








































もしSIerのエンジニアがSRE本を読んだら
- 3. whoami? 3 - Name: 安藤 知樹 - Twitter: @chataro0 - Role: インフラエンジニア? - Job: 株式会社エーピーコミュニケーションズ - インフラ中心のSIer - Interest: - OS: Linux - Language: Python - クラウド:AWS, Azure, GCP, OpenStack… - コンテナ:Docker, Kubernetes - Automation: Ansible, Terraform
- 6. 6 運用現場のイメージ 客 明日までに これ作って! なんでこんなミス したんだ!? 客 さっき頼んだの まだ? 全然終わらない!申し訳ありません! 早急に対処します! Alert!! 客 頼んだ内容と 違う!! わかりました!
- 7. よくある運用の現場の特徴 7 • 絶対的な力関係が決まっている • 無茶振りされても断れない • 非効率的 • 分厚い手順書でダブルチェック • 依頼・差し戻しなども多い • 終わりがない、先が見えない • 3K • きつい • 帰れない • 厳しい
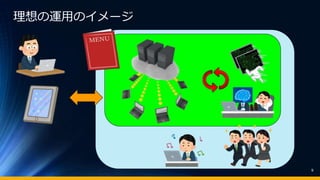
- 9. 9 理想の運用のイメージ
- 10. 運用の理想と現実 10 理想 現実 文化 合理的 保守的 姿勢 意味のあるものを 自分の意志でやる やらされ感 受け身 生産性 高 低
- 13. Googleが誇るSRE! 13
- 14. SRE サイトリライアビリティエンジニアリング - Googleの信頼性を支えるエンジニアリングチーム • Googleのサイト・サービスの信頼性を 支えるシステムとエンジニアリングチーム • ソフトウェアエンジニアリング + サーバ・ネットワークのインフラ知識 • サービスの品質、運用の効率を高める • DevOpsの一種?発展形? • 読み手によって様々な解釈がある 14 What is SRE ?
- 15. 我々が解釈した SRE 15
- 17. 17 運用のベストプラクティス 信頼性100%は目指さない ● サービスレベルの指標(SLI)を元に、 サービスレベルの目標(SLO)を決める。(≠SLA) ● データによる判断で標準化(≠人による判断) ● エラーバジェット = 100% - SLO 開発と運用がエラーバジェットを共有することで 対立関係から協力関係へ リスクを受容する
- 18. 1818 トイル ● 手作業で繰り返し行われ ● 自動化することが可能であり ● 戦術的で長期的な価値を持たず ● 作業量がサービスの成長に比例する といった傾向を持つ作業 ● トイルの撲滅(自動化) ● 50%ルール:運用業務は業務の50%以下に抑え、 50%以上を生産性の高い活動に当てる 運用のベストプラクティス
- 19. 19 • サイボウズ様 • ミクシィ様 • メルカリ様 • ・・・ Google含め 大きな自社サービスを展開している 高い技術力を活かしている企業が多い 19 SREを採用してる企業 運用のベストプラクティス
- 20. 今の運用の温度感から見ると… • リスクの受容 • あくまで目標は100%という意識が強い • お客様ありきの仕事(SLA>SLO) • 指標となるデータが見つからない • トイルの撲滅 • 自動化が可能な作業?!?! • 自動化を実現するための技術力が不足 • 自社サービス企業 • 顧客のシステムを運用。携わる部署・企業が多く、 関係者が多いと一度できた仕組みを変えるのは大変 20
- 23. 自分達なりのSREの実践 23
- 26. 1. 取捨選択 2. アウトソーシング 3. 順序の入れ替え 4. 特殊性の排除 5. 自動化 26 トイルへの対処法
- 31. 5. 自動化 1~4で残った or 整理した業務を自動化検討 ↓ ふるいを掛けている分、自動化する価値も高い! ふるいにかけないと、自動化自体が非効率に 31 トイルへの対処法
- 32. 変わるまでの大きな壁 32
- 33. • 品質を担保できるのか? • 周囲の理解が得られない • 関係各所との調整が必要 • 工数の捻出はどうする? • 学習・教育コストもかかる 変えることの リスク・コストが大きい 33 運用を変えるまでには大きな壁がある
- 36. • サービスが成長するとコストが増える可能性 ←トイルがあるから • 他社のサービスにシェアを奪われる • 企業努力(サービス向上、価格競争) • 新しい技術を開発・採用した新サービス • メンバーがクサる(特に変えたいと思ってる人) 36 変わらないリスク
- 37. 37 変わるべき vs 変わらないべき 過大評価せずに検討しましょう 進め方も大事 いきなり議論を始めてしまうと、 拒否反応を見せる人も • 動く所を見せてメリットをアピール • できるところからスモールスタート • 知見と実績を貯めながら進める • 乗ってくれそうな人を味方につける • 影響力のある人だと、なお良し
- 38. その後の展望 38
- 39. • こういった活動で時間が確保できるはず • 得られた時間で何をしていくか • さらなる改善・自動化 • 変化は一度きりではなく継続 • そのためのスキルアップ • 技術のトレンドを追いかける 39 その後の展望
- 40. 最後に 40
- 41. SREは当たり前になっている業務に 様々な気づきを与えてくれる • 自分の現状や経験と照らし合わせると、 様々な感想やアイディアが浮かんできます。 • 良いことばかりではなく悪いことも • それも含めて大事! • 異なる意見を持った人のやり方を聞くことが突破口に なることも • 自己流全然アリだと思います! 41 最後に
- 42. • 500ページを超えるボリューム • エッセンスが詰まってる! • 挫折注意 得られた気付きを元に 快適な良き運用ライフを! 42 最後に
Editor's Notes
- #2: それでは『もしSIerのエンジニアがSRE本を読んだら』というテーマで、 発表させていただきます。 よろしくお願いいたします。 今回は、 オライリーさんから出版されているSREという本があるんですが、 こちらをSIerとして主にシステム運用をやってるエンジニアが読んでみて、 どのように感じたのか、 それをどう取り入れて行こうと思ったのか ということについて発表させていただきます。
- #3: アジェンダはこちらのようになっております。 まずは軽く自己紹介させていただいた後に、 システム運用の理想と現実、というところから SREってどんなもの?というお話をしまして、 じゃあSREをどうやって実践していくか、 という流れでお話いたします。
- #4: まずは簡単に自己紹介させていただきます。 私はエーピーコミュニケーションズというインフラ中心のSIerで インフラエンジニアをやっている安藤と申します。 Linux中心のサーバエンジニアなんですが、 最近はPythonなどの開発言語も扱うようになってきました。 以前はVMwareなどの仮想基盤でのお仕事が多かったですが、 今はもっぱらAWSやAzure、OpenStackなどのクラウドを使っており、 PythonでこれらのAPIを叩いたりしています。 近頃は、DockerやKubernetesなどのコンテナ技術や AnsibleやTerraformといったInfrastructure as Codeな自動化ツールに興味を持っています。 それでは、本題のSREのお話に入ろうと思うのですが、 その前に少し、
- #5: システム運用の 理想と現実 ということで みなさまとシステムの運用のイメージを すり合わせさせていただきたいと思います。 [2:00]
- #6: まずみなさん、食べながらで結構ですので、 システム運用ってなんだろう?どういうことやってるんだろう?と ちょっとイメージを浮かべていただけますでしょうか? 開発をやってらっしゃる方が多いかと思いますので、 運用って何をやっているのか、ピンと来ないという方も 中にはいらっしゃるかもしれませんね。
- #7: そこで、私の周りでよく聞く運用のイメージを絵に描いてみました。 運用のオペレーターは定常業務やシステム監視といった業務を主にやっているのですが、 何かの作業の依頼だったり定常業務の手順の変更であったり、様々な依頼もやってきます。 中にはイレギュラーな依頼もされてしまったりします。例えば ・作業依頼は数日前にもらうというルールがあるにもかかわらず、今すぐやってくれと言われて、 お客様やサービスのことがあるので断るわけにもいかず受けることになった。 ・ここからここまでやります、という契約なのに、契約範囲外のレベルまで対応を求められて、 できないというと怒りだしてしまったり、事情を説明して納得してもらうのにすごく時間がかかったり、 みたいなことがあったりします。 そんな状況が継続していると 忙しくて確認不足だったり、手順の不備があったりでミスを起こしてしまい、 お客さんや、さらには守ってくれるはずの上司からも怒られたり、 職場に雰囲気が悪くなってしまいます。 そんな状況でも監視しているシステムからのアラートはおかまいなしに鳴り続けるので さらに忙しくなって帰れない、という負の連鎖が蔓延している、そんなお話でした。
- #8: 特徴としては 絶対的な力関係が決まっており、お金を出しているお客様の立場が強いです。 そのためどんな無茶振りであっても 基本的にはやらなきゃいけない、断れないことが多いです。 分厚い手順書を使ってダブルチェックをしながら進めたり、 上司や協力会社に依頼を出したり、それが差し戻ったりすることも多く とても非効率的なやり方が往々として残っています。 また運用は似たようなことの繰り返しなので終わりがなく、 キャリア的にも先が見えない そのため、 きつい、帰れない、厳しい という3Kな仕事とも言われています。
- #9: ここまで運用のイメージをお話ししてきましたが、 みなさんお食事中ということもありますので 、一旦辛い現実は忘れていただいて、 理想的な運用の姿というのを思い描いてみましょう。 どんな運用を思い描いたでしょうか?
- #10: 私たちはザックリとこのようなイメージを思い描きました。 システムが中心にある、というのは当然なのですが、 さきほどの絵は人が手動でやっていたような運用業務を プログラムやAIが自動でやってくれる。 運用面も含めてシステム化されている、というのが重要だと思いました。 他にも、サービスがしっかりメニュー化されていて 簡単な操作で利用できるセルフサービス型などのユーザーインターフェースが整っていて、 お客様自身が利用したいメニューを選んで利用できる。 結果的に対応のミスやクレームが少なくなって、 先程の絵では険悪だったチームも、良い雰囲気になって同じ方向を向いていける。 そういった良い雰囲気を心理的安全性がある状態、と呼んだりするのですが、 そういう空気のおかげで、いい仕事ができる。生産性が高くなる。 そんな運用が理想かなーとイメージしました。 現実も理想も人によってイメージしたものは違うかと思いますが、
- #11: 運用の理想と現実の違いをざっくりまとめてしまうと、 こんな違いになるんじゃないでしょうか。 理想の運用は 合理的な文化の中で、 意味のあるもの、価値の高いことを 自分の意思でできる その結果生産性も高くなる、 というのが理想なのですが、 現実は、 保守的な文化の中、 決まったことやお客様に言われたことをひたすらやり続ける そんなやらされ感や受け身な状態が続いており、 生産性も低くなってしまう。 というのが現実かと思います。 こういうギャップを少しでも感じてしまうと、
- #12: もっと理想の運用に近づきたい、 もっとイケてる運用をやりたい! そう思いませんか?
- #13: そんなイケてる運用の代表例として
- #14: Googleが誇るSRE! を取り上げたいと思います。
- #15: まずSREとはなんなのか、というと サイト・リライアビリティ・エンジニアリングの略で、 オライリーさんから出版されている書籍の副題にもあるように、 Googleの信頼性を支えるエンジニアリングチーム というというものを指しております。 このエンジニアリングチームのスキルとしてソフトウェアエンジニアリングに加えて、 サーバーやネットワークなどのインフラの専門知識を持つ方が多いそうです。 そのスキルを活用することでGoogleの数々のサイトやサービスの品質を高めたり、 運用の効率を高めるのが役割です。 SREについては、DevOpsの一種だといわれたり、 DevOpsの一歩先を行くものと言われたりと、 あるいは全く別物だ、というように 読んだ人によって様々な解釈があるようです。 私たちはこのSREの本を読んだ時、 非常に大きな衝撃を受けまるとともに、 最初にお話ししたような理想と現実のギャップに強く襲われたわけなんですね。
- #16: そこでSREについて 我々がどう解釈したかについてお話しします。 [8:00]
- #17: まず我々はSREを 大規模なサービスにおける 運用のベストプラクティス というふうに解釈しました。 中身を見ていきますと
- #18: まず第一に、リスクを受容して、信頼性100%を目指さない、ということです。 いきなりインパクトのあるものなんですけれど、 サービスの信頼性、すなわちレイテンシやスループット、あるいは可用性といった、 数値的に評価できる指標、というのをSLI、サービスレベルインジケーターと呼びます。 そしてその中で目標とする項目を決める、それがSLO、サービスレベルオブジェクティブとなります。 よく似た言葉で、SLA、サービスレベルアグリーメントがありますが、 SLAはサービス提供者が利用者に約束する、いわばビジネス的に契約する信頼性なので 違反すると払い戻しやペナルティがあったりするものに対して、 SLOはどちらかというと身内で目指す純粋な目標で、 SLOを達成するためにシステムを改善していく動機のようなものになります。 そして100%からSLOを引いた値をエラーバジェット、エラーの予算という考えがあります。 運用のチームは得てして100%の安定性を目指しがちですが、 エラーバジェットで許容する範囲なら新機能の追加やテスト、それによる障害のリスクを受け入れますよ、 そういった目安を作ることができます。 このようにエラーバジェットを開発と運用が共有することで、 対立しがちな関係を、良いサービスを動かすための協力関係に導きやすくなります。
- #19: 次にトイルという考え方です。 トイルというのは、サービスにかかわる作業の中で 手作業で何度も何度も繰り返し行われいて、 それでいて自動化することが可能であり、 戦術的で長期的な価値を持たず、 作業量がサービスの成長に比例する そんな傾向・性格を持つ作業のことです。 こういったトイルというのは運用の中にたくさんあるんじゃないかと思います。 SREでは、そんなトイルを撲滅するために 自動化というアプローチをとっています。 またSREには50%ルールというユニークなルールがあって、 運用業務を業務全体の50%以下に抑え、 残った50%以上を生産性の高い活動、 例えば、先ほどのレイテンシやスループット、可用性を高めるシステムを作ったり、 トイルを撲滅するためのコードの開発など、 そういったものに当てましょう、というルールがあります。
- #20: 他にも運用にSREを採用してる企業さんが 何社か公表されておりまして サイボウズ様 ミクシィ様 メルカリ様 ・・・ Google含め 大きな自社サービスを展開している 高い技術力を活かしている企業が多い
- #21: 今の運用の温度感から見ると… リスクの受容 あくまで目標は100%、100%以外ありえない!という意識が強いため、 ある程度のエラーを許容するエラーバジェットという概念は受け入れずらいでしょう。 お客様ありきのお仕事なので、 考え方がSLO的ではなくSLA的になってしまいます。 ミスをしたときに100回に1回だからいいじゃない、とはなりにくく、 二度とミスしません!みたいになってしまいますよね。 また指標にできるデータがあまりない、というのもSLOを定めづらいところになります。 次にトイルの撲滅ですが、 自動化可能な作業って言われても、困りますよね? 自動化を実現するための技術力が不足してたり、 検討したことはあっても自動化できる確証はないのが普通だと思います。 また自社サービスをやっている企業ではなく、 顧客のシステムを運用していることがほとんどです。 携わる部署・企業が多く、関係者が多いと一度できた仕組みを変えるのは非常に困難です。
- #22: カッコイイ! 憧れる! という気持ちはあるが、 以上のような理由で SRE的な運用への切り替えは 非常に困難なため、 眩しすぎて直視するのが辛くて、見なかったことにしてしまう、 「ウチはウチだから」と割り切って、あきらめてしまう、 そんな方も多いんじゃないでしょうか。 しかし、、、
- #23: 諦めるのはまだ早いんじゃないか? なんとか取り入れたいので、 できる方法はないか、と思いまして、 いくつか検討してみました。
- #24: そこで自分達なりのSREというものを考え それを実践してみよう、 ということで、その戦略をいくつか紹介させていただこうと思います。 まず、 [14:00]
- #25: 私たちが注目したのは、先ほど紹介した50%ルールになります。 こちらのルールを、 価値の高いことをするための時間を確保する戦略 というふうに捉えました。 現状の運用の現場では、運用業務が100%、 あるいは残業しても終わらない100%以上の稼働というところが多い(はず) 運用以外に割ける時間がないので運用改善もできないという状況に陥りがちです。 トイルの撲滅もその時間を確保するためにやる側面もある、 というところに注目しました。 そして、Googleでは自動化をよってトイルの撲滅を図っているのですが、 先にも触れたように自動化するのはハードルが高く、 トイルを撲滅する時間がない、という場合も多いです。 そこで、
- #26: トイルを撲滅するうえで、 自動化の他にも何かやり方はないんだろうか? ということを考えてみました。
- #27: というわけでトイルの対処法を いくつか考えてみました。 1つずつ説明していきます。
- #28: まず取捨選択、というものなんですが、 今行ってるそのタスク、それって 本当に必要なタスクなんでしょうか? もしかしたら、中にはやる必要のないタスクがあるかもしれません。 そんなタスクを勇気を持って捨てる!ということをやります。 もちろん、「このタスクめんどくさいから捨てようぜ」とは行かず、 タスクの整理・棚卸し・優先順位付けをやって見直す必要はある。 その中で、 ・目的もよくわからず、 ・やるのが当たり前になっているタスク そういったものを見つけて疑問を持つことが大事です。 捨てる、というとインパクトが強すぎると思われるかと思いますが、 例えば、アラートの対応というのは種類や対象によって様々なパターンが有ると思いますが、 その中の1つの対応、さらにそのうちの1工程、1手順を省く、というものだったり、 または同じようなことを2回も3回もやっていたら、まとめて1回にする、 そういったところから始めるのでも良いかと思います。
- #29: 次に、 アウトソーシングというものをあげました。 そのタスクをやるのは本当に私達がベストなんでしょうか? 自分の仕事の価値がどれくらいあるかって案外わかりにくいものだと思いますが、 他社にお願いしたり既存のサービスを使って代行してもらったらいくらになるんだろう? と調べてみると、自分の仕事の中に生産性高く出来てるものとそうでないものが出てくると思います。 タスクの種類によってハマるもの、ハマらないものが別れると思いますが、 ハマるものであれば、自力でやるよりも案外早かったり、安かったり、正確だったり そういった恩恵に預かれることもあるかもしれません。 再委託禁止なお仕事だったりすると難しいですが、 時間を確保するために、お金の力で解決するのも一つの作戦だと思います。
- #30: 3つめとして順序の入れ替えというのを上げました。 運用の業務というのはフロー図、フローチャートに従って行われることが多いです。 そのフローは実際に運用が始まる前に行われる 運用設計という段階で大体の形や順序が決まってきます。 ですので、想定した時間をもとに作られますが、 実際運用が始まってみると想定と違うことも結構あると思います。 そういったタスクの順序を入れ替えることで、フローがスムーズに流れたり、 まとまった待ち時間を作って並列でタスクを進められたりすることで、 作業時間やオーバーヘッドが減らせる可能性があります。
- #31: 4つ目に特殊性の排除というのを上げました。 運用の中でイレギュラーな対応や例外的な処理っていうのは結構ありがちで、 例えば、このサーバ、このアプリケーションのアラートの場合は、 至急連絡をくれ、だったり、こういう手順で再起動してくれ、みたいな特殊な手順があったり、 逆に翌営業日に連絡くれればいいよ、というものがあったりするんですが、 こういったものがあると確認する手間が増える分ワンテンポ対応に時間がかかったり、 頻度の低い慣れてない対応があると時間がかかりやすい上に、 初見殺しみたいに間違って別の対応をしてしまったりして、ミスの温床にもなりやすいです。 ↓ こういった特殊な手順を極力、汎用的な手順で処理できるようにする。 場合によっては手順書の書き方を変えて、特殊な手順を一般的なフローに落とし込んだり、 お客さんと手順の内容を改めて検討するような交渉をする、ということも視野に入れる必要もあるかと思います。 また、自動化・コード化する上でも共通のモジュールで処理できるほうが 可読性やメンテナンス性がよくなります。
- #32: ということで最後の5番目は自動化なのですが、 今までの取捨選択、アウトソーシング、順序の入れ替え、特殊性の排除、 というトイルへの対処を行ってきて、 その中で残った業務や、整理された業務というものがあるはずなので、 それに対して自動化を検討します。 結局自動化するんじゃないか、という思われると思いますが、 ふるいを掛けている分、自動化する価値も高いと思うんですね。 というのも、こういった整理せずに業務をそのまま自動化しようとすると、 捨てられる業務を自動化するために長い時間をかける。これってもったいないですよね。 冗長なコードや似たようなコードをいくつも書くことになったりして 管理しにくくなったり自動化自体が非効率になってしまいます。 以上のように、トイルへの対処方法がいくつか上がって、 さあやりましょう!とやる気になるんですが、
- #33: いざ変えようと思うと、 手段や方法論だけでは前に進まないですよね。 運用を変えるまでにはクリアしなければいけない大きな壁があります。 [20:00]
- #34: 一番に言われるのは、品質を担保できるのか? あとは周囲の理解が得られなかったり 関係各所との調整が必要 また、変えるための工数の捻出はどうする? 変わったら学習・教育コストもかかる 総じて変えることへのリスクやコストが大きくのしかかってきます。 しかし、リスクという話では、
- #35: 変えるリスクは確かに存在して目につきやすいですが、 変わらないリスクというのも存在するのではないでしょうか?
- #36: 変わらないほうが安心 という気持ちは非常によくわかるんですが、 果たして、 変わらなくても安泰 なのでしょうか?
- #37: ということで、変わらないリスクについて考えてみましょう。 最初に先ほどリスクの中に出てきたコストの問題ですが、 サービスが成長・スケールするとコストが増える可能性があります。 なぜならトイルがある状態だからです。 そのサービスが5年10年と続くものであれば、 トイルで増えるコストと変わるためのコスト、どちらを選ぶべきなんでしょうか。 他にも同業他社が企業努力によって サービスを向上させたり、低価格にして価格競争の結果、 サービスのシェアを奪われることもあります。 またいずれは新しい技術を開発したり、それを採用した新サービスが生まれるはずです。 変わらないサービスを続けていて、そういった技術に対応できるでしょうか? また見落とされがちですが身近なリスクとして、 新しいモノ・技術を勉強してもしょうがないという閉塞的な感じが、 人の成長を阻害してしまったり、 変えたいと思ってる人やデキる人が腐って転職してしまったりということが あるかと思います。
- #38: このように、 変わることにも、変わらないことにも、 メリット・デメリット両面があります。 あまりどちらかを過大評価・過小評価せずに検討しましょう。 また進め方も大事なところでして、 いきなり議論を始めてしまうと、 拒否反応を見せる人も出てくると思いますので、そのままポシャってしまうリスクがあります。 ・検証環境で自動化の動く所を見せてメリットをアピールしたり ・影響範囲やスキル的にできるところからスモールスタートして、知見と実績を貯めながら進めたり、 ・議論をする際も、乗ってくれそうな人を味方につける、といった作戦もあります。 影響力のある人を味方につけられると、かなり前進しますね。 戦略を練って進めていくことが大事です。
- #39: じゃあトイルを見つけて、自動かなりなんなり対処して、 少し楽になって時間ができた、としましょう。 そうなった後、私たちはどうしようか、という展望についても ちょっと触れたいと思います。 [25:00]
- #40: こういった活動を行うことで Googleの50%とは行かないまでも ある程度は時間が確保されるはずです。 そのあとは、その得られた時間で何をしていくか、 というのが重要になってくるんじゃないかと思います。 一つの時間の使い方として、私たちがやっていきたいことは さらなる改善・自動化を進める、ということです。 ちょっと変えることができた、という程度では理想の運用には程遠いです。 変えることは一度きりでは終わらず、トイルを見つけては潰す、そういったことを継続していく必要があるでしょう。 さらなる改善を進めるためには、ここはちょっと手を付けられないな、と自動化を敬遠してきたところも切り込んでいく そういった必要もでてきますので、そのためのスキルアップをします。 また、新しい技術やシステムによって大きな改善を望める可能性はどこにでも転がっているので、 技術のトレンドを追いかける、ということもやっていきたいと思います。
- #41: 最後にまとめとして皆様にお伝えしたいことですが、 [26:30]
- #42: SREの概念や要素というのは 当たり前になっている業務に 様々な気づきを与えてくれる、ということです。 今までお話ししてきたものは、 SREの本の中で書かれていることもありますが、 中には、そこに書かれているものと、自分の現状や実体験を照らし合わせて、 浮かんできた感想やアイディアから始まったものもあります。 すごい!とか、うちならこうやれば使えそう!みたいな良い感想・アイディアばかりではなく、 中には、いやいやこんなの無理でしょう、みたいなネガティブな感想も出てくると思います。 それを含めて大事なことだと思います。 異なる意見を持った人のやり方を聞くことが突破口になることもあり得ると思います。 Googleとはマインドやらサービス、実績など違いすぎるので、 そういったものがある前提で作られているSREをそのまま当てはめるのは しんどいというよりほぼ不可能だと思います。 まずは、やりたい・できそうと思った所からいいとこどりで、自己流にしていくのは全然ありだと思います。
- #43: また、SRE本は500ページを超えるボリュームがあり、今回ご紹介したのもそのごく一部です。 またこちらの本は2017年を代表する技術書の一つとも言われおりますので、 ぜひ実際に読んでみることをお勧めします。 また、このボリュームと内容の難しさから読み進めるのが大変で挫折してしまう、ということが多いようで、 こんな場にいながら恥ずかしながら私も読み切れてはいません。 ですので、身内なりパブリックなところでもSREの読書会なんかも行われているようですので、 そういった場を活用するのもよいかもしれません。 そしてSREから得られた気付きを元に、運用を自己流にアレンジして変えていただいて、 みなさんも快適な良き運用ライフを送っていただければと思います。 以上となります!ご清聴ありがとうございました!