Bayesian multivariate linear regression
Lua error in package.lua at line 80: module 'strict' not found. In statistics, Bayesian multivariate linear regression is a Bayesian approach to multivariate linear regression, i.e. linear regression where the predicted outcome is a vector of correlated random variables rather than a single scalar random variable. A more general treatment of this approach can be found in the article MMSE estimator.
Details
Consider a regression problem where the dependent variable to be predicted is not a single real-valued scalar but an m-length vector of correlated real numbers. As in the standard regression setup, there are n observations, where each observation i consists of k-1 explanatory variables, grouped into a vector 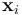 of length k (where a dummy variable with a value of 1 has been added to allow for an intercept coefficient). This can be viewed as a set of m related regression problems for each observation i:
of length k (where a dummy variable with a value of 1 has been added to allow for an intercept coefficient). This can be viewed as a set of m related regression problems for each observation i:


where the set of errors 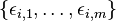 are all correlated. Equivalently, it can be viewed as a single regression problem where the outcome is a row vector
are all correlated. Equivalently, it can be viewed as a single regression problem where the outcome is a row vector 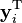 and the regression coefficient vectors are stacked next to each other, as follows:
and the regression coefficient vectors are stacked next to each other, as follows:
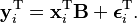
The coefficient matrix B is a  matrix where the coefficient vectors
matrix where the coefficient vectors 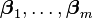 for each regression problem are stacked horizontally:
for each regression problem are stacked horizontally:

The noise vector 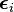 for each observation i is jointly normal, so that the outcomes for a given observation are correlated:
for each observation i is jointly normal, so that the outcomes for a given observation are correlated:
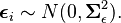
We can write the entire regression problem in matrix form as:
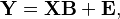
where Y and E are 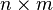 matrices. The design matrix X is an
matrices. The design matrix X is an 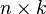 matrix with the observations stacked vertically, as in the standard linear regression setup:
matrix with the observations stacked vertically, as in the standard linear regression setup:

The classical, frequentists linear least squares solution is to simply estimate the matrix of regression coefficients 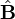 using the Moore-Penrose pseudoinverse:
using the Moore-Penrose pseudoinverse:
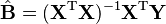 .
.
To obtain the Bayesian solution, we need to specify the conditional likelihood and then find the appropriate conjugate prior. As with the univariate case of linear Bayesian regression, we will find that we can specify a natural conditional conjugate prior (which is scale dependent).
Let us write our conditional likelihood as[1]
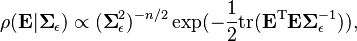
writing the error 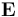 in terms of
in terms of  and
and 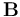 yields
yields
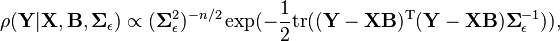
We seek a natural conjugate prior—a joint density  which is of the same functional form as the likelihood. Since the likelihood is quadratic in , we re-write the likelihood so it is normal in
which is of the same functional form as the likelihood. Since the likelihood is quadratic in , we re-write the likelihood so it is normal in 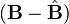 (the deviation from classical sample estimate).
(the deviation from classical sample estimate).
Using the same technique as with Bayesian linear regression, we decompose the exponential term using a matrix-form of the sum-of-squares technique. Here, however, we will also need to use the Matrix Differential Calculus (Kronecker product and vectorization transformations).
First, let us apply sum-of-squares to obtain new expression for the likelihood:
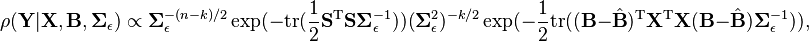
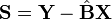
We would like to develop a conditional form for the priors:
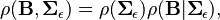
where 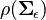 is an inverse-Wishart distribution and
is an inverse-Wishart distribution and 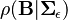 is some form of normal distribution in the matrix . This is accomplished using the vectorization transformation, which converts the likelihood from a function of the matrices
is some form of normal distribution in the matrix . This is accomplished using the vectorization transformation, which converts the likelihood from a function of the matrices 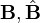 to a function of the vectors
to a function of the vectors 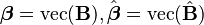 .
.
Write
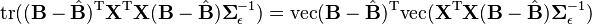
Let
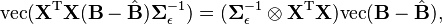
where 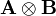 denotes the Kronecker product of matrices A and B, a generalization of the outer product which multiplies an
denotes the Kronecker product of matrices A and B, a generalization of the outer product which multiplies an 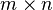 matrix by a
matrix by a 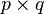 matrix to generate an
matrix to generate an 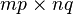 matrix, consisting of every combination of products of elements from the two matrices.
matrix, consisting of every combination of products of elements from the two matrices.
Then
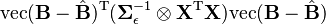
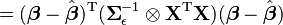
which will lead to a likelihood which is normal in 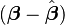 .
.
With the likelihood in a more tractable form, we can now find a natural (conditional) conjugate prior.
See also
References
- ↑ Peter E. Rossi, Greg M. Allenby, Rob McCulloch. Bayesian Statistics and Marketing. John Wiley & Sons, 2012, p. 32.
Lua error in package.lua at line 80: module 'strict' not found.
- Peter E. Rossi, Greg M. Allenby, and Robert McCulloch, Bayesian Statistics and Marketing, John Wiley & Sons, Ltd, 2006