From 921213d5c64fc867b3ceead2ba5c3137b1fff943 Mon Sep 17 00:00:00 2001
From: How_2_Play_Life <362294931@qq.com>
Date: Tue, 1 May 2018 16:10:20 +0000
Subject: [PATCH 01/16] Create README.md
---
README.md | 27 +++++++++++++++++++++++++++
1 file changed, 27 insertions(+)
create mode 100644 README.md
diff --git a/README.md b/README.md
new file mode 100644
index 0000000..dd4fadd
--- /dev/null
+++ b/README.md
@@ -0,0 +1,27 @@
+| [数据结构和算法](#算法) | [操作系统](#操作系统) | [网络](#网络) | [数据结构](#数据结构) | [数据库](#数据库) | [Java基础](#Java基础) | [Java进阶](#Java进阶) | [Web和Spring](#Web和Spring) | [分布式](#分布式) | [Hadoop](#Hadoop) | [工具](#工具) | [编码实践](#编码实践) |
+
+## 数据结构和算法
+## 操作系统
+## 网络
+## 数据库
+## Java基础
+## Java进阶
+## web和Spring
+## 分布式
+## Hadoop
+## 工具
+## 编码实践
+
+## 后记
+**关于仓库**
+本仓库是笔者在准备 2018 年秋招复习过程中的学习总结,内容以Java后端的知识总结为主,每个部分都会有笔者更加详细的原创文章可供参考,欢迎查看。
+**关于贡献**
+笔者能力有限,很多内容还不够完善。如果您希望和笔者一起完善这个仓库,可以发表一个 Issue,表明您想要添加的内容,笔者会及时查看。
+您也可以在 Issues 中发表关于改进本仓库的建议。
+**关于排版**
+笔记排版参考@CYC2018
+**关于转载**
+本仓库内容使用到的资料都会在最后面的参考资料中给出引用链接,希望您在使用本仓库的内容时也能给出相应的引用链接。
+**鸣谢**
+[CyC2018](https://github.com/CyC2018)
+
From 9dcbb9eb24b0bfacbf7f3cab36a743593c558b82 Mon Sep 17 00:00:00 2001
From: How_2_Play_Life <362294931@qq.com>
Date: Tue, 1 May 2018 16:10:52 +0000
Subject: [PATCH 02/16] Update README.md
---
README.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/README.md b/README.md
index dd4fadd..9a81fc5 100644
--- a/README.md
+++ b/README.md
@@ -1,4 +1,4 @@
-| [数据结构和算法](#算法) | [操作系统](#操作系统) | [网络](#网络) | [数据结构](#数据结构) | [数据库](#数据库) | [Java基础](#Java基础) | [Java进阶](#Java进阶) | [Web和Spring](#Web和Spring) | [分布式](#分布式) | [Hadoop](#Hadoop) | [工具](#工具) | [编码实践](#编码实践) |
+[数据结构和算法](#算法) | [操作系统](#操作系统) | [网络](#网络) | [数据结构](#数据结构) | [数据库](#数据库) | [Java基础](#Java基础) | [Java进阶](#Java进阶) | [Web和Spring](#Web和Spring) | [分布式](#分布式) | [Hadoop](#Hadoop) | [工具](#工具) | [编码实践](#编码实践)
## 数据结构和算法
## 操作系统
From 9fa55dfe65870c82d6b29f2c655a92181b4d1ba4 Mon Sep 17 00:00:00 2001
From: How_2_Play_Life <362294931@qq.com>
Date: Wed, 2 May 2018 01:45:26 +0000
Subject: [PATCH 03/16] Update README.md
---
README.md | 4 ++++
1 file changed, 4 insertions(+)
diff --git a/README.md b/README.md
index 9a81fc5..fb72617 100644
--- a/README.md
+++ b/README.md
@@ -15,13 +15,17 @@
## 后记
**关于仓库**
本仓库是笔者在准备 2018 年秋招复习过程中的学习总结,内容以Java后端的知识总结为主,每个部分都会有笔者更加详细的原创文章可供参考,欢迎查看。
+
**关于贡献**
笔者能力有限,很多内容还不够完善。如果您希望和笔者一起完善这个仓库,可以发表一个 Issue,表明您想要添加的内容,笔者会及时查看。
您也可以在 Issues 中发表关于改进本仓库的建议。
+
**关于排版**
笔记排版参考@CYC2018
+
**关于转载**
本仓库内容使用到的资料都会在最后面的参考资料中给出引用链接,希望您在使用本仓库的内容时也能给出相应的引用链接。
+
**鸣谢**
[CyC2018](https://github.com/CyC2018)
From 318edbfd4847a1b395115ff524349c4fc648b37e Mon Sep 17 00:00:00 2001
From: How_2_Play_Life <362294931@qq.com>
Date: Tue, 26 Jun 2018 18:26:49 +0800
Subject: [PATCH 04/16] Update README.md
---
README.md | 42 ++++++++++++++++++++++++------------------
1 file changed, 24 insertions(+), 18 deletions(-)
diff --git a/README.md b/README.md
index fb72617..b47b340 100644
--- a/README.md
+++ b/README.md
@@ -1,31 +1,37 @@
[数据结构和算法](#算法) | [操作系统](#操作系统) | [网络](#网络) | [数据结构](#数据结构) | [数据库](#数据库) | [Java基础](#Java基础) | [Java进阶](#Java进阶) | [Web和Spring](#Web和Spring) | [分布式](#分布式) | [Hadoop](#Hadoop) | [工具](#工具) | [编码实践](#编码实践)
## 数据结构和算法
+
## 操作系统
-## 网络
-## 数据库
-## Java基础
-## Java进阶
-## web和Spring
-## 分布式
-## Hadoop
-## 工具
-## 编码实践
+
+## 计算机网络
+
+## Mysql和Redis
+
+## Java核心技术
+
+## Java并发编程
+
+## 深入理解JVM
+
+## Java网络编程与NIO
+
+## JavaWeb技术世界
+
+## Spring与SpirngMVC
+
+## 分布式系统理论
+
+## 分布式技术与实践
+
+## Hadoop生态
+
## 后记
**关于仓库**
本仓库是笔者在准备 2018 年秋招复习过程中的学习总结,内容以Java后端的知识总结为主,每个部分都会有笔者更加详细的原创文章可供参考,欢迎查看。
-**关于贡献**
-笔者能力有限,很多内容还不够完善。如果您希望和笔者一起完善这个仓库,可以发表一个 Issue,表明您想要添加的内容,笔者会及时查看。
-您也可以在 Issues 中发表关于改进本仓库的建议。
-
-**关于排版**
-笔记排版参考@CYC2018
-
**关于转载**
本仓库内容使用到的资料都会在最后面的参考资料中给出引用链接,希望您在使用本仓库的内容时也能给出相应的引用链接。
-**鸣谢**
-[CyC2018](https://github.com/CyC2018)
From 39c20d13f8c7c4de94591ecff0aaf96413cbd33f Mon Sep 17 00:00:00 2001
From: How_2_Play_Life <362294931@qq.com>
Date: Tue, 26 Jun 2018 18:33:30 +0800
Subject: [PATCH 05/16] Update README.md
---
README.md | 17 +++++++++++++++--
1 file changed, 15 insertions(+), 2 deletions(-)
diff --git a/README.md b/README.md
index b47b340..0a4f506 100644
--- a/README.md
+++ b/README.md
@@ -1,4 +1,17 @@
-[数据结构和算法](#算法) | [操作系统](#操作系统) | [网络](#网络) | [数据结构](#数据结构) | [数据库](#数据库) | [Java基础](#Java基础) | [Java进阶](#Java进阶) | [Web和Spring](#Web和Spring) | [分布式](#分布式) | [Hadoop](#Hadoop) | [工具](#工具) | [编码实践](#编码实践)
+[数据结构和算法](#算法)
+[操作系统](#操作系统)
+[计算机网络](#计算机网络)
+[Mysql和Redis](#Mysql和Redis)
+[Java核心技术](#Java核心技术)
+[Java并发技术](#Java并发技术)
+[深入理解JVM](#深入理解JVM)
+[Java网络编程与NIO](#Java网络编程与NIO)
+[JavaWeb技术世界](#JavaWeb技术世界)
+[Spring与SpirngMVC](#Spring与SpirngMVC)
+[分布式系统理论](#分布式系统理论)
+[分布式技术与实践](#分布式技术与实践)
+[Hadoop生态](#Hadoop生态)
+
## 数据结构和算法
@@ -10,7 +23,7 @@
## Java核心技术
-## Java并发编程
+## Java并发技术
## 深入理解JVM
From de37fa024c0ab227f6c025ac37bfb95ded8f7396 Mon Sep 17 00:00:00 2001
From: How_2_Play_Life <362294931@qq.com>
Date: Tue, 26 Jun 2018 18:34:24 +0800
Subject: [PATCH 06/16] Update README.md
---
README.md | 16 ++++++++++++++--
1 file changed, 14 insertions(+), 2 deletions(-)
diff --git a/README.md b/README.md
index 0a4f506..3baa901 100644
--- a/README.md
+++ b/README.md
@@ -1,15 +1,27 @@
-[数据结构和算法](#算法)
+[数据结构和算法](#数据结构和算法)
+
[操作系统](#操作系统)
+
[计算机网络](#计算机网络)
+
[Mysql和Redis](#Mysql和Redis)
+
[Java核心技术](#Java核心技术)
+
[Java并发技术](#Java并发技术)
+
[深入理解JVM](#深入理解JVM)
+
[Java网络编程与NIO](#Java网络编程与NIO)
+
[JavaWeb技术世界](#JavaWeb技术世界)
+
[Spring与SpirngMVC](#Spring与SpirngMVC)
+
[分布式系统理论](#分布式系统理论)
+
[分布式技术与实践](#分布式技术与实践)
+
[Hadoop生态](#Hadoop生态)
@@ -39,8 +51,8 @@
## Hadoop生态
-
## 后记
+
**关于仓库**
本仓库是笔者在准备 2018 年秋招复习过程中的学习总结,内容以Java后端的知识总结为主,每个部分都会有笔者更加详细的原创文章可供参考,欢迎查看。
From 64f93ab4603794e01039ff410e323791ad789605 Mon Sep 17 00:00:00 2001
From: How_2_Play_Life <362294931@qq.com>
Date: Tue, 26 Jun 2018 18:34:49 +0800
Subject: [PATCH 07/16] Update README.md
---
README.md | 1 +
1 file changed, 1 insertion(+)
diff --git a/README.md b/README.md
index 3baa901..fe93b5d 100644
--- a/README.md
+++ b/README.md
@@ -25,6 +25,7 @@
[Hadoop生态](#Hadoop生态)
+
## 数据结构和算法
## 操作系统
From e55a2e8f3cf36ee81e95f5ff1c74d6f0c5b08b63 Mon Sep 17 00:00:00 2001
From: How_2_Play_Life <362294931@qq.com>
Date: Sun, 8 Jul 2018 21:34:38 +0800
Subject: [PATCH 08/16] Update README.md
---
README.md | 7 +++++++
1 file changed, 7 insertions(+)
diff --git a/README.md b/README.md
index fe93b5d..66e34aa 100644
--- a/README.md
+++ b/README.md
@@ -1,3 +1,10 @@
+
+| Ⅰ | Ⅱ | Ⅲ | Ⅳ | Ⅴ | Ⅵ | Ⅶ | Ⅷ | Ⅸ | Ⅹ |
+| :--------: | :---------: | :---------: | :---------: | :---------: | :---------:| :---------: | :-------: | :-------:| :------:|
+| 算法[:pencil2:](#算法-pencil2) | 操作系统[:computer:](#操作系统-computer)|网络[:cloud:](#网络-cloud) | 面向对象[:couple:](#面向对象-couple) |数据库[:floppy_disk:](#数据库-floppy_disk)| Java [:coffee:](#java-coffee)| 分布式 [:sweat_drops:](#分布式-sweat_drops)| 工具[:hammer:](#工具-hammer)| 编码实践[:speak_no_evil:](#编码实践-speak_no_evil)| 后记[:memo:](#后记-memo) |
+
+## 算法 :pencil2:
+
[数据结构和算法](#数据结构和算法)
[操作系统](#操作系统)
From e99c41adcd00e589298cbd974f6d51ab15b884b5 Mon Sep 17 00:00:00 2001
From: How_2_Play_Life <362294931@qq.com>
Date: Sun, 8 Jul 2018 21:48:38 +0800
Subject: [PATCH 09/16] Update README.md
---
README.md | 56 ++++++++++---------------------------------------------
1 file changed, 10 insertions(+), 46 deletions(-)
diff --git a/README.md b/README.md
index 66e34aa..0f9929a 100644
--- a/README.md
+++ b/README.md
@@ -1,64 +1,28 @@
| Ⅰ | Ⅱ | Ⅲ | Ⅳ | Ⅴ | Ⅵ | Ⅶ | Ⅷ | Ⅸ | Ⅹ |
| :--------: | :---------: | :---------: | :---------: | :---------: | :---------:| :---------: | :-------: | :-------:| :------:|
-| 算法[:pencil2:](#算法-pencil2) | 操作系统[:computer:](#操作系统-computer)|网络[:cloud:](#网络-cloud) | 面向对象[:couple:](#面向对象-couple) |数据库[:floppy_disk:](#数据库-floppy_disk)| Java [:coffee:](#java-coffee)| 分布式 [:sweat_drops:](#分布式-sweat_drops)| 工具[:hammer:](#工具-hammer)| 编码实践[:speak_no_evil:](#编码实践-speak_no_evil)| 后记[:memo:](#后记-memo) |
+| 数据结构和算法[:pencil2:](#数据结构和算法-pencil2) | 操作系统[:computer:](#操作系统-computer)|网络[:cloud:](#网络-cloud) | 数据库[:floppy_disk:](#数据库-floppy_disk)| Java[:couple:](#Java-couple) |JavaWeb [:coffee:](#JavaWeb-coffee)| 分布式 [:sweat_drops:](#分布式-sweat_drops)| 设计模式[:hammer:](#设计模式-hammer)| Hadoop[:speak_no_evil:](#Hadoop-speak_no_evil)| 后记[:memo:](#后记-memo) |
-## 算法 :pencil2:
+## 数据结构和算法 :pencil2:
-[数据结构和算法](#数据结构和算法)
+## 操作系统 :computer:
-[操作系统](#操作系统)
+## 网络 :cloud:
-[计算机网络](#计算机网络)
+## 数据库 :floppy_disk:
-[Mysql和Redis](#Mysql和Redis)
+## Java :couple:
-[Java核心技术](#Java核心技术)
+## JavaWeb :coffee:
-[Java并发技术](#Java并发技术)
+## 分布式 :sweat_drops:
-[深入理解JVM](#深入理解JVM)
+## 设计模式 :hammer:
-[Java网络编程与NIO](#Java网络编程与NIO)
-
-[JavaWeb技术世界](#JavaWeb技术世界)
-
-[Spring与SpirngMVC](#Spring与SpirngMVC)
-
-[分布式系统理论](#分布式系统理论)
-
-[分布式技术与实践](#分布式技术与实践)
-
-[Hadoop生态](#Hadoop生态)
+## Hadoop :speak_no_evil:
-## 数据结构和算法
-
-## 操作系统
-
-## 计算机网络
-
-## Mysql和Redis
-
-## Java核心技术
-
-## Java并发技术
-
-## 深入理解JVM
-
-## Java网络编程与NIO
-
-## JavaWeb技术世界
-
-## Spring与SpirngMVC
-
-## 分布式系统理论
-
-## 分布式技术与实践
-
-## Hadoop生态
-
## 后记
**关于仓库**
From 1fb6944979b6941d8b449a58d71ba433867cbd25 Mon Sep 17 00:00:00 2001
From: How_2_Play_Life <362294931@qq.com>
Date: Sun, 8 Jul 2018 21:50:11 +0800
Subject: [PATCH 10/16] Update README.md
---
README.md | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git a/README.md b/README.md
index 0f9929a..0d1dff1 100644
--- a/README.md
+++ b/README.md
@@ -1,9 +1,9 @@
| Ⅰ | Ⅱ | Ⅲ | Ⅳ | Ⅴ | Ⅵ | Ⅶ | Ⅷ | Ⅸ | Ⅹ |
| :--------: | :---------: | :---------: | :---------: | :---------: | :---------:| :---------: | :-------: | :-------:| :------:|
-| 数据结构和算法[:pencil2:](#数据结构和算法-pencil2) | 操作系统[:computer:](#操作系统-computer)|网络[:cloud:](#网络-cloud) | 数据库[:floppy_disk:](#数据库-floppy_disk)| Java[:couple:](#Java-couple) |JavaWeb [:coffee:](#JavaWeb-coffee)| 分布式 [:sweat_drops:](#分布式-sweat_drops)| 设计模式[:hammer:](#设计模式-hammer)| Hadoop[:speak_no_evil:](#Hadoop-speak_no_evil)| 后记[:memo:](#后记-memo) |
+| 算法[:pencil2:](#算法-pencil2) | 操作系统[:computer:](#操作系统-computer)|网络[:cloud:](#网络-cloud) | 数据库[:floppy_disk:](#数据库-floppy_disk)| Java[:couple:](#Java-couple) |JavaWeb [:coffee:](#JavaWeb-coffee)| 分布式 [:sweat_drops:](#分布式-sweat_drops)| 设计模式[:hammer:](#设计模式-hammer)| Hadoop[:speak_no_evil:](#Hadoop-speak_no_evil)| 后记[:memo:](#后记-memo) |
-## 数据结构和算法 :pencil2:
+## 算法 :pencil2:
## 操作系统 :computer:
From 7d19c1b1fc3cec1d0b6436fd0cc1c1efcbc84d6f Mon Sep 17 00:00:00 2001
From: How_2_Play_Life <362294931@qq.com>
Date: Sun, 8 Jul 2018 21:52:23 +0800
Subject: [PATCH 11/16] Update README.md
---
README.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/README.md b/README.md
index 0d1dff1..be7450b 100644
--- a/README.md
+++ b/README.md
@@ -1,6 +1,6 @@
| Ⅰ | Ⅱ | Ⅲ | Ⅳ | Ⅴ | Ⅵ | Ⅶ | Ⅷ | Ⅸ | Ⅹ |
-| :--------: | :---------: | :---------: | :---------: | :---------: | :---------:| :---------: | :-------: | :-------:| :------:|
+| :--------: | :---------: | :---------: | :---------: | :---------: | :---------:| :---------: | :---------: | :---------:| :------:|
| 算法[:pencil2:](#算法-pencil2) | 操作系统[:computer:](#操作系统-computer)|网络[:cloud:](#网络-cloud) | 数据库[:floppy_disk:](#数据库-floppy_disk)| Java[:couple:](#Java-couple) |JavaWeb [:coffee:](#JavaWeb-coffee)| 分布式 [:sweat_drops:](#分布式-sweat_drops)| 设计模式[:hammer:](#设计模式-hammer)| Hadoop[:speak_no_evil:](#Hadoop-speak_no_evil)| 后记[:memo:](#后记-memo) |
## 算法 :pencil2:
From 20de38c9425716bbbe1ac44557de04f135cd87ac Mon Sep 17 00:00:00 2001
From: How_2_Play_Life <362294931@qq.com>
Date: Sun, 8 Jul 2018 21:55:31 +0800
Subject: [PATCH 12/16] Update README.md
---
README.md | 7 +++----
1 file changed, 3 insertions(+), 4 deletions(-)
diff --git a/README.md b/README.md
index be7450b..250a91f 100644
--- a/README.md
+++ b/README.md
@@ -1,7 +1,6 @@
-
-| Ⅰ | Ⅱ | Ⅲ | Ⅳ | Ⅴ | Ⅵ | Ⅶ | Ⅷ | Ⅸ | Ⅹ |
-| :--------: | :---------: | :---------: | :---------: | :---------: | :---------:| :---------: | :---------: | :---------:| :------:|
-| 算法[:pencil2:](#算法-pencil2) | 操作系统[:computer:](#操作系统-computer)|网络[:cloud:](#网络-cloud) | 数据库[:floppy_disk:](#数据库-floppy_disk)| Java[:couple:](#Java-couple) |JavaWeb [:coffee:](#JavaWeb-coffee)| 分布式 [:sweat_drops:](#分布式-sweat_drops)| 设计模式[:hammer:](#设计模式-hammer)| Hadoop[:speak_no_evil:](#Hadoop-speak_no_evil)| 后记[:memo:](#后记-memo) |
+| Ⅰ | Ⅱ | Ⅲ | Ⅳ | Ⅴ | Ⅵ | Ⅶ | Ⅷ | Ⅸ |
+| :------: | :---------: | :-------: | :---------: | :---: | :---------:| :---------: | :---------: | :---------:|
+| 算法[:pencil2:](#算法-pencil2) | 操作系统[:computer:](#操作系统-computer)|网络[:cloud:](#网络-cloud) | 数据库[:floppy_disk:](#数据库-floppy_disk)| Java[:couple:](#Java-couple) |JavaWeb [:coffee:](#JavaWeb-coffee)| 分布式 [:sweat_drops:](#分布式-sweat_drops)| 设计模式[:hammer:](#设计模式-hammer)| Hadoop[:speak_no_evil:](#Hadoop-speak_no_evil)|
## 算法 :pencil2:
From 5f614f3d7b42ba9bdcb0b087dd60ad1064f70680 Mon Sep 17 00:00:00 2001
From: 724888 <362294931@qq.com>
Date: Sun, 8 Jul 2018 22:35:38 +0800
Subject: [PATCH 13/16] =?UTF-8?q?=E6=8A=80=E6=9C=AF=E6=80=BB=E7=BB=93?=
=?UTF-8?q?=E6=96=87=E7=AB=A0=E4=B8=8A=E4=BC=A0?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
...37\346\200\201\346\200\273\347\273\223.md" | 248 +++++++++
"md/JVM\346\200\273\347\273\223.md" | 135 +++++
...00\346\234\257\346\200\273\347\273\223.md" | 116 +++++
...66\345\217\221\346\200\273\347\273\223.md" | 206 ++++++++
...00\346\234\257\346\200\273\347\273\223.md" | 136 +++++
...344\270\216NIO\346\200\273\347\273\223.md" | 213 ++++++++
...10\347\261\273\346\200\273\347\273\223.md" | 108 ++++
...36\350\267\265\346\200\273\347\273\223.md" | 345 +++++++++++++
md/README.md | 27 +
...36\350\267\265\346\200\273\347\273\223.md" | 429 ++++++++++++++++
...43\346\236\220\346\200\273\347\273\223.md" | 87 ++++
...36\350\267\265\346\200\273\347\273\223.md" | 474 ++++++++++++++++++
...06\350\256\272\346\200\273\347\273\223.md" | 355 +++++++++++++
13 files changed, 2879 insertions(+)
create mode 100644 "md/Hadoop\347\224\237\346\200\201\346\200\273\347\273\223.md"
create mode 100644 "md/JVM\346\200\273\347\273\223.md"
create mode 100644 "md/JavaWeb\346\212\200\346\234\257\346\200\273\347\273\223.md"
create mode 100644 "md/Java\345\271\266\345\217\221\346\200\273\347\273\223.md"
create mode 100644 "md/Java\346\240\270\345\277\203\346\212\200\346\234\257\346\200\273\347\273\223.md"
create mode 100644 "md/Java\347\275\221\347\273\234\344\270\216NIO\346\200\273\347\273\223.md"
create mode 100644 "md/Java\351\233\206\345\220\210\347\261\273\346\200\273\347\273\223.md"
create mode 100644 "md/Mysql\345\216\237\347\220\206\344\270\216\345\256\236\350\267\265\346\200\273\347\273\223.md"
create mode 100644 md/README.md
create mode 100644 "md/Redis\345\216\237\347\220\206\344\270\216\345\256\236\350\267\265\346\200\273\347\273\223.md"
create mode 100644 "md/Spring\344\270\216SpringMVC\346\272\220\347\240\201\350\247\243\346\236\220\346\200\273\347\273\223.md"
create mode 100644 "md/\345\210\206\345\270\203\345\274\217\346\212\200\346\234\257\345\256\236\350\267\265\346\200\273\347\273\223.md"
create mode 100644 "md/\345\210\206\345\270\203\345\274\217\347\220\206\350\256\272\346\200\273\347\273\223.md"
diff --git "a/md/Hadoop\347\224\237\346\200\201\346\200\273\347\273\223.md" "b/md/Hadoop\347\224\237\346\200\201\346\200\273\347\273\223.md"
new file mode 100644
index 0000000..b71e6eb
--- /dev/null
+++ "b/md/Hadoop\347\224\237\346\200\201\346\200\273\347\273\223.md"
@@ -0,0 +1,248 @@
+---
+title: Hadoop生态学习总结
+date: 2018-07-08 22:15:53
+tags:
+ - Hadoop
+categories:
+ - 后端
+ - 技术总结
+---
+#Hadoop生态基础学习总结
+这篇总结主要是基于我之前Hadoop生态基础系列文章而形成的的。主要是把重要的知识点用自己的话说了一遍,可能会有一些错误,还望见谅和指点。谢谢
+
+#更多详细内容可以查看我的专栏文章:Hadoop生态学习
+#https://blog.csdn.net/a724888/article/category/7779280
+# Hadoop生态
+
+## hdfs
+
+### 架构
+hdfs是一个分布式文件系统。底层的存储采用廉价的磁盘阵列RAID,由于可以并发读写所以效率很高。
+
+基本架构是一个namenode和多个dataNode。node的意思是节点,一般指主机,也可以是虚拟机。
+
+每个文件都会有两个副本存放在datanode中。
+
+### 读写
+
+客户端写入文件时,先把请求发送到namenode,namenode会返回datanode的服务地址,接着客户端去访问datanode,进行文件写入,然后通知namenode,namenode接收到写入完成的消息以后,会另外选两个datanode存放冗余副本。
+
+读取文件时,从namenode获取一个datanode的地址,然后自己去读取即可。
+
+当一个文件的副本不足两份时,namenode自动会完成副本复制。并且,由于datanode一般会放在各个机架。namenode一般会把副本一个放在同一机架,一个放在其他机架,防止某个机架出问题导致整个文件读写不可用。
+
+### 高可用
+
+namenode节点是单点,所以宕机了就没救了,所以我们可以使用zookeeper来保证namenode的高可用。可以使用zookeeper选主来实现故障切换,namenode先注册一个节点在zk上,表示自己是主,宕机时zk会通知备份节点进行切换。
+
+Hadoop2.0中加入了hdfs namenode高可用的方案,也叫HDFS HA。namenode和一个备份节点绑定在一起,并且通过一个共享数据区域进行数据同步。同时支持故障切换。
+
+## MapReduce
+
+### 架构和流程
+
+MapReduce是基于Hadoop集群的分布式计算方案。一般先编写map函数进行数据分片,然后通过shuffle进行相同分片的整合,最后通过reduce把所有的数据结果进行整理。
+
+具体来说,用户提交一个MapReduce程序给namenode节点,namenode节点启动一个jobtracker进行子任务的调度和监控,然后派发每个子任务tasktracker到datanode进行任务执行,由于数据分布在各个节点,每个tasktracker只需要执行自己的那一部分即可。最后再将结果汇总给tasktracker。
+
+### wordcount
+
+首先是一个文本文件:hi hello good hello hi hi。
+三个节点,则进行三次map。hi hello,good hello,hi hi分别由三个节点处理。结果分别是hi 1 hello 1,good 1 hello 1,hi 1,hi 1。
+shuffle时进行combine操作,得到hi 1,hello 1,good 1 hello 1,hi 2。最终reduce的结果是hi 3 hello 2 good 1.
+
+## hive
+
+hive是一个基于hdfs文件系统的数据仓库。可以通过hive sql语句执行对hdfs上文件的数据查询。原理是hive把hdfs上的数据文件看成一张张数据表,把表结构信息存在关系数据库如mysql中。然后执行sql时通过对表结构的解析再去hdfs上查询真正的数据,最后也会以结构化的形式返回。
+
+## hbase
+
+### 简介
+
+hbase是基于列的数据库。
+
+他与传统关系数据库有很大不同。
+
+首先在表结构上,hbase使用rowkey行键作为唯一主键,通过行键唯一确定一行数据。
+
+同时,hbase使用列族的概念,每个表都有固定的列族,每一行的数据的列族都一样,但是每一行所在列族的实际列都可以不一样。
+比如列族是info,列可以是name age,也可以是sex address等。也就是说具体列可以在插入数据时再进行确认。
+
+并且,hbase的每一行数据还可以有多个版本,通过时间戳来表示不同的数据版本。
+### 存储
+
+一般情况下hbase使用hdfs作为底层存储,所以hdfs提供了数据的可靠性以及并发读写的高效率。
+
+hbase一个表的 每n行数据会存在一个region中,并且,对于列来说,每一个列族都会用一个region来存储,假设有m个列族,那么就会有n * m个region需要存储在hdfs上。
+
+同时hbase使用regionserver来管理这些region,他们可能存在不同的datanode里,所以通过regionserver可以找出每一个region的位置。
+
+hbase使用zookeeper来保证regionserver的高可用,会自动进行故障切换。
+
+## zk
+
+zk在Hadoop的作用有几个,通过选主等机制保证主节点高可用。
+
+使用zk进行配置资源的统一管理,保证服务器节点无状态,所有服务信息直接从zk获取即可。
+
+使用zookeeper进行节点间的通信等,也可以使用zk的目录顺序节点实现分布式锁,以及服务器选主。不仅在Hadoop中,zk在分布式系统中总能有用武之地。
+
+zookeeper本身的部署方式就是一个集群,一个master和多个slave。
+
+使用zab协议保证一致性和高可用。
+
+zab协议实现原理:
+
+1 使用两段式提交的方式确保一个协议需要半数以上节点同意以后再进行广播执行。
+
+2 使用基于机器编号加时间戳的id来表示每个事务,通过这个方式当初始选举或者主节点宕机时进行一轮选主,每个节点优先选择自己当主节点,在选举过程中节点优先采纳比较新的事务,将自己的选票更新,然后反馈个其他机器,最后当一个机器获得超过半数选票时当选为master。
+
+3选主结束以后,主节点与slave进行主从同步,保证数据一致性,然后对外提供服务,并且写入只能通过master而读取可以通过任意一台机器。
+
+## sqoop
+将hive表中的内容导入到MySQL数据库,也可以将MySQL中的数据导入hive中。
+
+## yarn
+
+没有yarn之前,hdfs使用jobtracker和tasktracker来执行和跟踪任务,jobtracker的任务太重,又要执行又要监控还要获取结果。
+并且不同机器的资源情况没有被考虑在内。
+
+yarn是一个资源调度系统。提供applicationmaster对一个调度任务进行封装,然后有一个resourcemanager专门负责各节点资源的管理和监控。同时nodemanager则运行每个节点中用于监控节点状态和向rm汇报。还有一个container则是对节点资源的一个抽象,applicationmaster任务将由节点上的一个container进行执行。rm会将他调度到最合适的机器上。
+## kafka
+
+架构
+
+> kafka是一个分布式的消息队列。
+>
+> 它组成一般包括kafka broker,每个broker中有多个的partition作为存储消息的队列。
+>
+> 并且向上提供服务时抽象为一个topic,我们访问topic时实际上执行的是对partition的写入和读取操作。
+
+
+读写和高可用
+
+> partition支持顺序写入,效率比较高,并且支持零拷贝机制,通过内存映射磁盘mmap的方式,写入partition的数据顺序写入到映射的磁盘中,比传统的IO要快。
+>
+> 由于partition可能会宕机,所以一般也要支持partition的备份,1个broker ,master通常会有多个
+> broker slave,是主从关系,通过zookeeper进行选主和故障切换。
+>
+> 当数据写入队列时,一般也会通过日志文件的方式进行数据备份,会把broker中的partition被分在各个slave中以便于均匀分布和恢复。
+
+生产者和消费者
+
+> 生产者消费者需要访问kafka的队列时,如果是写入,直接向zk发送请求,一般是向一个topic写入消息,broker会自动分配partition进行写入。然后zk会告诉生产者写入的partition所在的broker地址,然后进行写入。
+>
+> 如果是读取的话,也是通过zk获取partition所在位置,然后通过给定的offset进行读取,读取完后更新offset。
+>
+> 由于kafka的partition支持顺序读写。所以保证一个partition中的读取和写入时是顺序的,但是如果是多个partition则不保证顺序。
+>
+> 正常情况下kafka使用topic来实现消息点对点发送,并且每个consumer都要在一个consumer group中,而且comsumer group中每次只能有一个消费者能接受对应topic的消息。因为为了实现订阅也就是一对多发送,我们让每个consumer在一个单独的group,于是每个consumer都可以接受到该消息。
+
+
+## flume
+
+flume用于数据的收集和分发,flume可以监听端口的数据流入,监视文件的变动以及各种数据形式的数据流入,然后再把数据重新转发到其他需要数据的节点或存储中。
+
+1、Flume的概念
+
+flume是分布式的日志收集系统,它将各个服务器中的数据收集起来并送到指定的地方去,比如说送到图中的HDFS,简单来说flume就是收集日志的。
+
+2、Event的概念
+在这里有必要先介绍一下flume中event的相关概念:flume的核心是把数据从数据源(source)收集过来,在将收集到的数据送到指定的目的地(sink)。为了保证输送的过程一定成功,在送到目的地(sink)之前,会先缓存数据(channel),待数据真正到达目的地(sink)后,flume在删除自己缓存的数据。
+
+在整个数据的传输的过程中,流动的是event,即事务保证是在event级别进行的。那么什么是event呢?—–event将传输的数据进行封装,是flume传输数据的基本单位,如果是文本文件,通常是一行记录,event也是事务的基本单位。event从source,流向channel,再到sink,本身为一个字节数组,并可携带headers(头信息)信息。event代表着一个数据的最小完整单元,从外部数据源来,向外部的目的地去。
+
+flume使用
+## ambari
+ambari就是一个Hadoop的Web应用。
+
+## spark
+spark和MapReduce不同的地方就是,把计算过程放在内存中运行。
+
+spark提出了抽象的RDD分布式内存模型,把每一步的计算操作转换成一个RDD结构,然后形成一个RDD连接而成的有向图。
+
+比如data.map().filter().reduce();
+程序提交到master以后,会解析成多个RDD,并且形成一个有向图,然后spark再根据这些RD结构在内存中执行对应的操作。当然这个拓扑结构会被拆分为各个子任务分发到各个spark节点上,然后计算完以后再形成下一个rdd。最后汇总结果即可。
+
+由于是在内存中对数据进行操作,省去了不必要的IO操作,,不需要像Mapreduce一样还得先去hdfs读取文件再完成计算。
+
+
+
+
+## storm
+
+在运行一个Storm任务之前,需要了解一些概念:
+
+1. Topologies
+2. Streams
+3. Spouts
+4. Bolts
+5. Stream groupings
+6. Reliability
+7. Tasks
+8. Workers
+9. Configuration
+
+Storm集群和Hadoop集群表面上看很类似。但是Hadoop上运行的是MapReduce jobs,而在Storm上运行的是拓扑(topology),这两者之间是非常不一样的。一个关键的区别是: 一个MapReduce job最终会结束, 而一个topology永远会运行(除非你手动kill掉)。
+
+在Storm的集群里面有两种节点: 控制节点(master node)和工作节点(worker node)。控制节点上面运行一个叫Nimbus后台程序,它的作用类似Hadoop里面的JobTracker。Nimbus负责在集群里面分发代码,分配计算任务给机器, 并且监控状态。
+
+每一个工作节点上面运行一个叫做Supervisor的节点。Supervisor会监听分配给它那台机器的工作,根据需要启动/关闭工作进程。每一个工作进程执行一个topology的一个子集;一个运行的topology由运行在很多机器上的很多工作进程组成。
+
+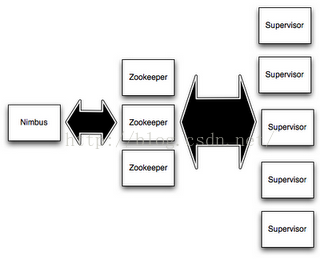
+
+Nimbus和Supervisor之间的所有协调工作都是通过Zookeeper集群完成。另外,Nimbus进程和Supervisor进程都是快速失败(fail-fast)和无状态的。所有的状态要么在zookeeper里面, 要么在本地磁盘上。这也就意味着你可以用kill -9来杀死Nimbus和Supervisor进程, 然后再重启它们,就好像什么都没有发生过。这个设计使得Storm异常的稳定。
+
+storm比起spark它的实时性能更高更强,storm可以做到亚秒级别的数据输入分析。而spark的方式是通过秒级的数据切分,来形成spark rdd数据集,然后再按照DAG有向图进行执行的。
+
+storm则不然。
+
+一:介绍Storm设计模型
+
+1.Topology
+
+ Storm对任务的抽象,其实 就是将实时数据分析任务 分解为 不同的阶段
+
+ 点: 计算组件 Spout Bolt
+
+ 边: 数据流向 数据从上一个组件流向下一个组件 带方向
+
+
+
+2.tuple
+
+ Storm每条记录 封装成一个tuple
+
+ 其实就是一些keyvalue对按顺序排列
+
+ 方便组件获取数据
+
+
+
+3.Spout
+
+ 数据采集器
+
+ 源源不断的日志记录 如何被topology接收进行处理?
+
+ Spout负责从数据源上获取数据,简单处理 封装成tuple向后面的bolt发射
+
+
+
+4.Bolt
+
+ 数据处理器
+
+二:开发wordcount案例
+
+1.书写整个大纲的点线图
+
+ 
+
+topology就是一个拓扑图,类似于spark中的dag有向图,只不过storm执行的流式的数据,比dag执行更加具有实时性。
+
+topology包含了spout和bolt。
+spout负责获取数据,并且将数据发送给bolt,这个过程就是把任务派发到多个节点,bolt则负责对数据进行处理,比如splitbolt负责把每个单词提取出来,countbolt负责单词数量的统计,最后的printbolt将每个结果集tuple打印出来。
+
+这就形成了一个完整的流程。
+
diff --git "a/md/JVM\346\200\273\347\273\223.md" "b/md/JVM\346\200\273\347\273\223.md"
new file mode 100644
index 0000000..1781f33
--- /dev/null
+++ "b/md/JVM\346\200\273\347\273\223.md"
@@ -0,0 +1,135 @@
+---
+title: JVM原理学习总结
+date: 2018-07-08 22:09:47
+tags:
+ - JVM
+categories:
+ - 后端
+ - 技术总结
+---
+#JVM原理学习总结
+
+这篇总结主要是基于我之前JVM系列文章而形成的的。主要是把重要的知识点用自己的话说了一遍,可能会有一些错误,还望见谅和指点。谢谢
+
+#更多详细内容可以查看我的专栏文章:深入理解JVM虚拟机
+https://blog.csdn.net/column/details/21960.html
+
+## JVM介绍和源码
+
+首先JVM是一个虚拟机,当你安装了jre,它就包含了jvm环境。JVM有自己的内存结构,字节码执行引擎,因此class字节码才能在jvm上运行,除了Java以外,Scala,groovy等语言也可以编译成字节码而后在jvm中运行。JVM是用c开发的。
+
+## JVM内存模型
+
+内存模型老生常谈了,主要就是线程共享的堆区,方法区,本地方法栈。还有线程私有的虚拟机栈和程序计数器。
+
+堆区存放所有对象,每个对象有一个地址,Java类jvm初始化时加载到方法区,而后会在堆区中生成一个Class对象,来负责这个类所有实例的实例化。
+
+
+
+栈区存放的是栈帧结构,栈帧是一段内存空间,包括参数列表,返回地址,局部变量表等,局部变量表由一堆slot组成,slot的大小固定,根据变量的数据类型决定需要用到几个slot。
+
+方法区存放类的元数据,将原来的字面量转换成引用,当然,方法区也提供常量池,常量池存放-128到127的数字类型的包装类。
+字符串常量池则会存放使用intern的字符串变量。
+## JVM OOM和内存泄漏
+
+这里指的是oom和内存泄漏这类错误。
+
+oom一般分为三种,堆区内存溢出,栈区内存溢出以及方法区内存溢出。
+
+堆内存溢出主要原因是创建了太多对象,比如一个集合类死循环添加一个数,此时设置jvm参数使堆内存最大值为10m,一会就会报oom异常。
+
+栈内存溢出主要与栈空间和线程有关,因为栈是线程私有的,如果创建太多线程,内存值超过栈空间上限,也会报oom。
+
+方法区内存溢出主要是由于动态加载类的数量太多,或者是不断创建一个动态代理,用不了多久方法区内存也会溢出,会报oom,这里在1.7之前会报permgem oom,1.8则会报meta space oom,这是因为1.8中删除了堆中的永久代,转而使用元数据区。
+
+内存泄漏一般是因为对象被引用无法回收,比如一个集合中存着很多对象,可能你在外部代码把对象的引用置空了,但是由于对象还被集合给引用着,所以无法被回收,导致内存泄漏。测试也很简单,就在集合里添加对象,添加完以后把引用置空,循环操作,一会就会出现oom异常,原因是内存泄漏太多了,导致没有空间分配新的对象。
+
+## 常见调试工具
+
+命令行工具有jstack jstat jmap 等,jstack可以跟踪线程的调用堆栈,以便追踪错误原因。
+
+jstat可以检查jvm的内存使用情况,gc情况以及线程状态等。
+
+jmap用于把堆栈快照转储到文件系统,然后可以用其他工具去排查。
+
+visualvm是一款很不错的gui调试工具,可以远程登录主机以便访问其jvm的状态并进行监控。
+
+## class文件结构
+
+class文件结构比较复杂,首先jvm定义了一个class文件的规则,并且让jvm按照这个规则去验证与读取。
+
+开头是一串魔数,然后接下来会有各种不同长度的数据,通过class的规则去读取这些数据,jvm就可以识别其内容,最后将其加载到方法区。
+
+## JVM的类加载机制
+
+jvm的类加载顺序是bootstrap类加载器,extclassloader加载器,最后是appclassloader用户加载器,分别加载的是jdk/bin ,jdk/ext以及用户定义的类目录下的类(一般通过ide指定),一般核心类都由bootstrap和ext加载器来加载,appclassloader用于加载自己写的类。
+
+双亲委派模型,加载一个类时,首先获取当前类加载器,先找到最高层的类加载器bootstrap让他尝试加载,他如果加载不了再让ext加载器去加载,如果他也加载不了再让appclassloader去加载。这样的话,确保一个类型只会被加载一次,并且以高层类加载器为准,防止某些类与核心类重复,产生错误。
+
+## defineclass findclass和loadclass
+
+类加载classloader中有两个方法loadclass和findclass,loadclass遵从双亲委派模型,先调用父类加载的loadclass,如果父类和自己都无法加载该类,则会去调用findclass方法,而findclass默认实现为空,如果要自定义类加载方式,则可以重写findclass方法。
+
+常见使用defineclass的情况是从网络或者文件读取字节码,然后通过defineclass将其定义成一个类,并且返回一个Class对象,说明此时类已经加载到方法区了。当然1.8以前实现方法区的是永久代,1.8以后则是元空间了。
+
+## JVM虚拟机字节码执行引擎
+
+jvm通过字节码执行引擎来执行class代码,他是一个栈式执行引擎。这部分内容比较高深,在这里就不献丑了。
+
+## 编译期优化和运行期优化
+
+编译期优化主要有几种
+
+1 泛型的擦除,使得泛型在编译时变成了实际类型,也叫伪泛型。
+
+2 自动拆箱装箱,foreach循环自动变成迭代器实现的for循环。
+
+3 条件编译,比如if(true)直接可得。
+
+运行期优化主要有几种
+
+1 JIT即时编译
+
+Java既是编译语言也是解释语言,因为需要编译代码生成字节码,而后通过解释器解释执行。
+
+但是,有些代码由于经常被使用而成为热点代码,每次都编译太过费时费力,干脆直接把他编译成本地代码,这种方式叫做JIT即时编译处理,所以这部分代码可以直接在本地运行而不需要通过jvm的执行引擎。
+
+2 公共表达式擦除,就是一个式子在后面如果没有被修改,在后面调用时就会被直接替换成数值。
+
+3 数组边界擦除,方法内联,比较偏,意义不大。
+
+4 逃逸分析,用于分析一个对象的作用范围,如果只局限在方法中被访问,则说明不会逃逸出方法,这样的话他就是线程安全的,不需要进行并发加锁。
+
+1
+
+## JVM的垃圾回收
+
+1 GC算法:停止复制,存活对象少时适用,缺点是需要两倍空间。标记清除,存活对象多时适用,但是容易产生随便。标记整理,存活对象少时适用,需要移动对象较多。
+
+2 GC分区,一般GC发生在堆区,堆区可分为年轻代,老年代,以前有永久代,现在没有了。
+
+年轻代分为eden和survior,新对象分配在eden,当年轻代满时触发minor gc,存活对象移至survivor区,然后两个区互换,等待下一场gc,
+当对象存活的阈值达到设定值时进入老年代,大对象也会直接进入老年代。
+
+老年代空间较大,当老年代空间不足以存放年轻代过来的对象时,开始进行full gc。同时整理年轻代和老年代。
+一般年轻代使用停止复制,老年代使用标记清除。
+
+3 垃圾收集器
+
+serial串行
+
+parallel并行
+
+它们都有年轻代与老年代的不同实现。
+
+然后是scanvage收集器,注重吞吐量,可以自己设置,不过不注重延迟。
+
+cms垃圾收集器,注重延迟的缩短和控制,并且收集线程和系统线程可以并发。
+
+cms收集步骤主要是,初次标记gc root,然后停顿进行并发标记,而后处理改变后的标记,最后停顿进行并发清除。
+
+g1收集器和cms的收集方式类似,但是g1将堆内存划分成了大小相同的小块区域,并且将垃圾集中到一个区域,存活对象集中到另一个区域,然后进行收集,防止产生碎片,同时使分配方式更灵活,它还支持根据对象变化预测停顿时间,从而更好地帮用户解决延迟等问题。
+
+## JVM的锁优化
+
+在Java并发中讲述了synchronized重量级锁以及锁优化的方法,包括轻量级锁,偏向锁,自旋锁等。详细内容可以参考我的专栏:Java并发技术指南
\ No newline at end of file
diff --git "a/md/JavaWeb\346\212\200\346\234\257\346\200\273\347\273\223.md" "b/md/JavaWeb\346\212\200\346\234\257\346\200\273\347\273\223.md"
new file mode 100644
index 0000000..ff93d34
--- /dev/null
+++ "b/md/JavaWeb\346\212\200\346\234\257\346\200\273\347\273\223.md"
@@ -0,0 +1,116 @@
+---
+title: JavaWeb技术总结
+date: 2018-07-08 22:13:33
+tags:
+ - JavaWeb
+categories:
+ - 后端
+ - 技术总结
+---
+# Java Web技术技术总结
+
+
+这篇总结主要是基于我之前两个系列的文章而来。主要是把重要的知识点用自己的话说了一遍,可能会有一些错误,还望见谅和指点。谢谢
+
+更多详细内容可以查看我的专栏文章:
+#JavaWeb技术世界
+# https://blog.csdn.net/column/details/21850.html
+#Spring与SpringMVC源码解析
+#https://blog.csdn.net/column/details/21851.html
+## Servlet及相关类
+
+servlet是一个接口,它的实现类有GenericServlet,而httpservlet是GenericServlet的一个子类,一般我们都会使用这个类。
+
+servletconfig是用于保存servlet配置信息的数据结构,而servletcontext则负责保持servlet的上下文,web应用启动时加载web.xml信息于servletconfig中。
+
+## Jsp和ViewResolver
+
+jsp页面需要编译成class文件并通过tomcat的类加载器进行加载,形成servlet实例,请求到来时实际上执行的是servlet代码,然后最终再通过viewresolver渲染成页面。
+
+## filter,listener
+
+filter是过滤器,也需要在web.xml中配置,是责任链式的调用,在servlet执行service方法前执行。
+listener则是监听器,由于容器组件都实现了lifecycle接口,所以可以在组件上添加监听器来控制生命周期。
+
+## web.xml
+
+web.xml用来配置servlet和servlet的配置信息,listener和filter。也可以配置静态文件的目录等。
+
+## war包
+
+waWAR包
+WAR(Web Archive file)网络应用程序文件,是与平台无关的文件格式,它允许将许多文件组合成一个压缩文件。war专用在web方面 。
+
+JAVA WEB工程,都是打成WAR包进行发布。
+
+典型的war包内部结构如下:
+
+webapp.war
+
+ | index.jsp
+
+ |
+
+ |— images
+
+ |— META-INF
+
+ |— WEB-INF
+
+ | web.xml // WAR包的描述文件
+
+ |
+
+ |— classes
+
+ | action.class // java类文件
+
+ |
+
+ |— lib
+
+ other.jar // 依赖的jar包
+
+ share.jar
+
+## tomcat基础
+
+上一篇文章关于网络编程和NIO已经讲过了,这里按住不表。
+
+## log4j
+
+log4j是非常常用的日志组件,不过现在为了使用更通用的日志组件,一般使用slf4j来配置日志管理器,然后再介入日志源,比如log4j这样的日志组件。
+
+## 数据库驱动和连接池
+
+一般我们会使用class.forname加载数据库驱动,但是随着Spring的发展,现在一般会进行数据源DataSource这个bean的配置,bean里面填写你的数据来源信息即可,并且在实现类中可以选择支持连接池的数据源实现类,比如c3poDataSource,非常方便。
+
+数据库连接池本身和线程池类似,就是为了避免频繁建立数据库连接,保存了一部分连接并存放在集合里,一般可以用队列来存放。
+
+除此之外,还可以使用tomcat的配置文件来管理数据库连接池,只需要简单的一些配置,就可以让tomcat自动管理数据库的连接池了。
+应用需要使用的时候,通过jndi的方式访问即可,具体方法就是调用jndi命名服务的look方法。
+
+## 单元测试
+
+单元测试是工程中必不可少的组件,maven项目在打包期间会自动运行所有单元测试。一般我们使用junit做单元测试,统一地在test包中分别测试service和dao层,并且使用mock方法来构造假的数据,以便跳过数据库或者其他外部资源来完成测试。
+
+## Maven
+
+maven是一个项目构建工具,基于约定大于配置的方式,规定了一个工程各个目录的用途,并且根据这些规则进行编译,测试和打包。
+同时他提供了方便的包管理方式,以及快速部署的优势。
+
+## Git
+
+git是分布式的代码管理工具,比起svn有着分布式的优势。太过常见了,略了。
+
+## Json和xml
+数据描述形式不同,json更简洁。
+
+## hibernate和mybatis
+
+由于jdbc方式的数据库连接和语句执行太过繁琐,重复代码太多,后来提出了jdbctemplate对数据进行bean转换。
+
+但是还是差强人意,于是转而出现了hibernate这类的持久化框架。可以做到数据表和bean一一映射,程序只需要操作bean就可以完成数据库的curd。
+
+mybatis比hibernate更轻量级,mybatis支持原生sql查询,并且也可以使用bean映射,同时还可以自定义地配置映射对象,更加灵活,并且在多表查询上更有优势。
+
diff --git "a/md/Java\345\271\266\345\217\221\346\200\273\347\273\223.md" "b/md/Java\345\271\266\345\217\221\346\200\273\347\273\223.md"
new file mode 100644
index 0000000..32ad101
--- /dev/null
+++ "b/md/Java\345\271\266\345\217\221\346\200\273\347\273\223.md"
@@ -0,0 +1,206 @@
+---
+title: Java并发总结
+date: 2018-07-08 22:06:18
+tags:
+ - Java并发
+categories:
+ - 后端
+ - 技术总结
+---
+# Java并发
+
+这篇总结主要是基于我Java并发技术系列的文章而形成的的。主要是把重要的知识点用自己的话说了一遍,可能会有一些错误,还望见谅和指点。谢谢
+
+#更多详细内容可以查看我的专栏文章:Java并发技术指南
+
+#https://blog.csdn.net/column/details/21961.html
+
+## 线程安全
+
+线程安全一般指多线程之间的操作结果不会因为线程调度的顺序不同而发生改变。
+
+## 互斥和同步
+
+ 互斥一般指资源的独占访问,同步则要求同步代码中的代码顺序执行,并且也是单线程独占的。
+
+## JMM内存模型
+
+ JVM中的内存分区包括堆,栈,方法区等区域,这些内存都是抽象出来的,实际上,系统中只有一个主内存,但是为了方便Java多线程语义的实现,以及降低程序员编写并发程序的难度,Java提出了JMM内存模型,将内存分为主内存和工作内存,工作内存是线程独占的,实际上它是一系列寄存器,编译器优化后的结果。
+
+## as-if-Serial,happens-before
+
+ as if serial语义提供单线程代码的顺序执行保证,虽然他允许指令重排序,但是前提是指令重排序不会改变执行结果。
+
+## volatile
+
+ volatile语义实际上是在代码中插入一个内存屏障,内存屏障分为读写,写读,读读,写写四种,可以用来避免volatile变量的读写操作发生重排序,从而保证了volatile的语义,实际上,volatile修饰的变量强制要求线程写时将数据从缓存刷入主内存,读时强制要求线程从主内存中读取,因此保证了它的可见性。
+
+ 而对于volatile修饰的64位类型数据,可以保证其原子性,不会因为指令重排序导致一个64位数据被分割成两个32位数据来读取。
+
+## synchronized和锁优化
+
+ synchronized是Java提供的同步标识,底层是操作系统的mutex lock调用,需要进行用户态到内核态的切换,开销比较大。
+ synchronized经过编译后的汇编代码会有monitor in和monitor out的字样,用于标识进入监视器模块和退出监视器模块,
+ 监视器模块watcher会监控同步代码块中的线程号,只允线程号正确的线程进入。
+
+ Java在synchronized关键字中进行了多次优化。
+
+ 比如轻量级锁优化,使用锁对象的对象头做文章,当一个线程需要获得该对象锁时,线程有一段空间叫做lock record,用于存储对象头的mask word,然后通过cas操作将对象头的mask word改成指向线程中的lockrecord。
+ 如果成功了就是获取到了锁,否则就是发生了互斥。需要锁粗化,膨胀为互斥锁。
+
+ 偏向锁,去掉了更多的同步措施,检查mask word是否是可偏向状态,然后检查mask word中的线程id是否是自己的id,如果是则执行同步代码,如果不是则cas修改其id,如果修改失败,则出现锁争用,偏向锁失效,膨胀为轻量级锁。
+
+ 自旋锁,每个线程会被分配一段时间片,并且听候cpu调度,如果发生线程阻塞需要切换的开销,于是使用自旋锁不需要阻塞,而是忙等循环,一获取时间片就开始忙等,这样的锁就是自旋锁,一般用于并发量比较小,又担心切换开销的场景。
+
+## CAS操作
+ CAS操作是通过硬件实现的原子操作,通过一条指令完成比较和赋值的操作,防止发生因指令重排导致的非原子操作,在Java中通过unsafe包可以直接使用,在Java原子类中使用cas操作来完成一系列原子数据类型的构建,保证自加自减等依赖原值的操作不会出现并发问题。
+
+ cas操作也广泛用在其他并发类中,通过循环cas操作可以完成线程安全的并发赋值,也可以通过一次cas操作来避免使用互斥锁。
+
+## Lock类
+
+### AQS
+
+AQS是Lock类的基石,他是一个抽象类,通过操作一个变量state来判断线程锁争用的情况,通过一系列方法实现对该变量的修改。一般可以分为独占锁和互斥锁。
+
+AQS维护着一个CLH阻塞队列,这个队列主要用来存放阻塞等待锁的线程节点。可以看做一个链表。
+
+一:独占锁
+独占锁的state只有0和1两种情况(如果是可重入锁也可以把state一直往上加,这里不讨论),state = 1时说明已经有线程争用到锁。线程获取锁时一般是通过aqs的lock方法,如果state为0,首先尝试cas修改state=1,成功返回,失败时则加入阻塞队列。非公共锁使用时,线程节点加入阻塞队列时依然会尝试cas获取锁,最后如果还是失败再老老实实阻塞在队列中。
+
+独占锁还可以分为公平锁和非公平锁,公平锁要求锁节点依据顺序加入阻塞队列,通过判断前置节点的状态来改变后置节点的状态,比如前置节点获取锁后,释放锁时会通知后置节点。
+
+非公平锁则不一定会按照队列的节点顺序来获取锁,如上面所说,会先尝试cas操作,失败再进入阻塞队列。
+
+二:共享锁
+共享锁的state状态可以是0到n。共享锁维护的阻塞队列和互斥锁不太一样,互斥锁的节点释放锁后只会通知后置节点,而共享锁获取锁后会通知所有的共享类型节点,让他们都来获取锁。共享锁用于countdownlatch工具类与cyliderbarrier等,可以很好地完成多线程的协调工作
+
+### 锁Lock和Conditon
+
+Lock 锁维护这两个内部类fairsync和unfairsync,都继承自aqs,重写了部分方法,实际上大部分方法还是aqs中的,Lock只是重新把AQS做了封装,让程序员更方便地使用Lock锁。
+
+和Lock锁搭配使用的还有condition,由于Lock锁只维护着一个阻塞队列,有时候想分不同情况进行锁阻塞和锁通知怎么办,原来我们一般会使用多个锁对象,现在可以使用condition来完成这件事,比如线程A和线程B分别等待事件A和事件B,可以使用两个condition分别维护两个队列,A放在A队列,B放在B队列,由于Lock和condition是绑定使用的,当事件A触发,线程A被唤醒,此时他会加入Lock自己的CLH队列中进行锁争用,当然也分为公平锁和非公平锁两种,和上面的描述一样。
+
+Lock和condtion的组合广泛用于JUC包中,比如生产者和消费者模型,再比如cyliderbarrier。
+
+###读写锁
+
+读写锁也是Lock的一个子类,它在一个阻塞队列中同时存储读线程节点和写线程节点,读写锁采用state的高16位和低16位分别代表独占锁和共享锁的状态,如果共享锁的state > 0可以继续获取读锁,并且state-1,如果=0,则加入到阻塞队列中,写锁节点和独占锁的处理一样,因此一个队列中会有两种类型的节点,唤醒读锁节点时不会唤醒写锁节点,唤醒写锁节点时,则会唤醒后续的节点。
+
+因此读写锁一般用于读多写少的场景,写锁可以降级为读锁,就是在获取到写锁的情况下可以再获取读锁。
+
+## 并发工具类
+
+countdownlatch主要通过AQS的共享模式实现,初始时设置state为N,N是countdownlatch初始化使用的size,每当有一个线程执行countdown,则state-1,state = 0之前所有线程阻塞在队列中,当state=0时唤醒队头节点,队头节点依次通知所有共享类型的节点,唤醒这些线程并执行后面的代码。
+
+cycliderbarrier主要通过lock和condition结合实现,首先设置state为屏障等待的线程数,在某个节点设置一个屏障,所有线程运行到此处会阻塞等待,其实就是等待在一个condition的队列中,并且每当有一个线程到达,state -=1 则当所有线程到达时,state = 0,则唤醒condition队列的所有结点,去执行后面的代码。
+
+samphere也是使用AQS的共享模式实现的,与countlatch大同小异,不再赘述。
+
+exchanger就比较复杂了。使用exchanger时会开辟一段空间用来让两个线程进行交互操作,这个空间一般是一个栈或队列,一个线程进来时先把数据放到这个格子里,然后阻塞等待其他线程跟他交换,如果另一个线程也进来了,就会读取这个数据,并把自己的数据放到对方线程的格子里,然后双双离开。当然使用栈和队列的交互是不同的,使用栈的话匹配的是最晚进来的一个线程,队列则相反。
+
+## 原子数据类型
+
+原子数据类型基本都是通过cas操作实现的,避免并发操作时出现的安全问题。
+
+## 同步容器
+
+同步容器主要就是concurrenthashmap了,在集合类中我已经讲了chm了,所以在这里简单带过,chm1.7通过分段锁来实现锁粗化,使用的死LLock锁,而1.8则改用synchronized和cas的结合,性能更好一些。
+
+还有就是concurrentlinkedlist,ConcurrentSkipListMap与CopyOnWriteArrayList。
+
+第一个链表也是通过cas和synchronized实现。
+
+而concurrentskiplistmap则是一个跳表,跳表分为很多层,每层都是一个链表,每个节点可以有向下和向右两个指针,先通过向右指针进行索引,再通过向下指针细化搜索,这个的搜索效率是很高的,可以达到logn,并且它的实现难度也比较低。通过跳表存map就是把entry节点放在链表中了。查询时按照跳表的查询规则即可。
+
+CopyOnWriteArrayList是一个写时复制链表,查询时不加锁,而修改时则会复制一个新list进行操作,然后再赋值给原list即可。
+适合读多写少的场景。
+
+## 阻塞队列
+
+ BlockingQueue 实现之 ArrayBlockingQueue
+
+ ArrayBlockingQueue其实就是数组实现的阻塞队列,该阻塞队列通过一个lock和两个condition实现,一个condition负责从队头插入节点,一个condition负责队尾读取节点,通过这样的方式可以实现生产者消费者模型。
+
+ BlockingQueue 实现之 LinkedBlockingQueue
+
+ LinkedBlockingQueue是用链表实现的阻塞队列,和arrayblockqueue有所区别,它支持实现为无界队列,并且它使用两个lock和对应的condition搭配使用,这是因为链表可以同时对头部和尾部进行操作,而数组进行操作后可能还要执行移位和扩容等操作。
+ 所以链表实现更灵活,读写分别用两把锁,效率更高。
+
+ BlockingQueue 实现之 SynchronousQueue
+
+ SynchronousQueue实现是一个不存储数据的队列,只会保留一个队列用于保存线程节点。详细请参加上面的exchanger实现类,它就是基于SynchronousQueue设计出来的工具类。
+
+ BlockingQueue 实现之 PriorityBlockingQueue
+
+ PriorityBlockingQueue
+
+ PriorityBlockingQueue是一个支持优先级的无界队列。默认情况下元素采取自然顺序排列,也可以通过比较器comparator来指定元素的排序规则。元素按照升序排列。
+
+ DelayQueue
+
+ DelayQueue是一个支持延时获取元素的无界阻塞队列。队列使用PriorityQueue来实现。队列中的元素必须实现Delayed接口,在创建元素时可以指定多久才能从队列中获取当前元素。只有在延迟期满时才能从队列中提取元素。我们可以将DelayQueue运用在以下应用场景:
+
+ 缓存系统的设计:可以用DelayQueue保存缓存元素的有效期,使用一个线程循环查询DelayQueue,一旦能从DelayQueue中获取元素时,表示缓存有效期到了。
+ 定时任务调度。使用DelayQueue保存当天将会执行的任务和执行时间,一旦从DelayQueue中获取到任务就开始执行,从比如TimerQueue就是使用DelayQueue实现的。
+
+## 线程池
+
+### 类图
+
+首先看看executor接口,只提供一个run方法,而他的一个子接口executorservice则提供了更多方法,比如提交任务,结束线程池等。
+
+然后抽象类abstractexecutorservice提供了更多的实现了,最后我们最常使用的类ThreadPoolExecutor就是继承它来的。
+
+
+ThreadPoolExecutor可以传入多种参数来自定义实现线程池。
+
+而我们也可以使用Executors中的工厂方法来实例化常用的线程池。
+
+### 常用线程池
+
+比如newFixedThreadPool
+
+newSingleThreadExecutor newCachedThreadPool
+
+newScheduledThreadPool等等,这些线程池即可以使用submit提交有返回结果的callable和futuretask任务,通过一个future来接收结果,或者通过callable中的回调函数call来回写执行结果。也可以用execute执行无返回值的runable任务。
+
+在探讨这些线程池的区别之前,先看看线程池的几个核心概念。
+
+任务队列:线程池中维护了一个任务队列,每当向线程池提交任务时,任务加入队列。
+
+工作线程:也叫worker,从线程池中获取任务并执行,执行后被回收或者保留,因情况而定。
+
+核心线程数和最大线程数,核心线程数是线程池需要保持存活的线程数量,以便接收任务,最大线程数是能创建的线程数上限。
+
+newFixedThreadPool可以设置固定的核心线程数和最大线程数,一个任务进来以后,就会开启一个线程去执行,并且这部分线程不会被回收,当开启的线程达到核心线程数时,则把任务先放进任务队列。当任务队列已满时,才会继续开启线程去处理,如果线程总数打到最大线程数限制,任务队列又是满的时候,会执行对应的拒绝策略。
+
+拒绝策略一般有几种常用的,比如丢弃任务,丢弃队尾任务,回退给调用者执行,或者抛出异常,也可以使用自定义的拒绝策略。
+
+newSingleThreadExecutor是一个单线程执行的线程池,只会维护一个线程,他也有任务队列,当任务队列已满并且线程数已经是1个的时候,再提交任务就会执行拒绝策略。
+
+newCachedThreadPool比较特别,第一个任务进来时会开启一个线程,而后如果线程还没执行完前面的任务又有新任务进来,就会再创建一个线程,这个线程池使用的是无容量的SynchronousQueue队列,要求请求线程和接受线程匹配时才会完成任务执行。
+所以如果一直提交任务,而接受线程来不及处理的话,就会导致线程池不断创建线程,导致cpu消耗很大。
+
+ScheduledThreadPoolExecutor内部使用的是delayqueue队列,内部是一个优先级队列priorityqueue,也就是一个堆。通过这个delayqueue可以知道线程调度的先后顺序和执行时间点。
+
+
+## Fork/Join框架
+
+又称工作窃取线程池。
+
+我们在大学算法课本上,学过的一种基本算法就是:分治。其基本思路就是:把一个大的任务分成若干个子任务,这些子任务分别计算,最后再Merge出最终结果。这个过程通常都会用到递归。
+
+而Fork/Join其实就是一种利用多线程来实现“分治算法”的并行框架。
+
+另外一方面,可以把Fori/Join看作一个单机版的Map/Reduce,只不过这里的并行不是多台机器并行计算,而是多个线程并行计算。
+
+与ThreadPool的区别
+通过上面例子,我们可以看出,它在使用上,和ThreadPool有共同的地方,也有区别点:
+(1) ThreadPool只有“外部任务”,也就是调用者放到队列里的任务。 ForkJoinPool有“外部任务”,还有“内部任务”,也就是任务自身在执行过程中,分裂出”子任务“,递归,再次放入队列。
+(2)ForkJoinPool里面的任务通常有2类,RecusiveAction/RecusiveTask,这2个都是继承自FutureTask。在使用的时候,重写其compute算法。
+
+工作窃取算法
+上面提到,ForkJoinPool里有”外部任务“,也有“内部任务”。其中外部任务,是放在ForkJoinPool的全局队列里面,而每个Worker线程,也有一个自己的队列,用于存放内部任务。
+
+窃取的基本思路就是:当worker自己的任务队列里面没有任务时,就去scan别的线程的队列,把别人的任务拿过来执行
\ No newline at end of file
diff --git "a/md/Java\346\240\270\345\277\203\346\212\200\346\234\257\346\200\273\347\273\223.md" "b/md/Java\346\240\270\345\277\203\346\212\200\346\234\257\346\200\273\347\273\223.md"
new file mode 100644
index 0000000..2eba287
--- /dev/null
+++ "b/md/Java\346\240\270\345\277\203\346\212\200\346\234\257\346\200\273\347\273\223.md"
@@ -0,0 +1,136 @@
+---
+title: JAVA后端开发学习之路 # 文章页面上的显示名称,可以任意修改,不会出现在URL中
+date: 2018-4-20 15:56:26 # 文章生成时间,一般不改
+categories:
+ - 个人总结
+tags:
+ - 心路历程
+---
+本文主要记录了我从Java初学者到专注于Java后端技术栈的开发者的学习历程。主要分享了学习过程中的一些经验和教训,让后来人看到,少走弯路,与君共勉,共同进步。如有错误,还请见谅。
+
+我的GitHub:
+> https://github.com/h2pl/MyTech
+
+喜欢的话麻烦点下星哈
+
+文章首发于我的个人博客:
+> https://h2pl.github.io/2018/04/20/java
+
+更多关于Java后端学习的内容请到我的CSDN博客上查看:
+
+https://blog.csdn.net/a724888
+
+相关链接:我和技术博客的这一年:https://blog.csdn.net/a724888/article/details/60879893
+> 不论你是不是网民,无论你远离互联网,还是沉浸其中;你的身影,都在这场伟大的迁徙洪流中。超越人类经验的大迁徙,温暖而无情地,开始了。
+ -----《互联网时代》
+
+
+
+## 选择方向
+
+ 0上大学前的那些事,让它们随风逝去吧。
+
+ 1 个人对计算机和互联网有情怀,有兴趣,本科时在专业和学校里选择了学校,当时专业不是计算机,只能接触到一点点计算机专业课程,所以选择了考研,花半年时间复习考进了一个还不错的985,考研经历有空会发到博客上。
+
+ 2 本科阶段接触过Java和Android,感觉app蛮有趣的,所以研一的时候想做Android,起初花大量时间看了计算机专业课的教材,效果很差。但也稍微了解了一些计算机基础,如网络,操作系统,组成原理,数据库,软工等。
+
+ 3 在没确定方向的迷茫时期看了大量视频和科普性文章,帮助理清头绪和方向。期间了解了诸如游戏开发,c++开发,Android,Java甚至前端等方向,其中还包含游戏策划岗。
+
+ 4 后来综合自身条件以及行业发展等因素,开始锁定自己的目标在Java后台方向。于是乎各种百度,知乎,查阅该学什么该怎么学如此类的问题,学习别人的经验。当然只靠搜索引擎很难找到精品内容,那段时间可谓是病急乱投医,走了不少弯路。
+
+---
+
+## 夯实基础
+
+ 1 研一的工程实践课让我知道了我的基础不够扎实,由于并非科班,需要比别人更加勤奋,古语有云,天道酬勤,勤能补拙。赶上了17年的春招实习招聘,期间开始各种海投,各种大厂面试一问三不知,才知道自身差距很大,开始疯狂复习面试题,刷面经,看经验等。死记硬背,之乎者也,倒也是能应付一些小公司,可谓是临阵磨枪不快也光。
+
+ 2 不过期间的屡屡受挫让我冷静思考了一段时间,我再度调研了岗位需求,学习方法,以及需要看的书等资料。再度开工时,我的桌上开始不断出现新的经典书籍。这还要归功于我的启蒙导师:江南白衣,在知乎上看到了他的一篇文章,我的Java后端书架。在这个书架里我找寻到了很多我想看的书,以及我需要学习的技术。
+
+ 3 遥想研一我还在看的书:教材就不提了,脱离实际并且年代久远,而我选的入门书籍竟然还有Java web从入门到精通这种烂大街的书籍,然后就是什么Java编程思想啦,深入理解计算机系统,算法导论这种高深莫测的书,感觉有点高不成低不就的意思。要么太过难懂要么过于粗糙,这些书在当时基本上没能帮到我。
+
+---
+
+## 书籍选择
+
+ 1 江南白衣的后端书架真是救我于水火。他的书架里收录了许多Java后端需要用到的技术书籍,并且十分经典,虽不说每本都适合入门,但是只要你用心去看都会有收获,高质量的书籍给人的启发要优于普通书籍。
+
+ 2 每个门类的书我都挑了一些。比如网络的两本(《tcp ip卷一》以及《计算机网络自顶向下》),操作系统两本(一本《Linux内核设计与实现》,一本高级操作系统,推荐先看完《深入理解计算机系统》再来看这两本),算法看的是《数据结构与算法(Java版)》,Java的四大件(《深入理解jvm虚拟机》,《java并发编程艺术》,《深入java web技术内幕》,《Java核心技术 卷一》这本没看)。
+
+ 3 当然还有像《Effective Java》,《Java编程思想》,《Java性能调优指南》这种,不过新手不推荐,太不友好。接着是spring的两本《Spring实战》和《Spring源码剖析》。当然也包括一些redis,mq之类的书,还有就是一些介绍分布式组件的书籍,如zk等。
+
+ 4 接下来就是扩展的内容了,比如分布式的三大件,《大型网站架构设计与实践》,《分布式网站架构设计与实践》,《Java中间件设计与实践》,外加一本《分布式服务框架设计与实践》。这几本书一看,绝对让你打开新世界的大门,醍醐灌顶,三月不知肉味。
+
+ 5 你以为看完这些书你就无敌了,就满足了?想得倒是挺美。这些书最多就是把我从悬崖边拉回正途,能让我在正确的道路上行走了。毕竟技术书籍这种东西还是有门槛的,没有一定的知识储备,看书的过程也绝对是十分痛苦的。
+
+ 6 比如《深入理解jvm虚拟机》和《java并发编程艺术》这两本书,我看了好几遍,第一遍基本当天书来看,第二遍挑着章节看,第三遍能把全部章节都看了。所以有时候你觉得你看完了一本书,对,你确实看完了,但过段时间是你能记得多少呢。可以说是很少了。
+
+---
+
+## 谈一谈学习方法
+
+ 1 人们在刚开始接触自己不熟悉的领域时,往往都会犯很多错误。刚开始学习Java时,就是摸着石头过河。从在极客学院慕课上看视频,到看书,再到看博客,再到工程实践,也是学习方式转变的一个过程。
+
+ 2 看视频:适合0基础小白,视频给你构建一个世界观,让你对你要做的东西有个大概的了解,想要深入理解其中的技术原理,只看视频的话很难。
+
+ 3 看书:就如上面一节所说,看书是一个很重要的环节。当你对技术只停留在大概的了解和基本会用的阶段时,经典书籍能够让你深入这些技术的原理,你可能会对书里的内容感到惊叹,也可能只是一知半解。所以第一遍的阅读一般读个大概就可以。一本书要吃透,不仅要看好几遍,还要多上手实践,才能变成自己的东西。
+
+ 4 看博客,光看一些总结性的博客或者是科普性的博客可能还不够,一开始我也经常看这样的博客,后来只看这些东西,发现对技术的理解只能停留在表面。高质量的博客一般会把一个知识点讲得很透彻,比你看十篇总结都强,例如讲jdk源码的博文,可以很好地帮助你理解其原理,避免自己看的时候一脸懵逼。这里先推荐几个博客和网站,后面写复习计划的时候,会详细写出。
+博客:江南白衣、酷壳、战小狼。
+网站:并发编程网,importnew。
+
+ 5 实践为王,Java后端毕竟还是工程方向,只是通过文字去理解技术点,可能有点纸上谈兵的感觉了。还有一个问题就是,没有进行上手实践的技术,一般很快就会忘了,做一些实践可以更好地巩固知识点。如果有项目中涉及不到的知识点,可以单独拿出来做一些demo,实在难以进行实践的技术点,可以参考别人的实践过程。
+
+---
+
+## 实习,提高工程能力的好机会
+
+ 1 这段时间以后就是实习期了,三个月的W厂实习经历。半年的B厂实习,让我着实过了一把大厂的瘾。但是其中做的工作无非就是增删改查写写业务逻辑,很难接触到比较核心的部分。
+
+ 2 于是乎我花了许多时间学习部门的核心技术。比如在W厂参与数据平台的工作时,我学习了hadoop以及数据仓库的架构,也写了一些博客,并且向负责后端架构的导师请教了许多知识,收获颇丰。
+
+ 3 在B厂实习期间则接触了许多云计算相关的技术。因为部门做的是私有云,所以业务代码和底层的服务也是息息相关的,比如平时的业务代码也会涉及到底层的接口调用,比如新建一个虚拟机或者启动一台虚拟机,需要通过多级的服务调用,首先是HTTP服务调用,经过多级的服务调用,最终完成流程。在这期间我花了一些时间学习了OpenStack的架构以及部门的实际应用情况,同时也玩了一下docker,看了kubenetes的一些书籍,算是入门。
+
+ 4 但是这些东西其实离后台开发还是有一定距离的,比如后台开发的主要问题就是高并发,分布式,Linux服务器开发等。而我做的东西,只能稍微接触到这一部门的内容,因为主要是to b的内部业务。所以这段时间其实我的进步有限,虽然扩大了知识面并且积累了开发经验,但是对于后台岗位来说还是有所欠缺的。
+
+ 5 不过将近一年的实习也让我收获了很多东西,大厂的实习体验很好,工作高效,团队合作,版本的快速迭代,技术氛围很不错。特别是在B厂了可以解到很多前沿的技术,对自己的视野扩展很有帮助。
+
+---
+
+## **实习转正,还是准备秋招?**
+
+ 1 离职以后,在考虑是否还要找实习,因为有两份实习经历了,在考虑要不要静下心来刷刷题,复习一下基础,并且回顾一下实习时用到的技术。同一时期,我了解到腾讯和阿里等大厂的实习留用率不高,并且可能影响到秋招,所以当时的想法是直接复习等到秋招内推。因此,那段时间比较放松,没什么复习状态,也导致了我在今年春招内推的阶段比较艰难。
+
+ 2 因为当时想着沉住气准备秋招,所以一开始对实习内推不太在意。但是由于AT招人的实习生转正比例较大,考虑到秋招的名额可能更少,所以还是不愿意错过这个机会。因为开始系统复习的时间比较晚,所以投的比较晚,担心准备不充分被刷。这次找实习主要是奔着转正去的,所以只投了bat和滴滴,京东,网易游戏等大厂。
+
+ 3 由于投递时间原因,所以面试的流程特别慢。并且在笔试方面还是有所欠缺,刷题刷的比较少,在线编程的算法题还是屡屡受挫。这让我有点后悔实习结束后的那段时间没有好好刷题了。
+
+---
+
+## **调整心态,重新上路**
+
+ 1 目前的状态是,一边刷题,一边复习基础,投了几家大厂的实习内推,打算选一个心仪的公司准备转正,但是事情总是没那么顺利,微软,头条等公司的笔试难度超过了我的能力范围,没能接到面试电话。腾讯投了一个自己比较喜欢的部门,可惜岗位没有匹配上,后台开发被转成了运营开发,最终没能通过。阿里面试的也不顺利,当时投了一个牛客上的蚂蚁金服内推,由于投的太晚,部门已经招满,只面了一面就没了下文,前几天接到了菜鸟的面试,这个未完待续。
+
+ 2 目前的想法是,因为我不怎么需要实习经历来加分了,所以想多花些时间复习基础,刷题,并且巩固之前的项目经历。当然如果有好的岗位并且转正机会比较大的话,也是会考虑去实习的,那样的话可能需要多挤点时间来复习基础和刷题了。
+
+ 3 在这期间,我会重新梳理一下自己的复习框架,有针对性地看一些高质量的博文,同时多做些项目实践,加深对知识的理解。当然这方面还会通过写博客进行跟进,写博客,做项目。前阵子在牛客上看到一位牛友CyC2018做的名为interview notebook的GitHub仓库,内容非常好,十分精品,我全部看完了,并且参考其LeetCode题解进行刷题。
+
+ 4 受到这位大佬的启发,我也打算做一个类似的代码仓库或者是博客专栏,尽量在秋招之前把总结做完,并且把好的文章都放进去。上述内容只是本人个人的心得体会,如果有错误或者说的不合理的地方,还请谅解和指正。希望与广大牛友共勉,一起进步。
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
diff --git "a/md/Java\347\275\221\347\273\234\344\270\216NIO\346\200\273\347\273\223.md" "b/md/Java\347\275\221\347\273\234\344\270\216NIO\346\200\273\347\273\223.md"
new file mode 100644
index 0000000..9bbbe42
--- /dev/null
+++ "b/md/Java\347\275\221\347\273\234\344\270\216NIO\346\200\273\347\273\223.md"
@@ -0,0 +1,213 @@
+---
+title: Java网络编程与NIO学习总结
+date: 2018-07-08 22:08:22
+tags:
+ - Java网络编程
+ - NIO
+categories:
+ - 后端
+ - 技术总结
+---
+#Java网络编程与NIO学习总结
+这篇总结主要是基于我之前Java网络编程与NIO系列文章而形成的的。主要是把重要的知识点用自己的话说了一遍,可能会有一些错误,还望见谅和指点。谢谢
+
+#更多详细内容可以查看我的专栏文章:Java网络编程与NIO
+
+#https://blog.csdn.net/column/details/21963.html
+## Java IO
+
+Java IO的基础知识已在前面讲过
+
+## Socket编程
+
+socket是操作系统提供的网络编程接口,他封装了对于TCP/IP协议栈的支持,用于进程间的通信,当有连接接入主机以后,操作系统自动为其分配一个socket套接字,套接字绑定着一个IP与端口号。通过socket接口,可以获取tcp连接的输入流和输出流,并且通过他们进行读取和写入此操作。
+
+Java提供了net包用于socket编程,同时支持像Inetaddress,URL等工具类,使用socket绑定一个endpoint(ip+端口号),可以用于客户端的请求处理和发送,使用serversocket绑定本地ip和端口号,可以用于服务端接收TCP请求。
+
+## 客户端,服务端的线程模型
+
+一般客户端使用单线程模型即可,当有数据到来时启动线程读取,需要写入数据时开启线程进行数据写入。
+
+服务端一般使用多线程模型,一个线程负责接收tcp连接请求,每当接收到请求后开启一个线程处理它的读写请求。
+
+udp的客户端和服务端就比较简单了,由于udp数据报长度是确定的,只需要写入一个固定的缓存和读取一个固定的缓存空间即可。
+
+一般通过DatagramPacket包装一个udp数据报,然后通过DatagramSocket发送
+
+## IO模型
+
+上述的socket在处理IO请求时使用的是阻塞模型。
+
+于是我们还是得来探讨一下IO模型。
+
+一般认为,应用程序处理IO请求需要将内核缓存区中的数据拷贝到用户缓冲区。这个步骤可以通过系统调用来完成,而用户程序处理IO请求的时候,需要先检查用户缓冲区是否准备好了数据,这个操作是系统调用recevfrom,如果数据没有准备好,默认会阻塞调用该方法的线程。
+
+这样就导致了线程处理IO请求需要频繁进行阻塞,特别是并发量大的时候,线程切换的开销巨大。
+
+一般认为有几种IO模型
+
+1 阻塞IO :就是线程会阻塞在系统调用recevfrom上,并且等待数据准备就绪以后才会返回。
+
+2 非阻塞IO : 不阻塞在系统调用recevfrom,而是通过自旋忙等的方式不断询问缓冲区数据是否准备就绪,避免线程阻塞的开销。
+
+3 IO多路复用 :使用IO多路复用器管理socket,由于每个socket是一个文件描述符,操作系统可以维护socket和它的连接状态,一般分为可连接,可读和可写等状态。
+
+每当用户程序接受到socket请求,将请求托管给多路复用器进行监控,当程序对请求感兴趣的事件发生时,多路复用器以某种方式通知或是用户程序自己轮询请求,以便获取就绪的socket,然后只需使用一个线程进行轮询,多个线程处理就绪请求即可。
+
+IO多路复用避免了每个socket请求都需要一个线程去处理,而是使用事件驱动的方式,让少数的线程去处理多数socket的IO请求。
+
+Linux操作系统对IO多路复用提供了较好的支持,select,poll,epoll是Linux提供的支持IO多路复用的API。一般用户程序基于这个API去开发自己的IO复用模型。比如NIO的非阻塞模型,就是采用了IO多路复用的方式,是基于epoll实现的。
+
+3.1 select方式主要是使用数组来存储socket描述符,系统将发生事件的描述符做标记,然后IO复用器在轮询描述符数组的时候,就可以知道哪些请求是就绪了的。缺点是数组的长度只能到1024,并且需要不断地在内核空间和用户空间之间拷贝数组。
+
+3.2 poll方式不采用数组存储描述符,而是使用独立的数据结构来描述,并且使用id来表示描述符,能支持更多的请求数量,缺点和select方式有点类似,就是轮询的效率很低,并且需要拷贝数据。
+
+当然,上述两种方法适合在请求总数较少,并且活跃请求数较多的情况,这种场景下他们的性能还是不错的。
+
+3.3 epoll
+
+epoll函数会在内核空间开辟一个特殊的数据结构,红黑树,树节点中存放的是一个socket描述符以及用户程序感兴趣的事件类型。同时epoll还会维护一个链表。用于存储已经就绪的socket描述符节点。
+
+由Linux内核完成对红黑树的维护,当事件到达时,内核将就绪的socket节点加入链表中,用户程序可以直接访问这个链表以便获取就绪的socket。
+
+当然了,这些操作都linux包装在epoll的api中了。
+
+epoll_create函数会执行红黑树的创建操作。
+
+epoll_ctl函数会将socket和感兴趣的事件注册到红黑树中。
+
+epoll_wait函数会等待内核空间发来的链表,从而执行IO请求。
+
+epoll的水平触发和边缘触发有所区别,水平触发的意思是,如果用户程序没有执行就绪链表里的任务,epoll仍会不断通知程序。
+
+而边缘触发只会通知程序一次,之后socket的状态不发生改变epoll就不会再通知程序了。
+
+4 信号驱动
+略
+
+5 异步非阻塞
+
+用户进程发起read操作之后,立刻就可以开始去做其它的事。而另一方面,从kernel的角度,当它受到一个asynchronous read之后,首先它会立刻返回,所以不会对用户进程产生任何block。然后,kernel会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都完成之后,kernel会给用户进程发送一个signal,告诉它read操作完成了。
+
+事实上就是,用户提交IO请求,然后直接返回,并且内核自动完成将数据从内核缓冲区复制到用户缓冲区,完成后再通知用户。
+
+当然,内核通知我们以后我们还需要执行剩余的操作,但是我们的代码已经继续往下运行了,所以AIO采用了回调的机制,为每个socket注册一个回调事件或者是回调处理器,在处理器中完成数据的操作,也就是内核通知到用户的时候,会自动触发回调函数,完成剩余操作。
+这样的方式就是异步的网络编程。
+
+但是,想要让操作系统支持这样的功能并非易事,windows的IOCP可以支持AIO方式,但是Linux的AIO支持并不是很好
+## NIO
+
+由于Java原生的socket只支持阻塞方式处理IO
+
+所以Java后来推出了新版IO 也叫New IO = NIO
+
+NIO提出了socketChannel,serversocketchannel,bytebuffer,selector和selectedkey等概念。
+
+1 socketchannel其实就是socket的替代品,他的好处是多个socket可以复用同一个bytebuffer,因为socket是从channel里打开的,所以多个socket都可以访问channel绑定着的buffer。
+
+2 serversocketchannel顾名思义,是用在服务端的channel。
+
+3 bytebuffer以前对用户是透明的,用户直接操作io流即可,所以之前的socket io操作都是阻塞的,引入bytebuffer以后,用户可以更灵活地进行io操作。
+
+buffer可以分为不同数据类型的buffer,但是常用的还是bytebuffer。写入数据时按顺序写入,写入完使用flip方法反转缓冲区,让接收端反向读取。这个操作比较麻烦,后来的netty对缓冲区进行了重新封装,封装了这个经常容易出错的方法。
+
+4 selector其实就是对io多路复用器的封装,一般基于linux的epoll来实现。
+socket把感兴趣的事件和描述符注册到selector上,然后通过遍历selectedKey来获取感兴趣的请求,进行IO操作。
+selectedkey应该就是epoll中就绪链表的实现了。
+
+5 所以一般的流程是:
+新建一个serversocket,启动一个线程进行while循环,当有请求接入时,使用accept方法阻塞获取socket,然后将socket和感兴趣的事件注册到selector上。再开启一个线程轮询selectoredKey,当请求就绪时开启一个线程去处理即可。
+
+## AIO
+
+后来NIO发展到2.0,Java又推出了AIO 的API,与上面描述的异步非阻塞模型类似。
+
+AIO使用回调的方式处理IO请求,在socket上注册一个回调函数,然后提交请求后直接返回。由操作系统完成数据拷贝操作,需要操作系统对AIO的支持。
+
+AIO的具体使用方式还是比较复杂的,感兴趣的可以自己查阅资料。
+
+## Tomcat中的NIO模型
+
+Tomcat作为一个应用服务器,分为connector和container两个部分,connector负责接收请求,而container负责解析请求。
+
+一般connector负责接收http请求,当然首先要建立tcp连接,所以涉及到了如何处理连接和IO请求。
+
+Tomcat使用endpoint的概念来绑定一个ip+port,首先,使用acceptor循环等待连接请求。然后开启一个线程池,也叫poller池,每个请求绑定一个poller进行后续处理,poller将socket请求封装成一个事件,并且将这个事件注册到selector中。
+
+poller还需要维护一个事件列表,以便获取selector上就绪的事件。然后poller再去列表中获取就绪的请求,将其封装成processor,交给后续的worker线程池,会有worker将其提交给container流程中进行处理。
+
+当然,到达container之后还有非常复杂的处理过程,稍微提几个点。
+
+## Tomcat的container
+
+container是一个多级容器,最外层到最内层依次是engine,host,context和wrapper
+
+下面是个server.xml文件实例,Tomcat根据该文件进行部署
+
+ //顶层类元素,可以包括多个Service
+ //顶层类元素,可包含一个Engine,多个Connecter
+ //连接器类元素,代表通信接口
+ //容器类元素,为特定的Service组件处理客户请求,要包含多个Host
+ //容器类元素,为特定的虚拟主机组件处理客户请求,可包含多个Context
+ //容器类元素,为特定的Web应用处理所有的客户请求
+
+
+
+
+
+
+
+
+根据配置文件初始化容器信息,当请求到达时进行容器间的请求传递,事实上整个链条被称作pipeline,pipeline连接了各个容器的入口,由于每个容器和组件都实现了lifecycle接口。
+
+tomcat可以在任意流程中通过加监听器的方式监听组件的生命周期,也就能够控制整个运行的流程,通过在pipeline上增加valve可以增加一些自定义的操作。
+
+一般到wrapper层才开始真正的请求解析,因为wrapper其实就是对servlet的简单封装,此时进来的请求和响应已经是httprequest和httpresponse,很多信息已经解析完毕,只需要按照service方法执行业务逻辑即可,当然在执行service方法之前,会调用filter链先执行过滤操作。
+
+## netty
+
+netty我也不是很在行,这里简单总结一下
+
+netty是一个基于事件驱动的网络编程框架。
+
+因为直接基于Java NIO编程复杂度太高,而且容易出错,于是netty对NIO进行了改造和封装。形成了一个比较完整的网络框架,可以通过他实现rpc,http服务。
+
+先了解一下两种线程模型。reactor和proactor。
+
+1 reactor就是netty采用的模型,首先也是使用一个acceptor线程接收连接请求,然后开启一个线程组reactor thread pool。
+
+server会事先在endpoint上注册一系列的回调方法,然后接收socket请求后交给底层的selector进行管理,当selector对应的事件响应以后,会通知用户进程,然后reactor工作线程会执行接下来的IO请求,执行操作是写在回调处理器中的。
+
+
+其实netty 支持三种reactor模型
+1.1.Reactor单线程模型:Reactor单线程模型,指的是所有的I/O操作都在同一个NIO线程上面完成。对于一些小容量应用场景,可以使用单线程模型。
+
+1.2.Reactor多线程模型:Rector多线程模型与单线程模型最大的区别就是有一组NIO线程处理I/O操作。主要用于高并发、大业务量场景。
+
+1.3.主从Reactor多线程模型:主从Reactor线程模型的特点是服务端用于接收客户端连接的不再是个1个单独的NIO线程,而是一个独立的NIO线程池。利用主从NIO线程模型,可以解决1个服务端监听线程无法有效处理所有客户端连接的性能不足问题
+
+2 proactor模型其实是基于异步非阻塞IO模型的,当accpetor接收到请求以后,直接提交异步的io请求给linux内核,内核完成io请求后会回写消息到proactor提供的事件队列中,此时工作线程查看到IO请求已完成,则会继续剩余的工作,也是通过回调处理器来进行的。
+
+所以两者最大的差别是,前者基于epoll的IO多路复用,后者基于AIO实现。
+
+3 netty的核心组件:
+
+bytebuf
+
+bytebuf是对NIO中Bytebuffer的优化和扩展,并且支持堆外内存分配,堆外内存避免gc,可以更好地与内核空间进行交换数据。
+
+channel和NIO的channel类似,但是NIO的socket代码改成nio实现非常麻烦,所以netty优化了这个过程,只需替换几个类就可以实现不更新太多代码就完成旧IO和新IO的切换。
+
+channelhandler就是任务的处理器了,使用回调函数的方式注册到channel中,更准确来说是注册到channelpipeline里。
+
+channelpipeline是用来管理和连接多个channelhandler的容器,执行任务时,会根据channelpipeline的调用链完成处理器的顺序调用,启动服务器时只需要将需要的channelhandler注册在上面就可以了。
+
+eventloop
+在Netty的线程模型中,一个EventLoop将由一个永远不会改变的Thread驱动,而一个Channel一生只会使用一个EventLoop(但是一个EventLoop可能会被指派用于服务多个Channel),在Channel中的所有I/O操作和事件都由EventLoop中的线程处理,也就是说一个Channel的一生之中都只会使用到一个线程。
+
+
+bootstrap
+
+在深入了解地Netty的核心组件之后,发现它们的设计都很模块化,如果想要实现你自己的应用程序,就需要将这些组件组装到一起。Netty通过Bootstrap类,以对一个Netty应用程序进行配置(组装各个组件),并最终使它运行起来。
+
+对于客户端程序和服务器程序所使用到的Bootstrap类是不同的,后者需要使用ServerBootstrap,这样设计是因为,在如TCP这样有连接的协议中,服务器程序往往需要一个以上的Channel,通过父Channel来接受来自客户端的连接,然后创建子Channel用于它们之间的通信,而像UDP这样无连接的协议,它不需要每个连接都创建子Channel,只需要一个Channel即可。
\ No newline at end of file
diff --git "a/md/Java\351\233\206\345\220\210\347\261\273\346\200\273\347\273\223.md" "b/md/Java\351\233\206\345\220\210\347\261\273\346\200\273\347\273\223.md"
new file mode 100644
index 0000000..f4a9636
--- /dev/null
+++ "b/md/Java\351\233\206\345\220\210\347\261\273\346\200\273\347\273\223.md"
@@ -0,0 +1,108 @@
+---
+title: Java集合框架学习总结
+date: 2018-07-08 22:03:44
+tags:
+ - Java集合
+categories:
+ - 后端
+ - 技术总结
+---
+# Java集合框架学习总结
+
+
+
+这篇总结是基于之前博客内容的一个整理和回顾。
+
+
+
+这里先简单地总结一下,更多详细内容请参考我的专栏:深入浅出Java核心技术
+
+https://blog.csdn.net/column/details/21930.html
+
+里面有包括Java集合类在内的众多Java核心技术系列文章。
+
+
+以下总结不保证全对,如有错误,还望能够指出。谢谢
+
+
+## Colletion,iterator,comparable
+
+
+一般认为Collection是最上层接口,但是hashmap实际上实现的是Map接口。iterator是迭代器,是实现iterable接口的类必须要提供的一个东西,能够使用for(i : A) 这种方式实现的类型能提供迭代器,以前有一个enumeration,现在早弃用了。
+
+
+## List
+
+
+List接口下的实现类有ArrayList,linkedlist,vector等等,一般就是用这两个,用法不多说,老生常谈。
+ArrayList的扩容方式是1.5倍扩容,这样扩容避免2倍扩容可能浪费空间,是一种折中的方案。
+另外他不是线程安全,vector则是线程安全的,它是两倍扩容的。
+
+
+linkedlist没啥好说的,多用于实现链表。
+
+
+
+
+## Map
+
+
+map永远都是重头戏。
+
+
+hashmap是数组和链表的组合结构,数组是一个Entry数组,entry是k-V键值对类型,所以一个entry数组存着很entry节点,一个entry的位置通过key的hashcode方法,再进行hash(移位等操作),最后与表长-1进行相与操作,其实就是取hash值到的后n - 1位,n代表表长是2的n次方。
+
+
+hashmap的默认负载因子是0.75,阈值是16 * 0.75 = 12;初始长度为16;
+
+
+hashmap的增删改查方式比较简单,都是遍历,替换。有一点要注意的是key相等时,替换元素,不相等时连成链表。
+
+
+除此之外,1.8jdk改进了hashmap,当链表上的元素个数超过8个时自动转化成红黑树,节点变成树节点,以提高搜索效率和插入效率到logn。
+
+
+还有一点值得一提的是,hashmap的扩容操作,由于hashmap非线程安全,扩容时如果多线程并发进行操作,则可能有两个线程分别操作新表和旧表,导致节点成环,查询时会形成死锁。chm避免了这个问题。
+
+
+另外,扩容时会将旧表元素移到新表,原来的版本移动时会有rehash操作,每个节点都要rehash,非常不方便,而1.8改成另一种方式,对于同一个index下的链表元素,由于一个元素的hash值在扩容后只有两种情况,要么是hash值不变,要么是hash值变为原来值+2^n次方,这是因为表长翻倍,所以hash值取后n位,第一位要么是0要么是1,所以hash值也只有两种情况。这两种情况的元素分别加到两个不同的链表。这两个链表也只需要分别放到新表的两个位置即可,是不是很酷。
+
+
+最后有一个比较冷门的知识点,hashmap1.7版本链表使用的是节点的头插法,扩容时转移链表仍然使用头插法,这样的结果就是扩容后链表会倒置,而hashmap.1.8在插入时使用尾插法,扩容时使用头插法,这样可以保证顺序不变。
+
+
+## CHM
+
+
+concurrenthashmap也稍微提一下把,chm1.7使用分段锁来控制并发,每个segment对应一个segmentmask,通过key的hash值相与这个segmentmask得到segment位置,然后在找到具体的entry数组下标。所以chm需要维护多个segment,每个segment对应一个数组。分段锁使用的是reetreetlock可重入锁实现。查询时不加锁。
+
+
+1.8则放弃使用分段锁,改用cas+synchronized方式实现并发控制,查询时不加锁,插入时如果没有冲突直接cas到成功为止,有冲突则使用synchronized插入。
+
+
+
+
+## Set
+
+
+set就是hashmap将value固定为一个object,只存key元素包装成一个entry即可,其他不变。
+
+
+## Linkedhashmap
+
+
+在原来hashmap基础上将所有的节点依据插入的次序另外连成一个链表。用来保持顺序,可以使用它实现lru缓存,当访问命中时将节点移到队头,当插入元素超过长度时,删除队尾元素即可。
+
+
+## collections和Arrays工具类
+两个工具类分别操作集合和数组,可以进行常用的排序,合并等操作。
+
+
+## comparable和comparator
+实现comparable接口可以让一个类的实例互相使用compareTo方法进行比较大小,可以自定义比较规则,comparator则是一个通用的比较器,比较指定类型的两个元素之间的大小关系。
+
+
+## treemap和treeset
+
+
+主要是基于红黑树实现的两个数据结构,可以保证key序列是有序的,获取sortedset就可以顺序打印key值了。其中涉及到红黑树的插入和删除,调整等操作,比较复杂,这里就不细说了。
\ No newline at end of file
diff --git "a/md/Mysql\345\216\237\347\220\206\344\270\216\345\256\236\350\267\265\346\200\273\347\273\223.md" "b/md/Mysql\345\216\237\347\220\206\344\270\216\345\256\236\350\267\265\346\200\273\347\273\223.md"
new file mode 100644
index 0000000..b7f96f4
--- /dev/null
+++ "b/md/Mysql\345\216\237\347\220\206\344\270\216\345\256\236\350\267\265\346\200\273\347\273\223.md"
@@ -0,0 +1,345 @@
+---
+title: Mysql原理与实践总结
+date: 2018-07-08 22:15:04
+tags:
+ - Mysql
+categories:
+ - 后端
+ - 技术总结
+---
+# 数据库(MySQL)
+
+本文根据自己对MySQL的学习和实践以及各类文章与书籍总结而来。
+囊括了MySQL数据库的基本原理和技术。本文主要是我的一个学习总结,基于之前的系列文章做了一个概括,如有错误,还望指出,谢谢。
+
+详细内容请参考我的系列文章:
+#重新学习MySQL与Redis
+#https://blog.csdn.net/column/details/21877.html?
+
+# 数据库原理
+Mysql是关系数据库。
+
+## 范式 反范式
+范式设计主要是避免冗余,以及数据不一致。反范式设计主要是避免多表连接,增加了冗余。
+
+## 主键 外键
+主键是一个表中一行数据的唯一标识。
+外键则是值某一列的键值是其他表的主键,外键的作用一般用来作为两表连接的键,并且保证数据的一致性。
+
+## 锁 共享锁和排它锁
+数据库的锁用来进行并发控制,排它锁也叫写锁,共享锁也叫行锁,根据不同粒度可以分为行锁和表锁。
+
+## 存储过程与视图
+存储过程是对sql语句进行预编译并且以文件形式包装为一个可以快速执行的程序。但是缺点是不易修改,稍微改动语句就需要重新开发储存过程,优点是执行效率快。视图就是对其他一个或多个表进行重新包装,是一个外观模式,对视图数据的改动也会影响到数据报本身。
+
+## 事务与隔离级别
+事务的四个性质:原子性,一致性,持久性,隔离性。
+
+原子性:一个事务中的操作要么全部成功要么全部失败。
+
+一致性:事务执行成功的状态都是一致的,即使失败回滚了,也应该和事务执行前的状态是一致的。
+
+隔离性:两个事务之间互不相干,不能互相影响。
+
+事务的隔离级别
+读未提交:事务A和事务B,A事务中执行的操作,B也可以看得到,因为级别是未提交读,别人事务中还没提交的数据你也看得到。这是没有任何并发措施的级别,也是默认级别。这个问题叫做脏读,为了解决这个问题,提出了读已提交。
+
+读已提交:事务A和B,A中的操作B看不到,只有A提交后,在B中才看得到。虽然A的操作B看不到,但是B可以修改A用到的数据,导致A读两次的数据结果不同。这就是不可重读问题。
+
+可重复读:事务A和B,事务A和B,A在数据行上加读锁,B虽然看得到但是改不了。所以是可重复读的,但是A的其他行仍然会被B访问并修改,所以导致了幻读问题。
+
+序列化:数据库强制事务A和B串行化操作,避免了并发问题,但是效率比较低。
+
+后面可以看一下mysql对隔离级别的实现。
+
+## 索引
+
+索引的作用就和书的目录类似,比如根据书名做索引,然后我们通过书名就可以直接翻到某一页。数据表中我们要找一条数据,也可以根据它的主键来找到对应的那一页。当然数据库的搜索不是翻书,如果一页一页翻书,就相当于是全表扫描了,效率很低,所以人翻书肯定也是跳着翻。数据库也会基于类似的原理"跳着”翻书,快速地找到索引行。
+
+# mysql原理
+
+MySQL是oracle公司的免费数据库,作为关系数据库火了很久了。所以我们要学他。
+
+## mysql客户端,服务端,存储引擎,文件系统
+
+MySQL数据库的架构可以分为客户端,服务端,存储引擎和文件系统。
+
+详细可以看下架构图,我稍微总结下
+
+ 最高层的客户端,通过tcp连接mysql的服务器,然后执行sql语句,其中涉及了查询缓存,执行计划处理和优化,接下来再到存储引擎层执行查询,底层实际上访问的是主机的文件系统。
+
+
+
+## mysql常用语法
+
+1 登录mysql
+
+mysql -h 127.0.0.1 -u 用户名 -p
+
+2 创建表
+语法还是比较复杂的,之前有腾讯面试官问这个,然后答不上来。
+
+ CREATE TABLE `user_accounts` (
+ `id` int(100) unsigned NOT NULL AUTO_INCREMENT primary key,
+ `password` varchar(32) NOT NULL DEFAULT '' COMMENT '用户密码',
+ `reset_password` tinyint(32) NOT NULL DEFAULT 0 COMMENT '用户类型:0-不需要重置密码;1-需要重置密码',
+ `mobile` varchar(20) NOT NULL DEFAULT '' COMMENT '手机',
+ `create_at` timestamp(6) NOT NULL DEFAULT CURRENT_TIMESTAMP(6),
+ `update_at` timestamp(6) NOT NULL DEFAULT CURRENT_TIMESTAMP(6) ON UPDATE CURRENT_TIMESTAMP(6),
+ -- 创建唯一索引,不允许重复
+ UNIQUE INDEX idx_user_mobile(`mobile`)
+ )
+ ENGINE=InnoDB DEFAULT CHARSET=utf8
+
+
+3 crud比较简单,不谈
+
+4 join用于多表连接,查询的通常是两个表的字段。
+
+union用于组合同一种格式的多个select查询。
+
+6 聚合函数,一般和group by一起使用,比如查找某部门员工的工资平均值。
+就是select AVE(money) from departmentA group by department
+
+7 建立索引
+
+
+唯一索引(UNIQUE)
+语法:ALTER TABLE 表名字 ADD UNIQUE (字段名字)
+
+添加多列索引
+语法:
+
+ALTER TABLE table_name ADD INDEX index_name ( column1, column2, column3)
+
+8 修改添加列
+
+添加列
+语法:alter table 表名 add 列名 列数据类型 [after 插入位置];
+
+删除列
+语法:alter table 表名 drop 列名称;
+
+9 清空表数据
+方法一:delete from 表名;
+方法二:truncate from "表名";
+
+DELETE:1. DML语言;2. 可以回退;3. 可以有条件的删除;
+
+TRUNCATE:1. DDL语言;2. 无法回退;3. 默认所有的表内容都删除;4. 删除速度比delete快。
+
+## MySQL的存储原理
+
+下面我们讨论的是innodb的存储原理
+
+innodb的存储引擎将数据存储单元分为多层。按此不表
+
+MySQL中的逻辑数据库只是一个shchme。事实上物理数据库只有一个。
+
+mysql使用两个文件分别存储数据库的元数据和数据库的真正数据。
+### 数据页page
+
+数据页结构
+页是 InnoDB 存储引擎管理数据的最小磁盘单位,而 B-Tree 节点就是实际存放表中数据的页面,我们在这里将要介绍页是如何组织和存储记录的;首先,一个 InnoDB 页有以下七个部分:
+
+
+
+每一个页中包含了两对 header/trailer:内部的 Page Header/Page Directory 关心的是页的状态信息,而 Fil Header/Fil Trailer 关心的是记录页的头信息。
+
+ 也就是说,外部的h-t对用来和其他页形成联系,而内部的h-t用来是保存内部记录的状态。
+
+
+
+User Records 就是整个页面中真正用于存放行记录的部分,而 Free Space 就是空余空间了,它是一个链表的数据结构,为了保证插入和删除的效率,整个页面并不会按照主键顺序对所有记录进行排序,它会自动从左侧向右寻找空白节点进行插入,行记录在物理存储上并不是按照顺序的,它们之间的顺序是由 next_record 这一指针控制的。
+
+ 也就是说,一个页中存了非常多行的数据,而每一行数据和相邻行使用指针进行链表连接。
+
+## mysql的索引,b树,聚集索引
+
+1 MySQL的innodb支持聚簇索引,myisam不支持聚簇索引。
+
+innodb在建表时自动按照第一个非空字段或者主键建立聚簇索引。mysql使用B+树建立索引。
+
+每一个非叶子结点只存储主键值,而叶子节点则是一个数据页,这个数据页就是上面所说的存储数据的page页。
+
+一个节点页对应着多行数据,每个节点按照顺序使用指针连成一个链表。mysql使用索引访问一行数据时,先通过log2n的时间访问到叶子节点,然后在数据页中按照行数链表执行顺序查找,直到找到那一行数据。
+
+2 b+树索引可以很好地支持范围搜索,因为叶子节点通过指针相连。
+
+## mysql的explain 慢查询日志
+
+explain主要用于检查sql语句的执行计划,然后分析sql是否使用到索引,是否进行了全局扫描等等。
+
+mysql慢查询日志可以在mysql的,my.cnf文件中配置开启,然后执行操作超过设置时间就会记录慢日志。
+
+比如分析一个sql:
+
+ explain查看执行计划
+
+ id select_type table partitions type possible_keys key key_len ref rows filtered Extra
+
+ 1 SIMPLE vote_record \N ALL votenum,vote \N \N \N 996507 50.00 Using where
+
+
+
+ 还是没用到索引,因为不符合最左前缀匹配。查询需要3.5秒左右
+
+
+
+ 最后修改一下sql语句
+
+ EXPLAIN SELECT * FROM vote_record WHERE id > 0 AND vote_num > 1000;
+
+ id select_type table partitions type possible_keys key key_len ref rows filtered Extra
+
+ 1 SIMPLE vote_record \N range PRIMARY,votenum,vote PRIMARY 4 \N 498253 50.00 Using where
+
+
+
+ 用到了索引,但是只用到了主键索引。再修改一次
+
+
+
+ EXPLAIN SELECT * FROM vote_record WHERE id > 0 AND vote_num = 1000;
+
+
+
+ id select_type table partitions type possible_keys key key_len ref rows filtered Extra
+
+ 1 SIMPLE vote_record \N index_merge PRIMARY,votenum,vote votenum,PRIMARY 8,4 \N 51 100.00 Using intersect(votenum,PRIMARY); Using where
+
+
+
+ 用到了两个索引,votenum,PRIMARY。
+
+## mysql的binlog,redo log和undo log。
+
+binlog就是二进制日志,用于记录用户数据操作的日志。用于主从复制。
+
+redolog负责事务的重做,记录事务中的每一步操作,记录完再执行操作,并且在数据刷入磁盘前刷入磁盘,保证可以重做成功。
+
+undo日志负责事务的回滚,记录事务操作中的原值,记录完再执行操作,在事务提交前刷入磁盘,保证可以回滚成功。
+
+这两个日志也是实现分布式事务的基础。
+
+## mysql的数据类型
+
+mysql一般提供多种数据类型,int,double,varchar,tinyint,datatime等等。文本的话有fulltext,mediumtext等。没啥好说的。
+
+## mysql的sql优化。
+
+sql能优化的点是在有点多。
+
+比如基本的,不使用null判断,不使用><
+分页的时候利用到索引,查询的时候注意顺序。
+
+如果是基于索引的优化,则要注意索引列是否能够使用到
+
+ 1 索引列不要使用>< != 以及 null,还有exists等。
+
+ 2 索引列不要使用聚集函数。
+
+ 3 如果是联合索引,排在第一位的索引一定要用到,否则后面的也会失效,为什么呢,因为第一列索引不同时才会找第二列,如果没有第一列索引,后续的索引页没有意义。
+
+ 举个例子。联合索引A,B,C。查询时必须要用到A,但是A的位置无所谓,只要用到就行,A,B,C或者C,B,A都可以。
+
+ 4 分页时直接limit n 5可能用不到索引,假设索引列是ID,那么我们使用where id > n limit 5就可以实现上述操作了。
+
+## MySQL的事务实现和锁
+
+
+innodb支持行级锁和事务,而myisam只支持表锁,它的所有操作都需要加锁。
+
+1 锁
+
+ 锁可以分为共享锁和排它锁,也叫读锁和写锁。
+
+ select操作默认不加锁,需要加锁时会用for update加排它锁,或者用in share mode表示加共享锁。
+
+ 这里的锁都是行锁。
+ innodb会使用行锁配合mvcc一同完成事务的实现。
+ 并且使用next-key lock来实现可重复读,而不必加表锁或者串行化执行。
+
+2 MVCC
+
+ MVCC是多版本控制协议。
+
+ 通过时间戳来判断先后顺序,并且是无锁的。但是需要额外存一个字段。
+
+ 读操作比较自己的版本号,自动读取比自己版本号新的版本。不读。
+
+ 写操作自动覆盖写版本号比自己的版本号早的版本。否则不写。
+
+ 这样保证一定程度上的一致性。
+
+ MVCC比较好地支持读多写少的情景。
+
+ 但是偶尔需要加锁时才会进行加锁。
+
+3 事务
+
+所以看看innodb如何实现事务的。
+
+首先,innodb的行锁是加在索引上的,因为innodb默认有聚簇索引,但实际上的行锁是对整个索引节点进行加锁,锁了该节点所有的行。
+
+看看innodb如何实现隔离级别以及解决一致问题
+
+ 未提交读,会导致脏读,没有并发措施
+
+ 已提交读,写入时需要加锁,使用行级写锁锁加锁指定行,其他事务就看不到未提交事务的数据了。但是会导致不可重读,
+
+ 可重复读:在原来基础上,在读取行时也需要加行级读锁,这样其他事务不能修改这些数据。就避免了不可重读。
+ 但是这样会导致幻读。
+
+ 序列化:序列化会串行化读写操作来避免幻读,事实上就是事务在读取数据时加了表级读锁。
+
+但是实际上。mysql的新版innodb引擎已经解决了幻读的问题,并且使用的是可重复读级别就能解决幻读了。
+
+实现的原理是next-key lock。是gap lock的加强版。不会锁住全表,只会锁住被读取行前后的间隙行。
+
+
+
+
+## 分库分表
+
+分库分表的方案比较多,首先看下分表。
+
+当一个大表没办法继续优化的时候,可以使用分表,横向拆分的方案就是把一个表的数据放到多个表中。一般可以按照某个键来分表。比如最常用的id,1-100w放在表一。100w-200w在表二,以此类推。
+
+如果是纵向分表,则可以按列拆分,比如用户信息的字段放在一个表,用户使用数据放在另一个表,这其实就是一次性拆表了。
+
+分库的话就是把数据表存到多个库中了,和横向分表的效果差不多。
+
+如果只是单机的分表分库,其性能瓶颈在于主机。
+
+我们需要考虑扩展性,所以需要使用分布式的数据库。
+
+==分布式数据库解决方案mycat==
+
+ mycat是一款支持分库分表的数据库中间件,支持单机也支持分布式。
+
+ 首先部署mycat,mycat的访问方式和一个mysqlserver是类似的。里面可以配置数据库和数据表。
+
+ 然后在mycat的配置文件中,我们可以指定分片,比如按照id分片,然后在每个分片下配置mysql节点,可以是本地的数据库实例也可以是其他主机上的数据库。
+
+ 这样的话,每个分片都能找到对应机器上的数据库和表了。
+
+ 用户连接mycat执行数据库操作,实际上会根据id映射到对应的数据库和表中,
+
+## 主从复制,读写分离
+
+主从复制大法好,为了避免单点mysql宕机和丢失数据,我们一般使用主从部署,主节点将操作日志写入binlog,然后日志文件通过一个连接传给从节点的relaylog。从节点定时去relaylog读取日志,并且执行操作。这样保证了主从的同步。
+
+读写分离大法好,为了避免主库的读写压力太大,由于业务以读操作为主,所以主节点一般作为主库,读节点作为从库,从库负责读,主库负责写,写入主库的数据通过日志同步给从库。这样的部署就是读写分离。
+
+使用mycat中间件也可以配置读写分离,只需在分片时指定某个主机是读节点还是写节点即可。
+
+## 分布式数据库
+
+分布式关系数据库无非就是关系数据库的分布式部署方案。
+
+真正的分布式数据库应该是nosql数据库,比如基于hdfs的hbase数据库。底层就是分布式的。
+
+redis的分布式部署方案也比较成熟。
+
+##
\ No newline at end of file
diff --git a/md/README.md b/md/README.md
new file mode 100644
index 0000000..9a81fc5
--- /dev/null
+++ b/md/README.md
@@ -0,0 +1,27 @@
+[数据结构和算法](#算法) | [操作系统](#操作系统) | [网络](#网络) | [数据结构](#数据结构) | [数据库](#数据库) | [Java基础](#Java基础) | [Java进阶](#Java进阶) | [Web和Spring](#Web和Spring) | [分布式](#分布式) | [Hadoop](#Hadoop) | [工具](#工具) | [编码实践](#编码实践)
+
+## 数据结构和算法
+## 操作系统
+## 网络
+## 数据库
+## Java基础
+## Java进阶
+## web和Spring
+## 分布式
+## Hadoop
+## 工具
+## 编码实践
+
+## 后记
+**关于仓库**
+本仓库是笔者在准备 2018 年秋招复习过程中的学习总结,内容以Java后端的知识总结为主,每个部分都会有笔者更加详细的原创文章可供参考,欢迎查看。
+**关于贡献**
+笔者能力有限,很多内容还不够完善。如果您希望和笔者一起完善这个仓库,可以发表一个 Issue,表明您想要添加的内容,笔者会及时查看。
+您也可以在 Issues 中发表关于改进本仓库的建议。
+**关于排版**
+笔记排版参考@CYC2018
+**关于转载**
+本仓库内容使用到的资料都会在最后面的参考资料中给出引用链接,希望您在使用本仓库的内容时也能给出相应的引用链接。
+**鸣谢**
+[CyC2018](https://github.com/CyC2018)
+
diff --git "a/md/Redis\345\216\237\347\220\206\344\270\216\345\256\236\350\267\265\346\200\273\347\273\223.md" "b/md/Redis\345\216\237\347\220\206\344\270\216\345\256\236\350\267\265\346\200\273\347\273\223.md"
new file mode 100644
index 0000000..2ef3830
--- /dev/null
+++ "b/md/Redis\345\216\237\347\220\206\344\270\216\345\256\236\350\267\265\346\200\273\347\273\223.md"
@@ -0,0 +1,429 @@
+---
+title: Redis原理与实践总结
+date: 2018-07-08 22:15:12
+tags:
+ - Redis
+categories:
+ - 后端
+ - 技术总结
+---
+# Redis设计与实现学习总结
+
+本文主要对Redis的设计和实现原理做了一个介绍很总结,有些东西我也介绍的不是很详细准确,尽量在自己的理解范围内把一些知识点和关键性技术做一个描述。如有错误,还望见谅,欢迎指出。
+这篇文章主要还是参考我之前的技术专栏总结而来的。欢迎查看:
+#重新学习Redis
+#https://blog.csdn.net/column/details/21877.html
+
+## 使用和基础数据结构(外观)
+
+redis的基本使用方式是建立在redis提供的数据结构上的。
+
+字符串
+REDIS_STRING (字符串)是 Redis 使用得最为广泛的数据类型,它除了是 SET 、GET 等命令 的操作对象之外,数据库中的所有键,以及执行命令时提供给 Redis 的参数,都是用这种类型 保存的。
+
+字符串类型分别使用 REDIS_ENCODING_INT 和 REDIS_ENCODING_RAW 两种编码
+
+只有能表示为 long 类型的值,才会以整数的形式保存,其他类型 的整数、小数和字符串,都是用 sdshdr 结构来保存
+
+哈希表
+REDIS_HASH (哈希表)是HSET 、HLEN 等命令的操作对象
+
+它使用 REDIS_ENCODING_ZIPLIST和REDIS_ENCODING_HT 两种编码方式
+
+Redis 中每个hash可以存储232-1键值对(40多亿)
+
+列表
+REDIS_LIST(列表)是LPUSH 、LRANGE等命令的操作对象
+
+它使用 REDIS_ENCODING_ZIPLIST和REDIS_ENCODING_LINKEDLIST 这两种方式编码
+
+一个列表最多可以包含232-1 个元素(4294967295, 每个列表超过40亿个元素)。
+
+集合
+REDIS_SET (集合) 是 SADD 、 SRANDMEMBER 等命令的操作对象
+
+它使用 REDIS_ENCODING_INTSET 和 REDIS_ENCODING_HT 两种方式编码
+
+Redis 中集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)。
+
+集合中最大的成员数为 232 - 1 (4294967295, 每个集合可存储40多亿个成员)
+
+有序集
+REDIS_ZSET (有序集)是ZADD 、ZCOUNT 等命令的操作对象
+
+它使用 REDIS_ENCODING_ZIPLIST和REDIS_ENCODING_SKIPLIST 两种方式编码
+
+不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。
+
+有序集合的成员是唯一的,但分数(score)却可以重复。
+
+集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)。 集合中最大的成员数为 232 - 1 (4294967295, 每个集合可存储40多亿个成员)
+
+下图说明了,外部数据结构和底层实际数据结构是通过realobject来连接的。一个外观类型里面必然存着一个realobject,通过它来访问底层数据结构。
+
+
+
+
+## 底层数据结构
+
+下面讨论redis底层数据结构
+
+
+1 SDS动态字符串
+
+sds字符串是字符串的实现
+
+动态字符串是一个结构体,内部有一个buf数组,以及字符串长度,剩余长度等字段,优点是通过长度限制写入,避免缓冲区溢出,另外剩余长度不足时会自动扩容,扩展性较好,不需要频繁分配内存。
+
+并且sds支持写入二进制数据,而不一定是字符。
+
+2 dict字典
+
+dict字典是哈希表的实现。
+
+dict字典与Java中的哈希表实现简直如出一辙,首先都是数组+链表组成的结构,通过dictentry保存节点。
+
+其中dict同时保存两个entry数组,当需要扩容时,把节点转移到第二个数组即可,平时只使用一个数组。
+
+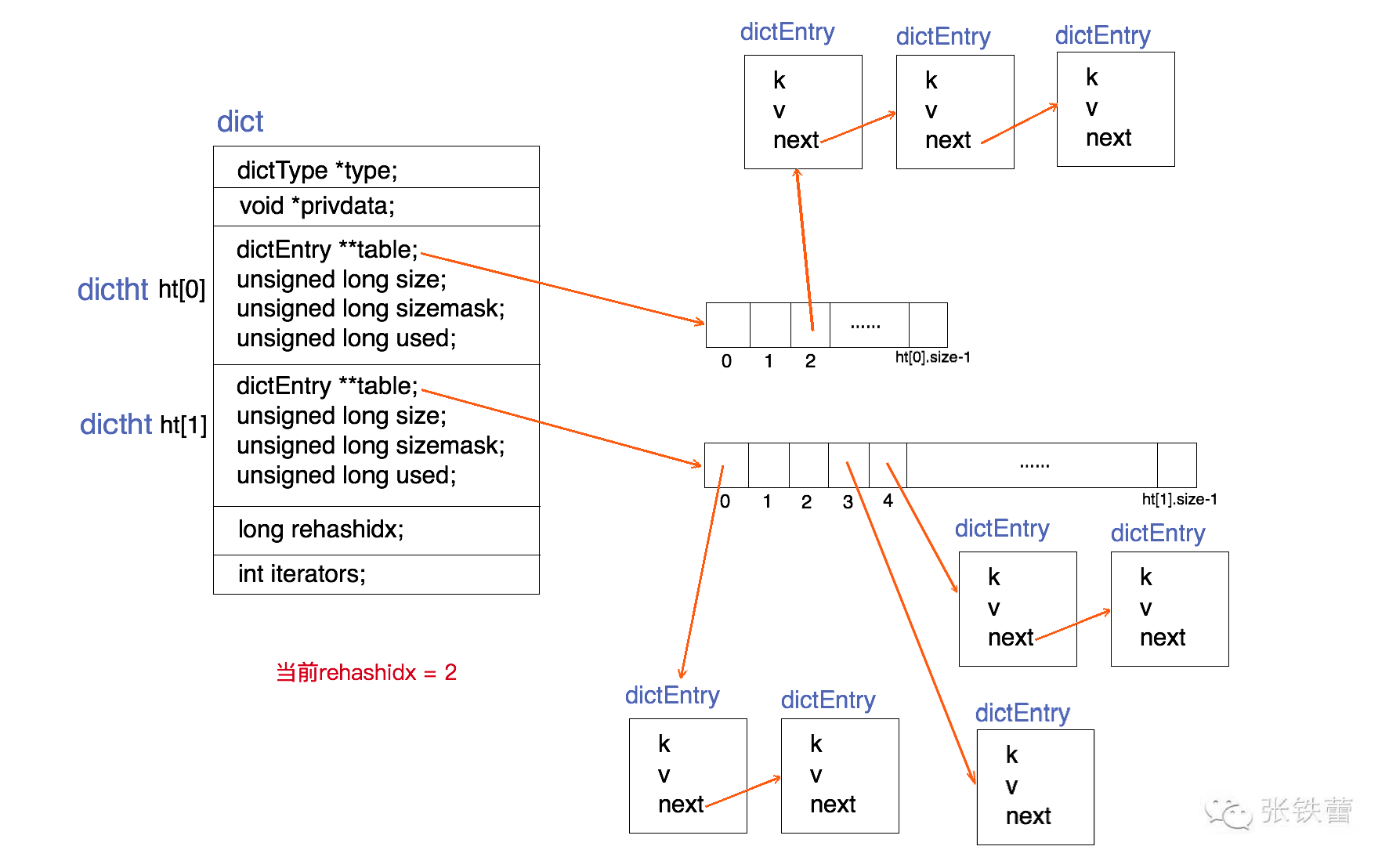
+
+3 压缩链表ziplist
+
+3.1 ziplist是一个经过特殊编码的双向链表,它的设计目标就是为了提高存储效率。ziplist可以用于存储字符串或整数,其中整数是按真正的二进制表示进行编码的,而不是编码成字符串序列。它能以O(1)的时间复杂度在表的两端提供push和pop操作。
+
+3.2 实际上,ziplist充分体现了Redis对于存储效率的追求。一个普通的双向链表,链表中每一项都占用独立的一块内存,各项之间用地址指针(或引用)连接起来。这种方式会带来大量的内存碎片,而且地址指针也会占用额外的内存。
+
+3.3 而ziplist却是将表中每一项存放在前后连续的地址空间内,一个ziplist整体占用一大块内存。它是一个表(list),但其实不是一个链表(linked list)。
+
+3.4 另外,ziplist为了在细节上节省内存,对于值的存储采用了变长的编码方式,大概意思是说,对于大的整数,就多用一些字节来存储,而对于小的整数,就少用一些字节来存储。
+
+实际上。redis的字典一开始的数据比较少时,会使用ziplist的方式来存储,也就是key1,value1,key2,value2这样的顺序存储,对于小数据量来说,这样存储既省空间,查询的效率也不低。
+
+当数据量超过阈值时,哈希表自动膨胀为之前我们讨论的dict。
+
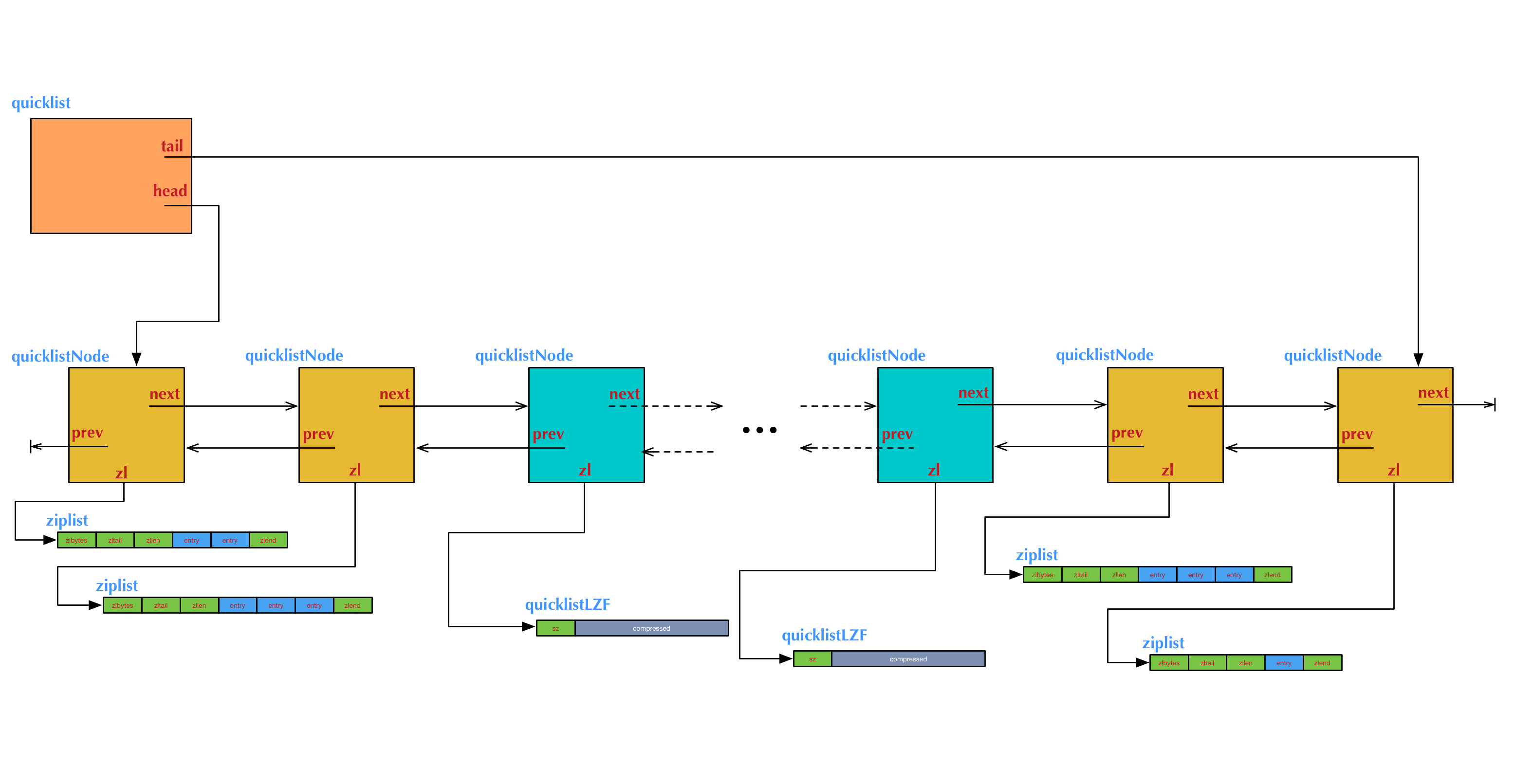
+4 quicklist
+
+quicklist是结合ziplist存储优势和链表灵活性与一身的双端链表。
+
+quicklist的结构为什么这样设计呢?总结起来,大概又是一个空间和时间的折中:
+
+4.1 双向链表便于在表的两端进行push和pop操作,但是它的内存开销比较大。
+
+首先,它在每个节点上除了要保存数据之外,还要额外保存两个指针;其次,双向链表的各个节点是单独的内存块,地址不连续,节点多了容易产生内存碎片。
+
+4.2 ziplist由于是一整块连续内存,所以存储效率很高。
+
+但是,它不利于修改操作,每次数据变动都会引发一次内存的realloc。特别是当ziplist长度很长的时候,一次realloc可能会导致大批量的数据拷贝,进一步降低性能。
+
+
+
+5 zset
+zset其实是两种结构的合并。也就是dict和skiplist结合而成的。dict负责保存数据对分数的映射,而skiplist用于根据分数进行数据的查询(相辅相成)
+
+6 skiplist
+
+sortset数据结构使用了ziplist+zset两种数据结构。
+
+Redis里面使用skiplist是为了实现sorted set这种对外的数据结构。sorted set提供的操作非常丰富,可以满足非常多的应用场景。这也意味着,sorted set相对来说实现比较复杂。
+
+sortedset是由skiplist,dict和ziplist组成的。
+
+当数据较少时,sorted set是由一个ziplist来实现的。
+当数据多的时候,sorted
+
+set是由一个叫zset的数据结构来实现的,这个zset包含一个dict + 一个skiplist。dict用来查询数据到分数(score)的对应关系,而skiplist用来根据分数查询数据(可能是范围查找)。
+
+ 在本系列前面关于ziplist的文章里,我们介绍过,ziplist就是由很多数据项组成的一大块连续内存。由于sorted set的每一项元素都由数据和score组成,因此,当使用zadd命令插入一个(数据, score)对的时候,底层在相应的ziplist上就插入两个数据项:数据在前,score在后。
+
+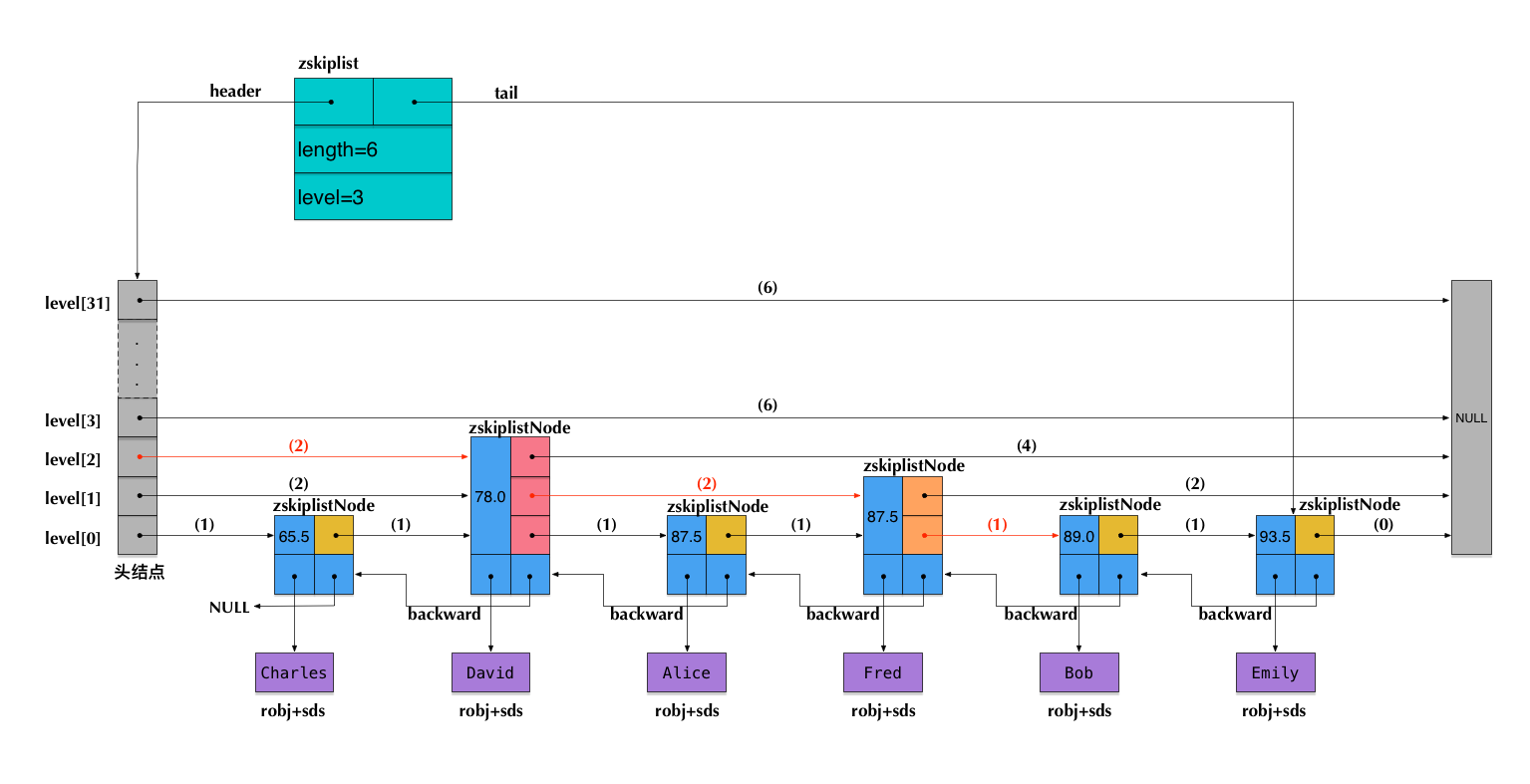
+
+skiplist的节点中存着节点值和分数。并且跳表是根据节点的分数进行排序的,所以可以根据节点分数进行范围查找。
+
+7inset
+
+inset是一个数字结合,他使用灵活的数据类型来保持数字。
+
+
+
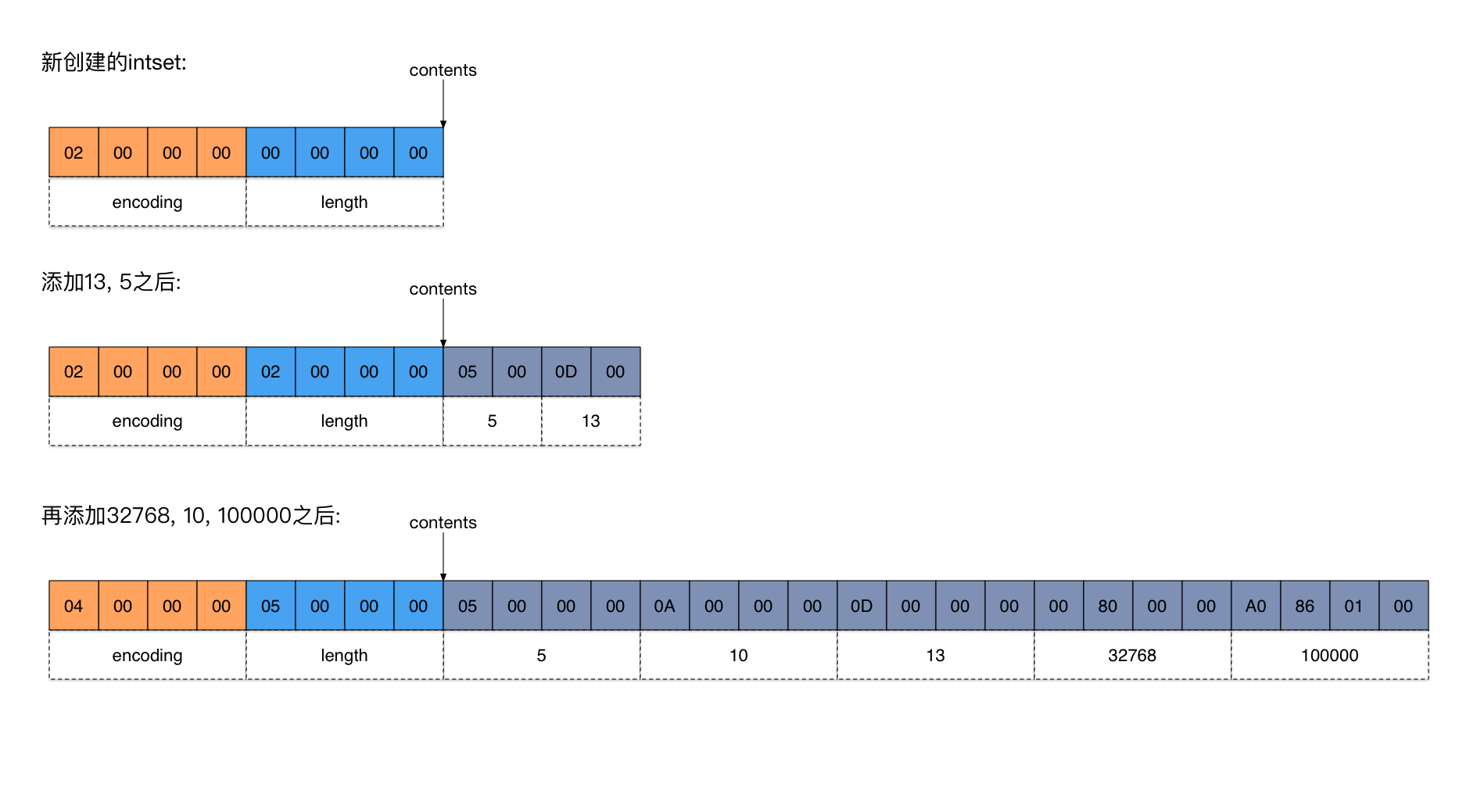
+新创建的intset只有一个header,总共8个字节。其中encoding = 2, length = 0。
+添加13, 5两个元素之后,因为它们是比较小的整数,都能使用2个字节表示,所以encoding不变,值还是2。
+当添加32768的时候,它不再能用2个字节来表示了(2个字节能表达的数据范围是-215~215-1,而32768等于215,超出范围了),因此encoding必须升级到INTSET_ENC_INT32(值为4),即用4个字节表示一个元素。
+
+8总结
+
+sds是一个灵活的字符串数组,并且支持直接存储二进制数据,同时提供长度和剩余空间的字段来保证伸缩性和防止溢出。
+
+dict是一个字典结构,实现方式就是Java中的hashmap实现,同时持有两个节点数组,但只使用其中一个,扩容时换成另外一个。
+
+ziplist是一个压缩链表,他放弃内存不连续的连接方式,而是直接分配连续内存进行存储,减少内存碎片。提高利用率,并且也支持存储二进制数据。
+
+quicklist是ziplist和传统链表的中和形成的链表结果,每个链表节点都是一个ziplist。
+
+skiplist一般有ziplist和zset两种实现方法,根据数据量来决定。zset本身是由skiplist和dict实现的。
+
+inset是一个数字集合,他根据插入元素的数据类型来决定数组元素的长度。并自动进行扩容。
+
+9 他们实现了哪些结构
+
+字符串由sds实现
+
+list由ziplist和quicklist实现
+
+sortset由ziplist和zset实现
+
+hash表由dict实现
+
+集合由inset实现。
+
+
+
+
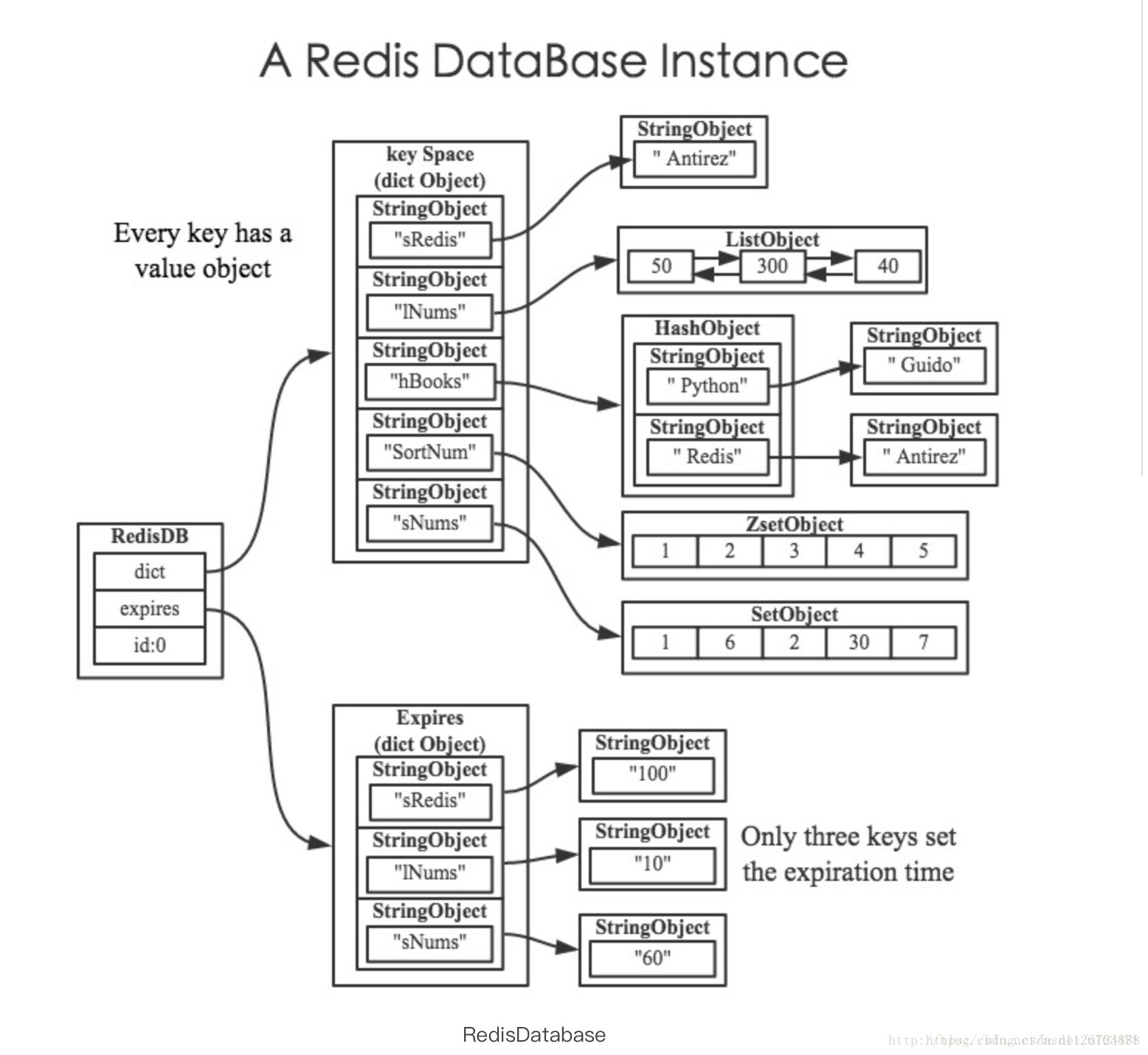
+## redis server结构和数据库redisDb
+
+1 redis服务器中维护着一个数据库名为redisdb,实际上他是一个dict结构。
+
+Redis的数据库使用字典作为底层实现,数据库的增、删、查、改都是构建在字典的操作之上的。
+
+2 redis服务器将所有数据库都保存在服务器状态结构redisServer(redis.h/redisServer)的db数组(应该是一个链表)里:
+
+同理也有一个redis client结构,通过指针可以选择redis client访问的server是哪一个。
+
+3 redisdb的键空间
+
+ typedef struct redisDb {
+ // 数据库键空间,保存着数据库中的所有键值对
+ dict *dict; /* The keyspace for this DB */
+ // 键的过期时间,字典的键为键,字典的值为过期事件 UNIX 时间戳
+ dict *expires; /* Timeout of keys with a timeout set */
+ // 数据库号码
+ int id; /* Database ID */
+ // 数据库的键的平均 TTL ,统计信息
+ long long avg_ttl; /* Average TTL, just for stats */
+ //..
+ } redisDb
+
+这部分的代码说明了,redisdb除了维护一个dict组以外,还需要对应地维护一个expire的字典数组。
+
+大的dict数组中有多个小的dict字典,他们共同负责存储redisdb的所有键值对。
+
+同时,对应的expire字典则负责存储这些键的过期时间
+
+
+4 过期键的删除策略
+
+2、过期键删除策略
+通过前面的介绍,大家应该都知道数据库键的过期时间都保存在过期字典里,那假如一个键过期了,那么这个过期键是什么时候被删除的呢?现在来看看redis的过期键的删除策略:
+
+a、定时删除:在设置键的过期时间的同时,创建一个定时器,在定时结束的时候,将该键删除;
+
+b、惰性删除:放任键过期不管,在访问该键的时候,判断该键的过期时间是否已经到了,如果过期时间已经到了,就执行删除操作;
+
+c、定期删除:每隔一段时间,对数据库中的键进行一次遍历,删除过期的键。
+
+## redis的事件模型
+
+redis处理请求的方式基于reactor线程模型,即一个线程处理连接,并且注册事件到IO多路复用器,复用器触发事件以后根据不同的处理器去执行不同的操作。总结以下客户端到服务端的请求过程
+
+总结
+
+ 远程客户端连接到 redis 后,redis服务端会为远程客户端创建一个 redisClient 作为代理。
+
+ redis 会读取嵌套字中的数据,写入 querybuf 中。
+
+ 解析 querybuf 中的命令,记录到 argc 和 argv 中。
+
+ 根据 argv[0] 查找对应的 recommand。
+
+ 执行 recommend 对应的执行函数。
+
+ 执行以后将结果存入 buf & bufpos & reply 中。
+
+ 返回给调用方。返回数据的时候,会控制写入数据量的大小,如果过大会分成若干次。保证 redis 的相应时间。
+
+ Redis 作为单线程应用,一直贯彻的思想就是,每个步骤的执行都有一个上限(包括执行时间的上限或者文件尺寸的上限)一旦达到上限,就会记录下当前的执行进度,下次再执行。保证了 Redis 能够及时响应不发生阻塞。
+
+## 备份方式
+
+快照(RDB):就是我们俗称的备份,他可以在定期内对数据进行备份,将Redis服务器中的数据持久化到硬盘中;
+
+只追加文件(AOF):他会在执行写命令的时候,将执行的写命令复制到硬盘里面,后期恢复的时候,只需要重新执行一下这个写命令就可以了。类似于我们的MySQL数据库在进行主从复制的时候,使用的是binlog二进制文件,同样的是执行一遍写命令;
+
+appendfsync同步频率的区别如下图:
+
+
+
+## redis主从复制
+
+Redis复制工作过程:
+
+slave向master发送sync命令。
+
+master开启子进程来讲dataset写入rdb文件,同时将子进程完成之前接收到的写命令缓存起来。
+
+子进程写完,父进程得知,开始将RDB文件发送给slave。
+
+master发送完RDB文件,将缓存的命令也发给slave。
+
+master增量的把写命令发给slave。
+
+ 注意有两步操作,一个是写入rdb的时候要缓存写命令,防止数据不一致。发完rdb后还要发写命令给salve,以后增量发命令就可以了
+
+## 分布式锁实现
+
+### 使用setnx加expire实现加锁和时限
+
+ 加锁时使用setnx设置key为1并设置超时时间,解锁时删除键
+
+ tryLock(){
+ SETNX Key 1
+ EXPIRE Key Seconds
+ }
+ release(){
+ DELETE Key
+ }
+
+这个方案的一个问题在于每次提交一个Redis请求,如果执行完第一条命令后应用异常或者重启,锁将无法过期,一种改善方案就是使用Lua脚本(包含SETNX和EXPIRE两条命令),但是如果Redis仅执行了一条命令后crash或者发生主从切换,依然会出现锁没有过期时间,最终导致无法释放。
+
+### 使用getset加锁和获取过期时间
+
+针对锁无法释放问题的一个解决方案基于GETSET命令来实现
+
+ 思路:
+
+ SETNX(Key,ExpireTime)获取锁
+
+ 如果获取锁失败,通过GET(Key)返回的时间戳检查锁是否已经过期
+
+ GETSET(Key,ExpireTime)修改Value为NewExpireTime
+
+ 检查GETSET返回的旧值,如果等于GET返回的值,则认为获取锁成功
+
+ 注意:这个版本去掉了EXPIRE命令,改为通过Value时间戳值来判断过期
+
+
+### 2.0的setnx可以配置过期时间。
+
+ V2.0 基于SETNX
+
+ tryLock(){
+ SETNX Key 1 Seconds
+ }
+ release(){
+ DELETE Key
+ }
+Redis 2.6.12版本后SETNX增加过期时间参数,这样就解决了两条命令无法保证原子性的问题。但是设想下面一个场景:
+1. C1成功获取到了锁,之后C1因为GC进入等待或者未知原因导致任务执行过长,最后在锁失效前C1没有主动释放锁 2. C2在C1的锁超时后获取到锁,并且开始执行,这个时候C1和C2都同时在执行,会因重复执行造成数据不一致等未知情况 3. C1如果先执行完毕,则会释放C2的锁,此时可能导致另外一个C3进程获取到了锁
+
+流程图如下
+
+
+### 使用sentx将值设为时间戳,通过lua脚本进行cas比较和删除操作
+
+ V3.0
+ tryLock(){
+ SETNX Key UnixTimestamp Seconds
+ }
+ release(){
+ EVAL(
+ //LuaScript
+ if redis.call("get",KEYS[1]) == ARGV[1] then
+ return redis.call("del",KEYS[1])
+ else
+ return 0
+ end
+ )
+ }
+这个方案通过指定Value为时间戳,并在释放锁的时候检查锁的Value是否为获取锁的Value,避免了V2.0版本中提到的C1释放了C2持有的锁的问题;另外在释放锁的时候因为涉及到多个Redis操作,并且考虑到Check And Set 模型的并发问题,所以使用Lua脚本来避免并发问题。
+
+ 如果在并发极高的场景下,比如抢红包场景,可能存在UnixTimestamp重复问题,另外由于不能保证分布式环境下的物理时钟一致性,也可能存在UnixTimestamp重复问题,只不过极少情况下会遇到。
+
+### 分布式Redis锁:Redlock
+
+redlock的思想就是要求一个节点获取集群中N/2 + 1个节点
+上的锁才算加锁成功。
+
+
+### 总结
+不论是基于SETNX版本的Redis单实例分布式锁,还是Redlock分布式锁,都是为了保证下特性
+
+ 1. 安全性:在同一时间不允许多个Client同时持有锁
+ 2. 活性
+ 死锁:锁最终应该能够被释放,即使Client端crash或者出现网络分区(通常基于超时机制)
+ 容错性:只要超过半数Redis节点可用,锁都能被正确获取和释放
+## 分布式方案
+
+1 主从复制,优点是备份简易使用。缺点是不能故障切换,并且不易扩展。
+
+2 使用sentinel哨兵工具监控和实现自动切换。
+
+3 codis集群方案
+
+首先codis使用代理的方式隐藏底层redis,这样可以完美融合以前的代码,不需要更改redis访问操作。
+
+然后codis使用了zookeeper进行监控和自动切换。同时使用了redis-group的概念,保证一个group里是一主多从的主从模型,基于此来进行切换。
+
+4 redis cluster集群
+
+该集群是一个p2p方式部署的集群
+
+Redis cluster是一个去中心化、多实例Redis间进行数据共享的集群。
+
+每个节点上都保存着其他节点的信息,通过任一节点可以访问正常工作的节点数据,因为每台机器上的保留着完整的分片信息,某些机器不正常工作不影响整体集群的工作。并且每一台redis主机都会配备slave,通过sentinel自动切换。
+
+
+
+## redis事务
+
+事务
+MULTI 、 EXEC 、 DISCARD 和 WATCH 是 Redis 事务相关的命令。事务可以一次执行多个命令, 并且带有以下两个重要的保证:
+
+事务是一个单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。
+
+事务是一个原子操作:事务中的命令要么全部被执行,要么全部都不执行。
+
+redis事务有一个特点,那就是在2.6以前,事务的一系列操作,如果有的成功有的失败,仍然会提交成功的那部分,后来改为全部不提交了。
+
+但是Redis事务不支持回滚,提交以后不能执行回滚操作。
+
+ 为什么 Redis 不支持回滚(roll back)
+ 如果你有使用关系式数据库的经验, 那么 “Redis 在事务失败时不进行回滚,而是继续执行余下的命令”这种做法可能会让你觉得有点奇怪。
+
+ 以下是这种做法的优点:
+
+ Redis 命令只会因为错误的语法而失败(并且这些问题不能在入队时发现),或是命令用在了错误类型的键上面:这也就是说,从实用性的角度来说,失败的命令是由编程错误造成的,而这些错误应该在开发的过程中被发现,而不应该出现在生产环境中。
+ 因为不需要对回滚进行支持,所以 Redis 的内部可以保持简单且快速。
+
+
+### redis脚本事务
+
+Redis 脚本和事务
+从定义上来说, Redis 中的脚本本身就是一种事务, 所以任何在事务里可以完成的事, 在脚本里面也能完成。 并且一般来说, 使用脚本要来得更简单,并且速度更快。
+
+因为脚本功能是 Redis 2.6 才引入的, 而事务功能则更早之前就存在了, 所以 Redis 才会同时存在两种处理事务的方法。
+
+redis事务的ACID特性
+在传统的关系型数据库中,尝尝用ACID特质来检测事务功能的可靠性和安全性。
+在redis中事务总是具有原子性(Atomicity),一致性(Consistency)和隔离性(Isolation),并且当redis运行在某种特定的持久化
+模式下,事务也具有耐久性(Durability).
+
+①原子性
+
+事务具有原子性指的是,数据库将事务中的多个操作当作一个整体来执行,服务器要么就执行事务中的所有操作,要么就一个操作也不执行。
+但是对于redis的事务功能来说,事务队列中的命令要么就全部执行,要么就一个都不执行,因此redis的事务是具有原子性的。
+
+②一致性
+
+ 事务具有一致性指的是,如果数据库在执行事务之前是一致的,那么在事务执行之后,无论事务是否执行成功,数据库也应该仍然一致的。
+ ”一致“指的是数据符合数据库本身的定义和要求,没有包含非法或者无效的错误数据。redis通过谨慎的错误检测和简单的设计来保证事务一致性。
+③隔离性
+
+ 事务的隔离性指的是,即使数据库中有多个事务并发在执行,各个事务之间也不会互相影响,并且在并发状态下执行的事务和串行执行的事务产生的结果完全
+ 相同。
+ 因为redis使用单线程的方式来执行事务(以及事务队列中的命令),并且服务器保证,在执行事务期间不会对事物进行中断,因此,redis的事务总是以串行
+ 的方式运行的,并且事务也总是具有隔离性的
+④持久性
+
+ 事务的耐久性指的是,当一个事务执行完毕时,执行这个事务所得的结果已经被保持到永久存储介质里面。
+ 因为redis事务不过是简单的用队列包裹起来一组redis命令,redis并没有为事务提供任何额外的持久化功能,所以redis事务的耐久性由redis使用的模式
+ 决定
+
\ No newline at end of file
diff --git "a/md/Spring\344\270\216SpringMVC\346\272\220\347\240\201\350\247\243\346\236\220\346\200\273\347\273\223.md" "b/md/Spring\344\270\216SpringMVC\346\272\220\347\240\201\350\247\243\346\236\220\346\200\273\347\273\223.md"
new file mode 100644
index 0000000..1b4fbbb
--- /dev/null
+++ "b/md/Spring\344\270\216SpringMVC\346\272\220\347\240\201\350\247\243\346\236\220\346\200\273\347\273\223.md"
@@ -0,0 +1,87 @@
+---
+title: Spring与SpringMVC源码解析总结
+date: 2018-07-08 22:13:58
+tags:
+ - Spring
+categories:
+ - 后端
+ - 技术总结
+---
+#Spring和SpringMVC源码学习总结
+这篇总结主要是基于我之前Spring和SpringMVC源码系列文章而形成的的。主要是把重要的知识点用自己的话说了一遍,可能会有一些错误,还望见谅和指点。谢谢
+
+#更多详细内容可以查看我的专栏文章:#Spring和SpringMVC源码解析
+#https://blog.csdn.net/column/details/21851.html
+# Spring和SpringMVC
+
+Spring是一个框架,除了提供IOC和AOP以外,还加入了web等众多内容。
+
+1 IOC:控制反转,改变类实例化的方式,通过xml等配置文件指定接口的实现类,让实现类和代码解耦,通过配置文件灵活调整实现类。
+
+2 AOP: 面向切面编程,将切面代码封装,比如权限验证,日志模块等,这些逻辑重复率大,通过一个增强器封装功能,然后定义需要加入这些功能的切面,切面一般用表达式或者注解去匹配方法,可以完成前置和后置的处理逻辑。
+
+3 SpringMVC是一个web框架,基于Spring之上,实现了web相关的功能,使用dispatcherservlet作为一切请求的处理入口。通过配置viewresolver解析页面,通过配置管理静态文件,还可以注入其他的配置信息,除此之外,springmvc可以访问spring容器的所有bean。
+
+
+## Spring源码总结
+
+IOC:
+
+1 Spring的bean容器也叫beanfactory,我们常用的applicationcontext实际上内部有一个listablebeanfactory实际存储bean的map。
+
+2 bean加载过程:spring容器加载时先读取配置文件,一般是xml,然后解析xml,找到其中所有bean,依次解析,然后生成每个bean的beandefinition,存在一个map中,根据beanid映射实际bean的map。
+
+3 bean初始化:加载完以后,如果不启用懒加载模式,则默认使用单例加载,在注册完bean以后,可以获取到beandefinition信息,然后根据该信息首先先检查依赖关系,如果依赖其他bean则先加载其他bean,然后通过反射的方式即newinstance创建一个单例bean。
+
+为什么要用反射呢,因为实现类可以通过配置改变,但接口是一致的,使用反射可以避免实现类改变时无法自动进行实例化。
+
+当然,bean也可以使用原型方式加载,使用原型的话,每次创建bean都会是全新的。
+
+AOP:
+
+AOP的切面,切点,增强器一般也是配置在xml文件中的,所以bean容器在解析xml时会找到这些内容,并且首先创建增强器bean的实例。
+
+基于上面创建bean的过程,AOP起到了什么作用呢,或者是是否有参与到其中呢,答案是有的。
+
+在获得beandefinition的时候,spring容器会检查该bean是否有aop切面所修饰,是否有能够匹配切点表达式的方法,如果有的话,在创建bean之前,会将bean重新封装成一个动态代理的对象。
+
+代理类会为bean增加切面中配置的advisor增强器,然后返回bean的时候实际上返回的是一个动态代理对象。
+
+所以我们在调用bean的方法时,会自动织入切面的增强器,当然,动态代理既可以选择jdk增强器,也可以选择cglib增强器。
+
+Spring事务:
+
+spring事务其实是一种特殊的aop方式。在spring配置文件中配置好事务管理器和声明式事务注解后,就可以使用@transactional进行事务方法的处理了。
+
+事务管理器的bean中会配置基本的信息,然后需要配置事务的增强器,不同方法使用不同的增强器。当然如果使用注解的话就不用这么麻烦了。
+
+然后和aop的动态代理方式类似,当Spring容器为bean生成代理时,会注入事务的增强器,其中实际上实现了事务中的begin和commit,所以执行方法的过程实际上就是在事务中进行的。
+
+# SpringMVC源码总结
+
+1 dispatcherservlet概述
+SpringMVC使用dispatcherservlet作为唯一如果,在web.xml中进行配置,他继承自frameworkservlet,向上继承自httpservletbean。
+
+httpservletbean为dispatcherservlet加载了来自web.xml配置信息中的信息,保存在servletcontext上下文中,而frameworkservletbean则初始化了spring web的bean容器。
+
+这个容器一般是配置在spring-mvc.xml中的,他独立于spring容器,但是把spring容器作为父容器,所以SpringMVC可以访问spring容器中的各种类。
+
+而dispatcherservlet自己做了什么呢,因为springmvc中配置了很多例如静态文件目录,自动扫描bean注解,以及viewresovler和httpconverter等信息,所以它需要初始化这些策略,如果没有配置则会使用默认值。
+
+2 dispatcherservlet的执行流程
+
+首先web容器会加载指定扫描bean并进行初始化。
+
+当请求进来后,首先执行service方法,然后到dodispatch方法执行请求转发,事实上,spring web容器已经维护了一个map,通过注解@requestmapping映射到对应的bean以及方法上。通过这个map可以获取一个handlerchain,真正要执行的方法被封装成一个handler,并且调用方法前要执行前置的一些过滤器。
+
+最终执行handler方法时实际上就是去执行真正的方法了。
+
+3 viewresolver
+
+解析完请求和执行完方法,会把modelandview对象解析成一个view对象,让后使用view.render方法执行渲染,至于使用什么样的视图解析器,就是由你配置的viewresolver来决定的,一般默认是jspviewresolver。
+
+4 httpmessageconverter
+
+一般配合responsebody使用,可以将数据自动转换为json和xml,根据http请求中适配的数据类型来决定使用哪个转换器。
+
+
diff --git "a/md/\345\210\206\345\270\203\345\274\217\346\212\200\346\234\257\345\256\236\350\267\265\346\200\273\347\273\223.md" "b/md/\345\210\206\345\270\203\345\274\217\346\212\200\346\234\257\345\256\236\350\267\265\346\200\273\347\273\223.md"
new file mode 100644
index 0000000..e12ce80
--- /dev/null
+++ "b/md/\345\210\206\345\270\203\345\274\217\346\212\200\346\234\257\345\256\236\350\267\265\346\200\273\347\273\223.md"
@@ -0,0 +1,474 @@
+---
+title: 分布式技术实践总结
+date: 2018-07-08 22:15:36
+tags:
+ - 分布式系统
+categories:
+ - 后端
+ - 技术总结
+---
+##本文基于之前的分布式系统理论系列文章总结而成,本部分主要是实践内容,详细内容可见我的专栏:分布式系统理论与实践
+
+##https://blog.csdn.net/column/details/24090.html
+
+本文主要是按照我自己的理解以及参考之前文章综合而成的,其中可能会有一些错误,还请见谅,也请指出。
+
+# 分布式技术
+
+## 分布式数据和nosql
+
+分布式一般是指分布式部署的数据库。
+
+比如Hbase基于HDFS分布式部署,所以他是一个分布式数据库。
+
+当然MySQL也可以分布式部署,比如按照不同业务部署,或者把单表内容拆成多个表乃至多个库进行部署。
+
+一般MySQL的扩展方式有:
+
+1 主从复制 使用冗余保证可用
+
+2 读写分离 主库负责写从库负责读,分担压力,并且保证数据一致性和备份。
+
+3 分表分库,横向拆分数据表放到多个表中或者多个库中,一般多个表或者多个库会使用不同节点部署,也就是一种分布式方案,提高并发的读写量。
+
+Nosql的话就比较多了,redis,memcache等。
+当然hbase也是,hbase按照region将数据文件分布在hdfs上,并且hdfs提供高可用和备份,同时hbase的regionserver也保证高可用,于是hbase的分布式方案也是比较成熟的。
+
+## 缓存 分布式缓存
+
+一般作为缓存的软件有redis,memcache等。当然我本地写一个hashmap也可以作为缓存。
+
+
+memcache提出了一致性哈希的算法,但是本身不支持数据持久化,也没有提供分布式方案,需要自己完成持久化以及分布式部署并且保证其可用性。
+
+redis作为新兴的内存数据库,提供了比memcache更多的数据结构,以及各种分布式方案。当然它也支持持久化。
+
+### redis的部署方案:
+
+> 1 redis的主从复制结构,和MySQL类似,使用日志aof或者持久化文件rdb进行主从同步。
+>
+> 2 读写分离,也可以做,但一般不需要。因为redis够快。
+>
+> 3 redis的哨兵方案,主节点配置哨兵,每当宕机时自动完成主从切换。
+>
+> 4 redis的集群方案,p2p的Redis Cluster部署了多台Redis服务器,每台Redis拥有全局的分片信息,所以任意节点都可以对外提供服务,当然每个节点只保存一部分分片,所以某台机器宕机时不会影响整个集群,当然每个节点也有slave,哨兵自动进行故障切换。
+>
+> 5 codis方案,codis屏蔽了集群的内部实现,可以不更改redis api的情况下使用代理的方式提供集群访问。并且使用 group的概念封装一组节点。
+
+### 缓存需要解决的问题:
+
+ 命中:缓存有数据
+ 不命中:去数据库读取
+ 失效:过期
+ 替换:缓存淘汰算法。
+
+ 一般有lru,fifo,随机缓存等。
+
+### 缓存更新的方法
+
+缓存更新可以先更新数据库再更新缓存,也可以先更新缓存再更新数据库。
+
+一般推荐先更新数据库,否则写一条数据时刚好有人读到缓存,把旧数据读到缓存中,此时新数据在数据库确不在缓存中。
+
+
+还有一种方法,就是让缓存自己去完成数据库更新,而不是让应用去选择如何更新数据库,这样的话缓存和数据库的更新操作就是透明的了,我们只需要操作缓存即可。
+
+### 缓存在springboot中的使用
+
+ springboot支持将缓存的curd操作配置在注解中,只需要在对应方法上配置好键和更新策略。
+
+ 则redis会根据该方法的操作类型执行对应操作,非常方便。
+### 一致性哈希
+
+分布式部署时,经常要面对的问题是,一个服务集群由谁来提供给这个客户度服务,需要一种算法来完成这一步映射。
+
+如果直接使用hash显然分布非常不均匀。那如果使用余数法呢,一共有N台机器,我对N取余可以映射到任意一台机器上。
+
+这种方法的缺点在于,当取余的值集中在某一范围时,就容易集中访问某些机器,导致热点问题。
+
+> 于是memcache推出了一个叫做一致性哈希的算法,一个哈希环,环上支持2^32次方个节点,也就是包含了所有的ip。
+>
+> 然后我们把主机通过hash值分布到这个环上,请求到来时会映射到某一个节点,如果该节点没有主机,则顺时针寻找真正主机。
+>
+> 当节点加入或者节点删除时,并不会影响服务的可用性,只是某些请求会被映射到别的节点。
+
+但是当请求集中到某个区域时,会产生倾斜,我们引入了虚拟节点来改善这个问题,虚拟节点对应到真实节点,所以加入虚拟节点可以更好地转移请求。
+
+
+## session和分布式session
+
+session是web应用必备的一个结构。
+一般有几种方案来管理session。
+
+1 web应用保存session到内存中,但是宕机会丢失
+
+2 web应用持久化到数据库或者redis,增加数据库负担。
+
+3 使用cookie保存加密后的session,浏览器压力大,可能被破解
+
+4 使用单独的session服务集群提供session服务,并且本身也可以采用分布式部署,部署的时候可以主从。
+
+保证session一致性的解决方法(客户端可以访问到自己的session):
+
+1 客户端cookie保存
+
+2 多个webserver进行同步,效率低
+
+3 反向代理绑定ip映射同一个服务器,但是宕机时出错
+
+4 后端统一存储,比如redis,或则部署session服务。
+
+## 负载均衡
+
+负载均衡一般可以分为七层,四层负载均衡。
+
+Nginx
+
+七层的负载均衡也就是http负载均衡,主要使用Nginx完成。
+
+> 配置Nginx进行反向代理的url,然后转发请求到上游服务器,请求进来时自动转发到上游服务器,通过url进行负载均衡,所以是七层负载均衡。既然是七层负载,那么上游服务器提供了http服务,也可以解析该请求。
+>
+> 四层负载均衡主要是tcp请求的负载均衡,因为tcp请求是绑定到一个端口上的,所以我们根据端口进行请求转发到上游服务器的。既然是四层负载,上游服务器监听该端口的服务就可以处理该请求。
+
+LVS
+
+LVS术语定义:
+
+ DS:Director Server,前端负载均衡器节点(后文用Director称呼);
+
+ RS:Real Server,后端真实服务器;
+
+ VIP:用户请求的目标的IP地址,一般是公网IP地址;
+
+ DIP:Director Server IP,Director和Real Server通讯的内网IP地址;
+
+ RIP:Real Server IP,Director和Real Server通讯的内网IP地址;
+
+LVS有三种实现负载均衡的方式
+
+NAT 四层负载均衡
+
+> NAT支持四层负载均衡,NAT中只有DS提供公网ip,并且VIP绑定在DS的mac地址上,客户端只能访问DS。同时DS和RS通过内网ip进行网络连接。当TCP数据报到达DS时,DS修改数据报,指向RS的ip和port。进行转发即可。
+>
+> 同时,RS处理完请求后,由于网关时DS,所以仍然要返回给DS处理。
+>
+>
+> NAT模式中,RS返回数据包是返回给Director,Director再返回给客户端;事实上这跟NAT网络协议没什么关系。
+
+DR 二层负载均衡
+
+
+> DR模式中,DS负责接收请求。接收请求后把数据报的mac地址改成指向RS的mac地址,并且由于三台机器拥有同样的vip地址。
+> 所以RS接收请求后认为该数据报应该由自己处理并相应。
+>
+> 同时为了避免RS再把相应转发会DS,我们禁用了对DS的arp,所以此时RS就会通过vip把响应通过vip网关返回给客户端。
+>
+> Director通过修改请求中目标地址MAC为选定的RS实现数据转发,这就要求Diretor和Real Server必须在同一个广播域内,也就是他们的mac地址是可达的。
+> DR(Direct Routing)模式中,RS返回数据是直接返回给客户端(通过额外的路由);
+>
+
+TUN
+
+> TUN中使用了IP隧道技术,客户端请求发给DS时,DS会通过隧道技术把数据报通过隧道发给实际的RS,然后RS解析数据以后可以直接响应给客户端,因为他有客户端的ip地址。这就不要求DS和RS在同一网段了,当然前提是RS有公网ip。
+>
+> TUN(IP Tunneling)模式中,RS返回的数据也是直接返回给客户端,这种模式通过Overlay协议(把一个IP数据包封装到另一个数据包内部叫Overlay)避免了DR的限制。
+
+## zookeeper
+
+zookeeper集群自身的特性:
+
+> 1 一个zookeeper服务器集群,一开始就会进行选主,主节点挂掉后也会进行选主。
+>
+> 使用zab协议中的选主机制进行选主,也就是每个节点进行一次提议,刚开始提议自己,如果有新的提议则覆盖自己原来的提议,不断重复,直到有节点获得过半的投票。完成一轮选主。
+>
+> 2 选主结束后,开始进行消息广播和数据同步,保证每一台服务器的数据都和leader同步。
+>
+> 3 开始提供服务,客户端向leader发送请求,leader首先发出提议,当有半数以上节点响应时,leader会发送commit信息,于是所有节点执行该操作。当有机器宕机时重启后会和leader同步。这是一个类似2pc的提交方式。
+
+zookeeper提供了分布式环境中常用的服务
+
+> 1 配置服务,多个机器可以通过文件节点共享配置。
+>
+> 2 选主服务,通过添加顺序节点,可以进行选主。
+>
+> 3 分布式锁,顺序节点和watcher
+>
+> 4 全局id,使用机器号+时间戳可以生成一个transactionid,是全局唯一的。
+
+
+## 数据库的分布式事务
+
+分布式事务的实现一般可以用2PC和3PC解决。
+
+成熟的方案有:
+
+> 1 TCC 补偿式事务,对每一个步骤都有一个补偿措施。
+>
+> 2 全局事务实现。
+>
+> 3 事务消息:rocketmq的事务实现,先发消息到队列中,然后本地执行事务并通知消息队列,若成功则消息主动推给另一个服务,直到服务二执行成功,消息从队列中删除。如果超时不成功,则消息要求事务A回滚。
+>
+> 如果过程中失败了,本地事务也会回滚。消息队列可以回调本地接口判断事务是否执行成功,防止超时。
+>
+> 4 本地实现消息表:
+> 本地实现消息表并且和事务记录存在一起,自己实现消息的轮询发送。
+> 首先把本地事务操作和消息增加放在一个事务里执行,然后轮询消息表进行发送,如果执行成功则消息达到服务B,通知其执行。执行成功后消息被删除,否则回滚事务删除消息。
+
+## 分布式锁问题
+
+分布式锁用于分布式环境中的资源互斥,因为单机可以通过共享内存实现,而分布式环境只能通过网络实现。
+
+### MySQL实现分布式锁
+
+ insert加锁,锁没有失效时间,容易产生死锁
+
+### redis实现分布式锁
+
+ 1. 基于setnx、expire两个命令来实现
+
+ 基于setnx(set if not exist)的特点,当缓存里key不存在时,才会去set,否则直接返回false。
+
+ 如果返回true则获取到锁,否则获取锁失败,为了防止死锁,我们再用expire命令对这个key设置一个超时时间来避免。
+
+ 但是这里看似完美,实则有缺陷,当我们setnx成功后,线程发生异常中断,expire还没来的及设置,那么就会产生死锁。
+
+ 2 使用getset实现,可以判断自己是否获得了锁,但是可能会出现并发的原子性问题。拆分成两个操作。
+
+ 3 避免原子性问题可以使用lua脚本保证事务的原子性。
+
+ 4 上述都是单点的redis,如果是分布式环境的redis集群,可以使用redlock,要求节点向半数以上redis机器请求锁。才算成功。
+
+### zookeeper实现分布式锁
+
+创建有序节点,最小的抢到锁,其他的监听他的上一个节点即可。并且抢到锁的节点释放时只会通知下一个节点。
+
+小结
+
+在分布式系统中,共享资源互斥访问问题非常普遍,而针对访问共享资源的互斥问题,常用的解决方案就是使用分布式锁,这里只介绍了几种常用的分布式锁,分布式锁的实现方式还有有很多种,根据业务选择合适的分布式锁,下面对上述几种锁进行一下比较:
+
+ 数据库锁:
+
+ 优点:直接使用数据库,使用简单。
+
+ 缺点:分布式系统大多数瓶颈都在数据库,使用数据库锁会增加数据库负担。
+
+ 缓存锁:
+
+ 优点:性能高,实现起来较为方便,在允许偶发的锁失效情况,不影响系统正常使用,建议采用缓存锁。
+
+ 缺点:通过锁超时机制不是十分可靠,当线程获得锁后,处理时间过长导致锁超时,就失效了锁的作用。
+
+ zookeeper锁:
+
+ 优点:不依靠超时时间释放锁;可靠性高;系统要求高可靠性时,建议采用zookeeper锁。
+
+ 缺点:性能比不上缓存锁,因为要频繁的创建节点删除节点。并且zookeeper只能单点写入。而Redis可以并发写入。
+
+## 消息队列
+
+适合场景:
+
+1 服务之间解耦,比如淘宝的买家服务和物流服务,中间需要消息传递订单信息。但又不需要强耦合。便于服务的划分和独立部署
+
+2 控制流量,大流量访问某服务时,避免服务出现问题,将其先存入队列,均匀释放流量。
+
+3 削峰,当某一个服务如秒杀,如果直接集中访问,服务器可能会冲垮,所以先存到队列中,控制访问量,避免服务器冲击。
+
+4 事务,消息事务
+
+5 异步请求处理,比如一些不重要的服务可以延缓执行,比如卖家评价,站内信等。
+
+常用消息队列:
+
+rabbitmq:使用consumer和producer的模型,并且使用了broker,broker中包含路由功能的exchanger,每个key绑定一个queue,应用通过key进行队列消费和生产。
+
+一般是点对点的消息,也可以支持一对多的消息,当然也可以支持消息的订阅。还有就是主题模式,和key的区别就是主题模式是多级的key表示。
+
+kafka:
+
+
+
+## 微服务和Dubbo
+
+分布式架构意味着服务的拆分,最早的SOA架构已经进行了服务拆分,但是每个服务还是太过庞大,不适合扩展和修改。
+
+微服务的拆分粒度更加细,服务可以独立部署和快速迭代,通知支持扩展。
+
+服务之间一般使用rpc调用进行访问,可以使用自定义协议也可以使用http服务,当然通过netty 实现TCP服务并且搭配合理的序列化方案也可以完成rpc功能。rpc是微服务的基础。
+
+微服务一般需要配置中心来进行服务注册和发现,以便服务信息更新和配置,dubbo中使用的是zookeeper,用于配置服务信息提供给生产者使用。
+
+一般情况下微服务需要有监控中心,心跳检测每一台服务器,及时完成故障切换和通知。同时监控服务的性能和使用情况。
+
+序列化方式一般可以使用protobuf,http服务一般使用json。
+
+微服务还支持更多的包括权限控制,流量控制,灰度发布,服务降级等内容,这里就不再细谈。
+
+
+### 全局id
+
+方法一:使用数据库的 auto_increment 来生成全局唯一递增ID
+
+
+
+ 优点:
+
+ 简单,使用数据库已有的功能
+
+ 能够保证唯一性
+
+ 能够保证递增性
+
+ 步长固定
+
+
+
+ 缺点:
+
+ 可用性难以保证:数据库常见架构是一主多从+读写分离,生成自增ID是写请求,主库挂了就玩不转了
+
+ 扩展性差,性能有上限:因为写入是单点,数据库主库的写性能决定ID的生成性能上限,并且难以扩展
+
+
+方法三:uuid/guid
+
+
+
+不管是通过数据库,还是通过服务来生成ID,业务方Application都需要进行一次远程调用,比较耗时。
+
+
+
+有没有一种本地生成ID的方法,即高性能,又时延低呢?
+
+
+
+uuid是一种常见的方案:
+
+string ID =GenUUID();
+
+
+
+优点:
+
+本地生成ID,不需要进行远程调用,时延低
+
+扩展性好,基本可以认为没有性能上限
+
+
+
+缺点:
+
+无法保证趋势递增
+
+uuid过长,往往用字符串表示,作为主键建立索引查询效率低,常见优化方案为“转化为两个uint64整数存储”或者“折半存储”(折半后不能保证唯一性)
+
+
+
+
+方法四:取当前毫秒数
+
+
+
+uuid是一个本地算法,生成性能高,但无法保证趋势递增,且作为字符串ID检索效率低,有没有一种能保证递增的本地算法呢?
+
+
+
+取当前毫秒数是一种常见方案:
+
+uint64 ID = GenTimeMS();
+
+
+
+优点:
+
+本地生成ID,不需要进行远程调用,时延低
+
+生成的ID趋势递增
+
+生成的ID是整数,建立索引后查询效率高
+
+
+
+缺点:
+
+如果并发量超过1000,会生成重复的ID
+
+
+方法五:类snowflake算法
+
+
+
+snowflake是twitter开源的分布式ID生成算法,其核心思想为,一个long型的ID:
+
+41bit作为毫秒数
+
+10bit作为机器编号
+
+12bit作为毫秒内序列号
+
+
+
+算法单机每秒内理论上最多可以生成1000*(2^12),也就是400W的ID,完全能满足业务的需求。
+
+## 秒杀系统
+
+
+
+
+### 第一层,客户端怎么优化(浏览器层,APP层)
+
+(a)产品层面,用户点击“查询”或者“购票”后,按钮置灰,禁止用户重复提交请求;
+
+(b)JS层面,限制用户在x秒之内只能提交一次请求;
+
+### 第二层,站点层面的请求拦截
+
+> 怎么拦截?怎么防止程序员写for循环调用,有去重依据么?ip?cookie-id?…想复杂了,这类业务都需要登录,用uid即可。在站点层面,对uid进行请求计数和去重,甚至不需要统一存储计数,直接站点层内存存储(这样计数会不准,但最简单)。一个uid,5秒只准透过1个请求,这样又能拦住99%的for循环请求。
+>
+> 5s只透过一个请求,其余的请求怎么办?缓存,页面缓存,同一个uid,限制访问频度,做页面缓存,x秒内到达站点层的请求,均返回同一页面。同一个item的查询,例如车次,做页面缓存,x秒内到达站点层的请求,均返回同一页面。如此限流,既能保证用户有良好的用户体验(没有返回404)又能保证系统的健壮性(利用页面缓存,把请求拦截在站点层了)。
+
+好,这个方式拦住了写for循环发http请求的程序员,有些高端程序员(黑客)控制了10w个肉鸡,手里有10w个uid,同时发请求(先不考虑实名制的问题,小米抢手机不需要实名制),这下怎么办,站点层按照uid限流拦不住了。
+
+
+### 第三层 服务层来拦截(反正就是不要让请求落到数据库上去)消息队列+缓存
+
+服务层怎么拦截?大哥,我是服务层,我清楚的知道小米只有1万部手机,我清楚的知道一列火车只有2000张车票,我透10w个请求去数据库有什么意义呢?没错,请求队列!
+
+对于写请求,做请求队列,每次只透有限的写请求去数据层(下订单,支付这样的写业务)
+
+1w部手机,只透1w个下单请求去db
+
+3k张火车票,只透3k个下单请求去db
+
+如果均成功再放下一批,如果库存不够则队列里的写请求全部返回“已售完”。
+
+
+
+对于读请求,怎么优化?cache抗,不管是memcached还是redis,单机抗个每秒10w应该都是没什么问题的。如此限流,只有非常少的写请求,和非常少的读缓存mis的请求会透到数据层去,又有99.9%的请求被拦住了。
+
+
+### 好了,最后是数据库层
+
+浏览器拦截了80%,站点层拦截了99.9%并做了页面缓存,服务层又做了写请求队列与数据缓存,每次透到数据库层的请求都是可控的。db基本就没什么压力了,闲庭信步,单机也能扛得住,还是那句话,库存是有限的,小米的产能有限,透这么多请求来数据库没有意义。
+
+全部透到数据库,100w个下单,0个成功,请求有效率0%。透3k个到数据,全部成功,请求有效率100%。
+
+
+
+
+### 总结
+上文应该描述的非常清楚了,没什么总结了,对于秒杀系统,再次重复下我个人经验的两个架构优化思路:
+
+(1)尽量将请求拦截在系统上游(越上游越好);
+
+(2)读多写少的常用多使用缓存(缓存抗读压力);
+
+浏览器和APP:做限速
+
+站点层:按照uid做限速,做页面缓存
+
+服务层:按照业务做写请求队列控制流量,做数据缓存
+
+数据层:闲庭信步
+
+并且:结合业务做优化
\ No newline at end of file
diff --git "a/md/\345\210\206\345\270\203\345\274\217\347\220\206\350\256\272\346\200\273\347\273\223.md" "b/md/\345\210\206\345\270\203\345\274\217\347\220\206\350\256\272\346\200\273\347\273\223.md"
new file mode 100644
index 0000000..78577df
--- /dev/null
+++ "b/md/\345\210\206\345\270\203\345\274\217\347\220\206\350\256\272\346\200\273\347\273\223.md"
@@ -0,0 +1,355 @@
+---
+title: 分布式理论学习总结
+date: 2018-07-08 22:15:23
+tags:
+ - 分布式系统
+categories:
+ - 后端
+ - 技术总结
+---
+##本文基于之前的分布式系统理论系列文章总结而成,主要是理论部分,详细内容可见我的专栏:分布式系统理论与实践
+
+##https://blog.csdn.net/column/details/24090.html
+
+本文主要是按照我自己的理解以及参考之前文章综合而成的,其中可能会有一些错误,还请见谅,也请指出。
+
+# 分布式理论
+## CAP
+CAP定理讲的是三个性。consistency数据一致性,availability可用性,partition tolerance分区容错性。
+
+三者只能选其中两者。为什么呢,看看这三个性质意味着什么吧。
+
+首先看看分区容错性,分区容错性指的是网络出现分区(丢包,断网,超时等情况都属于网络分区)时,整个服务仍然可用。
+
+由于网络分区在实际环境下一定存在,所以必须首先被考虑。于是分区容错性是必须要保证的,否则一旦出现分区服务就不可用,那就没办法弄了。
+
+所以实际上是2选1的问题。在可用性和一致性中做出选择。
+
+在一个分布式环境下,多个节点一起对外提供服务,如果要保证可用性,那么一台机器宕机了仍然有其他机器能提供服务。
+但是宕机的机器重启以后就会发现数据和其他机器存在不一致,那么一致性就无法得到保证。
+
+如果保证一致性,如果有机器宕机,那么其他节点就不能工作了,否则一定会产生数据不一致。
+
+## BASE
+
+在这么严苛的规定下,CAP一般很难实现一个健壮的系统。于是提出了BASE来削弱这些要求。
+
+BASE是基本可用basically available,soft state软状态,eventually consistent最终一致性。
+
+基本可用就是允许服务在某些时候降级,比如淘宝在高峰时期会关闭退货等服务。
+
+软状态就是允许数据出现中间状态,比如支付宝提交转账以后并不是立刻到账,中间经过了多次消息传递和转发。
+
+最终一致性就是指数据最终要是一致的,比如多个节点的数据需要定期同步,支付宝转账最终一定会到账。
+
+## 分布式系统关键词
+
+### 时钟,时间,事件顺序
+
+分布式系统的一个问题在与缺少全局时钟,所以大家没有一个统一的时间,就很难用时间去确定各个节点事件的发生顺序,为了保证事件的顺序执行,
+
+
+### Lamport timestamps
+
+Leslie Lamport 在1978年提出逻辑时钟的概念,并描述了一种逻辑时钟的表示方法,这个方法被称为Lamport时间戳(Lamport timestamps)[3]。
+
+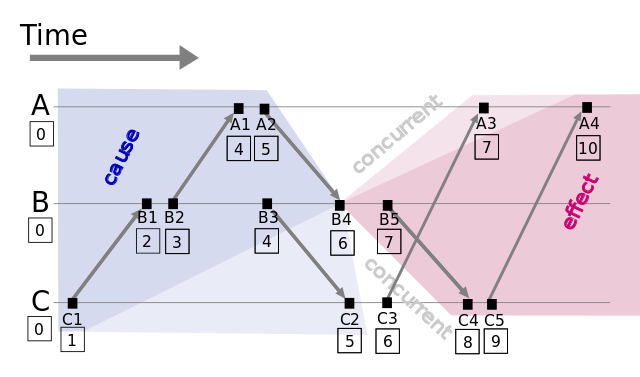
+
+分布式系统中按是否存在节点交互可分为三类事件,一类发生于节点内部,二是发送事件,三是接收事件。Lamport时间戳原理如下:
+
+ 每个事件对应一个Lamport时间戳,初始值为0
+ 如果事件在节点内发生,时间戳加1
+ 如果事件属于发送事件,时间戳加1并在消息中带上该时间戳
+ 如果事件属于接收事件,时间戳 = Max(本地时间戳,消息中的时间戳) + 1
+
+这样的话,节点内的事件有序,发送事件有序,接收事件一定在发送事件以后发生。再加上人为的一些规定,因此根据时间戳可以确定一个全序排列。
+
+### Vector clock
+
+Lamport时间戳帮助我们得到事件顺序关系,但还有一种顺序关系不能用Lamport时间戳很好地表示出来,那就是同时发生关系(concurrent)[4]。
+Vector clock是在Lamport时间戳基础上演进的另一种逻辑时钟方法,它通过vector结构不但记录本节点的Lamport时间戳,同时也记录了其他节点的Lamport时间戳[5][6]。
+
+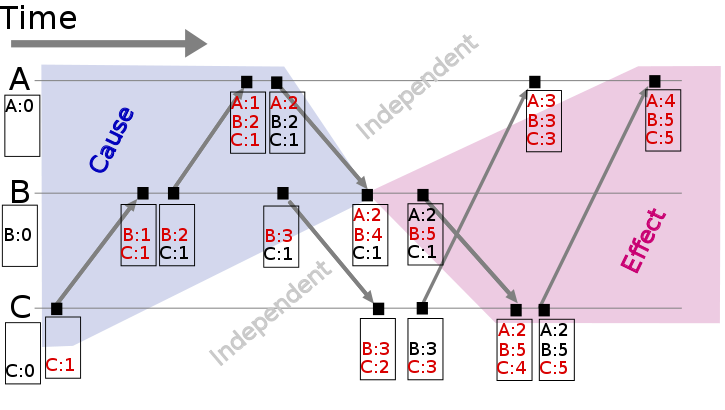
+
+如果 Tb[Q] > Ta[Q] 并且 Tb[P] < Ta[P],则认为a、b同时发生,记作 a <-> b。例如图2中节点B上的第4个事件 (A:2,B:4,C:1) 与节点C上的第2个事件 (B:3,C:2) 没有因果关系、属于同时发生事件。
+
+因为B4 > B3并且 C1 选举(election)是分布式系统实践中常见的问题,通过打破节点间的对等关系,选得的leader(或叫master、coordinator)有助于实现事务原子性、提升决议效率。
+>
+> 多数派(quorum)的思路帮助我们在网络分化的情况下达成决议一致性,在leader选举的场景下帮助我们选出唯一leader。
+>
+> 租约(lease)在一定期限内给予节点特定权利,也可以用于实现leader选举。
+
+选举(electioin)
+
+> 一致性问题(consistency)是独立的节点间如何达成决议的问题,选出大家都认可的leader本质上也是一致性问题,因而如何应对宕机恢复、网络分化等在leader选举中也需要考量。
+>
+> 在一致性算法Paxos、ZAB[2]、Raft[3]中,为提升决议效率均有节点充当leader的角色。
+>
+> ZAB、Raft中描述了具体的leader选举实现,与Bully算法类似ZAB中使用zxid标识节点,具有最大zxid的节点表示其所具备的事务(transaction)最新、被选为leader。
+
+多数派(quorum)
+
+> 在网络分化的场景下以上Bully算法会遇到一个问题,被分隔的节点都认为自己具有最大的序号、将产生多个leader,这时候就需要引入多数派(quorum)[4]。多数派的思路在分布式系统中很常见,其确保网络分化情况下决议唯一。
+
+ 租约(lease)
+
+选举中很重要的一个问题,以上尚未提到:怎么判断leader不可用、什么时候应该发起重新选举?
+>
+> 最先可能想到会通过心跳(heart beat)判别leader状态是否正常,但在网络拥塞或瞬断的情况下,这容易导致出现双主。
+
+
+
+租约(lease)是解决该问题的常用方法,其最初提出时用于解决分布式缓存一致性问题[6],后面在分布式锁[7]等很多方面都有应用。
+
+ (a). 节点0、1、2在Z上注册自己,Z根据一定的规则(例如先到先得)颁发租约给节点,该租约同时对应一个有效时长;这里假设节点0获得租约、成为leader
+
+ (b). leader宕机时,只有租约到期(timeout)后才重新发起选举,这里节点1获得租约、成为leader
+
+
+
+租约机制确保了一个时刻最多只有一个leader,避免只使用心跳机制产生双主的问题。在实践应用中,zookeeper、ectd可用于租约颁发。
+
+## 一致性,2pc和3pc
+
+一致性(consensus)
+
+何为一致性问题?简单而言,一致性问题就是相互独立的节点之间如何达成一项决议的问题。分布式系统中,进行数据库事务提交(commit transaction)、Leader选举、序列号生成等都会遇到一致性问题。
+
+为了保证执行的一致性,可以使用2pc两段式提交和3pc三段式提交。
+
+2PC
+>
+> 2PC(tow phase commit)两阶段提交[5]顾名思义它分成两个阶段,先由一方进行提议(propose)并收集其他节点的反馈(vote),再根据反馈决定提交(commit)或中止(abort)事务。我们将提议的节点称为协调者(coordinator),其他参与决议节点称为参与者(participants, 或cohorts):
+
+举个例子,首先用户想要执行一个事务,于是提交给leader,leader先让各个节点执行该事务。
+
+我们要知道,事务是通过日志来实现的。各个节点使用redo日志进行重做,使用undo日志进行回滚。
+
+于是各个节点执行事务,并把执行结果是否成功返回给leader,当leader收到全部确认消息后,发送消息让所有节点commit。如果有节点执行失败,则leader要求所有节点回滚。
+
+2pc可能出现的一些问题是:
+
+1 leader必须等待所有节点结果,如果有节点宕机或超时,则拒绝该事务,并向节点发送回滚的信息。
+
+2 如果leader宕机,则一般配置watcherdog自动切换成备用leader,然后进行下一次的请求提交。
+
+3这两种情况单独发生时都没有关系,有对应的措施可以进行回滚,但是如果当一个节点宕机时leader正在等待所有节点消息,其他节点也在等待leader最后的消息。
+
+此时leader也不幸宕机,切换之后leader并不知道一个节点宕机了,这样的话其他的节点也会被阻塞住导致无法回滚。
+>
+3PC
+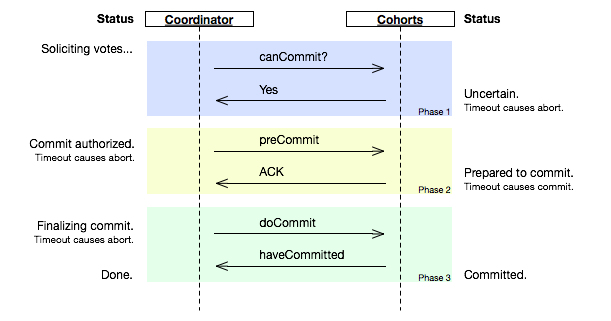
+coordinator接收完participant的反馈(vote)之后,进入阶段2,给各个participant发送准备提交(prepare to commit)指令
+
+。participant接到准备提交指令后可以锁资源,但要求相关操作必须可回滚。coordinator接收完确认(ACK)后进入阶段3、进行commit/abort,3PC的阶段3与2PC的阶段2无异。协调者备份(coordinator watchdog)、状态记录(logging)同样应用在3PC。
+
+participant如果在不同阶段宕机,我们来看看3PC如何应对:
+
+> 阶段1: coordinator或watchdog未收到宕机participant的vote,直接中止事务;宕机的participant恢复后,读取logging发现未发出赞成vote,自行中止该次事务
+>
+> 阶段2: coordinator未收到宕机participant的precommit ACK,但因为之前已经收到了宕机participant的赞成反馈(不然也不会进入到阶段2),coordinator进行commit;watchdog可以通过问询其他participant获得这些信息,过程同理;宕机的participant恢复后发现收到precommit或已经发出赞成vote,则自行commit该次事务
+>
+> 阶段3: 即便coordinator或watchdog未收到宕机participant的commit ACK,也结束该次事务;宕机的participant恢复后发现收到commit或者precommit,也将自行commit该次事务
+> 因为有了准备提交(prepare to
+commit)阶段,3PC的事务处理延时也增加了1个RTT,变为3个RTT(propose+precommit+commit),但是它防止participant宕机后整个系统进入阻塞态,增强了系统的可用性,对一些现实业务场景是非常值得的。
+>
+
+总结一下就是:阶段一leader要求节点准备,节点返回ack或者fail。
+
+如果节点都是ack,leader返回ack进入阶段二。
+(如果fail则回滚,因为节点没有接收到ack,所以最终都会回滚)
+
+阶段二时节点执行事务并且发送结果给leader,leader返回ack或者fail。由于阶段二的节点已经有了一个确定的状态ack,如果leader超时或宕机不返回,成功执行节点也会进行commit操作,这样即使有节点宕机也不会影响到其他节点。
+
+
+## 一致性算法paxos
+
+Basic Paxos
+
+何为一致性问题?简单而言,一致性问题是在节点宕机、消息无序等场景可能出现的情况下,相互独立的节点之间如何达成决议的问题,作为解决一致性问题的协议,Paxos的核心是节点间如何确定并只确定一个值(value)。
+
+和2PC类似,Paxos先把节点分成两类,发起提议(proposal)的一方为proposer,参与决议的一方为acceptor。假如只有一个proposer发起提议,并且节点不宕机、消息不丢包,那么acceptor做到以下这点就可以确定一个值。
+
+> proposer发出提议,acceptor根据提议的id和值来决定是否接收提议,接受提议则替换为自己的提议,并且返回之前id最大的提议,当超过一半节点提议该值时,则该值被确定,这样既保证了时序,也保证了多数派。
+
+ Multi Paxos
+
+通过以上步骤分布式系统已经能确定一个值,“只确定一个值有什么用?这可解决不了我面临的问题。” 你心中可能有这样的疑问。
+
+其实不断地进行“确定一个值”的过程、再为每个过程编上序号,就能得到具有全序关系(total order)的系列值,进而能应用在数据库副本存储等很多场景。我们把单次“确定一个值”的过程称为实例(instance),它由proposer/acceptor/learner组成。
+
+Fast Paxos
+
+在Multi Paxos中,proposer -> leader -> acceptor -> learner,从提议到完成决议共经过3次通信,能不能减少通信步骤?
+
+对Multi Paxos phase2a,如果可以自由提议value,则可以让proposer直接发起提议、leader退出通信过程,变为proposer -> acceptor -> learner,这就是Fast Paxos[2]的由来。
+
+> 多次paxos的确定值使用可以让多个proposer,acceptor一起运作。多个proposer提出提议,acceptor保留最大提议比返回之前提议,proposer当提议数量满足多数派则取出最大值向acceptor提议,于是过半数的acceptor比较提议后可以接受该提议,于是最终leader将提议写入acceptor,而acceptor再写入对应的learner。
+
+## raft和zab
+
+Zab
+
+Zab[5][6]的全称是Zookeeper atomic broadcast protocol,是Zookeeper内部用到的一致性协议。相比Paxos,Zab最大的特点是保证强一致性(strong consistency,或叫线性一致性linearizable consistency)。
+
+
+
+和Raft一样,Zab要求唯一Leader参与决议,Zab可以分解成discovery、sync、broadcast三个阶段:
+
+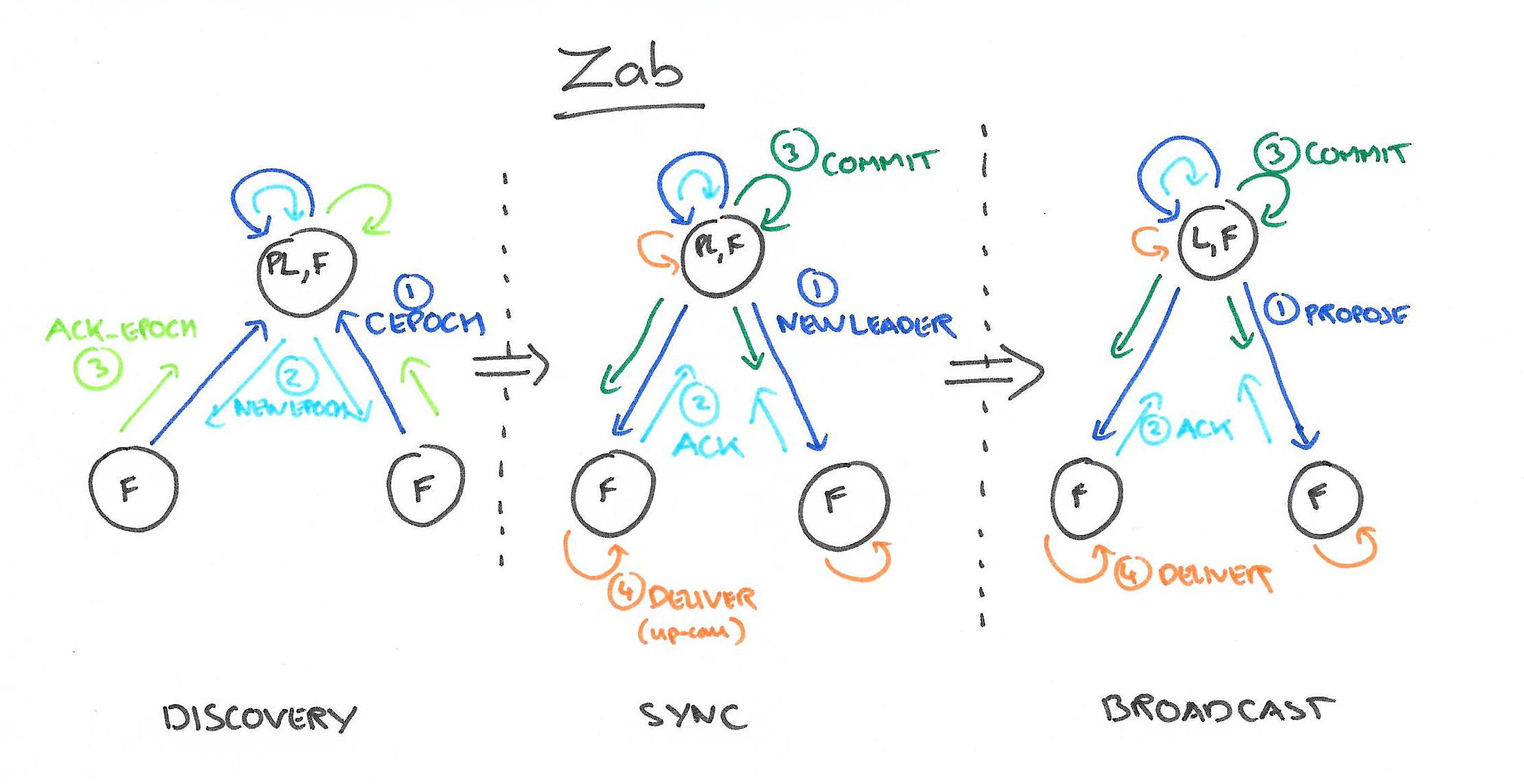
+>
+> discovery: 选举产生PL(prospective leader),PL收集Follower epoch(cepoch),根据Follower的反馈PL产生newepoch(每次选举产生新Leader的同时产生新epoch,类似Raft的term)
+
+> sync: PL补齐相比Follower多数派缺失的状态、之后各Follower再补齐相比PL缺失的状态,PL和Follower完成状态同步后PL变为正式Leader(established leader)
+
+> broadcast: Leader处理Client的写操作,并将状态变更广播至Follower,Follower多数派通过之后Leader发起将状态变更落地(deliver/commit)
+
+Raft:
+
+## 单个 Candidate 的竞选
+
+有三种节点:Follower、Candidate 和 Leader。Leader 会周期性的发送心跳包给 Follower。每个 Follower 都设置了一个随机的竞选超时时间,一般为 150ms~300ms,如果在这个时间内没有收到 Leader 的心跳包,就会变成 Candidate,进入竞选阶段。
+
+* 下图表示一个分布式系统的最初阶段,此时只有 Follower,没有 Leader。Follower A 等待一个随机的竞选超时时间之后,没收到 Leader 发来的心跳包,因此进入竞选阶段。
+
+[](https://github.com/CyC2018/Interview-Notebook/blob/master/pics/111521118015898.gif)
+
+* 此时 A 发送投票请求给其它所有节点。
+
+[](https://github.com/CyC2018/Interview-Notebook/blob/master/pics/111521118445538.gif)
+
+* 其它节点会对请求进行回复,如果超过一半的节点回复了,那么该 Candidate 就会变成 Leader。
+
+[](https://github.com/CyC2018/Interview-Notebook/blob/master/pics/111521118483039.gif)
+
+* 之后 Leader 会周期性地发送心跳包给 Follower,Follower 接收到心跳包,会重新开始计时。
+
+[](https://github.com/CyC2018/Interview-Notebook/blob/master/pics/111521118640738.gif)
+
+## [](https://github.com/CyC2018/Interview-Notebook/blob/master/notes/%E4%B8%80%E8%87%B4%E6%80%A7.md#%E5%A4%9A%E4%B8%AA-candidate-%E7%AB%9E%E9%80%89)多个 Candidate 竞选
+
+* 如果有多个 Follower 成为 Candidate,并且所获得票数相同,那么就需要重新开始投票,例如下图中 Candidate B 和 Candidate D 都获得两票,因此需要重新开始投票。
+
+[](https://github.com/CyC2018/Interview-Notebook/blob/master/pics/111521119203347.gif)
+
+* 当重新开始投票时,由于每个节点设置的随机竞选超时时间不同,因此能下一次再次出现多个 Candidate 并获得同样票数的概率很低。
+
+[](https://github.com/CyC2018/Interview-Notebook/blob/master/pics/111521119368714.gif)
+
+## [](https://github.com/CyC2018/Interview-Notebook/blob/master/notes/%E4%B8%80%E8%87%B4%E6%80%A7.md#%E6%97%A5%E5%BF%97%E5%A4%8D%E5%88%B6)日志复制
+
+* 来自客户端的修改都会被传入 Leader。注意该修改还未被提交,只是写入日志中。
+
+[](https://github.com/CyC2018/Interview-Notebook/blob/master/pics/7.gif)
+
+* Leader 会把修改复制到所有 Follower。
+
+[](https://github.com/CyC2018/Interview-Notebook/blob/master/pics/9.gif)
+
+* Leader 会等待大多数的 Follower 也进行了修改,然后才将修改提交。
+
+[](https://github.com/CyC2018/Interview-Notebook/blob/master/pics/10.gif)
+
+* 此时 Leader 会通知的所有 Follower 让它们也提交修改,此时所有节点的值达成一致。
+
+[](https://github.com/CyC2018/Interview-Notebook/blob/master/pics/11.gif)
+
+## zookeeper
+
+zookeeper在分布式系统中作为协调员的角色,可应用于Leader选举、分布式锁、配置管理等服务的实现。以下我们从zookeeper供的API、应用场景和监控三方面学习和了解zookeeper(以下简称ZK)。
+
+
+ZK API
+
+ZK以Unix文件系统树结构的形式管理存储的数据,图示如下:
+
+
+
+其中每个树节点被称为znode,每个znode类似一个文件,包含文件元信息(meta data)和数据。
+
+
+
+以下我们用server表示ZK服务的提供方,client表示ZK服务的使用方,当client连接ZK时,相应创建session会话信息。
+
+有两种类型的znode:
+
+Regular: 该类型znode只能由client端显式创建或删除
+
+Ephemeral: client端可创建或删除该类型znode;当session终止时,ZK亦会删除该类型znode
+
+znode创建时还可以被打上sequential标志,被打上该标志的znode,将自行加上自增的数字后缀
+
+
+
+ ZK提供了以下API,供client操作znode和znode中存储的数据:
+
+ create(path, data, flags):创建路径为path的znode,在其中存储data[]数据,flags可设置为Regular或Ephemeral,并可选打上sequential标志。
+
+ delete(path, version):删除相应path/version的znode
+
+ exists(path,watch):如果存在path对应znode,则返回true;否则返回false,watch标志可设置监听事件
+
+ getData(path, watch):返回对应znode的数据和元信息(如version等)
+
+ setData(path, data, version):将data[]数据写入对应path/version的znode
+
+ getChildren(path, watch):返回指定znode的子节点集合
+
+K应用场景
+
+基于以上ZK提供的znode和znode数据的操作,可轻松实现Leader选举、分布式锁、配置管理等服务。
+
+
+
+Leader选举
+
+> 利用打上sequential标志的Ephemeral,我们可以实现Leader选举。假设需要从三个client中选取Leader,实现过程如下:
+>
+> 1、各自创建Ephemeral类型的znode,并打上sequential标志:
+>
+> [zk: localhost:2181(CONNECTED) 4] ls /master
+> [lock-0000000241, lock-0000000243, lock-0000000242]
+>
+> 2、检查 /master 路径下的所有znode,如果自己创建的znode序号最小,则认为自己是Leader;否则记录序号比自己次小的znode
+>
+> 3、非Leader在次小序号znode上设置监听事件,并重复执行以上步骤2
+
+配置管理
+
+znode可以存储数据,基于这一点,我们可以用ZK实现分布式系统的配置管理,假设有服务A,A扩容设备时需要将相应新增的ip/port同步到全网服务器的A.conf配置,实现过程如下:
+>
+> 1、A扩容时,相应在ZK上新增znode,该znode数据形式如下:
+>
+> [zk: localhost:2181(CONNECTED) 30] get /A/blk-0000340369
+> {"svr_info": [{"ip": "1.1.1.1.", "port": "11000"}]}
+> cZxid = 0x2ffdeda3be
+> ……
+>
+> 2、全网机器监听 /A,当该znode下有新节点加入时,调用相应处理函数,将服务A的新增ip/port加入A.conf
+>
+> 3、完成步骤2后,继续设置对 /A监听
+
+ZK监控
+
+ZK自身提供了一些“四字命令”,通过这些四字命令,我们可以获得ZK集群中,某台ZK的角色、znode数、健康状态等信息:
+
+
+小结
+
+zookeeper以目录树的形式管理数据,提供znode监听、数据设置等接口,基于这些接口,我们可以实现Leader选举、配置管理、命名服务等功能。结合四字命令,加上模拟zookeeper client 创建/删除znode,我们可以实现对zookeeper的有效监控。在各种分布式系统中,我们经常可以看到zookeeper的身影。
\ No newline at end of file
From bf2d18ea6bb5beaceb43313f3bdb64c0009e37ae Mon Sep 17 00:00:00 2001
From: 724888 <362294931@qq.com>
Date: Sun, 8 Jul 2018 23:01:25 +0800
Subject: [PATCH 14/16] =?UTF-8?q?=E4=BF=AE=E6=94=B91?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
...00\346\234\257\346\200\273\347\273\223.md" | 369 ++++++++++++------
1 file changed, 254 insertions(+), 115 deletions(-)
diff --git "a/md/Java\346\240\270\345\277\203\346\212\200\346\234\257\346\200\273\347\273\223.md" "b/md/Java\346\240\270\345\277\203\346\212\200\346\234\257\346\200\273\347\273\223.md"
index 2eba287..973818b 100644
--- "a/md/Java\346\240\270\345\277\203\346\212\200\346\234\257\346\200\273\347\273\223.md"
+++ "b/md/Java\346\240\270\345\277\203\346\212\200\346\234\257\346\200\273\347\273\223.md"
@@ -1,136 +1,275 @@
---
-title: JAVA后端开发学习之路 # 文章页面上的显示名称,可以任意修改,不会出现在URL中
-date: 2018-4-20 15:56:26 # 文章生成时间,一般不改
-categories:
- - 个人总结
+title: Java核心技术学习总结
+date: 2018-05-02 22:37:47
tags:
- - 心路历程
+ - Java基础
+categories:
+ - 后端
+ - Java基础
---
-本文主要记录了我从Java初学者到专注于Java后端技术栈的开发者的学习历程。主要分享了学习过程中的一些经验和教训,让后来人看到,少走弯路,与君共勉,共同进步。如有错误,还请见谅。
-
-我的GitHub:
-> https://github.com/h2pl/MyTech
-
-喜欢的话麻烦点下星哈
-
-文章首发于我的个人博客:
-> https://h2pl.github.io/2018/04/20/java
-
-更多关于Java后端学习的内容请到我的CSDN博客上查看:
-
-https://blog.csdn.net/a724888
+本文主要是我最近复习Java基础原理过程中写的Java基础学习总结。Java的知识点其实非常多,并且有些知识点比较难以理解,有时候我们自以为理解了某些内容,其实可能只是停留在表面上,没有理解其底层实现原理。
-相关链接:我和技术博客的这一年:https://blog.csdn.net/a724888/article/details/60879893
-> 不论你是不是网民,无论你远离互联网,还是沉浸其中;你的身影,都在这场伟大的迁徙洪流中。超越人类经验的大迁徙,温暖而无情地,开始了。
- -----《互联网时代》
+纸上得来终觉浅,绝知此事要躬行。笔者之前对每部分的内容
+对做了比较深入的学习以及代码实现,基本上比较全面地讲述了每一个Java基础知识点,当然可能有些遗漏和错误,还请读者指正。
-## 选择方向
+**这里先把整体的学习大纲列出来,让大家对知识框架有个基本轮廓,具体每个部分的内容,笔者都对应写了一篇博文来加以讲解和剖析,并且发表在我的个人博客和csdn技术专栏里,下面给出地址**
- 0上大学前的那些事,让它们随风逝去吧。
- 1 个人对计算机和互联网有情怀,有兴趣,本科时在专业和学校里选择了学校,当时专业不是计算机,只能接触到一点点计算机专业课程,所以选择了考研,花半年时间复习考进了一个还不错的985,考研经历有空会发到博客上。
+专栏:深入理解Java原理
- 2 本科阶段接触过Java和Android,感觉app蛮有趣的,所以研一的时候想做Android,起初花大量时间看了计算机专业课的教材,效果很差。但也稍微了解了一些计算机基础,如网络,操作系统,组成原理,数据库,软工等。
+https://blog.csdn.net/column/details/21930.html
- 3 在没确定方向的迷茫时期看了大量视频和科普性文章,帮助理清头绪和方向。期间了解了诸如游戏开发,c++开发,Android,Java甚至前端等方向,其中还包含游戏策划岗。
+相关代码实现在我的GitHub里:
- 4 后来综合自身条件以及行业发展等因素,开始锁定自己的目标在Java后台方向。于是乎各种百度,知乎,查阅该学什么该怎么学如此类的问题,学习别人的经验。当然只靠搜索引擎很难找到精品内容,那段时间可谓是病急乱投医,走了不少弯路。
-
----
-
-## 夯实基础
-
- 1 研一的工程实践课让我知道了我的基础不够扎实,由于并非科班,需要比别人更加勤奋,古语有云,天道酬勤,勤能补拙。赶上了17年的春招实习招聘,期间开始各种海投,各种大厂面试一问三不知,才知道自身差距很大,开始疯狂复习面试题,刷面经,看经验等。死记硬背,之乎者也,倒也是能应付一些小公司,可谓是临阵磨枪不快也光。
-
- 2 不过期间的屡屡受挫让我冷静思考了一段时间,我再度调研了岗位需求,学习方法,以及需要看的书等资料。再度开工时,我的桌上开始不断出现新的经典书籍。这还要归功于我的启蒙导师:江南白衣,在知乎上看到了他的一篇文章,我的Java后端书架。在这个书架里我找寻到了很多我想看的书,以及我需要学习的技术。
-
- 3 遥想研一我还在看的书:教材就不提了,脱离实际并且年代久远,而我选的入门书籍竟然还有Java web从入门到精通这种烂大街的书籍,然后就是什么Java编程思想啦,深入理解计算机系统,算法导论这种高深莫测的书,感觉有点高不成低不就的意思。要么太过难懂要么过于粗糙,这些书在当时基本上没能帮到我。
-
----
+https://github.com/h2pl/MyTech
-## 书籍选择
+**喜欢的话麻烦star一下哈**
- 1 江南白衣的后端书架真是救我于水火。他的书架里收录了许多Java后端需要用到的技术书籍,并且十分经典,虽不说每本都适合入门,但是只要你用心去看都会有收获,高质量的书籍给人的启发要优于普通书籍。
+本系列技术文章首发于我的个人博客:
- 2 每个门类的书我都挑了一些。比如网络的两本(《tcp ip卷一》以及《计算机网络自顶向下》),操作系统两本(一本《Linux内核设计与实现》,一本高级操作系统,推荐先看完《深入理解计算机系统》再来看这两本),算法看的是《数据结构与算法(Java版)》,Java的四大件(《深入理解jvm虚拟机》,《java并发编程艺术》,《深入java web技术内幕》,《Java核心技术 卷一》这本没看)。
+https://h2pl.github.io
- 3 当然还有像《Effective Java》,《Java编程思想》,《Java性能调优指南》这种,不过新手不推荐,太不友好。接着是spring的两本《Spring实战》和《Spring源码剖析》。当然也包括一些redis,mq之类的书,还有就是一些介绍分布式组件的书籍,如zk等。
-
- 4 接下来就是扩展的内容了,比如分布式的三大件,《大型网站架构设计与实践》,《分布式网站架构设计与实践》,《Java中间件设计与实践》,外加一本《分布式服务框架设计与实践》。这几本书一看,绝对让你打开新世界的大门,醍醐灌顶,三月不知肉味。
-
- 5 你以为看完这些书你就无敌了,就满足了?想得倒是挺美。这些书最多就是把我从悬崖边拉回正途,能让我在正确的道路上行走了。毕竟技术书籍这种东西还是有门槛的,没有一定的知识储备,看书的过程也绝对是十分痛苦的。
-
- 6 比如《深入理解jvm虚拟机》和《java并发编程艺术》这两本书,我看了好几遍,第一遍基本当天书来看,第二遍挑着章节看,第三遍能把全部章节都看了。所以有时候你觉得你看完了一本书,对,你确实看完了,但过段时间是你能记得多少呢。可以说是很少了。
-
----
-
-## 谈一谈学习方法
-
- 1 人们在刚开始接触自己不熟悉的领域时,往往都会犯很多错误。刚开始学习Java时,就是摸着石头过河。从在极客学院慕课上看视频,到看书,再到看博客,再到工程实践,也是学习方式转变的一个过程。
-
- 2 看视频:适合0基础小白,视频给你构建一个世界观,让你对你要做的东西有个大概的了解,想要深入理解其中的技术原理,只看视频的话很难。
-
- 3 看书:就如上面一节所说,看书是一个很重要的环节。当你对技术只停留在大概的了解和基本会用的阶段时,经典书籍能够让你深入这些技术的原理,你可能会对书里的内容感到惊叹,也可能只是一知半解。所以第一遍的阅读一般读个大概就可以。一本书要吃透,不仅要看好几遍,还要多上手实践,才能变成自己的东西。
-
- 4 看博客,光看一些总结性的博客或者是科普性的博客可能还不够,一开始我也经常看这样的博客,后来只看这些东西,发现对技术的理解只能停留在表面。高质量的博客一般会把一个知识点讲得很透彻,比你看十篇总结都强,例如讲jdk源码的博文,可以很好地帮助你理解其原理,避免自己看的时候一脸懵逼。这里先推荐几个博客和网站,后面写复习计划的时候,会详细写出。
-博客:江南白衣、酷壳、战小狼。
-网站:并发编程网,importnew。
-
- 5 实践为王,Java后端毕竟还是工程方向,只是通过文字去理解技术点,可能有点纸上谈兵的感觉了。还有一个问题就是,没有进行上手实践的技术,一般很快就会忘了,做一些实践可以更好地巩固知识点。如果有项目中涉及不到的知识点,可以单独拿出来做一些demo,实在难以进行实践的技术点,可以参考别人的实践过程。
+更多关于Java后端学习的内容请到我的CSDN博客上查看:
----
+https://blog.csdn.net/a724888
-## 实习,提高工程能力的好机会
+## Java基础学习总结
+
+每部分内容会重点写一些常见知识点,方便复习和记忆,但是并不是全部内容,详细的内容请参见具体的文章地址。
+
+### 面向对象三大特性
+
+ 继承:一般类只能单继承,内部类实现多继承,接口可以多继承
+
+ 封装:访问权限控制public > protected > 包 > private 内部类也是一种封装
+
+ 多态:编译时多态,体现在向上转型和向下转型,通过引用类型判断调用哪个方法(静态分派)。
+
+ 运行时多态,体现在同名函数通过不同参数实现多种方法(动态分派)。
+
+### 基本数据类型
+
+ 基本类型位数,自动装箱,常量池
+
+ 例如byte类型是1byte也就是8位,可以表示的数字是-128到127,因为还有一个0,加起来一共是256,也就是2的八次方。
+
+ 32位和64位机器的int是4个字节也就是32位,char是1个字节就是8位,float是4个字节,double是8个字节,long是8个字节。
+
+ 所以它们占有字节数是相同的,这样的话两个版本才可以更好地兼容。(应该)
+
+ 基本数据类型的包装类只在数字范围-128到127中用到常量池,会自动拆箱装箱,其余数字范围的包装类则会新建实例
+
+### String及包装类
+
+ String类型是final类型,在堆中分配空间后内存地址不可变。
+
+ 底层是final修饰的char[]数组,数组的内存地址同样不可变。
+
+ 但实际上可以通过修改char[n] = 'a'来进行修改,不会改变String实例的内存值,不过在jdk中,用户无法直接获取char[],也没有方法能操作该数组。
+ 所以String类型的不可变实际上也是理论上的不可变。所以我们在分配String对象以后,如果将其 = "abc",那也只是改变了引用的指向,实际上没有改变原来的对象。
+
+ StringBuffer和StringBuilder底层是可变的char[]数组,继承父类AbstractStringBuilder的各种成员和方法,实际上的操作都是由父类方法来完成的。
+
+### final关键字
+
+ final修饰基本数据类型保证不可变
+
+ final修饰引用保证引用不能指向别的对象,否则会报错。
+
+ final修饰类,类的实例分配空间后地址不可变,子类不能重写所有父类方法。因此在cglib动态代理中,不能为一个类的final修饰的函数做代理,因为cglib要将被代理的类设置为父类,然后再生成字节码。
+
+ final修饰方法,子类不能重写该方法。
+
+### 抽象类和接口
+
+ 1 抽象类可以有方法实现。
+ 抽象类可以有非final成员变量。
+ 抽象方法要用abstract修饰。
+ 抽象类可以有构造方法,但是只能由子类进行实例化。
+
+ 2 接口可以用extends加多个接口实现多继承。
+ 接口只能有public final类型的成员变量。
+ 接口只能有抽象方法,不能有方法体、
+ 接口不能实例化,但是可以作为引用类型。
+
+### 代码块和加载顺序
+
+ 假设该类是第一次进行实例化。那么有如下加载顺序
+ 静态总是比非静态优先,从早到晚的顺序是:
+ 1 静态代码块 和 静态成员变量的顺序根据代码位置前后来决定。
+ 2 代码块和成员变量的顺序也根据代码位置来决定
+ 3 最后才调用构造方法构造方法
+### 包、内部类、外部类
+ 1 Java项目一般从src目录开始有com.*.*.A.java这样的目录结构。这就是包结构。所以一般编译后的结构是跟包结构一模一样的,这样的结构保证了import时能找到正确的class引用包访问权限就是指同包下的类可见。
+
+ import 一般加上全路径,并且使用.*时只包含当前目录的所有类文件,不包括子目录。
+
+ 2 外部类只有public和default两种修饰,要么全局可访问,要么包内可访问。
+
+ 3 内部类可以有全部访问权限,因为它的概念就是一个成员变量,所以访问权限设置与一般的成员变量相同。
+
+ 非静态内部类是外部类的一个成员变量,只跟外部类的实例有关。
+
+ 静态内部类是独立于外部类存在的一个类,与外部类实例无关,可以通过外部类.内部类直接获取Class类型。
+
+### 异常
+
+ 1 异常体系的最上层是Throwable类
+ 子类有Error和Exception
+ Exception的子类又有RuntimeException和其他具体的可检查异常。
+
+ 2 Error是jvm完全无法处理的系统错误,只能终止运行。
+
+ 运行时异常指的是编译正确但运行错误的异常,如数组越界异常,一般是人为失误导致的,这种异常不用try catch,而是需要程序员自己检查。
+
+ 可检查异常一般是jvm处理不了的一些异常,但是又经常会发生,比如Ioexception,Sqlexception等,是外部实现带来的异常。
+
+ 3 多线程的异常流程是独立的,互不影响。
+ 大型模块的子模块异常一般需要重新封装成外部异常再次抛出,否则只能看到最外层异常信息,难以进行调试。
+
+ 日志框架是异常报告的最好帮手,log4j,slf4j中,在工作中必不可少。
+
+### 泛型
+
+ Java中的泛型是伪泛型,只在编译期生效,运行期自动进行泛型擦除,将泛型替换为实际上传入的类型。
+
+ 泛型类用class A {
+
+ }这样的形式表示,里面的方法和成员变量都可以用T来表示类型。泛型接口也是类似的,不过泛型类实现泛型接口时可以选择注入实际类型或者是继续使用泛型。
+
+ 泛型方法可以自带泛型比如void E go();
+
+ 泛型可以使用?通配符进行泛化 Object可以接受任何类型
+
+ 也可以使用 这种方式进行上下边界的限制。
+
+### Class类和Object类
+
+ Java反射的基础是Class类,该类封装所有其他类的类型信息,并且在每个类加载后在堆区生成每个类的一个Class<类名>实例,用于该类的实例化。
+
+ Java中可以通过多种方式获取Class类型,比如A.class,new A().getClass()方法以及Class.forName("com.?.?.A")方法。
+
+ Object是所有类的父类,有着自己的一些私有方法,以及被所有类继承的9大方法。
+
+ 有人讨论Object和Class类型谁先加载谁后加载,因为每个类都要继承Object,但是又得先被加载到堆区,事实上,这个问题在JVM初始化时就解决了,没必要多想。
+
+### javac和java
+
+ javac 是编译一个java文件的基本命令,通过不同参数可以完成各种配置,比如导入其他类,指定编译路径等。
+
+ java是执行一个java文件的基本命令,通过参数配置可以以不同方式执行一个java程序或者是一个jar包。
+
+ javap是一个class文件的反编译程序,可以获取class文件的反编译结果,甚至是jvm执行程序的每一步代码实现。
+
+
+
+### 反射
+
+ Java反射包reflection提供对Class,Method,field,constructor等信息的封装类型。
+
+ 通过这些api可以轻易获得一个类的各种信息并且可以进行实例化,方法调用等。
+
+ 类中的private参数可以通过setaccessible方法强制获取。
+
+ 反射的作用可谓是博大精深,JDK动态代理生成代理类的字节码后,首先把这个类通过defineclass定义成一个类,然后用class.for(name)会把该类加载到jvm,之后我们就可以通过,A.class.GetMethod()获取其方法,然后通过invoke调用其方法,在调用这个方法时,实际上会通过被代理类的引用再去调用原方法。
- 1 这段时间以后就是实习期了,三个月的W厂实习经历。半年的B厂实习,让我着实过了一把大厂的瘾。但是其中做的工作无非就是增删改查写写业务逻辑,很难接触到比较核心的部分。
-
- 2 于是乎我花了许多时间学习部门的核心技术。比如在W厂参与数据平台的工作时,我学习了hadoop以及数据仓库的架构,也写了一些博客,并且向负责后端架构的导师请教了许多知识,收获颇丰。
-
- 3 在B厂实习期间则接触了许多云计算相关的技术。因为部门做的是私有云,所以业务代码和底层的服务也是息息相关的,比如平时的业务代码也会涉及到底层的接口调用,比如新建一个虚拟机或者启动一台虚拟机,需要通过多级的服务调用,首先是HTTP服务调用,经过多级的服务调用,最终完成流程。在这期间我花了一些时间学习了OpenStack的架构以及部门的实际应用情况,同时也玩了一下docker,看了kubenetes的一些书籍,算是入门。
-
- 4 但是这些东西其实离后台开发还是有一定距离的,比如后台开发的主要问题就是高并发,分布式,Linux服务器开发等。而我做的东西,只能稍微接触到这一部门的内容,因为主要是to b的内部业务。所以这段时间其实我的进步有限,虽然扩大了知识面并且积累了开发经验,但是对于后台岗位来说还是有所欠缺的。
-
- 5 不过将近一年的实习也让我收获了很多东西,大厂的实习体验很好,工作高效,团队合作,版本的快速迭代,技术氛围很不错。特别是在B厂了可以解到很多前沿的技术,对自己的视野扩展很有帮助。
-
----
-
-## **实习转正,还是准备秋招?**
-
- 1 离职以后,在考虑是否还要找实习,因为有两份实习经历了,在考虑要不要静下心来刷刷题,复习一下基础,并且回顾一下实习时用到的技术。同一时期,我了解到腾讯和阿里等大厂的实习留用率不高,并且可能影响到秋招,所以当时的想法是直接复习等到秋招内推。因此,那段时间比较放松,没什么复习状态,也导致了我在今年春招内推的阶段比较艰难。
-
- 2 因为当时想着沉住气准备秋招,所以一开始对实习内推不太在意。但是由于AT招人的实习生转正比例较大,考虑到秋招的名额可能更少,所以还是不愿意错过这个机会。因为开始系统复习的时间比较晚,所以投的比较晚,担心准备不充分被刷。这次找实习主要是奔着转正去的,所以只投了bat和滴滴,京东,网易游戏等大厂。
-
- 3 由于投递时间原因,所以面试的流程特别慢。并且在笔试方面还是有所欠缺,刷题刷的比较少,在线编程的算法题还是屡屡受挫。这让我有点后悔实习结束后的那段时间没有好好刷题了。
-
----
-
-## **调整心态,重新上路**
-
- 1 目前的状态是,一边刷题,一边复习基础,投了几家大厂的实习内推,打算选一个心仪的公司准备转正,但是事情总是没那么顺利,微软,头条等公司的笔试难度超过了我的能力范围,没能接到面试电话。腾讯投了一个自己比较喜欢的部门,可惜岗位没有匹配上,后台开发被转成了运营开发,最终没能通过。阿里面试的也不顺利,当时投了一个牛客上的蚂蚁金服内推,由于投的太晚,部门已经招满,只面了一面就没了下文,前几天接到了菜鸟的面试,这个未完待续。
-
- 2 目前的想法是,因为我不怎么需要实习经历来加分了,所以想多花些时间复习基础,刷题,并且巩固之前的项目经历。当然如果有好的岗位并且转正机会比较大的话,也是会考虑去实习的,那样的话可能需要多挤点时间来复习基础和刷题了。
-
- 3 在这期间,我会重新梳理一下自己的复习框架,有针对性地看一些高质量的博文,同时多做些项目实践,加深对知识的理解。当然这方面还会通过写博客进行跟进,写博客,做项目。前阵子在牛客上看到一位牛友CyC2018做的名为interview notebook的GitHub仓库,内容非常好,十分精品,我全部看完了,并且参考其LeetCode题解进行刷题。
-
- 4 受到这位大佬的启发,我也打算做一个类似的代码仓库或者是博客专栏,尽量在秋招之前把总结做完,并且把好的文章都放进去。上述内容只是本人个人的心得体会,如果有错误或者说的不合理的地方,还请谅解和指正。希望与广大牛友共勉,一起进步。
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
+### 枚举类
+
+ 枚举类继承Enum并且每个枚举类的实例都是唯一的。
+
+ 枚举类可以用于封装一组常量,取值从这组常量中取,比如一周的七天,一年的十二个月。
+
+ 枚举类的底层实现其实是语法糖,每个实例可以被转化成内部类。并且使用静态代码块进行初始化,同时保证内部成员变量不可变。
+
+### 序列化
+
+ 序列化的类要实现serializable接口
+
+ transient修饰符可以保证某个成员变量不被序列化
+
+ readObject和writeOject来实现实例的写入和读取。
+
+ 待更新。
+
+ 事实上,一些拥有数组变量的类都会把数组设为transient修饰,这样的话不会对整个数组进行序列化,而是利用专门的方法将有数据的数组范围进行序列化,以便节省空间。
+
+### 动态代理
+
+ jdk自带的动态代理可以代理一个已经实现接口的类。
+
+ cglib代理可以代理一个普通的类。
+
+ 动态代理的基本实现原理都是通过字节码框架动态生成字节码,并且在用defineclass加载类后,获取代理类的实例。
+
+ 一般需要实现一个代理处理器,用来处理被代理类的前置操作和后置操作。在JDK动态代理中,这个类叫做invocationHandler。
+
+ JDK动态代理首先获取被代理类的方法,并且只获取在接口中声明的方法,生成代理类的字节码后,首先把这个类通过defineclass定义成一个类,然后把该类加载到jvm,之后我们就可以通过,A.class.GetMethod()获取其方法,然后通过invoke调用其方法,在调用这个方法时,实际上会通过被代理类的引用再去调用原方法。
+
+ 而对于cglib动态代理,一般会把被代理类设为代理类的父类,然后获取被代理类中所有非final的方法,通过asm字节码框架生成代理类的字节码,这个代理类很神奇,他会保留原来的方法以及代理后的方法,通过方法数组的形式保存。
+
+ cglib的动态代理需要实现一个enhancer和一个interceptor,在interceptor中配置我们需要的代理内容。如果没有配置interceptor,那么代理类会调用被代理类自己的方法,如果配置了interceptor,则会使用代理类修饰过的方法。
+
+
+### 多线程
+ 这里先不讲juc包里的多线程类。juc相关内容会在Java并发专题讲解。
+
+ 线程的实现可以通过继承Thread类和实现Runable接口
+ 也可以使用线程池。callable配合future可以实现线程中的数据获取。
+
+ Java中的线程有7种状态,new runable running blocked waiting time_waiting terminate
+ blocked是线程等待其他线程锁释放。
+ waiting是wait以后线程无限等待其他线程使用notify唤醒
+ time_wating是有限时间地等待被唤醒,也可能是sleep固定时间。
+
+ Thread的join是实例方法,比如a.join(b),则说明a线程要等b线程运行完才会运行。
+
+ o.wait方法会让持有该对象o的线程释放锁并且进入阻塞状态,notify则是持有o锁对象的线程通知其他等待锁的线程获取锁。notify方法并不会释放锁。注意这两个方法都只能在synchronized同步方法或同步块里使用。
+
+ synchronized方法底层使用系统调用的mutex锁,开销较大,jvm会为每个锁对象维护一个等待队列,让等待该对象锁的线程在这个队列中等待。当线程获取不到锁时则让线程阻塞,而其他检查notify以后则会通知任意一个线程,所以这个锁时非公平锁。
+
+ Thread.sleep(),Thread.interrupt()等方法都是类方法,表示当前调用该方法的线程的操作。
+
+
+ 一个线程实例连续start两次会抛异常,这是因为线程start后会设置标识,如果再次start则判断为错误。
+
+### IO流
+
+ IO流也是Java中比较重要的一块,Java中主要有字节流,字符流,文件等。其中文件也是通过流的方式打开,读取和写入的。
+
+ IO流的很多接口都使用了装饰者模式,即将原类型通过传入装饰类构造函数的方式,增强原类型,以此获得像带有缓冲区的字节流,或者将字节流封装成字符流等等,其中需要注意的是编码问题,后者打印出来的结果可能是乱码哦。
+
+ IO流与网络编程息息相关,一个socket接入后,我们可以获取它的输入流和输出流,以获取TCP数据包的内容,并且可以往数据报里写入内容,因为TCP协议也是按照流的方式进行传输的,实际上TCP会将这些数据进行分包处理,并且通过差错检验,超时重传,滑动窗口协议等方式,保证了TCP数据包的高效和可靠传输。
+
+### 网络编程
+
+ 承接IO流的内容
+
+ IO流与网络编程息息相关,一个socket接入后,我们可以获取它的输入流和输出流,以获取TCP数据包的内容,并且可以往数据报里写入内容,因为TCP协议也是按照流的方式进行传输的,实际上TCP会将这些数据进行分包处理,并且通过差错检验,超时重传,滑动窗口协议等方式,保证了TCP数据包的高效和可靠传输。
+
+ 除了使用socket来获取TCP数据包外,还可以使用UDP的DatagramPacket来封装UDP数据包,因为UDP数据包的大小是确定的,所以不是使用流方式处理,而是需要事先定义他的长度,源端口和目标端口等信息。
+
+ 为了方便网络编程,Java提供了一系列类型来支持网络编程的api,比如URL类,InetAddress类等。
+
+ 后续文章会带来NIO相关的内容,敬请期待。
+
+
+
+
+### Java8
+
+ 接口中的默认方法,接口终于可以有方法实现了,使用注解即可标识出默认方法。
+
+ lambda表达式实现了函数式编程,通过注解可以声明一个函数式接口,该接口中只能有一个方法,这个方法正是使用lambda表达式时会调用到的接口。
+
+ Option类实现了非空检验
+
+ 新的日期API
+
+ 各种api的更新,包括chm,hashmap的实现等
+
+ Stream流概念,实现了集合类的流式访问,可以基于此使用map和reduce并行计算。
+
From 8dd2a615f14370b731047ce9f0707ba81e7c29c3 Mon Sep 17 00:00:00 2001
From: How_2_Play_Life <362294931@qq.com>
Date: Sun, 8 Jul 2018 23:11:10 +0800
Subject: [PATCH 15/16] Update README.md
---
README.md | 22 ++++++++++++++++++++++
1 file changed, 22 insertions(+)
diff --git a/README.md b/README.md
index 250a91f..b7618cc 100644
--- a/README.md
+++ b/README.md
@@ -10,16 +10,38 @@
## 数据库 :floppy_disk:
+> [Mysql原理与实践总结] (https://github.com/h2pl/Java-Tutorial/blob/master/md/Mysql%E5%8E%9F%E7%90%86%E4%B8%8E%E5%AE%9E%E8%B7%B5%E6%80%BB%E7%BB%93.md)
+
+> [Redis原理与实践总结]https://github.com/h2pl/Java-Tutorial/blob/master/md/Redis%E5%8E%9F%E7%90%86%E4%B8%8E%E5%AE%9E%E8%B7%B5%E6%80%BB%E7%BB%93.md
## Java :couple:
+> [Java核心技术总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/Java%E6%A0%B8%E5%BF%83%E6%8A%80%E6%9C%AF%E6%80%BB%E7%BB%93.md)
+
+> [Java集合类总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/Java%E9%9B%86%E5%90%88%E7%B1%BB%E6%80%BB%E7%BB%93.md)
+
+> [Java并发技术总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/Java%E5%B9%B6%E5%8F%91%E6%80%BB%E7%BB%93.md)
+
+> [JVM原理学习总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/JVM%E6%80%BB%E7%BB%93.md)
+
+> [Java网络与NIO总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/Java%E7%BD%91%E7%BB%9C%E4%B8%8ENIO%E6%80%BB%E7%BB%93.md)
+
## JavaWeb :coffee:
+> [JavaWeb技术学习总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/JavaWeb%E6%8A%80%E6%9C%AF%E6%80%BB%E7%BB%93.md)
+
+> [Spring与SpringMVC源码解析](https://github.com/h2pl/Java-Tutorial/blob/master/md/Spring%E4%B8%8ESpringMVC%E6%BA%90%E7%A0%81%E8%A7%A3%E6%9E%90%E6%80%BB%E7%BB%93.md)
+
## 分布式 :sweat_drops:
+> [分布式理论学习总结] (https://github.com/h2pl/Java-Tutorial/blob/master/md/%E5%88%86%E5%B8%83%E5%BC%8F%E7%90%86%E8%AE%BA%E6%80%BB%E7%BB%93.md)
+
+> [分布式技术学习总结] (https://github.com/h2pl/Java-Tutorial/blob/master/md/%E5%88%86%E5%B8%83%E5%BC%8F%E6%8A%80%E6%9C%AF%E5%AE%9E%E8%B7%B5%E6%80%BB%E7%BB%93.md)
## 设计模式 :hammer:
## Hadoop :speak_no_evil:
+> [分布式技术学习总结] (https://github.com/h2pl/Java-Tutorial/blob/master/md/Hadoop%E7%94%9F%E6%80%81%E6%80%BB%E7%BB%93.md)
+
## 后记
From 3d912288cd1f37c0db9ef7ca5d20ec0d341d7150 Mon Sep 17 00:00:00 2001
From: How_2_Play_Life <362294931@qq.com>
Date: Sun, 8 Jul 2018 23:15:05 +0800
Subject: [PATCH 16/16] Update README.md
---
README.md | 12 +++++++-----
1 file changed, 7 insertions(+), 5 deletions(-)
diff --git a/README.md b/README.md
index b7618cc..a667311 100644
--- a/README.md
+++ b/README.md
@@ -10,9 +10,10 @@
## 数据库 :floppy_disk:
-> [Mysql原理与实践总结] (https://github.com/h2pl/Java-Tutorial/blob/master/md/Mysql%E5%8E%9F%E7%90%86%E4%B8%8E%E5%AE%9E%E8%B7%B5%E6%80%BB%E7%BB%93.md)
+> [Mysql原理与实践总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/Mysql%E5%8E%9F%E7%90%86%E4%B8%8E%E5%AE%9E%E8%B7%B5%E6%80%BB%E7%BB%93.md)
+
+> [Redis原理与实践总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/Redis%E5%8E%9F%E7%90%86%E4%B8%8E%E5%AE%9E%E8%B7%B5%E6%80%BB%E7%BB%93.md)
-> [Redis原理与实践总结]https://github.com/h2pl/Java-Tutorial/blob/master/md/Redis%E5%8E%9F%E7%90%86%E4%B8%8E%E5%AE%9E%E8%B7%B5%E6%80%BB%E7%BB%93.md
## Java :couple:
> [Java核心技术总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/Java%E6%A0%B8%E5%BF%83%E6%8A%80%E6%9C%AF%E6%80%BB%E7%BB%93.md)
@@ -32,15 +33,16 @@
> [Spring与SpringMVC源码解析](https://github.com/h2pl/Java-Tutorial/blob/master/md/Spring%E4%B8%8ESpringMVC%E6%BA%90%E7%A0%81%E8%A7%A3%E6%9E%90%E6%80%BB%E7%BB%93.md)
## 分布式 :sweat_drops:
-> [分布式理论学习总结] (https://github.com/h2pl/Java-Tutorial/blob/master/md/%E5%88%86%E5%B8%83%E5%BC%8F%E7%90%86%E8%AE%BA%E6%80%BB%E7%BB%93.md)
-> [分布式技术学习总结] (https://github.com/h2pl/Java-Tutorial/blob/master/md/%E5%88%86%E5%B8%83%E5%BC%8F%E6%8A%80%E6%9C%AF%E5%AE%9E%E8%B7%B5%E6%80%BB%E7%BB%93.md)
+> [分布式理论学习总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/%E5%88%86%E5%B8%83%E5%BC%8F%E7%90%86%E8%AE%BA%E6%80%BB%E7%BB%93.md)
+
+> [分布式技术学习总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/%E5%88%86%E5%B8%83%E5%BC%8F%E6%8A%80%E6%9C%AF%E5%AE%9E%E8%B7%B5%E6%80%BB%E7%BB%93.md)
## 设计模式 :hammer:
## Hadoop :speak_no_evil:
-> [分布式技术学习总结] (https://github.com/h2pl/Java-Tutorial/blob/master/md/Hadoop%E7%94%9F%E6%80%81%E6%80%BB%E7%BB%93.md)
+> [Hadoop生态学习总结](https://github.com/h2pl/Java-Tutorial/blob/master/md/Hadoop%E7%94%9F%E6%80%81%E6%80%BB%E7%BB%93.md)