Canonical Huffman code
Lua error in package.lua at line 80: module 'strict' not found. A canonical Huffman code is a particular type of Huffman code with unique properties which allow it to be described in a very compact manner.
Data compressors generally work in one of two ways. Either the decompressor can infer what codebook the compressor has used from previous context, or the compressor must tell the decompressor what the codebook is. Since a canonical Huffman codebook can be stored especially efficiently, most compressors start by generating a "normal" Huffman codebook, and then convert it to canonical Huffman before using it.
In order for a symbol code scheme such as the Huffman code to be decompressed, the same model that the encoding algorithm used to compress the source data must be provided to the decoding algorithm so that it can use it to decompress the encoded data. In standard Huffman coding this model takes the form of a tree of variable-length codes, with the most frequent symbols located at the top of the structure and being represented by the fewest number of bits.
However, this code tree introduces two critical inefficiencies into an implementation of the coding scheme. Firstly, each node of the tree must store either references to its child nodes or the symbol that it represents. This is expensive in memory usage and if there is a high proportion of unique symbols in the source data then the size of the code tree can account for a significant amount of the overall encoded data. Secondly, traversing the tree is computationally costly, since it requires the algorithm to jump randomly through the structure in memory as each bit in the encoded data is read in.
Canonical Huffman codes address these two issues by generating the codes in a clear standardized format; all the codes for a given length are assigned their values sequentially. This means that instead of storing the structure of the code tree for decompression only the lengths of the codes are required, reducing the size of the encoded data. Additionally, because the codes are sequential, the decoding algorithm can be dramatically simplified so that it is computationally efficient.
Contents
Algorithm
The normal Huffman coding algorithm assigns a variable length code to every symbol in the alphabet. More frequently used symbols will be assigned a shorter code. For example, suppose we have the following non-canonical codebook:
A = 11 B = 0 C = 101 D = 100
Here the letter A has been assigned 2 bits, B has 1 bit, and C and D both have 3 bits. To make the code a canonical Huffman code, the codes are renumbered. The bit lengths stay the same with the code book being sorted first by codeword length and secondly by alphabetical value:
B = 0 A = 11 C = 101 D = 100
Each of the existing codes are replaced with a new one of the same length, using the following algorithm:
- The first symbol in the list gets assigned a codeword which is the same length as the symbol's original codeword but all zeros. This will often be a single zero ('0').
- Each subsequent symbol is assigned the next binary number in sequence, ensuring that following codes are always higher in value.
- When you reach a longer codeword, then after incrementing, append zeros until the length of the new codeword is equal to the length of the old codeword. This can be thought of as a left shift.
By following these three rules, the canonical version of the code book produced will be:
B = 0 A = 10 C = 110 D = 111
As a fractional binary number
Another perspective on the canonical codewords is that they are the digits past the radix point (binary decimal point) in a binary representation of a certain series. Specifically, suppose the lengths of the codewords are l1 ... ln. Then the canonical codeword for symbol i is the first li binary digits past the radix point in the binary representation of
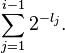
This perspective is particularly useful in light of Kraft's inequality, which says that the sum above will always be less than 1 (since the lengths come from a prefix free code). This shows that adding one in the algorithm above never overflows and creates a codeword that is longer than intended.
Encoding the codebook
The whole advantage of a canonical Huffman tree is that one can encode the description (the codebook) in fewer bits than a fully described tree.
Let us take our original Huffman codebook:
A = 11 B = 0 C = 101 D = 100
There are several ways we could encode this Huffman tree. For example, we could write each symbol followed by the number of bits and code:
('A',2,11), ('B',1,0), ('C',3,101), ('D',3,100)
Since we are listing the symbols in sequential alphabetical order, we can omit the symbols themselves, listing just the number of bits and code:
(2,11), (1,0), (3,101), (3,100)
With our canonical version we have the knowledge that the symbols are in sequential alphabetical order and that a later code will always be higher in value than an earlier one. The only parts left to transmit are the bit-lengths (number of bits) for each symbol. Note that our canonical Huffman tree always has higher values for longer bit lengths and that any symbols of the same bit length (C and D) have higher code values for higher symbols:
A = 10 (code value: 2 decimal, bits: 2) B = 0 (code value: 0 decimal, bits: 1) C = 110 (code value: 6 decimal, bits: 3) D = 111 (code value: 7 decimal, bits: 3)
Since two-thirds of the constraints are known, only the number of bits for each symbol need be transmitted:
2, 1, 3, 3
With knowledge of the canonical Huffman algorithm, it is then possible to recreate the entire table (symbol and code values) from just the bit-lengths. Unused symbols are normally transmitted as having zero bit length.
Another efficient way representing the codebook is to list all symbols in increasing order by their bit-lengths, and record the number of symbols for each bit-length. For the example mentioned above the encoding becomes:
(1,1,2), ('B','A','C','D')
It means that the first symbol B is of length 1, then the A of length 2, and remains of 3. Since the symbols are sorted by bit-length, we can efficiently reconstruct the codebook. A pseudo code describing the reconstruction is introduced on the next section.
This type of encoding take great advantages when only a few symbols in the alphabet are being compressed. For example, if the codebook contains only 4 letters C, O, D and E, each of length 2. To represent the letter O using the previous method we need to either add a lot of zeros:
0, 0, 2, 2, 2, 0, ... , 2, ...
or record which 4 letters we have used. Each way makes the description longer than:
(0,4), ('C','O','D','E')
The JPEG File Interchange Format actually adopts this way of encoding, because at most only 162 symbols out of the 8-bit alphabet, which has size 256, will be in the codebook.
Pseudo code
Given a list of symbols sorted by bit-length, the following pseudo code will print a canonical Huffman code book:
code = 0
while more symbols:
print symbol, code
code = (code + 1) << ((bit length of the next symbol) - (current bit length))
Algorithm
The algorithm described in: "A Method for the Construction of Minimum-Redundancy Codes" David A. Huffman, Proceedings of the I.R.E. is:
compute huffman code:
input: message ensemble (set of (message, probability)).
base D.
output: code ensemble (set of (message, code)).
algorithm:
1- sort the message ensemble by decreasing probability.
2- N is the cardinal of the message ensemble (number of different
messages).
3- compute the integer n_0 such as 2<=n_0<=D and (N-n_0)/(D-1) is integer.
4- select the n_0 least probable messages, and assign them each a
digit code.
5- substitute the selected messages by a composite message summing
their probability, and re-order it.
6- while there remains more than one message, do steps thru 8.
7- select D least probable messages, and assign them each a
digit code.
8- substitute the selected messages by a composite message
summing their probability, and re-order it.
9- the code of each message is given by the concatenation of the
code digits of the aggregate they've been put in.
References: 1. Managing Gigabytes: book with an implementation of canonical huffman codes for word dictionaries.
|
Data compression methods
|
|||||||
|---|---|---|---|---|---|---|---|
| Lossless |
|
||||||
| Audio |
|
||||||
| Image |
|
||||||
| Video |
|
||||||
| Theory | |||||||