Glottochronology
Lua error in package.lua at line 80: module 'strict' not found.
Glottochronology (from Attic Greek γλῶττα “tongue, language” and χρóνος “time”) is that part of lexicostatistics dealing with the chronological relationship between languages.[1]
The idea was developed by Morris Swadesh under two assumptions: first that there exists a relatively stable "basic vocabulary" (referred to as "Swadesh lists") in all languages of the world, and second that any replacements happen in a way analogical to that in radioactive decay in constant percentages per time elapsed. Meanwhile there exist many different methods, partly extensions of the Swadesh method, now more and more under the biological assumptions of replacements in genes. However, Swadesh's technique is so well known that, for many people, 'glottochronology' refers to it alone.[2][3]
Contents
Methodology
Word list
The original method presumed that the core vocabulary of a language is replaced at a constant (or constant average) rate across all languages and cultures, and can therefore be used to measure the passage of time. The process makes use of a list of lexical terms. Lists were compiled by Morris Swadesh and assumed to be resistant against borrowing (originally designed in 1952 as a list of 200 items; however, the refined 100 word list in Swadesh (1955)[4] is much more common among modern day linguists). This core vocabulary was designed to encompass concepts common to every human language (such as personal pronouns, body parts, heavenly bodies, verbs of basic actions, numerals 'one' and 'two', etc.), eliminating concepts that are specific to a particular culture or time. It has been found that this ideal is not in fact possible and that the meaning set may need to be tailored to the languages being compared. Many alternative word lists have been compiled by other linguists, often using fewer meaning slots.
The percentage of cognates (words that have a common origin) in these word lists is then measured. The larger the percentage of cognates, the more recently the two languages being compared are presumed to have separated.
Glottochronologic constant
Robert Lees obtained a value for the "glottochronological constant" (r) of words by considering the known changes in 13 pairs of languages using the 200 word list. He obtained a value of 0.805 ± 0.0176 with 90% confidence. For the 100 word list Swadesh obtained a value of 0.86, the higher value reflecting the elimination of semantically unstable words. This constant may be related to the retention rate of words by:-
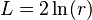
where L is the rate of replacement, ln is the logarithm to base e, and r is the glottochronological constant
Divergence time
The basic formula of glottochronology in its shortest form is:-

where t = a given period of time from one stage of the language to another, c = proportion of wordlist items retained at the end of that period, and L = rate of replacement for that word list.
By testing historically verifiable cases where we have knowledge of t through non-linguistic data (e. g. the approximate distance from Classical Latin to modern Romance languages), Swadesh arrived at the empirical value of approximately 0.14 for L (meaning that the rate of replacement constitutes around 14 words from the 100-wordlist per millennium).
Results
Glottochronology was found to work in the case of Indo-European, accounting for 87% of the variance. It is also postulated to work for Hamito-Semitic (Fleming 1973), Chinese (Munro 1978) and Amerind (Stark 1973; Baumhoff and Olmsted 1963). For the latter, correlations have been obtained with radiocarbon dating and blood groups as well as archaeology. Note that the approach of Gray and Atkinson,[5] as they say, has nothing to do with "glottochronology".
Discussion
The concept of language change is old and its history is reviewed in Hymes (1973) and Wells (1973). Glottochronology itself dates back to the mid-20th century.[4][6][7] An introduction to the subject is given in Embleton (1986)[8] and in McMahon and McMahon (2005).[9]
Glottochronology has been controversial ever since, partly owing to issues of accuracy, as well as the question of whether its basis is sound (see e.g. Bergsland 1958; Bergsland and Vogt 1962; Fodor 1961; Chretien 1962; Guy 1980). These concerns have been addressed by Dobson et al. (1972), Dyen (1973)[10] and Kruskal, Dyen and Black (1973).[11] The assumption of a single-word replacement rate can distort the divergence-time estimate when borrowed words are included (Thomason and Kaufman 1988). Chrétien purported to disprove the mathematics of the Swadesh-model. At a conference at Yale in 1971 his criticisms were shown to be invalid. See the published proceedings under Dyen (1973)[10] The same conference saw the application of the theory to Creole language (Wittmann 1973). An overview of recent arguments can be obtained from the papers of a conference held at the McDonald Institute in 2000.[12] These presentations vary from "Why linguists don't do dates" to the one by Starostin discussed above.[clarification needed] Since its original inception, glottochronology has been rejected by many linguists, mostly Indo-Europeanists of the school of the traditional comparative method. Criticisms have been answered in particular around three points of discussion.
- Criticism levelled against the higher stability of lexemes in Swadesh lists alone (Haarmann 1990) misses the point, because a certain amount of losses only enables the computations (Sankoff 1970).
- Traditional glottochronology did presume that language changes at a stable rate.
- Thus, in Bergsland & Vogt (1962), the authors make an impressive demonstration, on the basis of actual language data verifiable by extra-linguistic sources, that the "rate of change" for Icelandic constituted around 4% per millennium, whereas for closely connected Riksmal (Literary Norwegian) it would amount to as much as 20%. (Swadesh's proposed "constant rate" was supposed to be around 14% per millennium).
- This and several other similar examples effectively proved that Swadesh's formula would not work on all available material—a serious accusation considering that evidence that can be used to "calibrate" the meaning of L (i. e. language history recorded during prolonged periods of time) is not overwhelmingly large in the first place.
- It is highly likely that the chance of replacement is in fact different for every word or feature ("each word has its own history", among hundreds of other sources:[13]).
- This global assumption has been modified and downgraded to single words even in single languages in many newer attempts (see below).
- A serious argument is that language change arises from socio-historical events which are of course unforeseeable and, therefore, uncomputable.
- New methods developed by Gray & Atkinson are claimed to avoid these issues, but are still seen as controversial, primarily since they often produce results that are incompatible with known data and because of additional methodological issues.
Modified glottochronology
Somewhere in between the original concept of Swadesh and the rejection of glottochronology in its entirety lies the idea that glottochronology as a formal method of linguistic analysis becomes valid with the help of several important modifications. Thus, inhomogeneities in the replacement rate were dealt with by Van der Merwe (1966)[14] by splitting the word list into classes each with their own rate, while Dyen, James and Cole (1967)[15] allowed each meaning to have its own rate. Simultaneous estimation of divergence time and replacement rate was studied by Kruskal, Dyen and Black.[11]
Brainard (1970) allowed for chance cognation and drift effects was introduced by Gleason (1959). Sankoff (1973) suggested introducing a borrowing parameter and allowed synonyms.
A combination of these various improvements is given in Sankoff's "Fully Parameterised Lexicostatistics". In 1972 Sankoff in a biological context developed a model of genetic divergence of populations. Embleton (1981) derives a simplified version of this in a linguistic context. She carries out a number of simulations using this which are shown to give good results.
Improvements in statistical methodology related to a completely different branch of science – changes in DNA over time – have sparked a recent renewed interest. These methods are more robust than the earlier ones because they calibrate points on the tree with known historical events and smooth the rates of change across these. As such, they no longer require the assumption of a constant rate of change (Gray & Atkinson 2003).
Starostin's method
Another attempt to introduce such modifications was performed by the Russian linguist Sergei Starostin, who had proposed that
- systematic loanwords, borrowed from one language into another, are a disruptive factor and have to be eliminated from the calculations; the one thing that really matters is the "native" replacement of items by items from the same language. The failure to notice this factor was a major reason in Swadesh's original estimation of the replacement rate at under 14 words from the 100-wordlist per millennium, when the real rate is, in fact, much slower (around 5 or 6). Introducing this correction effectively cancels out the "Bergsland & Vogt" argument, since a thorough analysis of the Riksmal data shows that its basic wordlist includes about 15–16 borrowings from other Germanic languages (mostly Danish) – exclusion of these elements from the calculations brings the rate down to the expected rate of 5–6 "native" replacements per millennium;
- the rate of change is not really constant, but actually depends on the time period during which the word has existed in the language (i. e. chances of lexeme X being replaced by lexeme Y increase in direct proportion to the time elapsed – the so-called "aging of words", empirically understood as gradual "erosion" of the word's primary meaning under the weight of acquired secondary ones);
- individual items on the 100 wordlist have different stability rates (for instance, the word "I" generally has a much lower chance of being replaced than the word "yellow", etc.).
The resulting formula, taking into account both the time dependence and the individual stability quotients, looks as follows:
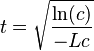
In this formula, −Lc reflects the gradual slowing down of the replacement process due to different individual rates (the less stable elements are the first and the quickest to be replaced), whereas the square root represents the reverse trend – acceleration of replacement as items in the original wordlist "age" and become more prone to shifting their meaning. The formula is obviously more complicated than Swadesh's original one, but, as shown in Starostin's work, yields more credible results than the former (and more or less agrees with all the cases of language separation that can be confirmed by historical knowledge). On the other hand, it shows that glottochronology can really only be used as a serious scientific tool on language families the historical phonology of which has been meticulously elaborated (at least to the point of being able to clearly distinguish between cognates and loanwords).
Time-depth estimation
The problem of time-depth estimation was the subject of a conference held by the McDonald Institute in 2000. The published papers[12] give an idea of the views on glottochronology at the time. These vary from "Why linguists don't do dates" to the one by Starostin discussed above. Note that in the referenced Gray and Atkinson paper, they hold that their methods can not be called "glottochronology", by confining this term to its original method.
See also
- Lexicostatistics
- Dolgopolsky list
- Leipzig–Jakarta list
- Swadesh list
- Mass lexical comparison
- Basic English
- Historical linguistics
- Proto-language
- Cognate
- Indo-European studies
References
- ↑ Sheila Embleton (1992). HISTORICAL LINGUISTICS: Mathematical concepts. In W. Bright (Ed.), International Encyclopedia of Linguistics, page 131
- ↑ Sheila Embleton: HISTORICAL LINGUSITICS: Mathematical concepts. In: W. Bright (ed., International Encyclopedia of Linguistics, 1992: 133)
- ↑ Holm, Hans J. (2007). The new Arboretum of Indo-European 'Trees'; Can new algorithms reveal the Phylogeny and even Prehistory of IE?. Journal of Quantitative Linguistics 14-2:167–214
- ↑ 4.0 4.1 Swadesh, Morris. (1955). Towards greater accuracy in lexicostatistic dating. International Journal of American Linguistics, 21, 121–137
- ↑ Language-tree divergence times support the Anatolian theory of Indo-European origin, Russell D. Gray & Quentin D. Atkinson, Nature 426, 435–439 2003
- ↑ Swadesh, Morris (1972). What is glottochronology? In M. Swadesh, The origin and diversification of languages (pp. 271–284). London: Routledge & Kegan Paul.
- ↑ Lees, Robert. (1953). The basis of glottochronology. Language, 29 (2), 113–127.
- ↑ Embleton, Sheila M. (1986). Statistics in Historical Linguistics [Quantitative linguistics, vol. 30]. Bochum: Brockmeyer. ISBN 3-88339-537-4. – State of the art up to then.
- ↑ McMahon, April and McMahon, Robert (2005) Language Classification by Numbers. Oxford: Oxford University Press (in particular p. 95)
- ↑ 10.0 10.1 Dyen, Isidore, ed. (1973). Lexicostatistics in genetic linguistics: Proceedings of the Yale conference, April 3–4, 1971. La Haye: Mouton.
- ↑ 11.0 11.1 Some Results From the Vocabulary Method of Reconstructing Language Trees, Joseph B. Kruskal, Isidore Dyen and Paul Black, Lexicostatistics in Genetic Linguistics, Isidore Dyen (editor), Mouton, The Hague, 1973, pp. 30-55
- ↑ 12.0 12.1 Renfrew, C., McMahon, A., & L. Trask, Eds. (2000). Time Depth in Historical LInguistics. Cambridge, England: The McDonald Institute for Archaeological Research.
- ↑ Kirk JM, St Anderson, & JDA Widdowson, 1985 Studies in Linguistic Geography: The Dialects of English in Britain and Ireland. London: Croom Helm
- ↑ van der Merwe, N. J. 1966 "New mathematics for glottochronology", Current Anthropology 7: 485--500
- ↑ Dyen, I., James, A. T., & J. W. L. Cole 1967 "Language divergence and estimated word retention rate", <Language 43: 150--171
Bibliography
- Arndt, Walter W. (1959). The performance of glottochronology in Germanic. Language, 35, 180–192.
- Bergsland, Knut; & Vogt, Hans. (1962). On the validity of glottochronology. Current Anthropology, 3, 115–153.
- Brainerd, Barron (1970). A Stochastic Process related to Language Change. Journal of Applied Probability 7, 69–78.
- Callaghan, Catherine A. (1991). Utian and the Swadesh list. In J. E. Redden (Ed.), Papers for the American Indian language conference, held at the University of California, Santa Cruz, July and August, 1991 (pp. 218–237). Occasional papers on linguistics (No. 16). Carbondale: Department of Linguistics, Southern Illinois University.
- Campbell, Lyle. (1998). Historical Linguistics; An Introduction [Chapter 6.5]. Edinburgh: Edinburgh University Press. ISBN 0-7486-0775-7.
- Chretien, Douglas (1962). The Mathematical Models of Glottochronology. Language 38, 11–37.
- Crowley, Terry (1997). An introduction to historical linguistics. 3rd ed. Auckland: Oxford Univ. Press. pp. 171–193.
- Dyen, Isidore (1965). "A Lexicostatistical classification of the Austronesian languages." International Journal of American Linguistics, Memoir 19.
- Gray, R.D. & Atkinson, Q.D. (2003): "Language-tree divergence times support the Anatolian theory of Indo-European origin." Nature 426-435-439.
- Gudschinsky, Sarah. (1956). The ABC's of lexicostatistics (glottochronology). Word, 12, 175–210.
- Haarmann, Harald. (1990). "Basic vocabulary and language contacts; the disillusion of glottochronology. In Indogermanische Forschungen 95:7ff.
- Hockett, Charles F. (1958). A course in modern linguistics (Chap. 6). New York: Macmillan.
- Hoijer, Harry. (1956). Lexicostatistics: A critique. Language, 32, 49–60.
- Holm, Hans J. (2003). The Proportionality Trap. Or: What is wrong with lexicostatistical Subgrouping.Indogermanische Forschungen, 108, 38–46.
- Holm, Hans J. (2005). Genealogische Verwandtschaft. Kap. 45 in Quantitative Linguistik; ein internationales Handbuch. Herausgegeben von R.Köhler, G. Altmann, R. Piotrowski, Berlin: Walter de Gruyter.
- Holm, Hans J. (2007). The new Arboretum of Indo-European 'Trees'; Can new algorithms reveal the Phylogeny and even Prehistory of IE?. Journal of Quantitative Linguistics 14-2:167–214
- Hymes, Dell H. (1960). Lexicostatistics so far. Current Anthropology, 1 (1), 3–44.
- McWhorter, John. (2001). The power of Babel. New York: Freeman. ISBN 978-0-7167-4473-3.
- Nettle, Daniel. (1999). Linguistic diversity of the Americas can be reconciled with a recent colonization. in PNAS 96(6):3325–9.
- Sankoff, David (1970). "On the Rate of Replacement of Word-Meaning Relationships." Language 46.564–569.
- Sjoberg, Andree; & Sjoberg, Gideon. (1956). Problems in glottochronology. American Anthropologist, 58 (2), 296–308.
- Starostin, Sergei. Methodology Of Long-Range Comparison. 2002. pdf
- Thomason, Sarah Grey, and Kaufman, Terrence. (1988). Language Contact, Creolization, and Genetic Linguistics. Berkeley: University of California Press.
- Tischler, Johann, 1973. Glottochronologie und Lexikostatistik [Innsbrucker Beiträge zur Sprachwissenschaft 11]; Innsbruck.
- Wittmann, Henri (1969). "A lexico-statistic inquiry into the diachrony of Hittite." Indogermanische Forschungen 74.1–10.[1]
- Wittmann, Henri (1973). "The lexicostatistical classification of the French-based Creole languages." Lexicostatistics in genetic linguistics: Proceedings of the Yale conference, April 3–4, 1971, dir. Isidore Dyen, 89–99. La Haye: Mouton.[2]
- Zipf, George K. (1965). The Psychobiology of Language: an Introduction to Dynamic Philology. Cambridge, MA: M.I.T.Press.
External links
- Swadesh list in Wiktionary.
- Discussion with some statistics
- A simplified explanation of the difference between glottochronology and lexicostatistics.
- Queryable experiment: quantification of the genetic proximity between 110 languages - with trees and discussion
| Key topics | |||||||||
|---|---|---|---|---|---|---|---|---|---|
|
|||||||||
| Calendars |
|
||||||||
| Astronomic time | |||||||||
| Geologic time |
|
||||||||
| Archaeological methods |
|
||||||||
| Genetic methods | |||||||||
| Linguistic methods |
|
||||||||
| Related topics | |||||||||