diff --git a/.github/workflows/push.yml b/.github/workflows/push.yml
new file mode 100644
index 0000000..16dab17
--- /dev/null
+++ b/.github/workflows/push.yml
@@ -0,0 +1,42 @@
+name: Github-Pages-push
+
+on:
+ push:
+ branches:
+ - master
+
+jobs:
+ deploy:
+ runs-on: ubuntu-18.04
+ defaults:
+ run:
+ working-directory: ./.tmp
+ steps:
+ - uses: actions/checkout@v1
+ with:
+ submodules: true
+
+ - name: create blog
+ run: |
+ cp -R ../* content/
+ cp content/README.md content/_index.md
+ find content/ -name "*.md" | xargs -n 1 sed -i 's/.md//g'
+
+ - name: Setup Hugo
+ uses: peaceiris/actions-hugo@v2
+ with:
+ hugo-version: '0.84.0'
+ extended: true
+
+ - name: Build
+ run: hugo --gc --minify --cleanDestinationDir
+
+ - name: Pushes to another repository
+ uses: nkoppel/push-files-to-another-repository@v1.1.0
+ env:
+ API_TOKEN_GITHUB: ${{ secrets.API_TOKEN_GITHUB }}
+ with:
+ source-files: '.tmp/public/*'
+ destination-username: 'golang-minibear2333'
+ destination-repository: 'golang-minibear2333.github.io'
+ commit-email: 'pzqu@qq.com'
diff --git a/.gitignore b/.gitignore
index d298be1..120bd6a 100644
--- a/.gitignore
+++ b/.gitignore
@@ -1 +1,23 @@
-public/
\ No newline at end of file
+# Binaries for programs and plugins
+*.exe
+*.exe~
+*.dll
+*.so
+*.dylib
+go_build_*
+.DS_Store
+
+# Test binary, built with `go test -c`
+*.test
+
+# Output of the go coverage tool, specifically when used with LiteIDE
+*.out
+
+# Dependency directories (remove the comment below to include it)
+vendor/
+
+# db tmp data
+storage/*
+node_modules/
+public/
+.idea/
diff --git a/.idea/.gitignore b/.idea/.gitignore
deleted file mode 100644
index 73f69e0..0000000
--- a/.idea/.gitignore
+++ /dev/null
@@ -1,8 +0,0 @@
-# Default ignored files
-/shelf/
-/workspace.xml
-# Datasource local storage ignored files
-/dataSources/
-/dataSources.local.xml
-# Editor-based HTTP Client requests
-/httpRequests/
diff --git a/.idea/golang.iml b/.idea/golang.iml
deleted file mode 100644
index 5e764c4..0000000
--- a/.idea/golang.iml
+++ /dev/null
@@ -1,9 +0,0 @@
-
-
-
-
-
-
-
-
-
\ No newline at end of file
diff --git a/.idea/modules.xml b/.idea/modules.xml
deleted file mode 100644
index ad900c8..0000000
--- a/.idea/modules.xml
+++ /dev/null
@@ -1,8 +0,0 @@
-
-
-
-
-
-
-
-
\ No newline at end of file
diff --git a/.idea/vcs.xml b/.idea/vcs.xml
deleted file mode 100644
index 94a25f7..0000000
--- a/.idea/vcs.xml
+++ /dev/null
@@ -1,6 +0,0 @@
-
-
-
-
-
-
\ No newline at end of file
diff --git a/.tmp/.gitignore b/.tmp/.gitignore
new file mode 100644
index 0000000..1f1025f
--- /dev/null
+++ b/.tmp/.gitignore
@@ -0,0 +1,2 @@
+.idea
+.DS_Store
\ No newline at end of file
diff --git a/blog/archetypes/default.md b/.tmp/archetypes/default.md
similarity index 100%
rename from blog/archetypes/default.md
rename to .tmp/archetypes/default.md
diff --git a/blog/config.toml b/.tmp/config.toml
similarity index 97%
rename from blog/config.toml
rename to .tmp/config.toml
index 7f6c54f..fb825ae 100644
--- a/blog/config.toml
+++ b/.tmp/config.toml
@@ -1,6 +1,6 @@
baseURL = "https://golang.coding3min.com/"
languageCode = "en-us"
-title = "go语言精进之路"
+title = "Go语言精进之路"
theme="book"
# (Optional) Set this to true to enable 'Last Modified by' date and git author
@@ -47,7 +47,8 @@ disableKinds = ['taxonomy', 'taxonomyTerm']
# Enable 'Edit this page' links for 'doc' page type.
# Disabled by default. Uncomment to enable. Requires 'BookRepo' param.
# Path must point to the site directory.
- BookEditPath = 'edit/master/blog'
+ BookEditPath = 'edit/master'
+ contentDir = '.'
# (Optional, default January 2, 2006) Configure the date format used on the pages
# - In git information
diff --git a/blog/themes/book/layouts/partials/docs/inject/body.html b/.tmp/content/.githold
similarity index 100%
rename from blog/themes/book/layouts/partials/docs/inject/body.html
rename to .tmp/content/.githold
diff --git a/blog/layouts/404.html b/.tmp/layouts/404.html
similarity index 100%
rename from blog/layouts/404.html
rename to .tmp/layouts/404.html
diff --git a/blog/layouts/partials/docs/inject/content-after.html b/.tmp/layouts/partials/docs/inject/content-after.html
similarity index 100%
rename from blog/layouts/partials/docs/inject/content-after.html
rename to .tmp/layouts/partials/docs/inject/content-after.html
diff --git a/blog/resources/_gen/assets/scss/book.scss_50fc8c04e12a2f59027287995557ceff.content b/.tmp/resources/_gen/assets/scss/book.scss_50fc8c04e12a2f59027287995557ceff.content
similarity index 100%
rename from blog/resources/_gen/assets/scss/book.scss_50fc8c04e12a2f59027287995557ceff.content
rename to .tmp/resources/_gen/assets/scss/book.scss_50fc8c04e12a2f59027287995557ceff.content
diff --git a/blog/resources/_gen/assets/scss/book.scss_50fc8c04e12a2f59027287995557ceff.json b/.tmp/resources/_gen/assets/scss/book.scss_50fc8c04e12a2f59027287995557ceff.json
similarity index 100%
rename from blog/resources/_gen/assets/scss/book.scss_50fc8c04e12a2f59027287995557ceff.json
rename to .tmp/resources/_gen/assets/scss/book.scss_50fc8c04e12a2f59027287995557ceff.json
diff --git a/blog/static/logo.png b/.tmp/static/logo.png
similarity index 100%
rename from blog/static/logo.png
rename to .tmp/static/logo.png
diff --git a/blog/themes/book/.github/workflows/main.yml b/.tmp/themes/book/.github/workflows/main.yml
similarity index 100%
rename from blog/themes/book/.github/workflows/main.yml
rename to .tmp/themes/book/.github/workflows/main.yml
diff --git a/blog/themes/book/.gitignore b/.tmp/themes/book/.gitignore
similarity index 100%
rename from blog/themes/book/.gitignore
rename to .tmp/themes/book/.gitignore
diff --git a/blog/themes/book/LICENSE b/.tmp/themes/book/LICENSE
similarity index 100%
rename from blog/themes/book/LICENSE
rename to .tmp/themes/book/LICENSE
diff --git a/blog/themes/book/README.md b/.tmp/themes/book/README.md
similarity index 100%
rename from blog/themes/book/README.md
rename to .tmp/themes/book/README.md
diff --git a/blog/themes/book/archetypes/docs.md b/.tmp/themes/book/archetypes/docs.md
similarity index 100%
rename from blog/themes/book/archetypes/docs.md
rename to .tmp/themes/book/archetypes/docs.md
diff --git a/blog/themes/book/archetypes/posts.md b/.tmp/themes/book/archetypes/posts.md
similarity index 100%
rename from blog/themes/book/archetypes/posts.md
rename to .tmp/themes/book/archetypes/posts.md
diff --git a/blog/themes/book/assets/_custom.scss b/.tmp/themes/book/assets/_custom.scss
similarity index 100%
rename from blog/themes/book/assets/_custom.scss
rename to .tmp/themes/book/assets/_custom.scss
diff --git a/blog/themes/book/assets/_defaults.scss b/.tmp/themes/book/assets/_defaults.scss
similarity index 100%
rename from blog/themes/book/assets/_defaults.scss
rename to .tmp/themes/book/assets/_defaults.scss
diff --git a/blog/themes/book/assets/_fonts.scss b/.tmp/themes/book/assets/_fonts.scss
similarity index 100%
rename from blog/themes/book/assets/_fonts.scss
rename to .tmp/themes/book/assets/_fonts.scss
diff --git a/blog/themes/book/assets/_main.scss b/.tmp/themes/book/assets/_main.scss
similarity index 100%
rename from blog/themes/book/assets/_main.scss
rename to .tmp/themes/book/assets/_main.scss
diff --git a/blog/themes/book/assets/_markdown.scss b/.tmp/themes/book/assets/_markdown.scss
similarity index 100%
rename from blog/themes/book/assets/_markdown.scss
rename to .tmp/themes/book/assets/_markdown.scss
diff --git a/blog/themes/book/assets/_print.scss b/.tmp/themes/book/assets/_print.scss
similarity index 100%
rename from blog/themes/book/assets/_print.scss
rename to .tmp/themes/book/assets/_print.scss
diff --git a/blog/themes/book/assets/_shortcodes.scss b/.tmp/themes/book/assets/_shortcodes.scss
similarity index 100%
rename from blog/themes/book/assets/_shortcodes.scss
rename to .tmp/themes/book/assets/_shortcodes.scss
diff --git a/blog/themes/book/assets/_utils.scss b/.tmp/themes/book/assets/_utils.scss
similarity index 100%
rename from blog/themes/book/assets/_utils.scss
rename to .tmp/themes/book/assets/_utils.scss
diff --git a/blog/themes/book/assets/_variables.scss b/.tmp/themes/book/assets/_variables.scss
similarity index 100%
rename from blog/themes/book/assets/_variables.scss
rename to .tmp/themes/book/assets/_variables.scss
diff --git a/blog/themes/book/assets/book.scss b/.tmp/themes/book/assets/book.scss
similarity index 100%
rename from blog/themes/book/assets/book.scss
rename to .tmp/themes/book/assets/book.scss
diff --git a/blog/themes/book/assets/clipboard.js b/.tmp/themes/book/assets/clipboard.js
similarity index 100%
rename from blog/themes/book/assets/clipboard.js
rename to .tmp/themes/book/assets/clipboard.js
diff --git a/blog/themes/book/assets/manifest.json b/.tmp/themes/book/assets/manifest.json
similarity index 100%
rename from blog/themes/book/assets/manifest.json
rename to .tmp/themes/book/assets/manifest.json
diff --git a/blog/themes/book/assets/menu-reset.js b/.tmp/themes/book/assets/menu-reset.js
similarity index 100%
rename from blog/themes/book/assets/menu-reset.js
rename to .tmp/themes/book/assets/menu-reset.js
diff --git a/blog/themes/book/assets/mermaid.json b/.tmp/themes/book/assets/mermaid.json
similarity index 100%
rename from blog/themes/book/assets/mermaid.json
rename to .tmp/themes/book/assets/mermaid.json
diff --git a/blog/themes/book/assets/normalize.css b/.tmp/themes/book/assets/normalize.css
similarity index 100%
rename from blog/themes/book/assets/normalize.css
rename to .tmp/themes/book/assets/normalize.css
diff --git a/blog/themes/book/assets/plugins/_numbered.scss b/.tmp/themes/book/assets/plugins/_numbered.scss
similarity index 100%
rename from blog/themes/book/assets/plugins/_numbered.scss
rename to .tmp/themes/book/assets/plugins/_numbered.scss
diff --git a/blog/themes/book/assets/plugins/_scrollbars.scss b/.tmp/themes/book/assets/plugins/_scrollbars.scss
similarity index 100%
rename from blog/themes/book/assets/plugins/_scrollbars.scss
rename to .tmp/themes/book/assets/plugins/_scrollbars.scss
diff --git a/blog/themes/book/assets/search-data.json b/.tmp/themes/book/assets/search-data.json
similarity index 100%
rename from blog/themes/book/assets/search-data.json
rename to .tmp/themes/book/assets/search-data.json
diff --git a/blog/themes/book/assets/search.js b/.tmp/themes/book/assets/search.js
similarity index 100%
rename from blog/themes/book/assets/search.js
rename to .tmp/themes/book/assets/search.js
diff --git a/blog/themes/book/assets/sw-register.js b/.tmp/themes/book/assets/sw-register.js
similarity index 100%
rename from blog/themes/book/assets/sw-register.js
rename to .tmp/themes/book/assets/sw-register.js
diff --git a/blog/themes/book/assets/sw.js b/.tmp/themes/book/assets/sw.js
similarity index 100%
rename from blog/themes/book/assets/sw.js
rename to .tmp/themes/book/assets/sw.js
diff --git a/blog/themes/book/assets/themes/_auto.scss b/.tmp/themes/book/assets/themes/_auto.scss
similarity index 100%
rename from blog/themes/book/assets/themes/_auto.scss
rename to .tmp/themes/book/assets/themes/_auto.scss
diff --git a/blog/themes/book/assets/themes/_dark.scss b/.tmp/themes/book/assets/themes/_dark.scss
similarity index 100%
rename from blog/themes/book/assets/themes/_dark.scss
rename to .tmp/themes/book/assets/themes/_dark.scss
diff --git a/blog/themes/book/assets/themes/_light.scss b/.tmp/themes/book/assets/themes/_light.scss
similarity index 100%
rename from blog/themes/book/assets/themes/_light.scss
rename to .tmp/themes/book/assets/themes/_light.scss
diff --git a/blog/themes/book/exampleSite/assets/_custom.scss b/.tmp/themes/book/exampleSite/assets/_custom.scss
similarity index 100%
rename from blog/themes/book/exampleSite/assets/_custom.scss
rename to .tmp/themes/book/exampleSite/assets/_custom.scss
diff --git a/blog/themes/book/exampleSite/assets/_variables.scss b/.tmp/themes/book/exampleSite/assets/_variables.scss
similarity index 100%
rename from blog/themes/book/exampleSite/assets/_variables.scss
rename to .tmp/themes/book/exampleSite/assets/_variables.scss
diff --git a/blog/themes/book/exampleSite/config.toml b/.tmp/themes/book/exampleSite/config.toml
similarity index 100%
rename from blog/themes/book/exampleSite/config.toml
rename to .tmp/themes/book/exampleSite/config.toml
diff --git a/blog/themes/book/exampleSite/config.yaml b/.tmp/themes/book/exampleSite/config.yaml
similarity index 100%
rename from blog/themes/book/exampleSite/config.yaml
rename to .tmp/themes/book/exampleSite/config.yaml
diff --git a/blog/themes/book/exampleSite/content.bn/_index.md b/.tmp/themes/book/exampleSite/content.bn/_index.md
similarity index 100%
rename from blog/themes/book/exampleSite/content.bn/_index.md
rename to .tmp/themes/book/exampleSite/content.bn/_index.md
diff --git a/blog/themes/book/exampleSite/content.ru/_index.md b/.tmp/themes/book/exampleSite/content.ru/_index.md
similarity index 100%
rename from blog/themes/book/exampleSite/content.ru/_index.md
rename to .tmp/themes/book/exampleSite/content.ru/_index.md
diff --git a/blog/themes/book/exampleSite/content.zh/_index.md b/.tmp/themes/book/exampleSite/content.zh/_index.md
similarity index 100%
rename from blog/themes/book/exampleSite/content.zh/_index.md
rename to .tmp/themes/book/exampleSite/content.zh/_index.md
diff --git a/blog/themes/book/exampleSite/content/_index.md b/.tmp/themes/book/exampleSite/content/_index.md
similarity index 100%
rename from blog/themes/book/exampleSite/content/_index.md
rename to .tmp/themes/book/exampleSite/content/_index.md
diff --git a/blog/themes/book/exampleSite/content/docs/example/_index.md b/.tmp/themes/book/exampleSite/content/docs/example/_index.md
similarity index 100%
rename from blog/themes/book/exampleSite/content/docs/example/_index.md
rename to .tmp/themes/book/exampleSite/content/docs/example/_index.md
diff --git a/blog/themes/book/exampleSite/content/docs/example/collapsed/3rd-level/4th-level.md b/.tmp/themes/book/exampleSite/content/docs/example/collapsed/3rd-level/4th-level.md
similarity index 100%
rename from blog/themes/book/exampleSite/content/docs/example/collapsed/3rd-level/4th-level.md
rename to .tmp/themes/book/exampleSite/content/docs/example/collapsed/3rd-level/4th-level.md
diff --git a/blog/themes/book/exampleSite/content/docs/example/collapsed/3rd-level/_index.md b/.tmp/themes/book/exampleSite/content/docs/example/collapsed/3rd-level/_index.md
similarity index 100%
rename from blog/themes/book/exampleSite/content/docs/example/collapsed/3rd-level/_index.md
rename to .tmp/themes/book/exampleSite/content/docs/example/collapsed/3rd-level/_index.md
diff --git a/blog/themes/book/exampleSite/content/docs/example/collapsed/_index.md b/.tmp/themes/book/exampleSite/content/docs/example/collapsed/_index.md
similarity index 100%
rename from blog/themes/book/exampleSite/content/docs/example/collapsed/_index.md
rename to .tmp/themes/book/exampleSite/content/docs/example/collapsed/_index.md
diff --git a/blog/themes/book/exampleSite/content/docs/example/hidden.md b/.tmp/themes/book/exampleSite/content/docs/example/hidden.md
similarity index 100%
rename from blog/themes/book/exampleSite/content/docs/example/hidden.md
rename to .tmp/themes/book/exampleSite/content/docs/example/hidden.md
diff --git a/blog/themes/book/exampleSite/content/docs/example/table-of-contents/_index.md b/.tmp/themes/book/exampleSite/content/docs/example/table-of-contents/_index.md
similarity index 100%
rename from blog/themes/book/exampleSite/content/docs/example/table-of-contents/_index.md
rename to .tmp/themes/book/exampleSite/content/docs/example/table-of-contents/_index.md
diff --git a/blog/themes/book/exampleSite/content/docs/example/table-of-contents/with-toc.md b/.tmp/themes/book/exampleSite/content/docs/example/table-of-contents/with-toc.md
similarity index 100%
rename from blog/themes/book/exampleSite/content/docs/example/table-of-contents/with-toc.md
rename to .tmp/themes/book/exampleSite/content/docs/example/table-of-contents/with-toc.md
diff --git a/blog/themes/book/exampleSite/content/docs/example/table-of-contents/without-toc.md b/.tmp/themes/book/exampleSite/content/docs/example/table-of-contents/without-toc.md
similarity index 100%
rename from blog/themes/book/exampleSite/content/docs/example/table-of-contents/without-toc.md
rename to .tmp/themes/book/exampleSite/content/docs/example/table-of-contents/without-toc.md
diff --git a/blog/themes/book/exampleSite/content/docs/shortcodes/_index.md b/.tmp/themes/book/exampleSite/content/docs/shortcodes/_index.md
similarity index 100%
rename from blog/themes/book/exampleSite/content/docs/shortcodes/_index.md
rename to .tmp/themes/book/exampleSite/content/docs/shortcodes/_index.md
diff --git a/blog/themes/book/exampleSite/content/docs/shortcodes/buttons.md b/.tmp/themes/book/exampleSite/content/docs/shortcodes/buttons.md
similarity index 100%
rename from blog/themes/book/exampleSite/content/docs/shortcodes/buttons.md
rename to .tmp/themes/book/exampleSite/content/docs/shortcodes/buttons.md
diff --git a/blog/themes/book/exampleSite/content/docs/shortcodes/columns.md b/.tmp/themes/book/exampleSite/content/docs/shortcodes/columns.md
similarity index 100%
rename from blog/themes/book/exampleSite/content/docs/shortcodes/columns.md
rename to .tmp/themes/book/exampleSite/content/docs/shortcodes/columns.md
diff --git a/blog/themes/book/exampleSite/content/docs/shortcodes/details.md b/.tmp/themes/book/exampleSite/content/docs/shortcodes/details.md
similarity index 100%
rename from blog/themes/book/exampleSite/content/docs/shortcodes/details.md
rename to .tmp/themes/book/exampleSite/content/docs/shortcodes/details.md
diff --git a/blog/themes/book/exampleSite/content/docs/shortcodes/expand.md b/.tmp/themes/book/exampleSite/content/docs/shortcodes/expand.md
similarity index 100%
rename from blog/themes/book/exampleSite/content/docs/shortcodes/expand.md
rename to .tmp/themes/book/exampleSite/content/docs/shortcodes/expand.md
diff --git a/blog/themes/book/exampleSite/content/docs/shortcodes/hints.md b/.tmp/themes/book/exampleSite/content/docs/shortcodes/hints.md
similarity index 100%
rename from blog/themes/book/exampleSite/content/docs/shortcodes/hints.md
rename to .tmp/themes/book/exampleSite/content/docs/shortcodes/hints.md
diff --git a/blog/themes/book/exampleSite/content/docs/shortcodes/katex.md b/.tmp/themes/book/exampleSite/content/docs/shortcodes/katex.md
similarity index 100%
rename from blog/themes/book/exampleSite/content/docs/shortcodes/katex.md
rename to .tmp/themes/book/exampleSite/content/docs/shortcodes/katex.md
diff --git a/blog/themes/book/exampleSite/content/docs/shortcodes/mermaid.md b/.tmp/themes/book/exampleSite/content/docs/shortcodes/mermaid.md
similarity index 100%
rename from blog/themes/book/exampleSite/content/docs/shortcodes/mermaid.md
rename to .tmp/themes/book/exampleSite/content/docs/shortcodes/mermaid.md
diff --git a/blog/themes/book/exampleSite/content/docs/shortcodes/section/_index.md b/.tmp/themes/book/exampleSite/content/docs/shortcodes/section/_index.md
similarity index 100%
rename from blog/themes/book/exampleSite/content/docs/shortcodes/section/_index.md
rename to .tmp/themes/book/exampleSite/content/docs/shortcodes/section/_index.md
diff --git a/blog/themes/book/exampleSite/content/docs/shortcodes/section/first-page.md b/.tmp/themes/book/exampleSite/content/docs/shortcodes/section/first-page.md
similarity index 100%
rename from blog/themes/book/exampleSite/content/docs/shortcodes/section/first-page.md
rename to .tmp/themes/book/exampleSite/content/docs/shortcodes/section/first-page.md
diff --git a/blog/themes/book/exampleSite/content/docs/shortcodes/section/second-page.md b/.tmp/themes/book/exampleSite/content/docs/shortcodes/section/second-page.md
similarity index 100%
rename from blog/themes/book/exampleSite/content/docs/shortcodes/section/second-page.md
rename to .tmp/themes/book/exampleSite/content/docs/shortcodes/section/second-page.md
diff --git a/blog/themes/book/exampleSite/content/docs/shortcodes/tabs.md b/.tmp/themes/book/exampleSite/content/docs/shortcodes/tabs.md
similarity index 100%
rename from blog/themes/book/exampleSite/content/docs/shortcodes/tabs.md
rename to .tmp/themes/book/exampleSite/content/docs/shortcodes/tabs.md
diff --git a/blog/themes/book/exampleSite/content/menu/index.md b/.tmp/themes/book/exampleSite/content/menu/index.md
similarity index 100%
rename from blog/themes/book/exampleSite/content/menu/index.md
rename to .tmp/themes/book/exampleSite/content/menu/index.md
diff --git a/blog/themes/book/exampleSite/content/posts/_index.md b/.tmp/themes/book/exampleSite/content/posts/_index.md
similarity index 100%
rename from blog/themes/book/exampleSite/content/posts/_index.md
rename to .tmp/themes/book/exampleSite/content/posts/_index.md
diff --git a/blog/themes/book/exampleSite/content/posts/creating-a-new-theme.md b/.tmp/themes/book/exampleSite/content/posts/creating-a-new-theme.md
similarity index 100%
rename from blog/themes/book/exampleSite/content/posts/creating-a-new-theme.md
rename to .tmp/themes/book/exampleSite/content/posts/creating-a-new-theme.md
diff --git a/blog/themes/book/exampleSite/content/posts/goisforlovers.md b/.tmp/themes/book/exampleSite/content/posts/goisforlovers.md
similarity index 100%
rename from blog/themes/book/exampleSite/content/posts/goisforlovers.md
rename to .tmp/themes/book/exampleSite/content/posts/goisforlovers.md
diff --git a/blog/themes/book/exampleSite/content/posts/hugoisforlovers.md b/.tmp/themes/book/exampleSite/content/posts/hugoisforlovers.md
similarity index 100%
rename from blog/themes/book/exampleSite/content/posts/hugoisforlovers.md
rename to .tmp/themes/book/exampleSite/content/posts/hugoisforlovers.md
diff --git a/blog/themes/book/exampleSite/content/posts/migrate-from-jekyll.md b/.tmp/themes/book/exampleSite/content/posts/migrate-from-jekyll.md
similarity index 100%
rename from blog/themes/book/exampleSite/content/posts/migrate-from-jekyll.md
rename to .tmp/themes/book/exampleSite/content/posts/migrate-from-jekyll.md
diff --git a/blog/themes/book/exampleSite/resources/_gen/assets/scss/book.scss_50fc8c04e12a2f59027287995557ceff.content b/.tmp/themes/book/exampleSite/resources/_gen/assets/scss/book.scss_50fc8c04e12a2f59027287995557ceff.content
similarity index 100%
rename from blog/themes/book/exampleSite/resources/_gen/assets/scss/book.scss_50fc8c04e12a2f59027287995557ceff.content
rename to .tmp/themes/book/exampleSite/resources/_gen/assets/scss/book.scss_50fc8c04e12a2f59027287995557ceff.content
diff --git a/blog/themes/book/exampleSite/resources/_gen/assets/scss/book.scss_50fc8c04e12a2f59027287995557ceff.json b/.tmp/themes/book/exampleSite/resources/_gen/assets/scss/book.scss_50fc8c04e12a2f59027287995557ceff.json
similarity index 100%
rename from blog/themes/book/exampleSite/resources/_gen/assets/scss/book.scss_50fc8c04e12a2f59027287995557ceff.json
rename to .tmp/themes/book/exampleSite/resources/_gen/assets/scss/book.scss_50fc8c04e12a2f59027287995557ceff.json
diff --git a/blog/themes/book/i18n/bn.yaml b/.tmp/themes/book/i18n/bn.yaml
similarity index 100%
rename from blog/themes/book/i18n/bn.yaml
rename to .tmp/themes/book/i18n/bn.yaml
diff --git a/blog/themes/book/i18n/cn.yaml b/.tmp/themes/book/i18n/cn.yaml
similarity index 100%
rename from blog/themes/book/i18n/cn.yaml
rename to .tmp/themes/book/i18n/cn.yaml
diff --git a/blog/themes/book/i18n/cs.yaml b/.tmp/themes/book/i18n/cs.yaml
similarity index 100%
rename from blog/themes/book/i18n/cs.yaml
rename to .tmp/themes/book/i18n/cs.yaml
diff --git a/blog/themes/book/i18n/de.yaml b/.tmp/themes/book/i18n/de.yaml
similarity index 100%
rename from blog/themes/book/i18n/de.yaml
rename to .tmp/themes/book/i18n/de.yaml
diff --git a/blog/themes/book/i18n/en.yaml b/.tmp/themes/book/i18n/en.yaml
similarity index 100%
rename from blog/themes/book/i18n/en.yaml
rename to .tmp/themes/book/i18n/en.yaml
diff --git a/blog/themes/book/i18n/es.yaml b/.tmp/themes/book/i18n/es.yaml
similarity index 100%
rename from blog/themes/book/i18n/es.yaml
rename to .tmp/themes/book/i18n/es.yaml
diff --git a/blog/themes/book/i18n/fa.yaml b/.tmp/themes/book/i18n/fa.yaml
similarity index 100%
rename from blog/themes/book/i18n/fa.yaml
rename to .tmp/themes/book/i18n/fa.yaml
diff --git a/blog/themes/book/i18n/fr.yaml b/.tmp/themes/book/i18n/fr.yaml
similarity index 100%
rename from blog/themes/book/i18n/fr.yaml
rename to .tmp/themes/book/i18n/fr.yaml
diff --git a/blog/themes/book/i18n/ja.yaml b/.tmp/themes/book/i18n/ja.yaml
similarity index 100%
rename from blog/themes/book/i18n/ja.yaml
rename to .tmp/themes/book/i18n/ja.yaml
diff --git a/blog/themes/book/i18n/jp.yaml b/.tmp/themes/book/i18n/jp.yaml
similarity index 100%
rename from blog/themes/book/i18n/jp.yaml
rename to .tmp/themes/book/i18n/jp.yaml
diff --git a/blog/themes/book/i18n/ko.yaml b/.tmp/themes/book/i18n/ko.yaml
similarity index 100%
rename from blog/themes/book/i18n/ko.yaml
rename to .tmp/themes/book/i18n/ko.yaml
diff --git a/blog/themes/book/i18n/nb.yaml b/.tmp/themes/book/i18n/nb.yaml
similarity index 100%
rename from blog/themes/book/i18n/nb.yaml
rename to .tmp/themes/book/i18n/nb.yaml
diff --git a/blog/themes/book/i18n/pt.yaml b/.tmp/themes/book/i18n/pt.yaml
similarity index 100%
rename from blog/themes/book/i18n/pt.yaml
rename to .tmp/themes/book/i18n/pt.yaml
diff --git a/blog/themes/book/i18n/ru.yaml b/.tmp/themes/book/i18n/ru.yaml
similarity index 100%
rename from blog/themes/book/i18n/ru.yaml
rename to .tmp/themes/book/i18n/ru.yaml
diff --git a/blog/themes/book/i18n/sv.yaml b/.tmp/themes/book/i18n/sv.yaml
similarity index 100%
rename from blog/themes/book/i18n/sv.yaml
rename to .tmp/themes/book/i18n/sv.yaml
diff --git a/blog/themes/book/i18n/tr.yaml b/.tmp/themes/book/i18n/tr.yaml
similarity index 100%
rename from blog/themes/book/i18n/tr.yaml
rename to .tmp/themes/book/i18n/tr.yaml
diff --git a/blog/themes/book/i18n/uk.yaml b/.tmp/themes/book/i18n/uk.yaml
similarity index 100%
rename from blog/themes/book/i18n/uk.yaml
rename to .tmp/themes/book/i18n/uk.yaml
diff --git a/blog/themes/book/i18n/zh-TW.yaml b/.tmp/themes/book/i18n/zh-TW.yaml
similarity index 100%
rename from blog/themes/book/i18n/zh-TW.yaml
rename to .tmp/themes/book/i18n/zh-TW.yaml
diff --git a/blog/themes/book/i18n/zh.yaml b/.tmp/themes/book/i18n/zh.yaml
similarity index 100%
rename from blog/themes/book/i18n/zh.yaml
rename to .tmp/themes/book/i18n/zh.yaml
diff --git a/blog/themes/book/images/screenshot.png b/.tmp/themes/book/images/screenshot.png
similarity index 100%
rename from blog/themes/book/images/screenshot.png
rename to .tmp/themes/book/images/screenshot.png
diff --git a/blog/themes/book/images/tn.png b/.tmp/themes/book/images/tn.png
similarity index 100%
rename from blog/themes/book/images/tn.png
rename to .tmp/themes/book/images/tn.png
diff --git a/blog/themes/book/layouts/404.html b/.tmp/themes/book/layouts/404.html
similarity index 100%
rename from blog/themes/book/layouts/404.html
rename to .tmp/themes/book/layouts/404.html
diff --git a/blog/themes/book/layouts/_default/_markup/render-heading.html b/.tmp/themes/book/layouts/_default/_markup/render-heading.html
similarity index 100%
rename from blog/themes/book/layouts/_default/_markup/render-heading.html
rename to .tmp/themes/book/layouts/_default/_markup/render-heading.html
diff --git a/blog/themes/book/layouts/_default/_markup/render-image.html b/.tmp/themes/book/layouts/_default/_markup/render-image.html
similarity index 100%
rename from blog/themes/book/layouts/_default/_markup/render-image.html
rename to .tmp/themes/book/layouts/_default/_markup/render-image.html
diff --git a/blog/themes/book/layouts/_default/_markup/render-link.html b/.tmp/themes/book/layouts/_default/_markup/render-link.html
similarity index 100%
rename from blog/themes/book/layouts/_default/_markup/render-link.html
rename to .tmp/themes/book/layouts/_default/_markup/render-link.html
diff --git a/blog/themes/book/layouts/_default/baseof.html b/.tmp/themes/book/layouts/_default/baseof.html
similarity index 100%
rename from blog/themes/book/layouts/_default/baseof.html
rename to .tmp/themes/book/layouts/_default/baseof.html
diff --git a/blog/themes/book/layouts/_default/list.html b/.tmp/themes/book/layouts/_default/list.html
similarity index 100%
rename from blog/themes/book/layouts/_default/list.html
rename to .tmp/themes/book/layouts/_default/list.html
diff --git a/blog/themes/book/layouts/_default/single.html b/.tmp/themes/book/layouts/_default/single.html
similarity index 100%
rename from blog/themes/book/layouts/_default/single.html
rename to .tmp/themes/book/layouts/_default/single.html
diff --git a/blog/themes/book/layouts/partials/docs/brand.html b/.tmp/themes/book/layouts/partials/docs/brand.html
similarity index 100%
rename from blog/themes/book/layouts/partials/docs/brand.html
rename to .tmp/themes/book/layouts/partials/docs/brand.html
diff --git a/blog/themes/book/layouts/partials/docs/comments.html b/.tmp/themes/book/layouts/partials/docs/comments.html
similarity index 100%
rename from blog/themes/book/layouts/partials/docs/comments.html
rename to .tmp/themes/book/layouts/partials/docs/comments.html
diff --git a/blog/themes/book/layouts/partials/docs/date.html b/.tmp/themes/book/layouts/partials/docs/date.html
similarity index 100%
rename from blog/themes/book/layouts/partials/docs/date.html
rename to .tmp/themes/book/layouts/partials/docs/date.html
diff --git a/blog/themes/book/layouts/partials/docs/footer.html b/.tmp/themes/book/layouts/partials/docs/footer.html
similarity index 100%
rename from blog/themes/book/layouts/partials/docs/footer.html
rename to .tmp/themes/book/layouts/partials/docs/footer.html
diff --git a/blog/themes/book/layouts/partials/docs/header.html b/.tmp/themes/book/layouts/partials/docs/header.html
similarity index 100%
rename from blog/themes/book/layouts/partials/docs/header.html
rename to .tmp/themes/book/layouts/partials/docs/header.html
diff --git a/blog/themes/book/layouts/partials/docs/html-head.html b/.tmp/themes/book/layouts/partials/docs/html-head.html
similarity index 100%
rename from blog/themes/book/layouts/partials/docs/html-head.html
rename to .tmp/themes/book/layouts/partials/docs/html-head.html
diff --git a/blog/themes/book/layouts/partials/docs/inject/content-after.html b/.tmp/themes/book/layouts/partials/docs/inject/body.html
similarity index 100%
rename from blog/themes/book/layouts/partials/docs/inject/content-after.html
rename to .tmp/themes/book/layouts/partials/docs/inject/body.html
diff --git a/blog/themes/book/layouts/partials/docs/inject/content-before.html b/.tmp/themes/book/layouts/partials/docs/inject/content-after.html
similarity index 100%
rename from blog/themes/book/layouts/partials/docs/inject/content-before.html
rename to .tmp/themes/book/layouts/partials/docs/inject/content-after.html
diff --git a/blog/themes/book/layouts/partials/docs/inject/footer.html b/.tmp/themes/book/layouts/partials/docs/inject/content-before.html
similarity index 100%
rename from blog/themes/book/layouts/partials/docs/inject/footer.html
rename to .tmp/themes/book/layouts/partials/docs/inject/content-before.html
diff --git a/blog/themes/book/layouts/partials/docs/inject/head.html b/.tmp/themes/book/layouts/partials/docs/inject/footer.html
similarity index 100%
rename from blog/themes/book/layouts/partials/docs/inject/head.html
rename to .tmp/themes/book/layouts/partials/docs/inject/footer.html
diff --git a/blog/themes/book/layouts/partials/docs/inject/menu-after.html b/.tmp/themes/book/layouts/partials/docs/inject/head.html
similarity index 100%
rename from blog/themes/book/layouts/partials/docs/inject/menu-after.html
rename to .tmp/themes/book/layouts/partials/docs/inject/head.html
diff --git a/blog/themes/book/layouts/partials/docs/inject/menu-before.html b/.tmp/themes/book/layouts/partials/docs/inject/menu-after.html
similarity index 100%
rename from blog/themes/book/layouts/partials/docs/inject/menu-before.html
rename to .tmp/themes/book/layouts/partials/docs/inject/menu-after.html
diff --git a/blog/themes/book/layouts/partials/docs/inject/toc-after.html b/.tmp/themes/book/layouts/partials/docs/inject/menu-before.html
similarity index 100%
rename from blog/themes/book/layouts/partials/docs/inject/toc-after.html
rename to .tmp/themes/book/layouts/partials/docs/inject/menu-before.html
diff --git a/blog/themes/book/layouts/partials/docs/inject/toc-before.html b/.tmp/themes/book/layouts/partials/docs/inject/toc-after.html
similarity index 100%
rename from blog/themes/book/layouts/partials/docs/inject/toc-before.html
rename to .tmp/themes/book/layouts/partials/docs/inject/toc-after.html
diff --git a/.tmp/themes/book/layouts/partials/docs/inject/toc-before.html b/.tmp/themes/book/layouts/partials/docs/inject/toc-before.html
new file mode 100644
index 0000000..e69de29
diff --git a/blog/themes/book/layouts/partials/docs/languages.html b/.tmp/themes/book/layouts/partials/docs/languages.html
similarity index 100%
rename from blog/themes/book/layouts/partials/docs/languages.html
rename to .tmp/themes/book/layouts/partials/docs/languages.html
diff --git a/blog/themes/book/layouts/partials/docs/menu-bundle.html b/.tmp/themes/book/layouts/partials/docs/menu-bundle.html
similarity index 100%
rename from blog/themes/book/layouts/partials/docs/menu-bundle.html
rename to .tmp/themes/book/layouts/partials/docs/menu-bundle.html
diff --git a/blog/themes/book/layouts/partials/docs/menu-filetree.html b/.tmp/themes/book/layouts/partials/docs/menu-filetree.html
similarity index 100%
rename from blog/themes/book/layouts/partials/docs/menu-filetree.html
rename to .tmp/themes/book/layouts/partials/docs/menu-filetree.html
diff --git a/blog/themes/book/layouts/partials/docs/menu-hugo.html b/.tmp/themes/book/layouts/partials/docs/menu-hugo.html
similarity index 100%
rename from blog/themes/book/layouts/partials/docs/menu-hugo.html
rename to .tmp/themes/book/layouts/partials/docs/menu-hugo.html
diff --git a/blog/themes/book/layouts/partials/docs/menu.html b/.tmp/themes/book/layouts/partials/docs/menu.html
similarity index 100%
rename from blog/themes/book/layouts/partials/docs/menu.html
rename to .tmp/themes/book/layouts/partials/docs/menu.html
diff --git a/blog/themes/book/layouts/partials/docs/post-meta.html b/.tmp/themes/book/layouts/partials/docs/post-meta.html
similarity index 100%
rename from blog/themes/book/layouts/partials/docs/post-meta.html
rename to .tmp/themes/book/layouts/partials/docs/post-meta.html
diff --git a/blog/themes/book/layouts/partials/docs/search.html b/.tmp/themes/book/layouts/partials/docs/search.html
similarity index 100%
rename from blog/themes/book/layouts/partials/docs/search.html
rename to .tmp/themes/book/layouts/partials/docs/search.html
diff --git a/blog/themes/book/layouts/partials/docs/taxonomy.html b/.tmp/themes/book/layouts/partials/docs/taxonomy.html
similarity index 100%
rename from blog/themes/book/layouts/partials/docs/taxonomy.html
rename to .tmp/themes/book/layouts/partials/docs/taxonomy.html
diff --git a/blog/themes/book/layouts/partials/docs/title.html b/.tmp/themes/book/layouts/partials/docs/title.html
similarity index 100%
rename from blog/themes/book/layouts/partials/docs/title.html
rename to .tmp/themes/book/layouts/partials/docs/title.html
diff --git a/blog/themes/book/layouts/partials/docs/toc.html b/.tmp/themes/book/layouts/partials/docs/toc.html
similarity index 100%
rename from blog/themes/book/layouts/partials/docs/toc.html
rename to .tmp/themes/book/layouts/partials/docs/toc.html
diff --git a/blog/themes/book/layouts/posts/list.html b/.tmp/themes/book/layouts/posts/list.html
similarity index 100%
rename from blog/themes/book/layouts/posts/list.html
rename to .tmp/themes/book/layouts/posts/list.html
diff --git a/blog/themes/book/layouts/posts/single.html b/.tmp/themes/book/layouts/posts/single.html
similarity index 100%
rename from blog/themes/book/layouts/posts/single.html
rename to .tmp/themes/book/layouts/posts/single.html
diff --git a/blog/themes/book/layouts/shortcodes/button.html b/.tmp/themes/book/layouts/shortcodes/button.html
similarity index 100%
rename from blog/themes/book/layouts/shortcodes/button.html
rename to .tmp/themes/book/layouts/shortcodes/button.html
diff --git a/blog/themes/book/layouts/shortcodes/columns.html b/.tmp/themes/book/layouts/shortcodes/columns.html
similarity index 100%
rename from blog/themes/book/layouts/shortcodes/columns.html
rename to .tmp/themes/book/layouts/shortcodes/columns.html
diff --git a/blog/themes/book/layouts/shortcodes/details.html b/.tmp/themes/book/layouts/shortcodes/details.html
similarity index 100%
rename from blog/themes/book/layouts/shortcodes/details.html
rename to .tmp/themes/book/layouts/shortcodes/details.html
diff --git a/blog/themes/book/layouts/shortcodes/expand.html b/.tmp/themes/book/layouts/shortcodes/expand.html
similarity index 100%
rename from blog/themes/book/layouts/shortcodes/expand.html
rename to .tmp/themes/book/layouts/shortcodes/expand.html
diff --git a/blog/themes/book/layouts/shortcodes/hint.html b/.tmp/themes/book/layouts/shortcodes/hint.html
similarity index 100%
rename from blog/themes/book/layouts/shortcodes/hint.html
rename to .tmp/themes/book/layouts/shortcodes/hint.html
diff --git a/blog/themes/book/layouts/shortcodes/katex.html b/.tmp/themes/book/layouts/shortcodes/katex.html
similarity index 100%
rename from blog/themes/book/layouts/shortcodes/katex.html
rename to .tmp/themes/book/layouts/shortcodes/katex.html
diff --git a/blog/themes/book/layouts/shortcodes/mermaid.html b/.tmp/themes/book/layouts/shortcodes/mermaid.html
similarity index 100%
rename from blog/themes/book/layouts/shortcodes/mermaid.html
rename to .tmp/themes/book/layouts/shortcodes/mermaid.html
diff --git a/blog/themes/book/layouts/shortcodes/section.html b/.tmp/themes/book/layouts/shortcodes/section.html
similarity index 100%
rename from blog/themes/book/layouts/shortcodes/section.html
rename to .tmp/themes/book/layouts/shortcodes/section.html
diff --git a/blog/themes/book/layouts/shortcodes/tab.html b/.tmp/themes/book/layouts/shortcodes/tab.html
similarity index 100%
rename from blog/themes/book/layouts/shortcodes/tab.html
rename to .tmp/themes/book/layouts/shortcodes/tab.html
diff --git a/blog/themes/book/layouts/shortcodes/tabs.html b/.tmp/themes/book/layouts/shortcodes/tabs.html
similarity index 100%
rename from blog/themes/book/layouts/shortcodes/tabs.html
rename to .tmp/themes/book/layouts/shortcodes/tabs.html
diff --git a/blog/themes/book/layouts/taxonomy/list.html b/.tmp/themes/book/layouts/taxonomy/list.html
similarity index 100%
rename from blog/themes/book/layouts/taxonomy/list.html
rename to .tmp/themes/book/layouts/taxonomy/list.html
diff --git a/blog/themes/book/layouts/taxonomy/taxonomy.html b/.tmp/themes/book/layouts/taxonomy/taxonomy.html
similarity index 100%
rename from blog/themes/book/layouts/taxonomy/taxonomy.html
rename to .tmp/themes/book/layouts/taxonomy/taxonomy.html
diff --git a/blog/themes/book/static/favicon.png b/.tmp/themes/book/static/favicon.png
similarity index 100%
rename from blog/themes/book/static/favicon.png
rename to .tmp/themes/book/static/favicon.png
diff --git a/blog/themes/book/static/favicon.svg b/.tmp/themes/book/static/favicon.svg
similarity index 100%
rename from blog/themes/book/static/favicon.svg
rename to .tmp/themes/book/static/favicon.svg
diff --git a/blog/themes/book/static/flexsearch.min.js b/.tmp/themes/book/static/flexsearch.min.js
similarity index 100%
rename from blog/themes/book/static/flexsearch.min.js
rename to .tmp/themes/book/static/flexsearch.min.js
diff --git a/blog/themes/book/static/fonts/roboto-mono-v13-latin-regular.woff b/.tmp/themes/book/static/fonts/roboto-mono-v13-latin-regular.woff
similarity index 100%
rename from blog/themes/book/static/fonts/roboto-mono-v13-latin-regular.woff
rename to .tmp/themes/book/static/fonts/roboto-mono-v13-latin-regular.woff
diff --git a/blog/themes/book/static/fonts/roboto-mono-v13-latin-regular.woff2 b/.tmp/themes/book/static/fonts/roboto-mono-v13-latin-regular.woff2
similarity index 100%
rename from blog/themes/book/static/fonts/roboto-mono-v13-latin-regular.woff2
rename to .tmp/themes/book/static/fonts/roboto-mono-v13-latin-regular.woff2
diff --git a/blog/themes/book/static/fonts/roboto-v27-latin-700.woff b/.tmp/themes/book/static/fonts/roboto-v27-latin-700.woff
similarity index 100%
rename from blog/themes/book/static/fonts/roboto-v27-latin-700.woff
rename to .tmp/themes/book/static/fonts/roboto-v27-latin-700.woff
diff --git a/blog/themes/book/static/fonts/roboto-v27-latin-700.woff2 b/.tmp/themes/book/static/fonts/roboto-v27-latin-700.woff2
similarity index 100%
rename from blog/themes/book/static/fonts/roboto-v27-latin-700.woff2
rename to .tmp/themes/book/static/fonts/roboto-v27-latin-700.woff2
diff --git a/blog/themes/book/static/fonts/roboto-v27-latin-regular.woff b/.tmp/themes/book/static/fonts/roboto-v27-latin-regular.woff
similarity index 100%
rename from blog/themes/book/static/fonts/roboto-v27-latin-regular.woff
rename to .tmp/themes/book/static/fonts/roboto-v27-latin-regular.woff
diff --git a/blog/themes/book/static/fonts/roboto-v27-latin-regular.woff2 b/.tmp/themes/book/static/fonts/roboto-v27-latin-regular.woff2
similarity index 100%
rename from blog/themes/book/static/fonts/roboto-v27-latin-regular.woff2
rename to .tmp/themes/book/static/fonts/roboto-v27-latin-regular.woff2
diff --git a/blog/themes/book/static/katex/auto-render.min.js b/.tmp/themes/book/static/katex/auto-render.min.js
similarity index 100%
rename from blog/themes/book/static/katex/auto-render.min.js
rename to .tmp/themes/book/static/katex/auto-render.min.js
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_AMS-Regular.ttf b/.tmp/themes/book/static/katex/fonts/KaTeX_AMS-Regular.ttf
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_AMS-Regular.ttf
rename to .tmp/themes/book/static/katex/fonts/KaTeX_AMS-Regular.ttf
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_AMS-Regular.woff b/.tmp/themes/book/static/katex/fonts/KaTeX_AMS-Regular.woff
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_AMS-Regular.woff
rename to .tmp/themes/book/static/katex/fonts/KaTeX_AMS-Regular.woff
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_AMS-Regular.woff2 b/.tmp/themes/book/static/katex/fonts/KaTeX_AMS-Regular.woff2
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_AMS-Regular.woff2
rename to .tmp/themes/book/static/katex/fonts/KaTeX_AMS-Regular.woff2
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_Caligraphic-Bold.ttf b/.tmp/themes/book/static/katex/fonts/KaTeX_Caligraphic-Bold.ttf
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_Caligraphic-Bold.ttf
rename to .tmp/themes/book/static/katex/fonts/KaTeX_Caligraphic-Bold.ttf
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_Caligraphic-Bold.woff b/.tmp/themes/book/static/katex/fonts/KaTeX_Caligraphic-Bold.woff
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_Caligraphic-Bold.woff
rename to .tmp/themes/book/static/katex/fonts/KaTeX_Caligraphic-Bold.woff
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_Caligraphic-Bold.woff2 b/.tmp/themes/book/static/katex/fonts/KaTeX_Caligraphic-Bold.woff2
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_Caligraphic-Bold.woff2
rename to .tmp/themes/book/static/katex/fonts/KaTeX_Caligraphic-Bold.woff2
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_Caligraphic-Regular.ttf b/.tmp/themes/book/static/katex/fonts/KaTeX_Caligraphic-Regular.ttf
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_Caligraphic-Regular.ttf
rename to .tmp/themes/book/static/katex/fonts/KaTeX_Caligraphic-Regular.ttf
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_Caligraphic-Regular.woff b/.tmp/themes/book/static/katex/fonts/KaTeX_Caligraphic-Regular.woff
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_Caligraphic-Regular.woff
rename to .tmp/themes/book/static/katex/fonts/KaTeX_Caligraphic-Regular.woff
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_Caligraphic-Regular.woff2 b/.tmp/themes/book/static/katex/fonts/KaTeX_Caligraphic-Regular.woff2
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_Caligraphic-Regular.woff2
rename to .tmp/themes/book/static/katex/fonts/KaTeX_Caligraphic-Regular.woff2
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_Fraktur-Bold.ttf b/.tmp/themes/book/static/katex/fonts/KaTeX_Fraktur-Bold.ttf
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_Fraktur-Bold.ttf
rename to .tmp/themes/book/static/katex/fonts/KaTeX_Fraktur-Bold.ttf
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_Fraktur-Bold.woff b/.tmp/themes/book/static/katex/fonts/KaTeX_Fraktur-Bold.woff
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_Fraktur-Bold.woff
rename to .tmp/themes/book/static/katex/fonts/KaTeX_Fraktur-Bold.woff
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_Fraktur-Bold.woff2 b/.tmp/themes/book/static/katex/fonts/KaTeX_Fraktur-Bold.woff2
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_Fraktur-Bold.woff2
rename to .tmp/themes/book/static/katex/fonts/KaTeX_Fraktur-Bold.woff2
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_Fraktur-Regular.ttf b/.tmp/themes/book/static/katex/fonts/KaTeX_Fraktur-Regular.ttf
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_Fraktur-Regular.ttf
rename to .tmp/themes/book/static/katex/fonts/KaTeX_Fraktur-Regular.ttf
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_Fraktur-Regular.woff b/.tmp/themes/book/static/katex/fonts/KaTeX_Fraktur-Regular.woff
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_Fraktur-Regular.woff
rename to .tmp/themes/book/static/katex/fonts/KaTeX_Fraktur-Regular.woff
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_Fraktur-Regular.woff2 b/.tmp/themes/book/static/katex/fonts/KaTeX_Fraktur-Regular.woff2
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_Fraktur-Regular.woff2
rename to .tmp/themes/book/static/katex/fonts/KaTeX_Fraktur-Regular.woff2
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_Main-Bold.ttf b/.tmp/themes/book/static/katex/fonts/KaTeX_Main-Bold.ttf
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_Main-Bold.ttf
rename to .tmp/themes/book/static/katex/fonts/KaTeX_Main-Bold.ttf
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_Main-Bold.woff b/.tmp/themes/book/static/katex/fonts/KaTeX_Main-Bold.woff
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_Main-Bold.woff
rename to .tmp/themes/book/static/katex/fonts/KaTeX_Main-Bold.woff
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_Main-Bold.woff2 b/.tmp/themes/book/static/katex/fonts/KaTeX_Main-Bold.woff2
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_Main-Bold.woff2
rename to .tmp/themes/book/static/katex/fonts/KaTeX_Main-Bold.woff2
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_Main-BoldItalic.ttf b/.tmp/themes/book/static/katex/fonts/KaTeX_Main-BoldItalic.ttf
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_Main-BoldItalic.ttf
rename to .tmp/themes/book/static/katex/fonts/KaTeX_Main-BoldItalic.ttf
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_Main-BoldItalic.woff b/.tmp/themes/book/static/katex/fonts/KaTeX_Main-BoldItalic.woff
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_Main-BoldItalic.woff
rename to .tmp/themes/book/static/katex/fonts/KaTeX_Main-BoldItalic.woff
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_Main-BoldItalic.woff2 b/.tmp/themes/book/static/katex/fonts/KaTeX_Main-BoldItalic.woff2
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_Main-BoldItalic.woff2
rename to .tmp/themes/book/static/katex/fonts/KaTeX_Main-BoldItalic.woff2
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_Main-Italic.ttf b/.tmp/themes/book/static/katex/fonts/KaTeX_Main-Italic.ttf
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_Main-Italic.ttf
rename to .tmp/themes/book/static/katex/fonts/KaTeX_Main-Italic.ttf
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_Main-Italic.woff b/.tmp/themes/book/static/katex/fonts/KaTeX_Main-Italic.woff
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_Main-Italic.woff
rename to .tmp/themes/book/static/katex/fonts/KaTeX_Main-Italic.woff
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_Main-Italic.woff2 b/.tmp/themes/book/static/katex/fonts/KaTeX_Main-Italic.woff2
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_Main-Italic.woff2
rename to .tmp/themes/book/static/katex/fonts/KaTeX_Main-Italic.woff2
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_Main-Regular.ttf b/.tmp/themes/book/static/katex/fonts/KaTeX_Main-Regular.ttf
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_Main-Regular.ttf
rename to .tmp/themes/book/static/katex/fonts/KaTeX_Main-Regular.ttf
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_Main-Regular.woff b/.tmp/themes/book/static/katex/fonts/KaTeX_Main-Regular.woff
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_Main-Regular.woff
rename to .tmp/themes/book/static/katex/fonts/KaTeX_Main-Regular.woff
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_Main-Regular.woff2 b/.tmp/themes/book/static/katex/fonts/KaTeX_Main-Regular.woff2
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_Main-Regular.woff2
rename to .tmp/themes/book/static/katex/fonts/KaTeX_Main-Regular.woff2
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_Math-BoldItalic.ttf b/.tmp/themes/book/static/katex/fonts/KaTeX_Math-BoldItalic.ttf
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_Math-BoldItalic.ttf
rename to .tmp/themes/book/static/katex/fonts/KaTeX_Math-BoldItalic.ttf
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_Math-BoldItalic.woff b/.tmp/themes/book/static/katex/fonts/KaTeX_Math-BoldItalic.woff
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_Math-BoldItalic.woff
rename to .tmp/themes/book/static/katex/fonts/KaTeX_Math-BoldItalic.woff
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_Math-BoldItalic.woff2 b/.tmp/themes/book/static/katex/fonts/KaTeX_Math-BoldItalic.woff2
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_Math-BoldItalic.woff2
rename to .tmp/themes/book/static/katex/fonts/KaTeX_Math-BoldItalic.woff2
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_Math-Italic.ttf b/.tmp/themes/book/static/katex/fonts/KaTeX_Math-Italic.ttf
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_Math-Italic.ttf
rename to .tmp/themes/book/static/katex/fonts/KaTeX_Math-Italic.ttf
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_Math-Italic.woff b/.tmp/themes/book/static/katex/fonts/KaTeX_Math-Italic.woff
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_Math-Italic.woff
rename to .tmp/themes/book/static/katex/fonts/KaTeX_Math-Italic.woff
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_Math-Italic.woff2 b/.tmp/themes/book/static/katex/fonts/KaTeX_Math-Italic.woff2
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_Math-Italic.woff2
rename to .tmp/themes/book/static/katex/fonts/KaTeX_Math-Italic.woff2
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_SansSerif-Bold.ttf b/.tmp/themes/book/static/katex/fonts/KaTeX_SansSerif-Bold.ttf
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_SansSerif-Bold.ttf
rename to .tmp/themes/book/static/katex/fonts/KaTeX_SansSerif-Bold.ttf
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_SansSerif-Bold.woff b/.tmp/themes/book/static/katex/fonts/KaTeX_SansSerif-Bold.woff
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_SansSerif-Bold.woff
rename to .tmp/themes/book/static/katex/fonts/KaTeX_SansSerif-Bold.woff
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_SansSerif-Bold.woff2 b/.tmp/themes/book/static/katex/fonts/KaTeX_SansSerif-Bold.woff2
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_SansSerif-Bold.woff2
rename to .tmp/themes/book/static/katex/fonts/KaTeX_SansSerif-Bold.woff2
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_SansSerif-Italic.ttf b/.tmp/themes/book/static/katex/fonts/KaTeX_SansSerif-Italic.ttf
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_SansSerif-Italic.ttf
rename to .tmp/themes/book/static/katex/fonts/KaTeX_SansSerif-Italic.ttf
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_SansSerif-Italic.woff b/.tmp/themes/book/static/katex/fonts/KaTeX_SansSerif-Italic.woff
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_SansSerif-Italic.woff
rename to .tmp/themes/book/static/katex/fonts/KaTeX_SansSerif-Italic.woff
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_SansSerif-Italic.woff2 b/.tmp/themes/book/static/katex/fonts/KaTeX_SansSerif-Italic.woff2
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_SansSerif-Italic.woff2
rename to .tmp/themes/book/static/katex/fonts/KaTeX_SansSerif-Italic.woff2
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_SansSerif-Regular.ttf b/.tmp/themes/book/static/katex/fonts/KaTeX_SansSerif-Regular.ttf
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_SansSerif-Regular.ttf
rename to .tmp/themes/book/static/katex/fonts/KaTeX_SansSerif-Regular.ttf
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_SansSerif-Regular.woff b/.tmp/themes/book/static/katex/fonts/KaTeX_SansSerif-Regular.woff
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_SansSerif-Regular.woff
rename to .tmp/themes/book/static/katex/fonts/KaTeX_SansSerif-Regular.woff
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_SansSerif-Regular.woff2 b/.tmp/themes/book/static/katex/fonts/KaTeX_SansSerif-Regular.woff2
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_SansSerif-Regular.woff2
rename to .tmp/themes/book/static/katex/fonts/KaTeX_SansSerif-Regular.woff2
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_Script-Regular.ttf b/.tmp/themes/book/static/katex/fonts/KaTeX_Script-Regular.ttf
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_Script-Regular.ttf
rename to .tmp/themes/book/static/katex/fonts/KaTeX_Script-Regular.ttf
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_Script-Regular.woff b/.tmp/themes/book/static/katex/fonts/KaTeX_Script-Regular.woff
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_Script-Regular.woff
rename to .tmp/themes/book/static/katex/fonts/KaTeX_Script-Regular.woff
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_Script-Regular.woff2 b/.tmp/themes/book/static/katex/fonts/KaTeX_Script-Regular.woff2
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_Script-Regular.woff2
rename to .tmp/themes/book/static/katex/fonts/KaTeX_Script-Regular.woff2
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_Size1-Regular.ttf b/.tmp/themes/book/static/katex/fonts/KaTeX_Size1-Regular.ttf
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_Size1-Regular.ttf
rename to .tmp/themes/book/static/katex/fonts/KaTeX_Size1-Regular.ttf
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_Size1-Regular.woff b/.tmp/themes/book/static/katex/fonts/KaTeX_Size1-Regular.woff
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_Size1-Regular.woff
rename to .tmp/themes/book/static/katex/fonts/KaTeX_Size1-Regular.woff
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_Size1-Regular.woff2 b/.tmp/themes/book/static/katex/fonts/KaTeX_Size1-Regular.woff2
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_Size1-Regular.woff2
rename to .tmp/themes/book/static/katex/fonts/KaTeX_Size1-Regular.woff2
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_Size2-Regular.ttf b/.tmp/themes/book/static/katex/fonts/KaTeX_Size2-Regular.ttf
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_Size2-Regular.ttf
rename to .tmp/themes/book/static/katex/fonts/KaTeX_Size2-Regular.ttf
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_Size2-Regular.woff b/.tmp/themes/book/static/katex/fonts/KaTeX_Size2-Regular.woff
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_Size2-Regular.woff
rename to .tmp/themes/book/static/katex/fonts/KaTeX_Size2-Regular.woff
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_Size2-Regular.woff2 b/.tmp/themes/book/static/katex/fonts/KaTeX_Size2-Regular.woff2
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_Size2-Regular.woff2
rename to .tmp/themes/book/static/katex/fonts/KaTeX_Size2-Regular.woff2
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_Size3-Regular.ttf b/.tmp/themes/book/static/katex/fonts/KaTeX_Size3-Regular.ttf
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_Size3-Regular.ttf
rename to .tmp/themes/book/static/katex/fonts/KaTeX_Size3-Regular.ttf
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_Size3-Regular.woff b/.tmp/themes/book/static/katex/fonts/KaTeX_Size3-Regular.woff
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_Size3-Regular.woff
rename to .tmp/themes/book/static/katex/fonts/KaTeX_Size3-Regular.woff
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_Size3-Regular.woff2 b/.tmp/themes/book/static/katex/fonts/KaTeX_Size3-Regular.woff2
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_Size3-Regular.woff2
rename to .tmp/themes/book/static/katex/fonts/KaTeX_Size3-Regular.woff2
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_Size4-Regular.ttf b/.tmp/themes/book/static/katex/fonts/KaTeX_Size4-Regular.ttf
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_Size4-Regular.ttf
rename to .tmp/themes/book/static/katex/fonts/KaTeX_Size4-Regular.ttf
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_Size4-Regular.woff b/.tmp/themes/book/static/katex/fonts/KaTeX_Size4-Regular.woff
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_Size4-Regular.woff
rename to .tmp/themes/book/static/katex/fonts/KaTeX_Size4-Regular.woff
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_Size4-Regular.woff2 b/.tmp/themes/book/static/katex/fonts/KaTeX_Size4-Regular.woff2
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_Size4-Regular.woff2
rename to .tmp/themes/book/static/katex/fonts/KaTeX_Size4-Regular.woff2
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_Typewriter-Regular.ttf b/.tmp/themes/book/static/katex/fonts/KaTeX_Typewriter-Regular.ttf
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_Typewriter-Regular.ttf
rename to .tmp/themes/book/static/katex/fonts/KaTeX_Typewriter-Regular.ttf
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_Typewriter-Regular.woff b/.tmp/themes/book/static/katex/fonts/KaTeX_Typewriter-Regular.woff
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_Typewriter-Regular.woff
rename to .tmp/themes/book/static/katex/fonts/KaTeX_Typewriter-Regular.woff
diff --git a/blog/themes/book/static/katex/fonts/KaTeX_Typewriter-Regular.woff2 b/.tmp/themes/book/static/katex/fonts/KaTeX_Typewriter-Regular.woff2
similarity index 100%
rename from blog/themes/book/static/katex/fonts/KaTeX_Typewriter-Regular.woff2
rename to .tmp/themes/book/static/katex/fonts/KaTeX_Typewriter-Regular.woff2
diff --git a/blog/themes/book/static/katex/katex.min.css b/.tmp/themes/book/static/katex/katex.min.css
similarity index 100%
rename from blog/themes/book/static/katex/katex.min.css
rename to .tmp/themes/book/static/katex/katex.min.css
diff --git a/blog/themes/book/static/katex/katex.min.js b/.tmp/themes/book/static/katex/katex.min.js
similarity index 100%
rename from blog/themes/book/static/katex/katex.min.js
rename to .tmp/themes/book/static/katex/katex.min.js
diff --git a/blog/themes/book/static/mermaid.min.js b/.tmp/themes/book/static/mermaid.min.js
similarity index 100%
rename from blog/themes/book/static/mermaid.min.js
rename to .tmp/themes/book/static/mermaid.min.js
diff --git a/blog/themes/book/static/svg/calendar.svg b/.tmp/themes/book/static/svg/calendar.svg
similarity index 100%
rename from blog/themes/book/static/svg/calendar.svg
rename to .tmp/themes/book/static/svg/calendar.svg
diff --git a/blog/themes/book/static/svg/edit.svg b/.tmp/themes/book/static/svg/edit.svg
similarity index 100%
rename from blog/themes/book/static/svg/edit.svg
rename to .tmp/themes/book/static/svg/edit.svg
diff --git a/blog/themes/book/static/svg/menu.svg b/.tmp/themes/book/static/svg/menu.svg
similarity index 100%
rename from blog/themes/book/static/svg/menu.svg
rename to .tmp/themes/book/static/svg/menu.svg
diff --git a/blog/themes/book/static/svg/toc.svg b/.tmp/themes/book/static/svg/toc.svg
similarity index 100%
rename from blog/themes/book/static/svg/toc.svg
rename to .tmp/themes/book/static/svg/toc.svg
diff --git a/blog/themes/book/static/svg/translate.svg b/.tmp/themes/book/static/svg/translate.svg
similarity index 100%
rename from blog/themes/book/static/svg/translate.svg
rename to .tmp/themes/book/static/svg/translate.svg
diff --git a/blog/themes/book/theme.toml b/.tmp/themes/book/theme.toml
similarity index 100%
rename from blog/themes/book/theme.toml
rename to .tmp/themes/book/theme.toml
diff --git a/blog/content/1.base/1-1-install-download.md b/1.base/1-1-install-download.md
similarity index 100%
rename from blog/content/1.base/1-1-install-download.md
rename to 1.base/1-1-install-download.md
diff --git a/blog/content/1.base/1-2-hello-world.md b/1.base/1-2-hello-world.md
similarity index 97%
rename from blog/content/1.base/1-2-hello-world.md
rename to 1.base/1-2-hello-world.md
index 0cbdc75..25b4023 100644
--- a/blog/content/1.base/1-2-hello-world.md
+++ b/1.base/1-2-hello-world.md
@@ -34,7 +34,7 @@ Go 语言专门针对多处理器系统应用程序的编程进行了优化,
网络编程:这一块目前应用最广,包括 Web 应用、API 应用、下载应用、内存数据库。
-云平台:google 开发的 groupcache,couchbase 的部分组建云平台,目前国外很多云平台在采用 Go 开发,CloudFoundy 的部分组建,前 VMare 的技术总监自己出来搞的 apcera 云平台。
+云平台:google 开发的 groupcache,couchbase 的部分组件云平台,目前国外很多云平台在采用 Go 开发,CloudFoundry 的部分组件,前 VMware 的技术总监自己出来搞的 apcera 云平台。
## 1.2.3 Go 语言成功的项目
@@ -43,10 +43,10 @@ docker:基于 lxc 的一个虚拟打包工具,能够实现 PAAS 平台的组
packer:用来生成不同平台的镜像文件,例如 VM、vbox、AWS 等,作者是 vagrant 的作者
skynet:分布式调度框架
Doozer:分布式同步工具,类似 ZooKeeper
-Heka:mazila 开源的日志处理系统
+Heka:mozilla 开源的日志处理系统
cbfs:couchbase 开源的分布式文件系统
tsuru:开源的 PAAS 平台,和 SAE 实现的功能一模一样
-groupcache:memcahe 作者写的用于 Google 下载系统的缓存系统
+groupcache:memcache 作者写的用于 Google 下载系统的缓存系统
god:类似 redis 的缓存系统,但是支持分布式和扩展性
gor:网络流量抓包和重放工具
diff --git a/blog/content/1.base/1-3-go-mod.md b/1.base/1-3-go-mod.md
similarity index 87%
rename from blog/content/1.base/1-3-go-mod.md
rename to 1.base/1-3-go-mod.md
index 37e467a..a7cce13 100644
--- a/blog/content/1.base/1-3-go-mod.md
+++ b/1.base/1-3-go-mod.md
@@ -89,6 +89,13 @@ golang.org/x/text v0.3.0 = > github.com/golang/text v0.3.0
* exclude:忽略指定版本的依赖包
* replace:由于在国内访问golang.org/x的各个包都需要翻墙,你可以在go.mod中使用replace替换成github上对应的库。
+注意上面的代码片段中出现了两个特殊的注释
+
+* `incompatible` 表示不兼容标识,假如其当前版本为v3.6.0,因为其Module名字未遵循Golang所推荐的风格,即Module名中附带版本信息,我们称这个Module为不规范的Module。
+在使用上没有区别,如果是我们自己开发的module,需要从 `xxx.com/xxx` 变到 `xxx.com/xxx/v2`
+
+* `indirect` 是指间接依赖的包,比如 a module 使用了 b module,但b module的go.mod不完整,或者未启用 go module的话,会把未记录在b的go.mod中又依赖了的包作为间接依赖,放到a的go.mod文件里
+
## 1.3.3 go.sum 文件
每一行都是由 模块路径,模块版本,哈希检验值 组成,其中哈希检验值是用来保证当前缓存的模块不会被篡改。hash 是以h1:开头的字符串,表示生成checksum的算法是第一版的hash算法(sha256)。
@@ -106,10 +113,15 @@ golang.org/x/text v0.3.0 = > github.com/golang/text v0.3.0
/go.mod
```
-那些有两行的包,区别就在于 hash 值不一行,一个是 `h1:hash`,一个是 go.mod `h1:hash`
+那些有两行的包,区别就在于 hash 值有两行,一行是 `h1:hash` 也就是模块包的hash,另一行是 go.mod `h1:hash`,举例如下
+
+```shell
+github.com/sirupsen/logrus v1.8.1 h1:dJKuHgqk1NNQlqoA6BTlM1Wf9DOH3NBjQyu0h9+AZZE=
+github.com/sirupsen/logrus v1.8.1/go.mod h1:yWOB1SBYBC5VeMP7gHvWumXLIWorT60ONWic61uBYv0=
+```
而 `h1:hash` 和 `go.mod` `h1:hash`两者,要不就是同时存在,要不就是只存在 `go.mod` `h1:hash`。那什么情况下会不存在 `h1:hash` 呢,就是当 Go
-认为肯定用不到某个模块版本的时候就会省略它的`h1 hash`,就会出现不存在 `h1 hash`,只存在 `go.mod` `h1:hash` 的情况。[引用自 3]
+认为肯定用不到某个模块版本的时候就会省略它的`h1 hash`,就会出现不存在 `h1 hash`,只存在 `go.mod` `h1:hash` 的情况。
`go.mod` 和 `go.sum` 是 go modules 版本管理的指导性文件,因此 `go.mod` 和 `go.sum` 文件都应该提交到你的 Git 仓库中去,避免其他人使用你写项目时,重新生成的`go.mod`
和 `go.sum` 与你开发的基准版本的不一致。
@@ -122,7 +134,7 @@ go mod download:手动触发下载依赖包到本地cache(默认为$GOPATH/p
go mod graph:打印项目的模块依赖结构
-图片 go mod tidy :添加缺少的包,且删除无用的包
+go mod tidy :添加缺少的包,且删除无用的包
go mod verify :校验模块是否被篡改过
@@ -132,7 +144,7 @@ go mod vendor :导出项目所有依赖到vendor下
写入go.mod有两种方法:
-* 你只要在项目中有 import 并使用或者使用下划线强制占用,然后 go build 就会 go module 就会自动下载并添加。
+* 你只要在项目中有 import 并使用或者使用下划线强制占用,然后 go build 时 go module 就会自动下载并添加。
* `go mod tidy`
## 1.3.5 vendor是什么
diff --git a/blog/content/1.base/1-4-variables.md b/1.base/1-4-variables.md
similarity index 100%
rename from blog/content/1.base/1-4-variables.md
rename to 1.base/1-4-variables.md
diff --git "a/blog/content/1.base/1-5-switch\345\222\214typeswitch.md" "b/1.base/1-5-switch\345\222\214typeswitch.md"
similarity index 86%
rename from "blog/content/1.base/1-5-switch\345\222\214typeswitch.md"
rename to "1.base/1-5-switch\345\222\214typeswitch.md"
index 302d084..a1572c3 100644
--- "a/blog/content/1.base/1-5-switch\345\222\214typeswitch.md"
+++ "b/1.base/1-5-switch\345\222\214typeswitch.md"
@@ -20,7 +20,7 @@ ifelse
```go
-if 20<0{
+ if 20<0{
}else{
fmt.Println("no")
@@ -36,6 +36,7 @@ no
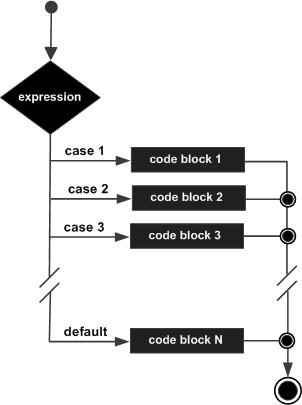
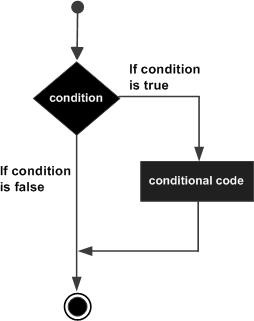
`switch` 好理解,是一个替代`if else else else`接口而提出的,如下,`switch` 后跟变量,`case` 后跟常量,只要变量值和常量匹配,就执行该分支下的语句。
+
```go
switch name {
case "coding3min":
@@ -46,9 +47,11 @@ switch name {
}
```
-当然`switch`语句会逐个匹配`case`语句,一个一个的判断过去,直到有符合的语句存在。
+和`c++`不同,不需要给每个`case`都手动加入`break`,当然`switch`语句会逐个匹配`case`语句,一个一个的判断过去,直到有符合的语句存在,执行匹配的语句内容后跳出`switch`。
+
```go
-switch {
+func switchDemo(number int) {
+ switch {
case number >= 90:
fmt.Println("优秀")
case number >= 80:
@@ -58,14 +61,18 @@ switch {
default:
fmt.Println("太搓了")
}
+}
```
+
如果没有一个是匹配的,就执行`default`后的语句。
-注意`switch`后可以跟空,如上
+注意`switch`后可以跟空,如上,原因是之前已经出现过`number`变量
+
```go
switch {
```
-这样`case`就必须是表达式。
+
+如果为空,这样`case`就必须是表达式。
## 1.5.3 switch 的高级玩法?
diff --git a/blog/content/1.base/1-6-for-range.md b/1.base/1-6-for-range.md
similarity index 100%
rename from blog/content/1.base/1-6-for-range.md
rename to 1.base/1-6-for-range.md
diff --git "a/blog/content/1.base/1-7-range\346\267\261\345\272\246\350\247\243\346\236\220.md" "b/1.base/1-7-range\346\267\261\345\272\246\350\247\243\346\236\220.md"
similarity index 80%
rename from "blog/content/1.base/1-7-range\346\267\261\345\272\246\350\247\243\346\236\220.md"
rename to "1.base/1-7-range\346\267\261\345\272\246\350\247\243\346\236\220.md"
index a631533..72475b3 100644
--- "a/blog/content/1.base/1-7-range\346\267\261\345\272\246\350\247\243\346\236\220.md"
+++ "b/1.base/1-7-range\346\267\261\345\272\246\350\247\243\346\236\220.md"
@@ -98,6 +98,33 @@ k:0, v:{1 a}
k:1, v:{2 b}
```
+`for-range`接收新值的变量地址都是同一个地址,所以,如果通过(取地址的方式访问)&key或者&value来访问值可能看到不期望的值。
+
+```go
+var tmpKey *int
+var tmpValue *struct{
+ int
+ string
+}
+for k,v := range tmp {
+ if k == 0 {
+ tmpKey = &k
+ tmpValue = &v
+ }
+}
+fmt.Println(*tmpKey)
+fmt.Println(*tmpValue)
+```
+
+`OutPut`
+
+```json
+1
+{2 b}
+```
+
+解释:这段代码因为在循环中加了`if k == 0` 的缘故,期望返回`0,{1,a}`,以上的值是不期望的值,因为go编译后的代码会使用一个中间变量存储从切片拷贝的元素值,取地址也是取的这个中间变量的地址。循环执行了两次,k和v的地址不变,导致了数值变化。
+
## 1.7.4 编程 Tips
- 遍历过程中可以适情况放弃接收 `index` 或 `value`,可以一定程度上提升性能
diff --git a/blog/content/2.func-containers/2-1-func.md b/2.func-containers/2-1-func.md
similarity index 93%
rename from blog/content/2.func-containers/2-1-func.md
rename to 2.func-containers/2-1-func.md
index 92d5253..421bd9b 100644
--- a/blog/content/2.func-containers/2-1-func.md
+++ b/2.func-containers/2-1-func.md
@@ -156,7 +156,7 @@ ps:go语言中只有三种引用类型,slice(切片)、map(字典)、channel(
## 2.1.4 函数进阶
-上面说的东西都很简单了,基本学过任何一门语言的人都能瞬间看懂,和`python`、`c++`、`javascript`一样,`go`中也有把函数打作参数传递的语法。
+上面说的东西都很简单了,基本学过任何一门语言的人都能瞬间看懂,和`python`、`c++`、`javascript`一样,`go`中也有把函数当作参数传递的语法。
像这样,`functionValue`函数的形参里有一个名为`do`的函数,需要提前指定`do`函数有什么参数和返回值。
@@ -203,22 +203,26 @@ func sub(a, b int) int {
你可以参考函数测速例子
+> 源码位置:https://github.com/golang-minibear2333/golang/blob/master/2.func-containers/2.1-func/append_string.go
+
定义一个测速函数。
```go
-func speedTime(handler func() (string), funcName string) {
+func speedTime(handler func() (string) {
t := time.Now()
handler()
elapsed := time.Since(t)
+ // 利用反射获得函数名
+ funcName := runtime.FuncForPC(reflect.ValueOf(handler).Pointer()).Name()
fmt.Println(funcName+"spend time:", elapsed)
-}
+})
```
传入不同的函数都可以测速度。
```go
-speedTime(appendStr, "appendStr")
-speedTime(appendStrQuick, "appendStrQuick")
+speedTime(appendStr)
+speedTime(appendStrQuick)
```
小`Tips`:
@@ -227,4 +231,4 @@ speedTime(appendStrQuick, "appendStrQuick")
## 2.1.6 小结
-本节讲述了Go中函数的基本语法,包括定义、多值返回,函数的值传递和引用传递,还可以当变量来用,可以把函数当参数来传递
\ No newline at end of file
+本节讲述了Go中函数的基本语法,包括定义、多值返回,函数的值传递和引用传递,还可以当变量来用,可以把函数当参数来传递
diff --git "a/blog/content/2.func-containers/2-2-\345\214\277\345\220\215\345\207\275\346\225\260\345\222\214\351\227\255\345\214\205.md" "b/2.func-containers/2-2-\345\214\277\345\220\215\345\207\275\346\225\260\345\222\214\351\227\255\345\214\205.md"
similarity index 100%
rename from "blog/content/2.func-containers/2-2-\345\214\277\345\220\215\345\207\275\346\225\260\345\222\214\351\227\255\345\214\205.md"
rename to "2.func-containers/2-2-\345\214\277\345\220\215\345\207\275\346\225\260\345\222\214\351\227\255\345\214\205.md"
diff --git "a/blog/content/2.func-containers/2-3-\345\217\257\345\217\230\345\217\202\346\225\260.md" "b/2.func-containers/2-3-\345\217\257\345\217\230\345\217\202\346\225\260.md"
similarity index 100%
rename from "blog/content/2.func-containers/2-3-\345\217\257\345\217\230\345\217\202\346\225\260.md"
rename to "2.func-containers/2-3-\345\217\257\345\217\230\345\217\202\346\225\260.md"
diff --git a/blog/content/2.func-containers/2-4-map.md b/2.func-containers/2-4-map.md
similarity index 50%
rename from blog/content/2.func-containers/2-4-map.md
rename to 2.func-containers/2-4-map.md
index c0445c8..6e4352b 100644
--- a/blog/content/2.func-containers/2-4-map.md
+++ b/2.func-containers/2-4-map.md
@@ -67,9 +67,89 @@ PS: 在取值的时候`m[key]`,假如`key`不存在,不会报错,会返回
}
```
-map容器就到这里了。
+## 2.4.3 map 内部元素的修改
-## 2.4.3 能够在并发环境中使用的`map`
+map 可以拷贝吗?
+
+`map` 其实是不能拷贝的,如果想要拷贝一个 `map` ,只有一种办法就是循环赋值,就像这样
+
+```go
+originalMap := make(map[string]int)
+originalMap["one"] = 1
+originalMap["two"] = 2
+
+// Create the target map
+targetMap := make(map[string]int)
+
+// Copy from the original map to the target map
+for key, value := range originalMap {
+ targetMap[key] = value
+}
+```
+
+如果 `map` 中有指针,还要考虑深拷贝的过程
+
+```go
+originalMap := make(map[string]*int)
+var num int = 1
+originalMap["one"] = &num
+
+// Create the target map
+targetMap := make(map[string]*int)
+
+// Copy from the original map to the target map
+for key, value := range originalMap {
+var tmpNum int = *value
+ targetMap[key] = &tmpNum
+}
+```
+
+如果想要更新 `map` 中的`value`,可以通过赋值来进行操作
+
+```go
+map["one"] = 1
+```
+
+但如果 `value` 是一个结构体,可以直接替换结构体,但无法更新结构体内部的值
+
+```go
+originalMap := make(map[string]Person)
+originalMap["minibear2333"] = Person{age: 26}
+originalMap["minibear2333"].age = 5
+```
+
+你可以 [试下源码函数 updateMapValue](https://github.com/golang-minibear2333/golang/blob/master/2.func-containers/2.4-map/map1.go#L89) ,会报这个错误
+
+> Cannot assign to originalMap["minibear2333"].age
+
+问题链接 [issue-3117](https://github.com/golang/go/issues/3117) , 其中 [ianlancetaylor](https://github.com/golang/go/issues/3117#issuecomment-430632750) 的回答很好的解释了这一点
+
+简单来说就是map不是一个并发安全的结构,所以,并不能修改他在结构体中的值。
+
+这如果目前的形式不能修改的话,就面临两种选择,
+
+* 1.修改原来的设计;
+* 2.想办法让map中的成员变量可以修改,
+
+因为懒得该这个结构体,就选择了方法2
+
+要么创建个临时变量,做拷贝,像这样
+
+```go
+tmp := m["foo"]
+tmp.x = 4
+m["foo"] = tmp
+```
+
+要么直接用指针,比较方便
+
+```go
+originalPointMap := make(map[string]*Person)
+originalPointMap["minibear2333"] = &Person{age: 26}
+originalPointMap["minibear2333"].age = 5
+```
+
+## 2.4.4 能够在并发环境中使用的`map`
`Go`中的`map`在并发读的时候没问题,但是并发写就不行了(线程不安全),会发生竞态问题。
@@ -113,9 +193,9 @@ coding3min
})
```
-## 2.4.4 小结
+## 2.4.5 小结
-本节介绍了字典`map`类型,这种类型在很多语言中都有,并且学习了它的增加删除元素的方法。
+本节介绍了字典`map`类型,这种类型在很多语言中都有,并且学习了它的增加删除元素的方法,以及更新value要注意的点。
还介绍了并发环境下使用的线程安全的 `sync.Map`。
diff --git "a/blog/content/2.func-containers/2-5-\346\225\260\347\273\204\345\222\214\345\210\207\347\211\207.md" "b/2.func-containers/2-5-\346\225\260\347\273\204\345\222\214\345\210\207\347\211\207.md"
similarity index 87%
rename from "blog/content/2.func-containers/2-5-\346\225\260\347\273\204\345\222\214\345\210\207\347\211\207.md"
rename to "2.func-containers/2-5-\346\225\260\347\273\204\345\222\214\345\210\207\347\211\207.md"
index 5f423d4..c8c152d 100644
--- "a/blog/content/2.func-containers/2-5-\346\225\260\347\273\204\345\222\214\345\210\207\347\211\207.md"
+++ "b/2.func-containers/2-5-\346\225\260\347\273\204\345\222\214\345\210\207\347\211\207.md"
@@ -177,6 +177,37 @@ len=6 cap=10 slice=[0 0 0 4 5 6]
但是有一种致命的缺点,这是浅拷贝,`slice3`和`slice2`是同一个切片,无论改动哪个,另一个都会产生变化。
+可能这么说你还是不能加深理解。在源码 [bytes.buffer](https://github.com/golang/go/blob/cb4cd9e17753b5cd8ee4cd5b1f23d46241b485f1/src/bytes/buffer.go#L54) 中出现了这一段
+
+```go
+func (b *Buffer) Bytes() []byte {
+ return b.buf[b.off:]
+}
+```
+
+我们在读入读出输入流的时候,极易出现这样的问题
+
+下面的例子,使用`abc`模拟读入内容,修改返回值内容
+
+```go
+ buffer := bytes.NewBuffer(make([]byte, 0, 100))
+ buffer.Write([]byte("abc"))
+ resBytes := buffer.Bytes()
+ fmt.Printf("%s \n", resBytes)
+ resBytes[0] = 'd'
+ fmt.Printf("%s \n", resBytes)
+ fmt.Printf("%s \n", buffer.Bytes())
+```
+
+输出,可以看出会影响到原切片内容
+
+```
+abc
+dbc
+dbc
+```
+
+这种情况在并发使用的时候尤为危险,特别是流式读写的时候容易出现上一次没处理完成,下一次的数据覆盖写入的错乱情况
## 2.5.7 截取部分元素
diff --git a/3.grammar-advancement/easy/string/append_string.go b/2.func-containers/2.1-func/append_string.go
similarity index 79%
rename from 3.grammar-advancement/easy/string/append_string.go
rename to 2.func-containers/2.1-func/append_string.go
index e440ae5..6591bd0 100644
--- a/3.grammar-advancement/easy/string/append_string.go
+++ b/2.func-containers/2.1-func/append_string.go
@@ -1,14 +1,11 @@
-/*
-* @Title: 快速拼接字符串
-* @Author: minibear2333
-* @Date: 2020-03-17 00:12
-* @url: https://github.com/golang-minibear2333/golang
-*/
+//快速拼接字符串
package main
import (
"bytes"
"fmt"
+ "reflect"
+ "runtime"
"time"
)
@@ -26,7 +23,7 @@ func init() {
base 里面的字符串都是不可变的,每次运算都会产生一个新的字符串,
所以会产生很多临时的无用的字符串,不仅没有用,还会给 gc 带来额外的负担,
所以性能比较差
- */
+*/
func appendStr() (resStr string) {
resStr = ""
for i := 0; i < len(S); i++ {
@@ -35,7 +32,7 @@ func appendStr() (resStr string) {
return resStr
}
-func appendStrQuick() (string) {
+func appendStrQuick() string {
var res bytes.Buffer
for i := 0; i < len(S); i++ {
res.WriteString(string(S[i]))
@@ -43,13 +40,14 @@ func appendStrQuick() (string) {
return res.String()
}
-func speedTime(handler func() (string), funcName string) {
+func speedTime(handler func() string) {
t := time.Now()
handler()
elapsed := time.Since(t)
+ funcName := runtime.FuncForPC(reflect.ValueOf(handler).Pointer()).Name()
fmt.Println(funcName+"spend time:", elapsed)
}
func main() {
- speedTime(appendStr, "appendStr")
- speedTime(appendStrQuick, "appendStrQuick")
+ speedTime(appendStr)
+ speedTime(appendStrQuick)
}
diff --git a/2.func-containers/2.4-map/map1.go b/2.func-containers/2.4-map/map1.go
index 5cb260c..e289a7b 100644
--- a/2.func-containers/2.4-map/map1.go
+++ b/2.func-containers/2.4-map/map1.go
@@ -3,7 +3,7 @@
* @Author: minibear2333
* @Date: 2020-04-08 22:11
* @url: https://github.com/golang-minibear2333/golang
-*/
+ */
package main
import "fmt"
@@ -45,8 +45,60 @@ func inMap(key string, m map[string]string) {
}
}
+// map 的拷贝
+func copyMap() {
+ fmt.Println("map 的拷贝")
+ originalMap := make(map[string]int)
+ originalMap["one"] = 1
+ originalMap["two"] = 2
+
+ // Create the target map
+ targetMap := make(map[string]int)
+
+ // Copy from the original map to the target map
+ for key, value := range originalMap {
+ targetMap[key] = value
+ }
+ fmt.Println(targetMap)
+}
+
+// 深度拷贝
+func copyDeepMap() {
+ fmt.Println("深度拷贝")
+ originalMap := make(map[string]*int)
+ var num int = 1
+ originalMap["one"] = &num
+
+ // Create the target map
+ targetMap := make(map[string]*int)
+
+ // Copy from the original map to the target map
+ for key, value := range originalMap {
+ var tmpNum int = *value
+ targetMap[key] = &tmpNum
+ }
+}
+
+type Person struct {
+ age int
+}
+
+// 注意修改map中value内部数据
+func updateMapValue() {
+ originalMap := make(map[string]Person)
+ originalMap["minibear2333"] = Person{age: 26}
+ // 放开以下注释体验报错
+ //originalMap["minibear2333"].age = 5
+
+ originalPointMap := make(map[string]*Person)
+ originalPointMap["minibear2333"] = &Person{age: 26}
+ originalPointMap["minibear2333"].age = 5
+}
func main() {
mapDemo1()
// 小熊的话:能用数组别用map,数组快占用空间小
// 但是要在保证快速开发的情况下再考虑用数组优化
+ copyMap()
+ copyDeepMap()
+
}
diff --git a/2.func-containers/2.5-arrray/array1.go b/2.func-containers/2.5-arrray/array1.go
index 05c4c97..eb3c3e5 100644
--- a/2.func-containers/2.5-arrray/array1.go
+++ b/2.func-containers/2.5-arrray/array1.go
@@ -1,20 +1,16 @@
-/*
-* @Title: 数组定义赋值与遍历
-* @Author: minibear2333
-* @Date: 2020-04-03 19:42
-* @url: https://github.com/golang-minibear2333/golang
-*/
+// 数组定义赋值与遍历
package main
import (
"fmt"
+
"github.com/golang-minibear2333/golang/tools"
)
func arrayDefine() {
//声明定长数组
var a1 [10]int
- //声明不定长数组
+ //声明不定长数组(切片)
var a2 []int
//初始化数组
@@ -27,7 +23,7 @@ func arrayDefine() {
}
/* 输出每个数组元素的值 */
for j := 0; j < 10; j++ {
- fmt.Printf("Element[%d] = %d\n", j, a1[j] )
+ fmt.Printf("Element[%d] = %d\n", j, a1[j])
}
//忽略未使用错误
@@ -37,6 +33,6 @@ func arrayDefine() {
tools.IgnoreUnused(b2)
}
-func main(){
+func main() {
}
diff --git a/2.func-containers/2.5-slice/slice1.go b/2.func-containers/2.5-slice/slice1.go
index 1c470dc..c68d211 100644
--- a/2.func-containers/2.5-slice/slice1.go
+++ b/2.func-containers/2.5-slice/slice1.go
@@ -3,19 +3,18 @@
* @Author: minibear2333
* @Date: 2020-04-05 23:54
* @url: https://github.com/golang-minibear2333/golang
-*/
+ */
package main
import (
"fmt"
- "github.com/golang-minibear2333/golang/tools"
)
func sliceDemo1() {
// 声明空切片,注意用var声明空切片,在使用前必须赋值。不然值为 nil
var sliceTmp []int
- if sliceTmp == nil{
+ if sliceTmp == nil {
fmt.Println("var []int is nil")
}
@@ -23,7 +22,7 @@ func sliceDemo1() {
slice1 := []int{1, 2}
fmt.Printf("输出切片:%v \n", slice1)
- for _,v := range slice1{
+ for _, v := range slice1 {
fmt.Println(v)
}
@@ -37,12 +36,11 @@ func sliceDemo1() {
fmt.Printf("arr[:3] : %v \n", arr[:3])
fmt.Printf("arr[2:3] : %v \n", arr[2:3])
- // 多维数组
+ // 多维数组(切片)
slice2 := [][]int{{1, 2}, {1, 2, 3}, {1, 2, 3, 4}}
fmt.Printf("输出多维切片: %v \n", slice2)
- // 忽略未使用切片
- utils.IgnoreUnused(sliceLen)
+ fmt.Println(sliceLen)
}
func main() {
diff --git a/2.func-containers/2.5-slice/slice4.go b/2.func-containers/2.5-slice/slice4.go
new file mode 100644
index 0000000..7f81c8d
--- /dev/null
+++ b/2.func-containers/2.5-slice/slice4.go
@@ -0,0 +1,17 @@
+// 切片陷阱
+package main
+
+import (
+ "bytes"
+ "fmt"
+)
+
+func main() {
+ buffer := bytes.NewBuffer(make([]byte, 0, 100))
+ buffer.Write([]byte("abc"))
+ resBytes := buffer.Bytes()
+ fmt.Printf("%s \n", resBytes)
+ resBytes[0] = 'd'
+ fmt.Printf("%s \n", resBytes)
+ fmt.Printf("%s \n", buffer.Bytes())
+}
diff --git a/blog/content/3.grammar-advancement/3-1-point.md b/3.grammar-advancement/3-1-point.md
similarity index 100%
rename from blog/content/3.grammar-advancement/3-1-point.md
rename to 3.grammar-advancement/3-1-point.md
diff --git a/blog/content/3.grammar-advancement/3-2-struct.md b/3.grammar-advancement/3-2-struct.md
similarity index 100%
rename from blog/content/3.grammar-advancement/3-2-struct.md
rename to 3.grammar-advancement/3-2-struct.md
diff --git "a/blog/content/3.grammar-advancement/3-3-\346\216\245\345\217\243\344\270\216\345\244\232\346\200\201.md" "b/3.grammar-advancement/3-3-\346\216\245\345\217\243\344\270\216\345\244\232\346\200\201.md"
similarity index 100%
rename from "blog/content/3.grammar-advancement/3-3-\346\216\245\345\217\243\344\270\216\345\244\232\346\200\201.md"
rename to "3.grammar-advancement/3-3-\346\216\245\345\217\243\344\270\216\345\244\232\346\200\201.md"
diff --git "a/blog/content/3.grammar-advancement/3-4-\345\274\202\345\270\270\345\244\204\347\220\206.md" "b/3.grammar-advancement/3-4-\345\274\202\345\270\270\345\244\204\347\220\206.md"
similarity index 100%
rename from "blog/content/3.grammar-advancement/3-4-\345\274\202\345\270\270\345\244\204\347\220\206.md"
rename to "3.grammar-advancement/3-4-\345\274\202\345\270\270\345\244\204\347\220\206.md"
diff --git "a/3.grammar-advancement/3-5-\345\217\215\345\260\204.md" "b/3.grammar-advancement/3-5-\345\217\215\345\260\204.md"
new file mode 100644
index 0000000..2d8ca97
--- /dev/null
+++ "b/3.grammar-advancement/3-5-\345\217\215\345\260\204.md"
@@ -0,0 +1,12 @@
+# 3.5 反射
+
+几乎每个后台语言都有反射,主要是因为强类型语言,在编译期间需要明确知道类型,反射的提供是为了允许程序在运行期间才拿到真实的类型。
+
+在不知道类型,或者说无法预期什么类型的时候,
+
+
+## 小结
+
+`C++`里为什么没有反射,你知道吗?
+
+TODO 本文待续,留言催更
\ No newline at end of file
diff --git a/3.grammar-advancement/3.2-struct/struct1.go b/3.grammar-advancement/3.2-struct/struct1.go
index 12cedec..f5d659d 100644
--- a/3.grammar-advancement/3.2-struct/struct1.go
+++ b/3.grammar-advancement/3.2-struct/struct1.go
@@ -3,7 +3,7 @@
* @Author: minibear2333
* @Date: 2020-04-05 22:01
* @url: https://github.com/golang-minibear2333/golang
-*/
+ */
package main
import "fmt"
@@ -25,9 +25,9 @@ func structDemo1() {
}
fmt.Println(body2)
- //结构体数组
+ //结构体切片
bodys := []Body{
- Body{"jack", 12}, Body{"lynn", 18},
+ {"jack", 12}, {"lynn", 18},
}
fmt.Println(bodys)
@@ -35,7 +35,7 @@ func structDemo1() {
class1 := struct {
bodys []Body
}{
- []Body{Body{"jerry", 24}},
+ []Body{{"jerry", 24}},
}
fmt.Println(class1)
}
@@ -55,7 +55,7 @@ func structDemo2() {
func funcGetStructPtr(bodyPtr *Body) {
bodyPtr.name = "lisa"
}
-func funGetStruct(body Body){
+func funGetStruct(body Body) {
body.name = "jj"
}
diff --git a/3.grammar-advancement/easy/json/parse_json.go b/3.grammar-advancement/easy/json/parse_json.go
deleted file mode 100644
index 3178aa2..0000000
--- a/3.grammar-advancement/easy/json/parse_json.go
+++ /dev/null
@@ -1,58 +0,0 @@
-/*
-* @Title: json解析与编码
-* @Author: minibear2333
-* @Date: 2020-03-15 11:46
-* @url: https://github.com/golang-minibear2333/golang
-*/
-
-package main
-
-import (
- "encoding/json"
- "fmt"
-)
-
-// 注意初学者最容易犯的两个致命错误,解析不出来某个字段,还不会报错
-// 1. 注意!!! 要被解析python的结构体,成员变量名称必须首字母大写(权限问题),否则会因为访问不到无法解析成功
-// 2. 注意!!! 不要定义两个 类似 `json:"_id"` 相同却不同名的字段,不然找到死也找不到为什么解析不出来
-type Coding3min struct {
- Data struct {
- Items []struct {
- ID string `json:"_id"`
- } `json:"items"`
- TotalCount int64 `json:"total_count"`
- } `json:"data"`
- Message string `json:"message"`
- ResultCode int64 `json:"result_code"`
-}
-
-//把string解析成struct
-func parseJson(jsonStr string) (Coding3min, error) {
- var coding3min Coding3min
- err := json.Unmarshal([]byte(jsonStr), &coding3min)
- return coding3min, err
-}
-
-//把struct编译成string
-func convertJson(c Coding3min) (res string, err error) {
- resBytes, err := json.Marshal(c)
- return string(resBytes), err
-}
-
-func main() {
- jsonStr := `{"data":{"items":[{"_id":"2"}],"total_count":1},"message":"","result_code":200}`
- //解析
- coding3min, err := parseJson(jsonStr)
- if err != nil {
- fmt.Println("parseJson error:" + err.Error())
- return
- }
- printStr := fmt.Sprintf("%v", coding3min)
- fmt.Println(printStr)
- //编译
- resStr, err := convertJson(coding3min)
- if err != nil {
- fmt.Println("convertJson error: " + err.Error())
- }
- fmt.Println(resStr)
-}
diff --git a/3.grammar-advancement/medium/chan/chan.go b/3.grammar-advancement/medium/chan/chan.go
deleted file mode 100644
index 1ef786e..0000000
--- a/3.grammar-advancement/medium/chan/chan.go
+++ /dev/null
@@ -1,63 +0,0 @@
-/*
-* @Title: 通道(chan)的发送与接收
-* @Author: minibear2333
-* @Date: 2020-03-27 20:44
-* @url: https://github.com/golang-minibear2333/golang
-*/
-package main
-
-import (
- "fmt"
- "time"
-)
-
-//本节需要先了解goroutine的知识, 示例代码:https://github.com/golang-minibear2333/golang/blob/master/golang/medium/chan/goroutine.go
-var c chan int
-
-/*
- 通道类型是引用类型,所以他的零值就是nil
- 换句话说,只声明但是没有用make函数初始化,改变量的值就是nil
- 对于值为nil的通道,不论具体是什么类型,它们所属的接收和发送操作都会永久处于阻塞状态(卡在那里,下面的代码都不会执行)
-*/
-func init() {
- c = make(chan int, 1)
-}
-
-//发送10个数
-func send() {
- fmt.Println("send start")
- for i := 1; i <= 10; i++ {
- fmt.Printf("send %v wait \n", i)
- c <- i
- fmt.Printf("send %v end \n", i)
- }
- fmt.Println("send end")
-}
-
-//只接收一次
-func receive() {
- fmt.Println("receiveChan start")
- var res int
- res = <-c
- fmt.Printf("receive %v \n", res)
- fmt.Println("receiveChan end")
-}
-
-//main 本身是一个goroutine
-func main() {
- //创建一个新的goroutine,这时它与main goroutine是并发的
- go receive()
- go send()
- //主线程结束的时候强制结束所有的goroutine,所以这里要等待1秒
- fmt.Println("main goroutine sleep start")
- time.Sleep(time.Second)
- /*过程
- 创建两个goroutine是,主线程休眠开始
- receive()开始接收,发现通道为空,阻塞receive
- send()发送数字1,尝试发送2,发现通道满了,阻塞send
- receive()发现通道不为空,开始接收,接收到1,只接收一次则关闭go send()
- send()发现通道空了,继续发送2,发送成功,尝试发送3,通道满了,阻塞send
- 主线程休眠结束,强制结束了send
- */
-}
-
diff --git a/3.grammar-advancement/medium/chan/select.go b/3.grammar-advancement/medium/chan/select.go
deleted file mode 100644
index 0c26736..0000000
--- a/3.grammar-advancement/medium/chan/select.go
+++ /dev/null
@@ -1,100 +0,0 @@
-/*
-* @Title: select语法
-* @Author: minibear2333
-* @Date: 2020-03-27 20:23
-* @url: https://github.com/golang-minibear2333/golang
-*/
-package main
-
-import (
- "fmt"
- "time"
-)
-
-//本节需要先了解chan的知识, 示例代码:https://github.com/golang-minibear2333/golang/blob/master/golang/medium/chan/chan.go
-var c2 chan int
-
-func init() {
- c2 = make(chan int, 1)
-}
-
-//发送10个数
-func sendDemo() {
- for i := 1; i <= 10; i++ {
- fmt.Printf("try send -> c2, times: %v \n", i)
- c2 <- 1
- fmt.Println("send ok")
- }
- close(c2)
- fmt.Println("send end")
-}
-
-// 要学习select就要先了解chan的知识,示例代码:https://github.com/golang-minibear2333/golang/blob/master/golang/medium/chan/chan.go
-func selectDemo() {
- go sendDemo()
-
- /*
- select 语句会随机执行一个case,如果没有case可以运行,就会一直阻塞,直到有case可以运行
- case 必须是一个通信操作,要么是发送,要么是接收
- 如果有default体,就只运行default,其他全部忽略
- */
-
- countAdd, countSub := 0, 0
- // 形式1:异步式,这里会接收一个值,然后sendDemo()会卡在插入3之前
- select {
- case _, ok := <-c2:
- if ok {
- countAdd++
- fmt.Printf("c2 <- 1 , countAdd: %v\n", countAdd)
- } else {
- fmt.Println("close")
- break
- }
-
- case _, ok := <-c2:
- if ok {
- countSub++
- fmt.Printf("c2 <- 1 , sub count: %v\n", countSub)
- } else {
- fmt.Println("close")
- break
- }
-
- }
- time.Sleep(time.Second)
-
- //阻塞式,一个返回值,如果c2里面是空的就一直阻塞了,这里会接收一个值,然后sendDemo()会卡在插入4之前
- select {
- case _ = <-c2:
- countAdd++
- fmt.Printf("c2 <- 1 , countAdd: %v\n", countAdd)
- case _ = <-c2:
- countSub++
- fmt.Printf("c2 <- 1 , sub count: %v\n", countSub)
- }
- time.Sleep(time.Second)
-
- //阻塞时,运行default
- select {
- case c2 <- -1:
- countAdd++
- fmt.Printf("c2 <- 1 , countAdd: %v\n", countAdd)
- default:
- fmt.Println("c2 chan is full!! can't insert number")
- }
- time.Sleep(time.Second)
-
- //不阻塞时,不运行default,运行任意一个可以运行的case
- select {
- case _ = <-c2:
- countAdd++
- fmt.Printf("c2 <- 1 , countAdd: %v\n", countAdd)
- default:
- fmt.Println("if case ok, default can't run")
- }
- //PS: 以上就是用法,但用法是这个用法,但是实在想不出具体的使用场景
-}
-
-func main() {
- selectDemo()
-}
diff --git "a/4.concurrent/4-1-go\350\257\255\350\250\200\344\270\255\347\232\204\345\271\266\345\217\221\347\211\271\346\200\247.md" "b/4.concurrent/4-1-go\350\257\255\350\250\200\344\270\255\347\232\204\345\271\266\345\217\221\347\211\271\346\200\247.md"
new file mode 100644
index 0000000..adf91a7
--- /dev/null
+++ "b/4.concurrent/4-1-go\350\257\255\350\250\200\344\270\255\347\232\204\345\271\266\345\217\221\347\211\271\346\200\247.md"
@@ -0,0 +1,141 @@
+# 4.1 go 语言中的并发特性
+
+> 本节源码位置 https://github.com/golang-minibear2333/golang/blob/master/4.concurrent/4.1-goroutine/
+
+以前我们写并发的程序一般是用多线程来实现,自己维护一个线程池,在恰当的时候创建、销毁、分配资源。
+
+`go` 在并发方面为我们提供了一个语言级别的支持, `goroutine` 和 `channel` 相互配合,这决定了他的先天优势。
+
+`goroutine` 也就是go协程,概念类似于线程, `Go` 程序运行时会自动调度和管理,系统能智能地将 `goroutine` 中的任务合理地分配给 `CPU` , 让这些任务尽量并发运作。
+
+这里说并发其实是不严谨的,只不过我们习惯了说并发,延展阅读见 [goroutine是并行还是并发?](https://coding3min.com/question/goroutine%e6%98%af%e5%b9%b6%e8%a1%8c%e8%bf%98%e6%98%af%e5%b9%b6%e5%8f%91%ef%bc%9f)
+
+## 4.1.1 他和线程对比
+
+**从使用上讲**
+
+- 比线程更轻量级,可以创建十万、百万不用担心资源问题。
+- 和 `channel` 搭配使用,实现高并发, `goroutine` 之间传输数据更方便。
+- 如果访问同一个数据块,要小心数据竞态问题、共享锁还是互斥锁的选择问题、并发操作的数据同步问题(后面会说)
+
+**从其实现上讲**
+
+- 从资源上讲,线程的栈内存大小一般是固定的一般为 `2MB` ,虽然这个数值可以设置,但是 太大了浪费,太小了容易不够用, 而 `goroutine` 栈内存是可变的,初始一般为 `2KB` ,随着需求可以扩大达到 1GB。 所以 `goroutine` 十分的轻量级,且能满足不同的需求。
+- 从调度上讲,线程的调度由 `OS` 的内核完成;线程的切换需要 **CPU 寄存器** 和 **内存的数据交换** ,从而切换不同的线程上下文。 其触发方式为 `CPU时钟` , 而 `goroutine` 的调度则比较轻量级,由自身的调度器完成。
+- 协程同线程的关系,有些类似于 线程同进程的关系。
+
+## 4.1.2 创建与使用
+
+创建一个 `goroutine` ,只需要在函数前加一个 `go` 关键字就成了。
+
+```Go
+go 函数名(参数)
+```
+
+看一个 `demo`
+
+```Go
+func quickFun(){
+ fmt.Println("maybe you can's see me!")
+}
+
+func main(){
+ go quickFun() // 创建了一个 goroutine
+ fmt.Println("hey")
+ time.Sleep(time.Second)
+}
+```
+
+- `goroutine` 和 `main` 主线程同时运行
+- `main` 运行结束会暴力终止所有协程,所以上面的程序多等待了 1 秒
+- `Go` 程序从 `main` 包的 `main()` 函数开始,在程序启动时, `Go` 程序就会为 `main()` 函数创建一个默认的 `goroutine` 。
+
+输出
+
+```
+hey
+maybe you can's see me!
+```
+
+对,就是这么简单,如果你的函数只在这里使用,也可以用匿名函数来创建 `goroutine` 。
+
+```Go
+func main(){
+ go func() {
+ fmt.Println("hello ")
+ }()
+ time.Sleep(time.Second) //main运行结束会暴力终止所有协程,所以这里先等待1秒
+}
+```
+
+PS: 和线程不同,`goroutine`没有唯一的`id`,所以我们没办法专门针对某个协程进行操作。
+
+## 4.1.3 体验并发
+
+当执行 goroutine 时候,Go 语言立即返回,接着执行剩余的代码,不会阻塞主线程。
+
+下面我们通过一小段代码来讲解 go 的使用:
+
+```go
+//首先我们先实现一个 Add()函数
+func Add(a, b int) {
+ c := a + b
+ fmt.Println(c)
+}
+
+go Add(1, 2) //使用go关键字让函数并发执行
+```
+
+该函数就会在一个新的 goroutine 中并发执行,当该函数执行完毕时,这个新的 goroutine 也就结束了。
+
+不过需要注意的是,如果该函数具有返回值,那么返回值会被丢弃。所以什么时候用 go 还需要酌情考虑。
+
+接着我们通过一个案例来体验一下 Go 的并发到底是怎么样的。新建源文件 goroutine2.go,输入以下代码:
+
+```go
+package main
+
+import "fmt"
+
+func Add(a, b int) {
+ c := a + b
+ fmt.Println(c)
+}
+
+func main() {
+ for i := 0; i < 10; i++ {
+ go Add(i, i)
+ }
+}
+```
+
+执行 goroutine.go 文件会发现屏幕上什么都没有,但程序并不会报错,这是什么原因呢?
+
+原来当主程序执行到 for 循环时启动了 10 个 goroutine,然后主程序就退出了,而启动的 10 个 goroutine 还没来得及执行
+Add() 函数,所以程序不会有任何输出。也就是说主 goroutine 并不会等待其他 goroutine 执行结束。
+
+并发等待的问题我将在下一节进行介绍。
+
+## 4.1.4 小结
+
+学 go 语言必学并发,通过本节我们知道了 `goroutine` 是 Go 语言并行设计的核心。十几个 `goroutine` 可能在底层就是几个线程。 实际上是 Go 在 `runtime` 系统调用等多方面对 `goroutine` 调度进行了封装和处理。
+
+协程是非常容易创建的,而且他非常轻量只占用2k,其他语言最小大多都是 `MB`,协程的使用还要配合数据传输,生产者消费者模型,关于协程的调度,我们后续再说。
+
+另外并发 bug 的定位和解决是老大难的问题了,平时就要注意的良好的代码风格和编程习惯。
+
+**拓展知识(栈内存)**:
+
+关于 goroutine stack size(栈内存大小) [官方的文档](https://golang.org/doc/go1.2#stack_size) 中所述,`1.2` 之前最小是4kb,在`1.2` 变成8kb,并且可以使用[SetMaxStack](https://golang.org/pkg/runtime/debug/#SetMaxStack) 设置栈最大大小。
+
+在 [runtime/debug](https://golang.org/pkg/runtime/debug) 包能控制最大的单个 `goroutine` 的堆栈的大小。在 64 位系统上默认为 1GB,在 32 位系统上默认为 250MB。
+
+因为每个goroutine需要能够运行,所以它们都有自己的栈。假如每个goroutine分配固定栈大小并且不能增长,太小则会导致溢出,太大又会浪费空间,无法存在许多的goroutine。
+
+所以在[1.3版本](https://golang.org/doc/go1.3#stacks)中,改为了 Contiguous stack( [连续栈](https://docs.google.com/document/d/1wAaf1rYoM4S4gtnPh0zOlGzWtrZFQ5suE8qr2sD8uWQ/pub) ),为了解决这个问题,goroutine可以初始时只给栈分配很小的空间(8KB),然后随着使用过程中的需要自动地增长。这就是为什么Go可以开千千万万个goroutine而不会耗尽内存。
+
+[1.4 版本](https://golang.org/doc/go1.4#runtime) goroutine 堆栈从 8Kb 减少到 2Kb
+
+拓展阅读
+* [连续栈](https://tiancaiamao.gitbooks.io/go-internals/content/zh/03.5.html)
+* [Go: How Does the Goroutine Stack Size Evolve?](https://medium.com/a-journey-with-go/go-how-does-the-goroutine-stack-size-evolve-447fc02085e5)
diff --git a/4.concurrent/4-10-pool.md b/4.concurrent/4-10-pool.md
new file mode 100644
index 0000000..0852279
--- /dev/null
+++ b/4.concurrent/4-10-pool.md
@@ -0,0 +1,3 @@
+# 4.10 协程池
+
+https://github.com/remeh/sizedwaitgroup/blob/master/sizedwaitgroup.go
diff --git a/4.concurrent/4-2-goroutine-wait.md b/4.concurrent/4-2-goroutine-wait.md
new file mode 100644
index 0000000..c782793
--- /dev/null
+++ b/4.concurrent/4-2-goroutine-wait.md
@@ -0,0 +1,167 @@
+# 4.2 并发等待
+
+> 本节源码位置 https://github.com/golang-minibear2333/golang/blob/master/4.concurrent/4.2-goroutine-wait/
+
+## 4.2.1 简介
+
+`goroutine` 是 `Golang` 中非常有用的功能,有时候 `goroutine` 没执行完函数就返回了,如果希望等待当前的 `goroutine` 执行完成再接着往下执行,该怎么办?
+
+```go
+func say(s string) {
+ for i := 0; i < 3; i++ {
+ time.Sleep(100 * time.Millisecond)
+ fmt.Println(s)
+ }
+}
+
+func main() {
+ go say("hello world")
+ fmt.Println("over!")
+}
+```
+
+输出 `over!` , 主线程没有等待
+
+## 4.2.2 使用 Sleep 等待
+
+```Go
+func main() {
+ go say("hello world")
+ time.Sleep(time.Second*1)
+ fmt.Println("over!")
+}
+```
+
+运行修改后的程序,结果如下:
+
+```go
+hello world
+hello world
+hello world
+over!
+```
+
+结果符合预期,但是太 low 了,我们不知道实际执行中应该等待多长时间,所以不能接受这个方案!
+
+## 4.2.3 发送信号
+
+```go
+func main() {
+ done := make(chan bool)
+ go func() {
+ for i := 0; i < 3; i++ {
+ time.Sleep(100 * time.Millisecond)
+ fmt.Println("hello world")
+ }
+ done <- true
+ }()
+
+ <-done
+ fmt.Println("over!")
+}
+```
+
+输出的结果和上面相同,也符合预期
+
+这种方式不能处理多个协程,所以也不是优雅的解决方式。
+
+## 4.2.4 WaitGroup
+
+Golang 官方在 sync 包中提供了 WaitGroup 类型可以解决这个问题。其文档描述如下:
+
+使用方法可以总结为下面几点:
+
+- 在父协程中创建一个 `WaitGroup` 实例,比如名称为:wg
+- 调用 `wg.Add(n)` ,其中 n 是等待的 `goroutine` 的数量
+- 在每个 `goroutine` 运行的函数中执行 `defer wg.Done()`
+- 调用 `wg.Wait()` 阻塞主逻辑
+- 直到所有 `goroutine` 执行完成。
+
+```Go
+func main() {
+ var wg sync.WaitGroup
+ wg.Add(2)
+ go say2("hello", &wg)
+ go say2("world", &wg)
+ fmt.Println("over!")
+ wg.Wait()
+}
+
+func say2(s string, waitGroup *sync.WaitGroup) {
+ defer waitGroup.Done()
+
+ for i := 0; i < 3; i++ {
+ fmt.Println(s)
+ }
+}
+```
+
+输出,注意顺序混乱是因为并发执行
+
+```go
+hello
+hello
+hello
+over!
+world
+world
+world
+```
+
+## 4.2.5 小心缺陷
+
+简短的例子,注意循环传入的变量用中间变量替代,防止闭包 `bug`
+
+```Go
+func errFunc() {
+ var wg sync.WaitGroup
+ sList := []string{"a", "b"}
+ wg.Add(len(sList))
+ for _, d := range sList {
+ go func() {
+ defer wg.Done()
+ fmt.Println(d)
+ }()
+ }
+ wg.Wait()
+}
+```
+
+输出,可以发现全部变成了最后一个
+
+```go
+b
+b
+```
+
+父协程与子协程是并发的。父协程上的`for`循环瞬间执行完了,内部的协程使用的是`d`最后的值,这就是闭包问题。
+
+解决方法当作参数传入
+
+```go
+func correctFunc() {
+ var wg sync.WaitGroup
+ sList := []string{"a", "b"}
+ wg.Add(len(sList))
+ for _, d := range sList {
+ go func(str string) {
+ defer wg.Done()
+ fmt.Println(str)
+ }(d)
+ }
+ wg.Wait()
+}
+```
+
+输出
+
+```go
+b
+a
+```
+
+要留意 `range` 中的`value`有可能出现 **1.7.3 有可能会遇到的坑!**
+
+## 引用
+
+[Golang 入门 : 等待 goroutine 完成任务](https://www.cnblogs.com/sparkdev/p/10917536.html)
diff --git a/4.concurrent/4-3-channel.drawio b/4.concurrent/4-3-channel.drawio
new file mode 100644
index 0000000..1585995
--- /dev/null
+++ b/4.concurrent/4-3-channel.drawio
@@ -0,0 +1 @@
+
\ No newline at end of file
diff --git a/4.concurrent/4-3-channel.md b/4.concurrent/4-3-channel.md
new file mode 100644
index 0000000..d76f49c
--- /dev/null
+++ b/4.concurrent/4-3-channel.md
@@ -0,0 +1,282 @@
+# 4.3 channel
+
+到这里你正在接触最核心和重要的知识!认真学习的你很棒!
+
+> 本节源码位置 https://github.com/golang-minibear2333/golang/blob/master/4.concurrent/4.3-channel/
+
+## 4.3.1 什么是 channel
+
+Go 是一门从语言级别就支持并发的编程语言, 它有一个设计哲学很特别 **不要通过共享内存来通信,而应通过通信来共享内存** ,听起来是有一点绕。
+
+在传统语言中并发使用全局变量来进行不同线程之间的数据共享,这种方式就是使用共享内存的方式进行通信。而 Go 会在协程和协程之间打一个隧道,通过这个隧道来传输数据(发送和接收)。
+
+
+
+打个比方,我们平时肯定没少接触过队列,队列的特点是先进先出,多方生产插入,多方消费接收。这个队列/隧道就是`channel`。
+
+`channel` 是 `goroutine` 之间互相通讯的东西,`goroutine` 之间用来发消息和接收消息。其实,就是在做 `goroutine` 之间的内存共享。
+
+我们来看看具体是什么使用的。
+
+## 4.3.2 声明与初始化
+
+`channel`是类型相关的,也就是说一个 `channel` 只能传递一种类型的值,这个类型需要在 `channel` 声明时指定。
+
+channel 的一般声明形式:
+
+```go
+var chanName chan 类型
+```
+
+与普通变量的声明不同的是在类型前面加了 `channel` 关键字,`类型` 则指定了这个 `channel` 所能传递的元素类型。示例:
+
+```go
+var a chan int //声明一个传递元素类型为int的channel
+var b chan float64
+var c chan string
+```
+
+通道是一个引用类型,初始值为`nil`,对于值为`nil`的通道,不论具体是什么类型,它们所属的接收和发送操作都会永久处于阻塞状态。
+
+所以必须手动`make`初始化,示例:
+
+```go
+a := make(chan int) //初始化一个int型的名为a的channel
+b := make(chan float64)
+c := make(chan string)
+```
+
+既然是队列,那就有大小,上面没声明具体的大小,被认为是*无缓冲*的(注意大小是 0,不是 1)也就是说必须有其他`goroutine`接收,不然就会阻塞在那。声明有缓冲的,指定大小就可以了。
+
+```go
+a := make(chan int,100)
+```
+
+## 4.3.3 如何使用
+
+我们进一步体验一下无缓冲 channel 会发生什么问题,同时熟悉下用法,示例:
+
+```go
+func pendingForever() {
+ a := make(chan int)
+ a <- 1 //将数据写入channel
+ z := <-a //从channel中读取数据
+ fmt.Println(z)
+}
+```
+
+- 观察上面三行代码,第 2 行往 `channel` 内写入了数据,第 3 行从 `channel` 中读取了数据
+- 但是这是在同一个方法中,并且没有使用 Go 关键字,说明他们在同一个协程
+
+我们说过 `channel` 是用来给不同 `goroutine` 通信的,所以是不能在同一个协程又发送又接收,这根本就达不到隧道通信的效果。所以上面的代码,会死锁:
+
+```go
+fatal error: all goroutines are asleep - deadlock!
+
+goroutine 1 [chan send]:
+main.main()
+ .../4.concurrent/channel.go:7 +0x59
+```
+
+死锁的原因是没有其他协程来接收数据,隧道因为是无缓冲的,所以直接永远的阻塞在发送方。
+
+要解决这个问题也好办。放到不同 `goroutine` 里就可以。
+
+```go
+func normal() {
+ chanInt := make(chan int)
+ go func() {
+ chanInt <- 1
+ }()
+
+ res := <-chanInt
+ fmt.Println(res)
+}
+```
+
+输出`1`。无缓冲通道在无数据发送时,接收端会阻塞,直到有新数据发送过来为止。
+
+上面的代码,一个发送一个接收,而实际使用中数据往往是连续不断发送的。来看一段代码:
+
+```go
+func standard() {
+ chanInt := make(chan int)
+ go func() {
+ defer close(chanInt)
+ var produceData = []int{1, 2, 3}
+ for _, v := range produceData {
+ chanInt <- v
+ }
+ }()
+ for v := range chanInt {
+ fmt.Println(v)
+ }
+}
+```
+
+输出
+
+```go
+1
+2
+3
+```
+
+- 循环传递数据,父协程循环接收。
+- `range chan` 的方式可以不断的接收数据,直到通道关闭,假如通道不关闭会永远阻塞,无法通过编译,直接报死锁。
+- 必须在发送端关闭通道,因为接收端无法预料是否还有数据没有接收完;向已关闭的`channel`发送数据会`panic`。
+- 建议使用 `defer` 来关闭通道,防止程序异常时未正常关闭。
+
+至此我们完成了一个简单的生产者消费者模型。
+
+## 4.3.4 channel 的关闭
+
+使用 Go 语言内置的 `close()` 函数即可关闭 `channel`,再强调一次建议使用`defer`关闭,示例:
+
+```go
+defer close(ch)
+```
+
+关闭了 `channel` 后如何查看 `channel` 是否关闭成功了呢?很简单,我们可以在读取 `channel` 时采用多重返回值的方式,示例:
+
+```go
+x, ok := <-ch
+```
+
+通过查看第二个返回值的 `bool` 值即可判断 `channel` 是否关闭,若为 `false` 则表示 `channel` 被关闭,反之则没有关闭(使用频率不高,了解即可)
+
+```go
+func main() {
+ var chanInt chan int = make(chan int, 10)
+ go func() {
+ defer fmt.Println("chanInt is closed")
+ defer close(chanInt)
+ chanInt <- 1
+ }()
+ res := <-chanInt
+ fmt.Println(res)
+}
+```
+
+输出
+
+```go
+chanInt is closed
+1
+```
+
+- 如上声明了一个有缓冲的通道,在缓冲大小允许的范围内不需要阻塞等待接收
+- 发送端发送完毕后主动关闭通道
+- 虽然通道已经关闭,接收端依然可以接收,接收完自行结束。
+
+PS1: 同一个通道只能关闭一次,重复关闭会`panic`。
+
+PS2: 如果传入`nil`,如 `close(nil)` 会 `panic`。
+
+## 4.3.5 多发送、多接收与单向通道
+
+我们结合前面知识,来实战练习一下!
+
+功能:实现一个多发送,多接收的例子。
+
+```go
+func send(c chan<- int, wg *sync.WaitGroup) {
+ c <- rand.Int()
+ wg.Done()
+}
+```
+
+- 发送端随机生成数字,并声明一个仅发送的单向通道
+- 使用`sync.WaitGroup`做等待(忘记的回顾上一节哈!)
+
+```go
+func received(c <-chan int, wg *sync.WaitGroup) {
+ for gotData := range c {
+ fmt.Println(gotData)
+ }
+ wg.Done()
+}
+```
+
+- 接收端使用`range`来接收数字并打印
+
+```go
+func main() {
+ chanInt := make(chan int, 10)
+ done := make(chan struct{})
+ defer close(done)
+ go func() {
+ defer close(chanInt)
+ // 发送
+ }()
+ go func() {
+ ...
+ // 接收
+ done <- struct{}{}
+ }()
+ <-done
+}
+```
+
+- 使用了两个通道,一个通道`chanInt`进行数据传输,另一个`done`控制完毕时结束主协程
+- 发送端负责生产数据,生产完毕后关闭通道
+- 接收端负责接收完毕后通知主协程
+
+发送端
+
+```go
+go func() {
+ var wg sync.WaitGroup
+ defer close(chanInt)
+ for i := 0; i < 5; i++ {
+ wg.Add(1)
+ go send(chanInt, &wg)
+ }
+ wg.Wait()
+}()
+```
+
+连续启动 5 个协程,使用`wg`做协程等待,发送完毕再结束是为了交给`defer`关闭`chanInt`
+
+接收端
+
+```go
+go func() {
+ var wg sync.WaitGroup
+ for i := 0; i < 8; i++ {
+ wg.Add(1)
+ go received(chanInt, &wg)
+ }
+ wg.Wait()
+ done <- struct{}{}
+}()
+```
+
+连续启动多个接收端,通道被关闭时纷纷退出,最后通知`done`
+
+输出 5 个随机数,程序正常关闭。
+
+```go
+5577006791947779410
+8674665223082153551
+4037200794235010051
+6129484611666145821
+3916589616287113937
+```
+
+单向通道限制了函数的使用方式,它可以用在循环比较耗时的场景,处理完一个数据立马发送出来,尽量减少内存的使用。
+
+## 4.3.6 小结
+
+这一节简单介绍了 go 语言中的 channel(信道),go 语言主张不要通过共享内存来通信,而应通过通信来共享内存,通过`channel`的方式可以完成不同`goroutine`之间的通信。
+
+我们学会了:
+
+- `channel` 是引用类型默认值是`nil`,需要手动`make`。
+- 通道必须在多个`goroutine`中使用
+- 有缓冲与无缓冲通道的特点,什么时候会阻塞。
+- 可以用`range`来做循环接收,通道关闭会自动停止。
+- 只能且必须在发送端使用`defer`关闭通道。
+- 正式使用一般多发送多接收,并使用`done`信号通知的方式进行通知。
+
+在工作中,通道的使用更为复杂,下一节将介绍两个面试高频的问题,敬请期待!
diff --git a/4.concurrent/4-4-deadlock.md b/4.concurrent/4-4-deadlock.md
new file mode 100644
index 0000000..9a24656
--- /dev/null
+++ b/4.concurrent/4-4-deadlock.md
@@ -0,0 +1,234 @@
+# 4.4 deadlock
+
+> 本节源码位置 https://github.com/golang-minibear2333/golang/blob/master/4.concurrent/4.4-deadlock/
+
+## 4.4.1 什么时候会导致死锁
+
+在计算机组成原理里说过 死锁有三个必要条件他们分别是 **循环等待、资源共享、非抢占式**,在并发中出现通道死锁只有两种情况:
+
+- 数据要发送,但是没有人接收
+- 数据要接收,但是没有人发送
+
+## 4.4.2 发送单个值时的死锁
+
+牢记这两点问题就很清晰了,复习下之前的例子,会死锁
+
+```go
+a := make(chan int)
+a <- 1 //将数据写入channel
+z := <-a //从channel中读取数据
+```
+
+- 有且只有一个协程时,无缓冲的通道
+- 先发送会阻塞在发送,先接收会阻塞在接收处。
+- 发送操作在接收者准备好之前是阻塞的,接收操作在发送之前是阻塞的,
+- 解决办法就是改为缓冲通道,或者使用协程配对
+
+解决方法一,协程配对,先发送还是先接收无所谓只要配对就好
+
+```go
+chanInt := make(chan int)
+go func() {
+ chanInt <- 1
+}()
+
+res := <-chanInt
+```
+
+解决方法二,缓冲通道
+
+```go
+chanInt := make(chan int,1)
+chanInt <- 2
+res := <-chanInt
+```
+
+- 缓冲通道内部的消息数量用`len()`函数可以测试出来
+- 缓冲通道的容量可以用`cap()`测试出来
+- 在满足`cap>len`时候,因为没有满,发送不会阻塞
+- 在`len>0`时,因为不为空,所以接收不会阻塞
+
+使用缓冲通道可以让生产者和消费者减少阻塞的可能性,对异步操作更友好,不用等待对方准备,但是容量不应设置过大,不然会占用较多内存。
+
+## 4.4.3 多个值发送的死锁
+
+配对可以让死锁消失,但发送多个值的时候又无法配对了,又会死锁
+
+```go
+func multipleDeathLock() {
+ chanInt := make(chan int)
+ defer close(chanInt)
+ go func() {
+ res := <-chanInt
+ fmt.Println(res)
+ }()
+ chanInt <- 1
+ chanInt <- 1
+}
+```
+
+不出所料死锁了
+
+```go
+fatal error: all goroutines are asleep - deadlock!
+
+goroutine 1 [chan send]:
+main.multipleDeathLock()
+```
+
+在工作中只有通知信号是一对一的情况,通知一次以后就不再使用了,其他这种要求多次读写配对的情况根本不会存在。
+
+## 4.4.4 解决多值发送死锁
+
+更常见的是用循环来不断接收值,接受一个处理一个,如下:
+
+```go
+func multipleLoop() {
+ chanInt := make(chan int)
+ defer close(chanInt)
+ go func() {
+ for {
+ //不使用ok会goroutine泄漏
+ //res := <-chanInt
+ res,ok := <-chanInt
+ if !ok {
+ break
+ }
+ fmt.Println(res)
+ }
+ }()
+ chanInt <- 1
+ chanInt <- 1
+}
+```
+
+输出:
+
+```go
+1
+1
+```
+
+- 给通道的接收加上二值,`ok` 代表通道是否正常,如果是关闭则为`false`值
+- 可以删掉那段逻辑试试,会输出`1 2 0 0 0`这样的数列,因为关闭是需要时间的,而循环接收关闭的通道拿到的是`0`
+- 在有缓冲的`channel`中,虽然通道关闭了,但直到读取完成所有数据才会输出0值,以及二值时返回`false`
+- 关于`goroutine`泄漏稍后会讲到
+
+## 4.4.5 应该先发送还是先接收
+
+假如我们调换一下位置,把接收放外面,写入放里面会发生什么
+
+```go
+func multipleDeathLock2() {
+ chanInt := make(chan int)
+ defer close(chanInt)
+ go func() {
+ chanInt <- 1
+ chanInt <- 2
+ }()
+ for {
+ res, ok := <-chanInt
+ if !ok {
+ break
+ }
+ fmt.Println(res)
+ }
+}
+```
+
+输出死锁
+
+```go
+1
+2
+fatal error: all goroutines are asleep - deadlock!
+
+goroutine 1 [chan receive]:
+main.multipleDeathLock2()
+```
+
+- 出现上面的结果是因为`for`循环一直在获取通道中的值,但是在读取完`1 2`后,通道中没有新的值传入,这样接收者就阻塞了。
+- 为什么先接收再发送可以,因为发送提前结束后会触发函数的`defer`自动关闭通道
+- 所以我们应该总是先接收后发送,并由发送端来关闭
+
+## 4.4.6 goroutine 泄漏
+
+`goroutine` 终止的场景有三个:
+
+- 当一个 `goroutine` 完成了它的工作
+- 由于发生了没有处理的错误
+- 有其他的协程告诉它终止
+
+当三个条件都没有满足,`goroutine` 就会一直运行下去
+
+```go
+func goroutineLeak() {
+ chanInt := make(chan int)
+ defer close(chanInt)
+ go func() {
+ for {
+ res := <-chanInt
+ //res,ok := <-chanInt
+ //if !ok {
+ // break
+ //}
+ fmt.Println(res)
+ }
+ }()
+ chanInt <- 1
+ chanInt <- 1
+}
+```
+
+- 上面的`goroutineLeak()`函数结束后触发`defer close(chanInt)`关闭了通道
+- 但是匿名函数中`goroutine`并没有关闭,而是一直在循环取值,并且取到是的关闭后的通道值(这里是`int`的默认值 0)
+- `goroutine`会永远运行下去,如果以后再次使用又会出现新的泄漏!导致内存、`cpu`占用越来越多
+
+输出,如果程序不停止就会一直输出`0`
+
+```go
+1
+1
+0
+0
+0
+...
+```
+
+假如不关闭且外部没有写入值,那接收处就会永远阻塞在那里,连输出都不会有
+
+```go
+func goroutineLeakNoClosed() {
+ chanInt := make(chan int)
+ go func() {
+ for {
+ res := <-chanInt
+ fmt.Println(res)
+ }
+ }()
+}
+```
+
+- 无任何输出的阻塞
+- 换成写入也是一样的
+- 如果是有缓冲的通道,换成已满的通道写没有读;或者换成向空的通道读没有写也是同样的情况
+- 除了阻塞,`goroutine`进入死循环也是泄露的原因
+
+## 4.4.7 如何发现泄露
+
+使用 golang 自带的`pprof`监控工具,可以发现内存上涨情况,这个后续会讲
+
+还可以监控进程的内存使用情况,比如`prometheus`提供的`process-exporter`
+
+如果你有内存泄露/goroutine 泄露代码扫描的工具,欢迎留言,感恩!
+
+## 4.4.8 小结
+
+今天我们学习了一些细节,但是相当重要的知识点,也是未来面试高频问题哦!
+
+- 如果是信号通知,应该保证一一对应,不然会死锁
+- 除了信号通知外,通常我们使用循环处理通道,在工作中不断的处理数据
+- 应该总是先接收后发送,并由发送端来关闭,不然容易死锁或者泄露
+- 在接收处,应该对通道是否关闭做好判断,已关闭应该退出接收,不然会泄露
+- 小心 goroutine 泄漏,应该在通道关闭的时候及时检查通道并退出
+- 除了阻塞,`goroutine`进入死循环也是泄露的原因
diff --git a/4.concurrent/4-5-select.md b/4.concurrent/4-5-select.md
new file mode 100644
index 0000000..5634e9b
--- /dev/null
+++ b/4.concurrent/4-5-select.md
@@ -0,0 +1,318 @@
+# 4.5 select
+
+> 本节源码位置 https://github.com/golang-minibear2333/golang/blob/master/4.concurrent/4.5-select
+
+## 4.5.1 select与switch
+
+让我们来复习一下`switch`语句,在`switch`语句中,会逐个匹配`case`语句(可以是值也可以是表达式),一个一个的判断过去,直到有符合的语句存在,执行匹配的语句内容后跳出`switch`。
+
+```go
+func demo(number int){
+ switch{
+ case number >= 90:
+ fmt.Println("优秀")
+ default:
+ fmt.Println("太搓了")
+ }
+}
+```
+
+而 `select` 用于处理通道,它的语法与 `switch` 非常类似。每个 `case` 语句里必须是一个 `channel` 操作。它既可以用于 `channel` 的数据接收,也可以用于 `channel` 的数据发送。
+
+```golang
+func foo() {
+ chanInt := make(chan int)
+ defer close(chanInt)
+ go func() {
+ select {
+ case data, ok := <-chanInt:
+ if ok {
+ fmt.Println(data)
+ }
+ default:
+ fmt.Println("全部阻塞")
+ }
+ }()
+ time.Sleep(time.Second)
+ chanInt <- 1
+}
+```
+
+输出`1`
+
+* 这是一个简单的接收发送模型。
+* 如果 select 的多个分支都满足条件,则会随机的选取其中一个满足条件的分支。
+* 第6行加上ok是因为上一节讲过,如果不加会导致通道关闭时收到零值。
+* 回忆之前的知识,接收和发送应该在不同的`goroutine`里。
+* 其次`select default`子协程,在`case`都处于阻塞状态时,会直接执行`default`的内容。导致子协程提前退出,主协程中的写入操作会一直阻塞(等待接收者,接收者已经退出了) 触发死锁
+* 倒数第二行加了`sleep` 1秒,是因为让`select`语句提前结束的问题暴露出来。
+
+```go
+全部阻塞
+fatal error: all goroutines are asleep - deadlock!
+
+goroutine 1 [chan send]:
+main.bar()
+```
+
+`select` 执行完了,退出了`goroutine`,而发送才刚刚执行到,没有与其匹配的接收,故死锁。
+
+正确的做法是把接收套在循环里面。
+
+```go
+func bar() {
+ chanInt := make(chan int)
+ defer close(chanInt)
+ go func() {
+ for {
+ select {
+ ...
+ }
+ }
+ }()
+ chanInt <- 1
+}
+```
+
+* 不再死锁了
+* 假如程序不停止,会出现一个泄露的`goroutine`,永远的在`for`循环中无法跳出,此时引入下一节的内容
+
+## 4.5.2 通知机制
+
+`Go` 语言总是简单和灵活的,虽然没有针对提供专门的机制来处理退出,但我们可以自己组合
+
+```go
+func main() {
+ chanInt, done := make(chan int), make(chan struct{})
+ defer close(chanInt)
+ defer close(done)
+ go func() {
+ for {
+ select {
+ case <-chanInt:
+ case <-done:
+ return
+ }
+ }
+ }()
+ done <- struct{}{}
+}
+```
+
+* 没有给`chanInt`发送任何东西,按理说会阻塞,导致`goroutine`泄露
+* 但可以使用额外的通道完成协程的退出控制
+* 这种方式还可以做到周期性处理任务,下一节我们再详细讲解
+
+## 4.5.3 case执行原理
+
+假如`case`后左边和右边跟了函数,会执行函数,我们来探索一下。
+
+定义`A`、`B`函数,作用相同
+
+```go
+func A() int {
+ fmt.Println("start A")
+ time.Sleep(1 * time.Second)
+ fmt.Println("end A")
+ return 1
+}
+```
+
+定义函数`lee`,请问该函数执行完成耗时多少呢?
+
+```go
+func lee() {
+ ch, done := make(chan int), make(chan struct{})
+ defer close(ch)
+ go func() {
+ select {
+ case ch <- A():
+ case ch <- B():
+ case <-done:
+ }
+ }()
+ done <- struct{}{}
+}
+```
+
+答案是2秒
+
+```go
+start A
+end A
+start B
+end B
+main.leespend time: 2.003504395s
+```
+
+* select扫描是从左到右从上到下的,按这个顺序先求值,如果是函数会先执行函数。
+* 然后立马判断是否可以立即执行(这里是指case是否会因为执行而阻塞)。
+* 所以两个函数都会进入,而且是先进入A再进入B,两个函数都会执行完,所以等待时间会累计。
+* 所以不应该在case判断中放函数。
+
+如果都不会阻塞,此时就会使用一个伪随机的算法,去选中一个case,只要选中了其他就被放弃了。
+
+## 4.5.4 超时控制
+
+我们来模拟一个更真实点的例子,让程序一段时间超时退出。
+
+定义一个结构体
+
+```go
+type Worker struct {
+ stream <-chan int //处理
+ timeout time.Duration //超时
+ done chan struct{} //结束信号
+}
+```
+
+定义初始化函数
+
+```go
+func NewWorker(stream <-chan int, timeout int) *Worker {
+ return &Worker{
+ stream: stream,
+ timeout: time.Duration(timeout) * time.Second,
+ done: make(chan struct{}),
+ }
+}
+```
+
+定义超时处理函数
+
+```go
+func (w *Worker) afterTimeStop() {
+ go func() {
+ time.Sleep(w.timeout)
+ w.done <- struct{}{}
+ }()
+}
+```
+
+* 超过时间发送结束信号
+
+接收数据并处理函数
+
+```go
+func (w *Worker) Start() {
+ w.afterTimeStop()
+ for {
+ select {
+ case data, ok := <-w.stream:
+ if !ok {
+ return
+ }
+ fmt.Println(data)
+ case <-w.done:
+ close(w.done)
+ return
+ }
+ }
+}
+```
+
+* 收到结束信号关闭函数
+* 这样的方法就可以让程序在等待 1 秒后继续执行,而不会因为 ch 读取等待而导致程序停滞。
+
+```go
+func main() {
+ stream := make(chan int)
+ defer close(stream)
+
+ w := NewWorker(stream, 3)
+ w.Start()
+}
+```
+
+实际3秒到程序运行结束。好在官方已经考虑到这一点,为我们提供了现成的方案。
+
+## 4.5.5 官方超时方案
+
+```go
+go func() {
+ t := time.NewTicker(timeout)
+ defer t.Stop()
+ for {
+ select {
+ case data := <-chanInt:
+ t.Reset(timeout)
+ case <-t.C:
+ case <-done:
+ return
+ }
+ }
+}()
+```
+
+* `time.NewTicker`创建了一个定时器,参数为时间间隔,并返回一个结构体`t`。
+* `t.C` 是一个仅可接收的`channel`,会根据时间间隔定时执行任务,也可以作为超时任务使用。
+* `t.Reset(timeout)` 重置时间,因为`select`进入一个`case`,后续的执行会有耗时,所以要重置时间保证时间的精准。
+
+这种方式巧妙地实现了超时处理机制,这种方法不仅简单,在实际项目开发中也是非常实用的。
+
+在生产中,常常把`buf`积累到一定数量然后`flush`出去,假如数据产生速度太慢,就要靠定时器定时消费,看下面完整的例子。
+
+```go
+func main() {
+ chanInt, done := make(chan int), make(chan struct{})
+ defer close(chanInt)
+ defer close(done)
+ go func() {
+ ...
+ }()
+ for i := 0; i < 100; i++ {
+ if i%10 == 0 {
+ time.Sleep(time.Second)
+ }
+ chanInt <- 1
+ }
+ done <- struct{}{}
+}
+```
+
+产生100个数,每10个数暂停1秒,用来模拟数据产生速度慢,`go func()` 内容如下:
+
+```go
+go func() {
+ timeout := time.Second
+ t := time.NewTicker(timeout)
+ defer t.Stop()
+ buf := make([]int, 0, 5)
+ for {
+ select {
+ case data := <-chanInt:
+ t.Reset(timeout)
+ if len(buf) < cap(buf) {
+ buf = append(buf, data)
+ } else {
+ go send(buf)
+ buf = make([]int, 0, cap(buf))
+ }
+ case <-t.C:
+ if len(buf) > 0 {
+ go send(buf)
+ buf = make([]int, 0, cap(buf))
+ }
+ case <-done:
+ return
+ }
+ }
+}()
+```
+
+* 接收到数据时,如果`buf`满了就进行上报,如果`buf`没满就追加数据。
+* 假如超时,就直接发送`buf`防止数据太少一直不发送的情况。
+* 需要在其他case里,`Reset`超时时间,以校准定时器。
+
+## 4.5.6 小结
+
+本节介绍了`select`的用法以及包含的陷阱,我们学会了:
+
+* `case`只针对通道传输阻塞做特殊处理,如果有计算将会先进行计算,所以不应该在`case`判断中放函数。
+* 扫描是从左到右从上到下的,按这个顺序先求值,如果是函数会先执行函数。如果函数运行时间长,时间会累计。
+* 在`case`全部阻塞时,会执行`default`中的内容。
+* 可使用结束信号,让`select`退出。
+* 延时发送结束信号可以实现超时自动退出的功能。
+* 官方的`time`包,提供了定时器,可作定时任务,也可作超时控制。
+
+我还写了可热更新的定时器,有兴趣了解的可以看看本节的源码哦。
\ No newline at end of file
diff --git a/4.concurrent/4-6-cron.md b/4.concurrent/4-6-cron.md
new file mode 100644
index 0000000..0d91310
--- /dev/null
+++ b/4.concurrent/4-6-cron.md
@@ -0,0 +1,87 @@
+# 4.6 定时器
+
+> 本节源码位置 https://github.com/golang-minibear2333/golang/tree/master/4.concurrent/4.6-cron
+
+很多时候需要周期性的执行某些操作,就需要用到定时器。定时器有三种思路。
+
+## 4.6.1 Sleep
+
+使用休眠,让当前`Goroutine`休眠一定的时间来实现定时的效果,缺点是程序执行速度不均匀,导致定时周期不均匀。
+
+```go
+for{
+fmt.Println(time.Now())
+time.Sleep(time.Second*1)
+}
+```
+
+## 4.6.2 Timer
+
+`Go` 语言的内置包,指定一个时间开始计时,时间到之后会向外发送通知,发送通知的方式就是使用`<-chan Time` 返回内容。
+
+第一种方式,直接在需要等待处使用,效果和`Sleep`一样,一使用就卡在那了内部就是使用了`Timer`。
+
+```go
+fmt.Println(time.Now())
+<-time.After(1*time.Second)
+fmt.Println(time.Now())
+```
+
+也可以把他拆分开,在任意地方进行等待
+
+```go
+timer := time.NewTimer(1 * time.Second)
+<-timer.C
+fmt.Println(time.Now())
+```
+
+但是以上只是做到延迟一次性执行,我们来改造一下,把他变成定时器。
+
+```go
+ done := make(chan struct{})
+timer := time.NewTimer(1 * time.Second)
+go func () {
+for {
+select {
+case <-timer.C:
+fmt.Println(time.Now())
+timer.Reset(1 * time.Second)
+case <-done:
+return
+}
+}
+}()
+<-time.After(5*time.Second + time.Millisecond*100)
+done <- struct{}{}
+```
+
+* 定义子`Goroutine`的目的是为了防止形成死锁,让定时器最终能退出,在实际项目中可能需要一个永久运行的定时器,一般为了不影响项目主逻辑也会这样定义。如果你的项目就是定时任务,我建议也这么写,这样可以注册很多个定时器互不影响。
+* `done`是为了判断执行是否结束,防止主`Goroutine`提前退出。
+* 这个示例只有两个`case`,实战中如果有加其他`case`需要给每个`case`内都做一次`Reset`,保证重置定时器。
+
+## 4.6.3 Ticker
+
+相比上述使用延迟执行功能实现的定时器,`Ticker` 本身就是一个定时器(内部封装了`Timer`),我们使用起来就非常简单。
+
+```go
+ticker := time.NewTicker(1 * time.Second)
+go func () {
+for {
+<-ticker.C
+fmt.Println(time.Now())
+}
+}()
+<-time.After(5 * time.Second + time.Millisecond*100)
+ticker.Stop()
+```
+
+在[select](https://golang.coding3min.com/4.concurrent/4-5-select/) 一节中讲述的官方超时控制方案非常的实用,也是使用的此函数。还使用到`timer.Stop`
+和`timer.Reset`这两个内置函数这里就不展开讲解了,建议进行复习。
+
+## 4.6.4 小结
+
+定时器一般用来周期性执行任务,比如定时同步数据、计算报表、发送通知。
+
+* `time.Sleep` 使用休眠,让当前`goroutine`休眠一定的时间来实现定时的效果,缺点是内部逻辑执行的速度会影响到定时器的时间差,无法做到精确间隔。
+* `Timer` 类似于`Sleep`的延迟处理,通过`channel`来获得通知,也可以改造成定时器。因为是延迟处理,所以要记得重置时间来实现定时执行的效果。
+* `Ticker` 现成的定时器,内部也是封装了 `Timer`。
\ No newline at end of file
diff --git a/4.concurrent/4-7-lock.md b/4.concurrent/4-7-lock.md
new file mode 100644
index 0000000..397edbc
--- /dev/null
+++ b/4.concurrent/4-7-lock.md
@@ -0,0 +1,117 @@
+# 4.7 并发安全与锁
+
+> 本节源码位置 https://github.com/golang-minibear2333/golang/tree/master/4.concurrent/4.7-lock/
+
+> 并发安全,就是多个并发体在同一段时间内访问同一个共享数据,共享数据能被正确处理。
+
+很多语言的并发编程很容易在同时修改某个变量的时候,因为操作不是原子的,而出现错误计算,比如一个加法运算使用中的变量被修改,而导致计算结果出错,典型的像统计商品库存。
+
+个人建议只要涉及到共享变量统统使用`channel`,因为`channel`源码中使用了互斥锁,它是并发安全的。
+
+我们可以不用,但不可以不了解,手中有粮心中不慌。
+
+## 4.7.1 并发不安全的例子
+
+数组是并发不安全的,在例子开始前我们要知道`append`函数的行为:长度足够在原数组`cap`内追加函数,增加`len`,长度不够则触发扩容,申请新数组`cap`增加一倍,赋值迁移。
+
+所以在这个过程中,仅讨论扩容操作的话可能存在同时申请并赋值的情况,导致漏掉某次扩容增加的数据。
+
+```go
+var s []int
+
+func appendValue(i int) {
+ s = append(s, i)
+}
+
+func main() {
+ for i := 0; i < 10000; i++ { //10000个协程同时添加切片
+ go appendValue(i)
+ }
+ time.Sleep(2)
+ fmt.Println(len(s))
+}
+```
+
+比如上例,`10000` 个协程同时为切片增加数据,你可以尝试运行一下,打印出来的一定不是 `10000` 。
+
+* 以上并发操作的同一个资源,专业名词叫做**临界区**。
+* 因为并发操作存在数据竞争,导致数据值意外改写,最后的结果与期待的不符,这种问题统称为**竞态问题**。
+
+常见于控制商品减库存,控制余额增减等情况。 那么有什么办法解决竞态问题呢?
+
+* 互斥锁:让访问某个临界区的时候,只有一个 `goroutine` 可以访问。
+* 原子操作:让某些操作变成原子的,这个后续讨论。
+
+这两个思路贯穿了无数的高并发/分布式方案,区别是在一个进程应用中使用,还是借助某些第三方手段来实现,比如中间件。独孤九剑森罗万象一定要牢牢记住。
+
+## 4.7.2 互斥锁
+
+`Go` 语言中互斥锁的用法如下:
+
+```go
+var lock sync.Mutex //互斥锁
+lock.Lock() //加锁
+s = append(s, i)
+lock.Unlock() //解锁
+```
+
+在访问临界区的前后加上互斥锁,就可以保证不会出现并发问题。
+
+我们修改还是上一个`4.7.1`的例子,为其增加互斥锁。
+
+```go
+var s []int
+var lock sync.Mutex
+
+appendValueSafe := func(i int) {
+ lock.Lock()
+ s = append(s, i)
+ lock.Unlock()
+}
+
+for i := 0; i < 10000; i++ { //10000个协程同时添加切片
+ go appendValueSafe(i)
+}
+time.Sleep(2)
+fmt.Println(len(s))
+```
+
+* 对共享变量`s`的写入操作加互斥锁,保证同一时刻只有一个`goroutine`修改内容。
+* 加锁之后到解锁之前的内容,同一时刻只有一个访问,无论读写。
+* 无论多少次都输出`10000`,不会再出现竞态问题。
+* 要注意:**如果在写的同时,有并发读操作时,为了防止不要读取到写了一半数据,需要为读操作也加锁。**
+
+## 4.7.3 读写锁
+
+互斥锁是完全互斥的,并发读没有修改的情况下是不会有问题的,也没有必要在并发读的时候加锁不然效率会变低。
+
+用法:
+
+```go
+rwlock sync.RWMutex
+//读锁
+rwlock.RLock()
+rwlock.RUnlock()
+
+//写锁
+rwlock.Lock()
+rwlock.Unlock()
+```
+
+并发读不互斥可以同时,在一个写锁获取时,其他所有锁都等待, 口诀:读读不互斥、读写互斥、写写互斥。具体测算速度的代码可以见4.7.3的源码,感兴趣的可以改下注释位置看下效率是有很明显的提升的。
+
+
+## 4.7.4 小结
+
+* 学习了几个名词:临界区、竞态问题、互斥锁、原子操作、读写锁。
+* 互斥锁:`sync.Mutex`, 读写锁:`sync.RWMutex` 都是 `sync` 包的。
+* 读写锁比互斥锁效率高。
+
+问题:只加写锁可以吗?为什么?
+
+## 引用
+
+* [并发安全和锁](https://www.topgoer.com/%E5%B9%B6%E5%8F%91%E7%BC%96%E7%A8%8B/%E5%B9%B6%E5%8F%91%E5%AE%89%E5%85%A8%E5%92%8C%E9%94%81.html)
+* [关于go的并发安全](https://zhuanlan.zhihu.com/p/511128412)
+* [golang_并发安全: slice和map并发不安全及解决方法](https://blog.csdn.net/weixin_43851310/article/details/87897247)
+
diff --git "a/4.concurrent/4-8-\345\216\237\345\255\220\346\223\215\344\275\234.md" "b/4.concurrent/4-8-\345\216\237\345\255\220\346\223\215\344\275\234.md"
new file mode 100644
index 0000000..3216ea7
--- /dev/null
+++ "b/4.concurrent/4-8-\345\216\237\345\255\220\346\223\215\344\275\234.md"
@@ -0,0 +1,113 @@
+# 4.8 原子操作
+
+> 本节源码位置 https://github.com/golang-minibear2333/golang/tree/master/4.concurrent/4.8-atomic/
+
+代码中的加锁操作因为涉及内核态的上下文切换会比较耗时、代价比较高。针对基本数据类型我们还可以使用原子操作来保证并发安全,因为原子操作是Go语言提供的方法它在用户态就可以完成,因此性能比加锁操作更好。Go语言中原子操作由内置的标准库`sync/atomic`
+提供。
+
+大多数情况下我们都是针对基本数据类型进行数据操作,能不加锁就不加锁。
+
+首先很多人都不相信基本类型并发修改会出现竞态问题。不妨尝试一下,并发加一。
+
+```go
+var wg sync.WaitGroup
+for i := 0; i < 10000; i++ {
+wg.Add(1)
+go func () {
+defer wg.Done()
+xInt32++
+}()
+}
+wg.Wait()
+print(xInt32)
+```
+
+无论输出多少次都无法达到`10000`,之所以如此就是因为此处的加1操作并不是原子的,都是先取当前值,加1,再赋值,会出现覆盖的情况。
+
+## 4.8.1 修改
+
+修改是最常用到的。
+
+```go
+func modify(delta int32) {
+atomic.AddInt32(&xInt32, delta)
+atomic.AddInt64(&xInt64, int64(delta))
+atomic.AddUint32(&xuInt32, uint32(delta))
+atomic.AddUint64(&xuInt64, uint64(delta))
+}
+```
+
+我们忽略了`Uintptr`的讨论,这是内存地址的整数表示,是用来存地址内容的,暂时没有遇到过指针的数据计算。
+
+```go
+var wg sync.WaitGroup
+for i := 0; i < 10000; i++ {
+wg.Add(1)
+go func () {
+defer wg.Done()
+//xInt32++
+modify(1)
+}()
+}
+wg.Wait()
+print(xInt32)
+```
+
+改为原子操作后,发现每次运行都可以得到预期的结果`10000`,
+
+## 4.8.2 赋值与读取
+
+在并发情况下,读取到某个变量后,在使用时变量内容可能会被篡改,所以使用原子读取。
+在并发情况下,为某个变量赋值的时候,必须要防止读取到写入一半的错误值,所以要用原子写入。
+
+```go
+var xInt32 int32
+atomic.StoreInt32(&xInt32, 100)
+println(xInt32)
+v := atomic.LoadInt32(&xInt32)
+println(v)
+```
+
+输出
+
+```go
+100
+100
+```
+
+就目前而言,原子读写都是为了防止读写一半导致数据错误,但我无法复现这种错误的场景,假如你可以复现请在本文底部放留言。
+
+```go
+var v atomic.Value
+v.Store([]int{})
+fmt.Println(v.Load().([]int))
+```
+
+也可以存储其他任意类型,但如果使用到类似`append`扩容原变量的语句,而不是使用直接替换的话,原子操作也是会失效的。
+
+## 4.8.3 比较并交换
+
+以下是节选自《Go并发编程实战》一书中的例子,比较并交换(Compare And Swap)简称CAS,是乐观锁的核心思想,所以简单介绍一下。
+
+```go
+var xInt32 int32
+for {
+ v := atomic.LoadInt32(&xInt32)
+ if atomic.CompareAndSwapInt32(&xInt32, v, v+100) {
+ break
+ }
+}
+print(xInt32)
+```
+
+* 这里一种无锁的结构,是一种思路,在需要改变数据的时候,反复判断数据是否和原数据一致
+* 一致时替换,不一致时说明被它处修改,则跳过
+* 在不创建互斥量和不形成临界区的情况下,完成并发安全的值替换操作。
+
+
+## 4.8.4 小结
+
+* 最常用原子操作中的修改、基本类型的值赋值,其他不常用
+* 在其他类型出现并发的时候尽可能使用`sync`包提供的并发安全的类型,下一节讲。
+* 通过通信共享内存;不要通过共享内存进行通信。尽量使用通道。
+
diff --git a/4.concurrent/4-9-sync.md b/4.concurrent/4-9-sync.md
new file mode 100644
index 0000000..afe63a8
--- /dev/null
+++ b/4.concurrent/4-9-sync.md
@@ -0,0 +1,278 @@
+# 4.9 sync包
+
+> 本节源码位置 https://github.com/golang-minibear2333/golang/tree/master/4.concurrent/4.9-sync/
+
+## 4.9.1 sync.Map 并发安全的Map
+
+反例如下,两个`Goroutine`分别读写。
+
+```go
+func unsafeMap(){
+ var wg sync.WaitGroup
+ m := make(map[int]int)
+ wg.Add(2)
+ go func() {
+ defer wg.Done()
+ for i := 0; i < 10000; i++ {
+ m[i] = i
+ }
+ }()
+
+ go func() {
+ defer wg.Done()
+ for i := 0; i < 10000; i++ {
+ fmt.Println(m[i])
+ }
+ }()
+ wg.Wait()
+}
+```
+
+执行报错:
+
+```go
+0
+fatal error: concurrent map read and map write
+
+goroutine 7 [running]:
+runtime.throw({0x10a76fa, 0x0})
+......
+```
+
+使用并发安全的`Map`
+
+```go
+func safeMap() {
+ var wg sync.WaitGroup
+ var m sync.Map
+ wg.Add(2)
+ go func() {
+ defer wg.Done()
+ for i := 0; i < 10000; i++ {
+ m.Store(i, i)
+ }
+ }()
+
+ go func() {
+ defer wg.Done()
+ for i := 0; i < 10000; i++ {
+ fmt.Println(m.Load(i))
+ }
+ }()
+ wg.Wait()
+}
+```
+
+* 不需要`make`就能使用
+* 还内置了`Store`、`Load`、`LoadOrStore`、`Delete`、`Range`等操作方法,自行体验。
+
+
+## 4.9.2 sync.Once 只执行一次
+
+很多场景下我们需要确保某些操作在高并发的场景下只执行一次,例如只加载一次配置文件、只关闭一次通道等。
+
+`init` 函数是当所在的 `package` 首次被加载时执行,若迟迟未被使用,则既浪费了内存,又延长了程序加载时间。
+
+`sync.Once` 可以在代码的任意位置初始化和调用,因此可以延迟到使用时再执行,并发场景下是线程安全的。
+
+在多数情况下,`sync.Once` 被用于控制变量的初始化,这个变量的读写满足如下三个条件:
+
+* 当且仅当第一次访问某个变量时,进行初始化(写);
+* 变量初始化过程中,所有读都被阻塞,直到初始化完成;
+* 变量仅初始化一次,初始化完成后驻留在内存里。
+
+```go
+var loadOnce sync.Once
+var x int
+for i:=0;i<10;i++{
+ loadOnce.Do(func() {
+ x++
+ })
+}
+fmt.Println(x)
+```
+
+输出1
+
+## 4.9.3 sync.Cond 条件变量控制
+
+`sync.Cond` 基于互斥锁/读写锁,它和互斥锁的区别是什么呢?
+
+互斥锁 `sync.Mutex` 通常用来保护临界区和共享资源,条件变量 `sync.Cond` 用来协调想要访问共享资源的 `goroutine`。
+
+也就是在存在共享变量时,可以直接使用`sync.Cond`来协调共享变量,比如最常见的共享队列,多消费多生产的模式。
+
+我一开始也很疑惑为什么不使用`channel`和`select`的模式来做生产者消费者模型(实际上也可以),这一节不是重点就不展开讨论了。
+
+创建实例
+
+```go
+func NewCond(l Locker) *Cond
+```
+
+`NewCond` 创建 `Cond` 实例时,需要关联一个锁。
+
+广播唤醒所有
+
+```go
+func (c *Cond) Broadcast()
+```
+
+`Broadcast` 唤醒所有等待条件变量 `c` 的 `goroutine`,无需锁保护。
+
+唤醒一个协程
+
+```go
+func (c *Cond) Signal()
+```
+
+`Signal` 只唤醒任意 1 个等待条件变量 `c` 的 `goroutine`,无需锁保护。
+
+等待
+
+```go
+func (c *Cond) Wait()
+```
+
+每个 Cond 实例都会关联一个锁 L(互斥锁 *Mutex,或读写锁 *RWMutex),当修改条件或者调用 Wait 方法时,必须加锁。
+
+举个不恰当的例子,实现一个经典的生产者和消费者模式,但有先决条件:
+
+* 边生产边消费,可以多生产多消费。
+* 生产后通知消费。
+* 队列为空时,暂停等待。
+* 支持关闭,关闭后等待消费结束。
+* 关闭后依然可以生产,但无法消费了。
+
+```go
+var (
+ cnt int
+ shuttingDown = false
+ cond = sync.NewCond(&sync.Mutex{})
+)
+```
+
+* `cnt` 为队列,这里直接用变量代替了,变量就是队列长度。
+* `shuttingDown` 消费关闭状态。
+* `cond` 现成的队列控制。
+
+生产者
+
+```go
+func Add(entry int) {
+ cond.L.Lock()
+ defer cond.L.Unlock()
+ cnt += entry
+ fmt.Println("生产咯,来消费吧")
+ cond.Signal()
+}
+```
+
+消费者
+
+```go
+func Get() (int, bool) {
+ cond.L.Lock()
+ defer cond.L.Unlock()
+ for cnt == 0 && !shuttingDown {
+ fmt.Println("未关闭但空了,等待生产")
+ cond.Wait()
+ }
+ if cnt == 0 {
+ fmt.Println("关闭咯,也消费完咯")
+ return 0, true
+ }
+ cnt--
+ return 1, false
+}
+```
+
+关闭程序
+
+```go
+func Shutdown() {
+ cond.L.Lock()
+ defer cond.L.Unlock()
+ shuttingDown = true
+ fmt.Println("要关闭咯,大家快消费")
+ cond.Broadcast()
+}
+```
+
+主程序
+
+```go
+var wg sync.WaitGroup
+ wg.Add(2)
+ time.Sleep(time.Second)
+ go func() {
+ defer wg.Done()
+ for i := 0; i < 10; i++ {
+ go Add(1)
+ if i%5 == 0 {
+ time.Sleep(time.Second)
+ }
+ }
+ }()
+ go func() {
+ defer wg.Done()
+ shuttingDown := false
+ for !shuttingDown {
+ var cur int
+ cur, shuttingDown = Get()
+ fmt.Printf("当前消费 %d, 队列剩余 %d \n", cur, cnt)
+ }
+ }()
+ time.Sleep(time.Second * 5)
+ Shutdown()
+ wg.Wait()
+```
+
+* 分别创建生产者与消费者。
+* 生产10个,每5个休息1秒。
+* 持续消费。
+* 主程序关闭队列。
+
+输出
+
+```go
+生产咯,来消费吧
+当前消费 1, 队列剩余 0
+未关闭但空了,等待生产
+生产咯,来消费吧
+生产咯,来消费吧
+当前消费 1, 队列剩余 1
+当前消费 1, 队列剩余 0
+未关闭但空了,等待生产
+生产咯,来消费吧
+生产咯,来消费吧
+生产咯,来消费吧
+当前消费 1, 队列剩余 2
+当前消费 1, 队列剩余 1
+当前消费 1, 队列剩余 0
+未关闭但空了,等待生产
+生产咯,来消费吧
+生产咯,来消费吧
+生产咯,来消费吧
+生产咯,来消费吧
+当前消费 1, 队列剩余 1
+当前消费 1, 队列剩余 2
+当前消费 1, 队列剩余 1
+当前消费 1, 队列剩余 0
+未关闭但空了,等待生产
+要关闭咯,大家快消费
+关闭咯,也消费完咯
+当前消费 0, 队列剩余 0
+```
+
+## 4.9.4 小结
+
+* sync.Map 并发安全的Map。
+* sync.Once 只执行一次,适用于配置读取、通道关闭。
+* sync.Cond 控制协调共享资源。
+
+
+## 引用
+
+* [Go sync.Once](https://geektutu.com/post/hpg-sync-once.html)
+* [k8s workerqueue源码](https://sourcegraph.com/github.com/kubernetes/client-go@b69cda3e4e09e1b956d42709fbadf12e6c0f24b7/-/blob/util/workqueue/queue_test.go?L269:5-269:22)
\ No newline at end of file
diff --git a/4.concurrent/4.2-goroutine-wait/1.go b/4.concurrent/4.2-goroutine-wait/1.go
new file mode 100644
index 0000000..7e3f215
--- /dev/null
+++ b/4.concurrent/4.2-goroutine-wait/1.go
@@ -0,0 +1,18 @@
+package main
+
+import (
+ "fmt"
+ "time"
+)
+
+func say(s string) {
+ for i := 0; i < 3; i++ {
+ time.Sleep(100 * time.Millisecond)
+ fmt.Println(s)
+ }
+}
+
+func main() {
+ go say("hello world")
+ fmt.Println("over!")
+}
diff --git a/4.concurrent/4.2-goroutine-wait/2.go b/4.concurrent/4.2-goroutine-wait/2.go
new file mode 100644
index 0000000..d653a18
--- /dev/null
+++ b/4.concurrent/4.2-goroutine-wait/2.go
@@ -0,0 +1,19 @@
+package main
+
+import (
+ "fmt"
+ "time"
+)
+
+func say(s string) {
+ for i := 0; i < 3; i++ {
+ time.Sleep(100 * time.Millisecond)
+ fmt.Println(s)
+ }
+}
+
+func main() {
+ go say("hello world")
+ time.Sleep(time.Second * 1)
+ fmt.Println("over!")
+}
diff --git a/4.concurrent/4.2-goroutine-wait/3.go b/4.concurrent/4.2-goroutine-wait/3.go
new file mode 100644
index 0000000..b98fc0d
--- /dev/null
+++ b/4.concurrent/4.2-goroutine-wait/3.go
@@ -0,0 +1,20 @@
+package main
+
+import (
+ "fmt"
+ "time"
+)
+
+func main() {
+ done := make(chan bool)
+ go func() {
+ for i := 0; i < 3; i++ {
+ time.Sleep(100 * time.Millisecond)
+ fmt.Println("hello world")
+ }
+ done <- true
+ }()
+
+ <-done
+ fmt.Println("over!")
+}
diff --git a/4.concurrent/4.2-goroutine-wait/4.go b/4.concurrent/4.2-goroutine-wait/4.go
new file mode 100644
index 0000000..a3b7b8a
--- /dev/null
+++ b/4.concurrent/4.2-goroutine-wait/4.go
@@ -0,0 +1,23 @@
+package main
+
+import (
+ "fmt"
+ "sync"
+)
+
+func main() {
+ var wg sync.WaitGroup
+ wg.Add(2)
+ go say2("hello", &wg)
+ go say2("world", &wg)
+ fmt.Println("over!")
+ wg.Wait()
+}
+
+func say2(s string, waitGroup *sync.WaitGroup) {
+ defer waitGroup.Done()
+
+ for i := 0; i < 3; i++ {
+ fmt.Println(s)
+ }
+}
diff --git a/4.concurrent/4.2-goroutine-wait/5.go b/4.concurrent/4.2-goroutine-wait/5.go
new file mode 100644
index 0000000..70d6403
--- /dev/null
+++ b/4.concurrent/4.2-goroutine-wait/5.go
@@ -0,0 +1,38 @@
+package main
+
+import (
+ "fmt"
+ "sync"
+)
+
+func errFunc() {
+ var wg sync.WaitGroup
+ sList := []string{"a", "b"}
+ wg.Add(len(sList))
+ for _, d := range sList {
+ go func() {
+ defer wg.Done()
+ fmt.Println(d)
+ }()
+ }
+ wg.Wait()
+}
+
+func correctFunc() {
+ var wg sync.WaitGroup
+ sList := []string{"a", "b"}
+ wg.Add(len(sList))
+ for _, d := range sList {
+ go func(str string) {
+ defer wg.Done()
+ fmt.Println(str)
+ }(d)
+ }
+ wg.Wait()
+}
+func main() {
+ fmt.Println("error function")
+ errFunc()
+ fmt.Println("correct function")
+ correctFunc()
+}
diff --git a/4.concurrent/4.3-channel/4.3.3.go b/4.concurrent/4.3-channel/4.3.3.go
new file mode 100644
index 0000000..b6a7f8a
--- /dev/null
+++ b/4.concurrent/4.3-channel/4.3.3.go
@@ -0,0 +1,45 @@
+package main
+
+import "fmt"
+
+// 阻塞
+func pendingForever() {
+ a := make(chan int)
+ a <- 1 //将数据写入channel
+ z := <-a //从channel中读取数据
+ fmt.Println(z)
+}
+
+// 正常使用
+func normal() {
+ fmt.Println("正常使用")
+ chanInt := make(chan int)
+ go func() {
+ chanInt <- 1
+ }()
+
+ res := <-chanInt
+ fmt.Println(res)
+}
+
+// 标准用法
+func standard() {
+ fmt.Println("标准用法")
+ chanInt := make(chan int)
+ go func() {
+ defer close(chanInt)
+ var produceData = []int{1, 2, 3}
+ for _, v := range produceData {
+ chanInt <- v
+ }
+ }()
+ for v := range chanInt {
+ fmt.Println(v)
+ }
+}
+func main() {
+ // 死锁,放开注释体验
+ //pendingForever()
+ normal()
+ standard()
+}
diff --git a/4.concurrent/4.3-channel/4.3.4.go b/4.concurrent/4.3-channel/4.3.4.go
new file mode 100644
index 0000000..d706297
--- /dev/null
+++ b/4.concurrent/4.3-channel/4.3.4.go
@@ -0,0 +1,15 @@
+package main
+
+import "fmt"
+
+// 关闭后的通道还是可以正常接收
+func main() {
+ var chanInt chan int = make(chan int, 10)
+ go func() {
+ defer fmt.Println("chanInt is closed")
+ defer close(chanInt)
+ chanInt <- 1
+ }()
+ res := <-chanInt
+ fmt.Println(res)
+}
diff --git a/4.concurrent/4.3-channel/4.3.5.go b/4.concurrent/4.3-channel/4.3.5.go
new file mode 100644
index 0000000..2dbff33
--- /dev/null
+++ b/4.concurrent/4.3-channel/4.3.5.go
@@ -0,0 +1,44 @@
+package main
+
+import (
+ "fmt"
+ "math/rand"
+ "sync"
+)
+
+func send(c chan<- int, wg *sync.WaitGroup) {
+ c <- rand.Int()
+ wg.Done()
+}
+
+func received(c <-chan int, wg *sync.WaitGroup) {
+ for gotData := range c {
+ fmt.Println(gotData)
+ }
+ wg.Done()
+}
+
+func main() {
+ chanInt := make(chan int, 10)
+ done := make(chan struct{})
+ defer close(done)
+ go func() {
+ var wg sync.WaitGroup
+ defer close(chanInt)
+ for i := 0; i < 5; i++ {
+ wg.Add(1)
+ go send(chanInt, &wg)
+ }
+ wg.Wait()
+ }()
+ go func() {
+ var wg sync.WaitGroup
+ for i := 0; i < 8; i++ {
+ wg.Add(1)
+ go received(chanInt, &wg)
+ }
+ wg.Wait()
+ done <- struct{}{}
+ }()
+ <-done
+}
diff --git a/4.concurrent/4.4-deadlock/4.4.2.go b/4.concurrent/4.4-deadlock/4.4.2.go
new file mode 100644
index 0000000..6a0926e
--- /dev/null
+++ b/4.concurrent/4.4-deadlock/4.4.2.go
@@ -0,0 +1,37 @@
+package main
+
+import "fmt"
+
+func main() {
+ // 死锁,放开注释体验
+ //pendingForever()
+ fmt.Println("死锁解决方法1")
+ foo()
+ foo2()
+ fmt.Println("死锁解决方法2")
+ bar()
+}
+
+func foo() {
+ chanInt := make(chan int)
+ go func() {
+ chanInt <- 1
+ }()
+ res := <-chanInt
+ fmt.Println(res)
+}
+func foo2() {
+ chanInt := make(chan int)
+ go func() {
+ res := <-chanInt
+ fmt.Println(res)
+ }()
+ chanInt <- 1
+}
+
+func bar() {
+ chanInt := make(chan int, 1)
+ chanInt <- 2
+ res := <-chanInt
+ fmt.Println(res)
+}
diff --git a/4.concurrent/4.4-deadlock/4.4.3.go b/4.concurrent/4.4-deadlock/4.4.3.go
new file mode 100644
index 0000000..62839ef
--- /dev/null
+++ b/4.concurrent/4.4-deadlock/4.4.3.go
@@ -0,0 +1,21 @@
+package main
+
+import (
+ "fmt"
+)
+
+func multipleDeathLock() {
+ fmt.Println("多值未匹配成功的死锁")
+ chanInt := make(chan int)
+ defer close(chanInt)
+ go func() {
+ res := <-chanInt
+ fmt.Println(res)
+ }()
+ chanInt <- 1
+ chanInt <- 1
+}
+
+func main() {
+ multipleDeathLock()
+}
diff --git a/4.concurrent/4.4-deadlock/4.4.4.go b/4.concurrent/4.4-deadlock/4.4.4.go
new file mode 100644
index 0000000..63a5911
--- /dev/null
+++ b/4.concurrent/4.4-deadlock/4.4.4.go
@@ -0,0 +1,24 @@
+package main
+
+import "fmt"
+
+func multipleLoop() {
+ fmt.Println("解决多值发送死锁")
+ chanInt := make(chan int)
+ defer close(chanInt)
+ go func() {
+ for {
+ res, ok := <-chanInt
+ if !ok {
+ break
+ }
+ fmt.Println(res)
+ }
+ }()
+ chanInt <- 1
+ chanInt <- 1
+}
+
+func main() {
+ multipleLoop()
+}
diff --git a/4.concurrent/4.4-deadlock/4.4.5.go b/4.concurrent/4.4-deadlock/4.4.5.go
new file mode 100644
index 0000000..bee4842
--- /dev/null
+++ b/4.concurrent/4.4-deadlock/4.4.5.go
@@ -0,0 +1,23 @@
+package main
+
+import "fmt"
+
+func multipleDeathLock2() {
+ chanInt := make(chan int)
+ defer close(chanInt)
+ go func() {
+ chanInt <- 1
+ chanInt <- 2
+ }()
+ for {
+ res, ok := <-chanInt
+ if !ok {
+ break
+ }
+ fmt.Println(res)
+ }
+}
+
+func main() {
+
+}
diff --git a/4.concurrent/4.4-deadlock/4.4.6.go b/4.concurrent/4.4-deadlock/4.4.6.go
new file mode 100644
index 0000000..8825e09
--- /dev/null
+++ b/4.concurrent/4.4-deadlock/4.4.6.go
@@ -0,0 +1,43 @@
+package main
+
+import "fmt"
+
+func goroutineLeak() {
+ chanInt := make(chan int)
+ defer close(chanInt)
+ go func() {
+ for {
+ //不使用ok会goroutine泄漏
+ res := <-chanInt
+ //res,ok := <-chanInt
+ //if !ok {
+ // break
+ //}
+ fmt.Println(res)
+ }
+ }()
+ chanInt <- 1
+ chanInt <- 1
+}
+func goroutineLeakNoClosed() {
+ chanInt := make(chan int)
+ go func() {
+ for {
+ res := <-chanInt
+ fmt.Println(res)
+ }
+ }()
+}
+func goroutineLeakNoClosed2() {
+ chanInt := make(chan int)
+ go func() {
+ for {
+ chanInt <- 1
+ }
+ }()
+}
+func main() {
+ goroutineLeak()
+ goroutineLeakNoClosed()
+ goroutineLeakNoClosed2()
+}
diff --git a/4.concurrent/4.5-select/4.5.1.go b/4.concurrent/4.5-select/4.5.1.go
new file mode 100644
index 0000000..0cbd6b6
--- /dev/null
+++ b/4.concurrent/4.5-select/4.5.1.go
@@ -0,0 +1,60 @@
+package main
+
+import (
+ "fmt"
+ "time"
+)
+
+func baz() {
+ chanInt := make(chan int)
+ defer close(chanInt)
+ go func() {
+ select {
+ case data, ok := <-chanInt:
+ if ok {
+ fmt.Println(data)
+ }
+ }
+ }()
+ time.Sleep(time.Second)
+ chanInt <- 1
+}
+func foo() {
+ chanInt := make(chan int)
+ defer close(chanInt)
+ go func() {
+ select {
+ case data, ok := <-chanInt:
+ if ok {
+ fmt.Println(data)
+ }
+ default:
+ fmt.Println("全部阻塞")
+ }
+ }()
+ time.Sleep(time.Second)
+ chanInt <- 1
+}
+func bar() {
+ chanInt := make(chan int)
+ defer close(chanInt)
+ go func() {
+ for {
+ select {
+ case data, ok := <-chanInt:
+ if ok {
+ fmt.Println(data)
+ }
+ default:
+ fmt.Println("全部阻塞")
+ }
+ }
+ }()
+ chanInt <- 1
+ time.Sleep(time.Second)
+}
+func main() {
+ //foo()
+ bar()
+ baz()
+}
diff --git a/4.concurrent/4.5-select/4.5.2.go b/4.concurrent/4.5-select/4.5.2.go
new file mode 100644
index 0000000..95480ce
--- /dev/null
+++ b/4.concurrent/4.5-select/4.5.2.go
@@ -0,0 +1,17 @@
+package main
+
+func main() {
+ chanInt, done := make(chan int), make(chan struct{})
+ defer close(chanInt)
+ defer close(done)
+ go func() {
+ for {
+ select {
+ case <-chanInt:
+ case <-done:
+ return
+ }
+ }
+ }()
+ done <- struct{}{}
+}
diff --git a/4.concurrent/4.5-select/4.5.3.go b/4.concurrent/4.5-select/4.5.3.go
new file mode 100644
index 0000000..96227b3
--- /dev/null
+++ b/4.concurrent/4.5-select/4.5.3.go
@@ -0,0 +1,45 @@
+package main
+
+import (
+ "fmt"
+ "reflect"
+ "runtime"
+ "time"
+)
+
+func A() int {
+ fmt.Println("start A")
+ time.Sleep(1 * time.Second)
+ fmt.Println("end A")
+ return 1
+}
+func B() int {
+ fmt.Println("start B")
+ time.Sleep(1 * time.Second)
+ fmt.Println("end B")
+ return 2
+}
+
+func SpeedTime(handler func()) {
+ t := time.Now()
+ handler()
+ elapsed := time.Since(t)
+ // 利用反射获得函数名
+ funcName := runtime.FuncForPC(reflect.ValueOf(handler).Pointer()).Name()
+ fmt.Println(funcName+"spend time:", elapsed)
+}
+func lee() {
+ ch, done := make(chan int), make(chan struct{})
+ defer close(ch)
+ go func() {
+ select {
+ case ch <- A():
+ case ch <- B():
+ case <-done:
+ }
+ }()
+ done <- struct{}{}
+}
+func main() {
+ SpeedTime(lee)
+}
diff --git a/4.concurrent/4.5-select/4.5.4.go b/4.concurrent/4.5-select/4.5.4.go
new file mode 100644
index 0000000..ccb93cb
--- /dev/null
+++ b/4.concurrent/4.5-select/4.5.4.go
@@ -0,0 +1,49 @@
+package main
+
+import (
+ "fmt"
+ "time"
+)
+
+type Worker struct {
+ stream <-chan int
+ timeout time.Duration
+ done chan struct{}
+}
+
+func NewWorker(stream <-chan int, timeout int) *Worker {
+ return &Worker{
+ stream: stream,
+ timeout: time.Duration(timeout) * time.Second,
+ done: make(chan struct{}),
+ }
+}
+func (w *Worker) Start() {
+ w.afterTimeStop()
+ for {
+ select {
+ case data, ok := <-w.stream:
+ if !ok {
+ return
+ }
+ fmt.Println(data)
+ case <-w.done:
+ close(w.done)
+ return
+ }
+ }
+}
+func (w *Worker) afterTimeStop() {
+ go func() {
+ time.Sleep(w.timeout)
+ w.done <- struct{}{}
+ }()
+}
+
+func main() {
+ stream := make(chan int)
+ defer close(stream)
+
+ w := NewWorker(stream, 3)
+ w.Start()
+}
diff --git a/4.concurrent/4.5-select/4.5.5.go b/4.concurrent/4.5-select/4.5.5.go
new file mode 100644
index 0000000..1b6bb29
--- /dev/null
+++ b/4.concurrent/4.5-select/4.5.5.go
@@ -0,0 +1,47 @@
+package main
+
+import (
+ "fmt"
+ "time"
+)
+
+func send(data []int) {
+ fmt.Println(len(data))
+}
+func main() {
+ chanInt, done := make(chan int), make(chan struct{})
+ defer close(chanInt)
+ defer close(done)
+ go func() {
+ timeout := time.Second
+ t := time.NewTicker(timeout)
+ defer t.Stop()
+ buf := make([]int, 0, 5)
+ for {
+ select {
+ case data := <-chanInt:
+ t.Reset(timeout)
+ if len(buf) < cap(buf) {
+ buf = append(buf, data)
+ } else {
+ go send(buf)
+ buf = make([]int, 0, cap(buf))
+ }
+ case <-t.C:
+ if len(buf) > 0 {
+ go send(buf)
+ buf = make([]int, 0, cap(buf))
+ }
+ case <-done:
+ return
+ }
+ }
+ }()
+ for i := 0; i < 100; i++ {
+ if i%10 == 0 {
+ time.Sleep(time.Second)
+ }
+ chanInt <- 1
+ }
+ done <- struct{}{}
+}
diff --git a/blog/content/a.timer/reset/reset_timer.go b/4.concurrent/4.5-select/reset_timer.go
similarity index 90%
rename from blog/content/a.timer/reset/reset_timer.go
rename to 4.concurrent/4.5-select/reset_timer.go
index 6096295..55ca94e 100644
--- a/blog/content/a.timer/reset/reset_timer.go
+++ b/4.concurrent/4.5-select/reset_timer.go
@@ -12,7 +12,6 @@ type Server struct {
Period int64
}
-
func main() {
s := CreateServer(1)
go s.Start()
@@ -21,6 +20,7 @@ func main() {
time.Sleep(time.Duration(10) * time.Second)
s.Stop()
fmt.Println("good bye")
+ time.Sleep(time.Duration(10) * time.Second)
}
func CreateServer(Period int64) *Server {
@@ -44,18 +44,17 @@ func (s *Server) Start() {
case <-s.tk.C:
fmt.Println("定时唤醒:", time.Now().Format("2006-01-02 15:04:05"))
case <-s.reset:
- s.tk.Stop()
- s.tk = time.NewTicker(time.Duration(s.Period) * time.Second)
+ s.tk.Reset(time.Duration(s.Period) * time.Second)
}
}
}
-func (s *Server) Stop() {
- close(s.Close)
- close(s.reset)
-}
-
func (s *Server) Update(p int64) {
s.Period = p
s.reset <- struct{}{}
}
+
+func (s *Server) Stop() {
+ close(s.Close)
+ close(s.reset)
+}
diff --git a/4.concurrent/4.6-cron/4.6.1.go b/4.concurrent/4.6-cron/4.6.1.go
new file mode 100644
index 0000000..6cee0dd
--- /dev/null
+++ b/4.concurrent/4.6-cron/4.6.1.go
@@ -0,0 +1,13 @@
+package main
+
+import (
+ "fmt"
+ "time"
+)
+
+func main(){
+ for{
+ fmt.Println(time.Now())
+ time.Sleep(time.Second*1)
+ }
+}
diff --git a/4.concurrent/4.6-cron/4.6.2.go b/4.concurrent/4.6-cron/4.6.2.go
new file mode 100644
index 0000000..2261c67
--- /dev/null
+++ b/4.concurrent/4.6-cron/4.6.2.go
@@ -0,0 +1,30 @@
+package main
+
+import (
+ "fmt"
+ "time"
+)
+
+func main() {
+ fmt.Println("同Sleep的方式1 time.After")
+ fmt.Println(time.Now())
+ <-time.After(1 * time.Second)
+ fmt.Println(time.Now())
+
+ fmt.Println("方式2 Timer")
+ done := make(chan struct{})
+ timer := time.NewTimer(1 * time.Second)
+ go func() {
+ for {
+ select {
+ case <-timer.C:
+ fmt.Println(time.Now())
+ timer.Reset(1 * time.Second)
+ case <-done:
+ return
+ }
+ }
+ }()
+ <-time.After(5*time.Second + time.Millisecond*100)
+ done <- struct{}{}
+}
diff --git a/4.concurrent/4.6-cron/4.6.3.go b/4.concurrent/4.6-cron/4.6.3.go
new file mode 100644
index 0000000..57ed61c
--- /dev/null
+++ b/4.concurrent/4.6-cron/4.6.3.go
@@ -0,0 +1,18 @@
+package main
+
+import (
+ "fmt"
+ "time"
+)
+
+func main() {
+ ticker := time.NewTicker(1 * time.Second)
+ go func() {
+ for {
+ <-ticker.C
+ fmt.Println(time.Now())
+ }
+ }()
+ <-time.After(5*time.Second + time.Millisecond*100)
+ ticker.Stop()
+}
diff --git a/4.concurrent/4.7-lock/4.7.1.go b/4.concurrent/4.7-lock/4.7.1.go
new file mode 100644
index 0000000..ad0c00b
--- /dev/null
+++ b/4.concurrent/4.7-lock/4.7.1.go
@@ -0,0 +1,20 @@
+package main
+
+import (
+ "fmt"
+ "time"
+)
+
+var s []int
+
+func appendValue(i int) {
+ s = append(s, i)
+}
+
+func main() {
+ for i := 0; i < 10000; i++ { //10000个协程同时添加切片
+ go appendValue(i)
+ }
+ time.Sleep(2)
+ fmt.Println(len(s))
+}
diff --git a/4.concurrent/4.7-lock/4.7.2.go b/4.concurrent/4.7-lock/4.7.2.go
new file mode 100644
index 0000000..6a3e3aa
--- /dev/null
+++ b/4.concurrent/4.7-lock/4.7.2.go
@@ -0,0 +1,26 @@
+package main
+
+import (
+ "fmt"
+ "sync"
+ "time"
+)
+
+
+
+func main() {
+ var s []int
+ var lock sync.Mutex
+
+ appendValueSafe := func(i int) {
+ lock.Lock()
+ s = append(s, i)
+ lock.Unlock()
+ }
+
+ for i := 0; i < 10000; i++ { //10000个协程同时添加切片
+ go appendValueSafe(i)
+ }
+ time.Sleep(2)
+ fmt.Println(len(s))
+}
diff --git a/4.concurrent/4.7-lock/4.7.3.go b/4.concurrent/4.7-lock/4.7.3.go
new file mode 100644
index 0000000..ad1266c
--- /dev/null
+++ b/4.concurrent/4.7-lock/4.7.3.go
@@ -0,0 +1,47 @@
+package main
+
+import (
+ "fmt"
+ "sync"
+ "time"
+)
+
+var (
+ rwlock sync.RWMutex
+ lock sync.Mutex
+ wg sync.WaitGroup
+)
+
+func read() {
+ defer wg.Done()
+ //lock.Lock()
+ rwlock.RLock()
+ time.Sleep(time.Millisecond)
+ rwlock.RUnlock()
+ //lock.Unlock()
+}
+func write() {
+ defer wg.Done()
+ //lock.Lock()
+ rwlock.Lock()
+ time.Sleep(time.Millisecond)
+ rwlock.Unlock()
+ //lock.Unlock()
+}
+
+func main() {
+ start := time.Now()
+ for i := 0; i < 10; i++ {
+ wg.Add(1)
+ go write()
+ }
+
+ for i := 0; i < 1000; i++ {
+ wg.Add(1)
+ go read()
+ }
+
+ wg.Wait()
+ end := time.Now()
+ fmt.Println(end.Sub(start))
+}
diff --git a/4.concurrent/4.8-atomic/4.8.1.go b/4.concurrent/4.8-atomic/4.8.1.go
new file mode 100644
index 0000000..0621e14
--- /dev/null
+++ b/4.concurrent/4.8-atomic/4.8.1.go
@@ -0,0 +1,33 @@
+package main
+
+import (
+ "sync"
+ "sync/atomic"
+)
+
+var (
+ xInt32 int32
+ xInt64 int64
+ xuInt32 uint32
+ xuInt64 uint64
+)
+
+func modify(delta int32) {
+ atomic.AddInt32(&xInt32, delta)
+ atomic.AddInt64(&xInt64, int64(delta))
+ atomic.AddUint32(&xuInt32, uint32(delta))
+ atomic.AddUint64(&xuInt64, uint64(delta))
+}
+func main() {
+ var wg sync.WaitGroup
+ for i := 0; i < 10000; i++ {
+ wg.Add(1)
+ go func() {
+ defer wg.Done()
+ //xInt32++
+ modify(1)
+ }()
+ }
+ wg.Wait()
+ print(xInt32)
+}
diff --git a/4.concurrent/4.8-atomic/4.8.2.go b/4.concurrent/4.8-atomic/4.8.2.go
new file mode 100644
index 0000000..b1485fb
--- /dev/null
+++ b/4.concurrent/4.8-atomic/4.8.2.go
@@ -0,0 +1,24 @@
+package main
+
+import (
+ "fmt"
+ "sync/atomic"
+)
+
+func foo1() {
+ var xInt32 int32
+ atomic.StoreInt32(&xInt32, 100)
+ println(xInt32)
+ v := atomic.LoadInt32(&xInt32)
+ println(v)
+}
+func foo2() {
+ var v atomic.Value
+ v.Store([]int{})
+ fmt.Println(v.Load().([]int))
+}
+
+func main() {
+ foo1()
+ foo2()
+}
diff --git a/4.concurrent/4.8-atomic/4.8.3.go b/4.concurrent/4.8-atomic/4.8.3.go
new file mode 100644
index 0000000..d0e1c61
--- /dev/null
+++ b/4.concurrent/4.8-atomic/4.8.3.go
@@ -0,0 +1,14 @@
+package main
+
+import "sync/atomic"
+
+func main() {
+ var xInt32 int32
+ for {
+ v := atomic.LoadInt32(&xInt32)
+ if atomic.CompareAndSwapInt32(&xInt32, v, v+100) {
+ break
+ }
+ }
+ print(xInt32)
+}
diff --git a/4.concurrent/4.9-sync/4.9.1.go b/4.concurrent/4.9-sync/4.9.1.go
new file mode 100644
index 0000000..3b3a222
--- /dev/null
+++ b/4.concurrent/4.9-sync/4.9.1.go
@@ -0,0 +1,50 @@
+package main
+
+import (
+ "fmt"
+ "sync"
+)
+
+func unsafeMap() {
+ var wg sync.WaitGroup
+ m := make(map[int]int)
+ wg.Add(2)
+ go func() {
+ defer wg.Done()
+ for i := 0; i < 10000; i++ {
+ m[i] = i
+ }
+ }()
+
+ go func() {
+ defer wg.Done()
+ for i := 0; i < 10000; i++ {
+ fmt.Println(m[i])
+ }
+ }()
+ wg.Wait()
+}
+
+func safeMap() {
+ var wg sync.WaitGroup
+ var m sync.Map
+ wg.Add(2)
+ go func() {
+ defer wg.Done()
+ for i := 0; i < 10000; i++ {
+ m.Store(i, i)
+ }
+ }()
+
+ go func() {
+ defer wg.Done()
+ for i := 0; i < 10000; i++ {
+ fmt.Println(m.Load(i))
+ }
+ }()
+ wg.Wait()
+}
+func main() {
+ //unsafeMap()
+ safeMap()
+}
diff --git a/4.concurrent/4.9-sync/4.9.2.go b/4.concurrent/4.9-sync/4.9.2.go
new file mode 100644
index 0000000..da73f2f
--- /dev/null
+++ b/4.concurrent/4.9-sync/4.9.2.go
@@ -0,0 +1,17 @@
+package main
+
+import (
+ "fmt"
+ "sync"
+)
+
+func main(){
+ var loadOnce sync.Once
+ var x int
+ for i:=0;i<10;i++{
+ loadOnce.Do(func() {
+ x++
+ })
+ }
+ fmt.Println(x)
+}
diff --git a/4.concurrent/4.9-sync/4.9.3.go b/4.concurrent/4.9-sync/4.9.3.go
new file mode 100644
index 0000000..279362c
--- /dev/null
+++ b/4.concurrent/4.9-sync/4.9.3.go
@@ -0,0 +1,72 @@
+package main
+
+import (
+ "fmt"
+ "sync"
+ "time"
+)
+
+var (
+ cnt int
+ shuttingDown = false
+ cond = sync.NewCond(&sync.Mutex{})
+)
+
+func Add(entry int) {
+ cond.L.Lock()
+ defer cond.L.Unlock()
+ cnt += entry
+ fmt.Println("生产咯,来消费吧")
+ cond.Signal()
+}
+func Get() (int, bool) {
+ cond.L.Lock()
+ defer cond.L.Unlock()
+ for cnt == 0 && !shuttingDown {
+ fmt.Println("未关闭但空了,等待生产")
+ cond.Wait()
+ }
+ if cnt == 0 {
+ fmt.Println("关闭咯,也消费完咯")
+ return 0, true
+ }
+ cnt--
+ return 1, false
+}
+func Shutdown() {
+ cond.L.Lock()
+ defer cond.L.Unlock()
+ shuttingDown = true
+ fmt.Println("要关闭咯,大家快消费")
+ cond.Broadcast()
+}
+func demo1() {
+ var wg sync.WaitGroup
+ wg.Add(2)
+ time.Sleep(time.Second)
+ go func() {
+ defer wg.Done()
+ for i := 0; i < 10; i++ {
+ go Add(1)
+ if i%5 == 0 {
+ time.Sleep(time.Second)
+ }
+ }
+ }()
+ go func() {
+ defer wg.Done()
+ shuttingDown := false
+ for !shuttingDown {
+ var cur int
+ cur, shuttingDown = Get()
+ fmt.Printf("当前消费 %d, 队列剩余 %d \n", cur, cnt)
+ }
+ }()
+ time.Sleep(time.Second * 5)
+ Shutdown()
+ wg.Wait()
+}
+
+func main() {
+ demo1()
+}
diff --git "a/blog/content/\347\225\252\345\244\226.\345\270\270\347\224\250\346\223\215\344\275\234/Go\344\273\243\347\240\201\345\237\272\346\234\254\346\240\207\345\207\206\350\247\204\350\214\203.md" "b/5.standard-library/5.1-Go\344\273\243\347\240\201\345\237\272\346\234\254\346\240\207\345\207\206\350\247\204\350\214\203.md"
similarity index 91%
rename from "blog/content/\347\225\252\345\244\226.\345\270\270\347\224\250\346\223\215\344\275\234/Go\344\273\243\347\240\201\345\237\272\346\234\254\346\240\207\345\207\206\350\247\204\350\214\203.md"
rename to "5.standard-library/5.1-Go\344\273\243\347\240\201\345\237\272\346\234\254\346\240\207\345\207\206\350\247\204\350\214\203.md"
index e9b0569..ba8226e 100644
--- "a/blog/content/\347\225\252\345\244\226.\345\270\270\347\224\250\346\223\215\344\275\234/Go\344\273\243\347\240\201\345\237\272\346\234\254\346\240\207\345\207\206\350\247\204\350\214\203.md"
+++ "b/5.standard-library/5.1-Go\344\273\243\347\240\201\345\237\272\346\234\254\346\240\207\345\207\206\350\247\204\350\214\203.md"
@@ -1,9 +1,10 @@
-## 文档
+# 5.1 Go代码基本标准规范
+## 5.1.1 文档
- 不刻意制定详细文档
- 编码级别文档化,支持一键导出文档
-## 统一的标准和习惯,提高可读性
+## 5.1.2 统一的标准和习惯,提高可读性
三个统一
@@ -11,7 +12,7 @@
- 统一的接口规范:错误码、返回格式、国际化
- 统一编码习惯
-## 统一编码习惯
+## 5.1.3 统一编码习惯
**变量常量**
diff --git a/5.standard-library/5.2-json.md b/5.standard-library/5.2-json.md
new file mode 100644
index 0000000..86c52c6
--- /dev/null
+++ b/5.standard-library/5.2-json.md
@@ -0,0 +1,333 @@
+# json处理
+
+日常工作中,最常用的数据传输格式就是`json`,而`encoding/json`库是内置做解析的库。这一节来看看它的用法,还有几个日常使用中隐晦的陷阱和处理技巧。
+
+## json与struct
+
+一个常见的接口返回内容如下:
+
+```json
+{
+ "data": {
+ "items": [
+ {
+ "_id": 2
+ }
+ ],
+ "total_count": 1
+ },
+ "message": "",
+ "result_code": 200
+}
+```
+
+在`golang`中往往是要把`json`格式转换成结构体对象使用的。 新版`Goland`粘贴`json`会自动生成结构体,也可以在 http://json2struct.mervine.net 获得 `json` 到`struct`的自动转换。
+
+```Go
+type ResponseData struct {
+ Data struct {
+ Items []struct {
+ Id int `json:"_id"`
+ } `json:"items"`
+ TotalCount int `json:"total_count"`
+ } `json:"data"`
+ Message string `json:"message"`
+ ResultCode int `json:"result_code"`
+}
+```
+
+用反斜杠加注解的方式表明属于`json`中哪个字段,要注意不应该嵌套层数过多,难以阅读容易出错。
+
+一般把内部结构体提出来,可能会另做他用。
+
+```go
+type ResponseData struct {
+ Data struct {
+ Items []Body `json:"items"`
+ TotalCount int64 `json:"total_count"`
+ } `json:"data"`
+ Message string `json:"message"`
+ ResultCode int64 `json:"result_code"`
+}
+
+type Body struct {
+ ID int `json:"_id"`
+}
+```
+
+## 解析
+
+解析就是`json`字符串,转`struct`类型。如下,第一个参数为字节数组,第二个为接收的结构体实体地址。如有报错返回错误信息,如没有返回`nil`。
+
+```go
+//函数签名
+func Unmarshal(data []byte, v interface{}) error
+// 用法
+err := json.Unmarshal([]byte(jsonStr), &responseData)
+```
+
+完整代码如下
+
+```go
+func foo() {
+ jsonStr := `{"data":{"items":[{"_id":2}],"total_count":1},"message":"","result_code":200}`
+ //把string解析成struct
+ var responseData ResponseData
+ err := json.Unmarshal([]byte(jsonStr), &responseData)
+ if err != nil {
+ fmt.Println("parseJson error:" + err.Error())
+ return
+ }
+ fmt.Println(responseData)
+}
+```
+
+输出如下,和`java`的`toString`不同,直接输出了值,如有需要要自行实现并绑定`ToString`方法。
+
+```go
+{{[{2}] 1} 200}
+```
+
+
+## 反解析
+
+第一步,复习初始化结构体的方法。
+
+```go
+r := ResponseData{
+ Data: struct {
+ Items []Body `json:"items"`
+ TotalCount int64 `json:"total_count"`
+ }{
+ Items: []Body{
+ {ID: 1},
+ {ID: 2},
+ },
+ TotalCount: 1,
+ },
+ Message: "",
+ ResultCode: 200,
+}
+```
+
+如上,无类型的结构体`Data`需要明确把类型再写一遍,再为其赋值。`[]Body`内直接赋值列表。
+
+反解析函数签名如下,传入结构体,返回编码好的`[]byte`,和可能的报错信息。
+
+```go
+func Marshal(v interface{}) ([]byte, error)
+```
+
+完整代码如下
+
+```go
+func bar() {
+ r := ResponseData{
+ ....
+ }
+ //把struct编译成string
+ resBytes, err := json.Marshal(r)
+ if err != nil {
+ fmt.Println("convertJson error: " + err.Error())
+ }
+ fmt.Println(string(resBytes))
+}
+```
+
+输出
+
+```go
+{"data":{"items":[{"_id":1},{"_id":2}],"total_count":1},"message":"","result_code":200}
+```
+
+## 陷阱1、忘记取地址
+
+解析的代码,结尾处应该是`&responseData)` 忘记取地址会导致无法赋值成功,返回报错。
+
+```go
+err := json.Unmarshal([]byte(jsonStr), responseData)
+```
+
+输出报错
+
+```go
+json: Unmarshal(non-pointer main.ResponseData)
+```
+
+## 陷阱2、大小写
+
+定义一个简单的结构体来演示这个陷阱。
+
+```go
+type People struct {
+ Name string `json:"name"`
+ age int `json:"age"`
+}
+```
+
+变量如果需要被外部使用,也就是`java`中的`public`权限,定义时首字母用大写就可以实现。
+
+```go
+type People struct
+```
+
+要用来解析`json`的`struct`内部假如使用了小写作为变量名,会导致无法解析成功,而且不会报错!
+
+```go
+func err1() {
+ reqJson := `{"name":"minibear2333","age":26}`
+ var person People
+ err := json.Unmarshal([]byte(reqJson), &person)
+ if err != nil {...}
+ fmt.Println(person)
+}
+```
+
+输出,没有成功取到`age`字段。
+
+```go
+{minibear2333 0}
+```
+
+这是因为标准库中是使用反射来获取的,私有字段是无法获取到的,所以内部不知道有这个字段,自然无法显示报错信息。
+
+我以前没有用自动解析,手敲上去结构体,很容易出现这样的问题,无论如何漏掉某个字段。好在编译器会有提示。
+
+
+
+
+## 陷阱3、十六进制或其他非 UTF8 字符串
+
+Go 默认使用的字符串编码是 UTF8 编码的。直接解析会出错
+
+```go
+func err2() {
+ raw := []byte(`{"name":"\xc2"}`)
+ var person People
+ if err := json.Unmarshal(raw, &person); err != nil {
+ fmt.Println(err)
+ }
+}
+```
+
+输出
+```go
+invalid character 'x' in string escape code
+```
+
+加上反斜杠转义可以成功,或者使用`base64`编码成字符串,要特别注意这一点,一下子就体现出单元测试的重要性了。
+
+```go
+raw := []byte(`{"name":"\\xc2"}`)
+raw := []byte(`{"name":"wg=="}`)
+```
+
+其他需要注意的是编码如果不是`UTF-8`格式,那么`Go`会用 `�` (`U+FFFD`) 来代替无效的 UTF8,不会报错,但是获得的字符串可能不是你需要的结果。
+
+## 陷阱四、数字转interface{}
+
+因为默认编码无类型数字视为 `float64` 。如果想用类型判断语句为`int`会直接`panic`。
+
+```go
+func err4() {
+ var data = []byte(`{"age": 26}`)
+ var result map[string]interface{}
+ ...
+ var status = result["age"].(int) //error
+}
+```
+
+* 上面的代码隐含一个知识点,`json`中`value`是简单类型时,可以直接解析成字典。
+* 如果有嵌套,那么内部类型也会解析成字典。
+
+运行时 Panic:
+
+```go
+panic: interface conversion: interface {} is float64, not int
+
+goroutine 1 [running]:
+main.err4()
+```
+
+* 可以先转换成`float64`再转换成`int`
+* 其实还有几种方法,太麻烦了没有必要,就不做介绍了。
+
+## 技巧、版本变更兼容
+
+你有没有遇到过一种场景,一个接口更新了版本,把`json`的某个字段变更了,在请求的时候每次都定义两套`struct`。
+
+比如`Age`在版本1中是`int`在版本2中是`string`,解析的过程中就会出错。
+
+```go
+json: cannot unmarshal number into Go struct field People.age of type string
+```
+
+我在下面介绍一个技巧,可以省去每次解析都要转换的工作。
+
+我在源码里面看到,无论反射获得的是哪种类型都会去调用相应的解析接口`UnmarshalJSON`。
+
+结合前面的知识,在`Go`里面看起来像鸭子就是鸭子,我们只要实现这个方法,并绑定到结构体对象上,就可以让源码来调用我们的方法。
+
+```go
+type People struct {
+ Name string `json:"name"`
+ Age int `json:"_"`
+}
+func (p *People) UnmarshalJSON(b []byte) error {
+ ...
+}
+```
+
+* 使用下划线,表示此类型不解析。
+* 必须用指针的方式绑定方法。
+* 必须与interface{}中定义的方法签名完全一致。
+
+一共有四个步骤
+
+1、定义临时类型。用来接受非`json:"_"`的字段,注意用的是`type`关键字。
+
+```go
+type tmp People
+```
+
+2、用中间变量接收json串,tmp以外的字段用来接受`json:"_"`属性字段
+
+```go
+var s = &struct {
+ tmp
+ // interface{}类型,这样才可以接收任意字段
+ Age interface{} `json:"age"`
+}{}
+// 解析
+err := json.Unmarshal(b, &s)
+```
+
+3、判断真实类型,并类型转换
+
+```go
+switch t := s.Age.(type) {
+case string:
+ var age int
+ age, err = strconv.Atoi(t)
+ if err != nil {...}
+ s.tmp.Age = age
+case float64:
+ s.tmp.Age = int(t)
+}
+```
+
+4、tmp类型转换回People,并赋值
+```go
+*p = People(s.tmp)
+```
+
+## 小结
+
+通过本节,我们掌握了标准库中`json`解析和反解析的方法,以及很有可能日常工作中踩到的几个坑。
+
+最后分享了一个技巧,实际使用中,这个技巧更加灵活。
+
+留一个作业:假如有`v1`和`v2`不同的两个版本`json`几乎完成不同,业务逻辑已经使用`v1`版本,是否可以把`v2`版本转换成`v1`版本,不用改动业务逻辑?
+
+提示: 可以通过深拷贝把`v2`版本解析出来的结构体完全转换成`v1`版本的结构体。
+要求:必须使用实现 `UnmarshalJSON`的技巧。
diff --git a/5.standard-library/5.2-json/fix_int/fix.go b/5.standard-library/5.2-json/fix_int/fix.go
new file mode 100644
index 0000000..6e61552
--- /dev/null
+++ b/5.standard-library/5.2-json/fix_int/fix.go
@@ -0,0 +1,62 @@
+package main
+
+import (
+ "encoding/json"
+ "fmt"
+ "strconv"
+)
+
+type People struct {
+ Name string `json:"name"`
+ Age int `json:"_"`
+}
+
+func (p *People) UnmarshalJSON(b []byte) error {
+ // 定义临时类型 用来接受非`json:"_"`的字段
+ type tmp People
+ // 用中间变量接收json串,tmp以外的字段用来接受`json:"_"`属性字段
+ var s = &struct {
+ tmp
+ // interface{}类型,这样才可以接收任意字段
+ Age interface{} `json:"age"`
+ }{}
+ // 解析
+ err := json.Unmarshal(b, &s)
+ if err != nil {
+ return err
+ }
+ // 判断真实类型,并类型转换
+ switch t := s.Age.(type) {
+ case string:
+ var age int
+ age, err = strconv.Atoi(t)
+ if err != nil {
+ return err
+ }
+ s.tmp.Age = age
+ case float64:
+ s.tmp.Age = int(t)
+ }
+ // tmp类型转换回People,并赋值
+ *p = People(s.tmp)
+ return nil
+}
+
+func main() {
+ var req1Json = []byte(`{"age":26}`)
+ var req2Json = []byte(`{"age":"26"}`)
+ var person People
+ err := json.Unmarshal(req1Json, &person)
+ if err != nil {
+ fmt.Println(err)
+ return
+ }
+ fmt.Println(person)
+
+ err = json.Unmarshal(req2Json, &person)
+ if err != nil {
+ fmt.Println(err)
+ return
+ }
+ fmt.Println(person)
+}
diff --git a/3.grammar-advancement/medium/json_interface/fixed_json.go b/5.standard-library/5.2-json/fixed/fixed_json.go
similarity index 100%
rename from 3.grammar-advancement/medium/json_interface/fixed_json.go
rename to 5.standard-library/5.2-json/fixed/fixed_json.go
diff --git a/5.standard-library/5.2-json/parse_json.go b/5.standard-library/5.2-json/parse_json.go
new file mode 100644
index 0000000..2ed51fa
--- /dev/null
+++ b/5.standard-library/5.2-json/parse_json.go
@@ -0,0 +1,74 @@
+package main
+
+import (
+ "encoding/json"
+ "fmt"
+)
+
+// 注意初学者最容易犯的两个致命错误,解析不出来某个字段,还不会报错
+// 1. 注意!!! 要被解析python的结构体,成员变量名称必须首字母大写(权限问题),否则会因为访问不到无法解析成功
+// 2. 注意!!! 不要定义两个 类似 `json:"_id"` 相同却不同名的字段,不然找到死也找不到为什么解析不出来
+type ResponseData struct {
+ Data struct {
+ Items []Body `json:"items"`
+ TotalCount int64 `json:"total_count"`
+ } `json:"data"`
+ Message string `json:"message"`
+ ResultCode int64 `json:"result_code"`
+}
+
+type Body struct {
+ ID int `json:"_id"`
+}
+
+func foo() {
+ jsonStr := `{"data":{"items":[{"_id":2}],"total_count":1},"message":"","result_code":200}`
+ //把string解析成struct
+ var responseData ResponseData
+ err := json.Unmarshal([]byte(jsonStr), &responseData)
+ if err != nil {
+ fmt.Println("parseJson error:" + err.Error())
+ return
+ }
+ fmt.Println(responseData)
+}
+
+func bar() {
+ r := ResponseData{
+ Data: struct {
+ Items []Body `json:"items"`
+ TotalCount int64 `json:"total_count"`
+ }{
+ Items: []Body{
+ {ID: 1},
+ {ID: 2},
+ },
+ TotalCount: 1,
+ },
+ Message: "",
+ ResultCode: 200,
+ }
+ //把struct编译成string
+ resBytes, err := json.Marshal(r)
+ if err != nil {
+ fmt.Println("convertJson error: " + err.Error())
+ }
+ fmt.Println(string(resBytes))
+}
+
+func fooErr() {
+ jsonStr := `{"data":{"items":[{"_id":2}],"total_count":1},"message":"","result_code":200}`
+ //把string解析成struct
+ var responseData ResponseData
+ err := json.Unmarshal([]byte(jsonStr), responseData)
+ if err != nil {
+ fmt.Println(err.Error())
+ return
+ }
+ fmt.Println(responseData)
+}
+func main() {
+ foo()
+ bar()
+ fooErr()
+}
diff --git a/5.standard-library/5.2-json/warning.go b/5.standard-library/5.2-json/warning.go
new file mode 100644
index 0000000..eb8498a
--- /dev/null
+++ b/5.standard-library/5.2-json/warning.go
@@ -0,0 +1,49 @@
+package main
+
+import (
+ "encoding/json"
+ "fmt"
+)
+
+type People struct {
+ Name string `json:"name"`
+ age int `json:"age"`
+}
+
+func err1() {
+ reqJson := `{"name":"minibear2333","age":26}`
+ var person People
+ err := json.Unmarshal([]byte(reqJson), &person)
+ if err != nil {
+ fmt.Println(err)
+ }
+ fmt.Println(person)
+}
+
+func err2() {
+ raw := []byte(`{"name":"\\xc2"}`)
+ var person People
+ if err := json.Unmarshal(raw, &person); err != nil {
+ fmt.Println(err)
+ }
+ fmt.Println(raw)
+}
+
+func err4() {
+ var data = []byte(`{"age": 26}`)
+
+ var result map[string]interface{}
+ if err := json.Unmarshal(data, &result); err != nil {
+ fmt.Println("error:", err)
+ return
+ }
+
+ var status = result["age"].(int) //error
+ fmt.Println("status value:", status)
+}
+
+func main() {
+ err1()
+ err2()
+ err4()
+}
diff --git "a/blog/content/\347\225\252\345\244\226.\345\270\270\347\224\250\346\223\215\344\275\234/Go\346\226\207\344\273\266\346\223\215\344\275\234\345\244\247\345\205\250.md" "b/5.standard-library/5.3-Go\346\226\207\344\273\266\346\223\215\344\275\234\345\244\247\345\205\250.md"
similarity index 100%
rename from "blog/content/\347\225\252\345\244\226.\345\270\270\347\224\250\346\223\215\344\275\234/Go\346\226\207\344\273\266\346\223\215\344\275\234\345\244\247\345\205\250.md"
rename to "5.standard-library/5.3-Go\346\226\207\344\273\266\346\223\215\344\275\234\345\244\247\345\205\250.md"
diff --git a/5.standard-library/5.4-cmd/5.4.1/5.4.1-flag.go b/5.standard-library/5.4-cmd/5.4.1/5.4.1-flag.go
new file mode 100644
index 0000000..fb64aa0
--- /dev/null
+++ b/5.standard-library/5.4-cmd/5.4.1/5.4.1-flag.go
@@ -0,0 +1,27 @@
+package main
+
+import (
+ "flag"
+ "fmt"
+ "os"
+)
+
+var (
+ version = "1.0.0"
+ showVersion = flag.Bool("version", false, "show version information")
+ isDebug = flag.Bool("debug", false, "is debug")
+ ip = flag.String("ip", "127.0.0.1", "Input bind address")
+ port = flag.Int("port", 80, "Input bind port")
+)
+
+func main() {
+ flag.Parse()
+ if *showVersion {
+ fmt.Println(version)
+ os.Exit(0)
+ }
+ if *isDebug {
+ fmt.Println("set log level: debug")
+ }
+ fmt.Println(fmt.Sprintf("bind address: %s:%d successfully",*ip,*port))
+}
diff --git a/5.standard-library/5.4-cmd/5.4.1/goapi b/5.standard-library/5.4-cmd/5.4.1/goapi
new file mode 100755
index 0000000..de379de
Binary files /dev/null and b/5.standard-library/5.4-cmd/5.4.1/goapi differ
diff --git a/5.standard-library/5.4-cmd/5.4.2/flag_easy.go b/5.standard-library/5.4-cmd/5.4.2/flag_easy.go
new file mode 100644
index 0000000..9fe3658
--- /dev/null
+++ b/5.standard-library/5.4-cmd/5.4.2/flag_easy.go
@@ -0,0 +1,20 @@
+package main
+
+import (
+ "flag"
+ "fmt"
+)
+
+var (
+ ip string
+ port int
+)
+
+func init() {
+ flag.StringVar(&ip, "ip", "127.0.0.1", "Input bind address(default: 127.0.0.1)")
+ flag.IntVar(&port, "port", 80, "Input bind port(default: 80)")
+}
+func main() {
+ flag.Parse()
+ fmt.Println(fmt.Sprintf("bind address: %s:%d successfully", ip, port))
+}
diff --git a/5.standard-library/5.4-cmd/5.4.2/k b/5.standard-library/5.4-cmd/5.4.2/k
new file mode 100755
index 0000000..b45af35
Binary files /dev/null and b/5.standard-library/5.4-cmd/5.4.2/k differ
diff --git a/5.standard-library/5.4-cmd/5.4.3/5.4.2.go b/5.standard-library/5.4-cmd/5.4.3/5.4.2.go
new file mode 100644
index 0000000..1c80532
--- /dev/null
+++ b/5.standard-library/5.4-cmd/5.4.3/5.4.2.go
@@ -0,0 +1,35 @@
+package main
+
+import (
+ "fmt"
+ "gopkg.in/alecthomas/kingpin.v2"
+ "os"
+)
+var(
+ showVersion = kingpin.Flag("version",
+ "show version information",
+ ).Default("false").Bool()
+ isDebug = kingpin.Flag("isDebug",
+ "is debug mode(default: false)",
+ ).Default("false").Bool()
+ ip = kingpin.Flag("ip",
+ "Input bind address(default: 127.0.0.1)",
+ ).Default("127.0.0.1").String()
+ port = kingpin.Flag("port",
+ "Input bind port(default: 80)",
+ ).Default("80").Int()
+)
+func main() {
+ kingpin.HelpFlag.Short('h')
+ kingpin.Parse()
+ if *showVersion{
+ fmt.Println("1.0.0")
+ os.Exit(0)
+ }
+ if *isDebug {
+ fmt.Println("set log level: debug")
+ }
+ fmt.Println(fmt.Sprintf("bind address: %s:%d successfully",*ip,*port))
+
+}
+
diff --git a/5.standard-library/5.4-cmd/5.4.3/go.mod b/5.standard-library/5.4-cmd/5.4.3/go.mod
new file mode 100644
index 0000000..0f91aaa
--- /dev/null
+++ b/5.standard-library/5.4-cmd/5.4.3/go.mod
@@ -0,0 +1,10 @@
+module k
+
+go 1.16
+
+require (
+ github.com/alecthomas/template v0.0.0-20190718012654-fb15b899a751 // indirect
+ github.com/alecthomas/units v0.0.0-20210208195552-ff826a37aa15 // indirect
+ github.com/stretchr/testify v1.7.0 // indirect
+ gopkg.in/alecthomas/kingpin.v2 v2.2.6
+)
diff --git a/5.standard-library/5.4-cmd/5.4.3/go.sum b/5.standard-library/5.4-cmd/5.4.3/go.sum
new file mode 100644
index 0000000..2b860b7
--- /dev/null
+++ b/5.standard-library/5.4-cmd/5.4.3/go.sum
@@ -0,0 +1,21 @@
+github.com/alecthomas/template v0.0.0-20190718012654-fb15b899a751 h1:JYp7IbQjafoB+tBA3gMyHYHrpOtNuDiK/uB5uXxq5wM=
+github.com/alecthomas/template v0.0.0-20190718012654-fb15b899a751/go.mod h1:LOuyumcjzFXgccqObfd/Ljyb9UuFJ6TxHnclSeseNhc=
+github.com/alecthomas/units v0.0.0-20210208195552-ff826a37aa15 h1:AUNCr9CiJuwrRYS3XieqF+Z9B9gNxo/eANAJCF2eiN4=
+github.com/alecthomas/units v0.0.0-20210208195552-ff826a37aa15/go.mod h1:OMCwj8VM1Kc9e19TLln2VL61YJF0x1XFtfdL4JdbSyE=
+github.com/davecgh/go-spew v1.1.0 h1:ZDRjVQ15GmhC3fiQ8ni8+OwkZQO4DARzQgrnXU1Liz8=
+github.com/davecgh/go-spew v1.1.0/go.mod h1:J7Y8YcW2NihsgmVo/mv3lAwl/skON4iLHjSsI+c5H38=
+github.com/pmezard/go-difflib v1.0.0 h1:4DBwDE0NGyQoBHbLQYPwSUPoCMWR5BEzIk/f1lZbAQM=
+github.com/pmezard/go-difflib v1.0.0/go.mod h1:iKH77koFhYxTK1pcRnkKkqfTogsbg7gZNVY4sRDYZ/4=
+github.com/stretchr/objx v0.1.0 h1:4G4v2dO3VZwixGIRoQ5Lfboy6nUhCyYzaqnIAPPhYs4=
+github.com/stretchr/objx v0.1.0/go.mod h1:HFkY916IF+rwdDfMAkV7OtwuqBVzrE8GR6GFx+wExME=
+github.com/stretchr/testify v1.4.0/go.mod h1:j7eGeouHqKxXV5pUuKE4zz7dFj8WfuZ+81PSLYec5m4=
+github.com/stretchr/testify v1.7.0 h1:nwc3DEeHmmLAfoZucVR881uASk0Mfjw8xYJ99tb5CcY=
+github.com/stretchr/testify v1.7.0/go.mod h1:6Fq8oRcR53rry900zMqJjRRixrwX3KX962/h/Wwjteg=
+gopkg.in/alecthomas/kingpin.v2 v2.2.6 h1:jMFz6MfLP0/4fUyZle81rXUoxOBFi19VUFKVDOQfozc=
+gopkg.in/alecthomas/kingpin.v2 v2.2.6/go.mod h1:FMv+mEhP44yOT+4EoQTLFTRgOQ1FBLkstjWtayDeSgw=
+gopkg.in/check.v1 v0.0.0-20161208181325-20d25e280405 h1:yhCVgyC4o1eVCa2tZl7eS0r+SDo693bJlVdllGtEeKM=
+gopkg.in/check.v1 v0.0.0-20161208181325-20d25e280405/go.mod h1:Co6ibVJAznAaIkqp8huTwlJQCZ016jof/cbN4VW5Yz0=
+gopkg.in/yaml.v2 v2.2.2 h1:ZCJp+EgiOT7lHqUV2J862kp8Qj64Jo6az82+3Td9dZw=
+gopkg.in/yaml.v2 v2.2.2/go.mod h1:hI93XBmqTisBFMUTm0b8Fm+jr3Dg1NNxqwp+5A1VGuI=
+gopkg.in/yaml.v3 v3.0.0-20200313102051-9f266ea9e77c h1:dUUwHk2QECo/6vqA44rthZ8ie2QXMNeKRTHCNY2nXvo=
+gopkg.in/yaml.v3 v3.0.0-20200313102051-9f266ea9e77c/go.mod h1:K4uyk7z7BCEPqu6E+C64Yfv1cQ7kz7rIZviUmN+EgEM=
diff --git a/5.standard-library/5.4-cmd/5.4.3/k b/5.standard-library/5.4-cmd/5.4.3/k
new file mode 100755
index 0000000..5340ad3
Binary files /dev/null and b/5.standard-library/5.4-cmd/5.4.3/k differ
diff --git a/5.standard-library/5.4-cmd/5.4.4/main.go b/5.standard-library/5.4-cmd/5.4.4/main.go
new file mode 100644
index 0000000..7f219b9
--- /dev/null
+++ b/5.standard-library/5.4-cmd/5.4.4/main.go
@@ -0,0 +1,36 @@
+package main
+
+import (
+ "flag"
+ "fmt"
+ "os"
+)
+
+func main() {
+ fooCmd := flag.NewFlagSet("foo", flag.ExitOnError)
+ fooEnable := fooCmd.Bool("enable", false, "enable")
+
+ barCmd := flag.NewFlagSet("bar", flag.ExitOnError)
+ barLevel := barCmd.Int("level", 0, "level")
+
+ if len(os.Args) < 2 {
+ fmt.Println("expected 'foo' or 'bar' subcommands")
+ os.Exit(1)
+ }
+
+ switch os.Args[1] {
+ case "foo":
+ fooCmd.Parse(os.Args[2:])
+ fmt.Println("subcommand 'foo'")
+ fmt.Println(" enable:", *fooEnable)
+ fmt.Println(" tail:", fooCmd.Args())
+ case "bar":
+ barCmd.Parse(os.Args[2:])
+ fmt.Println("subcommand 'bar'")
+ fmt.Println(" level:", *barLevel)
+ fmt.Println(" tail:", barCmd.Args())
+ default:
+ fmt.Println("expected 'foo' or 'bar' subcommands")
+ os.Exit(1)
+ }
+}
\ No newline at end of file
diff --git a/5.standard-library/5.4-cmd/5.4.4/subcommands b/5.standard-library/5.4-cmd/5.4.4/subcommands
new file mode 100755
index 0000000..911d3c8
Binary files /dev/null and b/5.standard-library/5.4-cmd/5.4.4/subcommands differ
diff --git "a/5.standard-library/5.4-\345\221\275\344\273\244\350\241\214\345\272\224\347\224\250.md" "b/5.standard-library/5.4-\345\221\275\344\273\244\350\241\214\345\272\224\347\224\250.md"
new file mode 100644
index 0000000..38fdd24
--- /dev/null
+++ "b/5.standard-library/5.4-\345\221\275\344\273\244\350\241\214\345\272\224\347\224\250.md"
@@ -0,0 +1,402 @@
+# 5.4 命令行应用
+
+## 5.4.1 标准库`flag`
+
+一个简单的命令行程序应该可以输出帮助信息,也可以通过传递参数改变程序的配置内容,`-h`是`flag`库的默认帮助参数。
+
+```shell
+./goapi -h
+Usage of ./goapi:
+ -debug
+ is debug
+ -ip string
+ Input bind address (default "127.0.0.1")
+ -port int
+ Input bind port (default 80)
+ -version
+ show version information
+```
+
+`goapi`是我`build`出来的一个二进制`go`程序,上面所示的四个参数,是自定义的。
+
+按提示的方法,可以像这样使用参数。
+
+```shell
+./goapi -debug -ip 192.168.1.1
+./goapi -port 8080
+./goapi -version
+```
+
+其中像`-version`这样的参数是`bool`类型的参数,只要指定了就会设置为`true`,不指定时为默认值,假如默认值不是`false`,想指定为`false`就要显式的指定。
+
+```shell
+./goapi -version=false
+```
+
+这几种格式都是兼容的
+
+```shell
+-isbool #同于 -isbool=true
+-age=x #-和等号
+-age x #-和空格
+--age=x #2个-和等号
+--age x #2个-和空格
+```
+
+这些参数用`flag`实现起来很简单,一个参数定义的格式为 `flag.XXX(参数名,默认值,提示信息) 返回指针`,如下:
+
+```go
+var (
+ showVersion = flag.Bool("version", false, "show version information")
+ isDebug = flag.Bool("debug", false, "is debug")
+ ip = flag.String("ip", "127.0.0.1", "Input bind address")
+ port = flag.Int("port", 80, "Input bind port")
+)
+```
+
+具体有哪些参数变量就要自己定义了,可以用它来设置是否debug模式启动、输出版本信息并退出、输入绑定的`ip`和端口等。
+
+然后在恰当的地方调用解析函数`flag.Parse()`,一定要在使用参数前调用,作为解析命令行程序的输入,不然是没有数据的,写法如下:
+
+```go
+func main() {
+ flag.Parse()
+ if *showVersion {
+ fmt.Println(version)
+ os.Exit(0)
+ }
+ if *isDebug {
+ fmt.Println("set log level: debug")
+ }
+ fmt.Println(fmt.Sprintf("bind address: %s:%d successfully",*ip,*port))
+}
+```
+
+可以把这些单独放到一个包中,便于阅读,也可以放到`init()`函数里自动加载。
+
+## 5.4.2 flag的简写方式
+
+有时候可能我们要给某个全局配置变量赋值,这样写可以省掉很多判断的代码,也避免了使用指针,而命令的使用方式没有变化,样例如下:
+
+```go
+var (
+ ip string
+ port int
+)
+
+func init() {
+ flag.StringVar(&ip, "ip", "127.0.0.1", "Input bind address(default: 127.0.0.1)")
+ flag.IntVar(&port, "port", 80, "Input bind port(default: 80)")
+}
+func main() {
+ flag.Parse()
+ fmt.Println(fmt.Sprintf("bind address: %s:%d successfully", ip, port))
+}
+```
+
+## 5.4.3 从源码来看`flag`如何解析参数
+
+其实之前的方式在源码里就是调用`xxVar`函数的,以`Bool`类型为例,源码内容如下:
+
+```go
+func (f *FlagSet) Bool(name string, value bool, usage string) *bool {
+ p := new(bool)
+ f.BoolVar(p, name, value, usage)
+ return p
+}
+```
+
+其中`BoolVal`函数解析传入参数,如果没有传入就使用默认值,并把`p`返回,如下:
+
+```go
+func (f *FlagSet) BoolVar(p *bool, name string, value bool, usage string) {
+ f.Var(newBoolValue(value, p), name, usage)
+}
+
+type boolValue bool
+
+func newBoolValue(val bool, p *bool) *boolValue {
+ *p = val
+ return (*boolValue)(p)
+}
+```
+
+* `newBoolValue` 函数作为封装,得到一个用`type`重命名的`bool`类型`boolValue` 把返回值设置为默认值
+* 在`flag`包的设计中有两个重要的类型,`Flag`和`FlagSet`分别表示某个参数,和不重复的参数列表。
+* `f.Var`函数的作用就是把参数封装成`Flag`,并合并到`FlagSet`中
+
+```go
+func (f *FlagSet) Var(value Value, name string, usage string) {
+ // Remember the default value as a string; it won't change.
+ flag := &Flag{name, usage, value, value.String()}
+ _, alreadythere := f.formal[name]
+ if alreadythere {
+ //...错误处理省略
+ }
+ if f.formal == nil {
+ f.formal = make(map[string]*Flag)
+ }
+ f.formal[name] = flag
+}
+```
+
+`FlagSet`结构体中起作用的是`formal map[string]*Flag`类型
+
+我们已经知道了,在调用`Parse`的时候,会对参数解析,使用时就可以得到真实值。
+
+```go
+// 返回一个FlagSet
+var CommandLine = NewFlagSet(os.Args[0], ExitOnError)
+func Parse() {
+ // Ignore errors; CommandLine is set for ExitOnError.
+ // 调用了FlagSet.Parse
+ CommandLine.Parse(os.Args[1:])
+}
+func (f *FlagSet) Parse(arguments []string) error {
+ f.parsed = true
+ f.args = arguments
+ for {
+ seen, err := f.parseOne()
+ if seen {
+ continue
+ }
+ if err == nil {
+ break
+ }
+ switch f.errorHandling {
+ case ContinueOnError:
+ return err
+ case ExitOnError:
+ if err == ErrHelp {
+ os.Exit(0)
+ }
+ os.Exit(2)
+ case PanicOnError:
+ panic(err)
+ }
+ }
+ return nil
+}
+```
+
+* 可看到解析的过程实际上是多次调用`parseOne()`解析出所有的`Flag`,就像翻页一样
+* 用`switch`对应处理错误,决定退出码或直接`panic`
+
+```go
+func (f *FlagSet) parseOne() (bool, error) {
+ //...
+ s := f.args[0]
+ //...
+ if s[1] == '-' {
+ //...
+ }
+ name := s[numMinuses:]
+ if len(name) == 0 || name[0] == '-' || name[0] == '=' {
+ return false, f.failf("bad flag syntax: %s", s)
+ }
+
+ // it's a flag. does it have an argument?
+ f.args = f.args[1:]
+ //...
+ m := f.formal
+ flag, alreadythere := m[name] // BUG
+ // ...如果不存在,或者需要输出帮助信息,则返回
+ // ...设置真实值调用到 flag.Value.Set(value)
+ if f.actual == nil {
+ f.actual = make(map[string]*Flag)
+ }
+ f.actual[name] = flag
+ return true, nil
+}
+
+```
+
+* `parseOne` 内部会解析一个输入参数,判断输入参数格式,获取参数值
+* 解析过程就是逐个取出程序参数,判断`-`、`=`取参数与参数值
+* 解析后查找之前提到的`formal map`中有没有存在此参数,并设置真实值
+* 把设置完毕真实值的参数放到`f.actual map`中,以供它用
+* 一些错误处理和细节的代码我省略掉了,感兴趣可以自行看源码
+* 实际上就是逐个参数解析并设置到对应的指针变量的指向上,让返回值出现变化。
+
+`flag.Value.Set(value)` 这里是设置数据真实值的代码,`Value`长这样
+
+```go
+type Value interface {
+ String() string
+ Set(string) error
+}
+```
+
+它被设计成一个接口,不同的数据类型自己实现这个接口,返回给用户的地址就是这个接口的实例数据,解析过程中,可以通过 Set 方法修改它的值,这个设计确实还挺巧妙的。
+
+```go
+func (b *boolValue) String() string { return strconv.FormatBool(bool(*b)) }
+func (b *boolValue) Set(s string) error {
+ v, err := strconv.ParseBool(s)
+ if err != nil {
+ err = errParse
+ }
+ *b = boolValue(v)
+ return err
+}
+```
+
+
+## 5.4.4 从源码想到的拓展用法
+
+`flag`的常用方法,基本原理也了解了,我注意到整个过程都围绕了`FlagSet`这个结构体,它是核心的解析类。
+
+在库内部提供了一个 `*FlagSet` 的实例对象 `CommandLine`,它通过`NewFlagSet`方法创建。并且为它的所有方法封装了一下直接对外,说明我们可以在外部用到它做某些更高级的事情。
+
+```go
+var CommandLine = NewFlagSet(os.Args[0], ExitOnError)
+```
+
+可以看到调用的时候是传入命令行第一个参数,第二个参数表示报错时应该呈现怎样的错误。
+
+那就意味着我们可以根据命令行第一个参数不同而呈现不同的表现!效果如下
+
+```shell
+$ ./subcommands
+expected 'foo' or 'bar' subcommands
+
+$ ./subcommands foo -h
+Usage of foo:
+ -enable
+ enable
+
+$./subcommands foo -enable
+subcommand 'foo'
+ enable: true
+ tail: []
+```
+
+怎么写?
+
+```go
+fooCmd := flag.NewFlagSet("foo", flag.ExitOnError)
+fooEnable := fooCmd.Bool("enable", false, "enable")
+
+barCmd := flag.NewFlagSet("bar", flag.ExitOnError)
+barLevel := barCmd.Int("level", 0, "level")
+
+if len(os.Args) < 2 {
+ fmt.Println("expected 'foo' or 'bar' subcommands")
+ os.Exit(1)
+}
+```
+
+* 定义两个不同的`FlagSet`,接受`foo`或`bar`参数
+* 绑定错误时退出
+* 分别为每个`FlagSet`绑定参数
+* 如果判断参数少于2个退出
+
+```go
+switch os.Args[1] {
+case "foo":
+ fooCmd.Parse(os.Args[2:])
+ fmt.Println("subcommand 'foo'")
+ fmt.Println(" enable:", *fooEnable)
+ fmt.Println(" tail:", fooCmd.Args())
+case "bar":
+ barCmd.Parse(os.Args[2:])
+ fmt.Println("subcommand 'bar'")
+ fmt.Println(" level:", *barLevel)
+ fmt.Println(" tail:", barCmd.Args())
+default:
+ fmt.Println("expected 'foo' or 'bar' subcommands")
+ os.Exit(1)
+}
+```
+
+* 使用`switch`来切换命令行参数,绑定不同的变量
+* 对应不同变量输出不同表现
+* `x.Args()`可以打印未匹配到的其他参数
+
+其他
+
+flag 提供三种错误处理的方式:
+
+* `ContinueOnError`: 通过 `Parse` 的返回值返回错误
+* `ExitOnError`: 调用 `os.Exit(2)` 直接退出程序,这是默认的处理方式
+* `PanicOnError`: 调用 `panic` 抛出错误
+
+## 小结
+
+通过本节我们了解到了标准库`flag`的使用方法,参数绑定的两种方式,还通过源码解析了内部是如何巧妙的实现的。
+
+我们还使用源码暴露出来的函数,接收不同参数呈现不同的表现,这种方式可以让应用呈现完成不同的功能,我想到的是用来通过环境变量改变命令用法、或者让程序复用大段逻辑呈现不同作用时使用。
+
+但现在微服务那么流行,大多功能集成在一个服务里是不科学的,如果有重复代码应该提炼成共同模块才是王道。
+
+你还想到哪些使用场景呢?
+
+## 引用
+
+* 源码包 https://golang.org/src/flag/flag.go
+* 命令行子命令 https://gobyexample-cn.github.io/command-line-subcommands
+* 命令行解析库 flag https://segmentfault.com/a/1190000021143456
+* 腾讯云文档flag https://cloud.tencent.com/developer/section/1141707#stage-100022105
+
+
+# 未完待续,拼命更新中。。。。
+
+
+## 5.4.2 第三方库`kingpin`
+
+`kingpin` 功能比 `flag` 库而言用法差不多,但更强大。 相比 `flag` 库,最重要的一点就是支持不加 `-` 的调用。
+
+比如一个命令行程序有三个函数分别为 `A` , `B` , `C` ,要实现根据命令行的输入运行不同的函数,如果用flag实现的话应该是下面这种使用方法:
+
+```shell
+./cli --method A
+./cli --method B
+./cli --method C
+```
+
+`flag`库每次都需要输入 `--method` ,然而用 `kingpin` 库实现的话就可以达到下面这种效果:
+
+```shell
+./cli A
+./cli B
+./cli C
+```
+
+一下子节省了很多不必要的输入。
+
+```go
+var(
+ showVersion = kingpin.Flag("version",
+ "show version information",
+ ).Default("false").Bool()
+)
+func main() {
+ kingpin.HelpFlag.Short('h')
+ kingpin.Parse()
+ if *showVersion{
+ fmt.Println("1.0.0")
+ os.Exit(0)
+ }
+}
+```
+
+最后,引入此包是
+
+``` BASH
+go get gopkg.in/alecthomas/kingpin.v2
+```
+
+
+官方文档参考 [package kingpin
+](http://godoc.org/gopkg.in/alecthomas/kingpin.v2)
+
+
+## 原理解析
+## 性能对比
+## 更成熟的第三方库`cobra`
+## 仿`python -m json.tool`
+## 简介
+
+## 引用
+
+[Golang命令行参数解析库kingpin](https://xuanyu.li/2017/08/05/golang-cli-args-parse/)
diff --git "a/5.standard-library/5.6-\345\255\227\347\254\246\344\270\262\345\244\204\347\220\206.md" "b/5.standard-library/5.6-\345\255\227\347\254\246\344\270\262\345\244\204\347\220\206.md"
new file mode 100644
index 0000000..7b9b1fe
--- /dev/null
+++ "b/5.standard-library/5.6-\345\255\227\347\254\246\344\270\262\345\244\204\347\220\206.md"
@@ -0,0 +1,238 @@
+# strings 库
+`strings` 库包含了许多高效的字符串常用操作的函数和方法,巧用这些函数与方法,能极大的提高我们程序的性能。下面介绍一些常用的函数和方法。
+# 高效拼接字符串:strings.Builder
+使用 `strings` 库里的 `Builder` 变量,结合其写入方法如 `WriteString` 方法,可以进行高效的拼接字符串。
+```go
+import (
+ "strings"
+)
+
+func main() {
+ var builder strings.Builder
+ builder.WriteString("你好")
+ builder.WriteString(",")
+ builder.WriteString("我是陈明勇")
+ builder.WriteString("!")
+ s := builder.String()
+ println(s) // 你好,我是陈明勇!
+}
+```
+`strings.Builder` 底层是通过其内部的 `slice` 来储存内容的。当调用其相关的写入方法(如 `WriteString` )的时,新的字节数据就会被追加到 `slice` 上。相比普通字符串的多次拼接,减少了拼接时需要创建新字符串的内存开销。
+# 大小写转换:ToUpper 与 ToLower
+- **小写转大写**
+
+ `ToUpper(s string) string`:将一个字符串里的小写字符转成大写,因为字符串不可变的特点,该函数会返回一个新的字符串。
+ ```go
+ import "strings"
+
+ func main() {
+ s1 := "hello"
+ s2 := strings.ToUpper(s1)
+ println(s2) // HELLO
+ }
+ ```
+- **大写转小写**
+
+ `ToLower(s string) string`:将一个字符串里的大写字符转成小写,因为字符串不可变的特点,该函数会返回一个新的字符串。
+ ```go
+ import "strings"
+
+ func main() {
+ s1 := "HELLO"
+ s2 := strings.ToLower(s1)
+ println(s2) // hello
+ }
+ ```
+# 比较两个字符串:== 与 EqualFold
+- 区分大小写比较
+ ```go
+ func main() {
+ s1 := "hello"
+ s2 := "hello"
+ s3 := "HELLO"
+ println(s1 == s2) // true
+ println(s1 == s3) // false
+ }
+ ```
+ 直接通过 `==` 操作符进行区分大小写的字符串比较即可。
+- 不区分大小写比较
+ 使用 `EqualFold(s, t string) bool` 函数进行比较,两个参数为需要比较的两个字符串,返回值为布尔值,如果是 `true` 说明字符串相等,反之 `false` 则字符串不相等。
+ ```go
+ func main() {
+ s1 := "hello"
+ s2 := "hello"
+ s3 := "HELLO"
+ isEual := strings.EqualFold(s1, s2)
+ println(isEual) // true
+ isEual2 := strings.EqualFold(s1, s3)
+ println(isEual2) // true
+ }
+ ```
+# 字符串的替换:Replace
+字符串替换的函数:`Replace(s, old, new string, n int) string`
+- 第一个参数 `s` 为原字符串。
+- 第二个参数 `old` 为需要替换的字符串。
+- 第三个参数 `new` 为替换后的字符串。
+- 第四个参数 `n` 为指定替换几个 `old` ,如果 `n` 小于 0,则替换全部。
+- 返回值为替换后的新字符串。
+
+案例:实现对敏感词的替换
+```go
+func main() {
+ s1 := "我靠啊靠"
+ s2 := strings.Replace(s1, "靠", "*", 1)
+ println(s2) // true 我*啊靠
+ s3 := "我靠啊靠"
+ s4 := strings.Replace(s3, "靠", "*", -1)
+ println(s4) // true 我*啊*
+}
+```
+第一次替换时,`n` 指定为 `1`,因此只替换了一个敏感词。
+第二次替换时,`n` 指定为 `-1`,小于 `0`,因此将所有敏感词都替换了。
+# 按照某个分割标识分割字符串:Split
+分割字符串的函数:`Split(s, sep string) []string`
+- 第一个参数 `s` 为需要分割的字符串。
+- 第二个参数 `sep` 为分割的标识。
+- 返回值为字符串切片,保存被分割出来的子字符串。
+```go
+import (
+ "fmt"
+ "strings"
+)
+
+func main() {
+ s1 := "golang-is-awesome"
+ strSlice := strings.Split(s1, "-")
+ fmt.Println(strSlice) // [golang is awesome]
+}
+```
+# 去掉字符串左右两边的空格:TrimSpace
+函数:`TrimSpace(s string) string`
+- 第一个参数 `s` 为需要去除空格的字符串。
+- 返回值为去除空格后的新字符串。
+```go
+import (
+ "strings"
+)
+
+func main() {
+ s1 := " golang is awesome "
+ s2 := strings.TrimSpace(s1)
+ println(s2) // "golang is awesome"
+}
+```
+# 将字符串[左边]或[右边]或[左右两边]所指定的字符(串)去掉:Trim
+- 将字符串[左右两边]所指定的字符(串)去掉
+
+ 函数:`Trim(s, cutset string) string`
+ - 第一个参数 `s` 为需要去除指定字符的字符串。
+ - 第二个参数为指定的字符(串)。
+ ```go
+ import (
+ "strings"
+ )
+
+ func main() {
+ s1 := "-golang is awesome-"
+ s2 := strings.Trim(s1, "-")
+ println(s2) // "golang is awesome"
+ }
+ ```
+- 将字符串[左边]所指定的字符(串)去掉
+
+ 函数:`TrimLeft(s, cutset string) string`
+ - 第一个参数 `s` 为需要去除指定字符的字符串。
+ - 第二个参数为指定的字符(串)。
+ ```go
+ import (
+ "strings"
+ )
+
+ func main() {
+ s1 := "-golang is awesome"
+ s2 := strings.TrimLeft(s1, "-")
+ println(s2) // "golang is awesome"
+ }
+ ```
+
+- 将字符串[右边]所指定的字符(串)去掉
+
+ 函数:`TrimRight(s, cutset string) string`
+ - 第一个参数 `s` 为需要去除指定字符的字符串。
+ - 第二个参数为指定的字符(串)。
+ ```go
+ import (
+ "strings"
+ )
+
+ func main() {
+ s1 := "golang is awesome-"
+ s2 := strings.TrimRight(s1, "-")
+ println(s2) // "golang is awesome"
+ }
+ ```
+# 判断字符串是否以指定的字符串开头:HasPrefix
+函数:`HasPrefix(s, prefix string) bool`
+
+- 第一个参数 `s` 为被判断字符串。
+- 第二个参数 `prefix` 为指定的字符串。
+```go
+import (
+ "strings"
+)
+
+func main() {
+ s1 := "hello world!"
+ flag := strings.HasPrefix(s1, "hello")
+ println(flag) // true
+}
+```
+# 判断字符串是否以指定的字符串结束:HasSuffix
+函数:`HasSuffix(s, prefix string) bool`
+- 第一个参数 `s` 为被判断字符串。
+- 第二个参数 `prefix` 为指定的字符串。
+```go
+import (
+ "strings"
+)
+
+func main() {
+ s1 := "hello world!"
+ flag := strings.HasSuffix(s1, "!")
+ println(flag) // true
+}
+```
+# 将字符串切片中的元素以指定字符串连接生成新字符串:Join
+函数:`Join(elems []string, sep string) string`
+- 第一个参数 `elems` 为字符串切片。
+- 第二个参数 `sep` 为连接符。
+- 返回值为新的字符串。
+```go
+import (
+ "strings"
+)
+
+func main() {
+ strSlice := []string{"golang", "is", "awesome"}
+ s := strings.Join(strSlice, "-")
+ println(s) // golang-is-awesome
+}
+```
+# 查找子串是否存在于指定的字符串中:Contains
+函数:` Contains(s, substr string) bool`
+- 第一个参数 `s` 为指定的字符串。
+- 第二个参数 `substr` 为子串。
+- 返回值为布尔值,如果是 `true` 说明存在,反之 `false` 则不存在。
+```go
+import (
+ "strings"
+)
+
+func main() {
+ s := "golang is awesome"
+ isContains := strings.Contains(s, "golang")
+ println(isContains) // true
+}
+```
+# 小结
+本文先对 `strings` 标准库里的 `Builder` 变量进行介绍,使用其写入方法可以高效地拼接字符串,然后对 `ToUpper`、`ToLower`、`Replace` 等常用函数的参数和返回值以及用法进行介绍。
diff --git a/5.standard-library/append_bug/main.go b/5.standard-library/append_bug/main.go
new file mode 100644
index 0000000..94001f6
--- /dev/null
+++ b/5.standard-library/append_bug/main.go
@@ -0,0 +1,14 @@
+package main
+
+import "fmt"
+
+func main() {
+ var a = make([]int, 0)
+ for i := 0; i < 3; i++ {
+ a = append(a, i)
+ }
+ b := append(a, 1)
+ c := append(a, 2)
+ d := append(a, 3)
+ fmt.Println(b[3], c[3], d[3])
+}
diff --git a/5.standard-library/copy/my_copy/copy.go b/5.standard-library/copy/my_copy/copy.go
new file mode 100644
index 0000000..d44c887
--- /dev/null
+++ b/5.standard-library/copy/my_copy/copy.go
@@ -0,0 +1,75 @@
+package my_copy
+
+import (
+ "bytes"
+ "encoding/gob"
+ "encoding/json"
+)
+
+type Foo struct {
+ List []int `json:"list"`
+ FooMap map[string]string `json:"foo_map"`
+ IntPtr *int `json:"int_ptr"`
+}
+
+func (f *Foo) Duplicate() Foo {
+ var tmp = Foo{
+ List: make([]int, 0, len(f.List)),
+ FooMap: make(map[string]string),
+ IntPtr: new(int),
+ }
+
+ copy(tmp.List, f.List)
+ for i := range f.FooMap {
+ tmp.FooMap[i] = f.FooMap[i]
+ }
+ if f.IntPtr != nil {
+ *tmp.IntPtr = *f.IntPtr
+ } else {
+ tmp.IntPtr = nil
+ }
+ return tmp
+}
+
+func DeepCopyByJson(dst, src interface{}) error {
+ b, err := json.Marshal(src)
+ if err != nil {
+ return err
+ }
+ err = json.Unmarshal(b, dst)
+
+ return err
+}
+func DeepCopyByGob(dst, src interface{}) error {
+ var buffer bytes.Buffer
+ if err := gob.NewEncoder(&buffer).Encode(src); err != nil {
+ return err
+ }
+
+ return gob.NewDecoder(&buffer).Decode(dst)
+}
+
+//
+//func main() {
+// fmt.Println("手动拷贝方法")
+// var a = 1
+// var t1 = Foo{IntPtr: &a}
+// t2 := t1.Duplicate()
+// a = 2
+// fmt.Println(*t1.IntPtr)
+// fmt.Println(*t2.IntPtr)
+// fmt.Println("json序列化反序列化方法")
+// a = 3
+// t1 = Foo{IntPtr: &a}
+// t2 = Foo{}
+// _ = DeepCopyByJson(&t2, t1)
+// fmt.Println(*t1.IntPtr)
+// fmt.Println(*t2.IntPtr)
+// fmt.Println("gob序列化反序列化方法")
+// a = 4
+// t1 = Foo{IntPtr: &a}
+// t2 = Foo{}
+// _ = DeepCopyByGob(&t2, t1)
+// fmt.Println(*t1.IntPtr)
+// fmt.Println(*t2.IntPtr)
+//}
diff --git a/5.standard-library/copy/my_copy/copy_b_test.go b/5.standard-library/copy/my_copy/copy_b_test.go
new file mode 100644
index 0000000..dda4e21
--- /dev/null
+++ b/5.standard-library/copy/my_copy/copy_b_test.go
@@ -0,0 +1,35 @@
+package my_copy
+
+import "testing"
+
+func BenchmarkFoo_Duplicate(b *testing.B) {
+ b.StopTimer()
+ var a = 1
+ var t1 = Foo{IntPtr: &a}
+ b.StartTimer()
+ for i := 0; i < b.N; i++ {
+ _ = t1.Duplicate()
+ }
+}
+
+func BenchmarkDeepCopyByGob(b *testing.B) {
+ b.StopTimer()
+ var a = 1
+ var t1 = Foo{IntPtr: &a}
+ t2 := Foo{}
+ b.StartTimer()
+ for i := 0; i < b.N; i++ {
+ _ = DeepCopyByGob(&t2, t1)
+ }
+}
+
+func BenchmarkDeepCopyByJson(b *testing.B) {
+ b.StopTimer()
+ var a = 1
+ var t1 = Foo{IntPtr: &a}
+ t2 := Foo{}
+ b.StartTimer()
+ for i := 0; i < b.N; i++ {
+ _ = DeepCopyByJson(&t2, t1)
+ }
+}
diff --git a/5.standard-library/copy/my_copy/go.mod b/5.standard-library/copy/my_copy/go.mod
new file mode 100644
index 0000000..bede29c
--- /dev/null
+++ b/5.standard-library/copy/my_copy/go.mod
@@ -0,0 +1,3 @@
+module my_copy
+
+go 1.16
diff --git "a/blog/content/\347\225\252\345\244\226.\345\270\270\347\224\250\346\223\215\344\275\234/\345\210\207\347\211\207\346\216\222\345\272\217sort\345\214\205\347\232\204\344\275\277\347\224\250.md" "b/5.standard-library/\345\210\207\347\211\207\346\216\222\345\272\217sort\345\214\205\347\232\204\344\275\277\347\224\250.md"
similarity index 70%
rename from "blog/content/\347\225\252\345\244\226.\345\270\270\347\224\250\346\223\215\344\275\234/\345\210\207\347\211\207\346\216\222\345\272\217sort\345\214\205\347\232\204\344\275\277\347\224\250.md"
rename to "5.standard-library/\345\210\207\347\211\207\346\216\222\345\272\217sort\345\214\205\347\232\204\344\275\277\347\224\250.md"
index 501688d..dc84944 100644
--- "a/blog/content/\347\225\252\345\244\226.\345\270\270\347\224\250\346\223\215\344\275\234/\345\210\207\347\211\207\346\216\222\345\272\217sort\345\214\205\347\232\204\344\275\277\347\224\250.md"
+++ "b/5.standard-library/\345\210\207\347\211\207\346\216\222\345\272\217sort\345\214\205\347\232\204\344\275\277\347\224\250.md"
@@ -55,41 +55,41 @@ func Example2() {
type stature float32
type weight float32
-type Pepole struct {
+type People struct {
name string
h stature
w weight
}
-// By is the type of a "less" function that defines the ordering of its Pepole arguments.
-type By func(p1, p2 *Pepole) bool
+// By is the type of a "less" function that defines the ordering of its People arguments.
+type By func(p1, p2 *People) bool
// Sort is a method on the function type, By, that sorts the argument slice according to the function.
-func (by By) Sort(p []Pepole) {
- ps := &pepoleSorter{
- pepole: pepole,
+func (by By) Sort(p []People) {
+ ps := &peopleSorter{
+ people: people,
by: by, // The Sort method's receiver is the function (closure) that defines the sort order.
}
sort.Sort(ps)
}
-// pepoleSorter joins a By function and a slice of Pepole to be sorted.
-type pepoleSorter struct {
- pepole []Pepole
- by func(p1, p2 *Pepole) bool // Closure used in the Less method.
+// peopleSorter joins a By function and a slice of People to be sorted.
+type peopleSorter struct {
+ people []People
+ by func(p1, p2 *People) bool // Closure used in the Less method.
}
// Len is part of sort.Interface.
-func (s *pepoleSorter) Len() int {
- return len(s.pepole)
+func (s *peopleSorter) Len() int {
+ return len(s.people)
}
// Swap is part of sort.Interface.
-func (s *pepoleSorter) Swap(i, j int) {
- s.pepole[i], s.pepole[j] = s.pepole[j], s.pepole[i]
+func (s *peopleSorter) Swap(i, j int) {
+ s.people[i], s.people[j] = s.people[j], s.people[i]
}
// Less is part of sort.Interface. It is implemented by calling the "by" closure in the sorter.
-func (s *pepoleSorter) Less(i, j int) bool {
- return s.by(&s.pepole[i], &s.pepole[j])
+func (s *peopleSorter) Less(i, j int) bool {
+ return s.by(&s.people[i], &s.people[j])
}
-var pepole = []Pepole{
+var people = []People{
{"Rose", 1.58, 66.6},
{"Daisley", 1.78, 58.4},
{"Lumiya", 1.65, 57.9},
@@ -99,28 +99,28 @@ var pepole = []Pepole{
// ExampleSortKeys demonstrates a technique for sorting a struct type using programmable sort criteria.
func Example_sortKeys() {
// Closures that order the Planet structure.
- name := func(p1, p2 *Pepole) bool {
+ name := func(p1, p2 *People) bool {
return p1.name < p2.name
}
- stature := func(p1, p2 *Pepole) bool {
+ stature := func(p1, p2 *People) bool {
return p1.h < p2.h
}
- weight := func(p1, p2 *Pepole) bool {
+ weight := func(p1, p2 *People) bool {
return p1.w < p2.w
}
- decreasingWeight := func(p1, p2 *Pepole) bool {
+ decreasingWeight := func(p1, p2 *People) bool {
return !weight(p1, p2)
}
- // Sort the pepole by the various criteria.
- By(name).Sort(pepole)
- fmt.Println("By name:", pepole)
- By(stature).Sort(pepole)
- fmt.Println("By stature:", pepole)
- By(weight).Sort(pepole)
- fmt.Println("By weight:", pepole)
- By(decreasingWeight).Sort(pepole)
- fmt.Println("By decreasing weight:", pepole)
+ // Sort the people by the various criteria.
+ By(name).Sort(people)
+ fmt.Println("By name:", people)
+ By(stature).Sort(people)
+ fmt.Println("By stature:", people)
+ By(weight).Sort(people)
+ fmt.Println("By weight:", people)
+ By(decreasingWeight).Sort(people)
+ fmt.Println("By decreasing weight:", people)
// Output:
// By name: [{Daisley 1.78 58.4} {Lumiya 1.65 57.9} {Rose 1.58 66.6} {Sola 1.68 55.77}]
@@ -130,4 +130,4 @@ func Example_sortKeys() {
}
```
-转自[golang切片排序sort包的使用](https://studygolang.com/articles/21713)
\ No newline at end of file
+转自[golang切片排序sort包的使用](https://studygolang.com/articles/21713)
diff --git a/README.md b/README.md
index db8e9fb..fa38ec0 100644
--- a/README.md
+++ b/README.md
@@ -2,7 +2,11 @@
大家好,我是小熊,本书基于Go语言版本 `1.16` 版本,后续可能会再调整,目录也还未明确,正在**努力持续更新中**,整体进度未明。
-如果对这个项目感兴趣,请点击一下 [**Star**](https://github.com/golang-minibear2333/golang) ,项目会 **持续更新**,感谢大家的支持。
+
+
+
+
+如果对这个项目感兴趣 请 --> [***点击这里跳转项目进行Star***](https://github.com/golang-minibear2333/golang) ,项目会 **持续更新**,感谢大家的支持。
-------
@@ -16,13 +20,15 @@
* 哪有那么多人生开挂,不过都是厚积薄发 。
* 我的个人网站: https://coding3min.com
-* 我用`Golang` 刷 [算法的项目](https://github.com/minibear2333/interview-leetcode)
+* 加我微信加Go语言交流群。
+* 我写的另一本书 [程序员的魔法书](https://leetcode.coding3min.com/) 专门针对面试。
基本会先更新在公众号,再同步到站点上。若想一起学习,欢迎加我的微信:qupzhi。
也可以关注公众号:
-
+
+
## 本书定位
@@ -30,6 +36,8 @@
在本书中会持续迭代总结各种Go语言脚手架的使用方式与基本原理,是一本速查笔记,也是一本深入笔记,适合中、高级工程师学习收藏。
+我以前做过私有云的应用开发,Go拿来写微服务,现在是做运维+开发,做运维平台/工具的时候用Python弄一套Django RFW走天下,特别是Go的ORM每次修改都是噩梦。所以这本书更侧重服务器编程、微服务、数据计算、运维相关、自动化相关和云相关的一些东西,要知道Go不止是开发web。
+
## 面向群体
* 有一定其他语言基础的 Go 语言爱好者
@@ -38,12 +46,20 @@
## 为什么要写这本书
-我的职业生涯非常丰富,做过研发、实施运维、架构的工作,数年前我学习过`Java`,接着从事`C++`开发的工作、后来工作中陆续接触过 `C#`、`Python`、`Golang`,目前专注于`Golang`研发。
+我的职业生涯非常丰富,做过研发、实施运维、架构的工作,数年前我学习过`Java`,接着从事`C++`开发的工作、后来工作中陆续接触过 `C#`、`Python`、`Golang`,目前工作中`Go`和`Python`混用。
虽然网上有很多入门与实战方面的书籍,但我想总结一下我工作或学习过程中接触到的知识,以供查阅。
-## 批评和建议
+## 贡献与勘误
-如果有任何建议或疑问欢迎随时在本书的评论区与我交流,会尽量在 1-2 天内回复你。
+欢迎一起完善此书,有任何问题可以直接在电子书评论区留言,或者直接提issue,我看到会第一时间回复和修订,也欢迎直接修改发起pr贡献,感谢大家。
+## 关于版权
+本书可能会借鉴其他书籍资料,一些网络图片,本书不作为商业用途,仅供学习交流,所借鉴内容来源于网络,会在文章末尾处标记引用位置。如源文章标记禁止引用则不会引用。
+
+因本书开源社区共同维护,难以控制,如有侵权,请留言提出,会在第一时间做出调整修改。
+
+## 批评和建议
+
+如果有任何建议或疑问欢迎随时在本书的评论区与我交流,会尽量在 1-2 天内回复你。
diff --git a/blog/.gitignore b/blog/.gitignore
deleted file mode 100644
index 723ef36..0000000
--- a/blog/.gitignore
+++ /dev/null
@@ -1 +0,0 @@
-.idea
\ No newline at end of file
diff --git "a/blog/content/4.concurrent/4-1-go\350\257\255\350\250\200\344\270\255\347\232\204\345\271\266\345\217\221\347\211\271\346\200\247.md" "b/blog/content/4.concurrent/4-1-go\350\257\255\350\250\200\344\270\255\347\232\204\345\271\266\345\217\221\347\211\271\346\200\247.md"
deleted file mode 100644
index 493843a..0000000
--- "a/blog/content/4.concurrent/4-1-go\350\257\255\350\250\200\344\270\255\347\232\204\345\271\266\345\217\221\347\211\271\346\200\247.md"
+++ /dev/null
@@ -1,118 +0,0 @@
-# 4.1 go语言中的并发特性
-
-> 本节源码位置 https://github.com/golang-minibear2333/golang/blob/master/4.concurrent/4.1-goroutine/goroutine1.go
-
-以前我们写并发的程序一般是用多线程来实现,自己维护一个线程池,在恰当的时候创建、销毁、分配资源。
-
-`go` 在并发方面为我们提供了一个语言级别的支持, `goroutine` 和 `chan` 相互配合,这决定了他的先天优势。
-
-`goroutine` 的概念类似于线程, `Go` 程序运行时会自动调度和管理,系统能智能地将 `goroutine` 中的任务合理地分配给 `CPU` , 让这些任务尽量并发运作。
-
-## 4.1.1 他和线程对比
-
-**从使用上讲**
-
-* 比线程更轻量级,可以创建十万、百万不用担心资源问题。
-* 和 `chan` 搭配使用,实现高并发, `goroutine` 之间传输数据更方便。
-* 如果访问同一个数据块,要小心数据竞态问题、共享锁还是互斥锁的选择问题、并发操作的数据同步问题(后面会说)
-
-**从其实现上讲**
-
-* 从资源上讲,线程的栈内存大小一般是固定的一般为 `2MB` ,虽然这个数值可以设置,但是 太大了浪费,太小了容易不够用, 而 `goroutine` 栈内存是可变的,初始一般为 `2KB` ,随着需求可以扩大达到1GB。 所以 `goroutine` 十分的轻量级,且能满足不同的需求。
-* 从调度上讲,线程的调度由 `OS` 的内核完成;线程的切换需要 **CPU寄存器** 和 **内存的数据交换** ,从而切换不同的线程上下文。 其触发方式为 `CPU时钟` , 而 `goroutine` 的调度则比较轻量级,由自身的调度器完成。
-* 协程同线程的关系,有些类似于 线程同进程的关系。
-
-## 4.1.2 创建与使用
-
-创建一个 `goroutine` ,只需要在函数前加一个 `go` 关键字就成了。
-
-``` Go
-go 函数名(参数)
-```
-
-看一个 `dome`
-
-``` Go
-func quickFun(){
- fmt.Println("maybe you can's see me!")
-}
-
-func main(){
- go quickFun() // 创建了一个 goroutine
- fmt.Println("hey")
- time.Sleep(time.Second)
-}
-```
-
-* `goroutine` 和 `main` 主线程同时运行
-* `main` 运行结束会暴力终止所有协程,所以上面的程序多等待了1秒
-* `Go` 程序从 `main` 包的 `main()` 函数开始,在程序启动时, `Go` 程序就会为 `main()` 函数创建一个默认的 `goroutine` 。
-
-输出
-
-```
-hey
-maybe you can's see me!
-```
-
-对,就是这么简单,如果你的函数只在这里使用,也可以用匿名函数来创建 `goroutine` 。
-
-``` Go
-func main(){
- go func() {
- fmt.Println("hello ")
- }()
- time.Sleep(time.Second) //main运行结束会暴力终止所有协程,所以这里先等待1秒
-}
-```
-
-PS: 和线程不同,`goroutine`没有唯一的`id`,所以我们没办法专门正对某个协程进行操作。
-
-# 4.1.3 goroutine
-
-> 本节源码位置 https://github.com/golang-minibear2333/golang/blob/master/4.concurrent/4.1-goroutine/goroutine2.go
-
-goroutine 是 Go 语言并行设计的核心。goroutine 是一种比线程更轻量的实现,十几个 goroutine 可能在底层就是几个线程。 不同的是,Golang 在 runtime、系统调用等多方面对 goroutine
-调度进行了封装和处理,当遇到长时间执行或者进行系统调用时,会主动把当前 goroutine 的 CPU (P) 转让出去,让其他 goroutine 能被调度并执行,也就是 Golang 从语言层面支持了协程。要使用 goroutine
-只需要简单的在需要执行的函数前添加 go 关键字即可。当执行 goroutine 时候,Go 语言立即返回,接着执行剩余的代码,goroutine 不阻塞主线程。下面我们通过一小段代码来讲解 go 的使用:
-
-```go
-//首先我们先实现一个 Add()函数
-func Add(a, b int) {
-c := a + b
-fmt.Println(c)
-}
-
-go Add(1, 2) //使用go关键字让函数并发执行
-```
-
-Go 的并发执行就是这么简单,当在一个函数前加上 go 关键字,该函数就会在一个新的 goroutine 中并发执行,当该函数执行完毕时,这个新的 goroutine
-也就结束了。不过需要注意的是,如果该函数具有返回值,那么返回值会被丢弃。所以什么时候用 go 还需要酌情考虑。
-
-接着我们通过一个案例来体验一下 Go 的并发到底是怎么样的。新建源文件 goroutine2.go,输入以下代码:
-
-```go
-package main
-
-import "fmt"
-
-func Add(a, b int) {
- c := a + b
- fmt.Println(c)
-}
-
-func main() {
- for i := 0; i < 10; i++ {
- go Add(i, i)
- }
-}
-```
-
-执行 goroutine.go 文件会发现屏幕上什么都没有,但程序并不会报错,这是什么原因呢?原来当主程序执行到 for 循环时启动了 10 个 goroutine,然后主程序就退出了,而启动的 10 个 goroutine 还没来得及执行
-Add() 函数,所以程序不会有任何输出。也就是说主 goroutine 并不会等待其他 goroutine 执行结束。那么如何解决这个问题呢?Go 语言提供的信道(channel)就是专门解决并发通信问题的,下一节我们将详细介绍。
-
-## 4.1.4 小结
-
-学go语言必学并发,轻量协程,还要配合数据传输,生产者消费者模型,生产环境开发利器。
-
-但要并发bug是老大难了,要注意的事良好的代码风格,编程习惯。
diff --git a/blog/content/4.concurrent/channel.go b/blog/content/4.concurrent/channel.go
deleted file mode 100644
index 220ab2e..0000000
--- a/blog/content/4.concurrent/channel.go
+++ /dev/null
@@ -1,30 +0,0 @@
-package main
-
-import "time"
-import "fmt"
-
-func main() {
- c1 := make(chan string)
- c2 := make(chan string)
- go func() {
- time.Sleep(time.Second * 1)
- c1 <- "one"
- }()
- go func() {
- time.Sleep(time.Second * 2)
- c2 <- "two"
- }()
- start := time.Now() // 获取当前时间
-
- for i := 0; i < 2; i++ {
- select {
- case msg1 := <-c1:
- fmt.Println("received", msg1)
- case msg2 := <-c2:
- fmt.Println("received", msg2)
- }
- }
- elapsed := time.Since(start)
- // 这里没有用到3秒,为什么?
- fmt.Println("该函数执行完成耗时:", elapsed)
-}
diff --git a/blog/content/4.concurrent/channel.md b/blog/content/4.concurrent/channel.md
deleted file mode 100644
index d39f738..0000000
--- a/blog/content/4.concurrent/channel.md
+++ /dev/null
@@ -1,32 +0,0 @@
-# channel
-
-channel 是goroutine 之间互相通讯的东西。类似我们 Unix 上的管道(可以在进程间传递消息),用来 goroutine 之间发消息和接收消息。其实,就是在做 goroutine 之间的内存共享。channel
-是类型相关的,也就是说一个 channel 只能传递一种类型的值,这个类型需要在 channel 声明时指定。
-
-## 声明与初始化
-
-channel 的一般声明形式:var chanName chan ElementType。
-
-与普通变量的声明不同的是在类型前面加了 channel 关键字,ElementType 则指定了这个 channel 所能传递的元素类型。示例:
-
-```go
-var a chan int //声明一个传递元素类型为int的channel
-var b chan float64
-var c chan string
-```
-
-初始化一个 channel 也非常简单,直接使用 Go 语言内置的 make() 函数,示例:
-
-```go
-a := make(chan int) //初始化一个int型的名为a的channel
-b := make(chan float64)
-c := make(chan string)
-```
-
-channel 最频繁的操作就是写入和读取,这两个操作也非常简单,示例:
-
-```go
-a := make(chan int)
-a <- 1 //将数据写入channel
-z := <-a //从channel中读取数据
-```
\ No newline at end of file
diff --git a/blog/content/4.concurrent/select.md b/blog/content/4.concurrent/select.md
deleted file mode 100644
index fb3a37a..0000000
--- a/blog/content/4.concurrent/select.md
+++ /dev/null
@@ -1,41 +0,0 @@
-# select
-
-select 用于处理异步 IO 问题,它的语法与 switch 非常类似。由 select 开始一个新的选择块,每个选择条件由 case 语句来描述,并且每个 case 语句里必须是一个 channel 操作。它既可以用于 channel
-的数据接收,也可以用于 channel 的数据发送。如果 select 的多个分支都满足条件,则会随机的选取其中一个满足条件的分支。
-
-新建源文件 [channel.go](channel.go),输入以下代码:
-
-```go
-func main() {
- c1 := make(chan string)
- c2 := make(chan string)
- go func() {
- time.Sleep(time.Second * 1)
- c1 <- "one"
- }()
- go func() {
- time.Sleep(time.Second * 2)
- c2 <- "two"
- }()
- start := time.Now() // 获取当前时间
-
- for i := 0; i < 2; i++ {
- select {
- case msg1 := <-c1:
- fmt.Println("received", msg1)
- case msg2 := <-c2:
- fmt.Println("received", msg2)
- }
- }
- elapsed := time.Since(start)
- // 这里没有用到3秒,为什么?
- fmt.Println("该函数执行完成耗时:", elapsed)
-}
-```
-
-以上代码先初始化两个 channel c1 和 c2,然后开启两个 goroutine 分别往 c1 和 c2 写入数据,再通过 select 监听两个 channel,从中读取数据并输出。
-
-运行结果如下:
-```shell
-$ go run channel.go received one received two
-```
diff --git a/blog/content/4.concurrent/timeout.go b/blog/content/4.concurrent/timeout.go
deleted file mode 100644
index afb3741..0000000
--- a/blog/content/4.concurrent/timeout.go
+++ /dev/null
@@ -1,25 +0,0 @@
-package main
-
-import "time"
-
-func main() {
- t := make(chan bool)
- ch := make(chan int)
- defer func() {
- close(ch)
- close(t)
- }()
- go func() {
- time.Sleep(1e9) //等待1秒
- t <- true
- }()
- go func() {
- time.Sleep(time.Second * 2)
- ch <- 123
- }()
- select {
- case <-ch: //从ch中读取数据
-
- case <-t: //如果1秒后没有从ch中读取到数据,那么从t中读取,并进行下一步操作
- }
-}
diff --git a/blog/content/4.concurrent/timeout.md b/blog/content/4.concurrent/timeout.md
deleted file mode 100644
index 2b6cf60..0000000
--- a/blog/content/4.concurrent/timeout.md
+++ /dev/null
@@ -1,91 +0,0 @@
-# timeout
-
-## 超时机制
-
-通过前面的内容我们了解到,channel 的读写操作非常简单,只需要通过 <- 操作符即可实现,但是 channel 的使用不当却会带来大麻烦。我们先来看之前的一段代码:
-
-```go
-a := make(chan int)
-a <- 1
-z := <-a
-```
-
-观察上面三行代码,第 2 行往 channel 内写入了数据,第 3 行从 channel 中读取了数据,如果程序运行正常当然不会出什么问题,可如果第二行数据写入失败,或者 channel 中没有数据,那么第 3 行代码会因为永远无法从 a
-中读取到数据而一直处于阻塞状态。
-
-相反的,如果 channel 中的数据一直没有被读取,那么写入操作也会一直处于阻塞状态。如果不正确处理这个情况,很可能会导致整个 goroutine 锁死,这就是超时问题。Go
-语言没有针对超时提供专门的处理机制,但是我们却可以利用 select 来巧妙地实现超时处理机制,下面看一个示例:
-
-```go
-t := make(chan bool)
-go func() {
- time.Sleep(1e9) //等待1秒
- t <- true
-}()
-
-select {
- case <-ch: //从ch中读取数据
-
- case <-t: //如果1秒后没有从ch中读取到数据,那么从t中读取,并进行下一步操作
-}
-```
-
-这样的方法就可以让程序在等待 1 秒后继续执行,而不会因为 ch 读取等待而导致程序停滞,从而巧妙地实现了超时处理机制,这种方法不仅简单,在实际项目开发中也是非常实用的。
-
-## channel 的关闭
-
-channel 的关闭非常简单,使用 Go 语言内置的 close() 函数即可关闭 channel,示例:
-
-```go
-ch := make(chan int)
-close(ch)
-```
-
-关闭了 channel 后如何查看 channel 是否关闭成功了呢?很简单,我们可以在读取 channel 时采用多重返回值的方式,示例:
-
-```go
-x, ok := <-ch
-```
-
-通过查看第二个返回值的 bool 值即可判断 channel 是否关闭,若为 false 则表示 channel 被关闭,反之则没有关闭。
-
-建议使用 defer 如下
-
-```go
-t := make(chan bool)
-ch := make(chan int)
-defer func() {
- close(ch)
- close(t)
-}()
-```
-
-[完整代码](timeout.go)
-
-```go
-package main
-
-import "time"
-
-func main() {
- t := make(chan bool)
- ch := make(chan int)
- defer func() {
- close(ch)
- close(t)
- }()
- go func() {
- time.Sleep(1e9) //等待1秒
- t <- true
- }()
- go func() {
- time.Sleep(time.Second * 2)
- ch <- 123
- }()
- select {
- case <-ch: //从ch中读取数据
-
- case <-t: //如果1秒后没有从ch中读取到数据,那么从t中读取,并进行下一步操作
- }
-}
-```
\ No newline at end of file
diff --git a/blog/content/_index.md b/blog/content/_index.md
deleted file mode 100644
index 9cc1310..0000000
--- a/blog/content/_index.md
+++ /dev/null
@@ -1,54 +0,0 @@
-# Go语言精进之路
-
-大家好,我是小熊,本书基于Go语言版本 `1.16` 版本,后续可能会再调整,目录也还未明确,正在**努力持续更新中**,整体进度未明。
-
-如果对这个项目感兴趣,请点击一下 [**Star**](https://github.com/golang-minibear2333/golang) ,项目会 **持续更新**,感谢大家的支持。
-
--------
-
-* 电子书见 -> [Go语言精进之路-在线电子书](http://golang.coding3min.com/)
-* 实战项目见 -> [Golang实战练习库](https://github.com/golang-minibear2333/)
-* [语法速查](https://coding3min.com/561.html)
-
---------
-
-## 学习与交流
-
-* 哪有那么多人生开挂,不过都是厚积薄发 。
-* 我的个人网站: https://coding3min.com
-* 我用`Golang` 刷 [算法的项目](https://github.com/minibear2333/interview-leetcode)
-
-基本会先更新在公众号,再同步到站点上。若想一起学习,欢迎加我的微信:qupzhi。
-
-也可以关注公众号:
-
-
-
-
-## 本书定位
-
-本书给快速入门学习Go语言使用。更偏向于实战,计划扫清Go语言一切障碍,包括Go语言实战、Go语言并发,也希望能给学习`Golang` 的你一些帮助。
-
-在本书中会持续迭代总结各种Go语言脚手架的使用方式与基本原理,是一本速查笔记,也是一本深入笔记,适合中、高级工程师学习收藏。
-
-## 面向群体
-
-* 有一定其他语言基础的 Go 语言爱好者
-* 后端、云计算、安全等领域工作涉及到 Go 语言的工程师
-* 想要进一步熟悉掌握Go并发、以及探索 Go 语言框架、开源项目的开发人员
-
-## 为什么要写这本书
-
-我的职业生涯非常丰富,做过研发、实施运维、架构的工作,数年前我学习过`Java`,接着从事`C++`开发的工作、后来工作中陆续接触过 `C#`、`Python`、`Golang`,目前专注于`Golang`研发。
-
-虽然网上有很多入门与实战方面的书籍,但我想总结一下我工作或学习过程中接触到的知识,以供查阅。
-
-## 关于版权
-
-本书可能会借鉴其他书籍资料,一起网络图片,本书不作为商业用途,仅供学习交流,所借鉴内容来源于网络,会在文章末尾处标记引用位置。如源文章标记禁止引用则不会引用。
-
-因本书开源社区共同维护,难以控制,如有侵权,请留言提出,会在第一时间做出调整修改。
-
-## 批评和建议
-
-如果有任何建议或疑问欢迎随时在本书的评论区与我交流,会尽量在 1-2 天内回复你。
diff --git a/blog/content/a.timer/reset/reset-time.md b/blog/content/a.timer/reset/reset-time.md
deleted file mode 100644
index 3ec3f81..0000000
--- a/blog/content/a.timer/reset/reset-time.md
+++ /dev/null
@@ -1,73 +0,0 @@
----
-title: "可热更新的定时器"
-date: 2021-06-26T02:39:47+08:00
-draft: false
----
-
-# 可热更新的定时器
-
-废话不多说,直接上代码
-```go
-package main
-
-import (
- "fmt"
- "time"
-)
-
-type Server struct {
- tk *time.Ticker
- reset chan struct{}
- Close chan struct{}
- Period int64
-}
-
-
-func main() {
- s := CreateServer(1)
- go s.Start()
- time.Sleep(time.Duration(10) * time.Second)
- s.Update(3)
- time.Sleep(time.Duration(10) * time.Second)
- s.Stop()
- fmt.Println("good bye")
-}
-
-func CreateServer(Period int64) *Server {
- return &Server{
- tk: nil,
- reset: make(chan struct{}),
- Close: make(chan struct{}),
- Period: Period,
- }
-}
-
-// 程序启动
-func (s *Server) Start() {
- // 定时
- s.tk = time.NewTicker(time.Duration(s.Period) * time.Second)
- defer s.tk.Stop()
- for {
- select {
- case <-s.Close:
- return
- case <-s.tk.C:
- fmt.Println("定时唤醒:", time.Now().Format("2006-01-02 15:04:05"))
- case <-s.reset:
- s.tk.Stop()
- s.tk = time.NewTicker(time.Duration(s.Period) * time.Second)
- }
- }
-}
-
-func (s *Server) Stop() {
- close(s.Close)
- close(s.reset)
-}
-
-func (s *Server) Update(p int64) {
- s.Period = p
- s.reset <- struct{}{}
-}
-
-```
\ No newline at end of file
diff --git a/blog/content/index.md b/blog/content/index.md
deleted file mode 100644
index fc7c6f8..0000000
--- a/blog/content/index.md
+++ /dev/null
@@ -1,81 +0,0 @@
----
-headless: true
----
-
-* [机智的程序员小熊](https://coding3min.com)
-* [GitHub](https://github.com/minibear2333/)
-* [微信公众号](qrcode)
-* **帮助与提示**
- * [0.0 如何参与贡献](howToContribute)
- * [0.1 书籍推荐](books-share)
-* **第一章、Go基础**
- * [1.1 安装与下载](1.base/1-1-install-download)
- * [1.2 跑起来](1.base/1-2-hello-world)
- * [1.3 go mod最佳实践](1.base/1-3-go-mod)
- * [1.4 变量与常量](1.base/1-4-variables)
- * [1.5 switch和type switch](1.base/1-5-switch和typeswitch)
- * [1.6 循环](1.base/1-6-for-range)
- * [1.7 range深度解析](1.base/1-7-range深度解析)
-* **第二章、函数和容器**
- * [2.1 函数简单使用和基本知识解析](2.func-containers/2-1-func)
- * [2.2 匿名函数和闭包](2.func-containers/2-2-匿名函数和闭包)
- * [2.3 可变参数](2.func-containers/2-3-可变参数)
- * [2.4 集合(map)](2.func-containers/2-4-map)
- * [2.5 数组和切片](2.func-containers/2-5-数组和切片)
-* **第三章、语法进阶**
- * [3.1 指针讨论](3.grammar-advancement/3-1-point)
- * [3.2 结构体](3.grammar-advancement/3-2-struct)
- * [3.3 接口与多态](3.grammar-advancement/3-3-接口与多态)
- * [3.4 异常处理](3.grammar-advancement/3-4-异常处理)
-* **第四章、并发和并行**
- * [4.1 并发特性](4.concurrent/4-1-go语言中的并发特性)
- * [4.2 channel](4.concurrent/channel)
- * [4.3 select](4.concurrent/select)
- * [4.4 设置超时](4.concurrent/timeout)
- * [设置可热更新的定时器](a.timer/reset/reset-time)
- * [goroutine等待](番外.常用操作/等待goroutine完成任务_循环中使用goroutine)
- * 并发安全
- * 协程池
- * 消费者生产者框架
-* **第x章、反射**
-* **第五章、性能调优**
- * cpu调度
- * 内存管理
- * 垃圾回收
- * PProf
- * 逃逸分析
- * 链路追踪
- * 自监控
-* **第六章、调试与测试**
- * 调试
- * 单元测试
- * mock
- * 自动化测试
-* **第七章、标准库**
- * [Go代码基本标准规范](番外.常用操作/Go代码基本标准规范)
- * 时间处理
- * 字符串处理
- * [文件操作](番外.常用操作/Go文件操作大全)
- * [排序](番外.常用操作/切片排序sort包的使用)
- * [命令行操作](番外.常用操作/flag包读取命令行配置)
- * 跨平台编译
-* **第八章、优秀开源组件**
- * 日志
- * 配置管理
- * 接口文档
- * 错误码控制
- * 数据库连接
- * 为开源项目贡献代码
-* **第十章、分布式系统**
- * 分布式ID生成器
- * 分布式锁
- * 分布式一致性算法
-* **第x章、web应用**
-* **第x章、微服务**
-* **第x章、服务治理**
-* **第x章、GO语言版本分析**
-* **番外1、拓展应用**
- * [小工具](tools/README)
- * [Go与Dockerfile](番外.常用操作/Golang打镜像Dockerfile的写法)
-* **番外2、陷阱与缺陷**
- * [range的第二个值实际上是值拷贝](impossible/range/README)
diff --git a/blog/content/project/http-client/main.go b/blog/content/project/http-client/main.go
deleted file mode 100644
index ffc9308..0000000
--- a/blog/content/project/http-client/main.go
+++ /dev/null
@@ -1,48 +0,0 @@
-package main
-
-import (
- "fmt"
- "io/ioutil"
- "net/http"
- "net/url"
-)
-
-func GetExporterMetrics(rawUrl string, paramMap map[string]string, headMap map[string]string) (text){
- Url, err := url.Parse(rawUrl)
- if err != nil {
- return
- }
- //如果参数中有中文参数,这个方法会进行URLEncode
- Url.RawQuery = GetParam(paramMap).Encode()
- urlPath := Url.String()
- fmt.Println(urlPath)
- client := &http.Client{}
- req, err := http.NewRequest("GET", urlPath, nil)
- if err != nil {
- fmt.Println("GET request failed :", err)
- return err
- }
-
- req.Header.Add("name", "zhaofan")
- req.Header.Add("age", "3")
- resp, _ := client.Do(req)
- defer resp.Body.Close()
- if err != nil || resp.StatusCode != http.StatusOK {
- fmt.Println("错误:发送请求", err)
- return nil, err
- }
- body, _ := ioutil.ReadAll(resp.Body)
- fmt.Println(string(body))
-}
-
-func GetParam(paramMap map[string]string) *url.Values {
- params := url.Values{}
- if paramMap == nil || len(paramMap) == 0 {
- return ¶ms
- }
- for k, v := range paramMap {
- params.Set(k, v)
- }
- return ¶ms
-}
-
diff --git a/blog/content/tools/speed.go b/blog/content/tools/speed.go
deleted file mode 100644
index 5fefa4f..0000000
--- a/blog/content/tools/speed.go
+++ /dev/null
@@ -1,19 +0,0 @@
-package tools
-
-import (
- "fmt"
- "time"
-)
-
-func doWhat() {
-
-}
-func SpeedTime(handler func(), funcName string) {
- t := time.Now()
- handler()
- elapsed := time.Since(t)
- fmt.Println(funcName+"spend time:", elapsed)
-}
-func main() {
- SpeedTime(doWhat, "doWhat")
-}
diff --git "a/blog/content/\347\225\252\345\244\226.\345\270\270\347\224\250\346\223\215\344\275\234/flag\345\214\205\350\257\273\345\217\226\345\221\275\344\273\244\350\241\214\351\205\215\347\275\256.md" "b/blog/content/\347\225\252\345\244\226.\345\270\270\347\224\250\346\223\215\344\275\234/flag\345\214\205\350\257\273\345\217\226\345\221\275\344\273\244\350\241\214\351\205\215\347\275\256.md"
deleted file mode 100644
index b0bfe4b..0000000
--- "a/blog/content/\347\225\252\345\244\226.\345\270\270\347\224\250\346\223\215\344\275\234/flag\345\214\205\350\257\273\345\217\226\345\221\275\344\273\244\350\241\214\351\205\215\347\275\256.md"
+++ /dev/null
@@ -1,80 +0,0 @@
-## 简介
-
-`kingpin` 功能比 `flag` 库强大,用法差不多。
-相比 `flag` 库,最重要的一点就是支持不加 `-` 的调用。
-比如一个命令行程序有三个函数分别为 `A` , `B` , `C` ,要实现根据命令行的输入运行不同的函数,如果用flag实现的话应该是下面这种使用方法:
-
-``` BASH
-./cli --method A
-./cli --method B
-./cli --method C
-```
-
-每次都需要输入 `--method` ,然而用 `kingpin` 库实现的话就可以达到下面这种效果:
-``` BASH
-./cli A
-./cli B
-./cli C
-
-```
-节省了很多输入操作。
-
-## 使用方法
-
-``` BASH
-go get gopkg.in/alecthomas/kingpin.v2
-go mod vendor
-```
-
-这样子 `go.mod` 文件里就引入了, `vendor` 文件夹就缓存了此包,然后直接在代码中使用。
-
-``` Go
-package main
-
-import (
- "fmt"
- "gopkg.in/alecthomas/kingpin.v2"
- "net/http"
-)
-
-func main() {
- var (
- listenAddress = kingpin.Flag(
- "web.listen-address",
- "Address on which to expose metrics and web interface.",
- ).Default(":18001").String()
- metricsPath = kingpin.Flag(
- "web.telemetry-path",
- "Path under which to expose metrics.",
- ).Default("/metrics").String()
-
- )
- kingpin.HelpFlag.Short('h')
- kingpin.Parse()
-
- conf.ApiMtncUrl = *apiMtncPath
-
- http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
- w.Write([]byte(`
- Node Exporter
-
- xxx Exporter
- Metrics
-
- `))
- })
-
- http.Handle("/metrics", XXXX.Handler())
-
- if err := http.ListenAndServe(*listenAddress, nil); err != nil {
- fmt.Printf("Error occur when start server %v", err)
- }
-}
-```
-
-官方文档参考 [package kingpin
-](http://godoc.org/gopkg.in/alecthomas/kingpin.v2)
-
-## 引用
-
-[Golang命令行参数解析库kingpin](https://xuanyu.li/2017/08/05/golang-cli-args-parse/)
diff --git "a/blog/content/\347\225\252\345\244\226.\345\270\270\347\224\250\346\223\215\344\275\234/\347\255\211\345\276\205goroutine\345\256\214\346\210\220\344\273\273\345\212\241_\345\276\252\347\216\257\344\270\255\344\275\277\347\224\250goroutine.md" "b/blog/content/\347\225\252\345\244\226.\345\270\270\347\224\250\346\223\215\344\275\234/\347\255\211\345\276\205goroutine\345\256\214\346\210\220\344\273\273\345\212\241_\345\276\252\347\216\257\344\270\255\344\275\277\347\224\250goroutine.md"
deleted file mode 100644
index cd26f28..0000000
--- "a/blog/content/\347\225\252\345\244\226.\345\270\270\347\224\250\346\223\215\344\275\234/\347\255\211\345\276\205goroutine\345\256\214\346\210\220\344\273\273\345\212\241_\345\276\252\347\216\257\344\270\255\344\275\277\347\224\250goroutine.md"
+++ /dev/null
@@ -1,88 +0,0 @@
-## 简介
-
-`Goroutine` 是 `Golang` 中非常有用的功能,有时候 `goroutine` 没执行完函数就返回了,如果希望等待当前的 `goroutine` 执行完成再接着往下执行,该怎么办?
-
-``` go
-package main
-
-import (
- "time"
- "fmt"
-)
-
-func say(s string) {
- for i := 0; i < 3; i++ {
- time.Sleep(100 * time.Millisecond)
- fmt.Println(s)
- }
-}
-
-func main() {
- go say("hello world")
- fmt.Println("over!")
-}
-```
-
-输出 `over!` , 主线程没有等待
-
-## 唯一好方案
-
-Golang 官方在 sync 包中提供了 WaitGroup 类型来解决这个问题。其文档描述如下:
-
-> A WaitGroup waits for a collection of goroutines to finish. The main goroutine calls Add to set the number of goroutines to wait for. Then each of the goroutines runs and calls Done when finished. At the same time, Wait can be used to block until all goroutines have finished.
-
-大意为: `WaitGroup` 用来等待单个或多个 `goroutines` 执行结束。在主逻辑中使用 `WaitGroup` 的 `Add` 方法设置需要等待的 `goroutines` 的数量。在每个 goroutine 执行的函数中,需要调用 `WaitGroup` 的 `Done` 方法。最后在主逻辑中调用 `WaitGroup` 的 `Wait` 方法进行阻塞等待,直到所有 `goroutine` 执行完成。
-使用方法可以总结为下面几点:
-
-* 创建一个 `WaitGroup` 实例,比如名称为:wg
-* 调用 `wg.Add(n)` ,其中 n 是等待的 `goroutine` 的数量
-* 在每个 `goroutine` 运行的函数中执行 `defer wg.Done()`
-* 调用 `wg.Wait()` 阻塞主逻辑
-
-``` Go
-package main
-
-import (
- "time"
- "fmt"
- "sync"
-)
-
-func main() {
- var wg sync.WaitGroup
- wg.Add(2)
- say2("hello", &wg)
- say2("world", &wg)
- fmt.Println("over!")
- wg.Wait()
-}
-
-func say2(s string, waitGroup *sync.WaitGroup) {
- defer waitGroup.Done()
-
- for i := 0; i < 3; i++ {
- fmt.Println(s)
- }
-}
-```
-
-简短的例子,注意循环传入的变量用中间变量替代,防止闭包 `bug`
-
-``` Go
-var wg sync.WaitGroup
- wg.Add(len(sList))
- for _, d := range sList {
- tmpD := d
- go func(waitGroup *sync.WaitGroup) {
- defer waitGroup.Done()
- // to do something
- // use tmpD
- }
- }(&wg)
- }
- wg.Wait()
-```
-
-## 引用
-
-[Golang 入门 : 等待 goroutine 完成任务](https://www.cnblogs.com/sparkdev/p/10917536.html)
diff --git a/blog/content/books-share.md b/books-share.md
similarity index 100%
rename from blog/content/books-share.md
rename to books-share.md
diff --git a/blog/content/goland.md b/goland.md
similarity index 100%
rename from blog/content/goland.md
rename to goland.md
diff --git a/blog/content/howToContribute.md b/howToContribute.md
similarity index 79%
rename from blog/content/howToContribute.md
rename to howToContribute.md
index 7fcc8ab..e545163 100644
--- a/blog/content/howToContribute.md
+++ b/howToContribute.md
@@ -33,6 +33,8 @@ $ git push
在 `GitHub` 网站上提交 `pull request`。
当然了,如果你不会提`pr`,你可以参考我[给开源大项目贡献代码的文章](https://coding3min.com/653.html)
+更详细请看 [开源指北](https://gitee.com/opensource-guide/guide/)
+
到这里就完成贡献的整个过程了。
## 同步代码
@@ -54,7 +56,6 @@ $ git push -f origin master
## 丰富的贡献方式
-其实你也不必提交代码来贡献,如果你发现项目中有任何不足、bug,或者疑问、新需求,你可以通过`issue`的方式让我提出。
-
-我看到了会立刻给你回复
+其实你也不必提交代码来贡献,如果你发现项目中有任何不足、bug,或者疑问、新需求,你可以通过`issue`的方式让我提出。 我看到了会立刻给你回复
+甚至你可以直接在电子书底部,直接点击`Edit this page`的链接,修改完毕后参考我的`commit`提交格式,提交后会自动`fork`到你的`github`里,此时直接发起`pr`即可!
diff --git a/blog/content/impossible/range/README.md b/impossible/range/README.md
similarity index 98%
rename from blog/content/impossible/range/README.md
rename to impossible/range/README.md
index 34211c5..f4b26ef 100644
--- a/blog/content/impossible/range/README.md
+++ b/impossible/range/README.md
@@ -41,7 +41,7 @@ for range是值拷贝出来的副本
fmt.Println(v.Index, v.Num)
}
```
-### 怎么做?
+## 怎么做?
两个办法,用下标(map也一样)
```go
@@ -68,7 +68,7 @@ for range是值拷贝出来的副本
}
```
-### for range 原理
+## for range 原理
通过查看 [源代码](https://github.com/golang/gofrontend) ,我们可以发现for range的实现是:
```go
diff --git a/blog/content/impossible/range/for_range.go b/impossible/range/for_range.go
similarity index 100%
rename from blog/content/impossible/range/for_range.go
rename to impossible/range/for_range.go
diff --git "a/impossible/\345\210\235\345\255\246\350\200\205\345\270\270\347\212\257\347\232\204\351\224\231\350\257\257.md" "b/impossible/\345\210\235\345\255\246\350\200\205\345\270\270\347\212\257\347\232\204\351\224\231\350\257\257.md"
new file mode 100644
index 0000000..4750738
--- /dev/null
+++ "b/impossible/\345\210\235\345\255\246\350\200\205\345\270\270\347\212\257\347\232\204\351\224\231\350\257\257.md"
@@ -0,0 +1,420 @@
+# 初学者常犯的错误
+
+> 引用:[Go 经典译文:50 个 Go 新手易犯的错误(2020版)](https://learnku.com/go/wikis/49781)
+
+## 索引运算符和字符串
+
+字符串上的 index 方法 (运算符) 返回一个字节值,而不是一个字符类型(就像在其他语言中一样)。
+
+```go
+package main
+
+import "fmt"
+
+func main() {
+ x := "text"
+ fmt.Println(x[0]) //print 116
+ fmt.Printf("%T",x[0]) //prints uint8
+}
+```
+
+如果需要访问特定字符串 “characters”(unicode 代码点 / 运行符),请使用 `for range` 语句。官方的 “unicode/utf8” 包和基础的 utf8string 包 (golang.org/x/exp/utf8string) 也很有用。utf8string 包有一个方便的 `At()` 方法,将字符串转换为切片也是一种选择。
+
+
+## 使用 「for range」子句遍历 Map
+
+* level:初学者
+
+如果你希望 Map 每项数据按照顺序排列 (例如,按键值顺序),这是不可能的,每次 Map 迭代会输出不一样的结果。GO 运行时可能会随机分配迭代顺序,因此你可能会得到几次相同的 Map 迭代结果也不用惊讶。
+
+```go
+package main
+
+import "fmt"
+
+func main() {
+ m := map[string]int{"one":1,"two":2,"three":3,"four":4}
+ for k,v := range m {
+ fmt.Println(k,v)
+ }
+}
+```
+
+而且,如果你使用 Go Playground ([play.golang.org/](https://play.golang.org/)) 运行这段代码,将始终得到相同的迭代结果,因为除非进行更改代码,否则它不会重新编译代码。
+
+## 增量和减量
+
+* 级别:初学者
+
+许多语言都有递增和递减运算符。与其他语言不同,Go 不支持操作的前缀版本。你也不能在表达式中使用这两个运算符。
+
+失败:
+
+```go
+package main
+
+import "fmt"
+
+func main(){
+ data := []int{1,2,3}
+ i := 0
+ ++i //错误
+ fmt.Println(data [i++])//错误
+}
+```
+
+编译错误:
+
+> /tmp/sandbox101231828/main.go:8:语法错误:意外的 ++ /tmp/sandbox101231828/main.go:9:语法错误:意外的 ++,期望:
+
+作品:
+
+```go
+package main
+
+import "fmt"
+
+func main(){
+ data := []int{1,2,3}
+ i := 0
+ i++
+ fmt.Println(data[i])
+}
+```
+
+## 按位 NOT 运算符
+
+* 级别:初学者
+
+许多语言都使用`〜`作为一元 NOT 运算符 (也称为按位补码),但是 Go 为此重用了 XOR 运算符 (`^`)。
+
+失败:
+
+```go
+package main
+
+import "fmt"
+
+func main(){
+ fmt.Println(〜2)//错误
+}
+```
+
+编译错误:
+
+> /tmp/sandbox965529189/main.go:6:按位补码运算符是 ^
+
+作品:
+
+```go
+package main
+
+import "fmt"
+
+func main(){
+ var d uint8 = 2
+ fmt.Printf(“%08b \ n”,^ d)
+}
+```
+
+Go 仍然使用 `^` 作为 XOR 运算符,这可能会使某些人感到困惑。
+
+如果你愿意,你可以用二进制的 XOR 操作 (例如,' NOT 0x02 ') 来表示一个单目的 NOT 操作 (例如,' 0x02 XOR 0xff ')。这可以解释为什么 `^` 被重用于表示一元 NOT 操作。
+
+Go 还具有一个特殊的 'AND NOT' 按位运算符 (`&^`),这增加了 NOT 运算符的困惑。看起来像一个特性 / 黑客,不需要括号就可以支持 `A AND (NOT B)`。
+
+```go
+package main
+
+import "fmt"
+
+func main() {
+ var a uint8 = 0x82
+ var b uint8 = 0x02
+ fmt.Printf("%08b [A]\n",a)
+ fmt.Printf("%08b [B]\n",b)
+
+ fmt.Printf("%08b (NOT B)\n",^b)
+ fmt.Printf("%08b ^ %08b = %08b [B XOR 0xff]\n",b,0xff,b ^ 0xff)
+
+ fmt.Printf("%08b ^ %08b = %08b [A XOR B]\n",a,b,a ^ b)
+ fmt.Printf("%08b & %08b = %08b [A AND B]\n",a,b,a & b)
+ fmt.Printf("%08b &^%08b = %08b [A 'AND NOT' B]\n",a,b,a &^ b)
+ fmt.Printf("%08b&(^%08b)= %08b [A AND (NOT B)]\n",a,b,a & (^b))
+}
+```
+
+## 运算符优先级差异
+
+* 级别:初学者
+
+除了「位清除」运算符 (`&^`) 之外,Go 还有许多其他语言共享的一组标准运算符。但是,运算符优先级并不总是相同。
+
+```go
+package main
+
+import "fmt"
+
+func main() {
+ fmt.Printf("0x2 & 0x2 + 0x4 -> %#x\n",0x2 & 0x2 + 0x4)
+ //prints: 0x2 & 0x2 + 0x4 -> 0x6
+ //Go: (0x2 & 0x2) + 0x4
+ //C++: 0x2 & (0x2 + 0x4) -> 0x2
+
+ fmt.Printf("0x2 + 0x2 << 0x1 -> %#x\n",0x2 + 0x2 << 0x1)
+ //prints: 0x2 + 0x2 << 0x1 -> 0x6
+ //Go: 0x2 + (0x2 << 0x1)
+ //C++: (0x2 + 0x2) << 0x1 -> 0x8
+
+ fmt.Printf("0xf | 0x2 ^ 0x2 -> %#x\n",0xf | 0x2 ^ 0x2)
+ //prints: 0xf | 0x2 ^ 0x2 -> 0xd
+ //Go: (0xf | 0x2) ^ 0x2
+ //C++: 0xf | (0x2 ^ 0x2) -> 0xf
+}
+```
+
+## 应用退出与活动的 Goroutines
+
+* 级别:初学者
+
+应用程序不会等待你的所有 goroutine 完成。对于一般的初学者来说,这是一个常见的错误。每个人都从某个地方开始,所以在犯菜鸟错误时不要觉得丢脸
+
+```go
+package main
+
+import (
+ "fmt"
+ "time"
+)
+
+func main() {
+ workerCount := 2
+
+ for i := 0; i < workerCount; i++ {
+ go doit(i)
+ }
+ time.Sleep(1 * time.Second)
+ fmt.Println("all done!")
+}
+
+func doit(workerId int) {
+ fmt.Printf("[%v] is running\n",workerId)
+ time.Sleep(3 * time.Second)
+ fmt.Printf("[%v] is done\n",workerId)
+}
+```
+
+你会看到的:
+
+> [0] 正在运行
+> [1] 正在运行
+> 全部完成!
+
+最常见的解决方案之一是使用 “WaitGroup” 变量。它将允许主 goroutine 等待直到所有工作程序 goroutine 完成。如果你的应用程序具有长时间运行的消息处理循环,则你还需要一种方法向那些 goroutine 发出退出信号的信号。你可以向每个工作人员发送 “杀死” 消息。另一个选择是关闭所有工作人员正在接收的渠道。这是一次发出所有 goroutine 信号的简单方法。
+
+```go
+package main
+
+import (
+ "fmt"
+ "sync"
+)
+
+func main() {
+ var wg sync.WaitGroup
+ done := make(chan struct{})
+ workerCount := 2
+
+ for i := 0; i < workerCount; i++ {
+ wg.Add(1)
+ go doit(i,done,wg)
+ }
+
+ close(done)
+ wg.Wait()
+ fmt.Println("all done!")
+}
+
+func doit(workerId int,done <-chan struct{},wg sync.WaitGroup) {
+ fmt.Printf("[%v] is running\n",workerId)
+ defer wg.Done()
+ <- done
+ fmt.Printf("[%v] is done\n",workerId)
+}
+```
+
+如果你运行此应用,将会看到:
+
+> [0] is running
+> [0] is done
+> [1] is running
+> [1] is done
+
+看起来 worker 在主 goroutine 退出之前已经完成。这太棒了!但是 1,你还会看到这样的情况:
+
+> fatal error: all goroutines are asleep - deadlock!
+
+这不太好 发生了什么?为什么会出现死锁?当 worker 离开时,它们执行了 `wg.Done()`。应用程序应该是可以工作的。
+
+发生死锁是因为每个 Worker 都会获得原始「WaitGroup」变量的副本。当工人执行 `wg.Done()` 时,它不会影响主 goroutine 中 的「WaitGroup」变量。
+
+```go
+package main
+
+import (
+ "fmt"
+ "sync"
+)
+
+func main() {
+ var wg sync.WaitGroup
+ done := make(chan struct{})
+ wq := make(chan interface{})
+ workerCount := 2
+
+ for i := 0; i < workerCount; i++ {
+ wg.Add(1)
+ go doit(i,wq,done,&wg)
+ }
+
+ for i := 0; i < workerCount; i++ {
+ wq <- i
+ }
+
+ close(done)
+ wg.Wait()
+ fmt.Println("all done!")
+}
+
+func doit(workerId int, wq <-chan interface{},done <-chan struct{},wg *sync.WaitGroup) {
+ fmt.Printf("[%v] is running\n",workerId)
+ defer wg.Done()
+ for {
+ select {
+ case m := <- wq:
+ fmt.Printf("[%v] m => %v\n",workerId,m)
+ case <- done:
+ fmt.Printf("[%v] is done\n",workerId)
+ return
+ }
+ }
+}
+```
+
+现在它可以按预期工作了
+
+
+## "nil" 使用 “nil” 通道
+
+Send and receive operations on a `nil` channel block forver. It's a well documented behavior, but it can be a surprise for new Go developers.
+
+```go
+package main
+
+import (
+ "fmt"
+ "time"
+)
+
+func main() {
+ var ch chan int
+ for i := 0; i < 3; i++ {
+ go func(idx int) {
+ ch <- (idx + 1) * 2
+ }(i)
+ }
+
+ //get first result
+ fmt.Println("result:",<-ch)
+ //do other work
+ time.Sleep(2 * time.Second)
+}
+```
+
+如果运行你的代码,你会看到这样的报错:
+`fatal error: all goroutines are asleep - deadlock!`
+
+出现这样的错误是因为你在 `select` 语句中 `case` 块中动态启用和禁用了管道。
+
+```go
+package main
+
+import "fmt"
+import "time"
+
+func main() {
+ inch := make(chan int)
+ outch := make(chan int)
+
+ go func() {
+ var in <- chan int = inch
+ var out chan <- int
+ var val int
+ for {
+ select {
+ case out <- val:
+ out = nil
+ in = inch
+ case val = <- in:
+ out = outch
+ in = nil
+ }
+ }
+ }()
+
+ go func() {
+ for r := range outch {
+ fmt.Println("result:",r)
+ }
+ }()
+
+ time.Sleep(0)
+ inch <- 1
+ inch <- 2
+ time.Sleep(3 * time.Second)
+}
+```
+
+## 方法中的接受者不能修改原始值
+
+* 级别:初学者
+
+方法接收者就像常规函数参数一样。如果声明为值,那么你的函数 / 方法将获得接收器参数的副本。这意味着对接收者进行更改不会影响原始值,除非你的接收者是映射或切片变量,并且你要更新集合中的项,或者你要在接收者中更新的字段是指针。
+
+```go
+package main
+
+import "fmt"
+
+type data struct {
+ num int
+ key *string
+ items map[string]bool
+}
+
+func (this *data) pmethod() {
+ this.num = 7
+}
+
+func (this data) vmethod() {
+ this.num = 8
+ *this.key = "v.key"
+ this.items["vmethod"] = true
+}
+
+func main() {
+ key := "key.1"
+ d := data{1,&key,make(map[string]bool)}
+
+ fmt.Printf("num=%v key=%v items=%v\n",d.num,*d.key,d.items)
+ //prints num=1 key=key.1 items=map[]
+
+ d.pmethod()
+ fmt.Printf("num=%v key=%v items=%v\n",d.num,*d.key,d.items)
+ //prints num=7 key=key.1 items=map[]
+
+ d.vmethod()
+ fmt.Printf("num=%v key=%v items=%v\n",d.num,*d.key,d.items)
+ //prints num=7 key=v.key items=map[vmethod:true]
+}
+```
\ No newline at end of file
diff --git "a/impossible/\346\226\260\346\211\213\345\270\270\347\212\257\347\232\204\351\224\231\350\257\257.md" "b/impossible/\346\226\260\346\211\213\345\270\270\347\212\257\347\232\204\351\224\231\350\257\257.md"
new file mode 100644
index 0000000..8f6e792
--- /dev/null
+++ "b/impossible/\346\226\260\346\211\213\345\270\270\347\212\257\347\232\204\351\224\231\350\257\257.md"
@@ -0,0 +1,963 @@
+# 新手常犯的错误
+
+> 引用:[Go 经典译文:50 个 Go 新手易犯的错误(2020版)](https://learnku.com/go/wikis/49781)
+
+## 花括号不能放在单独的一行
+
+大多数使用花括号的语言中,你可以选择放置花括号的位置。 但 Go 不一样。 Go 在编译时会自动注入分号,花括号单独一行会导致分号注入错误(无需自己书写分号)。 所以 Go 其实是有分号的
+
+错误的范例:
+
+```go
+package main
+
+import "fmt"
+
+func main()
+{ // 错误,不能将左大括号放在单独的行上
+ fmt.Println("hello there!")
+}
+```
+
+编译错误:
+
+> /tmp/sandbox826898458/main.go:6: 语法错误: `{` 前出现意外的分号或者新的一行
+
+正确的写法:
+
+```go
+package main
+
+import "fmt"
+
+func main() {
+ fmt.Println("works!")
+}
+```
+
+## 未使用的变量
+
+
+如果存在未使用的变量会导致编译失败。但是有一个例外, 只有在函数内部声明的变量未使用才会导致报错,如果你有未使用的全局变量是没问题的,也可以存在未使用的函数参数。
+
+如果给变量赋值但是没有使用该变量值,你的代码仍将无法编译。你需要以某种方式使用变量值以使编译器通过。
+
+错误的范例:
+
+```go
+package main
+
+var gvar int //not an error
+
+func main() {
+ var one int //error, unused variable
+ two := 2 //error, unused variable
+ var three int //error, even though it's assigned 3 on the next line
+ three = 3
+
+ func(unused string) {
+ fmt.Println("Unused arg. No compile error")
+ }("what?")
+}
+```
+
+编译错误:
+
+> /tmp/sandbox473116179/main.go:6: one declared and not used /tmp/sandbox473116179/main.go:7: two declared and not used /tmp/sandbox473116179/main.go:8: three declared and not used
+
+正确的写法:
+
+```go
+package main
+
+import "fmt"
+
+func main() {
+ var one int
+ _ = one
+
+ two := 2
+ fmt.Println(two)
+
+ var three int
+ three = 3
+ one = three
+
+ var four int
+ four = four
+}
+```
+
+另一种选择是注释掉或删除未使用的变量
+
+## 未使用的导入
+
+
+如果你导入一个包却没有使用它的任何导出函数,接口,结构体或变量,你的代码将会编译失败。
+
+如果确实需要导入包,你可以使用空白标识符`_`作为其包名,以避免此编译失败。对于这些副作用,使用空标识符来导入包。
+
+错误的范例:
+
+```go
+package main
+
+import (
+ "fmt"
+ "log"
+ "time"
+)
+
+func main() {
+}
+```
+
+编译错误:
+
+> /tmp/sandbox627475386/main.go:4:导入但未使用:“fmt” /tmp/sandbox627475386/main.go:5:导入但未使用:“ log” /tmp/sandbox627475386/main.go:6:导入但未使用:“time”
+
+正确的写法:
+
+```go
+package main
+
+import (
+ _ "fmt"
+ "log"
+ "time"
+)
+
+var _ = log.Println
+
+func main() {
+ _ = time.Now
+}
+```
+
+另一个选择是删除或注释掉未使用的导入 [`goimports`](http://godoc.org/golang.org/x/tools/cmd/goimports) 工具可以为你提供帮助。
+
+## 短变量声明只能在函数内部使用
+
+
+错误的范例:
+
+```go
+package main
+
+myvar := 1 //error
+
+func main() {
+}
+```
+
+编译错误:
+
+> /tmp/sandbox265716165/main.go:3: non-declaration statement outside function body
+
+正确的写法:
+
+```go
+package main
+
+var myvar = 1
+
+func main() {
+}
+```
+
+## 使用短变量声明重新声明变量
+
+你不能在独立的语句中重新声明变量,但在至少声明一个新变量的多变量声明中允许这样做。
+
+重新声明的变量必须位于同一块中,否则最终将得到隐藏变量。
+
+错误的范例:
+
+```go
+package main
+
+func main() {
+ one := 0
+ one := 1 //error
+}
+```
+
+编译错误:
+
+> /tmp/sandbox706333626/main.go:5: no new variables on left side of :=
+
+正确的写法:
+
+```go
+package main
+
+func main() {
+ one := 0
+ one, two := 1,2
+
+ one,two = two,one
+}
+```
+
+## 不能使用短变量声明来设置字段值
+
+错误的范例:
+
+```go
+package main
+
+import (
+ "fmt"
+)
+
+type info struct {
+ result int
+}
+
+func work() (int,error) {
+ return 13,nil
+ }
+
+func main() {
+ var data info
+
+ data.result, err := work() //error
+ fmt.Printf("info: %+v\n",data)
+}
+```
+
+编译错误:
+
+> prog.go:18: non-name data.result on left side of :=
+
+尽管有解决这个问题的办法,但它不太可能改变,因为 Rob Pike 喜欢它「按原样」
+
+使用临时变量或预先声明所有变量并使用标准赋值运算符。
+
+正确的写法:
+
+```go
+package main
+
+import (
+ "fmt"
+)
+
+type info struct {
+ result int
+}
+
+func work() (int,error) {
+ return 13,nil
+ }
+
+func main() {
+ var data info
+
+ var err error
+ data.result, err = work() //ok
+ if err != nil {
+ fmt.Println(err)
+ return
+ }
+
+ fmt.Printf("info: %+v\n",data) //prints: info: {result:13}
+}
+```
+
+## 偶然的变量隐藏
+
+
+简短的变量声明语法非常方便 (特别是对于那些来自动态语言的变量),以至于可以像对待常规赋值操作一样轻松地对待它。如果你在新的代码块中犯了此错误,将不会有编译器错误,但你的应用程序将无法达到你的期望。
+
+```go
+package main
+
+import "fmt"
+
+func main() {
+ x := 1
+ fmt.Println(x) //prints 1
+ {
+ fmt.Println(x) //prints 1
+ x := 2
+ fmt.Println(x) //prints 2
+ }
+ fmt.Println(x) //prints 1 (bad if you need 2)
+}
+```
+
+即使对于有经验的 Go 开发者来说,这也是一个非常常见的陷阱。这很容易出现,可能很难发现。
+
+你可以使用 [`vet`](http://godoc.org/golang.org/x/tools/cmd/vet) 命令来查找其中的一些问题。默认情况下,`vet` 将不执行任何隐藏变量的检查。确保使用 `-shadow` 标志:`go tool vet -shadow your_file.go`
+
+注意,`vet` 命令不会报告所有的隐藏变量。使用 [`go-nyet`](https://github.com/barakmich/go-nyet) 进行更全面的隐藏变量检查。
+
+## 不能使用 「nil」来初始化没有显式类型的变量
+
+
+「nil」标识符可以用作接口,函数,指针,映射,切片和通道的「零值」。如果不指定变量类型,则编译器将无法编译代码,因为它无法猜测类型。
+
+错误的范例:
+
+```go
+package main
+
+func main() {
+ var x = nil //error
+
+ _ = x
+}
+```
+
+编译错误:
+
+> /tmp/sandbox188239583/main.go:4: use of untyped nil
+
+正确的写法:
+
+```go
+package main
+
+func main() {
+ var x interface{} = nil
+
+ _ = x
+}
+```
+
+## 使用 「nil」 切片和映射
+
+
+可以将数据添加到「nil」切片中,但是对映射执行相同操作会产生运行时崩溃 (runtime panic)。
+
+正确的写法:
+
+```go
+package main
+
+func main() {
+ var s []int
+ s = append(s,1)
+}
+```
+
+错误的范例:
+
+```go
+package main
+
+func main() {
+ var m map[string]int
+ m["one"] = 1 //error
+
+}
+```
+
+## 映射容量
+
+
+你可以在创建映射时指定映射的容量,但不能在映射中使用 `cap()` 函数。
+
+错误的范例:
+
+```go
+package main
+
+func main() {
+ m := make(map[string]int,99)
+ cap(m) //error
+}
+```
+
+编译错误:
+
+> /tmp/sandbox326543983/main.go:5: invalid argument m (type map[string]int) for cap
+
+## 字符串不能为「nil」
+
+
+对于习惯于为字符串变量分配「nil」标识符的开发人员来说,这是一个陷阱。
+
+错误的范例:
+
+```go
+package main
+
+func main() {
+ var x string = nil //error
+
+ if x == nil { //error
+ x = "default"
+ }
+}
+```
+
+编译错误:
+
+> /tmp/sandbox630560459/main.go:4: cannot use nil as type string in assignment /tmp/sandbox630560459/main.go:6: invalid operation: x == nil (mismatched types string and nil)
+
+正确的写法:
+
+```go
+package main
+
+func main() {
+ var x string //defaults to "" (zero value)
+
+ if x == "" {
+ x = "default"
+ }
+}
+```
+
+## 数组函数参数
+
+
+如果你是 C 或 C++ 开发者,那么你的数组是指针。当你将数组传递给函数时,这些函数将引用相同的内存位置,因此它们可以更新原始数据。Go 中的数组是值,因此当你将数组传递给函数时,这些函数会获取原始数组数据的副本。如果你尝试更新数组数据,则可能会出现问题。
+
+```go
+package main
+
+import "fmt"
+
+func main() {
+ x := [3]int{1,2,3}
+
+ func(arr [3]int) {
+ arr[0] = 7
+ fmt.Println(arr) //prints [7 2 3]
+ }(x)
+
+ fmt.Println(x) //prints [1 2 3] (not ok if you need [7 2 3])
+}
+```
+
+如果你需要更新原始数组数据,请使用数组指针类型。
+
+```go
+package main
+
+import "fmt"
+
+func main() {
+ x := [3]int{1,2,3}
+
+ func(arr *[3]int) {
+ (*arr)[0] = 7
+ fmt.Println(arr) //prints &[7 2 3]
+ }(&x)
+
+ fmt.Println(x) //prints [7 2 3]
+}
+```
+
+另一种选择是使用切片。即使你的函数获得了切片变量的副本,它仍然引用原始数据。
+
+```go
+package main
+
+import "fmt"
+
+func main() {
+ x := []int{1,2,3}
+
+ func(arr []int) {
+ arr[0] = 7
+ fmt.Println(arr) //prints [7 2 3]
+ }(x)
+
+ fmt.Println(x) //prints [7 2 3]
+}
+```
+
+## 切片和数组「range」子句下的意外值
+
+
+如果你习惯于使用其他语言的「for-in」或 「foreach」语句,则可能发生这种情况。Go 中的「range」子句不同。它生成两个值:第一个值是索引,而第二个值是数据。
+
+错误的范例:
+
+```go
+package main
+
+import "fmt"
+
+func main() {
+ x := []string{"a","b","c"}
+
+ for v := range x {
+ fmt.Println(v) //prints 0, 1, 2
+ }
+}
+```
+
+正确的写法:
+
+```go
+package main
+
+import "fmt"
+
+func main() {
+ x := []string{"a","b","c"}
+
+ for _, v := range x {
+ fmt.Println(v) //prints a, b, c
+ }
+}
+```
+
+## 切片和数组是一维的
+
+
+Go 看起来它支持多维数组和切片,但它并不支持。创建数组的数组或切片的切片是可能的。对于依赖于动态多维数组的数值计算应用程序来说,在性能和复杂性方面远远不够理想。
+
+你可以使用原始的一维数组,「独立」切片的切片以及「共享数据」切片的切片来构建动态多维数组。
+
+如果使用的是原始一维数组,则需要在数组增长时负责索引,边界检查和内存重新分配。
+
+使用「独立」切片的切片创建动态多维数组是一个两步过程。首先,你必须创建外部切片。然后,你必须分配每个内部切片。内部切片彼此独立。你可以扩大和缩小它们,而不会影响其他内部切片。
+
+```go
+package main
+
+func main() {
+ x := 2
+ y := 4
+
+ table := make([][]int,x)
+ for i:= range table {
+ table[i] = make([]int,y)
+ }
+}
+```
+
+使用 「共享数据」切片的切片创建动态多维数组是一个三步过程。首先,你必须创建保存原始数据的数据「容器」切片。然后,创建外部切片。最后,通过重新排列原始数据切片来初始化每个内部切片。
+
+```go
+package main
+
+import "fmt"
+
+func main() {
+ h, w := 2, 4
+
+ raw := make([]int,h*w)
+ for i := range raw {
+ raw[i] = i
+ }
+ fmt.Println(raw,&raw[4])
+ //prints: [0 1 2 3 4 5 6 7]
+
+ table := make([][]int,h)
+ for i:= range table {
+ table[i] = raw[i*w:i*w + w]
+ }
+
+ fmt.Println(table,&table[1][0])
+ //prints: [[0 1 2 3] [4 5 6 7]]
+}
+```
+
+对于多维数组和切片有一个规范 / 建议,但目前看来这是低优先级的功能。
+
+## 访问不存在的映射键
+
+
+对于希望获得「nil」标识符的开发人员来说这是一个陷阱 (就像其他语言一样)。如果相应数据类型的「零值」为「 nil」,则返回值将为「 nil」,但对于其他数据类型,返回值将不同。检查适当的「零值」可用于确定映射记录是否存在,但是并不总是可靠的 (例如,如果你的布尔值映射中「零值」为 false,你会怎么做)。知道给定映射记录是否存在的最可靠方法是检查由映射访问操作返回的第二个值。
+
+错误的范例:
+
+```go
+package main
+
+import "fmt"
+
+func main() {
+ x := map[string]string{"one":"a","two":"","three":"c"}
+
+ if v := x["two"]; v == "" { //incorrect
+ fmt.Println("no entry")
+ }
+}
+```
+
+正确的写法:
+
+```go
+package main
+
+import "fmt"
+
+func main() {
+ x := map[string]string{"one":"a","two":"","three":"c"}
+
+ if _,ok := x["two"]; !ok {
+ fmt.Println("no entry")
+ }
+}
+```
+
+## 字符串是不可变的
+
+
+尝试使用索引运算符更新字符串变量中的单个字符将导致失败。字符串是只读字节片 (具有一些其他属性)。如果确实需要更新字符串,则在必要时使用字节片而不是将其转换为字符串类型。
+
+错误的范例:
+
+```go
+package main
+
+import "fmt"
+
+func main() {
+ x := "text"
+ x[0] = 'T'
+
+ fmt.Println(x)
+}
+```
+
+编译错误:
+
+> /tmp/sandbox305565531/main.go:7: cannot assign to x[0]
+
+正确的用法:
+
+```go
+package main
+
+import "fmt"
+
+func main() {
+ x := "text"
+ xbytes := []byte(x)
+ xbytes[0] = 'T'
+
+ fmt.Println(string(xbytes)) //prints Text
+}
+```
+
+请注意,这不是真正更新文本字符串中字符的正确方法,因为给定字符可以存储在多个字节中。如果确实需要更新文本字符串,请先将其转换为符文切片。即使使用符文切片,单个字符也可能跨越多个符文。例如,如果你的字符带有重音符号,则可能会发生这种情况。「字符」的这种复杂和模凌两可的性质是将 Go 字符串表示为字节序列的原因。
+
+## 字符串和字节片之间的转换
+
+
+当你将字符串转换为字节片 (反之亦然) 时,你将获得原始数据的完整副本。这不像其他语言中的强制转换操作,也不像在新切片变量指向原始字节片所使用的相同基础数组的切片一样。
+
+Go 对于 `[]byte` 转 `string` ,和 `string` 转 `[]byte` 确实做了一些优化,以免转换额外分配 (在待办事项列表中还对此进行了更多的优化)
+
+第一个优化避免了在 `map[string]` 获取 `m[string(key)]` 中使用 `[]byte` 的 keys 查找条目时的额外分配。
+
+第二个优化避免了在 `for range` 字符串被转换的语句 `[]byte`: `for i,v := range []byte(str) {...}`.
+
+
+## 字符串并不总是 UTF8 文本
+
+* 等级:新手
+
+字符串的值不一定是 UTF8 文本。它们可以包含任意字节。只有在使用字符串字面值时,字符串才是 UTF8。即使这样,它们也可以使用转译序列包括其他数据。若要了解你是否具有 UTF8 文本字符串,请使用 「unicode/uft8」包中的函数 `ValidString()`。
+
+```go
+package main
+
+import (
+ "fmt"
+ "unicode/utf8"
+)
+
+func main() {
+ data1 := "ABC"
+ fmt.Println(utf8.ValidString(data1)) //prints: true
+
+ data2 := "A\xfeC"
+ fmt.Println(utf8.ValidString(data2)) //prints: false
+}
+```
+
+## 字符串长度
+
+* 等级:新手
+
+假设你是 python 开发者,并且使用下面的代码:
+
+```go
+data = u'♥'
+print(len(data)) #prints: 1
+```
+
+当你将其转换为类似的 Go 代码时,你可能会感到惊讶。
+
+```go
+package main
+
+import "fmt"
+
+func main() {
+ data := "♥"
+ fmt.Println(len(data)) //prints: 3
+}
+```
+
+内置的 `len()` 函数返回字节数而不是字符数,就像 Python 中对 unicode 字符串所做的那样。
+
+要在 Go 中获得相同的结果,请使用 「unicode/utf8」包中的 `RuneCountInString()` 函数。
+
+```go
+package main
+
+import (
+ "fmt"
+ "unicode/utf8"
+)
+
+func main() {
+ data := "♥"
+ fmt.Println(utf8.RuneCountInString(data)) //prints: 1
+```
+
+从技术上讲, `RuneCountInString()` 函数不会返回字符数,因为单个字符可能跨越多个符文。
+
+```go
+package main
+
+import (
+ "fmt"
+ "unicode/utf8"
+)
+
+func main() {
+ data := "é"
+ fmt.Println(len(data)) //prints: 3
+ fmt.Println(utf8.RuneCountInString(data)) //prints: 2
+}
+```
+
+## 在多行切片,数组和映射字面值中缺少逗号
+
+* 等级:新手
+
+错误的范例:
+
+```go
+package main
+
+func main() {
+ x := []int{
+ 1,
+ 2 //error
+ }
+ _ = x
+}
+```
+
+编译错误:
+
+> /tmp/sandbox367520156/main.go:6: syntax error: need trailing comma before newline in composite literal /tmp/sandbox367520156/main.go:8: non-declaration statement outside function body /tmp/sandbox367520156/main.go:9: syntax error: unexpected }
+
+正确的写法:
+
+```go
+package main
+
+func main() {
+ x := []int{
+ 1,
+ 2,
+ }
+ x = x
+
+ y := []int{3,4,} //no error
+ y = y
+}
+```
+
+如果在声明折叠为一行时留下逗号,则不会出现编译错误。
+
+## log.Fatal 与 log.Panic 比 Log 要做的更多
+
+* 级别:新手
+
+日志库通常提供不同的日志级别。与那些日志记录库不同,Go 中的日志包的作用远不止于日志记录。如果在你的应用中调用 Go 的 `Fatal *()` 和 `Panic *()` 函数,Go 将会终止你的应用
+
+```go
+package main
+
+import "log"
+
+func main() {
+ log.Fatalln("Fatal Level: log entry") //app exits here
+ log.Println("Normal Level: log entry")
+}
+```
+
+## 内置数据结构操作不同步
+
+* 等级:新手
+
+尽管 Go 有很多支持并发的原生特性,但是并发安全的数据集合不在这些特性中。开发者需要保证对这些数据集合的并发更新操作是原子性的,比如对 map 的并发更新。Go 推荐使用 channels 来实现对集合数据的原子性操作。当然如果「sync」包更适合你的应用也可以利用「sync」包来实现。
+
+## 「range」语句对于字符串的操作
+
+* 等级:新手
+
+「range」语句的第一个返回值是当前「字符」(该字符可能是 unicode 码点 /rune)的第一个字节在字符串中按字节的索引值(unicode 是多字节编码),「range」语句的第二个返回值是当前的「字符」。这是 Go 其他语言不同的地方,其他语言的迭代操作大多是返回当前字符的位置,但 Go「range」返回的并不是当前字符的位置。在实际的使用中一个字符可能是由多个 rune 表示的,所以当我们需要处理字符时强烈推荐使用「norm」包(golang.org/x/text/unicode/norm)。
+
+带有字符串变量的 `for range` 子句将尝试把数据解释为 UTF8 文本。对于任何它无法理解的字节序列,它将返回 `0xfffd` runes (即 Unicode 替换字符),而不是实际数据。如果你在字符串变量中存储了任意 (非 UTF8 文本) 数据,请确保将其转换为字节切片,以按原样获取所有存储的数据。
+
+```go
+package main
+
+import "fmt"
+
+func main() {
+ data := "A\xfe\x02\xff\x04"
+ for _,v := range data {
+ fmt.Printf("%#x ",v)
+ }
+ //prints: 0x41 0xfffd 0x2 0xfffd 0x4 (not ok)
+
+ fmt.Println()
+ for _,v := range []byte(data) {
+ fmt.Printf("%#x ",v)
+ }
+ //prints: 0x41 0xfe 0x2 0xff 0x4 (good)
+}
+```
+
+## switch 语句中的 Fallthrough 行为
+
+* 级别:新手
+
+在 "switch" 语句中的 "case" 块,其缺省行为是 break 出 "switch"。这一行为与其它语言不同,其它语言的缺省行为是,继续执行下一个 "case" 块。
+
+```go
+package main
+
+import "fmt"
+
+func main() {
+ isSpace := func(ch byte) bool {
+ switch(ch) {
+ case ' ': //error
+ case '\t':
+ return true
+ }
+ return false
+ }
+
+ fmt.Println(isSpace('\t')) //prints true (ok)
+ fmt.Println(isSpace(' ')) //prints false (not ok)
+}
+```
+
+你可以通过在每个 "case" 块的最后加入 "fallthrough" 语句来迫使 "case" 块继续往下执行。你也可以重写你的 "switch" 语句,在 "case" 块中使用表达式列表来达到这一目的。
+
+```go
+package main
+
+import "fmt"
+
+func main() {
+ isSpace := func(ch byte) bool {
+ switch(ch) {
+ case ' ', '\t':
+ return true
+ }
+ return false
+ }
+
+ fmt.Println(isSpace('\t')) //prints true (ok)
+ fmt.Println(isSpace(' ')) //prints true (ok)
+}
+```
+
+## 发送到无缓冲通道的消息在目标接收器准备就绪后立即返回
+
+* 等级:新手
+
+直到接收方处理完你的消息后,发送才会被阻止。根据运行代码的机器,接收方 goroutine 可能会或可能没有足够的时间在发送方继续执行之前处理消息。
+
+```go
+package main
+
+import "fmt"
+
+func main() {
+ ch := make(chan string)
+
+ go func() {
+ for m := range ch {
+ fmt.Println("processed:",m)
+ }
+ }()
+
+ ch <- "cmd.1"
+ ch <- "cmd.2" //won't be processed
+}
+```
+
+## 发送到关闭通道会引起崩溃
+
+* 等级:新手
+
+从关闭的通道接收是安全的。接收语句中的 `ok` 返回值将设置为 `false` 表示未接收到任何数据。如果你是从缓冲通道接收到的数据,则将首先获取缓冲数据,一旦缓冲数据为空,返回的 `ok` 返回值将为 `false`。
+
+发送数据到一个已经关闭的 `channel` 会触发 `panic`。 这是一个不容争论的事实,但是对于一个 Go 开发新手来说这样的事实可能不太容易理解,可能会更期望发送行为像接收行为那样。
+
+```go
+package main
+
+import (
+ "fmt"
+ "time"
+)
+
+func main() {
+ ch := make(chan int)
+ for i := 0; i < 3; i++ {
+ go func(idx int) {
+ ch <- (idx + 1) * 2
+ }(i)
+ }
+
+ //获取第一个结果
+ fmt.Println(<-ch)
+ close(ch) //这样做很不好 (因为在协程中还有动作在向 channel 发送数据)
+ //做些其他的事情
+ time.Sleep(2 * time.Second)
+}
+```
+
+根据你的应用程序,修复这样的程序将会有所不同。修改细微的代码不让 `panic` 中断程序是次要的,因为可能你更加需要修改程序的逻辑设计。无论哪种方式,你都需要确保你的应用程序不会在 `channel` 已经关闭的情况下发送数据给它。
+
+可以通过使用特殊的取消渠道来通知剩余的工作人员不再需要他们的结果,从而解决该示例问题。
+
+```go
+package main
+
+import (
+ "fmt"
+ "time"
+)
+
+func main() {
+ ch := make(chan int)
+ done := make(chan struct{})
+ for i := 0; i < 3; i++ {
+ go func(idx int) {
+ select {
+ case ch <- (idx + 1) * 2: fmt.Println(idx,"sent result")
+ case <- done: fmt.Println(idx,"exiting")
+ }
+ }(i)
+ }
+
+ //get first result
+ fmt.Println("result:",<-ch)
+ close(done)
+ //do other work
+ time.Sleep(3 * time.Second)
+}
+```
diff --git "a/impossible/\350\277\233\351\230\266\345\270\270\347\212\257\347\232\204\351\224\231\350\257\257.md" "b/impossible/\350\277\233\351\230\266\345\270\270\347\212\257\347\232\204\351\224\231\350\257\257.md"
new file mode 100644
index 0000000..0407040
--- /dev/null
+++ "b/impossible/\350\277\233\351\230\266\345\270\270\347\212\257\347\232\204\351\224\231\350\257\257.md"
@@ -0,0 +1,1817 @@
+# 进阶常犯的错误
+
+> 引用:[Go 经典译文:50 个 Go 新手易犯的错误(2020版)](https://learnku.com/go/wikis/49781)
+
+## 关闭 HTTP 响应 Body
+
+* 级别:中级
+
+当使用 `net/http` 库发送 http 请求时,会返回一个 `*http.Respose` 变量。 如果你不读取响应 Body,依然需要关闭这个 Body。 注意对于空 Body 也必须关闭。 对于 GO 程序员新手很容易忘记这点。
+
+一些 GO 程序员新手尝试关闭响应 Body,但他们在错误的位置进行了关闭 Body。
+
+```go
+package main
+
+import (
+ "fmt"
+ "net/http"
+ "io/ioutil"
+)
+
+func main() {
+ resp, err := http.Get("https://api.ipify.org?format=json")
+ defer resp.Body.Close()//错误的方法
+ if err != nil {
+ fmt.Println(err)
+ return
+ }
+
+ body, err := ioutil.ReadAll(resp.Body)
+ if err != nil {
+ fmt.Println(err)
+ return
+ }
+
+ fmt.Println(string(body))
+}
+```
+
+这种方法适合请求成功的情况,但是如果 http 请求失败,则 `resp` 变量可能为 `nil`,这将导致运行触发 `panic`。
+
+关闭 http 响应 Body 的最常见方法,应该是在 http 响应检查错误之后使用 `defer` 调用 `Close` 方法。
+
+```go
+package main
+
+import (
+ "fmt"
+ "net/http"
+ "io/ioutil"
+)
+
+func main() {
+ resp, err := http.Get("https://api.ipify.org?format=json")
+ if err != nil {
+ fmt.Println(err)
+ return
+ }
+
+ defer resp.Body.Close()//ok, most of the time :-)
+ body, err := ioutil.ReadAll(resp.Body)
+ if err != nil {
+ fmt.Println(err)
+ return
+ }
+
+ fmt.Println(string(body))
+}
+```
+
+在大多数情况下,当 http 请求失败时,`resp` 变量将为 `nil`,而 `err` 变量将为非空。 但是当重定向失败时,两个变量都将为非空。 这意味着 Body 仍然可能会未关闭而导致泄漏。
+
+你可以通过在 http 响应错误处理时,添加一段关闭非空响应 Body 的代码这解决这个问题 (重定向时响应和 err 都是非空,检查了 err 返回错误而没有关闭 Body), 使用一个 `defer` 关闭所有失败和成功请求的响应 Body。
+
+```go
+package main
+
+import (
+ "fmt"
+ "net/http"
+ "io/ioutil"
+)
+
+func main() {
+ resp, err := http.Get("https://api.ipify.org?format=json")
+ if resp != nil {
+ defer resp.Body.Close()
+ }
+
+ if err != nil {
+ fmt.Println(err)
+ return
+ }
+
+ body, err := ioutil.ReadAll(resp.Body)
+ if err != nil {
+ fmt.Println(err)
+ return
+ }
+
+ fmt.Println(string(body))
+}
+```
+
+`resp.Body.Close()` 方法的底层实现是读取并丢弃响应 Body 的剩余数据。 这样可以保证使用了 `keepalive http` 长连接机制,可以将 http 连接复用,用来发送另外一个请求。 在最新的 http 客户端处理方法是不同的。 但是现在你需要读取并丢弃其余的响应数据。 如果你不读取并丢弃剩余数据,那么 http 连接可能会关闭而不是被长连接复用。 这个小陷阱应该记录在 Go 1.5 中。
+
+如果复用 http 长连接对于你的程序很重要,那么可能需要在响应处理逻辑的末尾添加以下内容:
+
+```go
+_, err = io.Copy(ioutil.Discard, resp.Body)
+```
+
+如果你没有读取全部响应 Body,则需要这样丢弃数据,如果使用以下代码处理 json API 响应,json 库只读取了部分 Body 就完成了 json 对象解析,未读取完毕 Body,则可能会发生这种情况:
+
+```go
+json.NewDecoder(resp.Body).Decode(&data)
+```
+
+## 关闭 HTTP 连接
+
+* 级别:中级
+
+某些 HTTP 服务器会打开长连接(基于 HTTP/1.1 规范和服务器的 `Keepalive` 机制)。 在默认情况下,net/http 库客户端在收到 HTTP 服务端要求关闭时,才会关闭长连接。 这意味着程序在某些情况下没有关闭长连接,可能会泄露系统 fd,用完操作系统的套接字 / 文件描述符。
+
+你可以在请求发送前将 `*http.Requsst` 对象的 `Close` 字段设置为 `true`, 用于关闭 net/http 库客户端连接。
+
+另一种方法是添加 `Connection` Header 并设置值为 `close`。目标 HTTP 服务器响应也应该返回 Header `Connection:close`。当 net/http 库客户端看到这个 Header 时,它也会关闭连接。
+
+```go
+package main
+
+import (
+ "fmt"
+ "net/http"
+ "io/ioutil"
+)
+
+func main() {
+ req, err := http.NewRequest("GET","http://golang.org",nil)
+ if err != nil {
+ fmt.Println(err)
+ return
+ }
+
+ req.Close = true
+ // 或者使用下面的这行方法:
+ //req.Header.Add("Connection", "close")
+
+ resp, err := http.DefaultClient.Do(req)
+ if resp != nil {
+ defer resp.Body.Close()
+ }
+
+ if err != nil {
+ fmt.Println(err)
+ return
+ }
+
+ body, err := ioutil.ReadAll(resp.Body)
+ if err != nil {
+ fmt.Println(err)
+ return
+ }
+
+ fmt.Println(len(string(body)))
+}
+```
+
+你还可以在全局范围内禁用使用 HTTP 长连接 (KeepAlives),创建一个自定义使用的 `*http.Transport` 对象,用于发送 http 客户端的请求。
+
+```go
+package main
+
+import (
+ "fmt"
+ "net/http"
+ "io/ioutil"
+)
+
+func main() {
+ tr := &http.Transport{DisableKeepAlives: true}
+ client := &http.Client{Transport: tr}
+
+ resp, err := client.Get("http://golang.org")
+ if resp != nil {
+ defer resp.Body.Close()
+ }
+
+ if err != nil {
+ fmt.Println(err)
+ return
+ }
+
+ fmt.Println(resp.StatusCode)
+
+ body, err := ioutil.ReadAll(resp.Body)
+ if err != nil {
+ fmt.Println(err)
+ return
+ }
+
+ fmt.Println(len(string(body)))
+}
+```
+
+如果你同时向一个 http 服务器发送大量请求,则可以打开 KeepAlives 选项使用长连接。但是如果你在应用是短时间内,向不同的 HTTP 服务器发送一两个请求 (少量请求),那么则最好在收到 http 响应后立刻关闭网络连,设置更大的操作系统打开文件句柄数量是一个好方法 (ulimit -n)。正确的解决方法取决于你的应用程序。
+
+## JSON 编码器添加换行符
+
+* 级别:中级
+
+你发现你为 JSON 编码功能编写的测试由于未获得期望值而导致测试失败,为什么会这样?如果你是用的是 JSON 编码器对象,则在编码的 JSON 对象的末尾将获得一个额外的换行符。
+
+```go
+package main
+
+import (
+ "fmt"
+ "encoding/json"
+ "bytes"
+)
+
+func main() {
+ data := map[string]int{"key": 1}
+
+ var b bytes.Buffer
+ json.NewEncoder(&b).Encode(data)
+
+ raw,_ := json.Marshal(data)
+
+ if b.String() == string(raw) {
+ fmt.Println("same encoded data")
+ } else {
+ fmt.Printf("'%s' != '%s'\n",raw,b.String())
+ //prints:
+ //'{"key":1}' != '{"key":1}\n'
+ }
+}
+```
+
+JSON 编码器对象旨在用于流传输。使用 JSON 进行流传输通常意味着用换行符分隔的 JSON 对象,这就是为什么 Encode 方法添加换行符的原因。这是正常的行为,但是通常被忽略或遗忘。
+
+## JSON 包在键和字符串值中转义特殊的 HTML 字符
+
+* 级别:中级
+
+这是已记录的行为,但是你必须仔细阅读所有 JSON 包文档以了解有关情况。`SetEscapeHTML` 方法描述讨论了 and 字符 (小于和大于) 的默认编码行为。
+
+由于许多原因,这是 Go 团队非常不幸的设计决定。首先,你不能为 `json.Marshal` 调用禁用此行为。其次,这是一个实施不当的安全功能,因为它假定执行 HTML 编码足以防止所有 Web 应用程序中的 XSS 漏洞。在许多可以使用数据的上下文中,每个上下文需要自己的编码方法。最后,这很糟糕,因为它假定 JSON 的主要用例是网页,默认情况下会破坏配置库和 REST / HTTP API。
+
+```go
+package main
+
+import (
+ "fmt"
+ "encoding/json"
+ "bytes"
+)
+
+func main() {
+ data := "x < y"
+
+ raw,_ := json.Marshal(data)
+ fmt.Println(string(raw))
+ //prints: "x \u003c y" <- probably not what you expected
+
+ var b1 bytes.Buffer
+ json.NewEncoder(&b1).Encode(data)
+ fmt.Println(b1.String())
+ //prints: "x \u003c y" <- probably not what you expected
+
+ var b2 bytes.Buffer
+ enc := json.NewEncoder(&b2)
+ enc.SetEscapeHTML(false)
+ enc.Encode(data)
+ fmt.Println(b2.String())
+ //prints: "x < y" <- looks better
+}
+```
+
+给 Go 团队的建议... 选择加入。
+
+## 比较结构体 / 数组 / 切片 / Map
+
+* 级别:中级
+
+如果结构体的每个字段都具有**可比性** , 那么则可以使用等号运算符 `==` 比较结构体变量。
+
+```go
+package main
+
+import "fmt"
+
+type data struct {
+ num int
+ fp float32
+ complex complex64
+ str string
+ char rune
+ yes bool
+ events <-chan string
+ handler interface{}
+ ref *byte
+ raw [10]byte
+}
+
+func main() {
+ v1 := data{}
+ v2 := data{}
+ fmt.Println("v1 == v2:",v1 == v2) //prints: v1 == v2: true
+}
+```
+
+如果结构体的任意一个属性不具有可比性,那么使用等号运算符在编译时就会显示报错。注意,数组的数据类型具有可比性时,数组才能比较。
+
+```go
+package main
+
+import "fmt"
+
+type data struct {
+ num int //ok
+ checks [10]func() bool //无法比较
+ doit func() bool //无法比较
+ m map[string] string //无法比较
+ bytes []byte //无法比较
+}
+
+func main() {
+ v1 := data{}
+ v2 := data{}
+ fmt.Println("v1 == v2:",v1 == v2)
+}
+```
+
+GO 提供了一些辅助函数用来比较无法比较的变量。
+
+最常见的方法就是使用反射库的 `DeepEqual()` 函数。
+
+```go
+package main
+
+import (
+ "fmt"
+ "reflect"
+)
+
+type data struct {
+ num int //ok
+ checks [10]func() bool //无法比较
+ doit func() bool //无法比较
+ m map[string] string //无法比较
+ bytes []byte //无法比较
+}
+
+func main() {
+ v1 := data{}
+ v2 := data{}
+ fmt.Println("v1 == v2:",reflect.DeepEqual(v1,v2)) //prints: v1 == v2: true
+
+ m1 := map[string]string{"one": "a","two": "b"}
+ m2 := map[string]string{"two": "b", "one": "a"}
+ fmt.Println("m1 == m2:",reflect.DeepEqual(m1, m2)) //prints: m1 == m2: true
+
+ s1 := []int{1, 2, 3}
+ s2 := []int{1, 2, 3}
+ fmt.Println("s1 == s2:",reflect.DeepEqual(s1, s2)) //prints: s1 == s2: true
+}
+```
+
+除了运行缓慢 (可能对你的应用程序造成破坏或可能不会破坏交易) 之外,`DeepEqual()` 也有自己的陷阱。
+
+```go
+package main
+
+import (
+ "fmt"
+ "reflect"
+)
+
+func main() {
+ var b1 []byte = nil
+ b2 := []byte{}
+ fmt.Println("b1 == b2:",reflect.DeepEqual(b1, b2)) //prints: b1 == b2: false
+}
+```
+
+`DeepEqual()` 认为空切片不等于 “nil” 切片。此行为与你使用 `bytes.Equal()` 函数获得的行为不同。`bytes.Equal()` 认为 “nil” 和空片相等。
+
+```go
+package main
+
+import (
+ "fmt"
+ "bytes"
+)
+
+func main() {
+ var b1 []byte = nil
+ b2 := []byte{}
+ fmt.Println("b1 == b2:",bytes.Equal(b1, b2)) //prints: b1 == b2: true
+}
+```
+
+`DeepEqual()` 比较切片并不总是完美的。
+
+```go
+package main
+
+import (
+ "fmt"
+ "reflect"
+ "encoding/json"
+)
+
+func main() {
+ var str string = "one"
+ var in interface{} = "one"
+ fmt.Println("str == in:",str == in,reflect.DeepEqual(str, in))
+ //prints: str == in: true true
+
+ v1 := []string{"one","two"}
+ v2 := []interface{}{"one","two"}
+ fmt.Println("v1 == v2:",reflect.DeepEqual(v1, v2))
+ //prints: v1 == v2: false (not ok)
+
+ data := map[string]interface{}{
+ "code": 200,
+ "value": []string{"one","two"},
+ }
+ encoded, _ := json.Marshal(data)
+ var decoded map[string]interface{}
+ json.Unmarshal(encoded, &decoded)
+ fmt.Println("data == decoded:",reflect.DeepEqual(data, decoded))
+ //prints: data == decoded: false (not ok)
+}
+```
+
+如果你的 `[]byte`(或字符串) 包含文本数据,当你需要使用不区分大小写比较值时,你可能倾向于使用使用 "bytes" 和 "string" 库的 `ToUpper()/ToLower()` 函数 (在使用 `==`,`bytes.Equal()` 或 `bytes.Compare()` 比较之前)。
+这种方法适合英文,但是却不适合许多其他语言的文本。正确的方法应该使用 `strings.EqualFold()` 和 `bytes.EqualFold()` 方法进行比较。
+
+如果你的 `[]byte` 中包含了验证用户信息的机密信息(例如,加密哈希,令牌等), 请不要使用 `reflect.DeepEqual()` 或 `bytes.Equal()` 或 `bytes.Compare()` 函数。因为这些函数可能是你受到[**定时攻击**](http://en.wikipedia.org/wiki/Timing_attack),为了比较泄露时间信息,请使用 'crypto/subtle' 库 (例如:`subtle.ConstantTimeCompare()`)。
+
+## 从 Panic 中恢复
+
+* 级别:中等
+
+`recover()` 函数可用于捕获 / 拦截 panic。 但是只有在 defer 函数中,调用 `recover()` 才能达到目的。
+
+不正确:
+
+```go
+package main
+
+import "fmt"
+
+func main() {
+ recover() // 什么也没执行
+ panic("not good")
+ recover() // 不会执行到 :)
+ fmt.Println("ok")
+}
+```
+
+生效:
+
+```go
+package main
+
+import "fmt"
+
+func main() {
+ defer func() {
+ fmt.Println("recovered:",recover())
+ }()
+
+ panic("not good")
+}
+```
+
+仅在你的 defer 函数中直接调用 `recover()` 时才有效。
+
+失败:
+
+```go
+package main
+
+import "fmt"
+
+func doRecover() {
+ fmt.Println("recovered =>",recover()) //prints: recovered =>
+}
+
+func main() {
+ defer func() {
+ doRecover() //panic is not recovered
+ }()
+
+ panic("not good")
+}
+```
+
+## 使用或更新切片 / 数组 / Map Rnage 遍历的数据
+
+* 级别:中等
+
+在 "Range" 范围的产生是数据是集合的元素副本,这些值不是原始数据的引用,这意味修改 Range 的值不会改变原始数据。这也意味获得的值地址也不会提供执行原始数据的指针。
+
+```go
+package main
+
+import "fmt"
+
+func main() {
+ data := []int{1,2,3}
+ for _,v := range data {
+ v *= 10 //原始项目不变
+ }
+
+ fmt.Println("data:",data) //prints data: [1 2 3]
+}
+```
+
+如果需要修改原始数据,需要使用索引访问数据。
+
+```go
+package main
+
+import "fmt"
+
+func main() {
+ data := []int{1,2,3}
+ for i,_ := range data {
+ data[i] *= 10
+ }
+
+ fmt.Println("data:",data) //prints data: [10 20 30]
+}
+```
+
+如果你的集合包含指针类型,那么规则有些不同。如果希望原始数据指向另外一个值,则仍然需要使用索引操作,但是也可以使用 "for range" 语法中第二个值来更新存储在目标的数据。
+
+```go
+package main
+
+import "fmt"
+
+func main() {
+ data := []*struct{num int} {{1},{2},{3}}
+
+ for _,v := range data {
+ v.num *= 10
+ }
+
+ fmt.Println(data[0],data[1],data[2]) //prints &{10} &{20} &{30}
+}
+```
+
+## 切片的隐藏数据
+
+* 级别:中级
+
+重新分割切片时,新切片将引用旧切片的底层数组。如果你忘记这个行为,并且分配相对较大切片,则从中创建了新建的切片引用了部分原始数据,则可能导致意外的底层数据使用。
+
+```go
+package main
+
+import "fmt"
+
+func get() []byte {
+ raw := make([]byte,10000)
+ fmt.Println(len(raw),cap(raw),&raw[0]) //prints: 10000 10000
+ return raw[:3]
+}
+
+func main() {
+ data := get()
+ fmt.Println(len(data),cap(data),&data[0]) //prints: 3 10000
+}
+```
+
+为避免此陷阱,请确保从临时切片中复制所需的数据(而不是切割切片)。
+
+```go
+package main
+
+import "fmt"
+
+func get() []byte {
+ raw := make([]byte,10000)
+ fmt.Println(len(raw),cap(raw),&raw[0]) //prints: 10000 10000
+ res := make([]byte,3)
+ copy(res,raw[:3])
+ return res
+}
+
+func main() {
+ data := get()
+ fmt.Println(len(data),cap(data),&data[0]) //prints: 3 3
+}
+```
+
+## 切片数据污染
+
+* 等级:中级
+
+假如需要修改路径 (存储在切片中)。你可以重新设置路径用来引用每个目录,从而修改第一个目录的名称,然后将这些名称合并创建新路径。
+
+```go
+package main
+
+import (
+ "fmt"
+ "bytes"
+)
+
+func main() {
+ path := []byte("AAAA/BBBBBBBBB")
+ sepIndex := bytes.IndexByte(path,'/')
+ dir1 := path[:sepIndex]
+ dir2 := path[sepIndex+1:]
+ fmt.Println("dir1 =>",string(dir1)) //prints: dir1 => AAAA
+ fmt.Println("dir2 =>",string(dir2)) //prints: dir2 => BBBBBBBBB
+
+ dir1 = append(dir1,"suffix"...)
+ path = bytes.Join([][]byte{dir1,dir2},[]byte{'/'})
+
+ fmt.Println("dir1 =>",string(dir1)) //prints: dir1 => AAAAsuffix
+ fmt.Println("dir2 =>",string(dir2)) //prints: dir2 => uffixBBBB (not ok)
+
+ fmt.Println("new path =>",string(path))
+}
+```
+
+结果并不是预料的 "AAAAsuffix/BBBBBBBBB" 这样,而是 "AAAAsuffix/uffixBBBB"。发送这种请求是因为两个路径切片的引用了相同的原始底层数据。这意味修改原始路径也会被修改。根据你的程序情况,这也可能会是一个问题。
+
+可以通过分配新的切片并复制数据来解决此问题。 另一种选择是使用完整切片表达式。
+
+```go
+package main
+
+import (
+ "fmt"
+ "bytes"
+)
+
+func main() {
+ path := []byte("AAAA/BBBBBBBBB")
+ sepIndex := bytes.IndexByte(path,'/')
+ dir1 := path[:sepIndex:sepIndex] //完整切片表达式
+ dir2 := path[sepIndex+1:]
+ fmt.Println("dir1 =>",string(dir1)) //prints: dir1 => AAAA
+ fmt.Println("dir2 =>",string(dir2)) //prints: dir2 => BBBBBBBBB
+
+ dir1 = append(dir1,"suffix"...)
+ path = bytes.Join([][]byte{dir1,dir2},[]byte{'/'})
+
+ fmt.Println("dir1 =>",string(dir1)) //prints: dir1 => AAAAsuffix
+ fmt.Println("dir2 =>",string(dir2)) //prints: dir2 => BBBBBBBBB (ok now)
+
+ fmt.Println("new path =>",string(path))
+}
+```
+
+完整切片表达式中的额外参数控制新切片的容量。 现在追加到该切片的数据将触发切片扩容,而不是覆盖第二个片中的数据。
+
+## 旧的切片
+
+* 级别:中等
+
+多个切片可以引用相同的数据。 例如当你使用现有切片创建新切片时,可能会发生这种情况。 如果程序依靠此行为来正常运行,那么将需要担心的旧的切片。
+
+在某些时候,当原始数组无法容纳更多新数据时,将数据添加到切片将导致新的数组扩容。现在其他切片将指向旧数组(包含旧数据)。
+
+```go
+import "fmt"
+
+func main() {
+ s1 := []int{1,2,3}
+ fmt.Println(len(s1),cap(s1),s1) //prints 3 3 [1 2 3]
+
+ s2 := s1[1:]
+ fmt.Println(len(s2),cap(s2),s2) //prints 2 2 [2 3]
+
+ for i := range s2 { s2[i] += 20 }
+
+ //仍然引用相同的数组
+ fmt.Println(s1) //prints [1 22 23]
+ fmt.Println(s2) //prints [22 23]
+
+ s2 = append(s2,4)
+
+ for i := range s2 { s2[i] += 10 }
+
+ //s1 is now "stale"
+ fmt.Println(s1) //prints [1 22 23]
+ fmt.Println(s2) //prints [32 33 14]
+}
+```
+
+## 类型声明和方法
+
+- 级别:中级
+
+通过从现有 (非接口) 类型定义新类型来创建类型声明时,你不会继承为该现有类型定义的方法。
+
+失败:
+
+```go
+package main
+
+import "sync"
+
+type myMutex sync.Mutex
+
+func main() {
+ var mtx myMutex
+ mtx.Lock() //error
+ mtx.Unlock() //error
+}
+```
+
+编译错误:
+
+> /tmp/sandbox106401185/main.go:9: mtx.Lock undefined (type myMutex has no field or method Lock) /tmp/sandbox106401185/main.go:10: mtx.Unlock undefined (type myMutex has no field or method Unlock)
+
+如果确实需要原始类型的方法,则可以定义一个将原始类型嵌入为匿名字段的新结构类型。
+
+作品:
+
+```go
+package main
+
+import "sync"
+
+type myLocker struct {
+ sync.Mutex
+}
+
+func main() {
+ var lock myLocker
+ lock.Lock() //ok
+ lock.Unlock() //ok
+}
+```
+
+接口类型声明也保留其方法集。
+
+作品:
+
+```go
+package main
+
+import "sync"
+
+type myLocker sync.Locker
+
+func main() {
+ var lock myLocker = new(sync.Mutex)
+ lock.Lock() //ok
+ lock.Unlock() //ok
+}
+```
+
+## 突破 “for switch” 和 “ for select” 代码块
+
+* 级别:中级
+
+没有标签的 “break” 语句只会使你脱离内部 switch /select 块。如果不能使用 “ return” 语句,则为外循环定义标签是第二件事。
+
+```go
+package main
+
+import "fmt"
+
+func main() {
+ loop:
+ for {
+ switch {
+ case true:
+ fmt.Println("breaking out...")
+ break loop
+ }
+ }
+
+ fmt.Println("out!")
+}
+```
+
+“goto” 语句也可以解决问题。
+
+## 句中的迭代变量和闭包
+
+* 级别:中级
+
+这是 Go 中最常见的陷阱。`for` 语句中的迭代变量在每次迭代中都会重复使用。这意味着在 `for` 循环中创建的每个闭包 (aka 函数文字) 都将引用相同的变量 (它们将在这些 goroutine 开始执行时获得该变量的值)。
+
+不正确:
+
+```go
+package main
+
+import (
+ "fmt"
+ "time"
+)
+
+func main() {
+ data := []string{"one","two","three"}
+
+ for _,v := range data {
+ go func() {
+ fmt.Println(v)
+ }()
+ }
+
+ time.Sleep(3 * time.Second)
+ //goroutines print: three, three, three
+}
+```
+
+最简单的解决方案 (不需要对 goroutine 进行任何更改) 是将当前迭代变量值保存在 `for` 循环块内的局部变量中。
+
+作品:
+
+```go
+package main
+
+import (
+ "fmt"
+ "time"
+)
+
+func main() {
+ data := []string{"one","two","three"}
+
+ for _,v := range data {
+ vcopy := v //
+ go func() {
+ fmt.Println(vcopy)
+ }()
+ }
+
+ time.Sleep(3 * time.Second)
+ //goroutines print: one, two, three
+}
+```
+
+另一种解决方案是将当前迭代变量作为参数传递给匿名 goroutine。
+
+作品:
+
+```go
+package main
+
+import (
+ "fmt"
+ "time"
+)
+
+func main() {
+ data := []string{"one","two","three"}
+
+ for _,v := range data {
+ go func(in string) {
+ fmt.Println(in)
+ }(v)
+ }
+
+ time.Sleep(3 * time.Second)
+ //goroutines print: one, two, three
+}
+```
+
+这是陷阱的稍微复杂一点的版本。
+
+不正确:
+
+```go
+package main
+
+import (
+ "fmt"
+ "time"
+)
+
+type field struct {
+ name string
+}
+
+func (p *field) print() {
+ fmt.Println(p.name)
+}
+
+func main() {
+ data := []field{{"one"},{"two"},{"three"}}
+
+ for _,v := range data {
+ go v.print()
+ }
+
+ time.Sleep(3 * time.Second)
+ //goroutines print: three, three, three
+}
+```
+
+作品:
+
+```go
+package main
+
+import (
+ "fmt"
+ "time"
+)
+
+type field struct {
+ name string
+}
+
+func (p *field) print() {
+ fmt.Println(p.name)
+}
+
+func main() {
+ data := []field{{"one"},{"two"},{"three"}}
+
+ for _,v := range data {
+ v := v
+ go v.print()
+ }
+
+ time.Sleep(3 * time.Second)
+ //goroutines print: one, two, three
+}
+```
+
+你认为运行此代码时会看到什么 (为什么)?
+
+```go
+package main
+
+import (
+ "fmt"
+ "time"
+)
+
+type field struct {
+ name string
+}
+
+func (p *field) print() {
+ fmt.Println(p.name)
+}
+
+func main() {
+ data := []*field{{"one"},{"two"},{"three"}}
+
+ for _,v := range data {
+ go v.print()
+ }
+
+ time.Sleep(3 * time.Second)
+}
+```
+
+## 延迟函数调用参数评估
+
+* 级别:中级
+
+在评估 `defer` 语句时 (而不是在函数实际执行时),评估延迟函数调用的参数。延迟方法调用时,将应用相同的规则。结构值也与显式方法参数和封闭变量一起保存。
+
+```go
+package main
+
+import "fmt"
+
+func main() {
+ var i int = 1
+
+ defer fmt.Println("result =>",func() int { return i * 2 }())
+ i++
+ //prints: result => 2 (not ok if you expected 4)
+}
+```
+
+如果具有指针参数,则可以更改它们指向的值,因为在评估 `defer` 语句时仅保存指针。
+
+```go
+package main
+
+import (
+ "fmt"
+)
+
+func main() {
+ i := 1
+ defer func (in *int) { fmt.Println("result =>", *in) }(&i)
+
+ i = 2
+ //prints: result => 2
+}
+```
+
+## 延迟函数调用执行
+
+* 级别:中级
+
+延迟的调用在包含函数的末尾 (以相反的顺序) 而不是在包含代码块的末尾执行。对于新的 Go 开发人员来说,这是一个容易犯的错误,将延迟的代码执行规则与变量作用域规则混为一谈。如果你具有一个长期运行的函数,且该函数具有 `for` 循环,该循环试图在每次迭代中延迟 `defer` 资源清理调用,则可能会成为问题。
+
+```go
+package main
+
+import (
+ "fmt"
+ "os"
+ "path/filepath"
+)
+
+func main() {
+ if len(os.Args) != 2 {
+ os.Exit(-1)
+ }
+
+ start, err := os.Stat(os.Args[1])
+ if err != nil || !start.IsDir(){
+ os.Exit(-1)
+ }
+
+ var targets []string
+ filepath.Walk(os.Args[1], func(fpath string, fi os.FileInfo, err error) error {
+ if err != nil {
+ return err
+ }
+
+ if !fi.Mode().IsRegular() {
+ return nil
+ }
+
+ targets = append(targets,fpath)
+ return nil
+ })
+
+ for _,target := range targets {
+ f, err := os.Open(target)
+ if err != nil {
+ fmt.Println("bad target:",target,"error:",err) //prints error: too many open files
+ break
+ }
+ defer f.Close() //will not be closed at the end of this code block
+ //do something with the file...
+ }
+}
+```
+
+解决该问题的一种方法是将代码块包装在一个函数中。
+
+```go
+package main
+
+import (
+ "fmt"
+ "os"
+ "path/filepath"
+)
+
+func main() {
+ if len(os.Args) != 2 {
+ os.Exit(-1)
+ }
+
+ start, err := os.Stat(os.Args[1])
+ if err != nil || !start.IsDir(){
+ os.Exit(-1)
+ }
+
+ var targets []string
+ filepath.Walk(os.Args[1], func(fpath string, fi os.FileInfo, err error) error {
+ if err != nil {
+ return err
+ }
+
+ if !fi.Mode().IsRegular() {
+ return nil
+ }
+
+ targets = append(targets,fpath)
+ return nil
+ })
+
+ for _,target := range targets {
+ func() {
+ f, err := os.Open(target)
+ if err != nil {
+ fmt.Println("bad target:",target,"error:",err)
+ return
+ }
+ defer f.Close() //ok
+ //do something with the file...
+ }()
+ }
+}
+```
+
+另一种方法是删除 `defer` 语句
+
+## 失败类型断言
+
+* 级别:中级
+
+失败的类型断言将为断言语句中使用的目标类型返回「零值」。当它与影子变量混合在一起时,可能导致意外行为。
+
+错误的范例:
+
+```go
+package main
+
+import "fmt"
+
+func main() {
+ var data interface{} = "great"
+
+ if data, ok := data.(int); ok {
+ fmt.Println("[is an int] value =>",data)
+ } else {
+ fmt.Println("[not an int] value =>",data)
+ //prints: [not an int] value => 0 (not "great")
+ }
+}
+```
+
+正确的范例:
+
+```go
+package main
+
+import "fmt"
+
+func main() {
+ var data interface{} = "great"
+
+ if res, ok := data.(int); ok {
+ fmt.Println("[is an int] value =>",res)
+ } else {
+ fmt.Println("[not an int] value =>",data)
+ //prints: [not an int] value => great (as expected)
+ }
+}
+```
+
+## 阻塞的 Goroutines 和资源泄漏
+
+* 级别:中级
+
+Rob Pike 在 Google I/O 大会上的演讲 [「Go Concurrency Patterns」](https://talks.golang.org/2012/concurrency.slide#1) 谈到了许多基本的并发模式。从多个目标中获取第一个结果就是其中之一。
+
+```go
+func First(query string, replicas ...Search) Result {
+ c := make(chan Result)
+ searchReplica := func(i int) { c <- replicas[i](query) }
+ for i := range replicas {
+ go searchReplica(i)
+ }
+ return <-c
+}
+```
+
+该函数为每个搜索副本启动 goroutines。每个 goroutine 将其搜索结果发送到结果通道。返回结果通道的第一个值。
+
+其他 goroutines 的结果如何?那 goroutines 本身呢?
+
+`First()` 函数中的结果通道未缓冲。这意味着仅第一个 goroutine 返回。所有其他 goroutine 都被困在尝试发送结果。这意味着,如果你有多个副本,则每个调用都会泄漏资源。
+
+为了避免泄漏,你需要确保所有 goroutine 都退出。一种潜在的解决方案是使用足够大的缓冲结果通道来保存所有结果。
+
+```go
+func First(query string, replicas ...Search) Result {
+ c := make(chan Result,len(replicas))
+ searchReplica := func(i int) { c <- replicas[i](query) }
+ for i := range replicas {
+ go searchReplica(i)
+ }
+ return <-c
+}
+```
+
+另一种可能的解决方案是使用 `select` 语句和 `default` 大小写以及可保存一个值的缓冲结果通道。`default` 情况确保即使结果通道无法接收消息,goroutine 也不会卡住。
+
+```go
+func First(query string, replicas ...Search) Result {
+ c := make(chan Result,1)
+ searchReplica := func(i int) {
+ select {
+ case c <- replicas[i](query):
+ default:
+ }
+ }
+ for i := range replicas {
+ go searchReplica(i)
+ }
+ return <-c
+}
+```
+
+你还可以使用特殊的取消通道来中断工作。
+
+```go
+func First(query string, replicas ...Search) Result {
+ c := make(chan Result)
+ done := make(chan struct{})
+ defer close(done)
+ searchReplica := func(i int) {
+ select {
+ case c <- replicas[i](query):
+ case <- done:
+ }
+ }
+ for i := range replicas {
+ go searchReplica(i)
+ }
+
+ return <-c
+}
+```
+
+为什么演示文稿中包含这些错误? Rob Pike 只是不想使幻灯片复杂化。这是有道理的,但是对于新的 Go 开发人员来说可能是个问题,他们会按原样使用该代码,而不认为它可能会出现问题。
+
+## 相同地址的不同零大小变量
+
+* 级别:中级
+
+如果你有两个不同的变量,它们不应该有不同的地址吗?好吧,Go 并不是这样:-) 如果变量大小为零,它们可能会在内存中共享完全相同的地址。
+
+```go
+package main
+
+import (
+ "fmt"
+)
+
+type data struct {
+}
+
+func main() {
+ a := &data{}
+ b := &data{}
+
+ if a == b {
+ fmt.Printf("same address - a=%p b=%p\n",a,b)
+ //prints: same address - a=0x1953e4 b=0x1953e4
+ }
+}
+```
+
+## iota 的第一次使用并不总是从零开始
+
+* 级别:中级
+
+它可能看起来像是一个 `iota` 标识符就像一个增量运算符。开始一个新的常量声明,第一次使用 iota 时得到 0,第二次使用时得到 1,依此类推。但情况并非总是如此。
+
+```go
+package main
+
+import (
+ "fmt"
+)
+
+const (
+ azero = iota
+ aone = iota
+)
+
+const (
+ info = "processing"
+ bzero = iota
+ bone = iota
+)
+
+func main() {
+ fmt.Println(azero,aone) //prints: 0 1
+ fmt.Println(bzero,bone) //prints: 1 2
+}
+```
+
+`iota` 实际上是常量声明块中当前行的索引运算符,因此,如果首次使用 `iota` 不是常量声明块中的第一行,则初始值将不为零。
+
+## 在值实例上使用指针接收器方法
+
+* 级别:高级
+
+只要该值是可寻址的,就可以在该值上调用指针接收器方法。换句话说,在某些情况下,你不需要该方法的值接收器版本。
+
+但是,并非每个变量都是可寻址的。map 元素不可寻址。通过接口引用的变量也是不可寻址的。
+
+```go
+package main
+
+import "fmt"
+
+type data struct {
+ name string
+}
+
+func (p *data) print() {
+ fmt.Println("name:",p.name)
+}
+
+type printer interface {
+ print()
+}
+
+func main() {
+ d1 := data{"one"}
+ d1.print() //ok
+
+ var in printer = data{"two"} //error
+ in.print()
+
+ m := map[string]data {"x":data{"three"}}
+ m["x"].print() //error
+}
+```
+
+编译错误:
+
+> /tmp/sandbox017696142/main.go:21: cannot use data literal (type data) as type printer in assignment: data does not implement printer (print method has pointer receiver)
+> /tmp/sandbox017696142/main.go:25: cannot call pointer method on m["x"] /tmp/sandbox017696142/main.go:25: cannot take the address of m["x"]
+
+## 更新 map 值字段
+
+* 级别:高级
+
+如果你具有结构值 map,则无法更新单个结构字段。
+
+失败的范例:
+
+```go
+package main
+
+type data struct {
+ name string
+}
+
+func main() {
+ m := map[string]data {"x":{"one"}}
+ m["x"].name = "two" //error
+}
+```
+
+编译错误:
+
+> /tmp/sandbox380452744/main.go:9: cannot assign to m["x"].name
+
+它不会工作,因为 map 元素不可寻址。
+
+对于 Go 新手开发者,可能会感到困惑,slice 元素是可寻址的。
+
+```go
+package main
+
+import "fmt"
+
+type data struct {
+ name string
+}
+
+func main() {
+ s := []data {{"one"}}
+ s[0].name = "two" //ok
+ fmt.Println(s) //prints: [{two}]
+}
+```
+
+请注意,前一阵子可以在其中一个 Go 编译器 (gccgo) 中更新 map 元素字段,但是该行为很快得到解决:-) 它也被认为是 Go 1.3 的潜在功能。当时还不足以提供支持,因此它仍在待办事项清单上。
+
+首先解决的是使用临时变量。
+
+```go
+package main
+
+import "fmt"
+
+type data struct {
+ name string
+}
+
+func main() {
+ m := map[string]data {"x":{"one"}}
+ r := m["x"]
+ r.name = "two"
+ m["x"] = r
+ fmt.Printf("%v",m) //prints: map[x:{two}]
+}
+```
+
+另一个解决方法是使用指针映射。
+
+```go
+package main
+
+import "fmt"
+
+type data struct {
+ name string
+}
+
+func main() {
+ m := map[string]*data {"x":{"one"}}
+ m["x"].name = "two" //ok
+ fmt.Println(m["x"]) //prints: &{two}
+}
+```
+
+顺便说一句,运行此代码会发生什么?
+
+```go
+package main
+
+type data struct {
+ name string
+}
+
+func main() {
+ m := map[string]*data {"x":{"one"}}
+ m["z"].name = "what?" //???
+}
+```
+
+## 「nil」接口和「nil」接口值
+
+* 级别:高级
+
+这是 Go 语言中第二常见的陷阱,因为即使接口看起来像指针,它们也不是指针。接口变量仅在其类型和值字段为「nil」时才为「nil」。
+
+接口类型和值字段基于用于创建相应接口变量的变量的类型和值进行填充。当你尝试检查接口变量是否等于「nil」时,这可能导致意外的行为。
+
+```go
+package main
+
+import "fmt"
+
+func main() {
+ var data *byte
+ var in interface{}
+
+ fmt.Println(data,data == nil) //prints: true
+ fmt.Println(in,in == nil) //prints: true
+
+ in = data
+ fmt.Println(in,in == nil) //prints: false
+ //'data' is 'nil', but 'in' is not 'nil'
+}
+```
+
+当你具有返回接口的函数时,请当心此陷阱。
+
+错误的范例:
+
+```go
+package main
+
+import "fmt"
+
+func main() {
+ doit := func(arg int) interface{} {
+ var result *struct{} = nil
+
+ if(arg > 0) {
+ result = &struct{}{}
+ }
+
+ return result
+ }
+
+ if res := doit(-1); res != nil {
+ fmt.Println("good result:",res) //prints: good result:
+ //'res' is not 'nil', but its value is 'nil'
+ }
+}
+```
+
+正确的范例:
+
+```go
+package main
+
+import "fmt"
+
+func main() {
+ doit := func(arg int) interface{} {
+ var result *struct{} = nil
+
+ if(arg > 0) {
+ result = &struct{}{}
+ } else {
+ return nil //return an explicit 'nil'
+ }
+
+ return result
+ }
+
+ if res := doit(-1); res != nil {
+ fmt.Println("good result:",res)
+ } else {
+ fmt.Println("bad result (res is nil)") //here as expected
+ }
+}
+```
+
+## 堆栈和堆变量
+
+* 级别:高级
+
+你并不总是知道你的变量是分配在堆栈还是堆上。在 C++ 中,使用 `new` 运算符创建变量始终意味着你具有堆变量。在 Go 语言中,即使使用 `new()` 或 `make()` 函数,编译器仍会决定将变量分配到何处。编译器根据变量的大小和「转义分析」的结果来选择存储变量的位置。这也意味着可以返回对局部变量的引用,而在其他语言 (如 C 或 C++) 中则不可以。
+
+如果你需要知道变量的分配位置,请将「-m」gc 标志传递给「go build」或「go run」(例如,`go run -gcflags -m app.go`)。
+
+## GOMAXPROCS,并发和并行
+
+* 级别:高级
+
+Go 1.4 以下版本仅使用一个执行上下文 / OS 线程。这意味着在任何给定时间只能执行一个 goroutine。从 Go 1.5 开始,将执行上下文的数量设置为 `runtime.NumCPU()` 返回的逻辑 CPU 内核的数量。该数字可能与系统上逻辑 CPU 内核的总数不匹配,具体取决于进程的 CPU 亲和力设置。你可以通过更改 `GOMAXPROCS` 环境变量或调用 `runtime.GOMAXPROCS()` 函数来调整此数字。
+
+常见的误解是 `GOMAXPROCS` 代表 Go 将用于运行 goroutine 的 CPU 数量。`runtime.GOMAXPROCS()` 函数文档使这个问题更加混乱。`GOMAXPROCS` 变量描述 ([golang.org/pkg/runtime/](https://golang.org/pkg/runtime/)) 在讨论 OS 线程方面做得更好。
+
+你可以将 `GOMAXPROCS` 设置为大于 CPU 的数量。从 1.10 版开始,GOMAXPROCS 不再受限制。`GOMAXPROCS` 的最大值以前是 256,后来在 1.9 中增加到 1024。
+
+```go
+package main
+
+import (
+ "fmt"
+ "runtime"
+)
+
+func main() {
+ fmt.Println(runtime.GOMAXPROCS(-1)) //prints: X (1 on play.golang.org)
+ fmt.Println(runtime.NumCPU()) //prints: X (1 on play.golang.org)
+ runtime.GOMAXPROCS(20)
+ fmt.Println(runtime.GOMAXPROCS(-1)) //prints: 20
+ runtime.GOMAXPROCS(300)
+ fmt.Println(runtime.GOMAXPROCS(-1)) //prints: 256
+}
+```
+
+## 读写操作重新排序
+
+* 级别:高级
+
+Go 可以对某些操作进行重新排序,但可以确保 goroutine 中发生该行为的整体行为不会改变。但是,它不能保证跨多个 goroutine 的执行顺序。
+
+```go
+package main
+
+import (
+ "runtime"
+ "time"
+)
+
+var _ = runtime.GOMAXPROCS(3)
+
+var a, b int
+
+func u1() {
+ a = 1
+ b = 2
+}
+
+func u2() {
+ a = 3
+ b = 4
+}
+
+func p() {
+ println(a)
+ println(b)
+}
+
+func main() {
+ go u1()
+ go u2()
+ go p()
+ time.Sleep(1 * time.Second)
+}
+```
+
+如果你多次运行此代码,则可能会看到以下 `a` 和 `b` 变量组合:
+
+> 1
+> 2
+>
+> 3
+> 4
+>
+> 0
+> 2
+>
+> 0
+> 0
+>
+> 1
+> 4
+
+`a` 和 `b` 最有趣的组合是「02」。它显示 `b` 已在 `a` 之前更新。
+
+如果你需要跨多个 goroutine 保留读取和写入操作的顺序,则需要使用通道或「sync」包中的适当的方法。
+
+## 抢占式调度
+
+- 级别:高级
+
+可能有一个流氓 goroutine 阻止了其他 goroutine 的运行。如果你的 `for` 循环不允许调度程序运行,则可能发生这种情况。
+
+```go
+package main
+
+import "fmt"
+
+func main() {
+ done := false
+
+ go func(){
+ done = true
+ }()
+
+ for !done {
+ }
+ fmt.Println("done!")
+}
+```
+
+`for` 循环不必为空。只要它包含不触发调度程序执行的代码,这将是一个问题。
+
+调度程序将在 GC,“go” 语句,阻塞通道操作,阻塞系统调用和锁定操作之后运行。当调用非内联函数时,它也可能运行。
+
+```go
+package main
+
+import "fmt"
+
+func main() {
+ done := false
+
+ go func(){
+ done = true
+ }()
+
+ for !done {
+ fmt.Println("not done!") //not inlined
+ }
+ fmt.Println("done!")
+}
+```
+
+要查明你在 `for` 循环中调用的函数是否内联,请将 “-m” gc 标志传递给 “ go build” 或 “ go run”(例如,`go build -gcflags -m`)。
+
+另一种选择是显式调用调度程序。你可以使用 “运行时” 包中的 `Gosched()` 函数来完成此操作。
+
+```go
+package main
+
+import (
+ "fmt"
+ "runtime"
+)
+
+func main() {
+ done := false
+
+ go func(){
+ done = true
+ }()
+
+ for !done {
+ runtime.Gosched()
+ }
+ fmt.Println("done!")
+}
+```
+
+请注意,上面的代码包含一个竞争条件。这样做是故意显示出隐藏的陷阱。
+
+## 导入 C 和多行导入块
+
+- 级别:Cgo
+
+你需要导入 “C” 包才能使用 Cgo。你可以单行 `import` 进行此操作,也可以使用 `import` 块进行此操作。
+
+```go
+package main
+
+/*
+#include
+*/
+import (
+ "C"
+)
+
+import (
+ "unsafe"
+)
+
+func main() {
+ cs := C.CString("my go string")
+ C.free(unsafe.Pointer(cs))
+}
+```
+
+如果以 `import` 块的方式引入此包 ,则无法在同一个块中引入其他包。
+
+```go
+package main
+
+/*
+#include
+*/
+import (
+ "C"
+ "unsafe"
+)
+
+func main() {
+ cs := C.CString("my go string")
+ C.free(unsafe.Pointer(cs))
+}
+```
+
+编译错误:
+
+> ./main.go:13:2: could not determine kind of name for C.free
+
+## 在 C 和 Cgo 注释之间不要有空白行
+
+* 级别: Cgo
+
+Cgo 的第一个陷阱是:cgo 注释需位于 `import C` 声明的上方。
+
+```go
+package main
+
+/*
+#include
+*/
+
+import "C"
+
+import (
+ "unsafe"
+)
+
+func main() {
+ cs := C.CString("my go string")
+ C.free(unsafe.Pointer(cs))
+}
+```
+
+编译错误:
+
+> ./main.go:15:2: could not determine kind of name for C.free
+
+确保在 `import C` 声明前没有任何空白行。
+
+## 不能调用带有可变参数的 C 函数
+
+* level: Cgo
+
+你不能直接调用带有可变参数的 C 函数
+
+```go
+package main
+
+/*
+#include
+#include
+*/
+import "C"
+
+import (
+ "unsafe"
+)
+
+func main() {
+ cstr := C.CString("go")
+ C.printf("%s\n",cstr) //not ok
+ C.free(unsafe.Pointer(cstr))
+}
+```
+
+编译错误:
+
+> ./main.go:15:2: unexpected type: ...
+
+你需要用已知数量参数的函数封装 C 可变数量参数的函数
+
+```go
+package main
+
+/*
+#include
+#include
+
+void out(char* in) {
+ printf("%s\n", in);
+}
+*/
+import "C"
+
+import (
+ "unsafe"
+)
+
+func main() {
+ cstr := C.CString("go")
+ C.out(cstr) //ok
+ C.free(unsafe.Pointer(cstr))
+}
+```
diff --git a/index.md b/index.md
new file mode 100644
index 0000000..51777b5
--- /dev/null
+++ b/index.md
@@ -0,0 +1,120 @@
+---
+headless: true
+---
+
+* [机智的程序员小熊](https://coding3min.com)
+* [GitHub](https://github.com/minibear2333/)
+* [微信公众号](qrcode.md)
+* **帮助与提示**
+ * [0.0 如何参与贡献](howToContribute.md)
+ * [0.1 书籍推荐](books-share.md)
+* **————基础篇————**
+* **第一章、Go基础**
+ * [1.1 安装与下载](1.base/1-1-install-download.md)
+ * [1.2 跑起来](1.base/1-2-hello-world.md)
+ * [1.3 go mod最佳实践](1.base/1-3-go-mod.md)
+ * [1.4 变量与常量](1.base/1-4-variables.md)
+ * [1.5 switch和type switch](1.base/1-5-switch和typeswitch.md)
+ * [1.6 循环](1.base/1-6-for-range.md)
+ * [1.7 range深度解析](1.base/1-7-range深度解析.md)
+* **第二章、函数和容器**
+ * [2.1 函数简单使用和基本知识解析](2.func-containers/2-1-func.md)
+ * [2.2 匿名函数和闭包](2.func-containers/2-2-匿名函数和闭包.md)
+ * [2.3 可变参数](2.func-containers/2-3-可变参数.md)
+ * [2.4 集合(map)](2.func-containers/2-4-map.md)
+ * [2.5 数组和切片](2.func-containers/2-5-数组和切片.md)
+* **第三章、语法进阶**
+ * [3.1 指针讨论](3.grammar-advancement/3-1-point.md)
+ * [3.2 结构体](3.grammar-advancement/3-2-struct.md)
+ * [3.3 接口与多态](3.grammar-advancement/3-3-接口与多态.md)
+ * [3.4 异常处理](3.grammar-advancement/3-4-异常处理.md)
+ * [3.5 反射](3.grammar-advancement/3-5-反射.md)
+* **第四章、并发和并行**
+ * [4.1 并发特性](4.concurrent/4-1-go语言中的并发特性.md)
+ * [4.2 并发等待 ](4.concurrent/4-2-goroutine-wait.md)
+ * [4.3 channel](4.concurrent/4-3-channel.md)
+ * [4.4 deadlock](4.concurrent/4-4-deadlock.md)
+ * [4.5 select](4.concurrent/4-5-select.md)
+ * [4.6 定时器](4.concurrent/4-6-cron.md)
+ * [4.7 并发安全和锁](4.concurrent/4-7-lock.md)
+ * [4.8 原子操作](4.concurrent/4-8-原子操作.md)
+ * [4.9 sync包](4.concurrent/4-9-sync.md)
+ * [4.10 pool](4.concurrent/4-10-pool.md)
+ * [4.11 GMP调度原理](https://coding3min.com/question/go-gmp)
+* **————框架篇————**
+* **第五章、常用标准库**
+ * [5.1 Go代码基本标准规范](5.standard-library/5.1-Go代码基本标准规范.md)
+ * [5.2 json库](5.standard-library/5.2-json.md)
+ * [5.3 文件操作](5.standard-library/5.3-Go文件操作大全.md)
+ * [5.3 排序](5.standard-library/切片排序sort包的使用.md)
+ * [5.4 命令行操作](https://mp.weixin.qq.com/s/y3MuEAY12PRlS2ARgzYtIA)
+ * [5.5 时间处理](https://mp.weixin.qq.com/s/OBkigY4x2KamsWR6iMP_uQ)
+ * -字符串处理 TODO
+ * -模板 TODO
+ * -在线工具系统实战 TODO
+* **第6章、常用数据操作**
+ * -说明
+ * -mysql
+ * -redis
+ * -mongo
+ * -rabbitmq
+ * -kafka
+ * -etcd
+ * -rabbitmq
+ * -zookeeper
+ * -ElasticSearch
+* **第x章、常用第三方包**
+ * -命令行工具
+ * -日志
+ * -配置管理
+ * -接口文档
+ * -错误码控制
+* **————测试调试篇————**
+* **第x章、调试与测试**
+ * [单元测试](https://mp.weixin.qq.com/s/ltRpuolYuOa8cXivLZLlUw)
+ * -基准测试
+ * -mock
+ * -自动化测试
+ * -调试
+* **第x章、性能调优**
+ * -cpu调度
+ * -内存管理
+ * -垃圾回收
+ * -PProf
+ * -逃逸分析
+ * -链路追踪
+* **————网络编程篇————**
+* **第x章、HTTP框架**
+ * -http库实现GET POST PUT DEL请求
+ * -websocket实现在线聊天室
+ * -gin框架
+ * -对go写web的态度
+* **第x章、RPC**
+* **第x章、微服务**
+ * 熔断与限流
+* **第x章、爬虫实战**
+* **第x章、分布式系统**
+ * -分布式ID生成器
+ * -分布式锁
+ * -分布式一致性算法
+ * -分布式定时任务
+ * -分布式计算
+* **————工程化篇————**
+* **第x章、Go语言工程化实战**
+ * 构建约束
+ * [Go与Dockerfile](工程化实践/Golang打镜像Dockerfile的写法.md)
+* **第x章、Go语言运维实战**
+* **第x章、Go语言监控实战**
+ * -自监控
+* **————拓展学习————**
+* **第x章、kubernetes开发实战**
+* **第x章、服务治理**
+* **番外1、拓展应用**
+ * [小工具](tools/README.md)
+* **番外2、陷阱与缺陷**
+ * [range的第二个值实际上是值拷贝](impossible/range/README.md)
+ * [新手常犯的错误](impossible/新手常犯的错误.md)
+ * [初学者常犯的错误](impossible/初学者常犯的错误.md)
+ * [进阶常犯的错误](impossible/进阶常犯的错误.md)
+* **第x章、GO语言版本分析**
+
diff --git a/blog/content/qrcode.jpg b/qrcode.jpg
similarity index 100%
rename from blog/content/qrcode.jpg
rename to qrcode.jpg
diff --git a/blog/content/qrcode.md b/qrcode.md
similarity index 100%
rename from blog/content/qrcode.md
rename to qrcode.md
diff --git a/blog/content/todo.md b/todo.md
similarity index 100%
rename from blog/content/todo.md
rename to todo.md
diff --git a/blog/content/tools/README.md b/tools/README.md
similarity index 100%
rename from blog/content/tools/README.md
rename to tools/README.md
diff --git a/blog/content/tools/cache.go b/tools/cache.go
similarity index 100%
rename from blog/content/tools/cache.go
rename to tools/cache.go
diff --git a/blog/content/tools/defer_panic.go b/tools/defer_panic.go
similarity index 100%
rename from blog/content/tools/defer_panic.go
rename to tools/defer_panic.go
diff --git a/blog/content/tools/func.go b/tools/func.go
similarity index 100%
rename from blog/content/tools/func.go
rename to tools/func.go
diff --git a/blog/content/tools/map.go b/tools/map.go
similarity index 100%
rename from blog/content/tools/map.go
rename to tools/map.go
diff --git a/blog/content/tools/slice.go b/tools/slice.go
similarity index 100%
rename from blog/content/tools/slice.go
rename to tools/slice.go
diff --git a/tools/speed.go b/tools/speed.go
new file mode 100644
index 0000000..a9f324e
--- /dev/null
+++ b/tools/speed.go
@@ -0,0 +1,23 @@
+package tools
+
+import (
+ "fmt"
+ "reflect"
+ "runtime"
+ "time"
+)
+
+func doWhat() {
+
+}
+func SpeedTime(handler func()) {
+ t := time.Now()
+ handler()
+ elapsed := time.Since(t)
+ // 利用反射获得函数名
+ funcName := runtime.FuncForPC(reflect.ValueOf(handler).Pointer()).Name()
+ fmt.Println(funcName+"spend time:", elapsed)
+}
+func main() {
+ SpeedTime(doWhat)
+}
diff --git a/blog/content/tools/static_proxy.go b/tools/static_proxy.go
similarity index 100%
rename from blog/content/tools/static_proxy.go
rename to tools/static_proxy.go
diff --git a/blog/content/tools/unused.go b/tools/unused.go
similarity index 100%
rename from blog/content/tools/unused.go
rename to tools/unused.go
diff --git "a/blog/content/\347\225\252\345\244\226.\345\270\270\347\224\250\346\223\215\344\275\234/Golang\346\211\223\351\225\234\345\203\217Dockerfile\347\232\204\345\206\231\346\263\225.md" "b/\345\267\245\347\250\213\345\214\226\345\256\236\350\267\265/Golang\346\211\223\351\225\234\345\203\217Dockerfile\347\232\204\345\206\231\346\263\225.md"
similarity index 100%
rename from "blog/content/\347\225\252\345\244\226.\345\270\270\347\224\250\346\223\215\344\275\234/Golang\346\211\223\351\225\234\345\203\217Dockerfile\347\232\204\345\206\231\346\263\225.md"
rename to "\345\267\245\347\250\213\345\214\226\345\256\236\350\267\265/Golang\346\211\223\351\225\234\345\203\217Dockerfile\347\232\204\345\206\231\346\263\225.md"
diff --git "a/\345\267\245\347\250\213\345\214\226\345\256\236\350\267\265/\346\236\204\345\273\272\347\272\246\346\235\237.md" "b/\345\267\245\347\250\213\345\214\226\345\256\236\350\267\265/\346\236\204\345\273\272\347\272\246\346\235\237.md"
new file mode 100644
index 0000000..3d468a8
--- /dev/null
+++ "b/\345\267\245\347\250\213\345\214\226\345\256\236\350\267\265/\346\236\204\345\273\272\347\272\246\346\235\237.md"
@@ -0,0 +1,4 @@
+nosplit 禁止内联 noescape 禁止逃逸
+gengrate 生成命令
+指定构建的版本,通过文件名或者注释约定代码在指定平台运行时起作用
+embed
\ No newline at end of file