【AWS】AWS Glue Visual ETL Jobでカスタム変換ノードを利用してPandasを使用する

はじめに
皆様こんにちは。DXソリューション営業本部の後藤です。
今回の記事では、AWS Glue Visual ETL Jobでカスタム変換ノードを利用してPandasを使用する方法についてご説明したいと思います。
AWS Glue Studioについて
「AWS Glue Studio」は、ETLプロセスをより直感的に、そして視覚的にデザイン・実行することが可能なグラフィカルインターフェイスです。AWS Glue Studioを使用すると、ドラッグアンドドロップのシンプルな操作で、データソースの選択、変換の設定、出力先の指定などのETLジョブの設計が可能になります。特にコーディングの経験が少ないユーザーや、複雑なETLプロセスを迅速に設計したいユーザーにとって、非常に役立つツールとなっています。さらに、AWS Glue Studioは、ジョブの実行結果やデータのフローをリアルタイムで確認することができるため、デバッグや最適化の作業も効率的に行えます。
今回行いたいこと
Glue Studioで行いたいETL処理の内容
RedshiftにあるデータをGlue Studioを使用して抽出・加工し、S3にCSV形式で出力させる 。
①Redshiftへデータをロード
②SQL文を使用したフィルタリング処理
・特定の値のみ表示させる
③Pandasを使用した条件分岐処理
・新しく列を追加する
・特定の列の値に基づいて新しい列に条件分岐で値を設定する
④ S3へCSV形式で出力
構成図
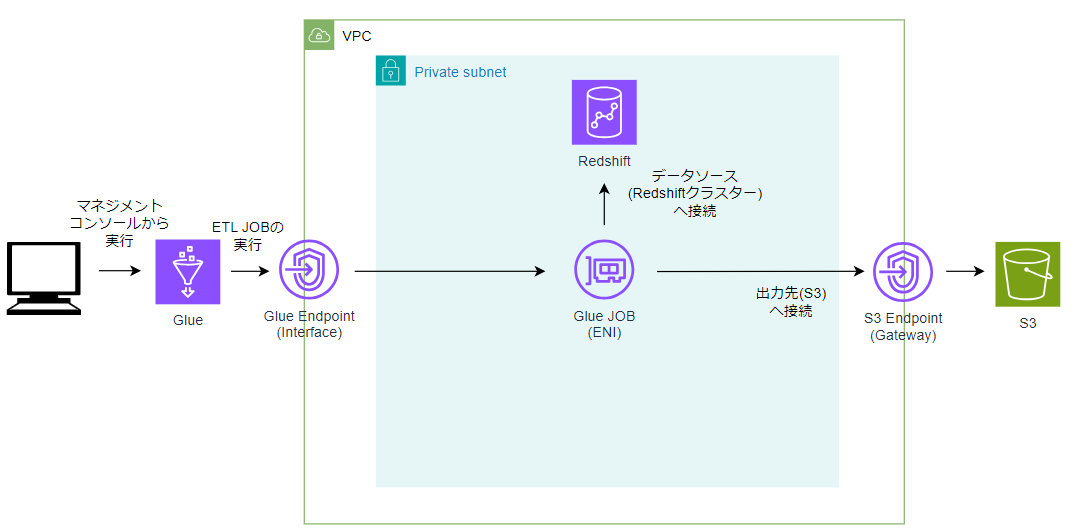
前提条件
・Redshiftに元データが格納されていること
・出力先のS3バケットを作成済みであること
・Glueジョブ用のENI向けのセキュリティグループを作成し、自己参照ルールを追加してから、Redshiftクラスターにアタッチされていること
・ゲートウェイ型S3エンドポイントが作成されていること。(プライベートサブネットからS3に出力するため)
・データソースを含むVPCにGlue VPCエンドポイントが作成されていること。(VPC内にあるデータソース(Redshift)でSpark SQL変換を使用するため)
・ETL Jobに必要なIAMロールの設定が完了していること
※上記インフラ設定の詳細については以下記事で紹介しているため、是非ご参照下さい!
【AWS】RedshiftとAWS Glue接続時のインフラ設定
全体フロー

各ノードの設定と解説
Data source - Redshift
sourceタブからRedshiftを選択することで、既存のテーブルからdata sourceを設定することができます。

SQL Query
SQL Queryノードを使ってSQL クエリの形式で独自の変換を記述できます。
TransformタブからSQL Queryノードを選択します。
今回は’性別’列を’男性’のみ出力するクエリを実行してみます。
SQL文はこちらになります。
select * from myDataSource
where `性別`='男性'

Custom Transform(カスタム変換)
Custom Transformノードでは、独自の関数を定義することで、自由にETL処理を行わせることが出来ます。
・使用可能な言語はpythonとscalaです。
・標準の変換ノードでは対応できない複雑なデータ変換や特定のビジネスロジックを適用する場合、カスタム変換ノードが必要になります。データ処理の柔軟性と効率性がさらに向上します。
TransformタブからCustom Transformノードを選択します。
今回は’種別’列を追加しSpecies列の値が "setosa"の場合は1をそれ以外の場合は0にする条件分岐を設定してみます。コードはPythonのPandasを使って実装していきます。

条件分岐のコードはこちらになります
def MyTransform (glueContext, dfc) -> DynamicFrameCollection:
import pandas as pd
df = dfc.select(list(dfc.keys())[0]).toDF()
pandas_df = df.toPandas()
pandas_df['種別'] = pandas_df.apply(lambda row: 1 if row['species'] == 'setosa' else 0, axis=1)
spark_df = glueContext.spark_session.createDataFrame(pandas_df)
dynamic_frame = DynamicFrame.fromDF(spark_df, glueContext, "dynamic_frame")
return DynamicFrameCollection({"CustomTransform0": dynamic_frame}, glueContext)
このコードについて詳しく解説します
カスタム変換ノードを追加するとコードブロックには以下の1行のコードが入力されています
def MyTransform (glueContext, dfc) -> DynamicFrameCollection:
MyTransform: 関数名で、これを任意の名前に変更することができる。
glueContext: Glueのコンテキストオブジェクトで、Glueの機能(データの読み書き、変換など)にアクセスするために使用される。
dfc: DynamicFrameCollectionオブジェクトで、複数のDynamicFrameを格納します。DynamicFrameは
Glueで使用されるデータ構造で、スキーマに柔軟性があり、分散データ処理に適している。
-> DynamicFrameCollection: この関数がDynamicFrameCollectionを返すことを示している。
ここからは自由にコードを入力できる部分です↓
import pandas as pd
pandasライブラリをインポート。
df = dfc.select(list(dfc.keys())[0]).toDF()
DynamicFrameCollectionの最初のDynamicFrameを選択します。dfc.keys()はコレクション内のDynamicFrameのキーのリストを返し、[0]はそのリストの最初のキーを選択します。.toDF()は、DynamicFrameをSparkのDataFrameに変換します。
pandas_df = df.toPandas().toPandas()は、SparkのDataFrameをPandasのDataFrameに変換します。
pandas_df['種別'] = pandas_df.apply(lambda row: 1 if row['species'] == 'setosa' else 0, axis=1)
Pandas DataFrameに種別という新しい列を追加します。.apply()メソッドを使用し、各行のspecies列の値をチェックします。'setosa'の場合は1、そうでない場合は0を設定します。axis=1は、行ごとに関数を適用することを意味します。
spark_df = glueContext.spark_session.createDataFrame(pandas_df)
変換されたPandas DataFrameを再びSpark DataFrameに変換します。
dynamic_frame = DynamicFrame.fromDF(spark_df, glueContext, "dynamic_frame")
Spark DataFrameをDynamicFrameに変換します。このDynamicFrameはAWS Glueで使用されます。
return DynamicFrameCollection({"CustomTransform0": dynamic_frame}, glueContext)
新しく変換されたDynamicFrameをDynamicFrameCollectionとして返却します。辞書形式でキーを指定し、結果のDynamicFrameを格納します。
SelectFromCollection
Custom TranfromノードはDynamicFrameCollectionの出力が固定となっていて、そのままでは出力先ノードが受け取ることができないのでSelectFromClollectionノードを間にはさんで単一のDynamicFrame型に変換します。
TransformタブからSelectFromCollectionノードを選択します。

Targetノード - S3
TargetsタブからS3ノードを選択し、出力先であるS3バケットにCSV形式で出力されるよう設定します。

jobを実行し、Run detailsの実行ステータスがSucceededになっていれば実行成功です!
S3バケットにアクセスし、出力されたデータを確認するとこのような出力結果になります。
まとめ
いかがでしたでしょうか。
今回はAWS Glueを使ったデータ変換とS3へのデータロード方法を紹介しました。
カスタム変換ノードとPandasを利用することで、高度なデータ処理が可能となります。ぜひ、実際のプロジェクトに活用してみてください。
最後までお読みいただき、誠にありがとうございました!
もし「このサービスについて知りたい」「AWS環境の構築、移行」などのリクエストがございましたら、弊社お問合せフォームまでお気軽にご連絡ください! のちほど当ブログにてご紹介させていただくか、複雑な内容に関するお問い合わせの内容の場合には直接営業からご連絡を差し上げます。
※Amazon Web Services、”Powered by Amazon Web Services”ロゴ、およびブログで使用されるその他のAWS商標は、米国その他の諸国における、Amazon.com, Inc.またはその関連会社の商標です。
※Pythonは、Python Software Foundationの登録商標です。
