From b6fe4e2b577ff60cf7e47c245998673abadfc992 Mon Sep 17 00:00:00 2001
From: =?UTF-8?q?=E9=BB=84=E5=B0=8F=E6=96=9C?= <362294931@qq.com>
Date: Sun, 3 Nov 2019 15:51:28 +0800
Subject: [PATCH 001/153] Update ReadMe.md
---
ReadMe.md | 4 +---
1 file changed, 1 insertion(+), 3 deletions(-)
diff --git a/ReadMe.md b/ReadMe.md
index ee4b25d..15703b9 100644
--- a/ReadMe.md
+++ b/ReadMe.md
@@ -1,5 +1,3 @@
-点击订阅[Java面试进阶指南](https://xiaozhuanlan.com/java-coder)(专为Java面试方向准备)
-
点击关注[微信公众号](#微信公众号)及时获取笔主最新更新文章,并可免费领取Java工程师必备学习资源。
@@ -178,7 +176,7 @@

-### 个人公众号:黄小斜
+### 个人公众号:程序员黄小斜
作者是 985 硕士,蚂蚁金服 JAVA 工程师,专注于 JAVA 后端技术栈:SpringBoot、MySQL、分布式、中间件、微服务,同时也懂点投资理财,偶尔讲点算法和计算机理论基础,坚持学习和写作,相信终身学习的力量!
From ed1e483715d0fae4306013ebe70afc2cdef27ab8 Mon Sep 17 00:00:00 2001
From: =?UTF-8?q?=E9=BB=84=E5=B0=8F=E6=96=9C?= <362294931@qq.com>
Date: Sun, 3 Nov 2019 15:52:39 +0800
Subject: [PATCH 002/153] upload all posts
---
...36\347\216\260\345\216\237\347\220\206.md" | 310 ++++
...70\345\277\203\346\246\202\345\277\265.md" | 141 ++
...72\346\234\254\346\246\202\345\277\265.md" | 67 +
...22\346\216\222\347\264\242\345\274\225.md" | 147 ++
...45\344\275\234\345\216\237\347\220\206.md" | 145 ++
...06\344\270\216\345\256\236\350\267\265.md" | 676 ++++++++
...45\351\227\250\345\256\236\350\267\265.md" | 940 +++++++++++
...15\344\270\226\344\273\212\347\224\237.md" | 309 ++++
...37\345\214\226\346\212\200\346\234\257.md" | 97 ++
...347\232\204\345\237\272\347\237\263KVM.md" | 354 +++++
...66\346\236\204\350\256\276\350\256\241.md" | 167 ++
...03\346\246\202\345\277\265\345\220\247.md" | 207 +++
...AI\347\232\204\346\225\205\344\272\213.md" | 373 +++++
...47\350\241\214\350\277\207\347\250\213.md" | 305 ++++
...60\347\241\254\347\233\230\344\270\255.md" | 195 +++
...73\344\273\216\345\244\215\345\210\266.md" | 219 +++
...24\350\277\233\345\256\236\344\276\213.md" | 270 ++++
...71\346\200\247\344\273\213\347\273\215.md" | 299 ++++
...01\350\277\233\345\214\226\345\217\262.md" | 221 +++
...23\346\236\204\346\246\202\350\247\210.md" | 246 +++
...50\247\243\342\200\224\342\200\224dict.md" | 377 +++++
...350\247\243\342\200\224\342\200\224sds.md" | 369 +++++
...247\243\342\200\224\342\200\224ziplist.md" | 370 +++++
...7\243\342\200\224\342\200\224quicklist.md" | 371 +++++
...47\243\342\200\224\342\200\224skiplist.md" | 453 ++++++
...\247\243\342\200\224\342\200\224intset.md" | 321 ++++
...46\215\256\347\273\223\346\236\204robj.md" | 338 ++++
...40\351\231\244\347\255\226\347\225\245.md" | 323 ++++
...4\273\200\344\271\210\346\230\257Redis.md" | 315 ++++
...33\346\227\245\345\277\227\344\273\254.md" | 115 ++
...350\201\212SQL\346\263\250\345\205\245.md" | 138 ++
...30\345\214\226\345\274\200\345\247\213.md" | 673 ++++++++
...13\345\212\241\344\270\216\351\224\201.md" | 478 ++++++
...01\347\232\204\345\205\263\347\263\273.md" | 332 ++++
...45\344\270\216\345\256\236\350\267\265.md" | 597 +++++++
...0\257\235MySQL\345\205\245\351\227\250.md" | 378 +++++
...2\343\200\217MySQL \345\222\214 InnoDB.md" | 399 +++++
...30\345\202\250\345\216\237\347\220\206.md" | 409 +++++
...23\346\236\204\347\256\227\346\263\225.md" | 855 ++++++++++
...20\344\270\216\344\274\230\345\214\226.md" | 486 ++++++
...04\351\224\201\345\256\236\347\216\260.md" | 308 ++++
...47\345\210\253\345\256\236\346\210\230.md" | 145 ++
...06\344\270\216\345\256\236\350\267\265.md" | 511 ++++++
...44\270\200\350\207\264\346\200\247hash.md" | 173 ++
...37\346\210\220\346\226\271\346\241\210.md" | 219 +++
...04\351\202\243\344\272\233\344\272\213.md" | 704 +++++++++
...6\210\220Redis\347\274\223\345\255\230.md" | 671 ++++++++
...60\347\232\204\345\245\227\350\267\257.md" | 81 +
...40\347\247\215\346\226\271\346\241\210.md" | 167 ++
...03\345\274\217\344\272\213\345\212\241.md" | 247 +++
...43\345\206\263\346\226\271\346\241\210.md" | 203 +++
...03\345\274\217\344\272\213\345\212\241.md" | 158 ++
...72\346\234\254\346\246\202\345\277\265.md" | 559 +++++++
...40\344\275\225\350\200\214\347\224\237.md" | 338 ++++
...\201\257\346\212\200\346\234\257 Kafka.md" | 266 ++++
...57\274\214Raft\347\256\227\346\263\225.md" | 432 +++++
...0\203\346\234\215\345\212\241zookeeper.md" | 173 ++
...01\347\250\213\350\257\246\350\247\243.md" | 552 +++++++
...41\347\220\206\345\256\236\346\210\230.md" | 311 ++++
...57\345\217\212\345\256\236\350\267\265.md" | 436 ++++++
...73\346\265\201\346\226\271\346\241\210.md" | 0
...37\347\220\206\345\211\226\346\236\220.md" | 0
...06\344\270\216\345\256\236\350\267\265.md" | 0
...\200\247\343\200\2012PC\345\222\2143PC.md" | 168 ++
...5\237\272\347\241\2002 \357\274\232CAP.md" | 116 ++
...13\344\273\266\351\241\272\345\272\217.md" | 112 ++
...\237\272\347\241\2004\357\274\232Paxos.md" | 148 ++
...76\345\222\214\347\247\237\347\272\246.md" | 88 ++
...41\2006\357\274\232Raft\343\200\201Zab.md" | 99 ++
...17\350\260\203\346\234\215\345\212\241.md" | 116 ++
...03\345\210\260\345\205\245\351\227\250.md" | 42 +
...15\345\222\214\344\274\230\345\214\226.md" | 76 +
...06\345\270\203\345\274\217\357\274\211.md" | 594 +++++++
...33\346\200\273\347\273\223\357\274\211.md" | 263 ++++
...31\346\235\241\350\267\257\357\274\237.md" | 79 +
...04\346\272\220\346\270\205\345\215\225.md" | 211 +++
...00\345\274\240\345\233\276\357\274\201.md" | 171 ++
...17\345\244\247\345\220\210\351\233\206.md" | 184 +++
docs/hxx/think/copy.md | 109 ++
...4\232SpringMVC\346\246\202\350\277\260.md" | 1224 +++++++++++++++
...5\277\265\344\270\216DispatcherServlet.md" | 327 ++++
...67\346\261\202\350\275\254\345\217\221.md" | 327 ++++
...\243\347\241\256\347\232\204Controller.md" | 332 ++++
...43\346\236\220\345\216\237\347\220\206.md" | 385 +++++
...6@ResponseBody\346\263\250\350\247\243.md" | 541 +++++++
...\274\232Spring\346\246\202\350\277\260.md" | 118 ++
...70\345\277\203\346\265\201\347\250\213.md" | 397 +++++
...40\350\275\275\350\277\207\347\250\213.md" | 1285 +++++++++++++++
...07\347\250\213\345\210\206\346\236\220.md" | 146 ++
...37\347\220\206\350\257\246\350\247\243.md" | 861 ++++++++++
...\232Spring AOP\346\246\202\350\277\260.md" | 462 ++++++
...37\347\220\206\350\257\246\350\247\243.md" | 1100 +++++++++++++
...13\345\212\241\346\246\202\350\277\260.md" | 598 +++++++
...20\347\240\201\345\211\226\346\236\220.md" | 263 ++++
...45\350\257\206\346\270\205\345\215\225.md" | 1057 +++++++++++++
...72\346\234\254\345\216\237\347\220\206.md" | 168 ++
...JavaBean\350\256\262\345\210\260Spring.md" | 264 ++++
...0\257\225\346\241\206\346\236\266Junit.md" | 454 ++++++
...5\273\272\345\267\245\345\205\267Maven.md" | 325 ++++
...43\345\274\217\345\274\200\345\217\221.md" | 1067 +++++++++++++
...274\232Mybatis\345\205\245\351\227\250.md" | 426 +++++
...\215\347\275\256\347\232\204SpringBoot.md" | 540 +++++++
...72\347\241\200\347\237\245\350\257\206.md" | 258 +++
...17\344\270\216\347\216\260\345\234\250.md" | 210 +++
...45\346\261\240\346\212\200\346\234\257.md" | 155 ++
...37\347\220\206\350\257\246\350\247\243.md" | 391 +++++
...67\346\261\202\350\277\207\347\250\213.md" | 362 +++++
...66\346\236\204\345\211\226\346\236\220.md" | 1153 ++++++++++++++
...50\347\232\204\345\214\272\345\210\253.md" | 164 ++
...50\347\275\262\350\277\207\347\250\213.md" | 175 +++
...37\344\270\216\345\217\221\345\261\225.md" | 238 +++
...13\343\200\201\346\263\233\345\236\213.md" | 7 -
...01\346\236\232\344\270\276\347\261\273.md" | 7 -
...71\350\261\241\345\237\272\347\241\200.md" | 1 +
...73\345\222\214\346\216\245\345\217\243.md" | 31 +-
...20\347\240\201\345\210\206\346\236\220.md" | 586 +++++++
...\351\230\237\345\210\227 BlockingQueue.md" | 836 ++++++++++
...20\347\240\201\345\256\236\347\216\260.md" | 1306 ++++++++++++++++
...p \345\205\250\350\247\243\346\236\220.md" | 1386 +++++++++++++++++
...7\232\204Unsafe\345\222\214Locksupport.md" | 349 +++++
...va\345\244\232\347\272\277\347\250\213.md" | 178 +++
...345\255\230\346\250\241\345\236\213JMM.md" | 391 +++++
...357\274\214CAS\346\223\215\344\275\234.md" | 546 +++++++
...1\224\201 Lock\345\222\214synchronized.md" | 517 ++++++
...56\345\255\227\350\247\243\346\236\220.md" | 205 +++
...345\236\213JMM\346\200\273\347\273\223.md" | 546 +++++++
...347\261\273AQS\350\257\246\350\247\243.md" | 561 +++++++
...71\263\351\224\201\357\274\214Condtion.md" | 1007 ++++++++++++
...73\347\232\204\345\256\236\347\216\260.md" | 921 +++++++++++
...27\346\263\225\345\211\226\346\236\220.md" | 163 ++
...14\346\234\237\344\274\230\345\214\226.md" | 235 +++
...03\344\274\230\345\256\236\350\267\265.md" | 410 +++++
...06\344\270\216\345\256\236\350\267\265.md" | 451 ++++++
...15\344\270\216\345\256\236\346\210\230.md" | 260 ++++
...\345\217\212GC\345\256\236\350\267\265.md" | 233 +++
...04\346\260\270\344\271\205\344\273\243.md" | 441 ++++++
...06\345\222\214\347\256\227\346\263\225.md" | 555 +++++++
...66\345\231\250\350\257\246\350\247\243.md" | 245 +++
...43\346\236\220\345\256\236\350\267\265.md" | 350 +++++
...47\350\241\214\345\274\225\346\223\216.md" | 290 ++++
...40\350\275\275\346\234\272\345\210\266.md" | 170 ++
...75\345\231\250\345\256\236\347\216\260.md" | 388 +++++
...12\346\226\255\345\256\236\350\267\265.md" | 389 +++++
...70\347\224\250\345\267\245\345\205\267.md" | 46 +
...347\232\204NIO\346\250\241\345\236\213.md" | 180 +++
...346\236\220\357\274\210NIO\357\274\211.md" | 822 ++++++++++
...67\346\261\202\346\250\241\345\236\213.md" | 526 +++++++
...3\200\201Channel \345\222\214 Selector.md" | 457 ++++++
...6\236\220mmap\345\222\214Direct Buffer.md" | 572 +++++++
...32\344\277\241\346\234\272\345\210\266.md" | 363 +++++
...26\347\250\213\346\250\241\345\236\213.md" | 302 ++++
...345\222\214\345\274\202\346\255\245 IO.md" | 657 ++++++++
...37\347\220\206\350\257\246\350\247\243.md" | 284 ++++
...36\347\216\260\345\216\237\347\220\206.md" | 660 ++++++++
...7\250\213\346\241\206\346\236\266Netty.md" | 1353 ++++++++++++++++
.../\347\224\265\345\255\220\344\271\246.md" | 255 +++
156 files changed, 59182 insertions(+), 44 deletions(-)
create mode 100644 "docs/big-backEnd/\345\220\216\347\253\257\346\212\200\346\234\257\346\235\202\350\260\21010\357\274\232Docker \346\240\270\345\277\203\346\212\200\346\234\257\344\270\216\345\256\236\347\216\260\345\216\237\347\220\206.md"
create mode 100644 "docs/big-backEnd/\345\220\216\347\253\257\346\212\200\346\234\257\346\235\202\350\260\21011\357\274\232\345\215\201\345\210\206\351\222\237\347\220\206\350\247\243Kubernetes\346\240\270\345\277\203\346\246\202\345\277\265.md"
create mode 100644 "docs/big-backEnd/\345\220\216\347\253\257\346\212\200\346\234\257\346\235\202\350\260\21012\357\274\232\346\215\213\344\270\200\346\215\213\345\244\247\346\225\260\346\215\256\347\240\224\345\217\221\347\232\204\345\237\272\346\234\254\346\246\202\345\277\265.md"
create mode 100644 "docs/big-backEnd/\345\220\216\347\253\257\346\212\200\346\234\257\346\235\202\350\260\2101\357\274\232\346\220\234\347\264\242\345\274\225\346\223\216\345\237\272\347\241\200\345\200\222\346\216\222\347\264\242\345\274\225.md"
create mode 100644 "docs/big-backEnd/\345\220\216\347\253\257\346\212\200\346\234\257\346\235\202\350\260\2102\357\274\232\346\220\234\347\264\242\345\274\225\346\223\216\345\267\245\344\275\234\345\216\237\347\220\206.md"
create mode 100644 "docs/big-backEnd/\345\220\216\347\253\257\346\212\200\346\234\257\346\235\202\350\260\2103\357\274\232Lucene\345\237\272\347\241\200\345\216\237\347\220\206\344\270\216\345\256\236\350\267\265.md"
create mode 100644 "docs/big-backEnd/\345\220\216\347\253\257\346\212\200\346\234\257\346\235\202\350\260\2104\357\274\232Elasticsearch\344\270\216solr\345\205\245\351\227\250\345\256\236\350\267\265.md"
create mode 100644 "docs/big-backEnd/\345\220\216\347\253\257\346\212\200\346\234\257\346\235\202\350\260\2105\357\274\232\344\272\221\350\256\241\347\256\227\347\232\204\345\211\215\344\270\226\344\273\212\347\224\237.md"
create mode 100644 "docs/big-backEnd/\345\220\216\347\253\257\346\212\200\346\234\257\346\235\202\350\260\2106\357\274\232\347\231\275\350\257\235\350\231\232\346\213\237\345\214\226\346\212\200\346\234\257.md"
create mode 100644 "docs/big-backEnd/\345\220\216\347\253\257\346\212\200\346\234\257\346\235\202\350\260\2107\357\274\232OpenStack\347\232\204\345\237\272\347\237\263KVM.md"
create mode 100644 "docs/big-backEnd/\345\220\216\347\253\257\346\212\200\346\234\257\346\235\202\350\260\2108\357\274\232OpenStack\346\236\266\346\236\204\350\256\276\350\256\241.md"
create mode 100644 "docs/big-backEnd/\345\220\216\347\253\257\346\212\200\346\234\257\346\235\202\350\260\2109\357\274\232\345\205\210\346\220\236\346\207\202Docker\346\240\270\345\277\203\346\246\202\345\277\265\345\220\247.md"
create mode 100644 "docs/big-backEnd/\345\220\216\347\253\257\346\212\200\346\234\257\346\235\202\350\260\210\345\274\200\347\257\207\357\274\232\344\272\221\350\256\241\347\256\227\357\274\214\345\244\247\346\225\260\346\215\256\344\270\216AI\347\232\204\346\225\205\344\272\213.md"
create mode 100644 "docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\26010\357\274\232Redis\347\232\204\344\272\213\344\273\266\351\251\261\345\212\250\346\250\241\345\236\213\344\270\216\345\221\275\344\273\244\346\211\247\350\241\214\350\277\207\347\250\213.md"
create mode 100644 "docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\26011\357\274\232\344\275\277\347\224\250\345\277\253\347\205\247\345\222\214AOF\345\260\206Redis\346\225\260\346\215\256\346\214\201\344\271\205\345\214\226\345\210\260\347\241\254\347\233\230\344\270\255.md"
create mode 100644 "docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\26012\357\274\232\346\265\205\346\236\220Redis\344\270\273\344\273\216\345\244\215\345\210\266.md"
create mode 100644 "docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\26013\357\274\232Redis\351\233\206\347\276\244\346\234\272\345\210\266\345\217\212\344\270\200\344\270\252Redis\346\236\266\346\236\204\346\274\224\350\277\233\345\256\236\344\276\213.md"
create mode 100644 "docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\26014\357\274\232Redis\344\272\213\345\212\241\346\265\205\346\236\220\344\270\216ACID\347\211\271\346\200\247\344\273\213\347\273\215.md"
create mode 100644 "docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\26015\357\274\232Redis\345\210\206\345\270\203\345\274\217\351\224\201\350\277\233\345\214\226\345\217\262.md"
create mode 100644 "docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\2601\357\274\232Redis \347\232\204\345\237\272\347\241\200\346\225\260\346\215\256\347\273\223\346\236\204\346\246\202\350\247\210.md"
create mode 100644 "docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\2602\357\274\232Redis\345\206\205\351\203\250\346\225\260\346\215\256\347\273\223\346\236\204\350\257\246\350\247\243\342\200\224\342\200\224dict.md"
create mode 100644 "docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\2603\357\274\232Redis\345\206\205\351\203\250\346\225\260\346\215\256\347\273\223\346\236\204\350\257\246\350\247\243\342\200\224\342\200\224sds.md"
create mode 100644 "docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\2604\357\274\232Redis\345\206\205\351\203\250\346\225\260\346\215\256\347\273\223\346\236\204\350\257\246\350\247\243\342\200\224\342\200\224ziplist.md"
create mode 100644 "docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\2605\357\274\232Redis\345\206\205\351\203\250\346\225\260\346\215\256\347\273\223\346\236\204\350\257\246\350\247\243\342\200\224\342\200\224quicklist.md"
create mode 100644 "docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\2606\357\274\232Redis\345\206\205\351\203\250\346\225\260\346\215\256\347\273\223\346\236\204\350\257\246\350\247\243\342\200\224\342\200\224skiplist.md"
create mode 100644 "docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\2607\357\274\232Redis\345\206\205\351\203\250\346\225\260\346\215\256\347\273\223\346\236\204\350\257\246\350\247\243\342\200\224\342\200\224intset.md"
create mode 100644 "docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\2608\357\274\232\350\277\236\346\216\245\345\272\225\345\261\202\344\270\216\350\241\250\351\235\242\347\232\204\346\225\260\346\215\256\347\273\223\346\236\204robj.md"
create mode 100644 "docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\2609\357\274\232\346\225\260\346\215\256\345\272\223redisDb\344\270\216\351\224\256\350\277\207\346\234\237\345\210\240\351\231\244\347\255\226\347\225\245.md"
create mode 100644 "docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\260\345\274\200\347\257\207\357\274\232\344\273\200\344\271\210\346\230\257Redis.md"
create mode 100644 "docs/database/\351\207\215\346\226\260\345\255\246\344\271\240MySQL\346\225\260\346\215\256\345\272\22310\357\274\232MySQL\351\207\214\347\232\204\351\202\243\344\272\233\346\227\245\345\277\227\344\273\254.md"
create mode 100644 "docs/database/\351\207\215\346\226\260\345\255\246\344\271\240MySQL\346\225\260\346\215\256\345\272\22311\357\274\232\344\273\245Java\347\232\204\350\247\206\350\247\222\346\235\245\350\201\212\350\201\212SQL\346\263\250\345\205\245.md"
create mode 100644 "docs/database/\351\207\215\346\226\260\345\255\246\344\271\240MySQL\346\225\260\346\215\256\345\272\22312\357\274\232\344\273\216\345\256\236\350\267\265sql\350\257\255\345\217\245\344\274\230\345\214\226\345\274\200\345\247\213.md"
create mode 100644 "docs/database/\351\207\215\346\226\260\345\255\246\344\271\240MySQL\346\225\260\346\215\256\345\272\2236\357\274\232\346\265\205\350\260\210MySQL\347\232\204\344\270\255\344\272\213\345\212\241\344\270\216\351\224\201.md"
create mode 100644 "docs/database/\351\207\215\346\226\260\345\255\246\344\271\240MySQL\346\225\260\346\215\256\345\272\2239\357\274\232Innodb\344\270\255\347\232\204\344\272\213\345\212\241\351\232\224\347\246\273\347\272\247\345\210\253\345\222\214\351\224\201\347\232\204\345\205\263\347\263\273.md"
create mode 100644 "docs/database/\351\207\215\346\226\260\345\255\246\344\271\240Mysql\346\225\260\346\215\25613\357\274\232Mysql\344\270\273\344\273\216\345\244\215\345\210\266\357\274\214\350\257\273\345\206\231\345\210\206\347\246\273\357\274\214\345\210\206\350\241\250\345\210\206\345\272\223\347\255\226\347\225\245\344\270\216\345\256\236\350\267\265.md"
create mode 100644 "docs/database/\351\207\215\346\226\260\345\255\246\344\271\240Mysql\346\225\260\346\215\256\345\272\2231\357\274\232\346\227\240\345\272\237\350\257\235MySQL\345\205\245\351\227\250.md"
create mode 100644 "docs/database/\351\207\215\346\226\260\345\255\246\344\271\240Mysql\346\225\260\346\215\256\345\272\2232\357\274\232\343\200\216\346\265\205\345\205\245\346\265\205\345\207\272\343\200\217MySQL \345\222\214 InnoDB.md"
create mode 100644 "docs/database/\351\207\215\346\226\260\345\255\246\344\271\240Mysql\346\225\260\346\215\256\345\272\2233\357\274\232Mysql\345\255\230\345\202\250\345\274\225\346\223\216\344\270\216\346\225\260\346\215\256\345\255\230\345\202\250\345\216\237\347\220\206.md"
create mode 100644 "docs/database/\351\207\215\346\226\260\345\255\246\344\271\240Mysql\346\225\260\346\215\256\345\272\2234\357\274\232Mysql\347\264\242\345\274\225\345\256\236\347\216\260\345\216\237\347\220\206\345\222\214\347\233\270\345\205\263\346\225\260\346\215\256\347\273\223\346\236\204\347\256\227\346\263\225.md"
create mode 100644 "docs/database/\351\207\215\346\226\260\345\255\246\344\271\240Mysql\346\225\260\346\215\256\345\272\2235\357\274\232\346\240\271\346\215\256MySQL\347\264\242\345\274\225\345\216\237\347\220\206\350\277\233\350\241\214\345\210\206\346\236\220\344\270\216\344\274\230\345\214\226.md"
create mode 100644 "docs/database/\351\207\215\346\226\260\345\255\246\344\271\240Mysql\346\225\260\346\215\256\345\272\2237\357\274\232\350\257\246\350\247\243MyIsam\344\270\216InnoDB\345\274\225\346\223\216\347\232\204\351\224\201\345\256\236\347\216\260.md"
create mode 100644 "docs/database/\351\207\215\346\226\260\345\255\246\344\271\240Mysql\346\225\260\346\215\256\345\272\2238\357\274\232MySQL\347\232\204\344\272\213\345\212\241\351\232\224\347\246\273\347\272\247\345\210\253\345\256\236\346\210\230.md"
create mode 100644 "docs/distrubuted/\345\256\236\346\210\230/\346\220\236\346\207\202\345\210\206\345\270\203\345\274\217\346\212\200\346\234\25710\357\274\232LVS\345\256\236\347\216\260\350\264\237\350\275\275\345\235\207\350\241\241\347\232\204\345\216\237\347\220\206\344\270\216\345\256\236\350\267\265.md"
create mode 100644 "docs/distrubuted/\345\256\236\346\210\230/\346\220\236\346\207\202\345\210\206\345\270\203\345\274\217\346\212\200\346\234\25711\357\274\232\345\210\206\345\270\203\345\274\217session\350\247\243\345\206\263\346\226\271\346\241\210\344\270\216\344\270\200\350\207\264\346\200\247hash.md"
create mode 100644 "docs/distrubuted/\345\256\236\346\210\230/\346\220\236\346\207\202\345\210\206\345\270\203\345\274\217\346\212\200\346\234\25712\357\274\232\345\210\206\345\270\203\345\274\217ID\347\224\237\346\210\220\346\226\271\346\241\210.md"
create mode 100644 "docs/distrubuted/\345\256\236\346\210\230/\346\220\236\346\207\202\345\210\206\345\270\203\345\274\217\346\212\200\346\234\25713\357\274\232\347\274\223\345\255\230\347\232\204\351\202\243\344\272\233\344\272\213.md"
create mode 100644 "docs/distrubuted/\345\256\236\346\210\230/\346\220\236\346\207\202\345\210\206\345\270\203\345\274\217\346\212\200\346\234\25714\357\274\232Spring Boot\344\275\277\347\224\250\346\263\250\350\247\243\351\233\206\346\210\220Redis\347\274\223\345\255\230.md"
create mode 100644 "docs/distrubuted/\345\256\236\346\210\230/\346\220\236\346\207\202\345\210\206\345\270\203\345\274\217\346\212\200\346\234\25715\357\274\232\347\274\223\345\255\230\346\233\264\346\226\260\347\232\204\345\245\227\350\267\257.md"
create mode 100644 "docs/distrubuted/\345\256\236\346\210\230/\346\220\236\346\207\202\345\210\206\345\270\203\345\274\217\346\212\200\346\234\25716\357\274\232\346\265\205\350\260\210\345\210\206\345\270\203\345\274\217\351\224\201\347\232\204\345\207\240\347\247\215\346\226\271\346\241\210.md"
create mode 100644 "docs/distrubuted/\345\256\236\346\210\230/\346\220\236\346\207\202\345\210\206\345\270\203\345\274\217\346\212\200\346\234\25717\357\274\232\346\265\205\346\236\220\345\210\206\345\270\203\345\274\217\344\272\213\345\212\241.md"
create mode 100644 "docs/distrubuted/\345\256\236\346\210\230/\346\220\236\346\207\202\345\210\206\345\270\203\345\274\217\346\212\200\346\234\25718\357\274\232\345\210\206\345\270\203\345\274\217\344\272\213\345\212\241\345\270\270\347\224\250\350\247\243\345\206\263\346\226\271\346\241\210.md"
create mode 100644 "docs/distrubuted/\345\256\236\346\210\230/\346\220\236\346\207\202\345\210\206\345\270\203\345\274\217\346\212\200\346\234\25719\357\274\232\344\275\277\347\224\250RocketMQ\344\272\213\345\212\241\346\266\210\346\201\257\350\247\243\345\206\263\345\210\206\345\270\203\345\274\217\344\272\213\345\212\241.md"
create mode 100644 "docs/distrubuted/\345\256\236\346\210\230/\346\220\236\346\207\202\345\210\206\345\270\203\345\274\217\346\212\200\346\234\2571\357\274\232\345\210\206\345\270\203\345\274\217\347\263\273\347\273\237\347\232\204\344\270\200\344\272\233\345\237\272\346\234\254\346\246\202\345\277\265.md"
create mode 100644 "docs/distrubuted/\345\256\236\346\210\230/\346\220\236\346\207\202\345\210\206\345\270\203\345\274\217\346\212\200\346\234\25720\357\274\232\346\266\210\346\201\257\351\230\237\345\210\227\345\233\240\344\275\225\350\200\214\347\224\237.md"
create mode 100644 "docs/distrubuted/\345\256\236\346\210\230/\346\220\236\346\207\202\345\210\206\345\270\203\345\274\217\346\212\200\346\234\25721\357\274\232\346\265\205\350\260\210\345\210\206\345\270\203\345\274\217\346\266\210\346\201\257\346\212\200\346\234\257 Kafka.md"
create mode 100644 "docs/distrubuted/\345\256\236\346\210\230/\346\220\236\346\207\202\345\210\206\345\270\203\345\274\217\346\212\200\346\234\2572\357\274\232\345\210\206\345\270\203\345\274\217\344\270\200\350\207\264\346\200\247\345\215\217\350\256\256\344\270\216Paxos\357\274\214Raft\347\256\227\346\263\225.md"
create mode 100644 "docs/distrubuted/\345\256\236\346\210\230/\346\220\236\346\207\202\345\210\206\345\270\203\345\274\217\346\212\200\346\234\2573\357\274\232\345\210\235\346\216\242\345\210\206\345\270\203\345\274\217\345\215\217\350\260\203\346\234\215\345\212\241zookeeper.md"
create mode 100644 "docs/distrubuted/\345\256\236\346\210\230/\346\220\236\346\207\202\345\210\206\345\270\203\345\274\217\346\212\200\346\234\2574\357\274\232ZAB\345\215\217\350\256\256\346\246\202\350\277\260\344\270\216\351\200\211\344\270\273\346\265\201\347\250\213\350\257\246\350\247\243.md"
create mode 100644 "docs/distrubuted/\345\256\236\346\210\230/\346\220\236\346\207\202\345\210\206\345\270\203\345\274\217\346\212\200\346\234\2575\357\274\232Zookeeper\347\232\204\351\205\215\347\275\256\344\270\216\351\233\206\347\276\244\347\256\241\347\220\206\345\256\236\346\210\230.md"
create mode 100644 "docs/distrubuted/\345\256\236\346\210\230/\346\220\236\346\207\202\345\210\206\345\270\203\345\274\217\346\212\200\346\234\2576\357\274\232Zookeeper\345\205\270\345\236\213\345\272\224\347\224\250\345\234\272\346\231\257\345\217\212\345\256\236\350\267\265.md"
create mode 100644 "docs/distrubuted/\345\256\236\346\210\230/\346\220\236\346\207\202\345\210\206\345\270\203\345\274\217\346\212\200\346\234\2577\357\274\232\350\264\237\350\275\275\345\235\207\350\241\241\346\246\202\345\277\265\344\270\216\344\270\273\346\265\201\346\226\271\346\241\210.md"
create mode 100644 "docs/distrubuted/\345\256\236\346\210\230/\346\220\236\346\207\202\345\210\206\345\270\203\345\274\217\346\212\200\346\234\2578\357\274\232\350\264\237\350\275\275\345\235\207\350\241\241\345\216\237\347\220\206\345\211\226\346\236\220.md"
create mode 100644 "docs/distrubuted/\345\256\236\346\210\230/\346\220\236\346\207\202\345\210\206\345\270\203\345\274\217\346\212\200\346\234\2579\357\274\232Nginx\350\264\237\350\275\275\345\235\207\350\241\241\345\216\237\347\220\206\344\270\216\345\256\236\350\267\265.md"
create mode 100644 "docs/distrubuted/\347\220\206\350\256\272/\345\210\206\345\270\203\345\274\217\347\263\273\347\273\237\347\220\206\350\256\272\345\237\272\347\241\2001\357\274\232 \344\270\200\350\207\264\346\200\247\343\200\2012PC\345\222\2143PC.md"
create mode 100644 "docs/distrubuted/\347\220\206\350\256\272/\345\210\206\345\270\203\345\274\217\347\263\273\347\273\237\347\220\206\350\256\272\345\237\272\347\241\2002 \357\274\232CAP.md"
create mode 100644 "docs/distrubuted/\347\220\206\350\256\272/\345\210\206\345\270\203\345\274\217\347\263\273\347\273\237\347\220\206\350\256\272\345\237\272\347\241\2003\357\274\232 \346\227\266\351\227\264\343\200\201\346\227\266\351\222\237\345\222\214\344\272\213\344\273\266\351\241\272\345\272\217.md"
create mode 100644 "docs/distrubuted/\347\220\206\350\256\272/\345\210\206\345\270\203\345\274\217\347\263\273\347\273\237\347\220\206\350\256\272\345\237\272\347\241\2004\357\274\232Paxos.md"
create mode 100644 "docs/distrubuted/\347\220\206\350\256\272/\345\210\206\345\270\203\345\274\217\347\263\273\347\273\237\347\220\206\350\256\272\345\237\272\347\241\2005\357\274\232\351\200\211\344\270\276\343\200\201\345\244\232\346\225\260\346\264\276\345\222\214\347\247\237\347\272\246.md"
create mode 100644 "docs/distrubuted/\347\220\206\350\256\272/\345\210\206\345\270\203\345\274\217\347\263\273\347\273\237\347\220\206\350\256\272\345\237\272\347\241\2006\357\274\232Raft\343\200\201Zab.md"
create mode 100644 "docs/distrubuted/\347\220\206\350\256\272/\345\210\206\345\270\203\345\274\217\347\263\273\347\273\237\347\220\206\350\256\272\345\237\272\347\241\2008\357\274\232zookeeper\345\210\206\345\270\203\345\274\217\345\215\217\350\260\203\346\234\215\345\212\241.md"
create mode 100644 "docs/distrubuted/\347\220\206\350\256\272/\345\210\206\345\270\203\345\274\217\347\263\273\347\273\237\347\220\206\350\256\272\345\237\272\347\241\200\345\274\200\347\257\207\357\274\232\344\273\216\346\224\276\345\274\203\345\210\260\345\205\245\351\227\250.md"
create mode 100644 "docs/distrubuted/\347\220\206\350\256\272/\345\210\206\345\270\203\345\274\217\347\263\273\347\273\237\347\220\206\350\256\272\350\277\233\351\230\2667\357\274\232Paxos\345\217\230\347\247\215\345\222\214\344\274\230\345\214\226.md"
create mode 100644 "docs/hxx/java/Java\345\220\216\347\253\257\345\267\245\347\250\213\345\270\210\345\277\205\345\244\207\344\271\246\345\215\225\357\274\210\344\273\216Java\345\237\272\347\241\200\345\210\260\345\210\206\345\270\203\345\274\217\357\274\211.md"
create mode 100644 "docs/hxx/java/Java\345\267\245\347\250\213\345\270\210\344\277\256\347\202\274\344\271\213\350\267\257\357\274\210\346\240\241\346\213\233\346\200\273\347\273\223\357\274\211.md"
create mode 100644 "docs/hxx/java/\344\270\272\344\273\200\344\271\210\346\210\221\344\274\232\351\200\211\346\213\251\350\265\260 Java \350\277\231\346\235\241\350\267\257\357\274\237.md"
create mode 100644 "docs/hxx/java/\344\275\240\344\270\215\345\217\257\351\224\231\350\277\207\347\232\204Java\345\255\246\344\271\240\350\265\204\346\272\220\346\270\205\345\215\225.md"
create mode 100644 "docs/hxx/java/\346\203\263\344\272\206\350\247\243Java\345\220\216\347\253\257\345\255\246\344\271\240\350\267\257\347\272\277\357\274\237\344\275\240\345\217\252\351\234\200\350\246\201\350\277\231\344\270\200\345\274\240\345\233\276\357\274\201.md"
create mode 100644 "docs/hxx/java/\346\210\221\347\232\204Java\347\247\213\346\213\233\351\235\242\347\273\217\345\244\247\345\220\210\351\233\206.md"
create mode 100644 docs/hxx/think/copy.md
create mode 100644 "docs/java-web/SSM/SpringMVC\346\272\220\347\240\201\345\210\206\346\236\2201\357\274\232SpringMVC\346\246\202\350\277\260.md"
create mode 100644 "docs/java-web/SSM/SpringMVC\346\272\220\347\240\201\345\210\206\346\236\2202\357\274\232SpringMVC\350\256\276\350\256\241\347\220\206\345\277\265\344\270\216DispatcherServlet.md"
create mode 100644 "docs/java-web/SSM/SpringMVC\346\272\220\347\240\201\345\210\206\346\236\2203\357\274\232DispatcherServlet\347\232\204\345\210\235\345\247\213\345\214\226\344\270\216\350\257\267\346\261\202\350\275\254\345\217\221.md"
create mode 100644 "docs/java-web/SSM/SpringMVC\346\272\220\347\240\201\345\210\206\346\236\2204\357\274\232DispatcherServlet\345\246\202\344\275\225\346\211\276\345\210\260\346\255\243\347\241\256\347\232\204Controller.md"
create mode 100644 "docs/java-web/SSM/SpringMVC\346\272\220\347\240\201\345\210\206\346\236\2206\357\274\232SpringMVC\347\232\204\350\247\206\345\233\276\350\247\243\346\236\220\345\216\237\347\220\206.md"
create mode 100644 "docs/java-web/SSM/SpringMVC\346\272\220\347\240\201\345\211\226\346\236\2205\357\274\232\346\266\210\346\201\257\350\275\254\346\215\242\345\231\250HttpMessageConverter\344\270\216@ResponseBody\346\263\250\350\247\243.md"
create mode 100644 "docs/java-web/Spring/Spring\346\272\220\347\240\201\345\211\226\346\236\2201\357\274\232Spring\346\246\202\350\277\260.md"
create mode 100644 "docs/java-web/Spring/Spring\346\272\220\347\240\201\345\211\226\346\236\2202\357\274\232\345\210\235\346\216\242Spring IOC\346\240\270\345\277\203\346\265\201\347\250\213.md"
create mode 100644 "docs/java-web/Spring/Spring\346\272\220\347\240\201\345\211\226\346\236\2203\357\274\232Spring IOC\345\256\271\345\231\250\347\232\204\345\212\240\350\275\275\350\277\207\347\250\213.md"
create mode 100644 "docs/java-web/Spring/Spring\346\272\220\347\240\201\345\211\226\346\236\2204\357\274\232\346\207\222\345\212\240\350\275\275\347\232\204\345\215\225\344\276\213Bean\350\216\267\345\217\226\350\277\207\347\250\213\345\210\206\346\236\220.md"
create mode 100644 "docs/java-web/Spring/Spring\346\272\220\347\240\201\345\211\226\346\236\2205\357\274\232JDK\345\222\214cglib\345\212\250\346\200\201\344\273\243\347\220\206\345\216\237\347\220\206\350\257\246\350\247\243.md"
create mode 100644 "docs/java-web/Spring/Spring\346\272\220\347\240\201\345\211\226\346\236\2206\357\274\232Spring AOP\346\246\202\350\277\260.md"
create mode 100644 "docs/java-web/Spring/Spring\346\272\220\347\240\201\345\211\226\346\236\2207\357\274\232AOP\345\256\236\347\216\260\345\216\237\347\220\206\350\257\246\350\247\243.md"
create mode 100644 "docs/java-web/Spring/Spring\346\272\220\347\240\201\345\211\226\346\236\2208\357\274\232Spring\344\272\213\345\212\241\346\246\202\350\277\260.md"
create mode 100644 "docs/java-web/Spring/Spring\346\272\220\347\240\201\345\211\226\346\236\2209\357\274\232Spring\344\272\213\345\212\241\346\272\220\347\240\201\345\211\226\346\236\220.md"
create mode 100644 "docs/java-web/Spring/\347\273\231\344\275\240\344\270\200\344\273\275Spring Boot\347\237\245\350\257\206\346\270\205\345\215\225.md"
create mode 100644 "docs/java-web/\346\267\261\345\205\245JavaWeb\346\212\200\346\234\257\344\270\226\347\225\21415\357\274\232\346\267\261\345\205\245\346\265\205\345\207\272Mybatis\345\237\272\346\234\254\345\216\237\347\220\206.md"
create mode 100644 "docs/java-web/\350\265\260\350\277\233JavaWeb\346\212\200\346\234\257\344\270\226\347\225\21410\357\274\232\344\273\216JavaBean\350\256\262\345\210\260Spring.md"
create mode 100644 "docs/java-web/\350\265\260\350\277\233JavaWeb\346\212\200\346\234\257\344\270\226\347\225\21411\357\274\232\345\215\225\345\205\203\346\265\213\350\257\225\346\241\206\346\236\266Junit.md"
create mode 100644 "docs/java-web/\350\265\260\350\277\233JavaWeb\346\212\200\346\234\257\344\270\226\347\225\21412\357\274\232\344\273\216\346\211\213\345\212\250\347\274\226\350\257\221\346\211\223\345\214\205\345\210\260\351\241\271\347\233\256\346\236\204\345\273\272\345\267\245\345\205\267Maven.md"
create mode 100644 "docs/java-web/\350\265\260\350\277\233JavaWeb\346\212\200\346\234\257\344\270\226\347\225\21413\357\274\232Hibernate\345\205\245\351\227\250\347\273\217\345\205\270\344\270\216\346\263\250\350\247\243\345\274\217\345\274\200\345\217\221.md"
create mode 100644 "docs/java-web/\350\265\260\350\277\233JavaWeb\346\212\200\346\234\257\344\270\226\347\225\21414\357\274\232Mybatis\345\205\245\351\227\250.md"
create mode 100644 "docs/java-web/\350\265\260\350\277\233JavaWeb\346\212\200\346\234\257\344\270\226\347\225\21416\357\274\232\346\236\201\347\256\200\351\205\215\347\275\256\347\232\204SpringBoot.md"
create mode 100644 "docs/java-web/\350\265\260\350\277\233JavaWeb\346\212\200\346\234\257\344\270\226\347\225\2141\357\274\232JavaWeb\347\232\204\347\224\261\346\235\245\345\222\214\345\237\272\347\241\200\347\237\245\350\257\206.md"
create mode 100644 "docs/java-web/\350\265\260\350\277\233JavaWeb\346\212\200\346\234\257\344\270\226\347\225\2142\357\274\232JSP\344\270\216Servlet\347\232\204\346\233\276\347\273\217\344\270\216\347\216\260\345\234\250.md"
create mode 100644 "docs/java-web/\350\265\260\350\277\233JavaWeb\346\212\200\346\234\257\344\270\226\347\225\2143\357\274\232JDBC\347\232\204\350\277\233\345\214\226\344\270\216\350\277\236\346\216\245\346\261\240\346\212\200\346\234\257.md"
create mode 100644 "docs/java-web/\350\265\260\350\277\233JavaWeb\346\212\200\346\234\257\344\270\226\347\225\2144\357\274\232Servlet \345\267\245\344\275\234\345\216\237\347\220\206\350\257\246\350\247\243.md"
create mode 100644 "docs/java-web/\350\265\260\350\277\233JavaWeb\346\212\200\346\234\257\344\270\226\347\225\2145\357\274\232\345\210\235\346\216\242Tomcat\347\232\204HTTP\350\257\267\346\261\202\350\277\207\347\250\213.md"
create mode 100644 "docs/java-web/\350\265\260\350\277\233JavaWeb\346\212\200\346\234\257\344\270\226\347\225\2146\357\274\232Tomcat5\346\200\273\344\275\223\346\236\266\346\236\204\345\211\226\346\236\220.md"
create mode 100644 "docs/java-web/\350\265\260\350\277\233JavaWeb\346\212\200\346\234\257\344\270\226\347\225\2147\357\274\232Tomcat\345\222\214\345\205\266\344\273\226WEB\345\256\271\345\231\250\347\232\204\345\214\272\345\210\253.md"
create mode 100644 "docs/java-web/\350\265\260\350\277\233JavaWeb\346\212\200\346\234\257\344\270\226\347\225\2148\357\274\232\346\265\205\346\236\220Tomcat9\350\257\267\346\261\202\345\244\204\347\220\206\346\265\201\347\250\213\344\270\216\345\220\257\345\212\250\351\203\250\347\275\262\350\277\207\347\250\213.md"
create mode 100644 "docs/java-web/\350\265\260\350\277\233JavaWeb\346\212\200\346\234\257\344\270\226\347\225\2149\357\274\232Java\346\227\245\345\277\227\347\263\273\347\273\237\347\232\204\350\257\236\347\224\237\344\270\216\345\217\221\345\261\225.md"
create mode 100644 "docs/java/currency/Java\345\271\266\345\217\221\346\214\207\345\215\22710\357\274\232Java \350\257\273\345\206\231\351\224\201 ReentrantReadWriteLock \346\272\220\347\240\201\345\210\206\346\236\220.md"
create mode 100644 "docs/java/currency/Java\345\271\266\345\217\221\346\214\207\345\215\22711\357\274\232\350\247\243\350\257\273 Java \351\230\273\345\241\236\351\230\237\345\210\227 BlockingQueue.md"
create mode 100644 "docs/java/currency/Java\345\271\266\345\217\221\346\214\207\345\215\22712\357\274\232\346\267\261\345\272\246\350\247\243\350\257\273 java \347\272\277\347\250\213\346\261\240\350\256\276\350\256\241\346\200\235\346\203\263\345\217\212\346\272\220\347\240\201\345\256\236\347\216\260.md"
create mode 100644 "docs/java/currency/Java\345\271\266\345\217\221\346\214\207\345\215\22713\357\274\232Java \344\270\255\347\232\204 HashMap \345\222\214 ConcurrentHashMap \345\205\250\350\247\243\346\236\220.md"
create mode 100644 "docs/java/currency/Java\345\271\266\345\217\221\346\214\207\345\215\22714\357\274\232JUC\344\270\255\345\270\270\347\224\250\347\232\204Unsafe\345\222\214Locksupport.md"
create mode 100644 "docs/java/currency/Java\345\271\266\345\217\221\346\214\207\345\215\2271\357\274\232\345\271\266\345\217\221\345\237\272\347\241\200\344\270\216Java\345\244\232\347\272\277\347\250\213.md"
create mode 100644 "docs/java/currency/Java\345\271\266\345\217\221\346\214\207\345\215\2272\357\274\232\346\267\261\345\205\245\347\220\206\350\247\243Java\345\206\205\345\255\230\346\250\241\345\236\213JMM.md"
create mode 100644 "docs/java/currency/Java\345\271\266\345\217\221\346\214\207\345\215\2273\357\274\232\345\271\266\345\217\221\344\270\211\345\244\247\351\227\256\351\242\230\344\270\216volatile\345\205\263\351\224\256\345\255\227\357\274\214CAS\346\223\215\344\275\234.md"
create mode 100644 "docs/java/currency/Java\345\271\266\345\217\221\346\214\207\345\215\2274\357\274\232Java\344\270\255\347\232\204\351\224\201 Lock\345\222\214synchronized.md"
create mode 100644 "docs/java/currency/Java\345\271\266\345\217\221\346\214\207\345\215\2275\357\274\232JMM\344\270\255\347\232\204final\345\205\263\351\224\256\345\255\227\350\247\243\346\236\220.md"
create mode 100644 "docs/java/currency/Java\345\271\266\345\217\221\346\214\207\345\215\2276\357\274\232Java\345\206\205\345\255\230\346\250\241\345\236\213JMM\346\200\273\347\273\223.md"
create mode 100644 "docs/java/currency/Java\345\271\266\345\217\221\346\214\207\345\215\2277\357\274\232JUC\347\232\204\346\240\270\345\277\203\347\261\273AQS\350\257\246\350\247\243.md"
create mode 100644 "docs/java/currency/Java\345\271\266\345\217\221\346\214\207\345\215\2278\357\274\232AQS\344\270\255\347\232\204\345\205\254\345\271\263\351\224\201\344\270\216\351\235\236\345\205\254\345\271\263\351\224\201\357\274\214Condtion.md"
create mode 100644 "docs/java/currency/Java\345\271\266\345\217\221\346\214\207\345\215\2279\357\274\232AQS\345\205\261\344\272\253\346\250\241\345\274\217\344\270\216\345\271\266\345\217\221\345\267\245\345\205\267\347\261\273\347\232\204\345\256\236\347\216\260.md"
create mode 100644 "docs/java/currency/Java\345\271\266\345\217\221\347\274\226\347\250\213\346\214\207\345\215\22715\357\274\232Fork join\345\271\266\345\217\221\346\241\206\346\236\266\344\270\216\345\267\245\344\275\234\347\252\203\345\217\226\347\256\227\346\263\225\345\211\226\346\236\220.md"
create mode 100644 "docs/java/jvm/\346\267\261\345\205\245\344\272\206\350\247\243JVM\350\231\232\346\213\237\346\234\2728\357\274\232Java\347\232\204\347\274\226\350\257\221\346\234\237\344\274\230\345\214\226\344\270\216\350\277\220\350\241\214\346\234\237\344\274\230\345\214\226.md"
create mode 100644 "docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\27210\357\274\232JVM\345\270\270\347\224\250\345\217\202\346\225\260\344\273\245\345\217\212\350\260\203\344\274\230\345\256\236\350\267\265.md"
create mode 100644 "docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\27211\357\274\232Java\345\206\205\345\255\230\345\274\202\345\270\270\345\216\237\347\220\206\344\270\216\345\256\236\350\267\265.md"
create mode 100644 "docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\27212\357\274\232JVM\346\200\247\350\203\275\347\256\241\347\220\206\347\245\236\345\231\250VisualVM\344\273\213\347\273\215\344\270\216\345\256\236\346\210\230.md"
create mode 100644 "docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\27213\357\274\232\345\206\215\350\260\210\345\233\233\347\247\215\345\274\225\347\224\250\345\217\212GC\345\256\236\350\267\265.md"
create mode 100644 "docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\2721\357\274\232JVM\345\206\205\345\255\230\347\232\204\347\273\223\346\236\204\344\270\216\346\266\210\345\244\261\347\232\204\346\260\270\344\271\205\344\273\243.md"
create mode 100644 "docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\2722\357\274\232JVM\345\236\203\345\234\276\345\233\236\346\224\266\345\237\272\346\234\254\345\216\237\347\220\206\345\222\214\347\256\227\346\263\225.md"
create mode 100644 "docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\2723\357\274\232\345\236\203\345\234\276\345\233\236\346\224\266\345\231\250\350\257\246\350\247\243.md"
create mode 100644 "docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\2724\357\274\232Java class\344\273\213\347\273\215\344\270\216\350\247\243\346\236\220\345\256\236\350\267\265.md"
create mode 100644 "docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\2725\357\274\232\350\231\232\346\213\237\346\234\272\345\255\227\350\212\202\347\240\201\346\211\247\350\241\214\345\274\225\346\223\216.md"
create mode 100644 "docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\2726\357\274\232\346\267\261\345\205\245\347\220\206\350\247\243JVM\347\261\273\345\212\240\350\275\275\346\234\272\345\210\266.md"
create mode 100644 "docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\2727\357\274\232JNDI\357\274\214OSGI\357\274\214Tomcat\347\261\273\345\212\240\350\275\275\345\231\250\345\256\236\347\216\260.md"
create mode 100644 "docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\2729\357\274\232JVM\347\233\221\346\216\247\345\267\245\345\205\267\344\270\216\350\257\212\346\226\255\345\256\236\350\267\265.md"
create mode 100644 "docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232GC\350\260\203\344\274\230\346\200\235\350\267\257\344\270\216\345\270\270\347\224\250\345\267\245\345\205\267.md"
create mode 100644 "docs/java/network-programming/Java\347\275\221\347\273\234\347\274\226\347\250\213\344\270\216NIO\350\257\246\350\247\24310\357\274\232\346\267\261\345\272\246\350\247\243\350\257\273Tomcat\344\270\255\347\232\204NIO\346\250\241\345\236\213.md"
create mode 100644 "docs/java/network-programming/Java\347\275\221\347\273\234\347\274\226\347\250\213\344\270\216NIO\350\257\246\350\247\24311\357\274\232Tomcat\344\270\255\347\232\204Connector\346\272\220\347\240\201\345\210\206\346\236\220\357\274\210NIO\357\274\211.md"
create mode 100644 "docs/java/network-programming/Java\347\275\221\347\273\234\347\274\226\347\250\213\344\270\216NIO\350\257\246\350\247\2432\357\274\232JAVA NIO \344\270\200\346\255\245\346\255\245\346\236\204\345\273\272IO\345\244\232\350\267\257\345\244\215\347\224\250\347\232\204\350\257\267\346\261\202\346\250\241\345\236\213.md"
create mode 100644 "docs/java/network-programming/Java\347\275\221\347\273\234\347\274\226\347\250\213\344\270\216NIO\350\257\246\350\247\2434\357\274\232\346\265\205\346\236\220NIO\345\214\205\344\270\255\347\232\204Buffer\343\200\201Channel \345\222\214 Selector.md"
create mode 100644 "docs/java/network-programming/Java\347\275\221\347\273\234\347\274\226\347\250\213\344\270\216NIO\350\257\246\350\247\2438\357\274\232\346\265\205\346\236\220mmap\345\222\214Direct Buffer.md"
create mode 100644 "docs/java/network-programming/Java\347\275\221\347\273\234\347\274\226\347\250\213\345\222\214NIO\350\257\246\350\247\2431\357\274\232JAVA \344\270\255\345\216\237\347\224\237\347\232\204 socket \351\200\232\344\277\241\346\234\272\345\210\266.md"
create mode 100644 "docs/java/network-programming/Java\347\275\221\347\273\234\347\274\226\347\250\213\345\222\214NIO\350\257\246\350\247\2433\357\274\232IO\346\250\241\345\236\213\344\270\216Java\347\275\221\347\273\234\347\274\226\347\250\213\346\250\241\345\236\213.md"
create mode 100644 "docs/java/network-programming/Java\347\275\221\347\273\234\347\274\226\347\250\213\345\222\214NIO\350\257\246\350\247\2435\357\274\232Java \351\235\236\351\230\273\345\241\236 IO \345\222\214\345\274\202\346\255\245 IO.md"
create mode 100644 "docs/java/network-programming/Java\347\275\221\347\273\234\347\274\226\347\250\213\345\222\214NIO\350\257\246\350\247\2436\357\274\232Linux epoll\345\256\236\347\216\260\345\216\237\347\220\206\350\257\246\350\247\243.md"
create mode 100644 "docs/java/network-programming/Java\347\275\221\347\273\234\347\274\226\347\250\213\345\222\214NIO\350\257\246\350\247\2437\357\274\232\346\265\205\350\260\210 Linux \344\270\255NIO Selector \347\232\204\345\256\236\347\216\260\345\216\237\347\220\206.md"
create mode 100644 "docs/java/network-programming/Java\347\275\221\347\273\234\347\274\226\347\250\213\345\222\214NIO\350\257\246\350\247\2439\357\274\232\345\237\272\344\272\216NIO\347\232\204\347\275\221\347\273\234\347\274\226\347\250\213\346\241\206\346\236\266Netty.md"
create mode 100644 "docs/\347\224\265\345\255\220\344\271\246.md"
diff --git "a/docs/big-backEnd/\345\220\216\347\253\257\346\212\200\346\234\257\346\235\202\350\260\21010\357\274\232Docker \346\240\270\345\277\203\346\212\200\346\234\257\344\270\216\345\256\236\347\216\260\345\216\237\347\220\206.md" "b/docs/big-backEnd/\345\220\216\347\253\257\346\212\200\346\234\257\346\235\202\350\260\21010\357\274\232Docker \346\240\270\345\277\203\346\212\200\346\234\257\344\270\216\345\256\236\347\216\260\345\216\237\347\220\206.md"
new file mode 100644
index 0000000..dc6207e
--- /dev/null
+++ "b/docs/big-backEnd/\345\220\216\347\253\257\346\212\200\346\234\257\346\235\202\350\260\21010\357\274\232Docker \346\240\270\345\277\203\346\212\200\346\234\257\344\270\216\345\256\236\347\216\260\345\216\237\347\220\206.md"
@@ -0,0 +1,310 @@
+
+
+
+
+
+
+**要搞懂docker的核心原理和技术,首先一定要对Linux内核有一定了解。**
+
+提到虚拟化技术,我们首先想到的一定是 Docker,经过四年的快速发展 Docker 已经成为了很多公司的标配,也不再是一个只能在开发阶段使用的玩具了。作为在生产环境中广泛应用的产品,Docker 有着非常成熟的社区以及大量的使用者,代码库中的内容也变得非常庞大。
+
+
+
+同样,由于项目的发展、功能的拆分以及各种奇怪的改名 [PR](https://github.com/moby/moby/pull/32691),让我们再次理解 Docker 的的整体架构变得更加困难。
+
+虽然 Docker 目前的组件较多,并且实现也非常复杂,但是本文不想过多的介绍 Docker 具体的实现细节,我们更想谈一谈 Docker 这种虚拟化技术的出现有哪些核心技术的支撑。
+
+
+
+首先,Docker 的出现一定是因为目前的后端在开发和运维阶段确实需要一种虚拟化技术解决开发环境和生产环境环境一致的问题,通过 Docker 我们可以将程序运行的环境也纳入到版本控制中,排除因为环境造成不同运行结果的可能。但是上述需求虽然推动了虚拟化技术的产生,但是如果没有合适的底层技术支撑,那么我们仍然得不到一个完美的产品。本文剩下的内容会介绍几种 Docker 使用的核心技术,如果我们了解它们的使用方法和原理,就能清楚 Docker 的实现原理。
+
+## [](https://draveness.me/docker?hmsr=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io#namespaces)Namespaces
+
+命名空间 (namespaces) 是 Linux 为我们提供的用于分离进程树、网络接口、挂载点以及进程间通信等资源的方法。在日常使用 Linux 或者 macOS 时,我们并没有运行多个完全分离的服务器的需要,但是如果我们在服务器上启动了多个服务,这些服务其实会相互影响的,每一个服务都能看到其他服务的进程,也可以访问宿主机器上的任意文件,这是很多时候我们都不愿意看到的,我们更希望运行在同一台机器上的不同服务能做到完全隔离,就像运行在多台不同的机器上一样。
+
+
+
+在这种情况下,一旦服务器上的某一个服务被入侵,那么入侵者就能够访问当前机器上的所有服务和文件,这也是我们不想看到的,而 Docker 其实就通过 Linux 的 Namespaces 对不同的容器实现了隔离。
+
+Linux 的命名空间机制提供了以下七种不同的命名空间,包括 `CLONE_NEWCGROUP`、`CLONE_NEWIPC`、`CLONE_NEWNET`、`CLONE_NEWNS`、`CLONE_NEWPID`、`CLONE_NEWUSER` 和 `CLONE_NEWUTS`,通过这七个选项我们能在创建新的进程时设置新进程应该在哪些资源上与宿主机器进行隔离。
+
+### [](https://draveness.me/docker?hmsr=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io#%E8%BF%9B%E7%A8%8B)进程
+
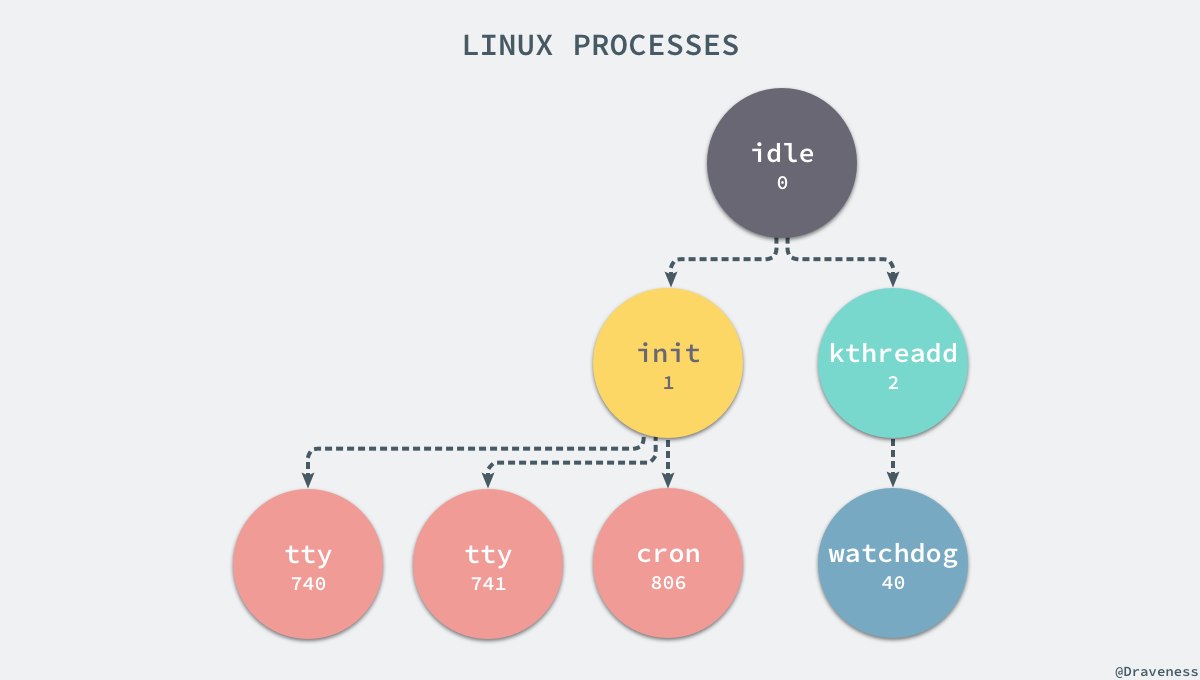
+进程是 Linux 以及现在操作系统中非常重要的概念,它表示一个正在执行的程序,也是在现代分时系统中的一个任务单元。在每一个 *nix 的操作系统上,我们都能够通过 `ps` 命令打印出当前操作系统中正在执行的进程,比如在 Ubuntu 上,使用该命令就能得到以下的结果:
+
+```
+$ ps -efUID PID PPID C STIME TTY TIME CMDroot 1 0 0 Apr08 ? 00:00:09 /sbin/initroot 2 0 0 Apr08 ? 00:00:00 [kthreadd]root 3 2 0 Apr08 ? 00:00:05 [ksoftirqd/0]root 5 2 0 Apr08 ? 00:00:00 [kworker/0:0H]root 7 2 0 Apr08 ? 00:07:10 [rcu_sched]root 39 2 0 Apr08 ? 00:00:00 [migration/0]root 40 2 0 Apr08 ? 00:01:54 [watchdog/0]...
+```
+
+当前机器上有很多的进程正在执行,在上述进程中有两个非常特殊,一个是 `pid` 为 1 的 `/sbin/init` 进程,另一个是 `pid` 为 2 的 `kthreadd` 进程,这两个进程都是被 Linux 中的上帝进程 `idle` 创建出来的,其中前者负责执行内核的一部分初始化工作和系统配置,也会创建一些类似 `getty` 的注册进程,而后者负责管理和调度其他的内核进程。
+
+
+
+如果我们在当前的 Linux 操作系统下运行一个新的 Docker 容器,并通过 `exec` 进入其内部的 `bash` 并打印其中的全部进程,我们会得到以下的结果:
+
+```
+root@iZ255w13cy6Z:~# docker run -it -d ubuntub809a2eb3630e64c581561b08ac46154878ff1c61c6519848b4a29d412215e79root@iZ255w13cy6Z:~# docker exec -it b809a2eb3630 /bin/bashroot@b809a2eb3630:/# ps -efUID PID PPID C STIME TTY TIME CMDroot 1 0 0 15:42 pts/0 00:00:00 /bin/bashroot 9 0 0 15:42 pts/1 00:00:00 /bin/bashroot 17 9 0 15:43 pts/1 00:00:00 ps -ef
+```
+
+在新的容器内部执行 `ps` 命令打印出了非常干净的进程列表,只有包含当前 `ps -ef` 在内的三个进程,在宿主机器上的几十个进程都已经消失不见了。
+
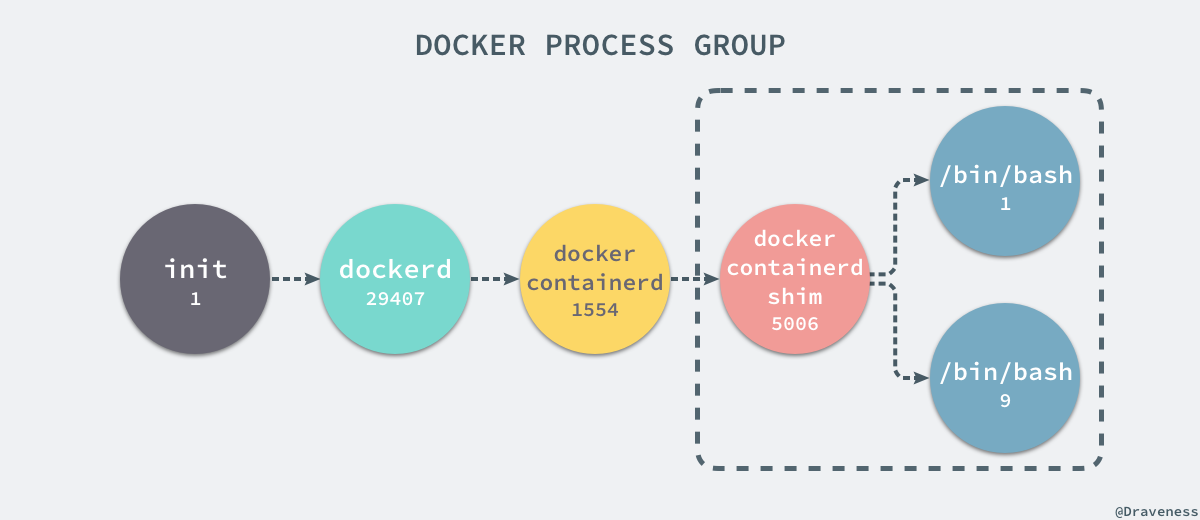
+当前的 Docker 容器成功将容器内的进程与宿主机器中的进程隔离,如果我们在宿主机器上打印当前的全部进程时,会得到下面三条与 Docker 相关的结果:
+
+```
+UID PID PPID C STIME TTY TIME CMDroot 29407 1 0 Nov16 ? 00:08:38 /usr/bin/dockerd --raw-logsroot 1554 29407 0 Nov19 ? 00:03:28 docker-containerd -l unix:///var/run/docker/libcontainerd/docker-containerd.sock --metrics-interval=0 --start-timeout 2m --state-dir /var/run/docker/libcontainerd/containerd --shim docker-containerd-shim --runtime docker-runcroot 5006 1554 0 08:38 ? 00:00:00 docker-containerd-shim b809a2eb3630e64c581561b08ac46154878ff1c61c6519848b4a29d412215e79 /var/run/docker/libcontainerd/b809a2eb3630e64c581561b08ac46154878ff1c61c6519848b4a29d412215e79 docker-runc
+```
+
+在当前的宿主机器上,可能就存在由上述的不同进程构成的进程树:
+
+
+
+这就是在使用 `clone(2)` 创建新进程时传入 `CLONE_NEWPID` 实现的,也就是使用 Linux 的命名空间实现进程的隔离,Docker 容器内部的任意进程都对宿主机器的进程一无所知。
+
+```
+containerRouter.postContainersStart└── daemon.ContainerStart └── daemon.createSpec └── setNamespaces └── setNamespace
+```
+
+Docker 的容器就是使用上述技术实现与宿主机器的进程隔离,当我们每次运行 `docker run` 或者 `docker start` 时,都会在下面的方法中创建一个用于设置进程间隔离的 Spec:
+
+```
+func (daemon *Daemon) createSpec(c *container.Container) (*specs.Spec, error) { s := oci.DefaultSpec() // ... if err := setNamespaces(daemon, &s, c); err != nil { return nil, fmt.Errorf("linux spec namespaces: %v", err) } return &s, nil}
+```
+
+在 `setNamespaces` 方法中不仅会设置进程相关的命名空间,还会设置与用户、网络、IPC 以及 UTS 相关的命名空间:
+
+```
+func setNamespaces(daemon *Daemon, s *specs.Spec, c *container.Container) error { // user // network // ipc // uts // pid if c.HostConfig.PidMode.IsContainer() { ns := specs.LinuxNamespace{Type: "pid"} pc, err := daemon.getPidContainer(c) if err != nil { return err } ns.Path = fmt.Sprintf("/proc/%d/ns/pid", pc.State.GetPID()) setNamespace(s, ns) } else if c.HostConfig.PidMode.IsHost() { oci.RemoveNamespace(s, specs.LinuxNamespaceType("pid")) } else { ns := specs.LinuxNamespace{Type: "pid"} setNamespace(s, ns) } return nil}
+```
+
+所有命名空间相关的设置 `Spec` 最后都会作为 `Create` 函数的入参在创建新的容器时进行设置:
+
+```
+daemon.containerd.Create(context.Background(), container.ID, spec, createOptions)
+
+```
+
+所有与命名空间的相关的设置都是在上述的两个函数中完成的,Docker 通过命名空间成功完成了与宿主机进程和网络的隔离。
+
+### [](https://draveness.me/docker?hmsr=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io#%E7%BD%91%E7%BB%9C)网络
+
+如果 Docker 的容器通过 Linux 的命名空间完成了与宿主机进程的网络隔离,但是却有没有办法通过宿主机的网络与整个互联网相连,就会产生很多限制,所以 Docker 虽然可以通过命名空间创建一个隔离的网络环境,但是 Docker 中的服务仍然需要与外界相连才能发挥作用。
+
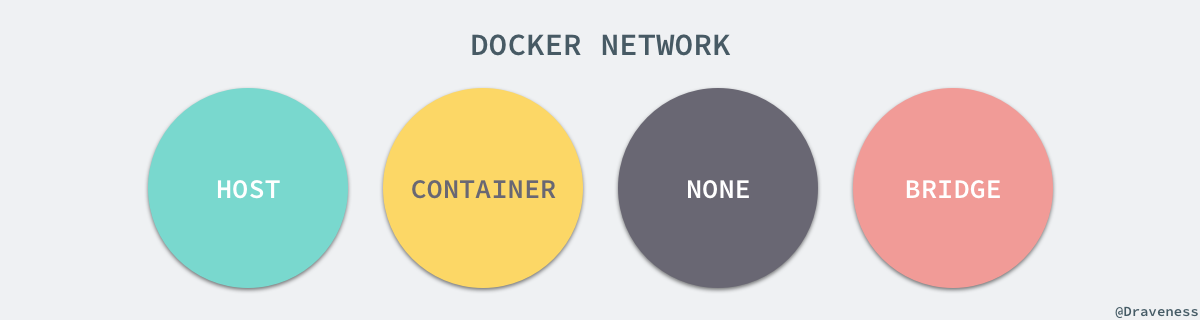
+每一个使用 `docker run` 启动的容器其实都具有单独的网络命名空间,Docker 为我们提供了四种不同的网络模式,Host、Container、None 和 Bridge 模式。
+
+
+
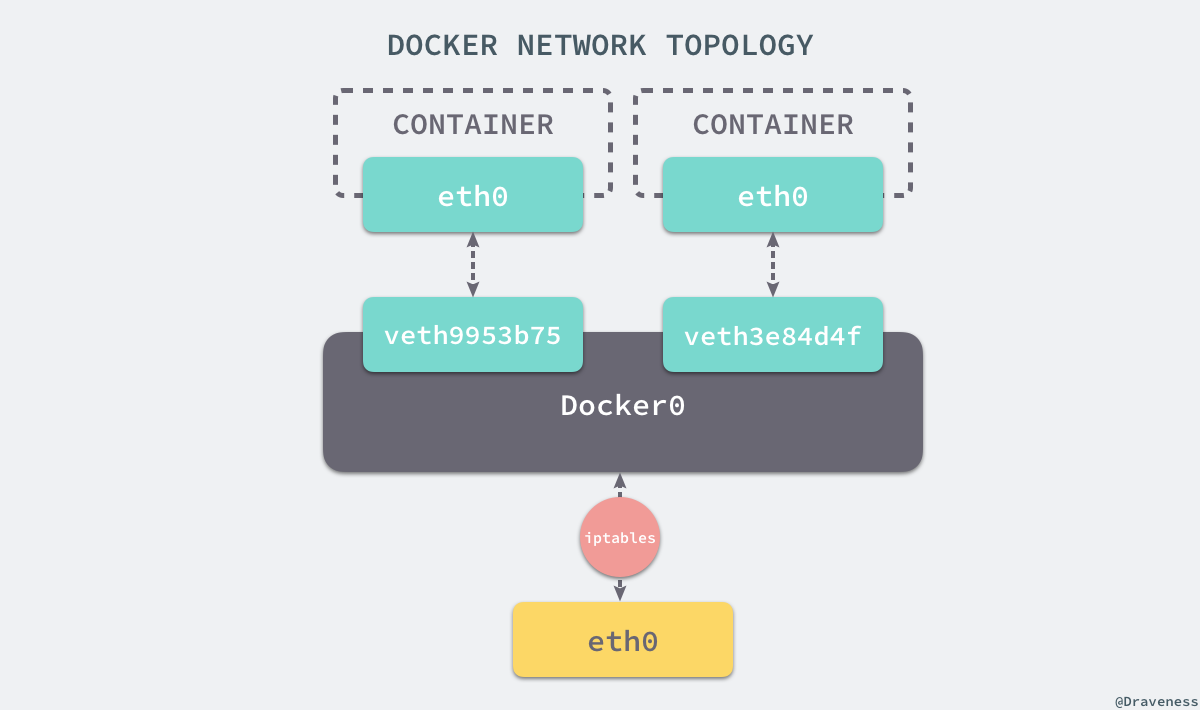
+在这一部分,我们将介绍 Docker 默认的网络设置模式:网桥模式。在这种模式下,除了分配隔离的网络命名空间之外,Docker 还会为所有的容器设置 IP 地址。当 Docker 服务器在主机上启动之后会创建新的虚拟网桥 docker0,随后在该主机上启动的全部服务在默认情况下都与该网桥相连。
+
+
+
+在默认情况下,每一个容器在创建时都会创建一对虚拟网卡,两个虚拟网卡组成了数据的通道,其中一个会放在创建的容器中,会加入到名为 docker0 网桥中。我们可以使用如下的命令来查看当前网桥的接口:
+
+```
+$ brctl showbridge name bridge id STP enabled interfacesdocker0 8000.0242a6654980 no veth3e84d4f veth9953b75
+```
+
+docker0 会为每一个容器分配一个新的 IP 地址并将 docker0 的 IP 地址设置为默认的网关。网桥 docker0 通过 iptables 中的配置与宿主机器上的网卡相连,所有符合条件的请求都会通过 iptables 转发到 docker0 并由网桥分发给对应的机器。
+
+```
+$ iptables -t nat -LChain PREROUTING (policy ACCEPT)target prot opt source destinationDOCKER all -- anywhere anywhere ADDRTYPE match dst-type LOCAL Chain DOCKER (2 references)target prot opt source destinationRETURN all -- anywhere anywhere
+```
+
+我们在当前的机器上使用 `docker run -d -p 6379:6379 redis` 命令启动了一个新的 Redis 容器,在这之后我们再查看当前 `iptables` 的 NAT 配置就会看到在 `DOCKER` 的链中出现了一条新的规则:
+
+```
+DNAT tcp -- anywhere anywhere tcp dpt:6379 to:192.168.0.4:6379
+
+```
+
+上述规则会将从任意源发送到当前机器 6379 端口的 TCP 包转发到 192.168.0.4:6379 所在的地址上。
+
+这个地址其实也是 Docker 为 Redis 服务分配的 IP 地址,如果我们在当前机器上直接 ping 这个 IP 地址就会发现它是可以访问到的:
+
+```
+$ ping 192.168.0.4PING 192.168.0.4 (192.168.0.4) 56(84) bytes of data.64 bytes from 192.168.0.4: icmp_seq=1 ttl=64 time=0.069 ms64 bytes from 192.168.0.4: icmp_seq=2 ttl=64 time=0.043 ms^C--- 192.168.0.4 ping statistics ---2 packets transmitted, 2 received, 0% packet loss, time 999msrtt min/avg/max/mdev = 0.043/0.056/0.069/0.013 ms
+```
+
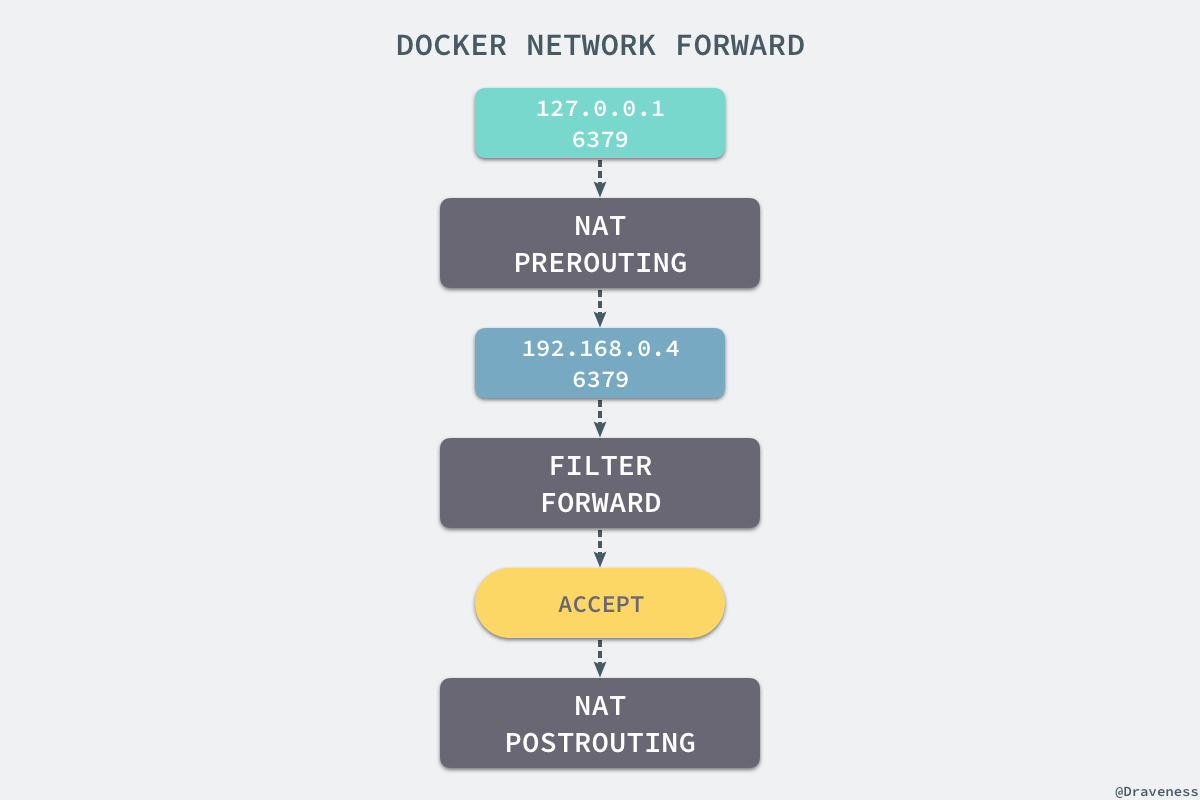
+从上述的一系列现象,我们就可以推测出 Docker 是如何将容器的内部的端口暴露出来并对数据包进行转发的了;当有 Docker 的容器需要将服务暴露给宿主机器,就会为容器分配一个 IP 地址,同时向 iptables 中追加一条新的规则。
+
+
+
+当我们使用 `redis-cli` 在宿主机器的命令行中访问 127.0.0.1:6379 的地址时,经过 iptables 的 NAT PREROUTING 将 ip 地址定向到了 192.168.0.4,重定向过的数据包就可以通过 iptables 中的 FILTER 配置,最终在 NAT POSTROUTING 阶段将 ip 地址伪装成 127.0.0.1,到这里虽然从外面看起来我们请求的是 127.0.0.1:6379,但是实际上请求的已经是 Docker 容器暴露出的端口了。
+
+```
+$ redis-cli -h 127.0.0.1 -p 6379 pingPONG
+```
+
+Docker 通过 Linux 的命名空间实现了网络的隔离,又通过 iptables 进行数据包转发,让 Docker 容器能够优雅地为宿主机器或者其他容器提供服务。
+
+#### [](https://draveness.me/docker?hmsr=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io#libnetwork)libnetwork
+
+整个网络部分的功能都是通过 Docker 拆分出来的 libnetwork 实现的,它提供了一个连接不同容器的实现,同时也能够为应用给出一个能够提供一致的编程接口和网络层抽象的容器网络模型。
+
+> The goal of libnetwork is to deliver a robust Container Network Model that provides a consistent programming interface and the required network abstractions for applications.
+
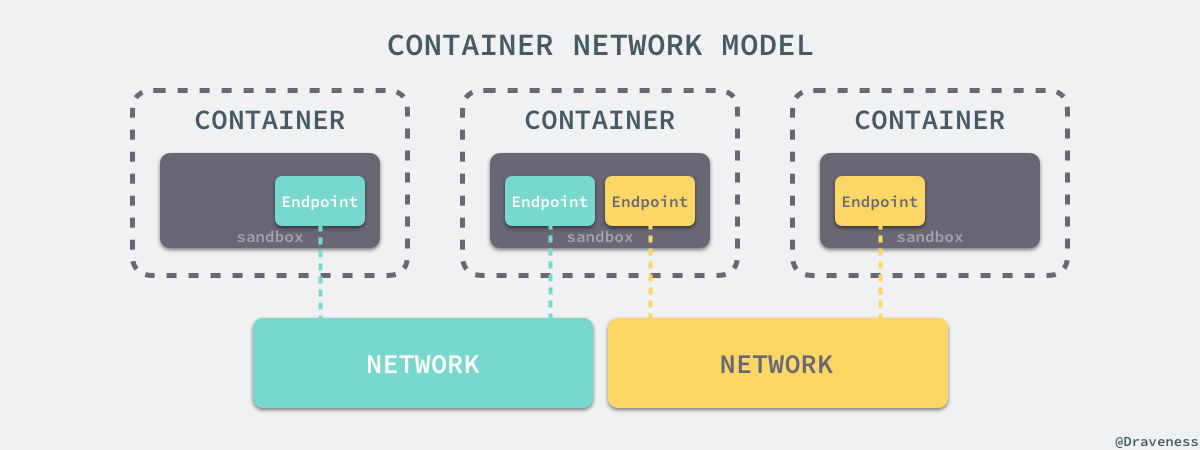
+libnetwork 中最重要的概念,容器网络模型由以下的几个主要组件组成,分别是 Sandbox、Endpoint 和 Network:
+
+
+
+在容器网络模型中,每一个容器内部都包含一个 Sandbox,其中存储着当前容器的网络栈配置,包括容器的接口、路由表和 DNS 设置,Linux 使用网络命名空间实现这个 Sandbox,每一个 Sandbox 中都可能会有一个或多个 Endpoint,在 Linux 上就是一个虚拟的网卡 veth,Sandbox 通过 Endpoint 加入到对应的网络中,这里的网络可能就是我们在上面提到的 Linux 网桥或者 VLAN。
+
+> 想要获得更多与 libnetwork 或者容器网络模型相关的信息,可以阅读 [Design · libnetwork](https://github.com/docker/libnetwork/blob/master/docs/design.md) 了解更多信息,当然也可以阅读源代码了解不同 OS 对容器网络模型的不同实现。
+
+### [](https://draveness.me/docker?hmsr=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io#%E6%8C%82%E8%BD%BD%E7%82%B9)挂载点
+
+虽然我们已经通过 Linux 的命名空间解决了进程和网络隔离的问题,在 Docker 进程中我们已经没有办法访问宿主机器上的其他进程并且限制了网络的访问,但是 Docker 容器中的进程仍然能够访问或者修改宿主机器上的其他目录,这是我们不希望看到的。
+
+在新的进程中创建隔离的挂载点命名空间需要在 `clone` 函数中传入 `CLONE_NEWNS`,这样子进程就能得到父进程挂载点的拷贝,如果不传入这个参数子进程对文件系统的读写都会同步回父进程以及整个主机的文件系统。
+
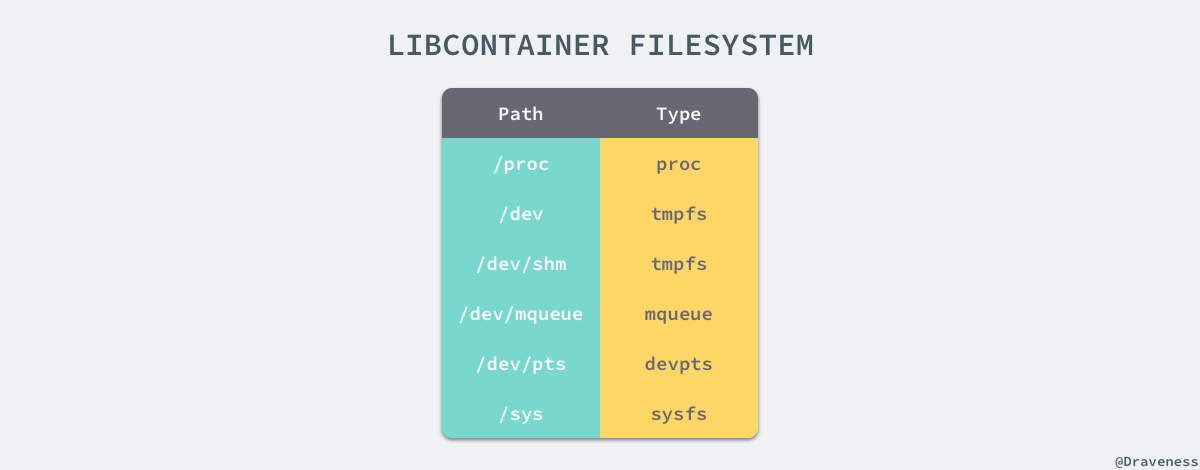
+如果一个容器需要启动,那么它一定需要提供一个根文件系统(rootfs),容器需要使用这个文件系统来创建一个新的进程,所有二进制的执行都必须在这个根文件系统中。
+
+
+
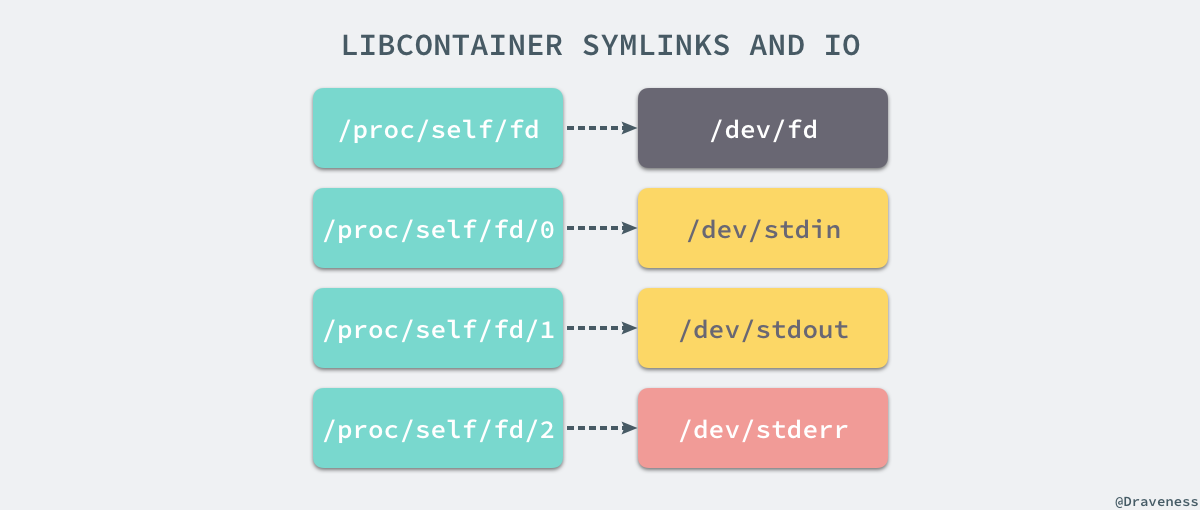
+想要正常启动一个容器就需要在 rootfs 中挂载以上的几个特定的目录,除了上述的几个目录需要挂载之外我们还需要建立一些符号链接保证系统 IO 不会出现问题。
+
+
+
+为了保证当前的容器进程没有办法访问宿主机器上其他目录,我们在这里还需要通过 libcontainer 提供的 `pivot_root` 或者 `chroot` 函数改变进程能够访问个文件目录的根节点。
+
+```
+// pivor_rootput_old = mkdir(...);pivot_root(rootfs, put_old);chdir("/");unmount(put_old, MS_DETACH);rmdir(put_old); // chrootmount(rootfs, "/", NULL, MS_MOVE, NULL);chroot(".");chdir("/");
+```
+
+到这里我们就将容器需要的目录挂载到了容器中,同时也禁止当前的容器进程访问宿主机器上的其他目录,保证了不同文件系统的隔离。
+
+> 这一部分的内容是作者在 libcontainer 中的 [SPEC.md](https://github.com/opencontainers/runc/blob/master/libcontainer/SPEC.md) 文件中找到的,其中包含了 Docker 使用的文件系统的说明,对于 Docker 是否真的使用 `chroot` 来确保当前的进程无法访问宿主机器的目录,作者其实也没有确切的答案,一是 Docker 项目的代码太多庞大,不知道该从何入手,作者尝试通过 Google 查找相关的结果,但是既找到了无人回答的 [问题](https://forums.docker.com/t/does-the-docker-engine-use-chroot/25429),也得到了与 SPEC 中的描述有冲突的 [答案](https://www.quora.com/Do-Docker-containers-use-a-chroot-environment) ,如果各位读者有明确的答案可以在博客下面留言,非常感谢。
+
+### [](https://draveness.me/docker?hmsr=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io#chroot)chroot
+
+在这里不得不简单介绍一下 `chroot`(change root),在 Linux 系统中,系统默认的目录就都是以 `/` 也就是根目录开头的,`chroot` 的使用能够改变当前的系统根目录结构,通过改变当前系统的根目录,我们能够限制用户的权利,在新的根目录下并不能够访问旧系统根目录的结构个文件,也就建立了一个与原系统完全隔离的目录结构。
+
+> 与 chroot 的相关内容部分来自 [理解 chroot](https://www.ibm.com/developerworks/cn/linux/l-cn-chroot/index.html) 一文,各位读者可以阅读这篇文章获得更详细的信息。
+
+## [](https://draveness.me/docker?hmsr=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io#cgroups)CGroups
+
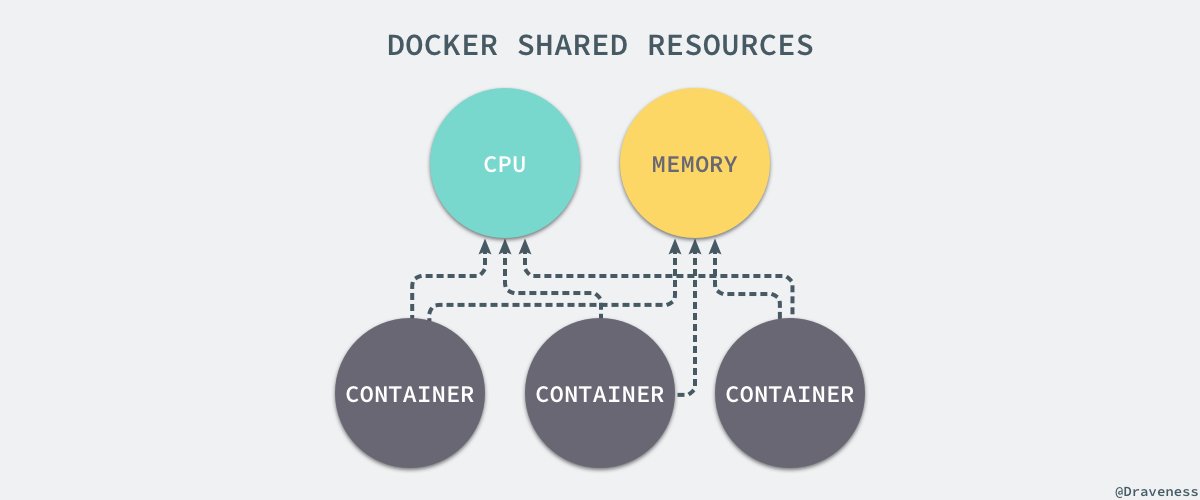
+我们通过 Linux 的命名空间为新创建的进程隔离了文件系统、网络并与宿主机器之间的进程相互隔离,但是命名空间并不能够为我们提供物理资源上的隔离,比如 CPU 或者内存,如果在同一台机器上运行了多个对彼此以及宿主机器一无所知的『容器』,这些容器却共同占用了宿主机器的物理资源。
+
+
+
+如果其中的某一个容器正在执行 CPU 密集型的任务,那么就会影响其他容器中任务的性能与执行效率,导致多个容器相互影响并且抢占资源。如何对多个容器的资源使用进行限制就成了解决进程虚拟资源隔离之后的主要问题,而 Control Groups(简称 CGroups)就是能够隔离宿主机器上的物理资源,例如 CPU、内存、磁盘 I/O 和网络带宽。
+
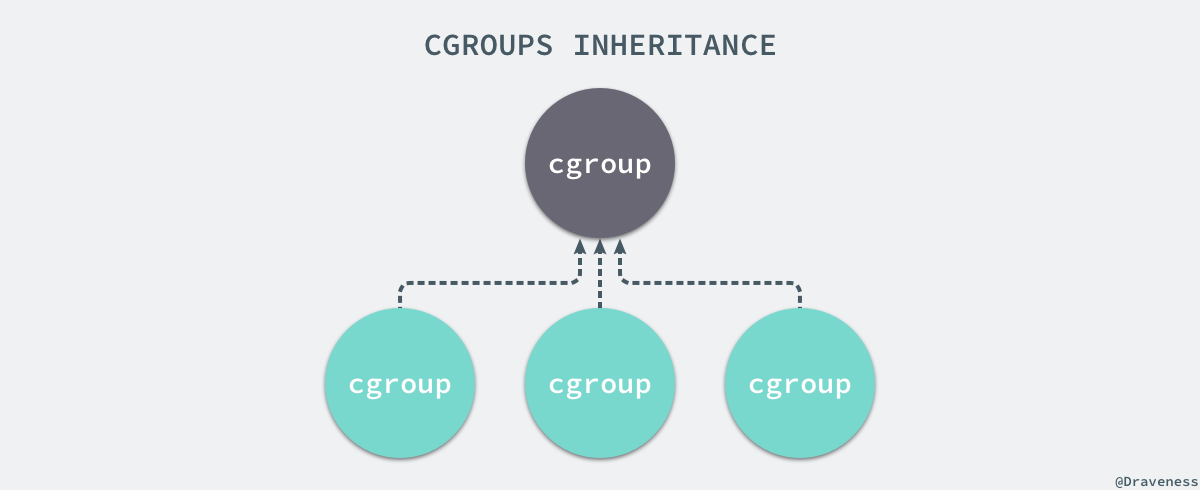
+每一个 CGroup 都是一组被相同的标准和参数限制的进程,不同的 CGroup 之间是有层级关系的,也就是说它们之间可以从父类继承一些用于限制资源使用的标准和参数。
+
+
+
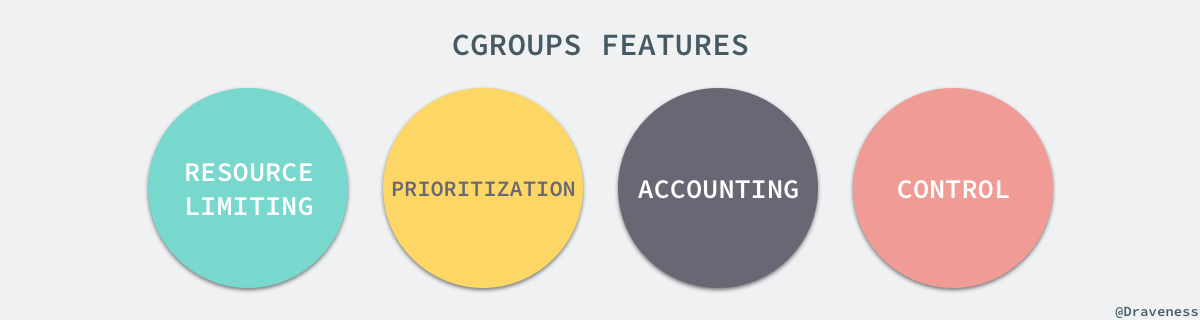
+Linux 的 CGroup 能够为一组进程分配资源,也就是我们在上面提到的 CPU、内存、网络带宽等资源,通过对资源的分配,CGroup 能够提供以下的几种功能:
+
+
+
+> 在 CGroup 中,所有的任务就是一个系统的一个进程,而 CGroup 就是一组按照某种标准划分的进程,在 CGroup 这种机制中,所有的资源控制都是以 CGroup 作为单位实现的,每一个进程都可以随时加入一个 CGroup 也可以随时退出一个 CGroup。
+>
+> – [CGroup 介绍、应用实例及原理描述](https://www.ibm.com/developerworks/cn/linux/1506_cgroup/index.html)
+
+Linux 使用文件系统来实现 CGroup,我们可以直接使用下面的命令查看当前的 CGroup 中有哪些子系统:
+
+```
+$ lssubsys -mcpuset /sys/fs/cgroup/cpusetcpu /sys/fs/cgroup/cpucpuacct /sys/fs/cgroup/cpuacctmemory /sys/fs/cgroup/memorydevices /sys/fs/cgroup/devicesfreezer /sys/fs/cgroup/freezerblkio /sys/fs/cgroup/blkioperf_event /sys/fs/cgroup/perf_eventhugetlb /sys/fs/cgroup/hugetlb
+```
+
+大多数 Linux 的发行版都有着非常相似的子系统,而之所以将上面的 cpuset、cpu 等东西称作子系统,是因为它们能够为对应的控制组分配资源并限制资源的使用。
+
+如果我们想要创建一个新的 cgroup 只需要在想要分配或者限制资源的子系统下面创建一个新的文件夹,然后这个文件夹下就会自动出现很多的内容,如果你在 Linux 上安装了 Docker,你就会发现所有子系统的目录下都有一个名为 docker 的文件夹:
+
+```
+$ ls cpucgroup.clone_children ...cpu.stat docker notify_on_release release_agent tasks $ ls cpu/docker/9c3057f1291b53fd54a3d12023d2644efe6a7db6ddf330436ae73ac92d401cf1 cgroup.clone_children ...cpu.stat notify_on_release release_agent tasks
+```
+
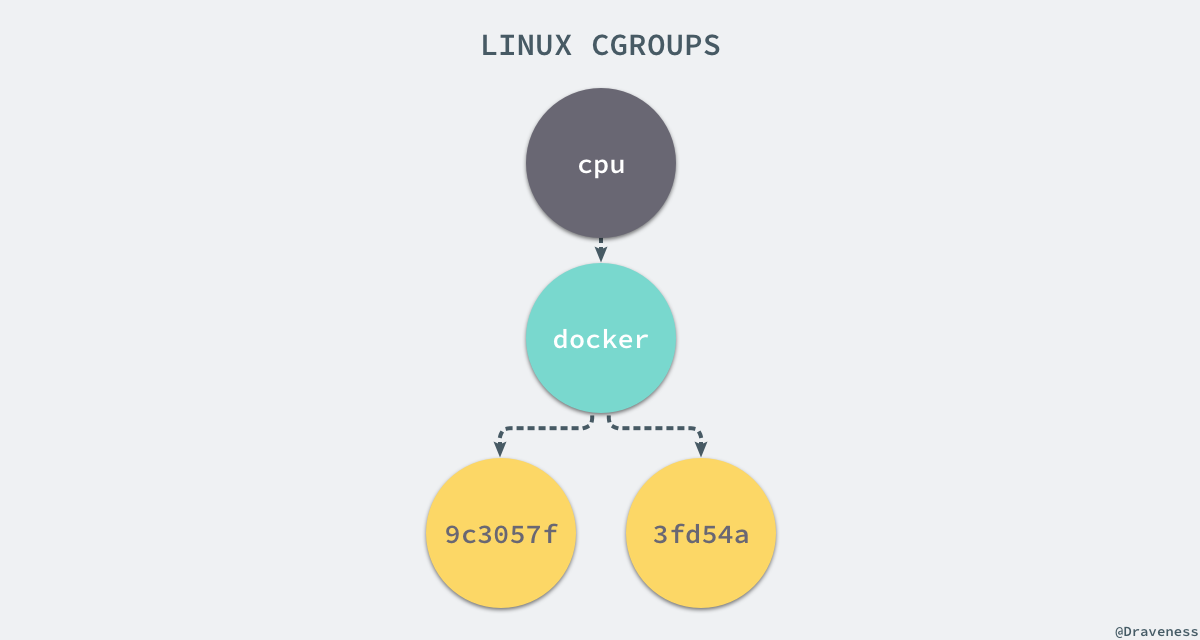
+`9c3057xxx` 其实就是我们运行的一个 Docker 容器,启动这个容器时,Docker 会为这个容器创建一个与容器标识符相同的 CGroup,在当前的主机上 CGroup 就会有以下的层级关系:
+
+
+
+每一个 CGroup 下面都有一个 `tasks` 文件,其中存储着属于当前控制组的所有进程的 pid,作为负责 cpu 的子系统,`cpu.cfs_quota_us` 文件中的内容能够对 CPU 的使用作出限制,如果当前文件的内容为 50000,那么当前控制组中的全部进程的 CPU 占用率不能超过 50%。
+
+如果系统管理员想要控制 Docker 某个容器的资源使用率就可以在 `docker`这个父控制组下面找到对应的子控制组并且改变它们对应文件的内容,当然我们也可以直接在程序运行时就使用参数,让 Docker 进程去改变相应文件中的内容。
+
+```
+$ docker run -it -d --cpu-quota=50000 busybox53861305258ecdd7f5d2a3240af694aec9adb91cd4c7e210b757f71153cdd274$ cd 53861305258ecdd7f5d2a3240af694aec9adb91cd4c7e210b757f71153cdd274/$ lscgroup.clone_children cgroup.event_control cgroup.procs cpu.cfs_period_us cpu.cfs_quota_us cpu.shares cpu.stat notify_on_release tasks$ cat cpu.cfs_quota_us50000
+```
+
+当我们使用 Docker 关闭掉正在运行的容器时,Docker 的子控制组对应的文件夹也会被 Docker 进程移除,Docker 在使用 CGroup 时其实也只是做了一些创建文件夹改变文件内容的文件操作,不过 CGroup 的使用也确实解决了我们限制子容器资源占用的问题,系统管理员能够为多个容器合理的分配资源并且不会出现多个容器互相抢占资源的问题。
+
+## [](https://draveness.me/docker?hmsr=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io#unionfs)UnionFS
+
+Linux 的命名空间和控制组分别解决了不同资源隔离的问题,前者解决了进程、网络以及文件系统的隔离,后者实现了 CPU、内存等资源的隔离,但是在 Docker 中还有另一个非常重要的问题需要解决 - 也就是镜像。
+
+镜像到底是什么,它又是如何组成和组织的是作者使用 Docker 以来的一段时间内一直比较让作者感到困惑的问题,我们可以使用 `docker run` 非常轻松地从远程下载 Docker 的镜像并在本地运行。
+
+Docker 镜像其实本质就是一个压缩包,我们可以使用下面的命令将一个 Docker 镜像中的文件导出:
+
+```
+$ docker export $(docker create busybox) | tar -C rootfs -xvf -$ lsbin dev etc home proc root sys tmp usr var
+```
+
+你可以看到这个 busybox 镜像中的目录结构与 Linux 操作系统的根目录中的内容并没有太多的区别,可以说 Docker 镜像就是一个文件。
+
+### [](https://draveness.me/docker?hmsr=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io#%E5%AD%98%E5%82%A8%E9%A9%B1%E5%8A%A8)存储驱动
+
+Docker 使用了一系列不同的存储驱动管理镜像内的文件系统并运行容器,这些存储驱动与 Docker 卷(volume)有些不同,存储引擎管理着能够在多个容器之间共享的存储。
+
+想要理解 Docker 使用的存储驱动,我们首先需要理解 Docker 是如何构建并且存储镜像的,也需要明白 Docker 的镜像是如何被每一个容器所使用的;Docker 中的每一个镜像都是由一系列只读的层组成的,Dockerfile 中的每一个命令都会在已有的只读层上创建一个新的层:
+
+```
+FROM ubuntu:15.04COPY . /appRUN make /appCMD python /app/app.py
+```
+
+容器中的每一层都只对当前容器进行了非常小的修改,上述的 Dockerfile 文件会构建一个拥有四层 layer 的镜像:
+
+
+
+当镜像被 `docker run` 命令创建时就会在镜像的最上层添加一个可写的层,也就是容器层,所有对于运行时容器的修改其实都是对这个容器读写层的修改。
+
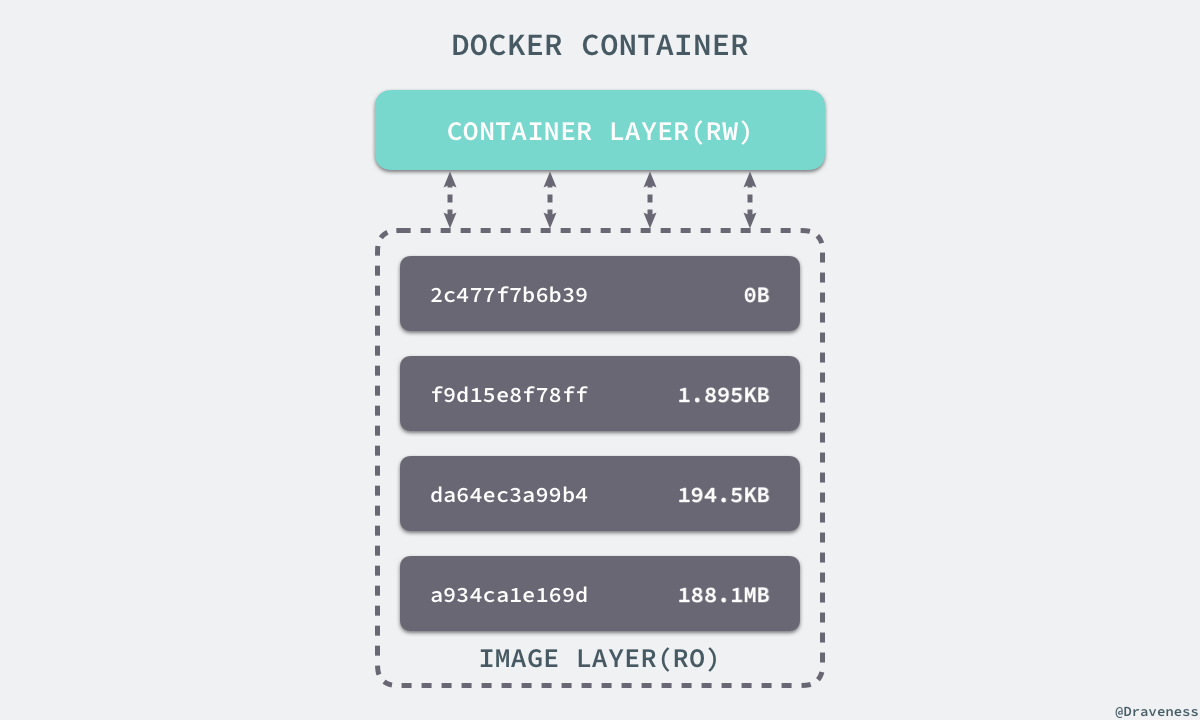
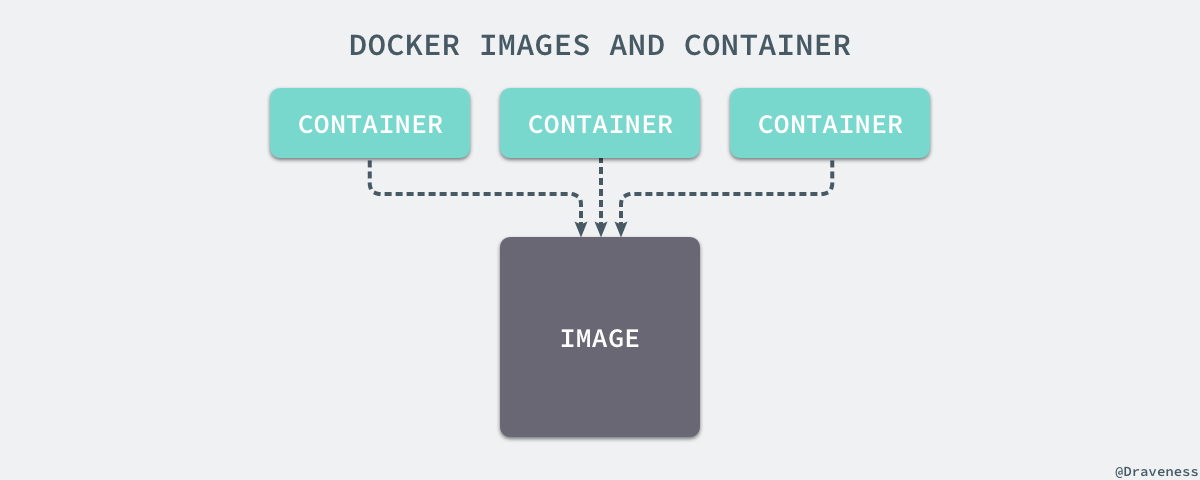
+容器和镜像的区别就在于,所有的镜像都是只读的,而每一个容器其实等于镜像加上一个可读写的层,也就是同一个镜像可以对应多个容器。
+
+
+
+### [](https://draveness.me/docker?hmsr=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io#aufs)AUFS
+
+UnionFS 其实是一种为 Linux 操作系统设计的用于把多个文件系统『联合』到同一个挂载点的文件系统服务。而 AUFS 即 Advanced UnionFS 其实就是 UnionFS 的升级版,它能够提供更优秀的性能和效率。
+
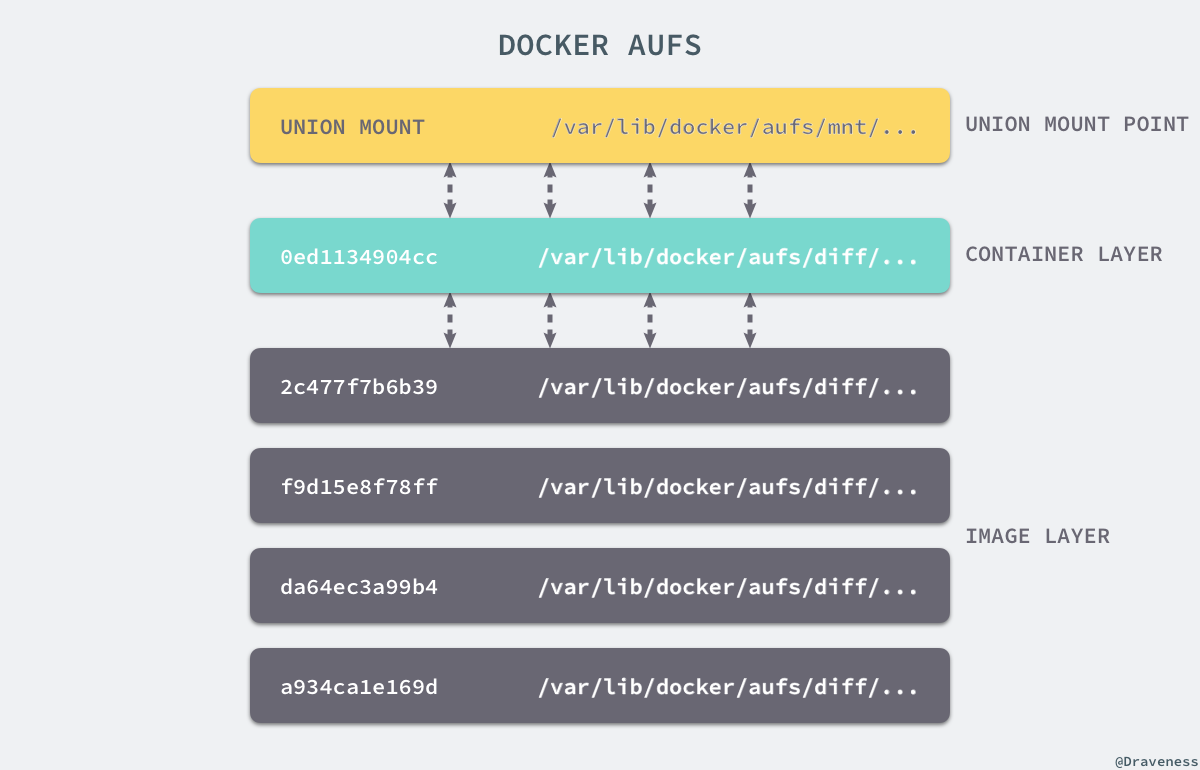
+AUFS 作为联合文件系统,它能够将不同文件夹中的层联合(Union)到了同一个文件夹中,这些文件夹在 AUFS 中称作分支,整个『联合』的过程被称为_联合挂载(Union Mount)_:
+
+
+
+每一个镜像层或者容器层都是 `/var/lib/docker/` 目录下的一个子文件夹;在 Docker 中,所有镜像层和容器层的内容都存储在 `/var/lib/docker/aufs/diff/` 目录中:
+
+```
+$ ls /var/lib/docker/aufs/diff/00adcccc1a55a36a610a6ebb3e07cc35577f2f5a3b671be3dbc0e74db9ca691c 93604f232a831b22aeb372d5b11af8c8779feb96590a6dc36a80140e38e764d800adcccc1a55a36a610a6ebb3e07cc35577f2f5a3b671be3dbc0e74db9ca691c-init 93604f232a831b22aeb372d5b11af8c8779feb96590a6dc36a80140e38e764d8-init019a8283e2ff6fca8d0a07884c78b41662979f848190f0658813bb6a9a464a90 93b06191602b7934fafc984fbacae02911b579769d0debd89cf2a032e7f35cfa...
+```
+
+而 `/var/lib/docker/aufs/layers/` 中存储着镜像层的元数据,每一个文件都保存着镜像层的元数据,最后的 `/var/lib/docker/aufs/mnt/` 包含镜像或者容器层的挂载点,最终会被 Docker 通过联合的方式进行组装。
+
+
+
+上面的这张图片非常好的展示了组装的过程,每一个镜像层都是建立在另一个镜像层之上的,同时所有的镜像层都是只读的,只有每个容器最顶层的容器层才可以被用户直接读写,所有的容器都建立在一些底层服务(Kernel)上,包括命名空间、控制组、rootfs 等等,这种容器的组装方式提供了非常大的灵活性,只读的镜像层通过共享也能够减少磁盘的占用。
+
+### [](https://draveness.me/docker?hmsr=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io#%E5%85%B6%E4%BB%96%E5%AD%98%E5%82%A8%E9%A9%B1%E5%8A%A8)其他存储驱动
+
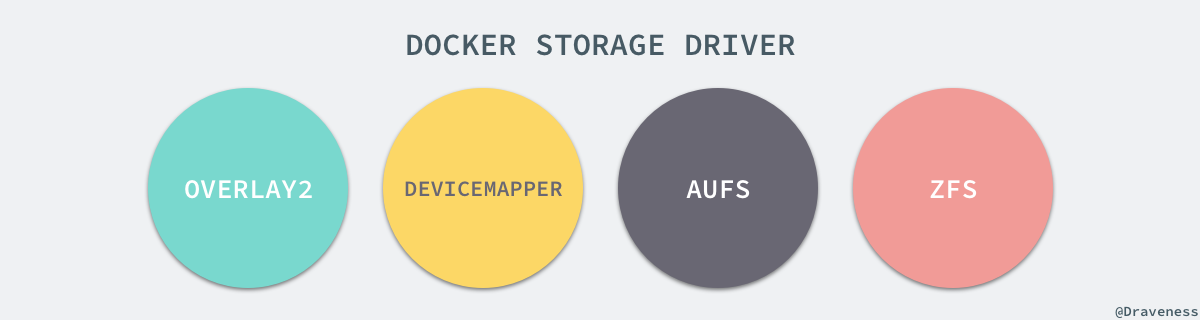
+AUFS 只是 Docker 使用的存储驱动的一种,除了 AUFS 之外,Docker 还支持了不同的存储驱动,包括 `aufs`、`devicemapper`、`overlay2`、`zfs` 和 `vfs` 等等,在最新的 Docker 中,`overlay2` 取代了 `aufs` 成为了推荐的存储驱动,但是在没有 `overlay2` 驱动的机器上仍然会使用 `aufs` 作为 Docker 的默认驱动。
+
+
+
+不同的存储驱动在存储镜像和容器文件时也有着完全不同的实现,有兴趣的读者可以在 Docker 的官方文档 [Select a storage driver](https://docs.docker.com/engine/userguide/storagedriver/selectadriver/) 中找到相应的内容。
+
+想要查看当前系统的 Docker 上使用了哪种存储驱动只需要使用以下的命令就能得到相对应的信息:
+
+```
+$ docker info | grep StorageStorage Driver: aufs
+```
+
+作者的这台 Ubuntu 上由于没有 `overlay2` 存储驱动,所以使用 `aufs` 作为 Docker 的默认存储驱动。
+
+## [](https://draveness.me/docker?hmsr=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io#%E6%80%BB%E7%BB%93)总结
+
+Docker 目前已经成为了非常主流的技术,已经在很多成熟公司的生产环境中使用,但是 Docker 的核心技术其实已经有很多年的历史了,Linux 命名空间、控制组和 UnionFS 三大技术支撑了目前 Docker 的实现,也是 Docker 能够出现的最重要原因。
+
+作者在学习 Docker 实现原理的过程中查阅了非常多的资料,从中也学习到了很多与 Linux 操作系统相关的知识,不过由于 Docker 目前的代码库实在是太过庞大,想要从源代码的角度完全理解 Docker 实现的细节已经是非常困难的了,但是如果各位读者真的对其实现细节感兴趣,可以从 [Docker CE](https://github.com/docker/docker-ce) 的源代码开始了解 Docker 的原理。
+
+
+
+
+
diff --git "a/docs/big-backEnd/\345\220\216\347\253\257\346\212\200\346\234\257\346\235\202\350\260\21011\357\274\232\345\215\201\345\210\206\351\222\237\347\220\206\350\247\243Kubernetes\346\240\270\345\277\203\346\246\202\345\277\265.md" "b/docs/big-backEnd/\345\220\216\347\253\257\346\212\200\346\234\257\346\235\202\350\260\21011\357\274\232\345\215\201\345\210\206\351\222\237\347\220\206\350\247\243Kubernetes\346\240\270\345\277\203\346\246\202\345\277\265.md"
new file mode 100644
index 0000000..cda0102
--- /dev/null
+++ "b/docs/big-backEnd/\345\220\216\347\253\257\346\212\200\346\234\257\346\235\202\350\260\21011\357\274\232\345\215\201\345\210\206\351\222\237\347\220\206\350\247\243Kubernetes\346\240\270\345\277\203\346\246\202\345\277\265.md"
@@ -0,0 +1,141 @@
+# 十分钟带你理解Kubernetes核心概念
+
+本文将会简单介绍[Kubernetes](http://kubernetes.io/v1.1/docs/whatisk8s.html)的核心概念。因为这些定义可以在Kubernetes的文档中找到,所以文章也会避免用大段的枯燥的文字介绍。相反,我们会使用一些图表(其中一些是动画)和示例来解释这些概念。我们发现一些概念(比如Service)如果没有图表的辅助就很难全面地理解。在合适的地方我们也会提供Kubernetes文档的链接以便读者深入学习。
+
+> 容器特性、镜像、网络;Kubernetes架构、核心组件、基本功能;Kubernetes设计理念、架构设计、基本功能、常用对象、设计原则;Kubernetes的数据库、运行时、网络、插件已经落地经验;微服务架构、组件、监控方案等。
+
+这就开始吧。
+
+### 什么是Kubernetes?
+
+Kubernetes(k8s)是自动化容器操作的开源平台,这些操作包括部署,调度和节点集群间扩展。如果你曾经用过Docker容器技术部署容器,那么可以将Docker看成Kubernetes内部使用的低级别组件。Kubernetes不仅仅支持Docker,还支持Rocket,这是另一种容器技术。
+使用Kubernetes可以:
+
+* 自动化容器的部署和复制
+* 随时扩展或收缩容器规模
+* 将容器组织成组,并且提供容器间的负载均衡
+* 很容易地升级应用程序容器的新版本
+* 提供容器弹性,如果容器失效就替换它,等等...
+
+实际上,使用Kubernetes只需一个[部署文件](https://github.com/kubernetes/kubernetes/blob/master/examples/guestbook/all-in-one/guestbook-all-in-one.yaml),使用一条命令就可以部署多层容器(前端,后台等)的完整集群:
+
+```
+$ kubectl create -f single-config-file.yaml
+
+```
+
+kubectl是和Kubernetes API交互的命令行程序。现在介绍一些核心概念。
+
+### 集群
+
+集群是一组节点,这些节点可以是物理服务器或者虚拟机,之上安装了Kubernetes平台。下图展示这样的集群。注意该图为了强调核心概念有所简化。[这里](http://kubernetes.io/v1.1/docs/design/architecture.html)可以看到一个典型的Kubernetes架构图。
+
+[](http://dockone.io/uploads/article/20151230/d56441427680948fb56a00af57bda690.png)
+
+
+
+
+
+
+
+
+
+ [1.png](http://dockone.io/uploads/article/20151230/d56441427680948fb56a00af57bda690.png)
+
+上图可以看到如下组件,使用特别的图标表示Service和Label:
+
+* Pod
+* Container(容器)
+* Label(标签)
+* Replication Controller(复制控制器)
+* Service(服务)
+* Node(节点)
+* Kubernetes Master(Kubernetes主节点)
+
+### Pod
+
+[Pod](http://kubernetes.io/v1.1/docs/user-guide/pods.html)(上图绿色方框)安排在节点上,包含一组容器和卷。同一个Pod里的容器共享同一个网络命名空间,可以使用localhost互相通信。Pod是短暂的,不是持续性实体。你可能会有这些问题:
+
+* 如果Pod是短暂的,那么我怎么才能持久化容器数据使其能够跨重启而存在呢? 是的,Kubernetes支持[卷](http://kubernetes.io/v1.1/docs/user-guide/volumes.html)的概念,因此可以使用持久化的卷类型。
+* 是否手动创建Pod,如果想要创建同一个容器的多份拷贝,需要一个个分别创建出来么?可以手动创建单个Pod,但是也可以使用Replication Controller使用Pod模板创建出多份拷贝,下文会详细介绍。
+* 如果Pod是短暂的,那么重启时IP地址可能会改变,那么怎么才能从前端容器正确可靠地指向后台容器呢?这时可以使用Service,下文会详细介绍。
+
+### Lable
+
+正如图所示,一些Pod有Label。一个Label是attach到Pod的一对键/值对,用来传递用户定义的属性。比如,你可能创建了一个"tier"和“app”标签,通过Label(**tier=frontend, app=myapp**)来标记前端Pod容器,使用Label(**tier=backend, app=myapp**)标记后台Pod。然后可以使用[Selectors](http://kubernetes.io/v1.1/docs/user-guide/labels.html#label-selectors)选择带有特定Label的Pod,并且将Service或者Replication Controller应用到上面。
+
+### Replication Controller
+
+_是否手动创建Pod,如果想要创建同一个容器的多份拷贝,需要一个个分别创建出来么,能否将Pods划到逻辑组里?_
+
+Replication Controller确保任意时间都有指定数量的Pod“副本”在运行。如果为某个Pod创建了Replication Controller并且指定3个副本,它会创建3个Pod,并且持续监控它们。如果某个Pod不响应,那么Replication Controller会替换它,保持总数为3.如下面的动画所示:
+
+[](http://dockone.io/uploads/article/20151230/5e2bad1a25e33e2d155da81da1d3a54b.gif)
+
+
+
+
+
+
+
+
+
+ [2.gif](http://dockone.io/uploads/article/20151230/5e2bad1a25e33e2d155da81da1d3a54b.gif)
+
+如果之前不响应的Pod恢复了,现在就有4个Pod了,那么Replication Controller会将其中一个终止保持总数为3。如果在运行中将副本总数改为5,Replication Controller会立刻启动2个新Pod,保证总数为5。还可以按照这样的方式缩小Pod,这个特性在执行滚动[升级](https://cloud.google.com/container-engine/docs/replicationcontrollers/#rolling_updates)时很有用。
+
+当创建Replication Controller时,需要指定两个东西:
+
+1. [Pod模板](http://kubernetes.io/v1.1/docs/user-guide/replication-controller.html#pod-template):用来创建Pod副本的模板
+2. [Label](http://kubernetes.io/v1.1/docs/user-guide/replication-controller.html#labels):Replication Controller需要监控的Pod的标签。
+
+现在已经创建了Pod的一些副本,那么在这些副本上如何均衡负载呢?我们需要的是Service。
+
+### Service
+
+_如果Pods是短暂的,那么重启时IP地址可能会改变,怎么才能从前端容器正确可靠地指向后台容器呢?_
+
+[Service](http://kubernetes.io/v1.1/docs/user-guide/services.html)是定义一系列Pod以及访问这些Pod的策略的一层**抽象**。Service通过Label找到Pod组。因为Service是抽象的,所以在图表里通常看不到它们的存在,这也就让这一概念更难以理解。
+
+现在,假定有2个后台Pod,并且定义后台Service的名称为‘backend-service’,lable选择器为(**tier=backend, app=myapp**)。_backend-service_ 的Service会完成如下两件重要的事情:
+
+* 会为Service创建一个本地集群的DNS入口,因此前端Pod只需要DNS查找主机名为 ‘backend-service’,就能够解析出前端应用程序可用的IP地址。
+* 现在前端已经得到了后台服务的IP地址,但是它应该访问2个后台Pod的哪一个呢?Service在这2个后台Pod之间提供透明的负载均衡,会将请求分发给其中的任意一个(如下面的动画所示)。通过每个Node上运行的代理(kube-proxy)完成。[这里](http://kubernetes.io/v1.1/docs/user-guide/services.html#virtual-ips-and-service-proxies)有更多技术细节。
+
+下述动画展示了Service的功能。注意该图作了很多简化。如果不进入网络配置,那么达到透明的负载均衡目标所涉及的底层网络和路由相对先进。如果有兴趣,[这里](http://www.dasblinkenlichten.com/kubernetes-101-networking/)有更深入的介绍。
+
+[](http://dockone.io/uploads/article/20151230/125bbccce0b3bbf42abab0e520d9250b.gif)
+
+
+
+
+
+
+
+
+
+ [3.gif](http://dockone.io/uploads/article/20151230/125bbccce0b3bbf42abab0e520d9250b.gif)
+
+有一个特别类型的Kubernetes Service,称为'[LoadBalancer](http://kubernetes.io/v1.1/docs/user-guide/services.html#type-loadbalancer)',作为外部负载均衡器使用,在一定数量的Pod之间均衡流量。比如,对于负载均衡Web流量很有用。
+
+### Node
+
+节点(上图橘色方框)是物理或者虚拟机器,作为Kubernetes worker,通常称为Minion。每个节点都运行如下Kubernetes关键组件:
+
+* Kubelet:是主节点代理。
+* Kube-proxy:Service使用其将链接路由到Pod,如上文所述。
+* Docker或Rocket:Kubernetes使用的容器技术来创建容器。
+
+### Kubernetes Master
+
+集群拥有一个Kubernetes Master(紫色方框)。Kubernetes Master提供集群的独特视角,并且拥有一系列组件,比如Kubernetes API Server。API Server提供可以用来和集群交互的REST端点。master节点包括用来创建和复制Pod的Replication Controller。
+
+### 下一步
+
+现在我们已经了解了Kubernetes核心概念的基本知识,你可以进一步阅读Kubernetes [用户手册](http://kubernetes.io/v1.1/docs/user-guide/README.html)。用户手册提供了快速并且完备的学习文档。
+如果迫不及待想要试试Kubernetes,可以使用[Google Container Engine](https://cloud.google.com/container-engine/docs/)。Google Container Engine是托管的Kubernetes容器环境。简单注册/登录之后就可以在上面尝试示例了。
+
+**原文链接:[Learn the Kubernetes Key Concepts in 10 Minutes](http://omerio.com/2015/12/18/learn-the-kubernetes-key-concepts-in-10-minutes/)(翻译:崔婧雯)**
+===========================
+译者介绍
+崔婧雯,现就职于IBM,高级软件工程师,负责IBM WebSphere业务流程管理软件的系统测试工作。曾就职于VMware从事桌面虚拟化产品的质量保证工作。对虚拟化,中间件技术,业务流程管理有浓厚的兴趣。
\ No newline at end of file
diff --git "a/docs/big-backEnd/\345\220\216\347\253\257\346\212\200\346\234\257\346\235\202\350\260\21012\357\274\232\346\215\213\344\270\200\346\215\213\345\244\247\346\225\260\346\215\256\347\240\224\345\217\221\347\232\204\345\237\272\346\234\254\346\246\202\345\277\265.md" "b/docs/big-backEnd/\345\220\216\347\253\257\346\212\200\346\234\257\346\235\202\350\260\21012\357\274\232\346\215\213\344\270\200\346\215\213\345\244\247\346\225\260\346\215\256\347\240\224\345\217\221\347\232\204\345\237\272\346\234\254\346\246\202\345\277\265.md"
new file mode 100644
index 0000000..61f5906
--- /dev/null
+++ "b/docs/big-backEnd/\345\220\216\347\253\257\346\212\200\346\234\257\346\235\202\350\260\21012\357\274\232\346\215\213\344\270\200\346\215\213\345\244\247\346\225\260\346\215\256\347\240\224\345\217\221\347\232\204\345\237\272\346\234\254\346\246\202\345\277\265.md"
@@ -0,0 +1,67 @@
+作者:[**木东居士**]
+
+个人主页:[http://www.mdjs.info](https://link.jianshu.com/?t=http%3A%2F%2Fwww.mdjs.info)
+也可以关注我:木东居士。
+
+
+_文章可以转载, 但必须以超链接形式标明文章原始出处和作者信息_
+## 0x00 前言
+
+> 你了解你的数据吗?
+
+前几天突然来了点灵感,想梳理一下自己对数据的理解,因此便有了这篇博客或者说这系列博客来聊聊数据。
+
+数据从业者有很多,比如说数据开发工程师、数据仓库工程师、数据分析师、数据挖掘工程师、数据产品经理等等,不同岗位的童鞋对数据的理解有很大的不一样,而且侧重点也不同。那么,是否有一些数据相关的基础知识是所有数据从业者都值得了解的?不同的岗位对数据的理解又有多大的不同?数据开发工程师是否有必要去了解数据分析师是如何看待数据的?
+
+本系列博客会尝试去学习、挖掘和总结这些内容,在数据的海洋中一起装x一起飞。
+
+## 0x01 数据?数据!
+
+开篇先上几个问题:
+
+1. 你知道自己的系统数据接入量是多少吗?
+2. 你知道数据的分布情况吗?
+3. 你知道自己常用的数据有什么隐藏的坑吗?
+
+如果你对前面说的问题有不太了解的,那么我们就可以在以后的内容中一起愉快地交流和探讨。如果前面说的问题你的回答都是 “Yes”,那么我还是会尝试用新的问题来留住你。比如说:
+
+1. 既然你知道系统的数据接入量,那你知道每天的数据量波动吗?波动量在多大范围内是正常情况?
+2. 你知道的数据分布情况是什么样子的?除了性别、年龄和城市的分布,还有什么分布?
+3. 在偌大的数据仓库中,哪些数据被使用最多,哪些数据又无人问津,这些你了解吗?
+4. 在最常用的那批数据中,有哪些核心的维度?有相同维度的两个表之间的数据口径是否也一样?
+
+假设你对上面的问题有稍许困惑或者感兴趣,我们正式开始对数据的认知之旅。
+
+## 0x02 概览
+
+现在,我们粗略地将数据从业者分为数据集群运维、数据开发工程师、数据仓库工程师、数据分析师、数据挖掘工程师和数据产品经理,这一小节先起一个引子来大致说明不同岗位对数据的了解是不同的,后文会详细地说明细节内容。
+
+首先要说明的是,在工作中数据相关的职位都是有很多重合的,很难一刀切区分不同岗位的职责,比如说数据开发工程师本身就是一个很大的概念,他可以做数据接入、数据清洗、数据仓库开发、数据挖掘算法开发等等,再比如说数据分析师,很多数据分析师既要做数据分析,又要做一些提数的需求,有时候还要自己做各种处理。
+
+公司的数据团队越大,相应的岗位职责就会越细分,反之亦然。在这里我们姑且用数据开发工程师和数据仓库工程师做对比来说明不同职责的同学对数据理解的侧重点有什么不同。我们假设**数据开发工程师侧重于数据的接入、存储和基本的数据处理**,**数据仓库工程师侧重于数据模型的设计和开发(比如维度建模)**。
+
+1. 数据开发工程师对数据最基本的了解是需要知道数据的接入状态,比如说每天总共接入多少数据,整体数据量是多大,接入的业务有多少,每个业务的接入量多大,多大波动范围是正常?然后还要对数据的存储周期有一个把握,比如说有多少表的存储周期是30天,有多少是90天?集群每日新增的存储量是多大,多久后集群存储会撑爆?
+
+2. 数据仓库工程师对上面的内容也要有一定的感知力,但是会有所区别,比如说,数据仓库工程师会更关注自己仓库建模中用到业务的数据状态。然后还需要知道终点业务的数据分布,比如说用户表中的年龄分布、性别分布、地域分布等。除此之外还应关注数据口径问题,比如说有很多份用户资料表,每张表的性别取值是否都是:男、女、未知,还是说会有用数值类型:1男、2女、0未知。
+
+3. 然后数据开发工程师对数据异常的侧重点可能会在今天的数据是否延迟落地,总量是否波动很大,数据可用率是否正常。
+
+4. 数据仓库工程师对数据异常的侧重点则可能是,今天落地的数据中性别为 0 的数据量是否激增(这可能会造成数据倾斜),某一个关键维度取值是否都为空。
+
+_上面的例子可能都会在一个数据质量监控系统中一起解决,但是我们在这里不讨论系统的设计,而是先有整体的意识和思路。_
+
+## 0x03 关于内容
+
+那么,后续博客的内容会是什么样子的呢?目前来看,我认为会有两个角度:
+
+1. **抛开岗位的区分度,从基本到高级来阐释对数据的了解**。比如说数据分布,最基本的程度只需要知道每天的接入量;深一点地话需要了解到其中重点维度的分布,比如说男女各多少;再深一点可能要需要知道重点维度的数据值分布,比如说年龄分布,怎样来合理划分年龄段,不同年龄段的比例。
+2. **每个岗位会关注的一些侧重点**。这点笔者认为不太好区分,因为很多岗位重合度比较高,但是笔者会尝试去总结,同时希望大家一起来探讨这个问题。
+
+## 0xFF 总结
+
+本篇主要是抛出一些问题,后续会逐步展开地细说数据从业者对数据理解。其实最开始我想用“数据敏感度”、“数据感知力”这类标题,但是感觉这种概念比较难定义,因此用了比较口语化的标题。
+
+笔者认为,在数据从业者的职业生涯中,不应只有编程、算法和系统,还应有一套数据相关的方法论,这套方法论会来解决某一领域的问题,即使你们的系统从Hadoop换到了Spark,数据模型从基本的策略匹配换到了深度学习,这些方法论也依旧会伴你整个职业生涯。因此这系列博客会尝试去学习、挖掘和总结一套这样的方法论,与君共勉。
+
+* * *
+
diff --git "a/docs/big-backEnd/\345\220\216\347\253\257\346\212\200\346\234\257\346\235\202\350\260\2101\357\274\232\346\220\234\347\264\242\345\274\225\346\223\216\345\237\272\347\241\200\345\200\222\346\216\222\347\264\242\345\274\225.md" "b/docs/big-backEnd/\345\220\216\347\253\257\346\212\200\346\234\257\346\235\202\350\260\2101\357\274\232\346\220\234\347\264\242\345\274\225\346\223\216\345\237\272\347\241\200\345\200\222\346\216\222\347\264\242\345\274\225.md"
new file mode 100644
index 0000000..ec82cbe
--- /dev/null
+++ "b/docs/big-backEnd/\345\220\216\347\253\257\346\212\200\346\234\257\346\235\202\350\260\2101\357\274\232\346\220\234\347\264\242\345\274\225\346\223\216\345\237\272\347\241\200\345\200\222\346\216\222\347\264\242\345\274\225.md"
@@ -0,0 +1,147 @@
+# [什么是倒排索引?](https://www.cnblogs.com/zlslch/p/6440114.html)
+
+
+
+
+
+ 见其名知其意,有倒排索引,对应肯定,有正向索引。
+
+ 正向索引(forward index),反向索引(inverted index)更熟悉的名字是倒排索引。
+
+ 在搜索引擎中每个文件都对应一个文件ID,文件内容被表示为一系列关键词的集合(实际上在搜索引擎索引库中,关键词也已经转换为关键词ID)。例如“文档1”经过分词,提取了20个关键词,每个关键词都会记录它在文档中的出现次数和出现位置。
+
+ 得到正向索引的结构如下:
+
+ “文档1”的ID > 单词1:出现次数,出现位置列表;单词2:出现次数,出现位置列表;…………。
+
+ “文档2”的ID > 此文档出现的关键词列表。
+
+ 
+
+ 一般是通过key,去找value。
+
+ 当用户在主页上搜索关键词“华为手机”时,假设只存在正向索引(forward index),那么就需要扫描索引库中的所有文档,找出所有包含关键词“华为手机”的文档,再根据打分模型进行打分,排出名次后呈现给用户。因为互联网上收录在搜索引擎中的文档的数目是个天文数字,这样的索引结构根本无法满足实时返回排名结果的要求。
+
+ 所以,搜索引擎会将正向索引重新构建为倒排索引,即把文件ID对应到关键词的映射转换为关键词到文件ID的映射,每个关键词都对应着一系列的文件,这些文件中都出现这个关键词。
+
+ 得到倒排索引的结构如下:
+
+ “关键词1”:“文档1”的ID,“文档2”的ID,…………。
+
+ “关键词2”:带有此关键词的文档ID列表。
+
+ 
+
+ 从词的关键字,去找文档。
+
+## 1.单词——文档矩阵
+
+ 单词-文档矩阵是表达两者之间所具有的一种包含关系的概念模型,图1展示了其含义。图3-1的每列代表一个文档,每行代表一个单词,打对勾的位置代表包含关系。
+
+ 
+
+ 图1 单词-文档矩阵
+
+ 从纵向即文档这个维度来看,每列代表文档包含了哪些单词,比如文档1包含了词汇1和词汇4,而不包含其它单词。从横向即单词这个维度来看,每行代表了哪些文档包含了某个单词。比如对于词汇1来说,文档1和文档4中出现过单词1,而其它文档不包含词汇1。矩阵中其它的行列也可作此种解读。
+
+ 搜索引擎的索引其实就是实现“单词-文档矩阵”的具体[数据结构](http://lib.csdn.net/base/datastructure "算法与数据结构知识库")。可以有不同的方式来实现上述概念模型,比如“倒排索引”、“签名文件”、“后缀树”等方式。但是各项实验数据表明,“倒排索引”是实现单词到文档映射关系的最佳实现方式,所以本博文主要介绍“倒排索引”的技术细节。
+
+## 2.倒排索引基本概念
+
+ 文档(Document):一般搜索引擎的处理对象是互联网网页,而文档这个概念要更宽泛些,代表以文本形式存在的存储对象,相比网页来说,涵盖更多种形式,比如Word,PDF,html,XML等不同格式的文件都可以称之为文档。再比如一封邮件,一条短信,一条微博也可以称之为文档。在本书后续内容,很多情况下会使用文档来表征文本信息。
+
+ 文档集合(Document Collection):由若干文档构成的集合称之为文档集合。比如海量的互联网网页或者说大量的电子邮件都是文档集合的具体例子。
+
+ 文档编号(Document ID):在搜索引擎内部,会将文档集合内每个文档赋予一个唯一的内部编号,以此编号来作为这个文档的唯一标识,这样方便内部处理,每个文档的内部编号即称之为“文档编号”,后文有时会用DocID来便捷地代表文档编号。
+
+ 单词编号(Word ID):与文档编号类似,搜索引擎内部以唯一的编号来表征某个单词,单词编号可以作为某个单词的唯一表征。
+
+ 倒排索引(Inverted Index):倒排索引是实现“单词-文档矩阵”的一种具体存储形式,通过倒排索引,可以根据单词快速获取包含这个单词的文档列表。倒排索引主要由两个部分组成:“单词词典”和“倒排文件”。
+
+ 单词词典(Lexicon):搜索引擎的通常索引单位是单词,单词词典是由文档集合中出现过的所有单词构成的字符串集合,单词词典内每条索引项记载单词本身的一些信息以及指向“倒排列表”的指针。
+
+ 倒排列表(PostingList):倒排列表记载了出现过某个单词的所有文档的文档列表及单词在该文档中出现的位置信息,每条记录称为一个倒排项(Posting)。根据倒排列表,即可获知哪些文档包含某个单词。
+
+ 倒排文件(Inverted File):所有单词的倒排列表往往顺序地存储在磁盘的某个文件里,这个文件即被称之为倒排文件,倒排文件是存储倒排索引的物理文件。
+
+ 关于这些概念之间的关系,通过图2可以比较清晰的看出来。
+
+ 
+
+## 3.倒排索引简单实例
+
+ 倒排索引从逻辑结构和基本思路上来讲非常简单。下面我们通过具体实例来进行说明,使得读者能够对倒排索引有一个宏观而直接的感受。
+
+ 假设文档集合包含五个文档,每个文档内容如图3所示,在图中最左端一栏是每个文档对应的文档编号。我们的任务就是对这个文档集合建立倒排索引。
+
+ 
+
+ 图3 文档集合
+
+ 中文和英文等语言不同,单词之间没有明确分隔符号,所以首先要用分词系统将文档自动切分成单词序列。这样每个文档就转换为由单词序列构成的数据流,为了系统后续处理方便,需要对每个不同的单词赋予唯一的单词编号,同时记录下哪些文档包含这个单词,在如此处理结束后,我们可以得到最简单的倒排索引(参考图3-4)。在图4中,“单词ID”一栏记录了每个单词的单词编号,第二栏是对应的单词,第三栏即每个单词对应的倒排列表。比如单词“谷歌”,其单词编号为1,倒排列表为{1,2,3,4,5},说明文档集合中每个文档都包含了这个单词。
+
+ 
+
+ 图4 简单的倒排索引
+
+ 之所以说图4所示倒排索引是最简单的,是因为这个索引系统只记载了哪些文档包含某个单词,而事实上,索引系统还可以记录除此之外的更多信息。图5是一个相对复杂些的倒排索引,与图4的基本索引系统比,在单词对应的倒排列表中不仅记录了文档编号,还记载了单词频率信息(TF),即这个单词在某个文档中的出现次数,之所以要记录这个信息,是因为词频信息在搜索结果排序时,计算查询和文档相似度是很重要的一个计算因子,所以将其记录在倒排列表中,以方便后续排序时进行分值计算。在图5的例子里,单词“创始人”的单词编号为7,对应的倒排列表内容为:(3:1),其中的3代表文档编号为3的文档包含这个单词,数字1代表词频信息,即这个单词在3号文档中只出现过1次,其它单词对应的倒排列表所代表含义与此相同。
+
+ 
+
+ 图 5 带有单词频率信息的倒排索引
+
+ 实用的倒排索引还可以记载更多的信息,图6所示索引系统除了记录文档编号和单词频率信息外,额外记载了两类信息,即每个单词对应的“文档频率信息”(对应图6的第三栏)以及在倒排列表中记录单词在某个文档出现的位置信息。
+
+ 
+
+ 图6 带有单词频率、文档频率和出现位置信息的倒排索引
+
+ “文档频率信息”代表了在文档集合中有多少个文档包含某个单词,之所以要记录这个信息,其原因与单词频率信息一样,这个信息在搜索结果排序计算中是非常重要的一个因子。而单词在某个文档中出现的位置信息并非索引系统一定要记录的,在实际的索引系统里可以包含,也可以选择不包含这个信息,之所以如此,因为这个信息对于搜索系统来说并非必需的,位置信息只有在支持“短语查询”的时候才能够派上用场。
+
+ 以单词“拉斯”为例,其单词编号为8,文档频率为2,代表整个文档集合中有两个文档包含这个单词,对应的倒排列表为:{(3;1;<4>),(5;1;<4>)},其含义为在文档3和文档5出现过这个单词,单词频率都为1,单词“拉斯”在两个文档中的出现位置都是4,即文档中第四个单词是“拉斯”。
+
+ 图6所示倒排索引已经是一个非常完备的索引系统,实际搜索系统的索引结构基本如此,区别无非是采取哪些具体的数据结构来实现上述逻辑结构。
+
+ 有了这个索引系统,搜索引擎可以很方便地响应用户的查询,比如用户输入查询词“Facebook”,搜索系统查找倒排索引,从中可以读出包含这个单词的文档,这些文档就是提供给用户的搜索结果,而利用单词频率信息、文档频率信息即可以对这些候选搜索结果进行排序,计算文档和查询的相似性,按照相似性得分由高到低排序输出,此即为搜索系统的部分内部流程,具体实现方案本书第五章会做详细描述。
+
+## 4\. 单词词典
+
+ 单词词典是倒排索引中非常重要的组成部分,它用来维护文档集合中出现过的所有单词的相关信息,同时用来记载某个单词对应的倒排列表在倒排文件中的位置信息。在支持搜索时,根据用户的查询词,去单词词典里查询,就能够获得相应的倒排列表,并以此作为后续排序的基础。
+ 对于一个规模很大的文档集合来说,可能包含几十万甚至上百万的不同单词,能否快速定位某个单词,这直接影响搜索时的响应速度,所以需要高效的数据结构来对单词词典进行构建和查找,常用的数据结构包括哈希加链表结构和树形词典结构。
+4.1 哈希加链表
+ 图7是这种词典结构的示意图。这种词典结构主要由两个部分构成:
+
+ 主体部分是哈希表,每个哈希表项保存一个指针,指针指向冲突链表,在冲突链表里,相同哈希值的单词形成链表结构。之所以会有冲突链表,是因为两个不同单词获得相同的哈希值,如果是这样,在哈希方法里被称做是一次冲突,可以将相同哈希值的单词存储在链表里,以供后续查找。
+
+ 
+
+ 在建立索引的过程中,词典结构也会相应地被构建出来。比如在解析一个新文档的时候,对于某个在文档中出现的单词T,首先利用哈希函数获得其哈希值,之后根据哈希值对应的哈希表项读取其中保存的指针,就找到了对应的冲突链表。如果冲突链表里已经存在这个单词,说明单词在之前解析的文档里已经出现过。如果在冲突链表里没有发现这个单词,说明该单词是首次碰到,则将其加入冲突链表里。通过这种方式,当文档集合内所有文档解析完毕时,相应的词典结构也就建立起来了。
+
+ 在响应用户查询请求时,其过程与建立词典类似,不同点在于即使词典里没出现过某个单词,也不会添加到词典内。以图7为例,假设用户输入的查询请求为单词3,对这个单词进行哈希,定位到哈希表内的2号槽,从其保留的指针可以获得冲突链表,依次将单词3和冲突链表内的单词比较,发现单词3在冲突链表内,于是找到这个单词,之后可以读出这个单词对应的倒排列表来进行后续的工作,如果没有找到这个单词,说明文档集合内没有任何文档包含单词,则搜索结果为空。
+
+4.2 树形结构
+ B树(或者B+树)是另外一种高效查找结构,图8是一个 B树结构示意图。B树与哈希方式查找不同,需要字典项能够按照大小排序(数字或者字符序),而哈希方式则无须数据满足此项要求。
+ B树形成了层级查找结构,中间节点用于指出一定顺序范围的词典项目存储在哪个子树中,起到根据词典项比较大小进行导航的作用,最底层的叶子节点存储单词的地址信息,根据这个地址就可以提取出单词字符串。
+
+ 
+
+ 图8 B树查找结构
+
+总结
+
+
+
+
+
+单词ID:记录每个单词的单词编号;
+单词:对应的单词;
+文档频率:代表文档集合中有多少个文档包含某个单词
+倒排列表:包含单词ID及其他必要信息
+DocId:单词出现的文档id
+TF:单词在某个文档中出现的次数
+POS:单词在文档中出现的位置
+ 以单词“加盟”为例,其单词编号为6,文档频率为3,代表整个文档集合中有三个文档包含这个单词,对应的倒排列表为{(2;1;<4>),(3;1;<7>),(5;1;<5>)},含义是在文档2,3,5出现过这个单词,在每个文档的出现过1次,单词“加盟”在第一个文档的POS是4,即文档的第四个单词是“加盟”,其他的类似。
+这个倒排索引已经是一个非常完备的索引系统,实际搜索系统的索引结构基本如此。
+
+
+
diff --git "a/docs/big-backEnd/\345\220\216\347\253\257\346\212\200\346\234\257\346\235\202\350\260\2102\357\274\232\346\220\234\347\264\242\345\274\225\346\223\216\345\267\245\344\275\234\345\216\237\347\220\206.md" "b/docs/big-backEnd/\345\220\216\347\253\257\346\212\200\346\234\257\346\235\202\350\260\2102\357\274\232\346\220\234\347\264\242\345\274\225\346\223\216\345\267\245\344\275\234\345\216\237\347\220\206.md"
new file mode 100644
index 0000000..9e49ab7
--- /dev/null
+++ "b/docs/big-backEnd/\345\220\216\347\253\257\346\212\200\346\234\257\346\235\202\350\260\2102\357\274\232\346\220\234\347\264\242\345\274\225\346\223\216\345\267\245\344\275\234\345\216\237\347\220\206.md"
@@ -0,0 +1,145 @@
+本文作者:顿炖
+链接:https://www.zhihu.com/question/19937854/answer/98791215
+来源:知乎
+
+写在前面
+
+Max Grigorev最近写了一篇文章,题目是[《What every software engineer should know about search》](https://link.juejin.im/?target=https%3A%2F%2Fmedium.com%2Fstartup-grind%2Fwhat-every-software-engineer-should-know-about-search-27d1df99f80d),这篇文章里指出了现在一些软件工程师的问题,他们认为开发一个搜索引擎功能就是搭建一个ElasticSearch集群,而没有深究背后的技术,以及技术发展趋势。Max认为,除了搜索引擎自身的搜索问题解决、人类使用方式等之外,也需要解决索引、分词、权限控制、国际化等等的技术点,看了他的文章,勾起了我多年前的想法。
+
+很多年前,我曾经想过自己实现一个搜索引擎,作为自己的研究生论文课题,后来琢磨半天没有想出新的技术突破点(相较于已发表的文章),所以切换到了大数据相关的技术点。当时没有写出来,心中有点小遗憾,毕竟凭借搜索引擎崛起的谷歌是我内心渴望的公司。今天我就想结合自己的一些积累,聊聊作为一名软件工程师,您需要了解的搜索引擎知识。
+
+搜索引擎发展过程
+
+现代意义上的搜索引擎的祖先,是1990年由蒙特利尔大学学生Alan Emtage发明的Archie。即便没有英特网,网络中文件传输还是相当频繁的,而且由于大量的文件散布在各个分散的FTP主机中,查询起来非常不便,因此Alan Emtage想到了开发一个可以以文件名查找文件的系统,于是便有了Archie。Archie工作原理与现在的搜索引擎已经很接近,它依靠脚本程序自动搜索网上的文件,然后对有关信息进行索引,供使用者以一定的表达式查询。
+
+互联网兴起后,需要能够监控的工具。世界上第一个用于监测互联网发展规模的“机器人”程序是Matthew Gray开发的World wide Web Wanderer,刚开始它只用来统计互联网上的服务器数量,后来则发展为能够检索网站域名。
+
+随着互联网的迅速发展,每天都会新增大量的网站、网页,检索所有新出现的网页变得越来越困难,因此,在Matthew Gray的Wanderer基础上,一些编程者将传统的“蜘蛛”程序工作原理作了些改进。现代搜索引擎都是以此为基础发展的。
+
+搜索引擎分类
+
+* 全文搜索引擎
+
+当前主流的是全文搜索引擎,较为典型的代表是Google、百度。全文搜索引擎是指通过从互联网上提取的各个网站的信息(以网页文字为主),保存在自己建立的数据库中。用户发起检索请求后,系统检索与用户查询条件匹配的相关记录,然后按一定的排列顺序将结果返回给用户。从搜索结果来源的角度,全文搜索引擎又可细分为两种,一种是拥有自己的检索程序(Indexer),俗称“蜘蛛”(Spider)程序或“机器人”(Robot)程序,并自建网页数据库,搜索结果直接从自身的数据存储层中调用;另一种则是租用其他引擎的数据库,并按自定的格式排列搜索结果,如Lycos引擎。
+
+* 目录索引类搜索引擎
+
+虽然有搜索功能,但严格意义上不能称为真正的搜索引擎,只是按目录分类的网站链接列表而已。用户完全可以按照分类目录找到所需要的信息,不依靠关键词(Keywords)进行查询。目录索引中最具代表性的莫过于大名鼎鼎的Yahoo、新浪分类目录搜索。
+
+* 元搜索引擎
+
+ 元搜索引擎在接受用户查询请求时,同时在其他多个引擎上进行搜索,并将结果返回给用户。著名的元搜索引擎有InfoSpace、Dogpile、Vivisimo等,中文元搜索引擎中具代表性的有搜星搜索引擎。在搜索结果排列方面,有的直接按来源引擎排列搜索结果,如Dogpile,有的则按自定的规则将结果重新排列组合,如Vivisimo。
+
+相关实现技术
+
+搜索引擎产品虽然一般都只有一个输入框,但是对于所提供的服务,背后有很多不同业务引擎支撑,每个业务引擎又有很多不同的策略,每个策略又有很多模块协同处理,及其复杂。
+
+搜索引擎本身包含网页抓取、网页评价、反作弊、建库、倒排索引、索引压缩、在线检索、ranking排序策略等等知识。
+
+* 网络爬虫技术
+
+网络爬虫技术指的是针对网络数据的抓取。因为在网络中抓取数据是具有关联性的抓取,它就像是一只蜘蛛一样在互联网中爬来爬去,所以我们很形象地将其称为是网络爬虫技术。网络爬虫也被称为是网络机器人或者是网络追逐者。
+
+网络爬虫获取网页信息的方式和我们平时使用浏览器访问网页的工作原理是完全一样的,都是根据HTTP协议来获取,其流程主要包括如下步骤:
+
+1)连接DNS域名服务器,将待抓取的URL进行域名解析(URL------>IP);
+
+2)根据HTTP协议,发送HTTP请求来获取网页内容。
+
+一个完整的网络爬虫基础框架如下图所示:
+
+
+
+整个架构共有如下几个过程:
+
+1)需求方提供需要抓取的种子URL列表,根据提供的URL列表和相应的优先级,建立待抓取URL队列(先来先抓);
+
+2)根据待抓取URL队列的排序进行网页抓取;
+
+3)将获取的网页内容和信息下载到本地的网页库,并建立已抓取URL列表(用于去重和判断抓取的进程);
+
+4)将已抓取的网页放入到待抓取的URL队列中,进行循环抓取操作;
+- 索引
+
+从用户的角度来看,搜索的过程是通过关键字在某种资源中寻找特定的内容的过程。而从计算机的角度来看,实现这个过程可以有两种办法。一是对所有资源逐个与关键字匹配,返回所有满足匹配的内容;二是如同字典一样事先建立一个对应表,把关键字与资源的内容对应起来,搜索时直接查找这个表即可。显而易见,第二个办法效率要高得多。建立这个对应表事实上就是建立逆向索引(inverted index)的过程。
+
+* Lucene
+
+Lucene是一个高性能的java全文检索工具包,它使用的是倒排文件索引结构。
+
+全文检索大体分两个过程,索引创建 (Indexing) 和搜索索引 (Search) 。
+
+索引创建:将现实世界中所有的结构化和非结构化数据提取信息,创建索引的过程。
+搜索索引:就是得到用户的查询请求,搜索创建的索引,然后返回结果的过程。
+
+
+
+非结构化数据中所存储的信息是每个文件包含哪些字符串,也即已知文件,欲求字符串相对容易,也即是从文件到字符串的映射。而我们想搜索的信息是哪些文件包含此字符串,也即已知字符串,欲求文件,也即从字符串到文件的映射。两者恰恰相反。于是如果索引总能够保存从字符串到文件的映射,则会大大提高搜索速度。
+
+由于从字符串到文件的映射是文件到字符串映射的反向过程,于是保存这种信息的索引称为反向索引 。
+
+反向索引的所保存的信息一般如下:
+
+假设我的文档集合里面有100篇文档,为了方便表示,我们为文档编号从1到100,得到下面的结构
+
+
+
+每个字符串都指向包含此字符串的文档(Document)链表,此文档链表称为倒排表 (Posting List)。
+
+* ElasticSearch
+
+Elasticsearch是一个实时的分布式搜索和分析引擎,可以用于全文搜索,结构化搜索以及分析,当然你也可以将这三者进行组合。Elasticsearch是一个建立在全文搜索引擎 Apache Lucene™ 基础上的搜索引擎,但是Lucene只是一个框架,要充分利用它的功能,需要使用JAVA,并且在程序中集成Lucene。Elasticsearch使用Lucene作为内部引擎,但是在使用它做全文搜索时,只需要使用统一开发好的API即可,而不需要了解其背后复杂的Lucene的运行原理。
+
+* Solr
+
+Solr是一个基于Lucene的搜索引擎服务器。Solr 提供了层面搜索、命中醒目显示并且支持多种输出格式(包括 XML/XSLT 和 JSON 格式)。它易于安装和配置,而且附带了一个基于 HTTP 的管理界面。Solr已经在众多大型的网站中使用,较为成熟和稳定。Solr 包装并扩展了 Lucene,所以Solr的基本上沿用了Lucene的相关术语。更重要的是,Solr 创建的索引与 Lucene 搜索引擎库完全兼容。通过对Solr 进行适当的配置,某些情况下可能需要进行编码,Solr 可以阅读和使用构建到其他 Lucene 应用程序中的索引。此外,很多 Lucene 工具(如Nutch、 Luke)也可以使用Solr 创建的索引。
+
+* Hadoop
+
+谷歌公司发布的一系列技术白皮书导致了Hadoop的诞生。Hadoop是一系列大数据处理工具,可以被用在大规模集群里。Hadoop目前已经发展为一个生态体系,包括了很多组件,如图所示。
+
+
+
+Cloudera是一家将Hadoop技术用于搜索引擎的公司,用户可以采用全文搜索方式检索存储在HDFS(Hadoop分布式文件系统)和Apache HBase里面的数据,再加上开源的搜索引擎Apache Solr,Cloudera提供了搜索功能,并结合Apache ZooKeeper进行分布式处理的管理、索引切分以及高性能检索。
+
+* PageRank
+
+谷歌Pagerank算法基于随机冲浪模型,基本思想是基于网站之间的相互投票,即我们常说的网站之间互相指向。如果判断一个网站是高质量站点时,那么该网站应该是被很多高质量的网站引用又或者是该网站引用了大量的高质量权威的站点。
+- 国际化
+
+坦白说,Google虽然做得非常好,无论是技术还是产品设计,都很好。但是国际化确实是非常难做的,很多时候在细分领域还是会有其他搜索引擎的生存余地。例如在韩国,Naver是用户的首选,它本身基于Yahoo的Overture系统,广告系统则是自己开发的。在捷克,我们则更多会使用Seznam。在瑞典,用户更多选择Eniro,它最初是瑞典的黄页开发公司。
+
+国际化、个性化搜索、匿名搜索,这些都是Google这样的产品所不能完全覆盖到的,事实上,也没有任何一款产品可以适用于所有需求。
+
+自己实现搜索引擎
+
+如果我们想要实现搜索引擎,最重要的是索引模块和搜索模块。索引模块在不同的机器上各自进行对资源的索引,并把索引文件统一传输到同一个地方(可以是在远程服务器上,也可以是在本地)。搜索模块则利用这些从多个索引模块收集到的数据完成用户的搜索请求。因此,我们可以理解两个模块之间相对是独立的,它们之间的关联不是通过代码,而是通过索引和元数据,如下图所示。
+
+
+
+对于索引的建立,我们需要注意性能问题。当需要进行索引的资源数目不多时,隔一定的时间进行一次完全索引,不会占用很长时间。但在大型应用中,资源的容量是巨大的,如果每次都进行完整的索引,耗费的时间会很惊人。我们可以通过跳过已经索引的资源内容,删除已不存在的资源内容的索引,并进行增量索引来解决这个问题。这可能会涉及文件校验和索引删除等。另一方面,框架可以提供查询缓存功能,提高查询效率。框架可以在内存中建立一级缓存,并使用如 OSCache或 EHCache缓存框架,实现磁盘上的二级缓存。当索引的内容变化不频繁时,使用查询缓存更会明显地提高查询速度、降低资源消耗。
+
+搜索引擎解决方案
+
+* Sphinx
+
+俄罗斯一家公司开源的全文搜索引擎软件Sphinx,单一索引最大可包含1亿条记录,在1千万条记录情况下的查询速度为0.x秒(毫秒级)。Sphinx创建索引的速度很快,根据网上的资料,Sphinx创建100万条记录的索引只需3~4分钟,创建1000万条记录的索引可以在50分钟内完成,而只包含最新10万条记录的增量索引,重建一次只需几十秒。
+
+* OmniFind
+
+OmniFind 是 IBM 公司推出的企业级搜索解决方案。基于 UIMA (Unstructured Information Management Architecture) 技术,它提供了强大的索引和获取信息功能,支持巨大数量、多种类型的文档资源(无论是结构化还是非结构化),并为 Lotus®Domino®和 WebSphere®Portal 专门进行了优化。
+下一代搜索引擎
+
+从技术和产品层面来看,接下来的几年,甚至于更长时间,应该没有哪一家搜索引擎可以撼动谷歌的技术领先优势和产品地位。但是我们也可以发现一些现象,例如搜索假期租房的时候,人们更喜欢使用Airbub,而不是Google,这就是针对匿名/个性化搜索需求,这些需求是谷歌所不能完全覆盖到的,毕竟原始数据并不在谷歌。我们可以看一个例子:DuckDuckGo。这是一款有别于大众理解的搜索引擎,DuckDuckGo强调的是最佳答案,而不是更多的结果,所以每个人搜索相同关键词时,返回的结果是不一样的。
+
+另一个方面技术趋势是引入人工智能技术。在搜索体验上,通过大量算法的引入,对用户搜索的内容和访问偏好进行分析,将标题摘要进行一定程度的优化,以更容易理解的方式呈现给用户。谷歌在搜索引擎AI化的步骤领先于其他厂商,2016年,随着Amit Singhal被退休,John Giannandrea上位的交接班过程后,正式开启了自身的革命。Giannandrea是深度神经网络、近似人脑中的神经元网络研究方面的顶级专家,通过分析海量级的数字数据,这些神经网络可以学习排列方式,例如对图片进行分类、识别智能手机的语音控制等等,对应也可以应用在搜索引擎。因此,Singhal向Giannandrea的过渡,也意味着传统人为干预的规则设置的搜索引擎向AI技术的过渡。引入深度学习技术之后的搜索引擎,通过不断的模型训练,它会深层次地理解内容,并为客户提供更贴近实际需求的服务,这才是它的有用,或者可怕之处。
+
+**Google搜索引擎的工作流程**
+
+贴个图,自己感受下。
+
+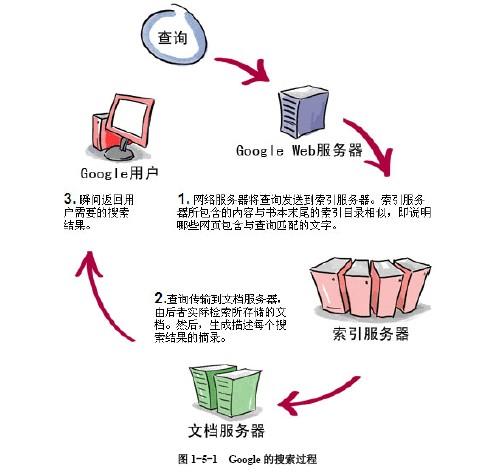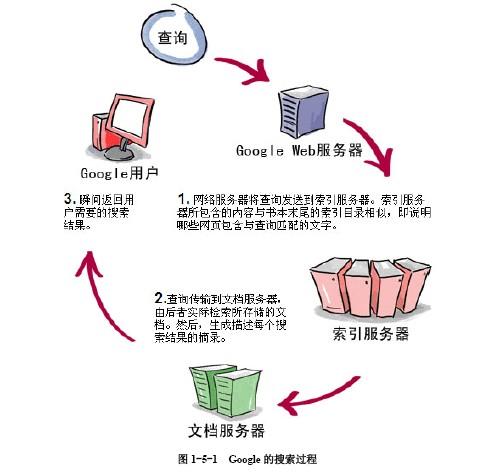
+
+**详细点的 :**
+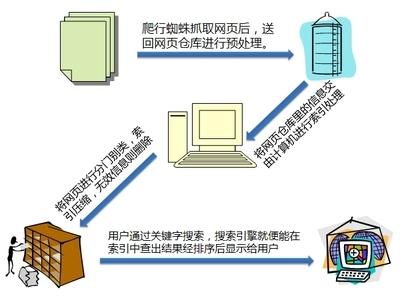
+
diff --git "a/docs/big-backEnd/\345\220\216\347\253\257\346\212\200\346\234\257\346\235\202\350\260\2103\357\274\232Lucene\345\237\272\347\241\200\345\216\237\347\220\206\344\270\216\345\256\236\350\267\265.md" "b/docs/big-backEnd/\345\220\216\347\253\257\346\212\200\346\234\257\346\235\202\350\260\2103\357\274\232Lucene\345\237\272\347\241\200\345\216\237\347\220\206\344\270\216\345\256\236\350\267\265.md"
new file mode 100644
index 0000000..35b1e35
--- /dev/null
+++ "b/docs/big-backEnd/\345\220\216\347\253\257\346\212\200\346\234\257\346\235\202\350\260\2103\357\274\232Lucene\345\237\272\347\241\200\345\216\237\347\220\206\344\270\216\345\256\236\350\267\265.md"
@@ -0,0 +1,676 @@
+
+
+
+
+
+
+**一、总论**
+
+根据[lucene.apache.org/java/docs/i…](https://link.juejin.im/?target=http%3A%2F%2Flucene.apache.org%2Fjava%2Fdocs%2Findex.html)定义:
+
+Lucene是一个高效的,基于Java的全文检索库。
+
+所以在了解Lucene之前要费一番工夫了解一下全文检索。
+
+那么什么叫做全文检索呢?这要从我们生活中的数据说起。
+
+我们生活中的数据总体分为两种:结构化数据和非结构化数据。
+
+* 结构化数据:指具有固定格式或有限长度的数据,如数据库,元数据等。
+* 非结构化数据:指不定长或无固定格式的数据,如邮件,word文档等。
+
+当然有的地方还会提到第三种,半结构化数据,如XML,HTML等,当根据需要可按结构化数据来处理,也可抽取出纯文本按非结构化数据来处理。
+
+非结构化数据又一种叫法叫全文数据。
+
+按照数据的分类,搜索也分为两种:
+
+* 对结构化数据的搜索:如对数据库的搜索,用SQL语句。再如对元数据的搜索,如利用windows搜索对文件名,类型,修改时间进行搜索等。
+* 对非结构化数据的搜索:如利用windows的搜索也可以搜索文件内容,Linux下的grep命令,再如用Google和百度可以搜索大量内容数据。
+
+对非结构化数据也即对全文数据的搜索主要有两种方法:
+
+一种是顺序扫描法(Serial Scanning):所谓顺序扫描,比如要找内容包含某一个字符串的文件,就是一个文档一个文档的看,对于每一个文档,从头看到尾,如果此文档包含此字符串,则此文档为我们要找的文件,接着看下一个文件,直到扫描完所有的文件。如利用windows的搜索也可以搜索文件内容,只是相当的慢。如果你有一个80G硬盘,如果想在上面找到一个内容包含某字符串的文件,不花他几个小时,怕是做不到。Linux下的grep命令也是这一种方式。大家可能觉得这种方法比较原始,但对于小数据量的文件,这种方法还是最直接,最方便的。但是对于大量的文件,这种方法就很慢了。
+
+有人可能会说,对非结构化数据顺序扫描很慢,对结构化数据的搜索却相对较快(由于结构化数据有一定的结构可以采取一定的搜索算法加快速度),那么把我们的非结构化数据想办法弄得有一定结构不就行了吗?
+
+这种想法很天然,却构成了全文检索的基本思路,也即将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对较快的目的。
+
+这部分从非结构化数据中提取出的然后重新组织的信息,我们称之索引。
+
+这种说法比较抽象,举几个例子就很容易明白,比如字典,字典的拼音表和部首检字表就相当于字典的索引,对每一个字的解释是非结构化的,如果字典没有音节表和部首检字表,在茫茫辞海中找一个字只能顺序扫描。然而字的某些信息可以提取出来进行结构化处理,比如读音,就比较结构化,分声母和韵母,分别只有几种可以一一列举,于是将读音拿出来按一定的顺序排列,每一项读音都指向此字的详细解释的页数。我们搜索时按结构化的拼音搜到读音,然后按其指向的页数,便可找到我们的非结构化数据——也即对字的解释。
+
+这种先建立索引,再对索引进行搜索的过程就叫全文检索(Full-text Search)。
+
+下面这幅图来自《Lucene in action》,但却不仅仅描述了Lucene的检索过程,而是描述了全文检索的一般过程。
+
+[](https://link.juejin.im/?target=http%3A%2F%2Fimages.cnblogs.com%2Fcnblogs_com%2Fforfuture1978%2FWindowsLiveWriter%2F185c4e9316f3_147FA%2Fimage_2.png)
+
+全文检索大体分两个过程,索引创建(Indexing)和搜索索引(Search)。
+
+* 索引创建:将现实世界中所有的结构化和非结构化数据提取信息,创建索引的过程。
+* 搜索索引:就是得到用户的查询请求,搜索创建的索引,然后返回结果的过程。
+
+于是全文检索就存在三个重要问题:
+
+1. 索引里面究竟存些什么?(Index)
+
+2. 如何创建索引?(Indexing)
+
+3. 如何对索引进行搜索?(Search)
+
+下面我们顺序对每个个问题进行研究。
+
+## 二、索引里面究竟存些什么
+
+索引里面究竟需要存些什么呢?
+
+首先我们来看为什么顺序扫描的速度慢:
+
+其实是由于我们想要搜索的信息和非结构化数据中所存储的信息不一致造成的。
+
+非结构化数据中所存储的信息是每个文件包含哪些字符串,也即已知文件,欲求字符串相对容易,也即是从文件到字符串的映射。而我们想搜索的信息是哪些文件包含此字符串,也即已知字符串,欲求文件,也即从字符串到文件的映射。两者恰恰相反。于是如果索引总能够保存从字符串到文件的映射,则会大大提高搜索速度。
+
+由于从字符串到文件的映射是文件到字符串映射的反向过程,于是保存这种信息的索引称为反向索引。
+
+反向索引的所保存的信息一般如下:
+
+假设我的文档集合里面有100篇文档,为了方便表示,我们为文档编号从1到100,得到下面的结构
+
+[](https://link.juejin.im/?target=http%3A%2F%2Fimages.cnblogs.com%2Fcnblogs_com%2Fforfuture1978%2FWindowsLiveWriter%2F185c4e9316f3_147FA%2Finverted%2520index_2.jpg)
+
+左边保存的是一系列字符串,称为词典。
+
+每个字符串都指向包含此字符串的文档(Document)链表,此文档链表称为倒排表(Posting List)。
+
+有了索引,便使保存的信息和要搜索的信息一致,可以大大加快搜索的速度。
+
+比如说,我们要寻找既包含字符串“lucene”又包含字符串“solr”的文档,我们只需要以下几步:
+
+1\. 取出包含字符串“lucene”的文档链表。
+
+2\. 取出包含字符串“solr”的文档链表。
+
+3\. 通过合并链表,找出既包含“lucene”又包含“solr”的文件。
+
+[](https://link.juejin.im/?target=http%3A%2F%2Fimages.cnblogs.com%2Fcnblogs_com%2Fforfuture1978%2FWindowsLiveWriter%2F185c4e9316f3_147FA%2Finverted%2520index%2520merge_2.jpg)
+
+看到这个地方,有人可能会说,全文检索的确加快了搜索的速度,但是多了索引的过程,两者加起来不一定比顺序扫描快多少。的确,加上索引的过程,全文检索不一定比顺序扫描快,尤其是在数据量小的时候更是如此。而对一个很大量的数据创建索引也是一个很慢的过程。
+
+然而两者还是有区别的,顺序扫描是每次都要扫描,而创建索引的过程仅仅需要一次,以后便是一劳永逸的了,每次搜索,创建索引的过程不必经过,仅仅搜索创建好的索引就可以了。
+
+这也是全文搜索相对于顺序扫描的优势之一:一次索引,多次使用。
+
+## 三、如何创建索引
+
+全文检索的索引创建过程一般有以下几步:
+
+### 第一步:一些要索引的原文档(Document)。
+
+为了方便说明索引创建过程,这里特意用两个文件为例:
+
+文件一:Students should be allowed to go out with their friends, but not allowed to drink beer.
+
+文件二:My friend Jerry went to school to see his students but found them drunk which is not allowed.
+
+### 第二步:将原文档传给分次组件(Tokenizer)。
+
+分词组件(Tokenizer)会做以下几件事情(此过程称为Tokenize):
+
+1. 将文档分成一个一个单独的单词。
+
+2. 去除标点符号。
+
+3. 去除停词(Stop word)。
+
+所谓停词(Stop word)就是一种语言中最普通的一些单词,由于没有特别的意义,因而大多数情况下不能成为搜索的关键词,因而创建索引时,这种词会被去掉而减少索引的大小。
+
+英语中挺词(Stop word)如:“the”,“a”,“this”等。
+
+对于每一种语言的分词组件(Tokenizer),都有一个停词(stop word)集合。
+
+经过分词(Tokenizer)后得到的结果称为词元(Token)。
+
+在我们的例子中,便得到以下词元(Token):
+
+“Students”,“allowed”,“go”,“their”,“friends”,“allowed”,“drink”,“beer”,“My”,“friend”,“Jerry”,“went”,“school”,“see”,“his”,“students”,“found”,“them”,“drunk”,“allowed”。
+
+### 第三步:将得到的词元(Token)传给语言处理组件(Linguistic Processor)。
+
+语言处理组件(linguistic processor)主要是对得到的词元(Token)做一些同语言相关的处理。
+
+对于英语,语言处理组件(Linguistic Processor)一般做以下几点:
+
+1. 变为小写(Lowercase)。
+
+2. 将单词缩减为词根形式,如“cars”到“car”等。这种操作称为:stemming。
+
+3. 将单词转变为词根形式,如“drove”到“drive”等。这种操作称为:lemmatization。
+
+Stemming 和 lemmatization的异同:
+
+* 相同之处:Stemming和lemmatization都要使词汇成为词根形式。
+* 两者的方式不同:
+ * Stemming采用的是“缩减”的方式:“cars”到“car”,“driving”到“drive”。
+ * Lemmatization采用的是“转变”的方式:“drove”到“drove”,“driving”到“drive”。
+* 两者的算法不同:
+ * Stemming主要是采取某种固定的算法来做这种缩减,如去除“s”,去除“ing”加“e”,将“ational”变为“ate”,将“tional”变为“tion”。
+ * Lemmatization主要是采用保存某种字典的方式做这种转变。比如字典中有“driving”到“drive”,“drove”到“drive”,“am, is, are”到“be”的映射,做转变时,只要查字典就可以了。
+* Stemming和lemmatization不是互斥关系,是有交集的,有的词利用这两种方式都能达到相同的转换。
+
+语言处理组件(linguistic processor)的结果称为词(Term)。
+
+在我们的例子中,经过语言处理,得到的词(Term)如下:
+
+“student”,“allow”,“go”,“their”,“friend”,“allow”,“drink”,“beer”,“my”,“friend”,“jerry”,“go”,“school”,“see”,“his”,“student”,“find”,“them”,“drink”,“allow”。
+
+也正是因为有语言处理的步骤,才能使搜索drove,而drive也能被搜索出来。
+
+### 第四步:将得到的词(Term)传给索引组件(Indexer)。
+
+索引组件(Indexer)主要做以下几件事情:
+
+1\. 利用得到的词(Term)创建一个字典。
+
+在我们的例子中字典如下:
+
+
+
+| Term | Document ID |
+| --- | --- |
+| student | 1 |
+| allow | 1 |
+| go | 1 |
+| their | 1 |
+| friend | 1 |
+| allow | 1 |
+| drink | 1 |
+| beer | 1 |
+| my | 2 |
+| friend | 2 |
+| jerry | 2 |
+| go | 2 |
+| school | 2 |
+| see | 2 |
+| his | 2 |
+| student | 2 |
+| find | 2 |
+| them | 2 |
+| drink | 2 |
+| allow | 2 |
+
+
+
+
+
+2. 对字典按字母顺序进行排序。
+
+
+
+| Term | Document ID |
+| --- | --- |
+| allow | 1 |
+| allow | 1 |
+| allow | 2 |
+| beer | 1 |
+| drink | 1 |
+| drink | 2 |
+| find | 2 |
+| friend | 1 |
+| friend | 2 |
+| go | 1 |
+| go | 2 |
+| his | 2 |
+| jerry | 2 |
+| my | 2 |
+| school | 2 |
+| see | 2 |
+| student | 1 |
+| student | 2 |
+| their | 1 |
+| them | 2 |
+
+
+
+
+
+3. 合并相同的词(Term)成为文档倒排(Posting List)链表。
+
+[](https://link.juejin.im/?target=http%3A%2F%2Fimages.cnblogs.com%2Fcnblogs_com%2Fforfuture1978%2FWindowsLiveWriter%2F185c4e9316f3_147FA%2Fpostinglist_2.jpg)
+
+在此表中,有几个定义:
+
+* Document Frequency 即文档频次,表示总共有多少文件包含此词(Term)。
+* Frequency 即词频率,表示此文件中包含了几个此词(Term)。
+
+所以对词(Term) “allow”来讲,总共有两篇文档包含此词(Term),从而词(Term)后面的文档链表总共有两项,第一项表示包含“allow”的第一篇文档,即1号文档,此文档中,“allow”出现了2次,第二项表示包含“allow”的第二个文档,是2号文档,此文档中,“allow”出现了1次。
+
+到此为止,索引已经创建好了,我们可以通过它很快的找到我们想要的文档。
+
+而且在此过程中,我们惊喜地发现,搜索“drive”,“driving”,“drove”,“driven”也能够被搜到。因为在我们的索引中,“driving”,“drove”,“driven”都会经过语言处理而变成“drive”,在搜索时,如果您输入“driving”,输入的查询语句同样经过我们这里的一到三步,从而变为查询“drive”,从而可以搜索到想要的文档。
+
+## 三、如何对索引进行搜索?
+
+到这里似乎我们可以宣布“我们找到想要的文档了”。
+
+然而事情并没有结束,找到了仅仅是全文检索的一个方面。不是吗?如果仅仅只有一个或十个文档包含我们查询的字符串,我们的确找到了。然而如果结果有一千个,甚至成千上万个呢?那个又是您最想要的文件呢?
+
+打开Google吧,比如说您想在微软找份工作,于是您输入“Microsoft job”,您却发现总共有22600000个结果返回。好大的数字呀,突然发现找不到是一个问题,找到的太多也是一个问题。在如此多的结果中,如何将最相关的放在最前面呢?
+
+[](https://link.juejin.im/?target=http%3A%2F%2Fimages.cnblogs.com%2Fcnblogs_com%2Fforfuture1978%2FWindowsLiveWriter%2F185c4e9316f3_147FA%2Fclip_image0024.jpg)
+
+当然Google做的很不错,您一下就找到了jobs at Microsoft。想象一下,如果前几个全部是“Microsoft does a good job at software industry…”将是多么可怕的事情呀。
+
+如何像Google一样,在成千上万的搜索结果中,找到和查询语句最相关的呢?
+
+如何判断搜索出的文档和查询语句的相关性呢?
+
+这要回到我们第三个问题:如何对索引进行搜索?
+
+搜索主要分为以下几步:
+
+### 第一步:用户输入查询语句。
+
+查询语句同我们普通的语言一样,也是有一定语法的。
+
+不同的查询语句有不同的语法,如SQL语句就有一定的语法。
+
+查询语句的语法根据全文检索系统的实现而不同。最基本的有比如:AND, OR, NOT等。
+
+举个例子,用户输入语句:lucene AND learned NOT hadoop。
+
+说明用户想找一个包含lucene和learned然而不包括hadoop的文档。
+
+### 第二步:对查询语句进行词法分析,语法分析,及语言处理。
+
+由于查询语句有语法,因而也要进行语法分析,语法分析及语言处理。
+
+1\. 词法分析主要用来识别单词和关键字。
+
+如上述例子中,经过词法分析,得到单词有lucene,learned,hadoop, 关键字有AND, NOT。
+
+如果在词法分析中发现不合法的关键字,则会出现错误。如lucene AMD learned,其中由于AND拼错,导致AMD作为一个普通的单词参与查询。
+
+2\. 语法分析主要是根据查询语句的语法规则来形成一棵语法树。
+
+如果发现查询语句不满足语法规则,则会报错。如lucene NOT AND learned,则会出错。
+
+如上述例子,lucene AND learned NOT hadoop形成的语法树如下:
+
+[](https://link.juejin.im/?target=http%3A%2F%2Fimages.cnblogs.com%2Fcnblogs_com%2Fforfuture1978%2FWindowsLiveWriter%2F185c4e9316f3_147FA%2F%25E8%25AF%25AD%25E6%25B3%2595%25E6%25A0%2591_2.jpg)
+
+3\. 语言处理同索引过程中的语言处理几乎相同。
+
+如learned变成learn等。
+
+经过第二步,我们得到一棵经过语言处理的语法树。
+
+[](https://link.juejin.im/?target=http%3A%2F%2Fimages.cnblogs.com%2Fcnblogs_com%2Fforfuture1978%2FWindowsLiveWriter%2F185c4e9316f3_147FA%2F%25E8%25AF%25AD%25E6%25B3%2595%25E6%25A0%25911_2.jpg)
+
+### 第三步:搜索索引,得到符合语法树的文档。
+
+此步骤有分几小步:
+
+1. 首先,在反向索引表中,分别找出包含lucene,learn,hadoop的文档链表。
+2. 其次,对包含lucene,learn的链表进行合并操作,得到既包含lucene又包含learn的文档链表。
+3. 然后,将此链表与hadoop的文档链表进行差操作,去除包含hadoop的文档,从而得到既包含lucene又包含learn而且不包含hadoop的文档链表。
+4. 此文档链表就是我们要找的文档。
+
+### 第四步:根据得到的文档和查询语句的相关性,对结果进行排序。
+
+虽然在上一步,我们得到了想要的文档,然而对于查询结果应该按照与查询语句的相关性进行排序,越相关者越靠前。
+
+如何计算文档和查询语句的相关性呢?
+
+不如我们把查询语句看作一片短小的文档,对文档与文档之间的相关性(relevance)进行打分(scoring),分数高的相关性好,就应该排在前面。
+
+那么又怎么对文档之间的关系进行打分呢?
+
+这可不是一件容易的事情,首先我们看一看判断人之间的关系吧。
+
+首先看一个人,往往有很多要素,如性格,信仰,爱好,衣着,高矮,胖瘦等等。
+
+其次对于人与人之间的关系,不同的要素重要性不同,性格,信仰,爱好可能重要些,衣着,高矮,胖瘦可能就不那么重要了,所以具有相同或相似性格,信仰,爱好的人比较容易成为好的朋友,然而衣着,高矮,胖瘦不同的人,也可以成为好的朋友。
+
+因而判断人与人之间的关系,首先要找出哪些要素对人与人之间的关系最重要,比如性格,信仰,爱好。其次要判断两个人的这些要素之间的关系,比如一个人性格开朗,另一个人性格外向,一个人信仰佛教,另一个信仰上帝,一个人爱好打篮球,另一个爱好踢足球。我们发现,两个人在性格方面都很积极,信仰方面都很善良,爱好方面都爱运动,因而两个人关系应该会很好。
+
+我们再来看看公司之间的关系吧。
+
+首先看一个公司,有很多人组成,如总经理,经理,首席技术官,普通员工,保安,门卫等。
+
+其次对于公司与公司之间的关系,不同的人重要性不同,总经理,经理,首席技术官可能更重要一些,普通员工,保安,门卫可能较不重要一点。所以如果两个公司总经理,经理,首席技术官之间关系比较好,两个公司容易有比较好的关系。然而一位普通员工就算与另一家公司的一位普通员工有血海深仇,怕也难影响两个公司之间的关系。
+
+因而判断公司与公司之间的关系,首先要找出哪些人对公司与公司之间的关系最重要,比如总经理,经理,首席技术官。其次要判断这些人之间的关系,不如两家公司的总经理曾经是同学,经理是老乡,首席技术官曾是创业伙伴。我们发现,两家公司无论总经理,经理,首席技术官,关系都很好,因而两家公司关系应该会很好。
+
+分析了两种关系,下面看一下如何判断文档之间的关系了。
+
+首先,一个文档有很多词(Term)组成,如search, lucene, full-text, this, a, what等。
+
+其次对于文档之间的关系,不同的Term重要性不同,比如对于本篇文档,search, Lucene, full-text就相对重要一些,this, a , what可能相对不重要一些。所以如果两篇文档都包含search, Lucene,fulltext,这两篇文档的相关性好一些,然而就算一篇文档包含this, a, what,另一篇文档不包含this, a, what,也不能影响两篇文档的相关性。
+
+因而判断文档之间的关系,首先找出哪些词(Term)对文档之间的关系最重要,如search, Lucene, fulltext。然后判断这些词(Term)之间的关系。
+
+找出词(Term)对文档的重要性的过程称为计算词的权重(Term weight)的过程。
+
+计算词的权重(term weight)有两个参数,第一个是词(Term),第二个是文档(Document)。
+
+词的权重(Term weight)表示此词(Term)在此文档中的重要程度,越重要的词(Term)有越大的权重(Term weight),因而在计算文档之间的相关性中将发挥更大的作用。
+
+判断词(Term)之间的关系从而得到文档相关性的过程应用一种叫做向量空间模型的算法(Vector Space Model)。
+
+下面仔细分析一下这两个过程:
+
+#### 1\. 计算权重(Term weight)的过程。
+
+影响一个词(Term)在一篇文档中的重要性主要有两个因素:
+
+* Term Frequency (tf):即此Term在此文档中出现了多少次。tf 越大说明越重要。
+* Document Frequency (df):即有多少文档包含次Term。df 越大说明越不重要。
+
+容易理解吗?词(Term)在文档中出现的次数越多,说明此词(Term)对该文档越重要,如“搜索”这个词,在本文档中出现的次数很多,说明本文档主要就是讲这方面的事的。然而在一篇英语文档中,this出现的次数更多,就说明越重要吗?不是的,这是由第二个因素进行调整,第二个因素说明,有越多的文档包含此词(Term), 说明此词(Term)太普通,不足以区分这些文档,因而重要性越低。
+
+这也如我们程序员所学的技术,对于程序员本身来说,这项技术掌握越深越好(掌握越深说明花时间看的越多,tf越大),找工作时越有竞争力。然而对于所有程序员来说,这项技术懂得的人越少越好(懂得的人少df小),找工作越有竞争力。人的价值在于不可替代性就是这个道理。
+
+道理明白了,我们来看看公式:
+
+[](https://link.juejin.im/?target=http%3A%2F%2Fimages.cnblogs.com%2Fcnblogs_com%2Fforfuture1978%2FWindowsLiveWriter%2F185c4e9316f3_147FA%2Fimage_6.png)
+
+[](https://link.juejin.im/?target=http%3A%2F%2Fimages.cnblogs.com%2Fcnblogs_com%2Fforfuture1978%2FWindowsLiveWriter%2F185c4e9316f3_147FA%2Fimage_4.png)
+
+这仅仅只term weight计算公式的简单典型实现。实现全文检索系统的人会有自己的实现,Lucene就与此稍有不同。
+
+#### 2\. 判断Term之间的关系从而得到文档相关性的过程,也即向量空间模型的算法(VSM)。
+
+我们把文档看作一系列词(Term),每一个词(Term)都有一个权重(Term weight),不同的词(Term)根据自己在文档中的权重来影响文档相关性的打分计算。
+
+于是我们把所有此文档中词(term)的权重(term weight) 看作一个向量。
+
+Document = {term1, term2, …… ,term N}
+
+Document Vector = {weight1, weight2, …… ,weight N}
+
+同样我们把查询语句看作一个简单的文档,也用向量来表示。
+
+Query = {term1, term 2, …… , term N}
+
+Query Vector = {weight1, weight2, …… , weight N}
+
+我们把所有搜索出的文档向量及查询向量放到一个N维空间中,每个词(term)是一维。
+
+如图:
+
+[](https://link.juejin.im/?target=http%3A%2F%2Fimages.cnblogs.com%2Fcnblogs_com%2Fforfuture1978%2FWindowsLiveWriter%2F185c4e9316f3_147FA%2Fvsm_2.jpg)
+
+我们认为两个向量之间的夹角越小,相关性越大。
+
+所以我们计算夹角的余弦值作为相关性的打分,夹角越小,余弦值越大,打分越高,相关性越大。
+
+有人可能会问,查询语句一般是很短的,包含的词(Term)是很少的,因而查询向量的维数很小,而文档很长,包含词(Term)很多,文档向量维数很大。你的图中两者维数怎么都是N呢?
+
+在这里,既然要放到相同的向量空间,自然维数是相同的,不同时,取二者的并集,如果不含某个词(Term)时,则权重(Term Weight)为0。
+
+相关性打分公式如下:
+
+[](https://link.juejin.im/?target=http%3A%2F%2Fimages.cnblogs.com%2Fcnblogs_com%2Fforfuture1978%2FWindowsLiveWriter%2F185c4e9316f3_147FA%2Fimage11.png)
+
+举个例子,查询语句有11个Term,共有三篇文档搜索出来。其中各自的权重(Term weight),如下表格。
+
+
+
+| | | | | | | | | | | t10 | t11 |
+| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
+| | | | .477 | | .477 | .176 | | | | .176 | |
+| | | .176 | | .477 | | | | | .954 | | .176 |
+| | | .176 | | | | .176 | | | | .176 | .176 |
+| | | | | | | .176 | | | .477 | | .176 |
+
+
+
+于是计算,三篇文档同查询语句的相关性打分分别为:
+
+[](https://link.juejin.im/?target=http%3A%2F%2Fimages.cnblogs.com%2Fcnblogs_com%2Fforfuture1978%2FWindowsLiveWriter%2F185c4e9316f3_147FA%2Fimage17.png)
+
+[](https://link.juejin.im/?target=http%3A%2F%2Fimages.cnblogs.com%2Fcnblogs_com%2Fforfuture1978%2FWindowsLiveWriter%2F185c4e9316f3_147FA%2Fimage20.png)
+
+[](https://link.juejin.im/?target=http%3A%2F%2Fimages.cnblogs.com%2Fcnblogs_com%2Fforfuture1978%2FWindowsLiveWriter%2F185c4e9316f3_147FA%2Fimage23.png)
+
+于是文档二相关性最高,先返回,其次是文档一,最后是文档三。
+
+到此为止,我们可以找到我们最想要的文档了。
+
+说了这么多,其实还没有进入到Lucene,而仅仅是信息检索技术(Information retrieval)中的基本理论,然而当我们看过Lucene后我们会发现,Lucene是对这种基本理论的一种基本的的实践。所以在以后分析Lucene的文章中,会常常看到以上理论在Lucene中的应用。
+
+在进入Lucene之前,对上述索引创建和搜索过程所一个总结,如图:
+
+此图参照[www.lucene.com.cn/about.htm](https://link.juejin.im/?target=http%3A%2F%2Fwww.lucene.com.cn%2Fabout.htm)中文章《开放源代码的全文检索引擎Lucene》
+
+[](https://link.juejin.im/?target=http%3A%2F%2Fimages.cnblogs.com%2Fcnblogs_com%2Fforfuture1978%2FWindowsLiveWriter%2F185c4e9316f3_147FA%2Fclip_image016_2.jpg)
+
+1\. 索引过程:
+
+1) 有一系列被索引文件
+
+2) 被索引文件经过语法分析和语言处理形成一系列词(Term)。
+
+3) 经过索引创建形成词典和反向索引表。
+
+4) 通过索引存储将索引写入硬盘。
+
+2\. 搜索过程:
+
+a) 用户输入查询语句。
+
+b) 对查询语句经过语法分析和语言分析得到一系列词(Term)。
+
+c) 通过语法分析得到一个查询树。
+
+d) 通过索引存储将索引读入到内存。
+
+e) 利用查询树搜索索引,从而得到每个词(Term)的文档链表,对文档链表进行交,差,并得到结果文档。
+
+f) 将搜索到的结果文档对查询的相关性进行排序。
+
+g) 返回查询结果给用户。
+
+下面我们可以进入Lucene的世界了。
+
+CSDN中此文章链接为[blog.csdn.net/forfuture19…](https://link.juejin.im/?target=http%3A%2F%2Fblog.csdn.net%2Fforfuture1978%2Farchive%2F2009%2F10%2F22%2F4711308.aspx)
+
+Javaeye中此文章链接为[forfuture1978.javaeye.com/blog/546771](https://link.juejin.im/?target=http%3A%2F%2Fforfuture1978.javaeye.com%2Fblog%2F546771)
+
+# Spring Boot 中使用 Java API 调用 lucene
+
+# Github 代码
+
+代码我已放到 Github ,导入`spring-boot-lucene-demo` 项目
+
+github [spring-boot-lucene-demo](https://link.juejin.im/?target=https%3A%2F%2Fgithub.com%2Fsouyunku%2Fspring-boot-examples%2Ftree%2Fmaster%2Fspring-boot-lucene-demo)
+
+## 添加依赖
+
+```
+ org.apache.lucene lucene-queryparser 7.1.0 org.apache.lucene lucene-highlighter 7.1.0 org.apache.lucene lucene-analyzers-smartcn 7.1.0 cn.bestwu ik-analyzers 5.1.0 com.chenlb.mmseg4j mmseg4j-solr 2.4.0 org.apache.solr solr-core
+```
+
+## 配置 lucene
+
+```
+private Directory directory; private IndexReader indexReader; private IndexSearcher indexSearcher; @Beforepublic void setUp() throws IOException { //索引存放的位置,设置在当前目录中 directory = FSDirectory.open(Paths.get("indexDir/")); //创建索引的读取器 indexReader = DirectoryReader.open(directory); //创建一个索引的查找器,来检索索引库 indexSearcher = new IndexSearcher(indexReader);} @Afterpublic void tearDown() throws Exception { indexReader.close();} ** * 执行查询,并打印查询到的记录数 * * @param query * @throws IOException */public void executeQuery(Query query) throws IOException { TopDocs topDocs = indexSearcher.search(query, 100); //打印查询到的记录数 System.out.println("总共查询到" + topDocs.totalHits + "个文档"); for (ScoreDoc scoreDoc : topDocs.scoreDocs) { //取得对应的文档对象 Document document = indexSearcher.doc(scoreDoc.doc); System.out.println("id:" + document.get("id")); System.out.println("title:" + document.get("title")); System.out.println("content:" + document.get("content")); }} /** * 分词打印 * * @param analyzer * @param text * @throws IOException */public void printAnalyzerDoc(Analyzer analyzer, String text) throws IOException { TokenStream tokenStream = analyzer.tokenStream("content", new StringReader(text)); CharTermAttribute charTermAttribute = tokenStream.addAttribute(CharTermAttribute.class); try { tokenStream.reset(); while (tokenStream.incrementToken()) { System.out.println(charTermAttribute.toString()); } tokenStream.end(); } finally { tokenStream.close(); analyzer.close(); }}
+```
+
+## 创建索引
+
+```
+@Testpublic void indexWriterTest() throws IOException { long start = System.currentTimeMillis(); //索引存放的位置,设置在当前目录中 Directory directory = FSDirectory.open(Paths.get("indexDir/")); //在 6.6 以上版本中 version 不再是必要的,并且,存在无参构造方法,可以直接使用默认的 StandardAnalyzer 分词器。 Version version = Version.LUCENE_7_1_0; //Analyzer analyzer = new StandardAnalyzer(); // 标准分词器,适用于英文 //Analyzer analyzer = new SmartChineseAnalyzer();//中文分词 //Analyzer analyzer = new ComplexAnalyzer();//中文分词 //Analyzer analyzer = new IKAnalyzer();//中文分词 Analyzer analyzer = new IKAnalyzer();//中文分词 //创建索引写入配置 IndexWriterConfig indexWriterConfig = new IndexWriterConfig(analyzer); //创建索引写入对象 IndexWriter indexWriter = new IndexWriter(directory, indexWriterConfig); //创建Document对象,存储索引 Document doc = new Document(); int id = 1; //将字段加入到doc中 doc.add(new IntPoint("id", id)); doc.add(new StringField("title", "Spark", Field.Store.YES)); doc.add(new TextField("content", "Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎", Field.Store.YES)); doc.add(new StoredField("id", id)); //将doc对象保存到索引库中 indexWriter.addDocument(doc); indexWriter.commit(); //关闭流 indexWriter.close(); long end = System.currentTimeMillis(); System.out.println("索引花费了" + (end - start) + " 毫秒");}
+```
+
+响应
+
+```
+17:58:14.655 [main] DEBUG org.wltea.analyzer.dic.Dictionary - 加载扩展词典:ext.dic17:58:14.660 [main] DEBUG org.wltea.analyzer.dic.Dictionary - 加载扩展停止词典:stopword.dic索引花费了879 毫秒
+```
+
+## 删除文档
+
+```
+@Testpublic void deleteDocumentsTest() throws IOException { //Analyzer analyzer = new StandardAnalyzer(); // 标准分词器,适用于英文 //Analyzer analyzer = new SmartChineseAnalyzer();//中文分词 //Analyzer analyzer = new ComplexAnalyzer();//中文分词 //Analyzer analyzer = new IKAnalyzer();//中文分词 Analyzer analyzer = new IKAnalyzer();//中文分词 //创建索引写入配置 IndexWriterConfig indexWriterConfig = new IndexWriterConfig(analyzer); //创建索引写入对象 IndexWriter indexWriter = new IndexWriter(directory, indexWriterConfig); // 删除title中含有关键词“Spark”的文档 long count = indexWriter.deleteDocuments(new Term("title", "Spark")); // 除此之外IndexWriter还提供了以下方法: // DeleteDocuments(Query query):根据Query条件来删除单个或多个Document // DeleteDocuments(Query[] queries):根据Query条件来删除单个或多个Document // DeleteDocuments(Term term):根据Term来删除单个或多个Document // DeleteDocuments(Term[] terms):根据Term来删除单个或多个Document // DeleteAll():删除所有的Document //使用IndexWriter进行Document删除操作时,文档并不会立即被删除,而是把这个删除动作缓存起来,当IndexWriter.Commit()或IndexWriter.Close()时,删除操作才会被真正执行。 indexWriter.commit(); indexWriter.close(); System.out.println("删除完成:" + count);}
+```
+
+响应
+
+```
+删除完成:1
+```
+
+## 更新文档
+
+```
+/** * 测试更新 * 实际上就是删除后新增一条 * * @throws IOException */@Testpublic void updateDocumentTest() throws IOException { //Analyzer analyzer = new StandardAnalyzer(); // 标准分词器,适用于英文 //Analyzer analyzer = new SmartChineseAnalyzer();//中文分词 //Analyzer analyzer = new ComplexAnalyzer();//中文分词 //Analyzer analyzer = new IKAnalyzer();//中文分词 Analyzer analyzer = new IKAnalyzer();//中文分词 //创建索引写入配置 IndexWriterConfig indexWriterConfig = new IndexWriterConfig(analyzer); //创建索引写入对象 IndexWriter indexWriter = new IndexWriter(directory, indexWriterConfig); Document doc = new Document(); int id = 1; doc.add(new IntPoint("id", id)); doc.add(new StringField("title", "Spark", Field.Store.YES)); doc.add(new TextField("content", "Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎", Field.Store.YES)); doc.add(new StoredField("id", id)); long count = indexWriter.updateDocument(new Term("id", "1"), doc); System.out.println("更新文档:" + count); indexWriter.close();}
+```
+
+响应
+
+```
+更新文档:1
+```
+
+## 按词条搜索
+
+```
+/** * 按词条搜索 *
* TermQuery是最简单、也是最常用的Query。TermQuery可以理解成为“词条搜索”, * 在搜索引擎中最基本的搜索就是在索引中搜索某一词条,而TermQuery就是用来完成这项工作的。 * 在Lucene中词条是最基本的搜索单位,从本质上来讲一个词条其实就是一个名/值对。 * 只不过这个“名”是字段名,而“值”则表示字段中所包含的某个关键字。 * * @throws IOException */@Testpublic void termQueryTest() throws IOException { String searchField = "title"; //这是一个条件查询的api,用于添加条件 TermQuery query = new TermQuery(new Term(searchField, "Spark")); //执行查询,并打印查询到的记录数 executeQuery(query);}
+```
+
+响应
+
+```
+总共查询到1个文档id:1title:Sparkcontent:Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎!
+```
+
+## 多条件查询
+
+```
+/** * 多条件查询 * * BooleanQuery也是实际开发过程中经常使用的一种Query。 * 它其实是一个组合的Query,在使用时可以把各种Query对象添加进去并标明它们之间的逻辑关系。 * BooleanQuery本身来讲是一个布尔子句的容器,它提供了专门的API方法往其中添加子句, * 并标明它们之间的关系,以下代码为BooleanQuery提供的用于添加子句的API接口: * * @throws IOException */@Testpublic void BooleanQueryTest() throws IOException { String searchField1 = "title"; String searchField2 = "content"; Query query1 = new TermQuery(new Term(searchField1, "Spark")); Query query2 = new TermQuery(new Term(searchField2, "Apache")); BooleanQuery.Builder builder = new BooleanQuery.Builder(); // BooleanClause用于表示布尔查询子句关系的类, // 包 括: // BooleanClause.Occur.MUST, // BooleanClause.Occur.MUST_NOT, // BooleanClause.Occur.SHOULD。 // 必须包含,不能包含,可以包含三种.有以下6种组合: // // 1.MUST和MUST:取得连个查询子句的交集。 // 2.MUST和MUST_NOT:表示查询结果中不能包含MUST_NOT所对应得查询子句的检索结果。 // 3.SHOULD与MUST_NOT:连用时,功能同MUST和MUST_NOT。 // 4.SHOULD与MUST连用时,结果为MUST子句的检索结果,但是SHOULD可影响排序。 // 5.SHOULD与SHOULD:表示“或”关系,最终检索结果为所有检索子句的并集。 // 6.MUST_NOT和MUST_NOT:无意义,检索无结果。 builder.add(query1, BooleanClause.Occur.SHOULD); builder.add(query2, BooleanClause.Occur.SHOULD); BooleanQuery query = builder.build(); //执行查询,并打印查询到的记录数 executeQuery(query);}
+```
+
+响应
+
+```
+总共查询到1个文档id:1title:Sparkcontent:Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎!
+```
+
+## 匹配前缀
+
+```
+/** * 匹配前缀 *
* PrefixQuery用于匹配其索引开始以指定的字符串的文档。就是文档中存在xxx% *
* * @throws IOException */@Testpublic void prefixQueryTest() throws IOException { String searchField = "title"; Term term = new Term(searchField, "Spar"); Query query = new PrefixQuery(term); //执行查询,并打印查询到的记录数 executeQuery(query);}
+```
+
+响应
+
+```
+总共查询到1个文档id:1title:Sparkcontent:Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎!
+```
+
+## 短语搜索
+
+```
+/** * 短语搜索 *
* 所谓PhraseQuery,就是通过短语来检索,比如我想查“big car”这个短语, * 那么如果待匹配的document的指定项里包含了"big car"这个短语, * 这个document就算匹配成功。可如果待匹配的句子里包含的是“big black car”, * 那么就无法匹配成功了,如果也想让这个匹配,就需要设定slop, * 先给出slop的概念:slop是指两个项的位置之间允许的最大间隔距离 * * @throws IOException */@Testpublic void phraseQueryTest() throws IOException { String searchField = "content"; String query1 = "apache"; String query2 = "spark"; PhraseQuery.Builder builder = new PhraseQuery.Builder(); builder.add(new Term(searchField, query1)); builder.add(new Term(searchField, query2)); builder.setSlop(0); PhraseQuery phraseQuery = builder.build(); //执行查询,并打印查询到的记录数 executeQuery(phraseQuery);}
+```
+
+响应
+
+```
+总共查询到1个文档id:1title:Sparkcontent:Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎!
+```
+
+## 相近词语搜索
+
+```
+/** * 相近词语搜索 *
* FuzzyQuery是一种模糊查询,它可以简单地识别两个相近的词语。 * * @throws IOException */@Testpublic void fuzzyQueryTest() throws IOException { String searchField = "content"; Term t = new Term(searchField, "大规模"); Query query = new FuzzyQuery(t); //执行查询,并打印查询到的记录数 executeQuery(query);}
+```
+
+响应
+
+```
+总共查询到1个文档id:1title:Sparkcontent:Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎!
+```
+
+## 通配符搜索
+
+```
+/** * 通配符搜索 *
* Lucene也提供了通配符的查询,这就是WildcardQuery。 * 通配符“?”代表1个字符,而“*”则代表0至多个字符。 * * @throws IOException */@Testpublic void wildcardQueryTest() throws IOException { String searchField = "content"; Term term = new Term(searchField, "大*规模"); Query query = new WildcardQuery(term); //执行查询,并打印查询到的记录数 executeQuery(query);}
+```
+
+响应
+
+```
+总共查询到1个文档id:1title:Sparkcontent:Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎!
+```
+
+## 分词查询
+
+```
+/** * 分词查询 * * @throws IOException * @throws ParseException */@Testpublic void queryParserTest() throws IOException, ParseException { //Analyzer analyzer = new StandardAnalyzer(); // 标准分词器,适用于英文 //Analyzer analyzer = new SmartChineseAnalyzer();//中文分词 //Analyzer analyzer = new ComplexAnalyzer();//中文分词 //Analyzer analyzer = new IKAnalyzer();//中文分词 Analyzer analyzer = new IKAnalyzer();//中文分词 String searchField = "content"; //指定搜索字段和分析器 QueryParser parser = new QueryParser(searchField, analyzer); //用户输入内容 Query query = parser.parse("计算引擎"); //执行查询,并打印查询到的记录数 executeQuery(query);}
+```
+
+响应
+
+```
+总共查询到1个文档id:1title:Sparkcontent:Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎!
+```
+
+## 多个 Field 分词查询
+
+```
+/** * 多个 Field 分词查询 * * @throws IOException * @throws ParseException */@Testpublic void multiFieldQueryParserTest() throws IOException, ParseException { //Analyzer analyzer = new StandardAnalyzer(); // 标准分词器,适用于英文 //Analyzer analyzer = new SmartChineseAnalyzer();//中文分词 //Analyzer analyzer = new ComplexAnalyzer();//中文分词 //Analyzer analyzer = new IKAnalyzer();//中文分词 Analyzer analyzer = new IKAnalyzer();//中文分词 String[] filedStr = new String[]{"title", "content"}; //指定搜索字段和分析器 QueryParser queryParser = new MultiFieldQueryParser(filedStr, analyzer); //用户输入内容 Query query = queryParser.parse("Spark"); //执行查询,并打印查询到的记录数 executeQuery(query);}
+```
+
+响应
+
+```
+总共查询到1个文档id:1title:Sparkcontent:Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎!
+```
+
+## 中文分词器
+
+```
+/** * IKAnalyzer 中文分词器 * SmartChineseAnalyzer smartcn分词器 需要lucene依赖 且和lucene版本同步 * * @throws IOException */@Testpublic void AnalyzerTest() throws IOException { //Analyzer analyzer = new StandardAnalyzer(); // 标准分词器,适用于英文 //Analyzer analyzer = new SmartChineseAnalyzer();//中文分词 //Analyzer analyzer = new ComplexAnalyzer();//中文分词 //Analyzer analyzer = new IKAnalyzer();//中文分词 Analyzer analyzer = null; String text = "Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎"; analyzer = new IKAnalyzer();//IKAnalyzer 中文分词 printAnalyzerDoc(analyzer, text); System.out.println(); analyzer = new ComplexAnalyzer();//MMSeg4j 中文分词 printAnalyzerDoc(analyzer, text); System.out.println(); analyzer = new SmartChineseAnalyzer();//Lucene 中文分词器 printAnalyzerDoc(analyzer, text);}
+```
+
+三种分词响应
+
+```
+apachespark专为大规模规模模数数据处理数据处理而设设计快速通用计算引擎
+```
+
+```
+apachespark是专为大规模数据处理而设计的快速通用的计算引擎
+```
+
+```
+apachspark是专为大规模数据处理而设计的快速通用的计算引擎
+```
+
+## 高亮处理
+
+```
+/** * 高亮处理 * * @throws IOException */@Testpublic void HighlighterTest() throws IOException, ParseException, InvalidTokenOffsetsException { //Analyzer analyzer = new StandardAnalyzer(); // 标准分词器,适用于英文 //Analyzer analyzer = new SmartChineseAnalyzer();//中文分词 //Analyzer analyzer = new ComplexAnalyzer();//中文分词 //Analyzer analyzer = new IKAnalyzer();//中文分词 Analyzer analyzer = new IKAnalyzer();//中文分词 String searchField = "content"; String text = "Apache Spark 大规模数据处理"; //指定搜索字段和分析器 QueryParser parser = new QueryParser(searchField, analyzer); //用户输入内容 Query query = parser.parse(text); TopDocs topDocs = indexSearcher.search(query, 100); // 关键字高亮显示的html标签,需要导入lucene-highlighter-xxx.jar SimpleHTMLFormatter simpleHTMLFormatter = new SimpleHTMLFormatter("", ""); Highlighter highlighter = new Highlighter(simpleHTMLFormatter, new QueryScorer(query)); for (ScoreDoc scoreDoc : topDocs.scoreDocs) { //取得对应的文档对象 Document document = indexSearcher.doc(scoreDoc.doc); // 内容增加高亮显示 TokenStream tokenStream = analyzer.tokenStream("content", new StringReader(document.get("content"))); String content = highlighter.getBestFragment(tokenStream, document.get("content")); System.out.println(content); } }
+```
+
+响应
+
+```
+Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎!
+```
+
+代码我已放到 Github ,导入`spring-boot-lucene-demo` 项目
+
+github [spring-boot-lucene-demo](https://link.juejin.im/?target=https%3A%2F%2Fgithub.com%2Fsouyunku%2Fspring-boot-examples%2Ftree%2Fmaster%2Fspring-boot-lucene-demo)
+
+* 作者:Peng Lei
+* 出处:[Segment Fault PengLei `Blog 专栏](https://link.juejin.im/?target=https%3A%2F%2Fsegmentfault.com%2Fa%2F1190000011916639)
+* 版权归作者所有,转载请注明出处
+
+
+
+
+
diff --git "a/docs/big-backEnd/\345\220\216\347\253\257\346\212\200\346\234\257\346\235\202\350\260\2104\357\274\232Elasticsearch\344\270\216solr\345\205\245\351\227\250\345\256\236\350\267\265.md" "b/docs/big-backEnd/\345\220\216\347\253\257\346\212\200\346\234\257\346\235\202\350\260\2104\357\274\232Elasticsearch\344\270\216solr\345\205\245\351\227\250\345\256\236\350\267\265.md"
new file mode 100644
index 0000000..d23a442
--- /dev/null
+++ "b/docs/big-backEnd/\345\220\216\347\253\257\346\212\200\346\234\257\346\235\202\350\260\2104\357\274\232Elasticsearch\344\270\216solr\345\205\245\351\227\250\345\256\236\350\267\265.md"
@@ -0,0 +1,940 @@
+# 阮一峰:全文搜索引擎 Elasticsearch 入门教程
+
+
+
+阅读 1093
+
+收藏 76
+
+2017-08-23
+
+
+
+原文链接:[www.ruanyifeng.com](https://link.juejin.im/?target=http%3A%2F%2Fwww.ruanyifeng.com%2Fblog%2F2017%2F08%2Felasticsearch.html)
+
+[9月7日-8日 北京,与 Google Twitch 等团队技术大咖面对面www.bagevent.com](https://www.bagevent.com/event/1291755?bag_track=juejin)
+
+
+
+[全文搜索](https://link.juejin.im/?target=https%3A%2F%2Fbaike.baidu.com%2Fitem%2F%25E5%2585%25A8%25E6%2596%2587%25E6%2590%259C%25E7%25B4%25A2%25E5%25BC%2595%25E6%2593%258E)属于最常见的需求,开源的 [Elasticsearch](https://link.juejin.im/?target=https%3A%2F%2Fwww.elastic.co%2F) (以下简称 Elastic)是目前全文搜索引擎的首选。
+
+它可以快速地储存、搜索和分析海量数据。维基百科、Stack Overflow、Github 都采用它。
+
+
+
+Elastic 的底层是开源库 [Lucene](https://link.juejin.im/?target=https%3A%2F%2Flucene.apache.org%2F)。但是,你没法直接用 Lucene,必须自己写代码去调用它的接口。Elastic 是 Lucene 的封装,提供了 REST API 的操作接口,开箱即用。
+
+本文从零开始,讲解如何使用 Elastic 搭建自己的全文搜索引擎。每一步都有详细的说明,大家跟着做就能学会。
+
+## 一、安装
+
+Elastic 需要 Java 8 环境。如果你的机器还没安装 Java,可以参考[这篇文章](https://link.juejin.im/?target=https%3A%2F%2Fwww.digitalocean.com%2Fcommunity%2Ftutorials%2Fhow-to-install-java-with-apt-get-on-debian-8),注意要保证环境变量`JAVA_HOME`正确设置。
+
+安装完 Java,就可以跟着[官方文档](https://link.juejin.im/?target=https%3A%2F%2Fwww.elastic.co%2Fguide%2Fen%2Felasticsearch%2Freference%2Fcurrent%2Fzip-targz.html)安装 Elastic。直接下载压缩包比较简单。
+
+> ```
+> $ wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.5.1.zip$ unzip elasticsearch-5.5.1.zip$ cd elasticsearch-5.5.1/
+> ```
+
+接着,进入解压后的目录,运行下面的命令,启动 Elastic。
+
+> ```
+> $ ./bin/elasticsearch
+> ```
+
+如果这时[报错](https://link.juejin.im/?target=https%3A%2F%2Fgithub.com%2Fspujadas%2Felk-docker%2Fissues%2F92)"max virtual memory areas vm.max_map_count [65530] is too low",要运行下面的命令。
+
+> ```
+> $ sudo sysctl -w vm.max_map_count=262144
+> ```
+
+如果一切正常,Elastic 就会在默认的9200端口运行。这时,打开另一个命令行窗口,请求该端口,会得到说明信息。
+
+> ```
+> $ curl localhost:9200 { "name" : "atntrTf", "cluster_name" : "elasticsearch", "cluster_uuid" : "tf9250XhQ6ee4h7YI11anA", "version" : { "number" : "5.5.1", "build_hash" : "19c13d0", "build_date" : "2017-07-18T20:44:24.823Z", "build_snapshot" : false, "lucene_version" : "6.6.0" }, "tagline" : "You Know, for Search"}
+> ```
+
+上面代码中,请求9200端口,Elastic 返回一个 JSON 对象,包含当前节点、集群、版本等信息。
+
+按下 Ctrl + C,Elastic 就会停止运行。
+
+默认情况下,Elastic 只允许本机访问,如果需要远程访问,可以修改 Elastic 安装目录的`config/elasticsearch.yml`文件,去掉`network.host`的注释,将它的值改成`0.0.0.0`,然后重新启动 Elastic。
+
+> ```
+> network.host: 0.0.0.0
+> ```
+
+上面代码中,设成`0.0.0.0`让任何人都可以访问。线上服务不要这样设置,要设成具体的 IP。
+
+## 二、基本概念
+
+### 2.1 Node 与 Cluster
+
+Elastic 本质上是一个分布式数据库,允许多台服务器协同工作,每台服务器可以运行多个 Elastic 实例。
+
+单个 Elastic 实例称为一个节点(node)。一组节点构成一个集群(cluster)。
+
+### 2.2 Index
+
+Elastic 会索引所有字段,经过处理后写入一个反向索引(Inverted Index)。查找数据的时候,直接查找该索引。
+
+所以,Elastic 数据管理的顶层单位就叫做 Index(索引)。它是单个数据库的同义词。每个 Index (即数据库)的名字必须是小写。
+
+下面的命令可以查看当前节点的所有 Index。
+
+> ```
+> $ curl -X GET 'http://localhost:9200/_cat/indices?v'
+> ```
+
+### 2.3 Document
+
+Index 里面单条的记录称为 Document(文档)。许多条 Document 构成了一个 Index。
+
+Document 使用 JSON 格式表示,下面是一个例子。
+
+> ```
+> { "user": "张三", "title": "工程师", "desc": "数据库管理"}
+> ```
+
+同一个 Index 里面的 Document,不要求有相同的结构(scheme),但是最好保持相同,这样有利于提高搜索效率。
+
+### 2.4 Type
+
+Document 可以分组,比如`weather`这个 Index 里面,可以按城市分组(北京和上海),也可以按气候分组(晴天和雨天)。这种分组就叫做 Type,它是虚拟的逻辑分组,用来过滤 Document。
+
+不同的 Type 应该有相似的结构(schema),举例来说,`id`字段不能在这个组是字符串,在另一个组是数值。这是与关系型数据库的表的[一个区别](https://link.juejin.im/?target=https%3A%2F%2Fwww.elastic.co%2Fguide%2Fen%2Felasticsearch%2Fguide%2Fcurrent%2Fmapping.html)。性质完全不同的数据(比如`products`和`logs`)应该存成两个 Index,而不是一个 Index 里面的两个 Type(虽然可以做到)。
+
+下面的命令可以列出每个 Index 所包含的 Type。
+
+> ```
+> $ curl 'localhost:9200/_mapping?pretty=true'
+> ```
+
+根据[规划](https://link.juejin.im/?target=https%3A%2F%2Fwww.elastic.co%2Fblog%2Findex-type-parent-child-join-now-future-in-elasticsearch),Elastic 6.x 版只允许每个 Index 包含一个 Type,7.x 版将会彻底移除 Type。
+
+## 三、新建和删除 Index
+
+新建 Index,可以直接向 Elastic 服务器发出 PUT 请求。下面的例子是新建一个名叫`weather`的 Index。
+
+> ```
+> $ curl -X PUT 'localhost:9200/weather'
+> ```
+
+服务器返回一个 JSON 对象,里面的`acknowledged`字段表示操作成功。
+
+> ```
+> { "acknowledged":true, "shards_acknowledged":true}
+> ```
+
+然后,我们发出 DELETE 请求,删除这个 Index。
+
+> ```
+> $ curl -X DELETE 'localhost:9200/weather'
+> ```
+
+## 四、中文分词设置
+
+首先,安装中文分词插件。这里使用的是 [ik](https://link.juejin.im/?target=https%3A%2F%2Fgithub.com%2Fmedcl%2Felasticsearch-analysis-ik%2F),也可以考虑其他插件(比如 [smartcn](https://link.juejin.im/?target=https%3A%2F%2Fwww.elastic.co%2Fguide%2Fen%2Felasticsearch%2Fplugins%2Fcurrent%2Fanalysis-smartcn.html))。
+
+> ```
+> $ ./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v5.5.1/elasticsearch-analysis-ik-5.5.1.zip
+> ```
+
+上面代码安装的是5.5.1版的插件,与 Elastic 5.5.1 配合使用。
+
+接着,重新启动 Elastic,就会自动加载这个新安装的插件。
+
+然后,新建一个 Index,指定需要分词的字段。这一步根据数据结构而异,下面的命令只针对本文。基本上,凡是需要搜索的中文字段,都要单独设置一下。
+
+> ```
+> $ curl -X PUT 'localhost:9200/accounts' -d '{ "mappings": { "person": { "properties": { "user": { "type": "text", "analyzer": "ik_max_word", "search_analyzer": "ik_max_word" }, "title": { "type": "text", "analyzer": "ik_max_word", "search_analyzer": "ik_max_word" }, "desc": { "type": "text", "analyzer": "ik_max_word", "search_analyzer": "ik_max_word" } } } }}'
+> ```
+
+上面代码中,首先新建一个名称为`accounts`的 Index,里面有一个名称为`person`的 Type。`person`有三个字段。
+
+> * user
+> * title
+> * desc
+
+这三个字段都是中文,而且类型都是文本(text),所以需要指定中文分词器,不能使用默认的英文分词器。
+
+Elastic 的分词器称为 [analyzer](https://link.juejin.im/?target=https%3A%2F%2Fwww.elastic.co%2Fguide%2Fen%2Felasticsearch%2Freference%2Fcurrent%2Fanalysis.html)。我们对每个字段指定分词器。
+
+> ```
+> "user": { "type": "text", "analyzer": "ik_max_word", "search_analyzer": "ik_max_word"}
+> ```
+
+上面代码中,`analyzer`是字段文本的分词器,`search_analyzer`是搜索词的分词器。`ik_max_word`分词器是插件`ik`提供的,可以对文本进行最大数量的分词。
+
+## 五、数据操作
+
+### 5.1 新增记录
+
+向指定的 /Index/Type 发送 PUT 请求,就可以在 Index 里面新增一条记录。比如,向`/accounts/person`发送请求,就可以新增一条人员记录。
+
+> ```
+> $ curl -X PUT 'localhost:9200/accounts/person/1' -d '{ "user": "张三", "title": "工程师", "desc": "数据库管理"}'
+> ```
+
+服务器返回的 JSON 对象,会给出 Index、Type、Id、Version 等信息。
+
+> ```
+> { "_index":"accounts", "_type":"person", "_id":"1", "_version":1, "result":"created", "_shards":{"total":2,"successful":1,"failed":0}, "created":true}
+> ```
+
+如果你仔细看,会发现请求路径是`/accounts/person/1`,最后的`1`是该条记录的 Id。它不一定是数字,任意字符串(比如`abc`)都可以。
+
+新增记录的时候,也可以不指定 Id,这时要改成 POST 请求。
+
+> ```
+> $ curl -X POST 'localhost:9200/accounts/person' -d '{ "user": "李四", "title": "工程师", "desc": "系统管理"}'
+> ```
+
+上面代码中,向`/accounts/person`发出一个 POST 请求,添加一个记录。这时,服务器返回的 JSON 对象里面,`_id`字段就是一个随机字符串。
+
+> ```
+> { "_index":"accounts", "_type":"person", "_id":"AV3qGfrC6jMbsbXb6k1p", "_version":1, "result":"created", "_shards":{"total":2,"successful":1,"failed":0}, "created":true}
+> ```
+
+注意,如果没有先创建 Index(这个例子是`accounts`),直接执行上面的命令,Elastic 也不会报错,而是直接生成指定的 Index。所以,打字的时候要小心,不要写错 Index 的名称。
+
+### 5.2 查看记录
+
+向`/Index/Type/Id`发出 GET 请求,就可以查看这条记录。
+
+> ```
+> $ curl 'localhost:9200/accounts/person/1?pretty=true'
+> ```
+
+上面代码请求查看`/accounts/person/1`这条记录,URL 的参数`pretty=true`表示以易读的格式返回。
+
+返回的数据中,`found`字段表示查询成功,`_source`字段返回原始记录。
+
+> ```
+> { "_index" : "accounts", "_type" : "person", "_id" : "1", "_version" : 1, "found" : true, "_source" : { "user" : "张三", "title" : "工程师", "desc" : "数据库管理" }}
+> ```
+
+如果 Id 不正确,就查不到数据,`found`字段就是`false`。
+
+> ```
+> $ curl 'localhost:9200/weather/beijing/abc?pretty=true' { "_index" : "accounts", "_type" : "person", "_id" : "abc", "found" : false}
+> ```
+
+### 5.3 删除记录
+
+删除记录就是发出 DELETE 请求。
+
+> ```
+> $ curl -X DELETE 'localhost:9200/accounts/person/1'
+> ```
+
+这里先不要删除这条记录,后面还要用到。
+
+### 5.4 更新记录
+
+更新记录就是使用 PUT 请求,重新发送一次数据。
+
+> ```
+> $ curl -X PUT 'localhost:9200/accounts/person/1' -d '{ "user" : "张三", "title" : "工程师", "desc" : "数据库管理,软件开发"}' { "_index":"accounts", "_type":"person", "_id":"1", "_version":2, "result":"updated", "_shards":{"total":2,"successful":1,"failed":0}, "created":false}
+> ```
+
+上面代码中,我们将原始数据从"数据库管理"改成"数据库管理,软件开发"。 返回结果里面,有几个字段发生了变化。
+
+> ```
+> "_version" : 2,"result" : "updated","created" : false
+> ```
+
+可以看到,记录的 Id 没变,但是版本(version)从`1`变成`2`,操作类型(result)从`created`变成`updated`,`created`字段变成`false`,因为这次不是新建记录。
+
+## 六、数据查询
+
+### 6.1 返回所有记录
+
+使用 GET 方法,直接请求`/Index/Type/_search`,就会返回所有记录。
+
+> ```
+> $ curl 'localhost:9200/accounts/person/_search' { "took":2, "timed_out":false, "_shards":{"total":5,"successful":5,"failed":0}, "hits":{ "total":2, "max_score":1.0, "hits":[ { "_index":"accounts", "_type":"person", "_id":"AV3qGfrC6jMbsbXb6k1p", "_score":1.0, "_source": { "user": "李四", "title": "工程师", "desc": "系统管理" } }, { "_index":"accounts", "_type":"person", "_id":"1", "_score":1.0, "_source": { "user" : "张三", "title" : "工程师", "desc" : "数据库管理,软件开发" } } ] }}
+> ```
+
+上面代码中,返回结果的 `took`字段表示该操作的耗时(单位为毫秒),`timed_out`字段表示是否超时,`hits`字段表示命中的记录,里面子字段的含义如下。
+
+> * `total`:返回记录数,本例是2条。
+> * `max_score`:最高的匹配程度,本例是`1.0`。
+> * `hits`:返回的记录组成的数组。
+
+返回的记录中,每条记录都有一个`_score`字段,表示匹配的程序,默认是按照这个字段降序排列。
+
+### 6.2 全文搜索
+
+Elastic 的查询非常特别,使用自己的[查询语法](https://link.juejin.im/?target=https%3A%2F%2Fwww.elastic.co%2Fguide%2Fen%2Felasticsearch%2Freference%2F5.5%2Fquery-dsl.html),要求 GET 请求带有数据体。
+
+> ```
+> $ curl 'localhost:9200/accounts/person/_search' -d '{ "query" : { "match" : { "desc" : "软件" }}}'
+> ```
+
+上面代码使用 [Match 查询](https://link.juejin.im/?target=https%3A%2F%2Fwww.elastic.co%2Fguide%2Fen%2Felasticsearch%2Freference%2F5.5%2Fquery-dsl-match-query.html),指定的匹配条件是`desc`字段里面包含"软件"这个词。返回结果如下。
+
+> ```
+> { "took":3, "timed_out":false, "_shards":{"total":5,"successful":5,"failed":0}, "hits":{ "total":1, "max_score":0.28582606, "hits":[ { "_index":"accounts", "_type":"person", "_id":"1", "_score":0.28582606, "_source": { "user" : "张三", "title" : "工程师", "desc" : "数据库管理,软件开发" } } ] }}
+> ```
+
+Elastic 默认一次返回10条结果,可以通过`size`字段改变这个设置。
+
+> ```
+> $ curl 'localhost:9200/accounts/person/_search' -d '{ "query" : { "match" : { "desc" : "管理" }}, "size": 1}'
+> ```
+
+上面代码指定,每次只返回一条结果。
+
+还可以通过`from`字段,指定位移。
+
+> ```
+> $ curl 'localhost:9200/accounts/person/_search' -d '{ "query" : { "match" : { "desc" : "管理" }}, "from": 1, "size": 1}'
+> ```
+
+上面代码指定,从位置1开始(默认是从位置0开始),只返回一条结果。
+
+### 6.3 逻辑运算
+
+如果有多个搜索关键字, Elastic 认为它们是`or`关系。
+
+> ```
+> $ curl 'localhost:9200/accounts/person/_search' -d '{ "query" : { "match" : { "desc" : "软件 系统" }}}'
+> ```
+
+上面代码搜索的是`软件 or 系统`。
+
+如果要执行多个关键词的`and`搜索,必须使用[布尔查询](https://link.juejin.im/?target=https%3A%2F%2Fwww.elastic.co%2Fguide%2Fen%2Felasticsearch%2Freference%2F5.5%2Fquery-dsl-bool-query.html)。
+
+> ```
+> $ curl 'localhost:9200/accounts/person/_search' -d '{ "query": { "bool": { "must": [ { "match": { "desc": "软件" } }, { "match": { "desc": "系统" } } ] } }}'
+> ```
+
+## 七、参考链接
+
+* [ElasticSearch 官方手册](https://link.juejin.im/?target=https%3A%2F%2Fwww.elastic.co%2Fguide%2Fen%2Felasticsearch%2Freference%2Fcurrent%2Fgetting-started.html)
+* [A Practical Introduction to Elasticsearch](https://link.juejin.im/?target=https%3A%2F%2Fwww.elastic.co%2Fblog%2Fa-practical-introduction-to-elasticsearch)
+
+(完)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+#### 一、前言
+
+在开发网站/App项目的时候,通常需要搭建搜索服务。比如,新闻类应用需要检索标题/内容,社区类应用需要检索用户/帖子。
+
+对于简单的需求,可以使用数据库的 LIKE 模糊搜索,示例:
+
+> SELECT * FROM news WHERE title LIKE '%法拉利跑车%'
+
+可以查询到所有标题含有 "法拉利跑车" 关键词的新闻,但是这种方式有明显的弊端:
+
+> 1、模糊查询性能极低,当数据量庞大的时候,往往会使数据库服务中断;
+>
+> 2、无法查询相关的数据,只能严格在标题中匹配关键词。
+
+因此,需要搭建专门提供搜索功能的服务,具备分词、全文检索等高级功能。 Solr 就是这样一款搜索引擎,可以让你快速搭建适用于自己业务的搜索服务。
+
+#### 二、安装
+
+到官网 [http://lucene.apache.org/solr/](https://link.jianshu.com/?t=http://lucene.apache.org/solr/) 下载安装包,解压并进入 Solr 目录:
+
+> wget 'http://apache.website-solution.net/lucene/solr/6.2.0/solr-6.2.0.tgz'
+>
+> tar xvf solr-6.2.0.tgz
+>
+> cd solr-6.2.0
+
+目录结构如下:
+
+
+
+
+
+
+
+
+
+Solr 6.2 目录结构
+
+
+
+启动 Solr 服务之前,确认已经安装 Java 1.8 :
+
+
+
+
+
+
+
+
+
+查看 Java 版本
+
+
+
+启动 Solr 服务:
+
+> ./bin/solr start -m 1g
+
+Solr 将默认监听 8983 端口,其中 -m 1g 指定分配给 JVM 的内存为 1 G。
+
+在浏览器中访问 Solr 管理后台:
+
+> http://127.0.0.1:8983/solr/#/
+
+
+
+
+
+
+
+
+
+Solr 管理后台
+
+
+
+创建 Solr 应用:
+
+> ./bin/solr create -c my_news
+
+可以在 solr-6.2.0/server/solr 目录下生成 my_news 文件夹,结构如下:
+
+
+
+
+
+
+
+
+
+my_news 目录结构
+
+
+
+同时,可以在管理后台看到 my_news:
+
+
+
+
+
+
+
+
+
+管理后台
+
+
+
+#### 三、创建索引
+
+我们将从 MySQL 数据库中导入数据到 Solr 并建立索引。
+
+首先,需要了解 Solr 中的两个概念: 字段(field) 和 字段类型(fieldType),配置示例如下:
+
+
+
+
+
+
+
+
+
+schema.xml 示例
+
+
+
+field 指定一个字段的名称、是否索引/存储和字段类型。
+
+fieldType 指定一个字段类型的名称以及在查询/索引的时候可能用到的分词插件。
+
+将 solr-6.2.0\server\solr\my_news\conf 目录下默认的配置文件 managed-schema 重命名为 schema.xml 并加入新的 fieldType:
+
+
+
+
+
+
+
+
+
+分词类型
+
+
+
+在 my_news 目录下创建 lib 目录,将用到的分词插件 ik-analyzer-solr5-5.x.jar 加到 lib 目录,结构如下:
+
+
+
+
+
+
+
+
+
+my_news 目录结构
+
+
+
+在 Solr 安装目录下重启服务:
+
+> ./bin/solr restart
+
+可以在管理后台看到新加的类型:
+
+
+
+
+
+
+
+
+
+text_ik 类型
+
+
+
+接下来创建和我们数据库字段对应的 field:title 和 content,类型选为 text_ik:
+
+
+
+
+
+
+
+
+
+新建字段 title
+
+
+
+将要导入数据的 MySQL 数据库表结构:
+
+
+
+
+
+
+
+
+
+
+
+编辑 conf/solrconfig.xml 文件,加入类库和数据库配置:
+
+
+
+
+
+
+
+
+
+类库
+
+
+
+
+
+
+
+
+
+
+
+dataimport config
+
+
+
+同时新建数据库连接配置文件 conf/db-mysql-config.xml ,内容如下:
+
+
+
+
+
+
+
+
+
+数据库配置文件
+
+
+
+将数据库连接组件 mysql-connector-java-5.1.39-bin.jar 放到 lib 目录下,重启 Solr,访问管理后台,执行全量导入数据:
+
+
+
+
+
+
+
+
+
+全量导入数据
+
+
+
+创建定时更新脚本:
+
+
+
+
+
+
+
+
+
+定时更新脚本
+
+
+
+加入到定时任务,每5分钟增量更新一次索引:
+
+
+
+
+
+
+
+
+
+定时任务
+
+
+
+在 Solr 管理后台测试搜索结果:
+
+
+
+
+
+
+
+
+
+分词搜索结果
+
+
+
+至此,基本的搜索引擎搭建完毕,外部应用只需通过 http 协议提供查询参数,就可以获取搜索结果。
+
+#### 四、搜索干预
+
+通常需要对搜索结果进行人工干预,比如编辑推荐、竞价排名或者屏蔽搜索结果。Solr 已经内置了 QueryElevationComponent 插件,可以从配置文件中获取搜索关键词对应的干预列表,并将干预结果排在搜索结果的前面。
+
+在 solrconfig.xml 文件中,可以看到:
+
+
+
+
+
+
+
+
+
+干预其请求配置
+
+
+
+定义了搜索组件 elevator,应用在 /elevate 的搜索请求中,干预结果的配置文件在 solrconfig.xml 同目录下的 elevate.xml 中,干预配置示例:
+
+
+
+
+
+
+
+
+
+
+
+重启 Solr ,当搜索 "关键词" 的时候,id 为 1和 4 的文档将出现在前面,同时 id = 3 的文档被排除在结果之外,可以看到,没有干预的时候,搜索结果为:
+
+
+
+
+
+
+
+
+
+无干预结果
+
+
+
+当有搜索干预的时候:
+
+
+
+
+
+
+
+
+
+干预结果
+
+
+
+通过配置文件干预搜索结果,虽然简单,但是每次更新都要重启 Solr 才能生效,稍显麻烦,我们可以仿照 QueryElevationComponent 类,开发自己的干预组件,例如:从 Redis 中读取干预配置。
+
+#### 五、中文分词
+
+中文的搜索质量,和分词的效果息息相关,可以在 Solr 管理后台测试分词:
+
+
+
+
+
+
+
+
+
+分词结果测试
+
+
+
+上例可以看到,使用 [IKAnalyzer](https://blog.csdn.net/a724888/article/details/80993677) 分词插件,对 “北京科技大学” 分词的测试结果。当用户搜索 “北京”、“科技大学”、“科技大”、“科技”、“大学” 这些关键词的时候,都会搜索到文本内容含 “北京科技大学” 的文档。
+
+常用的中文分词插件有 IKAnalyzer、mmseg4j和 Solr 自带的 smartcn 等,分词效果各有优劣,具体选择哪个,可以根据自己的业务场景,分别测试效果再选择。
+
+分词插件一般都有自己的默认词库和扩展词库,默认词库包含了绝大多数常用的中文词语。如果默认词库无法满足你的需求,比如某些专业领域的词汇,可以在扩展词库中手动添加,这样分词插件就能识别新词语了。
+
+
+
+
+
+
+
+
+
+分词插件扩展词库配置示例
+
+
+
+分词插件还可以指定停止词库,将某些无意义的词汇剔出分词结果,比如:“的”、“哼” 等,例如:
+
+
+
+
+
+
+
+
+
+去除无意义的词
+
+
+
+#### 六、总结
+
+以上介绍了 Solr 最常用的一些功能,Solr 本身还有很多其他丰富的功能,比如分布式部署。
+
+希望对你有所帮助。
+
+#### 七、附录
+
+1、参考资料:
+
+[https://wiki.apache.org/solr/](https://link.jianshu.com/?t=https://wiki.apache.org/solr/)
+
+[http://lucene.apache.org/solr/quickstart.html](https://link.jianshu.com/?t=http://lucene.apache.org/solr/quickstart.html)
+
+[https://cwiki.apache.org/confluence/display/solr/Apache+Solr+Reference+Guide](https://link.jianshu.com/?t=https://cwiki.apache.org/confluence/display/solr/Apache+Solr+Reference+Guide)
+
+2、上述 Demo 中用到的所有配置文件、Jar 包:
+
+[https://github.com/Ceelog/OpenSchool/blob/master/my_news.zip](https://link.jianshu.com/?t=https://github.com/Ceelog/OpenSchool/blob/master/my_news.zip)
+
+3、还有疑问?联系作者微博/微信 [@Ceelog](https://link.jianshu.com/?t=http://weibo.com/ceelog/)
+
+
+
+# 搜索引擎选型整理:Elasticsearch vs Solr
+
+
+
+> 本文首发于[我的博客](https://link.juejin.im/?target=https%3A%2F%2Fblog.kittypanic.com%2F)
+> 原文链接:[Elasticsearch 与 Solr 的比较](https://link.juejin.im/?target=https%3A%2F%2Fblog.kittypanic.com%2Felastic_vs_solr%2F)
+
+## Elasticsearch简介[*](https://link.juejin.im/?target=http%3A%2F%2Ffuxiaopang.gitbooks.io%2Flearnelasticsearch)
+
+Elasticsearch是一个实时的分布式搜索和分析引擎。它可以帮助你用前所未有的速度去处理大规模数据。
+
+它可以用于全文搜索,结构化搜索以及分析,当然你也可以将这三者进行组合。
+
+Elasticsearch是一个建立在全文搜索引擎 Apache Lucene(TM) 基础上的搜索引擎,可以说Lucene是当今最先进,最高效的全功能开源搜索引擎框架。
+
+但是Lucene只是一个框架,要充分利用它的功能,需要使用JAVA,并且在程序中集成Lucene。需要很多的学习了解,才能明白它是如何运行的,Lucene确实非常复杂。
+
+Elasticsearch使用Lucene作为内部引擎,但是在使用它做全文搜索时,只需要使用统一开发好的API即可,而不需要了解其背后复杂的Lucene的运行原理。
+
+当然Elasticsearch并不仅仅是Lucene这么简单,它不但包括了全文搜索功能,还可以进行以下工作:
+
+* 分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索。
+
+* 实时分析的分布式搜索引擎。
+
+* 可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。
+
+这么多的功能被集成到一台服务器上,你可以轻松地通过客户端或者任何你喜欢的程序语言与ES的RESTful API进行交流。
+
+Elasticsearch的上手是非常简单的。它附带了很多非常合理的默认值,这让初学者很好地避免一上手就要面对复杂的理论,
+
+它安装好了就可以使用了,用很小的学习成本就可以变得很有生产力。
+
+随着越学越深入,还可以利用Elasticsearch更多高级的功能,整个引擎可以很灵活地进行配置。可以根据自身需求来定制属于自己的Elasticsearch。
+
+使用案例:
+
+* 维基百科使用Elasticsearch来进行全文搜做并高亮显示关键词,以及提供search-as-you-type、did-you-mean等搜索建议功能。
+
+* 英国卫报使用Elasticsearch来处理访客日志,以便能将公众对不同文章的反应实时地反馈给各位编辑。
+
+* StackOverflow将全文搜索与地理位置和相关信息进行结合,以提供more-like-this相关问题的展现。
+
+* GitHub使用Elasticsearch来检索超过1300亿行代码。
+
+* 每天,Goldman Sachs使用它来处理5TB数据的索引,还有很多投行使用它来分析股票市场的变动。
+
+但是Elasticsearch并不只是面向大型企业的,它还帮助了很多类似DataDog以及Klout的创业公司进行了功能的扩展。
+
+## Elasticsearch的优缺点[*](https://link.juejin.im/?target=http%3A%2F%2Fstackoverflow.com%2Fquestions%2F10213009%2Fsolr-vs-elasticsearch)[*](https://link.juejin.im/?target=http%3A%2F%2Fhuangx.in%2F22%2Ftranslation-solr-vs-elasticsearch):
+
+### 优点
+
+1. Elasticsearch是分布式的。不需要其他组件,分发是实时的,被叫做"Push replication"。
+
+* Elasticsearch 完全支持 Apache Lucene 的接近实时的搜索。
+* 处理多租户([multitenancy](https://link.juejin.im/?target=http%3A%2F%2Fen.wikipedia.org%2Fwiki%2FMultitenancy))不需要特殊配置,而Solr则需要更多的高级设置。
+* Elasticsearch 采用 Gateway 的概念,使得完备份更加简单。
+* 各节点组成对等的网络结构,某些节点出现故障时会自动分配其他节点代替其进行工作。
+
+### 缺点
+
+1. 只有一名开发者(当前Elasticsearch GitHub组织已经不只如此,已经有了相当活跃的维护者)
+
+* 还不够自动(不适合当前新的Index Warmup API)
+
+## Solr简介[*](https://link.juejin.im/?target=http%3A%2F%2Fzh.wikipedia.org%2Fwiki%2FSolr)
+
+Solr(读作“solar”)是Apache Lucene项目的开源企业搜索平台。其主要功能包括全文检索、命中标示、分面搜索、动态聚类、数据库集成,以及富文本(如Word、PDF)的处理。Solr是高度可扩展的,并提供了分布式搜索和索引复制。Solr是最流行的企业级搜索引擎,Solr4 还增加了NoSQL支持。
+
+Solr是用Java编写、运行在Servlet容器(如 Apache Tomcat 或Jetty)的一个独立的全文搜索服务器。 Solr采用了 Lucene Java 搜索库为核心的全文索引和搜索,并具有类似REST的HTTP/XML和JSON的API。Solr强大的外部配置功能使得无需进行Java编码,便可对其进行调整以适应多种类型的应用程序。Solr有一个插件架构,以支持更多的高级定制。
+
+因为2010年 Apache Lucene 和 Apache Solr 项目合并,两个项目是由同一个Apache软件基金会开发团队制作实现的。提到技术或产品时,Lucene/Solr或Solr/Lucene是一样的。
+
+## Solr的优缺点
+
+### 优点
+
+1. Solr有一个更大、更成熟的用户、开发和贡献者社区。
+
+* 支持添加多种格式的索引,如:HTML、PDF、微软 Office 系列软件格式以及 JSON、XML、CSV 等纯文本格式。
+* Solr比较成熟、稳定。
+* 不考虑建索引的同时进行搜索,速度更快。
+
+### 缺点
+
+1. 建立索引时,搜索效率下降,实时索引搜索效率不高。
+
+## Elasticsearch与Solr的比较[*](https://link.juejin.im/?target=http%3A%2F%2Fblog.socialcast.com%2Frealtime-search-solr-vs-elasticsearch%2F)
+
+当单纯的对已有数据进行搜索时,Solr更快。
+
+Search Fesh Index While Idle
+
+当实时建立索引时, Solr会产生io阻塞,查询性能较差, Elasticsearch具有明显的优势。
+
+search_fresh_index_while_indexing
+
+随着数据量的增加,Solr的搜索效率会变得更低,而Elasticsearch却没有明显的变化。
+
+search_fresh_index_while_indexing
+
+综上所述,Solr的架构不适合实时搜索的应用。
+
+## 实际生产环境测试[*](https://link.juejin.im/?target=http%3A%2F%2Fblog.socialcast.com%2Frealtime-search-solr-vs-elasticsearch%2F)
+
+下图为将搜索引擎从Solr转到Elasticsearch以后的平均查询速度有了50倍的提升。
+
+average_execution_time
+
+## Elasticsearch 与 Solr 的比较总结
+
+* 二者安装都很简单;
+
+* Solr 利用 Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布式协调管理功能;
+* Solr 支持更多格式的数据,而 Elasticsearch 仅支持json文件格式;
+* Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高级功能多有第三方插件提供;
+* Solr 在传统的搜索应用中表现好于 Elasticsearch,但在处理实时搜索应用时效率明显低于 Elasticsearch。
+
+Solr 是传统搜索应用的有力解决方案,但 Elasticsearch 更适用于新兴的实时搜索应用。
+
+## 其他基于Lucene的开源搜索引擎解决方案[*](https://link.juejin.im/?target=http%3A%2F%2Fmail-archives.apache.org%2Fmod_mbox%2Fhbase-user%2F201006.mbox%2F%253C149150.78881.qm%40web50304.mail.re2.yahoo.com%253E)
+
+1. 直接使用 [Lucene](https://link.juejin.im/?target=http%3A%2F%2Flucene.apache.org)
+
+ 说明:Lucene 是一个 JAVA 搜索类库,它本身并不是一个完整的解决方案,需要额外的开发工作。
+
+ 优点:成熟的解决方案,有很多的成功案例。apache 顶级项目,正在持续快速的进步。庞大而活跃的开发社区,大量的开发人员。它只是一个类库,有足够的定制和优化空间:经过简单定制,就可以满足绝大部分常见的需求;经过优化,可以支持 10亿+ 量级的搜索。
+
+ 缺点:需要额外的开发工作。所有的扩展,分布式,可靠性等都需要自己实现;非实时,从建索引到可以搜索中间有一个时间延迟,而当前的“近实时”(Lucene Near Real Time search)搜索方案的可扩展性有待进一步完善
+
+* [Katta](https://link.juejin.im/?target=http%3A%2F%2Fkatta.sourceforge.net)
+
+ 说明:基于 Lucene 的,支持分布式,可扩展,具有容错功能,准实时的搜索方案。
+
+ 优点:开箱即用,可以与 Hadoop 配合实现分布式。具备扩展和容错机制。
+
+ 缺点:只是搜索方案,建索引部分还是需要自己实现。在搜索功能上,只实现了最基本的需求。成功案例较少,项目的成熟度稍微差一些。因为需要支持分布式,对于一些复杂的查询需求,定制的难度会比较大。
+
+* [Hadoop contrib/index](https://link.juejin.im/?target=http%3A%2F%2Fsvn.apache.org%2Frepos%2Fasf%2Fhadoop%2Fmapreduce%2Ftrunk%2Fsrc%2Fcontrib%2Findex%2FREADME)
+
+ 说明:Map/Reduce 模式的,分布式建索引方案,可以跟 Katta 配合使用。
+
+ 优点:分布式建索引,具备可扩展性。
+
+ 缺点:只是建索引方案,不包括搜索实现。工作在批处理模式,对实时搜索的支持不佳。
+
+* [LinkedIn 的开源方案](https://link.juejin.im/?target=http%3A%2F%2Fsna-projects.com)
+
+ 说明:基于 Lucene 的一系列解决方案,包括 准实时搜索 zoie ,facet 搜索实现 bobo ,机器学习算法 decomposer ,摘要存储库 krati ,数据库模式包装 sensei 等等
+
+ 优点:经过验证的解决方案,支持分布式,可扩展,丰富的功能实现
+
+ 缺点:与 linkedin 公司的联系太紧密,可定制性比较差
+
+* [Lucandra](https://link.juejin.im/?target=https%3A%2F%2Fgithub.com%2Ftjake%2FLucandra)
+
+ 说明:基于 Lucene,索引存在 cassandra 数据库中
+
+ 优点:参考 cassandra 的优点
+
+ 缺点:参考 cassandra 的缺点。另外,这只是一个 demo,没有经过大量验证
+
+* [HBasene](https://link.juejin.im/?target=https%3A%2F%2Fgithub.com%2Fakkumar%2Fhbasene)
+
+ 说明:基于 Lucene,索引存在 HBase 数据库中
+
+ 优点:参考 HBase 的优点
+
+ 缺点:参考 HBase 的缺点。另外,在实现中,lucene terms 是存成行,但每个 term 对应的 posting lists 是以列的方式存储的。随着单个 term 的 posting lists 的增大,查询时的速度受到的影响会非常大
+
+
+
+
+
diff --git "a/docs/big-backEnd/\345\220\216\347\253\257\346\212\200\346\234\257\346\235\202\350\260\2105\357\274\232\344\272\221\350\256\241\347\256\227\347\232\204\345\211\215\344\270\226\344\273\212\347\224\237.md" "b/docs/big-backEnd/\345\220\216\347\253\257\346\212\200\346\234\257\346\235\202\350\260\2105\357\274\232\344\272\221\350\256\241\347\256\227\347\232\204\345\211\215\344\270\226\344\273\212\347\224\237.md"
new file mode 100644
index 0000000..e6bd69e
--- /dev/null
+++ "b/docs/big-backEnd/\345\220\216\347\253\257\346\212\200\346\234\257\346\235\202\350\260\2105\357\274\232\344\272\221\350\256\241\347\256\227\347\232\204\345\211\215\344\270\226\344\273\212\347\224\237.md"
@@ -0,0 +1,309 @@
+**作者简介:**刘超,[网易云](https://www.163yun.com/product-cloudcompute?tag=M_smf_1190000008091499)解决方案首席架构师。10年云计算领域研发及架构经验,Open DC/OS贡献者。长期专注于kubernetes, OpenStack、Hadoop、Docker、Lucene、Mesos等开源软件的企业级应用及产品化。曾出版《Lucene应用开发揭秘》。
+
+**以下为正文:**
+
+# 云计算概述
+
+云计算主要解决了四个方面的内容:计算,网络,存储,应用。
+
+计算就是CPU和内存,例如“1+1”这个最简单的算法就是把“1”放在内存里面,然后CPU做加法,返回的结果“2”又保存在内存里面。网络就是你插根网线能上网。存储就是你下个电影有地方放。本次讨论就是围绕这四个部分来讲的。其中,计算、网络、存储三个是IaaS层面,应用是PaaS层面。
+
+# 云计算发展脉络
+
+云计算整个发展过程,用一句话来形容,就是“分久必合,合久必分”。
+
+
+## 第一阶段:合,即物理设备
+
+### 物理设备简介
+
+在互联网发展初期,大家都爱用物理设备:
+
+1. 服务器用物理机,像戴尔、惠普、IBM、联想等物理服务器,随着硬件设备的进步,物理服务器越来越强大了,64核128G内存都算是普通配置;
+2. 网络用的是硬件交换机和路由器,例如思科的,华为的,从1GE到10GE,现在有40GE和100GE,带宽越来越牛;
+3. 存储方面有的用普通的磁盘,也有更快的SSD盘。容量从M,到G,连笔记本电脑都能配置到T,更何况磁盘阵列;
+
+### 物理设备的缺点
+
+部署应用直接使用物理机,看起来很爽,有种土豪的感觉,却有大大的缺点:
+
+1. 人工运维。如果你在一台服务器上安装软件,把系统安装坏了,怎么办?只有重装。当你想配置一下交换机的参数,需要串口连上去进行配置;当你想增加一块磁盘,要买一块插进服务器,这些都需要人工来,而且很大可能要求机房。你们公司在北五环,机房在南六环,这酸爽。
+2. 浪费资源。其实你只想部署一个小小的网站,却要用128G的内存。混着部署吧,就有隔离性的问题。
+3. 隔离性差。你把好多的应用部署在同一台物理机上,他们之间抢内存、抢cpu,一个写满了硬盘,另一个就没法用了,一个弄挂了内核,另一个也跟著挂了,如果部署两个相同的应用,端口还会冲突,动不动就会出错。
+
+## 第二阶段:分,即虚拟化
+
+### 虚拟化简介
+
+因为物理设备的以上缺点,就有了第一次“合久必分”的过程,叫做虚拟化。所谓虚拟化,就是把实的变成虚的:
+
+1. 物理机变为虚拟机。cpu是虚拟的,内存是虚拟的,内核是虚拟的,硬盘是虚拟的;
+2. 物理交换机变为虚拟交换机。网卡是虚拟的,交换机是虚拟的,带宽也是虚拟的;
+3. 物理存储变成虚拟存储。多块硬盘虚拟成一大块;
+
+### 虚拟化解决的问题
+
+虚拟化很好地解决了在物理设备阶段存在的三个问题:
+
+1. 人工运维。虚拟机的创建和删除都可以远程操作,虚拟机被玩坏了,删了再建一个分钟级别的。虚拟网络的配置也可以远程操作,创建网卡、分配带宽都是调用接口就能搞定的;
+2. 资源浪费。虚拟化了以后,资源可以分配地很小很小,比如1个cpu,1G内存,1M带宽,1G硬盘,都可以被虚拟出来;
+3. 隔离性差。每个虚拟机都有独立的cpu、 内存、硬盘、网卡,不同虚拟机之间的应用互不干扰;
+
+### 虚拟化时代的生态
+
+在虚拟化阶段,领跑者是Vmware,可以实现基本的计算、网络、存储的虚拟化。
+如同这个世界有闭源就有开源、有windows就有linux、有Apple就有Android一样,有Vmware,就有Xen和KVM。
+
+在开源虚拟化方面,Xen 的Citrix做的不错,后来Redhat在KVM发力不少;对于网络虚拟化,有Openvswitch,可以通过命令创建网桥、网卡、设置VLAN、设置带宽;对于存储虚拟化,本地盘有LVM,可以将多个硬盘变成一大块盘,然后在里面切出一小块给用户。
+
+### 虚拟化的缺点
+
+但是虚拟化也有缺点。通过虚拟化软件创建虚拟机,需要人工指定放在哪台机器上、硬盘放在哪个存储设备上,网络的VLAN ID、带宽的具体配置等,都需要人工指定。所以仅使用虚拟化的运维工程师往往有一个Excel表格,记录有多少台物理机,每台机器部署了哪些虚拟机。受此限制,一般虚拟化的集群数目都不是特别大。
+
+## 第三阶段:合,即云计算
+
+### 云计算解决的问题
+
+为了解决虚拟化阶段遗留的问题,于是有了分久必合的过程。这个过程我们可以形象地称为池化。
+虚拟化将资源分得很细,但是如此细分的资源靠Excel去管理,成本太高。池化就是将资源打成一个大的池,当需要资源的时候,帮助用户自动地选择,而非用户指定。这个阶段的关键点:调度器Scheduler。
+
+### 私有云、公有云的两极分化
+
+这样,Vmware有了自己的Vcloud;也有了基于Xen和KVM的私有云平台CloudStack(后来Citrix将其收购后开源)。
+
+当这些私有云平台在用户的数据中心里卖得奇贵无比、赚得盆满钵盈的时候,有其他的公司开始了另外的选择。这就是AWS和Google,他们开始了公有云领域的探索。
+
+AWS最初就是基于Xen技术进行虚拟化的,并且最终形成了公有云平台。也许AWS最初只是不想让自己的电商领域的利润全部交给私有云厂商吧,所以自己的云平台首先支撑起了自己的业务。在这个过程中,AWS严肃地使用了自己的云计算平台,使得公有云平台并不是对资源的配置更加友好,而是对应用的部署更加友好,最终大放异彩。
+
+### 私有云厂商与公有云厂商的联系与区别
+
+如果仔细观察就会发现,私有云和公有云虽然使用的是类似的技术,但在产品设计上却是完全不同的两种生物。
+
+私有云厂商和公有云厂商也拥有类似的技术,但在产品运营上呈现出完全不同的基因。
+
+私有云厂商是卖资源的,所以往往在卖私有云平台的时候伴随着卖计算、网络、存储设备。在产品设计上,私有云厂商往往会对客户强调其几乎不会使用的计算、网络、存储的技术参数,因为这些参数可以在和友商对标的过程中占尽优势。私有云的厂商几乎没有自己的大规模应用,所以私有云厂商的平台做出来是给别人用的,自己不会大规模使用,所以产品往往围绕资源展开,而不会对应用的部署友好。
+
+公有云的厂商往往都是有自己大规模的应用需要部署,所以其产品的设计可以将常见的应用部署需要的模块作为组件提供出来,用户可以像拼积木一样,拼接一个适用于自己应用的架构。公有云厂商不必关心各种技术参数的PK,不必关心是否开源,是否兼容各种虚拟化平台,是否兼容各种服务器设备、网络设备、存储设备。你管我用什么,客户部署应用方便就好。
+
+### 公有云生态及老二的逆袭
+
+公有云的第一名AWS活的自然很爽,作为第二名Rackspace就不那么舒坦了。
+
+没错,互联网行业基本上就是一家独大,那第二名如何逆袭呢?开源是很好的办法,让整个行业一起为这个云平台出力。于是Rackspace与美国航空航天局(NASA)合作创始了开源云平台OpenStack。
+
+OpenStack现在发展的和AWS有点像了,所以从OpenStack的模块组成可以看到云计算池化的方法。
+
+### OpenStack的组件
+
+1. 计算池化模块Nova:OpenStack的计算虚拟化主要使用KVM,然而到底在哪个物理机上开虚拟机呢,这要靠nova-scheduler;
+2. 网络池化模块Neutron:OpenStack的网络虚拟化主要使用Openvswitch,然而对于每一个Openvswitch的虚拟网络、虚拟网卡、VLAN、带宽的配置,不需要登录到集群上配置,Neutron可以通过SDN的方式进行配置;
+3. 存储池化模块Cinder: OpenStack的存储虚拟化,如果使用本地盘,则基于LVM,使用哪个LVM上分配的盘,也是通过scheduler来的。后来就有了将多台机器的硬盘打成一个池的方式Ceph,而调度的过程,则在Ceph层完成。
+
+### OpenStack带来私有云市场的红海
+
+有了OpenStack,所有的私有云厂商都疯了,原来VMware在私有云市场赚的实在太多了,眼巴巴的看着,没有对应的平台可以和他抗衡。现在有了现成的框架,再加上自己的硬件设备,几乎所有的IT厂商巨头,全部都加入到社区里,将OpenStack开发为自己的产品,连同硬件设备一起,杀入私有云市场。
+
+### 公有or私有?[网易云](https://www.163yun.com/product-cloudcompute?tag=M_smf_1190000008091499)的选择
+
+[网易云](https://www.163yun.com/product-cloudcompute?tag=M_smf_1190000008091499)当然也没有错过这次风口,上线了自己的OpenStack集群,[网易云](https://www.163yun.com/product-cloudcompute?tag=M_smf_1190000008091499)基于OpenStack自主研发了IaaS服务,在计算虚拟化方面,通过裁剪KVM镜像,优化虚拟机启动流程等改进,实现了虚拟机的秒级别启动。在网络虚拟化方面,通过SDN和Openvswitch技术,实现了虚拟机之间的高性能互访。在存储虚拟化方面,通过优化Ceph存储,实现高性能云盘。
+
+但是[网易云](https://www.163yun.com/product-cloudcompute?tag=M_smf_1190000008091499)并没有杀进私有云市场,而是使用OpenStack支撑起了自己的应用,这是互联网的思维。而仅仅是资源层面弹性是不够的,还需要开发出对应用部署友好的组件。例如数据库,负载均衡,缓存等,这些都是应用部署必不可少的,也是[网易云](https://www.163yun.com/product-cloudcompute?tag=M_smf_1190000008091499)在大规模应用实践中,千锤百炼过的。这些组件称为PaaS。
+
+## 第四阶段:分,即容器
+
+### 现在来谈谈,应用层面,即PaaS层。
+
+前面一直在讲IaaS层的故事,也即基础设施即服务,基本上在谈计算、网络、存储的事情。现在应该说说应用层,即PaaS层的事情了。
+
+#### 1\. PaaS的定义与作用
+
+IaaS的定义比较清楚,PaaS的定义就没那么清楚了。有人把数据库、负载均衡、缓存作为PaaS服务;有人把大数据Hadoop,、Spark平台作为PaaS服务;还有人将应用的安装与管理,例如Puppet、 Chef,、Ansible作为PaaS服务。
+
+其实PaaS主要用于管理应用层。我总结为两部分:一部分是你自己的应用应当自动部署,比如Puppet、Chef、Ansible、 Cloud Foundry等,可以通过脚本帮你部署;另一部分是你觉得复杂的通用应用不用部署,比如数据库、缓存、大数据平台,可以在云平台上一点即得。
+
+要么就是自动部署,要么就是不用部署,总的来说就是应用层你也少操心,就是PaaS的作用。当然最好还是都不用去部署,一键可得,所以公有云平台将通用的服务都做成了PaaS平台。另一些你自己开发的应用,除了你自己其他人不会知道,所以你可以用工具变成自动部署。
+
+#### 2\. PaaS的优点
+
+PaaS最大的优点,就是可以实现应用层的弹性伸缩。比如在双十一期间,10个节点要变成100个节点,如果使用物理设备,再买90台机器肯定来不及,仅仅有IaaS实现资源的弹性是不够的,再创建90台虚拟机,也是空的,还是需要运维人员一台一台地部署。所以有了PaaS就好了,一台虚拟机启动后,马上运行自动部署脚本,进行应用的安装,90台机器自动安装好了应用,才是真正的弹性伸缩。
+
+#### 3\. PaaS部署的问题
+
+当然这种部署方式也有一个问题,就是无论Puppet、 Chef、Ansible把安装脚本抽象的再好,说到底也是基于脚本的,然而应用所在的环境千差万别。文件路径的差别,文件权限的差别,依赖包的差别,应用环境的差别,Tomcat、 PHP、 Apache等软件版本的差别,JDK、Python等版本的差别,是否安装了一些系统软件,是否占用了哪些端口,都可能造成脚本执行的不成功。所以看起来是一旦脚本写好,就能够快速复制了,但是环境稍有改变,就需要把脚本进行新一轮的修改、测试、联调。例如在数据中心写好的脚本移到AWS上就不一定直接能用,在AWS上联调好了,迁移到Google Cloud上也可能会再出问题。
+
+### 容器的诞生
+
+#### 1\. 容器的定义
+
+于是容器便应运而生。容器是Container,Container另一个意思是集装箱,其实容器的思想就是要变成软件交付的集装箱。集装箱的特点,一是打包,二是标准。设想没有集装箱的时代,如果将货物从A运到B,中间要经过三个码头,换三次船的话,货物每次都要卸下船来,摆的七零八落,然后换船的时候,需要重新摆放整齐,在没有集装箱的时候,船员们都需要在岸上待几天再走。而在有了集装箱后,所有的货物都打包在一起了,并且集装箱的尺寸全部一致,所以每次换船的时候,整体一个箱子搬过去就可以了,小时级别就能完成,船员再也不用长时间上岸等待了。
+
+#### 2.容器在开发中的应用
+
+设想A就是程序员,B就是用户,货物就是代码及运行环境,中间的三个码头分别是开发,测试,上线。
+假设代码的运行环境如下:
+
+1. Ubuntu操作系统
+2. 创建用户hadoop
+3. 下载解压JDK 1.7在某个目录下
+4. 将这个目录加入JAVA_HOME和PATH的环境变量里面
+5. 将环境变量的export放在hadoop用户的home目录下的.bashrc文件中
+6. 下载并解压tomcat 7
+7. 将war放到tomcat的webapp路径下面
+8. 修改tomcat的启动参数,将Java的Heap Size设为1024M
+
+看,一个简单的Java网站,就需要考虑这么多零零散散的东西,如果不打包,就需要在开发,测试,生产的每个环境上查看,保证环境的一致,甚至要将这些环境重新搭建一遍,就像每次将货物打散了重装一样麻烦。中间稍有差池,比如开发环境用了JDK 1.8,而线上是JDK 1.7;比如开发环境用了root用户,线上需要使用hadoop用户,都可能导致程序的运行失败。
+
+
+
+
+
+### 容器的诞生
+
+[云计算的前世今生(上)](https://link.jianshu.com/?t=https://segmentfault.com/a/1190000008091499)中提到:云计算解决了基础资源层的弹性伸缩,却没有解决PaaS层应用随基础资源层弹性伸缩而带来的批量、快速部署问题。于是容器应运而生。
+
+容器是Container,Container另一个意思是集装箱,其实容器的思想就是要变成软件交付的集装箱。集装箱的特点,一是打包,二是标准。
+
+
+
+
+
+
+
+
+
+
+
+在没有集装箱的时代,假设将货物从A运到B,中间要经过三个码头、换三次船。每次都要将货物卸下船来,摆的七零八落,然后搬上船重新整齐摆好。因此在没有集装箱的时候,每次换船,船员们都要在岸上待几天才能走。
+
+
+
+
+
+
+
+
+
+
+
+有了集装箱以后,所有的货物都打包在一起了,并且集装箱的尺寸全部一致,所以每次换船的时候,一个箱子整体搬过去就行了,小时级别就能完成,船员再也不能上岸长时间耽搁了。这是集装箱“打包”、“标准”两大特点在生活中的应用。下面用一个简单的案例来看看容器在开发部署中的实际应用。
+
+假设有一个简单的Java网站需要上线,代码的运行环境如下:
+
+
+
+
+
+
+
+
+
+
+
+看,一个简单的Java网站,就有这么多零零散散的东西!这就像很多零碎地货物,如果不打包,就需要在开发、测试、生产的每个环境上重新查看以保证环境的一致,有时甚至要将这些环境重新搭建一遍,就像每次将货物卸载、重装一样麻烦。中间稍有差池,比如开发环境用了JDK 1.8,而线上是JDK 1.7;比如开发环境用了root用户,线上需要使用hadoop用户,都可能导致程序的运行失败。
+
+那么容器如何对应用打包呢?还是要学习集装箱,首先要有个封闭的环境,将货物封装起来,让货物之间互不干扰,互相隔离,这样装货卸货才方便。好在ubuntu中的lxc技术早就能做到这一点。
+
+封闭的环境主要使用了两种技术,一种是看起来是隔离的技术,称为namespace,也即每个namespace中的应用看到的是不同的IP地址、用户空间、程号等。另一种是用起来是隔离的技术,称为cgroup,也即明明整台机器有很多的CPU、内存,而一个应用只能用其中的一部分。有了这两项技术,集装箱的铁盒子我们是焊好了,接下来是决定往里面放什么。
+
+最简单粗暴的方法,就是将上面列表中所有的都放到集装箱里面。但是这样太大了!因为即使你安装一个干干静静的ubuntu操作系统,什么都不装,就很大了。把操作系统装进容器相当于把船也放到了集装箱里面!传统的虚拟机镜像就是这样的,动辄几十G。答案当然是NO!所以第一项操作系统不能装进容器。
+
+撇下第一项操作系统,剩下的所有的加起来,也就几百M,就轻便多了。因此一台服务器上的容器是共享操作系统内核的,容器在不同机器之间的迁移不带内核,这也是很多人声称容器是轻量级的虚拟机的原因。轻不白轻,自然隔离性就差了,一个容器让操作系统崩溃了,其他容器也就跟着崩溃了,这相当于一个集装箱把船压漏水了,所有的集装箱一起沉。
+
+另一个需要撇下的就是随着应用的运行而产生并保存在本地的数据。这些数据多以文件的形式存在,例如数据库文件、文本文件。这些文件会随着应用的运行,越来越大,如果这些数据也放在容器里面,会让容器变得很大,影响容器在不同环境的迁移。而且这些数据在开发、测试、线上环境之间的迁移是没有意义的,生产环境不可能用测试环境的文件,所以往往这些数据也是保存在容器外面的存储设备上。也是为什么人们称容器是无状态的。
+
+至此集装箱焊好了,货物也装进去了,接下来就是如何将这个集装箱标准化,从而在哪艘船上都能运输。这里的标准一个是镜像,一个是容器的运行环境。
+
+所谓的镜像,就是将你焊好集装箱的那个时刻,将集装箱的状态保存下来,就像孙悟空说定,集装箱里面就定在了那一刻,然后将这一刻的状态保存成一系列文件。这些文件的格式是标准的,谁看到这些文件,都能还原当时定住的那个时刻。将镜像还原成运行时的过程(就是读取镜像文件,还原那个时刻的过程)就是容器的运行的过程。除了大名鼎鼎的Docker,还有其他的容器,例如AppC、Mesos Container,都能运行容器镜像。所以说容器不等于Docker。
+
+总而言之,容器是轻量级的、隔离差的、适用于无状态的,可以基于镜像标准实现跨主机、跨环境的随意迁移。
+
+有了容器,使得PaaS层对于用户自身应用的自动部署变得快速而优雅。容器快,快在了两方面,第一是虚拟机启动的时候要先启动操作系统,容器不用启动操作系统,因为是共享内核的。第二是虚拟机启动后使用脚本安装应用,容器不用安装应用,因为已经打包在镜像里面了。所以最终虚拟机的启动是分钟级别,而容器的启动是秒级。容器咋这么神奇。其实一点都不神奇,第一是偷懒少干活了,第二是提前把活干好了。
+
+因为容器的启动快,人们往往不会创建一个个小的虚拟机来部署应用,因为这样太费时间了,而是创建一个大的虚拟机,然后在大的虚拟机里面再划分容器,而不同的用户不共享大的虚拟机,可以实现操作系统内核的隔离。这又是一次合久必分的过程。由IaaS层的虚拟机池,划分为更细粒度的容器池。
+
+### 容器管理平台
+
+有了容器的管理平台,又是一次分久必合的过程。
+
+容器的粒度更加细,管理起来更难管,甚至是手动操作难以应对的。假设你有100台物理机,其实规模不是太大,用Excel人工管理是没问题的,但是一台上面开10台虚拟机,虚拟机的个数就是1000台,人工管理已经很困难了,但是一台虚拟机里面开10个容器,就是10000个容器,你是不是已经彻底放弃人工运维的想法了。
+
+所以容器层面的管理平台是一个新的挑战,关键字就是自动化:
+
+自发现:容器与容器之间的相互配置还能像虚拟机一样,记住IP地址,然后互相配置吗?这么多容器,你怎么记得住一旦一台虚拟机挂了重启,IP改变,应该改哪些配置,列表长度至少万行级别的啊。所以容器之间的配置通过名称来的,无论容器跑到哪台机器上,名称不变,就能访问到。
+
+自修复:容器挂了,或是进程宕机了,能像虚拟机那样,登陆上去查看一下进程状态,如果不正常重启一下么?你要登陆万台docker了。所以容器的进程挂了,容器就自动挂掉了,然后自动重启。
+
+弹性自伸缩 Auto Scaling:当容器的性能不足的时候,需要手动伸缩,手动部署么?当然也要自动来。
+
+当前火热的容器管理平台有三大流派:
+
+一个是Kubernetes,我们称为段誉型。段誉(Kubernetes)的父亲(Borg)武功高强,出身皇族(Google),管理过偌大的一个大理国(Borg是Google数据中心的容器管理平台)。作为大理段式后裔,段誉的武功基因良好(Kubernetes的理念设计比较完善),周围的高手云集,习武环境也好(Kubernetes生态活跃,热度高),虽然刚刚出道的段誉武功不及其父亲,但是只要跟着周围的高手不断切磋,武功既可以飞速提升。
+
+一个是Mesos,我们称为乔峰型。乔峰(Mesos)的主要功夫降龙十八掌(Mesos的调度功能)独步武林,为其他帮派所无。而且乔峰也管理过人数众多的丐帮(Mesos管理过Tweeter的容器集群)。后来乔峰从丐帮出来,在江湖中特例独行(Mesos的创始人成立了公司Mesosphere)。乔峰的优势在于,乔峰的降龙十八掌(Mesos)就是在丐帮中使用的降龙十八掌,相比与段誉初学其父的武功来说,要成熟很多。但是缺点是,降龙十八掌只掌握在少数的几个丐帮帮主手中(Mesos社区还是以Mesosphere为主导),其他丐帮兄弟只能远远崇拜乔峰,而无法相互切磋(社区热度不足)。
+
+一个是Swarm,我们称为慕容型。慕容家族(Swarm是Docker家族的集群管理软件)的个人功夫是非常棒的(Docker可以说称为容器的事实标准),但是看到段誉和乔峰能够管理的组织规模越来越大,有一统江湖的趋势,着实眼红了,于是开始想创建自己的慕容鲜卑帝国(推出Swarm容器集群管理软件)。但是个人功夫好,并不代表着组织能力强(Swarm的集群管理能力),好在慕容家族可以借鉴段誉和乔峰的组织管理经验,学习各家公司,以彼之道,还施彼身,使得慕容公子的组织能力(Swarm借鉴了很多前面的集群管理思想)也在逐渐的成熟中。
+
+三大容器门派,到底鹿死谁手,谁能一统江湖,尚未可知。
+
+网易之所以选型Kubernetes作为自己的容器管理平台,是因为基于 Borg 成熟的经验打造的 Kubernetes,为容器编排管理提供了完整的开源方案,并且社区活跃,生态完善,积累了大量分布式、服务化系统架构的最佳实践。
+
+### 容器初体验
+
+想不想尝试一下最先进的容器管理平台呢?我们先了解一下Docker的生命周期。如图所示。
+
+图中最中间就是最核心的两个部分,一个是镜像Images,一个是容器Containers。镜像运行起来就是容器。容器运行的过程中,基于原始镜像做了改变,比如安装了程序,添加了文件,也可以提交回去(commit)成为镜像。如果大家安装过系统,镜像有点像GHOST镜像,从GHOST镜像安装一个系统,运行起来,就相当于容器;容器里面自带应用,就像GHOST镜像安装的系统里面不是裸的操作系统,里面可能安装了微信,QQ,视频播放软件等。安装好的系统使用的过程中又安装了其他的软件,或者下载了文件,还可以将这个系统重新GHOST成一个镜像,当其他人通过这个镜像再安装系统的时候,则其他的软件也就自带了。
+
+普通的GHOST镜像就是一个文件,但是管理不方便,比如如果有十个GHOST镜像的话,你可能已经记不清楚哪个镜像里面安装了哪个版本的软件了。所以容器镜像有tag的概念,就是一个标签,比如dev-1.0,dev-1.1,production-1.1等,凡是能够帮助你区分不同镜像的,都可以。为了镜像的统一管理,有一个镜像库的东西,可以通过push将本地的镜像放到统一的镜像库中保存,可以通过pull将镜像库中的镜像拉到本地来。
+
+从镜像运行一个容器可使用下面的命令,如果初步使用Docker,记下下面这一个命令就可以了。
+
+这行命令会启动一个里面安装了mysql的容器。其中docker run就是运行一个容器;--name就是给这个容器起个名字;-v 就是挂数据盘,将外面的一个目录/my/own/datadir挂载到容器里面的一个目录/var/lib/mysql作为数据盘,外面的目录是在容器所运行的主机上的,也可以是远程的一个云盘;-e 是设置容器运行环境的环境变量,环境变量是最常使用的设置参数的方式,例如这里设置mysql的密码。mysql:tag就是镜像的名字和标签。
+
+docker stop可以停止这个容器,start可以再启动这个容器,restart可以重启这个容器。在容器内部做了改变,例如安装了新的软件,产生了新的文件,则调用docker commit变成新的镜像。
+
+镜像生产过程,除了可以通过启动一个docker,手动修改,然后调用docker commit形成新镜像之外,还可以通过书写Dockerfile,通过docker build来编译这个Dockerfile来形成新镜像。为什么要这样做呢?前面的方式太不自动化了,需要手工干预,而且还经常会忘了手工都做了什么。用Dockerfile可以很好的解决这个问题。
+
+Dockerfile的一个简单的例子如下:
+
+这其实是一个镜像的生产说明书,Docker build的过程就是根据这个生产说明书来生产镜像:
+
+FROM基础镜像,先下载这个基础镜像,然后从这个镜像启动一个容器,并且登陆到容器里面;
+
+RUN运行一个命令,在容器里面运行这个命令;
+
+COPY/ADD将一些文件添加到容器里面;
+
+最终给容器设置启动命令 ENTRYPOINT,这个命令不在镜像生成过程中执行,而是在容器运行的时候作为主程序执行;
+
+将所有的修改commit成镜像。
+
+这里需要说明一下的就是主程序,是Docker里面一个重要的概念,虽然镜像里面可以安装很多的程序,但是必须有一个主程序,主程序和容器的生命周期完全一致,主程序在则容器在,主程序亡则容器亡。
+
+就像图中展示的一样,容器是一个资源限制的框,但是这个框没有底,全靠主进程撑着,主进程挂了,衣服架子倒了,衣服也就垮了。
+
+了解了如何运行一个独立的容器,接下来介绍如何使用容器管理平台。
+
+### 容器管理平台初体验
+
+
+
+
+
+
+
+
+
+
+
+容器管理平台会对容器做更高的抽象,容器不再是单打独斗,而且组成集团军共同战斗。多个容器组成一个Pod,这几个容器亲如兄弟,干的也是相关性很强的活,能够通过localhost访问彼此,真是兄弟齐心,力可断金。有的任务一帮兄弟还刚不住,就需要多个Pod合力完成,这个由ReplicationController进行控制,可以将一个Pod复制N个副本,同时承载任务,众人拾柴火焰高。
+
+N个Pod如果对外散兵作战,一是无法合力,二是给人很乱的感觉,因而需要有一个老大,作为代言人,将大家团结起来,一致对外,这就是Service。老大对外提供统一的虚拟IP和端口,并将这个IP和服务名关联起来,访问服务名,则自动映射为虚拟IP。老大的意思就是,如果外面要访问我这个团队,喊一声名字就可以,例如”雷锋班,帮敬老院打扫卫生!”,你不用管雷锋班的那个人去打扫卫生,每个人打扫哪一部分,班长会统一分配。
+
+最上层通过namespace分隔完全隔离的环境,例如生产环境,测试环境,开发环境等。就像军队分华北野战军,东北野战军一样。野战军立正,出发,部署一个Tomcat的Java应用。
+
+
+
+作者:网易云基础服务
+链接:https://www.jianshu.com/p/52312b1eb633
+來源:简书
+简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
\ No newline at end of file
diff --git "a/docs/big-backEnd/\345\220\216\347\253\257\346\212\200\346\234\257\346\235\202\350\260\2106\357\274\232\347\231\275\350\257\235\350\231\232\346\213\237\345\214\226\346\212\200\346\234\257.md" "b/docs/big-backEnd/\345\220\216\347\253\257\346\212\200\346\234\257\346\235\202\350\260\2106\357\274\232\347\231\275\350\257\235\350\231\232\346\213\237\345\214\226\346\212\200\346\234\257.md"
new file mode 100644
index 0000000..0a695c9
--- /dev/null
+++ "b/docs/big-backEnd/\345\220\216\347\253\257\346\212\200\346\234\257\346\235\202\350\260\2106\357\274\232\347\231\275\350\257\235\350\231\232\346\213\237\345\214\226\346\212\200\346\234\257.md"
@@ -0,0 +1,97 @@
+内核,是指的操作系统内核。
+
+所有的操作系统都有内核,无论是Windows还是Linux,都管理着三个重要的资源:计算,网络,存储。
+
+
+
+计算指CPU和内存,网络即网络设备,存储即硬盘之类的。
+
+内核是个大管家,想象你的机器上跑着很多的程序,有word,有excel,看着视频,听着音乐,每个程序都要使用CPU和内存,都要上网,都要存硬盘,如果没有一个大管家管着,大家随便用,就乱了。所以需要管家来协调调度整个资源,谁先用,谁后用,谁用多少,谁放在这里,谁放在那里,都需要管家操心。
+
+所以在这个计算机大家庭里面,管家有着比普通的程序更高的权限,运行在内核态,而其他的普通程序运行在用户态,用户态的程序一旦要申请公共的资源,就需要向管家申请,管家帮它分配好,它才能用。
+
+为了区分内核态和用户态,CPU专门设置四个特权等级0,1,2,3 来做这个事情。
+
+
+
+当时写Linux内核的时候,估计大牛们还不知道将来虚拟机会大放异彩,大牛们想,一共两级特权,一个内核态,一个用户态,却有四个等级,好奢侈,好富裕,就敞开了用,内核态运行在第0等级,用户态运行在第3等级,占了两头,太不会过日子了。
+
+大牛们在写Linux内核的时候,如果用户态程序做事情,就将扳手掰到第3等级,一旦要申请使用更多的资源,就需要申请将扳手掰到第0等级,内核才能在高权限访问这些资源,申请完资源,返回到用户态,扳手再掰回去。
+
+这个程序一直非常顺利的运行着,直到虚拟机的出现。
+
+如果大家用过Vmware桌面版,或者Virtualbox桌面版,你可以用这个虚拟化软件创建虚拟机,在虚拟机里面安装一个Linux或者windows,外面的操作系统也可以是Linux或者Windows。
+
+当你使用虚拟机软件的时候,和你的excel一样,都是在你的任务栏里面并排的放着,是一个普通的应用。
+
+当你进入虚拟机的时候,虚拟机里面的excel也是一个普通的应用。
+
+但是当你设身处地的站在虚拟机里面的内核的角度思考一下人生,你就困惑了,我到底个啥?
+
+在硬件上的操作系统来看,我是一个普通的应用,只能运行在用户态。可是大牛们生我的时候,我的每一行代码,都告诉我,我是个内核啊,应该运行在内核态,当虚拟机里面的excel要访问网络的时候,向我请求,我的代码就要努力的去操作网络资源,我努力,但是我做不到,我没有权限!
+
+我分裂了。
+
+虚拟化层,也就是Vmware或者Virtualbox需要帮我解决这个问题。
+
+第一种方式,完全虚拟化,其实就是骗我。虚拟化软件模拟假的CPU,内存,网络,硬盘给我,让我自我感觉良好,终于又像个内核了。
+
+真正的工作模式是这样的。
+
+虚拟机内核:我要在CPU上跑一个指令!
+
+虚拟化软件:没问题,你是内核嘛,可以跑
+
+虚拟化软件转过头去找物理机内核:报告管家,我管理的虚拟机里面的一个要执行一个CPU指令,帮忙来一小段时间空闲的CPU时间,让我代他跑个指令。
+
+物理机内核:你等着,另一个跑着呢。好嘞,他终于跑完了,该你了。
+
+虚拟化软件:我代他跑,终于跑完了,出来结果了
+
+虚拟化软件转头给虚拟机内核:哥们,跑完了,结果是这个,我说你是内核吧,绝对有权限,没问题,下次跑指令找我啊。
+
+虚拟机内核:看来我真的是内核呢。可是哥,好像这点指令跑的有点慢啊。
+
+虚拟化软件:这就不错啦,好几个排着队跑呢。
+
+内存的申请模式如下。
+
+虚拟机内核:我启动需要4G内存,我好分给我上面的应用。
+
+虚拟化软件:没问题,才4G,你是内核嘛,马上申请好。
+
+虚拟化软件转头给物理机内核:报告,管家,我启动了一个虚拟机,需要4G内存,给我4个房间呗。
+
+物理机内核:怎么又一个虚拟机啊,好吧,给你90,91,92,93四个房间。
+
+虚拟化软件转头给虚拟机内核:哥们,内存有了,0,1,2,3这个四个房间都是你的,你看,你是内核嘛,独占资源,从0编号的就是你的。
+
+虚拟机内核:看来我真的是内核啊,能从头开始用。那好,我就在房间2的第三个柜子里面放个东西吧。
+
+虚拟化软件:要放东西啊,没问题。心里想:我查查看,这个虚拟机是90号房间开头的,他要在房间2放东西,那就相当于在房间92放东西。
+
+虚拟化软件转头给物理机内核:报告,管家,我上面的虚拟机要在92号房间的第三个柜子里面放个东西。
+
+好了,说完了CPU和内存的例子,不细说网络和硬盘了,也是类似,都是虚拟化软件模拟一个给虚拟机内核看的,其实啥事儿都需要虚拟化软件转一遍。
+
+这种方式一个坏处,就是慢,往往慢到不能忍受。
+
+于是虚拟化软件想,我能不能不当传话筒,还是要让虚拟机内核正视自己的身份,别说你是内核,你还真喘上了,你不是物理机,你是虚拟机。
+
+但是怎么解决权限等级的问题呢?于是Intel的VT-x和AMD的AMD-V从硬件层面帮上了忙。当初谁让你们这些写内核的大牛用等级这么奢侈,用完了0,就是3,也不省着点用,没办法,只好另起炉灶弄一个新的标志位,表示当前是在虚拟机状态下,还是真正的物理机内核下。
+
+对于虚拟机内核来讲,只要将标志位设为虚拟机状态,则可以直接在CPU上执行大部分的指令,不需要虚拟化软件在中间转述,除非遇到特别敏感的指令,才需要将标志位设为物理机内核态运行,这样大大提高了效率。
+
+所以安装虚拟机的时候,务必要将物理CPU的这个标志位打开,是否打开对于Intel可以查看grep "vmx" /proc/cpuinfo,对于AMD可以查看grep "svm" /proc/cpuinfo
+
+这叫做硬件辅助虚拟化。
+
+另外就是访问网络或者硬盘的时候,为了取得更高的性能,也需要让虚拟机内核加载特殊的驱动,也是让虚拟机内核从代码层面就重新定位自己的身份,不能像访问物理机一样访问网络或者硬盘,而是用一种特殊的方式:我知道我不是物理机内核,我知道我是虚拟机,我没那么高的权限,我很可能和很多虚拟机共享物理资源,所以我要学会排队,我写硬盘其实写的是一个物理机上的文件,那我的写文件的缓存方式是不是可以变一下,我发送网络包,根本就不是发给真正的网络设备,而是给虚拟的设备,我可不可以直接在内存里面拷贝给他,等等等等。
+
+一旦我知道我不是物理机内核,痛定思痛,只好重新认识自己,反而能找出很多方式来优化我的资源访问。
+
+这叫做类虚拟化或者半虚拟化。
+
+如果您想更技术的了解本文背后的原理,请看书《系统虚拟化——原理与实现》
+
+
\ No newline at end of file
diff --git "a/docs/big-backEnd/\345\220\216\347\253\257\346\212\200\346\234\257\346\235\202\350\260\2107\357\274\232OpenStack\347\232\204\345\237\272\347\237\263KVM.md" "b/docs/big-backEnd/\345\220\216\347\253\257\346\212\200\346\234\257\346\235\202\350\260\2107\357\274\232OpenStack\347\232\204\345\237\272\347\237\263KVM.md"
new file mode 100644
index 0000000..a749567
--- /dev/null
+++ "b/docs/big-backEnd/\345\220\216\347\253\257\346\212\200\346\234\257\346\235\202\350\260\2107\357\274\232OpenStack\347\232\204\345\237\272\347\237\263KVM.md"
@@ -0,0 +1,354 @@
+# [Qemu,KVM,Virsh傻傻的分不清](https://www.cnblogs.com/popsuper1982/p/8522535.html)
+
+原创文章,转载请注明: 转载自[Itweet](https://link.juejin.im/?target=http%3A%2F%2Fwww.itweet.cn)的博客
+
+
+
+
+
+
+当你安装了一台Linux,想启动一个KVM虚拟机的时候,你会发现需要安装不同的软件,启动虚拟机的时候,有多种方法:
+
+* virsh start
+
+* kvm命令
+
+* qemu命令
+
+* qemu-kvm命令
+
+* qemu-system-x86_64命令
+
+这些之间是什么关系呢?请先阅读上一篇《[白话虚拟化技术](https://blog.csdn.net/a724888/article/details/80996570)》
+
+有了上一篇的基础,我们就能说清楚来龙去脉。
+
+KVM(Kernel-based Virtual Machine的英文缩写)是内核内建的虚拟机。有点类似于 Xen ,但更追求更简便的运作,比如运行此虚拟机,仅需要加载相应的 kvm 模块即可后台待命。和 Xen 的完整模拟不同的是,KVM 需要芯片支持虚拟化技术(英特尔的 VT 扩展或者 AMD 的 AMD-V 扩展)。
+
+首先看qemu,其中关键字emu,全称emulator,模拟器,所以单纯使用qemu是采用的完全虚拟化的模式。
+
+Qemu向Guest OS模拟CPU,也模拟其他的硬件,GuestOS认为自己和硬件直接打交道,其实是同Qemu模拟出来的硬件打交道,Qemu将这些指令转译给真正的硬件。由于所有的指令都要从Qemu里面过一手,因而性能比较差
+
+
+
+按照上一次的理论,完全虚拟化是非常慢的,所以要使用硬件辅助虚拟化技术Intel-VT,AMD-V,所以需要CPU硬件开启这个标志位,一般在BIOS里面设置。查看是否开启
+
+对于Intel CPU 可用命令 grep "vmx" /proc/cpuinfo 判断
+
+对于AMD CPU 可用命令 grep "svm" /proc/cpuinfo 判断
+
+当确认开始了标志位之后,通过KVM,GuestOS的CPU指令不用经过Qemu转译,直接运行,大大提高了速度。
+
+所以KVM在内核里面需要有一个模块,来设置当前CPU是Guest OS在用,还是Host OS在用。
+
+查看内核模块中是否含有kvm, ubuntu默认加载这些模块
+
+
+
+KVM内核模块通过/dev/kvm暴露接口,用户态程序可以通过ioctl来访问这个接口,例如书写下面的程序
+
+
+
+Qemu将KVM整合进来,通过ioctl调用/dev/kvm接口,将有关CPU指令的部分交由内核模块来做,就是qemu-kvm (qemu-system-XXX)
+
+Qemu-kvm对kvm的整合从release_0_5_1开始有branch,在1.3.0正式merge到master
+
+
+
+qemu和kvm整合之后,CPU的性能问题解决了,另外Qemu还会模拟其他的硬件,如Network, Disk,同样全虚拟化的方式也会影响这些设备的性能。
+
+于是qemu采取半虚拟化或者类虚拟化的方式,让Guest OS加载特殊的驱动来做这件事情。
+
+例如网络需要加载virtio_net,存储需要加载virtio_blk,Guest需要安装这些半虚拟化驱动,GuestOS知道自己是虚拟机,所以数据直接发送给半虚拟化设备,经过特殊处理,例如排队,缓存,批量处理等性能优化方式,最终发送给真正的硬件,一定程度上提高了性能。
+
+至此整个关系如下:
+
+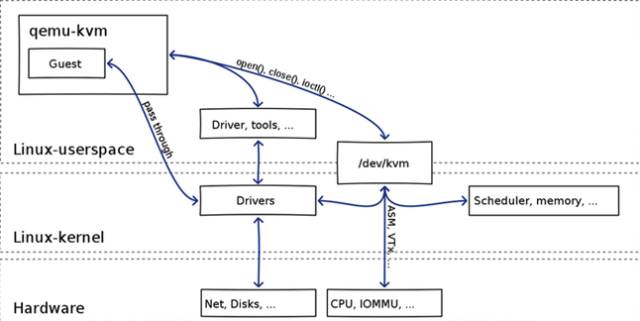
+
+qemu-kvm会创建Guest OS,当需要执行CPU指令的时候,通过/dev/kvm调用kvm内核模块,通过硬件辅助虚拟化方式加速。如果需要进行网络和存储访问,则通过类虚拟化或者直通Pass through的方式,通过加载特殊的驱动,加速访问网络和存储资源。
+
+然而直接用qemu或者qemu-kvm或者qemu-system-xxx的少,大多数还是通过virsh启动,virsh属于libvirt工具,libvirt是目前使用最为广泛的对KVM虚拟机进行管理的工具和API,可不止管理KVM。
+
+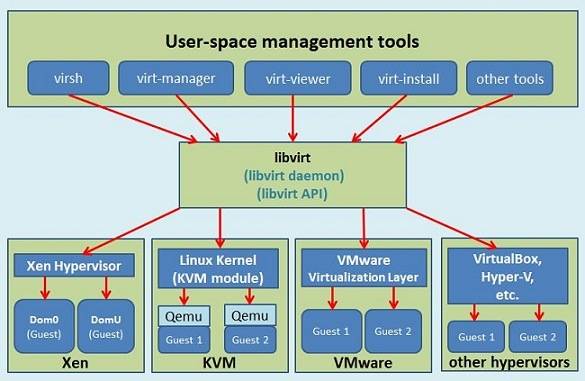
+
+Libvirt分服务端和客户端,Libvirtd是一个daemon进程,是服务端,可以被本地的virsh调用,也可以被远程的virsh调用,virsh相当于客户端。
+
+Libvirtd调用qemu-kvm操作虚拟机,有关CPU虚拟化的部分,qemu-kvm调用kvm的内核模块来实现
+
+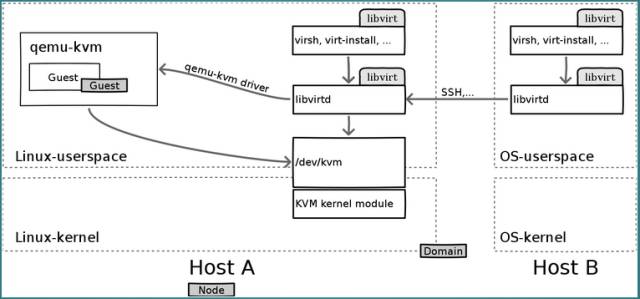
+
+这下子,整个相互关系才搞清楚了。
+
+虽然使用virsh创建虚拟机相对简单,但是为了探究虚拟机的究竟如何使用,下一次,我们来解析一下如何裸使用qemu-kvm来创建一台虚拟机,并且能上网。
+
+如果搭建使用过vmware桌面版或者virtualbox桌面版,创建一个能上网的虚拟机非常简单,但是其实背后做了很多事情,下一次我们裸用qemu-kvm,全部使用手工配置,看创建虚拟机都做了哪些事情。
+
+本章节我们主要介绍通过VMware技术虚拟出相关的Linux软件环境,在Linux系统中,安装KVM虚拟化软件,实实在在的去实践一下KVM到底是一个什么样的技术?
+
+## Kvm虚拟化技术实践
+
+### VMware虚拟机支持Kvm虚拟化技术?
+
+在VMware创建的虚拟机中,默认不支持Kvm虚拟化技术,需要芯片级的扩展支持,幸好VMware提供完整的解决方案,可以通过修改虚拟化引擎。
+
+VMware软件版本信息,`VMware® Workstation 11.0.0 build-2305329`
+
+首先,你需要启动VMware软件,新建一个`CentOS 6.x`类型的虚拟机,正常安装完成,这个虚拟机默认的`虚拟化引擎`,`首选模式`为”自动”。
+
+如果想让我们的VMware虚拟化出来的CentOS虚拟机支持KVM虚拟化,我们需要修改它支持的`虚拟化引擎`,打开新建的虚拟机,虚拟机状态必须处于`关闭`状态,通过双击`编辑虚拟机设置` > `硬件` ,选择`处理器`菜单,右边会出现`虚拟化引擎`区域,选择`首选模式`为 _Intel Tv-x/EPT或AMD-V/RVI_,接下来勾选`虚拟化Intel Tv-x/EPT或AMD-V/RVI(v)`,点击`确定`。
+
+KVM需要虚拟机宿主(host)的处理器带有虚拟化支持(对于Intel处理器来说是VT-x,对于AMD处理器来说是AMD-V)。你可以通过以下命令来检查你的处理器是否支持虚拟化:
+
+```
+ grep --color -E '(vmx|svm)' /proc/cpuinfo
+
+```
+
+如果运行后没有显示,那么你的处理器不支持硬件虚拟化,你不能使用KVM。
+
+* 注意: 如果是硬件服务器,您可能需要在BIOS中启用虚拟化支持,参考 [Private Cloud personal workstation](https://link.juejin.im/?target=http%3A%2F%2Fwww.itweet.cn%2Fblog%2F2016%2F06%2F14%2FPrivate%2520Cloud%2520personal%2520workstation)
+
+### 安装Kvm虚拟化软件
+
+安装kvm虚拟化软件,我们需要一个Linux操作系统环境,这里我们选择的Linux版本为`CentOS release 6.8 (Final)`,在这个VMware虚拟化出来的虚拟机中安装kvm虚拟化软件,具体步骤如下:
+
+* 首选安装epel源
+
+ ```
+ sudo rpm -ivh http://mirrors.ustc.edu.cn/fedora/epel/6/x86_64/epel-release-6-8.noarch.rpm
+
+ ```
+
+* 安装kvm虚拟化软件
+
+ ```
+ sudo yum install qemu-kvm qeum-kvm-tools virt-manager libvirt
+
+ ```
+
+* 启动kvm虚拟化软件
+
+ ```
+ sudo /etc/init.d/libvirtd start
+
+ ```
+
+启动成功之后你可以通过`/etc/init.d/libvirtd status`查看启动状态,这个时候,kvm会自动生成一个本地网桥 `virbr0`,可以通过命令查看他的详细信息
+
+```
+# ifconfig virbr0virbr0 Link encap:Ethernet HWaddr 52:54:00:D7:23:AD inet addr:192.168.122.1 Bcast:192.168.122.255 Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:0 errors:0 dropped:0 overruns:0 frame:0 TX packets:0 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:0 RX bytes:0 (0.0 b) TX bytes:0 (0.0 b)
+```
+
+KVM默认使用NAT网络模式。虚拟机获取一个私有 IP(例如 192.168.122.0/24 网段的),并通过本地主机的NAT访问外网。
+
+```
+# brctl showbridge name bridge id STP enabled interfacesvirbr0 8000.525400d723ad yes virbr0-nic
+```
+
+创建一个本地网桥virbr0,包括两个端口:virbr0-nic 为网桥内部端口,vnet0 为虚拟机网关端口(192.168.122.1)。
+
+虚拟机启动后,配置 192.168.122.1(vnet0)为网关。所有网络操作均由本地主机系统负责。
+
+DNS/DHCP的实现,本地主机系统启动一个 dnsmasq 来负责管理。
+
+```
+ps aux|grep dnsmasq
+
+```
+
+`注意:` 启动libvirtd之后自动启动iptables,并且写上一些默认规则。
+
+```
+# iptables -nvL -t natChain PREROUTING (policy ACCEPT 304 packets, 38526 bytes) pkts bytes target prot opt in out source destination Chain POSTROUTING (policy ACCEPT 7 packets, 483 bytes) pkts bytes target prot opt in out source destination 0 0 MASQUERADE tcp -- * * 192.168.122.0/24 !192.168.122.0/24 masq ports: 1024-65535 0 0 MASQUERADE udp -- * * 192.168.122.0/24 !192.168.122.0/24 masq ports: 1024-65535 0 0 MASQUERADE all -- * * 192.168.122.0/24 !192.168.122.0/24 Chain OUTPUT (policy ACCEPT 7 packets, 483 bytes) pkts bytes target prot opt in out source destination
+```
+
+### kvm创建虚拟机
+
+上传一个镜像文件:`CentOS-6.6-x86_64-bin-DVD1.iso`
+
+通过`qemu`创建一个raw格式的文件(注:QEMU使用的镜像文件:qcow2与raw,它们都是QEMU(KVM)虚拟机使用的磁盘文件格式),大小为5G。
+
+```
+qemu-img create -f raw /data/Centos-6.6-x68_64.raw 5G
+
+```
+
+查看创建的raw磁盘格式文件信息
+
+```
+qemu-img info /data/Centos-6.6-x68_64.raw image: /data/Centos-6.6-x68_64.rawfile format: rawvirtual size: 5.0G (5368709120 bytes)disk size: 0
+```
+
+启动,kvm虚拟机,进行操作系统安装
+
+```
+virt-install --virt-type kvm --name CentOS-6.6-x86_64 --ram 512 --cdrom /data/CentOS-6.6-x86_64-bin-DVD1.iso --disk path=/data/Centos-6.6-x68_64.raw --network network=default --graphics vnc,listen=0.0.0.0 --noautoconsole
+
+```
+
+启动之后,通过命令查看启动状态,默认会在操作系统开一个`5900`的端口,可以通过虚拟机远程管理软件`vnc`客户端连接,然后可视化的方式安装操作系统。
+
+```
+# netstat -ntlp|grep 5900tcp 0 0 0.0.0.0:5900 0.0.0.0:* LISTEN 2504/qemu-kvm
+```
+
+`注意`:kvm安装的虚拟机,不确定是那一台,在后台就是一个进程,每增加一台端口号+1,第一次创建的为5900!
+
+### 虚拟机远程管理软件
+
+我们可以使用虚拟机远程管理软件VNC进行操作系统的安装,我使用过的两款不错的虚拟机远程管理终端软件,一个是Windows上使用,一个在Mac上为了方便安装一个Google Chrome插件后即可开始使用,软件信息 `Tightvnc` 或者 `VNC[@Viewer](https://link.juejin.im/?target=https%3A%2F%2Fgithub.com%2FViewer "@Viewer") for Google Chrome`
+
+如果你和我一样使用的是`Google Chrome`提供的VNC插件,使用方式,在`Address`输入框中输入,宿主机IP:59000,`Picture Quality`选择框使用默认选项,点击`Connect`进入到安装操作系统的界面,你可以安装常规的方式进行安装,等待系统安装完成重启,然后就可以正常使用kvm虚拟化出来的操作系统了。
+
+`Tightvnc`软件的使用,请参考官方手册。
+
+* Tightvnc下载地址:[www.tightvnc.com/download.ph…](https://link.juejin.im/?target=http%3A%2F%2Fwww.tightvnc.com%2Fdownload.php)
+* Tightvnc下载地址:[www.tightvnc.com/download/2.…](https://link.juejin.im/?target=http%3A%2F%2Fwww.tightvnc.com%2Fdownload%2F2.7.10%2Ftightvnc-2.7.10-setup-64bit.msi)
+* Tightvnc下载地址:[www.tightvnc.com/download/2.…](https://link.juejin.im/?target=http%3A%2F%2Fwww.tightvnc.com%2Fdownload%2F2.7.10%2Ftightvnc-2.7.10-setup-32bit.msi)
+
+### KVM虚拟机管理
+
+kvm虚拟机是通过virsh命令进行管理的,libvirt是Linux上的虚拟化库,是长期稳定的C语言API,支持KVM/QEMU、Xen、LXC等主流虚拟化方案。链接:[libvirt.org/](https://link.juejin.im/?target=http%3A%2F%2Flibvirt.org%2F)
+virsh是Libvirt对应的shell命令。
+
+查看所有虚拟机状态
+
+```
+virsh list --all
+
+```
+
+启动虚拟机
+
+```
+virsh start [NAME]
+
+```
+
+列表启动状态的虚拟机
+
+```
+virsh list
+
+```
+
+* 常用命令查看
+
+ ```
+ virsh --help|more less
+
+ ```
+
+### libvirt虚拟机配置文件
+
+虚拟机libvirt配置文件在`/etc/libvirt/qemu`路径下,生产中我们需要去修改它的网络信息。
+
+```
+# lltotal 8-rw-------. 1 root root 3047 Oct 19 2016 Centos-6.6-x68_64.xmldrwx------. 3 root root 4096 Oct 17 2016 networks
+```
+
+`注意`:不能直接修改xml文件,需要通过提供的命令!
+
+```
+ virsh edit Centos-6.6-x68_64
+
+```
+
+kvm三种网络类型,桥接、NAT、仅主机模式,默认NAT模式,其他机器无法登陆,生产中一般选择桥接。
+
+### 监控kvm虚拟机
+
+* 安装软件监控虚拟机
+
+```
+yum install virt-top -y
+
+```
+
+* 查看虚拟机资源使用情况
+
+```
+virt-top virt-top 23:46:39 - x86_64 1/1CPU 3392MHz 3816MB1 domains, 1 active, 1 running, 0 sleeping, 0 paused, 0 inactive D:0 O:0 X:0CPU: 5.6% Mem: 2024 MB (2024 MB by guests) ID S RDRQ WRRQ RXBY TXBY %CPU %MEM TIME NAME 1 R 0 1 52 0 5.6 53.0 5:16.15 centos-6.8
+```
+
+### KVM修改NAT模式为桥接[案例]
+
+在开始案例之前,需要知道的必要信息,宿主机IP是`192.168.2.200`,操作系统版本`Centos-6.6-x68_64`。
+
+启动虚拟网卡
+
+```
+ifup eth0
+
+```
+
+这里网卡是NAT模式,可以上网,ping通其他机器,但是其他机器无法登陆!
+
+宿主机查看网卡信息
+
+```
+brctl show ifconfig virbr0 ifconfig vnet0
+```
+
+_实现网桥,在kvm宿主机完成_
+
+* 步骤1,创建一个网桥,新建网桥连接到eth0,删除eth0,让新的网桥拥有eth0的ip
+
+```
+brctl addbr br0 #创建一个网桥 brctl show #显示网桥信息 brctl addif br0 eth0 && ip addr del dev eth0 192.168.2.200/24 && ifconfig br0 192.168.2.200/24 up brctl show #查看结果ifconfig br0 #验证br0是否成功取代了eth0的IP
+```
+
+`注意`: 这里的IP地址为 _宿主机ip_
+
+* 修改虚拟机桥接到br0网卡,在宿主机修改
+
+```
+virsh list --all ps aux |grep kvm virsh stop Centos-6.6-x68_64 virsh list --all
+```
+
+修改虚拟机桥接到宿主机,修改52行type为`bridge`,第54行bridge为`br0`
+
+```
+# virsh edit Centos-6.6-x68_64 # 命令 52 53 54 55 56 修改为:52 53 54 55 56
+```
+
+启动虚拟机,看到启动前后,桥接变化,vnet0被桥接到了br0
+
+启动前:
+
+```
+# brctl showbridge name bridge id STP enabled interfacesbr0 8000.000c29f824c9 no eth0virbr0 8000.525400353d8e yes virbr0-nic
+```
+
+启动后:
+
+```
+# virsh start CentOS-6.6-x86_64Domain CentOS-6.6-x86_64 started # brctl show bridge name bridge id STP enabled interfacesbr0 8000.000c29f824c9 no eth0 vnet0virbr0 8000.525400353d8e yes virbr0-nic
+```
+
+Vnc登陆后,修改ip地址,看到dhcp可以使用,被桥接到现有的ip段,ip是自动获取,而且是和宿主机在同一个IP段.
+
+```
+# ifup eth0
+
+```
+
+从宿主机登陆此服务器,可以成功。
+
+```
+# ssh 192.168.2.108root@192.168.2.108's password: Last login: Sat Jan 30 12:40:28 2016
+```
+
+从同一网段其他服务器登陆此虚拟机,也可以成功,至此让kvm管理的服务器能够桥接上网就完成了,在生产环境中,桥接上网是非常必要的。
+
+### 总结
+
+通过kvm相关的命令来创建虚拟机,安装和调试是非常必要的,因为现有的很多私有云,公有云产品都使用到了kvm这样的技术,学习基本的kvm使用对维护`openstack`集群有非常要的作用,其次所有的`openstack image`制作也得通过kvm这样的底层技术来完成,最后上传到`openstack`的镜像管理模块,才能开始通过`openstack image`生成云主机。
+
+到此,各位应该能够体会到,其实kvm是一个非常底层和核心的虚拟化技术,而openstack就是对`kvm`这样的技术进行了一个上层封装,可以非常方便,可视化的操作和维护`kvm`虚拟机,这就是现在`牛`上天的`云计算`技术最底层技术栈,具体怎么实现请看下图。
+
+
+
+如上图,没有`openstack`我们依然可以通过,`libvirt`来对虚拟机进行操作,只不过比较繁琐和难以维护。通过openstack就可以非常方便的进行底层虚拟化技术的管理、维护、使用。
+
+
diff --git "a/docs/big-backEnd/\345\220\216\347\253\257\346\212\200\346\234\257\346\235\202\350\260\2108\357\274\232OpenStack\346\236\266\346\236\204\350\256\276\350\256\241.md" "b/docs/big-backEnd/\345\220\216\347\253\257\346\212\200\346\234\257\346\235\202\350\260\2108\357\274\232OpenStack\346\236\266\346\236\204\350\256\276\350\256\241.md"
new file mode 100644
index 0000000..154a8c8
--- /dev/null
+++ "b/docs/big-backEnd/\345\220\216\347\253\257\346\212\200\346\234\257\346\235\202\350\260\2108\357\274\232OpenStack\346\236\266\346\236\204\350\256\276\350\256\241.md"
@@ -0,0 +1,167 @@
+OpenStack 是开源云计算平台,支持多种虚拟化环境,并且其服务组件都提供了 API接口 便于二次开发。
+
+OpenStack通过各种补充服务提供基础设施即服务 Infrastructure-as-a-Service (IaaS)`的解决方案。每个服务都提供便于集成的应用程序接口`Application Programming Interface (API)。
+
+### openstack 逻辑架构图
+
+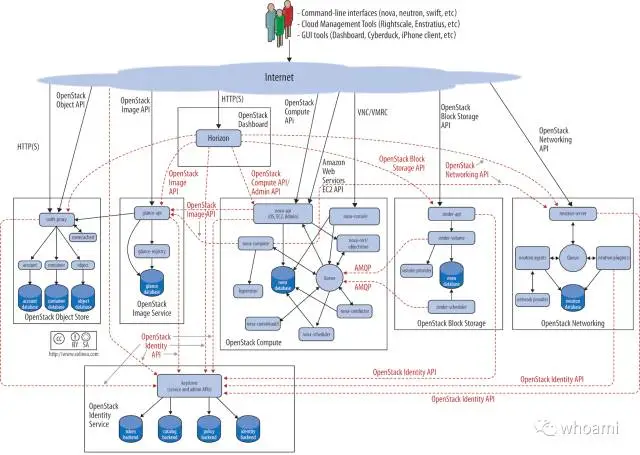
+
+OpenStack 本身是一个分布式系统,不但各个服务可以分布部署,服务中的组件也可以分布部署。 这种分布式特性让 OpenStack 具备极大的灵活性、伸缩性和高可用性。 当然从另一个角度讲,这也使得 OpenStack 比一般系统复杂,学习难度也更大。
+
+后面章节我们会深入学习 Keystone、Glance、Nova、Neutron 和 Cinder 这几个 OpenStack 最重要最核心的服务。
+
+openstack的核心和扩展的主要项目如下:
+
+* OpenStack Compute (code-name Nova) 计算服务
+
+* OpenStack Networking (code-name Neutron) 网络服务
+
+* OpenStack Object Storage (code-name Swift) 对象存储服务
+
+* OpenStack Block Storage (code-name Cinder) 块设备存储服务
+
+* OpenStack Identity (code-name Keystone) 认证服务
+
+* OpenStack Image Service (code-name Glance) 镜像文件服务
+
+* OpenStack Dashboard (code-name Horizon) 仪表盘服务
+
+* OpenStack Telemetry (code-name Ceilometer) 告警服务
+
+* OpenStack Orchestration (code-name Heat) 流程服务
+
+* OpenStack Database (code-name Trove) 数据库服务
+
+OpenStack的各个服务之间通过统一的REST风格的API调用,实现系统的松耦合。上图是OpenStack各个服务之间API调用的概览,其中实线代表client 的API调用,虚线代表各个组件之间通过rpc调用进行通信。松耦合架构的好处是,各个组件的开发人员可以只关注各自的领域,对各自领域的修改不会影响到其他开发人员。不过从另一方面来讲,这种松耦合的架构也给整个系统的维护带来了一定的困难,运维人员要掌握更多的系统相关的知识去调试出了问题的组件。所以无论对于开发还是维护人员,搞清楚各个组件之间的相互调用关系是怎样的都是非常必要的。
+
+对Linux经验丰富的OpenStack新用户,使用openstack是非常容易的,在后续`openstack系列`文章中会逐步展开介绍。
+
+### OpenStack 项目和组件
+
+OpenStack services
+
+* Dashboard 【Horizon】 提供了一个基于web的自服务门户,与OpenStack底层服务交互,诸如启动一个实例,分配IP地址以及配置访问控制。
+
+* Compute 【Nova】 在OpenStack环境中计算实例的生命周期管理。按需响应包括生成、调度、回收虚拟机等操作。
+
+* Networking 【Neutron】 确保为其它OpenStack服务提供网络连接即服务,比如OpenStack计算。为用户提供API定义网络和使用。基于插件的架构其支持众多的网络提供商和技术。
+
+* Object Storage 【Swift】 通过一个 RESTful,基于HTTP的应用程序接口存储和任意检索的非结构化数据对象。它拥有高容错机制,基于数据复制和可扩展架构。它的实现并像是一个文件服务器需要挂载目录。在此种方式下,它写入对象和文件到多个硬盘中,以确保数据是在集群内跨服务器的多份复制。
+
+* Block Storage 【Cinder】 为运行实例而提供的持久性块存储。它的可插拔驱动架构的功能有助于创建和管理块存储设备。
+
+* Identity service 【Keystone】 为其他OpenStack服务提供认证和授权服务,为所有的OpenStack服务提供一个端点目录。
+
+* Image service 【Glance】 存储和检索虚拟机磁盘镜像,OpenStack计算会在实例部署时使用此服务。
+
+* Telemetry服务 【Ceilometer】 为OpenStack云的计费、基准、扩展性以及统计等目的提供监测和计量。
+
+* Orchestration服务 【Heat服务】 Orchestration服务支持多样化的综合的云应用,通过调用OpenStack-native REST API和CloudFormation-compatible Query API,支持`HOT `格式模板或者AWS CloudFormation格式模板
+
+通过对这些组件的介绍,可以帮助我们在后续的内容中,了解各个组件的作用,便于排查问题,而在你对基础安装,配置,操作和故障诊断熟悉之后,你应该考虑按照生产架构来进行部署。
+
+### 生产部署架构
+
+建议使用自动化部署工具,例如Ansible, Chef, Puppet, or Salt来自动化部署,管理生产环境。
+
+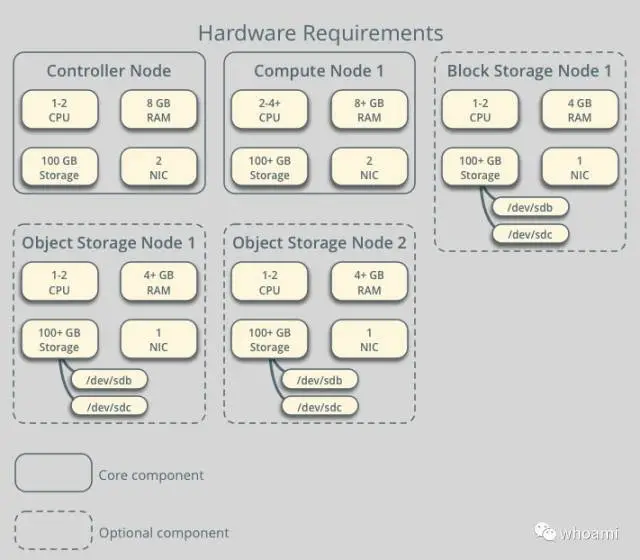
+
+这个示例架构需要至少2个(主机)节点来启动基础服务`virtual machine `或者实例。像块存储服务,对象存储服务这一类服务还需要额外的节点。
+
+* 网络代理驻留在控制节点上而不是在一个或者多个专用的网络节点上。
+
+* 私有网络的覆盖流量通过管理网络而不是专用网络
+
+#### 控制器
+
+控制节点上运行身份认证服务,镜像服务,计算服务的管理部分,网络服务的管理部分,多种网络代理以及仪表板。也需要包含一些支持服务,例如:SQL数据库,term:消息队列, and NTP。
+
+可选的,可以在计算节点上运行部分块存储,对象存储,Orchestration 和 Telemetry 服务。
+
+计算节点上需要至少两块网卡。
+
+#### 计算
+
+计算节点上运行计算服务中管理实例的管理程序部分。默认情况下,计算服务使用 KVM。
+
+你可以部署超过一个计算节点。每个结算节点至少需要两块网卡。
+
+#### 块设备存储
+
+可选的块存储节点上包含了磁盘,块存储服务和共享文件系统会向实例提供这些磁盘。
+
+为了简单起见,计算节点和本节点之间的服务流量使用管理网络。生产环境中应该部署一个单独的存储网络以增强性能和安全。
+
+你可以部署超过一个块存储节点。每个块存储节点要求至少一块网卡。
+
+#### 对象存储
+
+可选的对象存储节点包含了磁盘。对象存储服务用这些磁盘来存储账号,容器和对象。
+
+为了简单起见,计算节点和本节点之间的服务流量使用管理网络。生产环境中应该部署一个单独的存储网络以增强性能和安全。
+
+这个服务要求两个节点。每个节点要求最少一块网卡。你可以部署超过两个对象存储节点。
+
+#### 网络
+
+openstack网络是非常复杂的,并且也支持多种模式其中支持GRE,VLAN,VXLAN等,在openstack中网络是通过一个组件`Neutron`提供服务,Neutron 管理的网络资源包括如下。
+
+* network 是一个隔离的二层广播域。Neutron 支持多种类型的 network,包括 local, flat, VLAN, VxLAN 和 GRE。
+
+* local 网络与其他网络和节点隔离。local 网络中的 instance 只能与位于同一节点上同一网络的 instance 通信,local 网络主要用于单机测试。
+
+* flat 网络是无 vlan tagging 的网络。flat 网络中的 instance 能与位于同一网络的 instance 通信,并且可以跨多个节点。
+
+* vlan 网络是具有 802.1q tagging 的网络。vlan 是一个二层的广播域,同一 vlan 中的 instance 可以通信,不同 vlan 只能通过 router 通信。vlan 网络可以跨节点,是应用最广泛的网络类型。
+
+* vxlan 是基于隧道技术的 overlay 网络。vxlan 网络通过唯一的 segmentation ID(也叫 VNI)与其他 vxlan 网络区分。vxlan 中数据包会通过 VNI 封装成 UPD 包进行传输。因为二层的包通过封装在三层传输,能够克服 vlan 和物理网络基础设施的限制。
+
+* gre 是与 vxlan 类似的一种 overlay 网络。主要区别在于使用 IP 包而非 UDP 进行封装。 不同 network 之间在二层上是隔离的。以 vlan 网络为例,network A 和 network B 会分配不同的 VLAN ID,这样就保证了 network A 中的广播包不会跑到 network B 中。当然,这里的隔离是指二层上的隔离,借助路由器不同 network 是可能在三层上通信的。network 必须属于某个 Project( Tenant 租户),Project 中可以创建多个 network。 network 与 Project 之间是 1对多关系。
+
+* subnet 是一个 IPv4 或者 IPv6 地址段。instance 的 IP 从 subnet 中分配。每个 subnet 需要定义 IP 地址的范围和掩码。
+
+* port 可以看做虚拟交换机上的一个端口。port 上定义了 MAC 地址和 IP 地址,当 instance 的虚拟网卡 VIF(Virtual Interface) 绑定到 port 时,port 会将 MAC 和 IP 分配给 VIF。port 与 subnet 是 1对多 关系。一个 port 必须属于某个 subnet;一个 subnet 可以有多个 port。
+
+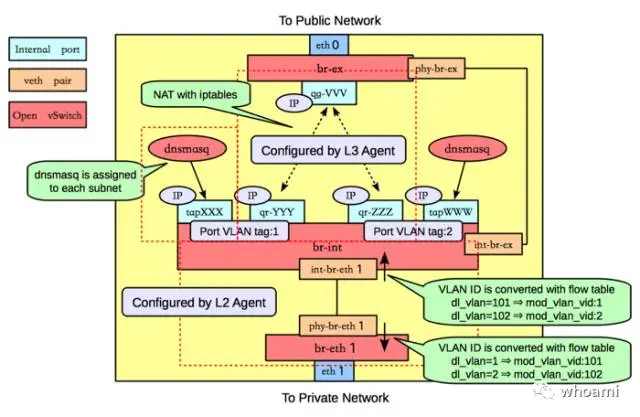
+
+如上图所示,为VLAN模式下,网络节点的通信方式。
+
+在我们后续实施安装的时候,选择使用VXLAN网络模式,下面我们来重点介绍一下VXLAN模式。
+
+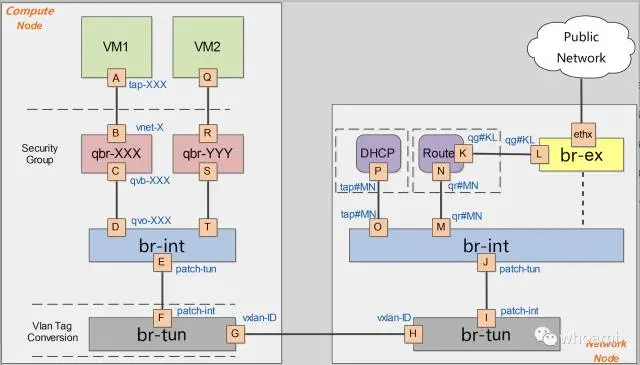
+
+VXLAN网络模式,可以隔离广播风暴,不需要交换机配置chunk口,解决了vlan id个数限制,解决了gre点对点隧道个数过多问题,实现了大2层网络,可以让vm在机房之间无缝迁移,便于跨机房部署。缺点是,vxlan增加了ip头部大小,需要降低vm的mtu值,传输效率上会略有下降。
+
+### 涉及的 Linux 网络技术
+
+Neutron 的设计目标是实现“网络即服务”,为了达到这一目标,在设计上遵循了基于“软件定义网络”实现网络虚拟化的原则,在实现上充分利用了 Linux 系统上的各种网络相关的技术。理解了 Linux 系统上的这些概念将有利于快速理解 Neutron 的原理和实现。
+
+* bridge:网桥,Linux中用于表示一个能连接不同网络设备的虚拟设备,linux中传统实现的网桥类似一个hub设备,而ovs管理的网桥一般类似交换机。
+
+* br-int:bridge-integration,综合网桥,常用于表示实现主要内部网络功能的网桥。
+
+* br-ex:bridge-external,外部网桥,通常表示负责跟外部网络通信的网桥。
+
+* GRE:General Routing Encapsulation,一种通过封装来实现隧道的方式。在openstack中一般是基于L3的gre,即original pkt/GRE/IP/Ethernet
+
+* VETH:虚拟ethernet接口,通常以pair的方式出现,一端发出的网包,会被另一端接收,可以形成两个网桥之间的通道。
+
+* qvb:neutron veth, Linux Bridge-side
+
+* qvo:neutron veth, OVS-side
+
+* TAP设备:模拟一个二层的网络设备,可以接受和发送二层网包。
+
+* TUN设备:模拟一个三层的网络设备,可以接受和发送三层网包。
+
+* iptables:Linux 上常见的实现安全策略的防火墙软件。
+
+* Vlan:虚拟 Lan,同一个物理 Lan 下用标签实现隔离,可用标号为1-4094。
+
+* VXLAN:一套利用 UDP 协议作为底层传输协议的 Overlay 实现。一般认为作为 VLan 技术的延伸或替代者。
+
+* namespace:用来实现隔离的一套机制,不同 namespace 中的资源之间彼此不可见。
+
+### 总结
+
+openstack是一个非法复杂的分布式软件,涉及到很多底层技术,我自己对一些网络的理解也是非常有限,主要还是应用层面的知识,所以本章内容写的比较浅显一些,有问题请留言?在下一章节我们会进入生产环境如何实施规划openstack集群,至于openstack底层的技术,我也没有很深入研究,如果有任何不恰当的地方可以进行留言,非常感谢!
\ No newline at end of file
diff --git "a/docs/big-backEnd/\345\220\216\347\253\257\346\212\200\346\234\257\346\235\202\350\260\2109\357\274\232\345\205\210\346\220\236\346\207\202Docker\346\240\270\345\277\203\346\246\202\345\277\265\345\220\247.md" "b/docs/big-backEnd/\345\220\216\347\253\257\346\212\200\346\234\257\346\235\202\350\260\2109\357\274\232\345\205\210\346\220\236\346\207\202Docker\346\240\270\345\277\203\346\246\202\345\277\265\345\220\247.md"
new file mode 100644
index 0000000..9572f7d
--- /dev/null
+++ "b/docs/big-backEnd/\345\220\216\347\253\257\346\212\200\346\234\257\346\235\202\350\260\2109\357\274\232\345\205\210\346\220\236\346\207\202Docker\346\240\270\345\277\203\346\246\202\345\277\265\345\220\247.md"
@@ -0,0 +1,207 @@
+# 可能是把Docker的概念讲的最清楚的一篇文章
+
+
+
+本文只是对Docker的概念做了较为详细的介绍,并不涉及一些像Docker环境的安装以及Docker的一些常见操作和命令。
+
+阅读本文大概需要15分钟,通过阅读本文你将知道一下概念:
+
+* 容器
+* 什么是Docker?
+* Docker思想、特点
+* Docker容器主要解决什么问题
+* 容器 VS 虚拟机
+* Docker基本概念: 镜像(Image),容器(Container),仓库(Repository)
+
+* * *
+
+> Docker 是世界领先的软件容器平台,所以想要搞懂Docker的概念我们必须先从容器开始说起。
+
+## 一 先从认识容器开始
+
+### 1.1 什么是容器?
+
+#### 先来看看容器较为官方的解释
+
+一句话概括容器:容器就是将软件打包成标准化单元,以用于开发、交付和部署。
+
+* 容器镜像是轻量的、可执行的独立软件包 ,包含软件运行所需的所有内容:代码、运行时环境、系统工具、系统库和设置。
+* 容器化软件适用于基于Linux和Windows的应用,在任何环境中都能够始终如一地运行。
+* 容器赋予了软件独立性 ,使其免受外在环境差异(例如,开发和预演环境的差异)的影响,从而有助于减少团队间在相同基础设施上运行不同软件时的冲突。
+
+#### 再来看看容器较为通俗的解释
+
+如果需要通俗的描述容器的话,我觉得容器就是一个存放东西的地方,就像书包可以装各种文具、衣柜可以放各种衣服、鞋架可以放各种鞋子一样。我们现在所说的容器存放的东西可能更偏向于应用比如网站、程序甚至是系统环境。
+
+
+
+### 1.2 图解物理机、虚拟机与容器
+
+关于虚拟机与容器的对比在后面会详细介绍到,这里只是通过网上的图片加深大家对于物理机、虚拟机与容器这三者的理解。
+
+物理机
+
+
+
+虚拟机:
+
+
+
+容器:
+
+
+
+通过上面这三张抽象图,我们可以大概可以通过类比概括出: 容器虚拟化的是操作系统而不是硬件,容器之间是共享同一套操作系统资源的。虚拟机技术是虚拟出一套硬件后,在其上运行一个完整操作系统。因此容器的隔离级别会稍低一些。
+
+* * *
+
+> 相信通过上面的解释大家对于容器这个既陌生又熟悉的概念有了一个初步的认识,下面我们就来谈谈Docker的一些概念。
+
+## 二 再来谈谈Docker的一些概念
+
+
+
+### 2.1 什么是Docker?
+
+说实话关于Docker是什么并太好说,下面我通过四点向你说明Docker到底是个什么东西。
+
+* Docker 是世界领先的软件容器平台。
+* Docker 使用 Google 公司推出的 Go 语言 进行开发实现,基于 Linux 内核 的cgroup,namespace,以及AUFS类的UnionFS等技术,对进程进行封装隔离,属于操作系统层面的虚拟化技术。 由于隔离的进程独立于宿主和其它的隔离的进 程,因此也称其为容器。Docke最初实现是基于 LXC.
+* Docker 能够自动执行重复性任务,例如搭建和配置开发环境,从而解放了开发人员以便他们专注在真正重要的事情上:构建杰出的软件。
+* 用户可以方便地创建和使用容器,把自己的应用放入容器。容器还可以进行版本管理、复制、分享、修改,就像管理普通的代码一样。
+
+
+
+### 2.2 Docker思想
+
+* 集装箱
+* 标准化: ①运输方式 ② 存储方式 ③ API接口
+* 隔离
+
+### 2.3 Docker容器的特点
+
+* #### 轻量
+
+ 在一台机器上运行的多个 Docker 容器可以共享这台机器的操作系统内核;它们能够迅速启动,只需占用很少的计算和内存资源。镜像是通过文件系统层进行构造的,并共享一些公共文件。这样就能尽量降低磁盘用量,并能更快地下载镜像。
+
+* #### 标准
+
+ Docker 容器基于开放式标准,能够在所有主流 Linux 版本、Microsoft Windows 以及包括 VM、裸机服务器和云在内的任何基础设施上运行。
+
+* #### 安全
+
+ Docker 赋予应用的隔离性不仅限于彼此隔离,还独立于底层的基础设施。Docker 默认提供最强的隔离,因此应用出现问题,也只是单个容器的问题,而不会波及到整台机器。
+
+### 2.4 为什么要用Docker
+
+* Docker 的镜像提供了除内核外完整的运行时环境,确保了应用运行环境一致性,从而不会再出现 “这段代码在我机器上没问题啊” 这类问题;——一致的运行环境
+* 可以做到秒级、甚至毫秒级的启动时间。大大的节约了开发、测试、部署的时间。——更快速的启动时间
+* 避免公用的服务器,资源会容易受到其他用户的影响。——隔离性
+* 善于处理集中爆发的服务器使用压力;——弹性伸缩,快速扩展
+* 可以很轻易的将在一个平台上运行的应用,迁移到另一个平台上,而不用担心运行环境的变化导致应用无法正常运行的情况。——迁移方便
+* 使用 Docker 可以通过定制应用镜像来实现持续集成、持续交付、部署。——持续交付和部署
+
+* * *
+
+> 每当说起容器,我们不得不将其与虚拟机做一个比较。就我而言,对于两者无所谓谁会取代谁,而是两者可以和谐共存。
+
+## 三 容器 VS 虚拟机
+
+ 简单来说: 容器和虚拟机具有相似的资源隔离和分配优势,但功能有所不同,因为容器虚拟化的是操作系统,而不是硬件,因此容器更容易移植,效率也更高。
+
+### 3.1 两者对比图
+
+ 传统虚拟机技术是虚拟出一套硬件后,在其上运行一个完整操作系统,在该系统上再运行所需应用进程;而容器内的应用进程直接运行于宿主的内核,容器内没有自己的内核,而且也没有进行硬件虚拟。因此容器要比传统虚拟机更为轻便.
+
+
+
+### 3.2 容器与虚拟机 (VM) 总结
+
+
+
+* 容器是一个应用层抽象,用于将代码和依赖资源打包在一起。 多个容器可以在同一台机器上运行,共享操作系统内核,但各自作为独立的进程在用户空间中运行 。与虚拟机相比, 容器占用的空间较少(容器镜像大小通常只有几十兆),瞬间就能完成启动 。
+
+* 虚拟机 (VM) 是一个物理硬件层抽象,用于将一台服务器变成多台服务器。 管理程序允许多个 VM 在一台机器上运行。每个VM都包含一整套操作系统、一个或多个应用、必要的二进制文件和库资源,因此 占用大量空间 。而且 VM 启动也十分缓慢 。
+
+ 通过Docker官网,我们知道了这么多Docker的优势,但是大家也没有必要完全否定虚拟机技术,因为两者有不同的使用场景。虚拟机更擅长于彻底隔离整个运行环境。例如,云服务提供商通常采用虚拟机技术隔离不同的用户。而 Docker通常用于隔离不同的应用 ,例如前端,后端以及数据库。
+
+### 3.3 容器与虚拟机 (VM)两者是可以共存的
+
+就我而言,对于两者无所谓谁会取代谁,而是两者可以和谐共存。
+
+
+
+* * *
+
+> Docker中非常重要的三个基本概念,理解了这三个概念,就理解了 Docker 的整个生命周期。
+
+## 四 Docker基本概念
+
+Docker 包括三个基本概念
+
+* 镜像(Image)
+* 容器(Container)
+* 仓库(Repository)
+
+理解了这三个概念,就理解了 Docker 的整个生命周期
+
+
+
+### 4.1 镜像(Image)——一个特殊的文件系统
+
+ 操作系统分为内核和用户空间。对于 Linux 而言,内核启动后,会挂载 root 文件系统为其提供用户空间支持。而Docker 镜像(Image),就相当于是一个 root 文件系统。
+
+ Docker 镜像是一个特殊的文件系统,除了提供容器运行时所需的程序、库、资源、配置等文件外,还包含了一些为运行时准备的一些配置参数(如匿名卷、环境变量、用户等)。 镜像不包含任何动态数据,其内容在构建之后也不会被改变。
+
+ Docker 设计时,就充分利用 Union FS的技术,将其设计为 分层存储的架构 。 镜像实际是由多层文件系统联合组成。
+
+ 镜像构建时,会一层层构建,前一层是后一层的基础。每一层构建完就不会再发生改变,后一层上的任何改变只发生在自己这一层。 比如,删除前一层文件的操作,实际不是真的删除前一层的文件,而是仅在当前层标记为该文件已删除。在最终容器运行的时候,虽然不会看到这个文件,但是实际上该文件会一直跟随镜像。因此,在构建镜像的时候,需要额外小心,每一层尽量只包含该层需要添加的东西,任何额外的东西应该在该层构建结束前清理掉。
+
+ 分层存储的特征还使得镜像的复用、定制变的更为容易。甚至可以用之前构建好的镜像作为基础层,然后进一步添加新的层,以定制自己所需的内容,构建新的镜像。
+
+### 4.2 容器(Container)——镜像运行时的实体
+
+ 镜像(Image)和容器(Container)的关系,就像是面向对象程序设计中的 类 和 实例 一样,镜像是静态的定义,容器是镜像运行时的实体。容器可以被创建、启动、停止、删除、暂停等。
+
+ 容器的实质是进程,但与直接在宿主执行的进程不同,容器进程运行于属于自己的独立的 命名空间。前面讲过镜像使用的是分层存储,容器也是如此。
+
+ 容器存储层的生存周期和容器一样,容器消亡时,容器存储层也随之消亡。因此,任何保存于容器存储层的信息都会随容器删除而丢失。
+
+ 按照 Docker 最佳实践的要求,容器不应该向其存储层内写入任何数据 ,容器存储层要保持无状态化。所有的文件写入操作,都应该使用数据卷(Volume)、或者绑定宿主目录,在这些位置的读写会跳过容器存储层,直接对宿主(或网络存储)发生读写,其性能和稳定性更高。数据卷的生存周期独立于容器,容器消亡,数据卷不会消亡。因此, 使用数据卷后,容器可以随意删除、重新 run ,数据却不会丢失。
+
+### 4.3 仓库(Repository)——集中存放镜像文件的地方
+
+ 镜像构建完成后,可以很容易的在当前宿主上运行,但是, 如果需要在其它服务器上使用这个镜像,我们就需要一个集中的存储、分发镜像的服务,Docker Registry就是这样的服务。
+
+ 一个 Docker Registry中可以包含多个仓库(Repository);每个仓库可以包含多个标签(Tag);每个标签对应一个镜像。所以说:镜像仓库是Docker用来集中存放镜像文件的地方类似于我们之前常用的代码仓库。
+
+ 通常,一个仓库会包含同一个软件不同版本的镜像,而标签就常用于对应该软件的各个版本 。我们可以通过`<仓库名>:<标签>`的格式来指定具体是这个软件哪个版本的镜像。如果不给出标签,将以 latest 作为默认标签.。
+
+这里补充一下Docker Registry 公开服务和私有 Docker Registry的概念:
+
+ Docker Registry 公开服务 是开放给用户使用、允许用户管理镜像的 Registry 服务。一般这类公开服务允许用户免费上传、下载公开的镜像,并可能提供收费服务供用户管理私有镜像。
+
+ 最常使用的 Registry 公开服务是官方的 Docker Hub ,这也是默认的 Registry,并拥有大量的高质量的官方镜像,网址为:[hub.docker.com/](https://link.juejin.im/?target=https%3A%2F%2Fhub.docker.com%2F) 。在国内访问Docker Hub 可能会比较慢国内也有一些云服务商提供类似于 Docker Hub 的公开服务。比如 [时速云镜像库](https://link.juejin.im/?target=https%3A%2F%2Fhub.tenxcloud.com%2F)、[网易云镜像服务](https://link.juejin.im/?target=https%3A%2F%2Fwww.163yun.com%2Fproduct%2Frepo)、[DaoCloud 镜像市场](https://link.juejin.im/?target=https%3A%2F%2Fwww.daocloud.io%2F)、[阿里云镜像库](https://link.juejin.im/?target=https%3A%2F%2Fwww.aliyun.com%2Fproduct%2Fcontainerservice%3Futm_content%3Dse_1292836)等。
+
+ 除了使用公开服务外,用户还可以在 本地搭建私有 Docker Registry 。Docker 官方提供了 Docker Registry 镜像,可以直接使用做为私有 Registry 服务。开源的 Docker Registry 镜像只提供了 Docker Registry API 的服务端实现,足以支持 docker 命令,不影响使用。但不包含图形界面,以及镜像维护、用户管理、访问控制等高级功能。
+
+* * *
+
+> Docker的概念基本上已经讲完,最后我们谈谈:Build, Ship, and Run。
+
+## 五 最后谈谈:Build, Ship, and Run
+
+如果你搜索Docker官网,会发现如下的字样:“Docker - Build, Ship, and Run Any App, Anywhere”。那么Build, Ship, and Run到底是在干什么呢?
+
+
+
+* Build(构建镜像) : 镜像就像是集装箱包括文件以及运行环境等等资源。
+* Ship(运输镜像) :主机和仓库间运输,这里的仓库就像是超级码头一样。
+* Run (运行镜像) :运行的镜像就是一个容器,容器就是运行程序的地方。
+
+Docker 运行过程也就是去仓库把镜像拉到本地,然后用一条命令把镜像运行起来变成容器。所以,我们也常常将Docker称为码头工人或码头装卸工,这和Docker的中文翻译搬运工人如出一辙。
+
+## 六 总结
+
+本文主要把Docker中的一些常见概念做了详细的阐述,但是并不涉及Docker的安装、镜像的使用、容器的操作等内容。这部分东西,希望读者自己可以通过阅读书籍与官方文档的形式掌握。如果觉得官方文档阅读起来很费力的话,这里推荐一本书籍《Docker技术入门与实战第二版》。
+
diff --git "a/docs/big-backEnd/\345\220\216\347\253\257\346\212\200\346\234\257\346\235\202\350\260\210\345\274\200\347\257\207\357\274\232\344\272\221\350\256\241\347\256\227\357\274\214\345\244\247\346\225\260\346\215\256\344\270\216AI\347\232\204\346\225\205\344\272\213.md" "b/docs/big-backEnd/\345\220\216\347\253\257\346\212\200\346\234\257\346\235\202\350\260\210\345\274\200\347\257\207\357\274\232\344\272\221\350\256\241\347\256\227\357\274\214\345\244\247\346\225\260\346\215\256\344\270\216AI\347\232\204\346\225\205\344\272\213.md"
new file mode 100644
index 0000000..7e3ca3c
--- /dev/null
+++ "b/docs/big-backEnd/\345\220\216\347\253\257\346\212\200\346\234\257\346\235\202\350\260\210\345\274\200\347\257\207\357\274\232\344\272\221\350\256\241\347\256\227\357\274\214\345\244\247\346\225\260\346\215\256\344\270\216AI\347\232\204\346\225\205\344\272\213.md"
@@ -0,0 +1,373 @@
+# [快速看懂云计算,大数据,人工智能](https://www.cnblogs.com/popsuper1982/p/8505203.html)
+
+
+
+
+
+我今天要讲这三个话题,一个是云计算,一个大数据,一个人工智能,我为什么要讲这三个东西呢?因为这三个东西现在非常非常的火,它们之间好像互相有关系,一般谈云计算的时候也会提到大数据,谈人工智能的时候也会提大数据,谈人工智能的时候也会提云计算。所以说感觉他们又相辅相成不可分割,如果是非技术的人员来讲可能比较难理解说这三个之间的相互关系,所以有必要解释一下。
+
+一、云计算最初是实现资源管理的灵活性
+
+我们首先来说云计算,云计算最初的目标是对资源的管理,管理的主要是计算资源,网络资源,存储资源三个方面。
+
+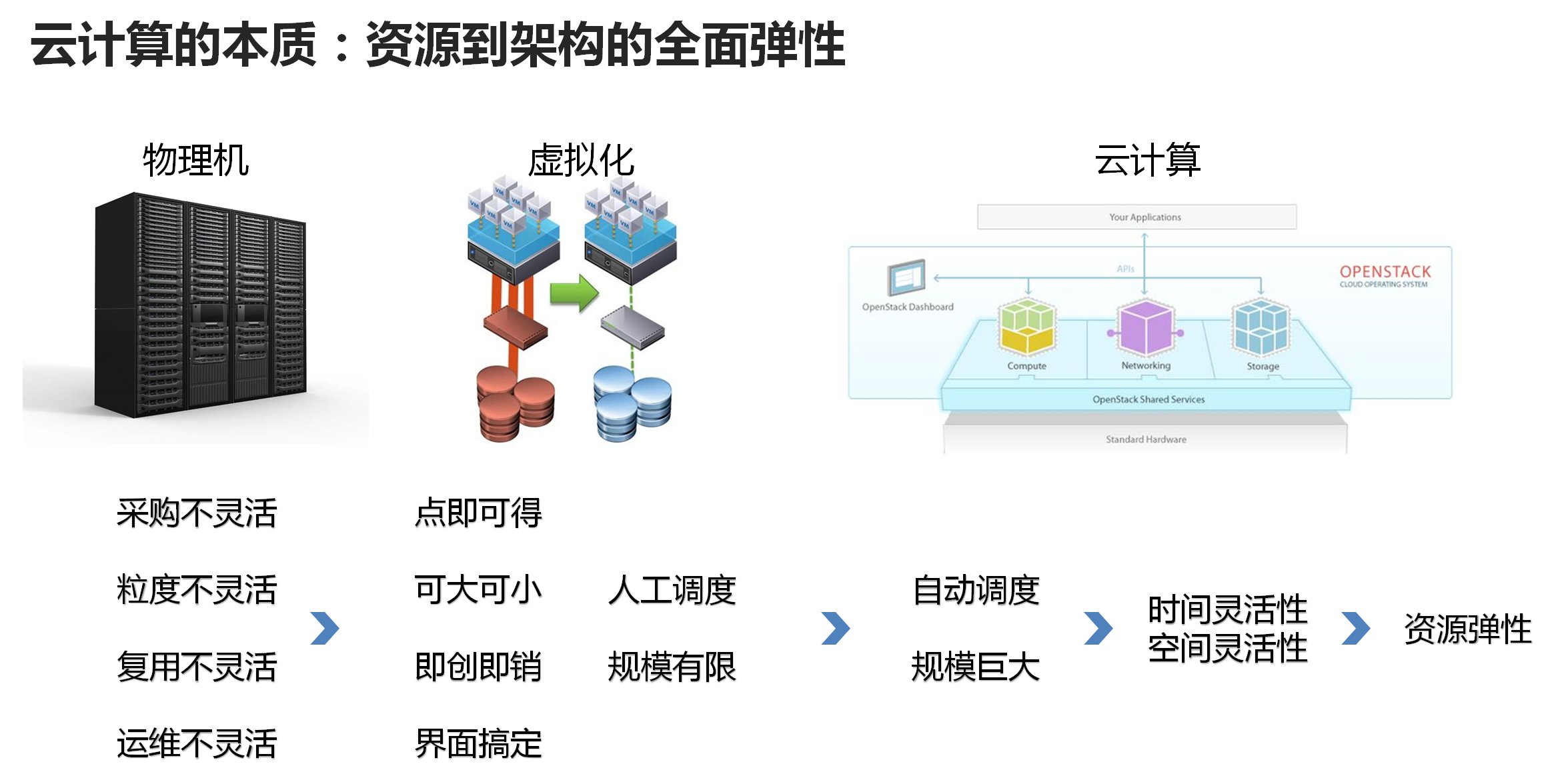
+
+
+
+1.1 管数据中心就像配电脑
+
+
+
+什么叫计算,网络,存储资源呢?就说你要买台笔记本电脑吧,你是不是要关心这台电脑什么样的CPU啊?多大的内存啊?这两个我们称为计算资源。
+
+
+
+这台电脑要能上网吧,需要有个网口可以插网线,或者有无线网卡可以连接我们家的路由器,您家也需要到运营商比如联通,移动,电信开通一个网络,比如100M的带宽,然后会有师傅弄一根网线到您家来,师傅可能会帮您将您的路由器和他们公司的网络连接配置好,这样您家的所有的电脑,手机,平板就都可以通过您的路由器上网了。这就是网络。
+
+
+
+您可能还会问硬盘多大啊?原来硬盘都很小,10G之类的,后来500G,1T,2T的硬盘也不新鲜了。(1T是1000G),这就是存储。
+
+
+
+对于一台电脑是这个样子的,对于一个数据中心也是同样的。想象你有一个非常非常大的机房,里面堆了很多的服务器,这些服务器也是有CPU,内存,硬盘的,也是通过类似路由器的设备上网的。这个时候的一个问题就是,运营数据中心的人是怎么把这些设备统一的管理起来的呢?
+
+1.2 灵活就是想啥时要都有,想要多少都行
+
+管理的目标就是要达到两个方面的灵活性。哪两个方面呢?比如有个人需要一台很小很小的电脑,只有一个CPU,1G内存,10G的硬盘,一兆的带宽,你能给他吗?像这种这么小规格的电脑,现在随便一个笔记本电脑都比这个配置强了,家里随便拉一个宽带都要100M。然而如果去一个云计算的平台上,他要想要这个资源的时候,只要一点就有了。
+
+所以说它就能达到两个方面灵活性。
+
+* 第一个方面就是想什么时候要就什么时候要,比如需要的时候一点就出来了,这个叫做时间灵活性。
+
+* 第二个方面就是想要多少呢就有多少,比如需要一个很小很小的电脑,可以满足,比如需要一个特别大的空间,以云盘为例,似乎云盘给每个人分配的空间动不动就就很大很大,随时上传随时有空间,永远用不完,这个叫做空间灵活性。
+
+空间灵活性和时间灵活性,也即我们常说的云计算的弹性。
+
+为了解决这个弹性的问题,经历了漫长时间的发展。
+
+1.3 物理设备不灵活
+
+首先第一个阶段就是物理机,或者说物理设备时期。这个时期相当于客户需要一台电脑,我们就买一台放在数据中心里。物理设备当然是越来越牛,例如服务器,内存动不动就是百G内存,例如网络设备,一个端口的带宽就能有几十G甚至上百G,例如存储,在数据中心至少是PB级别的(一个P是1000个T,一个T是1000个G)。
+
+然而物理设备不能做到很好的灵活性。首先它不能够达到想什么时候要就什么时候要、比如买台服务器,哪怕买个电脑,都有采购的时间。突然用户告诉某个云厂商,说想要开台电脑,如果使用物理服务器,当时去采购啊就很难,如果说供应商啊关系一般,可能采购一个月,供应商关系好的话也需要一个星期。用户等了一个星期后,这时候电脑才到位,用户还要登录上去开始慢慢部署自己的应用,时间灵活性非常差。第二是空间灵活性也不行,例如上述的用户,要一个很小很小的电脑,现在哪还有这么小型号的电脑啊。不能为了满足用户只要一个G的内存是80G硬盘的,就去买一个这么小的机器。但是如果买一个大的呢,因为电脑大,就向用户多收钱,用户说他只用这么小的一点,如果让用户多付钱就很冤。
+
+1.4 虚拟化灵活多了
+
+有人就想办法了。第一个办法就是虚拟化。用户不是只要一个很小的电脑么?数据中心的物理设备都很强大,我可以从物理的CPU,内存,硬盘中虚拟出一小块来给客户,同时也可以虚拟出一小块来给其他客户,每个客户都只能看到自己虚的那一小块,其实每个客户用的是整个大的设备上其中的一小块。虚拟化的技术能使得不同的客户的电脑看起来是隔离的,我看着好像这块盘就是我的,你看这呢这块盘就是你的,实际情况可能我这个10G和您这个10G是落在同样一个很大很大的这个存储上的。
+
+而且如果事先物理设备都准备好,虚拟化软件虚拟出一个电脑是非常快的,基本上几分钟就能解决。所以在任何一个云上要创建一台电脑,一点几分钟就出来了,就是这个道理。
+
+这个空间灵活性和时间灵活性就基本解决了。
+
+1.5 虚拟世界的赚钱与情怀
+
+在虚拟化阶段,最牛的公司是Vmware,是实现虚拟化技术比较早的一家公司,可以实现计算,网络,存储的虚拟化,这家公司很牛,性能也做得非常好,然后虚拟化软件卖的也非常好,赚了好多的钱,后来让EMC(世界五百强,存储厂商第一品牌)给收购了。
+
+但是这个世界上还是有很多有情怀的人的,尤其是程序员里面,有情怀的人喜欢做一件什么事情呢?开源。这个世界上很多软件都是有闭源就有开源,源就是源代码。就是说某个软件做的好,所有人都爱用,这个软件的代码呢,我封闭起来只有我公司知道,其他人不知道,如果其他人想用这个软件,就要付我钱,这就叫闭源。但是世界上总有一些大牛看不惯钱都让一家赚了去。大牛们觉得,这个技术你会我也会,你能开发出来,我也能,我开发出来就是不收钱,把代码拿出来分享给大家,全世界谁用都可以,所有的人都可以享受到好处,这个叫做开源。
+
+比如最近蒂姆·伯纳斯·李就是个非常有情怀的人,2017年,他因“发明万维网、第一个浏览器和使万维网得以扩展的基本协议和算法”而获得2016年度的图灵奖。图灵奖就是计算机界的诺贝尔奖。然而他最令人敬佩的是,他将万维网,也就是我们常见的www的技术无偿贡献给全世界免费使用。我们现在在网上的所有行为都应该感谢他的功劳,如果他将这个技术拿来收钱,应该和比尔盖茨差不多有钱。
+
+例如在闭源的世界里有windows,大家用windows都得给微软付钱,开源的世界里面就出现了Linux。比尔盖茨靠windows,Office这些闭源的软件赚了很多钱,称为世界首富,就有大牛开发了另外一种操作系统Linux。很多人可能没有听说过Linux,很多后台的服务器上跑的程序都是Linux上的,比如大家享受双十一,支撑双十一抢购的系统,无论是淘宝,京东,考拉,都是跑在Linux上的。
+
+再如有apple就有安卓。apple市值很高,但是苹果系统的代码我们是看不到的。于是就有大牛写了安卓手机操作系统。所以大家可以看到几乎所有的其他手机厂商,里面都装安卓系统,因为苹果系统不开源,而安卓系统大家都可以用。
+
+在虚拟化软件也一样,有了Vmware,这个软件非常非常的贵。那就有大牛写了两个开源的虚拟化软件,一个叫做Xen,一个叫做KVM,如果不做技术的,可以不用管这两个名字,但是后面还是会提到。
+
+1.6 虚拟化的半自动和云计算的全自动
+
+虚拟化软件似乎解决了灵活性问题,其实不全对。因为虚拟化软件一般创建一台虚拟的电脑,是需要人工指定这台虚拟电脑放在哪台物理机上的,可能还需要比较复杂的人工配置,所以使用Vmware的虚拟化软件,需要考一个很牛的证书,能拿到这个证书的人,薪资是相当的高,也可见复杂程度。所以仅仅凭虚拟化软件所能管理的物理机的集群规模都不是特别的大,一般在十几台,几十台,最多百台这么一个规模。这一方面会影响时间灵活性,虽然虚拟出一台电脑的时间很短,但是随着集群规模的扩大,人工配置的过程越来越复杂,越来越耗时。另一方面也影响空间灵活性,当用户数量多的时候,这点集群规模,还远达不到想要多少要多少的程度,很可能这点资源很快就用完了,还得去采购。所以随着集群的规模越来越大,基本都是千台起步,动辄上万台,甚至几十上百万台,如果去查一下BAT,包括网易,包括谷歌,亚马逊,服务器数目都大的吓人。这么多机器要靠人去选一个位置放这台虚拟化的电脑并做相应的配置,几乎是不可能的事情,还是需要机器去做这个事情。
+
+人们发明了各种各样的算法来做这个事情,算法的名字叫做调度(Scheduler)。通俗一点的说,就是有一个调度中心,几千台机器都在一个池子里面,无论用户需要多少CPU,内存,硬盘的虚拟电脑,调度中心会自动在大池子里面找一个能够满足用户需求的地方,把虚拟电脑启动起来做好配置,用户就直接能用了。这个阶段,我们称为池化,或者云化,到了这个阶段,才可以称为云计算,在这之前都只能叫虚拟化。
+
+1.7 云计算的私有与公有
+
+云计算大致分两种,一个是私有云,一个是公有云,还有人把私有云和公有云连接起来称为混合云,我们暂且不说这个。私有云就是把虚拟化和云化的这套软件部署在别人的数据中心里面,使用私有云的用户往往很有钱,自己买地建机房,自己买服务器,然后让云厂商部署在自己这里,Vmware后来除了虚拟化,也推出了云计算的产品,并且在私有云市场赚的盆满钵满。所谓公有云就是虚拟化和云化软件部署在云厂商自己数据中心里面的,用户不需要很大的投入,只要注册一个账号,就能在一个网页上点一下创建一台虚拟电脑,例如AWS也即亚马逊的公有云,例如国内的阿里云,腾讯云,网易云等。
+
+亚马逊呢为什么要做公有云呢?我们知道亚马逊原来是国外比较大的一个电商,它做电商的时候也肯定会遇到类似双11的场景,在某一个时刻大家都冲上来买东西。当大家都冲上买东西的时候,就特别需要云的时间灵活性和空间灵活性。因为它不能时刻准备好所有的资源,那样太浪费了。但也不能什么都不准备,看着双十一这么多用户想买东西登不上去。所以需要双十一的时候,创建一大批虚拟电脑来支撑电商应用,过了双十一再把这些资源都释放掉去干别的。所以亚马逊是需要一个云平台的。
+
+然而商用的虚拟化软件实在是太贵了,亚马逊总不能把自己在电商赚的钱全部给了虚拟化厂商吧。于是亚马逊基于开源的虚拟化技术,如上所述的Xen或者KVM,开发了一套自己的云化软件。没想到亚马逊后来电商越做越牛,云平台也越做越牛。而且由于他的云平台需要支撑自己的电商应用,而传统的云计算厂商多为IT厂商出身,几乎没有自己的应用,因而亚马逊的云平台对应用更加的友好,迅速发展成为云计算的第一品牌,赚了很多钱。在亚马逊公布其云计算平台财报之前,人们都猜测,亚马逊电商赚钱,云也赚钱吗?后来一公布财报,发现不是一般的赚钱,仅仅去年,亚马逊AWS年营收达122亿美元,运营利润31亿美元。
+
+1.8 云计算的赚钱与情怀
+
+公有云的第一名亚马逊过得很爽,第二名Rackspace过的就一般了。没办法,这就是互联网行业的残酷性,多是赢者通吃的模式。所以第二名如果不是云计算行业的,很多人可能都没听过了。第二名就想,我干不过老大怎么办呢?开源吧。如上所述,亚马逊虽然使用了开源的虚拟化技术,但是云化的代码是闭源的,很多想做又做不了云化平台的公司,只能眼巴巴的看着亚马逊挣大钱。Rackspace把源代码一公开,整个行业就可以一起把这个平台越做越好,兄弟们大家一起上,和老大拼了。
+
+于是Rackspace和美国航空航天局合作创办了开源软件OpenStack,如图所示OpenStack的架构图,不是云计算行业的不用弄懂这个图,但是能够看到三个关键字,Compute计算,Networking网络,Storage存储。还是一个计算,网络,存储的云化管理平台。
+
+当然第二名的技术也是非常棒的,有了OpenStack之后,果真像Rackspace想象的一样,所有想做云的大企业都疯了,你能想象到的所有如雷贯耳的大型IT企业,IBM,惠普,戴尔,华为,联想等等,都疯了。原来云平台大家都想做,看着亚马逊和Vmware赚了这么多钱,眼巴巴看着没办法,想自己做一个好像难度还挺大。现在好了,有了这样一个开源的云平台OpenStack,所有的IT厂商都加入到这个社区中来,对这个云平台进行贡献,包装成自己的产品,连同自己的硬件设备一起卖。有的做了私有云,有的做了公有云,OpenStack已经成为开源云平台的事实标准。
+
+1.9 IaaS, 资源层面的灵活性
+
+随着OpenStack的技术越来越成熟,可以管理的规模也越来越大,并且可以有多个OpenStack集群部署多套,比如北京部署一套,杭州部署两套,广州部署一套,然后进行统一的管理。这样整个规模就更大了。在这个规模下,对于普通用户的感知来讲,基本能够做到想什么时候要就什么什么药,想要多少就要多少。还是拿云盘举例子,每个用户云盘都分配了5T甚至更大的空间,如果有1亿人,那加起来空间多大啊。其实背后的机制是这样的,分配你的空间,你可能只用了其中很少一点,比如说它分配给你了5个T,这么大的空间仅仅是你看到的,而不是真的就给你了,你其实只用了50个G,则真实给你的就是50个G,随着你文件的不断上传,分给你的空间会越来越多。当大家都上传,云平台发现快满了的时候(例如用了70%),会采购更多的服务器,扩充背后的资源,这个对用户是透明的,看不到的,从感觉上来讲,就实现了云计算的弹性。其实有点像银行,给储户的感觉是什么时候取钱都有,只要不同时挤兑,银行就不会垮。
+
+这里做一个简单的总结,到了这个阶段,云计算基本上实现了时间灵活性和空间灵活性,实现了计算,网络,存储资源的弹性。计算,网络,存储我们常称为基础设施Infranstracture, 因而这个阶段的弹性称为资源层面的弹性,管理资源的云平台,我们称为基础设施服务,就是我们常听到的IaaS,Infranstracture As A Service。
+
+二、云计算不光管资源,也要管应用
+
+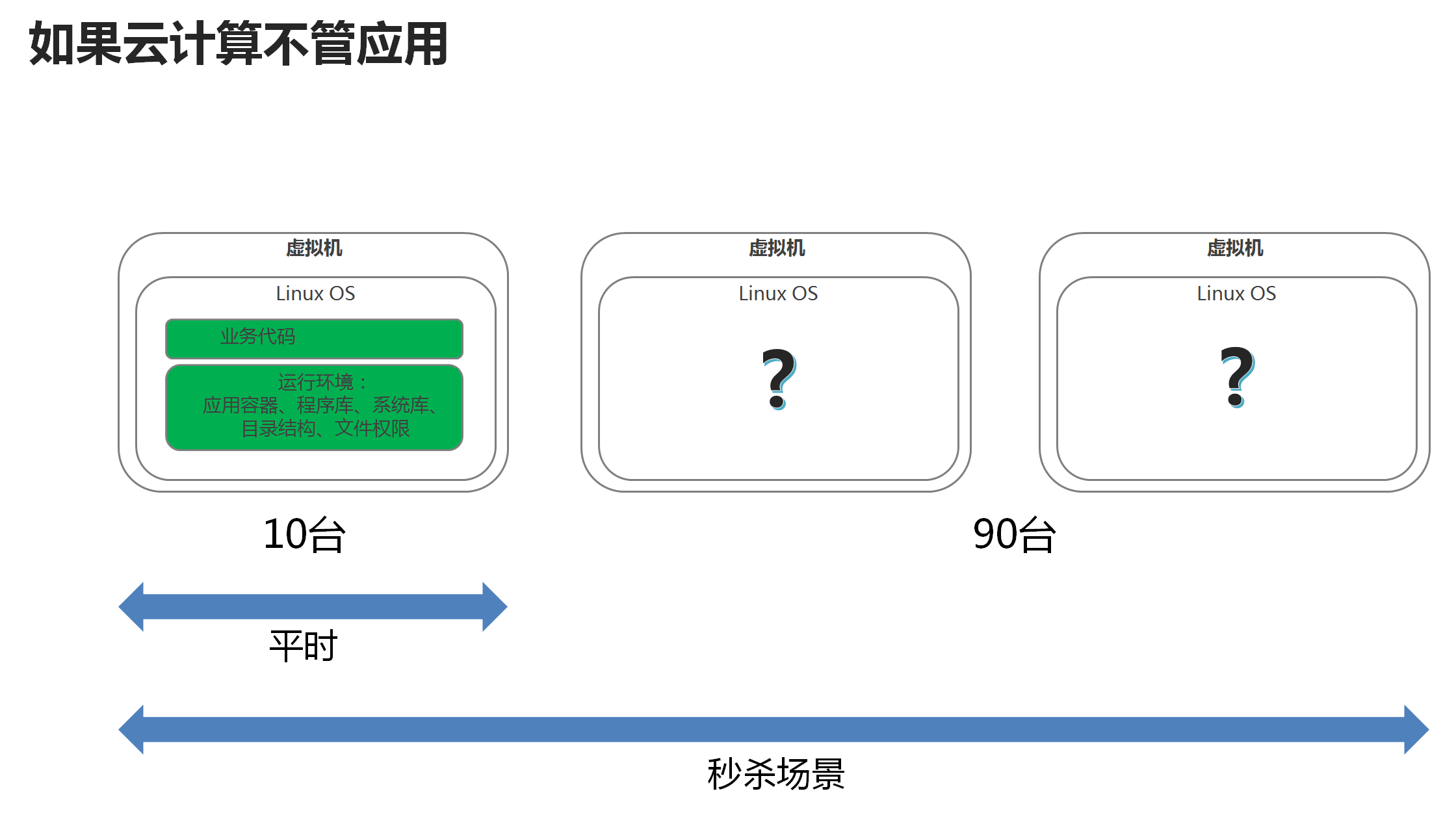
+
+有了IaaS,实现了资源层面的弹性就够了吗?显然不是。还有应用层面的弹性。这里举个例子,比如说实现一个电商的应用,平时十台机器就够了,双十一需要一百台。你可能觉得很好办啊,有了IaaS,新创建九十台机器就可以了啊。但是90台机器创建出来是空的啊,电商应用并没有放上去啊,只能你公司的运维人员一台一台的弄,还是需要很长时间才能安装好的。虽然资源层面实现了弹性,但是没有应用层的弹性,依然灵活性是不够的。
+
+有没有方法解决这个问题呢?于是人们在IaaS平台之上又加了一层,用于管理资源以上的应用弹性的问题,这一层通常称为PaaS(Platform As A Service)。这一层往往比较难理解,其实大致分两部分,一部分我称为你自己的应用自动安装,一部分我称为通用的应用不用安装。
+
+我们先来说第一部分,自己的应用自动安装。比如电商应用是你自己开发的,除了你自己,其他人是不知道怎么安装的,比如电商应用,安装的时候需要配置支付宝或者微信的账号,才能别人在你的电商上买东西的时候,付的钱是打到你的账户里面的,除了你,谁也不知道,所以安装的过程平台帮不了忙,但是能够帮你做的自动化,你需要做一些工作,将自己的配置信息融入到自动化的安装过程中方可。比如上面的例子,双十一新创建出来的90台机器是空的,如果能够提供一个工具,能够自动在这新的90台机器上将电商应用安装好,就能够实现应用层面的真正弹性。例如Puppet, Chef, Ansible, Cloud Foundary都可以干这件事情,最新的容器技术Docker能更好的干这件事情,不做技术的可以不用管这些词。
+
+第二部分,通用的应用不用安装。所谓通用的应用,一般指一些复杂性比较高,但是大家都在用的,例如数据库。几乎所有的应用都会用数据库,但是数据库软件是标准的,虽然安装和维护比较复杂,但是无论谁安装都是一样。这样的应用可以变成标准的PaaS层的应用放在云平台的界面上。当用户需要一个数据库的时候,一点就出来了,用户就可以直接用了。有人问,既然谁安装都一个样,那我自己来好了,不需要花钱在云平台上买。当然不是,数据库是一个非常难的东西,光Oracle这家公司,靠数据库就能赚这么多钱。买Oracle也是要花很多很多钱的。然而大多数云平台会提供Mysql这样的开源数据库,又是开源,钱不需要花这么多了,但是维护这个数据库,却需要专门招一个很大的团队,如果这个数据库能够优化到能够支撑双十一,也不是一年两年能够搞定的。比如您是一个做单车的,当然没必要招一个非常大的数据库团队来干这件事情,成本太高了,应该交给云平台来做这件事情,专业的事情专业的人来自,云平台专门养了几百人维护这套系统,您只要专注于您的单车应用就可以了。
+
+要么是自动部署,要么是不用部署,总的来说就是应用层你也要少操心,这就是PaaS层的重要作用。
+
+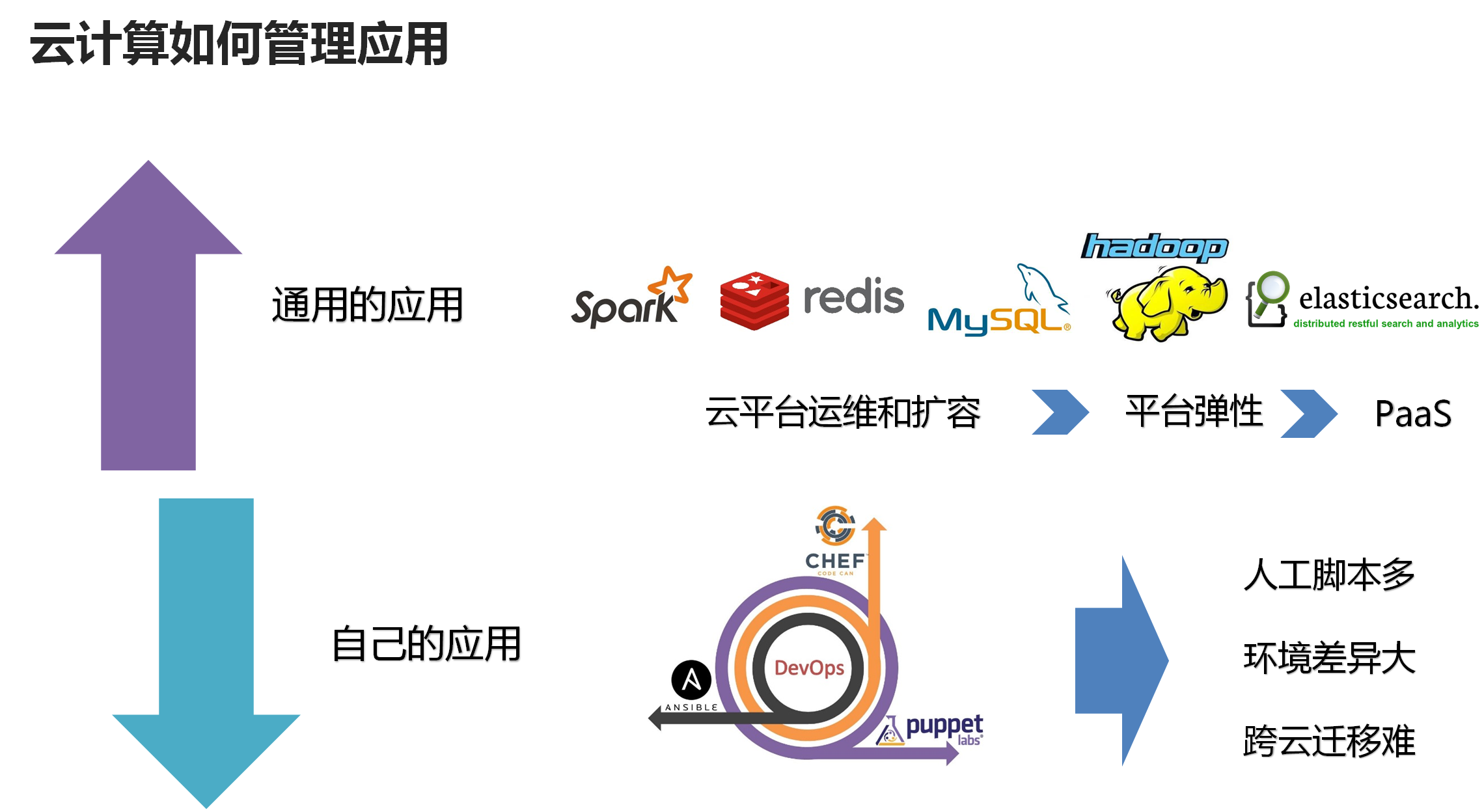
+
+ 虽说脚本的方式能够解决自己的应用的部署问题,然而不同的环境千差万别,一个脚本往往在一个环境上运行正确,到另一个环境就不正确了。
+
+而容器是能更好的解决这个问题的。
+
+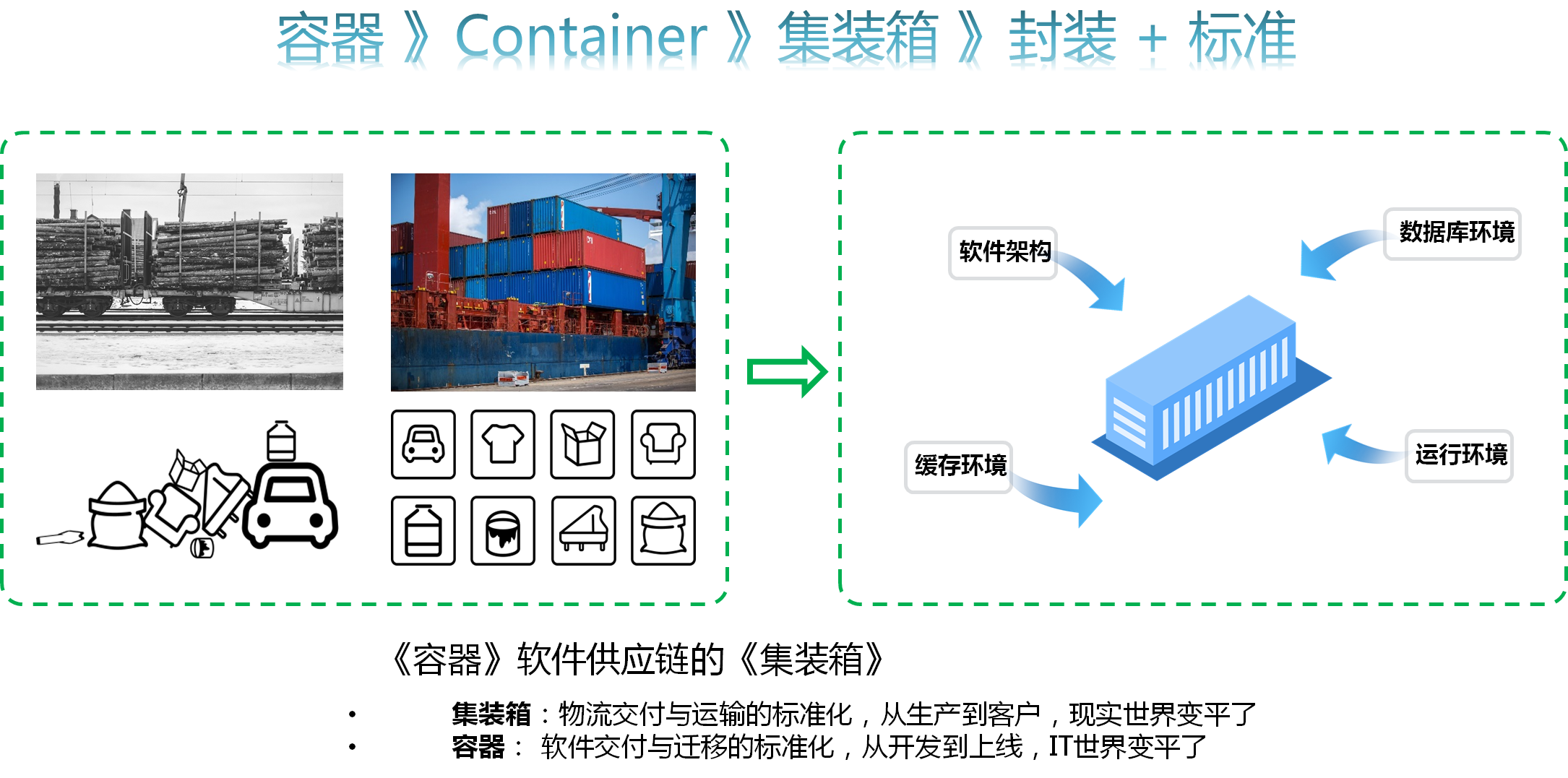
+
+容器是 Container,Container另一个意思是集装箱,其实容器的思想就是要变成软件交付的集装箱。集装箱的特点,一是封装,二是标准。
+
+
+
+
+
+
+
+在没有集装箱的时代,假设将货物从 A运到 B,中间要经过三个码头、换三次船。每次都要将货物卸下船来,摆的七零八落,然后搬上船重新整齐摆好。因此在没有集装箱的时候,每次换船,船员们都要在岸上待几天才能走。
+
+
+
+ 
+
+有了集装箱以后,所有的货物都打包在一起了,并且集装箱的尺寸全部一致,所以每次换船的时候,一个箱子整体搬过去就行了,小时级别就能完成,船员再也不用上岸长时间耽搁了。
+
+
+
+这是集装箱“封装”、“标准”两大特点在生活中的应用。
+
+
+
+
+
+
+
+
+
+那么容器如何对应用打包呢?还是要学习集装箱,首先要有个封闭的环境,将货物封装起来,让货物之间互不干扰,互相隔离,这样装货卸货才方便。好在 Ubuntu中的LXC技术早就能做到这一点。
+
+
+
+封闭的环境主要使用了两种技术,一种是看起来是隔离的技术,称为 Namespace,也即每个 Namespace中的应用看到的是不同的 IP地址、用户空间、程号等。另一种是用起来是隔离的技术,称为 Cgroups,也即明明整台机器有很多的 CPU、内存,而一个应用只能用其中的一部分。
+
+所谓的镜像,就是将你焊好集装箱的那一刻,将集装箱的状态保存下来,就像孙悟空说:“定”,集装箱里面就定在了那一刻,然后将这一刻的状态保存成一系列文件。这些文件的格式是标准的,谁看到这些文件都能还原当时定住的那个时刻。将镜像还原成运行时的过程(就是读取镜像文件,还原那个时刻的过程)就是容器运行的过程。
+
+有了容器,使得 PaaS层对于用户自身应用的自动部署变得快速而优雅。
+
+三、大数据拥抱云计算
+
+在PaaS层中一个复杂的通用应用就是大数据平台。大数据是如何一步一步融入云计算的呢?
+
+3.1 数据不大也包含智慧
+
+一开始这个大数据并不大,你想象原来才有多少数据?现在大家都去看电子书,上网看新闻了,在我们80后小时候,信息量没有那么大,也就看看书,看看报,一个星期的报纸加起来才有多少字啊,如果你不在一个大城市,一个普通的学校的图书馆加起来也没几个书架,是后来随着信息化的到来,信息才会越来越多。
+
+首先我们来看一下大数据里面的数据,就分三种类型,一种叫结构化的数据,一种叫非结构化的数据,还有一种叫半结构化的数据。什么叫结构化的数据呢?叫有固定格式和有限长度的数据。例如填的表格就是结构化的数据,国籍:中华人民共和国,民族:汉,性别:男,这都叫结构化数据。现在越来越多的就是非结构化的数据,就是不定长,无固定格式的数据,例如网页,有时候非常长,有时候几句话就没了,例如语音,视频都是非结构化的数据。半结构化数据是一些xml或者html的格式的,不从事技术的可能不了解,但也没有关系。
+
+数据怎么样才能对人有用呢?其实数据本身不是有用的,必须要经过一定的处理。例如你每天跑步带个手环收集的也是数据,网上这么多网页也是数据,我们称为Data,数据本身没有什么用处,但是数据里面包含一个很重要的东西,叫做信息Information,数据十分杂乱,经过梳理和清洗,才能够称为信息。信息会包含很多规律,我们需要从信息中将规律总结出来,称为知识knowledge,知识改变命运。信息是很多的,但是有人看到了信息相当于白看,但是有人就从信息中看到了电商的未来,有人看到了直播的未来,所以人家就牛了,你如果没有从信息中提取出知识,天天看朋友圈,也只能在互联网滚滚大潮中做个看客。有了知识,然后利用这些知识去应用于实战,有的人会做得非常好,这个东西叫做智慧intelligence。有知识并不一定有智慧,例如好多学者很有知识,已经发生的事情可以从各个角度分析的头头是道,但一到实干就歇菜,并不能转化成为智慧。而很多的创业家之所以伟大,就是通过获得的知识应用于实践,最后做了很大的生意。
+
+所以数据的应用分这四个步骤:数据,信息,知识,智慧。这是很多商家都想要的,你看我收集了这么多的数据,能不能基于这些数据来帮我做下一步的决策,改善我的产品,例如让用户看视频的时候旁边弹出广告,正好是他想买的东西,再如让用户听音乐的时候,另外推荐一些他非常想听的其他音乐。用户在我的应用或者网站上随便点点鼠标,输入文字对我来说都是数据,我就是要将其中某些东西提取出来,指导实践,形成智慧,让用户陷入到我的应用里面不可自拔,上了我的网就不想离开,手不停的点,不停的买,很多人说双十一我都想断网了,我老婆在上面不断的买买买,买了A又推荐B,老婆大人说,“哎呀,B也是我喜欢的啊,老公我要买”。你说这个程序怎么这么牛,这么有智慧,比我还了解我老婆,这件事情是怎么做到的呢?
+
+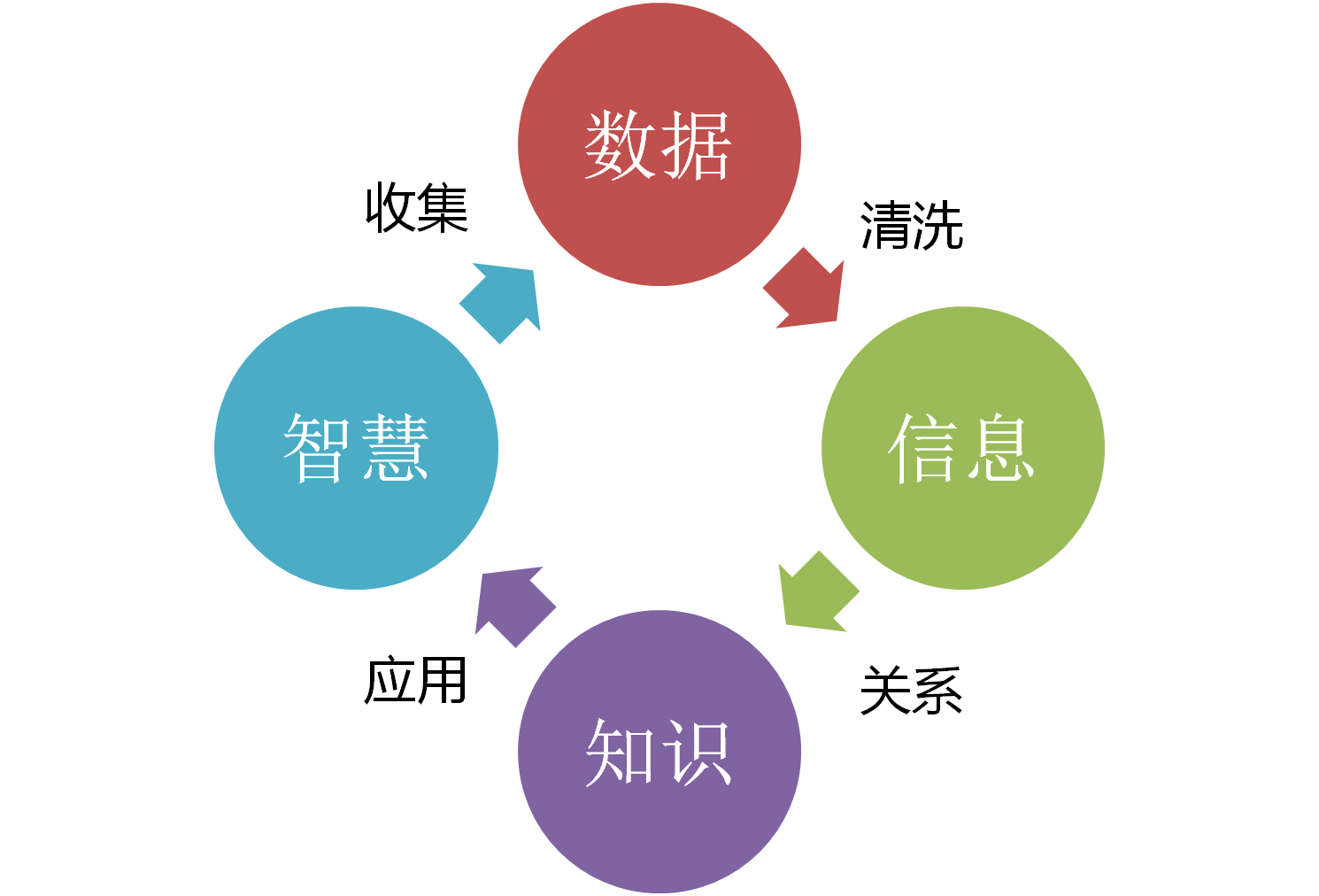
+
+3.2 数据如何升华为智慧
+
+数据的处理分几个步骤,完成了才最后会有智慧。
+
+第一个步骤叫数据的收集。首先得有数据,数据的收集有两个方式,第一个方式是拿,专业点的说法叫抓取或者爬取,例如搜索引擎就是这么做的,它把网上的所有的信息都下载到它的数据中心,然后你一搜才能搜出来。比如你去搜索的时候,结果会是一个列表,这个列表为什么会在搜索引擎的公司里面呢,就是因为他把这个数据啊都拿下来了,但是你一点链接,点出来这个网站就不在搜索引擎它们公司了。比如说新浪有个新闻,你拿百度搜出来,你不点的时候,那一页在百度数据中心,一点出来的网页就是在新浪的数据中心了。另外一个方式就是推送,有很多终端可以帮我收集数据,比如说小米手环,可以将你每天跑步的数据,心跳的数据,睡眠的数据都上传到数据中心里面。
+
+第二个步骤是数据的传输。一般会通过队列方式进行,因为数据量实在是太大了,数据必须经过处理才会有用,可是系统处理不过来,只好排好队,慢慢的处理。
+
+第三个步骤是数据的存储。现在数据就是金钱,掌握了数据就相当于掌握了钱。要不然网站怎么知道你想买什么呢?就是因为它有你历史的交易的数据,这个信息可不能给别人,十分宝贵,所以需要存储下来。
+
+第四个步骤是数据的处理和分析。上面存储的数据是原始数据,原始数据多是杂乱无章的,有很多垃圾数据在里面,因而需要清洗和过滤,得到一些高质量的数据。对于高质量的数据,就可以进行分析,从而对数据进行分类,或者发现数据之间的相互关系,得到知识。比如盛传的沃尔玛超市的啤酒和尿布的故事,就是通过对人们的购买数据进行分析,发现了男人一般买尿布的时候,会同时购买啤酒,这样就发现了啤酒和尿布之间的相互关系,获得知识,然后应用到实践中,将啤酒和尿布的柜台弄的很近,就获得了智慧。
+
+第五个步骤就是对于数据的检索和挖掘。检索就是搜索,所谓外事不决问google,内事不决问百度。内外两大搜索引擎都是讲分析后的数据放入搜索引擎,从而人们想寻找信息的时候,一搜就有了。另外就是挖掘,仅仅搜索出来已经不能满足人们的要求了,还需要从信息中挖掘出相互的关系。比如财经搜索,当搜索某个公司股票的时候,该公司的高管是不是也应该被挖掘出来呢?如果仅仅搜索出这个公司的股票发现涨的特别好,于是你就去买了,其实其高管发了一个声明,对股票十分不利,第二天就跌了,这不坑害广大股民么?所以通过各种算法挖掘数据中的关系,形成知识库,十分重要。
+
+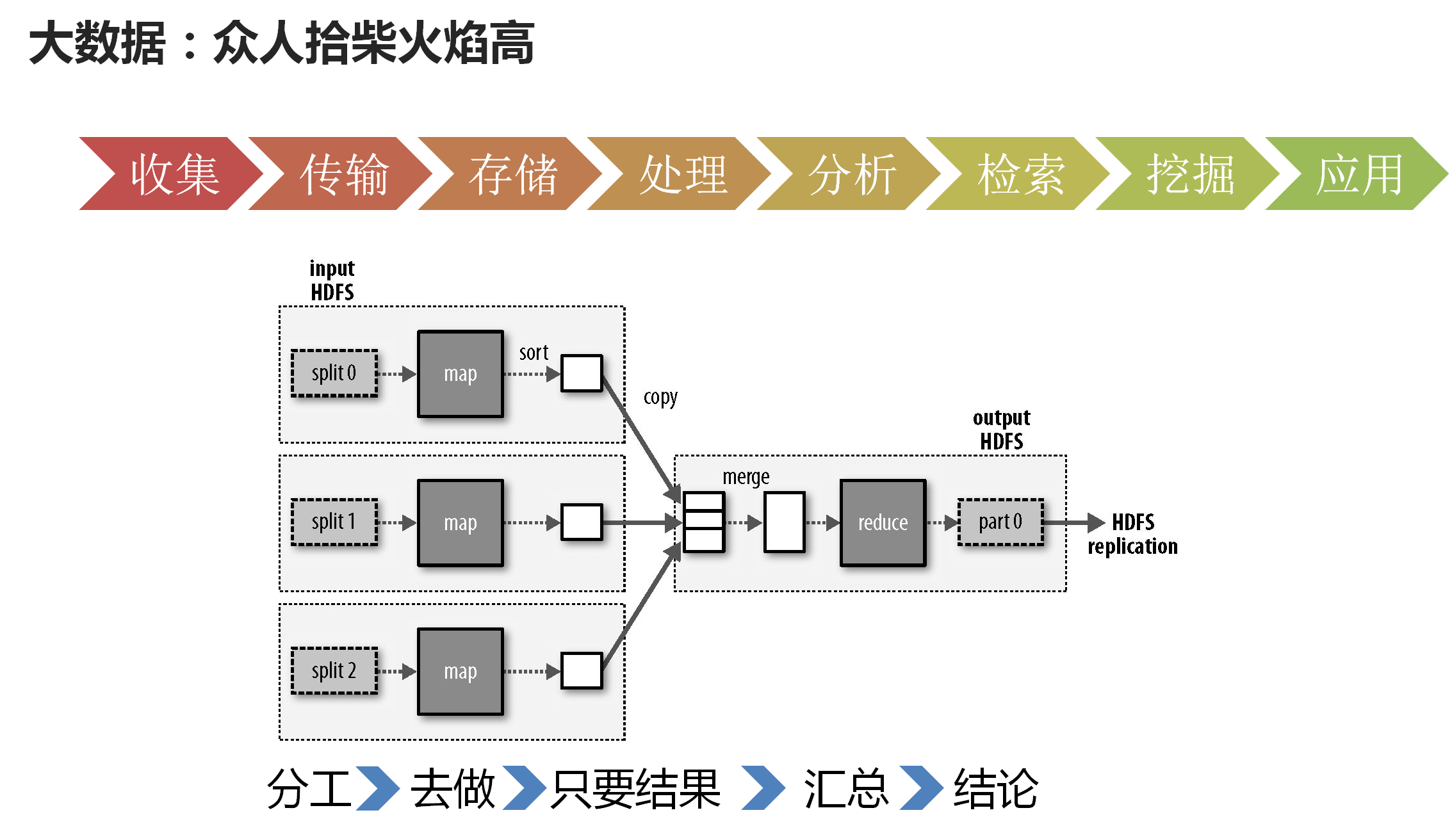
+
+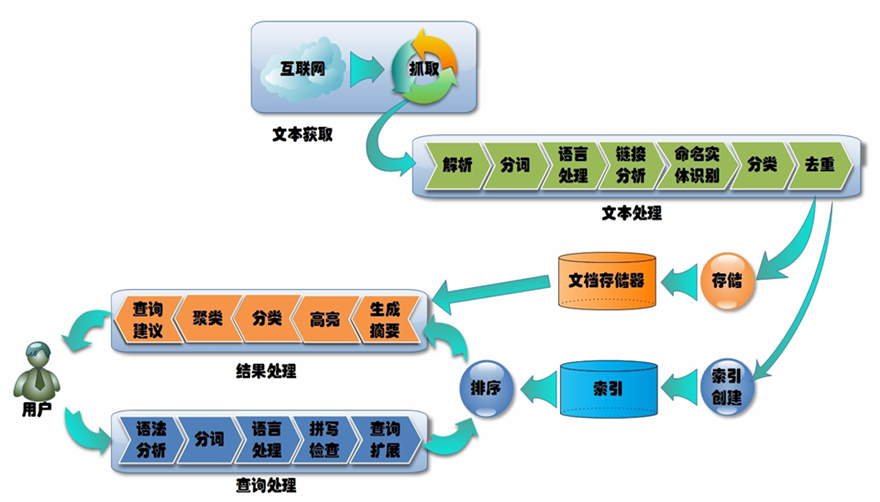
+
+3.3 大数据时代,众人拾柴火焰高
+
+当数据量很小的时候,很少的几台机器就能解决。慢慢的当数据量越来越大,最牛的服务器都解决不了问题的时候,就想怎么办呢?要聚合多台机器的力量,大家齐心协力一起把这个事搞定,众人拾柴火焰高。
+
+对于数据的收集,对于IoT来讲,外面部署这成千上万的检测设备,将大量的温度,适度,监控,电力等等数据统统收集上来,对于互联网网页的搜索引擎来讲,需要将整个互联网所有的网页都下载下来,这显然一台机器做不到,需要多台机器组成网络爬虫系统,每台机器下载一部分,同时工作,才能在有限的时间内,将海量的网页下载完毕。
+
+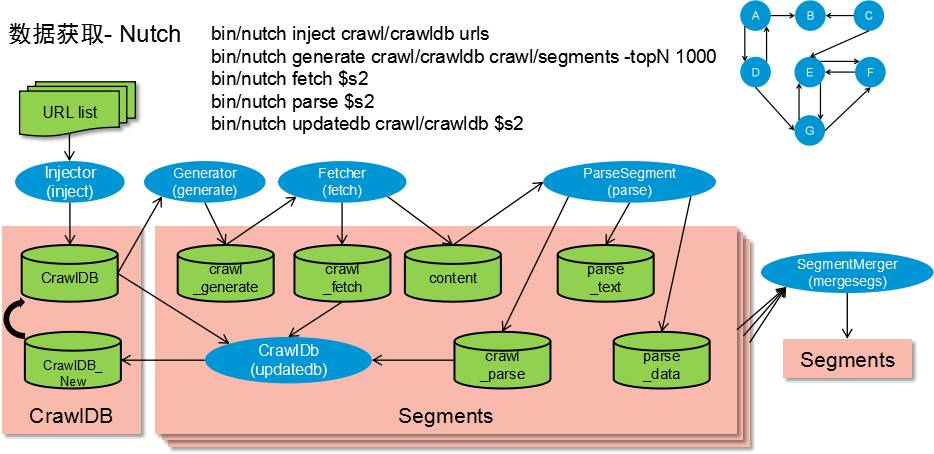
+
+
+
+对于数据的传输,一个内存里面的队列肯定会被大量的数据挤爆掉,于是就产生了基于硬盘的分布式队列,这样队列可以多台机器同时传输,随你数据量多大,只要我的队列足够多,管道足够粗,就能够撑得住。
+
+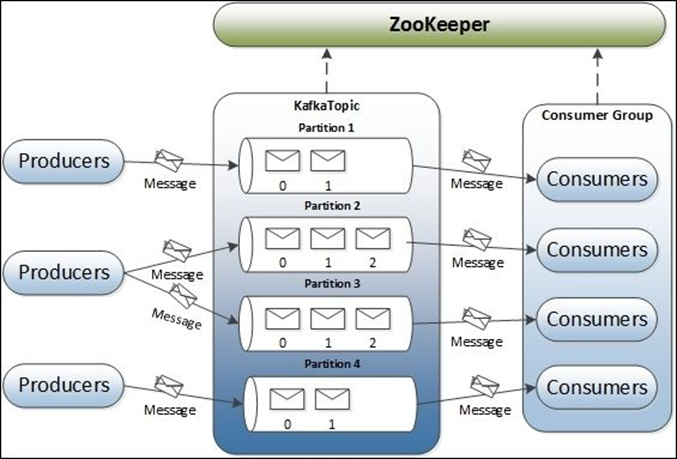
+
+对于数据的存储,一台机器的文件系统肯定是放不下了,所以需要一个很大的分布式文件系统来做这件事情,把多台机器的硬盘打成一块大的文件系统。
+
+
+
+
+
+再如数据的分析,可能需要对大量的数据做分解,统计,汇总,一台机器肯定搞不定,处理到猴年马月也分析不完,于是就有分布式计算的方法,将大量的数据分成小份,每台机器处理一小份,多台机器并行处理,很快就能算完。例如著名的Terasort对1个TB的数据排序,相当于1000G,如果单机处理,怎么也要几个小时,但是并行处理209秒就完成了。
+
+ 
+
+
+
+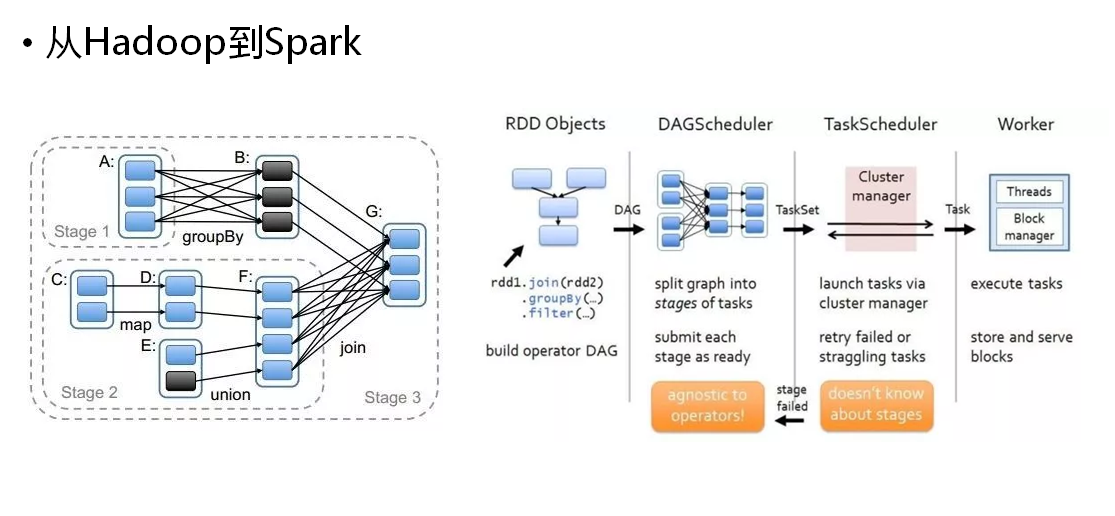
+
+所以说大数据平台,什么叫做大数据,说白了就是一台机器干不完,大家一起干。随着数据量越来越大,很多不大的公司都需要处理相当多的数据,这些小公司没有这么多机器可怎么办呢?
+
+3.4 大数据需要云计算,云计算需要大数据
+
+说到这里,大家想起云计算了吧。当想要干这些活的时候,需要好多好多的机器一块做,真的是想什么时候要,想要多少就要多少。例如大数据分析公司的财务情况,可能一周分析一次,如果要把这一百台机器或者一千台机器都在那放着,一周用一次对吧,非常浪费。那能不能需要计算的时候,把这一千台机器拿出来,然后不算的时候,这一千台机器可以去干别的事情。谁能做这个事儿呢?只有云计算,可以为大数据的运算提供资源层的灵活性。而云计算也会部署大数据放到它的PaaS平台上,作为一个非常非常重要的通用应用。因为大数据平台能够使得多台机器一起干一个事儿,这个东西不是一般人能开发出来的,也不是一般人玩得转的,怎么也得雇个几十上百号人才能把这个玩起来,所以说就像数据库一样,其实还是需要有一帮专业的人来玩这个东西。现在公有云上基本上都会有大数据的解决方案了,一个小公司我需要大数据平台的时候,不需要采购一千台机器,只要到公有云上一点,这一千台机器都出来了,并且上面已经部署好了的大数据平台,只要把数据放进去算就可以了。
+
+云计算需要大数据,大数据需要云计算,两个人就这样结合了。
+
+四、人工智能拥抱大数据
+
+4.1 机器什么时候才能懂人心
+
+虽说有了大数据,人的欲望总是这个不能够满足。虽说在大数据平台里面有搜索引擎这个东西,想要什么东西我一搜就出来了。但是也存在这样的情况,我想要的东西不会搜,表达不出来,搜索出来的又不是我想要的。例如音乐软件里面推荐一首歌,这首歌我没听过,当然不知道名字,也没法搜,但是软件推荐给我,我的确喜欢,这就是搜索做不到的事情。当人们使用这种应用的时候,会发现机器知道我想要什么,而不是说当我想要的时候,去机器里面搜索。这个机器真像我的朋友一样懂我,这就有点人工智能的意思了。
+
+人们很早就在想这个事情了。最早的时候,人们想象,如果要是有一堵墙,墙后面是个机器,我给它说话,它就给我回应,我如果感觉不出它那边是人还是机器,那它就真的是一个人工智能的东西了。
+
+4.2 让机器学会推理
+
+怎么才能做到这一点呢?人们就想:我首先要告诉计算机人类的推理的能力。你看人重要的是什么呀,人和动物的区别在什么呀,就是能推理。我要是把我这个推理的能力啊告诉机器,机器就能根据你的提问,推理出相应的回答,真能这样多好。推理其实人们慢慢的让机器能够做到一些了,例如证明数学公式。这是一个非常让人惊喜的一个过程,机器竟然能够证明数学公式。但是慢慢发现其实这个结果,也没有那么令人惊喜,因为大家发现了一个问题,数学公式非常严谨,推理过程也非常严谨,而且数学公式很容易拿机器来进行表达,程序也相对容易表达。然而人类的语言就没这么简单了,比如今天晚上,你和你女朋友约会,你女朋友说:如果你早来,我没来,你等着,如果我早来,你没来,你等着。这个机器就比比较难理解了,但是人都懂,所以你和女朋友约会,你是不敢迟到的。
+
+4.3 教给机器知识
+
+所以仅仅告诉机器严格的推理是不够的,还要告诉机器一些知识。但是知识这个事儿,一般人可能就做不来了,可能专家可以,比如语言领域的专家,或者财经领域的专家。语言领域和财经领域知识能不能表示成像数学公式一样稍微严格点呢?例如语言专家可能会总结出主谓宾定状补这些语法规则,主语后面一定是谓语,谓语后面一定是宾语,将这些总结出来,并严格表达出来不久行了吗?后来发现这个不行,太难总结了,语言表达千变万化。就拿主谓宾的例子,很多时候在口语里面就省略了谓语,别人问:你谁啊?我回答:我刘超。但是你不能规定在语音语义识别的时候,要求对着机器说标准的书面语,这样还是不够智能,就像罗永浩在一次演讲中说的那样,每次对着手机,用书面语说:请帮我呼叫某某某,这是一件很尴尬的事情。
+
+人工智能这个阶段叫做专家系统。专家系统不易成功,一方面是知识比较难总结,另一方面总结出来的知识难以教给计算机。因为你自己还迷迷糊糊,似乎觉得有规律,就是说不出来,就怎么能够通过编程教给计算机呢?
+
+4.4 算了,教不会你自己学吧
+
+于是人们想到,看来机器是和人完全不一样的物种,干脆让机器自己学习好了。机器怎么学习呢?既然机器的统计能力这么强,基于统计学习,一定能从大量的数字中发现一定的规律。
+
+其实在娱乐圈有很好的一个例子,可见一斑
+
+有一位网友统计了知名歌手在大陆发行的 9 张专辑中 117 首歌曲的歌词,同一词语在一首歌出现只算一次,形容词、名词和动词的前十名如下表所示(词语后面的数字是出现的次数):
+
+
+
+
+
+
+| a | 形容词 | b | 名词 | c | 动词 |
+| 0 | 孤独:34 | 0 | 生命:50 | 0 | 爱:54 |
+| 1 | 自由:17 | 1 | 路:37 | 1 | 碎:37 |
+| 2 | 迷惘:16 | 2 | 夜:29 | 2 | 哭:35 |
+| 3 | 坚强:13 | 3 | 天空:24 | 3 | 死:27 |
+| 4 | 绝望:8 | 4 | 孩子:23 | 4 | 飞:26 |
+| 5 | 青春:7 | 5 | 雨:21 | 5 | 梦想:14 |
+| 6 | 迷茫:6 | 6 | 石头:9 | 6 | 祈祷:10 |
+| 7 | 光明:6 | 7 | 鸟:9 | 7 | 离去:10 |
+
+
+
+
+
+如果我们随便写一串数字,然后按照数位依次在形容词、名词和动词中取出一个词,连在一起会怎么样呢?
+
+例如取圆周率 3.1415926,对应的词语是:坚强,路,飞,自由,雨,埋,迷惘。稍微连接和润色一下:
+
+坚强的孩子,
+
+依然前行在路上,
+
+张开翅膀飞向自由,
+
+让雨水埋葬他的迷惘。
+
+
+
+是不是有点感觉了?当然真正基于统计的学习算法比这个简单的统计复杂的多。
+
+然而统计学习比较容易理解简单的相关性,例如一个词和另一个词总是一起出现,两个词应该有关系,而无法表达复杂的相关性,并且统计方法的公式往往非常复杂,为了简化计算,常常做出各种独立性的假设,来降低公式的计算难度,然而现实生活中,具有独立性的事件是相对较少的。
+
+4.5 模拟大脑的工作方式
+
+
+
+于是人类开始从机器的世界,反思人类的世界是怎么工作的。
+
+
+
+
+
+人类的脑子里面不是存储着大量的规则,也不是记录着大量的统计数据,而是通过神经元的触发实现的,每个神经元有从其他神经元的输入,当接收到输入的时候,会产生一个输出来刺激其他的神经元,于是大量的神经元相互反应,最终形成各种输出的结果。例如当人们看到美女瞳孔放大,绝不是大脑根据身材比例进行规则判断,也不是将人生中看过的所有的美女都统计一遍,而是神经元从视网膜触发到大脑再回到瞳孔。在这个过程中,其实很难总结出每个神经元对最终的结果起到了哪些作用,反正就是起作用了。
+
+
+
+于是人们开始用一个数学单元模拟神经元
+
+这个神经元有输入,有输出,输入和输出之间通过一个公式来表示,输入根据重要程度不同(权重),影响着输出。
+
+
+
+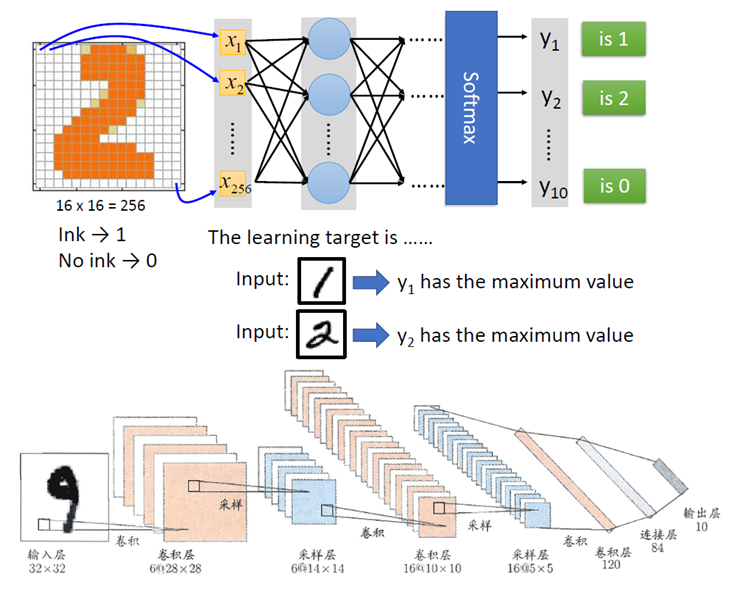
+
+
+
+于是将n个神经元通过像一张神经网络一样连接在一起,n这个数字可以很大很大,所有的神经元可以分成很多列,每一列很多个排列起来,每个神经元的对于输入的权重可以都不相同,从而每个神经元的公式也不相同。当人们从这张网络中输入一个东西的时候,希望输出一个对人类来讲正确的结果。例如上面的例子,输入一个写着2的图片,输出的列表里面第二个数字最大,其实从机器来讲,它既不知道输入的这个图片写的是2,也不知道输出的这一系列数字的意义,没关系,人知道意义就可以了。正如对于神经元来说,他们既不知道视网膜看到的是美女,也不知道瞳孔放大是为了看的清楚,反正看到美女,瞳孔放大了,就可以了。
+
+对于任何一张神经网络,谁也不敢保证输入是2,输出一定是第二个数字最大,要保证这个结果,需要训练和学习。毕竟看到美女而瞳孔放大也是人类很多年进化的结果。学习的过程就是,输入大量的图片,如果结果不是想要的结果,则进行调整。如何调整呢,就是每个神经元的每个权重都向目标进行微调,由于神经元和权重实在是太多了,所以整张网络产生的结果很难表现出非此即彼的结果,而是向着结果微微的进步,最终能够达到目标结果。当然这些调整的策略还是非常有技巧的,需要算法的高手来仔细的调整。正如人类见到美女,瞳孔一开始没有放大到能看清楚,于是美女跟别人跑了,下次学习的结果是瞳孔放大一点点,而不是放大鼻孔。
+
+4.6 没道理但做得到
+
+
+
+听起来也没有那么有道理,但是的确能做到,就是这么任性。
+
+神经网络的普遍性定理是这样说的,假设某个人给你某种复杂奇特的函数,f(x):
+
+
+
+不管这个函数是什么样的,总会确保有个神经网络能够对任何可能的输入x,其值f(x)(或者某个能够准确的近似)是神经网络的输出。
+
+如果在函数代表着规律,也意味着这个规律无论多么奇妙,多么不能理解,都是能通过大量的神经元,通过大量权重的调整,表示出来的。
+
+4.7 人工智能的经济学解释
+
+
+
+这让我想到了经济学,于是比较容易理解了。
+
+
+
+我们把每个神经元当成社会中从事经济活动的个体。于是神经网络相当于整个经济社会,每个神经元对于社会的输入,都有权重的调整,做出相应的输出,比如工资涨了,菜价也涨了,股票跌了,我应该怎么办,怎么花自己的钱。这里面没有规律么?肯定有,但是具体什么规律呢?却很难说清楚。
+
+基于专家系统的经济属于计划经济,整个经济规律的表示不希望通过每个经济个体的独立决策表现出来,而是希望通过专家的高屋建瓴和远见卓识总结出来。专家永远不可能知道哪个城市的哪个街道缺少一个卖甜豆腐脑的。于是专家说应该产多少钢铁,产多少馒头,往往距离人民生活的真正需求有较大的差距,就算整个计划书写个几百页,也无法表达隐藏在人民生活中的小规律。
+
+基于统计的宏观调控就靠谱的多了,每年统计局都会统计整个社会的就业率,通胀率,GDP等等指标,这些指标往往代表着很多的内在规律,虽然不能够精确表达,但是相对靠谱。然而基于统计的规律总结表达相对比较粗糙,比如经济学家看到这些统计数据可以总结出长期来看房价是涨还是跌,股票长期来看是涨还是跌,如果经济总体上扬,房价和股票应该都是涨的。但是基于统计数据,无法总结出股票,物价的微小波动规律。
+
+基于神经网络的微观经济学才是对整个经济规律最最准确的表达,每个人对于从社会中的输入,进行各自的调整,并且调整同样会作为输入反馈到社会中。想象一下股市行情细微的波动曲线,正是每个独立的个体各自不断交易的结果,没有统一的规律可循。而每个人根据整个社会的输入进行独立决策,当某些因素经过多次训练,也会形成宏观上的统计性的规律,这也就是宏观经济学所能看到的。例如每次货币大量发行,最后房价都会上涨,多次训练后,人们也就都学会了。
+
+4.8 人工智能需要大数据
+
+
+
+然而神经网络包含这么多的节点,每个节点包含非常多的参数,整个参数量实在是太大了,需要的计算量实在太大,但是没有关系啊,我们有大数据平台,可以汇聚多台机器的力量一起来计算,才能在有限的时间内得到想要的结果。
+
+人工智能可以做的事情非常多,例如可以鉴别垃圾邮件,鉴别黄色暴力文字和图片等。这也是经历了三个阶段的。第一个阶段依赖于关键词黑白名单和过滤技术,包含哪些词就是黄色或者暴力的文字。随着这个网络语言越来越多,词也不断的变化,不断的更新这个词库就有点顾不过来。第二个阶段时,基于一些新的算法,比如说贝叶斯过滤等,你不用管贝叶斯算法是什么,但是这个名字你应该听过,这个一个基于概率的算法。第三个阶段就是基于大数据和人工智能,进行更加精准的用户画像和文本理解和图像理解。
+
+由于人工智能算法多是依赖于大量的数据的,这些数据往往需要面向某个特定的领域(例如电商,邮箱)进行长期的积累,如果没有数据,就算有人工智能算法也白搭,所以人工智能程序很少像前面的IaaS和PaaS一样,将人工智能程序给某个客户安装一套让客户去用,因为给某个客户单独安装一套,客户没有相关的数据做训练,结果往往是很差的。但是云计算厂商往往是积累了大量数据的,于是就在云计算厂商里面安装一套,暴露一个服务接口,比如您想鉴别一个文本是不是涉及黄色和暴力,直接用这个在线服务就可以了。这种形势的服务,在云计算里面称为软件即服务,SaaS (Software AS A Service)
+
+于是工智能程序作为SaaS平台进入了云计算。
+
+五、云计算,大数据,人工智能过上了美好的生活
+
+终于云计算的三兄弟凑齐了,分别是IaaS,PaaS和SaaS,所以一般在一个云计算平台上,云,大数据,人工智能都能找得到。对一个大数据公司,积累了大量的数据,也会使用一些人工智能的算法提供一些服务。对于一个人工智能公司,也不可能没有大数据平台支撑。所以云计算,大数据,人工智能就这样整合起来,完成了相遇,相识,相知。
+
+
+
diff --git "a/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\26010\357\274\232Redis\347\232\204\344\272\213\344\273\266\351\251\261\345\212\250\346\250\241\345\236\213\344\270\216\345\221\275\344\273\244\346\211\247\350\241\214\350\277\207\347\250\213.md" "b/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\26010\357\274\232Redis\347\232\204\344\272\213\344\273\266\351\251\261\345\212\250\346\250\241\345\236\213\344\270\216\345\221\275\344\273\244\346\211\247\350\241\214\350\277\207\347\250\213.md"
new file mode 100644
index 0000000..a5cab32
--- /dev/null
+++ "b/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\26010\357\274\232Redis\347\232\204\344\272\213\344\273\266\351\251\261\345\212\250\346\250\241\345\236\213\344\270\216\345\221\275\344\273\244\346\211\247\350\241\214\350\277\207\347\250\213.md"
@@ -0,0 +1,305 @@
+本文转自互联网
+
+本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
+> https://github.com/h2pl/Java-Tutorial
+
+喜欢的话麻烦点下Star哈
+
+文章首发于我的个人博客:
+> www.how2playlife.com
+
+本文是微信公众号【Java技术江湖】的《探索Redis设计与实现》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。
+
+该系列博文会告诉你如何从入门到进阶,Redis基本的使用方法,Redis的基本数据结构,以及一些进阶的使用方法,同时也需要进一步了解Redis的底层数据结构,再接着,还会带来Redis主从复制、集群、分布式锁等方面的相关内容,以及作为缓存的一些使用方法和注意事项,以便让你更完整地了解整个Redis相关的技术体系,形成自己的知识框架。
+
+如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。
+
+
+
+原文地址:https://www.xilidou.com/2018/03/22/redis-event/
+
+Redis 是一个事件驱动的内存数据库,服务器需要处理两种类型的事件。
+
+文件事件
+时间事件
+下面就会介绍这两种事件的实现原理。
+
+文件事件
+Redis 服务器通过 socket 实现与客户端(或其他redis服务器)的交互,文件事件就是服务器对 socket 操作的抽象。 Redis 服务器,通过监听这些 socket 产生的文件事件并处理这些事件,实现对客户端调用的响应。
+
+Reactor
+Redis 基于 Reactor 模式开发了自己的事件处理器。
+
+这里就先展开讲一讲 Reactor 模式。看下图:
+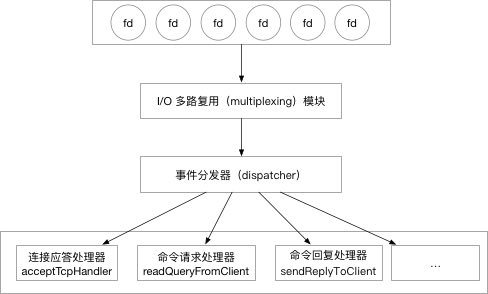
+reactor
+
+“I/O 多路复用模块”会监听多个 FD ,当这些FD产生,accept,read,write 或 close 的文件事件。会向“文件事件分发器(dispatcher)”传送事件。
+
+文件事件分发器(dispatcher)在收到事件之后,会根据事件的类型将事件分发给对应的 handler。
+
+我们顺着图,从上到下的逐一讲解 Redis 是怎么实现这个 Reactor 模型的。
+
+I/O 多路复用模块
+Redis 的 I/O 多路复用模块,其实是封装了操作系统提供的 select,epoll,avport 和 kqueue 这些基础函数。向上层提供了一个统一的接口,屏蔽了底层实现的细节。
+
+一般而言 Redis 都是部署到 Linux 系统上,所以我们就看看使用 Redis 是怎么利用 linux 提供的 epoll 实现I/O 多路复用。
+
+首先看看 epoll 提供的三个方法:
+
+ /*
+ * 创建一个epoll的句柄,size用来告诉内核这个监听的数目一共有多大
+ */
+ int epoll_create(int size);
+
+ /*
+ * 可以理解为,增删改 fd 需要监听的事件
+ * epfd 是 epoll_create() 创建的句柄。
+ * op 表示 增删改
+ * epoll_event 表示需要监听的事件,Redis 只用到了可读,可写,错误,挂断 四个状态
+ */
+ int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
+
+ /*
+ * 可以理解为查询符合条件的事件
+ * epfd 是 epoll_create() 创建的句柄。
+ * epoll_event 用来存放从内核得到事件的集合
+ * maxevents 获取的最大事件数
+ * timeout 等待超时时间
+ */
+ int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
+ 再看 Redis 对文件事件,封装epoll向上提供的接口:
+
+
+ /*
+ * 事件状态
+ */
+ typedef struct aeApiState {
+
+ // epoll_event 实例描述符
+ int epfd;
+
+ // 事件槽
+ struct epoll_event *events;
+
+ } aeApiState;
+
+ /*
+ * 创建一个新的 epoll
+ */
+ static int aeApiCreate(aeEventLoop *eventLoop)
+ /*
+ * 调整事件槽的大小
+ */
+ static int aeApiResize(aeEventLoop *eventLoop, int setsize)
+ /*
+ * 释放 epoll 实例和事件槽
+ */
+ static void aeApiFree(aeEventLoop *eventLoop)
+ /*
+ * 关联给定事件到 fd
+ */
+ static int aeApiAddEvent(aeEventLoop *eventLoop, int fd, int mask)
+ /*
+ * 从 fd 中删除给定事件
+ */
+ static void aeApiDelEvent(aeEventLoop *eventLoop, int fd, int mask)
+ /*
+ * 获取可执行事件
+ */
+ static int aeApiPoll(aeEventLoop *eventLoop, struct timeval *tvp)
+所以看看这个ae_peoll.c 如何对 epoll 进行封装的:
+
+aeApiCreate() 是对 epoll.epoll_create() 的封装。
+aeApiAddEvent()和aeApiDelEvent() 是对 epoll.epoll_ctl()的封装。
+aeApiPoll() 是对 epoll_wait()的封装。
+这样 Redis 的利用 epoll 实现的 I/O 复用器就比较清晰了。
+
+再往上一层次我们需要看看 ea.c 是怎么封装的?
+
+首先需要关注的是事件处理器的数据结构:
+
+
+ typedef struct aeFileEvent {
+
+ // 监听事件类型掩码,
+ // 值可以是 AE_READABLE 或 AE_WRITABLE ,
+ // 或者 AE_READABLE | AE_WRITABLE
+ int mask; /* one of AE_(READABLE|WRITABLE) */
+
+ // 读事件处理器
+ aeFileProc *rfileProc;
+
+ // 写事件处理器
+ aeFileProc *wfileProc;
+
+ // 多路复用库的私有数据
+ void *clientData;
+
+ } aeFileEvent;
+mask 就是可以理解为事件的类型。
+
+除了使用 ae_peoll.c 提供的方法外,ae.c 还增加 “增删查” 的几个 API。
+
+增:aeCreateFileEvent
+删:aeDeleteFileEvent
+查: 查包括两个维度 aeGetFileEvents 获取某个 fd 的监听类型和aeWait等待某个fd 直到超时或者达到某个状态。
+事件分发器(dispatcher)
+Redis 的事件分发器 ae.c/aeProcessEvents 不但处理文件事件还处理时间事件,所以这里只贴与文件分发相关的出部分代码,dispather 根据 mask 调用不同的事件处理器。
+
+ //从 epoll 中获关注的事件
+ numevents = aeApiPoll(eventLoop, tvp);
+ for (j = 0; j < numevents; j++) {
+ // 从已就绪数组中获取事件
+ aeFileEvent *fe = &eventLoop->events[eventLoop->fired[j].fd];
+
+ int mask = eventLoop->fired[j].mask;
+ int fd = eventLoop->fired[j].fd;
+ int rfired = 0;
+
+ // 读事件
+ if (fe->mask & mask & AE_READABLE) {
+ // rfired 确保读/写事件只能执行其中一个
+ rfired = 1;
+ fe->rfileProc(eventLoop,fd,fe->clientData,mask);
+ }
+ // 写事件
+ if (fe->mask & mask & AE_WRITABLE) {
+ if (!rfired || fe->wfileProc != fe->rfileProc)
+ fe->wfileProc(eventLoop,fd,fe->clientData,mask);
+ }
+
+ processed++;
+ }
+可以看到这个分发器,根据 mask 的不同将事件分别分发给了读事件和写事件。
+
+文件事件处理器的类型
+Redis 有大量的事件处理器类型,我们就讲解处理一个简单命令涉及到的三个处理器:
+
+acceptTcpHandler 连接应答处理器,负责处理连接相关的事件,当有client 连接到Redis的时候们就会产生 AE_READABLE 事件。引发它执行。
+readQueryFromClinet 命令请求处理器,负责读取通过 sokect 发送来的命令。
+sendReplyToClient 命令回复处理器,当Redis处理完命令,就会产生 AE_WRITEABLE 事件,将数据回复给 client。
+文件事件实现总结
+我们按照开始给出的 Reactor 模型,从上到下讲解了文件事件处理器的实现,下面将会介绍时间时间的实现。
+
+时间事件
+Reids 有很多操作需要在给定的时间点进行处理,时间事件就是对这类定时任务的抽象。
+
+先看时间事件的数据结构:
+
+ /* Time event structure
+ *
+ * 时间事件结构
+ */
+ typedef struct aeTimeEvent {
+
+ // 时间事件的唯一标识符
+ long long id; /* time event identifier. */
+
+ // 事件的到达时间
+ long when_sec; /* seconds */
+ long when_ms; /* milliseconds */
+
+ // 事件处理函数
+ aeTimeProc *timeProc;
+
+ // 事件释放函数
+ aeEventFinalizerProc *finalizerProc;
+
+ // 多路复用库的私有数据
+ void *clientData;
+
+ // 指向下个时间事件结构,形成链表
+ struct aeTimeEvent *next;
+
+ } aeTimeEvent;
+看见 next 我们就知道这个 aeTimeEvent 是一个链表结构。看图:
+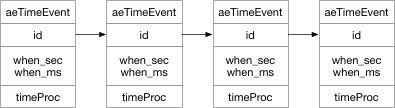
+
+timeEvent
+
+注意这是一个按照id倒序排列的链表,并没有按照事件顺序排序。
+
+processTimeEvent
+Redis 使用这个函数处理所有的时间事件,我们整理一下执行思路:
+
+记录最新一次执行这个函数的时间,用于处理系统时间被修改产生的问题。
+遍历链表找出所有 when_sec 和 when_ms 小于现在时间的事件。
+执行事件对应的处理函数。
+检查事件类型,如果是周期事件则刷新该事件下一次的执行事件。
+否则从列表中删除事件。
+综合调度器(aeProcessEvents)
+综合调度器是 Redis 统一处理所有事件的地方。我们梳理一下这个函数的简单逻辑:
+
+ // 1. 获取离当前时间最近的时间事件
+ shortest = aeSearchNearestTimer(eventLoop);
+
+ // 2. 获取间隔时间
+ timeval = shortest - nowTime;
+
+ // 如果timeval 小于 0,说明已经有需要执行的时间事件了。
+ if(timeval < 0){
+ timeval = 0
+ }
+
+ // 3. 在 timeval 时间内,取出文件事件。
+ numevents = aeApiPoll(eventLoop, timeval);
+
+ // 4.根据文件事件的类型指定不同的文件处理器
+ if (AE_READABLE) {
+ // 读事件
+ rfileProc(eventLoop,fd,fe->clientData,mask);
+ }
+ // 写事件
+ if (AE_WRITABLE) {
+ wfileProc(eventLoop,fd,fe->clientData,mask);
+ }
+以上的伪代码就是整个 Redis 事件处理器的逻辑。
+
+我们可以再看看谁执行了这个 aeProcessEvents:
+
+
+ void aeMain(aeEventLoop *eventLoop) {
+
+ eventLoop->stop = 0;
+
+ while (!eventLoop->stop) {
+
+ // 如果有需要在事件处理前执行的函数,那么运行它
+ if (eventLoop->beforesleep != NULL)
+ eventLoop->beforesleep(eventLoop);
+
+ // 开始处理事件
+ aeProcessEvents(eventLoop, AE_ALL_EVENTS);
+ }
+ }
+然后我们再看看是谁调用了 eaMain:
+
+ int main(int argc, char **argv) {
+ //一些配置和准备
+ ...
+ aeMain(server.el);
+
+ //结束后的回收工作
+ ...
+ }
+我们在 Redis 的 main 方法中找个了它。
+
+这个时候我们整理出的思路就是:
+
+Redis 的 main() 方法执行了一些配置和准备以后就调用 eaMain() 方法。
+
+eaMain() while(true) 的调用 aeProcessEvents()。
+
+所以我们说 Redis 是一个事件驱动的程序,期间我们发现,Redis 没有 fork 过任何线程。所以也可以说 Redis 是一个基于事件驱动的单线程应用。
+
+总结
+在后端的面试中 Redis 总是一个或多或少会问到的问题。
+
+读完这篇文章你也许就能回答这几个问题:
+
+为什么 Redis 是一个单线程应用?
+为什么 Redis 是一个单线程应用,却有如此高的性能?
+如果你用本文提供的知识点回答这两个问题,一定会在面试官心中留下一个高大的形象。
+
+大家还可以阅读我的 Redis 相关的文章:
\ No newline at end of file
diff --git "a/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\26011\357\274\232\344\275\277\347\224\250\345\277\253\347\205\247\345\222\214AOF\345\260\206Redis\346\225\260\346\215\256\346\214\201\344\271\205\345\214\226\345\210\260\347\241\254\347\233\230\344\270\255.md" "b/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\26011\357\274\232\344\275\277\347\224\250\345\277\253\347\205\247\345\222\214AOF\345\260\206Redis\346\225\260\346\215\256\346\214\201\344\271\205\345\214\226\345\210\260\347\241\254\347\233\230\344\270\255.md"
new file mode 100644
index 0000000..2bc1bd0
--- /dev/null
+++ "b/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\26011\357\274\232\344\275\277\347\224\250\345\277\253\347\205\247\345\222\214AOF\345\260\206Redis\346\225\260\346\215\256\346\214\201\344\271\205\345\214\226\345\210\260\347\241\254\347\233\230\344\270\255.md"
@@ -0,0 +1,195 @@
+本文转自互联网
+
+本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
+> https://github.com/h2pl/Java-Tutorial
+
+喜欢的话麻烦点下Star哈
+
+文章首发于我的个人博客:
+> www.how2playlife.com
+
+本文是微信公众号【Java技术江湖】的《探索Redis设计与实现》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。
+
+该系列博文会告诉你如何从入门到进阶,Redis基本的使用方法,Redis的基本数据结构,以及一些进阶的使用方法,同时也需要进一步了解Redis的底层数据结构,再接着,还会带来Redis主从复制、集群、分布式锁等方面的相关内容,以及作为缓存的一些使用方法和注意事项,以便让你更完整地了解整个Redis相关的技术体系,形成自己的知识框架。
+
+如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。
+
+
+
+# 转自https://blog.csdn.net/xlgen157387/article/details/61925524
+
+# 前言
+
+
+
+
+
+
+
+我们知道Redis是一款内存服务器,就算我们对自己的服务器足够的信任,不会出现任何软件或者硬件的故障,但也会有可能出现突然断电等情况,造成Redis服务器中的数据失效。因此,我们需要向传统的关系型数据库一样对数据进行备份,将Redis在内存中的数据持久化到硬盘等非易失性介质中,来保证数据的可靠性。
+
+将Redis内存服务器中的数据持久化到硬盘等介质中的一个好处就是,使得我们的服务器在重启之后还可以重用以前的数据,或者是为了防止系统出现故障而将数据备份到一个远程的位置。
+
+还有一些场景,例如:
+
+```
+对于一些需要进行大量计算而得到的数据,放置在Redis服务器,我们就有必要对其进行数据的持久化,如果需要对数据进行恢复的时候,我们就不需进行重新的计算,只需要简单的将这台机器上的数据复制到另一台需要恢复的Redis服务器就可以了。
+```
+
+
+Redis给我们提供了两种不同方式的持久化方法:快照(Snapshotting) 和 只追加文件(append-only-file)。
+
+(1)名词简介
+
+快照(RDB):就是我们俗称的备份,他可以在定期内对数据进行备份,将Redis服务器中的数据持久化到硬盘中;
+
+只追加文件(AOF):他会在执行写命令的时候,将执行的写命令复制到硬盘里面,后期恢复的时候,只需要重新执行一下这个写命令就可以了。类似于我们的MySQL数据库在进行主从复制的时候,使用的是`binlog`二进制文件,同样的是执行一遍写命令;
+
+(2)快照持久化通用的配置:
+
+```
+save 60 1000 #60秒时间内有1000次写入操作的时候执行快照的创建stop-writes-on-bgsave-error no #创建快照失败的时候是否仍然继续执行写命令rdbcompression yes #是否对快照文件进行压缩dbfilename dump.rdb #如何命名硬盘上的快照文件dir ./ #快照所保存的位置
+```
+
+
+(3)AOP持久化配置:
+
+```
+appendonly no #是否使用AOF持久化appendfsync everysec #多久执行一次将写入内容同步到硬盘上no-appendfsync-on-rewrite no #对AOF进行压缩的时候能否执行同步操作auto-aof-rewrite-percentage 100 #多久执行一次AOF压缩auto-aof-rewrite-min-size 64mb #多久执行一次AOF压缩dir ./ #AOF所保存的位置
+```
+
+
+需要注意的是:这两种持久化的方式既可以单独的使用,也可以同时使用,具体选择哪种方式需要根据具体的情况进行选择。
+
+## 快照持久化
+
+快照就是我们所说的备份。用户可以将Redis内存中的数据在某一个时间点进行备份,在创建快照之后,用户可以对快照进行备份。通常情况下,为了防止单台服务器出现故障造成所有数据的丢失,我们还可以将快照复制到其他服务器,创建具有相同数据的数据副本,这样的话,数据恢复的时候或者服务器重启的时候就可以使用这些快照信息进行数据的恢复,也可以防止单台服务器出现故障的时候造成数据的丢失。
+
+但是,没我们还需要注意的是,创建快照的方式,并不能完全保证我们的数据不丢失,这个大家可以很好的理解,因为快照的创建时定时的,并不是每一次更新操作都会创建一个快照的。系统发生崩溃的时候,用户将丢失最近一次生成快照之后更改的所有数据。因此,快照持久化的方式只适合于数据不经常修改或者丢失部分数据影响不大的场景。
+
+一、创建快照的方式:
+
+(1)客户端通过向Redis发送`BGSAVE` 命令来创建快照。
+
+使用BGSAVE的时候,Redis会调用fork来创建一个子进程,然后子进程负责将快照写到硬盘中,而父进程则继续处理命令请求。
+
+使用场景:
+
+如果用户使用了save设置,例如:`save 60 1000` ,那么从Redis最近一次创建快照之后开始计算,当“60秒之内有1000次写入操作”这个条件满足的时候,Redis就会自动触发BGSAVE命令。
+
+如果用户使用了多个save设置,那么当任意一个save配置满足条件的时候,Redis都会触发一次BGSAVE命令。
+
+(2)客户端通过向Redis发送`SAVE` 命令来创建快照。
+
+接收到SAVE命令的Redis服务器在快照创建完毕之前将不再响应任何其他命令的请求。SAVE命令并不常用,我们通常只在没有足够的内存去执行BGSAVE命令的时候才会使用SAVE命令,或者即使等待持久化操作执行完毕也无所谓的情况下,才会使用这个命令;
+
+使用场景:
+
+当Redis通过SHUTDOWN命令接收到关闭服务器的请求时,或者接收到标准的TERM信号时,会执行一次SAVE命令,阻塞所有的客户端,不再执行客户端发送的任何命令,并且在执行完SAVE命令之后关闭服务器。
+
+二、使用快照持久化注意事项:
+
+我们在使用快照的方式来保存数据的时候,如果Redis服务器中的数据量比较小的话,例如只有几个GB的时候。Redis会创建子进程并将数据保存到硬盘里边,生成快照所需的时间比读取数据所需要的时间还要短。
+
+但是,随着数据的增大,Redis占用的内存越来越大的时候,BGSAVE在创建子进程的时候消耗的时间也会越来越多,如果Redis服务器所剩下的内存不多的时候,这行BGSAVE命令会使得系统长时间地停顿,还有可能导致服务器无法使用。
+
+各虚拟机类别,创建子线程所耗时间:
+
+
+
+因此,为了防止Redis因为创建子进程的时候出现停顿,我们可以考虑关闭自动保存,转而通过手动的方式发送BGSAVE或者SAVE来进行持久化,
+
+手动的方式发送BGSAVE也会出现停顿的现象,但是我们可以控制发送该命令的时间来控制出现停顿的时候不影响具体的业务请求。
+
+另外,值得注意的是,在使用SAVE命令的时候,虽然会一直阻塞Redis直到快照生成完毕,但是其不需要创建子进程,所以不会向BGSAVE一样,因为创建子进程而导致Redis停顿。也正因为如此,SAVE创建快照的速度要比BGSAVE创建快照的速度更快一些。
+
+创建快照的时候,我们可以在业务请求,比较少的时候,比如凌晨三、四点,通过手写脚本的方式,定时执行。
+
+## AOF持久化
+
+AOF持久化会将被执行的写命令写到AOF文件的末尾,以此来记录数据发生的变化。这样,我们在恢复数据的时候,只需要从头到尾的执行一下AOF文件即可恢复数据。
+
+一、打开AOF持久化选项
+
+我们可以通过使用如下命令打开AOF:
+
+```
+appendonly yes
+```
+
+
+我们,通过如下命令来配置AOF文件的同步频率:
+
+```
+appendfsync everysec/always/no
+```
+
+
+二、appendfsync同步频率的区别
+
+appendfsync同步频率的区别如下图:
+
+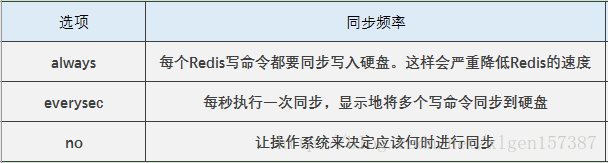
+
+(1)always的方式固然可以对没一条数据进行很好的保存,但是这种同步策略需要对硬盘进行大量的写操作,所以Redis处理命令的速度会受到硬盘性能的限制。
+
+普通的硬盘每秒钟只能处理大约200个写命令,使用固态硬盘SSD每秒可以处理几万个写命令,但是每次只写一个命令,这种只能怪不断地写入很少量的数据的做法有可能引发严重的写入放大问题,这种情况下降严重影响固态硬盘的使用寿命。
+
+(2)everysec的方式,Redis以每秒一次的频率大队AOF文件进行同步。这样的话既可以兼顾数据安全也可以兼顾写入性能。
+
+Redis以每秒同步一次AOF文件的性能和不使用任何持久化特性时的性能相差无几,使用每秒更新一次 的方式,可以保证,即使出现故障,丢失的数据也在一秒之内产生的数据。
+
+(3)no的方式,Redis将不对AOF文件执行任何显示的同步操作,而是由操作系统来决定应该何时对AOF文件进行同步。
+
+这个命令一般不会对Redis的性能造成多大的影响,但是当系统出现故障的时候使用这种选项的Redis服务器丢失不定数量的数据。
+
+另外,当用户的硬盘处理写入操作的速度不够快的话,那么缓冲区被等待写入硬盘的数据填满时,Redis的写入操作将被阻塞,并导致Redis处理命令请求的速度变慢,因为这个原因,一般不推荐使用这个选项。
+
+三、重写/压缩AOF文件
+
+随着数据量的增大,AOF的文件可能会很大,这样在每次进行数据恢复的时候就会进行很长的时间,为了解决日益增大的AOF文件,用户可以向Redis发送`BGREWRITEAOF` 命令,这个命令会通过移除AOF文件中的冗余命令来重写AOF文件,是AOF文件的体检变得尽可能的小。
+
+BGREWRITEAOF的工作原理和BGSAVE的原理很像:Redis会创建一个子进程,然后由子进程负责对AOF文件的重写操作。
+
+因为AOF文件重写的时候汇创建子进程,所以快照持久化因为创建子进程而导致的性能和内存占用问题同样会出现在AOF文件重写的 时候。
+
+四、触发重写/压缩AOF文件条件设定
+
+AOF通过设置`auto-aof-rewrite-percentage` 和 `auto-aof-rewrite-min-size` 选项来自动执行BGREWRITEAOF。
+
+其具体含义,通过实例可以看出,如下配置:
+
+```
+auto-aof-rewrite-percentage 100 auto-aof-rewrite-min-size 64mb
+```
+
+表示当前AOF的文件体积大于64MB,并且AOF文件的体积比上一次重写之后的体积变大了至少一倍(100%)的时候,Redis将执行重写BGREWRITEAOF命令。
+
+如果AOF重写执行的过于频繁的话,可以将`auto-aof-rewrite-percentage` 选项的值设置为100以上,这种最偶发就可以让Redis在AOF文件的体积变得更大之后才执行重写操作,不过,这也使得在进行数据恢复的时候执行的时间变得更加长一些。
+
+## 验证快照文件和AOF文件
+
+无论使用哪种方式进行持久化,我们在进行恢复数据的时候,Redis提供了两个命令行程序:
+
+```
+redis-check-aofredis-check-dump
+```
+
+他们可以再系统发生故障的时候,检查快照和AOF文件的状态,并对有需要的情况对文件进行修复。
+
+如果用户在运行redis-check-aof命令的时候,指定了`--fix` 参数,那么程序将对AOF文件进行修复。
+
+程序修复AOF文件的方法很简单:他会扫描给定的AOF文件,寻找不正确或者不完整的命令,当发现第一个出现错误命令的时候,程序会删除出错命令以及出错命令之后的所有命令,只保留那些位于出错命令之前的正确命令。大部分情况,被删除的都是AOF文件末尾的不完整的写命令。
+
+## 总结
+
+上述,一起学习了两种支持持久化的方式,一方面我们需要通过快照或者AOF的方式对数据进行持久化,另一方面,我们还需要将持久化所得到的文件进行备份,备份到不同的服务器上,这样才可以尽可能的减少数据丢失的损失。
+
+* * *
+
+参考文章:
+
+1、Redis in Action - [美] Josiah L.Carlsono
+
+
+
diff --git "a/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\26012\357\274\232\346\265\205\346\236\220Redis\344\270\273\344\273\216\345\244\215\345\210\266.md" "b/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\26012\357\274\232\346\265\205\346\236\220Redis\344\270\273\344\273\216\345\244\215\345\210\266.md"
new file mode 100644
index 0000000..a59247b
--- /dev/null
+++ "b/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\26012\357\274\232\346\265\205\346\236\220Redis\344\270\273\344\273\216\345\244\215\345\210\266.md"
@@ -0,0 +1,219 @@
+本文转自互联网
+
+本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
+> https://github.com/h2pl/Java-Tutorial
+
+喜欢的话麻烦点下Star哈
+
+文章首发于我的个人博客:
+> www.how2playlife.com
+
+本文是微信公众号【Java技术江湖】的《探索Redis设计与实现》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。
+
+该系列博文会告诉你如何从入门到进阶,Redis基本的使用方法,Redis的基本数据结构,以及一些进阶的使用方法,同时也需要进一步了解Redis的底层数据结构,再接着,还会带来Redis主从复制、集群、分布式锁等方面的相关内容,以及作为缓存的一些使用方法和注意事项,以便让你更完整地了解整个Redis相关的技术体系,形成自己的知识框架。
+
+如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。
+
+
+
+转自网络,侵删
+
+早期的RDBMS被设计为运行在单个CPU之上,读写操作都由经单个数据库实例完成,复制技术使得数据库的读写操作可以分散在运行于不同CPU之上的独立服务器上,Redis作为一个开源的、优秀的key-value缓存及持久化存储解决方案,也提供了复制功能,本文主要介绍Redis的复制原理及特性。
+
+
+
+# Redis复制概论
+
+数据库复制指的是发生在不同数据库实例之间,单向的信息传播的行为,通常由被复制方和复制方组成,被复制方和复制方之间建立网络连接,复制方式通常为被复制方主动将数据发送到复制方,复制方接收到数据存储在当前实例,最终目的是为了保证双方的数据一致、同步。
+
+
+
+复制示意图
+
+
+
+## Redis复制方式
+
+Redis的复制方式有两种,一种是主(master)-从(slave)模式,一种是从(slave)-从(slave)模式,因此Redis的复制拓扑图会丰富一些,可以像星型拓扑,也可以像个有向无环:
+
+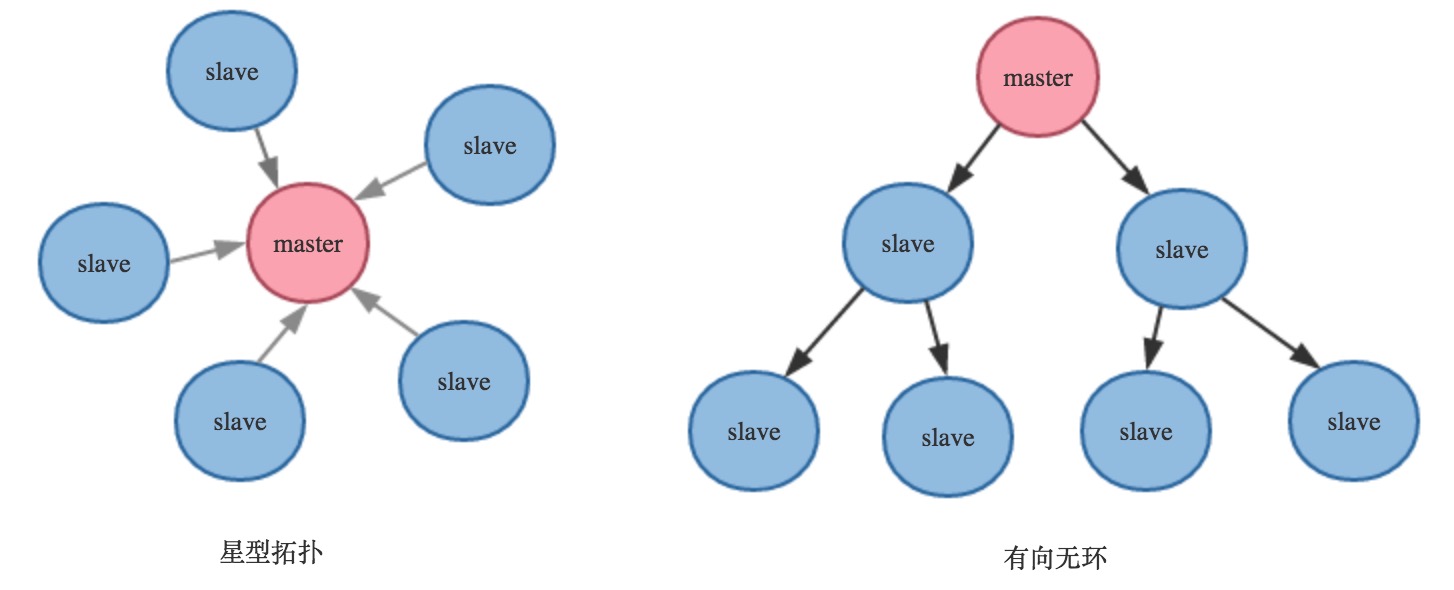
+
+Redis集群复制结构图
+
+通过配置多个Redis实例独立运行、定向复制,形成Redis集群,master负责写、slave负责读。
+
+
+
+## 复制优点
+
+通过配置多个Redis实例,数据备份在不同的实例上,主库专注写请求,从库负责读请求,这样的好处主要体现在下面几个方面:
+
+
+
+### 1、高可用性
+
+在一个Redis集群中,如果master宕机,slave可以介入并取代master的位置,因此对于整个Redis服务来说不至于提供不了服务,这样使得整个Redis服务足够安全。
+
+
+
+### 2、高性能
+
+在一个Redis集群中,master负责写请求,slave负责读请求,这么做一方面通过将读请求分散到其他机器从而大大减少了master服务器的压力,另一方面slave专注于提供读服务从而提高了响应和读取速度。
+
+
+
+### 3、水平扩展性
+
+通过增加slave机器可以横向(水平)扩展Redis服务的整个查询服务的能力。
+
+
+
+## 复制缺点
+
+复制提供了高可用性的解决方案,但同时引入了分布式计算的复杂度问题,认为有两个核心问题:
+
+1. 数据一致性问题,如何保证master服务器写入的数据能够及时同步到slave机器上。
+2. 编程复杂,如何在客户端提供读写分离的实现方案,通过客户端实现将读写请求分别路由到master和slave实例上。
+
+上面两个问题,尤其是第一个问题是Redis服务实现一直在演变,致力于解决的一个问题。
+
+
+
+## 复制实时性和数据一致性矛盾
+
+Redis提供了提高数据一致性的解决方案,本文后面会进行介绍,一致性程度的增加虽然使得我能够更信任数据,但是更好的一致性方案通常伴随着性能的损失,从而减少了吞吐量和服务能力。然而我们希望系统的性能达到最优,则必须要牺牲一致性的程度,因此Redis的复制实时性和数据一致性是存在矛盾的。
+
+
+
+# Redis复制原理及特性
+
+
+
+## slave指向master
+
+举个例子,我们有四台redis实例,M1,R1、R2、R3,其中M1为master,R1、R2、R3分别为三台slave redis实例。在M1启动如下:
+
+```
+./redis-server ../redis8000.conf --port 8000
+
+```
+
+下面分别为R1、R2、R3的启动命令:
+
+```
+ ./redis-server ../redis8001.conf --port 8001 --slaveof 127.0.0.1 8000 ./redis-server ../redis8002.conf --port 8002 --slaveof 127.0.0.1 8000 ./redis-server ../redis8003.conf --port 8003 --slaveof 127.0.0.1 8000
+```
+
+这样,我们就成功的启动了四台Redis实例,master实例的服务端口为8000,R1、R2、R3的服务端口分别为8001、8002、8003,集群图如下:
+
+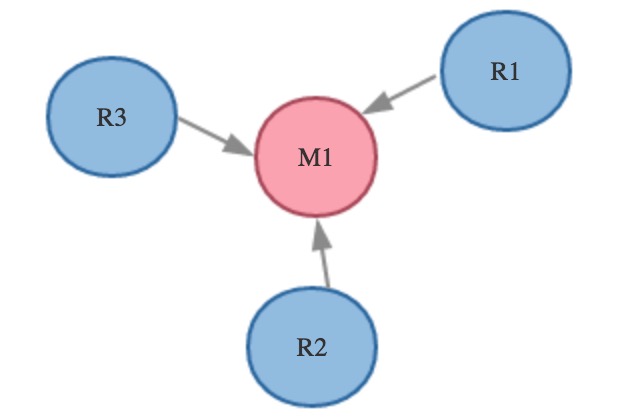
+
+Redis集群复制拓扑
+
+上面的命令在slave启动的时候就指定了master机器,我们也可以在slave运行的时候通过slaveof命令来指定master机器。
+
+
+
+## 复制过程
+
+Redis复制主要由SYNC命令实现,复制过程如下图:
+
+
+
+Redis复制过程
+
+上图为Redis复制工作过程:
+
+1. slave向master发送sync命令。
+2. master开启子进程来讲dataset写入rdb文件,同时将子进程完成之前接收到的写命令缓存起来。
+3. 子进程写完,父进程得知,开始将RDB文件发送给slave。
+4. master发送完RDB文件,将缓存的命令也发给slave。
+5. master增量的把写命令发给slave。
+
+值得注意的是,当slave跟master的连接断开时,slave可以自动的重新连接master,在redis2.8版本之前,每当slave进程挂掉重新连接master的时候都会开始新的一轮全量复制。如果master同时接收到多个slave的同步请求,则master只需要备份一次RDB文件。
+
+
+
+## 增量复制
+
+上面复制过程介绍的最后提到,slave和master断开了、当slave和master重新连接上之后需要全量复制,这个策略是很不友好的,从Redis2.8开始,Redis提供了增量复制的机制:
+
+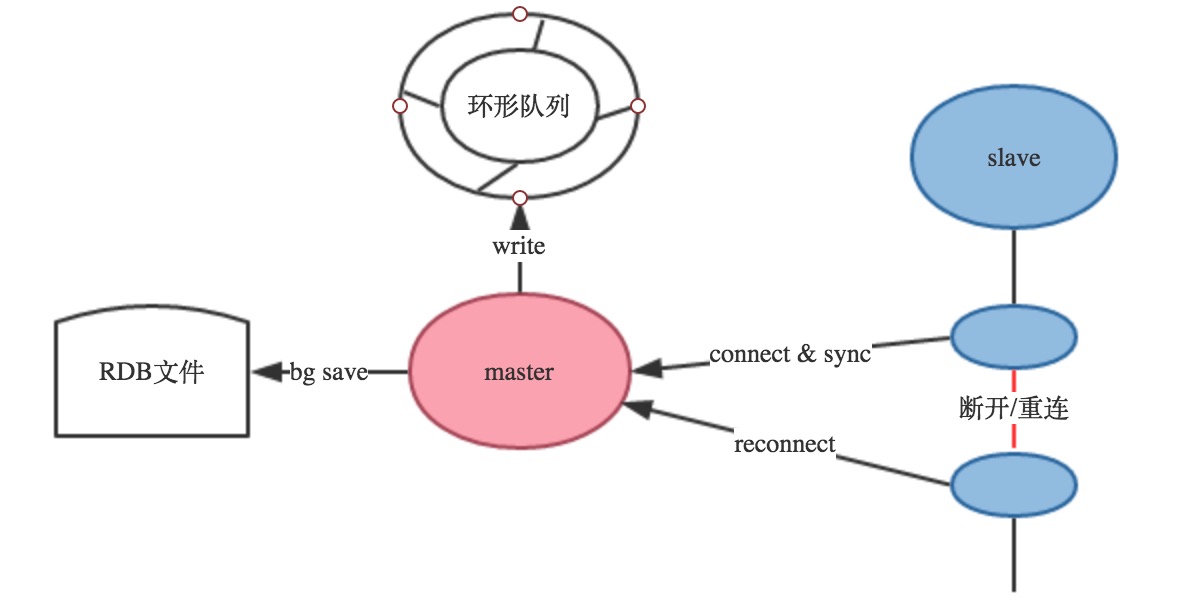
+
+增量复制机制
+
+master除了备份RDB文件之外还会维护者一个环形队列,以及环形队列的写索引和slave同步的全局offset,环形队列用于存储最新的操作数据,当slave和maste断开重连之后,会把slave维护的offset,也就是上一次同步到哪里的这个值告诉master,同时会告诉master上次和当前slave连接的master的runid,满足下面两个条件,Redis不会全量复制:
+
+1. slave传递的run id和master的run id一致。
+2. master在环形队列上可以找到对呀offset的值。
+
+满足上面两个条件,Redis就不会全量复制,这样的好处是大大的提高的性能,不做无效的功。
+
+增量复制是由psync命令实现的,slave可以通过psync命令来让Redis进行增量复制,当然最终是否能够增量复制取决于环形队列的大小和slave的断线时间长短和重连的这个master是否是之前的master。
+
+环形队列大小配置参数:
+
+```
+repl-backlog-size 1mb
+```
+
+Redis同时也提供了当没有slave需要同步的时候,多久可以释放环形队列:
+
+```
+repl-backlog-ttl 3600
+```
+
+
+
+## 免持久化复制
+
+免持久化机制官方叫做Diskless Replication,前面基于RDB文件写磁盘的方式可以看出,Redis必须要先将RDB文件写入磁盘,才进行网络传输,那么为什么不能直接通过网络把RDB文件传送给slave呢?免持久化复制就是做这个事情的,而且在Redis2.8.18版本开始支持,当然目前还是实验阶段。
+
+值得注意的是,一旦基于Diskless Replication的复制传送开始,新的slave请求需要等待这次传输完毕才能够得到服务。
+
+是否开启Diskless Replication的开关配置为:
+
+```
+repo-diskless-sync no
+```
+
+为了让后续的slave能够尽量赶上本次复制,Redis提供了一个参数配置指定复制开始的时间延迟:
+
+```
+repl-diskless-sync-delay 5
+```
+
+
+
+## slave只读模式
+
+自从Redis2.6版本开始,支持对slave的只读模式的配置,默认对slave的配置也是只读。只读模式的slave将会拒绝客户端的写请求,从而避免因为从slave写入而导致的数据不一致问题。
+
+
+
+## 半同步复制
+
+和MySQL复制策略有点类似,Redis复制本身是异步的,但也提供了半同步的复制策略,半同步复制策略在Redis复制中的语义是这样的:
+
+```
+允许用户给出这样的配置:在maste接受写操作的时候,只有当一定时间间隔内,至少有N台slave在线,否则写入无效。
+```
+
+上面功能的实现基于Redis下面特性:
+
+1. Redis slaves每秒钟会ping一次master,告诉master当前slave复制到哪里了。
+2. Redis master会记住每个slave复制到哪里了。
+
+我们可以通过下面配置来指定时间间隔和N这个值:
+
+```
+min-slaves-to-write min-slaves-max-lag
+```
+
+当配置了上面两个参数之后,一旦对于一个写操作没有满足上面的两个条件,则master会报错,并且将本次写操作视为无效。这有点像CAP理论中的“C”,即一致性实现,虽然半同步策略不能够完全保证master和slave的数据一致性,但是相对减少了不一致性的窗口期。
+
+
+
+# 总结
+
+本文在理解Redis复制概念和复制的优缺点的基础之上介绍了当前Redis复制工作原理以及主要特性,希望能够帮助大家。
\ No newline at end of file
diff --git "a/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\26013\357\274\232Redis\351\233\206\347\276\244\346\234\272\345\210\266\345\217\212\344\270\200\344\270\252Redis\346\236\266\346\236\204\346\274\224\350\277\233\345\256\236\344\276\213.md" "b/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\26013\357\274\232Redis\351\233\206\347\276\244\346\234\272\345\210\266\345\217\212\344\270\200\344\270\252Redis\346\236\266\346\236\204\346\274\224\350\277\233\345\256\236\344\276\213.md"
new file mode 100644
index 0000000..72f6230
--- /dev/null
+++ "b/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\26013\357\274\232Redis\351\233\206\347\276\244\346\234\272\345\210\266\345\217\212\344\270\200\344\270\252Redis\346\236\266\346\236\204\346\274\224\350\277\233\345\256\236\344\276\213.md"
@@ -0,0 +1,270 @@
+本文转自互联网
+
+本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
+> https://github.com/h2pl/Java-Tutorial
+
+喜欢的话麻烦点下Star哈
+
+文章首发于我的个人博客:
+> www.how2playlife.com
+
+本文是微信公众号【Java技术江湖】的《探索Redis设计与实现》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。
+
+该系列博文会告诉你如何从入门到进阶,Redis基本的使用方法,Redis的基本数据结构,以及一些进阶的使用方法,同时也需要进一步了解Redis的底层数据结构,再接着,还会带来Redis主从复制、集群、分布式锁等方面的相关内容,以及作为缓存的一些使用方法和注意事项,以便让你更完整地了解整个Redis相关的技术体系,形成自己的知识框架。
+
+如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。
+
+
+
+转自http://blog.720ui.com/2016/redis_action_04_cluster/#Replication%EF%BC%88%E4%B8%BB%E4%BB%8E%E5%A4%8D%E5%88%B6%EF%BC%89
+
+下面介绍Redis的集群方案。
+
+
+
+## [](http://blog.720ui.com/2016/redis_action_04_cluster/#Replication%EF%BC%88%E4%B8%BB%E4%BB%8E%E5%A4%8D%E5%88%B6%EF%BC%89 "Replication(主从复制)")Replication(主从复制)
+
+Redis的replication机制允许slave从master那里通过网络传输拷贝到完整的数据备份,从而达到主从机制。为了实现主从复制,我们准备三个redis服务,依次命名为master,slave1,slave2。
+
+### [](http://blog.720ui.com/2016/redis_action_04_cluster/#%E9%85%8D%E7%BD%AE%E4%B8%BB%E6%9C%8D%E5%8A%A1%E5%99%A8 "配置主服务器")配置主服务器
+
+为了测试效果,我们先修改主服务器的配置文件redis.conf的端口信息
+
+
+
+1. port 6300
+
+
+
+### [](http://blog.720ui.com/2016/redis_action_04_cluster/#%E9%85%8D%E7%BD%AE%E4%BB%8E%E6%9C%8D%E5%8A%A1%E5%99%A8 "配置从服务器")配置从服务器
+
+replication相关的配置比较简单,只需要把下面一行加到slave的配置文件中。你只需要把ip地址和端口号改一下。
+
+
+
+1. slaveof 192.168.1.1 6379
+
+
+
+我们先修改从服务器1的配置文件redis.conf的端口信息和从服务器配置。
+
+
+
+1. port 6301
+2. slaveof 127.0.0.1 6300
+
+
+
+我们再修改从服务器2的配置文件redis.conf的端口信息和从服务器配置。
+
+
+
+1. port 6302
+2. slaveof 127.0.0.1 6300
+
+
+
+值得注意的是,从redis2.6版本开始,slave支持只读模式,而且是默认的。可以通过配置项slave-read-only来进行配置。
+此外,如果master通过requirepass配置项设置了密码,slave每次同步操作都需要验证密码,可以通过在slave的配置文件中添加以下配置项
+
+
+
+1. masterauth
+
+
+
+### [](http://blog.720ui.com/2016/redis_action_04_cluster/#%E6%B5%8B%E8%AF%95 "测试")测试
+
+分别启动主服务器,从服务器,我们来验证下主从复制。我们在主服务器写入一条消息,然后再其他从服务器查看是否成功复制了。
+
+## [](http://blog.720ui.com/2016/redis_action_04_cluster/#Sentinel%EF%BC%88%E5%93%A8%E5%85%B5%EF%BC%89 "Sentinel(哨兵)")Sentinel(哨兵)
+
+主从机制,上面的方案中主服务器可能存在单点故障,万一主服务器宕机,这是个麻烦事情,所以Redis提供了Redis-Sentinel,以此来实现主从切换的功能,类似与zookeeper。
+
+Redis-Sentinel是Redis官方推荐的高可用性(HA)解决方案,当用Redis做master-slave的高可用方案时,假如master宕机了,Redis本身(包括它的很多客户端)都没有实现自动进行主备切换,而Redis-Sentinel本身也是一个独立运行的进程,它能监控多个master-slave集群,发现master宕机后能进行自动切换。
+
+它的主要功能有以下几点
+
+* 监控(Monitoring):不断地检查redis的主服务器和从服务器是否运作正常。
+* 提醒(Notification):如果发现某个redis服务器运行出现状况,可以通过 API 向管理员或者其他应用程序发送通知。
+* 自动故障迁移(Automatic failover):能够进行自动切换。当一个主服务器不能正常工作时,会将失效主服务器的其中一个从服务器升级为新的主服务器,并让失效主服务器的其他从服务器改为复制新的主服务器; 当客户端试图连接失效的主服务器时, 集群也会向客户端返回新主服务器的地址, 使得集群可以使用新主服务器代替失效服务器。
+
+Redis Sentinel 兼容 Redis 2.4.16 或以上版本, 推荐使用 Redis 2.8.0 或以上的版本。
+
+### [](http://blog.720ui.com/2016/redis_action_04_cluster/#%E9%85%8D%E7%BD%AESentinel "配置Sentinel")配置Sentinel
+
+必须指定一个sentinel的配置文件sentinel.conf,如果不指定将无法启动sentinel。首先,我们先创建一个配置文件sentinel.conf
+
+
+
+1. port 26379
+2. sentinel monitor mymaster 127.0.0.1 6300 2
+
+
+
+官方典型的配置如下
+
+
+
+1. sentinel monitor mymaster 127.0.0.1 6379 2
+2. sentinel down-after-milliseconds mymaster 60000
+3. sentinel failover-timeout mymaster 180000
+4. sentinel parallel-syncs mymaster 1
+5.
+6. sentinel monitor resque 192.168.1.3 6380 4
+7. sentinel down-after-milliseconds resque 10000
+8. sentinel failover-timeout resque 180000
+9. sentinel parallel-syncs resque 5
+
+
+
+配置文件只需要配置master的信息就好啦,不用配置slave的信息,因为slave能够被自动检测到(master节点会有关于slave的消息)。
+
+需要注意的是,配置文件在sentinel运行期间是会被动态修改的,例如当发生主备切换时候,配置文件中的master会被修改为另外一个slave。这样,之后sentinel如果重启时,就可以根据这个配置来恢复其之前所监控的redis集群的状态。
+
+接下来我们将一行一行地解释上面的配置项:
+
+
+
+1. sentinel monitor mymaster 127.0.0.1 6379 2
+
+
+
+这行配置指示 Sentinel 去监视一个名为 mymaster 的主服务器, 这个主服务器的 IP 地址为 127.0.0.1 , 端口号为 6300, 而将这个主服务器判断为失效至少需要 2 个 Sentinel 同意,只要同意 Sentinel 的数量不达标,自动故障迁移就不会执行。
+
+不过要注意, 无论你设置要多少个 Sentinel 同意才能判断一个服务器失效, 一个 Sentinel 都需要获得系统中多数(majority) Sentinel 的支持, 才能发起一次自动故障迁移, 并预留一个给定的配置纪元 (configuration Epoch ,一个配置纪元就是一个新主服务器配置的版本号)。换句话说, 在只有少数(minority) Sentinel 进程正常运作的情况下, Sentinel 是不能执行自动故障迁移的。sentinel集群中各个sentinel也有互相通信,通过gossip协议。
+
+除了第一行配置,我们发现剩下的配置都有一个统一的格式:
+
+
+
+1. sentinel
+
+
+
+接下来我们根据上面格式中的option_name一个一个来解释这些配置项:
+
+* down-after-milliseconds 选项指定了 Sentinel 认为服务器已经断线所需的毫秒数。
+* parallel-syncs 选项指定了在执行故障转移时, 最多可以有多少个从服务器同时对新的主服务器进行同步, 这个数字越小, 完成故障转移所需的时间就越长。
+
+### [](http://blog.720ui.com/2016/redis_action_04_cluster/#%E5%90%AF%E5%8A%A8-Sentinel "启动 Sentinel")启动 Sentinel
+
+对于 redis-sentinel 程序, 你可以用以下命令来启动 Sentinel 系统
+
+
+
+1. redis-sentinel sentinel.conf
+
+
+
+对于 redis-server 程序, 你可以用以下命令来启动一个运行在 Sentinel 模式下的 Redis 服务器
+
+
+
+1. redis-server sentinel.conf --sentinel
+
+
+
+以上两种方式,都必须指定一个sentinel的配置文件sentinel.conf, 如果不指定将无法启动sentinel。sentinel默认监听26379端口,所以运行前必须确定该端口没有被别的进程占用。
+
+
+### [](http://blog.720ui.com/2016/redis_action_04_cluster/#%E6%B5%8B%E8%AF%95-1 "测试")测试
+
+此时,我们开启两个Sentinel,关闭主服务器,我们来验证下Sentinel。发现,服务器发生切换了。
+
+当6300端口的这个服务重启的时候,他会变成6301端口服务的slave。
+
+## [](http://blog.720ui.com/2016/redis_action_04_cluster/#Twemproxy "Twemproxy")Twemproxy
+
+Twemproxy是由Twitter开源的Redis代理, Redis客户端把请求发送到Twemproxy,Twemproxy根据路由规则发送到正确的Redis实例,最后Twemproxy把结果汇集返回给客户端。
+
+Twemproxy通过引入一个代理层,将多个Redis实例进行统一管理,使Redis客户端只需要在Twemproxy上进行操作,而不需要关心后面有多少个Redis实例,从而实现了Redis集群。
+
+Twemproxy本身也是单点,需要用Keepalived做高可用方案。
+
+这么些年来,Twenproxy作为应用范围最广、稳定性最高、最久经考验的分布式中间件,在业界广泛使用。
+
+但是,Twemproxy存在诸多不方便之处,最主要的是,Twemproxy无法平滑地增加Redis实例,业务量突增,需增加Redis服务器;业务量萎缩,需要减少Redis服务器。但对Twemproxy而言,基本上都很难操作。其次,没有友好的监控管理后台界面,不利于运维监控。
+
+## [](http://blog.720ui.com/2016/redis_action_04_cluster/#Codis "Codis")Codis
+
+Codis解决了Twemproxy的这两大痛点,由豌豆荚于2014年11月开源,基于Go和C开发、现已广泛用于豌豆荚的各种Redis业务场景。
+
+Codis 3.x 由以下组件组成:
+
+* Codis Server:基于 redis-2.8.21 分支开发。增加了额外的数据结构,以支持 slot 有关的操作以及数据迁移指令。具体的修改可以参考文档 redis 的修改。
+* Codis Proxy:客户端连接的 Redis 代理服务, 实现了 Redis 协议。 除部分命令不支持以外(不支持的命令列表),表现的和原生的 Redis 没有区别(就像 Twemproxy)。对于同一个业务集群而言,可以同时部署多个 codis-proxy 实例;不同 codis-proxy 之间由 codis-dashboard 保证状态同步。
+* Codis Dashboard:集群管理工具,支持 codis-proxy、codis-server 的添加、删除,以及据迁移等操作。在集群状态发生改变时,codis-dashboard 维护集群下所有 codis-proxy 的状态的一致性。对于同一个业务集群而言,同一个时刻 codis-dashboard 只能有 0个或者1个;所有对集群的修改都必须通过 codis-dashboard 完成。
+* Codis Admin:集群管理的命令行工具。可用于控制 codis-proxy、codis-dashboard 状态以及访问外部存储。
+* Codis FE:集群管理界面。多个集群实例共享可以共享同一个前端展示页面;通过配置文件管理后端 codis-dashboard 列表,配置文件可自动更新。
+* Codis HA:为集群提供高可用。依赖 codis-dashboard 实例,自动抓取集群各个组件的状态;会根据当前集群状态自动生成主从切换策略,并在需要时通过 codis-dashboard 完成主从切换。
+* Storage:为集群状态提供外部存储。提供 Namespace 概念,不同集群的会按照不同 product name 进行组织;目前仅提供了 Zookeeper 和 Etcd 两种实现,但是提供了抽象的 interface 可自行扩展。
+ 
+
+Codis引入了Group的概念,每个Group包括1个Redis Master及一个或多个Redis Slave,这是和Twemproxy的区别之一,实现了Redis集群的高可用。当1个Redis Master挂掉时,Codis不会自动把一个Slave提升为Master,这涉及数据的一致性问题,Redis本身的数据同步是采用主从异步复制,当数据在Maste写入成功时,Slave是否已读入这个数据是没法保证的,需要管理员在管理界面上手动把Slave提升为Master。
+
+Codis使用,可以参考官方文档[https://github.com/CodisLabs/codis/blob/release3.0/doc/tutorial_zh.md](https://github.com/CodisLabs/codis/blob/release3.0/doc/tutorial_zh.md)
+
+## [](http://blog.720ui.com/2016/redis_action_04_cluster/#Redis-3-0%E9%9B%86%E7%BE%A4 "Redis 3.0集群")Redis 3.0集群
+
+Redis 3.0集群采用了P2P的模式,完全去中心化。支持多节点数据集自动分片,提供一定程度的分区可用性,部分节点挂掉或者无法连接其他节点后,服务可以正常运行。Redis 3.0集群采用Hash Slot方案,而不是一致性哈希。Redis把所有的Key分成了16384个slot,每个Redis实例负责其中一部分slot。集群中的所有信息(节点、端口、slot等),都通过节点之间定期的数据交换而更新。
+
+Redis客户端在任意一个Redis实例发出请求,如果所需数据不在该实例中,通过重定向命令引导客户端访问所需的实例。
+
+Redis 3.0集群,目前支持的cluster特性
+
+* 节点自动发现
+* slave->master 选举,集群容错
+* Hot resharding:在线分片
+* 集群管理:cluster xxx
+* 基于配置(nodes-port.conf)的集群管理
+* ASK 转向/MOVED 转向机制
+ 
+
+如上图所示,所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽。节点的fail是通过集群中超过半数的节点检测失效时才生效。客户端与redis节点直连,不需要中间proxy层。客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。redis-cluster把所有的物理节点映射到[0-16383]slot上cluster负责维护node<->slot<->value。
+
+
+选举过程是集群中所有master参与,如果半数以上master节点与master节点通信超时,认为当前master节点挂掉。
+
+当集群不可用时,所有对集群的操作做都不可用,收到((error) CLUSTERDOWN The cluster is down)错误。如果集群任意master挂掉,且当前master没有slave,集群进入fail状态,也可以理解成进群的slot映射[0-16383]不完成时进入fail状态。如果进群超过半数以上master挂掉,无论是否有slave集群进入fail状态。
+
+### [](http://blog.720ui.com/2016/redis_action_04_cluster/#%E7%8E%AF%E5%A2%83%E6%90%AD%E5%BB%BA "环境搭建")环境搭建
+
+现在,我们进行集群环境搭建。集群环境至少需要3个主服务器节点。本次测试,使用另外3个节点作为从服务器的节点,即3个主服务器,3个从服务器。
+
+修改配置文件,其它的保持默认即可。
+
+
+
+1. # 根据实际情况修改
+2. port 7000
+3. # 允许redis支持集群模式
+4. cluster-enabled yes
+5. # 节点配置文件,由redis自动维护
+6. cluster-config-file nodes.conf
+7. # 节点超时毫秒
+8. cluster-node-timeout 5000
+9. # 开启AOF同步模式
+10. appendonly yes
+
+
+
+### [](http://blog.720ui.com/2016/redis_action_04_cluster/#%E5%88%9B%E5%BB%BA%E9%9B%86%E7%BE%A4 "创建集群")创建集群
+
+目前这些实例虽然都开启了cluster模式,但是彼此还不认识对方,接下来可以通过Redis集群的命令行工具redis-trib.rb来完成集群创建。
+首先,下载 [https://raw.githubusercontent.com/antirez/redis/unstable/src/redis-trib.rb](https://raw.githubusercontent.com/antirez/redis/unstable/src/redis-trib.rb "redis-trib.rb")。
+
+然后,搭建Redis 的 Ruby 支持环境。这里,不进行扩展,参考相关文档。
+
+现在,接下来运行以下命令。这个命令在这里用于创建一个新的集群, 选项–replicas 1 表示我们希望为集群中的每个主节点创建一个从节点。
+
+
+
+1. redis-trib.rb create --replicas 1 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 127.0.0.1:7006
+
+
+
+
+
+5.3、测试
+
\ No newline at end of file
diff --git "a/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\26014\357\274\232Redis\344\272\213\345\212\241\346\265\205\346\236\220\344\270\216ACID\347\211\271\346\200\247\344\273\213\347\273\215.md" "b/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\26014\357\274\232Redis\344\272\213\345\212\241\346\265\205\346\236\220\344\270\216ACID\347\211\271\346\200\247\344\273\213\347\273\215.md"
new file mode 100644
index 0000000..d4baeb9
--- /dev/null
+++ "b/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\26014\357\274\232Redis\344\272\213\345\212\241\346\265\205\346\236\220\344\270\216ACID\347\211\271\346\200\247\344\273\213\347\273\215.md"
@@ -0,0 +1,299 @@
+
+本文转自互联网
+
+本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
+> https://github.com/h2pl/Java-Tutorial
+
+喜欢的话麻烦点下Star哈
+
+文章首发于我的个人博客:
+> www.how2playlife.com
+
+本文是微信公众号【Java技术江湖】的《探索Redis设计与实现》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。
+
+该系列博文会告诉你如何从入门到进阶,Redis基本的使用方法,Redis的基本数据结构,以及一些进阶的使用方法,同时也需要进一步了解Redis的底层数据结构,再接着,还会带来Redis主从复制、集群、分布式锁等方面的相关内容,以及作为缓存的一些使用方法和注意事项,以便让你更完整地了解整个Redis相关的技术体系,形成自己的知识框架。
+
+如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+# 事务
+
+[MULTI](http://www.redis.cn/commands/multi.html) 、 [EXEC](http://www.redis.cn/commands/exec.html) 、 [DISCARD](http://www.redis.cn/commands/discard.html) 和 [WATCH](http://www.redis.cn/commands/watch.html) 是 Redis 事务相关的命令。事务可以一次执行多个命令, 并且带有以下两个重要的保证:
+
+* 事务是一个单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。
+
+* 事务是一个原子操作:事务中的命令要么全部被执行,要么全部都不执行。
+
+[EXEC](http://www.redis.cn/commands/exec.html) 命令负责触发并执行事务中的所有命令:
+
+* 如果客户端在使用 [MULTI](http://www.redis.cn/commands/multi.html) 开启了一个事务之后,却因为断线而没有成功执行 [EXEC](http://www.redis.cn/commands/exec.html) ,那么事务中的所有命令都不会被执行。
+* 另一方面,如果客户端成功在开启事务之后执行 [EXEC](http://www.redis.cn/commands/exec.html) ,那么事务中的所有命令都会被执行。
+
+当使用 AOF 方式做持久化的时候, Redis 会使用单个 write(2) 命令将事务写入到磁盘中。
+
+然而,如果 Redis 服务器因为某些原因被管理员杀死,或者遇上某种硬件故障,那么可能只有部分事务命令会被成功写入到磁盘中。
+
+如果 Redis 在重新启动时发现 AOF 文件出了这样的问题,那么它会退出,并汇报一个错误。
+
+使用`redis-check-aof`程序可以修复这一问题:它会移除 AOF 文件中不完整事务的信息,确保服务器可以顺利启动。
+
+从 2.2 版本开始,Redis 还可以通过乐观锁(optimistic lock)实现 CAS (check-and-set)操作,具体信息请参考文档的后半部分。
+
+## 用法
+
+[MULTI](http://www.redis.cn/commands/multi.html) 命令用于开启一个事务,它总是返回 `OK` 。 [MULTI](http://www.redis.cn/commands/multi.html) 执行之后, 客户端可以继续向服务器发送任意多条命令, 这些命令不会立即被执行, 而是被放到一个队列中, 当 [EXEC](http://www.redis.cn/commands/exec.html)命令被调用时, 所有队列中的命令才会被执行。
+
+另一方面, 通过调用 [DISCARD](http://www.redis.cn/commands/discard.html) , 客户端可以清空事务队列, 并放弃执行事务。
+
+以下是一个事务例子, 它原子地增加了 `foo` 和 `bar` 两个键的值:
+
+
+
+```
+> MULTIOK> INCR fooQUEUED> INCR barQUEUED> EXEC1) (integer) 12) (integer) 1
+```
+
+
+
+[EXEC](http://www.redis.cn/commands/exec.html) 命令的回复是一个数组, 数组中的每个元素都是执行事务中的命令所产生的回复。 其中, 回复元素的先后顺序和命令发送的先后顺序一致。
+
+当客户端处于事务状态时, 所有传入的命令都会返回一个内容为 `QUEUED` 的状态回复(status reply), 这些被入队的命令将在 EXEC 命令被调用时执行。
+
+## 事务中的错误
+
+使用事务时可能会遇上以下两种错误:
+
+* 事务在执行 [EXEC](http://www.redis.cn/commands/exec.html) 之前,入队的命令可能会出错。比如说,命令可能会产生语法错误(参数数量错误,参数名错误,等等),或者其他更严重的错误,比如内存不足(如果服务器使用 `maxmemory` 设置了最大内存限制的话)。
+* 命令可能在 [EXEC](http://www.redis.cn/commands/exec.html) 调用之后失败。举个例子,事务中的命令可能处理了错误类型的键,比如将列表命令用在了字符串键上面,诸如此类。
+
+对于发生在 [EXEC](http://www.redis.cn/commands/exec.html) 执行之前的错误,客户端以前的做法是检查命令入队所得的返回值:如果命令入队时返回 `QUEUED` ,那么入队成功;否则,就是入队失败。如果有命令在入队时失败,那么大部分客户端都会停止并取消这个事务。
+
+不过,从 Redis 2.6.5 开始,服务器会对命令入队失败的情况进行记录,并在客户端调用 [EXEC](http://www.redis.cn/commands/exec.html) 命令时,拒绝执行并自动放弃这个事务。
+
+在 Redis 2.6.5 以前, Redis 只执行事务中那些入队成功的命令,而忽略那些入队失败的命令。 而新的处理方式则使得在流水线(pipeline)中包含事务变得简单,因为发送事务和读取事务的回复都只需要和服务器进行一次通讯。
+
+至于那些在 [EXEC](http://www.redis.cn/commands/exec.html) 命令执行之后所产生的错误, 并没有对它们进行特别处理: 即使事务中有某个/某些命令在执行时产生了错误, 事务中的其他命令仍然会继续执行。
+
+从协议的角度来看这个问题,会更容易理解一些。 以下例子中, [LPOP](http://www.redis.cn/commands/lpop.html) 命令的执行将出错, 尽管调用它的语法是正确的:
+
+
+
+```
+Trying 127.0.0.1...Connected to localhost.Escape character is '^]'.MULTI+OKSET a 3abc+QUEUEDLPOP a+QUEUEDEXEC*2+OK-ERR Operation against a key holding the wrong kind of value
+```
+
+
+
+[EXEC](http://www.redis.cn/commands/exec.html) 返回两条[bulk-string-reply](http://www.redis.cn/topics/protocol.html#bulk-string-reply): 第一条是 `OK` ,而第二条是 `-ERR` 。 至于怎样用合适的方法来表示事务中的错误, 则是由客户端自己决定的。
+
+最重要的是记住这样一条, 即使事务中有某条/某些命令执行失败了, 事务队列中的其他命令仍然会继续执行 —— Redis 不会停止执行事务中的命令。
+
+以下例子展示的是另一种情况, 当命令在入队时产生错误, 错误会立即被返回给客户端:
+
+
+
+```
+MULTI+OKINCR a b c-ERR wrong number of arguments for 'incr' command
+```
+
+
+
+因为调用 [INCR](http://www.redis.cn/commands/incr.html) 命令的参数格式不正确, 所以这个 [INCR](http://www.redis.cn/commands/incr.html) 命令入队失败。
+
+## 为什么 Redis 不支持回滚(roll back)
+
+如果你有使用关系式数据库的经验, 那么 “Redis 在事务失败时不进行回滚,而是继续执行余下的命令”这种做法可能会让你觉得有点奇怪。
+
+以下是这种做法的优点:
+
+* Redis 命令只会因为错误的语法而失败(并且这些问题不能在入队时发现),或是命令用在了错误类型的键上面:这也就是说,从实用性的角度来说,失败的命令是由编程错误造成的,而这些错误应该在开发的过程中被发现,而不应该出现在生产环境中。
+* 因为不需要对回滚进行支持,所以 Redis 的内部可以保持简单且快速。
+
+有种观点认为 Redis 处理事务的做法会产生 bug , 然而需要注意的是, 在通常情况下, 回滚并不能解决编程错误带来的问题。 举个例子, 如果你本来想通过 [INCR](http://www.redis.cn/commands/incr.html) 命令将键的值加上 1 , 却不小心加上了 2 , 又或者对错误类型的键执行了 [INCR](http://www.redis.cn/commands/incr.html), 回滚是没有办法处理这些情况的。
+
+## 放弃事务
+
+当执行 [DISCARD](http://www.redis.cn/commands/discard.html) 命令时, 事务会被放弃, 事务队列会被清空, 并且客户端会从事务状态中退出:
+
+
+
+```
+> SET foo 1OK> MULTIOK> INCR fooQUEUED> DISCARDOK> GET foo"1"
+```
+
+
+
+## 使用 check-and-set 操作实现乐观锁
+
+[WATCH](http://www.redis.cn/commands/watch.html) 命令可以为 Redis 事务提供 check-and-set (CAS)行为。
+
+被 [WATCH](http://www.redis.cn/commands/watch.html) 的键会被监视,并会发觉这些键是否被改动过了。 如果有至少一个被监视的键在 [EXEC](http://www.redis.cn/commands/exec.html) 执行之前被修改了, 那么整个事务都会被取消, [EXEC](http://www.redis.cn/commands/exec.html) 返回[nil-reply](http://www.redis.cn/topics/protocol.html#nil-reply)来表示事务已经失败。
+
+举个例子, 假设我们需要原子性地为某个值进行增 1 操作(假设 [INCR](http://www.redis.cn/commands/incr.html) 不存在)。
+
+首先我们可能会这样做:
+
+
+
+```
+val = GET mykeyval = val + 1SET mykey $val
+```
+
+
+
+上面的这个实现在只有一个客户端的时候可以执行得很好。 但是, 当多个客户端同时对同一个键进行这样的操作时, 就会产生竞争条件。举个例子, 如果客户端 A 和 B 都读取了键原来的值, 比如 10 , 那么两个客户端都会将键的值设为 11 , 但正确的结果应该是 12 才对。
+
+有了 [WATCH](http://www.redis.cn/commands/watch.html) , 我们就可以轻松地解决这类问题了:
+
+
+
+```
+WATCH mykeyval = GET mykeyval = val + 1MULTISET mykey $valEXEC
+```
+
+
+
+使用上面的代码, 如果在 [WATCH](http://www.redis.cn/commands/watch.html) 执行之后, [EXEC](http://www.redis.cn/commands/exec.html) 执行之前, 有其他客户端修改了 `mykey` 的值, 那么当前客户端的事务就会失败。 程序需要做的, 就是不断重试这个操作, 直到没有发生碰撞为止。
+
+这种形式的锁被称作乐观锁, 它是一种非常强大的锁机制。 并且因为大多数情况下, 不同的客户端会访问不同的键, 碰撞的情况一般都很少, 所以通常并不需要进行重试。
+
+## 了解 `WATCH`
+
+[WATCH](http://www.redis.cn/commands/watch.html) 使得 [EXEC](http://www.redis.cn/commands/exec.html) 命令需要有条件地执行: 事务只能在所有被监视键都没有被修改的前提下执行, 如果这个前提不能满足的话,事务就不会被执行。 [了解更多->](http://code.google.com/p/redis/issues/detail?id=270)
+
+[WATCH](http://www.redis.cn/commands/watch.html) 命令可以被调用多次。 对键的监视从 [WATCH](http://www.redis.cn/commands/watch.html) 执行之后开始生效, 直到调用 [EXEC](http://www.redis.cn/commands/exec.html) 为止。
+
+用户还可以在单个 [WATCH](http://www.redis.cn/commands/watch.html) 命令中监视任意多个键, 就像这样:
+
+
+
+```
+redis> WATCH key1 key2 key3OK
+```
+
+
+
+当 [EXEC](http://www.redis.cn/commands/exec.html) 被调用时, 不管事务是否成功执行, 对所有键的监视都会被取消。
+
+另外, 当客户端断开连接时, 该客户端对键的监视也会被取消。
+
+使用无参数的 [UNWATCH](http://www.redis.cn/commands/unwatch.html) 命令可以手动取消对所有键的监视。 对于一些需要改动多个键的事务, 有时候程序需要同时对多个键进行加锁, 然后检查这些键的当前值是否符合程序的要求。 当值达不到要求时, 就可以使用 [UNWATCH](http://www.redis.cn/commands/unwatch.html) 命令来取消目前对键的监视, 中途放弃这个事务, 并等待事务的下次尝试。
+
+### 使用 WATCH 实现 ZPOP
+
+[WATCH](http://www.redis.cn/commands/watch.html) 可以用于创建 Redis 没有内置的原子操作。举个例子, 以下代码实现了原创的 [ZPOP](http://www.redis.cn/commands/zpop.html) 命令, 它可以原子地弹出有序集合中分值(score)最小的元素:
+
+
+
+```
+WATCH zsetelement = ZRANGE zset 0 0MULTIZREM zset elementEXEC
+```
+
+
+
+程序只要重复执行这段代码, 直到 [EXEC](http://www.redis.cn/commands/exec.html) 的返回值不是[nil-reply](http://www.redis.cn/topics/protocol.html#nil-reply)回复即可。
+
+## Redis 脚本和事务
+
+从定义上来说, Redis 中的脚本本身就是一种事务, 所以任何在事务里可以完成的事, 在脚本里面也能完成。 并且一般来说, 使用脚本要来得更简单,并且速度更快。
+
+因为脚本功能是 Redis 2.6 才引入的, 而事务功能则更早之前就存在了, 所以 Redis 才会同时存在两种处理事务的方法。
+
+不过我们并不打算在短时间内就移除事务功能, 因为事务提供了一种即使不使用脚本, 也可以避免竞争条件的方法, 而且事务本身的实现并不复杂。
+
+不过在不远的将来, 可能所有用户都会只使用脚本来实现事务也说不定。 如果真的发生这种情况的话, 那么我们将废弃并最终移除事务功能。
+
+
+
+
+
+
+
+
+
+
+
+# redis事务的ACID特性
+
+```
+在传统的关系型数据库中,尝尝用ACID特质来检测事务功能的可靠性和安全性。
+```
+
+在redis中事务总是具有原子性(Atomicity),一致性(Consistency)和隔离性(Isolation),并且当redis运行在某种特定的持久化
+模式下,事务也具有耐久性(Durability).
+
+> ①原子性
+>
+> ```
+> 事务具有原子性指的是,数据库将事务中的多个操作当作一个整体来执行,服务器要么就执行事务中的所有操作,要么就一个操作也不执行。
+> ```
+>
+> 但是对于redis的事务功能来说,事务队列中的命令要么就全部执行,要么就一个都不执行,因此redis的事务是具有原子性的。我们通常会知道
+
+两种关于redis事务原子性的说法,一种是要么事务都执行,要么都不执行。另外一种说法是redis事务当事务中的命令执行失败后面的命令还
+会执行,错误之前的命令不会回滚。其实这个两个说法都是正确的。但是缺一不可。我们接下来具体分析下
+
+```
+ 我们先看一个可以正确执行的事务例子
+```
+
+```
+redis > MULTIOK redis > SET username "bugall"QUEUED redis > EXEC1) OK2) "bugall"
+```
+
+```
+与之相反,我们再来看一个事务执行失败的例子。这个事务因为命令在放入事务队列的时候被服务器拒绝,所以事务中的所有命令都不会执行,因为前面我们有介绍到,redis的事务命令是统一先放到事务队列里,在用户输入EXEC命令的时候再统一执行。但是我们错误的使用"GET"命令,在命令放入事务队列的时候被检测到事务,这时候还没有接收到EXEC命令,所以这个时候不牵扯到回滚的问题,在EXEC的时候发现事务队列里有命令存在错误,所以事务里的命令就全都不执行,这样就达到里事务的原子性,我们看下例子。
+```
+
+```
+redis > MULTIOK redis > GET(error) ERR wrong number of arguments for 'get' command redis > GET usernameQUEUED redis > EXEC(error) EXECABORT Transaction discarded because of previous errors
+```
+
+```
+redis的事务和传统的关系型数据库事务的最大区别在于,redis不支持事务的回滚机制,即使事务队列中的某个命令在执行期间出现错误,整个事务也会继续执行下去,直到将事务队列中的所有命令都执行完毕为止,我们看下面的例子
+```
+
+```
+redis > SET username "bugall"OK redis > MULTIOK redis > SADD member "bugall" "litengfe" "yangyifang"QUEUED redis > RPUSH username "b" "l" "y" //错误对键username使用列表键命令QUEUED redis > SADD password "123456" "123456" "123456"QUEUED redis > EXEC1) (integer) 32) (error) WRONGTYPE Operation against a key holding the wrong kind of value3) (integer) 3
+```
+
+```
+redis的作者在十五功能的文档中解释说,不支持事务回滚是因为这种复杂的功能和redis追求的简单高效的设计主旨不符合,并且他认为,redis事务的执行时错误通常都是编程错误造成的,这种错误通常只会出现在开发环境中,而很少会在实际的生产环境中出现,所以他认为没有必要为redis开发事务回滚功能。所以我们在讨论redis事务回滚的时候,一定要区分命令发生错误的时候。
+```
+
+> ②一致性
+>
+> ```
+> 事务具有一致性指的是,如果数据库在执行事务之前是一致的,那么在事务执行之后,无论事务是否执行成功,数据库也应该仍然一致的。 ”一致“指的是数据符合数据库本身的定义和要求,没有包含非法或者无效的错误数据。redis通过谨慎的错误检测和简单的设计来保证事务一致性。
+> ```
+>
+> ③隔离性
+>
+> ```
+> 事务的隔离性指的是,即使数据库中有多个事务并发在执行,各个事务之间也不会互相影响,并且在并发状态下执行的事务和串行执行的事务产生的结果完全 相同。 因为redis使用单线程的方式来执行事务(以及事务队列中的命令),并且服务器保证,在执行事务期间不会对事物进行中断,因此,redis的事务总是以串行 的方式运行的,并且事务也总是具有隔离性的
+> ```
+>
+> ④持久性
+>
+> ```
+> 事务的耐久性指的是,当一个事务执行完毕时,执行这个事务所得的结果已经被保持到永久存储介质里面。 因为redis事务不过是简单的用队列包裹起来一组redis命令,redis并没有为事务提供任何额外的持久化功能,所以redis事务的耐久性由redis使用的模式 决定 - 当服务器在无持久化的内存模式下运行时,事务不具有耐久性,一旦服务器停机,包括事务数据在内的所有服务器数据都将丢失 - 当服务器在RDB持久化模式下运作的时候,服务器只会在特定的保存条件满足的时候才会执行BGSAVE命令,对数据库进行保存操作,并且异步执行的BGSAVE不 能保证事务数据被第一时间保存到硬盘里面,因此RDB持久化模式下的事务也不具有耐久性 - 当服务器运行在AOF持久化模式下,并且appedfsync的选项的值为always时,程序总会在执行命令之后调用同步函数,将命令数据真正的保存到硬盘里面,因此 这种配置下的事务是具有耐久性的。 - 当服务器运行在AOF持久化模式下,并且appedfsync的选项的值为everysec时,程序会每秒同步一次
+> ```
+
+
+
+
+
+
+
diff --git "a/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\26015\357\274\232Redis\345\210\206\345\270\203\345\274\217\351\224\201\350\277\233\345\214\226\345\217\262.md" "b/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\26015\357\274\232Redis\345\210\206\345\270\203\345\274\217\351\224\201\350\277\233\345\214\226\345\217\262.md"
new file mode 100644
index 0000000..9218532
--- /dev/null
+++ "b/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\26015\357\274\232Redis\345\210\206\345\270\203\345\274\217\351\224\201\350\277\233\345\214\226\345\217\262.md"
@@ -0,0 +1,221 @@
+
+本文转自互联网
+
+本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
+> https://github.com/h2pl/Java-Tutorial
+
+喜欢的话麻烦点下Star哈
+
+文章首发于我的个人博客:
+> www.how2playlife.com
+
+本文是微信公众号【Java技术江湖】的《探索Redis设计与实现》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。
+
+该系列博文会告诉你如何从入门到进阶,Redis基本的使用方法,Redis的基本数据结构,以及一些进阶的使用方法,同时也需要进一步了解Redis的底层数据结构,再接着,还会带来Redis主从复制、集群、分布式锁等方面的相关内容,以及作为缓存的一些使用方法和注意事项,以便让你更完整地了解整个Redis相关的技术体系,形成自己的知识框架。
+
+如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。
+
+
+
+
+
+
+## Redis分布式锁进化史
+
+近两年来微服务变得越来越热门,越来越多的应用部署在分布式环境中,在分布式环境中,数据一致性是一直以来需要关注并且去解决的问题,分布式锁也就成为了一种广泛使用的技术,常用的分布式实现方式为Redis,Zookeeper,其中基于Redis的分布式锁的使用更加广泛。
+
+但是在工作和网络上看到过各个版本的Redis分布式锁实现,每种实现都有一些不严谨的地方,甚至有可能是错误的实现,包括在代码中,如果不能正确的使用分布式锁,可能造成严重的生产环境故障,本文主要对目前遇到的各种分布式锁以及其缺陷做了一个整理,并对如何选择合适的Redis分布式锁给出建议。
+
+### 各个版本的Redis分布式锁
+
+* V1.0
+
+```
+tryLock(){
+ SETNX Key 1
+ EXPIRE Key Seconds
+}
+release(){
+ DELETE Key
+}
+```
+
+这个版本应该是最简单的版本,也是出现频率很高的一个版本,首先给锁加一个过期时间操作是为了避免应用在服务重启或者异常导致锁无法释放后,不会出现锁一直无法被释放的情况。
+
+这个方案的一个问题在于每次提交一个Redis请求,如果执行完第一条命令后应用异常或者重启,锁将无法过期,一种改善方案就是使用Lua脚本(包含SETNX和EXPIRE两条命令),但是如果Redis仅执行了一条命令后crash或者发生主从切换,依然会出现锁没有过期时间,最终导致无法释放。
+
+另外一个问题在于,很多同学在释放分布式锁的过程中,无论锁是否获取成功,都在finally中释放锁,这样是一个锁的错误使用,这个问题将在后续的V3.0版本中解决。
+
+针对锁无法释放问题的一个解决方案基于[GETSET](https://redis.io/commands/getset)命令来实现
+
+* V1.1 基于[GETSET](https://redis.io/commands/getset)
+
+```
+tryLock(){
+ NewExpireTime=CurrentTimestamp+ExpireSeconds
+ if(SETNX Key NewExpireTime Seconds){
+ oldExpireTime = GET(Key)
+ if( oldExpireTime < CurrentTimestamp){
+ NewExpireTime=CurrentTimestamp+ExpireSeconds
+ CurrentExpireTime=GETSET(Key,NewExpireTime)
+ if(CurrentExpireTime == oldExpireTime){
+ return 1;
+ }else{
+ return 0;
+ }
+ }
+ }
+}
+release(){
+ DELETE key
+ }
+```
+
+思路:
+
+1. SETNX(Key,ExpireTime)获取锁
+
+2. 如果获取锁失败,通过GET(Key)返回的时间戳检查锁是否已经过期
+
+3. GETSET(Key,ExpireTime)修改Value为NewExpireTime
+
+4. 检查GETSET返回的旧值,如果等于GET返回的值,则认为获取锁成功
+
+ > 注意:这个版本去掉了EXPIRE命令,改为通过Value时间戳值来判断过期
+
+问题:
+
+```
+ 1. 在锁竞争较高的情况下,会出现Value不断被覆盖,但是没有一个Client获取到锁
+
+ 2. 在获取锁的过程中不断的修改原有锁的数据,设想一种场景C1,C2竞争锁,C1获取到了锁,C2锁执行了GETSET操作修改了C1锁的过期时间,如果C1没有正确释放锁,锁的过期时间被延长,其它Client需要等待更久的时间
+```
+
+* V2.0 基于[SETNX](https://redis.io/commands/setnx)
+
+```
+tryLock(){ SETNX Key 1 Seconds}release(){ DELETE Key}
+```
+
+Redis 2.6.12版本后SETNX增加过期时间参数,这样就解决了两条命令无法保证原子性的问题。但是设想下面一个场景:
+
+1\. C1成功获取到了锁,之后C1因为GC进入等待或者未知原因导致任务执行过长,最后在锁失效前C1没有主动释放锁
+
+2\.
+C2在C1的锁超时后获取到锁,并且开始执行,这个时候C1和C2都同时在执行,会因重复执行造成数据不一致等未知情况
+
+3\. C1如果先执行完毕,则会释放C2的锁,此时可能导致另外一个C3进程获取到了锁
+
+大致的流程图
+
+
+
+存在问题:
+
+```
+1\. 由于C1的停顿导致C1 和C2同都获得了锁并且同时在执行,在业务实现间接要求必须保证幂等性
+
+2\. C1释放了不属于C1的锁
+```
+
+* V3.0
+
+```
+tryLock(){
+ SETNX Key UnixTimestamp Seconds
+}
+release(){
+ EVAL(
+ //LuaScript
+ if redis.call("get",KEYS[1]) == ARGV[1] then
+ return redis.call("del",KEYS[1])
+ else
+ return 0
+ end
+ )
+}
+```
+
+这个方案通过指定Value为时间戳,并在释放锁的时候检查锁的Value是否为获取锁的Value,避免了V2.0版本中提到的C1释放了C2持有的锁的问题;另外在释放锁的时候因为涉及到多个Redis操作,并且考虑到Check And Set 模型的并发问题,所以使用Lua脚本来避免并发问题。
+
+存在问题:
+
+
+如果在并发极高的场景下,比如抢红包场景,可能存在UnixTimestamp重复问题,另外由于不能保证分布式环境下的物理时钟一致性,也可能存在UnixTimestamp重复问题,只不过极少情况下会遇到。
+
+
+* V3.1
+
+```
+tryLock(){
+ SET Key UniqId Seconds
+}
+release(){
+ EVAL(
+ //LuaScript
+ if redis.call("get",KEYS[1]) == ARGV[1] then
+ return redis.call("del",KEYS[1])
+ else
+ return 0
+ end
+ )
+}
+
+```
+
+Redis 2.6.12后[SET](https://redis.io/commands/set)同样提供了一个NX参数,等同于SETNX命令,官方文档上提醒后面的版本有可能去掉[SETNX](https://redis.io/commands/setnx), [SETEX](https://redis.io/commands/setex), [PSETEX](https://redis.io/commands/psetex),并用SET命令代替,另外一个优化是使用一个自增的唯一UniqId代替时间戳来规避V3.0提到的时钟问题。
+
+这个方案是目前最优的分布式锁方案,但是如果在Redis集群环境下依然存在问题:
+
+由于Redis集群数据同步为异步,假设在Master节点获取到锁后未完成数据同步情况下Master节点crash,此时在新的Master节点依然可以获取锁,所以多个Client同时获取到了锁
+
+### 分布式Redis锁:Redlock
+
+V3.1的版本仅在单实例的场景下是安全的,针对如何实现分布式Redis的锁,国外的分布式专家有过激烈的讨论, antirez提出了分布式锁算法Redlock,在[distlock](https://redis.io/topics/distlock)话题下可以看到对Redlock的详细说明,下面是Redlock算法的一个中文说明(引用)
+
+假设有N个独立的Redis节点
+
+1. 获取当前时间(毫秒数)。
+
+2. 按顺序依次向N个Redis节点执行获取锁的操作。这个获取操作跟前面基于单Redis节点的获取锁的过程相同,包含随机字符串_my_random_value_,也包含过期时间(比如_PX 30000_,即锁的有效时间)。为了保证在某个Redis节点不可用的时候算法能够继续运行,这个获取锁的操作还有一个超时时间(time out),它要远小于锁的有效时间(几十毫秒量级)。客户端在向某个Redis节点获取锁失败以后,应该立即尝试下一个Redis节点。这里的失败,应该包含任何类型的失败,比如该Redis节点不可用,或者该Redis节点上的锁已经被其它客户端持有(注:Redlock原文中这里只提到了Redis节点不可用的情况,但也应该包含其它的失败情况)。
+
+3. 计算整个获取锁的过程总共消耗了多长时间,计算方法是用当前时间减去第1步记录的时间。如果客户端从大多数Redis节点(>= N/2+1)成功获取到了锁,并且获取锁总共消耗的时间没有超过锁的有效时间(lock validity time),那么这时客户端才认为最终获取锁成功;否则,认为最终获取锁失败。
+
+4. 如果最终获取锁成功了,那么这个锁的有效时间应该重新计算,它等于最初的锁的有效时间减去第3步计算出来的获取锁消耗的时间。
+
+5. 如果最终获取锁失败了(可能由于获取到锁的Redis节点个数少于N/2+1,或者整个获取锁的过程消耗的时间超过了锁的最初有效时间),那么客户端应该立即向所有Redis节点发起释放锁的操作(即前面介绍的Redis Lua脚本)。
+
+6. 释放锁:对所有的Redis节点发起释放锁操作
+
+然而Martin Kleppmann针对这个算法提出了[质疑](http://martin.kleppmann.com/2016/02/08/how-to-do-distributed-locking.html),提出应该基于fencing token机制(每次对资源进行操作都需要进行token验证)
+
+```
+ 1. Redlock在系统模型上尤其是在分布式时钟一致性问题上提出了假设,实际场景下存在时钟不一致和时钟跳跃问题,而Redlock恰恰是基于timing的分布式锁 2. 另外Redlock由于是基于自动过期机制,依然没有解决长时间的gc pause等问题带来的锁自动失效,从而带来的安全性问题。
+```
+
+接着antirez又[回复](http://antirez.com/news/101)了Martin Kleppmann的质疑,给出了过期机制的合理性,以及实际场景中如果出现停顿问题导致多个Client同时访问资源的情况下如何处理。
+
+针对Redlock的问题,[基于Redis的分布式锁到底安全吗](http://zhangtielei.com/posts/blog-Redlock-reasoning.html)给出了详细的中文说明,并对Redlock算法存在的问题提出了分析。
+
+### 总结
+
+不论是基于SETNX版本的Redis单实例分布式锁,还是Redlock分布式锁,都是为了保证下特性
+
+```
+ 1\. 安全性:在同一时间不允许多个Client同时持有锁 2\. 活性 死锁:锁最终应该能够被释放,即使Client端crash或者出现网络分区(通常基于超时机制) 容错性:只要超过半数Redis节点可用,锁都能被正确获取和释放
+```
+
+所以在开发或者使用分布式锁的过程中要保证安全性和活性,避免出现不可预测的结果。
+
+另外每个版本的分布式锁都存在一些问题,在锁的使用上要针对锁的实用场景选择合适的锁,通常情况下锁的使用场景包括:
+
+Efficiency(效率):只需要一个Client来完成操作,不需要重复执行,这是一个对宽松的分布式锁,只需要保证锁的活性即可;
+
+Correctness(正确性):多个Client保证严格的互斥性,不允许出现同时持有锁或者对同时操作同一资源,这种场景下需要在锁的选择和使用上更加严格,同时在业务代码上尽量做到幂等
+
+在Redis分布式锁的实现上还有很多问题等待解决,我们需要认识到这些问题并清楚如何正确实现一个Redis 分布式锁,然后在工作中合理的选择和正确的使用分布式锁。
+
+
+
+
+
diff --git "a/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\2601\357\274\232Redis \347\232\204\345\237\272\347\241\200\346\225\260\346\215\256\347\273\223\346\236\204\346\246\202\350\247\210.md" "b/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\2601\357\274\232Redis \347\232\204\345\237\272\347\241\200\346\225\260\346\215\256\347\273\223\346\236\204\346\246\202\350\247\210.md"
new file mode 100644
index 0000000..1da319d
--- /dev/null
+++ "b/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\2601\357\274\232Redis \347\232\204\345\237\272\347\241\200\346\225\260\346\215\256\347\273\223\346\236\204\346\246\202\350\247\210.md"
@@ -0,0 +1,246 @@
+本文转自互联网
+
+本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
+> https://github.com/h2pl/Java-Tutorial
+
+喜欢的话麻烦点下Star哈
+
+文章首发于我的个人博客:
+> www.how2playlife.com
+
+本文是微信公众号【Java技术江湖】的《探索Redis设计与实现》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。
+
+该系列博文会告诉你如何从入门到进阶,Redis基本的使用方法,Redis的基本数据结构,以及一些进阶的使用方法,同时也需要进一步了解Redis的底层数据结构,再接着,还会带来Redis主从复制、集群、分布式锁等方面的相关内容,以及作为缓存的一些使用方法和注意事项,以便让你更完整地了解整个Redis相关的技术体系,形成自己的知识框架。
+
+如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。
+
+
+
+
+这周开始学习 Redis,看看Redis是怎么实现的。所以会写一系列关于 Redis的文章。这篇文章关于 Redis 的基础数据。阅读这篇文章你可以了解:
+
+* 动态字符串(SDS)
+* 链表
+* 字典
+
+三个数据结构 Redis 是怎么实现的。
+
+
+
+# [](https://www.xilidou.com/2018/03/12/redis-data/#SDS "SDS")SDS
+
+SDS (Simple Dynamic String)是 Redis 最基础的数据结构。直译过来就是”简单的动态字符串“。Redis 自己实现了一个动态的字符串,而不是直接使用了 C 语言中的字符串。
+
+sds 的数据结构:
+
+
+ struct sdshdr {
+ // buf 中已占用空间的长度 int len;
+ // buf 中剩余可用空间的长度 int free;
+ // 数据空间
+ char buf[];
+
+ }
+
+
+
+所以一个 SDS 的就如下图:
+
+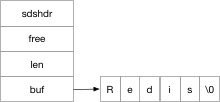
+
+所以我们看到,sds 包含3个参数。buf 的长度 len,buf 的剩余长度,以及buf。
+
+为什么这么设计呢?
+
+* 可以直接获取字符串长度。
+ C 语言中,获取字符串的长度需要用指针遍历字符串,时间复杂度为 O(n),而 SDS 的长度,直接从len 获取复杂度为 O(1)。
+
+* 杜绝缓冲区溢出。
+ 由于C 语言不记录字符串长度,如果增加一个字符传的长度,如果没有注意就可能溢出,覆盖了紧挨着这个字符的数据。对于SDS 而言增加字符串长度需要验证 free的长度,如果free 不够就会扩容整个 buf,防止溢出。
+
+* 减少修改字符串长度时造成的内存再次分配。
+ redis 作为高性能的内存数据库,需要较高的相应速度。字符串也很大概率的频繁修改。 SDS 通过未使用空间这个参数,将字符串的长度和底层buf的长度之间的额关系解除了。buf的长度也不是字符串的长度。基于这个分设计 SDS 实现了空间的预分配和惰性释放。
+
+ 1. 预分配
+ 如果对 SDS 修改后,如果 len 小于 1MB 那 len = 2 * len + 1byte。 这个 1 是用于保存空字节。
+ 如果 SDS 修改后 len 大于 1MB 那么 len = 1MB + len + 1byte。
+ 2. 惰性释放
+ 如果缩短 SDS 的字符串长度,redis并不是马上减少 SDS 所占内存。只是增加 free 的长度。同时向外提供 API 。真正需要释放的时候,才去重新缩小 SDS 所占的内存
+* 二进制安全。
+ C 语言中的字符串是以 ”\0“ 作为字符串的结束标记。而 SDS 是使用 len 的长度来标记字符串的结束。所以SDS 可以存储字符串之外的任意二进制流。因为有可能有的二进制流在流中就包含了”\0“造成字符串提前结束。也就是说 SDS 不依赖 “\0” 作为结束的依据。
+
+* 兼容C语言
+ SDS 按照惯例使用 ”\0“ 作为结尾的管理。部分普通C 语言的字符串 API 也可以使用。
+
+# [](https://www.xilidou.com/2018/03/12/redis-data/#%E9%93%BE%E8%A1%A8 "链表")链表
+
+C语言中并没有链表这个数据结构所以 Redis 自己实现了一个。Redis 中的链表是:
+
+ typedef struct listNode {
+ // 前置节点 struct listNode *prev;
+ // 后置节点 struct listNode *next;
+ // 节点的值 void *value;} listNode;
+
+
+非常典型的双向链表的数据结构。
+
+同时为双向链表提供了如下操作的函数:
+
+
+ /* * 双端链表迭代器 */typedef struct listIter {
+ // 当前迭代到的节点 listNode *next;
+ // 迭代的方向 int direction;} listIter;
+
+ /* * 双端链表结构
+
+ */typedef struct list {
+ // 表头节点 listNode *head;
+ // 表尾节点 listNode *tail;
+ // 节点值复制函数 void *(*dup)(void *ptr);
+ // 节点值释放函数 void (*free)(void *ptr);
+ // 节点值对比函数 int (*match)(void *ptr, void *key);
+ // 链表所包含的节点数量 unsigned long len;} list;
+
+
+链表的结构比较简单,数据结构如下:
+
+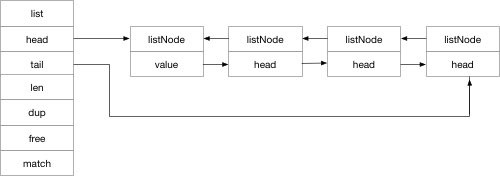
+
+总结一下性质:
+
+* 双向链表,某个节点寻找上一个或者下一个节点时间复杂度 O(1)。
+* list 记录了 head 和 tail,寻找 head 和 tail 的时间复杂度为 O(1)。
+* 获取链表的长度 len 时间复杂度 O(1)。
+
+# [](https://www.xilidou.com/2018/03/12/redis-data/#%E5%AD%97%E5%85%B8 "字典")字典
+
+字典数据结构极其类似 java 中的 Hashmap。
+
+Redis的字典由三个基础的数据结构组成。最底层的单位是哈希表节点。结构如下:
+
+ typedef struct dictEntry {
+
+ // 键
+ void *key;
+
+ // 值
+ union {
+ void *val;
+ uint64_t u64;
+ int64_t s64;
+ } v;
+
+ // 指向下个哈希表节点,形成链表
+ struct dictEntry *next;
+
+ } dictEntry;
+
+实际上哈希表节点就是一个单项列表的节点。保存了一下下一个节点的指针。 key 就是节点的键,v是这个节点的值。这个 v 既可以是一个指针,也可以是一个 `uint64_t`或者 `int64_t` 整数。*next 指向下一个节点。
+
+通过一个哈希表的数组把各个节点链接起来:
+ typedef struct dictht {
+
+ // 哈希表数组
+ dictEntry **table;
+
+ // 哈希表大小
+ unsigned long size;
+
+ // 哈希表大小掩码,用于计算索引值
+ // 总是等于 size - 1
+ unsigned long sizemask;
+
+ // 该哈希表已有节点的数量
+ unsigned long used;
+
+ } dictht;
+dictht
+
+通过图示我们观察:
+
+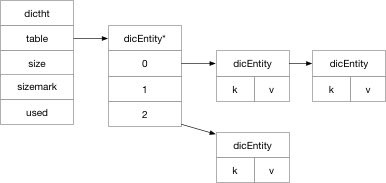
+
+实际上,如果对java 的基本数据结构了解的同学就会发现,这个数据结构和 java 中的 HashMap 是很类似的,就是数组加链表的结构。
+
+字典的数据结构:
+
+ typedef struct dict {
+
+ // 类型特定函数
+ dictType *type;
+
+ // 私有数据
+ void *privdata;
+
+ // 哈希表
+ dictht ht[2];
+
+ // rehash 索引
+ // 当 rehash 不在进行时,值为 -1
+ int rehashidx; /* rehashing not in progress if rehashidx == -1 */
+
+ // 目前正在运行的安全迭代器的数量
+ int iterators; /* number of iterators currently running */
+
+ } dict;
+
+其中的dictType 是一组方法,代码如下:
+
+
+
+ /*
+ * 字典类型特定函数
+ */
+ typedef struct dictType {
+
+ // 计算哈希值的函数
+ unsigned int (*hashFunction)(const void *key);
+
+ // 复制键的函数
+ void *(*keyDup)(void *privdata, const void *key);
+
+ // 复制值的函数
+ void *(*valDup)(void *privdata, const void *obj);
+
+ // 对比键的函数
+ int (*keyCompare)(void *privdata, const void *key1, const void *key2);
+
+ // 销毁键的函数
+ void (*keyDestructor)(void *privdata, void *key);
+
+ // 销毁值的函数
+ void (*valDestructor)(void *privdata, void *obj);
+
+ } dictType;
+
+字典的数据结构如下图:
+
+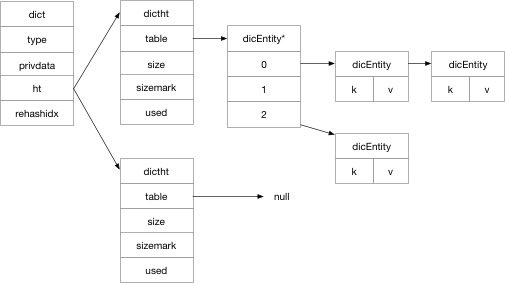
+
+这里我们可以看到一个dict 拥有两个 dictht。一般来说只使用 ht[0],当扩容的时候发生了rehash的时候,�ht[1]才会被使用。
+
+当我们观察或者研究一个hash结构的时候偶我们首先要考虑的这个 dict 如何插入一个数据?
+
+我们梳理一下插入数据的逻辑。
+
+* 计算Key 的 hash 值。找到 hash 映射到� �table 数组的位置。
+
+* 如果数据已经有一个 key �存在了。那就意味着发生了 hash 碰撞。新加入的节点,就会作为链表的一个节点接到之前节点的 next �指针上。
+
+* 如果�� key 发生了多次碰撞,造成链表的长度越来越长。会使得字典的查询速度下降。为了维持正常的负载。Redis 会对 字典进行 rehash 操作。来增加 �table 数组的长度。所以我们要着重了解一下 Redis 的 rehash。步骤如下:
+
+ 1. 根据�ht[0] 的数据和操作的类型(扩大或缩小),分配 ht[1] 的大小。
+ 2. 将 ht[0] 的数据 rehash 到 ht[1] 上。
+ 3. rehash 完成以后,将ht[1] 设置为 ht[0],生成一个新的ht[1]备用。
+* 渐进式的 rehash 。
+ 其实如果字典的 key 数量很大,达到千万级以上,rehash 就会是一个相对较长的时间。所以为了字典能够在 rehash 的时候能够继续提供服务。Redis 提供了一个渐进式的 rehash 实现,rehash的步骤如下:
+
+ 1. 分配 �ht[1] 的空间,让字典同时持有 ht[1] 和 ht[0]。
+ 2. 在字典中维护一个 rehashidx,设置为 0 ,表示字典正在 rehash。
+ 3. 在rehash期间,每次对字典的操作除了进行指定的操作以外,都会根据 ht[0] 在 rehashidx 上对应的键值对 rehash 到 ht[1]上。
+ 4. 随着操作进行, ht[0] 的数据就会全部 rehash 到 ht[1] 。设置ht[0] 的 rehashidx 为 -1,渐进的 rehash 结束。
+
+这样保证数据能够平滑的进行 rehash。防止 rehash 时间过久阻塞线程。
+
+* 在进行 rehash 的过程中,如果进行了 delete 和 update 等操作,会在两个哈希表上进行。如果是 find 的话优先在ht[0] 上进行,如果没有找到,再去 ht[1] 中查找。如果是 insert 的话那就只会在 ht[1]中插入数据。这样就会保证了 ht[1] 的数据只增不减,ht[0]的数据只减不增。
+
diff --git "a/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\2602\357\274\232Redis\345\206\205\351\203\250\346\225\260\346\215\256\347\273\223\346\236\204\350\257\246\350\247\243\342\200\224\342\200\224dict.md" "b/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\2602\357\274\232Redis\345\206\205\351\203\250\346\225\260\346\215\256\347\273\223\346\236\204\350\257\246\350\247\243\342\200\224\342\200\224dict.md"
new file mode 100644
index 0000000..dd7c597
--- /dev/null
+++ "b/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\2602\357\274\232Redis\345\206\205\351\203\250\346\225\260\346\215\256\347\273\223\346\236\204\350\257\246\350\247\243\342\200\224\342\200\224dict.md"
@@ -0,0 +1,377 @@
+本文转自互联网
+
+本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
+> https://github.com/h2pl/Java-Tutorial
+
+喜欢的话麻烦点下Star哈
+
+文章首发于我的个人博客:
+> www.how2playlife.com
+
+本文是微信公众号【Java技术江湖】的《探索Redis设计与实现》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。
+
+该系列博文会告诉你如何从入门到进阶,Redis基本的使用方法,Redis的基本数据结构,以及一些进阶的使用方法,同时也需要进一步了解Redis的底层数据结构,再接着,还会带来Redis主从复制、集群、分布式锁等方面的相关内容,以及作为缓存的一些使用方法和注意事项,以便让你更完整地了解整个Redis相关的技术体系,形成自己的知识框架。
+
+如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。
+
+
+
+如果你使用过Redis,一定会像我一样对它的内部实现产生兴趣。《Redis内部数据结构详解》是我准备写的一个系列,也是我个人对于之前研究Redis的一个阶段性总结,着重讲解Redis在内存中的数据结构实现(暂不涉及持久化的话题)。Redis本质上是一个数据结构服务器(data structures server),以高效的方式实现了多种现成的数据结构,研究它的数据结构和基于其上的算法,对于我们自己提升局部算法的编程水平有很重要的参考意义。
+
+当我们在本文中提到Redis的“数据结构”,可能是在两个不同的层面来讨论它。
+
+第一个层面,是从使用者的角度。比如:
+
+* string
+* list
+* hash
+* set
+* sorted set
+
+这一层面也是Redis暴露给外部的调用接口。
+
+第二个层面,是从内部实现的角度,属于更底层的实现。比如:
+
+* dict
+* sds
+* ziplist
+* quicklist
+* skiplist
+
+第一个层面的“数据结构”,Redis的官方文档([http://redis.io/topics/data-types-intro](http://redis.io/topics/data-types-intro))有详细的介绍。本文的重点在于讨论第二个层面,Redis数据结构的内部实现,以及这两个层面的数据结构之间的关系:Redis如何通过组合第二个层面的各种基础数据结构来实现第一个层面的更高层的数据结构。
+
+在讨论任何一个系统的内部实现的时候,我们都要先明确它的设计原则,这样我们才能更深刻地理解它为什么会进行如此设计的真正意图。在本文接下来的讨论中,我们主要关注以下几点:
+
+* 存储效率(memory efficiency)。Redis是专用于存储数据的,它对于计算机资源的主要消耗就在于内存,因此节省内存是它非常非常重要的一个方面。这意味着Redis一定是非常精细地考虑了压缩数据、减少内存碎片等问题。
+* 快速响应时间(fast response time)。与快速响应时间相对的,是高吞吐量(high throughput)。Redis是用于提供在线访问的,对于单个请求的响应时间要求很高,因此,快速响应时间是比高吞吐量更重要的目标。有时候,这两个目标是矛盾的。
+* 单线程(single-threaded)。Redis的性能瓶颈不在于CPU资源,而在于内存访问和网络IO。而采用单线程的设计带来的好处是,极大简化了数据结构和算法的实现。相反,Redis通过异步IO和pipelining等机制来实现高速的并发访问。显然,单线程的设计,对于单个请求的快速响应时间也提出了更高的要求。
+
+本文是《Redis内部数据结构详解》系列的第一篇,讲述Redis一个重要的基础数据结构:dict。
+
+dict是一个用于维护key和value映射关系的数据结构,与很多语言中的Map或dictionary类似。Redis的一个database中所有key到value的映射,就是使用一个dict来维护的。不过,这只是它在Redis中的一个用途而已,它在Redis中被使用的地方还有很多。比如,一个Redis hash结构,当它的field较多时,便会采用dict来存储。再比如,Redis配合使用dict和skiplist来共同维护一个sorted set。这些细节我们后面再讨论,在本文中,我们集中精力讨论dict本身的实现。
+
+dict本质上是为了解决算法中的查找问题(Searching),一般查找问题的解法分为两个大类:一个是基于各种平衡树,一个是基于哈希表。我们平常使用的各种Map或dictionary,大都是基于哈希表实现的。在不要求数据有序存储,且能保持较低的哈希值冲突概率的前提下,基于哈希表的查找性能能做到非常高效,接近O(1),而且实现简单。
+
+在Redis中,dict也是一个基于哈希表的算法。和传统的哈希算法类似,它采用某个哈希函数从key计算得到在哈希表中的位置,采用拉链法解决冲突,并在装载因子(load factor)超过预定值时自动扩展内存,引发重哈希(rehashing)。Redis的dict实现最显著的一个特点,就在于它的重哈希。它采用了一种称为增量式重哈希(incremental rehashing)的方法,在需要扩展内存时避免一次性对所有key进行重哈希,而是将重哈希操作分散到对于dict的各个增删改查的操作中去。这种方法能做到每次只对一小部分key进行重哈希,而每次重哈希之间不影响dict的操作。dict之所以这样设计,是为了避免重哈希期间单个请求的响应时间剧烈增加,这与前面提到的“快速响应时间”的设计原则是相符的。
+
+下面进行详细介绍。
+
+#### dict的数据结构定义
+
+为了实现增量式重哈希(incremental rehashing),dict的数据结构里包含两个哈希表。在重哈希期间,数据从第一个哈希表向第二个哈希表迁移。
+
+dict的C代码定义如下(出自Redis源码dict.h):
+
+ typedef struct dictEntry {
+ void *key;
+ union {
+ void *val;
+ uint64_t u64;
+ int64_t s64;
+ double d;
+ } v;
+ struct dictEntry *next;
+ } dictEntry;
+
+ typedef struct dictType {
+ unsigned int (*hashFunction)(const void *key);
+ void *(*keyDup)(void *privdata, const void *key);
+ void *(*valDup)(void *privdata, const void *obj);
+ int (*keyCompare)(void *privdata, const void *key1, const void *key2);
+ void (*keyDestructor)(void *privdata, void *key);
+ void (*valDestructor)(void *privdata, void *obj);
+ } dictType;
+
+ /* This is our hash table structure. Every dictionary has two of this as we
+ * implement incremental rehashing, for the old to the new table. */
+ typedef struct dictht {
+ dictEntry **table;
+ unsigned long size;
+ unsigned long sizemask;
+ unsigned long used;
+ } dictht;
+
+ typedef struct dict {
+ dictType *type;
+ void *privdata;
+ dictht ht[2];
+ long rehashidx; /* rehashing not in progress if rehashidx == -1 */
+ int iterators; /* number of iterators currently running */
+ } dict;
+
+
+为了能更清楚地展示dict的数据结构定义,我们用一张结构图来表示它。如下。
+
+[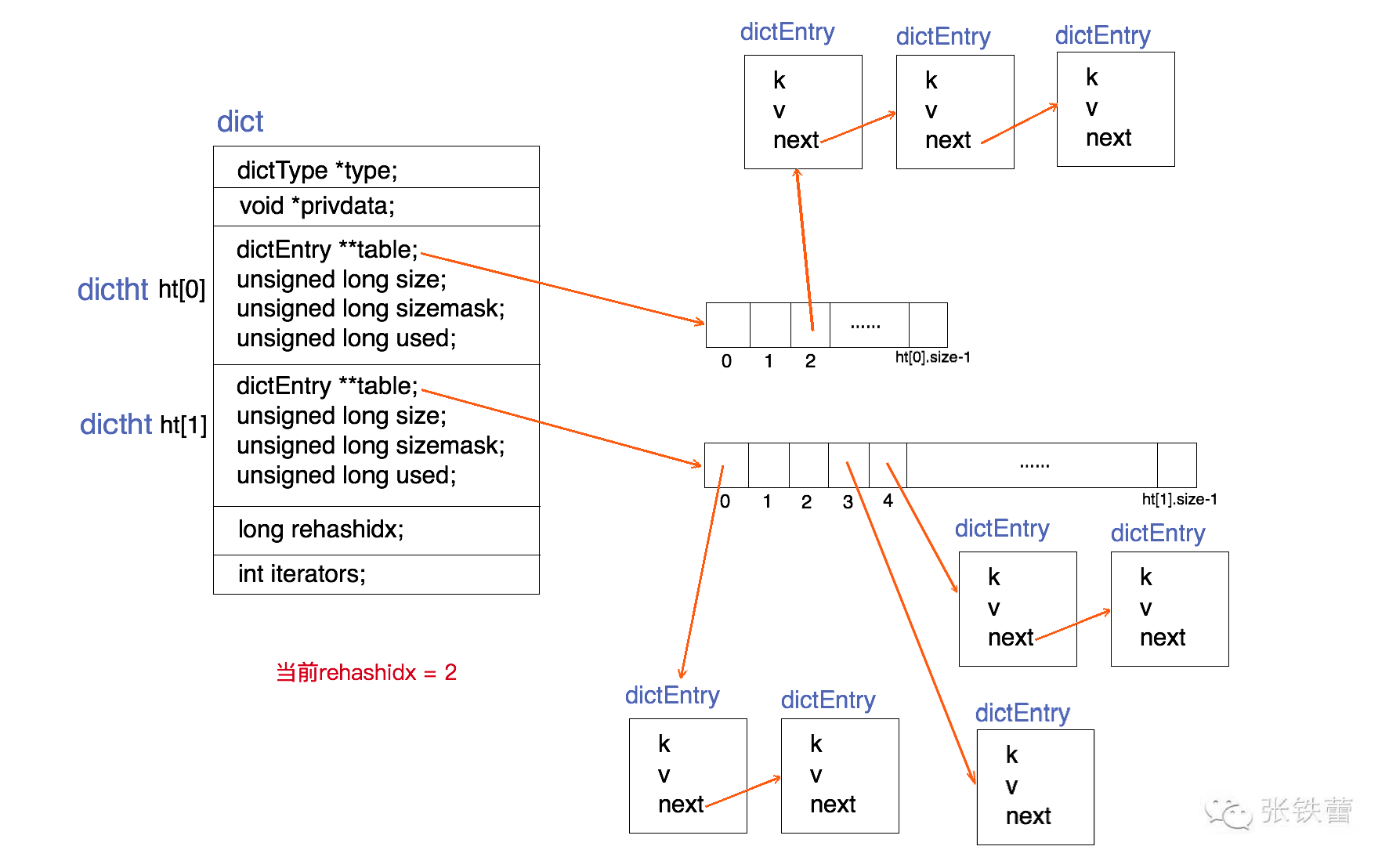](http://zhangtielei.com/assets/photos_redis/redis_dict_structure.png)
+
+结合上面的代码和结构图,可以很清楚地看出dict的结构。一个dict由如下若干项组成:
+
+* 一个指向dictType结构的指针(type)。它通过自定义的方式使得dict的key和value能够存储任何类型的数据。
+* 一个私有数据指针(privdata)。由调用者在创建dict的时候传进来。
+* 两个哈希表(ht[2])。只有在重哈希的过程中,ht[0]和ht[1]才都有效。而在平常情况下,只有ht[0]有效,ht[1]里面没有任何数据。上图表示的就是重哈希进行到中间某一步时的情况。
+* 当前重哈希索引(rehashidx)。如果rehashidx = -1,表示当前没有在重哈希过程中;否则,表示当前正在进行重哈希,且它的值记录了当前重哈希进行到哪一步了。
+* 当前正在进行遍历的iterator的个数。这不是我们现在讨论的重点,暂时忽略。
+
+dictType结构包含若干函数指针,用于dict的调用者对涉及key和value的各种操作进行自定义。这些操作包含:
+
+* hashFunction,对key进行哈希值计算的哈希算法。
+* keyDup和valDup,分别定义key和value的拷贝函数,用于在需要的时候对key和value进行深拷贝,而不仅仅是传递对象指针。
+* keyCompare,定义两个key的比较操作,在根据key进行查找时会用到。
+* keyDestructor和valDestructor,分别定义对key和value的析构函数。
+
+私有数据指针(privdata)就是在dictType的某些操作被调用时会传回给调用者。
+
+需要详细察看的是dictht结构。它定义一个哈希表的结构,由如下若干项组成:
+
+* 一个dictEntry指针数组(table)。key的哈希值最终映射到这个数组的某个位置上(对应一个bucket)。如果多个key映射到同一个位置,就发生了冲突,那么就拉出一个dictEntry链表。
+* size:标识dictEntry指针数组的长度。它总是2的指数。
+* sizemask:用于将哈希值映射到table的位置索引。它的值等于(size-1),比如7, 15, 31, 63,等等,也就是用二进制表示的各个bit全1的数字。每个key先经过hashFunction计算得到一个哈希值,然后计算(哈希值 & sizemask)得到在table上的位置。相当于计算取余(哈希值 % size)。
+* used:记录dict中现有的数据个数。它与size的比值就是装载因子(load factor)。这个比值越大,哈希值冲突概率越高。
+
+dictEntry结构中包含k, v和指向链表下一项的next指针。k是void指针,这意味着它可以指向任何类型。v是个union,当它的值是uint64_t、int64_t或double类型时,就不再需要额外的存储,这有利于减少内存碎片。当然,v也可以是void指针,以便能存储任何类型的数据。
+
+#### dict的创建(dictCreate)
+
+ dict *dictCreate(dictType *type,
+ void *privDataPtr)
+ {
+ dict *d = zmalloc(sizeof(*d));
+
+ _dictInit(d,type,privDataPtr);
+ return d;
+ }
+
+ int _dictInit(dict *d, dictType *type,
+ void *privDataPtr)
+ {
+ _dictReset(&d->ht[0]);
+ _dictReset(&d->ht[1]);
+ d->type = type;
+ d->privdata = privDataPtr;
+ d->rehashidx = -1;
+ d->iterators = 0;
+ return DICT_OK;
+ }
+
+ static void _dictReset(dictht *ht)
+ {
+ ht->table = NULL;
+ ht->size = 0;
+ ht->sizemask = 0;
+ ht->used = 0;
+ }
+
+
+dictCreate为dict的数据结构分配空间并为各个变量赋初值。其中两个哈希表ht[0]和ht[1]起始都没有分配空间,table指针都赋为NULL。这意味着要等第一个数据插入时才会真正分配空间。
+
+#### dict的查找(dictFind)
+
+ #define dictIsRehashing(d) ((d)->rehashidx != -1)
+
+ dictEntry *dictFind(dict *d, const void *key)
+ {
+ dictEntry *he;
+ unsigned int h, idx, table;
+
+ if (d->ht[0].used + d->ht[1].used == 0) return NULL; /* dict is empty */
+ if (dictIsRehashing(d)) _dictRehashStep(d);
+ h = dictHashKey(d, key);
+ for (table = 0; table <= 1; table++) {
+ idx = h & d->ht[table].sizemask;
+ he = d->ht[table].table[idx];
+ while(he) {
+ if (key==he->key || dictCompareKeys(d, key, he->key))
+ return he;
+ he = he->next;
+ }
+ if (!dictIsRehashing(d)) return NULL;
+ }
+ return NULL;
+ }
+
+
+上述dictFind的源码,根据dict当前是否正在重哈希,依次做了这么几件事:
+
+* 如果当前正在进行重哈希,那么将重哈希过程向前推进一步(即调用_dictRehashStep)。实际上,除了查找,插入和删除也都会触发这一动作。这就将重哈希过程分散到各个查找、插入和删除操作中去了,而不是集中在某一个操作中一次性做完。
+* 计算key的哈希值(调用dictHashKey,里面的实现会调用前面提到的hashFunction)。
+* 先在第一个哈希表ht[0]上进行查找。在table数组上定位到哈希值对应的位置(如前所述,通过哈希值与sizemask进行按位与),然后在对应的dictEntry链表上进行查找。查找的时候需要对key进行比较,这时候调用dictCompareKeys,它里面的实现会调用到前面提到的keyCompare。如果找到就返回该项。否则,进行下一步。
+* 判断当前是否在重哈希,如果没有,那么在ht[0]上的查找结果就是最终结果(没找到,返回NULL)。否则,在ht[1]上进行查找(过程与上一步相同)。
+
+下面我们有必要看一下增量式重哈希的_dictRehashStep的实现。
+
+
+ static void _dictRehashStep(dict *d) {
+ if (d->iterators == 0) dictRehash(d,1);
+ }
+
+ int dictRehash(dict *d, int n) {
+ int empty_visits = n*10; /* Max number of empty buckets to visit. */
+ if (!dictIsRehashing(d)) return 0;
+
+ while(n-- && d->ht[0].used != 0) {
+ dictEntry *de, *nextde;
+
+ /* Note that rehashidx can't overflow as we are sure there are more
+ * elements because ht[0].used != 0 */
+ assert(d->ht[0].size > (unsigned long)d->rehashidx);
+ while(d->ht[0].table[d->rehashidx] == NULL) {
+ d->rehashidx++;
+ if (--empty_visits == 0) return 1;
+ }
+ de = d->ht[0].table[d->rehashidx];
+ /* Move all the keys in this bucket from the old to the new hash HT */
+ while(de) {
+ unsigned int h;
+
+ nextde = de->next;
+ /* Get the index in the new hash table */
+ h = dictHashKey(d, de->key) & d->ht[1].sizemask;
+ de->next = d->ht[1].table[h];
+ d->ht[1].table[h] = de;
+ d->ht[0].used--;
+ d->ht[1].used++;
+ de = nextde;
+ }
+ d->ht[0].table[d->rehashidx] = NULL;
+ d->rehashidx++;
+ }
+
+ /* Check if we already rehashed the whole table... */
+ if (d->ht[0].used == 0) {
+ zfree(d->ht[0].table);
+ d->ht[0] = d->ht[1];
+ _dictReset(&d->ht[1]);
+ d->rehashidx = -1;
+ return 0;
+ }
+
+ /* More to rehash... */
+ return 1;
+ }
+
+dictRehash每次将重哈希至少向前推进n步(除非不到n步整个重哈希就结束了),每一步都将ht[0]上某一个bucket(即一个dictEntry链表)上的每一个dictEntry移动到ht[1]上,它在ht[1]上的新位置根据ht[1]的sizemask进行重新计算。rehashidx记录了当前尚未迁移(有待迁移)的ht[0]的bucket位置。
+
+如果dictRehash被调用的时候,rehashidx指向的bucket里一个dictEntry也没有,那么它就没有可迁移的数据。这时它尝试在ht[0].table数组中不断向后遍历,直到找到下一个存有数据的bucket位置。如果一直找不到,则最多走n*10步,本次重哈希暂告结束。
+
+最后,如果ht[0]上的数据都迁移到ht[1]上了(即d->ht[0].used == 0),那么整个重哈希结束,ht[0]变成ht[1]的内容,而ht[1]重置为空。
+
+根据以上对于重哈希过程的分析,我们容易看出,本文前面的dict结构图中所展示的正是rehashidx=2时的情况,前面两个bucket(ht[0].table[0]和ht[0].table[1])都已经迁移到ht[1]上去了。
+
+#### dict的插入(dictAdd和dictReplace)
+
+dictAdd插入新的一对key和value,如果key已经存在,则插入失败。
+
+dictReplace也是插入一对key和value,不过在key存在的时候,它会更新value。
+
+
+ int dictAdd(dict *d, void *key, void *val)
+ {
+ dictEntry *entry = dictAddRaw(d,key);
+
+ if (!entry) return DICT_ERR;
+ dictSetVal(d, entry, val);
+ return DICT_OK;
+ }
+
+ dictEntry *dictAddRaw(dict *d, void *key)
+ {
+ int index;
+ dictEntry *entry;
+ dictht *ht;
+
+ if (dictIsRehashing(d)) _dictRehashStep(d);
+
+ /* Get the index of the new element, or -1 if
+ * the element already exists. */
+ if ((index = _dictKeyIndex(d, key)) == -1)
+ return NULL;
+
+ /* Allocate the memory and store the new entry.
+ * Insert the element in top, with the assumption that in a database
+ * system it is more likely that recently added entries are accessed
+ * more frequently. */
+ ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0];
+ entry = zmalloc(sizeof(*entry));
+ entry->next = ht->table[index];
+ ht->table[index] = entry;
+ ht->used++;
+
+ /* Set the hash entry fields. */
+ dictSetKey(d, entry, key);
+ return entry;
+ }
+
+ static int _dictKeyIndex(dict *d, const void *key)
+ {
+ unsigned int h, idx, table;
+ dictEntry *he;
+
+ /* Expand the hash table if needed */
+ if (_dictExpandIfNeeded(d) == DICT_ERR)
+ return -1;
+ /* Compute the key hash value */
+ h = dictHashKey(d, key);
+ for (table = 0; table <= 1; table++) {
+ idx = h & d->ht[table].sizemask;
+ /* Search if this slot does not already contain the given key */
+ he = d->ht[table].table[idx];
+ while(he) {
+ if (key==he->key || dictCompareKeys(d, key, he->key))
+ return -1;
+ he = he->next;
+ }
+ if (!dictIsRehashing(d)) break;
+ }
+ return idx;
+ }
+
+以上是dictAdd的关键实现代码。我们主要需要注意以下几点:
+
+* 它也会触发推进一步重哈希(_dictRehashStep)。
+* 如果正在重哈希中,它会把数据插入到ht[1];否则插入到ht[0]。
+* 在对应的bucket中插入数据的时候,总是插入到dictEntry的头部。因为新数据接下来被访问的概率可能比较高,这样再次查找它时就比较次数较少。
+* _dictKeyIndex在dict中寻找插入位置。如果不在重哈希过程中,它只查找ht[0];否则查找ht[0]和ht[1]。
+* _dictKeyIndex可能触发dict内存扩展(_dictExpandIfNeeded,它将哈希表长度扩展为原来两倍,具体请参考dict.c中源码)。
+
+dictReplace在dictAdd基础上实现,如下:
+
+
+ int dictReplace(dict *d, void *key, void *val)
+ {
+ dictEntry *entry, auxentry;
+
+ /* Try to add the element. If the key
+ * does not exists dictAdd will suceed. */
+ if (dictAdd(d, key, val) == DICT_OK)
+ return 1;
+ /* It already exists, get the entry */
+ entry = dictFind(d, key);
+ /* Set the new value and free the old one. Note that it is important
+ * to do that in this order, as the value may just be exactly the same
+ * as the previous one. In this context, think to reference counting,
+ * you want to increment (set), and then decrement (free), and not the
+ * reverse. */
+ auxentry = *entry;
+ dictSetVal(d, entry, val);
+ dictFreeVal(d, &auxentry);
+ return 0;
+ }
+
+在key已经存在的情况下,dictReplace会同时调用dictAdd和dictFind,这其实相当于两次查找过程。这里Redis的代码不够优化。
+
+#### dict的删除(dictDelete)
+
+dictDelete的源码这里忽略,具体请参考dict.c。需要稍加注意的是:
+
+* dictDelete也会触发推进一步重哈希(_dictRehashStep)
+* 如果当前不在重哈希过程中,它只在ht[0]中查找要删除的key;否则ht[0]和ht[1]它都要查找。
+* 删除成功后会调用key和value的析构函数(keyDestructor和valDestructor)。
+
+* * *
+
+dict的实现相对来说比较简单,本文就介绍到这。在下一篇中我们将会介绍Redis中动态字符串的实现——sds,敬请期待。
+
+**原创文章,转载请注明出处,并包含下面的二维码!否则拒绝转载!**
+**本文链接:**[http://zhangtielei.com/posts/blog-redis-dict.html](http://zhangtielei.com/posts/blog-redis-dict.html)
+
+
\ No newline at end of file
diff --git "a/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\2603\357\274\232Redis\345\206\205\351\203\250\346\225\260\346\215\256\347\273\223\346\236\204\350\257\246\350\247\243\342\200\224\342\200\224sds.md" "b/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\2603\357\274\232Redis\345\206\205\351\203\250\346\225\260\346\215\256\347\273\223\346\236\204\350\257\246\350\247\243\342\200\224\342\200\224sds.md"
new file mode 100644
index 0000000..35821bf
--- /dev/null
+++ "b/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\2603\357\274\232Redis\345\206\205\351\203\250\346\225\260\346\215\256\347\273\223\346\236\204\350\257\246\350\247\243\342\200\224\342\200\224sds.md"
@@ -0,0 +1,369 @@
+本文转自互联网
+
+本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
+> https://github.com/h2pl/Java-Tutorial
+
+喜欢的话麻烦点下Star哈
+
+文章首发于我的个人博客:
+> www.how2playlife.com
+
+本文是微信公众号【Java技术江湖】的《探索Redis设计与实现》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。
+
+该系列博文会告诉你如何从入门到进阶,Redis基本的使用方法,Redis的基本数据结构,以及一些进阶的使用方法,同时也需要进一步了解Redis的底层数据结构,再接着,还会带来Redis主从复制、集群、分布式锁等方面的相关内容,以及作为缓存的一些使用方法和注意事项,以便让你更完整地了解整个Redis相关的技术体系,形成自己的知识框架。
+
+如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。
+
+
+## 前言
+
+本文是《Redis内部数据结构详解》系列的第二篇,讲述Redis中使用最多的一个基础数据结构:sds。
+
+不管在哪门编程语言当中,字符串都几乎是使用最多的数据结构。sds正是在Redis中被广泛使用的字符串结构,它的全称是Simple Dynamic String。与其它语言环境中出现的字符串相比,它具有如下显著的特点:
+
+可动态扩展内存。sds表示的字符串其内容可以修改,也可以追加。在很多语言中字符串会分为mutable和immutable两种,显然sds属于mutable类型的。
+二进制安全(Binary Safe)。sds能存储任意二进制数据,而不仅仅是可打印字符。
+与传统的C语言字符串类型兼容。这个的含义接下来马上会讨论。
+看到这里,很多对Redis有所了解的同学可能已经产生了一个疑问:Redis已经对外暴露了一个字符串结构,叫做string,那这里所说的sds到底和string是什么关系呢?可能有人会猜:string是基于sds实现的。这个猜想已经非常接近事实,但在描述上还不太准确。有关string和sds之间关系的详细分析,我们放在后面再讲。现在为了方便讨论,让我们先暂时简单地认为,string的底层实现就是sds。
+
+在讨论sds的具体实现之前,我们先站在Redis使用者的角度,来观察一下string所支持的一些主要操作。下面是一个操作示例:
+
+
+Redis string操作示例
+
+
+
+以上这些操作都比较简单,我们简单解释一下:
+
+初始的字符串的值设为”tielei”。
+第3步通过append命令对字符串进行了追加,变成了”tielei zhang”。
+然后通过setbit命令将第53个bit设置成了1。bit的偏移量从左边开始算,从0开始。其中第48~55bit是中间的空格那个字符,它的ASCII码是0x20。将第53个bit设置成1之后,它的ASCII码变成了0x24,打印出来就是’$’。因此,现在字符串的值变成了”tielei$zhang”。
+最后通过getrange取从倒数第5个字节到倒数第1个字节的内容,得到”zhang”。
+这些命令的实现,有一部分是和sds的实现有关的。下面我们开始详细讨论。
+
+## sds的数据结构定义
+我们知道,在C语言中,字符串是以’\0’字符结尾(NULL结束符)的字符数组来存储的,通常表达为字符指针的形式(char *)。它不允许字节0出现在字符串中间,因此,它不能用来存储任意的二进制数据。
+
+我们可以在sds.h中找到sds的类型定义:
+
+typedef char *sds;
+肯定有人感到困惑了,竟然sds就等同于char *?我们前面提到过,sds和传统的C语言字符串保持类型兼容,因此它们的类型定义是一样的,都是char *。在有些情况下,需要传入一个C语言字符串的地方,也确实可以传入一个sds。但是,sds和char *并不等同。sds是Binary Safe的,它可以存储任意二进制数据,不能像C语言字符串那样以字符’\0’来标识字符串的结束,因此它必然有个长度字段。但这个长度字段在哪里呢?实际上sds还包含一个header结构:
+
+ struct __attribute__ ((__packed__)) sdshdr5 {
+ unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
+ char buf[];
+ };
+ struct __attribute__ ((__packed__)) sdshdr8 {
+ uint8_t len; /* used */
+ uint8_t alloc; /* excluding the header and null terminator */
+ unsigned char flags; /* 3 lsb of type, 5 unused bits */
+ char buf[];
+ };
+ struct __attribute__ ((__packed__)) sdshdr16 {
+ uint16_t len; /* used */
+ uint16_t alloc; /* excluding the header and null terminator */
+ unsigned char flags; /* 3 lsb of type, 5 unused bits */
+ char buf[];
+ };
+ struct __attribute__ ((__packed__)) sdshdr32 {
+ uint32_t len; /* used */
+ uint32_t alloc; /* excluding the header and null terminator */
+ unsigned char flags; /* 3 lsb of type, 5 unused bits */
+ char buf[];
+ };
+ struct __attribute__ ((__packed__)) sdshdr64 {
+ uint64_t len; /* used */
+ uint64_t alloc; /* excluding the header and null terminator */
+ unsigned char flags; /* 3 lsb of type, 5 unused bits */
+ char buf[];
+ };
+sds一共有5种类型的header。之所以有5种,是为了能让不同长度的字符串可以使用不同大小的header。这样,短字符串就能使用较小的header,从而节省内存。
+
+一个sds字符串的完整结构,由在内存地址上前后相邻的两部分组成:
+
+一个header。通常包含字符串的长度(len)、最大容量(alloc)和flags。sdshdr5有所不同。
+一个字符数组。这个字符数组的长度等于最大容量+1。真正有效的字符串数据,其长度通常小于最大容量。在真正的字符串数据之后,是空余未用的字节(一般以字节0填充),允许在不重新分配内存的前提下让字符串数据向后做有限的扩展。在真正的字符串数据之后,还有一个NULL结束符,即ASCII码为0的’\0’字符。这是为了和传统C字符串兼容。之所以字符数组的长度比最大容量多1个字节,就是为了在字符串长度达到最大容量时仍然有1个字节存放NULL结束符。
+除了sdshdr5之外,其它4个header的结构都包含3个字段:
+
+ len: 表示字符串的真正长度(不包含NULL结束符在内)。
+ alloc: 表示字符串的最大容量(不包含最后多余的那个字节)。
+ flags: 总是占用一个字节。其中的最低3个bit用来表示header的类型。header的类型共有5种,在sds.h中有常量定义。
+ #define SDS_TYPE_5 0
+ #define SDS_TYPE_8 1
+ #define SDS_TYPE_16 2
+ #define SDS_TYPE_32 3
+ #define SDS_TYPE_64 4
+sds的数据结构,我们有必要非常仔细地去解析它。
+
+## Redis dict结构举例
+
+上图是sds的一个内部结构的例子。图中展示了两个sds字符串s1和s2的内存结构,一个使用sdshdr8类型的header,另一个使用sdshdr16类型的header。但它们都表达了同样的一个长度为6的字符串的值:”tielei”。下面我们结合代码,来解释每一部分的组成。
+
+sds的字符指针(s1和s2)就是指向真正的数据(字符数组)开始的位置,而header位于内存地址较低的方向。在sds.h中有一些跟解析header有关的宏定义:
+
+ #define SDS_TYPE_MASK 7
+ #define SDS_TYPE_BITS 3
+ #define SDS_HDR_VAR(T,s) struct sdshdr##T *sh = (void*)((s)-(sizeof(struct sdshdr##T)));
+ #define SDS_HDR(T,s) ((struct sdshdr##T *)((s)-(sizeof(struct sdshdr##T))))
+ #define SDS_TYPE_5_LEN(f) ((f)>>SDS_TYPE_BITS)
+其中SDS_HDR用来从sds字符串获得header起始位置的指针,比如SDS_HDR(8, s1)表示s1的header指针,SDS_HDR(16, s2)表示s2的header指针。
+
+当然,使用SDS_HDR之前我们必须先知道到底是哪一种header,这样我们才知道SDS_HDR第1个参数应该传什么。由sds字符指针获得header类型的方法是,先向低地址方向偏移1个字节的位置,得到flags字段。比如,s1[-1]和s2[-1]分别获得了s1和s2的flags的值。然后取flags的最低3个bit得到header的类型。
+
+由于s1[-1] == 0x01 == SDS_TYPE_8,因此s1的header类型是sdshdr8。
+由于s2[-1] == 0x02 == SDS_TYPE_16,因此s2的header类型是sdshdr16。
+有了header指针,就能很快定位到它的len和alloc字段:
+
+s1的header中,len的值为0x06,表示字符串数据长度为6;alloc的值为0x80,表示字符数组最大容量为128。
+s2的header中,len的值为0x0006,表示字符串数据长度为6;alloc的值为0x03E8,表示字符数组最大容量为1000。(注意:图中是按小端地址构成)
+在各个header的类型定义中,还有几个需要我们注意的地方:
+
+在各个header的定义中使用了__attribute__ ((packed)),是为了让编译器以紧凑模式来分配内存。如果没有这个属性,编译器可能会为struct的字段做优化对齐,在其中填充空字节。那样的话,就不能保证header和sds的数据部分紧紧前后相邻,也不能按照固定向低地址方向偏移1个字节的方式来获取flags字段了。
+
+在各个header的定义中最后有一个char buf[]。我们注意到这是一个没有指明长度的字符数组,这是C语言中定义字符数组的一种特殊写法,称为柔性数组(flexible array member),只能定义在一个结构体的最后一个字段上。
+
+它在这里只是起到一个标记的作用,表示在flags字段后面就是一个字符数组,或者说,它指明了紧跟在flags字段后面的这个字符数组在结构体中的偏移位置。而程序在为header分配的内存的时候,它并不占用内存空间。
+
+如果计算sizeof(struct sdshdr16)的值,那么结果是5个字节,其中没有buf字段。
+sdshdr5与其它几个header结构不同,它不包含alloc字段,而长度使用flags的高5位来存储。
+
+因此,它不能为字符串分配空余空间。如果字符串需要动态增长,那么它就必然要重新分配内存才行。所以说,这种类型的sds字符串更适合存储静态的短字符串(长度小于32)。
+
+至此,我们非常清楚地看到了:sds字符串的header,其实隐藏在真正的字符串数据的前面(低地址方向)。这样的一个定义,有如下几个好处:
+
+header和数据相邻,而不用分成两块内存空间来单独分配。这有利于减少内存碎片,提高存储效率(memory efficiency)。
+
+虽然header有多个类型,但sds可以用统一的char *来表达。且它与传统的C语言字符串保持类型兼容。
+
+如果一个sds里面存储的是可打印字符串,那么我们可以直接把它传给C函数,比如使用strcmp比较字符串大小,或者使用printf进行打印。
+弄清了sds的数据结构,它的具体操作函数就比较好理解了。
+
+ sds的一些基础函数
+ sdslen(const sds s): 获取sds字符串长度。
+ sdssetlen(sds s, size_t newlen): 设置sds字符串长度。
+ sdsinclen(sds s, size_t inc): 增加sds字符串长度。
+ sdsalloc(const sds s): 获取sds字符串容量。
+ sdssetalloc(sds s, size_t newlen): 设置sds字符串容量。
+ sdsavail(const sds s): 获取sds字符串空余空间(即alloc - len)。
+ sdsHdrSize(char type): 根据header类型得到header大小。
+ sdsReqType(size_t string_size):
+
+根据字符串数据长度计算所需要的header类型。
+这里我们挑选sdslen和sdsReqType的代码,察看一下。
+
+ static inline size_t sdslen(const sds s) {
+ unsigned char flags = s[-1];
+ switch(flags&SDS_TYPE_MASK) {
+ case SDS_TYPE_5:
+ return SDS_TYPE_5_LEN(flags);
+ case SDS_TYPE_8:
+ return SDS_HDR(8,s)->len;
+ case SDS_TYPE_16:
+ return SDS_HDR(16,s)->len;
+ case SDS_TYPE_32:
+ return SDS_HDR(32,s)->len;
+ case SDS_TYPE_64:
+ return SDS_HDR(64,s)->len;
+ }
+ return 0;
+ }
+
+ static inline char sdsReqType(size_t string_size) {
+ if (string_size < 1<<5)
+ return SDS_TYPE_5;
+ if (string_size < 1<<8)
+ return SDS_TYPE_8;
+ if (string_size < 1<<16)
+ return SDS_TYPE_16;
+ if (string_size < 1ll<<32)
+ return SDS_TYPE_32;
+ return SDS_TYPE_64;
+ }
+
+跟前面的分析类似,sdslen先用s[-1]向低地址方向偏移1个字节,得到flags;然后与SDS_TYPE_MASK进行按位与,得到header类型;然后根据不同的header类型,调用SDS_HDR得到header起始指针,进而获得len字段。
+
+通过sdsReqType的代码,很容易看到:
+
+长度在0和2^5-1之间,选用SDS_TYPE_5类型的header。
+长度在2^5和2^8-1之间,选用SDS_TYPE_8类型的header。
+长度在2^8和2^16-1之间,选用SDS_TYPE_16类型的header。
+长度在2^16和2^32-1之间,选用SDS_TYPE_32类型的header。
+长度大于2^32的,选用SDS_TYPE_64类型的header。能表示的最大长度为2^64-1。
+注:sdsReqType的实现代码,直到3.2.0,它在长度边界值上都一直存在问题,直到最近3.2 branch上的commit 6032340才修复。
+
+## sds的创建和销毁
+ sds sdsnewlen(const void *init, size_t initlen) {
+ void *sh;
+ sds s;
+ char type = sdsReqType(initlen);
+ /* Empty strings are usually created in order to append. Use type 8
+ * since type 5 is not good at this. */
+ if (type == SDS_TYPE_5 && initlen == 0) type = SDS_TYPE_8;
+ int hdrlen = sdsHdrSize(type);
+ unsigned char *fp; /* flags pointer. */
+
+ sh = s_malloc(hdrlen+initlen+1);
+ if (!init)
+ memset(sh, 0, hdrlen+initlen+1);
+ if (sh == NULL) return NULL;
+ s = (char*)sh+hdrlen;
+ fp = ((unsigned char*)s)-1;
+ switch(type) {
+ case SDS_TYPE_5: {
+ *fp = type | (initlen << SDS_TYPE_BITS);
+ break;
+ }
+ case SDS_TYPE_8: {
+ SDS_HDR_VAR(8,s);
+ sh->len = initlen;
+ sh->alloc = initlen;
+ *fp = type;
+ break;
+ }
+ case SDS_TYPE_16: {
+ SDS_HDR_VAR(16,s);
+ sh->len = initlen;
+ sh->alloc = initlen;
+ *fp = type;
+ break;
+ }
+ case SDS_TYPE_32: {
+ SDS_HDR_VAR(32,s);
+ sh->len = initlen;
+ sh->alloc = initlen;
+ *fp = type;
+ break;
+ }
+ case SDS_TYPE_64: {
+ SDS_HDR_VAR(64,s);
+ sh->len = initlen;
+ sh->alloc = initlen;
+ *fp = type;
+ break;
+ }
+ }
+ if (initlen && init)
+ memcpy(s, init, initlen);
+ s[initlen] = '\0';
+ return s;
+ }
+
+ sds sdsempty(void) {
+ return sdsnewlen("",0);
+ }
+
+ sds sdsnew(const char *init) {
+ size_t initlen = (init == NULL) ? 0 : strlen(init);
+ return sdsnewlen(init, initlen);
+ }
+
+ void sdsfree(sds s) {
+ if (s == NULL) return;
+ s_free((char*)s-sdsHdrSize(s[-1]));
+ }
+
+
+sdsnewlen创建一个长度为initlen的sds字符串,并使用init指向的字符数组(任意二进制数据)来初始化数据。如果init为NULL,那么使用全0来初始化数据。它的实现中,我们需要注意的是:
+
+如果要创建一个长度为0的空字符串,那么不使用SDS_TYPE_5类型的header,而是转而使用SDS_TYPE_8类型的header。这是因为创建的空字符串一般接下来的操作很可能是追加数据,但SDS_TYPE_5类型的sds字符串不适合追加数据(会引发内存重新分配)。
+需要的内存空间一次性进行分配,其中包含三部分:header、数据、最后的多余字节(hdrlen+initlen+1)。
+初始化的sds字符串数据最后会追加一个NULL结束符(s[initlen] = ‘\0’)。
+关于sdsfree,需要注意的是:内存要整体释放,所以要先计算出header起始指针,把它传给s_free函数。这个指针也正是在sdsnewlen中调用s_malloc返回的那个地址。
+
+## sds的连接(追加)操作
+ sds sdscatlen(sds s, const void *t, size_t len) {
+ size_t curlen = sdslen(s);
+
+ s = sdsMakeRoomFor(s,len);
+ if (s == NULL) return NULL;
+ memcpy(s+curlen, t, len);
+ sdssetlen(s, curlen+len);
+ s[curlen+len] = '\0';
+ return s;
+ }
+
+ sds sdscat(sds s, const char *t) {
+ return sdscatlen(s, t, strlen(t));
+ }
+
+ sds sdscatsds(sds s, const sds t) {
+ return sdscatlen(s, t, sdslen(t));
+ }
+
+ sds sdsMakeRoomFor(sds s, size_t addlen) {
+ void *sh, *newsh;
+ size_t avail = sdsavail(s);
+ size_t len, newlen;
+ char type, oldtype = s[-1] & SDS_TYPE_MASK;
+ int hdrlen;
+
+ /* Return ASAP if there is enough space left. */
+ if (avail >= addlen) return s;
+
+ len = sdslen(s);
+ sh = (char*)s-sdsHdrSize(oldtype);
+ newlen = (len+addlen);
+ if (newlen < SDS_MAX_PREALLOC)
+ newlen *= 2;
+ else
+ newlen += SDS_MAX_PREALLOC;
+
+ type = sdsReqType(newlen);
+
+ /* Don't use type 5: the user is appending to the string and type 5 is
+ * not able to remember empty space, so sdsMakeRoomFor() must be called
+ * at every appending operation. */
+ if (type == SDS_TYPE_5) type = SDS_TYPE_8;
+
+ hdrlen = sdsHdrSize(type);
+ if (oldtype==type) {
+ newsh = s_realloc(sh, hdrlen+newlen+1);
+ if (newsh == NULL) return NULL;
+ s = (char*)newsh+hdrlen;
+ } else {
+ /* Since the header size changes, need to move the string forward,
+ * and can't use realloc */
+ newsh = s_malloc(hdrlen+newlen+1);
+ if (newsh == NULL) return NULL;
+ memcpy((char*)newsh+hdrlen, s, len+1);
+ s_free(sh);
+ s = (char*)newsh+hdrlen;
+ s[-1] = type;
+ sdssetlen(s, len);
+ }
+ sdssetalloc(s, newlen);
+ return s;
+ }
+
+sdscatlen将t指向的长度为len的任意二进制数据追加到sds字符串s的后面。本文开头演示的string的append命令,内部就是调用sdscatlen来实现的。
+
+在sdscatlen的实现中,先调用sdsMakeRoomFor来保证字符串s有足够的空间来追加长度为len的数据。sdsMakeRoomFor可能会分配新的内存,也可能不会。
+
+sdsMakeRoomFor是sds实现中很重要的一个函数。关于它的实现代码,我们需要注意的是:
+
+如果原来字符串中的空余空间够用(avail >= addlen),那么它什么也不做,直接返回。
+
+如果需要分配空间,它会比实际请求的要多分配一些,以防备接下来继续追加。它在字符串已经比较长的情况下要至少多分配SDS_MAX_PREALLOC个字节,这个常量在sds.h中定义为(1024*1024)=1MB。
+
+按分配后的空间大小,可能需要更换header类型(原来header的alloc字段太短,表达不了增加后的容量)。
+
+如果需要更换header,那么整个字符串空间(包括header)都需要重新分配(s_malloc),并拷贝原来的数据到新的位置。
+
+如果不需要更换header(原来的header够用),那么调用一个比较特殊的s_realloc,试图在原来的地址上重新分配空间。s_realloc的具体实现得看Redis编译的时候选用了哪个allocator(在Linux上默认使用jemalloc)。
+
+但不管是哪个realloc的实现,它所表达的含义基本是相同的:它尽量在原来分配好的地址位置重新分配,如果原来的地址位置有足够的空余空间完成重新分配,那么它返回的新地址与传入的旧地址相同;否则,它分配新的地址块,并进行数据搬迁。参见http://man.cx/realloc。
+
+从sdscatlen的函数接口,我们可以看到一种使用模式:调用它的时候,传入一个旧的sds变量,然后它返回一个新的sds变量。由于它的内部实现可能会造成地址变化,因此调用者在调用完之后,原来旧的变量就失效了,而都应该用新返回的变量来替换。不仅仅是sdscatlen函数,sds中的其它函数(比如sdscpy、sdstrim、sdsjoin等),还有Redis中其它一些能自动扩展内存的数据结构(如ziplist),也都是同样的使用模式。
+
+## 浅谈sds与string的关系
+
+现在我们回过头来看看本文开头给出的string操作的例子。
+
+append操作使用sds的sdscatlen来实现。前面已经提到。
+
+setbit和getrange都是先根据key取到整个sds字符串,然后再从字符串选取或修改指定的部分。由于sds就是一个字符数组,所以对它的某一部分进行操作似乎都比较简单。
+
+但是,string除了支持这些操作之外,当它存储的值是个数字的时候,它还支持incr、decr等操作。那么,当string存储数字值的时候,它的内部存储还是sds吗?
+
+实际上,不是了。而且,这种情况下,setbit和getrange的实现也会有所不同。这些细节,我们放在下一篇介绍robj的时候再进行系统地讨论。
+
diff --git "a/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\2604\357\274\232Redis\345\206\205\351\203\250\346\225\260\346\215\256\347\273\223\346\236\204\350\257\246\350\247\243\342\200\224\342\200\224ziplist.md" "b/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\2604\357\274\232Redis\345\206\205\351\203\250\346\225\260\346\215\256\347\273\223\346\236\204\350\257\246\350\247\243\342\200\224\342\200\224ziplist.md"
new file mode 100644
index 0000000..3ae4b7b
--- /dev/null
+++ "b/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\2604\357\274\232Redis\345\206\205\351\203\250\346\225\260\346\215\256\347\273\223\346\236\204\350\257\246\350\247\243\342\200\224\342\200\224ziplist.md"
@@ -0,0 +1,370 @@
+本文转自互联网
+
+本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
+> https://github.com/h2pl/Java-Tutorial
+
+喜欢的话麻烦点下Star哈
+
+文章首发于我的个人博客:
+> www.how2playlife.com
+
+本文是微信公众号【Java技术江湖】的《探索Redis设计与实现》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。
+
+该系列博文会告诉你如何从入门到进阶,Redis基本的使用方法,Redis的基本数据结构,以及一些进阶的使用方法,同时也需要进一步了解Redis的底层数据结构,再接着,还会带来Redis主从复制、集群、分布式锁等方面的相关内容,以及作为缓存的一些使用方法和注意事项,以便让你更完整地了解整个Redis相关的技术体系,形成自己的知识框架。
+
+如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。
+
+
+
+
+本文是《[Redis内部数据结构详解](http://zhangtielei.com/posts/blog-redis-dict.html)》系列的第四篇。在本文中,我们首先介绍一个新的Redis内部数据结构——ziplist,然后在文章后半部分我们会讨论一下在robj, dict和ziplist的基础上,Redis对外暴露的hash结构是怎样构建起来的。
+
+我们在讨论中还会涉及到两个Redis配置(在redis.conf中的ADVANCED CONFIG部分):
+
+
+
+
+
+```
+hash-max-ziplist-entries 512
+hash-max-ziplist-value 64
+
+```
+
+
+
+
+
+本文的后半部分会对这两个配置做详细的解释。
+
+#### 什么是ziplist
+
+Redis官方对于ziplist的定义是(出自ziplist.c的文件头部注释):
+
+> The ziplist is a specially encoded dually linked list that is designed to be very memory efficient. It stores both strings and integer values, where integers are encoded as actual integers instead of a series of characters. It allows push and pop operations on either side of the list in O(1) time.
+
+翻译一下就是说:ziplist是一个经过特殊编码的双向链表,它的设计目标就是为了提高存储效率。ziplist可以用于存储字符串或整数,其中整数是按真正的二进制表示进行编码的,而不是编码成字符串序列。它能以O(1)的时间复杂度在表的两端提供`push`和`pop`操作。
+
+实际上,ziplist充分体现了Redis对于存储效率的追求。一个普通的双向链表,链表中每一项都占用独立的一块内存,各项之间用地址指针(或引用)连接起来。这种方式会带来大量的内存碎片,而且地址指针也会占用额外的内存。而ziplist却是将表中每一项存放在前后连续的地址空间内,一个ziplist整体占用一大块内存。它是一个表(list),但其实不是一个链表(linked list)。
+
+另外,ziplist为了在细节上节省内存,对于值的存储采用了变长的编码方式,大概意思是说,对于大的整数,就多用一些字节来存储,而对于小的整数,就少用一些字节来存储。我们接下来很快就会讨论到这些实现细节。
+
+#### ziplist的数据结构定义
+
+ziplist的数据结构组成是本文要讨论的重点。实际上,ziplist还是稍微有点复杂的,它复杂的地方就在于它的数据结构定义。一旦理解了数据结构,它的一些操作也就比较容易理解了。
+
+我们接下来先从总体上介绍一下ziplist的数据结构定义,然后举一个实际的例子,通过例子来解释ziplist的构成。如果你看懂了这一部分,本文的任务就算完成了一大半了。
+
+从宏观上看,ziplist的内存结构如下:
+
+`...`
+
+各个部分在内存上是前后相邻的,它们分别的含义如下:
+
+* ``: 32bit,表示ziplist占用的字节总数(也包括``本身占用的4个字节)。
+* ``: 32bit,表示ziplist表中最后一项(entry)在ziplist中的偏移字节数。``的存在,使得我们可以很方便地找到最后一项(不用遍历整个ziplist),从而可以在ziplist尾端快速地执行push或pop操作。
+* ``: 16bit, 表示ziplist中数据项(entry)的个数。zllen字段因为只有16bit,所以可以表达的最大值为2^16-1。这里需要特别注意的是,如果ziplist中数据项个数超过了16bit能表达的最大值,ziplist仍然可以来表示。那怎么表示呢?这里做了这样的规定:如果``小于等于2^16-2(也就是不等于2^16-1),那么``就表示ziplist中数据项的个数;否则,也就是``等于16bit全为1的情况,那么``就不表示数据项个数了,这时候要想知道ziplist中数据项总数,那么必须对ziplist从头到尾遍历各个数据项,才能计数出来。
+* ``: 表示真正存放数据的数据项,长度不定。一个数据项(entry)也有它自己的内部结构,这个稍后再解释。
+* ``: ziplist最后1个字节,是一个结束标记,值固定等于255。
+
+上面的定义中还值得注意的一点是:``, ``, ``既然占据多个字节,那么在存储的时候就有大端(big endian)和小端(little endian)的区别。ziplist采取的是小端模式来存储,这在下面我们介绍具体例子的时候还会再详细解释。
+
+我们再来看一下每一个数据项``的构成:
+
+``
+
+我们看到在真正的数据(``)前面,还有两个字段:
+
+* ``: 表示前一个数据项占用的总字节数。这个字段的用处是为了让ziplist能够从后向前遍历(从后一项的位置,只需向前偏移prevrawlen个字节,就找到了前一项)。这个字段采用变长编码。
+* ``: 表示当前数据项的数据长度(即``部分的长度)。也采用变长编码。
+
+那么``和``是怎么进行变长编码的呢?各位读者打起精神了,我们终于讲到了ziplist的定义中最繁琐的地方了。
+
+先说``。它有两种可能,或者是1个字节,或者是5个字节:
+
+1. 如果前一个数据项占用字节数小于254,那么``就只用一个字节来表示,这个字节的值就是前一个数据项的占用字节数。
+2. 如果前一个数据项占用字节数大于等于254,那么``就用5个字节来表示,其中第1个字节的值是254(作为这种情况的一个标记),而后面4个字节组成一个整型值,来真正存储前一个数据项的占用字节数。
+
+有人会问了,为什么没有255的情况呢?
+
+这是因为:255已经定义为ziplist结束标记``的值了。在ziplist的很多操作的实现中,都会根据数据项的第1个字节是不是255来判断当前是不是到达ziplist的结尾了,因此一个正常的数据的第1个字节(也就是``的第1个字节)是不能够取255这个值的,否则就冲突了。
+
+而``字段就更加复杂了,它根据第1个字节的不同,总共分为9种情况(下面的表示法是按二进制表示):
+
+1. |00pppppp| - 1 byte。第1个字节最高两个bit是00,那么``字段只有1个字节,剩余的6个bit用来表示长度值,最高可以表示63 (2^6-1)。
+2. |01pppppp|qqqqqqqq| - 2 bytes。第1个字节最高两个bit是01,那么``字段占2个字节,总共有14个bit用来表示长度值,最高可以表示16383 (2^14-1)。
+3. |10**__**|qqqqqqqq|rrrrrrrr|ssssssss|tttttttt| - 5 bytes。第1个字节最高两个bit是10,那么len字段占5个字节,总共使用32个bit来表示长度值(6个bit舍弃不用),最高可以表示2^32-1。需要注意的是:在前三种情况下,``都是按字符串来存储的;从下面第4种情况开始,``开始变为按整数来存储了。
+4. |11000000| - 1 byte。``字段占用1个字节,值为0xC0,后面的数据``存储为2个字节的int16_t类型。
+5. |11010000| - 1 byte。``字段占用1个字节,值为0xD0,后面的数据``存储为4个字节的int32_t类型。
+6. |11100000| - 1 byte。``字段占用1个字节,值为0xE0,后面的数据``存储为8个字节的int64_t类型。
+7. |11110000| - 1 byte。``字段占用1个字节,值为0xF0,后面的数据``存储为3个字节长的整数。
+8. |11111110| - 1 byte。``字段占用1个字节,值为0xFE,后面的数据``存储为1个字节的整数。
+9. |1111xxxx| - - (xxxx的值在0001和1101之间)。这是一种特殊情况,xxxx从1到13一共13个值,这时就用这13个值来表示真正的数据。注意,这里是表示真正的数据,而不是数据长度了。也就是说,在这种情况下,后面不再需要一个单独的``字段来表示真正的数据了,而是``和``合二为一了。另外,由于xxxx只能取0001和1101这13个值了(其它可能的值和其它情况冲突了,比如0000和1110分别同前面第7种第8种情况冲突,1111跟结束标记冲突),而小数值应该从0开始,因此这13个值分别表示0到12,即xxxx的值减去1才是它所要表示的那个整数数据的值。
+
+好了,ziplist的数据结构定义,我们介绍完了,现在我们看一个具体的例子。
+
+[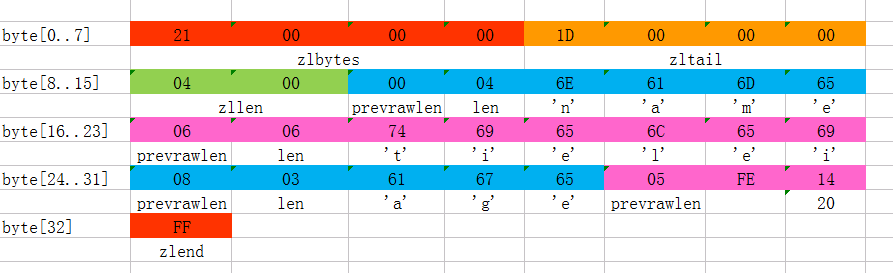](http://zhangtielei.com/assets/photos_redis/redis_ziplist_sample.png)
+
+上图是一份真实的ziplist数据。我们逐项解读一下:
+
+* 这个ziplist一共包含33个字节。字节编号从byte[0]到byte[32]。图中每个字节的值使用16进制表示。
+* 头4个字节(0x21000000)是按小端(little endian)模式存储的``字段。什么是小端呢?就是指数据的低字节保存在内存的低地址中(参见维基百科词条[Endianness](https://en.wikipedia.org/wiki/Endianness))。因此,这里``的值应该解析成0x00000021,用十进制表示正好就是33。
+* 接下来4个字节(byte[4..7])是``,用小端存储模式来解释,它的值是0x0000001D(值为29),表示最后一个数据项在byte[29]的位置(那个数据项为0x05FE14)。
+* 再接下来2个字节(byte[8..9]),值为0x0004,表示这个ziplist里一共存有4项数据。
+* 接下来6个字节(byte[10..15])是第1个数据项。其中,prevrawlen=0,因为它前面没有数据项;len=4,相当于前面定义的9种情况中的第1种,表示后面4个字节按字符串存储数据,数据的值为”name”。
+* 接下来8个字节(byte[16..23])是第2个数据项,与前面数据项存储格式类似,存储1个字符串”tielei”。
+* 接下来5个字节(byte[24..28])是第3个数据项,与前面数据项存储格式类似,存储1个字符串”age”。
+* 接下来3个字节(byte[29..31])是最后一个数据项,它的格式与前面的数据项存储格式不太一样。其中,第1个字节prevrawlen=5,表示前一个数据项占用5个字节;第2个字节=FE,相当于前面定义的9种情况中的第8种,所以后面还有1个字节用来表示真正的数据,并且以整数表示。它的值是20(0x14)。
+* 最后1个字节(byte[32])表示``,是固定的值255(0xFF)。
+
+总结一下,这个ziplist里存了4个数据项,分别为:
+
+* 字符串: “name”
+* 字符串: “tielei”
+* 字符串: “age”
+* 整数: 20
+
+(好吧,被你发现了~~tielei实际上当然不是20岁,他哪有那么年轻啊……)
+
+实际上,这个ziplist是通过两个`hset`命令创建出来的。这个我们后半部分会再提到。
+
+好了,既然你已经阅读到这里了,说明你还是很有耐心的(其实我写到这里也已经累得不行了)。可以先把本文收藏,休息一下,回头再看后半部分。
+
+接下来我要贴一些代码了。
+
+#### ziplist的接口
+
+我们先不着急看实现,先来挑几个ziplist的重要的接口,看看它们长什么样子:
+
+
+
+
+
+```
+unsigned char *ziplistNew(void);
+unsigned char *ziplistMerge(unsigned char **first, unsigned char **second);
+unsigned char *ziplistPush(unsigned char *zl, unsigned char *s, unsigned int slen, int where);
+unsigned char *ziplistIndex(unsigned char *zl, int index);
+unsigned char *ziplistNext(unsigned char *zl, unsigned char *p);
+unsigned char *ziplistPrev(unsigned char *zl, unsigned char *p);
+unsigned char *ziplistInsert(unsigned char *zl, unsigned char *p, unsigned char *s, unsigned int slen);
+unsigned char *ziplistDelete(unsigned char *zl, unsigned char **p);
+unsigned char *ziplistFind(unsigned char *p, unsigned char *vstr, unsigned int vlen, unsigned int skip);
+unsigned int ziplistLen(unsigned char *zl);
+
+```
+
+
+
+
+
+我们从这些接口的名字就可以粗略猜出它们的功能,下面简单解释一下:
+
+* ziplist的数据类型,没有用自定义的struct之类的来表达,而就是简单的unsigned char *。这是因为ziplist本质上就是一块连续内存,内部组成结构又是一个高度动态的设计(变长编码),也没法用一个固定的数据结构来表达。
+* ziplistNew: 创建一个空的ziplist(只包含``)。
+* ziplistMerge: 将两个ziplist合并成一个新的ziplist。
+* ziplistPush: 在ziplist的头部或尾端插入一段数据(产生一个新的数据项)。注意一下这个接口的返回值,是一个新的ziplist。调用方必须用这里返回的新的ziplist,替换之前传进来的旧的ziplist变量,而经过这个函数处理之后,原来旧的ziplist变量就失效了。为什么一个简单的插入操作会导致产生一个新的ziplist呢?这是因为ziplist是一块连续空间,对它的追加操作,会引发内存的realloc,因此ziplist的内存位置可能会发生变化。实际上,我们在之前介绍sds的文章中提到过类似这种接口使用模式(参见sdscatlen函数的说明)。
+* ziplistIndex: 返回index参数指定的数据项的内存位置。index可以是负数,表示从尾端向前进行索引。
+* ziplistNext和ziplistPrev分别返回一个ziplist中指定数据项p的后一项和前一项。
+* ziplistInsert: 在ziplist的任意数据项前面插入一个新的数据项。
+* ziplistDelete: 删除指定的数据项。
+* ziplistFind: 查找给定的数据(由vstr和vlen指定)。注意它有一个skip参数,表示查找的时候每次比较之间要跳过几个数据项。为什么会有这么一个参数呢?其实这个参数的主要用途是当用ziplist表示hash结构的时候,是按照一个field,一个value来依次存入ziplist的。也就是说,偶数索引的数据项存field,奇数索引的数据项存value。当按照field的值进行查找的时候,就需要把奇数项跳过去。
+* ziplistLen: 计算ziplist的长度(即包含数据项的个数)。
+
+#### ziplist的插入逻辑解析
+
+ziplist的相关接口的具体实现,还是有些复杂的,限于篇幅的原因,我们这里只结合代码来讲解插入的逻辑。插入是很有代表性的操作,通过这部分来一窥ziplist内部的实现,其它部分的实现我们也就会很容易理解了。
+
+ziplistPush和ziplistInsert都是插入,只是对于插入位置的限定不同。它们在内部实现都依赖一个名为__ziplistInsert的内部函数,其代码如下(出自ziplist.c):
+
+
+
+
+
+```
+static unsigned char *__ziplistInsert(unsigned char *zl, unsigned char *p, unsigned char *s, unsigned int slen) {
+ size_t curlen = intrev32ifbe(ZIPLIST_BYTES(zl)), reqlen;
+ unsigned int prevlensize, prevlen = 0;
+ size_t offset;
+ int nextdiff = 0;
+ unsigned char encoding = 0;
+ long long value = 123456789; /* initialized to avoid warning. Using a value
+ that is easy to see if for some reason
+ we use it uninitialized. */
+ zlentry tail;
+
+ /* Find out prevlen for the entry that is inserted. */
+ if (p[0] != ZIP_END) {
+ ZIP_DECODE_PREVLEN(p, prevlensize, prevlen);
+ } else {
+ unsigned char *ptail = ZIPLIST_ENTRY_TAIL(zl);
+ if (ptail[0] != ZIP_END) {
+ prevlen = zipRawEntryLength(ptail);
+ }
+ }
+
+ /* See if the entry can be encoded */
+ if (zipTryEncoding(s,slen,&value,&encoding)) {
+ /* 'encoding' is set to the appropriate integer encoding */
+ reqlen = zipIntSize(encoding);
+ } else {
+ /* 'encoding' is untouched, however zipEncodeLength will use the
+ * string length to figure out how to encode it. */
+ reqlen = slen;
+ }
+ /* We need space for both the length of the previous entry and
+ * the length of the payload. */
+ reqlen += zipPrevEncodeLength(NULL,prevlen);
+ reqlen += zipEncodeLength(NULL,encoding,slen);
+
+ /* When the insert position is not equal to the tail, we need to
+ * make sure that the next entry can hold this entry's length in
+ * its prevlen field. */
+ nextdiff = (p[0] != ZIP_END) ? zipPrevLenByteDiff(p,reqlen) : 0;
+
+ /* Store offset because a realloc may change the address of zl. */
+ offset = p-zl;
+ zl = ziplistResize(zl,curlen+reqlen+nextdiff);
+ p = zl+offset;
+
+ /* Apply memory move when necessary and update tail offset. */
+ if (p[0] != ZIP_END) {
+ /* Subtract one because of the ZIP_END bytes */
+ memmove(p+reqlen,p-nextdiff,curlen-offset-1+nextdiff);
+
+ /* Encode this entry's raw length in the next entry. */
+ zipPrevEncodeLength(p+reqlen,reqlen);
+
+ /* Update offset for tail */
+ ZIPLIST_TAIL_OFFSET(zl) =
+ intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+reqlen);
+
+ /* When the tail contains more than one entry, we need to take
+ * "nextdiff" in account as well. Otherwise, a change in the
+ * size of prevlen doesn't have an effect on the *tail* offset. */
+ zipEntry(p+reqlen, &tail);
+ if (p[reqlen+tail.headersize+tail.len] != ZIP_END) {
+ ZIPLIST_TAIL_OFFSET(zl) =
+ intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+nextdiff);
+ }
+ } else {
+ /* This element will be the new tail. */
+ ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(p-zl);
+ }
+
+ /* When nextdiff != 0, the raw length of the next entry has changed, so
+ * we need to cascade the update throughout the ziplist */
+ if (nextdiff != 0) {
+ offset = p-zl;
+ zl = __ziplistCascadeUpdate(zl,p+reqlen);
+ p = zl+offset;
+ }
+
+ /* Write the entry */
+ p += zipPrevEncodeLength(p,prevlen);
+ p += zipEncodeLength(p,encoding,slen);
+ if (ZIP_IS_STR(encoding)) {
+ memcpy(p,s,slen);
+ } else {
+ zipSaveInteger(p,value,encoding);
+ }
+ ZIPLIST_INCR_LENGTH(zl,1);
+ return zl;
+}
+
+```
+
+
+
+
+
+我们来简单解析一下这段代码:
+
+* 这个函数是在指定的位置p插入一段新的数据,待插入数据的地址指针是s,长度为slen。插入后形成一个新的数据项,占据原来p的配置,原来位于p位置的数据项以及后面的所有数据项,需要统一向后移动,给新插入的数据项留出空间。参数p指向的是ziplist中某一个数据项的起始位置,或者在向尾端插入的时候,它指向ziplist的结束标记``。
+* 函数开始先计算出待插入位置前一个数据项的长度`prevlen`。这个长度要存入新插入的数据项的``字段。
+* 然后计算当前数据项占用的总字节数`reqlen`,它包含三部分:``, ``和真正的数据。其中的数据部分会通过调用`zipTryEncoding`先来尝试转成整数。
+* 由于插入导致的ziplist对于内存的新增需求,除了待插入数据项占用的`reqlen`之外,还要考虑原来p位置的数据项(现在要排在待插入数据项之后)的``字段的变化。本来它保存的是前一项的总长度,现在变成了保存当前插入的数据项的总长度。这样它的``字段本身需要的存储空间也可能发生变化,这个变化可能是变大也可能是变小。这个变化了多少的值`nextdiff`,是调用`zipPrevLenByteDiff`计算出来的。如果变大了,`nextdiff`是正值,否则是负值。
+* 现在很容易算出来插入后新的ziplist需要多少字节了,然后调用`ziplistResize`来重新调整大小。ziplistResize的实现里会调用allocator的`zrealloc`,它有可能会造成数据拷贝。
+* 现在额外的空间有了,接下来就是将原来p位置的数据项以及后面的所有数据都向后挪动,并为它设置新的``字段。此外,还可能需要调整ziplist的``字段。
+* 最后,组装新的待插入数据项,放在位置p。
+
+#### hash与ziplist
+
+hash是Redis中可以用来存储一个对象结构的比较理想的数据类型。一个对象的各个属性,正好对应一个hash结构的各个field。
+
+我们在网上很容易找到这样一些技术文章,它们会说存储一个对象,使用hash比string要节省内存。实际上这么说是有前提的,具体取决于对象怎么来存储。如果你把对象的多个属性存储到多个key上(各个属性值存成string),当然占的内存要多。但如果你采用一些序列化方法,比如[Protocol Buffers](https://github.com/google/protobuf),或者[Apache Thrift](https://thrift.apache.org/),先把对象序列化为字节数组,然后再存入到Redis的string中,那么跟hash相比,哪一种更省内存,就不一定了。
+
+当然,hash比序列化后再存入string的方式,在支持的操作命令上,还是有优势的:它既支持多个field同时存取(`hmset`/`hmget`),也支持按照某个特定的field单独存取(`hset`/`hget`)。
+
+实际上,hash随着数据的增大,其底层数据结构的实现是会发生变化的,当然存储效率也就不同。在field比较少,各个value值也比较小的时候,hash采用ziplist来实现;而随着field增多和value值增大,hash可能会变成dict来实现。当hash底层变成dict来实现的时候,它的存储效率就没法跟那些序列化方式相比了。
+
+当我们为某个key第一次执行 `hset key field value` 命令的时候,Redis会创建一个hash结构,这个新创建的hash底层就是一个ziplist。
+
+
+
+
+
+```
+robj *createHashObject(void) {
+ unsigned char *zl = ziplistNew();
+ robj *o = createObject(OBJ_HASH, zl);
+ o->encoding = OBJ_ENCODING_ZIPLIST;
+ return o;
+}
+
+```
+
+
+
+
+
+上面的`createHashObject`函数,出自object.c,它负责的任务就是创建一个新的hash结构。可以看出,它创建了一个`type = OBJ_HASH`但`encoding = OBJ_ENCODING_ZIPLIST`的robj对象。
+
+实际上,本文前面给出的那个ziplist实例,就是由如下两个命令构建出来的。
+
+
+
+
+
+```
+hset user:100 name tielei
+hset user:100 age 20
+
+```
+
+
+
+
+
+每执行一次`hset`命令,插入的field和value分别作为一个新的数据项插入到ziplist中(即每次`hset`产生两个数据项)。
+
+当随着数据的插入,hash底层的这个ziplist就可能会转成dict。那么到底插入多少才会转呢?
+
+还记得本文开头提到的两个Redis配置吗?
+
+
+
+
+
+```
+hash-max-ziplist-entries 512
+hash-max-ziplist-value 64
+
+```
+
+
+
+
+
+这个配置的意思是说,在如下两个条件之一满足的时候,ziplist会转成dict:
+
+* 当hash中的数据项(即field-value对)的数目超过512的时候,也就是ziplist数据项超过1024的时候(请参考t_hash.c中的`hashTypeSet`函数)。
+* 当hash中插入的任意一个value的长度超过了64的时候(请参考t_hash.c中的`hashTypeTryConversion`函数)。
+
+Redis的hash之所以这样设计,是因为当ziplist变得很大的时候,它有如下几个缺点:
+
+* 每次插入或修改引发的realloc操作会有更大的概率造成内存拷贝,从而降低性能。
+* 一旦发生内存拷贝,内存拷贝的成本也相应增加,因为要拷贝更大的一块数据。
+* 当ziplist数据项过多的时候,在它上面查找指定的数据项就会性能变得很低,因为ziplist上的查找需要进行遍历。
+
+总之,ziplist本来就设计为各个数据项挨在一起组成连续的内存空间,这种结构并不擅长做修改操作。一旦数据发生改动,就会引发内存realloc,可能导致内存拷贝。
\ No newline at end of file
diff --git "a/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\2605\357\274\232Redis\345\206\205\351\203\250\346\225\260\346\215\256\347\273\223\346\236\204\350\257\246\350\247\243\342\200\224\342\200\224quicklist.md" "b/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\2605\357\274\232Redis\345\206\205\351\203\250\346\225\260\346\215\256\347\273\223\346\236\204\350\257\246\350\247\243\342\200\224\342\200\224quicklist.md"
new file mode 100644
index 0000000..f7a5907
--- /dev/null
+++ "b/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\2605\357\274\232Redis\345\206\205\351\203\250\346\225\260\346\215\256\347\273\223\346\236\204\350\257\246\350\247\243\342\200\224\342\200\224quicklist.md"
@@ -0,0 +1,371 @@
+本文转自互联网
+
+本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
+> https://github.com/h2pl/Java-Tutorial
+
+喜欢的话麻烦点下Star哈
+
+文章首发于我的个人博客:
+> www.how2playlife.com
+
+本文是微信公众号【Java技术江湖】的《探索Redis设计与实现》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。
+
+该系列博文会告诉你如何从入门到进阶,Redis基本的使用方法,Redis的基本数据结构,以及一些进阶的使用方法,同时也需要进一步了解Redis的底层数据结构,再接着,还会带来Redis主从复制、集群、分布式锁等方面的相关内容,以及作为缓存的一些使用方法和注意事项,以便让你更完整地了解整个Redis相关的技术体系,形成自己的知识框架。
+
+如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。
+
+
+
+本文是《[Redis内部数据结构详解](http://zhangtielei.com/posts/blog-redis-dict.html)》系列的第五篇。在本文中,我们介绍一个Redis内部数据结构——quicklist。Redis对外暴露的list数据类型,它底层实现所依赖的内部数据结构就是quicklist。
+
+我们在讨论中还会涉及到两个Redis配置(在redis.conf中的ADVANCED CONFIG部分):
+
+
+
+
+
+```
+list-max-ziplist-size -2
+list-compress-depth 0
+
+```
+
+
+
+
+
+我们在讨论中会详细解释这两个配置的含义。
+
+注:本文讨论的quicklist实现基于Redis源码的3.2分支。
+
+#### quicklist概述
+
+Redis对外暴露的上层list数据类型,经常被用作队列使用。比如它支持的如下一些操作:
+
+* `lpush`: 在左侧(即列表头部)插入数据。
+* `rpop`: 在右侧(即列表尾部)删除数据。
+* `rpush`: 在右侧(即列表尾部)插入数据。
+* `lpop`: 在左侧(即列表头部)删除数据。
+
+这些操作都是O(1)时间复杂度的。
+
+当然,list也支持在任意中间位置的存取操作,比如`lindex`和`linsert`,但它们都需要对list进行遍历,所以时间复杂度较高,为O(N)。
+
+概况起来,list具有这样的一些特点:它是一个能维持数据项先后顺序的列表(各个数据项的先后顺序由插入位置决定),便于在表的两端追加和删除数据,而对于中间位置的存取具有O(N)的时间复杂度。这不正是一个双向链表所具有的特点吗?
+
+list的内部实现quicklist正是一个双向链表。在quicklist.c的文件头部注释中,是这样描述quicklist的:
+
+> A doubly linked list of ziplists
+
+它确实是一个双向链表,而且是一个ziplist的双向链表。
+
+这是什么意思呢?
+
+我们知道,双向链表是由多个节点(Node)组成的。这个描述的意思是:quicklist的每个节点都是一个ziplist。ziplist我们已经在[上一篇](http://zhangtielei.com/posts/blog-redis-ziplist.html)介绍过。
+
+ziplist本身也是一个能维持数据项先后顺序的列表(按插入位置),而且是一个内存紧缩的列表(各个数据项在内存上前后相邻)。比如,一个包含3个节点的quicklist,如果每个节点的ziplist又包含4个数据项,那么对外表现上,这个list就总共包含12个数据项。
+
+quicklist的结构为什么这样设计呢?总结起来,大概又是一个空间和时间的折中:
+
+* 双向链表便于在表的两端进行push和pop操作,但是它的内存开销比较大。首先,它在每个节点上除了要保存数据之外,还要额外保存两个指针;其次,双向链表的各个节点是单独的内存块,地址不连续,节点多了容易产生内存碎片。
+* ziplist由于是一整块连续内存,所以存储效率很高。但是,它不利于修改操作,每次数据变动都会引发一次内存的realloc。特别是当ziplist长度很长的时候,一次realloc可能会导致大批量的数据拷贝,进一步降低性能。
+
+于是,结合了双向链表和ziplist的优点,quicklist就应运而生了。
+
+不过,这也带来了一个新问题:到底一个quicklist节点包含多长的ziplist合适呢?比如,同样是存储12个数据项,既可以是一个quicklist包含3个节点,而每个节点的ziplist又包含4个数据项,也可以是一个quicklist包含6个节点,而每个节点的ziplist又包含2个数据项。
+
+这又是一个需要找平衡点的难题。我们只从存储效率上分析一下:
+
+* 每个quicklist节点上的ziplist越短,则内存碎片越多。内存碎片多了,有可能在内存中产生很多无法被利用的小碎片,从而降低存储效率。这种情况的极端是每个quicklist节点上的ziplist只包含一个数据项,这就蜕化成一个普通的双向链表了。
+* 每个quicklist节点上的ziplist越长,则为ziplist分配大块连续内存空间的难度就越大。有可能出现内存里有很多小块的空闲空间(它们加起来很多),但却找不到一块足够大的空闲空间分配给ziplist的情况。这同样会降低存储效率。这种情况的极端是整个quicklist只有一个节点,所有的数据项都分配在这仅有的一个节点的ziplist里面。这其实蜕化成一个ziplist了。
+
+可见,一个quicklist节点上的ziplist要保持一个合理的长度。那到底多长合理呢?这可能取决于具体应用场景。实际上,Redis提供了一个配置参数`list-max-ziplist-size`,就是为了让使用者可以来根据自己的情况进行调整。
+
+
+
+
+
+```
+list-max-ziplist-size -2
+
+```
+
+
+
+
+
+我们来详细解释一下这个参数的含义。它可以取正值,也可以取负值。
+
+当取正值的时候,表示按照数据项个数来限定每个quicklist节点上的ziplist长度。比如,当这个参数配置成5的时候,表示每个quicklist节点的ziplist最多包含5个数据项。
+
+当取负值的时候,表示按照占用字节数来限定每个quicklist节点上的ziplist长度。这时,它只能取-1到-5这五个值,每个值含义如下:
+
+* -5: 每个quicklist节点上的ziplist大小不能超过64 Kb。(注:1kb => 1024 bytes)
+* -4: 每个quicklist节点上的ziplist大小不能超过32 Kb。
+* -3: 每个quicklist节点上的ziplist大小不能超过16 Kb。
+* -2: 每个quicklist节点上的ziplist大小不能超过8 Kb。(-2是Redis给出的默认值)
+* -1: 每个quicklist节点上的ziplist大小不能超过4 Kb。
+
+另外,list的设计目标是能够用来存储很长的数据列表的。比如,Redis官网给出的这个教程:[Writing a simple Twitter clone with PHP and Redis](http://redis.io/topics/twitter-clone),就是使用list来存储类似Twitter的timeline数据。
+
+当列表很长的时候,最容易被访问的很可能是两端的数据,中间的数据被访问的频率比较低(访问起来性能也很低)。如果应用场景符合这个特点,那么list还提供了一个选项,能够把中间的数据节点进行压缩,从而进一步节省内存空间。Redis的配置参数`list-compress-depth`就是用来完成这个设置的。
+
+
+
+
+
+```
+list-compress-depth 0
+
+```
+
+
+
+
+
+这个参数表示一个quicklist两端不被压缩的节点个数。注:这里的节点个数是指quicklist双向链表的节点个数,而不是指ziplist里面的数据项个数。实际上,一个quicklist节点上的ziplist,如果被压缩,就是整体被压缩的。
+
+参数`list-compress-depth`的取值含义如下:
+
+* 0: 是个特殊值,表示都不压缩。这是Redis的默认值。
+* 1: 表示quicklist两端各有1个节点不压缩,中间的节点压缩。
+* 2: 表示quicklist两端各有2个节点不压缩,中间的节点压缩。
+* 3: 表示quicklist两端各有3个节点不压缩,中间的节点压缩。
+* 依此类推…
+
+由于0是个特殊值,很容易看出quicklist的头节点和尾节点总是不被压缩的,以便于在表的两端进行快速存取。
+
+Redis对于quicklist内部节点的压缩算法,采用的[LZF](http://oldhome.schmorp.de/marc/liblzf.html)——一种无损压缩算法。
+
+#### quicklist的数据结构定义
+
+quicklist相关的数据结构定义可以在quicklist.h中找到:
+
+
+
+
+
+```
+typedef struct quicklistNode {
+ struct quicklistNode *prev;
+ struct quicklistNode *next;
+ unsigned char *zl;
+ unsigned int sz; /* ziplist size in bytes */
+ unsigned int count : 16; /* count of items in ziplist */
+ unsigned int encoding : 2; /* RAW==1 or LZF==2 */
+ unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
+ unsigned int recompress : 1; /* was this node previous compressed? */
+ unsigned int attempted_compress : 1; /* node can't compress; too small */
+ unsigned int extra : 10; /* more bits to steal for future usage */
+} quicklistNode;
+
+typedef struct quicklistLZF {
+ unsigned int sz; /* LZF size in bytes*/
+ char compressed[];
+} quicklistLZF;
+
+typedef struct quicklist {
+ quicklistNode *head;
+ quicklistNode *tail;
+ unsigned long count; /* total count of all entries in all ziplists */
+ unsigned int len; /* number of quicklistNodes */
+ int fill : 16; /* fill factor for individual nodes */
+ unsigned int compress : 16; /* depth of end nodes not to compress;0=off */
+} quicklist;
+
+```
+
+
+
+
+
+quicklistNode结构代表quicklist的一个节点,其中各个字段的含义如下:
+
+* prev: 指向链表前一个节点的指针。
+* next: 指向链表后一个节点的指针。
+* zl: 数据指针。如果当前节点的数据没有压缩,那么它指向一个ziplist结构;否则,它指向一个quicklistLZF结构。
+* sz: 表示zl指向的ziplist的总大小(包括`zlbytes`, `zltail`, `zllen`, `zlend`和各个数据项)。需要注意的是:如果ziplist被压缩了,那么这个sz的值仍然是压缩前的ziplist大小。
+* count: 表示ziplist里面包含的数据项个数。这个字段只有16bit。稍后我们会一起计算一下这16bit是否够用。
+* encoding: 表示ziplist是否压缩了(以及用了哪个压缩算法)。目前只有两种取值:2表示被压缩了(而且用的是[LZF](http://oldhome.schmorp.de/marc/liblzf.html)压缩算法),1表示没有压缩。
+* container: 是一个预留字段。本来设计是用来表明一个quicklist节点下面是直接存数据,还是使用ziplist存数据,或者用其它的结构来存数据(用作一个数据容器,所以叫container)。但是,在目前的实现中,这个值是一个固定的值2,表示使用ziplist作为数据容器。
+* recompress: 当我们使用类似lindex这样的命令查看了某一项本来压缩的数据时,需要把数据暂时解压,这时就设置recompress=1做一个标记,等有机会再把数据重新压缩。
+* attempted_compress: 这个值只对Redis的自动化测试程序有用。我们不用管它。
+* extra: 其它扩展字段。目前Redis的实现里也没用上。
+
+quicklistLZF结构表示一个被压缩过的ziplist。其中:
+
+* sz: 表示压缩后的ziplist大小。
+* compressed: 是个柔性数组([flexible array member](https://en.wikipedia.org/wiki/Flexible_array_member)),存放压缩后的ziplist字节数组。
+
+真正表示quicklist的数据结构是同名的quicklist这个struct:
+
+* head: 指向头节点(左侧第一个节点)的指针。
+* tail: 指向尾节点(右侧第一个节点)的指针。
+* count: 所有ziplist数据项的个数总和。
+* len: quicklist节点的个数。
+* fill: 16bit,ziplist大小设置,存放`list-max-ziplist-size`参数的值。
+* compress: 16bit,节点压缩深度设置,存放`list-compress-depth`参数的值。
+
+[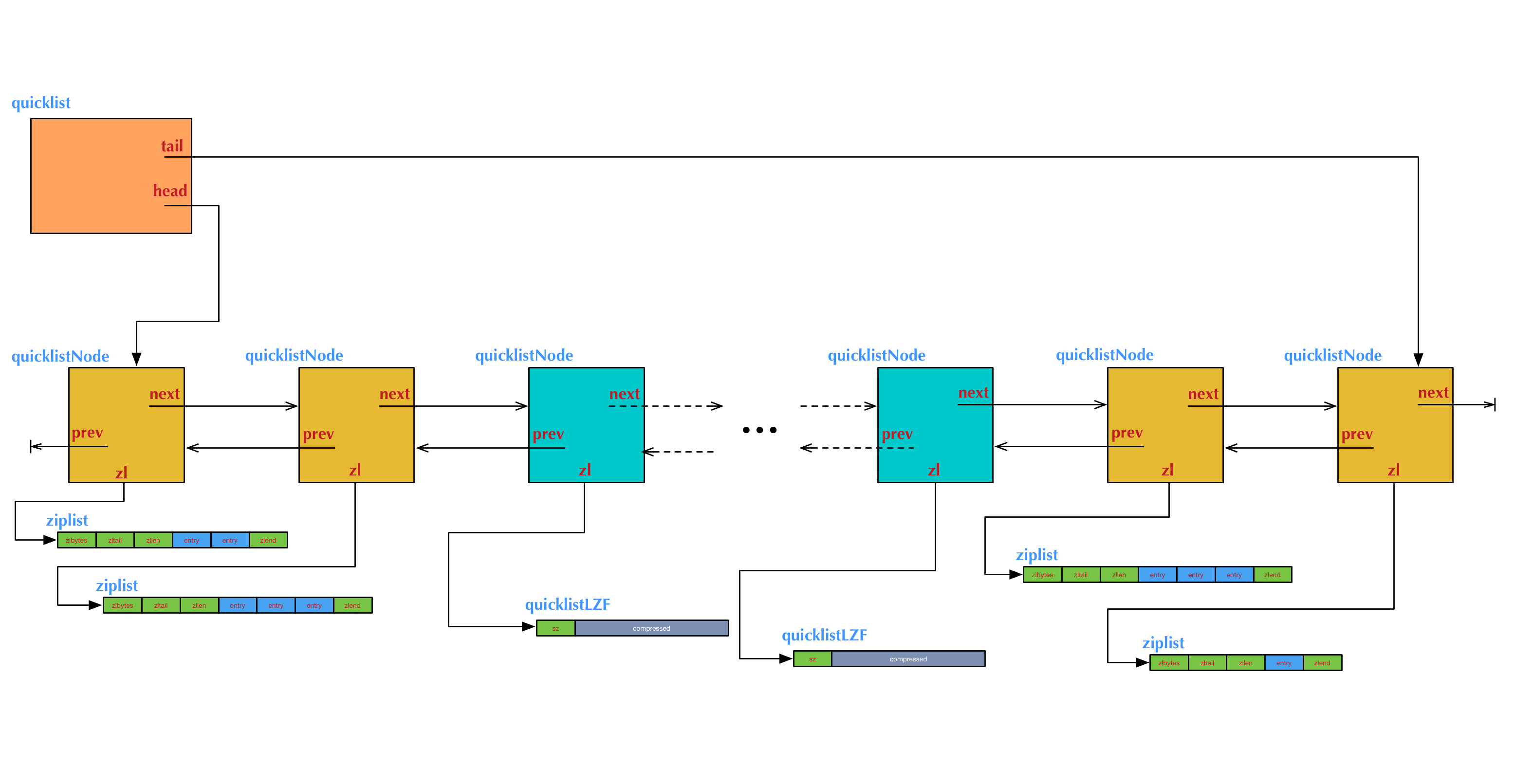](http://zhangtielei.com/assets/photos_redis/redis_quicklist_structure.png)
+
+上图是一个quicklist的结构图举例。图中例子对应的ziplist大小配置和节点压缩深度配置,如下:
+
+
+
+
+
+```
+list-max-ziplist-size 3
+list-compress-depth 2
+
+```
+
+
+
+
+
+这个例子中我们需要注意的几点是:
+
+* 两端各有2个橙黄色的节点,是没有被压缩的。它们的数据指针zl指向真正的ziplist。中间的其它节点是被压缩过的,它们的数据指针zl指向被压缩后的ziplist结构,即一个quicklistLZF结构。
+* 左侧头节点上的ziplist里有2项数据,右侧尾节点上的ziplist里有1项数据,中间其它节点上的ziplist里都有3项数据(包括压缩的节点内部)。这表示在表的两端执行过多次`push`和`pop`操作后的一个状态。
+
+现在我们来大概计算一下quicklistNode结构中的count字段这16bit是否够用。
+
+我们已经知道,ziplist大小受到`list-max-ziplist-size`参数的限制。按照正值和负值有两种情况:
+
+* 当这个参数取正值的时候,就是恰好表示一个quicklistNode结构中zl所指向的ziplist所包含的数据项的最大值。`list-max-ziplist-size`参数是由quicklist结构的fill字段来存储的,而fill字段是16bit,所以它所能表达的值能够用16bit来表示。
+* 当这个参数取负值的时候,能够表示的ziplist最大长度是64 Kb。而ziplist中每一个数据项,最少需要2个字节来表示:1个字节的`prevrawlen`,1个字节的`data`(`len`字段和`data`合二为一;详见[上一篇](http://zhangtielei.com/posts/blog-redis-ziplist.html))。所以,ziplist中数据项的个数不会超过32 K,用16bit来表达足够了。
+
+实际上,在目前的quicklist的实现中,ziplist的大小还会受到另外的限制,根本不会达到这里所分析的最大值。
+
+下面进入代码分析阶段。
+
+#### quicklist的创建
+
+当我们使用`lpush`或`rpush`命令第一次向一个不存在的list里面插入数据的时候,Redis会首先调用`quicklistCreate`接口创建一个空的quicklist。
+
+
+
+
+
+```
+quicklist *quicklistCreate(void) {
+ struct quicklist *quicklist;
+
+ quicklist = zmalloc(sizeof(*quicklist));
+ quicklist->head = quicklist->tail = NULL;
+ quicklist->len = 0;
+ quicklist->count = 0;
+ quicklist->compress = 0;
+ quicklist->fill = -2;
+ return quicklist;
+}
+
+```
+
+
+
+
+
+在很多介绍数据结构的书上,实现双向链表的时候经常会多增加一个空余的头节点,主要是为了插入和删除操作的方便。从上面`quicklistCreate`的代码可以看出,quicklist是一个不包含空余头节点的双向链表(`head`和`tail`都初始化为NULL)。
+
+#### quicklist的push操作
+
+quicklist的push操作是调用`quicklistPush`来实现的。
+
+
+
+
+
+```
+void quicklistPush(quicklist *quicklist, void *value, const size_t sz,
+ int where) {
+ if (where == QUICKLIST_HEAD) {
+ quicklistPushHead(quicklist, value, sz);
+ } else if (where == QUICKLIST_TAIL) {
+ quicklistPushTail(quicklist, value, sz);
+ }
+}
+
+/* Add new entry to head node of quicklist.
+ *
+ * Returns 0 if used existing head.
+ * Returns 1 if new head created. */
+int quicklistPushHead(quicklist *quicklist, void *value, size_t sz) {
+ quicklistNode *orig_head = quicklist->head;
+ if (likely(
+ _quicklistNodeAllowInsert(quicklist->head, quicklist->fill, sz))) {
+ quicklist->head->zl =
+ ziplistPush(quicklist->head->zl, value, sz, ZIPLIST_HEAD);
+ quicklistNodeUpdateSz(quicklist->head);
+ } else {
+ quicklistNode *node = quicklistCreateNode();
+ node->zl = ziplistPush(ziplistNew(), value, sz, ZIPLIST_HEAD);
+
+ quicklistNodeUpdateSz(node);
+ _quicklistInsertNodeBefore(quicklist, quicklist->head, node);
+ }
+ quicklist->count++;
+ quicklist->head->count++;
+ return (orig_head != quicklist->head);
+}
+
+/* Add new entry to tail node of quicklist.
+ *
+ * Returns 0 if used existing tail.
+ * Returns 1 if new tail created. */
+int quicklistPushTail(quicklist *quicklist, void *value, size_t sz) {
+ quicklistNode *orig_tail = quicklist->tail;
+ if (likely(
+ _quicklistNodeAllowInsert(quicklist->tail, quicklist->fill, sz))) {
+ quicklist->tail->zl =
+ ziplistPush(quicklist->tail->zl, value, sz, ZIPLIST_TAIL);
+ quicklistNodeUpdateSz(quicklist->tail);
+ } else {
+ quicklistNode *node = quicklistCreateNode();
+ node->zl = ziplistPush(ziplistNew(), value, sz, ZIPLIST_TAIL);
+
+ quicklistNodeUpdateSz(node);
+ _quicklistInsertNodeAfter(quicklist, quicklist->tail, node);
+ }
+ quicklist->count++;
+ quicklist->tail->count++;
+ return (orig_tail != quicklist->tail);
+}
+
+```
+
+
+
+
+
+不管是在头部还是尾部插入数据,都包含两种情况:
+
+* 如果头节点(或尾节点)上ziplist大小没有超过限制(即`_quicklistNodeAllowInsert`返回1),那么新数据被直接插入到ziplist中(调用`ziplistPush`)。
+* 如果头节点(或尾节点)上ziplist太大了,那么新创建一个quicklistNode节点(对应地也会新创建一个ziplist),然后把这个新创建的节点插入到quicklist双向链表中(调用`_quicklistInsertNodeAfter`)。
+
+在`_quicklistInsertNodeAfter`的实现中,还会根据`list-compress-depth`的配置将里面的节点进行压缩。它的实现比较繁琐,我们这里就不展开讨论了。
+
+#### quicklist的其它操作
+
+quicklist的操作较多,且实现细节都比较繁杂,这里就不一一分析源码了,我们简单介绍一些比较重要的操作。
+
+quicklist的pop操作是调用`quicklistPopCustom`来实现的。`quicklistPopCustom`的实现过程基本上跟quicklistPush相反,先从头部或尾部节点的ziplist中把对应的数据项删除,如果在删除后ziplist为空了,那么对应的头部或尾部节点也要删除。删除后还可能涉及到里面节点的解压缩问题。
+
+quicklist不仅实现了从头部或尾部插入,也实现了从任意指定的位置插入。`quicklistInsertAfter`和`quicklistInsertBefore`就是分别在指定位置后面和前面插入数据项。这种在任意指定位置插入数据的操作,情况比较复杂,有众多的逻辑分支。
+
+* 当插入位置所在的ziplist大小没有超过限制时,直接插入到ziplist中就好了;
+* 当插入位置所在的ziplist大小超过了限制,但插入的位置位于ziplist两端,并且相邻的quicklist链表节点的ziplist大小没有超过限制,那么就转而插入到相邻的那个quicklist链表节点的ziplist中;
+* 当插入位置所在的ziplist大小超过了限制,但插入的位置位于ziplist两端,并且相邻的quicklist链表节点的ziplist大小也超过限制,这时需要新创建一个quicklist链表节点插入。
+* 对于插入位置所在的ziplist大小超过了限制的其它情况(主要对应于在ziplist中间插入数据的情况),则需要把当前ziplist分裂为两个节点,然后再其中一个节点上插入数据。
+
+`quicklistSetOptions`用于设置ziplist大小配置参数(`list-max-ziplist-size`)和节点压缩深度配置参数(`list-compress-depth`)。代码比较简单,就是将相应的值分别设置给quicklist结构的fill字段和compress字段。
+
+* * *
+
+下一篇我们将介绍skiplist和它所支撑的Redis数据类型sorted set,敬请期待。
+
+**原创文章,转载请注明出处,并包含下面的二维码!否则拒绝转载!**
+**本文链接:**[http://zhangtielei.com/posts/blog-redis-quicklist.html](http://zhangtielei.com/posts/blog-redis-quicklist.html)
+
+
\ No newline at end of file
diff --git "a/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\2606\357\274\232Redis\345\206\205\351\203\250\346\225\260\346\215\256\347\273\223\346\236\204\350\257\246\350\247\243\342\200\224\342\200\224skiplist.md" "b/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\2606\357\274\232Redis\345\206\205\351\203\250\346\225\260\346\215\256\347\273\223\346\236\204\350\257\246\350\247\243\342\200\224\342\200\224skiplist.md"
new file mode 100644
index 0000000..c5f6137
--- /dev/null
+++ "b/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\2606\357\274\232Redis\345\206\205\351\203\250\346\225\260\346\215\256\347\273\223\346\236\204\350\257\246\350\247\243\342\200\224\342\200\224skiplist.md"
@@ -0,0 +1,453 @@
+本文转自互联网
+
+本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
+> https://github.com/h2pl/Java-Tutorial
+
+喜欢的话麻烦点下Star哈
+
+文章首发于我的个人博客:
+> www.how2playlife.com
+
+本文是微信公众号【Java技术江湖】的《探索Redis设计与实现》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。
+
+该系列博文会告诉你如何从入门到进阶,Redis基本的使用方法,Redis的基本数据结构,以及一些进阶的使用方法,同时也需要进一步了解Redis的底层数据结构,再接着,还会带来Redis主从复制、集群、分布式锁等方面的相关内容,以及作为缓存的一些使用方法和注意事项,以便让你更完整地了解整个Redis相关的技术体系,形成自己的知识框架。
+
+如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。
+
+
+
+本文是《[Redis内部数据结构详解](http://zhangtielei.com/posts/blog-redis-dict.html)》系列的第六篇。在本文中,我们围绕一个Redis的内部数据结构——skiplist展开讨论。
+
+Redis里面使用skiplist是为了实现sorted set这种对外的数据结构。sorted set提供的操作非常丰富,可以满足非常多的应用场景。这也意味着,sorted set相对来说实现比较复杂。同时,skiplist这种数据结构对于很多人来说都比较陌生,因为大部分学校里的算法课都没有对这种数据结构进行过详细的介绍。因此,为了介绍得足够清楚,本文会比这个系列的其它几篇花费更多的篇幅。
+
+我们将大体分成三个部分进行介绍:
+
+1. 介绍经典的skiplist数据结构,并进行简单的算法分析。这一部分的介绍,与Redis没有直接关系。我会尝试尽量使用通俗易懂的语言进行描述。
+2. 讨论Redis里的skiplist的具体实现。为了支持sorted set本身的一些要求,在经典的skiplist基础上,Redis里的相应实现做了若干改动。
+3. 讨论sorted set是如何在skiplist, dict和ziplist基础上构建起来的。
+
+我们在讨论中还会涉及到两个Redis配置(在redis.conf中的ADVANCED CONFIG部分):
+
+
+
+
+
+```
+zset-max-ziplist-entries 128
+zset-max-ziplist-value 64
+
+```
+
+
+
+
+
+我们在讨论中会详细解释这两个配置的含义。
+
+注:本文讨论的代码实现基于Redis源码的3.2分支。
+
+### skiplist数据结构简介
+
+skiplist本质上也是一种查找结构,用于解决算法中的查找问题(Searching),即根据给定的key,快速查到它所在的位置(或者对应的value)。
+
+我们在《Redis内部数据结构详解》系列的[第一篇](http://zhangtielei.com/posts/blog-redis-dict.html)中介绍dict的时候,曾经讨论过:一般查找问题的解法分为两个大类:一个是基于各种平衡树,一个是基于哈希表。但skiplist却比较特殊,它没法归属到这两大类里面。
+
+这种数据结构是由[William Pugh](https://en.wikipedia.org/wiki/William_Pugh)发明的,最早出现于他在1990年发表的论文《[Skip Lists: A Probabilistic Alternative to Balanced Trees](ftp://ftp.cs.umd.edu/pub/skipLists/skiplists.pdf)》。对细节感兴趣的同学可以下载论文原文来阅读。
+
+skiplist,顾名思义,首先它是一个list。实际上,它是在有序链表的基础上发展起来的。
+
+我们先来看一个有序链表,如下图(最左侧的灰色节点表示一个空的头结点):
+
+[](http://zhangtielei.com/assets/photos_redis/skiplist/sorted_linked_list.png)
+
+在这样一个链表中,如果我们要查找某个数据,那么需要从头开始逐个进行比较,直到找到包含数据的那个节点,或者找到第一个比给定数据大的节点为止(没找到)。也就是说,时间复杂度为O(n)。同样,当我们要插入新数据的时候,也要经历同样的查找过程,从而确定插入位置。
+
+假如我们每相邻两个节点增加一个指针,让指针指向下下个节点,如下图:
+
+[](http://zhangtielei.com/assets/photos_redis/skiplist/skip2node_linked_list.png)
+
+这样所有新增加的指针连成了一个新的链表,但它包含的节点个数只有原来的一半(上图中是7, 19, 26)。现在当我们想查找数据的时候,可以先沿着这个新链表进行查找。当碰到比待查数据大的节点时,再回到原来的链表中进行查找。比如,我们想查找23,查找的路径是沿着下图中标红的指针所指向的方向进行的:
+
+[](http://zhangtielei.com/assets/photos_redis/skiplist/search_path_on_skip2node_list.png)
+
+* 23首先和7比较,再和19比较,比它们都大,继续向后比较。
+* 但23和26比较的时候,比26要小,因此回到下面的链表(原链表),与22比较。
+* 23比22要大,沿下面的指针继续向后和26比较。23比26小,说明待查数据23在原链表中不存在,而且它的插入位置应该在22和26之间。
+
+在这个查找过程中,由于新增加的指针,我们不再需要与链表中每个节点逐个进行比较了。需要比较的节点数大概只有原来的一半。
+
+利用同样的方式,我们可以在上层新产生的链表上,继续为每相邻的两个节点增加一个指针,从而产生第三层链表。如下图:
+
+[](http://zhangtielei.com/assets/photos_redis/skiplist/skip2node_level3_linked_list.png)
+
+在这个新的三层链表结构上,如果我们还是查找23,那么沿着最上层链表首先要比较的是19,发现23比19大,接下来我们就知道只需要到19的后面去继续查找,从而一下子跳过了19前面的所有节点。可以想象,当链表足够长的时候,这种多层链表的查找方式能让我们跳过很多下层节点,大大加快查找的速度。
+
+skiplist正是受这种多层链表的想法的启发而设计出来的。实际上,按照上面生成链表的方式,上面每一层链表的节点个数,是下面一层的节点个数的一半,这样查找过程就非常类似于一个二分查找,使得查找的时间复杂度可以降低到O(log n)。但是,这种方法在插入数据的时候有很大的问题。新插入一个节点之后,就会打乱上下相邻两层链表上节点个数严格的2:1的对应关系。如果要维持这种对应关系,就必须把新插入的节点后面的所有节点(也包括新插入的节点)重新进行调整,这会让时间复杂度重新蜕化成O(n)。删除数据也有同样的问题。
+
+skiplist为了避免这一问题,它不要求上下相邻两层链表之间的节点个数有严格的对应关系,而是为每个节点随机出一个层数(level)。比如,一个节点随机出的层数是3,那么就把它链入到第1层到第3层这三层链表中。为了表达清楚,下图展示了如何通过一步步的插入操作从而形成一个skiplist的过程:
+
+[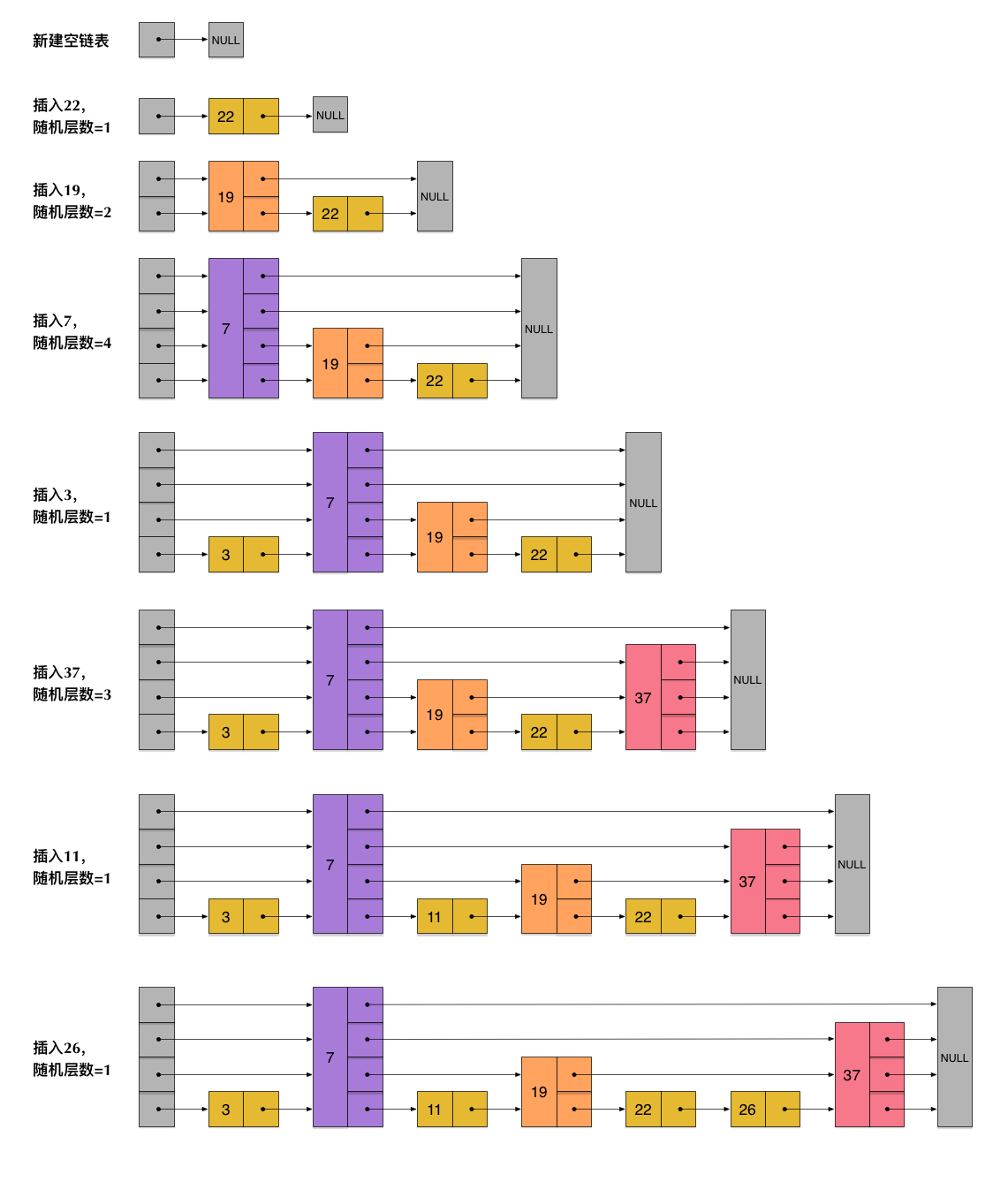](http://zhangtielei.com/assets/photos_redis/skiplist/skiplist_insertions.png)
+
+从上面skiplist的创建和插入过程可以看出,每一个节点的层数(level)是随机出来的,而且新插入一个节点不会影响其它节点的层数。因此,插入操作只需要修改插入节点前后的指针,而不需要对很多节点都进行调整。这就降低了插入操作的复杂度。实际上,这是skiplist的一个很重要的特性,这让它在插入性能上明显优于平衡树的方案。这在后面我们还会提到。
+
+根据上图中的skiplist结构,我们很容易理解这种数据结构的名字的由来。skiplist,翻译成中文,可以翻译成“跳表”或“跳跃表”,指的就是除了最下面第1层链表之外,它会产生若干层稀疏的链表,这些链表里面的指针故意跳过了一些节点(而且越高层的链表跳过的节点越多)。这就使得我们在查找数据的时候能够先在高层的链表中进行查找,然后逐层降低,最终降到第1层链表来精确地确定数据位置。在这个过程中,我们跳过了一些节点,从而也就加快了查找速度。
+
+刚刚创建的这个skiplist总共包含4层链表,现在假设我们在它里面依然查找23,下图给出了查找路径:
+
+[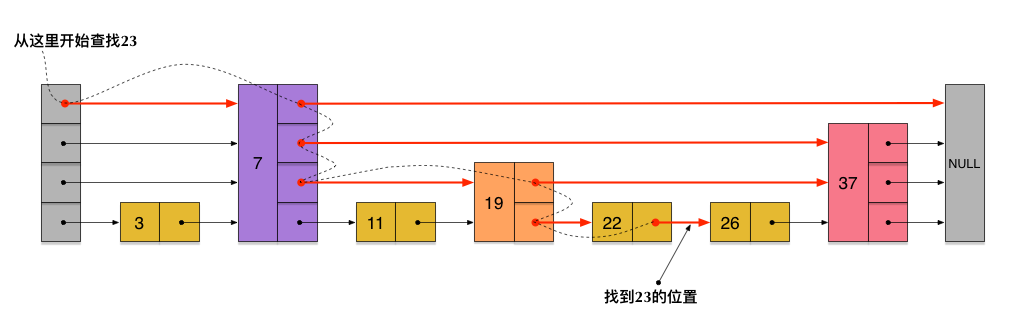](http://zhangtielei.com/assets/photos_redis/skiplist/search_path_on_skiplist.png)
+
+需要注意的是,前面演示的各个节点的插入过程,实际上在插入之前也要先经历一个类似的查找过程,在确定插入位置后,再完成插入操作。
+
+至此,skiplist的查找和插入操作,我们已经很清楚了。而删除操作与插入操作类似,我们也很容易想象出来。这些操作我们也应该能很容易地用代码实现出来。
+
+当然,实际应用中的skiplist每个节点应该包含key和value两部分。前面的描述中我们没有具体区分key和value,但实际上列表中是按照key进行排序的,查找过程也是根据key在比较。
+
+但是,如果你是第一次接触skiplist,那么一定会产生一个疑问:节点插入时随机出一个层数,仅仅依靠这样一个简单的随机数操作而构建出来的多层链表结构,能保证它有一个良好的查找性能吗?为了回答这个疑问,我们需要分析skiplist的统计性能。
+
+在分析之前,我们还需要着重指出的是,执行插入操作时计算随机数的过程,是一个很关键的过程,它对skiplist的统计特性有着很重要的影响。这并不是一个普通的服从均匀分布的随机数,它的计算过程如下:
+
+* 首先,每个节点肯定都有第1层指针(每个节点都在第1层链表里)。
+* 如果一个节点有第i层(i>=1)指针(即节点已经在第1层到第i层链表中),那么它有第(i+1)层指针的概率为p。
+* 节点最大的层数不允许超过一个最大值,记为MaxLevel。
+
+这个计算随机层数的伪码如下所示:
+
+
+
+
+
+```
+randomLevel()
+ level := 1
+ // random()返回一个[0...1)的随机数
+ while random() < p and level < MaxLevel do
+ level := level + 1
+ return level
+
+```
+
+
+
+
+
+randomLevel()的伪码中包含两个参数,一个是p,一个是MaxLevel。在Redis的skiplist实现中,这两个参数的取值为:
+
+
+
+
+
+```
+p = 1/4
+MaxLevel = 32
+
+```
+
+
+
+
+
+### skiplist的算法性能分析
+
+在这一部分,我们来简单分析一下skiplist的时间复杂度和空间复杂度,以便对于skiplist的性能有一个直观的了解。如果你不是特别偏执于算法的性能分析,那么可以暂时跳过这一小节的内容。
+
+我们先来计算一下每个节点所包含的平均指针数目(概率期望)。节点包含的指针数目,相当于这个算法在空间上的额外开销(overhead),可以用来度量空间复杂度。
+
+根据前面randomLevel()的伪码,我们很容易看出,产生越高的节点层数,概率越低。定量的分析如下:
+
+* 节点层数至少为1。而大于1的节点层数,满足一个概率分布。
+* 节点层数恰好等于1的概率为1-p。
+* 节点层数大于等于2的概率为p,而节点层数恰好等于2的概率为p(1-p)。
+* 节点层数大于等于3的概率为p2,而节点层数恰好等于3的概率为p2(1-p)。
+* 节点层数大于等于4的概率为p3,而节点层数恰好等于4的概率为p3(1-p)。
+* ……
+
+因此,一个节点的平均层数(也即包含的平均指针数目),计算如下:
+
+[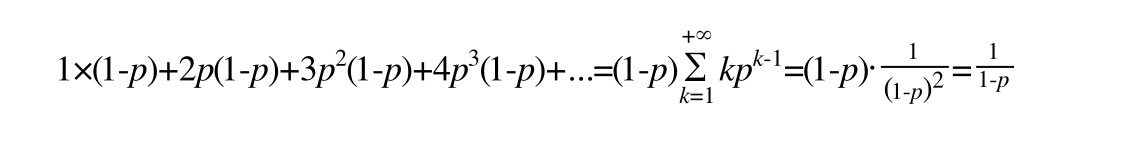](http://zhangtielei.com/assets/photos_redis/skiplist/skiplist_avg_level.png)
+
+现在很容易计算出:
+
+* 当p=1/2时,每个节点所包含的平均指针数目为2;
+* 当p=1/4时,每个节点所包含的平均指针数目为1.33。这也是Redis里的skiplist实现在空间上的开销。
+
+接下来,为了分析时间复杂度,我们计算一下skiplist的平均查找长度。查找长度指的是查找路径上跨越的跳数,而查找过程中的比较次数就等于查找长度加1。以前面图中标出的查找23的查找路径为例,从左上角的头结点开始,一直到结点22,查找长度为6。
+
+为了计算查找长度,这里我们需要利用一点小技巧。我们注意到,每个节点插入的时候,它的层数是由随机函数randomLevel()计算出来的,而且随机的计算不依赖于其它节点,每次插入过程都是完全独立的。所以,从统计上来说,一个skiplist结构的形成与节点的插入顺序无关。
+
+这样的话,为了计算查找长度,我们可以将查找过程倒过来看,从右下方第1层上最后到达的那个节点开始,沿着查找路径向左向上回溯,类似于爬楼梯的过程。我们假设当回溯到某个节点的时候,它才被插入,这虽然相当于改变了节点的插入顺序,但从统计上不影响整个skiplist的形成结构。
+
+现在假设我们从一个层数为i的节点x出发,需要向左向上攀爬k层。这时我们有两种可能:
+
+* 如果节点x有第(i+1)层指针,那么我们需要向上走。这种情况概率为p。
+* 如果节点x没有第(i+1)层指针,那么我们需要向左走。这种情况概率为(1-p)。
+
+这两种情形如下图所示:
+
+[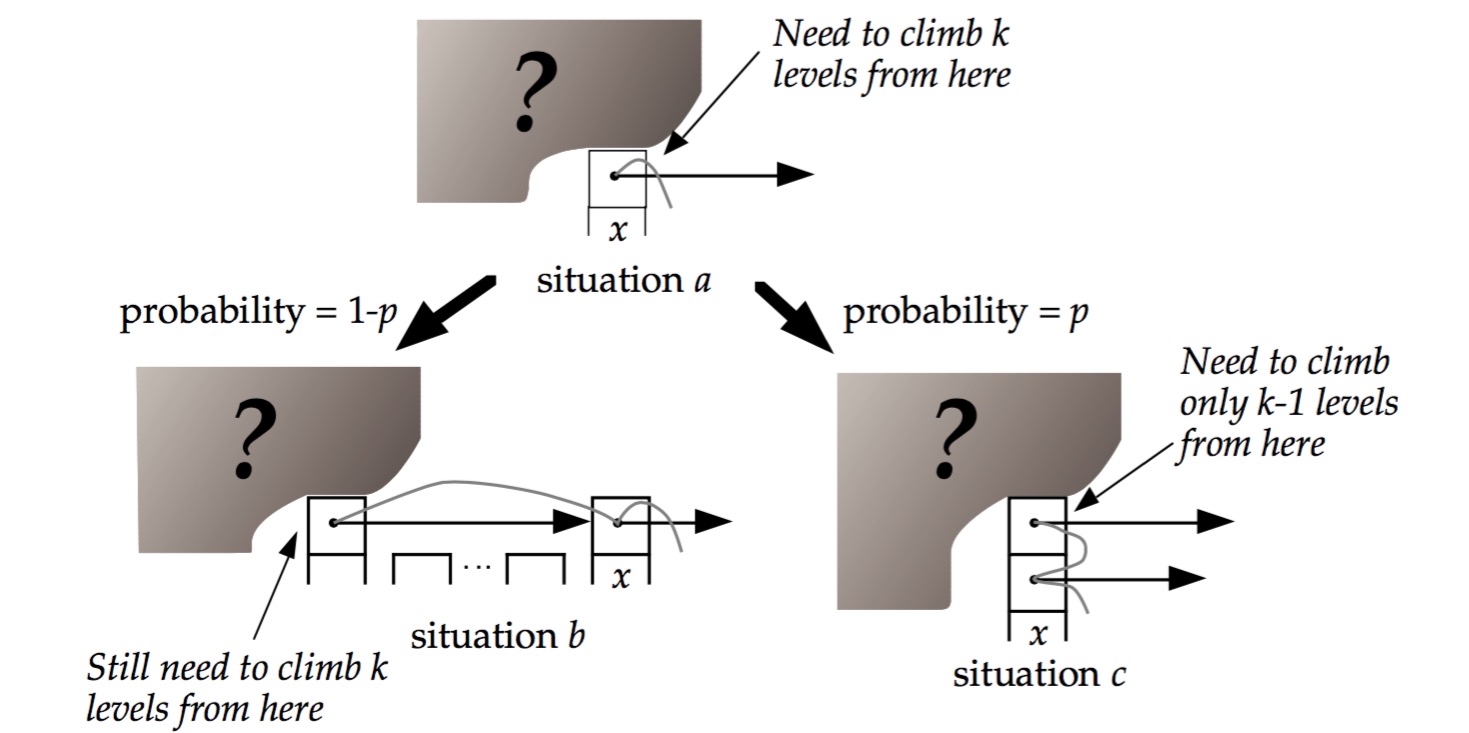](http://zhangtielei.com/assets/photos_redis/skiplist/skiplist_backwards.png)
+
+用C(k)表示向上攀爬k个层级所需要走过的平均查找路径长度(概率期望),那么:
+
+
+
+
+
+```
+C(0)=0
+C(k)=(1-p)×(上图中情况b的查找长度) + p×(上图中情况c的查找长度)
+
+```
+
+
+
+
+
+代入,得到一个差分方程并化简:
+
+
+
+
+
+```
+C(k)=(1-p)(C(k)+1) + p(C(k-1)+1)
+C(k)=1/p+C(k-1)
+C(k)=k/p
+
+```
+
+
+
+
+
+这个结果的意思是,我们每爬升1个层级,需要在查找路径上走1/p步。而我们总共需要攀爬的层级数等于整个skiplist的总层数-1。
+
+那么接下来我们需要分析一下当skiplist中有n个节点的时候,它的总层数的概率均值是多少。这个问题直观上比较好理解。根据节点的层数随机算法,容易得出:
+
+* 第1层链表固定有n个节点;
+* 第2层链表平均有n*p个节点;
+* 第3层链表平均有n*p2个节点;
+* …
+
+所以,从第1层到最高层,各层链表的平均节点数是一个指数递减的等比数列。容易推算出,总层数的均值为log1/pn,而最高层的平均节点数为1/p。
+
+综上,粗略来计算的话,平均查找长度约等于:
+
+* C(log1/pn-1)=(log1/pn-1)/p
+
+即,平均时间复杂度为O(log n)。
+
+当然,这里的时间复杂度分析还是比较粗略的。比如,沿着查找路径向左向上回溯的时候,可能先到达左侧头结点,然后沿头结点一路向上;还可能先到达最高层的节点,然后沿着最高层链表一路向左。但这些细节不影响平均时间复杂度的最后结果。另外,这里给出的时间复杂度只是一个概率平均值,但实际上计算一个精细的概率分布也是有可能的。详情还请参见[William Pugh](https://en.wikipedia.org/wiki/William_Pugh)的论文《[Skip Lists: A Probabilistic Alternative to Balanced Trees](ftp://ftp.cs.umd.edu/pub/skipLists/skiplists.pdf)》。
+
+### skiplist与平衡树、哈希表的比较
+
+* skiplist和各种平衡树(如AVL、红黑树等)的元素是有序排列的,而哈希表不是有序的。因此,在哈希表上只能做单个key的查找,不适宜做范围查找。所谓范围查找,指的是查找那些大小在指定的两个值之间的所有节点。
+* 在做范围查找的时候,平衡树比skiplist操作要复杂。在平衡树上,我们找到指定范围的小值之后,还需要以中序遍历的顺序继续寻找其它不超过大值的节点。如果不对平衡树进行一定的改造,这里的中序遍历并不容易实现。而在skiplist上进行范围查找就非常简单,只需要在找到小值之后,对第1层链表进行若干步的遍历就可以实现。
+* 平衡树的插入和删除操作可能引发子树的调整,逻辑复杂,而skiplist的插入和删除只需要修改相邻节点的指针,操作简单又快速。
+* 从内存占用上来说,skiplist比平衡树更灵活一些。一般来说,平衡树每个节点包含2个指针(分别指向左右子树),而skiplist每个节点包含的指针数目平均为1/(1-p),具体取决于参数p的大小。如果像Redis里的实现一样,取p=1/4,那么平均每个节点包含1.33个指针,比平衡树更有优势。
+* 查找单个key,skiplist和平衡树的时间复杂度都为O(log n),大体相当;而哈希表在保持较低的哈希值冲突概率的前提下,查找时间复杂度接近O(1),性能更高一些。所以我们平常使用的各种Map或dictionary结构,大都是基于哈希表实现的。
+* 从算法实现难度上来比较,skiplist比平衡树要简单得多。
+
+### Redis中的skiplist实现
+
+在这一部分,我们讨论Redis中的skiplist实现。
+
+在Redis中,skiplist被用于实现暴露给外部的一个数据结构:sorted set。准确地说,sorted set底层不仅仅使用了skiplist,还使用了ziplist和dict。这几个数据结构的关系,我们下一章再讨论。现在,我们先花点时间把sorted set的关键命令看一下。这些命令对于Redis里skiplist的实现,有重要的影响。
+
+#### sorted set的命令举例
+
+sorted set是一个有序的数据集合,对于像类似排行榜这样的应用场景特别适合。
+
+现在我们来看一个例子,用sorted set来存储代数课(algebra)的成绩表。原始数据如下:
+
+* Alice 87.5
+* Bob 89.0
+* Charles 65.5
+* David 78.0
+* Emily 93.5
+* Fred 87.5
+
+这份数据给出了每位同学的名字和分数。下面我们将这份数据存储到sorted set里面去:
+
+[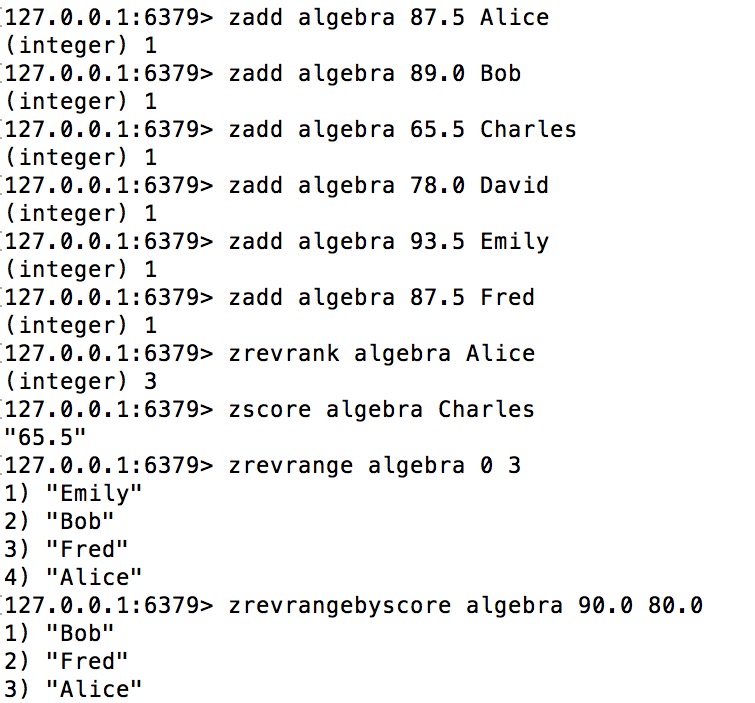](http://zhangtielei.com/assets/photos_redis/skiplist/sorted_set_cmd_examples.png)
+
+对于上面的这些命令,我们需要的注意的地方包括:
+
+* 前面的6个zadd命令,将6位同学的名字和分数(score)都输入到一个key值为algebra的sorted set里面了。注意Alice和Fred的分数相同,都是87.5分。
+* zrevrank命令查询Alice的排名(命令中的rev表示按照倒序排列,也就是从大到小),返回3。排在Alice前面的分别是Emily、Bob、Fred,而排名(rank)从0开始计数,所以Alice的排名是3。注意,其实Alice和Fred的分数相同,这种情况下sorted set会把分数相同的元素,按照字典顺序来排列。按照倒序,Fred排在了Alice的前面。
+* zscore命令查询了Charles对应的分数。
+* zrevrange命令查询了从大到小排名为0~3的4位同学。
+* zrevrangebyscore命令查询了分数在80.0和90.0之间的所有同学,并按分数从大到小排列。
+
+总结一下,sorted set中的每个元素主要表现出3个属性:
+
+* 数据本身(在前面的例子中我们把名字存成了数据)。
+* 每个数据对应一个分数(score)。
+* 根据分数大小和数据本身的字典排序,每个数据会产生一个排名(rank)。可以按正序或倒序。
+
+#### Redis中skiplist实现的特殊性
+
+我们简单分析一下前面出现的几个查询命令:
+
+* zrevrank由数据查询它对应的排名,这在前面介绍的skiplist中并不支持。
+* zscore由数据查询它对应的分数,这也不是skiplist所支持的。
+* zrevrange根据一个排名范围,查询排名在这个范围内的数据。这在前面介绍的skiplist中也不支持。
+* zrevrangebyscore根据分数区间查询数据集合,是一个skiplist所支持的典型的范围查找(score相当于key)。
+
+实际上,Redis中sorted set的实现是这样的:
+
+* 当数据较少时,sorted set是由一个ziplist来实现的。
+* 当数据多的时候,sorted set是由一个dict + 一个skiplist来实现的。简单来讲,dict用来查询数据到分数的对应关系,而skiplist用来根据分数查询数据(可能是范围查找)。
+
+这里sorted set的构成我们在下一章还会再详细地讨论。现在我们集中精力来看一下sorted set与skiplist的关系,:
+
+* zscore的查询,不是由skiplist来提供的,而是由那个dict来提供的。
+* 为了支持排名(rank),Redis里对skiplist做了扩展,使得根据排名能够快速查到数据,或者根据分数查到数据之后,也同时很容易获得排名。而且,根据排名的查找,时间复杂度也为O(log n)。
+* zrevrange的查询,是根据排名查数据,由扩展后的skiplist来提供。
+* zrevrank是先在dict中由数据查到分数,再拿分数到skiplist中去查找,查到后也同时获得了排名。
+
+前述的查询过程,也暗示了各个操作的时间复杂度:
+
+* zscore只用查询一个dict,所以时间复杂度为O(1)
+* zrevrank, zrevrange, zrevrangebyscore由于要查询skiplist,所以zrevrank的时间复杂度为O(log n),而zrevrange, zrevrangebyscore的时间复杂度为O(log(n)+M),其中M是当前查询返回的元素个数。
+
+总结起来,Redis中的skiplist跟前面介绍的经典的skiplist相比,有如下不同:
+
+* 分数(score)允许重复,即skiplist的key允许重复。这在最开始介绍的经典skiplist中是不允许的。
+* 在比较时,不仅比较分数(相当于skiplist的key),还比较数据本身。在Redis的skiplist实现中,数据本身的内容唯一标识这份数据,而不是由key来唯一标识。另外,当多个元素分数相同的时候,还需要根据数据内容来进字典排序。
+* 第1层链表不是一个单向链表,而是一个双向链表。这是为了方便以倒序方式获取一个范围内的元素。
+* 在skiplist中可以很方便地计算出每个元素的排名(rank)。
+
+#### skiplist的数据结构定义
+
+
+
+
+
+```
+#define ZSKIPLIST_MAXLEVEL 32
+#define ZSKIPLIST_P 0.25
+
+typedef struct zskiplistNode {
+ robj *obj;
+ double score;
+ struct zskiplistNode *backward;
+ struct zskiplistLevel {
+ struct zskiplistNode *forward;
+ unsigned int span;
+ } level[];
+} zskiplistNode;
+
+typedef struct zskiplist {
+ struct zskiplistNode *header, *tail;
+ unsigned long length;
+ int level;
+} zskiplist;
+
+```
+
+
+
+
+
+这段代码出自server.h,我们来简要分析一下:
+
+* 开头定义了两个常量,ZSKIPLIST_MAXLEVEL和ZSKIPLIST_P,分别对应我们前面讲到的skiplist的两个参数:一个是MaxLevel,一个是p。
+* zskiplistNode定义了skiplist的节点结构。
+ * obj字段存放的是节点数据,它的类型是一个string robj。本来一个string robj可能存放的不是sds,而是long型,但zadd命令在将数据插入到skiplist里面之前先进行了解码,所以这里的obj字段里存储的一定是一个sds。有关robj的详情可以参见系列文章的第三篇:《[Redis内部数据结构详解(3)——robj](http://zhangtielei.com/posts/blog-redis-robj.html)》。这样做的目的应该是为了方便在查找的时候对数据进行字典序的比较,而且,skiplist里的数据部分是数字的可能性也比较小。
+ * score字段是数据对应的分数。
+ * backward字段是指向链表前一个节点的指针(前向指针)。节点只有1个前向指针,所以只有第1层链表是一个双向链表。
+ * level[]存放指向各层链表后一个节点的指针(后向指针)。每层对应1个后向指针,用forward字段表示。另外,每个后向指针还对应了一个span值,它表示当前的指针跨越了多少个节点。span用于计算元素排名(rank),这正是前面我们提到的Redis对于skiplist所做的一个扩展。需要注意的是,level[]是一个柔性数组([flexible array member](https://en.wikipedia.org/wiki/Flexible_array_member)),因此它占用的内存不在zskiplistNode结构里面,而需要插入节点的时候单独为它分配。也正因为如此,skiplist的每个节点所包含的指针数目才是不固定的,我们前面分析过的结论——skiplist每个节点包含的指针数目平均为1/(1-p)——才能有意义。
+* zskiplist定义了真正的skiplist结构,它包含:
+ * 头指针header和尾指针tail。
+ * 链表长度length,即链表包含的节点总数。注意,新创建的skiplist包含一个空的头指针,这个头指针不包含在length计数中。
+ * level表示skiplist的总层数,即所有节点层数的最大值。
+
+下图以前面插入的代数课成绩表为例,展示了Redis中一个skiplist的可能结构:
+
+[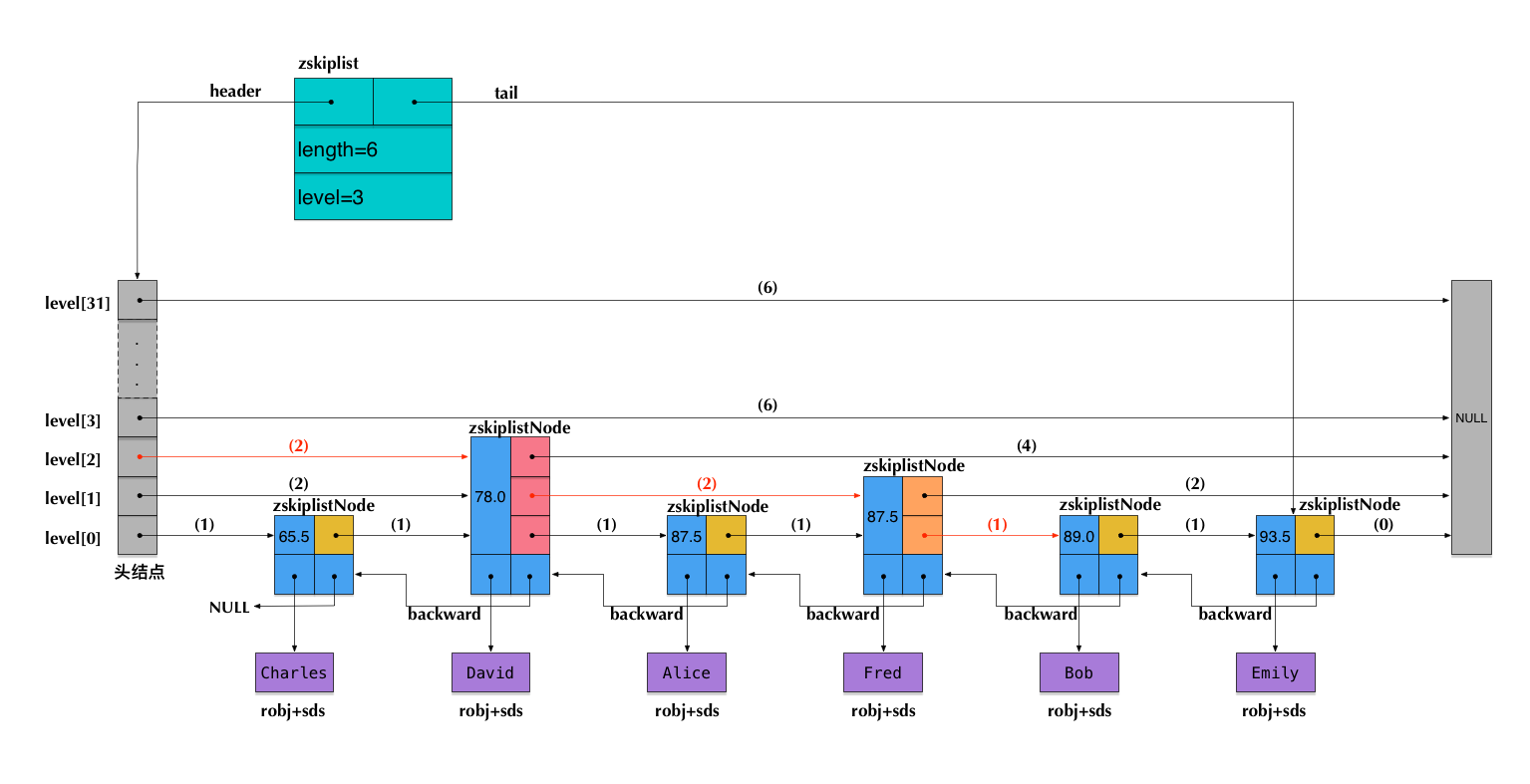](http://zhangtielei.com/assets/photos_redis/skiplist/redis_skiplist_example.png)
+
+注意:图中前向指针上面括号中的数字,表示对应的span的值。即当前指针跨越了多少个节点,这个计数不包括指针的起点节点,但包括指针的终点节点。
+
+假设我们在这个skiplist中查找score=89.0的元素(即Bob的成绩数据),在查找路径中,我们会跨域图中标红的指针,这些指针上面的span值累加起来,就得到了Bob的排名(2+2+1)-1=4(减1是因为rank值以0起始)。需要注意这里算的是从小到大的排名,而如果要算从大到小的排名,只需要用skiplist长度减去查找路径上的span累加值,即6-(2+2+1)=1。
+
+可见,在查找skiplist的过程中,通过累加span值的方式,我们就能很容易算出排名。相反,如果指定排名来查找数据(类似zrange和zrevrange那样),也可以不断累加span并时刻保持累加值不超过指定的排名,通过这种方式就能得到一条O(log n)的查找路径。
+
+### Redis中的sorted set
+
+我们前面提到过,Redis中的sorted set,是在skiplist, dict和ziplist基础上构建起来的:
+
+* 当数据较少时,sorted set是由一个ziplist来实现的。
+* 当数据多的时候,sorted set是由一个叫zset的数据结构来实现的,这个zset包含一个dict + 一个skiplist。dict用来查询数据到分数(score)的对应关系,而skiplist用来根据分数查询数据(可能是范围查找)。
+
+在这里我们先来讨论一下前一种情况——基于ziplist实现的sorted set。在本系列前面[关于ziplist的文章](http://zhangtielei.com/posts/blog-redis-ziplist.html)里,我们介绍过,ziplist就是由很多数据项组成的一大块连续内存。由于sorted set的每一项元素都由数据和score组成,因此,当使用zadd命令插入一个(数据, score)对的时候,底层在相应的ziplist上就插入两个数据项:数据在前,score在后。
+
+ziplist的主要优点是节省内存,但它上面的查找操作只能按顺序查找(可以正序也可以倒序)。因此,sorted set的各个查询操作,就是在ziplist上从前向后(或从后向前)一步步查找,每一步前进两个数据项,跨域一个(数据, score)对。
+
+随着数据的插入,sorted set底层的这个ziplist就可能会转成zset的实现(转换过程详见t_zset.c的zsetConvert)。那么到底插入多少才会转呢?
+
+还记得本文开头提到的两个Redis配置吗?
+
+
+
+
+
+```
+zset-max-ziplist-entries 128
+zset-max-ziplist-value 64
+
+```
+
+
+
+
+
+这个配置的意思是说,在如下两个条件之一满足的时候,ziplist会转成zset(具体的触发条件参见t_zset.c中的zaddGenericCommand相关代码):
+
+* 当sorted set中的元素个数,即(数据, score)对的数目超过128的时候,也就是ziplist数据项超过256的时候。
+* 当sorted set中插入的任意一个数据的长度超过了64的时候。
+
+最后,zset结构的代码定义如下:
+
+
+
+
+
+```
+typedef struct zset {
+ dict *dict;
+ zskiplist *zsl;
+} zset;
+
+```
+
+
+
+
+
+### Redis为什么用skiplist而不用平衡树?
+
+在前面我们对于skiplist和平衡树、哈希表的比较中,其实已经不难看出Redis里使用skiplist而不用平衡树的原因了。现在我们看看,对于这个问题,Redis的作者 @antirez 是怎么说的:
+
+> There are a few reasons:
+>
+> 1) They are not very memory intensive. It’s up to you basically. Changing parameters about the probability of a node to have a given number of levels will make then less memory intensive than btrees.
+>
+> 2) A sorted set is often target of many ZRANGE or ZREVRANGE operations, that is, traversing the skip list as a linked list. With this operation the cache locality of skip lists is at least as good as with other kind of balanced trees.
+>
+> 3) They are simpler to implement, debug, and so forth. For instance thanks to the skip list simplicity I received a patch (already in Redis master) with augmented skip lists implementing ZRANK in O(log(N)). It required little changes to the code.
+
+这段话原文出处:
+
+> [https://news.ycombinator.com/item?id=1171423](https://news.ycombinator.com/item?id=1171423)
+
+这里从内存占用、对范围查找的支持和实现难易程度这三方面总结的原因,我们在前面其实也都涉及到了。
+
+* * *
+
+系列下一篇我们将介绍intset,以及它与Redis对外暴露的数据类型set的关系,敬请期待。
+
+(完)
+
+**原创文章,转载请注明出处,并包含下面的二维码!否则拒绝转载!**
+**本文链接:**[http://zhangtielei.com/posts/blog-redis-skiplist.html](http://zhangtielei.com/posts/blog-redis-skiplist.html)
+
+
\ No newline at end of file
diff --git "a/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\2607\357\274\232Redis\345\206\205\351\203\250\346\225\260\346\215\256\347\273\223\346\236\204\350\257\246\350\247\243\342\200\224\342\200\224intset.md" "b/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\2607\357\274\232Redis\345\206\205\351\203\250\346\225\260\346\215\256\347\273\223\346\236\204\350\257\246\350\247\243\342\200\224\342\200\224intset.md"
new file mode 100644
index 0000000..c2ad59b
--- /dev/null
+++ "b/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\2607\357\274\232Redis\345\206\205\351\203\250\346\225\260\346\215\256\347\273\223\346\236\204\350\257\246\350\247\243\342\200\224\342\200\224intset.md"
@@ -0,0 +1,321 @@
+本文转自互联网
+
+本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
+> https://github.com/h2pl/Java-Tutorial
+
+喜欢的话麻烦点下Star哈
+
+文章首发于我的个人博客:
+> www.how2playlife.com
+
+本文是微信公众号【Java技术江湖】的《探索Redis设计与实现》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。
+
+该系列博文会告诉你如何从入门到进阶,Redis基本的使用方法,Redis的基本数据结构,以及一些进阶的使用方法,同时也需要进一步了解Redis的底层数据结构,再接着,还会带来Redis主从复制、集群、分布式锁等方面的相关内容,以及作为缓存的一些使用方法和注意事项,以便让你更完整地了解整个Redis相关的技术体系,形成自己的知识框架。
+
+如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。
+
+
+
+本文是《[Redis内部数据结构详解](http://zhangtielei.com/posts/blog-redis-dict.html)》系列的第七篇。在本文中,我们围绕一个Redis的内部数据结构——intset展开讨论。
+
+Redis里面使用intset是为了实现集合(set)这种对外的数据结构。set结构类似于数学上的集合的概念,它包含的元素无序,且不能重复。Redis里的set结构还实现了基础的集合并、交、差的操作。与Redis对外暴露的其它数据结构类似,set的底层实现,随着元素类型是否是整型以及添加的元素的数目多少,而有所变化。概括来讲,当set中添加的元素都是整型且元素数目较少时,set使用intset作为底层数据结构,否则,set使用[dict](http://zhangtielei.com/posts/blog-redis-dict.html)作为底层数据结构。
+
+在本文中我们将大体分成三个部分进行介绍:
+
+1. 集中介绍intset数据结构。
+2. 讨论set是如何在intset和[dict](http://zhangtielei.com/posts/blog-redis-dict.html)基础上构建起来的。
+3. 集中讨论set的并、交、差的算法实现以及时间复杂度。注意,其中差集的计算在Redis中实现了两种算法。
+
+我们在讨论中还会涉及到一个Redis配置(在redis.conf中的ADVANCED CONFIG部分):
+
+
+
+
+
+```
+set-max-intset-entries 512
+
+```
+
+
+
+
+
+注:本文讨论的代码实现基于Redis源码的3.2分支。
+
+### intset数据结构简介
+
+intset顾名思义,是由整数组成的集合。实际上,intset是一个由整数组成的有序集合,从而便于在上面进行二分查找,用于快速地判断一个元素是否属于这个集合。它在内存分配上与[ziplist](http://zhangtielei.com/posts/blog-redis-ziplist.html)有些类似,是连续的一整块内存空间,而且对于大整数和小整数(按绝对值)采取了不同的编码,尽量对内存的使用进行了优化。
+
+intset的数据结构定义如下(出自intset.h和intset.c):
+
+
+
+
+
+```
+typedef struct intset {
+ uint32_t encoding;
+ uint32_t length;
+ int8_t contents[];
+} intset;
+
+#define INTSET_ENC_INT16 (sizeof(int16_t))
+#define INTSET_ENC_INT32 (sizeof(int32_t))
+#define INTSET_ENC_INT64 (sizeof(int64_t))
+
+```
+
+
+
+
+
+各个字段含义如下:
+
+* `encoding`: 数据编码,表示intset中的每个数据元素用几个字节来存储。它有三种可能的取值:INTSET_ENC_INT16表示每个元素用2个字节存储,INTSET_ENC_INT32表示每个元素用4个字节存储,INTSET_ENC_INT64表示每个元素用8个字节存储。因此,intset中存储的整数最多只能占用64bit。
+* `length`: 表示intset中的元素个数。`encoding`和`length`两个字段构成了intset的头部(header)。
+* `contents`: 是一个柔性数组([flexible array member](https://en.wikipedia.org/wiki/Flexible_array_member)),表示intset的header后面紧跟着数据元素。这个数组的总长度(即总字节数)等于`encoding * length`。柔性数组在Redis的很多数据结构的定义中都出现过(例如[sds](http://zhangtielei.com/posts/blog-redis-sds.html), [quicklist](http://zhangtielei.com/posts/blog-redis-quicklist.html), [skiplist](http://zhangtielei.com/posts/blog-redis-skiplist.html)),用于表达一个偏移量。`contents`需要单独为其分配空间,这部分内存不包含在intset结构当中。
+
+其中需要注意的是,intset可能会随着数据的添加而改变它的数据编码:
+
+* 最开始,新创建的intset使用占内存最小的INTSET_ENC_INT16(值为2)作为数据编码。
+* 每添加一个新元素,则根据元素大小决定是否对数据编码进行升级。
+
+下图给出了一个添加数据的具体例子(点击看大图)。
+
+[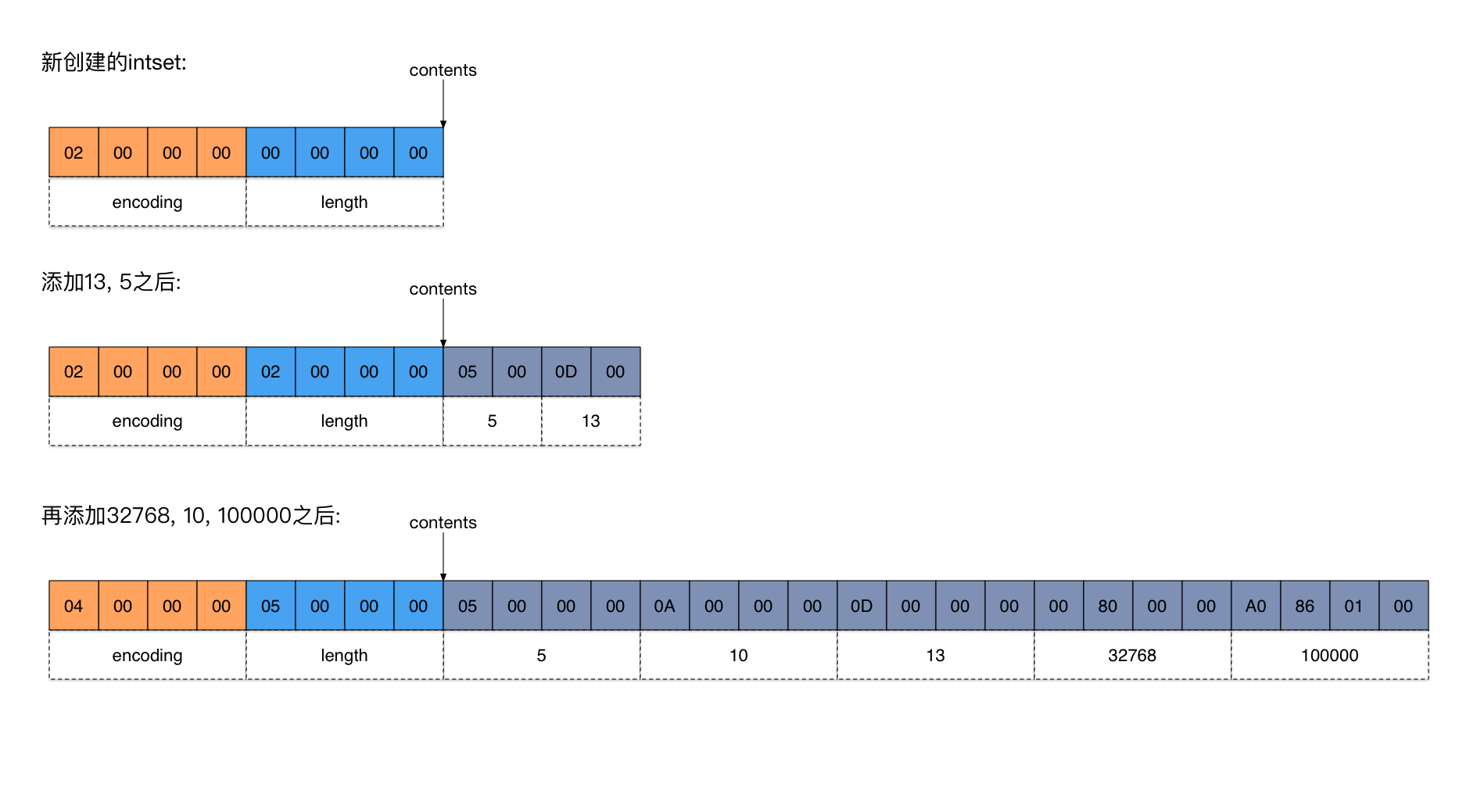](http://zhangtielei.com/assets/photos_redis/intset/redis_intset_add_example.png)
+
+在上图中:
+
+* 新创建的intset只有一个header,总共8个字节。其中`encoding` = 2, `length` = 0。
+* 添加13, 5两个元素之后,因为它们是比较小的整数,都能使用2个字节表示,所以`encoding`不变,值还是2。
+* 当添加32768的时候,它不再能用2个字节来表示了(2个字节能表达的数据范围是-215~215-1,而32768等于215,超出范围了),因此`encoding`必须升级到INTSET_ENC_INT32(值为4),即用4个字节表示一个元素。
+* 在添加每个元素的过程中,intset始终保持从小到大有序。
+* 与[ziplist](http://zhangtielei.com/posts/blog-redis-ziplist.html)类似,intset也是按小端(little endian)模式存储的(参见维基百科词条[Endianness](https://en.wikipedia.org/wiki/Endianness))。比如,在上图中intset添加完所有数据之后,表示`encoding`字段的4个字节应该解释成0x00000004,而第5个数据应该解释成0x000186A0 = 100000。
+
+intset与[ziplist](http://zhangtielei.com/posts/blog-redis-ziplist.html)相比:
+
+* ziplist可以存储任意二进制串,而intset只能存储整数。
+* ziplist是无序的,而intset是从小到大有序的。因此,在ziplist上查找只能遍历,而在intset上可以进行二分查找,性能更高。
+* ziplist可以对每个数据项进行不同的变长编码(每个数据项前面都有数据长度字段`len`),而intset只能整体使用一个统一的编码(`encoding`)。
+
+### intset的查找和添加操作
+
+要理解intset的一些实现细节,只需要关注intset的两个关键操作基本就可以了:查找(`intsetFind`)和添加(`intsetAdd`)元素。
+
+`intsetFind`的关键代码如下所示(出自intset.c):
+
+
+
+
+
+```
+uint8_t intsetFind(intset *is, int64_t value) {
+ uint8_t valenc = _intsetValueEncoding(value);
+ return valenc <= intrev32ifbe(is->encoding) && intsetSearch(is,value,NULL);
+}
+
+static uint8_t intsetSearch(intset *is, int64_t value, uint32_t *pos) {
+ int min = 0, max = intrev32ifbe(is->length)-1, mid = -1;
+ int64_t cur = -1;
+
+ /* The value can never be found when the set is empty */
+ if (intrev32ifbe(is->length) == 0) {
+ if (pos) *pos = 0;
+ return 0;
+ } else {
+ /* Check for the case where we know we cannot find the value,
+ * but do know the insert position. */
+ if (value > _intsetGet(is,intrev32ifbe(is->length)-1)) {
+ if (pos) *pos = intrev32ifbe(is->length);
+ return 0;
+ } else if (value < _intsetGet(is,0)) {
+ if (pos) *pos = 0;
+ return 0;
+ }
+ }
+
+ while(max >= min) {
+ mid = ((unsigned int)min + (unsigned int)max) >> 1;
+ cur = _intsetGet(is,mid);
+ if (value > cur) {
+ min = mid+1;
+ } else if (value < cur) {
+ max = mid-1;
+ } else {
+ break;
+ }
+ }
+
+ if (value == cur) {
+ if (pos) *pos = mid;
+ return 1;
+ } else {
+ if (pos) *pos = min;
+ return 0;
+ }
+}
+
+```
+
+
+
+
+
+关于以上代码,我们需要注意的地方包括:
+
+* `intsetFind`在指定的intset中查找指定的元素`value`,找到返回1,没找到返回0。
+* `_intsetValueEncoding`函数会根据要查找的`value`落在哪个范围而计算出相应的数据编码(即它应该用几个字节来存储)。
+* 如果`value`所需的数据编码比当前intset的编码要大,则它肯定在当前intset所能存储的数据范围之外(特别大或特别小),所以这时会直接返回0;否则调用`intsetSearch`执行一个二分查找算法。
+* `intsetSearch`在指定的intset中查找指定的元素`value`,如果找到,则返回1并且将参数`pos`指向找到的元素位置;如果没找到,则返回0并且将参数`pos`指向能插入该元素的位置。
+* `intsetSearch`是对于二分查找算法的一个实现,它大致分为三个部分:
+ * 特殊处理intset为空的情况。
+ * 特殊处理两个边界情况:当要查找的`value`比最后一个元素还要大或者比第一个元素还要小的时候。实际上,这两部分的特殊处理,在二分查找中并不是必须的,但它们在这里提供了特殊情况下快速失败的可能。
+ * 真正执行二分查找过程。注意:如果最后没找到,插入位置在`min`指定的位置。
+* 代码中出现的`intrev32ifbe`是为了在需要的时候做大小端转换的。前面我们提到过,intset里的数据是按小端(little endian)模式存储的,因此在大端(big endian)机器上运行时,这里的`intrev32ifbe`会做相应的转换。
+* 这个查找算法的总的时间复杂度为O(log n)。
+
+而`intsetAdd`的关键代码如下所示(出自intset.c):
+
+
+
+
+
+```
+intset *intsetAdd(intset *is, int64_t value, uint8_t *success) {
+ uint8_t valenc = _intsetValueEncoding(value);
+ uint32_t pos;
+ if (success) *success = 1;
+
+ /* Upgrade encoding if necessary. If we need to upgrade, we know that
+ * this value should be either appended (if > 0) or prepended (if < 0),
+ * because it lies outside the range of existing values. */
+ if (valenc > intrev32ifbe(is->encoding)) {
+ /* This always succeeds, so we don't need to curry *success. */
+ return intsetUpgradeAndAdd(is,value);
+ } else {
+ /* Abort if the value is already present in the set.
+ * This call will populate "pos" with the right position to insert
+ * the value when it cannot be found. */
+ if (intsetSearch(is,value,&pos)) {
+ if (success) *success = 0;
+ return is;
+ }
+
+ is = intsetResize(is,intrev32ifbe(is->length)+1);
+ if (pos < intrev32ifbe(is->length)) intsetMoveTail(is,pos,pos+1);
+ }
+
+ _intsetSet(is,pos,value);
+ is->length = intrev32ifbe(intrev32ifbe(is->length)+1);
+ return is;
+}
+
+```
+
+
+
+
+
+关于以上代码,我们需要注意的地方包括:
+
+* `intsetAdd`在intset中添加新元素`value`。如果`value`在添加前已经存在,则不会重复添加,这时参数`success`被置为0;如果`value`在原来intset中不存在,则将`value`插入到适当位置,这时参数`success`被置为0。
+* 如果要添加的元素`value`所需的数据编码比当前intset的编码要大,那么则调用`intsetUpgradeAndAdd`将intset的编码进行升级后再插入`value`。
+* 调用`intsetSearch`,如果能查到,则不会重复添加。
+* 如果没查到,则调用`intsetResize`对intset进行内存扩充,使得它能够容纳新添加的元素。因为intset是一块连续空间,因此这个操作会引发内存的`realloc`(参见[http://man.cx/realloc](http://man.cx/realloc))。这有可能带来一次数据拷贝。同时调用`intsetMoveTail`将待插入位置后面的元素统一向后移动1个位置,这也涉及到一次数据拷贝。值得注意的是,在`intsetMoveTail`中是调用`memmove`完成这次数据拷贝的。`memmove`保证了在拷贝过程中不会造成数据重叠或覆盖,具体参见[http://man.cx/memmove](http://man.cx/memmove)。
+* `intsetUpgradeAndAdd`的实现中也会调用`intsetResize`来完成内存扩充。在进行编码升级时,`intsetUpgradeAndAdd`的实现会把原来intset中的每个元素取出来,再用新的编码重新写入新的位置。
+* 注意一下`intsetAdd`的返回值,它返回一个新的intset指针。它可能与传入的intset指针`is`相同,也可能不同。调用方必须用这里返回的新的intset,替换之前传进来的旧的intset变量。类似这种接口使用模式,在Redis的实现代码中是很常见的,比如我们之前在介绍[sds](http://zhangtielei.com/posts/blog-redis-sds.html)和[ziplist](http://zhangtielei.com/posts/blog-redis-ziplist.html)的时候都碰到过类似的情况。
+* 显然,这个`intsetAdd`算法总的时间复杂度为O(n)。
+
+### Redis的set
+
+为了更好地理解Redis对外暴露的set数据结构,我们先看一下set的一些关键的命令。下面是一些命令举例:
+
+[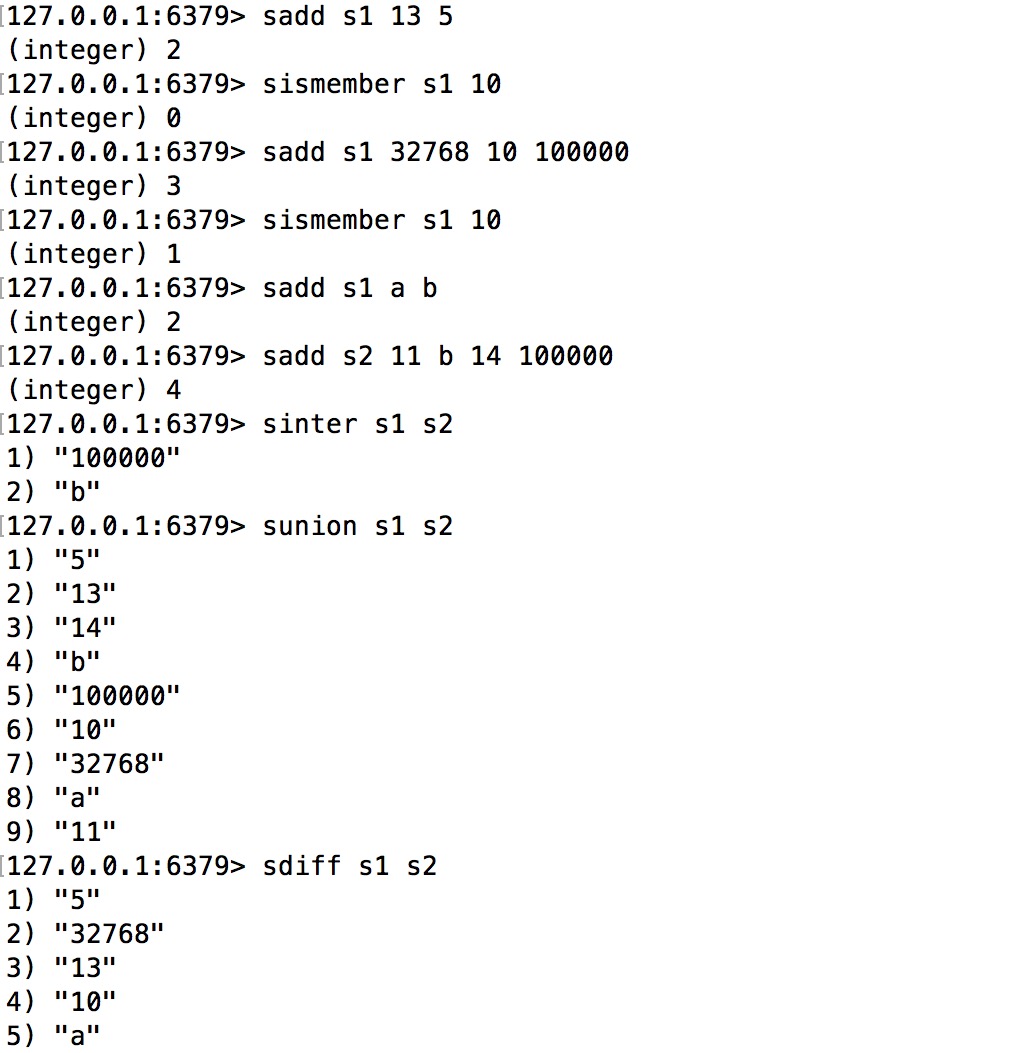](http://zhangtielei.com/assets/photos_redis/intset/redis_set_cmd_example.png)
+
+上面这些命令的含义:
+
+* `sadd`用于分别向集合`s1`和`s2`中添加元素。添加的元素既有数字,也有非数字(”a”和”b”)。
+* `sismember`用于判断指定的元素是否在集合内存在。
+* `sinter`, `sunion`和`sdiff`分别用于计算集合的交集、并集和差集。
+
+我们前面提到过,set的底层实现,随着元素类型是否是整型以及添加的元素的数目多少,而有所变化。例如,具体到上述命令的执行过程中,集合`s1`的底层数据结构会发生如下变化:
+
+* 在开始执行完`sadd s1 13 5`之后,由于添加的都是比较小的整数,所以`s1`底层是一个intset,其数据编码`encoding` = 2。
+* 在执行完`sadd s1 32768 10 100000`之后,`s1`底层仍然是一个intset,但其数据编码`encoding`从2升级到了4。
+* 在执行完`sadd s1 a b`之后,由于添加的元素不再是数字,`s1`底层的实现会转成一个dict。
+
+我们知道,dict是一个用于维护key和value映射关系的数据结构,那么当set底层用dict表示的时候,它的key和value分别是什么呢?实际上,key就是要添加的集合元素,而value是NULL。
+
+除了前面提到的由于添加非数字元素造成集合底层由intset转成dict之外,还有两种情况可能造成这种转换:
+
+* 添加了一个数字,但它无法用64bit的有符号数来表达。intset能够表达的最大的整数范围为-264~264-1,因此,如果添加的数字超出了这个范围,这也会导致intset转成dict。
+* 添加的集合元素个数超过了`set-max-intset-entries`配置的值的时候,也会导致intset转成dict(具体的触发条件参见t_set.c中的`setTypeAdd`相关代码)。
+
+对于小集合使用intset来存储,主要的原因是节省内存。特别是当存储的元素个数较少的时候,dict所带来的内存开销要大得多(包含两个哈希表、链表指针以及大量的其它元数据)。所以,当存储大量的小集合而且集合元素都是数字的时候,用intset能节省下一笔可观的内存空间。
+
+实际上,从时间复杂度上比较,intset的平均情况是没有dict性能高的。以查找为例,intset是O(log n)的,而dict可以认为是O(1)的。但是,由于使用intset的时候集合元素个数比较少,所以这个影响不大。
+
+### Redis set的并、交、差算法
+
+Redis set的并、交、差算法的实现代码,在t_set.c中。其中计算交集调用的是`sinterGenericCommand`,计算并集和差集调用的是`sunionDiffGenericCommand`。它们都能同时对多个(可以多于2个)集合进行运算。当对多个集合进行差集运算时,它表达的含义是:用第一个集合与第二个集合做差集,所得结果再与第三个集合做差集,依次向后类推。
+
+我们在这里简要介绍一下三个算法的实现思路。
+
+#### 交集
+
+计算交集的过程大概可以分为三部分:
+
+1. 检查各个集合,对于不存在的集合当做空集来处理。一旦出现空集,则不用继续计算了,最终的交集就是空集。
+2. 对各个集合按照元素个数由少到多进行排序。这个排序有利于后面计算的时候从最小的集合开始,需要处理的元素个数较少。
+3. 对排序后第一个集合(也就是最小集合)进行遍历,对于它的每一个元素,依次在后面的所有集合中进行查找。只有在所有集合中都能找到的元素,才加入到最后的结果集合中。
+
+需要注意的是,上述第3步在集合中进行查找,对于intset和dict的存储来说时间复杂度分别是O(log n)和O(1)。但由于只有小集合才使用intset,所以可以粗略地认为intset的查找也是常数时间复杂度的。因此,如Redis官方文档上所说([http://redis.io/commands/sinter](http://redis.io/commands/sinter)),`sinter`命令的时间复杂度为:
+
+> O(N*M) worst case where N is the cardinality of the smallest set and M is the number of sets.
+
+#### 并集
+
+计算并集最简单,只需要遍历所有集合,将每一个元素都添加到最后的结果集合中。向集合中添加元素会自动去重。
+
+由于要遍历所有集合的每个元素,所以Redis官方文档给出的`sunion`命令的时间复杂度为([http://redis.io/commands/sunion](http://redis.io/commands/sunion)):
+
+> O(N) where N is the total number of elements in all given sets.
+
+注意,这里同前面讨论交集计算一样,将元素插入到结果集合的过程,忽略intset的情况,认为时间复杂度为O(1)。
+
+#### 差集
+
+计算差集有两种可能的算法,它们的时间复杂度有所区别。
+
+第一种算法:
+
+* 对第一个集合进行遍历,对于它的每一个元素,依次在后面的所有集合中进行查找。只有在所有集合中都找不到的元素,才加入到最后的结果集合中。
+
+这种算法的时间复杂度为O(N*M),其中N是第一个集合的元素个数,M是集合数目。
+
+第二种算法:
+
+* 将第一个集合的所有元素都加入到一个中间集合中。
+* 遍历后面所有的集合,对于碰到的每一个元素,从中间集合中删掉它。
+* 最后中间集合剩下的元素就构成了差集。
+
+这种算法的时间复杂度为O(N),其中N是所有集合的元素个数总和。
+
+在计算差集的开始部分,会先分别估算一下两种算法预期的时间复杂度,然后选择复杂度低的算法来进行运算。还有两点需要注意:
+
+* 在一定程度上优先选择第一种算法,因为它涉及到的操作比较少,只用添加,而第二种算法要先添加再删除。
+* 如果选择了第一种算法,那么在执行该算法之前,Redis的实现中对于第二个集合之后的所有集合,按照元素个数由多到少进行了排序。这个排序有利于以更大的概率查找到元素,从而更快地结束查找。
+
+对于`sdiff`的时间复杂度,Redis官方文档([http://redis.io/commands/sdiff](http://redis.io/commands/sdiff))只给出了第二种算法的结果,是不准确的。
+
+* * *
+
+系列下一篇待续,敬请期待。
+
+
+
+**原创文章,转载请注明出处,并包含下面的二维码!否则拒绝转载!**
+**本文链接:**[http://zhangtielei.com/posts/blog-redis-intset.html](http://zhangtielei.com/posts/blog-redis-intset.html)
+
+
\ No newline at end of file
diff --git "a/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\2608\357\274\232\350\277\236\346\216\245\345\272\225\345\261\202\344\270\216\350\241\250\351\235\242\347\232\204\346\225\260\346\215\256\347\273\223\346\236\204robj.md" "b/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\2608\357\274\232\350\277\236\346\216\245\345\272\225\345\261\202\344\270\216\350\241\250\351\235\242\347\232\204\346\225\260\346\215\256\347\273\223\346\236\204robj.md"
new file mode 100644
index 0000000..2692351
--- /dev/null
+++ "b/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\2608\357\274\232\350\277\236\346\216\245\345\272\225\345\261\202\344\270\216\350\241\250\351\235\242\347\232\204\346\225\260\346\215\256\347\273\223\346\236\204robj.md"
@@ -0,0 +1,338 @@
+本文转自互联网
+
+本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
+> https://github.com/h2pl/Java-Tutorial
+
+喜欢的话麻烦点下Star哈
+
+文章首发于我的个人博客:
+> www.how2playlife.com
+
+本文是微信公众号【Java技术江湖】的《探索Redis设计与实现》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。
+
+该系列博文会告诉你如何从入门到进阶,Redis基本的使用方法,Redis的基本数据结构,以及一些进阶的使用方法,同时也需要进一步了解Redis的底层数据结构,再接着,还会带来Redis主从复制、集群、分布式锁等方面的相关内容,以及作为缓存的一些使用方法和注意事项,以便让你更完整地了解整个Redis相关的技术体系,形成自己的知识框架。
+
+如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。
+
+
+
+本文是《[Redis内部数据结构详解](http://zhangtielei.com/posts/blog-redis-dict.html)》系列的第三篇,讲述在Redis实现中的一个基础数据结构:robj。
+
+那到底什么是robj呢?它有什么用呢?
+
+从Redis的使用者的角度来看,一个Redis节点包含多个database(非cluster模式下默认是16个,cluster模式下只能是1个),而一个database维护了从key space到object space的映射关系。这个映射关系的key是string类型,而value可以是多种数据类型,比如:string, list, hash等。我们可以看到,key的类型固定是string,而value可能的类型是多个。
+
+而从Redis内部实现的角度来看,在前面第一篇文章中,我们已经提到过,一个database内的这个映射关系是用一个dict来维护的。dict的key固定用一种数据结构来表达就够了,这就是动态字符串sds。而value则比较复杂,为了在同一个dict内能够存储不同类型的value,这就需要一个通用的数据结构,这个通用的数据结构就是robj(全名是redisObject)。举个例子:如果value是一个list,那么它的内部存储结构是一个quicklist(quicklist的具体实现我们放在后面的文章讨论);如果value是一个string,那么它的内部存储结构一般情况下是一个sds。当然实际情况更复杂一点,比如一个string类型的value,如果它的值是一个数字,那么Redis内部还会把它转成long型来存储,从而减小内存使用。而一个robj既能表示一个sds,也能表示一个quicklist,甚至还能表示一个long型。
+
+#### robj的数据结构定义
+
+在server.h中我们找到跟robj定义相关的代码,如下(注意,本系列文章中的代码片段全部来源于Redis源码的3.2分支):
+
+ /* Object types */
+ #define OBJ_STRING 0
+ #define OBJ_LIST 1
+ #define OBJ_SET 2
+ #define OBJ_ZSET 3
+ #define OBJ_HASH 4
+
+ /* Objects encoding. Some kind of objects like Strings and Hashes can be
+ * internally represented in multiple ways. The 'encoding' field of the object
+ * is set to one of this fields for this object. */
+ #define OBJ_ENCODING_RAW 0 /* Raw representation */
+ #define OBJ_ENCODING_INT 1 /* Encoded as integer */
+ #define OBJ_ENCODING_HT 2 /* Encoded as hash table */
+ #define OBJ_ENCODING_ZIPMAP 3 /* Encoded as zipmap */
+ #define OBJ_ENCODING_LINKEDLIST 4 /* Encoded as regular linked list */
+ #define OBJ_ENCODING_ZIPLIST 5 /* Encoded as ziplist */
+ #define OBJ_ENCODING_INTSET 6 /* Encoded as intset */
+ #define OBJ_ENCODING_SKIPLIST 7 /* Encoded as skiplist */
+ #define OBJ_ENCODING_EMBSTR 8 /* Embedded sds string encoding */
+ #define OBJ_ENCODING_QUICKLIST 9 /* Encoded as linked list of ziplists */
+
+ #define LRU_BITS 24
+ typedef struct redisObject {
+ unsigned type:4;
+ unsigned encoding:4;
+ unsigned lru:LRU_BITS; /* lru time (relative to server.lruclock) */
+ int refcount;
+ void *ptr;
+ } robj;
+
+
+一个robj包含如下5个字段:
+
+* type: 对象的数据类型。占4个bit。可能的取值有5种:OBJ_STRING, OBJ_LIST, OBJ_SET, OBJ_ZSET, OBJ_HASH,分别对应Redis对外暴露的5种数据结构(即我们在第一篇文章中提到的第一个层面的5种数据结构)。
+* encoding: 对象的内部表示方式(也可以称为编码)。占4个bit。可能的取值有10种,即前面代码中的10个OBJ_ENCODING_XXX常量。
+* lru: 做LRU替换算法用,占24个bit。这个不是我们这里讨论的重点,暂时忽略。
+* refcount: 引用计数。它允许robj对象在某些情况下被共享。
+* ptr: 数据指针。指向真正的数据。比如,一个代表string的robj,它的ptr可能指向一个sds结构;一个代表list的robj,它的ptr可能指向一个quicklist。
+
+这里特别需要仔细察看的是encoding字段。对于同一个type,还可能对应不同的encoding,这说明同样的一个数据类型,可能存在不同的内部表示方式。而不同的内部表示,在内存占用和查找性能上会有所不同。
+
+比如,当type = OBJ_STRING的时候,表示这个robj存储的是一个string,这时encoding可以是下面3种中的一种:
+
+* OBJ_ENCODING_RAW: string采用原生的表示方式,即用sds来表示。
+* OBJ_ENCODING_INT: string采用数字的表示方式,实际上是一个long型。
+* OBJ_ENCODING_EMBSTR: string采用一种特殊的嵌入式的sds来表示。接下来我们会讨论到这个细节。
+
+再举一个例子:当type = OBJ_HASH的时候,表示这个robj存储的是一个hash,这时encoding可以是下面2种中的一种:
+
+* OBJ_ENCODING_HT: hash采用一个dict来表示。
+* OBJ_ENCODING_ZIPLIST: hash采用一个ziplist来表示(ziplist的具体实现我们放在后面的文章讨论)。
+
+本文剩余主要部分将针对表示string的robj对象,围绕它的3种不同的encoding来深入讨论。前面代码段中出现的所有10种encoding,在这里我们先简单解释一下,在这个系列后面的文章中,我们应该还有机会碰到它们。
+
+* OBJ_ENCODING_RAW: 最原生的表示方式。其实只有string类型才会用这个encoding值(表示成sds)。
+* OBJ_ENCODING_INT: 表示成数字。实际用long表示。
+* OBJ_ENCODING_HT: 表示成dict。
+* OBJ_ENCODING_ZIPMAP: 是个旧的表示方式,已不再用。在小于Redis 2.6的版本中才有。
+* OBJ_ENCODING_LINKEDLIST: 也是个旧的表示方式,已不再用。
+* OBJ_ENCODING_ZIPLIST: 表示成ziplist。
+* OBJ_ENCODING_INTSET: 表示成intset。用于set数据结构。
+* OBJ_ENCODING_SKIPLIST: 表示成skiplist。用于sorted set数据结构。
+* OBJ_ENCODING_EMBSTR: 表示成一种特殊的嵌入式的sds。
+* OBJ_ENCODING_QUICKLIST: 表示成quicklist。用于list数据结构。
+
+我们来总结一下robj的作用:
+
+* 为多种数据类型提供一种统一的表示方式。
+* 允许同一类型的数据采用不同的内部表示,从而在某些情况下尽量节省内存。
+* 支持对象共享和引用计数。当对象被共享的时候,只占用一份内存拷贝,进一步节省内存。
+
+#### string robj的编码过程
+
+当我们执行Redis的set命令的时候,Redis首先将接收到的value值(string类型)表示成一个type = OBJ_STRING并且encoding = OBJ_ENCODING_RAW的robj对象,然后在存入内部存储之前先执行一个编码过程,试图将它表示成另一种更节省内存的encoding方式。这一过程的核心代码,是object.c中的tryObjectEncoding函数。
+
+ robj *tryObjectEncoding(robj *o) {
+ long value;
+ sds s = o->ptr;
+ size_t len;
+
+ /* Make sure this is a string object, the only type we encode
+ * in this function. Other types use encoded memory efficient
+ * representations but are handled by the commands implementing
+ * the type. */
+ serverAssertWithInfo(NULL,o,o->type == OBJ_STRING);
+
+ /* We try some specialized encoding only for objects that are
+ * RAW or EMBSTR encoded, in other words objects that are still
+ * in represented by an actually array of chars. */
+ if (!sdsEncodedObject(o)) return o;
+
+ /* It's not safe to encode shared objects: shared objects can be shared
+ * everywhere in the "object space" of Redis and may end in places where
+ * they are not handled. We handle them only as values in the keyspace. */
+ if (o->refcount > 1) return o;
+
+ /* Check if we can represent this string as a long integer.
+ * Note that we are sure that a string larger than 21 chars is not
+ * representable as a 32 nor 64 bit integer. */
+ len = sdslen(s);
+ if (len <= 21 && string2l(s,len,&value)) {
+ /* This object is encodable as a long. Try to use a shared object.
+ * Note that we avoid using shared integers when maxmemory is used
+ * because every object needs to have a private LRU field for the LRU
+ * algorithm to work well. */
+ if ((server.maxmemory == 0 ||
+ (server.maxmemory_policy != MAXMEMORY_VOLATILE_LRU &&
+ server.maxmemory_policy != MAXMEMORY_ALLKEYS_LRU)) &&
+ value >= 0 &&
+ value < OBJ_SHARED_INTEGERS)
+ {
+ decrRefCount(o);
+ incrRefCount(shared.integers[value]);
+ return shared.integers[value];
+ } else {
+ if (o->encoding == OBJ_ENCODING_RAW) sdsfree(o->ptr);
+ o->encoding = OBJ_ENCODING_INT;
+ o->ptr = (void*) value;
+ return o;
+ }
+ }
+
+ /* If the string is small and is still RAW encoded,
+ * try the EMBSTR encoding which is more efficient.
+ * In this representation the object and the SDS string are allocated
+ * in the same chunk of memory to save space and cache misses. */
+ if (len <= OBJ_ENCODING_EMBSTR_SIZE_LIMIT) {
+ robj *emb;
+
+ if (o->encoding == OBJ_ENCODING_EMBSTR) return o;
+ emb = createEmbeddedStringObject(s,sdslen(s));
+ decrRefCount(o);
+ return emb;
+ }
+
+ /* We can't encode the object...
+ *
+ * Do the last try, and at least optimize the SDS string inside
+ * the string object to require little space, in case there
+ * is more than 10% of free space at the end of the SDS string.
+ *
+ * We do that only for relatively large strings as this branch
+ * is only entered if the length of the string is greater than
+ * OBJ_ENCODING_EMBSTR_SIZE_LIMIT. */
+ if (o->encoding == OBJ_ENCODING_RAW &&
+ sdsavail(s) > len/10)
+ {
+ o->ptr = sdsRemoveFreeSpace(o->ptr);
+ }
+
+ /* Return the original object. */
+ return o;
+ }
+
+
+这段代码执行的操作比较复杂,我们有必要仔细看一下每一步的操作:
+
+* 第1步检查,检查type。确保只对string类型的对象进行操作。
+* 第2步检查,检查encoding。sdsEncodedObject是定义在server.h中的一个宏,确保只对OBJ_ENCODING_RAW和OBJ_ENCODING_EMBSTR编码的string对象进行操作。这两种编码的string都采用sds来存储,可以尝试进一步编码处理。
+
+
+ #define sdsEncodedObject(objptr) (objptr->encoding == OBJ_ENCODING_RAW || objptr->encoding == OBJ_ENCODING_EMBSTR)
+
+* 第3步检查,检查refcount。引用计数大于1的共享对象,在多处被引用。由于编码过程结束后robj的对象指针可能会变化(我们在前一篇介绍sdscatlen函数的时候提到过类似这种接口使用模式),这样对于引用计数大于1的对象,就需要更新所有地方的引用,这不容易做到。因此,对于计数大于1的对象不做编码处理。
+* 试图将字符串转成64位的long。64位的long所能表达的数据范围是-2^63到2^63-1,用十进制表达出来最长是20位数(包括负号)。这里判断小于等于21,似乎是写多了,实际判断小于等于20就够了(如果我算错了请一定告诉我哦)。string2l如果将字符串转成long转成功了,那么会返回1并且将转好的long存到value变量里。
+* 在转成long成功时,又分为两种情况。
+ * 第一种情况:如果Redis的配置不要求运行LRU替换算法,且转成的long型数字的值又比较小(小于OBJ_SHARED_INTEGERS,在目前的实现中这个值是10000),那么会使用共享数字对象来表示。之所以这里的判断跟LRU有关,是因为LRU算法要求每个robj有不同的lru字段值,所以用了LRU就不能共享robj。shared.integers是一个长度为10000的数组,里面预存了10000个小的数字对象。这些小数字对象都是encoding = OBJ_ENCODING_INT的string robj对象。
+ * 第二种情况:如果前一步不能使用共享小对象来表示,那么将原来的robj编码成encoding = OBJ_ENCODING_INT,这时ptr字段直接存成这个long型的值。注意ptr字段本来是一个void *指针(即存储的是内存地址),因此在64位机器上有64位宽度,正好能存储一个64位的long型值。这样,除了robj本身之外,它就不再需要额外的内存空间来存储字符串值。
+* 接下来是对于那些不能转成64位long的字符串进行处理。最后再做两步处理:
+ * 如果字符串长度足够小(小于等于OBJ_ENCODING_EMBSTR_SIZE_LIMIT,定义为44),那么调用createEmbeddedStringObject编码成encoding = OBJ_ENCODING_EMBSTR;
+ * 如果前面所有的编码尝试都没有成功(仍然是OBJ_ENCODING_RAW),且sds里空余字节过多,那么做最后一次努力,调用sds的sdsRemoveFreeSpace接口来释放空余字节。
+
+其中调用的createEmbeddedStringObject,我们有必要看一下它的代码:
+
+ robj *createEmbeddedStringObject(const char *ptr, size_t len) {
+ robj *o = zmalloc(sizeof(robj)+sizeof(struct sdshdr8)+len+1);
+ struct sdshdr8 *sh = (void*)(o+1);
+
+ o->type = OBJ_STRING;
+ o->encoding = OBJ_ENCODING_EMBSTR;
+ o->ptr = sh+1;
+ o->refcount = 1;
+ o->lru = LRU_CLOCK();
+
+ sh->len = len;
+ sh->alloc = len;
+ sh->flags = SDS_TYPE_8;
+ if (ptr) {
+ memcpy(sh->buf,ptr,len);
+ sh->buf[len] = '\0';
+ } else {
+ memset(sh->buf,0,len+1);
+ }
+ return o;
+ }
+
+createEmbeddedStringObject对sds重新分配内存,将robj和sds放在一个连续的内存块中分配,这样对于短字符串的存储有利于减少内存碎片。这个连续的内存块包含如下几部分:
+
+* 16个字节的robj结构。
+* 3个字节的sdshdr8头。
+* 最多44个字节的sds字符数组。
+* 1个NULL结束符。
+
+加起来一共不超过64字节(16+3+44+1),因此这样的一个短字符串可以完全分配在一个64字节长度的内存块中。
+
+#### string robj的解码过程
+
+当我们需要获取字符串的值,比如执行get命令的时候,我们需要执行与前面讲的编码过程相反的操作——解码。
+
+这一解码过程的核心代码,是object.c中的getDecodedObject函数。
+
+ robj *getDecodedObject(robj *o) {
+ robj *dec;
+
+ if (sdsEncodedObject(o)) {
+ incrRefCount(o);
+ return o;
+ }
+ if (o->type == OBJ_STRING && o->encoding == OBJ_ENCODING_INT) {
+ char buf[32];
+
+ ll2string(buf,32,(long)o->ptr);
+ dec = createStringObject(buf,strlen(buf));
+ return dec;
+ } else {
+ serverPanic("Unknown encoding type");
+ }
+ }
+
+
+这个过程比较简单,需要我们注意的点有:
+
+* 编码为OBJ_ENCODING_RAW和OBJ_ENCODING_EMBSTR的字符串robj对象,不做变化,原封不动返回。站在使用者的角度,这两种编码没有什么区别,内部都是封装的sds。
+* 编码为数字的字符串robj对象,将long重新转为十进制字符串的形式,然后调用createStringObject转为sds的表示。注意:这里由long转成的sds字符串长度肯定不超过20,而根据createStringObject的实现,它们肯定会被编码成OBJ_ENCODING_EMBSTR的对象。createStringObject的代码如下:
+
+ robj *createStringObject(const char *ptr, size_t len) {
+ if (len <= OBJ_ENCODING_EMBSTR_SIZE_LIMIT)
+ return createEmbeddedStringObject(ptr,len);
+ else
+ return createRawStringObject(ptr,len);
+ }
+
+#### 再谈sds与string的关系
+
+在上一篇文章中,我们简单地提到了sds与string的关系;在本文介绍了robj的概念之后,我们重新总结一下sds与string的关系。
+
+* 确切地说,string在Redis中是用一个robj来表示的。
+* 用来表示string的robj可能编码成3种内部表示:OBJ_ENCODING_RAW, OBJ_ENCODING_EMBSTR, OBJ_ENCODING_INT。其中前两种编码使用的是sds来存储,最后一种OBJ_ENCODING_INT编码直接把string存成了long型。
+* 在对string进行incr, decr等操作的时候,如果它内部是OBJ_ENCODING_INT编码,那么可以直接进行加减操作;如果它内部是OBJ_ENCODING_RAW或OBJ_ENCODING_EMBSTR编码,那么Redis会先试图把sds存储的字符串转成long型,如果能转成功,再进行加减操作。
+* 对一个内部表示成long型的string执行append, setbit, getrange这些命令,针对的仍然是string的值(即十进制表示的字符串),而不是针对内部表示的long型进行操作。比如字符串”32”,如果按照字符数组来解释,它包含两个字符,它们的ASCII码分别是0x33和0x32。当我们执行命令setbit key 7 0的时候,相当于把字符0x33变成了0x32,这样字符串的值就变成了”22”。而如果将字符串”32”按照内部的64位long型来解释,那么它是0x0000000000000020,在这个基础上执行setbit位操作,结果就完全不对了。因此,在这些命令的实现中,会把long型先转成字符串再进行相应的操作。由于篇幅原因,这三个命令的实现代码这里就不详细介绍了,有兴趣的读者可以参考Redis源码:
+ * t_string.c中的appendCommand函数;
+ * biops.c中的setbitCommand函数;
+ * t_string.c中的getrangeCommand函数。
+
+值得一提的是,append和setbit命令的实现中,都会最终调用到db.c中的dbUnshareStringValue函数,将string对象的内部编码转成OBJ_ENCODING_RAW的(只有这种编码的robj对象,其内部的sds 才能在后面自由追加新的内容),并解除可能存在的对象共享状态。这里面调用了前面提到的getDecodedObject。
+
+
+ robj *dbUnshareStringValue(redisDb *db, robj *key, robj *o) {
+ serverAssert(o->type == OBJ_STRING);
+ if (o->refcount != 1 || o->encoding != OBJ_ENCODING_RAW) {
+ robj *decoded = getDecodedObject(o);
+ o = createRawStringObject(decoded->ptr, sdslen(decoded->ptr));
+ decrRefCount(decoded);
+ dbOverwrite(db,key,o);
+ }
+ return o;
+ }
+
+
+#### robj的引用计数操作
+
+将robj的引用计数加1和减1的操作,定义在object.c中:
+
+
+ void incrRefCount(robj *o) {
+ o->refcount++;
+ }
+
+ void decrRefCount(robj *o) {
+ if (o->refcount <= 0) serverPanic("decrRefCount against refcount <= 0");
+ if (o->refcount == 1) {
+ switch(o->type) {
+ case OBJ_STRING: freeStringObject(o); break;
+ case OBJ_LIST: freeListObject(o); break;
+ case OBJ_SET: freeSetObject(o); break;
+ case OBJ_ZSET: freeZsetObject(o); break;
+ case OBJ_HASH: freeHashObject(o); break;
+ default: serverPanic("Unknown object type"); break;
+ }
+ zfree(o);
+ } else {
+ o->refcount--;
+ }
+ }
+
+我们特别关注一下将引用计数减1的操作decrRefCount。如果只剩下最后一个引用了(refcount已经是1了),那么在decrRefCount被调用后,整个robj将被释放。
+
+注意:Redis的del命令就依赖decrRefCount操作将value释放掉。
+
+* * *
+
+经过了本文的讨论,我们很容易看出,robj所表示的就是Redis对外暴露的第一层面的数据结构:string, list, hash, set, sorted set,而每一种数据结构的底层实现所对应的是哪个(或哪些)第二层面的数据结构(dict, sds, ziplist, quicklist, skiplist, 等),则通过不同的encoding来区分。可以说,robj是联结两个层面的数据结构的桥梁。
+
+本文详细介绍了OBJ_STRING类型的字符串对象的底层实现,其编码和解码过程在Redis里非常重要,应用广泛,我们在后面的讨论中可能还会遇到。现在有了robj的概念基础,我们下一篇会讨论ziplist,以及它与hash的关系。
+
+* * *
+
+**后记**(追加于2016-07-09): 本文在解析“将string编码成long型”的代码时提到的判断21字节的问题,后来已经提交给@antirez并合并进了unstable分支,详见[commit f648c5a](https://github.com/antirez/redis/commit/f648c5a70c802aeb60ee9773dfdcf7cf08a06357)。
\ No newline at end of file
diff --git "a/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\2609\357\274\232\346\225\260\346\215\256\345\272\223redisDb\344\270\216\351\224\256\350\277\207\346\234\237\345\210\240\351\231\244\347\255\226\347\225\245.md" "b/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\2609\357\274\232\346\225\260\346\215\256\345\272\223redisDb\344\270\216\351\224\256\350\277\207\346\234\237\345\210\240\351\231\244\347\255\226\347\225\245.md"
new file mode 100644
index 0000000..84da8c0
--- /dev/null
+++ "b/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\2609\357\274\232\346\225\260\346\215\256\345\272\223redisDb\344\270\216\351\224\256\350\277\207\346\234\237\345\210\240\351\231\244\347\255\226\347\225\245.md"
@@ -0,0 +1,323 @@
+本文转自互联网
+
+本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
+> https://github.com/h2pl/Java-Tutorial
+
+喜欢的话麻烦点下Star哈
+
+文章首发于我的个人博客:
+> www.how2playlife.com
+
+本文是微信公众号【Java技术江湖】的《探索Redis设计与实现》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。
+
+该系列博文会告诉你如何从入门到进阶,Redis基本的使用方法,Redis的基本数据结构,以及一些进阶的使用方法,同时也需要进一步了解Redis的底层数据结构,再接着,还会带来Redis主从复制、集群、分布式锁等方面的相关内容,以及作为缓存的一些使用方法和注意事项,以便让你更完整地了解整个Redis相关的技术体系,形成自己的知识框架。
+
+如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。
+
+
+
+一. 数据库
+Redis的数据库使用字典作为底层实现,数据库的增、删、查、改都是构建在字典的操作之上的。
+redis服务器将所有数据库都保存在服务器状态结构redisServer(redis.h/redisServer)的db数组(应该是一个链表)里:
+
+ struct redisServer {
+ //..
+ // 数据库数组,保存着服务器中所有的数据库
+ redisDb *db;
+ //..
+ }
+
+在初始化服务器时,程序会根据服务器状态的dbnum属性来决定应该创建多少个数据库:
+
+ struct redisServer {
+ // ..
+ //服务器中数据库的数量
+ int dbnum;
+ //..
+ }
+
+dbnum属性的值是由服务器配置的database选项决定的,默认值为16;
+
+二、切换数据库原理
+每个Redis客户端都有自己的目标数据库,每当客户端执行数据库的读写命令时,目标数据库就会成为这些命令的操作对象。
+
+ 127.0.0.1:6379> set msg 'Hello world'
+ OK
+ 127.0.0.1:6379> get msg
+ "Hello world"
+ 127.0.0.1:6379> select 2
+ OK
+ 127.0.0.1:6379[2]> get msg
+ (nil)
+ 127.0.0.1:6379[2]>
+
+在服务器内部,客户端状态redisClient结构(redis.h/redisClient)的db属性记录了客户端当前的目标数据库,这个属性是一个指向redisDb结构(redis.h/redisDb)的指针:
+
+ typedef struct redisClient {
+ //..
+ // 客户端当前正在使用的数据库
+ redisDb *db;
+ //..
+ } redisClient;
+
+redisClient.db指针指向redisServer.db数组中的一个元素,而被指向的元素就是当前客户端的目标数据库。
+我们就可以通过修改redisClient指针,让他指向服务器中的不同数据库,从而实现切换数据库的功能–这就是select命令的实现原理。
+实现代码:
+
+ int selectDb(redisClient *c, int id) {
+ // 确保 id 在正确范围内
+ if (id < 0 || id >= server.dbnum)
+ return REDIS_ERR;
+ // 切换数据库(更新指针)
+ c->db = &server.db[id];
+ return REDIS_OK;
+ }
+
+三、数据库的键空间
+1、数据库的结构(我们只分析键空间和键过期时间)
+ typedef struct redisDb {
+ // 数据库键空间,保存着数据库中的所有键值对
+ dict *dict; /* The keyspace for this DB */
+ // 键的过期时间,字典的键为键,字典的值为过期事件 UNIX 时间戳
+ dict *expires; /* Timeout of keys with a timeout set */
+ // 数据库号码
+ int id; /* Database ID */
+ // 数据库的键的平均 TTL ,统计信息
+ long long avg_ttl; /* Average TTL, just for stats */
+ //..
+ } redisDb
+
+
+上图是一个RedisDb的示例,该数据库存放有五个键值对,分别是sRedis,INums,hBooks,SortNum和sNums,它们各自都有自己的值对象,另外,其中有三个键设置了过期时间,当前数据库是服务器的第0号数据库。现在,我们就从源码角度分析这个数据库结构:
+我们知道,Redis是一个键值对数据库服务器,服务器中的每一个数据库都是一个redis.h/redisDb结构,其中,结构中的dict字典保存了数据库中所有的键值对,我们就将这个字典成为键空间。
+Redis数据库的数据都是以键值对的形式存在,其充分利用了字典高效索引的特点。
+a、键空间的键就是数据库中的键,一般都是字符串对象;
+b、键空间的值就是数据库中的值,可以是5种类型对象(字符串、列表、哈希、集合和有序集合)之一。
+数据库的键空间结构分析完了,我们先看看数据库的初始化。
+
+2、键空间的初始化
+在redis.c中,我们可以找到键空间的初始化操作:
+
+ //创建并初始化数据库结构
+ for (j = 0; j < server.dbnum; j++) {
+ // 创建每个数据库的键空间
+ server.db[j].dict = dictCreate(&dbDictType,NULL);
+ // ...
+ // 设定当前数据库的编号
+ server.db[j].id = j;
+ }
+
+初始化之后就是对键空间的操作了。
+
+3、键空间的操作
+我先把一些常见的键空间操作函数列出来:
+
+ // 从数据库中取出键key的值对象,若不存在就返回NULL
+ robj *lookupKey(redisDb *db, robj *key);
+
+ /* 先删除过期键,以读操作的方式从数据库中取出指定键对应的值对象
+ * 并根据是否成功找到值,更新服务器的命中或不命中信息,
+ * 如不存在则返回NULL,底层调用lookupKey函数 */
+ robj *lookupKeyRead(redisDb *db, robj *key);
+
+ /* 先删除过期键,以写操作的方式从数据库中取出指定键对应的值对象
+ * 如不存在则返回NULL,底层调用lookupKey函数,
+ * 不会更新服务器的命中或不命中信息
+ */
+ robj *lookupKeyWrite(redisDb *db, robj *key);
+
+ /* 先删除过期键,以读操作的方式从数据库中取出指定键对应的值对象
+ * 如不存在则返回NULL,底层调用lookupKeyRead函数
+ * 此操作需要向客户端回复
+ */
+ robj *lookupKeyReadOrReply(redisClient *c, robj *key, robj *reply);
+
+ /* 先删除过期键,以写操作的方式从数据库中取出指定键对应的值对象
+ * 如不存在则返回NULL,底层调用lookupKeyWrite函数
+ * 此操作需要向客户端回复
+ */
+ robj *lookupKeyWriteOrReply(redisClient *c, robj *key, robj *reply);
+
+ /* 添加元素到指定数据库 */
+ void dbAdd(redisDb *db, robj *key, robj *val);
+ /* 重写指定键的值 */
+ void dbOverwrite(redisDb *db, robj *key, robj *val);
+ /* 设定指定键的值 */
+ void setKey(redisDb *db, robj *key, robj *val);
+ /* 判断指定键是否存在 */
+ int dbExists(redisDb *db, robj *key);
+ /* 随机返回数据库中的键 */
+ robj *dbRandomKey(redisDb *db);
+ /* 删除指定键 */
+ int dbDelete(redisDb *db, robj *key);
+ /* 清空所有数据库,返回键值对的个数 */
+ long long emptyDb(void(callback)(void*));
+
+下面我选取几个比较典型的操作函数分析一下:
+
+查找键值对函数–lookupKey
+robj *lookupKey(redisDb *db, robj *key) {
+ // 查找键空间
+ dictEntry *de = dictFind(db->dict,key->ptr);
+ // 节点存在
+ if (de) {
+ // 取出该键对应的值
+ robj *val = dictGetVal(de);
+ // 更新时间信息
+ if (server.rdb_child_pid == -1 && server.aof_child_pid == -1)
+ val->lru = LRU_CLOCK();
+ // 返回值
+ return val;
+ } else {
+ // 节点不存在
+ return NULL;
+ }
+}
+
+添加键值对–dbAdd
+添加键值对使我们经常使用到的函数,底层由dbAdd()函数实现,传入的参数是待添加的数据库,键对象和值对象,源码如下:
+
+void dbAdd(redisDb *db, robj *key, robj *val) {
+ // 复制键名
+ sds copy = sdsdup(key->ptr);
+ // 尝试添加键值对
+ int retval = dictAdd(db->dict, copy, val);
+ // 如果键已经存在,那么停止
+ redisAssertWithInfo(NULL,key,retval == REDIS_OK);
+ // 如果开启了集群模式,那么将键保存到槽里面
+ if (server.cluster_enabled) slotToKeyAdd(key);
+ }
+
+好了,关于键空间操作函数就分析到这,其他函数(在文件db.c中)大家可以自己去分析,有问题的话可以回帖,我们可以一起讨论!
+
+四、数据库的过期键操作
+在前面我们说到,redisDb结构中有一个expires指针(概况图可以看上图),该指针指向一个字典结构,字典中保存了所有键的过期时间,该字典称为过期字典。
+过期字典的初始化:
+
+// 创建并初始化数据库结构
+ for (j = 0; j < server.dbnum; j++) {
+ // 创建每个数据库的过期时间字典
+ server.db[j].expires = dictCreate(&keyptrDictType,NULL);
+ // 设定当前数据库的编号
+ server.db[j].id = j;
+ // ..
+ }
+
+a、过期字典的键是一个指针,指向键空间中的某一个键对象(就是某一个数据库键);
+b、过期字典的值是一个long long类型的整数,这个整数保存了键所指向的数据库键的时间戳–一个毫秒精度的unix时间戳。
+下面我们就来分析过期键的处理函数:
+
+1、过期键处理函数
+设置键的过期时间–setExpire()
+/*
+ * 将键 key 的过期时间设为 when
+ */
+void setExpire(redisDb *db, robj *key, long long when) {
+ dictEntry *kde, *de;
+ // 从键空间中取出键key
+ kde = dictFind(db->dict,key->ptr);
+ // 如果键空间找不到该键,报错
+ redisAssertWithInfo(NULL,key,kde != NULL);
+ // 向过期字典中添加该键
+ de = dictReplaceRaw(db->expires,dictGetKey(kde));
+ // 设置键的过期时间
+ // 这里是直接使用整数值来保存过期时间,不是用 INT 编码的 String 对象
+ dictSetSignedIntegerVal(de,when);
+}
+
+获取键的过期时间–getExpire()
+long long getExpire(redisDb *db, robj *key) {
+ dictEntry *de;
+ // 如果过期键不存在,那么直接返回
+ if (dictSize(db->expires) == 0 ||
+ (de = dictFind(db->expires,key->ptr)) == NULL) return -1;
+ redisAssertWithInfo(NULL,key,dictFind(db->dict,key->ptr) != NULL);
+ // 返回过期时间
+ return dictGetSignedIntegerVal(de);
+}
+
+删除键的过期时间–removeExpire()
+// 移除键 key 的过期时间
+int removeExpire(redisDb *db, robj *key) {
+ // 确保键带有过期时间
+ redisAssertWithInfo(NULL,key,dictFind(db->dict,key->ptr) != NULL);
+ // 删除过期时间
+ return dictDelete(db->expires,key->ptr) == DICT_OK;
+}
+
+2、过期键删除策略
+通过前面的介绍,大家应该都知道数据库键的过期时间都保存在过期字典里,那假如一个键过期了,那么这个过期键是什么时候被删除的呢?现在来看看redis的过期键的删除策略:
+a、定时删除:在设置键的过期时间的同时,创建一个定时器,在定时结束的时候,将该键删除;
+b、惰性删除:放任键过期不管,在访问该键的时候,判断该键的过期时间是否已经到了,如果过期时间已经到了,就执行删除操作;
+c、定期删除:每隔一段时间,对数据库中的键进行一次遍历,删除过期的键。
+其中定时删除可以及时删除数据库中的过期键,并释放过期键所占用的内存,但是它为每一个设置了过期时间的键都开了一个定时器,使的cpu的负载变高,会对服务器的响应时间和吞吐量造成影响。
+惰性删除有效的克服了定时删除对CPU的影响,但是,如果一个过期键很长时间没有被访问到,且若存在大量这种过期键时,势必会占用很大的内存空间,导致内存消耗过大。
+定时删除可以算是上述两种策略的折中。设定一个定时器,每隔一段时间遍历数据库,删除其中的过期键,有效的缓解了定时删除对CPU的占用以及惰性删除对内存的占用。
+在实际应用中,Redis采用了惰性删除和定时删除两种策略来对过期键进行处理,上面提到的lookupKeyWrite等函数中就利用到了惰性删除策略,定时删除策略则是在根据服务器的例行处理程序serverCron来执行删除操作,该程序每100ms调用一次。
+
+惰性删除函数–expireIfNeeded()
+源码如下:
+
+/* 检查key是否已经过期,如果是的话,将它从数据库中删除
+ * 并将删除命令写入AOF文件以及附属节点(主从复制和AOF持久化相关)
+ * 返回0代表该键还没有过期,或者没有设置过期时间
+ * 返回1代表该键因为过期而被删除
+ */
+int expireIfNeeded(redisDb *db, robj *key) {
+ // 获取该键的过期时间
+ mstime_t when = getExpire(db,key);
+ mstime_t now;
+ // 该键没有设定过期时间
+ if (when < 0) return 0;
+ // 服务器正在加载数据的时候,不要处理
+ if (server.loading) return 0;
+ // lua脚本相关
+ now = server.lua_caller ? server.lua_time_start : mstime();
+ // 主从复制相关,附属节点不主动删除key
+ if (server.masterhost != NULL) return now > when;
+ // 该键还没有过期
+ if (now <= when) return 0;
+ // 删除过期键
+ server.stat_expiredkeys++;
+ // 将删除命令传播到AOF文件和附属节点
+ propagateExpire(db,key);
+ // 发送键空间操作时间通知
+ notifyKeyspaceEvent(NOTIFY_EXPIRED,
+ "expired",key,db->id);
+ // 将该键从数据库中删除
+ return dbDelete(db,key);
+}
+
+定期删除策略
+过期键的定期删除策略由redis.c/activeExpireCycle()函数实现,服务器周期性地操作redis.c/serverCron()(每隔100ms执行一次)时,会调用activeExpireCycle()函数,分多次遍历服务器中的各个数据库,从数据库中的expires字典中随机检查一部分键的过期时间,并删除其中的过期键。
+删除过期键的操作由activeExpireCycleTryExpire函数(activeExpireCycle()调用了该函数)执行,其源码如下:
+
+/* 检查键的过期时间,如过期直接删除*/
+int activeExpireCycleTryExpire(redisDb *db, dictEntry *de, long long now) {
+ // 获取过期时间
+ long long t = dictGetSignedIntegerVal(de);
+ if (now > t) {
+ // 执行到此说明过期
+ // 创建该键的副本
+ sds key = dictGetKey(de);
+ robj *keyobj = createStringObject(key,sdslen(key));
+ // 将删除命令传播到AOF和附属节点
+ propagateExpire(db,keyobj);
+ // 在数据库中删除该键
+ dbDelete(db,keyobj);
+ // 发送事件通知
+ notifyKeyspaceEvent(NOTIFY_EXPIRED,
+ "expired",keyobj,db->id);
+ // 临时键对象的引用计数减1
+ decrRefCount(keyobj);
+ // 服务器的过期键计数加1
+ // 该参数影响每次处理的数据库个数
+ server.stat_expiredkeys++;
+ return 1;
+ } else {
+ return 0;
+ }
+}
+
+删除过期键对AOF、RDB和主从复制都有影响,等到了介绍相关功能时再讨论。
+今天就先到这里~
diff --git "a/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\260\345\274\200\347\257\207\357\274\232\344\273\200\344\271\210\346\230\257Redis.md" "b/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\260\345\274\200\347\257\207\357\274\232\344\273\200\344\271\210\346\230\257Redis.md"
new file mode 100644
index 0000000..81269ab
--- /dev/null
+++ "b/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\260\345\274\200\347\257\207\357\274\232\344\273\200\344\271\210\346\230\257Redis.md"
@@ -0,0 +1,315 @@
+本文转自互联网
+
+本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
+> https://github.com/h2pl/Java-Tutorial
+
+喜欢的话麻烦点下Star哈
+
+文章首发于我的个人博客:
+> www.how2playlife.com
+
+本文是微信公众号【Java技术江湖】的《探索Redis设计与实现》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。
+
+该系列博文会告诉你如何从入门到进阶,Redis基本的使用方法,Redis的基本数据结构,以及一些进阶的使用方法,同时也需要进一步了解Redis的底层数据结构,再接着,还会带来Redis主从复制、集群、分布式锁等方面的相关内容,以及作为缓存的一些使用方法和注意事项,以便让你更完整地了解整个Redis相关的技术体系,形成自己的知识框架。
+
+如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。
+
+
+
+## redis 学习笔记
+
+> 这篇 redis 学习笔记主要介绍 redis 的数据结构和数据类型,并讨论数据结构的选择以及应用场景的优化。
+
+### redis 是什么?
+
+> Redis是一种面向“键/值”对类型数据的分布式NoSQL数据库系统,特点是高性能,持久存储,适应高并发的应用场景。
+
+### Redis 数据结构
+
+* 动态字符串 (Sds)
+* 双端列表 (LINKEDLIST)
+* 字典
+* 跳跃表 (SKIPLIST)
+* 整数集合 (INTSET)
+* 压缩列表 (ZIPLIST)
+
+HUGOMORE42
+
+[动态字符串](https://link.juejin.im/?target=http%3A%2F%2Forigin.redisbook.com%2Finternal-datastruct%2Fsds.html)
+
+Sds (Simple Dynamic String,简单动态字符串)是 Redis 底层所使用的字符串表示,它被用 在几乎所有的 Redis 模块中
+
+Redis 是一个键值对数据库(key-value DB),数据库的值可以是字符串、集合、列表等多种类 型的对象,而数据库的键则总是字符串对象
+
+在 Redis 中, 一个字符串对象除了可以保存字符串值之外,还可以保存 long 类型的值当字符串对象保存的是字符串时,它包含的才是 sds 值,否则的话,它就 是一个 long 类型的值
+
+动态字符串主要有两个作用:
+
+1. 实现字符串对象(StringObject)
+2. 在 Redis 程序内部用作 char * 类型的替代品
+
+[双端列表](https://link.juejin.im/?target=http%3A%2F%2Forigin.redisbook.com%2Finternal-datastruct%2Fadlist.html)
+
+双端链表还是 Redis 列表类型的底层实现之一,当对列表类型的键进行操作——比如执行 RPUSH 、LPOP 或 LLEN 等命令时,程序在底层操作的可能就是双端链表
+
+双端链表主要有两个作用:
+
+* 作为 Redis 列表类型的底层实现之一;
+* 作为通用数据结构,被其他功能模块所使用;
+
+[字典](https://link.juejin.im/?target=http%3A%2F%2Forigin.redisbook.com%2Finternal-datastruct%2Fdict.html)
+
+字典(dictionary),又名映射(map)或关联数组(associative array), 它是一种抽象数据结 构,由一集键值对(key-value pairs)组成,各个键值对的键各不相同,程序可以将新的键值对 添加到字典中,或者基于键进行查找、更新或删除等操作
+
+字典的应用
+
+1. 实现数据库键空间(key space);
+2. 用作 Hash 类型键的其中一种底层实现;
+
+> Redis 是一个键值对数据库,数据库中的键值对就由字典保存:每个数据库都有一个与之相对应的字典,这个字典被称之为键空间(key space)。
+
+Redis 的 Hash 类型键使用**字典和压缩列表**两种数据结构作为底层实现
+
+[跳跃表](https://link.juejin.im/?target=http%3A%2F%2Forigin.redisbook.com%2Finternal-datastruct%2Fskiplist.html)
+
+跳跃表(skiplist)是一种随机化的数据,由 William Pugh 在论文《Skip lists: a probabilistic alternative to balanced trees》中提出,这种数据结构以有序的方式在层次化的链表中保存元素,它的效率可以和平衡树媲美——查找、删除、添加等操作都可以在对数期望时间下完成, 并且比起平衡树来说,跳跃表的实现要简单直观得多
+
+和字典、链表或者字符串这几种在 Redis 中大量使用的数据结构不同,跳跃表在 Redis 的唯一作用,就是实现有序集数据类型
+跳跃表将指向有序集的 score 值和 member 域的指针作为元素,并以 score 值为索引,对有序集元素进行排序。
+
+[整数集合](https://link.juejin.im/?target=http%3A%2F%2Forigin.redisbook.com%2Fcompress-datastruct%2Fintset.html)
+
+整数集合(intset)用于有序、无重复地保存多个整数值,它会根据元素的值,自动选择该用什么长度的整数类型来保存元素
+
+Intset 是集合键的底层实现之一,如果一个集合:
+
+1. 只保存着整数元素;
+2. 元素的数量不多;
+ 那么 Redis 就会使用 intset 来保存集合元素。
+
+[压缩列表](https://link.juejin.im/?target=http%3A%2F%2Forigin.redisbook.com%2Fcompress-datastruct%2Fziplist.html)
+
+Ziplist 是由一系列特殊编码的内存块构成的列表,一个 ziplist 可以包含多个节点(entry),每个节点可以保存一个长度受限的字符数组(不以 \0 结尾的 char 数组)或者整数
+
+### Redis 数据类型
+
+[RedisObject](https://link.juejin.im/?target=http%3A%2F%2Forigin.redisbook.com%2Fdatatype%2Fobject.html%23redisobject-redis)
+
+redisObject 是 Redis 类型系统的核心,数据库中的每个键、值,以及 Redis 本身处理的参数,都表示为这种数据类型
+
+redisObject 的定义位于 redis.h :
+
+```
+/** Redis 对象*/typedef struct redisObject { // 类型 unsigned type:4; // 对齐位 unsigned notused:2; // 编码方式 unsigned encoding:4; // LRU 时间(相对于 server.lruclock) unsigned lru:22; // 引用计数 int refcount; // 指向对象的值 void *ptr;} robj;
+```
+
+type 、encoding 和 ptr 是最重要的三个属性。
+
+type 记录了对象所保存的值的类型,它的值可能是以下常量的其中一个
+
+```
+/** 对象类型*/#define REDIS_STRING 0 // 字符串#define REDIS_LIST 1 // 列表#define REDIS_SET 2 // 集合#define REDIS_ZSET 3 // 有序集#define REDIS_HASH 4 // 哈希表
+```
+
+encoding 记录了对象所保存的值的编码,它的值可能是以下常量的其中一个
+
+```
+/** 对象编码*/#define REDIS_ENCODING_RAW 0 // 编码为字符串#define REDIS_ENCODING_INT 1 // 编码为整数#define REDIS_ENCODING_HT 2 // 编码为哈希表#define REDIS_ENCODING_ZIPMAP 3 // 编码为 zipmap(2.6 后不再使用)#define REDIS_ENCODING_LINKEDLIST 4 // 编码为双端链表#define REDIS_ENCODING_ZIPLIST 5 // 编码为压缩列表#define REDIS_ENCODING_INTSET 6 // 编码为整数集合#define REDIS_ENCODING_SKIPLIST 7 // 编码为跳跃表
+```
+
+ptr 是一个指针,指向实际保存值的数据结构,这个数据结构由 type 属性和 encoding 属性决定。
+
+当执行一个处理数据类型的命令时,Redis 执行以下步骤:
+
+1. 根据给定key,在数据库字典中查找和它像对应的redisObject,如果没找到,就返回 NULL 。
+2. 检查redisObject的type属性和执行命令所需的类型是否相符,如果不相符,返回类 型错误。
+3. 根据redisObject的encoding属性所指定的编码,选择合适的操作函数来处理底层的 数据结构。
+4. 返回数据结构的操作结果作为命令的返回值。
+
+[字符串](https://link.juejin.im/?target=http%3A%2F%2Fredisdoc.com%2Fstring%2Findex.html)
+
+REDIS_STRING (字符串)是 Redis 使用得最为广泛的数据类型,它除了是 SET 、GET 等命令 的操作对象之外,数据库中的所有键,以及执行命令时提供给 Redis 的参数,都是用这种类型 保存的。
+
+字符串类型分别使用 REDIS_ENCODING_INT 和 REDIS_ENCODING_RAW 两种编码
+
+> 只有能表示为 long 类型的值,才会以整数的形式保存,其他类型 的整数、小数和字符串,都是用 sdshdr 结构来保存
+
+[哈希表](https://link.juejin.im/?target=http%3A%2F%2Fredisdoc.com%2Fhash%2Findex.html)
+
+REDIS_HASH (哈希表)是HSET 、HLEN 等命令的操作对象
+
+它使用 REDIS_ENCODING_ZIPLIST和REDIS_ENCODING_HT 两种编码方式
+
+Redis 中每个hash可以存储232-1键值对(40多亿)
+
+[列表](https://link.juejin.im/?target=http%3A%2F%2Fredisdoc.com%2Flist%2Findex.html)
+
+REDIS_LIST(列表)是LPUSH 、LRANGE等命令的操作对象
+
+它使用 REDIS_ENCODING_ZIPLIST和REDIS_ENCODING_LINKEDLIST 这两种方式编码
+
+一个列表最多可以包含232-1 个元素(4294967295, 每个列表超过40亿个元素)。
+
+[集合](https://link.juejin.im/?target=http%3A%2F%2Fredisdoc.com%2Fset%2Findex.html)
+
+REDIS_SET (集合) 是 SADD 、 SRANDMEMBER 等命令的操作对象
+
+它使用 REDIS_ENCODING_INTSET 和 REDIS_ENCODING_HT 两种方式编码
+
+Redis 中集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)。
+
+集合中最大的成员数为 232 - 1 (4294967295, 每个集合可存储40多亿个成员)
+
+[有序集](https://link.juejin.im/?target=http%3A%2F%2Fredisdoc.com%2Fsorted_set%2Findex.html)
+
+REDIS_ZSET (有序集)是ZADD 、ZCOUNT 等命令的操作对象
+
+它使用 REDIS_ENCODING_ZIPLIST和REDIS_ENCODING_SKIPLIST 两种方式编码
+
+不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。
+
+有序集合的成员是唯一的,但分数(score)却可以重复。
+
+集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)。 集合中最大的成员数为 232 - 1 (4294967295, 每个集合可存储40多亿个成员)
+
+Redis各种数据类型_以及它们的编码方式
+
+Redis各种数据类型_以及它们的编码方式
+
+### 过期时间
+
+在数据库中,所有键的过期时间都被保存在 redisDb 结构的 expires 字典里:
+
+```
+typedef struct redisDb { // ... dict *expires; // ...} redisDb;
+```
+
+expires 字典的键是一个指向 dict 字典(键空间)里某个键的指针,而字典的值则是键所指 向的数据库键的到期时间,这个值以 long long 类型表示
+
+过期时间设置
+
+Redis 有四个命令可以设置键的生存时间(可以存活多久)和过期时间(什么时候到期):
+
+* EXPIRE 以秒为单位设置键的生存时间;
+* PEXPIRE 以毫秒为单位设置键的生存时间;
+* EXPIREAT 以秒为单位,设置键的过期 UNIX 时间戳;
+* PEXPIREAT 以毫秒为单位,设置键的过期 UNIX 时间戳。
+
+> 虽然有那么多种不同单位和不同形式的设置方式,但是 expires 字典的值只保存“以毫秒为单位的过期 UNIX 时间戳” ,这就是说,通过进行转换,所有命令的效果最后都和 PEXPIREAT 命令的效果一样。
+
+**如果一个键是过期的,那它什么时候会被删除?**
+
+下边是参考答案
+
+1. 定时删除:在设置键的过期时间时,创建一个定时事件,当过期时间到达时,由事件处理 器自动执行键的删除操作。
+2. 惰性删除:放任键过期不管,但是在每次从 dict 字典中取出键值时,要检查键是否过 期,如果过期的话,就删除它,并返回空;如果没过期,就返回键值。
+3. 定期删除:每隔一段时间,对expires字典进行检查,删除里面的过期键
+
+Redis 使用的过期键删除策略是惰性删除加上定期删除
+
+### 应用场景
+
+* 缓存
+* 队列
+* 需要精准设定过期时间的应用
+
+> 比如你可以把上面说到的sorted set的score值设置成过期时间的时间戳,那么就可以简单地通过过期时间排序,定时清除过期数据了,不仅是清除Redis中的过期数据,你完全可以把Redis里这个过期时间当成是对数据库中数据的索引,用Redis来找出哪些数据需要过期删除,然后再精准地从数据库中删除相应的记录
+
+* 排行榜应用,取TOP N操作
+
+ > 这个需求与上面需求的不同之处在于,前面操作以时间为权重,这个是以某个条件为权重,比如按顶的次数排序,这时候就需要我们的sorted set出马了,将你要排序的值设置成sorted set的score,将具体的数据设置成相应的value,每次只需要执行一条ZADD命令即可
+
+* 统计页面访问次数
+
+> 使用 incr 命令 定时使用 getset 命令 读取数据 并设置新的值 0
+
+* 使用set 设置标签
+
+例如假设我们的话题D 1000被加了三个标签tag 1,2,5和77,就可以设置下面两个集合:
+
+```
+$ redis-cli sadd topics:1000:tags 1(integer) 1$ redis-cli sadd topics:1000:tags 2(integer) 1$ redis-cli sadd topics:1000:tags 5(integer) 1$ redis-cli sadd topics:1000:tags 77(integer) 1$ redis-cli sadd tag:1:objects 1000(integer) 1$ redis-cli sadd tag:2:objects 1000(integer) 1$ redis-cli sadd tag:5:objects 1000(integer) 1$ redis-cli sadd tag:77:objects 1000(integer) 1
+```
+
+要获取一个对象的所有标签:
+
+```
+$ redis-cli smembers topics:1000:tags1. 52. 13. 774. 2
+```
+
+获得一份同时拥有标签1, 2,10和27的对象列表。
+这可以用SINTER命令来做,他可以在不同集合之间取出交集
+
+### 内存优化
+
+`问题`: Instagram的照片数量已经达到3亿,而在Instagram里,我们需要知道每一张照片的作者是谁,下面就是Instagram团队如何使用Redis来解决这个问题并进行内存优化的。
+
+具体方法,参考下边这篇文章:[节约内存:Instagram的Redis实践](https://link.juejin.im/?target=http%3A%2F%2Fblog.nosqlfan.com%2Fhtml%2F3379.html)。
+
+## 天下无难试之Redis面试刁难大全
+
+Redis在互联网技术存储方面使用如此广泛,几乎所有的后端技术面试官都要在Redis的使用和原理方面对小伙伴们进行各种刁难。作为一名在互联网技术行业打击过成百上千名【请允许我夸张一下】的资深技术面试官,看过了无数落寞的身影失望的离开,略感愧疚,故献上此文,希望各位读者以后面试势如破竹,永无失败!
+
+Redis有哪些数据结构?
+
+字符串String、字典Hash、列表List、集合Set、有序集合SortedSet。
+
+如果你是Redis中高级用户,还需要加上下面几种数据结构HyperLogLog、Geo、Pub/Sub。
+
+如果你说还玩过Redis Module,像BloomFilter,RedisSearch,Redis-ML,面试官得眼睛就开始发亮了。
+
+使用过Redis分布式锁么,它是什么回事?
+
+先拿setnx来争抢锁,抢到之后,再用expire给锁加一个过期时间防止锁忘记了释放。
+
+这时候对方会告诉你说你回答得不错,然后接着问如果在setnx之后执行expire之前进程意外crash或者要重启维护了,那会怎么样?
+
+这时候你要给予惊讶的反馈:唉,是喔,这个锁就永远得不到释放了。紧接着你需要抓一抓自己得脑袋,故作思考片刻,好像接下来的结果是你主动思考出来的,然后回答:我记得set指令有非常复杂的参数,这个应该是可以同时把setnx和expire合成一条指令来用的!对方这时会显露笑容,心里开始默念:摁,这小子还不错。
+
+假如Redis里面有1亿个key,其中有10w个key是以某个固定的已知的前缀开头的,如果将它们全部找出来?
+
+使用keys指令可以扫出指定模式的key列表。
+
+对方接着追问:如果这个redis正在给线上的业务提供服务,那使用keys指令会有什么问题?
+
+这个时候你要回答redis关键的一个特性:redis的单线程的。keys指令会导致线程阻塞一段时间,线上服务会停顿,直到指令执行完毕,服务才能恢复。这个时候可以使用scan指令,scan指令可以无阻塞的提取出指定模式的key列表,但是会有一定的重复概率,在客户端做一次去重就可以了,但是整体所花费的时间会比直接用keys指令长。
+
+使用过Redis做异步队列么,你是怎么用的?
+
+一般使用list结构作为队列,rpush生产消息,lpop消费消息。当lpop没有消息的时候,要适当sleep一会再重试。
+
+如果对方追问可不可以不用sleep呢?list还有个指令叫blpop,在没有消息的时候,它会阻塞住直到消息到来。
+
+如果对方追问能不能生产一次消费多次呢?使用pub/sub主题订阅者模式,可以实现1:N的消息队列。
+
+如果对方追问pub/sub有什么缺点?在消费者下线的情况下,生产的消息会丢失,得使用专业的消息队列如rabbitmq等。
+
+如果对方追问redis如何实现延时队列?我估计现在你很想把面试官一棒打死如果你手上有一根棒球棍的话,怎么问的这么详细。但是你很克制,然后神态自若的回答道:使用sortedset,拿时间戳作为score,消息内容作为key调用zadd来生产消息,消费者用zrangebyscore指令获取N秒之前的数据轮询进行处理。
+
+到这里,面试官暗地里已经对你竖起了大拇指。但是他不知道的是此刻你却竖起了中指,在椅子背后。
+
+如果有大量的key需要设置同一时间过期,一般需要注意什么?
+
+如果大量的key过期时间设置的过于集中,到过期的那个时间点,redis可能会出现短暂的卡顿现象。一般需要在时间上加一个随机值,使得过期时间分散一些。
+
+Redis如何做持久化的?
+
+bgsave做镜像全量持久化,aof做增量持久化。因为bgsave会耗费较长时间,不够实时,在停机的时候会导致大量丢失数据,所以需要aof来配合使用。在redis实例重启时,会使用bgsave持久化文件重新构建内存,再使用aof重放近期的操作指令来实现完整恢复重启之前的状态。
+
+对方追问那如果突然机器掉电会怎样?取决于aof日志sync属性的配置,如果不要求性能,在每条写指令时都sync一下磁盘,就不会丢失数据。但是在高性能的要求下每次都sync是不现实的,一般都使用定时sync,比如1s1次,这个时候最多就会丢失1s的数据。
+
+对方追问bgsave的原理是什么?你给出两个词汇就可以了,fork和cow。fork是指redis通过创建子进程来进行bgsave操作,cow指的是copy on write,子进程创建后,父子进程共享数据段,父进程继续提供读写服务,写脏的页面数据会逐渐和子进程分离开来。
+
+Pipeline有什么好处,为什么要用pipeline?
+
+可以将多次IO往返的时间缩减为一次,前提是pipeline执行的指令之间没有因果相关性。使用redis-benchmark进行压测的时候可以发现影响redis的QPS峰值的一个重要因素是pipeline批次指令的数目。
+
+Redis的同步机制了解么?
+
+Redis可以使用主从同步,从从同步。第一次同步时,主节点做一次bgsave,并同时将后续修改操作记录到内存buffer,待完成后将rdb文件全量同步到复制节点,复制节点接受完成后将rdb镜像加载到内存。加载完成后,再通知主节点将期间修改的操作记录同步到复制节点进行重放就完成了同步过程。
+
+是否使用过Redis集群,集群的原理是什么?
+
+Redis Sentinal着眼于高可用,在master宕机时会自动将slave提升为master,继续提供服务。
+
+Redis Cluster着眼于扩展性,在单个redis内存不足时,使用Cluster进行分片存储。
\ No newline at end of file
diff --git "a/docs/database/\351\207\215\346\226\260\345\255\246\344\271\240MySQL\346\225\260\346\215\256\345\272\22310\357\274\232MySQL\351\207\214\347\232\204\351\202\243\344\272\233\346\227\245\345\277\227\344\273\254.md" "b/docs/database/\351\207\215\346\226\260\345\255\246\344\271\240MySQL\346\225\260\346\215\256\345\272\22310\357\274\232MySQL\351\207\214\347\232\204\351\202\243\344\272\233\346\227\245\345\277\227\344\273\254.md"
new file mode 100644
index 0000000..b071b03
--- /dev/null
+++ "b/docs/database/\351\207\215\346\226\260\345\255\246\344\271\240MySQL\346\225\260\346\215\256\345\272\22310\357\274\232MySQL\351\207\214\347\232\204\351\202\243\344\272\233\346\227\245\345\277\227\344\273\254.md"
@@ -0,0 +1,115 @@
+本文转自互联网
+
+本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
+> https://github.com/h2pl/Java-Tutorial
+
+喜欢的话麻烦点下Star哈
+
+文章首发于我的个人博客:
+> www.how2playlife.com
+
+本文是微信公众号【Java技术江湖】的《重新学习MySQL数据库》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。
+
+该系列博文会告诉你如何从入门到进阶,从sql基本的使用方法,从MySQL执行引擎再到索引、事务等知识,一步步地学习MySQL相关技术的实现原理,更好地了解如何基于这些知识来优化sql,减少SQL执行时间,通过执行计划对SQL性能进行分析,再到MySQL的主从复制、主备部署等内容,以便让你更完整地了解整个MySQL方面的技术体系,形成自己的知识框架。
+
+如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。
+
+
+
+
+## 重新学习MySQL数据库10:MySQL里的那些日志们
+
+同大多数关系型数据库一样,日志文件是MySQL数据库的重要组成部分。MySQL有几种不同的日志文件,通常包括错误日志文件,二进制日志,通用日志,慢查询日志,等等。这些日志可以帮助我们定位mysqld内部发生的事件,数据库性能故障,记录数据的变更历史,用户恢复数据库等等。本文主要描述错误日志文件。
+
+### 1.MySQL日志文件系统的组成
+
+a、错误日志:记录启动、运行或停止mysqld时出现的问题。 b、通用日志:记录建立的客户端连接和执行的语句。 c、更新日志:记录更改数据的语句。该日志在MySQL 5.1中已不再使用。 d、二进制日志:记录所有更改数据的语句。还用于复制。 e、慢查询日志:记录所有执行时间超过long_query_time秒的所有查询或不使用索引的查询。 f、Innodb日志:innodb redo log 和undo log
+
+缺省情况下,所有日志创建于mysqld数据目录中。 可以通过刷新日志,来强制mysqld来关闭和重新打开日志文件(或者在某些情况下切换到一个新的日志)。 当你执行一个FLUSH LOGS语句或执行mysqladmin flush-logs或mysqladmin refresh时,则日志被老化。 对于存在MySQL复制的情形下,从复制服务器将维护更多日志文件,被称为接替日志。
+
+### 2.错误日志
+
+错误日志是一个文本文件。 错误日志记录了MySQL Server每次启动和关闭的详细信息以及运行过程中所有较为严重的警告和错误信息。 可以用--log-error[=file_name]选项来开启mysql错误日志,该选项指定mysqld保存错误日志文件的位置。 对于指定--log-error[=file_name]选项而未给定file_name值,mysqld使用错误日志名host_name.err 并在数据目录中写入日志文件。 在mysqld正在写入错误日志到文件时,执行FLUSH LOGS 或者mysqladmin flush-logs时,服务器将关闭并重新打开日志文件。 建议在flush之前手动重命名错误日志文件,之后mysql服务将使用原始文件名打开一个新文件。 以下为错误日志备份方法: shell> mv host_name.err host_name.err-old shell> mysqladmin flush-logs shell> mv host_name.err-old backup-directory
+
+### 3.InnoDB中的日志
+
+MySQL数据库InnoDB存储引擎Log漫游
+
+1 – Undo Log
+
+**Undo Log 是为了实现事务的原子性**,在MySQL数据库InnoDB存储引擎中,还用Undo Log来实现多版本并发控制(简称:MVCC)。
+
+* 事务的原子性(Atomicity) 事务中的所有操作,要么全部完成,要么不做任何操作,不能只做部分操作。如果在执行的过程中发生 了错误,要回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过。
+
+* 原理 Undo Log的原理很简单,为了满足事务的原子性,在操作任何数据之前,首先将数据备份到一个地方 (这个存储数据备份的地方称为Undo Log)。然后进行数据的修改。如果出现了错误或者用户执行了 ROLLBACK语句,系统可以利用Undo Log中的备份将数据恢复到事务开始之前的状态。
+
+除了可以保证事务的原子性,**Undo Log也可以用来辅助完成事务的持久化**。
+
+* 事务的持久性(Durability) 事务一旦完成,该事务对数据库所做的所有修改都会持久的保存到数据库中。为了保证持久性,数据库 系统会将修改后的数据完全的记录到持久的存储上。
+
+* 用Undo Log实现原子性和持久化的事务的简化过程 假设有A、B两个数据,值分别为1,2。 A.事务开始. B.记录A=1到undo log. C.修改A=3. D.记录B=2到undo log. E.修改B=4. F.将undo log写到磁盘。 G.将数据写到磁盘。 H.事务提交 这里有一个隐含的前提条件:‘数据都是先读到内存中,然后修改内存中的数据,最后将数据写回磁盘’。
+
+ 之所以能同时保证原子性和持久化,是因为以下特点: A. 更新数据前记录Undo log。 B. 为了保证持久性,必须将数据在事务提交前写到磁盘。只要事务成功提交,数据必然已经持久化。 C. Undo log必须先于数据持久化到磁盘。如果在G,H之间系统崩溃,undo log是完整的, 可以用来回滚事务。 D. 如果在A-F之间系统崩溃,因为数据没有持久化到磁盘。所以磁盘上的数据还是保持在事务开始前的状态。
+
+缺陷:每个事务提交前将数据和Undo Log写入磁盘,这样会导致大量的磁盘IO,因此性能很低。
+
+如果能够将数据缓存一段时间,就能减少IO提高性能。但是这样就会丧失事务的持久性。因此引入了另外一 种机制来实现持久化,即Redo Log.
+
+2 – Redo Log
+
+* 原理 和Undo Log相反,**Redo Log记录的是新数据的备份**。在事务提交前,只要将Redo Log持久化即可, 不需要将数据持久化。当系统崩溃时,虽然数据没有持久化,但是Redo Log已经持久化。系统可以根据 Redo Log的内容,将所有数据恢复到最新的状态。
+
+* Undo + Redo事务的简化过程 假设有A、B两个数据,值分别为1,2. A.事务开始. B.记录A=1到undo log. C.修改A=3. D.记录A=3到redo log. E.记录B=2到undo log. F.修改B=4. G.记录B=4到redo log. H.将redo log写入磁盘。 I.事务提交
+
+ **undo log 保存的是修改前的数据,并且保存到内存中,回滚的时候在读取里面的内容(从而实现了原子性),redolog保存的是修改后的数据(对新数据的备份,同时也会将redo log备份),在事务提交写入到磁盘,从而保证了持久性**
+
+### 4- 慢查询日志
+
+概述 数据库查询快慢是影响项目性能的一大因素,对于数据库,我们除了要优化 SQL,更重要的是得先找到需要优化的 SQL。如何找到低效的 SQL 是写这篇文章的主要目的。
+
+ MySQL 数据库有一个“慢查询日志”功能,用来记录查询时间超过某个设定值的SQL,这将极大程度帮助我们快速定位到问题所在,以便对症下药。至于查询时间的多少才算慢,每个项目、业务都有不同的要求,传统企业的软件允许查询时间高于某个值,但是把这个标准放在互联网项目或者访问量大的网站上,估计就是一个bug,甚至可能升级为一个功能性缺陷。
+
+ 为避免误导读者,特申明本文的讨论限制在 Win 64位 + MySQL 5.6 范围内。其他平台或数据库种类及版本,我没有尝试过,不做赘述。
+
+设置日志功能 关于慢查询日志,主要涉及到下面几个参数:
+
+slow_query_log :是否开启慢查询日志功能(必填) long_query_time :超过设定值,将被视作慢查询,并记录至慢查询日志文件中(必填) log-slow-queries :慢查询日志文件(不可填),自动在 \data\ 创建一个 [hostname]-slow.log 文件 也就是说,只有满足以上三个条件,“慢查询功能”才可能正确开启或关闭。
+
+### 5.二进制日志
+
+* 主从复制的基础:binlog日志和relaylog日志
+
+什么是MySQL主从复制 简单来说就是保证主SQL(Master)和从SQL(Slave)的数据是一致性的,向Master插入数据后,Slave会自动从Master把修改的数据同步过来(有一定的延迟),通过这种方式来保证数据的一致性,就是主从复制
+
+复制方式 MySQL5.6开始主从复制有两种方式:基于日志(binlog)、基于GTID(全局事务标示符)。 本文只涉及基于日志binlog的主从配置
+
+复制原理 1、Master将数据改变记录到二进制日志(binary log)中,也就是配置文件log-bin指定的文件,这些记录叫做二进制日志事件(binary log events) 2、Slave通过I/O线程读取Master中的binary log events并写入到它的中继日志(relay log) 3、Slave重做中继日志中的事件,把中继日志中的事件信息一条一条的在本地执行一次,完成数据在本地的存储,从而实现将改变反映到它自己的数据(数据重放)
+
+1、什么是binlog binlog是一个二进制格式的文件,用于记录用户对数据库更新的SQL语句信息,例如更改数据库表和更改内容的SQL语句都会记录到binlog里,但是对库表等内容的查询不会记录。
+
+默认情况下,binlog日志是二进制格式的,不能使用查看文本工具的命令(比如,cat,vi等)查看,而使用mysqlbinlog解析查看。
+
+2.binlog的作用 当有数据写入到数据库时,还会同时把更新的SQL语句写入到对应的binlog文件里,这个文件就是上文说的binlog文件。使用mysqldump备份时,只是对一段时间的数据进行全备,但是如果备份后突然发现数据库服务器故障,这个时候就要用到binlog的日志了。
+
+主要作用是用于数据库的主从复制及数据的增量恢复。
+
+1.啥是binlog? 记录数据库增删改,不记录查询的二进制日志. 2.作用:用于数据同步. 3、如何开启binlog日志功能 在mysql的配置文件my.cnf中,增加log_bin参数即可开启binlog日志,也可以通过赋值来指定binlog日志的文件名,实例如下:
+
+[root@DB02 ~]# grep log_bin /etc/my.cnf log_bin = /application/mysql/logs/dadong-bin
+
+
+log_bin
+
+[root@DB02 ~]# 提示:也可以按“log_bin = /application/mysql/logs/dadong-bin”命名,目录要存在 为什么要刷新binlog?找到全备数据和binlog文件的恢复临界点.
+
+## 总结
+
+mysql数据库的binlog和relay log日志有着举足轻重的作用,并且relay log仅仅存在于mysql 的slave库,它的作用就是记录slave库中的io进程接收的从主库传过来的binlog,然后等待slave库的sql进程去读取和应用,保证主从同步,但是binlog主库和从库(slave)都可以存在,记录对数据发生或潜在发生更改的SQL语句,并以二进制的形式保存在磁盘,所以可以通过binlog来实时备份和恢复数据库。
+
+1、什么是binlog binlog是一个二进制格式的文件,用于记录用户对数据库更新的SQL语句信息,例如更改数据库表和更改内容的SQL语句都会记录到binlog里,但是对库表等内容的查询不会记录。
+
+默认情况下,binlog日志是二进制格式的,不能使用查看文本工具的命令(比如,cat,vi等)查看,而使用mysqlbinlog解析查看。
+
+2.binlog的作用 当有数据写入到数据库时,还会同时把更新的SQL语句写入到对应的binlog文件里,这个文件就是上文说的binlog文件。使用mysqldump备份时,只是对一段时间的数据进行全备,但是如果备份后突然发现数据库服务器故障,这个时候就要用到binlog的日志了。
+
+主要作用是用于数据库的主从复制及数据的增量恢复。
\ No newline at end of file
diff --git "a/docs/database/\351\207\215\346\226\260\345\255\246\344\271\240MySQL\346\225\260\346\215\256\345\272\22311\357\274\232\344\273\245Java\347\232\204\350\247\206\350\247\222\346\235\245\350\201\212\350\201\212SQL\346\263\250\345\205\245.md" "b/docs/database/\351\207\215\346\226\260\345\255\246\344\271\240MySQL\346\225\260\346\215\256\345\272\22311\357\274\232\344\273\245Java\347\232\204\350\247\206\350\247\222\346\235\245\350\201\212\350\201\212SQL\346\263\250\345\205\245.md"
new file mode 100644
index 0000000..5b9296d
--- /dev/null
+++ "b/docs/database/\351\207\215\346\226\260\345\255\246\344\271\240MySQL\346\225\260\346\215\256\345\272\22311\357\274\232\344\273\245Java\347\232\204\350\247\206\350\247\222\346\235\245\350\201\212\350\201\212SQL\346\263\250\345\205\245.md"
@@ -0,0 +1,138 @@
+本文转自互联网
+
+本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
+> https://github.com/h2pl/Java-Tutorial
+
+喜欢的话麻烦点下Star哈
+
+文章首发于我的个人博客:
+> www.how2playlife.com
+
+本文是微信公众号【Java技术江湖】的《重新学习MySQL数据库》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。
+
+该系列博文会告诉你如何从入门到进阶,从sql基本的使用方法,从MySQL执行引擎再到索引、事务等知识,一步步地学习MySQL相关技术的实现原理,更好地了解如何基于这些知识来优化sql,减少SQL执行时间,通过执行计划对SQL性能进行分析,再到MySQL的主从复制、主备部署等内容,以便让你更完整地了解整个MySQL方面的技术体系,形成自己的知识框架。
+
+如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。
+
+
+
+本文转自互联网
+
+本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
+> https://github.com/h2pl/Java-Tutorial
+
+喜欢的话麻烦点下Star哈
+
+文章首发于我的个人博客:
+> www.how2playlife.com
+
+本文是微信公众号【Java技术江湖】的《重新学习MySQL数据库》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。
+
+该系列博文会告诉你如何从入门到进阶,从sql基本的使用方法,从MySQL执行引擎再到索引、事务等知识,一步步地学习MySQL相关技术的实现原理,更好地了解如何基于这些知识来优化sql,减少SQL执行时间,通过执行计划对SQL性能进行分析,再到MySQL的主从复制、主备部署等内容,以便让你更完整地了解整个MySQL方面的技术体系,形成自己的知识框架。
+
+如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。
+
+
+
+
+## 前言
+
+
+
+
+### 靶场准备
+
+首先我们来准备一个web接口服务,该服务可以提供管理员的信息查询,这里我们采用springboot + jersey 来构建web服务框架,数据库则采用最常用的mysql。下面,我们来准备测试环境,首先建立一张用户表jwtk_admin,SQL如下:
+
+然后插入默认的管理员:
+
+这样我们就有了两位系统内置管理员了,管理员密码采用MD5进行Hash,当然这是一个很简单的为了作为研究靶场的表,所以没有很全的字段。
+
+接下来,我们创建 spring boot + jersey 构建的RESTFul web服务,这里我们提供了一个通过管理员用户名查询管理员具体信息的接口,如下:
+
+
+
+### SQL注入测试
+
+首先我们以开发者正向思维向web服务发送管理员查询请求,这里我们用PostMan工具发送一个GET请求
+
+不出我们和开发者所料,Web接口返回了我们想要的结果,用户名为admin的管理员信息。OK,现在开发任务完成,Git Push,Jira任务点为待测试,那么这样的接口就真的没有问题了吗?现在我们发送这样一条GET请求:
+
+发送该请求后,我们发现PostMan没有接收到返回结果,而Web服务后台却开始抛 MySQLSyntaxErrorException异常了,错误如下:
+
+You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near ‘‘xxxx’’’ at line 1
+
+原因是在我们查询的 xxxx’ 处sql语句语法不正确导致。这里我们先不讨论SQL语法问题,我们继续实验,再次构造一条GET查询请求:
+
+此时,我们可以惊讶的发现,查询接口非但没有报错,反而将我们数据库jwti_admin表中的所有管理员信息都查询出来了:
+
+这是什么鬼,难道管理员表中还有 name=xxxx’or’a’='a 的用户?这就是 SQL Injection。
+
+## 注入原理分析
+
+在接口中接受了一个String类型的name参数,并且通过字符串拼接的方式构建了查询语句。在正常情况下,用户会传入合法的name进行查询,但是黑客却会传入精心构造的参数,只要参数通过字符串拼接后依然是一句合法的SQL查询,此时SQL注入就发生了。正如我们上文输入的name=xxxx’or’a’='a与我们接口中的查询语句进行拼接后构成如下SQL语句:
+
+当接口执行此句SQL后,系统后台也就相当于拱手送给黑客了,黑客一看到管理员密码这个hash,都不用去cmd5查了,直接就用123456密码去登录你的后台系统了。Why?因为123456的md5哈希太常见了,别笑,这就是很多中小网站的现实,弱口令横行,不见棺材不落泪!
+
+好了,现在我们应该明白了,SQL Injection原因就是由于传入的参数与系统的SQL拼接成了合法的SQL而导致的,而其本质还是将用户输入的数据当做了代码执行。在系统中只要有一个SQL注入点被黑客发现,那么黑客基本上可以执行任意想执行的SQL语句了,例如添加一个管理员,查询所有表,甚至“脱裤” 等等,当然本文不是讲解SQL注入技巧的文章,这里我们只探讨SQL注入发生的原因与防范方法。
+
+## JDBC的预处理
+
+在上文的接口中,DAO使用了比较基础的JDBC的方式进行数据库操作,直接使JDBC构建DAO在比较老的系统中还是很常见的,但这并不意味着使用JDBC就一定不安全,如果我将传入的参数 xxxx’or’a’='a 整体作为参数进行name查询,那就不会产生SQL注入。在JDBC中,提供了 PreparedStatement (预处理执行语句)的方式,可以对SQL语句进行查询参数化,使用预处理后的代码如下:
+
+同样,我们使用上文的注入方式注入 ,此时我们发现,SQL注入没能成功。现在,我们来打印一下被被预处理后的SQL,看看有什么变化:
+
+看到了吗?所有的 ’ 都被 ’ 转义掉了,从而可以确保SQL的查询参数就是参数,不会被恶意执行,从而防止了SQL注入。
+
+## Mybatis下注入防范
+
+MyBatis 是支持定制化 SQL、存储过程以及高级映射的优秀的持久层框架, 其几乎避免了所有的 JDBC 代码和手动设置参数以及获取结果集。同时,MyBatis 可以对配置和原生Map使用简单的 XML 或注解,将接口和 Java 的 POJOs(Plain Old Java Objects,普通的 Java对象)映射成数据库中的记录,因此mybatis现在在市场中采用率也非常高。这里我们定义如下一个mapper,来实现通过用户名查询管理员的接口:
+
+同样提供Web访问接口:
+
+接下来,我们尝试SQL注入name字段,可以发现注入并没有成功,通过打印mybatis的Log可以看到mybatis框架对参数进行了预处理处理,从而防止了注入:
+
+那是否只要使用了mybatis就一定可以避免SQL注入的危险?我们把mapper做如下修改,将参数#{name}修改为${name},并使用name=‘xxxx’ or ‘a’=‘a’ 作为GET请求的参数,可以发现SQL注入还是发生了:
+
+那这是为什么,mybatis ${}与#{}的差别在哪里?
+
+原来在mybatis中如果以形式声明为SQL传递参数,mybatis将不会进行参数预处理,会直接动态拼接SQL语句,此时就会存在被注入的风险,所以在使用mybatis作为持久框架时应尽量避免采用
+
+形式声明为SQL传递参数,mybatis将不会进行参数预处理,会直接动态拼接SQL语句,此时就会存在被注入的风险,所以在使用mybatis作为持久框架时应尽量避免采用形式声明为SQL传递参数。
+
+mybatis将不会进行参数预处理,会直接动态拼接SQL语句,此时就会存在被注入的风险,所以在使用mybatis作为持久框架时应尽量避免采用{}的形式进行参数传递,如果无法避免(有些SQL如like、in、order by等,程序员可能依旧会选择${}的方式传参),那就需要对传入参数自行进行转义过滤。
+
+## JPA注入防范
+
+JPA是Sun公司用来整合ORM技术,实现天下归一的ORM标准而定义的Java Persistence API(java持久层API),JPA只是一套接口,目前引入JPA的项目都会采用Hibernate作为其具体实现,随着无配置Spring Boot框架的流行,JPA越来越具有作为持久化首选的技术,因为其能让程序员写更少的代码,就能完成现有的功能。
+
+例如强大的JpaRepository,常规的SQL查询只需按照命名规则定义接口,便可以不写SQL(JPQL/SQL)就可以实现数据的查询操作,从SQL注入防范的角度来说,这种将安全责任抛给框架远比依靠程序员自身控制来的保险。因此如果项目使用JPA作为数据访问层,基本上可以很大程度的消除SQL注入的风险。
+
+但是话不能说的太死,在我见过的一个Spring Boot项目中,虽然采用了JPA作为持久框架,但是有一位老程序员不熟悉于使用JPQL来构建查询接口,依旧使用字符串拼接的方式来实现业务,而为项目安全埋下了隐患。
+
+安全需要一丝不苟,安全是100 - 1 = 0的业务,即使你防御了99%的攻击,那还不算胜利,只要有一次被入侵了,那就有可能给公司带来很严重的后果。
+
+关于JPA的SQL注入,我们就不详细讨论了,因为框架下的注入漏洞属于框架漏洞范畴(如CVE-2016-6652),程序员只要遵循JPA的开发规范,就无需担心注入问题,框架都为你做好幕后工作了。
+
+## SQL注入的其他防范办法
+
+很多公司都会存在老系统中有大量SQL注入风险代码的问题,但是由于其已稳定支持公司业务很久,不宜采用大面积代码更新的方式来消除注入隐患,所以需要考虑其采用他方式来防范SQL注入。除了在在SQL执行方式上防范SQL注入,很多时候还可以通过架构上,或者通过其他过滤方式来达到防止SQL注入的效果。
+
+一切输入都是不安全的:对于接口的调用参数,要进行格式匹配,例如admin的通过name查询的接口,与之匹配的Path应该使用正则匹配(因为用户名中不应该存在特殊字符),从而确保传入参数是程序控制范围之内的参数,即只接受已知的良好输入值,拒绝不良输入。注意:验证参数应将它与输出编码技术结合使用。
+
+利用分层设计来避免危险:前端尽量静态化,尽量少的暴露可以访问到DAO层的接口到公网环境中,如果现有项目,很难修改存在注入的代码,可以考虑在web服务之前增加WAF进行流量过滤,当然代码上就不给hacker留有攻击的漏洞才最好的方案。也可以在拥有nginx的架构下,采用OpenRestry做流量过滤,将一些特殊字符进行转义处理。
+
+尽量使用预编译SQL语句:由于动态SQL语句是引发SQL注入的根源。应使用预编译语句来组装SQL查询。
+
+规范化:将输入安装规定编码解码后再进行输入参数过滤和输出编码处理;拒绝一切非规范格式的编码。
+
+## 小结
+
+其实随着ORM技术的发展,Java web开发在大趋势上已经越来越远离SQL注入的问题了,而有着Entity Framework框架支持的ASP.NET MVC从来都是高冷范。在现在互联网中,使用PHP和Python构建的web应用是目前SQL注入的重灾区。本文虽然是从JAVA的角度来研究SQL注入的问题,但原理上同样适用于其他开发语言,希望读者可以通过此文,触类旁通。
+
+珍爱数据,远离拼接,有输入的地方就会有江湖…
+
+
+
+
+
diff --git "a/docs/database/\351\207\215\346\226\260\345\255\246\344\271\240MySQL\346\225\260\346\215\256\345\272\22312\357\274\232\344\273\216\345\256\236\350\267\265sql\350\257\255\345\217\245\344\274\230\345\214\226\345\274\200\345\247\213.md" "b/docs/database/\351\207\215\346\226\260\345\255\246\344\271\240MySQL\346\225\260\346\215\256\345\272\22312\357\274\232\344\273\216\345\256\236\350\267\265sql\350\257\255\345\217\245\344\274\230\345\214\226\345\274\200\345\247\213.md"
new file mode 100644
index 0000000..8d97691
--- /dev/null
+++ "b/docs/database/\351\207\215\346\226\260\345\255\246\344\271\240MySQL\346\225\260\346\215\256\345\272\22312\357\274\232\344\273\216\345\256\236\350\267\265sql\350\257\255\345\217\245\344\274\230\345\214\226\345\274\200\345\247\213.md"
@@ -0,0 +1,673 @@
+本文转自互联网
+
+本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
+> https://github.com/h2pl/Java-Tutorial
+
+喜欢的话麻烦点下Star哈
+
+文章首发于我的个人博客:
+> www.how2playlife.com
+
+本文是微信公众号【Java技术江湖】的《重新学习MySQL数据库》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。
+
+该系列博文会告诉你如何从入门到进阶,从sql基本的使用方法,从MySQL执行引擎再到索引、事务等知识,一步步地学习MySQL相关技术的实现原理,更好地了解如何基于这些知识来优化sql,减少SQL执行时间,通过执行计划对SQL性能进行分析,再到MySQL的主从复制、主备部署等内容,以便让你更完整地了解整个MySQL方面的技术体系,形成自己的知识框架。
+
+如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。
+
+
+
+
+除非单表数据未来会一直不断上涨,否则不要一开始就考虑拆分,拆分会带来逻辑、部署、运维的各种复杂度,一般以整型值为主的表在`千万级`以下,字符串为主的表在`五百万`以下是没有太大问题的。而事实上很多时候MySQL单表的性能依然有不少优化空间,甚至能正常支撑千万级以上的数据量:
+
+## 字段
+
+* 尽量使用`TINYINT`、`SMALLINT`、`MEDIUM_INT`作为整数类型而非`INT`,如果非负则加上`UNSIGNED`
+
+* `VARCHAR`的长度只分配真正需要的空间
+
+* 使用枚举或整数代替字符串类型
+
+* 尽量使用`TIMESTAMP`而非`DATETIME`,
+
+* 单表不要有太多字段,建议在20以内
+
+* 避免使用NULL字段,很难查询优化且占用额外索引空间
+
+* 用整型来存IP
+
+## 索引
+
+* 索引并不是越多越好,要根据查询有针对性的创建,考虑在`WHERE`和`ORDER BY`命令上涉及的列建立索引,可根据`EXPLAIN`来查看是否用了索引还是全表扫描
+
+* 应尽量避免在`WHERE`子句中对字段进行`NULL`值判断,否则将导致引擎放弃使用索引而进行全表扫描
+
+* 值分布很稀少的字段不适合建索引,例如"性别"这种只有两三个值的字段
+
+* 字符字段只建前缀索引
+
+* 字符字段最好不要做主键
+
+* 不用外键,由程序保证约束
+
+* 尽量不用`UNIQUE`,由程序保证约束
+
+* 使用多列索引时主意顺序和查询条件保持一致,同时删除不必要的单列索引
+
+## 查询SQL
+
+* 可通过开启慢查询日志来找出较慢的SQL
+
+* 不做列运算:`SELECT id WHERE age + 1 = 10`,任何对列的操作都将导致表扫描,它包括数据库教程函数、计算表达式等等,查询时要尽可能将操作移至等号右边
+
+* sql语句尽可能简单:一条sql只能在一个cpu运算;大语句拆小语句,减少锁时间;一条大sql可以堵死整个库
+
+* 不用`SELECT *`
+
+* `OR`改写成`IN`:`OR`的效率是n级别,`IN`的效率是log(n)级别,in的个数建议控制在200以内
+
+* 不用函数和触发器,在应用程序实现
+
+* 避免`%xxx`式查询
+
+* 少用`JOIN`
+
+* 使用同类型进行比较,比如用`'123'`和`'123'`比,`123`和`123`比
+
+* 尽量避免在`WHERE`子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描
+
+* 对于连续数值,使用`BETWEEN`不用`IN`:`SELECT id FROM t WHERE num BETWEEN 1 AND 5`
+
+* 列表数据不要拿全表,要使用`LIMIT`来分页,每页数量也不要太大
+
+## 引擎
+
+目前广泛使用的是MyISAM和InnoDB两种引擎:
+
+### MyISAM
+
+MyISAM引擎是MySQL 5.1及之前版本的默认引擎,它的特点是:
+
+* 不支持行锁,读取时对需要读到的所有表加锁,写入时则对表加排它锁
+
+* 不支持事务
+
+* 不支持外键
+
+* 不支持崩溃后的安全恢复
+
+* 在表有读取查询的同时,支持往表中插入新纪录
+
+* 支持`BLOB`和`TEXT`的前500个字符索引,支持全文索引
+
+* 支持延迟更新索引,极大提升写入性能
+
+* 对于不会进行修改的表,支持压缩表,极大减少磁盘空间占用
+
+### InnoDB
+
+InnoDB在MySQL 5.5后成为默认索引,它的特点是:
+
+* 支持行锁,采用MVCC来支持高并发
+
+* 支持事务
+
+* 支持外键
+
+* 支持崩溃后的安全恢复
+
+* 不支持全文索引
+
+总体来讲,MyISAM适合`SELECT`密集型的表,而InnoDB适合`INSERT`和`UPDATE`密集型的表
+
+### 0、自己写的海量数据sql优化实践
+
+首先是建表和导数据的过程。
+
+参考[https://nsimple.top/archives/mysql-create-million-data.html](https://nsimple.top/archives/mysql-create-million-data.html)
+
+> 有时候我们需要对大数据进行测试,本地一般没有那么多数据,就需要我们自己生成一些。下面会借助内存表的特点进行生成百万条测试数据。
+
+1. 创建一个临时内存表, 做数据插入的时候会比较快些
+
+SQL
+
+```
+-- 创建一个临时内存表DROP TABLE IF EXISTS `vote_record_memory`;CREATE TABLE `vote_record_memory` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `user_id` varchar(20) NOT NULL DEFAULT '', `vote_num` int(10) unsigned NOT NULL DEFAULT '0', `group_id` int(10) unsigned NOT NULL DEFAULT '0', `status` tinyint(2) unsigned NOT NULL DEFAULT '1', `create_time` datetime NOT NULL DEFAULT '0000-00-00 00:00:00', PRIMARY KEY (`id`), KEY `index_user_id` (`user_id`) USING HASH) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
+```
+
+1. -- 创建一个普通表,用作模拟大数据的测试用例
+
+SQL
+
+```
+DROP TABLE IF EXISTS `vote_record`;CREATE TABLE `vote_record` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `user_id` varchar(20) NOT NULL DEFAULT '' COMMENT '用户Id', `vote_num` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '投票数', `group_id` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '用户组id 0-未激活用户 1-普通用户 2-vip用户 3-管理员用户', `status` tinyint(2) unsigned NOT NULL DEFAULT '1' COMMENT '状态 1-正常 2-已删除', `create_time` int(10) unsigned NOT NULL DEFAULT '0000-00-00 00:00:00' COMMENT '创建时间', PRIMARY KEY (`id`), KEY `index_user_id` (`user_id`) USING HASH COMMENT '用户ID哈希索引') ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='投票记录表';
+```
+
+1. 为了数据的随机性和真实性,我们需要创建一个可生成长度为n的随机字符串的函数。
+
+SQL
+
+```
+-- 创建生成长度为n的随机字符串的函数DELIMITER // -- 修改MySQL delimiter:'//'DROP FUNCTION IF EXISTS `rand_string` //SET NAMES utf8 //CREATE FUNCTION `rand_string` (n INT) RETURNS VARCHAR(255) CHARSET 'utf8'BEGIN DECLARE char_str varchar(100) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789'; DECLARE return_str varchar(255) DEFAULT ''; DECLARE i INT DEFAULT 0; WHILE i < n DO SET return_str = concat(return_str, substring(char_str, FLOOR(1 + RAND()*62), 1)); SET i = i+1; END WHILE; RETURN return_str;END //
+```
+
+1. 为了操作方便,我们再创建一个插入数据的存储过程
+
+SQL
+
+```
+-- 创建插入数据的存储过程DROP PROCEDURE IF EXISTS `add_vote_record_memory` //CREATE PROCEDURE `add_vote_record_memory`(IN n INT)BEGIN DECLARE i INT DEFAULT 1; DECLARE vote_num INT DEFAULT 0; DECLARE group_id INT DEFAULT 0; DECLARE status TINYINT DEFAULT 1; WHILE i < n DO SET vote_num = FLOOR(1 + RAND() * 10000); SET group_id = FLOOR(0 + RAND()*3); SET status = FLOOR(1 + RAND()*2); INSERT INTO `vote_record_memory` VALUES (NULL, rand_string(20), vote_num, group_id, status, NOW()); SET i = i + 1; END WHILE;END //DELIMITER ; -- 改回默认的 MySQL delimiter:';'
+```
+
+1. 开始执行存储过程,等待生成数据(10W条生成大约需要40分钟)
+
+SQL
+
+```
+-- 调用存储过程 生成100W条数据CALL add_vote_record_memory(1000000);
+```
+
+1. 查询内存表已生成记录(为了下步测试,目前仅生成了105645条)
+
+SQL
+
+```
+SELECT count(*) FROM `vote_record_memory`;-- count(*)-- 105646
+```
+
+1. 把数据从内存表插入到普通表中(10w条数据13s就插入完了)
+
+SQL
+
+```
+INSERT INTO vote_record SELECT * FROM `vote_record_memory`;
+```
+
+1. 查询普通表已的生成记录
+
+SQL
+
+```
+SELECT count(*) FROM `vote_record`;-- count(*)-- 105646
+```
+
+1. 如果一次性插入普通表太慢,可以分批插入,这就需要写个存储过程了:
+
+SQL
+
+```
+-- 参数n是每次要插入的条数-- lastid是已导入的最大idCREATE PROCEDURE `copy_data_from_tmp`(IN n INT)BEGIN DECLARE lastid INT DEFAULT 0; SELECT MAX(id) INTO lastid FROM `vote_record`; INSERT INTO `vote_record` SELECT * FROM `vote_record_memory` where id > lastid LIMIT n;END
+```
+
+1. 调用存储过程:
+
+SQL
+
+```
+-- 调用存储过程 插入60w条CALL copy_data_from_tmp(600000);
+```
+
+SELECT * FROM vote_record;
+
+全表查询
+
+建完表以后开启慢查询日志,具体参考下面的例子,然后学会用explain。windows慢日志的位置在c盘,另外,使用client工具也可以记录慢日志,所以不一定要用命令行来执行测试,否则大表数据在命令行中要显示的非常久。
+
+**1 全表扫描select * from vote_record**
+
+* * *
+
+**慢日志**
+
+SET timestamp=1529034398; select * from vote_record;
+
+ Time: 2018-06-15T03:52:58.804850Z
+
+ User[@Host](https://my.oschina.net/u/116016): root[root] @ localhost [::1] Id: 74
+
+ Query_time: 3.166424 Lock_time: 0.000000 Rows_sent: 900500 Rows_examined: 999999
+
+耗时3秒,我设置的门槛是一秒。所以记录了下来。
+
+**explain执行计划**
+
+id select_type table partitions type possible_keys key key_len ref rows filtered Extra
+
+1 SIMPLE vote_record \N ALL \N \N \N \N 996507 100.00 \N
+
+全表扫描耗时3秒多,用不到索引。
+
+**2 select * from vote_record where vote_num > 1000**
+
+没有索引,所以相当于全表扫描,一样是3.5秒左右
+
+**3 select * from vote_record where vote_num > 1000**
+
+**加索引create **
+
+**CREATE INDEX vote ON vote_record(vote_num);**
+
+**explain查看执行计划**
+
+id select_type table partitions type possible_keys key key_len ref rows filtered Extra
+
+1 SIMPLE vote_record \N ALL votenum,vote \N \N \N 996507 50.00 Using where
+
+还是没用到索引,因为不符合最左前缀匹配。查询需要3.5秒左右
+
+最后修改一下sql语句
+
+EXPLAIN SELECT * FROM vote_record WHERE id > 0 AND vote_num > 1000;
+
+id select_type table partitions type possible_keys key key_len ref rows filtered Extra
+
+1 SIMPLE vote_record \N range PRIMARY,votenum,vote PRIMARY 4 \N 498253 50.00 Using where
+
+用到了索引,但是只用到了主键索引。再修改一次
+
+EXPLAIN SELECT * FROM vote_record WHERE id > 0 AND vote_num = 1000;
+
+id select_type table partitions type possible_keys key key_len ref rows filtered Extra
+
+1 SIMPLE vote_record \N index_merge PRIMARY,votenum,vote votenum,PRIMARY 8,4 \N 51 100.00 Using intersect(votenum,PRIMARY); Using where
+
+用到了两个索引,votenum,PRIMARY。
+
+这是为什么呢。
+
+再看一个语句
+
+EXPLAIN SELECT * FROM vote_record WHERE id = 1000 AND vote_num > 1000
+
+id select_type table partitions type possible_keys key key_len ref rows filtered Extra
+
+1 SIMPLE vote_record \N const PRIMARY,votenum PRIMARY 4 const 1 100.00 \N
+
+也只有主键用到了索引。这是因为只有最左前缀索引可以用>或<,其他索引用<或者>会导致用不到索引。
+
+下面是几个网上参考的例子:
+
+一:索引是sql语句优化的关键,学会使用慢日志和执行计划分析sql
+
+背景:使用A电脑安装mysql,B电脑通过xshell方式连接,数据内容我都已经创建好,现在我已正常的进入到mysql中
+
+步骤1:设置慢查询日志的超时时间,先查看日志存放路径查询慢日志的地址,因为有慢查询的内容,就会到这个日志中:
+
+show global variables like "%slow%";
+
+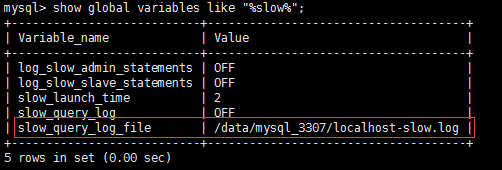
+
+2.开启慢查询日志
+
+set global slow_query_log=on;
+
+3.查看慢查询日志的设置时间,是否是自己需要的
+
+show global variables like "%long%";
+
+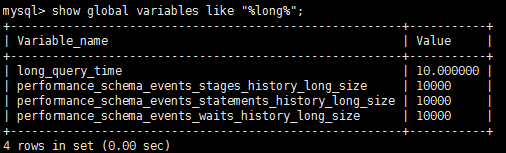
+
+4.如果不是自己想的时间,修改慢查询时间,只要超过了以下的设置时间,查询的日志就会到刚刚的日志中,我设置查询时间超过1S就进入到慢查询日志中
+
+set global long_query_time=1;
+
+5.大数据已准备,进行数据的查询,xshell最好开两个窗口,一个查看日志,一个执行内容
+
+Sql查询语句:select sql_no_cache * from employees_tmp where first_name='Duangkaew' and gender='M'
+
+
+
+发现查数据的总时间去掉了17.74S
+
+查看日志:打开日志
+
+
+
+
+
+标记1:执行的sql语句
+
+标记2:执行sql的时间,我的是10点52执行的
+
+标记3:使用那台机器
+
+标记4:执行时间,query_tims,查询数据的时间
+
+标记5:不知道是干嘛的
+
+标记6:执行耗时的sql语句,我在想我1的应该是截取错了!但是记住最后一定是显示耗时是因为执行什么sql造成的
+
+6.执行打印计划,主要是查看是否使用了索引等其他内容,主要就是在sql前面加上explain 关键字
+
+explain select sql_no_cache * from employees_tmp where first_name='Duangkaew' and gender='M';
+
+
+
+描述extra中,表示只使用了where条件,没有其他什么索引之类的
+
+7.进行sql优化,建一个fist_name的索引,索引就是将你需要的数据先给筛选出来,这样就可以节省很多扫描时间
+
+create index firstname on employees_tmp(first_name);
+
+ 
+
+注:创建索引时会很慢,是对整个表做了一个复制功能,并进行数据的一些分类(我猜是这样,所以会很慢)
+
+8.查看建立的索引
+
+show index from employees_tmp;
+
+ 
+
+9.在执行查询语句,查看语句的执行时间
+
+select sql_no_cache * from employees_tmp where first_name='Duangkaew' and gender='M'
+
+
+
+ 发现时间已经有所提升了,其实选择索引也不一开始就知道,我们在试试使用性别,gender进行索引
+
+10.删除已经有的索引,删除索引:
+
+drop index first_name on employees_tmp;
+
+11.创建性别的索引(性别是不怎么好的索引方式,因为有很多重复数据)
+
+create index index_gendar on employees_tmp(gender);
+
+在执行sql语句查询数据,查看查询执行时间,没有创建比较优秀的索引,导致查询时间还变长了,
+
+为嘛还变长了,这个我没有弄懂
+
+
+
+12.我们在试试使用创建组合索引,使用性别和姓名
+
+alter table employees_tmp add index idx_union (first_name,gender);
+
+在执行sql查看sql数据的执行时间
+
+select sql_no_cache * from employees_tmp where first_name='Duangkaew' and gender='M'
+
+速度提升了N多倍啊
+
+
+
+查看创建的索引
+
+show index from employees_tmp;
+
+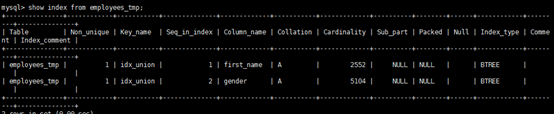
+
+索引建的好真的一个好帮手,建不好就是费时的一个操作
+
+ 目前还不知道为什么建立性别的索引会这么慢
+
+二:sql优化注意要点,比如索引是否用到,查询优化是否改变了执行计划,以及一些细节
+
+场景
+
+我用的数据库是mysql5.6,下面简单的介绍下场景
+
+课程表
+
+```
+create table Course( c_id int PRIMARY KEY, name varchar(10) )
+```
+
+数据100条
+
+学生表:
+
+```
+create table Student( id int PRIMARY KEY, name varchar(10) )
+```
+
+数据70000条
+
+学生成绩表SC
+
+```
+CREATE table SC( sc_id int PRIMARY KEY, s_id int, c_id int, score int )
+```
+
+数据70w条
+
+查询目的:
+
+查找语文考100分的考生
+
+查询语句:
+
+```
+select s.* from Student s where s.s_id in (select s_id from SC sc where sc.c_id = 0 and sc.score = 100 )
+
+```
+
+执行时间:30248.271s
+
+晕,为什么这么慢,先来查看下查询计划:
+
+```
+EXPLAIN select s.* from Student s where s.s_id in (select s_id from SC sc where sc.c_id = 0 and sc.score = 100 )
+```
+
+
+
+发现没有用到索引,type全是ALL,那么首先想到的就是建立一个索引,建立索引的字段当然是在where条件的字段。
+
+先给sc表的c_id和score建个索引
+
+```
+CREATE index sc_c_id_index on SC(c_id);
+
+```
+
+```
+CREATE index sc_score_index on SC(score);
+
+```
+
+再次执行上述查询语句,时间为: 1.054s
+
+快了3w多倍,大大缩短了查询时间,看来索引能极大程度的提高查询效率,看来建索引很有必要,很多时候都忘记建
+
+索引了,数据量小的的时候压根没感觉,这优化感觉挺爽。
+
+但是1s的时间还是太长了,还能进行优化吗,仔细看执行计划:
+
+
+
+查看优化后的sql:
+
+```
+SELECT `YSB`.`s`.`s_id` AS `s_id`, `YSB`.`s`.`name` AS `name`FROM `YSB`.`Student` `s`WHERE < in_optimizer > ( `YSB`.`s`.`s_id` ,< EXISTS > ( SELECT 1 FROM `YSB`.`SC` `sc` WHERE ( (`YSB`.`sc`.`c_id` = 0) AND (`YSB`.`sc`.`score` = 100) AND ( < CACHE > (`YSB`.`s`.`s_id`) = `YSB`.`sc`.`s_id` ) ) ) )
+```
+
+补充:这里有网友问怎么查看优化后的语句
+
+方法如下:
+
+在命令窗口执行
+
+
+
+
+
+有type=all
+
+按照我之前的想法,该sql的执行的顺序应该是先执行子查询
+
+```
+select s_id from SC sc where sc.c_id = 0 and sc.score = 100
+
+```
+
+耗时:0.001s
+
+得到如下结果:
+
+
+
+然后再执行
+
+```
+select s.* from Student s where s.s_id in(7,29,5000)
+
+```
+
+耗时:0.001s
+
+这样就是相当快了啊,Mysql竟然不是先执行里层的查询,而是将sql优化成了exists子句,并出现了EPENDENT SUBQUERY,
+
+mysql是先执行外层查询,再执行里层的查询,这样就要循环70007*11=770077次。
+
+那么改用连接查询呢?
+
+```
+SELECT s.* from Student s INNER JOIN SC sc on sc.s_id = s.s_id where sc.c_id=0 and sc.score=100
+```
+
+这里为了重新分析连接查询的情况,先暂时删除索引sc_c_id_index,sc_score_index
+
+执行时间是:0.057s
+
+效率有所提高,看看执行计划:
+
+
+
+这里有连表的情况出现,我猜想是不是要给sc表的s_id建立个索引
+
+CREATE index sc_s_id_index on SC(s_id);
+
+show index from SC
+
+
+
+在执行连接查询
+
+时间: 1.076s,竟然时间还变长了,什么原因?查看执行计划:
+
+
+
+优化后的查询语句为:
+
+```
+SELECT `YSB`.`s`.`s_id` AS `s_id`, `YSB`.`s`.`name` AS `name`FROM `YSB`.`Student` `s`JOIN `YSB`.`SC` `sc`WHERE ( ( `YSB`.`sc`.`s_id` = `YSB`.`s`.`s_id` ) AND (`YSB`.`sc`.`score` = 100) AND (`YSB`.`sc`.`c_id` = 0) )
+```
+
+貌似是先做的连接查询,再执行的where过滤
+
+回到前面的执行计划:
+
+
+
+这里是先做的where过滤,再做连表,执行计划还不是固定的,那么我们先看下标准的sql执行顺序:
+
+
+
+正常情况下是先join再where过滤,但是我们这里的情况,如果先join,将会有70w条数据发送join做操,因此先执行where
+
+过滤是明智方案,现在为了排除mysql的查询优化,我自己写一条优化后的sql
+
+```
+SELECT s.*FROM ( SELECT * FROM SC sc WHERE sc.c_id = 0 AND sc.score = 100 ) tINNER JOIN Student s ON t.s_id = s.s_id
+```
+
+即先执行sc表的过滤,再进行表连接,执行时间为:0.054s
+
+和之前没有建s_id索引的时间差不多
+
+查看执行计划:
+
+
+
+先提取sc再连表,这样效率就高多了,现在的问题是提取sc的时候出现了扫描表,那么现在可以明确需要建立相关索引
+
+```
+CREATE index sc_c_id_index on SC(c_id);
+
+```
+
+```
+CREATE index sc_score_index on SC(score);
+
+```
+
+再执行查询:
+
+```
+SELECT s.*FROM ( SELECT * FROM SC sc WHERE sc.c_id = 0 AND sc.score = 100 ) tINNER JOIN Student s ON t.s_id = s.s_id
+```
+
+执行时间为:0.001s,这个时间相当靠谱,快了50倍
+
+执行计划:
+
+
+
+我们会看到,先提取sc,再连表,都用到了索引。
+
+那么再来执行下sql
+
+```
+SELECT s.* from Student s INNER JOIN SC sc on sc.s_id = s.s_id where sc.c_id=0 and sc.score=100
+```
+
+执行时间0.001s
+
+执行计划:
+
+
+
+这里是mysql进行了查询语句优化,先执行了where过滤,再执行连接操作,且都用到了索引。
+
+总结:
+
+1.mysql嵌套子查询效率确实比较低
+
+2.可以将其优化成连接查询
+
+3.建立合适的索引
+
+4.学会分析sql执行计划,mysql会对sql进行优化,所以分析执行计划很重要
+
+由于时间问题,这篇文章先写到这里,后续再分享其他的sql优化经历。
+
+三、海量数据分页查找时如何使用主键索引进行优化
+
+## mysql百万级分页优化
+
+### 普通分页
+
+ 数据分页在网页中十分多见,分页一般都是limit start,offset,然后根据页码page计算start
+
+ select * from user limit **1**,**20**
+
+ 这种分页在几十万的时候分页效率就会比较低了,MySQL需要从头开始一直往后计算,这样大大影响效率
+
+SELECT * from user limit **100001**,**20**; //time **0**.151s explain SELECT * from user limit **100001**,**20**;
+
+ 我们可以用explain分析下语句,没有用到任何索引,MySQL执行的行数是16W+,于是我们可以想用到索引去实现分页
+
+ 
+
+### 优化分页
+
+ 使用主键索引来优化数据分页
+
+ select * from user where id>(select id from user where id>=**100000** limit **1**) limit **20**; //time **0**.003s
+
+ 使用explain分析语句,MySQL这次扫描的行数是8W+,时间也大大缩短。
+
+ explain select * from user where id>(select id from user where id>=**100000** limit **1**) limit **20**;
+
+ 
+
+## 总结
+
+ 在数据量比较大的时候,我们尽量去利用索引来优化语句。上面的优化方法如果id不是主键索引,查询效率比第一种还要低点。我们可以先使用explain来分析语句,查看语句的执行顺序和执行性能。
+
+
+
+转载于:https://my.oschina.net/alicoder/blog/3097141
\ No newline at end of file
diff --git "a/docs/database/\351\207\215\346\226\260\345\255\246\344\271\240MySQL\346\225\260\346\215\256\345\272\2236\357\274\232\346\265\205\350\260\210MySQL\347\232\204\344\270\255\344\272\213\345\212\241\344\270\216\351\224\201.md" "b/docs/database/\351\207\215\346\226\260\345\255\246\344\271\240MySQL\346\225\260\346\215\256\345\272\2236\357\274\232\346\265\205\350\260\210MySQL\347\232\204\344\270\255\344\272\213\345\212\241\344\270\216\351\224\201.md"
new file mode 100644
index 0000000..82b413b
--- /dev/null
+++ "b/docs/database/\351\207\215\346\226\260\345\255\246\344\271\240MySQL\346\225\260\346\215\256\345\272\2236\357\274\232\346\265\205\350\260\210MySQL\347\232\204\344\270\255\344\272\213\345\212\241\344\270\216\351\224\201.md"
@@ -0,0 +1,478 @@
+本文转自互联网
+
+本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
+> https://github.com/h2pl/Java-Tutorial
+
+喜欢的话麻烦点下Star哈
+
+文章首发于我的个人博客:
+> www.how2playlife.com
+
+本文是微信公众号【Java技术江湖】的《重新学习MySQL数据库》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。
+
+该系列博文会告诉你如何从入门到进阶,从sql基本的使用方法,从MySQL执行引擎再到索引、事务等知识,一步步地学习MySQL相关技术的实现原理,更好地了解如何基于这些知识来优化sql,减少SQL执行时间,通过执行计划对SQL性能进行分析,再到MySQL的主从复制、主备部署等内容,以便让你更完整地了解整个MySQL方面的技术体系,形成自己的知识框架。
+
+如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。
+
+
+
+
+
+## 『浅入深出』MySQL 中事务的实现
+
+在关系型数据库中,事务的重要性不言而喻,只要对数据库稍有了解的人都知道事务具有 ACID 四个基本属性,而我们不知道的可能就是数据库是如何实现这四个属性的;在这篇文章中,我们将对事务的实现进行分析,尝试理解数据库是如何实现事务的,当然我们也会在文章中简单对 MySQL 中对 ACID 的实现进行简单的介绍。
+
+事务其实就是并发控制的基本单位;相信我们都知道,事务是一个序列操作,其中的操作要么都执行,要么都不执行,它是一个不可分割的工作单位;数据库事务的 ACID 四大特性是事务的基础,了解了 ACID 是如何实现的,我们也就清除了事务的实现,接下来我们将依次介绍数据库是如何实现这四个特性的。
+
+### 原子性
+
+在学习事务时,经常有人会告诉你,事务就是一系列的操作,要么全部都执行,要都不执行,这其实就是对事务原子性的刻画;虽然事务具有原子性,但是原子性并不是只与事务有关系,它的身影在很多地方都会出现。
+
+由于操作并不具有原子性,并且可以再分为多个操作,当这些操作出现错误或抛出异常时,整个操作就可能不会继续执行下去,而已经进行的操作造成的副作用就可能造成数据更新的丢失或者错误。
+
+事务其实和一个操作没有什么太大的区别,它是一系列的数据库操作(可以理解为 SQL)的集合,如果事务不具备原子性,那么就没办法保证同一个事务中的所有操作都被执行或者未被执行了,整个数据库系统就既不可用也不可信。
+
+### 回滚日志
+
+想要保证事务的原子性,就需要在异常发生时,对已经执行的操作进行回滚,而在 MySQL 中,恢复机制是通过回滚日志(undo log)实现的,所有事务进行的修改都会先记录到这个回滚日志中,然后在对数据库中的对应行进行写入。
+
+这个过程其实非常好理解,为了能够在发生错误时撤销之前的全部操作,肯定是需要将之前的操作都记录下来的,这样在发生错误时才可以回滚。
+
+回滚日志除了能够在发生错误或者用户执行 ROLLBACK 时提供回滚相关的信息,它还能够在整个系统发生崩溃、数据库进程直接被杀死后,当用户再次启动数据库进程时,还能够立刻通过查询回滚日志将之前未完成的事务进行回滚,这也就需要回滚日志必须先于数据持久化到磁盘上,是我们需要先写日志后写数据库的主要原因。
+
+回滚日志并不能将数据库物理地恢复到执行语句或者事务之前的样子;它是逻辑日志,当回滚日志被使用时,它只会按照日志逻辑地将数据库中的修改撤销掉看,可以理解为,我们在事务中使用的每一条 INSERT 都对应了一条 DELETE,每一条 UPDATE 也都对应一条相反的 UPDATE 语句。
+
+在这里,我们并不会介绍回滚日志的格式以及它是如何被管理的,本文重点关注在它到底是一个什么样的东西,究竟解决了、如何解决了什么样的问题,如果想要了解具体实现细节的读者,相信网络上关于回滚日志的文章一定不少。
+
+### 事务的状态
+
+因为事务具有原子性,所以从远处看的话,事务就是密不可分的一个整体,事务的状态也只有三种:Active、Commited 和 Failed,事务要不就在执行中,要不然就是成功或者失败的状态:
+
+但是如果放大来看,我们会发现事务不再是原子的,其中包括了很多中间状态,比如部分提交,事务的状态图也变得越来越复杂。
+
+> 事务的状态图以及状态的描述取自 [Database System Concepts](https://www.amazon.com/Database-System-Concepts-Computer-Science/dp/0073523321 "按住 Ctrl 点击访问 https://www.amazon.com/Database-System-Concepts-Computer-Science/dp/0073523321") 一书中第 14 章的内容。
+
+* Active:事务的初始状态,表示事务正在执行;
+
+* Partially Commited:在最后一条语句执行之后;
+
+* Failed:发现事务无法正常执行之后;
+
+* Aborted:事务被回滚并且数据库恢复到了事务进行之前的状态之后;
+
+* Commited:成功执行整个事务;
+
+虽然在发生错误时,整个数据库的状态可以恢复,但是如果我们在事务中执行了诸如:向标准输出打印日志、向外界发出邮件、没有通过数据库修改了磁盘上的内容甚至在事务执行期间发生了转账汇款,那么这些操作作为可见的外部输出都是没有办法回滚的;这些问题都是由应用开发者解决和负责的,在绝大多数情况下,我们都需要在整个事务提交后,再触发类似的无法回滚的操作
+
+以订票为例,哪怕我们在整个事务结束之后,才向第三方发起请求,由于向第三方请求并获取结果是一个需要较长事件的操作,如果在事务刚刚提交时,数据库或者服务器发生了崩溃,那么我们就非常有可能丢失发起请求这一过程,这就造成了非常严重的问题;而这一点就不是数据库所能保证的,开发者需要在适当的时候查看请求是否被发起、结果是成功还是失败。
+
+### 并行事务的原子性
+
+到目前为止,所有的事务都只是串行执行的,一直都没有考虑过并行执行的问题;然而在实际工作中,并行执行的事务才是常态,然而并行任务下,却可能出现非常复杂的问题:
+
+当 Transaction1 在执行的过程中对 id = 1 的用户进行了读写,但是没有将修改的内容进行提交或者回滚,在这时 Transaction2 对同样的数据进行了读操作并提交了事务;也就是说 Transaction2 是依赖于 Transaction1 的,当 Transaction1 由于一些错误需要回滚时,因为要保证事务的原子性,需要对 Transaction2 进行回滚,但是由于我们已经提交了 Transaction2,所以我们已经没有办法进行回滚操作,在这种问题下我们就发生了问题,[Database System Concepts](https://www.amazon.com/Database-System-Concepts-Computer-Science/dp/0073523321 "按住 Ctrl 点击访问 https://www.amazon.com/Database-System-Concepts-Computer-Science/dp/0073523321") 一书中将这种现象称为不可恢复安排(Nonrecoverable Schedule),那什么情况下是可以恢复的呢?
+
+> A recoverable schedule is one where, for each pair of transactions Ti and Tj such that Tj reads a data item previously written by Ti , the commit operation of Ti appears before the commit operation of Tj .
+
+简单理解一下,如果 Transaction2 依赖于事务 Transaction1,那么事务 Transaction1 必须在 Transaction2 提交之前完成提交的操作:
+
+然而这样还不算完,当事务的数量逐渐增多时,整个恢复流程也会变得越来越复杂,如果我们想要从事务发生的错误中恢复,也不是一件那么容易的事情。
+
+在上图所示的一次事件中,Transaction2 依赖于 Transaction1,而 Transaction3 又依赖于 Transaction1,当 Transaction1 由于执行出现问题发生回滚时,为了保证事务的原子性,就会将 Transaction2 和 Transaction3 中的工作全部回滚,这种情况也叫做级联回滚(Cascading Rollback),级联回滚的发生会导致大量的工作需要撤回,是我们难以接受的,不过如果想要达到绝对的原子性,这件事情又是不得不去处理的,我们会在文章的后面具体介绍如何处理并行事务的原子性。
+
+### 持久性
+
+既然是数据库,那么一定对数据的持久存储有着非常强烈的需求,如果数据被写入到数据库中,那么数据一定能够被安全存储在磁盘上;而事务的持久性就体现在,一旦事务被提交,那么数据一定会被写入到数据库中并持久存储起来。
+
+当事务已经被提交之后,就无法再次回滚了,唯一能够撤回已经提交的事务的方式就是创建一个相反的事务对原操作进行『补偿』,这也是事务持久性的体现之一。
+
+### 重做日志
+
+与原子性一样,事务的持久性也是通过日志来实现的,MySQL 使用重做日志(redo log)实现事务的持久性,重做日志由两部分组成,一是内存中的重做日志缓冲区,因为重做日志缓冲区在内存中,所以它是易失的,另一个就是在磁盘上的重做日志文件,它是持久的
+
+当我们在一个事务中尝试对数据进行修改时,它会先将数据从磁盘读入内存,并更新内存中缓存的数据,然后生成一条重做日志并写入重做日志缓存,当事务真正提交时,MySQL 会将重做日志缓存中的内容刷新到重做日志文件,再将内存中的数据更新到磁盘上,图中的第 4、5 步就是在事务提交时执行的。
+
+在 InnoDB 中,重做日志都是以 512 字节的块的形式进行存储的,同时因为块的大小与磁盘扇区大小相同,所以重做日志的写入可以保证原子性,不会由于机器断电导致重做日志仅写入一半并留下脏数据。
+
+除了所有对数据库的修改会产生重做日志,因为回滚日志也是需要持久存储的,它们也会创建对应的重做日志,在发生错误后,数据库重启时会从重做日志中找出未被更新到数据库磁盘中的日志重新执行以满足事务的持久性。
+
+### 回滚日志和重做日志
+
+到现在为止我们了解了 MySQL 中的两种日志,回滚日志(undo log)和重做日志(redo log);在数据库系统中,事务的原子性和持久性是由事务日志(transaction log)保证的,在实现时也就是上面提到的两种日志,前者用于对事务的影响进行撤销,后者在错误处理时对已经提交的事务进行重做,它们能保证两点:
+
+1. 发生错误或者需要回滚的事务能够成功回滚(原子性);
+
+2. 在事务提交后,数据没来得及写会磁盘就宕机时,在下次重新启动后能够成功恢复数据(持久性);
+
+在数据库中,这两种日志经常都是一起工作的,我们可以将它们整体看做一条事务日志,其中包含了事务的 ID、修改的行元素以及修改前后的值。
+
+一条事务日志同时包含了修改前后的值,能够非常简单的进行回滚和重做两种操作,在这里我们也不会对重做和回滚日志展开进行介绍,可能会在之后的文章谈一谈数据库系统的恢复机制时提到两种日志的使用。
+
+### 隔离性
+
+其实作者在之前的文章 [『浅入浅出』MySQL 和 InnoDB](http://draveness.me/mysql-innodb.html "按住 Ctrl 点击访问 http://draveness.me/mysql-innodb.html") 就已经介绍过数据库事务的隔离性,不过为了保证文章的独立性和完整性,我们还会对事务的隔离性进行介绍,介绍的内容可能稍微有所不同。
+
+事务的隔离性是数据库处理数据的几大基础之一,如果没有数据库的事务之间没有隔离性,就会发生在 [并行事务的原子性](https://draveness.me/mysql-transaction#%E5%B9%B6%E8%A1%8C%E4%BA%8B%E5%8A%A1%E7%9A%84%E5%8E%9F%E5%AD%90%E6%80%A7 "按住 Ctrl 点击访问 https://draveness.me/mysql-transaction#%E5%B9%B6%E8%A1%8C%E4%BA%8B%E5%8A%A1%E7%9A%84%E5%8E%9F%E5%AD%90%E6%80%A7") 一节中提到的级联回滚等问题,造成性能上的巨大损失。如果所有的事务的执行顺序都是线性的,那么对于事务的管理容易得多,但是允许事务的并行执行却能能够提升吞吐量和资源利用率,并且可以减少每个事务的等待时间。
+
+当多个事务同时并发执行时,事务的隔离性可能就会被违反,虽然单个事务的执行可能没有任何错误,但是从总体来看就会造成数据库的一致性出现问题,而串行虽然能够允许开发者忽略并行造成的影响,能够很好地维护数据库的一致性,但是却会影响事务执行的性能。
+
+### 事务的隔离级别
+
+所以说数据库的隔离性和一致性其实是一个需要开发者去权衡的问题,为数据库提供什么样的隔离性层级也就决定了数据库的性能以及可以达到什么样的一致性;在 SQL 标准中定义了四种数据库的事务的隔离级别:READ UNCOMMITED、READ COMMITED、REPEATABLE READ 和 SERIALIZABLE;每个事务的隔离级别其实都比上一级多解决了一个问题:
+
+* RAED UNCOMMITED:使用查询语句不会加锁,可能会读到未提交的行(Dirty Read);
+
+* READ COMMITED:只对记录加记录锁,而不会在记录之间加间隙锁,所以允许新的记录插入到被锁定记录的附近,所以再多次使用查询语句时,可能得到不同的结果(Non-Repeatable Read);
+
+* REPEATABLE READ:多次读取同一范围的数据会返回第一次查询的快照,不会返回不同的数据行,但是可能发生幻读(Phantom Read);
+
+* SERIALIZABLE:InnoDB 隐式地将全部的查询语句加上共享锁,解决了幻读的问题;
+
+以上的所有的事务隔离级别都不允许脏写入(Dirty Write),也就是当前事务更新了另一个事务已经更新但是还未提交的数据,大部分的数据库中都使用了 READ COMMITED 作为默认的事务隔离级别,但是 MySQL 使用了 REPEATABLE READ 作为默认配置;从 RAED UNCOMMITED 到 SERIALIZABLE,随着事务隔离级别变得越来越严格,数据库对于并发执行事务的性能也逐渐下降。
+
+对于数据库的使用者,从理论上说,并不需要知道事务的隔离级别是如何实现的,我们只需要知道这个隔离级别解决了什么样的问题,但是不同数据库对于不同隔离级别的是实现细节在很多时候都会让我们遇到意料之外的坑。
+
+如果读者不了解脏读、不可重复读和幻读究竟是什么,可以阅读之前的文章 [『浅入浅出』MySQL 和 InnoDB](http://draveness.me/mysql-innodb.html "按住 Ctrl 点击访问 http://draveness.me/mysql-innodb.html"),在这里我们仅放一张图来展示各个隔离层级对这几个问题的解决情况。
+
+### 隔离级别的实现
+
+数据库对于隔离级别的实现就是使用并发控制机制对在同一时间执行的事务进行控制,限制不同的事务对于同一资源的访问和更新,而最重要也最常见的并发控制机制,在这里我们将简单介绍三种最重要的并发控制器机制的工作原理。
+
+### 锁
+
+锁是一种最为常见的并发控制机制,在一个事务中,我们并不会将整个数据库都加锁,而是只会锁住那些需要访问的数据项, MySQL 和常见数据库中的锁都分为两种,共享锁(Shared)和互斥锁(Exclusive),前者也叫读锁,后者叫写锁。
+
+读锁保证了读操作可以并发执行,相互不会影响,而写锁保证了在更新数据库数据时不会有其他的事务访问或者更改同一条记录造成不可预知的问题。
+
+### 时间戳
+
+除了锁,另一种实现事务的隔离性的方式就是通过时间戳,使用这种方式实现事务的数据库,例如 PostgreSQL 会为每一条记录保留两个字段;读时间戳中报错了所有访问该记录的事务中的最大时间戳,而记录行的写时间戳中保存了将记录改到当前值的事务的时间戳。
+
+使用时间戳实现事务的隔离性时,往往都会使用乐观锁,先对数据进行修改,在写回时再去判断当前值,也就是时间戳是否改变过,如果没有改变过,就写入,否则,生成一个新的时间戳并再次更新数据,乐观锁其实并不是真正的锁机制,它只是一种思想,在这里并不会对它进行展开介绍。
+
+### 多版本和快照隔离
+
+通过维护多个版本的数据,数据库可以允许事务在数据被其他事务更新时对旧版本的数据进行读取,很多数据库都对这一机制进行了实现;因为所有的读操作不再需要等待写锁的释放,所以能够显著地提升读的性能,MySQL 和 PostgreSQL 都对这一机制进行自己的实现,也就是 MVCC,虽然各自实现的方式有所不同,MySQL 就通过文章中提到的回滚日志实现了 MVCC,保证事务并行执行时能够不等待互斥锁的释放直接获取数据。
+
+### 隔离性与原子性
+
+在这里就需要简单提一下在在原子性一节中遇到的级联回滚等问题了,如果一个事务对数据进行了写入,这时就会获取一个互斥锁,其他的事务就想要获得改行数据的读锁就必须等待写锁的释放,自然就不会发生级联回滚等问题了。
+
+不过在大多数的数据库,比如 MySQL 中都使用了 MVCC 等特性,也就是正常的读方法是不需要获取锁的,在想要对读取的数据进行更新时需要使用 SELECT ... FOR UPDATE 尝试获取对应行的互斥锁,以保证不同事务可以正常工作。
+
+### 一致性
+
+作者认为数据库的一致性是一个非常让人迷惑的概念,原因是数据库领域其实包含两个一致性,一个是 ACID 中的一致性、另一个是 CAP 定义中的一致性。
+
+这两个数据库的一致性说的完全不是一个事情,很多很多人都对这两者的概念有非常深的误解,当我们在讨论数据库的一致性时,一定要清楚上下文的语义是什么,尽量明确的问出我们要讨论的到底是 ACID 中的一致性还是 CAP 中的一致性。
+
+### ACID
+
+数据库对于 ACID 中的一致性的定义是这样的:如果一个事务原子地在一个一致地数据库中独立运行,那么在它执行之后,数据库的状态一定是一致的。对于这个概念,它的第一层意思就是对于数据完整性的约束,包括主键约束、引用约束以及一些约束检查等等,在事务的执行的前后以及过程中不会违背对数据完整性的约束,所有对数据库写入的操作都应该是合法的,并不能产生不合法的数据状态。
+
+> A transaction must preserve database consistency - if a transaction is run atomically in isolation starting from a consistent database, the database must again be consistent at the end of the transaction.
+
+我们可以将事务理解成一个函数,它接受一个外界的 SQL 输入和一个一致的数据库,它一定会返回一个一致的数据库。
+
+而第二层意思其实是指逻辑上的对于开发者的要求,我们要在代码中写出正确的事务逻辑,比如银行转账,事务中的逻辑不可能只扣钱或者只加钱,这是应用层面上对于数据库一致性的要求。
+
+> Ensuring consistency for an individual transaction is the responsibility of the application programmer who codes the transaction. - [Database System Concepts](https://www.amazon.com/Database-System-Concepts-Computer-Science/dp/0073523321 "按住 Ctrl 点击访问 https://www.amazon.com/Database-System-Concepts-Computer-Science/dp/0073523321")
+
+数据库 ACID 中的一致性对事务的要求不止包含对数据完整性以及合法性的检查,还包含应用层面逻辑的正确。
+
+CAP 定理中的数据一致性,其实是说分布式系统中的各个节点中对于同一数据的拷贝有着相同的值;而 ACID 中的一致性是指数据库的规则,如果 schema 中规定了一个值必须是唯一的,那么一致的系统必须确保在所有的操作中,该值都是唯一的,由此来看 CAP 和 ACID 对于一致性的定义有着根本性的区别。
+
+## 总结
+
+事务的 ACID 四大基本特性是保证数据库能够运行的基石,但是完全保证数据库的 ACID,尤其是隔离性会对性能有比较大影响,在实际的使用中我们也会根据业务的需求对隔离性进行调整,除了隔离性,数据库的原子性和持久性相信都是比较好理解的特性,前者保证数据库的事务要么全部执行、要么全部不执行,后者保证了对数据库的写入都是持久存储的、非易失的,而一致性不仅是数据库对本身数据的完整性的要求,同时也对开发者提出了要求 - 写出逻辑正确并且合理的事务。
+
+最后,也是最重要的,当别人在将一致性的时候,一定要搞清楚他的上下文,如果对文章的内容有疑问,可以在评论中留言。
+
+## 浅谈数据库并发控制 - 锁和 MVCC
+
+转自https://draveness.me/database-concurrency-control
+
+在学习几年编程之后,你会发现所有的问题都没有简单、快捷的解决方案,很多问题都需要权衡和妥协,而本文介绍的就是数据库在并发性能和可串行化之间做的权衡和妥协 - 并发控制机制。
+
+如果数据库中的所有事务都是串行执行的,那么它非常容易成为整个应用的性能瓶颈,虽然说没法水平扩展的节点在最后都会成为瓶颈,但是串行执行事务的数据库会加速这一过程;而并发(Concurrency)使一切事情的发生都有了可能,它能够解决一定的性能问题,但是它会带来更多诡异的错误。
+
+引入了并发事务之后,如果不对事务的执行进行控制就会出现各种各样的问题,你可能没有享受到并发带来的性能提升就已经被各种奇怪的问题折磨的欲仙欲死了。
+
+### 概述
+
+如何控制并发是数据库领域中非常重要的问题之一,不过到今天为止事务并发的控制已经有了很多成熟的解决方案,而这些方案的原理就是这篇文章想要介绍的内容,文章中会介绍最为常见的三种并发控制机制:
+
+分别是悲观并发控制、乐观并发控制和多版本并发控制,其中悲观并发控制其实是最常见的并发控制机制,也就是锁;而乐观并发控制其实也有另一个名字:乐观锁,乐观锁其实并不是一种真实存在的锁,我们会在文章后面的部分中具体介绍;最后就是多版本并发控制(MVCC)了,与前两者对立的命名不同,MVCC 可以与前两者中的任意一种机制结合使用,以提高数据库的读性能。
+
+既然这篇文章介绍了不同的并发控制机制,那么一定会涉及到不同事务的并发,我们会通过示意图的方式分析各种机制是如何工作的。
+
+### 悲观并发控制
+
+控制不同的事务对同一份数据的获取是保证数据库的一致性的最根本方法,如果我们能够让事务在同一时间对同一资源有着独占的能力,那么就可以保证操作同一资源的不同事务不会相互影响。
+
+最简单的、应用最广的方法就是使用锁来解决,当事务需要对资源进行操作时需要先获得资源对应的锁,保证其他事务不会访问该资源后,在对资源进行各种操作;在悲观并发控制中,数据库程序对于数据被修改持悲观的态度,在数据处理的过程中都会被锁定,以此来解决竞争的问题。
+
+### 读写锁
+
+为了最大化数据库事务的并发能力,数据库中的锁被设计为两种模式,分别是共享锁和互斥锁。当一个事务获得共享锁之后,它只可以进行读操作,所以共享锁也叫读锁;而当一个事务获得一行数据的互斥锁时,就可以对该行数据进行读和写操作,所以互斥锁也叫写锁。
+
+共享锁和互斥锁除了限制事务能够执行的读写操作之外,它们之间还有『共享』和『互斥』的关系,也就是多个事务可以同时获得某一行数据的共享锁,但是互斥锁与共享锁和其他的互斥锁并不兼容,我们可以很自然地理解这么设计的原因:多个事务同时写入同一数据难免会发生各种诡异的问题。
+
+如果当前事务没有办法获取该行数据对应的锁时就会陷入等待的状态,直到其他事务将当前数据对应的锁释放才可以获得锁并执行相应的操作。
+
+### 两阶段锁协议
+
+两阶段锁协议(2PL)是一种能够保证事务可串行化的协议,它将事务的获取锁和释放锁划分成了增长(Growing)和缩减(Shrinking)两个不同的阶段。
+
+在增长阶段,一个事务可以获得锁但是不能释放锁;而在缩减阶段事务只可以释放锁,并不能获得新的锁,如果只看 2PL 的定义,那么到这里就已经介绍完了,但是它还有两个变种:
+
+1. Strict 2PL:事务持有的互斥锁必须在提交后再释放;
+
+2. Rigorous 2PL:事务持有的所有锁必须在提交后释放;
+
+虽然锁的使用能够为我们解决不同事务之间由于并发执行造成的问题,但是两阶段锁的使用却引入了另一个严重的问题,死锁;不同的事务等待对方已经锁定的资源就会造成死锁,我们在这里举一个简单的例子:
+
+两个事务在刚开始时分别获取了 draven 和 beacon 资源面的锁,然后再请求对方已经获得的锁时就会发生死锁,双方都没有办法等到锁的释放,如果没有死锁的处理机制就会无限等待下去,两个事务都没有办法完成。
+
+### 死锁的处理
+
+死锁在多线程编程中是经常遇到的事情,一旦涉及多个线程对资源进行争夺就需要考虑当前的几个线程或者事务是否会造成死锁;解决死锁大体来看有两种办法,一种是从源头杜绝死锁的产生和出现,另一种是允许系统进入死锁的状态,但是在系统出现死锁时能够及时发现并且进行恢复。
+
+### 预防死锁
+
+有两种方式可以帮助我们预防死锁的出现,一种是保证事务之间的等待不会出现环,也就是事务之间的等待图应该是一张有向无环图,没有循环等待的情况或者保证一个事务中想要获得的所有资源都在事务开始时以原子的方式被锁定,所有的资源要么被锁定要么都不被锁定。
+
+但是这种方式有两个问题,在事务一开始时很难判断哪些资源是需要锁定的,同时因为一些很晚才会用到的数据被提前锁定,数据的利用率与事务的并发率也非常的低。一种解决的办法就是按照一定的顺序为所有的数据行加锁,同时与 2PL 协议结合,在加锁阶段保证所有的数据行都是从小到大依次进行加锁的,不过这种方式依然需要事务提前知道将要加锁的数据集。
+
+另一种预防死锁的方法就是使用抢占加事务回滚的方式预防死锁,当事务开始执行时会先获得一个时间戳,数据库程序会根据事务的时间戳决定事务应该等待还是回滚,在这时也有两种机制供我们选择,一种是 wait-die 机制:
+
+当执行事务的时间戳小于另一事务时,即事务 A 先于 B 开始,那么它就会等待另一个事务释放对应资源的锁,否则就会保持当前的时间戳并回滚。
+
+另一种机制叫做 wound-wait,这是一种抢占的解决方案,它和 wait-die 机制的结果完全相反,当前事务如果先于另一事务执行并请求了另一事务的资源,那么另一事务会立刻回滚,将资源让给先执行的事务,否则就会等待其他事务释放资源:
+
+两种方法都会造成不必要的事务回滚,由此会带来一定的性能损失,更简单的解决死锁的方式就是使用超时时间,但是超时时间的设定是需要仔细考虑的,否则会造成耗时较长的事务无法正常执行,或者无法及时发现需要解决的死锁,所以它的使用还是有一定的局限性。
+
+### 死锁检测和恢复
+
+如果数据库程序无法通过协议从原理上保证死锁不会发生,那么就需要在死锁发生时及时检测到并从死锁状态恢复到正常状态保证数据库程序可以正常工作。在使用检测和恢复的方式解决死锁时,数据库程序需要维护数据和事务之间的引用信息,同时也需要提供一个用于判断当前数据库是否进入死锁状态的算法,最后需要在死锁发生时提供合适的策略及时恢复。
+
+在上一节中我们其实提到死锁的检测可以通过一个有向的等待图来进行判断,如果一个事务依赖于另一个事务正在处理的数据,那么当前事务就会等待另一个事务的结束,这也就是整个等待图中的一条边:
+
+如上图所示,如果在这个有向图中出现了环,就说明当前数据库进入了死锁的状态 TransB -> TransE -> TransF -> TransD -> TransB,在这时就需要死锁恢复机制接入了。
+
+如何从死锁中恢复其实非常简单,最常见的解决办法就是选择整个环中一个事务进行回滚,以打破整个等待图中的环,在整个恢复的过程中有三个事情需要考虑:
+
+每次出现死锁时其实都会有多个事务被波及,而选择其中哪一个任务进行回滚是必须要做的事情,在选择牺牲品(Victim)时的黄金原则就是最小化代价,所以我们需要综合考虑事务已经计算的时间、使用的数据行以及涉及的事务等因素;当我们选择了牺牲品之后就可以开始回滚了,回滚其实有两种选择一种是全部回滚,另一种是部分回滚,部分回滚会回滚到事务之前的一个检查点上,如果没有检查点那自然没有办法进行部分回滚。
+
+> 在死锁恢复的过程中,其实还可能出现某些任务在多次死锁时都被选择成为牺牲品,一直都不会成功执行,造成饥饿(Starvation),我们需要保证事务会在有穷的时间内执行,所以要在选择牺牲品时将时间戳加入考虑的范围。
+
+### 锁的粒度
+
+到目前为止我们都没有对不同粒度的锁进行讨论,一直以来我们都讨论的都是数据行锁,但是在有些时候我们希望将多个节点看做一个数据单元,使用锁直接将这个数据单元、表甚至数据库锁定起来。这个目标的实现需要我们在数据库中定义不同粒度的锁:
+
+当我们拥有了不同粒度的锁之后,如果某个事务想要锁定整个数据库或者整张表时只需要简单的锁住对应的节点就会在当前节点加上显示(explicit)锁,在所有的子节点上加隐式(implicit)锁;虽然这种不同粒度的锁能够解决父节点被加锁时,子节点不能被加锁的问题,但是我们没有办法在子节点被加锁时,立刻确定父节点不能被加锁。
+
+在这时我们就需要引入意向锁来解决这个问题了,当需要给子节点加锁时,先给所有的父节点加对应的意向锁,意向锁之间是完全不会互斥的,只是用来帮助父节点快速判断是否可以对该节点进行加锁:
+
+这里是一张引入了两种意向锁,意向共享锁和意向互斥锁之后所有的锁之间的兼容关系;到这里,我们通过不同粒度的锁和意向锁加快了数据库的吞吐量。
+
+### 乐观并发控制
+
+除了悲观并发控制机制 - 锁之外,我们其实还有其他的并发控制机制,乐观并发控制(Optimistic Concurrency Control)。乐观并发控制也叫乐观锁,但是它并不是真正的锁,很多人都会误以为乐观锁是一种真正的锁,然而它只是一种并发控制的思想。
+
+在这一节中,我们将会先介绍基于时间戳的并发控制机制,然后在这个协议的基础上进行扩展,实现乐观的并发控制机制。
+
+### 基于时间戳的协议
+
+锁协议按照不同事务对同一数据项请求的时间依次执行,因为后面执行的事务想要获取的数据已将被前面的事务加锁,只能等待锁的释放,所以基于锁的协议执行事务的顺序与获得锁的顺序有关。在这里想要介绍的基于时间戳的协议能够在事务执行之前先决定事务的执行顺序。
+
+每一个事务都会具有一个全局唯一的时间戳,它即可以使用系统的时钟时间,也可以使用计数器,只要能够保证所有的时间戳都是唯一并且是随时间递增的就可以。
+
+基于时间戳的协议能够保证事务并行执行的顺序与事务按照时间戳串行执行的效果完全相同;每一个数据项都有两个时间戳,读时间戳和写时间戳,分别代表了当前成功执行对应操作的事务的时间戳。
+
+该协议能够保证所有冲突的读写操作都能按照时间戳的大小串行执行,在执行对应的操作时不需要关注其他的事务只需要关心数据项对应时间戳的值就可以了:
+
+无论是读操作还是写操作都会从左到右依次比较读写时间戳的值,如果小于当前值就会直接被拒绝然后回滚,数据库系统会给回滚的事务添加一个新的时间戳并重新执行这个事务。
+
+### 基于验证的协议
+
+乐观并发控制其实本质上就是基于验证的协议,因为在多数的应用中只读的事务占了绝大多数,事务之间因为写操作造成冲突的可能非常小,也就是说大多数的事务在不需要并发控制机制也能运行的非常好,也可以保证数据库的一致性;而并发控制机制其实向整个数据库系统添加了很多的开销,我们其实可以通过别的策略降低这部分开销。
+
+而验证协议就是我们找到的解决办法,它根据事务的只读或者更新将所有事务的执行分为两到三个阶段:
+
+在读阶段,数据库会执行事务中的全部读操作和写操作,并将所有写后的值存入临时变量中,并不会真正更新数据库中的内容;在这时候会进入下一个阶段,数据库程序会检查当前的改动是否合法,也就是是否有其他事务在 RAED PHASE 期间更新了数据,如果通过测试那么直接就进入 WRITE PHASE 将所有存在临时变量中的改动全部写入数据库,没有通过测试的事务会直接被终止。
+
+为了保证乐观并发控制能够正常运行,我们需要知道一个事务不同阶段的发生时间,包括事务开始时间、验证阶段的开始时间以及写阶段的结束时间;通过这三个时间戳,我们可以保证任意冲突的事务不会同时写入数据库,一旦由一个事务完成了验证阶段就会立即写入,其他读取了相同数据的事务就会回滚重新执行。
+
+作为乐观的并发控制机制,它会假定所有的事务在最终都会通过验证阶段并且执行成功,而锁机制和基于时间戳排序的协议是悲观的,因为它们会在发生冲突时强制事务进行等待或者回滚,哪怕有不需要锁也能够保证事务之间不会冲突的可能。
+
+### 多版本并发控制
+
+到目前为止我们介绍的并发控制机制其实都是通过延迟或者终止相应的事务来解决事务之间的竞争条件(Race condition)来保证事务的可串行化;虽然前面的两种并发控制机制确实能够从根本上解决并发事务的可串行化的问题,但是在实际环境中数据库的事务大都是只读的,读请求是写请求的很多倍,如果写请求和读请求之前没有并发控制机制,那么最坏的情况也是读请求读到了已经写入的数据,这对很多应用完全是可以接受的。
+
+在这种大前提下,数据库系统引入了另一种并发控制机制 - 多版本并发控制(Multiversion Concurrency Control),每一个写操作都会创建一个新版本的数据,读操作会从有限多个版本的数据中挑选一个最合适的结果直接返回;在这时,读写操作之间的冲突就不再需要被关注,而管理和快速挑选数据的版本就成了 MVCC 需要解决的主要问题。
+
+MVCC 并不是一个与乐观和悲观并发控制对立的东西,它能够与两者很好的结合以增加事务的并发量,在目前最流行的 SQL 数据库 MySQL 和 PostgreSQL 中都对 MVCC 进行了实现;但是由于它们分别实现了悲观锁和乐观锁,所以 MVCC 实现的方式也不同。
+
+## MySQL 与 MVCC
+
+MySQL 中实现的多版本两阶段锁协议(Multiversion 2PL)将 MVCC 和 2PL 的优点结合了起来,每一个版本的数据行都具有一个唯一的时间戳,当有读事务请求时,数据库程序会直接从多个版本的数据项中具有最大时间戳的返回。
+
+更新操作就稍微有些复杂了,事务会先读取最新版本的数据计算出数据更新后的结果,然后创建一个新版本的数据,新数据的时间戳是目前数据行的最大版本 +1:
+
+数据版本的删除也是根据时间戳来选择的,MySQL 会将版本最低的数据定时从数据库中清除以保证不会出现大量的遗留内容。
+
+### PostgreSQL 与 MVCC
+
+与 MySQL 中使用悲观并发控制不同,PostgreSQL 中都是使用乐观并发控制的,这也就导致了 MVCC 在于乐观锁结合时的实现上有一些不同,最终实现的叫做多版本时间戳排序协议(Multiversion Timestamp Ordering),在这个协议中,所有的的事务在执行之前都会被分配一个唯一的时间戳,每一个数据项都有读写两个时间戳:
+
+当 PostgreSQL 的事务发出了一个读请求,数据库直接将最新版本的数据返回,不会被任何操作阻塞,而写操作在执行时,事务的时间戳一定要大或者等于数据行的读时间戳,否则就会被回滚。
+
+这种 MVCC 的实现保证了读事务永远都不会失败并且不需要等待锁的释放,对于读请求远远多于写请求的应用程序,乐观锁加 MVCC 对数据库的性能有着非常大的提升;虽然这种协议能够针对一些实际情况做出一些明显的性能提升,但是也会导致两个问题,一个是每一次读操作都会更新读时间戳造成两次的磁盘写入,第二是事务之间的冲突是通过回滚解决的,所以如果冲突的可能性非常高或者回滚代价巨大,数据库的读写性能还不如使用传统的锁等待方式。
+
+1\. MVCC简介与实践
+
+MySQL 在InnoDB引擎下有当前读和快照读两种模式。
+
+1 当前读即加锁读,读取记录的最新版本号,会加锁保证其他并发事物不能修改当前记录,直至释放锁。插入/更新/删除操作默认使用当前读,显示的为select语句加lock in share mode或for update的查询也采用当前读模式。
+
+2 快照读:不加锁,读取记录的快照版本,而非最新版本,使用MVCC机制,最大的好处是读取不需要加锁,读写不冲突,用于读操作多于写操作的应用,因此在不显示加[lock in share mode]/[for update]的select语句,即普通的一条select语句默认都是使用快照读MVCC实现模式。所以楼主的为了让大家明白所做的演示操作,既有当前读也有快照读……
+
+1.1 什么是MVCC
+
+MVCC是一种多版本并发控制机制。
+
+1.2 MVCC是为了解决什么问题?
+
+* 大多数的MYSQL事务型存储引擎,如,InnoDB,Falcon以及PBXT都不使用一种简单的行锁机制.事实上,他们都和MVCC–多版本并发控制来一起使用.
+
+* 大家都应该知道,锁机制可以控制并发操作,但是其系统开销较大,而MVCC可以在大多数情况下代替行级锁,使用MVCC,能降低其系统开销.
+
+1.3 MVCC实现
+
+MVCC是通过保存数据在某个时间点的快照来实现的. 不同存储引擎的MVCC. 不同存储引擎的MVCC实现是不同的,典型的有乐观并发控制和悲观并发控制.
+
+2.MVCC 具体实现分析
+
+下面,我们通过InnoDB的MVCC实现来分析MVCC使怎样进行并发控制的. InnoDB的MVCC,是通过在每行记录后面保存两个隐藏的列来实现的,这两个列,分别保存了这个行的创建时间,一个保存的是行的删除时间。这里存储的并不是实际的时间值,而是系统版本号(可以理解为事务的ID),没开始一个新的事务,系统版本号就会自动递增,事务开始时刻的系统版本号会作为事务的ID.下面看一下在REPEATABLE READ隔离级别下,MVCC具体是如何操作的.
+
+2.1简单的小例子
+
+create table yang( id int primary key auto_increment, name varchar(20));
+
+> 假设系统的版本号从1开始.
+
+INSERT
+
+InnoDB为新插入的每一行保存当前系统版本号作为版本号. 第一个事务ID为1;
+
+start transaction; insert into yang values(NULL,'yang') ; insert into yang values(NULL,'long'); insert into yang values(NULL,'fei'); commit;
+
+
+
+
+对应在数据中的表如下(后面两列是隐藏列,我们通过查询语句并看不到)
+
+| id | name | 创建时间(事务ID) | 删除时间(事务ID) |
+| --- | --- | --- | --- |
+| 1 | yang | 1 | undefined |
+| 2 | long | 1 | undefined |
+| 3 | fei | 1 | undefined |
+
+SELECT
+
+InnoDB会根据以下两个条件检查每行记录: a.InnoDB只会查找版本早于当前事务版本的数据行(也就是,行的系统版本号小于或等于事务的系统版本号),这样可以确保事务读取的行,要么是在事务开始前已经存在的,要么是事务自身插入或者修改过的. b.行的删除版本要么未定义,要么大于当前事务版本号,这可以确保事务读取到的行,在事务开始之前未被删除. 只有a,b同时满足的记录,才能返回作为查询结果.
+
+DELETE
+
+InnoDB会为删除的每一行保存当前系统的版本号(事务的ID)作为删除标识. 看下面的具体例子分析: 第二个事务,ID为2;
+
+start transaction; select * from yang; //(1) select * from yang; //(2) commit;
+
+
+
+
+假设1
+
+假设在执行这个事务ID为2的过程中,刚执行到(1),这时,有另一个事务ID为3往这个表里插入了一条数据; 第三个事务ID为3;
+
+start transaction; insert into yang values(NULL,'tian'); commit;
+
+
+
+
+这时表中的数据如下:
+
+| id | name | 创建时间(事务ID) | 删除时间(事务ID) |
+| --- | --- | --- | --- |
+| 1 | yang | 1 | undefined |
+| 2 | long | 1 | undefined |
+| 3 | fei | 1 | undefined |
+| 4 | tian | 3 | undefined |
+
+然后接着执行事务2中的(2),由于id=4的数据的创建时间(事务ID为3),执行当前事务的ID为2,而InnoDB只会查找事务ID小于等于当前事务ID的数据行,所以id=4的数据行并不会在执行事务2中的(2)被检索出来,在事务2中的两条select 语句检索出来的数据都只会下表:
+
+| id | name | 创建时间(事务ID) | 删除时间(事务ID) |
+| --- | --- | --- | --- |
+| 1 | yang | 1 | undefined |
+| 2 | long | 1 | undefined |
+| 3 | fei | 1 | undefined |
+
+假设2
+
+假设在执行这个事务ID为2的过程中,刚执行到(1),假设事务执行完事务3后,接着又执行了事务4; 第四个事务:
+
+start transaction; delete from yang where id=1; commit;
+
+
+
+
+此时数据库中的表如下:
+
+| id | name | 创建时间(事务ID) | 删除时间(事务ID) |
+| --- | --- | --- | --- |
+| 1 | yang | 1 | 4 |
+| 2 | long | 1 | undefined |
+| 3 | fei | 1 | undefined |
+| 4 | tian | 3 | undefined |
+
+接着执行事务ID为2的事务(2),根据SELECT 检索条件可以知道,它会检索创建时间(创建事务的ID)小于当前事务ID的行和删除时间(删除事务的ID)大于当前事务的行,而id=4的行上面已经说过,而id=1的行由于删除时间(删除事务的ID)大于当前事务的ID,所以事务2的(2)select * from yang也会把id=1的数据检索出来.所以,事务2中的两条select 语句检索出来的数据都如下:
+
+| id | name | 创建时间(事务ID) | 删除时间(事务ID) |
+| --- | --- | --- | --- |
+| 1 | yang | 1 | 4 |
+| 2 | long | 1 | undefined |
+| 3 | fei | 1 | undefined |
+
+UPDATE
+
+InnoDB执行UPDATE,实际上是新插入了一行记录,并保存其创建时间为当前事务的ID,同时保存当前事务ID到要UPDATE的行的删除时间.
+
+假设3
+
+假设在执行完事务2的(1)后又执行,其它用户执行了事务3,4,这时,又有一个用户对这张表执行了UPDATE操作: 第5个事务:
+
+start transaction; update yang set name='Long' where id=2; commit;
+
+
+
+
+根据update的更新原则:会生成新的一行,并在原来要修改的列的删除时间列上添加本事务ID,得到表如下:
+
+| id | name | 创建时间(事务ID) | 删除时间(事务ID) |
+| --- | --- | --- | --- |
+| 1 | yang | 1 | 4 |
+| 2 | long | 1 | 5 |
+| 3 | fei | 1 | undefined |
+| 4 | tian | 3 | undefined |
+| 2 | Long | 5 | undefined |
+
+继续执行事务2的(2),根据select 语句的检索条件,得到下表:
+
+| id | name | 创建时间(事务ID) | 删除时间(事务ID) |
+| --- | --- | --- | --- |
+| 1 | yang | 1 | 4 |
+| 2 | long | 1 | 5 |
+| 3 | fei | 1 | undefined |
+
+还是和事务2中(1)select 得到相同的结果.
\ No newline at end of file
diff --git "a/docs/database/\351\207\215\346\226\260\345\255\246\344\271\240MySQL\346\225\260\346\215\256\345\272\2239\357\274\232Innodb\344\270\255\347\232\204\344\272\213\345\212\241\351\232\224\347\246\273\347\272\247\345\210\253\345\222\214\351\224\201\347\232\204\345\205\263\347\263\273.md" "b/docs/database/\351\207\215\346\226\260\345\255\246\344\271\240MySQL\346\225\260\346\215\256\345\272\2239\357\274\232Innodb\344\270\255\347\232\204\344\272\213\345\212\241\351\232\224\347\246\273\347\272\247\345\210\253\345\222\214\351\224\201\347\232\204\345\205\263\347\263\273.md"
new file mode 100644
index 0000000..f53452b
--- /dev/null
+++ "b/docs/database/\351\207\215\346\226\260\345\255\246\344\271\240MySQL\346\225\260\346\215\256\345\272\2239\357\274\232Innodb\344\270\255\347\232\204\344\272\213\345\212\241\351\232\224\347\246\273\347\272\247\345\210\253\345\222\214\351\224\201\347\232\204\345\205\263\347\263\273.md"
@@ -0,0 +1,332 @@
+本文转自互联网
+
+本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
+> https://github.com/h2pl/Java-Tutorial
+
+喜欢的话麻烦点下Star哈
+
+文章首发于我的个人博客:
+> www.how2playlife.com
+
+本文是微信公众号【Java技术江湖】的《重新学习MySQL数据库》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。
+
+该系列博文会告诉你如何从入门到进阶,从sql基本的使用方法,从MySQL执行引擎再到索引、事务等知识,一步步地学习MySQL相关技术的实现原理,更好地了解如何基于这些知识来优化sql,减少SQL执行时间,通过执行计划对SQL性能进行分析,再到MySQL的主从复制、主备部署等内容,以便让你更完整地了解整个MySQL方面的技术体系,形成自己的知识框架。
+
+如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。
+
+
+
+
+## Innodb中的事务隔离级别和锁的关系
+
+> 前言:
+>
+> 我们都知道事务的几种性质,数据库为了维护这些性质,尤其是一致性和隔离性,一般使用加锁这种方式。同时数据库又是个高并发的应用,同一时间会有大量的并发访问,如果加锁过度,会极大的降低并发处理能力。所以对于加锁的处理,可以说就是数据库对于事务处理的精髓所在。这里通过分析MySQL中InnoDB引擎的加锁机制,来抛砖引玉,让读者更好的理解,在事务处理中数据库到底做了什么。
+
+一次封锁or两段锁? 因为有大量的并发访问,为了预防死锁,一般应用中推荐使用**一次封锁法**,就是**在方法的开始阶段,已经预先知道会用到哪些数据,然后全部锁住,在方法运行之后,再全部解锁**。这种方式可以有效的避免循环死锁,但在数据库中却不适用,因为在事务开始阶段,**数据库并不知道会用到哪些数据**。 数据库遵循的是两段锁协议,将事务分成两个阶段,加锁阶段和解锁阶段(所以叫两段锁)
+
+* 加锁阶段:在该阶段可以进行加锁操作。在对任何数据进行读操作之前要申请并获得S锁(共享锁,其它事务可以继续加共享锁,但不能加排它锁),在进行写操作之前要申请并获得X锁(排它锁,其它事务不能再获得任何锁)。**加锁不成功,则事务进入等待状态,直到加锁成功才继续执行。**
+
+* 解锁阶段:当事务释放了一个封锁以后,事务进入解锁阶段,在该阶段只能进行解锁操作不能再进行加锁操作。
+
+| 事务 | 加锁/解锁处理 |
+| --- | --- |
+| begin; | |
+| insert into test ..... | 加insert对应的锁 |
+| update test set... | 加update对应的锁 |
+| delete from test .... | 加delete对应的锁 |
+| commit; | 事务提交时,同时释放insert、update、delete对应的锁 |
+
+这种方式虽然**无法避免死锁**,但是两段锁协议**可以保证事务的并发调度是串行化**(串行化很重要,尤其是在数据恢复和备份的时候)的。
+
+## 事务中的加锁方式
+
+##事务的四种隔离级别 在数据库操作中,为了有效保证并发读取数据的正确性,提出的事务隔离级别。我们的数据库锁,也是为了构建这些隔离级别存在的。
+
+| 隔离级别 | 脏读(Dirty Read) | 不可重复读(NonRepeatable Read) | 幻读(Phantom Read) |
+| --- | --- | --- | --- |
+| 未提交读(Read uncommitted) | 可能 | 可能 | 可能 |
+| 已提交读(Read committed) | 不可能 | 可能 | 可能 |
+| 可重复读(Repeatable read) | 不可能 | 不可能 | 可能 |
+| 可串行化(Serializable ) | 不可能 | 不可能 | 不可能 |
+
+* 未提交读(Read Uncommitted):允许脏读,也就是可能读取到其他会话中未提交事务修改的数据
+
+* 提交读(Read Committed):只能读取到已经提交的数据。Oracle等多数数据库默认都是该级别 (不重复读)
+
+* 可重复读(Repeated Read):可重复读。在同一个事务内的查询都是事务开始时刻一致的,InnoDB默认级别。在SQL标准中,该隔离级别消除了不可重复读,但是还存在幻读
+
+* 串行读(Serializable):完全串行化的读,每次读都需要获得**表级共享锁**,读写相互都会阻塞
+
+Read Uncommitted这种级别,数据库一般都不会用,而且任何操作都不会加锁,这里就不讨论了。
+
+## MySQL中锁的种类
+
+MySQL中锁的种类很多,有常见的表锁和行锁,也有新加入的Metadata Lock等等,表锁是对一整张表加锁,虽然可分为读锁和写锁,但毕竟是锁住整张表,会导致并发能力下降,一般是做ddl处理时使用。
+
+行锁则是锁住数据行,这种加锁方法比较复杂,但是由于只锁住有限的数据,对于其它数据不加限制,所以并发能力强,MySQL一般都是用行锁来处理并发事务。这里主要讨论的也就是行锁。
+
+### Read Committed(读取提交内容)
+
+在RC级别中,数据的读取都是不加锁的,但是数据的写入、修改和删除是需要加锁的。效果如下
+
+MySQL> show create table class_teacher \G\
+
+
+
+Table: class_teacher
+
+
+
+Create Table: CREATE TABLE `class_teacher` (
+
+
+
+ `id` int(11) NOT NULL AUTO_INCREMENT,
+
+
+
+ `class_name` varchar(100) COLLATE utf8mb4_unicode_ci NOT NULL,
+
+
+
+ `teacher_id` int(11) NOT NULL,
+
+
+
+ PRIMARY KEY (`id`),
+
+
+
+ KEY `idx_teacher_id` (`teacher_id`)
+
+
+
+) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci
+
+
+
+1 row in set (0.02 sec)
+
+
+
+MySQL> select * from class_teacher;
+
+
+
++----+--------------+------------+
+
+
+
+| id | class_name | teacher_id |
+
+
+
++----+--------------+------------+
+
+
+
+| 1 | 初三一班 | 1 |
+
+
+
+| 3 | 初二一班 | 2 |
+
+
+
+| 4 | 初二二班 | 2 |
+
+
+
++----+--------------+------------+
+
+由于MySQL的InnoDB默认是使用的RR级别,所以我们先要将该session开启成RC级别,并且设置binlog的模式
+
+SET session transaction isolation level read committed;
+
+
+
+SET SESSION binlog_format = 'ROW';(或者是MIXED)
+
+| 事务A | 事务B |
+| --- | --- |
+| begin; | begin; |
+| update class_teacher set class_name='初三二班' where teacher_id=1; | update class_teacher set class_name='初三三班' where teacher_id=1; |
+| | ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction |
+| commit; | |
+
+为了防止并发过程中的修改冲突,事务A中MySQL给teacher_id=1的数据行加锁,并一直不commit(释放锁),那么事务B也就一直拿不到该行锁,wait直到超时。
+
+这时我们要注意到,teacher_id是有索引的,如果是没有索引的class_name呢?update class_teacher set teacher_id=3 where class_name = '初三一班'; 那么MySQL会给整张表的所有数据行的加行锁。这里听起来有点不可思议,但是当sql运行的过程中,MySQL并不知道哪些数据行是 class_name = '初三一班'的(没有索引嘛),如果一个条件无法通过索引快速过滤,存储引擎层面就会将所有记录加锁后返回,再由MySQL Server层进行过滤。
+
+但在实际使用过程当中,MySQL做了一些改进,在MySQL Server过滤条件,发现不满足后,会调用unlock_row方法,把不满足条件的记录释放锁 (违背了二段锁协议的约束)。这样做,保证了最后只会持有满足条件记录上的锁,但是每条记录的加锁操作还是不能省略的。可见即使是MySQL,为了效率也是会违反规范的。(参见《高性能MySQL》中文第三版p181)
+
+这种情况同样适用于MySQL的默认隔离级别RR。所以对一个数据量很大的表做批量修改的时候,如果无法使用相应的索引,MySQL Server过滤数据的的时候特别慢,就会出现虽然没有修改某些行的数据,但是它们还是被锁住了的现象。
+
+### Repeatable Read(可重读)
+
+这是MySQL中InnoDB默认的隔离级别。我们姑且分“读”和“写”两个模块来讲解。
+
+####读 读就是可重读,可重读这个概念是一事务的多个实例在并发读取数据时,会看到同样的数据行,有点抽象,我们来看一下效果。
+
+RC(不可重读)模式下的展现
+
+| 事务A | 事务B |
+| --- | --- |
+| begin; | begin; |
+| select id,class_name,teacher_id from class_teacher where teacher_id=1; idclass_name,teacher_id1初三二班12初三一班1 | |
+| | update class_teacher set class_name='初三三班' where id=1; |
+| | commit; |
+| select id,class_name,teacher_id from class_teacher where teacher_id=1; idclass_name,teacher_id1初三三班12初三一班1 读到了事务B修改的数据,和第一次查询的结果不一样,是不可重读的。 | |
+| commit; | |
+
+事务B修改id=1的数据提交之后,事务A同样的查询,后一次和前一次的结果不一样,这就是不可重读(重新读取产生的结果不一样)。这就很可能带来一些问题,那么我们来看看在RR级别中MySQL的表现:
+
+| 事务A | 事务B | 事务C |
+| --- | --- | --- |
+| begin; | begin; | begin; |
+| select id,class_name,teacher_id from class_teacher where teacher_id=1;idclass_nameteacher_id1初三二班12初三一班1 | | |
+| | update class_teacher set class_name='初三三班' where id=1;commit; | |
+| | | insert into class_teacher values (null,'初三三班',1); commit; |
+| select id,class_name,teacher_id from class_teacher where teacher_id=1;idclass_nameteacher_id1初三二班12初三一班1 没有读到事务B修改的数据,和第一次sql读取的一样,是可重复读的。没有读到事务C新添加的数据。 | | |
+| commit; | | |
+
+我们注意到,当teacher_id=1时,事务A先做了一次读取,事务B中间修改了id=1的数据,并commit之后,事务A第二次读到的数据和第一次完全相同。所以说它是可重读的。那么MySQL是怎么做到的呢?这里姑且卖个关子,我们往下看。
+
+### 不可重复读和幻读的区别
+
+很多人容易搞混不可重复读和幻读,确实这两者有些相似。但不可重复读重点在于update和delete,而幻读的重点在于insert。
+
+如果使用锁机制来实现这两种隔离级别,在可重复读中,该sql第一次读取到数据后,就将这些数据加锁,其它事务无法修改这些数据,就可以实现可重复读了。但这种方法却无法锁住insert的数据,所以当事务A先前读取了数据,或者修改了全部数据,事务B还是可以insert数据提交,这时事务A就会发现莫名其妙多了一条之前没有的数据,这就是幻读,不能通过行锁来避免。需要Serializable隔离级别 ,读用读锁,写用写锁,读锁和写锁互斥,这么做可以有效的避免幻读、不可重复读、脏读等问题,但会极大的降低数据库的并发能力。
+
+所以说不可重复读和幻读最大的区别,就在于如何通过锁机制来解决他们产生的问题。
+
+上文说的,是使用悲观锁机制来处理这两种问题,但是MySQL、ORACLE、PostgreSQL等成熟的数据库,出于性能考虑,都是使用了以乐观锁为理论基础的MVCC(多版本并发控制)来避免这两种问题。
+
+### 悲观锁和乐观锁
+
+* 悲观锁
+
+正如其名,它指的是对数据被外界(包括本系统当前的其他事务,以及来自外部系统的事务处理)修改持保守态度,因此,在整个数据处理过程中,将数据处于锁定状态。悲观锁的实现,往往依靠数据库提供的锁机制(也只有数据库层提供的锁机制才能真正保证数据访问的排他性,否则,即使在本系统中实现了加锁机制,也无法保证外部系统不会修改数据)。
+
+在悲观锁的情况下,为了保证事务的隔离性,就需要一致性锁定读。读取数据时给加锁,其它事务无法修改这些数据。修改删除数据时也要加锁,其它事务无法读取这些数据。
+
+* 乐观锁
+
+相对悲观锁而言,乐观锁机制采取了更加宽松的加锁机制。悲观锁大多数情况下依靠数据库的锁机制实现,以保证操作最大程度的独占性。但随之而来的就是数据库性能的大量开销,特别是对长事务而言,这样的开销往往无法承受。
+
+而乐观锁机制在一定程度上解决了这个问题。乐观锁,大多是基于数据版本( Version )记录机制实现。何谓数据版本?即为数据增加一个版本标识,在基于数据库表的版本解决方案中,一般是通过为数据库表增加一个 “version” 字段来实现。读取出数据时,将此版本号一同读出,之后更新时,对此版本号加一。此时,将提交数据的版本数据与数据库表对应记录的当前版本信息进行比对,如果提交的数据版本号大于数据库表当前版本号,则予以更新,否则认为是过期数据。
+
+要说明的是,MVCC的实现没有固定的规范,每个数据库都会有不同的实现方式,这里讨论的是InnoDB的MVCC。
+
+## MVCC在MySQL的InnoDB中的实现
+
+在InnoDB中,会在**每行数据后添加两个额外的隐藏的值来实现MVCC**,这两个值一个记录这行数据何时被创建,另外一个记录这行数据何时过期(或者被删除)。 在实际操作中,**存储的并不是时间,而是事务的版本号**,每开启一个新事务,事务的版本号就会递增。 在**可重读**Repeatable reads事务隔离级别下:
+
+* **SELECT时,读取创建版本号<=当前事务版本号,删除版本号为空或>当前事务版本号。**
+
+* **INSERT时,保存当前事务版本号为行的创建版本号**
+
+* **DELETE时,保存当前事务版本号为行的删除版本号**
+
+* **UPDATE时,插入一条新纪录,保存当前事务版本号为行创建版本号,同时保存当前事务版本号到原来删除的行**
+
+通过MVCC,虽然每行记录都需要额外的存储空间,更多的行检查工作以及一些额外的维护工作,但可以减少锁的使用,大多数读操作**都不用加锁**,读数据操作很简单,性能很好,并且也能保证只会读取到符合标准的行,也只锁住必要行。
+
+我们不管从数据库方面的教课书中学到,还是从网络上看到,大都是上文中事务的四种隔离级别这一模块列出的意思,RR级别是可重复读的,但无法解决幻读,而只有在Serializable级别才能解决幻读。于是我就加了一个事务C来展示效果。在事务C中添加了一条teacher_id=1的数据commit,RR级别中应该会有幻读现象,事务A在查询teacher_id=1的数据时会读到事务C新加的数据。但是测试后发现,在MySQL中是不存在这种情况的,在事务C提交后,事务A还是不会读到这条数据。可见在MySQL的RR级别中,是解决了幻读的读问题的。参见下图
+
+读问题解决了,根据MVCC的定义,并发提交数据时会出现冲突,那么冲突时如何解决呢?我们再来看看InnoDB中RR级别对于写数据的处理。
+
+## “读”与“读”的区别
+
+可能有读者会疑惑,事务的隔离级别其实都是对于读数据的定义,但到了这里,就被拆成了读和写两个模块来讲解。这主要是因为MySQL中的读,和事务隔离级别中的读,是不一样的。
+
+我们且看,在**RR级别中,通过MVCC机制,虽然让数据变得可重复读**,但我们读到的数据可能是历史数据,是不及时的数据,不是数据库当前的数据!这在一些对于数据的时效特别敏感的业务中,就很可能出问题。
+
+对于这种读取历史数据的方式,我们叫它**快照读 (snapshot read)**,而读取数据库当前版本数据的方式,叫当前读 (current read)。很显然,在MVCC中:
+
+* 快照读:就是select
+
+ * select * from table ....;
+
+* 当前读:特殊的读操作,插入/更新/删除操作,属于当前读,处理的都是当前的数据,需要加锁。
+
+ * select * from table where ? lock in share mode;
+
+ * select * from table where ? for update;
+
+ * insert;
+
+ * update ;
+
+ * delete;
+
+事务的隔离级别实际上都是定义了当前读的级别,MySQL为了减少锁处理(包括等待其它锁)的时间,提升并发能力,引入了快照读的概念,使得select不用加锁。而update、insert这些“当前读”,就需要另外的模块来解决了。
+
+###写("当前读") 事务的隔离级别中虽然只定义了读数据的要求,实际上这也可以说是写数据的要求。上文的“读”,实际是讲的快照读;而这里说的“写”就是当前读了。 为了解决当前读中的幻读问题,MySQL事务使用了Next-Key锁。
+
+####Next-Key锁 Next-Key锁是行锁和GAP(间隙锁)的合并,行锁上文已经介绍了,接下来说下GAP间隙锁。
+
+行锁可以防止不同事务版本的数据修改提交时造成数据冲突的情况。但如何避免别的事务插入数据就成了问题。我们可以看看RR级别和RC级别的对比
+
+RC级别:
+
+| 事务A | 事务B |
+| --- | --- |
+| begin; | begin; |
+| select id,class_name,teacher_id from class_teacher where teacher_id=30;idclass_nameteacher_id2初三二班30 | |
+| update class_teacher set class_name='初三四班' where teacher_id=30; | |
+| | insert into class_teacher values (null,'初三二班',30);commit; |
+| select id,class_name,teacher_id from class_teacher where teacher_id=30;idclass_nameteacher_id2初三四班3010初三二班30 | |
+
+RR级别:
+
+| 事务A | 事务B |
+| --- | --- |
+| begin; | begin; |
+| select id,class_name,teacher_id from class_teacher where teacher_id=30;idclass_nameteacher_id2初三二班30 | |
+| update class_teacher set class_name='初三四班' where teacher_id=30; | |
+| | insert into class_teacher values (null,'初三二班',30);waiting.... |
+| select id,class_name,teacher_id from class_teacher where teacher_id=30;idclass_nameteacher_id2初三四班30 | |
+| commit; | 事务Acommit后,事务B的insert执行。 |
+
+通过对比我们可以发现,在RC级别中,事务A修改了所有teacher_id=30的数据,但是当事务B insert进新数据后,事务A发现莫名其妙多了一行teacher_id=30的数据,而且没有被之前的update语句所修改,这就是“当前读”的幻读。
+
+RR级别中,事务A在update后加锁,事务B无法插入新数据,这样事务A在update前后读的数据保持一致,避免了幻读。这个锁,就是Gap锁。
+
+MySQL是这么实现的:
+
+在class_teacher这张表中,teacher_id是个索引,那么它就会维护一套B+树的数据关系,为了简化,我们用链表结构来表达(实际上是个树形结构,但原理相同)
+
+如图所示,InnoDB使用的是聚集索引,teacher_id身为二级索引,就要维护一个索引字段和主键id的树状结构(这里用链表形式表现),并保持顺序排列。
+
+Innodb将这段数据分成几个个区间
+
+* (negative infinity, 5],
+
+* (5,30],
+
+* (30,positive infinity);
+
+update class_teacher set class_name='初三四班' where teacher_id=30;不仅用行锁,锁住了相应的数据行;同时也在两边的区间,(5,30]和(30,positive infinity),都加入了gap锁。这样事务B就无法在这个两个区间insert进新数据。
+
+受限于这种实现方式,Innodb很多时候会锁住不需要锁的区间。如下所示:
+
+| 事务A | 事务B | 事务C |
+| --- | --- | --- |
+| begin; | begin; | begin; |
+| select id,class_name,teacher_id from class_teacher;idclass_nameteacher_id1初三一班52初三二班30 | | |
+| update class_teacher set class_name='初一一班' where teacher_id=20; | | |
+| | insert into class_teacher values (null,'初三五班',10);waiting ..... | insert into class_teacher values (null,'初三五班',40); |
+| commit; | 事务A commit之后,这条语句才插入成功 | commit; |
+| | commit; | |
+
+update的teacher_id=20是在(5,30]区间,即使没有修改任何数据,Innodb也会在这个区间加gap锁,而其它区间不会影响,事务C正常插入。
+
+如果使用的是没有索引的字段,比如update class_teacher set teacher_id=7 where class_name='初三八班(即使没有匹配到任何数据)',那么会给全表加入gap锁。同时,它不能像上文中行锁一样经过MySQL Server过滤自动解除不满足条件的锁,因为没有索引,则这些字段也就没有排序,也就没有区间。除非该事务提交,否则其它事务无法插入任何数据。
+
+行锁防止别的事务修改或删除,GAP锁防止别的事务新增,行锁和GAP锁结合形成的的Next-Key锁共同解决了RR级别在写数据时的幻读问题。
+
+###Serializable 这个级别很简单,**读加共享锁,写加排他锁,读写互斥**。使用的**悲观锁的理论**,实现简单,数据更加安全,但是并发能力非常差。如果你的业务并发的特别少或者没有并发,同时又要求数据及时可靠的话,可以使用这种模式。
+
+这里要吐槽一句,**不要看到select就说不会加锁了,在Serializable这个级别,还是会加锁的**!
\ No newline at end of file
diff --git "a/docs/database/\351\207\215\346\226\260\345\255\246\344\271\240Mysql\346\225\260\346\215\25613\357\274\232Mysql\344\270\273\344\273\216\345\244\215\345\210\266\357\274\214\350\257\273\345\206\231\345\210\206\347\246\273\357\274\214\345\210\206\350\241\250\345\210\206\345\272\223\347\255\226\347\225\245\344\270\216\345\256\236\350\267\265.md" "b/docs/database/\351\207\215\346\226\260\345\255\246\344\271\240Mysql\346\225\260\346\215\25613\357\274\232Mysql\344\270\273\344\273\216\345\244\215\345\210\266\357\274\214\350\257\273\345\206\231\345\210\206\347\246\273\357\274\214\345\210\206\350\241\250\345\210\206\345\272\223\347\255\226\347\225\245\344\270\216\345\256\236\350\267\265.md"
new file mode 100644
index 0000000..89deb93
--- /dev/null
+++ "b/docs/database/\351\207\215\346\226\260\345\255\246\344\271\240Mysql\346\225\260\346\215\25613\357\274\232Mysql\344\270\273\344\273\216\345\244\215\345\210\266\357\274\214\350\257\273\345\206\231\345\210\206\347\246\273\357\274\214\345\210\206\350\241\250\345\210\206\345\272\223\347\255\226\347\225\245\344\270\216\345\256\236\350\267\265.md"
@@ -0,0 +1,597 @@
+本文转自互联网
+
+本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
+> https://github.com/h2pl/Java-Tutorial
+
+喜欢的话麻烦点下Star哈
+
+文章首发于我的个人博客:
+> www.how2playlife.com
+
+本文是微信公众号【Java技术江湖】的《重新学习MySQL数据库》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。
+
+该系列博文会告诉你如何从入门到进阶,从sql基本的使用方法,从MySQL执行引擎再到索引、事务等知识,一步步地学习MySQL相关技术的实现原理,更好地了解如何基于这些知识来优化sql,减少SQL执行时间,通过执行计划对SQL性能进行分析,再到MySQL的主从复制、主备部署等内容,以便让你更完整地了解整个MySQL方面的技术体系,形成自己的知识框架。
+
+如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。
+
+
+
+
+一、MySQL扩展具体的实现方式
+
+随着业务规模的不断扩大,需要选择合适的方案去应对数据规模的增长,以应对逐渐增长的访问压力和数据量。
+
+关于数据库的扩展主要包括:业务拆分、主从复制、读写分离、数据库分库与分表等。这篇文章主要讲述数据库分库与分表
+
+(1)业务拆分
+
+在 [大型网站应用之海量数据和高并发解决方案总结一二](http://blog.csdn.net/xlgen157387/article/details/53230138) 一篇文章中也具体讲述了为什么要对业务进行拆分。
+
+业务起步初始,为了加快应用上线和快速迭代,很多应用都采用集中式的架构。随着业务系统的扩大,系统变得越来越复杂,越来越难以维护,开发效率变得越来越低,并且对资源的消耗也变得越来越大,通过硬件提高系统性能的方式带来的成本也越来越高。
+
+因此,在选型初期,一个优良的架构设计是后期系统进行扩展的重要保障。
+
+例如:电商平台,包含了用户、商品、评价、订单等几大模块,最简单的做法就是在一个数据库中分别创建users、shops、comment、order四张表。
+
+
+
+但是,随着业务规模的增大,访问量的增大,我们不得不对业务进行拆分。每一个模块都使用单独的数据库来进行存储,不同的业务访问不同的数据库,将原本对一个数据库的依赖拆分为对4个数据库的依赖,这样的话就变成了4个数据库同时承担压力,系统的吞吐量自然就提高了。
+
+
+
+(2)主从复制
+
+一般是主写从读,一主多从
+
+1、[MySQL5.6 数据库主从(Master/Slave)同步安装与配置详解](http://blog.csdn.net/xlgen157387/article/details/51331244)
+
+2、[MySQL主从复制的常见拓扑、原理分析以及如何提高主从复制的效率总结](http://blog.csdn.net/xlgen157387/article/details/52451613)
+
+3、[使用mysqlreplicate命令快速搭建 Mysql 主从复制](http://blog.csdn.net/xlgen157387/article/details/52452394)
+
+上述三篇文章中,讲述了如何配置主从数据库,以及如何实现数据库的读写分离,这里不再赘述,有需要的选择性点击查看。
+
+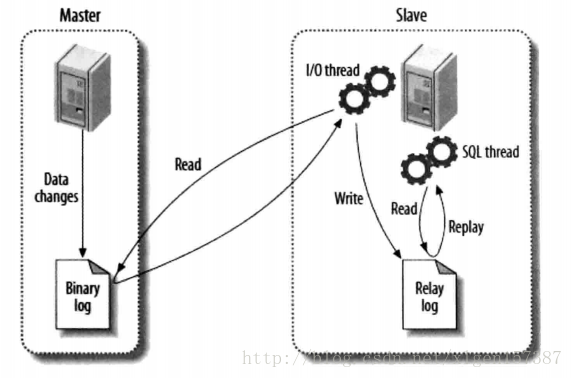
+
+上图是网上的一张关于MySQL的Master和Slave之间数据同步的过程图。
+
+主要讲述了MySQL主从复制的原理:数据复制的实际就是Slave从Master获取Binary log文件,然后再本地镜像的执行日志中记录的操作。由于主从复制的过程是异步的,因此Slave和Master之间的数据有可能存在延迟的现象,此时只能保证数据最终的一致性。
+
+(3)数据库分库与分表
+
+我们知道每台机器无论配置多么好它都有自身的物理上限,所以当我们应用已经能触及或远远超出单台机器的某个上限的时候,我们惟有寻找别的机器的帮助或者继续升级的我们的硬件,但常见的方案还是通过添加更多的机器来共同承担压力。
+
+我们还得考虑当我们的业务逻辑不断增长,我们的机器能不能通过线性增长就能满足需求?因此,使用数据库的分库分表,能够立竿见影的提升系统的性能,关于为什么要使用数据库的分库分表的其他原因这里不再赘述,主要讲具体的实现策略。请看下边章节。
+
+## 二、分表实现策略
+
+关键字:用户ID、表容量
+
+对于大部分数据库的设计和业务的操作基本都与用户的ID相关,因此使用用户ID是最常用的分库的路由策略。用户的ID可以作为贯穿整个系统用的重要字段。因此,使用用户的ID我们不仅可以方便我们的查询,还可以将数据平均的分配到不同的数据库中。(当然,还可以根据类别等进行分表操作,分表的路由策略还有很多方式)
+
+接着上述电商平台假设,订单表order存放用户的订单数据,sql脚本如下(只是为了演示,省略部分细节):
+
+```
+CREATE TABLE `order` (
+ `order_id` bigint(32) primary key auto_increment,
+ `user_id` bigint(32),
+ ...
+)
+```
+
+当数据比较大的时候,对数据进行分表操作,首先要确定需要将数据平均分配到多少张表中,也就是:表容量。
+
+这里假设有100张表进行存储,则我们在进行存储数据的时候,首先对用户ID进行取模操作,根据 `user_id%100` 获取对应的表进行存储查询操作,示意图如下:
+
+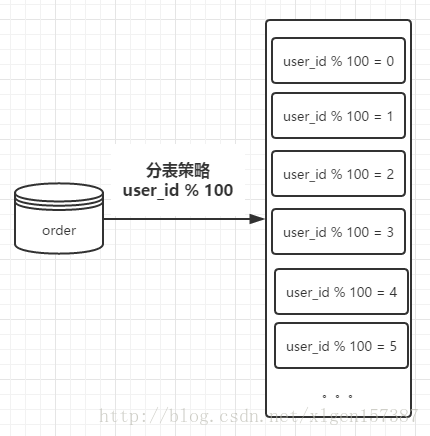
+
+例如,`user_id = 101` 那么,我们在获取值的时候的操作,可以通过下边的sql语句:
+
+```
+select * from order_1 where user_id= 101
+```
+
+其中,`order_1`是根据 `101%100` 计算所得,表示分表之后的第一章order表。
+
+注意:
+
+在实际的开发中,如果你使用MyBatis做持久层的话,MyBatis已经提供了很好得支持数据库分表的功能,例如上述sql用MyBatis实现的话应该是:
+
+接口定义:
+
+```
+
+/**
+ * 获取用户相关的订单详细信息
+ * @param tableNum 具体某一个表的编号
+ * @param userId 用户ID
+ * @return 订单列表
+ */
+public List getOrder(@Param("tableNum") int tableNum,@Param("userId") int userId);
+```
+
+xml配置映射文件:
+
+```
+
+```
+
+其中`${tableNum}` 含义是直接让参数加入到sql中,这是MyBatis支持的特性。
+
+注意:
+
+```
+另外,在实际的开发中,我们的用户ID更多的可能是通过UUID生成的,这样的话,我们可以首先将UUID进行hash获取到整数值,然后在进行取模操作。
+```
+
+## 三、分库实现策略
+
+数据库分表能够解决单表数据量很大的时候数据查询的效率问题,但是无法给数据库的并发操作带来效率上的提高,因为分表的实质还是在一个数据库上进行的操作,很容易受数据库IO性能的限制。
+
+因此,如何将数据库IO性能的问题平均分配出来,很显然将数据进行分库操作可以很好地解决单台数据库的性能问题。
+
+分库策略与分表策略的实现很相似,最简单的都是可以通过取模的方式进行路由。
+
+还是上例,将用户ID进行取模操作,这样的话获取到具体的某一个数据库,同样关键字有:
+
+用户ID、库容量
+
+路由的示意图如下:
+
+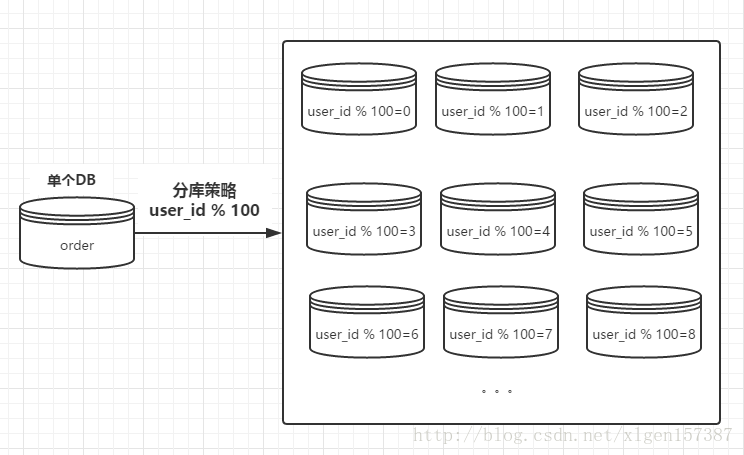
+
+上图中库容量为100。
+
+同样,如果用户ID为UUID请先hash然后在进行取模。
+
+## 四、分库与分表实现策略
+
+上述的配置中,数据库分表可以解决单表海量数据的查询性能问题,分库可以解决单台数据库的并发访问压力问题。
+
+有时候,我们需要同时考虑这两个问题,因此,我们既需要对单表进行分表操作,还需要进行分库操作,以便同时扩展系统的并发处理能力和提升单表的查询性能,就是我们使用到的分库分表。
+
+分库分表的策略相对于前边两种复杂一些,一种常见的路由策略如下:
+
+```
+1、中间变量 = user_id%(库数量*每个库的表数量);
+2、库序号 = 取整(中间变量/每个库的表数量);
+3、表序号 = 中间变量%每个库的表数量;
+```
+
+例如:数据库有256 个,每一个库中有1024个数据表,用户的user_id=262145,按照上述的路由策略,可得:
+
+```
+1、中间变量 = 262145%(256*1024)= 1;
+2、库序号 = 取整(1/1024)= 0;
+3、表序号 = 1%1024 = 1;
+```
+
+这样的话,对于user_id=262145,将被路由到第0个数据库的第1个表中。
+
+示意图如下:
+
+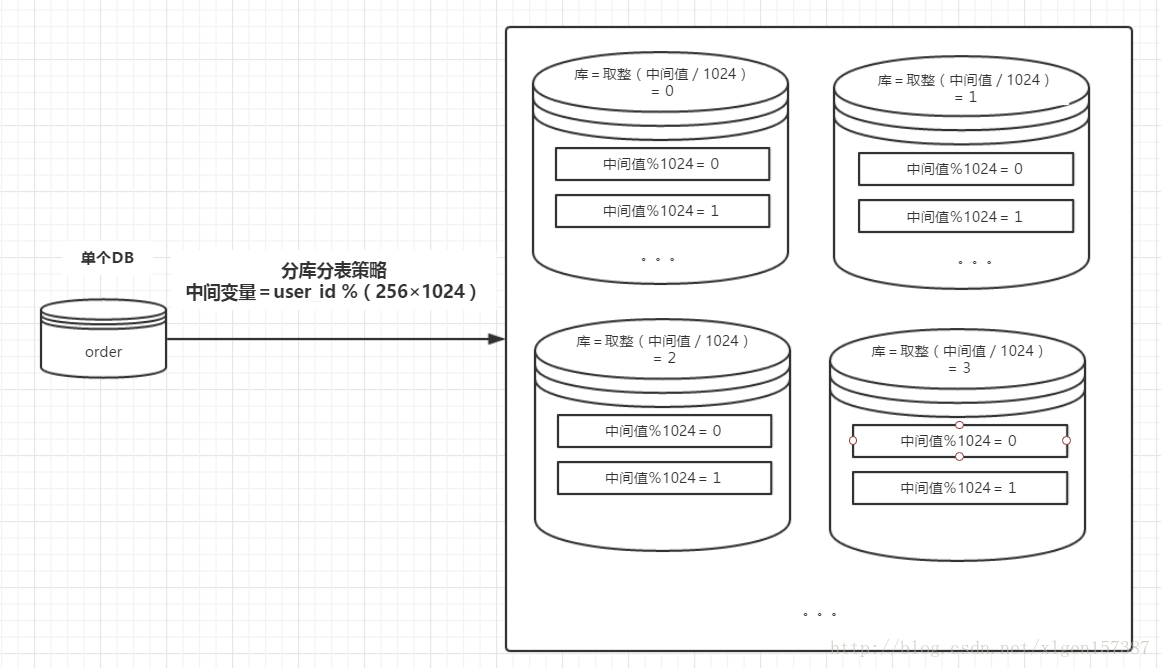
+
+## 五、分库分表总结
+
+关于分库分表策略的选择有很多种,上文中根据用户ID应该是比较简单的一种。其他方式比如使用号段进行分区或者直接使用hash进行路由等。有兴趣的可以自行查找学习。
+
+关于上文中提到的,如果用户的ID是通过UUID的方式生成的话,我们需要单独的进行一次hash操作,然后在进行取模操作等,其实hash本身就是一种分库分表的策略,使用hash进行路由策略的时候,我们需要知道的是,也就是hash路由策略的优缺点,优点是:数据分布均匀;缺点是:数据迁移的时候麻烦,不能按照机器性能分摊数据。
+
+上述的分库和分表操作,查询性能和并发能力都得到了提高,但是还有一些需要注意的就是,例如:原本跨表的事物变成了分布式事物;由于记录被切分到不同的数据库和不同的数据表中,难以进行多表关联查询,并且不能不指定路由字段对数据进行查询。分库分表之后,如果我们需要对系统进行进一步的扩阵容(路由策略变更),将变得非常不方便,需要我们重新进行数据迁移。
+
+* * *
+
+最后需要指出的是,分库分表目前有很多的中间件可供选择,最常见的是使用淘宝的中间件Cobar。
+
+GitHub地址:[https://github.com/alibaba/cobara](https://github.com/alibaba/cobara)
+
+文档地址为:[https://github.com/alibaba/cobar/wiki](https://github.com/alibaba/cobar/wiki)
+
+关于淘宝的中间件Cobar本篇内容不具体介绍,会在后边的学习中在做介绍。
+
+另外Spring也可以实现数据库的读写分离操作,后边的文章,会进一步学习。
+
+## 六、总结
+
+上述中,我们学到了如何进行数据库的读写分离和分库分表,那么,是不是可以实现一个可扩展、高性能、高并发的网站那?很显然还不可以!一个大型的网站使用到的技术远不止这些,可以说,这些都是其中的最基础的一个环节,因为还有很多具体的细节我们没有掌握到,比如:数据库的集群控制,集群的负载均衡,灾难恢复,故障自动切换,事务管理等等技术。因此,还有很多需要去学习去研究的地方。
+
+总之:
+
+```
+路漫漫其修远兮,吾将上下而求索。
+```
+
+前方道路美好而光明,2017年新征程,不泄步!
+
+## Mycat实现主从复制,读写分离,以及分库分表的实践
+
+### Mycat是什么
+
+一个彻底开源的,面向企业应用开发的大数据库集群
+
+支持事务、ACID、可以替代MySQL的加强版数据库
+
+一个可以视为MySQL集群的企业级数据库,用来替代昂贵的Oracle集群
+
+一个融合内存缓存技术、NoSQL技术、HDFS大数据的新型SQL Server
+
+结合传统数据库和新型分布式数据仓库的新一代企业级数据库产品
+
+一个新颖的数据库中间件产品
+
+以上内容来自[Mycat官网](http://www.mycat.io/),简单来说,Mycat就是一个数据库中间件,对于我们开发来说,就像是一个代理,当我们需要使用到多个数据库和需要进行分库分表的时候,我们只需要在mycat里面配置好相关规则,程序无需做任何修改,只是需要将原本的数据源链接到mycat而已,当然如果以前有多个数据源,需要将数据源切换为单个数据源,这样有个好处就是当我们的数据量已经很大的时候,需要开始分库分表或者做读写分离的时候,不用修改代码(只需要改一下数据源的链接地址)
+
+**使用Mycat分表分库实践**
+
+haha,首先这不是一篇入门Mycat的博客但小编感觉又很入门的博客!这篇博客主要讲解Mycat中数据分片的相关知识,同时小编将会在本机数据库上进行测试验证,图文并茂展示出来。
+
+数据库分区分表,咋一听非常地高大上,总有一种高高在上,望尘莫及的感觉,但小编想说的是,其实,作为一个开发人员,该来的总是会来,该学的东西你还是得学,区别只是时间先后顺序的问题。
+
+### 一、分区分表
+
+分区就是把一个数据表的文件和索引分散存储在不同的物理文件中。
+
+mysql支持的分区类型包括Range、List、Hash、Key,其中Range比较常用:
+
+RANGE分区:基于属于一个给定连续区间的列值,把多行分配给分区。
+
+LIST分区:类似于按RANGE分区,区别在于LIST分区是基于列值匹配一个离散值集合中的某个值来进行选择。
+
+HASH分区:基于用户定义的表达式的返回值来进行选择的分区,该表达式使用将要插入到表中的这些行的列值进行计算。这个函数可以包含MySQL 中有效的、产生非负整数值的任何表达式。
+
+KEY分区:类似于按HASH分区,区别在于KEY分区只支持计算一列或多列,且MySQL服务器提供其自身的哈希函数。必须有一列或多列包含整数值。
+
+分表是指在逻辑上将一个表拆分成多个逻辑表,在整体上看是一张表,分表有水平拆分和垂直拆分两种,举个例子,将一张大的存储商户信息的表按照商户号的范围进行分表,将不同范围的记录分布到不同的表中。
+
+### 二、Mycat 数据分片的种类
+
+Mycat 的分片其实和分表差不多意思,就是当数据库过于庞大,尤其是写入过于频繁且很难由一台主机支撑是,这时数据库就会面临瓶颈。我们将存放在同一个数据库实例中的数据分散存放到多个数据库实例(主机)上,进行多台设备存取以提高性能,在切分数据的同时可以提高系统的整体性。
+
+数据分片是指将数据全局地划分为相关的逻辑片段,有水平切分、垂直切分、混合切分三种类型,下面主要讲下Mycat的水平和垂直切分。有一点很重要,那就是Mycat是分布式的,因此分出来的数据片分布到不同的物理机上是正常的,靠网络通信进行协作。
+
+水平切分
+
+就是按照某个字段的某种规则分散到多个节点库中,每个节点中包含一部分数据。可以将数据水平切分简单理解为按照数据行进行切分,就是将表中的某些行切分到一个节点,将另外某些行切分到其他节点,从分布式的整体来看它们是一个整体的表。
+
+垂直切分
+
+一个数据库由很多表构成,每个表对应不同的业务,垂直切分是指按照业务将表进行分类并分不到不同的节点上。垂直拆分简单明了,拆分规则明确,应用程序模块清晰、明确、容易整合,但是某个表的数据量达到一定程度后扩展起来比较困难。
+
+混合切分
+
+为水平切分和垂直切分的结合。
+
+### 三、Mycat 垂直切分、水平切分实战
+
+#### 1、垂直切分
+
+上面说到,垂直切分主要是根据具体业务来进行拆分的,那么,我们可以想象这么一个场景,假设我们有一个非常大的电商系统,那么我们需要将订单表、流水表、用户表、用户评论表等分别分不到不同的数据库中来提高吞吐量,架构图大概如下:
+
+