# # Quickstart - Analyze Dataset for Potential Issues
#
# [](https://colab.research.google.com/github/visual-layer/fastdup/blob/main/examples/quickstart.ipynb)
# [](https://kaggle.com/kernels/welcome?src=https://github.com/visual-layer/fastdup/blob/main/examples/quickstart.ipynb)
# [](https://docs.visual-layer.com/docs/getting-started-with-fastdup)
#
# Welcome to the fastdup Quickstart Guide! 🎉
#
# This notebook demonstrates how to efficiently analyze an image dataset for potential issues using [fastdup](https://github.com/visual-layer/fastdup), a powerful tool designed for image and video dataset exploration.
#
# ### Objectives
# By the end of this tutorial, you'll be able to:
# - Detect and identify **broken images**.
# - Spot **duplicates** or **near-duplicates** within your dataset.
# - Discover **outliers** that may affect model performance.
# - Find **dark, bright, or blurry images** for potential quality adjustments.
#
# ### What's Included
# In addition to identifying dataset issues, this guide will help you:
# - Visualize **clusters of visually similar images**, enabling a high-level understanding of your dataset's structure.
# - Learn the core functionalities of fastdup with simple, step-by-step examples.
# ## Installation
# First, let's start with the installation:
#
# > ✅ **Tip** - If you're new to fastdup, we encourage you to run the notebook in [Google Colab](https://colab.research.google.com/github/visual-layer/fastdup/blob/main/examples/quick-dataset-analysis.ipynb) or [Kaggle](https://kaggle.com/kernels/welcome?src=https://github.com/visual-layer/fastdup/blob/main/quick-dataset-analysis.ipynb) for the best experience. If you'd like to just view and skim through the notebook, we recommend viewing using [nbviewer](https://nbviewer.org/github/visual-layer/fastdup/blob/main/examples/quick-dataset-analysis.ipynb).
#
#
# In[1]:
import sys
if "google.colab" in sys.modules:
# Running in Google Colab
get_ipython().system('pip install --force-reinstall --no-cache-dir numpy==1.26.4 scipy fastdup')
else:
# Running outside Colab
get_ipython().system('pip install -Uq fastdup')
# Now, test the installation by printing out the version. If there's no error message, we are ready to go!
# In[2]:
import os
os.environ['JPY_PARENT_PID'] = '1'
# Verify fastdup installation
import fastdup
fastdup.__version__
# ## Download Dataset
#
# For demonstration, we will use a generally curated [Oxford IIIT Pet dataset](https://www.robots.ox.ac.uk/~vgg/data/pets/). Feel free to swap this dataset with your own.
#
# The dataset consists of images and annotations for 37 category pets with roughly 200 images for each class.
#
# > 🗒 **Note** - fastdup works on both unlabeled and labeled images. But for now, we are only interested in finding issues in the images and not the annotations.
# > If you're interested in finding annotation issues, head to:
# > + 🖼 [**Analyze Image Classification Dataset**](https://nbviewer.org/github/visual-layer/fastdup/blob/main/examples/analyzing-image-classification-dataset.ipynb)
# > + 🎁 [**Analyze Object Detection Dataset**](https://nbviewer.org/github/visual-layer/fastdup/blob/main/examples/analyzing-object-detection-dataset.ipynb).
#
#
# Let's download only from the dataset and extract them into the local directory:
# In[ ]:
get_ipython().system('wget https://thor.robots.ox.ac.uk/~vgg/data/pets/images.tar.gz -O images.tar.gz')
get_ipython().system('tar xf images.tar.gz')
# ## Run fastdup
#
# Once the extraction completes, we can run fastdup on the images.
#
# For that let's initialize fastdup and specify the input directory which points to the folder of images.
# In[6]:
fd = fastdup.create(input_dir="images/")
# > 🗒 **Note** - The `.create` method also has an optional `work_dir` parameter which specifies the directory to store artifacts from the run.
#
# In other words you can run `fastdup.create(input_dir="images/", work_dir="my_work_dir/")` if you'd like to store the artifacts in a `my_work_dir`.
#
# Now, let's run fastdup.
# In[ ]:
fd.run(overwrite=True)
# ## View Run Summary
#
# After the run is completed, you can optionally view the summary with:
# In[15]:
fd.summary()
# ## Invalid Images
# From the summary above, we see there are a few invalid images. These are broken images that cannot be read.
#
# You can get a list of broken images with:
# In[5]:
fd.invalid_instances()
# ## Interactive Exploration
# In addition to the static visualizations presented above, fastdup also offers interactive exploration of the dataset.
#
# To explore the dataset and issues interactively in a browser, run:
# In[ ]:
fd.explore()
# > 🗒 **Note** - This currently requires you to sign-up (for free) to view the interactive exploration. Alternatively, you can visualize fastdup in a non-interactive way using fastdup's built in galleries shown in the upcoming cells.
#
# You'll be presented with a web interface that lets you conveniently view, filter, and curate your dataset in a web interface.
#
#
# 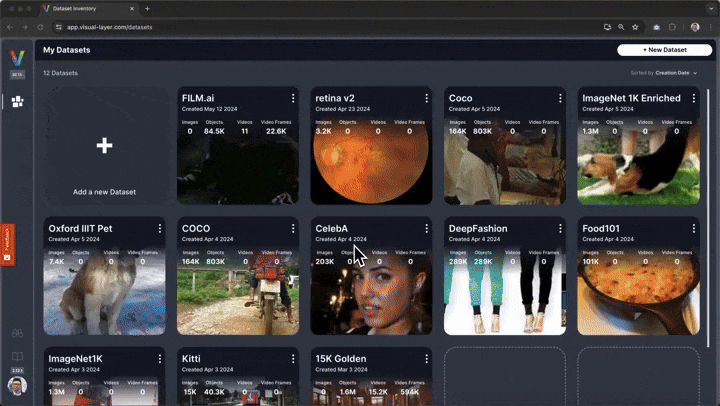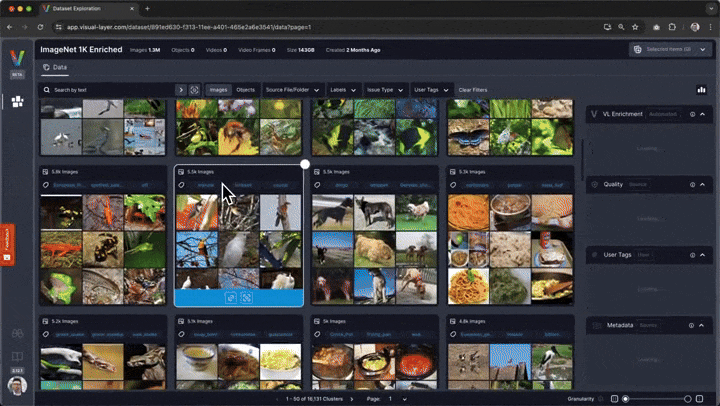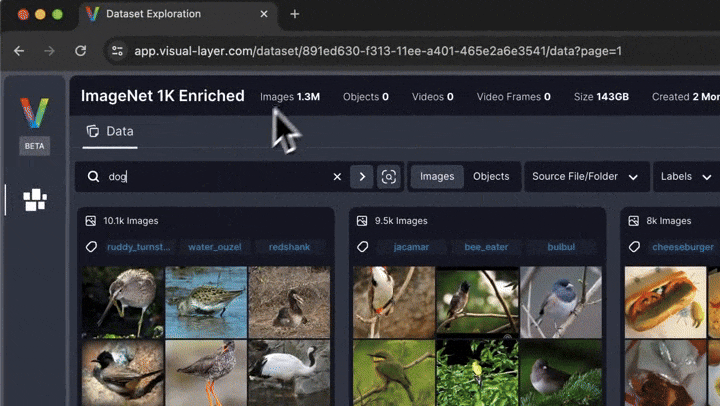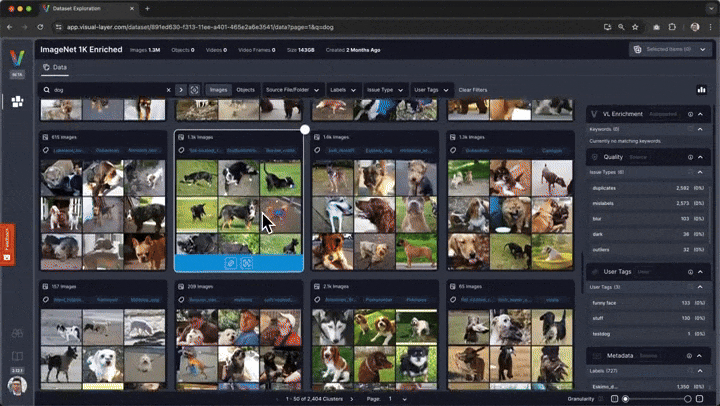
# ## Visualize Image Clusters
#
# One of fastdup's coolest features is visualizing image clusters. In this section, we group similar-looking images (or even duplicates) as a cluster and visualize them in the gallery.
#
# To do so, run:
#
#
# In[ ]:
fd.vis.component_gallery()
# ## Duplicate/Near-duplicates
#
# One of the lowest hanging fruits in cleaning a dataset is finding and eliminating duplicates.
#
# fastdup provides a handy way of visualizing duplicates/near-duplicates using the `duplicates_gallery` method. The `Distance` value indicates how visually similar are the image pairs in the gallery. A `Distance` of `1.0` indicates an exact copy and vice-versa.
# In[6]:
fd.vis.duplicates_gallery()
# ## Outliers
#
# Similar to duplicate pairs, you can visualize potential outliers in your dataset with:
# In[7]:
fd.vis.outliers_gallery()
# ## Blurry, Dark and Bright Images
#
# fastdup also lets you visualize images from your dataset using statistical metrics.
#
# For example, with `metric='blur'` we can visualize the blur images from the dataset.
# In[8]:
fd.vis.stats_gallery(metric='dark')
# In[9]:
fd.vis.stats_gallery(metric='bright')
# In[10]:
fd.vis.stats_gallery(metric='blur')
# ## Wrap Up
#
# That's a wrap! In this notebook we showed how you can run fastdup on a dataset or any folder of images.
#
# We've seen how to use fastdup to find:
#
# + Broken images.
# + Duplicate/near-duplicates.
# + Outliers.
# + Dark, bright and blurry images.
# + Image clusters.
#
# Next, feel free to check out other tutorials -
#
# + 🧹 [**Clean Image Folder**](https://nbviewer.org/github/visual-layer/fastdup/blob/main/examples/cleaning-image-dataset.ipynb): Learn how to analyze and clean a folder of images from potential issues and export a list of problematic files for further action. If you have an unorganized folder of images, this is a good place to start.
# + 🖼 [**Analyze Image Classification Dataset**](https://nbviewer.org/github/visual-layer/fastdup/blob/main/examples/analyzing-image-classification-dataset.ipynb): Learn how to load a labeled image classification dataset and analyze for potential issues. If you have labeled ImageNet-style folder structure, have a go!
# + 🎁 [**Analyze Object Detection Dataset**](https://nbviewer.org/github/visual-layer/fastdup/blob/main/examples/analyzing-object-detection-dataset.ipynb): Learn how to load bounding box annotations for object detection and analyze for potential issues. If you have a COCO-style labeled object detection dataset, give this example a try.
#
# As usual, feedback is welcome! Questions? Drop by our [Slack channel](https://visualdatabase.slack.com/join/shared_invite/zt-19jaydbjn-lNDEDkgvSI1QwbTXSY6dlA#/shared-invite/email) or open an issue on [GitHub](https://github.com/visual-layer/fastdup/issues).
#
#






