Sequential probability ratio test
The sequential probability ratio test (SPRT) is a specific sequential hypothesis test, developed by Abraham Wald.[1] Neyman and Pearson's 1933 result inspired Wald to reformulate it as a sequential analysis problem. The Neyman-Pearson lemma, by contrast, offers a rule of thumb for when all the data is collected (and its likelihood ratio known).
While originally developed for use in quality control studies in the realm of manufacturing, SPRT has been formulated for use in the computerized testing of human examinees as a termination criterion.[2][3][4]
Contents
Theory
As in classical hypothesis testing, SPRT starts with a pair of hypotheses, say 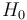 and
and 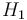 for the null hypothesis and alternative hypothesis respectively. They must be specified as follows:
for the null hypothesis and alternative hypothesis respectively. They must be specified as follows:
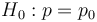
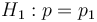
The next step is calculate the cumulative sum of the log-likelihood ratio, 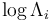 , as new data arrive: with
, as new data arrive: with 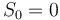 , then, for i=1,2,...,
, then, for i=1,2,...,
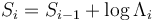
The stopping rule is a simple thresholding scheme:
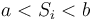 : continue monitoring (critical inequality)
: continue monitoring (critical inequality)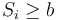 : Accept
: Accept 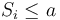 : Accept
: Accept
where a and b (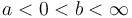 ) depend on the desired type I and type II errors,
) depend on the desired type I and type II errors, 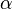 and
and 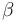 . They may be chosen as follows:
. They may be chosen as follows:
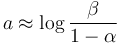 and
and 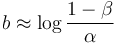
In other words, and must be decided beforehand in order to set the thresholds appropriately. The numerical value will depend on the application. The reason for using approximation signs is that, in the discrete case, the signal may cross the threshold between samples. Thus, depending on the penalty of making an error and the sampling frequency, one might set the thresholds more aggressively. Of course, the exact bounds may be used in the continuous case.
Example
A textbook example is parameter estimation of a probability distribution function. Let us consider the exponential distribution:
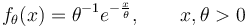
The hypotheses are
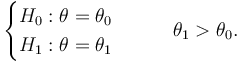
Then the log-likelihood function (LLF) for one sample is
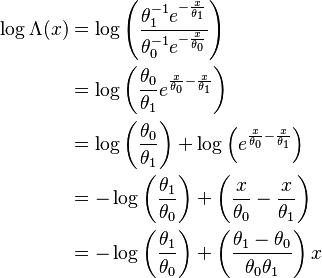
The cumulative sum of the LLFs for all x is
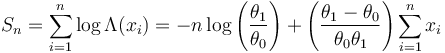
Accordingly, the stopping rule is:
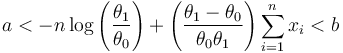
After re-arranging we finally find
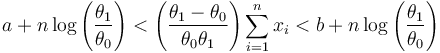
The thresholds are simply two parallel lines with slope 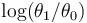 . Sampling should stop when the sum of the samples makes an excursion outside the continue-sampling region.
. Sampling should stop when the sum of the samples makes an excursion outside the continue-sampling region.
Applications
Manufacturing
The test is done on the proportion metric, and tests that a variable p is equal to one of two desired points, p1 or p2. The region between these two points is known as the indifference region (IR). For example, suppose you are performing a quality control study on a factory lot of widgets. Management would like the lot to have 3% or less defective widgets, but 1% or less is the ideal lot that would pass with flying colors. In this example, p1 = 0.01 and p2 = 0.03 and the region between them is the IR because management considers these lots to be marginal and is OK with them being classified either way. Widgets would be sampled one at a time from the lot (sequential analysis) until the test determines, within an acceptable error level, that the lot is ideal or should be rejected.
Testing of human examinees
The SPRT is currently the predominant method of classifying examinees in a variable-length computerized classification test (CCT)[citation needed]. The two parameters are p1 and p2 are specified by determining a cutscore (threshold) for examinees on the proportion correct metric, and selecting a point above and below that cutscore. For instance, suppose the cutscore is set at 70% for a test. We could select p1 = 0.65 and p2 = 0.75 . The test then evaluates the likelihood that an examinee's true score on that metric is equal to one of those two points. If the examinee is determined to be at 75%, they pass, and they fail if they are determined to be at 65%.
These points are not specified completely arbitrarily. A cutscore should always be set with a legally defensible method, such as a modified Angoff procedure. Again, the indifference region represents the region of scores that the test designer is OK with going either way (pass or fail). The upper parameter p2 is conceptually the highest level that the test designer is willing to accept for a Fail (because everyone below it has a good chance of failing), and the lower parameter p1 is the lowest level that the test designer is willing to accept for a pass (because everyone above it has a decent chance of passing). While this definition may seem to be a relatively small burden, consider the high-stakes case of a licensing test for medical doctors: at just what point should we consider somebody to be at one of these two levels?
While the SPRT was first applied to testing in the days of classical test theory, as is applied in the previous paragraph, Reckase (1983) suggested that item response theory be used to determine the p1 and p2 parameters. The cutscore and indifference region are defined on the latent ability (theta) metric, and translated onto the proportion metric for computation. Research on CCT since then has applied this methodology for several reasons:
- Large item banks tend to be calibrated with IRT
- This allows more accurate specification of the parameters
- By using the item response function for each item, the parameters are easily allowed to vary between items.
Detection of anomalous medical outcomes
Spiegelhalter et al. [5] have shown that SPRT can be used to monitor the performance of doctors, surgeons and other medical practitioners in such a way as to give early warning of potentially anomalous results. In their 2003 paper, they showed how it could have helped identify Harold Shipman as a murderer well before he was actually identified.
Extensions
MaxSPRT
More recently, in 2011, an extension of the SPRT method called Maximized Sequential Probability Ratio Test (MaxSPRT) [6] was introduced. The salient feature of MaxSPRT is the allowance of a composite, one-sided alternative hypothesis, and the introduction of an upper stopping boundary. The method has been used in several medical research studies [7]
See also
References
- ↑ Lua error in package.lua at line 80: module 'strict' not found.
- ↑ Ferguson, Richard L. (1969). The development, implementation, and evaluation of a computer-assisted branched test for a program of individually prescribed instruction. Unpublished doctoral dissertation, University of Pittsburgh.
- ↑ Reckase, M. D. (1983). A procedure for decision making using tailored testing. In D. J. Weiss (Ed.), New horizons in testing: Latent trait theory and computerized adaptive testing (pp. 237-254). New York: Academic Press.
- ↑ Lua error in package.lua at line 80: module 'strict' not found.
- ↑ Risk-adjusted sequential probability ratio tests: application to Bristol, Shipman and adult cardiac surgery Spiegelhalter, D. et al Int J Qual Health Care vol 15 7-13 (2003)
- ↑ http://www.tandfonline.com/doi/full/10.1080/07474946.2011.539924 A Maximized Sequential Probability Ratio Test for Drug and Vaccine Safety Surveillance Kulldorff, M. et al Sequential Analysis: Design Methods and Applications vol 30, issue 1
- ↑ 2nd to last paragraph of section 1: http://www.tandfonline.com/doi/full/10.1080/07474946.2011.539924 A Maximized Sequential Probability Ratio Test for Drug and Vaccine Safety Surveillance Kulldorff, M. et al Sequential Analysis: Design Methods and Applications vol 30, issue 1
- Lua error in package.lua at line 80: module 'strict' not found.
- Holger Wilker: Sequential-Statistik in der Praxis, BoD, Norderstedt 2012, ISBN 978-3848232529.