Automatic differentiation
In mathematics and computer algebra, automatic differentiation (AD), also called algorithmic differentiation or computational differentiation,[1][2] is a set of techniques to numerically evaluate the derivative of a function specified by a computer program. AD exploits the fact that every computer program, no matter how complicated, executes a sequence of elementary arithmetic operations (addition, subtraction, multiplication, division, etc.) and elementary functions (exp, log, sin, cos, etc.). By applying the chain rule repeatedly to these operations, derivatives of arbitrary order can be computed automatically, accurately to working precision, and using at most a small constant factor more arithmetic operations than the original program.
Automatic differentiation is not:
- Symbolic differentiation, nor
- Numerical differentiation (the method of finite differences).
These classical methods run into problems: symbolic differentiation leads to inefficient code (unless carefully done) and faces the difficulty of converting a computer program into a single expression, while numerical differentiation can introduce round-off errors in the discretization process and cancellation. Both classical methods have problems with calculating higher derivatives, where the complexity and errors increase. Finally, both classical methods are slow at computing the partial derivatives of a function with respect to many inputs, as is needed for gradient-based optimization algorithms. Automatic differentiation solves all of these problems, at the expense of introducing more software dependencies.
Contents
The chain rule, forward and reverse accumulation
Fundamental to AD is the decomposition of differentials provided by the chain rule. For the simple composition y = g(h(x)) = g(w) the chain rule gives
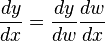
Usually, two distinct modes of AD are presented, forward accumulation (or forward mode) and reverse accumulation (or reverse mode). Forward accumulation specifies that one traverses the chain rule from inside to outside (that is, first one computes dw/dx and then dy/dw, while reverse accumulation has the traversal from outside to inside.
Forward accumulation
In forward accumulation AD, one first fixes the independent variable to which differentiation is performed and computes the derivative of each sub-expression recursively. In a pen-and-paper calculation, one can do so by repeatedly substituting the derivative of the inner functions in the chain rule:
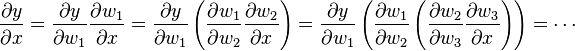
This can be generalized to multiple variables as a matrix product of Jacobians.
Compared to reverse accumulation, forward accumulation is very natural and easy to implement as the flow of derivative information coincides with the order of evaluation. One simply augments each variable w with its derivative ẇ (stored as a numerical value, not a symbolic expression),
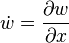
as denoted by the dot. The derivatives are then computed in sync with the evaluation steps and combined with other derivatives via the chain rule.
As an example, consider the function:
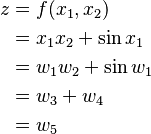
For clarity, the individual sub-expressions have been labeled with the variables wi.
The choice of the independent variable to which differentiation is performed affects the seed values ẇ1 and ẇ2. Suppose one is interested in the derivative of this function with respect to x1. In this case, the seed values should be set to:
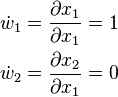
With the seed values set, one may then propagate the values using the chain rule as shown in both the table below. Figure 2 shows a pictorial depiction of this process as a computational graph.
| Operations to compute value | Operations to compute derivative |
|---|---|
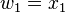 |
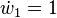 (seed) (seed) |
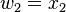 |
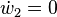 (seed) (seed) |
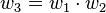 |
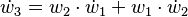 |
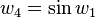 |
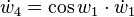 |
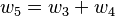 |
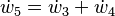 |
To compute the gradient of this example function, which requires the derivatives of f with respect to not only x1 but also x2, one must perform an additional sweep over the computational graph using the seed values 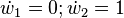 .
.
The computational complexity of one sweep of forward accumulation is proportional to the complexity of the original code.
Forward accumulation is more efficient than reverse accumulation for functions f : ℝn → ℝm with m ≫ n as only n sweeps are necessary, compared to m sweeps for reverse accumulation.
Reverse accumulation
In reverse accumulation AD, one first fixes the dependent variable to be differentiated and computes the derivative with respect to each sub-expression recursively. In a pen-and-paper calculation, one can perform the equivalent by repeatedly substituting the derivative of the outer functions in the chain rule:
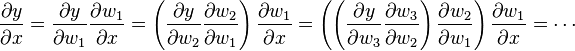
In reverse accumulation, the quantity of interest is the adjoint, denoted with a bar (w̄); it is a derivative of a chosen dependent variable with respect to a subexpression w:
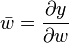
Reverse accumulation traverses the chain rule from outside to inside, or in the case of the computational graph in Figure 3, from top to bottom. The example function is real-valued, and thus there is only one seed for the derivative computation, and only one sweep of the computational graph is needed in order to calculate the (two-component) gradient. This is only half the work when compared to forward accumulation, but reverse accumulation requires the storage of the intermediate variables wi as well as the instructions that produced them in a data structure known as a Wengert list (or "tape"),[3] which may represent a significant memory issue if the computational graph is large. This can be mitigated to some extent by storing only a subset of the intermediate variables and then reconstructing the necessary work variables by repeating the evaluations, a technique known as checkpointing.
The operations to compute the derivative using reverse accumulation are shown in the table below (note the reversed order):
| Operations to compute derivative |
|---|
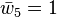 (seed) (seed) |
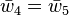 |
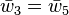 |
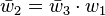 |
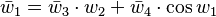 |
The data flow graph of a computation can be manipulated to calculate the gradient of its original calculation. This is done by adding an adjoint node for each primal node, connected by adjoint edges which parallel the primal edges but flow in the opposite direction. The nodes in the adjoint graph represent multiplication by the derivatives of the functions calculated by the nodes in the primal. For instance, addition in the primal causes fanout in the adjoint; fanout in the primal causes addition in the adjoint; a unary function y = f(x) in the primal causes x̄ = ȳ f′(x) in the adjoint; etc.
Reverse accumulation is more efficient than forward accumulation for functions f : ℝn → ℝm with m ≪ n as only m sweeps are necessary, compared to n sweeps for forward accumulation.
Backpropagation of errors in multilayer perceptrons, a technique used in machine learning, is a special case of reverse mode AD.
Beyond forward and reverse accumulation
Forward and reverse accumulation are just two (extreme) ways of traversing the chain rule. The problem of computing a full Jacobian of f : ℝn → ℝm with a minimum number of arithmetic operations is known as the optimal Jacobian accumulation (OJA) problem, which is NP-complete.[4] Central to this proof is the idea that there may exist algebraic dependencies between the local partials that label the edges of the graph. In particular, two or more edge labels may be recognized as equal. The complexity of the problem is still open if it is assumed that all edge labels are unique and algebraically independent.
Automatic differentiation using dual numbers
Forward mode automatic differentiation is accomplished by augmenting the algebra of real numbers and obtaining a new arithmetic. An additional component is added to every number which will represent the derivative of a function at the number, and all arithmetic operators are extended for the augmented algebra. The augmented algebra is the algebra of dual numbers.
Replace every number  with the number
with the number 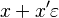 , where
, where  is a real number, but
is a real number, but  is an abstract number with the property
is an abstract number with the property 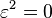 (an infinitesimal; see Smooth infinitesimal analysis). Using only this, we get for the regular arithmetic
(an infinitesimal; see Smooth infinitesimal analysis). Using only this, we get for the regular arithmetic
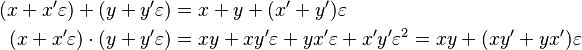
and likewise for subtraction and division.
Now, we may calculate polynomials in this augmented arithmetic. If 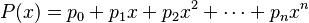 , then
, then
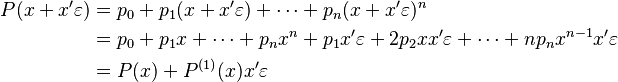
where 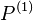 denotes the derivative of
denotes the derivative of 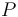 with respect to its first argument, and , called a seed, can be chosen arbitrarily.
with respect to its first argument, and , called a seed, can be chosen arbitrarily.
The new arithmetic consists of ordered pairs, elements written 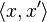 , with ordinary arithmetics on the first component, and first order differentiation arithmetic on the second component, as described above. Extending the above results on polynomials to analytic functions we obtain a list of the basic arithmetic and some standard functions for the new arithmetic:
, with ordinary arithmetics on the first component, and first order differentiation arithmetic on the second component, as described above. Extending the above results on polynomials to analytic functions we obtain a list of the basic arithmetic and some standard functions for the new arithmetic:
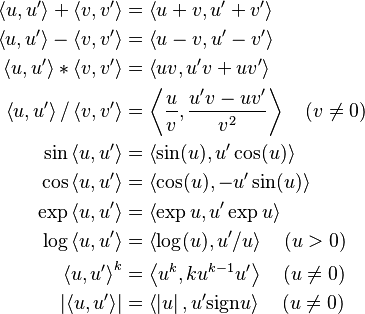
and in general for the primitive function  ,
,
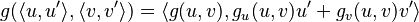
{kind=link}
{kind=link}
{kind=link}
where 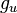 and
and 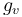 are the derivatives of with respect to its first and second arguments, respectively.
are the derivatives of with respect to its first and second arguments, respectively.
When a binary basic arithmetic operation is applied to mixed arguments—the pair 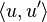 and the real number
and the real number  —the real number is first lifted to
—the real number is first lifted to 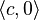 . The derivative of a function
. The derivative of a function 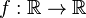 at the point
at the point 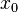 is now found by calculating
is now found by calculating 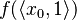 using the above arithmetic, which gives
using the above arithmetic, which gives 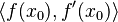 as the result.
as the result.
Vector arguments and functions
Multivariate functions can be handled with the same efficiency and mechanisms as univariate functions by adopting a directional derivative operator. That is, if it is sufficient to compute 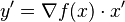 , the directional derivative
, the directional derivative 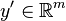 of
of 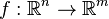 at
at 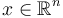 in the direction
in the direction 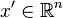 , this may be calculated as
, this may be calculated as 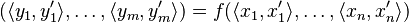 using the same arithmetic as above. If all the elements of
using the same arithmetic as above. If all the elements of 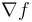 are desired, then
are desired, then 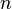 function evaluations are required. Note that in many optimization applications, the directional derivative is indeed sufficient.
function evaluations are required. Note that in many optimization applications, the directional derivative is indeed sufficient.
High order and many variables
The above arithmetic can be generalized to calculate second order and higher derivatives of multivariate functions. However, the arithmetic rules quickly grow very complicated: complexity will be quadratic in the highest derivative degree. Instead, truncated Taylor polynomial algebra can be used. The resulting arithmetic, defined on generalized dual numbers, allows to efficiently compute using functions as if they were a new data type. Once the Taylor polynomial of a function is known, the derivatives are easily extracted. Currently there are a few software projects that implement the Taylor polynomial truncated algebra. AuDi, CTaylor and COSY infinity. Only the first two are open source.
Implementation
Forward-mode AD is implemented by a nonstandard interpretation of the program in which real numbers are replaced by dual numbers, constants are lifted to dual numbers with a zero epsilon coefficient, and the numeric primitives are lifted to operate on dual numbers. This nonstandard interpretation is generally implemented using one of two strategies: source code transformation or operator overloading.
Source code transformation (SCT)
{kind=link}
The source code for a function is replaced by an automatically generated source code that includes statements for calculating the derivatives interleaved with the original instructions.
Source code transformation can be implemented for all programming languages, and it is also easier for the compiler to do compile time optimizations. However, the implementation of the AD tool itself is more difficult.
Operator overloading (OO)
{kind=link}
Operator overloading is a possibility for source code written in a language supporting it. Objects for real numbers and elementary mathematical operations must be overloaded to cater for the augmented arithmetic depicted above. This requires no change in the form or sequence of operations in the original source code for the function to be differentiated, but often requires changes in basic data types for numbers and vectors to support overloading and often also involves the insertion of special flagging operations.
Operator overloading for forward accumulation is easy to implement, and also possible for reverse accumulation. However, current compilers lag behind in optimizing the code when compared to forward accumulation.
Software
- C/C++
-
Package License Approach Brief info ADC Version 4.0 nonfree OO Adept Apache 2.0 OO First-order forward and reverse modes. Very fast due to its use of expression templates and an efficient tape structure. ADIC free for noncommercial SCT forward mode ADMB BSD SCT+OO Uses a template approach. See http://admb-project.org/ ADNumber dual license OO arbitrary order forward/reverse ADOL-C CPL 1.0 or GPL 2.0 OO arbitrary order forward/reverse, part of COIN-OR AuDi GPL 2.0 OO AuDI is an open source, header only, C++ library that allows for AUtomated DIfferentiation implementing the Taylor truncated polynomial algebra (forward mode automated differentiation). It was created with the aim to offer a generic solution to the user in need of an automated differentiation system. AuDi is thread-safe and, when possible, use of Piranha fine-grained parallelization of the truncated polynomial multiplication. The benefits of this fine grained parallelization are well visible for many variables and high orders. AMPL free for students SCT FADBAD++ free for
noncommercialOO uses operator new CasADi LGPL SCT Forward/reverse modes, matrix-valued atomic operations. ceres-solver BSD OO A portable C++ library that allows for modeling and solving large complicated nonlinear least squares problems CppAD EPL 1.0 or GPL 3.0 OO arbitrary order forward/reverse, AD<Base> for arbitrary Base including AD<Other_Base>, part of COIN-OR; can also be used to produce C source code using the CppADCodeGen library. Eigen Auto Diff MPL2 OO OpenAD depends on components SCT Sacado GNU GPL OO A part of the Trilinos collection, forward/reverse modes. Stan (software) BSD OO forward- and reverse-mode automatic differentiation with library of special functions, probability functions, matrix operators, and linear algebra solvers TAPENADE Free for noncommercial SCT CTaylor free OO truncated taylor series, multi variable, high performance, calculating and storing only potentially nonzero derivatives, calculates higher order derivatives, order of derivatives increases when using matching operations until maximum order (parameter) is reached, example source code and executable available for testing performance
- Fortran
-
Package License Approach Brief info ADF Version 4.0 nonfree OO ADIFOR >>>
(free for non-commercial)SCT AUTO_DERIV free for non-commercial OO OpenAD depends on components SCT TAPENADE Free for noncommercial SCT GADfit Free (GPL 3) OO First (forward, reverse) and second (forward) order, principal use is nonlinear curve fitting, includes the differentiation of integrals
- Matlab
-
Package License Approach Brief info AD for MATLAB GNU GPL OO Forward (1st & 2nd derivative, Uses MEX files & Windows DLLs) Adiff BSD OO Forward (1st derivative) MAD Proprietary OO Forward (1st derivative) full/sparse storage of derivatives ADiMat Proprietary SCT Forward (1st & 2nd derivative) & Reverse (1st), proprietary server side transform MADiff GNU GPL OO Reverse
- Python
-
Package License Approach Brief info ad BSD OO first and second-order, reverse accumulation, transparent on-the-fly calculations, basic NumPy support, written in pure python FuncDesigner BSD OO uses NumPy arrays and SciPy sparse matrices,
also allows to solve linear/non-linear/ODE systems and
to perform numerical optimizations by OpenOptScientificPython CeCILL OO see modules Scientific.Functions.FirstDerivatives and
Scientific.Functions.Derivativespycppad BSD OO arbitrary order forward/reverse, implemented as wrapper for CppAD including AD<double> and AD< AD<double> >. pyadolc BSD OO wrapper for ADOL-C, hence arbitrary order derivatives in the (combined) forward/reverse mode of AD, supports sparsity pattern propagation and sparse derivative computations uncertainties BSD OO first-order derivatives, reverse mode, transparent calculations algopy BSD OO same approach as pyadolc and thus compatible, support to differentiate through numerical linear algebra functions like the matrix-matrix product, solution of linear systems, QR and Cholesky decomposition, etc. pyderiv GNU GPL OO automatic differentiation and (co)variance calculation CasADi LGPL SCT Python front-end to CasADi. Forward/reverse modes, matrix-valued atomic operations. Theano BSD OO Theano is a Python library that allows you to define, optimize, and evaluate mathematical expressions involving multi-dimensional arrays both on CPU and GPU efficiently. Autograd MIT OO Autograd can reverse-mode differentiate native Python and Numpy code. It can handle a large subset of Python's features, including loops, ifs, recursion and closures. It is closed under its own operation and hence can compute derivatives of any order.
- Lua
-
Package License Approach Brief info Torch BSD OO Torch is a LuaJIT library used for Deep Learning. Its nn package is divided into modular objects that share a common Moduleinterface. Modules have aforwardandbackwardfunction that allow them to feedforward and backpropagate (first-order derivatives). Modules can be joined together using module composites to create complex task-tailored graphs.SciLua MIT OO SciLua, a framework for general purpose scientific computing in LuaJIT, features complete and transparent support for forward-mode automatic differentiation.
- .NET
-
Package License Approach Brief info AutoDiff GNU LGPL OO Automatic differentiation with C# operator overloading. FuncLib MIT OO Automatic differentiation and numerical optimization, operator overloading, unlimited order of differentiation, compilation to IL code for very fast evaluation. DiffSharp GNU LGPL OO An automatic differentiation library implemented in the F# language. It supports C# and the other CLI languages. The library provides gradients, Hessians, Jacobians, directional derivatives, and matrix-free Hessian- and Jacobian-vector products, which can be incorporated with minimal change into existing algorithms. Operations can be nested to any level, meaning that you can compute exact higher-order derivatives and differentiate functions that are internally making use of differentiation.
- Haskell
-
Package License Approach Brief info ad BSD OO Forward Mode (1st derivative or arbitrary order derivatives via lazy lists and sparse tries)
Reverse Mode
Combined forward-on-reverse Hessians.
Uses Quantification to allow the implementation automatically choose appropriate modes.
Quantification prevents perturbation/sensitivity confusion at compile time.fad BSD OO Forward Mode (lazy list). Quantification prevents perturbation confusion at compile time. rad BSD OO Reverse Mode. (Subsumed by 'ad').
Quantification prevents sensitivity confusion at compile time.
- Java
-
Package License Approach Brief info JAutoDiff - OO Provides a framework to compute derivatives of functions on arbitrary types of field using generics. Coded in 100% pure Java. Apache Commons Math Apache License v2 OO This class is an implementation of the extension to Rall's numbers described in Dan Kalman's paper[5] Deriva Eclipse Public License v1.0 DSL+Code Generation Deriva automates algorithmic differentiation in Java and Clojure projects. It defines DSL for building extended arithmetic expressions (the extension being support for conditionals, allowing to express non analytic functions). The DSL is used to generate flat byte-code at runtime, providing implementation without overhead of function calls. Jap Public OO/SCT Jap is a tools using Virtual Operator Overloading for java class. Jap was developed in the thesis of Phuong PHAM-QUANG 2008-2011.
-
Package License Approach Brief info ForwardDiff.jl MIT OO A unified package for forward-mode automatic differentiation, combining both DualNumbers and vector-based gradient accumulations. DualNumbers.jl MIT OO Implements a Dual number type which can be used for forward-mode automatic differentiation of first derivatives via operator overloading. HyperDualNumers.jl MIT OO Implements a Hyper number type which can be used for forward-mode automatic differentiation of first and second derivatives via operator overloading. ReverseDiffSource.jl MIT SCT Implements reverse-mode automatic differentiation for gradients and high-order derivatives given user-supplied expressions or generic functions. Accepts a subset of valid Julia syntax, including intermediate assignments. TaylorSeries.jl MIT OO Implements truncated multivariate power series for high-order integration of ODEs and forward-mode automatic differentiation of arbitrary order derivatives via operator overloading.
- Clojure
-
Package License Approach Brief info Deriva Eclipse Public License v1.0 DSL+Code Generation Deriva automates algorithmic differentiation in Java and Clojure projects. It defines DSL for building extended arithmetic expressions (the extension being support for conditionals, allowing to express non analytic functions). The DSL is used to generate flat byte-code at runtime, providing implementation without overhead of function calls.
-
Package License Approach Brief info ad Apache 2.0 DSL+Code Generation Creates source code corresponding to algebraic expressions. See https://autodiff.info for a demo.
-
Package License Approach Brief info PBSadmb GNU GPL SCT+OO Uses a template approach. See http://admb-project.org/ .
References
- ↑ Lua error in package.lua at line 80: module 'strict' not found.
- ↑ http://www.ec-securehost.com/SIAM/SE24.html
- ↑ Lua error in package.lua at line 80: module 'strict' not found.
- ↑ Lua error in package.lua at line 80: module 'strict' not found.
- ↑ Lua error in package.lua at line 80: module 'strict' not found.
Literature
- Lua error in package.lua at line 80: module 'strict' not found.
- Lua error in package.lua at line 80: module 'strict' not found.
- Lua error in package.lua at line 80: module 'strict' not found.
External links
- www.autodiff.org, An "entry site to everything you want to know about automatic differentiation"
- Automatic Differentiation of Parallel OpenMP Programs
- Automatic Differentiation, C++ Templates and Photogrammetry
- Automatic Differentiation, Operator Overloading Approach
- Compute analytic derivatives of any Fortran77, Fortran95, or C program through a web-based interface Automatic Differentiation of Fortran programs
- Description and example code for forward Automatic Differentiation in Scala
- Adjoint Algorithmic Differentiation: Calibration and Implicit Function Theorem
- [1], Exact First- and Second-Order Greeks by Algorithmic Differentiation
- [2], Adjoint Algorithmic Differentiation of a GPU Accelerated Application
- [3], Adjoint Methods in Computational Finance Software Tool Support for Algorithmic Differentiation