Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
fix(rcm): publisher subscriber system (#5464)
Remote Configuration Publisher-Subscriber system. # Motivation A common Python web application uses a WSGI server (e.g., Gunicorn) that employs multiple workers. For each worker, a Remote Config instance polls new configuration from the Agent. In the context of ASM, the typical scenario follows this flow: - Remote Config enables the ASM_FEATURES product (with 1 click activation). The RC starts polling. - RC receives a payload to enable ASM_FEATURES. RC activates ASM and registers new products (ASM_DD, ASM_DATA, ASM_DD). - RC receives a payload with all products and updates the WAF configuration. This flow takes around 10-15 seconds (i.e., with a polling interval of 5s, RC needs 2-3 requests to the agent to keep all information updated). However, there is a problem with the Gunicorn application: sometimes, Gunicorn may restart a worker, which needs to retrieve all RC data again and repeat the aforementioned flow. During this interval, ASM with Remote Config could raise unexpected behaviors, the new worker wouldn’t block it since it may not have yet applied all the new configuration. ## Example The following example runs a Gunicorn application. ``` ddtrace-run gunicorn -w 4 app:app ``` We use [Locust](https://locust.io/) to request the /block endpoint with a blocked IP. Then, we kill a Gunicorn child process. As a result, we have the following table: 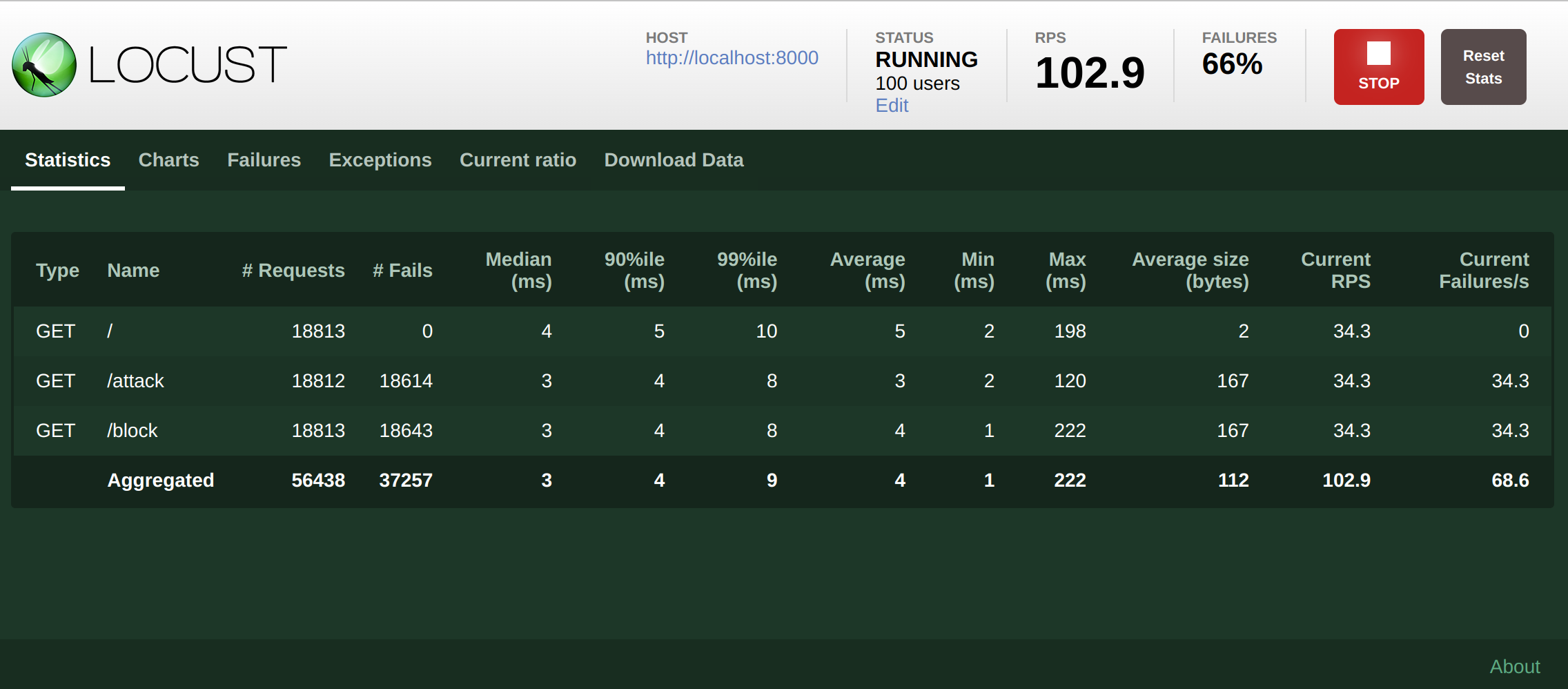 ``` /block: 19495 (request) 19325 (request blocked) ``` The `19495 > 19325` means we have 170 requests that return 200 instead of 403 (blocked). # Description Remote Configuration needs to keep all workers updated as soon as possible. Therefore, Remote Configuration may start BEFORE the Gunicorn server in sitecustomize.py, it starts to poll information from the RC Agent, and for each new payload, through this Pub-sub system, share this information with all child processes. In addition to this, there are different Remote Configuration behaviors: - When the Remote Configuration Client receives a new product target file payload, we need to call a callback. - When the Remote Configuration Client receives a new product target file payload, we need to aggregate this target file data for each product. After that, call the callback with all aggregated information. - Remote Configuration may have a callback for each product. - Remote Configuration may have a callback for one or more products. - For each payload, Remote Configuration needs to execute specific actions on the main process and a different action on child processes. To achieve this goal, a Remote Configuration product may register a PubSub instance. A PubSub class contains a publisher that receives the Remote Configuration payload and shares it with Pubsub Subscriber instance. The Subscriber starts a thread on each child process, waiting for a new update of the shared data between the Publisher on the main process and the child process. Remote Configuration creates a thread listening to the main process for each instance of PubSub. To connect this publisher and the child processes subscribers, we need a connector class: Shared Memory or File. Each instance of PubSub works as a singleton when Remote Configuration dispatches the callbacks. That means if we register the same instance of PubSub class on different products, we would have one thread waiting to the main process. Each DD Product (APM, ASM, DI, CI) may implement its PubSub Class. Example 1: A callback for one or more Remote Configuration Products AppSec needs to aggregate different products in the same callback for all child processes. ``` class AppSecRC(PubSubMergeFirst): __shared_data = ConnectorSharedMemory() def __init__(self, _preprocess_results, callback, name="Default"): self._publisher = self.__publisher_class__(self.__shared_data, _preprocess_results) self._subscriber = self.__subscriber_class__(self.__shared_data, callback, name) asm_callback = AppSecRC(preprocess_1click_activation, appsec_callback, "ASM") remoteconfig_poller.register("ASM_PRODUCT", asm_callback) remoteconfig_poller.register("ASM_FEATURES_PRODUCT", asm_callback) ``` Example 2: One Callback for each product DI needs to aggregate different products in the same callback for all child processes. ``` class DynamicInstrumentationRC(PubSub): __shared_data = ConnectorSharedMemory() def __init__(self, _preprocess_results, callback, name="Default"): self._publisher = self.__publisher_class__(self.__shared_data, _preprocess_results) self._subscriber = self.__subscriber_class__(self.__shared_data, callback, name) di_callback_1 = DynamicInstrumentationRC(callback=di_callback_1, name="ASM") di_callback_2 = DynamicInstrumentationRC(callback=di_callback_2, name="ASM") remoteconfig_poller.register("DI_1_PRODUCT", di_callback) remoteconfig_poller.register("DI_2_PRODUCT", di_callback_2) ``` ## Results Following the previous example, if we run a application with gunicorn and we kill some Gunicorn child worker, the result is: 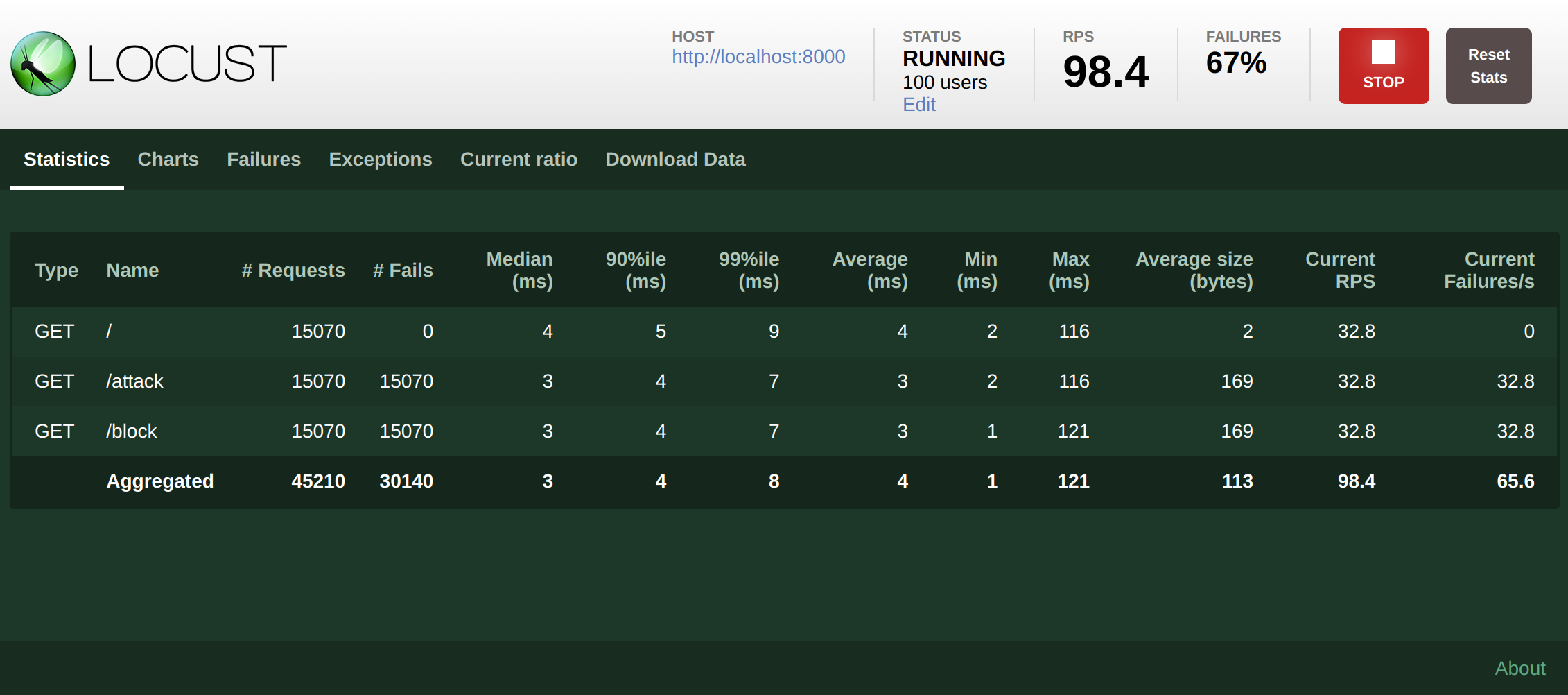 ``` /block: 15070 (request) 15070 (request blocked) ``` `19495 == 19325` Hurray! ## Extra improvements of this refactor if we compare with `docker stats` both branches (1.x and this branch) we see an improvement of memory usage and CPU: `1.x` branch: ``` CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS e487b87bc5e0 showcase-flask_showcase_1 34.23% 204.1MiB / 31.07GiB 0.64% 44.8MB / 62.3MB 0B / 451kB 17 ``` `avara1986/rc_refactor` branch: ``` CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS b90ac73a23b6 showcase-flask_showcase_1 14.99% 169.2MiB / 31.07GiB 0.53% 31.3MB / 55.6MB 4.36MB / 303kB 18 ``` ## PR related This PR fix this system test problem: DataDog/system-tests#932 ## Checklist - [x] Change(s) are motivated and described in the PR description. - [x] Testing strategy is described if automated tests are not included in the PR. - [x] Risk is outlined (performance impact, potential for breakage, maintainability, etc). - [x] Change is maintainable (easy to change, telemetry, documentation). - [x] [Library release note guidelines](https://ddtrace.readthedocs.io/en/stable/contributing.html#Release-Note-Guidelines) are followed. - [x] Documentation is included (in-code, generated user docs, [public corp docs](https://github.com/DataDog/documentation/)). - [x] PR description includes explicit acknowledgement/acceptance of the performance implications of this PR as reported in the benchmarks PR comment. ## Reviewer Checklist - [x] Title is accurate. - [x] No unnecessary changes are introduced. - [x] Description motivates each change. - [x] Avoids breaking [API](https://ddtrace.readthedocs.io/en/stable/versioning.html#interfaces) changes unless absolutely necessary. - [x] Testing strategy adequately addresses listed risk(s). - [x] Change is maintainable (easy to change, telemetry, documentation). - [x] Release note makes sense to a user of the library. - [x] Reviewer has explicitly acknowledged and discussed the performance implications of this PR as reported in the benchmarks PR comment. --------- Co-authored-by: Zachary Groves <32471391+ZStriker19@users.noreply.github.com>
{kind=link}
{kind=link}
- Loading branch information
1 parent
5cd5f6a
commit 9146377