Error correction model
An error correction model belongs to a category of multiple time series models most commonly used for data where the underlying variables have a long-run stochastic trend, also known as cointegration. ECMs are a theoretically-driven approach useful for estimating both short-term and long-term effects of one time series on another. The term error-correction relates to the fact that last-periods deviation from a long-run equilibrium, the error, influences its short-run dynamics. Thus ECMs directly estimate the speed at which a dependent variable returns to equilibrium after a change in other variables.
Contents
History of ECM
Yule(1936) and Granger and Newbold (1974) were the first to draw attention to the problem of spurious correlation and find solutions on how to address it in time series analysis. Given two completely unrelated but integrated (non-stationary) time series, the regression analysis of one on the other will tend to produce an apparently statistically significant relationship and thus a researcher might falsely believe to have found evidence of a true relationship between these variables. Ordinary least squares will no longer be consistent and commonly used test-statistics will be non-valid. In particular, Monte Carlo simulations show that one will get a very high R squared, very high individual t-statistic and a low Durbin–Watson statistic. Technically speaking, Phillips (1986) proved that parameter estimates will not converge in probability, the intercept will diverge and the slope will have a non-degenerate distribution as the sample size increases. However, there might a common stochastic trend to both series that a researcher is genuinely interested in because it reflects a long-run relationship between these variables. Because of the stochastic nature of the trend it is not possible to break up integrated series into a deterministic (predictable) trend and a stationary series containing deviations from trend. Even in deterministically detrended random walks walks spurious correlations will eventually emerge. Thus detrending doesn't solve the estimation problem. In order to still use the Box–Jenkins approach, one could difference the series and then estimate models such as ARIMA, given that many commonly used time series (e.g. in economics) appear to be stationary in first differences. Forecasts from such a model will still reflect cycles and seasonality that are present in the data. However, any information about long-run adjustments that the data in levels may contain is omitted and longer term forecasts will be unreliable. This lead Sargan (1964) to develop the ECM methodology, which retains the level information.
Estimation
Several methods are known in the literature for estimating a refined dynamic model as described above. Among these are the Engel and Granger 2-step approach, estimating their ECM in one step and the vector-based VECM using Johansen's method.
Engel and Granger 2-Step Approach
The first step of this method is to pretest the individual time series one uses in order to confirm that they are non-stationary in the first place. This can be done by standard unit root testing such as Augmented Dickey–Fuller test. Take the case of two different series 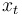 and
and 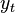 . If both are I(0), standard regression analysis will be valid. If they are integrated of a different order, e.g. one being I(1) and the other being I(0), one has to transform the model.
. If both are I(0), standard regression analysis will be valid. If they are integrated of a different order, e.g. one being I(1) and the other being I(0), one has to transform the model.
If they are both integrated to the same order (commonly I(1)), we can estimate an ECM model of the form: 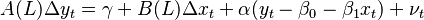 . If both variables are integrated and this ECM exists, they are cointegrated by the Engle-Granger representation theorem.
. If both variables are integrated and this ECM exists, they are cointegrated by the Engle-Granger representation theorem.
The second step is then to estimate the model using Ordinary least squares: 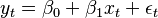 If the regression is not spurious as determined by test criteria described above, Ordinary least squares will not only be valid, but in fact super consistent (Stock, 1987). Then the predicted residuals
If the regression is not spurious as determined by test criteria described above, Ordinary least squares will not only be valid, but in fact super consistent (Stock, 1987). Then the predicted residuals 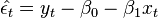 from this regression are saved and used in a regression of differenced variables plus a lagged error term:
from this regression are saved and used in a regression of differenced variables plus a lagged error term: 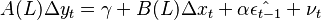 . One can then test for cointegration using a standard t-statistic on
. One can then test for cointegration using a standard t-statistic on 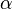 . While this approach is easy to apply, there are, however numerous problems:
. While this approach is easy to apply, there are, however numerous problems:
- The univariate unit root tests used in the first stage have low statistical power
- The choice of dependent variable in the first stage influences test results, i.e. we need weak exogeneity for as determined by Granger causality
- One can potentially have a small sample bias
- The cointegration test on does not follow a standard distribution
- The validity of the long-run parameters in the first regression stage where one obtains the residuals cannot be verified because the distribution of the OLS estimator of the cointegrating vector is highly complicated and non-normal
- At most one cointegrating relationship can be examined
VECM
The Engle-Granger approach as described above suffers from a number of weaknesses. Namely it is restricted to only a single equation with one variable designated as the dependent variable, explained by another variable that is assumed to be weakly exogeneous for the parameters of interest. It also relies on pretesting the time series to find out whether variables are I(0) or I(1). These weaknesses can be addressed through the use of Johansen's procedure. Its advantages include that pretesting is not necessary, there can be numerous cointegrating relationships, all variables are treated as endogenous and tests relating to the long-run parameters are possible. The resulting model is known as a vector error correction model (VECM), as it adds error correction features to a multi-factor model known as vector autoregression (VAR). The procedure is done as follows:
- Step 1: estimate an unrestricted VAR involving potentially non-stationary variables
- Step 2: Test for cointegration using Johansen test
- Step 3: Form and analyse the VECM
An example of ECM
The idea of cointegration may be demonstrated in a simple macroeconomic setting. Suppose, consumption 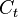 and disposable income
and disposable income 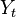 are macroeconomic time series that are related in the long run (see Permanent income hypothesis). Specifically, let average propensity to consume be 90%, that is, in the long run
are macroeconomic time series that are related in the long run (see Permanent income hypothesis). Specifically, let average propensity to consume be 90%, that is, in the long run 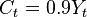 . From the econometrician's point of view, this long run relationship (aka cointegration) exists if errors from the regression
. From the econometrician's point of view, this long run relationship (aka cointegration) exists if errors from the regression 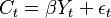 are a stationary series, although and are non-stationary. Suppose also that if suddenly changes by
are a stationary series, although and are non-stationary. Suppose also that if suddenly changes by 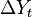 , then changes by
, then changes by 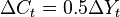 , that is, marginal propensity to consume equals 50%. Our last assumption is that the gap between current and equilibrium consumption decreases each period by 20%.
, that is, marginal propensity to consume equals 50%. Our last assumption is that the gap between current and equilibrium consumption decreases each period by 20%.
In this setting a change 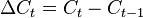 in consumption level can be modelled as
in consumption level can be modelled as 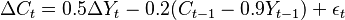 . The first term in the RHS describes short-run impact of change in on , the second term explains long-run gravitation towards the equilibrium relationship between the variables, and the third term reflects random shocks that the system receives (e.g. shocks of consumer confidence that affect consumption). To see how the model works, consider two kinds of shocks: permanent and transitory (temporary). For simplicity, let
. The first term in the RHS describes short-run impact of change in on , the second term explains long-run gravitation towards the equilibrium relationship between the variables, and the third term reflects random shocks that the system receives (e.g. shocks of consumer confidence that affect consumption). To see how the model works, consider two kinds of shocks: permanent and transitory (temporary). For simplicity, let 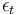 be zero for all t. Suppose in period t-1 the system is in equilibrium, i.e.
be zero for all t. Suppose in period t-1 the system is in equilibrium, i.e. 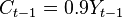 . Suppose that in the period t increases by 10 and then returns to its previous level. Then first (in period t) increases by 5 (half of 10), but after the second period begins to decrease and converges to its initial level. In contrast, if the shock to is permanent, then slowly converges to a value that exceeds the initial
. Suppose that in the period t increases by 10 and then returns to its previous level. Then first (in period t) increases by 5 (half of 10), but after the second period begins to decrease and converges to its initial level. In contrast, if the shock to is permanent, then slowly converges to a value that exceeds the initial  by 9.
by 9.
This structure is common to all ECM models. In practice, econometricians often first estimate the cointegration relationship (equation in levels), and then insert it into the main model (equation in differences).
Further reading
- Lua error in package.lua at line 80: module 'strict' not found.
- Lua error in package.lua at line 80: module 'strict' not found.
- Lua error in package.lua at line 80: module 'strict' not found.
- Lua error in package.lua at line 80: module 'strict' not found.
- Lua error in package.lua at line 80: module 'strict' not found.
- Lua error in package.lua at line 80: module 'strict' not found.
- Lua error in package.lua at line 80: module 'strict' not found.
- Lua error in package.lua at line 80: module 'strict' not found.
- Sargan, J. D. (1964). "Wages and Prices in the United Kingdom: A Study in Econometric Methodology", 16, 25–54. in Econometric Analysis for National Economic Planning, ed. by P. E. Hart, G. Mills, and J. N. Whittaker. London: Butterworths
- Lua error in package.lua at line 80: module 'strict' not found.