Akaike information criterion
The Akaike information criterion (AIC) is a measure of the relative quality of statistical models for a given set of data. Given a collection of models for the data, AIC estimates the quality of each model, relative to each of the other models. Hence, AIC provides a means for model selection.
AIC is founded on information theory: it offers a relative estimate of the information lost when a given model is used to represent the process that generates the data. In doing so, it deals with the trade-off between the goodness of fit of the model and the complexity of the model.
AIC does not provide a test of a model in the sense of testing a null hypothesis; i.e. AIC can tell nothing about the quality of the model in an absolute sense. If all the candidate models fit poorly, AIC will not give any warning of that.
Contents
Definition
Suppose that we have a statistical model of some data. Let L be the maximum value of the likelihood function for the model; let k be the number of estimated parameters in the model. Then the AIC value of the model is the following.[1][2]

Given a set of candidate models for the data, the preferred model is the one with the minimum AIC value. Hence AIC rewards goodness of fit (as assessed by the likelihood function), but it also includes a penalty that is an increasing function of the number of estimated parameters. The penalty discourages overfitting (increasing the number of parameters in the model almost always improves the goodness of the fit).
AIC is founded in information theory. Suppose that the data is generated by some unknown process f. We consider two candidate models to represent f: g1 and g2. If we knew f, then we could find the information lost from using g1 to represent f by calculating the Kullback–Leibler divergence, DKL(f ‖ g1); similarly, the information lost from using g2 to represent f could be found by calculating DKL(f ‖ g2). We would then choose the candidate model that minimized the information loss.
We cannot choose with certainty, because we do not know f. Akaike (1974) showed, however, that we can estimate, via AIC, how much more (or less) information is lost by g1 than by g2. The estimate, though, is only valid asymptotically; if the number of data points is small, then some correction is often necessary (see AICc, below).
How to apply AIC in practice
To apply AIC in practice, we start with a set of candidate models, and then find the models' corresponding AIC values. There will almost always be information lost due to using a candidate model to represent the "true" model (i.e. the process that generates the data). We wish to select, from among the candidate models, the model that minimizes the information loss. We cannot choose with certainty, but we can minimize the estimated information loss.
Suppose that there are R candidate models. Denote the AIC values of those models by AIC1, AIC2, AIC3, …, AICR. Let AICmin be the minimum of those values. Then exp((AICmin − AICi)/2) can be interpreted as the relative probability that the ith model minimizes the (estimated) information loss.[3]
As an example, suppose that there are three candidate models, whose AIC values are 100, 102, and 110. Then the second model is exp((100 − 102)/2) = 0.368 times as probable as the first model to minimize the information loss. Similarly, the third model is exp((100 − 110)/2) = 0.007 times as probable as the first model to minimize the information loss.
In this example, we would omit the third model from further consideration. We then have three options: (1) gather more data, in the hope that this will allow clearly distinguishing between the first two models; (2) simply conclude that the data is insufficient to support selecting one model from among the first two; (3) take a weighted average of the first two models, with weights 1 and 0.368, respectively, and then do statistical inference based on the weighted multimodel.[4]
The quantity exp((AICmin − AICi)/2) is the relative likelihood of model i.
If all the models in the candidate set have the same number of parameters, then using AIC might at first appear to be very similar to using the likelihood-ratio test. There are, however, important distinctions. In particular, the likelihood-ratio test is valid only for nested models, whereas AIC (and AICc) has no such restriction.[5]
AICc
AICc is AIC with a correction for finite sample sizes. The formula for AICc depends upon the statistical model. Assuming that the model is univariate, linear, and has normally-distributed residuals (conditional upon regressors), the formula for AICc is as follows:[6][7]
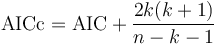
where n denotes the sample size and k denotes the number of parameters.
If the assumption of a univariate linear model with normal residuals does not hold, then the formula for AICc will generally change. Further discussion of the formula, with examples of other assumptions, is given by Burnham & Anderson (2002, ch. 7) and Konishi & Kitagawa (2008, ch. 7–8). In particular, with other assumptions, bootstrap estimation of the formula is often feasible.
AICc is essentially AIC with a greater penalty for extra parameters. Using AIC, instead of AICc, when n is not many times larger than k2, increases the probability of selecting models that have too many parameters, i.e. of overfitting. The probability of AIC overfitting can be substantial, in some cases.[8][9]
Brockwell & Davis (1991, p. 273) advise using AICc as the primary criterion in selecting the orders of an ARMA model for time series. McQuarrie & Tsai (1998) ground their high opinion of AICc on extensive simulation work with regression and time series. Burnham & Anderson (2004) note that, since AICc converges to AIC as n gets large, AICc—rather than AIC—should generally be employed.
Note that if all the candidate models have the same k, then AICc and AIC will give identical (relative) valuations; hence, there will be no disadvantage in using AIC instead of AICc. Furthermore, if n is many times larger than k2, then the correction will be negligible; hence, there will be negligible disadvantage in using AIC instead of AICc.
History
The Akaike information criterion was developed by Hirotugu Akaike, originally under the name "an information criterion". It was first announced by Akaike at a 1971 symposium, the proceedings of which were published in 1973.[10] The 1973 publication, though, was only an informal presentation of the concepts.[11] The first formal publication was in a 1974 paper by Akaike.[2] As of October 2014, the 1974 paper had received more than 14000 citations in the Web of Science: making it the 73rd most-cited research paper of all time.[12]
The initial derivation of AIC relied upon some strong assumptions. Takeuchi (1976) showed that the assumptions could be made much weaker. Takeuchi's work, however, was in Japanese and was not widely known outside Japan for many years.
AICc was originally proposed for linear regression (only) by Sugiura (1978). That instigated the work of Hurvich & Tsai (1989), and several further papers by the same authors, which extended the situations in which AICc could be applied. The work of Hurvich & Tsai contributed to the decision to publish a second edition of the volume by Brockwell & Davis (1991), which is the standard reference for linear time series; the second edition states, "our prime criterion for model selection [among ARMA models] will be the AICc".[13]
The first general exposition of the information-theoretic approach was the volume by Burnham & Anderson (2002). It includes an English presentation of the work of Takeuchi. The volume led to far greater use of AIC, and it now has more than 29000 citations on Google Scholar.
Akaike originally called his approach an "entropy maximization principle", because the approach is founded on the concept of entropy in information theory. Indeed, minimizing AIC in a statistical model is effectively equivalent to maximizing entropy in a thermodynamic system; in other words, the information-theoretic approach in statistics is essentially applying the Second Law of Thermodynamics. As such, AIC has roots in the work of Ludwig Boltzmann on entropy. For more on these issues, see Akaike (1985) and Burnham & Anderson (2002, ch. 2).
Usage tips
Counting parameters
A statistical model must fit all the data points. Thus, a straight line, on its own, is not a model of the data, unless all the data points lie exactly on the line. We can, however, choose a model that is "a straight line plus noise"; such a model might be formally described thus: yi = b0 + b1xi + εi. Here, the εi are the residuals from the straight line fit. If the εi are assumed to be i.i.d. Gaussian (with zero mean), then the model has three parameters: b0, b1, and the variance of the Gaussian distributions. Thus, when calculating the AIC value of this model, we should use k=3. More generally, for any least squares model with i.i.d. Gaussian residuals, the variance of the residuals’ distributions should be counted as one of the parameters.[14]
As another example, consider a first-order autoregressive model, defined by xi = c + φxi−1 + εi, with the εi being i.i.d. Gaussian (with zero mean). For this model, there are three parameters: c, φ, and the variance of the εi. More generally, a pth-order autoregressive model has p + 2 parameters. (If, however, c is not estimated, but given in advance, then there are only p + 1 parameters.)
Transforming data
The AIC values of the candidate models must all be computed with the same data set. Sometimes, though, we might want to compare a model of the data with a model of the logarithm of the data; more generally, we might want to compare a model of the data with a model of transformed data. Here is an illustration of how to deal with data transforms (adapted from Burnham & Anderson (2002, §2.11.3)).
Suppose that we want to compare two models: a normal distribution of the data and a normal distribution of the logarithm of the data. We should not directly compare the AIC values of the two models. Instead, we should transform the normal cumulative distribution function to first take the logarithm of the data. To do that, we need to perform the relevant integration by substitution: thus, we need to multiply by the derivative of the (natural) logarithm function, which is 1/x. Hence, the transformed distribution has the following probability density function:
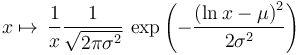
—which is the probability density function for the log-normal distribution. We then compare the AIC value of the normal model against the AIC value of the log-normal model.
Software unreliability
Some statistical software will report the value of AIC or the maximum value of the log-likelihood function, but the reported values are not always correct. Typically, any incorrectness is due to a constant in the log-likelihood function being omitted. For example, the log-likelihood function for n independent identical normal distributions is
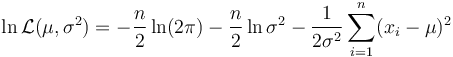
—this is the function that is maximized, when obtaining the value of AIC. Some software, however, omits the term (n/2)ln(2π), and so reports erroneous values for the log-likelihood maximum—and thus for AIC. Such errors do not matter for AIC-based comparisons, if all the models have their residuals as normally-distributed: because then the errors cancel out. In general, however, the constant term needs to be included in the log-likelihood function.[15] Hence, before using software to calculate AIC, it is generally good practice to run some simple tests on the software, to ensure that the function values are correct.
Comparisons with other model selection methods
Comparison with BIC
The AIC penalizes the number of parameters less strongly than does the Bayesian information criterion (BIC). A comparison of AIC/AICc and BIC is given by Burnham & Anderson (2002, §6.4). The authors show that AIC and AICc can be derived in the same Bayesian framework as BIC, just by using a different prior. The authors also argue that AIC/AICc has theoretical advantages over BIC. First, because AIC/AICc is derived from principles of information; BIC is not, despite its name. Second, because the (Bayesian-framework) derivation of BIC has a prior of 1/R (where R is the number of candidate models), which is "not sensible", since the prior should be a decreasing function of k. Additionally, they present a few simulation studies that suggest AICc tends to have practical/performance advantages over BIC. See too Burnham & Anderson (2004).
Further comparison of AIC and BIC, in the context of regression, is given by Yang (2005). In particular, AIC is asymptotically optimal in selecting the model with the least mean squared error, under the assumption that the exact "true" model is not in the candidate set (as is virtually always the case in practice); BIC is not asymptotically optimal under the assumption. Yang additionally shows that the rate at which AIC converges to the optimum is, in a certain sense, the best possible.
For a more detailed comparison of AIC and BIC, see Vrieze (2012) and Aho et al. (2014).
Comparison with least squares
Sometimes, each candidate model assumes that the residuals are distributed according to independent identical normal distributions (with zero mean). That gives rise to least squares model fitting.
In this case, the maximum likelihood estimate for the variance of a model's residuals distributions, σ2, is RSS/n, where RSS is the residual sum of squares: 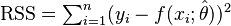 . Then, the maximum value of a model's log-likelihood function is
. Then, the maximum value of a model's log-likelihood function is
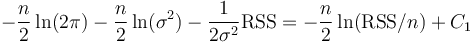
—where C1 is a constant independent of the model, and dependent only on the particular data points, i.e. it does not change if the data does not change.
That gives AIC = 2k + n ln(RSS/n) − 2C1 = 2k + n ln(RSS) + C2.[16] Because only differences in AIC are meaningful, the constant C2 can be ignored, which conveniently allows us to take AIC = 2k + n ln(RSS) for model comparisons. Note that if all the models have the same k, then selecting the model with minimum AIC is equivalent to selecting the model with minimum RSS—which is a common objective of least squares fitting.
Comparison with cross-validation
Leave-one-out cross-validation is asymptotically equivalent to the AIC, for ordinary linear regression models.[17] Such asymptotic equivalence also holds for mixed-effects models.[18]
Comparison with Mallows's Cp
Mallows's Cp is equivalent to AIC in the case of (Gaussian) linear regression.[19]
See also
- Deviance information criterion
- Focused information criterion
- Hannan–Quinn information criterion
- Occam's razor
- Principle of maximum entropy
Notes
- ↑ Burnham & Anderson 2002, §2.2
- ↑ 2.0 2.1 Akaike 1974
- ↑ Burnham & Anderson 2002, §6.4.5
- ↑ Burnham & Anderson 2002
- ↑ Burnham & Anderson 2002, §2.12.4
- ↑ Burnham & Anderson 2002
- ↑ Cavanaugh 1997
- ↑ Claeskens & Hjort 2008, §8.3
- ↑ Giraud 2015, §2.9.1
- ↑ Akaike 1973
- ↑ deLeeuw 1992
- ↑ Van Noordon R., Maher B., Nuzzo R. (2014), "The top 100 papers", Nature, 514.
- ↑ Brockwell & Davis 1991, p. 273
- ↑ Burnham & Anderson 2002, p. 63
- ↑ Burnham & Anderson 2002, p. 82
- ↑ Burnham & Anderson 2002, p. 63
- ↑ Stone 1977
- ↑ Fang 2011
- ↑ Boisbunon et al. 2014
References
- Lua error in package.lua at line 80: module 'strict' not found..
- Lua error in package.lua at line 80: module 'strict' not found..
- Lua error in package.lua at line 80: module 'strict' not found..
- Lua error in package.lua at line 80: module 'strict' not found..
- Lua error in package.lua at line 80: module 'strict' not found..
- Lua error in package.lua at line 80: module 'strict' not found..
- Lua error in package.lua at line 80: module 'strict' not found.. Republished in 2009: ISBN 1441903194.
- Lua error in package.lua at line 80: module 'strict' not found..
- Lua error in package.lua at line 80: module 'strict' not found..
- Lua error in package.lua at line 80: module 'strict' not found..
- Lua error in package.lua at line 80: module 'strict' not found..
- Lua error in package.lua at line 80: module 'strict' not found..
- Lua error in package.lua at line 80: module 'strict' not found..
- Lua error in package.lua at line 80: module 'strict' not found..
- Lua error in package.lua at line 80: module 'strict' not found..
- Lua error in package.lua at line 80: module 'strict' not found..
- Lua error in package.lua at line 80: module 'strict' not found..
- Lua error in package.lua at line 80: module 'strict' not found..
- Lua error in package.lua at line 80: module 'strict' not found..
- Lua error in package.lua at line 80: module 'strict' not found..
- Lua error in package.lua at line 80: module 'strict' not found..
- Lua error in package.lua at line 80: module 'strict' not found..
Further reading
- Lua error in package.lua at line 80: module 'strict' not found..
- Lua error in package.lua at line 80: module 'strict' not found..
- Lua error in package.lua at line 80: module 'strict' not found..
- Lua error in package.lua at line 80: module 'strict' not found..
- Lua error in package.lua at line 80: module 'strict' not found..
External links
- Hirotogu Akaike comments on how he arrived at the AIC, in This Week's Citation Classic (21 December 1981)
- AIC (Aalto University)
- Akaike Information Criterion (North Carolina State University)
- Example AIC use (Honda USA, Noesis Solutions, Belgium)
- Model Selection (University of Iowa)
|
|||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||