E go();
+
+ 泛型可以使用?通配符进行泛化 Object可以接受任何类型
+
+ 也可以使用 这种方式进行上下边界的限制。
+
+### Class类和Object类
+
+ Java反射的基础是Class类,该类封装所有其他类的类型信息,并且在每个类加载后在堆区生成每个类的一个Class<类名>实例,用于该类的实例化。
+
+ Java中可以通过多种方式获取Class类型,比如A.class,new A().getClass()方法以及Class.forName("com.?.?.A")方法。
+
+ Object是所有类的父类,有着自己的一些私有方法,以及被所有类继承的9大方法。
+
+ 有人讨论Object和Class类型谁先加载谁后加载,因为每个类都要继承Object,但是又得先被加载到堆区,事实上,这个问题在JVM初始化时就解决了,没必要多想。
+
+### javac和java
+
+ javac 是编译一个java文件的基本命令,通过不同参数可以完成各种配置,比如导入其他类,指定编译路径等。
+
+ java是执行一个java文件的基本命令,通过参数配置可以以不同方式执行一个java程序或者是一个jar包。
+
+ javap是一个class文件的反编译程序,可以获取class文件的反编译结果,甚至是jvm执行程序的每一步代码实现。
+
+
+
+### 反射
+
+ Java反射包reflection提供对Class,Method,field,constructor等信息的封装类型。
+
+ 通过这些api可以轻易获得一个类的各种信息并且可以进行实例化,方法调用等。
+
+ 类中的private参数可以通过setaccessible方法强制获取。
+
+ 反射的作用可谓是博大精深,JDK动态代理生成代理类的字节码后,首先把这个类通过defineclass定义成一个类,然后用class.for(name)会把该类加载到jvm,之后我们就可以通过,A.class.GetMethod()获取其方法,然后通过invoke调用其方法,在调用这个方法时,实际上会通过被代理类的引用再去调用原方法。
- 1 这段时间以后就是实习期了,三个月的W厂实习经历。半年的B厂实习,让我着实过了一把大厂的瘾。但是其中做的工作无非就是增删改查写写业务逻辑,很难接触到比较核心的部分。
-
- 2 于是乎我花了许多时间学习部门的核心技术。比如在W厂参与数据平台的工作时,我学习了hadoop以及数据仓库的架构,也写了一些博客,并且向负责后端架构的导师请教了许多知识,收获颇丰。
-
- 3 在B厂实习期间则接触了许多云计算相关的技术。因为部门做的是私有云,所以业务代码和底层的服务也是息息相关的,比如平时的业务代码也会涉及到底层的接口调用,比如新建一个虚拟机或者启动一台虚拟机,需要通过多级的服务调用,首先是HTTP服务调用,经过多级的服务调用,最终完成流程。在这期间我花了一些时间学习了OpenStack的架构以及部门的实际应用情况,同时也玩了一下docker,看了kubenetes的一些书籍,算是入门。
-
- 4 但是这些东西其实离后台开发还是有一定距离的,比如后台开发的主要问题就是高并发,分布式,Linux服务器开发等。而我做的东西,只能稍微接触到这一部门的内容,因为主要是to b的内部业务。所以这段时间其实我的进步有限,虽然扩大了知识面并且积累了开发经验,但是对于后台岗位来说还是有所欠缺的。
-
- 5 不过将近一年的实习也让我收获了很多东西,大厂的实习体验很好,工作高效,团队合作,版本的快速迭代,技术氛围很不错。特别是在B厂了可以解到很多前沿的技术,对自己的视野扩展很有帮助。
-
----
-
-## **实习转正,还是准备秋招?**
-
- 1 离职以后,在考虑是否还要找实习,因为有两份实习经历了,在考虑要不要静下心来刷刷题,复习一下基础,并且回顾一下实习时用到的技术。同一时期,我了解到腾讯和阿里等大厂的实习留用率不高,并且可能影响到秋招,所以当时的想法是直接复习等到秋招内推。因此,那段时间比较放松,没什么复习状态,也导致了我在今年春招内推的阶段比较艰难。
-
- 2 因为当时想着沉住气准备秋招,所以一开始对实习内推不太在意。但是由于AT招人的实习生转正比例较大,考虑到秋招的名额可能更少,所以还是不愿意错过这个机会。因为开始系统复习的时间比较晚,所以投的比较晚,担心准备不充分被刷。这次找实习主要是奔着转正去的,所以只投了bat和滴滴,京东,网易游戏等大厂。
-
- 3 由于投递时间原因,所以面试的流程特别慢。并且在笔试方面还是有所欠缺,刷题刷的比较少,在线编程的算法题还是屡屡受挫。这让我有点后悔实习结束后的那段时间没有好好刷题了。
-
----
-
-## **调整心态,重新上路**
-
- 1 目前的状态是,一边刷题,一边复习基础,投了几家大厂的实习内推,打算选一个心仪的公司准备转正,但是事情总是没那么顺利,微软,头条等公司的笔试难度超过了我的能力范围,没能接到面试电话。腾讯投了一个自己比较喜欢的部门,可惜岗位没有匹配上,后台开发被转成了运营开发,最终没能通过。阿里面试的也不顺利,当时投了一个牛客上的蚂蚁金服内推,由于投的太晚,部门已经招满,只面了一面就没了下文,前几天接到了菜鸟的面试,这个未完待续。
-
- 2 目前的想法是,因为我不怎么需要实习经历来加分了,所以想多花些时间复习基础,刷题,并且巩固之前的项目经历。当然如果有好的岗位并且转正机会比较大的话,也是会考虑去实习的,那样的话可能需要多挤点时间来复习基础和刷题了。
-
- 3 在这期间,我会重新梳理一下自己的复习框架,有针对性地看一些高质量的博文,同时多做些项目实践,加深对知识的理解。当然这方面还会通过写博客进行跟进,写博客,做项目。前阵子在牛客上看到一位牛友CyC2018做的名为interview notebook的GitHub仓库,内容非常好,十分精品,我全部看完了,并且参考其LeetCode题解进行刷题。
-
- 4 受到这位大佬的启发,我也打算做一个类似的代码仓库或者是博客专栏,尽量在秋招之前把总结做完,并且把好的文章都放进去。上述内容只是本人个人的心得体会,如果有错误或者说的不合理的地方,还请谅解和指正。希望与广大牛友共勉,一起进步。
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
+### 枚举类
+
+ 枚举类继承Enum并且每个枚举类的实例都是唯一的。
+
+ 枚举类可以用于封装一组常量,取值从这组常量中取,比如一周的七天,一年的十二个月。
+
+ 枚举类的底层实现其实是语法糖,每个实例可以被转化成内部类。并且使用静态代码块进行初始化,同时保证内部成员变量不可变。
+
+### 序列化
+
+ 序列化的类要实现serializable接口
+
+ transient修饰符可以保证某个成员变量不被序列化
+
+ readObject和writeOject来实现实例的写入和读取。
+
+ 待更新。
+
+ 事实上,一些拥有数组变量的类都会把数组设为transient修饰,这样的话不会对整个数组进行序列化,而是利用专门的方法将有数据的数组范围进行序列化,以便节省空间。
+
+### 动态代理
+
+ jdk自带的动态代理可以代理一个已经实现接口的类。
+
+ cglib代理可以代理一个普通的类。
+
+ 动态代理的基本实现原理都是通过字节码框架动态生成字节码,并且在用defineclass加载类后,获取代理类的实例。
+
+ 一般需要实现一个代理处理器,用来处理被代理类的前置操作和后置操作。在JDK动态代理中,这个类叫做invocationHandler。
+
+ JDK动态代理首先获取被代理类的方法,并且只获取在接口中声明的方法,生成代理类的字节码后,首先把这个类通过defineclass定义成一个类,然后把该类加载到jvm,之后我们就可以通过,A.class.GetMethod()获取其方法,然后通过invoke调用其方法,在调用这个方法时,实际上会通过被代理类的引用再去调用原方法。
+
+ 而对于cglib动态代理,一般会把被代理类设为代理类的父类,然后获取被代理类中所有非final的方法,通过asm字节码框架生成代理类的字节码,这个代理类很神奇,他会保留原来的方法以及代理后的方法,通过方法数组的形式保存。
+
+ cglib的动态代理需要实现一个enhancer和一个interceptor,在interceptor中配置我们需要的代理内容。如果没有配置interceptor,那么代理类会调用被代理类自己的方法,如果配置了interceptor,则会使用代理类修饰过的方法。
+
+
+### 多线程
+ 这里先不讲juc包里的多线程类。juc相关内容会在Java并发专题讲解。
+
+ 线程的实现可以通过继承Thread类和实现Runable接口
+ 也可以使用线程池。callable配合future可以实现线程中的数据获取。
+
+ Java中的线程有7种状态,new runable running blocked waiting time_waiting terminate
+ blocked是线程等待其他线程锁释放。
+ waiting是wait以后线程无限等待其他线程使用notify唤醒
+ time_wating是有限时间地等待被唤醒,也可能是sleep固定时间。
+
+ Thread的join是实例方法,比如a.join(b),则说明a线程要等b线程运行完才会运行。
+
+ o.wait方法会让持有该对象o的线程释放锁并且进入阻塞状态,notify则是持有o锁对象的线程通知其他等待锁的线程获取锁。notify方法并不会释放锁。注意这两个方法都只能在synchronized同步方法或同步块里使用。
+
+ synchronized方法底层使用系统调用的mutex锁,开销较大,jvm会为每个锁对象维护一个等待队列,让等待该对象锁的线程在这个队列中等待。当线程获取不到锁时则让线程阻塞,而其他检查notify以后则会通知任意一个线程,所以这个锁时非公平锁。
+
+ Thread.sleep(),Thread.interrupt()等方法都是类方法,表示当前调用该方法的线程的操作。
+
+
+ 一个线程实例连续start两次会抛异常,这是因为线程start后会设置标识,如果再次start则判断为错误。
+
+### IO流
+
+ IO流也是Java中比较重要的一块,Java中主要有字节流,字符流,文件等。其中文件也是通过流的方式打开,读取和写入的。
+
+ IO流的很多接口都使用了装饰者模式,即将原类型通过传入装饰类构造函数的方式,增强原类型,以此获得像带有缓冲区的字节流,或者将字节流封装成字符流等等,其中需要注意的是编码问题,后者打印出来的结果可能是乱码哦。
+
+ IO流与网络编程息息相关,一个socket接入后,我们可以获取它的输入流和输出流,以获取TCP数据包的内容,并且可以往数据报里写入内容,因为TCP协议也是按照流的方式进行传输的,实际上TCP会将这些数据进行分包处理,并且通过差错检验,超时重传,滑动窗口协议等方式,保证了TCP数据包的高效和可靠传输。
+
+### 网络编程
+
+ 承接IO流的内容
+
+ IO流与网络编程息息相关,一个socket接入后,我们可以获取它的输入流和输出流,以获取TCP数据包的内容,并且可以往数据报里写入内容,因为TCP协议也是按照流的方式进行传输的,实际上TCP会将这些数据进行分包处理,并且通过差错检验,超时重传,滑动窗口协议等方式,保证了TCP数据包的高效和可靠传输。
+
+ 除了使用socket来获取TCP数据包外,还可以使用UDP的DatagramPacket来封装UDP数据包,因为UDP数据包的大小是确定的,所以不是使用流方式处理,而是需要事先定义他的长度,源端口和目标端口等信息。
+
+ 为了方便网络编程,Java提供了一系列类型来支持网络编程的api,比如URL类,InetAddress类等。
+
+ 后续文章会带来NIO相关的内容,敬请期待。
+
+
+
+
+### Java8
+
+ 接口中的默认方法,接口终于可以有方法实现了,使用注解即可标识出默认方法。
+
+ lambda表达式实现了函数式编程,通过注解可以声明一个函数式接口,该接口中只能有一个方法,这个方法正是使用lambda表达式时会调用到的接口。
+
+ Option类实现了非空检验
+
+ 新的日期API
+
+ 各种api的更新,包括chm,hashmap的实现等
+
+ Stream流概念,实现了集合类的流式访问,可以基于此使用map和reduce并行计算。
+
From 8dd2a615f14370b731047ce9f0707ba81e7c29c3 Mon Sep 17 00:00:00 2001
From: How_2_Play_Life <362294931@qq.com>
Date: Sun, 8 Jul 2018 23:11:10 +0800
Subject: [PATCH 15/23] Update README.md
---
README.md | 22 ++++++++++++++++++++++
1 file changed, 22 insertions(+)
diff --git a/README.md b/README.md
index 250a91f..b7618cc 100644
--- a/README.md
+++ b/README.md
@@ -10,16 +10,38 @@
## 数据库 :floppy_disk:
+> [Mysql原理与实践总结] (https://github.com/h2pl/Java-Tutorial/blob/master/md/Mysql%E5%8E%9F%E7%90%86%E4%B8%8E%E5%AE%9E%E8%B7%B5%E6%80%BB%E7%BB%93.md)
+
+> [Redis原理与实践总结]https://github.com/h2pl/Java-Tutorial/blob/master/md/Redis%E5%8E%9F%E7%90%86%E4%B8%8E%E5%AE%9E%E8%B7%B5%E6%80%BB%E7%BB%93.md
## Java :couple:
+> [Java核心技术总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/Java%E6%A0%B8%E5%BF%83%E6%8A%80%E6%9C%AF%E6%80%BB%E7%BB%93.md)
+
+> [Java集合类总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/Java%E9%9B%86%E5%90%88%E7%B1%BB%E6%80%BB%E7%BB%93.md)
+
+> [Java并发技术总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/Java%E5%B9%B6%E5%8F%91%E6%80%BB%E7%BB%93.md)
+
+> [JVM原理学习总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/JVM%E6%80%BB%E7%BB%93.md)
+
+> [Java网络与NIO总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/Java%E7%BD%91%E7%BB%9C%E4%B8%8ENIO%E6%80%BB%E7%BB%93.md)
+
## JavaWeb :coffee:
+> [JavaWeb技术学习总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/JavaWeb%E6%8A%80%E6%9C%AF%E6%80%BB%E7%BB%93.md)
+
+> [Spring与SpringMVC源码解析](https://github.com/h2pl/Java-Tutorial/blob/master/md/Spring%E4%B8%8ESpringMVC%E6%BA%90%E7%A0%81%E8%A7%A3%E6%9E%90%E6%80%BB%E7%BB%93.md)
+
## 分布式 :sweat_drops:
+> [分布式理论学习总结] (https://github.com/h2pl/Java-Tutorial/blob/master/md/%E5%88%86%E5%B8%83%E5%BC%8F%E7%90%86%E8%AE%BA%E6%80%BB%E7%BB%93.md)
+
+> [分布式技术学习总结] (https://github.com/h2pl/Java-Tutorial/blob/master/md/%E5%88%86%E5%B8%83%E5%BC%8F%E6%8A%80%E6%9C%AF%E5%AE%9E%E8%B7%B5%E6%80%BB%E7%BB%93.md)
## 设计模式 :hammer:
## Hadoop :speak_no_evil:
+> [分布式技术学习总结] (https://github.com/h2pl/Java-Tutorial/blob/master/md/Hadoop%E7%94%9F%E6%80%81%E6%80%BB%E7%BB%93.md)
+
## 后记
From 3d912288cd1f37c0db9ef7ca5d20ec0d341d7150 Mon Sep 17 00:00:00 2001
From: How_2_Play_Life <362294931@qq.com>
Date: Sun, 8 Jul 2018 23:15:05 +0800
Subject: [PATCH 16/23] Update README.md
---
README.md | 12 +++++++-----
1 file changed, 7 insertions(+), 5 deletions(-)
diff --git a/README.md b/README.md
index b7618cc..a667311 100644
--- a/README.md
+++ b/README.md
@@ -10,9 +10,10 @@
## 数据库 :floppy_disk:
-> [Mysql原理与实践总结] (https://github.com/h2pl/Java-Tutorial/blob/master/md/Mysql%E5%8E%9F%E7%90%86%E4%B8%8E%E5%AE%9E%E8%B7%B5%E6%80%BB%E7%BB%93.md)
+> [Mysql原理与实践总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/Mysql%E5%8E%9F%E7%90%86%E4%B8%8E%E5%AE%9E%E8%B7%B5%E6%80%BB%E7%BB%93.md)
+
+> [Redis原理与实践总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/Redis%E5%8E%9F%E7%90%86%E4%B8%8E%E5%AE%9E%E8%B7%B5%E6%80%BB%E7%BB%93.md)
-> [Redis原理与实践总结]https://github.com/h2pl/Java-Tutorial/blob/master/md/Redis%E5%8E%9F%E7%90%86%E4%B8%8E%E5%AE%9E%E8%B7%B5%E6%80%BB%E7%BB%93.md
## Java :couple:
> [Java核心技术总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/Java%E6%A0%B8%E5%BF%83%E6%8A%80%E6%9C%AF%E6%80%BB%E7%BB%93.md)
@@ -32,15 +33,16 @@
> [Spring与SpringMVC源码解析](https://github.com/h2pl/Java-Tutorial/blob/master/md/Spring%E4%B8%8ESpringMVC%E6%BA%90%E7%A0%81%E8%A7%A3%E6%9E%90%E6%80%BB%E7%BB%93.md)
## 分布式 :sweat_drops:
-> [分布式理论学习总结] (https://github.com/h2pl/Java-Tutorial/blob/master/md/%E5%88%86%E5%B8%83%E5%BC%8F%E7%90%86%E8%AE%BA%E6%80%BB%E7%BB%93.md)
-> [分布式技术学习总结] (https://github.com/h2pl/Java-Tutorial/blob/master/md/%E5%88%86%E5%B8%83%E5%BC%8F%E6%8A%80%E6%9C%AF%E5%AE%9E%E8%B7%B5%E6%80%BB%E7%BB%93.md)
+> [分布式理论学习总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/%E5%88%86%E5%B8%83%E5%BC%8F%E7%90%86%E8%AE%BA%E6%80%BB%E7%BB%93.md)
+
+> [分布式技术学习总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/%E5%88%86%E5%B8%83%E5%BC%8F%E6%8A%80%E6%9C%AF%E5%AE%9E%E8%B7%B5%E6%80%BB%E7%BB%93.md)
## 设计模式 :hammer:
## Hadoop :speak_no_evil:
-> [分布式技术学习总结] (https://github.com/h2pl/Java-Tutorial/blob/master/md/Hadoop%E7%94%9F%E6%80%81%E6%80%BB%E7%BB%93.md)
+> [Hadoop生态学习总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/Hadoop%E7%94%9F%E6%80%81%E6%80%BB%E7%BB%93.md)
From 32b3f5c52225f1e3c40f1cfb771a80c31359ab95 Mon Sep 17 00:00:00 2001
From: 724888 <362294931@qq.com>
Date: Mon, 9 Jul 2018 22:43:24 +0800
Subject: [PATCH 17/23] add new md
---
README.md | 44 ++++++++-----------
...37\346\200\201\346\200\273\347\273\223.md" | 1 -
md/README.md | 27 ------------
3 files changed, 19 insertions(+), 53 deletions(-)
delete mode 100644 md/README.md
diff --git a/README.md b/README.md
index 250a91f..9a81fc5 100644
--- a/README.md
+++ b/README.md
@@ -1,33 +1,27 @@
-| Ⅰ | Ⅱ | Ⅲ | Ⅳ | Ⅴ | Ⅵ | Ⅶ | Ⅷ | Ⅸ |
-| :------: | :---------: | :-------: | :---------: | :---: | :---------:| :---------: | :---------: | :---------:|
-| 算法[:pencil2:](#算法-pencil2) | 操作系统[:computer:](#操作系统-computer)|网络[:cloud:](#网络-cloud) | 数据库[:floppy_disk:](#数据库-floppy_disk)| Java[:couple:](#Java-couple) |JavaWeb [:coffee:](#JavaWeb-coffee)| 分布式 [:sweat_drops:](#分布式-sweat_drops)| 设计模式[:hammer:](#设计模式-hammer)| Hadoop[:speak_no_evil:](#Hadoop-speak_no_evil)|
-
-## 算法 :pencil2:
-
-## 操作系统 :computer:
-
-## 网络 :cloud:
-
-## 数据库 :floppy_disk:
-
-## Java :couple:
-
-## JavaWeb :coffee:
-
-## 分布式 :sweat_drops:
-
-## 设计模式 :hammer:
-
-## Hadoop :speak_no_evil:
-
+[数据结构和算法](#算法) | [操作系统](#操作系统) | [网络](#网络) | [数据结构](#数据结构) | [数据库](#数据库) | [Java基础](#Java基础) | [Java进阶](#Java进阶) | [Web和Spring](#Web和Spring) | [分布式](#分布式) | [Hadoop](#Hadoop) | [工具](#工具) | [编码实践](#编码实践)
+## 数据结构和算法
+## 操作系统
+## 网络
+## 数据库
+## Java基础
+## Java进阶
+## web和Spring
+## 分布式
+## Hadoop
+## 工具
+## 编码实践
## 后记
-
**关于仓库**
本仓库是笔者在准备 2018 年秋招复习过程中的学习总结,内容以Java后端的知识总结为主,每个部分都会有笔者更加详细的原创文章可供参考,欢迎查看。
-
+**关于贡献**
+笔者能力有限,很多内容还不够完善。如果您希望和笔者一起完善这个仓库,可以发表一个 Issue,表明您想要添加的内容,笔者会及时查看。
+您也可以在 Issues 中发表关于改进本仓库的建议。
+**关于排版**
+笔记排版参考@CYC2018
**关于转载**
本仓库内容使用到的资料都会在最后面的参考资料中给出引用链接,希望您在使用本仓库的内容时也能给出相应的引用链接。
-
+**鸣谢**
+[CyC2018](https://github.com/CyC2018)
diff --git "a/md/Hadoop\347\224\237\346\200\201\346\200\273\347\273\223.md" "b/md/Hadoop\347\224\237\346\200\201\346\200\273\347\273\223.md"
index b71e6eb..3165d7f 100644
--- "a/md/Hadoop\347\224\237\346\200\201\346\200\273\347\273\223.md"
+++ "b/md/Hadoop\347\224\237\346\200\201\346\200\273\347\273\223.md"
@@ -7,7 +7,6 @@ categories:
- 后端
- 技术总结
---
-#Hadoop生态基础学习总结
这篇总结主要是基于我之前Hadoop生态基础系列文章而形成的的。主要是把重要的知识点用自己的话说了一遍,可能会有一些错误,还望见谅和指点。谢谢
#更多详细内容可以查看我的专栏文章:Hadoop生态学习
diff --git a/md/README.md b/md/README.md
deleted file mode 100644
index 9a81fc5..0000000
--- a/md/README.md
+++ /dev/null
@@ -1,27 +0,0 @@
-[数据结构和算法](#算法) | [操作系统](#操作系统) | [网络](#网络) | [数据结构](#数据结构) | [数据库](#数据库) | [Java基础](#Java基础) | [Java进阶](#Java进阶) | [Web和Spring](#Web和Spring) | [分布式](#分布式) | [Hadoop](#Hadoop) | [工具](#工具) | [编码实践](#编码实践)
-
-## 数据结构和算法
-## 操作系统
-## 网络
-## 数据库
-## Java基础
-## Java进阶
-## web和Spring
-## 分布式
-## Hadoop
-## 工具
-## 编码实践
-
-## 后记
-**关于仓库**
-本仓库是笔者在准备 2018 年秋招复习过程中的学习总结,内容以Java后端的知识总结为主,每个部分都会有笔者更加详细的原创文章可供参考,欢迎查看。
-**关于贡献**
-笔者能力有限,很多内容还不够完善。如果您希望和笔者一起完善这个仓库,可以发表一个 Issue,表明您想要添加的内容,笔者会及时查看。
-您也可以在 Issues 中发表关于改进本仓库的建议。
-**关于排版**
-笔记排版参考@CYC2018
-**关于转载**
-本仓库内容使用到的资料都会在最后面的参考资料中给出引用链接,希望您在使用本仓库的内容时也能给出相应的引用链接。
-**鸣谢**
-[CyC2018](https://github.com/CyC2018)
-
From a7cb53e8a94d5d08e90c728f4d54fa1ee9d5273e Mon Sep 17 00:00:00 2001
From: 724888 <362294931@qq.com>
Date: Mon, 9 Jul 2018 22:49:44 +0800
Subject: [PATCH 18/23] add mds
---
...46\344\271\240\346\200\273\347\273\223.md" | 849 +++++++++
"md/\345\211\221\346\214\207offer.md" | 1630 +++++++++++++++++
...46\344\271\240\346\200\273\347\273\223.md" | 304 +++
...46\344\271\240\346\200\273\347\273\223.md" | 640 +++++++
4 files changed, 3423 insertions(+)
create mode 100644 "md/Linux\345\206\205\346\240\270\344\270\216\345\237\272\347\241\200\345\221\275\344\273\244\345\255\246\344\271\240\346\200\273\347\273\223.md"
create mode 100644 "md/\345\211\221\346\214\207offer.md"
create mode 100644 "md/\346\223\215\344\275\234\347\263\273\347\273\237\345\255\246\344\271\240\346\200\273\347\273\223.md"
create mode 100644 "md/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\345\255\246\344\271\240\346\200\273\347\273\223.md"
diff --git "a/md/Linux\345\206\205\346\240\270\344\270\216\345\237\272\347\241\200\345\221\275\344\273\244\345\255\246\344\271\240\346\200\273\347\273\223.md" "b/md/Linux\345\206\205\346\240\270\344\270\216\345\237\272\347\241\200\345\221\275\344\273\244\345\255\246\344\271\240\346\200\273\347\273\223.md"
new file mode 100644
index 0000000..3656f63
--- /dev/null
+++ "b/md/Linux\345\206\205\346\240\270\344\270\216\345\237\272\347\241\200\345\221\275\344\273\244\345\255\246\344\271\240\346\200\273\347\273\223.md"
@@ -0,0 +1,849 @@
+---
+title: Linux内核与基础命令学习总结
+date: 2018-07-09 22:33:14
+tags:
+ - Linux
+categories:
+ - 后端
+ - 技术总结
+---
+##这部分内容主要是基于一些关于Linux系统的内核基础和基本命令的学习总结,内容不全面,只讲述了其中的一小部分,后续会再补充,如有错误,还请见谅。
+
+
+# Linux操作系统
+
+
+
+Linux操作系统博大精深,其中对线程,IO,文件系统等概念的实现都很有借鉴意义。
+
+
+
+## 文件系统和VFS
+
+文件系统的inode上面讲过了。VFS主要用于屏蔽底层的不同文件系统,比如接入网络中的nfs文件系统,亦或是windows文件系统,正常情况下难以办到,而vfs通过使用IO操作的posix规范来规定所有文件读写操作,每个文件系统只需要实现这些操作就可以接入VFS,不需要重新安装文件系统。
+## 进程和线程
+
+ > 进程、程序与线程
+ >
+ > 程序
+ >
+ > 程序,简单的来说就是存在磁盘上的二进制文件,是可以内核所执行的代码
+ >
+ > 进程
+ >
+ > 当一个用户启动一个程序,将会在内存中开启一块空间,这就创造了一个进程,一个进程包含一个独一无二的PID,和执行者的权限属性参数,以及程序所需代码与相关的资料。
+ > 进程是系统分配资源的基本单位。
+ > 一个进程可以衍生出其他的子进程,子进程的相关权限将会沿用父进程的相关权限。
+ >
+ > 线程
+ >
+ > 每个进程包含一个或多个线程,线程是进程内的活动单元,是负责执行代码和管理进程运行状态的抽象。
+ > 线程是独立运行和调度的基本单位。
+
+
+
+> 子进程和父进程
+> 进程的层次结构(父进程与子进程)在进程执行的过程中可能会衍生出其他的进程,称之为子进程,子进程拥有一个指明其父进程PID的PPID。子进程可以继承父进程的环境变量和权限参数。
+>
+> 于是,linux系统中就诞生了进程的层次结构——进程树。
+> 进程树的根是第一个进程(init进程)。
+>
+> 过程调用的流程: fork & exec一个进程生成子进程的过程是,系统首先复制(fork)一份父进程,生成一个暂存进程,这个暂存进程和父进程的区别是pid不一样,而且拥有一个ppid,这时候系统再去执行(exec)这个暂存进程,让他加载实际要运行的程序,最终成为一个子进程的存在。
+>
+> 服务与进程
+>
+> 简单的说服务(daemon)就是常驻内存的进程,通常服务会在开机时通过init.d中的一段脚本被启动。
+>
+> 进程通信
+>
+> 进程通信的几种基本方式:管道,信号量,消息队列,共享内存,快速用户控件互斥。
+>
+## fork方法
+ 一个进程,包括代码、数据和分配给进程的资源。fork()函数通过系统调用创建一个与原来进程几乎完全相同的进程,
+
+也就是两个进程可以做完全相同的事,但如果初始参数或者传入的变量不同,两个进程也可以做不同的事。
+
+
+ 一个进程调用fork()函数后,系统先给新的进程分配资源,例如存储数据和代码的空间。然后把原来的进程的所有值都
+
+复制到新的新进程中,只有少数值与原来的进程的值不同。相当于克隆了一个自己。
+
+ fork调用的一个奇妙之处就是它仅仅被调用一次,却能够返回两次,它可能有三种不同的返回值:
+ 1)在父进程中,fork返回新创建子进程的进程ID;
+ 2)在子进程中,fork返回0;
+ 3)如果出现错误,fork返回一个负值;
+
+如何理解pid在父子进程中不同?
+
+其实就相当于链表,进程形成了链表,父进程的pid指向了子进程的pid,因为子进程没有子进程,所以pid为0。
+
+## 写时复制
+
+ 传统的fork机制是,调用fork时,内核会复制所有的内部数据结构,复制进程的页表项,然后把父进程的地址空间按页复制给子进程(非常耗时)。
+
+ 现代的fork机制采用了一种惰性算法的优化策略。
+
+ 为了避免复制时系统开销,就尽可能的减少“复制”操作,当多个进程需要读取他们自己那部分资源的副本时,并不复制多个副本出来,而是为每个进程设定一个文件指针,让它们读取同一个实际文件。
+
+ 显然这样的方式会在写入时产生冲突(类似并发),于是当某个进程想要修改自己的那个副本时,再去复制该资源,(只有写入时才复制,所以叫写时复制)这样就减少了复制的频率。
+
+## 父子进程,僵尸进程,孤儿进程,守护进程
+
+父进程通过fork产生子进程。
+
+孤儿进程:当子进程未结束时父进程异常退出,原本需要由父进程进行处理的子进程变成了孤儿进程,init系统进程会把这些进程领养,避免他们成为孤儿。
+
+僵尸进程:当子进程结束时,会在内存中保留一部分数据结构等待父亲进程显式结束,如果父进程没有执行结束操作,则会导致子进程的剩余结构无法被释放,占用空间造成严重后果。
+
+守护进程:守护进程用于监控其他进程,当发现大量僵尸进程时,会找到他们的父节点并杀死,同时让init线程认养他们以便释放这些空间。
+
+僵尸进程是有害的,孤儿进程由于内核进程的认养不会造成危害。
+
+## 进程组和会话
+
+> 会话和进程组进程组每个进程都属于某个进程组,进程组就是由一个或者多个为了实现作业控制而相互关联的进程组成的。
+>
+> 一个进程组的id是进程组首进程的pid(如果一个进程组只有一个进程,那进程组和进程其实没啥区别)。
+>
+> 进程组的意义在于,信号可以发送给进程组中的所有进程。这样可以实现对多个进程的同时操作。
+> 会话会话是一个或者多个进程组的集合。
+>
+> 一般来说,会话(session)和shell没有什么本质上的区别。
+> 我们通常使用用户登录一个终端进行一系列操作这样的例子来描述一次会话。
+
+举例
+
+$cat ship-inventory.txt | grep
+
+booty|sort上面就是在某次会话中的一个shell命令,它会产生一个由3个进程组成的进程组。
+## 守护进程
+守护进程(服务)守护进程(daemon)运行在后台,不与任何控制终端相关联。通常在系统启动时通过init脚本被调用而开始运行。
+
+在linux系统中,守护进程和服务没有什么区别。
+对于一个守护进程,有两个基本的要求:其一:必须作为init进程的子进程运行,其二:不与任何控制终端交互。
+
+
+## 硬连接和软连接
+
+硬链接指的是不同的文件名指向同一个inode节点,比如某个目录下的a和另一个目录下的b,建立一个软连接让a指向b,则a和b共享同一个inode。
+
+软连接是指一个文件的inode节点不存数据,而是存储着另一个文件的绝对路径,访问文件内容时实际上是去访问对应路径下的文件inode,这样的话文件发生改动或者移动都会导致软连接失效。
+
+## 线程
+
+线程基础概念线程是进程内的执行单元(比进程更低一层的概念),具体包括 虚拟处理器,堆栈,程序状态等。
+可以认为 线程是操作系统调度的最小执行单元。
+
+现代操作系统对用户空间做两个基础抽象:虚拟内存和虚拟处理器。这使得进程内部“感觉”自己独占机器资源。
+
+虚拟内存系统会为每个进程分配独立的内存空间,这会让进程以为自己独享全部的RAM。
+
+但是同一个进程内的所有线程共享该进程的内存空间。
+虚拟处理器这是一个针对线程的概念,它让每个线程都“感觉”自己独享CPU。实际上对于进程也是一样的。
+
+## 线程模型
+
+线程模型线程的概念同时存在于内核和用户空间中。下面介绍三种线程模型。
+
+ 内核级线程模型每个内核线程直接转换成用户空间的线程。即内核线程:用户空间线程=1:1
+
+ 用户级线程模型这种模型下,一个保护了n个线程的用户进程只会映射到一个内核进程。即n:1。
+ 可以减少上下文切换的成本,但在linux下没什么意义,因为linux下进程间的上下文切换本身就没什么消耗,所以很少使用。
+
+ 混合式线程模型上述两种模型的混合,即n:m型。
+ 很难实现。
+## 内核线程实现
+
+系统线程实现:PThreads
+原始的linux系统调用中,没有像C++11或者是Java那样完整的线程库。
+
+整体看来pthread的api比较冗余和复杂,但是基本操作也主要是 创建、退出等。
+
+1.创建线程
+
+ int pthread_create
+
+ (若线程创建成功,则返回0。若线程创建失败,则返回出错编号)
+
+ 注意:线程创建者和新建线程之间没有fork()调用那样的父子关系,它们是对等关系。调用pthread_create()创建线程后,线程创建者和新建线程哪个先运行是不确定的,特别是在多处理机器上。
+
+2.终止线程
+
+ void pthread_exit(void *value_ptr);
+
+ 线程调用pthread_exit()结束自己,参数value_ptr作为线程的返回值被调用pthread_join的线程使用。由于一个进程中的多个线程是共享数据段的,因此通常在线程退出之后,退出线程所占用的资源并不会随着线程的终止而得到释放,但是可以用pthread_join()函数来同步并释放资源
+
+
+3.取消线程
+
+ int pthread_cancel(pthread_t thread);
+
+ 注意:若是在整个程序退出时,要终止各个线程,应该在成功发送 CANCEL指令后,使用 pthread_join函数,等待指定的线程已经完全退出以后,再继续执行;否则,很容易产生 “段错误”。
+
+4.连接线程(阻塞)
+
+ int pthread_join(pthread_t thread, void **value_ptr);
+
+ 等待线程thread结束,并设置*value_ptr为thread的返回值。pthread_join阻塞调用者,一直到线程thread结束为止。当函数返回时,被等待线程的资源被收回。如果进程已经结束,那么该函数会立即返回。并且thread指定的线程必须是joinable的。
+
+ 需要留意的一点是linux机制下,线程存在一个被称为joinable的状态。下面简要了解一下:
+
+Join和Detach
+这块的概念,非常类似于之前父子进程那部分,等待子进程退出的内容(一系列的wait函数)。
+
+linux机制下,线程存在两种不同的状态:joinable和unjoinable。
+
+ 如果一个线程被标记为joinable时,即便它的线程函数执行完了,或者使用了pthread_exit()结束了该线程,它所占用的堆栈资源和进程描述符都不会被释放(类似僵尸进程),这种情况应该由线程的创建者调用pthread_join()来等待线程的结束并回收其资源(类似wait系函数)。默认情况下创建的线程都是这种状态。
+
+ 如果一个线程被标记成unjoinable,称它被分离(detach)了,这时候如果该线程结束,所有它的资源都会被自动回收。省去了给它擦屁股的麻烦。
+
+ 因为创建的线程默认都是joinable的,所以要么在父线程调用pthread_detach(thread_id)将其分离,要么在线程内部,调用pthread_detach(pthread_self())来把自己标记成分离的。
+
+
+
+## 文件系统
+
+ 文件描述符在linux内核中,文件是用一个整数来表示的,称为 文件描述符,通俗的来说,你可以理解它是文件的id(唯一标识符)
+
+ 普通文件
+ 普通文件就是字节流组织的数据。
+ 文件并不是通过和文件名关联来实现的,而是通过关联索引节点来实现的,文件节点拥有文件系统为普通文件分配的唯一整数值(ino),并且存放着一些文件的相关元数据。
+
+ 目录与链接
+ 正常情况下文件是通过文件名来打开的。
+ 目录是可读名称到索引编号之间的映射,名称和索引节点之间的配对称为链接。
+ 可以把目录看做普通文件,只是它包含着文件名称到索引节点的映射(链接)
+
+
+
+文件系统是基于底层存储建立的一个树形文件结构。比较经典的是Linux的文件系统,首先在硬盘的超级块中安装文件系统,磁盘引导时会加载文件系统的信息。
+
+linux使用inode来标识任意一个文件。inode存储除了文件名以外的文件信息,包括创建时间,权限,以及一个指向磁盘存储位置的指针,那里才是真正存放数据的地方。
+
+一个目录也是一个inode节点。
+
+详细阐述一次文件访问的过程:
+
+ 首先用户ls查看目录。由于一个目录也是一个文件,所以相当于是看目录文件下有哪些东西。
+
+ 实际上目录文件是一个特殊的inode节点,它不需要存储实际数据,而只是维护一个文件名到inode的映射表。
+
+ 于是我们ls到另一个目录。同理他也是一个inode。我们在这个inode下执行vi操作打开某个文件,于是linux通过inode中的映射表找到了我们请求访问的文件名对应的inode。
+
+ 然后寻道到对应的磁盘位置,读取内容到缓冲区,通过系统调用把内容读到内存中,最后进行访问。
+## IO操作
+
+# 文件描述符
+
+ 对于内核而言,所有打开的文件都通过文件描述符引用。文件描述符是一个非负整数。当打开一个现有文件或创建一个新文件时,内核向进程返回一个文件描述符。当读或写一个文件时,使用open或create返回的文件描述符表示该文件,将其作为参数传给read或write函数。
+
+# write函数
+
+ write函数定义如下:
+
+
+
+#include ssize_t write(int filedes, void *buf, size_t nbytes); // 返回:若成功则返回写入的字节数,若出错则返回-1 // filedes:文件描述符 // buf:待写入数据缓存区 // nbytes:要写入的字节数
+
+
+
+ 同样,为了保证写入数据的完整性,在《UNIX网络编程 卷1》中,作者将该函数进行了封装,具体程序如下:
+
+
+
+
+
+
+
+ 1 ssize_t /* Write "n" bytes to a descriptor. */
+ 2 writen(int fd, const void *vptr, size_t n)
+ 3 {
+ 4 size_t nleft;
+ 5 ssize_t nwritten;
+ 6 const char *ptr;
+ 7
+ 8 ptr = vptr; 9 nleft = n; 10 while (nleft > 0) { 11 if ( (nwritten = write(fd, ptr, nleft)) <= 0) { 12 if (nwritten < 0 && errno == EINTR) 13 nwritten = 0; /* and call write() again */
+14 else
+15 return(-1); /* error */
+16 } 17
+18 nleft -= nwritten; 19 ptr += nwritten; 20 } 21 return(n); 22 } 23 /* end writen */
+24
+25 void
+26 Writen(int fd, void *ptr, size_t nbytes) 27 { 28 if (writen(fd, ptr, nbytes) != nbytes) 29 err_sys("writen error"); 30 }
+
+
+
+
+
+
+
+# read函数
+
+ read函数定义如下:
+
+
+
+#include ssize_t read(int filedes, void *buf, size_t nbytes); // 返回:若成功则返回读到的字节数,若已到文件末尾则返回0,若出错则返回-1 // filedes:文件描述符 // buf:读取数据缓存区 // nbytes:要读取的字节数
+
+
+
+ 有几种情况可使实际读到的字节数少于要求读的字节数:
+
+ 1)读普通文件时,在读到要求字节数之前就已经达到了文件末端。例如,若在到达文件末端之前还有30个字节,而要求读100个字节,则read返回30,下一次再调用read时,它将返回0(文件末端)。
+
+ 2)当从终端设备读时,通常一次最多读一行。
+
+ 3)当从网络读时,网络中的缓存机构可能造成返回值小于所要求读的字结束。
+
+ 4)当从管道或FIFO读时,如若管道包含的字节少于所需的数量,那么read将只返回实际可用的字节数。
+
+ 5)当从某些面向记录的设备(例如磁带)读时,一次最多返回一个记录。
+
+ 6)当某一个信号造成中断,而已经读取了部分数据。
+
+ 在《UNIX网络编程 卷1》中,作者将该函数进行了封装,以确保数据读取的完整,具体程序如下:
+
+
+
+
+
+
+
+ 1 ssize_t /* Read "n" bytes from a descriptor. */
+ 2 readn(int fd, void *vptr, size_t n)
+ 3 {
+ 4 size_t nleft;
+ 5 ssize_t nread;
+ 6 char *ptr;
+ 7
+ 8 ptr = vptr; 9 nleft = n; 10 while (nleft > 0) { 11 if ( (nread = read(fd, ptr, nleft)) < 0) { 12 if (errno == EINTR) 13 nread = 0; /* and call read() again */
+14 else
+15 return(-1); 16 } else if (nread == 0) 17 break; /* EOF */
+18
+19 nleft -= nread; 20 ptr += nread; 21 } 22 return(n - nleft); /* return >= 0 */
+23 } 24 /* end readn */
+25
+26 ssize_t 27 Readn(int fd, void *ptr, size_t nbytes) 28 { 29 ssize_t n; 30
+31 if ( (n = readn(fd, ptr, nbytes)) < 0) 32 err_sys("readn error"); 33 return(n); 34 }
+
+
+
+
+
+
+
+本文下半部分摘自博文[浅谈TCP/IP网络编程中socket的行为](http://www.cnblogs.com/promise6522/archive/2012/03/03/2377935.html)。
+
+# **read/write的语义:为什么会阻塞?**
+
+ 先从write说起:
+
+
+
+#include ssize_t write(int fd, const void *buf, size_t count);
+
+
+
+ 首先,write成功返回,**只是buf中的数据被复制到了kernel中的TCP发送缓冲区。**至于数据什么时候被发往网络,什么时候被对方主机接收,什么时候被对方进程读取,系统调用层面不会给予任何保证和通知。
+
+ write在什么情况下会阻塞?当kernel的该socket的发送缓冲区已满时。对于每个socket,拥有自己的send buffer和receive buffer。从Linux 2.6开始,两个缓冲区大小都由系统来自动调节(autotuning),但一般在default和max之间浮动。
+
+
+
+# 获取socket的发送/接受缓冲区的大小:(后面的值是在Linux 2.6.38 x86_64上测试的结果)
+
+sysctl net.core.wmem_default #126976
+sysctl net.core.wmem_max #131071
+
+
+
+ 已经发送到网络的数据依然需要暂存在send buffer中,只有收到对方的ack后,kernel才从buffer中清除这一部分数据,为后续发送数据腾出空间。接收端将收到的数据暂存在receive buffer中,自动进行确认。但如果socket所在的进程不及时将数据从receive buffer中取出,最终导致receive buffer填满,由于TCP的滑动窗口和拥塞控制,接收端会阻止发送端向其发送数据。这些控制皆发生在TCP/IP栈中,对应用程序是透明的,应用程序继续发送数据,最终导致send buffer填满,write调用阻塞。
+
+ 一般来说,由于**接收端进程从socket读数据的速度**跟不上**发送端进程向socket写数据的速度**,最终导致**发送端write调用阻塞。**
+
+ 而read调用的行为相对容易理解,从socket的receive buffer中拷贝数据到应用程序的buffer中。read调用阻塞,通常是发送端的数据没有到达。
+
+## Linux常用命令和基础知识
+
+### 查看进程
+
+ 1. ps
+ 查看某个时间点的进程信息
+
+ 示例一:查看自己的进程
+
+ # ps -l
+ 示例二:查看系统所有进程
+
+ # ps aux
+ 示例三:查看特定的进程
+
+ # ps aux | grep threadx
+
+ 2. top
+ 实时显示进程信息
+
+ 示例:两秒钟刷新一次
+
+ # top -d 2
+ 3. pstree
+ 查看进程树
+
+ 示例:查看所有进程树
+
+ # pstree -A
+ 4. netstat
+ 查看占用端口的进程
+
+ 示例:查看特定端口的进程
+
+ # netstat -anp | grep port
+
+### 文件操作
+ls -a ,all列出全部文件包括隐藏
+
+ls -l,list显示文件的全部属性
+
+ls -d,仅列出目录本身
+
+cd mkdir rmdir 常用不解释 rm -rf永久删除 cp复制 mv移动或改名
+
+touch,更新文件时间或者建立新文件。
+
+
+### 权限操作
+
+ chmod rwx 分别对应 421
+
+ chmod 754 .bashrc 将权限改为rwxr-xr--
+
+ 对应权限分配是对于 拥有者,所属群组,以及其他人。
+
+
+文件默认权限
+
+文件默认权限:文件默认没有可执行权限,因此为 666,也就是 -rw-rw-rw- 。
+
+目录默认权限:目录必须要能够进入,也就是必须拥有可执行权限,因此为 777 ,也就是 drwxrwxrwx。
+
+
+目录的权限
+
+ps:拥有目录权限才能修改文件名,拥有文件权限是没用的
+
+ 文件名不是存储在一个文件的内容中,而是存储在一个文件所在的目录中。因此,拥有文件的 w 权限并不能对文件名进行修改。
+
+目录存储文件列表,一个目录的权限也就是对其文件列表的权限。因此,目录的 r 权限表示可以读取文件列表;w 权限表示可以修改文件列表,具体来说,就是添加删除文件,对文件名进行修改;x 权限可以让该目录成为工作目录,x 权限是 r 和 w 权限的基础,如果不能使一个目录成为工作目录,也就没办法读取文件列表以及对文件列表进行修改了。
+
+
+## 连接操作
+
+
+硬链接:
+
+ 使用ln建立了一个硬连接,通过ll -i获得他们的inode节点。发现他们的inode节点是相同的。符合硬连接规定。
+
+
+ # ln /etc/crontab .
+ # ll -i /etc/crontab crontab
+
+ 34474855 -rw-r--r--. 2 root root 451 Jun 10 2014 crontab
+ 34474855 -rw-r--r--. 2 root root 451 Jun 10 2014 /etc/crontab
+
+软连接:
+
+ 符号链接文件保存着源文件所在的绝对路径,在读取时会定位到源文件上,可以理解为 Windows 的快捷方式。
+
+ 当源文件被删除了或者被移动到其他位置了,链接文件就打不开了。
+
+ 可以为目录建立链接。
+
+ # ll -i /etc/crontab /root/crontab2
+
+ 34474855 -rw-r--r--. 2 root root 451 Jun 10 2014 /etc/crontab
+ 53745909 lrwxrwxrwx. 1 root root 12 Jun 23 22:31 /root/crontab2 -> /etc/crontab
+
+## 获取内容
+
+cat 读取内容 加上-n 按行打印
+
+tac是cat的反向操作
+
+more允许翻页查看,而不像cat一次显示全部内容
+
+less可以先前翻页和向后翻页,more只能向前翻页
+
+head 和tail 负责取得文件的前几行和后几行
+
+## 搜索和定位
+
+ 1 which负责指令搜索,并显示第一条 比如which pwd,会找到pwd对应的程序。加-a 打印全部。
+
+ 2 whereis负责搜索文件, 后面接上dirname/filename
+
+ 文件搜索。速度比较快,因为它只搜索几个特定的目录。
+ 比如 whereis /bin hello.c
+
+ 3 locate
+ 文件搜索。可以用关键字或者正则表达式进行搜索。
+
+ locate 使用 /var/lib/mlocate/ 这个数据库来进行搜索,它存储在内存中,并且每天更新一次,所以无法用 locate 搜索新建的文件。可以使用 updatedb 来立即更新数据库。
+
+ # locate [-ir] keyword
+ -r:正则表达式
+
+ locate hello
+ locate he*
+ vi heeee
+ updatedb
+ locate he?
+
+ 4. find
+ 文件搜索。可以使用文件的属性和权限进行搜索。
+
+ # find [basedir] [option]
+ example: find . -name "shadow*"
+
+ find -name "hike"
+ find +属性后缀 "属性"
+
+ (一)与时间有关的选项
+
+ -mtime n :列出在 n 天前的那一天修改过内容的文件
+
+ (二)与文件拥有者和所属群组有关的选项
+
+ -uid n
+ -gid n
+ -user name
+
+ (三)与文件权限和名称有关的选项
+
+ -name filename
+ -size [+-]SIZE:搜寻比 SIZE 还要大 (+) 或小 (-) 的文件。这个 SIZE 的规格有:c: 代表 byte,k: 代表 1024bytes。所以,要找比 50KB 还要大的文件,就是 -size +50k
+ -type TYPE
+
+## 压缩
+ gzip压缩和解压,还有bzip,xz等压缩
+
+ 而tar可以用打包,打包的时候也可以执行压缩
+
+ 压缩指令只能对一个文件进行压缩,而打包能够将多个文件打包成一个大文件。tar 不仅可以用于打包,也可以使用 gip、bzip2、xz 将打包文件进行压缩。
+
+ $ tar [-z|-j|-J] [cv] [-f 新建的 tar 文件] filename... ==打包压缩
+ $ tar [-z|-j|-J] [tv] [-f 已有的 tar 文件] ==查看
+ $ tar [-z|-j|-J] [xv] [-f 已有的 tar 文件] [-C 目录] ==解压缩
+
+
+## 管道指令
+
+1 |
+
+2 cut切分数据,分成多列,last显示登陆者信息
+
+## 正则
+
+
+grep
+
+ g/re/p(globally search a regular expression and print),使用正则表示式进行全局查找并打印。
+
+ $ grep [-acinv] [--color=auto] 搜寻字符串 filename
+ -c : 计算找到个数
+ -i : 忽略大小写
+ -n : 输出行号
+ -v : 反向选择,亦即显示出没有 搜寻字符串 内容的那一行
+ --color=auto :找到的关键字加颜色显示
+
+awk
+
+ $ awk '条件类型 1 {动作 1} 条件类型 2 {动作 2} ...' filename
+ 示例 2:/etc/passwd 文件第三个字段为 UID,对 UID 小于 10 的数据进行处理。
+
+ $ cat /etc/passwd | awk 'BEGIN {FS=":"} $3 < 10 {print $1 "\t " $3}'
+ root 0
+ bin 1
+ daemon 2
+ sed
+
+ 示例 3:输出正在处理的行号,并显示每一行有多少字段
+
+ $ last -n 5 | awk '{print $1 "\t lines: " NR "\t columns: " NF}'
+ dmtsai lines: 1 columns: 10
+ dmtsai lines: 2 columns: 10
+ dmtsai lines: 3 columns: 10
+ dmtsai lines: 4 columns: 10
+ dmtsai lines: 5 columns: 9
+
+sed:
+
+ awk用于匹配每一行中的内容并打印
+ 而sed负责把文件内容重定向到输出,所以sed读取完文件并重定向到输出并且通过awk匹配这些内容并打印。
+
+ 他们俩经常搭配使用。
+
+## linux指令实践和常见场景
+
+## 查看进程状态
+
+Linux进程状态(ps stat)之R、S、D、T、Z、X
+
+
+
+ D 不可中断 Uninterruptible sleep (usually IO)
+ R 正在运行,或在队列中的进程
+ S 处于休眠状态
+ T 停止或被追踪
+ Z 僵尸进程
+ W 进入内存交换(从内核2.6开始无效)
+ X 死掉的进程
+
+
+ < 高优先级
+ N 低优先级
+ L 有些页被锁进内存
+ s 包含子进程
+ + 位于后台的进程组;
+ l 多线程,克隆线程 multi-threaded (using CLONE_THREAD, like NPTL pthreads do)
+
+
+ps aux
+
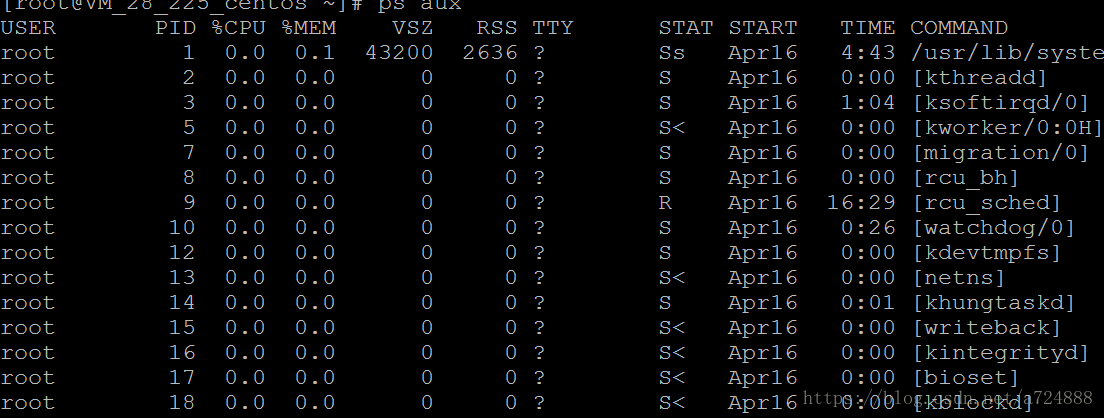
+
+
+## strace
+strace用于跟踪程序执行过程中的系统调用,如跟踪test进程,只需要:
+
+strace -p [test_pid] 或直接strace ./test
+
+比如,跟踪pid为12345的进程中所有线程的read和write系统调用,输出字符串的长度限制为1024:
+
+strace -s 1024 -f -e trace=read,write -p 12345
+
+## tcpdump
+tcpdump是Linux上的抓包工具,如抓取eth0网卡上的包,使用:
+
+sudo tcpdump -i eth0
+
+比如,抓取80端口的HTTP报文,以文本形式展示:
+
+sudo tcpdump -i any port 80 -A
+这样你就可以清楚看到GET、POST请求的内容了。
+
+## nc
+
+nc可以在Linux上开启TCP Server、TCP Client、UDP Server、UDP Client。
+
+如在端口号12345上开启TCP Server和Client模拟TCP通信:
+
+Server: nc -l 127.0.0.1 12345
+Client: nc 127.0.0.1 12345
+在端口号12345上开启UDP Server和Client模拟TCP通信:
+
+Server: nc -ul 127.0.0.1 12345
+Client: nc -u 127.0.0.1 12345
+Unix Socket通信示例:
+
+Server: nc -Ul /tmp/1.sock
+Client: nc -U /tmp/1.sock
+
+## curl
+curl用于模拟HTTP请求,在终端模拟请求时常用,如最基本的用法:
+
+curl http://www.baidu.com
+
+## lsof
+
+lsof命令主要用法包括:
+
+sudo lsof -i :[port] 查看端口占用进程信息,经常用于端口绑定失败时确认端口被哪个进程占用
+
+sudo lsof -p [pid] 查看进程打开了哪些文件或套接字
+
+## ss
+Linux上的ss命令可以用于替换netstat,ss直接读取解析/proc/net下的统计信息,相比netstat遍历/proc下的每个PID目录,速度快很多。
+
+## awk/sed
+awk和sed在文本处理方面十分强大,其中,awk按列进行处理,sed按行进行处理。
+
+如采用冒号分隔数据,输出第一列数据($0代表行全部列数据,$1代表第一列,$2代表第二列...)
+
+awk -F ":" '{print $1}'
+在awk的结果基础上,结合sort、uniq和head等命令可以轻松完成频率统计等功能
+
+查看文件的第100行到第200行:
+sed -n '100,200p' log.txt
+替换字符串中的特定子串
+echo "int charset=gb2312 float"|sed "s/charset=gb2312/charset=UTF-8/g"
+替换test文件每行匹配ab的部分为cd
+sed -i 's/ab/cd/g' test
+
+## vim
+打开文件并跳到第10行
+
+$ vim +10 filename.txt
+打开文件跳到第一个匹配的行
+
+$ vim +/search-term filename.txt
+以只读模式打开文件
+
+$ vim -R /etc/passwd
+
+## crontab
+查看某个用户的crontab入口
+
+$ crontab -u john -l
+设置一个每十分钟执行一次的计划任务
+
+*/10 * * * * /home/ramesh/check-disk-space
+更多示例:Linux Crontab: 15 Awesome Cron Job Examples
+
+## service
+service命令用于运行System V init脚本,这些脚本一般位于/etc/init.d文件下,这个命令可以直接运行这个文件夹里面的脚本,而不用加上路径
+
+查看服务状态
+
+$ service ssh status
+查看所有服务状态
+
+$ service --status-all
+重启服务
+
+$ service ssh restart
+
+## free
+这个命令用于显示系统当前内存的使用情况,包括已用内存、可用内存和交换内存的情况
+
+默认情况下free会以字节为单位输出内存的使用量
+
+ $ free
+ total used free shared buffers cached
+ Mem: 3566408 1580220 1986188 0 203988 902960
+ -/+ buffers/cache: 473272 3093136
+ Swap: 4000176 0 4000176
+
+如果你想以其他单位输出内存的使用量,需要加一个选项,-g为GB,-m为MB,-k为KB,-b为字节
+
+ $ free -g
+ total used free shared buffers cached
+ Mem: 3 1 1 0 0 0
+ -/+ buffers/cache: 0 2
+ Swap: 3 0 3
+
+如果你想查看所有内存的汇总,请使用-t选项,使用这个选项会在输出中加一个汇总行
+
+ ramesh@ramesh-laptop:~$ free -t
+ total used free shared buffers cached
+ Mem: 3566408 1592148 1974260 0 204260 912556
+ -/+ buffers/cache: 475332 3091076
+ Swap: 4000176 0 4000176
+ Total: 7566584 1592148 5974436
+
+## top
+
+top命令会显示当前系统中占用资源最多的一些进程(默认以CPU占用率排序)如果你想改变排序方式,可以在结果列表中点击O(大写字母O)会显示所有可用于排序的列,这个时候你就可以选择你想排序的列
+
+ Current Sort Field: P for window 1:Def
+ Select sort field via field letter, type any other key to return
+
+ a: PID = Process Id v: nDRT = Dirty Pages count
+ d: UID = User Id y: WCHAN = Sleeping in Function
+ e: USER = User Name z: Flags = Task Flags
+ ........
+
+如果只想显示某个特定用户的进程,可以使用-u选项
+
+$ top -u oracle
+
+## df
+显示文件系统的磁盘使用情况,默认情况下df -k 将以字节为单位输出磁盘的使用量
+
+$ df -k
+
+ Filesystem 1K-blocks Used Available Use% Mounted on
+ /dev/sda1 29530400 3233104 24797232 12% /
+ /dev/sda2 120367992 50171596 64082060 44% /home
+
+使用-h选项可以以更符合阅读习惯的方式显示磁盘使用量
+
+$ df -h
+
+ Filesystem Size Used Avail Capacity iused ifree %iused Mounted on
+ /dev/disk0s2 232Gi 84Gi 148Gi 37% 21998562 38864868 36% /
+ devfs 187Ki 187Ki 0Bi 100% 648 0 100% /dev
+ map -hosts 0Bi 0Bi 0Bi 100% 0 0 100% /net
+ map auto_home 0Bi 0Bi 0Bi 100% 0 0 100% /home
+ /dev/disk0s4 466Gi 45Gi 421Gi 10% 112774 440997174 0% /Volumes/BOOTCAMP
+ //app@izenesoft.cn/public 2.7Ti 1.3Ti 1.4Ti 48%
+
+## kill
+kill用于终止一个进程。一般我们会先用ps -ef查找某个进程得到它的进程号,然后再使用kill -9 进程号终止该进程。你还可以使用killall、pkill、xkill来终止进程
+
+$ ps -ef | grep vim
+ramesh 7243 7222 9 22:43 pts/2 00:00:00 vim
+
+$ kill -9 7243
+
+## mount
+如果要挂载一个文件系统,需要先创建一个目录,然后将这个文件系统挂载到这个目录上
+
+mkdir /u01
+mount /dev/sdb1 /u01
+也可以把它添加到fstab中进行自动挂载,这样任何时候系统重启的时候,文件系统都会被加载
+
+/dev/sdb1 /u01 ext2 defaults 0 2
+## chmod
+chmod用于改变文件和目录的权限
+
+给指定文件的属主和属组所有权限(包括读、写、执行)
+
+$ chmod ug+rwx file.txt
+删除指定文件的属组的所有权限
+
+$ chmod g-rwx file.txt
+修改目录的权限,以及递归修改目录下面所有文件和子目录的权限
+
+$ chmod -R ug+rwx file.txt
+更多示例:7 Chmod Command Examples for Beginners
+
+## chown
+chown用于改变文件属主和属组
+
+同时将某个文件的属主改为oracle,属组改为db
+
+$ chown oracle:dba dbora.sh
+使用-R选项对目录和目录下的文件进行递归修改
+
+$ chown -R oracle:dba /home/oracle
+
+## ifconfig
+ifconfig用于查看和配置Linux系统的网络接口
+
+## uname
+uname可以显示一些重要的系统信息,例如内核名称、主机名、内核版本号、处理器类型之类的信息
+
+## 实际场景问题
+
+ 1 cpu占用率
+
+ top可以看
+ ps看不了
+ 但是ps -aux可以看到各个线程的cpu和内存占用
+
+ 2 进程状态:
+
+ ps -ef看不了
+ ps aux可以看进程状态S R之类
+
+ 3 IO
+ iostat查看io状态
+
+ 4网络
+ netstat查看tcp连接状态和socket情况,
+
+ ipconfig查看网络设备
+
+ lsof可以查看端口使用情况
+
+ 5内存
+ free
\ No newline at end of file
diff --git "a/md/\345\211\221\346\214\207offer.md" "b/md/\345\211\221\346\214\207offer.md"
new file mode 100644
index 0000000..193d42b
--- /dev/null
+++ "b/md/\345\211\221\346\214\207offer.md"
@@ -0,0 +1,1630 @@
+---
+title: 剑指offer算法学习总结
+date: 2018-07-09 22:32:40
+tags:
+ - 算法
+categories:
+ - 后端
+ - 技术总结
+---
+##节选剑指offer比较经典和巧妙的一些题目,以便复习使用。一部分题目给出了完整代码,一部分题目比较简单直接给出思路。但是不保证我说的思路都是正确的,个人对算法也不是特别在行,只不过这本书的算法多看了几遍多做了几遍多了点心得体会。于是想总结一下。如果有错误也希望能指出,谢谢。
+
+#具体代码可以参考我的GitHub仓库:
+
+#https://github.com/h2pl/SwordToOffer
+
+# 数论和数字规律
+
+## 从1到n整数中1出现的次数
+
+题目描述
+求出1~13的整数中1出现的次数,并算出100~1300的整数中1出现的次数?为此他特别数了一下1~13中包含1的数字有1、10、11、12、13因此共出现6次,但是对于后面问题他就没辙了。ACMer希望你们帮帮他,并把问题更加普遍化,可以很快的求出任意非负整数区间中1出现的次数。
+
+1暴力办法,把整数转为字符串,依次枚举相加。复杂度是O(N * k)k为数字长度。
+
+2第二种办法看不懂,需要数学推导,太长不看
+
+## 排数组排成最小的数
+
+输入一个正整数数组,把数组里所有数字拼接起来排成一个数,打印能拼接出的所有数字中最小的一个。例如输入数组{3,32,321},则打印出这三个数字能排成的最小数字为321323。
+
+解析:本题的关键是,两个数如何排成最小的,答案是,如果把数字看成字符串a,b那么如果a+b>b+a,则a应该放在b后面。
+例如 3和32 3 + 32 = 332,32 + 3 = 323,332>323,所以32要放在前面。
+
+根据这个规律,构造一个比较器,使用排序方法即可。
+
+## 丑数
+
+题目描述
+把只包含因子2、3和5的数称作丑数(Ugly Number)。例如6、8都是丑数,但14不是,因为它包含因子7。 习惯上我们把1当做是第一个丑数。求按从小到大的顺序的第N个丑数。
+
+解析
+
+1 暴力枚举每个丑数,找出第N个即可。
+
+2 这个思路比较巧妙,由于丑数一定是由2,3,5三个因子构成的,所以我们每次构造出一个比前面丑数大但是比后面小的丑数,构造N次即可。
+
+ public class Solution {
+ public static int GetUglyNumber_Solution(int index) {
+ if (index == 0) return 0;
+ int []res = new int[index];
+ res[0] = 1;
+ int i2,i3,i5;
+ i2 = i3 = i5 = 0;
+ for (int i = 1;i < index;i ++) {
+ res[i] = Math.min(res[i2] * 2, Math.min(res[i3] * 3, res[i5] * 5));
+ if (res[i] == res[i2] * 2) i2 ++;
+ if (res[i] == res[i3] * 3) i3 ++;
+ if (res[i] == res[i5] * 5) i5 ++;
+ }
+ return res[index - 1];
+ }
+ }
+ }
+ i2,i3,i5分别代表目前有几个2,3,5的因子,每次选一个最小的丑数,然后开始找下一个。当然i2,i3,i5也要跟着变。
+# 数组和矩阵
+
+
+## 二维数组的查找
+
+ /**
+ * Created by 周杰伦 on 2018/2/25.
+ * 题目描述
+ 在一个二维数组中,每一行都按照从左到右递增的顺序排序,
+ 每一列都按照从上到下递增的顺序排序。请完成一个函数,
+ 输入这样的一个二维数组和一个整数,判断数组中是否含有该整数。
+ 1 2 3
+ 2 3 4
+ 3 4 5
+ */
+
+ 解析:比较经典的一题,解法也比较巧妙,由于数组从左向右和从上到下的都是递增的,所以找一个数可以先从最右开始找。
+ 假设最右值为a,待查数为x,那么如果x < a说明x在a的左边,往左找即可,如果x > a,说明x 在 a的下面一行,到下面一行继续按照该规则查找,就可以遍历所有数。
+
+ 算法的时间复杂度是O(M * N)
+
+ public class 二维数组中的查找 {
+ public static boolean Find(int target, int[][] array) {
+
+ if(array[0][0] > target) {
+ return false;
+ }
+
+ int row = 0;
+ int col = 0;
+ while (row < array.length && col >0) {
+ if (target == array[row][col]) {
+ return true;
+ }
+ else if (target array[row][col]) {
+ col ++;
+ }
+ else row++;
+ }
+ return false;
+ }
+ }
+## 顺时针打印矩阵。
+
+输入一个矩阵,按照从外向里以顺时针的顺序依次打印出每一个数字,例如,如果输入如下矩阵: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 则依次打印出数字1,2,3,4,8,12,16,15,14,13,9,5,6,7,11,10.
+
+这题还是有点麻烦的,因为要顺时针打印,所以实际上是由外向内打印,边界的处理和递归调用需要谨慎。
+
+这题我自己没写出标准答案。参考一个答案吧。关键在于四个循环中的分界点设置。
+
+ //主体循环部分才5行。其实是有规律可循的。将每一层的四个边角搞清楚就可以打印出来了
+
+ import java.util.ArrayList;
+ public class Solution {
+ public ArrayList printMatrix(int [][] array) {
+ ArrayList result = new ArrayList ();
+ if(array.length==0) return result;
+ int n = array.length,m = array[0].length;
+ if(m==0) return result;
+ int layers = (Math.min(n,m)-1)/2+1;//这个是层数
+ for(int i=0;i=i)&&(n-i-1!=i);k--) result.add(array[n-i-1][k]);//右至左
+ for(int j=n-i-2;(j>i)&&(m-i-1!=i);j--) result.add(array[j][i]);//左下至左上
+ }
+ return result;
+ }
+ }
+
+## 调整数组中数字的顺序,使正数在负数的前面
+
+双指针即可以解决,变式有正负,奇偶等等。
+
+## 数组中出现次数超过一半的数字
+
+本题有很多种解法。
+
+1 最笨的解法,统计每个数的出现次数,O(n2)
+
+2 使用hashmap,空间换时间O(n)
+
+3 由于出现超过一半的数字一定也是中位数,所以可以先排序,再找到第n/2位置上的节点。
+
+4 使用快速排序的复杂度是O(nlogn),基于快排的特性,每一轮的过程都会把一个数放到最终位置,所以我们可以判断一下这个数的位置是不是n/2,如果是的话,那么就直接返回即可。这样就优化了快排的步骤。
+
+4.5事实上,上述办法的复杂度仍然是O(nlogn)
+
+ 快速排序的partition函数将一个数组分为左右两边,并且我们可以知道,如果flag值在k位置左边,那么往左找,如果在k位置右边,那么往左找。
+
+ 这里科普一下经典快排中的一个方法partition,剑指offer书中直接跳过了这部分,让我摸不着头脑。
+
+ 虽然快排用到了经典的分而治之的思想,但是快排实现的前提还是在于 partition 函数。正是有了 partition 的存在,才使得可以将整个大问题进行划分,进而分别进行处理。
+
+ 除了用来进行快速排序,partition 还可以用 O(N) 的平均时间复杂度从无序数组中寻找第K大的值。和快排一样,这里也用到了分而治之的思想。首先用 partition 将数组分为两部分,得到分界点下标 pos,然后分三种情况:
+
+ pos == k-1,则找到第 K 大的值,arr[pos];
+ pos > k-1,则第 K 大的值在左边部分的数组。
+ pos < k-1,则第 K 大的值在右边部分的数组。
+ 下面给出基于迭代的实现(用来寻找第 K 小的数):
+
+
+ int find_kth_number(vector &arr, int k){
+ int begin = 0, end = arr.size();
+ assert(k>0 && k<=end);
+ int target_num = 0;
+ while (begin < end){
+ int pos = partition(arr, begin, end);
+ if(pos == k-1){
+ target_num = arr[pos];
+ break;
+ }
+ else if(pos > k-1){
+ end = pos;
+ }
+ else{
+ begin = pos + 1;
+ }
+ }
+ return target_num;
+ }
+
+
+ 该算法的时间复杂度是多少呢?考虑最坏情况下,每次 partition 将数组分为长度为 N-1 和 1 的两部分,然后在长的一边继续寻找第 K 大,此时时间复杂度为 O(N^2 )。不过如果在开始之前将数组进行随机打乱,那么可以尽量避免最坏情况的出现。而在最好情况下,每次将数组均分为长度相同的两半,运行时间 T(N) = N + T(N/2),时间复杂度是 O(N)。
+
+所以也就是说,本题用这个方法解的话,复杂度只需要O(n),因为第一次交换需要N/2,j接下来的交换的次数越来越少,最后加起来就是O(N)了。
+
+5 由于数字出现次数超过长度的一半,也就是平均每两个数字就有一个该数字,但他们不一定连续,所以变量time保存一个数的出现次数,然后变量x代表目前选择的数字,遍历中,如果x与后一位不相等则time--,time=0时x改为后一位,time重新变为1。最终x指向的数字就是出现次数最多的。
+
+举两个例子,比如1,2,3,4,5,6,6,6,6,6,6。明显符合。1,6,2,6,3,6,4,6,5,6,6 遍历到最后得到x=6,以此类推,可以满足要求。
+
+## 找出前k小的数
+ * 输入n个整数,找出其中最小的K个数。例如输入4,5,1,6,2,7,3,8这8个数字,则最小的4个数字是1,2,3,4,。
+ */
+
+解析:
+
+1如果允许改变数组,那么则可以继承上一题的思想。,使用快速排序中的partition方法,只需要O(N)的复杂度
+
+2使用堆排序
+
+ 解析:用前k个数构造一个大小为k的大顶堆,然后遍历余下数字,如果比堆顶大,则跳过,如果比堆顶小,则替换掉堆顶元素,然后执行一次堆排序(即根节点向下调整)。此时的堆顶元素已被替换,
+
+ 然后遍历完所有元素,堆中的元素就是最小的k个元素了。
+
+ 如果要求最大的k个元素,则构造小顶堆就可以了。
+
+ 构造堆的方法是,数组的第N/2号元素到0号元素依次向下调整,此时数组就构成了堆。
+
+ 实际上我们可以使用现成的集合类,红黑树是一棵搜索树,他是排序的,所以可以得到最大和最小值,那么我们每次和最小值比较,符合条件就进行替换即可。复杂度是O(nlogn)
+
+
+ public ArrayList GetLeastNumbers_Solution(int [] input, int k) {
+
+ ArrayListarrayList=new ArrayList<>();
+ if(input==null || input.length==0 ||k==0 ||k>input.length)return arrayList;
+
+ TreeSet treeSet=new TreeSet<>();
+
+
+ for(int i=0;i 0)
+
+
+## 逆序对
+
+/**
+ * Created by 周杰伦 on 2017/3/23.
+ * 题目描述
+ 在数组中的两个数字,如果前面一个数字大于后面的数字,则这两个数字组成一个逆序对。
+ 输入一个数组,求出这个数组中的逆序对的总数P。并将P对1000000007取模的结果输出。
+ 即输出P%1000000007
+ */
+
+ 解析:本题采用归并排序的框架,只是在归并的时候做出逆序对查找,具体参见下面代码。
+ 核心点是,在归并两个有序数组时,如果a数组的元素a1比b数组的元素b1大时,说明有mid - i + 1个数都比b1大。i为a1元素的位置。
+ 这样子我们就可以统计逆序对的个数了。经典巧妙。!
+
+ public class 逆序对 {
+ public double Pairs = 0;
+ public int InversePairs(int [] array) {
+ if (array.length==0 ||array==null)
+ return 0;
+ mergesort(array,0,array.length-1);
+ Pairs = Pairs + 1000000007;
+ return (int) (Pairs % 1000000007);
+ }
+ public void merge(int []array,int left,int mid,int right){
+ //有一点很重要的是,归并分成两部分,其中一段是left到mid,第二段是mid+1到right。
+ //不能从0到mid-1,然后mid到right。因为这样左右不均分,会出错。千万注意。
+ //mid=(left+right)/2
+ if (array.length==0 ||array==null ||left>=right)
+ return ;
+ int p=left,q=mid+1,k=0;
+
+ int []temp=new int[right-left+1];
+
+ while (p<=mid && q<=right){
+ if(array[p]>array[q]){
+ temp[k++]=array[q++];
+ //当前半数组中有一个数p比后半个数组中的一个数q大时,由于两个数组
+ //已经分别有序,所以说明p到中间数之间的所有数都比q大。
+ Pairs+=mid-p+1;
+ }
+ else temp[k++]=array[p++];
+ }
+
+ while (p<=mid){
+ temp[k++]=array[p++];}
+ while (q<=right){
+ temp[k++]=array[q++];}
+
+
+
+ for (int m = 0; m < temp.length; m++)
+ array[left + m] = temp[m];
+
+ }
+
+ public void mergesort(int []arr,int left,int right){
+ if (arr.length==0 ||arr==null)
+ return ;
+ int mid=(right+left)/2;
+ if(left list = new ArrayList<>();
+ public static void Insert(Integer num) {
+ list.add(num);
+ Collections.sort(list);
+ }
+
+ public static Double GetMedian() {
+ if (list.size() % 2 == 0) {
+ int l = list.get(list.size()/2);
+ int r = list.get(list.size()/2 - 1);
+ return (l + r)/2.0;
+ }
+ else {
+ return list.get(list.size()/2)/1.0;
+ }
+ }
+
+
+ }
+
+## 滑动窗口中的最大值
+
+给定一个数组和滑动窗口的大小,找出所有滑动窗口里数值的最大值。例如,如果输入数组{2,3,4,2,6,2,5,1}及滑动窗口的大小3,那么一共存在6个滑动窗口,他们的最大值分别为{4,4,6,6,6,5}; 针对数组{2,3,4,2,6,2,5,1}的滑动窗口有以下6个: {[2,3,4],2,6,2,5,1}, {2,[3,4,2],6,2,5,1}, {2,3,[4,2,6],2,5,1}, {2,3,4,[2,6,2],5,1}, {2,3,4,2,[6,2,5],1}, {2,3,4,2,6,[2,5,1]}。
+
+解析:
+1 保持窗口为3进行右移,每次计算出一个最大值即可。
+
+2 使用两个栈实现一个队列,复杂度O(N),使用两个栈实现最大值栈,复杂度O(1)。两者结合可以完成本题。但是太麻烦了。
+
+3 使用双端队列解决该问题。
+
+ import java.util.*;
+ /**
+ 用一个双端队列,队列第一个位置(队头)保存当前窗口的最大值,当窗口滑动一次
+ 1.判断当前最大值是否过期(如果最大值所在的下标已经不在窗口范围内,则过期)
+ 2.对于一个新加入的值,首先一定要先放入队列,即使他比队头元素小,因为队头元素可能过期。
+ 3.新增加的值从队尾开始比较,把所有比他小的值丢掉(因为队列只存最大值,所以之前比他小的可以丢掉)
+
+ */
+ public class Solution {
+ public ArrayList maxInWindows(int [] num, int size)
+ {
+ ArrayList res = new ArrayList<>();
+ if(size == 0) return res;
+ int begin;
+ ArrayDeque q = new ArrayDeque<>();
+ for(int i = 0; i < num.length; i++){
+ begin = i - size + 1;
+ if(q.isEmpty())
+ q.add(i);
+ else if(begin > q.peekFirst())
+ q.pollFirst();
+
+ while((!q.isEmpty()) && num[q.peekLast()] <= num[i])
+ q.pollLast();
+ q.add(i);
+ if(begin >= 0)
+ res.add(num[q.peekFirst()]);
+ }
+ return res;
+ }
+ }
+
+# 字符串
+
+## 字符串的排列
+
+输入一个字符串,按字典序打印出该字符串中字符的所有排列。例如输入字符串abc,则打印出由字符a,b,c所能排列出来的所有字符串abc,acb,bac,bca,cab和cba。
+
+ 解析:这是一个全排列问题,也就是N个不同的数排成所有不同的序列,只不过把数换成了字符串。
+ 全排列的过程就是,第一个元素与后续的某个元素交换,然后第二个元素也这么做,直到最后一个元素为之,过程是一个递归的过程,也是一个dfs的过程。
+
+ 注意元素也要和自己做一次交换,要不然会漏掉自己作为头部的情况。
+
+ 然后再进行一次字典序的排序即可。
+
+ public static ArrayList Permutation(String str) {
+ char []arr = str.toCharArray();
+ List list = new ArrayList<>();
+ all(arr, 0, arr.length - 1, list);
+ Collections.sort(list, (o1, o2) -> String.valueOf(o1).compareTo(String.valueOf(o2)));
+ ArrayList res = new ArrayList<>();
+ for (char[] c : list) {
+ if (!res.contains(String.valueOf(c)))
+ res.add(String.valueOf(c));
+ }
+ return res;
+ }
+
+ //注意要换完为之,因为每换一次可以去掉头部一个数字,这样可以避免重复
+ public static void all(char []arr, int cur, int end, List list) {
+ if (cur == end) {
+ // System.out.println(Arrays.toString(arr));
+ list.add(Arrays.copyOf(arr, arr.length));
+ }
+ for (int i = cur;i <= end;i ++) {
+ //这里的交换包括跟自己换,所以只有一轮换完才能确定一个结果
+ swap(arr, cur, i);
+ all(arr, cur + 1, end, list);
+ swap(arr, cur, i);
+ }
+ }
+ public static void swap(char []arr, int i, int j) {
+ if (i > arr.length || j > arr.length || i >= j)return;
+ char temp = arr[i];
+ arr[i] = arr[j];
+ arr[j] = temp;
+ }
+
+## 替换空格
+
+ /**
+ * Created by 周杰伦 on 2018/2/25.
+ * 请实现一个函数,将一个字符串中的空格替换成“%20”。例如,当字符串为We Are Happy.则经过替换之后的字符串为We%20Are%20Happy。
+ */
+
+ 解析:如果单纯地按顺序替换空格,每次替换完还要将数组扩容,再右移,这部操作的时间复杂度就是O(2*N)=O(N),所以总的复杂度是O(n^2),所以应该采取先扩容的办法,统计出空格数,然后扩容,接下来按顺序添加字符,遇到空格直接改成添加%20即可,这样避免了右移操作和多次扩容,复杂度是O(N)
+
+
+ public class 替换空格 {
+ public static String replaceSpace(StringBuffer str) {
+ int newlen = 0;
+ for(int i = 0; i < str.length(); i++) {
+ if(str.charAt(i) == ' ') {
+ newlen = newlen + 3;
+ }
+ else {
+ newlen ++;
+ }
+ }
+ char []newstr = new char[newlen];
+ int j = 0;
+ for(int i = 0 ; i < str.length(); i++) {
+ if (str.charAt(i) == ' ') {
+ newstr[j++] = '%';
+ newstr[j++] = '2';
+ newstr[j++] = '0';
+ }else {
+ newstr[j++] = str.charAt(i);
+ }
+ }
+ return String.valueOf(newstr);
+ }
+
+
+## 第一次只出现一次的字符
+
+哈希表可解
+
+## 翻转单词顺序和左旋转字符串
+
+1
+题目描述
+牛客最近来了一个新员工Fish,每天早晨总是会拿着一本英文杂志,写些句子在本子上。同事Cat对Fish写的内容颇感兴趣,有一天他向Fish借来翻看,但却读不懂它的意思。例如,“student. a am I”。后来才意识到,这家伙原来把句子单词的顺序翻转了,正确的句子应该是“I am a student.”。Cat对一一的翻转这些单词顺序可不在行,你能帮助他么?
+
+ 这个解法很经典,先把每个单词逆序,再把整个字符串逆序,结果就是把每个单词都进行了翻转。
+
+2
+汇编语言中有一种移位指令叫做循环左移(ROL),现在有个简单的任务,就是用字符串模拟这个指令的运算结果。对于一个给定的字符序列S,请你把其循环左移K位后的序列输出。例如,字符序列S=”abcXYZdef”,要求输出循环左移3位后的结果,即“XYZdefabc”。是不是很简单?OK,搞定它!
+
+ 字符串循环左移N位的处理方法也很经典,先把前N位逆序,再把剩余字符串逆序,最后整体逆序。
+
+ abcXYZdef -> cbafedZYX -> XYZdefabc
+
+## 把字符串转换为整数
+
+题目描述
+将一个字符串转换成一个整数,要求不能使用字符串转换整数的库函数。 数值为0或者字符串不是一个合法的数值则返回0
+
+解析:首先需要判断正负号,然后判断每一位是否是数字,然后判断是否溢出,判断溢出可以通过加完第n位的和与未加第n位的和进行比较。最后可以得出结果。所以需要3-4步判断。
+
+
+## 表示数值的字符串
+
+请实现一个函数用来判断字符串是否表示数值(包括整数和小数)。例如,字符串"+100","5e2","-123","3.1416"和"-1E-16"都表示数值。 但是"12e","1a3.14","1.2.3","+-5"和"12e+4.3"都不是。
+
+ 不得不说这种题型太恶心了,就是需要一直判断边界条件
+
+ 参考一个答案。比较完整
+
+ bool isNumeric(char* str) {
+ // 标记符号、小数点、e是否出现过
+ bool sign = false, decimal = false, hasE = false;
+ for (int i = 0; i < strlen(str); i++) {
+ if (str[i] == 'e' || str[i] == 'E') {
+ if (i == strlen(str)-1) return false; // e后面一定要接数字
+ if (hasE) return false; // 不能同时存在两个e
+ hasE = true;
+ } else if (str[i] == '+' || str[i] == '-') {
+ // 第二次出现+-符号,则必须紧接在e之后
+ if (sign && str[i-1] != 'e' && str[i-1] != 'E') return false;
+ // 第一次出现+-符号,且不是在字符串开头,则也必须紧接在e之后
+ if (!sign && i > 0 && str[i-1] != 'e' && str[i-1] != 'E') return false;
+ sign = true;
+ } else if (str[i] == '.') {
+ // e后面不能接小数点,小数点不能出现两次
+ if (hasE || decimal) return false;
+ decimal = true;
+ } else if (str[i] < '0' || str[i] > '9') // 不合法字符
+ return false;
+ }
+ return true;
+ }
+
+## 字符流中第一个不重复的字符
+
+题目描述
+请实现一个函数用来找出字符流中第一个只出现一次的字符。例如,当从字符流中只读出前两个字符"go"时,第一个只出现一次的字符是"g"。当从该字符流中读出前六个字符“google"时,第一个只出现一次的字符是"l"。
+
+本题主要要注意的是流。也就是说每次输入一个字符就要做一次判断。比如输入aaaabbbcd,输出就是a###b##cd
+
+ StringBuilder sb = new StringBuilder();
+ int []map = new int[256];
+ public void Insert(char ch)
+ {
+ sb.append(ch);
+ if (map[ch] == 0) {
+ map[ch] = 1;
+ }else {
+ map[ch] ++;
+ }
+ System.out.println(FirstAppearingOnce());
+
+ }
+ //return the first appearence once char in current stringstream
+ public char FirstAppearingOnce()
+ {
+ for (int i = 0;i < sb.length();i ++) {
+ if (map[sb.charAt(i)] == 1) {
+ return sb.charAt(i);
+ }
+ }
+ return '#';
+ }
+
+# 链表
+
+## 从尾到头打印链表
+
+考查递归,递归可以使输出的顺序倒置
+
+ public static void printReverse(Node node) {
+ if (node.next != null) {
+ printReverse(node.next);
+ }
+ System.out.print(node.val + " ");
+ }
+
+
+## 链表倒数第k个节点
+
+使用两个指针,一个先走k步。然后一起走即可。
+
+## 反转链表
+
+老生常谈,但是容易写错。
+
+ public ListNode ReverseList(ListNode head) {
+ if(head==null || head.next==null)return head;
+ ListNode pre,next;
+ pre=null;
+ next=null;
+ while(head!=null){
+ //保存下一个结点
+ next=head.next;
+ //连接下一个结点
+ head.next=pre;
+ pre=head;
+ head=next;
+ }
+ return pre;
+ }
+ }
+
+## 合并两个排序链表
+
+与归并排序的合并类似
+
+## 复杂链表的复制
+
+题目描述
+输入一个复杂链表(每个节点中有节点值,以及两个指针,一个指向下一个节点,另一个特殊指针指向任意一个节点),返回结果为复制后复杂链表的head。(注意,输出结果中请不要返回参数中的节点引用,否则判题程序会直接返回空)
+
+这题比较恶心。
+
+解析:
+
+1 直接复制链表,然后再去复制特殊指针,复杂度是O(n2)
+
+2 使用hash表保存特殊指针的映射关系,第二步简化操作,复杂度是O(n)
+
+3 复制每个节点并且连成一个大链表A-A'-B-B',然后从头到尾判断特殊指针,如果有特殊指针,则让后续节点的特殊指针指向原节点特殊指针指向的节点的后置节点,晕了吧,其实就是原来是A指向B,现在是A’指向B‘。
+
+最后我们根据奇偶序号把链表拆开,复杂度是O(N)且不用额外空间。
+
+## 两个链表的第一个公共节点
+
+1 逆置链表,反向找第一个不同节点,前一个就是公共节点
+
+2 求长度并相减得n,短的链表先走n步,然后一起走即可。
+
+## 孩子们的游戏(圆圈中最后剩下的数)
+
+这是一个约瑟夫环问题。
+
+1 使用循环链表求解,每次走n步摘取一个节点,然后继续,直到最后一个节点就是剩下的数,空间复杂度为O(n)
+
+2 使用数组来做
+public static int LastRemaining_Solution(int n, int m) {
+ int []arr = new int[n];
+ for (int i = 0;i < n;i ++) {
+ arr[i] = i;
+ }
+
+ int cnt = 0;
+ int sum = 0;
+ for (int i = 0;i < n;i = (i + 1) % n) {
+ if (arr[i] == -1) {
+ continue;
+ }
+ cnt ++;
+ if (cnt == m) {
+ arr[i] = -1;
+ cnt = 0;
+ sum ++;
+ }
+ if (sum == n) {
+ return i;
+ }
+ }
+ return n - 1;
+ }
+
+3 使用余数法求解
+
+
+ int LastRemaining_Solution(int n, int m) {
+ if (m == 0 || n == 0) {
+ return -1;
+ }
+ ArrayList data = new ArrayList();
+ for (int i = 0; i < n; i++) {
+ data.add(i);
+ }
+ int index = -1;
+ while (data.size() > 1) {
+ // System.out.println(data);
+ index = (index + m) % data.size();
+ // System.out.println(data.get(index));
+ data.remove(index);
+ index--;
+ }
+ return data.get(0);
+ }
+
+## 链表的环的入口结点
+
+一个链表中包含环,请找出该链表的环的入口结点。
+
+解析:
+
+1 指定两个指针,一个一次走两步,一个一次走一步,然后当两个节点相遇时,这个节点必定在环中。既然这个节点在环中,那么让这个节点走一圈直到与自己相等为之,可以得到环的长度n。
+
+2 得到了环的长度以后,根据数学推导的结果,我们可以指定两个指针,一个先走n步,然后两者同时走,这样的话,当慢节点到达入口节点时,快节点也转了一圈刚好又到达入口节点,所以也就是他们相等的时候就是入口节点了。
+
+## 删除链表中重复的节点
+
+题目描述
+在一个排序的链表中,存在重复的结点,请删除该链表中重复的结点,重复的结点不保留,返回链表头指针。 例如,链表1->2->3->3->4->4->5 处理后为 1->2->5
+
+保留头结点,然后找到下一个不重复的节点,与他相连,重复的节点直接跳过即可。
+
+#二叉树
+
+## 二叉搜索树转换为双向链表
+
+输入一棵二叉搜索树,将该二叉搜索树转换成一个排序的双向链表。要求不能创建任何新的结点,只能调整树中结点指针的指向。
+
+二叉搜索树要转换成有序的双向链表,实际上就是使用中序遍历把节点连入链表中,并且题目要求在原来节点上进行操作,也就是使用左指针和右指针表示链表的前置节点和后置节点。
+
+使用栈实现中序遍历的非递归算法,便可以找出节点的先后关系,依次连接即可。
+
+ public TreeNode Convert(TreeNode root) {
+ if(root==null)
+ return null;
+ Stack stack = new Stack();
+ TreeNode p = root;
+ TreeNode pre = null;// 用于保存中序遍历序列的上一节点
+ boolean isFirst = true;
+ while(p!=null||!stack.isEmpty()){
+ while(p!=null){
+ stack.push(p);
+ p = p.left;
+ }
+ p = stack.pop();
+ if(isFirst){
+ root = p;// 将中序遍历序列中的第一个节点记为root
+ pre = root;
+ isFirst = false;
+ }else{
+ pre.right = p;
+ p.left = pre;
+ pre = p;
+ }
+ p = p.right;
+ }
+ return root;
+ }
+ }
+
+## 重建二叉树
+
+ * 题目描述
+ 输入某二叉树的前序遍历和中序遍历的结果,请重建出该二叉树。假设输入的前序遍历和中序遍历的结果中都不含重复的数字。例如输入前序遍历序列{1,2,4,7,3,5,6,8}和中序遍历序列{4,7,2,1,5,3,8,6},则重建二叉树并返回。
+ */
+
+ 解析:首先,头结点一定是先序遍历的首位,并且该节点把中序分为左右子树,根据这个规则,左子树由左边数组来完成,右子树由右边数组来完成,根节点由中间节点来构建,于是便有了如下的递归代码。该题的难点就在于边界的判断。
+
+ public TreeNode reConstructBinaryTree(int [] pre, int [] in) {
+ if(pre.length == 0||in.length == 0){
+ return null;
+ }
+ TreeNode node = new TreeNode(pre[0]);
+ for(int i = 0; i < in.length; i++){
+ if(pre[0] == in[i]){
+ node.left = reConstructBinaryTree(Arrays.copyOfRange(pre, 1, i+1), Arrays.copyOfRange(in, 0, i));//为什么不是i和i-1呢,因为要避免出错,中序找的元素需要再用一次。
+ node.right = reConstructBinaryTree(Arrays.copyOfRange(pre, i+1, pre.length), Arrays.copyOfRange(in, i+1,in.length));
+ }
+ }
+ return node;
+ }
+
+## 树的子结构
+
+ /**
+ * Created by 周杰伦 on 2018/3/27.
+ * 输入两棵二叉树A,B,判断B是不是A的子结构。(ps:我们约定空树不是任意一个树的子结构)
+ */
+
+ 解析:本题还是有点难度的,子结构要求节点完全相同,所以先判断节点是否相同,然后使用先序遍历进行递判断,判断的依据是如果子树为空,则说明节点都找到了,如果原树节点为空,说明找不到对应节点,接着递归地判断该节点的左右子树是否符合要求.
+
+ public class 树的子结构 {
+
+ public boolean HasSubtree(TreeNode root1, TreeNode root2) {
+ boolean res = false;
+ if (root1 != null && root2 != null) {
+ if (root1.val == root2.val) {
+ res = aHasb(root1, root2);
+ }
+ if (res == false) {
+ res = HasSubtree(root1.left,root2);
+ }
+ if (res == false) {
+ res = HasSubtree(root1.right,root2);
+ }
+ return res;
+ }
+ else return false;
+ }
+ public boolean aHasb(TreeNode t1, TreeNode t2){
+ if (t2 == null) return true;
+ if (t1 == null) return false;
+ if (t1.val != t2.val) return false;
+
+ return aHasb(t1.left,t2.left) && aHasb(t1.right,t2.right);
+ }
+ }
+
+
+## 镜像二叉树
+
+ /**
+ * Created by 周杰伦 on 2017/3/19.操作给定的二叉树,将其变换为源二叉树的镜像。
+ 输入描述:
+ 二叉树的镜像定义:源二叉树
+ 8
+ / \
+ 6 10
+ / \ / \
+ 5 7 9 11
+ 镜像二叉树
+ 8
+ / \
+ 10 6
+ / \ / \
+ 11 9 7 5
+ */
+
+
+ 解析:其实镜像二叉树就是交换所有节点的左右子树,所以使用遍历并且进行交换即可。
+
+ /**
+ public class TreeNode {
+ int val = 0;
+ TreeNode left = null;
+ TreeNode right = null;
+
+ public TreeNode(int val) {
+ this.val = val;
+
+ }
+
+ }
+ */
+ public class 镜像二叉树 {
+ public void Mirror(TreeNode root) {
+ if(root == null)return;
+ if(root.left!=null || root.right!=null)
+ {
+ TreeNode temp=root.left;
+ root.left=root.right;
+ root.right=temp;
+ }
+ Mirror(root.left);
+ Mirror(root.right);
+
+ }
+
+
+## 树的层次遍历
+
+也就是从上到下打印节点,使用队列即可完成。
+
+## 二叉树的深度
+
+经典遍历。
+
+## 判断是否平衡二叉树
+
+判断左右子树的高度差是否 <= 1即可。
+
+## 二叉搜索树的后序遍历
+
+题目描述
+输入一个整数数组,判断该数组是不是某二叉搜索树的后序遍历的结果。如果是则输出Yes,否则输出No。假设输入的数组的任意两个数字都互不相同。
+
+解析:这题其实也非常巧妙。二叉搜索树的特点就是他的左子树都比根节点小,右子树都比跟节点大。而后序遍历的根节点在最后,所以后续遍历的第1到N-1个节点应该是左右子树的节点(不一定左右子树都存在)。
+
+后续遍历的序列是先左子树,再右子树,最后根节点,那么就要求,左半部分比根节点小,右半部分比根节点大,当然,左右部分不一定都存在。
+
+所以,找出根节点后,首先找出左半部分,要求小于根节点,然后找出右半部分,要求大于根节点,如果符合,则递归地判断左右子树到的根节点(本步骤已经将左右部分划分,割据中间节点进行递归),如果不符合,直接返回false。
+
+同理也可以判断前序遍历和中序遍历。
+
+ public class 二叉搜索树的后序遍历序列 {
+ public static void main(String[] args) {
+ int []a = {7,4,6,5};
+ System.out.println(VerifySquenceOfBST(a));
+ }
+ public static boolean VerifySquenceOfBST(int [] sequence) {
+ if (sequence == null || sequence.length == 0) {
+ return false;
+ }
+ return isBST(sequence, 0, sequence.length - 1);
+ }
+ public static boolean isBST(int []arr, int start, int end) {
+ if (start >= end) return true;
+ int root = arr[end];
+ int mid = start;
+ for (mid = start;mid < end && arr[mid] < root;mid ++) {
+
+ }
+ for (int i = mid;i < end; i ++) {
+ if (arr[i] < root)return false;
+ }
+ return isBST(arr, start, mid - 1) && isBST(arr, mid, end - 1);
+ }
+ }
+
+## 二叉树中和为某一值的路径
+
+/**
+ * Created by 周杰伦 on 2018/3/29.
+ * 题目描述
+ 输入一颗二叉树和一个整数,打印出二叉树中结点值的和为输入整数的所有路径。路径定义为从树的根结点开始往下一直到叶结点所经过的结点形成一条路径。
+ */
+
+ 解析:由于要求从根节点到达叶子节点,并且要打印出所有路径,所以实际上用到了回溯的思想。
+
+ 通过target跟踪当前和,进行先序遍历,当和满足要求时,加入集合,由于有多种结果,所以需要回溯,将访问过的节点弹出访问序列,才能继续访问下一个节点。
+
+ 终止条件是和满足要求,并且节点是叶节点,或者已经访问到空节点也会返回。
+
+
+ public class 二叉树中和为某一值的路径 {
+ private ArrayList> listAll = new ArrayList>();
+ private ArrayList list = new ArrayList();
+ public ArrayList> FindPath(TreeNode root,int target) {
+ if(root == null) return listAll;
+ list.add(root.val);
+ target -= root.val;
+ if(target == 0 && root.left == null && root.right == null)
+ listAll.add(new ArrayList(list));
+ FindPath(root.left, target);
+ FindPath(root.right, target);
+ list.remove(list.size()-1);
+ return listAll;
+ }
+
+ static int count = 0;
+ static Stack path = new Stack<>();
+ static Stack stack = new Stack<>();
+ static ArrayList> lists = new ArrayList<>();
+ }
+
+## 二叉树的下一个节点
+
+给定一个二叉树和其中的一个结点,请找出中序遍历顺序的下一个结点并且返回。注意,树中的结点不仅包含左右子结点,同时包含指向父结点的指针。
+
+ 解析:给出一个比较好懂的解法,中序遍历的结果存在集合中,找到根节点,进行中序遍历,然后找到该节点,下一个节点就是集合后一位
+
+ public TreeLinkNode GetNext(TreeLinkNode TreeLinkNode)
+ {
+ return findNextNode(TreeLinkNode);
+ }
+ public TreeLinkNode findNextNode(TreeLinkNode anynode) {
+ if (anynode == null) return null;
+ TreeLinkNode p = anynode;
+ while (p.next != null) {
+ p = p.next;
+ }
+ ArrayList list = inOrderSeq(p);
+ for (int i = 0;i < list.size();i ++) {
+ if (list.get(i) == anynode) {
+ if (i + 1 < list.size()) {
+ return list.get(i + 1);
+ }
+ else return null;
+ }
+ }
+ return null;
+
+ }
+ static ArrayList list = new ArrayList<>();
+ public static ArrayList inOrderSeq(TreeLinkNode TreeLinkNode) {
+ if (TreeLinkNode == null) return null;
+ inOrderSeq(TreeLinkNode.left);
+ list.add(TreeLinkNode);
+ inOrderSeq(TreeLinkNode.right);
+ return list;
+ }
+
+## 对称的二叉树
+
+请实现一个函数,用来判断一颗二叉树是不是对称的。注意,如果一个二叉树同此二叉树的镜像是同样的,定义其为对称的。
+
+解析,之前有一题是二叉树的镜像,递归交换左右子树即可求出镜像,然后递归比较两个树的每一个节点,则可以判断是否对称。
+
+ boolean isSymmetrical(TreeNode pRoot)
+ {
+ TreeNode temp = copyTree(pRoot);
+ Mirror(pRoot);
+ return isSameTree(temp, pRoot);
+ }
+
+
+ void Mirror(TreeNode root) {
+ if(root == null)return;
+ Mirror(root.left);
+ Mirror(root.right);
+ if(root.left!=null || root.right!=null)
+ {
+ TreeNode temp=root.left;
+ root.left=root.right;
+ root.right=temp;
+ }
+
+
+ }
+ boolean isSameTree(TreeNode t1,TreeNode t2){
+ if(t1==null && t2==null)return true;
+ else if(t1!=null && t2!=null && t1.val==t2.val) {
+ boolean left = isSameTree(t1.left, t2.left);
+ boolean right = isSameTree(t1.right, t2.right);
+ return left && right;
+ }
+ else return false;
+ }
+
+ TreeNode copyTree (TreeNode root) {
+ if (root == null) return null;
+ TreeNode t = new TreeNode(root.val);
+ t.left = copyTree(root.left);
+ t.right = copyTree(root.right);
+ return t;
+ }
+## 把二叉树打印成多行
+
+题目描述
+从上到下按层打印二叉树,同一层结点从左至右输出。每一层输出一行。
+
+解析:1 首先要知道到本题的基础思想,层次遍历。
+
+2 然后是进阶的思想,按行打印二叉树并输出行号,方法是,一个节点last指向当前行的最后一个节点,一个节点nlast指向下一行最后一个节点。使用t表示现在遍历的节点,当t = last时,表示本行结束。此时last = nlast,开始下一行遍历。
+
+同时,当t的左右子树不为空时,令nlast = t的左子树和右子树。每当last 赋值为nlast时,行号加一即可。
+
+## 按之字形顺序打印二叉树
+
+请实现一个函数按照之字形打印二叉树,即第一行按照从左到右的顺序打印,第二层按照从右至左的顺序打印,第三行按照从左到右的顺序打印,其他行以此类推。
+
+解析:1 首先要知道到本题的基础思想,层次遍历。
+
+2 然后是进阶的思想,按行打印二叉树并输出行号,方法是,一个节点last指向当前行的最后一个节点,一个节点nlast指向下一行最后一个节点。使用t表示现在遍历的节点,当t = last时,表示本行结束。此时last = nlast,开始下一行遍历。
+
+同时,当t的左右子树不为空时,令nlast = t的左子树和右子树。每当last 赋值为nlast时,行号加一即可。
+
+3 基于第2步的思想,现在要z字型打印,只需把偶数行逆序即可。所以把每一行的数存起来,然后偶数行逆置即可。
+
+ ArrayList > Print(TreeNode pRoot) {
+ LinkedList queue = new LinkedList<>();
+ TreeNode root = pRoot;
+ if(root == null) {
+ return new ArrayList<>();
+ }
+ TreeNode last = root;
+ TreeNode nlast = root;
+ queue.offer(root);
+ ArrayList list = new ArrayList<>();
+ list.add(root.val);
+ ArrayList one = new ArrayList<>();
+ one.addAll(list);
+ ArrayList> lists = new ArrayList<>();
+ lists.add(one);
+ list.clear();
+
+ int row = 1;
+ while (!queue.isEmpty()){
+
+ TreeNode t = queue.poll();
+
+ if(t.left != null) {
+ queue.offer(t.left);
+ list.add(t.left.val);
+ nlast = t.left;
+ }
+ if(t.right != null) {
+ queue.offer(t.right);
+ list.add(t.right.val);
+ nlast = t.right;
+ }
+ if(t == last) {
+ if(!queue.isEmpty()) {
+ last = nlast;
+ row ++;
+ ArrayList temp = new ArrayList<>();
+ temp.addAll(list);
+ list.clear();
+ if (row % 2 == 0) {
+ Collections.reverse(temp);
+ }
+ lists.add(temp);
+
+ }
+ }
+ }
+
+ return lists;
+ }
+
+## 序列化和反序列化二叉树
+
+解析:序列化和反序列化关键是要确定序列化方式。我么使用字符串来序列化。
+
+用#代表空,用!分隔左右子树。
+
+比如 1
+ 2 3
+ 4 5
+
+使用先序遍历
+序列化结果是1!2!4!###3!#5!##
+
+反序列化先让根节点指向第一位字符,然后左子树递归进行连接,右子树
+
+ public class Solution {
+ public int index = -1;
+ StringBuffer sb = new StringBuffer();
+
+ String Serialize(TreeNode root) {
+ if(root == null) {
+ sb.append("#!") ;
+ }
+ else {
+ sb.append(root.val + "!");
+ Serialize(root.left);
+ Serialize(root.right);
+ }
+
+ return sb.toString();
+ }
+ TreeNode Deserialize(String str) {
+ index ++;
+ int len = str.length();
+ if(index >= len) {
+ return null;
+ }
+ String[] strr = str.split("!");
+ TreeNode node = null;
+ if(!strr[index].equals("#")) {
+ node = new TreeNode(Integer.valueOf(strr[index]));
+ node.left = Deserialize(str);
+ node.right = Deserialize(str);
+ }
+ return node;
+ }
+ }
+
+## 二叉搜索树的第k个结点
+
+ 解析:二叉搜索树的中序遍历是有序的,只需要在中序中判断数字是否在第k个位置即可。
+ 如果在左子树中发现了,那么递归返回该节点,如果在右子树出现,也递归返回该节点。注意必须要返回,否则结果会被递归抛弃掉。
+
+ TreeNode KthNode(TreeNode pRoot, int k)
+ {
+ count = 0;
+ return inOrderSeq(pRoot, k);
+ }
+ static int count = 0;
+ public TreeNode inOrderSeq(TreeNode treeNode, int k) {
+ if (treeNode == null) return null;
+ TreeNode left = inOrderSeq(treeNode.left, k);
+ if (left != null) return left;
+ if (++ count == k) return treeNode;
+ TreeNode right = inOrderSeq(treeNode.right, k);
+ if (right != null) return right;
+ return null;
+ }
+
+# 栈和队列
+
+## 用两个队列实现栈,用两个栈实现队列。
+
+
+简单说下思路
+
+1 两个栈实现队列,要求先进先出,入队时节点先进入栈A,如果栈A满并且栈B空则把全部节点压入栈B。
+
+出队时,如果栈B为空,那么直接把栈A节点全部压入栈B,再从栈B出栈,如果栈B不为空,则从栈B出栈。
+
+2 两个队列实现栈,要求后进先出。入栈时,节点先加入队列A,出栈时,如果队列B不为空,则把头结点以后的节点出队并加入到队列B,然后自己出队。
+
+如果出栈时队列B不为空,则把B头结点以后的节点移到队列A,然后出队头结点,以此类推。
+
+## 包含min函数的栈
+
+/**
+ * 设计一个返回最小值的栈
+ * 定义栈的数据结构,请在该类型中实现一个能够得到栈最小元素的min函数。
+ * Created by 周杰伦 on 2017/3/22.
+ */
+
+ 解析:这道题的解法也是非常巧妙的。因为每次进栈和出栈都有可能导致最小值发生改变。而我们要维护的是整个栈的最小值。
+
+ 如果单纯使用一个数来保存最小值,会出现一种情况,最小值出栈时,你此时的最小值只能改成栈顶元素,但这个元素不一定时最小值。
+
+ 所以需要一个数组来存放最小值,或者是一个栈。
+
+ 使用另一个栈B存放最小值,每次压栈时比较节点值和栈B顶端节点值,如果比它小则压栈,否则不压栈,这样就可以从b的栈顶到栈顶依次访问最小值,次小值。以此类推。
+
+ 当最小值节点出栈时,判断栈B顶部的节点和出栈节点是否相同,相同则栈B也出栈。
+
+ 这样就可以维护一个最小值的函数了。
+
+ 同理,最大值也是这样。
+
+
+ public class 包含min函数的栈 {
+ Stack stack=new Stack<>();
+ Stack minstack=new Stack<>();
+
+ public void push(int node) {
+ if(stack.isEmpty())
+ {
+ stack.push(node);
+ minstack.push(node);
+ }
+ else if(node stack = new Stack<>();
+ int j = 0;
+ int i = 0;
+ while (i < pushA.length) {
+ stack.push(pushA[i]);
+ i++;
+ while (!stack.empty() && stack.peek() == popA[j]) {
+ stack.pop();
+ j++;
+ }
+ if (i == pushA.length) {
+ if (!stack.empty()) {
+ return false;
+ } else return true;
+ }
+ }
+ return false;
+ }
+
+
+# 排序和查找
+
+## 旋转数组的最小数字
+
+ 把一个数组最开始的若干个元素搬到数组的末尾,我们称之为数组的旋转。 输入一个非递减排序的数组的一个旋转,输出旋转数组的最小元素。 例如数组{3,4,5,1,2}为{1,2,3,4,5}的一个旋转,该数组的最小值为1。 NOTE:给出的所有元素都大于0,若数组大小为0,请返回0。
+
+ 解析:这题的思路很巧妙,如果直接遍历复杂度为O(N),但是使用二分查找可以加快速度,因为两边的数组都是递增的最小值一定在两边数组的边缘,于是通过二分查找,逐渐缩短左右指针的距离,知道左指针和右指针只差一步,那么右指针所在的数就是最小值了。
+ 复杂度是O(logN)
+
+ //这段代码忽略了三者相等的情况
+ public int minNumberInRotateArray(int [] array) {
+ if (array.length == 0) return 0;
+ if (array.length == 1) return array[0];
+ int min = 0;
+
+ int left = 0, right = array.length - 1;
+ //只有左边值大于右边值时,最小值才可能出现在中间
+ while (array[left] > array[right]) {
+ int mid = (left + right)/2;
+ if (right - left == 1) {
+ min = array[right];
+ break;
+ }
+ //如果左半部分递增,则最小值在右侧
+ if (array[left] < array[mid]) {
+ left = mid;
+ }
+ //如果右半部分递增,则最小值在左侧。
+ //由于左边值比右边值大,所以两种情况不会同时发生
+ else if (array[right] > array[mid]) {
+ right = mid ;
+ }
+ }
+ return array[min];
+
+ }
+
+
+ 注意:但是当arr[left] = arr[right] = arr[min]时。三个数都相等无法确定最小值,此时只能遍历。
+
+# 递归
+
+## 斐波那契数列
+
+1递归做法
+
+2记忆搜索,用数组存放使用过的元素。
+
+3DP,本题中dp就是记忆化搜索
+
+## 青蛙跳台阶
+
+一次跳两步或者跳一步,问一共多少种跳法到达n级,所以和斐波那契数列是一样的。
+
+## 变态跳台阶
+
+一次跳1到n步,问一共几种跳法,这题是找数字规律的,一共有2^(n-1)种方法
+
+## 矩形覆盖
+
+和上题一样,也是找规律,答案也是2^(n-1)
+
+# 位运算
+
+## 二进制中1的个数
+
+ * Created by 周杰伦 on 2018/6/29.
+ * 题目描述
+ * 输入一个整数,输出该数二进制表示中1的个数。其中负数用补码表示。
+
+ 解析:
+ 1 循环右移数字n,每次判断最低位是否为1,但是可能会导致死循环。
+
+ 2 使用数字a = 1和n相与,a每次左移一位,再与n相与得到次低位,最多循环32次,当数字1左移32次也会等于0,所以结束循环。
+
+ 3 非常奇葩的做法,把一个整数减去1,再与原整数相与,会把最右边的一个1变成0,于是统计可以完成该操作的次数即可知道有多少1了。
+
+ public class 二进制中1的个数 {
+ public static int NumberOf1(int n) {
+ int count = 0;
+ while (n != 0) {
+ ++count;
+ n = (n - 1) & n;
+ }
+ return count;
+ }
+ }
+
+## 数组中只出现一次的数字
+
+题目描述
+一个整型数组里除了一个数字之外,其他的数字都出现了两次。请写程序找出这一个只出现一次的数字。
+
+解析:左神称之为神仙题。
+
+利用位运算的异或操作^。
+由于a^a = 0,0^b=b,所以。所有数执行异或操作,结果就是只出现一次的数。
+
+## 不用加减乘除做加法
+
+解析:不用加减乘,那么只能用二进制了。
+
+两个数a和b,如果不考虑进位,则0 + 1 = 1,1 + 1 = 0,0 + 0 = 0,这就相当于异或操作。
+如果考虑进位,则只有1 + 1有进位,所以使用相与左移的方法得到每一位的进位值,再通过异或操作和原来的数相加。当没有进位值的时候,运算结束。
+ public static int Add(int num1,int num2) {
+ if( num2 == 0 )return num1;
+ if( num1 == 0 )return num2;
+
+ int temp = num2;
+ while(num2!=0) {
+ temp = num1 ^num2;
+ num2 = (num1 & num2)<<1;
+ num1 = temp;
+ }
+ return num1;
+ }
+
+# 回溯和DFS
+
+## 矩阵中的路径
+
+题目描述
+请设计一个函数,用来判断在一个矩阵中是否存在一条包含某字符串所有字符的路径。路径可以从矩阵中的任意一个格子开始,每一步可以在矩阵中向左,向右,向上,向下移动一个格子。如果一条路径经过了矩阵中的某一个格子,则之后不能再次进入这个格子。 例如 a b c e s f c s a d e e 这样的3 X 4 矩阵中包含一条字符串"bcced"的路径,但是矩阵中不包含"abcb"路径,因为字符串的第一个字符b占据了矩阵中的第一行第二个格子之后,路径不能再次进入该格子。
+
+解析:回溯法也就是特殊的dfs,需要找到所有的路径,所以每当到达边界条件或抵达目标时,递归返回,由于需要保存路径中的字母,所以递归返回时需要删除路径最后的节点,来保证路径合法。不过本题只有一个解,所以找到即可返回。
+
+ public class 矩阵中的路径 {
+ public static void main(String[] args) {
+ char[][]arr = {{'a','b','c','e'},{'s','f','c','s'},{'a','d','e','e'}};
+ char []str = {'b','c','c','e','d'};
+ System.out.println(hasPath(arr, arr.length, arr[0].length, str));
+ }
+ static int flag = 0;
+ public static boolean hasPath(char[][] matrix, int rows, int cols, char[] str)
+ {
+ int [][]visit = new int[rows][cols];
+ StringBuilder sb = new StringBuilder();
+ for (int i = 0;i < rows;i ++) {
+ for (int j = 0;j < cols;j ++) {
+ if (matrix[i][j] == str[0]) {
+ visit[i][j] = 1;
+ sb.append(str[0]);
+ dfs(matrix, i, j, visit, str, 1, sb);
+ visit[i][j] = 0;
+ sb.deleteCharAt(sb.length() - 1);
+ }
+ }
+ }
+ return flag == 1;
+ }
+ public static void dfs(char [][]matrix, int row, int col, int [][]visit, char []str, int cur, StringBuilder sb) {
+ if (sb.length() == str.length) {
+ // System.out.println(sb.toString());
+ flag = 1;
+ return;
+ }
+
+ int [][]pos = {{1,0},{-1,0},{0,1},{0,-1}};
+ for (int i = 0;i < pos.length;i ++) {
+ int x = row + pos[i][0];
+ int y = col + pos[i][1];
+ if (x >= matrix.length || x < 0 || y >= matrix[0].length || y < 0) {
+ continue;
+ }
+ if (visit[x][y] == 0 && matrix[x][y] == str[cur]) {
+ sb.append(matrix[x][y]);
+ visit[x][y] = 1;
+ dfs(matrix, x, y, visit, str, cur + 1, sb);
+ sb.deleteCharAt(sb.length() - 1);
+ visit[x][y] = 0;
+ }
+ }
+ }
+
+
+## 机器人的运动范围
+
+题目描述
+地上有一个m行和n列的方格。一个机器人从坐标0,0的格子开始移动,每一次只能向左,右,上,下四个方向移动一格,但是不能进入行坐标和列坐标的数位之和大于k的格子。 例如,当k为18时,机器人能够进入方格(35,37),因为3+5+3+7 = 18。但是,它不能进入方格(35,38),因为3+5+3+8 = 19。请问该机器人能够达到多少个格子?
+
+ 解析:这是一个可达性问题,使用dfs方法,走到的每一格标记为走过,走到无路可走时就是最终的结果。每次都有四个方向可以选择,所以写四个递归即可。
+
+ public class Solution {
+ static int count = 0;
+ public static int movingCount(int threshold, int rows, int cols)
+ {
+ count = 0;
+ int [][]visit = new int[rows][cols];
+ dfs(0, 0, visit, threshold);
+ return count;
+ }
+
+ public static void dfs(int row, int col, int[][]visit, int k) {
+ if (row >= visit.length || row < 0 || col >= visit[0].length || col < 0) {
+ return;
+ }
+ if (sum(row) + sum(col) > k) {
+ return;
+ }
+
+ if (visit[row][col] == 1){
+ return;
+ }
+
+ visit[row][col] = 1;
+ count ++;
+ dfs(row + 1,col,visit, k);
+ dfs(row - 1,col,visit, k);
+ dfs(row,col + 1,visit, k);
+ dfs(row,col - 1,visit, k);
+
+ }
+
+ public static int sum(int num) {
+ String s = String.valueOf(num);
+ int sum = 0;
+ for (int i = 0;i < s.length();i ++) {
+ sum += Integer.valueOf(s.substring(i, i + 1));
+ }
+ return sum;
+ }
+ }
\ No newline at end of file
diff --git "a/md/\346\223\215\344\275\234\347\263\273\347\273\237\345\255\246\344\271\240\346\200\273\347\273\223.md" "b/md/\346\223\215\344\275\234\347\263\273\347\273\237\345\255\246\344\271\240\346\200\273\347\273\223.md"
new file mode 100644
index 0000000..2740f29
--- /dev/null
+++ "b/md/\346\223\215\344\275\234\347\263\273\347\273\237\345\255\246\344\271\240\346\200\273\347\273\223.md"
@@ -0,0 +1,304 @@
+---
+title: 操作系统学习总结
+date: 2018-07-09 22:33:03
+tags:
+ - 操作系统
+categories:
+ - 后端
+ - 技术总结
+---
+##这部分内容主要是基于一些关于操作系统基础的学习总结,内容不全面,只讲述了其中的一小部分,后续会再补充,如有错误,还请见谅。
+# 操作系统
+
+## CPU
+cpu是中央处理器,他是计算机的核心。
+cpu通过和寄存器,高速缓存,以及内存交互来执行程序。
+
+主板分为南桥和北桥,北桥主要是内存总线,通往内存。
+而南桥主要是慢速设备的IO总线,包括硬盘,网卡等IO设备。
+
+32位cpu最多寻址4g内存,而64位cpu目前来说没有上限。
+
+### 程序执行过程
+cpu发出指令,将硬盘上的一段程序读入内存,由于cpu和硬盘的速度差距更大,一般使用中断,dma等方式来将硬盘数据载入内存。
+然后cpu通过寄存器以及指令集执行指令,cpu读取内存上的代码,内存上的方法执行是一个栈调用的过程。
+
+### 高速缓存 读写缓冲区
+为了弥补cpu和内存的速度差,cpu配有多级缓存。
+
+一般有一级缓存和二级缓存,缓存根据局部性原理把经常使用的代码加载如缓存,能比直接访问内存快上几百倍。
+
+同样的,内存和硬盘间的速度差距也很大,需要通过读写缓冲区来进行速度匹配,内存写入磁盘时先写入缓冲区,读数据时从缓冲区读取硬盘准备好的数据。
+
+
+## 内存管理和虚拟内存
+
+由于程序的大小越来越大,而计算机想要支持多道程序,当一个程序遇到IO操作时转而去执行另一个程序,这就要求内存中装有多个程序的代码了。
+
+然而程序的内存消耗与日俱增,同时装载多个程序越来越困难,所以人们提出了,只在程序需要使用到的时候再把他装入内存,平时把代码放在硬盘中即可。
+
+### 分页
+
+由于内存需要装载硬盘中的数据,所以需要约定一个存储单元,操作系统把它叫做页,一个页一般长度是8kb或者16kb。内存从硬盘读取数据时读取的是一个页或多个页。
+
+### 虚拟内存
+
+
+由于这些代码持久化在硬盘中,占用了一部分空间,并且需要运行时会加载到内存中,所以这部分的空间一般也成为虚拟内存的空间(大小)。
+
+### 页表和页面置换算法
+
+为了知道每个程序对应的代码存在硬盘中的位置,操作系统需要维护一个程序到页面的映射表,cpu要内存加载一个页面时,首先要访问页表,来得知页面在硬盘中的位置,然后让内存去该位置把对应的页面调入内存中。
+
+为了提升页面调入的效率,也使用了多种的页面置换算法,比如lru最近最久未使用,fifo先进先出,时钟法,多级队列法等。
+
+当然,为了进一步提高效率,还会使用多级页表的方式,不过一般需要硬件维护一个页表映射页面的快速转换结构,以便能迅速地完成页面解析和调度。
+
+### 中断和缺页中断
+
+计算机提供一系列中断指令与硬件进行交互,操作系统可以使用这些中断去控制硬件,比如使用中断通知cpu硬盘的IO操作已经准备好,键盘通过一次又一次的中断来输入字符。
+
+中断一般适用于快速返回的字符设备,比如鼠标键盘,而硬盘这类耗时IO操作,使用中断后cpu仍然需要等待硬盘把数据装入内存。是非常缓慢的。
+
+于是才会使用DMA来完成IO操作,DMA额外提供一个处理器去处理IO操作,当硬盘数据加载到内存中后再去通知CPU操作已完成。
+
+ 缺页中断就是因为内存中没有cpu需要访问的页面,必须根据页表到硬盘中获取页面,并根据置换算法进行页面调度。如果找不到对应页面,则程序执行会报错。
+
+### 分页和分段
+
+分页是上述所说的,通过内存和硬盘的约定,将调度单元设定为一个页面。
+
+ 分段则不同,分段并不是物理意义上的分段,而是逻辑上把代码使用到的空间划分成多个部分,比如受保护部分,公开部分,核心部分等,这样可以更好地描述每个段的代码信息,为使用者提供便利,为了支持程序员的这种需求,操作系统加入了分段的概念,将代码对应的一段虚拟内存划分为不同的逻辑段。
+
+ 同时为了根据不同段来以不同方式访问内存,操作系统需要另外维护一个段表,以用于段的映射。
+
+由于分段只是逻辑上的概念,所以底层的内存分页仍然是必不可少的,因此在逻辑段的基础上,物理上又会划分为多个页,一个段中可能包含了多个页面。
+
+因此,完善的虚拟内存管理器需要支持段页表,先映射段,再映射页面。
+
+## 进程与线程
+
+### 进程
+进程是资源分配的资本单位,操作系统为进程开辟一段内存空间,内存空间从高位向低位,包括函数调用栈,变量以及其他区域。cpu根据这些信息配合寄存器进行函数调用和程序执行。
+
+### 多进程
+由于计算机是分时系统,所以多进程的使用不可避免,操作系统需要进行进程的切换,方法是内存指针指向新位置,保存原来的进程信息,同时刷新寄存器等数据。然后开始执行新的进程.
+
+一般操作系统会使用pcb结构来记录进程的信息和上下文。通过他和cpu配合来完成进程切换。
+
+### 线程
+线程是系统调度的基本单位,没有线程以前,一般会使用多进程模型,一个程序往往需要多个进程配合使用,但是多进程之间并没有共享内存,导致进程间通信非常麻烦。
+
+比如文本输入工具,一边键入文字一边需要保存数据,如果是单进程执行,则每次输入都触发IO操作,非常费时,如果一个进程负责输入展示一个进程负责输入保存,确实速度很快,但是两个进程没办法共享数据。除非使用额外的通讯手段。
+### 多线程
+
+而多线程就好办了,多线程都是基于进程产生的,线程被创建后只需要分配少量空间支持堆栈操作即可,同时线程还共享进程中的内存,所以一般使用进程分配资源,线程进行调度的方式。
+
+ 操作系统对线程的支持:
+ 一般情况下操作系统都支持线程,并且可以创建内核级线程,内核可以识别线程并且为其分配空间,进行线程调度。
+ 但是内核级线程实现比较复杂,使用起来也不甚方便。
+
+ 所以往往开发人员会使用用户级线程,用户级线程比如Java的多线程,通过简单的api实现,当需要操作系统支持时,才使用底层调用api接口进行内核级的系统调用。
+
+ 但是一般情况下用户级线程是不被内核识别的,也就是说,用户级线程会被内核认为是一个进程,从而执行进程的调度。这样的话就没有意义了。
+
+ 所以一般情况下用户级线程会映射到对应的内核级线程中,内核为进程创建一定数量的内核级线程以供使用。Java中的线程基本上都是使用这种方式实现的。
+
+### 线程通信和进程通信
+
+线程通信一般只需要使用共享内存的方式即可实现。
+
+而进程通信则需要额外的通信机制。
+
+> 1 信号量,一般多进程间的同步使用信号量来完成,系统为临界区添加支持并发量为n的信号量,多进程访问临界区资源时,首先需要执行p操作来减少信号量,如果信号量等于0则操作失败,并且挂起进程,否则成功进入临界区执行。
+>
+> 当进程退出临界区时,执行v操作,将信号量加一,并唤醒挂起的进程进行操作。
+>
+> 2 管程,管程是对信号量的一个包装,避免使用信号量时出错。
+>
+> 3 管道,直接连接两个进程,一个进程写入管道,另一个进程可以读取管道,但是他不支持全双工,并且只能在父子进程间使用,所以局限性比较大
+>
+> 4 消息队列
+>
+> 操作系统维护一个消息队列,进程将消息写入队列中,其他进程轮询消息队列看是否有自己的消息,增加了轮询的开销,但是提高了消息的可靠性和易用性,同时支持了订阅消息。
+>
+> 5 socket
+>
+> socket一般用于不同主机上的进程通信,双方通过ip和port的方式寻址到对方主机并找到监听该端口的进程,为了完成通信,他们先建立tcp连接,在此基础上交换数据,也就完成了进程间的通信。
+
+### 进程调度
+
+不小心把这茬忘了,进程调度算法有几种,fifo先来先服务,短作业优先,时间片轮转,优先级调度,多级反馈队列等。
+基本上可以通过名字知道算法的大概实现。
+
+### 死锁
+
+死锁的必要条件:
+
+ 1互斥:资源必须是互斥的,只能给一个进程使用
+
+ 2占有和等待:占有资源时可以请求其他资源
+
+ 3不可抢占:资源占有时不会被抢
+
+ 4环路等待:有两个以上的进程组成一个环路,每个进程都在等待下一个进程的资源释放。
+
+死锁的处理方法:
+
+1鸵鸟
+
+2死锁预防
+
+在程序运行之前预防发生死锁。
+
+ (一)破坏互斥条件
+
+ 例如假脱机打印机技术允许若干个进程同时输出,唯一真正请求物理打印机的进程是打印机守护进程。
+
+ 这样子就破坏了互斥条件,转而使用单个队列串行执行操作。
+
+ (二)破坏占有和等待条件
+
+ 一种实现方式是规定所有进程在开始执行前请求所需要的全部资源。
+
+ 分配了全部资源就不需要去等待其他资源。
+
+ (三)破坏不可抢占条件
+
+ 允许抢占式调度。
+
+ (四)破坏环路等待
+
+ 给资源统一编号,进程只能按编号顺序来请求资源。
+
+ 按正确顺序请求资源,就不会发生死锁。
+3死锁避免
+
+==银行家算法用于在程序运行时避免发生死锁。==
+
+银行家算法用于在程序运行时判断资源的分配情况是否是安全状态,如果某一步骤使程序可能发生死锁,银行家算法会拒绝该操作执行,从而避免进入不安全状态。
+
+(一)安全状态
+
+[](https://github.com/CyC2018/Interview-Notebook/blob/master/pics/ed523051-608f-4c3f-b343-383e2d194470.png)
+
+图 a 的第二列 Has 表示已拥有的资源数,第三列 Max 表示总共需要的资源数,Free 表示还有可以使用的资源数。从图 a 开始出发,先让 B 拥有所需的所有资源(图 b),运行结束后释放 B,此时 Free 变为 5(图 c);接着以同样的方式运行 C 和 A,使得所有进程都能成功运行,因此可以称图 a 所示的状态时安全的。
+
+定义:如果没有死锁发生,并且即使所有进程突然请求对资源的最大需求,也仍然存在某种调度次序能够使得每一个进程运行完毕,则称该状态是安全的。
+
+(二)单个资源的银行家算法
+
+一个小城镇的银行家,他向一群客户分别承诺了一定的贷款额度,算法要做的是判断对请求的满足是否会进入不安全状态,如果是,就拒绝请求;否则予以分配。
+
+[](https://github.com/CyC2018/Interview-Notebook/blob/master/pics/d160ec2e-cfe2-4640-bda7-62f53e58b8c0.png)
+
+上图 c 为不安全状态,因此算法会拒绝之前的请求,从而避免进入图 c 中的状态。
+
+4死锁检测和恢复
+
+==银行家算法检测程序并且阻止死锁发生,而死锁检测和恢复则
+不试图阻止死锁,而是当检测到死锁发生时,采取措施进行恢复。==
+
+(一)每种类型一个资源的死锁检测
+
+[](https://github.com/CyC2018/Interview-Notebook/blob/master/pics/b1fa0453-a4b0-4eae-a352-48acca8fff74.png)
+
+上图为==资源分配图==,其中方框表示资源,圆圈表示进程。资源指向进程表示该资源已经分配给该进程,进程指向资源表示进程请求获取该资源。
+
+如果有环则说明有死锁。
+
+(二)每种类型多个资源的死锁检测
+
+[](https://github.com/CyC2018/Interview-Notebook/blob/master/pics/e1eda3d5-5ec8-4708-8e25-1a04c5e11f48.png)
+
+==资源分配矩阵==
+
+上图中,有三个进程四个资源,每个数据代表的含义如下:
+
+* E 向量:资源总量
+* A 向量:资源剩余量
+* C 矩阵:每个进程所拥有的资源数量,每一行都代表一个进程拥有资源的数量
+* R 矩阵:每个进程请求的资源数量
+
+如果存在请求数量无法被满足时,就会出现死锁。
+
+==(三)死锁恢复==
+
+利用抢占恢复,允许其他进程抢占资源。
+
+利用回滚恢复,回滚进程操作,释放其资源。
+
+通过杀死进程恢复,杀死进程后释放资源。
+
+## IO和磁盘
+
+磁盘是块设备,键盘是字符设备,网卡是网络设备。他们都接在IO总线上,属于慢速设备。
+
+### 磁盘和寻址
+
+磁盘的结构比较复杂,主要通过扇区,盘面和磁头位置决定当前访问的磁盘位置。
+
+cpu为了能够访问磁盘内容,首先要把磁盘的内容载入内存中,于是要和内存约定统一的寻址单元,cpu指定一个起始位置,访问该位置以后的n个存储单元,一般存储单元是一个页,16K或者8K。
+
+这一操作中,指向起始位置需要随机寻址,而接下来的访问操作是顺序访问,磁盘的随机读写和顺序读写的速度差距是很大的。所以一般会通过缓冲区来缓存IO数据。
+
+ 磁盘内部一般也会分为很多部分,比如操作系统会将磁盘做一个分区,使用磁盘的一些位置存储元数据信息,以保证磁盘能够支持操作系统以及文件系统。
+
+ 一般在物理分区的起始位置会有一个引导区和分区表,BIOS自动将磁盘中引导区的内核程序载入内存,此时操作系统才开始运行,并且根据分区表操作系统可以知道每个分区的起始位置在哪。
+
+读写一个磁盘块的时间的影响因素有:
+
+旋转时间(主轴旋转磁盘,使得磁头移动到适当的扇区上)
+寻道时间(制动手臂移动,使得磁头移动到适当的磁道上)
+实际的数据传输时间
+其中,寻道时间最长,因此磁盘调度的主要目标是使磁盘的平均寻道时间最短。
+
+1. 先来先服务
+FCFS, First Come First Served
+
+按照磁盘请求的顺序进行调度。
+
+优点是公平和简单。缺点也很明显,因为未对寻道做任何优化,使平均寻道时间可能较长。
+
+2. 最短寻道时间优先
+SSTF, Shortest Seek Time First
+
+优先调度与当前磁头所在磁道距离最近的磁道。
+
+虽然平均寻道时间比较低,但是不够公平。如果新到达的磁道请求总是比一个在等待的磁道请求近,那么在等待的磁道请求会一直等待下去,也就是出现饥饿现象。具体来说,两边的磁道请求更容易出现饥饿现象。
+
+3. 电梯算法
+SCAN
+
+电梯总是保持一个方向运行,直到该方向没有请求为止,然后改变运行方向。
+
+电梯算法(扫描算法)和电梯的运行过程类似,总是按一个方向来进行磁盘调度,直到该方向上没有未完成的磁盘请求,然后改变方向。
+
+因为考虑了移动方向,因此所有的磁盘请求都会被满足,解决了 SSTF 的饥饿问题。
+
+### IO设备
+
+除了硬盘以外,还有键盘,网卡等IO设备,这些设备需要操作系统通过驱动程序来进行交互,驱动程序用于适配这些设备。
+
+为了执行IO操作,内核一般要为IO设备提供一个缓存区,比如网卡的IO操作,会为socket提供一个缓存区,当多个socket使用一个缓冲区进行通信,就是复用了缓冲区,也就是IO复用的一种方式。
+
+同时,内核还会维护一个IO请求的列表,当IO请求就绪时,让几个线程去执行IO操作,实现了线程的复用。
+
+### 文件系统
+
+文件系统是基于底层存储建立的一个树形文件结构。比较经典的是Linux的文件系统,首先在硬盘的超级块中安装文件系统,磁盘引导时会加载文件系统的信息。
+
+linux使用inode来标识任意一个文件。inode存储除了文件名以外的文件信息,包括创建时间,权限,以及一个指向磁盘存储位置的指针,那里才是真正存放数据的地方。
+
+一个目录也是一个inode节点。
+
+详细阐述一次文件访问的过程:
+
+ 首先用户ls查看目录。由于一个目录也是一个文件,所以相当于是看目录文件下有哪些东西。
+
+ 实际上目录文件是一个特殊的inode节点,它不需要存储实际数据,而只是维护一个文件名到inode的映射表。
+
+ 于是我们ls到另一个目录。同理他也是一个inode。我们在这个inode下执行vi操作打开某个文件,于是linux通过inode中的映射表找到了我们请求访问的文件名对应的inode。
+
+ 然后寻道到对应的磁盘位置,读取内容到缓冲区,通过系统调用把内容读到内存中,最后进行访问。
+
diff --git "a/md/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\345\255\246\344\271\240\346\200\273\347\273\223.md" "b/md/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\345\255\246\344\271\240\346\200\273\347\273\223.md"
new file mode 100644
index 0000000..cae10ae
--- /dev/null
+++ "b/md/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\345\255\246\344\271\240\346\200\273\347\273\223.md"
@@ -0,0 +1,640 @@
+---
+title: 计算机网络学习总结
+date: 2018-07-09 22:32:57
+tags:
+ - 计算机网络
+categories:
+ - 后端
+ - 技术总结
+---
+##这部分内容主要是基于一些关于计算机网络基础的学习总结,内容不全面,只讲述了其中的一小部分,后续会再补充,如有错误,还请见谅。
+
+# 计算机网络常见概念
+
+## 网卡和路由器
+
+网卡是一个有mac地址的物理设备,通过mac地址与局域网内的交换机通信,交换机可以识别mac地址。
+
+而单纯的中继器,集线器,双绞线等设备只识别物理层设备。
+
+路由器则工作在3层ip层,必须要有ip才能工作,所以路由器每一个接口都对应一个ip,维护一个可以识别ip的路由表,进行ip数据报转发。
+
+## 交换机
+交换机具有自学习能力,学习的是交换表的内容。交换表中存储着 MAC 地址到接口的映射。
+
+## 以太网
+以太网是一种星型拓扑结构局域网。
+
+早期使用集线器进行连接,它是一种物理层设备,作用于比特而不是帧,当一个比特到达接口时,集线器重新生成这个比特,并将其能量强度放大,从而扩大网络的传输距离。之后再将这个比特向其它所有接口。特别是,如果集线器同时收到同时从两个不同接口的帧,那么就发生了碰撞。
+
+目前以太网使用交换机替代了集线器,它不会发生碰撞,能根据 MAC 地址进行存储转发。
+
+## 虚拟局域网VLAN
+正常情况下,局域网中的链路层广播在整个局域网可达,而vlan可以在物理局域网中划分虚拟局域网,使广播帧只有在vlan当中的主机才能收到。
+
+虚拟局域网可以建立与物理位置无关的逻辑组,只有在同一个虚拟局域网中的成员才会收到链路层广播信息,例如下图中 (A1, A2, A3, A4) 属于一个虚拟局域网,A1 发送的广播会被 A2、A3、A4 收到,而其它站点收不到。
+
+## DHCP协议(动态主机配置协议)
+
+首先DHCP是为了让主机获得一个ip地址,所以主机会发一个0.0.0.0为发送方,255.255.255.255为接收方的ip数据报,也就是广播数据报,并且广播数据包只在局域网中有效,然后链路层解析为数据帧,发送给局域网内的DHCP服务器。
+
+## ARP协议
+arp负责把ip地址解析成局域网内的一个mac地址,只在局域网中有效。逆arp则把mac地址解析成ip地址。
+
+网络层实现主机之间的通信,而链路层实现具体每段链路之间的通信。因此在通信过程中,IP 数据报的源地址和目的地址始终不变,而 MAC 地址随着链路的改变而改变。
+
+[](https://github.com/CyC2018/Interview-Notebook/blob/master/pics/66192382-558b-4b05-a35d-ac4a2b1a9811.jpg)
+
+ARP 实现由 IP 地址得到 MAC 地址。
+
+[](https://github.com/CyC2018/Interview-Notebook/blob/master/pics/b9d79a5a-e7af-499b-b989-f10483e71b8b.jpg)
+
+每个主机都有一个 ARP 高速缓存,里面有本局域网上的各主机和路由器的 IP 地址到硬件地址的映射表。
+
+> 如果主机 A 知道主机 B 的 IP 地址,但是 ARP 高速缓存中没有该 IP 地址到 MAC 地址的映射,此时主机 A 通过广播的方式发送 ARP 请求分组,主机 B 收到该请求后会发送 ARP 响应分组给主机 A 告知其 MAC 地址,随后主机 A 向其高速缓存中写入主机 B 的 IP 地址到 MAC 地址的映射。
+
+## 网关和NAT
+当需要和外部局域网访问时,需要经过网关服务器以便兼容不同协议栈。局域网内部使用内网ip,经过网关时要转成外网ip,网关会帮你完成改写操作,当收到数据报时,网关又会帮你把ip改为内网ip。这种修改ip隐藏内部网络的方式叫做NAT。
+
+nat穿透的方式是主机和网关服务器协定一个ip地址作为主机服务的ip,所以主机可以通过这个ip和外网交流。
+
+## DNS协议和http请求过程
+访问一个域名时,会发送dns报文请求(应用层)给本地的DNS服务器,解析出域名对应的ip,然后三次握手建立连接,(当然TCP数据报由本地局域网经过网关转给外网,再经过多次路由才到达目标主机),然后发送http请求获得响应报文
+
+## ICMP
+ICMP 是为了更有效地转发 IP 数据报和提高交付成功的机会。它封装在 IP 数据报中,但是不属于高层协议。
+
+[](https://github.com/CyC2018/Interview-Notebook/blob/master/pics/e3124763-f75e-46c3-ba82-341e6c98d862.jpg)
+
+ICMP 报文分为差错报告报文和询问报文。
+
+[](https://github.com/CyC2018/Interview-Notebook/blob/master/pics/aa29cc88-7256-4399-8c7f-3cf4a6489559.png)
+
+
+ 1. Ping
+ Ping 是 ICMP 的一个重要应用,主要用来测试两台主机之间的连通性。
+
+ Ping 发送的 IP 数据报封装的是无法交付的 UDP 用户数据报。
+
+ 2. Traceroute
+ Traceroute 是 ICMP 的另一个应用,用来跟踪一个分组从源点到终点的路径,事实上,traceroute也封装着无法交付的udp,和ping类似。。
+
+源主机向目的主机发送一连串的 IP 数据报,每个数据包的ttl时间不同,所以可以跟踪每一跳路由的信息。
+
+==但是因为数据报封装的是无法交付的UDP报文,因此目的主机要向源主机发送 ICMP终点不可达差错报告报文。之后源主机知道了到达目的主机所经过的路由器 IP地址以及到达每个路由器的往返时间。==
+
+## 虚拟专用网VPN和内网ip
+
+由于 IP 地址的紧缺,一个机构能申请到的 IP 地址数往往远小于本机构所拥有的主机数。并且一个机构并不需要把所有的主机接入到外部的互联网中,机构内的计算机可以使用仅在本机构有效的 IP 地址(专用地址)。
+
+有三个专用地址块:
+
+* 10.0.0.0 ~ 10.255.255.255
+* 172.16.0.0 ~ 172.31.255.255
+* 192.168.0.0 ~ 192.168.255.255
+
+这些ip也称为内网ip,用于局域网间的通信,只能通过网关抵达公网。
+
+[](https://github.com/CyC2018/Interview-Notebook/blob/master/pics/1556770b-8c01-4681-af10-46f1df69202c.jpg)
+
+使用隧道技术实现vpn。
+
+ 原理是;普通的内网ip无法被访问到,一般可以使用nat技术让网关作为中转人,而ip数据报也会改写成网关服务器的地址。
+
+ 如果想让数据报保留内网地址,并且实现跨公网访问,那么只能通过隧道技术,把内网数据报加密包装在公网ip数据报中,然后通过公网ip抵达对方的专用网络,进行拆包和发送。
+
+ 为什么vpn能翻墙呢,因为我们通过对vpn服务器的连接,可以将内网ip数据报装在里面,发送给vpn,vpn解析后再发送给真正的服务器。
+
+ 由于本地网关阻拦了某些网站的请求,所以我们要把这个请求加密封装,然后通过隧道把数据发给一个海外服务器,让他真正完成请求。
+
+## 应用层
+
+应用层的协议主要是http,ftp这类协议,http访问超文本html,而ftp访问文件系统。
+
+### http
+
+通过浏览器可以方便地进行dns解析,建立tcp连接,发送http请求,得到http响应,这些工作都是浏览器完成的。
+
+### http1.0 1.1和2.0
+
+#### 1.0和1.1的主要变化
+
+ 1 http1.0经过多年发展,在1.1提出了改进。
+ 首先是提出了长连接,http请求可以在一次tcp连接中不断发送。
+
+ 2 然后是http1.1支持只发送header而不发送body。原因是先用header判断能否成功,再发数据,节约带宽,事实上,post请求默认就是这样做的。
+
+ 3 http1.1的host字段。由于虚拟主机可以支持多个域名,所以一般将域名解析后得到host。
+
+#### http1.0和http2.0的区别。
+
+ http2.0变化巨大。
+
+ 1 http支持多路复用,同一个连接可以并发处理多个请求,方法是把http数据包拆为多个帧,并发有序的发送,根据序号在另一端进行重组,而不需要一个个http请求顺序到达。
+
+ 2 http2.0支持服务端推送,就是服务端在http请求到达后,除了返回数据之外,还推送了额外的内容给客户端。
+
+ 3HTTP2.0压缩了请求头,同时基本单位是二进制帧流,这样的数据占用空间更少。
+
+ 4http2.0只适用于https场景,因为其在http和tcp中间加了一层ssl层。
+
+### get和post
+
+ get和post本质都是http请求,只不过对他们的作用做了界定和适配,并且让他们适应各自的场景。
+
+ 1本质区别是get只是一次http请求,post先发请求体再发请求体,实际上是两次请求
+
+ 2表面区别:
+
+ get可以cache而post不能,因为浏览器是这么安排的
+
+ 一般设计get是幂等的而post不是
+
+ get的参数放在url传递,而post放在请求体里,因为get没有请求体。
+ 所以get请求不安全,并且有长度限制(url不能太长),而post几乎没有限制,请求体可以很大。
+
+###
+
+
+#### session和cookie
+
+并且浏览器还维护了cookie以便记录用于对网站的一些信息,下次请求时在http报文中带上这些数据,服务器接收以后根据cookie中的sessionid获取对应的session即可
+
+#### token
+
+session一般维护在内存中,有时候也会持久化到数据库,但是如果session由单点维护可能出现宕机等情况,于是一般会采用分布式的方案。
+
+
+ session存放的几种方案。
+ 0 存在内存中。用sessionid标识用户。
+ 这样的session十分依赖于cookie。如果浏览器禁用了cookie则session无用武之地。
+
+ 当然也可以把内容存在数据库里,缺点是数据库访问压力较大。
+
+ 1有做法会将session内容存在cookie中,但前提是经过了加密,然后下次服务器对其进行解密,但是这样浏览器需要维护太多内容了。
+
+ 2当用户登录或者执行某些操作,则使用用户的一部分字段信息进行加密算法得到一串字符串成为token,用于唯一标识用户,或者是某些操作,比如登录,支付,服务端生成该token返回给用户,用户提交请求时必须带上这个token,就可以确认用户信息以及操作是否合法了。
+
+ 这样我们不需要存session,只需要在想得到用户信息时解密token即可。
+
+ token还有一个好处就是可以在移动端和pc端兼容,因为移动端不支持cookie。
+
+ 3token和oauth。经常有第三方授权登录的例子,本质就是使用token。首先我们打开授权登录页,登陆后服务端返回token,我们提交第三方的请求时,带上这个token,第三方不知道他是啥意思,并且token过段时间就过期了。
+
+#### cas单点登录
+
+单点登录是为了多个平台之间公用一个授权系统,做法是,所有登录都要指向统一登录服务,登陆成功以后在认证中心建立session,并且得到ticket,然后重定向页面,此时页面也会向认证中心确认ticket是否合法,然后就可以访问其他系统的页面了。
+
+从而访问其他系统时,由于已经有了认证中心的cookie,所以直接带上ticket访问即可。
+
+每次访问新系统时需要在认证中心注册session,然后单点退出时再把这些session退出,才能实现用户登出。
+
+## web安全和https
+
+### 密码加密
+
+MD5等加密方法可以用来对密码进行加密。一般还会加盐
+
+### xss跨站脚本攻击
+
+利用有输入功能网站的输入框来注入JavaScript脚本代码,用户访问该页面时会自动执行某些脚本代码,导致cookie等个人信息泄露,可能会被转发到其他网站。
+
+解决办法是对输入进行检验,利用一个些工具类就可以做到。
+
+### 跨站点请求伪造csrf
+首先用户访问了一个网站并登陆,会把cookie保留在浏览器,
+然后某些网站用一些隐性链接诱导用户点击,点击时发送请求会携带浏览器中的cookie,比如支付宝的账号密码,通过该cookie再去伪造一个支付宝支付请求,达到伪造请求的目的。
+
+解决这个问题的办法就是禁止js请求跨域名。但是他为ajax提供了特殊定制。
+
+### SQL 注入攻击
+1. 概念
+服务器上的数据库运行非法的 SQL 语句,主要通过拼接来完成。
+
+3. 防范手段
+(一)使用参数化查询
+
+以下以 Java 中的 PreparedStatement 为例,它是预先编译的 SQL 语句,可以传入适当参数并且多次执行。由于没有拼接的过程,因此可以防止 SQL 注入的发生。
+
+(二)单引号转换
+
+将传入的参数中的单引号转换为连续两个单引号,PHP 中的 Magic quote 可以完成这个功能。
+
+### 拒绝服务攻击
+拒绝服务攻击(denial-of-service attack,DoS),亦称洪水攻击,其目的在于使目标电脑的网络或系统资源耗尽,使服务暂时中断或停止,导致其正常用户无法访问。
+
+分布式拒绝服务攻击(distributed denial-of-service attack,DDoS),指攻击者使用网络上两个或以上被攻陷的电脑作为“僵尸”向特定的目标发动“拒绝服务”式攻击。
+
+DDoS攻击通过大量合法的请求占用大量网络资源,以达到瘫痪网络的目的。
+
+这种攻击方式可分为以下几种:
+
+ 通过使网络过载来干扰甚至阻断正常的网络通讯;
+ 通过向服务器提交大量请求,使服务器超负荷;
+ 阻断某一用户访问服务器;
+ 阻断某服务与特定系统或个人的通讯。
+
+攻击现象
+
+ 被攻击主机上有大量等待的TCP连接;
+ 网络中充斥着大量的无用的数据包;
+ 源地址为假 制造高流量无用数据,造成网络拥塞,使受害主机无法正常和外界通讯;
+ 利用受害主机提供的传输协议上的缺陷反复高速的发出特定的服务请求,使主机无法处理所有正常请求;
+ 严重时会造成系统死机。
+
+总体来说,对DoS和DDoS的防范主要从下面几个方面考虑:
+
+ 尽可能对系统加载最新补丁,并采取有效的合规性配置,降低漏洞利用风险;
+
+ 采取合适的安全域划分,配置防火墙、入侵检测和防范系统,减缓攻击。
+
+ 采用分布式组网、负载均衡、提升系统容量等可靠性措施,增强总体服务能力。
+### https
+
+https博大精深,首先先来看看他的基础知识
+
+ 1对称加密和非对称加密
+
+ 对称加密两方使用同一把密钥加密和解密,传输密钥时如果丢失就会被破解。
+
+ 2非对称加密两方各有一把私钥,而公钥公开,A用私钥加密,把公钥和数据传给B,B用公钥解密。同理,B用私钥对数据进行加密,返回给A,A也用公钥进行解密。
+
+ 3非对称加密只要私钥不丢就很安全,但是效率比较低,所以一般使用非对称加密传输对称加密的密钥,使用对称加密完成数据传输。
+
+ 4数字签名,为了避免数据在传输过程中被替换,比如黑客修改了你的报文内容,但是你并不知道,所以我们让发送端做一个数字签名,把数据的摘要消息进行一个加密,比如MD5,得到一个签名,和数据一起发送。然后接收端把数据摘要进行md5加密,如果和签名一样,则说明数据确实是真的。
+
+ 5数字证书,对称加密中,双方使用公钥进行解密。虽然数字签名可以保证数据不被替换,但是数据是由公钥加密的,如果公钥也被替换,则仍然可以伪造数据,因为用户不知道对方提供的公钥其实是假的。
+
+ 所以为了保证发送方的公钥是真的,CA证书机构会负责颁发一个证书,里面的公钥保证是真的,用户请求服务器时,服务器将证书发给用户,这个证书是经由系统内置证书的备案的。
+
+
+
+ 6 https过程
+
+ 用户发送请求,服务器返回一个数字证书。
+
+ 用户在浏览器端生成一个随机数,使用证书中的公钥加密,发送给服务端。
+
+ 服务端使用公钥解密该密文,得到随机数。
+
+ 往后两者使用该随机数作为公钥进行对称加密。
+
+
+ 番外:关于公钥加密私钥解密与私钥加密公钥解密说明
+ 第一种是签名,使用私钥加密,公钥解密,用于让所有公钥所有者验证私钥所有者的身份并且用来防止私钥所有者发布的内容被篡改.但是不用来保证内容不被他人获得.
+
+ 第二种是加密,用公钥加密,私钥解密,用于向公钥所有者发布信息,这个信息可能被他人篡改,但是无法被他人获得.搜索
+
+
+## 传输层
+
+ UDP 和 TCP 的特点
+ 用户数据报协议 UDP(User Datagram Protocol)是无连接的,尽最大可能交付,没有拥塞控制,面向报文(对于应用程序传下来的报文不合并也不拆分,只是添加 UDP 首部),支持一对一、一对多、多对一和多对多的交互通信。
+
+ 传输控制协议 TCP(Transmission Control Protocol)是面向连接的,提供可靠交付,有流量控制,拥塞控制,提供全双工通信,面向字节流(把应用层传下来的报文看成字节流,把字节流组织成大小不等的数据块),每一条 TCP 连接只能是点对点的(一对一)。
+
+TCP是传输层最重要的协议。
+>
+> 由于网络层只提供最大交付的服务,尽可能地完成路由转发,以及把链路层报文传送给任意一台主机。他做的工作很专注,所以不会提供其他的可靠性保证。
+>
+> 但是真实网络环境下随时会发生丢包,乱序,数据内容出错等情况,这些情况必须得到处理,于是我们使用传输层tcp来解决这些问题。
+
+### UDP报文
+
+伪首部的意义:伪首部并非TCP&UDP数据报中实际的有效成分。伪首部是一个虚拟的数据结构,其中的信息是从数据报所在IP分组头的分组头中提取的,既不向下传送也不向上递交,而仅仅是为计算校验和。
+
+
+
+首部字段只有 8 个字节,包括源端口、目的端口、长度、检验和。12 字节的伪首部是为了计算检验和临时添加的。
+
+### TCP 首部格式
+
+[](https://github.com/CyC2018/Interview-Notebook/blob/master/pics/55dc4e84-573d-4c13-a765-52ed1dd251f9.png)
+
+* **序号** :用于对字节流进行编号,例如序号为 301,表示第一个字节的编号为 301,如果携带的数据长度为 100 字节,那么下一个报文段的序号应为 401。
+
+* **确认号** :期望收到的下一个报文段的序号。例如 B 正确收到 A 发送来的一个报文段,序号为 501,携带的数据长度为 200 字节,因此 B 期望下一个报文段的序号为 701,B 发送给 A 的确认报文段中确认号就为 701。
+
+* **数据偏移** :指的是数据部分距离报文段起始处的偏移量,实际上指的是首部的长度。
+
+* **确认 ACK** :当 ACK=1 时确认号字段有效,否则无效。TCP 规定,在连接建立后所有传送的报文段都必须把 ACK 置 1。
+
+* **同步 SYN** :在连接建立时用来同步序号。当 SYN=1,ACK=0 时表示这是一个连接请求报文段。若对方同意建立连接,则响应报文中 SYN=1,ACK=1。
+
+* **终止 FIN** :用来释放一个连接,当 FIN=1 时,表示此报文段的发送方的数据已发送完毕,并要求释放连接。
+
+* **窗口** :窗口值作为接收方让发送方设置其发送窗口的依据。之所以要有这个限制,是因为接收方的数据缓存空间是有限的。
+*
+
+### 三次握手和四次挥手
+ 为了保证tcp的可靠传输,需要建立起一条通路,也就是所谓连接。这条通路必须保证有效并且能正确结束。
+
+[](https://github.com/CyC2018/Interview-Notebook/blob/master/pics/e92d0ebc-7d46-413b-aec1-34a39602f787.png)
+
+
+
+ 三次握手
+
+ 1 首先客户端发送连接请求syn,携带随机数x。
+ 2 服务端返回请求ack,x + 1,说明服务端对x进行了回复。
+ 3 客户端返回请求ack,y,说明接受到了信息并且开始传输数据,起始数据为y。
+
+ 客户端状态时syn_send和establish
+ 服务端则是从listen到syn_rcvd,再到establish
+
+[](https://github.com/CyC2018/Interview-Notebook/blob/master/pics/f87afe72-c2df-4c12-ac03-9b8d581a8af8.jpg)
+
+ 四次挥手
+
+ 1 首先客户端请求断开连接,发送fin请求,服务端返回fin的ack,继续处理断开前需要处理完的数据。
+
+ 2 过了一会,服务端处理完数据发送给客户端ack,表明已经关闭,客户端最后再发一个ack给服务端,如果服务端已关闭则无反应,客户端经过两个ttl后挥手完毕,确认服务端断开。这两个ttl成为time wait状态,用于确定服务端真的关闭。
+
+ 3 客户端发完fin后的状态从establish变为fin1——wait,服务端发完ack后的状态从establish变为closewait。
+
+ 4 客户端收到第一个ack后进入fin_2wait状态,服务端过了一会发送last——ack给客户端,说明关闭好了,客户端收到ack后进入timewait,然后发送ack。双方都closed。
+
+### 半连接syn和洪泛法攻击
+
+黑客开启大量的syn请求而不发送ack,服务端开启半连接等待ack,直到资源耗尽,所以必须检测来访ip
+### 为什么要三次握手
+
+三次握手的原因
+
+第三次握手是为了防止失效的连接请求到达服务器,让服务器错误打开连接。
+
+也就是说,如果只有两次握手,服务端返回ack后直接通信,那么如果客户端因为网络问题没有收到ack,可能会再次请求连接,但时服务端不知道这其实是同一个请求,于是又打开了一个连接,相当于维护了很多的无用连接。
+### time wait的作用
+
+1 需要服务端可靠地终止连接,如果处于time_wait客户端发给服务端的ack报文丢失,则服务端会再发一次fin,此时客户端不应该关闭。
+
+2 保证迟来的tcp报文有时间被丢弃,因为2msl里超时抵达的报文都会被丢弃。
+
+## 可靠传输协议
+
+TCP协议有三个重要属性。
+
+ 可靠传输,主要通过有序接收,确认后发送,以及超时重传来实现,并且使用分片来提高发送效率,通过检验和避免错误。
+
+ 流量控制,主要通过窗口限制接收和发送速率。
+
+ 拥塞控制,主要通过不同拥塞状态的算法来处理拥塞,一开始发的比较慢,然后指数增加,当丢包时再降低速度,重新开始第一阶段,避免拥塞。
+
+总结以下就是几个特点:
+
+TCP 可靠传输
+
+ TCP 使用超时重传来实现可靠传输:
+
+ 1 如果一个已经发送的报文段在超时时间内没有收到确认,那么就重传这个报文段。
+
+
+ 2 滑动窗口可以连续发送多个数据再统一进行确认。
+
+ 因为发送端希望在收到确认前,继续发送其它报文段。比如说在收到0号报文的确认前还发出了1-3号的报文,这样提高了信道的利用率。
+
+ 3 滑动窗口只重传丢失的数据报
+
+ 但可以想想,0-4发出去后可能要重传,所以需要一个缓冲区维护这些报文,所以就有了窗口。
+
+ 4每当完成一个确认窗口往前滑动一格,可以传新的一个数据,因此可以顺序发送顺序确认
+
+TCP 流量控制
+
+ 流量控制是为了控制发送方发送速率,保证接收方来得及接收。
+
+ 接收方发送的确认报文中的窗口字段可以用来控制发送方窗口大小,从而影响发送方的发送速率。将窗口字段设置为 0,则发送方不能发送数据。
+
+TCP 拥塞控制
+
+ 如果网络出现拥塞,分组将会丢失,此时发送方会继续重传,从而导致网络拥塞程度更高。因此当出现拥塞时,应当控制发送方的速率。这一点和流量控制很像,但是出发点不同。流量控制是为了让接收方能来得及接受,而拥塞控制是为了降低整个网络的拥塞程度。
+
+ TCP 主要通过四种算法来进行拥塞控制:慢开始、拥塞避免、快重传、快恢复。
+
+ 一般刚开始时慢开始,然后拥塞避免,出现个别丢包时(连续三个包序号不对),
+
+ 则执行快重传,然后进入快恢复阶段,接着继续拥塞避免。如果发生多次超时也就是拥塞时,直接进入慢开始。
+>
+>这种情况下,只是丢失个别报文段,而不是网络拥塞,因此执行快恢复,令 ssthresh = cwnd/2 ,cwnd = ssthresh,注意到此时直接进入拥塞避免。慢开始和快恢复的快慢指的是 cwnd 的设定值,而不是 cwnd 的增长速率。慢开始 cwnd 设定为 1,而快恢复 cwnd 设定为 ssthresh。
+
+ ==发送方需要维护一个叫做拥塞窗口(cwnd)的状态变量,注意拥塞窗口与发送方窗口的区别:拥塞窗口只是一个状态变量,实际决定发送方能发送多少数据的是发送方窗口==。
+
+滑动窗口协议综合实现了上述这一些内容:
+
+为什么要使用滑动窗口,因为滑动窗口可以实现可靠传输,流量控制和拥塞控制(拥塞控制用的是拥塞窗口变量)
+
+### tcp的粘包拆包
+
+tcp报文是流式的数据,没有标识数据结束,只有序号等字段,tcp协议自动完成数据报的切分。由于tcp使用缓冲区发送,又没有标识结束,当缓冲区的数据没清空又有新数据进来,就会发生粘包,如果数据太大存装不下,就会被拆包。
+
+## 网络层
+
+## IP 数据报格式
+
+[](https://github.com/CyC2018/Interview-Notebook/blob/master/pics/85c05fb1-5546-4c50-9221-21f231cdc8c5.jpg)
+
+* **版本** : 有 4(IPv4)和 6(IPv6)两个值;
+
+* **首部长度** : 占 4 位,因此最大值为 15。
+
+* **总长度** : 包括首部长度和数据部分长度。
+
+* **生存时间** :TTL,它的存在是为了防止无法交付的数据报在互联网中不断兜圈子。以路由器跳数为单位,当 TTL 为 0 时就丢弃数据报。
+
+==* **协议** :指出携带的数据应该上交给哪个协议进行处理,例如 ICMP、TCP、UDP 等。==
+
+* **首部检验和** :因为数据报每经过一个路由器,都要重新计算检验和,因此检验和不包含数据部分可以减少计算的工作量。
+
+
+* **片偏移** : 和标识符一起,用于发生分片的情况。片偏移的单位为 8 字节。
+
+[](https://github.com/CyC2018/Interview-Notebook/blob/master/pics/23ba890e-e11c-45e2-a20c-64d217f83430.png)
+
+总结:
+
+ ip层只保证尽最大努力交付,他所承载的一切都是对路由,转发,已经网络传输最友好的设计。
+
+ 路由器负责记录路由表和转发ip数据报,路由表记录着ip地址和下一跳路由的端口的对应关系。
+
+ 由于路由聚合的缘故,一般用170.177.233.0/24就可以标识好几个网络了。
+
+ 以前会使用A,B,C类地址,和子网,现在直接使用地址聚合,前24位是网络号,后面8位是主机号。
+
+ ## 某个聚合路由地址划分网络给n台机器,是否符合要求。。
+
+ 要看这个网络中的主机号能否达到n个。
+
+### IP 地址编址方式
+
+IP 地址的编址方式经历了三个历史阶段:
+
+* 分类
+* 子网划分
+* 无分类
+
+### [](https://github.com/CyC2018/Interview-Notebook/blob/master/notes/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BD%91%E7%BB%9C.md#1-%E5%88%86%E7%B1%BB)1\. 分类
+
+由两部分组成,网络号和主机号,其中不同分类具有不同的网络号长度,并且是固定的。
+
+IP 地址 ::= {< 网络号 >, < 主机号 >}
+
+[](https://github.com/CyC2018/Interview-Notebook/blob/master/pics/cbf50eb8-22b4-4528-a2e7-d187143d57f7.png)
+
+2. 子网划分
+
+
+ 通过在主机号字段中拿一部分作为子网号,把两级 IP 地址划分为三级 IP 地址。注意,外部网络看不到子网的存在。
+
+ IP 地址 ::= {< 网络号 >, < 子网号 >, < 主机号 >}
+
+ 要使用子网,必须配置子网掩码。一个 B 类地址的默认子网掩码为 255.255.0.0,如果 B 类地址的子网占两个比特,那么子网掩码为 11111111 11111111 11000000 00000000,也就是 255.255.192.0。
+
+3. 无分类
+
+
+ 无分类编址 CIDR 消除了传统 A 类、B 类和 C 类地址以及划分子网的概念,使用网络前缀和主机号来对 IP 地址进行编码,网络前缀的长度可以根据需要变化。
+
+ IP 地址 ::= {< 网络前缀号 >, < 主机号 >}
+
+ CIDR 的记法上采用在 IP 地址后面加上网络前缀长度的方法,例如 128.14.35.7/20 表示前 20 位为网络前缀。
+
+ CIDR 的地址掩码可以继续称为子网掩码,子网掩码首 1 长度为网络前缀的长度。
+
+一个 CIDR 地址块中有很多地址,一个 CIDR 表示的网络就可以表示原来的很多个网络,并且在路由表中只需要一个路由就可以代替原来的多个路由,减少了路由表项的数量。
+
+把这种通过使用网络前缀来减少路由表项的方式称为路由聚合,也称为 构成超网 。
+
+在路由表中的项目由“网络前缀”和“下一跳地址”组成,在查找时可能会得到不止一个匹配结果,应当采用最长前缀匹配来确定应该匹配哪一个。
+
+总结
+
+ 使用分类法的ip必须标识是哪一类地址,比较麻烦,而且一旦设置为某类地址它就只能使用那一部分地址空间了。
+
+ 使用子网掩码可以避免使用分类并且更灵活地决定网络号和主机号的划分。但是需要配置子网掩码,比较复杂。
+
+ CIDR 138.1.2.11/24
+ 使用CIDR避免了子网划分,直接使用后n位作为网络号,简化了子网的配置(实际上用n代替了子网掩码)。并且在路由器中可以使用地址聚合,一个ip可以聚合多个网络号。
+
+### ip分片详谈
+
+在TCP/IP分层中,数据链路层用MTU(Maximum Transmission Unit,最大传输单元)来限制所能传输的数据包大小,MTU是指一次传送的数据最大长度,不包括数据链路层数据帧的帧头,如以太网的MTU为1500字节,实际上数据帧的最大长度为1512字节,其中以太网数据帧的帧头为12字节。
+
+当发送的IP数据报的大小超过了MTU时,IP层就需要对数据进行分片,否则数据将无法发送成功。
+
+IP分片的实现
+
+> IP分片发生在IP层,不仅源端主机会进行分片,中间的路由器也有可能分片,因为不同的网络的MTU是不一样的,如果传输路径上的某个网络的MTU比源端网络的MTU要小,路由器就可能对IP数据报再次进行分片。而分片数据的重组只会发生在目的端的IP层。
+
+==避免IP分片==
+> 在网络编程中,我们要避免出现IP分片,那么为什么要避免呢?原因是IP层是没有超时重传机制的,如果IP层对一个数据包进行了分片,只要有一个分片丢失了,只能依赖于传输层进行重传,结果是所有的分片都要重传一遍,这个代价有点大。由此可见,IP分片会大大降低传输层传送数据的成功率,所以我们要避免IP分片。
+>
+
+ 对于UDP包,我们需要在应用层去限制每个包的大小,一般不要超过1472字节,即以太网MTU(1500)—UDP首部(8)—IP首部(20)。
+
+ 对于TCP数据,应用层就不需要考虑这个问题了,因为传输层已经帮我们做了。
+
+在建立连接的三次握手的过程中,连接双方会相互通告MSS(Maximum Segment =Size,最大报文段长度),MSS一般是MTU—IP首部(20)—TCP首部(20),每次发送的TCP数据都不会超过双方MSS的最小值,所以就保证了IP数据报不会超过MTU,避免了IP分片。
+
+3. 外部网关协议 BGP
+
+
+ BGP(Border Gateway Protocol,边界网关协议)
+
+ AS 之间的路由选择很困难,主要是因为互联网规模很大。并且各个 AS 内部使用不同的路由选择协议,就无法准确定义路径的度量。并且 AS 之间的路由选择必须考虑有关的策略,比如有些 AS 不愿意让其它 AS 经过。
+
+ BGP 只能寻找一条比较好的路由,而不是最佳路由。
+
+ 每个 AS 都必须配置 BGP 发言人,通过在两个相邻 BGP 发言人之间建立 TCP 连接来交换路由信息。
+
+### 路由选择协议和算法
+>
+> 路由选择协议
+> 路由选择协议都是自适应的,能随着网络通信量和拓扑结构的变化而自适应地进行调整。
+>
+> 互联网可以划分为许多较小的自治系统 AS,一个 AS 可以使用一种和别的 AS 不同的路由选择协议。
+>
+> 可以把路由选择协议划分为两大类:
+>
+> 自治系统内部的路由选择:RIP 和 OSPF
+> 自治系统间的路由选择:BGP
+
+
+总结:
+
+ 1. 内部网关协议 RIP
+ RIP 是一种基于距离向量的路由选择协议。距离是指跳数,直接相连的路由器跳数为 1,跳数最多为 15,超过 15 表示不可达。
+
+ RIP 按固定的时间间隔仅和相邻路由器交换自己的路由表,经过若干次交换之后,所有路由器最终会知道到达本自治系统中任何一个网络的最短距离和下一跳路由器地址。
+
+ 2. 内部网关协议 OSPF
+ 开放最短路径优先 OSPF,是为了克服 RIP 的缺点而开发出来的。
+
+ 开放表示 OSPF 不受某一家厂商控制,而是公开发表的;最短路径优先表示使用了 Dijkstra 提出的最短路径算法 SPF。
+
+OSPF 具有以下特点:
+
+ 计算出最短路径,然后向本自治系统中的所有路由器发送信息,这种方法是洪泛法。
+
+ 发送的信息就是与相邻路由器的链路状态,链路状态包括与哪些路由器相连以及链路的度量,度量用费用、距离、时延、带宽等来表示。
+
+ 变化时,路由器才会发送信息。
+
+ 所有路由器都具有全网的拓扑结构图,并且是一致的。相比于 RIP,OSPF 的更新过程收敛的很快。
+
+总结:
+
+ AS是一个自治域,一般是指相似度很大公用一个协议的路由器族,比如同一个运营商的网络。
+
+ 因特网中AS之间的路由选择协议是BGP。
+
+ AS内的路由选择协议有RIP和OSPF。
+
+ RIP两两交换,最后大家都同步。
+
+ OSPF找到最短路径。告诉大家。
+
+## 链路层
+链路层最主要是指局域网内的网络交互了,使用mac地址通过交换机进行通信,其中用得最多的局域网协议就是以太网。
+
+链路层使用MTU表示最大传输帧长度,报文长度不能超过MTU,否则会进行分片,比如比较大的IP数据报就会被分片,为了避免被分片。一般要控制IP报文长度。
+
+广播:
+
+要理解什么是广播风暴,就必须先理解网络通信技术。 网络上的一个节点,它发送一个数据帧或包,被传输到由广播域定义的本地网段上的每个节点就是广播。
+
+> 网络广播分为第2层广播和第3层广播。第2层广播也称硬件广播,用于在局域网内向所有的结点发送数据,通常不会穿过局域网的边界(路由器),除非它变成一个单播。广播将是一个二进制的全1或者十六进制全F的地址。而第3层广播用于在这个网络内向所有的结点发送数据。
+
+帧的传输方式,即单播帧(Unicast Frame)、多播帧(Multicast Frame)和广播帧(Broadcast Frame)。
+
+ 1、单播帧
+ 单播帧也称“点对点”通信。此时帧的接收和传递只在两个节点之间进行,帧的目的MAC地址就是对方的MAC地址,网络设备(指交换机和路由器)根据帧中的目的MAC地址,将帧转发出去。
+
+ 2、多播帧
+ 多播帧可以理解为一个人向多个人(但不是在场的所有人)说话,这样能够提高通话的效率。多播占网络中的比重并不多,主要应用于网络设备内部通信、网上视频会议、网上视频点播等。
+
+ 3、广播帧
+ 广播帧可以理解为一个人对在场的所有人说话,这样做的好处是通话效率高,信息一下子就可以传递到全体。在广播帧中,帧头中的目的MAC地址是“FF.FF.FF.FF.FF.FF”,代表网络上所有主机网卡的MAC地址。
+
+ 广播帧在网络中是必不可少的,如客户机通过DHCP自动获得IP地址的过程就是通过广播帧来实现的。而且,由于设备之间也需要相互通信,因此在网络中即使没有用户人为地发送广播帧,网络上也会出现一定数量的广播帧。
+
+ 同单播和多播相比,广播几乎占用了子网内网络的所有带宽。网络中不能长时间出现大量的广播帧,否则就会出现所谓的“广播风暴”(每秒的广播帧数在1000以上)。拿开会打一个比方,在会场上只能有一个人发言,如果所有人都同时发言的话,会场上就会乱成一锅粥。广播风暴就是网络长时间被大量的广播数据包所占用,使正常的点对点通信无法正常进行,其外在表现为网络速度奇慢无比。出现广播风暴的原因有很多,一块故障网卡就可能长时间地在网络上发送广播包而导致广播风暴。
+
+ 使用路由器或三层交换机能够实现在不同子网间隔离广播风暴的作用。当路由器或三层交换机收到广播帧时并不处理它,使它无法再传递到其他子网中,从而达到隔离广播风暴的目的。因此在由几百台甚至上千台电脑构成的大中型局域网中,为了隔离广播风暴,都要进行子网划分。
+ 使用vlan完全可以隔离广播风暴。
+
+> 在交换以太网上运行TCP/IP环境下:
+> 二层广播是在数据链路层的广播,它 的广播范围是二层交换机连接的所有端口;二层广播不能通过路由器。
+>
+> 三层广播就是在网络层的广播,它的范围是同一IP子网内的设备,子网广播也不能通过路由器。
+>
+> 第三层的数据必须通过第二层的封装再发送,所以三层广播必然通过二层广播来实现。
+>
+> 设想在同一台二层交换机上连接2个ip子网的设备,所有的设备都可以接收到二层广播,但三层广播只对本子网设备有效,非本子网的设备也会接收到广播包,但会被丢弃。
+
+广播风暴(broadcast storm)
+
+简单的讲是指当广播数据充斥网络无法处理,并占用大量网络带宽,导致正常业务不能运行,甚至彻底瘫痪,这就发生了“广播风暴”
+
+。一个数据帧或包被传输到本地网段 (由广播域定义)上的每个节点就是广播;由于网络拓扑的设计和连接问题,或其他原因导致广播在网段内大量复制,传播数据帧,导致网络性能下降,甚至网络瘫痪,这就是广播风暴。
+
+要避免广播风暴,可以采用恰当划分VLAN、缩小广播域、隔离广播风暴,还可在千兆以太网口上启用广播风暴控制,最大限度地避免网络再次陷入瘫痪。
\ No newline at end of file
From 15b71a95047d41a4b068f624442a415ac0434868 Mon Sep 17 00:00:00 2001
From: How_2_Play_Life <362294931@qq.com>
Date: Mon, 9 Jul 2018 22:52:40 +0800
Subject: [PATCH 19/23] Create README.md
---
README.md | 66 +++++++++++++++++++++++++++++++++++++++++++++++++++++++
1 file changed, 66 insertions(+)
create mode 100644 README.md
diff --git a/README.md b/README.md
new file mode 100644
index 0000000..f7b1daf
--- /dev/null
+++ b/README.md
@@ -0,0 +1,66 @@
+| Ⅰ | Ⅱ | Ⅲ | Ⅳ | Ⅴ | Ⅵ | Ⅶ | Ⅷ | Ⅸ |
+| :------: | :---------: | :-------: | :---------: | :---: | :---------:| :---------: | :---------: | :---------:|
+| 算法[:pencil2:](#算法-pencil2) | 操作系统[:computer:](#操作系统-computer)|网络[:cloud:](#网络-cloud) | 数据库[:floppy_disk:](#数据库-floppy_disk)| Java[:couple:](#Java-couple) |JavaWeb [:coffee:](#JavaWeb-coffee)| 分布式 [:sweat_drops:](#分布式-sweat_drops)| 设计模式[:hammer:](#设计模式-hammer)| Hadoop[:speak_no_evil:](#Hadoop-speak_no_evil)|
+
+## 算法 :pencil2:
+
+> [Mysql原理与实践总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/Mysql%E5%8E%9F%E7%90%86%E4%B8%8E%E5%AE%9E%E8%B7%B5%E6%80%BB%E7%BB%93.md)
+
+## 操作系统 :computer:
+
+> [操作系统学习总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/%E6%93%8D%E4%BD%9C%E7%B3%BB%E7%BB%9F%E5%AD%A6%E4%B9%A0%E6%80%BB%E7%BB%93.md)
+
+> [Mysql原理与实践总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/Mysql%E5%8E%9F%E7%90%86%E4%B8%8E%E5%AE%9E%E8%B7%B5%E6%80%BB%E7%BB%93.md)
+
+## 网络 :cloud:
+
+> [计算机网络学习总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BD%91%E7%BB%9C%E5%AD%A6%E4%B9%A0%E6%80%BB%E7%BB%93.md)
+
+## 数据库 :floppy_disk:
+
+> [Mysql原理与实践总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/Mysql%E5%8E%9F%E7%90%86%E4%B8%8E%E5%AE%9E%E8%B7%B5%E6%80%BB%E7%BB%93.md)
+
+> [Redis原理与实践总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/Redis%E5%8E%9F%E7%90%86%E4%B8%8E%E5%AE%9E%E8%B7%B5%E6%80%BB%E7%BB%93.md)
+
+## Java :couple:
+
+> [Java核心技术总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/Java%E6%A0%B8%E5%BF%83%E6%8A%80%E6%9C%AF%E6%80%BB%E7%BB%93.md)
+
+> [Java集合类总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/Java%E9%9B%86%E5%90%88%E7%B1%BB%E6%80%BB%E7%BB%93.md)
+
+> [Java并发技术总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/Java%E5%B9%B6%E5%8F%91%E6%80%BB%E7%BB%93.md)
+
+> [JVM原理学习总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/JVM%E6%80%BB%E7%BB%93.md)
+
+> [Java网络与NIO总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/Java%E7%BD%91%E7%BB%9C%E4%B8%8ENIO%E6%80%BB%E7%BB%93.md)
+
+## JavaWeb :coffee:
+
+> [JavaWeb技术学习总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/JavaWeb%E6%8A%80%E6%9C%AF%E6%80%BB%E7%BB%93.md)
+
+> [Spring与SpringMVC源码解析](https://github.com/h2pl/Java-Tutorial/blob/master/md/Spring%E4%B8%8ESpringMVC%E6%BA%90%E7%A0%81%E8%A7%A3%E6%9E%90%E6%80%BB%E7%BB%93.md)
+
+## 分布式 :sweat_drops:
+
+> [分布式理论学习总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/%E5%88%86%E5%B8%83%E5%BC%8F%E7%90%86%E8%AE%BA%E6%80%BB%E7%BB%93.md)
+
+> [分布式技术学习总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/%E5%88%86%E5%B8%83%E5%BC%8F%E6%8A%80%E6%9C%AF%E5%AE%9E%E8%B7%B5%E6%80%BB%E7%BB%93.md)
+
+## 设计模式 :hammer:
+
+## Hadoop :speak_no_evil:
+
+> [Hadoop生态学习总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/Hadoop%E7%94%9F%E6%80%81%E6%80%BB%E7%BB%93.md)
+
+
+
+## 后记
+
+**关于仓库**
+本仓库是笔者在准备 2018 年秋招复习过程中的学习总结,内容以Java后端的知识总结为主,每个部分都会有笔者更加详细的原创文章可供参考,欢迎查看。
+
+**关于转载**
+本仓库内容使用到的资料都会在最后面的参考资料中给出引用链接,希望您在使用本仓库的内容时也能给出相应的引用链接。
+
+
+
From a226ce9a12754fc621dbf0432b5416eb813d110c Mon Sep 17 00:00:00 2001
From: 724888 <362294931@qq.com>
Date: Mon, 9 Jul 2018 23:12:32 +0800
Subject: [PATCH 20/23] update
---
...46\344\271\240\346\200\273\347\273\223.md" | 189 ++++++++++++++++++
1 file changed, 189 insertions(+)
create mode 100644 "md/\350\256\276\350\256\241\346\250\241\345\274\217\345\255\246\344\271\240\346\200\273\347\273\223.md"
diff --git "a/md/\350\256\276\350\256\241\346\250\241\345\274\217\345\255\246\344\271\240\346\200\273\347\273\223.md" "b/md/\350\256\276\350\256\241\346\250\241\345\274\217\345\255\246\344\271\240\346\200\273\347\273\223.md"
new file mode 100644
index 0000000..d1196eb
--- /dev/null
+++ "b/md/\350\256\276\350\256\241\346\250\241\345\274\217\345\255\246\344\271\240\346\200\273\347\273\223.md"
@@ -0,0 +1,189 @@
+---
+title: 设计模式学习总结
+date: 2018-07-09 23:05:07
+tags:
+ - 设计模式
+categories:
+ - 后端
+ - 技术总结
+---
+设计模式基础学习总结
+这篇总结主要是基于我之前设计模式基础系列文章而形成的的。主要是把重要的知识点用自己的话说了一遍,可能会有一些错误,还望见谅和指点。谢谢
+
+更多详细内容可以查看我的专栏文章:设计模式学习
+https://blog.csdn.net/a724888/article/category/6780980
+
+
+# 设计模式
+
+# 创建型模式
+
+创建型模式
+创建型模式的作用就是创建对象,说到创建一个对象,最熟悉的就是 new 一个对象,然后 set 相关属性。但是,在很多场景下,我们需要给客户端提供更加友好的创建对象的方式,尤其是那种我们定义了类,但是需要提供给其他开发者用的时候。
+
+## 单例
+
+ 单例模式保证全局的单例类只有一个实例,这样的话使用的时候直接获取即可,比如数据库的一个连接,Spring里的bean,都可以是单例的。
+
+ 单例模式一般有5种写法。
+
+ 第一种是饿汉模式,先把单例进行实例化,获取的时候通过静态方法直接获取即可。缺点是类加载后就完成了类的实例化,浪费部分空间。
+
+ 第二种是饱汉模式,先把单例置为null,然后通过静态方法获取单例时再进行实例化,但是可能有多线程同时进行实例化,会出现并发问题。
+
+ 第三种是逐步改进的方法,一开始可以用synchronized关键字进行同步,但是开销太大,而后改成使用volatile修饰单例,然后通过一次检查判断单例是否已初始化,如果未初始化就使用synchronized代码块,再次检查单例防止在这期间被初始化,而后才真正进行初始化。
+
+ 第四种是使用静态内部类来实现,静态内部类只在被使用的时候才进行初始化,所以在内部类中进行单例的实例化,只有用到的时候才会运行实例化代码。然后外部类再通过静态方法返回静态内部类的单例即可。
+
+ 第五种是枚举类,枚举类的底层实现其实也是内部类。枚举类确保每个类对象在全局是唯一的。所以保证它是单例,这个方法是最简单的。
+
+## 工厂模式
+
+ 简单工厂一般是用一个工厂创建多个类的实例。
+
+ 工厂模式一般是指一个工厂服务一个接口,为这个接口的实现类进行实例化
+
+ 抽象工厂模式是指一个工厂服务于一个产品族,一个产品族可能包含多个接口,接口又会包含多个实现类,通过一个工厂就可以把这些绑定在一起,非常方便。
+
+## 原型模式
+
+ 一般通过一个实例进行克隆从而获得更多同一原型的实例。使用实例的clone方法即可完成。
+
+## 建造者模式
+
+ 建造者模式中有一个概念叫做链式调用,链式调用为一个类的实例化提供便利,一般提供系列的方法进行实例化,实际上就是将set方法改造一下,将原本返回为空的set方法改为返回this实例,从而实现链式调用。
+
+ 建造者模式在此基础上加入了builder方法,提供给外部进行调用,同样使用链式调用来完成参数注入。
+
+# 结构型模式
+
+
+结构型模式
+前面创建型模式介绍了创建对象的一些设计模式,这节介绍的结构型模式旨在通过改变代码结构来达到解耦的目的,使得我们的代码容易维护和扩展。
+
+## 桥接模式
+
+有点复杂。建议参考原文
+
+## 适配器模式
+
+适配器模式用于将两个不同的类进行适配。
+
+适配器模式和代理模式的异同
+
+ 比较这两种模式,其实是比较对象适配器模式和代理模式,在代码结构上,
+ 它们很相似,都需要一个具体的实现类的实例。
+ 但是它们的目的不一样,代理模式做的是增强原方法的活;
+ 适配器做的是适配的活,为的是提供“把鸡包装成鸭,然后当做鸭来使用”,
+ 而鸡和鸭它们之间原本没有继承关系。
+
+ 适配器模式可以分为类适配器,对象适配器等。
+
+ 类适配器通过继承父类就可以把自己适配成父类了。
+ 而对象适配器则需要把对象传入另一个对象的构造方法中,以便进行包装。
+
+## 享元模式
+
+/ 享元模式的核心在于享元工厂类,
+// 享元工厂类的作用在于提供一个用于存储享元对象的享元池,
+// 用户需要对象时,首先从享元池中获取,
+// 如果享元池中不存在,则创建一个新的享元对象返回给用户,
+// 在享元池中保存该新增对象。
+
+//享元模式
+// 英文是 Flyweight Pattern,不知道是谁最先翻译的这个词,感觉这翻译真的不好理解,我们试着强行关联起来吧。Flyweight 是轻量级的意思,享元分开来说就是 共享 元器件,也就是复用已经生成的对象,这种做法当然也就是轻量级的了。
+//
+// 复用对象最简单的方式是,用一个 HashMap 来存放每次新生成的对象。每次需要一个对象的时候,先到 HashMap 中看看有没有,如果没有,再生成新的对象,然后将这个对象放入 HashMap 中。
+//
+// 这种简单的代码我就不演示了。
+
+## 代理模式
+
+// 我们发现没有,代理模式说白了就是做 “方法包装” 或做 “方法增强”。
+// 在面向切面编程中,算了还是不要吹捧这个名词了,在 AOP 中,
+// 其实就是动态代理的过程。比如 Spring 中,
+// 我们自己不定义代理类,但是 Spring 会帮我们动态来定义代理,
+// 然后把我们定义在 @Before、@After、@Around 中的代码逻辑动态添加到代理中。
+
+## 外观模式
+
+外观模式一般封装具体的实现细节,为用户提供一个更加简单的接口。
+
+通过一个方法调用就可以获取需要的内容。
+
+## 组合模式
+
+//组合模式用于表示具有层次结构的数据,使得我们对单个对象和组合对象的访问具有一致性。
+
+//直接看一个例子吧,每个员工都有姓名、部门、薪水这些属性,
+// 同时还有下属员工集合(虽然可能集合为空),
+// 而下属员工和自己的结构是一样的,
+// 也有姓名、部门这些属性,
+// 同时也有他们的下属员工集合。
+
+ class Employee {
+ private String name;
+ private String dept;
+ private int salary;
+ private List subordinates; // 下属
+ }
+
+## 装饰者模式
+
+## 装饰者
+装饰者模式把每个增强类都继承最高级父类。然后需要功能增强时把类实例传入增强类即可,然后增强类在使用时就可以增强原有类的功能了。
+
+和代理模式不同的是,装饰者模式每个装饰类都继承父类,并且可以进行多级封装。
+
+
+# 行为型模式
+
+行为型模式
+行为型模式关注的是各个类之间的相互作用,将职责划分清楚,使得我们的代码更加地清晰。
+
+## 策略模式
+
+策略模式一般把一个策略作为一个类,并且在需要指定策略的时候传入实例,于是我们可以在需要使用算法的地方传入指定算法。
+
+## 命令模式
+
+命令模式一般分为命令发起者,命令以及命令接受者三个角色。
+
+命令发起者在使用时需要注入命令实例。然后执行命令调用。
+
+命令调用实际上会调用命令接收者的方法进行实际调用。
+
+比如遥控器按钮相当于一条命令,点击按钮时命令运行,自动调用电视机提供的方法即可。
+
+## 模板方法模式
+
+模板方法一般指提供了一个方法模板,并且其中有部分实现类和部分抽象类,并且规定了执行顺序。
+
+实现类是模板提供好的方法。而抽象类则需要用户自行实现。
+
+模板方法规定了一个模板中方法的执行顺序,非常适合一些开发框架,于是模板方法也广泛运用在开源框架中。
+
+## 状态模式
+
+少见。
+
+## 观察者模式和事件监听机制
+
+观察者模式一般用于订阅者和消息发布者之间的数据订阅。
+
+一般分为观察者和主题,观察者订阅主题,把实例注册到主题维护的观察者列表上。
+
+而主题更新数据时自动把数据推给观察者或者通知观察者数据已经更新。
+
+但是由于这样的方式消息推送耦合关系比较紧。并且很难在不打开数据的情况下知道数据类型是什么。
+
+知道后来为了使数据格式更加灵活,使用了事件和事件监听器的模式,事件包装的事件类型和事件数据,从主题和观察者中解耦。
+
+主题当事件发生时,触发该事件的所有监听器,把该事件通过监听器列表发给每个监听器,监听得到事件以后,首先根据自己支持处理的事件类型中找到对应的事件处理器,再用处理器处理对应事件。
+
+
+
+## 责任链模式
+
+责任链通常需要先建立一个单向链表,然后调用方只需要调用头部节点就可以了,后面会自动流转下去。比如流程审批就是一个很好的例子,只要终端用户提交申请,根据申请的内容信息,自动建立一条责任链,然后就可以开始流转了。
+
From 96cca0ac09726f15a2c19732aa655fda3f738739 Mon Sep 17 00:00:00 2001
From: How_2_Play_Life <362294931@qq.com>
Date: Mon, 9 Jul 2018 23:16:24 +0800
Subject: [PATCH 21/23] Update README.md
---
README.md | 5 +++--
1 file changed, 3 insertions(+), 2 deletions(-)
diff --git a/README.md b/README.md
index f7b1daf..4bb6502 100644
--- a/README.md
+++ b/README.md
@@ -4,13 +4,13 @@
## 算法 :pencil2:
-> [Mysql原理与实践总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/Mysql%E5%8E%9F%E7%90%86%E4%B8%8E%E5%AE%9E%E8%B7%B5%E6%80%BB%E7%BB%93.md)
+> [剑指offer算法总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/%E5%89%91%E6%8C%87offer.md)
## 操作系统 :computer:
> [操作系统学习总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/%E6%93%8D%E4%BD%9C%E7%B3%BB%E7%BB%9F%E5%AD%A6%E4%B9%A0%E6%80%BB%E7%BB%93.md)
-> [Mysql原理与实践总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/Mysql%E5%8E%9F%E7%90%86%E4%B8%8E%E5%AE%9E%E8%B7%B5%E6%80%BB%E7%BB%93.md)
+> [Linux内核与基础命令学习总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/Linux%E5%86%85%E6%A0%B8%E4%B8%8E%E5%9F%BA%E7%A1%80%E5%91%BD%E4%BB%A4%E5%AD%A6%E4%B9%A0%E6%80%BB%E7%BB%93.md)
## 网络 :cloud:
@@ -47,6 +47,7 @@
> [分布式技术学习总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/%E5%88%86%E5%B8%83%E5%BC%8F%E6%8A%80%E6%9C%AF%E5%AE%9E%E8%B7%B5%E6%80%BB%E7%BB%93.md)
## 设计模式 :hammer:
+> [设计模式学习总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/%E8%AE%BE%E8%AE%A1%E6%A8%A1%E5%BC%8F%E5%AD%A6%E4%B9%A0%E6%80%BB%E7%BB%93.md)
## Hadoop :speak_no_evil:
From 13b1e9dbfba8979140d913642de437e40ab108ee Mon Sep 17 00:00:00 2001
From: How_2_Play_Life <362294931@qq.com>
Date: Tue, 24 Jul 2018 18:14:08 +0800
Subject: [PATCH 22/23] Update README.md
---
README.md | 30 +++++++++++++++++++++++-------
1 file changed, 23 insertions(+), 7 deletions(-)
diff --git a/README.md b/README.md
index 4bb6502..ca8c799 100644
--- a/README.md
+++ b/README.md
@@ -1,3 +1,26 @@
+## 声明
+
+**关于仓库**
+
+本仓库是笔者在准备 2018 年秋招复习过程中的学习总结,内容以Java后端的知识总结为主,其中大部分都是笔者根据自己的理解总结而来的。
+
+其中有少数内容可能会包含瞎XX说,语句不通顺,内容不全面等各方面问题,还请见谅。
+
+每个部分都会有笔者更加详细的原创文章可供参考,这些文章也被我发表在CSDN技术博客上,整理成博客专栏,欢迎查看━(*`∀´*)ノ亻!
+
+具体内容请见我的CSDN技术博客:https://blog.csdn.net/a724888
+
+也可以来我个人技术小站逛逛:https://h2pl.github.io/
+
+**关于转载**
+
+转载的时候请注明一下出处就行啦。
+
+另外我这个仓库的格式模仿的是@CyC2018 大佬的仓库
+
+并且其中一篇LeetCode刷题指南也是fork这位大佬而来的。我只是自己刷了一遍然后稍微加了一些解析,站在大佬肩膀上。
+
+
| Ⅰ | Ⅱ | Ⅲ | Ⅳ | Ⅴ | Ⅵ | Ⅶ | Ⅷ | Ⅸ |
| :------: | :---------: | :-------: | :---------: | :---: | :---------:| :---------: | :---------: | :---------:|
| 算法[:pencil2:](#算法-pencil2) | 操作系统[:computer:](#操作系统-computer)|网络[:cloud:](#网络-cloud) | 数据库[:floppy_disk:](#数据库-floppy_disk)| Java[:couple:](#Java-couple) |JavaWeb [:coffee:](#JavaWeb-coffee)| 分布式 [:sweat_drops:](#分布式-sweat_drops)| 设计模式[:hammer:](#设计模式-hammer)| Hadoop[:speak_no_evil:](#Hadoop-speak_no_evil)|
@@ -55,13 +78,6 @@
-## 后记
-
-**关于仓库**
-本仓库是笔者在准备 2018 年秋招复习过程中的学习总结,内容以Java后端的知识总结为主,每个部分都会有笔者更加详细的原创文章可供参考,欢迎查看。
-
-**关于转载**
-本仓库内容使用到的资料都会在最后面的参考资料中给出引用链接,希望您在使用本仓库的内容时也能给出相应的引用链接。
From 4eca6dfa30c4a192a1bc49a3c6910a7d0daceece Mon Sep 17 00:00:00 2001
From: How_2_Play_Life <362294931@qq.com>
Date: Tue, 24 Jul 2018 18:23:21 +0800
Subject: [PATCH 23/23] Update README.md
---
README.md | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git a/README.md b/README.md
index ca8c799..04868b6 100644
--- a/README.md
+++ b/README.md
@@ -2,11 +2,11 @@
**关于仓库**
-本仓库是笔者在准备 2018 年秋招复习过程中的学习总结,内容以Java后端的知识总结为主,其中大部分都是笔者根据自己的理解总结而来的。
+本仓库是笔者在准备 2018 年秋招复习过程中的学习总结,内容以Java后端的知识总结为主,其中大部分都是笔者根据自己的理解加上个人博客总结而来的。
其中有少数内容可能会包含瞎XX说,语句不通顺,内容不全面等各方面问题,还请见谅。
-每个部分都会有笔者更加详细的原创文章可供参考,这些文章也被我发表在CSDN技术博客上,整理成博客专栏,欢迎查看━(*`∀´*)ノ亻!
+每篇文章都会有笔者更加详细的一系列博客可供参考,这些文章也被我发表在CSDN技术博客上,整理成博客专栏,欢迎查看━(*`∀´*)ノ亻!
具体内容请见我的CSDN技术博客:https://blog.csdn.net/a724888