JPAのキャッシュを使ったアプリケーション高速化手法
•
23 likes•14,501 views

JPOUG Tech Talk Night #2 で話した内容に飲み会で質問された内容を加えています。












































JPAのキャッシュを使ったアプリケーション高速化手法
- 3. 注意 • 都合上、省略している部分もあります • スペースの都合上、SQLでは*を多用します • DBの表名やJavaのクラス名などは論理名を使用します • JPAの実装系により、動作が異なる可能性があります 3
- 4. 目次 4 • 自己紹介 • JPAとは • キャッシュの効果 • キャッシュ使う前に • N+1問題を考える • よくある改善策 • キャッシュならではの改善策 • キャッシュチューニング
- 5. 自己紹介 • 名前: – 伊藤 智博(いとう ちひろ) • 勤務先: – 日本オラクル株式会社 • 仕事で使う製品/技術: – Java EE/SE/ME, JVM, OEP, Coherence, SQL • 連載: – Javaはどのように動くのか~図解でわかるJVMの仕組み – http://gihyo.jp/dev/serial/01/jvm-arc 5
- 6. はじめに • データベースにアクセスしないシステムは存在します。 • その理由は、 – データを保存しない – 保存先をデータベースにする必要は無く、ファイルで十分 – データベースにアクセスしていたら処理が間に合わない • という理由でしょう 6
- 7. はじめに • DBにアクセスしたら負けな処理は存在し、その多くはメモリ にデータをキャッシュすることで処理時間を短縮します • 他のシステムでもメモリにデータをキャッシュすれば処理時 間の短縮を見込めますが、メモリは揮発性のため永続化は難 しく、メモリ<->DB間での永続化の仕組みが必要です • 自分でこんな仕組みを作るのは難しいです • そんな時は、JPAを使いましょう! 7
- 8. JPAとは? 8
- 9. JPAって何なの? • JPA は Java Persistence API の略です。 • Java の規格である JSR317 として策定 • 以下の3つからなる – API (javax.persistenceパッケージ) – Java Persistence Query Language (JPQL) – オブジェクト/関係メタデータ 9 出典:wikipedia
- 10. JPAって何ができるの? • Entity の自動生成ができます • JPQL / Criteria API / Native Queryによる問い合わせ • IDE による JPQL のコードチェック • キャッシュ 10 今回はキャッシュのお話しです
- 11. キャッシュの効果 11
- 12. キャッシュの効果 • アプリの処理時間短縮 • Entityオブジェクトの共有 • SQL実行の負荷低減 12
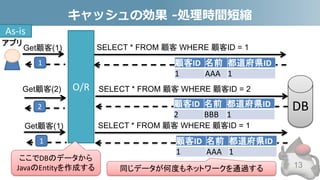
- 13. キャッシュの効果 -処理時間短縮 13 SELECT * FROM 顧客 WHERE 顧客ID = 1 O/R Get顧客(1) 1 2 SELECT * FROM 顧客 WHERE 顧客ID = 2 顧客ID 名前 都道府県ID 2 BBB 1 顧客ID 名前 都道府県ID 1 AAA 1 Get顧客(2) ここでDBのデータから JavaのEntityを作成する SELECT * FROM 顧客 WHERE 顧客ID = 1Get顧客(1) 1 顧客ID 名前 都道府県ID 1 AAA 1 同じデータが何度もネットワークを通過する As-is アプリ DB
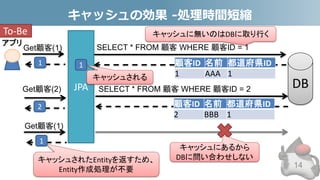
- 14. キャッシュの効果 -処理時間短縮 14 SELECT * FROM 顧客 WHERE 顧客ID = 1 JPA Get顧客(1) 1 2 SELECT * FROM 顧客 WHERE 顧客ID = 2 顧客ID 名前 都道府県ID 2 BBB 1 顧客ID 名前 都道府県ID 1 AAA 1 Get顧客(2) キャッシュされたEntityを返すため、 Entity作成処理が不要 Get顧客(1) 1 キャッシュされる 1 キャッシュに無いのはDBに取り行くTo-Be キャッシュにあるから DBに問い合わせしない アプリ DB
- 15. キャッシュの効果 -Entityオブジェクトの共用 15 SELECT * FROM 顧客 WHERE 顧客ID = 1 O/R Get顧客(1) 1 顧客ID 名前 都道府県ID 1 AAA 1 複数スレッドで同じ処理をしていると、 スレッド数分だけリソースを消費する SELECT * FROM 顧客 WHERE 顧客ID = 1Get顧客(1) 1 顧客ID 名前 都道府県ID 1 AAA 1 As-is DB
- 16. キャッシュの効果 -Entityオブジェクトの共用 16 DB SELECT * FROM 顧客 WHERE 顧客ID = 1 JPA Get顧客(1) 1 顧客ID 名前 都道府県ID 1 AAA 1 複数スレッドで同じ処理をしていると、 最初に処理したスレッドがキャッシュに載せて、 他のスレッドはキャッシュのEntityを使う Get顧客(1) 1 1 キャッシュにあるから このスレッドでは DBに問い合わせしない To-Be
- 17. キャッシュの効果 -SQLの負荷低減の例 • SELECT 顧客.*, 血液型.*, 性別.*, 都道府県.*, 郵便番 号.* FROM 顧客 JOIN 血液型 ON (顧客.血液型ID = 血液型.ID) JOIN 性別 ON (顧客.性別ID = 性別.ID) JOIN 都道府県 ON (顧客.都道府県ID = 都道府県.ID) JOIN 郵便番号 ON (顧客.郵便番号ID = 郵便番号.ID) WHERE 年齢 = ? 17 実際は*ではなく、各カラムが羅列されます 5つのテーブルを結合するのか、 大変だなぁ As-is
- 18. キャッシュの効果 -SQLの負荷低減の例 • キャッシュを使うと、外部キーでの参照は参照先のオブ ジェクトがキャッシュにあればキャッシュから取れます。 • そのため、SQLでJoinする必要がなくなり、DB側のI/O やJoin処理が無くなります。 • SELECT * FROM 顧客 WHERE 年齢 = ? 18 実際は*ではなく、各カラムが羅列されます 結合が無くなった♪ To-Be Joinの無くなったSQL
- 19. キャッシュを使う前に 19
- 20. キャッシュの種類 • 以下の2つのキャッシュがあります。 • Entityキャッシュ – Key-Valueの組み合わせでキャッシュされます – 主キー(複合キーも可能)をKeyとして、Entity(レコードに相当) をValueとして取得します • 問合せ結果キャッシュ – 問合せとパラメータの組合せで問合せ結果をキャッシュします 20 今回はEntityキャッシュを 重点的に紹介します
- 21. 検討項目 • キャッシュ対象を決めるために以下を検討しましょう – アクセス方法 • どのようにデータにアクセスするのか – データ数 • データはどのくらいあるのか 21
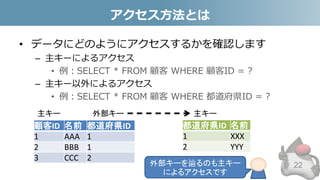
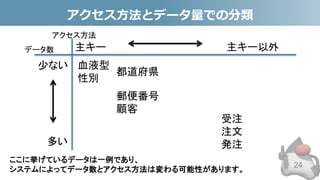
- 22. アクセス方法とは • データにどのようにアクセスするかを確認します – 主キーによるアクセス • 例:SELECT * FROM 顧客 WHERE 顧客ID = ? – 主キー以外によるアクセス • 例:SELECT * FROM 顧客 WHERE 都道府県ID = ? 顧客ID 名前 都道府県ID 1 AAA 1 2 BBB 1 3 CCC 2 主キー 外部キー 都道府県ID 名前 1 XXX 2 YYY 主キー 外部キーを辿るのも主キー によるアクセスです 22
- 23. データ数 • キャッシュサイズの概算見積もり方法 – キャッシュするデータ数 × データのオブジェクトサイズ • データ数が多いとヒープをたくさん使います。 23
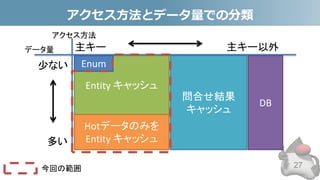
- 25. アクセス方法とデータ量での分類 • Entityキャッシュと相性が良いパターン • 主キーによるアクセス/データ量が少ない – Entityキャッシュとの相性は非常に高い – 更新が無ければDatabaseに入れずEnumにしてしまうのもアリ – 例:血液型、性別など • データ量問わず主キーによるアクセスがほとんど – 全てキャッシュしきれない場合は、アクセス数の多いもの(Hot データ)のみをキャッシュする – 例:都道府県、郵便番号、顧客 25
- 26. アクセス方法とデータ量での分類 • 問合せ結果キャッシュと相性が良いもの • 主キー以外でのアクセスが多いがパターンが限られてい る – 顧客を年齢や性別で検索などはコレと相性が良い。 – パターンが多いが殆どは特定のパターンしか使わない場合は、 使用頻度の高いHotパターンのみをキャッシュする – 例:受注、注文、発注で日付が新しい物だけをキャッシュ 26
- 27. アクセス方法とデータ量での分類 27 血液型 性別 都道府県 郵便番号 顧客 受注 注文 発注 少ない 多い 主キー 主キー以外 Entity キャッシュ Enum Hotデータのみを Entity キャッシュ 問合せ結果 キャッシュ DB データ量 アクセス方法 今回の範囲
- 28. N+1問題を考える 28
- 29. 要件 • 顧客とその居住都道府県の情報をDBへ問い合わせます 29 DB 顧客表:n行 都道府県表:m行 一般的には n > m (≒47) 問い合わせ(SQL) 結果 アプリ
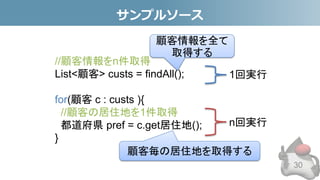
- 30. サンプルソース 30 //顧客情報をn件取得 List<顧客> custs = findAll(); for(顧客 c : custs ){ //顧客の居住地を1件取得 都道府県 pref = c.get居住地(); } n回実行 1回実行 顧客毎の居住地を取得する 顧客情報を全て 取得する
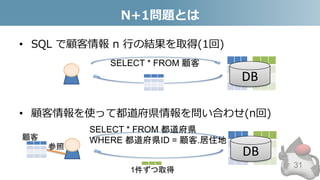
- 31. N+1問題とは • SQL で顧客情報 n 行の結果を取得(1回) • 顧客情報を使って都道府県情報を問い合わせ(n回) 31 DB SELECT * FROM 顧客 DB SELECT * FROM 都道府県 WHERE 都道府県ID = 顧客.居住地顧客 参照 1件ずつ取得
- 32. SELECT * FROM 都道府県 ・・・ SELECT * FROM 都道府県 ・・・ シーケンス 32 顧客ID 名前 都道府県ID 1 AAA 1 2 BBB 1 3 CCC 2 DB SELECT * FROM 顧客 SELECT * FROM 都道府県 WHERE 都道府県ID = 1 都道府県ID 名前 2 YYY 都道府県ID 名前 1 XXX findAll() O/R 1 2 3 .get居住地() 1 .get居住地() 1 .get居住地() 2 1 2 3 都道府県ID 名前 1 XXX n回SQLが 発効される n件取得
- 33. よくある改善策は? 33
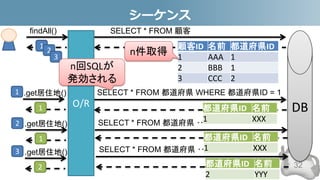
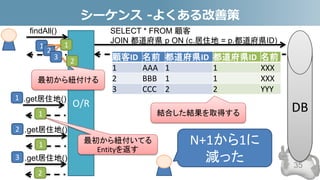
- 34. N+1問題 -よくある改善策 • 最初から結合しておく 34 DB SELECT * FROM 顧客 c JOIN 都道府県 p ON (c.居住地 = p.都道府県ID) 結合された結果 結合したSQL
- 35. シーケンス -よくある改善策 35 顧客ID 名前 都道府県ID 1 AAA 1 2 BBB 1 3 CCC 2 DB SELECT * FROM 顧客 JOIN 都道府県 p ON (c.居住地 = p.都道府県ID) findAll() O/R 1 2 3 .get居住地() 1 .get居住地() 1 .get居住地() 2 1 2 3 1 2 最初から紐付ける 都道府県ID 名前 1 XXX 1 XXX 2 YYY 結合した結果を取得する 最初から紐付いてる Entityを返す N+1から1に 減った
- 37. 結合したSQLが発行されるようにするには • JPQL に JOIN FETCH を付けて結合する • フィールドに @JoinFetch を付与 37 SELECT c FROM 顧客 c JOIN FETCH c.居住地 @JoinFetch @OneToOne private 都道府県 居住地 または 都道府県を保存し ているフィールド
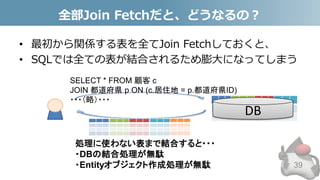
- 39. 全部Join Fetchだと、どうなるの? • 最初から関係する表を全てJoin Fetchしておくと、 • SQLでは全ての表が結合されるため膨大になってしまう 39 SELECT * FROM 顧客 c JOIN 都道府県 p ON (c.居住地 = p.都道府県ID) ・・・(略)・・・ 処理に使わない表まで結合すると・・・ ・DBの結合処理が無駄 ・Entityオブジェクト作成処理が無駄 DB
- 40. 全部に @JoinFetch してはいけない • 一対多のように、 相手が多の関係が増えるとSQLの結果が爆発的に増加 • キャッシュに乗っていればEntityが使われますが、 乗っていなければEntityが作成されるため、 Java側の使用オブジェクト数も爆発的に増加する 40
- 41. @JoinFetch をどう使うのか • “必ず”セットで使うものを @JoinFetch する • それ以外は処理に応じてJPQL で JOIN FETCHする 41
- 43. キャッシュならではの改善策 43
- 44. 改善策のおさらい • 事前に複数のデータを結合すると – 実行回数:1回 – 転送量:n * (顧客のサイズ+都道府県のサイズ) 44 顧客ID 名前 都道府県ID 1 AAA 1 2 BBB 1 3 CCC 2 都道府県ID 名前 1 XXX 1 XXX 2 YYY n行
- 45. 改善策のおさらい 45 ん? 都道府県の情報って重複してない? 顧客ID 名前 都道府県ID 1 AAA 1 2 BBB 1 3 CCC 2 都道府県ID 名前 1 XXX 1 XXX 2 YYY n行
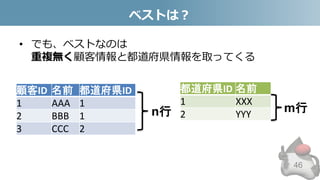
- 46. ベストは? • でも、ベストなのは 重複無く顧客情報と都道府県情報を取ってくる 46 顧客ID 名前 都道府県ID 1 AAA 1 2 BBB 1 3 CCC 2 都道府県ID 名前 1 XXX 2 YYYn行 m行
- 47. 47 そんなに都合良くいくのか?
- 48. キャッシュならではの改善策 • 関係へのアクセスは主キーによるアクセスのため Entityキャッシュを参照する • JPAでは事前に結合しなくてもn+1より良い – 最大SQL実行回数:m+1回 • ( n > 47 >= m なのでn+1より少ない) – 最大データサイズ:n * 顧客のサイズ + m * 都道府県のサイズ • 全てキャッシュされていれば – SQL実行回数:1回 – データサイズ:n * 顧客のサイズ 48 ↑で満足してはダメ ←これを目指します
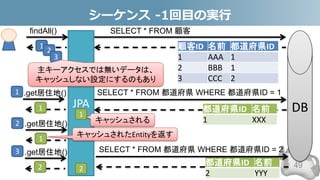
- 49. シーケンス -1回目の実行 49 顧客ID 名前 都道府県ID 1 AAA 1 2 BBB 1 3 CCC 2 DB SELECT * FROM 顧客 SELECT * FROM 都道府県 WHERE 都道府県ID = 1 都道府県ID 名前 2 YYY 都道府県ID 名前 1 XXX findAll() JPA 1 2 3 .get居住地() 1 .get居住地() 1 .get居住地() 2 1 2 SELECT * FROM 都道府県 WHERE 都道府県ID = 2 キャッシュされる キャッシュされたEntityを返す 1 2 3 主キーアクセスでは無いデータは、 キャッシュしない設定にするのもあり
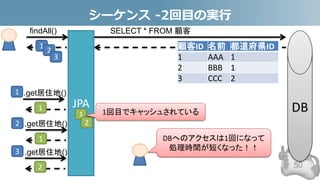
- 50. シーケンス -2回目の実行 50 顧客ID 名前 都道府県ID 1 AAA 1 2 BBB 1 3 CCC 2 DB SELECT * FROM 顧客findAll() JPA 1 2 3 .get居住地() 1 .get居住地() 1 .get居住地() 2 1 2 1回目でキャッシュされている 1 2 3 DBへのアクセスは1回になって 処理時間が短くなった!!
- 51. コラム –Lazy/Eager Joinとの違い- • キャッシュすることと、Lazy/Eager Joinは別物になります。 • Lazy Joinは関連先のEntityを使用するときに、関連先のデータを新 たに問い合わせます。 • Eager Joinは問合せ時に、関連先のデータをさらに新たに問い合わ せてEntityを構築しておき、使用時に新たな問合せをしません。 • Eager/Lazy Joinで、新たに問い合わせる際に、キャッシュされてい ればキャッシュを使用し、キャッシュされていなければDBに問い合 わせます。 • Lazy/Eager Joinは新たに問い合わせるタイミングが異なるだけです。 51 実装系やバージョンにより、動作が異なる可能性があります
- 52. キャッシュチューニング 52
- 54. チューニング事項 • ウォーミングアップ – 処理を受け付ける前に、必要なデータを全てを読み込んで キャッシュさせる • データ毎にキャッシュ数を検討する • データ特性に合わせた参照を検討する 54 まず考えるのはこの3つ
- 55. データの特性に合わせたキャッシュ設計 • キャッシュ数 – デフォルトは100個入るList構造を作成する – 適切な数にしないと、無駄なヒープを消費することもある • 参照方法 – デフォルトはSoft参照のため、ヒープが足りなくなると削除さ れる。 – 強参照(FULL)にすると常にキャッシュし続ける 55
- 56. データの特性に合わせたキャッシュ設計例 • 都道府県情報 – 全てキャッシュしておくならFULLで47個にする • 郵便番号 – 7桁なので最大10,000,000個の可能性がある – メモリに余裕があれば、ヒープサイズを大きくして全てキャッ シュするのもアリ。 – メモリに余裕が無ければ、全てキャッシュすることは現実的で は無い。ホットデータだけをキャッシュする 56 53個分すら勿体ない
- 57. まとめ 57
- 58. まとめ • JPAはJavaの標準規格 • キャッシュを使うとシステム全体の負荷を減らせる • アプリの処理時間が短くなる • Entityオブジェクトを保持するため常にメモリは使う • 使われないデータをキャッシュしても無駄なので、なん でもキャッシュすれば良い訳ではない。 • データ特性に合わせたキャッシュ設計が重要 58
- 59. FIN. 59