所以建议刚入门的同学可以看看视频跟着学,参与工作一段时间后可以尝试多看看书。
+
+当然这不是绝对的,找到适合自己的学习方式就好。但不管是视频还是看书都要多做多实践。
+
+## 打造个人品牌
+
+个人品牌看似很程序员这个职业不怎么沾边,但在现今的互联网时代对于每个人来说都很重要。
+
+以往我们在写简历或是评估他人简历的时候往往不会想到去网络搜索他的个人信息,但在这个信息爆炸的时代你在网上留下的一点印记都能被发现。
+
+### 博客
+
+因此我们需要维护好自己的名片,比如先搭建自己的个人博客。
+
+博客的好处我也谈过几次了,前期关注人少没关系,重要的是坚持,当你写到 50、100篇文章后你会发现自己在这过程中一定是的到了提高。
+
+
+### GitHub
+
+第二点就和技术人比较相关了:参与维护好自己的 GitHub。
+
+由于 GitHub 的特殊属性,维护好后可以更好的打造个人品牌。
+
+`Talk is cheap. Show me the code` 可不是随便说说的。
+
+想要维护好可以从几个方面着手:
+
+- 参与他人的项目,不管是代码库还是知识库都可以,先融入进社区。
+- 发起自己的开源项目,不管是平时开发过程中的小痛点,还是精心整理的知识点都可以。
+
+但这过程中有几点还是要注意:
+
+- 我们需要遵守 GitHub 的社交礼仪。能用英文尽量就用英文,特别是在国外厂库中。
+- 尽量少 push 一些与代码工作无关的内容,我认为这并不能提高自己的品牌。
+- `别去刷 star`。这也是近期才流行起来,不知道为什么总有一些人会钻这种空子,刷起来的热度对自己并没有任何提高。
+
+这里有一篇国外大佬写的 `How to build your personal brand as a new developer` :
+
+[https://medium.freecodecamp.org/building-your-personal-brand-as-a-new-web-developer-f6d4150fd217](https://medium.freecodecamp.org/building-your-personal-brand-as-a-new-web-developer-f6d4150fd217)
+
+
+## English 挺重要
+
+再来谈谈英语的重要性,我记得刚上大学时老师以及一些培训机构都会说:
+
+> 别怕自己英语差就学不了编程,真正常用的就那些词语。
+
+这句话虽没错,但英语在对 IT 这行来说还是有着极大的加分能力。
+
+拿常见的 JDK 里的源码注释也是纯英文的,如果英语还不错的话,一些 Spring 的东西完全可以自学,直接去 Spring 官网就可以查看,甚至后面出的 SpringCloud,官方资料就是最好的教程。
+
+再有就是平时查资料时,有条件的可以尝试用 `Google + 英文` 搜索,你会发现新的世界。
+
+不然也不会有面向 `Google/Stack Overflow` 编程。
+
+对于英语好的同学自然不怕,那不怎么好的咋办呢?
+
+比如我,但我在坚持以下几点:
+
+- 所有的手机、电脑系统统统换成英语语言,养成习惯(不过也有尴尬的连菜单都找不到的情况)。
+- 订阅一些英语周刊,比如 ”湾区日报“。
+- 定期去类似于 [https://medium.com/](https://medium.com/) 这样具有影响力的国外社区阅读文章。
+
+虽然现在我也谈不上多好,但目前我也在努力,希望大家也一起坚持。
+
+
+推荐一本近期在看的书《程序员的英语》。
+
+## 保持竞争力
+
+技术这个行业发展迅速、变化太快,每年也都有无数相关行业毕业生加入竞争,稍不留神就会被赶上甚至超越。
+
+所以我们无时无刻都得保持竞争力。
+
+多的谈不上,我只能谈下目前我在做的事情:
+
+- **打好基础**。不是学了之后就忘了,需要不停的去看,巩固,基础是万变不离其宗的。
+- 多看源码,了解原理,不要停留在调参侠的境界。
+- 关注行业发展、新技术、新动态至少不能落伍了。
+- 争取每周产出一篇技术相关文章。
+- 积极参与开源项目。
+
+
+## 思维导图
+
+
+
+结合上文产出了一个思维导图更直观些。
+
+## 总结
+
+本文结合了自身的一些经验列举了一些方法,不一定对每位都有效需要自行判断。
+
+也反反复复写了差不多一周的时间,希望对在这条路上和正在路上的朋友们起到一些作用。
+
+大部分都只是谈了个思路,其实每一项单聊都能写很多。每个点都有推荐一本书籍,有更好建议欢迎留言讨论。
+
+上文大部分的知识点都有维护在 GitHub 上,感兴趣的朋友可以自行查阅:
+
+
+
+[https://github.com/crossoverJie/JCSprout](https://github.com/crossoverJie/JCSprout)
\ No newline at end of file
diff --git a/MD/spring/spring-bean-lifecycle.md b/MD/spring/spring-bean-lifecycle.md
index b9693567..60f2796a 100644
--- a/MD/spring/spring-bean-lifecycle.md
+++ b/MD/spring/spring-bean-lifecycle.md
@@ -7,7 +7,7 @@ Spring Bean 的生命周期在整个 Spring 中占有很重要的位置,掌握
首先看下生命周期图:
-
+
再谈生命周期之前有一点需要先明确:
diff --git a/MD/third-party-component/cicada.md b/MD/third-party-component/cicada.md
new file mode 100644
index 00000000..39e207bf
--- /dev/null
+++ b/MD/third-party-component/cicada.md
@@ -0,0 +1,265 @@
+
\ No newline at end of file
diff --git a/MD/soft-skills/Interview-experience.md b/MD/soft-skills/Interview-experience.md
new file mode 100644
index 00000000..6c0bd3ba
--- /dev/null
+++ b/MD/soft-skills/Interview-experience.md
@@ -0,0 +1,359 @@
+
+
+## 前言
+
+最近有些朋友在面试阿里,加上 [Java-Interview](https://github.com/crossoverJie/Java-Interview) 项目的原因也有小伙伴和我讨论,近期也在负责部门的招聘,这让我想起年初那段长达三个月的奇葩面试经历🤣。
+
+本来没想拿出来说的,毕竟最后也没成。
+
+但由于那几个月的经历让我了解到了大厂的工作方式、对候选同学的考察重点以及面试官的套路等都有了全新的认识。
+
+当然最重要的是这段时间的查漏补缺也让自己精进不少。
+
+
+先交代下背景吧:
+
+
+从去年 12 月到今年三月底,我前前后后面了阿里三个部门。
+
+其中两个部门通过了技术面试,还有一个跪在了三面。
+
+光看结果还不错,但整个流程堪称曲折。
+
+下面我会尽量描述流程以及大致的面试题目大纲,希望对想要跳槽、正在面试的同学带来点灵感,帮助可能谈不上,但启发还是能有。
+
+以下内容较长,请再次备好瓜子板凳。
+
+
+
+
+## A 部门
+
+首先是第一次机会,去年 12 月份有位大佬加我,后来才知道是一个部门的技术 Leader 在网上看到我的博客,问我想不想来阿里试试。
+
+这时距离上次面阿里也过去一年多了,也想看看现在几斤几两,于是便同意了。
+
+在推荐一周之后收到了杭州打来的电话,说来也巧,那时候我正在机场候机,距离登记还有大概一个小时,心想时间肯定够了。
+
+那是我时隔一年多第一次面试,还是在机场这样嘈杂的环境里。多多少少还是有些紧张。
+
+### 一面
+
+以下是我印象比较深刻的内容:
+
+**面试官:**
+
+谈谈你做过项目中印象较深或自认为做的比较好的地方?
+
+**博主:**
+
+我觉得我在 XX 做的不错,用了 XX 需求实现 XX 功能,性能提高了 N 倍。
+
+**面试官:**
+
+你说使用到了 AOP ,能谈谈它的实现原理嘛?
+
+**博主:**
+
+它是依靠动态代理实现的,动态代理又分为 JDK 自身的以及 CGLIB 。。。。
+
+**面试官:**
+
+嗯,能说说他们的不同及优缺点嘛?
+
+**博主:**
+
+JDK 是基于接口实现,而 CGLIB 继承代理类。。。
+
+就是这样会一直问下去,如果聊的差不多了就开始问一些零散的问题:
+
+- JMM 内存模型,如何划分的?分别存储什么内容?线程安全与否?
+- 类加载机制,谈到双亲委派模型后会问到哪些违反了双亲委派模型?为什么?为什么要双亲委派?好处是什么?
+- 平时怎么使用多线程?有哪些好处?线程池的几个核心参数的意义?
+- 线程间通信的方式?
+- HashMap 的原理?当谈到线程不安全时自然引申出 ConcurrentHashMap ,它的实现原理?
+- 分库分表如何设计?垂直拆分、水平拆分?
+- 业务 ID 的生成规则,有哪些方式?
+- SQL 调优?平时使用数据库有哪些注意点?
+- 当一个应用启动缓慢如何优化?
+
+大概是以上这些,当聊到倒数第二个时我已经登机了。最后不得不提前挂断,结束之前告诉我之后会换一个同事和我沟通,听到这样的回复一面应该是过了,
+后面也确实证实了这点。
+
+### 二面
+
+大概过了一周,二面如期而至。
+
+我听声音很熟,就尝试问下是不是之前一面的面试官,结果真是。
+
+由于二面的面试官临时有事所以他来替一下。于是我赶紧问他能否把之前答的不好的再说说?的到了肯定的答复后开始了我的表演。
+
+有了第一次的经验这一次自然也轻车熟路,原本感觉一切尽在掌握却被告知需要笔试突然被激醒。
+
+笔试是一个在线平台,需要在网页中写代码,会有一个明确的题目:
+
+> 从一个日志文件中根据关键字读取日志,记录出现的次数,最后按照次数排序打印。
+
+在这过程中切记要和面试官多多交流,因为笔试有时间限制,别到最后发现题目理解错了,这就和高考作文写完发现方向错了一样要命。
+
+而且在沟通过程中体现出你解题的思路,即使最终结果不对,但说不定思考的过程很符合面试官的胃口哦。这也和今年的高考改卷一样;过程正确得高分,只有结果得低分。
+
+### 三面
+
+又过了差不多一周的时间接到了三面的电话,一般到了三面会是技术 Leader 之类的角色。
+
+这个过程中不会过多强调技术细节,更多的考察软件能,比如团队协作、学习能力等。
+
+但我记得也问了以下一些技术问题:
+
+- 谈谈你所理解的 HTTP 协议?
+- 对 TCP 的理解?三次握手?滑动窗口?
+- 基本算法,Base64 等。
+- Java 内存模型,Happen Before 的理解。
+
+一周之后我接到了 HR 助理的电话约了和 HRBP 以及产品技术负责人的视频面试。
+
+但是我却没有面下去,具体原因得往下看。
+
+
+## B 部门
+
+在 A 部门三面完成后,我等了差不多一星期,这期间我却收到了一封邮件。
+
+大概内容是他在 GitHub 上看到的我,他们的技术总监对我很感兴趣(我都不敢相信我的眼镜),问我想不想来阿里试试。
+
+我对比了 A B 部门的区别发现 B 部门在做的事情上确实更加有诱惑力,之后我表达了有一个面试正在流程中的顾虑;对方表示可以私下和我快速的进行三面,如果一切没问题再交由我自行选择。至少对双方都是一个双赢嘛。
+
+我想也不亏,并且对方很有诚意,就答应试试;于是便有了下面的面试:
+
+
+### 一面
+
+**面试官:**
+
+对 Java 锁的理解?
+
+**博主:**
+
+我谈到了 synchronize,Lock 接口的应用。
+
+**面试官:**
+
+他们两者的区别以及优缺点呢?
+
+**博主:**
+
+`synchronize` 在 JDK1.6 之前称为重量锁,是通过进出对象监视器来实现同步的;1.6 之后做了 XX 优化。。。
+
+而 `ReentrantLock` 是利用了一个巧妙数据结构实现的,并且加锁解锁是显式的。。。
+
+之后又引申到[分布式锁](https://crossoverjie.top/%2F2018%2F03%2F29%2Fdistributed-lock%2Fdistributed-lock-redis%2F),光这块就聊了差不多半个小时。
+
+之后又聊到了我的[开源项目](https://github.com/crossoverJie):
+- 是如何想做这个项目的?
+- 已经有一些关注了后续是如何规划的?
+- 你今后的学习计划是什么?
+- 平时看哪些书?
+
+之后技术聊的不是很多,但对于个人发展却聊了不少。
+
+
+> 关于锁相关的内容可以参考这里:[ReentrantLock 实现原理](https://crossoverjie.top/%2F2018%2F01%2F25%2FReentrantLock%2F) [synchronize 关键字原理](https://crossoverjie.top/%2F2018%2F01%2F14%2FSynchronize%2F)
+
+
+### 二面
+
+隔了差不多一天的时间,二面很快就来了。
+
+内容不是很多:
+
+- [线程间通信的多种方式](https://crossoverjie.top/%2F2018%2F03%2F16%2Fjava-senior%2Fthread-communication%2F)?
+- 限流算法?单机限流?分布式限流?
+- 提到了 Guava Cache ,了解它的[实现原理](https://crossoverjie.top/2018/06/13/guava/guava-cache/)嘛?
+- 如何定位一个线上问题?
+- CPU 高负载?OOM 排查等?
+
+聊完之后表示第二天应该会有三面。
+
+### 三面
+
+三面的面试官应该是之前邮件中提到的那位总监大佬,以前应该也是一线的技术大牛;聊的问题不是很多:
+
+- 谈谈对 Netty 的理解?
+- Netty 的线程模型?
+- [写一个 LRU 缓存](https://crossoverjie.top/2018/04/07/algorithm/LRU-cache/)。
+
+
+### 笔试
+
+本以为技术面试完了,结果后面告知所有的面试流程都得有笔试了,于是又参与了一次笔试:
+
+> [交替打印奇偶数](https://github.com/crossoverJie/Java-Interview/blob/master/src/main/java/com/crossoverjie/actual/TwoThread.java)
+
+这个相对比较简单,基于锁、等待唤醒机制都是可以的。最后也告知笔试通过。
+
+之后在推荐我的那位大佬的帮助下戏剧般的通过了整个技术轮(真的很感谢他的认可),并且得知这个消息是在我刚好和 A 部门约好视频面试时间之后。
+
+也就意味着我必须**拒掉一个部门!**
+
+没看错,是我要拒掉一个。这对我来说确实太难了,我压根没想过还有两个机会摆在我面前。
+
+最后凭着个人的爱好以及 B 部门的热情我很不好意思的拒掉了 A 部门。。。
+
+
+
+
+### HR 面
+
+在面这之前我从来没有面过这样大厂的 HR 流程,于是疯狂搜索,希望能弥补点经验。
+
+也许这就是乐极生悲吧,我确实猜中了 HR 问的大部分问题,但遗憾的是最终依然没能通过。
+
+后来我在想如果我没有拒掉 A ,会不会结局不一样了?
+
+但现实就是如此,没有那么多假设,并且每个人也得为自己的选择负责!
+
+大概的问题是:
+- 为什么想来阿里?
+- 个人做的最成功最有挑战的事情是什么?
+- 工作中最难忘的经历?
+- 对加入我们团队有何期待?
+
+## C 部门
+
+HR 这关被 Pass 之后没多久我居然又收到了第三个部门的邀约。
+
+说实话当时我是拒绝的,之前经历了将近两个月的时间却没能如愿我内心是崩溃的。
+
+我向联系我的大佬表达了我的想法,他倒觉得我最后被 pass 的原因是个小问题,再尝试的话会有很大的几率通过。
+
+我把这事给朋友说了之后也支持我再试试,反正也没啥损失嘛,而且面试的状态还在。
+
+所以我又被打了鸡血,才有了下面的面试经过:
+
+### 一面
+
+
+**面试官:**
+
+服务化框架的选型和差异?
+
+**博主:**
+
+一起探讨了 SpringCloud、Dubbo、Thrift 的差异,优缺点等。
+
+**面试官:**
+
+[一致性 Hash 算法的原理](https://crossoverjie.top/2018/01/08/Consistent-Hash/)?
+
+**博主:**
+
+将数据 Hash 之后落到一个 `0 ~ 2^32-1` 构成的一个环上。。。。
+
+**面试官:**
+
+谈谈你理解的 Zookeeper?
+
+**博主:**
+
+作为一个分布式协调器。。。
+
+**面试官:**
+
+如何处理 MQ 重复消费?
+
+**博主:**
+
+业务幂等处理。。。。
+
+**面试官:**
+
+客户端负载算法?
+
+**博主:**
+
+轮询、随机、一致性 Hash、故障转移、LRU 等。。
+
+**面试官:**
+
+long 类型的赋值是否是原子的?
+
+**博主:**
+
+不是。。。
+
+**面试官:**
+
+[volatile 关键字的原理及作用?happen Before?](https://crossoverjie.top/2018/03/09/volatile/)
+
+**博主:**
+
+可见性、一致性。。
+
+
+### 二面
+
+一面之后大概一周的时间接到了二面的电话:
+
+原以为会像之前一样直接进入笔试,这次上来先简单聊了下:
+
+- 谈谈对微服务的理解,好处以及弊端?
+- 分布式缓存的设计?热点缓存?
+
+之后才正式进入笔试流程:
+
+> 这次主要考察设计能力,其实就是对设计模式的理解?能否应对后续的扩展性。
+
+笔试完了之后也和面试官交流,原以为会是算法之类的测试,后来得知他能看到前几轮的笔试情况,特地挑的没有做过的方向。
+
+所以大家也不用刻意去押题,总有你想不到的,平时多积累才是硬道理。
+
+### 三面
+
+又过了两周左右,得到 HR 通知;希望能过去杭州参加现场面试。并且阿里包了来回的机票酒店等。
+
+可见阿里对人才渴望还是舍得下成本的。
+
+既然都这样了,就当成一次旅游所以去了一趟杭州。
+
+现场面的时候有别于其他面试,是由两个面试官同时参与:
+
+> 给一个场景,谈谈你的架构方式。
+
+这就对平时的积累要求较高了。
+
+还有一个印象较深的是:
+
+> 在网页上点击一个按钮到服务器的整个流程,尽量完整。
+
+其实之前看过,好像是 Google 的一个面试题。
+
+完了之后让我回去等通知,没有见到 HR 我就知道凉了,果不其然。
+
+## 总结
+
+看到这里的朋友应该都是老铁了,我也把上文提到的大多数面试题整理在了 GitHub:
+
+
+
+厂库地址:
+
+[https://github.com/crossoverJie/JCSprout](https://github.com/crossoverJie/JCSprout)
+
+最后总结下这将近四个月的面试心得:
+
+- 一定要积极的推销自己,像在 A 部门的三面时,由于基础答得不是很好;所以最后我表达了自己的态度,对工作、技术的积极性。让面试官看到你的潜力值得一个 HC 名额。
+- 面试过程中遇到自己的不会的可以主动提出,切不可不懂装懂,这一问就露馅。可以将面试官引导到自己擅长的领域。比如当时我正好研究了锁,所以和面试官一聊就是半小时这就是加分项。
+- 平时要主动积累知识。写博客和参与开源项目就是很好的方式。
+- 博客可以记录自己踩过的坑,加深印象,而且在写的过程中可以查漏补缺,最后把整个知识体系巩固的比较牢固,良好的内容还可以得到意想不到的收获,比如我第一次面试的机会。
+- GitHub 是开发者的一张名片,积极参与开源项目可以和全球大佬头脑风暴,并且在面试过程中绝对是一个加分利器。
+- 面试官一般最后都会问你有什么要问我的?千万不要问一些公司福利待遇之类的问题。可以问下本次面试的表现?还有哪些需要完善的?从而知道自己答得如何也能补全自己。
+
+还有一点:不要在某次面试失利后否定自己,有时真的不是自己能力不行。这个也讲缘分。
+
+**塞翁失马焉知非福**
+
+我就是个例子,虽然最后没能去成阿里,现在在公司也是一个部门的技术负责人,在我们城市还有个窝,温馨的家,和女朋友一起为想要的生活努力奋斗。
+
+
+> 欢迎关注作者公众号于我交流🤗。
\ No newline at end of file
diff --git a/MD/soft-skills/how-to-be-developer.md b/MD/soft-skills/how-to-be-developer.md
new file mode 100644
index 00000000..4bf400f8
--- /dev/null
+++ b/MD/soft-skills/how-to-be-developer.md
@@ -0,0 +1,345 @@
+
+
+## 前言
+
+已经记不清有多少读者问过:
+
+> 博主,你是怎么学习的?像我这样的情况有啥好的建议嘛?
+
+
+也不知道啥时候我居然成人生导师了。当然我不排斥这些问题,和大家交流都是学习的过程。
+
+因此也许诺会准备一篇关于学习方面的文章;所以本文其实准备了很久,篇幅较长,大家耐心看完希望能有收获。
+
+> 以下内容仅代表我从业以来所积累的相关经验,我会从硬技能、软实力这些方面尽量阐述我所认为的 `“不那么差的程序员”` 应当做到哪些技能。
+
+
+
+## 技能树
+
+作为一名码代码的技术工人,怎么说干的还是技术活。
+
+既然是技术活那专业实力就得过硬,下面我会按照相关类别谈谈我们应该掌握哪些。
+
+### 计算机基础
+
+一名和电脑打交道的工种,计算机是我们赖以生存的工具。所以一些基础技能是我们应该和必须掌握的。
+
+> 比如网络相关的知识。
+
+其中就包含了 TCP 协议,它和 UDP 的差异。需要理解 TCP 三次握手的含义,[拆、粘包](http://t.cn/RDYBny8)等问题。
+
+当然上层最常见的 HTTP 也需要了解,甚至是熟悉。
+
+这块推荐[《图解 HTTP》](https://book.douban.com/subject/25863515/)一书。
+
+> 接着是操作系统相关知识。
+
+由于工作后你写的大部分代码都是运行在 Linux 服务器上,所以对于这个看它脸色行事主你也得熟悉才行。
+
+比如进程、线程、内存等概念;服务器常见的命令使用,这个没啥窍门就是得平时多敲敲多总结。
+
+我也是之前兼职了半年运维才算是对这一块比较熟悉。
+
+Linux 这个自然是推荐业界非常出名的[《鸟哥的 Linux 私房菜》](https://book.douban.com/subject/4889838/)。
+
+
+当作为一个初学者学习这些东西时肯定会觉得枯燥乏味,大学一般在讲专业课之前都会有这些基础学科。我相信大部分同学应该都没怎么仔细听讲,因为确实这些东西就算是学会了记熟了也没有太多直接的激励。
+
+但当你工作几年之后会发现,只要你还在做计算机相关的工作,这些都是绕不开的,当哪天这些知识不经意的帮助到你时你会庆幸当初正确的选择。
+
+
+### 数据结构与算法
+
+接下来会谈到另一门枯燥的课程:数据结构。
+
+这块当初在大学时也是最不受待见的一门课程,也是我唯一挂过的科目。
+
+记得当时每次上课老师就让大家用 C 语言练习书上的习题,看着一个个拆开都认识的字母组合在一起就六亲不认我果断选择了放弃。
+
+这也造成现在的我每隔一段时间就要看二叉树、红黑树、栈、队列等知识,加深印象。
+
+算法这个东西我确实没有啥发言权,之前坚持刷了部分 [LeetCode](https://github.com/crossoverJie/leetcode) 的题目也大多停留在初中级。
+
+但像基本的查找、排序算法我觉得还是要会的,不一定要手写出来但要理解其思路。
+
+所以**强烈建议**还在大学同学们积极参与一些 ACM 比赛,绝对是今后的加分利器。
+
+这一块内容可能会在应届生校招时发挥较大作用,在工作中如果你的本职工作是 `Java Web` 开发的话,这一块涉猎的几率还是比较低。
+
+不过一旦你接触到了模型设计、中间件、高效存储、查询等内容这些也是绕不过的坎。
+
+这块内容和上面的计算机基础差不多,对于我们 Java 开发来说我觉得平时除了多刷刷 LeetCode 加深印象之外,在日常开发中每选择一个容器存放数据时想想为什么选它?有没有更好的存储方式?写入、查询效率如何?
+
+同样的坚持下去,今后肯定收货颇丰。
+
+同时推荐[《算法(第4版)》](https://book.douban.com/subject/19952400/)
+
+
+### Java 基础
+
+这里大部分的读者都是 Java 相关,所以这个强相关的技能非常重要。
+
+Java 基础则是走向 Java 高级的必经之路。
+
+这里抛开基本语法不谈,重点讨论实际工作中高频次的东西。
+
+- 基本容器,如:HashMap、ArrayList、HashSet、LinkedList 等,不但要会用还得了解其中的原理。这样才能在不同的场景选择最优的设计。
+- IO、NIO 也是需要掌握。日常开发中大部分是在和磁盘、网络(写日志、数据库、Redis)打交道,这些都是 IO 的过程。
+- 常见的设计模式如:代理、工厂、回调、构建者模式,这对开发灵活、扩展性强的应用有很大帮助。
+- Java 多线程是非常重要的特性,日常开发很多。能理解线程模型、多线程优缺点、以及如何避免。
+- 良好的单测习惯,很多人觉得写单测浪费时间没有意义。但正是有了单测可以提前暴露出许多问题,减少测试返工几率,提高代码质量。
+- 良好的编程规范,这个可以参考《阿里巴巴 Java 开发手册》以及在它基础上优化的[《唯品会 Java 手册》](https://vipshop.github.io/vjtools/#/standard/)
+
+
+> [《Java核心技术·卷 I》](https://book.douban.com/subject/26880667/)值得推荐。
+
+
+### 多线程应用
+
+有了扎实的基础之后来谈谈多线程、并发相关的内容。
+
+想让自己的 title 里加上“高级”两字肯定得经过并发的洗礼。
+
+> 这里谈论的并发主要是指单应用里的场景,多应用的可以看后文的分布式内容。
+
+多线程的出现主要是为了提高 CPU 的利用率、任务的执行效率。但并不是用了多线程就一定能达到这样的效果,因为它同时也带来了一些问题:
+
+- 上下文切换
+- 共享资源
+- 可见性、原子性、有序性等。
+
+一旦使用了多线程那肯定会比单线程的程序要变得复杂和不可控,甚至使用不当还会比单线程慢。所以要考虑清楚是否真的需要多线程。
+
+
+会用了之后也要考虑为啥多线程会出现那样的问题,这时就需要理解内存模型、可见性之类的知识点。
+
+同样的解决方式又有哪些?各自的优缺点也需要掌握。
+
+谈到多线程就不得不提并发包下面的内容 `java.util.concurrent`。
+
+最常用及需要掌握的有:
+
+- 原子类:用于并发场景的原子操作。
+- 队列。常用于解耦,需要了解其实现原理。
+- 并发工具,如 [ConcurrentHashMap](https://crossoverjie.top/2018/07/23/java-senior/ConcurrentHashMap/)、[CountDownLatch](https://crossoverjie.top/%2F2018%2F03%2F16%2Fjava-senior%2Fthread-communication%2F#CountDownLatch-%E5%B9%B6%E5%8F%91%E5%B7%A5%E5%85%B7) 之类的工具使用以及原理。
+- [线程池使用](https://crossoverjie.top/2018/07/29/java-senior/ThreadPool/),以及相关原理。
+- 锁相关内容:[synchronized](https://crossoverjie.top/2018/01/14/Synchronize/)、[ReentrantLock](https://crossoverjie.top/2018/01/25/ReentrantLock/) 的使用及原理。
+
+
+这一块的内容可以然我们知道写 JDK 大牛处理并发的思路,对我们自己编写高质量的多线程程序也有很多帮助。
+
+推荐[《Java 并发编程的艺术》](https://book.douban.com/subject/26591326/)很好的并发入门书籍。
+
+### JVM 虚拟机
+
+想要深入 Java ,JVM 是不可或缺的。对于大部分工作 1~3 年的开发者来说直接接触这一些内容是比较少的。
+
+到了 3~5 年这个阶段就必须得了解了,以下内容我觉得是必须要掌握的:
+
+- JVM 内存划分,[知道哪块内存存放哪些内容](https://crossoverjie.top/%2F2018%2F01%2F18%2FnewObject%2F);线程安全与否;内存不够怎么处理等。
+- 不同情况的[内存溢出、栈溢出](https://github.com/crossoverJie/Java-Interview/blob/master/MD/OOM-analysis.md#oom-%E5%88%86%E6%9E%90),以及定位解决方案。
+- [分代的垃圾回收策略。](https://github.com/crossoverJie/Java-Interview/blob/master/MD/GarbageCollection.md)
+- [线上问题定位及相关解决方案](https://crossoverjie.top/2018/07/08/java-senior/JVM-Troubleshoot/)。
+- 一个类的加载、创建对象、垃圾回收、类卸载的整个过程。
+
+掌握这些内容真的对实际分析问题起到巨大帮助。
+
+> 对此强力推荐[《深入理解Java虚拟机](https://book.douban.com/subject/24722612/)》,这本书反反复复看过好几遍,每个阶段阅读都有不同的收获。
+
+### 数据库
+
+做 WEB 应用开发的同学肯定要和数据库打不少交道,而且通常来说一个系统最先出现瓶颈往往都是数据库,说数据库是压到系统的最后一根稻草一点也不为过。
+
+所以对数据库的掌握也是非常有必要。拿互联网用的较多的 MySQL 数据库为例,一些必须掌握的知识点:
+
+
+- 索引的数据结构及原理、哪些字段应当创建索引。
+- 针对于一个慢 SQL 的优化思路。
+- 数据库水平垂直拆分的方案,需要了解业界常用的 MyCAT、sharding-sphere 等中间件。
+
+常规使用可以参考《阿里巴巴 Java 开发手册》中的数据库章节,想要深入了解 MySQL 那肯定得推荐经典的[《高性能 MySQL》](https://book.douban.com/subject/23008813/)一书了。
+
+### 分布式技术
+
+随着互联网的发展,传统的单体应用越来越不适合现有场景。
+
+因此分布式技术出现了,这块涵盖的内容太多了,经验有限只能列举我日常使用到的一些内容:
+
+- 首先是一些基础理论如:CAP 定理,知道分布式系统会带来的一些问题以及各个应用权衡的方式。
+- 了解近些年大热的微服务相关定义、来源以及对比,有条件的可以阅读 `martin fowler` 的原文 [Microservices](https://martinfowler.com/articles/microservices.html),或者也可以搜索相关的国内翻译。
+- 对 Dubbo、SpringCloud 等分布式框架的使用,最好是要了解原理。
+- 接着要对分布式带来的问题提出解决方案。如[分布式锁](https://crossoverjie.top/2018/03/29/distributed-lock/distributed-lock-redis/)、[分布式限流](https://crossoverjie.top/2018/04/28/sbc/sbc7-Distributed-Limit/)、分布式事务、[分布式缓存](https://github.com/crossoverJie/Java-Interview/blob/master/MD/Cache-design.md)、分布式 ID、消息中间件等。
+- 也要了解一些分布式中的负载算法:权重、Hash、一致性 Hash、故障转移、[LRU](https://crossoverjie.top/2018/04/07/algorithm/LRU-cache/) 等。
+- 最好能做一个实践如:[秒杀架构实践
+ ](https://crossoverjie.top/%2F2018%2F05%2F07%2Fssm%2FSSM18-seconds-kill%2F)
+
+之前有开源一个分布式相关解决组件:
+
+[https://github.com/crossoverJie/distributed-redis-tool](https://github.com/crossoverJie/distributed-redis-tool)
+
+同时推荐一本入门科普[《大型网站技术架构》](https://book.douban.com/subject/25723064/),出版时间有点早,从中可以学习一些思路。
+
+
+### 懂点架构
+
+相信大家都有一个架构师的梦想。
+
+架构师给人的感觉就是画画图纸,搭好架子,下面的人员来添砖加瓦最终产出。
+
+但其实需要的内功也要非常深厚,就上面列举的样样需要掌握,底层到操作系统、算法;上层到应用、框架都需要非常精通。(PPT 架构师除外)
+
+我自身参与架构经验也不多,所以只能提供有限的建议。
+
+首先分布式肯定得掌握,毕竟现在大部分的架构都是基于分布式的。
+
+这其中就得根据 CAP 理论结合项目情况来选择一致性还是可用性,同时如何做好适合现有团队的技术选型。
+
+这里推荐下开涛老师的[《亿级流量网站架构核心技术》](https://book.douban.com/subject/26999243/),列举了很多架构实例,不过网上褒贬不一,但对于刚入门架构的能科普不少知识。
+
+## 如何学习
+
+谈完了技能树,现在来聊聊如何学习,这也是被问的最多的一个话题。
+
+而关于学习讨论的最多的也是看视频还是看书?
+
+### 视频
+
+不得不承认视频是获取知识最便捷的来源,毕竟包含了图、文、声。
+
+大学几年时间其实我也没好好上专业课,我记得真正入门 Java 还是一个暑假花了两个月的时间天天在家里看 ”马士兵“ 老师的视频教程,当时的资源也很老了,记得好像是 07 年出的视频(用的还是 Google )。
+
+那段时间早起晚睡,每天学到东西之后马上实践,心里也很有成就感。后来开学之后一度成为同学们眼中的”学霸“人物。
+
+> 现在打开我 12 年的电脑,硬盘里还躺着好几十 G 的教学视频。
+
+### 看书
+
+工作后时间真的很宝贵,完全没有了学生生涯的想学就学的自由。所以现在我主要知识来源还是书籍。
+
+这些是我最近看的书:
+
+
+
+
+看书又会涉及到电子书和纸质书的区别,我个人比较喜欢纸质书。毕竟我可以方便的记笔记以及可以随时切换章节。最主要的还是从小养成的闻书香的习惯。
+
+
+### 知识付费
+
+近几年知识付费越来越流行,许多大佬也加入了这个行列,人们也逐渐在习惯为知识去付费。
+
+说实话写一好篇文章出一份视频都非常不容易,能有正向的激励,作者才能持续输出更好的内容。
+
+这块我觉得国内做的比较好我也为之付费的有极客时间、大佬的知识星球等。
+
+这三点没有绝对的好坏之分,其实可以看出我刚入门的时候看视频,工作之后看书及知识付费内容。
+
+视频的好处是可以跟着里面老师的思路一步一步往下走,比较有音视频代入感强,就像学校老师讲课一样。
+
+但由于内容较长使读者没法知晓其中的重点,甚至都不敢快进生怕错过了哪个重要知识,现在由于 IT 越来越火,网上的视频也很多导致质量参差不齐也不成体系。
+
+而看书可以选择性的浏览自己感兴趣的章节,费解的内容也方便反复阅读
+
+所以建议刚入门的同学可以看看视频跟着学,参与工作一段时间后可以尝试多看看书。
+
+当然这不是绝对的,找到适合自己的学习方式就好。但不管是视频还是看书都要多做多实践。
+
+## 打造个人品牌
+
+个人品牌看似很程序员这个职业不怎么沾边,但在现今的互联网时代对于每个人来说都很重要。
+
+以往我们在写简历或是评估他人简历的时候往往不会想到去网络搜索他的个人信息,但在这个信息爆炸的时代你在网上留下的一点印记都能被发现。
+
+### 博客
+
+因此我们需要维护好自己的名片,比如先搭建自己的个人博客。
+
+博客的好处我也谈过几次了,前期关注人少没关系,重要的是坚持,当你写到 50、100篇文章后你会发现自己在这过程中一定是的到了提高。
+
+
+### GitHub
+
+第二点就和技术人比较相关了:参与维护好自己的 GitHub。
+
+由于 GitHub 的特殊属性,维护好后可以更好的打造个人品牌。
+
+`Talk is cheap. Show me the code` 可不是随便说说的。
+
+想要维护好可以从几个方面着手:
+
+- 参与他人的项目,不管是代码库还是知识库都可以,先融入进社区。
+- 发起自己的开源项目,不管是平时开发过程中的小痛点,还是精心整理的知识点都可以。
+
+但这过程中有几点还是要注意:
+
+- 我们需要遵守 GitHub 的社交礼仪。能用英文尽量就用英文,特别是在国外厂库中。
+- 尽量少 push 一些与代码工作无关的内容,我认为这并不能提高自己的品牌。
+- `别去刷 star`。这也是近期才流行起来,不知道为什么总有一些人会钻这种空子,刷起来的热度对自己并没有任何提高。
+
+这里有一篇国外大佬写的 `How to build your personal brand as a new developer` :
+
+[https://medium.freecodecamp.org/building-your-personal-brand-as-a-new-web-developer-f6d4150fd217](https://medium.freecodecamp.org/building-your-personal-brand-as-a-new-web-developer-f6d4150fd217)
+
+
+## English 挺重要
+
+再来谈谈英语的重要性,我记得刚上大学时老师以及一些培训机构都会说:
+
+> 别怕自己英语差就学不了编程,真正常用的就那些词语。
+
+这句话虽没错,但英语在对 IT 这行来说还是有着极大的加分能力。
+
+拿常见的 JDK 里的源码注释也是纯英文的,如果英语还不错的话,一些 Spring 的东西完全可以自学,直接去 Spring 官网就可以查看,甚至后面出的 SpringCloud,官方资料就是最好的教程。
+
+再有就是平时查资料时,有条件的可以尝试用 `Google + 英文` 搜索,你会发现新的世界。
+
+不然也不会有面向 `Google/Stack Overflow` 编程。
+
+对于英语好的同学自然不怕,那不怎么好的咋办呢?
+
+比如我,但我在坚持以下几点:
+
+- 所有的手机、电脑系统统统换成英语语言,养成习惯(不过也有尴尬的连菜单都找不到的情况)。
+- 订阅一些英语周刊,比如 ”湾区日报“。
+- 定期去类似于 [https://medium.com/](https://medium.com/) 这样具有影响力的国外社区阅读文章。
+
+虽然现在我也谈不上多好,但目前我也在努力,希望大家也一起坚持。
+
+
+推荐一本近期在看的书《程序员的英语》。
+
+## 保持竞争力
+
+技术这个行业发展迅速、变化太快,每年也都有无数相关行业毕业生加入竞争,稍不留神就会被赶上甚至超越。
+
+所以我们无时无刻都得保持竞争力。
+
+多的谈不上,我只能谈下目前我在做的事情:
+
+- **打好基础**。不是学了之后就忘了,需要不停的去看,巩固,基础是万变不离其宗的。
+- 多看源码,了解原理,不要停留在调参侠的境界。
+- 关注行业发展、新技术、新动态至少不能落伍了。
+- 争取每周产出一篇技术相关文章。
+- 积极参与开源项目。
+
+
+## 思维导图
+
+
+
+结合上文产出了一个思维导图更直观些。
+
+## 总结
+
+本文结合了自身的一些经验列举了一些方法,不一定对每位都有效需要自行判断。
+
+也反反复复写了差不多一周的时间,希望对在这条路上和正在路上的朋友们起到一些作用。
+
+大部分都只是谈了个思路,其实每一项单聊都能写很多。每个点都有推荐一本书籍,有更好建议欢迎留言讨论。
+
+上文大部分的知识点都有维护在 GitHub 上,感兴趣的朋友可以自行查阅:
+
+
+
+[https://github.com/crossoverJie/JCSprout](https://github.com/crossoverJie/JCSprout)
\ No newline at end of file
diff --git a/MD/spring/spring-bean-lifecycle.md b/MD/spring/spring-bean-lifecycle.md
index b9693567..60f2796a 100644
--- a/MD/spring/spring-bean-lifecycle.md
+++ b/MD/spring/spring-bean-lifecycle.md
@@ -7,7 +7,7 @@ Spring Bean 的生命周期在整个 Spring 中占有很重要的位置,掌握
首先看下生命周期图:
-
+
再谈生命周期之前有一点需要先明确:
diff --git a/MD/third-party-component/cicada.md b/MD/third-party-component/cicada.md
new file mode 100644
index 00000000..39e207bf
--- /dev/null
+++ b/MD/third-party-component/cicada.md
@@ -0,0 +1,265 @@
+ +
+ +
+ +
+ +
+
+> `Java Core Sprout`:处于萌芽阶段的 Java 核心知识库。
+
+[GitHub](https://github.com/crossoverJie/JCSprout)
+[Get Started](#introduction)
\ No newline at end of file
diff --git a/docs/_media/icon-above-font.png b/docs/_media/icon-above-font.png
new file mode 100644
index 00000000..cb9b2535
Binary files /dev/null and b/docs/_media/icon-above-font.png differ
diff --git a/docs/_media/icon-left-font-monochrome-black.png b/docs/_media/icon-left-font-monochrome-black.png
new file mode 100644
index 00000000..a754b12d
Binary files /dev/null and b/docs/_media/icon-left-font-monochrome-black.png differ
diff --git a/docs/_sidebar.md b/docs/_sidebar.md
new file mode 100644
index 00000000..50f96c93
--- /dev/null
+++ b/docs/_sidebar.md
@@ -0,0 +1,88 @@
+- 集合
+
+ - [ArrayList/Vector](collections/ArrayList.md)
+ - [LinkedList](collections/LinkedList.md)
+ - [HashMap](collections/HashMap.md)
+ - [HashSet](collections/HashSet.md)
+ - [LinkedHashMap](collections/LinkedHashMap.md)
+
+- Java 多线程
+
+ - [多线程中的常见问题](thread/Thread-common-problem.md)
+ - [synchronized 关键字原理](thread/Synchronize.md)
+ - [多线程的三大核心](thread/Threadcore.md)
+ - [对锁的一些认知](thread/Java-lock.md)
+ - [ReentrantLock 实现原理 ](thread/ReentrantLock.md)
+ - [ConcurrentHashMap 的实现原理](thread/ConcurrentHashMap.md)
+ - [如何优雅的使用和理解线程池](thread/ThreadPoolExecutor.md)
+ - [深入理解线程通信](thread/thread-communication.md)
+ - [一个线程罢工的诡异事件](thread/thread-gone.md)
+ - [线程池中你不容错过的一些细节](thread/thread-gone2.md)
+ - [『并发包入坑指北』之阻塞队列](thread/ArrayBlockingQueue.md)
+
+- JVM
+
+ - [Java 运行时内存划分](jvm/MemoryAllocation.md)
+ - [类加载机制](jvm/ClassLoad.md)
+ - [OOM 分析](jvm/OOM-analysis.md)
+ - [垃圾回收](jvm/GarbageCollection.md)
+ - [对象的创建与内存分配](jvm/newObject.md)
+ - [你应该知道的 volatile 关键字](jvm/volatile.md)
+ - [一次内存溢出排查优化实战](jvm/OOM-Disruptor.md)
+ - [一次 HashSet 所引起的并发问题](jvm/JVM-concurrent-HashSet-problem.md)
+ - [一次生产 CPU 100% 排查优化实践](jvm/cpu-percent-100.md)
+
+- 分布式
+
+ - [分布式限流](distributed/Distributed-Limit.md)
+ - [基于 Redis 的分布式锁](distributed/distributed-lock-redis.md)
+ - [分布式缓存设计](distributed/Cache-design.md)
+ - [分布式 ID 生成器](distributed/ID-generator.md)
+
+- 常用框架
+
+ - [Spring Bean 生命周期](frame/spring-bean-lifecycle.md)
+ - [Spring AOP 的实现原理](frame/SpringAOP.md)
+ - [Guava 源码分析(Cache 原理)](frame/guava-cache.md)
+ - [Kafka produce 源码分析](frame/kafka-product.md)
+ - [Kafka 消费实践](frame/kafka-consumer.md)
+
+
+- 架构设计
+
+ - [秒杀系统设计](architecture-design/Spike.md)
+ - [秒杀架构实践](architecture-design/seconds-kill.md)
+ - [设计一个百万级的消息推送系统](architecture-design/million-sms-push.md)
+
+- 数据库
+
+ - [MySQL 索引原理](db/MySQL-Index.md)
+ - [SQL 优化](db/SQL-optimization.md)
+ - [数据库水平垂直拆分](db/DB-split.md)
+ - [一次分表踩坑实践的探讨](db/sharding-db.md)
+
+- 数据结构与算法
+
+ - [常见算法](algorithm/common-algorithm.md)
+ - [一致性 Hash 算法原理](algorithm/Consistent-Hash.md)
+ - [一致性 Hash 算法实践](algorithm/consistent-hash-implement.md)
+ - [限流算法](algorithm/Limiting.md)
+ - [动手实现一个 LRU cache](algorithm/LRU-cache.md)
+ - [亿级数据中判断数据是否不存在](algorithm/guava-bloom-filter.md)
+
+
+- Netty 相关
+
+ - [SpringBoot 整合长连接心跳机制](netty/Netty(1)TCP-Heartbeat.md)
+ - [从线程模型的角度看 Netty 为什么是高性能的?](netty/Netty(2)Thread-model.md)
+ - [自己实现一个轻量级 HTTP 框架](netty/cicada.md)
+ - [为自己搭建一个分布式 IM(即时通讯) 系统](netty/cim.md)
+
+- 附加技能
+
+ - [TCP/IP 协议](soft-skills/TCP-IP.md)
+ - [一个学渣的阿里之路](soft-skills/Interview-experience.md)
+ - [如何成为一位「不那么差」的程序员](soft-skills/how-to-be-developer.md)
+ - [如何高效的使用 Git](soft-skills/how-to-use-git-efficiently.md)
+
+- [联系作者](contactme.md)
diff --git a/docs/algorithm/Consistent-Hash.md b/docs/algorithm/Consistent-Hash.md
new file mode 100644
index 00000000..83c433f3
--- /dev/null
+++ b/docs/algorithm/Consistent-Hash.md
@@ -0,0 +1,62 @@
+# 一致 Hash 算法
+
+当我们在做数据库分库分表或者是分布式缓存时,不可避免的都会遇到一个问题:
+
+如何将数据均匀的分散到各个节点中,并且尽量的在加减节点时能使受影响的数据最少。
+
+## Hash 取模
+随机放置就不说了,会带来很多问题。通常最容易想到的方案就是 `hash 取模`了。
+
+可以将传入的 Key 按照 `index = hash(key) % N` 这样来计算出需要存放的节点。其中 hash 函数是一个将字符串转换为正整数的哈希映射方法,N 就是节点的数量。
+
+这样可以满足数据的均匀分配,但是这个算法的容错性和扩展性都较差。
+
+比如增加或删除了一个节点时,所有的 Key 都需要重新计算,显然这样成本较高,为此需要一个算法满足分布均匀同时也要有良好的容错性和拓展性。
+
+## 一致 Hash 算法
+
+一致 Hash 算法是将所有的哈希值构成了一个环,其范围在 `0 ~ 2^32-1`。如下图:
+
+
+
+之后将各个节点散列到这个环上,可以用节点的 IP、hostname 这样的唯一性字段作为 Key 进行 `hash(key)`,散列之后如下:
+
+
+
+之后需要将数据定位到对应的节点上,使用同样的 `hash 函数` 将 Key 也映射到这个环上。
+
+
+
+这样按照顺时针方向就可以把 k1 定位到 `N1节点`,k2 定位到 `N3节点`,k3 定位到 `N2节点`。
+
+### 容错性
+这时假设 N1 宕机了:
+
+
+
+依然根据顺时针方向,k2 和 k3 保持不变,只有 k1 被重新映射到了 N3。这样就很好的保证了容错性,当一个节点宕机时只会影响到少少部分的数据。
+
+### 拓展性
+
+当新增一个节点时:
+
+
+
+在 N2 和 N3 之间新增了一个节点 N4 ,这时会发现受印象的数据只有 k3,其余数据也是保持不变,所以这样也很好的保证了拓展性。
+
+## 虚拟节点
+到目前为止该算法依然也有点问题:
+
+当节点较少时会出现数据分布不均匀的情况:
+
+
+
+这样会导致大部分数据都在 N1 节点,只有少量的数据在 N2 节点。
+
+为了解决这个问题,一致哈希算法引入了虚拟节点。将每一个节点都进行多次 hash,生成多个节点放置在环上称为虚拟节点:
+
+
+
+计算时可以在 IP 后加上编号来生成哈希值。
+
+这样只需要在原有的基础上多一步由虚拟节点映射到实际节点的步骤即可让少量节点也能满足均匀性。
diff --git a/docs/algorithm/LRU-cache.md b/docs/algorithm/LRU-cache.md
new file mode 100644
index 00000000..ca512d10
--- /dev/null
+++ b/docs/algorithm/LRU-cache.md
@@ -0,0 +1,851 @@
+
+
+## 前言
+LRU 是 `Least Recently Used` 的简写,字面意思则是`最近最少使用`。
+
+通常用于缓存的淘汰策略实现,由于缓存的内存非常宝贵,所以需要根据某种规则来剔除数据保证内存不被撑满。
+
+如常用的 Redis 就有以下几种策略:
+
+| 策略 | 描述 |
+| :--: | :--: |
+| volatile-lru | 从已设置过期时间的数据集中挑选最近最少使用的数据淘汰 |
+| volatile-ttl | 从已设置过期时间的数据集中挑选将要过期的数据淘汰 |
+|volatile-random | 从已设置过期时间的数据集中任意选择数据淘汰 |
+| allkeys-lru | 从所有数据集中挑选最近最少使用的数据淘汰 |
+| allkeys-random | 从所有数据集中任意选择数据进行淘汰 |
+| no-envicition | 禁止驱逐数据 |
+
+> 摘抄自:[https://github.com/CyC2018/Interview-Notebook/blob/master/notes/Redis.md#%E5%8D%81%E4%B8%89%E6%95%B0%E6%8D%AE%E6%B7%98%E6%B1%B0%E7%AD%96%E7%95%A5](https://github.com/CyC2018/Interview-Notebook/blob/master/notes/Redis.md#%E5%8D%81%E4%B8%89%E6%95%B0%E6%8D%AE%E6%B7%98%E6%B1%B0%E7%AD%96%E7%95%A5)
+
+
+
+
+
+## 实现一
+
+之前也有接触过一道面试题,大概需求是:
+
+- 实现一个 LRU 缓存,当缓存数据达到 N 之后需要淘汰掉最近最少使用的数据。
+- N 小时之内没有被访问的数据也需要淘汰掉。
+
+以下是我的实现:
+
+```java
+public class LRUAbstractMap extends java.util.AbstractMap {
+
+ private final static Logger LOGGER = LoggerFactory.getLogger(LRUAbstractMap.class);
+
+ /**
+ * 检查是否超期线程
+ */
+ private ExecutorService checkTimePool ;
+
+ /**
+ * map 最大size
+ */
+ private final static int MAX_SIZE = 1024 ;
+
+ private final static ArrayBlockingQueue
+
+
+> `Java Core Sprout`:处于萌芽阶段的 Java 核心知识库。
+
+[GitHub](https://github.com/crossoverJie/JCSprout)
+[Get Started](#introduction)
\ No newline at end of file
diff --git a/docs/_media/icon-above-font.png b/docs/_media/icon-above-font.png
new file mode 100644
index 00000000..cb9b2535
Binary files /dev/null and b/docs/_media/icon-above-font.png differ
diff --git a/docs/_media/icon-left-font-monochrome-black.png b/docs/_media/icon-left-font-monochrome-black.png
new file mode 100644
index 00000000..a754b12d
Binary files /dev/null and b/docs/_media/icon-left-font-monochrome-black.png differ
diff --git a/docs/_sidebar.md b/docs/_sidebar.md
new file mode 100644
index 00000000..50f96c93
--- /dev/null
+++ b/docs/_sidebar.md
@@ -0,0 +1,88 @@
+- 集合
+
+ - [ArrayList/Vector](collections/ArrayList.md)
+ - [LinkedList](collections/LinkedList.md)
+ - [HashMap](collections/HashMap.md)
+ - [HashSet](collections/HashSet.md)
+ - [LinkedHashMap](collections/LinkedHashMap.md)
+
+- Java 多线程
+
+ - [多线程中的常见问题](thread/Thread-common-problem.md)
+ - [synchronized 关键字原理](thread/Synchronize.md)
+ - [多线程的三大核心](thread/Threadcore.md)
+ - [对锁的一些认知](thread/Java-lock.md)
+ - [ReentrantLock 实现原理 ](thread/ReentrantLock.md)
+ - [ConcurrentHashMap 的实现原理](thread/ConcurrentHashMap.md)
+ - [如何优雅的使用和理解线程池](thread/ThreadPoolExecutor.md)
+ - [深入理解线程通信](thread/thread-communication.md)
+ - [一个线程罢工的诡异事件](thread/thread-gone.md)
+ - [线程池中你不容错过的一些细节](thread/thread-gone2.md)
+ - [『并发包入坑指北』之阻塞队列](thread/ArrayBlockingQueue.md)
+
+- JVM
+
+ - [Java 运行时内存划分](jvm/MemoryAllocation.md)
+ - [类加载机制](jvm/ClassLoad.md)
+ - [OOM 分析](jvm/OOM-analysis.md)
+ - [垃圾回收](jvm/GarbageCollection.md)
+ - [对象的创建与内存分配](jvm/newObject.md)
+ - [你应该知道的 volatile 关键字](jvm/volatile.md)
+ - [一次内存溢出排查优化实战](jvm/OOM-Disruptor.md)
+ - [一次 HashSet 所引起的并发问题](jvm/JVM-concurrent-HashSet-problem.md)
+ - [一次生产 CPU 100% 排查优化实践](jvm/cpu-percent-100.md)
+
+- 分布式
+
+ - [分布式限流](distributed/Distributed-Limit.md)
+ - [基于 Redis 的分布式锁](distributed/distributed-lock-redis.md)
+ - [分布式缓存设计](distributed/Cache-design.md)
+ - [分布式 ID 生成器](distributed/ID-generator.md)
+
+- 常用框架
+
+ - [Spring Bean 生命周期](frame/spring-bean-lifecycle.md)
+ - [Spring AOP 的实现原理](frame/SpringAOP.md)
+ - [Guava 源码分析(Cache 原理)](frame/guava-cache.md)
+ - [Kafka produce 源码分析](frame/kafka-product.md)
+ - [Kafka 消费实践](frame/kafka-consumer.md)
+
+
+- 架构设计
+
+ - [秒杀系统设计](architecture-design/Spike.md)
+ - [秒杀架构实践](architecture-design/seconds-kill.md)
+ - [设计一个百万级的消息推送系统](architecture-design/million-sms-push.md)
+
+- 数据库
+
+ - [MySQL 索引原理](db/MySQL-Index.md)
+ - [SQL 优化](db/SQL-optimization.md)
+ - [数据库水平垂直拆分](db/DB-split.md)
+ - [一次分表踩坑实践的探讨](db/sharding-db.md)
+
+- 数据结构与算法
+
+ - [常见算法](algorithm/common-algorithm.md)
+ - [一致性 Hash 算法原理](algorithm/Consistent-Hash.md)
+ - [一致性 Hash 算法实践](algorithm/consistent-hash-implement.md)
+ - [限流算法](algorithm/Limiting.md)
+ - [动手实现一个 LRU cache](algorithm/LRU-cache.md)
+ - [亿级数据中判断数据是否不存在](algorithm/guava-bloom-filter.md)
+
+
+- Netty 相关
+
+ - [SpringBoot 整合长连接心跳机制](netty/Netty(1)TCP-Heartbeat.md)
+ - [从线程模型的角度看 Netty 为什么是高性能的?](netty/Netty(2)Thread-model.md)
+ - [自己实现一个轻量级 HTTP 框架](netty/cicada.md)
+ - [为自己搭建一个分布式 IM(即时通讯) 系统](netty/cim.md)
+
+- 附加技能
+
+ - [TCP/IP 协议](soft-skills/TCP-IP.md)
+ - [一个学渣的阿里之路](soft-skills/Interview-experience.md)
+ - [如何成为一位「不那么差」的程序员](soft-skills/how-to-be-developer.md)
+ - [如何高效的使用 Git](soft-skills/how-to-use-git-efficiently.md)
+
+- [联系作者](contactme.md)
diff --git a/docs/algorithm/Consistent-Hash.md b/docs/algorithm/Consistent-Hash.md
new file mode 100644
index 00000000..83c433f3
--- /dev/null
+++ b/docs/algorithm/Consistent-Hash.md
@@ -0,0 +1,62 @@
+# 一致 Hash 算法
+
+当我们在做数据库分库分表或者是分布式缓存时,不可避免的都会遇到一个问题:
+
+如何将数据均匀的分散到各个节点中,并且尽量的在加减节点时能使受影响的数据最少。
+
+## Hash 取模
+随机放置就不说了,会带来很多问题。通常最容易想到的方案就是 `hash 取模`了。
+
+可以将传入的 Key 按照 `index = hash(key) % N` 这样来计算出需要存放的节点。其中 hash 函数是一个将字符串转换为正整数的哈希映射方法,N 就是节点的数量。
+
+这样可以满足数据的均匀分配,但是这个算法的容错性和扩展性都较差。
+
+比如增加或删除了一个节点时,所有的 Key 都需要重新计算,显然这样成本较高,为此需要一个算法满足分布均匀同时也要有良好的容错性和拓展性。
+
+## 一致 Hash 算法
+
+一致 Hash 算法是将所有的哈希值构成了一个环,其范围在 `0 ~ 2^32-1`。如下图:
+
+
+
+之后将各个节点散列到这个环上,可以用节点的 IP、hostname 这样的唯一性字段作为 Key 进行 `hash(key)`,散列之后如下:
+
+
+
+之后需要将数据定位到对应的节点上,使用同样的 `hash 函数` 将 Key 也映射到这个环上。
+
+
+
+这样按照顺时针方向就可以把 k1 定位到 `N1节点`,k2 定位到 `N3节点`,k3 定位到 `N2节点`。
+
+### 容错性
+这时假设 N1 宕机了:
+
+
+
+依然根据顺时针方向,k2 和 k3 保持不变,只有 k1 被重新映射到了 N3。这样就很好的保证了容错性,当一个节点宕机时只会影响到少少部分的数据。
+
+### 拓展性
+
+当新增一个节点时:
+
+
+
+在 N2 和 N3 之间新增了一个节点 N4 ,这时会发现受印象的数据只有 k3,其余数据也是保持不变,所以这样也很好的保证了拓展性。
+
+## 虚拟节点
+到目前为止该算法依然也有点问题:
+
+当节点较少时会出现数据分布不均匀的情况:
+
+
+
+这样会导致大部分数据都在 N1 节点,只有少量的数据在 N2 节点。
+
+为了解决这个问题,一致哈希算法引入了虚拟节点。将每一个节点都进行多次 hash,生成多个节点放置在环上称为虚拟节点:
+
+
+
+计算时可以在 IP 后加上编号来生成哈希值。
+
+这样只需要在原有的基础上多一步由虚拟节点映射到实际节点的步骤即可让少量节点也能满足均匀性。
diff --git a/docs/algorithm/LRU-cache.md b/docs/algorithm/LRU-cache.md
new file mode 100644
index 00000000..ca512d10
--- /dev/null
+++ b/docs/algorithm/LRU-cache.md
@@ -0,0 +1,851 @@
+
+
+## 前言
+LRU 是 `Least Recently Used` 的简写,字面意思则是`最近最少使用`。
+
+通常用于缓存的淘汰策略实现,由于缓存的内存非常宝贵,所以需要根据某种规则来剔除数据保证内存不被撑满。
+
+如常用的 Redis 就有以下几种策略:
+
+| 策略 | 描述 |
+| :--: | :--: |
+| volatile-lru | 从已设置过期时间的数据集中挑选最近最少使用的数据淘汰 |
+| volatile-ttl | 从已设置过期时间的数据集中挑选将要过期的数据淘汰 |
+|volatile-random | 从已设置过期时间的数据集中任意选择数据淘汰 |
+| allkeys-lru | 从所有数据集中挑选最近最少使用的数据淘汰 |
+| allkeys-random | 从所有数据集中任意选择数据进行淘汰 |
+| no-envicition | 禁止驱逐数据 |
+
+> 摘抄自:[https://github.com/CyC2018/Interview-Notebook/blob/master/notes/Redis.md#%E5%8D%81%E4%B8%89%E6%95%B0%E6%8D%AE%E6%B7%98%E6%B1%B0%E7%AD%96%E7%95%A5](https://github.com/CyC2018/Interview-Notebook/blob/master/notes/Redis.md#%E5%8D%81%E4%B8%89%E6%95%B0%E6%8D%AE%E6%B7%98%E6%B1%B0%E7%AD%96%E7%95%A5)
+
+
+
+
+
+## 实现一
+
+之前也有接触过一道面试题,大概需求是:
+
+- 实现一个 LRU 缓存,当缓存数据达到 N 之后需要淘汰掉最近最少使用的数据。
+- N 小时之内没有被访问的数据也需要淘汰掉。
+
+以下是我的实现:
+
+```java
+public class LRUAbstractMap extends java.util.AbstractMap {
+
+ private final static Logger LOGGER = LoggerFactory.getLogger(LRUAbstractMap.class);
+
+ /**
+ * 检查是否超期线程
+ */
+ private ExecutorService checkTimePool ;
+
+ /**
+ * map 最大size
+ */
+ private final static int MAX_SIZE = 1024 ;
+
+ private final static ArrayBlockingQueue